
Graduado en Ingeniería Informáticaoa.upm.es/54265/1/TFG_MARCOS_AMOEDO_FERNANDEZ.pdf•Apache Kafka...
49
TRABAJO FIN DE GRADO Autor: Director: Escuela Técnica Superior de Ingenieros Informáticos Universidad Politécnica de Madrid Graduado en Ingeniería Informática MADRID, ENERO 2019 Escalabilidad en sistemas de data streaming Marcos Amoedo Fernández Marta Patiño Martínez
Transcript of Graduado en Ingeniería Informáticaoa.upm.es/54265/1/TFG_MARCOS_AMOEDO_FERNANDEZ.pdf•Apache Kafka...

TRABAJO FIN DE GRADO
Autor: Director:
Escuela Técnica Superior deIngenieros Informáticos
Universidad Politécnica de Madrid
Graduado en Ingeniería Informática
MADRID, ENERO 2019
Escalabilidad en sistemas de data streaming
Marcos Amoedo Fernández Marta Patiño Martínez


ESCALABILIDAD EN SISTEMAS DE DATA STREAMING
Autor: Marcos Amoedo FernándezDirector: Marta Patiño Martínez
Departamento de Sistemas DistribuidosEscuela Técnica Superior de Ingenieros Informáticos
Universidad Politécnica de Madrid
13 de enero de 2019

Dedicatoria
A todos los que me han acompañado durante estos bonitos años. En especial a miscompañeros de equipo de la facultad y mis compañeros del día a día en las prácticas tansufridas.
C Escalabilidad en sistemas de data streaming


Agradecimientos
A todos los que me han formado en todas las aptitudes posibles durante mi etapa enla Universidad.
A mi tutora, Marta Patiño, por abrirme los ojos a una pequeñísima parte de este granmundo de los datos y proporcionarme el material necesario para poder desarrollar estetrabajo.
E Escalabilidad en sistemas de data streaming


Resumen
Resumen — Los sistemas de data streaming son capaces de procesar de maneradistribuida una gran cantidad datos en memoria, sin necesidad de almacenarlos en disco.Sin embargo, es necesario disponer de un mecanismo de tolerancia a fallos que permitaal sistema recuperar su estado de procesamiento en caso de un fallo de cualquiera de suscomponentes. Apache Flink es un framework de data streaming que dispone de variosmecanismos de tolerancia a fallos. HiBench es un benchmark de Intel que usaré paracomparar el rendimiento de los distintos mecanismos.
Palabras clave — Apache Flink, Sistemas Distribuidos, Tolerancia a fallos, HiBench
i Escalabilidad en sistemas de data streaming


Abstract
Abstract — Data Streaming systems are able to compute an enormous load of dataon memory, without storing it on disk. However, it is neccesary to implement a faulttolerance mechanism, which prevents de data loss in case of a component failure. ApacheFlink is a data streaming framework which implements some fault tolerance mechanisms.Hibench is an Intel benchmark which I will use to compare the performance of saidmechanisms.
Key words — Apache Flink, Distributed Systems, Fault Tolerance, Hibench
iii Escalabilidad en sistemas de data streaming


Índice general
1. Introducción 11.1. Alcance y objetivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.2. Estructura del documento . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
2. Estado del Arte 3
3. Arquitectura 5
4. Desarrollo 94.1. Tolerancia a fallos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94.2. Configuración . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
4.2.1. Hadoop Distributed Filesystem . . . . . . . . . . . . . . . . . . . . 104.2.2. Apache Kafka . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114.2.3. Apache Zookeeper . . . . . . . . . . . . . . . . . . . . . . . . . . . 124.2.4. Apache Flink . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 134.2.5. Prometheus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 154.2.6. Hibench . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
4.3. Despliegue . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 184.4. Monitorización . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 194.5. Recursos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 194.6. Experimentos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
5. Resultados 21
6. Conclusiones 27
Bibliografía 29
v Escalabilidad en sistemas de data streaming


Índice de figuras
3.1. Arquitectura. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
4.1. Despliegue de los experimentos. . . . . . . . . . . . . . . . . . . . . . . . . 18
5.1. Resultados del experimento con 1K eventos. . . . . . . . . . . . . . . . . . 225.2. Resultados del experimento con 3K eventos. . . . . . . . . . . . . . . . . . 235.3. Resultados del experimento con 8K eventos. . . . . . . . . . . . . . . . . . 245.4. Resultados agregados de todos los experimentos. . . . . . . . . . . . . . . . 25
vii Escalabilidad en sistemas de data streaming


Índice de tablas
4.1. Tabla de configuración de experimentos. . . . . . . . . . . . . . . . . . . . 20
ix Escalabilidad en sistemas de data streaming


1Introducción
En la actualidad, el uso de sistemas de data streaming para procesar datos generadosal instante se multiplica año tras año. Sus usos varían desde el procesamiento de redes desensores y dispositivos IoT conectados, a procesamiento de paquetes de comunicaciones enuna red, pasando por sistemas de detección de fraude, sistemas de detección de anomalías,etc.
Apache Flink [1] es un framework y un motor de procesamiento distribuido paraoperaciones sin estado sobre flujos de datos. Flink ha sido diseñado para ejecutarse sobrelos entornos de cluster más comunes, realizar operaciones a velocidad de memoria y acualquier escala. Los casos de uso de Apache Flink se pueden resumir en tres: AplicacionesEvent-driven, Aplicaciones de Análisis de Datos y Aplicaciones de Data Pipeline. En estetrabajo nos centraremos en la primera aplicación mencionada, una aplicación event-driven.Una aplicación event-driven es una aplicación sin estado que consume eventos de una ovarias fuentes de eventos y reacciona a ellos realizando las tareas y/o procesamientosdefinidos. [2]
En un sistema de data streaming como Flink, los datos sólo se retienen en memoria eltiempo necesario para procesarlos y después son descartados. Sin embargo, en caso de fallode alguno de los componentes del sistema, se podría perder el estado de la ejecución. Porello es necesario implementar algún tipo de mecanismo de tolerancia a fallos que garanticeque el estado de la ejecución no se pierda en caso de un fallo. Para ser tolerante a fallos,Flink hace «checkpoints», o «puntos de control» en español, del estado. Estos checkpointspermiten a Flink recuperar el estado de la ejecución y los punteros en las fuentes de datos.Este mecanismo se explicará más adelante, en la Sección 4.1.
1 Escalabilidad en sistemas de data streaming

1.1. ALCANCE Y OBJETIVOS CAPÍTULO 1. INTRODUCCIÓN
1.1. Alcance y objetivos
A grandes rasgos, en este trabajo se pretende configurar un entorno de procesamientodistribuido con Apache Flink y evaluar el impacto en el rendimiento de los diferentesmecanismos de tolerancia a fallos que implementa. En concreto, se configurarán todoslos componentes que se detallan en el apartado de la arquitectura, Sección 3, y seevaluará el impacto en el rendimiento del sistema en múltiples despliegues con diferentesconfiguraciones de estos componentes, y en concreto de los mecanismos de tolerancia afallos de Apache Flink.
1.2. Estructura del documento
El documento se basa la estructura definida por la asignatura Trabajo de Fin de Grado[3] y que se refleja en el índice de este documento, con los puntos adicionales que he creídoconvenientes, como «Estado del Arte», «Arquitectura» o este propio punto «Estructuradel documento» que se encuentra dentro de la «Introducción».
El «Resumen», tanto en español como en inglés, se encuentran antes del «Índice».A continuación, la «Introducción» al trabajo seguida del «Estado del Arte» y la«Arquitectura». El grueso del trabajo se encuentra en las tres secciones principales:«Desarrollo», «Resultados» y «Conclusiones». Por último, la «Bibliografía», sin ningúnanexo adicional.
2

2Estado del Arte
Big Data y Data Streaming son áreas que surgieron hace muy poco tiempo y, portanto, la literatura y los experimentos al respecto no abundan. Apache Flink en concretotiene poco más de 4 años:
En 2010, el proyecto de investigación «Stratosphere: Information Managementon the Cloud» [4](fundado por la Fundación de Invesigación Alemana (DFG))empezó como una colaboración entre Technical University Berlin, «Humboldt-Universität zu Berlin», y Hasso-Plattner-Institut Potsdam. Flink empezó comoun fork del motor de ejecución distribuida de Stratosphere y se convirtió enproyecto Incubadora Apache en marzo de 2014. En diciembre de 2014, Flinkera aceptado como proyecto de alto nivel de Apache. [5]
Desde 2015 se celebra la conferencia más importante respecto a Flink, la Flink Forward[6]:
Flink Forward es una conferencia anual sobre Apache Flink. La primera ediciónde Flink Forward se celebró en 2015, en Berlín. La conferencia duró dos díasy tuvo una asistencia de más de 250 personas de 16 paises. [...] Ponentesde las siguientes organizaciones han participado en esta conferencia: Alibaba,Amadeus, Bouygues Telecom, Capital One, Cloudera, data Artisans, EMC,Ericsson, Hortonworks, Huawei, IBM, Google, MapR, MongoDB, Netflix, NewRelic, Otto Group, Red Hat, ResearchGate, Uber y Zalando. [7]
Apache Flink es desarrollado bajo licencia «Apache 2.0» por la comunidad ApacheFlink dentro de la «Apache Software Foundation». El proyecto es dirigido por más de25 desarrolladores y más de 340 colaboradores. Data Artisans es una empresa que fue
3 Escalabilidad en sistemas de data streaming

CAPÍTULO 2. ESTADO DEL ARTE
fundada por los creadores originales de Apache Flink y, actualmente, 12 desarrolladoresde Apache Flink son empleados por Data Artisans. [8]
Respecto al estudio del impacto en el rendimiento de sus mecanismos de toleranciaa fallos, la única referencia encontrada es «Cost of Fault-tolerance on Data StreamProcessing» [9], trabajo realizado por Valerio Vianello, Marta Patiño Martínez, AinhoaAzqueta Alzúaz y Ricardo Jiménez Péris y publicado en mayo de 2018. Este trabajo evaluaprincipalmente el overhead introducido por los diferentes mecanismos de tolerancia a fallosde Apache Flink usando como unidades de medida la latencia y el throughput.
4

3Arquitectura
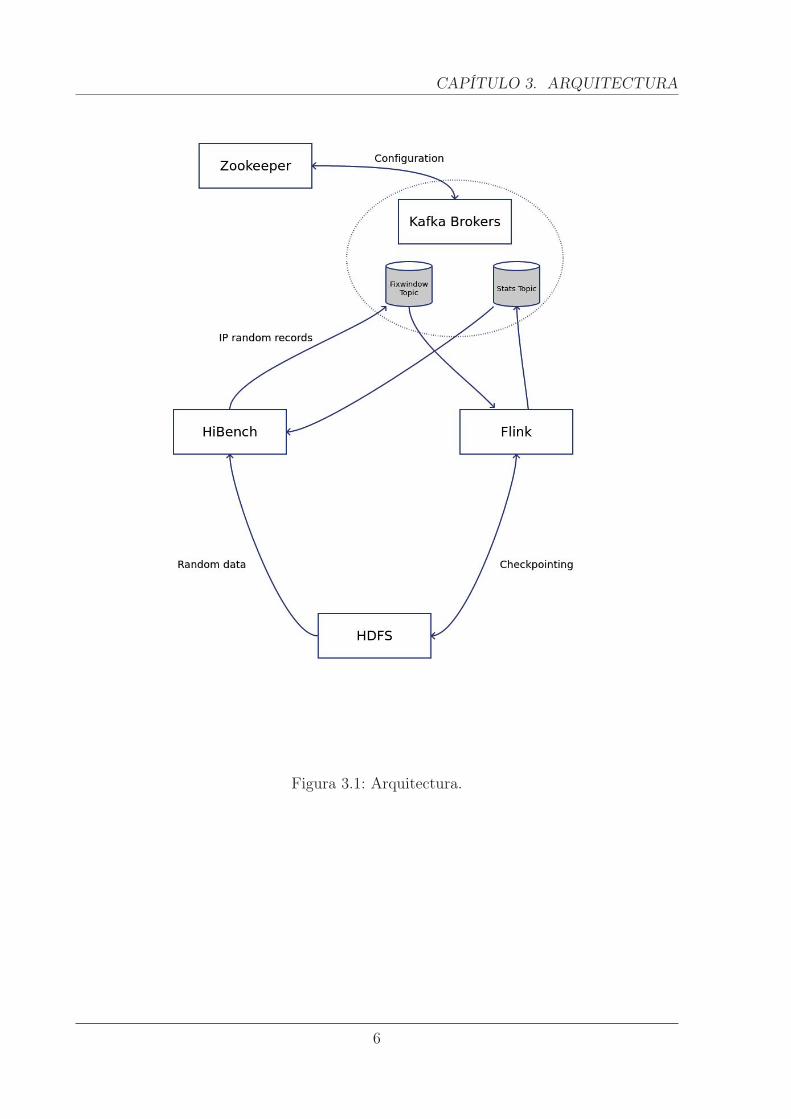
La arquitectura típica de un sistema en el que se utiliza Apache Flink comoaplicación orientada al procesamiento de eventos consta, como mínimo, de los siguientescomponentes:
• Un sistema de ficheros [10], el cual proporciona persistencia de datos y en el cual sealmacenan, por ejemplo, los checkpoints o snapshots correspondientes de acuerdoal mecanismo de tolerancia a fallos en uso. Típicamente se usa HDFS (HadoopDistributed File System), pero también destacan Amazon S3 file system y GCS(Google Cloud Storage)
• Una plataforma que actue como pipeline de datos y que permita la obtención de flujosfiables de datos. Destaca Apache Kafka [11], una plataforma que con sus topicsprovee de fuentes y sumideros de datos fiables, donde estos datos se almacenan demanera distribuida hasta que son procesados.
• Apache Zookeeper [12], normalmente usado junto con Kafka, el cual hace la funciónde orquestador de los diferentes brokers de Kafka y sus configuraciones.
La arquitectura de este trabajo consta, además, del framework HiBench [13], el cualinteractura con todos los componentes anteriormente mencionados. Por último, paramonitorizar el rendimiento de Flink, se usa el componente adicional Prometheus [14].
5 Escalabilidad en sistemas de data streaming
CAPÍTULO 3. ARQUITECTURA
Figura 3.1: Arquitectura.
6

CAPÍTULO 3. ARQUITECTURA
En concreto, la arquitectura de este trabajo consta de los siguientes componentes:
• Hadoop Distributed File System versión 2.8.5
• Apache Kafka versión 0.11.0.3
• Apache Zookeeper versión 3.4.8
• Apache Flink versión 1.4.2
• Prometheus versión 2.5.0
• Hibench versión 7.0 1
Las versiones elegidas tienen varias razones de ser. La primera, es que a partir de laversión 1.4.0 de Apache Flink se implementa por primera vez el two-phase commit [15].Esto permite a las aplicaciones de Apache Flink implementar un mecanismo de toleranciaa fallos el cual asegure que cada dato sea procesado una sóla vez y no al menos una vezcomo ocurría anteriormente. Se elige la 1.4.2 al ser la última versión estable de la rama1.4.0. La funcionalidad de two-phase commit requiere una versión mínima de ApacheKafka 0.11, y de nuevo se elige la versión de Apache Kafka 0.11.0.3 al ser la rama másestable de su versión. Hibench recomienda el uso de la versión 0.8.2.2. En el caso deHDFS se elige la última versión estable que recomienda HiBench 2.X. Apache Zookeeperusa exactamente la versión recomendada por Hibench, y por último Prometheus se usala última versión disponible. La segunda razón, y no menos importante, del incrementode versiones es obtener una reflejo más actual del estado del rendimiento y el cual sirvacomo comparativa respecto a trabajos previos relacionados. Esto es importante ya quecada uno de estos componentes está teniendo una fuerte inversión y desarrollo constante,lo cual puede dejar obsoleto cualquier análisis en cuestión de poco tiempo.
1La versión 7.0 necesitó ser modificada por problemas de versionado. Esto se explicará en la secciónde Desarrollo de este documento.
7


4Desarrollo
4.1. Tolerancia a fallos
Apache Flink guarda el estado de la ejecución y los punteros en las fuentes dedatos en los denominados «checkpoints», o «puntos de control» en español. Para hacerposible este mecanismo de checkpoiting Flink necesita de flujos de datos con estado yalmacenamiento persistente [16]. Estos prerequisitos se podrían enumerar en dos puntos,según la documentación oficial de Apache Flink:
• Una fuente de datos persistente que pueda repetir datos durante un determinadoperiodo de tiempo. Un ejemplo son colas persistentes de mensajes (e.g., ApacheKafka, RabbitMQ, Amazon Kinesis, Google PubSub) o sistemas de ficheros (e.g.,HDFS, S3, GFS, NFS, Ceph, . . . )
• Un almacenamiento persistente para el estado, normalmente un sistema de ficherosdistribuido (e.g., HDFS, S3, GFS, NFS, Ceph, . . . )
En nuestro caso concreto usaremos Apache Kafka y Hadoop Distributed Filesystem parasatisfacer estos prerequisitos.
El mecanismo de tolerancia a fallos asegura, dependiendo de la versión de Apache Flinky su fuente de datos, que cada dato sea procesado «al menos» una vez o «exactamente»una vez, en caso de fallo.
9 Escalabilidad en sistemas de data streaming

4.2. CONFIGURACIÓN CAPÍTULO 4. DESARROLLO
4.2. Configuración
A continuación se detalla el proceso de configuración de todos los componentes delsistema para poder ejecutar los experimentos en local.
4.2.1. Hadoop Distributed Filesystem
La instalación de HDFS puede ser más o menos compleja dependiendo de si se usa juntoal gestor de recursos YARN (Yet Another Resource Manager) [17] o si por el contrario seprescinde de él. En nuestro caso prescindiremos de YARN, ya que para lanzar el clusteren local no será necesario la asignación de recursos.
A continuación se muestran los ficheros a configurar, que se encuentran en el directorioetc/hadoop [18]:
En primer lugar, es necesario definir las variables de entorno que usará HDFS.Típicamente se definen en el .bashrc.
Código 4.1: Variables de entornoexport HADOOP_PREFIX="/home/ usuar io /opt/hadoop −2.8.5"
export HADOOP_HOME=$HADOOP_PREFIXexport HADOOP_COMMON_HOME=$HADOOP_PREFIXexport HADOOP_CONF_DIR=$HADOOP_PREFIX/ etc /hadoopexport HADOOP_HDFS_HOME=$HADOOP_PREFIXexport HADOOP_MAPRED_HOME=$HADOOP_PREFIXexport HADOOP_YARN_HOME=$HADOOP_PREFIX
Código 4.2: hdfs-site.xml<con f i gu r a t i on>
<property><name>df s . r e p l i c a t i o n</name><value>1</value>
</ property><property>
<name>f s . de fau ltFS</name><value>hd f s : // l o c a l h o s t : 9 0 0 0</ value>
</ property><property>
<name>df s . datanode . data . d i r</name><value> f i l e : ///home/ usuar io /opt/hadoop −2.8.5/ hdfs /
↪→ datanode</ value>
10

CAPÍTULO 4. DESARROLLO 4.2. CONFIGURACIÓN
<de s c r i p t i o n>Comma separated l i s t o f paths on the l o c a l↪→ f i l e s y s t em o f a DataNode where i t should s t o r e i t s↪→ b locks .</ d e s c r i p t i o n>
</ property><property>
<name>df s . namenode . name . d i r</name><value> f i l e : ///home/ usuar io /opt/hadoop −2.8.5/ hdfs /
↪→ namenode</ value><de s c r i p t i o n>Path on the l o c a l f i l e s y s t em where the
↪→ NameNode s t o r e s the namespace and t r an s a c t i on l o g s↪→ p e r s i s t e n t l y .</ d e s c r i p t i o n>
</ property></ con f i gu r a t i on>
Código 4.3: core-site.xml<con f i gu r a t i on>
<property><name>f s . de fau ltFS</name><value>hd f s : // l o c a l h o s t : 9 0 0 0 /</ value>
</ property><property>
<name>hadoop . tmp . d i r</name><value>/app/hadoop/tmp</ value><de s c r i p t i o n>A base f o r other temporary d i r e c t o r i e s .
↪→ </ de s c r i p t i o n></ property>
</ con f i gu r a t i on>
Además, en el fichero slaves será necesario introducir la entrada localhost.
4.2.2. Apache Kafka
La configuración de Apache Kafka es bastante sencilla y se encuentra en el directorioconfig. En nuestro caso será simplemente editar los ficheros de configuración de cadabroker de Kafka, que variará en número entre experimentos, pero cuya configuración seráigual pero cambiando los puertos asignados a cada broker. A continuación se detallan losapartados modificados:
11

4.2. CONFIGURACIÓN CAPÍTULO 4. DESARROLLO
Código 4.4: server.properties# The id o f the broker . This must be s e t to a unique i n t e g e r f o r
↪→ each broker .broker . id=0
# Switch to enable t op i c d e l e t i o n or not , d e f au l t va lue i s f a l s ed e l e t e . t op i c . enable=true
######## Socket Server S e t t i n g s #########
# The address the socket s e r v e r l i s t e n s on . I t w i l l get the↪→ value returned from
# java . net . InetAddress . getCanonicalHostName ( ) i f not con f i gu r ed .# FORMAT:# l i s t e n e r s = l istener_name :// host_name : port# EXAMPLE:# l i s t e n e r s = PLAINTEXT:// your . host . name :9092l i s t e n e r s=PLAINTEXT:// : 9092
# The de f au l t number o f l og p a r t i t i o n s per t op i c . More↪→ p a r t i t i o n s a l low g r e a t e r
# pa r a l l e l i sm f o r consumption , but t h i s w i l l a l s o r e s u l t in more↪→ f i l e s a c r o s s
# the broker s .num. p a r t i t i o n s=1
######## Zookeeper #########
# Zookeeper connect ion s t r i n g ( s ee zookeeper docs f o r d e t a i l s ) .# This i s a comma separated host : port pa i r s , each corre spond ing
↪→ to a zk# se r v e r . e . g . " 1 2 7 . 0 . 0 . 1 : 3 0 0 0 , 1 2 7 . 0 . 0 . 1 : 3 0 0 1 , 1 2 7 . 0 . 0 . 1 : 3 0 0 2 " .# You can a l s o append an opt i ona l chroot s t r i n g to the u r l s to
↪→ s p e c i f y the# root d i r e c t o r y f o r a l l kafka znodes .zookeeper . connect=l o c a l h o s t :2181
4.2.3. Apache Zookeeper
Apache Zookeeper también es muy sencillo de configurar, los ficheros de configuraciónse encuentran en el directorio conf. A continuación se muestra el único fichero a modificary el cual seguramente venga configurado correctamente por defecto, ya que se usan losvalores por defecto:
12

CAPÍTULO 4. DESARROLLO 4.2. CONFIGURACIÓN
Código 4.5: zoo.cfg# The number o f m i l l i s e c ond s o f each t i c ktickTime=2000# The number o f t i c k s that the i n i t i a l# synchron i za t i on phase can takei n i tL im i t=10# The number o f t i c k s that can pass between# sending a reque s t and ge t t i n g an acknowledgementsyncLimit=5# the d i r e c t o r y where the snapshot i s s to r ed .# do not use /tmp f o r s torage , /tmp here i s j u s t# example sakes .dataDir=/usuar io /opt/tmp/ zookeeper# the port at which the c l i e n t s w i l l connectc l i e n tPo r t =2181
4.2.4. Apache Flink
Esta configuración es la más importante y la explicaré en dos partes, la relacionadacon el funcionamiento general y la relacionada con la tolerancia a fallos. La configuraciónse encuentra en el directorio conf :
En este fichero configuramos el puerto del JobManager y la memoria dedicada tanto aél como a los TaskManagers. También definimos el nivel de paralelismo (en nuestro caso1, al ejecutarse en local) y el puerto de la interfaz web, donde podremos ver el estado delJobManager.
Código 4.6: flink-conf.yaml configuración generaljobmanager . rpc . address : l o c a l h o s t
# The RPC port where the JobManager i s r eachab l e .
jobmanager . rpc . port : 41097
# The heap s i z e f o r the JobManager JVM
jobmanager . heap .mb: 1024
# The heap s i z e f o r the TaskManager JVM
taskmanager . heap .mb: 1024
13

4.2. CONFIGURACIÓN CAPÍTULO 4. DESARROLLO
# The number o f task s l o t s that each TaskManager o f f e r s . Each↪→ s l o t runs one p a r a l l e l p i p e l i n e .
taskmanager . numberOfTaskSlots : 1
# The pa r a l l e l i sm used f o r programs that did not s p e c i f y and↪→ other p a r a l l e l i sm .
p a r a l l e l i sm . d e f au l t : 1
# The port under which the web−based runtime monitor l i s t e n s .# A value o f −1 dea c t i v a t e s the web s e r v e r .
web . port : 8081
A continuación configuramos el mecanismo de tolerancia a fallos. Existen 3 opcionesprincipales, JobManager, Filesystem y RocksDB. El primero almacena los checkpointsen memoria y está indicado para desarrollo en local, pero no en producción. El segundopuede ir solo o combinado con el tercero y representa en nuestro caso HDFS, el sistemade ficheros distribuido donde almacenar los checkpoints y que puede llevar por encima unRocksDB para gestionarlo.
Código 4.7: flink-conf.yaml configuración específica
#==============================# Streaming s t a t e checkpo int ing#==============================
# The backend that w i l l be used to s t o r e operator s t a t e↪→ checkpo int s i f
# checkpo int ing i s enabled .## Supported backends : jobmanager , f i l e s y s t em , rocksdb , <c l a s s−
↪→ name−of−f a c to ry>#s t a t e . backend : f i l e s y s t em
# Direc to ry f o r s t o r i n g checkpo int s in a Flink−supported↪→ f i l e s y s t em
# Note : State backend must be a c c e s s i b l e from the JobManager and↪→ a l l TaskManagers .
# Use " hdfs ://" f o r HDFS setups , " f i l e : //" f o r UNIX/POSIX−↪→ compliant f i l e systems ,
# ( or any l o c a l f i l e system under Windows) , or " s3 ://" with
14

CAPÍTULO 4. DESARROLLO 4.2. CONFIGURACIÓN
↪→ lower case ’ s ’ f o r S3 f i l e system .#s t a t e . backend . f s . checkpo in td i r : hdfs : // l o c a l h o s t :9000/ user / f l i n k
↪→ / f l i n k−checkpo int s
Por último, la configuración relativa a la monitorización con Prometheus que esnecesaria añadir en este fichero.
Código 4.8: flink-conf.yaml configuración de monitorización
metr i c s . r e p o r t e r s : prommetr i c s . r e po r t e r . prom . c l a s s : org . apache . f l i n k . metr i c s . prometheus
↪→ . PrometheusReportermet r i c s . r e po r t e r . prom . port : 9999
4.2.5. Prometheus
La configuración de monitorización se explicará en detalle en el apartado demonitorización Sección 4.4. El único fichero a modificar se encuentra en el directorioraíz de instalación de Prometheus y es el siguiente:
Código 4.9: prometheus.yml
sc rape_con f i g s :− job_name : ’ f l ink_jobmanager ’
s t a t i c_con f i g s :− t a r g e t s : [ ’ l o c a l h o s t : 9 9 9 9 ’ ]
metrics_path : ’/ jobmanager/metr ics ’
− job_name : ’ f l ink_taskmanager ’s t a t i c_con f i g s :− t a r g e t s : [ ’ l o c a l h o s t : 9 9 9 9 ’ ]
metrics_path : ’/ taskmanagers /metr ics ’
− job_name : ’ f l ink_jobs ’s t a t i c_con f i g s :− t a r g e t s : [ ’ l o c a l h o s t : 9 9 9 9 ’ ]
metrics_path : ’/ jobs /metr ics ’
15

4.2. CONFIGURACIÓN CAPÍTULO 4. DESARROLLO
4.2.6. Hibench
El benchmark, junto con Flink, es el componente que más configuración necesita paralos distintos despliegues de los experimentos. Básicamente se trata de configurar Hibenchpara que sepa donde encontrar cada uno de los componentes del experimento y configurarla ejecución del benchmark. A continuación se muestran los principales ficheros, que seencuentran en el directorio conf :
Código 4.10: hadoop.conf# Hadoop homehibench . hadoop . home /home/ usuar io /opt/hadoop −2.8.5
# The path o f hadoop executab l ehibench . hadoop . executab l e ${hibench . hadoop . home}/ bin /hadoop
# Hadoop con f i g r au t i on d i r e c t o r yhibench . hadoop . c on f i gu r e . d i r ${hibench . hadoop . home}/ etc /hadoop
# The root HDFS path to s t o r e HiBench datahibench . hdfs . master hdfs : // l o c a l h o s t :9000/ usuar io
# Hadoop r e l e a s e prov ide r . Supported value : apache , cdh5 , hdphibench . hadoop . r e l e a s e apache
Código 4.11: flink.confhibench . streambench . f l i n k . home /home/ usuar io /
↪→ opt/ f l i n k −1.4.2
hibench . f l i n k . master l o c a l h o s t :41097
# Defau l t p a r a l l e l i sm o f f l i n k jobhibench . streambench . f l i n k . p a r a l l e l i sm 1hibench . streambench . f l i n k . buf ferTimeout 10hibench . streambench . f l i n k . checkpointDurat ion 1000
El siguiente fichero es el más grande y contiene la configuración tanto de ApacheKafka como de la generación de datos para el posterior consumo del job de Flink. Enla configuración se puede ver cómo se usarán 4 brokers de Kafka con 3 particiones porcada topic. El offset del consumidor de Kafka es latest, que difiere con configuraciones deversiones de Kafka previas y que no soportan la que Hibench trae por defecto, largest.En cuanto a la generación de datos, en este ejemplo esta definido 6000 pero será unvalor a cambiar entre experimentos. A continuación sólo se muestra la configuración másrelevante:
16

CAPÍTULO 4. DESARROLLO 4.2. CONFIGURACIÓN
Código 4.12: hibench.conf#===============================# Kafka f o r streaming benchmarks#===============================hibench . streambench . kafka . home /home/ usuar io /opt
↪→ /kafka_2 .11 −0 .11 .0 .3# zookeeper host : port o f kafka c l u s t e r , host1 : port1 , host2 : port2
↪→ . . .hibench . streambench . zkHost l o c a l h o s t :2181# Kafka broker l i s t s , wr i t t en in mode host : port , host : port , . .hibench . streambench . kafka . b roke rL i s t l o c a l h o s t : 9092 ,
↪→ l o c a l h o s t : 9093 , l o c a l h o s t : 9094 , l o c a l h o s t :9095hibench . streambench . kafka . consumerGroup HiBench# number o f p a r t i t i o n s o f generated top i c ( d e f au l t 20)hibench . streambench . kafka . t o p i cPa r t i t i o n s 3# consumer group o f the consumer f o r kafka ( d e f au l t : HiBench )hibench . streambench . kafka . consumerGroup HiBench# Set the s t a r t i n g o f f s e t o f kafkaConsumer ( d e f au l t : l a r g e s t )hibench . streambench . kafka . o f f s e tR e s e t l a t e s t
#=========================================# Data genera to r f o r streaming benchmarks#=========================================# In t e r v a l span in m i l l i s e c ond ( d e f au l t : 50)hibench . streambench . datagen . in te rva lSpan 50# Number o f r e co rd s to generate per i n t e r v a l span ( d e f au l t : 5)hibench . streambench . datagen . r e c o rd sPe r I n t e r va l 5# f i x ed l ength o f record ( d e f au l t : 200)hibench . streambench . datagen . recordLength 200# Number o f KafkaProducer running on d i f f e r e n t thread ( d e f au l t :
↪→ 1)hibench . streambench . datagen . producerNumber 1# Total round count o f data send ( d e f au l t : −1 means i n f i n i t y )hibench . streambench . datagen . totalRounds −1# Number o f t o t a l r e co rd s that w i l l be generated ( d e f au l t : −1
↪→ means i n f i n i t y )hibench . streambench . datagen . to ta lRecords 6000
Por último, para poder usar el benchmark es necesario compilarlo. Para ello hay queresolver algún problema de compatibilidad de versiones de Apache Flink, ya que la versiónque soporta el benchmark es la 1.0.3 y la que se usa en este trabajo es una más moderna1.4.2. Adicionalmente, he sustituido los conectores del benchmark de Apache Kafka porlos de la última versión a probar, aunque este cambio no es necesario para poder compilarcorrectamente con las versiones indicadas.
17
4.3. DESPLIEGUE CAPÍTULO 4. DESARROLLO
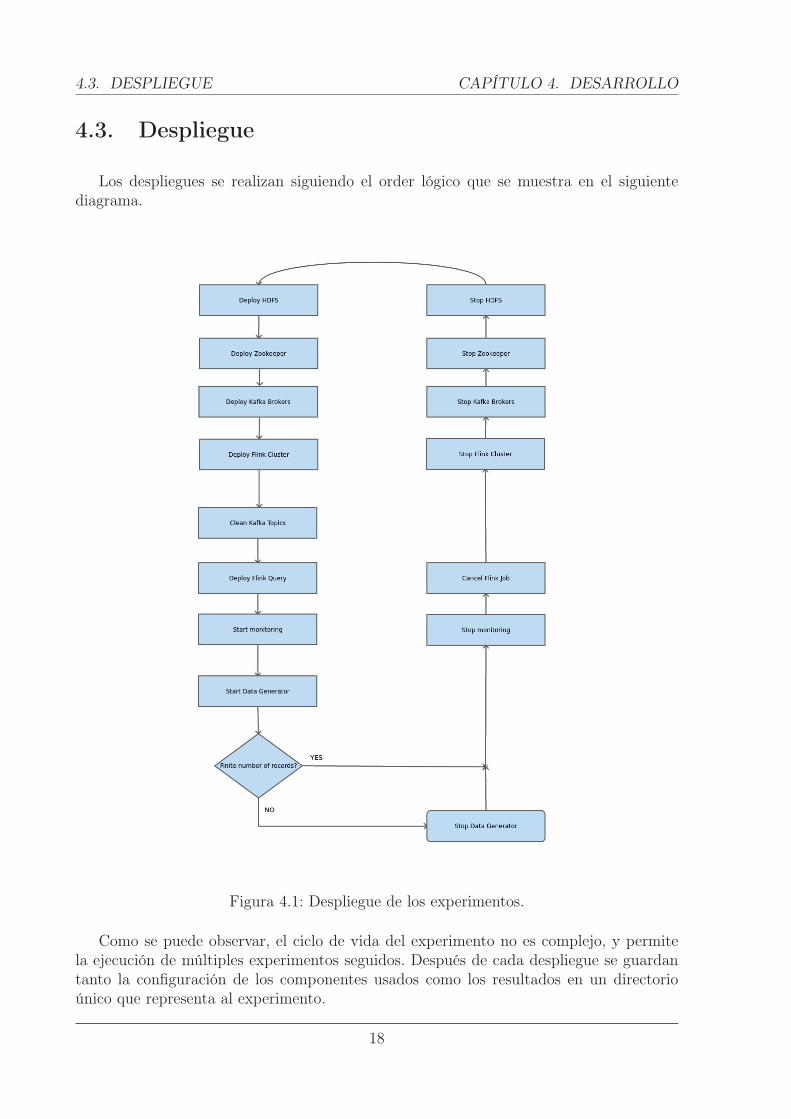
4.3. Despliegue
Los despliegues se realizan siguiendo el order lógico que se muestra en el siguientediagrama.
Figura 4.1: Despliegue de los experimentos.
Como se puede observar, el ciclo de vida del experimento no es complejo, y permitela ejecución de múltiples experimentos seguidos. Después de cada despliegue se guardantanto la configuración de los componentes usados como los resultados en un directorioúnico que representa al experimento.
18

CAPÍTULO 4. DESARROLLO 4.4. MONITORIZACIÓN
4.4. Monitorización
Como he mencionado antes, la monitorización se realiza gracias a una API RESTque provee Apache Flink [19] y que Prometheus consume. También se recogen medidasadicionales de los comandos iostat, vmstat y mpstat, que se guardan en el directoriode resultados después de cada despliegue. Sin embargo, estas medidas no son mas queun apoyo, ya que miden el consumo de recursos del equipo en el que se realizan losexperimentos, el cual puede estar condicionado directamente por otros procesos, aunquesiempre se lancen los experimentos desde una sesión sin procesos de usuario innecesariosactivos. Por contra, las métricas que provee la API de Apache Flink se refieren alrendimiento directo del JobManager, el TaskManager y el job. Más allá de las métricasque Apache Flink provee por defecto, también permite crear métricas personalizadas [20],aunque en este caso no ha sido necesario. En total, Prometheus nos devolverá 347 métricasdiferentes relacionadas con cada experimento.
Para configurar la monitorización con Prometheus simplemente es necesario configurartal como se indica previamente, en la Sección 4.2 de configuración, configurando ApacheFlink y Prometheus, pero además siendo necesario mover el .jar correspondiente dePrometheus del directorio de Apache Flink opt/flink-metrics-prometheus-1.4.2.jar a lib,dentro de la misma carpeta de instalación de Flink.
4.5. Recursos
Para realizar la memoria se ha utilizado LaTex [21], partiendo de una plantilla para elTrabajo de Fin de Master de MUIA-UPM [22] la cual he adaptado al formato requeridopor la asignatura y he subido bajo la misma licencia [23].
Para el trabajo diario y control de versiones he usado un repositorio privado en GitHub,gracias a la licencia de estudiante que se otorga a los alumnos de la UPM.
El entorno de ejecución de los experimentos se compone de una máquina con lossiguientes recursos:
• OS Arch Linux x86_64
• Kernel 4.19.12-arch1-1-ARCH
• CPU Intel i7-4600U (4) @ 3.300GHz
• GPU Intel Haswell-ULT
• GPU AMD ATI Radeon HD 8730M
• Memoria 15464MiB
• SSD / 32GB
• HDD /home 256GB
19

4.6. EXPERIMENTOS CAPÍTULO 4. DESARROLLO
4.6. Experimentos
El trabajo a ejecutar por Flink se llama fixwindow y consiste en el procesamiento deregistros que emulan las peticiones de un usuario a una web. El job recibe a través delconector de Kafka registros que contienen la IP de origen de la petición y la fecha en laque se realizó, y tras su procesado escribe en Kafka con la cuenta de todos los registrosprocedentes de la misma IP durante una ventana de tiempo y la fecha de la primerapetición recibida en esa ventana. Adicionalmente se añade la fecha previa a la escritura enKafka para que el benchmark posteriormente pueda calcular la latencia de la operaciónde procesado completa.
Los registros que se escriben en el topic de Kafka «fixwindow» son generados porel benchmark de manera aleatoria basándose en unas semillas que se almacenan en undirectorio previamente configurado en el HDFS.
Para poder tener una referencia contra la que comparar los resultados obtenidos, seusará una metodología similar a la del paper publicado por Valerio Vianello [9]. Lasdiferentes configuraciones se muestran en la Tabla 4.6. Los experimentos se lanzarán condiferentes cargas de datos y con el checkpointing activado, introduciendo cambios enla configuración del «state backend» del checkpoiting (JobManager, HDFS o HDFS +RocksDB), lo cual impactará en el tamaño del checkpoint a realizar.
Tabla 4.1: Tabla de configuración de experimentos.Carga total (eventos) Checkpointing
1.000 JobManager3.000 HDFS8.000 HDFS + RocksDB
20

5Resultados
Por parte del benchmark, Hibench nos ofrece las siguientes estadísticas de cadaejecución, de las cuales he seleccionado las que he considerado que son más relevantes decara al análisis: número de eventos procesados, throughput(msgs/s), máxima latencia(ms),mediana de latencias(ms), mínima latencia(ms), desviación estándar de las latencias(ms),percentil 50 de la latencia(ms), percentil 75 de la latencia(ms), percentil 95 de lalatencia(ms), percentil 98 de la latencia(ms), percentil 99 de la latencia(ms), percentil999 de la latencia(ms).
En los casos de menor carga y con checkpoiting activado, el impacto en el rendimientoes muy leve y apenas perceptible respecto al checkpointing desactivado, debido a que Flinkguarda checkpoint del estado de manera asíncrona, de forma que si la carga respecto a lacapacidad del sistema es muy baja, es capaz de realizar ambas operaciones sin impactarde manera apreciable el rendimiento [9].
A continuación se analizan los resultados obtenidos a través de HiBench.
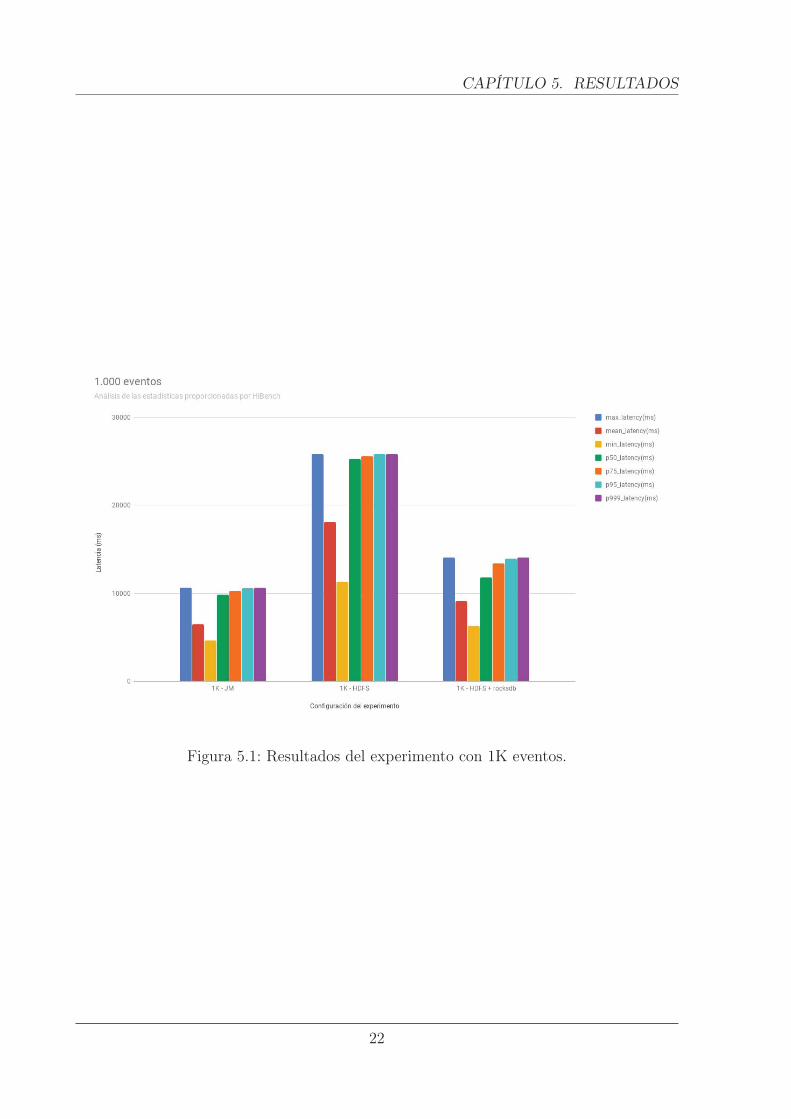
En primer lugar, se realiza un experimento con un job de flink que procesará un totalde 1000 registros o eventos, enviados a los diferentes brokers de Kafka. Podemos observarque el mayor impacto general en el rendimiento se produce utilizando sólamente HDFScomo «state backend» de los checkpoints, con unas latencias de prácticamente el dobleque los otros dos mecanismos. También podemos apreciar que con este mecanismo, lalatencia mínima se sitúa muy alejada de la máxima y la mediana, y que junto con elpercentil 50 confirma que el rendimiento general es bastante peor que los demás.
21 Escalabilidad en sistemas de data streaming
CAPÍTULO 5. RESULTADOS
Figura 5.1: Resultados del experimento con 1K eventos.
22
CAPÍTULO 5. RESULTADOS
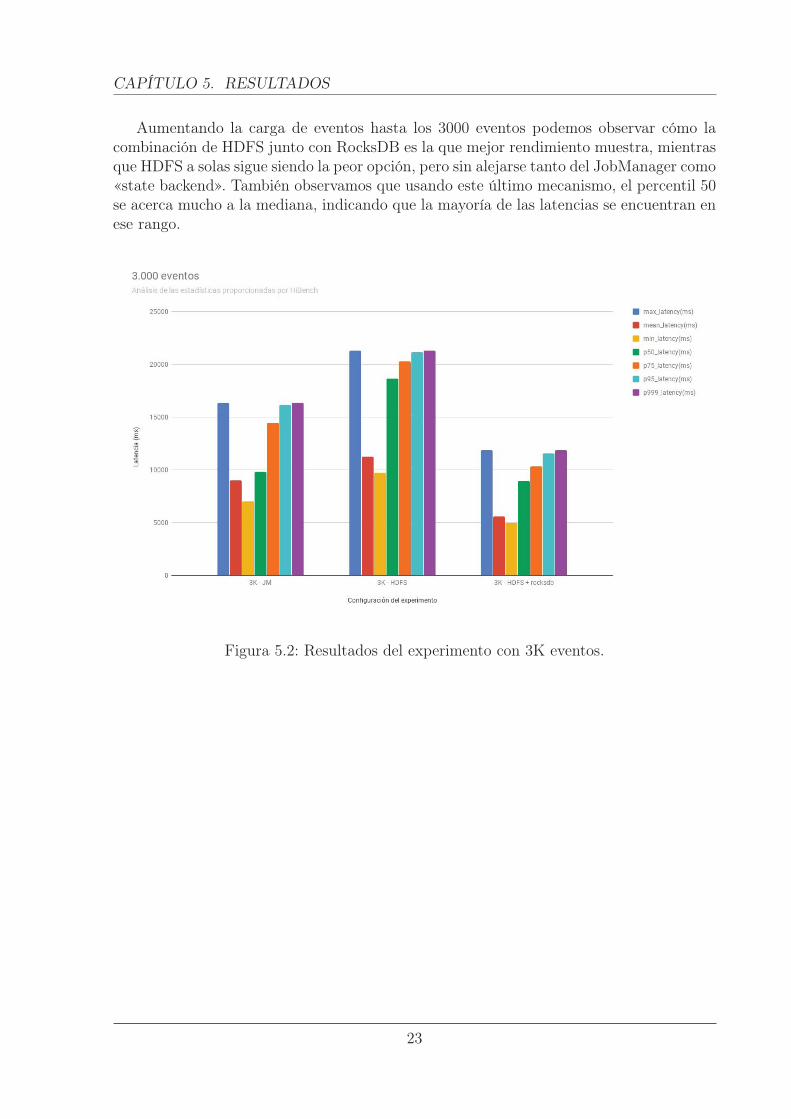
Aumentando la carga de eventos hasta los 3000 eventos podemos observar cómo lacombinación de HDFS junto con RocksDB es la que mejor rendimiento muestra, mientrasque HDFS a solas sigue siendo la peor opción, pero sin alejarse tanto del JobManager como«state backend». También observamos que usando este último mecanismo, el percentil 50se acerca mucho a la mediana, indicando que la mayoría de las latencias se encuentran enese rango.
Figura 5.2: Resultados del experimento con 3K eventos.
23
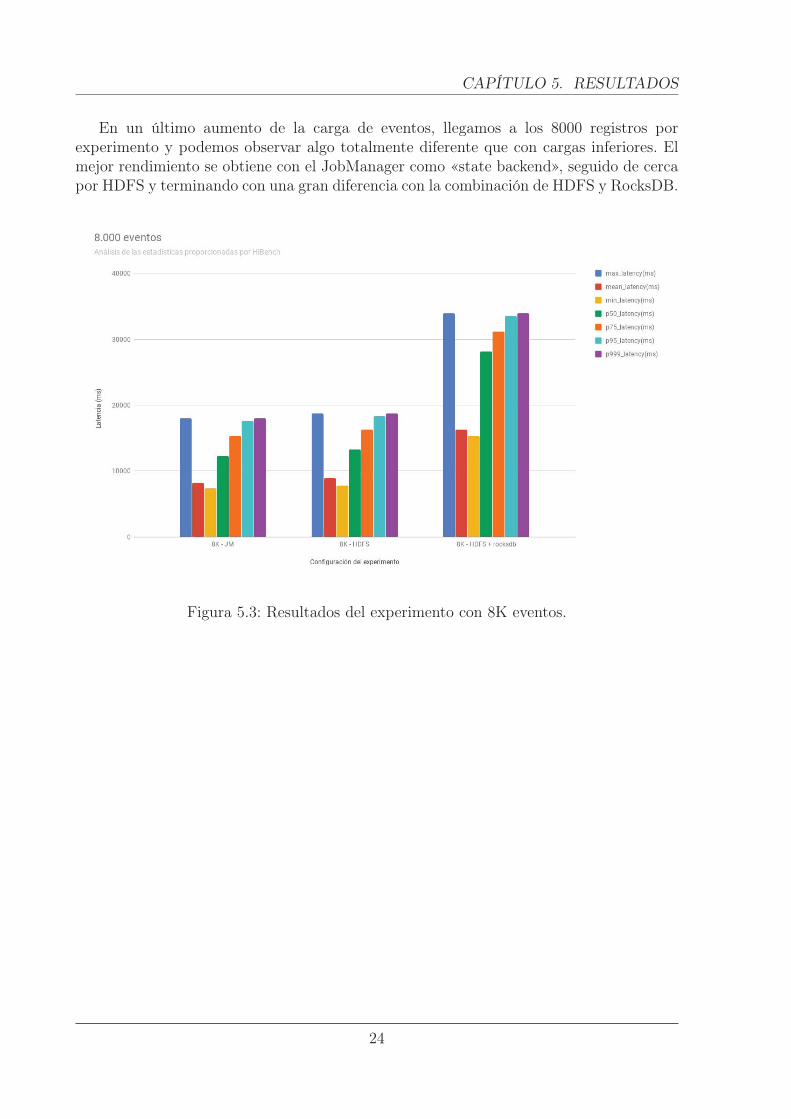
CAPÍTULO 5. RESULTADOS
En un último aumento de la carga de eventos, llegamos a los 8000 registros porexperimento y podemos observar algo totalmente diferente que con cargas inferiores. Elmejor rendimiento se obtiene con el JobManager como «state backend», seguido de cercapor HDFS y terminando con una gran diferencia con la combinación de HDFS y RocksDB.
Figura 5.3: Resultados del experimento con 8K eventos.
24
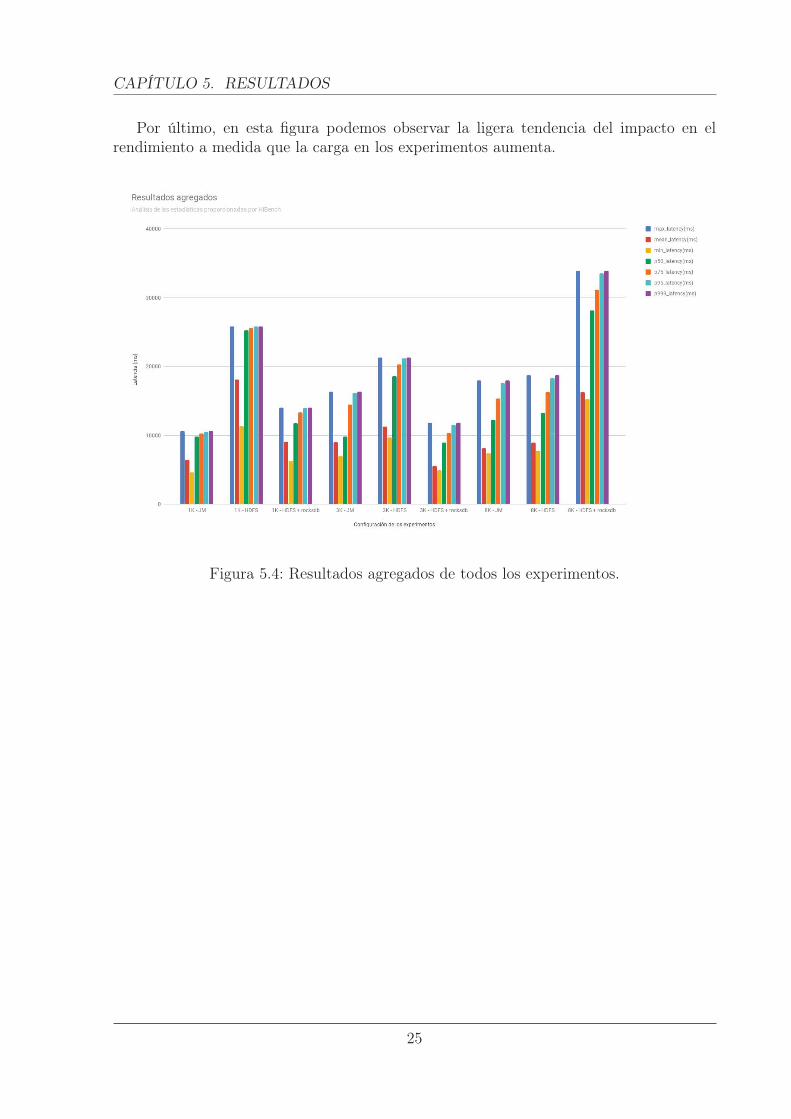
CAPÍTULO 5. RESULTADOS
Por último, en esta figura podemos observar la ligera tendencia del impacto en elrendimiento a medida que la carga en los experimentos aumenta.
Figura 5.4: Resultados agregados de todos los experimentos.
25

CAPÍTULO 5. RESULTADOS
De entre las 347 métricas obtenidas por Prometheus, 171 son directamente relacionadascon la API de monitorización de Flink, y de ellas 38 con el jobmanager he seleccionadolas que he creído que eran más representativas e interesantes sobre el estado de cadaejecución. Sin embargo, en ellas no podemos visualizar ninguna tendencia en concreto encuanto a recursos del sistema consumidos ya que al ser desplegado en un cluster local, ladisposición de los recursos cae a nivel del multithreading de cada nucleo del procesadoren concreto sin poder asignar nucleos concretos para cada componente.
26

6Conclusiones
A la vista de los resultados obtenidos, podemos concluir que un sistema en el queinterviene Apache Flink, el detrimento u overhead en el rendimiento de sus diferentesmecanismos de tolerancia a fallos sigue siendo notable en escenarios con una cargaimportante para el sistema, pero si transpolamos los resultados podríamos decir quelevemente inferior en comparación con el observado en anteriores estudios, de manera quese puede observar directamente el resultado de un continuo desarrollo en funcionalidad yrendimiento tanto del framework Apache Flink como de sus conectores con los distintoscomponentes del sistema, como Apache Kafka. Cabe recordar que esto es posible graciasa un equipo formado por más de 25 desarrolladores y más de 340 colaboradores bajola Apache Software Fundation y de cuyo trabajo nos beneficiamos prácticamente todosdebido a su amplio uso en multinacionales de renombre como Google, Huawei o Netflix,entre otras.
De cara a futuras investigaciones sería interesante evaluar el impacto en el rendimientode mecanismos de tolerancia a fallos que implementen semánticas «end to end» congarantías de que se procesan «una vez y solo una vez» los datos («exactly once» eninglés).
27 Escalabilidad en sistemas de data streaming


Bibliografía
[1] Apache Flink. https://flink.apache.org. [Online; accessed 29-December-2018].The Apache Software Foundation.
[2] Apache Flink Architecture. https://flink.apache.org/flink-architecture.html. [Online; accessed 29-December-2018]. The Apache Software Foundation.
[3] Recomendaciones sobre el contenido de la memoria del TFG. http://www.fi.upm.es/?pagina=1475. [Online; accessed 29-December-2018]. Escuela Técnica Superiorde Ingenieros Informáticos.
[4] Stratosphere. http://stratosphere.eu/. [Online; accessed 29-December-2018].
[5] Wikipedia contributors. Apache Flink — Wikipedia, The Free Encyclopedia. https://en.wikipedia.org/w/index.php?title=Apache_Flink&oldid=871852581#History. [Online; accessed 29-December-2018]. 2018.
[6] Flink Forward. https://flink-forward.org/. [Online; accessed 29-December-2018].
[7] Wikipedia contributors. Apache Flink — Wikipedia, The Free Encyclopedia. https://en.wikipedia.org/w/index.php?title=Apache_Flink&oldid=871852581#Flink_Forward. [Online; accessed 29-December-2018]. 2018.
[8] Wikipedia contributors. Apache Flink — Wikipedia, The Free Encyclopedia. https://en.wikipedia.org/w/index.php?title=Apache_Flink&oldid=871852581#Development. [Online; accessed 29-December-2018]. 2018.
[9] Valerio Vianello. Cost of Fault-tolerance on Data Stream Processing. English.Universidad Politécnica de Madrid, 2018.
[10] Apache Flink Filesystems. https://ci.apache.org/projects/flink/flink-docs - stable / internals / filesystems . html. [Online; accessed 29-December-2018]. The Apache Software Foundation.
[11] Apache Kafka. https://kafka.apache.org. [Online; accessed 29-December-2018].The Apache Software Foundation.
[12] Apache Zookeeper. https : / / zookeeper . apache . org. [Online; accessed 29-December-2018]. The Apache Software Foundation.
[13] Hibench Suite. https://github.com/intel-hadoop/HiBench. [Online; accessed29-December-2018]. Intel.
[14] Prometheus. https://prometheus.io/. [Online; accessed 29-December-2018].
29 Escalabilidad en sistemas de data streaming

BIBLIOGRAFÍA BIBLIOGRAFÍA
[15] Apache Flink Two-phase commit. https://flink.apache.org/features/2018/03/01/end-to-end-exactly-once-apache-flink.html. [Online; accessed 29-December-2018]. The Apache Software Foundation.
[16] Apache Flink Checkpointing. https://ci.apache.org/projects/flink/flink-docs- stable/dev/stream/state/checkpointing.html. [Online; accessed 29-December-2018]. The Apache Software Foundation.
[17] YARN. https : / / es . hortonworks . com / blog / apache - hadoop - yarn -resourcemanager/. [Online; accessed 29-December-2018].
[18] How to configure HDFS and YARN. https : / / www . alexjf . net / blog /distributed - systems / hadoop - yarn - installation - definitive - guide/.[Online; accessed 29-December-2018].
[19] Apache Flink Monitoring REST API. https://ci.apache.org/projects/flink/flink - docs - stable / monitoring / metrics . html # rest - api - integration.[Online; accessed 29-December-2018]. The Apache Software Foundation.
[20] Monitoring Flink with Prometheus. https : / / www . slideshare . net /MaximilianBode1/monitoring-flink-with-prometheus. [Online; accessed 29-December-2018].
[21] LaTex project. https://www.latex-project.org/. [Online; accessed 29-December-2018].
[22] Plantilla LaTex TFM. https : / / github . com / igcontreras / tfm - plantilla.[Online; accessed 29-December-2018].
[23] Plantilla LaTex TFG. https://github.com/mamoedo/tfg-plantilla. [Online;accessed 29-December-2018].
30

BIBLIOGRAFÍA BIBLIOGRAFÍA
Esta obra está bajo una licencia Creative Commons«Reconocimiento-NoCommercial-CompartirIgual 3.0 Espa-ña».
31

Este documento esta firmado porFirmante CN=tfgm.fi.upm.es, OU=CCFI, O=Facultad de Informatica - UPM,
C=ES
Fecha/Hora Mon Jan 14 18:14:29 CET 2019
Emisor delCertificado
[email protected], CN=CA Facultad deInformatica, O=Facultad de Informatica - UPM, C=ES
Numero de Serie 630
Metodo urn:adobe.com:Adobe.PPKLite:adbe.pkcs7.sha1 (AdobeSignature)


















