
CLASIFICACION MEDIANTE K-MODAS PARA EL CASO DE...
60
CLASIFICACI ´ ON MEDIANTE K-MODAS PARA EL CASO DE VARIABLES CATEGORICAS Luisa Fernanda Pastr´ an Ram´ ırez Nataly Jineth Roa Pe˜ na Universidad del Tolima Facultad de Ciencias Departamento de Matem´aticas y Estad´ ıstica Ibagu´ e- Tolima Febrero 2015
Transcript of CLASIFICACION MEDIANTE K-MODAS PARA EL CASO DE...

CLASIFICACION MEDIANTE K-MODAS PARA EL CASODE VARIABLES CATEGORICAS
Luisa Fernanda Pastran RamırezNataly Jineth Roa Pena
Universidad del TolimaFacultad de Ciencias
Departamento de Matematicas y EstadısticaIbague- TolimaFebrero 2015

CLASIFICACION MEDIANTE K-MODAS PARA EL CASODE VARIABLES CATEGORICAS
Luisa Fernanda Pastran Ramirez.Nataly Jineth Roa Pena.
Trabajo de grado como requisito parcial para optar al tıtulo deProfesional en Matematicas con Enfasis en Estadıstica
Director:Jairo Alfonso Clavijo
Magister en Estadıstica
Universidad del TolimaFacultad de Ciencias
Departamento de Matematicas y EstadısticaIbague - Tolima
Febrero 2015

Indice general
Agradecimientos 5
Resumen 7
Introduccion 8
Objetivos 9
1. PRELIMINARES 121.1. Distribucion de probabilidad para Variables Categoricas . . . . 121.2. Clasificacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
1.2.1. Semejanza, similaridad, disimilaridad y medidas de di-similaridad . . . . . . . . . . . . . . . . . . . . . . . . 13
1.3. Clasificacion Jerarquica . . . . . . . . . . . . . . . . . . . . . . 181.4. Clasificacion no Jerarquica . . . . . . . . . . . . . . . . . . . . 22
1.4.1. Metodo de K-Means . . . . . . . . . . . . . . . . . . . 231.4.2. Nubes Dinamicas . . . . . . . . . . . . . . . . . . . . . 25
2. CLASIFICACION CON VARIABLES CATEGORICAS 272.1. Variable categorica . . . . . . . . . . . . . . . . . . . . . . . . 272.2. Clasificacion de Variables Categoricas . . . . . . . . . . . . . . 292.3. Disimilaridad en variables categoricas . . . . . . . . . . . . . . 30
2.3.1. Metodo de K-Modas . . . . . . . . . . . . . . . . . . . 362.3.2. Algoritmo de K-Modas . . . . . . . . . . . . . . . . . . 36
3. APLICACION 383.1. Fases del Algoritmo de K-Modas . . . . . . . . . . . . . . . . 38
3.1.1. Ejemplo . . . . . . . . . . . . . . . . . . . . . . . . . . 46
3

INDICE GENERAL 4
3.2. Estudio de un Caso Especıfico . . . . . . . . . . . . . . . . . . 483.2.1. Resultados encuesta de salud . . . . . . . . . . . . . . 49
4. CONCLUSIONES 54
5. ANEXOS 555.1. Encuesta, Anexo 1: . . . . . . . . . . . . . . . . . . . . . . . . 55
Bibliografıa 60

INDICE GENERAL 5
Agradecimientos
Agradecimientos Luisa Fernanda Pastran Ramırez
Primeramente quiero dar gracias a Dios, por llenarme de sabidurıa, tran-
quilidad, inteligencia, ser mi fortaleza en momentos de debilidad y por brin-
darme tantos anos de aprendizaje, experiencias y felicidad.
Gracias a mis padres Fermın y Amparo por estar conmigo en cada mo-
mento que los necesitaba, por darme amor, animo y fuerza en los momentos
que sentıa flaquear. Gracias por inculcarme tantos valores en el transcurso
de mi vida.
A mis hermanos Ricardo y Sandra, y a su esposo,por ser parte de mi
vida, representar el amor sincero, la union familiar, apoyarme, y ademas, por
ser mi ejemplo a seguir como personas y profesionales que son. Amis lindos
sobrinos gracias por llenar mis dıas de felicidad.
A todos los profesores de la UT, en especial, a los profesores Leonardo
Solanilla, Jesus Avila, Maximiliano Machado y Horacio Molano,por cada en-
senanza que me brindaron, por cada granito de arena que aportaron a mi
formacion como profesional.
Gracias a todos!!!
Agradecimientos Nataly Jineth Roa Pena
Hoy doy gracias a Dios y a mi familia que ha permitido con su apoyo en
estos duros anos de carrera, en especial a mi madre que no solo con el apoyo

INDICE GENERAL 6
economico, sino tambien emocional en los momentos de tristeza y tambien
en los momentos de alegrıa que han sido muchos mas, ella ah estado ahı pa-
ra mı, ha mi esposo que con su ayuda academica ha sabido guiarme en las
correcciones de este documento.
Agradecimientos por las autoras
Queremos agradecer a nuestro director de tesis Jairo Clavijo, quien siem-
pre nos brindo su apoyo desde el dıa que le dijimos que querıamos que fuera
nuestro director. Gracias profesor por su paciencia y las ensenanzas dıa a dıa.
Queremos dar las gracias especialmente al Ph.D. Hector Andres Granada
Diaz por su gran apoyo en este proyecto de grado, el cual con su gran cono-
cimiento, orientacion y paciencia, logramos la elaboracion del algoritmo, ya
que el fue autor del codigo en Matlab.

INDICE GENERAL 7
Resumen
El presente trabajo presenta un metodo particular para clasificar indi-
viduos caracterizados por variables aleatorias de tipo categorico las cuales
difieren sustancialmente de las variables numericas usualmente usadas para
clasificar y formar conglomerados.
La primera parte del trabajo esta dedicada a la presentacion de los ele-
mentos basicos que rigen la teorıa de variables categoricas ası como a la
presentacion del metodo k-means que es el prototipo de tecnica utilizada con
los cambios convenientes para manejar variables categoricas, dando origen al
metodo de k-modas.
La segunda parte proporciona la esencia del metodo k-modas al igual que
el algoritmo que lo implementa y las rutinas de programacion necesarias para
su aplicacion.
Finalmente se aplica los temas anteriores a un caso particular de una
muestra tomada en Empresas Prestadoras de Salud en el Tolima

INDICE GENERAL 8
Introduccion
En el presente trabajo de grado se enuncian las acciones desarrolladas
para realizar la clasificacion de variables categoricas mediante k-Modas. La
teorıa expuesta en el trabajo se ilustra mediante la clasificacion realizada a
una encuesta que se hizo en entidades de salud en Ibague y el Espinal.
Debıdo al caracter especial de las variables categoricas que no permiten
operaciones aritmeticas, los metodos tradicionalmente usados para variables
de tipo continuo no pueden ser implementados con variables categoricas, lo
que hace necesario recurrir a otro tipo de herramientas, entre las cuales se
puede citar el metodo de k-Modas, al que se dedica este trabajo.
Como una ilustracion del metodo este fue aplicado a un caso particu-
lar, en 3 entidades de salud (dos en Ibague y una en el Espinal) en las que,
mediante preguntas de tipo categorico, se pretendio evaluar la calidad del
servicio prestado. Se debe recalcar sin embargo, que el objetivo perseguido
en el trabajo no fue la evaluacion del servicio sino la clasificacion de los en-
cuestados.

INDICE GENERAL 9
Objetivo General
Hacer una presentacion del metodo k-Modas como herramienta de clasi-
ficacion para individuos caracterizados mediante variables categoricas.
Objetivos Especıficos
1. Mostrar los fundamentos teoricos en que se basa el metodo k modas.
2. Disenar y programar el algoritmo de clasificacion.
3. Aplicar el metodo a una situacion concreta.

Indice de figuras
1.1. Ejemplo de clasificacion en la biologıa . . . . . . . . . . . . . . 13
1.2. Dendograma que muestra la clasificacion segun el metodo Sin-
gle Linkage . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
1.3. Esquema de agrupacion de K-MEANS . . . . . . . . . . . . . 24
2.1. variables definidas sobre el individuo hj . . . . . . . . . . . . . 28
2.2. Asignacion de valores de las caracterısticas de la poblacion . . 32
3.1. clasificacion de los elementos, grupo 1 . . . . . . . . . . . . . . 49
3.2. clasificacion de los elementos, grupo 2 y grupo 3 . . . . . . . . 50
3.3. Modas finales . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
10

Indice de cuadros
1.1. Indices de similaridad. . . . . . . . . . . . . . . . . . . . . . . . 15
1.2. Valor de por parametros los cuales determinan casos particu-
lares de Lance-Williams. . . . . . . . . . . . . . . . . . . . . . 20
2.1. Tabla de poblacion . . . . . . . . . . . . . . . . . . . . . . . . 32
2.2. Posibles distancias . . . . . . . . . . . . . . . . . . . . . . . . 34
2.3. Posibles Modas . . . . . . . . . . . . . . . . . . . . . . . . . . 35
5.1. Base de datos . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
5.2. Base de datos . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
11

Capıtulo 1
PRELIMINARES
Este primer capıtulo muestra algunos conceptos basicos de la estadıstica,
aplicables a variables categoricas. Cabe resaltar que en la clasificacion el
analisis exploratorio de datos y la Estadıstica Multivariada juegan un papel
muy importante.
1.1. Distribucion de probabilidad para Varia-
bles Categoricas
Puesto que una variable categorica X asume valores de acuerdo con cier-
to grado de probabilidad, pi, la suma de tales valores pi es igual a 1. En
consecuencia , el valor 1 se distribuye entre las diferentes categorıas. Por es-
ta razon se dice que el conjunto p1, p2, . . . , pk forma una distribucion de
probabilidad para X. Si X tiene k categorıas C1, C2, . . . , Ck,se acostumbra a
escribir P (X = Ci) = pi, con lo cual se indicara como es la funcion f(·) de
distribucion.
1.2. Clasificacion
Clasificar es una actividad frecuente en la que se busca organizar un
conjunto de elementos en grupos caracterizados por una alta homogeneidad
12

CAPITULO 1. PRELIMINARES 13
o semejanza en su interior, y a la vez una gran diferenciacion entre grupos
distintos. Un ejemplo tıpico de clasificacion se da en biologıa como lo muestra
en la Figura 1 · 1:
Figura 1.1: Ejemplo de clasificacion en la biologıa
Una clasificacion se dice jerarquica si en ella esta explıcito el orden o
jerarquıa en el que se agrupan los individuos vistos como conglomerados y
es no jerarquica cuando es una simple particion de un conjunto.
1.2.1. Semejanza, similaridad, disimilaridad y medidas
de disimilaridad
De acuerdo con lo anterior, la clasificacion de individuos se basa en una
medida de la semejanza que hay entre ellos. Se han ideado varias formas de
medir la similaridad o similitud entre individuos, basados en los valores que
tomen algunas variables observadas sobre ellos. [3]
En general una similaridad en H es una funcion S : H × H → R+ que
cumple:
∀(i, j) ∈ HxH
S(i.j) = S(j, i),∀i, j ∈ H

CAPITULO 1. PRELIMINARES 14
S(j.j) = S(i, i) = M
donde M es el maximo valor de similaridad casi siempre, M = 1.
Dada una similaridad en H se define automaticamente una disimilardad
en H mediante la formula:
d(i, j) = M − S(i, j)
Y se cumple:
∀i ∈ H, d(i, i) = 0
d(i, i) > 0
d(i, j) = d(j, i)
Dado un conjunto de individuos H = h1, h2, . . . , hn se define la matriz
de distancias (o disimilaridades) como:
D = (di,j)n×n donde di,j = d(hi, hj), ∀i, j. Esto es:
D=
h1 h2 . . . hj . . . hn
h1 d11 d12 . . . d1j . . . d1n
h2 d21 d22 . . . d2j . . . d2n...
hj dj1 dj2 . . . dij . . . din...
hn dn1 dn2 . . . dnj . . . dnn
Donde D es claramente una matriz simetrica, ya que di,j = d(hi, hj) =
d(hj, hi) = dj,i

CAPITULO 1. PRELIMINARES 15
En el caso particular en que di,j sean distancia se cumple las siguientes
propiedades:
d(i, j) ≥ 0; d(i, j) = 0 si y solamente si i = j
d(i, j) = d(j, i), ∀i, j ∈ I
d(i, j) ≤ d(i, k) + d(k, j), ∀i, j, k ∈ H
En el caso mas general de que di,j sea una disimilaridad no se puede garan-
tizar el cumplimiento de la tercera propiedad, en estos casos dos individuos
i, j son mas cercanos o mas parecidos cuanto mas pequeno sea el valor d(i, j).
Nota: Una forma muy frecuente de definir similaridades y por tanto,
disimilaridades, es el uso de ındices de similaridad, como los que se mencionan
el cuadro 1 · 1:
INDICES En terminos de a,b,c
Jaccard aa+b+c
Sorensen; Dice 2a2a+b+c
Ochiai a[(a+b)(a+c)]1/2
Russel-Rao aa+b+c+d
Sokal- Sneath 1 2(a+d)2(a+d)+b+c
Sokal- Sneath 2 aa+2(b+c)
Sokal- Sneath 3 a+db+c
Cuadro 1.1: Indices de similaridad.
Tomando a el numero de caracterısticas comunes entre los objetos i y j;
b el numero de caracterısticas i que no tiene j; c el numero de caracterısticas
j que no tiene i; d el numero de caracterısticas de ninguno.

CAPITULO 1. PRELIMINARES 16
De acuerdo con lo dicho anteriormente se concluye que toda distancia es
una disimilaridad mas no al contrario. La notacion de distancia entre indi-
viduos puede generalizarse a conjuntos, lo que resulta util en el momento de
”fusionar”dos conglomeados para formar uno nuevo. Los casos mas utiliza-
dos de distancias entre grupos se definen mediante las distancias entre sus
elementos, de acuerdo con las formulas siguientes:
Single Linkage (Vecino mas cercano) Este metodo consiste en unir
los grupos considerando la menor de las distancias existentes entre los
objetos mas cercanos de distintos grupos. Es decir, mide la proximidad
entre dos grupos calculando la distancia entre sus objetos mas proximos
o la similitud entre sus objetos mas semejantes [1].
d(A,B) = mind(a, b)/a ∈ A, b ∈ B (1.1)
Complete Linkage (Enlace completo): En este metodo los grupos
se unen considerando la mayor de las distancias existentes entre los
miembros mas lejanos de los dos conjuntos [1].
d(A,B) = maxd(a, b)/a ∈ A, b ∈ B (1.2)

CAPITULO 1. PRELIMINARES 17
Centroide Linkage (Centroide): En este metodo, la distancia entre
dos grupos esta dada por la distancia (usualmente la distancia euclıdea
o euclıdea cuadrada) entre sus centros o centroides. Los centroides de
los grupos corresponden a la media o el promedio del grupo [1].
d(A,B) = d(a, b) (1.3)
Average Linkage (Promedio): Se unen los grupos cuya distancia
entre los grupos se define como el promedio de las distancias entre
sus elementoss, este metodo no depende de un par de elementos extre-
mos.[1]
d(A,B) =1
nAnB
∑a∈Ab∈B
d(a, b) (1.4)

CAPITULO 1. PRELIMINARES 18
Ward: Con frecuencia se usa tambien la distancia de ward, basada en
la variabilidad ENTRE y DENTRO. Este metodo agrupa elementos de
modo que se minimice una determinada funcion objetivo que por lo
general es la suma de las distancias cuadradas intra-grupo [1].
SSEA =
nA∑i=1
(yi − yA)′(yi − yA) (1.5)
SSEB =
nB∑i=1
(yi − yB)′(yi − yB) (1.6)
SSEAB =
nAB∑i=1
(yi − yAB)′(yi − yAB) (1.7)
1.3. Clasificacion Jerarquica
La clasificacion jerarquica es util cuando el numero de individuos a cla-
sificar es relativamente pequeno. Podemos saber que tan separados estan los
grupos como los individuos, mediante dendogramas.
Estos metodos tienen por objetivo agrupar clusters para formar uno nue-
vo o bien separar alguno ya existente para dar origen a otros dos, de tal forma
que se minimice alguna funcion de distancia o bien se maximice alguna me-

CAPITULO 1. PRELIMINARES 19
dida de similitud.
Los metodos jerarquicos se subdividen a su vez en aglomerativos y di-
sociativos. Los aglomerativos comienzan el analisis con tantos grupos como
individuos haya en el estudio, a partir de ahı, se van formando grupos de
forma ascendente, hasta que al final del proceso, todos los casos estan en-
globados en un mismo conglomerado. Los metodos disociativos o divisivos
realizan el proceso inverso al anterior. Empiezan con un conglomerado que
engloba a todos los individuos, a partir de este grupo inicial se van formando,
a traves de sucesivas divisiones o grupos cada vez mas pequenos. Al final del
proceso se tienen tantos grupos como individuos hay en la muestra estudiada
[2].
Segun el tipo de distancia que se usan entre conglomerados, se tienen
deferentes metodos de fusion a saber:
1. Metodo del single linkage(vecino mas cercano)
2. Metodo del complete linkage (enlace completo)
3. Metodo del centroide linkage (centroide)
4. Metodo del average linkage (promedio)
5. Metodo de Ward
Lance y Williams en 1967, lograron unificar todos los metodos anteriores
bajo un solo esquema que depende de 4 parametros, como se muestra a con-
tinuacion.
Concretamente la expresion que dedujeron dichos autores proporciona
la distancia entre un grupo K y otro grupo (I, J) formado en una etapa
anterior por la fusion de dos grupos. Dicha expresion permite la construccion

CAPITULO 1. PRELIMINARES 20
Metodo Cluster αA αB β γsingle linkage 1
212
0 −12
complete linkage 12
12
0 12
Promedio nA
nA+nB
nB
nA+nB0 0
Centroide nA
nA+nB
nB
nA+nB− nAnB
(nA+nB)20
Mediana 12
12
−14
0Ward nA+nc
nA+nB+nc
nB+nC
nA+nB+nC
−nC
nA+nB+nC0
Beta flexible 1−β2
1−β2
β(< 1) 0
Cuadro 1.2: Valor de por parametros los cuales determinan casos particularesde Lance-Williams.
de nuevos metodos con solo una modificacion adecuada de los parametros,
tiene importantes aplicaciones desde el punto de vista computacional ya que
permite una reduccion considerable en los caculos. La formula en cuestion es
la siguiente:
d(K, (I, J)) = αId(K, I) + αJd(K, J) + βd(I, J) + γ|d(K, I)− d(K, J)|(1.8)
De esta manera el calculo de las distancias entre grupos usadas por las
tecnicas jerarquicas descritas anteriormente son casos particulares de la ex-
presion anterior, mediante una eleccion conveniente de los parametros αI , αJ ,
β y γ. Algunos de estos coeficientes han sido ya deducidos en la descripcion
de los metodos anteriores (metodos del promedio ponderado y no ponderado,
metodo del centroide, metodo de la mediana y metodo de Ward) [2].
Muestra como los metodos ya mencionados pueden obtenerse a partir de
la propuesta de Lance-Williams. El valor que se de a los parametros deter-
mina el metodo correspondiente como caso particular de Lance-Williams.
Las clasificaciones jerarquicas siempre se dan en funcion de distancia o
disimilaridades .

CAPITULO 1. PRELIMINARES 21
Ejemplo
Considerese I = A,B,C,D,E con la matriz de distancias D. Se clasifica-
ran estos elementos usando Single Linkage :
D=
A B C D E
A 0 2 1 3 4
B 2 0 4 3 5
C 1 4 0 6 7
D 3 3 6 0 8
E 4 5 7 8 0
Como primer paso se fusionan los dos elementos mas cercanos y se calcula
nuevamente la matriz de distancias.
D=
AC B D E
AC 0 2 3 4
B 2 0 3 5
D 3 3 0 8
E 4 5 8 0
Repitiendo el proceso anterior para AC,B y D.

CAPITULO 1. PRELIMINARES 22
D=
AC,B D E
AC,B 0 3 4
D 3 0 8
E 4 8 0
Repitiendo el proceso anterior para AC,B,D y E.
D=
AC,B,D E
AC,B,D 0 4
E 4 0
Finalmente se obtiene el siguiente dendograma.
Figura 1.2: Dendograma que muestra la clasificacion segun el metodo SingleLinkage
1.4. Clasificacion no Jerarquica
Es un tipo de clasificacion en el que una muestra de n individuos,se agru-
pa en k clusters o subconjuntos de modo que existe una alta homogeneidad

CAPITULO 1. PRELIMINARES 23
en el interior de cada uno de ellos y una alta heterogeneidad entre los grupos.
El numero de clases se establece previamente y el algoritmo de clasifica-
cion asigna los individuios a las clases, partiendo de algunos valores iniciales
y buscando optimizar algun criterio establecido.
Ello implica que el investigador debe especificar a priori los grupos que
deben ser formados, siendo esta, posiblemente, la principal diferencia res-
pecto de los metodos jerarquicos. La asignacion de individuos a los grupos
se hace mediante algun proceso que optimice el criterio de seleccion. Otra
diferencia de estos metodos respecto a los jerarquicos reside en que trabajan
con la matriz de datos original y no precisan del calculo de una matriz de
distancias o disimilaridades [2].
Los metodos mas conocidos son:
1. El metodo K-Means.
2. El metodo de las nubes dinamicas.
1.4.1. Metodo de K-Means
Es conocido por su eficacia en la agrupacion de grandes conjuntos de
datos. Tiene como objetivo la particion de un conjunto de n elementos en
k grupos en el que cada observacion se asigna al grupo mas cercano a una
media.
Equivale a minimizar:
P (W,Q) =k∑l=1
n∑i=1
ωi,ld(Xi, Ql) (1.9)

CAPITULO 1. PRELIMINARES 24
Sujeto a
k∑l=1
ωi,l = 1 ωi,l ∈ 0, 1 1 ≤ i ≤ n 1 ≤ l ≤ k (1.10)
Una representacion esquematica se puede encontrar en la figura 1,7.
Figura 1.3: Esquema de agrupacion de K-MEANS
Algoritmo del Metodo de K-Means
El numero k de conglomerados es definido en cada caso por el usuario.
Consideremos n individuos X1, X2, ..., Xm, definidos por m variables ca-
tegoricas, los cuales se van a agrupar en k clusters [3]:
1. Seleccione k nucleos iniciales (pueden ser los k primeros individuos),
estos son los nucleos de los conglomerados iniciales

CAPITULO 1. PRELIMINARES 25
2. Comparar cada individuo con cada uno de los nucleos anteriores.
Asignarlo al grupo cuyo nucleo este mas cerca. Actualizar las medias
(nucleo), del cluster (donde fue asignado) despues de cada asignacion.
3. Despues de que todos los individuos hayan sido asignados a los clus-
ters, se verifica que la disimilaridad de cada individuo contra las medias
(nucleos) actuales, si se encontrase un individuo que esta mas cerca al
nucleo de otro grupo distinto a el suyo, se traslada al grupo y actualizar
las medias de los grupos.
4. Se repite el paso 3 cuantas veces sea necesario, hasta que no haya cam-
bio.
1.4.2. Nubes Dinamicas
Es un procedimiento propuesto por Forgy en 1965 y perfeccionado por
la escuela francesa en el que la particion de un conjunto de individuos Ω =
x1, x2, . . . , xn en clases Ci tales que Ω =⋃ki=1Ci con Ci
⋂Ch = φ para i = h
se logra a traves de una matriz U = (µli) que cumple las siguientes condicio-
nes:
1. Para todo 1 ≤ l ≤ k, 1 ≤ i ≤ n, uli ∈ 0, 1
2. Para todo 1 ≤ i ≤ n,∑k
l=1 uli = 1
3. Para todo 1 ≤ l ≤ k, 0 <∑n
i=1 uli < n
La condicion 2 indica que cada Xi esta en una sola clase y la condicion
3 significa que cada clase Cl tiene al menos un individuo. Debemos tener en

CAPITULO 1. PRELIMINARES 26
cuenta que ninguna clase puede quedar vacıa.

Capıtulo 2
CLASIFICACION CON
VARIABLES CATEGORICAS
2.1. Variable categorica
Una variable categorica X es una variable que toma valores en un conjun-
to A = C1, C2, .., Ck donde cada Ci se denomina una categorıa o modalidad
de X.
Se puede usar la siguiente representacion::
27

CAPITULO 2. CLASIFICACION CON VARIABLES CATEGORICAS 28
Donde pi = p(X = Ci), es claro que
k∑i=1
pi = 1
Aquı se pretende clasificar un conjunto de individuos h1, h2, .., hn = H
donde cada individuo hi tiene asociadas m variables, A1, A2, . . . , Am. Como
se indica en la figura 2.1.
Figura 2.1: variables definidas sobre el individuo hj
Puesto que el individuo asume una categorıa de cada una de las variables,
el puede ser identificado con una m-upla.

CAPITULO 2. CLASIFICACION CON VARIABLES CATEGORICAS 29
(Ci1,1, Ci2,2, . . . , Cij ,j, . . . , Cim,m)
Donde cada Cir,j es una de las categorıas de Ai para j = 1, 2, ...m, usual-
mente estas categorıas se recodifican con los dıgitos 1, 2, ..., ki.
Por ejemplo, si se consideran tres variables:
Sexo (con dos categorıas: 1=masculino, 2=femenino )
Edad (con tres categorıas:1 (edad ≤ 20), 2 (entre 20 y 50), 3 (edad> 50)
Nivel de estudio con 3 categorıas:(1 = primaria, 2 = segundaria, 3 =
universidad)
Una mujer de 30 anos, con estudios universtarios, se identificara con la tripla,
(2, 2, 3).
2.2. Clasificacion de Variables Categoricas
Segun el numero de categorıas, las variables categoricas se clasifican en
dos grupos: dicotomicas y politomicas:
Dicotomicas: Solo hay dos categorıas. Ejemplo, padecer una en-
fermedad (Sı, No), Sexo (Hombre, Mujer), Resultado de una oposi-
cion (Aprobar, rechazar), en general los fenomenos de respuesta binaria
(Se describe por medio de variables dicotomicas ).
Politomicas: Cuando hay mas de dos categorıas.
Por ejemplo:
• Estrato economico de viviendas.
• Grupo sanguıneo .

CAPITULO 2. CLASIFICACION CON VARIABLES CATEGORICAS 30
2.3. Disimilaridad en variables categoricas
Aunque hay varias posibilidades de medicion de la disimilaridad entre
dos individuos caracterizados por variables categoricas, en este trabajo se
usa la propuesta de Zhexue Huang (1998)[4], que define la distancia, en-
tre dos individuos por el numero de discrepancias entre las m − uplas que
los definen, asumiendo que X = hi = (Ci1,1, Ci2,2, . . . , Cim,m); Y = hj =
(Cj1,1, Cj2,2, . . . , Cjm,m), entonces:
d(X, Y ) =m∑k=1
δ(Cik,k, yjk,k) (2.1)
Lo que se puede abreviar
d(X, Y ) =m∑j=1
δ(xj, yj) (2.2)
donde
δ(xk, yk) =
0 ; Si xk = yk
1 ; Si xk 6= yk(2.3)
Puesto que se quiere establecer una analogıa con el metodo k-medias pero
usando modas en lugar de medias, se define una moda en un conjunto de
m− uplas correspondientes a n individuos.
Definicion 1. Sea X = X1, X2, . . . , Xn un conjunto de n individuos ca-
racterizados por variables categoricas de tipo (A1, A2, . . . , Am).Una moda de
X = X1, X2, . . . , Xn es un vector Q = [q1, q2, . . . , qm] que minimiza
D(X, Q) =n∑i=1
d(Xi, Q)

CAPITULO 2. CLASIFICACION CON VARIABLES CATEGORICAS 31
Aquı, Q no es necesariamente un elemento de X.
Se define la frecuencia de la k−esima categorıa de cada variable Aj como:
fr(Aj = nck,j |X) = fr(Aj = nck,j) =nck,jn
Una manera rapida de identificar modas en un conjunto es la que nos
ofrece el siguiente teorema.
Teorema La funcion D(X, Q) es minimizada si y solo si fr(Aj = qj|X) ≥fr(Aj = Ck,j|X) para qj 6= Ck,j para todo j = 1, ...,m.
Demostracion. Sea fr(Aj = Ck,j‖X) =nck,j
nla frecuencia relativa de la ca-
tegorıa k − esima Ck,j, donde n es el numero total de objetos en X y nck,jel numero de objetos en la categorıa Ck,j. Por la medida de disimilaridad
d(X, Y ) =m∑j=1
δ(xj, yj), tenemos:
n∑i=1
d1(Xi, Q) =n∑i=1
m∑j=1
δxi,j, qj (2.4)
=m∑j=1
(n∑i=1
δxi,j, qj
)(2.5)
=m∑j=1
n(
1− nq,jn
)(2.6)
=m∑j=1
n(1− fr(Aj = qj|X)) (2.7)

CAPITULO 2. CLASIFICACION CON VARIABLES CATEGORICAS 32
porque n(1 − fr(Aj = qj|X)) ≥ 0 para 1 ≤ j ≤ m,∑n
i=1 d1(Xi, Q) es
minimizado si y solo si cualquier n(1 − fr(Aj = qj|X)) es mınimo. Por lo
tanto, fr(Aj = qj|X) debera ser maxima.
El concepto de moda se puede generalizar teniendo en cuenta el teorema
y la definicion de distancia, como se expone en el siguiente ejemplo:
Ejemplo:
Se considera tres variables categoricas, sexo, edad y estado civil.
Figura 2.2: Asignacion de valores de las caracterısticas de la poblacion
Si X1, X2, . . . , X9 son individuos cuyo valor en las variables A1, A2, A3 se
muestra en el cuadro siguiente:
I A1 A2 A3
X1 1 2 2X2 2 2 2X3 2 1 1X4 2 3 3X5 2 3 2X6 1 3 2X7 1 2 1X8 2 2 1X9 1 3 3
Cuadro 2.1: Tabla de poblacion
Al aplicar la definicion de frecuencia dada anteriormente, se obtiene:

CAPITULO 2. CLASIFICACION CON VARIABLES CATEGORICAS 33
sexo ni fr1
1 4 49
2 5 59
Edad ni fr2
1 1 19
2 4 49
3 4 49
E. Civil ni fr3
1 3 39
2 4 49
3 2 29
Este concepto se puede generalizar a cualquier subconjunto X y Y . Por
ejemplo se tomaron Y = X3, X5, X7, X8 se tiene:
I A1 A2 A3
X3 2 1 1
X5 2 3 2
X7 1 2 1
X8 2 2 1
Entonces encontrando las tablas de frecuencia aplicando el Teorema den-
tro de Y se obtiene:
sexo ni fr1
1 1 14
2 3 34
Edad ni fr2
1 1 14
2 2 24
3 1 14
E. Civil ni fr3
1 3 34
2 1 14
3 0 04
Si se quire hallar una moda para el conjunto Y debemos buscar un punto
Q = (q1, q2, q3) tal que:
fr(Aj = qj) ≥ fr(Aj = Ck,j)
Esto es para cada j = 1, 2, 3 = m, ası q1 debe ser tal que:

CAPITULO 2. CLASIFICACION CON VARIABLES CATEGORICAS 34
fr(sexo = qi) ≥ fr(sexo = c1,1)
fr(sexo = qi) ≥ fr(sexo = c2,1)
entonces se toma los mayores de ni, con q1 = 2, ya que la frecuencia
3 > 1 y 3 ≥ 3.Se toma la categorıa correspondiente al mayor ni es decir,
Q = (2, 2, 1)
Se verifica que este Q satisface la definicion de una moda en Y
Se debe observar D(Y, Q) = d(X3, Q) + d(X5, Q) + d(X7, Q) + d(X8, Q)
sea la menor distancia, donde Q son las posibles ternas (X1, X2, X3)
D(Y, Q) = d((2, 1, 1), (2, 2, 1)) + d((2, 3, 2), (2, 2, 1)) (2.8)
+ d((1, 2, 1), (2, 2, 1)) + d((2, 2, 1), (2, 2, 1)) (2.9)
= 1 + 2 + 1 + 0 (2.10)
= 4 (2.11)
Todos los posibles valores que podrıa tomar una moda son:
1,1,1 2,1,11,1,2 2,1,21,1,3 2,1,31,2,1 2,2,11,2,2 2,2,21,2,3 2,2,31,3,1 2,3,11,3,2 2,3,21,3,3 2,3,3
Cuadro 2.2: Posibles distancias
La D(Y, Q) para cada uno de los 18 casos Q.
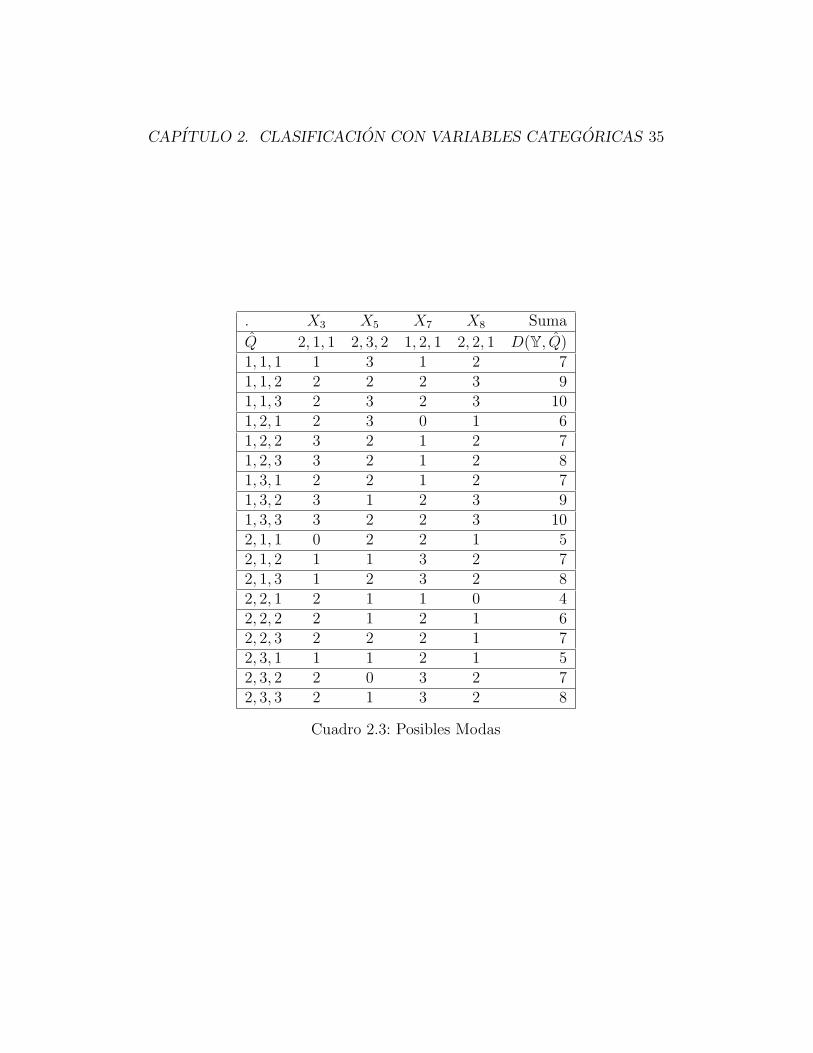
CAPITULO 2. CLASIFICACION CON VARIABLES CATEGORICAS 35
. X3 X5 X7 X8 Suma
Q 2, 1, 1 2, 3, 2 1, 2, 1 2, 2, 1 D(Y, Q)1, 1, 1 1 3 1 2 71, 1, 2 2 2 2 3 91, 1, 3 2 3 2 3 101, 2, 1 2 3 0 1 61, 2, 2 3 2 1 2 71, 2, 3 3 2 1 2 81, 3, 1 2 2 1 2 71, 3, 2 3 1 2 3 91, 3, 3 3 2 2 3 102, 1, 1 0 2 2 1 52, 1, 2 1 1 3 2 72, 1, 3 1 2 3 2 82, 2, 1 2 1 1 0 42, 2, 2 2 1 2 1 62, 2, 3 2 2 2 1 72, 3, 1 1 1 2 1 52, 3, 2 2 0 3 2 72, 3, 3 2 1 3 2 8
Cuadro 2.3: Posibles Modas

CAPITULO 2. CLASIFICACION CON VARIABLES CATEGORICAS 36
Como se ve D(Y, Q) ≤ D(Y, Q), ∀Q entonces efectivamente Q = (2, 2, 1)
es moda para el conjunto Y .
2.3.1. Metodo de K-Modas
El metodo propuesto en el trabajo para la clasificacion de individuos ge-
nerando modas es completamente analogo al descrito en el algoritmo de las
k −means de variables numericas.
2.3.2. Algoritmo de K-Modas
El numero k de conglomerados es definido en cada caso por el usuario.
Se considera n individuos X1, X2, ..., Xm, definidos por m variables ca-
tegoricas, los cuales se van a agrupar en k clusters:
1. Se seleccionan k modas iniciales (pueden ser los k primeros individuos),
estos son los nucleos de conglomerados iniciales iniciales.
2. Para cada uno (de los otros individuos) comparar con cada una de las
modas anteriores y asignarlo al grupo cuyo nucleo este mas cerca. Ac-
tualice la moda (nucleo), del cluster (donde fue asignado) despues de
cada asignacion, de acuerdo con el Teorema.
3. Despues de que todos los individuos hayan sido asignados a los clus-
ters, se verifica la disimilaridad de cada individuo contra las modas
(nucleos) actuales, si se encuentra un individuo que esta mas cerca al
nucleo de otro clusters distinto a la suya, si se encuentra a ese clusters
y se actualizan las modas de los grupos.

CAPITULO 2. CLASIFICACION CON VARIABLES CATEGORICAS 37
4. Se repite el paso 3 cuantas veces sea necesario, hasta que no haya cam-
bios.

Capıtulo 3
APLICACION
Se describira en forma detallada la aplicacion del metodos de K-modas
a un caso real. Para ello, se ha disenado y programado un algoritmo en dos
partes. En la primera de ellas, se hace una asignacion de individuos a los gru-
pos determinados por unos nucleos iniciales, mientras que la segunda se hace
un refinamiento de la asignacion para garantizar una mayor homogeneidad
entre los individuos de cada conglomerado.
3.1. Fases del Algoritmo de K-Modas
La asignacion de los individuos se basa en el calculo de la disimilaridad
entre ellos, como se afirmo en el capıtulo anterior, razon por la cual, el algo-
ritmo contempla una subrutina que calcula dicha similaridad.
Fase 1 Se toma como nucleo inicial los k primeros individuos (en este caso
k = 3). Uno a uno , se asigna cada elemento del conjunto original al gru-
po donde aparezca el nucleo mas cercano en terminos de disimilaridad
y se calcula la moda en el grupo al cual se hizo la afirmacion.
Fase 2 Una vez se haya asignado los n elementos del grupo original se ini-
cia una fase de refinamiento en la que cada elemento de cada uno de
los subgrupos formados en la fase anterior, se compara con todos los
38

CAPITULO 3. APLICACION 39
nucleos anteriores.
Si se diese el caso de que un nucleo distinto al de su propio nucleo
estuviera mas cercano a un elemento que el nucleo propio, reasigna-
mos dicho elemento al grupo y recalculamos las modas tanto del grupo
receptor como el grupo emisor.
Este paso se repite cuantas veces sea necesario hasta que no haya cambios.
Estos procedimientos se plasman en los siguientes diagramas de flujo.
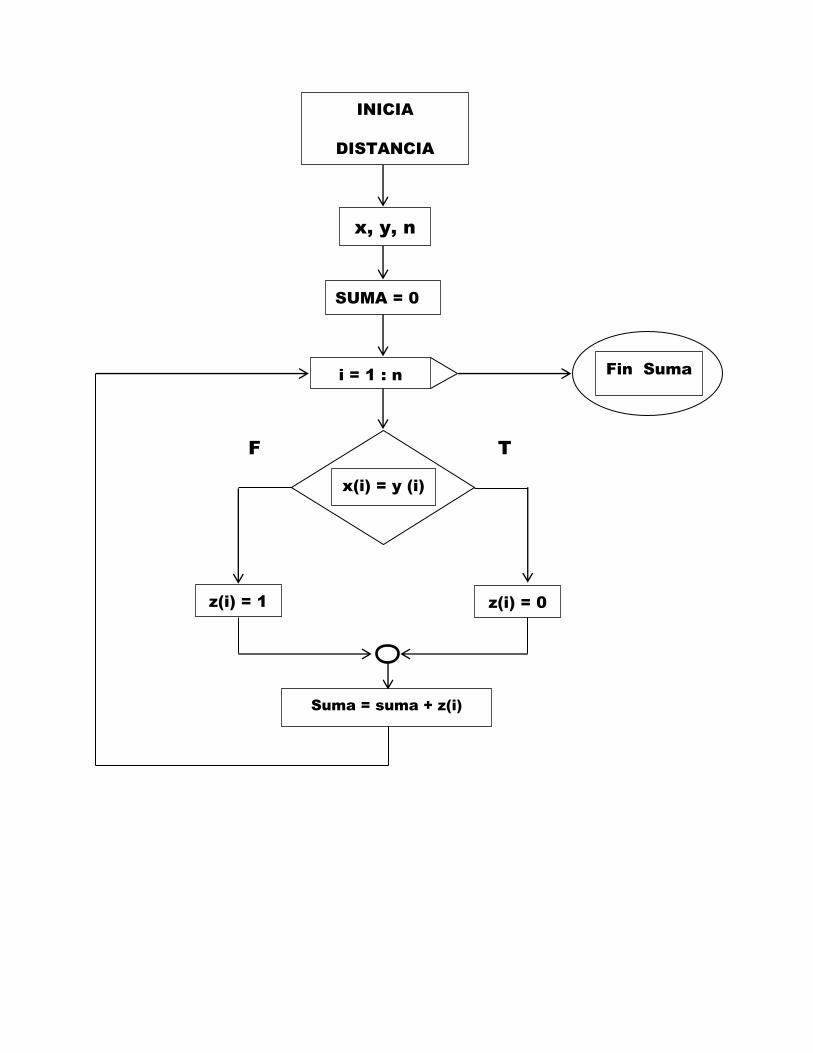
F T
INICIA
DISTANCIA
x, y, n
SUMA = 0
i = 1 : n
x(i) = y (i)
z(i) = 1 z(i) = 0
Suma = suma + z(i)
Fin Suma
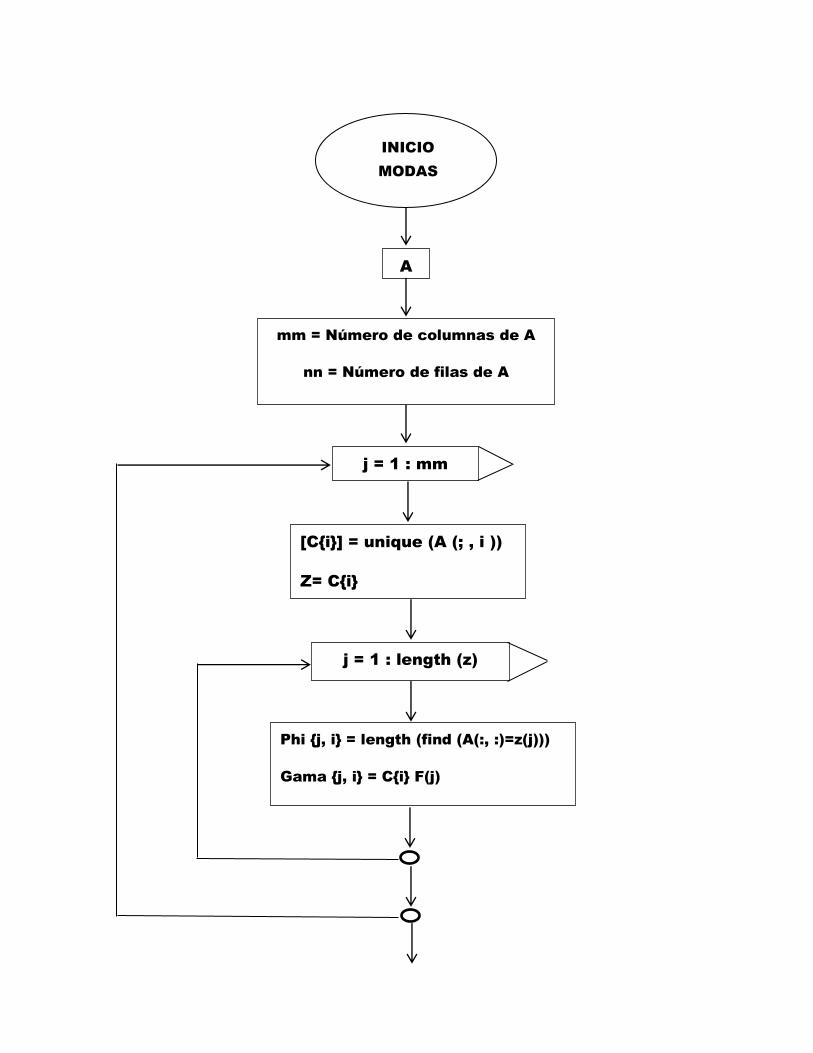
INICIO
MODAS
A
mm = Número de columnas de A
nn = Número de filas de A
j = 1 : mm
[Ci] = unique (A (; , i ))
Z= Ci
j = 1 : length (z)
Phi j, i = length (find (A(:, :)=z(j)))
Gama j, i = Ci F(j)
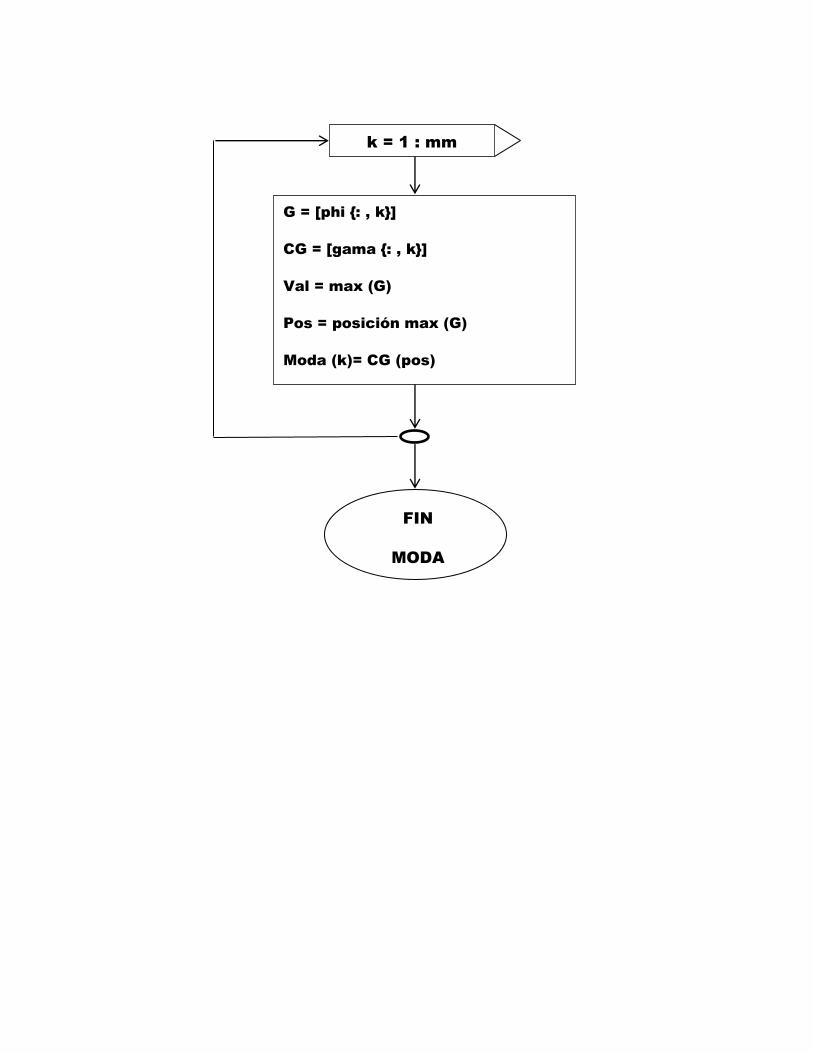
k = 1 : mm
G = [phi : , k]
CG = [gama : , k]
Val = max (G)
Pos = posición max (G)
Moda (k)= CG (pos)
FIN
MODA
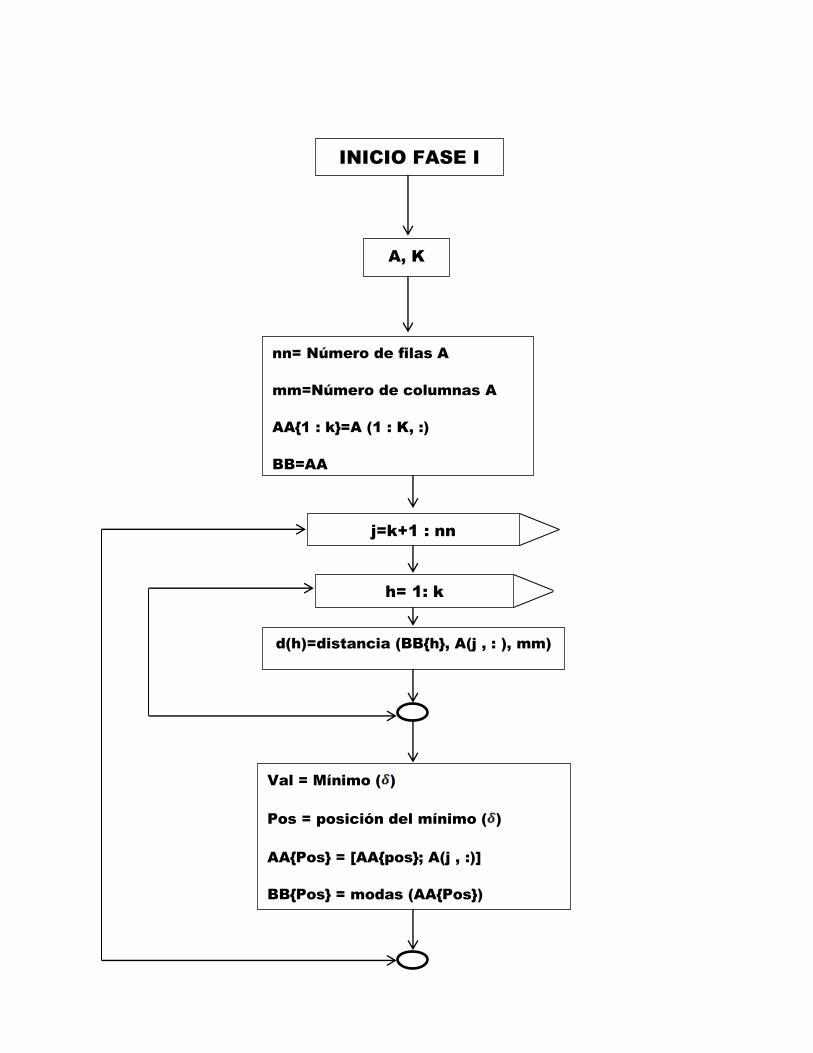
INICIO FASE I
A, K
nn= Número de filas A
mm=Número de columnas A
AA1 : k=A (1 : K, :)
BB=AA
j=k+1 : nn
d(h)=distancia (BBh, A(j , : ), mm)
Val = Mínimo ( )
Pos = posición del mínimo ( )
AAPos = [AApos; A(j , :)]
BBPos = modas (AAPos)
h= 1: k
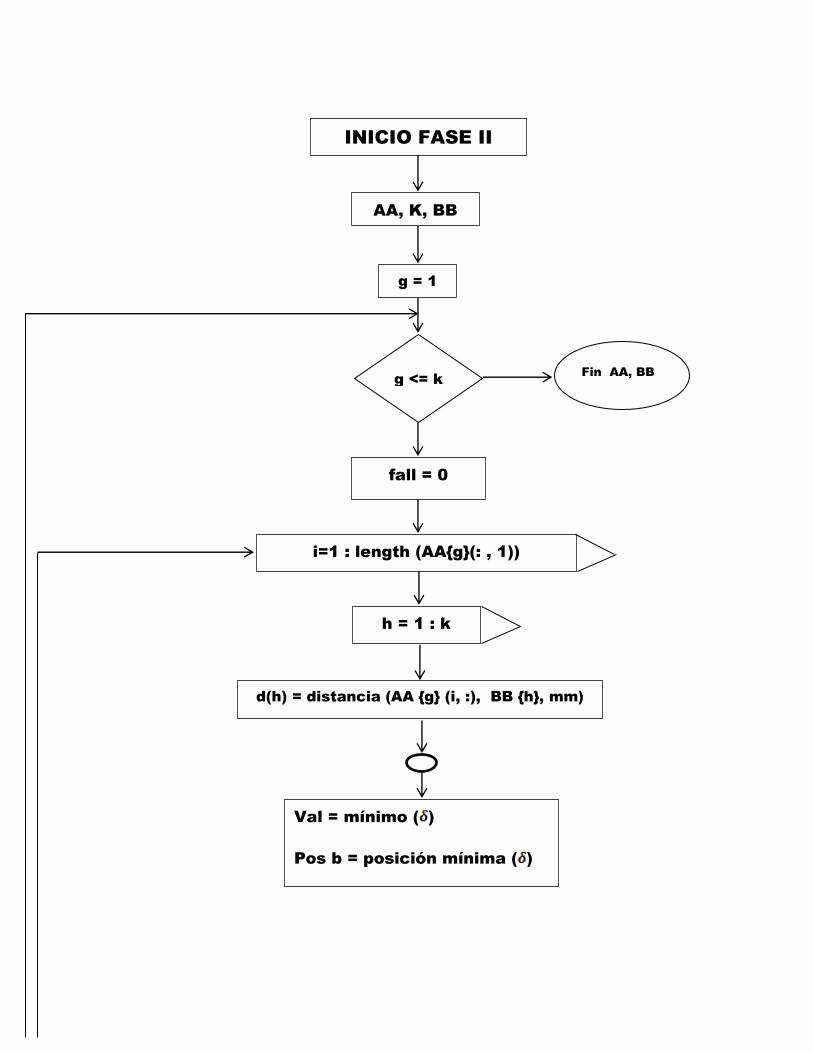
INICIO FASE II
AA, K, BB
g = 1
fall = 0
i=1 : length (AAg(: , 1))
d(h) = distancia (AA g (i, :), BB h, mm)
g <= k
h = 1 : k
Val = mínimo ( )
Pos b = posición mínima ( )
Fin AA, BB
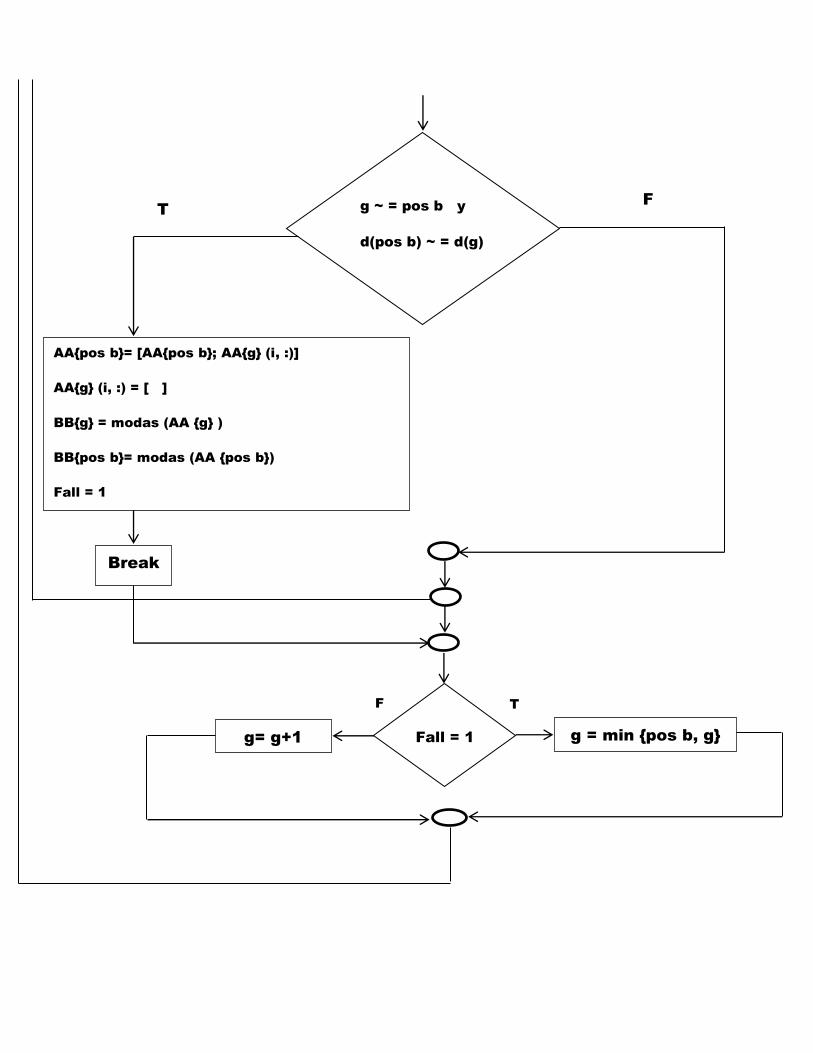
g ~ = pos b y
d(pos b) ~ = d(g)
AApos b= [AApos b; AAg (i, :)]
AAg (i, :) = [ ]
BBg = modas (AA g )
BBpos b= modas (AA pos b)
Fall = 1
Break
Fall = 1 g = min pos b, g g= g+1
T
F
F
T

CAPITULO 3. APLICACION 46
3.1.1. Ejemplo
Para ilustrar la manera en que las fases se emplean en el algoritmo, se
puede apreciar en el siguiente ejemplo como estas actuan en un problema
especıfico. Este se centra en calcular las modas de las tres variables para seis
individuos.
Sea la matriz de individuos A:
A =
1 2 2
2 2 1
2 2 2
2 1 1
2 3 2
1 2 1
Se quiere agrupar dichos individuos en tres grupos. Para la fase 1, se toma
como centroides o nucleos iniciales los tres primeros individuos. Que son los
siguientes:
k1 =(
1 2 2)
k2 =(
2 2 1)
k3 =(
2 2 2)
Es decir, las modas iniciales X para los primeros centroides son:
k1 =(
1 2 2)
k2 =(
2 2 1)
k3 =(
2 2 2)
De la matrız A se calcula la moda de los tres primeros grupos y Cada elemento
de A se compara con estos nucleos, escogiendo la menor distancia entre ellas.
Una vez realizado esto, se calculan nuevamente las modas ya actualizadas y
se repite este procedimiento hasta pasar por cada uno de los individuos de
la matriz, quedando las siguientes modas:

CAPITULO 3. APLICACION 47
k1 =(
1 2 2)
k2 =(
2 1 1)
k3 =(
2 2 2)
Aplicando lo dicho anteriormente, se compara el elemento (2, 3, 2) de la
matriz A con cada clusters actuales y se actualizan las modas:
k1 =(
1 2 2)
k2 =(
2 1 1)
k3 =(
2 2 2)
Y ası para el siguente elemento (1, 2, 1), actualizando las modas
k1 =(
1 2 1)
k2 =(
2 1 1)
k3 =(
2 2 2)
terminados los calculos de la fase 1, le damos paso a la explicacion de la
fase 2.
En este caso asignaremos el primer elemento del conjunto 2 al primer con-
junto siguiendo esta metodologıa como criterio de orden. Quedando los gru-
pos de la siguiente manera k1 con 3 elementos que son ((1, 2, 2), (2, 1, 1), (1, 2, 1)),
k2 con un elemento que es (2, 2, 1) y por ultimo el k3 con dos elementos que
son ((2, 2, 2), (2, 3, 2)),donde el conjunto A serıa clasificado de la siguiente
manera:
k1 =
1 2 2
2 1 1
1 2 1
k2 =(
2 1 1)
k3 =
(2 2 2
2 3 2
)
cuyas modas actualizadas para los conjuntos k1, k2 y k3 son:
k1 =(
1 2 1)
k2 =(
2 1 1)
k3 =(
2 2 2)

CAPITULO 3. APLICACION 48
3.2. Estudio de un Caso Especıfico
Se aplico una encuesta de 7 preguntas (Ver anexo 1 encuesta) en tres
poblaciones diferentes, con respecto a la prestacion de servicio en las entida-
des medicas, las tres poblaciones fueron tomadas en: Espinal (Nueva EPS),
Ibague (Nueva EPS) y (Medicadez); de cada poblacion se tomo una muestra
de 15 indivıduos para un total de 45 personas encuestadas.
Se aplico el algoritmo mostrado en el capıtulo anterior, usando el software
MatLab 2009, donde los resultados de dicha encuesta muestra las distancias
y posiciones de cada grupo de la base datos, como se observa en los anexos
(base de datos).
Se esperaba que el algoritmo agrupara los 45 individuos de la muestra de
pacientes de las (Entidades de salud) en 3 grupos aproximadamente simila-
res a la clasificacion inicial es decir, que dejara tres grupos aproximadamente
iguales en tamano y coincidentes con los originales en un alto porcentaje.
No ocurrio ası, ya que el algoritmo clasifico en tres grupos, uno de ellos con
33 elementos y los otros con 10 y 2. Una posible explicacion de este hecho
es que quizas los grupos originales no fueran suficientemente diferenciados.
Es decir, que a pesar de que la muestra fue tomada en tres sitios diferentes,
las respuestas en general fueron semejantes en los tres sitios, razon por la
cual el algoritmo, al detectar dichas semejanzas agrupo a la mayorıa de los
individuos en un unico grupo de tamano 33. Esto se corrobora al realizar un
conteo de frecuencias dentro del grupo mayoritario, en todas las variables se
encontro una categorıa absolutamente dominante por su alta frecuencia. Ver
tablas.

CAPITULO 3. APLICACION 49
3.2.1. Resultados encuesta de salud
Los resultados obtenidos despues de la aplicacion del algoritmo, se mues-
tran en los siguientes cuadros, los cuales muestran la distancia y la posicion
de la distancia de cada elemento y la respectiva clasificacion.
Distancias
6 4 5
6 5 5
6 4 6
4 3 5
5 2 5
1 2 3
1 3 3
4 5 6
3 4 4
Posicion
1 3 2
1 10 2
1 11 2
1 1 2
1 13 2
2 2 1
2 2 1
2 7 1
2 1 1
Figura 3.1: clasificacion de los elementos, grupo 1

CAPITULO 3. APLICACION 50
Figura 3.2: clasificacion de los elementos, grupo 2 y grupo 3
Y las modas finales de cada grupo se observan en la siguente figura:
Figura 3.3: Modas finales
A continuacion se muestran las preguntas realizadas en la encuesta y sus
respectivas tablas de frecuencias para el grupo de 33 elementos.
1. Considera Ud, que la comodidad, el aspecto y la funcionalidad del
sitio de atencion en esta clınica son adecuados para los afiliados o usua-

CAPITULO 3. APLICACION 51
rios?:
Modalidad Frec Abs
1.NO 29
2.Si 4
2. ¿Se encuentra Ud. satisfecho con el servicio de solicitud de citas? :
Modalidad Frec Abs
1.NO 5
2.Si 28
3. ¿Califique el grado de dificultad que usted experimento para conse-
guir que lo antendieran?:
Modalidad Frec Abs
1. Muy difıcil 1
2. Medianamente difıcil 6
3. Facil 26
4. Independiente del medio por el cual le asignaron la cita, por favor
indıqueme el tiempo transcurrido entre el dıa que solicito la cita y la
fecha para la cual se la asignaron:

CAPITULO 3. APLICACION 52
Modalidad Frec Abs
1. Mas de 6 dıas 6
2. 4 a 6 dıas 15
3. 1 a 3 dıas 12
5. ¿Cual es su nivel de satisfaccion con el proceso de entrega de medi-
camentos en la farmacia?:
Modalidad Frec Abs
1. Totalmente insatisfecho 3
2 0
3 3
4 3
5. Totalmente satisfecho 24
6. ¿Se encuentra Ud. Satisfecho con el servicio prestado por el profe-
sional (medico) que lo atendio?:
Modalidad Frec Abs
1. Totalmente insatisfecho 0
2 1
3 2
4 2
5. Totalmente satisfecho 28

CAPITULO 3. APLICACION 53
7. ¿Cual de las siguientes opciones describe de mejor manera su opinion
acerca de como ha cambiado su EPS?:
Modalidad Frec Abs
1. Ha desmejorado mucho 0
2. Ha mejorado poco 0
3. Ha permanecido basicamente igual 16
4. Ha mejorado poco 6
5. Ha mejorado mucho 11

Capıtulo 4
CONCLUSIONES
Despues de ejecutar el algoritmo para clasificacion con variables ca-
tegoricas a los datos recolectados en las diferentes entidades de salud
de Ibague y Espinal se esperaba que los datos se clasificaran en grupos
con igual tamano, pero se muestra que los datos se clasificaron en tres
grupos con tamanos diferentes lo que implica que no fueron suficiente-
mente diferenciados.
Al hacer un estudio sobre variables, se observa que resulta mas com-
plicado trabajar con datos categorizados que con datos numericos, al
momento de hacer un estudio estadıstico. Si se utilizan datos numericos
existen varios metodos, dependiendo de la condicion de la poblacion,
a diferencia de utilizar datos categoricos, ya que es imposible realizar
calculos aritmeticos.
Cabe resaltar la importancia del concepto de frecuencia relativa den-
tro del definicion de distancias en la construccion de las modas, una
mala interpretacion de este tema puede conducir facilmente a calculos
erroneos.
54

Capıtulo 5
ANEXOS
En esta parte del documento encontramos los resultados de toda la inves-
tigacion que se hizo durante la elaboracion de esta tesis, como es la encuesta
que fue aplicada para poder obtener la base de datos, la base de datos y los
resultados de Matlab con respecto al algoritmo K-Modas
5.1. Encuesta, Anexo 1:
55

ENCUESTA DE SATISFACCIÓN DEL USUARIO DEL SERVICIO DE SALUD
La presente encuesta tiene como objetivo la recopilación de información que será utilizada en nuestro trabajo de grado como estudiantes de Estadística en la Universidad del Tolima. Le agradecemos sus respuestas muy sinceras y el corto tiempo que usted nos dedica para contestar.
P1.Considera Ud. que la comodidad, el aspecto y la funcionalidad del sitio de atención en esta clínica son adecuados para los afiliados o usuarios?
Descripción 1 Si 2 NO
P2. ¿Se encuentra Ud. satisfecho con el servicio de solicitud de citas?
Descripción 1 No 2 Si
P3. ¿Califique el grado de dificultad que usted experimentó para conseguir que lo antendieran?
Grado de dificultad Cód
a. Muy difícil 1
b. Medianamente difícil
2
c. Fácil 3
P4.Independiente del medio por el cual le asignaron la cita, por favor indíqueme el tiempo transcurrido entre el día que solicitó la cita y la fecha para la cual se la asignaron.
Descripción 1 Más de 6 días
2 4 a 6 días 3 1 a 3 días
P5. ¿Cuál es su nivel de satisfacción con el proceso de entrega de medicamentos en la farmacia?
Totalmente
Insatisfecho
Totalmente
Satisfecho
1 2 3 4 5
P6. ¿Se encuentra Ud. Satisfecho con el servicio prestado por él profesional (médico) que lo atendió?
Totalmente
Insatisfecho
Totalmente
Satisfecho
1 2 3 4 5
P7. ¿Cuál de las siguientes opciones describe de mejor manera su opinión acerca de cómo ha cambiado su EPS?
¡MUCHAS GRACIAS POR SU COLABORACIÓN!
Ha desmejorado
mucho
Ha desmejorado
poco
Ha permanecido básicamente
igual
Ha mejorado
poco
Ha mejorado
mucho
1 2 3 4 5

CAPITULO 5. ANEXOS 57
Anexo 2:
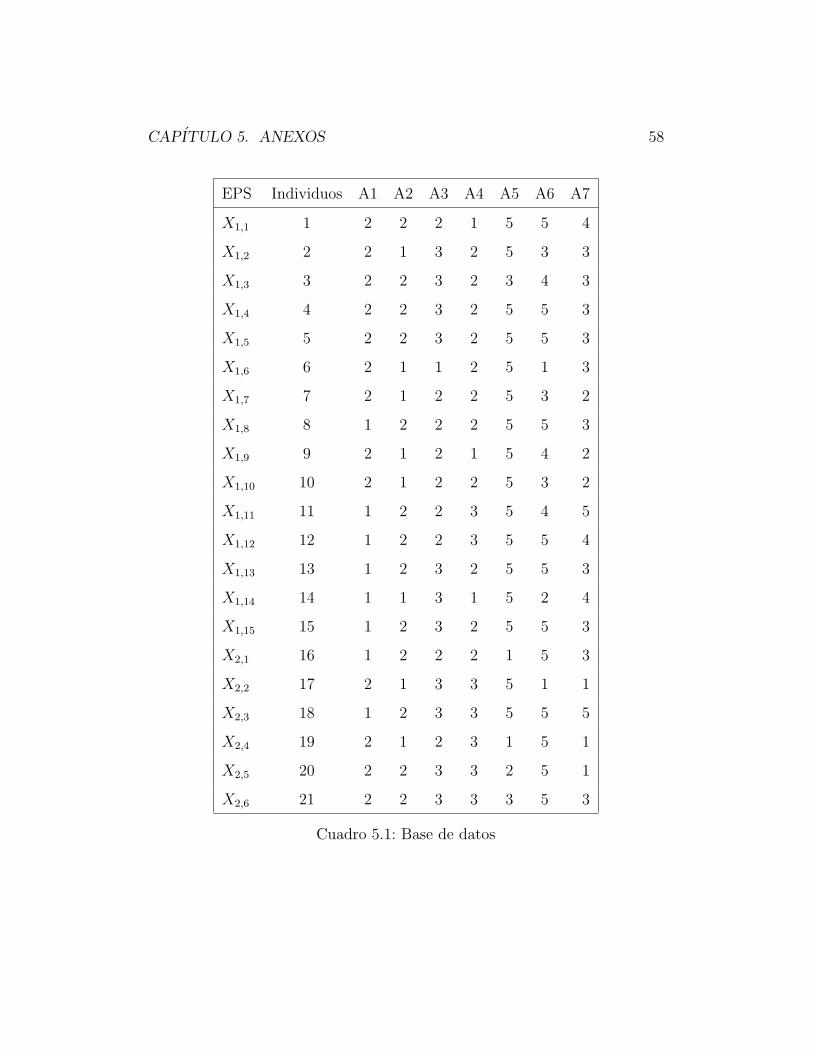
CAPITULO 5. ANEXOS 58
EPS Individuos A1 A2 A3 A4 A5 A6 A7
X1,1 1 2 2 2 1 5 5 4
X1,2 2 2 1 3 2 5 3 3
X1,3 3 2 2 3 2 3 4 3
X1,4 4 2 2 3 2 5 5 3
X1,5 5 2 2 3 2 5 5 3
X1,6 6 2 1 1 2 5 1 3
X1,7 7 2 1 2 2 5 3 2
X1,8 8 1 2 2 2 5 5 3
X1,9 9 2 1 2 1 5 4 2
X1,10 10 2 1 2 2 5 3 2
X1,11 11 1 2 2 3 5 4 5
X1,12 12 1 2 2 3 5 5 4
X1,13 13 1 2 3 2 5 5 3
X1,14 14 1 1 3 1 5 2 4
X1,15 15 1 2 3 2 5 5 3
X2,1 16 1 2 2 2 1 5 3
X2,2 17 2 1 3 3 5 1 1
X2,3 18 1 2 3 3 5 5 5
X2,4 19 2 1 2 3 1 5 1
X2,5 20 2 2 3 3 2 5 1
X2,6 21 2 2 3 3 3 5 3
Cuadro 5.1: Base de datos
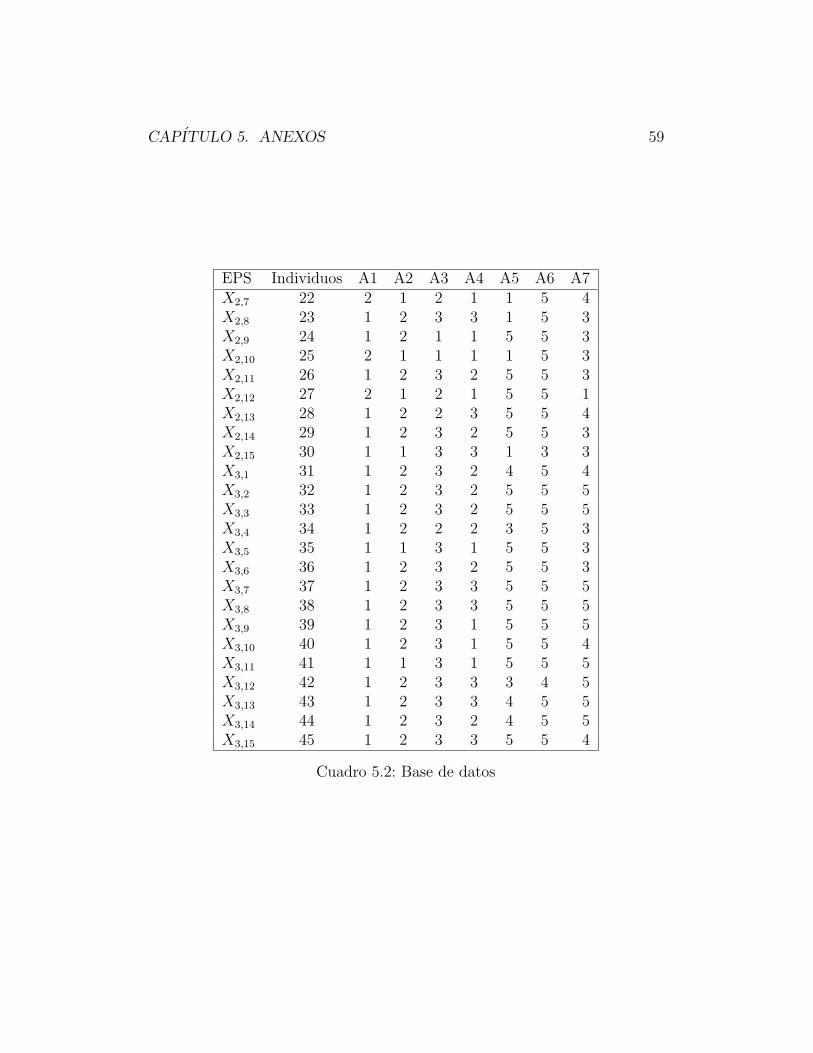
CAPITULO 5. ANEXOS 59
EPS Individuos A1 A2 A3 A4 A5 A6 A7X2,7 22 2 1 2 1 1 5 4X2,8 23 1 2 3 3 1 5 3X2,9 24 1 2 1 1 5 5 3X2,10 25 2 1 1 1 1 5 3X2,11 26 1 2 3 2 5 5 3X2,12 27 2 1 2 1 5 5 1X2,13 28 1 2 2 3 5 5 4X2,14 29 1 2 3 2 5 5 3X2,15 30 1 1 3 3 1 3 3X3,1 31 1 2 3 2 4 5 4X3,2 32 1 2 3 2 5 5 5X3,3 33 1 2 3 2 5 5 5X3,4 34 1 2 2 2 3 5 3X3,5 35 1 1 3 1 5 5 3X3,6 36 1 2 3 2 5 5 3X3,7 37 1 2 3 3 5 5 5X3,8 38 1 2 3 3 5 5 5X3,9 39 1 2 3 1 5 5 5X3,10 40 1 2 3 1 5 5 4X3,11 41 1 1 3 1 5 5 5X3,12 42 1 2 3 3 3 4 5X3,13 43 1 2 3 3 4 5 5X3,14 44 1 2 3 2 4 5 5X3,15 45 1 2 3 3 5 5 4
Cuadro 5.2: Base de datos

Bibliografıa
[1] Alvin C. Rencher, Methods of Multivariate Analysis, Cluster Analy-
sis(14), pags. 452–490 Estados Unidos, 2002.
[2] Universidad Granada, Clasificacion jerarquica y no jerarquica,
http://www.ugr.es/ gallardo/pdf/cluster-3.pdf , Capıtulo 3, Espana.
[3] Forgy, Nubes dinamicas, www.eio.uva.es/ valen-
tin/ad3d/anadat/transp/cluster7.doc, pags. 23–26, Espana.
[4] Zhexue, H., Extensions to the k-means algorithm for clustering large
data sets with categorial values, ACSys CRC, CSIRO Mathematical and
Information Sciences(2), pags. 283–304 Australia, 1998.
60


















