
1 Los motores de búsqueda Autor: Stefano Chiazza Tutor: Xavier Sánchez Búsqueda en Wibo a través...
23
1 Los motores de búsqueda Autor: Stefano Chiazza Tutor: Xavier Sánchez Búsqueda en Wibo a través de más de 650 páginas Abat Oliba
-
Upload
horacio-salvador -
Category
Documents
-
view
12 -
download
1
Transcript of 1 Los motores de búsqueda Autor: Stefano Chiazza Tutor: Xavier Sánchez Búsqueda en Wibo a través...

1
Los motores de búsquedaAutor: Stefano Chiazza
Tutor: Xavier Sánchez
Búsqueda en Wibo a través de más de 650 páginas Abat Oliba

2
Objetivos
El estudio de los motores de búsqueda en cuanto a su funcionamiento.
La programación de un prototipo, implementado en Java, MySQL, HTML y JSP.

3
Los buscadores

4
Qué son
Los buscadores son programas informáticos que se dedican a analizar la Web para posteriormente poder buscar en ella.
Están formados por las cinco partes que se presentan a continuación:
1. INTERFAZ: punto de interconexión con el usuario. En la interfaz se introducirán las palabras a buscar y se recibirán los resultados.
2. RASTREADOR: Programa que analiza la red.3. BASE DE DATOS: Lugar en el que se almacenará la información
encontrada.4. ÍNDICES: Algoritmos que modelarán la base de datos.5. PROGRAMA DE BÚSQUEDA: Programa que buscará en la base de
datos.

5
Por qué se utilizan
“Aunque es sumamente difícil medir el tamaño de la Web, se estima que hoy en día unos 1.000.000.000 usuarios utilizan la Web, y que esta contiene del orden de 4.000.000.000 documentos, un volumen equivalente a entre catorce y veintiocho millones de libros” Pablo Castells, La Web Semántica
Así, podemos admitir que una estructuración de esta información es necesaria.
¿Se imaginan el tiempo que tardaría una persona para encontrar todos los libros que contengan una palabra determinada en una pequeña biblioteca de cien libros?
“Ahora se puede buscar a lo equivalente a 70 millas de altura en papel en menos de un segundo. Creemos que es fantástico” Lawrence Page, cofundador de Google

6
Situación actual
Según el portal SearchEngineWath.com se realizan unos 213 millones de búsquedas al día, con un total de 6.400 millones en Marzo de 2006 en EEUU.
Por este motivo, el mundo de los buscadores mueve grandes cantidades de dinero (el 99% del cual es publicidad, según El País).
El mercado actual está dominado por Google, que indexaba hace un tiempo el 71.16% de toda la red y que cuenta con más de 9.500 empleados bajo un lema: “organizar la información mundial y hacerla universalmente accesible y útil”.
7
En vista al futuro
Dos son las tendencias actuales:
1. Búsqueda semántica: de esta nueva generación de motores de búsqueda se espera que consigan entender a la perfección al usuario. A modo de ejemplo: buscadores capaces de entender la diferencia entre ‘libros de niños’, ‘libros para niños’, ‘libros con niños’.
2. Búsqueda personalizada: buscadores que almacenan todos los movimientos de los usuarios en sus cuentas (búsquedas, e-mails, etc.) para dar con temas de interés personal.
8
Prototipo

9
Idea
El objetivo de este trabajo ha sido la implementación de un prototipo de buscador.
Hacerlo a escala de red de redes es una tarea que se me presenta hoy por hoy inabarcable: hacer una base de datos eficiente, un rastreador rápido, etc.
De esta manera, Wibo rastreará sólo las páginas Abat Oliba y permitirá buscar en ellas.

10
Tecnologías
Java, JSP y HTML como lenguajes de programación
MySQL como herramienta de base de datos

11
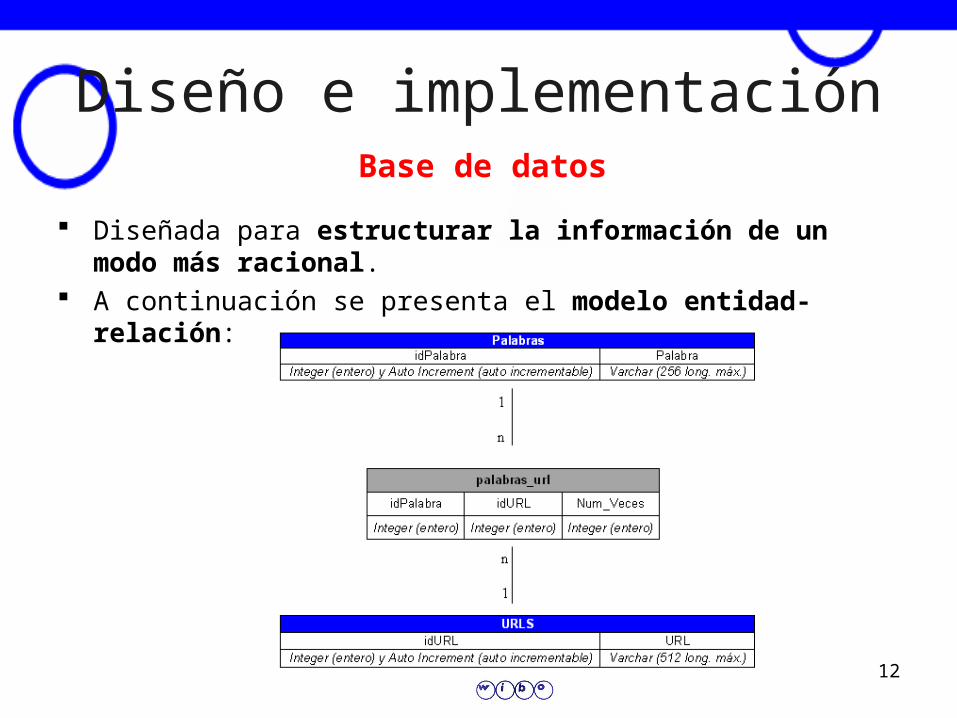
Diseño e implementación
Wibo ha sido diseñado para que sea de lo más eficiente.
Este motor de búsqueda está orientado a páginas Abat Oliba.
Por este motivo, no controla muchos de los posibles errores con los que un buscador a gran escala debe tratar.
Está formado por un crawler, una base de datos, un programa de búsqueda y una interfaz.
12
Diseño e implementación
Diseñada para estructurar la información de un modo más racional.
A continuación se presenta el modelo entidad-relación:
Base de datos

13
Diseño e implementación
Las imágenes que seguidamente se presentan muestran muy bien su estructura:
Tabla URLS:
Tabla PALABRAS:
Tabla PALABRAS_URL:
Base de datos

14
Diseño e implementación
Rastrea las páginas de la fundación Abat Oliba.
Analiza en un proceso completo y sólo cuando alguien decide ejecutarlo.
Está formado por dos clases: DatosURL y Rastreador.
Rastreador

15
Diseño e implementación
Es la clase que contiene el cuerpo principal del programa y, por lo tanto, será la que se ejecutará.
La primera URL que rastrea (y es la única establecida antes de ejecutar el programa) es http://www.uao.es.
Se basa en una sentencia iterativa y, por lo tanto, se ejecutará siempre y cuando tenga en espera más páginas por rastrear.
Clase Rastreador:
Rastreador

16
Diseño e implementación
El proceso que sigue al analizar una Web es el siguiente:1. Verificará que la URL que está analizando no está en la base de
datos para añadirla si no lo está. Si la URL es incorrecta, tendrá métodos para controlar el error.
2. Analiza la página. Aquí, existirán dos procesos: el de extracción de palabras y el de análisis de hipervínculos hacia otras páginas.
3. Una vez analizada la página, con las palabras contadas y los vínculos extraídos, actualizará la base de datos.
4. Volverá a empezar de nuevo y analizará la página primera en la cola de por analizar.
Clase Rastreador:
Rastreador

17
Diseño e implementación
Es una clase que sirve para que el programador tenga una visión más precisa de los errores que puedan acaecer durante la tarea de rastreo.
A modo de ejemplo, el encuentro inesperado con una URL mal formada (*http://www.uaoes)
Clase DatosURL:
Rastreador

18
Diseño e implementación
El algoritmo de búsqueda de Wibo ordena los resultados según el número de veces que aparece una de las palabras buscadas en cada página de la base de datos (siempre y cuando aparezca al menos una vez).
Permite buscar documentos conteniendo las palabras buscadas, con la posibilidad de introducir todas las que se quieran.
Se devolverán aquellos documentos que las contengan todas.
Algoritmo de búsqueda

19
Diseño e implementación
Sigue los siguientes pasos:
1. A partir de lo que recibe por parte del usuario, fragmenta el texto según los espacios en blanco para obtener las palabras.
2. Cogerá de la base de datos las páginas que contengan la primera palabra en orden descendiente de apariciones.
3. A partir de esta lista de páginas, la recorrerá comenzando de la primera URL hasta la última, y para cada palabra comprobará si aparece en la URL que se está analizando. Si no aparece, la eliminará de la lista.
4. Presentará los resultados.
Algoritmo de búsqueda

20
Diseño e implementación
Programada en HTML y JSP.
Simple …
Interfaz

21
Resultados
694 páginas analizadas.
17.155 palabras encontradas.
272.727 relaciones palabras-url.
Tiempo de ejecución del rastreador: 3.4 horas con una media de 18s por página.

22
Mejoras
Aplicar el protocolo de robots.txt.
Hacerlo a escala de red de redes.
No almacenar los metatags de las páginas.
Mejorar la base de datos.
Optimizar al conjunto.

23
Gracias


















