5. Filtrado en Snortbibing.us.es/proyectos/abreproy/12077/fichero/memoria%2Fpor_capi… · Snort,...
17
Capítulo 5: Filtrado en Snort 5. Filtrado en Snort 5.1. Introducción En esta parte del documento se retoma la idea del uso de un filtrado previo a la búsqueda exacta de patrones, cuya estructura ocuparía un espacio en memoria mucho menor que el del algoritmo de búsqueda exacta. Con este filtrado, según las ideas lanzadas por el equipo de sigMatch, explicadas en el capítulo tres, se reduciría el número de cache misses, puesto que se evitarían muchas llamadas a la unidad de verificación y, por tanto, se conseguiría una ejecución más rápida de la aplicación. Será en este capítulo donde se iniciará la puesta en práctica de esta idea de filtrado. Para ello se ha debido trabajar bastante. No ha bastado únicamente haber entendido y asimilado la propuesta de Jignesh M. Patel y su equipo, también se ha tenido que realizar un estudio de la teoría algorítmica y, no menos importante, se ha debido profundizar en el funcionamiento de Snort para así poder llegar a una conclusión y decidir cuál es el punto óptimo del código fuente en el que se podría situar un filtrado previo. Durante este capítulo, en primer lugar se realizará un recorrido por los posibles puntos de implementación del filtro dentro de Snort. Estas localizaciones fueron las que se barajaron como candidatas para albergar el filtro. Se explicarán los aspectos que llevaron a elegir una única localización posible, descartando las demás. Una vez seleccionada la localización final, se estudiará el funcionamiento interno del motor de detección de Snort a nivel de código fuente para, de esta forma, poder decidir de qué manera se integrará el filtrado previo. Antes de ello se hará un repaso por los distintos métodos de búsqueda que Snort pone a disposición del usuario y se comprobará que casi todos implementan el algoritmo Aho-Corasick, pero en diferentes variantes. Finalmente, se explicará a nivel de código fuente cómo se integrará el filtro dentro del motor de detección de Snort, indicando de qué forma el usuario podrá activar o desactivar el filtro, qué ficheros han debido modificarse para ello y cómo se ha preparado el motor de detección para albergar la implementación de un filtrado previo. 5.2. Situación del filtro en Snort Después de plantear los objetivos del proyecto, de haber estudiado los principios de la algoritmia desde sus inicios hasta la actualidad, de comprender y asimilar la propuesta del filtrado previo 1
Transcript of 5. Filtrado en Snortbibing.us.es/proyectos/abreproy/12077/fichero/memoria%2Fpor_capi… · Snort,...

Capítulo 5: Filtrado en Snort
5. Filtrado en Snort
5.1. Introducción
En esta parte del documento se retoma la idea del uso de un filtrado previo a la búsqueda exacta de patrones, cuya estructura ocuparía un espacio en memoria mucho menor que el del algoritmo de búsqueda exacta. Con este filtrado, según las ideas lanzadas por el equipo de sigMatch, explicadas en el capítulo tres, se reduciría el número de cache misses, puesto que se evitarían muchas llamadas a la unidad de verificación y, por tanto, se conseguiría una ejecución más rápida de la aplicación. Será en este capítulo donde se iniciará la puesta en práctica de esta idea de filtrado.
Para ello se ha debido trabajar bastante. No ha bastado únicamente haber entendido y asimilado la propuesta de Jignesh M. Patel y su equipo, también se ha tenido que realizar un estudio de la teoría algorítmica y, no menos importante, se ha debido profundizar en el funcionamiento de Snort para así poder llegar a una conclusión y decidir cuál es el punto óptimo del código fuente en el que se podría situar un filtrado previo.
Durante este capítulo, en primer lugar se realizará un recorrido por los posibles puntos de implementación del filtro dentro de Snort. Estas localizaciones fueron las que se barajaron como candidatas para albergar el filtro. Se explicarán los aspectos que llevaron a elegir una única localización posible, descartando las demás.
Una vez seleccionada la localización final, se estudiará el funcionamiento interno del motor de detección de Snort a nivel de código fuente para, de esta forma, poder decidir de qué manera se integrará el filtrado previo. Antes de ello se hará un repaso por los distintos métodos de búsqueda que Snort pone a disposición del usuario y se comprobará que casi todos implementan el algoritmo Aho-Corasick, pero en diferentes variantes.
Finalmente, se explicará a nivel de código fuente cómo se integrará el filtro dentro del motor de detección de Snort, indicando de qué forma el usuario podrá activar o desactivar el filtro, qué ficheros han debido modificarse para ello y cómo se ha preparado el motor de detección para albergar la implementación de un filtrado previo.
5.2. Situación del filtro en Snort
Después de plantear los objetivos del proyecto, de haber estudiado los principios de la algoritmia desde sus inicios hasta la actualidad, de comprender y asimilar la propuesta del filtrado previo
1

Capítulo 5: Filtrado en Snort
bautizada como sigMatch y de haber conocido en profundidad el funcionamiento de Snort, ha llegado el momento de discutir el diseño general que adquirirá la implementación del filtrado previo en Snort.
Al plantear el desarrollo de un filtrado de tráfico que pudiera agilizar la búsqueda de patrones de Snort, se establecieron varios principios que la implementación final debería cumplir. Uno de ellos fue la escalabilidad, que estaba íntimamente ligada al diseño general que establecería dónde debía introducirse el filtro dentro de Snort.
Snort es una aplicación en continua evolución, con un alto ritmo de lanzamiento de versiones nuevas. Por tanto, la solución elegida para el diseño debía facilitar su portabilidad a nuevas versiones. Esto también beneficiaría al hecho de que cualquier usuario pudiera implantar el filtrado en su propia instalación de Snort, simplemente siguiendo unas sencillas instrucciones que no le obligarían a modificar excesivamente el código fuente ni a poseer unos conocimientos de Snort elevados. Para cumplir este objetivo, el código original de Snort debía ser lo menos modificado posible.
Puesto que el motor de detección es el componente en el que se encuentra el algoritmo de búsqueda multi-patrón, las posibilidades de implementación del filtro previo se limitan a insertarlo entre el final del descodificador de paquetes y antes del inicio del motor de detección, estando situado el preprocesador entre estos dos componentes.
Se recuerda que la función del descodificador es la de recibir el paquete entrante del módulo DAQ y descodificarlo para que pueda ser organizado en estructuras de datos que posteriormente serán utilizadas por el resto de componentes de Snort. Sin embargo, el preprocesador se dedica al estudio del paquete e incluso existen casos, ya vistos en el cuarto capítulo, en los que se modifica el contenido del mismo antes de que continúe su camino hacia el motor de detección.
Seguidamente, se hará un recorrido por el camino definido entre la salida del descodificador y la entrada del motor de detección. En este recorrido se explicará el razonamiento llevado a cabo para decidir cuáles serían los posibles puntos de implementación del filtrado, analizando en cada caso su viabilidad. Finalmente, se planteará la conclusión a la que se llegó en su momento y que determinó el lugar donde se decidió situar el filtro.
5.2.1. Propuestas iniciales
Se eligieron tres puntos posibles en los que el filtro podría tener cabida. El primero de ellos se situaría a la salida del descodificador y antes del paso por el preprocesador. La siguiente opción propuesta fue situar el filtro como un módulo de preprocesador más que se ejecutara al final de todos ellos, una vez que cada uno hubiera ejecutado su tarea. La tercera y última opción que se planteó fue colocarlo justo antes de la llamada al motor de detección.
5.2.1.1. Entre el Descodificador y el Preprocesador
El primer punto que se encuentra en el camino es la unión del final del descodificador con el inicio
2
Capítulo 5: Filtrado en Snort
del preprocesador, como se muestra en la figura 5.1. Se podría considerar la posibilidad de implementar el filtro previo en este punto, pero se mostrarán los motivos que llevaron a pensar que no era éste el lugar adecuado.
Antes de seguir, se sugiere al lector repasar el ejemplo que se presentaba como demostración de la utilidad del componente preprocesador, concretamente del preprocesador HTTP Inspect, explicado en el capítulo cuatro. En él se presentaba el caso en el que un cliente solicitaba una petición de la dirección web http://servidor/%61%74%61%71%75%65%2E%65%78%65 a un servidor. Se comprobó que al no usar un preprocesador que modificara la URI el paquete no se detectaba como una amenaza.
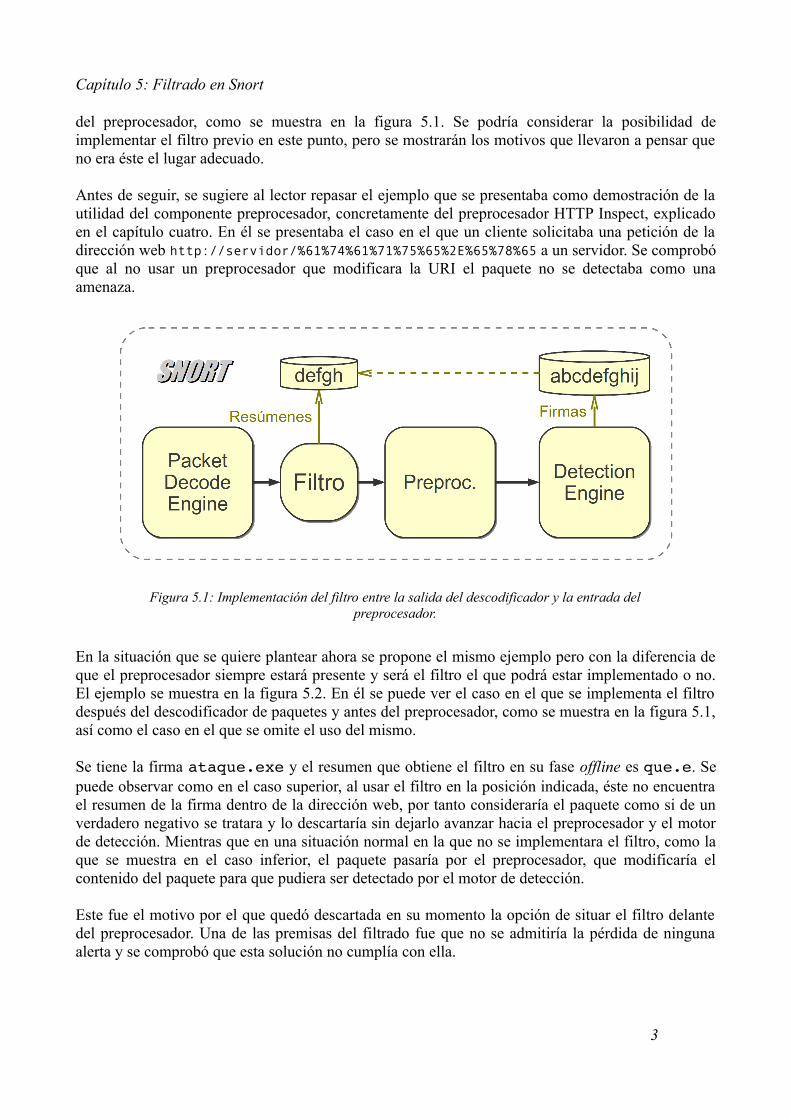
En la situación que se quiere plantear ahora se propone el mismo ejemplo pero con la diferencia de que el preprocesador siempre estará presente y será el filtro el que podrá estar implementado o no. El ejemplo se muestra en la figura 5.2. En él se puede ver el caso en el que se implementa el filtro después del descodificador de paquetes y antes del preprocesador, como se muestra en la figura 5.1, así como el caso en el que se omite el uso del mismo.
Se tiene la firma ataque.exe y el resumen que obtiene el filtro en su fase offline es que.e. Se puede observar como en el caso superior, al usar el filtro en la posición indicada, éste no encuentra el resumen de la firma dentro de la dirección web, por tanto consideraría el paquete como si de un verdadero negativo se tratara y lo descartaría sin dejarlo avanzar hacia el preprocesador y el motor de detección. Mientras que en una situación normal en la que no se implementara el filtro, como la que se muestra en el caso inferior, el paquete pasaría por el preprocesador, que modificaría el contenido del paquete para que pudiera ser detectado por el motor de detección.
Este fue el motivo por el que quedó descartada en su momento la opción de situar el filtro delante del preprocesador. Una de las premisas del filtrado fue que no se admitiría la pérdida de ninguna alerta y se comprobó que esta solución no cumplía con ella.
3
Figura 5.1: Implementación del filtro entre la salida del descodificador y la entrada del preprocesador.
Capítulo 5: Filtrado en Snort
5.2.1.2. Como último módulo del Preprocesador
La segunda posibilidad fue la de colocar el filtro después de haber ejecutado cada módulo del preprocesador. De esta forma, el paquete llegaría a este punto con las modificaciones necesarias realizadas por preprocesadores como el HTTP Inspect o el Frag3.
La solución propuesta para este caso sería la que se representa en la figura 5.3, en la que aparece el filtro como un módulo más del preprocesador y cuya función sería la de analizar el contenido de cada paquete en busca de los resúmenes de firmas obtenidas del conjunto de reglas de Snort. Este nuevo módulo de filtrado debería ejecutarse en último lugar, detrás de los módulos ya existentes en el preprocesador, para así evitar casos como el de la figura 5.2, en los que al no preprocesar un ataque podía darse el caso de que no pudiera ser detectado. No obstante, se verá que este punto tampoco es el adecuado para implementar el filtro.
Para demostrarlo se debe retroceder de nuevo al capítulo cuatro y repasar el esquema de la función Preprocess, mostrada en la figura 4.15. En él se puede apreciar el modo en el que se invoca a la función Detect. El proceso no consiste en ejecutar todos los módulos de los preprocesadores para después pasar el control al motor de detección, sino que se puede invocar al motor de detección después de la ejecución de un único preprocesador. En el siguiente párrafo, y con la ayuda de la
4
Figura 5.2: Ejemplo en el que se coloca el filtro entre el descodificador y el preprocesador.

Capítulo 5: Filtrado en Snort
figura 5.4, se aclara esta situación.
Ya se ha visto en el capítulo anterior que los módulos de preprocesador se pueden dividir en dos tipos: el que no modifica el contenido del paquete y el que sí lo hace. Ahora bien, suponiendo que existan M módulos del primer tipo y N del segundo, se llamarían 1+N veces a la función Detect. La primera llamada se produciría después de ejecutar los M módulos que no modifican el contenido del paquete y las siguientes N llamadas se realizarían después de ejecutar cada módulo de los que modifican el paquete. Por tanto, como se muestra en la figura 5.4, situar el filtro como último módulo de preprocesador no serviría de mucho, puesto que antes de poder filtrar los paquetes, éstos ya se habrían enviado hacia el motor de detección en varias ocasiones.
Una alternativa sería colocar el filtro antes de cada llamada a la función Detect, como se muestra en la figura 5.5. En principio, esta sería la solución óptima; no se obstaculizaría la tarea de los módulos del preprocesador y ningún paquete dejaría de pasar por el filtro. No obstante, en cuanto a eficiencia, presenta algunos puntos débiles que se describen en los siguientes párrafos.
En el capítulo cuatro se ha estudiado una estructura denominada lista enlazada 3D en la que se almacenan las reglas y las estructuras de detección del algoritmo de búsqueda multi-patrón. También, se ha visto que un paquete recorre esta lista enlazada hasta llegar al RTN al que pertenece y una vez allí comprueba si cumple con alguna de las reglas representadas por los OTNs. Este camino que sigue el paquete no se realiza hasta entrar en el motor de detección, es decir, hasta que no se ejecuta la función Detect. Por tanto, en el punto en el que se sitúa el filtro en la figura 5.5 aún no se habría recorrido la lista enlazada, y realizar un filtrado en esa parte del código sería cuanto menos un problema.
Una de las ventajas que aporta la lista enlazada es el hecho de evitar que se deba realizar una búsqueda multi-patrón sobre todas las reglas. La lista permite que la búsqueda que se realice incluya únicamente a un grupo reducido de reglas que tengan en común sus cabeceras. Esto quiere decir que el hecho de que el paquete no haya recorrido todavía la lista enlazada hasta el nivel de las RTN obligaría a realizar un filtrado usando resúmenes obtenidos de todo el conjunto de reglas, puesto que no se conoce aún a qué grupo de reglas pertenece el paquete.
5
Figura 5.3: Implementación del filtro antes de la salida del preprocesador, considerándolo así como un módulo más del preprocesador.

Capítulo 5: Filtrado en Snort
Ya se explicó en el capítulo cuatro, cuando se planteó el ejemplo de la búsqueda de palabras en libros de varios colores, que este camino llevaba a dos soluciones diferentes. La primera de ellas era ineficiente, mientras que la segunda daba un mejor rendimiento. Trasladando el ejemplo a la problemática presente, la primera solución sería la equivalente a realizar una búsqueda de todos los patrones del conjunto de resúmenes y, en el caso de obtener una coincidencia, se comprobaría si el protocolo y direcciones IP y puertos coincidiera con la cabecera de la regla en cuestión. La segunda solución, consistiría en organizar los resúmenes en conjuntos cuyas cabeceras correspondiesen con el protocolo y direcciones IP y puertos del paquete, para después realizar una búsqueda de patrones sobre un único conjunto.
Como en el ejemplo de los libros, esta última solución proporcionaría un mejor rendimiento, pero llevaría a cabo una tarea que ya la realiza el motor de búsqueda de patrones, que es recorrer la lista enlazada para llegar a un RTN. Por tanto, en cuanto a rendimiento, podría decirse que no es muy óptimo realizar este recorrido por la lista dos veces: antes de entrar en el motor de detección y una vez dentro.
Como conclusión, se podría pensar que el mejor punto en el que se podría implementar el filtro sería aquél en el que el paquete ya hubiera recorrido la lista enlazada, pero siempre antes de haber
6
Figura 5.4: Implementación del filtro como último módulo del preprocesador.

Capítulo 5: Filtrado en Snort
ejecutado la búsqueda de patrones.
5.2.1.3. Dentro del Motor de Búsqueda de Patrones (MPSE)
Esto nos lleva al tercer punto posible de la implementación del filtro. Podría parecer una buena opción incluir el filtrado dentro del motor de búsqueda multi-patron, como se muestra en la figura 5.6. De esta forma bastaría con recorrer sólo una vez la lista enlazada y, en lugar de invocar directamente la búsqueda de patrones, se pasaría el paquete por el filtro para que éste decidiera si reenviarlo a la búsqueda multi-patrón, o no.
El modo en el que está programada la búsqueda de patrones en Snort hace posible la implementación en este punto. Esta es la situación que menos interfiere en la tarea esencial de la aplicación, por lo que facilita la integración en cada cambio de versión, algo importante para el usuario final de Snort que desee incorporar un filtrado previo.
Con todo esto, y puesto que no se encontraron mayores inconvenientes, se puso en marcha el desarrollo de esta idea de implementación.
En la siguiente sección se explicará con detalle el funcionamiento del motor de detección, para que
7
Figura 5.5: Implementación del filtro antes de cada llamada al motor de detección.

Capítulo 5: Filtrado en Snort
de esta forma se pueda entender mejor el próximo capítulo, en el que se explica detalladamente el desarrollo de filtro.
5.3. Motor de detección de Snort
Después de haber decidido, sobre el esquema de Snort, cuál es el lugar óptimo donde situar el filtro, se procede al estudio del código fuente del IDS para así poder comenzar con la implementación de la idea de filtrado que propuso el equipo de sigMatch. Concretamente, esta sección se centrará en el funcionamiento del motor de detección de Snort, ya que es en este punto donde se implementará el filtrado y por tanto se requerirá un conocimiento en profundidad del funcionamiento interno de este componente.
Ya se ha visto que, cuando Snort recibe un paquete, éste atraviesa la aplicación hasta llegar a la lista enlazada de reglas, recorriéndola hasta el último nivel, en el cual se decidirá si el paquete debe pasar por el motor de detección, o no. También se sabe que la invocación al motor de detección se realiza mediante la función mpseSearch, localizada en el fichero mpse.c. Cada función contenida en el archivo en cuestión se encarga de redirigir el curso de la aplicación hacia el algoritmo de búsqueda de patrones que se haya elegido en el archivo de configuración snort.conf.
A continuación se enumerarán algunos de los algoritmos de búsqueda de patrones, así como ciertos aspectos interesantes que convendría saber de ellos para, de esta forma, conocer en mayor medida el funcionamiento del motor de detección.
5.3.1. Algoritmos en Snort
8
Figura 5.6: Implementación del filtro al principio del motor de detección.

Capítulo 5: Filtrado en Snort
El algoritmo más usado en Snort es Aho-Corasick. No obstante, a la hora de implementarlo existen diversas variantes que pueden ser seleccionadas a través del archivo de configuración. Ya se introdujeron en el capítulo tres algunas de estas variantes, como son Full matrix, Sparse, Banded y Sparsebands. Es la primera variante que se menciona la que ofrece mayor rendimiento pero, como inconveniente, requiere un consumo de memoria mayor. También, se explicó que el consumo de memoria elevado podría reducir considerablemente este rendimiento. En cambio, las demás variantes no ofrecen un rendimiento tan alto pero cuentan con un consumo de memoria moderado.
En 2009, la variante de Aho-Corasick establecida por defecto en el archivo de configuración de Snort era Aho-Corasick Binary NFA (acbnfa), la cual contaba con un bajo consumo de memoria y un alto rendimiento. A finales de ese mismo año se introdujo la opción splitanyany, que permitía construir en un modo diferente la lista enlazada de reglas.
Por defecto, las reglas cuyos puertos de origen y destino son anyany se incluyen en todos los grupos de puertos que no son del tipo anyany, como se muestra en la figura 5.7. De esta forma sólo sería necesario evaluar una vez cada paquete entrante.
La nueva opción agrupa todas las reglas del tipo anyany en un nuevo grupo, como se puede ver en la figura 5.8, con lo que se consigue reducir drásticamente el uso de memoria, puesto que solo existe una copia de las reglas del tipo anyany en toda la lista enlazada, en lugar de una copia por cada grupo de la lista. Por tanto, si en el primer modo hay N grupos, aplicando la nueva opción quedarían N+1 grupos, pero se reduciría bastante el uso de memoria de cada uno de ellos. No obstante, esta solución requiere dos evaluaciones por paquete en los casos en los que el puerto de
9
Figura 5.7: Lista enlazada de reglas sin la opción split-any-any.

Capítulo 5: Filtrado en Snort
origen y destino del paquete se corresponda con algún grupo que no sea anyany, ya que tendría que evaluar su propio grupo de reglas así como el nuevo grupo introducido correspondiente a las reglas anyany.
La opción splitanyany se puede usar con cualquier método de búsqueda disponible en Snort, pero su desarrollo fue ideado especialmente para el método ac, que corresponde con la variante Aho-Corasick Full, y que era la que requería un consumo de memoria mayor. Al combinarlo con este método el consumo de memoria se ve drásticamente reducido y aunque sería lógico pensar que el rendimiento podría llegar a bajar a la mitad no sucede así puesto que, como ya se sabe, un bajo consumo de memoria puede mejorar el rendimiento mediante, entre otros factores, la reducción del número de cache misses.
La conjunción del método de búsqueda ac junto con el uso de la opción splitanyany fue acotada como el nuevo método de búsqueda acsplit, que es el método establecido por defecto actualmente.
Esta mejora no hubiera sido posible sin las ideas aportadas por Charlie Lasswell, un miembro de la comunidad de Snort. Este tipo de situaciones son las que deben concienciar a los desarrolladores de software de las ventajas que supone el hecho de crear aplicaciones Open Source.
5.3.2. Dentro del Motor de detección
En este punto del capítulo se analizará el código fuente correspondiente al motor de detección. Ya en el capítulo cuatro se hizo un estudio interno de Snort, desde la ejecución de la aplicación hasta la llamada a las funciones del motor de detección. A partir de aquí se retomará el mismo estudio, continuando con el análisis de las funciones implicadas en el proceso de búsqueda de patrones.
En capítulos anteriores se ha explicado que el funcionamiento de Snort, así como el de su motor de detección, se puede separar en dos fases: offline y online. Para el estudio de su código fuente se continuará con esta división, por lo que en primer lugar se hará un recorrido interno a lo largo de la fase offline y en segundo lugar se analizará la fase online.
10
Figura 5.8: Lista enlazada de reglas construida con la opción split-any-any.

Capítulo 5: Filtrado en Snort
5.3.2.1. Fase offline
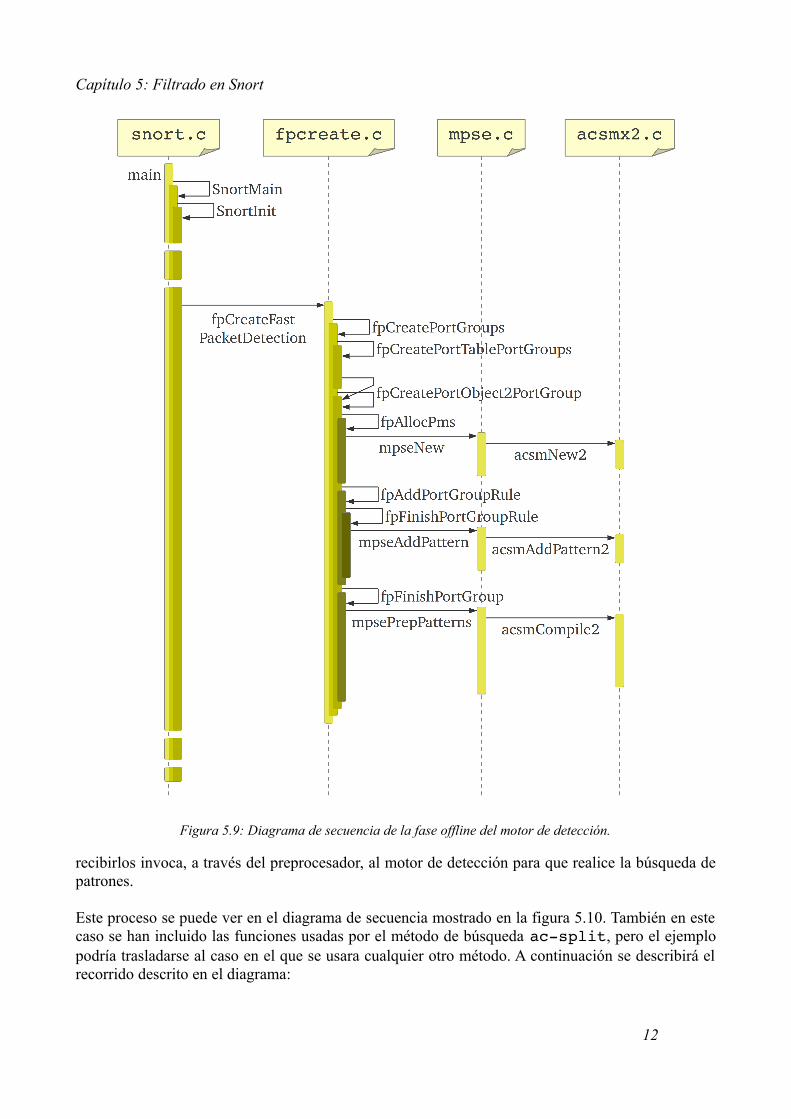
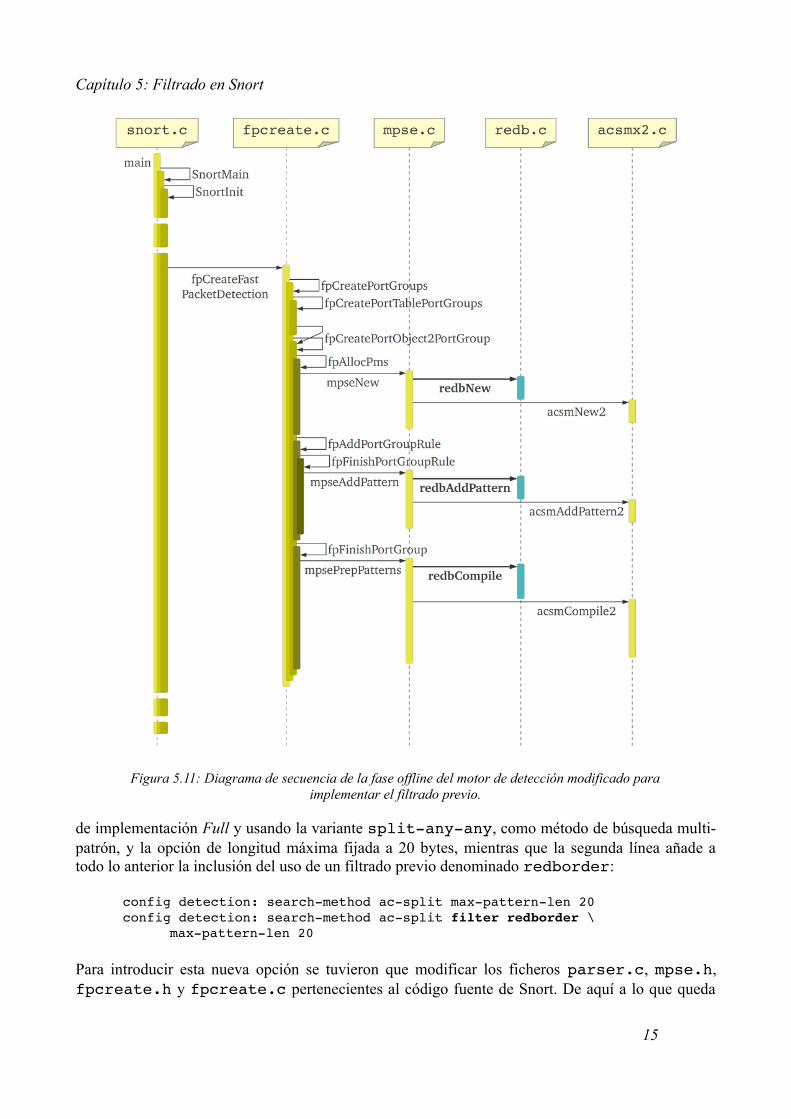
A continuación, y con ayuda de la figura 5.9, se recorrerá la fase offline desde que es invocada por la función fpCreateFastPacketDetection hasta que alcanza el algoritmo de búsqueda de patrones, que creará su estructura de detección, nombrando cada función implicada y describiendo la tarea que lleva a cabo1:
1. Una vez que, desde SnortInit, se han registrado y configurado los preprocesadores y módulos de salida, obtenido las reglas y creada la lista enlazada, se realiza la llamada a la función fpCreateFastPacketDetection, que se encargará de realizar la llamada al motor de búsqueda de patrones para que gestione la creación de la estructura de detección.
2. Desde fpCreateFastPacketDetection se llega, después de pasar por algunas funciones intermedias, ya vistas en el capítulo cuatro, y dedicadas al posicionamiento sobre la lista enlazada de reglas, a la función fpCreatePortObject2PortGroup, que ejecutará las funciones fpAllocPms, fpAddPortGroupRule y fpFinishPortGroup, en ese orden. Cada una de estas tres funciones realizará llamadas al motor de detección.
3. La primera de ellas es fpAllocPms, invocará a mpseNew, para asignar en memoria la estructura de búsqueda de patrones.
4. La siguiente, fpAddPortGroupRule, y a través de fpFinishPortGroupRule, invocará a mpseAddPattern para añadir los patrones que formarán parte del diccionario que use el algoritmo de búsqueda multi-patrón.
5. La última, fpFinishPortGroup, ejecutará la función mpsePrepPatterns, que creará la estructura de detección en base a todos los patrones que fueron añadidos en el paso anterior.
Hay que tener en cuenta que una vez dentro del motor de búsqueda de patrones (MPSE), este invocará al algoritmo correspondiente para realizar todas las tareas mencionadas anteriormente, como son la asignación inicial de memoria de la estructura de detección, realizada por acsmNew2, la inclusión de patrones en la estructura de detección, por parte de acsmAddPattern2, y la creación definitiva de la estructura de detección, llevada a cabo por acsmCompile2.
En este caso se han incluido las funciones usadas por el método de búsqueda acsplit, las cuales están contenidas en el fichero acsmx2.c. Pero podría haberse usado cualquier otro método sin haber alterado apenas el esquema del diagrama de secuencia de la figura 5.9.
5.3.2.2. Fase online
A partir de aquí, Snort se mantiene a la espera de la llegada de paquetes. Cuando comienza a
1 En el anexo II se muestran fragmentos del código fuente de las funciones más importantes involucradas en los procesos offline y online de la búsqueda de patrones de Snort que se describen en este capítulo.
11
Capítulo 5: Filtrado en Snort
recibirlos invoca, a través del preprocesador, al motor de detección para que realice la búsqueda de patrones.
Este proceso se puede ver en el diagrama de secuencia mostrado en la figura 5.10. También en este caso se han incluido las funciones usadas por el método de búsqueda acsplit, pero el ejemplo podría trasladarse al caso en el que se usara cualquier otro método. A continuación se describirá el recorrido descrito en el diagrama:
12
Figura 5.9: Diagrama de secuencia de la fase offline del motor de detección.

Capítulo 5: Filtrado en Snort
1. Recordando el diagrama de secuencia de la fase online de Snort propuesto en el capítulo cuatro, desde snort.c se invocaba al módulo preprocesador a través de la función Preprocess, localizada en el fichero detect.c. Ésta a su vez ejecutaba la función Detect, que sería la que llamaría a fpEvalPacket, contenida en fpdetect.c. Este camino ya se vio en el capítulo anterior, por lo que se ha omitido en la figura 5.10.
2. Una vez invocada la función fpEvalPacket, ésta, en función del protocolo del paquete, llamará a la siguiente función. En el caso de tratarse de un paquete TCP invocará a fpEvalHeaderTcp, mientras que al tratarse de paquetes UDP, IP o ICMP, se invocarán a las funciones fpEvalHeaderUdp, fpEvalHeaderIp o fpEvalHeaderIcmp, respectivamente.
3. A continuación, e independientemente del protocolo del paquete, la función a la que se haya redirigido la ejecución llamará a fpEvalHeaderSW, que será la encargada de invocar al motor de detección.
4. Esta invocación se realizará a través de la llamada a la función mpseSearch, contenida en el fichero mpse.c, y que a su vez ejecutará el método de búsqueda de patrones elegido en
13
Figura 5.10: Diagrama de secuencia de la fase online del motor de detección.

Capítulo 5: Filtrado en Snort
el fichero de configuración, siendo acsplit en el caso del ejemplo y, por tanto, llamándose a la función acsmSearch2.
5.4. Implementación del filtro en el Motor de detección
Llegados a este punto, había que decidir dónde implementar el filtrado previo dentro del motor de detección. Se sabe que desde el fichero mpse.c se realizan todas las llamadas relacionadas con la búsqueda de patrones, tanto las correspondientes a la fase offline como a la fase online. Por lo que se consideró que este fichero podría ser la situación óptima a partir de la cual implementar el filtro.
El objetivo del filtrado propuesto por el equipo de sigMatch no era otro que el de analizar el tráfico captado por Snort antes de enviarlo al algoritmo de búsqueda de patrones, para decidir si se debía llevar a cabo el análisis final a manos de la unidad de verificación o, si por el contrario, se debía descartar el paquete. La unidad de verificación mencionada sería el algoritmo elegido en el archivo de configuración, que en el ejemplo correspondería con las funciones del fichero acsmx2.c. Por tanto, habría que situar el filtrado antes de que, en la fase online, se ejecutara la función acsmSearch2, encargada de realizar la búsqueda de patrones.
En el caso de la realización de la fase offline del filtrado, también se tomó la decisión de llevarla a cabo antes de la ejecución de la fase offline de la unidad de verificación final. Aunque en este caso no hubiera sido determinante colocarla antes o después, puesto que durante la fase offline no se toman decisiones que afecten a la ejecución del algoritmo definitivo.
La propuesta de implementación del filtrado previo a la búsqueda de patrones se puede ver en las figuras 5.11 y 5.12, en las que se muestran los diagramas de secuencia de las fases offline y online del motor de detección modificadas para poder llevar a cabo la integración de dicho filtrado.
En ambos diagramas aparece un nuevo fichero llamado redb.c. Este fichero se crea para albergar las distintas funciones, entre las que se encuentran redbNew, redbAddPatterns, redbCompile y redbSearch, que se encargarán de llevar a cabo la tarea de filtrado propuesta por los autores de sigMatch.
Una vez decidida la localización que ocupará la implementación del filtro, se debe que preparar Snort para que contemple la opción de activar o desactivar un filtrado previo. En el desarrollo del proyecto se propuso que esta opción pudiera ser establecida desde el archivo de configuración de Snort; así, del mismo modo que se elegía el método de búsqueda deseado, se pudiera elegir también si se deseaba incluir un filtrado previo en la búsqueda de patrones.
La nueva opción incluida en Snort se representa por la palabra filter y va seguida del tipo de filtro que se quiera añadir. Note el lector que se ha elegido esta sintaxis para seguir con la línea ya propuesta en el archivo de configuración de Snort.
A continuación se muestran, como ejemplo, dos líneas del fichero de configuración relacionadas con la configuración del motor de detección; en la primera se establece Aho-Corasick en su modo
14
Capítulo 5: Filtrado en Snort
de implementación Full y usando la variante splitanyany, como método de búsqueda multi-patrón, y la opción de longitud máxima fijada a 20 bytes, mientras que la segunda línea añade a todo lo anterior la inclusión del uso de un filtrado previo denominado redborder:
config detection: searchmethod acsplit maxpatternlen 20config detection: searchmethod acsplit filter redborder \
maxpatternlen 20
Para introducir esta nueva opción se tuvieron que modificar los ficheros parser.c, mpse.h, fpcreate.h y fpcreate.c pertenecientes al código fuente de Snort. De aquí a lo que queda
15
Figura 5.11: Diagrama de secuencia de la fase offline del motor de detección modificado para implementar el filtrado previo.

Capítulo 5: Filtrado en Snort
de documento conviene saber que cada modificación llevada a cabo en cualquier fichero del código fuente de Snort quedó señalada con las reseñas rbw o rbc, según el tipo de modificación adoptada, para que de esta forma pudiera ser localizada más fácilmente.
A continuación se describen los cambios realizados en cada uno de los cuatro ficheros anteriores, pudiendo ver los fragmentos de código fuente modificados en el anexo III:
• parser.c: Este fichero contiene algunas de las funciones encargadas de recoger las opciones del fichero snort.conf para almacenarlas en las estructuras de Snort. En este fichero se define la nueva opción filter, para que posteriormente sea leída en la función ConfigDetection. Si se detecta la nueva opción en el fichero de configuración, entonces se llama a la función fpSetDetectFilter, situada en fpcreate.c.
• mpse.h: En este fichero residen las definiciones de los distintos métodos de búsqueda de patrones disponibles. Será aquí donde se incluirán las definiciones relativas a los distintos tipos de filtrado que se quieran añadir.
• fpcreate.h: Aquí se encuentra la estructura FastPatternConfig y se almacenan las opciones que se leyeron desde el fichero de configuración relativas al motor de detección. Por lo que se decidió añadir una opción más que indicara la inclusión del tipo de filtrado
16
Figura 5.12: Diagrama de secuencia de la fase online del motor de detección modificado para implementar el filtrado previo.

Capítulo 5: Filtrado en Snort
previo definido en snort.conf. También se declara la función fpSetDetectFilter, que se usará en fpcreate.c.
• fpcreate.c: A este fichero se llega al ejecutar desde parser.c la función fpSetDetectFilter. Esta función se encarga de almacenar en la estructura FastPatternConfig la opción de filtrado que se especificó en el archivo de configuración.
Hasta este momento, la única opción de filtrado que se incluye es redborder, que corresponde con la implementación del filtro sigMatch. Una vez que se añadió esta opción en el fichero de configuración, hubo que preparar al motor de detección y modificar su código fuente para que contemplara la implementación de un filtro previo. Para ello, se realizaron variaciones en la estructura MPSE, así como en funciones como mpseNew, mpseAddPattern, mpsePrepPatterns y mpseSearch, entre otras. Todas estas modificaciones se realizaron dentro del archivo mpse.c y están disponibles para su consulta en el anexo III.
Básicamente, lo que se hizo en cada una de las funciones modificadas fue realizar una comprobación de la opción de filtrado que se estableció desde el fichero de configuración. Si esta opción estaba activada, entonces en cada una de las funciones se llevaría a cabo una tarea similar a la que realizaría cualquier algoritmo de búsqueda de patrones. Por ejemplo, en el caso de que el filtrado estuviera activo, en la función mpseNew se asignaría en memoria la estructura del filtro, en mpseAddPattern se añadirían los patrones de firmas de los cuales se extraerían sus resúmenes, en la función mpsePrepPatterns se compilaría la estructura de detección del filtro y en mpseSearch se realizaría la búsqueda a través de dicha estructura, reenviando el control a la unidad de verificación final en el caso en que se hubiera marcado un paquete como candidato.
Como resumen de este capítulo, se podría decir que se ha elegido la situación del filtrado que parecía más óptima, se ha propuesto un modo de integración dentro del motor de detección y se ha construido, sobre el código fuente de Snort, el esqueleto que soportará la integración de dicho filtrado. En el siguiente capítulo se estudiará y se explicará cómo se ha llevado a cabo el desarrollo del filtro sigMatch dentro de Snort.
17