
Escuela Técnica Superior de Ingeniería de Sistemas...
181
25/01/2017 Escuela Técnica Superior de Ingeniería de Sistemas Informáticos Máster en Software de Sistemas Distribuidos y Empotrados Trabajo de fin de master: Estudio y aplicación de tecnologías de Fast Data y Fog Computing a las Smart Cities D. Álvarez Argüero, Lucas TUTORES ACADEMICOS: D. Arévalo Viñuales, Sergio Dña. Muñoz Fernández, Isabel TUTOR PROFESIONAL: D. López Peña, Miguel Ángel FECHA: 01/2017
Transcript of Escuela Técnica Superior de Ingeniería de Sistemas...

25/01/2017
Escuela Técnica Superior de Ingeniería de
Sistemas Informáticos
Máster en Software de Sistemas Distribuidos y
Empotrados
Trabajo de fin de master:
Estudio y aplicación de tecnologías de Fast Data y Fog
Computing a las Smart Cities
D. Álvarez Argüero, Lucas
TUTORES ACADEMICOS:
D. Arévalo Viñuales, Sergio
Dña. Muñoz Fernández, Isabel
TUTOR PROFESIONAL:
D. López Peña, Miguel Ángel
FECHA: 01/2017

2
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 2 de 181

3
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 3 de 181
Índice
1 | Introducción ................................................................. 10 1.1 Motivaciones 10 1.1.1 Smart Cities 10 1.1.2 Internet Of Things 12 1.1.3 Big Data 15 1.1.4 Fast Data 17 1.1.5 Fog computing 18 1.1.6 Conclusiones 21 1.2 Objetivos 23
2 | Estudios previos ........................................................... 26 2.1 Estudio del problema 26 2.1.1 Parámetros a monitorizar 26 2.2 Estado del arte 28 2.2.1 Fog computing 28 2.2.1.1 Cisco 28 2.2.1.2 Kafka 29 2.2.1.3 Edgent 30 2.2.2 Sistemas publicador subscripor 31 2.2.2.1 MQTT 32 2.2.2.2 Watson IoT Platform 35 2.2.2.3 Kafka 36 2.2.3 Fast Data 37 2.2.3.1 Spark streams 38 2.2.3.2 Apache Storm 40 2.2.3.3 Akka Streams 42 2.2.3.4 Apache Bean 43 2.2.3.5 Kafka streams 46 2.2.3.6 IBM Streams 46 2.2.4 Almacenamiento 47 2.2.4.1 Base de datos relacional. 48 2.2.4.2 Base de datos no relacional. 48 2.2.4.3 SQL sobre bases de datos no relaciones. 49 2.3 Arquitectura del sistema 50 2.3.1 Posibles Arquitecturas conceptuales. 50 2.3.1.1 Arquitectura conceptual. 51 2.3.1.2 Posibles arquitecturas reales 52 2.3.1.3 Posibles arquitecturas fisicas. 54

4
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 4 de 181
2.3.2 Arquitectura final. 60 2.4 Especificación de requisitos de software 65 2.4.1 Introducción 65 2.4.1.1 Propósito 65 2.4.1.2 Ámbito 65 2.4.1.3 Referencias 65 2.4.2 Descripción General 65 2.4.2.1 Perspectivas del producto 65 2.4.2.1.1 Interfaces del sistema 66 2.4.2.1.2 Interfaces de usuario 68 2.4.2.1.3 Interfaces hardware 68 2.4.2.1.4 Interfaces Software 69 2.4.2.1.5 Interfaces de cominicacion 70 2.4.2.1.6 Restricciones de memoria 71 2.4.2.1.7 Operaciones 72 2.4.2.1.8 Requisitos de despliegue 72 2.4.2.2 Funciones del producto 72 2.4.2.3 Características del usuario 72 2.4.2.4 Restricciones 72 2.4.2.5 Suposiciones y dependencias. 73 2.4.2.6 Requisitos pospuestos 73
3 | Planificacion y presupuesto .......................................... 74
4 | Desarrollo de la aplicación ............................................ 77 4.1 Tecnologias y hardware utilizado 77 4.1.1 Capa IoT 77 4.1.1.1 Creación de un prototipo real 77 4.1.1.2 Obtención de datos de fuentes existentes. 80 4.1.1.3 Generación de datos simulados. 80 4.1.2 Capa publicador/subscriptor. 80 4.1.3 Capa Fast Data 82 4.1.3.1 Sistema de procesamiento 82 4.1.3.2 Sistema de almacenamiento 86 4.1.4 Capa presentación 88 4.1.4.1 Servidor Web 88 4.1.4.2 Pagina Web 90 4.1.4.3 Servidor Rest 90 4.2 Especificaciones del sistema 91 4.2.1 Limites del sistema 91 4.2.2 Casos de uso 91

5
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 5 de 181
4.3 Descripción de la aplicación 106 4.3.1 Dagramas de clase 106 4.3.1.1 Simulador. 107 4.3.1.2 Procesador principal. 113 4.3.1.3 Interfaz de datos 128 4.3.1.4 Servidor web 145 4.3.1 Diagramas de actividad y estado. 148 4.3.1.1 Simulador. 148 4.3.1.2 Procesador principal. 149 4.3.1.3 Interfaz de datos. 149 4.3.1.4 Servidor web 162 4.4 Pruebas 162 4.5 Despliegue 165 4.5.1 Despliegue de desarrollo 166 4.5.2 Despliege empresarial 167
5 | Manual ...................................................................... 170 5.1 Accediendo al interfaz por primera vezx 170 5.2 Añadiendo una vista 172 5.3 Visionado de la graficas 172 5.4 Eliminando una lista 173 5.5 Guardar una configuracion de vistas 174 5.6 Cargar una configuracion de vistas 174
6 | Conclusiones .............................................................. 176
7 | Lecciones aprendidas ................................................. 177
8 | Glosario ..................................................................... 179
9 | Referencias ................................................................ 180

6
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 6 de 181
Índice ilustraciones Ilustración 1 Imagen promocional Smart Cities .................................................................... 11 Ilustración 2 Imagen promocional IoT .................................................................................... 13 Ilustración 3 Análisis en tiempo real del tráfico por google Maps ..................................... 14 Ilustración 4 Imagen promocional Big Data .......................................................................... 15 Ilustración 5 Las 4 uves de Big Data ..................................................................................... 16 Ilustración 6 Ejemplo de despliegue Fast data aplicado a la empresa ............................. 18 Ilustración 7 Imagen promocional Fog Computing .............................................................. 19 Ilustración 8 Ejemplo arquitectura Fog computing ............................................................... 20 Ilustración 9 Ejemplo despliegue Fog computing ................................................................ 21 Ilustración 10 Imagen promocional Smart Cities .................................................................. 22 Ilustración 11 Las 4 capas base del proyecto ...................................................................... 23 Ilustración 12 Despliegue fog computing de ejemplo de Cisco ......................................... 28 Ilustración 13 Arquitectura Fog computing de Cisco ........................................................... 29 Ilustración 14 Logo Kafka ........................................................................................................ 29 Ilustración 15 Logo Edgent ...................................................................................................... 30 Ilustración 16 Vista de la interfaz web de administración de Edgent................................ 31 Ilustración 17 Despliegue de ejemplo de Edgent ................................................................. 32 Ilustración 18 Logo MQTT ....................................................................................................... 32 Ilustración 19 Despliegue de ejemplo MQTT ........................................................................ 33 Ilustración 20 Despliegue distribuido con niveles de jerarquía de MQTT ........................ 33 Ilustración 21 Despliegue distribuido con balanceador de carga de MQTT .................... 34 Ilustración 22 Logo IBM Watson ............................................................................................. 35 Ilustración 23 Despliegue de ejemplo de Watson ................................................................ 35 Ilustración 24 Arquitectura Kafka ............................................................................................ 36 Ilustración 25 Despliegue completo Fast Data ..................................................................... 37 Ilustración 26 Despliegue completo Big Data ....................................................................... 38 Ilustración 27 Logo Spark Streaming ..................................................................................... 38 Ilustración 28 Ejemplo de DAG (Directed Acyclic Graph)................................................... 39 Ilustración 29 Paso de datos de tipo Stream a micro Batches .......................................... 39 Ilustración 30 Orden de procesamiento de los micro batches ........................................... 40 Ilustración 31 Logo Apache Storm ......................................................................................... 41 Ilustración 32 Arquitectura de trabajo de apache Storm. .................................................... 41 Ilustración 33 Logo Akka .......................................................................................................... 42 Ilustración 34 Jerarquía de actores de Akka ........................................................................ 43 Ilustración 35 Logo apache Beam .......................................................................................... 44 Ilustración 36 Unificación de lenguajes en Beam ................................................................ 45 Ilustración 37 Arquitectura de Apache Kafka........................................................................ 46 Ilustración 38 Logo IBM Streams ........................................................................................... 47 Ilustración 39 Primer modelo de arquitectura conceptual .................................................. 51 Ilustración 40 Segundo modelo de arquitectura conceptual .............................................. 52 Ilustración 41 Tercer modelo de arquitectura conceptual. .................................................. 52 Ilustración 42 primer modelo de posible despliegue del sistema ...................................... 53 Ilustración 43 Segundo modelo de posible despliegue del sistema ................................. 54 Ilustración 44 Despliegue de dispositivos con tecnología red móvil ................................. 55

7
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 7 de 181
Ilustración 45 Despliegue físico de dispositivos con una red del tipo malla .................... 56 Ilustración 46 Despliegue físico de motas con tecnología centralizada ........................... 58 Ilustración 47 Despliegue fisico de motas centralizado con mas de una central. ........... 59 Ilustración 48 Despliegue final de las tecnologías del sistema .......................................... 61 Ilustración 49 Despliegue final de las tecnologías del sistema detallado ........................ 62 Ilustración 50 Despliegue físico final. ..................................................................................... 64 Ilustración 51 Diagrama de componentes del sistema ....................................................... 66 Ilustración 52 diseño de la interfaz gráfica a implementar ................................................. 68 Ilustración 53 Tabla de planificación de trabajo. .................................................................. 75 Ilustración 54 Completado/costes .......................................................................................... 76 Ilustración 55 Raspberry Pi 3 .................................................................................................. 77 Ilustración 56 Sonar .................................................................................................................. 78 Ilustración 57 GPS Ublock ....................................................................................................... 79 Ilustración 58 Generación de áreas con el movimiento del GPS ...................................... 79 Ilustración 59 Arquitectura de kafka implementada al sistema .......................................... 81 Ilustración 60 Arquitectura de elementos de Streams ........................................................ 84 Ilustración 61 Arquitectura interna IBM.................................................................................. 85 Ilustración 62 Arquitectura de nodos de Streams ................................................................ 86 Ilustración 63 Arquitectura de HDFS...................................................................................... 87 Ilustración 64 Arquitectura HBASE ........................................................................................ 88 Ilustración 65 funcionamiento del servidor Web .................................................................. 89 Ilustración 66 Diagrama general de actores ......................................................................... 91 Ilustración 67 Diagrama de casos de uso del sistema ........................................................ 92 Ilustración 68 Diagrama de flujo del simulador .................................................................. 112 Ilustración 69 Diagrama de flujo del procesador principal ................................................ 127 Ilustración 70 Diagrama de clases de la interfaz de datos ............................................... 144 Ilustración 71 Diagrama de clases del servidor Web ........................................................ 147 Ilustración 72 Diagrama de estados del componente TruckRSim .................................. 148 Ilustración 73 Diagrama de estados del componente Container_................................... 149 Ilustración 74 Diagrama de secuencia: Integral de calidad del servicio ......................... 150 Ilustración 75 Diagrama de secuencia: Integral de calidad del servicio (versión
simulación) ........................................................................................................................ 151 Ilustración 76 Diagrama de secuencia: Última medición .................................................. 152 Ilustración 77 Diagrama de secuencia: Mediciones de lo n últimos días ....................... 153 Ilustración 78 Diagrama de secuencia: Mediciones de lo n últimos días (versión
simulación) ........................................................................................................................ 154 Ilustración 79 Diagrama de secuencia: Máximos, mínimos y medias de lo n últimos
días. ................................................................................................................................... 155 Ilustración 80 Diagrama de secuencia: más, min y medias de los n últimos días
(versión simulación). ....................................................................................................... 156 Ilustración 81 Diagrama de secuencia: Porcentaje del último día. ................................. 157 Ilustración 82 Diagrama de secuencia: Porcentajes de los N últimos días ................... 158 Ilustración 83 Diagrama de secuencia: Porcentajes de los N últimos días (versión
simuladora) ....................................................................................................................... 159 Ilustración 84 Diagrama de secuencia: Predicción continua ............................................ 160 Ilustración 85 Diagrama de secuencia: Predicción de máximos. .................................... 161 Ilustración 86 Diagrama de secuencia: Solicitud Web ...................................................... 162

8
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 8 de 181
Ilustración 87 Arquitectura Kappa ........................................................................................ 165 Ilustración 88 Despliegue de desarrollo .............................................................................. 166 Ilustración 89 Despliegue Empresarial ................................................................................ 169 Ilustración 90 Panel de inicio ................................................................................................. 171 Ilustración 91 Añadir nuevo panel ........................................................................................ 172 Ilustración 92 Grafica de muestra ......................................................................................... 173 Ilustración 93 Botón de eliminar. .......................................................................................... 173 Ilustración 94 Guardar una vista ........................................................................................... 174 Ilustración 95 Cambiar una vista .......................................................................................... 175

9
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 9 de 181
Índice tablas Tabla 1 Presupuesto................................................................................................................. 75 Tabla 2 Requisitos de Hardware ............................................................................................ 82 Tabla 3 Requisitos del SO ....................................................................................................... 83 Tabla 4 Caso de uso: Recargar Web ..................................................................................... 93 Tabla 5 Caso de uso: Leer predicciones ............................................................................... 94 Tabla 6 Caso de uso: Leer predicciones máximas .............................................................. 95 Tabla 7 Caso de uso: Leer mediciones ................................................................................. 95 Tabla 8 Caso de uso: Leer última predicción ....................................................................... 96 Tabla 9 Caso de uso: Leer máximos, mínimos y medias ................................................... 97 Tabla 10 Caso de uso: Leer última proporción diaria .......................................................... 97 Tabla 11 Caso de uso: Leer proporciones diarias ............................................................... 98 Tabla 12 Caso de uso: Leer datos ......................................................................................... 99 Tabla 13 Caso de uso: Generar datos de simulación ......................................................... 99 Tabla 14 Caso de uso: Leer valor ........................................................................................ 100 Tabla 15 Caso de uso: Recibir Datos .................................................................................. 101 Tabla 16 Caso de uso: Diezmar ........................................................................................... 101 Tabla 17 Caso de uso: Predecir máximo ............................................................................ 102 Tabla 18 Caso de uso: Calcular máximo, mínimo y media .............................................. 102 Tabla 19 Caso de uso: Predecir en modo continuo .......................................................... 103 Tabla 20 Caso de uso: Integrar ............................................................................................ 104 Tabla 21 Caso de uso: Enviar Datos ................................................................................... 104 Tabla 22 Caso de uso: Introducir datos ............................................................................... 105

10
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 10 de 181
1 | Introducción
1.1 Motivaciones
Como cualquier proyecto, se debe tener unas buenas motivaciones para justificar el desarrollo
del mismo, en este caso, es la implementación de tecnologías de la información y el procesado
en el ámbito de las Smart Cities, por lo que las motivaciones se han escrito de manera
organizada por conceptos.
1.1.1 Smart Cities
Desde siempre una ciudad ha podido ofrecer una cantidad de información increíblemente grande y valiosa, pero hasta hace poco más de una década era imposible captar dicha información y mucho menos obtener el valor real de ella. Actualmente las urbes están en continua expansión, por ello cada vez se necesita invertir más recursos en la gestión de los servicios, puesto que esos cada vez se vuelven más voluminosos y complejos, por otro lado, esta expansión también suele afectar a la calidad de vida, los ciudadanos cada vez exigen la mejora de servicios o la creación de nuevos. En este punto entra el concepto de Smart City que permite suplir dichas exigencias. Smart Cities o ciudades inteligentes es el concepto que engloba parte de esta filosofía, se basa en obtener información de la ciudad para poder aprovecharla, es decir, al tener una ciudad monitorizada podemos usar los datos para ofrecer nuevos servicios, optimizar los actuales u obtener valores añadidos.

11
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 11 de 181
Ilustración 1 Imagen promocional Smart Cities En marzo de 2015, se publicó el plan nacional de ciudades inteligentes, en el cual se les ofrecía un presupuesto de 152,9 millones de euros, centrándose en las cinco ramas principales: transportes, residuos, e-Sanidad, energía y gobernabilidad. Este hecho que advierte que España y Europa están más que interesadas dicho concepto, puesto que puede llevar al ahorro de costes, optimización de servicios o creación de nuevos, que hasta el momento no eran posibles, lo que aumentaría la calidad de vida.
Transportes: La optimización del transporte cubre campos como la administración de
las redes de transporte público, el ofrecer información adicional sobre el mismo, el
control del tráfico, etc… Este punto es muy importante puesto que casi toda la
industria y los servicios dependen de este factor, por lo que su optimización y mejora
influirá directamente sobre la eficiencia de la ciudad en sí.
Residuos: Con el aumento de la población, la gestión residuos se ha vuelto mucho más
compleja, las razones son: Por un lado, la cantidad de residuos, que está en continuo
aumento y por otro, la variedad del ellos, en este punto las ciudades inteligentes

12
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 12 de 181
requieren mecanismo de recolección de datos que sirva para la mejora y optimización
en la recogida y en su tratamiento.
Energía: Otro punto muy importante con gran margen de optimización y mejora es la
energía, gracias al uso de la información recogida tanto en los productores como en
los usuarios de la misma se puede optimizar el sistema.
E-sanidad: Entre los muchos puntos que ofrece este sector se encuentra e pronóstico,
prevención y seguimiento de enfermedades, la personalización del sistema sanitario,
mejora de servicios relacionados con la atención en salud, el seguimiento de
indicadores del estado de salud, registro metódico de datos e informes del estado de
salud del paciente.
Gobernabilidad: Actualmente gracias a la capacidad de los servicios TIC los ciudadanos
exigen cada vez más información sobre o que ocurre en el gobierno y su entorno por lo
que otro de los puntos importantes de una ciudad inteligente es la transparencia de
información.
Un buen ejemple es lo que expone Santiago Olivares, Consejero Delegado de Ferrovial Servicios, en el Libro Blanco de las Smart Cities: [1] “El movimiento de Smart Cities es una apuesta clara para la mejora del atractivo y la habitabilidad de nuestras ciudades, apoyándose en un modelo de gestión más eficiente y sostenible. El reto es saber aprovechar el gran volumen de información que proporcionará una sociedad hiperconectada. El éxito vendrá del talento que nuestra sociedad tenga para sumar las capacidades de nuestras ciudades, nuestros ciudadanos y nuestras empresas.” Pero para llegar al concepto de Smart Cities tenemos que pasar por una serie de conceptos y filosofías que nos permitirán llegar a ofrecer todas sus funcionalidades. Estos conceptos son: “Internet of Things”, Big Data, …. En los apartados siguientes se definirán dichos conceptos.
1.1.2 Internet Of Things
El primero de dichos conceptos es IoT. Actualmente Internet of things (internet de las cosas) que es muy mencionado en muchos campos de desarrollo diferentes, pero ¿qué es el internet de las cosas? y ¿cómo puede afectar al día a día de una ciudad?

13
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 13 de 181
Ilustración 2 Imagen promocional IoT Como buena introducción lo mejor será citar el documento de Kevin Aston llamado “Esa cosa del “Internet de las Cosas” publicado en el RFID Journal [2] . Una mayoría de los casi 50 Petabytes (un Petabyte son 1024 terabytes) de datos disponibles en internet fueron inicialmente creados por humanos, a base de teclear, presionar un botón, tomar una imagen digital o escanear un código de barras. Los diagramas convencionales de internet. Dejan fuera a los routers más importantes de todos: las personas. El problema es que las personas tienen un tiempo, una atención y una precisión limitados, y no se les da muy bien conseguir información sobre cosas en el mundo real. Y eso es un gran obstáculo. Somos cuerpos físicos, al igual que el medio que nos rodea. No podemos comer bits, ni quemarlos para resguardarnos del frío, ni meterlos en tanques de gas. Las ideas y la información son importantes, pero las cosas cotidianas tienen mucho más valor. Aunque, la tecnología de la información actual es tan dependiente de los datos escritos por personas que nuestros ordenadores saben más sobre ideas que sobre cosas. Si tuviéramos ordenadores que supieran todo lo que tuvieran que saber sobre las “cosas”, mediante el uso de datos que ellos mismos pudieran recoger sin nuestra ayuda, nosotros podríamos monitorizar, contar y localizar todo a nuestro alrededor, de esta manera se reducirían increíblemente gastos, pérdidas y costes. Sabríamos cuando reemplazar, reparar o recuperar lo que fuera, así como conocer si su funcionamiento estuviera siendo correcto. El internet de las cosas tiene el potencial para cambiar el mundo tal y como hizo la revolución digital hace unas décadas. Tal vez incluso hasta más.”

14
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 14 de 181
La razón de que este concepto haya tomado tanta fuerza, es el precio, como siempre ha pasado un producto no se ha extendido al público general a no ser que tuviera un precio accesible, tal y como paso con los ordenadores personales o como paso con las conexiones a internet en el hogar. En este caso ha sido por un lado la bajada de precio de componentes electrónicos, que afecta desde los teléfonos móviles a los sensores más sencillos y por otro el abaratamiento de las comunicaciones de datos, en especial las inalámbricas que han permitido ese grado de libertad a estos nuevos dispositivos IoT. El Smartphone, por ejemplo, es uno de los elementos que mayor obtención de datos permiten dentro de IoT, esto es debido a que casi todos tenemos uno y que recogen información anónima sobre sus dueños y su entorno. Lo que permite obtener información muy importante para crear una un sistema para una Smart Cities. ¿Y cuál es la relación entre IoT y Smart Cities? Si pensamos en ello, la primera idea que se nos pasa por la cabeza es el colocar sensores por toda la ciudad, aprovechando que ahora es mucho más económico fabricarlos y hacer que recojan los datos que nos interesan, pero la obtención de datos a través de IoT no se limitaría a este punto, si se usa el Smart Phone para captar datos podemos obtener servicios del estilo de Google Maps que a través de la información de los obtiene información del el tráfico en tiempo real de las calles de una ciudad.
Ilustración 3 Análisis en tiempo real del tráfico por google Maps Otra solución muy usada actualmente es dotar de conectividad a los elementos cotidianos del día a día, como por ejemplo coches, contenedores, neveras, semáforos, estaciones

15
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 15 de 181
meteorológicas…. Al dotarles de acceso a la red nos brindan el acceso a numerosos datos que serán de gran utilidad para la ciudad. Una vez comprendido el concepto IoT comprendemos que podemos obtener una gran cantidad de información de la ciudad, tanto de dispositivos existentes en ella como de nuevos dispositivos, pero ¿Pero ¿qué se puede hacer con dicha información y donde se guarda? La información en sí, en crudo, pocas veces nos va a ofrecer un valor palpable, para obtener dicho valor debemos procesarla y currelarlas con otras fuentes.
1.1.3 Big Data
En este punto entra otro concepto importante, Big data, este concepto hoy en día se escucha incluso más que IoT, la razón es que no solo se aplica a IoT y a ciudades inteligentes, si no que su campo es mucho más amplio, pero ¿qué es Big data? Y ¿de qué nos sirve?
Ilustración 4 Imagen promocional Big Data Según Edd Dumbill para O`Reilly en su libro “Big Data Now” "Big Data" son datos que exceden la capacidad de procesamiento de sistemas de bases de datos convencionales. Los datos son demasiado grandes, se mueven demasiado rápido o no encajan en su arquitectura de base de daros. Para obtener valor de estos datos, Usted debe elegir una manera alternativa de procesarla.

16
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 16 de 181
[3] Denominamos Big Data a la gestión y análisis de enormes volúmenes de datos que no pueden ser tratados de manera convencional, ya que superan los límites y capacidades de las herramientas de software habitualmente utilizadas para la captura, gestión y procesamiento de datos. Cuando se analizan datos es importante tener en cuenta el valor del mismo para ello lo normal es fijarse en características como las 4 Vs, aunque cada vez van apareciendo nuevas Vs estas son las más básicas. [4] Se presentan como las 4 Vs de BigData a las 4 características de los datos que analiza.
Ilustración 5 Las 4 uves de Big Data
Veracidad: Se refiere tanto a la calidad del dato como a su predictibilidad
Variedad: Este es uno de los puntos más importantes de BigData, el tratamiento de
datos que requieren de diferente comportamiento en el análisis para cada uno por si
variedad de esquemas y formas.
Volumen: Como se comentó antes, la cantidad de datos que se generan actualmente
son enormes
Velocidad: También se ha incrementado en los últimos años la velocidad a la que se
generan dichos datos.
Es decir, Big data nace de la necesidad de procesar y almacenar la creciente cantidad y variedad de datos, por ello se requieren nuevas maneras de procesamiento, como es el procesamiento distribuido. Para explicar esto se puede poner un ejemplo fácilmente asimilable: Los bancos con los sistemas originales de un mainframe centralizado (básicamente un único súper ordenador de alto coste y potencia), cada vez tardaban más en procesar las transacciones, esto era debido a que la cantidad de datos por los que navegar y procesar y la ingesta de información cada vez era mayor, causado por el aumento de clientes y de información sobre los mismos. Lo cual obligaba al banco a mejorar su sistema para reducir esta latencia en sus operaciones. Por lo que si quería mejorar sus sistemas (teniendo en cuenta que las bases de datos

17
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 17 de 181
relacionales tienen un límite lógico de tamaño) solo tenía dos opciones, ampliar el mainframe (lo cual tiene un límite, no se pueden añadir/mejorar nuevos componentes indefinidamente) o comprar uno nuevo mucho más potente y desechando el antiguo, lo que viene siendo escalabilidad vertical. En este punto entra el concepto de Big Data, ¿y si en vez de tener un súper computador, tengo varios computadores trabajando en conjunto? Aplicando esta idea, el banco ya no requiere tanta espera en hacer una transacción por que la cantidad de datos a analizar sea demasiado para un computador, si no, que, al repartirse el trabajo entre varios computadores, el tiempo de respuesta se minimiza enormemente. Además, con la inclusión de bases de datos no relacionales, al poder dividirlas entre varios computadores, también se amplía la capacidad máxima lógica de almacenamiento. En el caso de querer aumentar su capacidad de cómputo y almacenamiento, el banco simplemente tenga que adquirir más computadores para que trabajen en conjunto con los ya existentes, lo que viene siendo escalabilidad horizontal. Otra ventaja que se obtiene con el procesamiento distribuido es que al ser un sistema repartido se le puede añadir tolerancia a fallos a través de la replicación de datos, es decir en caso de que uno de los computadores deje de funcionar otro asumirá sus tareas. Una vez introducido que solución obtenemos con Big Data, ¿cómo la unimos con IoT y la aplicamos a las ciudades inteligentes? El problema en las ciudades inteligentes es básicamente el mismo que el del banco, la cantidad de datos que se obtienen son cada vez más y tienen que ser almacenados y procesados para obtener su valor. Esto es debido a lo que comentábamos antes, con el abaratamiento de los dispositivos se observa un crecimiento exponencial de la cantidad de ellos conectados a la red. Por lo que soluciones del tipo de Big data, que nos ofrecen una gran escalabilidad horizontal, pueden ser las compañeras ideales para IoT en las Smart Cities, pero, aunque Big data nos soluciona los problemas de procesamiento y de almacenamiento, su concepto está orientado al análisis de datos en Batch, es decir, ir almacenándolos y posteriormente analizarlos. Este hecho es muy limitante cuando se quiere aplicar en situaciones que se requiere un análisis en el momento que se generan los datos.
1.1.4 Fast Data
A menudo se dice que una ciudad está viva, y la verdad es que está en constante cambio, por ello, es muy importante que estos análisis de los datos se obtengan en el mínimo tiempo posible, debido a que, si se espera mucho, pueden perder su valor. En este punto entra en escena un concepto menos conocido que el anterior, que es Fast Data, básicamente es aplicar el concepto de Big data a procesamiento en tiempo pseudo real.

18
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 18 de 181
Ilustración 6 Ejemplo de despliegue Fast data aplicado a la empresa Esto nos permite obtener una respuesta casi inmediata a los datos según nos van llegando, por lo cual en el campo de las ciudades inteligentes ofrece una infinidad posibilidades, como por ejemplo el control de los semáforos según el estado actual del tráfico, en este ejemplo los datos se obtienen siguiendo el concepto de IoT de sensores o de los propios dispositivos personales de los conductores (semáforos, teléfonos , GPS, sensores de los coches, cámaras de tráfico, etc.), a continuación se procesan según la filosofía de Fast Data la cual obtiene el valor del dato que es en este caso, la capacidad de controlar los semáforos en tiempo real para optimizar el flujo de tráfico. Aunque de la sensación de que Fast Data y Big Data son filosofías excluyentes entre sí, nada más lejos de la realidad, normalmente se complementan a la perfección , Fast data ofrece el análisis en tiempo real para obtener una salida al poco tiempo de ingerir los datos, cuyo procesamiento no debe de ser excesivamente pesado para que no aumentar la latencia de la salida de información, más tarde para hacer procesados más pesados entraría en juego Big Data analizando los datos obtenidos antes, durante y/o después de la etapa de Fast Data.
1.1.5 Fog computing
El último concepto que se debe introducir es Fog computing o computación al filo de la red, para ello vamos a seguir con el ejemplo de los semáforos. Pongámonos en situación de una ciudad grande, como por ejemplo Madrid, como se comentó anteriormente, queremos obtener la mayor cantidad de datos relevantes posibles, para ello por un lado obtenemos datos de dispositivos personales y por otro de dispositivos específicos que se han colocado, siendo Madrid una ciudad con una población de más 3,165 millones la cantidad de datos que se genera es enorme, podríamos procesarla toda con Fast Data si fuera

19
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 19 de 181
necesario, añadiendo los computadores necesarios al clúster pero aun así se tendría que enviar por la red pagando el coste de dicha transmisión ¿entonces es esta situación óptima?¿Y si procesamos parte de la información en los propios dispositivos o en los primeros concentradores, ahorrándonos transferirla toda? ¿Y si los dispositivos requieren una respuesta mas inmediata que lo que ofrece Fast Data?
Ilustración 7 Imagen promocional Fog Computing Aquí es donde entra el concepto de Fog Computing o computación al filo de la red. Como se comentó anteriormente, en las últimas décadas el precio de la electrónica ha bajado de manera vertiginosa y ha aumentado la capacidad de cómputo, esto nos permite añadir pequeños procesamientos dentro de los propios dispositivos que toman datos o dentro de los aparatos de red que los interconectan. De esta manera por un lado se ahorra procesamiento en el clúster de la nube y por otro, él envió de información lo cual se puede traducir en una reducción de la latencia. Por lo que se pasa del concepto de Cloud a Fog, es decir en vez de estar todos los nodos de procesamiento en un clúster, se reparte de manera vertical permitiendo que se procese en los puntos más bajos de la red y evitando el envío de información innecesaria reduciendo la latencia de las peticiones puesto que tienen que viajar mucho menos recorrido por la red.

20
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 20 de 181
Ilustración 8 Ejemplo arquitectura Fog computing Por lo que, si se implementa esta filosofía, reservando una pequeña parte del procesamiento del dispositivo se obtienen una gran cantidad de mini nodos de procesamiento, por poner un ejemplo, en el 3º trimestre de 2015 se han vendido 353 millones de teléfonos inteligentes, si se usara una pequeña parte del procesamiento de todos estos dispositivos tendríamos más de 353 millones de mini servidores procesando información de forma local antes de enviarla a la nube. A esto hay que añadirle el poder introducir esos elementos de procesamiento también dentro de los elementos de red, haciendo varias capas de Fog Computing, un tras de otra.

21
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 21 de 181
Ilustración 9 Ejemplo despliegue Fog computing
1.1.6 Conclusiones
Una vez explicado dicho concepto queda claro que la combinación de las tecnologías IoT Fog computing Fast Data Big Data, permite a un sistema del estilo de las Smart Cities crecer de manera exponencial, tolerancia a fallos y alta reactividad.

22
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 22 de 181
Ilustración 10 Imagen promocional Smart Cities
IoT: ofrece el obtener todo tipo de información al tener una gran cantidad de objetos
conectados en la red como por ejemplo semáforos, contenedores, papeleras, cámaras,
teléfonos móviles, etc.
Fog Computing: Ofrecerá esta primera línea de procesamiento reduciendo en gran
cantidad los datos que son enviados a la nube para su procesamiento gracias a
filtrados o reducciones de los datos a enviar.
Fast Data: Permitirá el procesamiento de datos con una latencia mínima por lo que
podremos obtener reacciones instantáneas a dichos datos cuyo valor se reduce con el
tiempo.
Big data: Se encarga de almacenar y procesar tanto los datos procesados por Fast data
como los datos en crudo que se obtienen de IoT, esto permite obtener valores que
requieren más procesamiento pero que por otra parte no tienen importancia que se
obtengan en el momento.

23
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 23 de 181
1.2 Objetivos
El objetivo del trabajo propuesto consiste en la especificación, análisis, diseño e
implementación de un prototipo de sistema de información basado en IoT y aplicado a las
Smart Cities que integre las nuevas tecnologías y modelos de Fog Computing y Fast Data, así
como otras de nivel más bajo que soporten la implementación más adecuada.
El sistema concreto elegido es el de gestión del servicio de la recogida de residuos urbanos con
un alcance que cubrirá desde la monitorización de elementos del servicio mediante sensores
(contenedores de basura, etc.) Hasta servicios de medida y control de la calidad del servicio y
de optimización.
Este sistema entra dentro de la rama de residuos una de las principales del plan nacional de
ciudades inteligentes de 2015 del Gobierno de España.
El proyecto se divide en cuatro capas, de manera ascendente según cercanía al clúster central,
las más bajas son las más alejadas del clúster y las más altas están en él, esto es especialmente
útil para comprender como se distribuye Fog computing en el sistema
Ilustración 11 Las 4 capas base del proyecto

24
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 24 de 181
IoT Devices: En esta capa se encuentran los dispositivos físicos IoT que se encargaran
de la obtención de datos, además de contener la primera línea de pre procesamiento
de Fog Computing.
Delivery System: Subsistema encargado de la comunicación entre la capa Fast data y
los dispositivos IoT, a su vez puede incluir también otra línea de pre procesamiento
Fog Computing.
Fast Data Core: Encargada de procesamiento en tiempo real de los datos y de su
almacenamiento.
Presentación: Capa encargada de hacer de interfaz para el usuario.
La forma de desarrollo del proyecto será a través de hitos de manera cíclica, se empezarán con
unos hitos básicos que crearan la infraestructura principal del proyecto, es decir las capas
comentadas antes, a continuación, se cumplirán los hitos de expansión, que serán
características y mejoras añadidas sobre la arquitectura base.
Hitos Base
Capa IoT
o Diseño y fabricación de un dispositivo de seguimiento para camiones de
recolección de residuos
o Diseño y fabricación de un dispositivo de monitorización de cantidad de
residuos en un contenedor.
o Diseño e implementación de un emulador de los contenedores y de camiones
que los recogen que permitirá simular un escenario real.
o Adición en los dispositivos de una capa de pre procesamiento siguiendo la
filosofía Fog computing.
Capa Delivery System
o Investigación y selección de un sistema de comunicación que soporte una gran
cantidad de mensajes de la capa IoT en dirección a la capa Fast Data y a ser
posible que integre también ciertas capacidades de incluir procesamiento Fog
computing.

25
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 25 de 181
Capa Fast Data Core
o Sistema de procesamiento principal: Investigación y selección de una
plataforma de procesamiento orientado a Fast data, que debe de ofrecer una
respuesta casi inmediata a los datos que se le introducen.
o Añadir funcionalidad al sistema de procesamiento principal para medir la
calidad del servicio de recogida, midiendo elementos como máximos mínimos
medias e integrales de la cantidad de residuos que hay en los contenedores y
así medir que calidad ofrece.
o Sistema de almacenamiento Distribuido: En esta capa se guardará toda la
información necesaria, tanto para procesamiento posterior como para acceso
desde la capa de prestación para ser mostrada.
Capa Presentación:
o Investigación, diseño e implementación de una interfaz de usuario con la cual
se pueda acceder a los datos procesados y administrar funcionalidades del
sistema.
Hitos expansión
Capa Delivery System
o Añadir una capa de procesamiento Fog computing
Capa Fast Data Core
o Predicción del llenado de los contenedores a dos días futuros
o Predicción del llenado de los contenedores al día siguiente si no se recogiera
en el día actual.
o Diseño e implementación de un sistema de eventos causados por predicciones
y mediciones de calidad.

26
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 26 de 181
2 | Estudios previos
En esta sección se agrupan los estudios previos requeridos para el desarrollo del proyecto
2.1 Estudio del problema
Actualmente la recogida de basuras es un servicio que, aunque este contratado por el
ayuntamiento, la medición de calidad del mismo y la gestión del servicio, están ambos en
manos de la empresa contratada.
Con este proyecto se quieren solucionar dos problemas, por un lado, se quiere dar acceso
directo al ayuntamiento al estado de los contenedores de residuos para que así pueda medir
por sí mismo la calidad del servicio que le está entregando la empresa de recogida, por el otro,
añadir métodos con los que optimizar el servicio de recogida de basuras para que así sea más
eficiente lo cual implica menos polución, menos gasto y mejores resultados que se verán
reflejados en la calidad.
Para la medición de la calidad del servicio de recogida de basuras, hay que centrarse en lo que
más afecta al ciudadano, es decir, por ejemplo, el estado del camión no afecta mucho, sin
embargo, la cantidad de residuos en el contenedor sí, por lo que el análisis de la calidad del
servicio se centrara en la cantidad depositada en los contenedores a lo largo del tiempo.
Por otro lado, para la gestión óptima del servicio, se requiere, además de información sobre el
estado de los contenedores, información sobre los camiones, por ejemplo la posición o el
llenado del depósito, de esta manera se puede predecir si el camión se va a llenar en medio de
la ruta de recogida o si los contenedores antes del final del día se van a llenar por completo, y
así evitar que los ciudadanos depositen residuos fuera de los contenedores que afecta
directamente a la calidad de vida por los los olores y la sensación visual de limpieza de la
ciudad que dan.
2.1.1 Parámetros a monitorizar
Contenedores:
En esta sección lo importante es medir el llenado del mismo, para ello se requiere una
unidad de medida que sea fiable y sea capaz de permitir medir la calidad.
Por un lado, se podría pensar en el peso, colocando una base que midiera la presión,
se podría obtener el peso de los residuos, pero el problema es que no todo lo que se
deposita en el contenedor pesa lo mismo, por lo que no sería indicativo del llenado.
La solución es medir directamente el llenado del contenedor, para ello se usará un
sónar. Dicho sonar estará colocado en la parte superior o en la tapa del contenedor y
apuntando hacia la base del mismo.

27
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 27 de 181
El sónar enviará una señal de ultrasonidos que rebotará contra objeto físico más
cercano, y volverá al receptor de ultrasonidos, si se mide la diferencia de tiempo que
hay entre la emisión y la recepción, se puede usar junto a la ya conocida velocidad del
sonido para hallar la distancia entre el sónar y la parte más alta de residuos en el
contenedor y así obtener el porcentaje de llenado del mismo.
Camión:
En este caso se requieren dos parámetros, por un lado, el llenado del depósito interno
que o bien ya está integrado en el propio camión o se pude usar el mismo método que
con el contenedor.
Por otro lado, la posición en la que se encuentra e camión, que nos servirá para hacer
un seguimiento del mismo a través de su ruta de recogida, para ello lo más adecuado
es usar GPS y obtener en el momento la posición del camión.

28
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 28 de 181
2.2 Estado del arte
En esta sección se repasan el estado actual de las tecnologías y conceptos que se van a aplicar
en el proyecto.
2.2.1 Fog computing
Actualmente el “procesamiento en la niebla” está ganando cierta fama gracias a ciertas compañías que ven interés en este concepto, una de las cuales es el gigante de las telecomunicaciones Cisco. Otro nombre muy común para Fog computing es Edge computing, es decir computación al filo de la red.
2.2.1.1 Cisco
El concepto de Fog computing de cisco, se establece sobre la filosofía IoX (Internet of everything, una versión expandida de IoT). El concepto se basa en desplazar parte del procesamiento a las capas de interconexión de red para así repartir el trabajo de procesamiento.
Ilustración 12 Despliegue fog computing de ejemplo de Cisco La idea es sencilla: dentro de los elementos de red de cisco, se reserva unos recursos para procesamiento, en el cual se pueden instalar variedad de programas y demonios.

29
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 29 de 181
Ilustración 13 Arquitectura Fog computing de Cisco
2.2.1.2 Kafka
Otro concepto que puede llegar a entrar en el de Fog computing es Kafka (del cual también se comentará en la sección de Fast Data y de publicador subscriptor)puesto que el cluster central también es parte de Fog computing.
Ilustración 14 Logo Kafka Kafka lo podemos entender como un bus de datos al cual las aplicaciones de pueden subscribir a temas, puesto que la idea es que en un sistema todas las aplicaciones estén conectadas a dicho bus, este sistema se despliega de manera distribuida para así tener alta disponibilidad, tolerancia a fallos y escalabilidad horizontal. Lo más inteligente una vez se tiene desplegado una arquitectura así, es implementar un sistema de procesamiento sobre el mismo que procese en tiempo real añadiendo agregaciones, filtrados, etc. sobre el flujo de datos que recorre el bus.

30
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 30 de 181
El uso más común de Kafka es en clústeres de datos para la interconexión de aplicaciones de manera más organizada y tolerante a fallos, pero como toda esta sección está en el propio clúster contaría como si estuviera en la nube. Pero si en vez de eso se despliega de manera distribuida en elementos de red como por ejemplo los routers de cisco IoX, en este caso si se trataría de Fog computing puesto que habría procesamiento en los niveles más bajos de la red. En este ámbito los usos más comunes de las tecnologías de Fog Computing es el análisis de la red en busca de amenazas y el análisis de logs en busca de anomalías.
2.2.1.3 Edgent
Por otro lado, se encuentra apache Edgent (antes Quarks).
Ilustración 15 Logo Edgent
Su enfoque es todavía más bajo, no se trata de componentes distribuidos que trabajan coordinados, si no de pequeños elementos de procesamiento que trabajan de manera individual, su concepto es desplazar el procesamiento a los propios dispositivos IoT para ello ofrece un framework que permite trabajar en forma de streaming, facilitando el diseño y la comprensión de aplicaciones orientadas a flujos de información. Por ejemplo, la aplicabilidad de Edgent podría ser el ejemplo que tienen con IBM en el cual instalan Edgent en unos aspersores de agua, dentro de los se hacen pequeñas agregaciones y filtrados para monitorizar el estado del suelo, aliviando así por un lado la red por el exceso de envió de datos y por otro la cantidad de datos a procesas. La manera de trabajar en Edgent es por sistemas del estilo “pipes and filters”

31
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 31 de 181
Ilustración 16 Vista de la interfaz web de administración de Edgent.
Este sistema facilita la monitorización, pudiendo encontrar cuellos de botella o nodos que estén ociosos. Aunque principalmente lo anuncian como IoT también sirve para instalación en dispositivos de red o clústeres en los que se requiere pequeños agentes para analizar flujos de logs o paquetes de red.
2.2.2 Sistemas publicador subscripor
Actualmente hay muchas tecnologías publicador subscriptor, pero se va a centrar a las más conocidas en el ámbito de IoT.

32
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 32 de 181
Ilustración 17 Despliegue de ejemplo de Edgent
2.2.2.1 MQTT
Es un protocolo usado para la comunicación machine-to-machine (M2M) en el “Internet of
Things “. Este protocolo está orientado a la comunicación de sensores, debido a que consume
muy poco ancho de banda y puede ser utilizado en la mayoría de los dispositivos empotrados
con pocos recursos (CPU, RAM,…).
Ilustración 18 Logo MQTT
[5] La arquitectura de MQTT sigue una topología de estrella, con un nodo central que hace de
servidor o “bróker” con una capacidad de hasta 10000 clientes. El bróker es el encargado de
gestionar la red y de transmitir los mensajes, para mantener activo el canal, los clientes

33
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 33 de 181
mandan periódicamente un paquete (PINGREQ) y esperan la respuesta del bróker (PINGRESP).
La comunicación puede ser cifrada entre otras muchas opciones.
Ilustración 19 Despliegue de ejemplo MQTT
MQTT también permite el escalado horizontal, aunque su arquitectura no está ideada para ello
por lo que a la larga tiene ciertas limitaciones.
Por ejemplo, en este caso el servidor central de MQTT sería el eslabón débil de la cadena y
también el que podría a llegar crear un cuello de botella por pasar todos los elementos por él.
Ilustración 20 Despliegue distribuido con niveles de jerarquía de MQTT

34
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 34 de 181
En este otro ejemplo el punto débil por un lado seria el balanceador que, si se cae, necesitaría
otro de respaldó y por otro lado la comunicación entre bróker, que cuantos más brókeres
haya, más comunicación será requerida y más complicado de coordinar será.
Ilustración 21 Despliegue distribuido con balanceador de carga de MQTT

35
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 35 de 181
2.2.2.2 Watson IoT Platform
Ilustración 22 Logo IBM Watson En este caso es una solución propietaria de IBM, no es solo un sistema de publicación
suscripción, la plataforma Watson sirve para una gran cantidad de tareas, como por ejemplo
análisis Fast data, machine learning, etc.
Ilustración 23 Despliegue de ejemplo de Watson
Para funcionar como sistema de publicador subscriptor, en la capa baja (más cercana a los
dispositivos IoT) usa MQTT para obtener todos los mensajes, después lo hace pasar por la
plataforma en la cual puede hacer pequeñas tareas de procesamiento, por ultimo para
enviárselo a los programas de procesamiento principal. Se usa IBM Message Hub que sirve de
pasarela para que a los programas de procesamiento le lleguen los eventos y mensajes.

36
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 36 de 181
2.2.2.3 Kafka
[6]Apache Kafka es un sistema de almacenamiento publicador/subscriptor distribuido, particionado y replicado. Estas características, añadidas a que es muy rápido en lecturas y escrituras lo convierten en una herramienta excelente para comunicar streams de información que se generan a gran velocidad y que deben ser gestionados por uno o varias aplicaciones. Se destacan las siguientes características:
Funciona como un servicio de mensajería, categoriza los mensajes en topics. Los procesos que publican se denominan bróker y los subscriptores son los
consumidores de los topics. Utiliza un protocolo propio basado en TCP y Apache Zookeeper para almacenar el
estado de los brokers. Cada broker mantiene un conjunto de particiones (primaria y secundaria) de cada topic.
Se pueden programar productores/consumidores en diferentes lenguajes: Java, Scala, Python, Ruby, C++ …
Escalable y tolerante a fallos. Se puede utilizar para servicios de mensajería (tipo ActiveMQ o RabbitMQ),
procesamiento de streams, web tracking, trazas operacionales, etc. Escrito en Scala. Creado por LinkedIn.
Ilustración 24 Arquitectura Kafka

37
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 37 de 181
A diferencia de MQTT, Kafka si es un sistema distribuido, por lo que para sistemas que tienen una gran cantidad de datos a transportar o requieren una alta disponibilidad es el más adecuado, sin embargo, también es mucho más pesado en comparación con MQTT.
2.2.3 Fast Data
Como se comentó en la introducción Fast Data permite el procesamiento de grandes cantidades de datos en tiempo real de manera distribuida (y en algunos casos, tolerante a fallos). Actualmente, existe ya, una cierta cantidad de herramientas para el desarrollo de aplicaciones en este tipo, en esta sección se da un repaso a las ya casi abandonas pero que tuvieron su importancia y a las existentes que son tendencia.
Ilustración 25 Despliegue completo Fast Data
En el diagrama superior se puede ver un despliegue de Fast data. Como se puede observar
tiene ciertas similitudes con el despliegue de Big data que se muestra abajo, puesto que un
despliegue normal suele incluir ambos conceptos por ofrecer características diferentes.

38
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 38 de 181
Ilustración 26 Despliegue completo Big Data
2.2.3.1 Spark streams
[7]Apache Spark combina un sistema de computación distribuida a través de clústeres de
ordenadores con una manera sencilla y elegante de escribir programas. Fue creado en la
Universidad de Berkeley en California y es considerado el primer software de código abierto
que hace la programación distribuida realmente accesible a los científicos de datos.
Ilustración 27 Logo Spark Streaming
Spark mantiene la escalabilidad lineal y la tolerancia a fallos de MapReduce, pero amplía sus
bondades gracias a varias funcionalidades: DAG y RDD
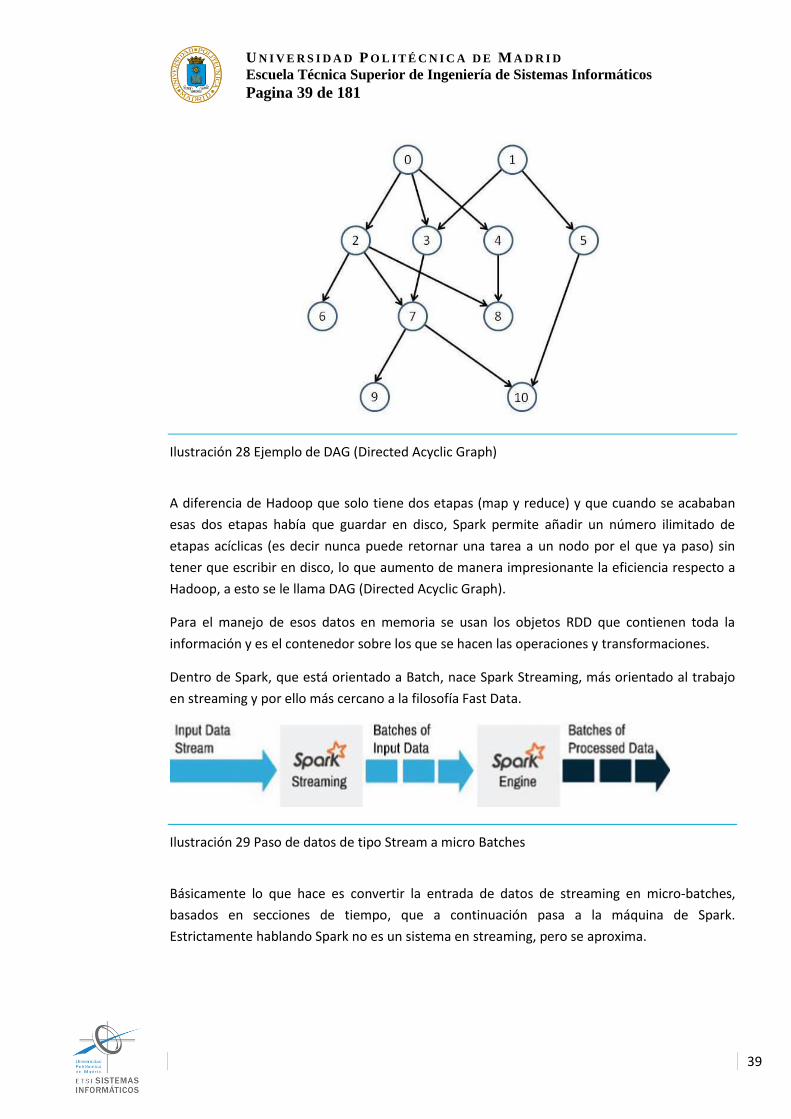
39
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 39 de 181
Ilustración 28 Ejemplo de DAG (Directed Acyclic Graph)
A diferencia de Hadoop que solo tiene dos etapas (map y reduce) y que cuando se acababan
esas dos etapas había que guardar en disco, Spark permite añadir un número ilimitado de
etapas acíclicas (es decir nunca puede retornar una tarea a un nodo por el que ya paso) sin
tener que escribir en disco, lo que aumento de manera impresionante la eficiencia respecto a
Hadoop, a esto se le llama DAG (Directed Acyclic Graph).
Para el manejo de esos datos en memoria se usan los objetos RDD que contienen toda la
información y es el contenedor sobre los que se hacen las operaciones y transformaciones.
Dentro de Spark, que está orientado a Batch, nace Spark Streaming, más orientado al trabajo
en streaming y por ello más cercano a la filosofía Fast Data.
Ilustración 29 Paso de datos de tipo Stream a micro Batches
Básicamente lo que hace es convertir la entrada de datos de streaming en micro-batches,
basados en secciones de tiempo, que a continuación pasa a la máquina de Spark.
Estrictamente hablando Spark no es un sistema en streaming, pero se aproxima.

40
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 40 de 181
Ilustración 30 Orden de procesamiento de los micro batches
[8]Spark Streaming soporta distintos modelos correspondientes a las semánticas típicamente
utilizadas para el procesamiento de flujos. Esto asegura que el sistema entrega resultados
confiables, aún en caso de fallos en nodos. Los flujos de datos pueden ser procesados de
acuerdo a los siguientes modelos:
Exactamente una vez (exactly once). Cada elemento es procesado una sola vez.
Como mucho una vez (at most once). Cada elemento puede ser procesado un máximo
de una vez, y es posible que no sea procesado.
Por lo menos una vez (at least once): Cada elemento debe ser procesado por lo menos
una vez. Esto aumenta la posibilidad de que no se pierdan datos, pero también es
posible que se generen duplicados.
Como se puede ver no es tiempo real de manera estricta, si no que separa por franjas de
tiempo (frecuentemente 5 segundos), se puede reducir las franjas de tiempo a menos de un
segundo, pero afectará a la latencia del sistema, por requerir más recursos. Adicionalmente,
un argumento en contra del esquema de micro-batches es que puede ser que los datos no se
reciban en el orden exacto en el que sucedieron.
2.2.3.2 Apache Storm
[9]Apache Storm es un sistema que sirve para recuperar streams de datos en tiempo real
desde múltiples fuentes de manera distribuida, tolerante a fallos y en alta disponibilidad.
Storm está principalmente pensado para trabajar con datos que deben ser analizados en
tiempo real, por ejemplo, datos de sensores que se emiten con una alta frecuencia o datos que
provengan de las redes sociales donde a veces es importante saber qué se está compartiendo
en este momento.

41
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 41 de 181
Ilustración 31 Logo Apache Storm
Se compone principalmente de dos partes. La primera es la que se denomina Spot y es la
encargada de recoger el flujo de datos de entrada. La segunda se denomina Volt y es la
encargada del procesado o transformación de los datos.
En la documentación oficial representan los Spots con grifos simulando la entrada de un
stream de datos al sistema y a los Bolts con un rayo que es donde se realizan las acciones
pertinentes con los datos de entrada.
Ilustración 32 Arquitectura de trabajo de apache Storm.
Uno de los puntos fuertes de Storm es que podemos crear una topología donde añadimos
instancias de Bolts y Spouts para que escale el sistema desplegándola en el clúster de Storm

42
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 42 de 181
que es quién se encargará de particionar los datos de entrada y redistribuirlos por los
diferentes componentes.
Storm fue programado en clojure y en java en 2011, en 2013 paso a ser parte del programa de
incubación de apache y en 2014 se convirtió en un proyecto de alta importancia para apache
(Apache Top-Level Project).
Actualmente está algo abandonado y ha sido desplazado por otros frameworks.
2.2.3.3 Akka Streams
[10]Akka es una plataforma (o framework) inspirado por Erlang que busca el desarrollo simple
de aplicaciones escalables y multihilo. Akka funciona sobre Scala y por tanto corre sobre la
máquina virtual Java JVM.
Ilustración 33 Logo Akka
Si en los lenguajes más tradicionales como Java la concurrencia se basa en la memoria
compartida entre varios hilos y los métodos de sincronización Akka ofrece un modelo de
concurrencia basado en actores.
Un actor es un objeto con el que puedes interactuar enviándole mensajes: cada actor
puede procesar mensajes y enviarles mensajes a otros actores.
En una máquina virtual JVM pueden correr millones de actores a la vez construyendo
una jerarquía padre (supervisor)-hijo con los padres monitorizando el comportamiento
de los hijos.
Además, Akka permite, de una forma sencilla, repartir nuestros actores entre varios
nodos de un cluster.

43
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 43 de 181
Los actores pueden tener un estado interno pero la comunicación sólo ocurre pasando
mensajes y nunca a través de estructuras compartidas.
Ilustración 34 Jerarquía de actores de Akka
El sistema de actores de Akka sigue una jerarquía de padres e hijos al estilo de ficheros de
Unix, aunque se pueden enviar menajes de unos a otros, tiene que hacerlo a través de las
líneas de jerarquía.
El sistema de actores permite una baja latencia, lo cual permite que por su estructura ser una
muy buena opción para el procesamiento en Streaming.
2.2.3.4 Apache Bean
Antes de la creación de Beam Google creo el llamado Dataflow Model, un modelo que unifica
el procesamiento en Batch y en Stream, para conseguir correrlo en su servicio de cloud
“Google Cloud Dataflow”.

44
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 44 de 181
Ilustración 35 Logo apache Beam
Más tarde Google dono el modelo de programación al proyecto de incubación de Apache,
punto en el que nación Apache Bean.
[11]Es un modelo de programación unificado open source, que permite crear pipelines para el
procesamiento de datos aptos para Batch y streaming que se pueden correr sobre diferentes
plataformas

45
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 45 de 181
Ilustración 36 Unificación de lenguajes en Beam
El concepto básico traído de Dataflow Model es responder a las siguientes preguntas:
¿Qué resultados son calculados? Esta cuestión se centra en qué tipo de operaciones se tiene
que hacer sobre el flujo de datos.
¿Dónde en el evento los resultados son calculados? Se basa en el uso de ventanas de tiempo
con las cuales se decide cuando se procesan los datos y si se llega a procesar.
¿Cuándo los resultados son materializados? Es decir, en qué momento del procesamiento
damos una respuesta a los cálculos hechos.
¿Cómo relacionamos los resultados? La respuesta a esta pregunta es la manera de que los
resultados materializados de relacionan unos con otros, sobre todo cuando son de la misma
ventana.
Actualmente google está detrás de este proyecto, con mucho interés debido a que permite
crear programas para su servicio cloud Dataflow, pero también puede correr sobre Apache
Flink y Apache Spark. Por ahora solo soporta Java, pero dentro de poco soportara Python.

46
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 46 de 181
Los Apache Beam Pipeline Runners son los programas en sí, en él se tiene que definir sobre
que plataforma se va a desplegar. Aunque para desarrollo, debugging y testeo se puede
ejecutar en local si ningún problema.
2.2.3.5 Kafka streams
Kafka aparte de su sistema de publicador subscriptor añade una capa superior con la que se
puede añadir procesamiento en streaming de manera paralela.
Ilustración 37 Arquitectura de Apache Kafka
En esta capa se pueden hacer agregaciones, filtrados, etc. sobre los flujos de información que
recorren Kafka de manera distribuida y tolerante a fallos.
2.2.3.6 IBM Streams
[12]InfoSphere Streams es un producto de IBM que se define como “una plataforma de
computación avanzada que permite desarrollar aplicaciones a los usuarios para ingerir,
analizar y correlacionar información desde un gran número de fuentes en tiempo real,
permitiendo procesar alto volúmenes de datos y millones de eventos por segundo”.

47
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 47 de 181
Ilustración 38 Logo IBM Streams
Es uno de los primeros sistemas orientados a Fast data, fue solicitado por el gobierno de USA a
IBM para poder analizar todas las llamadas del país teniendo la mínima latencia posible para
evitar ataques terroristas después del 11-S.
Tiene su propio lenguaje de programación llamado SPL, aunque también soporta otros
lenguajes como Java o Scala. Una vez escrito el programa se traducen en lenguaje C++ y se
compila.
También tiene gran compatibilidad con otros sistemas ya sean privativos de IBM o de código
abierto, gracias a sus numerosos conectores.
Además, permite introducir programas en C++, R y java de manera nativa
InfoSphere Streams permite:
Analizar streams en el momento: con tiempos de respuesta de milisegundos
Desarrollar aplicaciones de streaming de forma sencilla a través de su IDE
Extender el valor de sistemas existentes integrando con aplicaciones y fuentes de
datos
2.2.4 Almacenamiento
Actualmente las dos maneras más comunes para el almacenamiento de datos son las bases de datos relacionales (SQL) y no relacionales (NO-SQL).

48
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 48 de 181
2.2.4.1 Base de datos relacional.
[13]Una base de datos relacional es una colección de elementos de datos organizados en un
conjunto de tablas formalmente descritas desde la que se puede acceder a los datos o volver a
montarlos de muchas maneras diferentes sin tener que reorganizar las tablas de la base. La
base de datos relacional fue inventada por E.F. Codd en IBM en 1970.
La interfaz estándar de programa de usuario y aplicación a una base de datos relacional es el
lenguaje de consultas estructuradas (SQL). Los comandos de SQL se utilizan tanto para
consultas interactivas para obtener información de una base de datos relacional y para la
recopilación de datos para los informes.
[14]Ventajas:
Está más adaptado su uso y los perfiles que los conocen son mayoritarios y más
baratos.
Debido al largo tiempo que llevan en el mercado, estas herramientas tienen un mayor
soporte y mejores suites de productos y add-ons para gestionar estas bases de datos.
La atomicidad de las operaciones en la base de datos. Esto es, que en estas bases de
datos o se hace la operación entera o no se hace utilizando la famosa técnica del
rollback.
Los datos deben cumplir requisitos de integridad tanto en tipo de dato como en
compatibilidad.
Desventajas:
Las atomicidades de las operaciones juegan un papel crucial en el rendimiento de las
bases de datos.
Escalabilidad, que, aunque probada en muchos entornos productivos suele, por
norma, ser inferior a las bases de datos NoSQL.
2.2.4.2 Base de datos no relacional.
[13]Las bases de datos NoSQL, también llamadas No Solo SQL, son un enfoque hacia la gestión
de datos y el diseño de base de datos que es útil para grandes conjuntos de datos distribuidos.
NoSQL, que abarca una amplia gama de tecnologías y arquitecturas, busca resolver los
problemas de escalabilidad y rendimiento de big data que las bases de datos relacionales no
fueron diseñadas para abordar. NoSQL es especialmente útil cuando una empresa necesita
acceder y analizar grandes cantidades de datos no estructurados o datos que se almacenan de
forma remota en varios servidores virtuales en la nube.

49
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 49 de 181
[14]Ventajas:
La escalabilidad y su carácter descentralizado. Soportan estructuras distribuidas.
Suelen ser bases de datos mucho más abiertos y flexibles. Permiten adaptarse a
necesidades de proyectos mucho más fácilmente que los modelos de Entidad Relación.
Se pueden hacer cambios de los esquemas sin tener que parar bases de datos.
Escalabilidad horizontal: son capaces de crecer en número de máquinas, en lugar de
tener que residir en grandes máquinas.
Se pueden ejecutar en máquinas con pocos recursos.
Optimización de consultas en base de datos para grandes cantidades de datos.
Desventajas de una base de datos NoSQL
No todas las bases de datos NoSQL contemplan la atomicidad de las instrucciones y la
integridad de los datos. Soportan lo que se llama consistencia eventual.
Problemas de compatibilidad entre instrucciones SQL. Las nuevas bases de datos
utilizan sus propias características en el lenguaje de consulta y no son 100%
compatibles con el SQL de las bases de datos relacionales. El soporte a problemas con
las queries de trabajo en una base de datos NoSQL es más complicado.
Falta de estandarización. Hay muchas bases de datos NoSQL y aún no hay un estándar
como si lo hay en las bases de datos relacionales. Se presume un futuro incierto en
estas bases de datos.
Soporte multiplataforma. Aún quedan muchas mejoras en algunos sistemas para que
soporten sistemas operativos que no sean Linux.
Suelen tener herramientas de administración no muy usables o se accede por consola.
2.2.4.3 SQL sobre bases de datos no relaciones.
Una metodología que también está ganando mucha fuerza es el usar una capa de abstracción
SQL sobre una NoSQL, este método es útil por un lado por la sencillez de comprensión de SQL
y por otro por la capacidad para adaptar programas que funcionaban con SQL a NO-SQL sin
muchas modificaciones.

50
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 50 de 181
Los principales desarrollos son:
Apache Hive: el original, intenta emular el comportamiento de MySQL, es lento por
que usa muchos maps para sacar los datos y solo vale para leer.
Stinger: Apache Hive con posibilidad de modificación y rendimiento mejorado.
Apache drill: implementación open source de Google’s Dremel herramienta altamente
escalable, compatible con muchos tipos de datastores.
Apache Phoenix: SQL skin para hbase, rendimiento óptimo y curva de aprendizaje fácil,
se puede montar un servidor que haga de servidor SQL, y hacerle peticiones a través
de SQL que él a posteriori convierte, es muy útil para adaptar aplicaciones que usaban
SQL.
Apache impala: otra implementación de apache drill, orientado a Bussines Inteligent.
HAWQ for pivotal HD: Sistema propietario de la compañía pivotal, es la interfaz SQL
para su propia distribución de pago de Hadoop.
Presto: Implementación de Facebook usa ANSI SQL, no permite updates por lo que
solo permite leer.
Oracle Big Data SQL: Solo para Oracle database 12c que son las bases de datos no
relacionales de pago de la compañía Oracle.
IBM BigSL: Versión propietaria de IBM compatible con el conjunto de herramientas de
IBM InfoSphere.
2.3 Arquitectura del sistema
A continuación, se muestran diagramas que muestran posibles arquitecturas del sistema.
2.3.1 Posibles Arquitecturas conceptuales.
Es sistema se compone de 4 elementos principales:
Fuentes de información: Son las fuentes que suministran datos en tiempo real, hay dos
tipos de fuentes:
o Contenedores: Ofrecen información sobre su llenado.
o Camiones: Ofrecen información sobre su posición y su llenado.
Procesamiento: Elemento encargado del procesamiento, predicción y análisis de los
datos de entrada.

51
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 51 de 181
Almacenamiento: Lugar donde se guardan los datos procesados.
Presentación: interfaz gráfica que muestra información sobre el estado del servicio de
una manera amigable a través de mapas y gráficos.
Ilustración 39 Primer modelo de arquitectura conceptual
2.3.1.1 Arquitectura conceptual.
El sistema conceptual se basa en los principios de Fog Computing y FastData. A continuación, se listan los elementos que lo componen:
RestDB: Representa las fuentes de datos que no transmiten continuamente, sino que
hay que solicitarles datos periódicamente, pueden ser fuentes de información que
puedan afectar a la calidad del servicio, en el caso de recogida de basuras la
temperatura ambiental que aumenta el hedor de los contenedores sería un buen
ejemplo.
Edge Computing: Engloba todos los elementos que son capaces de preprocesar la
información haciendo ciertas modificaciones y filtrados (Fog Computing) y a
continuación envían periódicamente sus resultados a la red.
Este elemento coincide con las fuentes de información (Contenedores y camiones) del
diagrama conceptual.
Pubs/Subs System: Sistema encargado de recoger todos los mensajes que le llegan de
los dos anteriores (publicadores) y enviárselos a Stream Computing (consumidor) todo
esto en tiempo real y sin requerir que el consumidor solicite información
periódicamente.
En el diagrama conceptual es la unión entre las fuentes de información y el
procesamiento.

52
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 52 de 181
Stream Computing: Es el que tiene la mayor capacidad de procesamiento de todo el
sistema, se encarga de procesar dato a dato todos los mensajes que le llegan para con
ellos realizar análisis o hacer funcionar motores de eventos.
Batch Computing: Aunque no será parte del desarrollo del proyecto en sí es
interesante tener en cuenta que Big data también tiene acogida en el sistema, una vez
analizados los datos en streaming para las tareas en tiempo real, siempre es
interesante realizar un análisis más meticuloso que nos pueda dar más información.
Presentación: Sera el encargado de mostrar la información relevante al usuario o
administrador del sistema.
Lógicamente coincide con el elemento de presentación del conceptual.
Ilustración 40 Segundo modelo de arquitectura conceptual
Una ampliación al sistema podría ser ampliar el concepto de Fog computing no solo a los propios dispositivos, si no elevarlo a los primeros elementos de red y comunicación, en este caso se sustituiría el elemento Pubs/Subs System y se introduciría en él una capa de procesamiento en streaming rodeándolo de dos Pubs/Subs System para su comunicación.
Ilustración 41 Tercer modelo de arquitectura conceptual.
2.3.1.2 Posibles arquitecturas reales
Una de las posibles soluciones para la implementación de la arquitectura seria la que sigue a continuación.

53
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 53 de 181
Fog Layer 1: En esta capa encontramos todas las fuentes de información, tanto las que
ofrecen datos en tiempo real (Quarks Devices) que además ofrece pequeños
elementos de procesamiento orientado a flujos de datos como fuentes de datos no
streaming con datos útiles para el sistema.
Pubs/Subs System: Ofrece un canal de comunicaciones fiable orientado a publicador
subscriptor que se implementa con Kafka que ofrece de manera sencilla, tolerante a
fallos y escalable el envido de datos entre publicadores y subscriptores.
Fog Layer 2: Segunda capa de procesamiento en streaming con el uso de quarks para
aligerar el procesamiento en capas superiores.
Fast Data Computing: Elemento encargado del procesamiento principal r usa como
principal herramienta IBM InfoStreams, un software de pago orientado al
procesamiento de flujos de datos que ofrece escalabilidad horizontal, redundancia y
tolerancia a fallos.
Por otro lado también se puede añadir un módulo de procesamiento y
almacenamiento de datos en lotes para análisis posteriores con técnicas Big data.
Presentación: La información procesada es introducida en una base de datos para que
posteriormente lo use un servidor web que ponga a disposición del usuario una
interfaz con la que monitorizar el sistema.
Ilustración 42 primer modelo de posible despliegue del sistema Otra posible arquitectura es el substituir Quarks en la segunda capa Fog por Kafka streams que ofrece también una capa de procesamiento distribuido antes de enviar los datos a los subscriptores. Este elemento Kafka streams estaría embebido dentro de los propios brókeres por lo que se ejecutaría de manera distribuida.

54
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 54 de 181
Ilustración 43 Segundo modelo de posible despliegue del sistema
2.3.1.3 Posibles arquitecturas fisicas.
En el caso del despliegue de dispositivos, se requiere un estudio de cuáles son las mejores
opciones para el despliegue de dispositivos sensores en los cubos y camiones y su manera de
comunicarse con el sistema de publicación.
A. Dispositivos sensores con comunicación directa con la red.
En este despliegue cada dispositivo sensor en los cubos y en los camiones tiene
comunicación directa a la red a través de la red de telefonía móvil. Es muy útil para cuando
los cubos están muy separados unos de otros (por ejemplo, en una ruta de recogida que
pase por pueblos de pocos habitantes).
Por otro lado, el camión tendría también su enlace de comunicaciones.

55
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 55 de 181
Ilustración 44 Despliegue de dispositivos con tecnología red móvil
Ventajas:
o Fallo en un contenedor no afecta a los otros
o Uso de la infraestructura existente de red móvil.
o Fácil despliegue.
Desventajas:
o Alto precio del hardware por contenedor debido a que requiere un módulo
conexión a la red móvil
o Alto precio en el envío de datos por tener un enlace a la red móvil por
contenedor.
o Alto consumo de energía
Ejemplo: Tanto los contenedores como el camión incluyen un enlace GSM o GPRS para
enviar las mediciones por SMS o por datos.
B. Red de tipo malla (mesh)

56
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 56 de 181
En este caso existe un Gateway que tiene conexión a internet, ya sea por red móvil, WiFi o
cable, este dispositivo crea una red del tipo Mesh (es decir que los elementos son capaces
de darse cobertura unos a otros) a la que se le van agregando los contenedores.
De esta manera un contendor que este alejado del Gateway puede pasar sus datos por
otros contenedores que están entre ellos y así conseguir enviarlos al sistema de
publicación.
Este sistema es muy apto para lugares en los que los contenedores se concentran por
zonas, como pueblos de tamaño medio.
Ilustración 45 Despliegue físico de dispositivos con una red del tipo malla
Ventajas:
o Bajo coste en el hardware de los contenedores.
o Tolerancia a fallos del enlace entre los contendores siempre y cuando haya
otro enlace redundante.
o Se puede añadir Fog Computing de manera sencilla en el Gateway.

57
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 57 de 181
o Bajo coste de envió de datos, puesto que solo se requieren pocos enlaces a la
red.
o Muy bajo consumo de energía
Desventajas:
o En caso de caída del gateway toda la red se quedaría sin servicio (se puede
tener un gateway de respaldo).
o En caso de caída de un contenedor, si era el único enlace para acceder al
gateway de otros contenedores, estos se quedarían sin acceso a la red.
Ejemplo: En este caso se pueden usar módulos XBee, que usan el protocolo de
comunicaciones Zigbee para crear una red mesh, como coordinador se usara el
gateway que creara la red. Cuando halla datos que enviar, el contenedor lo envía a
través de los otros nodos de la red (que serán los otros contenedores) hasta llegar al
gateway una vez allí se puede hacer un cierto pre procesado y enviarlo a la red.
También se podría dotar de comunicación XBee a los camiones, pero estarían sin red
cuando pasaran de una red a otra.
C. Red en Estrella.
En este caso todos los contenedores consiguen acceso a la red a través de un punto de acceso
central que cubre una gran zona con su cobertura. Es una arquitectura muy útil para grandes
núcleos urbanos en los que todos los contenedores están muy juntos.

58
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 58 de 181
Ilustración 46 Despliegue físico de motas con tecnología centralizada
En este sistema se pueden hacer una serie de mejoras aumentando la complejidad. Puesto que
la cobertura de la arquitectura es muy amplia se puede también dotar de conectividad a los
camiones de recogida. También si se añaden más puntos de acceso, se puede añadir tolerancia
a fallos y si un dispositivo (contenedor o camión) está conectado a 3 o más puntos de acceso,
se puede obtener la geolocalización del mismo mediante triangulación.

59
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 59 de 181
Ilustración 47 Despliegue fisico de motas centralizado con mas de una central.
Ventajas:
o Geolocalización en caso de tener 3 o más puntos de acceso al alcance.
o Fácil implementación de Fog Computing en los puntos de acceso.
o Precio muy reducido en los contenedores.
o Bajo consumo energético en los contenedores.
o En caso de fallo en un contenedor no afecta a la conectividad de los otros
Desventajas:
o Alto precio de despliegue de los puntos de acceso por requerir una
localización elevada.
o Alto precio del hardware de los puntos de acceso.
o En caso de fallo de un punto de acceso toda la red se quedaría sin
conectividad (a no ser que haya más de un punto de acceso que los cubra
todos)
Ejemplo: Actualmente hay una tecnología de bajo consumo energético de
topología centralizada llamada Lora, permite el uso de varios puntos de acceso,
usa banda ultra ancha, por lo que no se ve atenuado por tecnologías como WiFi o
red móvil y con más de dos puntos de acceso permite la geolocalización de

60
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 60 de 181
dispositivos. Con dicha tecnología se podría dotar de comunicación a todos los
contenedores de una ciudad pequeña como León u Oviedo con 1 solo punto de
acceso, y además dar también conectividad a los camiones de residuos puesto que
estarían dentro del radio de cobertura.
2.3.2 Arquitectura final.
Después de diversos estudios y reconsideraciones, al final se ha optado por usar el modelo que incluye procesamiento de Fog computing dentro del sistema pubs/Subs. Aunque se han añadido y substituido ciertos elementos:
HBASE: Servicio que permite accesos a bases de datos HDSF de la forma clave y valor.
REST Server: Servidor que recibe peticiones del tipo GET, obtiene la información
solicitada de HBASE y la devuelve en formato REST.
Web Server: Servidor que recibe peticiones tipo GET y devuelve páginas web. También
recibe peticiones del tipo post para modificar la web que se recibe.
Dashboard Web: En la web que devuelve el servidor, dentro de ella se incluye software
encargado de hacer peticiones REST y dibujar los datos en gráficas.
Convencional Big Data analytics: En este elemento se analizarían los datos en modo
Batch para hacer análisis demás profundidad pero que no requieran tener baja
latencia.
Las modificaciones realizadas son las siguientes:
En vez de guardar los resultados en dos bases de datos diferentes (relacional y no
relacional), se guarda directamente sobre Hbase que corre sobre HDFS, hbase permite
usar HDFS como tablas de clave-valor.
En la capa de presentación, se han separado los servicios, S ha creado un servidor web
que responde a peticiones http devolviendo la página solicitada, pero sin acceder a los
datos procesados.
Dentro de la página generada por el servidor hay un software de creación de graficas
llamado C3, que es el encargado de por un lado solicitar los datos procesados por
medio de REST y por otro de dibujarlos en gráficas. Así la solicitud de datos ya se hace
directamente desde el lado del cliente sin tener que pasar por el servidor WEB.

61
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 61 de 181
Por último, se ha añadido una interfaz REST para la obtención de datos, este servidor
REST está a cargo de recibir peticiones GET acceder a HBASE obtener los datos,
filtrarlos según criterios y devolverlos en formato REST
Ilustración 48 Despliegue final de las tecnologías del sistema En este diagrama se pueden ver los componentes más detallados y su arquitectura

62
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 62 de 181
Ilustración 49 Despliegue final de las tecnologías del sistema detallado

63
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 63 de 181
Truck Device: Dispositivo situado en el camión de recogida de residuos.
o GPS: Obtiene la posición del camión.
o Fill Sensor: Obtiene el llenado del depósito.
Container Device: Dispositivos situado en cada contenedor.
o Fill Sensor: Obtiene el llenado del contenedor.
Infosphere Streams (container simulator): Genera una simulación con los llenados de
los contenedores de una ruta.
o Management host: Encargado de coordinar y mandar tareas a los application
host
o Zookeeper: Se encargar de mantener la información de coordinación entre los
hosts.
o Application host: Elemento que realiza las tareas que se asignan.
Kafka: Sistema publicador/subscriptor distribuido y tolerante a fallos que también
incluye procesamiento orientado a flujos de datos. Se encarga de que todos los
eventos o mensajes que son enviados desde los dispositivos lleguen a InfoSphere.
o Zookeeper: Se encargar de mantener la información de coordinación entre los
elementos de Kafka.
o Broker: Su función es trabajar en conjunto unos con otros para recibir
publicaciones y enviarlas a los subscriptores.
o Streams: encargada de hacer procesamiento en streaming sobre los flujos de
datos que llegan a Kafka
File System: Sistema de ficheros de Linux donde se guardan los archivos con las
mediciones del simulador
o File: Cada uno de los archivos con mediciones.
Infosphere Streams (container simulator): Analiza todos los datos que le llegan por
Kafka o lee de ficheros y a continuación los guarda en HBASE.
o Management host: Encargado de coordinar y mandar tareas a los application
host
o Zookeeper: Se encargar de mantener la información de coordinación entre los
hosts.
o Application host: Elemento que realiza las tareas que se asignan.
Hadoop: conjunto de herramientas para procesamiento y almacenamiento de Big
data. En este caso solo se usan las herramientas para el almacenamiento distribuido
tolerante a fallos.
o Zookeeper: Se encargar de mantener la información de coordinación entre los
hosts.
o HDFS: Sistema de ficheros distribuidos de Hadoop, distribuye los archivos en
diferentes nodos para un acceso y una escritura tolerante a fallos.
o HBASE: Servicio que añade a bases de datos HDSF accesos de la forma clave y
valor.

64
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 64 de 181
REST Web Servicie: Servicio que recibe peticiones del tipo GET, obtiene la información
solicitada de HBASE y la devuelve en formato REST.
o Web Access: Parte del servicio que se encarga de recibir las peticiones y
enviar las respuestas.
o Core: Parte del servicio que solicita a HBASE la información y realiza filtrados
sobre ellas según las necesidades de la petición.
WebServer: Servidor que recibe peticiones tipo GET y devuelve páginas web. También
recibe peticiones del tipo post para modificar la web que se recibe.
WebPage: Es la web que devuelve el servidor, dentro de ella se incluye software
encargado de hacer peticiones REST y dibujarlo en gráficas.
o C3 Charts: Software en JavaScript orientado a navegadores con el que se
pueden generar gráficas y realizar peticiones REST para obtener los datos para
ellas.
Para la arquitectura física se ha optado por el modelo en estrella
Ilustración 50 Despliegue físico final.
Sin embargo, como enlace de comunicación para el prototipo, en vez de tecnologías con un alto precio como Lora, se ha optado por usar Wi-Fi siendo este más sencillo y barato de implementar en un prototipo.

65
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 65 de 181
2.4 Especificación de requisitos de software
2.4.1 Introducción
2.4.1.1 Propósito
Esta sección detalla las especificaciones de requisitos de software de una aplicación que permite la captura de mediciones de células sensoras distribuidas por contenedores y camiones y el análisis de dichas mediciones para la optimización del servicio de recogida de residuos y la medición de la calidad del servicio. El contenido de esta sección está destinado a ingenieros de casos de uso, analistas, arquitectos, diseñadores de bajo nivel, codificadores, personal de pruebas y mantenimiento, y personal técnico en general.
2.4.1.2 Ámbito
Esta sección contiene la especificación de requisitos software (SRS) del Sistema para la obtención y análisis de medidas de contenedores de residuos.
Este sistema permitirá la recolección y envío de las mediciones a un sistema de procesamiento Fast Data por medio de las células sensoras colocadas en contenedores y camiones de residuos, el análisis posterior y visualización
Con la recolección de mediciones se espera obtener la información para optimizar la eficiencia y controlar la calidad del servicio de las rutas de recogida de residuos, repercutiendo positivamente, en el confort y experiencia del ciudadano.
2.4.1.3 Referencias
IEEE Recommended Practice for Software Requirements Specifications, in IEEE Std
830-1998, vol., no., pp.1-40, Oct. 20 1998. doi: 10.1109/IEEESTD.1998.88286.
2.4.2 Descripción General
2.4.2.1 Perspectivas del producto
El producto será un sistema integral, que cubrirá desde la recogida de datos hasta su
visualización, pasando por el análisis y almacenamiento. En la siguiente ilustración se
muestra la estructura de este subsistema.
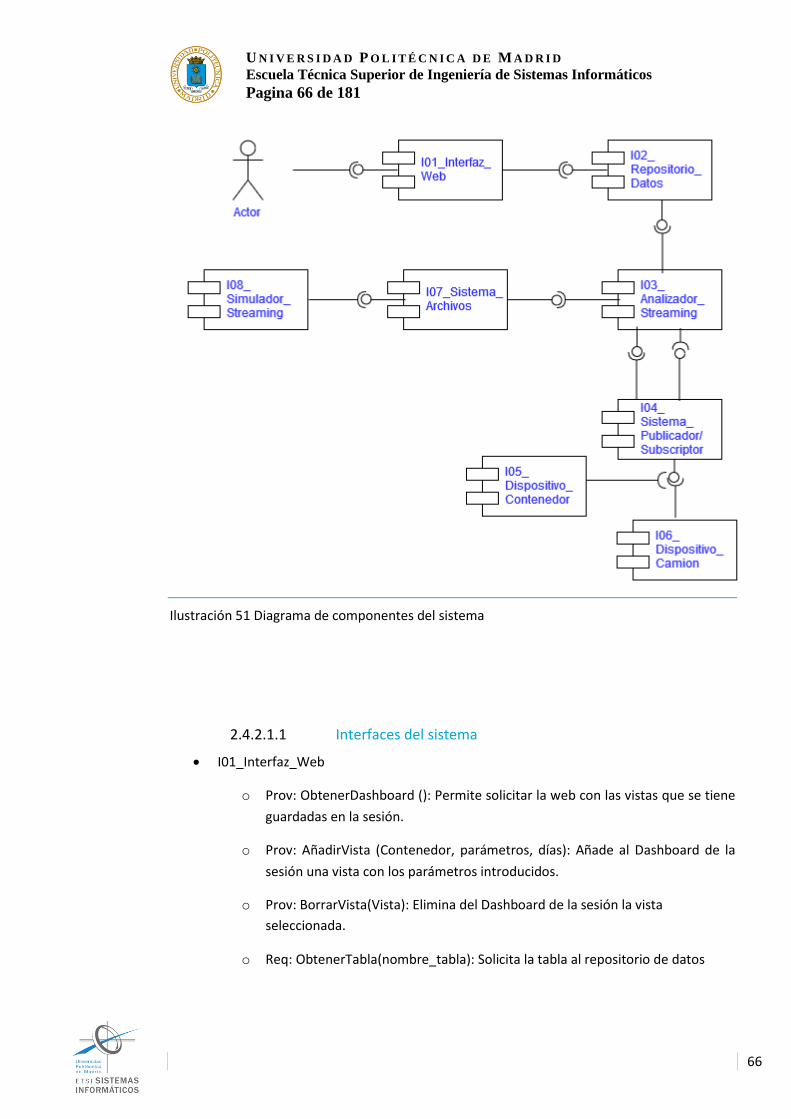
66
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 66 de 181
Ilustración 51 Diagrama de componentes del sistema
2.4.2.1.1 Interfaces del sistema
I01_Interfaz_Web
o Prov: ObtenerDashboard (): Permite solicitar la web con las vistas que se tiene
guardadas en la sesión.
o Prov: AñadirVista (Contenedor, parámetros, días): Añade al Dashboard de la
sesión una vista con los parámetros introducidos.
o Prov: BorrarVista(Vista): Elimina del Dashboard de la sesión la vista
seleccionada.
o Req: ObtenerTabla(nombre_tabla): Solicita la tabla al repositorio de datos

67
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 67 de 181
I02_Repositorio_Datos
o Prov: ObtenerTabla (nombre, tabla): Devuelve la tabla al repositorio de datos
solicitada.
o Req: IntroducirEnTabla (tabla, datos): introduce los datos en la tabla.
I03_Analizador_Streaming
o Prov: RecibirMensajeSubscriptor (mensaje): Recibe un mensaje para ser
analizado
o Req: IntroducirEnTabla (tabla, datos): introduce los datos en la tabla.
o Req: SubscribirseATopic(topic): Se subscribe a un topic para recibir mensajes
de dicho topic.
o Req: LeerFicher(path): Lee un fichero para extraer las tuplas que hay en él.
I04_Sistema_Publicador/Subscriptor
o Prov: SubscribirseATopic(topic): Permite la suscripción a topics para recibir
mensajes del mismo.
o Prov: RecibirMensajePublicador (mensaje, topic): Recibe todos los mensajes y
los organiza en colas por topics.
o Req: RecibirMensajeSubscriptor(mensaje): Envía el mensaje a los subscriptores
del topic.
I05_Dispositivo_Contenedor
o Req: RecibirMensajePublicador (mensaje, topic): Envía el mensaje junto al
topic al que debe ir dicho mensaje.
I06_Dispositivo_Camion
o Req: RecibirMensajePublicador (mensaje, topic): Envía el mensaje junto al
topic al que debe ir dicho mensaje.
I07_Sistema_archivos
o Prov: LeerFicher(path): Permite leer un fichero del sistema de archivos
o Prov: EscribirFichero (input, path): Permite escribir en un fichero del sistema
de archivos.

68
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 68 de 181
I08_Simulador_Streaming:
o Req: EscribirFichero (input, path): Escribe en el fichero las tuplas que va
generando según la simulación.
2.4.2.1.2 Interfaces de usuario
Interfaz Web para la monitorización del servicio, se pueden añadir (configurando
opciones y pulsando añadir lista) y borrar vistas de seguimiento de contenedores
(pulsando la X de su respectivo recuadro), la información de las gráficas se debe de
actualizar periódicamente.
Ilustración 52 diseño de la interfaz gráfica a implementar
2.4.2.1.3 Interfaces hardware
Interfaz Web ↔ Repositorio de datos: Ethernet

69
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 69 de 181
o Interfaz Web: Interfaz Ethernet
o Repositorio de datos: Interfaz Ethernet
Repositorio de datos ↔ Analizador streaming: Ethernet
o Repositorio de datos: Interfaz Ethernet
o Analizador streaming: Interfaz Ethernet
Analizador streaming ↔ Sistema publicador subscriptor: Ethernet
o Analizador streaming: Interfaz Ethernet
o Sistema publicador subscriptor: Interfaz Ethernet
Sistema publicador subscriptor ↔ Dispositivo Camión: Ethernet/WiFi/3G
o Sistema publicador subscriptor: Interfaz Ethernet
o Dispositivo Camión: Interfaz WiFi/3G
Sistema publicador subscriptor ↔ Dispositivo Contenedor: Ethernet/WiFi/3G
o Sistema publicador subscriptor: Interfaz Ethernet
o Dispositivo Contenedor: Interfaz WiFi/3G
Analizador streaming ↔ Sistema de Archivos: Llamada al sistema SO
o Analizador streaming: Interfaz SO
o Sistema de Archivos: Interfaz SO
Sistema de Archivos ↔: Simulador streaming: Llamada al sistema SO
o Sistema de Archivos: Interfaz SO
o Simulador streaming: Interfaz SO
2.4.2.1.4 Interfaces Software
CentOS:
o Mnemónico: CentOS
o Versión: 7

70
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 70 de 181
o Source: https://www.centos.org/
o Motivación: SO de libre distribución compatible con los requisitos del
Analizador streaming, Sistema de archivos e interfaz web, ya sea en una
maquina o varias.
Raspbian:
o Mnemónico: RSBI.
o Versión: 08/19/12.
o Source: https://www.raspbian.org/RaspbianInstaller
o Motivación: Uso de un sistema operativo gratuito, con una gran comunidad de
usuarios y ya incluido en la RPi, compatible con framework Fog para el
dispositivo contenedor y el dispositivo camión.
Ubuntu Server:
o Mnemónico: UBSE.
o Versión: 14.04 LTS.
o Source: http://www.ubuntu.com/server.
o Motivación: Uso de un sistema operativo de libre distribución, con una gran
comunidad de usuarios, compatible con sistemas publicador subscriptor.
2.4.2.1.5 Interfaces de cominicacion
Interfaz Web ↔ Repositorio de datos: conexión HBASE
Repositorio de datos ↔ Analizador streaming: conexión HBASE
Analizador streaming ↔ Sistema publicador subscriptor: Conexión Kafka
Sistema publicador subscriptor ↔ Dispositivo Camión: Conexión Kafka
Sistema publicador subscriptor ↔ Dispositivo Contenedor: Conexión Kafka
Analizador streaming ↔ Sistema de Archivos: Sistema de ficheros del SO
Sistema de Archivos ↔: Simulador streaming: Sistema de ficheros del SO

71
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 71 de 181
2.4.2.1.6 Restricciones de memoria
Servidor Interfaz Web
o Primaria: 2 Gbyte
o Secundaria: 6 Gbyte
Servidor Repositorio datos
o Primaria: 2 Gbytes
o Secundaria: 1 Gbyte (distribuida)
Servidor Analizador Streaming
o Primaria: 16 Gbytes
o Secundaria: 30 Gbytes
Servidor Publicador/Subscriptor
o Primaria: 4 Gbyte
o Secundaria: 30 Gbyte
Dispositivo contenedor
o Primaria: 1 Gbyte
o Secundaria: 8 Gbyte
Dispositivo Camión
o Primaria: 1 Gbytes
o Secundaria: 8 Gbytes
Servidor Simulador Streaming
o Primaria: 8 Gbytes
o Secundaria: 30 Gbytes

72
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 72 de 181
2.4.2.1.7 Operaciones
Crear vista: Permite al usuario crear una vista con gráficas y elementos de información
que se añadirá al dashboard de su sesión.
Borrar vista: El usuario es capaz de borrar una vista de su dashboard.
Obtener dashboard: el usuario solicita una web donde se muestra el Dashboard con
todas vistas que haya creado hasta ahora y no hayan sido eliminar.
2.4.2.1.8 Requisitos de despliegue
Colocación de los dispositivos de los contenedores y los camiones, en puntos que
tengan cobertura 3G o WiFi.
Despliegue de los servidores en instancias virtuales o reales en la red.
Alimentación por placa solar o por batería de los dispositivos de los contenedores.
Los servidores de datos, de análisis y de simulación pueden desplegarse en distribuido.
2.4.2.2 Funciones del producto
Las principales funciones que soportará el sistema son las siguientes:
Recogida de medidas de llenado de contenedores y camiones.
Recogida de la posición de los camiones.
Análisis de los datos para obtener predicciones y calidad del servicio.
Almacenamiento de los datos analizados y de los análisis.
Presentación de los datos anualizados y de los análisis en una interfaz WEB
Simulación de las medidas de los contenedores.
2.4.2.3 Características del usuario
Los usuarios deberán tener conocimientos básicos de navegación Web.
2.4.2.4 Restricciones
Las principales restricciones a las que se enfrenta el sistema son:

73
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 73 de 181
El sistema de análisis en streaming debe de ser IBM Streams
Los dispositivos de contenedor y camión deben ser implementados en RPi.
La interfaz debe de ser Web
2.4.2.5 Suposiciones y dependencias.
Los dispositivos de contenedores y de camiones deben tener acceso hacia la red.
Los dispositivos se supone que estarán continuamente alimentados ya sea batería,
panel solar o red eléctrica
2.4.2.6 Requisitos pospuestos
Añadir procesamiento en el servidor de publicación suscripción
Análisis por lotes mediante Big data
Auto regulación de rutas.

74
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 74 de 181
3 | Planificacion y presupuesto
Antes del desarrollo de la aplicación se requiere una planificación de la misma y generar un
presupuesto acorde a dicha planificación, así se podrá aproximar el gasto en tiempo y dinero
del proyecto.
Planificación:
Con el uso de Microsoft Proyect se han creado una serie de tareas en las cuales se ha
tenido en cuenta la relación de dependencia entre unas y otras, es decir, por ejemplo,
no se puede implementar un desarrollo o documentarlo sin antes haberlo diseñado.
El sistema automático de Microsoft organiza las tareas en el tiempo teniendo en
cuenta dichas dependencias, además marca en rojo las tareas más críticas y administra
los trabajadores (aunque en este caso solo hay uno).
Hay que tener en cuenta que las tareas se han establecido con unas fechas muy
permisibles para tener claro la fecha límite y coste máximos.

75
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 75 de 181
Ilustración 53 Tabla de planificación de trabajo.
Presupuesto:
Una vez hecha la planificación se da paso al presupuesto, se establecen los activos y se
tienen en cuenta los trabajadores y su jornada.
Tabla 1 Presupuesto
Nombre del
recurso Tipo
Capacidad
máxima Tasa estándar
Costo/Us
o Acumular Calendario base
Lucas Alvarez Trabajo 100% 2,61 €/hora 0,00 € Prorrateo Estándar
Portátil Material
0,00 € 0,00 € Prorrateo
Impresión Costo
Prorrateo
Sonar Material
5,00 € 5,00 € Prorrateo
Raspberry Pi Material
45,00 € 45,00 € Prorrateo
GPS Material
30,00 € 30,00 € Prorrateo
Una vez desarrollado el proyecto, como coste máximo esperado se obtiene 2.979€

76
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 76 de 181
Ilustración 54 Completado/costes
0,00 € 500,00 € 1.000,00 € 1.500,00 € 2.000,00 € 2.500,00 € 3.000,00 € 3.500,00 €
0%
20%
40%
60%
80%
100%
120%
09
/05
/16
06
/06
/16
04
/07
/16
01
/08
/16
29
/08
/16
26
/09
/16
24
/10
/16
21
/11
/16
19
/12
/16
16
/01
/17
13
/02
/17
13
/03
/17
10
/04
/17
CO
STO
AC
UM
ULA
DO
% C
OM
PLE
TAD
O
Título del gráfico
Porcentaje completado acumulado Costo acumulado

77
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 77 de 181
4 | Desarrollo de la aplicación
En esta sección se desarrollan aspectos de la implementación del sistema
4.1 Tecnologias y hardware utilizado
4.1.1 Capa IoT
Estos elementos son los que ofrecerán todos los datos al sistema de procesamiento por lo que se requiere explorar varias vertientes para tener una entrada de datos útil, las vertientes son las siguientes:
Creación de un dispositivo prototipo que envía obtiene los datos mediante sensores y
los envía.
Obtención de datos existentes de alguna fuente de datos de alguna ciudad inteligente.
Generar dichos datos de manera simulada mediante funciones de distribución que se
asemejen a la realidad.
4.1.1.1 Creación de un prototipo real
Para esta tarea, tanto para la obtención de datos de contenedores de residuos como de camiones, se usará como base una Raspberry Pi model 3 por tener un gran respaldo por la comunidad, su compatibilidad probada con Apache Edgent y venir con WiFi integrado de serie.
Ilustración 55 Raspberry Pi 3

78
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 78 de 181
Una de las grandes ventajas del modelo 3 es que incluye de serie conectividad Wi-Fi por lo que solo es necesario concentrarse en la obtención de datos y su procesamiento.
Contenedor de residuos
Para la creación del cubo de basura se conectará mediante los puertos GPIO un sonar, dicho dispositivo se coloca en la parte superior del cubo de residuos apuntando hacia la base, el sonar medirá la distancia que hay entre el dispositivo y el objeto más cercano, por lo que cuantos más residuos menos distancia medirá y mayor porcentaje de llenado marcará el dispositivo.
Ilustración 56 Sonar Una vez obtenidos los datos del sensor mediante Edgent se añaden agregaciones a los datos, y se envía periódicamente a través de Kafka en función del llenado del cubo, es decir cuánto más lleno está el cubo menor será el periodo de envió de la información al sistema de procesamiento principal para así disminuir la cantidad de datos a transmitir.
Sistema de seguimiento GPS para el camión de recogida
El otro prototipo se implementará con un GPS U-block 6M Un GPS con una gran relación calidad/precio y bastante usado para prototipado y hobby de aeromodelismo. Por lo que ofrecerá la precisión necesaria para el prototipo.

79
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 79 de 181
Ilustración 57 GPS Ublock
El procesamiento Edgent para ahorrar el envió de datos a las capas superiores en los camiones será un sistema de área, cuando se arranque el sistema enviara la posición en la que se encuentra, en ese momento creara un área circular alrededor suyo, siempre y en cuando se mantenga dentro de ese área el dispositivo no enviara su posición, en el momento que sale de ella envía su posición para procesado y generara una nueva área centrada en sí mismo para así solo enviar datos cuando se ha desplazado cierto espacio.
Ilustración 58 Generación de áreas con el movimiento del GPS

80
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 80 de 181
Este sistema es muy útil en ciudad, lugar en el que hay una gran cantidad de semáforos y tráfico por lo que el vehículo quedara quieto durante ciertos tiempos lo que causa que la información a enviar es poco relevante porque sigue siendo la misma o muy aproximada.
4.1.1.2 Obtención de datos de fuentes existentes.
Otra metodología a tener en cuenta es la búsqueda a través de la red de almacenes de datos de ciudades digitales tanto a nivel nacional como a nivel internacional. Para ello la tarea más complicada es la búsqueda de mediciones de llenado de contenedores puesto que de toda la administración de ello se encarga la empresa privada contratada. Por otro lado, el seguimiento de un camión de basura es de la misma manera que el anterior, al ser de una empresa privada es posible que sea difícil su obtención, se puede suplir usando una línea de bus urbano y colocando en su trayecto los puntos de recogida de residuos.
4.1.1.3 Generación de datos simulados.
La manera más útil para experimentar, es la generación de unos datos aleatorios que sigan una cierta distribución. La simulación se hace sobre IBM Streams en conjunto con el toolkit de R un programa estadístico que tiene una gran capacidad. Se simularán las dos fuentes de datos pero en principio solo se exportara la capacidad de cubos de basura sin embargo se deben simular ambos, camiones y cubos puesto que los cubos tendrán una simulación propia con una distribución que simula el llenado de los mismos, por otro lado se simula el paso del camión, de manera que obtenemos el porcentaje de la ruta que ha recorrido, al no ser una simulación bidimensional sobre un mapa , no nos permite simular por donde va el camión, sin embargo si nos dice cuanto de la ruta ha efectuado y cuando pasa por un cubo , momento en el que el cubo se vacía.
4.1.2 Capa publicador/subscriptor.
En esta capa se optó por utilizar Kafka, debido a su capacidad de procesamiento FastData y Fog Computing. El despliegue de desarrollo, se basa en un kafka corriendo en modo standalone (modo en el que solo hay un broker e incluye un Zookeeper embebido listo para funcionar) sobre una máquina virtual Ubuntu. En el despliegue para producción se creará un cluster con varios Brokers, dichos brokers son los encargados de transmitir los mensajes de los productores (contenedores/camiones) a los consumidores (IBM Streams), para coordinar los brokers y los consumidores, se usará

81
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 81 de 181
Zookeeper. La idea es que cada broker este en una maquina diferente y Zookeeper en otra aparte (se recomienda que Zookeeper también este en varias máquinas diferentes para añadir tolerancia a fallos).
Ilustración 59 Arquitectura de kafka implementada al sistema En Kafka los canales a los que enviar los mensajes se denominan topics, dentro de un topic se pueden establecer dos parámetros principales: Particionado: En este caso divide los mensajes en X partes y las reparte entre los brokers, lo que permite un aumento en el rendimiento al repartir el trabajo entre varios brokers. Replicación: Por otro lado, se puede especificar el nivel de replicación, que especifica cuantas veces va a estar repetida en otros brokers cada partición. Si el broker que tiene la partición activa se cae, uno de los brokers que tengan una replicación marcará la suya como activa y sustituirá al antiguo broker como encargado de enviar y recibir mensajes.

82
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 82 de 181
4.1.3 Capa Fast Data
En esta sección se verán las tecnologías utilizadas para la implementación del procesamiento en Fast Data y el almacenamiento de los datos en crudo y procesados.
4.1.3.1 Sistema de procesamiento
En el caso de Fast Data se usa IBM InfoSphere Streams, su rendimiento es muy alto en comparación con competidores, aunque no tiene las características de elasticidad que pueden tener otros sistemas como Kafka o Spark. El despliegue de desarrollo es en una máquina virtual con CentOS. Streams ofrece una versión de inicio para el desarrollo que incluye además del sistema de streams, un Zookeeper embebido y una versión de eclipse personalizada para el desarrollo de aplicaciones en Streams.
Operating system System hardware and architecture
Supported operating system versions
RHEL x86_64 (64-bit) Version 6.1, or later
Version 7.0, or later
IBM Power Systems (64-bit) IBM Streams supports the POWER7® and
POWER8™ processors (big endian).
Version 6.3, or later
Version 7.0, or later
IBM Power Systems (64-bit) IBM Streams supports the POWER8™ processors
(little endian).
Version 7.1, or later
CentOS x86_64 (64-bit) Version 6.1, or later
Version 7.0, or later
SLES x86_64 (64-bit) Version 11.2, or later
Tabla 2 Requisitos de Hardware

83
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 83 de 181
Por lo que se puede observar la cantidad de sistemas operativos que admite es mínima, en nuestro caso hemos optado por CentOS por ser el único gratuito. Streams usa una arquitectura de pipes and filters, es decir los pipes (streams) se encargan de pasar las tuplas de un filter (PE) a otro, donde se hacen las trasformaciones, filtrados, agregaciones, etc.
Component
Minimum requirements Comments
System x86_64 (64-bit) IBM Streams supports Red Hat Enterprise Linux (RHEL), the Community Enterprise Operating System (CentOS), and SUSE Linux Enterprise Server (SLES).
IBM® Power Systems™ (64-bit)
On RHEL systems that are running big endian, IBM Streams supports the POWER7® and POWER8® processors. RHEL systems that are running little endian support the POWER8 processor only.
Display 1280 x 1024 Lower resolutions are supported but not preferred for Streams Studio.
Memory 2 GB The amount of memory that is required by IBM Streams is dependent on the applications that are developed and deployed. This minimum requirement is based on the memory requirements of the Commodity Purchasing sample application and other samples that are provided with the product.
Disk space 7.5 GB, if installing the main installation package
Includes disk space required for installation and development resources. For more information about installation packages, see Main and domain host installation
packages for IBM Streams.
2 GB, if installing the domain host installation package
Tabla 3 Requisitos del SO

84
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 84 de 181
Ilustración 60 Arquitectura de elementos de Streams
Domain (Dominio): El dominio es el conjunto de recursos que se pone a disposición
para correr las instancias.
Instance (Instancia): Es donde se colocan los trabajos para ser ejecutados, dentro de
una instancia los trabajos pueden compartir información de manera sencilla.
Job(trabajo): Son las aplicaciones propiamente dichas, cuando se despliega un
programa se hace en forma de trabajo.
Processing Element (PE): Es la unidad de procesamiento mínimo, con ella se hacen las
operaciones sobre los flujos de datos.
Streams(flujos): Son los canales que permiten transmitir los flujos de datos entre PEs.
Node (nodo): Permite agrupar los PEs dentro de los trabajos para poder ponerles
parámetros juntos.
La arquitectura interna de streams básicamente se divide en tres elementos:
Management host: Encargado de dirigir los trabajos, repartirlos, crear una interfaz web
para la administración etc. básicamente es el que orquesta todo el sistema dirigiendo a
los Application hosts.
Application host: Son los encargados de hacer las tareas.
ZooKeeper: Es quien permite que la información de coordinación este distribuida entre
los Application hosts y el management host.

85
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 85 de 181
Ilustración 61 Arquitectura interna IBM
Cuando se crea un dominio sobre un cluster de máquinas (virtuales o no) por cada máquina que se denomina nodo X86 se crea un PEC (Procesing Element Container), sobre dicho Dominio se crea una instancia que es donde se van a colocar los trabajos.

86
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 86 de 181
Ilustración 62 Arquitectura de nodos de Streams En el momento en el que se lanza un trabajo sobre la instancia el Management Host se encarga de repartir los diferentes PEs en los Application host que corren sobre los PEC, aunque en algunos casos nos puede interesar que algún PE corra sobre un nodo especifico por que el hardware de ese nodo está más adaptado a esa necesidad (como por ejemplo una entrada TCP en el nodo que tiene una tarjeta de red potente). En caso de que un X86 Node se caiga, si no se ha fijado un PEC específico, el Management Host automáticamente relocaliza los Pes de ese PEC en otro, sin parar el sistema.
4.1.3.2 Sistema de almacenamiento
Puesto que la cantidad de datos procesados y no procesados a almacenar son una gran
cantidad, se opta por un sistema de almacenamiento no relacional que es capaz de trabajar de
manera distribuido.
En este caso, se ha usado HBASE corriendo sobre HDFS, por ofrecer escalabilidad y
organización clave-valor.
Para el despliegue de desarrollo se ha usado HBASE con el Zookeeper que viene embebido y en
vez de usar HDFS se usa el sistema de ficheros de Linux. Todo esto está corriendo en una
máquina virtual CentOS (la misma que corre IBM Streams).
Para explicar el despliegue de producción de HBASE primero hay que explicar el de HDFS

87
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 87 de 181
Ilustración 63 Arquitectura de HDFS
HDFS usa una arquitectura Maestro-esclavo, básicamente el NameNode es el encargado de
balancear, replicar, etc. los datos entre los DataNode. También es el encargado de las
peticiones de datos, si un cliente llega y solicita un dato, el NameNode es el que le informa a
que DataNode debe solicitarlo.
En principio solo se tiene un NameNode (se puede tener otro de respaldo, pero no activo) y
multitud de DataNodes (en principio lo adecuado es colocar uno por maquina) que se reparten
el trabajo d almacenamiento.

88
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 88 de 181
Ilustración 64 Arquitectura HBASE
En HBASE al igual que en otros sistemas que hemos visto, Zookeeper sirve para mantener la
información de coordinación además se tienen un nodo de administración llamado HMaster,
que es el encargado entre otras cosas de especificar las regiones a los HRegionServer y
coordinarlos. Aunque a diferencia de HDFS pocas veces tiene contacto con el cliente.
Dentro de un Hregion se almacenan las filas y columnas de la tabla, pero en caso de pasar un
tiempo por decisión de HMaster y liberar memoria, se escriben sobre HDFS.
4.1.4 Capa presentación
Para la Capa de presentación se han usado diferentes componentes para promover el desacoplamiento y así poder cambiar de tecnologías sin tener que modificar el sistema por completo.
4.1.4.1 Servidor Web
El servidor Web por un lado recibe peticiones tipo Get de la página del dashboard, entonces el
servidor genera la página Web según la sesión del solicitante. En la sesión se guarda las
gráficas y opciones que quiere el usuario.
Por otro lado, admite también peticiones del tipo Post que servirán tanto para añadir nuevas
vistas al Dashboard que se muestra en la Web como para eliminar las existentes.
Para estas tareas se ha usado Java Servlets y paginas JSP.

89
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 89 de 181
Los Servlets son un reemplazo efectivo para los CGI en los servidores que los soporten ya que
proporcionan una forma de generar documentos dinámicos utilizando las ventajas de la
programación en Java como conexión a alguna base de datos, manejo de peticiones
concurrentes, programación distribuida, etc.
[15]JavaServer Pages (JSP) es una tecnología que ayuda a los desarrolladores de software a
crear páginas web dinámicas basadas en HTML, XML, entre otros tipos de documentos. JSP es
similar a PHP, pero usa el lenguaje de programación Java.
Ilustración 65 funcionamiento del servidor Web
El funcionamiento de este sistema es el que sigue:
1. El navegador Web hace una petición Get o Post
2. Dentro del Servlet controller se hacen las operaciones pertinentes con dicha petición y
se selecciona una vista, que puede ser un JSP o Directamente un HTML
3. Cuando lo que se selecciona es una página JSP, se ejecuta el código que java que hay
dentro de la página que generara el resto del HTML
4. Una vez obtenido el HTML se le envía al navegador para que el usuario lo visualice.

90
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 90 de 181
Normalmente lo que se hace es que cuando se genera el JSP se soliciten los datos externos,
pero en este caso, se introduce un framework dentro del HTML que relegara el trabajo en el
navegador del cliente.
En el caso de despliegue tanto para desarrollo como para producción se usa un servidor
compatible con java Servlets, en este caso sea usado Apache TomCat 9 por su compatibilidad
con Java 8. Una ventaja de usar Servlets es que una vez finalizada la etapa de desarrollo se
puede exportar un fichero WAR y simplemente introduciendo este fichero en un servidor, ya
se puede desplegar la web en él.
4.1.4.2 Pagina Web
Puesto que la solicitud de datos recae sobre el cliente, requiere su propio apartado.
Para la visualización de la página se ha usado Bootstrap, un framework para el diseño de
Webs, que permite crear páginas web con un diseño muy minimalista y elegante y por otro
lado ya incluye funcionalidades de responsividad, es decir que según el tamaño y resolución de
la pantalla que visualice la pagina el contenido se reorganizara y redimensionara.
Por otro lado, las gráficas son generadas por la librería C3 que permite que las gráficas gocen
de efectos, interactividad y responsividad, además la propia librería es la encargada de hacer
las peticiones REST de los datos necesarios para generar las gráficas.
4.1.4.3 Servidor Rest
Este servidor es el encargado de recibir peticiones Web del tipo Get, y según los parámetros de
la petición conectarse a HBASE, descargar las tablas requeridas, y hacer los filtrados y
modificaciones pertinentes sobre las tablas para entregarlas acorde a la solicitud.
La ventaja de desacoplar esto del servidor Web es que en un futuro se pueden añadir nuevas
plataformas como aplicaciones móviles nativas o aplicaciones de ordenador en Windows o
Linux.
Para este servidor se ha usado Spring Boot App que permite de manera sencilla generar
servicios Rest con java, además al igual que con Servlets permite exportar un fichero WAR para
desplegar en cualquier servidor compatible.

91
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 91 de 181
4.2 Especificaciones del sistema
4.2.1 Limites del sistema
Se entiende como sistema al conjunto de todas las funcionalidades que se ofrece en los diferentes elementos del sistema StreamCity. Este sistema obtiene datos de los dos tipos de dispositivos, el del camión y el del contenedor, a través de un sistema de publicación /suscripción, una vez la información dentro de dicho sistema se puede recibir por el subsistema de procesamiento en streaming donde se le añadirán los filtrados y agregaciones pertinentes. Una vez hecho, se almacenan en repositorio. Para la interfaz de usuario con la que se pueden visualizar los datos almacenados se ha usado por un lado un subsistema de datos que ofrece los datos del repositorio mediante un interfaz común para navegadores y otro subsistema que despliega la interfaz web del usuario. Actores:
Usuario: Es la persona que solicita las vistas de las tablas y configura la web a su gusto.
Dispositivo (temporizador): Se encarga de cada X tiempo generar un evento para
marcar el tiempo r, ese evento se usa para enviar mediciones al sistema StreamCity.
Dispositivo (temporizador): Se encarga de cada X tiempo de manera simulada generar
un evento para marcar el tiempo, ese evento se usa para enviar mediciones al sistema
StreamCity.
Ilustración 66 Diagrama general de actores
4.2.2 Casos de uso
En este apartado se van a detallar el caso de uso del sistema, que se puede dividir en 3 actores y 6 subsistemas. Subsistemas:

92
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 92 de 181
Interfaz Web: Parte del sistema que se encarga de hacer de interfaz al usuario para
poder solicitar nuevas tablas o ver las actuales.
Interfaz Datos: Encargado de acceder al repositorio de datos y devolver la información
que es solicitada por el Interfaz Web.
Repositorio de Datos: punto del sistema donde se leen y almacenan los datos.
Simulador: Subsistema encargado de realizar una simulación para probar el correcto
funcionamiento del sistema en el desarrollo del mismo.
Dispositivo: Elemento real que toma mediciones del llenado del mismo para enviarlo
para su procesamiento.
Procesador Streaming: Es la parte más importante del sistema, es el encargado de
procesar en tiempo real todos los datos que le llegan.
Ilustración 67 Diagrama de casos de uso del sistema
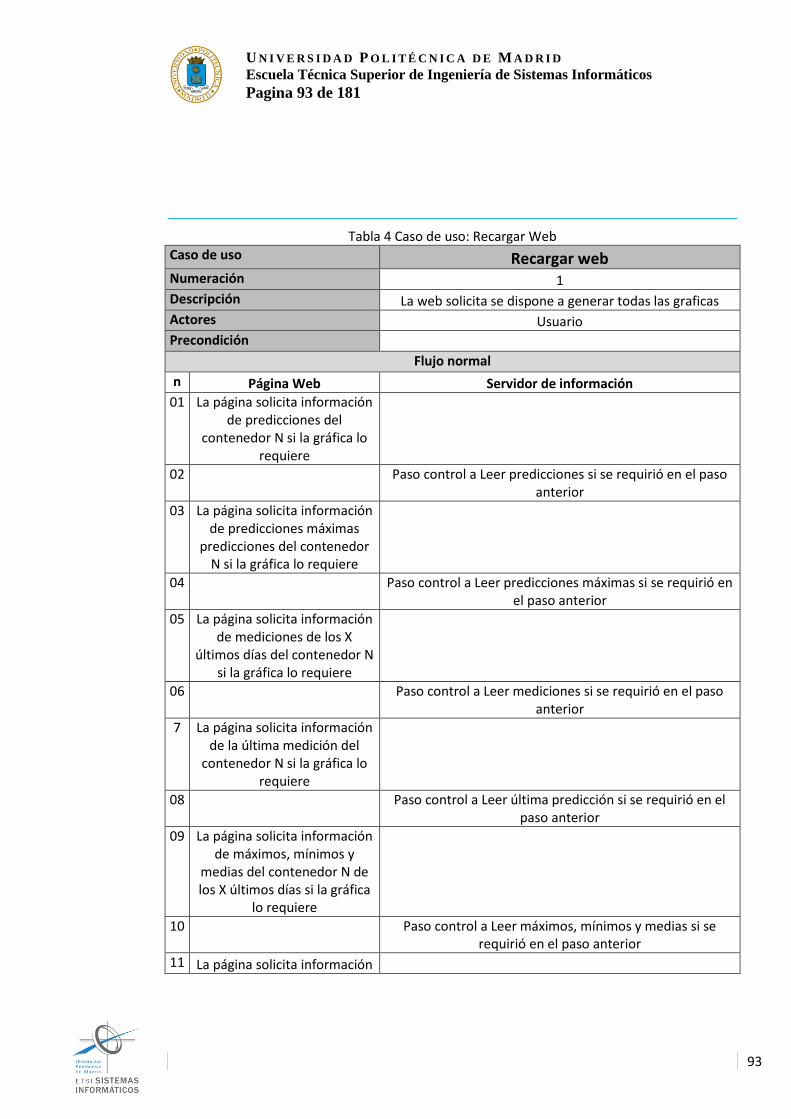
93
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 93 de 181
Tabla 4 Caso de uso: Recargar Web Caso de uso Recargar web Numeración 1
Descripción La web solicita se dispone a generar todas las graficas
Actores Usuario
Precondición
Flujo normal
n Página Web Servidor de información
01 La página solicita información de predicciones del
contenedor N si la gráfica lo requiere
02
Paso control a Leer predicciones si se requirió en el paso anterior
03 La página solicita información de predicciones máximas
predicciones del contenedor N si la gráfica lo requiere
04
Paso control a Leer predicciones máximas si se requirió en el paso anterior
05 La página solicita información de mediciones de los X
últimos días del contenedor N si la gráfica lo requiere
06
Paso control a Leer mediciones si se requirió en el paso anterior
7 La página solicita información de la última medición del
contenedor N si la gráfica lo requiere
08
Paso control a Leer última predicción si se requirió en el paso anterior
09 La página solicita información de máximos, mínimos y
medias del contenedor N de los X últimos días si la gráfica
lo requiere
10
Paso control a Leer máximos, mínimos y medias si se requirió en el paso anterior
11 La página solicita información

94
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 94 de 181
de la proporción del contenedor N de los X últimos
días si la gráfica lo requiere
12
Paso control a Leer última proporción si se requirió en el paso anterior
13 La página solicita información de las últimas proporciones diarias del contenedor N de
los X últimos días si la gráfica lo requiere
14
Paso control a Leer proporciones diarias si se requirió en el paso anterior
15 Retorno de control
Postcondición
Tabla 5 Caso de uso: Leer predicciones Caso de uso Leer predicciones Numeración 2
Descripción Se obtienen los datos de predicciones
Actores Usuario
Precondición
Flujo normal
N Interfaz datos Repositorio Datos
01 Solicitud de todos los datos de predicción
02 Paso controla leer datos
03 Se guardan los datos en variables ordenados de forma jerárquica por contenedor y
por fecha de evento.
04 Se filtra el resultado por el contenedor que se solicitó
05 Se convierten a formato adecuado para la Web
06 Se envían todos los datos al solicitante
07 Retorno de control
Postcondición
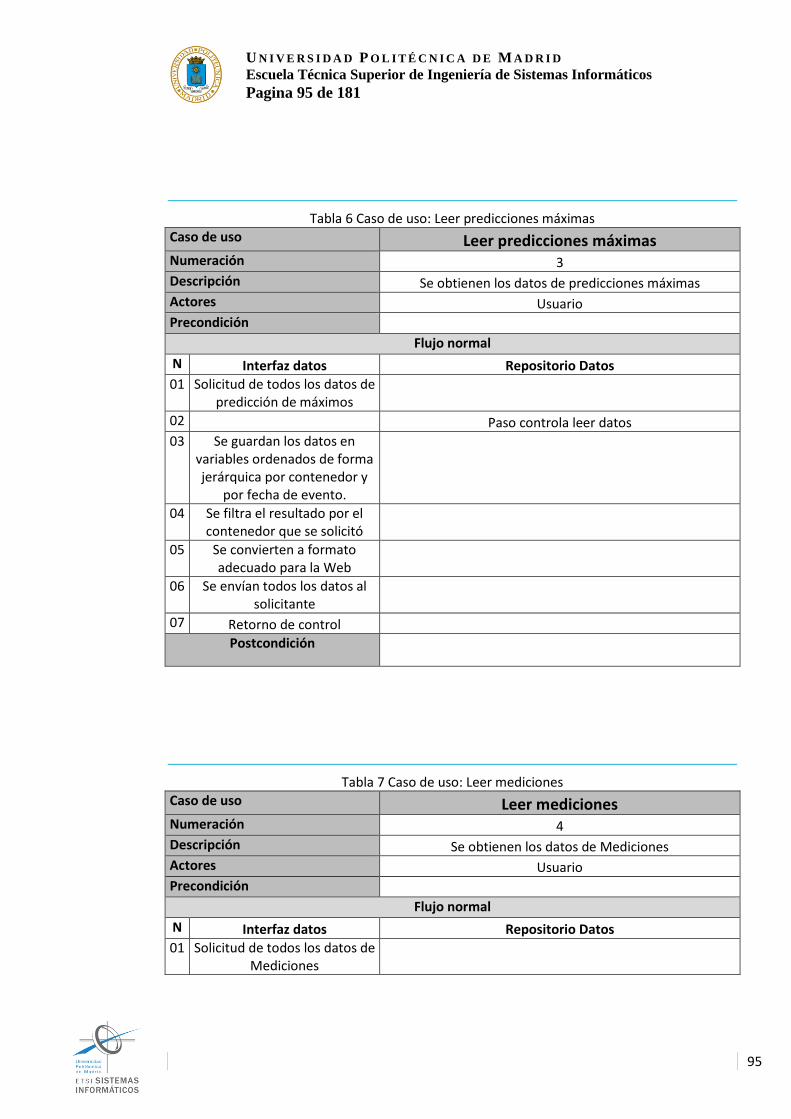
95
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 95 de 181
Tabla 6 Caso de uso: Leer predicciones máximas Caso de uso Leer predicciones máximas Numeración 3
Descripción Se obtienen los datos de predicciones máximas
Actores Usuario
Precondición
Flujo normal
N Interfaz datos Repositorio Datos
01 Solicitud de todos los datos de predicción de máximos
02
Paso controla leer datos
03 Se guardan los datos en variables ordenados de forma jerárquica por contenedor y
por fecha de evento.
04 Se filtra el resultado por el contenedor que se solicitó
05 Se convierten a formato adecuado para la Web
06 Se envían todos los datos al solicitante
07 Retorno de control
Postcondición
Tabla 7 Caso de uso: Leer mediciones Caso de uso Leer mediciones Numeración 4
Descripción Se obtienen los datos de Mediciones
Actores Usuario
Precondición
Flujo normal
N Interfaz datos Repositorio Datos
01 Solicitud de todos los datos de Mediciones

96
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 96 de 181
02 Paso controla leer datos
03 Se guardan los datos en variables ordenados de forma jerárquica por contenedor y
por fecha de evento.
04 Se filtra el resultado por el contenedor que se solicitó y en las fechas que se solicitó
05 Se convierten a formato adecuado para la Web
06 Se envían todos los datos al solicitante
07 Retorno de control
Postcondición
Tabla 8 Caso de uso: Leer última predicción
Caso de uso Leer última medición Numeración 5
Descripción Se obtienen los datos de última medición
Actores Usuario
Precondición
Flujo normal
N Interfaz datos Repositorio Datos
01 Solicitud de todos los datos de las últimas mediciones
02 Paso controla leer datos
03 Se guardan los datos en variables ordenados de forma jerárquica por contenedor y
por fecha de evento.
04 Se filtra el resultado por el contenedor que se solicitó.
05 Se convierten a formato adecuado para la Web
06 Se envían todos los datos al solicitante
07 Retorno de control
Postcondición
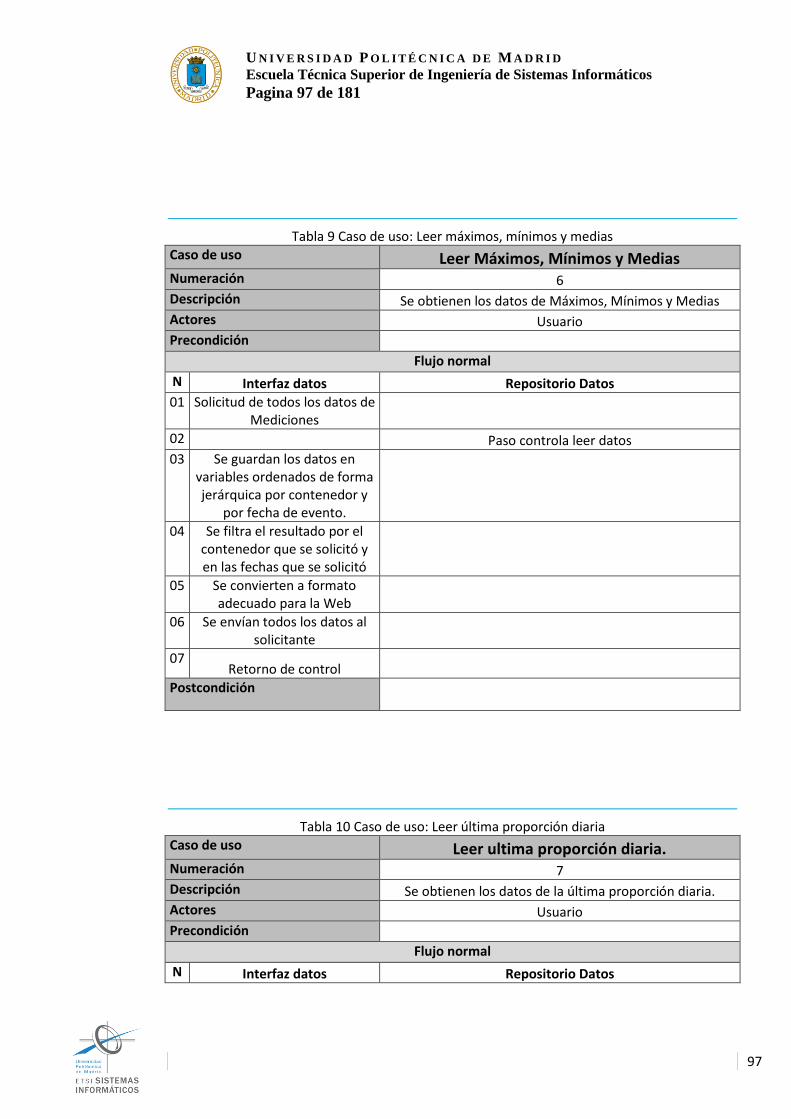
97
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 97 de 181
Tabla 9 Caso de uso: Leer máximos, mínimos y medias Caso de uso Leer Máximos, Mínimos y Medias Numeración 6
Descripción Se obtienen los datos de Máximos, Mínimos y Medias
Actores Usuario
Precondición
Flujo normal
N Interfaz datos Repositorio Datos
01 Solicitud de todos los datos de Mediciones
02 Paso controla leer datos
03 Se guardan los datos en variables ordenados de forma jerárquica por contenedor y
por fecha de evento.
04 Se filtra el resultado por el contenedor que se solicitó y en las fechas que se solicitó
05 Se convierten a formato adecuado para la Web
06 Se envían todos los datos al solicitante
07 Retorno de control
Postcondición
Tabla 10 Caso de uso: Leer última proporción diaria Caso de uso Leer ultima proporción diaria. Numeración 7
Descripción Se obtienen los datos de la última proporción diaria.
Actores Usuario
Precondición
Flujo normal
N Interfaz datos Repositorio Datos

98
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 98 de 181
01 Solicitud de todos los datos de proporciones
02 Paso controla leer datos
03 Se guardan los datos en variables ordenados de forma jerárquica por contenedor y
por fecha de evento.
04 Se filtra el resultado por el contenedor que se solicitó y
se filtra a el dato más reciente
05 Se convierten a formato adecuado para la Web
06 Se envían todos los datos al solicitante
07 Retorno de control
Postcondición
Tabla 11 Caso de uso: Leer proporciones diarias
Caso de uso Leer proporciones diarias. Numeración 8
Descripción Se obtienen los datos de proporciones diarias.
Actores Usuario
Precondición
Flujo normal
N Interfaz datos Repositorio Datos
01 Solicitud de todos los datos de proporciones
02 Paso controla leer datos
03 Se guardan los datos en variables ordenados de forma jerárquica por contenedor y
por fecha de evento.
04 Se guardan los datos en variables ordenados de forma jerárquica por contenedor y
por fecha de evento.
05 Se convierten a formato adecuado para la Web
06 Se envían todos los datos al solicitante

99
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 99 de 181
07 Retorno de control
Postcondición
Tabla 12 Caso de uso: Leer datos
Caso de uso Leer Datos. Numeración 9
Descripción Se envían los datos del repositorio.
Actores Usuario
Precondición
Flujo normal
N Repositorio Datos Interfaz datos
01 Se obtiene la tabla de la que se quiere obtener datos
02 Se envían hacia el interfaz de datos
03 Se reciben los datos.
04
Retorno de control
Postcondición
Tabla 13 Caso de uso: Generar datos de simulación Caso de uso Generar datos de simulación Numeración 10
Descripción Se genera señal a señal la simulación de los contenedores respecto a los camiones de recogida
Actores Temporizador
Precondición
Flujo normal
n Temporizador Simulador
01 Se emite una señal de

100
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 100 de 181
temporización
02
Se recibe la señal y se avanza el tiempo de la ruta del camión disminuyendo la cantidad de tiempo hasta el
siguiente contenedor.
03
Se notifica a todos los contenedores el paso del tiempo.
04
Los contenedores se llenan una cantidad aleatoria dependiente de la hora de la simulación.
05 Se obtiene la cantidad de llenado actual.
06 Se añade una marca de tiempo
07 Se envía hacia el sistema de procesamiento Fast Data
08 Paso control a recibir Datos.
Postcondición
Flujo alternativo: Paso por contenedor
Usuario sistema
02
Se recibe la señal, se detecta que se ha llegado a un contenedor, se genera el tiempo aleatorio necesario para
llegar al siguiente y se avanza el tiempo de la ruta del camión disminuyendo la cantidad de tiempo hasta el
siguiente contenedor.
03
Se notifica a todos los contenedores el paso del tiempo.
04
Los contenedores se llenan una cantidad aleatoria dependiente de la hora de la simulación a excepción del
contendor que se alcanzado que se vacía hasta un mínimo aleatorio.
Tabla 14 Caso de uso: Leer valor Caso de uso Leer Valor Numeración 11
Descripción Se obtienen las mediciones de la cantidad de residuos en el contendor con cada señal.
Actores Temporizador
Precondición
Flujo normal
n Temporizador Simulador
01 Se emite una señal de temporización
02
Se recibe la señal y se mide el llenado del contenedor
03
Si la diferencia absoluta entre la medida anterior y la

101
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 101 de 181
nueva es muy grande y el flag de descartada esta bajada, se descartada la nueva medición, se mantiene la vieja y
se pone el flag de descartada a alto. En caso contrario se baja el flag y guarda la nueva
medición.
04 Se añade una marca de tiempo
05 Se envía hacia el sistema de procesamiento Fast Data
06 Paso control a recibir Datos.
Postcondición
Tabla 15 Caso de uso: Recibir Datos
Caso de uso Recibir Datos Numeración 12
Descripción Se reciben los datos de las mediciones de contenedores
Actores Temporizador
Precondición
Flujo normal
n Sistema Fast Data
01 Se recibe el mensaje de valor del contenedor
02 Se pasa el control a enviar datos con los datos recibidos en bruto
03 Se pasa control a diezmar
04 Se pasa control a Calcular máximos mínimos y medias
05 Se pasa control a Calcular proporción diaria
06 Retorno de control
Postcondición
Tabla 16 Caso de uso: Diezmar
Caso de uso Diezmar Numeración 13
Descripción Se hacen medidas de 20 en 20
Actores Temporizador

102
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 102 de 181
Precondición
Flujo normal
n Sistema Fast Data
01 Se añade al conjunto de datos la medición actual
02 Retorno de control
Postcondición
Flujo alternativo más de 20 mediciones acumuladas
N Sistema Fast Data
01 Se halla la media del conjunto de 20 mediciones
02 Se vacía el conjunto
03 Se pasa control a Integrar
04 Se pasa control a Predecir en modo continuo
05 Se pasa control a Enviar datos
06 Retorno de control
Postcondición
Tabla 17 Caso de uso: Predecir máximo
Caso de uso Predecir el máximo Numeración 14
Descripción Se reciben los datos de las mediciones de contenedores
Actores Temporizador
Precondición
Flujo normal
n Sistema Fast Data
01 Se toma la última medición del máximo diario
02 En conjunto con las anteriores mediciones de máximos diarios se predicen los dos siguientes máximos de los próximos días
03 Se pasa control a enviar datos
04 Retorno de control
Postcondición
Tabla 18 Caso de uso: Calcular máximo, mínimo y media Caso de uso Calcular Máximo mínimo y media

103
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 103 de 181
Numeración 15
Descripción Se reciben los datos de las mediciones de contenedores
Actores Temporizador
Precondición
Flujo normal
n Sistema Fast Data
01 Se añade al conjunto de datos la medición actual
02 Retorno de control
Postcondición
Flujo alternativo más de 74 mediciones acumulada
N Sistema Fast Data
01 Se halla el máximo, el mínimo y la media del conjunto de 74 mediciones y se vacía de conjunto
02 Se pasa control a Predecir Máximo
03 Se pasa control a Enviar datos
04 Retorno de control
Tabla 19 Caso de uso: Predecir en modo continuo Caso de uso Predecir en modo continuo Numeración 16
Descripción Se predicen las siguientes 48 horas del comportamiento del contenedor
Actores Temporizador
Precondición
Flujo normal
n Sistema Fast Data
01 Se toma la última medición de la media del diezmado
02 En conjunto con las anteriores mediciones de las medias se predicen las siguientes mediciones de los próximos dos días
03 Se pasa control a enviar datos
04 Retorno de control

104
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 104 de 181
Postcondición
Tabla 20 Caso de uso: Integrar Caso de uso Integrar Numeración 17
Descripción Se integra de manera discreta las medidas de las últimas 24 horas
Actores Temporizador
Precondición
Flujo normal
n Sistema Fast Data
01 Se suman todas las medidas que ha habido en las últimas 24 horas
02 Se dividen entre el número de medidas sumadas
03 Se pasa control a enviar datos
04 Retorno de control
Postcondición
Tabla 21 Caso de uso: Enviar Datos
Caso de uso Enviar datos Numeración 18
Descripción Se integra de manera discreta las medidas de las últimas 24 horas
Actores Temporizador
Precondición
Flujo normal
n Sistema Fast Data
01 Se convierten los datos a un formato adecuado para el repositorio de datos
02 Se pasa control a introducir datos
03 Retorno de control
Postcondición

105
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 105 de 181
Tabla 22 Caso de uso: Introducir datos Caso de uso Introducir Datos Numeración 19
Descripción Se obtienen las mediciones de la cantidad de residuos en el contendor con cada señal.
Actores Temporizador
Precondición
Flujo normal
n Sistema Fast Data Repositorio Datos
01 Se envían los datos formateados al repositorio
de datos
02
Se reciben los datos y se almacenan en la tabla adecuada
03
Retorno de control
Postcondición
Caso de uso Ver Web Numeración 20
Descripción Se solicita ver la web con las vistas
Actores Usuario
Precondición
Flujo normal
n Navegador usuario Servidor de web
01 El usuario solicita la web al servidor.
02
Se genera la web con las vistas ya creadas en caso de que las haya.
03
Se envía al Usuario la web generada
04 La web se visualiza en el navegador
05 Se pasa control a recargar web
Postcondición
Caso de uso Crear panel Numeración 21
Descripción En la web se crea una nueva vista

106
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 106 de 181
Actores Usuario
Precondición
Flujo normal
n Navegador usuario Servidor de web
01 Se selecciona el contenedor que se desea ver
02 Se seleccionan los dias que se quieren ver al pasado
03 Se marcan las opciones que se quieren ver en las graficas
04 Se selecciona que información adicional se quiere
05 Se pulsa añadir
06
Se genera la nueva vista que se añade a las ya hechas en la sesión.
07 Se pasa control a ver web
Postcondición
Caso de uso Borrar panel Numeración 22
Descripción En la web se elimina una vista
Actores Usuario
Precondición Tener un panel como mínimo en la sesión actual.
Flujo normal
n Navegador usuario Servidor de web
01 Se pulsa el botón eliminar en la vista deseada
02
Se elimina la vista a la sesión.
03 Se pasa control a ver web
Postcondición
4.3 Descripción de la aplicación
En este punto se describe como se compone la aplicación de una manera técnica, dividiendo
en subsistemas para una mayor comprensión.
4.3.1 Dagramas de clase
En este apartado se revisan los diferentes subsistemas con sus diagramas de clases para poder analizar mejor la arquitectura del programa. Para el interfaz de datos se ha usado un diagrama de clases, sin embargo, para el simulador y
para el analizador al ser sistemas orientados a streaming se ha decidido plasmarlos a modo de

107
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 107 de 181
“pipes and filters”, básicamente en las cajas que son los filters, se realizan operaciones y quien
se encarga de transmitir datos entre ellos son los pipes, que son las tuberías que los conectan.
4.3.1.1 Simulador.
El subsistema simulador es el encargado de que en tiempo real (o en tiempo simulado) generar
tuplas para enviar hacia el sistema de procesamiento, simulando un contenedor real de
basura.
Pipes
Pulse
o Integer: counter
PulseNumberEmpty
o Integer: emptyNumber
o Integer: counter
PulseEmpty
o Integer: empty
o Integer: counter
FillContainerOut
o Float: fill
o Date: timeStamp
o Integer: id
o Double: lat
o Double: lng
FillContainerOutWTopic
o String: JSON
o String: Topic
FillContainerOutJSON

108
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 108 de 181
o String: JSON
Filters
PulseGenerator:
o Output: Pulse
Genera X tuplas vacías, y envía todas por la salida.
Según la cantidad de tupla generadas varia la duración de la simulación
ThrottledPulse:
o Input: Pulse
o Output: Pulse
Actúa de regulador de flujo de tuplas, toma todo lo que llega por la entrada y lo va
introduciendo en la salida a una frecuencia X establecida.
CicleCount:
o Input: Pulse
o Output: Pulse
Guarda internamente un contador que va de 0 a 1439, que son los minutos que
tiene un día. Con cada tupla que entre aumenta dicho contador y lo adjunta a la
tupla cuando la envía por la salida. En caso de llegar a 1439 el contador se reinicia.
TruckRSim:
o Input: Pulse
o Output: PulseNumberEmpty
Genera una simulación por medio de distribuciones.
Puesto que las tuplas de entrada marcan el transcurso del tiempo, este
componente simula el comportamiento de una ruta de recogida de residuos.

109
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 109 de 181
Es decir, simula el viaje de un camión por una ruta que incluye 6 contenedores de
residuos.
Hace uso del toolkit com.ibm.streams.rproject
Hay dos tipos de posibles salidas:
o Salida 0: en este caso señaliza que ha pasado un minuto pero que no se ha
recogido ningún contenedor.
o Salida Xⱻ [1-6]: En este caso además de señaliza el paso de un minuto de
tiempo señaliza también que se ha vaciado el contenedor X, siendo X el
número que se envía por la salida.
MuxOutput:
o Input: PulseNumberEmpty
o Output: PulseEmpty
Actúa a modo de multiplexor, si le entra un 0, envía un 0 por todas sus salidas, en
caso de recibir X ⱻ [1-6] envía un 0 por todas las salidas a excepción de la salida X
por la cual envía un 1.
FailGenerator_:
o Input: PulseEmpty
o Output: PulseEmpty
Sirve para simular fallos en el servicio, haciendo que no se vacié ese día el
contenedor.
Si recibe un 0 envía un 0 por la salida, en caso de recibir un 1 hay X% de
posibilidades de que en la salida se envié un 0 en vez de un 1, ese parámetro X es
modificable.
Container_:
o Input: PulseEmpty
o Output: FillContainerOut
Simula el comportamiento de un contenedor a lo largo de un día.
Por medio de distribuciones, simula cuanto se llena el contendor por cada tupla
que le entra (que le indica que ha pasado un minuto)

110
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 110 de 181
En caso de recibir un 0 se llena una cantidad aleatorias variable según el minuto
del día (usa el campo que se le escribió a la tupla en cicleCount)
Si recibe un 1 vacía el contenedor a un valor bajo aleatorio.
Por cada entrada de una tupla emite por la salida otra tupla con la cantidad de
llenado que tiene el contenedor en ese momento.
Hace uso del toolkit com.ibm.streams.rproject
DateAdd_:
o Input: FillContainerOut
o Output: FillContainerOut
Agrega a la tupla que le entra una etiqueta con la fecha simulada (se incrementa
un minuto con cada tupla que pasa), el número del contenedor y la posición en la
que se encuentra y la envía por la salida.
UnionContainers:
o Input: FillContainerOut
o Output: FillContainerOut
Todo lo que le llega por las entradas los emite por las salidas.
• TupleToJSON:
o Input: FillContainerOut
o Output: FillContainerOutJSON
Convierte la tupla en otra pero que solo tiene un campo del topo String en la que
se meten los datos en formato JSON.
Hace uso del toolkit com.ibm.streamsx.json
TopicAdd:
o Input: FillContainerOutJSON
o Output: FillContainerWTopic
Añade a la tupla el topic al que se tiene que enviar.

111
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 111 de 181
FileSinkOut:
o Input: FillContainerOut
Todas las tuplas que le entran, las escribe en un fichero en formato CSV.
KafkaExplorer
o Input: FillContainerOut
Todas las tuplas que le entran, las escribe las envía a un sistema Kafka.
Hace uso del toolkit com.ibm.streamsx.messaging 3.0.0

112
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 112 de 181
Ilustración 68 Diagrama de flujo del simulador

113
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 113 de 181
4.3.1.2 Procesador principal.
Es el encargado de procesar todos los datos en tiempo real, añadiendo agregaciones que serán
útil tanto para la administración del sistema como de la medición de la calidad del servicio.
Pipes
FillContainerIn
o Float: fill
o Date: timeStamp
o Integer: id
o Double: lat
o Double: lng
FillContainerInString
o String: JSONString
FillContainerInConverted
o String: fill
o String: timeStamp
o String: id
o String: lat
o String: lng
FillContainerDayIn
o Array Float: fill
o Date: timeStamp
o Integer: id
FillContainerDayPred
o Array Float: fill
o Array Date: timeStamp

114
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 114 de 181
o Integer: id
FillContainerDayPredConverted
o Array Float: fill
o Date: timeStamp
o Integer: id
o Integer: index
FillContainerDayQuarts
o Float: firstQuart
o Float: secondQuart
o Float: thirdQuart
o Float: fourthQuart
o Date: timeStamp
o Integer: id
FillContainerDayQuartsConverted
o String: firstQuart
o String: secondQuart
o String: thirdQuart
o String: fourthQuart
o String: timeStamp
o String: id
FillContainerMinMaxMean
o Float: min
o Float: max
o Float: mean
o Date: timeStamp

115
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 115 de 181
o Integer: id
FillContainerMinMaxMeanConverted
o Float: min
o Float: max
o Float: mean
o Date: timeStamp
o Integer: id
Filters
El parámetro “partition by” significa que trabaja de manera completamente independiente
con las tuplas que tengan diferentes IDs, es decir que, si hace una media o un sumatorio
de 20 tuplas, lo hace por separado para cada ID, hace la media o el sumatorio de las 20
tuplas que tengan el mismo ID.
En el caso de los componentes que escriban sobre repositorios, en los parámetros de
output cuando están entre “comillas” significa que el valor siempre es ese tupla tras tupla,
si no está entre comillas es un valor tomado de la tupla que ha llegado.
InputSource:
o Output: FillContainerInString
Lee de un fichero CSV tuplas y las envía por la salida.

116
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 116 de 181
KafkaImporter:
o Output: FillContainerInString
Lee las tuplas que le llegan por kafka y las envía por la salida.
Usa el toolkit com.ibm.streamsx.messaging.
JSONToTuple
o Input: FillContainerInString
o OutPut: FillContainerIn
Usa el toolkit com.ibm.streamsx.json
UnionInput:
o Input: FillContainerIn
o Output: FillContainerIn
Todo lo que le llega por las entradas los emite por las salidas.
Diezmator:
o Input: FillContainerIn
o Output: FillContainerIn
o Partition by: id
La versión de producción lo que hace es una media de las tuplas que han llegado
en los últimos 10 minutos, en la versión para el simulador por cada 20 tuplas que
le llegan, envía una cuyo valor de llenado es la media de las 20 recibidas y la
etiqueta de tiempo de la última recibida.
AllDayPack:
o Input: FillContainerIn
o Output: FillContainerDayIn
o Partition by: id

117
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 117 de 181
Cuando recibe todas las tuplas de un día (72) envía una tupla por la sálica con la
fecha de la última recibida, el id de la partición y un array con todas las tuplas del
día juntas.
CountDay:
o Input: FillContainerDayIn.
o Output: FillContainerDayQuarts
Por cada tupla que le llega haya sobre el array de llenados el porcentaje de ellas
que se encuentran entre [<0.25, 0.25-0.50, 0.50-0.75, >0.75], y los envía por las
salidas junto al id y a la etiqueta de tiempo recibida.
ConversorCountDay:
o Input: FillContainerDayQuarts
o Output: FillContainerDayQuartsConverted
Por cada tupla que le llega convierte los campos a String para poder introducirlo
en el repositorio y poder leer los datos directamente.
SinkCountFirst:
o Input: FillContainerDayQuartsConverted
o Output:
Table:” countDay”
Row Key: timeStamp
Column family:” firstQuart”
Column qualifiers: id
Value: firstQuart
Por cada tupla que le llega convierte la introduce en el repositorio Hbase
siguiendo los campos descritos en output.
Hace uso del toolkit com.ibm.streamsx.hbase 2.0.0.
SinkCountSecond:

118
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 118 de 181
o Input: FillContainerDayQuartsConverted
o Output:
Table:” countDay”
Row Key: timeStamp
Column family: “secondQuart”
Column qualifiers: id
Value: secondQuart
Por cada tupla que le llega convierte la introduce en el repositorio Hbase
siguiendo los campos descritos en output.
Hace uso del toolkit com.ibm.streamsx.hbase 2.0.0.
SinkCountThird:
o Input: FillContainerDayQuartsConverted
o Output:
Table: “countDay”
Row Key: timeStamp
Column family: “thirdQuart”
Column qualifiers: id
Value: thirdQuart
Por cada tupla que le llega convierte la introduce en el repositorio Hbase
siguiendo los campos descritos en output.
Hace uso del toolkit com.ibm.streamsx.hbase 2.0.0.
SinkCountFourth:
o Input: FillContainerDayQuartsConverted
o Output:
Table: “countDay”
Row Key: timeStamp

119
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 119 de 181
Column family: “fourthQuart”
Column qualifiers: id
Value: fourthQuart
Por cada tupla que le llega convierte la introduce en el repositorio Hbase
siguiendo los campos descritos en output.
Hace uso del toolkit com.ibm.streamsx.hbase 2.0.0.
AutoFore:
o Input: FillContainerIn.
o Output: FillContainerDayPred
o Partition by: id
Por cada tupla que le llega hace una predicción de los valores de llenado de los 2
días siguientes (144 mediciones) en la salida introduce un array con los 144
valores, otro con las 144 etiquetas de tiempo y el Id del contenedor.
El método utilizado para la predicción es el uso de las mediciones de la última
semana como mínimo (504 mediciones) junto con métodos de análisis como son
regresión lineal, ARIMA etc.
Hace uso del toolkit com.ibm.streams.timeseries.
ConversorCountDay:
o Input: FillContainerDayPred
o Output: FillContainerInConverted
Por cada tupla que le llega, recorre todos los valores de llenados y de etiquetas de
tiempo y los envía por separado por la salida convirtiendo los campos a String
añadiéndole un índice para poder introducirlo en el repositorio y poder leer los
datos directamente.
SinkPredDate:

120
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 120 de 181
o Input: FillContainerDayPredConverted
o Output:
Table: “predictions”
Row Key: id
Column family:” values”
Column qualifiers: index
Value: timeStamp
Por cada tupla que le llega convierte la introduce en el repositorio Hbase
siguiendo los campos descritos en output, en este caso sobre escribe la tupla
anterior con mismo id y con mismo índice.
Hace uso del toolkit com.ibm.streamsx.hbase 2.0.0.
SinkPredValue:
o Input: FillContainerDayPredConverted
o Output:
Table: “predictions”
Row Key: id
Column family: “values”
Column qualifiers: index
Value: fill
Por cada tupla que le llega convierte la introduce en el repositorio Hbase
siguiendo los campos descritos en output, en este caso sobre escribe la tupla
anterior con mismo id y con mismo índice.
Hace uso del toolkit com.ibm.streamsx.hbase 2.0.0.
ConversorMeasures:
o Input: FillContainerIn
o Output: FillContainerInConverted

121
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 121 de 181
Por cada tupla que le llega convierte los campos a String para poder introducirlo en el
repositorio y poder leer los datos directamente.
SinkMeasures:
o Input: FillContainerInConverted
o Output:
Table: “measures”
Row Key: timeStamp
Column family: “container”
Column qualifiers: id
Value: fill
Por cada tupla que le llega convierte la introduce en el repositorio Hbase
siguiendo los campos descritos en output.
Hace uso del toolkit com.ibm.streamsx.hbase 2.0.0.
SinkLastMEasure:
o Input: FillContainerInConverted
o Output:
Table: “lastMeasures”
Row Key: id
Column family:” lastFill”
Column qualifiers:” fill”
Value: fill
Por cada tupla que le llega convierte la introduce en el repositorio Hbase
siguiendo los campos descritos en output, en este caso sobrescribe la tupla
anterior con mismo id.
Hace uso del toolkit com.ibm.streamsx.hbase 2.0.0.

122
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 122 de 181
Integer:
o Input: FillContainerIn.
o Output: FillContainerIn
o Partition by: id
Por cada tupla que le llega hace el sumatorio de ella y las 72 anteriores (un día de
mediciones) y la divide entre el número de mediciones sumadas, es decir hace la
media de ella y de las 71 anteriores mediciones por cada tupla que entra.
La salida es el resultado de esa media y la id y la fecha de la última que entro
ConversorInteger:
o Input: FillContainerIn
o Output: FillContainerInConverted
Por cada tupla que le llega, recorre todos los valores de llenados y de etiquetas de
tiempo y los envía por separado por la salida convirtiendo los campos a String para
poder introducirlo en el repositorio y poder leer los datos directamente.
SinkInteger:
o Input: FillContainerInConverted
o Output:
Table:” integral”
Row Key: timeStamp
Column family:” container”
Column qualifiers: id
Value: fill
Por cada tupla que le llega convierte la introduce en el repositorio Hbase
siguiendo los campos descritos en output.
Hace uso del toolkit com.ibm.streamsx.hbase 2.0.0.
MinMaxMean:

123
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 123 de 181
o Input: FillContainerIn.
o Output: FillContainerMinMaxMean
o Partition by: id
Por cada 1440 tuplas que le llegan (1 día de mediciones), envía una que incluye
el máximo, el mínimo y la media de las 1440 l recibidas y la etiqueta de tiempo
de la última recibida.
ConversorMinMaxMean:
o Input: FillContainerMinMaxMeanConverted
o Output: FillContainerMinMaxMeanConverted
Por cada tupla que le llega convierte los campos a String para poder introducirlo
en el repositorio y poder leer los datos directamente.
SinkMean:
o Input: FillContainerMinMaxMeanConverted
o Output:
Table: “MaxMeanMin”
Row Key: timeStamp
Column family:” MMM”
Column qualifiers:” mean”
Value: mean
Por cada tupla que le llega convierte la introduce en el repositorio Hbase
siguiendo los campos descritos en output.
Hace uso del toolkit com.ibm.streamsx.hbase 2.0.0.
SinkMax:
o Input: FillContainerMinMaxMeanConverted
o Output:
Table: “MaxMeanMin”

124
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 124 de 181
Row Key: timeStamp
Column family:” MMM”
Column qualifiers:” max”
Value: max
Por cada tupla que le llega convierte la introduce en el repositorio Hbase
siguiendo los campos descritos en output.
Hace uso del toolkit com.ibm.streamsx.hbase 2.0.0.
SinkMin:
o Input: FillContainerMinMaxMeanConverted
o Output:
Table:” MaxMeanMin”
Row Key: timeStamp
Column family:” MMM”
Column qualifiers:” min”
Value: min
Por cada tupla que le llega convierte la introduce en el repositorio Hbase
siguiendo los campos descritos en output.
Hace uso del toolkit com.ibm.streamsx.hbase 2.0.0.
AutoForeMax:
o Input: FillContainerMinMaxMean.
o Output: FillContainerDayPred
o Partition by: id
Por cada tupla que le llega hace una predicción de los valores de llenado máximos
de los 2 días siguientes (2 mediciones)
En la salida introduce un array con los 2 valores, otro con las 2 etiquetas de tiempo
y el Id del contenedor.

125
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 125 de 181
El método utilizado para la predicción es el uso de las mediciones máximas del
último año como mínimo (365 mediciones) junto con métodos de análisis como
son regresión lineal, ARIMA etc.
Hace uso del toolkit com.ibm.streams.timeseries.
ConversorCountDay:
o Input: FillContainerDayPred
o Output: FillContainerDayPredConverted
Por cada tupla que le llega, recorre todos los valores de llenados y de etiquetas de
tiempo y los envía por separado por la salida convirtiendo los campos a String y
añadiendo un numero de índice para poder introducirlo en el repositorio y poder
leer los datos directamente.
SinkAFMaxDate:
o Input: FillContainerDayPredConverted
o Output:
Table:” predicionsMax”
Row Key: id
Column family:” timestamps”
Column qualifiers: index
Value: timeStamp
Por cada tupla que le llega convierte la introduce en el repositorio Hbase
siguiendo los campos descritos en output, en este caso sobre escribe la tupla
anterior con mismo id y con mismo índice.
Hace uso del toolkit com.ibm.streamsx.hbase 2.0.0.
SinkAFmaxValue:
o Input: FillContainerDayPredConverted
o Output:

126
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 126 de 181
Table:” predicionsMax”
Row Key: id
Column family:” values”
Column qualifiers: index
Value: fill
Por cada tupla que le llega convierte la introduce en el repositorio Hbase
siguiendo los campos descritos en output, en este caso sobre escribe la tupla
anterior con mismo id y con mismo índice
Hace uso del toolkit com.ibm.streamsx.hbase 2.0.0.

127
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 127 de 181
Ilustración 69 Diagrama de flujo del procesador principal .

128
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 128 de 181
4.3.1.3 Interfaz de datos
Es el subsistema encargado de recibir peticiones GET HTTP, descargarse la información del
repositorio de datos, filtrar los datos importantes y enviarlos al solicitante en formato REST.
Application
Encargada de arrancar todos los servicios REST de la aplicación.
o +main (args: String)
Función que arranca los servicios.
FacadeController
Clase que contiene todas las interfaces de acceso desde peticiones GET.
o +LastIntegerDays (container: String, days: String): String
Función web que devuelve los valores dela integral deslizante continua de los
“days” últimos días del contenedor “container”.
o +LastIntegerDaysSim (container: String, days: String): String
Función web que devuelve los valores dela integral deslizante continua “days”
últimos días del contenedor “container” (versión para simulación).
o +LastMeasureDays (container: String, days: String): String
Función web que devuelve los valores de llenado n últimos días del
contenedor “container”.
o +LastMeasureDaysSim (container: String, days: String): String
Función web que devuelve los valores de los “days” últimos días del
contenedor “container” (versión para simulación).
o +MaxMeanMin (container: String, days: String): String
Función web que devuelve los máximos, mínimos y medias de los “days”
últimos días del contenedor “container”.
o +MaxMeanMinSim (container: String, days: String): String

129
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 129 de 181
Función web que devuelve los máximos mínimos y medias de los “days”
últimos días del contenedor “container” (versión para simulación).
o +Prediction (container: String): String
Función web que devuelve los valores que se predicen que tendrá el
contenedor “container”.
o +PredictionMax (container: String): String
Función web que devuelve los valores que se predicen que tendrá el
contenedor “container”.
o +Percent (container: String, days: String): String
Función web que devuelve el porcentaje de tiempo en cada estado del
contenedor de los “days” últimos días del contenedor “container”.
o +PercentSim (container: String, days: String): String
Función web que devuelve el porcentaje de tiempo en cada estado del
contenedor de los “days” últimos días del contenedor “container” (versión
para simulación).
o +thelastmeasure (container: String): String
Función web que devuelve el último valor de llenado del contenedor
“container”.
o +LastPercent (container: String): String
Función web que devuelve el porcentaje de tiempo en cada estado del
contenedor “container” del último día
Conversors
Clase que ofrece funciones de conversión a formatos REST, para algunos frameworks
de graficado de tablas.
o +convertLastIntegerDays (input: TreeMap<TreeMap<long, UmeasureDTO>>):
JSONIntegralValues.
Función que convierte un objeto UMeasureDTO de integrales en apto para
parsearlo a JSON y enviarlo.

130
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 130 de 181
o +convertLastIntegerDaysSim (input: TreeMap<TreeMap<long,
UmeasureDTO>>, n: int): JSONIntegralValues.
Función que convierte un objeto UMeasureDTO de integrales en apto para
parsearlo a JSON y enviarlo (versión para simulación, filtra y se queda con las
“n” últimas mediciones).
o +convertLastMeasureDays (input: TreeMap<TreeMap<long, UmeasureDTO>>):
JSONMeasuresValues.
Función que convierte un objeto UMeasureDTO de mediciones en apto para
parsearlo a JSON y enviarlo.
o +convertLastMeasureDays (input: TreeMap<TreeMap<long, UmeasureDTO>>,
n: int): JSONMeasuresValues.
Función que convierte un objeto UMeasureDTO de mediciones en apto para
parsearlo a JSON y enviarlo (versión para simulación, filtra y se queda con las
“n” últimas mediciones).
o +convertMaxMeanMin (input: TreeMap<TreeMap<long,
UMaxmeanMinDTO>>): JSON4Values.
Función que convierte un objeto UMaxmeanMinDTO en apto para parsearlo a
JSON y enviarlo.
o +convertMaxMeanMinSim (input: TreeMap<TreeMap<long,
UMaxmeanMinDTO>>, n: int): JSON4Values
Función que convierte un objeto UMaxmeanMinDTO en apto para parsearlo a
JSON y enviarlo (versión para simulación, filtra y se queda con las “n” últimas
mediciones).
o +convertPrediction (input: TreeMap<TreeMap<long, UPredictionsDTO>>):
JSONPredictionsValues
Función que convierte un objeto UPredictionsDTO de predicciones continúas
en apto para parsearlo a JSON y enviarlo.
o +convertPredictionMax (input: TreeMap<TreeMap<long, UPredictionsDTO>>):
JSONPredictionsMaxValues
Función que convierte un objeto UPredictionsDTO de predicciones de
máximos en apto para parsearlo a JSON y enviarlo.

131
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 131 de 181
o +convertPercent (input: TreeMap<TreeMap<long, UPercentDayDTO>>):
JSONPercentValues.
Función que convierte un objeto UPercentDayDTO en apto para parsearlo a
JSON y enviarlo.
o +convertPercentSim (input: TreeMap<TreeMap<long, UPercentDayDTO>>, n:
int): JSONPercentValues.
Función que convierte un objeto UPercentDayDTO en apto para parsearlo a
JSON y enviarlo (versión para simulación, filtra y se queda con las “n” últimas
mediciones).
o +convertLastPercentSim (input: TreeMap<TreeMap<long, UPercentDayDTO>>,
n: int): JSONLastPercentValues.
Función que convierte un objeto UPercentDayDTO con el ultimo porcentaje en
apto para parsearlo a JSON y enviarlo.
o +convertTheLastMeasureDays (input: UMeasureDTO):
JSONLastMeasuresValues
Función que convierte un objeto UMeasureDTO con la última medición en
apto para parsearlo a JSON y enviarlo.
JSONPredictionsValues
+predictions: List <float>
+timestamps: List <String>
o +setpreditions (fill: List <float>): void
Establece la variable indicada en el campo de entrada.
o +getpredictions (): List <float>
Devuelve la variable que se especifica en el nombre.
o +setTimestamp (timestamp: List <String>)
Establece la variable indicada en el campo de entrada.
o +getTimestamp (): List <String>
Devuelve la variable que se especifica en el nombre.

132
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 132 de 181
JSONIntegralValues
+integral: List <float>
+timestamps: List <String>
o +setintegral (fill: List <float>): void
Establece la variable indicada en el campo de entrada.
o +getintegral (): List <float>
Devuelve la variable que se especifica en el nombre.
o +setTimestamp (timestamp: List <String>)
Establece la variable indicada en el campo de entrada.
o +getTimestamp (): List <String>
JSONMeasuresValues
+measures: List <float>
+timestamps: List <String>
o +setmeasures (fill: List <float>): void
Establece la variable indicada en el campo de entrada.
o +getmeasures (): List <float>
Devuelve la variable que se especifica en el nombre.
o +setTimestamp (timestamp: List <String>)
Establece la variable indicada en el campo de entrada.
o +getTimestamp (): List <String>
Devuelve la variable que se especifica en el nombre.
JSONPredictionsMaxValues
+predictionsMax: List <float>

133
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 133 de 181
+timestamps: List <String>
o +setpreditionsMax (fill: List <float>): void
Establece la variable indicada en el campo de entrada.
o +getpredictionsMax (): List <float>
Devuelve la variable que se especifica en el nombre.
o +setTimestamp (timestamp: List <String>)
Establece la variable indicada en el campo de entrada.
o +getTimestamp (): List <String>
Devuelve la variable que se especifica en el nombre.
JSONLastMeasuresValues
+measure: List <float>
o +setmeasures (fill: List <float>): void
Establece la variable indicada en el campo de entrada.
o +getmeasures (): List <float>
Devuelve la variable que se especifica en el nombre.
JSONMaxMeanMinValues
+max: List <float>
+mean: List <float>
+min: List <float>
+timestamps: List <String>
o +setMax (fill: List <float>): void
Establece la variable indicada en el campo de entrada.
o +getMax (): List <float>

134
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 134 de 181
Devuelve la variable que se especifica en el nombre.
o +setTimestamp (timestamp: List <String>)
Establece la variable indicada en el campo de entrada.
o +getTimestamp (): List <String>
Devuelve la variable que se especifica en el nombre.
o +setMin (fill: List <float>): void
Establece la variable indicada en el campo de entrada.
o +getMin (): List <float>
Devuelve la variable que se especifica en el nombre.
o +setMean (fill: List <float>): void
Establece la variable indicada en el campo de entrada.
o +getMean (): List <float>
Devuelve la variable que se especifica en el nombre.
JSONPercentValues
+firstQuart: List <float>
+secondQuart: List <float>
+thirdQuart: List <float>
+fourthQuart: List <float>
+timestamps: List <String>
o +setFirstQuart (fill: List <float>): void
Establece la variable indicada en el campo de entrada.
o +getFirstQuart (): List <float>
Devuelve la variable que se especifica en el nombre.
o +setSecondQuart (timestamp: List <String>)

135
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 135 de 181
Establece la variable indicada en el campo de entrada.
o +getSecondQuart (): List <String>
Devuelve la variable que se especifica en el nombre.
o +setThirdQuart (fill: List <float>): void
Establece la variable indicada en el campo de entrada.
o +getThirdQuart (): List <float>
Devuelve la variable que se especifica en el nombre.
o +setFourthQuart (fill: List <float>): void
Establece la variable indicada en el campo de entrada.
o +getFourthQuart (): List <float>
Devuelve la variable que se especifica en el nombre.
o +setTimestamp (timestamp: List <String>)
Establece la variable indicada en el campo de entrada.
o +getTimestamp (): List <String>
Devuelve la variable que se especifica en el nombre.
Facade
Interfaz de acceso a las funciones básica, sirve como acceso a otras clases, por
ejemplo, en este caso sirve como acceso a las funciones para Facade Web, pero si se
diera el caso de que se quisiera creas un servidor web que accediera a la información
del lado del servidor, el punto de acceso a las clases seria este.
o +getLastIntegerDays (remain: int): TreeMap<TreeMap<long, UmeasureDTO>>
Hace una petición a Hbase y devuelve las integrales de calidad del servicio que
estén en el servidor de los “remain” últimos días.
o +getAllIntegerDays: TreeMap<TreeMap<long, UmeasureDTO>>

136
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 136 de 181
Hace una petición a Hbase y devuelve todas las integrales de calidad del
servicio que estén en el servidor Esta toma los datos insertados en hbase de
todos días.
o +getLastIntegerDaysSim (remain: int): TreeMap<TreeMap<long,
UmeasureDTO>>
Hace una petición a Hbase y devuelve las integrales de calidad del servicio que
estén en el servidor de los “remain” últimos días (Versión para simulado, en
caso de usar en servidor Web, toma todas las medidas de la base de datos y
filtra por fecha de los “remain” últimos días).
o +getLastMeasureDays (remain: int): TreeMap<TreeMap<long,
UmeasureDTO>>
Hace una petición a Hbase y devuelve las mediciones que estén en el servidor
de los “remain” últimos días.
o +getAllMeasureDays: TreeMap<TreeMap<long, UmeasureDTO>>
Hace una petición a Hbase y devuelve todas las mediciones que estén en el
servidor Esta toma los datos insertados en hbase de todos días.
o +getLastMeasureDaysSim (remain: int): TreeMap<TreeMap<long,
UmeasureDTO>>
Hace una petición a Hbase y devuelve las mediciones que estén en el servidor
de los “remain” últimos días (Versión para simulado, en caso de usar en
servidor Web, toma todas las medidas de la base de datos y filtra por fecha de
los “remain” últimos días).
o +getMaxMeanMin (remain: int): TreeMap<TreeMap<long,
UMaxMeanMinDTO>>
Hace una petición a Hbase y devuelve los máximos, mínimos y medias que
estén en el servidor de los “remain” últimos días.
o +getAllMaxMeanMin: TreeMap<TreeMap<long, UMaxMeanMinDTO>>
Hace una petición a Hbase y devuelve todos los máximos, mínimos y medias
que estén en el servidor Esta toma los datos insertados en hbase de todos
días.
o +getMaxMeanMinSim (remain: int): TreeMap<TreeMap<long,
UMaxMeanMinDTO>>

137
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 137 de 181
Hace una petición a Hbase y devuelve los máximos, mínimos y medias que
estén en el servidor de los “remain” últimos días (Versión para simulado, en
caso de usar en servidor Web, toma todas las medidas de la base de datos y
filtra por fecha de los “remain” últimos días).
o +getPrediction (): TreeMap<TreeMap<long, UPredictionsDTO>>
Hace una petición a Hbase y devuelve todas las predicciones que estén en él.
o +getPredictionMax (): TreeMap<TreeMap<long, UPredictionsDTO>>
Hace una petición a Hbase y devuelve todas las predicciones que estén en él.
o +getPercentSim (remain: int): TreeMap<TreeMap<long, UPercentDTO>
Hace una petición a Hbase y devuelve los porcentajes que estén en el servidor
de los “remain” últimos días (Versión para simulado, en caso de usar en
servidor Web, toma todas las medidas de la base de datos y filtra por fecha de
los “remain” últimos días).
o +getPercent (remain: int): TreeMap<TreeMap<long, UPercentDTO>>
Hace una petición a Hbase y devuelve los porcentajes que estén en el servidor
de los “remain” últimos días.
o +getAllPercent (): TreeMap<TreeMap<long, UPercentDTO>>
Hace una petición a Hbase y devuelve todos los porcentajes que estén en el
servidor Esta toma los datos insertados en hbase de todos días.
PercentDAO
o +getPercentSim ((start: Calendar, stop: Calendar)): TreeMap<TreeMap<long,
UPercentDTO>>
Dados las fechas “start” y “stop”, obtiene de la tabla de porcentajes todas las
mediciones comprendidas entre dichas fechas (versión de simulación, baja
todas las mediciones de HBASE y a posteriori las filtra para obtener solo las
que estén entre las fechas).
o +getPercent (start: Calendar, stop: Calendar): TreeMap<TreeMap<long,
UPercentDTO>>

138
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 138 de 181
Dados las fechas “start” y “stop”, obtiene de la tabla de porcentajes todas las
mediciones comprendidas entre dichas fechas.
o +getAllPercent (): TreeMap<TreeMap<long, UPercentDTO>>
Obtiene todas las mediciones existentes de la tabla de porcentajes.
MeasureDAO
o +getlastdays (table: String, start: Calendar, stop: Calendar):
TreeMap<TreeMap<long, UmeasureDTO>>
Dados las fechas “start” y “stop”, obtiene de la tabla “table” todas las
mediciones comprendidas entre dichas fechas (versión de simulación, baja
todas las mediciones de HBASE y a posteriori las filtra para obtener solo las
que estén entre las fechas).
o +getlastdays (table: String, start: Calendar, stop: Calendar):
TreeMap<TreeMap<long, UmeasureDTO>>
Dados las fechas “start” y “stop”, obtiene de la tabla “table” todas las
mediciones comprendidas entre dichas fechas.
o +getAlldays (table: String): TreeMap<TreeMap<long, UmeasureDTO>>
Obtiene todas las mediciones existentes de la tabla “table” de mediciones.
PredictionsDAO
o +getPredictions (tabla: String): TreeMap<TreeMap<long, UPredictionsDTO>>
Obtiene todas las mediciones existentes de la tabla “table” de predicciones.
MaxMeanMinDAO
o +getMaxMeanMinSim ((start: Calendar, stop: Calendar)):
TreeMap<TreeMap<long, UMaxMeanMinDTO>>
Dados las fechas “start” y “stop”, obtiene de la tabla de máximos, mínimos y
medias todas las mediciones comprendidas entre dichas fechas (versión de

139
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 139 de 181
simulación, baja todas las mediciones de HBASE y a posteriori las filtra para
obtener solo las que estén entre las fechas).
o +getMaxMeanMin (start: Calendar, stop: Calendar): TreeMap<TreeMap<long,
UMaxMeanMinDTO>>
Dados las fechas “start” y “stop”, obtiene de la tabla “table” todos los
máximos, mínimos y medias comprendidas entre dichas fechas.
o +getAllMaxMeanMin (): TreeMap<TreeMap<long, UMaxMeanMinDTO>>
Obtiene todas las mediciones existentes de la tabla de máximos, mínimos y
medias.
UPercentDTO
+id: int
+firstQuart: float
+secondQuart: float
+thirdQuart: float
+fourthQuart: float
+timestamps: Date
o +setFirstQuart (fill: float): void
Establece la variable indicada en el campo de entrada.
o +getFirstQuart (): float
Devuelve la variable que se especifica en el nombre.
o +setSecondQuart (fill: float)
Establece la variable indicada en el campo de entrada.
o +getSecondQuart (): float
Devuelve la variable que se especifica en el nombre.
o +setThirdQuart (fill: float): void
Establece la variable indicada en el campo de entrada.

140
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 140 de 181
o +getThirdQuart (): float
Devuelve la variable que se especifica en el nombre.
o +setFourthQuart (fill: float): void
Establece la variable indicada en el campo de entrada.
o +getFourthQuart (): float
Devuelve la variable que se especifica en el nombre.
o +setTimestamp (timestamp: Date)
Establece la variable indicada en el campo de entrada.
o +getTimestamp (): Date
Devuelve la variable que se especifica en el nombre.
o +setID (id: int): void
Establece la variable indicada en el campo de entrada.
o +getID (): int
Devuelve la variable que se especifica en el nombre.
UMeasureDTO
+id: int
+fill: float
+timestamp: Date
o +setID (id: int): void
Establece la variable indicada en el campo de entrada.
o +getID (): int
Devuelve la variable que se especifica en el nombre.
o +setFil (fill: float): void
Establece la variable indicada en el campo de entrada.

141
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 141 de 181
o +getFill (): float
Devuelve la variable que se especifica en el nombre.
o +setTimestamp (timestamp: Date)
Establece la variable indicada en el campo de entrada.
o +getTimestamp (): Date
Devuelve la variable que se especifica en el nombre.
o +ToString: String
Convierte el objeto en texto para su mejor compresión cuando se debuguea.
UPredictionsDTO
+id: int
+fill: float
+timestamp: Date
+key: int
o +setID (id: int): void
Establece la variable indicada en el campo de entrada.
o +getID (): int
Devuelve la variable que se especifica en el nombre.
o +setKey (key: int): void
Establece la variable indicada en el campo de entrada.
o +getKey (): int
Devuelve la variable que se especifica en el nombre.
o +setFil (fill: float): void
Establece la variable indicada en el campo de entrada.
o +getFill (): float

142
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 142 de 181
Devuelve la variable que se especifica en el nombre.
o +setTimestamp (timestamp: Date)
Establece la variable indicada en el campo de entrada.
o +getTimestamp (): Date
Devuelve la variable que se especifica en el nombre.
o +ToString: String
Convierte el objeto en texto para su mejor compresión cuando se debuguea.
UMaxMeanMinDTO
+id: int
+max: float
+mean: float
+min: float
+timestamp: Date
o +setID (id: int): void
Establece la variable indicada en el campo de entrada.
o +getID (): int
Devuelve la variable que se especifica en el nombre.
o +setMax (max: float): void
Establece la variable indicada en el campo de entrada.
o +getMax (): float
Devuelve la variable que se especifica en el nombre.
o +setMean (mean: float): void
Establece la variable indicada en el campo de entrada.
o +getMean (): float

143
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 143 de 181
Devuelve la variable que se especifica en el nombre.
o +setMin (min: float): void
Establece la variable indicada en el campo de entrada.
o +getMin (): float
Devuelve la variable que se especifica en el nombre.
o +setTimestamp (timestamp: Date)
Establece la variable indicada en el campo de entrada.
o +getTimestamp (): Date
Devuelve la variable que se especifica en el nombre.
o +ToString: String
Convierte el objeto en texto para su mejor compresión cuando se debuguea.

144
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 144 de 181
Ilustración 70 Diagrama de clases de la interfaz de datos

145
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 145 de 181
4.3.1.4 Servidor web
Es el servidor encargado de servir la página web y de crear las vistas.
UMaxMeanMinDTO
+medias: boolean
+integral: boolean
+prediccion: boolean
+prediccionMax: boolean
+MMM: boolean
+porcentaje: boolean
+dias: String
+extra: String
+contenedor: String
o +setMedias (medias: boolean): void
Establece la variable indicada en el campo de entrada.
o +getMedias (): Boolean
Devuelve la variable que se especifica en el nombre.
o +setIntegral (integral: boolean): void
Establece la variable indicada en el campo de entrada.
o +getIntegral (): Boolean
Devuelve la variable que se especifica en el nombre.
o +setPrediccion (prediccion: boolean): void
Establece la variable indicada en el campo de entrada.
o +getPrediccion (): Boolean

146
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 146 de 181
Devuelve la variable que se especifica en el nombre.
o +setPrediccionMax (prediccionMax: boolean): void
Establece la variable indicada en el campo de entrada.
o +getPrediccionMax (): Boolean
Devuelve la variable que se especifica en el nombre.
o +setMMM (MMM: boolean): void
Establece la variable indicada en el campo de entrada.
o +getMMM (): Boolean
Devuelve la variable que se especifica en el nombre.
o +setPorcentaje (porcentaje: boolean): void
Establece la variable indicada en el campo de entrada.
o +hasSomething (): Boolean
Devuelve true si en cualquiera de las variables booleanas sea true
o +hasArea (): Boolean
Devuelve true si cualquiera de las variables que representan área o líneas es
true
o +setDias (dias: string): void
Establece la variable indicada en el campo de entrada.
o +getDias (): string
Devuelve la variable que se especifica en el nombre.
o +setExtra (extra: string): void
Establece la variable indicada en el campo de entrada.
o +getExtra (): string
Devuelve la variable que se especifica en el nombre.
o +setContenedor (contenedor: string): void
Establece la variable indicada en el campo de entrada.

147
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 147 de 181
o +getContenedor (): string
Devuelve la variable que se especifica en el nombre.
o +getID (): int
Devuelve la variable que se especifica en el nombre.
UMaxMeanMinDTO
o +init (): void
Se ejecuta cuando se inicia el Servlet
o doPost (request: HttpServletRequest, response: HttpServlet Response): Void
Cuando se recibe una petición Post entra por esta función, hay dos tipos de
actividad, “crear” que añade a la sesión del usuario una nueva tabla que se
muestra y “borrar” que elimina de la sesión la tabla seleccionada.
Ilustración 71 Diagrama de clases del servidor Web

148
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 148 de 181
4.3.1 Diagramas de actividad y estado.
En esta sección, se ven diferentes diagramas de funcionamiento interno del sistema, para una correcta comprensión del mismo.
4.3.1.1 Simulador.
En el caso del simulador, el diagrama de pipes & filters ofrece toda la información necesaria de
cómo funciona, a excepción de dos tipos de elementos, TruckRSim y container_ hechos en
colaboración con Alejando González por sus conocimientos de estadística y R-project.
TruckRSim
En este caso el diagrama de estados de la ruta del camión, cada vez que se generan
tiempos de viaje se usa una distribución para hacerlo de manera aleatoria.
Ilustración 72 Diagrama de estados del componente TruckRSim
Container_
De manera similar a TruckRSim, cuando se genera cuanto se tiene que llenar el
contenedor se hace de manera aleatoria mediante una distribución beta lo mismo
pasa cuando se vacía y se establece un mínimo de residuos que quedan en el
contenedor.

149
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 149 de 181
Ilustración 73 Diagrama de estados del componente Container_
4.3.1.2 Procesador principal.
En este caso no se requieren diagramas de actividad puesto que el diagrama de clases de
“pipes & filters” explica el comportamiento.
4.3.1.3 Interfaz de datos.
En este caso se han hecho diagramas de actividad para cada tipo de solicitud que entra por
WebFacade.
Integral de calidad del servicio

150
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 150 de 181
Ilustración 74 Diagrama de secuencia: Integral de calidad del servicio
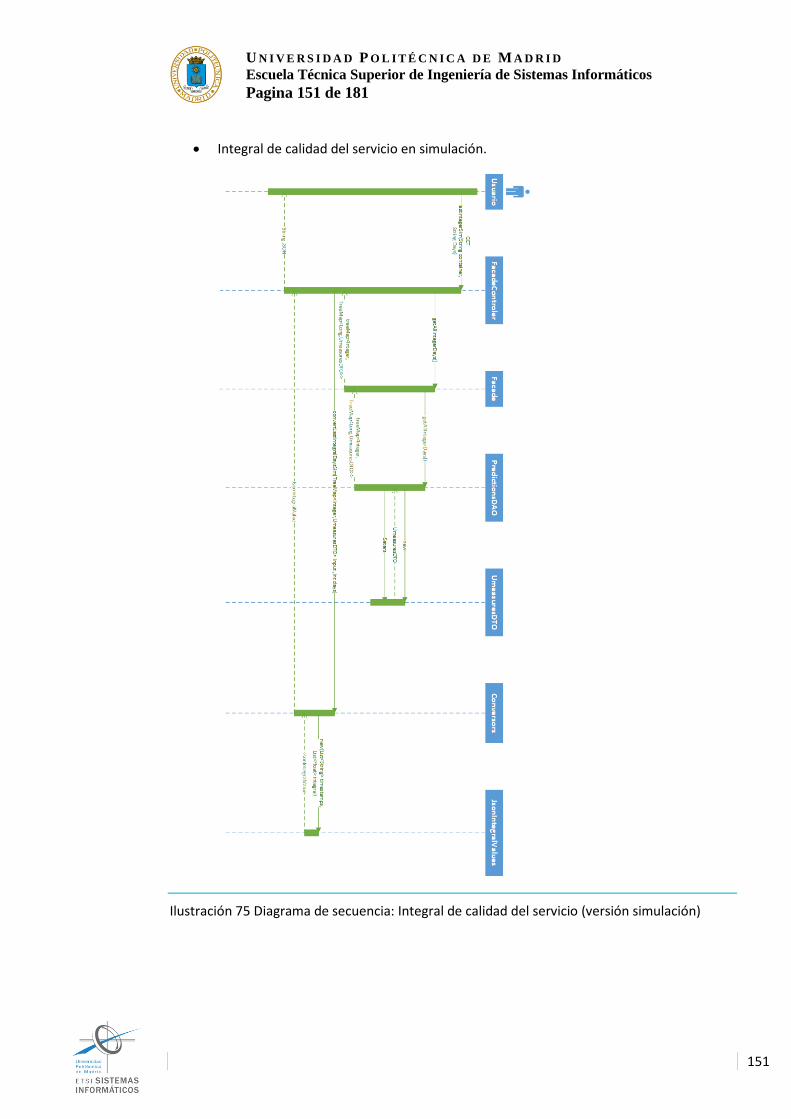
151
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 151 de 181
Integral de calidad del servicio en simulación.
Ilustración 75 Diagrama de secuencia: Integral de calidad del servicio (versión simulación)

152
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 152 de 181
Última medición del contenedor X.
Ilustración 76 Diagrama de secuencia: Última medición

153
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 153 de 181
Mediciones de lo n últimos días del contenedor X
Ilustración 77 Diagrama de secuencia: Mediciones de lo n últimos días

154
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 154 de 181
Mediciones de lo n últimos días del contenedor X (versión simulación)
Ilustración 78 Diagrama de secuencia: Mediciones de lo n últimos días (versión simulación)

155
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 155 de 181
Máximos, mínimos y medias de lo n últimos días del contenedor X
Ilustración 79 Diagrama de secuencia: Máximos, mínimos y medias de lo n últimos días.

156
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 156 de 181
• Máximos, mínimos y medias de lo n últimos días del contenedor X (versión simulación).
Ilustración 80 Diagrama de secuencia: más, min y medias de los n últimos días (versión simulación).
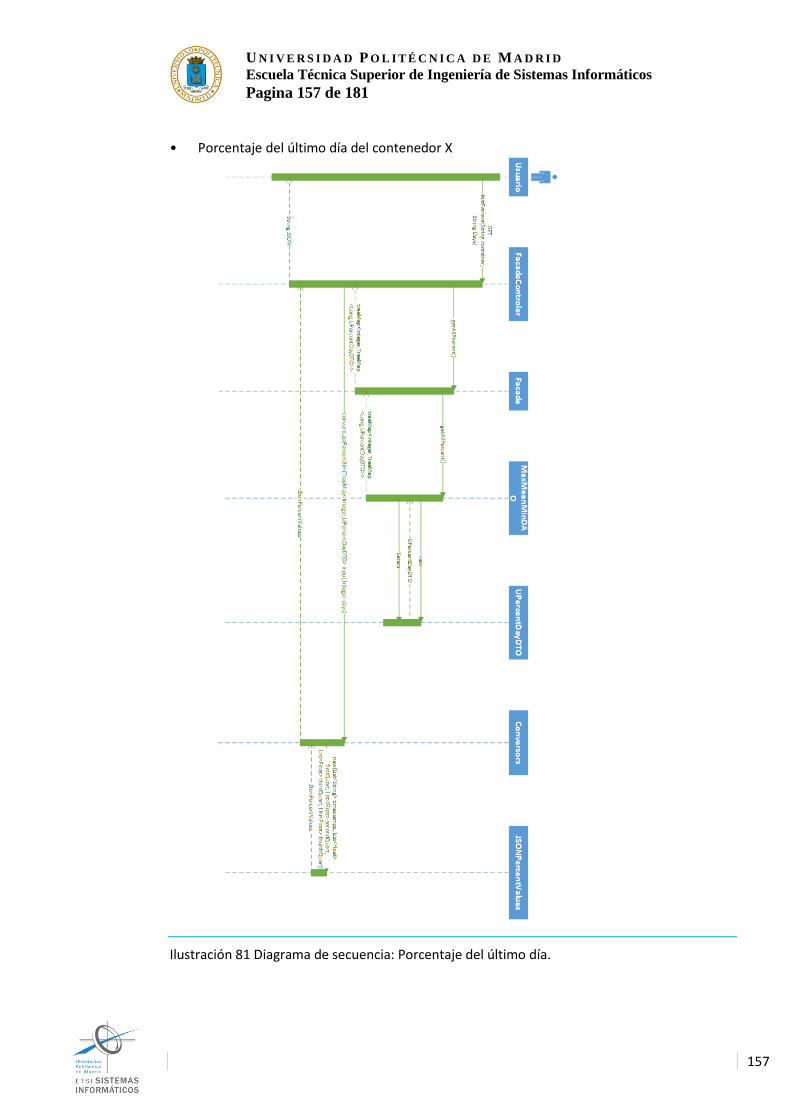
157
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 157 de 181
• Porcentaje del último día del contenedor X
Ilustración 81 Diagrama de secuencia: Porcentaje del último día.

158
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 158 de 181
• Porcentajes de lo n últimos días del contenedor X
Ilustración 82 Diagrama de secuencia: Porcentajes de los N últimos días • Porcentajes de lo n últimos días del contenedor X (versión simuladora)

159
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 159 de 181
Ilustración 83 Diagrama de secuencia: Porcentajes de los N últimos días (versión simuladora)

160
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 160 de 181
Obtener las predicciones del contenedor X.
Ilustración 84 Diagrama de secuencia: Predicción continua • Obtener las predicciones de máximos del contenedor X.
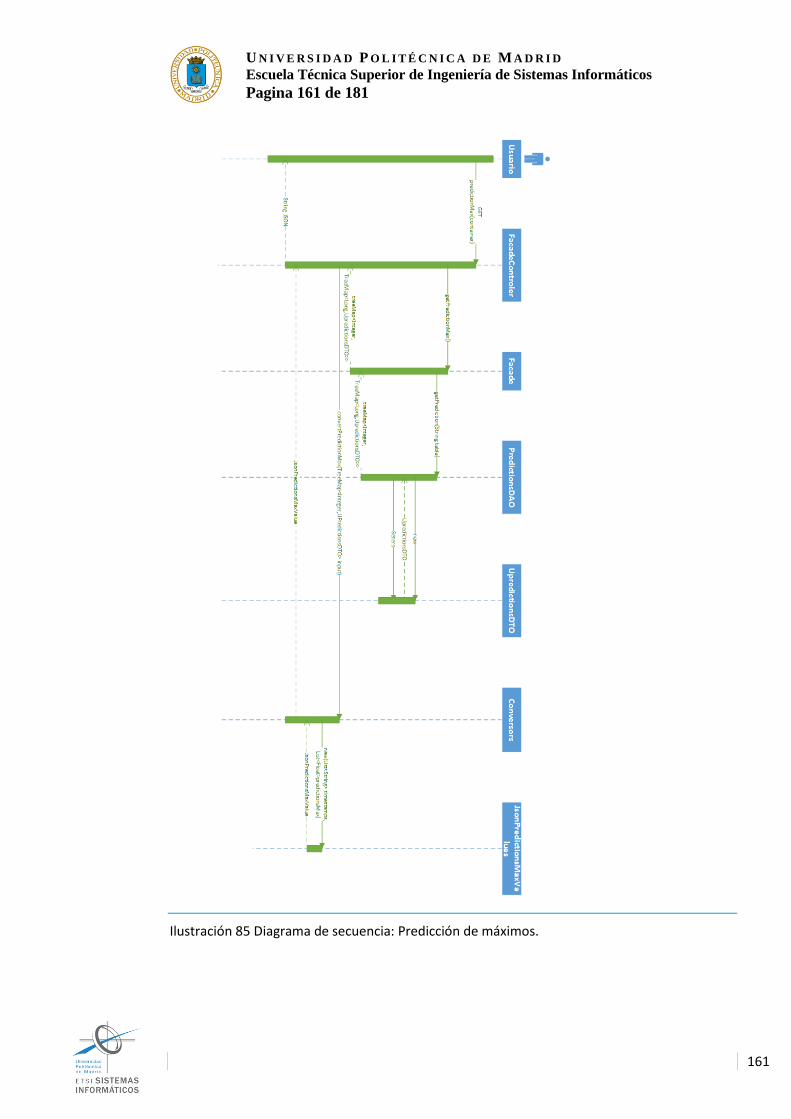
161
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 161 de 181
Ilustración 85 Diagrama de secuencia: Predicción de máximos.

162
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 162 de 181
4.3.1.4 Servidor web
En este caso solo hay un diagrama de actividad, que es cuando se solicita al servidor crear una
nueva vista en la web o eliminar una vista de la misma.
En el caso de solicitar la web está implícita en el framework.
Ilustración 86 Diagrama de secuencia: Solicitud Web
4.4 Pruebas
En este apartado se describen las pruebas realizadas en el sistema y se relaciona con el caso de
uso, la mayoría de ellas son por acciones del usuario.
PRUEBA “Añadir nuevo panel”
Numeración:1
Relación: 21
Descripción: Añadir nuevo panel seleccionando la información deseada
Salida esperada: Se genera un panel nuevo
Salida obtenida: Se genera un panel nuevo.

163
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 163 de 181
PRUEBA “No seleccionar nada en información extra”
Numeración:2
Relación: 21
Descripción: Cuando se agrega un nuevo contendor a la vista se puede dejar sin seleccionar
información extra.
Salida esperada: No se genera panel de información extra
Salida obtenida: No se genera panel de información extra
PRUEBA “Pulsar el botón de borrar”
Numeración:3
Relación: 22
Descripción: Una vez agregado un contenedor se puede borrar pulsando el correspondiente
botón.
Salida esperada: Se recarga la página, pero sin la vista eliminada
Salida obtenida: Se recarga la página, pero sin la vista eliminada
PRUEBA “Dejar todos los checkbox sin marcar”
Numeración:4
Relación: 21
Descripción: Cuando se agrega un nuevo contendor a la vista se puede dejar sin marcar todos
los check box
Salida esperada: No se genera panel de gráficas para la vista
Salida obtenida: No se genera panel de gráficas para la vista

164
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 164 de 181
PRUEBA “Se marcan y desmarcan los elementos de una gráfica ya generada”
Numeración:5
Relación: 20
Descripción: Una vez hecha la gráfica se pueden seleccionar elementos para quitarlos y
ponerlos de la vista.
Salida esperada: Lo elementos se quitan y se ponen de la vista correctamente.
Salida obtenida: En ocasiones lo elementos se quitan correctamente, en otros casos se
colocan de manera errónea o con colores erróneos.
PRUEBA “Se desliza el puntero por la gráfica”
Numeración:6
Relación: 20
Descripción: Las gráficas permiten el deslizar el puntero para poder ver información detallada
de la gráfica.
Salida esperada: Se ve correctamente todos los detalles de la gráfica.
Salida obtenida: Cuando las gráficas tienen diferente punto de comienzo o diferente densidad
de puntos, el selector erra al seleccionar el punto adecuado.
PRUEBA “No hacer nada”
Numeración:7
Relación: 1
Descripción: Cada cierto tiempo las gráficas tienen que actualizarse con nueva información.
Salida esperada: Las gráficas se recargan sin necesidad de recargar la página.
Salida obtenida: Las gráficas se recargan sin necesidad de recargar la página.

165
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 165 de 181
PRUEBA “Se cierra y se abre el navegador”
Numeración:8
Relación: 20
Descripción: La información de las vistas se guarda por sesión.
Salida esperada: Se vuelve a ver las mismas vistas que cuando se cerró.
Salida obtenida: Se vuelve a ver las mismas vistas que cuando se cerró.
4.5 Despliegue
En esta sección se describen dos despliegues, por un lado, el despliegue de desarrollo usado
para la creación y testeo del sistema y por otro el despliegue real que sería el despliegue
óptimo para una empresa incluyendo elementos no implementados en la arquitectura.
Como arquitectura base para el sistema se ha usado la arquitectura kappa que se basa en tres partes por un lado la admisión de datos donde encontraríamos a Kafka, a continuación, el sistema de procesado en streaming donde se encuentra Streams y por ultimo todos los demás elementos que son los encargados de almacenar y servir los datos ya procesados.
Ilustración 87 Arquitectura Kappa

166
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 166 de 181
4.5.1 Despliegue de desarrollo
Este despliegue se ha usado para el desarrollo del sistema y sus componentes, todo corre sobre la misma maquina CentOS puesto que es el único OS de libre distribución que soporta IBM Streams.
Ilustración 88 Despliegue de desarrollo
Tanto para los contenedores como para los camiones, se ha usado Apache Edgent, con el cual se recolectan los datos, se le añaden cierto filtrado y agregaciones según la filosofía Fog y se envían al cluster. Dentro del cluster el encargado de recibir los datos y encolarlos es kafka, cualquiera aplicación que quiera procesar dichos datos, simplemente se tiene que apuntar al topic de kafka que tiene esos datos.

167
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 167 de 181
Eso hace IBM Streams, recibe los datos del topic de Kafka y a continuación procesa generando filtrados y agregaciones. Además, dentro también tiene implementado un simulador que permite no necesitar ni a Kafka ni a los dispositivos Edgent para generar pruebas simuladas. Todos los datos procesados por IBM son almacenados en HBASE que permite el almacenamiento mediante clave-valor, además a su vez por debajo tiene HDFS que es donde almacena los archivos guardados. En el caso de las aplicaciones distribuidas que requieran Zookeeper, como son IBM Streams, Kafka y HBASE, cada uno usa el suyo propio embebido en modo standalone. Por otro lado, cuando el usuario quiere solicitar ver los datos, lo hace a través del navegador web solicitando una página con el dashboard al servidor Web TomCat. TomCat le devuelve dicho dashboard que incluye por un lado el framework Bootstrap para la arquitectura de la página dotándola de responsividad y por otro D3 que es el encargado de generar las gráficas. Además, D3 también es el encargado de solicitar mediante peticiones REST los datos para generar las gráficas, esto permite que no se requiera n recargar la página entera ni depender del servidor web para la obtención de datos. El encargado de proveer dicha información es el servicio REST un servidor hecho con el framework de Spring que se encarga de recibir peticiones de HTTP datos del tipo GET, acceder a HBASE, tomar y filtrar los datos solicitados y por ultimo enviárselos al solicitante mediante REST. Este servidor añade la ventaja de que en un futuro se pueden añadir nuevas interfaces que no sean Web que usen este servicio REST.
4.5.2 Despliege empresarial
A continuación, se muestra un despliegue empresarial del sistema que incluye nuevos elementos no implementados en el prototipo y otros modificados pero que da una idea de lo que podría ser el sistema si se continuara con el desarrollo en el mismo. El sistema se despliega en un cluster de máquinas físicas que a su vez tienen máquinas virtuales, es importante que los sistemas que sean varios nodos no corran todos sobre la misma maquina física para así en caso de fallo de la maquina el sistema pueda seguir funcionando. Esto es debido a que está diseñado para ser tolerante a fallos la mayoría de elementos encargados del procesamiento y almacenamiento de información funcionan de manera distribuida por lo que si se cae un nodo otro ocupara su lugar. Por otro lado, esto permite añadir nuevos nodos para por un lado aumentar la tolerancia a fallos y por otro escalar el sistema para que pueda procesar y almacenar más datos. Para describir este despliegue, se va a usar el de desarrollo como base, es decir, primero se comentarán las modificaciones del sistema y a continuación las agregaciones al mismo.

168
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 168 de 181
Modificaciones
o IBM Streams, Kafka y HBASE: Estos elementos pueden funcionar de manera
distribuida, por lo que en vez de ser un solo nodo corriendo el elemento con
un Zookeeper embebido, se usaran varios nodos corriendo en máquinas físicas
distintas y usando un Zookeeper externo, así se les añade tolerancia a fallos y
escalabilidad.
o HDFS: De igual manera que los anteriores, HDFS también funcionaria de
manera distribuida, aunque en este caso no requiere de un Zookeeper.
o IBM streams: en este caso lo ideal es añadir procesamiento de eventos
complejos, que permitiría añadir funcionalidades como modificación de rutar,
gestión de alarmas etc. Además, el canal de comunicaciones con Kafka se
convertiría en bidireccional debido a que los resultados de dichos eventos se
volverían a mandar a Kafka.
o REST server: puesto que HBASE envía las tablas enteras sin hacer ningún tipo
de filtrado como haría una base de datos SQL, era el propio REST Server el
encargado de hacerlas, puesto que el servidor no corre de manera distribuida
cuando la cantidad de datos aumente aumentara la latencia de las peticiones
Por ello se ha optado por delegar esa función en apache Phenix por lo que el
servidor REST solo tendría ahora que solicitar la información en formato SQL.
o Edgent: En pos reducir los costes de despliegue, usando la filosofía Fog se ha
sustituido el diseño de que cada contenedor y camión tuvieran su pequeño
procesamiento por uno en el que todos los cubos y camiones tendrían lo más
básico, un medio para capturar la información y transmitirla a una centralita
(que puede tener otra de respaldo, en dicha centralita) se añadiría los
procesamientos pertinentes según la filosofía Fog (agregaciones, fechas horas,
etc.) y se enviarían al cluster. Para la comunicación entre los contenedores y
camiones y la centralita se usaría Lora para una arquitectura en estrella y
Zigbee para cuando se requiera una arquitectura en malla.
o Kafka: Puesto que kafka incluye dentro Kafka streams, lo lógico sería intentar
aprovechar dicha capacidad Fast Data para añadir agregaciones a los datos y
eventos que corren por sus topics.
Agregaciones
o Zookeeper: Puesto que gran cantidad de aplicaciones dependen de él, si fallara
Zookeeper, el sistema se vería gravemente afectado, por ello se corre un
cluster de nodos en modo Quorum para asegurar la tolerancia a fallos del
sistema preferiblemente impar.
o MQTT: Uno de los problemas de Kafka es que está ideado para correr dentro
de un cluster, por lo que tiene muchos problemas para trabajar con un firewall
de por medio, por ello se ha usado un sistema publicador/subscriptor llamado
MQTT que si se lleva mejor con los firewalls y serviría de pasarela entre el

169
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 169 de 181
exterior del cluster y Kafka. Puesto que MQTT no es distribuido para añadir
tolerancia a fallos y escalabilidad necesitaremos usar un balanceador de carga,
que se encargue por un lado de repartir los datos que le llegan entre los
diferentes MQTT y detectar que están en funcionamiento. Para añadir
tolerancia a fallos al balanceador se le añade uno de respaldo que entra en
funcionamiento en caso de caída del primero.
o Apache Phoenix: Es el encargado de que cuando le llegue una petición SQL,
tomar la información de HBASE y filtrarla y devolverla en forma SQL. Corre de
manera distribuida usando Zookeeper, por lo que es escalable y tolerante a
fallos.
o Spark/IBM BigInsights: Puesto que IBM streams está centrado en FastData no
puede hacer procesamientos muy pesados debido a que añadiría latencia al
sistema, para dichas tareas se proponen tecnologías de procesamiento en
Batch como son Spark e IBM BigInsights para hacer análisis pesados sobre los
datos del sistema.
Ilustración 89 Despliegue Empresarial
También es importante comentar que el uso de Kafka en el cluster permite que, si se quieren añadir nuevas herramientas de procesamiento o de tratamiento de eventos, simplemente las tenemos que conectar a kafka que nos ofrece un bus unificado por el que pasan todos los datos.

170
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 170 de 181
5 | Manual
En este apartado se encuentra un breve manual para el manejo de la interfaz web.
5.1 Accediendo al interfaz por primera vezx
Cuando se inicia el sistema y se conecta uno por primera vez a la página, lo que se puede ver
es esto:
1. A la de recha de la barra de navegación superior están los controles de vistas donde
podemos cargar y guardar vistas para visionar en otras ocasiones. Esta barra es
siempre visible, aunque se haga desplazamiento a la parte baja de la web.
2. Justo debajo de la barra de navegación, se encuentra el mapa, dicho mapa contiene los
contenedores que se monitorizan. El color del icono de cada contenedor puedes ser
verde, amarillo o rojo según su nivel de llenado. Si se deja el cursor quieto sobre el
icono se puede ver el porcentaje de llenado exacto del mismo.
3. En este punto se irán añadiendo las nuevas vistas que se vayan creando.
4. Este panel sirve para agregar nuevas vistas.
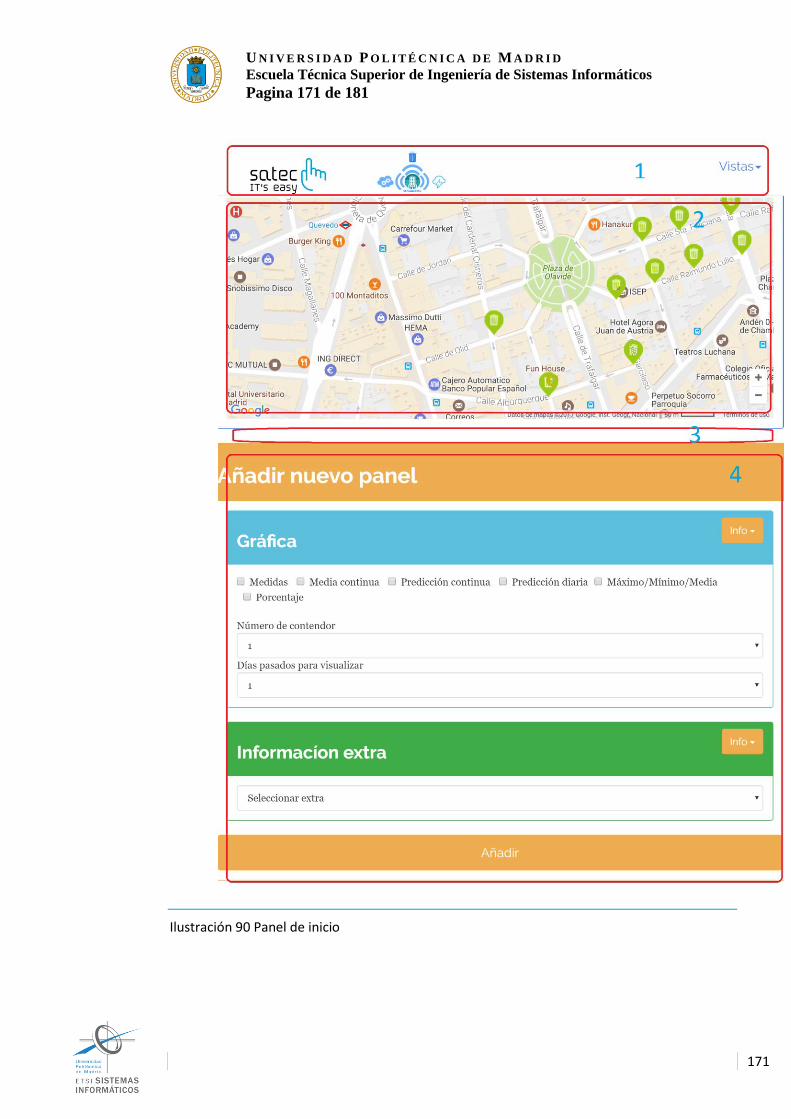
171
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 171 de 181
Ilustración 90 Panel de inicio

172
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 172 de 181
5.2 Añadiendo una vista
En primer lugar, en el cuadro de graficas se tiene que seleccionar que información se desea en
la misma, hay que tener en cuenta que cuanta más información menos legible es el visionado
de la misma.
A continuación, se selecciona el contenedor que se desea ver y el número de dias en el pasado
se quiere visionar (este número es irrelevante para información como son las predicciones).
Opcionalmente, si se desea se puede añadir información extra en el panel auxiliar de la
derecha, simplemente seleccionan el que se quiere ver.
Por último, se pulsa el botón añadir.
Ilustración 91 Añadir nuevo panel
5.3 Visionado de la graficas
Las gráficas permiten unas ciertas acciones una vez construidas.
Si se pasa el cursor por la gráfica mostrara información exacta sobre los valores que
tiene la gráfica en ese punto.
Si se hace click sobre las leyendas inferiores se pueden quitar o poner elementos de la
gráfica.
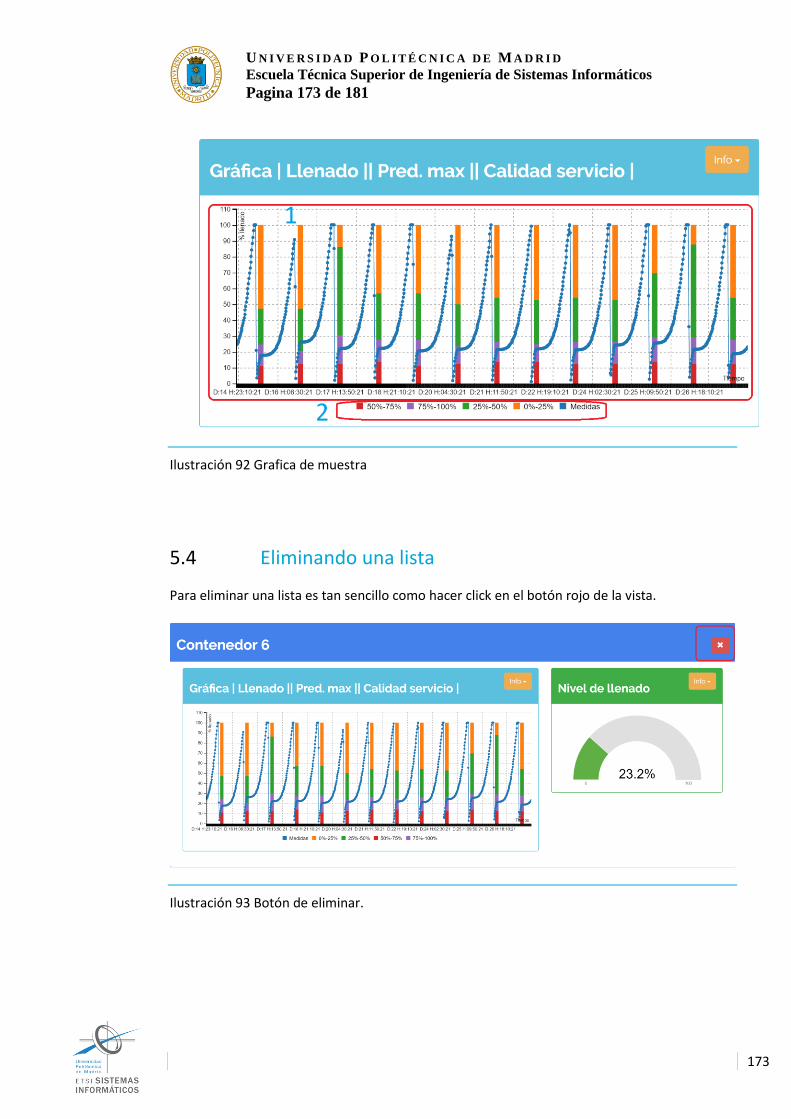
173
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 173 de 181
Ilustración 92 Grafica de muestra
5.4 Eliminando una lista
Para eliminar una lista es tan sencillo como hacer click en el botón rojo de la vista.
Ilustración 93 Botón de eliminar.

174
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 174 de 181
5.5 Guardar una configuracion de vistas
Para poder acceder de manera rápida a una serie de vistas, se puede guardar la configuración
actual.
Simplemente se hace clic en el desplegable superior izquierdo de la barra de navegación, se
introduce el nombre con el que se quiere identificar a la vista y se pulsa agregar.
Ilustración 94 Guardar una vista
5.6 Cargar una configuracion de vistas
Para restaurar una configuración de vistas previamente cargada, se hace clic en el desplegable
superior izquierdo de la barra de navegación, se selecciona la vista deseada del desplegable y
se pulsa cambiar.
Además, si se marca la casilla se puede borrar la vista de la sección de vistas guardadas.

175
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 175 de 181
Ilustración 95 Cambiar una vista

176
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 176 de 181
6 | Conclusiones
El proyecto cumple el objetivo que es el uso de tecnologías de big data, Fast data y Fog
computing en el ámbito de las Smart Cities.
Aparte de ello se llega a los siguientes
El uso de microservicios, es decid, que cada elemento este separado de los otros,
permite cambiar elementos del proyecto, es decir usando este proyecto como base se
puede crear nuevos proyectos especializados sustituyendo o modificando uno o varios
microservicios. También ofrece facilidad a la hora de añadir cambios puesto que no se
tiene que modificar el sistema entero si no que se pueden substituir los elementos que
se requiera. La desventaja de esto es que el control de todo el sistema se complica
puesto que hay que controlar cada microservicio por separado.
Se demuestra a través del despliegue empresarial que la arquitectura Kappa que
procesa de manera distribuida permite un sistema que tiene capacidades de escalado
horizontal completas, es decir si en un momento se requiere aumentar la capacidad de
alguno de los microservicios simplemente añadiendo nuevos nodos a dicho servicios se
incrementa las capacidades horizontales del sistema.
Los sistemas distribuidos, además de la escalabilidad horizontal, ofrecen tolerancia a
fallos, es decir si uno de los nodos falla los otros se encargarán de suplantarlos
mientras se recupera por ello no hay perdidas de información.
Los sistemas de FastData permiten el procesamiento de los eventos en tiempo real, sin
embargo, tiene un alto coste de procesamiento el tener una visión general de todo lo
ocurrido hasta ahora, por ello es recomendable el uso de tecnologías Batch cuando se
requiera de un proceso teniendo en cuenta mucha información en el pasado ya
almacenada.
El uso de Kafka y la arquitectura kappa permiten que se le puedan añadir nuevos
módulos al sistema, es decir como todos los datos relevantes van a pasar por Kafka,
otros microservicios pueden apuntarse a recibir es información, procesarla y volver a
crear un nuevo flujo de datos que envían a Kafka, por lo que el uso de Kafka como
núcleo común de comunicación entre microservicios mejora la fiabilidad y la facilidad
en la ampliación de proyectos.

177
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 177 de 181
7 | Lecciones aprendidas
Enteste apartado se detallan una serie de lecciones aprendidas y consejos a tener en cuenta
cuando se hace un proyecto BigData/FastData.
Elección de la base de datos: uno de los puntos más importantes es donde vas a
almacenar los datos guardados, en este caso se usó HBASE, aunque sirvió para un
primer prototipo, a la hora de un despliegue real se denoto la incapacidad de HBASE
para hacer querys complejas. En una empresa se requiere instalar un Phoenix o similar
por encima para hacer las querys necesarias o escribir a mano dichos procesamientos
de información de manera que sean escalables una vez colocadas en un Hadoop o en
un Spark. Por ello es muy importante seleccionar la base datos para no requerir
parches en el futuro, el uso de una influxDB en el proyecto en vez de una HBASE habría
facilitado mucho su uso. En resumen, cada base de datos SQL o NOSQL tiene una
utilidad el estudio de los datos a almacenar es altamente recomendable.
Uso de herramientas según los requisitos del problema: básicamente esta sección
trata sobre el dicho de “matar moscas a cañonazos”, el primer ejemplo es el uso de
Streams, que está preparado para procesar cantidades ingentes de procesamiento sin
embargo es una herramienta de pago muy cara por lo que para proyectos que no
requieran un procesamiento tan alto es posible que haya alternativas más asequibles.
Otro ejemplo es Kafka, en el caso de prototipo y si no se tuviera planes de ampliar el
sistema a usar algo diferente a streams, es decir solo hubiera un microservicio de
procesamiento y no hubiera planes de nuevos microservicios, el uso de MQTT sería
más adecuado puesto que es mucho más ligero y se comporta mejor cuando se usan
túneles , VPNs o firewalls.
Despliegue: Cuando se despliega una aplicación monolítica en producción,
simplemente hay que desplegar ese elemento y como mucho una base de datos, pero
cuando se trata de microservicios hay que desplegar cada microservicio por separado.
Como aliados podemos tener orquestadores y tecnologías de contenedores, un buen
ejemplo es Docker que nos permite generar un contenedor que contiene el
microservicio que ya se auto despliega sobre cualquier SO que soporte Docker por lo
que el paso de desarrollo a despliegue es mínimo y además independiente del sistema
operativo que use el nodo. Por otro lado, compatible con Docker encontramos los
orquestadores Compose y kubernetes que permiten desplegar contenedores
interconectarlos entre ellos y publicar los puertos de acceso entre otras funciones de
manera automática. Usando estos dos conceptos simplemente usando Compose o
Kubernetes, se llevaría el despliegue a cualquier nodo o clúster (en el caso de

178
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 178 de 181
Kubernetes) y automáticamente se desplegaría y se arrancarían los microservicios sin
necesidad de intervención.

179
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 179 de 181
8 | Glosario
Servicios TIC [16]:
El término tecnologías de la información y la comunicación (TIC) a menudo se
usa para referirse a cualquier forma de hacer computo.
M2M [17]:
La tecnología Machine to Machine permite la comunicación inteligente entre dos
máquinas remotas en tiempo real. Con ella podrás reducir tiempos de producción y
errores incluso antes de que sucedan además de gestionar tus negocios de
manera sencilla y cómoda desde tus dispositivos móviles.
GSM [18]:
El sistema global para las comunicaciones móviles (del inglés Global System for
Mobile communications, GSM, y originariamente del francés groupe spécial mobile)
es un sistema estándar, libre de regalías, de telefonía móvil digital.
GPRS [18]:
(General Packet Radio Services) es una técnica de conmutación de paquetes, que
es integrable con la estructura actual de las redes GSM. Esta tecnología permitirá
una velocidad de datos de 115 kbs. Sus ventajas son múltiples, y se aplican
fundamentalmente a las transmisiones de datos que produzcan tráfico "a ráfagas",
es decir, discontinuo. Por ejemplo, Internet y mensajería. Puede utilizar a la vez
diversos canales, y aprovechar los "huecos" disponibles para las transmisiones de
diversos usuarios. Por ello, no necesitamos un circuito dedicado para cada usuario
conectado. De esta forma desaparece el concepto de tiempo de conexión, dejando
paso al de cantidad de información transmitida: El cliente podrá ser facturado por
los paquetes realmente enviados y recibidos. El ancho de banda podrá ser
entregado bajo demanda, en función de las necesidades de la comunicación. En
cuanto a los cambios que supone, las redes GSM deben implementar una serie de
nuevos equipos y cambios Hardware y Software, tanto en la parte radio como en la
parte de conmutación.
Gateway [19]:
La pasarela (en inglés gateway) o puerta de enlace es el dispositivo que actúa de
interfaz de conexión entre aparatos o dispositivos, y también posibilita compartir
recursos entre dos o más computadoras.

180
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 180 de 181
9 | Referencias
[1] C. D. d. F. S. Santiago Olivares.
[2] K. Ashton, «Esa cosa del 'interet de las cosas',» RFID, 2009.
[3] J. C. L. López, «La moda del Big Data: ¿En qué consiste en realidad?,» 27 02 2014. [En línea]. Available: http://www.eleconomista.es/tecnologia/noticias/5578707/02/14/La-moda-del-Big-Data-En-que-consiste-en-realidad.html.
[4] M. D. Tenorio, «Las 4V del Big Data,» 24 06 2014. [En línea]. Available: http://manueldelgado.com/las-4v-del-big-data/.
[5] J. A. Y. Gálvez, « geeky theory,» [En línea]. Available: https://geekytheory.com/que-es-mqtt/.
[6] J. A. Ramos, «Adictos al trabajo,» [En línea]. Available: https://www.adictosaltrabajo.com/tutoriales/kafka-logs/.
[7] M. P. Esteso, «geeky theory,» [En línea]. Available: https://geekytheory.com/apache-spark-que-es-y-como-funciona/.
[8] P. Galván, «SG Buzz,» [En línea]. Available: https://sg.com.mx/revista/50/un-vistazo-apache-spark-streaming#.V_dO68ftaM9.
[9] J. A. Ramos, «Adictos al trabajo,» [En línea]. Available: https://www.adictosaltrabajo.com/tutoriales/introduccion-storm/.
[10] L. M. Gracia, «Un poco de Java,» [En línea]. Available: https://unpocodejava.wordpress.com/2013/02/19/que-es-akka/.
[11] Apache, «Apache Beam,» [En línea]. Available: http://beam.incubator.apache.org/.
[12] L. M. Gracia, «Un poco de Java,» [En línea]. Available: https://unpocodejava.wordpress.com/2013/08/22/que-es-infosphere-streams/.
[13] M. Rouse, «Searchdatacenter,» [En línea]. Available: http://searchdatacenter.techtarget.com/es/definicion/Base-de-datos-relacional.
[14] Javier, «PandoraFMS,» [En línea]. Available: https://blog.pandorafms.org/es/nosql-vs-sql-diferencias-y-cuando-elegir-cada-una/.
[15] «Wikipedia,» [En línea]. Available: https://es.wikipedia.org/wiki/JavaServer_Pages.
[16] computingcareers, «computingcareers,» [En línea]. Available: http://computingcareers.acm.org/?page_id=7.
[17] telcelsoluciones, «telcelsoluciones,» [En línea]. Available: http://www.telcelsoluciones.com/m2m.
[18] gsmspain, «gsmspain,» [En línea]. Available: http://www.gsmspain.com/glosario/?palabra=GPRS.
[19] wikipedia, «wikipedia,» [En línea]. Available: https://es.wikipedia.org/wiki/Puerta_de_enlace.
[20] wikipedia, «wikipedia,» [En línea]. Available: https://es.wikipedia.org/wiki/Sistema_global_para_las_comunicaciones_m%C3%B3viles.

181
U N I V E R S I D A D P O L I T É C N I C A D E M A D R I D
Escuela Técnica Superior de Ingeniería de Sistemas Informáticos
Pagina 181 de 181


















