
Inteligencia Artificial e Ingenier´ıa del...
96
Inteligencia Artificial e Ingenier´ ıa del Conocimiento F´ elix G´ omez M´ armol 4 o Ingenier´ ıa Inform´ atica
Transcript of Inteligencia Artificial e Ingenier´ıa del...

Inteligencia Artificial e Ingenierıadel Conocimiento
Felix Gomez Marmol
4o Ingenierıa Informatica

2

Indice general
I Inteligencia Artificial 7
1. Resolucion de Problemas 91.1. Estrategias de busqueda en grafos: heurısticas . . . . . . . . . . . . . . . . . . 9
1.1.1. Busqueda primero el mejor . . . . . . . . . . . . . . . . . . . . . . . . 101.1.2. Busqueda A* . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121.1.3. Busqueda con memoria acotada . . . . . . . . . . . . . . . . . . . . . . 14
1.2. Estrategias de Busqueda en Grafos YO: Heurısticas . . . . . . . . . . . . . . . 161.2.1. Caracterısticas de las funciones de evaluacion para grafos YO . . . . . 181.2.2. Busqueda mejor nodo para grafos YO . . . . . . . . . . . . . . . . . . 19
1.3. Funciones Heurısticas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 231.3.1. Efecto de la precision heurıstica en el rendimiento . . . . . . . . . . . 231.3.2. Inventando funciones heurısticas . . . . . . . . . . . . . . . . . . . . . 24
1.4. Estrategias de Busqueda Local y Problemas de Optimizacion . . . . . . . . . 251.4.1. Busqueda de ascension de colinas (mejor avara) . . . . . . . . . . . . . 251.4.2. Busqueda tabu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 271.4.3. Busqueda por haz local . . . . . . . . . . . . . . . . . . . . . . . . . . 301.4.4. Algoritmo genetico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
1.5. Estrategias de Busqueda Online . . . . . . . . . . . . . . . . . . . . . . . . . . 311.6. Estrategias en adversarios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
1.6.1. Juegos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 331.6.2. Decisiones en tiempo real imperfectas . . . . . . . . . . . . . . . . . . 351.6.3. Juegos que incluyen un elemento de posibilidad . . . . . . . . . . . . . 36
2. Representacion del Conocimiento. Razonamiento 372.1. Representacion del Conocimiento mediante Logicas no Clasicas . . . . . . . . 37
2.1.1. Logicas no monotonas . . . . . . . . . . . . . . . . . . . . . . . . . . . 372.1.2. Logica de situaciones . . . . . . . . . . . . . . . . . . . . . . . . . . . . 372.1.3. Logica difusa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
2.2. Representacion y Razonamiento con Incertidumbre . . . . . . . . . . . . . . . 402.2.1. Representacion y fuentes de incertidumbre . . . . . . . . . . . . . . . . 402.2.2. Teorıa de Dempster-Shafer de la evidencia . . . . . . . . . . . . . . . . 41
2.3. Representaciones Estructuradas del Conocimiento . . . . . . . . . . . . . . . . 452.3.1. Redes Semanticas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 452.3.2. Marcos o Frames . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 482.3.3. Guiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
3. Planificar para la Resolucion de Problemas 533.1. Planificacion y Resolucion de Problemas . . . . . . . . . . . . . . . . . . . . . 53
3.1.1. El problema de la planificacion . . . . . . . . . . . . . . . . . . . . . . 533.1.2. Tipos de planificadores, estados y operadores . . . . . . . . . . . . . . 543.1.3. Metodos de planificacion . . . . . . . . . . . . . . . . . . . . . . . . . . 55
3

4 INDICE GENERAL
3.2. Planificacion de Orden Total . . . . . . . . . . . . . . . . . . . . . . . . . . . 563.2.1. Planificacion usando una pila de objetivos (STRIPS) . . . . . . . . . . 563.2.2. STRIP con proteccion de objetivos (RSTRIP) . . . . . . . . . . . . . . 59
3.3. Planificacion Ordenada Parcialmente . . . . . . . . . . . . . . . . . . . . . . . 603.3.1. Planificacion no lineal sistematica (PNLS) . . . . . . . . . . . . . . . . 61
3.4. Planificacion Jerarquica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
4. El Aprendizaje Computacional 634.1. El Problema del Aprendizaje Computacional . . . . . . . . . . . . . . . . . . 634.2. Conceptos Basicos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
4.2.1. Tipos, fases y caracterısticas del aprendizaje . . . . . . . . . . . . . . 634.2.2. Estimacion del error . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
5. Aprendizaje por Induccion en Modo Estructural 675.1. Programa de aprendizaje de Winston . . . . . . . . . . . . . . . . . . . . . . . 67
5.1.1. Generalizacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 675.1.2. Especializacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
5.2. Espacio de versiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
6. Aprendizaje Basado en Instancias 736.1. Convergencia de los Metodos Basados en Instancias . . . . . . . . . . . . . . . 736.2. Aprendizaje mediante kM vecinos . . . . . . . . . . . . . . . . . . . . . . . . . 746.3. Aprendizaje mediante el metodo de Parzen . . . . . . . . . . . . . . . . . . . 756.4. Mejora de los metodos basados en instancias . . . . . . . . . . . . . . . . . . 75
6.4.1. Multiedicion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 766.4.2. Condensacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
6.5. Funciones Distancia Heterogeneas . . . . . . . . . . . . . . . . . . . . . . . . . 786.5.1. Normalizacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 786.5.2. Discretizacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 786.5.3. Distintas metricas para el calculo de distancias . . . . . . . . . . . . . 79
7. Maquinas de Aprendizaje 817.1. El Perceptron como Discriminante Lineal . . . . . . . . . . . . . . . . . . . . 81
7.1.1. Criterio y construccion del perceptron . . . . . . . . . . . . . . . . . . 827.2. Redes de Perceptrones Multicapa . . . . . . . . . . . . . . . . . . . . . . . . . 827.3. Arboles de Clasificacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 847.4. Arboles de Regresion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
8. Aprendizaje por Descubrimiento 878.1. Clustering o Agrupamiento . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
8.1.1. Algoritmo de k-medias . . . . . . . . . . . . . . . . . . . . . . . . . . . 878.1.2. Mapas autoasociativos de Kohonen . . . . . . . . . . . . . . . . . . . . 88
II Ingenierıa del Conocimiento 91
9. Principios de la Ingenierıa del Conocimiento 93
10.La Adquisicion del Conocimiento 95

Indice de figuras
1.1. Grafo de mapa de carreteras . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111.2. Busqueda Primero Mejor Avaro . . . . . . . . . . . . . . . . . . . . . . . . . . 111.3. Busqueda A* . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121.4. Funcion heurıstica e-admisible . . . . . . . . . . . . . . . . . . . . . . . . . . . 131.5. Busqueda Primero el Mejor Recursiva . . . . . . . . . . . . . . . . . . . . . . 151.6. Busqueda A* con memoria acotada simplificada (A*MS) . . . . . . . . . . . . 151.7. Arbol YO con la profundidad de cada nodo . . . . . . . . . . . . . . . . . . . 161.8. Arbol YO no puro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 161.9. Hipergrafo o grafo YO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 171.10. Soluciones del Hipergrafo de la figura 1.9 . . . . . . . . . . . . . . . . . . . . 171.11. Ejemplo de busqueda del grafo solucion optimo . . . . . . . . . . . . . . . . . 181.12. Grafo YO con h(n) no monotona . . . . . . . . . . . . . . . . . . . . . . . . . 191.13. Solucion al grafo de la figura 1.12 propagando por conectores marcados . . . 211.14. Solucion al grafo de la figura 1.12 propagando por todos los antecesores . . . 211.15. Grafo YO con h(n) monotona . . . . . . . . . . . . . . . . . . . . . . . . . . . 221.16. Solucion al grafo de la figura 1.15 propagando por conectores marcados . . . 221.17. Grafo YO con varias soluciones con distintos costos . . . . . . . . . . . . . . . 221.18. Soluciones al Grafo YO de la figura 1.17 . . . . . . . . . . . . . . . . . . . . . 231.19. Funcion admisible h = max(h1, h2, h3) ≤ h∗ . . . . . . . . . . . . . . . . . . . 251.20. Funcion Objetivo vs Espacio de Estados . . . . . . . . . . . . . . . . . . . . . 251.21. Juego de las 3 en raya . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 331.22. Estados terminales en el juego de las 3 en raya . . . . . . . . . . . . . . . . . 341.23. Estrategia MiniMax . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 341.24. Ejemplo de juego con 3 jugadores . . . . . . . . . . . . . . . . . . . . . . . . . 341.25. Poda alfa-beta . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 351.26. Juego de las 3 en raya con profundidad limitada . . . . . . . . . . . . . . . . 351.27. Ejemplo de estrategia MiniMax Esperada . . . . . . . . . . . . . . . . . . . . 36
2.1. Ejemplo de logica de situaciones . . . . . . . . . . . . . . . . . . . . . . . . . 382.2. Funcion de pertenencia continua ser joven . . . . . . . . . . . . . . . . . . . 382.3. Funciones de pertenencia µA y µNO A . . . . . . . . . . . . . . . . . . . . . . 382.4. Funcion de pertenencia discreta ser joven . . . . . . . . . . . . . . . . . . . . 392.5. Operadores de Zadeh . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 392.6. Extension Cilındrica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 402.7. Ejemplo de Red Semantica . . . . . . . . . . . . . . . . . . . . . . . . . . . . 462.8. Ejemplo de regla en una Red Semantica . . . . . . . . . . . . . . . . . . . . . 462.9. Ejemplo de Red Semantica con un hecho y una regla . . . . . . . . . . . . . . 462.10. Ejemplo de reglas que relacionan elementos temporales . . . . . . . . . . . . . 472.11. Ejemplo de inferencia en redes semanticas (1) . . . . . . . . . . . . . . . . . . 472.12. Ejemplo de inferencia en redes semanticas (2) . . . . . . . . . . . . . . . . . . 482.13. Ejemplo de inferencia en redes semanticas (3) . . . . . . . . . . . . . . . . . . 48
5

6 INDICE DE FIGURAS
2.14. Ejemplo de frame “Empleado” y “Padre de Familia” . . . . . . . . . . . . . . 482.15. Ejemplo de jerarquıa de frames . . . . . . . . . . . . . . . . . . . . . . . . . . 49
3.1. Ejemplo de planificacion no lineal . . . . . . . . . . . . . . . . . . . . . . . . . 603.2. Operador MOVER(X,Y,Z) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 613.3. Ejemplo de planificacion no lineal sistematica . . . . . . . . . . . . . . . . . . 62
4.1. Fases del aprendizaje . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
5.1. Ejemplos de la base de entrenamiento. Generalizacion . . . . . . . . . . . . . 685.2. Ejemplos de la base de entrenamiento. Especializacion (1) . . . . . . . . . . . 685.3. Ejemplos de la base de entrenamiento. Especializacion (2) . . . . . . . . . . . 695.4. Ejemplo de aprendizaje del concepto “arco” . . . . . . . . . . . . . . . . . . . 715.5. Frame Coche . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
6.1. Fases del aprendizaje basado en instancias . . . . . . . . . . . . . . . . . . . . 736.2. Aprendizaje basado en k-vecinos . . . . . . . . . . . . . . . . . . . . . . . . . 746.3. Aprendizaje basado en Parzen . . . . . . . . . . . . . . . . . . . . . . . . . . . 756.4. Multiedicion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 766.5. Base de ejemplos particionada . . . . . . . . . . . . . . . . . . . . . . . . . . . 776.6. Base de ejemplos particionada y parcialmente multieditada . . . . . . . . . . 776.7. Condensacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 776.8. Discretizacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
7.1. Esquema de un Perceptron . . . . . . . . . . . . . . . . . . . . . . . . . . . . 817.2. Ejemplo de clases linealmente separables . . . . . . . . . . . . . . . . . . . . . 817.3. Ejemplo de clases NO linealmente separables . . . . . . . . . . . . . . . . . . 827.4. Ejemplo de perceptron multicapa . . . . . . . . . . . . . . . . . . . . . . . . . 837.5. Estructura de un perceptron multicapa . . . . . . . . . . . . . . . . . . . . . . 837.6. Ejemplo de arbol de clasificacion . . . . . . . . . . . . . . . . . . . . . . . . . 847.7. Ejemplo de poda por estimacion del error . . . . . . . . . . . . . . . . . . . . 85
8.1. Mapa autoasociativo de Kohonen . . . . . . . . . . . . . . . . . . . . . . . . . 88

Parte I
Inteligencia Artificial
7


Capıtulo 1
Resolucion de Problemas
funcion BUSQUEDA-ARBOLES(problema,frontera) devuelve una solucion o fallofrontera ← INSERTA(HACER-NODO(ESTADO-INICIAL[problema]),frontera)hacer
si VACIA(frontera) entonces devolver fallonodo ← BORRAR-PRIMERO(frontera)si TEST-OBJETIVO[problema] aplicado al ESTADO[nodo] es ciertoentonces devolver SOLUCION(nodo)frontera ← INSERTA-TODO(EXPANDIR(nodo,problema),frontera)
Function BUSQUEDA-ARBOLES(problema,frontera)
funcion EXPANDIR(nodo,problema) devuelve un conjunto de nodossucesores ← conjunto vacıopara cada (accion, resultado) en SUCESOR[problema](ESTADO[nodo]) hacer
s ← un nuevo NODOESTADO[s] ← resultadoNODO-PADRE[s] ← nodoACCION[s] ← accionCOSTO-CAMINO[s] ←COSTO-CAMINO[nodo]+COSTO-INDIVIDUAL(nodo,accion,s)PROFUNDIDAD[s] ← PROFUNDIDAD[nodo] + 1anadir s a sucesores
devolver sucesoresFunction EXPANDIR(nodo,problema)
1.1. Estrategias de busqueda en grafos: heurısticas
Definicion 1.1 Llamaremos estado a la configuracion del problema en un momento deter-minado.
Definicion 1.2 Llamaremos nodo al conjunto formado por el estado del problema, el padredel nodo, la profundidad del mismo, el coste asociado con el y la accion que lo produjo.
Definicion 1.3 Llamaremos conjunto de cerrados al conjunto de nodos que ya han sidoestudiados.
9

10 Capıtulo 1. Resolucion de Problemas
funcion BUSQUEDA-GRAFOS(problema,frontera) devuelve una solucion o fallocerrado ← conjunto vacıofrontera ← INSERTA(HACER-NODO(ESTADO-INICIAL[problema]),frontera)hacer
si VACIA(frontera) entonces devolver fallonodo ← BORRAR-PRIMERO(frontera)si TEST-OBJETIVO[problema](ESTADO[nodo]) es ciertoentonces devolver SOLUCION(nodo)si ESTADO[nodo] no esta en cerrado entonces
anadir ESTADO[nodo] a cerradofrontera ← INSERTA-TODO(EXPANDIR(nodo,problema),frontera)
Function BUSQUEDA-GRAFOS(problema,frontera)
Definicion 1.4 Llamaremos conjunto de abiertos o frontera al conjunto de nodos quehan sido expandidos, pero que aun no han sido estudiados.
En arboles no existen nodos repetidos y es por esto que no existe el conjunto de cerrados,ni se comprueba este hecho. En grafos, sin embargo, si a un nodo se llega por varios caminos,nos quedamos siempre con un solo nodo: el mejor.
Los nodos internos de una estructura de arbol expandido1 pertenecen siempre a cerrados,mientras que las hojas pertenecen a la frontera (salvo aquellas hojas que no son solucion, lascuales tambien estaran en el conjunto de cerrados).
1.1.1. Busqueda primero el mejor
Para anadir informacion heurıstica, ordenamos la frontera segun una funcion f(n)2 quemide el costo necesario para llegar hasta la solucion. Ası, en cada paso del algoritmo, tomamosel primer nodo de la lista (aquel que menor valor de f tenga).
Esta funcion f(n) se compone total o parcialmente de otra funcion h(n) (llamada funcionheurıstica), que siempre cumple que h(objetivo) = 0. Ademas, dicha funcion f(n) se vaadaptando segun se resuelve el problema (la funcion de costo uniforme, por ejemplo, no).
Las estrategias de busqueda vistas en cursos anteriores (profundidad, anchura, costo uni-forme, etc.) no son mas que un caso particular de la Busqueda Primero el Mejor.
Definicion 1.5 Diremos que un algoritmo es completo si siempre devuelve una solucion,cuando esta existe.
Definicion 1.6 Diremos que un algoritmo es admisible si siempre devuelve una solucionoptima, cuando esta existe.
Definicion 1.7 Llamaremos funcion heurıstica a aquella funcion h que cumple que
h(n) ≤ h∗(n), ∀ n
(siendo h∗ la funcion heurıstica optima y h una estimacion).
Nota.- Nosotros vamos a suponer que la expansion de un nodo es siempre com-pleta y que la informacion heurıstica “solo” sirve para decidir que nodo (de entrelos expandidos) debemos estudiar.
1El arbol que resulta de expandir un grafo2Donde n representa a un nodo cualquiera

1.1 Estrategias de busqueda en grafos: heurısticas 11
Busqueda Primero el Mejor Avaro
Para este tipo de busqueda la funcion f se define como
f(n) = h(n), ∀ n
Ejemplo 1.1 Sea el grafo de la figura 1.1 que representa un mapa de carreteras entre ciu-dades. Nuestro objetivo es buscar el mejor camino entre la ciudad A y la ciudad B.
Figura 1.1: Grafo de mapa de carreteras
Para ello tomamos como funcion heurıstica la distancia en lınea recta desde un nodo enconcreto hasta la solucion. A continuacion se observan los valores de h para cada nodo n:
n h(n) n h(n) n h(n) n h(n) n h(n)A 366 B 0 C 160 D 242 E 161F 176 G 77 H 151 I 266 L 244M 241 N 234 O 380 P 100 R 193S 253 T 329 U 80 V 199 Z 374
Esta funcion es claramente admisible, pues, por la propiedad triangular, se tiene que h(n) <a + b, siendo a y b dos lados cualesquiera que formen junto con h(n) un triangulo. Y, en elextremo, podrıa ocurrir que h(n) = h∗(n) (si existiera un camino directo entre A y B).
En la figura 1.2 se muestra el arbol expandido correspondiente a aplicar la busqueda pri-mero el mejor avaro, ası como la evolucion de la frontera en cada paso del algoritmo.
Figura 1.2: Busqueda Primero Mejor Avaro
Tras ver este ejemplo, podemos comprobar que la Busqueda Primero el Mejor Avaro no escompleta, pues podrıa entrar en un ciclo sin fin. Tampoco se trata de un algoritmo admisible.

12 Capıtulo 1. Resolucion de Problemas
1.1.2. Busqueda A*
La funcion heurıstica para este tipo de busquedas se define como
f(n) = g(n) + h(n), ∀ n
donde:
g(n) es el costo real del camino recorrido hasta el nodo n.
h(n) es una estimacion del costo del camino desde el nodo n hasta el nodo objetivo.
f(n) es una estimacion del costo del camino desde el nodo inicial hasta el nodo objetivo,pasando por el nodo n.
Una funcion f definida de esta manera es admisible, puesto que, por la componente g,se evita entrar en ciclos y se realiza una busqueda en anchura. Ası, una funcion f admisiblehace que un algoritmo A sea admisible y completo.
Ejemplo 1.2 Siguiendo el enunciado del ejemplo anterior, la figura 1.3 muestra ahora elarbol expandido resultado de aplicar el algoritmo A*, ası como la evolucion de la frontera encada paso del algoritmo.
Figura 1.3: Busqueda A*
Supongamos un nodo G, no optimo, con h(G) = 0 y c∗ solucion optima. Entonces secumple que:
f(G) = g(G) + h(G) = g(G) > c∗
Supongamos ahora un nodo n, perteneciente al camino optimo. Entonces tenemos losiguiente:
f(n) = g(n) + h(n) ≤ c∗ y f(n) ≤ c∗ < f(G)
Por lo tanto, queda demostrado que el hecho de que f sea admisible implica que siemprese estudiara cualquier nodo del camino optimo antes que otro nodo objetivo no optimo (comoocurre en el ejemplo 1.2, en el que el nodo objetivo B no se estudia en cuanto aparece en laestructura, sino cuando realmente es solucion optima).

1.1 Estrategias de busqueda en grafos: heurısticas 13
Tambien podemos afirmar que si la funcion heurıstica es admisible y se trabaja con es-tructura de grafos, el primer nodo que entre en cerrados sera siempre mejor que cualquierotro nodo igual que ese, que aparezca despues de el.
Sin embargo, determinar si h(n) ≤ h∗(n), ∀ n es un problema intratable; y por lo tantodefinimos las dos siguientes propiedades sobre funciones heurısticas.
Definicion 1.8 Una funcion heurıstica se dice que es monotona si cumple que:
h(n) ≤ c(n, a, n′) + h(n′), ∀ n, n′ sucesores inmediatos
donde c(n, a, n′) es el costo asociado a la accion a que hace pasar del nodo n al n′ (sucesoresinmediatos).
Definicion 1.9 Una funcion heurıstica se dice que es consistente si cumple que:
h(n) ≤ K(n, n′) + h(n′), ∀ n, n′
donde K(n, n′) es el costo asociado al camino que une n y n′ al aplicar una secuencia deacciones.
Proposicion 1.1 Una funcion heurıstica que sea o bien monotona, o bien consistente es unafuncion admisible y, por tanto, con ellas se encuentra la solucion optima.
Nota.- ¡Ojo! Estas propiedades, que son equivalentes entre sı, no se puedencomprobar si no se conoce la estructura del problema (arbol, grafo, arbol YO,...).
En ocasiones sera interesante obviar la condicion de optimalidad y para ello, en vez deemplear funciones admisibles que cumplan h(n) ≤ h∗(n) ∀ n, emplearemos funciones e-admisibles que cumplan
h(n) ≤ h∗(n) + e ∀ n
Figura 1.4: Funcion heurıstica e-admisible
Una funcion e-admisible proporciona soluciones e-optimas (con las que se puede conocerel error cometido al encontrar una solucion no optima).
Pero, como decıamos antes, h∗(n) es muy difıcil de conocer y por ello hemos introducidolas propiedades de monotonıa y consistencia.
h(n) h(n′) + c(n, n′)
peroh(n) ≤ h(n′) + c(n, n′) + e

14 Capıtulo 1. Resolucion de Problemas
1.1.3. Busqueda con memoria acotada
La busqueda A* sigue adoleciendo del problema de la explosion combinatoria (se gene-ran nodos segun una funcion exponencial), por lo que se consume rapidamente la memoriadisponible.
Busqueda A* con profundidad iterativa (A*PI)
En este algoritmo, cada iteracion es una busqueda primero en profundidad, igual que encualquier busqueda con profundidad iterativa.
Sin embargo, la busqueda primero en profundidad se modifica para que utilice un lımitede costo f(n) en vez del tradicional lımite de profundidad.
De este modo en cada iteracion se expanden todos los nodos que estan dentro del contornode f .
Busqueda Primero Mejor Recursiva (BPMR)
funcion BUSQUEDA-PRIMERO-MEJOR-RECURSIVA(problema) devuelve unasolucion o fallo
BPMR(problema,HACER-NODO(ESTADO-INICIAL[problema]),∞)Function BUSQUEDA-PRIMERO-MEJOR-RECURSIVA(problema)
funcion BPMR(problema,nodo,f lımite) devuelve solucion o fallo y nuevo lımitef -costo
si TEST-OBJETIVO[problema](estado) entonces devolver nodosucesores ← EXPANDIR(nodo,problema)si sucesores esta vacıo entonces devolver fallo,∞para cada s en sucesores hacer
f [s] ← max(g(s)+h(s),f [nodo])repetir
mejor ← el nodo con el f -valor mas pequeno de sucesoressi f [mejor] > f lımite entonces devuelve fallo,f [mejor]alternativa ← el f -valor segundo mas pequeno entre los sucesoresresultado,f [mejor] ← BPMR(problema,mejor,min(f lımite,alternativa))si resultado 6= fallo entonces devolver resultado
Function BPMR(problema,nodo,f lımite)
Ejemplo 1.3 En la figura 1.5 se muestra el arbol expandido resultado de aplicar el algoritmoBUSQUEDA-PRIMERO-MEJOR-RECURSIVA al ejemplo de siempre.
La crıtica a este metodo es que solo emplea un numero para representar la bondad deuna rama.
Busqueda A* con memoria acotada simplificada (A*MS)
Se ejecuta el algoritmo A* tal cual. Si la memoria se agota antes de encontrar la solucion,se elimina el peor nodo segun su funcion heurıstica y se introduce el nuevo.
Ejemplo 1.4 En la figura 1.6 se muestra la evolucion del arbol expandido resultado de aplicarel algoritmo de busqueda A* con memoria acotada simplificada al ejemplo de siempre.

1.1 Estrategias de busqueda en grafos: heurısticas 15
Figura 1.5: Busqueda Primero el Mejor Recursiva
Figura 1.6: Busqueda A* con memoria acotada simplificada (A*MS)

16 Capıtulo 1. Resolucion de Problemas
1.2. Estrategias de Busqueda en Grafos YO: Heurısticas
Se dice que un problema es descomponible si se puede descomponer en un conjunto desubproblemas independientes mas sencillos; y es en estos casos en los que una representaciondel problema por reduccion es la mas apropiada.
Los arboles YO, empleados en la representacion por reduccion, son aquellos en los quecada nodo representa un subproblema simple (nodo O) o un conjunto de subproblemas aresolver (nodo Y).
Un nodo que no se descompone o simplifica se llama nodo terminal. Un nodo terminalcon solucion se corresponde con un problema primitivo y se llama Primitiva.
Si al aplicar un operador se produce un conjunto de subproblemas solucion alternativos,entonces se genera un nodo O. Si por el contrario se produce un conjunto de subproblemasque deben ser resueltos necesariamente, entonces se produce un nodo Y.
Un nodo de un arbol YO tiene solucion (es resoluble) si se cumple alguna de las siguientescondiciones:
1. Es un nodo primitiva
2. Es un nodo no terminal de tipo Y y sus sucesores son todos resolubles.
3. Es un nodo no terminal de tipo O y alguno de sus sucesores es resoluble.
En un arbol YO puro cada nodo o bien es Y, o bien es O.
Figura 1.7: Arbol YO con la profundidad de cada nodo
Figura 1.8: Arbol YO no puro
Trataremos los grafos YO como hipergrafos y los arcos como hiperarcos, conectores queconectan un nodo con varios nodos o k-conectores.
Un hipergrafo que solo contiene 1-conectores es un grafo ordinario.Con representacion mediante estados se necesita conocer el estado inicial, los operadores
y el estado final. Con representacion mediante reduccion, por otra parte, se necesita saber elnodo distinguido, los operadores y las primitivas.
La solucion en este tipo de problemas es un subgrafo que una el nodo distinguido contodos o algunos de los nodos primitiva.
Supondremos, para simplificar, que el hipergrafo no tiene ciclos.

1.2 Estrategias de Busqueda en Grafos YO: Heurısticas 17
Figura 1.9: Hipergrafo o grafo YO
Figura 1.10: Soluciones del Hipergrafo de la figura 1.9
Definicion 1.10 Vamos a designar como G′ a un grafo solucion desde el nodo n al conjuntoN (conjunto de nodos primitiva) dentro de un grafo G.
Si n es un elemento de N , G′ consta solo de n.
En otro caso:
• Si n tiene un k-conector que parte de el dirigido a los nodos n1, n2, . . . , nk tal quehaya un grafo solucion para cada ni hasta N , entonces G′ consta:
del nodo n, del k-conector, de los nodos n1, n2, . . . , nk mas los grafos solucion desdecada ni hasta N .
• En otro caso, no hay grafo solucion de n a N .
Costo asociado al grafo solucion de n a N : K(n, N)
Si n es un elemento de N , K = 0
En otro caso
• Si n tiene un k-conector que parte de el dirigido a los nodos n1, n2, . . . , nk en elgrafo solucion entonces
K(n, N) = ck +k∑
i=1
K(ni, N)
siendo ck el costo del k-conector.

18 Capıtulo 1. Resolucion de Problemas
Ejemplo 1.5 Si ck = k:Para la solucion 1:K(n0, N) = 1 + K(n1, N) = 1 + 1 + K(n3, N) = 1 + 1 + 2 + K(n5, N) + K(n6, N) =
1+1+2+2+K(n7, N)+K(n8, N)+2+K(n7, N)+K(n8, N) = 1+1+2+2+0+0+2+0+0 = 8Para la solucion 2:K(n0, N) = 2 + K(n4, N) + K(n5, N) = 2 + 1 + K(n5, N) + 2 + K(n7, N) + K(n8, N) =
2 + 1 + 2 + K(n7, N) + K(n8, N) + 2 + 0 + 0 = 2 + 1 + 2 + 0 + 0 + 2 + 0 + 0 = 7
1.2.1. Caracterısticas de las funciones de evaluacion para grafos YO
Llamaremos grafo solucion optimo a aquel grafo solucion que tenga costo mınimo. Dichocosto esta denotado por h∗(n), pero, como ya sabemos, este valor es muy difıcil de conocer ypor lo tanto tenemos que estimarlo.
Para buscar en un grafo YO es necesario hacer tres cosas en cada paso:
1. Atravesar el grafo empezando por el nodo inicial y siguiendo el mejor camino actual,acumulando el conjunto de nodos que van en ese camino y aun no se han expandido.
2. Coger uno de estos nodos no expandidos y expandirlo. Anadir sus sucesores al grafo ycalcular h para cada uno de ellos.
3. Cambiar la h estimada del nodo recientemente expandido para reflejar la nueva infor-macion proporcionada por sus sucesores. Propagar este cambio hacia atras a traves delgrafo. Para cada nodo que se visita mientras se va avanzando en el grafo, decidir cualde sus conectores es mas prometedor y marcarlo como parte del mejor grafo solucionparcial actual. Esto puede hacer que dicho grafo solucion parcial cambie.
Ejemplo 1.6 En la figura 1.11 se muestra un ejemplo del proceso que acabamos de describir.
Figura 1.11: Ejemplo de busqueda del grafo solucion optimo
Nota.- En los nodos Y es aconsejable estudiar primero aquellos sucesores conmayor valor de funcion heurıstica, pues si el nodo Y que estamos estudiandofinalmente no pertenecera al grafo solucion optimo, lo descartaremos antes deesta manera.

1.2 Estrategias de Busqueda en Grafos YO: Heurısticas 19
1.2.2. Busqueda mejor nodo para grafos YO
Proposicion 1.2 Si h(n) es admisible (h(n) ≤ h∗(n), ∀ n) la solucion encontrada sera siem-pre optima.
Algoritmo A (YO) ⇒ f(n) = g(n) + h(n).Algoritmo A* (YO*) ⇒ f(n) = g(n) + h(n) y h(n) admisible.
Definicion 1.11 h(n) es monotona si cumple que:
h(n) ≤ ck +k∑
i=1
h(ni), ∀ n
Proposicion 1.3 Recordemos que si n es solucion, entonces h(n) = 0. Y por lo tanto, sih(n) es monotona, entonces es admisible.
Ejemplo 1.7 Dado el grafo de la figura 1.12 (en el que cada nodo va acompanado de suvalor de h(n)), observamos que la funcion h(n) no es monotona, pues se cumple que
h(G) c + h(I) ≡ 5 1 + 1
Figura 1.12: Grafo YO con h(n) no monotona
Ejemplo 1.8 En la figura 1.13 se muestra el arbol solucion resultado de aplicar el algoritmoYO* al grafo de la figura 1.12, pero propagando los nuevos valores heurısticos solo a travesde los conectores marcados.
El orden de expansion esta indicado por el numero dentro del cırculo y una X significaque ese nodo ha sido resuelto.
El costo de esta solucion es 9.

20 Capıtulo 1. Resolucion de Problemas
funcion YO*(problema) devuelve grafo solucionlocales: G, G′ grafosG grafo vacıoG← G+iniciocosto(inicio)←h(inicio)si inicio∈TERMINAL entonces inicio marcado resueltorepetir hasta inicio marcado resuelto o costo(inicio) > futilidad
Construir G′ ⊆ G con los conectores marcadosnodo∈frontera(G′)si no hay ningun sucesor en EXPANDIR(nodo) entonces costo(nodo)=futilidaden otro caso ∀ sucesor∈EXPANDIR(nodo) hacer
G← G+sucesorsi sucesor∈TERMINAL entonces sucesor marcado resuelto y costo(sucesor)=0si sucesor/∈TERMINAL y no estaba en G entonces costo(sucesor)=h(sucesor)
S=nodo (S conjunto de nodos que se han marcado resuelto o cambiado su costo)repetir hasta S vacıo
actual∈S de modo que ningun descendiente en G de actual este en SS ← S−actualpara cada k-conector de actual ni1, ni2, . . . , nik calcular
costoi(actual) = c + costo(ni1) + · · ·+ costo(nik)costo(actual)← minicostoi(actual)marcar conector por el que se ha obtenido ese mınimo (borrar otra marca previa)si todos los sucesores a traves de ese conector estan etiquetados como resueltosentonces etiquetar como resuelto actualsi actual se ha etiquetado como resuelto o se ha cambiado su costoentonces propagar esa informacion hacia el principio del grafo y
S ← S+antecesores de actualFunction YO*(problema)

1.2 Estrategias de Busqueda en Grafos YO: Heurısticas 21
Figura 1.13: Solucion al grafo de la figura 1.12 propagando por conectores marcados
Ejemplo 1.9 En la figura 1.14 se muestra el arbol solucion optimo resultado de aplicar elalgoritmo YO* al grafo de la figura 1.12, propagando los nuevos valores heurısticos a todoslos antecesores.
El orden de expansion esta indicado por el numero dentro del cırculo y una X significaque ese nodo ha sido resuelto.
Figura 1.14: Solucion al grafo de la figura 1.12 propagando por todos los antecesores
El costo de esta solucion es 7.
Como conclusion podemos decir que:Si h(n) es admisible, no es necesario propagar los valores heurısticos a todos los antece-
sores para encontrar la solucion optima, sino que basta con propagarlos por los conectoresmarcados.
Sin embargo, si h(n) no es admisible, es necesario propagar los valores a todos los ante-cesores si se quiere encontrar la solucion optima (en caso de que exista).
Ejemplo 1.10 Dado el grafo de la figura 1.15 (en el que cada nodo va acompanado de suvalor de h(n)), observamos que la funcion h(n) ahora sı es monotona.
En la figura 1.16 se muestra el grafo solucion optimo resultado de aplicar el algoritmoYO* propagando los nuevos valores heurısticos solo por los conectores marcados.

22 Capıtulo 1. Resolucion de Problemas
Figura 1.15: Grafo YO con h(n) monotona
Figura 1.16: Solucion al grafo de la figura 1.15 propagando por conectores marcados
Ya vimos como calcular el costo de un grafo solucion, y vimos que en ocasiones un arcotenıa que contabilizarse mas de una vez y en otras ocasiones no.
Ejemplo 1.11 Dado el grafo YO de la figura 1.17, en la figura 1.18 se muestran dos posiblessoluciones.
Figura 1.17: Grafo YO con varias soluciones con distintos costos
Si tratamos con un problema fısico (por ejemplo, soldar un circuito) tendremos quecosto1 = 7 y costo2 = 9, y la solucion optima es la 1.
Pero si tratamos con un problema logico (por ejemplo, resolver una integral) tendremosque costo1 = 7 y costo2 = 6, y la solucion optima es la 2.

1.3 Funciones Heurısticas 23
Figura 1.18: Soluciones al Grafo YO de la figura 1.17
1.3. Funciones Heurısticas
1.3.1. Efecto de la precision heurıstica en el rendimiento
Vamos a tratar sobre el problema del 8-puzzle.
Ejemplo 1.12
7 2 45 68 3 1
26 pasos−→1 2
3 4 56 7 8
Estado Inicial Estado Final
El coste medio para resolver este problema con estados inicial y final aleatorios es de 22pasos.
El factor de ramificacion medio es 3. En una busqueda exhaustiva se expanden 322 nodos.h1 ≡ Numero de piezas mal colocadas h1(EI) = 8f(n) = g(n) + h(n)h2 ≡ Distancia de Manhattan h2(EI) = 18h1 y h2 son admisibles
h ≤ h∗
En el ejemplo anterior se tiene que h1(n) ≤ h2(n) ∀ n y se dice que h2 domina a h1.Ademas tambien se cumple que h1(n) ≤ h2(n) ≤ h∗ ⇒ h2 es mejor que h1 porque se acercamas a h∗.
Definicion 1.12 Factor de ramificacion eficaz: b∗.
Sea N el numero de nodos generados por un algoritmo A∗ y sea la longitud de la soluciond, entonces b∗ es el factor de ramificacion que un arbol uniforme de profundidad d debe tenerpara contener N + 1 nodos.
Es decir
N + 1 = 1 + b∗ + (b∗)2 + · · ·+ (b∗)d
Vamos a realizar un estudio comparativo en el que generamos 1200 8-puzzles con solucionde longitud 2, 4, 6, ..., 22, 24 (100 problemas de cada tipo). Por un lado los resolveremos conProfundidad Iterativa (BPI) y por otro lado mediante una busqueda A∗ con las funciones h1
y h2.

24 Capıtulo 1. Resolucion de Problemas
Costo de la Busqueda Factor de Ramificacion Eficazd BPI A∗(h1) A∗(h2) BPI A∗(h1) A∗(h2)2 10 6 6 2’45 1’79 1’794 112 13 12 2’87 1’48 1’456 680 20 18 2’73 1’34 1’308 6384 39 28 2’80 1’33 1’2410 47127 93 39 2’79 1’38 1’2212 3644305 227 73 2’78 1’42 1’2414 - 539 113 - 1’44 1’2316 - 1301 211 - 1’45 1’2518 - 3056 363 - 1’46 1’2620 - 7276 676 - 1’47 1’2722 - 18094 1219 - 1’48 1’2824 - 39135 1641 - 1’48 1’26
Como conclusiones del estudio podemos afirmar que:
1. A∗ es mucho mejor que BPI
2. h2 es mejor que h1 porque A∗(h2) ≤ A∗(h1) y b∗h2≤ b∗h1
Nota.- Observese que si se utilizara h∗ siempre tendrıamos que b∗ = 1, es decir,encontrarıa la solucion directamente en un numero de pasos igual a la longitudde la solucion.
1.3.2. Inventando funciones heurısticas
Vamos a ver tres maneras de obtener buenas funciones heurısticas.La primera de ellas hace uso de un procedimiento que nos permite averiguar funciones
heurısticas admisibles (no necesariamente eficientes), y que consiste en resolver el problemarelajando alguna de las condiciones del problema original.
No olvidemos que cuanto mas se acerque h a h∗, mas difıcil sera de evaluar.
Ejemplo 1.13 En el problema del 8-puzzle, la casilla A se mueve a la casilla B si A esvertical u horizontal y adyacente a B y B esta vacıa.
Tres posibles formas de relajar el problema son:
1. A se mueve a B si A es vertical u horizontal y adyacente a B −→ Distancia de Man-hattan
2. A se mueve a B si B esta vacıo
3. A se mueve a B −→ No de piezas mal colocadas
La segunda manera consiste en tomar varias funciones admisibles de las cuales no cono-cemos cual domina sobre cual. Si tomamos el maximo de todas ellas obtenemos una funcionheurıstica admisible mejor (o igual) que cualquiera de ellas (h = max(h1, h2, . . . , hn)), comose observa en la figura 1.19
Por ultimo, tambien se puede obtener una funcion heurıstica a partir de la experiencia,mediante el aprendizaje (lo veremos mas adelante).
h = c1 · x1 + · · · + ck · xk y los coeficientes c1, . . . , ck se van ajustando dinamicamente apartir de la experiencia, para aproximarse cada vez mas a h∗.

1.4 Estrategias de Busqueda Local y Problemas de Optimizacion25
Figura 1.19: Funcion admisible h = max(h1, h2, h3) ≤ h∗
1.4. Estrategias de Busqueda Local y Problemas de Optimi-zacion
El problema de las 8 reinas es un problema en el que nos interesa el estado final, no elcamino para llegar a el.
La busqueda local, en vez de almacenar todos los nodos estudiados hasta el momento,almacena solo uno: el que actualmente se esta estudiando.
Este tipo de busqueda es muy rapida y se suele encontrar buenas soluciones.
Figura 1.20: Funcion Objetivo vs Espacio de Estados
Definicion 1.13 Maximo local. Aquel estado en el que todos sus vecinos tienen peor valorheurıstico que el.
Definicion 1.14 Crestas. Conjunto de maximos locales proximos entre sı
Definicion 1.15 Meseta. Aquel estado en el que todos sus vecinos tienen peor valor heurısti-co que el o, a lo sumo, igual.
1.4.1. Busqueda de ascension de colinas (mejor avara)
El algoritmo de ascension de colinas, como se puede observar en la funcion ASCENSION-COLINAS, devuelve un maximo local.

26 Capıtulo 1. Resolucion de Problemas
funcion ASCENSION-COLINAS(problema) devuelve un estado que es un maximolocal
entradas: problema, un problemavariables locales: actual, un nodo
vecino, un nodoactual←HACER-NODO(ESTADO-INICIAL[problema])bucle hacer
vecino←sucesor de valor mas alto de actualsi VALOR[vecino]≤VALOR[actual] entonces devolver ESTADO[actual]actual←vecino
Function ASCENSION-COLINAS(problema)
Ejemplo 1.14 Sea el juego de las 8 reinas con funcion heurıstica h(n): numero de jaquesque se dan, directa o indirectamente.
Dado el siguiente tablero inicial
RR R
R R RR R
su valor heurıstico es h = 17.Cada estado tiene 8 · 7 = 56 hijos, de los cuales tomamos siempre aquel que tenga menor
valor de h.La solucion devuelta no tiene por que ser optima, es decir, no tiene por que cumplir que
h = 0. De hecho, la solucion obtenida a partir del tablero anterior es la siguiente:
RR
RR
RR
RR
Que es un mınimo local con valor heurıstico h = 1.
Vamos a intentar ahora salir de un optimo local para encontrar el optimo global mediantedos maneras:
1. Para superar una terraza realizamos movimientos laterales, de modo que se siguenmirando los vecinos con igual valor, hasta encontrar uno con mejor valor.
El problema surge cuando no se trata de una terraza sino de una meseta, en cuyo casoel algoritmo se quedarıa colgado yendo de un lado para otro.

1.4 Estrategias de Busqueda Local y Problemas de Optimizacion27
Para evitar esto se establece un numero maximo de movimientos laterales lo suficien-temente grande como para saltar terrazas y lo suficientemente pequeno como para noquedarse colgado en las mesetas.
2. Busqueda primero mejor avara con reinicio aleatorio.
Si se alcanza un optimo local, se toma otro estado inicial aleatorio y se vuelve a aplicarel algoritmo.
Si p es la probabilidad de encontrar la solucion optima, necesitaremos 1p reinicios para
encontrar dicha solucion.
No de pasos = Coste de iteracion acertada +1− p
p· (Coste de iteracion fracasada)
1.4.2. Busqueda tabu
funcion TABU(problema) devuelve un estadoentradas: problema, un problemavariables locales: actual, un nodo
vecino, un nodomejor, un nodo
actual←HACER-NODO(ESTADO-INICIAL[problema])mejor←actualmejorcosto←VALOR[mejor]bucle hacer
vecino←sucesor∈CandidatosN (actual)⊆ N(H,actual) que minimiceVALOR(H,actual) sobre el conjunto anterior
actual←vecinoActualizar Hsi VALOR(actual)<mejorcosto entonces
mejor←actualmejorcosto←VALOR[mejor]
si una iteracion maxima u otra regla de parada entonces devolver mejorFunction TABU(problema)
En la busqueda tabu se elige un sucesor de entre un subconjunto de vecinos. El procedi-miento en sı es heurıstico, pues tiene en cuenta:
Ultimos movimientos hechos
Frecuencia de un movimiento
Calidad de un movimiento
Influencia en el proceso de buscar la mejor solucion
En ocasiones puede ocurrir que el sucesor no pertenezca a los vecinos de actual (es el casoen el que se emplea la historia con toda su potencia).

28 Capıtulo 1. Resolucion de Problemas
Ejemplo 1.15 En una fabrica se produce un material compuesto por 7 elementos (numeradosdel 1 al 7). Cada ordenacion de esos elementos tiene un valor que mide una propiedad quebuscamos. No existe un estado inicial predefinido.
Tomamos, por ejemplo, 2 5 7 3 4 6 1 con valor de aislamiento 10.En este caso, un vecino sera una ordenacion en la que se intercambian pares de elementos.
En total hay 21 vecinos.El algoritmo hace uso de dos tablas. La primera de ellas es como sigue:
2 3 4 5 6 71
23
4 35
6
En esta tabla, la casilla (i, j) indica el numero de veces que
esta prohibido intercambiar el elemento i y el j. En cada iteracion, cada casilla se decrementaen 1. En realidad se trata de una memoria a corto plazo utilizada como historia para modificarel subconjunto de candidatos.
La segunda tabla tiene tantas filas como sucesores (21 en nuestro caso) en las que se indicacual es el incremento (o decremento) del valor de aislamiento si se producen cada uno de losintercambios. Las filas estan ordenadas de mejor a peor y se puede indicar que intercambiose escoge (mediante un *) ası como los intercambios prohibidos (mediante una T3).
Por ejemplo, segun la tabla:1 5 4 62 7 4 43 3 6 24 2 3 05 4 1 -1...
...
si se intercambian los elementos 5 y 4, se produce un incremento en el
valor de aislamiento de 6.Los 21 sucesores seran siempre los mismos, pero en cada iteracion el incremento del valor
de aislamiento (y en consecuencia la ordenacion de los 21 sucesores) es distinto.Iteracion 1
2 4 7 3 5 6 1 con valor de aislamiento 16
3 1 22 3 13 6 -17 1 -26 1 -4
...Iteracion 22 4 7 1 5 6 3 con valor de aislamiento 18
1 3 -2 T2 4 -4 *7 6 -64 5 -7 T5 3 -9
...
2 3 4 5 6 71 3
23
4 25
6La ascension de colinas habrıa parado aquı, pero vease como prohibir el intercambio 1,3
(que acaba de realizarse) diversifica la busqueda.
3Tabu

1.4 Estrategias de Busqueda Local y Problemas de Optimizacion29
Iteracion 34 2 7 1 5 6 3 con valor de aislamiento 14 (mejor valor guardado = 18)
4 5 6 T5 3 27 1 01 3 3 T2 6 -6
...
2 3 4 5 6 71 2
2 33
4 15
6Criterio de aspiracion: Si algun vecino tabu mejora la mejor solucion (no la actual) se le
quita el tabu y se selecciona.Es el caso del intercambio 4, 5.Iteracion 45 2 7 1 4 6 3 con valor de aislamiento 20
7 1 04 3 -36 3 -55 4 -6 T2 6 -8
...
2 3 4 5 6 71 1
2 23
4 35
6Iteracion 261 3 6 2 7 5 4 con valor de aislamiento 12 (mejor valor guardado = 20)
1 4 3 T2 4 -13 7 -31 6 -56 5 -6
...
1 2 3 4 5 6 71 323 3 24 1 5 15 4 46 1 27 2 3
Esta ultima tabla indica, en las casillas de su mitad inferior izquierda, el numero de vecesque se ha usado cada intercambio de pares.
Vamos a penalizar los intercambios mas frecuentemente usados, restando a su incremento,su frecuencia.
1 4 3 2 T2 4 -1 -63 7 -3 -3 *1 6 -5 -56 5 -6 -8
...
Y ahora reordenamos la tabla segun la nueva columna.
El conjunto de vecinos son 21, pero los candidatos son solo 18, porque hay 3 que son tabu.En realidad la penalizacion con frecuencia, influencia, calidad, etc., se realiza desde la
primera iteracion.

30 Capıtulo 1. Resolucion de Problemas
1.4.3. Busqueda por haz local
Como estado inicial se generan k estados iniciales aleatorios.Para cada estado se generan los sucesores y entre todos los sucesores, tomamos los k
mejores.Si alguno de esos k es solucion, se para. Y si se llega a la condicion de parada extrema se
devuelve la mejor solucion hasta el momento.
1.4.4. Algoritmo genetico
La diferencia con los algoritmos vistos hasta ahora es que en estos hay una relacion asexualentre los estados, mientras que en el algoritmo genetico se dice que entre los estados hay unarelacion sexual.
Hay que decidir cuantos individuos (estados) hay en cada poblacion (conjunto de estados).
Definicion 1.16 Idoneidad: La funcion de fitness mide como de bueno es un individuo.
Y en funcion de como de bueno sea un individuo se seleccionara para cruzarse y generarindividuos para la nueva poblacion.
Los pasos que se siguen para conseguir una nueva poblacion a partir de la actual son:Poblacionantigua
−→ Poblacionseleccionada
−→ Poblacioncruzada
−→ Poblacionmutada
−→ Poblacionnueva
La nueva poblacion obtenida pasa a ser la poblacion actual y se repite el ciclo.El cruce de individuos intensifica la busqueda, mientras que la mutacion la diversifica.
Ejemplo 1.16 Vamos a estudiar el problema de las 8 reinas con el algoritmo genetico.La representacion de cada individuo (su fenotipo) sera como sigue:I1 2 4 7 4 8 5 5 2 24 31 %
Que significa:
I1 es el individuo 1
La 1a reina esta en la fila 2, la 2a en la 4, la 3a en la 7, etc.
La funcion de fitness para este individuo vale 24, y en este caso mide el numero deno-jaques.
El porcentaje se calcula comoh(I1)∑ni=1 h(Ii)
· 100
y representa el peso que el individuo I1 tiene en la poblacion
Su genotipo puede ser, por ejemplo: (001 011 110 011 111 100 100 001)Dependiendo de la representacion escogida, ası sera el cruce y la mutacion.La poblacion total es la siguiente:I1 2 4 7 4 8 5 5 2 24 31 %I2 3 2 7 5 2 4 1 1 23 29 %I3 2 4 4 1 5 1 2 4 20 26 %I4 3 2 5 4 3 2 1 3 11 14 %
Ahora generamos una nueva poblacion de otros cuatro individuos con probabilidad de crucepc = 0′2 y probabilidad de mutacion pm = 0′01.
Este algoritmo se emplea en problemas combinatorios y de optimizacion, no en problemasde cualquier camino o de mejor camino.

1.5 Estrategias de Busqueda Online 31
1.5. Estrategias de Busqueda Online
En la busqueda off-line se conoce a priori el espacio de busqueda, mientras que en labusqueda on-line, este se conoce a posteriori. Por eso tambien se le llama busqueda en am-bientes desconocidos.
Definicion 1.17 Acciones(s): Funcion que devuelve todas las acciones posibles a partir delestado s.
Definicion 1.18 c(s, a, s′): Funcion coste que devuelve el coste asociado a aplicar la acciona al estado s para pasar al s′. Esta funcion se calcula despues de haber aplicado la accion a,cuando ya nos encontramos en el estado s′.
funcion BPP-ONLINE(s’) devuelve una accionentradas: s’, una percepcion que identifica el estado actualvariables locales: resultado, una tabla indexada por la accion y el estado,inicialmente vacıa
noexplorados, una tabla que enumera, para cada estado visitado,las acciones todavıa no intentadasnohaciatras, una tabla que enumera, para cada estado visitado,los nodos hacia atras todavıa no intentadoss,a, el estado y accion previa, inicialmente nula
si TEST-OBJETIVO(s’) entonces devolver pararsi s’ es un nuevo estado entonces noexplorados[s’]←ACCIONES(s’)si s es no nulo entonces hacer
resultado[a,s]←s’anadir s al frente de nohaciatras[s’]
si noexplorados[s’] esta vacıo entoncessi nohaciatras[s’] esta vacıo entonces devolver pararen caso contrario a←una accion b tal que resultado[b,s’]=POP(nohaciatras[s’])
en caso contrario a←POP(noexplorados[s’])s←s’devolver a
Function BPP-ONLINE(s’)
Ejemplo 1.17 Dado el siguiente “laberinto”:
Y U B
X T N
A Z V
Aplicamos el algoritmo BPP-ONLINE para llegar desde A hasta B.
BPP-Online(A)s, a vacıos s′ = Anoexplorados[A]=Arriba, Derechaa =Arriba, s = A Aparece estado X

32 Capıtulo 1. Resolucion de Problemas
BPP-Online(X)s = A, a =Arriba s′ = Xnoexplorados[X]=Abajoresultado[Arriba,A]=Xnohaciatras[X]=Aa =Abajo, s = X Aparece estado A
BPP-Online(A)s = X, a =Abajo s′ = Anoexplorados[A]=Derecharesultado[Abajo,X]=Anohaciatras[A]=Xa =Derecha, s = A Aparece estado Z
BPP-Online(Z)s = A, a =Derecha s′ = Znoexplorados[Z]=Izquierda, Arriba, Derecharesultado[Derecha,A]=Znohaciatras[Z]=Aa =Izquierda, s = Z Aparece estado A
BPP-Online(A)s = Z, a =Izquierda s′ = Aresultado[Izquierda,Z]=Anohaciatras[A]=Za = b tal que resultado[b,A]=nohaciatras[A]=Za =Derecha, s = A Aparece estado Z
BPP-Online(Z)s = A, a =Derecha s′ = Za =Arriba, s = Z Aparece estado T
BPP-Online(T)s = Z, a =Arriba s′ = Tnoexplorados[T]=Abajo, Arribaresultado[Arriba,Z]=Tnohaciatras[T]=Za =Abajo, s = T Aparece estado Z
BPP-Online(Z)s = T, a =Abajo s′ = Zresultado[Abajo,T]=Znohaciatras[Z]=Ta =Derecha, s = Z Aparece estado V

1.6 Estrategias en adversarios 33
BPP-Online(V)s = Z, a =Derecha s′ = Vnoexplorados[V]=Arriba, Izquierdaresultado[Derecha,Z]=Vnohaciatras[V]=Za =Arriba, s = V Aparece estado N
BPP-Online(N)s = V, a =Arriba s′ = Nnoexplorados[N]=Arriba, Abajoresultado[Arriba,V]=Nnohaciatras[N]=Va =Arriba, s = N Aparece estado B
BPP-Online(B)s = N, a =Arriba s′ = BESTADO-DESTINO(B) CIERTO
En este tipo de problemas el objetivo en general suele ser llegar al destino, no el caminorecorrido (pensemos, por ejemplo, en un robot que apaga incendios).
1.6. Estrategias en adversarios
1.6.1. Juegos
Supongamos dos contrincantes llamados MAX y MIN, un estado inicial con la posiciondel tablero y con la decision de quien empieza. MAX y MIN juegan alternativamente.
Definicion 1.19 Sucesor. Movimientos legales a partir del estado actual.
Definicion 1.20 Test Terminal. Determina cuando un estado es terminal.
Definicion 1.21 Funcion de Utilidad. Da un valor a cada estado terminal (se suelen usar losvalores 1, 0 y -1 correspondientes a que gana MAX, empatan o gana MIN, respectivamente).
Ejemplo 1.18 Juego de las 3 en raya. Nosotros somos MAX y jugamos con X, mientras queMIN juega con O.
Figura 1.21: Juego de las 3 en raya

34 Capıtulo 1. Resolucion de Problemas
Figura 1.22: Estados terminales en el juego de las 3 en raya
La estrategia que vamos a usar, desde el punto de vista optimo (es decir, suponiendo quetanto MIN como MAX siempre toman la decision optima), es la siguiente:
Valor Minimax(n)=
utilidad(n) si n es terminalmaxs∈sucesores(n)V alor Minimax(s) si n es nodo MAXmins∈sucesores(n)V alor Minimax(s) si n es nodo MIN
Figura 1.23: Estrategia MiniMax
Juegos con 3 jugadoresAhora en cada nodo habra un vector con 3 valores, correspondientes a la puntuacion de
cada jugador. El objetivo de cada jugador es maximizar su puntuacion.
Figura 1.24: Ejemplo de juego con 3 jugadores
Nota.- No todos los nodos terminales tiene por que tener la misma profundidad(ni tienen que tener una profundidad multiplo del numero de jugadores).
Poda alfa-betaLa poda no interfiere en la busqueda de la solucion optima.α es el valor de la mejor alternativa (maximo valor) para MAX a lo largo del camino.β es el valor de la mejor alternativa (mınimo valor) para MIN a lo largo del camino.El orden en que se visitan los nodos influye en la poda.Vease la figura 1.25.

1.6 Estrategias en adversarios 35
Figura 1.25: Poda alfa-beta
1.6.2. Decisiones en tiempo real imperfectas
En juegos como el ajedrez es inviable aplicar Minimax y por ello se anade una profundidadlımite.
Si hay dos jugadores interesa poner una profundidad lımite que sea par. Si se realiza podapuede ocurrir que perdamos la solucion optima.
Por lo tanto, tenemos que definir una nueva funcion que nos diga como de bueno es unestado no terminal.
si TEST-CORTE(estado,profundidad) entonces devolver EVAL(estado)
EVAL(n)
UTILIDAD(n) si n es terminalFUNCION HEURISTICA(n) si n es no terminal
Cuanto mayor sea la profundidad de corte, evidentemente, mas y mejor informacionheurıstica tendremos. Nosotros hemos supuesto que los terminales estan por debajo de laprofundidad lımite.
Ejemplo 1.19 Para el juego de las 3 en raya de la figura 1.26, se ha cortado la busqueda aprofundidad 2 (teniendo en cuenta que la profundidad de la raız es 0).
Figura 1.26: Juego de las 3 en raya con profundidad limitada
Como funcion heurıstica se ha usado: f(n) = No de filas, columnas y diagonales librespara MAX - No de filas, columnas y diagonales libres para MIN.

36 Capıtulo 1. Resolucion de Problemas
1.6.3. Juegos que incluyen un elemento de posibilidad
Ademas de los nodos MAX y MIN, aparecen los nodos de posibilidad.
Ejemplo 1.20 En el juego del parchıs, tiramos un dado, con 16 de probabilidades de sacar
cada uno de los numeros del 1 al 6. Hay cuatro fichas por cada jugador.
Si se limita la profundidad tiene que ser a la altura de un nodo MIN o un nodo MAX,pero no de un nodo de posibilidad.
MiniMax Esperada(n)
utilidad(n) si n es terminalmaxs∈sucesores(n)MiniMax Esperado(s) si n es nodo MAXmins∈sucesores(n)MiniMax Esperado(s) si n es nodo MIN∑
s∈sucesores(n) P (s) ·MiniMax Esperado(s) si n es nodo posibilidad
Figura 1.27: Ejemplo de estrategia MiniMax Esperada

Capıtulo 2
Representacion del Conocimiento.Razonamiento
Para resolver un problema, lo basico necesario es:
Representacion
Operadores
Control
2.1. Representacion del Conocimiento mediante Logicas noClasicas
2.1.1. Logicas no monotonas
La logica clasica es una logica monotona, en la cual la incorporacion de nuevo conocimientodebe ser consistente (no contradictorio). En la logica no monotona, la incorporacion de nuevainformacion podrıa invalidar parte de la informacion previa existente.
En un problema con conocimiento incompleto puede aplicarse la logica no monotona (perono la logica monotona) y se aplica un razonamiento llamado “por defecto”.
Ejemplo 2.1 “Juan y Marıa yacen en el suelo muertos. Hay cristales en el suelo y agua.¿Que ha pasado?” Solucion: Juan y Marıa son dos peces.
2.1.2. Logica de situaciones
Soporta una estructura dinamica (en un momento algo puede ser cierto, y, mas tarde,puede ser falso).
Ejemplo 2.2 .SOBRE(B1, B2): “B1 esta sobre B2”
Si quitamos B1 de encima de B2, entonces ¬SOBRE(B1, B2)Estas dos sentencias no podrıan coexistir en una logica clasica. Para que sı puedan coe-
xistir, la logica de situaciones dice:SOBRE(B1, B2, S1): “B1 esta sobre B2 en la situacion S1”Y ası, ¬SOBRE(B1, B2, S2) tambien es cierto.Para pasar de una situacion a otra debemos aplicar una secuencia de operadores.∀ x [SOBRE(B1, B2, S)∧¬SOBRE(x, B3, S)→ SOBRE(x, B3, R(MOV ER(B1, B3), S)︸ ︷︷ ︸
S′
)]
37

38 Capıtulo 2. Representacion del Conocimiento. Razonamiento
Figura 2.1: Ejemplo de logica de situaciones
Este tipo de logica se emplea en planificacion
2.1.3. Logica difusa
Empleada cuando se usa una notacion imprecisa.
Ejemplo 2.3 “Juan es joven”
Muchas veces un concepto vago depende del contexto y de la subjetividad. Toda la logicadifusa esta montada sobre la definicion de una serie de elementos:
Definicion 2.1 Conjunto difuso:x ∈ A donde A es un conjunto difusoµA(x) ∈ [0, 1], µA es la funcion de pertenencia al conjunto A.
La diferencia con la probabilidad es que esta precisa de una experimentacion previa antesde obtener un resultado. Con los conjuntos difusos no es necesaria experiencia previa.
Figura 2.2: Funcion de pertenencia continua ser joven
Definicion 2.2 Modificadores: Definidos a partir del conjunto base.
µF (A) = F [µA(x)]
µMUY A(x) = [µA(x)]2
µMAS O MENOS A(x) = [µA(x)]12
µNO A(x) = 1− µA(x)
Figura 2.3: Funciones de pertenencia µA y µNO A
2.1 Representacion del Conocimiento mediante Logicas noClasicas 39
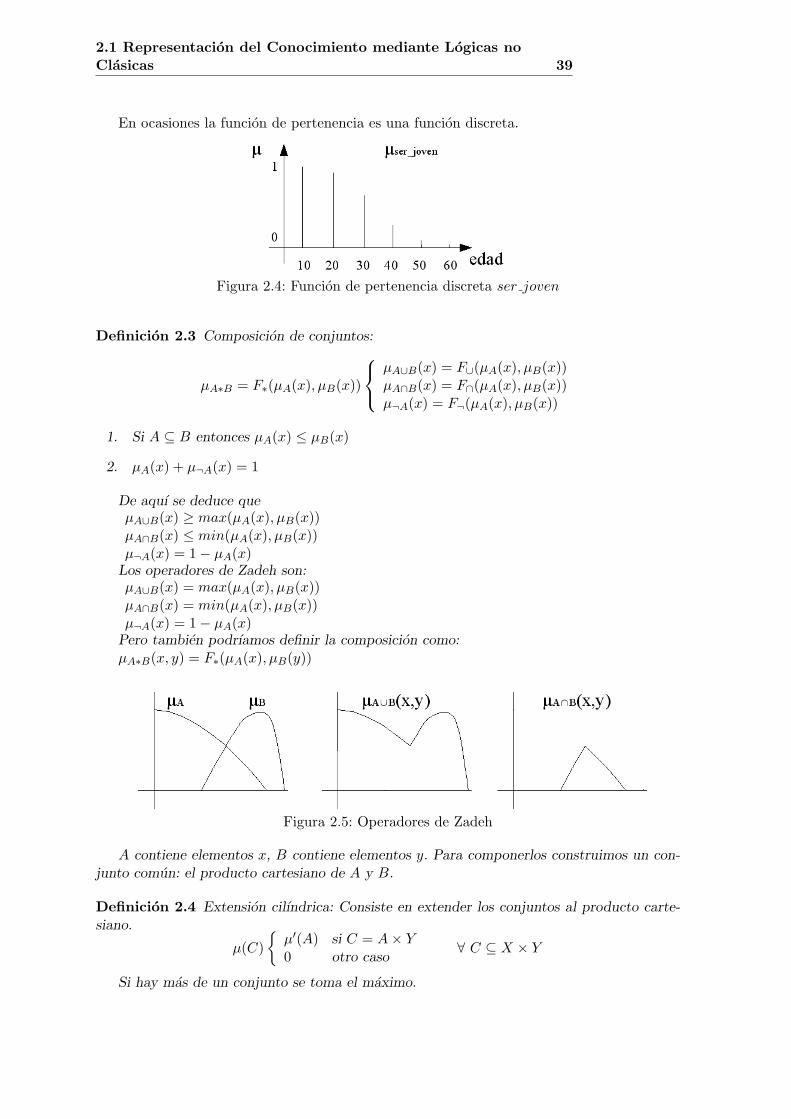
En ocasiones la funcion de pertenencia es una funcion discreta.
Figura 2.4: Funcion de pertenencia discreta ser joven
Definicion 2.3 Composicion de conjuntos:
µA∗B = F∗(µA(x), µB(x))
µA∪B(x) = F∪(µA(x), µB(x))µA∩B(x) = F∩(µA(x), µB(x))µ¬A(x) = F¬(µA(x), µB(x))
1. Si A ⊆ B entonces µA(x) ≤ µB(x)
2. µA(x) + µ¬A(x) = 1
De aquı se deduce queµA∪B(x) ≥ max(µA(x), µB(x))µA∩B(x) ≤ min(µA(x), µB(x))µ¬A(x) = 1− µA(x)
Los operadores de Zadeh son:µA∪B(x) = max(µA(x), µB(x))µA∩B(x) = min(µA(x), µB(x))µ¬A(x) = 1− µA(x)
Pero tambien podrıamos definir la composicion como:µA∗B(x, y) = F∗(µA(x), µB(y))
Figura 2.5: Operadores de Zadeh
A contiene elementos x, B contiene elementos y. Para componerlos construimos un con-junto comun: el producto cartesiano de A y B.
Definicion 2.4 Extension cilındrica: Consiste en extender los conjuntos al producto carte-siano.
µ(C)
µ′(A) si C = A× Y0 otro caso
∀ C ⊆ X × Y
Si hay mas de un conjunto se toma el maximo.

40 Capıtulo 2. Representacion del Conocimiento. Razonamiento
Figura 2.6: Extension Cilındrica
Definicion 2.5 Proyeccion cilındrica
µ(C) = supyµ′(x, y), ∀ C
En la logica tendremos hechos simples y compuestos.
Definicion 2.6 Hechos simples:
p : x ∈ A (µp(x) = µA(x))
Definicion 2.7 Hechos compuestos:
p ∨ q : (x es A) ∨ (x es B)p ∧ q : (x es A) ∧ (x es B)¬p : (x es ¬A)
µp∨q(x) ≥ max(µp(x), µq(x))µp∧q(x) ≤ min(µp(x), µq(x))µ¬p(x) = 1− µp(x)
µp∨q(x) = OR(µp(x), µq(x))µp∧q(x) = AND(µp(x), µq(x))µ¬p(x) = NOT (µp(x))
Definicion 2.8 Inferencia:
p→ q : si (x es A) entonces (y es B)µp→q(x, y) = IMPLIC(µp(x), µq(y)) = OR(NOT (µp(x)), µq(y))
Modus Ponens:p→ qp
qµq(y) = supxMP (µp(x), µp→q(x, y))
Ejemplo 2.4 Si (el coche es viejo) entonces (el coche es ruidoso)El coche es bastante viejo.Si ahora aplicamos MP, obtenemos un modificador de ruidoso: El coche es bastante rui-
doso.
2.2. Representacion y Razonamiento con Incertidumbre
2.2.1. Representacion y fuentes de incertidumbre
Los elementos a la hora de resolver un problema son:
Representacion
Operadores
Control
Definicion 2.9 Impreciso: negacion de preciso.

2.2 Representacion y Razonamiento con Incertidumbre 41
Definicion 2.10 Preciso: Un hecho es preciso cuando su significado es equivalente a exacto,claro, ..., y concreto.
Por lo tanto imprecisos son los hechos ambiguos, abstractos, no concretos o no detallados.
Definicion 2.11 Incierto: negacion de cierto.
Definicion 2.12 Cierto es analogo a verdadero y seguro.
Por lo tanto incierto son los hechos carentes de verdad absoluta o de seguridad de queocurra.
Ejemplo 2.5 “Algun dıa llovera” Tiene gran cantidad de imprecision, pero es muy cierta.“Manana llovera” es muy preciso, pero es incierto (tiene gran cantidad de incertidumbre).
Nosotros trabajaremos con conocimiento preciso, aunque incierto.
Ejemplo 2.6 p → q, c1 = 0′7, donde c1 representa el grado de certidumbre de que la reglap→ q sea cierta.
pe → qh c1 = 0′7 Representacion de una reglape c2 = 0′55 Representacion de un hechoqh c3 =? Tecnica de Inferencia
c1 = P (h|e)c2 = P (e)c3 = P (h)
Fuentes de Incertidumbre
1. Situaciones en las que el universo de discurso es verdaderamente aleatorio.
2. Situaciones en las que el universo de discurso es verdaderamente aleatorio aunque po-drıamos decir que es estrictamente aleatorio, pero por alguna razon, no hay datos sufi-cientes.
3. Situaciones en las que el conocimiento del que se dispone (o parte de el) se debe al“olfato” del observador (“yo creo que ...”).
4. Situaciones en las que el conocimiento del que se dispone esta representado en terminosvagos.
5. Situaciones en las que el conocimiento del que se dispone no es totalmente fiable.
Nosotros vamos a usar la segunda fuente de incertidumbre.
2.2.2. Teorıa de Dempster-Shafer de la evidencia
En el ejemplo de las urnas puede ocurrir que perdamos en el camino parte de la informa-cion. Ahora el resultado no sera una probabilidad sino un intervalo.
TDS: Teorıa de Dempster-ShaferTPr: Teorıa de la ProbabilidadTPos: Teorıa de la Posibilidad
Definicion 2.13 Frame de decision θ: conjunto de hipotesis mutuamente exclusivas y ex-haustivo en el cual tratamos de obtener la respuesta mas adecuada mediante la concentracionde sucesivas evidencias.
Definicion 2.14 2θ: conjunto de todas las decisiones del frame de decision.
Definicion 2.15 A: cualquier elemento del conjunto de decision.

42 Capıtulo 2. Representacion del Conocimiento. Razonamiento
A las hipotesis se les llama singulares.Como en 2θ tambien esta el ∅, a ese ∅ se le llama hipotesis vacıa y corresponde a una
hipotesis totalmente falsa.
Ejemplo 2.7 θ = HEP, CIRR,PIE, PANA partir de las evidencias se determinara que enfermedades hepaticas hay.
Cuanto mas restrictiva sea la hipotesis mejor. El complemento de A es ¬A si A∨¬A = θ.
Ejemplo 2.8 .A = HEP¬A = CIRR, PIE, PAN
En 2θ hay hipotesis mas generales y mas restrictivas. Nos interesara tomar decisiones enconjuntos de hipotesis del menor tamano posible.
Ejemplo 2.9 Es mejor tener A = HEP, que tener A = HEP, CIRRDecir A = HEP ≡ “Con la informacion que tengo puedo decir que se puede tener
hepatitis”.Decir A = HEP, CIRR ≡ “Con la informacion que tengo puedo decir que se puede
tener hepatitis, pero tambien se puede tener cirrosis”.
Funcion de asignacion basica de probabilidadNos sirve para asignar valores a las hipotesis, segun la evidencia que se tenga.m(A): cantidad de certeza que posee el elemento A (que es una hipotesis y por tanto
A ∈ 2θ, o bien A ⊆ θ), de manera que m(A) ∈ [0, 1].
m : 2θ −→ [0, 1]
Se dice que m es una a.b.p (asignacion basica de probabilidad) si cumple que:
m(∅) = 0∑A⊆θ m(A) = 1
Ejemplo 2.10 θ = blancas, rojasm(blancas) = 0′35m(rojas) = 0′4¿Que pasa con el 0’25 restante? Solucion: m(θ) = 0′25
Construimos m1. m(∅) = 0Si una evidencia confirma una hipotesis A con un valor p, entonces2. m(A) = p
m(θ) = 1− pSi una evidencia desconfirma una hipotesis A con un valor p, entonces3. m(¬A) = p
m(θ) = 1− pA cualquier hipotesis sobre la que no haya ninguna evidencia se le da el valor 0.

2.2 Representacion y Razonamiento con Incertidumbre 43
Ejemplo 2.11 Se tiene una evidencia que desconfirma una hipotesis de HEP con un valorde 0’7
m(CIRR, PIE, PAN) = 0′7m(θ) = 0′3m(∗) = 0m(∅) = 0
∑
= 1
A partir de m vamos a construir las dos siguientes funciones:Credibilidad de una hipotesis A
Cr(A) =∑B⊆A
m(B)
Plausibilidad de APl(A) =
∑B∩A6=∅
m(B)
Tanto Cr como Pl son funciones de probabilidad.Todas las hipotesis B de la credibilidad estan incluidas en las hipotesis B de la plausibi-
lidad.Cr(A) ≤ Pr(A) ≤ Pl(A)
|Pl(A)− Cr(A)| mide la falta de informacion.Por lo tanto con esta teorıa (que es una generalizacion de la probabilidad) se mide tanto
incertidumbre, como falta de informacion.Propiedades.Cr(∅) = Pl(∅) = 0Cr(θ) = Pl(θ) = 1Cr(A) + Pl(¬A) = 1Cr(A) + Cr(¬A) ≤ 1Pl(A) + Pl(¬A) ≥ 1
Ejemplo 2.12 Calcular la credibilidad y plausibilidad de la hipotesis A = CIRR, PIE, PANy su complemento sabiendo que:
m(A) = 0′7m(θ) = 0′3m(∗) = 0m(∅) = 0
Cr(A) = m(A)+m(CIRR, PIE)+m(CIRR, PAN)+m(PIE, PAN)+m(CIRR)+m(PIE) + m(PAN) + m(∅) = 0′7 + 0 + · · ·+ 0 = 0′7
Pl(A) = m(A)+m(HEP, CIRR)+m(HEP, PIE)+m(HEP, PAN)+m(CIRR)+m(PIE) + m(PAN) + m(θ) = 0′7 + 0 + 0 + 0 + 0 + 0 + 0 + 0′3 = 1
0′7 ≤ Pr(A) ≤ 1
Regla de Combinacion de a.b.p. de Dempster-ShaferSean m1 y m2 dos a.b.p. sobre dos hipotesis.
m1 ⊕m2(Ck) =∑
Aj∩Bj=Ck
m1(Aj) ·m2(Bj)
m1 ⊕m2 tambien es una a.b.p.
Propiedadesm1 ⊕m2 = m2 ⊕m1
m1 ⊕ (m2 ⊕m3) = (m1 ⊕m2)⊕m3
De donde se deduce que no importa el orden de combinacion de la informacion.

44 Capıtulo 2. Representacion del Conocimiento. Razonamiento
Ejemplo 2.13 Sea m1 una a.b.p. que confirma la hipotesis HEP, CIRR con un valor 0’6.
m1(HEP, CIRR) = 0′6 m1(θ) = 0′4
Y seam2(CIRR, PIE, PAN) = 0′7 m2(θ) = 0′3m3(HEP) = 0′8 m3(θ) = 0′2
m1
m2
CIRR, PIE, PAN 0′7 θ 0′3HEP, CIRR 0′6 CIRR 0′6 · 0′7 HEP, CIRR 0′6 · 0′3
θ 0′4 CIRR, PIE, PAN 0′4 · 0′7 θ 0′4 · 0′3
m1 ⊕m2(CIRR) = 0′42m1 ⊕m2(HEP, CIRR) = 0′18m1 ⊕m2(CIRR, PIE, PAN) = 0′28m1 ⊕m2(θ) = 0′12
∑A⊆θ
m1 ⊕m2(A) = 1
m3
m1 ⊕ m2
CIRR 0′42 HEP, CIRR 0′18 CIRR, PIE, PAN 0′28 θ 0′12
HEP 0′8 ∅ 0′8 · 0′42 HEP 0′8 · 0′18 ∅ 0′8 · 0′28 HEP 0′8 · 0′12
θ 0′2 CIRR 0′2 · 0′42 HEP, CIRR 0′2 · 0′18 CIRR, PIE, PAN 0′2 · 0′28 θ 0′2 · 0′12
m1 ⊕m2 ⊕m3(∅) = 0′336 + 0′224 = 0′56→ 0
m1 ⊕m2 ⊕m3(HEP) = 0′144 + 0′096 = 0′24→ 0′241− 0′56
= 0′545
m1 ⊕m2 ⊕m3(CIRR) = 0′084→ 0′0840′44
= 0′191
m1 ⊕m2 ⊕m3(HEP, CIRR) = 0′036→ 0′082m1 ⊕m2 ⊕m3(CIRR, PIE, PAN) = 0′056→ 0′127m1 ⊕m2 ⊕m3(θ) = 0′024→ 0′055
Segun vemos, la evidencia de θ va siendo cada vez mas pequena, segun se va combinandoinformacion.
Si m1⊕m2⊕m3(∅) = p 6= 0 entonces hay que normalizar el resto de valores, dividiendolosentre 1 − p, para que su suma sea igual a 1. Si se da esta situacion es porque ha habidocontradiccion.
Al normalizar estamos perdiendo informacion; y podrıa ocurrir que la contradiccion fueramuy alta y al normalizar no se reflejara fielmente la realidad.
Introduccion a la InferenciaComo representar los hechos:
Hechos
Simples “x es A”
Compuestos
“x1 es A1 o x2 es A2” ⇒ (x1, x2) es A1 + A2
“x1 es A1 y x2 es A2” ⇒ (x1, x2) es A1 ×A2
donde A1 + A2 = A1 ×A2 = (A1 ×X2) ∪ (X1 ×A2), siendo Xi el mundo de discurso de Ai.La teorıa de la evidencia permite trabajar con vaguedad, mientras que la probabilidad no
puede.Como representar las reglas:Si x es A entonces y es B ⇒ (x1, x2) es A + B = A×B

2.3 Representaciones Estructuradas del Conocimiento 45
Ahora que sabemos representar hechos y reglas, sean un hecho y una regla con un ciertogrado de incertidumbre medida con un intervalo:
F : [CrF , P lF ]R : [CrR, P lR]
Para poder aplicar la regla de Dempster tenemos que transformar estos dos intervalos enmasas de evidencia.
CrF (A) = α PLF (A) = β ≥ αmF (A) = α mF (A) = 1− β
mF (δ) = β − αCrR(A + B) = α PlR(A + B) = β ≥ αmR(A + B) = α mR(A× B) = 1− β
mR(X1 ×X2) = β − α
Metodo general de razonamiento (o inferencia)Tenemos F1, F2, . . . , Fm y R1, R2, . . . , Rn inciertas (cada una con su intervalo).Queremos saber la verdad de que se establezca F y su valor de incertidumbre asociado a
partir de las reglas y hechos previos. Los pasos a seguir son:
1. Construir una estructura Ω lo mas pequena posible que contenga Fi, Rj y F .
Ω = X1 ×X2 × · · · ×Xp p = m + n + 1
2. Calcular la extension cilındrica de las a.b.p. mFi y mRj sobre Ω (para poder mezclar).
3. Combinar por la regla de Dempster (se obtiene m).
4. Proyectar la a.b.p. m sobre Xp (que corresponde a F ).
5. Calcular CrF y PlF a partir de dicha proyeccion.
Este metodo es una generalizacion del Modus Ponens clasico, pues si tanto los hechoscomo las reglas fueran ciertos (Cr = 1, Pl = 1) obtendrıamos conclusiones tambien ciertas.
2.3. Representaciones Estructuradas del Conocimiento
2.3.1. Redes Semanticas
Nos sirven para representar el conocimiento de manera que se parezca a como represen-tamos nosotros el conocimiento. Es una representacion parecida a la logica, pero mas visual,mas grafica.
Definicion 2.16 Una red semantica es una estructura de datos compuesta de nodos y “links”(arcos) y cada elemento tiene un asociado semantico.
Un nodo se corresponde con un hecho, suceso, evento u objeto.Un link tiene una relacion binaria entre los nodos que une:
n1r−→ n2
n1, n2 : nodosr : link
Representacion de una red semantica generalizadaNuestro conocimiento tiene relaciones n-arias, pero solo podemos usar relaciones binarias
si queremos usar una red semantica.
Ejemplo 2.14 “Juan regalo a Marıa un libro en el parque” se trata de una relacion 5-aria.Creamos un ente generico abstracto e que relaciona todos los objetos; y a partir de el
construimos todas las relaciones binarias.

46 Capıtulo 2. Representacion del Conocimiento. Razonamiento
Figura 2.7: Ejemplo de Red Semantica
Veamos ahora como se representan las reglas: aparecen dos tipos de links.
Conclusion −→ (Asociados a los nodos que pertenecen al consecuente de una regla).
Condicion 99K (Asociados a los nodos que pertenecen al antecedente de una regla).
Ejemplo 2.15 Regla: “Todo acto de dar tiene su recıproco de recibir”Tomamos el evento x
Figura 2.8: Ejemplo de regla en una Red Semantica
Ya tenemos dos trozos de red semantica: un hecho y una regla.
Ejemplo 2.16 “Juan da un libro a Marıa y el acto recıproco de dar es recibir”
Figura 2.9: Ejemplo de Red Semantica con un hecho y una regla
El link es un denota las relaciones es un, parte de, subconjunto, un tipo de. Estos tiposde links crean una red semantica jerarquica.
Ejemplo 2.17 elefantees un−→mamıfero es un−→ animal
Por la herencia, las propiedades del caso general las tiene el caso particular. Ademas estoslinks cumplen la propiedad transitiva.
Tambien existen links que denotan restricciones temporales: antes de, despues de, simultaneo,causa.
Ejemplo 2.18 .e1
despues−→ e2
e1simultaneo−→ e2
e1causa−→ e2

2.3 Representaciones Estructuradas del Conocimiento 47
Ejemplo 2.19 En la figura 2.10 podemos ver un ejemplo de reglas que relacionan elementostemporales.
Figura 2.10: Ejemplo de reglas que relacionan elementos temporales
InferenciaDebemos tener en cuenta dos procesos:
1. Unificacion de nodos
2. Inferencia de links
Un link antecedente y uno consecuente se eliminan si son del mismo tipo y los nodos queunen son unificables entre sı.
El proceso de inferencia es destructivo, por lo tanto antes de empezar hay que realizaruna copia de la red semantica. La inferencia termina cuando se llega a la red semantica vacıa.
Por lo tanto, lo primero que hay que hacer es extraer de la base de conocimiento lainformacion suficiente y necesaria para hacer la inferencia que nos interesa.
Si usaramos la base de conocimiento completa habrıa que destruirla entera para poderinferir (y estarıamos destruyendo informacion que no harıa ninguna falta para inferir lo quequeremos).
Ejemplo 2.20 .“Turing es humano”
“Socrates es humano”“Socrates es griego”“Todo humano es falible”¿Hay algun griego falible?
Figura 2.11: Ejemplo de inferencia en redes semanticas (1)
Una pregunta es siempre el antecedente de una regla.

48 Capıtulo 2. Representacion del Conocimiento. Razonamiento
Figura 2.12: Ejemplo de inferencia en redes semanticas (2)
x = yx = y = Socrates
Figura 2.13: Ejemplo de inferencia en redes semanticas (3)
Hemos llegado a la red semantica vacıa (pues la informacion que queda no deberıamoshaberla cogido desde el principio). Y concluimos que sı hay algun griego falible: x = y =Socrates
2.3.2. Marcos o Frames
Subimos un grado de abstraccion.Las redes semanticas estan muy proximas a la logica, por lo tanto se necesita todo el
conocimiento para poder inferir (si falta conocimiento no se llega a una red semantica vacıa).
Definicion 2.17 Un frame va a ser una estructura de datos que representa un tipo entidady consta de una coleccion de ranuras con un nombre cada una, denominadas slots, dondecada ranura puede rellenarse mediante valores o apuntadores a otros frames.
Ejemplo 2.21 Una persona nos dice que comio muy bien ayer en un restaurante. A partirde esa informacion podrıamos responder a preguntas como:
¿Entro en el restaurante y pidio una mesa libre?¿Pago la comida al salir?
Ejemplo 2.22 Vamos a representar los frames “Empleado” y “Padre de Familia” y los va-mos a instanciar los dos con la misma entidad.
Figura 2.14: Ejemplo de frame “Empleado” y “Padre de Familia”

2.3 Representaciones Estructuradas del Conocimiento 49
Cuando se rellena un frame (sus ranuras) se dice que esta instanciado y que representa auna entidad particular.
Si no se dice ningun valor para una ranura se le pone el valor por defecto (incluso puedeque antes de instanciar el frame), por ejemplo, num piernas = 2.
El slot Estado civil tiene valores genericos.Cuando una entidad puede instanciar frames distintos se dice que esos frames son frames
desde puntos de vista “alternativos”.Hay frames que, por la propia definicion, son disjuntos (por ejemplo, Padre de Familia
y No Padre de Familia). La instanciacion por dos frames disjuntos de una misma entidadsignifica que hay un error.
Los slots con el mismo nombre en dos frames que instancian la misma entidad, debentener el mismo valor (salvo excepciones, como Disposicion); en otro caso se renombra el slot.
Hay slots que tienen valores restringidos (por ejemplo, la edad en el frame Empleado debeestar entre 18 y 65).
Cuando se nos da cierta informacion, buscamos aquel frame que mejor se ajuste (mayorgrado de emparejamiento) a esa informacion, y a partir de ese momento ese frame instanciadorepresenta a esa entidad.
Propiedades genericas de las ranuras.
Propiedad asociada con un conjunto entidad de tal forma que cada miembro de eseconjunto posee esa propiedad.
Ejemplo 2.23 En el frame “Persona”, propiedades genericas son: sangre caliente, tie-ne madre, un corazon, ...
Un valor por defecto es aquel que se espera encontrar en casos normales. Las ranurascon valores por defecto pueden conducir a errores.
Ejemplo 2.24 “Juan y Marıa yacen muertos en el suelo. Hay un charco de agua,...”
Cometemos un error al presuponer que Juan y Marıa son personas, pues en realidadson dos peces.
Condiciones de ranura son condiciones que restringen los valores con los que se va arellenar.
Representacion jerarquica de los frames
Figura 2.15: Ejemplo de jerarquıa de frames
−→ es equivalente a la relacion es un. Todos los frames con el mismo padre son hermanosy heredan las propiedades de este.

50 Capıtulo 2. Representacion del Conocimiento. Razonamiento
Metodos de inferencia
1. Existencia inferida
Tenemos una entidad E (informacion recibida) que se desconoce de que tipo es.
Emparejamos E con el frame F que mejor se adapte a E, pero con un grado de creencia.Dicho grado de creencia vendra dado por el grado de emparejamiento entre E y F .
2. Propiedades genericas inferidas
Una vez emparejados E y F , a E se le asocian todas las propiedades genericas del frameF con un grado de creencia (dependiente del grado de emparejamiento y del grado decreencia de la ranura de la propiedad generica).
3. Valores por defecto inferidos
Una vez emparejados E y F , si alguna de las ranuras de valores por defecto del frameno se han rellenado por la entidad, toman el valor por defecto del frame.
El grado de creencia de esos valores por defecto depende del grado de emparejamientoy del grado de creencia de esas ranuras con valores por defecto.
4. Reconocimiento de situaciones anormales
Rellenar ranuras con valores no esperados o no rellenar ranuras que es importanterellenarlas puede ser un error del sistema.
Ejemplo 2.25 “Una persona tiene 5 piernas”
“Un empleado tiene 8 anos”
5. Inferencia por analogıa
No es exclusiva de los frames y consiste en tomar informacion de un frame para aso-ciarsela a otro frame.
Ejemplo 2.26 “La persona Pedro es como una apisonadora”
“La Bolsa es como una montana rusa”
2.3.3. Guiones
Un guion es un frame que describe una secuencia de acontecimientos en un contexto (comoun guion de cine o teatro).
Los elementos de que consta son:
Conjunto de condiciones de entrada (o prerrequisitos)
Ejemplo 2.27 .“Tiene hambre”
“Tiene dinero”
Un guion representa una situacion si se cumplen las condiciones de entrada.
Conjunto de resultados

2.3 Representaciones Estructuradas del Conocimiento 51
Ejemplo 2.28 .“El cliente tiene menos dinero”
“El cliente no tiene hambre”
“El cliente esta complacido”
“El dueno tiene mas dinero”
Conjunto de materiales
Ranuras para objetos que van a intervenir en el guion.
Conjunto de papeles
Ranuras para personas que van a intervenir en el guion.
Un lugar
Donde se va a realizar ese guion (es una ranura del mismo).
Conjunto de escenas
Todos los elementos que van a ir apareciendo secuencialmente en el guion.

52 Capıtulo 2. Representacion del Conocimiento. Razonamiento

Capıtulo 3
Planificar para la Resolucion deProblemas
3.1. Planificacion y Resolucion de Problemas
3.1.1. El problema de la planificacion
Definicion 3.1 Planificar es la tarea de obtener una secuencia de acciones que permita llegara un estado objetivo.
Definicion 3.2 A esa secuencia de acciones se le llama plan.
En la planificacion las reglas u operadores deben ser modulares (es decir, si quitamos oponemos una, las demas no se ven afectadas) y el sistema debe ser completo (esto es, se debenrecoger todas las posibilidades que puedan aparecer).
Y antes de comenzar a tratar con mas detalle el tema de la planificacion debemos teneren cuenta las tres siguientes cuestiones:
1. Marco de referencia
Cuando se ejecuta una regla, ¿que permanece sin cambios? ¿Cual es el fondo de laescena en que se desarrolla la accion?
Ejemplo 3.1 Al mover una mesa, se mueve lo que haya encima. Pero si decimos queuna mesa esta debajo de una ventana, al mover la mesa no se mueve la ventana.
2. Problema de la cualificacion
¿En que condiciones puede ejecutarse una regla? ¿Que necesita en su entorno paraejecutarse?
El planificador sera el encargado de decidir que regla aplicar en cada momento.
3. Problema de la ramificacion
Cuando se ejecuta una regla, ¿que elementos de su entorno se modifican?
53

54 Capıtulo 3. Planificar para la Resolucion de Problemas
3.1.2. Tipos de planificadores, estados y operadores
Tipos de planificadores
De Orden Total. Encuentran un camino desde el estado inicial al estado final.
De Orden Parcial. Encuentran todos los posibles caminos desde el estado inicial alestado final.
Jerarquicos
Estados
Estado Inicial
LIBRE(B), SOBRE(C,A), SOBREMESA(A), LIBRE(C), MANOVACIA, SOBREME-SA(B)
Estado Objetivo
SOBRE(A,B), SOBRE(B,C)
OperadoresVienen descritos por tres elementos:
Lista de precondiciones (P)
Conjunto de elementos que si son ciertos hacen al operador candidato para ser aplicado.
Lista de adicion (A)
Elementos que se anaden al estado actual
Lista de supresion (S)
Elementos que se suprimen al estado actual
Ejemplo 3.2 .
COGER(X):P: SOBREMESA(X), MANOVACIA, LIBRE(X)A: COGIDO(X)S: SOBREMESA(X), MANOVACIA, LIBRE(X)
DEJAR(X):P: COGIDO(X)A: SOBREMESA(X), MANOVACIA, LIBRE(X)S: COGIDO(X)
APILAR(X,Y):P: COGIDO(X), LIBRE(Y)A: MANOVACIA, SOBRE(X,Y), LIBRE(X)S: COGIDO(X), LIBRE(Y)
DESAPILAR(X,Y):P: MANOVACIA, LIBRE(X), SOBRE(X,Y)A: COGIDO(X), LIBRE(Y)S: MANOVACIA, LIBRE(X), SOBRE(X,Y)

3.1 Planificacion y Resolucion de Problemas 55
3.1.3. Metodos de planificacion
Resolucion hacia adelante
Ejemplo 3.3 Dado el estado inicial descrito como:
SOBREMESA(A)SOBREMESA(B)SOBREMESA(C)LIBRE(A)LIBRE(B)LIBRE(C)MANOVACIA
Y el estado final descrito como:
SOBRE(A,B), SOBRE(B,C)
Se van aplicando operadores para llegar desde el estado inicial al estado final.
Resolucion hacia atrasPartimos del estado final e intentamos llegar al estado inicial. Pero para luego dar una
solucion necesitamos aplicar unos operadores inversos.
OBJETIV O = L ∧G1 ∧G2 ∧ . . . ∧GNSUBOBJETIV O = PD ∧G′
1 ∧G′2 ∧ . . . ∧G′
N
La regla D sera candidata a ser aplicada sobre L si en su lista de adicion esta L′ y existeun unificador que hace Ly L′ iguales.
Si se aplica D sobre L, entonces L se transforma en las precondiciones de D, esto es, enPD.
G′i son los elementos obtenidos por regresion despues de haber aplicado la regla D, para
lo cual necesitamos una funcion de regresion.
Definicion 3.3 R[Q,DU ] es la regresion del objetivo Q = G1, G2, . . . , GN al aplicar DU
(regla D aplicandole el unificador U).
1. Si QU es un literal de AU (lista de adicion) entonces
R[QU , DU ] = V (Verdadero)
2. Si QU es un literal de SU (lista de supresion) entonces
R[QU , DU ] = F (Falso)
3. En otro caso
R[QU , DU ] = QU
Todos los elementos cuya regresion sea verdadera no es necesario comprobarlos en elfuturo (y por lo tanto no aparecen en el siguiente subobjetivo).
Si la regresion de algun elemento es falsa, no se puede aplicar dicha regla.
Ejemplo 3.4 Sea OBJETIVO=COGIDO(A), LIBRE(B), SOBRE(B,C)Observamos que COGIDO(A) pertenece a la lista de adicion de DESAPILAR(X,Y) si
aplicamos el unificador X=A. Por lo tanto, en el siguiente subobjetivo desaparecera COGI-DO(A), que sera sustituido por la lista de precondiciones de DESAPILAR(X,Y).

56 Capıtulo 3. Planificar para la Resolucion de Problemas
Ahora aplicamos regresion al resto de elementos del OBJETIVO, para lo cual tenemosque ampliar el unificador que tenıamos para que incluya Y=B. Ası, tenemos que
R[LIBRE(B),DESAPILAR(A,B)] = V, pues LIBRE[B] pertenece a la lista de adiccion deDESAPILAR(A,B) y por lo tanto, no aparecera en el siguiente subobjetivo (no es necesariocomprobarlo en el futuro).
R[SOBRE(B,C),DESAPILAR(A,B)] = SOBRE(B,C), pues SOBRE(B,C) no aparece nien la lista de supresion, ni en la de adicion de DESAPILAR(A,B). Por lo tanto SOBRE(B,C)pasa tal cual al siguiente subobjetivo.
En resumen, tenemos queSUBOBJETIVO=MANOVACIA, LIBRE(A), SOBRE(A,B), SOBRE(B,C)
Ejemplo 3.5 OBJETIVO=SOBRE(B,C), SOBRE(A,B)Aplicamos APILAR(B,C) y obtenemos, tras la regresion, queSUBOBJETIVO=COGIDO(B), LIBRE(C), SOBRE(A,B)¡¡Pero COGIDO(B) y SOBRE(A,B) son inconsistentes!!
Nota.- Antes de seguir avanzando hay que comprobar la (in)consistencia deaquellos nuevos subobjetivos que hayan conseguido superar la regresion (recorde-mos que si la funcion de regresion aplicada sobre algun elemento devuelve falso,no se puede aplicar la regla).
3.2. Planificacion de Orden Total
3.2.1. Planificacion usando una pila de objetivos (STRIPS)
Se realiza una busqueda hacia atras empezando por el objetivo que se quiere alcanzar. Sidicho objetivo es compuesto, se descompone en subobjetivos, formando una pila.
Resuelve problemas en los que no hay interaccion entre subobjetivos (o bien hay interac-ciones “debiles”).
Ejemplo 3.6 .
SOBRE(B,C)SOBRE(A,B)
SOBRE(A,B) ∧ SOBRE(B,C)
Los pasos a seguir en STRIPS son:
1. Se comienza con una pila de objetivos que solo contiene el objetivo principal. Si elobjetivo de la parte superior de la pila se empareja con la descripcion del estado real,se suprime este objetivo de la pila y se aplica la sustitucion de emparejamiento a todaslas expresiones que esten por debajo en la pila.
2. En otro caso, si el objetivo que esta en la cima de la pila es compuesto, el sistemaanade encima de ese objetivo compuesto cada uno de los literales componentes (encierto orden).
3. Cuando han sido resueltos todos los objetivos componentes, si el objetivo compuesto nose empareja con el estado real el sistema reconsidera el objetivo compuesto, volviendoa listar sus componentes en la parte superior de la pila.
Cada vez que se listan de nuevo los componentes de un objetivo el estado real puedeser distinto, y puede que en un momento no se resuelva el objetivo, pero mas adelantesı.

3.2 Planificacion de Orden Total 57
Si se resuelven todos los subobjetivos, pero no el objetivo compuesto, es porque al resol-ver subobjetivos se deshacen cambios hechos por subobjetivos previamente resueltos.
4. Cuando el objetivo “no resuelto” de la cima de la pila es un unico literal STRIP buscauna regla cuya lista de adicion contenga un literal que se pueda emparejar con el.
Ese emparejamiento reemplaza al literal de la cima. Encima de el se anade la regla (conese valor de emparejamiento) y encima de la regla se ponen las precondiciones de dicharegla particularizadas para ese emparejamiento.
Si las precondiciones se emparejan con el estado real, se aplica la regla. Si las precon-diciones son compuestas, se descomponen y se anaden sus componentes a la cima de lapila.
5. Cuando el elemento de la cima es una regla es porque las precondiciones de esa reglase emparejan con la descripcion del estado y se suprimieron de la pila.
Entonces la regla es aplicable y se aplica efectivamente a la descripcion del estado,suprimiendola de la pila (el sistema debe recordar las reglas que se aplican y el ordenen que se aplican).
Tres cuestiones interesantes a tener en cuenta a la hora de resolver un problema practicoson:
1. Ordenacion de los componentes de un objetivo compuesto
2. Eleccion entre las particularizaciones posibles
3. Eleccion de la regla aplicable, en caso de haber mas de una
Ejemplo 3.7 Estado inicial:LIBRE(B)LIBRE(C)SOBRE(C,A)SOBREMESA(A)SOBREMESA(B)MANOVACIA
Estado final: SOBRE(C,B), SOBRE(A,C)El contenido de la pila a lo largo de la ejecucion de STRIPS es:
SOBRE(C,B) ∧ SOBRE(A,C)SOBRE(C,B)SOBRE(A,C)
SOBRE(C,B) ∧ SOBRE(A,C)
APILAR(C,B)SOBRE(C,B)SOBRE(A,C)
SOBRE(C,B) ∧ SOBRE(A,C)
LIBRE(B) ∧ COGIDO(C)APILAR(C,B)SOBRE(C,B)SOBRE(A,C)
SOBRE(C,B) ∧ SOBRE(A,C)

58 Capıtulo 3. Planificar para la Resolucion de Problemas
COGIDO(C)LIBRE(B)
LIBRE(B) ∧ COGIDO(C)APILAR(C,B)SOBRE(C,B)SOBRE(A,C)
SOBRE(C,B) ∧ SOBRE(A,C)
MANOVACIA, LIBRE(C), SOBRE(C,Y)DESAPILAR(C,Y)
COGIDO(C)LIBRE(B)
LIBRE(B) ∧ COGIDO(C)APILAR(C,B)SOBRE(C,B)SOBRE(A,C)
SOBRE(C,B) ∧ SOBRE(A,C)
Ahora la cima de la pila se empareja con el estado real, de modo que se desapila la cima yse aplica la regla que queda en la cima (y se anota que se ha aplicado dicha regla).
A continuacion se muestra el estado real, junto con la pila, a lo largo de la ejecucion deSTRIP:
LIBRE(B)LIBRE(A)COGIDO(C)SOBREMESA(A)SOBREMESA(B)
APILAR(C,B)SOBRE(C,B)SOBRE(A,C)
SOBRE(C,B) ∧ SOBRE(A,C)
LIBRE(A)LIBRE(C)SOBRE(C,B)SOBREMESA(A)SOBREMESA(B)MANOVACIA
SOBRE(A,C)SOBRE(C,B) ∧ SOBRE(A,C)
LIBRE(A)LIBRE(C)SOBRE(C,B)SOBREMESA(A)SOBREMESA(B)MANOVACIA
LIBRE(C)COGIDO(A)
LIBRE(C) ∧ COGIDO(A)APILAR(A,C)SOBRE(A,C)
SOBRE(C,B) ∧ SOBRE(A,C)
LIBRE(A)LIBRE(C)SOBRE(C,B)SOBREMESA(A)SOBREMESA(B)MANOVACIA
SOBREMESA(A), LIBRE(A), MANOVACIACOGER(A)COGIDO(A)
LIBRE(C) ∧ COGIDO(A)APILAR(A,C)SOBRE(A,C)
SOBRE(C,B) ∧ SOBRE(A,C)
LIBRE(C)COGIDO(A)SOBRE(C,B)SOBREMESA(B)
COGIDO(A)LIBRE(C) ∧ COGIDO(A)
APILAR(A,C)SOBRE(A,C)
SOBRE(C,B) ∧ SOBRE(A,C)

3.2 Planificacion de Orden Total 59
LIBRE(A)SOBRE(A,C)SOBRE(C,B)SOBREMESA(B)MANOVACIA
SOBRE(A,C)SOBRE(C,B) ∧ SOBRE(A,C)
Finalmente, no olvidemos devolver el plan que hemos encontrado y que en este caso es elsiguiente:
DESAPILAR(A,C)APILAR(C,B)COGER(A)APILAR(A,C)
Ejemplo 3.8 Un problema que STRIP no puede resolver es el de permutar los valores dedos registros del procesador.
Estado inicial:CONTENIDO(X,A)CONTENIDO(Y,B)CONTENIDO(Z,0)
Estado final:CONTENIDO(X,B)CONTENIDO(Y,A)
Contamos con la siguiente operacion:ASIGNA(U,R,T,S):
P: CONTENIDO(R,S), CONTENIDO(U,T)S: CONTENIDO(U,T)A: CONTENIDO(U,S)
CONTENIDO(X,A)CONTENIDO(Y,B)CONTENIDO(Z,0)
CONTENIDO(R,B) ∧ CONTENIDO(X,T)ASIGNA(X,R,T,B)CONTENIDO(X,B)CONTENIDO(Y,A)
CONTENIDO(X,B) ∧ CONTENIDO(Y,A)
CONTENIDO(X,B)CONTENIDO(Y,B)CONTENIDO(Z,0)
CONTENIDO(Y,A)CONTENIDO(X,B) ∧ CONTENIDO(Y,A)
Hemos llegado a un punto en el que no se puede continuar, ya que la interaccion entresubobjetivos es demasiado fuerte.
3.2.2. STRIP con proteccion de objetivos (RSTRIP)
En este nuevo metodo, cuando se empareja la cima de la pila con el estado real, no sedesapila la cima sino que se marca con un asterisco (*). Y si una regla va a deshacer algunobjetivo marcado, no se aplica.
Una lınea horizontal divide a la pila en dos. Lo que haya por encima de ella esta yaresuelto, y lo que este por debajo esta por resolver.
Los corchetes laterales indican los componentes de un objetivo compuesto. Si la lıneahorizontal atraviesa un corchete, ninguno de los subobjetivos por debajo de la lınea dentrodel corchete puede deshacer los subobjetivos por encima de la lınea dentro del corchete.
RSTRIP encuentra siempre el plan mas corto.

60 Capıtulo 3. Planificar para la Resolucion de Problemas
Si resolvieramos el ejemplo 3.7 con RSTRIP obtendrıamos el mismo resultado que conSTRIP, ya que no hay interaccion entre subobjetivos.
Definicion 3.4 Regresion: se aplica regresion entre el violador y cada una de las reglas porencima del violado. Si pasa la regresion, el violador se coloca como una precondicion mas deesa regla.
Sı se permiten violaciones temporales, esto es, una regla viola un objetivo protegido, perootra regla por debajo de la primera en la pila vuelve a resolver ese objetivo.
3.3. Planificacion Ordenada Parcialmente
En este tipo de planificacion (tambien llamada no lineal) se trabaja con subplanes, en vezde con subproblemas.
Primero se construye un grafo con los subplanes. Despues se anaden unas restriccionesque imponen un cierto orden entre los operadores. Y finalmente, para devolver una solucion,es necesario linealizar el plan.
Ejemplo 3.9 Objetivo: “Tener el zapato derecho puesto y tener el zapato izquierdo puesto”Operadores:ZapatoDerecho
P: Calcetın derecho puestoA: Zapato derecho puesto
CalcetinDerechoA: Calcetın derecho puesto
ZapatoIzquierdoP: Calcetın izquierdo puestoA: Zapato izquierdo puesto
CalcetinIzquierdoA: Calcetın izquierdo puesto
Figura 3.1: Ejemplo de planificacion no lineal
En la figura 3.1 se muestra un conjunto de subplanes que resuelven el problema. Ahorahay que linealizar este conjunto para dar una secuencia concreta de operadores.
Hay 6 planes posibles. Uno de ellos puede ser, por ejemplo:CalcetinIzquierdo, CalcetinDerecho, ZapatoDerecho, ZapatoIzquierdo.

3.3 Planificacion Ordenada Parcialmente 61
3.3.1. Planificacion no lineal sistematica (PNLS)
Ahora se devuelve un conjunto de (sub)planes con (posibles) conflictos entre ellos. Alaplicar un nuevo operador se comprueba que no se deshaga lo que ya se tenıa resuelto.
Construimos una estructura que conecte los operadores ficticios FIN e INICIO, descom-poniendo el estado final para intentar llegar al inicial.
A continuacion se indican las precedencias entre todos los operadores. Al igual que antes,por ultimo, se debe linealizar para buscar un plan concreto que resuelva el problema (losoperadores deberan aplicarse de inicio a fin).
Ejemplo 3.10 En la figura 3.2 se muestra la representacion grafica del operadorMOVER(X,Y,Z)
P: SOBRE(X,Y), LIBRE(Z), LIBRE(X)A: LIBRE(Y), SOBRE(X,Z)S: SOBRE(X,Y), LIBRE(Z)
Que significa que mueve X, que esta sobre Y , encima de Z.
Figura 3.2: Operador MOVER(X,Y,Z)
Observese que la lista de supresion no aparece explıcitamente. X, Y y Z son variablesque deben instanciarse.
El estado inicial para nuestro problema sera:SOBRE(C,A)SOBRE(B,SUELO)
Por su parte, el estado final sera:SOBRE(A,B)SOBRE(B,C)
En la figura 3.3 se muestra la estructura que conecta FIN e INICIO.En vista de dicha figura, los dos subplanes que hay son:Subplan del primer subobjetivo −→ b < aSubplan del segundo subobjetivo −→ cPor lo que podrıamos pensar que hay tres posibles planes, a saber
c < b < ab < c < ab < a < c
Pero si somos observadores veremos que no todos son factibles. En realidad el unico planvalido es
b < c < a

62 Capıtulo 3. Planificar para la Resolucion de Problemas
Figura 3.3: Ejemplo de planificacion no lineal sistematica
3.4. Planificacion Jerarquica
Se priorizan las precondiciones para definir operadores simplificados, y aplicamos un pla-nificador cualquiera (STRIP, ...) para obtener un esbozo del plan.
PrecondicionesNo operadores que
lo hacen ciertoPrioridad
LIBRE 3 1MANOVACIA 2 2COGIDO 2 2SOBREMESA 1 3SOBRE 1 3
Intentamos resolver solo los literales de prioridad 3 (mayor dificultad) y el resto se consi-deran siempre ciertos.
Ejemplo 3.11 .ESTADO OBJETIVO El plan que se encuentra es
APILAR(C,B),APILAR(A,C). Si este planno tiene suficiente detalle, sevuelve a aplicar elplanificador con nivel deprioridad 2.
LIBRE(B)LIBRE(C)SOBRE(C,A)SOBREMESA(A)SOBREMESA(B)MANOVACIA SOBRE(C,B) ∧ SOBRE(A,C)

Capıtulo 4
El Aprendizaje Computacional
4.1. El Problema del Aprendizaje Computacional
El aprendizaje denota cambios en el sistema que son adaptativos en el sentido de quepermiten al sistema hacer la misma tarea o tareas a partir de la misma poblacion mas eficientey/o eficientemente la proxima vez.
El aprendizaje memorıstico es el mas basico y consiste en memorizar (nada de razonar).
4.2. Conceptos Basicos
4.2.1. Tipos, fases y caracterısticas del aprendizaje
Tipos de aprendizajeCatalogacion en funcion de lo que sabemos del sistema que queremos aprender (o mode-
lar).
Aprendizaje supervisado
Se conoce la salida que se espera del ejemplo que se le ensena al sistema que queremosque aprenda.
Ejemplo 4.1 Se le muestra una silla a un nino y se le dice: “eso es una silla”
Aprendizaje no supervisado
Se le muestra un ejemplo al sistema que queremos que aprenda, pero no le decimos deque clase es. El sistema, a partir de lo que hay aprendido “debe” dar una respuesta.
Ejemplo 4.2 Se le muestra una silla a un nino que el nunca haya visto y se le preguntaque tipo de objeto es.
De ultimas, lo que se pretende es construir modelos que representen tanto a los ejemplosque se le han mostrado al sistema, como a aquellos ejemplos que NO se le han mostrado.
Fases del aprendizajeEn la figura 4.1 se muestran las fases mas importantes del aprendizaje. Algunos comen-
tarios al respecto:El Modelo Aprendido debe representar (cuando ya se haya construido finalmente) todos
los rasgos implıcitos en los ejemplos mostrados (es decir, en los Datos de Entrenamiento).Los Datos de Prueba nos serviran para comprobar si el modelo aprendido es correcto
(suficientemente fiable).
63

64 Capıtulo 4. El Aprendizaje Computacional
La Prediccion, que no es propiamente una fase del aprendizaje, tiene lugar una vez queel modelo ya sea adecuado.
Figura 4.1: Fases del aprendizaje
En el modelo encontramos 2 tipos de parametros:
1. Parametros internos: Los que se aprenden en la fase de aprendizaje (a partir de losexternos).
2. Parametros externos: No se aprenden, sino que son dados a priori en base a un conoci-miento experto.
Caracterısticas del aprendizajeCuatro son las principales caracterısticas del aprendizaje:
1. Precision: fiabilidad del modelo (caracterıstica importante).
2. Velocidad: velocidad de prediccion a partir del modelo.
Por ejemplo, un modelo fiable al 90 % muchas veces es preferible a otro modelo fiableal 99 %, siempre que el primero sea mucho mas veloz que el segundo.
3. Comprensibilidad: el modelo debe ser comprensible para el usuario.
4. Tiempo en aprender: tiempo necesario para aprender el modelo.
A partir de los datos de entrenamiento obtenemos varios modelos (que a su vez puedenvariar con los parametros externos e internos). Con los datos de prueba obtenemos el modelo(segun las caracterısticas que busquemos) con su fiabilidad. Una vez terminado el modelo consu fiabilidad, comenzamos a predecir.
El hecho de realimentar la fase de prediccion para intentar que el sistema aprenda, esmucho mas probable que disminuyamos la fiabilidad.

4.2 Conceptos Basicos 65
4.2.2. Estimacion del error
En la matriz de confusion se reflejan todos los ejemplos de la base de prueba con respectoa la clase real de cada ejemplo y la clase predicha por el modelo.
Ejemplo 4.3 Enfermedad del corazon.Clases predichaspor el modelo
150 ejemplos Ausente PresenteClases reales Ausente 80 10
de los ejemplos Presente 20 40
80 (de los 150) ejemplos realmente no tenıan ataque al corazon y el modelo acierta.10 (de los 150) ejemplos realmente no tenıan ataque al corazon y el modelo falla.20 (de los 150) ejemplos realmente sı tenıan ataque al corazon y el modelo falla.40 (de los 150) ejemplos realmente sı tenıan ataque al corazon y el modelo acierta.
Matriz de costos:Clases predichaspor el modelo
150 ejemplos Ausente PresenteClases reales Ausente 0 1
de los ejemplos Presente 5 0
Observese que tiene mayor costo si realmente hay ataque al corazon y el modelo falla, queel caso en que no hay ataque al corazon y el modelo falla.
Error = 20× 5 + 10× 1 = 110
Vamos a estudiar tres estimadores de errores para la matriz de confusion:
1. Estimador del error de los ejemplos
Suponemos que se tienen N ejemplos de prueba. Contamos cuantas predicciones sonincorrectas, llamado E. El estimador del error es E
N .
Para el ejemplo anterior 30150
Para poder aplicar este estimador se necesita que la base de prueba sea distinta que labase de entrenamiento.
2. Estimador del error de resustitucion
Igual que 1), pero la base de prueba es igual o un subconjunto de la base de entrena-miento. Este estimador tiende a subestimar el error.
¡Ojo! No se pueden comparar modelos distintos con distintos estimadores del error.
3. Estimador del error por validacion cruzada
Sea S el conjunto de ejemplos, lo dividimos en v partes mas o menos de igual tamanoy disjuntas S1, . . . , Sv
Usaremos S−Si, i = 1, . . . , v como base de entrenamiento y Si como base de prueba.Para estimar el error se usa el estimador para el error de los ejemplos, y lo llamamosRi
v∑i=1
|Si||S|·Ri
Este estimador evalua una tecnica (metodo) de aprendizaje, mientras que 1) y 2) evaluanun modelo.

66 Capıtulo 4. El Aprendizaje Computacional
Ademas de por la clase, se puede clasificar a partir de atributos multivaluados (con unnumero de valores finito).
En contraste, los atributos reales no pueden usar los estimadores vistos, sino que se usala recta de regresion, mediante el error cuadratico medio, que se calcula como:∑N
i=1(y∗i − yi)2
N
donde y∗i es el valor real y yi es el valor estimado.Cuanto menor sea este valor, mejor sera el modelo.El costo de un modelo, por su parte, se calcula como:
c =Nc∑i=1
Nc∑j=1,i6=j
cijεij
εij : ejemplos de la clase i, predichos en la clase j.cij : costo de la clase i predicha como j.Nc: numero de clases existentes.Para el ejemplo anterior: c = 10× 1 + 20× 5 = 110

Capıtulo 5
Aprendizaje por Induccion enModo Estructural
Nota.- Los capıtulos que vienen ahora, salvo el ultimo, estudian aprendizajesupervisado, bien por clasificacion, bien por regresion. El aprendizaje, ademas,se hace a partir de los ejemplos, lo cual recibe el nombre de aprendizaje porinduccion.
Ejemplo 5.1 Para clasificar como silla se dice que tiene 4 patas, un tablero,...Pero no se dice que las patas tienen que estar separadas, el tablero tiene que estar sobre
las patas...Esto ultimo se le conoce como estructura del ejemplo y es lo que vamos a estudiar en este
capıtulo.
5.1. Programa de aprendizaje de Winston
Usa redes semanticas para representar tanto los ejemplos como los modelos.Empieza siempre a partir de un ejemplo llamado positivo, que no es mas que un ejemplo
que pertenece a la clase que queremos aprender, (por contraposicion, un ejemplo negativo esaquel que no pertenece a la clase que queremos aprender).
Tambien se usan casi-ejemplos que no es mas que un ejemplo negativo, pero no es positivopor muy pocos rasgos (normalmente uno solamente).
El procedimiento de Winston tiene 2 subprocedimientos:
Para ejemplos positivos −→ Generalizacion
Para ejemplos negativos o casi-ejemplos −→ Especializacion
5.1.1. Generalizacion
Empleada cuando durante el aprendizaje se nos muestra un ejemplo positivo, hace uso decuatro funciones heurısticas:
1. Heurıstica de subida de arboles (generaliza conceptos subiendo de nivel en la estructurajerarquica de conceptos)
2. Heurıstica de conjunto ampliado (igual que 1, pero sin conocer la estructura jerarquica)
3. Heurıstica de enlace eliminado
4. Heurıstica de intervalo cerrado
67

68 Capıtulo 5. Aprendizaje por Induccion en Modo Estructural
Figura 5.1: Ejemplos de la base de entrenamiento. Generalizacion
Ejemplo 5.2 Queremos aprender el concepto de arco.En la figura 5.1(a) vemos el ejemplo positivo primero, la figura 5.1(b) es un ejemplo ne-
gativo y la figura 5.1(c) es otro ejemplo positivo.
Heurıstica de conjunto ampliadoSi decimos que la parte superior del arco es de color rojo y luego se dice que es verde, el
sistema aprende que el color de la parte superior puede ser rojo o verde.Si luego mostramos una de color amarilla, aprendera que el color puede ser rojo, verde o
amarillo.
Heurıstica de enlace eliminadoSi a continuacion nos dicen que ya no hay mas colores podemos eliminar el enlace del
color porque es una caracterıstica que no es determinante.
Heurıstica de intervalo cerradoSi se ensena un arco cuyas bases miden 20 cm y luego otro cuyas bases miden 10 cm, se
aprende que la base puede estar en el intervalo [10,20] cm.
5.1.2. Especializacion
Empleada cuando durante el aprendizaje se nos muestra un ejemplo negativo o un casi-ejemplo, hace uso de dos funciones heurısticas:
1. Heurıstica del enlace requerido
Cuando el modelo evolucionado tiene un enlace en el lugar donde el casi-ejemplo no lotiene.
Ejemplo 5.3 En el ejemplo positivo de la figura 5.2(a) sı existe el enlace soporta a,mientras que en el casi-ejemplo de la figura 5.2(b), no existe dicho enlace.
Figura 5.2: Ejemplos de la base de entrenamiento. Especializacion (1)
Conseguimos enfatizar el enlace soporta a diciendo que debe soportar a.

5.2 Espacio de versiones 69
2. Heurıstica del enlace olvidado
Cuando el casi-ejemplo tiene un enlace donde el modelo evolucionado no lo tiene.
Ejemplo 5.4 En el ejemplo positivo de la figura 5.3(a) no existe el enlace toca, mien-tras que en el casi-ejemplo de la figura 5.3(b), sı existe dicho enlace.
Figura 5.3: Ejemplos de la base de entrenamiento. Especializacion (2)
Se enfatiza el negativo del enlace toca diciendo que no debe tocar
Ejemplo 5.5 En la figura 5.4 se muestran los pasos en el aprendizaje del concepto “arco”,mediante el proceso de Winston, con generalizaciones y especializaciones a partir de ejemplospositivos y casi-ejemplos.
Una vez tengamos la red semantica que represente el modelo (es decir, el ultimo modeloevolucionado), tenemos que probar el modelo (muy importante) para medir la fiabilidad delmismo.
Para ello el sistema debe emparejar las redes semanticas de los ejemplos de prueba con ladel modelo, para obtener un valor de “similitud” que nos pueda decir si ha acertado o no.
5.2. Espacio de versiones
La representacion de los ejemplos se hace mediante frames.
Ejemplo 5.6 Queremos aprender cuando un coche es economico. El frame de la figura 5.5es equivalente a decir lo siguiente:
origen = x1 ∈USA, Japon, Alemania, ...marca = x2 ∈Toyota, Seat, Ford, ...color = x3 ∈Blanco, Azul, ...ano = x4 ∈1960, 1970, ...tipo = x5 ∈lujo, economico, deportivo, ...
Un instanciacion del frame coche puede ser:x1 Japonx2 Hondax3 Azulx4 1970x5 economicoG ︸ ︷︷ ︸ S
(general) Espacio de versiones (ej positivo)
Conforme se van mostrando ejemplos, G se va especializando y S se va generalizando,hasta que lleguen a encontrarse.
En la especializacion de G apareceran varias opciones (. . .), (. . .), . . .Si G y S son unitarios y coinciden, devolvemos G(= S).Si G y S son unitarios y no coinciden, hay contradiccion en la base de conocimiento.

70 Capıtulo 5. Aprendizaje por Induccion en Modo Estructural
Ejemplo 5.7 G = (x1, x2, x3, x4, x5) (G es unitario)
Primer ejemplopositivo
JaponHondaAzul1970
economico
S=(Japon,Honda,Azul,1970,economico)(S es unitario)
Segundo ejemplonegativo
JaponToyotaVerde1970
deportivo
G=(x1,Honda,x3, x4, x5),(x1, x2,Azul,x4, x5),(x1, x2, x3, x4,economico)S no cambia
Tercer ejemplopositivo
JaponToyotaAzul1990
economico
G=(x1, x2,Azul,x4, x5),(x1, x2, x3, x4,economico)S=(Japon,x2,Azul,x4,economico)
Cuarto ejemplonegativo
USAChrysler
Azul1980
economico
G=(Japon,x2,Azul,x4, x5),(Japon,x2, x3, x4,economico)S no cambia
Quinto ejemplopositivo
JaponHondaBlanco1980
economico
G=(Japon,x2, x3, x4,economico)S=(Japon,x2, x3, x4,economico)
Como ya G = S y ambos son unitarios, terminamos y devolvemos G (o S).
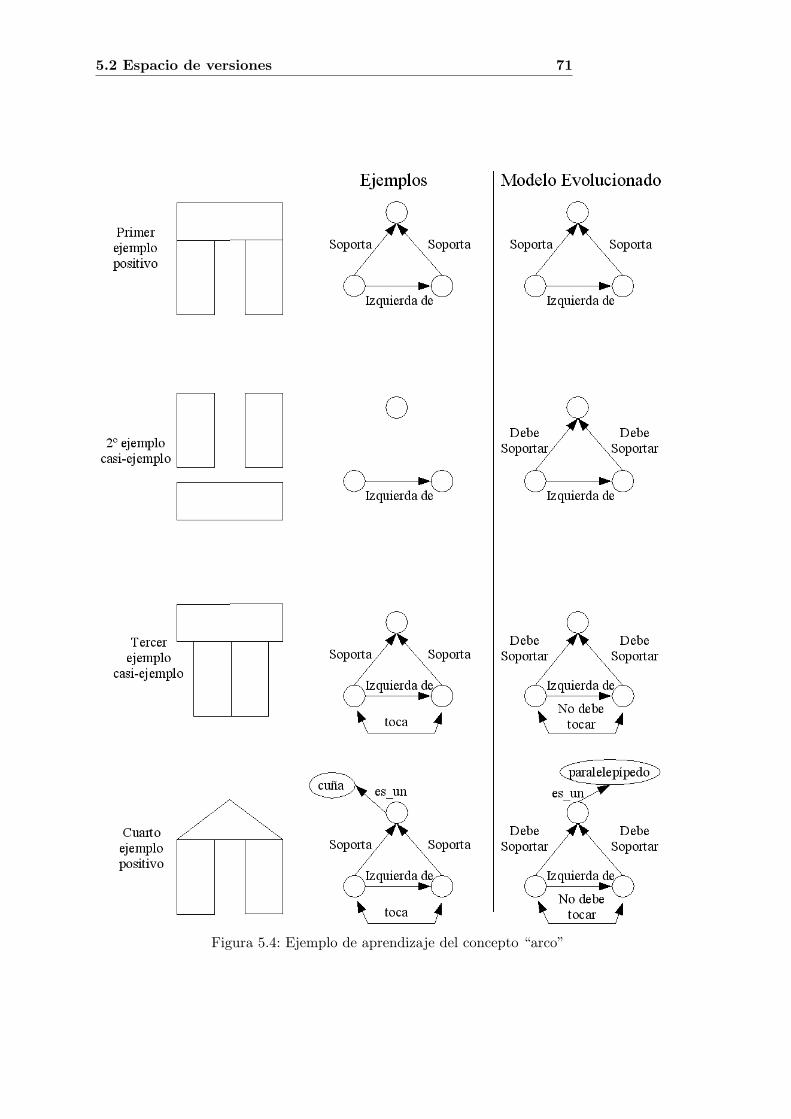
5.2 Espacio de versiones 71
Figura 5.4: Ejemplo de aprendizaje del concepto “arco”

72 Capıtulo 5. Aprendizaje por Induccion en Modo Estructural
Figura 5.5: Frame Coche

Capıtulo 6
Aprendizaje Basado en Instancias
Existen sistemas en los que es inviable encontrar un modelo global que represente todoslos ejemplos posibles y por lo tanto tenemos que conformarnos con una expresion local quemodele solo una parte del sistema.
Figura 6.1: Fases del aprendizaje basado en instancias
El modelo es directamente el conjunto de ejemplos de entrenamiento.
6.1. Convergencia de los Metodos Basados en Instancias
∫R p(x)d(x)
V≡ p∗(x)
dondep(x): distribucion de probabilidadp∗(x): distribucion real de probabilidadR: regionV : volumenY por otra parte:
pM (x) =KMM
VM
dondeM : conjunto de ejemplosV : volumen que ocupan esos ejemplosKM : subconjunto de ejemplos de M
73

74 Capıtulo 6. Aprendizaje Basado en Instancias
Cumpliendose las siguientes propiedades:
lımM→∞ VM = 0lımM→∞ KM =∞
lımM→∞KM
M= 0
Si se cumplen estas tres propiedades se dice que pM (x) converge a p∗(x)
En el plano teorico esto funciona muy bien, pero en la practica no podemos disponerde infinitos ejemplos (y por lo tanto tampoco podemos obtener un subconjunto infinito deejemplos, ni el volumen tiende a cero, etc).
En consecuencia el valor que obtengamos de p∗(x) (a partir de pM (x)) sera un valoraproximado.
Existen 2 formas de calcular pM (x):
1. KM =√
M → Metodo de los k-vecinos
2. VM =1√M→ Metodo de Parzen
6.2. Aprendizaje mediante kM vecinos
Definicion 6.1 X = x1, x2, . . . , xM −→ El conjunto de ejemplos, suponiendo que M esmuy grande (que tambien sera el modelo).
Definicion 6.2 C = c1, c2, . . . , cL −→ Conjunto de clases en las que estan los xi ejemplos.
Definicion 6.3 xi = (xi1, . . . , x
in) −→ Vector de caracterısticas.
Dados los n atributos de cada ejemplo (que pueden ser reales o multivaluados), tenemosdos posibilidades:
1. Clasificar: inferir una clase o atributo multivaluado
2. Hacer regresion: inferir un atributo real
Regla del vecino mas cercano para clasificarSe le asignan atributos a un ejemplo nuevo a partir de los atributos de su vecino mas
cercano conocido.Para hallar el vecino mas cercano del nuevo ejemplo z calculamos la distancia euclıdea
hasta todos los ejemplos de M .Como clase de z se le asigna la clase de su vecino mas cercano.Realmente, el metodo de los kM vecinos lo que hace es buscar los k vecinos mas cercanos
a z. Y puesto que solo trabajamos con k (del total de M) ejemplos, el aprendizaje es local.
Figura 6.2: Aprendizaje basado en k-vecinos

6.3 Aprendizaje mediante el metodo de Parzen 75
Supongamos que z = (z1, z2, z3, . . . , zn, c) y que no conocemos z2 ni c (la clase).Hallamos que la clase predominante entre los k vecinos mas cercanos a z es cq. Y como
desconocemos la clase de z, le asignamos cq.Si z2 es multivaluado, se le asigna el atributo predominante de entre los ejemplos (k
vecinos mas cercanos) que tienen la misma clase que z.Si z2 es real, se le asigna la media de los valores del atributo x2 en los k vecinos mas
cercanos que tienen la misma clase que z.
Supongamos ahora que z = (z1, z2, z3, . . . , zn, c) y que solo desconocemos z2.Si en los k vecinos mas cercanos la clase predominante coincide con c, z2 se infiere igual
que antes.Si por el contrario no coincide con c, no se puede inferir nada. A este tipo de ejemplos se
le llaman espureos.
Para hallar la distancia euclıdea se usan todos los atributos reales que tenga cada ejemplo
de(z, xj) =
√√√√ n∑i=1
(zi − xji )2
6.3. Aprendizaje mediante el metodo de Parzen
Dado un nuevo ejemplo z, se nos da un volumen (o ventana) y trabajaremos, igual queantes, con todos aquellos ejemplos que caigan dentro de la ventana dada centrada en z
Figura 6.3: Aprendizaje basado en Parzen
Si dentro de la ventana no hay ningun ejemplo, puede ser por lo siguiente:
La ventana es demasiado pequena
El ejemplo z esta demasiado alejado de la distribucion normal de los datos (este hechono se conoce con k-vecinos).
Por eso, la ventana que generalmente se utiliza es de la forma
K(z, xe) =1
(2π)r2 hr|Cov|
12
exp(− 1
2h2(z − xe)−tCov−1(z − xe)
)y recibe el nombre de ventana gaussiana.
6.4. Mejora de los metodos basados en instancias
Cuando la base de ejemplos es muy grande (millones de ejemplos), surge un problema deeficiencia, pues para encontrar los k vecinos mas cercanos hay que examinar la base de datoscompleta.
Para resolver esto, vamos a ver dos maneras: la multiedicion y la condensacion.

76 Capıtulo 6. Aprendizaje Basado en Instancias
6.4.1. Multiedicion
Puesto que los errores se condensan en la frontera que delimita las clases de los ejemplos,la multiedicion elimina dichos ejemplos, reduciendo ası el error cometido (tambien se diceque reduce el ruido de la base de ejemplos).
Figura 6.4: Multiedicion
La figura 6.4(a) muestra la base de ejemplos original, mientras que en la figura 6.4(b) seobserva la misma base de ejemplos multieditada.
funcion Hold-out Editing(R,k,M) devuelve conjunto editado de ejemplosentradas: R: Conjunto inicial de ejemplos a editar
k: Numero de vecinos para la regla de clasificacionM: Numero de bloques para hacer la particion hold-out
resultado: R: Conjunto editado de ejemplos1. Dividir aleatoriamente R en M subconjuntos disjuntos Ri, i = 1, . . . ,M2. Para i = 1, . . . ,M clasificar los ejemplos de Ri mediante la regla km usandoR(i+1)mod M como conjunto de entrenamiento3. Eliminar de R los ejemplos mal clasificados en el paso 2
Function Hold-out Editing(R,k,M )
funcion Multiedit(R,M,I) devuelve conjunto editado de ejemplosSe basa en la repeticion iterativa de Hold-out Editing con k = 1entradas: R: Conjunto inicial de ejemplos a editar
M: Numero de bloques para hacer la particion hold-outI: Numero de iteraciones sin cambios (criterio de parada)
resultado: R: Conjunto editado de ejemplos1. Ejecutar Hold-out Editing(R, k = 1,M)2. si en las ultimas I iteraciones no ha habido edicion entonces PARAR.en otro caso ir al paso 1.
Function Multiedit(R,M,I )
Nota.- ¡Ojo! Aplicar multiedicion de forma indiscriminada sobre bases de ejem-plos que realmente no la necesiten podrıa provocar incluso la eliminacion de unaclase.

6.4 Mejora de los metodos basados en instancias 77
Ejemplo 6.1 Vamos a clasificar R1 con respecto a R2, segun la base de ejemplos particionadaque se muestra en la figura 6.5
Figura 6.5: Base de ejemplos particionada
R2, con 1-vecino mas cercano, asigna a todos los ejemplos de R1 la clase 1. Como no hayerrores no se modifica R.
Ahora clasificamos R2 con respecto a R3. R3 asigna la clase 2 a todos los ejemplos deR2. Los ejemplos erroneamente clasificados se eliminan de la base de ejemplos, tal y como semuestra en la figura 6.6.
Figura 6.6: Base de ejemplos particionada y parcialmente multieditada
6.4.2. Condensacion
Se genera una base de ejemplos reducida y consistente (es decir, a la hora de inferir, elresultado es el mismo que si usaramos la base completa). Ası, se mejora la eficiencia.
La base de ejemplos reducida esta formada por los ejemplos de las fronteras.
Figura 6.7: Condensacion
En la figura 6.7(a) se muestra la base de ejemplos multieditada, mientras que en la figura6.7(b) se muestra la misma base de ejemplos multieditada y condensada.
La inferencia seguira siendo igual, pero ahora hay menos error y es mas eficiente.La delimitacion de la frontera a partir de un conjunto condensado depende de dicho
conjunto.

78 Capıtulo 6. Aprendizaje Basado en Instancias
funcion Condensing(R) devuelve conjunto condensado de ejemplosentradas: R: Conjunto (multieditado) de ejemplosresultado: S: Conjunto condensado de R consistente con R1. Seleccionar un ejemplo arbitrariamente, p ∈ RR← R− pS = p2. n← 0para todo p′ ∈ R hacer
si clase(p′) 6= clase1m(p′, S) entoncesR← R− p′S ← S + p′n← n + 1
3. si n = 0 o bien tamano(R) = 0 entonces PARARen otro caso ir al paso 2
Function Condensing(R)
6.5. Funciones Distancia Heterogeneas
6.5.1. Normalizacion
La normalizacion es necesaria para que todos los atributos tengan el mismo peso.
Ejemplo 6.2
A(900, 9)B(1000, 3)C(300, 3)
x1 ∈ [0, 1000] d(A,C) =√
(900− 300)2 + (9− 3)2 = 600′03x2 ∈ [0, 10] d(B,C) =
√(1000− 300)2 + (3− 3)2 = 700
Vemos que x1 domina a x2, ya que sea cual sea el valor de x2, el punto mas cercano a Csiempre sera A.
Una opcion para normalizar es dividir cada atributo entre el valor maximo de su rango.
Ejemplo 6.3
d(A,C) =
√(900− 300
1000
)2
+(
9− 310
)2
= 0′848
d(B,C) =
√(1000− 300
1000
)2
+(
3− 310
)2
= 0′555
Y vemos como ahora el punto mas cercano a C es B.
6.5.2. Discretizacion
En ocasiones puede no interesar tener atributos reales (por ejemplo, porque utilizamosun metodo discreto, no continuo).
Para ello, dividimos el rango de valores reales en distintos subrangos y entonces se trabajacomo si ese atributo fuera multivaluado, como se muestra en la figura 6.8
Figura 6.8: Discretizacion

6.5 Funciones Distancia Heterogeneas 79
6.5.3. Distintas metricas para el calculo de distancias
Metrica heterogenea coincidencia euclıdea MHCE
MHCE(x, y) =
√√√√ n∑i=1
di(xi, yi)2x = (x1, x2, . . . , xn)y = (y1, y2, . . . , yn)
di(xi, yi)
1 si xi o yi desconocidocoincidencia(xi, yi) si i multivaluadori Normalizado(xi, yi) en otro caso
coincidencia(xi, yi)
0 si xi = yi
1 en otro caso
ri Normalizado(xi, yi) =|xi − yi|rangoi
rangoi = maxi −mini
Metrica heterogenea de diferencia de valores MHDV
MHDV (x, y) = MHCE(x, y) =
√√√√ n∑i=1
di(xi, yi)2x = (x1, x2, . . . , xn)y = (y1, y2, . . . , yn)
di(xi, yi)
1 si xi o yi desconocidoMDVi Normalizado(xi, yi) si i multivaluadori Normalizado(xi, yi) en otro caso
ri Normalizado(xi, yi) =|xi − yi|
4σi
MDVi Normalizado(xi, yi) =c∑
k=1
∣∣∣∣Ni xi k
Ni xi
−Ni yi k
Ni yi
∣∣∣∣donde
c es el numero de clasesNi xi es el numero de ejemplos en el conjunto de entrenamiento que tiene el valor xi para
el atributo i-esimoNi xi k es el numero de ejemplos en el conjunto de entrenamiento que toman el valor xi
para el atributo i-esimo y como salida la clase k.

80 Capıtulo 6. Aprendizaje Basado en Instancias

Capıtulo 7
Maquinas de Aprendizaje
7.1. El Perceptron como Discriminante Lineal
Figura 7.1: Esquema de un Perceptron
En la figura 7.1 se muestra la imagen de un perceptron, en la cual se tiene que:
x = (x1, x2, . . . , xn, xn+1) = (x1, x2, . . . , xn, c)
d(x) =n∑
i=1
xiwi + w0
La funcion (*) filtra d(x) para devolver una clase, por ejemplo
x ∈ c1 si d(x) ≥ 0x ∈ c2 si d(x) < 0
La capacidad de informacion de cada atributo xi depende de su correspondiente pesowi
Las clases que va a poder discriminar este perceptron son clases linealmente separables,como las mostradas en la figura 7.2
Figura 7.2: Ejemplo de clases linealmente separables
81

82 Capıtulo 7. Maquinas de Aprendizaje
7.1.1. Criterio y construccion del perceptron
Los ejemplos de entrenamiento son
x1 = (x11, x12, . . . , x1n)x2 = (x21, x22, . . . , x2n)
...xM = (xM1, xM2, . . . , xMn)
Se comienza con un vector de pesos w0 aleatorio (y con valores proximos a cero). A partirde el, con el ejemplo x1 se obtiene w1, es decir
wk+1 = f(wk, xk+1)
donde f es el gradiente descendiente.
wk+1 = wk − αk∇J(wk)
dondewk es el vector de pesos actualαk ∈ [0, 1] es el paso de iteracion de aprendizajeJ(wk) es lo que se conoce como criterio del perceptron, y es una funcion que hay que
derivar
J(wk) =∑
x∈MC
(−w · x)
donde MC es el conjunto de los ejemplos mal clasificados
x ∈ c2 ⇔ −x ∈ c1
De este modo hacemos que todos los ejemplos de la clase c2 sean de la clase c1 y ası solohay que comprobar d(x) > 0.
∇J(w) =∑
x∈MC
(−x)
Y finalmente tenemos que
wk+1 = wk + αk∑
x∈MCx
El vector de pesos se va calculando hasta que no hayan ejemplos mal separados (supo-niendo que las clases son linealmente separables).
7.2. Redes de Perceptrones Multicapa
Figura 7.3: Ejemplo de clases NO linealmente separables
Un perceptron tradicional como el visto hasta ahora serıa incapaz de aprender un ejemplocomo el mostrado en la figura 7.3(a). El resultado que deberıa dar es el que se muestra en lafigura 7.3(b).

7.2 Redes de Perceptrones Multicapa 83
Figura 7.4: Ejemplo de perceptron multicapa
Figura 7.5: Estructura de un perceptron multicapa
Para conseguirlo lo que se hace es encadenar perceptrones formando lo que se conocecomo una red de perceptrones multicapa, como la que se muestra en la figura 7.4
En la capa de salida de la red de perceptrones multicapa ya no se usa la funcion que seusaba antes para decidir la clase del ejemplo de entrada. Ahora se emplea la funcion sigmoide:
11 + e−
∑w·x
la cual devuelve valores en (0, 1)El numero de capas ocultas y el numero de neuronas en ellas es variable. Sin embargo se
ha demostrado que con una sola capa oculta es suficiente.El numero de neuronas en la capa de salida depende del numero de clases que tengamos.
Por ejemplo, si tenemos dos clases, c1 y c2, podemos usar una o dos neuronas. En general
n clases ⇒ log2 n neuronas, como mınimo
La representacion del modelo aprendido es la propia red neuronal, con todas sus conexio-nes, los vectores de pesos w1 y w2, el numero de capas ocultas y el numero de neuronas decada capa (definido por el usuario).
Ahora hay que optimizar el error cuadratico, es decir, cuanto se desvıa la salida de la redcon respecto a la salida que se espera, puesto que ahora la red da valores continuos en elintervalo (0, 1).
E(w) =12
M∑j=1
(yj − oj)2 dondeyj clase real del ejemplooj clase inferida por la red
El algoritmo va modificando los vectores de pesos en funcion del error cometido con elultimo ejemplo, hasta que la variacion de todos los elementos de los vectores de pesos sea

84 Capıtulo 7. Maquinas de Aprendizaje
suficientemente pequena durante varias epocas1.Pero como a menudo no sabemos cuantas epocas son necesarias para que el modelo
converja, se suele poner una cota superior (por ejemplo, si en 1000 epocas el modelo noconverge, termina).
Cuantas mas neuronas hayan en la capa oculta mas complejo es el sistema que se deseaaprender y siempre es posible encontrar un modelo (pero mas neuronas implican mas tiempode aprendizaje).
Este es un aprendizaje local.La formula para obtener los vectores de pesos en cada iteracion es la siguiente:
wc(t + 1) = wc(t)− ρ∇wcE(wc) = wc(t) +4wc(t + 1)
Algoritmo BackpropagationA grandes rasgos, los pasos de este algoritmo son:
1. Inicializar la red.
2. Inicializar los vectores de pesos.
3. El termino h0 y o0 de la capa oculta y de salida, respectivamente, se pone a 1, porqueno depende de los ejemplos.
4. Se toma un ejemplo y se le pasa a la red.
Para clasificar usaremos como funcion de decision n intervalos (si hay n clases) con unafiabilidad que depende directamente de la base de prueba.
7.3. Arboles de Clasificacion
Usados cuando la clase (o el atributo por el que queremos catalogar) es multivaluado.Para clases (o atributos) reales se usan los arboles de regresion.
Cada nodo interno del arbol es un atributo (real o multivaluado) de los ejemplos, y solorecogera aquellas caracterısticas que considere necesarias para discriminar.
Las hojas son las clases o los valores del atributo multivaluado por el que queremoscatalogar.
Figura 7.6: Ejemplo de arbol de clasificacion
1Una epoca es una pasada completa a todos los ejemplos de la base de entrenamiento

7.4 Arboles de Regresion 85
Definicion 7.1 Un nodo se dice que es puro si todos los ejemplos contenidos en el tienen lamisma clase.
Si un nodo no puro cumple el criterio de parada se etiqueta con la clase que predomineen sus ejemplos. Un atributo multivaluado no se puede usar para dividir los ejemplos de masde un nodo; un atributo real sı puede.
Poda por estimacion del errorSea Ck el numero de ejemplos de la clase k que hay en un nodo.Si la suma del error de los hijos es mayor que el error del padre, se podan los hijos y al
padre se le asigna la clase que predomine.
Figura 7.7: Ejemplo de poda por estimacion del error
Ejemplo 7.1 En el arbol de clasificacion de la figura 7.7 el padre tiene un error de
1001100
≈ 0′1
mientras que la suma de los errores de los hijos vale
10960
+50140≈ 0′4
7.4. Arboles de Regresion
El nodo hoja ahora es un atributo real y no vale la condicion de nodo puro como condicionde parada.
Ahora en vez del valor predominante, se le asigna al nodo hoja la media de los valores delatributo por el que se clasifica.
El sobreaprendizaje consiste en seguir preguntando repetitivamente por algun atributoreal hasta que se llega a un arbol en cuyas hojas solo hay un ejemplo.
Para evitar esto se usa como condicion de parada el numero de ejemplos en un nodo y/ola profundidad del nodo.

86 Capıtulo 7. Maquinas de Aprendizaje

Capıtulo 8
Aprendizaje por Descubrimiento
En este capıtulo vamos a tratar el aprendizaje no supervisado, es decir, en vez de tenercomo hasta ahora x = (x1, . . . , xn, c), se tiene x = (x1, . . . , xn) que no significa que no seconozca la clase, sino que no existe tal clase.
8.1. Clustering o Agrupamiento
En este tipo de aprendizaje por descubrimiento no se habla de clasificacion (puesto que noexisten clases) sino de agrupamiento. Los ejemplos se agrupan segun su similitud o semejanza(ya no se habla de caracterısticas).
Uno de los problemas del clustering es que se van a producir un numero (normalmente)desconocido de agrupamientos. Para evitar esto, el numero de agrupamientos que se quieranformar se pasa como parametro.
La validacion de un cluster consiste en averiguar cual es el mejor numero de dichosagrupamientos.
8.1.1. Algoritmo de k-medias
Como medida de similitud entre los ejemplos se usa la distancia entre los mismos (en-tendiendo por distancia la distancia euclıdea si todos los atributos son reales o alguna delas distancias heterogeneas vistas anteriormente si hay atributos multivaluados). Cuanto mascercanos sean dos ejemplos, mas semejantes.
Cada cluster tiene un centro (media) que acabara estando en el centro de gravedad de lamasa de los ejemplos.
Ejemplo 8.1 Seax1 = (x1
1, . . . , x1n)
x2 = (x21, . . . , x
2n)
x3 = (x31, . . . , x
3n)
la base de ejemplos.Entonces la media se calcula como
x =(
x11 + x2
1 + x31
3, . . . ,
x1n + x2
n + x3n
3
)En el algoritmo de k-medias ||x−mi|| es la norma que nos indica cual es la similitud de
los ejemplos.La funcion J mide el error del modelo aprendido y, por lo tanto, debe ser minimizada.
87

88 Capıtulo 8. Aprendizaje por Descubrimiento
En cada iteracion del algoritmo se calcula la distancia de cada ejemplo a cada una delas k medias y cada ejemplo se asocia con el cluster cuya media mejor lo represente (la mascercana al ejemplo).
Si algun ejemplo cambia de cluster hay que recalcular las medias y, por consiguiente,recalcular J (la cual ira disminuyendo en cada iteracion).
El algoritmo para cuando J no cambie, es decir, cuando J haya alcanzado su valor mınimoy ningun ejemplo haya cambiado de cluster.
Lo que hay que devolver al usuario es el modelo con el menor error y para ello se pruebandistintos numeros de agrupamientos.
El modelo con menor error (J = 0) es aquel que tenga tantos agrupamientos como ejem-plos. Pero este modelo no es nada bueno porque no se puede inferir (se ha producido sobre-aprendizaje).
De aquı se deduce que cuanto mayor sea el numero de agrupamientos, menor error habra.Por eso la validacion consiste en encontrar el numero optimo de agrupamientos.
8.1.2. Mapas autoasociativos de Kohonen
Se trata de redes neuronales no supervisadas, como la que se muestra en la figura 8.1.
Figura 8.1: Mapa autoasociativo de Kohonen
Cada neurona representa un vector de pesos. Se calcula la distancia entre los ejemplos deentrada y los vectores de pesos.
Cuando entra el ejemplo todas las neuronas se activan y aquella con menor distanciarecibe el nombre de unidad ganadora. Esta unidad ganadora se mueve y se acerca al ejemplopara representarlo.
Es decir, la unidad ganadora cumple que wc = mini|x− wi|
LASON
La unidad ganadora, al moverse hacia el ejemplo de entrada para representarlo, arrastraa sus vecinos (es decir, estos tambien se mueven, aunque menos que la unidad ganadora).
De esta forma se aprende la topologıa de los datos. Esta tecnica se utiliza, por ejemplo,en el reconocimiento de caracteres.
wih(t + 1)
wih(t) +α(t)
d(ch, cj)(xi(t)− wih(t)) si cj es la unidad ganadora y d(ch, cj) ≤ θ
wih(t) en otro caso
∀ i = 1, . . . , n, dondeα(t) es variable con el tiempo y dara el criterio de parada cuando alcance un cierto umbral.
Suele ser una funcion logarıtmica.

8.1 Clustering o Agrupamiento 89
d(ch, cj) es la distancia entre la unidad ganadora cj y el resto de neuronas ch.
Ejemplo 8.2 Definimos d(ch, cj) como el numero de neuronas por las que hay que pasarpara llegar desde ch hasta cj, y sea θ = 2.
Entonces d(cj , cj) = 1 y wij(t) + α(t)(xi(t)− wij(t))
Si d(ch, cj) = 2 entonces wih(t) +α(t)2
(xi(t)− wih(t))
Algoritmo
1. Se inicializan los pesos con valores aleatorios y pequenos
2. Se introduce un nuevo ejemplo y se actualiza α(t)
3. Se propaga el ejemplo a la capa de competicion y se obtienen los valores de salida decada neurona (es decir, la distancia del vector de pesos al ejemplo de entrada)
4. Se selecciona la neurona c ganadora
5. Se actualizan las conexiones entre la capa de entrada y la neurona c, ası como la de suvecindad segun su grado de vecindad
6. Si α(t) esta por encima de un umbral volvemos al paso 2. En caso contrario, parar.

90 Capıtulo 8. Aprendizaje por Descubrimiento

Parte II
Ingenierıa del Conocimiento
91


Capıtulo 9
Principios de la Ingenierıa delConocimiento
Historia de los SE
Caracterısticas de los SE
Deficiencias de los SE
Representaciondel Conocimiento
LogicaSistemas de ProduccionesRedes SemanticasMarcos
Personasinvolucradas
Ingeniero del ConocimientoExpertoUsuario
Conocimiento
Accesibilidad
TacitoExplıcito
Representacion
DeclarativoSemanticoProcedimentalEpisodico
Naturaleza
PublicoExperiencia compartidaPersonal
Niveles
IdealısticoSistematicoPragmaticoAutomatico
Ingenierıa del Conocimiento
SBC
Nivel de Conocimiento
SE basadoen Reglas
Hacia adelanteHacia atrasVentajasInconvenientes
93

94 Capıtulo 9. Principios de la Ingenierıa del Conocimiento
SE basadoen Modelos
VentajasInconvenientes
SE basadoen Casos
VentajasInconvenientes
Reglas + Casos
Reglas + Modelos
Modelos + Casos

Capıtulo 10
La Adquisicion del Conocimiento
NivelContextual
Personal deInteres
Proveedores de ConocimientoUsuarios de ConocimientoGestores de Conocimiento
ModeloContextual
Caracterısticas mas importantes de la organizacionDecidir donde es util un SBCViabilidadImpacto
Modelo deTareas
Refinamiento del modelo de la organizacion
Descubre tareas relevantes
Entradas/SalidasPrecondicionesRecursos
Modelo deAgentes
Ejecutor de las tareas
Analiza
Cargo en la organizacionTipo (humano/software)Tareas en las que esta involucradoAgentes con los que se comunicaConocimiento que poseeResponsabilidad que tiene
Formulario Resumen
Impacto y cambios en la organizacionImpacto y cambios en las tareas y agentesActitudes y compromisoAcciones propuestas
NivelConceptual
Modelo deConocimiento
Conocimientodel Dominio
Esquema del
Dominio
ConceptosRelacionesReglas
Base de Conocimiento
Conocimientosobre Inferencias
InferenciasRolesFunciones de transferenciaDiagramas de Inferencia
Conocimientosobre Tareas
TareasMetodos
Modelo deComunicacion
Plan de Comunicacion −→ organiza las transacciones
Transferencias
Objetos de informacion intercambiadosTareas y agentes involucrados
Mensaje −→ detalles de la estructura de la transaccionNivel deSistema
Modelo deDiseno
95

96 Capıtulo 10. La Adquisicion del Conocimiento
SesionAC
Fases
PlanificacionEncuentroAnalisis
Tecnicasde AC
Entrevistas no estructuradas −→ elementos graficosEntrevistas estructuradas −→ elementos formales
Basadas enConstruccionesRepertory Grid
Estructuracion de conceptos1. Identificar elementos2. Identificar caracterısticas3. Disenar parrilla con valoraciones4a. Agrupar por elementos y construir el arbol4a. Agrupar por caracterısticas y construir el arbol5. Analizar
Traza deProcesos
Analisis TareasDiseno Protocolo


















