
ANALISIS ESTADISTICO DE DATOS CUANTITATIVOS · PDF fileAnálisis de Datos Cuantitativos...
21
ANALISIS ESTADISTICO DE DATOS CUANTITATIVOS Jose Tessler y Carlos Tajer En los capítulos previos hemos descrito aspectos conceptuales del análisis comparativo de datos cualitativos. Veremos que para la comparación de datos cuantitativos podemos extender el mismo armazón conceptual. Partamos de un ejemplo sencillo. La presión arterial de un grupo de 200 adultos es en promedio 135 ± 10. Dividiendo al grupo en obesos (OB) y no obesos (NoOB), (100 y 100 respectivamente) observamos que la presión arterial es 140±11 y 130±11 respectivamente. La hipótesis de nulidad que exploraremos en el análisis estadístico será que no existen diferencias en la presión arterial entre los obesos y no obesos. Es decir, la tensión arterial en OB=NoOB o lo que es igual: OB-NoOB=0 Si rechazamos la hipótesis de nulidad, aceptaremos la hipótesis alternativa: la presión arterial es diferente en obesos y no obesos. En este caso se trata de un factor de asociación, pero el mismo concepto se aplica a un eventual tratamiento. Para la comparación de datos cualitativos, partíamos de la fórmula: %A-%B /error standard. Es decir, evaluábamos a que distancia en términos de errores estándar de esa distribución se encontraba el % en A vs. el % en B. Ese valor se expresaba como Z, es decir, y proyectando a la distribución de Gauss podíamos asumir que probabilidad tenía esa diferencia de ser atribuible al azar. Por convención, se ha establecido que si la Z es superior a 1,96, lo que es lo mismo, si la p es < 0,05, se rechaza la hipótesis de nulidad. Para la comparación de datos cuantitativos razonamos de la misma manera, con la diferencia que restaremos las medias y las dividiremos por el error estándar del parámetro medido. (media A – Media B)/ error estándar del parámetro medido. Xa Xb t ES - = Esto nos dará un valor de Z o t, con las misma significación que en el ejemplo anterior. Esta explicación es básica, pero aporta los fundamentos para la comprensión de la estrategia de análisis estadístico: siempre compararemos medias entre dos o más grupos, y estandarizaremos la diferencia entre las medias por un parámetro de dispersión de los datos, como el error estándar y otros conceptos en diferentes modelos de análisis. Distribución de los datos y selección de métodos estadísticos En el capítulo de estadística descriptiva de datos cuantitativos, referimos que algunos datos pueden tener distribución gaussiana, es decir, que con la
Transcript of ANALISIS ESTADISTICO DE DATOS CUANTITATIVOS · PDF fileAnálisis de Datos Cuantitativos...

ANALISIS ESTADISTICO DE DATOS CUANTITATIVOS Jose Tessler y Carlos Tajer
En los capítulos previos hemos descrito aspectos conceptuales del análisis comparativo de datos cualitativos. Veremos que para la comparación de datos cuantitativos podemos extender el mismo armazón conceptual.
Partamos de un ejemplo sencillo. La presión arterial de un grupo de 200 adultos es en promedio 135 ± 10. Dividiendo al grupo en obesos (OB) y no obesos (NoOB), (100 y 100 respectivamente) observamos que la presión arterial es 140±11 y 130±11 respectivamente.
La hipótesis de nulidad que exploraremos en el análisis estadístico será que no existen diferencias en la presión arterial entre los obesos y no obesos. Es decir, la tensión arterial en OB=NoOB o lo que es igual: OB-NoOB=0 Si rechazamos la hipótesis de nulidad, aceptaremos la hipótesis alternativa: la presión arterial es diferente en obesos y no obesos. En este caso se trata de un factor de asociación, pero el mismo concepto se aplica a un eventual tratamiento.
Para la comparación de datos cualitativos, partíamos de la fórmula: %A-%B /error standard.
Es decir, evaluábamos a que distancia en términos de errores estándar de esa distribución se encontraba el % en A vs. el % en B. Ese valor se expresaba como Z, es decir, y proyectando a la distribución de Gauss podíamos asumir que probabilidad tenía esa diferencia de ser atribuible al azar. Por convención, se ha establecido que si la Z es superior a 1,96, lo que es lo mismo, si la p es < 0,05, se rechaza la hipótesis de nulidad.
Para la comparación de datos cuantitativos razonamos de la misma manera, con la diferencia que restaremos las medias y las dividiremos por el error estándar del parámetro medido.
(media A – Media B)/ error estándar del parámetro medido.
Xa Xbt
ES
−=
Esto nos dará un valor de Z o t, con las misma significación que en el ejemplo anterior.
Esta explicación es básica, pero aporta los fundamentos para la comprensión de la estrategia de análisis estadístico: siempre compararemos medias entre dos o más grupos, y estandarizaremos la diferencia entre las medias por un parámetro de dispersión de los datos, como el error estándar y otros conceptos en diferentes modelos de análisis.
Distribución de los datos y selección de métodos estadísticos
En el capítulo de estadística descriptiva de datos cuantitativos, referimos que algunos datos pueden tener distribución gaussiana, es decir, que con la

Análisis de Datos Cuantitativos – Hoja 2
media y el desvío estándar podemos tener una idea muy acabada de la distribución de los datos en la población. En estos casos la comparación será más sencilla, con métodos estadísticos más poderosos, denominados métodos paramétricos.
Otra distribución posible es la logarítmica normal. Cuando los datos tienen moda a la izquierda (muchos datos con valores bajos y pocos con valores altos) no son gaussianos. Podemos intentar la transformación logarítmica y evaluar si la distribución del dato logarítmico resulta gaussiano. En ese caso denominaremos al dato “logarítmico normal” y la estadística que se aplicará será similar que para los datos gaussianos.
Cuando los datos no tienen distribución gaussiana o son puntajes, aplicaremos otros métodos estadísticos denominados no paramétricos.
De tal manera que antes de encarar el análisis estadístico de datos cuantitativos es necesario establecer si los datos numéricos tienen o no una distribución gaussiana, o si se trata de escores o puntajes.
En la primera parte expondremos las metodologías para determinar si la distribución de los datos es gaussiana o no, y luego la selección de pruebas para datos gaussianos y no gaussianos
PRUEBAS DE DISTRIBUCIÓN GAUSSIANA
CRITERIOS APROXIMADOS
El primer paso para comenzar un análisis de datos cuantitativos es establecer para cada parámetro si tiene o no distribución gaussiana. De acuerdo a eso y el número de grupos a comparar se seleccionan los métodos estadísticos correspondientes.
Comenzamos por rever los expuesto en el capítulo de estadística descriptiva de datos cuantitativos:
� ¿La distribución es aproximadamente simétrica? Un histograma nos una idea de este aspecto. Algunos software permiten superponer una curva de Gauss al histograma.
Si la distribución no es aproximadamente simétrica rechazamos distribución gaussiana.
� ¿Media, mediana y moda son aproximadamente iguales? Si la respuesta es NO, rechazamos distribución de Gauss. Recordemos que carece de sentido calcular la moda si los datos no están agrupados.
� ¿El IC95% de la población (calculado como media ± 1,96*DS) coincide aproximadamente con los percentilos 2,5 y 97,5? Si la respuesta es NO, rechazamos distribución gaussiana. Tener presente que nos referimos al

Análisis de Datos Cuantitativos – Hoja 3
IC95 (intervalo de confianza para la población) y no al IC95(µ) (intervalo de confianza para la media que es igual a media ± Error estándar).
PRUEBAS ESTADÍSTICAS PARA DISTRIBUCIÓN
Los programas estadísticos aportan diferentes métodos para evaluar si la distribución es gaussiana o no: los tres más comunes son el test de asimetría, curtosis y bondad de ajuste. Basta con rechazar la hipótesis nula (H0) en una de ellas para rechazar que la distribución es gaussiana.
Asimetría
La distribución de Gauss es simétrica. Por lo tanto la asimetría debe valer cero. Existe un test para probar la H0: asimetría = 0. En inglés a la asimetría se la denomina skewness.
Una asimetría significativamente menor de 0 indica una distribución asimétrica con moda a la izquierda. Una asimetría significativamente mayor de 0 indica una distribución asimétrica con moda a la derecha.
Curtosis
No basta con que una distribución sea simétrica para que sea gaussiana. La distribución de Student es simétrica, pero difiere de la de Gauss (salvo cuando N = ∞) en que es más ancha.
La curtosis es una medida del ancho de la curva de Gauss. En la distribución de Gauss la curtosis vale 3 y existe una prueba para probar H0: curtosis = 3. En inglés curtosis se escribe con k (kurtosis).
Una curtosis menor de 3 indica una curva más estrecha que la de Gauss y una curtosis mayor de 3 indica una curva más ancha que la de Gauss. La distribución de Student es un ejemplo de distribución simétrica con curtosis mayor de 3.
Varios software (como el Statistix®) calculan la curtosis restándole 3, por lo que es necesario sumar 3 al resultado de esos software.
Bondad de ajuste
Como vimos en el capítulo 5, a µ ± 1 σ corresponde el 68,27 % del área bajo la curva de Gauss; a µ ± 2 σ corresponde el 95,5 % (a µ ± 1,96 σ corresponde el 95 %), etc. Utilizando estos porcentajes como esperados, es posible efectuar una prueba de bondad de ajuste (goodness of fit) para probar H0: la distribución de los datos observados es igual a la esperada de acuerdo a la distribución de Gauss.
Son pocos los software que hacen esta prueba que, por otra parte, casi nunca es necesaria si se han efectuado las dos anteriores.
Curvas asimétricas con moda a la izquierda

Análisis de Datos Cuantitativos – Hoja 4
En este caso podemos probar transformar a los datos en sus logaritmos (). Si los logaritmos tienen una distribución gaussiana, entonces decimos que la distribución es log-normal (logarítmica normal). En este caso pueden aplicarse las pruebas para datos gaussianos, pero aplicadas a los logaritmos, NO a los datos.
Estudios con gran número de pacientes
En estos casos el poder para rechazar distribución gaussiana es muy alto y es factible que hallemos que ninguna variable tiene distribución gaussiana. Por este motivo, si no rechazamos distribución de Gauss con los criterios aproximados indicados y en la literatura se utilizan pruebas para datos gaussianos, podemos utilizar estas pruebas.
Estudios con pequeño número de pacientes
Las pruebas de distribución gaussiana tienen bajo poder si el tamaño de la muestra es pequeño (digamos N < 100). En este caso conviene fijarse qué pruebas estadísticas se utilizan en la literatura para evaluar la variable en estudio. Si las pruebas que se utilizan son las que veremos más abajo para datos gaussianos, consideramos a nuestra variable como gaussiana. Si, en cambio, utilizan las pruebas que veremos para datos no gaussianos, consideramos a nuestra variable como no gaussiana.
En caso de duda:
Por los motivos que explicaremos más adelante, si no podemos decidir si los datos pueden ser considerados gaussianos o no, debemos considerarlos como no gaussianos.
PRUEBAS ESTADÍSTICAS PARA DATOS GAUSSIANOS
Vamos a indicar primero los criterios para elegir las pruebas (figura 1) y luego nos referiremos muy someramente a cada una de ellas. Seguiremos el flujograma de la figura:
a) En los datos cuantitativos debemos tener en cuenta si son continuos o no. Si la respuesta es NO aplicaremos estadística para datos no gaussianos (ver más adelante).
b) Si la respuesta en “a” fue SÍ, debemos verificar si los datos son gaussianos o no . Si la respuesta es NO, pasamos a la tercera parte de este capítulo.
c) Si los datos son gaussianos, debemos tener en cuenta si son apareados (propio individuo como control) o no (grupos paralelos) .

Análisis de Datos Cuantitativos – Hoja 5
d) Para los diseños de grupos paralelos elegiremos la prueba de Student si
son 2 grupos o el análisis de variancia (ANOVA ó AOV de acuerdo al programa estadístico) de 1 vía si son más de dos.
e) Para los diseños apareados debemos tener en cuenta si son dos o más de dos . Para 2 datos apareados no cruzados utilizamos la prueba de Student apareada y para más de dos (ó 2 en un diseño cruzado) diversos análisis de la varianza (ANOVA), con múltiples nomenclaturas, que dependen del diseño.
STUDENTAPAREADO
STUDENT
2
>2
NO
SI
SI
SI NO
NO(PUNTAJES)
>2
ANOVA 1 VIA
OTROS
BLOQUESAL AZAR
ANOVAMED REP
CRUZADO ENBLOQUE 2 x 2
2
OTROS ANOVA
CONTINUOS
GRUPOS
GAUSS
APAREADO
ANOVAGRIZZLE
DISEÑO
TRATA-MIENTOS
CUANTITATIVOSDATOS
Figura 1: Pruebas estadísticas para datos gaussianos. ANOVA: análisis de variancia.MED REP: mediciones repetidas.
El ANOVA de Grizzle fue ubicado junto a los otros ANOVA aunque se aplica a 2 datos por individuo.
GRUPOS PARALELOS
Prueba de Student
La prueba de Student prueba la hipótesis de que los dos grupos provienen de poblaciones con medias iguales. Es decir, H0: µµµµ1 = µµµµ2. Si p ≤ α entonces

Análisis de Datos Cuantitativos – Hoja 6
rechazamos la hipótesis nula y decimos que las diferencias son estadísticamente significativas. Por ejemplo, si α = 0,05, cuando p ≤ 0,05 decimos que las diferencias son estadísticamente significativas.
La prueba de Student utiliza la distribución de t. La distribución de t es similar a la gaussiana o de Z cuando el número de pacientes o muestras es numeroso, mayor de 100, y es un poco más ancha cuando los datos son menores de 100. De tal manera que la p < 0,05 estará a 1,96 errores estándar de la distribución de Z o t cuando los datos son numerosos, y para grupos pequeños la t podrá ser incluso 2 o más, siendo su significación estadística dependiente del número de casos. Tradicionalmente esto se buscaba en tablas de valores de t y grados de libertad, pero actualmente todos los programas estadísticos aportan el valor de t y la p de significación.
El test de T asume que no sólo los datos tienen distribución gaussiana, sino que la dispersión de los datos en los grupos que se compararán será aproximadamente similar. En otros términos, que su desvío estándar es similar. En el caso que no lo sea, se corrige el resultado para desvíos estándar desiguales. La similitud de los desvíos estándar se denomina homoscedasticidad y los programas estadísticos habituales informan algún test que la establece (por ejemplo en el epi2000 el test de Barlett) y el valor de p para el caso que se acepte o rechace. Ver ejemplo al final del capítulo.
Análisis de variancia o varianza
Los conceptos del análisis de la varianza son un tanto complejos, e intentaremos aquí sólo una aproximación conceptual. En el CD en el capítulo extendido de análisis de datos cuantitativos se extiende más la explicación matemática.
Cuando analizamos dos grupos, el test de T resume en forma sencilla nuestro objetivo: medimos la distancia entre las dos medias y la estimamos en términos de errores estándar, obteniendo el valor de t o Z y así la significación estadística. Cuanto analizamos tres o más grupos, esto no es posible, dado que existirían múltiples comparaciones.
La primera pregunta, al incluir análisis de tres o más grupos será si existe diferencia entre ellos, y luego analizaremos entre qué grupos existe diferencia.
Partiremos de un análisis sencillo para fundamentar el concepto de análisis de la varianza:
Tenemos 10 pacientes en los cuales se evaluó la glucemia en ayunas divididos en tres grupos: 1-2 y 3. Nos interesa saber si la glucemia es similar en los tres grupos, o existen diferencias entre ellos. Como son más de dos grupos, no podemos aplicar un test de T, haremos un ANOVA.

Análisis de Datos Cuantitativos – Hoja 7
tres de los cuales son diabéticos tratados, tres normales y cuatro diabéticos no tratados.
Tabla 1: valores de glucemia en cada individuo y cálculo de la variación respecto al promedio poblacional.
Paciente Grupo Glucemia en mg/dl
Promedio Diferencia Diferencia al cuadrado
1 1 145 146,4 -1,4 1,96
2 2 69 146,4 -77,4 5990,76
3 2 76 146,4 -70,4 4956,16
4 2 80 146,4 -66,4 4408,96
5 3 210 146,4 63,6 4044,96
6 1 120 146,4 -26,4 696,96
7 3 240 146,4 93,6 8760,96
8 1 167 146,4 20,6 424,36
9 1 97 146,4 -49,4 2440,36
10 3 260 146,4 113,6 12904,96
Promedio 146,4 44630,4
Calculamos el promedio, que resulta 146,4 mg/dl y nos interesa conocer la dispersión de los datos respecto de la media. El procedimiento es similar al que efectuamos para calcular el desvío estándar. En primera instancia restamos cada dato individual del promedio, y lo elevamos al cuadrado. Hacemos luego la sumatoria de ese cálculo, que llamamos variación total o suma de cuadrados. Si lo dividiéramos por n-1 tendríamos la varianza y con la raíz cuadrada el desvío estándar. Por el momento nos interesa sólo la variación total o suma de cuadrados, que en este caso es 44630. Tabla 1.
El siguiente paso del análisis de la varianza es calcular el promedio de cada uno de los grupos, y establecer luego la variación que aporta reemplazar cada dato individual por el promedio de su grupo. El grupo 1 tuvo un promedio de 132,5, el promedio del grupo 2 fue 75 mg/dl y el del grupo 3 resultó 236,67.
En la tabla 2 reemplazamos a cada paciente por el promedio de su grupo, y repetimos el cálculo de la diferencia con el promedio poblacional, lo
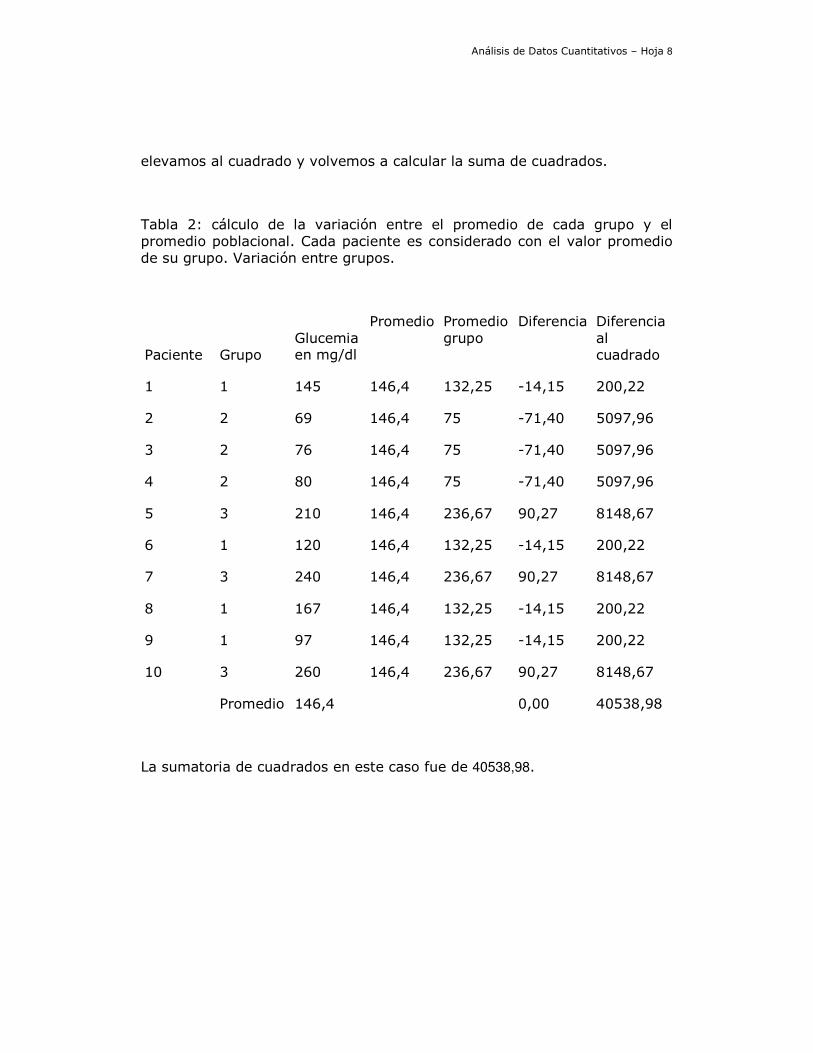
Análisis de Datos Cuantitativos – Hoja 8
elevamos al cuadrado y volvemos a calcular la suma de cuadrados.
Tabla 2: cálculo de la variación entre el promedio de cada grupo y el promedio poblacional. Cada paciente es considerado con el valor promedio de su grupo. Variación entre grupos.
Paciente Grupo Glucemia en mg/dl
Promedio Promedio grupo
Diferencia Diferencia al cuadrado
1 1 145 146,4 132,25 -14,15 200,22
2 2 69 146,4 75 -71,40 5097,96
3 2 76 146,4 75 -71,40 5097,96
4 2 80 146,4 75 -71,40 5097,96
5 3 210 146,4 236,67 90,27 8148,67
6 1 120 146,4 132,25 -14,15 200,22
7 3 240 146,4 236,67 90,27 8148,67
8 1 167 146,4 132,25 -14,15 200,22
9 1 97 146,4 132,25 -14,15 200,22
10 3 260 146,4 236,67 90,27 8148,67
Promedio 146,4 0,00 40538,98
La sumatoria de cuadrados en este caso fue de 40538,98.

Análisis de Datos Cuantitativos – Hoja 9
4091,42
40538,98
otra entre grupos
Figura 3: componentes de la variación total o suma de cuadrados. Entre grupos, de acuerdo a tabla 2.
A esta variación, obtenida al reemplazar a cada paciente por el promedio de su grupo, la denominamos sumatoria de cuadrados “entre grupos”, INTERGRUPAL. En este caso abarca la mayor parte de la torta de la variación total, que era 40540. Nos queda un valor de variación de 4091,42 en forma residual.
Segundo paso
Tomemos el paciente 7, con una glucemia de 240, que pertenece al grupo 3. Este paciente individualmente aportó a la suma de cuadrados 8760,98. Al reemplazar su valor por el promedio de su grupo, 236,5, aporta a la suma de cuadrados 8147. Podemos calcular el otro componente de la variación, comparando la glucemia del paciente con la media de su grupo: en este caso 240-236,67 = 3,33. Si lo elevamos al cuadrado resulta 11,08.
En la tabla 3 repetimos este cálculo para cada uno de los pacientes, es decir, calculamos la diferencia entre cada valor inidividual y el promedio de su grupo.
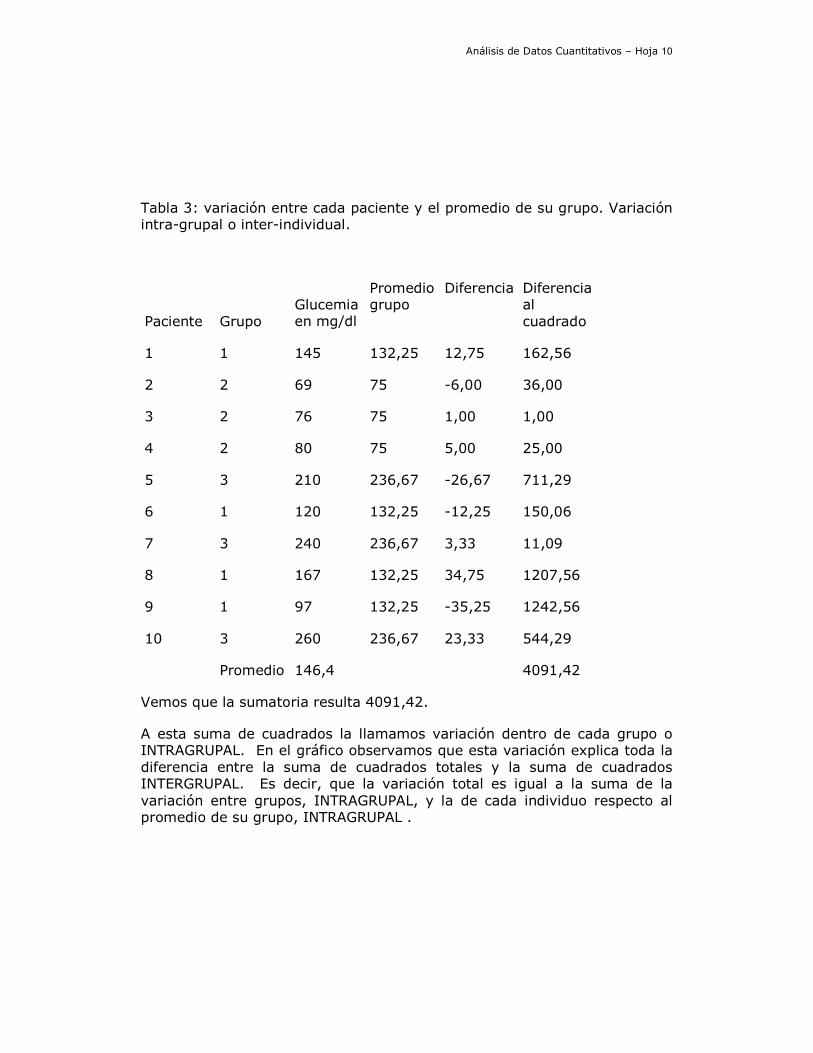
Análisis de Datos Cuantitativos – Hoja 10
Tabla 3: variación entre cada paciente y el promedio de su grupo. Variación intra-grupal o inter-individual.
Paciente Grupo Glucemia en mg/dl
Promedio grupo
Diferencia Diferencia al cuadrado
1 1 145 132,25 12,75 162,56
2 2 69 75 -6,00 36,00
3 2 76 75 1,00 1,00
4 2 80 75 5,00 25,00
5 3 210 236,67 -26,67 711,29
6 1 120 132,25 -12,25 150,06
7 3 240 236,67 3,33 11,09
8 1 167 132,25 34,75 1207,56
9 1 97 132,25 -35,25 1242,56
10 3 260 236,67 23,33 544,29
Promedio 146,4 4091,42
Vemos que la sumatoria resulta 4091,42.
A esta suma de cuadrados la llamamos variación dentro de cada grupo o INTRAGRUPAL. En el gráfico observamos que esta variación explica toda la diferencia entre la suma de cuadrados totales y la suma de cuadrados INTERGRUPAL. Es decir, que la variación total es igual a la suma de la variación entre grupos, INTRAGRUPAL, y la de cada individuo respecto al promedio de su grupo, INTRAGRUPAL .

Análisis de Datos Cuantitativos – Hoja 11
Figura 4: Componentes de la variación total. Entre grupos (intergrupal) y dentro de los grupos (intragrupal)
El procedimiento que hemos seguido ha consistido en descomponer la variación que cada paciente aporta respecto del promedio poblacional en dos componentes, en este caso su pertenencia a un determinado grupo y la diferencia entre cada individuo y el promedio de su grupo. Con el mismo razonamiento podemos analizar otros modelos estadísticos, descomponiendo la variación total en diferentes componentes.
Análisis formal de la varianza
El análisis estadístico en el test de T puede contestar la pregunta: a cuantos errores estándar de la distribución de T se encuentra la diferencia entre el promedio de los grupos.
En el caso del análisis de la varianza, estableceremos a cuántas varianzas intragrupales promedio se encuentra la varianza intergrupal. Es decir, compararemos la varianza por pertenecer a un grupo en términos de la dispersión de los datos respecto del promedio de cada grupo. Cuanta mayor sea la diferencia aportada por los promedios de los grupos y menor la varianza intragrupal, mayor posibilidad de diferencia significativa.
Para calcular la varianza promedio necesitamos dividir cada varianza por n-1. En el caso de la intergrupal, resulta
Variación intergrupal / ngrupos -1 = 40540,79/2 =20270,39
La varianza intragrupal promedio se calcula como
4091,42
40538,98
dentro de los gruposentre grupos

Análisis de Datos Cuantitativos – Hoja 12
Varianza intragrupal / (pacientes – n grupos) = 4091,42 /(10-3) = 584,4881
Procedemos ahora al cálculo final
Varianza intergrupal / varianza intragrupal = 20270,39/548,49= 34,68
El cociente entre dos varianzas nos aporta un valor estadístico denominado F. Si analizáramos sólo dos grupos, el valor de F es igual a elevar al cuadrado el valor de T. La significación estadística surge de la distribución de F, pero los programas estadísticos lo aportan automáticamente.
En la tabla 4 copiamos el ANOVA del ejemplo previo calculado por el programa EPI2000. SS es sumatoria de cuadrados (square), df grados de libertad, MS es la media de las sumatorias, between indica entre grupos y within dentro de los grupos.
Tabla 4: cálculo del ANOVA en EPI2000
Resumiendo: el análisis de la varianza descompone la variación aportada entre cada dato y el promedio general y diferentes componentes. Conceptualmente sigue el mismo razonamiento que la comparación a través del test de T: a mayor distancia entre los promedios y menor dispersión, es más posible que la diferencia no se deba al azar.
Pruebas post-hoc
El ANOVA evalúa al conjunto de los grupos, pero si se rechaza H0 seguimos sin saber entre qué grupos hay diferencias estadísticamente significativas y entre cuáles no. Para ello se utilizan diversas pruebas denominadas pruebas post-hoc (pues se realizan sólo si se rechaza H0), pruebas de comparaciones múltiples o pruebas de comparación entre medias. Las 3 denominaciones son sinónimos.
Todas estas pruebas efectúan las comparaciones de a pares de manera tal que el error α total no sea mayor de 0,05. En la práctica ello implica que
ANOVA
(For normally distributed data only)
Variation SS df MS F statistic p-value
Between 40538.983 2 20269.492 34.679 0.000519
Within 4091.417 7 584.488
Total 44630.400 9

Análisis de Datos Cuantitativos – Hoja 13
cuanto mayor sea el número de comparaciones a efectuar, mayor debe ser la diferencia entre dos medias para que sean significativas.
La prueba de Bonferroni es muy popular pero tiene como defecto sobrecorregir, por lo que se dice que es muy conservadora. El principio del criterio de Bonferroni es dividir α por el número de comparaciones. Así, si α = 0,05 y se efectuarán 3 comparaciones, se considera significativo a p ≤ 0,05 / 3 = 0,0167. Si en el ANOVA se rechaza H0 con un valor de p cercano a 0,05 es factible que con la prueba de Bonferroni no se encuentre ninguna diferencia significativa.
Copiamos aquí un análisis de Bonferroni del programa statistix, que corresponde al ejemplo del final del capítulo. Tabla 5. Nos indica en este caso que la tensión sistólica, que había sido diferente globalmente de acuerdo a los tercilos de peso en el ANOVA, es diferente entre los tres grupos (grupeso 1-2-3).
Tabla 5: Análisis de Bonferroni. Comparación de las medias de tensión arterial sistólica (TAS1) en tres grupos determinados por los tercilos de peso. El grupo 3 es el de mayor peso.
HOMOGENEOUS
GRUPESO MEAN GROUPS
--------- ---------- -----------
3 113.29 I
2 105.64 .. I
1 102.59 .... I
La prueba de Tukey y la prueba de Scheffe son menos conservadoras y más convenientes. Tukey llamó a la suya, modestamente, "Honest Significative Difference".
Hay numerosas otras pruebas que pueden utilizarse con el mismo propósito. Cuando p ≅ 0,05, es factible que con una prueba sea p ≤ 0,05 y con otra p > 0,05. Por este motivo se debe tener la honestidad de decidir qué prueba de comparaciones múltiples se utilizará antes de comenzar el análisis estadístico. Es deshonesto realizar varias pruebas y utilizar aquella que más convenga a la hipótesis experimental. PRUEBAS PARA DATOS APAREADOS
Prueba de Student apareada
Aplicaciones
La prueba de Student apareada puede aplicarse en todos los casos de dos

Análisis de Datos Cuantitativos – Hoja 14
datos en un mismo individuo, en los que el orden de los tratamientos no constituya una variable a tener en cuenta. Por ejemplo:
� Antes y después de un único tratamiento.
� En el momento de la internación y a las 6 horas.
� Al nacimiento y a las 48 horas.
� Etcétera.
Si se efectúan dos tratamientos en un mismo individuo, el orden de los mismos puede influir en los resultados. Por este motivo en estos casos es necesario utilizar alguna prueba estadística que permita evaluar la influencia del orden de los tratamientos.
Prueba de Student apareada
Supongamos que efectuamos el dosaje de una variable bioquímica en neonatos inmediatamente después del parto y a las 48 horas de vida. Supongamos también que esa variable es gaussiana. La hipótesis de nulidad es que la diferencia entre los dos momentos es nula. Expresada en denominación estadística, la prueba de Student apareada prueba la hipótesis H0: δδδδ = 0, donde δ es la media de las diferencias entre los valores obtenidos en los dos momentos en la población, para lo cual efectúa las diferencias (DIF = valor a las 48 horas menos valor al nacimiento) y calcula
DIF DIFt X /ES= . Como vemos, toma en cuenta solamente las diferencias y no los valores de cada momento por separado. Como se trabaja con un único grupo de pacientes, los grados de libertad son N – 1.

Análisis de Datos Cuantitativos – Hoja 15
PRUEBAS PARA DATOS CUANTITATIVOS NO NUMÉRICOS Y NUMÉRICOS NO GAUSSIANOS
Ordinales (ranks)
En la figura 6 mostramos los resultados de 2 grupos : A (N = 7) y B (N = 5). Con estos valores podemos calcular media y DS o ES y efectuar pruebas estadísticas referidas a µ y σ2 (los parámetros de la distribución de Gauss), motivo por el cual se habla de estadística paramétrica .
12
11
4
1
9
5
100
79
39
11
76
40
44 6
7
2
8
3
64
21
71
38
77 10
GRUPO A GRUPO B
VALORES
Estadística no paramétrica
MEDIA YDS o ES
Estadísticaparamétrica
ORDINALES(RANKS)
Figura 5. Concepto de ordinales y de pruebas paramétricas y no paramétricas.
Ahora, buscamos al más pequeño de los 12 valores (el 11) y le adjudicamos el número 1. Al valor que le sigue en orden creciente (el 21) le adjudicamos el número 2. Al que sigue a éste (el 38) le adjudicamos el número 3, y así sucesivamente . Es decir, hemos transformados a los números en ordinales (ranks en inglés). Obsérvese que si en lugar de 11 tuviéramos cualquier número entre 0 y 20, igualmente tendría como ordinal el 1 y que si en lugar de 44 hubiera cualquier número entre 41 y 63, igualmente su ordinal sería el 6. Es decir, los ordinales sólo toman en cuenta el orden de los datos, no su valor numérico. La estadística que utiliza estos ordinales se denomina estadística no paramétrica .
Si los dos grupos tiene un promedio de orden similar, no existirá diferencias significativas. Si por el contrario los valores de un grupo se concentran en

Análisis de Datos Cuantitativos – Hoja 16
los órdenes mayores y del otro grupo en los menores, es posible que existan diferencias significativas.
Por ese motivo es que esta estadística es denominada también de ordinales, y en inglés los métodos llevan el agregado de la palabra Rank.
Esta estadística se aplica a:
� Datos numéricos no gaussianos.
� Datos cuantitativos no numéricos (puntajes).
� Existencia de outliers (datos extremos), especialmente si las muestras son pequeñas. (Ejemplo: si tenemos los datos 2, 3, 4, 5, 6 y 21, el 21 es un outlier).
En inglés a la estadística no paramétrica se la denomina non-parametric statistics o rank-statistics.
Pruebas no paramétricas
Estas pruebas no requieren una distribución determinada. Por este motivo pueden aplicarse tanto a distribuciones gaussianas (perdiendo algo de poder) como a las no gaussianas. En cambio, la estadística paramétrica solamente debe utilizarse cuando los datos son gaussianos. Por este motivo decíamos al comienzo del capítulo que en caso de duda los datos deben ser considerados no gaussianos.
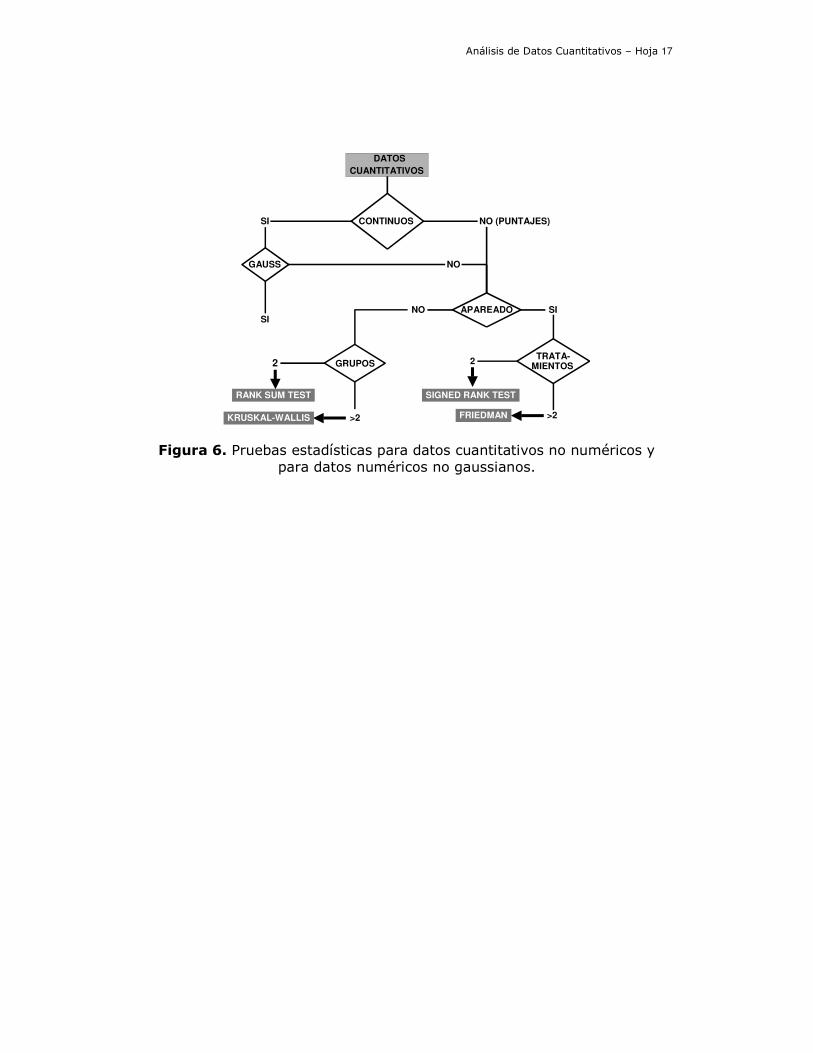
Seguiremos el flujograma de la figura 6:
f) Cuando tenemos datos cuantitativos debemos tener en cuenta si son continuos o puntajes.
g)
Análisis de Datos Cuantitativos – Hoja 17
SIGNED RANK TEST
2
FRIEDMAN
NO
NO
2
>2
GRUPOS
KRUSKAL-WALLIS
RANK SUM TEST
SI
SI NO (PUNTAJES)CONTINUOS
SI
GAUSS
>2
TRATA-MIENTOS
CUANTITATIVOSDATOS
APAREADO
Figura 6. Pruebas estadísticas para datos cuantitativos no numéricos y para datos numéricos no gaussianos.

Análisis de Datos Cuantitativos – Hoja 18
h) Si son continuos debemos verificar si son o no gaussianos . Si la respuesta es SÍ aplicamos estadística paramétrica.
i) Ya sea que los datos sean puntajes o continuos no gaussianos, debemos tener en cuenta si son apareados (propio individuo como control) o no.
j) Si son apareados aplicamos el signed rank test si son 2 datos en un mismo individuo y la prueba de Friedman si son más de 2.
k) Si no son apareados aplicamos el rank sum test si son 2 grupos y la prueba de Kruskal-Wallis si son más de dos. Recordemos que esta prueba la utilizamos también para datos gaussianos cuando rechazamos homoscedasticidad.
l) Tanto para la prueba de Friedman como para la de Kruskal-Wallis existen pruebas post-hoc para efectuar comparaciones de a pares.
Hipótesis nulas
Las hipótesis nulas de las pruebas no paramétricas son similares a las de las paramétricas, según la correspondencia indicada en la tabla 3, con la diferencia de que se refieren a mediana de la población en lugar de media de la población. Es decir, en lugar de probar la hipótesis de medias iguales, prueban la de medianas iguales.
Sinonimia
� Signed rank test. Se lo denomina también prueba de Wilcoxon, pero como existen numerosas pruebas no paramétricas de Wilcoxon, es conveniente aclarar: signed rank test de Wilcoxon. El término inglés puede traducirse como prueba de los rangos con signos (rango en el sentido de ordinal). Existen en la literatura traducciones no adecuadas y que recomendamos no usar: “prueba de los signos de Wilcoxon”, “prueba de los rangos señalados”, etc.
� Rank sum test. Se lo denomina también prueba de Mann-Whitney, prueba de Wilcoxon para grupos paralelos, prueba de Wilcoxon para 2 grupos, prueba de Mann-Whitney-Wilcoxon, prueba de U. Hay varias maneras de estimar el valor de p en esta prueba y U es un estadístico que puede utilizarse para este fin. El término inglés puede traducirse como prueba de la suma de rangos (rango en el sentido de ordinal).

Análisis de Datos Cuantitativos – Hoja 19
INTEGRACIÓN
En la tabla 6 se resumen las aplicaciones de las principales pruebas estadísticas mencionadas en este capítulo. La tabla sólo contiene los conceptos principales, para más detalles es necesario leer el texto.
Tabla 6. Pruebas paramétricas y no paramétricas para análisis de datos cuantitativos.
ANOVA: análisis de variancia.
Pruebas no paramétricas
Aplicación Pruebas paramétricas (Datos numéricos
gaussianos)
Datos numéricos
no gaussianos Puntajes
2 Student Rank sum test Grupos paralelos Más de 2 ANOVA de 1 vía Kruskal-Walis a
Mediciones repetidas en
el mismo individuo
2 (diseños
no cruzados) Student apareado Signed rank test
a: Puede aplicarse también a datos gaussianos cuando se rechaza
homoscedastidad.
En el capítulo ampliado del CD se resumen otros análisis como el Anova de Grizzle para los diseños cruzados (cross-over trials) y el ANOVA para mediciones repetitivas, cuando existen múltiples cálculos para el mismo parámetro en el mismo paciente.
Ejemplo de integración.
En un estudio epidemiológico en Mendoza, base facilitada por el Dr. Emilio Marigliano, se relevaron 1019 adolescentes de 12 a 14 años de edad, con el objeto de analizar la presión arterial y su relación con parámetros demográficos.
Se obtuvieron diferentes variables cuantitativas, de las cuales analizaremos dos: Tensión sistólica y frecuencia cardíaca. Nos interesa analizar si estos parámetros son diferentes entre varones y mujeres a esa edad, y su comportamiento en tres grupos delimitados por tercilos de peso corporal.
El primer paso es establecer que distribución tienen las variables a analizar (tabla 7)

Análisis de Datos Cuantitativos – Hoja 20
Tabla 7: Parámetros de distribución de las variables TAS1 (tensión sistólica) y pulso1 (frecuencia cardíaca. Media DS Mediana Percentilo SKEW KURT Gaussiana
25 75 TAS1 107,3 11,5 108 100 115 0,4 0,4 SI Pulso1 86,2 12,4 84 79,5 94 1,6 1,9 NO
Observamos que en tensión arterial, media y jmediana son casi idénticas, el intervalo intercuartilo es simétrico respecto de la media y los test de asimetría (skewness) y curtosis (KurtI) son cercanos a 0: la variable tiene distribución gaussiana. En el pulso, Media y mediana no coinciden, el intervalo intercuartilo es más asimétrico respecto de la media, y los test se alejan de 0: la variable no tiene distribución gaussiana.
Elijamos ahora las pruebas a aplicar para comparar varones y mujeres (dos grupos) y los tercilos de peso (tres grupos). Utilizamos los algoritmos y tablas de este capítulo.
Tabla 8: Elección de pruebas de acuerdo a la distribución y el número de grupos a comparar.
Pruebas estadísticas Distribución
Dos grupos Tres grupos TAS1
Gaussiana Test de T ANOVA Pulso1
No gaussiana Rank sum test Kruskall Wallis
En la tabla 9 mostramos los resultados: La tensión sistólica fue algo mayor en mujeres, y aumentó significativamente en los tercilos de adolescentes de mayor peso. Aplicamos una prueba pos-hoc de Bonferroni para establecer entre qué tercilos se concentraba la diferencia, y nos informó que los tres grupos diferían entre sí. Los datos para tensión sistólica están expresados como media y desvío estándar, dado que la variable es gaussiana.
La frecuencia cardíaca fue mayor en mujeres, y fue similar en los tres grupos de peso. Los datos están expresados en mediana e intervalo intercuartilo, por tratarse de una variable no gaussiana.
Tabla 9: Resultados del análisis estadístico comparativo de la presión arterial sistólica y la frecuencia cardíaca de acuerdo al género y grupos divididos por tercilos de peso.
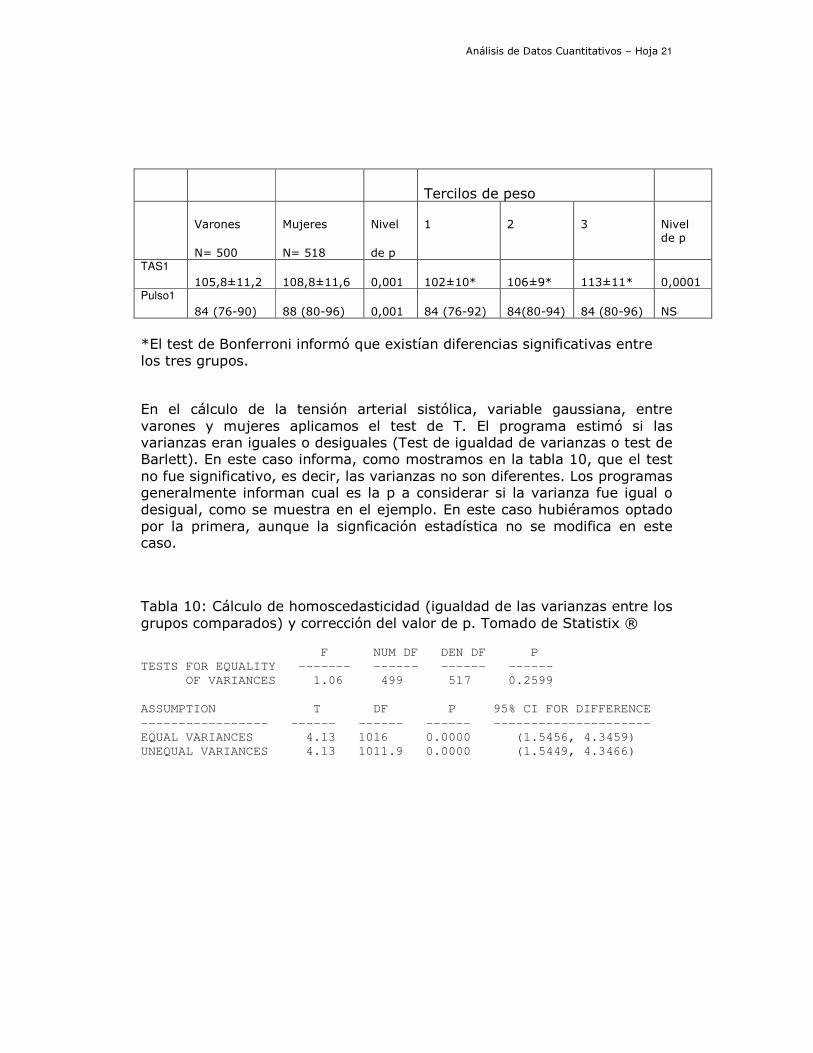
Análisis de Datos Cuantitativos – Hoja 21
Tercilos de peso
Varones
N= 500
Mujeres
N= 518
Nivel
de p
1 2 3 Nivel de p
TAS1
105,8±11,2 108,8±11,6 0,001 102±10* 106±9* 113±11* 0,0001 Pulso1
84 (76-90) 88 (80-96) 0,001 84 (76-92) 84(80-94) 84 (80-96) NS *El test de Bonferroni informó que existían diferencias significativas entre los tres grupos.
En el cálculo de la tensión arterial sistólica, variable gaussiana, entre varones y mujeres aplicamos el test de T. El programa estimó si las varianzas eran iguales o desiguales (Test de igualdad de varianzas o test de Barlett). En este caso informa, como mostramos en la tabla 10, que el test no fue significativo, es decir, las varianzas no son diferentes. Los programas generalmente informan cual es la p a considerar si la varianza fue igual o desigual, como se muestra en el ejemplo. En este caso hubiéramos optado por la primera, aunque la signficación estadística no se modifica en este caso.
Tabla 10: Cálculo de homoscedasticidad (igualdad de las varianzas entre los grupos comparados) y corrección del valor de p. Tomado de Statistix ®
F NUM DF DEN DF P
TESTS FOR EQUALITY ------- ------ ------ ------
OF VARIANCES 1.06 499 517 0.2599
ASSUMPTION T DF P 95% CI FOR DIFFERENCE
----------------- ------ ------ ------ ---------------------
EQUAL VARIANCES 4.13 1016 0.0000 (1.5456, 4.3459)
UNEQUAL VARIANCES 4.13 1011.9 0.0000 (1.5449, 4.3466)


















