
Enfoques de PL y MILP para Clasificación de Patrones
46
1
Transcript of Enfoques de PL y MILP para Clasificación de Patrones
1

2
Enfoques basados en programación lineal y entera mixta para la clasificación de
patrones
Miembros del Grupo de Investigación: Prof. Ubaldo M. García Palomares (USB), Ing. Adriana Torres, Ing. Ana Serra, Ing. Aura Ramírez, Prof. Jesús Espinal (UNA). Colaboradora: T.S.U. Juvili Hernández.Junio de 2012
Prof. Orestes G. Manzanilla Salazar
Dpto. Procesos y Sistemas - Centro de Estadística y Software Matemático (USB)

3
Agenda
1. Introducción• Aprendizaje (artifical) Supervisado• Caso: Clasificación de Patrones
2. Antecedentes• Árboles de Clasificación (CTs)• Redes Neurales Artificiales (ANNs)• Máquinas de Vectores de Soporte (SVMs)• Perspectiva de Optimización• Análisis comparativo
3. Los métodos Multi-Superficie (MSMs)• Método• Modelo básico• Variantes• Comparación de características• Uso como Método de Visualización Científica de Datos
4. Conclusion y trabajo futuro5. Agradecimientos
4
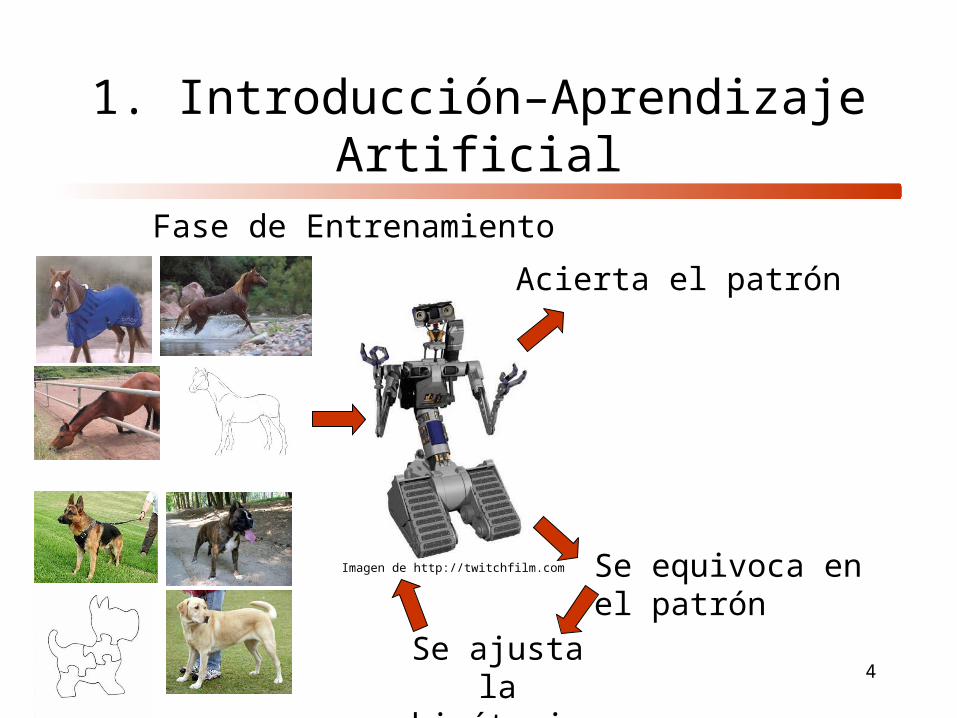
1. Introducción–Aprendizaje Artificial
Fase de Entrenamiento
Imagen de http://twitchfilm.com Se equivoca en el patrón
Acierta el patrón
Se ajusta la hipótesis

5
Fase de Uso
Imagen de http://twitchfilm.com
1. Introducción–Aprendizaje Artificial
Perro, Caballo
6
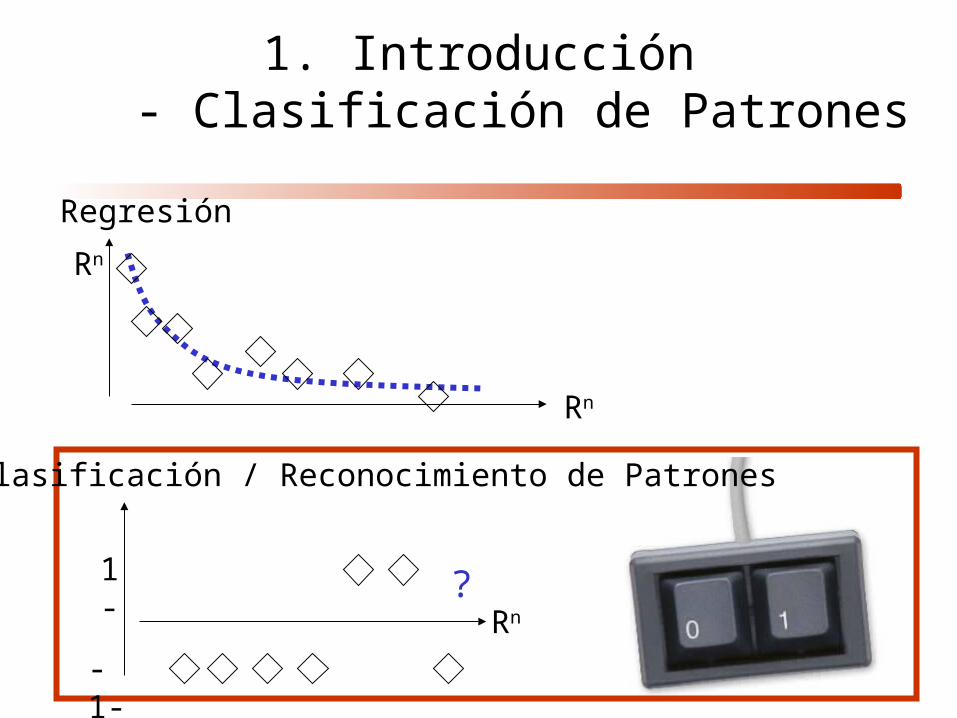
Regresión
Rn
Rn
Clasificación / Reconocimiento de Patrones
Rn
1-
-1-
?
1. Introducción- Clasificación de Patrones

7
1. Introducción- ¿Problemas prácticos?
•Determinar si un tumor de seno es maligno o benigno, en base a la siguiente data obtenida de una biopsia de aguja (tratada con procesamiento de imágenes): Espesor de tumor, uniformidad de tamaño celular, uniformidad de forma celular (excentricidad), Tamaño epitelial, Tamaño de núcleos, etc.•Determinar la presencia o no de la condición diabética, en base a: número de embarazos, concentración de glucosa, presión diastólica, grosor de pliegues de piel, indice de masa corporal, edad, etc.•Determinar la presencia o no de enfermedades del corazón, en base a: edad, sexo, localización de dolor de pecho, tipo de dolor, si baja o no al descansar, presión sanguínea en reposo, tipo de respuesta de EC, etc...

8
1. Introducción- ¿Problemas prácticos?
•Determinar de cuál cultivo de uvas viene un vino, en base a análisis químico: % alcohol, % ácido Málico, Magnesio, - Fenoles totales, intensidad de color, etc.•Determinar rango de edad de conchas marinas, partiendo del sexo, longitud, diámetro, altura, peso total, peso de las vísceras, y peso de la concha (en lugar de anillos al microscopio).•Determinar el valor de inmobiliario de suburbios de Boston, en base a: tasa de crímenes per capita en la ciudad, proporción de acres de comercios mayoristas por ciudad, colinda o no con un río, concentración de óxido nítrico, numero promedio de cuartos por construcción, proporción de casas construídas antes de 1940 ocupadas por sus dueños, distancias ponderadas respecto a 5 centros de empleo, indice de accesabilidad a autopistas radiales, taza de alumnos por profesor, etc.

9
Función Discriminante (en R2)
x2
x1Indice de sobre-peso
Niv
el d
e C
oles
tero
l
Notación:
y = a.x + b
w1.x1+w2.x2 =
wi.xi =
w,x =
f(w,x) =
x1x2
x3 x4
x6
x7
x5
x11x10
x9
x8
1, si w,x ≥
-1, si w,x < s(x,w)=
w
w,x3 >
w,x3 <
w,xf =
xf
1. Introducción- Clasificación de Patrones
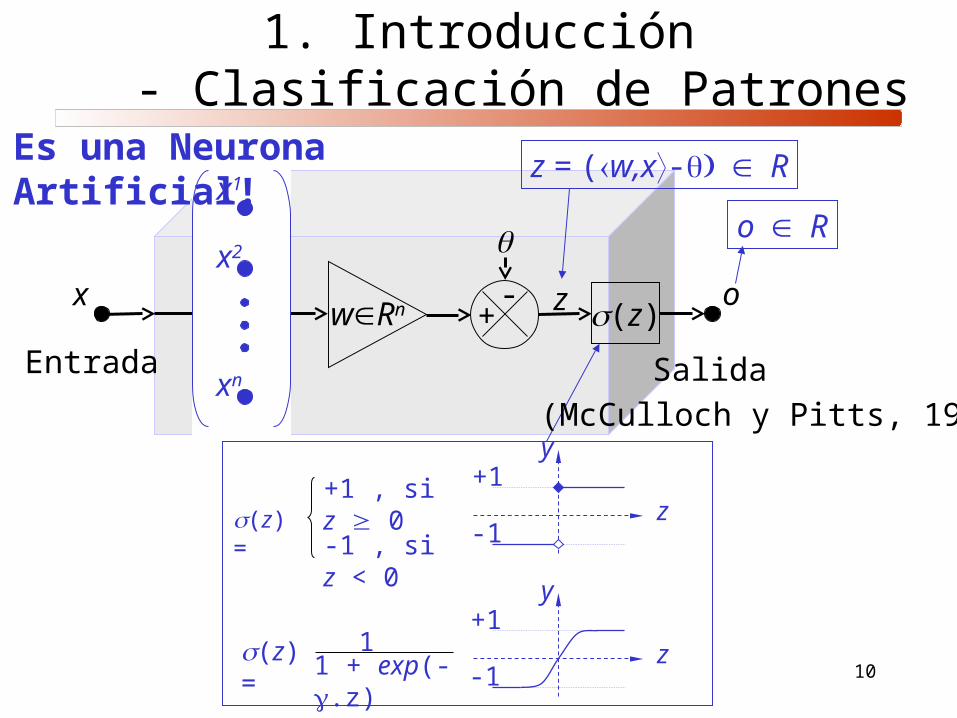
10
oxwRn (z)
-+
z
z = (w,x-Rx1
x2
xn Salida Entrada
oR
(z) =+1 , si z 0
-1 , si z < 0
(z) =
1 + exp(-.z) 1 z
y+1
-1
z
y+1
-1
Es una Neurona Artificial!
(McCulloch y Pitts, 1943)
1. Introducción- Clasificación de Patrones
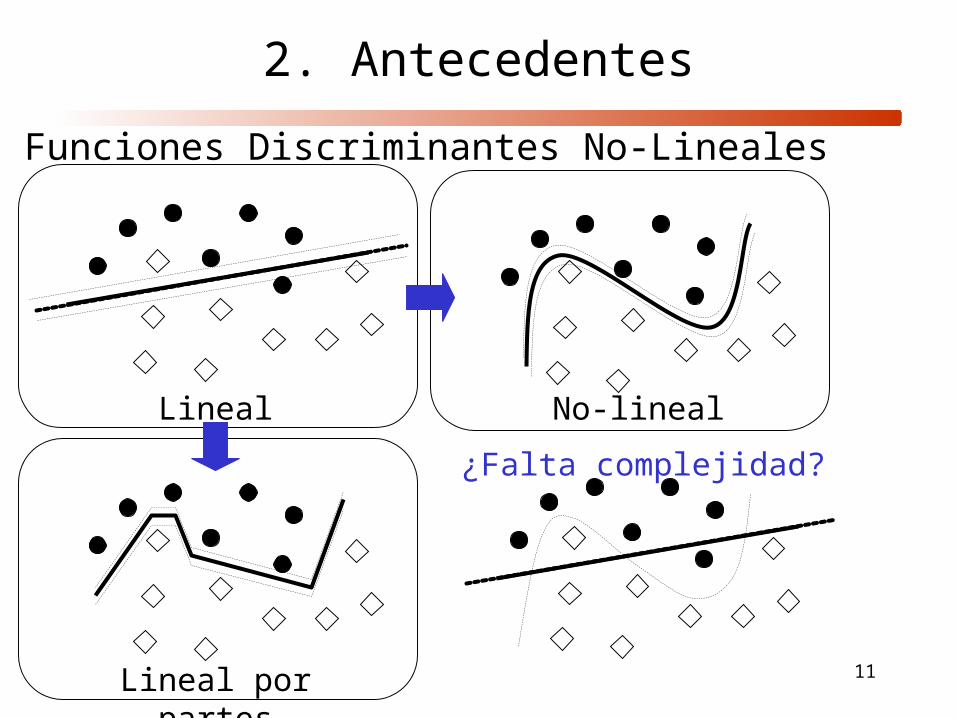
11
Funciones Discriminantes No-Lineales
Lineal No-lineal
Lineal por partes
¿Falta complejidad?
2. Antecedentes
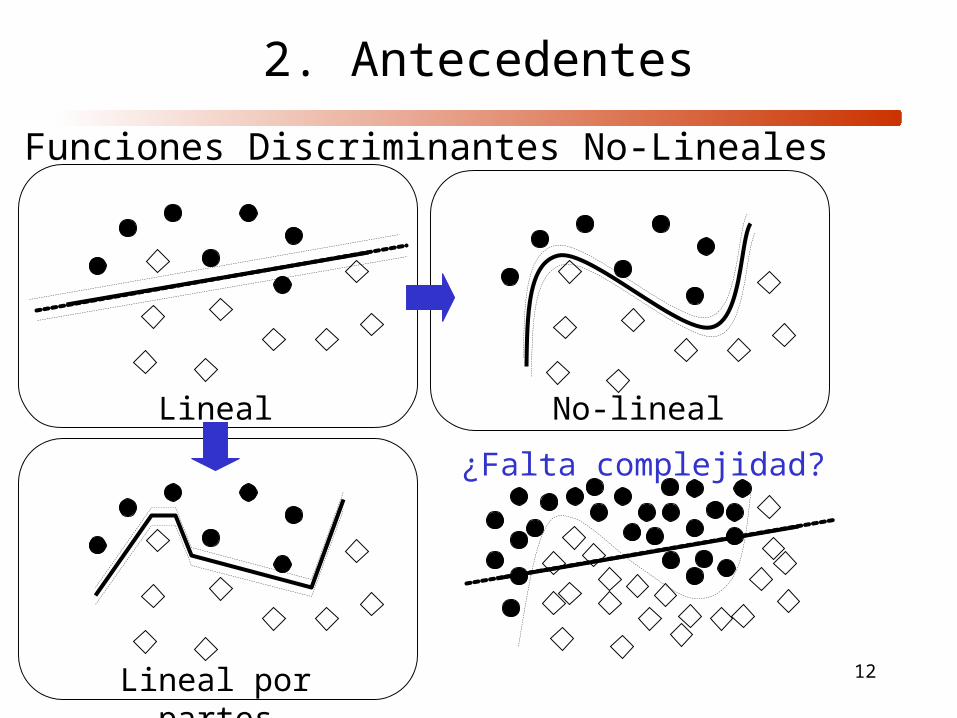
12
Funciones Discriminantes No-Lineales
Lineal No-lineal
Lineal por partes
¿Falta complejidad?
2. Antecedentes

13
Funciones Discriminantes No-Lineales
Lineal No-lineal
Lineal por partes
o... Por el contrario...
2. Antecedentes

14
Funciones Discriminantes No-Lineales
Lineal No-lineal
Lineal por partes
...¿Sobra complejidad?
2. Antecedentes
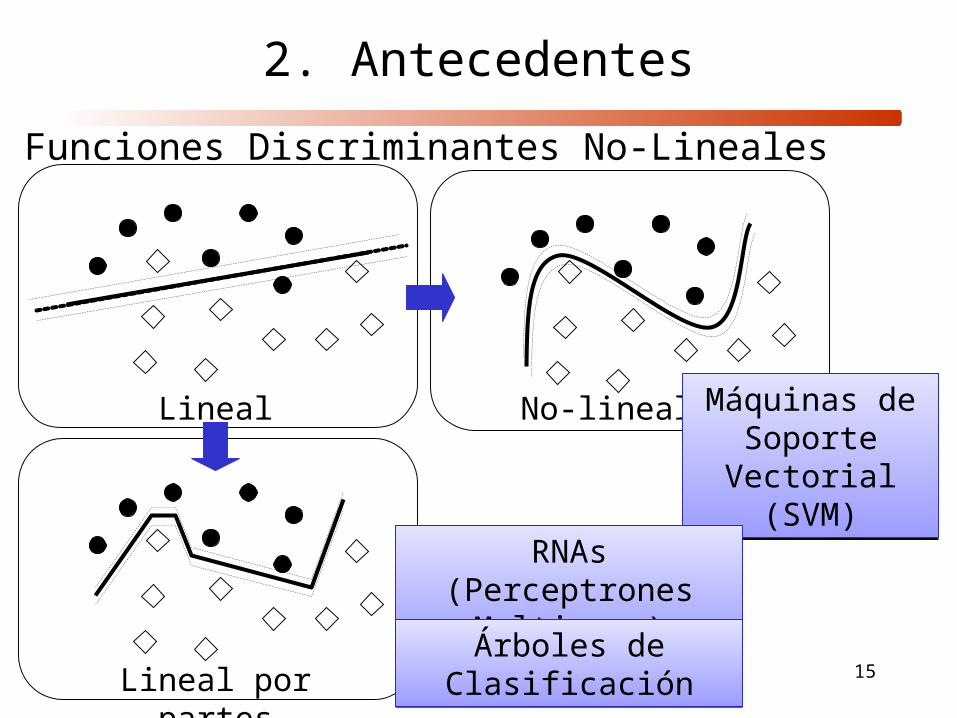
15
Funciones Discriminantes No-Lineales
Lineal No-lineal
Lineal por partes
Máquinas de Soporte Vectorial
(SVM)
Máquinas de Soporte Vectorial
(SVM)
RNAs(Perceptrones Multicapa)
RNAs(Perceptrones Multicapa)
Árboles de ClasificaciónÁrboles de Clasificación
2. Antecedentes

16
(Vapnik, 1998)
1. Antecedentes- Máquinas de Soporte Vectorial
Funciones Discriminantes No-Lineales
Las Máquinas de Vectores de Soporte (SVM)
Espacio de atributos aumentado,
Debo hallar w1, w2, w3, w4, w5 y
Espacio de atributos original.
Debo hallar w1, w2 y
Atributos: x1, x2x1
x2
_
Atributos:
x1, x2, 2 x1 x2, (x1)2, ( x2)2
z1
z2
z3
Margen
NOTAR QUE:NOTAR QUE:
- Propiedades estadísticas interesantes
-Implica pre-suponer la complejidadImplica pre-suponer la complejidad
-Puedo entrenar como Perceptrón, o mediante optimización PL o cuadrática.

17

18
Funciones Discriminantes No-Lineales
Las Máquinas de Vectores de Soporte (SVM)
x2
x1Indice de sobre-peso
Niv
el d
e C
oles
tero
lx1
x2
x3
x4
x6
x7
x5
x11
x10
x9
x8
ecuación de rectawT.xk =
Indicador de clase
w
“margen” / capacidad de generalización
Capacidad de reconocer data de entrenamiento
“brecha” de dato mal clasificado
y10>0y4>0
(Vapnik, 1998)
1. Antecedentes- Máquinas de Soporte Vectorial
¡Errores Simétricos!

19
1. Antecedentes- Máquinas de Soporte Vectorial
SVM discriminante sin transformación del “kernel”
http://www.buenasalud.net
R
Rn
Ens
ayo
y er
ror,
con
las
tran
sfor
mac
ione
s no
-lin
eale
s

20
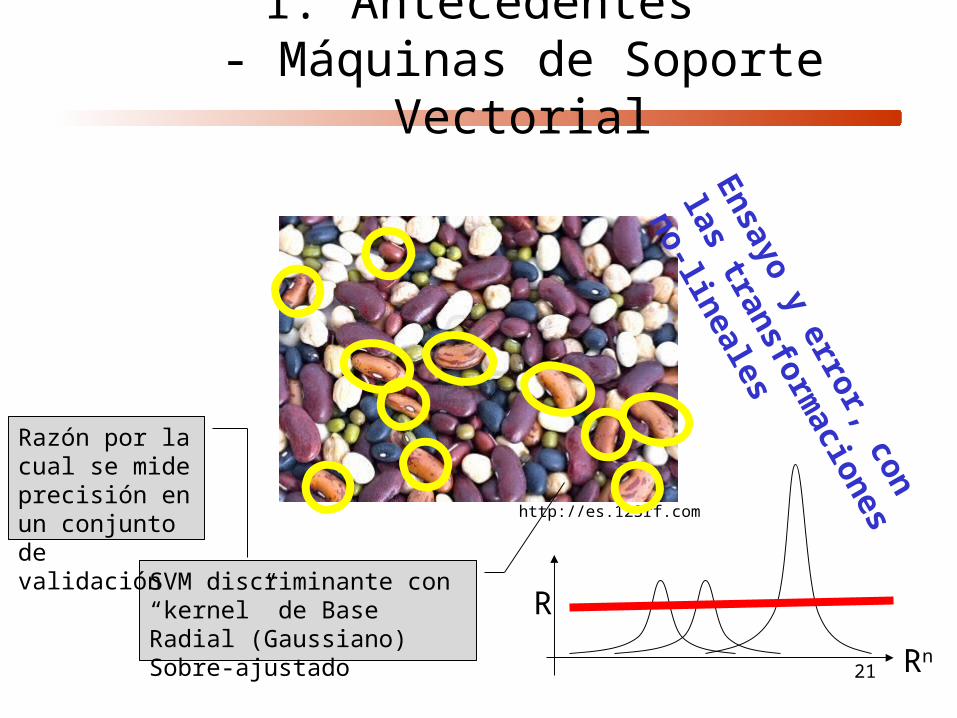
1. Antecedentes- Máquinas de Soporte Vectorial
SVM discriminante con “kernel” cuadrático
http://www.buenasalud.net
R
Rn
Ens
ayo
y er
ror,
con
las
tran
sfor
mac
ione
s no
-lin
eale
s
21
1. Antecedentes- Máquinas de Soporte Vectorial
http://es.123rf.com
SVM discriminante con “kernel” de Base Radial (Gaussiano)Sobre-ajustado
Razón por la cual se mide precisión en un conjunto de validación
R
Rn
Ensayo y error, con las
transformaciones no-lineales
22
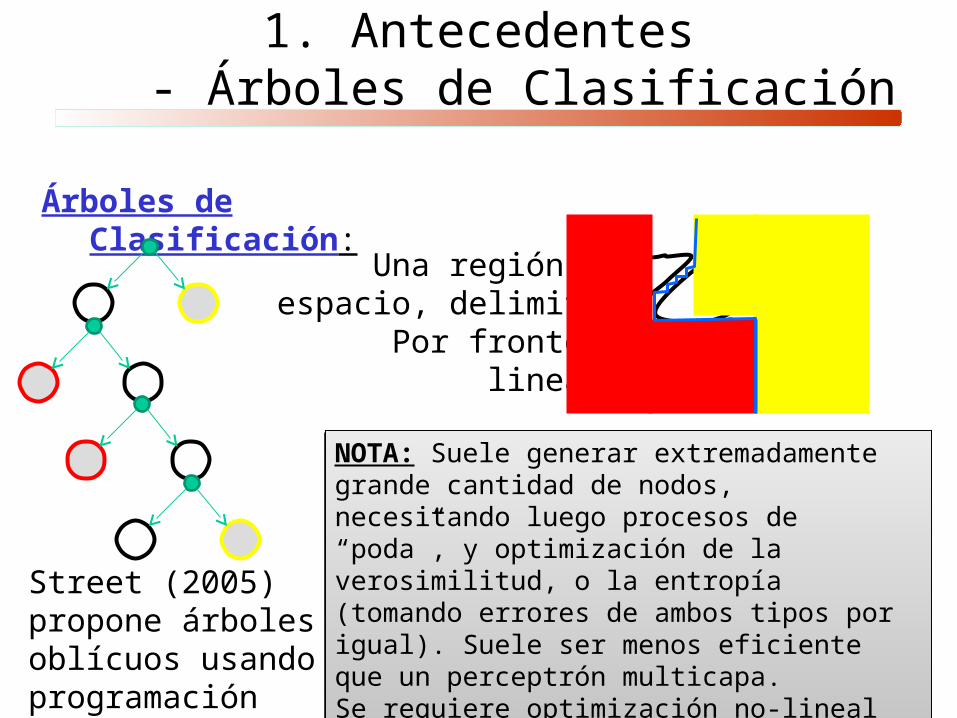
Árboles de Clasificación:
B
AUna región del
espacio, delimitadaPor fronteras
lineales
NOTA: Suele generar extremadamente grande cantidad de nodos, necesitando luego procesos de “poda”, y optimización de la verosimilitud, o la entropía (tomando errores de ambos tipos por igual). Suele ser menos eficiente que un perceptrón multicapa.Se requiere optimización no-lineal para poder considerar nodos oblícuos.
NOTA: Suele generar extremadamente grande cantidad de nodos, necesitando luego procesos de “poda”, y optimización de la verosimilitud, o la entropía (tomando errores de ambos tipos por igual). Suele ser menos eficiente que un perceptrón multicapa.Se requiere optimización no-lineal para poder considerar nodos oblícuos.
Street (2005) propone árboles oblícuos usando programación no-lineal
1. Antecedentes- Árboles de Clasificación

23
Funciones Discriminantes Lineales por PartesLineales por Partes
Perceptrones:
a) De una capao(x)x Un semi-espacio
bordeado por unhiper-plano B
A
B
AUna región del
espacio, delimitadaPor fronteras
lineales
b) Multi-capa
o(x)x
(Lippmann, 87)
1. Antecedentes- Redes Neurales Artificiales

24
Funciones Discriminantes Lineales por PartesLineales por Partes
Entrenando Perceptrones Multi-capa:
o(x)x
1
2
q
q
w1
w2
wq
NOTAR QUE:o(x)=[1.(w1,x-1) + 2.(w2,x-2) + .... + q.(wq,x-q)]
El problema de entrenar un perceptrón es un problema de optimización:
MinimizarMinimizar
w1,...,wq,q,q,
12
o(xt)-c(xt)]2
Errores
(Lippmann, 1987)
1. Antecedentes- Redes Neurales Artificiales

25
Funciones Discriminantes Lineales por PartesLineales por Partes
Entrenando Perceptrones Multi-capa: (forma clásica)
MinimizarMinimizar
w1,...,wq,q,q,
12
o(xt)-c(xt)]2
w1,...,wq,q,q,
PROBLEMAS:PROBLEMAS:
1. Función Objetivo “Plana”
2. Óptimos Locales y puntos “estacionarios” abundantes
3. No-Convexa
4. Hay que suponer la estructura de la red
1. Antecedentes- Redes Neurales Artificiales
¡Viacrucis de
¡Viacrucis de Optimización!
Optimización!

26
1. Antecedentes- Enfoque de Optimización
Problemas de Optimización:Problemas de Optimización:
Rn
R
LinealRn
R
Cuadrática
No-lineal convexa
Rn
R
No-Lineal, no-convexa, múltiples óptimos locales y puntos estacionarios
SVM
CT
SVM
ANN
También, para problemas pequeños, Programación Entera
27
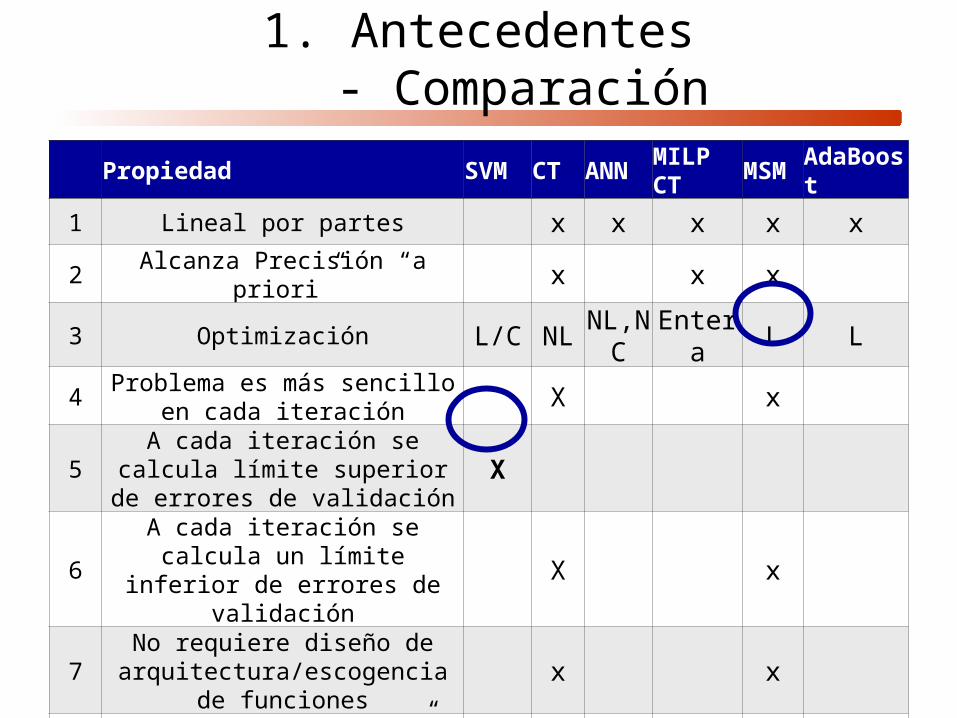
1. Antecedentes- Comparación
Propiedad SVM CT ANN MILP CT MSM AdaBoost
1 Lineal por partes x x x x x
2 Alcanza Precisión “a priori” x x x
3 Optimización L/C NL NL,NC Entera L L
4 Problema es más sencillo en cada iteración X x
5 A cada iteración se calcula límite superior de errores de validación X
6 A cada iteración se calcula un límite inferior de errores de validación X x
7No requiere diseño de
arquitectura/escogencia de funciones
x x
8 No Requiere “tuning” x X x
9 Maximización de margen x x

28
1. Antecedentes- Comparación
Bondades de los nuevos Métodos propuestos (Multi-Superficie):
1. Lineal por partes
2. Alcanza Precisión “a priori”
3. Optimización Lineal
4. Problema es más sencillo en cada iteración
5. A cada iteración se calcula límite inferior de errores de validación
6. No requiere diseño de arquitctura / escogencia de función
7. No requiere “tunning”
8. Opcional maximización de margen
9. Opcionalmente, Entera, pero aplicable a problemas grandes
10. Fácilmente resuelto con procesamiento distribuído/paralelo (problemas masivos)
11. Permiten la generación de métodos de visualización de patrones
29
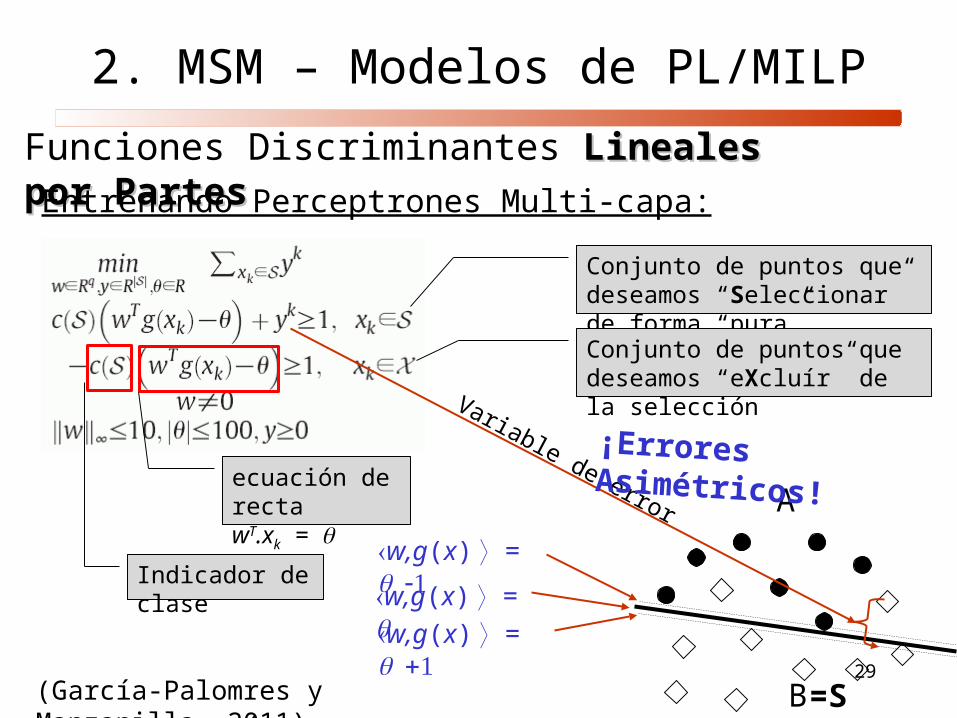
Funciones Discriminantes Lineales por PartesLineales por Partes
Entrenando Perceptrones Multi-capa:
(García-Palomres y Manzanilla, 2011)
A
B
w,g(x) =
w,g(x) =
w,g(x) =
=S
Conjunto de puntos que deseamos “Seleccionar” de forma “pura”
Conjunto de puntos que deseamos “eXcluír” de la selección
Variable de errorecuación de rectawT.xk =
Indicador de clase
2. MSM – Modelos de PL/MILP
¡Errores Asimétricos!

30
2. MSM – Modelos de PL/MILP
Funciones Discriminantes Lineales por PartesLineales por Partes
Entrenando Perceptrones Multi-capa: (PL Propuesto)
para A=S
para B=X
para A=X
para B=S
A
B
¡Errores Asimétricos!

31
Funciones Discriminantes Lineales por PartesLineales por Partes
Entrenando Perceptrones Multi-capa: (MILP Propuesto)
A
B
Suma de los puntos mal clasificados
Debe escogerse “” lo suficientemente grande
¡Variable binaria!
S A, o S B,Tantos elementos como el poder computacional lo permita
Tiene la bondad de no “adherir” los Planos a los puntos de X, y ser “robusto” ante datos marginales
2. MSM – Modelos de PL/MILP

32
Funciones Discriminantes Lineales por PartesLineales por Partes
Entrenando Perceptrones Multi-capa: (MILP Propuesto)
Se ha demostrado que siempre se puede clasificar al menos un punto, con transformaciones g(x) como las siguientes:
Esto puede:1. Usarse cuando no se consigue un
hiperplano2. Usarse siempre, de tal forma que
siempre el algoritmo genera esferas en lugar de planos
En el primer caso, puede elegir comoconjunto S , por ejemplo:
(En última instancia, estaría clasificandose los datos de uno en uno)
2. MSM – Modelos de PL/MILP

33
c(A)2-1c(A)w 2 c(A)/2 2
Entrenando Perceptrones Multi-capa: (MSM de Mangasarian)
Representación como Perceptrón Multi-capa:
2. MSM – Método
A
B
i=2
g(x)
c(B)1-1c(B
)w 1
c(St)/2t+1
b1c(B)/2 1b2
b3c(B)3-1
c(B)w3c(B)/23
b4c(A)4-1
c(A)w4
c(A)/24
b5c(B)5-1
c(B)w5
c(B)/2
5
c(B)/26
¡Red Neural sin Viacrucis
de Optimización!

34
Procedimiento Multi-superficiePaso 1: Sean A y B los conjuntos de elementos aún no clasificadosPaso 2: Encontrar dos superficies:
a)Una que separe elementos de A yb) Otra que separe elementos de B(orden arbitrario)
Paso 3: Actualizar A y B eliminando los ya clasificados(en caso de que no se clasifique a nadie, aplicar transformación
tipo “esférica”)Paso 6: Repetir pasos del 2 al 5 hasta que:
a) A o B sean iguales a , ob) Haya algún indicio de pérdida de generalidad
2. MSM – Método
35
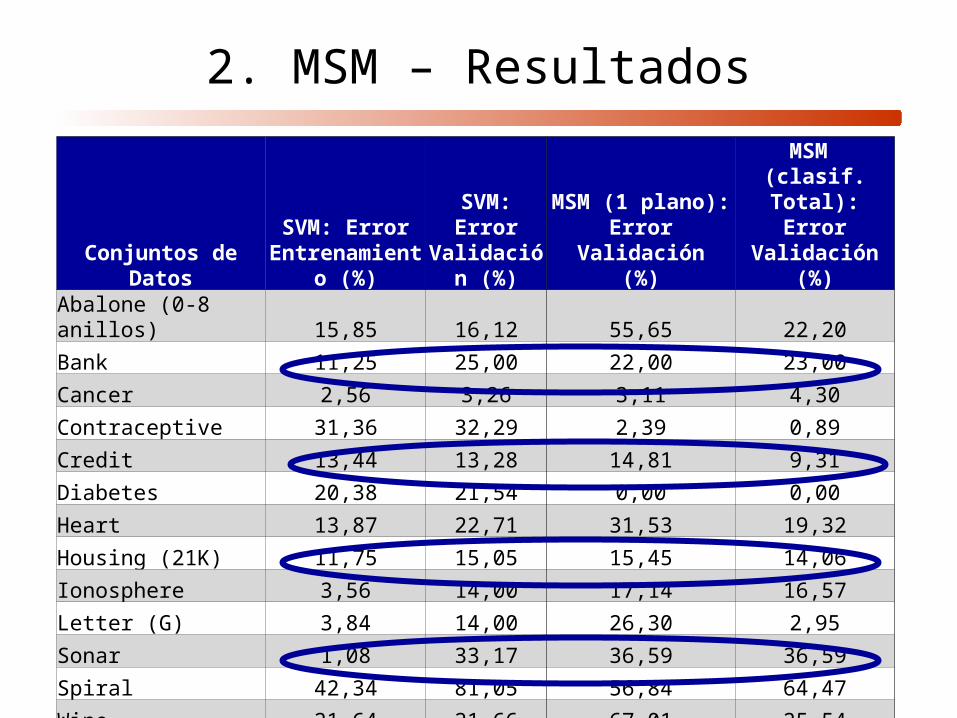
2. MSM – Resultados
Conjuntos de Datos
SVM: Error Entrenamiento
(%)
SVM: Error Validación
(%)
MSM (1 plano):Error Validación
(%)
MSM (clasif. Total):
Error Validación(%)
Abalone (0-8 anillos) 15,85 16,12 55,65 22,20
Bank 11,25 25,00 22,00 23,00
Cancer 2,56 3,26 3,11 4,30
Contraceptive 31,36 32,29 2,39 0,89
Credit 13,44 13,28 14,81 9,31
Diabetes 20,38 21,54 0,00 0,00
Heart 13,87 22,71 31,53 19,32
Housing (21K) 11,75 15,05 15,45 14,06
Ionosphere 3,56 14,00 17,14 16,57
Letter (G) 3,84 14,00 26,30 2,95
Sonar 1,08 33,17 36,59 36,59
Spiral 42,34 81,05 56,84 64,47
Wine 21,64 21,66 67,01 25,54
36
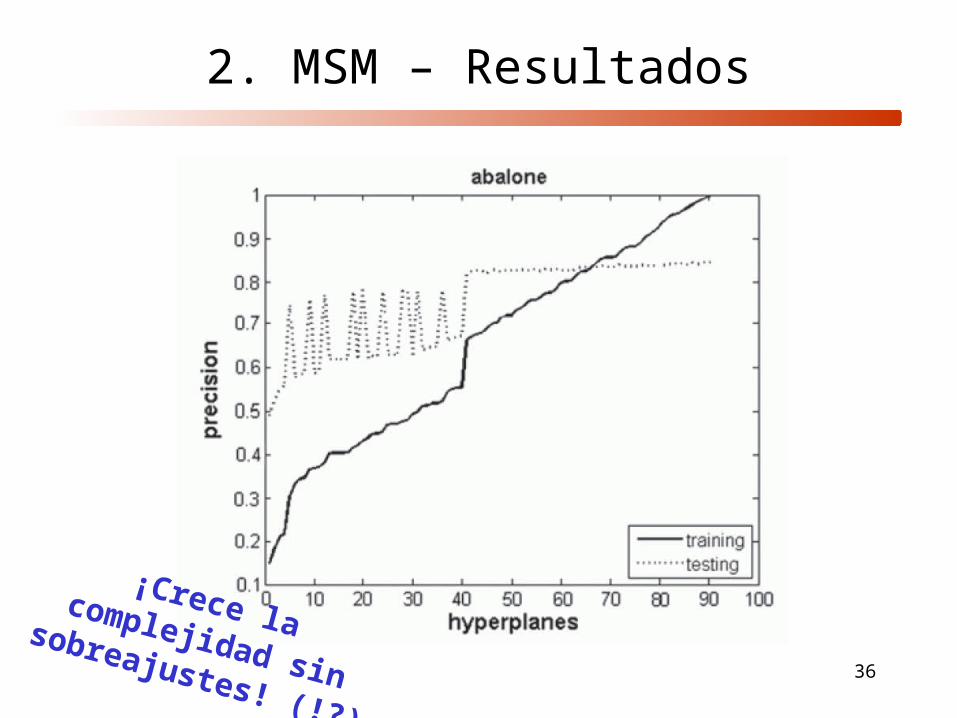
2. MSM – Resultados
¡Crece la complejidad sin sobreajustes! (!?)

37
2. MSM – Variantes
Bondades de los nuevos Métodos propuestos (Multi-Superficie):
1. Descomposición de nodos: no tomar como conjunto a “Seleccionar puros”, todos los puntos restantes de un conjunto, sino dividir el conjunto en varios más pequeños, y resolver modelos LP/MLP arbitrariamente pequeños (manejable por el computador). En cada iteración, permite trabajar cada sub-conjunto en un computador distinto. Disminuye el número de variables de error y de restricciones. Requiere resolver una mayor cantidad de modelos de optimización (finita).
2. Agrupamiento de variables de error. Disminuye el número de variables de error (puede combinarse con (1) ). Disminuye en cierta medida la cantidad de clasificados por cada hiperplano, aumentando el tamaño de red (finito). Requiere resolver una mayor cantidad de modelos de optimización (finita). En algunos casos SUPERA al publicado en febrero en precisión (!?).
3. Aplicación multi-categoría de la misma filosofía de “cortes”, con éxito.
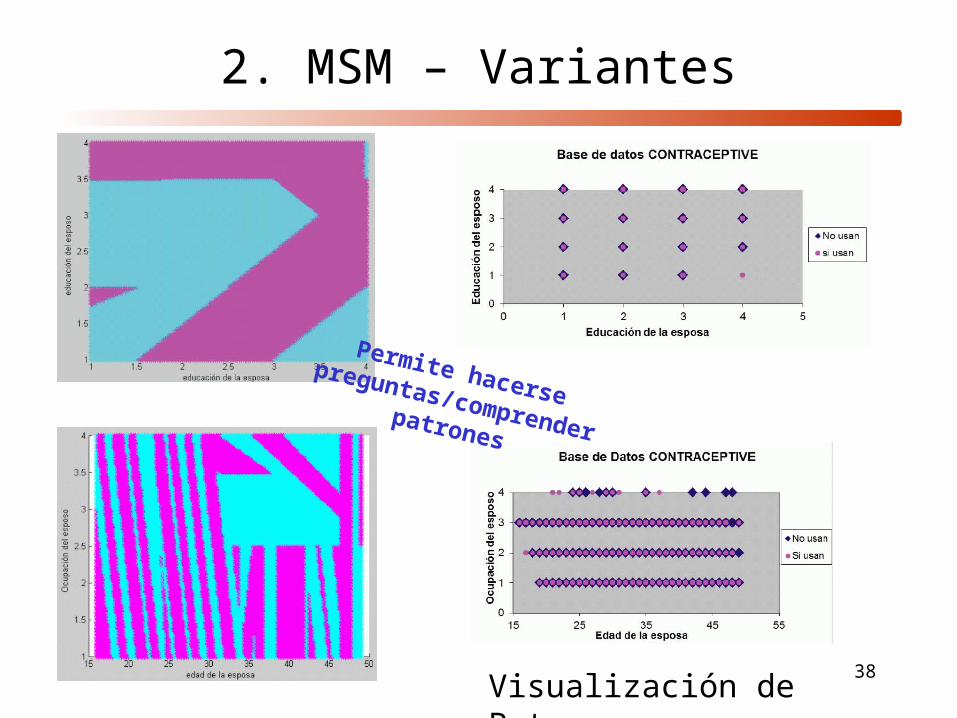
4. Automatizar generación de gráficos de cortes multi-dimensionales de la geometría de los hiperplanos, convirtiéndose en un método de visualización cientifica de datos.
38
2. MSM – Variantes
Visualización de Patrones
Permite hacerse preguntas/comprender patrones
39
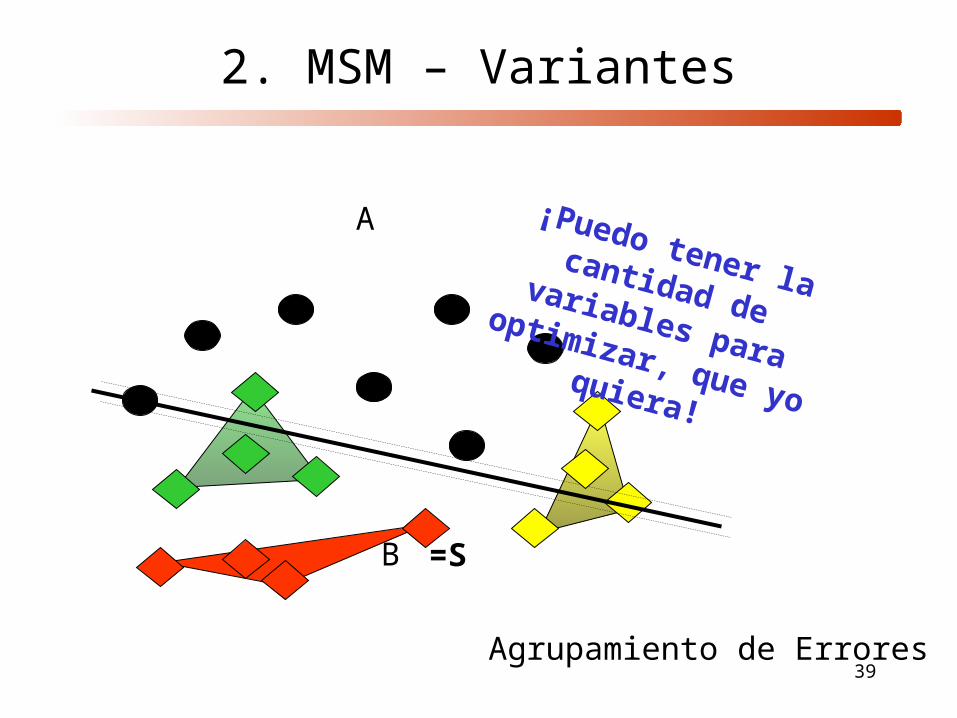
2. MSM – Variantes
Agrupamiento de Errores
A
B =S
¡Puedo tener la cantidad de variables para
optimizar, que yo quiera!
40
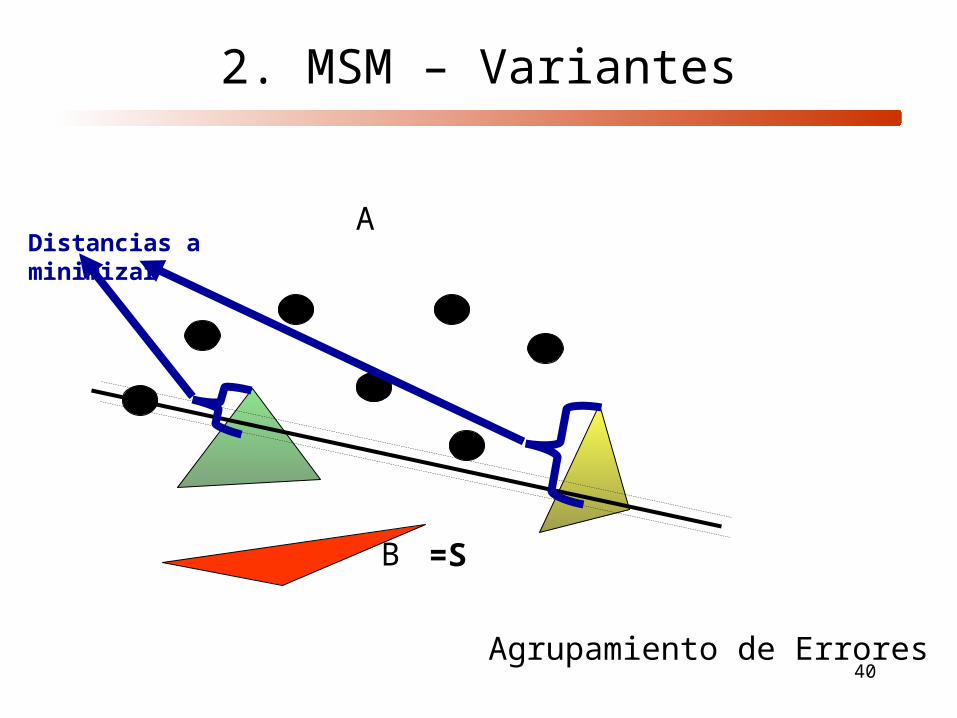
2. MSM – Variantes
Agrupamiento de Errores
A
B =S
Distancias a minimizar

41
2. MSM – Comparación
… retomando los antecedentes para comparar las
propiedades…
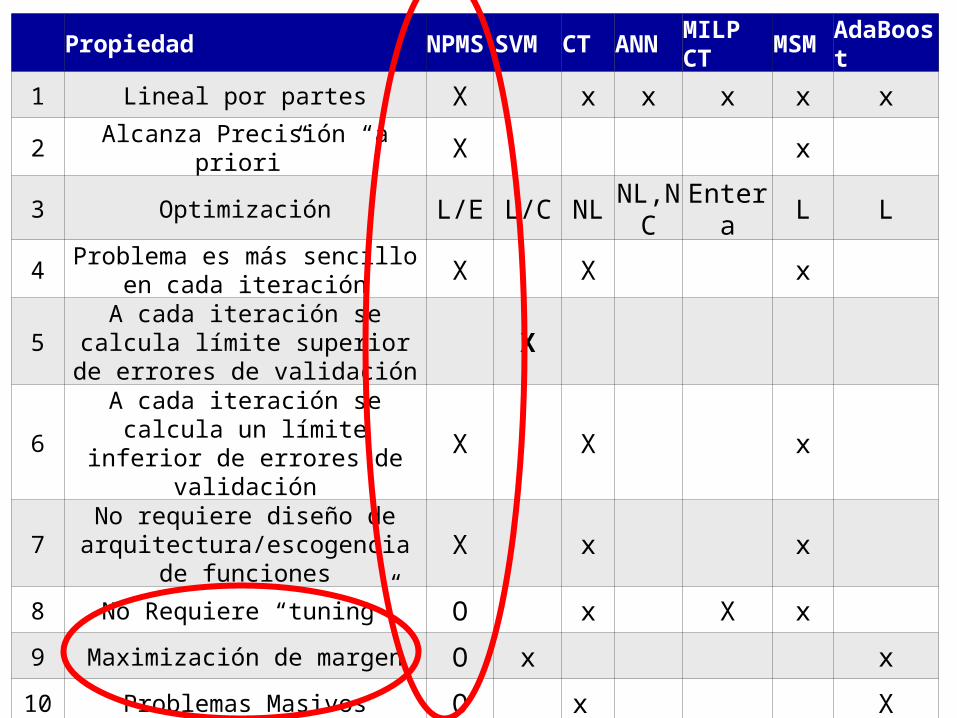
42
Propiedad NPMS SVM CT ANN MILP CT MSM AdaBoost
1 Lineal por partes X x x x x x
2 Alcanza Precisión “a priori” X x
3 Optimización L/E L/C NL NL,NC Entera L L
4 Problema es más sencillo en cada iteración X X x
5 A cada iteración se calcula límite superior de errores de validación X
6 A cada iteración se calcula un límite inferior de errores de validación X X x
7No requiere diseño de
arquitectura/escogencia de funciones
X x x
8 No Requiere “tuning” O x X x
9 Maximización de margen O x x
10 Problemas Masivos O x X
11 Cómputo paralelo/distribuído X O
12 Permite visualizar patrones o x x

43
• Aprendizaje Automático sin necesidad de un experto.
• Sirve cualquier computador• Facilita visualización para exploración de patrones• Cómputo distribuído/paralelo totalmente factible.• Poca tendencia a sobre-ajuste• Línea de investigación teórica y computacional
abierta• Linea de investigación de APLICACIONES,
abierta!
3. Conclusiones y futuro trabajo

44
Preguntas por responder:• ¿Por qué no sobre-ajusta?• ¿Combinación de agrupamiento de variables de error con
descomposición de nodos?• ¿Métodos de generación de columnas para aprovechar la
estructura del modelo PL?• ¿Heurística para modelo MILP que aproveche la estructura?
• ¿Función Objetivo multi-criterio (frente pareto)?• ¿Uso para regresión?• ¿Teoría de complejidad estructural para parada temprana?
3. Conclusiones y futuro trabajo

45
C.J. Ong, S.Y. Shao, J.B. Yang, An improved algorithm for the solution of the entire regulation path of support vector machine, Technical Report http://www.optimizationonline. org/DB HTML/2009/04/2284.html, Optimization on line, Argonne, IL, 2009.
Street, W. N. (2005). Oblique Multicategory Decision Trees Using Nonlinear Programming. INFORMS Journal on Computing , 17 (1), pp. 25-31.
McCulloch W., Pitts W., “A logical calculus of the ideas immanent in nervous activity”. Bulletin of Mathematical Biophysics, No.7 (1943), 115-133.
Vapnik V.N., “The Nature of Statistical Learning Theory”, Springer, 2nd Edition, New York, 193 pp, 1998.
Lippmann R.P., “An Introduction to Computing with Neural Nets”. IEEE ASSP Magazine, Abril (1987), 4-22.
Mangasarian O.L., “Mathematical programming in neural networks”. Computer Sciences Department Technical Report 1129, University of Wisconsin, Madison, Wisconsin, 1992.
Bennett K.P., Mangasarian O.L., “Robust linear programming discrimination of two linearly inseparable sets¨. Optimization Methods and Software, Vol. 1 (1992), 23-34.
Referencias

46
¿Preguntas?

![Estudi sociomorfològic a Manresa - COnnecting REpositoriespresència del segment velar en 1[-pl] del present dindicatiu i en 1[-pl], 2[-pl], 3[-pl] i 3[+pl] del present de subjuntiu](https://static.fdocuments.es/doc/165x107/6031ff87e30ce55053557c57/estudi-sociomorfolgic-a-manresa-connecting-repositories-presncia-del-segment.jpg)
















