IMPLEMENTACION DE UN MODELO PREDICTIVO DE ...Revisión de datos en SPSS Clementine 38 Fígura 5....
119
IMPLEMENTACION DE UN MODELO PREDICTIVO DE MINERIA DE DATOS UTILIZANDO CLEMENTINE DIANA CAROLINA BEDOYA PADILLA HERBERTH JOIMAN GOMEZ CASTANEDA UNIVERSIDAD AUTONOMA DE OCCIDENTE FACULTAD DE INGENIERIA DEPARTAMENTO DE CIENCIAS DE LA INFORMACION PROGRAMA DE INGENIERIA INFORMATICA SANTIAGO DE CALI 2008
Transcript of IMPLEMENTACION DE UN MODELO PREDICTIVO DE ...Revisión de datos en SPSS Clementine 38 Fígura 5....

IMPLEMENTACION DE UN MODELO PREDICTIVO DE MINERIA D E DATOS UTILIZANDO CLEMENTINE
DIANA CAROLINA BEDOYA PADILLA HERBERTH JOIMAN GOMEZ CASTANEDA
UNIVERSIDAD AUTONOMA DE OCCIDENTE FACULTAD DE INGENIERIA
DEPARTAMENTO DE CIENCIAS DE LA INFORMACION PROGRAMA DE INGENIERIA INFORMATICA
SANTIAGO DE CALI 2008

IMPLEMENTACION DE UN MODELO PREDICTIVO DE MINERIA D E DATOS UTILIZANDO CLEMENTINE
DIANA CAROLINA BEDOYA PADILLA HERBERTH JOIMAN GOMEZ CASTAÑEDA
Trabajo de Pasantía para optar al título de Ingeniero Informático
Directora LYDA PEÑA PAZ
Ingeniera de Sistemas Magíster en Ciencias Computacionales
UNIVERSIDAD AUTONOMA DE OCCIDENTE FACULTAD DE INGENIERIA
DEPARTAMENTO DE CIENCIAS DE LA INFORMACION PROGRAMA DE INGENIERIA INFORMATICA
SANTIAGO DE CALI 2008

Nota de aceptación:
Aprobado por el Comité de Grado en cumplimiento de los requisitos exigidos por la Universidad Autónoma de Occidente para optar al título de Ingeniero Informático Ing. Oscar Marino Carvajal Docente.
Santiago de Cali, 18 de Febrero de 2008

CONTENIDO
Pág. GLOSARIO 12
RESUMEN 14
INTRODUCCION 15
1 PLANTEAMIENTO DEL PROBLEMA 17
2 MARCO TEORICO 19
2.1 MINERÍA DE DATOS 19
2.1.1 Los fundamentos de la minería de datos 20
2.1.2 El alcance de la minería de datos 20
2.1.3 Metodología de minería de datos 21
2.1.4 Arquitectura para minería de datos 22
2.2 SISTEMA DE CALIFICACIÓN CREDITICIA 23
2.2.1 Funcionamiento de un sistema de calificación crediticia 24
2.2.2 Beneficios del sistema de calificación crediticia 24
2.2.3 Confiabilidad del sistema de calificación crediticia 25
2.3 DEFINICION MODELO PREDICTIVO 25
2.3.1 Metodología CRISP_DM 26
2.4 ESTANDAR PMML 28
2.4.1 Formato del pmml 28
2.4.2 Estructura de regresión en pmml 29
2.4.3 Software para el procesamiento de pmml 34

2.5 IMPORTAR UN MODELO PMML EN CLEMENTINE 35
2.6 EJECUCION DE UN MODELO EN CLEMENTINE 37
2.7 COMPARACION DE RESULTADO EN SPSS Y SPSS CLEMENTINE 39
3 ANTECEDENTES 41
3.1 HERRAMIENTAS DE MINERIA EN FINANCIERA COOMEVA 42
3.2 SPSS CLEMENTINE 43
3.3 SPSS 43
3.4 SQL SERVER ANALYTICAL SERVICES 44
3.5 ORACLE MINERIA DE DATOS 44
3.6 CUADRO COMPARATIVO 45
4 OBJETIVOS 47
4.1 OBJETIVO GENERAL 47
4.2 OBJETIVOS ESPECIFICOS 47
5 JUSTIFICACION 48
6 METODOLOGÍA 49
6.1 ESQUEMA GENERAL DEL PROYECTO 49
7. DESARROLLO 52
7.1 ESPECIFICACIONES DE REQUERIMIENTOS 52
7.2 REVISION DE LOS REQUERIMIENTOS 53
7.3 ANALISIS DE LOS REQUERIMIENTOS 54
7.4 RESOLUCION DE INQUIETUDES 56
7.5 LEVANTAMIENTO DE INFORMACION 56

7.5.1 Requerimiento 001: Extracción de información fuente 57
7.5.2 Requerimiento 002: Transformación de Variables 57
7.5.3 Requerimiento 003: Ejecución PMML 57
7.5.4 Requerimiento 004: Calculo 57
7.5.5 Requerimiento 005, Requerimiento 006 : Calificación 58
7.5.6 Requerimiento 007: Esquema 58
7.5.7 Requerimiento 008: Generar Reporte 58
7.5.8 Requerimiento 009: Almacenar en el AS/400 58
7.6 MODIFICACION DE REQUERIMIENTOS 53
7.7 VALIDACION Y VERIFICACION 59
7.8 ELABORACIÓN DE CASOS DE USO 60
7.8.1 Modelo de operación del software 61
7.8.2 Listado casos de uso 63
7.8.3 Especificación casos de uso 65
7.8.4 Aprobación de casos de uso 65
7.8.5 Validación y verificación 65
7.9. DISEÑO DE LA SOLUCIÓN 65
7.9.1 Arquitectura usada 65
7.9.2 Perspectivas de análisis de arquitectura 66
7.9.3 Vista de descomposición funcional 67
7.9.4 Vista de capas y componentes 68
7.9.5 Vista de distribución física 73

7.10 CONSTRUCCIÓN: EJECUCIÓN DEL MODELO DE MINERÍA 74
7.10.1 Desarrollo del software de procesamiento pmml 74
7.10.2 Ejecución del modelo logístico multinomial. 79
7.11 ASEGURAMIENTO DE CALIDAD Y PRUEBAS 83
8. CONCLUSIONES 85
BIBLIOGRAFÍA 87
ANEXOS 89

LISTA DE FIGURAS
Pág. Figura 1. Esquema de fases en CRISP-DM 27
Figura 2. Ejemplo de flujo de trabajo en SPSS Clementine 37
Figura 3. Definición de variables en SPSS Clementine. 38
Figura 4. Revisión de datos en SPSS Clementine 38
Fígura 5. Visualización de resultados del modelo en SPSS Clementine 39
Figura 6. Esquema de actividades del proyecto 51
Figura 7. Esquema de la fase de especificación de requerimientos 52
Figura 8. Esquema de la fase de elaboración de casos de uso 60
Figura 9. Modelo de operación del modelo de otorgamiento 61
Figura 10. Modelo de operación de la generación del reporte 63
Figura 11. Esquema de vista de arquitectura funcional 68
Figura 12. Esquema de arquitectura de tres capas 69
Figura 13. Esquema de funcionamiento de la capa de presentación 70
Figura 14. Esquema de funcionamiento capa de lógica de dominio 71
Figura 15. Esquema de funcionamiento capa de acceso a datos 71
Figura 16. Esquema de funcionamiento de las diferentes capas 72
Figura 17. Esquema de vista física de arquitectura 73
Figura 18. Modelo de operación de ejecución del PMML 75
Figura 19. Esquema de la generación de Java a partir de XSD 77
Figura 20. Esquema de un Modelo de minería como una función paramétrica 79

Figura 21. Ejemplo de modelo de Minería para Cálculo de PI 80
Figura 22. Esquema de la fase de Pruebas 84

LISTA DE TABLAS
Pág. Tabla 1. Cuadro comparativo de herramientas de minería 45
Tabla 2. Ejemplo de transformación requerida 57
Tabla 3. Listado de módulos del sistema 64
Tabla 4. Listado de casos de uso del sistema 64
Tabla 5. Perspectivas seleccionadas de Análisis de Arquitectura 67
Tabla 6. Mecanismos de procesamiento XML en Java 76
Tabla 7. Ejemplos de errores en generación de Java a partir de XSD 77
Tabla 8. Ejemplos de soluciones para generación de Java a partir de XSD 78
Tabla 9. Ejemplo de variable categorial (Discreta) Edad 79
Tabla 10. Ejemplo de variable categorial (Discreta) Sexo 80
Tabla 11. Ejemplo de valores para los predictores 82
Tabla 12. Ejemplo de valores para los predictores 82

LISTA DE CODIGOS
Pág.
Código 1. Esquema general de un archivo PMML 29
Código 2. Estructura general de un archivo PMML 2.1 30
Código 3. Modelo de regresión en PMML 2.1 31
Código 4. Modelo de regresión en PMML 3.1 32
Código 5. Matriz de parámetros en PMML 33
Código 6. Uso de JAXP para cargar un modelo PMML 78
Código 7. Ejemplo de diccionario de datos en PMML 80
Código 8. Ejemplo de listado de parámetros PMML 81
Código 9. Ejemplo de matriz de conversión de parámetros en PMML 82
Código 10. Ejemplo de matriz de parámetros en PMML 83

LISTA DE ANEXOS
Pág. Anexo A. Caso de Uso 001: Extracción variables 89
Anexo B. Caso de Uso 002: Transformación variables 92
Anexo C. Caso de Uso 003: Ejecución PMML 964
Anexo D. Caso de Uso 004: Cálculo puntaje y homologación 964
Anexo E. Caso de Uso 005: Calificación riesgo endeudamiento 67
Anexo F. Caso de Uso 006: Calificación crédito monto 101
Anexo G. Caso de Uso 007: Esquema 35
Anexo H. Caso de Uso 008: Reporte 10576
Anexo I. Caso de Uso 009: Almacenamiento AS400 107
Anexo J. Desarrollo del algoritmo de regresión logística polinomial 109

GLOSARIO AS/400: el servidor AS/400 es un ordenador de IBM de gamas baja y media, llegando a solaparse con los grandes host y con los pequeños servidores Windows y GNU/Linux, para todo tipo de empresas y departamentos. BODEGA DE DATOS : data warehouse (bodega o almacén de datos) lo asocia con una colección de datos de gran volumen, provenientes de sistemas en operación y otras fuentes, después de aplicarles los procesos de análisis, selección y transferencia de datos seleccionados. CASO DE USO: en ingeniería del software, un caso de uso es una técnica para la captura de requisitos potenciales de un nuevo sistema o una actualización software. Cada caso de uso proporciona uno o más escenarios que indican cómo debería interactuar el sistema con el usuario o con otro sistema para conseguir un objetivo específico. INTELIGENCIA DE NEGOCIOS: la Inteligencia de Negocios, es una alternativa tecnológica y de administración de negocios, que permite manejar la información para la toma de decisiones acertadas en todos los niveles de la organización, desde la extracción, depuración y transformación de datos, hasta la explotación y distribución de la información mediante herramientas de fácil uso para los usuarios. IU: (user interface) Interfaz grafica de usuario MINERIA DE DATOS: la minería de datos es un proceso analítico diseñado para explorar grandes volúmenes de datos (generalmente datos de negocio y mercado) con el objeto de descubrir patrones y modelos de comportamiento o relaciones entre diferentes variables. Esto permite generar conocimiento que ayuda a mejorar la toma de decisiones en los procesos fundamentales de un negocio PMML: es un lenguaje de marcas basado en el estándar XML que sirve para describir modelos estadísticos y de minería de datos. Para ello requiere definir los datos de entrada al modelo, las transformaciones realizadas sobre los mismos y los parámetros propios que lo definen. SARC: el SARC se ocupa en forma integral de todas y cada una de las etapas del ciclo de crédito (otorgamiento, seguimiento, control, recuperación, etc.)

RESUMEN
Al interior de los procesos de otorgamiento de crédito, es necesario analizar al cliente para determinar el nivel de riesgo asociado y los montos que pueden aprobarse en las diferentes transacciones. Tareas que son necesarias no solo debido a las políticas internas de la institución, sino también debido a las normatividades legales. Con el fin de realizar estas evaluaciones y valoraciones de los clientes, Coomeva trabajó en un modelo de minería de datos. Este modelo de minería de datos tiene establecidas unas reglas, de acuerdo al comportamiento histórico de la población asociada a Coomeva, que permite calificar a las personas que solicitan crédito. Este modelo de minería, sin embargo, incluye un conjunto adicional de reglas y transformaciones e integrarse al sistema operacional de la entidad Taylor & Johnson, con el fin de poder ser utilizado al interior de la compañía. En este informe se documenta el proceso para la implementación de un modelo predictivo de minería de datos para el modelo de otorgamiento en Coomeva Financiero, que permite integrar esta funcionalidad al software de Taylor & Johnson para agilizar los estudios y llegar a una decisión rápida para las solicitudes de crédito. Para la ejecución del modelo de minería, se empleó el mismo modelo entrenado que posee Coomeva Financiero en una herramienta llamada SPSS (statistical package for the social science) o Clementine exportándolo a un archivo PMML (predictive model markup language), el cual se ejecuta directamente desde la aplicación.

15
INTRODUCCION En la actualidad, los bancos y entidades de financiamiento, requieren establecer sistemas que permitan determinar, mitigar y controlar el nivel de riesgo crediticio de sus operaciones. Debido a una serie de normatividades legales, las compañías del sector financiero deben determinar la probabilidad que los créditos que manejan dejen de ser pagados o tengan complicaciones en su pago oportuno. Esto con el fin que el banco tome medidas y haga las reservas requeridas para que los problemas que puedan ocurrir con los créditos y las inversiones no terminen afectando los ahorros y depósitos del público y los inversionistas. Como parte del proceso de otorgamiento de crédito personal y financiero, las entidades bancarias suelen usar modelos estadísticos y/o de minería de datos que permitan determinar la probabilidad de incumplimiento del crédito. Si la probabilidad es muy alta, muy probablemente el crédito no será aprobado. Un crédito con una probabilidad de incumplimiento muy alta puede no ser un buen negocio, no solo por el riesgo de no pago del cliente, sino por los altos niveles de reservas que se pueden requerir. La Cooperativa Coomeva, y la nueva Financiera Coomeva, han estado trabajando durante varios años en la definición y perfeccionamiento de modelos de minería de datos que permitan determinar con el mayor nivel de precisión el nivel de riesgo crediticio. Para la nueva oferta de servicios para 2008, la Financiera Coomeva desea establecer un nuevo modelo de otorgamiento crediticio que aproveche estos modelos de minería de datos y desarrollar un sistema que genere recomendaciones de aprobación o no del crédito de acuerdo a la probabilidad de incumplimiento que se pueden calcular. Geniar, compañía que ha desarrollado algunos proyectos de integración de aplicaciones e inteligencia de negocios en Coomeva y otras compañías de la región, ha sido designada para construir una solución que permita integrar los modelos de minería de datos desarrollados en SPSS Clementine en las aplicaciones de negocio de la entidad financiera. La solución planteada se basa en el uso del estándar PMML para el intercambio de modelos de minería de datos. Empleando este estándar, el modelo de minería de datos puede ser creado en SPSS Clemetine, exportado en un archivo especial e importado en una solución de software. Como parte de la solución se construyó un módulo de software que ejecuta el modelo de minería basado en el PMML y otro módulo que usa al primero para ejecutar el modelo de otorgamiento y hacer la recomendación de acuerdo a los datos del solicitante.

16
El presente trabajo incluye un informe de la pasantía de los estudiantes Herberth Joiman Gómez y Diana Carolina Bedoya, quienes participaron en la construcción del modelo de otorgamiento y el mecanismo de ejecución de PMML dentro del proyecto desarrollado por Geniar para la Financiera Coomeva.

17
1. PLANTEAMIENTO DEL PROBLEMA Desde hace mucho tiempo poder conocer, controlar y cambiar la realidad financiera de la empresa es uno de los puntos donde se encuentran más dificultades. Sin duda, disponer de los recursos adecuados para afrontar las acciones necesarias, permite adoptar una buena planificación de la estrategia financiera y conocer la realidad de la empresa, enfrentando de esta forma los retos y problemas diarios con máxima eficiencia. Las diferentes crisis bancarias que han ocurrido en América Latina en las últimas décadas, incluyendo la crisis del sector financiero en Colombia a finales de la década de los 90, han creado una mayor conciencia sobre la necesidad de contar con mecanismos para evaluar y mitigar los riesgos. Para una institución financiera, brindar créditos a personas que no están en capacidad de pagarlos, representa un gran riesgo. Los clientes que incumplen en sus créditos generan procesos complejos de expropiación, descontento del público y pérdidas de dinero que pueden llevar a una compañía a la quiebra, por esta razón, analizar adecuadamente los clientes es una necesidad indudable y la práctica de la evaluación de capacidad y calificación crediticia se han convertido en prácticas bien establecidas. Determinar si un cliente es apto o no para acceder a un crédito, se basa normalmente en la probabilidad de incumplimiento de ese cliente. Aunque las estimaciones de probabilidad en su mayoría son subjetivas, las técnicas de evaluación de crédito se han mejorado en los últimos años. Un buen administrador de crédito en una institución financiera puede hacer juicios razonables exactos acerca de la probabilidad de incumplimiento de diferentes clases de clientes. Una institución financiera entonces, de acuerdo a su visión de negocio, debe establecer los márgenes de riesgo permitidos. Márgenes que le permitan lograr la mayor colocación posible en niveles apropiados de probabilidad de incumplimiento. Desde hace algunos años en Colombia, es obligatorio que todas las compañías financieras cuenten con sistemas de administración de riesgo crediticio (SARC) que le permitan conocer, monitorear y controlar los niveles de riesgo asociados a su colocación. Las áreas de negocio evalúan constantemente la situación financiera de cada cliente, realizando cuando menos una vez al año, revisión exhaustiva y análisis del riesgo de cada préstamo. Si se llegara a detectar cualquier deterioro de la situación financiera del cliente, se cambia su calificación de inmediato. De esta manera, el Grupo determina los cambios experimentados por los perfiles de riesgo

18
de cada cliente. En estas revisiones se considera el riesgo de crédito global, incluyendo operaciones con instrumentos financieros, derivados financieros y cambios. En el caso de los riesgos superiores a lo aceptable, se realizan revisiones complementarias con mayor frecuencia, mínimo trimestralmente. Las empresas se basan en la aplicación de estrategias bien definidas para controlar cualquier tipo de riesgo, entre las que destacan la centralización de los procesos de crédito, la diversificación de la cartera, un mejor análisis del crédito, una estrecha vigilancia y un modelo de calificación del riesgo crediticio. En los últimos años, la práctica de evaluación crediticia de los clientes ha involucrado cada vez más diferentes variables y factores. Situación la cual genera, en muchos casos, que los modelos de evaluación excedan las posibilidades reales de hacer el proceso de forma manual. Adicionalmente, la tendencia a emplear la gran cantidad de información histórica de las transacciones de los clientes, llevan a las instituciones financieras cada vez más hacia la automatización de estos procesos. El negocio y el proceso de otorgamiento crediticio en la cooperativa Coomeva y financiera Coomeva se ha estado refinando y evolucionando con el tiempo. Desde hace algunos años se ha estado trabajando en tema de minería de datos para mejorar los esquemas de análisis de riesgo crediticio y para ser más asertivos en los procesos de otorgamiento de los créditos. Hoy en día el software bancario de Coomeva, Taylor & Jhonson, no incluye algunas de las definiciones más recientes del negocio. El software soporta un modelo de operación, con una serie de pasos basados en reglas, que no soporta el nuevo modelo basado en el esquema de minería de datos. Para lograr que el software bancario soporte el nuevo modelo de otorgamiento basado en minería de datos, es necesario construir un servicio de software que permita ejecutar el modelo predictivo con los datos del solicitante del crédito. Debido a que el grupo estadístico de Coomeva trabaja con herramientas de minería de datos SPSS Clementine, los modelos predictivos se hallan construidos en este sistema. Modelos que incluyen algunos modelos de cálculo de riesgo crediticio y de probabilidad de incumplimiento que deberían ser integrados en el corto y mediano plazo al software bancario. ¿Cómo implementar un servicio de ejecución de un modelo predictivo desarrollado en SPSS Clementine, de forma que pueda ser integrado a la solución del sistema bancario en la Financiera y la Cooperativa Coomeva?

19
2. MARCO TEORICO 2.1 MINERÍA DE DATOS
La Minería de Datos (Data Mining), es la extracción de información oculta y predecible de grandes bases de datos, es una tecnología con gran potencial para ayudar a las compañías a concentrarse en la información más importante de sus Bases y Bodegas de Información (Data Warehouse). Las herramientas de Minería de Datos predicen futuras tendencias y comportamientos, permitiendo en los negocios tomar decisiones proactivas y conducidas por un conocimiento acabado de la información. Los análisis prospectivos automatizados ofrecidos por un producto así van más allá de los eventos pasados provistos por herramientas retrospectivas típicas de sistemas de soporte de decisión. Las herramientas de Minería de Datos pueden responder a preguntas de negocios que tradicionalmente consumen demasiado tiempo para poder ser resueltas y a los cuales los usuarios de esta información casi no están dispuestos a aceptar. Estas herramientas exploran las bases de datos en busca de patrones ocultos, encontrando información predecible que un experto no puede llegar a encontrar porque se encuentra fuera de sus expectativas. Muchas compañías ya colectan y refinan cantidades masivas de datos. Las técnicas de Minería de Datos pueden ser implementadas rápidamente en plataformas ya existentes de software y hardware para acrecentar el valor de las fuentes de información existentes y pueden ser integradas con nuevos productos y sistemas ya que son traídas en línea. Una vez que las herramientas de Minería de Datos fueron implementadas en computadoras cliente servidor de alto rendimiento o de procesamiento paralelo, pueden analizar bases de datos masivas para brindar respuesta a preguntas tales como, "¿Cuáles clientes tienen más probabilidad de responder al próximo correo promocional, y por qué? y presentar los resultados en formas de tablas, con gráficos, reportes, texto, hipertexto, etc.1
1 Página de Consultas Monografias, [en línea] Data Mining, Argentina: Monografias SA, 2004 [consultado 01 de septiembre de 2007] Disponible en internet:
http://www.monografias.com/trabajos7/dami/dami.shtml

20
2.1.1 Los fundamentos de la minería de datos. Las técnicas de Minería de Datos son el resultado de un largo proceso de investigación y desarrollo de productos. Esta evolución comenzó cuando los datos de negocios fueron almacenados por primera vez en computadoras, y continuó con mejoras en el acceso a los datos, y más recientemente con tecnologías generadas para permitir a los usuarios navegar a través de los datos en tiempo real. La Minería de Datos toma este proceso de evolución más allá del acceso y navegación retrospectiva de los datos, hacia la entrega de información prospectiva y proactiva. La Minería de Datos está soportada por tres tecnologías que son suficientemente maduras: • Recolección masiva de datos • Potente computadoras con multiprocesadores • Algoritmos de Minería de Datos
Los algoritmos de Minería de Datos utilizan técnicas que han existido por lo menos desde la década de los 90, pero que sólo han sido implementadas recientemente como herramientas maduras, confiables, entendibles que consistentemente tienen mejor rendimiento que métodos estadísticos tradicionales. 2.1.2 El alcance de la minería de datos. El nombre de Minería de Datos deriva de las similitudes entre buscar valiosa información de negocios en grandes bases de datos. Dadas bases de datos de suficiente tamaño y calidad, la tecnología de Minería de Datos puede generar nuevas oportunidades de negocios al proveer estas capacidades: Predicción automatizada de tendencias y comportamientos. La minería de datos automatiza el proceso de encontrar información predecible en grandes bases de datos. Preguntas que tradicionalmente requerían un intenso análisis manual, ahora pueden ser contestadas directa y rápidamente desde los datos. Problemas predecibles incluyen pronósticos de problemas financieros futuros y otras formas de incumplimiento, e identificar segmentos de población que probablemente respondan similarmente a eventos dados. Descubrimiento automatizado de modelos previamente desconocidos. Las herramientas de Minería de Datos barren las bases de datos e identifican modelos previamente escondidos en un sólo paso. Otros problemas de descubrimiento de modelos donde puede aplicarse minería incluyen la detección de transacciones fraudulentas de tarjetas de créditos y la identificación de datos anormales que pueden representar errores de digitación en la carga de datos.

21
Las técnicas de Minería de Datos pueden redituar los beneficios de automatización en las plataformas de hardware y software existentes y puede ser implementada en sistemas nuevos a medida que las plataformas existentes se actualicen y nuevos productos sean desarrollados. Algunas de las técnicas más comúnmente usadas en Minería de Datos son: • Redes neuronales artificiales: modelos predecibles no-lineales que aprenden a través del entrenamiento y semejan la estructura de una red neuronal biológica. • Árboles de decisión : estructuras de forma de árbol que representan conjuntos de decisiones. Estas decisiones generan reglas para la clasificación de un conjunto de datos. Métodos específicos de árboles de decisión incluyen Árboles de Clasificación y Regresión. • Algoritmos genéticos: técnicas de optimización que usan procesos tales como combinaciones genéticas, mutaciones y selección natural en un diseño basado en los conceptos de evolución. • Método del vecino más cercano : una técnica que clasifica cada registro en un conjunto de datos basado en una combinación de las clases del/de los k registro (s) más similar/es a él en un conjunto de datos históricos. • Regla de introducción: la extracción de reglas “Si x Entonces y” (if-then) a partir de datos basados en significado estadístico. 2.1.3 Metodología de minería de datos. La Minería de Datos es el acto de construir un modelo en una situación donde usted conoce la respuesta y luego la aplica en otra situación de la cual desconoce la respuesta. Este acto de construcción de un modelo es algo que la gente ha estado haciendo desde hace mucho tiempo, seguramente desde antes del auge de las computadoras y de la tecnología de Minería de Datos. Las computadoras son cargadas con mucha información acerca de una variedad de situaciones donde una respuesta es conocida y luego el software de Minería de Datos en la computadora debe correr a través de los datos y distinguir las características de los datos que llevarán al modelo. Una vez que el modelo se construyó, puede ser usado en situaciones similares donde usted no conoce la respuesta. Para determinar si un modelo es bueno el primer paso que se debe realizar es probar con un modelo donde se conoce la respuesta. Con Minería de Datos, la mejor manera para realizar esto es dejando de lado ciertos datos para aislarlos del proceso de Minería de Datos. Una vez que el proceso está completo, los

22
resultados pueden ser probados contra los datos excluidos para confirmar la validez del modelo. Si el modelo funciona, las observaciones deben mantenerse para los datos excluidos. Las principales metodologías utilizadas por los analistas para la realización de proyectos de Minería de Datos son CRISP-DM y SEMMA. Estas metodologías presentan diferentes fases que proporciona una idea más amplia respecto a la realización de proyectos de Minería de Datos y me permiten adaptarlas al desarrollo de los proyectos específicos de cada organización. Así mismo, la presentación de las fortalezas y debilidades de cada una de las metodologías hace posible la selección informada de una técnica de desarrollo apropiada para cada caso, donde comparten la misma esencia, estructurando el proyecto de Minería de Datos en fases que se encuentran interrelacionadas entre sí, convirtiendo el proceso de Minería de datos en un proceso iterativo e interactivo. La metodología CRISP-DM mantiene una perspectiva más amplia respecto a los objetivos empresariales del proyecto ya que desde la primera fase del proyecto comienza realizando un análisis del problema empresarial para su transformación en un problema técnico, de esta manera, esta metodología permite estar mucho más cerca al concepto real del proyecto y ser integrada con una metodología de Gestión de Proyectos específica que completaría las tareas administrativas y técnicas. CRISP-DM ha sido diseñada como una metodología neutra respecto a la herramienta que se utilice para el desarrollo del proyecto de Minería de Datos siendo su distribución libre y gratuita. La metodología SEMMA se centra más en las características técnicas del desarrollo del proceso y desde la primera fase comienza realizando un muestreo de datos y sólo es abierta en sus aspectos generales ya que está muy ligada a los productos SAS donde se encuentra implementada. 2.1.4 Arquitectura para minería de datos. Para aplicar estas técnicas avanzadas, éstas deben estar totalmente integradas con las Bodegas de Datos, así como con herramientas flexibles e interactivas para el análisis de negocios. Varias herramientas de Minería de Datos actualmente operan fuera de la Bodega de Datos, requiriendo pasos extra para extraer, importar y analizar los datos. Además, cuando nuevos conceptos requieren implementación operacional, la integración con la Bodega de Datos simplifica la aplicación de los resultados desde Minería de Datos. La Bodega de Datos analítica resultante puede ser aplicada para mejorar procesos de negocios en toda la organización, en áreas

23
tales como manejo de campañas promocionales, detección de fraudes, lanzamiento de nuevos productos, etc. El punto de inicio ideal es una Bodega de Datos que contenga una combinación de datos de seguimiento interno de todos los clientes junto con datos externos de mercado acerca de la actividad de los competidores. Información histórica sobre potenciales clientes también provee una excelente base para prospectación. Esta Bodega de Datos puede ser implementada en una variedad de sistemas de bases relacionales y debe ser optimizado para un acceso a los datos flexible y rápido. Un servidor multidimensional OLAP permite que un modelo de negocios más sofisticado pueda ser aplicado cuando se navega por la Bodega de Datos. Las estructuras multidimensionales permiten que el usuario analice los datos de acuerdo a como quiera mirar el negocio. El servidor de Minería de Datos debe estar integrado con la Bodega de Datos y el servidor OLAP para insertar el análisis de negocios directamente en esta infraestructura. Un avanzado conjunto de metadatos centrado en procesos define los objetivos de la Minería de Datos para resultados específicos tales como manejos de campaña, prospectación, y optimización de promociones. La integración con la Bodega de Datos permite que decisiones operacionales sean implementadas directamente y monitoreadas. A medida que la Bodega de Datos crece con nuevas decisiones y resultados, la organización puede "minar" (detectar) las mejores prácticas y aplicarlas en futuras decisiones. Este diseño además de proveer datos a los usuarios finales a través de software de consultas y reportes, el servidor de Análisis Avanzado aplica los modelos de negocios del usuario directamente a la Bodega de Datos y devuelve un análisis proactivo de la información más relevante. Estos resultados mejoran los metadatos en el servidor OLAP proveyendo un nivel de metadatos que representa una vista fraccionada de los datos. Generadores de reportes, visualizadores y otras herramientas de análisis pueden ser aplicadas para planificar futuras acciones y confirmar el impacto de esos planes. 2.2 SISTEMA DE CALIFICACIÓN CREDITICIA
El sistema de calificación crediticia es un sistema estadístico de evaluación automática para la concesión de créditos, que predice la entrada en mora de una operación de riesgo. Produce una clasificación ordenada, basada sobre la mora y el riesgo, mediante la suma de puntos asociados. • A las respuestas a los cuestionarios de la solicitud de crédito. • Al perfil crediticio que surja de los registros del comité de créditos.

24
• Al perfil económico - financiero que surja de los estados financieros del solicitante.
2.2.1 Funcionamiento de un sistema de calificación crediticia. El funcionamiento de un sistema de calificación crediticia puede esquematizarse en los siguientes pasos:
• Se obtiene información de la solicitud de crédito o del informe de crédito o de otras fuentes como los estados financieros. • Utilizando un programa computarizado se compara la información obtenida con el desempeño crediticio de otros solicitantes con perfiles similares. Se otorgan puntos por cada uno de los factores que ayudan a predecir cuál perfil de solicitante es el que tendrá el mejor desempeño en el cumplimiento de sus obligaciones. • El total de puntos constituye la calificación (score) y así determina si el solicitante es merecedor de crédito, es decir si su perfil predice el mejor desempeño en el cumplimiento de sus obligaciones.
2.2.2 Beneficios del sistema de calificación credit icia. El Sistema de Calificación crediticia ofrece una variedad de beneficios para las entidades financieras que lo implementan. Entre tale beneficios, es posible mencionar:
• Disminuye el tiempo necesario para la concesión de crédito, siendo posible la evaluación instantánea. • Reduce la cartera irregular. • Uniforma los criterios de concesión de créditos. • Disminuye los costes de análisis de créditos. • Facilita los cambios en la política de créditos. • Mejora la utilización de la experiencia de los analistas de la entidad. • Está basado sobre datos reales y estadísticas, por lo tanto es más confiable que los métodos basados sobre la subjetividad o el criterio del analista. • Trata a todos los solicitantes por igual, en forma objetiva (los métodos subjetivos o de criterios generalmente se basan sobre pautas que no han sido evaluadas sistemática-mente y cuyos resultados pueden variar según el individuo que las aplica) En resumen, un sistema de este tipo permite a las entidades evaluar solicitantes en forma rápida, consistente e imparcial, tomando en cuenta un gran número de las características de los solicitantes.

25
2.2.3 Confiabilidad del sistema de calificación cre diticia. El sistema de calificación crediticia tiene asociado un margen de error. El nivel de confiabilidad del sistema depende de la confiabilidad del modelo predictivo que propone. Un Sistema de Calificación Crediticia es más confiable si se tiene las siguientes características: • Cuanto mejor y más amplia sea la fuente de información. • Si tiene un diseño correcto. • Si es estadísticamente válido, es decir si está basado sobre una base de datos reales suficientemente amplia. • Si está validado contra una amplia muestra de clientes cumplidores y no- cumplidores. • Si esta verificado en su utilización contra los resultados reales. Estas características nos muestran que la calificación crediticia es más útil en la atención de operaciones de banca individual, donde existe un gran número de solicitudes que debe ser resuelto en un lapso de tiempo muy corto. Pero también existe una variedad de calificaciones crediticias aptas para su utilización con empresas como ser pruebas de "pasa/no pasa", préstamo por fórmula, clasificación de deudores, calificaciones crediticias para micro-emprendimientos, la matriz de crédito comercial, etc.2
2.3 DEFINICIÓN MODELO PREDICTIVO El desarrollo del modelo predictivo debe seguir los lineamientos de un proyecto de minería de datos. En la actualidad, las metodologías más conocidas en esta área son CRISP-DM y SEMMA. Coomeva hace uso de la metodología CRISP-DM ya que esta es directamente soportada por la herramienta SPSS Clementine. El Modelo Predictivo de Probabilidad de Incumplimiento incluido en el modelo de otorgamiento fue desarrollado por el grupo estadístico de Coomeva y suministrado al grupo de trabajo para su incorporación al servicio que debía construirse. A continuación se incluye una breve descripción de la metodología CRISP-DM y de algunos de los pasos requeridos para construir un modelo predictivo en Clementine, y para exportar e importar el modelo en formato PMML.
2 Página de Consultas Monografias [en línea] Data Mining, Argentina: Monografias SA, 2004 [consultado 01 de septiembre de 2007]. Disponible en internet: http://www.monografias.com/trabajos7/dami/dami.shtml

26
Algunas de estas tareas fueron desarrolladas por Geniar y los autores del trabajo para revisar el modelo de minería, verificar la ejecución del mismo y realizar las pruebas del funcionamiento del software desarrollado comparando los resultados obtenidos con los valores esperados arrojados por estas herramientas. 2.3.1 Metodología Crisp-Dm. CRISP-DM es, en realidad, un proceso estándar para minería de datos establecido por un consorcio internacional de compañías que define estándares en torno al tema de minería de datos. La versión inicial se definió en 1999 por las compañías SPSS, AG, NCR y OHRA. El proceso define una serie de fases y actividades que deben llevarse a cabo para el desarrollo de un proyecto de minería de datos. Cada una de las actividades con un conjunto de tareas y entregables definidos. La metodología incluye un conjunto de fases: • Entendimiento del Negocio • Entendimiento de los Datos • Preparación de los Datos • Modelamiento • Evaluación • Despliegue

27
Figura 1. Esquema de fases en CRISP-DM A continuación se relacionan los objetivos de cada una de las fases definidas en CRISP-DM. • Entendimiento del negocio. Comprender los objetivos y requerimientos del proyecto desde una perspectiva de negocio. Básicamente, definir los objetivos de negocio en torno del proyecto de minería de datos. • Comprensión de los datos . Recopilar y familiarizarse con los datos, identificar los problemas de calidad de datos y ver las primeras potencialidades o subconjuntos de datos que puede ser interesante de analizar (según los objetivos de negocio definidos en la fase anterior). • Preparación de los datos . Definición de la “vista minable”, el conjunto de datos que será usado en el modelo de minería. Aquí se incluyen actividades de integración, selección, limpieza y transformación. • Modelado . Aplicación de técnicas de modelado o de minería de datos propiamente dichas sobre las vistas de datos minables definidas.
Entendimiento del
Negocio
Entendimiento de
los datos
Preparación de los
datos
Modelamiento
Evaluación
Despliegue

28
• Evaluación . Revisión de los modelos de minería encontrados (desde el punto de vista de los objetivos del negocio). Se definen experimentos y pruebas que permiten comprobar si el modelo nos sirve para responder a algunos de los requerimientos del negocio. • Despliegue . Uso y explotación de la potencialidad de los modelos, integrarlos en los procesos de toma de decisión de la organización, difundir informes sobre el conocimiento extraído, y hacer uso dentro de las actividades de toma de decisiones de la compañía. 2.4 ESTÁNDAR PMML El estándar PMML (Predictive Model Markup Language) es un lenguaje basado en XML que permite el intercambio de modelos predictivos y de minería de datos en diferentes lenguajes y herramientas. Usando PMML es posible exportar un modelo de minería de datos de un sistema e importarlo en otro. Por ejemplo, es posible exportar un modelo de minería incluyendo el pre-procesamiento de una aplicativo como SPSS y luego importar el mismo modelo en otro aplicativo como Clementine. El mecanismo de intercambio PMML está diseñado no solo para utilizar modelos creados en un sistema en otro sistema, sino también para incorporar la ejecución del modelo predictivo en aplicaciones de negocio. Los modelos exportados en PMML incluyen la información requerida para la ejecución del modelo predictivo. Esto puede aprovecharse para incluir la ejecución del modelo predictivo directamente en las aplicaciones. Algunas librerías y sistemas permiten la ejecución directa del modelo predictivo desde la aplicación. Sistemas como Clementine Server, DB2 Datawarehouse edition, IBM Scoring Beans u Oracle Database Server, permiten importar el modelo PMML y ejecutarlo directamente desde un aplicativo. El API estándar Java Datamining (JDM) está diseñado para ofrecer esta funcionalidad desde Java. 2.4.1 Formato del pmml. El formato PMML está definido por un archivo estándar de definición de estructura. El formato estándar es administrado por el Data Mining Group (DMG). Las primeras versiones del estándar PMML están definidas a través de documentos DTD (Document Type Definition). Las versiones más modernas del estándar (versiones 2.1 y posteriores) están definidas a través de un archivo de esquema XSD (Xml Schema Definition).

29
El formato PMML representa en realidad una estructura de datos con una o varias subestructuras. Las subestructuras pueden representar diferentes algoritmos de minería de datos. Un archivo PMML puede incluir definiciones de diferentes modelos de minería de datos. Podría, por ejemplo, incluir la definición de un modelo de regresión lineal y un modelo de redes neuronales. Cada uno de los tipos de modelos está definido en un tipo de estructura diferente. Existe una estructura que permite definir los modelos de regresión lineal, por ejemplo, y otra estructura que permite definir los modelos de redes neuronales. 2.4.2 Estructura de regresión en pmml. El modelo de minería de datos empleado en el modelo de otorgamiento de Coomeva corresponde al algoritmo de regresión logística multinomial. El cual maneja una serie de estructuras concretas de acuerdo a la versión de PMML utilizada.
• Estructura general de PMML Un archivo PMML es fundamentalmente un archivo XML que sigue un esquema definido. Desde la versión 2.1 este esquema está definido a través de un esquema XSD, por lo cual es necesario definir un namespace por defecto. Un documento PMML incluye un elemento raíz con el tipo PMML, que define la versión y el namespace por defecto. El namespace por defecto establece, el archivo XSD a utilizar, uno diferente de acuerdo a la versión del PMML. Un archivo PMML en versión 2.1 incluye un elemento raíz como el que se muestra en el ejemplo. Código 1. Esquema general de un archivo PMML
<?xml version="1.0" > <PMML version="2.1" xmlns="http://www.dmg.org/PMML-2_1" xmlns:xsi="http://www.w3.org/2001/XMLSchema-insta nce" > <Header copyright="Example.com"/> <DataDictionary> ... </DataDictionary> ... modelos de minería ... </PMML>
El archivo PMML, en versión 2.1 tiene una estructura general como se detalla en el siguiente esquema XSD.

30
Código 2. Estructura General de un archivo PMML 2.1
<xs:element name='PMML'> <xs:complexType> <xs:sequence> <xs:element ref='Header'/> <xs:element ref='MiningBuildTask' minOccurs='0' maxOccurs='1'/> <xs:element ref='DataDictionary'/> <xs:element ref='TransformationDictionary' minO ccurs='0' maxOccurs='1'/> <xs:sequence minOccurs='0' maxOccurs='unbounded '> <xs:choice> <xs:element ref='TreeModel'/> <xs:element ref='NeuralNetwork'/> <xs:element ref='ClusteringModel'/> <xs:element ref='RegressionModel'/> <xs:element ref='GeneralRegressionModel'/> <xs:element ref='NaiveBayesModel'/> <xs:element ref='AssociationModel'/> <xs:element ref='SequenceModel'/> </xs:choice> </xs:sequence> <xs:element ref='Extension' minOccurs='0' maxOc curs='unbounded'/> </xs:sequence> <xs:attribute name='version' type='xs:string' us e='required'/> </xs:complexType> </xs:element>
El esquema define al elemento PMML, el elemento raíz del archivo. Elemento que incluye el atributo versión obligatorio, definiendo el tipo de PMML que está siendo definido. Básicamente el archivo incluye un encabezado y un diccionario de datos obligatorios. Un encabezado que define el nombre y la versión de la aplicación que ha generado el archivo y un diccionario de datos que define los tipos de datos y las restricciones de los valores que son entradas y salidas de los modelos de minería definidos en el archivo. Adicionalmente, opcionalmente, el archivo puede definir una Tarea de Construcción y/o un Diccionario de Transformación, que define el conjunto de tareas de preprocesamiento que se pueden requerir para ejecutar los modelos. El archivo puede definir tareas de sumatorias, productos, generación de promedios y otros que sean requeridos para ejecutar los modelos. Un archivo puede definir cero, uno o muchos modelos de minería de datos. Modelos que pueden ser de diferentes tipos de acuerdo a la versión de PMML usada. Cada versión de PMML incluye un listado de tipos de modelos que pueden

31
ser definidos. Cada versión ha incluido nuevos tipos de modelos. Para el caso de la versión 2.1, el PMML permite definir uno o varios modelos de árboles, redes neuronales, clusters, regresiones, redes Naive Bayes, reglas de asociación o modelos de secuencia.
• Modelos de regresión en PMML 2.1 .Los diferentes tipos de regresión se incluyen en un único tipo de estructura. Básicamente un elemento “RegressionModel” que incluye información del algoritmo utilizado y las matrices de valores del modelo. Un ejemplo de elemento RegressionModel para una regresión logística multinomial en versión PMML 2.1. se presenta a continuación Código 3. Modelo de regresión en PMML 2.1
<RegressionModel functionName="classification" modelName="Ejemplo de regresión logística" modelType="logisticRegression" normalizationMethod="none" targetFieldName="job"> <RegressionTable intercept="46.418" targetCategory="clerical"> <NumericPredictor name="age" exponent="1" coefficient="-0.132"/> <NumericPredictor name="work" exponent="1" coefficient="7.867E-02"/ > <CategoricalPredictor name="sex" value="0" coefficient="-20.525"/> <CategoricalPredictor name="sex" value="1" coefficient="0"/> <CategoricalPredictor name="minority" value=" 0" coefficient="-19.054"/> <CategoricalPredictor name="minority" value=" 1" coefficient="0"/> </RegressionTable> </RegressionModel>
En el caso de PMML 2.1 toda la información del modelo de regresión se halla en una única matriz. La matriz define por cada una de las categorías de predicción, los diferentes parámetros del modelo (predictores), el tipo de predictor (numérico o categorial) y el factor coeficiente.

32
• Modelos de regresión en PMML 3.1. En PMML 3.1, el modelo de regresión se define en un elemento “RegressionModel”, de forma similar al PMML 2.1. Pero la estructura permite la inclusión de una serie adicional de extensiones, los predictores están definidos en el diccionario de datos y la matriz de regresión solo define los coeficientes. Para un modelo de regresión logística multinomial, las variables y predictores deben estar definidas en el diccionario de datos del documento. Código 4. Modelo de Regresión en PMML 3.1
<?xml version="1.0" ?> <PMML version="3.1" xmlns="http://www.dmg.org/PMM L- 3_1" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instanc e"> <Header copyright="DMG.org"/> <DataDictionary numberOfFields="5"> <DataField name="age" optype="continuous" dat aType="double"/> <DataField name="work" optype="continuous" da taType="double"/> <DataField name="sex" optype="categorical" da taType="string"> <Value value="0"/> <Value value="1"/> </DataField> <DataField name="minority" optype="categorica l" dataType="integer"> <Value value="0"/> <Value value="1"/> </DataField> <DataField name="job" optype="categorical" da taType="string"> <Value value="clerical"/> </DataField> </DataDictionary> :
El modelo de regresión hace referencia a las variables definidas en el diccionario de datos. Estableciendo los valores que son objetivo de predicción y los coeficientes del algoritmo.

33
Código 5. Matriz de Parámetros en PMML
<RegressionModel modelName="Sample for logistic regression" functionName="classification" algorithmName="logisticRegression" normalizationMethod="softmax" targetFieldName="jobcat"> <MiningSchema> <MiningField name="age"/> <MiningField name="work"/> <MiningField name="sex"/> <MiningField name="minority"/> <MiningField name="job" usageType="predicte d"/> </MiningSchema> <RegressionTable intercept="46.418" targetCat egory="clerical"> <NumericPredictor name="age" exponent="1" c oefficient="-0.132"/> <NumericPredictor name="work" exponent="1" coefficient="7.867E-02"/> <CategoricalPredictor name="sex" value="0" coefficient="-20.525"/> <CategoricalPredictor name="sex" value="1" coefficient="0.5"/> <CategoricalPredictor name="minority" value ="0" coefficient="-19.054"/> <CategoricalPredictor name= "minority" value="1" coefficient="0"/> </RegressionTable> </RegressionModel> </PMML>
• Modelos de regresión en PMML de SPSS. Los aplicativos de SPSS generan los archivos PMML en un formato diferente, basado en la versión 3.1 pero con una serie de extensiones e información adicional para el proceso estadístico y análisis gráfico. Información adicional que no es necesariamente relevante para la ejecución del modelo predictivo. El formato usado por SPSS está definido en un archivo separado para los diferentes tipos de modelos de minería. El modelo de regresión logística está definido el archivo “spss-logreg-1.0.xsd”. El modelo incluye una serie de matrices diferentes a las definidas en el estándar PMML, incluyendo información de covarianza, relación entre variables y otros factores que no son requeridos en el estándar y que no son necesarios para la ejecución del modelo predictivo.

34
2.4.3 Software para el procesamiento de pmml. Con el fin de procesar el modelo de minería de datos en PMML y poder ser usado en la aplicación de modelo de otorgamiento para Coomeva, varias librerías y aplicaciones de software fueron evaluadas y analizadas. Algunas librerías y aplicaciones de código abierto (opensource) y otras librerías y aplicaciones comerciales. Los productos de código abierto analizados se relacionan a continuación: Tabla 1. Productos evaluados de código abierto para ejecutar PMML
Producto Soporte PMML
Comentarios
Augustus http://augustus.sourceforge.net/
Soporta PMML 2.1, 3.0 y 3.1
Soporta el uso de scoring con tareas de preprocesamiento y con varios tipos diferentes de procesamiento. El software esta en Python y, de acuerdo a las políticas de Coomeva, no podría usarse en aplicativos corporativos.
Rattle http://rattle.togaware.com/
Soporta PMML 2.1
El software esta en R, y de acuerdo a las políticas de Coomeva, no podrá usarse en aplicativos corporativos
Weka http://www.cs.waikato.ac.nz/ml/weka/
No soporta PMML
No soporta la lectura de modelos en PMML.
RapidMiner (Yale) http://rapid-i.com/
Soporta la grabación de PMML v.2.1
No soporta la lectura de modelos en PMML.
AlphaMiner http://www.eti.hku.hk/alphaminer
Soporta la grabación de PMML v.2.1
No soporta la lectura de modelos en PMML.
Los productos comerciales analizados se relacionan en la tabla a continuación:

35
Tabla 2. Productos evaluados comerciales para ejecu tar PMML
Producto Soporte PMML Comentarios Clementine 11 Soporta PMML 3.1 El software está basado en java, pero
ejecuta el modelo de minería empleando una librería en código nativo. No puede usarse en aplicaciones sin comprar licencias adicionales.
SPSS v16 Soporta PMML 3.1 El software está basado en java, pero ejecuta el modelo de minería empleando una librería en código nativo. No puede usarse en aplicaciones.
DB2 Datawarehouse Edition v.9.1
Soporta PMML 3.0 y 3.1.
La librería de scoring de Java utiliza una serie de procedimientos almacenados DB2 con librerías en código nativo. No puede usarse en aplicaciones sin comprar licencias adicionales.
DB2 Intelligent Miner Scoring v8.2
Soporta PMML 1.1, 2.0 y 2.1
La librería de scoring en Java utiliza una serie de procedimientos almacenados con librerías en código nativo. Las librerías deben instalarse en una base de datos DB2 u Oracle. Ya no es posible licenciar este software por fuera del producto de DB2 Datawarehouse Edition.
2.5 IMPORTAR UN MODELO PMML EN CLEMENTINE El lenguaje de marcado de modelos predictivos (PMML), es un estándar basado en XML que permite a una aplicación de minería de datos intercambiar modelos predictivos con otras aplicaciones. Usando este formato, es posible por ejemplo, exportar un modelo de SPSS y cargarlo en SPSS Clemetine para su ejecución o consulta. Con el fin de construir la aplicación, se espera hacer uso del estándar PMML para importar las definiciones obtenidas en la herramienta SPSS Clementine por parte del grupo estadístico de Coomeva y ejecutarlo como parte del sistema del modelo de otorgamiento. En cada punto del proceso de minería de datos, la interfaz visual de Clementine implica el uso de técnicas empresariales. Los algoritmos de modelado, tales como predicción, clasificación, segmentación y detección de asociaciones, garantizan la

36
obtención de modelos exactos y potentes. Los resultados del modelo se pueden distribuir y leer fácilmente en bases de datos, SPSS y en una amplia variedad de aplicaciones En esta ruta de datos existe una secuencia de operaciones y los datos fluyen registro por registro desde el origen pasando por cada manipulación y, finalmente, llega al destino, que puede ser un modelo o un tipo de datos de resultados. Coomeva suministró un modelo entrenado en Clementine y SPSS, un conjunto de datos de prueba y un conjunto de datos obtenidos después de ejecutar el modelo entrenado. Se utilizó Clementine para ejecutar el modelo y verificar que los resultados obtenidos fueran los correctos y los mas precisos posibles, debido a que SPSS y Clementine manejan algoritmos diferentes, es necesario establecer el algoritmo que se debe utilizar en el sistema. De esta forma, si se modifica el PMML, el programa funcionará de acuerdo a lo esperado por los usuarios de Coomeva Financiero. En la figura 2 se muestra un flujo de trabajo en SPSS Clementine en donde se muestra una fuente de datos en Excel (de donde se extraen los datos) y los modelos de minería importados. Los modelos de minería se ven como unas poliedros de color amarillo sobre los cuales podemos hacer consultas. El resultado de aplicar los datos de Excel se muestra en unas tablas adicionales que pueden ser visualizadas en pantalla o exportadas a otros archivos o bases de datos.

37
Figura 2. Ejemplo de flujo de trabajo en SPSS Cleme ntine
2.6 EJECUCIÓN DE UN MODELO EN CLEMENTINE Para poder ejecutar un modelo de SPSS Clementine es necesario especificar la correspondencia de las variables de la fuente de datos con los parámetros del modelo de minería. Es necesario indicar las columnas de las fuentes de datos que se deberían usar como parámetros del modelo de minería de datos. Para el caso de las pruebas se tomaron los archivos de datos y se hicieron asignaciones automáticas de los tipos de datos y rangos de valores. Luego de manera manual es necesario asignar las variables de entrada y de salida del modelo predictivo. Para nuestro caso, varias variables de entrada y una sola variable de salida (probabilidad de incumplimiento).

38
Figura 3. Definición de variables en SPSS Clementin e.
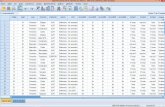
Una vez definidas las variables, estas pueden ser visualizadas y revisadas en el mismo entorno de trabajo de SPSS Clementine. La figura muestra el conjunto de datos de prueba extraídos de Excel. Figura 4. Revisión de datos en SPSS Clementine
Después de importar y ejecutar el modelo PMML generado en SPSS y Clementine podemos observar los resultados arrojados por el modelo entrenado que define si va a cumplir o no con el crédito y las probabilidades de incumplimiento.

39
El archivo PMML exportado del SPSS y Clementine incluye toda la información para ejecutar la predicción usando el modelo. El modelo recibe unos valores de entrada, que se convierten en una serie de parámetros. Si las variables son categoriales o discretas, se convierten en parámetros para cada tipo de valor. Si las variables son de valor o continuas se convierten en un solo parámetro. La siguiente imagen muestra cada uno de los valores de entrada y las variables de predicción que definen si una persona va a cumplir o no con el crédito y las probabilidades de incumplimiento. Fígura 5. Visualización de resultados del modelo en SPSS Clementine
2.7 COMPARACIÓN DE RESULTADOS EN SPSS Y SPSS CLEMEN TINE Como parte del proyecto, se revisaron los resultados del modelo de minería aplicado en SPSS y SPSS Clementine. En las pruebas realizadas se obtienen los resultados precisos y se observan diferencias en las probabilidades calculadas por el SPSS y por el PMML importado a SPSS Clementine. El modelo exportado a PMML en SPSS y subido a SPSS

40
Clementine genera dos variables de resultado, una es la clasificación ($X-INCUMPLE que toma el valor 0 si el cliente no incumplirá y 1 si el cliente incumplirá) y otra es la probabilidad ($XC-INCUMPLE). Cuando en la variable de clasificación $X-INCUMPLE el modelo arroja para un cliente el valor 0, se debe hallar el complemento de la variable $XC-INCUMPLE (1 - $XC-INCUMPLE) y el valor resultante es el que corresponde a la probabilidad de que incumpla.

41
3. ANTECEDENTES Las diferentes crisis financieras han hecho que los bancos sean cada vez más cautelosos en el manejo de sus riesgos y operaciones. La profunda crisis financiera de 1994 que llevó a la quiebra a una gran cantidad de empresas y bancos en México, Venezuela y todo Suramérica, fue uno de los principales factores de alerta. Con el fin de prevenir estos posibles colapsos financieros, los principales bancos a nivel mundial han establecido una serie de acuerdos que permiten regular su comportamiento y definir parámetros para sus procesos regulatorios. Acuerdos que se han definido normalmente a partir de un Comité de Supervisión Bancaria en Basilea (Suiza). Los acuerdos del comité de supervisión bancaria, conocidos como Acuerdos de Basilea, se establecieron en 1988 (Basilea I) y fueron revisados posteriormente en 2004 (Basilea II). Los acuerdos recogen pautas para la adecuación de capital y sirven como la base para que instituciones financieras, incluyendo cooperativas de ahorro y crédito, determinen sus requerimientos de capital. Este modelo define una metodología estándar para calcular la proporción de capitales sobre bienes, o la cantidad de capital en una institución financiera sobre los bienes de esa institución de acuerdo al riesgo. Con el reconocimiento del Fondo Monetario Internacional y del Banco Mundial como una buena práctica internacional, el gobierno colombiano ha establecido una serie de normas que garanticen su aplicación en nuestro país desde 2002. A partir de esas medidas los bancos en Colombia deben implementar un sistema de administración de riesgo crediticio (SARC). Normas de obligatorio cumplimiento por todas las entidades financieras. Los sistemas SARC típicamente involucra el establecimiento de estrategias de minería de datos que permitan determinar con mayor certeza el nivel de riesgo que maneja una institución financiera. La idea es lograr determinar el nivel de riesgo que afronta una organización en sus operaciones crediticias y cubrimiento de pérdidas esperadas con la construcción de provisiones. El SARC se ocupa de forma integral de todas y cada una de las etapas del ciclo de crédito (otorgamiento, seguimiento, control, recuperación, etc.) La Cooperativa Coomeva Financiera desarrolla actividades propias de una institución financiera, incluyendo préstamos y otros tipos de operaciones bancarios. Para el desarrollo de estas actividades, la cooperativa ha debido establecer modelos de riesgo que le permitan cumplir con las exigencias de ley en torno del Sistema de Administración de Riesgo Crediticio.

42
En un principio Coomeva utilizaba SPSS, una herramienta líder en tecnología de análisis predictivo, capaz de dirigir y automatizar las decisiones del negocio que permitían obtener una pequeña ventaja competitiva en el mercado, pero el énfasis de esta herramienta era solucionar problemas estadísticos y no se trabajaba con un enfoque de minería de datos. En la búsqueda de una herramienta más adecuada, que permitiera realizar los análisis de riesgo basado en modelos predictivos, se optó por incorporar el producto Clementine de SPSS. Herramienta de Minería de Datos que permite soportar la implementación de los modelos predictivos y de análisis que permitiesen analizar los recaudos y el nivel de riesgo del conjunto de créditos de la institución. La Cooperativa Coomeva Financiera seleccionó a Clementine debido a que, como resultado de la evaluación, se estableció como una herramienta que apoya el ciclo completo de Minería de Datos, y está diseñada de acuerdo a los estándares de la industria de Minería de Datos en términos de técnicas y algoritmos de minería y de la metodología de aplicación – CRISP-DM (Cross Industry Standard Process for Data Mining) desarrollado y respaldado por un consorcio de algunas de las mayores compañías en la industria de la minería de datos, el cual abarca todo el ciclo de vida de un proyecto de minería de datos. En la metodología CRISP-DM, el proceso de minería de datos se divide en seis fases: análisis del problema, análisis de los datos, preparación de los datos, modelado, evaluación y desarrollo. La metodología CRISP-DM hace de Minería de Datos un proceso de negocio al enfocar la tecnología de Minería de Datos en resolver problemas de negocio específicos. El principal énfasis de todo el proceso se centra entonces en hallar y resolver modelos de los problemas de negocio. Los primeros proyectos de Minería de Datos al interior de la Cooperativa Coomeva Financiera se centraron entonces en brindar el soporte adecuado a los procesos de administración de riesgo crediticio. Trabajo centrado en la fundamentación del sistema de administración de riesgo crediticio y la constitución de un esquema de calificación crediticia para los diferentes clientes y asociados a la cooperativa. 3.1 HERRAMIENTAS DE MINERÍA EN FINANCIERA COOMEVA La Cooperativa Multiactiva y la Financiera Coomeva cuentan en la actualidad con varias herramientas de software que puedan aplicarse para desarrollar modelos de minería de datos. Las herramientas de software revisadas son: • SPSS Clementine 9 • SPSS 15

43
• SQL Server 2005 Analytical Services (opción de SQL Server 2005) • Oracle Data Miner 10g (opción de Oracle Database 10g Enterprise) 3.2 SPSS CLEMENTINE SPSS Clementine es uno de los productos líderes del mercado de minería de datos, junto con las aplicaciones de SAS. Uno de las principales características de SPSS Clementine, es la interfaz de usuario basada en flujos de trabajo. Esta interfaz permite en un solo entorno de trabajo, definir los procesos y transformaciones para construir los modelos de minería de datos, así como los reportes y consultas sobre el modelo. SPSS Clementine incluye soporte a la metodología CRISP-DM. Los proyectos se organizan en una serie de carpetas por cada una de las etapas de la metodología y es posible hacer seguimiento al proyecto allí mismo en el aplicativo. SPSS Clementine ofrece soporte a una gran cantidad de algoritmos diferentes de minería de datos. Incluyendo modelos de regresión y de redes neuronales. Adicionalmente ofrece soporte para importar y exportar modelos PMML de acuerdo a la versión 3.1 y al formato con extensiones de SPSS. SPSS Clementine incluye una aplicación cliente desarrollada en Java, en donde se definen, visualizan y consultan los modelos de minería de datos. Los algoritmos de minería, sin embargo, están contenidos en unos archivos compilados (.DLL), lo que hace suponer que algunos de los procesos se hacen en código nativo por razones de velocidad. El SPSS Clementine incluye un servidor central de procesamiento que es usado por la aplicación cliente y puede ser utilizado remotamente por aplicaciones de usuario. 3.3 SPSS SPSS es una de las herramientas de procesamiento estadístico líderes en el mercado. Usando la herramienta es posible realizar procesamiento estadístico avanzada para una gran variedad de aplicaciones, incluyendo procesamiento de encuestas, mejoramiento continuo y minería de datos. SPSS no incluye una interfaz de usuario especialmente diseñada para proyectos de minería de datos, ni incluye un soporte directo a la metodología CRISP-DM. En su lugar, la aplicación ofrece una gran variedad de herramientas para procesar conjuntos de datos y puede ser usada por personal especializado en la realización de un sinnúmero de experimentos y técnicas.

44
SPSS ofrece soporte a varios algoritmos de minería de datos y soporta el uso de PMML para exportar e importar modelos. Las versiones anteriores de SPSS utilizaban la versión PMML 2.1. La versión 15, usada en la actualidad en Coomeva, utiliza la versión PMML 3.1 con extensiones de SPSS, con el cual es posible interactuar directamente con SPSS Clementine. Al igual que SPSS Clementine, el software parece ser una combinación de módulos escritos en Java y en código nativo. Algunas de las librerías son compartidas entre las dos herramientas. 3.4 SQL SERVER ANALYTICAL SERVICES Microsoft SQL Server es el servidor de bases de datos de Microsoft. Desde la versión SQL Server 2000 incluye una serie de opciones para la creación y consulta de sistemas de bodegas de datos y herramientas analíticas en línea (OLAP) y soporte a unos primeros modelos de minería de datos. Este servicio inicialmente conocido como OLAP Services ahora se conoce como Analytical Services. En Microsoft SQL Server 2005 Analytical Services, se incluye un modelo unificado de trabajo que permite construir modelos de bodegas de datos y de minería de datos usando sentencias parecidas a SQL y usando el mismo conjunto de herramientas. Microsoft SQL Server 2005 Analytical Services provee un conjunto de algoritmos de minería de datos que pueden ser extendidos por el usuario. El sistema ofrece un API que permite que los desarrolladores construyan nuevos modelos de minería de datos y usarlos en las mismas herramientas e interfaces, tal como si fuesen algoritmos incluidos en la aplicación. Microsoft SQL Server 2005 Analytical Services permite importar y exportar modelos de minería de datos empleando PMML 2.1, pero no soporta esto para todos los tios de algoritmos. En la actualidad, no puede interactuar directamente con modelos creados en SPSS Clementine o SPSS. 3.5 ORACLE MINERIA DE DATOS Oracle ofrece como una opción de su sistema de base de datos, una serie de módulos de minería de datos. En las versiones de la base de datos Oracle Database 9i y anteriores, las herramientas de minería de datos eran aplicaciones separadas del sistema, desarrolladas en Java y conocidas como Oracle Darwin. A partir de la versión Oracle Database 10g, las herramientas de minería están integradas al motor de la base de datos y ofrecen un nivel superior de rendimiento y capacidad de procesamiento.

45
En la actualidad, existe un producto conocido como Oracle Data Miner que permite definir y ejecutar remotamente los modelos de minería de datos y una serie de módulos internos en el sistema de base de datos que incluyen las funcionalidades de entrenamiento y consulta de los modelos. Los módulos de minería de datos son opciones del servidor de base de datos Oracle Database Enterprise 10g y debe licenciarse por separado. Los sistemas de minería de datos de Oracle soportan una gran cantidad de algoritmos de minería, incluyendo algoritmos avanzados de bioinformática (como Blast) que normalmente no se encuentran en este tipo de herramientas. Los aplicativos clientes de Oracle están en Java y el sistema en general incluye una serie de APIs en Java y PL/SQL que permiten ejecutar y consultar los modelos de minería desde las aplicaciones de negocio. 3.6 CUADRO COMPARATIVO Con el fin de resumir algunos de los temas revisados de las diferentes herramientas, se presenta a continuación una tabla resumen. Tabla 1. Cuadro comparativo de herramientas de Mine ría Característica SPSS
Clementine SPSS Oracle SQL Server
Algoritmos soportados
Predicción y Clasificación: Red neuronal, Arboles decisión, Inducción de reglas, Regresión lineal, Regresión logística, Regresión logística multinomial. Cluster: Red de Kohonen, K medias, Conglomerado Two Step Detección de asociaciones: GRI, A priori y diagrama de Malla Reducción de datos: Análisis factorial y de
Análisis estadístico (Correlación, regresiones,...) Con algoritmo de aprendizaje: •Redes neuronales y algoritmos genéticos • Inducción de árboles y reglas Otros algoritmos: • Inducción de reglas de asociación • Inducción de clasificadores bayesianos
Algoritmos de clasificación, regresión, cluster, asociaciones, detección de anomalías, minería de texto, importancia de atributos y extracción de características. Incluye algoritmos avanzados de Naive Bayes, árboles de decisión, redes adaptativas, máquinas de soporte vectorial (SVM), Cluster O-cluster y Blast
Algoritmo de clasificación: -Arboles de decisión Algoritmos de Regresión -Series de Tiempo Algoritmos de Segmentación: -Clústeres Algoritmos de Asociación -Asociación Algoritmos de Análisis de secuencia -Clústeres e secuencia

46
componentes principales.
entre otros.
Modelo de Regresión Logística Multinomial
Si Si Si Si
PMML versión 3.1 con extensiones de SPSS
versión 3.1 con extensiones de SPSS
versión 2.1-3.2. (No se revisó el funcionamiento de extensiones de SPSS)
versión 2.1 (no se soportan todos los modelos)
Integración con la base de datos
Uso de JDBC y ODBC
Uso de JDBC y ODBC
Integración nativa solo con Oracle
Integración nativa solo con SQL Server
Integración con aplicaciones
APIs en Java (estándar JDM) y XMLA
APIs en Java APIs en Java (estándar JDM) y PL/SQL
APIs en .Net (DMO – Data Mining Object).
Fuente: Página Oficial de MTBase [en línea], Algoritmos de Minería de Datos, España: Microsoft Corporation,2008 [consultado 01 de septiembre de 2007]. Disponible en Internet: http://technet.microsoft.com/es-es/library/ms175595.aspx

47
4. OBJETIVOS 4.1 OBJETIVO GENERAL El objetivo del proyecto es desarrollo e implementación de un Servicio de Software que permita ejecutar modelos predictivos de minería de datos, para el Otorgamiento Crediticio de la Financiera Coomeva. 4.2 OBJETIVOS ESPECIFICOS • Analizar los principios básicos de la aplicación de minería de datos en un problema de negocio empleando una metodología como CRISP-DM • Analizar los principales componentes de las herramientas de minería de datos Clementine. • Analizar los principales componentes de las herramientas de minería de datos y revisar las diferencias y similitudes de las herramientas SPSS y Clementine • Revisar una solución actual de minería de datos aplicada para la calificación crediticia al interior de la Cooperativa Coomeva Financiera. • Implementar un modelo predictivo, aplicable para la calificación crediticia, empleando Clementine • Desarrollar el Servicio Web del modelo de otorgamiento, de acuerdo a los requerimientos definidos. • Construir el mecanismo de ejecución del modelo de minería en PMML. • Construir las librerías clientes del servicio web de acuerdo al estándar de Coomeva • Construir un programa de ejemplo, para ejecutar pruebas del servicio.

48
5. JUSTIFICACION El proyecto de "Implementación de un modelo predictivo de minería de datos utilizando Clementine" se justifica gracias a la variedad de beneficios que acarrea tanto para la compañía Geniar Architect, la Universidad y los autores del mismo. Para Geniar Architect, el proyecto representa una oportunidad ideal para consolidar una metodología de trabajo para proyectos de minería de datos y para establecer consideraciones sobre el uso de herramientas de minería para este propósito en sus clientes. Para la empresa, el proyecto representa la oportunidad de consolidar la experiencia propia y de uno de sus clientes más grandes, en la consolidación de una metodología de trabajo que pueda aplicarse en otros clientes de diferente tamaño, representa la oportunidad de evaluar y conocer las herramientas de minería de datos de Clementine y sus posibilidades en la solución de problemas de negocio. Representa el primer paso para consolidar un grupo de expertos en inteligencia de negocios en minería de datos, tendiente a la certificación de los profesionales y a la certificación de competencias de la compañía en el área Para la Universidad Autónoma de Occidente, el proyecto aporta un conjunto de experiencias prácticas, y un caso real de aplicación de minería de datos, que le permite a los miembros de la Facultad aprender sobre el tema, iniciar nuevos proyectos de investigación al respecto y sentar las bases para consolidar cursos, talleres y proyectos de investigación posteriores sobre la aplicación de técnicas de minería de datos en aplicaciones de negocio. Para la universidad, representa uno de los primeros proyectos de práctica en aplicación de minería de datos, brindando la oportunidad para crear espacios de práctica en esta área y consolidar nuevas temáticas que puedan ser seleccionadas por las empresas y estudiantes para suplir los requisitos de grado. Para los autores Diana Carolina Bedoya y Herberth Joiman Gómez, el proyecto representa una oportunidad de profundizar en un conjunto de temas que son de gran interés para su desarrollo profesional, considerando especialmente su preferencia hacia sistemas de bases de datos y esquemas de inteligencia de negocios. Representa la oportunidad de aprender más sobre los sistemas de bases de datos, el manejo de la información en las grandes empresas, las técnicas de minería de datos y las aplicaciones de estas técnicas en la solución de problemas reales de negocio. Representa la posibilidad de iniciarse en el área de consultoría en inteligencia de negocios, área que es de su interés profesional.

49
6. METODOLOGÍA Para el desarrollo del proyecto de construcción del servicio de ejecución del modelo predictivo de minería para otorgamiento crediticio al interior de Coomeva, se siguieron una serie de fases y actividades enmarcadas en el proyecto general que definió Coomeva para implementar el modelo de otorgamiento. Como parte del proyecto, Coomeva estableció el modelo de otorgamiento incluyendo el modelo predictivo de minería de datos. Geniar, por su parte, desarrolló la solución de software que permite ejecutar el modelo de minería y que cuenta con mecanismos para ser integrado al aplicativo bancario de la entidad financiera. Para el desarrollo de la solución de software, Geniar aplicó la metodología de desarrollo de aplicaciones definida al interior de la compañía. Esta metodología de trabajo permite el desarrollo de forma organizada y administrada de proyectos para la implementación de soluciones de software y la construcción de servicios y aplicaciones web. Esta metodología fue aplicada en el proyecto, buscando lograr la mayor calidad en el producto final y el mayor nivel de satisfacción del cliente. 6.1 ESQUEMA GENERAL DEL PROYECTO Para el desarrollo completo del modelo de otorgamiento para Financiera Coomeva se desarrollaron las siguientes actividades: • Definición del modelo predictivo (minería de datos) • Definición del modelo de otorgamiento • Especificación de Requerimientos • Revisión de los Requerimientos • Elaboración de los casos de uso • Diseño de la Solución • Construcción de la Solución • Aseguramiento de Calidad • Pruebas del Sistema • Despliegue de la solución Para desarrollar el modelo de otorgamiento, algunas actividades se definieron como responsabilidad del grupo de trabajo de Financiera Coomeva y otras actividades se definieron como responsabilidad de Geniar.

50
Las tareas relacionadas con la definición del modelo de otorgamiento, el modelo de minería de datos, las pruebas y el despliegue de la aplicación serían responsabilidad de Coomeva. Las tareas relacionadas con la construcción del software estarían a cargo de Geniar. Para desarrollar la fase de especificación de requerimientos y Revisión de los requerimientos se aplican metodologías de desarrollo de Software de Geniar que y una vez aprobados los requerimientos del proyecto se realizan unas actividades en la fase elaboración de los casos de uso. Para acometer el proceso de construcción del software, se aplicó la metodología de desarrollo de software definida al interior de Geniar. Metodología con una diversidad de pasos y formatos que permiten ejecutar, controlar y administrar el proyecto de forma que pueda ser ejecutado con la mayor calidad y el mayor nivel de satisfacción de los clientes. Por efecto de una serie de acuerdos de confidencialidad suscritos entre Geniar y Coomeva y entre los desarrolladores del proyecto y Geniar, algunos de los documentos, formatos y procedimientos no se presentan como parte del informe. Sin embargo, se ha procurado incluir en todo el documento información general y específica que da cuenta del trabajo realizado sin afectar los acuerdos de confidencialidad suscritos. La figura 6 resume las tareas del proyecto y las responsabilidades de Coomeva y Geniar en las mismas.

51
Figura 6. Esquema de Actividades del Proyecto
Dirección Nacional Otorgamiento y Crédito Coomeva
Geniar (Pasantía)
Definición modelo
predictivo (minería)
Definición modelo de
otorgamiento
Especificación de
Requerimientos
Pruebas del Sistema
Despliegue
Revisión de los
Requerimientos
Elaboración de casos
de uso
Diseño de la solución
Construcción de la solución
Aseguramiento de
Calidad

52
7. DESARROLLO
7.1 ESPECIFICACIONES DE REQUERIMIENTOS
Para desarrollar la especificación de los requerimientos, se aplicó la metodología de desarrollo de software implementada en Geniar y usada en ciclos de vida de desarrollo basados en requerimientos entregados por el cliente. La metodología de desarrollo de Geniar define diferentes tipos de ciclo de vida de desarrollo de acuerdo a ciertas condiciones de los proyectos como se muestra en la figura 7. De acuerdo al ciclo de vida seleccionado, una serie de fases, actividades y formatos deben desarrollarse. No todos los proyectos siguen el mismo conjunto de fases, actividades y formatos. Figura 7. Esquema de la fase de Especificación de R equerimientos
Geniar (Pasantía)
Comité de Trabajo Geniar - Coomeva
Revisión de los
requerimientos
Análisis de
Requerimientos
Validación y Verificación
Resolución inquietudes
Levantamiento
información
Modificación de
requerimientos

53
El anterior ciclo de vida fue utilizado en el proyecto ya que el usuario especificó los requerimientos y es necesario trabajar en conjunto con el cliente en la revisión y aseguramiento de calidad de los requerimientos. Normalmente el cliente desarrolla el conjunto de requerimientos y los documenta, pero deben ser analizados y revisados con el fin de lograr un conjunto adecuado de requisitos, consiste, sin contradicciones, y completo como base para la construcción del sistema de software. 7.2 REVISIÓN DE LOS REQUERIMIENTOS La Financiera Coomeva suministró un documento de soporte de requerimientos desde el punto de vista de negocio, el cual describe todas las condiciones para aplicar el modelo de otorgamiento. Este conjunto de requerimientos fue preparado por el grupo de trabajo de Coomeva a partir del análisis y revisión de los procesos, y la experiencia previa que han tenido en el modelo de otorgamiento existente el aplicativo actual y la definición de modelos de minería de datos para el manejo del riesgo crediticio. El documento de requerimientos define una serie de necesidades de procesamiento y se organiza dividido en cinco procesos: • Extracción de Información Fuente . De acuerdo a la solicitud del crédito, se extrae la información requerida del aplicativo Taylor & Johnson del sistema AS/400. Entre la información que se extrae se incluyen algunos variables sociodemográficas y crediticias del cliente para realizar los cálculos del PI y calificación de otorgamiento. • Transformación de variables . Debido a que el modelo de minería de datos requiere de las variables en un formato particular, posiblemente diferente al formato existente en el aplicativo de Taylor & Johnson, se transforman las variables que así lo requieran. • Cálculo de recomendación de otorgamiento. De acuerdo al modelo de otorgamiento definido, se ejecuta el modelo de minería en PMML, se realizan unos cálculos de acuerdo a unas tablas predefinidas en Coomeva. Al final de esta serie de pasos se obtiene la decisión sugerida y el modelo genera una recomendación de otorgamiento. • Reportes. Se genera un reporte de decisión de otorgamiento que contiene toda la información relacionada con la información básica del cliente,

54
características del crédito solicitado, perfil del cliente, Resultados de la calificación (scoring), Resultados de Capacidad de Pago y Endeudamiento Mensual. • Almacenamiento de parámetros y resultados. Para cada una de las ejecuciones del modelo, es necesario dejar un registro de todos los parámetros, variables y cálculos realizados. Esto con fines de auditoría y manejo de información histórica. El sistema debe almacenar esta información en una base de datos en el AS/400 de donde se extraerá información para la bodega de datos del sistema de administración de riesgo crediticio (SARC). En base a estos requerimientos se realiza una propuesta y determinación del tiempo del proyecto. La propuesta presenta la cotización de la consultoría para el desarrollo e implementación de un Servicio Web que soporte el modelo de Otorgamiento de Coomeva, ejecutando el modelo de minería de datos en PMML y manejando las reglas de negocio definidas por Coomeva Financiero. 7.3 ANÁLISIS DE LOS REQUERIMIENTOS Al revisar el documento de requerimientos entregado por Coomeva se encontró que el conjunto inicial incluía una serie de requerimientos funcionales, y que algunos de los temas requeridos en el desarrollo no habían sido mencionados. Entre los principales temas que se requirió información adicional, debido a que el documento no los mencionaba, se encontraron: • Necesidad de integración del servicio con Clementine para poder modificar fácilmente el modelo predictivo. • Necesidades de integración del servicio con el software bancario de Taylor & Johnson. • Modelo de Datos en el AS/400 de donde se requiere extraer la información. • Esquema de seguridad a utilizar. • Esquema de registros de auditoría a utilizar.
En cuanto a la posibilidad de integración con Clementine, se estableció que el mecanismo más apropiado era el uso de archivos en formato PMML para intercambiar la información del modelo predictivo. La idea sería que el grupo de Coomeva pueda revisar y actualizar el modelo de minería en Clementine, y se pueda actualizar fácilmente el modelo en el servicio de software que se va a construir.

55
A partir de esta revisión inicial se organizó una reunión, en donde se revisó detenidamente el documento de soporte de requerimientos para un mejor entendimiento de los requisitos y las condiciones planteadas. Entre las aclaraciones realizadas al documento en la reunión, se revisaron las siguientes: • En las pruebas iníciales por parte de Coomeva, el software de SPSS y de SPSS Clementine, al parecer ejecutan de forma diferente el modelo PMML. Es necesario importar ambos modelos PMML de forma que se pueden verificar los resultados, y determinar el mecanismo más apropiado para que funcione apropiadamente y se pueda generar el resultado de otorgamiento.
• Al ejecutar el modelo, se predice la variable de “incumple”, que determina si el cliente va a incumplir con el pago del crédito o no. Si este valor es positivo (es decir el cliente va a incumplir), la probabilidad es la que arroja el modelo. Si el valor es negativo (es decir el cliente no va a incumplir), la probabilidad que arroja es la probabilidad de cumplir con el pago. Si se desea obtener la probabilidad de incumplimiento, se calcula hallando el complemento de la probabilidad que arroja el modelo.
• Después de obtener los datos requeridos por el modelo desde el AS/400 se deben realizar unas transformaciones de las variables antes de poder ser usado por el algoritmo.
• Con los datos transformados se calcula la probabilidad de incumplimiento usando el modelo predictivo definido en PMML, con este resultado se homologa y clasifican las variables.
• De acuerdo a la probabilidad de incumplimiento y el nivel de riesgo asociado se determina la sugerencia para determinar si se otorga el crédito.
• Cuando que se ejecuta el algoritmo se debe actualizar una tabla que registra todos los datos del proceso en cada ocasión. Estos datos luego serán usados por Coomeva para actualizar una parte de la Bodega de Datos que ellos están definiendo. Este proceso de carga esta por fuera del alcance del proyecto.
• En el momento en que Taylor & Johnson realice un cambio de cualquier clase en los datos del crédito, se debe invocar al componente que se está construyendo.

56
7.4 RESOLUCIÓN DE INQUIETUDES Se realizaron las siguientes especificaciones del documento de soporte de requerimientos: • Para que la ejecución del PMML funcione correctamente y los valores obtenidos del PMML en SPSS ó Clementine sean lo más precisos posibles, se especifican las librerías y tablas a extraer del AS/400. • El proceso involucra consultar en las bases de datos de AS/400 los datos del asociado y su transformación para poder ser usados en el algoritmo. • Con los datos se realizan cálculos para determinar las probabilidades de incumplimiento usando el modelo PMML, las dos variables que arroja el PMML de acierto o no y la probabilidad de incumplimiento son el resultado que se homologa a una banda de riesgo de acuerdo a unos rangos que dependen del tipo de crédito. • Todos los datos de entradas del algoritmo, cálculos y resultados se deben almacenar en una tabla del sistema. Esta tabla es definida por Geniar como parte del software a desarrollar. • Los datos de la tabla podrán ser importados a una bodega de datos por el personal de Coomeva. Este proceso de carga esta por fuera del alcance del proyecto. Este es una primera versión del modelo de otorgamiento. El software estará basado en este primer modelo de operación del negocio. Modelo que está orientado al otorgamiento de crédito personal de asociados a la cooperativa. La idea de Coomeva Financiero es ser más específicos en el futuro e incluir nuevos tipos de modelos para otros dominios. Hoy en día el modelo no está segmentado y es el mismo para todas las líneas de crédito. En un futuro probablemente se construirán modelos específicos para cada línea de crédito. Adicionalmente, seguramente se crearán modelos para clientes que no sean asociados a la cooperativa y para compañías, no solo personas naturales. 7.5 LEVANTAMIENTO DE INFORMACIÓN Los requerimientos definidos están explicados de manera general y agrupados debido al documento de acuerdo de confidencialidad establecido entre Coomeva y Geniar.

57
7.5.1 requerimiento 001: Extracción de información fuente. Una vez autenticado el usuario en la aplicación, el sistema extrae del aplicativo Taylor la información sociodemográfica y crediticia del cliente a partir de tres variables de entrada las cuales permiten realizar el cálculo de la calificación (score), de la probabilidad de incumplimiento (PI) y la calificación de otorgamiento. 7.5.2 requerimiento 002: Transformación de Variabl es. Una vez autenticado el usuario en la aplicación se transforman las variables extraídas de a acuerdo a una tabla establecida, ya que los códigos que se usan en el sistema de Taylor & Johnson no son los mismos que se utilizan dentro del modelo de minería del AS/400. Tabla 2. Ejemplo de Transformación Requerida
Variable: Numero de hijos Variable de tipo categórica que se debe agrupar por categorías.
Categoría (valor en AS/400)
Descripción Categoría Transformación (valor en el modelo)
1 1 1 2 2, 3 1 3 4, 5 2 4 6 ó mas 2
7.5.3 Requerimiento 003: Ejecución PMML. Una vez autenticado el usuario en la aplicación se utilizan las variables transformadas y se asignan calores a los parámetros del modelo, luego se obtiene el estado del valor puntaje acierta y las probabilidades de que cumpla o no utilizando el algoritmo de regresión lineal definida en el modelo PMML. Se almacenan unas variables específicas de forma temporal en una tabla del AS/400 para que posteriormente se ingrese en la bodega de datos en una estructura predefinida. Esta tabla también podrá ser usado para efecto de tareas de auditoría y seguimiento. 7.5.4 Requerimiento 004: Calculo. Una vez autenticado el usuario en la aplicación se utiliza el valor calculado de la probabilidad de incumplimiento y se calcula el puntaje “Score” de acuerdo a una fórmula establecida y el resultado deber un número comprendido en determinado rango. Se deben extraer unas variables establecidas del AS400 aplicativo Taylor y clasificarlas de acuerdo a unas tablas e intervalos, finalmente se almacena la

58
información de las variables en la misma tabla de manera temporal establecida por Taylor donde se almacenó los resultados de la probabilidad de incumplimiento y el valor del puntaje acierta.
7.5.5 Requerimiento 005, Requerimiento 006: Calific ación. Una vez autenticado el usuario se obtienen unas variables específicas del aplicativo Taylor y se realizan unos cálculos internos de acuerdo a unas reclasificaciones y se define la zona de ubicación de la solicitud de crédito. Se almacenan en la misma tabla del aplicativo Taylor de forma temporal para que posteriormente se ingrese a la bodega de datos en una estructura predefinida. 7.5.6 Requerimiento 007: Esquema. Una vez autenticado el usuario en la aplicación con los resultados obtenidos en los requerimientos anteriores se debe utilizar una matriz predefinida para determinar la acción sugerida por la calificación (Scoring), posteriormente se almacena de forma temporal en la misma tabla donde se almacenen los resultados de los requerimientos anteriores para que posteriormente se ingrese a la bodega de datos en una estructura predefinida. 7.5.7 Requerimiento 008: Generar Reporte. Una vez autenticado el usuario en la aplicación se genera un reporte en pantalla que muestre información básica del cliente, características del crédito solicitado, perfil del cliente, resultado del Scoring, entre otros cálculos realizados, con el fin de que pueda ser observado por el analista y por la mesa de créditos. 7.5.8 Requerimiento 009: Almacenar en el AS/400. Una vez autenticado el usuario en la aplicación se requiere almacenar en la bodega de datos SARC por cliente y para cada evento (Análisis crediticio) los resultados de los requerimientos. 7.6 MODIFICACIÓN DE REQUERIMIENTOS A partir de la especificación de los requerimientos y el proceso de revisión de los mismos, se realizaron finalmente algunas modificaciones al conjunto de requerimientos. Información relacionada con estos cambios, se detallan en el acta de reunión 004 “Revisión y definición de requerimientos y prototipos de interfaz”. En el documento inicial se habían definido tres variables de entrada, a través de las cuales deberíamos obtener la información requerida para el modelo de

59
otorgamiento dentro del AS/400. Al revisar el modelo de datos y analizar la información, se encontró que las variables definidas inicialmente no estaban correctamente establecidas y que debía usarse un conjunto diferente de variables. Como aparece consignado en el acta de reunión 005 “Primer avance de la aplicación”, se definieron las nuevas variables de entrada requeridas para la consulta inicial. Usando un conjunto diferente de datos, es posible obtener la información sociodemográfica y crediticia del cliente directamente del sistema financiero de Taylor & Johnson en Coomeva. Adicionalmente, se clarificaron las fuentes de los diferentes datos requeridos. En la definición inicial de los requerimientos se habían establecido las fuentes de cada una de las variables y en algunos casos estas tablas no eran las más apropiadas para obtener la información. Se aclara, por ejemplo, que la información de actividad laboral no se obtiene de la tabla FINCLIDAT.CLIMAE cómo se tenía especificado inicialmente, sino que se obtiene de la tabla FINCLIDAT.CLIEMP donde está más completo y actualizado. Se menciona que el modelo de minería se ejecuta diferente en SPSS y en SPSS Clementine. El valor de la variable y la probabilidad se muestran de manera diferente en los dos sistemas. Se definió que se va a usar solamente el esquema de visualización utilizado por SPSS que es de mayor claridad para el grupo estadístico de Coomeva. Se propone incluir un modelo de parámetros que permita modificar los rangos de valores que significan cada una de las recomendaciones y calificaciones en las diferentes tablas. De esta forma, será posible hacer ajustes sobre el modelo de otorgamiento sin modificar la aplicación. Podrá modificarse el modelo de otorgamiento cambiando la parametrización de las tablas de clasificación. Se determinó que el modelo de parámetros introduce un conjunto de nuevos requerimientos funcionales no establecidos en la versión inicial del proyecto. 7.7 VALIDACIÓN Y VERIFICACIÓN Los requerimientos definidos nuevamente en la aplicación fueron revisados y aprobados nuevamente de forma conjunta por el grupo de Coomeva y de Geniar. Se revisó cada uno de los requerimientos definidos y se aprobaron con el cliente.

60
7.8. ELABORACIÓN DE CASOS DE USO Una vez aprobados los requerimientos del proyecto, el grupo de Geniar procedió a realizar la especificación de los casos de uso. Los casos de uso son un esquema que permite documentar claramente los requerimientos funcionales de la aplicación de forma que puedan ser desarrollados posteriormente sin inconvenientes. La siguiente figura muestra un esquema de las diferentes actividades realizadas en la fase de Elaboración de los casos de uso. Figura 8. Esquema de la fase de elaboración de Caso s de Uso
Geniar (Pasantía)
Comité de Trabajo Geniar - Coomeva
Listado de
casos de uso
Especificación de casos
de uso
Validación y Verificación
Aprobación de
casos de uso

61
7.8.1 Modelo de operación del software. Con el fin de clarificar los casos de uso, se elaboró un modelo que explica la operación del software a construir. A continuación se presenta el esquema del modelo de operación definidos para el software: Figura 9. Modelo de operación del modelo de otorgam iento
Software Taylor & Johnson
Software Modelo de Otorgamiento
(pasantía)
Comentario
Cuando se requiere dentro del proceso de otorgamiento y/o se hace algún cambio sobre los datos de la solicitud del crédito, es necesario invocar nuevamente el modelo de otorgamiento.
El software debe obtener los datos del usuario y la solicitud de crédito del sistema de Taylor & Johnson. Debido a que el software de T&J no ofrece servicios para esto, se obtienen los datos directamente de la BD en AS/400.
El software transforma los datos, convirtiendo los códigos y los valores del AS/400 en valores de parámetros válidos para el modelo de minería.
Invoca el modelo
de otorgamiento
Obtiene la información
de la solicitud
Transformación
de los datos
A

62
Software Taylor &
Johnson Software Modelo de
Otorgamiento (pasantía)
Comentario
Cálculo de la probabilidad de incumplimiento (PI) empleando el modelo de minería en PMML.
Cálculo de la calificación crediticia (Score) a partir de la probabilidad de incumplimiento y el tipo de crédito solicitado.
Clasificación de la solicitud de acuerdo a las condiciones definidas por Coomeva.
De acuerdo al cálculo de PI y nivel de riesgo se realiza la recomendación.
El software de Taylor & Johnson, toma la recomendación, almacena el resultado en el AS/400 y ejecuta el procesamiento correspondiente.
Adicionalmente, considerando que la generación de reportes que deben ser incluidas como parte del servicio, se planteó adicionalmente un modelo de operación para la generación del reporte de otorgamiento. A continuación se presenta una figura con el esquema de modelo de operación de la generación del reporte.
A
Cálculo de la
recomendación
Grabación y
procesamiento
Cálculo de PI
(uso de PMML)
Cálculo del score
Clasificación
B

63
Figura 10. Modelo de operación de la generación del reporte
Software Taylor & Johnson
Software Modelo de Otorgamiento
(pasantía)
Comentario
Como parte del proceso de otorgamiento se genera un reporte con la información de la solicitud, el nivel de endeudamiento, el score, las calificaciones y la recomendación.
De acuerdo al número de la solicitud obtiene la información del modelo de otorgamiento y genera el reporte.
El software de Taylor & Johnson ejecuta el procesamiento correspondiente.
7.8.2 Listado casos de uso. Como paso inicial del proceso de elaboración de los casos de uso, se elabora un listado de los mismos. A partir de los requerimientos y el modelo de operación propuesto, se establece un listado inicial de casos de uso. Para efectos de análisis, especificación y diseño, los casos de uso fueron clasificados en un conjunto de módulos.
Invoca el reporte
de la solicitud
Genera reporte
de la solicitud
Procesamiento
de la solicitud

64
Tabla 3. Listado de Módulos del sistema
Nº Módulo Abreviatura 001 EXTRACCION DE INFORMACION EIN 002 TRANSFORMACION TRA 003 EJECUCION EJE 004 PARAMETROS PAR 005 REPORTES RPT
El listado de casos de uso define, adicionalmente, el módulo al cual pertenece cada uno. La siguiente tabla relaciona los casos de uso definidos y los módulos a los cuales pertenecen: Tabla 4. Listado de Casos de Uso del sistema
Nº Modulo Caso de Uso CU001 EIN Conexión al AS/400 CU002 EIN Extracción De Variables CU003 TRA Transformación Variables CU004 TRA Transformación Variables CU005 TRA Transformación Variables CU006 TRA Transformación Variables CU007 TRA Transformación Variables CU008 TRA Transformación Variables CU009 TRA Transformación Variables CU010 TRA Transformación Variables CU011 TRA Transformación Variables CU012 TRA Calculo Variable CU013 TRA Calculo Variable CU014 TRA Calculo Variable CU015 EJE Calcular Probabilidad De Incumplimiento CU016 EJE Almacenar Información en el As/400 CU017 EJE Calculo Variables CU018 EJE Consulta Parámetro CU019 EJE Zona de la solicitud de variables CU020 EJE Zona de la solicitud de variables CU021 EJE Determinar Acción CU022 EJE Almacenamiento Información Consulta CU023 PAR Modificar Parámetro CU024 PAR Crear Parámetro CU025 RPT Generar Reporte Cliente Crédito

65
7.8.3 Especificación casos de uso. A partir del listado de los casos de uso, se trabajó en la especificación de cada uno. Para ellos se utilizó un formato de especificación de casos de uso definido al interior de Geniar. Ver Anexo 1. 7.8.4 Aprobación de casos de uso. Las especificación de los casos de uso fueron entregados al grupo de trabajo de Coomeva para su revisión y aprobación. Proceso que se permite revisar con mayor nivel de detalle las funcionalidades y que permite confirmar el trabajo realizado con la especificación y aprobación de los requerimientos. 7.8.5 Validación y verificación. Una vez elaboradas las especificaciones de los casos de uso, estos fueron revisados al interior de Geniar por ingenieros del grupo de Procesos y Calidad. Dentro de la metodología de desarrollo de Geniar, la especificación de los casos de uso es fundamental para continuar con el desarrollo del software. No solo es la base para la matriz de planeación del proyecto (el plan de desarrollo), sino que es el insumo para que los desarrolladores construyan el software y el grupo de procesos y calidad elabore las matrices de requerimientos de pruebas y hagan la ejecución de las mismas. Después de una reunión para efectuar la revisión de los casos de uso, se validaron con el cliente. 7.9 DISEÑO DE LA SOLUCIÓN Como parte de la metodología de Geniar, es importante definir un modelo de arquitectura de solución para todo desarrollo de software. La definición de la arquitectura establece que no es posible definir una única estructura de componentes. En realidad, la definición de la arquitectura se basa en un conjunto de diferentes perspectivas del sistema que ofrecen información diversa de los componentes. La documentación de la arquitectura de software se basa en la presentación de las vistas relevantes y en documentar la información que aplica a ellas. 7.9.1 Arquitetura usada. En cumplimiento con la normatividad ANSI/IEEE 1471-2000, es necesario revisar la lista de roles y partes interesadas (stakeholders) participantes en el desarrollo de la arquitectura. La norma recomienda contar con

66
representantes de los usuarios, directivos (compradores), desarrolladores y personal de mantenimiento. • Partes interesadas del proyecto. Para el desarrollo de la presente documentación, se ha contado con la realización de sesiones de trabajo y la participación de: • Usuarios • Desarrolladores • Personal de Mantenimiento 7.9.2 Perspectivas de análisis de arquitectura. El documento de Arquitectura de Software emplea una aproximación de múltiples vistas basadas en las partes interesadas (stakeholder), de acuerdo a la práctica recomendada en la norma ANSI/IEEE 1471-2000. Cada parte interesada en el sistema tiene preocupaciones diferentes sobre el sistema, afectando la perspectiva de análisis que emplea y la visión de la arquitectura que tiene. Las vistas de arquitectura deben ser seleccionadas de acuerdo a los diferentes intereses de las partes. Cada punto de vista (perspectiva) representa el conjunto de preocupaciones que deben ser analizados a nivel de arquitectura. Cada vista representa la aplicación de un punto de vista a un sistema en particular. Las vistas de arquitectura pueden ser divididas en tres grupos, dependiendo de los elementos que se muestran: • Vistas de Módulos, donde se representan los módulos del sistema como elementos de la arquitectura, asignando a ellos responsabilidades funcionales y equipos para su implementación. • Vistas de Componentes y Conectores, donde los elementos representan las unidades de computación (componentes) y mecanismos de comunicación (conectores) que definen la estructura de desarrollo y ejecución de las aplicaciones. • Vistas de Distribución, en donde se muestran las relaciones entre los elementos de software y los elementos en uno o más entornos externos en los cuales los productos de software son creados y ejecutados.

67
• Perspectivas seleccionadas. La siguiente tabla representa las partes involucradas en el sistema servicio web del modelo de otorgamiento de Coomeva y los puntos de vista que son incluidos para revisar sus preocupaciones. Tabla 5. Perspectivas seleccionadas de Análisis de Arquitectura
Partes Perspectivas de Análisis Usuarios - Módulos del sistema a desarrollar
- Integración del sistema Web con los sistemas transaccionales y de inteligencia de negocios existentes.
- Funcionalidades del Sistema Desarrolladores - Modelo de desarrollo de las aplicaciones
- Capas y componentes que deben desarrollarse
Personal de Mantenimiento - Facilidad de Mantenimiento - Unicidad de Cambios para el sistema
DelatIn y el Sistema SoMovil.
• Vistas seleccionadas. De acuerdo a las perspectivas de análisis revisadas, se seleccionaron un conjunto de vistas de arquitectura a documentar: • Vista de Descomposición Funcional • Vista de Capas y Componentes • Vista de Distribución Física 7.9.3 Vista de descomposición funcional. El Sistema Servicio Web del Modelo de Otorgamiento para Financiera Coomeva incluye varios módulos: • Extracción de Información • Transformación de Variables • Ejecución del Modelo de Minería (PMML) • Parámetros y Funcionamiento del Sistema • Reportes de Otorgamiento

68
Figura 11. Esquema de Vista de Arquitectura Funcion al
Cada uno de los módulos incluye un conjunto de funcionalidades específico de acuerdo al alcance definido para el proyecto. • Extracción de Información • Transformación de Variables • Ejecución del Modelo de Minería (PMML) • Parámetros y Funcionamiento del Sistema • Reportes de Otorgamiento 7.9.4 Vista de capas y componentes. El Sistema Servicio Web del Modelo de Otorgamiento se basa en un modelo de arquitectura en 3 capas:
• Una capa de Presentación , encargada de la visualización de los datos, la exposición de servicios y el manejo de los eventos de la interfaz de usuario. • Una capa de Lógica de Dominio , encargada del manejo de validaciones, reglas y procesos de negocio de la aplicación.
Sistema Servicio Web Modelo
de Otorgamiento Coomeva
<<Módulo>>
Extracción de
Información
<<Módulo>>
Transformación de
Variables
<<Módulo>>
Parámetros y
Funcionamiento
<<Módulo>>
Ejecución del Modelo
PMML <<Módulo>>
Reportes de
Otorgamiento

69
• Una capa de Acceso a Datos , encargada del acceso a los datos en las otras aplicaciones y en bases de datos. Figura 12. Esquema de Arquitectura de Tres Capas
Con el fin de facilitar el desarrollo y contar con un mecanismo simple de despliegue y operación, el modelo se basa en objetos planos (conocido como POJOs, Plain Old Java Objects), y no en un esquema basado en componentes empresariales (EJB, Enterprise Java Beans) o en un Bus de Servicios (ESB, Enterprise Service Bus). El esquema basado en objetos planos, permite desarrollar toda la aplicación empleando un esquema basado en objetos de entidad transversales a todas las capas. Los objetos de entidad que se obtienen a partir de la capa de acceso a datos, pueden ser utilizados en las capas de lógica de dominio y de presentación. Para hacer uso del esquema basado en objetos planos, se usan librerías que soportan este modo de operación: • Una serie de componentes en Javascript, para la visualización y edición de las hojas de cálculo directamente en el navegador web. • Java Server Faces (JSF), para la generación de pantallas y el manejo de los eventos de la interfaz de usuarios • El modelo de Expresiones de JSF o Spring, para el manejo de las configuraciones de la lógica de negocio. • Hibernate, para el manejo de la persistencia de los datos. En particular, para el acceso a los metadatos y la actualización de la base de datos.
Presentación Lógica de Dominio Acceso a Datos

70
• Apache Axis 2 como mecanismo para exponer los servicios en un modelo multicanal, incluyendo la exposición como servicios web. La capa de presentación se construye basada en el uso de Java Server Faces (JSF). Cada una de las pantallas de la aplicación es construida en un archivo separado empleando una página Java Server Pages (JSP) con los componentes Java Server Faces (JSF). Por cada uno de los formularios, con el archivo JSP con JSF, se cuenta con un objeto plano con el manejo de los campos y los eventos asociados a los formularios. Este objeto conocido como un “Backing Bean”, es un objeto que se maneja a nivel de petición web (request). Los formularios y pantallas, cuando requieren datos de la aplicación o que son mantenidos en memoria, hacen uso de otros objetos planos conocidos como “Managed Beans”. Estos objetos representan el Modelo, la representación de los datos que se obtiene de la lógica de dominio y el acceso a datos. Estos objetos se manejan a nivel de sesión de usuario (session). Figura 13. Esquema de funcionamiento de la capa de presentación
Cuando los objetos de la capa de presentación requieren ejecutar alguna operación sobre la lógica de dominio, hacen uso de una serie de objetos delegados para tal fin. Los objetos delegados son definidos a partir de una Interfaz establecida que puede ser implementada de diversas formas. El delegado es obtenido a partir de una fábrica que revisa la configuración del sistema y retorna un objeto de la clase apropiada. Este mecanismo permite aislar la capa de presentación de la implementación del manejo de la lógica de dominio, permitiendo que pueda
Presentación
JSP <<request>>
Backing Bean
<<session>>
Managed Bean

71
realizarse localmente empleando objetos planos o remotamente usando componentes de servidor (EJBs) o servicios web. Figura 14. Esquema de funcionamiento capa de lógica de dominio
El acceso a datos se realiza empleando el manejador de sesiones y de transacciones establecido en Hibernate con los objetos planos definidos como objetos de entidad.
Figura 15. Esquema de funcionamiento Capa de acceso a datos
Acceso a Datos
<<hibernate>>
Manejador
Transacciones
Presentación Lógica de Dominio
<<interfaz>>
Interfaz de
Servicio
<<clase>>
Servicio
Objetos de
Entidad

72
Figura 16. Esquema de funcionamiento de las diferen tes capas
El mecanismo de acceso a datos para actualización y consulta de los mismos se logra por medio del manejador de transacciones hibernate. Con el fin de permitir el acceso a la funcionalidad de la lógica de negocio desde otras aplicaciones, en este caso el aplicativo bancario de Taylor & Johnson, se exponer estas funcionalidades como servicios web. Para exponer estas funcionalidades se hace uso de las funcionalidades de Apache Axis 2. Para ello, basta con definir un archivo de definición de despliegue que establece los servicios que desean exponerse, las clases y métodos que ejecutan la funcionalidad y los diferentes filtros y necesidades de preprocesamiento de entrada y salida en cada uno de los canales. Normalmente solo es necesario definir filtros de preprocesamiento para el canal de servicios a través de la web.
Presentación
Lógica de Dominio
Acceso a Datos
JSP <<request>>
Backing Bean
<<session>>
Managed Bean
<<interfaz>>
Interfaz de
Servicio
<<clase>>
Servicio
Objetos de
Entidad
<<hibernate>>
Manejador
Transacciones

73
7.9.5 Vista de distribución física. El Sistema Servicio Web del Modelo de Otorgamiento de Coomeva se basa en un modelo de arquitectura en 4 niveles: • Equipos Clientes: en donde se ejecuta la presentación de la aplicación de consultas, parametrización y generación de reportes en navegadores web. Para el caso de Coomeva equipos corriendo sistemas operativos Windows con navegadores Internet Explorer y/o Mozilla Firefox. • Equipo Aplicación Bancaria: en donde funciona el aplicativo bancario de Taylor & Johnson que interactúa con la aplicación y servicio web. • Equipo Servidor de Aplicaciones: en donde funcionan el aplicativo y el servicio web y los componentes de ejecución del modelo de minería de datos. • Equipo Servidor de Base de Datos: en donde funciona la base de datos AS/400 en donde se tendrá el repositorio de información de ejecución y auditoría del sistema. Figura 17. Esquema de Vista Física de Arquitectura Para efectos de la ejecución del proyecto, se han definido varios entornos de operación:
Clientes
Windows
Navegador
Web
Servidor de Apps JBoss
Aplicación
Web
Servicio
Web
Servidor BD
AS/400
Base de
Datos
App Bancaria
AS/400
Taylor &
Johnson

74
• Entorno de Desarrollo, utilizado por los desarrolladores para la construcción del software. • Entorno de Pruebas, utilizado para hacer pruebas de integración del software y pruebas con usuarios. • Entorno de Producción, utilizado para colocar en operación definitiva la aplicación en la compañía. El entorno de desarrollo se ha configurado en cada una de las máquinas de los desarrolladores. En cada uno de estos equipos, los desarrolladores usan su propio navegador y su propio servidor de aplicaciones. Situación que es bastante útil para las tareas de programación, depuración y pruebas de unidad. El entorno de desarrollo, sin embargo, no involucra de ninguna forma interacción con la aplicación Taylor & Johnson. El entorno de desarrollo fue construido en forma conjunta por ingenieros de Geniar y Coomeva, y puede en la actualidad puede ser instalado fácilmente en cualquier nuevo equipo de desarrollo. El entorno de pruebas se ha configurado en una máquina especialmente destinada en Coomeva. Una máquina especialmente acondicionada para ejecutar el servidor de aplicaciones en un entorno similar al de producción y utilizando una base de datos con información de prueba acondicionada por Coomeva. Este entorno de pruebas puede ser usado desde la aplicación bancaria Taylor & Johnson para acceder y revisar la funcionalidad del servicio. El entorno de producción, está conformado por equipos de la Financiera Coomeva en donde en la actualidad funcionan varias aplicaciones de negocio en AS/400 y Java. Servidores de alto rendimiento integrados a las aplicaciones y bases de datos reales de la compañía. 7.10 CONSTRUCCIÓN: EJECUCIÓN DEL MODELO DE MINERÍA 7.10.1 Desarrollo del software de procesamiento PMM L. Debido a la imposibilidad de procesar los PMML 3.1. de Clementine directamente en Java con un software de código abierto se optó por construir el módulo de software que fuese capaz de cargar el PMML y ejecutar el modelo logístico multinomial como lo vemos en la figura 18.

75
Figura 18. Modelo de Operación de Ejecución del PMM L
Software Modelo de Otorgamiento (pasantía)
Comentario
Procesa el archivo PMML y carga las matrices y coeficientes del modelo de regresión logística multinomial.
Toma los valores de entrada y lo convierte en parámetros del modelo de acuerdo a la matriz de entradas y parámetros obtenida del modelo PMML
Toma los valores de los parámetros y los multiplica por los valores beta de acuerdo a la matriz de coeficientes obtenida del modelo PMML.
Determina el logit sumando los valores de los valores multiplicados por los beta.
Calcula la probabilidad ejecutando fórmulas sobre el logit.
Carga el modelo del archivo
PMML
Cálculo de la
probabilidad
Determina los valores
de los parámetros
Multiplica los parámetros
por los factores beta
Cálculo
del Logit

76
• Carga del PMML. Para cargar el documento PMML se optó por usar la librería de JAXB (Java XML Binding) ya que permite la revisión de los datos en un modelo de objetos.
• Mecanismos de procesamiento XML en JAVA. Java provee varios mecanismos de procesamiento XML que podrían ser usados para cargar el documento XML. • JAXP (Java XML Processing) usando un parser DOM • JAXP (Java XML Processing) usando un parser SAX • JAXB (Java XML Binding) Al revisar los diferentes mecanismos de procesamiento, se revisaron las implicaciones para el desarrollo de la aplicación. Tabla 6. Mecanismos de procesamiento XML en Java
Librería Modelo de operación
Comentarios
JAXP, DOM Crea un árbol de objetos que representa el XML
Crea un árbol de Nodos y Elementos XML, con propiedades y métodos propios y genéricos. Requiere de métodos que permitan recorrer y procesar los diferentes nodos.
JAXP, SAX Ejecuta una serie de eventos de acuerdo a los elementos que se encuentran en el XML
Requiere de la definición de eventos que deben ejecutarse al encontrar cada uno de los nodos y elementos en el archivo XML.
JAXB Crea una estructura de objetos POJO a partir del XML
Permite crear objetos que son independientes de la librería de procesamiento y que luego pueden persistirse o visualizar fácilmente.
Luego de la revisión de los diferentes mecanismos de procesamiento se optó por el uso de JAXB.

77
• Uso de JAXB para cargar el PMML. Las librerías de JAXB permiten el mapeo de los elementos XML a un conjunto arbitrario de objetos Java. Mapeo que puede realizarse mediante anotaciones o archivos de configuración, de forma similar al mapeo que se realiza usando Hibernate o JPA para usar objetos Java y bases de datos relacionales. Una de las opciones más simples, sin embargo, consiste en generar de forma automática las clases de objetos a partir de la estructura del XML. Usando esta opción, se suministra un esquema XSD, DTD o RelaxNG, y la librería genera una clase por cada elemento definido. Para generar las clases, se usa la herramienta XJC (XML Java Compiler) incluida en el JAXB. Figura 19. Esquema de la generación de Java a parti r de XSD Al intentar generar las clases a partir de los XSD estándar de PMML se generaron errores debidos a la duplicidad de nombres del esquema. Ejemplos de los errores encontrados se relacionan en la siguiente tabla. Tabla 7. Ejemplos de errores en generación de Java a partir de XSD
Elemento Error Con No se puede crear un archivo Con en Windows o
DOS. No es un nombre válido para una clase Java. Delimiter Existen dos elementos, uno llamado “Delimiter” y
otro llamado “DELIMITER”, que aunque son diferentes en XML no pueden ser creados como clases diferentes en Java. En Windows o DOS no es posible crear dos archivos con nombres diferentes solamente en
Con el fin de poder generar las clases, se modificaron los esquemas XSD de forma que incluyesen anotaciones JXB que permitan cambiar las opciones de generación de código. Usando estas extensiones se modificó el nombre de las clases que se generan para los elementos conflictivos.
.xsd
xjc
.java

78
Tabla 3. Ejemplos de soluciones para generación de Java a partir de XSD
Elemento Solución Con Se cambió el nombre de la clase por Connection
usando una anotación. <xs:element name="Con"> <xs:annotation> <xs:appinfo> <jxb:class name="Connection" /> </xs:appinfo> </xs:annotation> <xs:complexType>
: Delimiter Se cambió el nombre de una de las clases por
SequenceDelimiter empleando una anotación. <xs:element name="Delimiter"> <xs:annotation> <xs:appinfo> <jxb:class name="SequenceDelimiter" /> </xs:appinfo> </xs:annotation> <xs:complexType>
: Los archivos de esquema XSD modificados pueden ser consultados (Anexo 10) Una vez se han generado las clases, es posible cargar la estructura de objetos empleando el API de JAXB. Código 6. Uso de JAXP para cargar un modelo PMML
// create the context JAXBContext context = JAXBContext. newInstance( // "geniar.pmml.v3r1.model" "geniar.spss.logreg.v1r0.model" ); // read the model file InputStream input = MiningModelLoader. class.getResourceAsStream( fileName); // create the unmarshaller - translator XML --> Ob jects Unmarshaller unmarshaller = context.createUnmarsha ller(); // get the object from the XML PMML pmml = (PMML) unmarshaller.unmarshal(input); return pmml;

79
7.10.2 Ejecución del modelo logístico multinomial. El archivo PMML define un conjunto de variables como parte del diccionario de datos. Este conjunto de variables representa las variables de entrada y de salida del modelo. Por ejemplo, si un modelo de minería incluyera tres variables de entrada y una de salida, estas deben aparecer como parte del diccionario de datos. Figura 20. Esquema de un modelo de minería como una función paramétrica Las variables pueden ser de dos tipos diferentes: • Variables continuas • Variables categoriales Las variables continuas son variables que pueden tomar cualquier valor numérico en un rango determinado. En estos casos, la variable puede tomar un número infinito de valores. Las variables categoriales son variables que toman valores discretos. En estos casos la variable solo puede tomar un valor de un conjunto de valores posibles. Normalmente este aplica cuando se usan rangos para convertir discreta una variable o cuando se tienen valores numéricos para representar un conjunto de valores posibles. Por ejemplo, la edad de una persona, que es un valor continuo y puede tomar infinitos valores, puede ser clasificada en rangos de valores para convertirla en una variable categorial. Por ejemplo, si se tienen cuatro rangos diferentes, la variable solo podrá tomar uno de cuatro valores. Tabla 4. Ejemplo de variable categorial (Discreta) Edad
Variable Valor Significado Edad Edad(1) Menor de 18 años Edad(2) Entre 18 y 30 años Edad(3) Entre 30 y 50 años Edad(4) Mayor de 30 años
f(a, b, c)
a
b
c
y

80
Una variable categorial, puede usarse cuando se usan valores numéricos para representar situaciones discretas del mundo real. Por ejemplo, el género o sexo de una persona, puede considerarse como una variable categorial. Tabla 5. Ejemplo de variable categorial (Discreta) Sexo
Variable Valor Significado Sexo Sexo(1) Hombre Sexo(2) Mujer
Como parte del proceso de ejecución del modelo logístico multinomial es necesario convertir las variables de entrada y salida en el conjunto de parámetros o los que predicen el modelo. • Si la variable es continua, se definirá un solo predictor con el valor de la variable. • Si la variable es categorial, se definirá un predictor por cada posible valor de la variable. El predictor que corresponda con el valor de la variable tendrá un valor de 1 y los demás predictores un valor de cero. Supongamos un modelo predictivo de probabilidad de incumplimiento que incluya tres variables de entrada: (1) edad, (2) sexo y (3) monto del crédito, y una sola variable de salida: (1) probabilidad de incumplimiento. Figura 21. Ejemplo de modelo de minería para cálcul o de PI Si la variable edad y sexo son variables categoriales de acuerdo al esquema de los ejemplos previos y el monto del crédito es una variable continua, el PMML deberá incluir un diccionario de datos de la siguiente forma. Listado 7. Ejemplo de diccionario de datos en PMML
<DataDictionary numberOfFields="5"> <DataField name="EDAD" displayName="Edad" optype="categorical" dataType="double"> <Value value="0" displayValue="menor de 18" /> <Value value="1" displayValue="entre 18 y 30" / > <Value value="2" displayValue="entre 30 y 50" / >
Cálculo de
PI
edad
sexo
monto
PI

81
<Value value="3" displayValue="mayor de 50" /> </DataField> <DataField name="SEXO" displayName="Sexo" optype="categorical" dataType="double"> <Value value="0" displayValue="hombre" /> <Value value="1" displayValue="mujer" /> </DataField> <DataField name="MONTO" displayName="Monto del cr édito" optype="continuous" dataType="double"/> <DataField name="INCUMPLE" displayName="Incumple" optype="categorical" dataType="string"> <Value value="0" displayValue="incumple" /> <Value value="1" displayValue="no incumple" /> </DataField> </DataDictionary>
Los parámetros del modelo de minería determinado, se definen en una serie de matrices adicionales. Por ejemplo, el listado de parámetros para este modelo estaría definido de la siguiente forma. Código 8. Ejemplo de listado de parámetros PMML
<ParameterList > <Parameter name="P0000001" label="Constant" /> <Parameter name="P0000002" label="EDAD(1)" /> <Parameter name="P0000003" label="EDAD(2)" /> <Parameter name="P0000004" label="EDAD(3)" /> <Parameter name="P0000005" label="EDAD(4)" /> <Parameter name="P0000006" label="SEXO(1)" /> <Parameter name="P0000007" label="SEXO(2)" /> <Parameter name="P0000008" label="MONTO" /> </ParameterList>
Para un conjunto de datos de entrada determinados, los parámetros o predictores tomarán valores específicos. Por ejemplo, si un crédito es solicitado por una mujer, de menos de 18 años con un monto de $ 12.000, los valores para los predictores serán los siguientes:

82
Tabla 6. Ejemplo de valores para los predictores Parámetro (Predictor) Valor EDAD(1) 1 EDAD(2) 0 EDAD(3) 0 EDAD(4) 0 SEXO(1) 0 SEXO(2) 1 MONTO 12000
Por ejemplo, si el crédito es solicitado por un hombre, de 42 años, por un monto de $ 20.000, los valores de los predictores serán los siguientes: Tabla 7. Ejemplo de valores para los predictores Parámetro (Predictor) Valor EDAD(1) 0 EDAD(2) 0 EDAD(3) 1 EDAD(4) 0 SEXO(1) 1 SEXO(2) 0 MONTO 20000
La conversión de las variables categoriales en parámetros por cada posible valor está definida en la mátriz de conversión de Parámetro a Parámetro. Por ejemplo, la conversión propuesta en el ejemplo, podría definirse de la siguiente forma: Código 9. Ejemplo de matriz de conversión de paráme tros en PMML
<PPMatrix > <PPCell value="1" predictorName="EDAD" paramet erName="P0000002" /> <PPCell value="2" predictorName="EDAD" paramet erName="P0000003" /> <PPCell value="3" predictorName="EDAD" paramet erName="P0000004" /> <PPCell value="4" predictorName="EDAD" paramet erName="P0000005" /> <PPCell value="1" predictorName="SEXO" paramet erName="P0000006" /> <PPCell value="2" predictorName="SEXO" paramet erName="P0000007" /> </PPMatrix >
El modelo de regresión logística multinomial incluye un conjunto de factores para cada uno de los predictores. Estos valores en el PMML están definidos en una estructura de matriz de parámetros.

83
Código 10. Ejemplo de matriz de parámetros en PMML
<ParamMatrix > <PCell targetCategory="1" parameterName="P00000 01" beta="-2.01" df="1" /> <PCell targetCategory="1" parameterName="P00000 02" beta="0.45" df="1" /> <PCell targetCategory="1" parameterName="P00000 03" beta="0.24" df="1" /> <PCell targetCategory="1" parameterName="P00000 04" beta="0.06" df="1" /> <PCell targetCategory="1" parameterName="P00000 05" beta="-0.13" df="1" /> <PCell targetCategory="1" parameterName="P00000 06" beta="0.29" df="1" /> <PCell targetCategory="1" parameterName="P00000 07" beta="0.29" df="1" /> <PCell targetCategory="1" parameterName="P00000 08" beta="-0.11" df="1" /> </ParamMatrix >
Para ejecutar el modelo se debe tomar el valor de cada uno de los parámetros y multiplicarlos por el factor beta correspondiente. Al sumar estos valores con la constante inicial se obtiene un valor conocido como logit. De acuerdo a la matriz de parámetros de ejemplo, el valor de logit sería: Logit = -2.01 + EDAD(1) * 0.45 + EDAD(2) * 0.24 + EDAD(3) * 0.06 + EDAD(4) * -0.13 + SEXO(1) * 0.29 + SEXO(2) * 0.29 + MONTO * -0.11 La probabilidad se calcula basada en este logit, aplicando la fórmula de regresión logística. Probabilidad = 1 / (1 + exp(-logit))
7.11 ASEGURAMIENTO DE CALIDAD Y PRUEBAS En la metodología de Geniar existen una serie de actividades de validación y verificación en cada una de las diferentes etapas del proyecto. Actividades que incluyen revisiones y análisis de cada uno de los entregables en cada una de las etapas, incluyendo por ejemplo, las revisiones de los casos de uso, de los requerimientos y de los artefactos de diseño y construcción. En la etapa final del proyecto, actividades adicionales de pruebas deben ser realizadas para asegurar la calidad del producto antes de ser entregado al cliente y puesto en producción.

84
Para estas actividades se establecen un conjunto de actividades que ejecuta el grupo de desarrolladores y otro conjunto de actividades que deben ser realizadas por el grupo de procesos y calidad de la compañía. La figura 22 muestra un esquema de las actividades de la fase de pruebas indicando las actividades responsabilidad del grupo de desarrollo y del grupo de procesos y calidad. Figura 22. Esquema de la fase de pruebas
Geniar (Pasantía)
Geniar (Procesos y Calidad)
Informe de entrega de
software
Ejecución de Pruebas
Validación y Verificación
Elaboración Matriz de
Pruebas (MRP)
Elaboración Informe de
Pruebas
Solución no conformidades

85
8 CONCLUSIONES La minería de datos es una herramienta relativamente nueva y su implementación es complicada y costosa en los sistemas de información. Sin embargo, su uso se esparcirá cada vez más y su utilidad será cada vez mayor orientado a la estratégica toma de decisiones y de soluciones globales al negocio que incluyan esta herramienta como otra opción disponible dentro de la gama de ofertas. Es importante resaltar que aunque los diferentes campos de aplicación de la minería de datos han demandado el surgimiento de poderosas herramientas para desarrollar estos métodos de búsqueda de patrones -que incluyen productos tales como "Intelligent Miner" de IBM o "SPSS Clementine" de SPSS, no es este el único camino, y en muchos sitios o sectores se recurre a métodos y aplicaciones propias dependiendo de las necesidades del negocio y de las herramientas con las que cuenta. Las técnicas de minería de datos pueden ser implementadas con el software y hardware existente en las organizaciones para mejorar el valor y la gestión de los recursos existentes y la toma de decisiones. En el modelo de otorgamiento utilizamos el algoritmo de regresión logística la cual se presenta como una herramienta efectiva para la predicción de probabilidades de incumplimiento, no solo a nivel de capacidad de discriminación (potencia), estabilidad a través del tiempo, sino como una herramienta de fácil entendimiento que permite potencializar sus usos y servir además de la predicción, para la planeación de estrategias comerciales de venta de servicios, estrategias de cobranza entre muchas otras. La importancia de tener un modelo de cálculo de probabilidad de incumplimiento confiable y con una alta capacidad de discriminación al interior de una entidad financiera radica en que esta impacta considerablemente el cálculo de provisiones, afectando directamente el balance y las utilidades que podría llegar a tener la entidad. Adicionalmente como los modelos son empleados para otorgamiento de créditos, mantenimiento de cuentas, hacen parte fundamental de la gestión integral de riesgo, por tanto un cálculo u operación inapropiada podría llevar a una institución financiera a situaciones de insolvencia. Es posible utilizar el lenguaje estándar PMML basado en XML para poder intercambiar los modelos predictivos en diferentes lenguajes y herramientas de Minería de datos, ya que me permite exportar e importar un modelo de Minería de datos. Gracias al diseño del mecanismo de intercambio, el PMML me permite no

86
solo utilizar modelos creados de un sistema en otro sistema, sino también incorporar la ejecución del modelo predictivo en aplicaciones de negocio. En la aplicación bancaria de Coomeva específicamente, para integrar modelos de minería a las aplicaciones de negocios de Taylor & Jhonson se pudo utilizar un modelo basado en Java que ejecuta el componente PMML y que usa la arquitectura de desarrollo de web basada en Java Server faces.

87
BIBLIOGRAFÍA Acuerdo de Basilea II [en linea]. Su Momento ha llegado Madison, Washington: Credit Unión World, 2004. [consultado 01 de septiembre de 2007]. Disponible en Internet: http://www.woccu.org/pubs/cu_world/article.php?article_id=374 Administración Integral de Riesgos [en linea] Mexico: Grupo Financiero Scotianbank Inverlat., 2004. [consultado 01 de septiembre de 2007], Disponible en Internet: http://www.scotiabank.com.mx/resources/PDFs/estados_financieros/2004/ariesgo_4t04.PDF Documento de Divulgación del Manual de Supervisión del SARC [en linea]. Aspectos formales y de cumplimiento en el otorgamiento y el seguimiento crediticio, Bogotá: Superintendencia Bancaria de Colombia,2004.[consultado 01 de septiembre de 2007], Disponible en Internet: http://www.superfinanciera.gov.co/ComunicadosyPublicaciones/supervisionsarc0805.pdf El Acuerdo de Basilea [en linea]. Estado del Arte del SARC en Colombia, Medellín: Centro de Publicaciones Universidad EAFIT, 2005. [consultado 01 de septiembre de 2007], Disponible en Internet: http://www.eafit.edu.co/NR/rdonlyres/4667142A-D120-48CE-9CE0-9CB093F15866/0/Basilea.pdf El nuevo Acuerdo de Capital de Basilea [en linea]. Documento Consultivo, Basilea: Comité de Supervisión Bancaria de Basilea, 2001, [consultado 01 de septiembre de 2007], Disponible en Internet: http://www.bis.org/publ/bcbsca03_s.pdf Metodologías para la realización de Proyectos de Data Mining [en linea]. Metodología Crisp-DM, España: Gondar Nores, José Emilio, 2004. [consultado 01 de septiembre de 2007], Disponible en Internet: http://www.estadistico.com/arts.html?20040426 PMML Standard [en linea]. Seattle: Datamining Group, PMML User Group, 2007 [consultado 02 de septiembre de 2007], Disponible en Internet: http://www.dmg.org/

88
________., version 2.1 [en linea]. Seattle: Datamining Group, PMML User Group, 2007 [consultado 02 de septiembre de 2007], Disponible en Internet: http://www.dmg.org/pmml-v2-1.html ________., version 3.1, [en linea] Seattle: Datamining Group, PMML User Group, 2007 [consultado 02 de septiembre de 2007], Disponible en Internet: http://www.dmg.org/pmml-v3-1.html ________., version 3.2, [en linea] Seattle: DATAMINING GROUP, PMML User Group, 2007 [consultado 02 de septiembre de 2007], Disponible en Internet: http://www.dmg.org/pmml-v3-2.html PMML el estándar de programación para Minería de Datos, [en linea] Latinoamérica: SAS User Group, 2005, [consultado 02 de septiembre de 2007], Disponible en Internet: http://www.lasug.org/home//index.php?option=com_content&task=view&id=47

89
ANEXOS
Anexo A. Caso de Uso: Extracción de variables
REQUERIMIENTOS FUNCIONALES
Nro. Req. Nombre Req. Fecha Módulo ó Proceso Prioridad Versión
001
Extracción de información
fuente 04-01-2008
Extracción de información
AS400 ALTA 1.0
DESCRIPCIÓN / ALCANCE DEL REQUERIMIENTO
Una vez autenticado el usuario en la aplicación
- El sistema recibe la información del cliente y necesita obtener la información relacionada con ese cliente en el sistema bancario de Taylor & Johnson
o Identificación del cliente o Número de Operación crediticia o Agencia de radicación de crédito
- Se requiere extraer del AS400 aplicativo Taylor, las variables que necesita el modelo para el cálculo del score, de la probabilidad de incumplimiento (PI) y de la calificación de otorgamiento.
- A partir de esta información se debe obtener del sistema de Taylor & Johnson los siguientes datos o Estrato

90
o Nivel académico o Valor de vehículo o Puntaje acierta de data crédito o Fecha ingreso a la cooperativa o Fecha radicación del crédito o Actividad laboral o Estado civil o Fecha nacimiento o Fecha radicación del crédito o Ítems de ingreso o Monto solicitado o Plazo del crédito
A continuación se encuentra la descripción de las variables en la fuente, la homologación de las mismas en el modelo.

91

92
Anexo B. Caso de Uso: Transformación de variables
REQUERIMIENTOS FUNCIONALES
Nro. Req. Nombre Req. Fecha Módulo ó Proceso Prioridad Versión
002 Transformación de variables 04/01/2008 Transformación de variables ALTA 1.0
DESCRIPCIÓN / ALCANCE DEL REQUERIMIENTO
Una vez autenticado el usuario en la aplicación
- La información de Taylor & Johnson extraídas del AS400 (ver CoomevaFin.ModelodeOtorgamiento.REQ.20080401_001.ExtracciónVariables) deben ser transformadas para poder ser utilizada en el modelo de minería de otorgamiento. Los códigos que se usan en el sistema de Taylor & Johnson no son los mismos que se utilizan dentro del modelo de minería. Es necesario convertir los códigos de un modelo a otro.
- Se deben convertir los siguientes códigos
• FINCLIDAT/CLIMAE.ESTRAT • FINCLIDAT/CLIMAE.TIPVIV • FINCLIDAT/CLIMAE.INDEST • Valor de Vehículo • FINCLIDAT/CLIDATACOO

93
• FINPAPDAT/PAPOTORGF • FINCLIDAT/CLIMAE.FECING • FINCLIDAT/CLIEMP.OCUPAC • FINCLIDAT/CLIMAE.ESTCIV • FINCLIDAT/CLIMAE.FECCON • FINCLIDAT/CLIMAE.CONFIN • Item de Ingreso • Monto Solicitado
- La conversión sobre las variables fuente debe realizarse de acuerdo a la tabla (CoomevaFin.ModelodeOrtorgamiento.anexo 1)

94
Anexo C. Caso de Uso: Ejecución PMML
REQUERIMIENTOS FUNCIONALES
Nro. Req. Nombre Req. Fecha Módulo ó Proceso Prioridad Versión
003 Ejecución del PMML 04/01/2008 Calculo PI ALTA 1.0
DESCRIPCIÓN / ALCANCE DEL REQUERIMIENTO
Una vez autenticado el usuario en la aplicación
- Las actividades que debe realizar este requerimiento son:
1) Tomar las variables transformadas (ver CoomevaFin.ModelodeOtorgamiento.REQ.20080401_002.Transformación Variables). 2) Asignar valores a los parámetros del modelo (revisar el archivo en Excel que se pasa a clementine anexo 2)
a. Incumplimiento
3) Calcular probabilidad de incumplimiento ejecutando la función de regresión logística definida en el modelo PMML
- La información resultante de este proceso debe ser almacenada de forma temporal en una tabla del AS400 para que posteriormente se ingrese a la Bodega de Datos en una estructura predefinida. Las variables a almacenar de este requerimiento son:
1) Número de identificación del cliente

95
2) Número de operación crediticia 3) Agencia de radicación del crédito 4) Línea solicitada 5) Monto 6) Plazo 7) Fecha de radicación 8) Probabilidad de incumplimiento por cliente 9) Clasificación (Incumple, No incumple)

96
Anexo D. Caso de Uso: Cálculo de puntaje y homologa ción
REQUERIMIENTOS FUNCIONALES
Nro. Req. Nombre Req. Fecha Módulo ó Proceso Prioridad Versión
004
Cálculo Puntaje y
Homologación Calificación de
Riesgo 04/01/2008 Calculo PI ALTA 1.0
DESCRIPCIÓN / ALCANCE DEL REQUERIMIENTO
Una vez autenticado el usuario en la aplicación
1. La actividad que debe realizar este requerimiento es Calcular puntaje o score.
- Con la probabilidad de incumplimiento calculada (ver CoomevaFin.ModelodeOtorgamiento.REQ.20080401_003.EjecucionPMM
), se debe calcular el puntaje o scoring de la siguiente forma: Redondear a cero decimales el valor resultante del cálculo (1 – PI) *1000. El resultado debe ser un número comprendido entre
cero y mil.
2. Homologar puntaje en calificación de riesgo (AA, A, BB, B, CC, C, D, E)

97
- Los pasos para realizar esta actividad son:
• Tomar la variable de clasificación de cartera (Hipotecaria, Consumo y Comercial) del sistema AS400 aplicativo Taylor & Johnson. • Homologar el puntaje o score (ver punto 1), en calificaciones o bandas de riesgo (AA, A, BB, B, CC, C, D, E) de acuerdo a la clase de
cartera (hipotecaria, consumo, comercial) a la que pertenezca el crédito solicitado y utilizando las siguientes tablas de intervalos:
3. Almacenamiento de Información
La información resultante debe ser almacenada en la misma tabla donde se almacenen los resultados del requerimiento
CoomevaFin.ModelodeOtorgamiento.REQ.20080401_003.EjecucionPMMl.
Las variables a almacenar son:
1) Valor puntual del puntaje o scoring

98
2) Valor de calificación de riesgo.
Estas variables se almacenan en una tabla definida en el AS400

99
Anexo E. Caso de Uso: Calificación de riesgo y ende udamiento
REQUERIMIENTOS FUNCIONALES
Nro. Req. Nombre Req. Fecha Módulo ó Proceso Prioridad Versión
005
Calificación de riesgo de
acuerdo endeudamiento 04/01/2008 Cálculo PI ALTA 1.0
DESCRIPCIÓN / ALCANCE DEL REQUERIMIENTO
Una vez autenticado el usuario en la aplicación
Este requerimiento debe realizar los siguientes cálculos internos:
1) Traer el endeudamiento mensual (porcentaje) del cliente calculado en Taylor según los soportes de ingresos y egresos. (ver CoomevaFin.ModelodeOrtorgamiento.Anexo 3.doc)
2) Reclasificar la variable del punto anterior de la siguiente forma: • 1. [0 – 50%] • 2. (50 – 60%] • 3. (60 – 70%] • 4. (70 – 85%] • 5. (85 – 100%] • 6. Más de 100%

100
3) Definir la zona de ubicación de la solicitud de crédito (Aprobación, Verificación, Rechazo) en la siguiente matriz utilizando la variable del punto anterior reclasificada vs. Calificación de Riesgo (ver CoomevaFin.ModelodeOrtorgamiento.REQ.20080401_004CalculoPuntajeyHomologacion.doc)
4) Almacenar de forma temporal en la misma tabla donde se almacenen los resultados del requerimiento (ver CoomevaFin.ModelodeOtorgamiento.REQ.20080401_003.EjecucionPMML), el resultado de los puntos 1, 2 y 3 (Variable Porcentaje de endeudamiento y rango, zona de ubicación de la solicitud) para que posteriormente se ingrese a la Bodega de Datos en una estructura predefinida

101
Anexo F. Caso de Uso: Calificación credito monto
REQUERIMIENTOS FUNCIONALES
Nro. Req. Nombre Req. Fecha Módulo ó Proceso Prioridad Versión
006
Calificación de crédito de
acuerdo al monto 04/01/2008 Cálculo PI ALTA 1.0
DESCRIPCIÓN / ALCANCE DEL REQUERIMIENTO
Una vez autenticado el usuario en la aplicación
- Este requerimiento debe realizar los siguientes cálculos internos:
1) Reclasificar la variable VLR_DSB (monto solicitado por el cliente en millones) de acuerdo a los siguientes rangos: • 1. Hasta 10 MM • 2. (10 MM – 20 MM] • 3. (20 MM – 50 MM] • 4. (50 MM – 80 MM] • 5. Más de 80MM
2) Definir la zona de ubicación de la solicitud del crédito (Aprobación, Verificación, Rechazo) en la siguiente matriz utilizando la variable VLR_DSB reclasificada vs. Calificación de Riesgo

102
(ver CoomevaFin.ModelodeOrtorgamiento.REQ.20080401_004CalculoPuntajeyHomologacion.doc).
3) Almacenar de forma temporal en la misma tabla donde se almacenen los resultados del requerimiento (CoomevaFin.ModelodeOtorgamiento.REQ.20080401_003.EjecucionPMMl), el resultado del punto 1 y 2 (Variable Monto en millones y en rango, zona de ubicación de la solicitud de crédito) para que posteriormente se ingrese a la Bodega de Datos en una estructura predefinida.

103
Anexo G. Casos de Uso: Esquema
REQUERIMIENTOS FUNCIONALES
Nro. Req. Nombre Req. Fecha Módulo ó Proceso Prioridad Versión
007 Esquema 04/01/2008 Calculo PI ALTA 1.0
DESCRIPCIÓN / ALCANCE DEL REQUERIMIENTO
Una vez autenticado el usuario en la aplicación
- Este requerimiento debe realizar lo siguiente:
1) Con los resultados de los requerimientos (CoomevaFin.ModelodeOrtorgamiento.REQ.20080401_005.Calificacionriesgoendeudamiento.doc) y requerimiento (CoomevaFin.ModelodeOrtorgamiento.REQ.20080401_006.Calificacioncreditomonto.doc), se debe utilizar la siguiente matriz para determinar la acción sugerida por el scoring:

104
2) Almacenar de forma temporal en la misma tabla donde se almacenen los resultados del requerimiento (CoomevaFin.ModelodeOtorgamiento.REQ.20080401_003.EjecucionPMMl), el resultado del punto 1 (Decisión sugerida) para que posteriormente se ingrese a la Bodega de Datos en una estructura predefinida.

105
Anexo H. Casos de Uso: Reporte
REQUERIMIENTOS FUNCIONALES
Nro. Req. Nombre Req. Fecha Módulo ó Proceso Prioridad Versión
008 Generar Reporte 04/01/2008 Reporte ALTA 1.0
DESCRIPCIÓN / ALCANCE DEL REQUERIMIENTO
Una vez autenticado el usuario en la aplicación
- Se debe generar un reporte en pantalla que le informe al analista los resultados obtenidos. Este reporte debe poder ser visto por el Analista y por la mesa de créditos. Debe estar dividido de la siguiente forma:
1. Información básica del cliente
Número de identificación del cliente, Nombre, agencia, Sucursal
2. Características del crédito solicitado
Número de Operación, línea, destino, clase de cartera, tasa, tipo de tasa, plazo, monto, condiciones especiales (periodo gracia,
muerto), Fecha de radicación, Fecha de análisis.

106
3. Perfil del cliente
Valores originales de las siguientes variables: Estrato, Tipo de vivienda, Estado civil, Nivel académico, Edad, Actividad laboral,
Ingresos, Antigüedad con Coomeva Multiactiva, Mora máxima con la Cooperativa (Financiera y Multiactiva) en el último año, Puntaje
Acierta.
4. Resultados del Scoring
Probabilidad de incumplimiento, Resultado final del puntaje (score) asignado a la solicitud, Calificación de Riesgo correspondiente
(AA, A, BB, B, CC, C, D, E) y Decisión sugerida por el sistema de acuerdo a parámetros establecidos.
5. Resultados de capacidad de pago y endeudamiento Mensual
Se debe traer del aplicativo Taylor & Johnson los datos de: Capacidad de pago mensual estimada (en pesos y en porcentaje) y Nivel de
endeudamiento mes estimado (en porcentaje)

107
Anexo I. Casos de Uso: Almacenamiento AS-400
REQUERIMIENTOS FUNCIONALES
Nro. Req. Nombre Req. Fecha Módulo ó Proceso Prioridad Versión
009 Almacenar en el AS/400 04/01/2008 Almacenamiento ALTA 1.0
DESCRIPCIÓN / ALCANCE DEL REQUERIMIENTO
Una vez autenticado el usuario en la aplicación
Se requiere almacenar en la bodega de datos SARC por cliente y para cada evento (Análisis crediticio) los resultados de los
requerimientos (CoomevaFin.ModelodeOrtorgamiento.REQ.20080401_003.EjecucionPMML.doc) al
(CoomevaFin.ModelodeOrtorgamiento.REQ.20080401_007.Esquema.doc).
Variable Requerimiento
Número de identificación del cliente 003
Número de operación crediticia 003
Agencia de radicación del crédito 003
Línea solicitada 003

108
Monto del crédito 003
Plazo 003
Fecha de radicación 003
Probabilidad de incumplimiento por cliente 003
Clasificación (Incumple, No incumple) 003
Valor puntual del puntaje o scoring 004
Valor de calificación de riesgo. 004
Porcentaje de endeudamiento 005
Rango de endeudamiento 005
Capacidad de pago mensual estimada en pesos 008
Capacidad de pago mensual estimada en % 008
Zona de ubicación de la solicitud por endeudamiento 005
Capital solicitado en millones 006
Rango de Capital solicitado 006
Zona de ubicación de la solicitud por Capital solicitado 006
Decisión Sugerida por el Modelo 007

109
Anexo J. Desarrollo del algoritmo de regresión logí stica polinomial Para la implementación del algoritmo de minería de una regresión logística polinomial utilizamos las siguientes clases: La clase que lee el PMML y lo convierte en objetos, que son usados para obtener la formula que usa Coomeva Financiero para calcular la probabilidad de incumplimiento, usando el método unmarshal de las librerías de JAXB package geniar.datamining.pmml. import geniar.spss.logreg.v1r0.model.PMML; import java.io.InputStream; import javax.xml.bind.JAXBContext; import javax.xml.bind.Unmarshaller; public class MiningModelLoader { public static PMML loadPMML(String fileName) throws Exception { try { // Creamos el contexto JAXBContext context = JAXBContext.newInstance( // "geniar.pmml.v3r1.model" "geniar.spss.logreg.v1r0.model" ); // Se lee el archive del modelo InputStream input = MiningModelLoader.class.getResourceAsStream( fileName); // Se crea el unmarshaller - translator XML --> Objects Unmarshaller unmarshaller = context.createUnmarshaller(); // Se obtiene el objeto del XML PMML pmml = (PMML) unmarshaller.unmarshal(input); return pmml; } catch (Exception e) { } } }

110
La clase recibe una serie de parámetros previamente definidos por Coomeva financiero se realiza la operación de la regresión logística polinomial de acuerdo al algoritmo de SPSS y a los parámetros enviados. package geniar.datamining.pmml; import geniar.spss.logreg.v1r0.model.MiningSchema; import geniar.spss.logreg.v1r0.model.CovariateList; import geniar.spss.logreg.v1r0.model.DataField; import geniar.spss.logreg.v1r0.model.FactorList; import geniar.spss.logreg.v1r0.model.GeneralRegressionModel; import geniar.spss.logreg.v1r0.model.MiningField; import geniar.spss.logreg.v1r0.model.PCell; import geniar.spss.logreg.v1r0.model.PCovCell; import geniar.spss.logreg.v1r0.model.PCovMatrix; import geniar.spss.logreg.v1r0.model.PMML; import geniar.spss.logreg.v1r0.model.PPCell; import geniar.spss.logreg.v1r0.model.PPMatrix; import geniar.spss.logreg.v1r0.model.ParamMatrix; import geniar.spss.logreg.v1r0.model.Parameter; import geniar.spss.logreg.v1r0.model.ParameterList; import geniar.spss.logreg.v1r0.model.Predictor; import geniar.spss.logreg.v1r0.model.Value; import java.math.BigDecimal; import java.math.MathContext; import java.util.HashMap; import java.util.List; import java.util.Map; public class PolynomialLogisticModel { PMML pmml; GeneralRegressionModel model; List<DataField> fields = null; List<Parameter> parameters = null; List<Predictor> factorList = null; List<Predictor> covariateList = null; List<PPCell> ppMatrix = null; List<PCell> paramMatrix = null; List<PCovCell> pCovMatrix = null; List<MiningField> miningSchema = null; //El constructor de la clase PolynomialLogisticModel public PolynomialLogisticModel(PMML pmml) { this.pmml = pmml;

111
this.model = pmml.getGeneralRegressionModel().get(0); } public List<DataField> getFields() { if (model != null) { if (fields == null) { fields = pmml.getDataDictionary().getDataField(); } } return fields; } public List<Parameter> getParameters() { if (model != null) { if (parameters == null) { for (Object obj : model.getContent()) { if (obj.getClass().equals(ParameterList.class)) { ParameterList pl = (ParameterList) obj; parameters = pl.getParameter(); break; } } } } return parameters; } public List<Predictor> getFactorList() { if (model != null) { if (factorList == null) { for (Object obj : model.getContent()) { if (obj.getClass().equals(FactorList.class)) { FactorList pl = (FactorList) obj; factorList = pl.getPredictor(); break; } } } } return factorList; } public List<Predictor> getCovariateList() { if (model != null) { if (covariateList == null) {

112
for (Object obj : model.getContent()) { if (obj.getClass().equals(CovariateList.class)) { CovariateList pl = (CovariateList) obj; covariateList = pl.getPredictor(); break; } } } } return covariateList; } public List<PPCell> getPpMatrix() { if (model != null) { if (ppMatrix == null) { for (Object obj : model.getContent()) { if (obj.getClass().equals(PPMatrix.class)) { PPMatrix pl = (PPMatrix) obj; ppMatrix = pl.getPPCell(); break; } } } } return ppMatrix; } public List<PCell> getParamMatrix() { if (model != null) { if (paramMatrix == null) { for (Object obj : model.getContent()) { if (obj.getClass().equals(ParamMatrix.class)) { ParamMatrix pl = (ParamMatrix) obj; paramMatrix = pl.getPCell(); break; } } } } return paramMatrix; } public List<PCovCell> getPCovMatrix() {

113
if (model != null) { if (pCovMatrix == null) { for (Object obj : model.getContent()) { if (obj.getClass().equals(PCovMatrix.class)) { PCovMatrix pl = (PCovMatrix) obj; pCovMatrix = pl.getPCovCell(); break; } } } } return pCovMatrix; } public List<MiningField> getMiningSchema() { if (model != null) { if (miningSchema == null) { for (Object obj : model.getContent()) { if (obj.getClass().equals(MiningSchema.class)) { MiningSchema pl = (MiningSchema) obj; miningSchema = pl.getMiningField(); break; } } } } return miningSchema; } public GeneralRegressionModel getModel() { return model; } public BigDecimal getScore(String... parameters) { BigDecimal[] bigDecimalParameters = new BigDecimal[parameters.length]; int i = 0; for (String parameter : parameters) { bigDecimalParameters[i++] = new BigDecimal(parameter); } return getScore(bigDecimalParameters); }

114
public BigDecimal getScore(Double... parameters) { BigDecimal[] bigDecimalParameters = new BigDecimal[parameters.length]; int i = 0; for (Double parameter : parameters) { bigDecimalParameters[i++] = new BigDecimal(parameter); } return getScore(bigDecimalParameters); } Map<String, BigDecimal> valores = new HashMap<String, BigDecimal>(); Map<String, String> paramDescriptions = new HashMap<String, String>(); Map<String, BigDecimal> paramValues = new HashMap<String, BigDecimal>(); Map<String, BigDecimal> betaValues = new HashMap<String, BigDecimal>(); //Recibe una seria de parámetros previamente definidos con Coomeva Financiero para //calcular la probabilidad de incumpliento usando el algoritmo de regresión logística //polinomial de SPSS public BigDecimal getScore(BigDecimal... parameters) { // Map<String, BigDecimal> valores = new HashMap<String, BigDecimal>(); Map<String, List<Value>> fieldTypes = new HashMap<String, List<Value>>(); Map<String, String> parameterTypes = new HashMap<String, String>(); List<MiningField> fields = getMiningSchema(); int fieldNumber = 0; while(fieldNumber < fields.size() && fields.get(fieldNumber).getUsageType().equals("predicted")) { fieldNumber++; } for (BigDecimal parameter: parameters) { valores.put(fields.get(fieldNumber++).getName(), parameter); } List<DataField> dataFields = getFields(); for (DataField dataField : dataFields) { fieldTypes.put( dataField.getName(), dataField.getValue()); }

115
List<Parameter> params = getParameters(); for (Parameter param : params) { parameterTypes.put(param.getName(), param.getLabel()); } List<PPCell> ppCells = getPpMatrix(); for (PPCell ppCell : ppCells) { // es de valor if (fieldTypes.get(ppCell.getPredictorName()) == null || fieldTypes.get(ppCell.getPredictorName()).size() == 0) { paramDescriptions.put(ppCell.getParameterName(), parameterTypes.get(ppCell.getParameterName())+ " (value)"); paramValues.put( ppCell.getParameterName(), valores.get(ppCell.getPredictorName())); // es categorical } else { BigDecimal valorPredictor = valores.get(ppCell.getPredictorName()); BigDecimal valorEsperado = new BigDecimal(ppCell.getValue()); if (valorPredictor.compareTo(valorEsperado) == 0) { paramDescriptions.put(ppCell.getParameterName(), parameterTypes.get(ppCell.getParameterName()) + " (categorical)"); paramValues.put( ppCell.getParameterName(), new BigDecimal(1)); } else { paramDescriptions.put(ppCell.getParameterName(), parameterTypes.get(ppCell.getParameterName()) + " (categorical)"); paramValues.put( ppCell.getParameterName(), new BigDecimal(0)); } } } System.out.println("Cantidad de Parámetros : " + params.size());

116
for (Parameter param : params) { if (paramValues.get(param.getName()) == null) { paramValues.put(param.getName(), new BigDecimal(1)); } } List<PCell> cells = getParamMatrix(); BigDecimal sum = new BigDecimal(0); for (PCell cell : cells) { if (cell.getTargetCategory().equals("1")) { BigDecimal value = paramValues.get(cell.getParameterName()); BigDecimal beta = new BigDecimal(cell.getBeta()); BigDecimal bx = value.multiply(beta); betaValues.put(cell.getParameterName(), beta); sum = sum.add(bx); } } BigDecimal exp = exp(sum); BigDecimal denominator = exp.add(new BigDecimal(1.0)); BigDecimal prob = exp.divide(denominator, MathContext.DECIMAL128); System.out.println("$XC-INCUMPLE : " + prob); return prob; } BigDecimal epsilon; // based on desired precision BigDecimal natural_e; int prec = 301; // precision in digits int bits = 1000; // precision in bits = about 3.32 precision in public void initMath() { natural_e = naturalE(prec); /* precision */ epsilon = new BigDecimal("1"); for(int i=0; i<bits; i++) { epsilon = epsilon.multiply(new BigDecimal("0.5")); } epsilon = epsilon.setScale(prec,BigDecimal.ROUND_DOWN); }

117
BigDecimal exp_series(BigDecimal x) { BigDecimal fact = new BigDecimal("1"); // factorial BigDecimal xp = new BigDecimal("1"); // power of x BigDecimal y = new BigDecimal("1"); // sum of series on x int n; n = (2*prec)/3; for(int i=1; i<n; i++) { fact = fact.multiply(new BigDecimal(i)); fact = fact.setScale(prec,BigDecimal.ROUND_DOWN); xp = xp.multiply(x); xp = xp.setScale(prec,BigDecimal.ROUND_DOWN); y = y.add(xp.divide(fact, BigDecimal.ROUND_DOWN)); } y = y.setScale(prec,BigDecimal.ROUND_DOWN); return y; } BigDecimal exp(BigDecimal x) { initMath(); BigDecimal y = new BigDecimal("1.0"); // sum of series on xc BigDecimal xc; // x - j BigDecimal ep = natural_e; // e^j BigDecimal j = new BigDecimal("1"); BigDecimal one = new BigDecimal("1.0"); BigDecimal half = new BigDecimal("0.5"); BigDecimal xp; // positive, then invert if(x.abs().compareTo(half) <0) return exp_series(x); if(x.compareTo(new BigDecimal("0"))>0) // positive { while(x.compareTo(j.add(one))>0) { ep = ep.multiply(natural_e); j = j.add(one); } xc = x.subtract(j); y = ep.multiply(exp_series(xc)); y = y.setScale(prec,BigDecimal.ROUND_DOWN); return y; } else // negative

118
{ xp = x.negate(); while(xp.compareTo(j.add(one))>0) { ep = ep.multiply(natural_e); j = j.add(one); } xc = xp.subtract(j); y = ep.multiply(exp_series(xc)); y = y.setScale(prec,BigDecimal.ROUND_DOWN); return (one.add(epsilon)).divide(y, BigDecimal.ROUND_DOWN); } } // end exp BigDecimal naturalE(int prec_dig) { BigDecimal sum = new BigDecimal("1"); BigDecimal fact = new BigDecimal("1"); BigDecimal del = new BigDecimal("1"); BigDecimal one = new BigDecimal("1"); BigDecimal ten = new BigDecimal("10"); int prec_bits = (prec_dig*332)/100; one = one.setScale(prec_dig,BigDecimal.ROUND_DOWN); for(int i=0; i<prec_dig; i++) del = del.multiply(ten); for(int i=1; i<prec_bits; i++) { fact = fact.multiply(new BigDecimal(i)); fact = fact.setScale(prec_dig,BigDecimal.ROUND_DOWN); sum = sum.add(one.divide(fact, BigDecimal.ROUND_DOWN)); if(del.compareTo(fact) <0) break; } return sum.setScale(prec_dig,BigDecimal.ROUND_DOWN); } //Getters public Map<String, String> getParamDescriptions() { return paramDescriptions; } public Map<String, BigDecimal> getParamValues() { return paramValues; }

119
public Map<String, BigDecimal> getBetaValues() { return betaValues; } public Map<String, BigDecimal> getValores() { return valores; }
public PMML getPmml() { return pmml; } } Adicionalmente para poder ejecutar este proceso, hemos mapeado previamente las clases necesarias para usar el algoritmo de regresión logística polinomial del SPSS. Las clases son las siguientes: MiningSchema CovariateList DataField FactorList GeneralRegressionModel MiningField PCell PCovCell PCovMatrix PMML PPCell PPMatrix ParamMatrix Parameter ParameterList Predictor Value


















