
eoríaT de la Decisión Regresión lineal y k-NN · eoríaT de la Decisión Regresión lineal y...
77
Transcript of eoríaT de la Decisión Regresión lineal y k-NN · eoríaT de la Decisión Regresión lineal y...

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Métodos de Regresión y Clasi�cación Lineales
Alvaro J. Riascos Villegas
Febrero de 2017
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Contenido
1 Teoría de la Decisión
2 Regresión lineal y k-NN
3 Ejemplo: Cáncer de próstata
4 Selección de variables
5 Métodos de contracción (shrinkage)
6 Modelo de clasi�cación óptimo
7 Modelos de lineales de clasi�cación
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Modelo de Regresión Óptimo
Supongamos que Y es una variable real y X es un p-vector:
X ∈ Rp
Denotamos la distribución conjunta por Pr(X ,Y ).Nuestro objetivo es encontrar f (X ) para predecir Y pero
necesitamos una noción de pérdida.
Vamos a utilizar el error al cuadrado (alternativamente podría
ser del error absoluto):
EPE (f ) = E [(Y − f (X ))2] (1)
EPE denota el error de prueba (o Riesgo de acuerdo a la
terminología introducida en las clases anteriores).
El problema es minimizar este error en un espacio de funciones
F.Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Modelo de Regresión Óptimo
Supongamos que Y es una variable real y X es un p-vector:
X ∈ Rp
Denotamos la distribución conjunta por Pr(X ,Y ).Nuestro objetivo es encontrar f (X ) para predecir Y pero
necesitamos una noción de pérdida.
Vamos a utilizar el error al cuadrado (alternativamente podría
ser del error absoluto):
EPE (f ) = E [(Y − f (X ))2] (1)
EPE denota el error de prueba (o Riesgo de acuerdo a la
terminología introducida en las clases anteriores).
El problema es minimizar este error en un espacio de funciones
F.Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Modelo de Regresión Óptimo
Supongamos que Y es una variable real y X es un p-vector:
X ∈ Rp
Denotamos la distribución conjunta por Pr(X ,Y ).Nuestro objetivo es encontrar f (X ) para predecir Y pero
necesitamos una noción de pérdida.
Vamos a utilizar el error al cuadrado (alternativamente podría
ser del error absoluto):
EPE (f ) = E [(Y − f (X ))2] (1)
EPE denota el error de prueba (o Riesgo de acuerdo a la
terminología introducida en las clases anteriores).
El problema es minimizar este error en un espacio de funciones
F.Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Modelo de Regresión Óptimo
Supongamos que Y es una variable real y X es un p-vector:
X ∈ Rp
Denotamos la distribución conjunta por Pr(X ,Y ).Nuestro objetivo es encontrar f (X ) para predecir Y pero
necesitamos una noción de pérdida.
Vamos a utilizar el error al cuadrado (alternativamente podría
ser del error absoluto):
EPE (f ) = E [(Y − f (X ))2] (1)
EPE denota el error de prueba (o Riesgo de acuerdo a la
terminología introducida en las clases anteriores).
El problema es minimizar este error en un espacio de funciones
F.Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Modelo de Regresión Óptimo
Supongamos que Y es una variable real y X es un p-vector:
X ∈ Rp
Denotamos la distribución conjunta por Pr(X ,Y ).Nuestro objetivo es encontrar f (X ) para predecir Y pero
necesitamos una noción de pérdida.
Vamos a utilizar el error al cuadrado (alternativamente podría
ser del error absoluto):
EPE (f ) = E [(Y − f (X ))2] (1)
EPE denota el error de prueba (o Riesgo de acuerdo a la
terminología introducida en las clases anteriores).
El problema es minimizar este error en un espacio de funciones
F.Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Modelo de Regresión Óptimo
Supongamos que Y es una variable real y X es un p-vector:
X ∈ Rp
Denotamos la distribución conjunta por Pr(X ,Y ).Nuestro objetivo es encontrar f (X ) para predecir Y pero
necesitamos una noción de pérdida.
Vamos a utilizar el error al cuadrado (alternativamente podría
ser del error absoluto):
EPE (f ) = E [(Y − f (X ))2] (1)
EPE denota el error de prueba (o Riesgo de acuerdo a la
terminología introducida en las clases anteriores).
El problema es minimizar este error en un espacio de funciones
F.Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Modelo de Regresión Óptimo
EPE(f) se puede escribir como:
EPE (f ) = EXEY |X[(Y − f (X ))2|X
]
Ahora, si para cada X = x hacemos que f (x) sea tal que:
EY |X[(Y − f (x))2|X = x
](2)
sea mínimo, entonces la función que a x le asocia f (x)resuelve el problema.
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Modelo de Regresión Óptimo
EPE(f) se puede escribir como:
EPE (f ) = EXEY |X[(Y − f (X ))2|X
]
Ahora, si para cada X = x hacemos que f (x) sea tal que:
EY |X[(Y − f (x))2|X = x
](2)
sea mínimo, entonces la función que a x le asocia f (x)resuelve el problema.
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Modelo de Regresión Óptimo
Luego, formalmente el problema que queremos resolver es:
f (x) = argminc
EY |X[(Y − c)2|X = x
]
Se puede demostrar que la solución a este problema es:
f (x) = E (Y |X = x)
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Modelo de Regresión Óptimo
Luego, formalmente el problema que queremos resolver es:
f (x) = argminc
EY |X[(Y − c)2|X = x
]
Se puede demostrar que la solución a este problema es:
f (x) = E (Y |X = x)
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Otras funciones de pérdida
Si usamos como función de pérdida E [|Y − f (X )|] se puede
demostrar que la solución óptima es:
f (x) = Median (Y |X = x )
Esta es menos sensible a datos atípicos pero mas difícil de
trabajar analíticamente (no es diferencible).
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Otras funciones de pérdida
Si usamos como función de pérdida E [|Y − f (X )|] se puede
demostrar que la solución óptima es:
f (x) = Median (Y |X = x )
Esta es menos sensible a datos atípicos pero mas difícil de
trabajar analíticamente (no es diferencible).
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Contenido
1 Teoría de la Decisión
2 Regresión lineal y k-NN
3 Ejemplo: Cáncer de próstata
4 Selección de variables
5 Métodos de contracción (shrinkage)
6 Modelo de clasi�cación óptimo
7 Modelos de lineales de clasi�cación
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Regresión lineal
El modelo de regresión lineal asume que:
f (x))≈ XTβ
Si minimizamos el riesgo sujeto a que las funciones deben ser
lineales obtenemos:
β = E(XXT
)−1E (XY )
El modelo de regresión lineal asume f (x) es globalmente lineal.
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Regresión lineal
El modelo de regresión lineal asume que:
f (x))≈ XTβ
Si minimizamos el riesgo sujeto a que las funciones deben ser
lineales obtenemos:
β = E(XXT
)−1E (XY )
El modelo de regresión lineal asume f (x) es globalmente lineal.
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Regresión lineal
El modelo de regresión lineal asume que:
f (x))≈ XTβ
Si minimizamos el riesgo sujeto a que las funciones deben ser
lineales obtenemos:
β = E(XXT
)−1E (XY )
El modelo de regresión lineal asume f (x) es globalmente lineal.
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
k-NN: k-vecinos más cercanos
k-NN estima la esperanza condicional localmente como una
función constante.
f (x) = Ave (y |x ∈ Nk(x))
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Comparación entre la regresión lineal y k-NN
Ambos métodos aproximan E (Y |X = x) con promedios perohacen supuestos muy distintos sobre la verdadera función deaprendizaje.
El modelo de regresión lineal asume f (x) es globalmente lineal.k-NN asume que f (x) es localmente constante.
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Comparación entre la regresión lineal y k-NN
Ambos métodos aproximan E (Y |X = x) con promedios perohacen supuestos muy distintos sobre la verdadera función deaprendizaje.
El modelo de regresión lineal asume f (x) es globalmente lineal.k-NN asume que f (x) es localmente constante.
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales
Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Contenido
1 Teoría de la Decisión
2 Regresión lineal y k-NN
3 Ejemplo: Cáncer de próstata
4 Selección de variables
5 Métodos de contracción (shrinkage)
6 Modelo de clasi�cación óptimo
7 Modelos de lineales de clasi�cación
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales
Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
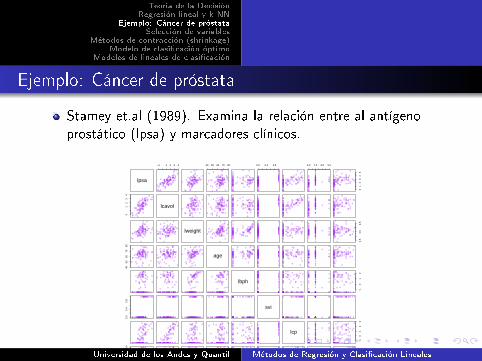
Ejemplo: Cáncer de próstata
Stamey et.al (1989). Examina la relación entre al antígeno
prostático (lpsa) y marcadores clínicos.Elements of Statistical Learning (2nd Ed.) c©Hastie, Tibshirani & Friedman 2009 Chap 1
lpsa
−1 1 2 3 4
oo oooo ooo ooo ooooo oo o o oo oo ooo o ooo ooo ooo ooo oo ooo oo ooo oo o ooooo oo o oooo ooo o ooo o ooo oooo oooo ooo oo ooo o
ooo
o oo ooo oooo oooo oo ooo ooooo oo ooo o ooo oo ooo ooo ooooo oooo o oo oo oo o oo ooo oo ooo o ooo oo oo ooo oo o oooo oo oo oo ooo o o
40 50 60 70 80
o o oooo ooo oooo oo o ooo oooo o oooooooo oo oo oo oo o ooo oo ooo oooo oo ooo oo oo oooo o oooo ooo oo o ooooo ooo oo oo ooo oo
o oo
oooooo o oooo ooooo ooo oo oo o ooo ooo ooooo ooo oooo oo oo ooo oo oooo oo oo o ooo oo o o oo oo oo oo o oooo ooo o oo ooo oo oooo oo
0.0 0.4 0.8
oooooooooooooooooooooooooooooooooooooo oooooooo ooooooooooooooo oo ooooooo oo oooooo oooo ooo oo oooo oo
oooo
oooooooooooo oo oo o oooo oo ooo oo o ooooo oo oo oooo o ooo ooo ooo o ooo ooooo oo oo o ooo o oo o o o ooo ooo oo oo oo o oooo o o
oo o
6.0 7.0 8.0 9.0
oo oooooooooo oooo ooooo oo ooo ooooooooo o oooo ooo ooo oooo oo oooooo ooo o ooo oooo oooo oooooooooo oooo oooo oo
oooo
01
23
45
oo oooooooooo oooo ooooo oo ooo oo oooooooo oo oo oooo oo oooo oo ooo ooo o oo o ooo o oooo ooo oo o oo ooo oo oo oo o o oo o oo
o oo
−1
12
34
oooo
o
o
oo
o
oo
o
oooo
o
o
oo
o
o
o
o
o
o
o
o
o
o
oo
o
oo
oo
o
o
oooo
ooo
o
ooooo
o
o
o
oooooo
ooooooo
o
ooooo
oo
oooo
o
ooo
o
o
oo
o
o
ooo
o
ooo
lcavolo
oo
o
o
o
oo
o
o o
o
oo oo
o
o
oo
o
o
o
o
o
o
o
o
o
o
oo
o
oo
oo
o
o
ooo
o
ooo
o
ooo o
o
o
o
o
ooo oo
o
oo
ooooo
o
oo
o oo
oo
ooo o
o
o oo
o
o
oo
o
o
oo o
o
o oo
oo
oo
o
o
oo
o
oo
o
o oo o
o
o
oo
o
o
o
o
o
o
o
o
o
o
oo
o
o o
o o
o
o
o oo
o
o oo
o
oo
ooo
o
o
o
ooo o
oo
oo
ooo
o o
o
oo
ooo
oo
oooo
o
o oo
o
o
o o
o
o
oo o
o
o oo
oooo
o
o
o o
o
oo
o
oooo
o
o
oo
o
o
o
o
o
o
o
o
o
o
oo
o
oo
oo
o
o
ooo
o
o oo
o
oo
ooo
o
o
o
oooo
oo
oo
ooo
o o
o
oo
ooo
o o
oooo
o
oo o
o
o
oo
o
o
ooo
o
o oo
oooo
o
o
oo
o
oo
o
oooo
o
o
oo
o
o
o
o
o
o
o
o
o
o
oo
o
oo
oo
o
o
oooo
ooo
o
ooooo
o
o
o
oooooo
oo
ooooo
o
oo
o oo
oo
oo oo
o
o oo
o
o
o o
o
o
ooo
o
ooo
oooo
o
o
oo
o
oo
o
oo oo
o
o
oo
o
o
o
o
o
o
o
o
o
o
oo
o
o o
o o
o
o
ooo
o
ooo
o
oo
ooo
o
o
o
o ooooo
oo
ooo
oo
o
oo
o oo
o o
oo oo
o
oo o
o
o
o o
o
o
oo o
o
ooo
oo
oo
o
o
oo
o
oo
o
oooo
o
o
oo
o
o
o
o
o
o
o
o
o
o
oo
o
oo
o o
o
o
o oo
o
ooo
o
ooo oo
o
o
o
ooo o
oo
oo
ooooo
o
oooo
o
oo
oooo
o
oo o
o
o
o o
o
o
ooo
o
ooo
oo
oo
o
o
oo
o
oo
o
oooo
o
o
oo
o
o
o
o
o
o
o
o
o
o
oo
o
oo
o o
o
o
o oo
o
o oo
o
ooo oo
o
o
o
ooo o
oo
oo
ooo
oo
o
oo
ooo
o o
oo oo
o
oo o
o
o
o o
o
o
oo o
o
o oo
o
o
o
o oooooooo
oo
oo
ooo
oooooo
o
oo
oo
oo
ooo
o
o
o
o
oo
ooo
oo
oo
oo
oo
o
o
o
o
o
o
oo
o
ooooooooo
oo
o
o
o
o
oo
oo
oo
oooooo
o
oo
ooo
ooo
o
o
o
o oo
oooooo
oo
oo
o oo
oo oo o
o
o
oo
oo
oo
ooo
o
o
o
o
oo
oo o
oo
oo
oo
oo
o
o
o
o
o
o
oo
o
oo
oo
o oo
oo
oo
o
o
o
o
o o
oo
oo
oooo
oo
o
oo
oo o
oo
o
lweighto
o
o
o oo
oooooo
o o
oo
ooo
oooo o
o
o
oo
oo
oo
oo o
o
o
o
o
o o
ooo
oo
oo
o o
oo
o
o
o
o
o
o
oo
o
oo
oo
o oo
oo
oo
o
o
o
o
o o
oo
oo
oooo
oo
o
oo
ooo
ooo
o
o
o
oooo oo
oo o
oo
oo
ooo
oo oo o
o
o
o o
oo
oo
ooo
o
o
o
o
oo
ooo
oo
oo
o o
oo
o
o
o
o
o
o
oo
o
oo
oo
o oo
oo
oo
o
o
o
o
oo
oo
oo
o o oo
oo
o
oo
ooo
oo
o
o
o
o
ooooooooo
oo
oo
ooo
oooooo
o
oo
oo
oo
ooo
o
o
o
o
oo
ooo
oo
oo
oo
oo
o
o
o
o
o
o
oo
o
oo
ooooooo
oo
o
o
o
o
oo
oo
oo
oooo
oo
o
oo
ooo
ooo
o
o
o
ooooooooo
oo
oo
o oo
oo oo oo
o
oo
oo
oo
oo o
o
o
o
o
oo
oo o
oo
oo
o o
oo
o
o
o
o
o
o
oo
o
oo
oo
o oo
oo
oo
o
o
o
o
oo
oo
oo
o ooo
oo
o
oo
oo o
oo
o
o
o
o
ooooooooo
oo
oo
ooo
oo oo oo
o
oo
oo
oo
ooo
o
o
o
o
o o
oo o
oo
oo
oo
oo
o
o
o
o
o
o
oo
o
oo
oo
ooo
oo
oo
o
o
o
o
oo
oo
oo
o ooo
oo
o
oo
ooo
ooo
2.5
3.5
4.5
o
o
o
ooooooooo
oo
oo
ooo
oo oo oo
o
oo
oo
oo
ooo
o
o
o
o
o o
ooo
oo
oo
oo
oo
o
o
o
o
o
o
oo
o
oo
oo
o oo
oo
oo
o
o
o
o
oo
oo
oo
o ooo
oo
o
oo
ooo
oo
o
4050
6070
80
o
o
o
oo
o
oo
o
ooooo
o
ooo
o
o
ooooooooooooo
o
oo
o
oo
oo
ooooo
o
o
o
ooooo
o
o
oo
o
o
o
o
oooo
oooo
o
o
o
o
oooo
ooo
o
o
oooooo
o
o
o
o
o
o
oo
o
o
o
oo
o
oo
o
ooo oo
o
oo
o
o
o
o ooo
o ooo o ooo
o
o
o o
o
oo
oo
oo o
oo
o
o
o
oooo
o
o
o
oo
o
o
o
o
ooo
o
oo
oo
o
o
o
o
ooo
o
oo
o
o
o
oo
oo
oo
o
o
o
o
o
o
o o
o
o
o
oo
o
oo
o
o oooo
o
ooo
o
o
oooo
ooooo o oo
o
o
o o
o
oo
oo
ooo
oo
o
o
o
o ooo
o
o
o
o o
o
o
o
o
ooo
o
oo
oo
o
o
o
o
oooo
oo
o
o
o
oo
oo
oo
o
o
o
o
o
o
o o
ageo
o
o
oo
o
oo
o
oo ooo
o
oo
o
o
o
o ooo
ooo ooo oo
o
o
o o
o
oo
oo
oooo
o
o
o
o
oooo
o
o
o
o o
o
o
o
o
ooo
o
oo
oo
o
o
o
o
o ooo
oo
o
o
o
oo
oo
oo
o
o
o
o
o
o
oo
o
o
o
oo
o
oo
o
ooooo
o
ooo
o
o
ooooooooooooo
o
oo
o
oo
oo
ooooo
o
o
o
ooooo
o
o
oo
o
o
o
o
ooo
o
oooo
o
o
o
o
oooo
ooo
o
o
oo
oo
oo
o
o
o
o
o
o
oo
o
o
o
oo
o
oo
o
ooo oo
o
oo
o
o
o
o ooo
oooo o ooo
o
o
oo
o
oo
oo
oo oo
o
o
o
o
ooo o
o
o
o
oo
o
o
o
o
ooo
o
oo
oo
o
o
o
o
o oo
o
oo
o
o
o
oo
oo
oo
o
o
o
o
o
o
o o
o
o
o
oo
o
oo
o
ooo oo
o
oo
o
o
o
o ooo
oooooooo
o
o
o o
o
oo
oo
oo o
oo
o
o
o
o oo o
o
o
o
oo
o
o
o
o
oooo
oo
oo
o
o
o
o
oooo
ooo
o
o
ooo
ooo
o
o
o
o
o
o
oo
o
o
o
oo
o
oo
o
ooo oo
o
oo
o
o
o
o ooo
oooo oooo
o
o
oo
o
oo
oo
ooo
oo
o
o
o
o oo o
o
o
o
oo
o
o
o
o
ooo
o
oo
oo
o
o
o
o
o oo
o
oo
o
o
o
oo
oo
oo
o
o
o
o
o
o
oo
oooo oo
o
o
ooo
o
oooo
o
oo
o
o
o
o
o
o
o
o
o
o
o
ooo
oo
o
o
o
oo
oo
o
o
o
o
oo
o
o
o
ooo
o
o
o
o
o
o
o
o
o
o
o
ooo
o
o
o
o
o
o
o
o
oo
oo
oo
o
oo
o
o
oo
o
o
o
ooo
o
o
oo oo oo
o
o
o oo
o
oooo
o
oo
o
o
o
o
o
o
o
o
o
o
o
oo
o
oo
o
o
o
oo
o o
o
o
o
o
oo
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
ooo
o
o
o
o
o
o
o
o
o o
oo
o o
o
oo
o
o
o o
o
o
o
o oo
o
o
o oo ooo
o
o
oo o
o
oo oo
o
oo
o
o
o
o
o
o
o
o
o
o
o
oo
o
oo
o
o
o
oo
o o
o
o
o
o
oo
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
oo
o o
o o
o
oo
o
o
o o
o
o
o
ooo
o
o
o o oo oo
o
o
o oo
o
o oo o
o
oo
o
o
o
o
o
o
o
o
o
o
o
oo
o
o o
o
o
o
oo
o o
o
o
o
o
oo
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
o o
oo
oo
o
oo
o
o
oo
o
o
o
oo o
o
o lbph
oooooo
o
o
ooo
o
oooo
o
oo
o
o
o
o
o
o
o
o
o
o
o
ooo
oo
o
o
o
oo
oo
o
o
o
o
oo
o
o
o
ooo
o
o
o
o
o
o
o
o
o
o
o
ooo
o
o
o
o
o
o
o
o
oo
oo
oo
o
oo
o
o
oo
o
o
o
ooo
o
o
oooooo
o
o
ooo
o
oo oo
o
oo
o
o
o
o
o
o
o
o
o
o
o
ooo
o o
o
o
o
oo
oo
o
o
o
o
oo
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
oo
oo
o o
o
oo
o
o
o o
o
o
o
o oo
o
o
oo oooo
o
o
ooo
o
oooo
o
oo
o
o
o
o
o
o
o
o
o
o
o
ooo
oo
o
o
o
oo
oo
o
o
o
o
oo
o
o
o
ooo
o
o
o
o
o
o
o
o
o
o
o
ooo
o
o
o
o
o
o
o
o
oo
oo
oo
o
oo
o
o
oo
o
o
o
ooo
o
o
−1
01
2
oo oooo
o
o
ooo
o
oooo
o
oo
o
o
o
o
o
o
o
o
o
o
o
ooo
oo
o
o
o
oo
oo
o
o
o
o
oo
o
o
o
oo
o
o
o
o
o
o
o
o
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
oo
oo
o o
o
oo
o
o
o o
o
o
o
ooo
o
o
0.0
0.4
0.8
oooo oooooooooooooooooooooooooooooooooo
o
ooooooo
o
oooooooooooooo
o
o
o
oooooo
o
o
oooo
oo
o
ooo
o
oo
o
o
ooo
o
oooooo
oo oo oo ooo ooo ooooo oo o o oo oo ooo o ooo ooo ooo
o
oo oo ooo
o
o ooo oo o ooooo oo
o
o
o
oo ooo o
o
o
o o oo
o o
o
oo o
o
oo
o
o
o oo
o
oo ooo o
o oo ooo oooo oooo oo ooo ooooo oo ooo o ooo oo ooo
o
oo ooooo
o
ooo o oo oo oo o oo o
o
o
o
o ooo o o
o
o
oo oo
oo
o
oo o
o
oo
o
o
o oo
o
o ooo o o
o o oo oo ooo oooo oo o ooo oooo o oooooooo oo oo oo
o
o o ooo oo
o
oo oooo oo ooo oo o
o
o
o
oo o ooo
o
o
oo oo
o o
o
ooo
o
oo
o
o
oo o
o
o oo o oo
oooooo o oooo ooooo ooo oo oo o ooo ooo ooooo ooo
o
ooo oo oo
o
oo oo oooo oo oo o o
o
o
o
o o o oo o
o
o
o oo o
oo
o
o oo
o
o o
o
o
oo o
o
oooo oo
svi
oooooooooooo oo oo o oooo oo ooo oo o ooooo oo oo
o
ooo o ooo
o
oo ooo o ooo ooooo
o
o
o
o o ooo o
o
o
o o o o
oo
o
oo o
o
oo
o
o
o oo
o
o o ooo o
oo oooooooooo oooo ooooo oo ooo ooooooooo o oo
o
o ooo ooo
o
ooo oo oooooo ooo
o
o
o
o oooo o
o
o
o ooo
oo
o
ooo
o
oo
o
o
ooo
o
oooooo
oo oooooooooo oooo ooooo oo ooo oo oooooooo oo
o
o oooo oo
o
ooo oo ooo ooo o oo
o
o
o
o o oooo
o
o
o oo o
oo
o
oo o
o
oo
o
o
o o o
o
o ooo oo
oooo oooooooo
o
o
o
o
o
o
ooo
o
o
o
oooo
o
o
oooooo
o
o
o
o
oo
o
o
o
o
o
o
oooo
o
o
oo
o
oooo
ooo
o
o
o
o
oo
o
o
o
ooo
o
o
o
oo
o
o
o
o
o
o
o
o
o
oo
o
oo
o
o
oo oo oo ooo ooo
o
o
o
o
o
o
o o o
o
o
o
o oo
o
o
o
oo oo
oo
o
o
o
o
o o
o
o
o
o
o
o
ooo o
o
o
oo
o
oo oo
oo
o
o
o
o
o
oo
o
o
o
ooo
o
o
o
oo
o
o
o
o
o
o
o
o
o
oo
o
oo
o
o
o oo ooo oooo oo
o
o
o
o
o
o
o oo
o
o
o
oooo
o
o
ooo o
oo
o
o
o
o
o o
o
o
o
o
o
o
oo
o o
o
o
o o
o
o oo o
oo
o
o
o
o
o
oo
o
o
o
oo
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
oo
o
oo
o
o
o o oo oo ooo ooo
o
o
o
o
o
o
o oo
o
o
o
oooo
o
o
oo oo
oo
o
o
o
o
o o
o
o
o
o
o
o
oo
oo
o
o
o o
o
o oo o
oo
o
o
o
o
o
oo
o
o
o
ooo
o
o
o
oo
o
o
o
o
o
o
o
o
o
oo
o
o o
o
o
oooooo o oooo o
o
o
o
o
o
o
o oo
o
o
o
ooo
o
o
o
oooo
oo
o
o
o
o
oo
o
o
o
o
o
o
oo
o o
o
o
o o
o
oo o o
oo
o
o
o
o
o
oo
o
o
o
oo
o
o
o
o
o o
o
o
o
o
o
o
o
o
o
o o
o
oo
o
o
oooooooooooo
o
o
o
o
o
o
ooo
o
o
o
oooo
o
o
oooooo
o
o
o
o
oo
o
o
o
o
o
o
oooo
o
o
oo
o
oooo
oo
o
o
o
o
o
oo
o
o
o
ooo
o
o
o
oo
o
o
o
o
o
o
o
o
o
o o
o
oo
o
o
lcp
oo oooooooooo
o
o
o
o
o
o
ooo
o
o
o
oooo
o
o
ooooo
o
o
o
o
o
oo
o
o
o
o
o
o
oo
oo
o
o
oo
o
o ooo
oo
o
o
o
o
o
oo
o
o
o
ooo
o
o
o
oo
o
o
o
o
o
o
o
o
o
o o
o
oo
o
o
−1
01
23
oo oooooooooo
o
o
o
o
o
o
ooo
o
o
o
ooo
o
o
o
oooooo
o
o
o
o
oo
o
o
o
o
o
o
oo
oo
o
o
o o
o
o o oo
oo
o
o
o
o
o
oo
o
o
o
oo
o
o
o
o
oo
o
o
o
o
o
o
o
o
o
o o
o
oo
o
o
6.0
7.0
8.0
9.0
oo
o
o oooooooo
ooo
o
o
oooo
o
o
o
oo
ooo
oooooo
o
o
ooo
o
o
o
ooo
o
o
oo
o
o
ooooo
o
oo
o
o
o
o
o
ooo
o
oooo
o
ooooooooo
o
oo
o
ooo
o
oooooo
oo
o
o oo ooo ooo
ooo
o
o
oo o o
o
o
o
o o
oo o
ooo ooo
o
o
o oo
o
o
o
ooo
o
o
oo
o
o
o o ooo
o
o o
o
o
o
o
o
o oo
o
o ooo
o
ooo oooo oo
o
o o
o
o oo
o
oo ooo o
o o
o
ooo oooo oo
oo o
o
o
oo oo
o
o
o
oo
ooo
o ooo oo
o
o
o oo
o
o
o
ooo
o
o
oo
o
o
o oo oo
o
oo
o
o
o
o
o
ooo
o
ooo o
o
oo ooo oo o o
o
oo
o
o oo
o
o ooo o o
o o
o
o oo ooo ooo
o oo
o
o
oo oo
o
o
o
oo
ooo
ooo oo o
o
o
o oo
o
o
o
o oo
o
o
o o
o
o
o oo oo
o
oo
o
o
o
o
o
o o o
o
oo oo
o
oo o ooooo o
o
o o
o
oo o
o
o oo o oo
oo
o
ooo o oooo o
ooo
o
o
oo oo
o
o
o
oo
o oo
o ooooo
o
o
o oo
o
o
o
o oo
o
o
o o
o
o
ooo oo
o
o o
o
o
o
o
o
o o o
o
oo oo
o
o o oooo ooo
o
oo
o
oo o
o
oooo oo
oo
o
ooooooooo
ooo
o
o
oooo
o
o
o
oo
ooo
oooooo
o
o
o oo
o
o
o
ooo
o
o
oo
o
o
ooooo
o
oo
o
o
o
o
o
ooo
o
o oo o
o
oooo oooo o
o
o o
o
ooo
o
oooooo
oo
o
ooooooooo
oo o
o
o
oooo
o
o
o
oo
oo o
ooooo o
o
o
o oo
o
o
o
ooo
o
o
o o
o
o
o ooo o
o
oo
o
o
o
o
o
o oo
o
o oo o
o
o ooo ooo oo
o
o o
o
o oo
o
o o ooo ogleason
oo
o
ooooooooo
ooo
o
o
oooo
o
o
o
oo
oo o
oooooo
o
o
o oo
o
o
o
o oo
o
o
oo
o
o
ooo oo
o
o o
o
o
o
o
o
o oo
o
o ooo
o
o o oo ooo oo
o
o o
o
o o o
o
o ooo oo
0 1 2 3 4 5
oo
o
o oooooooo
o
ooo
o
oooo
o
o
o
oo
o
o
o
ooooooooo
o
o
o
ooooo
o
o
oo
o
o
o
o
oooo
o
o
o
o
o
o
o
o
o
ooo
o
oo
o
o
oo
o
o
oo
o
o
o
o
o
o
o
oo
oo
o
o
o
o
o
oo
o
o oo ooo ooo
o
ooo
o
oo o o
o
o
o
o o
o
o
o
ooo ooo ooo
o
o
o
oo o
oo
o
o
oo
o
o
o
o
oo
oo
o
o
o
o
o
o
o
o
o
oo o
o
oo
o
o
oo
o
o
oo
o
o
o
o
o
o
o
oo
oo
o
o
o
o
o
2.5 3.5 4.5
o o
o
ooo oooo oo
o
o oo
o
oo oo
o
o
o
oo
o
o
o
o ooo oo ooo
o
o
o
ooo
oo
o
o
oo
o
o
o
o
oo
o o
o
o
o
o
o
o
o
o
o
oo o
o
o o
o
o
oo
o
o
oo
o
o
o
o
o
o
o
oo
oo
o
o
o
o
o
o o
o
o oo ooo ooo
o
oo o
o
oo oo
o
o
o
oo
o
o
o
ooo oo oooo
o
o
o
ooo
oo
o
o
o o
o
o
o
o
oo
oo
o
o
o
o
o
o
o
o
o
ooo
o
oo
o
o
oo
o
o
oo
o
o
o
o
o
o
o
oo
oo
o
o
o
o
o
−1 0 1 2
oo
o
ooo o oooo o
o
ooo
o
oo oo
o
o
o
oo
o
o
o
o ooooo ooo
o
o
o
ooooo
o
o
o o
o
o
o
o
oo
o o
o
o
o
o
o
o
o
o
o
oo o
o
oo
o
o
oo
o
o
oo
o
o
o
o
o
o
o
oo
oo
o
o
o
o
o
oo
o
ooooooooo
o
ooo
o
oooo
o
o
o
oo
o
o
o
ooooooooo
o
o
o
ooooo
o
o
oo
o
o
o
o
oooo
o
o
o
o
o
o
o
o
o
ooo
o
o o
o
o
oo
o
o
oo
o
o
o
o
o
o
o
oo
oo
o
o
o
o
o
−1 0 1 2 3
oo
o
ooooooooo
o
o oo
o
oooo
o
o
o
oo
o
o
o
ooooo oooo
o
o
o
oo ooo
o
o
o o
o
o
o
o
oo
oo
o
o
o
o
o
o
o
o
o
oo o
o
o o
o
o
oo
o
o
oo
o
o
o
o
o
o
o
oo
oo
o
o
o
o
o
oo
o
ooooooooo
o
ooo
o
oooo
o
o
o
oo
o
o
o
oooooo ooo
o
o
o
oo o
oo
o
o
oo
o
o
o
o
oooo
o
o
o
o
o
o
o
o
o
oo o
o
oo
o
o
oo
o
o
oo
o
o
o
o
o
o
o
oo
oo
o
o
o
o
o
0 20 60 100
020
6010
0
pgg45
FIGURE 1.1. Scatterplot matrix of the prostate can-cer data. The first row shows the response against eachof the predictors in turn. Two of the predictors, svi
and gleason, are categorical.
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales
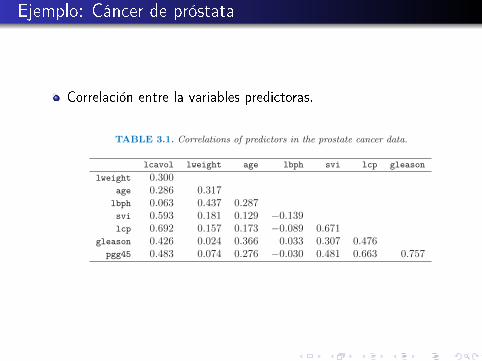
Ejemplo: Cáncer de próstata
Correlación entre la variables predictoras.50 3. Linear Methods for Regression
TABLE 3.1. Correlations of predictors in the prostate cancer data.
lcavol lweight age lbph svi lcp gleason
lweight 0.300age 0.286 0.317lbph 0.063 0.437 0.287svi 0.593 0.181 0.129 −0.139lcp 0.692 0.157 0.173 −0.089 0.671
gleason 0.426 0.024 0.366 0.033 0.307 0.476pgg45 0.483 0.074 0.276 −0.030 0.481 0.663 0.757
TABLE 3.2. Linear model fit to the prostate cancer data. The Z score is thecoefficient divided by its standard error (3.12). Roughly a Z score larger than twoin absolute value is significantly nonzero at the p = 0.05 level.
Term Coefficient Std. Error Z Score
Intercept 2.46 0.09 27.60lcavol 0.68 0.13 5.37lweight 0.26 0.10 2.75
age −0.14 0.10 −1.40lbph 0.21 0.10 2.06svi 0.31 0.12 2.47lcp −0.29 0.15 −1.87
gleason −0.02 0.15 −0.15pgg45 0.27 0.15 1.74
example, that both lcavol and lcp show a strong relationship with theresponse lpsa, and with each other. We need to fit the effects jointly tountangle the relationships between the predictors and the response.
We fit a linear model to the log of prostate-specific antigen, lpsa, afterfirst standardizing the predictors to have unit variance. We randomly splitthe dataset into a training set of size 67 and a test set of size 30. We ap-plied least squares estimation to the training set, producing the estimates,standard errors and Z-scores shown in Table 3.2. The Z-scores are definedin (3.12), and measure the effect of dropping that variable from the model.A Z-score greater than 2 in absolute value is approximately significant atthe 5% level. (For our example, we have nine parameters, and the 0.025 tailquantiles of the t67−9 distribution are ±2.002!) The predictor lcavol showsthe strongest effect, with lweight and svi also strong. Notice that lcp isnot significant, once lcavol is in the model (when used in a model withoutlcavol, lcp is strongly significant). We can also test for the exclusion ofa number of terms at once, using the F -statistic (3.13). For example, weconsider dropping all the non-significant terms in Table 3.2, namely age,

Ejemplo: Cáncer de próstata
Regresión lineal entre lpsa y las variables predictoras.
50 3. Linear Methods for Regression
TABLE 3.1. Correlations of predictors in the prostate cancer data.
lcavol lweight age lbph svi lcp gleason
lweight 0.300age 0.286 0.317lbph 0.063 0.437 0.287svi 0.593 0.181 0.129 −0.139lcp 0.692 0.157 0.173 −0.089 0.671
gleason 0.426 0.024 0.366 0.033 0.307 0.476pgg45 0.483 0.074 0.276 −0.030 0.481 0.663 0.757
TABLE 3.2. Linear model fit to the prostate cancer data. The Z score is thecoefficient divided by its standard error (3.12). Roughly a Z score larger than twoin absolute value is significantly nonzero at the p = 0.05 level.
Term Coefficient Std. Error Z Score
Intercept 2.46 0.09 27.60lcavol 0.68 0.13 5.37lweight 0.26 0.10 2.75
age −0.14 0.10 −1.40lbph 0.21 0.10 2.06svi 0.31 0.12 2.47lcp −0.29 0.15 −1.87
gleason −0.02 0.15 −0.15pgg45 0.27 0.15 1.74
example, that both lcavol and lcp show a strong relationship with theresponse lpsa, and with each other. We need to fit the effects jointly tountangle the relationships between the predictors and the response.
We fit a linear model to the log of prostate-specific antigen, lpsa, afterfirst standardizing the predictors to have unit variance. We randomly splitthe dataset into a training set of size 67 and a test set of size 30. We ap-plied least squares estimation to the training set, producing the estimates,standard errors and Z-scores shown in Table 3.2. The Z-scores are definedin (3.12), and measure the effect of dropping that variable from the model.A Z-score greater than 2 in absolute value is approximately significant atthe 5% level. (For our example, we have nine parameters, and the 0.025 tailquantiles of the t67−9 distribution are ±2.002!) The predictor lcavol showsthe strongest effect, with lweight and svi also strong. Notice that lcp isnot significant, once lcavol is in the model (when used in a model withoutlcavol, lcp is strongly significant). We can also test for the exclusion ofa number of terms at once, using the F -statistic (3.13). For example, weconsider dropping all the non-significant terms in Table 3.2, namely age,
Ejemplo: Cáncer de próstata
Primero se estandarizan variables para tener varianza unitaria.
Se elige muestra de entrenamiento de 67 observaciones y
prueba de 30.
Los Z Score son estadísticos de pruebas de hipótesis de
coe�cientes iguales a cero (valor absoluto mayor que 2
representa una signi�cancia de 5%).
Si se usa como predictor de la lpsa el promedio de la variable
en la muestra de entrenamiento, el error de prueba es 1.057(i.e., error base). El modelo arroja un error de predicción de
0.521.

Ejemplo: Cáncer de próstata
Primero se estandarizan variables para tener varianza unitaria.
Se elige muestra de entrenamiento de 67 observaciones y
prueba de 30.
Los Z Score son estadísticos de pruebas de hipótesis de
coe�cientes iguales a cero (valor absoluto mayor que 2
representa una signi�cancia de 5%).
Si se usa como predictor de la lpsa el promedio de la variable
en la muestra de entrenamiento, el error de prueba es 1.057(i.e., error base). El modelo arroja un error de predicción de
0.521.

Ejemplo: Cáncer de próstata
Primero se estandarizan variables para tener varianza unitaria.
Se elige muestra de entrenamiento de 67 observaciones y
prueba de 30.
Los Z Score son estadísticos de pruebas de hipótesis de
coe�cientes iguales a cero (valor absoluto mayor que 2
representa una signi�cancia de 5%).
Si se usa como predictor de la lpsa el promedio de la variable
en la muestra de entrenamiento, el error de prueba es 1.057(i.e., error base). El modelo arroja un error de predicción de
0.521.

Ejemplo: Cáncer de próstata
Primero se estandarizan variables para tener varianza unitaria.
Se elige muestra de entrenamiento de 67 observaciones y
prueba de 30.
Los Z Score son estadísticos de pruebas de hipótesis de
coe�cientes iguales a cero (valor absoluto mayor que 2
representa una signi�cancia de 5%).
Si se usa como predictor de la lpsa el promedio de la variable
en la muestra de entrenamiento, el error de prueba es 1.057(i.e., error base). El modelo arroja un error de predicción de
0.521.

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Contenido
1 Teoría de la Decisión
2 Regresión lineal y k-NN
3 Ejemplo: Cáncer de próstata
4 Selección de variables
5 Métodos de contracción (shrinkage)
6 Modelo de clasi�cación óptimo
7 Modelos de lineales de clasi�cación
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Selección de variables
Dos problemas típicos:1 Error de prueba: Es posible reducir el error de prueba
disminuyendo el número de variables (reduciendo complejidady varianza) aunque aumente el sesgo: reducir error deestimación por más error de aproximación.
2 Interpretación: Un menor número de variables usualmentepermite una mejor interpretación.
Vamos a discutir diferentes formas de reducir el número de
variables, Todas estas técnicas son ejemplos de técnicas de
selección de modelos.
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Selección de variables
Dos problemas típicos:1 Error de prueba: Es posible reducir el error de prueba
disminuyendo el número de variables (reduciendo complejidady varianza) aunque aumente el sesgo: reducir error deestimación por más error de aproximación.
2 Interpretación: Un menor número de variables usualmentepermite una mejor interpretación.
Vamos a discutir diferentes formas de reducir el número de
variables, Todas estas técnicas son ejemplos de técnicas de
selección de modelos.
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Selección de variables: Mejor subconjunto de variables
Mejor subconjunto de variables.
Se elige el subconjunto de variables que minimiza el error deprueba.Computacionalmente intensivo. Es computacionalmente viablesolo para casos con menos de 40 variables predictoras.

Selección de variables: Mejor subconjunto de variables
Mejor subconjunto de variables.
Se elige el subconjunto de variables que minimiza el error deprueba.Computacionalmente intensivo. Es computacionalmente viablesolo para casos con menos de 40 variables predictoras.

Selección de variables: Mejor subconjunto de variables58 3. Linear Methods for Regression
Subset Size k
Res
idua
l Sum
−of
−S
quar
es
020
4060
8010
0
0 1 2 3 4 5 6 7 8
•
•
•••••••
••••••••••••••••••••••••••
•••••••••••••••••••••••••••••••••••••••••••••••••
••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••
•••••••••••••••••••••••••••••••••••••••••••••
••••••••••••••••••••••••••
•••••••
•
•
•
•• • • • • • •
FIGURE 3.5. All possible subset models for the prostate cancer example. Ateach subset size is shown the residual sum-of-squares for each model of that size.
cross-validation to estimate prediction error and select k; the AIC criterionis a popular alternative. We defer more detailed discussion of these andother approaches to Chapter 7.
3.3.2 Forward- and Backward-Stepwise Selection
Rather than search through all possible subsets (which becomes infeasiblefor pmuch larger than 40), we can seek a good path through them. Forward-stepwise selection starts with the intercept, and then sequentially adds intothe model the predictor that most improves the fit. With many candidatepredictors, this might seem like a lot of computation; however, clever up-dating algorithms can exploit the QR decomposition for the current fit torapidly establish the next candidate (Exercise 3.9). Like best-subset re-gression, forward stepwise produces a sequence of models indexed by k, thesubset size, which must be determined.
Forward-stepwise selection is a greedy algorithm, producing a nested se-quence of models. In this sense it might seem sub-optimal compared tobest-subset selection. However, there are several reasons why it might bepreferred:

Selección de variables: Froward Backward selection
Forward: Comenzar con un modelo que solo tiene una
constante y añadir secuencialmente la variable que mas ayude
a reducir el error de predicción.
Es computacionalmente menos demandante.
En la medida que es un busqueda restringida (a la forma
especi�ca como se camina por la variables) tiene mayor sesgo
pero potencialmente menos varianza que el mejor subconjunto.
Backward: Comienza con el modelo que tiene todas la
variables y va eliminando la variable que menos contribuye al
poder predictivo (una forma de implementarlo es eliminando la
variable con el menor Z-score).

Selección de variables: Froward Backward selection
Forward: Comenzar con un modelo que solo tiene una
constante y añadir secuencialmente la variable que mas ayude
a reducir el error de predicción.
Es computacionalmente menos demandante.
En la medida que es un busqueda restringida (a la forma
especi�ca como se camina por la variables) tiene mayor sesgo
pero potencialmente menos varianza que el mejor subconjunto.
Backward: Comienza con el modelo que tiene todas la
variables y va eliminando la variable que menos contribuye al
poder predictivo (una forma de implementarlo es eliminando la
variable con el menor Z-score).

Selección de variables: Froward Backward selection
Forward: Comenzar con un modelo que solo tiene una
constante y añadir secuencialmente la variable que mas ayude
a reducir el error de predicción.
Es computacionalmente menos demandante.
En la medida que es un busqueda restringida (a la forma
especi�ca como se camina por la variables) tiene mayor sesgo
pero potencialmente menos varianza que el mejor subconjunto.
Backward: Comienza con el modelo que tiene todas la
variables y va eliminando la variable que menos contribuye al
poder predictivo (una forma de implementarlo es eliminando la
variable con el menor Z-score).

Selección de variables: Froward Backward selection
Forward: Comenzar con un modelo que solo tiene una
constante y añadir secuencialmente la variable que mas ayude
a reducir el error de predicción.
Es computacionalmente menos demandante.
En la medida que es un busqueda restringida (a la forma
especi�ca como se camina por la variables) tiene mayor sesgo
pero potencialmente menos varianza que el mejor subconjunto.
Backward: Comienza con el modelo que tiene todas la
variables y va eliminando la variable que menos contribuye al
poder predictivo (una forma de implementarlo es eliminando la
variable con el menor Z-score).

Selección de variables: Froward stagewise
Comienza con el intercepto y va añadiendo variables con según
la variable que más correlación tenga con el residuo del modelo
anterior.
Es una busqueda más restringida que forward stepwise.
A diferencia de forward stepwise, genera un conjunto anidado
de variables (i.e. solo aumentan y no cambian en cada
iteración).
Es un método competitivo cuando existen muchas variables.

Selección de variables: Froward stagewise
Comienza con el intercepto y va añadiendo variables con según
la variable que más correlación tenga con el residuo del modelo
anterior.
Es una busqueda más restringida que forward stepwise.
A diferencia de forward stepwise, genera un conjunto anidado
de variables (i.e. solo aumentan y no cambian en cada
iteración).
Es un método competitivo cuando existen muchas variables.

Selección de variables: Froward stagewise
Comienza con el intercepto y va añadiendo variables con según
la variable que más correlación tenga con el residuo del modelo
anterior.
Es una busqueda más restringida que forward stepwise.
A diferencia de forward stepwise, genera un conjunto anidado
de variables (i.e. solo aumentan y no cambian en cada
iteración).
Es un método competitivo cuando existen muchas variables.

Selección de variables: Froward stagewise
Comienza con el intercepto y va añadiendo variables con según
la variable que más correlación tenga con el residuo del modelo
anterior.
Es una busqueda más restringida que forward stepwise.
A diferencia de forward stepwise, genera un conjunto anidado
de variables (i.e. solo aumentan y no cambian en cada
iteración).
Es un método competitivo cuando existen muchas variables.
Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Contenido
1 Teoría de la Decisión
2 Regresión lineal y k-NN
3 Ejemplo: Cáncer de próstata
4 Selección de variables
5 Métodos de contracción (shrinkage)
6 Modelo de clasi�cación óptimo
7 Modelos de lineales de clasi�cación
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Métodos de contracción
El mejor subconjunto puede tener el menor error de prueba.
Pero es un método discreto. Las variables o se incluyen o se
descartan.
El método puede tener una varianza alta.
Los métodos de contracción son más continuos y usualmente
tiene menor varianza.
Vamos a considerar la regresin de Ridge y Lasso.
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Métodos de contracción
El mejor subconjunto puede tener el menor error de prueba.
Pero es un método discreto. Las variables o se incluyen o se
descartan.
El método puede tener una varianza alta.
Los métodos de contracción son más continuos y usualmente
tiene menor varianza.
Vamos a considerar la regresin de Ridge y Lasso.
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Métodos de contracción
El mejor subconjunto puede tener el menor error de prueba.
Pero es un método discreto. Las variables o se incluyen o se
descartan.
El método puede tener una varianza alta.
Los métodos de contracción son más continuos y usualmente
tiene menor varianza.
Vamos a considerar la regresin de Ridge y Lasso.
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Métodos de contracción
El mejor subconjunto puede tener el menor error de prueba.
Pero es un método discreto. Las variables o se incluyen o se
descartan.
El método puede tener una varianza alta.
Los métodos de contracción son más continuos y usualmente
tiene menor varianza.
Vamos a considerar la regresin de Ridge y Lasso.
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Métodos de contracción
El mejor subconjunto puede tener el menor error de prueba.
Pero es un método discreto. Las variables o se incluyen o se
descartan.
El método puede tener una varianza alta.
Los métodos de contracción son más continuos y usualmente
tiene menor varianza.
Vamos a considerar la regresión de Ridge y Lasso.

Métodos de contracción
El mejor subconjunto puede tener el menor error de prueba.
Pero es un método discreto. Las variables o se incluyen o se
descartan.
El método puede tener una varianza alta.
Los métodos de contracción son más continuos y usualmente
tiene menor varianza.
Vamos a considerar la regresión de Ridge y Lasso.

Métodos de contracción
El mejor subconjunto puede tener el menor error de prueba.
Pero es un método discreto. Las variables o se incluyen o se
descartan.
El método puede tener una varianza alta.
Los métodos de contracción son más continuos y usualmente
tiene menor varianza.
Vamos a considerar la regresión de Ridge y Lasso.

Métodos de contracción
El mejor subconjunto puede tener el menor error de prueba.
Pero es un método discreto. Las variables o se incluyen o se
descartan.
El método puede tener una varianza alta.
Los métodos de contracción son más continuos y usualmente
tiene menor varianza.
Vamos a considerar la regresión de Ridge y Lasso.

Métodos de contracción: Ridge
Resuelve el problema:
min{N
∑i=1
(yi −β0−xTi β )2 + λ‖(β )‖2} (3)

Métodos de contracción: Ridge
3.4 Shrinkage Methods 63
TABLE 3.3. Estimated coefficients and test error results, for different subsetand shrinkage methods applied to the prostate data. The blank entries correspondto variables omitted.
Term LS Best Subset Ridge Lasso PCR PLS
Intercept 2.465 2.477 2.452 2.468 2.497 2.452lcavol 0.680 0.740 0.420 0.533 0.543 0.419lweight 0.263 0.316 0.238 0.169 0.289 0.344
age −0.141 −0.046 −0.152 −0.026lbph 0.210 0.162 0.002 0.214 0.220svi 0.305 0.227 0.094 0.315 0.243lcp −0.288 0.000 −0.051 0.079
gleason −0.021 0.040 0.232 0.011pgg45 0.267 0.133 −0.056 0.084
Test Error 0.521 0.492 0.492 0.479 0.449 0.528Std Error 0.179 0.143 0.165 0.164 0.105 0.152
squares,
βridge = argminβ
{ N∑
i=1
(yi − β0 −
p∑
j=1
xijβj
)2+ λ
p∑
j=1
β2j
}. (3.41)
Here λ ≥ 0 is a complexity parameter that controls the amount of shrink-age: the larger the value of λ, the greater the amount of shrinkage. Thecoefficients are shrunk toward zero (and each other). The idea of penaliz-ing by the sum-of-squares of the parameters is also used in neural networks,where it is known as weight decay (Chapter 11).
An equivalent way to write the ridge problem is
βridge = argminβ
N∑
i=1
(yi − β0 −
p∑
j=1
xijβj
)2
,
subject to
p∑
j=1
β2j ≤ t,
(3.42)
which makes explicit the size constraint on the parameters. There is a one-to-one correspondence between the parameters λ in (3.41) and t in (3.42).When there are many correlated variables in a linear regression model,their coefficients can become poorly determined and exhibit high variance.A wildly large positive coefficient on one variable can be canceled by asimilarly large negative coefficient on its correlated cousin. By imposing asize constraint on the coefficients, as in (3.42), this problem is alleviated.
The ridge solutions are not equivariant under scaling of the inputs, andso one normally standardizes the inputs before solving (3.41). In addition,
Métodos de contracción: Ridge3.4 Shrinkage Methods 65
Coe
ffici
ents
0 2 4 6 8
−0.
20.
00.
20.
40.
6
•
••••
••
••
••
••
••
••
••
••
•••
•
lcavol
••••••••••••••••••••••••
•
lweight
••••••••••••••••••••••••
•
age
•••••••••••••••••••••••••
lbph
••••••••••••••••••••••••
•
svi
•
•••
••
••
••
••
••••••••••••
•
lcp
••••••••••••••••••••••••
•gleason
•
•••••••••••••••••••••••
•
pgg45
df(λ)
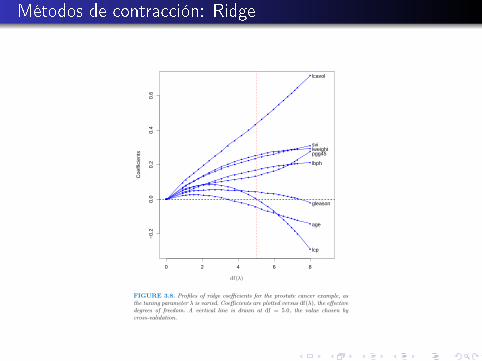
FIGURE 3.8. Profiles of ridge coefficients for the prostate cancer example, asthe tuning parameter λ is varied. Coefficients are plotted versus df(λ), the effectivedegrees of freedom. A vertical line is drawn at df = 5.0, the value chosen bycross-validation.

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Contenido
1 Teoría de la Decisión
2 Regresión lineal y k-NN
3 Ejemplo: Cáncer de próstata
4 Selección de variables
5 Métodos de contracción (shrinkage)
6 Modelo de clasi�cación óptimo
7 Modelos de lineales de clasi�cación
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Clasi�cador de Bayes
Supongamos que Y solamente toma un conjunto �nito de
valores. En este caso vamos a usar G como la variable
aleatoria. La función de aprendizaje la denotamos por g .
Para determinar el clasi�cador óptimo necesitamos una medida
de pérdida.
L : Ξ×Υ×Υ→{0,1}. Dado una observación (x ,y), sif (x) 6= y entonces L(x ,y , f (x)) = 1 y L(x ,y , f (x)) = 0 en caso
contrario.
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Clasi�cador de Bayes
Supongamos que Y solamente toma un conjunto �nito de
valores. En este caso vamos a usar G como la variable
aleatoria. La función de aprendizaje la denotamos por g .
Para determinar el clasi�cador óptimo necesitamos una medida
de pérdida.
L : Ξ×Υ×Υ→{0,1}. Dado una observación (x ,y), sif (x) 6= y entonces L(x ,y , f (x)) = 1 y L(x ,y , f (x)) = 0 en caso
contrario.
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Clasi�cador de Bayes
Supongamos que Y solamente toma un conjunto �nito de
valores. En este caso vamos a usar G como la variable
aleatoria. La función de aprendizaje la denotamos por g .
Para determinar el clasi�cador óptimo necesitamos una medida
de pérdida.
L : Ξ×Υ×Υ→{0,1}. Dado una observación (x ,y), sif (x) 6= y entonces L(x ,y , f (x)) = 1 y L(x ,y , f (x)) = 0 en caso
contrario.
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Clasi�cador de Bayes
En este caso queremos minimizar EPE (g)
EPE (g) = E [L(G ,g(X ))]
Donde el valor esperado se toma con respecto a la distribución
conjunta Pr(G ,X ).
Supongamos que G solo puede tomar los valores g1, ...,gKentonces el problema anterior se puede escribir como:
EPE = EX
K
∑k=1
L [gk ,g(X )]Pr (gk |X )
Un argumento similar al utilizado anteriormentge para el
modelo de regresión nos enseña que la solución a este
problema es de la forma:
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Clasi�cador de Bayes
En este caso queremos minimizar EPE (g)
EPE (g) = E [L(G ,g(X ))]
Donde el valor esperado se toma con respecto a la distribución
conjunta Pr(G ,X ).
Supongamos que G solo puede tomar los valores g1, ...,gKentonces el problema anterior se puede escribir como:
EPE = EX
K
∑k=1
L [gk ,g(X )]Pr (gk |X )
Un argumento similar al utilizado anteriormentge para el
modelo de regresión nos enseña que la solución a este
problema es de la forma:
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Clasi�cador de Bayes
En este caso queremos minimizar EPE (g)
EPE (g) = E [L(G ,g(X ))]
Donde el valor esperado se toma con respecto a la distribución
conjunta Pr(G ,X ).
Supongamos que G solo puede tomar los valores g1, ...,gKentonces el problema anterior se puede escribir como:
EPE = EX
K
∑k=1
L [gk ,g(X )]Pr (gk |X )
Un argumento similar al utilizado anteriormentge para el
modelo de regresión nos enseña que la solución a este
problema es de la forma:
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Clasi�cador de Bayes
En este caso queremos minimizar EPE (g)
EPE (g) = E [L(G ,g(X ))]
Donde el valor esperado se toma con respecto a la distribución
conjunta Pr(G ,X ).
Supongamos que G solo puede tomar los valores g1, ...,gKentonces el problema anterior se puede escribir como:
EPE = EX
K
∑k=1
L [gk ,g(X )]Pr (gk |X )
Un argumento similar al utilizado anteriormentge para el
modelo de regresión nos enseña que la solución a este
problema es de la forma:
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Clasi�cador de Bayes
g(x) = argming∈G
K
∑k=1
L [gk , g ]Pr (gk |X = x)
Con la función de pérdida 0-1 estándar esto se puede escribir
como:
g(x) = argming∈G
[1−Pr (g |X = x)]
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Clasi�cador de Bayes
g(x) = argming∈G
K
∑k=1
L [gk , g ]Pr (gk |X = x)
Con la función de pérdida 0-1 estándar esto se puede escribir
como:
g(x) = argming∈G
[1−Pr (g |X = x)]
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Clasi�cador de Bayes
Un forma más sencilla de expresarlo es
g(x) = gk if Pr(gk |X = x) = maxg∈G
Pr(g |X = x)
Es decir, g(x) es la clase que maximiza la probabilidad
condicional a x de estar en esa clase.
Este clasi�cados se conoce como el clasi�cados de Bayes.
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Clasi�cador de Bayes
Un forma más sencilla de expresarlo es
g(x) = gk if Pr(gk |X = x) = maxg∈G
Pr(g |X = x)
Es decir, g(x) es la clase que maximiza la probabilidad
condicional a x de estar en esa clase.
Este clasi�cados se conoce como el clasi�cados de Bayes.
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Clasi�cador de Bayes
Un forma más sencilla de expresarlo es
g(x) = gk if Pr(gk |X = x) = maxg∈G
Pr(g |X = x)
Es decir, g(x) es la clase que maximiza la probabilidad
condicional a x de estar en esa clase.
Este clasi�cados se conoce como el clasi�cados de Bayes.
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Contenido
1 Teoría de la Decisión
2 Regresión lineal y k-NN
3 Ejemplo: Cáncer de próstata
4 Selección de variables
5 Métodos de contracción (shrinkage)
6 Modelo de clasi�cación óptimo
7 Modelos de lineales de clasi�cación
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Regresión lineal
Se ajusta una regresión lineal por cada clase
fk(x) = βk0 + βTk x
Un punto x se clasi�ca k si fk(x)≥fl(x) ∀l .De esta forma la frontera de decisión entre la clase k y l seríacuando fk(x) = fl(x) que corresponde a un plano.
Esto pasaría para cualquier 2 clases.
El espacio se divide en regiones separadas por fronteras de
decisión hiperplanas (no necesariamente pasan por el origen).
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Regresión lineal
Se ajusta una regresión lineal por cada clase
fk(x) = βk0 + βTk x
Un punto x se clasi�ca k si fk(x)≥fl(x) ∀l .De esta forma la frontera de decisión entre la clase k y l seríacuando fk(x) = fl(x) que corresponde a un plano.
Esto pasaría para cualquier 2 clases.
El espacio se divide en regiones separadas por fronteras de
decisión hiperplanas (no necesariamente pasan por el origen).
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Regresión lineal
Se ajusta una regresión lineal por cada clase
fk(x) = βk0 + βTk x
Un punto x se clasi�ca k si fk(x)≥fl(x) ∀l .De esta forma la frontera de decisión entre la clase k y l seríacuando fk(x) = fl(x) que corresponde a un plano.
Esto pasaría para cualquier 2 clases.
El espacio se divide en regiones separadas por fronteras de
decisión hiperplanas (no necesariamente pasan por el origen).
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Regresión lineal
Se ajusta una regresión lineal por cada clase
fk(x) = βk0 + βTk x
Un punto x se clasi�ca k si fk(x)≥fl(x) ∀l .De esta forma la frontera de decisión entre la clase k y l seríacuando fk(x) = fl(x) que corresponde a un plano.
Esto pasaría para cualquier 2 clases.
El espacio se divide en regiones separadas por fronteras de
decisión hiperplanas (no necesariamente pasan por el origen).
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Regresión lineal
Se ajusta una regresión lineal por cada clase
fk(x) = βk0 + βTk x
Un punto x se clasi�ca k si fk(x)≥fl(x) ∀l .De esta forma la frontera de decisión entre la clase k y l seríacuando fk(x) = fl(x) que corresponde a un plano.
Esto pasaría para cualquier 2 clases.
El espacio se divide en regiones separadas por fronteras de
decisión hiperplanas (no necesariamente pasan por el origen).
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Regresión logística
Este método de clasi�cación es lineal porque las fronteras de
decisión son lineales. Luego transformaciones monótonas de
fk(x) también van a de�nir modelos de clasi�cación lineales.
Por ejemplo: el modelo logístico.
Pr(G = 1|X = x) =eβ1,0+βT
1 x
1+ ∑K−1l=0
eβl ,0+βTl x
Pr(G = k |X = x) =eβk,0+βT
k x
1+ ∑K−1l=0
eβl ,0+βTl x
Pr(G = K |X = x) =1
1+1+ ∑K−1l=0
eβl ,0+βTl x
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Regresión logística
Este método de clasi�cación es lineal porque las fronteras de
decisión son lineales. Luego transformaciones monótonas de
fk(x) también van a de�nir modelos de clasi�cación lineales.
Por ejemplo: el modelo logístico.
Pr(G = 1|X = x) =eβ1,0+βT
1 x
1+ ∑K−1l=0
eβl ,0+βTl x
Pr(G = k |X = x) =eβk,0+βT
k x
1+ ∑K−1l=0
eβl ,0+βTl x
Pr(G = K |X = x) =1
1+1+ ∑K−1l=0
eβl ,0+βTl x
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales

Teoría de la DecisiónRegresión lineal y k-NN
Ejemplo: Cáncer de próstataSelección de variables
Métodos de contracción (shrinkage)Modelo de clasi�cación óptimo
Modelos de lineales de clasi�cación
Regresión logística
Las fronteras de decisión se pueden calcular cómo:
log(Pr(G = 1|X = x)
Pr(G = K |X = x) = β1,0 + β
T1 x
log(Pr(G = k−1|X = x)
Pr(G = K |X = x) = βk−1,0 + β
Tk−1x
Universidad de los Andes y Quantil Métodos de Regresión y Clasi�cación Lineales










![FANUC GLOBAL - ROBOSHOT @ + series...ÿ d P ¨Ú A T H ³ 1 ¨¥ cb 6 ô Æ å ] î Hq V ? s Yb W % f h](https://static.fdocuments.es/doc/165x107/612542c9798b8f7ecf13f89f/fanuc-global-roboshot-series-d-p-a-t-h-1-cb-6-.jpg)







