
Centro de Investigación en Inteligencia Artificial ... · por lo que, es necesario encontrar...
59
Centro de Investigación en Inteligencia Artificial Universidad Veracruzana Reconstrucción de objetos mediante cámaras estéreo, utilizando múltiples vistas. Tesis Para obtener el grado de Maestro en Inteligencia Artificial Presenta I.I.E. Jesús Orlando Wong Quijano Universidad Veracruzana Xalapa Veracruz Director de tesis: Dr. Homero Vladimir Rios Figueroa
Transcript of Centro de Investigación en Inteligencia Artificial ... · por lo que, es necesario encontrar...

Centro de Investigación en Inteligencia Artificial
Universidad Veracruzana
Reconstrucción de objetos mediante cámaras estéreo, utilizando múltiples
vistas.
Tesis
Para obtener el grado de
Maestro en Inteligencia Artificial
Presenta
I.I.E. Jesús Orlando Wong Quijano
Universidad Veracruzana
Xalapa Veracruz
Director de tesis:
Dr. Homero Vladimir Rios Figueroa

Índice general
Tabla de Contenido viii
Índice general viii
Índice de figuras xi
Índice de tablas xiii
Índice de Algoritmos xiv
1. Introducción 1
1.1. Contenido de la tesis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2. Fundamentos teóricos 4
2.1. Estado del arte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.2. Visión y cámaras estéreo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.2.1. Líneas y planos epipolares . . . . . . . . . . . . . . . . . . . . . . . . 7
2.2.2. Calibración . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2.3. Búsqueda de correspondencia (Match estéreo) . . . . . . . . . . . . . 10
2.2.4. Reconstrucción 3D . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.2.5. Reconstrucción mediante múltiples vistas . . . . . . . . . . . . . . . . 12
2.2.6. Triangulación de Delaunay . . . . . . . . . . . . . . . . . . . . . . . . 13
viii

ÍNDICE GENERAL ix
2.3. Objetivo y aportación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3. Metodología 16
3.1. Obtención de imágenes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.2. Preprocesar las imágenes . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.3. Rectificación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.4. Segmentación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.4.1. Flood Fill . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.5. Obtener el mapa de disparidad (SGBM) . . . . . . . . . . . . . . . . . . . . 22
3.6. Ajuste y combinación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
3.6.1. Generar nube de puntos . . . . . . . . . . . . . . . . . . . . . . . . . 25
3.6.2. Rotación y Ajuste . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3.7. Triangulación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.8. Guía de observación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
4. Pruebas y resultados 30
4.1. Cubo de Rubik . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
4.2. Pasta de dientes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4.3. Flexómetro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
4.4. Caballo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
4.5. Dragón . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
4.6. Caballero . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.7. Discusión de resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
5. Conclusiones y trabajo futuro 42
5.1. Logros de la tesis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
5.2. Limitaciones y Trabajo futuro . . . . . . . . . . . . . . . . . . . . . . . . . . 43

ÍNDICE GENERAL x
5.3. Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
Bibliografía 45
Apéndice A. Características de la cámara xv
Apéndice B. Características del equipo xviii

Índice de figuras
2.1. Ejemplo de disparidad entre ojos izquierdo y derecho. . . . . . . . . . . . . . 6
(a). Imagen izquierda . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
(b). Imagen derecha . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.2. Ejemplo de línea epipolar (Prince, 2012) . . . . . . . . . . . . . . . . . . . . 7
2.3. Plano epipolar (Hartley y Zisserman, 2008) . . . . . . . . . . . . . . . . . . . 8
2.4. Ejemplo de línea epipolar (Hartley y Zisserman, 2008) . . . . . . . . . . . . 9
2.5. Búsqueda de profundidad de un punto. . . . . . . . . . . . . . . . . . . . . . 12
2.6. Ejemplo de captura de múltiples vistas de un objeto (Eisert et al., 2012) . . 12
2.7. Ejemplo de triangulacion de Delaunay (Spada, s.f.) . . . . . . . . . . . . . . 13
2.8. (a) Muestra una imagen en color, mientras que (b) se muestra la misma
imagen convertida a escala de grises. . . . . . . . . . . . . . . . . . . . . . . 14
(a). Imagen a color . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
(b). Imagen en escala de gris . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.1. Diagrama de flujo del algoritmo de digitalización . . . . . . . . . . . . . . . . 17
3.2. Ejemplo de par estéreo jpg side-by-side . . . . . . . . . . . . . . . . . . . . . 19
3.3. Los 8 pares de estéreo usados para la calibración de la cámara . . . . . . . . 19
3.4. (a) Ejemplo antes de rectificar la imagen. (b) Ejemplo después de aplicar los
parámetros de rectificación. . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
xi

ÍNDICE DE FIGURAS xii
(a). Antes de rectificar . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
(b). Rectificada . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.5. Diagrama de cámaras estereo paralelas . . . . . . . . . . . . . . . . . . . . . 26
4.1. Imagen de muestra. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
4.2. Reconstrucción del cubo de Rubik . . . . . . . . . . . . . . . . . . . . . . . . 31
4.3. Reconstrucción del cubo de Rubik, vista superior . . . . . . . . . . . . . . . 32
4.4. Imagen de muestra. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4.5. Reconstrucción de la caja de pasta de dientes, primera vista . . . . . . . . . 33
4.6. Reconstrucción de la caja de pasta de dientes, segunda vista . . . . . . . . . 33
4.7. Imagen de referencia. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
4.8. Reconstrucción del flexómetro, vista lateral . . . . . . . . . . . . . . . . . . . 34
4.9. Reconstrucción del flexómetro, vista frontal . . . . . . . . . . . . . . . . . . 34
4.10. Imagen de muestra del caballo de bronce. . . . . . . . . . . . . . . . . . . . . 35
4.11. Reconstrucción del caballo, vista lateral. . . . . . . . . . . . . . . . . . . . . 35
4.12. Reconstrucción del caballo, vista frontal . . . . . . . . . . . . . . . . . . . . 36
4.13. Imagen de muestra. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
4.14. Reconstrucción del dragón, vista lateral . . . . . . . . . . . . . . . . . . . . . 37
4.15. Reconstrucción del dragón, vista frontal . . . . . . . . . . . . . . . . . . . . 37
4.16. Imagen de muestra. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
4.17. Reconstrucción del caballero, primera vista . . . . . . . . . . . . . . . . . . . 38
4.18. Reconstrucción del caballero, segunda vista . . . . . . . . . . . . . . . . . . . 38
4.19. Gráfica de tamaño vs tiempo . . . . . . . . . . . . . . . . . . . . . . . . . . . 41

Índice de tablas
3.1. Algunos valores de giro. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
4.1. Datos estadísticos de la calificación de los modelos. . . . . . . . . . . . . . . 39
4.2. Datos estadísticos de los tiempos de ejecución y el número de puntos. . . . . 40
A.1. Características de la cámara . . . . . . . . . . . . . . . . . . . . . . . . . . . xvii
B.1. Características del equipo utilizado . . . . . . . . . . . . . . . . . . . . . . . xviii
xiii

Índice de Algoritmos
1. Algoritmo de segmentación . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2. Algoritmo Flood Fill. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
xiv

Capítulo 1
Introducción
En términos generales la visión es el conjunto de procesos que nos otorgan la capacidad
de interpretar nuestro entorno y es gracias a los rayos de luz que alcanzan nuestros ojos
que somos capaces de saber la forma de los objetos, reconocer patrones de luces y sombras
e incluso delimitar uno o varios objetos. Por ejemplo, si miramos una foto familiar somos
capaces de reconocer y nombrar a todos los presentes y en algunos casos incluso percibir su
estado emocional de acuerdo a la expresión facial.
De forma análoga la visión por computadora, también llamada “visión artificial”, es un
área cuyo objetivo es desarrollar maquinas capaces de "ver". Durante el tiempo que esta
área de investigación ha progresado se han desarrollado diversas técnicas para: la recupera-
ción de la forma y apariencia de los objetos en tres dimensiones, seguimiento de personas
y, con cierto éxito, identificar a las personas de una fotografía, sin embargo, todavía no se
está ni cerca de lograr lo que hace un adulto o, incluso, un niño.
A pesar de lo anterior la visión artificial está ganando terreno en múltiples áreas, algunos
ejemplos que mencionan González (2010), Horn (1986) y Anagnostopoulos et al. (2001) son:
1

CAPÍTULO 1. INTRODUCCIÓN 2
Navegación robótica: Es un proceso que combina la información proveniente de mul-
tiples sensores, por ejemplo camaras, sonares, láseres, entre otros.
Biología, geología y meteorología: Para la segmentación automática de imágenes, ya
sea para identificar un área de interés o identificación de regiones.
Medicina: En el procesamiento de imágenes provenientes de radiografías, resonancias
magnéticas, tomografías, etc.
Reconocimiento y clasificación: Diferenciar de objetos según, su tamaño y/o forma,
además de computar su cantidad.
Topografia: Mediante la técnica llamada fotogrametría, se hacen mediciones de un área
a partir de imágenes.
Industria: Control de calidad, para mantener estándares altos e incrementar la com-
petitividad de las compañias.
Por ello, y gracias al avance de la tecnología, la reconstrucción de modelos 3D ha llegado
a un gran número de personas, sin embargo, los usuarios exigen experiencias cada vez mas
realistas, para satisfacer dicha demanda los desarrolladores investigan tecnologías cada vez
más precisas, rápidas y económicas.
La reconstrucción de modelos 3D, también conocida como digitalización de objetos o
simplemente reconstrucción 3D, es el proceso de capturar la forma de un objeto y recrearlo
en un espacio virtual, de acuerdo a Revelo-Luna et al. (2012) se define como: “ el proceso
de establecer coordenadas 3D a partir de las proyecciones 2D de los emparejamientos y su
visualización en un escenario tridimensional”. Normalmente dicho proceso requiere de un

CAPÍTULO 1. INTRODUCCIÓN 3
equipo altamente especializado, como el caso de Trakic et al. (2011) que utilizan láseres,
debido a la precisión que proveen; sin embargo su alto costo limita el acceso a los mismos,
por lo que, es necesario encontrar alternativas más económicas como las cámaras digitales
cuya relacion calidad de imagen/costo las perfilan como una opción viable y más aún si se
toma como modelo la visión estereoscópica. Por lo anterior en el presente trabajo se busca
utilizar dichos equipos para la reconstrucción de modelos 3D en lugar de sensores de rango,
lo que genera restricciones inherentes a la técnica: se debe encontrar una forma de medir la
distancia entre la cámara y el objeto a digitalizar, además, es necesario transformar las dis-
tancias obtenidas a un modelo en 3 dimensiones que la computadora pueda representar a fin
de generar un modelo funcional, esto se logra por medio de un proceso de reconstrucción 3D.
1.1. Contenido de la tesis
En el capítulo 2 se explica el estado del arte, lo que incluye las técnicas existentes sobre
reconstrucción y visión estéreo. Mientras que en el capítulo 3 se detalla la metodología uti-
lizada.
Posteriormente en el capítulo 4 se detallan los resultados obtenidos. Y finalmente en el
capítulo 5 lo componen las conclusiones, recomendaciones y posibles trabajos futuros.

Capítulo 2
Fundamentos teóricos
Uno de los sentidos más importantes para los seres humanos es la visión la cual, se
calcula, ocupa cerca del 70 % de las funciones del cerebro (Platero, s.f.), es el sentido más
desarrollado y, sin embargo, el menos comprendido debido a su enorme complejidad, no
obstante existen muchos estudios que intentan descifrarlo, por ejemplo, en 1960 Béla Julesz
demostró mediante estereogramas de puntos aleatorios que la percepción de profundidad
puede ser computada en ausencia de objetos identificables (Siegel, s.f.)
2.1. Estado del arte
En el caso de Po-Han et al. (2012) realizan reconstrucción de modelos 3D poco densos
utilizando múltiples vistas utilizando cámaras simples en lugar cámaras estéreo, y lo com-
plementan con una técnica llamada estructura a partir de movimiento (SfM por sus siglas
en inglés), la cual presenta problemas muy similares a los encontrados en el uso de cámaras
estéreo, ya que ocupa imágenes consecutivas para la detección de la profundidad. Una ven-
taja respecto al presente trabajo es que no necesitan cámaras estéreo ya que SfM funciona
con cámaras simples, por otro lado la desventaja es que necesitan algunas docenas de imá-
4

CAPÍTULO 2. FUNDAMENTOS TEÓRICOS 5
genes para realizar la reconstrucción, además utilizar cámaras estéreo debería de mejorar la
precisión de la reconstrucción, ya que se genera un aumento en la información disponible.
Por otro lado Hernández y Schmitt (2004) emplean el algoritmo de los modelos defor-
mables (snakes) y adicionalmente hacen uso de cámaras estéreo, junto con una secuencia de
imágenes a color calibradas. Los snakes ofrecen la ventaja de que son fáciles de implemen-
tar y de ajustar sus parámetros, por otro lado la restricción de topologia constante es una
desventaja. En el presente trabajo se utiliza la disparidad estéreo que aunque no es tan fácil
de implementar puede trabajar con objetos discontinuos.
Finalmente, Eisert et al. (2012) plantearon un sistema que utiliza una imagen estéreo
y múltiples vistas para generar los modelos 3D, se puede afirmar que, de los aqui presen-
tados, este sistema es el más similar al propuesto; de manera general, hace uso de cámaras
sin calibrar con un objeto de referencia, genera una imagen estéreo y siguientes las vistas
son agregadas mediante SfM para ajustar la forma y la textura. En contraste, la presente
propuesta utiliza de un método de calibración de las cámaras y la información de todas
las vistas provendrá de imágenes estéreo, partiendo del supuesto de que el uso de múltiples
imágenes estéreo deberia proporcionar un aumento en la información obtenida.
En cuanto a los ambientes utilizados tanto Hernández y Schmitt (2004) como Eisert et
al. (2012) utilizan un fondo negro para la captura los objetos, mientras que en el trabajo
de Po-Han et al. (2012) el objeto es colocado sobre una superficie blanca y no necesitan
que todo el fondo sea controlado, en este sentido la presente tesis se encuentra en un punto
medio ya que aunque el color de fondo tiene que ser uniforme puede ser de cualquier color.
2.2. Visión y cámaras estéreo
Desde hace mucho tiempo se sabe que los seres humanos perciben la profundidad me-
diante visión estéreo, esto es gracias a la diferencia entre las imágenes de los ojos izquierdo y

CAPÍTULO 2. FUNDAMENTOS TEÓRICOS 6
derecho. De acuerdo a Bebis (2004), la visión estéreo tiene como objetivo la recuperación de
la estructura de una escena (todo aquello que aparece dentro del campo de visión) median-
te el uso múltiples imágenes de la misma donde cada una obtenida desde una perspectiva
diferente, lo que provoca que los objetos más cercanos tengan un movimiento aparente ma-
yor respecto de los objetos que más lejanos, como se puede apreciar en la figura 2.1. Esa
diferencia entre las dos imágenes es conocida como disparidad y puede ser utilizada para
calcular la distancia entre los objetos y las cámaras.
Aunado a lo anterior se sabe que la disparidad es inversamente proporcional a la distan-
cia, lo que nos permite medir con mayor precisión la distancia que existe entre la cámara y
los objetos cercanos que la existe a los objetos lejanos. Dicha disparidad es la que nuestro
cerebro utiliza a fin de estimar la distancia relativa de los objetos observados, este proceso
consta de 3 pasos:
1. Una ubicación específica de una superficie en particular debe ser seleccionada en la
primera imagen.
2. La misma ubicación de la misma superficie debe ser identificada en la otra imagen.
3. La disparidad entre los puntos correspondientes en ambas imágenes debe ser medida.
(a) Imagen izquierda (b) Imagen derecha
Figura 2.1: Ejemplo de disparidad entre ojos izquierdo y derecho.
El proceso que permite identificar el punto correspondiente en la segunda imagen a un
punto específico de la primera imagen se conoce como búsqueda de correspondencia, proceso
que se aborda en la sección 2.2.3.

CAPÍTULO 2. FUNDAMENTOS TEÓRICOS 7
2.2.1. Líneas y planos epipolares
La geometría que rige la visión desde dos puntos de vista se llama geometría epipolar,
se caracteriza por ser independiente de la estructura pero dependiente de los parámetros
internos de las cámaras y de la posición relativa.
Como se explica en Prince (2012): Si en el campo de visión de una única cámara existe
un punto w sabemos que el punto w se encuentra en algún punto del rayo que pasa a través
del lente de la cámara y que tiene una posición X1, sin ser posible conocer la distancia de
dicho punto utilizando únicamente una cámara.
Al agregar una segunda cámara que observe el mismo punto w y sabiendo que dicho
punto se encuentra en un rayo en particular en el espacio, la posición proyectada X2 del
punto en la segunda imagen (cámara), debe estar en algún punto de la proyección del
rayo, como se muestra en la figura 2.2. A esa proyección en 2 dimensiones de un rayo de 3
dimensiones se le conoce como línea epipolar.
Figura 2.2: Ejemplo de línea epipolar (Prince, 2012)
La forma alternativa de representar la geometría epipolar es utilizando planos epipolares,
los cuales están delimitados por una línea que une los centros de los lentes (conocida como
línea base) y las líneas que van desde los lentes al punto observado, como se muestra en la
figura 2.3. Es importante mencionar que las líneas epipolares son la intersección del plano

CAPÍTULO 2. FUNDAMENTOS TEÓRICOS 8
epipolar con los planos de proyección.
Adicionalmente es importante señalar que en el centro del punto focal de cada cámara
el plano forma una proyeccion cónica que permitira calcular las profundidades, al utilizar
ambas proyecciones cónicas ya que no guardan la información de los ángulos o las distancias
(Etayo y Fernando, 2012).
Figura 2.3: Plano epipolar (Hartley y Zisserman, 2008)
La geometría de las lineas y planos antes descritos es la base para la restricción epipolar la
cual tiene como principio que para cualquier punto en una imagen el punto correspondiente
está restringido a estar en una línea. Esa línea,llamada línea epipolar, está restringida por
los parámetros intrínsecos y extrínsecos de las cámaras; los primeros son lo que relacionan
el sistema coordenado de la cámara con el sistema coordenado de la imagen, mientras que
los segundos son los que relacionan el sistema coordenado de la cámara con el mundo y
especifican su posición y orientación en el espacio.
La restricción epipolar tiene dos principales aportaciones:
Si se conocen los parámetros intrínsecos y extrínsecos es relativamente fácil localizar
las correspondencias de puntos, ya que para cada punto en la primera imagen solo
debemos realizar una búsqueda en una dimensión en la segunda imagen.
Si se conocen los parámetros intrínsecos y se observa un patrón conocido de pun-

CAPÍTULO 2. FUNDAMENTOS TEÓRICOS 9
tos se pueden determinar los parámetros extrínsecos (la relación geométrica entre las
cámaras).
Adicionalmente se debe aclarar que un punto específico puede o no aparecer en ambas
imágenes, y en caso de que así sea debe de encontrarse en la misma línea epipolar como se
muestra en la figura 2.4. Una vez que se encuentra un par de puntos que son correspondientes
en ambas imágenes se les llama par conjugado.
Figura 2.4: Ejemplo de línea epipolar (Hartley y Zisserman, 2008)
2.2.2. Calibración
La calibración estima los parámetros intrínsecos y extrínsecos de una cámara, de acuerdo
a Medioni y Kang (2004), es necesaria para obtener información 3D a partir de imágenes 2D,
por ello ha sido muy estudiada tanto en la visión por computadora como en la fotogrametría.
Existen diferentes técnicas para realizar este proceso por lo que dependiendo del objeto
utilizado la calibración puede caer dentro de una de las siguientes categorías:
Calibración basada en objetos 3D: Utilizan objetos cuya geometría 3D es conocida con
alta precisión.
Calibración basada en planos: Requieren observar un patrón en diferentes orientacio-
nes.

CAPÍTULO 2. FUNDAMENTOS TEÓRICOS 10
Calibración basada en lineas: Mediante el uso de puntos colineales.
Auto-calibración: Basandose en el movimiento de la cámara en una escena estática.
En el presente trabajo se utiliza la calibración basada en planos debido a que es un punto
medio entre complejidad y precisión.
2.2.3. Búsqueda de correspondencia (Match estéreo)
La búsqueda de correspondencia es un procedimiento que todavia no ha sido solucionado
completamente, dicha tarea consiste en “la identificación de las características en ambas
imágenes que son proyecciones de la misma entidad en el mundo tridimensional“ Horn
(1986). En este sentido, y de acuerdo a la literatura consultada, para desarrollar un sistema
de visión estéreo automático es necesario encontrar un método para determinar que punto
de una imagen corresponde con qué punto de la otra imagen. Sin embargo, aunque se
conocen bastante bien la física y la geometría (epipolar) que componen una escena, la
búsqueda automática de las correspondencias es una tarea complicada debido al problema
de correspondencia, este se dá cuando un punto de la primera imagen tiene 2 o más, o ningún,
correspondientes en la segunda imagen, por ejemplo: si se tienen 2 imágenes conformadas por
un color liso no hay manera de saber que punto de una imagen corresponde con que punto
de la otra imagen. Dado lo complejo que es obtener correspondencias los avances en esta
área han sido lentos, entre los primeros autores en plantear las dificultades de este proceso
se encuentran D. Marr y T. Poggio que en 1979 en su artículo ”A computational theory of
human stereo vision” (D. C. Marr y Poggio, 1979) mencionan las siguientes restricciones:
Un punto en una superficie física solo puede estar en una ubicación a la vez, la materia es
cohesiva, está separada en objetos y la superficie de dichos objetos es normalmente suave
(pequeños cambios en las superficies, como fracturas, son pequeños en relación a la distancia
al espectador). Lo que permite generar las siguientes reglas:

CAPÍTULO 2. FUNDAMENTOS TEÓRICOS 11
1. Compatibilidad: Los puntos oscuros solo pueden emparejar con puntos oscuros (lo
mismo aplica para cualquier tono de gris o color).
2. Unicidad: Casi siempre un punto de una imagen solo puede emparejar con un único
punto de la otra imagen.
3. Continuidad: La disparidad de los pares conjugados varia suavemente casi en toda la
imagen.
No obstante el problema sigue siendo como hallar los pares conjugados, para solucionarlo
se han desarrollado varias estrategias, una de ellas se basa en analizar las imágenes por
separado y buscar las características distintivas de ellas para usarlas como referencia, estas
características pueden ser bordes o esquinas, por ejemplo. Lo que resulta en un mapa de
correspondencia poco denso (discreto), como es el caso de Scharstein y Szeliski (2002).
La otra se basa en la idea de que los pares conjugados tienen una vecindad igual o
similar (las intensidades de los pixeles cercanos son similares), aunque es común que existan
vecindades con más de una correspondencia, donde el problema sigue siendo como seleccionar
la vecindad correcta. En el presente trabajo se utiliza la técnica de SGBM (explicada en la
sección 3.5) para solucionar el problema de correspondencia. Y al final obtener un mapa de
disparidad denso.
2.2.4. Reconstrucción 3D
El proceso de reconstrucción consiste en obtener las coordenadas respecto a la cámara
de un punto a partir de su par conjugado. Las coordenadas X y Y se obtienen al seleccionar
una de las imágenes (en el caso de estéreo la convención es utilizar la imagen izquierda)
mientras que la coordenada Z (figura 2.5) es calculada mediante el mapa de disparidad
obtenido de la busqueda de correspondencia. Una vez que se une la información de las 3
coordenadas se obtiene un modelo 3D de la escena.

CAPÍTULO 2. FUNDAMENTOS TEÓRICOS 12
Figura 2.5: Búsqueda de profundidad de un punto.
2.2.5. Reconstrucción mediante múltiples vistas
La reconstrucción mediante múltiples vistas es una variación de la reconstrucción "sim-
ple", en este caso se intentan recuperar tanto la forma como la apariencia de un objeto a
partir de un conjunto de imágenes del mismo, como las que se obtendrían en la figura 2.6.
Aunque en algunos trabajos como el de Hartley y Zisserman (2008) no hacen uso de los
parámetros intrínsecos y extrínsecos de las cámaras la mayoría de la bibliografica consultada
si hace uso de los parámetros de calibración, debido a esto y a las razones antes expuestas
en el presente trabajo si serán utilizados.
Figura 2.6: Ejemplo de captura de múltiples vistas de un objeto (Eisert et al., 2012)

CAPÍTULO 2. FUNDAMENTOS TEÓRICOS 13
2.2.6. Triangulación de Delaunay
Aunque existen diferentes técnicas para la representación de los modelos 3D, en el pre-
sente trabajo y a traves del uso de la libreria PCL, se emplea la nube de puntos para la
representación en el espacio tridimensional de los puntos obtenidos mediante la reconstruc-
ción debido en gran medida a la facilidad de uso y la gran cantidad de algoritmos con que
cuenta dicha libreria.
Una vez que el modelo está completo es necesario convertir de una nube de puntos a
una malla, una de las técnicas más utilizadas para dicho proceso, es la triangulación de
Delaunay.
La triangulación consiste en dividir una superficie (poligono) en un conjunto de trián-
gulos, con la condicion de que cada lado del triangulo se reparta entre dos triángulos adya-
centes. Para considerarla triangulación de Delaunay (1934) se debe de cumplir la siguientes
condición: es necesario que las circunferencias cincunscritas en todos los triángulos esten
vacías; esto significa que dicha circunferencia no contenga vértices de otros triángulos, a fin
de que los angulos dentro de cada triángulo sean lo mas grandes posible, la longitud de los
lados sea mínima y, por lo tanto, la triangulación formada sea única. Un ejemplo de ello se
puede ver en la figura 2.7.
Figura 2.7: Ejemplo de triangulacion de Delaunay (Spada, s.f.)

CAPÍTULO 2. FUNDAMENTOS TEÓRICOS 14
2.3. Objetivo y aportación
La presente tesis está enfocada en la creación de modelos 3D de objetos, mediante la
unión de múltiples mapas de disparidad a fin de poder reconstruir un objeto rígido y opaco
utilizando la información proveniente de varios puntos de vista, haciendo uso del color y/o
la textura del mismo siempre que sea posible. Lo anterior está basado en las siguientes
observaciones:
Las técnicas tradicionales de procesamiento de imágenes (incluyendo reconstrucción)
trabajan con imágenes en escala de grises debido, entre otras razones, a que se desea
que los procesos sean más rápidos; sin embargo, en aplicaciones que no son de tiempo
real, como en la presente, es posible utilizar la informacion proveniente del color a fin
de que los resultados sean mas robustos.
La escala de grises puede presentar problemas debido a que el proceso de conversión
asigna el mismo tono de gris a diferentes colores, como se ve en la figura 2.8.
El utilizar múltiples vistas permite una reconstrucción más completa del objeto.
(a) Imagen a color
(b) Imagen en escala de gris
Figura 2.8: (a) Muestra una imagen en color, mientras que (b) se muestra la misma imagenconvertida a escala de grises.

CAPÍTULO 2. FUNDAMENTOS TEÓRICOS 15
Debido a lo anterior la presente tesis se enfoca en crear, encontrar o desarrollar un
algoritmo que permita:
Segmentar un objeto de un fondo de color liso contrastante con dicho objeto.
Calcular el mapa de disparidad entre pares estéreo.
Generar nubes de puntos a partir de mapas de disparidad.
Unir nubes de puntos para crear un modelo incremental en 3D del objeto.
Por lo tanto esta tesis no intenta solucionar la reconstrucción de objetos que rotan en
más de un eje ni el problema de la localización de un objeto fuera de un ambiente con las
siguientes características:
Objeto solido y opaco.
Color de fondo uniforme.
Las esquinas de todas las imágenes son fondo.
Color(es) del objeto contrasta con el fondo.
Finalmente los datos serán evaluados de dos formas, la primera es cualitativa, por medio
de observación directa y utilizando una guía de observación propuesta, y la segunda es
cuantitativa mediante los datos estadísticos generados por diferentes ejecuciones para cada
caso probado.

Capítulo 3
Metodología
En gran medida debido a la dificultad de medir cuantitativamente el error en los modelos
3D aqui generados se decidío utilizar dos parámetros, el primero cualificar mediante obser-
vación directa la similitud de dichos modelos respecto al objeto original utilizando la guía de
observación propuesta en la seccion 3.8, y el segundo es cuantitativo mediante los datos es-
tadísticos generados por diferentes ejecuciones para cada caso probado; por ello la metología
expuesta a continuación se desarrolló partiendo de un enfoque mixto (Hernandez Sampieri
et al., 2006).
Dicho lo anterior el algoritmo de digitalización se representa en la figura 3.1. Donde cada
módulo representa un paso en dicho proceso, los coloreados en azul son llevados a cabo por
software externo, mientras que los de color naranja son ejecutados desde el programa creado
durante el presente trabajo. Adicionalmente cada uno de ellos se detalla más adelante en su
sección correspondiente.
16

CAPÍTULO 3. METODOLOGÍA 17
Inicio Obtencion de imagenes 3.1
Preprocesar las imágenes 3.2
Rectificar todas las imágenes 3.3
Segmentación 3.4
Obtener el mapa de disparidad 3.5
Ajuste y combinación 3.6
¿Hay más imágenes? Procesar siguiente imagen
Triangulación 3.7
Evaluación 3.8Fin
Si
No
Figura 3.1: Diagrama de flujo del algoritmo de digitalización

CAPÍTULO 3. METODOLOGÍA 18
3.1. Obtención de imágenes
Las imágenes fueron tomadas con una cámara fujifilm 3DW3 RealPix la cual se mantuvo
fija y girando el objeto para capturar las diferentes vistas del mismo; debido a las limitaciones
inherentes a la visión estéreo es indispensble conocer los rango de captura óptimos que
permitan a los algoritmos funcionar adecuadamente, para ello se obtuvo el horópter a partir
de las características de la cámara y la fórmula 3.1(Konolige, s.f.), donde B es la linea base,
f la distancia focal, s el tamaño de cada pixel de la cámara y d la disparidad, obteniendo
que el valor para el mismo es de 29 a 148 cm.
Horopter =B ∗ f
s ∗ d(3.1)
De acuerdo a las características del sofware desarrollado se deben tener las siguientes
consideraciones para la toma de imágenes:
Enfocarse en un objeto opaco y rígido, preferiblemente centrado.
Contar con un fondo que contraste con el objeto a digitalizar.
Seriar las imágenes a fin de que muestren las diferentes vistas del mismo en secuencia.
El giro debe ser en sentido de las manecillas del reloj.
3.2. Preprocesar las imágenes
Debido a la escasez de algoritmos capaces de trabajar con el formato MPO (propio de
la cámara), es necesario convertir las fotografías a formato “jpg side-by-side” (lado-a-lado)
donde el par estéreo se ve como se muestra en la figura 3.2. Finalmente, y a fin de disminuir
el tiempo de procesamiento, la imagen resultante es escalada hasta tener un ancho de 2000
pixeles (1000 para cada imagen).

CAPÍTULO 3. METODOLOGÍA 19
Figura 3.2: Ejemplo de par estéreo jpg side-by-side
3.3. Rectificación
Para el proceso de rectificación se utilizaron los parámetros de calibración generados por
el programa creado por Peris (2011), el cual a partir de un conjunto de imágenes estéreo
(pares de imágenes) de un objeto visualmente similar a un tablero de ajedrez en diferentes
posiciones calcula dichos parámetros. Para el presente caso se utilizaron los 8 pares estéreo
de la figura 3.3 y los parámetros obtenidos del paso anterior se utilizaron sobre una de las
imágenes de calibración para poder observar el efecto que se tuvo y que se muestra en la
figura 3.4.
Figura 3.3: Los 8 pares de estéreo usados para la calibración de la cámara
En las figuras 3.4a y 3.4b se advierten unas líneas verdes que funcionan como guía

CAPÍTULO 3. METODOLOGÍA 20
(a) Antes de rectificar
(b) Rectificada
Figura 3.4: (a) Ejemplo antes de rectificar la imagen. (b) Ejemplo después de aplicar losparámetros de rectificación.
para comprobar si la rectificación fue o no exitosa, esto se puede saber ya que al observar
las líneas antes de la rectificación estas no están alineadas con los cuadros de la imagen,
mientras que después de la rectificación esto si ocurre. Adicionalmente, en la imagen 3.4b
se pueden observar unas zonas en negro que son las que quedaron sin información (y se
rellenaron) cuando la imagen fue rectificada.
3.4. Segmentación
La segmentación busca dividir una imagen en regiones que tengan un significado para
la tarea actual, o que correspondan a objetos (o partes de objetos) físicos; en este caso se

CAPÍTULO 3. METODOLOGÍA 21
busca separar un objeto del fondo, para facilitar dicho proceso se utiliza un fondo cuyo color
sea lo más homogéneo posible y que al mismo tiempo contraste con los colores del objeto a
reconstruir.
El algoritmo utilizado en el presente trabajo se encuentra en el algoritmo 1, el cual,
de acuerdo a la metodología utilizada asume que el objeto no ocupará nunca las esquinas
porque son consideradas parte del fondo y, por ello, las emplea como referencia para la
segmentación.
Segmentación de objetos
1. Seleccionar el color que se encuentra en el punto (0,0) que equivale a laesquina superior izquierda.
2. Establecer los parámetros de segmentación, si el color del punto (0,0) esmenor a un umbral significa que es negro, por lo que los parámetros dela segmentación serán diferentes.
3. Ejecutar el algoritmo de Flood Fill, con semilla en los puntos (0,0),(0,fi-las),(columnas,0),(columnas,filas). A fin de seleccionar todo el borde.
4. Buscar cualquier punto que esté dentro de un rango del valor del punto(0,0). En caso de que la imagen tenga orificios estos podrán ser elimina-dos.
5. Sumar las máscaras obtenidas y aplicarlas a la imagen.
Fin de la segmentación.Algoritmo 1: Algoritmo de segmentación
3.4.1. Flood Fill
El Flood Fill, también llamado “Llenado por difusión” o “algoritmo de relleno”, es una
técnica que se utiliza para marcar o aislar porciones de una imagen para procesamiento o
análisis; se ocupa para determinar el área formada por elementos contiguos (y de valor igual
o cercanos) en una matriz multidimensional (bidimensional para el caso de las imágenes).
El algoritmo necesita básicamente 3 parámetros de entrada: nodo o semilla (punto inicial),

CAPÍTULO 3. METODOLOGÍA 22
color objetivo, color de reemplazo; una de las formas de implementarlo es como se muestra
en el algoritmo 2.
Flood Fill
1. Si el color de la semilla es diferente del color objetivo Salir.
2. Agregar la semilla a la cola (Q).
3. Para cada elemento N en Q:
a) Seleccionar todos los puntos a la derecha y a la izquierda de N quetienen el color objetivo.
b) Para cada punto n de los seleccionados:
1) Establecer el valor de n al valor del color de reemplazo.
2) Si el valor del punto arriba de n es el color objetivo se agregaa Q.
3) Si el valor del punto abajo de n es el color objetivo se agrega aQ.
c) Continuar hasta que Q se vacíe.
Fin de la segmentación.Algoritmo 2: Algoritmo Flood Fill.
3.5. Obtener el mapa de disparidad (SGBM)
A pesar de que existe una gran cantidad de algoritmos para calcular la disparidad estereo,
entre los más utilizados se encuentran el de Mayhew et al. (1985) y el de Hirschmuller
(2008). El primero se caracteriza por el uso de gradientes que generan mapas de disparidad
obtenidos poco densos mientras que Hirschmuller es un método global que resulta en un
mapa de disparidad densos; de acuerdo a las necesidades de la metología desarrollada en
este trabajo llevaron a elegir el modelo de Hirschmuller.
Aclarado lo anterior la obtención de mapas de disparidad se hizo mediante el algoritmo de
SGBM incluido en la libreria de OpenCV, se seleccionó debido a que está bien documentado,

CAPÍTULO 3. METODOLOGÍA 23
la salida se ajusta a las necesidades de este trabajo, es compatible con las imágenes utilizadas
y es de fácil acceso en caso que fuera necesario replicar los resultados, es una variante del
desarrollado por Hirschmuller (2008), con la diferencia de que en lugar de trabajar pixel a
pixel lo hace mediante “bloques”. El algoritmo realiza un emparejamiento bloque a bloque
entre pares de imágenes con orientación externa e interna conocidas, es decir, asume que las
imágenes están rectificadas. Con ese supuesto trata de minimizar la función de energía que
se muestra en la ecuación 3.2.
E(D) =∑
p
C (p,Dp) +∑
qǫNp
P1I [|Dp −Dq| = 1] +∑
qǫNp
[|Dp −Dq| > 1]
(3.2)
Dónde:
D es la imagen de disparidad.
E(D) es la energía para la imagen de disparidad D.
p,q representan índices de pixeles en la imagen.
Np es la vecindad de pixeles del punto p.
C(p,Dp) es el costo del emparejamiento con la disparidad en Dp.
P1 es la penalización para un cambio en el valor de la disparidad de 1 entre pixeles
vecinos.
P2 es la penalización para cambios en el valor de la disparidad mayores a 1.
I[.] es la función que regresa 1 si los argumentos son verdaderos y 0 en caso contrario.
El valor de C(p, d) es calculado como se muestra en la ecuación 3.3.
C(p,D) = min(d(p, p− d), d(p− d, p, IR, IL)) (3.3)

CAPÍTULO 3. METODOLOGÍA 24
Donde IR y IL son las imágenes rectificadas donde respectivamente: d(p − d, p, IR, IL)) =
minp−d−0,5≤p−d+0,5|IL(p)− IL(q)|.
La función minimizada produce un mapa de disparidad cuya “suavidad” depende de los
valores de P1 y P2. Si S(p, d) es el costo agregado por pixel p y disparidad d, entonces la
fórmula es como se muestra en la ecuación 3.4.
S(p, d) =∑
r
Lr(p, d) (3.4)
Dónde:
r es la dirección usada para converger con el pixel p.
Lr(p, d) es el costo mínimo de la ruta tomada en dirección r del pixel para la disparidad
d.
A su vez, el costo Lr(p, d) está dado por la ecuación 3.5.
Lr(p, d) =C(p, d) +min(Lr(p− r, d), Lr(p− r, d− 1) + P1, Lr(p, d+ 1)+
P1,miniLr(p− r, i) + P2)−minkLr(p− r, k)
(3.5)
La ecuación utiliza los siguientes costos para encontrar la disparidad al sumar el costo
actual (C(p, d)) al pixel anterior en direccion r:
El costo mínimo en el pixel anterior con disparidad d.
El costo en el pixel anterior con disparidad d− 1 y d+ 1 con la penalización P1.
El costo en el pixel anterior con disparidades menores a d − 1 y mayores a d + 1 con
la penalización P2.

CAPÍTULO 3. METODOLOGÍA 25
A fin de limitar el crecimiento de Lr(p, d) se resta el valor mínimo del pixel anterior, mientras
que el mayor valor de Lr(p, d) es limitado por C(max) +P2, donde C(max) es el máximo valor
de costo C.
Para el caso del SGBM el valor de C es sumado para el tamaño de ventana deseado.
Después de probar S(p, d) para cada pixel p y cada disparidad d, el algoritmo selecciona la
disparidad cuyo costo sea el mínimo para ese pixel (o bloque). La función de correspondencia
suma los costos de todos los caminos que convergen en el pixel que está siendo evaluado,
dicho costo es computado para el rango definido entre el número de disparidades permitidas
y la mínima disparidad.
Además, no se debe olvidar que minimizar dicha función para el espacio 2D es un pro-
blema NP-completo, es decir, al aumentar la complejidad el tiempo de procesamiento no
crece de forma polinomial sino exponencialmente, por lo anterior esta técnica aproxima la
minimización 2D mediante múltiples minimizaciones 1D (lineales); con lo que la complejidad
está dada por la ecuación 3.6.
θ(ω · h · η) (3.6)
Donde w es el ancho de la imagen, h la altura de la imagen y n el número de disparidades.
3.6. Ajuste y combinación
3.6.1. Generar nube de puntos
Una vez que se obtiene el mapa de disparidad para cada imagen hay que obtener la nube
de puntos correspondiente a fin de generar un modelo 3D de la vista en cuestión, siendo la
primera imagen la que nos dará el modelo inicial sobre el cual se agregarán todas los demás
modelos.
El primer paso es proyectar el mapa de disparidad al espacio tridimensional, esto se hace

CAPÍTULO 3. METODOLOGÍA 26
mediante la función reprojectImageTo3D, cuya fórmula es 3.7, donde Z es la profundidad
(distancia a la cámara), f es la distancia focal, B es la linea base, Xl y Xr son las coordenadas
horizontales para cada imagen y D es la disparidad.
Z = f ∗B
Xl −Xr
= f ∗B
D(3.7)
Figura 3.5: Diagrama de cámaras estereo paralelas
Partiendo del supuesto de que los ejes de las cámaras son paralelos, como se ve en la
figura 3.5, y utilizando la matriz Q (o matriz de transformación de perspectiva) obtenida
durante la calibración, se genera la nube de puntos que será el nuevo objeto de trabajo en
lugar de las imágenes, ya que estas son la representación tridimensional de la información
recuperada de los pares estéreo.
A continuación, se debe mover el centroide de la nube de puntos al origen del sistema
coordenado a fin de que los centroides coincidan facilitando el procesamiento posterior.
Finalmente se procesa la nube de puntos de tres maneras diferentes:
1. Submuestrar la nube de puntos.
2. Remover outliers.
3. Suavizar nube de puntos.

CAPÍTULO 3. METODOLOGÍA 27
El primer paso es realizar un submuestro que consiste en utilizar un voxel (unidad cúbica
que compone un objeto tridimensional o pixeles tridimensionales) de un tamaño predefinido,
donde, para cada voxel todos los puntos se aproximarán a su centroide de tal forma que
al final se tenga un menor número de puntos, esto con el objetivo de agilizar los siguientes
pasos.
Los outliers son puntos que están lejos de los grupos principales de puntos, por lo que se
consideran como de ruido, he ahí la importancia de eliminarlos. Esto se logra al buscar el
número de “vecinos” que tiene cada punto y si es menor a un umbral el punto es eliminado.
Finalmente podemos afirmar que, los datos que forman las nubes de puntos tienen irre-
gularidades en gran medida dado su origen, es por ello que es necesario realizar un suavizado
de los mismos. Para lograrlo se utiliza el remuestreo (resampling en inglés), que consiste en
recrear las partes faltantes de las superficies mediante interpolaciones polinomiales entre los
datos a su alrededor, corrigiendo pequeños errores.
3.6.2. Rotación y Ajuste
Posteriormente la nube de puntos rota los de grados que indique la formula 3.8, asu-
miendo que las imágenes completan un circulo, que están separadas por la misma rotación
entre si y que giran en el sentido de las manecillas del reloj. Algunos ejemplos se muestran
en el cuadro 3.1 (sin estar limitado el algoritmo a esos valores).
Rotacion = 360/Numerodeimagenes (3.8)
El ajuste está conformado por dos pasos: el primero consiste en medir la altura de la
nube de puntos y escalar las nubes para que tengan la misma altura que la nube inicial, y

CAPÍTULO 3. METODOLOGÍA 28
Número de imágenes Grados de separación2 1803 1204 906 60
Tabla 3.1: Algunos valores de giro.
el segundo consiste en desplazar la nube de puntos en los ejes x y z de acuerdo a un valor
predefinido por el usuario, para dar el volumen al objeto final.
3.7. Triangulación
Finalmente, después de haber unido todas las nubes de puntos provenientes de los dife-
rentes pares estéreo, se debe preparar la nube para exportarla a un formato compatible con
los programas comerciales, permitiendo la importación y edicion de los modelos generados.
Para lograrlo se deben realizar los siguientes pasos:
1. Triangular: Los puntos “sueltos” se transforman a una superficie.
2. Exportar: La superficie se convierte y se guarda a formato STL.
El producto final es un modelo que se puede importar desde diversos programas de
gráficos 3D (como Blenderr).
3.8. Guía de observación
Como se mencionó anteriormente en el presente trabajo se propone una guía de obser-
vación, a fin de poder medir la similitud entre el modelo final y el objeto original, y observa
las siguientes caracteristicas:

CAPÍTULO 3. METODOLOGÍA 29
Textura: El modelo es liso en las zonas del objeto que son lisas y rugoso en las que
así lo son.
Forma exterior: La silueta del objeto es visualmente similar a la del modelo.
Forma interior: El modelo cuenta con “agujeros"donde el objeto los presenta y, en
contraparte, no los presenta donde el objeto tampoco.
Profundidad: La superficie del modelo tiene un mayor valor absoluto en el eje Z en
las zonas donde la superficie del objeto está mas lejos de la cámara.
Cada uno de estos parámetros debe ser calificado para la superficie resultante de cada par
estéreo, donde 0 indica que no se cumple dicha propiedad y 1 que si, y se promedia entre
todas las vistas; para finalmente realizar una sumatoria de todos los parámetros y obtener
un valor entre 0 y 4, donde 0 significa que no se cumple ninguna de dichas caracteristicas
para ninguna cara y 4 que se cumplen todas para todas las caras.

Capítulo 4
Pruebas y resultados
Los resultados obtenidos de la reconstrucción se presentan estructurados de la siguiente
manera: en primera instancia aparecerá una explicación del modelo obtenido junto a los
promedios de la calificación de cada modelo para 5 ejecuciones distintas, seguido de un par
estéreo de muestra, finalizando con imágenes una reconstrucción; cabe señalar que la imagen
de la izquierda incluye únicamente la superficie del objeto mientras que la imagen derecha
incluye la textura, aclarando que para los ejemplos aqui mostrados se utilizaron 4 vistas.
Al final de la sección, a modo de resumen, se presentan los datos estadísticos obtenidos de
todas las corridas para cada objeto reconstruido.
Los objetos seleccionados parten desde lo más simple a lo mas complejo: el primero es
un cubo de Rubik, cuya simplicidad se debe a su forma y textura, mientras que el mas
complicado es el caballero, que presenta multiples texturas, oclusiones, apéndices delgados
y zonas de fondo aisladas por el objeto (el espacio entre las piernas).
30

CAPÍTULO 4. PRUEBAS Y RESULTADOS 31
4.1. Cubo de Rubik
El primer objeto que se digitalizó fue un cubo de Rubik al cual, debido a que el diseño
metodológico asume que la rotación del objeto es únicamente sobre un eje, le faltan la cara
superior e inferior, como se puede ver en la figura 4.3. Mientras que en la figura 4.2 se puede
apreciar la reconstrucción de la parte que se visible en los pares estéreo. Este objeto obtuvo
una calificación promedio de 3.8 en la escala propuesta.
Figura 4.1: Imagen de muestra.
Figura 4.2: Reconstrucción del cubo de Rubik

CAPÍTULO 4. PRUEBAS Y RESULTADOS 32
Figura 4.3: Reconstrucción del cubo de Rubik, vista superior
4.2. Pasta de dientes
Para el siguiente caso se utilizó un objeto rectangular: una caja de pasta de dientes
(figura 4.4) ya que contrario al cubo de Rubik, el desplazamiento en x y z es diferente. En la
figura 4.5 se observa que el modelo de la pasta de dientes presenta una notoria curvatura en
los lados derecho e izquierdo de la caja, lo cual, tiene como consecuencia que el lado derecho
no encaje con los demás (figura 4.6), dicha curvatura se deriva del error producido durante
el proceso de match estéreo. La calificación promedio de este modelo fue de 3.35.
Figura 4.4: Imagen de muestra.

CAPÍTULO 4. PRUEBAS Y RESULTADOS 33
Figura 4.5: Reconstrucción de la caja de pasta de dientes, primera vista
Figura 4.6: Reconstrucción de la caja de pasta de dientes, segunda vista
4.3. Flexómetro
Con el objetivo de aumentar la complejidad del objeto a digitalizar se seleccionó un
flexómetro, el cual, en la vista lateral (figura 4.8) mantiene la forma del objeto en términos
generales aunque existen algunas zonas faltantes en la vista frontal (figura 4.9); lo descrito
anteriormente se debe en gran medida a que el algoritmo de match estéreo no encontró
coincidencias entre los puntos de esas zonas en los pares estéreo, presumiblemente porque
son zonas con pocos puntos distintivos (figura 4.7). La calificación promedio fue de 3.5 para
este modelo.

CAPÍTULO 4. PRUEBAS Y RESULTADOS 34
Figura 4.7: Imagen de referencia.
Figura 4.8: Reconstrucción del flexómetro, vista lateral
Figura 4.9: Reconstrucción del flexómetro, vista frontal

CAPÍTULO 4. PRUEBAS Y RESULTADOS 35
4.4. Caballo
El siguiente objeto digitalizado fue un caballo de bronce, el cual se muestra en la figura
4.10. Mientras que en la figura 4.11 se observa que la reconstrucción en las caras laterales
respeta la forma, sin embargo la cara frontal y trasera carecen de información que permita
una reconstrucción fiel al objeto, esto se puede apreciar en la figura 4.12. Este problema se
debe a que una superficie menor limita la búsqueda de pares conjugados. Las caras frontal
y trasera tuvieron un gran impacto por lo que la calificación promedio de este modelo fue
de 2.85.
Figura 4.10: Imagen de muestra del caballo de bronce.
Figura 4.11: Reconstrucción del caballo, vista lateral.

CAPÍTULO 4. PRUEBAS Y RESULTADOS 36
Figura 4.12: Reconstrucción del caballo, vista frontal
4.5. Dragón
A continuación se digitalizó el modelo de un dragón (figura 4.13), como se puede apreciar
en la figura 4.14 en terminos generales la información obtenida se consideraria suficiente
para reconstruir el objeto, sin embargo, la textura del mismo propició que el match estéreo
calculará los pares conjugados de forma errónea, generando un modelo con ruido (la textura
del modelo no corresponde con la del objeto). Por ello la calificación este modelo fue de 2.75
en promedio.
Figura 4.13: Imagen de muestra.

CAPÍTULO 4. PRUEBAS Y RESULTADOS 37
Figura 4.14: Reconstrucción del dragón, vista lateral
Figura 4.15: Reconstrucción del dragón, vista frontal
4.6. Caballero
Finalmente se digitalizó el modelo de un caballero (figura 4.16) y como se puede apreciar
en las figuras 4.17 y 4.17 aunque la forma general es mantenida, el match estéreo presenta
problemas con las estructuras delgadas, detalles, oclusion, sombras y patrones finos. Por ello
la calificación promedio para este modelo es de 3.2.

CAPÍTULO 4. PRUEBAS Y RESULTADOS 38
Figura 4.16: Imagen de muestra.
Figura 4.17: Reconstrucción del caballero, primera vista
Figura 4.18: Reconstrucción del caballero, segunda vista

CAPÍTULO 4. PRUEBAS Y RESULTADOS 39
4.7. Discusión de resultados
El propósito de este trabajo fue la creación de modelos 3D a partir de imágenes estéreo,
además, a fin de medir la calidad de dichos modelos se propuso una guía de observación
(sección 3.8) cuyos valores estadísticos se muestran en la gráfica 4.1, es importante señalar
que existe una baja desviación estandar entre las corridas del mismo objeto, lo que indica
que aunque hay diferencias entre sus calificaciones pero estas no son muy grandes, que se
puede traducir en que es un algoritmo estable.
Objeto Calificación
Promedio Mediana σ Min. Max.
Cubo de Rubik 3.8 3.75 0.1 3.75 4
Flexómetro 3.3 3.25 0.18 3 3.5
Pasta de dientes 3.25 3.25 0.25 3 3.75
Caballero 3.2 3.25 0.18 3 3.5
Caballo 2.85 3 0.2 2.5 3
Dragón 2.8 2.75 0.1 2.75 3
Tabla 4.1: Datos estadísticos de la calificación de los modelos.
El cubo de Rubik fue el que mejor resultados dio y el dragón el modelo cuya calificación
fue la mas baja de todo el proyecto, el problema principal para este ultimo fue la textura
que no se logró digitalizar correctamente, lo anterior puede atribuirse a que la superficie del
objeto confunde al algoritmo de match estéreo, el cual no puede encontrar las corresponden-
cias correctamente; en el caso del flexómetro y el caballo hubo problemas en la profundidad
en las caras frontal y trasera, presumiblemente por la combinación del color negro con la
angosta superficie de dichas caras, donde el color disminuye la cantidad de puntos caracte-
rísticos y el área angosta disminuye el campo de busqueda. En general la forma tanto interna
CAPÍTULO 4. PRUEBAS Y RESULTADOS 40
como externa se mantienen, la profundidad es mayormente la correcta aunque con claras
excepciones (la pasta de dientes, las caras frontal y trasera del caballo y el flexómetro), por
otro lado los objetos cuya superficie es principalmente lisa no presentaron problemas para la
reconstrucción de la textura, no asi los objetos con una superficie mas intrincada (el dragón
y algunas zonas del caballero).
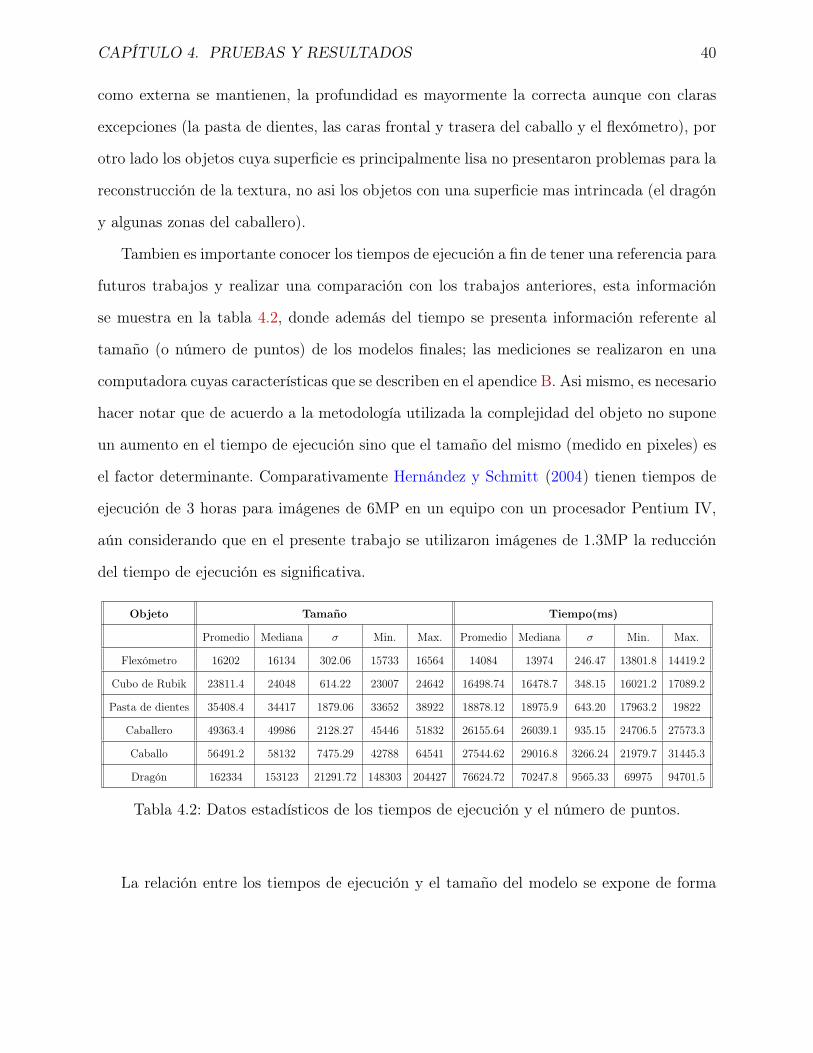
Tambien es importante conocer los tiempos de ejecución a fin de tener una referencia para
futuros trabajos y realizar una comparación con los trabajos anteriores, esta información
se muestra en la tabla 4.2, donde además del tiempo se presenta información referente al
tamaño (o número de puntos) de los modelos finales; las mediciones se realizaron en una
computadora cuyas características que se describen en el apendice B. Asi mismo, es necesario
hacer notar que de acuerdo a la metodología utilizada la complejidad del objeto no supone
un aumento en el tiempo de ejecución sino que el tamaño del mismo (medido en pixeles) es
el factor determinante. Comparativamente Hernández y Schmitt (2004) tienen tiempos de
ejecución de 3 horas para imágenes de 6MP en un equipo con un procesador Pentium IV,
aún considerando que en el presente trabajo se utilizaron imágenes de 1.3MP la reducción
del tiempo de ejecución es significativa.
Objeto Tamaño Tiempo(ms)
Promedio Mediana σ Min. Max. Promedio Mediana σ Min. Max.
Flexómetro 16202 16134 302.06 15733 16564 14084 13974 246.47 13801.8 14419.2
Cubo de Rubik 23811.4 24048 614.22 23007 24642 16498.74 16478.7 348.15 16021.2 17089.2
Pasta de dientes 35408.4 34417 1879.06 33652 38922 18878.12 18975.9 643.20 17963.2 19822
Caballero 49363.4 49986 2128.27 45446 51832 26155.64 26039.1 935.15 24706.5 27573.3
Caballo 56491.2 58132 7475.29 42788 64541 27544.62 29016.8 3266.24 21979.7 31445.3
Dragón 162334 153123 21291.72 148303 204427 76624.72 70247.8 9565.33 69975 94701.5
Tabla 4.2: Datos estadísticos de los tiempos de ejecución y el número de puntos.
La relación entre los tiempos de ejecución y el tamaño del modelo se expone de forma
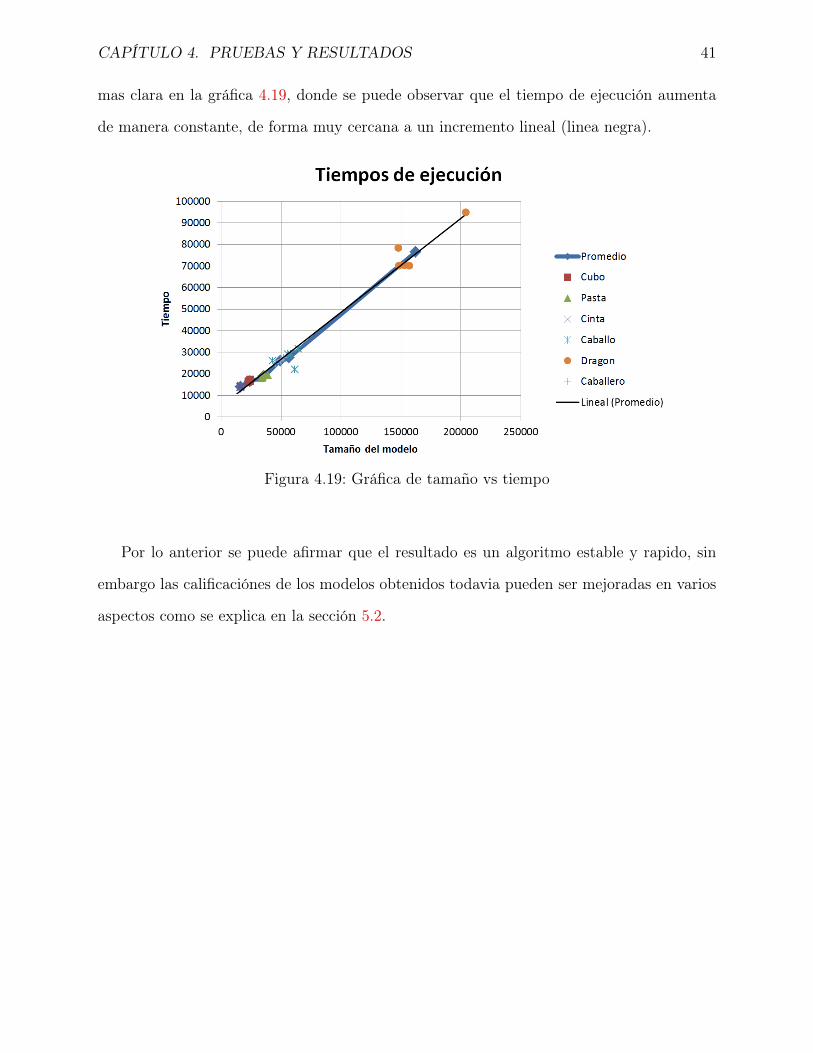
CAPÍTULO 4. PRUEBAS Y RESULTADOS 41
mas clara en la gráfica 4.19, donde se puede observar que el tiempo de ejecución aumenta
de manera constante, de forma muy cercana a un incremento lineal (linea negra).
Figura 4.19: Gráfica de tamaño vs tiempo
Por lo anterior se puede afirmar que el resultado es un algoritmo estable y rapido, sin
embargo las calificaciónes de los modelos obtenidos todavia pueden ser mejoradas en varios
aspectos como se explica en la sección 5.2.

Capítulo 5
Conclusiones y trabajo futuro
En el presente capítulo se exponen los logros de la tesis (sección 5.1), propuestas pa-
ra trabajos futuros y los limites del trabajo (sección 5.2), para finalmente presentar las
conclusiones (sección 5.3).
5.1. Logros de la tesis
Esta tesis desarrolló un método para generar modelos 3D de objetos opacos y rigidos a
partir de una secuencia de pares estéreo capturadas a partir del movimiento de este en el
sentido de las manecillas del reloj. Entre las aportaciones del presente trabajo, a la generación
de modelos 3D, se encuentra el desarrollo de un programa modular, facilmente modificable
y ampliable, asi como la creación de un marco general para la digitalización de objetos a
partir de series de pares estéreo, por medio de la siguiente secuencia:
1. Pre procesar las imágenes
2. Rectificación
3. Segmentación
42

CAPÍTULO 5. CONCLUSIONES Y TRABAJO FUTURO 43
4. Obtener el mapa de disparidad
5. Rotar y sumar
6. Triangulación
5.2. Limitaciones y Trabajo futuro
El principal problema que se enfrentó durante la presente tesis fue que el algoritmo de
match estéreo no fue lo suficientemente robusto, produciendo que algunos modelos no man-
tuvieran la forma original (sección 4.2), presentaban áreas incompletas cuando las areas
tenian un ancho cercano o menor a 100 pixeles y de color negro debido, en gran medida, a
que el algoritmo no tiene suficiente información para encontrar los pares conjugados. (sec-
ciones 4.4,4.5) o ruido derivado de ciertas texturas presentes en los objeto (sección 4.5);
lo anterior se origina del problema de correspondencia estéreo que no ha sido solucionado
dentro del área de visión por computadora. En este sentido, cabe señalar que aunque en
ningún momento el objetivo fue solucionar el problema del match estéreo sería conveniente
encontrar o desarrollar un algoritmo de match estéreo que dé mejores resultados.
Una vez que se cuente con un algoritmo de match estéreo que provea de información sufi-
cientemente robusta, se puede esperar que los pasos subsecuentes reflejen esta mejoría en
la calidad del modelo final. Se considera que para trabajos futuros, se podría incluir un
algoritmo de registro automático para las nubes de puntos que permitiera girar el objeto a
reconstruir en ángulos y ejes arbitrarios, mejorando la robustez final.
5.3. Conclusiones
La reconstrucción de objetos mediante cámaras estéreo ha avanzado enormemente en los
últimos años, sin embargo, todavía tiene mucho camino por recorrer. Existe un enorme po-

CAPÍTULO 5. CONCLUSIONES Y TRABAJO FUTURO 44
der de cómputo comparado al que existía hace unos años y que se ha reflejado en algoritmos
más rápidos y con menores tiempos de ejecución.
A pesar de ello todavía hay muchos problemas por resolver, el principal a enfrentar
durante la reconstrucción de modelos mediante cámaras estéreo es el algoritmo de match
estéreo ya que sus limitantes entorpecen todo el proceso independientemente de la calidad
de los procesos previos y posteriores.
Aunque técnicamente es posible generar un modelo 3D de un objeto utilizando múltiples
vistas y cámaras estéreo, es necesario un algoritmo de match estéreo que proporcione un
mapa de disparidad preciso, a fin de que las nubes de puntos también lo sean.

Bibliografía
Anagnostopoulos, C., Vergados, D., Kayafas, E., Loumos, V., y Stassinopoulos, G. (2001,
February). A computer vision approach for textile quality control. The Journal of Visua-
lization and Computer Animation, 12 .
Bebis, G. (2004). Stereo vision. Reno. Descargado de http://www.cse.unr.edu/~bebis/
CS791E/Notes/StereoCamera.pdf
Delaunay, B. (1934). Sur la sphère vide. a la mémoire de georges voronoï. Classe des
sciences mathématiques et naturelles.
Eisert, P., Steinbach, E., y Girod, B. (2012). Automatic reconstruction of stationary 3d
objects from multiple uncalibrated camera views.
Etayo, M., y Fernando, E. (2012). Hasta el infinito y más allá. Universidad de Cantabria.
González, Y. (2010). Aplicaciones de la visión por computador. Descargado de http://
dmi.uib.es/~ygonzalez/VI/Material_del_Curso/Teoria/Aplicaciones_VC.PDF
Hartley, R., y Zisserman, A. (2008). Multiple view geometry in computer vision. Cambridge
University Press.
Hernández, C., y Schmitt, F. (2004, Diciembre). Silhouette and stereo fusion for 3D object
modeling.
45

BIBLIOGRAFÍA 46
Hernandez Sampieri, R., Fernández-Collado, C., y Pilar Baptista, L. (2006). McGraw-Hill.
Hirschmuller, H. (2008, Febrero). Stereo processing by semiglobal matching and mutual
information. IEEE Trans. Pattern Anal. Mach. Intell., 30 (2).
Horn, B. K. P. (1986). Robot vision. Cambridge, Massachusetts: The MIT press.
Konolige, K. (s.f.). Stereo geometry.
Marr, D. (s.f.). Vision: A computational investigation into human representation and
processing of visual information. Cambridge, Massachusetts: The MIT press.
Marr, D. C., y Poggio, T. (1979). A computational theory of human stereo vision.
Mayhew, J. E., Pollard, S. B., y Frisby, J. P. (1985). Pmf: A stereo correspondence
algorithm using a disparity gradient limit. Perception(14).
Medioni, G., y Kang, S. B. (2004). Prentice Hall.
Peris, M. (2011, Enero). Opencv: Stereo camera calibration. Descargado de http://
blog.martinperis.com/2011/01/opencv-stereo-camera-calibration.html
Platero, C. (s.f.). Introducción a la visión artificial. Descargado de
http://www.elai.upm.es/webantigua/spain/Asignaturas/MIP_VisionArtificial/
ApuntesVA/cap1IntroVA.pdf
Po-Han, L., Jui-Wen, H., y Huei-Yung, L. (2012, Noviembre). 3d model reconstruction
based on multiple view image capture.
Prince, S. J. D. (2012). Computer vision: models, learning and inference. Cambridge
University. Descargado de http://www.computervisionmodels.com

BIBLIOGRAFÍA 47
Revelo-Luna, D. A., Usama, F. D., y Flórez-Marulanda, J. F. (2012). reconstrucción 3D
de escenas mediante un sistema de visión estéreo basado en extracción de características y
desarrollado en opencv". Ingeniería y Universidad, vol. 16, num. 2, julio-diciembre.
Scharstein, D., y Szeliski, R. (2002). A taxonomy and evaluation of dense two-frame stereo
correspondence algorithms.
Siegel, R. M. (s.f.). Choices: The science of bela julesz. Descargado de https://www.ncbi
.nlm.nih.gov/pmc/articles/PMC423145/
Spada, M. (s.f.). Php: triangolazioni di delaunay in 2d.
Szeliski, R. (2010). Computer vision: Algorithms and applications (draft). Springer. Des-
cargado de http://szeliski.org/Book/
Trakic, E., Saric, B., Osmanovic, A., y Lovric, S. (2011, Abril). Integration mechatric
components of laser triagulation for 3D digitalization of the object. International Journal
of Mechanical & Mechatronics Engineering IJMME-IJENS Vol: 11 No: 02 .

Apéndice A
Características de la cámara
A continuación se muestran las características principales de la cámara usada. La lista
completa está disponible en http://www.fujifilm.com.mx/productos/camaras_finepix/
real_3d/real3DW3/specifications/.
Número de pixeles efectivos 10 millones de pixeles
Sensor CCD 1/2.3 pulgadas x2
Soporte de almacenamiento
Memoria interna (aprox. 34MB) /
tarjeta de memoria SD /
tarjeta de memoria SDHC
ObjetivoZoom óptico Fujinon 3x, F3,7 (gran angular) -
F4,2 (teleobjetivo)
Longitud focal del objetivof=6,3 mm - 18,9 mm (equivalente a 35-105 mm
en una cámara de 35 mm)
Zoom
3D: hasta 3,4x (combinación entre
zoom óptico y digital)
2D: hasta 17,1x (combinación entre
zoom óptico 3x y zoom digital 5,7x)
xv

APÉNDICE A. CARACTERÍSTICAS DE LA CÁMARA xvi
AberturaGran angular: F3,7 - F8,
teleobjetivo: F4,2 - F9
Distancia de enfoque
(desde la superficie del objetivo)
Normal: aprox. 60 cm a infinito.
Macro (3D): gran angular: aprox. 38 cm a 70 cm
Teleobjetivo: aprox. 1,1 m a 2,3 m
Macro (2D): gran angular: aprox. 8 cm a 80 cm
Teleobjetivo: aprox. 60 cm a 3 m
Distancia de disparo
recomendada para 3D
Normal: (gran angular) aprox. 1.3 m
(teleobjetivo) aprox. 3.7 m
Macro: (gran angular) aprox. 48 cm - 70 cm
(teleobjetivo) aprox. 1.4 cm - 2.2 m
Sensibilidad
AUTO(400)/AUTO(800)/AUTO(1600) /
Equivalente a 100/200/400/800/1600
ISO (Salida Estndar de Sensibilidad)
Velocidad de obturador
Escenas nocturnas: 1/8 de seg. - 1/500 de seg.
Escenas nocturnas (trípode): 3 seg. - 1/500 de seg.
Manual: seg. - 1/1000 de seg.
Todos los demás modos incluyendo AUTO: de seg. a
1/1000 de seg.
Disparos continuos
3D: 40 primeros (mx. 2 fps, sólo “S”)
2D: 40 primeros (mx. 1 fps)
2D: Alta velocidad: 40 primeros (mx. 3 fps, slo “S“)

APÉNDICE A. CARACTERÍSTICAS DE LA CÁMARA xvii
Enfoque
Modo: AF Simple
Modo AF: 3D: Centro
2D: Centro, Múltiple (sólo con detección
de rostros desactivado)
Autodisparador Aprox. 10 seg./2 seg. de retardo
Pantalla LCD
Pantalla LCD de color TFT de 3,5 pulgadas,
aprox. 1.150.000 puntos,
tipo lenticular, cobertura aproximada del 100 %
Funciones de fotografía
3D: control automático de paralaje,
control de energía,
líneas guías de encuadre,
memoria de número de fotograma
2D: Detección de rostros
(con eliminación de ojos rojos),
control de energía,
líneas guías de encuadre,
memoria de número de fotograma
Tabla A.1: Características de la cámara

Apéndice B
Características del equipo
Las características del equipo utilizado para las pruebas realizadas se describen en la
tabla B.1.
Sistema operativo Linux (Ubuntu 14.10)Procesador Intel(R) Core(TM) i7-3610QM CPU @ 2.30GHz
Memoria Ram 16266MBDisco duro ST1000LM014-1EJ164 (931 GB)
Tarjeta de video GeForce GT 650M
Tabla B.1: Características del equipo utilizado
xviii


















