Análisis de Datos - tamps.cinvestav.mxwgomez/diapositivas/RP/Clase08.pdf · Análisis de Datos...
15
Análisis de Datos Métodos de mínimos cuadrados Profesor: Dr. Wilfrido Gómez Flores 1
Transcript of Análisis de Datos - tamps.cinvestav.mxwgomez/diapositivas/RP/Clase08.pdf · Análisis de Datos...

Análisis de Datos Métodos de mínimos cuadrados
Profesor: Dr. Wilfrido Gómez Flores
1

Introducción
• Recordemos que los clasificadores lineales se utilizan ampliamente debido a que son computacionalmente simples y eficientes.
• En los casos donde las clases no son linealmente separables aún se puede utilizar un clasificador lineal aunque se obtenga un desempeño subóptimo desde el punto de vista de la probabilidad de error de clasificación.
• Los métodos de mínimos cuadrados se enfocan en minimizar la diferencia entre la salida del clasificador lineal, wTx, y la salida deseada (o clase real), y.
• Métodos: error cuadrático medio y error de suma de cuadrados.
2

Error cuadrático medio
• Partiendo del caso de dos clases, diseñar un clasificador lineal a partir de los patrones de entrenamiento con media cero (yi,xi) para i=1,…,N y xxxxxxxxxxxx.
• En caso que la media de las muestras no sea cero, se les resta.
• El objetivo es estimar xxxxxx para el modelo lineal wTx, de modo que el error cuadrático medio (MSE) entre la salida del clasificador y la salida deseada
3
sea mínimo, esto es
w = argminwJ(w)
(1)
(2)
yi 2 {−1,+1}
w 2 RD
J(w) = E⇥(y w
Tx)2
⇤

• Minimizando la función de costo J(w) se tiene:
4
Error cuadrático medio
(3)rJ(w) = rE[(y −w
Tx)(y − x
Tw)]
= r�E[y2]− 2wTE[xy] +w
TE(xxT )w
= −2E[xy] + 2E[xxT ]w = 0
donde xxxxxxxxx es el vector de correlación cruzada entrada-salida y xxxxxxxxxxx es la matriz de covarianza:
r
xy.= E(xy)
⌃x
.= E(xxT )
(4)(5)
⌃x
=
2
6664
E[x1x1] · · · E[x1xD]E[x2x1] · · · E[x2x1]
.... . .
...E[xDx1] · · · E[xDxD]
3
7775yrxy =
2
6664
E[x1y]E[x2y]
...E[xDy]
3
7775

5
Error cuadrático medio
w = Σx−1rxy (6)
• Entonces, resolviendo para w se tiene:
• Nótese que los pesos del estimador lineal óptimo son obtenidos mediante un sistema de ecuaciones lineales si se provee una matriz de covarianza definida positiva la cual es invertible.
• El método MSE asume que las muestras de entrenamiento poseen distribución normal.
• Además, si la distribución de los datos es normal, es preferible usar un clasificador Bayesiano, de modo que se perdería el sentido de usar un clasificador lineal.
• S in embargo, se desea encontrar resultados similares sin tener que estimar medias y covarianzas, de modo que el método MSE deriva en el método error de suma de cuadrados (SSE).

Error de suma de cuadrados• En el método SSE el vector de pesos y el vector de características
han sido aumentados: w=[w0,w1,…,wD]T y x=[1,x1,…,xD]T.
• Para el caso de dos clases, los patrones de entrenamiento son (yi,xi), para i=1,…,N y xxxxxxxxxxxx.
• La función de costo SSE es:
6
J(w) = (yi− wTx
i)2
i=1
N
∑ (7)
de modo que se tiene que encontrar un vector de pesos w que minimice la distancia Euclidiana cuadrada entre la salida del clasificador lineal, wTx, y la salida deseada, y:
w = argminwJ(w) (8)
yi 2 {−1,+1}

• Minimizando la función de costo en (7) se tiene:
7
Error de suma de cuadrados
∇J(w) = ∇ (yi− wTx
i)(y
i− x
iTw)
i=1
N
∑⎧⎨⎩
⎫⎬⎭
= ∇ yi2
i=1
N
∑ − 2wT xiyi
i=1
N
∑ + wT xixiT
i=1
N
∑⎛⎝⎜
⎞⎠⎟w
⎧⎨⎪
⎩⎪
⎫⎬⎪
⎭⎪
= −2 xiyi
i=1
N
∑ + 2 xixiT
i=1
N
∑⎛⎝⎜
⎞⎠⎟w = 0
(9)
(10)
(11)
∇J(w) = −2XyT + 2XXTw = 0
• Expresando (11) en forma matricial:
(12)
donde
X = [x1,…,x
N] y y = [y
1,…,y
N].

8
Error de suma de cuadrados
w = (XXT )−1XyT
= X +yT(13)
• Entonces, resolviendo para w se tiene:
(14)
donde la matriz de tamaño (D+1)×N
X + = (XXT )−1X (15)
se le conoce como la pseudoinversa de X. Si X es cuadrada y no singular, la pseudoinversa coincide con la inversa regular.
• Existirá siempre una solución de mínimo SSE si X+ se define de manera más general como:
X + ≡ limδ→0(XXT + δI )−1X (16)
donde dI es un término de regularización.I

9
Error de suma de cuadrados
ω1 :12
⎛⎝⎜
⎞⎠⎟,20
⎛⎝⎜
⎞⎠⎟
, ω 2 :31⎛⎝⎜
⎞⎠⎟,23
⎛⎝⎜
⎞⎠⎟
XT =
1 1 21 2 01 3 11 2 3
⎛
⎝
⎜⎜⎜⎜
⎞
⎠
⎟⎟⎟⎟
, yT =
+1+1−1−1
⎛
⎝
⎜⎜⎜⎜
⎞
⎠
⎟⎟⎟⎟
• Supóngase que se tienen los siguientes puntos en dos dimensiones para dos clases:
• La pseudoinversa de X es:
X + =5 4 13 12 −3 4 −7 12−1 2 −1 6 1 2 1 6
0 −1 3 0 −1 3
⎛
⎝
⎜⎜⎜
⎞
⎠
⎟⎟⎟
• El vector de pesos es:
w = X +yT =11 3
−4 3−2 3
⎛
⎝
⎜⎜⎜
⎞
⎠
⎟⎟⎟
x1
x2
R1
R2
wTx = 0

10
Error de suma de cuadrados• El principal problema del método SSE es su sensibilidad a
patrones extremos (outliers).
• El hiperplano de decisión es atraído hacia los outliers, ya que también reduce la distancia a esos puntos. Esto generará errores de clasificación, aún cuando las clases sean linealmente separables.
x1
x2
x2
x1
outlier

Método LMS• La función de costo SSE J(w)=||y−wTX||2 puede minimizarse mediante
un procedimiento de descenso de gradiente.
• Ventajas con respecto al método de la pseudoinversa: 1) evita problemas que surgen cuando XXT es singular y 2) evita trabajar con matrices muy grandes.
• Debido a que ∇J(w)=−2(y−wTX)X y considerando las muestras de manera secuencial, la regla de actualización de Widrow-Hoff es:
11
w(1) arbitrario
w(k + 1) = w(k)+ η(k)(y(k)− wT(k)xk )xk k ≥ 1 (17)
• Este algoritmo es similar al criterio de relajación del perceptrón, donde y(k) es el margen. La diferencia es que el perceptrón corrige el error de clasificación y en el caso de LMS la función wTxk nunca será igual a y; por tanto, la corrección nunca terminará.
• Para que exista convergencia, η(k) debe disminuir en función de k, donde una forma común es η(k)=η(1)/k.

12
Método LMSAlgoritmo LMS (least-mean-squared) o Widrow-Hoff
Begin initialize: w, umbral θ, η(·), k←0do k←(k+1)modN
w←w + η(k)(yk − wTxk)xk
until |η(k)(yk − wTxk)xk |<θreturn w
end
x1
x2
Solución LMS
Hiperplano de separación
De manera similar que en el entrenamiento del perceptrón, los patrones de la clase ω2 son “normalizados”; por tanto, las etiquetas de ambas clases son iguales tal que yi=1, para i=1,…,N.
Nótese que el algoritmo LMS no converge al hiperplano de separación, aún si las clases son linealmente separables. Esto se debe a que la solución LMS minimiza la suma de los cuadrados de las distancias de los patrones de entrenamiento al hiperplano.

Método de Ho-Kashyap• El método LMS puede modificarse para obtener un vector de
pesos w y un margen y tal que wTX=y>0.
• Si se define una función de costo SSE que permita variar w y y como:
13
J(y,w) = y − wTX2 (18)
entonces el mínimo valor de J es cero y el vector w que alcanza el mínimo es un vector de separación.
• Derivando J con respecto de w y y:
∇wJ(y,w) = −2(y − wTX)X
∇yJ(y,w) = 2(y − wTX)
y para cualquier valor de y siempre se toma:
w = X +yT
(19)
(20)
(21)

• A partir de (20) y (21) se obtiene la regla de Ho-Kashyap para minimizar J(y,w):
14
Método de Ho-Kashyap
y(1) > 0w(1) = X +y(1)T
y(k + 1) = y(k)+ η(e(k)+ e(k))
w(k + 1) = w(k)+ ηX + e(k)T
(22)
donde e(k) es un vector de error definido como:
e(k) = w(k)TX − y(k) (23)
• La regla de Ho-Kashyap garantiza un hiperplano de separación en el caso separable, aunque para el caso no separable se puede establecer una condición de paro como:
w(k − 1)− w(k) < θ (24)donde denota norma L2 y θ es un umbral. ⋅

15
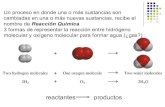
Método de Ho-Kashyap
x1 x
1
x2
x2
Caso separable Caso no separable Con outliers
x2
x1
Algoritmo de Ho-Kashyap
Begin initialize: w, y, umbral θ, η<1do
e←wTX − y y←y + η(e + abs(e)) w←w + ηX+abs(e)T
until ||w(k−1)−w(k)||<θreturn w
end
De manera similar que en el entrenamiento del perceptrón, los patrones de la clase ω2 son “normalizados”; por tanto, las etiquetas de ambas clases son iguales tal que yi=1, para i=1,…,N.