
Herramientas de Minería de Textos e Inteligencia ...
94
UNIVERSIDAD CENTRAL “MARTA ABREU” DE LAS VILLAS FACULTAD DE MATEMÁTICA, FÍSICA Y COMPUTACIÓN DEPARTAMENTO DE CIENCIA DE LA COMPUTACIÓN Herramientas de Minería de Textos e Inteligencia Artificial aplicadas a la gestión de la información científico-técnica Tesis presentada en opción al título académico de Máster en Ciencia de la Computación Autor: Lic. Michel Artiles Egüe Tutora: Dra. Leticia Arco García Santa Clara, 2011
Transcript of Herramientas de Minería de Textos e Inteligencia ...

UNIVERSIDAD CENTRAL “MARTA ABREU” DE LAS VILLAS FACULTAD DE MATEMÁTICA, FÍSICA Y COMPUTACIÓN
DEPARTAMENTO DE CIENCIA DE LA COMPUTACIÓN
Herramientas de Minería de Textos e Inteligencia Artificial aplicadas a la gestión de la información científico-técnica
Tesis presentada en opción al título académico de Máster en Ciencia de la Computación
Autor: Lic. Michel Artiles Egüe
Tutora: Dra. Leticia Arco García
Santa Clara, 2011

Dedicatoria
A mi familia

Agradecimientos
Agradezco a todas las personas que han contribuido al desarrollo de este trabajo:
A mi familia por todo el apoyo que me han brindado durante todos estos años.
A la Dra. Lecicia Arco García por su paciencia, dedicación y guía.
Al grupo de Ingienería de Software de CEI-UCLV en especial a:
Dra. Gheisa Fereira por su visión y guía.
Ing. Lianny Ofarrill Fernandez y Msc. Juliet Suarez Ferreira por sus sugerencias.
A todos mis colegas por ayudarme, especialmente a los colegas y amigos del grupo de Inteligencia Artificial del CEI-UCLV.
A los colegas del Joven Club de Esperanza, en especial al Lic. Jaylo Escariz Llanes.
A todos mis amigos…

Resumen
Resumen La cantidad de información está continuamente creciendo; pero la información en sí misma tiene pocas ventajas, su sistematización, incorporación y utilización son los elementos que aportan su valor añadido: el conocimiento. En el laboratorio de Inteligencia Artificial del CEI-UCLV se han desarrollado los sistemas SATEX y GARLucene que si bien permiten gestionar información siguiendo el esquema de indexado, recuperación, agrupamiento y valoración de los grupos textuales obtenidos, no brindan un entorno de trabajo amigable que permita la introducción y generalización de los mismos, ya que no garantizan una interacción efectiva entre usuarios y grandes repositorios de información. Por otro lado, en el CEI-UCLV existe un gran número de artículos científicos y documentos relacionados con diversos temas de investigación, y se hace tedioso para los investigadores descubrir conocimiento que requieren para encausar una investigación a partir de estos grandes volúmenes textuales. De ahí que el objetivo de esta investigación consiste en desarrollar una aplicación que permita gestionar de forma efectiva la información científico-técnica disponible en grandes repositorios de información. Los principales resultados alcanzados son: un conjunto de herramientas que permiten la gestión y recuperación de información científico-técnica, el preprocesamiento y representación de los corpus, y el agrupamiento y valoración de los grupos textuales, y una aplicación web que utiliza el conjunto de herramientas desarrolladas y permita el indexado, recuperación y agrupamiento de documentos científicos, así como etiquetar y evaluar los grupos obtenidos, garantizando una adecuada conexión con los repositorios de información científico-técnica del CEI-UCLV.

Abstract
Abstract The amount of information is continually growing, but the information itself has few advantages, its systematization, incorporation and usage are the elements that bring its added value: knowledge. The Artificial Intelligence Laboratory from the CEI-UCLV has developed the systems GARLucene and SATEX, which allow to manage the information following the scheme of indexing, retrieval, clustering and textual assessment of the obtained groups, but these systems do not provide a friendly environment for the introduction and generalization of the mentioned groups, because they do not guarantee an effective interaction between users and large data repositories. On the other hand, the CEI-UCLV has a huge number of scientific papers and documents related to different research topics, and it becomes tedious for the researchers to discover the knowledge they need from this high-volume text. Hence, the objective of this research is to develop an application that can effectively manage the scientific and technical information available in large repositories of information. The main results obtained are: a set of tools that enable the management and retrieval of scientific and technical information, the preprocessing and representation of the corpus, as well as the grouping and evaluation of textual groups, and a web application which uses the set of developed tools allowing the indexing, retrieval and grouping of scientific papers, together with the labeling and evaluation of the obtained groups, ensuring a proper connection with the repositories of scientific and technical information from the CEI-UCLV.

Tabla de contenidos
Tabla de contenidos
INTRODUCCIÓN .................................................................................................................................................. 1
1 Acerca de la gestión de documentos ............................................................................................................ 8
1.1 Generalidades de la gestión de documentos ......................................................................................... 8
1.1.1 Indexado y recuperación de información .................................................................................... 11
1.1.2 Agrupamiento .............................................................................................................................. 11
1.1.3 Validación ................................................................................................................................... 15
1.1.4 Etiquetamiento ............................................................................................................................ 16
1.2 Herramientas que permiten el desarrollo de sistemas gestores de documentos .................................. 18
1.2.1 Lucene ......................................................................................................................................... 19
1.2.2 Tika .............................................................................................................................................. 20
1.2.3 Jung ............................................................................................................................................. 20
1.3 Sistemas gestores de documentos desarrollados en la UCLV ............................................................ 21
1.3.1 Sistema para el Agrupamiento, etiquetamiento y evaluación de colecciones TEXtuales (SATEX) 23
1.3.2 Sistema para la Gestión de Artículos científicos Recuperados usando Lucene (GARLucene) ... 25
1.4 Consideraciones finales del capítulo .................................................................................................. 26
2 Herramientas que permiten el desarrollo de sistemas gestores de documentos .................................... 28
2.1 Indexado y recuperación de la información ........................................................................................ 32
2.1.1 Herramienta para extraer contenido ........................................................................................... 32
2.1.2 Herramienta para indexar contenido .......................................................................................... 35
2.1.3 Herramienta para recuperar información .................................................................................. 36
2.2 Representación del corpus textual ...................................................................................................... 39
2.2.1 Herramienta para transformar información ............................................................................... 39
2.2.2 Herramienta para estructurar información ................................................................................ 42
2.3 Agrupamiento de documentos ............................................................................................................ 45
2.3.1 Herramienta para crear matriz de similitud ............................................................................... 45
2.3.2 Herramienta para agrupar documentos ...................................................................................... 47
2.4 Valoración del agrupamiento .............................................................................................................. 51
2.4.1 Herramienta para validar y etiquetar los grupos ........................................................................ 51
2.5 Conclusiones parciales ....................................................................................................................... 54
3 Aplicación web que permite la gestión de información científica ........................................................... 55
3.1 Descripción del dominio ..................................................................................................................... 56
3.2 Requisitos del sistema ........................................................................................................................ 56
3.2.1 Requisitos funcionales ................................................................................................................. 57
3.2.2 Requisitos no funcionales ............................................................................................................ 57
3.3 Casos de usos ...................................................................................................................................... 57
3.3.1 Diagramas de casos de usos ........................................................................................................ 58

Tabla de contenidos
3.3.2 Especificaciones de los casos de usos ......................................................................................... 59
3.4 Diseño general del sistema ................................................................................................................. 65
3.4.1 Marco de trabajo utilizado para realizar la aplicación .............................................................. 65
3.4.2 Diseño de la estructura de la aplicación ..................................................................................... 66
3.4.3 Principales clases del sistema ..................................................................................................... 67
3.5 Configuraciones de la aplicación web en las fases de gestión de la información científico-técnica
aplicando técnicas de minería de textos e inteligencia artificial .................................................................. 69
3.5.1 Módulo de recuperación de la información ................................................................................ 693.5.1.1 Indexado de la información contenida en los documentos ..................................................................... 69
3.5.1.2 Recuperación de la información indexada en las bases de índices ....................................................... 69
3.5.2 Módulo del procesamiento de la información recopilada ........................................................... 703.5.2.1 Transformación del contenido de los documentos recuperados ............................................................ 70
3.5.2.2 Estructuración de la información transformada de los documentos ....................................................... 70
3.5.3 Módulo para el agrupamiento de los documentos ...................................................................... 703.5.3.1 Matriz de Similitud ................................................................................................................................. 70
3.5.3.2 Agrupamiento ........................................................................................................................................ 70
3.5.4 Módulo para la validación del agrupamiento ............................................................................. 71
3.6 Mapa de navegación ........................................................................................................................... 71
3.7 Valoración preliminar de las herramientas y aplicación web ............................................................. 71
3.8 Conclusiones parciales ....................................................................................................................... 72
CONCLUSIONES Y RECOMENDACIONES .................................................................................................. 73
Referencias bibliográficas .................................................................................................................................... 75
Anexos .................................................................................................................................................................... 79
Anexo 1. Distancias, similitudes y disimilitudes más usadas para comparar objetos ............................ 79
Anexo 2. Algunas medidas internas para la validación del agrupamiento ............................................. 81
Anexo 3. Esquema general de la aplicación ........................................................................................... 83
Anexo 4. Descripción general de la interfaz de usuario de SATEX ...................................................... 84
Anexo 5. Descripción general de la interfaz de usuarios de GARLucene .............................................. 85
Anexo 6. Descripción de las variables a medir para evaluar la aplicación ............................................. 87

Introducción
1
INTRODUCCIÓN La cantidad de información está continuamente creciendo; sin embargo, la habilidad de los humanos para procesarla y asimilarla permanece constante [1, 2]. Además, la información en sí misma tiene pocas ventajas, su sistematización, incorporación y utilización son los elementos que aportan su valor añadido: el conocimiento1
3-6
. Es necesario crear sistemas que generen conocimiento, para asegurar el uso productivo de la información y guiar una toma de decisiones óptima, contribuyendo de esta forma a la Gestión del Conocimiento (GC) [ ].
Aproximadamente un 80% de la información se almacena en forma textual no estructurada [7], de ésta una cantidad significativa está dada por el crecimiento de las publicaciones científicas en diferentes campos. Por ejemplo, Medline2
8
ya tiene más de 10 millones de publicaciones, con un incremento semanal entre 7000 y 8000 resúmenes científicos. Gestionar el conocimiento a partir de la información encontrada es fundamental en el trabajo científico [ ]. Sin embargo, la gestión de información científica se vuelve cada vez más compleja y desafiante, sobre todo porque las colecciones textuales generalmente son heterogéneas, grandes, diversas y dinámicas. Superar estos desafíos es esencial para proporcionar a los científicos mejores condiciones de administrar el tiempo necesario para procesar la información científica, lo cual constituye la motivación principal de este trabajo.
Hoy día, tanto las comunidades científicas, organizaciones y gobiernos, invierten en función del desarrollo de la gestión de la información y el conocimiento, a través de proyectos, congresos, postgrados y desarrollo de sistemas con este fin. Algunos ejemplos son: las políticas trazadas por la Unión Europea para incrementar la competitividad de una economía basada en el conocimiento3, las acciones realizadas por la OPS/OMS en países en desarrollo4 y las facilidades brindadas por la UNESCO para desarrollar software para el procesamiento de la información5. Universidades e institutos científicos desarrollan esta línea de investigación, como el grupo de investigación en la gestión del conocimiento y minería de textos de la Universidad de West Bohemia6
1 Considerado un recurso estratégico para el desarrollo económico, científico y social contemporáneo.
, el grupo de investigación en descubrimiento de conocimiento
2 Base de datos de 11 millones de citas y resúmenes de revistas de medicina y otras fuentes. http://medline.cos.com 3 Comunicación de la comisión de comunidades europeas al parlamento europeo “Información científica en la era digital”.
Bruselas. 2007. http://ec.europa.eu/research/science-society/document_library/pdf_06/communication-022007_en.pdf 4 Newsletter BVS 056. 10 de agosto de 2006. http://newsletter.bireme.br/new/index.php?lang=pt&newsletter=20060810 5 CDS/ISIS de UNESCO http://hrueda-isis.blogspot.com/2007_11_01_archive.html 6 http://textmining.zcu.cz

Introducción
2
a partir de datos no estructurados de la Universidad de Texas7, el centro nacional del Reino Unido para la minería de textos (The Nacional Centre for Text Mining; NaCTeM)8, el centro europeo para la computación blanda (European Centre for Soft Computing)9, el grupo de recuperación de información de la Universidad de Magdeburgo Otto-von-Guericke10 y el Instituto Kaieteur para la gestión del conocimiento (Kaieteur Institute for Knowledge Management11). Cuba no está exenta del desarrollo de investigaciones que contribuyan a la gestión de la información y el conocimiento. Ejemplos de ello lo constituyen los trabajos realizados en el Centro de Aplicaciones de Tecnologías de Avanzada (CENATAV) de la Ciudad de La Habana y en el Centro de Reconocimiento de Patrones y Minería de Datos de la Universidad de Oriente en Santiago de Cuba; así como la labor desarrollada por la Asociación Cubana de Reconocimiento de Patrones (ACRP)12
El conocimiento se puede gestionar de diversas formas y hacerlo requiere de la integración de varias áreas del saber: el descubrimiento de conocimiento en bases de datos, la minería de datos y de textos. Esta última integra la recuperación y extracción de información, el análisis de textos, el resumen, la categorización, la clasificación, el agrupamiento, la visualización, la tecnología de bases de datos, el aprendizaje automático y la minería de datos [
.
1, 9]. En la actualidad los usuarios se enfrentan a grandes colecciones de información o a grandes cantidades de enlaces web recuperados por un buscador y tienen que ser muy pacientes para navegar a través de los enlaces y analizar la información que verdaderamente necesitan. La categorización, clasificación y agrupamiento se pueden utilizar para refinar resultados de la recuperación y extracción de información, y así contribuir al descubrimiento de conocimiento. Especialmente el agrupamiento y los procesos post-agrupamiento permiten organizar la información, determinar información relevante y crear nuevo conocimiento a partir de la información disponible en una colección especificada o resultante de un proceso de recuperación de información.
Las organizaciones requieren utilizar la información no sólo para darle significado en su entorno, sino para crear nuevo conocimiento, compartirlo y tomar decisiones [10]. Sus principales incentivos para la gestión del conocimiento son [11, 12]: buscar, aportar,
7 http://www.cs.utexas.edu/~ml/publication/text-mining.html 8 http://www.cs.manchester.ac.uk/research/groups/infosystems/textmining/ 9 http://www.softcomputing.es 10 http://irgroup.cs.uni-magdeburg.de 11 http://www.kikm.org/
12 http://acrp.cenatav.co.cu

Introducción
3
contribuir, diseminar, explotar y evaluar el conocimiento. Se necesita transformar información en conocimiento: estructuración de datos e información y la acción humana sobre éstos [10].
Las organizaciones deben considerar servicios de conocimiento para lograr la integración de fuentes locales (por ejemplo, intranet local, servidores de ficheros, sitios públicos), intra-redes y extra-redes [11]. Pero esto no es suficiente, es necesario utilizar adecuadamente las tecnologías de la información para desarrollar gestores de conocimiento.
Los sistemas de gestión de documentos13 14 han tomado un gran auge en la actualidad [ ]. Docyoument, Text Miner14 , Worldox15, Autonomy16 , Knexa17 y otros18 que fueron identificados por el Instituto Kaieteur19
Automatizar la gestión de información y el conocimiento conlleva al desarrollo de sistemas que ayuden a los usuarios al enfrentarse a grandes colecciones textuales, mediante la organización y extracción de conocimiento de las mismas. La entrada a estos sistemas debe provenir del resultado de un proceso de recuperación de información de un servidor o colección personal de información textual; y las salidas deben ser los grupos homogéneos de documentos afines, los términos relevantes y los documentos más representativos de cada grupo, así como los que se relacionan con ellos y la calidad con que fueron obtenidos los grupos; garantizando el control para la evaluación de los resultados del agrupamiento [13].
constituyen algunos ejemplos. La gran mayoría son sistemas más dirigidos al comercio del conocimiento en Internet y no la gestión del conocimiento en las organizaciones. Los sistemas dirigidos a las organizaciones tienen un alto precio en el mercado internacional, debido esencialmente a los beneficios que les reportan. Por eso a las instituciones cubanas les resulta casi imposible adquirir este tipo de sistema. Las universidades no están exentas de esta limitante y son de las organizaciones en el país que más requieren manipular grandes cantidades de documentos científicos por la actividad académica y científica que desarrollan [13]. Debido a esta limitante se hace necesario el desarrollo de nuevos sistemas gestores de información y conocimiento en función de tareas específicas para cubrir las necesidades de automatización en las universidades cubanas.
En [13] se presenta un esquema general que describe cómo procesar colecciones textuales de
13 Sistemas de almacenamiento, sistemas de soporte de búsquedas, modelos de categorización y análisis de contenidos, ontologías y servicios
de control de acceso y coordinadores de trabajo colaborativo. 14 http://www.sas.com/technologies/analytics/datamining/textminer 15 http://www.worldox.com/ 16 http://www.autonomy.com 17 http://www.knexa.com 18 Knowinc.com, Keen.com, Yet2.com, iExchange.com, Saba.com, cordis.lu, IQ4Hire.com, petrocore.com y eBrainx.com 19 Instituto para la gestión del conocimiento (Kaieteur Institute for Knowledge Management http://www.kikm.org)

Introducción
4
forma tal que se extraiga la información organizada y se señalen los elementos relevantes de cada grupo de documentos afines. Este esquema está compuesto por cuatro módulos: recuperación de la información o especificación del corpus textual a procesar, representación del corpus textual obtenido o fijado por el usuario, agrupamiento de los documentos y valoración (validación y etiquetamiento) de los grupos textuales obtenidos.
En el Centro de Estudios de Informática (CEI) de la Universidad Central “Marta Abreu” de las Villas (UCLV) se han desarrollado los sistemas para la gestión de la información y el conocimiento (SATEX y GARLucene) que siguen el esquema propuesto en [13] para la confección de sistemas gestores de información en dominios textuales. Estos sistemas brindan amplias ventajas para la gestión de la información y del conocimiento. Sin embargo, el diseño de estos sistemas no permite la utilización de algunos de sus módulos en otras aplicaciones, o la incorporación de otras formas de representación textual, u otros métodos de indexado y recuperación de la información. Por otra parte, estas aplicaciones son de escritorio, limitándose significativamente los procesos de indexado y recuperación de la información, los usuarios necesitan especificar valores a parámetros que desconocen y los términos que se utilizan no son familiares a los usuarios. Aunque los sistemas realizan procesamientos de calidad y logran agrupar correctamente los documentos, así como extraer la información relevante de cada grupo, las desventajas antes mencionadas impiden la introducción y generalización de los mismos, y conllevan a que los usuarios finales no aprecien las ventajas de los mismos al utilizarlos para el procesamiento de grandes volúmenes de información.
A pesar de que existe un esquema general correctamente diseñado para indexar, recuperar y agrupar documentos, así como etiquetar y evaluar los grupos obtenidos, y sistemas que implementan este esquema general, aun persisten insuficiencias al llevar a la práctica la introducción de estos resultados en el procesamiento de grandes volúmenes de datos, y en la manipulación de los sistemas por diversos tipos de usuarios. Todo ello constituye una problemática a la cual aún no se le ha dado respuestas definitivas, lo cual justifica el planteamiento del problema de investigación siguiente:
Por un lado, existen los sistemas CorpusMiner, SATEX y GARLucene que si bien permiten gestionar información siguiendo el esquema de indexado, recuperación, agrupamiento y valoración de los grupos textuales obtenidos, no brindan un entorno de trabajo amigable que permita la introducción y generalización de los mismos, ya que no garantizan una interacción efectiva entre usuarios y grandes repositorios de información. Por otro lado, en el CEI-UCLV

Introducción
5
existe un gran número de artículos científicos y documentos relacionados con diversos temas de investigación, y se hace tedioso para los investigadores descubrir conocimiento que requieren para encausar una investigación a partir de estos grandes volúmenes textuales.
El objetivo general de la investigación consiste en desarrollar una aplicación que permita gestionar de forma efectiva la información científico-técnica disponible en grandes repositorios de información.
Este se desglosa en los siguientes objetivos específicos:
1. Desarrollar herramientas que permitan la gestión y recuperación de información científico-técnica que faciliten el intercambio de información con otras etapas de la gestión de información.
2. Desarrollar herramientas que permitan el preprocesamiento y representación de corpus textuales.
3. Desarrollar herramientas que permitan el agrupamiento y valoración de los grupos textuales obtenidos, contribuyendo al desarrollo de sistemas gestores de información en dominios textuales.
4. Desarrollar una aplicación web que utilice el conjunto de herramientas desarrolladas y permita el indexado, recuperación y agrupamiento de documentos científicos, así como etiquetar y evaluar los grupos obtenidos, garantizando una adecuada conexión con los repositorios de información científico-técnica del CEI-UCLV.
Las preguntas de investigación planteadas son:
¿Cómo diseñar las herramientas de forma tal que sean extensibles y que el intercambio de información entre ellas pueda ser utilizado por aplicaciones externas?
¿Qué tecnología utilizar para el desarrollo de la aplicación web y las herramientas que faciliten una buena integración entre las mismas?
Después de haber realizado el marco teórico se formuló la siguiente hipótesis de investigación como presunta respuesta a las preguntas de investigación:
H1: El desarrollo de herramientas asociadas a los módulos del esquema general para el procesamiento de información textual a través de la definición de interfaces en Java, definiendo el intercambio de información mediante ficheros XML y desarrollando la aplicación web utilizando Java Server Faces, garantiza la extensibilidad, el intercambio de las herramientas con aplicaciones externas y facilita la integración entre las herramientas y la

Introducción
6
aplicación web.
Para lograr los objetivos trazados y demostrar la hipótesis establecida se acometieron las tareas de investigación siguientes:
• Análisis de las principales técnicas y sistemas que existen para realizar gestión documental, tales como Lucene, LIUS, Tika y Jung.
• Estudio del esquema general para el procesamiento textual a partir del indexado, recuperación y agrupamiento de documentos textuales, así como valoración de los grupos textuales obtenidos.
• Diseño e implementación de herramientas que trabajen de forma independiente, sean extensibles y faciliten el intercambio de información, con el objetivo de auxiliar el desarrollo de sistemas gestores de información en dominios textuales.
• Diseño de una aplicación web que permita el indexado, recuperación y agrupamiento de documentos científicos, así como etiquetar y evaluar los grupos obtenidos.
• Implementación de la aplicación web utilizando Java Server Faces.
• Análisis del desempeño de la aplicación web en la conexión con los repositorios de información científico-técnica del CEI-UCLV y la adecuada gestión de la información.
El valor práctico del trabajo está dado por:
• Las herramientas desarrolladas para la gestión de la información son independientes entre sí, extensibles, reutilizables por sistemas externos, y se comunican mediante ficheros XML, permitiendo indexar, recuperar, representar colecciones textuales, agrupar documentos, validar resultados de agrupamientos, y seleccionar documentos más representativos de cada grupo, tareas muy demandadas por aplicaciones de minería de textos.
• La concepción del conjunto de herramientas facilita el desarrollo de servicios web que permitan utilizar de manera remota cada una de las tareas de la minería de textos implementadas en las herramientas.
• La aplicación web desarrollada permite el indexado, recuperación y agrupamiento de documentos científicos, así como etiquetar y evaluar los grupos obtenidos, garantizando una adecuada conexión con los repositorios de información científico-técnica del CEI-UCLV, facilitándole a los investigadores y docentes comenzar una revisión del estado del arte, organizar por temáticas los artículos que le han llegado al comité científico del

Introducción
7
programa de un evento, así como tener una idea de las asociaciones que existen entre los documentos recuperados.
La tesis está estructurada en tres capítulos. En el Capítulo 1 se abordan los elementos generales de la gestión de documentos, enfatizando en el indexado y recuperación de información, el agrupamiento, y la validación y etiquetamiento de los grupos textuales obtenidos; así como los principales sistemas y herramientas que permiten la gestión de documentos, particularmente los sistemas SATEX y GARLucene. En el capítulo 2 se describen las herramientas desarrolladas que permiten el desarrollo de sistemas gestores de documentos. Estas herramientas siguen el esquema de indexado, recuperación, agrupamiento y valoración, y facilitan el intercambio de información entre ellas y con sistemas externos. En el capítulo 3 se presenta la aplicación web que utiliza el conjunto de herramientas desarrolladas y a partir de una adecuada conexión con los repositorios de información científico-técnica del CEI-UCLV, permite gestionar información científico-técnica. Se presentan elementos del análisis y requisitos del sistema, diagramas de casos de uso, los usuarios y privilegios, así como el resto de los elementos que permitieron arribar a un correcto diseño de la aplicación. Se muestra una valoración de las potencialidades que tiene la aplicación, a partir de la evaluación de algunos indicadores de calidad de sistemas de este tipo. Este documento culmina con las conclusiones, recomendaciones, referencias bibliográficas y los anexos.

Capítulo 1. Acerca de la gestión de documentos
8
1 Acerca de la gestión de documentos En este capítulo se abordan los elementos generales de la gestión de documentos, enfatizando en el indexado y recuperación de información, el agrupamiento, y la validación y etiquetamiento de los grupos textuales obtenidos; así como los principales sistemas y herramientas que permiten la gestión de documentos, tomando como punto de partida los sistemas SATEX y GARLucene.
1.1 Generalidades de la gestión de documentos
La información y el conocimiento surgen de acciones humanas que interconectan señales, signos y artefactos en diversos medios. El espacio de información está dado por su codificación, abstracción y difusión [10]. Las dos primeras se refieren a la creación de categorías que faciliten la clasificación de fenómenos y la minimización del número de categorías necesarias, mientras que la tercera combina las dos primeras. Las organizaciones requieren utilizar la información no sólo para darle significado en su entorno, sino para crear nuevo conocimiento, compartirlo y tomar decisiones [10]. Sus principales incentivos para la gestión del conocimiento son [11, 12]: buscar, aportar, contribuir, diseminar, explotar y evaluar el conocimiento. Se necesita transformar información en conocimiento: estructuración de datos e información y la acción humana sobre éstos [10].
La manipulación de documentos trabaja con conocimiento objetivo, formalizado acorde a algún esquema de codificación; por ejemplo, patente, reporte, artículo, norma. Este conocimiento se clasifica como explícito. Otras dos clasificaciones son: tácito, cuando es personal, en un contexto específico y es difícil formalizarlo, e implícito, cuando es subjetivo [10, 15].
El conocimiento explícito tiene gran importancia porque codifica aprendizaje pasado, habilita la coordinación de actividades y funciones y reduce el procesamiento de información mediante la estipulación de premisas, criterios y opiniones [10, 15]. Además, se comunica fácilmente, aunque transferirlo requiere conocimiento colateral del receptor para entenderlo y aplicarlo. Conocimiento colateral que tiene naturaleza tácita porque los expertos interpretan el significado de la nueva información y surgen incógnitas cuando tratan de usarlo.
Las organizaciones deben considerar servicios de conocimiento para lograr la integración de fuentes locales (por ejemplo, intranet local, servidores de ficheros, sitios públicos), intra-redes

Capítulo 1. Acerca de la gestión de documentos
9
y extra-redes [11]. Pero sólo esto no es suficiente, es necesario utilizar adecuadamente las componentes de las tecnologías de la información para desarrollar gestores de conocimiento.
Los sistemas de gestión de documentos20 14 han tomado un gran auge en la actualidad [ ]. Docyoument, creado por Media-style21, encuentra y lista información relevante en varias fuentes a partir de tópicos y preguntas definidas por los usuarios, genera reportes y resúmenes de los documentos, y descubre relaciones entre contenidos. El grupo de herramientas Text Miner22 descubre y extrae conocimiento desde textos. Otro ejemplo lo constituye Worldox23, que permite la seguridad de los documentos, el control del acceso, búsquedas a texto completo, visualizadores de documentos en diversos formatos, archivar y guardar la historia de un documento. Autonomy24 permite un servicio de búsqueda inteligente en Internet a partir de fuentes en 65 lenguajes, deriva el significado de las palabras en el contexto dado y genera los perfiles de los usuarios. Knexa25 es un ejemplo de plaza de mercado electrónico para conocimiento documentado y el Instituto Kaieteur26 identificó otros ejemplos27. Estos sistemas y herramientas han sido desarrollados en su inmensa mayoría por importantes compañías28
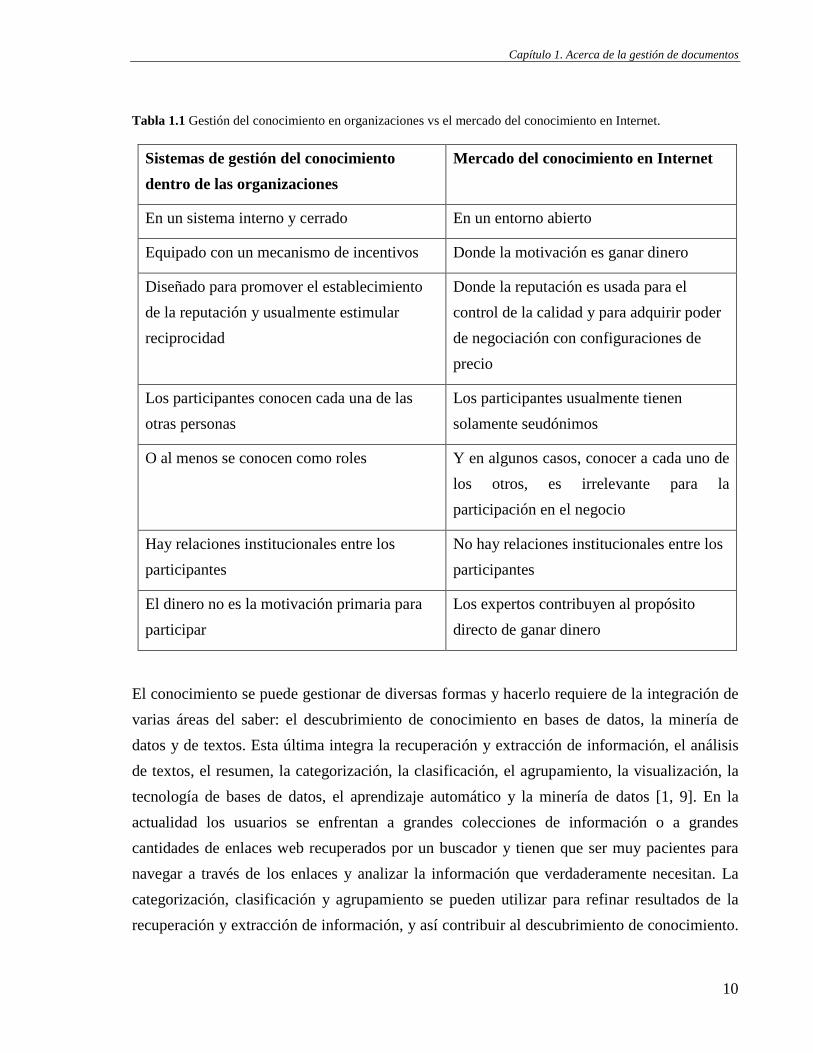
La mayoría de los sistemas mencionados están más dirigidos al comercio del conocimiento en Internet que a la gestión del conocimiento en las organizaciones; las diferencias se muestran en
que han invertido gran capital en la manipulación de documentos para contribuir a la gestión de información y el conocimiento.
Tabla 1.1. Aquellos dirigidos a las organizaciones tienen un alto precio en el mercado internacional, debido esencialmente a los beneficios que les reportan. Esto provoca que para las instituciones cubanas sea muy difícil adquirir este tipo de sistemas. Las universidades no están exentas de esta limitante y son entre las organizaciones del país las que más requieren manipular grandes cantidades de documentos científicos debido a la actividad académica y científica que desarrollan.
20 Sistemas de almacenamiento, sistemas de soporte de búsquedas, modelos de categorización y análisis de contenidos,
ontologías y servicios de control de acceso y coordinadores de trabajo colaborativo. 21 Creación, publicación, gestión, organización, descubrimiento y análisis de contenidos. http://www.media-style.com 22 http://www.sas.com/technologies/analytics/datamining/textminer 23 http://www.worldox.com/ 24 http://www.autonomy.com 25 http://www.knexa.com 26 Instituto para la gestión del conocimiento (Kaieteur Institute for Knowledge Management http://www.kikm.org) 27 Knowinc.com, Keen.com, Yet2.com, iExchange.com, Saba.com, cordis.lu, IQ4Hire.com, petrocore.com y eBrainx.com 28 Autonomy http://www.autonomy.com, ClearForest http://www.clearforest.com, IBM Intelligent Miner for Text
http://www-306.ibm.com/software, LexiQuest http://www.lexiquest.com, Teragram http://www.teregram.com y SAS http://www.sas.com
Capítulo 1. Acerca de la gestión de documentos
10
Tabla 1.1 Gestión del conocimiento en organizaciones vs el mercado del conocimiento en Internet.
Sistemas de gestión del conocimiento dentro de las organizaciones
Mercado del conocimiento en Internet
En un sistema interno y cerrado En un entorno abierto
Equipado con un mecanismo de incentivos Donde la motivación es ganar dinero
Diseñado para promover el establecimiento de la reputación y usualmente estimular reciprocidad
Donde la reputación es usada para el control de la calidad y para adquirir poder de negociación con configuraciones de precio
Los participantes conocen cada una de las otras personas
Los participantes usualmente tienen solamente seudónimos
O al menos se conocen como roles Y en algunos casos, conocer a cada uno de los otros, es irrelevante para la participación en el negocio
Hay relaciones institucionales entre los participantes
No hay relaciones institucionales entre los participantes
El dinero no es la motivación primaria para participar
Los expertos contribuyen al propósito directo de ganar dinero
El conocimiento se puede gestionar de diversas formas y hacerlo requiere de la integración de varias áreas del saber: el descubrimiento de conocimiento en bases de datos, la minería de datos y de textos. Esta última integra la recuperación y extracción de información, el análisis de textos, el resumen, la categorización, la clasificación, el agrupamiento, la visualización, la tecnología de bases de datos, el aprendizaje automático y la minería de datos [1, 9]. En la actualidad los usuarios se enfrentan a grandes colecciones de información o a grandes cantidades de enlaces web recuperados por un buscador y tienen que ser muy pacientes para navegar a través de los enlaces y analizar la información que verdaderamente necesitan. La categorización, clasificación y agrupamiento se pueden utilizar para refinar resultados de la recuperación y extracción de información, y así contribuir al descubrimiento de conocimiento.

Capítulo 1. Acerca de la gestión de documentos
11
Especialmente el agrupamiento y los procesos post-agrupamiento permiten organizar la información, determinar información relevante y crear nuevo conocimiento a partir de la información disponible en una colección especificada o resultante de un proceso de recuperación de información.
1.1.1 Indexado y recuperación de información
Recuperación de información (Information Retrieval; IR) puede ser definida como una aplicación de las tecnologías de la computación para la adquisición, organización, almacenamiento, recuperación, y distribución de información. IR está estrechamente relacionada con elementos prácticos y teóricos sobre la mejora de la tecnología de los motores de búsqueda, incluyendo la construcción y mantenimiento de grandes repositorios de información. En años recientes, los investigadores han incrementado y expandido su preocupación acerca de la bibliografía y búsqueda a texto completo en repositorios en la Web, tanto en datos de hipertextos pertenecientes a bases de datos como en multimedia.
La recuperación de información es una actividad, y como la mayoría de las actividades tiene sus propósitos. Un usuario de un motor de búsqueda comienza con la información que él necesita, para lo cual realiza una consulta con el objetivo de encontrar documentos relevantes. Esta consulta puede que no sea la mejor conexión que él necesita para encontrar lo que desea. Ésta puede contener errores ortográficos, desaprovechar palabras o haber realizado una selección pobre de las palabras. Sin embargo, esta es la única pista que tiene el motor de búsqueda respecto al objetivo de los usuarios.
Generalmente se dice que los documentos resultantes de la búsqueda pueden ser más o menos relevantes respecto a la consulta, pero, estrictamente hablando, esta expresión es errada. Los usuarios juzgan la relevancia respecto a la información que necesitan, no respecto a la consulta. Si se retornan documentos irrelevantes, los usuarios pueden o no darse cuenta de cuáles son los irrelevantes, y pueden o no encontrar la forma de mejorar la consulta.
1.1.2 Agrupamiento
El análisis de grupos es descrito como una herramienta para el descubrimiento porque tiene la potencialidad de revelar relaciones no detectadas previamente, basadas en datos complejos. Los algoritmos de agrupamiento son usados para encontrar una estructura de grupos que se ajuste al conjunto de datos, logrando homogeneidad dentro de los grupos y heterogeneidad entre ellos [16].

Capítulo 1. Acerca de la gestión de documentos
12
Debe existir un alto grado de asociación entre los objetos de un mismo grupo y un bajo grado entre los miembros de grupos diferentes [16]. Cuando el agrupamiento se basa en la similitud de los objetos, se desea que los objetos que pertenecen al mismo grupo sean tan similares como se pueda y los objetos que pertenecen a grupos diferentes sean tan diferentes como sea posible [17, 18]. En otras palabras, seguir el principio de maximizar la similitud dentro del grupo y minimizar la similitud entre los grupos.
El concepto de “similitud” tiene que ser especificado acorde a los datos. En la mayoría de los casos los datos son vectores de valores reales, entonces se requieren algunas medidas (distancias, similitudes, o disimilitudes) para cuantificar el grado de asociación entre ellos. Las medidas más usadas para comparar objetos se muestran en el Anexo 1.
Por otra parte, un reto para la minería de datos es descubrir grupos en datos que al relacionarse forman una estructura interesante para el análisis. Este tipo de datos tiene una mejor descripción cuando se representa como una colección de objetos interrelacionados y enlazados [19]. El enlace entre objetos es un conocimiento que puede explotarse en el agrupamiento, ya que rasgos de objetos enlazados están correlacionados, y es probable la existencia de enlaces entre objetos que tienen elementos comunes. Así, varios métodos parten de representar los objetos y sus relaciones en un grafo y explotan su topología para descubrir los grupos. Estas propuestas ven el conjunto de datos desde la perspectiva de las conexiones entre los objetos más que los objetos en sí mismos [20]. Los conjuntos de datos pueden intrínsecamente formar un grafo o se pueden obtener grafos de similitud a partir de la matriz de similitud entre los objetos.
En la actualidad se presupone que el conocimiento de la estructura de los datos es tan importante como los objetos en sí. Ese conocimiento puede ayudar a descubrir grupos que se ocultan en las comunicaciones entre los objetos [19, 21, 22]. Propiedades de los grafos, sobre todo cuando éstos representan redes complejas, pueden ser indicadores importantes para el agrupamiento.
Los métodos de agrupamiento se clasifican siguiendo varios criterios: tipo de los datos de entrada del algoritmo, criterios para definir la similitud entre los objetos, conceptos en los cuales se basa el análisis y forma de representación de los datos, entre otros [23]. Una clasificación general distingue dos tipos: aquellos basados en una función objetivo y los jerárquicos [24, 25].

Capítulo 1. Acerca de la gestión de documentos
13
Esta primera categoría más general se refiere a la construcción de particiones (grupos) del conjunto de datos sobre la base del perfeccionamiento de algún índice, conocido también como función objetivo. En esencia, dividir n objetos en un número positivo k de grupos, generalmente especificado a priori. El objetivo de estos métodos es encontrar la mejor división de los datos en k grupos basada en una medida de similitud dada y conservar el espacio de particiones posibles en k subconjuntos solamente. La mayoría de los algoritmos que siguen esta técnica son esencialmente basados en prototipos, comienzan con una partición inicial, usualmente aleatoria, y proceden con su refinamiento [18].
Los algoritmos jerárquicos, por su parte, hacen una descomposición jerárquica de los objetos. Dentro de ellos, los aglomerativos (bottom-up), consideran que cada objeto constituye un grupo, por tanto, inicialmente existen tantos grupos como objetos tiene la colección, y sucesivamente los unen, hasta que todos los objetos formen un único grupo. Mientras que los divisivos (top-down
Otros tipos de métodos han emergido para el análisis de grupos, principalmente motivados en problemas específicos de minería de datos [24]. El agrupamiento basado en densidad (
) consideran inicialmente que existe un único grupo al cual pertenecen todos los objetos y sucesivamente dividen los grupos en grupos más pequeños, hasta que cada grupo contenga un único objeto. La construcción de la jerarquía se puede detener por criterios automáticos o del usuario. Muchas veces combinar o dividir grupos es comprometido, y no puede ser deshecho o refinado. En [26, 27] se presenta una nueva metodología que combina la estrategia divisiva y la aglomerativa.
density-based clustering
Otra clasificación, no mutuamente excluyente a las ya presentadas, considera la forma de manipular la incertidumbre en términos del solapamiento de los grupos: agrupamiento duro y borroso [17]. Las técnicas duras pueden ser deterministas o con solapamiento. Las deterministas crean una partición, donde los grupos son mutuamente excluyentes y exhaustivos del universo de objetos. Los algoritmos con solapamiento crean un cubrimiento, donde un objeto puede pertenecer a más de un grupo. Las técnicas borrosas se subdividen en probabilísticas y posibilísticas [18].
) agrupa objetos vecinos de un conjunto de datos basándose en condiciones de densidad. Existe una clasificación que divide el agrupamiento en conceptual y estadístico [28]. Por otra parte, aquellos algoritmos que utilizan métodos geométricos y técnicas de proyección se clasifican en agrupamiento incompleto o heurístico [17].

Capítulo 1. Acerca de la gestión de documentos
14
La teoría de grafos constituye una herramienta valiosa para desarrollar modelos de abstracción para el agrupamiento, proporcionando el formalismo matemático requerido. Sus conceptos básicos han sido utilizados para el desarrollo de algoritmos de agrupamiento y de índices de validación. Los grafos proveen modelos estructurales para el análisis de grupos. Generalmente este tipo de algoritmos no requieren que se especifique el número de grupos a obtener, descubren grupos de formas arbitrarias, no uniformes y de densidades diversas, y son menos sensibles a la presencia de ruido.
Las técnicas de agrupamiento tienen ventajas y desventajas en dependencia del tipo de problema al cual son aplicadas. El conocimiento del dominio puede, en muchos casos, ayudar a determinar qué tipo de grupo se va a formar y qué tipo de agrupamiento se va utilizar con el objetivo de obtener los mejores resultados. Se han desarrollado muchos algoritmos para el agrupamiento de documentos, pero muy pocas propuestas toman en consideración las ventajas de las estructuras inherentes en el lenguaje. Cuando se representa una colección textual como un grafo de similitud coseno entre los documentos, sucede que, como se muestra en la Figura 1.1, algunos documentos tienen alta pertenencia a los grupos, otros pertenecen a puentes entre grupos y algunos tienen una pertenencia débil a los grupos; por tanto, es fundamental explotar las propiedades topológicas del grafo y el flujo de información entre los nodos para detectar las estructuras ocultas en él [29]. En algunos casos dos documentos pueden tratar temas diferentes y tener alta similitud coseno. Estos documentos no necesariamente son tan similares a sus vecinos respectivos, y sólo el uso de la similitud no logra identificarlos en grupos diferentes, se requiere analizar los enlaces entre ellos.
Figura 1.1. Grafo donde se han representado dos grupos, el nodo 6 es puente entre los grupos y el nodo 13 tiene muy baja pertenencia a los grupos. Fuente: [29].
Se considera de gran utilidad explotar las propiedades topológicas de los lenguajes y corpus textuales, de ahí que resulta útil aplicar métodos de análisis de redes complejas para abordar

Capítulo 1. Acerca de la gestión de documentos
15
problemas de la minería de textos. Por tanto, en este trabajo se sigue el enfoque de las técnicas de agrupamiento que trabajan sobre una representación de los objetos en un grafo y que explotan la estructura de las interrelaciones de los objetos en el proceso de agrupamiento.
1.1.3 Validación
“El agrupamiento es un proceso subjetivo; el mismo conjunto de datos usualmente necesita ser agrupado de formas diferentes dependiendo de las aplicaciones” [30]. Esta subjetividad hace el agrupamiento difícil, y aún más su validación.
Una forma de evaluación del agrupamiento muy sencilla puede ser, por ejemplo, mediante la visualización del conjunto de datos cuando éste es pequeño y los datos son bidimensionales. Sin embargo, esta forma de evaluación puede ser difícil al intentar una visualización efectiva de un conjunto de datos de alta dimensionalidad [31], aunque técnicas bien establecidas para la reducción de dimensionalidad, como el análisis de componentes principales (Principal Component Analysis; PCA) [32] y el análisis de componentes principales categórico (Categorical Principal Component Analysis
Por otra parte, muchos algoritmos de agrupamiento varían sus resultados dependiendo de las características de los datos, por ejemplo, geometría y densidad de distribución [28]. Otros dependen fuertemente de los valores asignados a los parámetros. Por ejemplo, si hay un parámetro que controle la resolución a la cual son vistos los datos, el algoritmo produce un dendrograma en función de ese parámetro. En este caso es necesario decidir cuál nivel del dendrograma refleja mejor los grupos según las propiedades que se desea que el agrupamiento satisfaga. Algunos algoritmos necesitan que se especifique inicialmente el número de grupos a obtener, otros requieren que se especifique el número de vecinos de cada punto como un parámetro externo. Así, los resultados producidos son en función de los parámetros fijados y se hace necesario verificar cuáles se ajustan a los datos [33].
; CATPCA), pueden contribuir a la evaluación de este tipo de conjuntos de datos mediante la visualización.
Variaciones a partir de características de los datos, diferentes técnicas de análisis de grupos y definición de parámetros para el algoritmo a aplicar, indican que una evaluación de los resultados es necesaria para medir la calidad del agrupamiento. Una práctica común, en tal sentido, es aplicar medidas de validación de grupos [34].
El procedimiento de evaluar los resultados de algoritmos de agrupamiento se conoce por validación del agrupamiento [35, 36]. Se llama medida de validación de grupos a una función

Capítulo 1. Acerca de la gestión de documentos
16
que hace corresponder un número real a un agrupamiento, indicando en qué grado el agrupamiento es correcto o no [17]. Estas medidas en su mayoría son heurísticas por naturaleza para conservar una complejidad computacional plausible.
Las medidas de evaluación del agrupamiento se clasifican en: globales y locales, subjetivas y objetivas; internas, externas y relativas; y supervisadas y no supervisadas [17, 37, 38].
Las medidas globales describen la calidad del resultado completo de un agrupamiento usando un único valor real, mientras que las locales evalúan cada grupo obtenido [17]. Las medidas objetivas miden propiedades estructurales de los resultados de los agrupamientos, por ejemplo, la separación entre los grupos y la compactación o densidad de los mismos [28]. La presencia de tales propiedades no garantiza que los resultados sean interesantes para el usuario, estas medidas carecen de enlace con los usuarios, aunque su principal atractivo es que son independientes del dominio. Las medidas subjetivas evalúan considerando la usabilidad de los grupos [34]. Las investigaciones en medidas subjetivas han sido menos intensas que las realizadas en las objetivas [39].
Una clasificación muy usada divide la validación del agrupamiento en: medidas internas, externas y relativas [35, 38]. Otra división consiste en medidas supervisadas y no supervisadas, refiriéndose a externas e internas, respectivamente. Las medidas externas se basan en un criterio externo que es impuesto sobre los datos, por ejemplo, una estructura previamente especificada que refleje la intuición que se tenga del agrupamiento de los datos. No se puede aplicar estas medidas a situaciones del mundo real donde usualmente no está disponible una clasificación de referencia. Las medidas internas evalúan considerando solamente los resultados del agrupamiento en términos de cantidades que involucran los vectores de datos. Las medidas relativas se basan en la comparación del agrupamiento a evaluar con otros esquemas de agrupamiento o con resultados del mismo algoritmo con diferentes valores en los parámetros.
1.1.4 Etiquetamiento
Un creciente número de herramientas soporta la creación y diseminación de la información provocando su proliferación arrolladora. Con esta cantidad de información cada vez más grande, es difícil para un investigador encontrar fácilmente los artículos que responden a sus necesidades y además resulta imposible que pueda leerla y comprenderla toda. Estas son razones por las cuales los problemas de la minería de textos requieren el agrupamiento de documentos y después recuperar las etiquetas de los grupos de las grandes colecciones

Capítulo 1. Acerca de la gestión de documentos
17
textuales. Algunos trabajos han sido desarrollados en esta área; sin embargo, etiquetar es usualmente ignorado por los investigadores en agrupamiento y se le ha prestado menos atención a crear buenos descriptores de grupos, debido a que el problema del agrupamiento no ha sido aún resuelto. Emergen más y más algoritmos de agrupamiento efectivos y que típicamente no tienen una complejidad lineal, entonces la etapa de etiquetamiento se hace crítica para grandes conjuntos de datos, especialmente cuando los puntos en las regiones fronteras de los grupos son significativos para las aplicaciones [40]. Por lo tanto, se requiere del desarrollo y aplicación de un conjunto de procedimientos, instrumentos y métodos que permitan obtener eficientemente el etiquetamiento de grupos de documentos.
Las etiquetas a obtener deben ser únicas, sintetizadoras, expresivas, tener poder discriminante, contiguas, poseer consistencia jerárquica, y no ser redundantes [34]. Es deseado que el proceso de etiquetamiento sea no supervisado, de forma tal que se puedan producir etiquetas rápidamente sin el alto costo de la intervención humana en la anotación de conjuntos de entrenamiento [41].
Una forma de etiquetar es representando adecuadamente los grupos [40]. Las representaciones de los grupos pueden ser basadas en centros, puntos representativos, árboles de clasificación y reglas. El uso de centroides es el esquema más popular, el mismo funciona bien cuando los grupos son compactos. Sin embargo, cuando los grupos son alargados, este esquema falla, en este caso, el uso de una colección de puntos soluciona el problema, además funciona mejor ya que describe los grupos con más detalles [30].
Una nueva interrogante surge: ¿cómo definir los puntos más representativos? Hacerlo desde grupos con formas arbitrarias es una tarea tan difícil como el propio problema del agrupamiento. A continuación se presentarán algunas técnicas existentes en la literatura científica para etiquetar grupos, enfatizando en aquellas que etiquetan basadas en los puntos más representativos.
Un enfoque muy sencillo puede ser etiquetar los grupos con las palabras de mayor frecuencia de aparición en estos , pero estas etiquetas son muy generales y generalmente no son buenos descriptores discriminantes. Otras propuestas han tenido en cuenta para etiquetar la distribución de las palabras en una jerarquía. Popescul y Glover proponen un método estadístico para la selección de los descriptores de un grupo, basados en el contexto de grupos
circundantes (grupos “padres y hermanos”) [41].

Capítulo 1. Acerca de la gestión de documentos
18
Popescul propone el uso del estadístico χ2 para detectar diferencias en la distribución de las palabras a través de la jerarquía. Glover muestra cómo un simple modelo que sólo se basa en la frecuencia de los términos en cada documento se puede utilizar para seleccionar los descriptores de los grupos (nodos) padre, hijo y del propio grupo, especialmente para páginas Web. Las etiquetas candidatas son extraídas desde el contenido de la página Web, incluyendo los hipervínculos. Las etiquetas son seleccionadas y ordenadas usando su frecuencia en los documentos teniendo en cuenta límites predefinidos [41].
Pucktada y Jaime presentan un algoritmo para etiquetar grupos resultantes de un agrupamiento jerárquico, para esto utilizan la frecuencia del documento y del término con respecto al grupo. Un proceso de etiquetamiento basado en la visualización de los datos es propuesto en [40]. Su desventaja es que requiere involucrar parcialmente la influencia humana en el proceso, y sus ventajas son que etiqueta y adapta las regiones límites preservando la calidad del agrupamiento y que tiene bajo costo computacional, al menos si se compara con algoritmos para el etiquetamiento basados en la comparación de distancias.
Las etiquetas con puntos más representativos logran describir los grupos con más detalles. Entre los trabajos reportados en la literatura para etiquetar con puntos más representativos se encuentra el de Pedersen y Kulkarni donde tratan cada grupo como un corpus y así encuentran las etiquetas que serían un número n de bi –gramas [41].
Los algoritmos de etiquetamiento de grupos de documentos pueden escoger los documentos cercanos a los centroides de cada grupo, como una forma de etiquetamiento. Un ejemplo de algoritmo que usa esta representación es Scatter/Gather, el cual representa un grupo con una lista de documentos cercanos al centroide del grupo y una lista de tópicos. La lista de tópicos son los términos con mayor peso en el centroide del grupo. Este enfoque sólo es posible para etiquetar resultados de agrupamientos que forman particiones y cubrimientos. Requerir centros de grupos es una de las desventajas de esta propuesta [41].
1.2 Herramientas que permiten el desarrollo de sistemas gestores de documentos
La explosión de Internet y el surgimiento de repositorios de datos electrónicos han provocado que grandes cantidades de información se encuentren disponibles al alcance de la sociedad. Precisamente, el volumen de toda esa información hace prácticamente imposible la gestión de la información mediante la aplicación de métodos tradicionales[42].

Capítulo 1. Acerca de la gestión de documentos
19
La necesidad de localizar en un tiempo prudencial información específica, no desde un ordenador personal que contiene la información localizada en sus discos, ni tan siquiera en uno que esté dentro de la misma compañía o subred, sino desde casi cualquier rincón del planeta utilizando medios tan diversos como un teléfono celular, una agenda electrónica, una computadora portátil, etc.
Por tanto, esta abundancia de información que constituye un tesoro de la humanidad hay que lograr gestionarla adecuadamente, de forma rápida y eficiente, permitiendo encontrar exactamente lo que se está buscando con el menor esfuerzo posible. Entonces, la creación, desarrollo y mantenimiento y uso de herramientas informáticas que permitan gestionar la información constituye una necesidad de la humanidad en la “era de la Información”.
1.2.1 Lucene
La indexación y la búsqueda de información son pasos claves para una correcta gestión de la información. Lucene es una potente biblioteca de búsqueda e indexación basada en Java y de código abierto, que fácilmente permite la integración con cualquier aplicación.
En los últimos años Lucene se ha convertido en una popular biblioteca de recuperación de información que ha sido integrada a las funciones de búsquedas de muchas aplicaciones web y de escritorio. Aunque originalmente fue escrito en java debido a su popularidad ya ha sido implementado en otros lenguajes de programación como (C / C + +, C #, Ruby, Perl, Python, PHP, etc.). Uno de los factores clave detrás de la popularidad de Lucene es su aparente simplicidad, pues realmente cuenta con algoritmos que implementan técnicas de recuperación de la información de última generación. Además, para utilizarla no es necesario un conocimiento profundo acerca de cómo Lucene indexa y recupera información.
Resumiendo: Lucene constituye una novedosa herramienta para la gestión de la información. Creada bajo una metodología orientada a objetos e implementada completamente en Java, no se trata de una aplicación que pueda ser descargada, instalada y ejecutada sino de una interfaz de programación de aplicaciones (Application Program Interfaces; API) flexible, muy potente y realmente fácil de utilizar, a través de la cual se pueden añadir, con pocos esfuerzos de programación, capacidades de indexación y búsqueda a cualquier sistema para la gestión de la información. Además, Lucene presenta características importantísimas en una API como: su alto rendimiento entre sus métodos, es escalable y su diseño es compacto y simple.

Capítulo 1. Acerca de la gestión de documentos
20
1.2.2 Tika
Uno de los más difíciles pero vitales pasos en la construcción de aplicaciones de gestión de la información es la extracción del contenido de las múltiples fuentes de información para su posterior indexación. Las fuentes de información pueden ser muy diversas que varían desde grandes repositorios de información con archivos en diferentes formatos electrónicos, aplicaciones o sitios web, bases de datos, etc. Ante la ausencia de homogeneidad de formato de los archivos los desarrolladores de aplicaciones para la gestión de la información debían buscar los diferentes filtros propios de cada formato de archivo e interactuar con sus APIs, simplemente con el fin de extraer el texto que se necesitaba de los documentos.
Tika es un marco de trabajo desarrollado en Java y de código abierto que aloja plugins
1.2.3 Jung
analizadores para cada tipo de documento admitido. Además, presenta una API de aplicación con la cual los desarrolladores de aplicaciones pueden interactuar para realizar la extracción de texto y los metadatos de un documento, independientemente del tipo de formato de los documentos[42]. La extracción de metadatos y contenido de documentos está soportada para múltiples formatos de documentos, entre los cuales están los documentos de: Microsoft Office (Excel, Word, PowerPoint, Visio, Outlook), Adobe Portable Document Format (PDF), Rich Text Format (RTF), Texto Plano HTML, XML, ZIP, TAR, GZIP, BZIP2.
JUNG29
• Soporte para la representación de una variedad de entidades y sus relaciones, incluyendo grafos dirigidos o no dirigidos, grafos multi modales (grafos que contienen más de un tipo de vértice o arista), grafos con aristas paralelas (también conocidos como multigrafos), e hipergrafos (los que contienen hiperaristas, cada una de las cuales puede conectar cualquier número de vértices).
[43] (Java Universal Network/Graph framework) es una biblioteca de software de código abierto y escrita en Java que proporciona un lenguaje común y extensible para el modelado, análisis y visualización de datos que pueden ser representados como grafos o redes. Entre sus principales características se encuentran:
• Mecanismos para la anotación de grafos, entidades y relaciones con metadatos. Los cuales, facilitan la creación de herramientas analíticas para conjuntos de datos
29 Disponible en http://jung.sourceforge.net

Capítulo 1. Acerca de la gestión de documentos
21
complejos que pueden examinar las relaciones entre entidades, así como los metadatos adjuntos a cada entidad y relación.
• Implementación de un número de algoritmos de la teoría de grafos, el análisis exploratorio de datos, análisis de redes sociales y aprendizaje de máquina. Estos incluyen: rutinas para el agrupamiento, la descomposición, optimización, la generación aleatoria de grafos, análisis estadístico y cálculos de las distancias en las redes, flujos, y medidas de ranking (centralidad, rango de página, HITS, etc.)
1.3 Sistemas gestores de documentos desarrollados en la UCLV
La gestión del conocimiento juega un rol importante en las universidades e institutos de investigación porque sus procesos son estables, generan y preservan valiosa información proveniente de diversos procesos, tienen acceso a importantes fuentes de información externa, poseen capital humano bien capacitado y buen desarrollo de las tecnologías de la información.
En estas organizaciones se requiere el desarrollo de sistemas gestores de información y conocimiento en función de tareas específicas que tienen que asumir y en dependencia de las características y recursos de las mismas. Algunas de estas tareas son: recomendar a investigadores y docentes cómo enfrentarse a grandes volúmenes de artículos científicos al comenzar la revisión del marco teórico de un tema de investigación (toda nueva investigación comienza con una amplia revisión bibliográfica sobre el tema en cuestión), organizar materiales por equipos de estudiantes para la docencia, organizar por temáticas los artículos que le han llegado al comité científico de un evento, o tener una idea de las asociaciones que existen entre los documentos recuperados y así organizarlos. Estas tareas son ejemplos de necesidades de automatización sobre todo en las universidades cubanas, donde existen grandes depósitos centrales de información que se comparten y publican libremente. Por otra parte, el gran contenido de trabajo de los profesores e investigadores hace que el tiempo sea limitado y mucho mas si hay que enfrentarse a revisiones bibliográficas. Además, las tareas mencionadas, en su mayoría, tributan a la producción científica que se lleva a cabo en las universidades, actividad relevante que se refleja en un gran número de los indicadores para la medición del capital intelectual en estas organizaciones [44].
Debido a la gran necesidad que tiene principalmente las universidades de tener sistemas gestores de información, es que en [13] se propone un esquema general de aplicación que contribuye a una forma de transformación de la información en conocimiento, porque

Capítulo 1. Acerca de la gestión de documentos
22
manipula documentos mediante el agrupamiento y post-agrupamiento, revelando el orden de los datos e imponiendo patrones en los grupos descubiertos. Este esquema general incorpora el agrupamiento y el post-agrupamiento para recomendar a los usuarios cómo enfrentarse a grandes colecciones textuales, mediante la organización y extracción de conocimiento de las mismas, contribuyendo a la gestión de información y conocimiento. La entrada a este proviene del resultado de un proceso de recuperación de información [45], de un servidor o colección personal de información textual. Las salidas son los grupos homogéneos de documentos afines, los términos relevantes y los documentos más representativos de cada grupo, así como los que se relacionan con ellos y la calidad con que fueron obtenidos los grupos; garantizando el control para la evaluación de los resultados del agrupamiento. En el Anexo 3 se muestran los cuatro módulos que conforman el esquema propuesto:
Módulo 1. Recuperación de la información o especificación del corpus textual a procesar.
Módulo 2. Representación del corpus textual obtenido o fijado por el usuario.
Módulo 3. Agrupamiento de los documentos.
Módulo 4. Valoración (validación y etiquetamiento) de los grupos textuales obtenidos.
Una de las formas de creación de conocimiento se alcanza moviéndolo desde el nivel de individuos hasta el de grupos, durante cuatro etapas del ciclo de conversión del mismo: socialización, exteriorización, combinación e internalización [46]. Este esquema de aplicación contribuye a la manipulación del conocimiento partiendo del conocimiento codificado (explícito, repositorio de conocimiento compartido) y tributa a las dos últimas etapas del ciclo. Por un lado, se crea conocimiento explícito mediante el agrupamiento y valoración de los grupos textuales a partir de la recopilación del conocimiento explícito de múltiples fuentes. Así, se pone en práctica una de las formas de llevar a cabo la combinación: producir nuevo conocimiento explícito mediante la combinación (agrupamiento y organización) del conocimiento explícito acumulado [10]. Por otro lado, se recomienda a los usuarios cómo enfrentarse a la colección textual, y por tanto, tienen más elementos para personificar el conocimiento explícito y aumentar sus experiencias en el tácito.
La estrategia de informatización del Centro de Estudios de Informática (CEI) de la Universidad Central “Marta Abreu” de Las Villas (UCLV), consta de cuatro componentes principales: el portal del centro, los servicios de apoyo a la docencia de pregrado y postgrado, los servicios de apoyo a la gestión administrativa y el módulo de información científico-técnica. Este último está formado por dos componentes principales: el repositorio de

Capítulo 1. Acerca de la gestión de documentos
23
información y sistemas de ayuda al procesamiento de información, orientados a facilitarles a los investigadores (profesores y estudiantes) el proceso de revisión bibliográfica, y así contribuir a una mejor administración del tiempo necesario para hacer ciencia.
Investigadores del Laboratorio de Inteligencia Artificial del CEI-UCLV desarrollaron dos sistemas que siguen este esquema general para el desarrollo de sistemas gestores de información: el Sistema para el Agrupamiento, etiquetamiento y evaluación de colecciones TEXtuales (SATEX)30 y el Sistema para la Gestión de Artículos científicos Recuperados usando Lucene (GARLucene)31. El primero, parte de una colección textual especificada por los usuarios, y el segundo, utiliza las ventajas de LIUS32 y Lucene33
1.3.1 Sistema para el Agrupamiento, etiquetamiento y evaluación de colecciones TEXtuales (SATEX)
para indexar y recuperar información textual que posteriormente se procesará. El objetivo del desarrollo de estos sistemas fue darle cumplimiento al cuarto componente de la estrategia de información del CEI-UCLV, sin embargo, como se verá a continuación, dichos sistemas no logran satisfacer todas las necesidades.
SATEX es un sistema manipulador de documentos que fue concebido para recomendar a los usuarios cómo enfrentarse a una colección de documentos, mediante el agrupamiento y su validación y etiquetamiento usando Teoría de los Conjuntos Aproximados (Rough Set Theory; RST).
El sistema fue desarrollado en Borland Delphi 7.0. Su ejecutable ocupa 630 KB y requiere, que junto con éste, se encuentre la carpeta Dictionary, con los cinco diccionarios necesarios en la etapa de representación textual; la carpeta PDFBox, que contiene el convertidor PDFBox34 de ficheros en formato pdf a documentos textos y la carpeta Util con utilitarios para la aplicación. SATEX funciona en cualquier versión de Windows donde esté instalada la máquina virtual de JAVA y el marco de trabajo de .NET, por requerimientos del PDFBox
El sistema no implementa los módulos 2 y 3 del esquema general [13], porque reutiliza la representación textual y el agrupamiento de la herramienta CorpusMiner
.
35
30 Registro CENDA 1145-2008
. Esta herramienta
31 Registro CENDA 1777-2008 32 http://sourceforge.net/projects/lius 33 http://lucene.apache.org 34 PDFBox es una biblioteca realizada en Java para el trabajo con documentos PDF. http://www.pdfbox.org 35 Resultado de las etapas por las que ha transitado esta investigación.

Capítulo 1. Acerca de la gestión de documentos
24
requiere la especificación de diccionarios para la lematización, homogeneidad ortográfica, contracciones, abreviaturas y palabras gramaticales. Su diseño permite que sea extensible, flexible y reutilizable con facilidad. En CorpusMiner cada funcionalidad es desarrollada por múltiples algoritmos, por tanto, cada resultado puede obtenerse de distintas formas: variando el algoritmo o sus parámetros.
En el Anexo 4 se muestra la interfaz gráfica de SATEX y sus funcionalidades principales. El sistema parte de una colección de documentos en idioma inglés y formato pdf especificada por el usuario. El primer módulo sólo se encarga de conformar el corpus textual a partir de todos los ficheros especificados. El módulo 2 en SATEX se encarga de la representación textual. La primera fase de la transformación textual convierte ficheros pdf a textos utilizando el PDFBox como una caja negra. Este es el proceso más costoso en todo el procesamiento con SATEX, por lo que es posible guardar el corpus creado para reutilizarlo en futuros agrupamientos. Las principales transformaciones incluidas en la segunda fase son: la lematización, la sustitución de términos, la homogenización ortográfica y la reexpresión de símbolos. Se sugiere el pesado de la matriz usando TF_IDF I y su normalización por frecuencias [41]. La reducción de la dimensionalidad se realiza eliminando las palabras de parada, realizando la lematización36
El tercer módulo se lleva a cabo en SATEX utilizando la variante de agrupamiento concatenado de CorpusMiner [47], donde se refina la salida del algoritmo Estrella Extendido (Extended Star; ES) [48] con el algoritmo SKWIC [49]. El cuarto módulo parte de las salidas del agrupamiento y se encarga de la etapa post-agrupamiento para valorar grupos textuales, enriqueciendo la interpretabilidad de diversos resultados de agrupamientos. En SATEX se valoran los grupos textuales mediante un listado de las palabras claves [50, 51], los documentos más representativos, otros documentos relacionados con el grupo, y el resultado de medidas internas de validación. Estas últimas tres formas de valoración son posibles debido a la aplicación de RST al post-agrupamiento. Los documentos más representativos se corresponden a la aproximación inferior del grupo y los documentos de otros grupos que se relacionan con documentos de un grupo en cuestión, están incluidos en la aproximación superior de este grupo.
y seleccionando aquellos términos, en un rango de 500 a 1000, con mayor calidad para el agrupamiento.
36 La lematización se realiza consultando listas de palabras que contienen todas las variaciones morfológicas.

Capítulo 1. Acerca de la gestión de documentos
25
1.3.2 Sistema para la Gestión de Artículos científicos Recuperados usando Lucene (GARLucene)
GARLucene es otro sistema manipulador de documentos, que al igual que SATEX, sigue el esquema general propuesto en [13], pero a diferencia de éste, organiza y caracteriza los resultados de un proceso de recuperación de información. El sistema fue desarrollado completamente en JAVA, su código es libre y multiplataforma. Sólo requiere que el sistema operativo tenga instalado Java Runtime Enviroment (JRE). Su archivo “.jar” ocupa 286 KB y requiere que junto con éste se encuentren los archivos necesarios para la configuración del sistema y las bibliotecas necesarias para el proceso de creación de índices, recuperación, agrupamiento y evaluación de los grupos. GARLucene permite la creación de índices de múltiples tipos de ficheros37
LIUS y Lucene se utilizaron en el primer módulo de GARLucene. El proyecto Apache Lucene desarrolló una biblioteca que permite la búsqueda y recuperación de información, sobre una indexación utilizando LIUS. Ambos han sido desarrollados sobre tecnología Java y sus fuentes se encuentran totalmente disponibles. Lucene es multiplataforma, tiene un alto rendimiento y es escalable, permite la creación incremental de índices, los algoritmos de búsqueda son potentes, fiables y eficientes, permitiendo: ordenar resultados por relevancia, utilizar un amplio lenguaje de consulta, realizar búsquedas por campos y por rangos de fechas, ordenar por cualquier campo, y buscar mientras se actualiza el índice. LIUS es un marco de trabajo para la indexación y búsqueda de documentos. Éste funciona como una capa por encima de Lucene para organizar el trabajo de extraer datos de distintos tipos de documentos y establecer su correspondencia a campos de Lucene. LIUS permite manipular qué campos se crean, de qué tipo y qué analizadores se deben usar, entre otros. Así, ofrece más comodidad al configurar Lucene y decidir qué, cómo y dónde se indexa.
y el usuario puede especificar el visualizador a utilizar.
El primer módulo en GARLucene se dedica esencialmente a la creación de índices y recuperación. La creación de índices se basa en LIUS, sólo hay que especificarle la dirección de los documentos a indexar y los parámetros de configuración necesarios. LIUS procesa las consultas de los usuarios y Lucene comprueba la existencia del índice y obtiene las propiedades de los documentos; permitiendo la recuperación de información. El usuario puede
37 Tipos de ficheros: Ms Word, Ms Excel, Ms PowerPoint, RTF, PDF, XML, HTML, TXT, Open Office.

Capítulo 1. Acerca de la gestión de documentos
26
tener más de un directorio de índices para realizar el proceso de búsqueda y recuperación. Es posible realizar múltiples tipos de búsquedas en los textos indexados38
GARLucene reutiliza las facilidades de Lucene para la representación textual, correspondiente al módulo 2 del esquema general. La primera fase de la transformación se realiza en la creación de índices y recuperación de información. Lucene permite la representación espacio-vectorial de la colección recuperada.
.
GARLucene aplica métodos basados en la intermediación de las aristas [13] y por tanto representa los documentos recuperados como grafos no dirigidos y ponderados, donde cada documento es un nodo y las aristas entre ellos están ponderadas con su similitud Coseno. Inicialmente este grafo es completo, por tanto, con el objetivo de reducir el número de aristas, GARLucene calcula reiteradamente umbrales de similitud entre los documentos y elimina aquellas aristas con ponderación inferior al umbral calculado. De esta forma se facilitan los cálculos y se hacen más efectivos. GARLucene implementa tres variantes de agrupamiento jerárquicos divisivos utilizando la intermediación de las aristas. El sistema muestra los grupos en forma de árbol jerárquico. El proceso de agrupamiento comienza por la raíz que está formada por los artículos científicos recuperados que guardan relación con la palabra o frase que originó la búsqueda. Cada grupo que el sistema dividió en varios subgrupos, es decir, que no es una hoja de la jerarquía generada, puede expandirse o contraerse. Si el usuario selecciona un grupo, su contenido se visualiza en el recuadro derecho de la aplicación. Cada configuración de la jerarquía, dada por contracciones y expansiones de los grupos, puede ser evaluada como una partición. Esta evaluación se lleva a cabo calculando las medidas locales y globales basadas en RST. El sistema también ofrece un listado de los documentos más representativos de cada grupo, utilizando para ello las aproximaciones inferiores. El umbral utilizado para conformar la relación de similitud coincide con el umbral de corte utilizado en el grafo original.
En el Anexo 5 se muestra la interfaz gráfica de GARLucene y sus funcionalidades principales.
1.4 Consideraciones finales del capítulo
Los sistemas gestores de documentos son importantes en las organizaciones ya que garantizan convertir grandes volúmenes de información textual en conocimiento. Estos sistemas 38 Tipos de búsquedas: por palabra, por frase, apoyado por comodines de textos, borrosas, por proximidad, por rango,
fomentando un término, usando operadores booleanos y paréntesis para agrupar expresiones, y cualquier combinación de éstas. En el manual de usuarios de GARLucene es posible acceder a los detalles de cada búsqueda.

Capítulo 1. Acerca de la gestión de documentos
27
requieren el desarrollo y aplicación de técnicas de minería de textos como la representación textual, el agrupamiento, el indexado y recuperación, la clasificación y el etiquetamiento, entre otras.
Es posible encontrar en internet varios sistemas gestores de documentos, sin embargo, la mayoría de ellos están más dirigidos al comercio del conocimiento en Internet que a la gestión del conocimiento en las organizaciones. Aquellos dirigidos a las organizaciones tienen un alto precio en el mercado internacional, y ésta es una de las causas que hace que para las instituciones cubanas sea muy difícil adquirir este tipo de sistemas.
De ahí, investigadores de universidades cubanas se han dado a la tarea de desarrollar sistemas gestores de documentos. Dos ejemplos los contituyen los sistemas SATEX y GARLucene que brindan amplias ventajas para la gestión de la información y del conocimiento. Sin embargo, el diseño de estos sistemas no permite la utilización de algunos de sus módulos en otras aplicaciones, o la incorporación de otras formas de representación textual, u otros métodos de indexado y recuperación de la información. Por otra parte, estas aplicaciones son de escritorio, limitándose significativamente los procesos de indexado y recuperación de la información, los usuarios necesitan especificar valores a parámetros que desconocen y los términos que se utilizan no son familiares a los usuarios. Aunque los sistemas realizan procesamientos de calidad y logran agrupar correctamente los documentos, así como extraer la información relevante de cada grupo, las desventajas antes mencionadas impiden la introducción y generalización de los mismos, y conllevan a que los usuarios finales no aprecien las ventajas de los mismos al utilizarlos para el procesamiento de grandes volúmenes de información.
Por tales motivos, resulta imprescindible partir de los sistemas ya existentes, así como de herramientas que facilitan el desarrollo de sistemas gestores de documentos, para desarrollar aplicaciones que permitan gestionar el conocimiento de manera efectiva. Para ello, se deben integrar las ventajas de Lucene que permite el indexado y recuperación de información textual, Tika que permite la extracción del contenido textual de documentos en diferentes formatos, y Jung que proporciona un lenguaje común y extensible para el modelado, análisis y visualización de datos que pueden ser representados como grafos o redes.

Capítulo 2. Herramientas que permiten el desarrollo de sistemas gestores de documentos
28
2 Herramientas que permiten el desarrollo de sistemas gestores de documentos
Las aplicaciones desarrolladas y presentadas en forma de herramientas en este documento pertenecen a la categoría de software libre; cumpliendo con la política trazada por la dirección de nuestro país que aboga por el uso de software que pertenezca a dicha categoría. Además, estas trabajan de forma independiente entre sí, pueden retroalimentarse de proyectos externos o ser utilizadas por cualquier otra aplicación como bibliotecas o marcos de trabajos y cumplen como conjunto con el esquema propuesto en [13] para el desarrollo de de sistemas gestores de la información.
En el desarrollo de estas herramientas se utilizó el lenguaje de programación JAVA utilizando el JDK 1.7, la versión 7.0 del IDE NetBeans, la biblioteca 3.0.2 de Apache Lucene para las aplicaciones de indexado, recuperación y transformación de textos, la versión 0.6 de Tika en la extracción de contenidos y metadatos en los diferentes tipos de documento, la versión 2.0.1 del marco de trabajo Jung para la aplicación de agrupamiento, así como bibliotecas que incorporan medidas internas de validación y etiquetamiento de grupos desarrolladas en el CEI-UCLV.
Como parte de la necesidad de interactuar con el repositorio de información existente en el CEI-UCLV se desarrolló un módulo para la aplicación encargada de extraer la información contenida en los documentos, dicho módulo es capaz de recuperar información a partir de repositorios locales o remotos a través del protocolo de transferencia de archivos (FTP). Además, como los resultados obtenidos por las aplicaciones son datos con un formato estructurado se decidió utilizar el Lenguaje de marcado extensible (XML) para representar esa información y el uso de esquemas de XML (XSD) para validar la estructura del documento resultante, permitiendo que el intercambio de datos entre las aplicaciones puedan ser validadas y utilizadas por aplicaciones externas; ya sea como bibliotecas o aplicaciones independientes. El uso del proyecto de Apache Lucene “SnowBall” permite que las aplicaciones sean capaces de identificar el idioma de los textos de los documentos, optimizando los procesos en donde este juega un papel fundamental como en la indexación, recuperación, transformación de los mismos. Actualmente el conjunto de herramientas distingue entre los idiomas (inglés, español y alemán).

Capítulo 2. Herramientas que permiten el desarrollo de sistemas gestores de documentos
29
Para facilitar el desarrollo de las aplicaciones se creó una biblioteca común para todas las herramientas denominada “tools.jar
Todas las herramientas desarrolladas tienen una interfaz de comandos por consola, donde se puede acceder a la ayuda de cada herramienta con el comando
” que contiene las clases y bibliotecas que son comunes para algunas herramientas o que requieren de algunas bibliotecas externas con un único fin, ejemplo: la biblioteca jdoom.jar que facilita el trabajo con archivos XML. Además, las clases implementadas en todas las herramientas o bibliotecas desarrolladas pertenecen o son subdirectorios del paquete “cu.edu.uclv.cei.textmining” y cada herramienta tiene una clase controladora en la raíz de su paquete principal.
–ayuda
Figura 2.1
. Para el desarrollo de de esta interfaz de comando se desarrollaron un conjunto de clases con el fin de estructurar jerárquicamente los posibles comandos de cada una de las herramientas desarrolladas y poder estructurar la cadena introducida por consola y realizar el pase de parámetros específicos a cada comando o subcomando, la muestra el diagrama de las principales clases encargadas de realizar esta tarea, las mismas se encuentran implementadas dentro del subpaquete “args”, donde se destaca la clase “Option” y de la cual heredan todas las demás clases que representan algún tipo de comando. A continuación se detallan algunas descripciones de las clases representadas en la Figura 2.1:
• “Option”: Clase abstracta que define algunos atributos o métodos necesarios para guardar la lista de cadenas que representan los parámetros, ejemplos:
o boolean isRequired(): devuelve un valor booleano significando si el comando es una opción requerida o no dentro de los parámetros.
o String getDescription(): devuelve información sobre el comando.
o boolean checkArgs(List<String> list_args): chequea si la lista de argumentos a establecer es aceptable o no.
o abstract boolean setArgs(List<String> list_args): establece en el comando la lista de argumentos.
o boolean isActived(): devuelve un valor booleano significando si el comando fue activado o no, mediante el pase de parámetros.
• “Command”: Clase abstracta que hereda de la clase “Option” e implementa algunos de los métodos abstractos de esa clase.

Capítulo 2. Herramientas que permiten el desarrollo de sistemas gestores de documentos
30
• “Struct”: Clase abstracta que hereda de la clase “Command” y redefine algunos métodos. Además, contiene una lista de instancias de la clase “Option” como parte de su estructura, representa un comando que contiene otros comandos internamente.
• “SuperStruct”: Clase abstracta que hereda de la clase Struct y tiene un método abstracto “execute” con el fin de realizar ejecuciones aprovechando la información de los comandos que contiene la clase.
• “Module”: Clase abstracta que hereda de la clase “SuperStruct” y define métodos para el volcado de los resultados obtenidos en un documento XML al aplicar el método “execute”.
• “Assemble”: Clase que hereda de la clase “SuperStruct” y define un conjunto de métodos para iniciar todo el procesamiento de la cadena entrada por consola, la cual tiene un método estático “exec” que recibe como parámetro un objeto de tipo “Assemble” y executa su método “execute”.
Entonces, con la estructura de clases descritas anteriormente basta con crear una nueva clase, heredar de alguna de ellas e implementar los métodos abstractos correspondientes para crear un comando personalizado.

Capítulo 2. Herramientas que permiten el desarrollo de sistemas gestores de documentos
31
Figura 2.1. Clases principales de la herramienta para estructurar la cadena de línea de comando recibida por
consola.

Capítulo 2. Herramientas que permiten el desarrollo de sistemas gestores de documentos
32
2.1 Indexado y recuperación de la información
El Indexado y recuperación de la información está constituido por tres herramientas básicas: una encargada de recuperar la información de repositorios de información, otra que indexa información textual recuperada de documentos y una última que permite recuperar información desde la bases de índices a partir de alguna consulta del tipo soportado por Lucene.
2.1.1 Herramienta para extraer contenido
La herramienta desarrollada encargada de extraer contenido y metadatos de diferentes tipos de documentos puede realizar estas tareas con archivos locales o remotos, siempre y cuando estos últimos se encuentren compartidos en la red mediante un servicio de red del tipo FTP. Esto es posible gracias a bibliotecas de código abierto programadas en Java que sirven de interfaz para conectarse a servidores remotos como la biblioteca FTP del proyecto de la Fundación Apache o la biblioteca JvFTP39
• Nombre: nombre del documento (DOCUMENT-NAME)
. Además, esta herramienta utiliza la biblioteca Tika, permitiendo que la extracción de texto de los documentos pueda realizarse sobre los mismos documentos permitidos por esta. Por defecto la aplicación extrae los siguientes metadatos:
• Contenido: todo el contenido del documento (FULL-TEXT)
• Lenguaje: lenguaje en que está escrito la mayor parte del documento (LANGUAGE).
Las especificaciones de los metadatos a extraer deben estar en un archivo XML el cual puede ser validado utilizando el esquema “XSD” de la Figura 2.2, donde se puede apreciar la existencia de campos de tipo “GENERAL” que pueden ser extraídos de todos o casi todos los tipos de documentos y algunos específicos para aplicaciones “MSOFFICE” que son compatibles con casi todos los paquetes Office
http://sourceforge.net/projects/jvftp
, ya sea “Microsoft Office”, “Open Office”, “Libre Office”, etc.

Capítulo 2. Herramientas que permiten el desarrollo de sistemas gestores de documentos
33
Figura 2.2. Esquema para validar los metadatos soportados por la herramienta.
Los resultados obtenidos por esta herramienta de extracción de información son devueltos mediante un archivo XML que contiene la información extraída de los documentos, separada por los campos “FIELD” de los metadatos especificados por el atributo “NODE-NAME”, estos documentos XML pueden ser validados con el esquema mostrado en Figura 2.3.
Figura 2.3. Esquema para validar el contenido extraído de los documentos.
El pase de parámetros de la herramienta es el siguiente:
• Parámetros: [-ayuda] -ext -salida
• Comando: [-ayuda]

Capítulo 2. Herramientas que permiten el desarrollo de sistemas gestores de documentos
34
• Comando: -ext
o Parámetros: [-ftp], -dir, [-campos]
o [-ftp]: SERVIDOR [USUARIO CONTRASEÑA]
o -dir: Directorio del cual se extraerán los documentos.
o [-campos]: Dirección de un documento XML con los campos que serán extraídos de los documentos e indexados, por defecto la lista campos a extraer son: [FULL-TEXT].
• Comando: -salida, recibe la dirección de un archivo XML que contendrá la salida de los datos del módulo principal.
La Figura 2.4 muestra el diseño de las principales clases de esta herramienta, donde existe una clase controladora “Controller” que se encarga de gestionar el listado y extracción de los documentos en un directorio, que puede estar ubicado localmente o remoto en un servidor “FTP”. Esta clase controladora gestiona la extracción de los datos de los documentos a partir de la recuperación de un objeto “InputStream” facilitado por la clase “aExtract”; la interacción necesaria con la biblioteca “Tika” para extraer la información textual de los documentos también es gestionada por esta clase a través del método “getDocumentMetadata”.
Figura 2.4. Diagrama de las principales clases de la herramienta para la recuperación de la información.

Capítulo 2. Herramientas que permiten el desarrollo de sistemas gestores de documentos
35
2.1.2 Herramienta para indexar contenido
Indexa el contenido de los documentos almacenado por campos en un archivo XML que cumpla con el esquema que se muestra en la Figura 2.3, teniendo en cuenta el campo que describe el lenguaje del contenido del documento original “LANGUAGE”. Separar los índices de documentos según el lenguaje de estos permite que los índices sean más pequeños y la búsqueda por índice sea mucho más rápida y específica.
En caso de ocurrir algún error durante la indexación, la aplicación imprime en la salida estándar los mensajes originados por las excepciones o errores reportados. Además, trata de recuperarse del error al seguir indexando el próximo contenido de documento.
Como la herramienta se apoya en la biblioteca “Apache Lucene” para indexar documentos mantiene las mismas características de rendimiento y eficiencia en los procesos necesarios para la indexación.
El pase de parámetros de la aplicación y sus respectivas descripciones son las siguientes:
• Parámetros: [-ayuda] -index
• Comando: [-ayuda]
• Comando: -index
o Parámetros: -entrada, -bIndex
o -entrada: Este comando recibe la dirección de un archivo XML que contiene la entrada de datos al módulo principal.
o -bIndex: Dirección del índice base donde se indexaran los documentos clasificados por idioma.
La Figura 2.5 muestra el diseño de las principales clases de esta herramienta, donde existe una clase controladora “Controller” que se encarga de gestionar la indexación del contenido textual de los documentos; indexación que logra a través de la representación de un documento mediante una instancia de la clase “DocumentForIndex” y la creación de instancias de la clase “Indexer” que representa a un indexador, el cual indexará instancias de la clase “DocumentForIndex”. Estas posibles tareas son adicionadas a una instancia de la clase “Tasks”, que relaciona indexadores con documentos según el idioma de los mismos.

Capítulo 2. Herramientas que permiten el desarrollo de sistemas gestores de documentos
36
Figura 2.5. Diagrama de las principales clases de la herramienta para indexar información recuperada.
2.1.3 Herramienta para recuperar información
Recupera información a partir de los índices de documentos que se encuentren ubicados dentro de una carpeta, siempre y cuando esta mantenga subdirectorios de carpetas identificadas con las siglas de los idiomas de los documentos indexados dentro de ellas. Por tanto, esta herramienta permite recuperar documentos indexados con la herramienta para el indexado de información descrita anteriormente o con bases de índices creados por cualquier otra aplicación que utilice la biblioteca de “Apache Lucene” para indexar documentos y mantenga la estructura de carpetas requeridas por esta herramienta para la recuperación de la información.
El pase de parámetros de la aplicación y sus respectivas descripciones son las siguientes:
• Parámetros: [-ayuda] -búsqueda -salida
• Comando: [-ayuda]:

Capítulo 2. Herramientas que permiten el desarrollo de sistemas gestores de documentos
37
• Comando: -búsqueda, módulo para realizar búsquedas sobre índices basados en Apache Lucene.
o Parámetros: -entrada, -idioma, -consulta
o -entrada
Figura 2.6
: Este comando recibe la dirección de un archivo XML que contiene la entrada de datos al módulo principal, este archivo XML debe cumplir con las especificaciones del esquema descrito en la .
o -idioma
o -
: Comando para especificar el idioma en que se realizará la búsqueda.
consulta
• Comando: -salida, este comando recibe la dirección de un archivo XML que contendrá la salida de los datos del módulo principal, este archivo XML debe cumplir con las especificaciones del esquema descrito en la
: Comando para especificar la consulta a realizar.
Figura 2.7.
La Figura 2.6 representa un esquema que describe la especificación de los parámetros de configuración necesarios para realizar las búsquedas de esta herramienta. En vez de requerir especificaciones como parámetros en cada recuperación, se decidió que estas estuvieran descritas previamente en un archivo XML debido a que estos parámetros no cambian frecuentemente con las búsquedas. Los parámetros que conforman el documento XML son: los directorios raíces de los índices, campo por el cual se requiere que efectúe la búsqueda y los campos que se requieren recuperar de los documentos que concuerden con el criterio de búsqueda.
Además de salvar los campos solicitados y la información especificada en el documento XML (-entrada
), la aplicación por defecto salva en el documento XML resultante (-salida) algunos datos como la fecha en que fue realizada la consulta, la consulta en sí, el campo que fue consultado en la base de datos y el lenguaje en el cual se realizó la consulta. El esquema que
Figura 2.6. Esquema de las especificaciones de búsqueda.

Capítulo 2. Herramientas que permiten el desarrollo de sistemas gestores de documentos
38
describe el documento XML que contiene la información recuperada del repositorio se muestra en la Figura 2.7.
La Figura 2.8 muestra el diseño de las principales clases de esta herramienta, donde existe una clase controladora “Controller_Search” que se encarga de gestionar las búsquedas de documentos a partir del campo “Full-Text”. La recuperación de los documentos se realiza a través del método “execute” que recibe parámetros como el idioma de los documentos a recuperar, la consulta en sí y una instancia de la clase “Search” que representa un contenedor de parámetros necesarios para las búsquedas. Los documentos recuperados son representados utilizando instancias de la clase “Metadocuments” y los resultados de la consulta de forma general se representan mediante una instancia de la clase “Found_Metadocuments”.
Figura 2.7. Información recuperada del repositorio.

Capítulo 2. Herramientas que permiten el desarrollo de sistemas gestores de documentos
39
Figura 2.8. Diagrama de las principales clases de la herramienta para realizar búsquedas a partir de una consulta.
2.2 Representación del corpus textual
La representación del corpus textual está constituida por dos herramientas: una encargada de transformar información recuperada y otra encargada de estructurar la información transformada.
2.2.1 Herramienta para transformar información
Transforma un documento XML de información que contenga una estructura de documento que concuerde con el esquema que se muestra en la Figura 2.7. La aplicación recibe como parámetros la dirección del documento XML con la información y una lista de nombres de campos a transformar. Además, agrega un nuevo elemento denominado

Capítulo 2. Herramientas que permiten el desarrollo de sistemas gestores de documentos
40
“TRANSFORMATION” al elemento “ROOT” del documento XML con la información resultante, detalles se muestran en la Figura 2.9.
El elemento “TRANSFORMATION” contiene dos elementos esenciales: “FIELDS” y “TRANSFORMED”.
• “FIELDS”: contiene una lista de elementos denominados FIELD que contienen los campos que fueron transformados.
• “TRANSFORMED”: contiene una lista de documentos formados por una lista de campos denominados “FIELD” que contienen una lista de campos “TOKEN” conformados por las raíces de las palabras.
Los tokens son obtenidos luego de haber pasado por un conjunto de filtros a partir de una modificación de la clase “StandardAnalyzer” de la biblioteca Apache Lucene para realizar las transformaciones que se aplican en este módulo, agregándole la eliminación de los tokens alfanuméricos y la obtención de raíces gramaticales, método que se encuentra en “Apache Lucene” pero que fue enriquecido utilizando los stemmer del proyecto de “Lucene Snowball40
• Eliminar las marcas de puntuación al final de los
”. Algunos de los filtros utilizados fueron:
tokens
• Eliminar los apóstrofes del tipo ’s y la eliminación de los acrónimos al quitarles los puntos.
.
• Convertir las letras todas a minúsculas.
• Eliminar las palabras conformadas por otros caracteres que no sean alfanuméricos.
• Quitar los tokens
que están dentro de la lista de palabras de paradas del idioma correspondiente al texto. Las listas de paradas fueron conformadas utilizando las listas de paradas ofrecidas por el proyecto Snowball de Apache Lucene.
Figura 2.9. Transformación del texto de los campos.
40 http://snowball.tartarus.org/

Capítulo 2. Herramientas que permiten el desarrollo de sistemas gestores de documentos
41
La Figura 2.10 muestra el diseño de las principales clases de esta herramienta, donde existe una clase controladora “Controller_Transformation” que se encarga de transformar un conjunto de tokens
Figura 2.7
que representan los ítems lingüísticos de los campos o secciones de un conjunto de documentos específicos de una instancia de la clase “Found_Metadocuments” o desde un archivo XML que cumpla con las especificaciones del esquema de la .
Figura 2.10. Diagrama de las principales clases de la herramienta para transformar la información en tokens de palabras.

Capítulo 2. Herramientas que permiten el desarrollo de sistemas gestores de documentos
42
2.2.2 Herramienta para estructurar información
Crea un VSM por cada campo que fue transformado a partir de sus tokens o simplemente por campos de tokens
Figura 2.9
. La aplicación recibe como parámetro la dirección del documento XML que contiene las especificaciones de campos a estructurar, el documento XML debe cumplir con las especificaciones del esquema presentado en la . Al campo “ROOT” se le agrega un elemento llamado “Vector Space Models” que cumple con la especificación del esquema que se muestra en la Figura 2.11.
Hasta el momento la aplicación no permite ninguna otra transformación que las que hace por defecto, aunque se pueden elegir omitir alguna o algunas. Por defecto la aplicación crea una representación espacio vectorial basada en la normalización de la frecuencia de aparición de los tokens
• Aplicar la medida “TF-IDF” clásica a la representación espacio vectorial.
en el documento y permite realizar otras como:
• Reducir la dimensionalidad basándose en la medida de calidad de términos, asociándole a cada término el valor de su calidad, teniendo en cuenta la aparición de este en la colección de documentos. La cantidad máxima de términos es 600, según se propone en [49].
• Adicionalmente y pensando en el trabajo con documentos de textos estructurados (XML) se permite que se combinen VSM, donde cada VSM representa una estructura o sección del documento XML.
Para la combinación de varias VSM el único requerimiento es que cada VSM debe tener la misma cantidad de filas correspondientes a los documentos. Además, la fórmula utilizada para la combinación de las VSM es la denominada “TM” [52].
La Figura 2.11 representa un esquema por el cual se rige la herramienta para representar la estructura del documento XML resultante. Con las siguientes características: el elemento denominado “VECTOR-SPACE-MODELS” contiene una lista de elementos “VSM” que está conformado por un campo “KEY” que representa el nombre del campo para el cual se creó la “VSM”, un elemento “TRANSFORMATIONS” que contiene una lista de elementos “TRANSFORMATION” que representan las transformaciones que se han llevado a cabo sobre la “VSM”, un elemento “TERMS” que contiene una lista de elementos “T” con los términos que están representados en la “VSM”, un elemento “VALUES” conformado por elementos “DOCUMENT” que representan los documentos, que a su vez contienen una lista

Capítulo 2. Herramientas que permiten el desarrollo de sistemas gestores de documentos
43
de elementos “T” representando a los términos que son identificados por un atributo “ID” y con un valor de tipo double
.
Figura 2.11. Esquema para validar una representación de VSM.
El pase de parámetros de la aplicación y sus respectivas descripciones son las siguientes:
• Parámetros: [-ayuda] -transformacion -salida
• Comando: [-ayuda]:
• Comando: -transformacion: Este comando transforma el contenido de los documentos recuperados.
o Parámetros: -entrada, [-campos]
o -entrada: Este comando recibe la dirección de un archivo XML que contiene la entrada de datos al módulo principal.
o [-campos]: Este comando no es obligatorio y recibe una lista de campos a transformar. La cantidad mínima de campos a transformar es 1 y la máxima es 100. En caso de no estar dentro de la lista de comandos del módulo principal entonces se incluirán los siguientes campos: FULL-TEXT.
• Comando: -salida, este comando recibe la dirección de un archivo XML que contendrá la salida de los datos del módulo principal.
La Figura 2.12 muestra el diseño de las principales clases de esta herramienta, donde existe una clase controladora “Controller” encargada de gestionar la estructuración de la información en sus diferentes fases: crear la VSM, Aplicar la medida “TF-IDF”, Reducir la dimensionalidad y posiblemente combinar VSM.

Capítulo 2. Herramientas que permiten el desarrollo de sistemas gestores de documentos
44
Figura 2.12. Diagrama de las principales clases de la herramienta para estructurar información textual.

Capítulo 2. Herramientas que permiten el desarrollo de sistemas gestores de documentos
45
2.3 Agrupamiento de documentos
El agrupamiento de documentos está constituido por dos herramientas: una encargada de crear la matriz de similitud y otra que se encarga de agrupar documentos.
2.3.1 Herramienta para crear matriz de similitud
Crea una matriz de similitud representando un grafo no dirigido y ponderado a partir de un archivo XML que cumpla con las especificaciones del esquema representado en la Figura 2.11. La matriz de similitud puede ser creada utilizando una de las siguientes funciones de similitud: COSENO, DICE, JACCARD mostradas en el Anexo 1. Adicionalmente esta herramienta permite realizar un corte de valores en la matriz siguiendo un criterio dado, en esta versión las opciones para el corte son: valor fijo y valor promedio de todas las aristas, eliminando de la matriz todas las aristas que están por debajo del valor establecido o calculado; a consideración de los usuarios esta matriz puede remplazar a la matriz similitud creada originalmente o adicionarse a la salida como otra matriz.
La o las matrices de similitud creadas son representadas utilizando un archivo XML el cual es validado con el esquema representado en Figura 2.13, el mismo tiene atributos como “KEY” que representa el valor del campo o sección por el cual se creó la matriz de similitud, “MEASURE_NAME” representa de la función utilizada para crear la matriz. Además, el campo que representa a la matriz de similitud contiene información adicional en el campo “TRIMS” sobre los parámetros o valores utilizados para crear la matriz. Los valores relacionados con la similitud entre los documentos se encuentran en el campo “VALUE” que contiene atributos que representan los identificadores “ID” de los documentos, así como el valor de la similitud entre ellos de tipo doubl
e.
Figura 2.13. Esquema para validar una representación de matriz de similitud.

Capítulo 2. Herramientas que permiten el desarrollo de sistemas gestores de documentos
46
El pase de parámetros de la aplicación y sus respectivas descripciones son las siguientes:
• Parámetros: [-ayuda] -matrix -salida
• Comando: [-ayuda]:
• Comando: -matrix, este módulo crea una matriz de valores de similitud a partir de un VSM.
o Parámetros: [-filtrar], [-medida], -entrada
o [-filtrar]: Filtra un conjunto de matrices
Parámetros: [-duplicar:], [-filtro]
[-duplicar:]: Parámetro booleano que decide si la matriz a filtrar será duplicada, por defecto la matriz será sustituida (FALSE).
[-filtro]: Nombre del filtro a utilizar, los filtros pueden ser:
• AVERAGE: Calcula el promedio de todas las aristas y devuelve ese valor. Constituye el valor por defecto si no se especifica ninguna opción en el comando -filtro.
• FIXED: Valor fijo.
o [-medida]: Este comando recibe como entrada el nombre de una función de medida que pueden ser: COSENO, DICE, JACCARD, la medida por defecto es: COSENO.
o -entrada: Este comando recibe la dirección de un archivo XML que contiene la entrada de datos al módulo principal.
• Comando: -salida, este comando recibe la dirección de un archivo XML que contendrá la salida de los datos del módulo principal.
La Figura 2.14 muestra el diseño de las principales clases de esta herramienta, donde existe una clase controladora “Controller” encargada de gestionar la creación y filtrado de esta matriz.

Capítulo 2. Herramientas que permiten el desarrollo de sistemas gestores de documentos
47
Figura 2.14. Diagrama de las principales clases de la herramienta para la creación de matrices de similitud.
2.3.2 Herramienta para agrupar documentos
La herramienta para agrupar documentos crea grupos a partir de una matriz de similitud entre objetos, esta matriz debe estar representada mediante un archivo XML que cumpla con las especificaciones del esquema representado en la Figura 2.13.
La herramienta incorpora dos algoritmos de agrupamiento, uno basado en la intermediación diferencial de aristas [13] y otro basado en la intermediación de aristas [53], a la herramienta se le pueden incorporar adicionalmente nuevos algoritmos de agrupamiento. Estos algoritmos pueden ser algunos ya implementados en Jung como son “VoltageClusterer” [54], “Blockmodelling algorithms” [55] o otros que se encuentren en bibliotecas, marcos de trabajo externos o que simplemente sean implementados e incorporados a la herramienta. El único requisito para incorporar un nuevo algoritmo sería que el mismo tendría que devolver la información de los grupos como una lista de interfaces tipo “iGroup” y recibir la matriz de similitud como un grafo donde los nodos están representados por enteros y las aristas vienen dadas por la interfaz “Edge” ejemplo: “Graph<Integer, Edge>”.
Los resultados obtenidos por la herramienta son representados mediante un archivo XML, descrito por el esquema representado en la Figura 2.15. El documento XML agrega un nodo “GROUPS” al nodo raíz del documento, este nodo tiene un atributo “CLUSTER” que contiene

Capítulo 2. Herramientas que permiten el desarrollo de sistemas gestores de documentos
48
una cadena con información sobre el algoritmo de agrupamiento utilizado para crear los grupos. También es agregada una lista de nodos “GROUP” que contiene los “ID” de los documentos contenidos en cada grupo separados por el carácter “,” y atributos como “ID” del grupo y “PARENT” representando el valor del atributo “ID” de un grupo padre. Aunque en esta versión la herramienta crea una partición dura del universo en próximas versiones se piensa incluir opciones como la de crear subparticiones a grupos específicos, posibilitando así la creación de dendrogramas siguiendo criterios como: profundidad del árbol de particiones, cantidad de objetos dentro de cada grupo, etc. Por tanto el atributo “PARENT” es absolutamente necesario para mantener compatibilidades con futuras versiones.
Figura 2.15. Esquema para agrupar documentos.
El pase de parámetros de la aplicación y sus respectivas descripciones son las siguientes:
• Parámetros: [-ayuda] -agrupar -salida
• Comando: [-ayuda]:
• Comando: -agrupar, agrupa un conjunto de objetos, por defecto el algoritmo que se utiliza es: -intermeDiferencial
o Parámetros: [-intermed], [-intermeDiferencial], -entrada
o [-intermed]: Agrupa un conjunto de objetos utilizando el algoritmo de intermediación de aristas.
Parámetros: [-pAristas]
[-pAristas]: Porciento de aristas a borrar, por defecto es el 30%.
o [-intermeDiferencial]: Agrupa un conjunto de objetos utilizando el algoritmo de intermediación diferencial de aristas.

Capítulo 2. Herramientas que permiten el desarrollo de sistemas gestores de documentos
49
o Parámetros: [-pAristas], [-lamda], [-cVencindad]
[-pAristas]: Porciento de aristas a borrar, por defecto es el 30%.
[-lamda]: Parámetro específico del algoritmo, el valor debe estar entre 0 y 1, por defecto el valor es 0.01.
[-cVencindad]: Cantidad de nodos incluidos en la vecindad, por defecto el valor es 2.
o -entrada: Este comando recibe la dirección de un archivo XML que contiene la entrada de datos al módulo principal.
• Comando: -salida, este comando recibe la dirección de un archivo XML que contendrá la salida de los datos del módulo principal.
La Figura 2.16 muestra el diseño de las principales clases de esta herramienta, donde existe una clase controladora “Controller” encargada de gestionar el proceso de agrupamiento de los documentos.

Capítulo 2. Herramientas que permiten el desarrollo de sistemas gestores de documentos
50
Figura 2.16. Diagrama de las principales clases de la herramienta agrupar documentos.

Capítulo 2. Herramientas que permiten el desarrollo de sistemas gestores de documentos
51
2.4 Valoración del agrupamiento
La valoración del agrupamiento está compuesto por una única herramienta encargada de validad y etiquetar los grupos.
2.4.1 Herramienta para validar y etiquetar los grupos
La herramienta para validar y etiquetar grupos valida y etiqueta grupos a partir de uno o dos documentos XML que contengan la matriz de similitud con que fueron agrupados los documentos y otro que tenga la representación del agrupamiento obtenido a partir de esa matriz de similitud, este o estos archivos deben cumplir con las especificaciones de los esquemas descritos en la Figura 2.13 y Figura 2.15. Todas las medidas de agrupamiento que tiene implementada la herramienta son medidas internas, en el Anexo 2 se encuentran algunas de estas medidas. Las medidas implementadas son basadas en Rough Set Theory (RST), Overall Similarity y Modularity; las medidas basadas en RST son las siguientes: Rough FMeasure, Rough Quality, Rough Accuracy, Mean Rough Membership, Lower Approximation
Los resultados obtenidos por esta herramienta son plasmados en un documento XML que pueden ser validados mediante el esquema representado en la
[13].
Figura 2.17. En este esquema existe un nodo denominado “GENERAL” que contiene nodos que representan los valores de las medidas de evaluación generales para el agrupamiento, los cuales son representados mediante el atributo “NAME” del nodo “MEASURE”. Adicionalmente, los valores de las medidas específicas de los grupos son representados mediante el valor del nodo “MEASURE” e identificados mediante el atributo “NAME”; mediante el atributo “ID” del nodo “GROUP” se determina a qué grupo pertenece esa evaluación

Capítulo 2. Herramientas que permiten el desarrollo de sistemas gestores de documentos
52
Figura 2.17. Esquema para la validación de agrupamientos.
El pase de parámetros de esta herramienta y sus respectivas descripciones son los siguientes:
• Parámetros: [-ayuda] -medida -salida
• Comando: -medida
o Parámetros: [-todos], [-RST], [-MODULARITY],
[-OVERALL_SIMILARITY], -xmlSimilitud, -xmlAgrupamiento
o [-todos]: Implementa todos los métodos soportados por el módulo para evaluar grupos o conjuntos de grupos. Requiere un único parámetro que representa el valor que define el concepto de relación utilizado en la Teoría de los Conjuntos Aproximados (RST), debe ser un valor real entre 0 y 1.
o [-RST]: Realiza un conjunto de evaluaciones basadas en la Teoría de los Conjuntos Aproximados y requiere un único parámetro de tipo real entre 0 y 1, representa el concepto de relación entre los documentos.
o [-MODULARITY]: Devuelve un valor para el agrupamiento que permite tener una idea de la calidad del agrupamiento.
o [-OVERALL_SIMILARITY]: Para cada grupo del agrupamiento devuelve un valor que da una idea de la calidad del grupo.
o -xmlSimilitud: recibe la dirección un archivo XML que contiene las matrices de similitud correspondiente a los agrupamientos.
o -xmlAgrupamiento: recibe la dirección un archivo XML que contiene los agrupamientos.
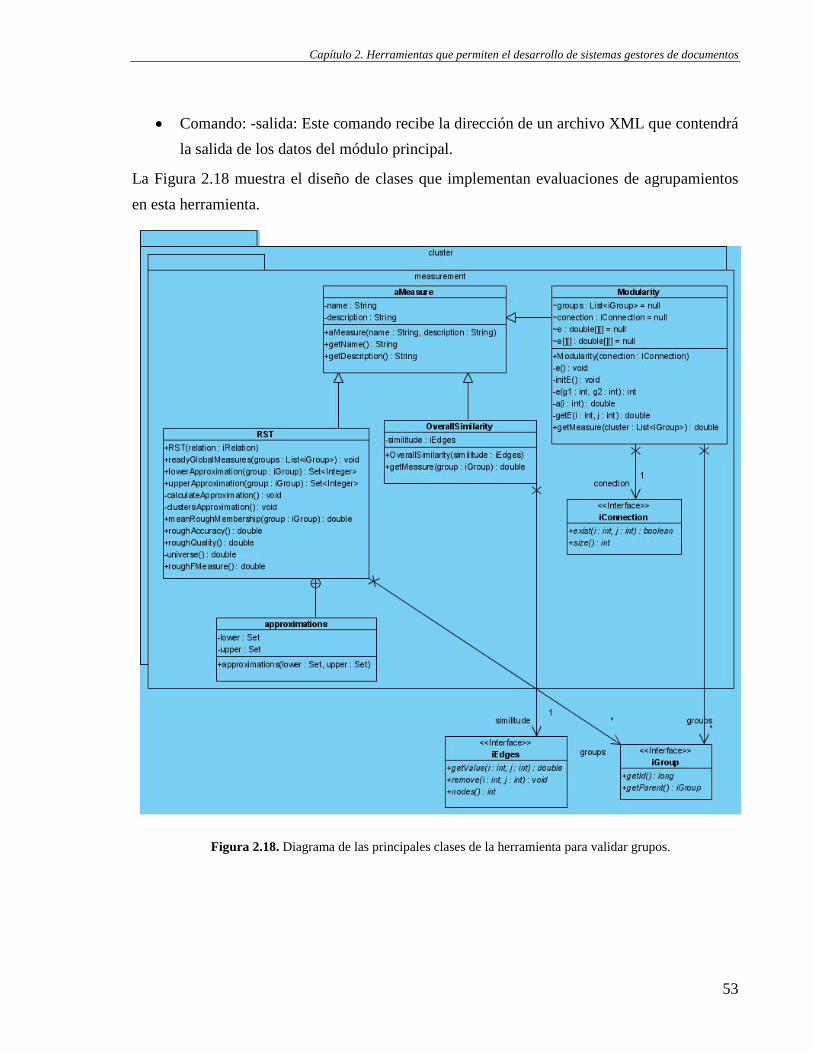
Capítulo 2. Herramientas que permiten el desarrollo de sistemas gestores de documentos
53
• Comando: -salida: Este comando recibe la dirección de un archivo XML que contendrá la salida de los datos del módulo principal.
La Figura 2.18 muestra el diseño de clases que implementan evaluaciones de agrupamientos en esta herramienta.
Figura 2.18. Diagrama de las principales clases de la herramienta para validar grupos.

Capítulo 2. Herramientas que permiten el desarrollo de sistemas gestores de documentos
54
2.5 Conclusiones parciales
En este capítulo se presentó un conjunto de herramientas que permiten el desarrollo de sistemas gestores de documentos. Estas herramientas se diseñaron siguiendo el esquema propuesto en [13] y realizan el intercambio de información entre ellas utilizando ficheros XML que pueden ser validados utilizando esquemas XML (XSD). Esta característica permite la retroalimentación de las herramientas con sistemas externos.
Para cubrir el proceso de indexado y recuperación de información se desarrollaron tres herramientas que utilizan las bondades de Tika y Lucene para este proceso. Dos herramientas fueron desarrolladas para realizar la representación de los corpus textuales. Ellas permiten realizar la representación espacio vectorial de cada documento teniendo en cuenta cada una de las secciones de los artículos científicos recuperados, de tal forma que los métodos de agrupamiento que se apliquen se pueden focalizar en una u otra representación realizada.
Teniendo en cuenta que la mayoría de los métodos de agrupamiento parten de las similitudes que existen entre los documentos a agrupar, se desarrolló una herramienta que sustenta esta etapa pre-agrupamiento y otra que permite aplicar propiamente el método de agrupamiento implementado. Finalmente, existe una herramienta que permite validar y etiquetar los grupos textuales obtenidos.

Capítulo 3. Aplicación web que permite la gestión de información científica
55
3 Aplicación web que permite la gestión de información científica
Las aplicaciones web utilizan una arquitectura cliente-servidor, donde el procesamiento de la información se realiza en una computadora que desempeña el rol de servidor, y en las computadoras clientes solamente se muestra la información procesada y enviada desde el servidor. Esta arquitectura permite múltiples conexiones de clientes con el servidor mediante el protocolo de transferencia de hipertexto (HTTP), este protocolo es utilizado por aplicaciones conocidas como navegadores web desde la parte del cliente y los denominados servidores web desde el servidor.
La arquitectura Cliente–Servidor es un modelo para el desarrollo de sistemas de información en el que las transacciones se dividen en procesos independientes que cooperan entre sí para intercambiar información, servicios o recursos; denominándose:
• Cliente al proceso que inicia el diálogo o solicita los recursos, los clientes interactúan con el usuario, usualmente en forma gráfica, frecuentemente se comunican con procesos auxiliares que se encargan de establecer conexión con el servidor, enviar el pedido, recibir la respuesta, manejar las fallas y realizar actividades de sincronización y de seguridad.
• Servidor al proceso que responde a las solicitudes, los servidores proporcionan un servicio al cliente y devuelven los resultados, deben manejar servicios como administración de la red, mensajes, control y administración de la entrada al sistema, auditoría, recuperación y contabilidad.
Entre las principales características de la arquitectura Cliente – Servidor están:
• El cliente no necesita conocer la lógica del servidor, sólo su interfaz externa.
• El cliente no depende de la ubicación física del servidor, ni del tipo de equipo físico en el que se encuentra, ni de su sistema operativo.
• El servidor presenta a todos sus clientes una interfaz única y bien definida.
• Los cambios en el servidor implican pocos o ningún cambio en el cliente.

Capítulo 3. Aplicación web que permite la gestión de información científica
56
Por tanto, las aplicaciones Web ofrecen amplias ventajas tanto a clientes como a organizaciones, instituciones y empresas; porque: no requieren ser instaladas previamente en las computadoras para ser usadas por los usuarios, son fáciles de usar, presentan una alta disponibilidad, compatibilidad, movilidad, etc. Además, los esfuerzos de instalación y mantenimiento de la aplicación solo deben concentrarse en la computadora servidor. Entonces, la utilización de la arquitectura cliente-servidor mediante el desarrollo de una aplicación web para solventar los problemas existentes en el CEI-UCLV constituye una buena opción.
La aplicación web para la gestión de la información textual que se desarrolló incorpora las herramientas para asistir el desarrollo de sistemas gestores de información que fueron presentadas en el capítulo 2. Las herramientas son utilizadas en forma de bibliotecas por la aplicación para: realizar las tareas de recuperación de la información textual de los documentos presentes en un servidor “FTP”, indexar esta información recuperada, realizar búsquedas de documentos en base a una palabra clave, frase o combinación de estas y para realizar el agrupamiento y la validación de los grupos de documentos obtenidos a partir de la consulta.
En caso de ocurrir algún error durante la ejecución de la aplicación desde el lado del servidor, el sistema debe ser capaz de recuperarse y mostrar en la vista del navegador web un mensaje de error con descripción sobre el mismo. Este mensaje puede ser en forma de cuadro emergente o aparecer en un recuadro de texto en la parte baja de la ventana de la aplicación.
3.1 Descripción del dominio
En el CEI-UCLV existe un gran número de artículos científicos y documentos relacionados con diversos temas de investigación y se encuentran disponibles para la red del Ministerio de Educación Superior (MES) mediante el protocolo FTP. A los investigadores, profesores y estudiantes del centro les resulta tedioso en gran medida realizar búsquedas de documentos relacionados con algún tema en específico o descubrir conocimiento entre los mismos. Por tanto, se requiere de la creación de una aplicación que sea la encargada de gestionar la información científico-técnica disponibles en grandes repositorios de información a través del protocolo FTP, mediante la utilización de técnicas de minería de datos e inteligencia artificial. Además, la aplicación a desarrollar debe cumplir con el esquema propuesto en [13].
3.2 Requisitos del sistema
Después de haber realizado un exhaustivo análisis se identificaron los siguientes requisitos:

Capítulo 3. Aplicación web que permite la gestión de información científica
57
3.2.1 Requisitos funcionales
rf1. Establecer un directorio de índice local para indexar documentos
rf2. Indexar documentos provenientes de un servidor FTP
rf3. Permitir cambiar la contraseña de configuración.
rf4. Realizar búsquedas de documentos que contengan palabras, frases o combinaciones de
palabras o frases.
rf5. Realizar búsquedas de documentos que contengan palabras, frases o combinaciones de
palabras o frases y que adicionalmente se creen grupos etiquetado y evaluados de
documentos según su contenido.
rf6. Cambiar el idioma de los documentos que se quieren recuperar.
3.2.2 Requisitos no funcionales
rnf1. Instalar la maquina virtual de java, JDK 1.7
rnf2. Proteger con contraseña la configuración referente a las bases de índices e
indexación de documentos.
rnf3. Utilizar la arquitectura Java y los lenguajes de programación Java y JSF 2.0
rnf4. Usar el IDE NetBeans 7 para la construcción del sitio.
rnf5. Reutilizar las herramientas confeccionadas para asistir el desarrollo de sistemas
gestores de la información descritas en el capítulo 2.
rnf6. Realizar los procesamientos y los cálculos en una velocidad adecuada.
rnf7. Mantener en la aplicación web una eficiencia, disponibilidad, precisión, tiempo de
respuesta, tiempo de recuperación ante fallos, aprovechamiento de los recursos,
frecuencia y severidad de los fallos adecuados.
3.3 Casos de usos
Luego de haber analizado los requisitos se definieron los siguientes actores y el diagrama de casos de usos mostrado en la Figura 3.1:
• Usuario: puede realizar búsquedas, búsquedas con agrupamiento y seleccionar un idioma para la realización de cualquiera de las tareas anteriores.
• Administrador: puede realizar cualquiera de las mismas opciones del caso de uso “Usuario” pero adicionalmente puede cambiar la contraseña del sistema, definir los

Capítulo 3. Aplicación web que permite la gestión de información científica
58
índices de documentos e indexar en un índice específico documentos presentes en un directorio de un sitio FTP.
3.3.1 Diagramas de casos de usos
Figura 3.1 Diagrama de casos de uso.

Capítulo 3. Aplicación web que permite la gestión de información científica
59
3.3.2 Especificaciones de los casos de usos
Nombre del CU Recuperar Información
Actor(es) Usuario
Propósito Un usuario realice una búsqueda de documentos que contengan una palabra específica, una frase o combinación de estas.
Descripción: El caso de uso se inicia cuando un profesor, investigador o estudiante necesita documentación relacionada con un tema y procede a realizar una búsqueda de información sobre los documento. El sistema recupera en las bases de índices del sistema documentos que hayan sido clasificados con el idioma seleccionado por el usuario y contengan el patrón establecido en la caja de texto para establecer las consultas. Además, el caso de uso termina cuando los documentos recuperados son mostrados en un nuevo panel en forma de lista, donde cada documento es encerrado en un área dividida en 3 secciones: la primera muestra un enlace hacia la dirección física y absoluta del documento con el texto correspondiente al nombre físico de dicho documento, la segunda muestra las primeras 500 palabras correspondientes al documento, y la tercera muestra los metadatos del documento relacionados con el autor y las palabras claves.
Referencia rf4
econdiciones El administrador del sistema debe haber definido al menos un directorio de índice y haber indexado sobre estos documentos presentes en algún repositorio de información que comparta la información utilizando el protocolo FTP.
Post-condiciones
Requisitos especiales

Capítulo 3. Aplicación web que permite la gestión de información científica
60
Nombre del CU Recuperar y agrupar información
Actor(es) Usuario
Propósito Un usuario pueda descubrir conocimiento a partir de la búsqueda, agrupamiento y evaluación de grupos de documentos que contengan una palabra específica, una frase o combinación de estas.
Descripción: El caso de uso se inicia cuando un profesor, investigador o estudiante necesita descubrir conocimiento sobre cierta documentación relacionada con algún tema y procede a realizar una búsqueda de información con agrupamiento. El sistema recupera en las bases de índices del sistema documentos que hayan sido clasificados con el idioma seleccionado por el usuario y contengan el patrón establecido en la caja de texto para establecer las consultas.
Los documentos recuperados son agrupados en grupos y dichos grupos son evaluados y etiquetados. Para representar toda esa información el sistema divide la ventana en tres secciones principales y contienen:
o Un listado de grupos creados por el sistema en forma de árbol, este listado se encuentra contenido dentro de un panel ubicado a la izquierda de la ventana.
o Un panel central en forma de lista que contiene los documentos pertenecientes a cada grupo, donde cada documento es encerrado en un área dividida en 3 secciones: la primera muestra un enlace hacia la dirección física y absoluta del documento con el texto correspondiente al nombre físico de dicho documento, la segunda muestra las primeras 500 palabras correspondientes al documento, y la tercera muestra los metadatos del documento relacionados con el autor y las palabras claves. Adicionalmente, este panel contiene un subpanel desplegable que muestra información relevante sobre la calidad del agrupamiento.
o Un panel inferior que contiene información sobre los resultados generales del agrupamiento.
Referencia Rf5
Precondiciones El administrador del sistema debe haber definido al menos un directorio de índice y haber indexado sobre estos documentos presentes en algún repositorio de información que comparta la información utilizando el protocolo FTP.
Post-condiciones .
Requisitos especiales

Capítulo 3. Aplicación web que permite la gestión de información científica
61

Capítulo 3. Aplicación web que permite la gestión de información científica
62
Nombre del CU Definir idioma
Actor(es) Usuario Registrado
Propósito Un usuario defina el idioma con que desea que el sistema le devuelva los documentos recuperados o recuperados y agrupados.
Descripción: El caso de uso se inicia cuando un profesor, investigador o estudiante necesita seleccionar otro idioma para la selección de documentos. Ya sea con el fin de realizar búsquedas de documentos o de descubrir conocimiento sobre cierta documentación relacionada con algún tema.
Referencia Rf6
Precondiciones El administrador del sistema debe haber definido al menos un directorio de índice y haber indexado sobre estos documentos presentes en algún repositorio de información que comparta la información utilizando el protocolo FTP.
Post-condiciones .
Requisitos especiales
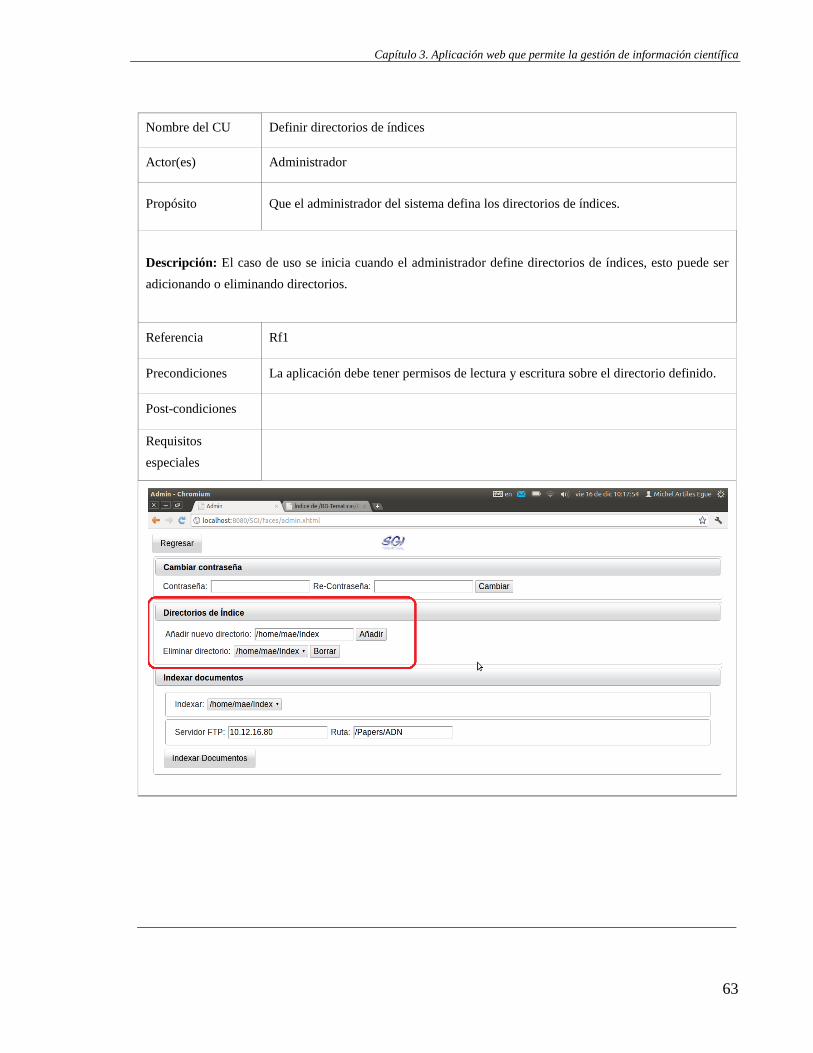
Capítulo 3. Aplicación web que permite la gestión de información científica
63
Nombre del CU Definir directorios de índices
Actor(es) Administrador
Propósito Que el administrador del sistema defina los directorios de índices.
Descripción: El caso de uso se inicia cuando el administrador define directorios de índices, esto puede ser adicionando o eliminando directorios.
Referencia Rf1
Precondiciones La aplicación debe tener permisos de lectura y escritura sobre el directorio definido.
Post-condiciones
Requisitos especiales

Capítulo 3. Aplicación web que permite la gestión de información científica
64
Nombre del CU Indexar documentos
Actor(es) Administrador
Propósito Indexar en la base de índice seleccionado los documentos presentes en el directorio establecido del servidor FTP especificado.
Descripción: El caso de uso se inicia cuando el administrador establece un directorio de índice en el cual se establecerán los datos recopilados de un servidor FTP que debe ser especificado por el administrador, así como el directorio a listar e indexar dentro de este sitio FTP. Para ello el sistema:
• Establece una conexión un servidor FTP a partir de la dirección establecida en la caja de texto para especificar la dirección del servidor.
• Cambia el directorio actual de la conexión con el servidor según el directorio establecido en la caja de texto para recopilar el directorio que se quiere indexar.
• Lista el directorio y sus subdirectorios de forma recursiva en busca de archivos soportados por la biblioteca para la extracción de contenido y metadatos “Tika”.
• Recupera la información almacenada en los documentos listados a partir de metadatos fijados por la aplicación y de todo el contenido del documento.
• Indexa toda esa información recuperada en la base de índice establecida según el idioma identificado en el documento.
Referencia Rf2
Precondiciones El servidor FTP debe existir, estar disponible en ese momento y debe aceptar conexiones del usuario “anonymous”. Además, el directorio a listar de forma recursiva debe existir y ser accesible para este usuario.
Post-condiciones .
Requisitos especiales

Capítulo 3. Aplicación web que permite la gestión de información científica
65
3.4 Diseño general del sistema
La arquitectura del sistema seleccionada como se mencionó anteriormente pertenece a la categoría cliente-servidor, donde el usuario mediante algún navegador web puede realizar una conexión HTTP con el servidor web de la aplicación. Por tanto, se tiene un único servidor y muchos posibles clientes, esto se puede apreciar en el diagrama de despliegue mostrado en la Figura 3.2.
Figura 3.2. Diagrama de despliegue de la aplicación
3.4.1 Marco de trabajo utilizado para realizar la aplicación
Las tecnologías Java de código abierto han tenido un gran auge en la actualidad, principalmente por las amplias facilidades que brindan a los programadores para un rápido desarrollo de aplicaciones y por la integración que se logra entre las mismas, permitiendo la confección de aplicaciones complejas con mínimos esfuerzos. Entre las tecnologías de Java para el desarrollo de aplicaciones web más populares se encuentran:
• “Spring”: Marco de trabajo de aplicaciones Java/J2EE que proporciona una potente gestión de configuraciones basadas en JavaBeans, aplicando los principios de Inversión de Control (IoC).
• “Google Guice”: Proporciona soporte para la inyección de dependencias usando anotaciones con el objetivo de configurar los objetos Java.
• “EJB”: Enterprise JavaBeans (también conocidos por sus siglas EJB) es uno de las API que forman parte del estándar de construcción de aplicaciones empresariales J2EE.
• “Java Server Pages” (JSP): tecnología Java que permite generar contenido dinámico para web, en forma de documentos HTML, XML o de otro tipo.
• “Richfaces”: RichFaces es una biblioteca de componentes visuales basada en Java Server Faces (JSF) programada tomando como base en marco de trabajo de código abierto Ajax4jsf.

Capítulo 3. Aplicación web que permite la gestión de información científica
66
Java Server Faces (JSF) pretende facilitar la construcción de aplicaciones JSP proporcionando un entorno de trabajo vía web que gestiona las acciones producidas por el usuario en su página web HTML y las traduce a eventos que son enviados al servidor con el objetivo de regenerar la página original y reflejar los cambios pertinentes provocados por dichas acciones.
La tecnología JSF constituye un marco de trabajo de interfaces de usuario del lado de servidor para aplicaciones web basadas en tecnología Java y en el patrón “Modelo Vista Controlador” (MVC). Este modelo de programación bien definido y la biblioteca de etiquetas para componentes UI facilita de forma significativa la tarea de la construcción y mantenimiento de aplicaciones web con UI en el lado servidor. Con apenas un mínimo esfuerzo, es posible:
• Conectar eventos generados en el cliente a código de la aplicación en el lado servidor.
• Mapear componentes UI a una página de datos en el lado servidor.
• Construir una interfaz de usuario con componentes reutilizables y extensibles.
Entonces podemos decir que una de las grandes ventajas de la tecnología JSF es que ofrece una clara separación entre el comportamiento y la presentación.
Por tanto, dadas las características de JSF que brinda amplias facilidades para la programación web, su integración con clases y bibliotecas hechas en Java y teniendo en cuenta el dominio del problema a resolver, así como, los requisitos que se han de tener en cuenta durante la fase de desarrollo de la aplicación web se decidió utilizar este marco de trabajo JSF en su versión 2.0 para la confección de la aplicación web que tiene como objetivo la gestión de la información científica-técnica utilizando técnicas de minería de textos e inteligencia artificial.
3.4.2 Diseño de la estructura de la aplicación
La concepción del sistema está estructurada en capas que están representadas visualmente en Figura 3.3 y explicadas siguientemente en más detalles:
1. Capa de presentación: Interfaz web mostrada al usuario mediante la comunicación cliente-servidor.
2. Capa de procesamiento: Compuesta por las clases encargadas de gestionar la información textual utilizando métodos de inteligencia artificial y minería de textos implementados en las herramientas descritas en el capítulo 2, así como clases encargadas de gestionar el intercambio con la capa de datos y el contenido de la capa de presentación mediante “beans”.

Capítulo 3. Aplicación web que permite la gestión de información científica
67
3. Capa de datos: La capa de datos está compuesta por los datos de las bases de índices del sistema creados por mediante la biblioteca de “Apache Lucene”, el cual maneja tanto el almacenamiento de información como la recuperación de la misma. Esto es posible gracias al manejo por “Apache Lucene” desde el propio centro de su arquitectura lógica el concepto de documento “Document” que contiene campos “Fields” de texto; esta flexibilidad le permite a “Lucene” ser independiente de los distintos formatos ficheros. Entonces, aprovechando esta capacidad en la aplicación web se utiliza “Tika” para extraer el contenido de los documentos o los metadatos y “Apache Lucene” para las tareas de indexación y recuperación de esa información recuperada sobre las bases de índices.
Figura 3.3. Representación visual del diseño en capas de la aplicación web.
3.4.3 Principales clases del sistema
La aplicación web utiliza las herramientas desarrolladas en el capítulo 2 como bibliotecas para el procesamiento de la gestión de información textual utilizando técnicas de inteligencia artificial y minería de textos. En la Figura 3.4 se muestra las principales clases del sistema. Esencialmente existen dos paquetes “config” y “search” que están dentro de “cu.edu.cei.textmining.sgi”, estos paquetes contienen las clases principales de la aplicación y muestran algunos de los métodos y atributos más importantes de ellas.
Capa
de
Pres
enta
ción
Interfaz Web
Capa
de
proc
esam
ient
o Beans controladores de la interfaz web Clases encargadas de gestionar la información textual utilizando los métodos de inteligencia artificial y minería de textos presentes en las herramientas desarrolladas
Capa
de
dato
s Bases de índices del sistema

Capítulo 3. Aplicación web que permite la gestión de información científica
68
Figura 3.4. Principales clases de la aplicación.
Descripción de algunas clases:
• El paquete “config” contiene las clases relativas a la configuración de parámetros y valores de configuración, dicho paquete alberga dos clases: “IndiceBusqueda” y “Admin”.
• La clase “IndiceBusqueda” es la clase encargada de gestionar los directorios de índices almacenados o que se almacenarán en el documento XML de configuración. Aunque la clase retorna una lista de directorios de índices para recuperar documentos solamente permite establecer un directorio para indexar documentos.
• La clase “Admin” realmente es un beans
• El paquete “search” contiene dos clases: “Search” y “SearchConfig”, estas clases controlan las búsquedas, búsquedas y agrupamientos, así como su configuración.
que controla la vista para el administrador y que adicionalmente tiene un método para indexar documentos, este método recupera los valores almacenados en los valores de las variables encargadas de almacenar la información, ejemplos: servidor, directorio, campos a almacenar, etc.

Capítulo 3. Aplicación web que permite la gestión de información científica
69
• La clase “SearchConfig” es la encargada de procesar correctamente las direcciones de las bases de índices por idioma, por lo que controla además el idioma escogido por el usuario para recuperar documentos.
• La clase “Search” es quizás la clase más importante porque es la encargada de realizar una gran parte de la gestión de la información porque como mínimo debe recuperar los documentos de la base de índice que concuerden con el valor de la consulta y mostrárselos a los usuarios y si no, tiene que transformar esa información recuperada, estructurarla, crear la matriz de similitud, agrupar los documentos según los valores almacenados en la matriz de similitud, validar los grupos obtenidos; en fin, todos los pasos correspondientes para gestionar información textual utilizando técnicas de inteligencia artificial y minería de textos.
3.5 Configuraciones de la aplicación web en las fases de gestión de la información científico-técnica aplicando técnicas de minería de textos e inteligencia artificial
Muchas de las configuraciones de métodos utilizadas fueron establecidas a partir de experiencias recopiladas anteriormente y de la realización de diferentes análisis, pruebas e interpretación de resultados obtenidos utilizando la propia aplicación web; siempre con el objetivo de lograr un refinamiento aceptable de los resultados para el usuario final. Las configuraciones serán presentadas utilizando el esquema propuesto en [13] que sirve de guía para el desarrollo de sistemas gestores de la información:
3.5.1 Módulo de recuperación de la información
Este módulo consta de dos fases:
3.5.1.1 Indexado de la información contenida en los documentos
Se indexan los metadatos de los documentos y todo su contenido textual para su posterior recuperación. Algunos de los metadatos recuperados con “Tika” son los siguientes: nombre del recurso, comentarios, palabras claves, titulo del documento, autor.
3.5.1.2 Recuperación de la información indexada en las bases de índices
Se recupera información textual a partir de las bases de índices del sistema, el contenido recuperado es exactamente el mismo que se indexa. La recuperación de la información se realiza a través de una búsqueda sobre todo el contenido del documento, no por los metadatos.

Capítulo 3. Aplicación web que permite la gestión de información científica
70
3.5.2 Módulo del procesamiento de la información recopilada
En este módulo el contenido de los documentos es transformado y estructurado.
3.5.2.1 Transformación del contenido de los documentos recuperados
La transformación del contenido de los documentos recuperados ocurre de la siguiente forma:
1. Se crean tokens
2. Los caracteres que representan a los
de palabras con el contenido textual de los documentos recuperados.
tokens
3. Se eliminan los
se convierten todos a minúscula.
tokens
4. Se eliminan los
que contienen caracteres alphanuméricos.
tokens
5. Los
que perteneces al conjunto de palabras de parada.
tokens
3.5.2.2 Estructuración de la información transformada de los documentos
se reducen a sus raíces gramaticales.
Se crea inicialmente un VSM con el contenido de los documentos recuperados que fue transformado, donde las filas representan los documentos y las columnas los rasgos representados en este caso como los tokens y las celdas la frecuencia de aparición normalizada de los tokens
3.5.3 Módulo para el agrupamiento de los documentos
en los documentos. Posteriormente los valores de las celdas son pesados utilizando la función TF-IDF. Adicionalmente, la cantidad de rasgos es reducida utilizando la medida de calidad de término a 600 términos.
3.5.3.1 Matriz de Similitud
En nuestro caso, antes que agrupar documentos, es necesario construir una matriz de similitud porque los algoritmos implementados en la herramienta para el agrupamiento parten de un grafo no dirigido y pesado. Para la creación de la matriz de similitud se usó la función de medida “Coseno”, esta matriz posteriormente fue filtrada eliminando los valores que pueden causar ruidos en los agrupamientos y hacer más lenta la ejecución de estos algoritmos. El filtrado de la matriz se realizó eliminando los valores que tenían un valor inferior al valor del promedio de todos los valores de la matriz.
3.5.3.2 Agrupamiento
El agrupamiento se realizó utilizando el algoritmo de intermediación diferencial de las aristas de un grafo, para el cual se utilizaron los siguientes parámetros: lamda= 0.0.1, cantidad de nodos en la vecindad a considerar= 2, y porciento de aristas a eliminar= 70 %.

Capítulo 3. Aplicación web que permite la gestión de información científica
71
3.5.4 Módulo para la validación del agrupamiento
Para la validación de los grupos se utilizaron funciones de medidas internas basadas en RST y la medida “Overall Similarity”. Para las medidas basadas en “RST” el umbral de similaridad que se utilizó fue calculado como el valor del promedio de todos los valores de la matriz de similitud. Las medidas basadas en “RST” utilizadas son las siguientes: “Rough FMeasure”, “Rough Quality”, “Rough Accuracy”, “Mean Rough Membership”, “Lower Approximation”, “Upper Aproximation
3.6 Mapa de navegación
”.
La aplicación tiene una navegación sencilla, normalmente el usuario se mantiene en la página principal a no ser que desee descubrir conocimiento a partir de una especificación de consulta, en ese caso la aplicación web lo redirigirá hacia la página encargada de gestionar el conocimiento descubierto por las técnicas de minería de texto e inteligencia artificial; el otro caso es que el usuario concuerde con la persona denominada administrador y este desee realizar tareas de administración, entonces la aplicación redirigirá al administrador de la aplicación hacia la página web encargada de gestionar las tareas administrativas. La Figura 3.5 muestra una representación del mapa de navegación de la aplicación web.
Figura 3.5. Mapa de navegación de la aplicación web.
3.7 Valoración preliminar de las herramientas y aplicación web
El desarrollo de la aplicación web a partir de las herramientas ratifica que las mismas facilitan el desarrollo de sistemas gestores de documentos, ya que:
• Independizan el desarrollo de los sistemas respecto a las etapas de la gestión de documentos.
• Permiten la integración de la aplicación con sistemas externos.
index.xhtml faces/agrupamiento.xhtml
faces/Administrar

Capítulo 3. Aplicación web que permite la gestión de información científica
72
Aunque la aplicación web desarrollada aún no es un resultado introducido en el CEI-UCLV, las pruebas preliminares muestran buenos resultados. Se pretende evaluar la aplicación teniendo en cuenta las variables descritas en el Anexo 6 a partir de los criterios de los investigadores del CEI-UCLV después de ser sometidos a una etapa de explotación de la aplicación.
La aplicación web desarrollada reutiliza las ventajas de los sistemas SATEX y GARLucene y resuelve algunas de las desventajas de estos sistemas, facilitando la gestión de la información en el CEI-UCLV. El desarrollar el sistema final como una aplicación web facilita la búsqueda de información en grandes repositorios disponibles en la intranet. La aplicación desarrollada tiene definidos valores por defecto para cada uno de los parámetros requeridos por los algoritmos implicados en la gestión de documentos, de forma tal que es fácil de utilizar por cualquier tipo de usuario.
3.8 Conclusiones parciales
En este capítulo se presentó la aplicación web que permite la gestión de información científica a partir de la integración de las herramientas desarrolladas que sustentan el esquema de gestión de documentos considerando: indexado y recuperación de información, representación textual, agrupamiento, y validación y etiquetamiento de los grupos textuales obtenidos.
El administrador de la aplicación se encargará de definir los directorios de índices donde serán indexados posteriormente los documentos, así como realizar propiamente la actividad de indexado. Los usuarios, que en este caso serán estudiantes, profesores e investigadores en general, pueden realizar búsquedas a partir de la información ya indexada y obtener el resultado de la búsqueda organizado por grupos textuales donde se identifican los documentos más representativos del grupos, así como aquellos que pertenecen a otros grupos porque que tienen relación con un grupo dado. Los usuarios reciben una valoración de la calidad del agrupamiento que obtienen.

Conclusiones y recomendaciones
73
CONCLUSIONES Y RECOMENDACIONES Como resultado de esta investigación se desarrolló una aplicación que permite gestionar de forma efectiva la información científico-técnica disponible en grandes repositorios de información a partir del desarrollo y aplicación de herramientas que trabajan de manera independiente y que explotan las ventajas de Tika, Lucene y Jung, garantizando independencia en el desarrollo de los sistemas respecto a las etapas de la gestión de documentos y la integración de la aplicación con sistemas externos; cumpliéndose de esta forma el objetivo general planteado, ya que:
1. El conjunto de herramientas desarrolladas permiten el desarrollo de sistemas gestores de documentos. Estas fueron diseñadas siguiendo el esquema propuesto en [13] y realizan el intercambio de información entre ellas utilizando ficheros XML que pueden ser validados utilizando esquemas de XML (XSD). Esta caraterística permite la retroalimentación de las herramientas con sistemas externos.
2. Para cubrir el proceso de indexado y recuperación de información se desarrollaron tres herramientas que utilizan las bondades de Tika y Lucene para este proceso. Las herramientas desarrolladas para realizar la representación de los corpus textuales permiten obtener la representación espacio vectorial de cada documento teniendo en cuenta cada una de las secciones de los artículos científicos recuperados, de tal forma que los métodos de agrupamiento que se apliquen se pueden focalizar en una u otra representación realizada.
3. Teniendo en cuenta que la mayoría de los métodos de agrupamiento parten de las similitudes existentes entre los documentos a agrupar, se desarrolló una herramienta que sustenta esta etapa de pre-agrupamiento y otra que permite aplicar propiamente el método de agrupamiento implementado. Otra herramienta desarrollada permite validar y etiquetar los grupos textuales obtenidos, brindando a los usuarios información acerca del resultado del agrupamiento.
4. La aplicación web desarrollada permite la gestión de información científica a partir de la integración de las herramientas que sustentan el esquema de gestión de documentos, explotando las ventajas de los sistemas precedentes SATEX y GARLucene, y eliminando desventajas de éstos ya que facilitan la búsqueda de información en grandes repositorios disponibles en la intranet y tiene definidos valores por defecto

Conclusiones y recomendaciones
74
para cada uno de los parámetros requeridos por los algoritmos implicados en la gestión de documentos, de forma tal que es fácil de utilizar por cualquier tipo de usuario.
Derivadas del estudio realizado, así como de las conclusiones generales emanadas del mismo, se recomienda:
• Incluir en las herramientas para la gestión de documentos nuevos métodos de agrupamientos, validación y etiquetamiento de los grupos para ofrecer a los usuarios una mayor diversidad de formas de organización de la información recuperada.
• Incluir nuevos formas de estimación de los parámetros asociados a los métodos incorporados en las herramientas.
• Introducir la aplicación en el CEI-UCLV y recibir criterios de los usuarios acerca de la factibilidad de su uso.

Referencias bibliográficas
75
Referencias bibliográficas 1. Dixon, M., An overview of document mining technology. 1997:
http://www.geocities.com/ResearchTriangle/Thinktank/1997/mark/writings/dixm97_dm.ps.
2. Lanquillon, C., Enhancing Text Classification to Improve Information Filtering, in Research Group Neural Networks and Fuzzy Systems. 2001, University of Magdeburg "Otto von Guericke": Magdeburg. p. 231.
3. Bueno, E. Estado del arte y tendencias en creación y gestión del conocimiento. in Congreso Iberoamericano de Gestión del Conocimiento y la Tecnología (IBERGECYT 2001). 2001. La Habana, Cuba.
4. Canals, A., M. Boisot, and A. Cornella, Gestión del conocimiento. 2003, Gestión: 2000: Barcelona, España.
5. Frappaolo, C., Knowledge Management. 2006, West Sussex, England: Capstone Publishing Ltd. (A Wiley company).
6. Dalkir, K., Knowledge Management in Theory and Practice. 2005, Burlington, USA: Elsevier.
7. Swoyer, S. Unstructured Data: Attacking a Myth. Enterprise Systems 2007; Available from: http://esj.com/business_intelligence/article.aspx?EditorialsID=8577.
8. Passoni, L., Gestión del conocimiento: una aplicación en departamentos académicos. Gestión y Política Pública, 2005. XIV(1): p. 57-74.
9. Tan, A. Text Mining: The state of the art and the challenges. in Proceedings of the Conference Knowledge Discovery and Data Mining (PAKDD'99): Workshop Knowledge Discovery from Advanced Databases. 1999. Pacific Asia.
10. Choo, C.W., B. Detlor, and D. Turnbull, Web Work: Information Seeking and Knowledge Work on the World Wide Web. Information Science and Knowledge Management. 2000: Klumer Academic Publishers.
11. Tiwana, A., The Knowledge Management Toolkit. 2000: Prentice Hall Inc. 12. Müller, R.M., M. Spiliopoulou, and H.-J. Lenz. The influence of incentives and culture
on knowledge sharing. in Proceedings of the 38th International Conference on System Sciences (HICSS-38 2005). 2005. Big Island, Hawaii, USA: IEEE Computer Society.
13. Arco, L., Agrupamiento basado en la intermediación diferencial y su valoración utilizando la teoría de los conjuntos aproximados, in Ciencia de la Computación. 2008, Universidad Central "Marta Abreu" de Las Villas: Santa Clara.
14. Müller, R.M., M. Spiliopoulou, and H.-J. Lenz. Electronic marketplaces of knowledge: Characteristics and sharing of knowledge assets. in Proceedings of the International Conference on Advances in Infrastructure for e-Business (SSGRR 2002). 2002. L'Aquila, Italy.
15. Fürnkranz, J., T. Scheffer, and M. Spiliopoulou. Knowledge discovery in databases. in Proceedings of the 10th European Conference on Principles and Practice of Knowledge Discovery in Databases (PKDD 2006). 2006. Berlin, Germany: Springer.
16. Anderberg, M.R., Clustering Analysis for Applications. 1973: New York: Academic.

Referencias bibliográficas
76
17. Höppner, F., et al., Fuzzy cluster analysis: methods for classification, data analysis and image recognition. 1999, West Sussex, England: John Wiley & Sons Ltd.
18. Kruse, R., C. Döring, and M.-J. Lesor, Fundamentals of Fuzzy Clustering, in Advances in Fuzzy Clustering and its Applications, J.V.d. Oliveira and W. Pedrycz, Editors. 2007, John Wiley and Sons: Est Sussex, England. p. 3-27.
19. Getoor, L. and C.P. Diehl, Link mining: a survey. SIGKDD Exploration Newsletter, 2005. 7(2): p. 3-12.
20. Girvan, M. and M.E.J. Newman, Community structure in social and biological networks. Proceedings of the National Academy of Sciences (PNAS USA), 2002. 99(12): p. 7821-7826.
21. Baumes, J., A. Goldberg, and M. Magdon-Ismail, Efficient identification of overlapping communities, in Intelligence and Security Informatics. 2005, Springer Berlin / Heidelberg: Berlin. p. 27-36.
22. Tong, H. and C. Faloutsos. Center-piece subgraphs: problem definition and fast solutions. in Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2006. Philadelphia, PA, USA ACM Press.
23. Halkidi, M., Y. Batistakis, and M. Vazirgiannis. Clustering algorithms and validity measures. in Proceedings of the 13th International Conference on Scientific and Statistical Database Management. 2001: IEEE Computer Society.
24. Han, J. and M. Kamber, Data mining: concepts and techniques. Data Management Systems. 2001, San Francisco: Morgan Kaufmann.
25. Pedrycz, W., Knowledge-based Clustering: from Data to Information Granules. 2005: Wiley.
26. Cheng, D., et al. A divide-and-merge methodology for clustering. in Proceedings of the 24th ACM SIGMOD SIGACT SIGART Symposium on Principles of Database Systems (PODS 2005). 2005. Baltimore, Maryland: ACM Press.
27. Cheng, D., et al., A divide-and-merge methodology for clustering. ACM Transaction on Database Systems (TODS), 2006. 31(4): p. 1499-1525.
28. Halkidi, M., Y. Batistakis, and M. Vazirgiannis, On clustering validation techniques. Journal of Intelligent Information Systems, 2001. 17(2/3): p. 107-145.
29. Xu, X., et al. SCAN: a structural clustering algorithm for networks. in Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD 2007). 2007. San Jose, California, USA: ACM Press.
30. Jain, A.K., M.N. Murty, and P.J. Flynn, Data clustering: a review. ACM Computing Surveys, 1999. 31(3): p. 264-323.
31. Hansen, C.D. and C.R. Johnson, eds. The Visualization handbook. 2005, Elsevier Academic press.
32. Jolliffe, I.T., Principal Component Analysis. Springer Series in Statistics. 1986, New York: Springer.
33. Levine, E. and E. Domany, Resampling method for unsupervised estimation of cluster validity. Neural Computation, 2001. 13(11): p. 2573-2593.

Referencias bibliográficas
77
34. Stein, B., S. Meyer, and F. Wißbrock. On clustering validity and the information need of users. in Proceedings of 3rd IASTED International Conference on Artificial Intelligence and Applications (AIA 2003). 2003. Benalmádena, Spain: ACTA Press.
35. Theodoridis, S. and K. Koutroubas, Pattern Recognition. 1999: Academic Press. 36. Halkidi, M., Y. Batistakis, and M. Vazirgiannis, Clustering validity checking methods:
Part II. ACM SIGMOD Record, 2002. 31(3): p. 19-27. 37. Silberschatz, A. and A. Tuzhilin, What makes patterns interesting in knowledge
discovery systems. IEEE Transactions on Knowledge and Data Engineering, 1996. 8(6): p. 940-974.
38. Kaufman, L. and P.J. Rousseeuw, Finding groups in data: an introduction to cluster analysis. Wiley Series in probability and mathematical statistics. 1990: John Wiley and Sons.
39. Tuzhilin, A., Usefulness, novelty, and integration of interestingness measures, in Handbook of Data Mining and Knowledge Discovery, Z. Klösgen, Editor. 2002, Oxford University Press.
40. Chen, K. and L. Liu. ClusterMap: labeling clusters in large datasets via visualization. in Proceedings of the ACM IEEE 13th Conference on Information and Knowledge Management (CIKM 2004). 2004. Washington, D.C.
41. Magdaleno, D., Refinamiento, evaluación y etiquetamiento de grupos textuales basados en la teoría de los conjuntos aproximados, in Ciencia de la Computación. 2008, Universidad Central "Marta Abreu" de Las Villas: Santa Clara.
42. Hatcher, E., O. Gospodnetic, and M. McCandless, Lucene in Action. Second ed. 2009. 43. O’Madadhain, J., et al., Analysis and Visualization of Network Data using JUNG.
Journal of Statistical Software, 2009. 44. Bueno, E. Gestión del conocimiento y capital intelectual: análisis de experiencias en
la empresa española. in Actas del X Congreso AECA. 1999. Zaragoza, España. 45. Manning, C.D., P. Raghan, and H. Schütze, Introduction to Information Retrieval.
2008: Cambridge University Press. 46. Nonaka, I. and H. Takeuchi, The Knowledge-Creating Company: How Japanese
Companies Create the Dynamics of Innovations. 1995: Oxford University Press. 47. Arco, L., et al., Agrupamiento de documentos textuales mediante métodos
concatenados. Revista Iberoamericana de Inteligencia Artificial, 2006. 10(30): p. 43-53.
48. Gil-García, R., J.M. Badía-Contelles, and A. Pons-Porrata. Extended Star clustering algorithm. in Proceedings of the Iberoamerican Congress on Pattern Recognition, Speech and Image Analysis (CIARP 2003). 2003. Havana, Cuba: Springer.
49. Berry, M.W., Survey of Text mining: Clustering, Classification, and Retrieval. 2004, New York, USA: Springer Verlag.
50. Arco, L., D. Magdaleno, and R. Bello, Keywords extraction in clusters of related documents. Research in Computer Science, 2007. 27: p. 137-148.
51. Arco, L., et al. CorpusMiner 2.0: Agrupamiento, extracción de palabras claves y obtención de la aproximación inferior y superior de los grupos textuales homogéneos.

Referencias bibliográficas
78
in II Simposio Internacional sobre Tecnologías de la Información en las Organizaciones Informacionales (SITIO 2007). 2007. Santa Clara, Cuba: Editorial Samuel Feijó.
52. Batyrshin, I. and G. Sidorov, Advances in Soft Computing Algorithms, in RESEARCH IN COMPUTING SCIENCE. 2011.
53. Girvan, M. and M. Newman (2002) Community structure in social and biological networks.
54. Wu, F. and B. Huberman, Discovering Communities in Linear Time: A Physics Approach. 2004.
55. Wasserman, S. and K. Faust, Social Network Analysis. 1994: Cambridge University Press.
56. Batchelor, B., Pattern Recognition: Ideas in Practice. 1978, New York: Plenum Press. 57. Hand, D.J., Discrimination and classification. Wiley Series in Probability and
Statistics. 1981: John Wiley and Sons. 58. Reed, S.K., Pattern recognition and categorization. Cognitive Pshychology, 1972. 3:
p. 382-407. 59. Michalski, R.S., R.E. Stepp, and E. Diday, A recent advance in data analysis:
clustering objects into classes characterized by conjuntive concepts. Progress in Pattern Recognition, 1981. 1: p. 33-56.
60. Diday, E. Recent progress in distance and similarity measures in pattern recognition. in Second International Joint Conference on Pattern Recognition. 1974. Copenhagen, Denmark.
61. Wilson, D.R. and T.R. Martínez, Improved heterogeneous distance functions. Journal of Artificial Intelligence Research, 1997. 6: p. 1-34.
62. Duch, W., Similarity-based methods: a general framework for classification. Control and Cybernetics, 2002. 29(4): p. 937-968.
63. Frakes, W.B. and R. Baeza-Yates, Information Retrieval. Data Structure & Algorithms. 1992, New York: Prentice Hall.
64. Strehl, A., J. Ghosh, and R. Mooney. Impact of similarity measures on Web-page clustering. in Proceedings of the 17th National Conference on Artificial Intelligence (AAAI 2000): Workshop of Artificial Intelligence for Web Search. 2000. Austin, Texas.
65. Brun, M., et al., Model-based evaluation of clustering validation measures. Pattern Recognition, 2007. 40: p. 807-824.
66. Steinbach, M., G. Karypis, and V. Kumar. A comparison of document clustering techniques. in Proceedings of 6th ACM SIGKDD World Text Mining Conference. 2000. Boston: ACM Press.
67. Davies, D.L. and D.W. Bouldin, A cluster separation measure. IEEE Transactions on Pattern Analysis and Machine Learning, 1979. 1(4): p. 224-227.
68. Newman, M.E.J. and M. Girvan, Finding and evaluating community structure in networks. Physical Review E, 2004. 69(2): p. 026113.

Anexos
79
Anexos
Anexo 1. Distancias, similitudes y disimilitudes más usadas para comparar objetos
Sean los objetos Oi y Oj descritos por m rasgos, donde Oi=(oi1, …, oim) y Oj=(oj1, …, ojm
Distancia Euclidiana
)
( ) ( )∑=
−=m
kjkikjiEuclideana ooOOD
1
2, (A1.1)
Distancia Minkowski
( ) γγ
1
1,
−= ∑
=
m
kjkikjiMinkowski ooOOD
[56]
donde γ ≥ 1 (A1.2)
La distancia Minkowsky es equivalente a la distancia Manhattan o city-block, y a la distancia
Euclidiana cuando γ es 1 y 2, respectivamente [56]. Para los valores de γ ≥ 2, la distancia Minkowsky equivale a Supermum
Distancia Euclidiana heterogénea (
[57, 58].
Heterogenous Euclidean – Overlap Metric
( ) ( )∑=
=m
kjkiklocaljiHEOM oodOOD
1
2,,
; HEOM)
, donde
( ) ( )( )
=numéricoksiood
simbólicoksioodood
jkikeanNormEuclid
jkikOverlapjkiklocal ,
,,
( ) =
=casootroenoosi
ood jkikjkikOverlap ,1
,0, y ( )
kk
jkikjkikeanNormEuclid
ooood
minmax,
−
−=
(A1.3)
Distancia Camberra
( ) ∑= +
−=
m
k jkik
jkikjiCamberra oo
ooOOD
1,
[59, 60]
(A1.4)
Correlación de Pearson
( )( )( )
( ) ( )∑∑
∑
==
=
−−
−−=
m
kkjk
m
kkik
m
kkjkkik
jiPearson
atributooatributoo
atributooatributooOOD
1
2
1
2
1,
[61]
(A1.5)

Anexos
80
donde katributo es el valor promedio que toma el atributok
Las expresiones de
en el conjunto de datos.
Chebychev, Mahalanobis, distancia de Hamming
A partir de estudios realizados, se ha demostrado que al agrupar documentos, los coeficientes Dice, Jaccard y Coseno, han reportado los mejores resultados [63]. Una valoración del impacto de la distancia Euclidiana y los coeficientes Dice, Jaccard y Coseno en dominios textuales se presenta en [64].
y la máxima distancia son otras variantes de cálculo de distancias entre objetos [61]. En [62] se presentan formas de medir la similitud considerando una relación asimétrica entre los objetos y teniendo en cuenta la probabilidad condicional de un objeto respecto al otro.
Coeficiente
( )( )
∑∑
∑
==
=
+
⋅= m
kjk
m
kik
m
kjkik
jiDice
oo
ooOOS
1
2
1
2
12
,
Dice
(A1.6)
Coeficiente de
( )( )
( )∑∑∑
∑
===
=
⋅−+
⋅= m
kjkik
m
kjk
m
kik
m
kjkik
jiJaccad
oooo
ooOOS
11
2
1
2
1,
Jaccard
(A1.7)
Coeficiente Coseno
( )( )
∑∑
∑
==
=
⋅
⋅=
m
kjk
m
kik
m
kjkik
jiCoseno
oo
ooOOS
1
2
1
2
1, (A1.8)

Anexos
81
Anexo 2. Algunas medidas internas para la validación del agrupamiento
Similitud global (Overall Similarity
( ) ∑∈
=GrupoOO
jiji
OOGrupo
GrupoilarityOverallSim,
2 ),(distancia1
) [66]
(A2.1)
Índices Dunn
( ))}({max)},({min
1 lkl
jiji
CCC
CI∆
=≤≤
≠ δ (A2.2)
donde C={C1, …, Ck
),(min),(,
yxdCCji CyCx
ji∈∈
=δ
} es el agrupamiento de un conjunto de objetos O, δ:C×C→R es una
medida de distancia de grupo a grupo y :C→R es una medida de diámetro del grupo.
y ),(max)(,
yxdCiCyxi ∈
=∆ (A2.3)
donde d:C×C→R es una función que mide la distancia entre los objetos de O.
Una de las propuestas de Bezdek para el cálculo de ( )ji CC ,δ y ( )iC∆
∑∈∈
=ji CyCxji
ji yxdCC
CC,
),(1),(δ y
=∆
∑ ∈
i
Cx ii C
cxdC i
),(2)( (A2.4)
donde ci es el centro del grupo Ci
Índice Davies – Bouldin [67]
.
( ) ∑=
⋅=k
iiR
kCDB
1
1 (A2.5)
ijji
nji RR≠=
=,,...,1
max , donde ),(
))()((
ji
jiij CC
CsCsR
δ+
= y ∑ ∈ −=iCx i
ii cx
CCs 1)( (A2.6)
donde C = {C1, …, Ck} es un agrupamiento de objetos, ci es el centro del grupo Ci
Las medidas Λ y ρ consideran la colección de objetos como un grafo pesado G=(V,E,w) con el
conjunto de nodos V, aristas E y la función de peso w:E→[0,1] donde V representa los objetos y w define la similitud entre dos objetos adyacentes. Considérese C={C
, s:C→R
mide la dispersión dentro del grupo y δ:C×C→R mide la distancia entre grupos.
1,…,Ck
} un agrupamiento de un grafo pesado G=(V,E,w).

Anexos
82
Medida de conectividad parcial pesada Λ
∑=
⋅=Λk
iiiCC
1)( λ (A2.7)
donde λ i designa la conectividad de las aristas pesadas de G(Ci
∑ ∈ '},{),(min
Evuvuw
). λ de un grafo G=(V, E, w) es
definida como , donde E’⊂E y G’=(V, E\E’) es no conexo. λ es también
designada como la capacidad de un corte mínimo de G.
Medida de densidad esperada ρ
θρi
ik
i
i
V
GwVV
C)(
)(1
⋅= ∑=
, donde )(GwV =θ y ∑ ∈+= Ee ewVGw )()( (A2.8)
donde θ se calcula para grafos ponderados según la expresión (A2.9).
)ln())(ln()(
VGwVGw =⇔= θθ
(A2.9)
Modularidad (Modularity
( ) 22 ee Tr −=−=∑i
iii aeQ
) [68]
(A2.10)
donde e es una matriz simétrica de orden k cuyo elemento eij
e
es la razón de todas las aristas en
el grafo que conectan nodos del grupo i con nodos del grupo j, indica la suma de los
elementos de la matriz e y ∑= i iiee Tr es la traza de la matriz que da la razón de aristas en el
grafo que conectan nodos en el mismo grupo.

Anexos
83
Anexo 3. Esquema general de la aplicación
MÓDULO 1
Recuperación de la información
Especificación del corpus textual a procesar
MÓDULO 2
2.1 Transformación del corpus 2.2 Extracción de términos 2.3 Reducción de la dimensionalidad 2.4 Normalización y pesado de la matriz
VSM Matriz de similitud Grafo de similitud
MÓDULO 3
MÓDULO 4
4.1 Identificación de documentos más representativos por grupos y los relacionados con cada grupo 4.2 Evaluación local y global de los resultados del agrupamiento 4.3 Extracción de las palabras claves
A*(Grupo) ⊆ Grupo ⊆ A*(Grupo) Precisión, calidad e inconsistencia
Agrupamiento jerárquico
Agrupamiento duro y determinista

Anexos
84
Anexo 4. Descripción general de la interfaz de usuario de SATEX
1. Seleccionar la colección de documentos que se desea procesar.
2. Especificar el número de palabras claves que se desean obtener por cada grupo textual.
3. Parámetros asociados a la normalización y pesado de la representación VSM y la reducción de la dimensionalidad mediante la selección de mejores términos.
4. Parámetros asociados al cálculo de la similitud entre documentos y umbrales de similitud para el agrupamiento y post-agrupamiento.
5. Árbol con los resultados del procesamiento. En la raíz se hace referencia a los resultados generales y cada nodo corresponde a un grupo textual obtenido, permitiendo acceder a los documentos del grupo, conjunto de documentos más representativos y relacionados, palabras claves y evaluación del grupo.
6. Descripción detallada de los resultados del procesamiento en correspondencia con el nodo que se haya seleccionado en el árbol de resultados.
1
5
2
3
4
6

Anexos
85
Anexo 5. Descripción general de la interfaz de usuarios de GARLucene
Figura A5.1 Menú principal del sistema GARLucene. (1) Realización de búsquedas sobre los documentos indexados, (2) Especificación de l alocalización, creación y actualización de los índices, (3) Selección del algoritmo de agrupamiento y las medidas de validación a utilizar y (4) Ayuda del sistema.
Figura A5.2 Ventana de GARLucene con los resultados agrupados de un proceso de recuperación de
información.
1. Especificación de la palabra, frase o expresión regular para realizar la búsqueda.
2. Resultado de una búsqueda.
3. Jerarquía de documentos.
4. Enlace a cada documento perteneciente al grupo seleccionado y su resumen. Se marcan con estrellas los documentos más representativos y se muestra al final la evaluación del grupo.

Anexos
86
5. Resultados globales de las búsquedas realizadas.
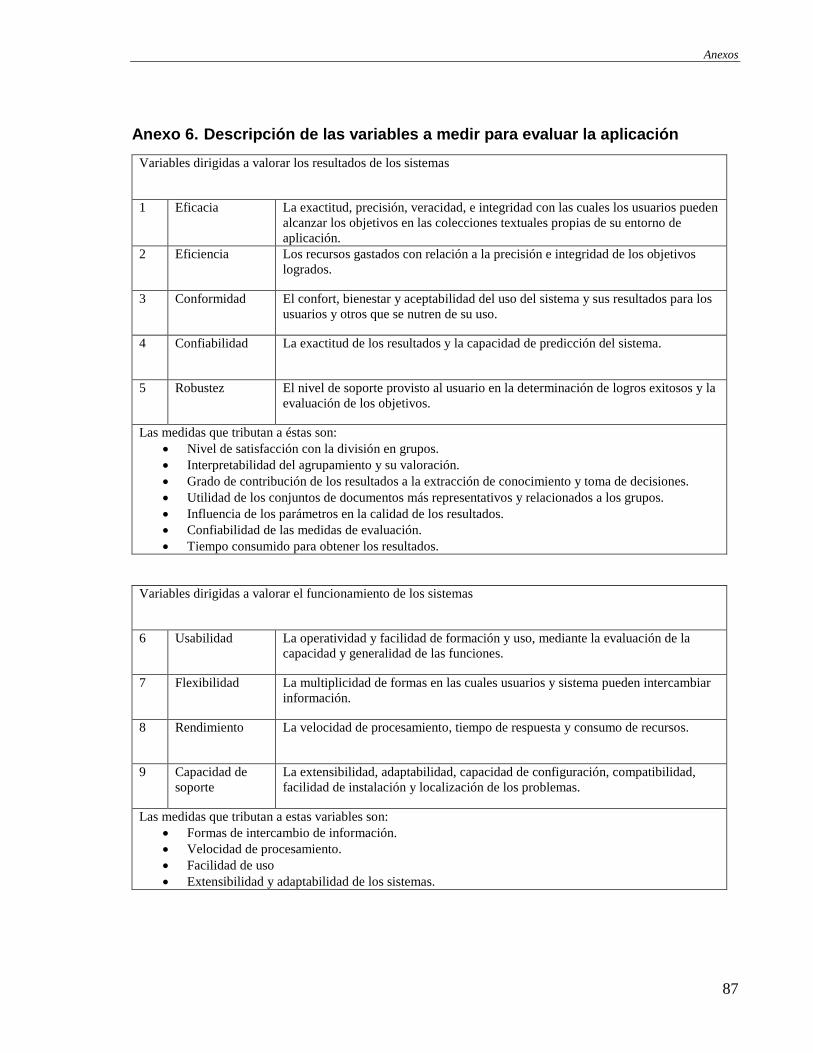
Anexos
87
Anexo 6. Descripción de las variables a medir para evaluar la aplicación Variables dirigidas a valorar los resultados de los sistemas
1 Eficacia La exactitud, precisión, veracidad, e integridad con las cuales los usuarios pueden alcanzar los objetivos en las colecciones textuales propias de su entorno de aplicación.
2 Eficiencia Los recursos gastados con relación a la precisión e integridad de los objetivos logrados.
3 Conformidad El confort, bienestar y aceptabilidad del uso del sistema y sus resultados para los usuarios y otros que se nutren de su uso.
4 Confiabilidad La exactitud de los resultados y la capacidad de predicción del sistema.
5 Robustez El nivel de soporte provisto al usuario en la determinación de logros exitosos y la evaluación de los objetivos.
Las medidas que tributan a éstas son: • Nivel de satisfacción con la división en grupos. • Interpretabilidad del agrupamiento y su valoración. • Grado de contribución de los resultados a la extracción de conocimiento y toma de decisiones. • Utilidad de los conjuntos de documentos más representativos y relacionados a los grupos. • Influencia de los parámetros en la calidad de los resultados. • Confiabilidad de las medidas de evaluación. • Tiempo consumido para obtener los resultados.
Variables dirigidas a valorar el funcionamiento de los sistemas
6 Usabilidad La operatividad y facilidad de formación y uso, mediante la evaluación de la capacidad y generalidad de las funciones.
7 Flexibilidad La multiplicidad de formas en las cuales usuarios y sistema pueden intercambiar información.
8 Rendimiento La velocidad de procesamiento, tiempo de respuesta y consumo de recursos.
9 Capacidad de soporte
La extensibilidad, adaptabilidad, capacidad de configuración, compatibilidad, facilidad de instalación y localización de los problemas.
Las medidas que tributan a estas variables son: • Formas de intercambio de información. • Velocidad de procesamiento. • Facilidad de uso • Extensibilidad y adaptabilidad de los sistemas.


















