
Generación de modelos digitales de elevación
25
1 Máster Universitario en Tecnologías de la Información Geográfica para la Ordenación del Territorio Luis Miguel Vila Villarroel “Generación de Modelos Digitales del Terreno”
description
Esta revista introduce algunos métodos para la generación de modelos digitales de elevación y posterior validación de su calidad.
Transcript of Generación de modelos digitales de elevación

1
Máster Universitario en Tecnologías de la
Información Geográfica para la Ordenación
del Territorio
Luis Miguel Vila Villarroel
“Generación de Modelos Digitales del Terreno”

2
ÍNDICE
Introducción…………………………………………………………………………...Pág. 3
1: Selección de los datos a utilizar en la generación del MDE…Pág. 3
2: Generación de MDEs……………………………………………………….….Pp. 3-4
3. Corrección de posibles errores en el modelo……………….…….Pp. 5-8
4: Delimitación de cuencas y modelado hidrológico……………….Pp. 9-10
5: Detección y análisis del error atributivo en el MDE……………Pp. 11-23
6: Estándares de calidad de nuestros modelos………………….….Pp. 24-25

3
Introducción:
Para la evaluación de esta asignatura, se plantea un ejercicio que tiene como objetivos:
• Modelar la topografía de la cuenca de recepción del embalse de Maidevera
• Localizar los puntos desagüe de la cuenca principal
• Estimar el volumen de agua evacuado en el supuesto de unas precipitaciones de 30 litros por
metro cuadrado
Para realizarlo, hemos utilizado como base la cartografía topográfica a escala 1/5.000.
Mediante una serie de tratamientos geográficos y estadísticos, hemos generado los modelos
necesarios y evaluado su calidad final.
1: Selección de los datos a utilizar en la generación del MDE: análisis de los datos
topográficos originales y criterios para su selección y corrección de posibles errores.
A partir de la cartografía topográfica en formato DFX, hemos seleccionado las capas que nos
interesan para la generación del modelo. Las capas las hemos filtrado a través de una serie de
procesos para realizar la selección. A través del tipo de entidad, color y código hemos obtenido
las capas de ríos, curvas de nivel, cotas, carreteras y embalse.
Layer Color Tipo Útil?
Curvas de nivel 2, 3 y 4 34 Polyline Curvas de nivel validas
Curvas de nivel 10, 11 y 13 5 3D Polyline Ríos
Curvas de nivel 17 5 Continuous Embalse
Puntos layer 0 7 Continuous No sirve. Valor 0
Puntos layer 5 y 7 7 Continuous Cotas. Útil
2: Generación de MDEs por los métodos más usuales (TIN, “Inverse Distance Weigted” (IDW)
y “Kriging”) y determinación del más adecuado de acuerdo a los estándares de precisión y a
la evaluación del error observado
Vamos a proceder a la generación de modelos digitales del terreno mediante métodos de
interpolación. El primer paso a realizar, será transformar las curvas de nivel a puntos, y generar
una segunda capa resultado de la unión del resultado de pasar curvas de nivel a puntos con las
cotas de altitud. A continuación, generaremos dos “subset” de puntos: uno de muestreo (80%
del total) y otro de de chequeo (20% del total). El subset de puntos de muestreo servirá para
generar los modelos IDW y Kriging, mientras que los de chequeo los reservaremos para
comprobar con que precisión se ajustan los modelos generados a la realidad.
El primer modelo a realizar, será el TIN. Este es el más complejo de generar, ya que nos
permite introducir variables que el IDW y Kriging no utilizan (estos métodos de interpolación
solamente generan modelos a partir de puntos). Para generar el TIN, trabajaremos con las
capas de ríos, el embalse, el 80% de los puntos de cota y las curvas de nivel de la siguiente
manera, obteniendo el siguiente resultado:

4
TEMA Campo de altitud Tipo de elemento Input as
Línea de Ruptura None Ríos Soft Breaklines
Área de Altitud constante Elevación Embalse Hard replace
Isohipsas Elevación Curvas de nivel Mass Points
Cotas Elevación Cotas de elevación Mass Points
Observamos las características del modelo que hemos elaborado, y nos damos cuenta de que
se han generado zonas planas resultado de la triangulación entre puntos. Este modelo ha de
ser depurado, ya que como vemos en la imagen siguiente, en los barrancos el modelo genera
“cascadas”. Esto un claro error y debe ser subsanado.
Para mejorar el modelo, debemos generar un Modelo matricial a partir del TIN, ya que no
podemos trabajar con este formato. Convertimos el TIN a Raster con una resolución de celda
de 20m.
5
3: Corrección, si se cree conveniente, de posibles errores en el modelo, y, tanto en caso
afirmativo como negativo, justificarlo.
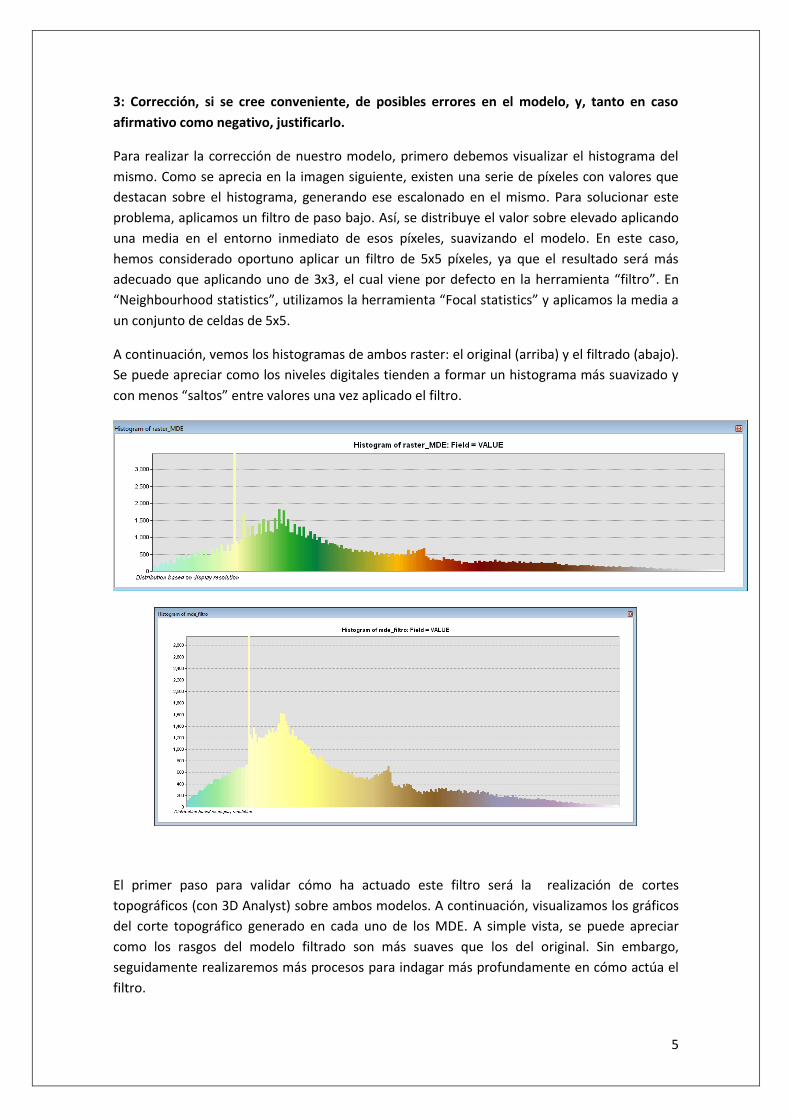
Para realizar la corrección de nuestro modelo, primero debemos visualizar el histograma del
mismo. Como se aprecia en la imagen siguiente, existen una serie de píxeles con valores que
destacan sobre el histograma, generando ese escalonado en el mismo. Para solucionar este
problema, aplicamos un filtro de paso bajo. Así, se distribuye el valor sobre elevado aplicando
una media en el entorno inmediato de esos píxeles, suavizando el modelo. En este caso,
hemos considerado oportuno aplicar un filtro de 5x5 píxeles, ya que el resultado será más
adecuado que aplicando uno de 3x3, el cual viene por defecto en la herramienta “filtro”. En
“Neighbourhood statistics”, utilizamos la herramienta “Focal statistics” y aplicamos la media a
un conjunto de celdas de 5x5.
A continuación, vemos los histogramas de ambos raster: el original (arriba) y el filtrado (abajo).
Se puede apreciar como los niveles digitales tienden a formar un histograma más suavizado y
con menos “saltos” entre valores una vez aplicado el filtro.
El primer paso para validar cómo ha actuado este filtro será la realización de cortes
topográficos (con 3D Analyst) sobre ambos modelos. A continuación, visualizamos los gráficos
del corte topográfico generado en cada uno de los MDE. A simple vista, se puede apreciar
como los rasgos del modelo filtrado son más suaves que los del original. Sin embargo,
seguidamente realizaremos más procesos para indagar más profundamente en cómo actúa el
filtro.

6
Gráfico del perfil topográfico aplicado al MDE sin filtrar:
Gráfico del perfil topográfico aplicado al MDE filtrado:

7
A continuación, generamos las curvas de nivel de ambos modelos para visualizar diferencias.
En la imagen siguiente, se pueden comparar las curvas de nivel obtenidas de ambos modelos.
En color rojo, visualizamos las del modelo raster sin haberle aplicado el filtro. En azul, las
curvas de nivel obtenidas del raster resultado de haberle aplicado el filtro, y en verde las
curvas de nivel originales. Se puede apreciar cómo las obtenidas del TIN filtrado están
claramente más suavizadas con respecto a las otras, por lo que el modelo digital resultado
también lo estará.
Finalmente, para comprobar cómo ha actuado el filtro de paso bajo, procederemos a restar el
modelo original obtenido del TIN con el raster resultante del filtrado. Así, los valores negativos
marcarán zonas donde el valor del ráster filtrado es mayor que el del modelo original; y los
valores positivos significarán que en esas zonas se reducido el valor, con respecto al modelo
original, al aplicar el filtro. El resultado obtenido es el siguiente:

8
Si interpretamos el modelo obtenido, podemos determinar que el filtrado ha hecho que el
modelo gane altura en las zonas bajas llanas y en los valles (superficie en rojo, que indica que
el modelo filtrado tiene más altura que el modelo original), mientras que en las zonas de
elevada altitud y en las cimas de las formaciones montañosas, el modelo filtrado pierde altura
con respecto al original.

9
4: Delimitación de la cuenca hidrográfica principal, modelado hidrológico, puntos de desagüe
y estimación del volumen de agua evacuada al embalse en el supuesto de unas
precipitaciones de 30 litros por metro cuadrado.
Para realizar el modelado hidrológico de esta cuenca trabajaremos con el MDE obtenido a
partir del TIN y posteriormente filtrado. El primer paso a realizar, es llenar los “huecos” de
nuestro modelo con la herramienta “Fill” para simular perfectamente como fluiría el agua por
la zona. Tras esto, se establecerá la dirección del flujo de cada celda con la herramienta “Flow
Direction”. Con este modelo ya podemos obtener las cuencas aplicando a la capa de dirección
de flujo la función “Basin”. La capa obtenida ha sido la siguiente:
A continuación, hay que generar la capa de acumulación del flujo a partir de la capa de
dirección del flujo. Con esta capa, calcularemos el volumen del caudal evacuado, ya que el
píxel final tendrá el valor de todas las celdas que drenan hacia su cuenca. Si sabemos que ha
llovido 30 litros por metro cuadrado, y que el tamaño del píxel es de 20 metros de largo,
solamente tenemos que multiplicar el número de celdas por el caudal y por las precipitaciones
por metro cuadrado (caudal = 30x20x20x94400). Obtenemos el valor de 113,280,000 litros de
caudal evacuado.

10
Con el mapa de salida, ejecutamos la calculadora de raster y de esta capa seleccionamos las
zonas mayores que 200, que es el umbral mínimo a partir del cual se estima que se produce
acumulación de caudal y formación del cauce de un río. La capa resultado será binaria, y el
valor 1 lo tendrán las celdas que forman la red hidrográfica.
Finalmente, con los modelos de acumulación binario y el dirección de flujo, generamos la red
hidrológica con la herramienta stream link. Tras esto, se ordenaran con stream order. El último
paso será pasar esta red a polilínea con la herramienta stream to feature. El resultado es el
siguiente:
La red generada tendrá un campo de entidad generado como consecuencia de aplicar el
anterior método de ordenación de tramos (Strahler o Shreve).
Los pozos que presenta nuestra zona de estudio han sido obtenidos con la herramienta de
geoproceso “Sink”, y son los siguientes:
11
5: Detección y análisis del error atributivo en el MDE:
Para realizar esta parte del ejercicio, se realizan los restantes modelos digitales utilizando los
métodos de interpolación Kriging y IDW a partir de la capa de puntos de control y de testeo
generada en el ejercicio 1.
A continuación, procederemos a medir el error de cada uno de los modelos generados para
determinar si cumplen los requisitos de calidad establecidos y valorar cuál de ellos ofrece una
mejor calidad.
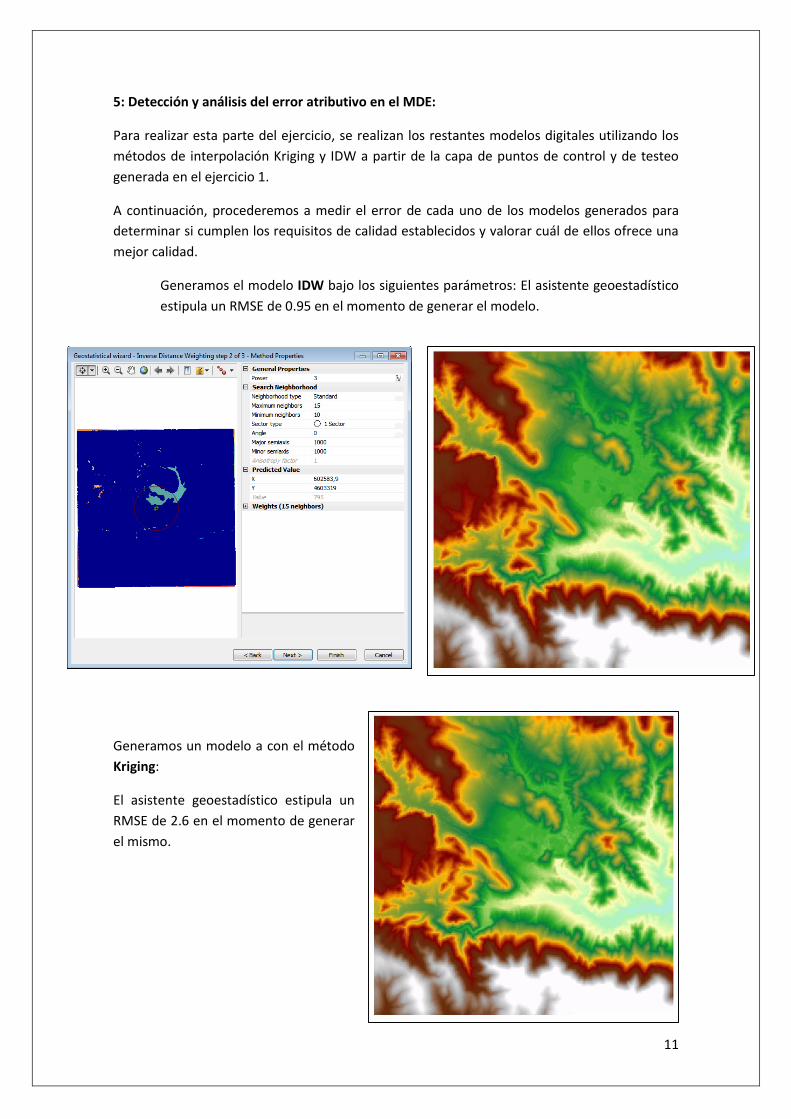
Generamos el modelo IDW bajo los siguientes parámetros: El asistente geoestadístico
estipula un RMSE de 0.95 en el momento de generar el modelo.
Generamos un modelo a con el método
Kriging:
El asistente geoestadístico estipula un
RMSE de 2.6 en el momento de generar
el mismo.
12
Modelo TIN convertido a GRID y filtrado (además de este modelo, utilizaremos el MDE con los
puntos de desagüe llenos para ver si este geoproceso influye en la calidad de nuestro modelo):
A continuación, procederemos a calcular el error medio de cada uno de los modelos. Este se
define como el promedio de los errores de altitud, y sirve para determinar si el error existente

13
es sistemático o aleatorio. Lo ideal es que su valor se acerque lo máximo posible a 0. Si el error
medio es diferente de cero, existe un error sistemático que se refleja por igual en todo el
modelo.
Si la media y la mediana son cercanas a cero, las infra y sobreestimaciones de la altitud en el
MDE está equilibradas y son simétricas en sus magnitudes. Es importante observar si la
distribución está muy o poco extendida. Cuanto mayor sea la varianza, más se extiende la
distribución de los errores. Lo ideal es una distribución del error poco extendida con una media
próxima a cero.
Posteriormente, veremos la distribución del error respecto a la medida algebraica. Este, se
distribuye en una campana de gauss (distribución normal). Para que nuestro modelo sea de
calidad, el 68,27% de los valores estará +-1 desviación estándar, el 95,4% a +-2 desviaciones
estándar y el 99,73% a +-3.
Generamos una capa para cortar los puntos test, para hacer que queden todos dentro de los
modelos generados y evitar que nos salgan valores de cero que nos alteren las estadísticas.
Aplicamos los valores de cada uno de los modelos a nuestra capa de puntos de chequeo, y en
la tabla de atributos, restamos en cada campo el valor real menos el interpolado y vemos las
estadísticas. Los resultados obtenidos son mostrados a continuación:
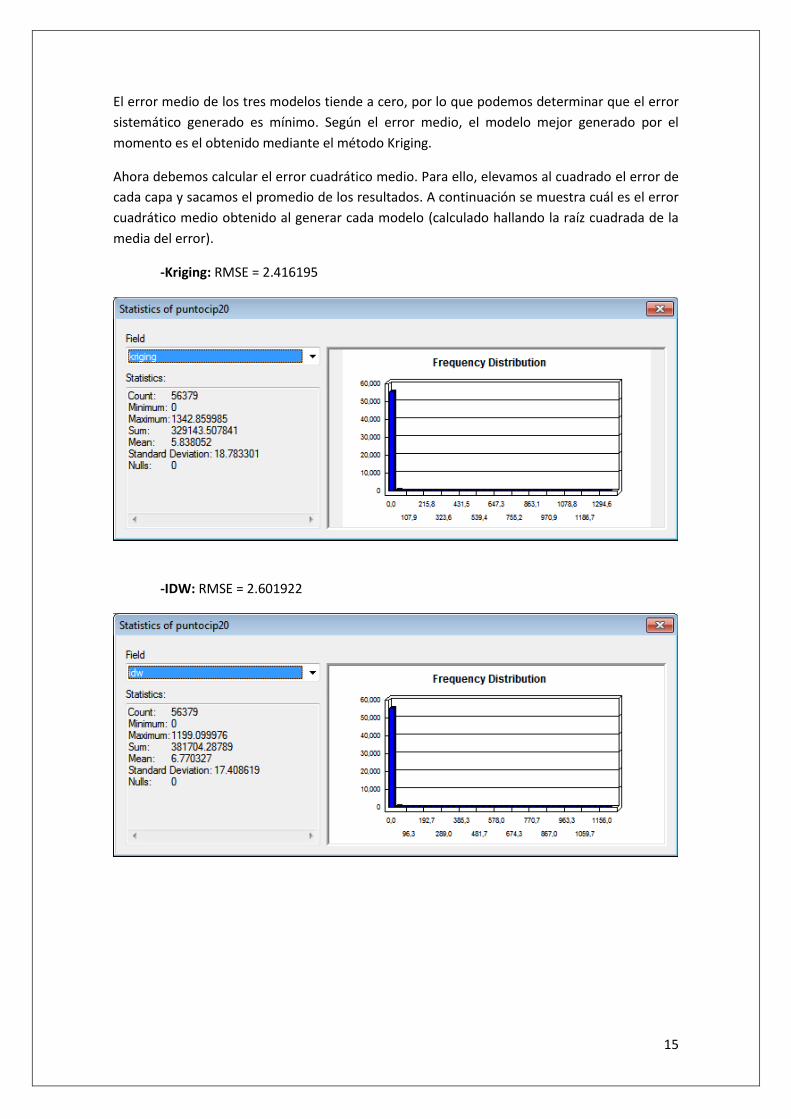
-Estadísticas del error del Kriging: Error medio = -0.000087

14
-Estadísticas del error del IDW: Error medio = -0.008167
-Estadísticas del error del TIN: Error medio = 0.036141
-Estadísticas del TIN con los puntos de desagüe llenos (“Filled”): Error medio = 0.019
15
El error medio de los tres modelos tiende a cero, por lo que podemos determinar que el error
sistemático generado es mínimo. Según el error medio, el modelo mejor generado por el
momento es el obtenido mediante el método Kriging.
Ahora debemos calcular el error cuadrático medio. Para ello, elevamos al cuadrado el error de
cada capa y sacamos el promedio de los resultados. A continuación se muestra cuál es el error
cuadrático medio obtenido al generar cada modelo (calculado hallando la raíz cuadrada de la
media del error).
-Kriging: RMSE = 2.416195
-IDW: RMSE = 2.601922
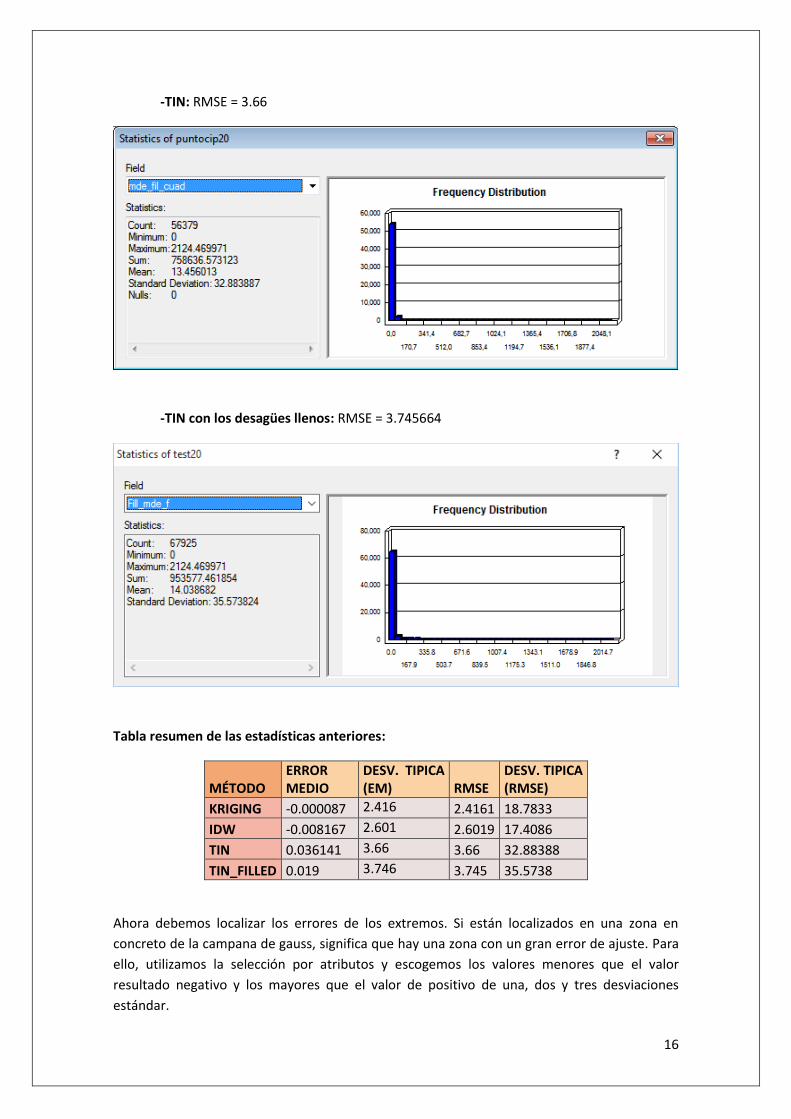
16
-TIN: RMSE = 3.66
-TIN con los desagües llenos: RMSE = 3.745664
Tabla resumen de las estadísticas anteriores:
MÉTODO ERROR MEDIO
DESV. TIPICA (EM) RMSE
DESV. TIPICA (RMSE)
KRIGING -0.000087 2.416 2.4161 18.7833
IDW -0.008167 2.601 2.6019 17.4086
TIN 0.036141 3.66 3.66 32.88388
TIN_FILLED 0.019 3.746 3.745 35.5738
Ahora debemos localizar los errores de los extremos. Si están localizados en una zona en
concreto de la campana de gauss, significa que hay una zona con un gran error de ajuste. Para
ello, utilizamos la selección por atributos y escogemos los valores menores que el valor
resultado negativo y los mayores que el valor de positivo de una, dos y tres desviaciones
estándar.

17
En la siguiente tabla se resumen los resultados obtenidos de la aplicación de desviaciones
estándar a cada uno de nuestros modelos. La última de las columnas corresponde al
porcentaje de puntos de muestreo que tienen un error menor a la mitad de la distancia entre
curvas de nivel.
MÉTODO 1 D.E. 2 D.E. 3 D.E. % error menor a 2.5m
KRIGING 92.73758 98.27015 99.25801 74.59
IDW 83.95731 98.41443 99.14906 70.02
TIN 88.98785 96.41811 98.5057 54.8
TIN_FILLED 90.23923 96.9216 98.70445 53.8
Como podemos ver en la tabla, todos nuestros modelos cumplirían el requisito descrito
previamente de comprender el 68,27% de los valores dentro de +-1 desviación estándar, el
95,4% en +-2 desviaciones estándar. Sin embargo, el 99,73% de los errores comprendidos en
+-3 desviaciones estándar no se cumple en ninguno de los tres casos, por lo que podemos
determinar que el error sistemático que presentan nuestros modelos lo producen los valores
que se encuentran en esa zona de la distribución típica.
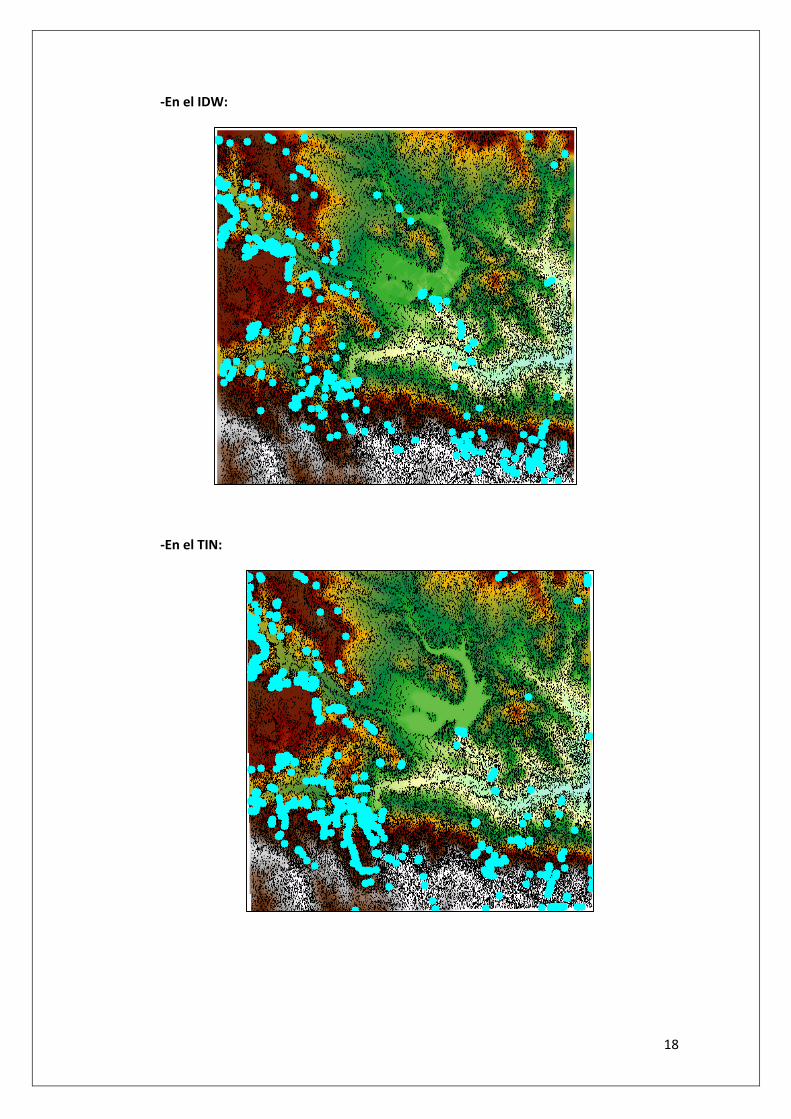
A continuación, seleccionaremos los valores que se encuentran dentro de tres desviaciones
estándar e invertiremos la selección con la finalidad de obtener los puntos que superan este
error. Los siguientes mapas muestran, para cada modelo, donde se localizan estos puntos de
error sistemático.
-En el kriging:
18
-En el IDW:
-En el TIN:
19
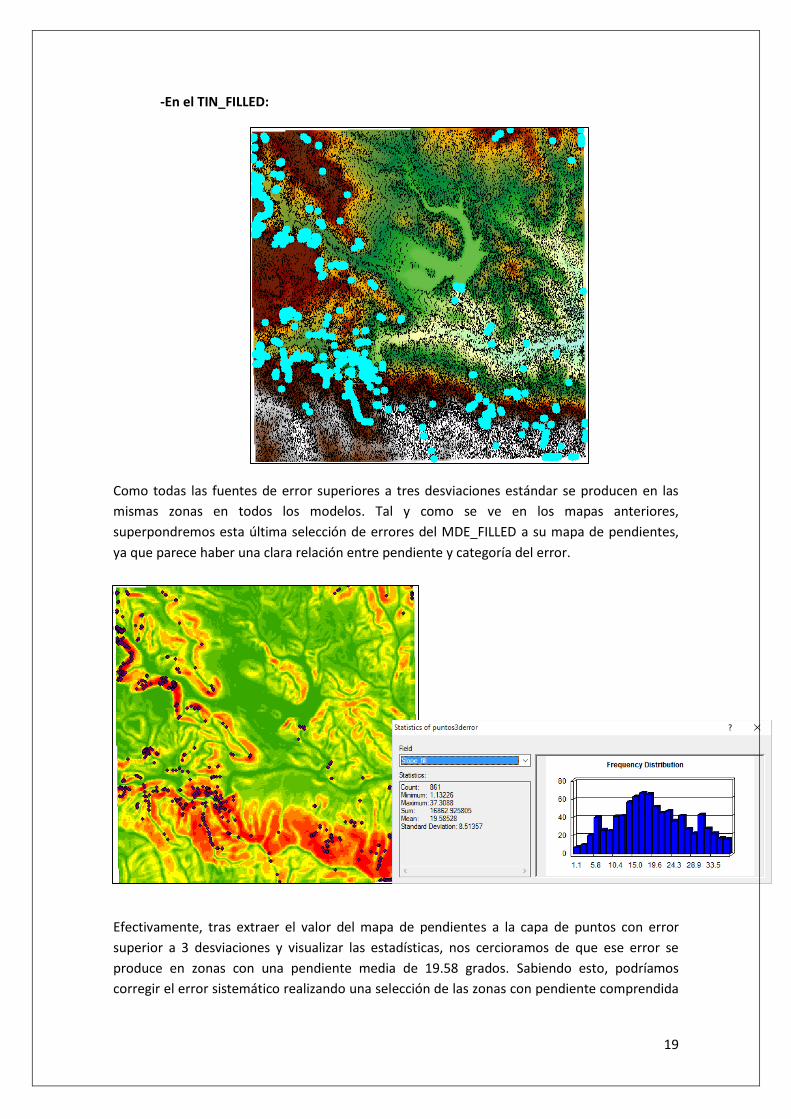
-En el TIN_FILLED:
Como todas las fuentes de error superiores a tres desviaciones estándar se producen en las
mismas zonas en todos los modelos. Tal y como se ve en los mapas anteriores,
superpondremos esta última selección de errores del MDE_FILLED a su mapa de pendientes,
ya que parece haber una clara relación entre pendiente y categoría del error.
Efectivamente, tras extraer el valor del mapa de pendientes a la capa de puntos con error
superior a 3 desviaciones y visualizar las estadísticas, nos cercioramos de que ese error se
produce en zonas con una pendiente media de 19.58 grados. Sabiendo esto, podríamos
corregir el error sistemático realizando una selección de las zonas con pendiente comprendida

20
en una desviación estándar a partir de la media del error y aplicando una mayor cantidad de
puntos en la misma.
Distribución de las zonas con error menor a 2.5 metros del IDW:
Hemos tomado como ejemplo la capa generada con el IDW para ver donde el error generado
es menor a la mitad del intervalo de las curvas de nivel. Podemos ver, que las zonas donde el
error es menor a 2.5m son las zonas con pendiente pronunciada. En las zonas con topografía
llana, el error supera este umbral. También hemos realizado esta misma comprobación con el
Kriging y el TIN, siendo las zonas de error equivalentes. En las siguientes imágenes se puede
ver la distribución geográfica del ajuste sobre el MDE creado a partir del TIN.

21
Seguidamente, realizaremos una serie de operaciones de resta entre modelos interpolados.
Esto nos permite ver donde se producen las mayores diferencias entre ambos y donde
aumenta o disminuye el valor de un modelo con respecto a otro.
El siguiente modelo lo hemos obtenido restando kriging-MDE:
Las zonas sombreadas con rojo, son las que pierden altura, y las sombreadas con azul son las
que ganan. Es decir, que lo azul significa que en esas zonas el valor del TIN es superior al valor
del Kriging. Sin embargo, las zonas rojas indican que el valor del Kriging es superior al del TIN.
Por lo general, el TIN genera valores más elevados que el Kriging en las zonas de baja altitud así
como en las cimas.

22
Modelo generado al restar IDW-TIN:
Al igual que el caso anterior, los valores en azul determinan las zonas en las que el valor del TIN
es superior al del IDW. Las zonas de menor altitud y las cimas de las formaciones montañosas,
aparecen con un valor mayor en el TIN que en el IDW.
Modelo generado al restar IDW-Kriging:
En este modelo, los colores azules representan zonas en las que el valor del Kriging es mayor
que el del IDW. Se puede apreciar como la diferencia entre ambas capas se corresponde con la
distribución de las curvas de nivel en los valles. En zonas bajas de topografía plana, el valor del
Kriging es mayor al del IDW.
23
Reclasificación:
por intervalos
de 5 en 5 grados
(0-5, 5-10…)
Error medio
Error cuadrático
medio
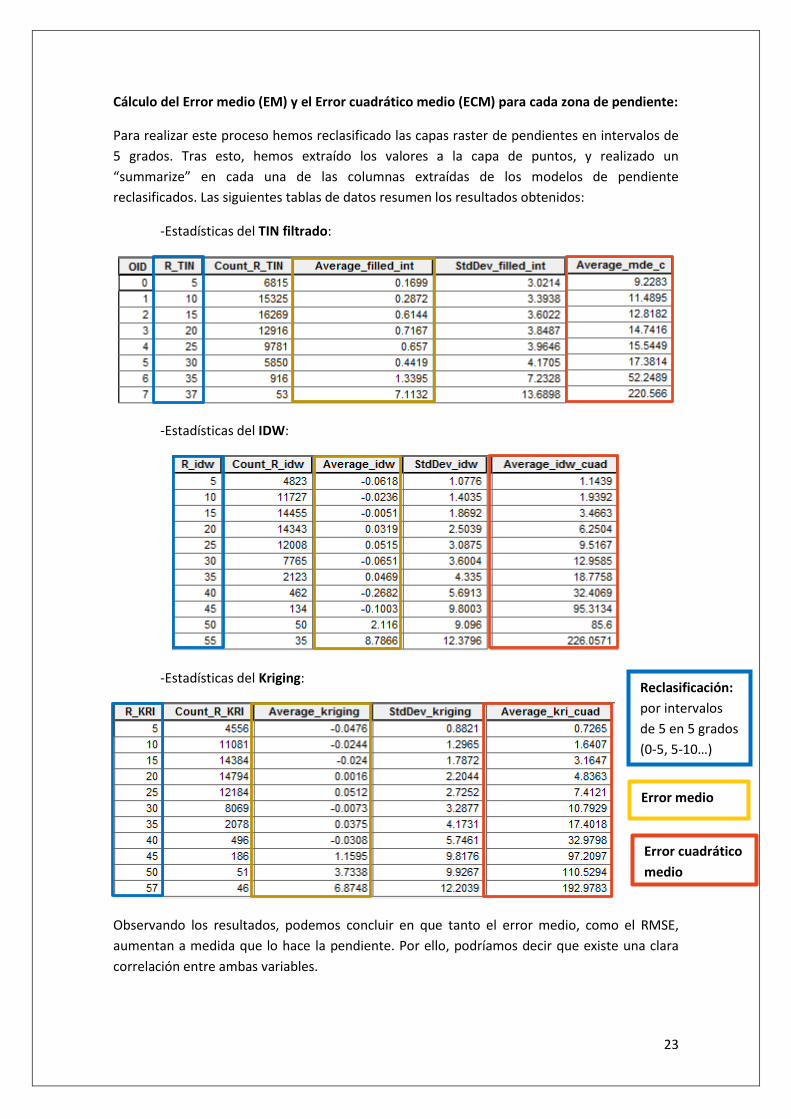
Cálculo del Error medio (EM) y el Error cuadrático medio (ECM) para cada zona de pendiente:
Para realizar este proceso hemos reclasificado las capas raster de pendientes en intervalos de
5 grados. Tras esto, hemos extraído los valores a la capa de puntos, y realizado un
“summarize” en cada una de las columnas extraídas de los modelos de pendiente
reclasificados. Las siguientes tablas de datos resumen los resultados obtenidos:
-Estadísticas del TIN filtrado:
-Estadísticas del IDW:
-Estadísticas del Kriging:
Observando los resultados, podemos concluir en que tanto el error medio, como el RMSE,
aumentan a medida que lo hace la pendiente. Por ello, podríamos decir que existe una clara
correlación entre ambas variables.
24
6: Determinar si nuestros modelos cumplen los estándares de calidad y escoger uno como el
mejor ajustado a la realidad:
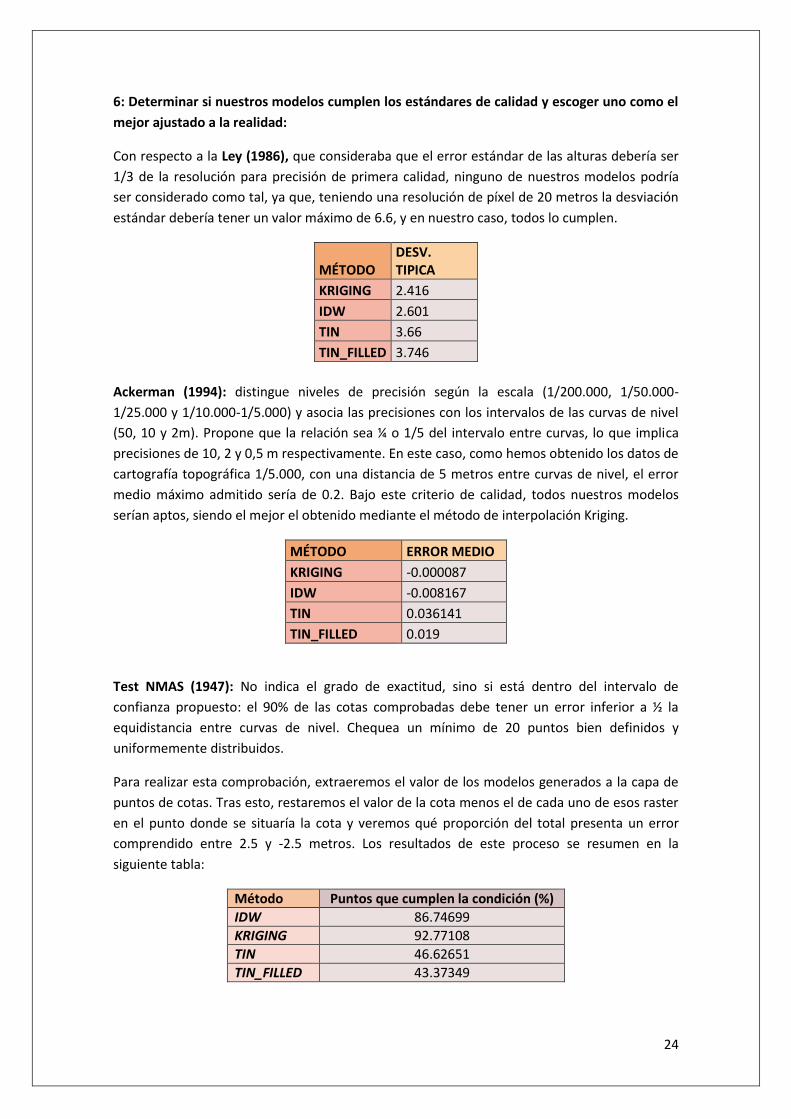
Con respecto a la Ley (1986), que consideraba que el error estándar de las alturas debería ser
1/3 de la resolución para precisión de primera calidad, ninguno de nuestros modelos podría
ser considerado como tal, ya que, teniendo una resolución de píxel de 20 metros la desviación
estándar debería tener un valor máximo de 6.6, y en nuestro caso, todos lo cumplen.
MÉTODO DESV. TIPICA
KRIGING 2.416
IDW 2.601
TIN 3.66
TIN_FILLED 3.746
Ackerman (1994): distingue niveles de precisión según la escala (1/200.000, 1/50.000-
1/25.000 y 1/10.000-1/5.000) y asocia las precisiones con los intervalos de las curvas de nivel
(50, 10 y 2m). Propone que la relación sea ¼ o 1/5 del intervalo entre curvas, lo que implica
precisiones de 10, 2 y 0,5 m respectivamente. En este caso, como hemos obtenido los datos de
cartografía topográfica 1/5.000, con una distancia de 5 metros entre curvas de nivel, el error
medio máximo admitido sería de 0.2. Bajo este criterio de calidad, todos nuestros modelos
serían aptos, siendo el mejor el obtenido mediante el método de interpolación Kriging.
MÉTODO ERROR MEDIO
KRIGING -0.000087
IDW -0.008167
TIN 0.036141
TIN_FILLED 0.019
Test NMAS (1947): No indica el grado de exactitud, sino si está dentro del intervalo de
confianza propuesto: el 90% de las cotas comprobadas debe tener un error inferior a ½ la
equidistancia entre curvas de nivel. Chequea un mínimo de 20 puntos bien definidos y
uniformemente distribuidos.
Para realizar esta comprobación, extraeremos el valor de los modelos generados a la capa de
puntos de cotas. Tras esto, restaremos el valor de la cota menos el de cada uno de esos raster
en el punto donde se situaría la cota y veremos qué proporción del total presenta un error
comprendido entre 2.5 y -2.5 metros. Los resultados de este proceso se resumen en la
siguiente tabla:
Método Puntos que cumplen la condición (%)
IDW 86.74699
KRIGING 92.77108
TIN 46.62651
TIN_FILLED 43.37349
25
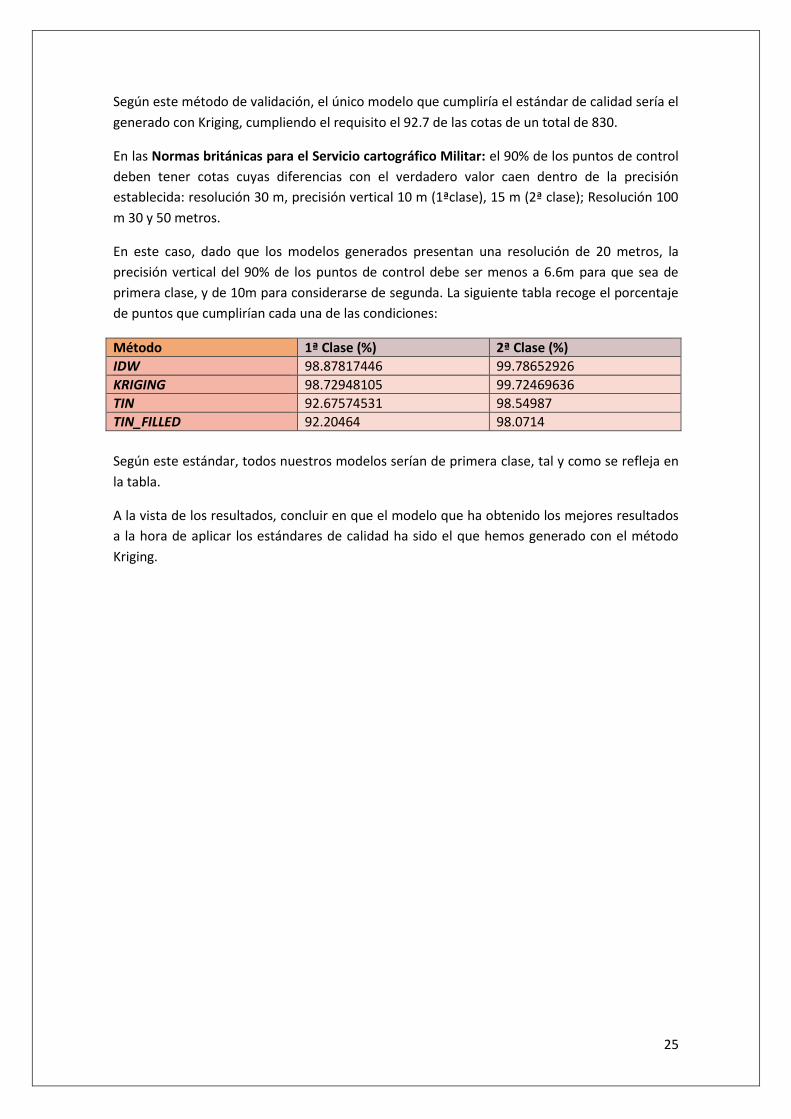
Según este método de validación, el único modelo que cumpliría el estándar de calidad sería el
generado con Kriging, cumpliendo el requisito el 92.7 de las cotas de un total de 830.
En las Normas británicas para el Servicio cartográfico Militar: el 90% de los puntos de control
deben tener cotas cuyas diferencias con el verdadero valor caen dentro de la precisión
establecida: resolución 30 m, precisión vertical 10 m (1ªclase), 15 m (2ª clase); Resolución 100
m 30 y 50 metros.
En este caso, dado que los modelos generados presentan una resolución de 20 metros, la
precisión vertical del 90% de los puntos de control debe ser menos a 6.6m para que sea de
primera clase, y de 10m para considerarse de segunda. La siguiente tabla recoge el porcentaje
de puntos que cumplirían cada una de las condiciones:
Método 1ª Clase (%) 2ª Clase (%)
IDW 98.87817446 99.78652926
KRIGING 98.72948105 99.72469636
TIN 92.67574531 98.54987
TIN_FILLED 92.20464 98.0714
Según este estándar, todos nuestros modelos serían de primera clase, tal y como se refleja en
la tabla.
A la vista de los resultados, concluir en que el modelo que ha obtenido los mejores resultados
a la hora de aplicar los estándares de calidad ha sido el que hemos generado con el método
Kriging.


















