
las nuevas tecnologías y la investigación educativa
20
revista española de pedagogía año LXX, nº 251, enero-abril 2012, 111-130 111 Introducción En el contexto general de un número especial monográfico dedicado a las apor- taciones de las nuevas tecnologías a la in- vestigación educativa, conviene en primer lugar centrar y delimitar el objeto de nues- tro trabajo. Y éste se centra en el análisis estadístico de datos con variables catego- riales, lo que en la terminología anglosa- jona se identifica habitualmente con el tér- mino Categorical Data Analysis (CDA; de ahora en adelante usaremos el acrónimo inglés por ser de uso más frecuente). Una vez realizada esta afirmación, quedan aún cuestiones por aclarar. La pri- mera y fundamental es qué se entiende por variables categoriales. Una posible res- puesta es limitar este término a aquellos fenómenos cuyo nivel de medida sea es- trictamente nominal. Pero junto a éste, la mayoría de los autores incluyen bajo este término las variables ordinales. Por ejem- plo, Agresti (2007) afirma que las variables categoriales tienen dos tipos de niveles de medida: el nominal y el ordinal (cfr. página 2). Y en la misma línea apunta Friendly (2000) en su manual sobre visualización de datos categoriales. Dicho de otra manera, las variables categoriales serían las no cuantitativas, aquellos fenómenos que ca- recen de una métrica fuerte. Pero las cuestiones de demarcación tampoco acaban aquí. Si asumimos un es- quema clásico de dependencia, podemos distinguir entre variables explicativas y variables de respuesta, entre variables in- dependientes y dependientes. En la mayo- ría de los manuales estadísticos de CDA se incluyen aquellas técnicas en las que la variable de respuesta sea categorial, pu- diendo ser las explicativas de cualquier ni- vel de medida. No creemos que el foco principal de este trabajo deba centrarse en discutir es- tas cuestiones en profundidad. Por simpli- Las nuevas tecnologías y la investigación educativa. El análisis de datos de variables categoriales por Luis LIZASOAIN y Luis JOARISTI Universidad del País Vasco-Euskal Herriko Unibertsitatea
-
Upload
jorge-mora -
Category
Documents
-
view
14 -
download
1
Transcript of las nuevas tecnologías y la investigación educativa

revistaespañola
depedagogía
añoLXX,nº
251,enero-abril2012,111-130
111
IntroducciónEn el contexto general de un número
especial monográfico dedicado a las apor-taciones de las nuevas tecnologías a la in-vestigación educativa, conviene en primerlugar centrar y delimitar el objeto de nues-tro trabajo. Y éste se centra en el análisisestadístico de datos con variables catego-riales, lo que en la terminología anglosa-jona se identifica habitualmente con el tér-mino Categorical Data Analysis (CDA; deahora en adelante usaremos el acrónimoinglés por ser de uso más frecuente).
Una vez realizada esta afirmación,quedan aún cuestiones por aclarar. La pri-mera y fundamental es qué se entiendepor variables categoriales. Una posible res-puesta es limitar este término a aquellosfenómenos cuyo nivel de medida sea es-trictamente nominal. Pero junto a éste, lamayoría de los autores incluyen bajo estetérmino las variables ordinales. Por ejem-plo, Agresti (2007) afirma que las variables
categoriales tienen dos tipos de niveles demedida: el nominal y el ordinal (cfr. página2). Y en la misma línea apunta Friendly(2000) en su manual sobre visualización dedatos categoriales. Dicho de otra manera,las variables categoriales serían las nocuantitativas, aquellos fenómenos que ca-recen de una métrica fuerte.
Pero las cuestiones de demarcacióntampoco acaban aquí. Si asumimos un es-quema clásico de dependencia, podemosdistinguir entre variables explicativas yvariables de respuesta, entre variables in-dependientes y dependientes. En la mayo-ría de los manuales estadísticos de CDA seincluyen aquellas técnicas en las que lavariable de respuesta sea categorial, pu-diendo ser las explicativas de cualquier ni-vel de medida.
No creemos que el foco principal deeste trabajo deba centrarse en discutir es-tas cuestiones en profundidad. Por simpli-
Las nuevas tecnologías y la investigacióneducativa. El análisis de datos
de variables categorialespor Luis LIZASOAIN y Luis JOARISTI
Universidad del País Vasco-Euskal Herriko Unibertsitatea

revi
sta
espa
ñola
depe
dago
gía
añoLXX,nº251,enero-abril2012,111-130
112
Luis LIZASOAIN y Luis JOARISTI
cidad y por razones de espacio, vamos aprestar una especial atención a aquellastécnicas de análisis de datos en que lasvariables cualitativas juegan un papel bá-sico o preponderante empezando por aque-llas en las que todas las variables son cua-litativas.
No vamos a insistir tampoco en la im-portancia que este tipo de técnicas tienenen la investigación educativa y en las cien-cias sociales y humanas en general, ha-bida cuenta de que en nuestro campo de in-vestigación son muchos –y relevantes– losfenómenos que carecen de una métricafuerte y que sólo pueden ser incorporadosa la investigación como variables nomina-les o en su caso ordinales.
La primera conclusión que queremosavanzar ya es que, dado el actual nivel dedesarrollo de las técnicas estadísticas, noes preciso forzar el nivel de medida de unfenómeno considerándolo como cuantita-tivo por razones de tratamiento estadístico.El desarrollo de la Estadística, con el im-prescindible soporte de los procedimien-tos e instrumentos de cómputo, pone a dis-posición del investigador un conjunto detécnicas y procedimientos estadísticos ca-paces de incorporar y operar con cualquiertipo de variables y con casi cualquier com-binación de las mismas.
Y ya que acabamos de referirnos al so-porte de cálculo y computación, bueno seráque finalicemos esta introducción con unabreve síntesis de dónde radican las princi-pales aportaciones de las nuevas tecnolo-gías al CDA, aunque quizá sería más pre-ciso decir al análisis estadístico de datos engeneral, puesto que estas cuestiones son,
en la mayoría de los casos, independientesdel nivel de medida de las variables.
No se debe olvidar que la fundamen-tación matemática de muchas de las téc-nicas estadísticas que se van a abordarestá desarrollada desde hace muchotiempo, en muchos casos desde antes de laaparición de las tecnologías de cálculo. Loque éstas han posibilitado ha sido su de-sarrollo y aplicación.
Pero si esto es cierto, no lo es menosque las tecnologías informáticas tambiénhan contribuido al desarrollo de nuevastécnicas y procedimientos y esto es asíhasta el punto de que autores como Lind-say, Kettenring y Siegmund (2004) en suinforme sobre el futuro de la Estadísticaafirman que “la actividad central de losestadísticos es la construcción de herra-mientas matemáticas, conceptuales y com-putacionales que puedan ser usadas parala extracción de información”; y más ade-lante afirman que la ciencia de la Estadís-tica tiene sus raíces en la probabilidad y laMatemática junto con la más reciente in-fluencia de la ciencia informática. (Cfr. pp.392 y 405. El subrayado y la traducción sonnuestros).
Y entre las aportaciones y desarrollosmás sobresalientes que la tecnologíainformática conlleva señalemos los si-guientes.
En primer lugar, el incremento expo-nencial de las capacidades de los sistemasinformáticos permite procesar cada vezmás información, lo que lleva aparejada laposibilidad de analizar mayor cantidad dedatos y de realizar cálculos más complejos.

revistaespañola
depedagogía
añoLXX,nº
251,enero-abril2012,111-130
113
Las nuevas tecnologías y la investigación educativa. El análisis de datos…
Ejemplos evidentes de todo esto lo consti-tuyen ámbitos como el de la minería dedatos orientado al análisis y extracción deinformación relevante en grandes bancosde datos.
Pero el desarrollo de las tecnologías in-formáticas no ha sido sólo una cuestión depotencia, de fuerza bruta. Los primeros or-denadores y los primeros programas ya lle-vaban a cabo operaciones y cálculos com-plejos. Recordemos, por ejemplo, que laprimera versión del popular SPSS data de1970 (Nie, Bent y Hull, 1970).
Pero junto a esto, la aparición y gene-ralización en la década de los 80 de los or-denadores personales supuso también uncambio importante. Su capacidad de al-macenamiento y proceso no ha parado decrecer, pero sobre todo, su uso trajo apare-jada la interactividad. Los grandes siste-mas informáticos eran de acceso compli-cado y restringido, y habitualmente losprogramas se ejecutaban por lotes (batch)de forma que el usuario enviaba su pro-grama, éste se ejecutaba y posteriormenterecibía los listados con los resultados. A lavista de los mismos podía elaborar unnuevo programa y reiniciar la secuencia.Era un procedimiento de trabajo habitual-mente lento, farragoso y sin supervisióndirecta por parte del usuario, procedi-miento que el modo interactivo de operarde los programas diseñados para ordena-dores personales cambió drásticamente.
No vamos a extendernos sobre la ope-ración interactiva (habitualmente me-diante interfaces gráficos de usuario) delos recursos informáticos porque estamosya tan acostumbrados a la misma que casi
nos pasa inadvertida. Pero desde el puntode vista del análisis estadístico de datos esinnegable la flexibilización que lleva apa-rejada y, sobre todo, las vías que ha posi-bilitado para el enfoque exploratorio de losdatos en la línea que Tukey apuntó.
Y continuando con los planteamientosde Tukey (1977), las posibilidades gráficasde los actuales sistemas informáticos hancontribuido al desarrollo de lo que es ahorauna rama de la Estadística, a saber, la vi-sualización de datos cuyo objetivo es pre-sentar de forma gráfica la información másrelevante contenida en datos y resultados.Más adelante veremos esta cuestión conalgo más de detalle, pero no está de másque señalemos la importancia que este tipode recursos tienen para la presentación deresultados a audiencias no expertas, cues-tión ésta muy relevante en ámbitos comopor ejemplo la evaluación de programas.
Otras cuestiones muy importantescomo las comunicaciones o las redes infor-máticas ya son tratadas en otros trabajosde este número, por lo que no insistimosaquí en ellas; pero para finalizar, no que-remos dejar de señalar una última cuestiónque pensamos tiene su importancia, comoes el auge y desarrollo de los programas in-formáticos de código abierto (free and opensoftware).
Se trata de una corriente importantedentro de la comunidad de usuarios y de-sarrolladores de software consistente endesarrollar programas y aplicaciones quese pueden leer, modificar y distribuir sinapenas restricciones. Esto origina que el có-digo fuente de un programa evoluciona,mejora, corrige errores y se adapta a las

nuevas necesidades de forma rápida y sindepender de las políticas comerciales de lasempresas.
En nuestro caso, el ejemplo más nota-ble de esto lo tenemos en el programa R deanálisis estadístico de datos. En este mo-mento no hay técnica o desarrollo estadís-tico que no lleve aparejado su paquete de Rpara poder ser utilizada. Como prueba delo dicho, en el momento de escribir estas lí-neas (mayo de 2011) el repositorio de pa-quetes de R tiene disponibles 3049(http://www.r-project.org/). Igualmente,si se entra en una revista como el Journalof Statistical Software (http://www.jstat-soft.org/) y se recorren los diferentes nú-meros, se puede ver la gran cantidad detrabajos centrados en R. Por ejemplo, el vo-lumen 40 correspondiente a abril de 2011consta de 14 artículos de los cuales 11 serefieren a paquetes de R.
Tomando en cuenta estas considera-ciones, a continuación vamos a presentarde forma muy sucinta algunas de las téc-nicas estadísticas más empleadas con da-tos categoriales teniendo muy presenteque, en nuestra opinión, la más relevanteaportación del desarrollo conjunto de latecnología informática y de la Estadísticaestriba en que posibilita que nuestro acer-camiento a la realidad educativa que in-vestigamos pueda llevarse a cabo tomandoen consideración las principales notas dis-tintivas de la misma, como son su comple-jidad y su carácter multivariado y multi-nivel.
Y para analizar los datos de una reali-dad compleja, multivariada y multinivel,los procedimientos más adecuados son los
de modelización estadística a sabiendasde que, como afirman Little, Schnabel yBaumert (2000), los resultados obtenidosmediante estas técnicas adolecen de unacierta ambigüedad y relatividad. Esta am-bigüedad, esta necesidad de formular yvalidar modelos surge del hecho de em-plear diseños no experimentales; en pala-bras de los citados autores: las técnicasinferenciales clásicas tienen poca o nin-guna ambigüedad en el modelo cuando seaplican a datos obtenidos en el contexto dediseños experimentales completamentealeatorizados. Así por ejemplo, la adecua-ción del modelo implícito subyacente alanálisis de datos está determinada por elgrado en que correctamente refleja el di-seño experimental, siendo la única fuentede incertidumbre las suposiciones sobre ladistribución de variables o variables en lapoblación.
Pero, como sabemos, nuestras investi-gaciones raramente pueden llevarse a caboen dichas condiciones, por lo que las técni-cas de modelización estadística se nos ofre-cen como procedimientos viables a sabien-das de que el precio que hemos de pagarsea esa cierta ambigüedad. Como afirmanCook y Campbell (1979) “el cambio del es-tricto contraste de hipótesis a la lógica dela validación de modelos no se realiza por-que se empleen procedimientos de modelosde ecuaciones estructurales, sino porque seusan datos cuasi-experimentales”.
En cualquier caso, y para una visióncompleta y detallada de los procedimien-tos y técnicas estadísticos para variablescategoriales recomendamos el ya citadomanual de Agresti (2007) que es un refe-rente en la materia. Un excelente análisis
revi
sta
espa
ñola
depe
dago
gía
añoLXX,nº251,enero-abril2012,111-130
114
Luis LIZASOAIN y Luis JOARISTI

revistaespañola
depedagogía
añoLXX,nº
251,enero-abril2012,111-130
115
Las nuevas tecnologías y la investigación educativa. El análisis de datos…
relativo a la evolución de estas técnicas seencuentra en el trabajo de Goodman(2007).
Análisis de frecuencia de configura-ciones
Esta técnica estadística, más conocidacomo Configural Frequency Analysis(CFA), fue inicialmente diseñada y pro-puesta por Lienert (1968) siendo Von Eyeel autor de referencia que ha desarrolladola misma (von Eye, 2002; von Eye y Gu-tiérrez Peña, 2004). Tiene como objetivo elanálisis de tablas de contingencia bi omultidimensionales generadas por laclasificación cruzada de variables catego-riales.
A diferencia de otras técnicas como losmodelos logarítmico lineales, que se cen-tran en el examen y análisis de las rela-ciones entre las variables, aquí el enfoquese centra en los casos, en los individuos. Suobjetivo es identificar grupos de indivi-duos, configuraciones, que se puedan con-siderar –desde un punto de vista estadís-tico– especiales.
Y tal consideración se refiere al hechode que sean casillas de la tabla de contin-gencia que no se ajusten a lo esperado,que sus frecuencias observadas sean sig-nificativamente distintas de las frecuen-cias estimadas esperadas. Por tanto, nosencontramos ante una técnica de clasifi-cación de casos, pero, a diferencia del aná-lisis de conglomerados o el de clase latente,que crean grupos desconocidos de casos apartir de los datos brutos, el CFA se centraen analizar si los grupos existentes en laclasificación cruzada contienen más o me-nos casos que los esperables.
Se trata de una herramienta funda-mentalmente exploratoria cuyos resulta-dos se consideran de fácil interpretación,pues se centra en analizar si un determi-nado patrón de categorías de las variables(configuraciones) se da más veces de lo es-perado, menos o tanto como cabía espe-rar. Una configuración que contenga máscasos que los esperados es denominada untipo mientras que la que contiene menoscasos de los esperados constituye un anti-tipo.
Un CFA se desarrolla en 4 etapas o fa-ses (Von Eye, 2010): la primera conciernea la elección de un modelo base, la se-gunda se centra en la estimación de lasfrecuencias esperadas de cada casilla, latercera es la selección y realización de laprueba estadística y la última es la iden-tificación e interpretación de los tipos yantitipos. Veamos muy brevemente cadauna de ellas.
El modelo base consta de todas las re-laciones entre variables que no son objetode hipótesis sustantivas, o dicho de otramanera, el modelo base está formado portodos los términos que no son de interéspara el investigador. Tomando en conside-ración este modelo base, se estiman lasfrecuencias esperadas habitualmente ba-sándose en modelos logarítmico lineales.Una vez estimadas las frecuencias espera-das se comparan con las empíricas y se re-aliza un contraste estadístico. Aquellas ca-sillas, aquellas configuraciones cuyasfrecuencias observadas sean significativa-mente mayores que las esperadas confor-man un tipo y, simétricamente, aquellasdonde la diferencia sea significativamentemenor constituyen los antitipos.

El supuesto básico es que si emergen ti-pos y antitipos, estas configuraciones refle-jan o representan los efectos que sí resultande interés. El proceso finaliza interpretandoestas configuraciones a la luz del papel quejuegan las variables (por ejemplo explicati-vas vs. criterio), las características del mo-delo base y la teoría sustantiva.
Lógicamente en un enfoque como elpresentado es crucial la elección del modelobase. Von Eye (2004) describe y analizapormenorizadamente diferentes grupos demodelos base.
Aunque estas técnicas son empleadasen la investigación en Psicología o en Me-dicina, no lo son tanto en nuestro campo.El trabajo de Wagner, Schober y Spiel(2008) ilustra el empleo de esta técnica enuna investigación educativa reciente. En elmismo emplean CFA para analizar elefecto del género de los estudiantes en larelación entre el tiempo dedicado a la rea-lización de tareas escolares y el rendi-miento académico. Como suele ser habitualen este tipo de estudios, variables como elrendimiento o el tiempo son dicotomizadasen función de la mediana. En este caso delas 8 posibles configuraciones, sólo emergeun tipo que muestra que son más frecuen-tes las chicas que obtienen altas puntua-ciones y que dedican mayor cantidad detiempo al estudio. También en nuestrocampo, y más específicamente en el de laorientación, Reitzle y Vondracek (2000)emplean CFA y análisis de corresponden-cias para estudiar las transiciones fami-liares y laborales de jóvenes alemanes re-saltando las diferencias entre enfoquesanalíticos centrados en las variables y loscentrados en las personas.
Para un análisis detallado de las posi-bilidades de esta técnica, de sus diversoscampos y modos de aplicación (explorato-rio, confirmatorio, predictivo o longitudi-nal), remitimos al libro recientemente pu-blicado por Von Eye, Mair y Mum (2010)en el que abordan los últimos avances enCFA. Por último, el paquete de R que eje-cuta este tipo de análisis se denomina cfay se encuentra en http://cran.r-project.-org/web/packages/cfa/.
Tablas de contingencia tridimensiona-les
El problema más sencillo con varia-bles cualitativas y que presenta una es-tructura no simple se plantea como una ta-bla de contingencia bidimensional. Sucomplejidad es mínima desde el punto devista inferencial, centrándose la compleji-dad en el estudio de la independencia en-tre dos factores bajo los diversos diseños demuestreo, obteniendo estimadores máximoverosímiles de la distribución empírica, lapartición de tablas, las medidas de asocia-ción, tanto simétricas como asimétricas,basadas en las razones de ventajas ordi-narias (odds ratios, OR), locales y globales.
Sin embargo la complejidad crece con-siderablemente si se trata del análisis deuna tabla tridimensional, complejidad porotra parte más acorde a la realidad educa-tiva; surgen conceptos sobre los distintostipos de independencia, así como las razo-nes de ventajas, que desembocan en probaruna numerosa serie de hipótesis sobre in-dependencia global, conjunta entre dos fac-tores, mutua entre tres factores, condicio-nal, parcial y marginal, así como deausencia de interacción y las relacionesentre ellas. El esquema más asequible se
revi
sta
espa
ñola
depe
dago
gía
añoLXX,nº251,enero-abril2012,111-130
116
Luis LIZASOAIN y Luis JOARISTI

refiere a tablas 2 x 2 x K que representanla relación entre dos factores dicotómicoscontrolando un tercer factor no dicotómico.Una vez especificada una medida de laasociación parcial entre los factores, seprueba la existencia de interacción o entrelos factores; en su caso se plantea la hipó-tesis de homogeneidad de la medida deasociación entre niveles y aplicar por finuna prueba de no asociación entre factores.Para ello se utilizan como medidas de aso-ciación las OR, que en este caso son las or-dinarias.
Por su parte, en las tablas tridimen-sionales de factores no dicotómicos las ORa utilizar son las locales, lo que enmarañaconsiderablemente resultados e interpre-taciones. Si además, para tablas de más detres dimensiones, el número de estructu-ras jerárquicas (formas de independenciay asociación) se incrementa tanto que re-sulta muy trabajoso analizarlas indivi-dualmente mediante contrastes de Chicuadrado de independencia, la generali-zación del análisis de tres a cuatrodimensiones, por poco práctica, dirige elenfoque metodológico a los modelos Log-li-neales.
Modelos log-linealesSiguiendo a Ruiz-Maya (1995), el aná-
lisis clásico de las tablas de contingencia noresuelve cuestiones como la estimación delpeso sobre las frecuencias de cada factor através de sus niveles, ni la influencia con-junta de varios factores. Además, por otrasrazones más arriba mencionadas, se recu-rre a los modelos Log-lineales, ya que tie-nen una interpretación natural en térmi-nos de probabilidad y de independenciacondicional (Aguilera, 2006)
Se busca expresar en términos aditi-vos, por transformación logarítmica de lostérminos multiplicativos, la frecuencia delos casos en las combinaciones de niveles omodalidades de los distintos factores segúnlas distribuciones marginales y las inte-racciones.
Correa (2002) plantea las siguientesetapas en la construcción de un modelo:proponerlo, derivar un conjunto de expec-tativas bajo él, someter a prueba el ajustedel modelo (Chi cuadrado o la razón de ve-rosimilitudes de Chi cuadrado), decidir simantener el modelo o no y por fin, estimarlos parámetros del modelo definitivo.
Por lo tanto la primera etapa consisteen ajustar modelos Log-lineales jerárqui-cos a una tabla de contingencia multidi-mensional para encontrar las variables ca-tegoriales o factores que están asociados.Este proceso, que puede ser automático, serealiza habitualmente por pasos.
Se empieza por el modelo saturado.Hay que recordar que el modelo nulo esaquel que no tiene efectos y el saturado elque tiene tantos efectos como celdas tieneel hipercubo de contingencia (Lebart,1985), lo que implica que no hay ningunapérdida de información. Entre ambos ex-tremos se encuentra el óptimo según elpostulado de parsimonia. Inicialmente seelimina la interacción de orden más alto.Cada vez que se elimina un efecto, se eva-lúa el cambio del estadístico Chi cuadrado,de manera que si no es significativo, talefecto se puede eliminar del modelo. Encada paso se elimina el efecto cuyo cambioen la razón de verosimilitudes tiene mayornivel de significación. Se continúa así
revistaespañola
depedagogía
añoLXX,nº
251,enero-abril2012,111-130
117
Las nuevas tecnologías y la investigación educativa. El análisis de datos…

hasta llegar a un modelo en que todos losefectos son significativos. Al tratarse demodelos jerárquicos, hay que tener pre-sente que unmodelo con algún efecto de in-teracción incluirá también a los efectossimples que lo componen y a las interac-ciones de orden inferior.
Siguiendo el proceso, la hipótesis sobrela nulidad de ciertos efectos ha generadoun modelo; a partir de él se estiman las fre-cuencias teóricas (por el método de má-xima verosimilitud y suponiendo que losdatos siguen una distribución multinomialo una de Poisson, según que el tamaño dela muestra esté o no limitado previamente)utilizando el método iterativo de Newton-Raphson, para compararlas a las empíricasa través de pruebas de bondad del ajuste yasí rechazar o no la hipótesis sobre las aso-ciaciones incluidas en el modelo. Las prue-bas más utilizadas son la de Chi cuadradode Pearson y la G cuadrado de la razón deverosimilitudes, resultando que cuantomás se aproximan a 0 mejor es el ajuste.Así, una estrategia para obtener unmodeloadecuado consiste en partir del saturado eir eliminando sucesivamente las interac-ciones, haciendo que los estadísticos men-cionados aumenten, pudiendo detener elproceso cuando se produzca un saltobrusco. Es posible utilizar los criterios AICy BIC para la selección del modelo.
Conviene dejar claro que no convieneaplicar esta técnica con más de tres facto-res, pues téngase en cuenta que con 4 fac-tores hay 167 modelos jerárquicos posibles(Lebart, 1985)
En SPSS, el Análisis Log-lineal se en-cuentra en el submenú Loglineal con sus
tres posibilidades: General, Logit y Selec-ción de modelo.
En R se pueden usar varias funcionespara ajustar modelos Log-lineales. En labiblioteca “stats” (que se carga por defecto)está la función loglin y glm. En el paquete“MASS” las funciones loglm y loglin ajus-tan modelos jerárquicos Log-lineales.Como tutorial, proponemos el de WilliamB. King que está accesible en la webhttp://ww2.coastal.edu/kingw/statistics/R-tutorials/loglin.html.
Modelos logit, probit y análisis deregresión logística
A diferencia de lo que se ha expuestohasta aquí, introduciremos una variabledependiente y una o más independientes.Por otro lado hay que tener presente la in-viabilidad del modelo lineal de probabili-dad, pues puede dar resultados con proba-bilidades estimadas fuera del intervalo [0,1]. Sin embargo, ésta y otras condicionesimprescindibles son cumplidas por dos ti-pos de funciones, la logística y la normal.A partir de estas funciones de enlace, sur-gen los modelos denominados Logit y Pro-bit, pertenecientes ambos a los denomina-dos Modelos lineales generalizados(GLMM).
En general se aborda este tema dis-tinguiendo claramente entre la respuestabinaria y la multinomial, pues al basarseen las OR de la variable dependiente hayque recordar la complejidad de las OR lo-cales, asociadas sólo a las variables poli-tómicas. Y como el modelo Logit es una re-formulación del Log-lineal, lo relativo a labondad de ajuste y estimación de los pa-rámetros se realiza empleando las herra-
revi
sta
espa
ñola
depe
dago
gía
añoLXX,nº251,enero-abril2012,111-130
118
Luis LIZASOAIN y Luis JOARISTI

mientas estadísticas del modelo Log-li-neal.
En su estructura, la Regresión logís-tica es semejante a los modelos Logit (tantoque es frecuente no distinguir entre ellos,dada la asociación del modelo Logit a la Re-gresión logística) y en sus objetivos, al Aná-lisis discriminante, siendo menos restric-tivo que éste. Su principal aplicación secentra en variables dependientes dicotó-micas y en estimar la probabilidad de quese produzca el suceso definido por ellas(Silva, 2004), aunque recientemente se de-sarrollan cada vez más modelos más ge-nerales y complejos, como los de variablede respuesta politómica y ordinal.
La regresión logística en R es realiza-ble mediante la función glm que está in-corporada en el módulo básico. El tutorialde Manning (2007) aporta información de-tallada al respecto.
Análisis factorial de correspondenciasLas exposiciones y desarrollos sobre
análisis factorial en general, muy nume-rosas, difieren entre sí en aspectos mera-mente matemáticos y didácticos, siendofrecuentes textos en los que se prima lacomprensibilidad sobre el rigor. Autorescomo Benzécri (1984), Volle (1997), Bertier(1981), etc. apuestan por la profundiza-ción matemática para conseguir una con-siderable competencia en la aplicaciónpráctica (Joaristi, 1999)
Son técnicas del grupo de las de inter-dependencia y su objetivo son las tablas decontingencia. A diferencia del análisis Log-lineal, es preponderante el enfoque explo-ratorio. En el caso de sólo dos dimensiones,
hablamos del AFC simples. Si fuesen másde dos dimensiones, se trataría del AFCmúltiples.
Centrándonos en las correspondenciassimples, definir una correspondencia entredos conjuntos consiste en asociar a cadaelemento del producto cartesiano de ambosconjuntos un número no negativo. Lo másclásico es tratar una tabla de contingencia,aunque puede ser aplicado a cualquier ta-bla de números positivos. Si todos los va-lores son enteros se trata de una corres-pondencia estadística, pues los númerosindican cuántas veces se presenta cadapar; estas son las tablas de contingencia.Sin embargo, si son probabilidades, setrata de una correspondencia probabilís-tica. También se pueden analizar tablas demedidas, tablas de intensidades con notasde mérito, tablas de preferencias y tablasde Burt (Lizasoain, 1999).
Entre los problemas que más habi-tualmente se plantean está el de descom-poner una tabla de grandes dimensiones,es decir, que sea inasequible a la inspec-ción visual, en otras “fáciles de entender”.Se puede representar la información fun-damental de una tabla grande en unas po-cas dimensiones, dando lugar a unas pocasrepresentaciones gráficas planas (del tipode un diagrama de dispersión), que sonmás asequibles e ilustrativas. Otra aplica-ción consiste en transformar una informa-ción sin métrica en otra bajo factores orto-gonales y con métrica euclídea con el fin,entre otros, de realizar una clasificación delos sujetos.
En este tipo de técnicas multivariantesde análisis de datos hay que caracterizar a
revistaespañola
depedagogía
añoLXX,nº
251,enero-abril2012,111-130
119
Las nuevas tecnologías y la investigación educativa. El análisis de datos…

los elementos (filas y columnas) por sus co-ordenadas en el espacio correspondiente,además es preciso tener presente su masay por fin hay que definir una distancia en-tre ellos; el problema matemático consistehabitualmente en la optimización de unafunción objetivo. En el caso que nos ocupa,la ponderación de un elemento (fila o co-lumna) se realiza por las marginales co-rrespondientes. En cuanto a la distancia,se trata de Chi-cuadrado, la cual posee laimportante propiedad de la equivalenciadistribucional, consistente en que la dis-tancia entre filas no se altera si se fusionandos columnas de perfil semejante. Estapropiedad es deseable frente a arbitrarie-dades de la codificación, garantizando asíla robustez, pues ni se gana informacióndescomponiendo una clase en subclaseshomogéneas, ni se pierde fusionando claseshomogéneas en otra. El objetivo matemá-tico es encontrar los ejes principales, o demáxima inercia o varianza de las nubes depuntos de las filas y de las columnas.
Los elementos utilizados para calcularlos planos factoriales se denominan ele-mentos activos y deben formar un conjuntohomogéneo y exhaustivo (describir com-pletamente el tema) para que las distanciasentre elementos puedan ser fácilmente in-terpretables. Así, se analizan como ele-mentos suplementarios o ilustrativos lasobservaciones recogidas bajo condicionespoco claras o distintas de las del resto, obien, elementos aberrantes, o casos nuevos,o elementos de distinta naturaleza delresto; asimismo se tratarían como suple-mentarios los elementos recogidos con pos-terioridad a la realización del análisis. Ade-más la dicotomía entre elementos activos eilustrativos es tan fundamental como la
distinción que se establece entre variablesendógenas (a explicar) y exógenas (expli-cativas) en la regresión múltiple.
En cuanto a la interpretación de los re-sultados, una importante ventaja al trataruna tabla de números por AFC es la aso-ciada a las relaciones de transición: el po-der representar las coordenadas de unafila en función de las coordenadas de las co-lumnas, lo que implica que los dos conjun-tos se pueden representar gráficamentede forma simultánea.
Para representar adecuadamente laimportancia de un elemento en la creaciónde un eje factorial se recurre a las contri-buciones relativas. Además, con el fin deevaluar cómo están representadas una filao una columna por los distintos factores, serecurre a las contribuciones relativas delfactor sobre el elemento en cuestión; se en-tiende por calidad de la reconstitución deun elemento por medio de los primerosejes como la suma de las contribuciones re-lativas de esos ejes sobre él. Para inter-pretar un factor es conveniente elegir unreducido número de modalidades cuyacontribución a la inercia del factor seafuerte. Para interpretar un factor convienebuscar los puntos para los que la contri-bución relativa de modalidad a factor eselevada.
Una vez resumidas las ideas funda-mentales del AFC simples, poco queda pordecir sobre el AFC múltiples, pues básica-mente es análogo. Habitualmente los datosvienen bajo el formato que Diday (1982)denomina tabla de modalidades, en quelas filas son casos y las columnas son lasvariables cualitativas; por lo tanto, una
revi
sta
espa
ñola
depe
dago
gía
añoLXX,nº251,enero-abril2012,111-130
120
Luis LIZASOAIN y Luis JOARISTI

diferencia sustancial con el AFC simples esque las filas no son modaliades de varia-bles. Además no es ésta la tabla que se vaa analizar, debido a que modificaciones–lícitas– en la codificación numérica de lasmodalidades, afectarían a los resultados.Es por lo que se recurre a la codificacióndisyuntiva completa de las modalidadesen un procesamiento automático que serealiza de forma temporal.
Otra forma de analizar una tabla decontingencia multidimensional es a travésde la matriz de Burt, que es una matriz si-métrica que contiene todas las tablas decontingencia simple entre las variables ysu principal ventaja es que es más “eco-nómica” desde el punto de vista del proce-samiento informático. Su análisis no esde correspondencias múltiples sino el de latabla binaria asociada a la corresponden-cia múltiple, siendo analizados los casoscomo filas suplementarias de la matriz deBurt.
En SPSS el AFC simples se realiza enel submenú Reducción de datos, en Análi-sis de correspondencias y el AFCmúltiplesen el mismo submenú en Escalamientoóptimo.
El análisis de correspondencias, tantosimple como múltiple, se puede ejecutar enR mediante los paquetes ca y anacorr. Enla página web específica de R dedicada alos modelos y métodos psicométricos(CRAN Task View: Psychometric Modlesand Methods) hay un apartado específicodedicado al análisis de correspondenciascon información adicional muy detallada.Como trabajo de referencia recomendamosel artículo de Nenadic y Greenacre (2007).
Clasificación automática con varia-bles categoriales
Todo ello, sin embargo, produce un vo-lumen de resultados cuya interpretación,por no ser sencilla ni estandarizada, estásometida a un aspecto más subjetivo que lohabitual en las técnicas estadísticas deanálisis de datos. Ante ello se recurre a re-alizar una clasificación; por medio del AFCse pueden obtener las puntuaciones facto-riales, tanto de filas como de columnas,pudiendo así someter a ambos tipos de ele-mentos a alguna de las técnicas de clasifi-cación, aclarando así la disposición y agru-pamientos de los elementos perceptiblesen los distintos planos factoriales en claseshomogéneas.
Pero al tratarse de técnicas de clasifi-cación con variables cuantitativas, quedanal margen de este artículo. Abordaremossin embargo las técnicas de clasificaciónque operan directamente sobre variablescualitativas.
Conocida bajo varios nombres (análisisde clusters, análisis de conglomerados, ta-xonomía numérica), constituye un conjuntode técnicas que se puede situar en el grupode las de interdependencia. Es ademáseminentemente exploratoria. Se trata desuperar una visualización plana y continuade las asociaciones estadísticas, para poneren evidencia clases de casos o clases devariables (Lebart, 1985). Se diferencia delanálisis discriminante en que éste asignalos casos a grupos preexistentes.
Las técnicas requieren de cálculos pormedio de algoritmos, son por tanto recur-sivos y repetitivos. Como consecuencia, esprácticamente imprescindible la utiliza-
revistaespañola
depedagogía
añoLXX,nº
251,enero-abril2012,111-130
121
Las nuevas tecnologías y la investigación educativa. El análisis de datos…

ción de herramientas informáticas: “El cál-culo electrónico es uno de los dominios dela ciencia aplicada en que el progreso es enla actualidad el más rápido y sorpren-dente…Tales problemas no se resolverán sino es mediante algoritmos de clasificacióno de reducción del número de dimensio-nes”, afirma Benzécri (1984). Evidente-mente cuanto mayor sea la rapidez y la ca-pacidad de proceso, problemas con mayorvolumen de datos podrán ser tratados. Porotra parte, los desarrollos matemáticos sonen general elementales, basándose en elsentido común más que en teorías forma-lizadas (Lebart, 1985).
Como ya se ha mencionado, en las téc-nicas multivariantes los elementos se ca-racterizan por sus coordenadas y su masa,definiendo también una distancia entreellos. La situación aquí no es muy distinta.Partiendo de la posición de los elementosen el espacio correspondiente (los casos enel de las variables y viceversa), el procesoconsiste en obtener una medida de la se-mejanza, similitud o disimilitud (que nohay que confundir con la distancia, puesésta es más restrictiva) entre ellos y desa-rrollar algún procedimiento que construyalas clases basándose en ellas.
Como ya ha sido apuntado, en lo quesigue vamos a limitarnos a las técnicas declasificación con variables cualitativas.Ello va a condicionar tanto la elección de lamétrica o distancia como el algoritmo declasificación. En general, los algoritmos declasificación pueden ser jerárquicos o no.
La clasificación jerárquica se basa enuna familia de algoritmos calificables dedeterministas” (Lebart, 2000), pero están
mal adaptados a conjuntos de datos am-plios. Un algoritmo de clasificación jerár-quica consiste en transformar la disimili-tud inicial para convertirla en unadistancia ultramétrica y a continuaciónconstruir la jerarquía indexada (Hernán-dez, 2001); esto es, a través de la ultramé-trica se pueden ir agrupando las clasesmás próximas hasta llegar a una jerar-quía indexada. El proceso para realizaruna clasificación jerárquica ascendente sepuede resumir en, partiendo de elementossin agrupación alguna, buscar los 2 ele-mentos más próximos y agregarlos en unonuevo; a continuación se calcula la distan-cia entre el nuevo elemento (grupo) y elresto. Los métodos de agregación habitua-les son los del Vecino más próximo, Vecinomás lejano, Vinculación inter-grupos, Vin-culación intra-grupos, Agrupación de cen-troides, Agrupación de medianas y Métodode Ward. El proceso iterativo consiste enrepetir este proceso hasta que al final todoslos elementos estén en un sólo grupo. Estoda origen a una jerarquía indexada que serepresenta en forma de árbol o dendro-grama, representando en un eje los ele-mentos ordenados según se van agregandoy en el otro las distancias correspondientesa los distintos niveles de agregación.
Por su parte la clasificación en dos pa-sos o fases permite clasificar los casos, quepueden ser muy numerosos, basándose envariables tanto cuantitativas como cuali-tativas, utilizando para ello como medidapara la agregación la verosimilitud. Se su-pone que las variables categoriales siguenleyes multinomiales y se parte de que to-das las variables son independientes; sinembargo, el procedimiento es lo suficien-temente robusto ante violaciones de estos
revi
sta
espa
ñola
depe
dago
gía
añoLXX,nº251,enero-abril2012,111-130
122
Luis LIZASOAIN y Luis JOARISTI

dos supuestos. Esto hace que este algo-ritmo sea preferible a las técnicas tradi-cionales. Además no hay que especificar unnúmero concreto de clases. Siguiendo a Yu(2010), en el primer paso o de preclasifica-ción se crea el árbol de características delos conglomerados, explorando cada ele-mento y aplicando la distancia de verosi-militud para determinar si el elementodebe agregarse con otros o formar unaclase nueva; explorados todos los casos,las clases creadas son tratadas como nue-vos datos. En el segundo paso se aplica laclasificación jerárquica a estas clases, ob-teniéndose una jerarquía indexada. Paraseleccionar el número óptimo de clases sedispone de los criterios de información AICde Akaike, que es un índice del ajuste deun modelo, que compromete la bondad desu ajuste con su complejidad. Ya que elíndice AIC es optimista, es más conve-niente aplicar el criterio BIC de Bayes,que penaliza la complejidad con más in-tensidad. La gráfica de la importancia delas variables en cada clase resulta una va-liosa herramienta; en ella se muestra el va-lor de Chi-cuadrado o su significación comoíndice de la importancia de cada variablecategórica en cada clase.
Se presenta de forma resumida la cla-sificación alrededor de centros móviles (Kmedias) ya que puede ser la primera etapaauxiliar de otros métodos de clasificación,pues este algoritmo es mucho más rápidoy requiere menor capacidad de procesa-miento informático y almacenamiento. Lasdistancias a utilizar son la euclídea y laChi-cuadrado. Este algoritmo consiste enespecificar una serie de centros provisio-nales de las clases, constituyéndose unaprimera partición de los elementos, asig-
nando cada elemento a la clase de centromás próximo. Después se determinan losnuevos centros de las clases formadas en laetapa anterior, dando origen a una nuevapartición. Repitiendo el proceso, se llega ala estabilidad de la clasificación, lo que dafin al proceso.
Respecto de la clasificación mixta, esadecuada para grandes volúmenes de da-tos. La primera fase consiste en realizaruna clasificación no jerárquica, agrupandolos elementos en torno a centros móviles enmuchas clases (pero considerablementemenos que el número de elementos). En lafase siguiente se realiza una clasificaciónjerárquica ascendente a las clases obteni-das en el paso anterior. El proceso finalizaobteniendo la partición final por corte delárbol de la clasificación jerárquica ascen-dente (habitualmente cortando por las ra-mas más largas).
Programas informáticos con técnicasde clasificación para datos categoriales:
En SPSS desde la versión 11.5 hastalas actuales, se encuentran en el submenúClasificar tres subprogramas: Conglome-rados en dos fases y Conglomerados jerár-quicos y Conglomerados de K medias.
Las técnicas de análisis de conglome-rados son realizables en R mediante el pa-quete cluster que viene incorporado con elprograma, de forma que cualquier instala-ción de R dispone del mismo sin que seanecesaria ninguna carga adicional. La fun-ción dendrogram permite la realización deeste tipo de representación gráfica. Infor-mación adicional muy detallada se puedeencontrar en la página específica que
revistaespañola
depedagogía
añoLXX,nº
251,enero-abril2012,111-130
123
Las nuevas tecnologías y la investigación educativa. El análisis de datos…

R tiene sobre clasificación: http://cran.es.r-project.org/web/views/Cluster.html
Por último, como textos de ayuda re-comendamos los tutoriales de Holland(2006) y de Oksanen (2010).
Visualización de datos categorialesAunque el uso de recursos gráficos es
casi tan antiguo como la Estadística [1], eldesarrollo de las tecnologías informáticasha supuesto un enorme impulso en estecampo permitiendo en primer lugar el di-seño y realización de gráficos cada vez máscomplejos y completos; segundo, la gene-ración interactiva de los mismos mediantela selección por parte del usuario de va-riables, parámetros y opciones; y tercero, lavinculación dinámica de los gráficos a lastablas y a los archivos de datos.
La visualización de datos se puede con-siderar una parte de la Estadística exis-tiendo revistas científicas centradas eneste campo como Journal of Computatio-nal and Graphical Statistics o Informa-tion Visualization siendo además muy nu-merosas las páginas web centradas en estacuestión.
Este conjunto de técnicas tiene comoobjetivos complementar las habituales ta-blas y resúmenes estadísticos medianterecursos gráficos y visuales orientados a fa-cilitar la exploración de los datos, así comoel diseño y ajuste de modelos mostrandopatrones en los datos.
Y todo ello con la doble finalidad de seruna herramienta que facilite tanto la pre-sentación de datos y resultados, como elpropio análisis de los mismos. Friendly
(2000) en la introducción de su obra sobrevisualización de datos categoriales afirmaque el foco de la visualización de datos hade estar en los gráficos intuitivos de formaque estos sean capaces de revelar aspectosde los datos que no pueden ser percibidosmediante otros medios (cfr. pág. 1).
En definitiva, la visualización tratade ser una herramienta para facilitar lacomprensión de los datos. Este enfoque esasumido por la obra de Young, Valero-Mora y Friendly (2006) que se centra en eluso de gráficos dinámicos interactivoscomo herramienta del análisis estadísticode datos.
Aunque en sus inicios, la visualizaciónestaba sobre todo centrada en variablescuantitativas, en la actualidad se disponetambién de un amplio repertorio de gráfi-cos (y de programas informáticos) para lasvariables categoriales y la citada obra deFriendly (2000) en un referente en la ma-teria a la que remitimos al lector para unexamen detallado y pormenorizado.
Ahora vamos a mostrar un ejemplo yalgunas direcciones útiles tanto para elestudio de estas cuestiones como para lo-calizar los recursos informáticos necesa-rios.
Normalmente los gráficos para varia-bles categoriales se agrupan en aquelloscentrados en la representación de distri-buciones discretas, en los que su interésestá en las tablas de contingencia bi omultidimensionales y en los asociados atécnicas o modelos específicos como la re-gresión logística, el análisis de correspon-dencias o los modelos logarítmicos-lineales.
revi
sta
espa
ñola
depe
dago
gía
añoLXX,nº251,enero-abril2012,111-130
124
Luis LIZASOAIN y Luis JOARISTI
revistaespañola
depedagogía
añoLXX,nº
251,enero-abril2012,111-130
125
Las nuevas tecnologías y la investigación educativa. El análisis de datos…
Dado que los primeros se refieren aun enfoque univariado y que los terceroshan de contemplarse junto con los proce-dimientos asociados, vamos a centrarnosen las tablas de contingencia. Y aquí losgráficos más habituales son los mosaicos,y para el caso de tablas de 2x2 los gráficoscuádruples (fourfold displays) y los dia-gramas que muestran los niveles deacuerdo o desacuerdo (diagrama de Bang-diwala). Dado que los mosaicos son de apli-cación a tablas de cualquier dimensión yque se usan también con los modelos lo-garítmico lineales, vamos a ver sucinta-mente un ejemplo, remitiendo para el restoa la bibliografía y páginas web recomen-dadas.
Los gráficos de mosaico fueron plante-ados por Hartigan y Kleiner (1984) y porFriendly (1994). La idea central es que,dada una tabla de contingencia, se repre-sentan tantos rectángulos como casillastenga tabla, siendo el área de los rectángu-los proporcional a la frecuencia observada yla intensidad del sombreado a las frecuen-cias esperadas o a los residuos (de este plan-teamiento general hay diversas variacio-nes, pero éste es el modelo más habitual).
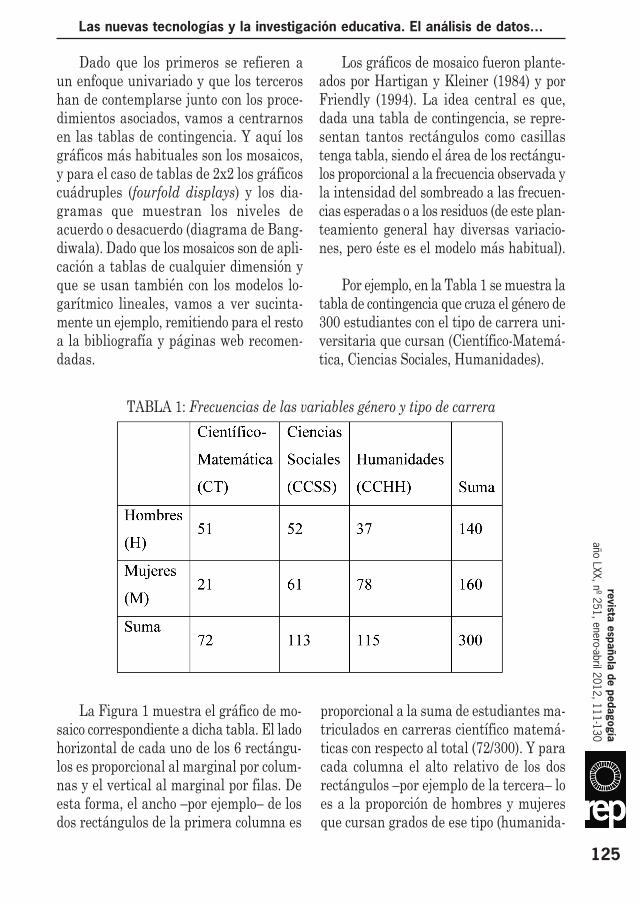
Por ejemplo, en la Tabla 1 se muestra latabla de contingencia que cruza el género de300 estudiantes con el tipo de carrera uni-versitaria que cursan (Científico-Matemá-tica, Ciencias Sociales, Humanidades).
TABLA 1: Frecuencias de las variables género y tipo de carrera
La Figura 1 muestra el gráfico de mo-saico correspondiente a dicha tabla. El ladohorizontal de cada uno de los 6 rectángu-los es proporcional al marginal por colum-nas y el vertical al marginal por filas. Deesta forma, el ancho –por ejemplo– de losdos rectángulos de la primera columna es
proporcional a la suma de estudiantes ma-triculados en carreras científico matemá-ticas con respecto al total (72/300). Y paracada columna el alto relativo de los dosrectángulos –por ejemplo de la tercera– loes a la proporción de hombres y mujeresque cursan grados de ese tipo (humanida-

des: hombres 37/140; mujeres 78/160). Ypara cada rectángulo, su área es propor-cional a la frecuencia de cada casilla.
Pero además, la intensidad del color(aquí sombreado en blanco y negro quehace perder algunos matices) está en fun-ción de las frecuencias esperadas o, si sequiere, de los residuos. De esta forma,cuanto más intenso sea el color o el som-breado, más importante será el efecto deinteracción. Y así vemos como en la co-lumna central el sombreado es muy tenue,casi inexistente, denotando que los estu-
diantes matriculados en grados de cien-cias sociales no difieren en su número conrespecto a su sexo. Por el contrario, el rec-tángulo superior de la primera columna oel inferior de la tercera muestran un som-breado intenso pues la proporción de estu-diantes masculinos en carreras científico-matemáticas es muy superior a la deestudiantes femeninas, dándose la rela-ción contraria en el caso de las humanida-des. En los gráficos en color, el signo de losresiduos se representa empleando coloresdistintos y la magnitud mediante la in-tensidad de dicho color.
revi
sta
espa
ñola
depe
dago
gía
añoLXX,nº251,enero-abril2012,111-130
126
Luis LIZASOAIN y Luis JOARISTI
FIGURA 1:Mosaico correspondiente a la Tabla 1
H-CT
M-CT
H-CCSS
M-CCSS
H-CCHH
M-CCHH
Es muy difícil plasmar en un trabajode estas características y en soporte papellas enormes potencialidades que tienenlos actuales programas de visualizaciónde datos, por lo que remitimos al lector alas páginas web que a continuación rese-ñamos y donde podrá encontrar una de-tallada galería de gráficos con multitud deefectos y posibilidades. Por ejemplo, el
paquete vcdExtra de R permite desarro-llar mosaicos en tres dimensiones paratablas de contingencia que crucen tresvariables.
De entre la amplia variedad de sitios ypáginas web centrados en visualización dedatos, nos permitimos reseñar los siguien-tes:

La galería gráfica de R (http://addic-tedtor.free.fr/graphiques/) es un referenteobligado donde aparecen todos los recursosgráficos de R. En el caso concreto de la vi-sualización de datos categoriales los pa-quetes más habituales son vcd y vcdExtra:
• (http://cran.r-project.org/web/pack-ges/vcd/)
• (http://cran.r-project.org/web/-packages/vcdExtra/)
La página de Friendly sobre visuali-zación de datos (http://www.datavis.ca/) ala que aludimos al inicio de este apartado,es una referencia en la materia. Contieneuna excelente galería con útiles (y en oca-siones divertidos) ejemplos de buenas ymalas gráficas, enlaces, material de suscursos, etc. Por ejemplo, en el apartado decursos se puede descargar un excelentetutorial escrito por Friendly (2010) sobrelos paquetes de R vcd y vcdExtra(http://www.datavis.ca/courses/VCD/-vcd-tutorial.pdf).
Por último, en la página web del pro-fesor Valero Mora de la facultad de Psico-logía de la Universidad de Valencia(http://www.uv.es/valerop/) hay un apar-tado dedicado a la visualización de datos yotro al programa informático ViSta (Youngy Bann, 1997; Valero-Mora, Young yFriendly, 2003) de visualización estadísticaque es de descarga libre y gratuita.
Dirección para la correspondencia: Luis Lizasoain.Departamento de Métodos de Investigación y Diag-nóstico en Educación. Universidad del País Vasco, Avda.Tolosa 70, 20018 San Sebastián.E-mail: [email protected].
Fecha de recepción de la versión definitiva de este artículo:15.VI.2011
Notas[1] Véase al respecto la página web de visualización man-
tenida por el profesor Friendly http://www.datavis.-ca/milestones/ centrada en los hitos en la historia de losgráficos y la visualización, o el trabajo del propio Friendly(2009) titulado Milestones in the history of thematic car-tography, statistical graphics, and data visualization.
BibliografíaAGRESTI, A. (2007) An Introduction to categorical data analy-
sis (New Jersey, John Wiley and Sons, 2nd Ed.).
AGUILERA, A. M. (2002) Tablas de contingencia bidimensio-nales (Madrid, La Muralla).
AGUILERA, A. M. (2006) Modelización de tablas de contingen-cia multidimensionales (Madrid, La Muralla).
BENZECRI, J. P. (1984) L’Analyse des Données, Vol.1. La Ta-xinomie (París, Dunod).
BERTIER, P. y BOUROCHE, J. M. (1981) Analyse des donnéesmultidimensionnelles (París, PUF).
COOK, T. D. y CAMPBELL, D. T. (1979) Quasi-Experimentation:Design & Analysis Issues for field settings (Boston, Hough-ton Mifflin Company).
CORREA, A. D. (2002) Análisis logarítmico lineal (Madrid, La Mu-ralla).
DIDAY, E.; LEMAIRE, J.; POUGET, J. y TESTU, F. (1982) Éle-ments d’analyse de données (París, Dunod).
FRIENDLY, M. (1994) Mosaic displays for multi-way contin-gency tables, Journal of the American Statistical Asso-ciation, 89, pp. 190-200.
FRIENDLY, M. (2000) Visualizing Categorical Data (Cary, NC,SAS Institute Inc.).
FRIENDLY, M. (2009) Milestones in the history of thematic car-tography, statistical graphics, and data visualization. Verhttp://www.math.yorku.ca/SCS/Gallery/milestone/milestone.pdf (Consultado el 16.V.2011).
FRIENDLY, M. (2010) Working with categorical data with R andthe vcd and vcdExtra packages. Ver http://www.data-vis.ca/courses/VCD/vcd-tutorial.pdf (Consultado el16.V.2011).
revistaespañola
depedagogía
añoLXX,nº
251,enero-abril2012,111-130
127
Las nuevas tecnologías y la investigación educativa. El análisis de datos…

GOODMAN, L. A. (2007) Statistical Magic and/or Statistical Se-rendipity: An Age of Progress in the Analysis of Catego-rical Data, Annual Review of Sociology. 33, pp.1-19.
HABERMAN, S. J. (1973) The Analysis of Residuals in Cross-Classified Tables, Biometrics, 29, pp. 205-220.
HARTIGAN, J. A. y KLEINER, B. (1984) A mosaic of televisionratings, The American Statistician, 38, pp. 32-35.
HERNÁNDEZ, L. (2001) Técnicas de taxonomía numérica (Ma-drid, La Muralla).
HOLLAND, S. M. (2006) Cluster Analysis. Ver http://www.uga.-edu/strata/software/pdf/clusterTutorial.pdf (Consultadoel 16.V.2011).
JOARISTI, L. y LIZASOAIN, L. (1999) Análisis de correspon-dencias (Madrid, La Muralla).
LEBART, L.; MORINEAU, A. y FENELON, J. P. (1985) Statistiqueexploratoire multidimensionelle (París, Dunod).
LEBART, L.; MORINEAU, A. y PIRON, M. (2000) Tratamiento es-tadístico de datos (Barcelona, Marcombo).
LIZASOAIN, L. y JOARISTI, L. (1999) Análisis de Correspon-dencia, en TEJEDOR, F. J. y NIETO, S. (coords.) Técnicasde análisis multivariante (Salamanca, Tesitex), pp. 15-62.
LIZASOAIN, L. y JOARISTI, L. (1999) El programa SPAD paraWindows, en TEJEDOR, F. J. y NIETO, S. (coords.) Téc-nicas de análisis multivariante (Salamanca, Tesitex), pp.63-92.
LIENERT, G. A. (1968) Die “Konfigurationsfrequenzanalyse”als Klassifikationsmethode in der klinischen Psychologie[Configural Frequency Analysis – A classification met-hod of clinical psychology]. Paper presented at the 26.Kongress der Deutschen Gesellschaft für Psychologie inTübingen 1968.
LINDSAY, B. G.; KETTENRING, J. y SIEGMUND D. O. (2004) AReport on the Future of Statistics, Statistical Science,19:3, pp. 387-413.
LITTLE, T. D.; SCHNABEL, K. U. y BAUMERT, J. (2000) Mode-ling longitudinal and multilevel data (New Jersey, Erlbaum).
MANNING, C. (2007) Logistic regression (with R). Verhttp://nlp.stanford.edu/~manning/courses/ling289/logistic (Consultado el 16.V.2011).
NENADIC, O. y GREENACRE, M. (2007) Correspondence Analy-sis in R, with Two- and Three-dimensional Graphics: Theca Package, Journal of Statistical Software, 20:3.
NIE, N.; BENT, D. H. y HULL, C. H. (1970) SPSS: Statistical Pac-kage for the Social Sciences (New York, McGraw-Hill).
OKSANEN, J. (2010) Cluster Analysis. Tutorial with R. Verhttp://cc.oulu.fi/~jarioksa/opetus/metodi/sessio3.pdf(Consultado el 16.V.2011).
REITZLE. M. y VONDRACEK, F. W. (2000) Methodological Ave-nues for the Study of Career Pathways, Journal of Voca-tional Behavior, 57, pp. 445-467.
RUIZ-MAYA, L.; MARTÍN, F. J.; MONTERO, J. M. y URIZ, P.(1995) Análisis estadístico de encuestas: datos cualita-tivos (Madrid, AC).
SILVA, L. C. y BARROSO, I. M. (2004) Regresión logística (Ma-drid, La Muralla).
TUKEY, J. W. (1977) Exploratory Data Analysis (Boston, Addi-son-Wesley).
VALERO-MORA, P. M.; YOUNG, F. W. y FRIENDLY, M. (2003) Vi-sualizing categorical data in vista, Computational Statis-tics & Data Analysis, 43:4, pp. 495-508.
VOLLE, M. (1997) Analyse des données (París, Economica).
VON EYE, A. (2002) Configural frequency analysis – Methods,models, and applications (Mahwah, NJ, Erlbaum).
VON EYE, A. (2004) Base models for Configural FrequencyAnalysis, Psychology Science, 46, pp. 150-170.
VON EYE, A. y GUTIÉRREZ PEÑA, E. (2004) Configural fre-quency analysis – The search for extreme cells, Journalof Applied Statistics, 31, pp. 981-997.
VON EYE, A.; MAIR, P. y MUN, E. Y. (2010) Advances in Confi-gural Frequency Analysis (New York, Guilford).
WAGNER, P.; SCHOBER, B. y SPIEL, C. (2008) Time studentsspend working at home for school, Learning and Ins-truction, 18, pp. 309-320.
YOUNG, F. W. y BANN, C. (1997) ViSta: A Visual Statistics Sys-tem, en STINE, R. y FOX, J. (eds.) Statistical ComputingEnvironments for Social Research (Thousand Oaks,Sage), pp. 207-235.
revi
sta
espa
ñola
depe
dago
gía
añoLXX,nº251,enero-abril2012,111-130
128
Luis LIZASOAIN y Luis JOARISTI

YOUNG, F. W.; VALERO-MORA, P. M. y FRIENDLY, M. (2006) Vi-sual Statistics Seeing Data with Dynamic Interactive Grap-hics (New J., Wiley).
YU, C. H. (2010) Exploratory data analysis in the context of datamining and resampling, International Journal of Psycho-logical Research, 3:1, pp. 9-22.
Resumen:Las nuevas tecnologías y la investiga-ción educativa. El análisis de datos devariables categoriales
El objetivo de este artículo es analizarel impacto de las nuevas tecnologías de lainformación y la comunicación en la in-vestigación educativa, y más espcífica-mente en el análisis de datos categoriales.Desde este punto de vista se presentan ydescriben las principales característicasde técnicas estadísticas como las siguien-tes : Análisis de Frecuencia de Configura-ciones, Análisis de Tablas de ContingenciaTridimensionales, Modelos Log-lineales,Modelos Logit, Probit y Regresión Logís-tica, Análisis Factorial de Corresponden-cias, Clasificación Automática con Varia-bles Categoriales y Visualización de DatosCategoriales. En todos los casos se descri-ben los programas informáticos adecua-dos con especial atención a los programasde código abierto, libres y gratuitos como R.
Descriptores:Análisis de datos categoria-les/Análisis de Frecuencia de Configuracio-nes/ Modelos Log-lineales/ RegresiónLogística/Análisis de Correspondencias,/-Clasificación Automática/Visualización deDatos Categoriales/R.
Summary:The new information and communica-tion technologies and the educationalresearch. Categorical Data Analysis
The aim of this paper is to analyze theimpact of the information and communi-cation technologies on the educational re-search, and more specifically on the cate-gorical data analysis. From this point ofview, the main features of several statisti-cal techniques for categorical data are des-cribed: Configural Frequency Analysis(CFA), 3-way Contingency Tables, Log-li-near Models, Logit and Probit Models andLogistic Regression, CorrespondenceAnalysis, Categorical Cluster Analysis andCategorical Data Visualization. In all thecases, the software is described and specialattention is paid to the open source andfree software such as R.
Key Words: Categorical Data Analy-sis/Configural Frequency Analysis(CFA)/Log-linear Models/Logistic Regressi-on/Correspondence Analysis/Cluster Ana-ysis/Categorical Data Visualization/R.
revistaespañola
depedagogía
añoLXX,nº
251,enero-abril2012,111-130
129
Las nuevas tecnologías y la investigación educativa. El análisis de datos…

Copyright of Revista Española de Pedagogía is the property of Instituto Europeo de Iniciativas Educativas and
its content may not be copied or emailed to multiple sites or posted to a listserv without the copyright holder's
express written permission. However, users may print, download, or email articles for individual use.


















