
Manual Del Spss
59
-
Upload
edidson-fuentes -
Category
Documents
-
view
301 -
download
7
description
MATERIAL DE APOYO
Transcript of Manual Del Spss


Manual de Practica de SPSS II CICLO
1
MANEJO DEL PROGRAMA
1.- ENTRAR EN SPSS
Para entrar en SPSS, si no se dispone de acceso directo en el escritorio, se
seguirá la secuencia Inicio – Programas – SPSS - SPSS 10.0 para Windows. Una vez
que se ha entrado al programa, aparece la siguiente pantalla:
2.- CREACIÓN DEL FICHERO DE DATOS
Para empezar a trabajar con el programa SPSS lo primero que hay que hacer
es construir el fichero de datos. Para ello se seguirán una serie de pasos, antes o
después de introducir los valores.
Desde esta pantalla se puede acceder
directamente a una base de datos utilizada
recientemente (Abrir una fuente de datos
existente), o crear una base de datos en
blanco para introducir datos (Introducir
Datos), etc.
Para salir de la pantalla, pulsar Cancelar.
En caso de no querer que aparezca esta
pantalla la próxima vez que se acceda al
programa, señalar la opción
Este es el aspecto que
presenta una base de
datos vacía.
Nótese la existencia de
dos pestañas en la
parte inferior, una
llamada "Vista de
datos" (activada) y la
otra "Vista de variables"
(desactivada)
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
12
En la "Vista de datos" aparecen las variables colocadas en columnas y los
sujetos en filas.
2.1.- DEFINICIÓN DE VARIABLES
Las variables se definen desde la "Vista de variables", donde encontramos,
como hemos visto antes, una columna para cada característica:
2.1.1.- Nombre � Pinchando con el ratón sobre la celdilla correspondiente al nombre
de la variable que estamos definiendo, podemos escribir directamente el nombre de la
misma (máximo 8 caracteres).
2.1.2.- Tipo � Al pinchar sobre la celdilla, aparece un cuadro gris y al
pinchar sobre el, accedemos a la siguiente pantalla:
2.1.3.- Anchura � A través de esta opción se puede modificar la anchura de las
celdillas que se había seleccionado en la pantalla anterior
2.1.4.- Decimales � Igualmente, a través de esta opción modificar el número de
decimales que tendrán los datos, ya seleccionado en el apartado 2.2.1.Tipo
En esta opción se le indica al
programa con qué tipo de datos
estamos trabajando, así como el
ancho de las celdillas y si quieren
incluirse decimales.
En la "Vista de variables" encontramos
que éstas están colocadas en filas,
mientras que en las columnas se sitúa
cada una de las características que
las define, y que veremos más
adelante.
En ambos casos se puede escribir directamente el número de
decimales en la celdilla activada (seleccionada con el ratón) o
mover las flechas hasta encontrar el que se quiere.
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
13
2.1.5.- Etiqueta � La etiqueta de la variable corresponde al nombre completo de la misma,
que aparecerá en las salidas. Para asignarla etiqueta de la variable, se escribe directamente
sobre la celdilla activada (seleccionada con el ratón)
2.1.6.-Valores � Son los diferentes valores que puede tomar la variable. Se van añadiendo
a la lista, mediante el botón Añadir. Se pueden introducir modificaciones con los botones
Cambiar y Borrar.
Ejemplo � En el caso de estar definiendo la variable sexo, los valores que puede tomar la
variable son dos: Mujer y Hombre, le asignamos a las mujeres un 1 y a los hombres un 2.
2.1.7.- Valores perdidos � Accediendo a esta ventana, el programa pide que se le
especifiquen los valores que no tiene que incluir en el análisis (errores del sistema,
espacios en blanco, etc.)
2.1.8.- Columnas � Esta opción permite rectificar, si fuera necesario, el ancho de la
columna (especificado ya en 2.1.2.- Tipo)
Tal como hicimos en las opciones 2.1.3. y 2.1.4, se puede escribir directamente
el ancho de la columna en la celdilla activada (seleccionada con el ratón) o mover las
flechas hasta encontrar el que se quiere.
En Valor se escribe el valor de la
categoría y el Etiqueta de valor, su
nombre correspondiente. Para que sea
aceptado hay que pinchar Añadir y se
sitúa en la ventana de abajo.
Se accede a esta ventana pinchando el
extremo derecho (sombreado en gris) de la
celdilla.
OFIMATICA II PROFESOR EDIDSON FUENTES
Manual de Practica de SPSS II CICLO
14
2.1.9.- Alineación � En esta opción se ajusta al gusto la alineación de los caracteres,
es decir, se especifica como se quiere que aparezcan los datos en las columnas,
alineados a la derecha, en el centro, o alineados a la izquierda.
2.1.10. Medida � Por último, en esta opción se determina el nivel de medición de la
variable, pudiendo elegir entre Nominal, Ordinal o Intervalo.
Al ir definiendo cada una de las variables del fichero, puede ocurrir que
queramos utilizar la misma opción para más de una variable. En lugar de ir definiendo
cada variable, se puede copiar la información de una (con Ctrl + C o Edición + Copiar)
y pegarla en otra/s (con Ctrl + V o Edición + Pegar).
Por ejemplo, si queremos utilizar los mismos "Valores" para más de una
variable, basta definirlos para una, a continuación se selecciona la celdilla que
corresponde la los Valores de esa variable, se pincha Ctrl + C o Edición + Copiar, y se
selecciona el resto de variables que van a llevar los mismos valores (seleccionado con
el ratón las celdillas correspondientes a los valores), y se pincha Ctrl + V o Edición +
Pegar. Esto puede hacerse con todas las opciones menos con el Nombre de la
variable.
Una vez que están todas las variables definidas se meten los datos (la
operación puede realizarse a la inversa, metiendo primero los datos y definiendo
después las variables), el fichero de datos presentaría un aspecto similar al de la figura
siguiente:
Al acceder a la celdilla (pinchando con el ratón en su extremo derecho,
en el que aparece una flecha), se despliega un cuadro en el que hay
que seleccionar la opción deseada, pinchando sobre ella.
Al acceder a la celdilla (pinchando con el ratón en su extremo derecho,
en el que aparece una flecha), se despliega un cuadro en el que hay
que seleccionar la opción deseada, pinchando sobre ella.
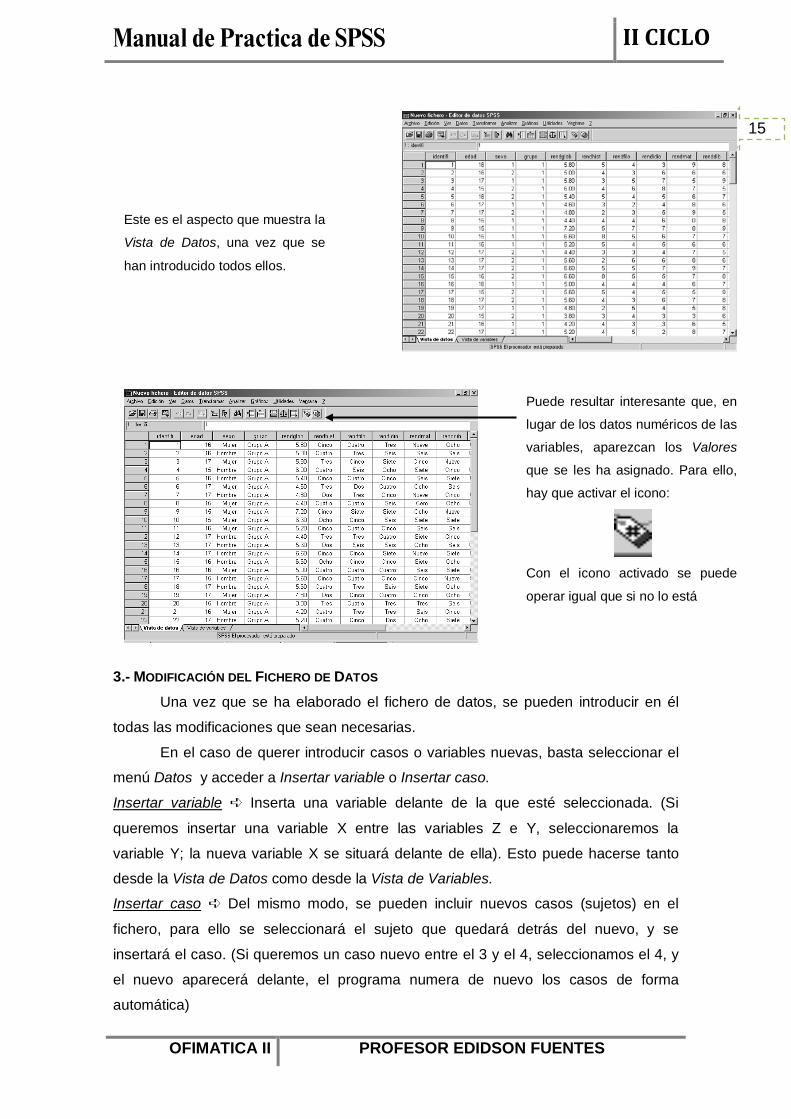
Este es el aspecto que muestra la
Vista de Variables, una vez que
se han definido todas, con la
información correspondiente a
cada opción.
OFIMATICA II PROFESOR EDIDSON FUENTES
Manual de Practica de SPSS II CICLO
15
3.- MODIFICACIÓN DEL FICHERO DE DATOS
Una vez que se ha elaborado el fichero de datos, se pueden introducir en él
todas las modificaciones que sean necesarias.
En el caso de querer introducir casos o variables nuevas, basta seleccionar el
menú Datos y acceder a Insertar variable o Insertar caso.
Insertar variable � Inserta una variable delante de la que esté seleccionada. (Si
queremos insertar una variable X entre las variables Z e Y, seleccionaremos la
variable Y; la nueva variable X se situará delante de ella). Esto puede hacerse tanto
desde la Vista de Datos como desde la Vista de Variables.
Insertar caso � Del mismo modo, se pueden incluir nuevos casos (sujetos) en el
fichero, para ello se seleccionará el sujeto que quedará detrás del nuevo, y se
insertará el caso. (Si queremos un caso nuevo entre el 3 y el 4, seleccionamos el 4, y
el nuevo aparecerá delante, el programa numera de nuevo los casos de forma
automática)
Este es el aspecto que muestra la
Vista de Datos, una vez que se
han introducido todos ellos.
Puede resultar interesante que, en
lugar de los datos numéricos de las
variables, aparezcan los Valores
que se les ha asignado. Para ello,
hay que activar el icono:
Con el icono activado se puede
operar igual que si no lo está
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
16
Eliminar variables o casos � Para realizar esta operación, se selecciona la variable o
caso a eliminar y se pincha el botón Suprimir
4.- VER RESUMEN DE VARIABLES
Una vez que hemos elaborado todo el fichero de datos, podemos ver un
resumen de las variables sin tener que ir a una a una viendo cómo se han definido.
Para ello, se accederá al menú Utilidades – Variables, donde se despliega una
ventana en la que se encuentra información detallada de cada una de las variables. En
esta ventana aparece un listado de variables así como la información de la que esté
seleccionada.
5.- ORDENAR CASOS
En un momento determinado, puede resultar útil tener los casos ordenados en
una de las variables, el programa lo permite a través del menú Datos – Ordenar
casos.
Pinchando Ir a se accede directamente al
lugar del fichero de datos donde se
encuentra esa variable, sin necesidad de
buscarla, lo que facilita el trabajo cuando
trabajamos con un fichero extenso.
La ventana no permite realizar ningún
cambio, para hacerlo hay que acudir a la
variable y realizarlos en ella.
Nota: Igualmente se puede ir a un sujeto determinado sin tener
que pasarlos uno por uno. Para ello, se accede a Datos – Ir a
caso, y se escribe el caso al que se quiere ir, pulsando después
Aceptar.
En la ventana desplegada, sólo hay que
seleccionar la variable que queremos que
ordene, determinar el orden de
clasificación, y Aceptar. En el fichero de
los datos se reordenarán los casos a
partir de esta variable
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
17
6.- ALMACENAMIENTO Y ACCESO A LOS DATOS
Estas son las funciones básicas del editor de datos del programa SPSS, una
vez que tenemos el fichero de datos preparado, ya se puede empezar con el análisis
estadístico, sin olvidar antes guardar el fichero.
6.1.- GUARDAR EL FICHERO DE DATOS
Seleccionar Archivo – Guardar, y especificar el lugar donde se quiere guardar,
así como el nombre asignado
6.2.- ACCESO A LOS DATOS
Se procede del mismo modo, especificando el nombre y ubicación del archivo
que queremos abrir, desde Archivo – Abrir - Datos
Otra forma de acceder a un fichero de datos utilizado recientemente es a través
de Archivo - Datos usados recientemente y seleccionando el que se quiere abrir
7.- EL VISOR DE RESULTADOS
El visor de resultados es la pantalla en la que el programa SPSS presenta los
resultados de los análisis. Una vez que hemos hecho el primer análisis, y si no se
especifica lo contrario, los sucesivos resultados se acumularán en el mismo visor.
Como puede verse, el procedimiento es el
mismo que se sigue en cualquiera de los
programas del entorno Windows.
A esta opción se accede igualmente pinchando
en el icono
A esta opción se accede igualmente
pinchando en el icono
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
18
La apariencia del visor es la siguiente:
A través de los botones de la barra de tareas, podemos movernos del editor de
datos al visor de resultados de manera rápida y sencilla
8.- GUARDAR LOS RESULTADOS
Los resultados de los análisis pueden guardarse de diferentes formas:
8.1.- EN FORMATO SPSS � Se guardarán de esta forma cuando vayan a abrirse
posteriormente en este formato, es decir, en equipos que tengan instalado el SPSS.
Para ello basta con acceder a Archivo - Guardar y asignar el nombre y la ubicación
deseados
8.2.- EN OTROS FORMATOS � El programa SPSS tiene su propio editor de
resultados, editor que es incompatible con el procesador de textos que se utiliza
habitualmente (Word, o Word Perfect). Por esta razón, para poder visualizar los
resultados en aquellos equipos que no tengan instalado el programa SPSS, es
necesario exportar el visor de resultados a un documento HTML, que puede abrirse, y
modificarse en Word. Para ello, en el menú Archivo (del visor de resultados),
seleccionamos la opción Exportar y aparece la siguiente ventana
RESULTADOS INDICE
El visor se divide en dos partes (de ancho
regulable por el usuario). A la izquierda
aparece el índice de lo que contiene el visor,
que nos permite desplazarnos por los
resultados que pinchemos sin necesidad de
pasar por todos los demás.
La parte de la derecha, es la que muestra los
resultados de los análisis efectuados.
De nuevo encontramos una ventana de aspecto
idéntico a la proporcionada por cualquier
programa del entorno Windows. De nuevo
también, es posible acceder a esta ventana a
través del icono:
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
19
8.2.1.- Qué queremos exportar � Podemos exportar el documento completo (tablas y
gráficos, si los hubiera), solo los gráfico, o sólo las tablas.
8.2.2.- Dónde lo queremos exportar � Hay que especificar dónde se quiere exportar
el visor de resultados, para lo que hay que ir a Exportar archivo.
Pulsando examinar, se accede a una pantalla en la que especificaremos
dónde queremos guardar el archivo y con qué nombre (si no se especifica nombre, el
programa por defecto lo llama OUTPUT.TXT).
8.2.3.- Cómo lo queremos exportar � Especificaremos el Formato de exportación,
donde se seleccionará la opción Archivo HTML (*.htm), que suele estar marcada por
defecto
9.- RECUPERAR LA SALIDA
En esta opción seleccionaremos la opción que más se ajuste a nuestra necesidad
En esta ventana hay que especificar:
Qué queremos exportar
Dónde lo queremos exportar
Cómo lo queremos exportar
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
20
9.1.- EN FORMATO SPSS � Desde el Visor de Resultados, se accede a Archivo - Abrir
y se busca el archivo que se quiere abrir.
9.2.- EN FORMATO HTML � El archivo exportado puede ahora abrirse desde cualquier
ordenador que no tenga instalado el programa SPSS, ahora con formato HTML. Para
ello abriremos el procesadores de texto Word. Para abrirlo, accedemos a Archivo –
abrir en tipo de archivo, seleccionamos Documento HTML o Todos los archivos,
buscamos el que queremos abrir y aparece un documento con el aspecto siguiente:
La apariencia de los resultados en el visor de
resultados del SPSS es tal como aparece en
la figura
La ventaja que tiene exportar en
este formato es que permite
modificar las tablas, tal y como
se hace en Word, posibilidad
que en la salida de SPSS es
mucho más limitada
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
21
ANALISIS ESTADÍSTICO DESCRIPTIVO Y DE FRECUENCIAS
1.- ANÁLISIS DESCRIPTIVO
Para realizar un análisis descriptivo de datos, una vez recuperados los datos en la
pantalla, acceder al menú Analizar – Estadísticos descriptivos – Descriptivos. Aparece una
pantalla en la que se da la opción de escoger una, varias o todas las variables de la base
de datos para hacer el análisis.
En este caso seleccionamos las variables: Rendimiento en Historia, Rendimiento en
Filosofía, Rendimiento en Idioma, Rendimiento en Matemáticas y Rendimiento en Dibujo.
Para seleccionar las variables, se pinchan con el ratón y se arrastran a la ventana
Variables.
Esta opción nos permite obtener estadísticos de resumen univariados para varias
variables en una única tabla y calcula valores tipificados (puntuaciones z), que pueden
guardarse, si así se especifica, en el fichero de datos como una variable nueva.
Accediendo a las OPCIONES encontramos una pantalla en la que podremos
especificar los estadísticos que nos interesen
Volvemos a la pantalla presentada en la página anterior, y pinchamos Aceptar. El
visor de resultados de los estadísticos descriptivos es de muy fácil interpretación, presenta
una tabla en la que muestra, para cada variable, los estadísticos que se han pedido.
Seleccionando esta opción,
aparecerán las puntuaciones
tipificadas en el fichero de datos.
En esta pantalla marcaremos con el ratón (� ) los
estadísticos que queramos, así como el orden de
visualización de las variables en el visor de resultados.
Las variables se pueden ordenar por el tamaño de sus
medias (en orden ascendente o descendente),
alfabéticamente o por el orden en el que se seleccionen las
variables (el valor por defecto).
Una vez especificado lo que queremos, pinchamos
Continuar
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
15
Si se marcó la opción Guardar valores tipificados como variable, en el fichero de
datos se crearán unas variables nuevas, llamadas znombrevariable, con la puntuación
típica de cada sujeto en cada variable.
2.- ANÁLISIS DE FRECUENCIAS
Accedemos a esta opción a través del menú Analizar – Estadísticos descriptivos –
Frecuencias. Esta opción proporciona estadísticos y representaciones gráficas que
resultan útiles para describir muchos tipos de variables. Es un procedimiento útil para
realizar una inspección inicial de los datos.
Se da la opción de mostrar / no mostrar la tabla de frecuencias. Para obtenerlas, debe estar marcado (� )
En esta pantalla se seleccionarán los Gráficos
que se desean (se seleccionan conjuntamente
para todas las variables seleccionadas) así
como los valores a partir de los que se generará
el mismo.
Estadísticos descriptivos
100 0 10 5.73 2.27
100 0 10 5.50 2.34
100 0 9 5.32 2.08
100 0 10 5.70 1.96
100 0 10 5.50 2.19
100
Rendimiento en historia
Rendimiento en filosofía
Rendimiento en idioma
Rendimiento enmatemáticas
Rendimiento en dibujo
N válido (según lista)
N Mínimo Máximo Media Desv. típ.
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
16
Los resultados obtenidos aparecen en una tabla similar a la presentada en la figura
siguiente:
A continuación se presentan las tablas de frecuencias, una para cada variable, en la que se aparece
la frecuencia directa, su porcentaje directo, así como el válido (después de eliminar valores
perdidos), y el acumulado.
La opción ESTADÍSTICOS permitiría
seleccionar aquellos que se desee
incluir en los resultados (procedimiento
similar al presentado en la opción 1.-
Análisis descriptivo)
E
1 1 1 1
0 0 0 0
V
P
N
Ed
Pd
E l
Pd
En una primera tabla aparecen los estadísticos seleccionados para cada una de las variables incluidas en el análisis.
E
7 7 7 7
1 1 1 2
1 1 1 3
2 2 2 5
1 1 1 7
1 1 1 9
8 8 8 1
1 1 1
S
P
S
B
U
U
O
T
VF P
Pv
Pa
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
17
ESTADÍSTICA PARAMÉTRICA:
PRUEBA T DE STUDENT
Con la prueba “t de Student” se intenta probar la diferencia de medias para
uno, dos o más grupos. Se trata de una prueba paramétrica, es decir, que entre otras
cosas, la/s variable/s dependiente/s deben estar medidas en nivel de intervalo o razón.
1.- PRUEBA T PARA MUESTRAS INDEPENDIENTES
El programa SPSS, dentro del menú Analizar, tiene una opción para comparar
medias y dentro de esta opción accedemos a Prueba T para muestras independientes.
En el ejemplo que se desarrolla en este caso seleccionamos como variable de
agrupación o variable independiente el Sexo que tiene dos categorías: MUJER (1) y
HOMBRE (2). Como variables dependientes seleccionamos Rendimiento en Historia,
Rendimiento en Filosofía, Rendimiento en Idioma, Rendimiento en Matemáticas y
Rendimiento en Dibujo.
En esta pantalla seleccionamos
las variables dependientes, así
como la variable independiente
(de agrupación) a partir de la que
se calcula la diferencia de
medias.
En DEFINIR GRUPOS hay que introducir los valores
que puede tomar la variable de agrupación, en
nuestro caso 1 (hombre) y 2 (mujer), hasta que no
En OPCIONES el programa nos sugiere un
intervalo de confianza de 95%, es decir, α =
0,05. Normalmente se utiliza este nivel de
confianza aunque puede modificarse al 98% o
al 99%. Si continuamos, aceptamos el 95%
sugerido.
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
20
Las Ho quedan formuladas de la forma siguiente:
Ho (1): No existen diferencias estadísticamente significativas en el Rendimiento de los
alumnos en Historia en función de la variable Sexo.
Ho (2): No existen diferencias estadísticamente significativas en el Rendimiento de los
alumnos en Filosofía en función de la variable Sexo.
Ho (3): No existen diferencias estadísticamente significativas en el Rendimiento de los
alumnos en Idioma en función de la variable Sexo.
Ho (4): No existen diferencias estadísticamente significativas en el Rendimiento de los
alumnos en Matemáticas en función de la variable Sexo.
Ho (5): No existen diferencias estadísticamente significativas en el Rendimiento de los
alumnos en Dibujo en función de la variable Sexo.
Interpretación de resultados
En el visor de resultados encontramos dos tablas (aquí se presenta la segunda
en dos partes). En la primera tabla, el programa calcula los ESTADISTICOS DEL
GRUPO, concretamente la media, la desviación típica y el error típico de medida de
cada categoría de la variable independiente, sexo en este caso.
A continuación aparece una tabla que consta de dos partes, en la primera, el programa
realiza una prueba a priori, la F de Levene, para comprobar si existe o no homogeneidad de
varianzas (uno de los requisitos para aplicar pruebas paramétricas).
Por último, en la segunda parte de la tabla, aparecen los resultados de la
prueba, el valor de la t, los grados de libertad y su probabilidad asociada. Por
ejemplo, la variable Rendimiento en Historia tiene un valor de t = -0,677y una
E
5 5 2 .
4 5 2 .
5 5 2 .
4 5 2 .
5 5 1 .
4 5 2 .
5 5 1 .
4 5 1 .
5 5 2 .
4 5 2 .
SM
H
M
H
M
H
M
H
M
H
R
R
R
R m
R
N MD
tE
l
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
21
probabilidad asociada de 0,500. Si la hipótesis nula planteada Ho (1) era que no
existen diferencias estadísticamente significativas en el Rendimiento de los alumnos
en Historia en función de la variable Sexo, con los resultados obtenidos, y trabajando a
un α = 0,05, podemos aceptarla (porque 0,500 > 0,05) y afirmar que no existen
diferencias estadísticamente significativas entre hombres y mujeres en el
Rendimiento en Historia.
En las siguientes columnas, el programa nos ofrece los diferentes intervalos
confidenciales (nivel de confianza 95%) para cada una de las comparaciones.
Para el resto de las Hipótesis Nulas planteadas Ho (2), Ho (3), Ho (4), Ho (5), podemos
aceptarlas ya que las probabilidades asociadas al estadístico t (0,702 - 0,699 - 0,470 -
0,891 respectivamente) son mayores que α (0,05), por lo que:
No existen diferencias estadísticamente significativas en el Rendimiento de los
alumnos en Filosofía en función de la variable Sexo . Ho (2)
No existen diferencias estadísticamente significativas en el Rendimiento de los
alumnos en Idioma en función de la variable Sexo. Ho (3)
No existen diferencias estadísticamente significativas en el Rendimiento de los
alumnos en Matemáticas en función de la variable Sexo Ho (4)
No existen diferencias estadísticamente significativas en el Rendimiento de los
alumnos en Dibujo en función de la variable Sexo Ho (5)
P r
- 9 . - . - .
- 9 . - . - .
. 9 . . . - 1
. 9 . . . - 1
. 9 . . . - .
. 9 . . . - 1
- 9 . - . - .
- 9 . - . - .
- 9 . - . - .
- 9 . - . - .
S v
N v
S v
N v
S v
N v
S v
N v
S v
N v
R
R
R
R m
R
t g S Dd
E l I S
9 c
d
P
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
22
Contrastes Posteriores
En caso de haber encontrado diferencias significativas, y para ver hacia que dirección
de dan, se consulta la tabla ESTADÍSTICOS DE GRUPO, y en la columna MEDIA, se
puede ver qué grupo obtiene una media superior.
2.- PRUEBA T PARA MUESTRAS RELACIONADAS
Dentro del menú Analizar, entramos en la opción comparar medias y dentro de
esta opción accedemos a Prueba T para muestras relacionadas. En este caso se trata
de comprobar si existen diferencias estadísticamente significativas entre la Capacidad
de Concentración antes (de recibir un programa de entrenamiento de la concentración
PEC), y la Capacidad de Concentración después (del PEC). Seleccionamos estas
variables porque están medidas en nivel de razón.
La H0 planteada es que no existen diferencias estadísticamente significativas
entre la Capacidad de Concentración antes y la Capacidad de Concentración después.
Interpretación de resultados
Aparece en primer lugar una tabla que resumen la información de las variables
incluidas en el análisis. Podríamos haber metido más de un par de variables, en los
resultados se identifican como Par 1, Par 2, etc.
En este caso, hay que seleccionar las
dos variables a la vez y llevarlas a la
ventana de la derecha
E
6 1 2 2
7 1 1 1
C c
C c
P M N
Dt
E l
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
23
A continuación aparece una tabla que nos proporciona la correlación entre las
variables:
Podemos ver que la correlación es significativa (sig. = 0,000 < α = 0,05) y muy alta
(ver práctica de correlación)
Por último aparece la tabla en la que se contrasta la hipótesis que poníamos en juego:
Podemos ver que la probabilidad asociada al estadístico t es menos que α, por lo que
rechazamos la H0 planteada y afirmamos que existen diferencias estadísticamente
significativas entre la Capacidad de Concentración antes y la Capacidad de
Concentración después.
Contrastes posteriores
Una vez que hemos visto que las diferencias entre la capacidad de concentración
antes y la capacidad de concentración después son significativas, puede interesar en
qué dirección se dan estas diferencias. Para ello, volvemos a la tabla primera que
proporciona el programa, y vemos en que variable a media es más alta.
C
1 . .
C c C c
P N C S
P
- 1 1 - - - 9 .
C ca d d
P M
Dn
E d m I S
9 c
d
D
t gS
(
61.29
71.61
Capacidad deconcentración antes
Capacidad deconcetración despues
Par 1Media
Es superior la media en
Capacidad de concentración
después de recibir el PEC, por lo
que puede decirse que es un
programa eficaz.
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
24
ESTADÍSTICA NO PARAMÉTRICA
Las pruebas no paramétricas se utilizan para contrastar la existencia de
diferencias significativas cuando la/s variable/s dependiente/s están medidas en nivel
nominal u ordinal. El programa SPSS, dentro del menú Analizar, tiene una opción para
Pruebas no Paramétricas. Dentro de esta opción podemos encontrar varios casos
entre los que cabe destacar: para 2 muestras independientes, para más de dos
muestras independientes, para 2 muestras relacionadas, para más de dos muestras
relacionadas, Chi cuadrado. Vamos a entrar únicamente en tres de estos casos, para
el resto, se procede de la misma forma, seleccionando la opción correspondiente.
1.- PRUEBA NO PARAMÉTRICA PARA DOS MUESTRAS INDEPENDIENTES
Accedemos al menú Analizar – Pruebas no paramétricas – 2 muestras
independientes. Seleccionamos como variable dependiente el Interés Profesional de
los alumnos, y como independiente o variable de agrupación, el sexo. Queremos
comprobar si existen diferencias estadísticamente significativas entre los intereses
profesionales de hombres y mujeres. Para adaptarnos al programa del curso,
utilizaremos la prueba U de Mann-Whitney, aunque como se puede comprobar, el
programa da otras opciones (Z de Kolmogorov-Smirnov, Reacciones extremas de
Moses)
En OPCIONES se da la opción de pedir descriptivos o cuartiles. En el caso que nos
ocupa no pediremos estadísticos ya que con anterioridad se ha presentado cómo se
calculan e interpretan los estadísticos descriptivos y frecuencias. Una vez completo el
menú, aceptamos y pasamos al visor de resultados.
Como variable de agrupación (o
variable independiente) seleccionamos
la variable Sexo y definimos los grupos
como 1 (MUJER) y 2 (HOMBRE).
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
26
Como siempre, enunciamos la Hipótesis nula a contrastar:
H0: No existen diferencias estadísticamente significativas en los intereses
profesionales de los alumnos en función del sexo.
Interpretación de resultados
En los resultados aparece una tabla en la que se muestra el número de sujetos que
hay en cada categoría de la variable independiente, el rango promedio y la suma de
rangos.
A continuación encontramos la tabla en la que aparecen los estadísticos de contraste.
Aunque aparecen por defecto la U de Mann Whitney, W de Wilcoxon y la Z,
interpretaremos solo la primera de ellas, aunque como puede verse, la significatividad
asociada a los tres estadísticos es la misma.
Así pues, en función de la probabilidad asociada al valor del estadístico U de Mann
Whitney, podemos concluir que no existen diferencias estadísticamente
significativas en los intereses profesionales de los alumnos en función del sexo,
ya que este valor (0,479) es mayor que α (0,05)
R
5 5 2
4 4 2
1
SM
H
T
I d
NR
pS r
E a
1
2
-
.
U
W
Z
S
Ipd
V a
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
27
2.- PRUEBA NO PARAMÉTRICA PARA K MUESTRAS INDEPENDIENTES
Para el caso de más de dos muestras independientes vamos a utilizar la
Prueba H de Kruskal-Wallis. Accedemos al menú Analizar – Pruebas no paramétricas
– K muestras independientes Del mismo modo que el anterior contraste no pediremos
estadísticos descriptivos en el menú opciones y seleccionaremos las variables
dependientes. En este caso vamos a utilizar como variables dependientes el nivel de
estudios y profesional de los padres, y como variable independiente, el nivel social de
la familia.
Vamos a contrastar las siguientes hipótesis:
H0 (1): No existen diferencias estadísticamente significativas entre el nivel de estudios
del padre en función del nivel social de la familia.
H0 (2): No existen diferencias estadísticamente significativas entre el nivel profesional
del padre en función del nivel social de la familia.
H0 (3): No existen diferencias estadísticamente significativas entre el nivel de estudios
de la madre en función del nivel social de la familia.
H0 (4): No existen diferencias estadísticamente significativas entre el nivel profesional
de la madre en función del nivel social de la familia.
Para definir el rango, se
introducen los valores máximo y
mínimo que puede tomar la
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
28
Interpretación de resultados
En los resultados aparecen las siguientes tablas:
A continuación aparece una tabla en la que aparece el estadístico correspondiente a
cada una de los contrastes de hipótesis realizados (Chi-cuadrado), así como los
grados de libertad (gl) y la significatividad asociada al estadístico de contraste
(Sig.asintót.).
Podemos comprobar que existen diferencias significativas entre el nivel
educativo y el nivel profesional del padre en función de la clase social a la que
pertenece el familia, ya que las probabilidades asociadas al estadístico en ambos
casos son 0,000, valor inferior a α =0,05. (Rechazamos H0 (1) y H0 (2))
Por el contrario, comprobamos que no existen diferencias significativas
entre el nivel educativo y el nivel profesional de la madre en función de la clase
social a la que pertenece el familia, ya que las probabilidades asociadas al
estadístico en ambos casos, 0,393 y 0,098, son superiores a α =0,05. (Aceptamos H0
(3) y H0 (4))
R a
1 7
3 6
2 4
1 2
1 6
1
N B
M
M
M
A
T
P
NR
p
Para cada variable
dependiente introducida
en el análisis, aparece el
número de casos que hay
en cada categoría (N) y el
Rango Promedio para
cada una de ellas.
E a
5 2 4 7
4 4 4 4
. . . .
C
g
S
Pd
Ed
E l
Pd
P a
V b
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
29
3.- PRUEBA CHI CUADRADO
Dentro de las pruebas no paramétricas, es decir las que se realizan con
variables medidas en escala ordinal o nominal, se encuentra el CHI CUADRADO. Con
esta prueba podemos comprobar si existen o no diferencias estadísticamente
significativas entre frecuencias observadas (datos extraídos de la realidad) y
frecuencias teóricas (o esperadas). Hablamos en términos de frecuencias ya que con
variables nominales o categóricas sólo podemos utilizar estadísticos de este tipo.
Podemos encontrar la Prueba Chi Cuadrado en el menú Analizar-Pruebas no
parametricas- Chi cuadrado.
En OPCIONES podríamos pedir descriptivos, como en el resto de las pruebas no
paramétricas anteriormente presentadas, pero no vamos a hacerlo en esta práctica por
la misma razón que no lo hicimos anteriormente.
Las H0 a contrastar son:
H0 (1): No existen diferencias estadísticamente significativas entre la distribución real
de los sujetos en la variable Sexo y la distribución que cabría esperar al azar
H0 (2): No existen diferencias estadísticamente significativas entre la distribución real
de los sujetos en la variable Grupo de clase y la distribución que cabría esperar al azar
H0 (3): No existen diferencias estadísticamente significativas entre la distribución real
de los sujetos en la variable Nivel Social Familiar y la distribución que cabría esperar al
azar
Las variables que vamos a
seleccionar para realizar el
análisis son Sexo, Grupo de
clase y Nivel Social Familiar. Se
trata de tres variables medidas
en escala nominal y aptas por
tanto para incluir en el análisis.
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
30
Interpretación de resultados
Aparecen en primer lugar las tablas con las frecuencias encontradas en cada
categoría de cada una de las variables, así como lo que cabría esperar al azar (N / nº
de categorías) y el residual.
A continuación aparece la tabla con los valores del estadístico Chi cuadrado, los
grados de libertad y la probabilidad asociada al estadístico.
Las probabilidades asociadas a los valores de chi cuadrado son 0,549 - 1,000 y 0,002,
en el caso de Sexo y del Grupo mayores que el valor de α = 0,05, y en el caso de
Nivel Social Familiar, inferior a este valor, por lo que afirmamos que no existen
diferencias (mayores que las esperadas por azar) entre las diferentes categorías de
las variables Sexo y Grupo de Clase, y si que las hay en la variable Nivel Social
Familiar
En estas tablas aparecen las
frecuencias empíricas (N observado),
que es cómo se distribuyen realmente
los sujetos en las diferentes
categorías.
A continuación aparecen las
frecuencias teóricas (N esperado),
que es cómo se distribuirían al azar,
igual número de sujetos en cada
categoría.
Aparecerán tantas tablas como
variables se incluyan en el análisis.
A partir de esta tabla se realiza el
contraste de hipótesis,
comparando la probabilidad
asociada a Chi-Cuadrado con el α
l b j d
S
5 5 3
4 5 -
1
M
H
T
N N R
G
2 2 .
2 2 .
2 2 .
2 2 .
1
G
G
G
G
T
N N R
N
1 2 -
3 2 1
2 2 6
1 2 -
1 2 -
1
B
M
M
M
A
T
N N R
E
. . 1
1 3 4
. 1 .
C
g
S
S GN
f
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
31
ANALISIS DE VARIANZA
1.- ANÁLISIS DE VARIANZA SIMPLE.
El Análisis de Varianza simple (ANOVA) es una técnica estadística utilizada para
contrastar la existencia de diferencias estadísticamente significativas entre las medias de
las muestras sometidas a diferentes tratamientos.
La hipótesis nula (H0) general que se pretende contrastar es la siguiente: No
existen diferencias estadísticamente significativas en la Variable Dependiente
(Rendimiento, por ejemplo) provocadas por la Variable Independiente (Sexo, por ejemplo)
Esta prueba, en SPSS, la encontramos en el menú Analizar – Comparar Medias –
ANOVA de un factor.
En esta práctica, y al ser el ANOVA una prueba paramétrica. Seleccionamos las
variables Rendimiento en Historia, Rendimiento en Filosofía, Rendimiento en Idioma,
Rendimiento en Matemáticas, y Rendimiento en Dibujo ya que se trata de variables
medidas en nivel de intervalo. Como variable independiente seleccionamos la variable
Grupo. Las H0 a contrastar queda pues formulada en los siguientes términos:
H0 (1): No existen diferencias estadísticamente significativas en Rendimiento en Historia
en función del grupo al que pertenecen los alumnos.
H0 (2): No existen diferencias estadísticamente significativas en Rendimiento en Filosofía
en función del grupo al que pertenecen los alumnos.
H0 (3): No existen diferencias estadísticamente significativas en Rendimiento en Idioma
en función del grupo al que pertenecen los alumnos.
H0 (4): No existen diferencias estadísticamente significativas en Rendimiento en
Matemáticas en función del grupo al que pertenecen los alumnos.
En este menú se da la opción de
seleccionar más de una variable
dependiente, aunque los contrastes
son de ANOVA simple, es decir, de
cada variable dependiente con la
independiente, por separado.
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
32
H0 (5): No existen diferencias estadísticamente significativas en Rendimiento en Dibujo en
función del grupo al que pertenecen los alumnos.
En el caso de querer también los contrastes posteriores, es decir, que además de saber
si hay diferencias, saber hacia qué dirección se dan estas diferencias, hay que
especificarlo en este momento. Para ello, desde la ventana principal, entramos a la
opción Post Hoc...
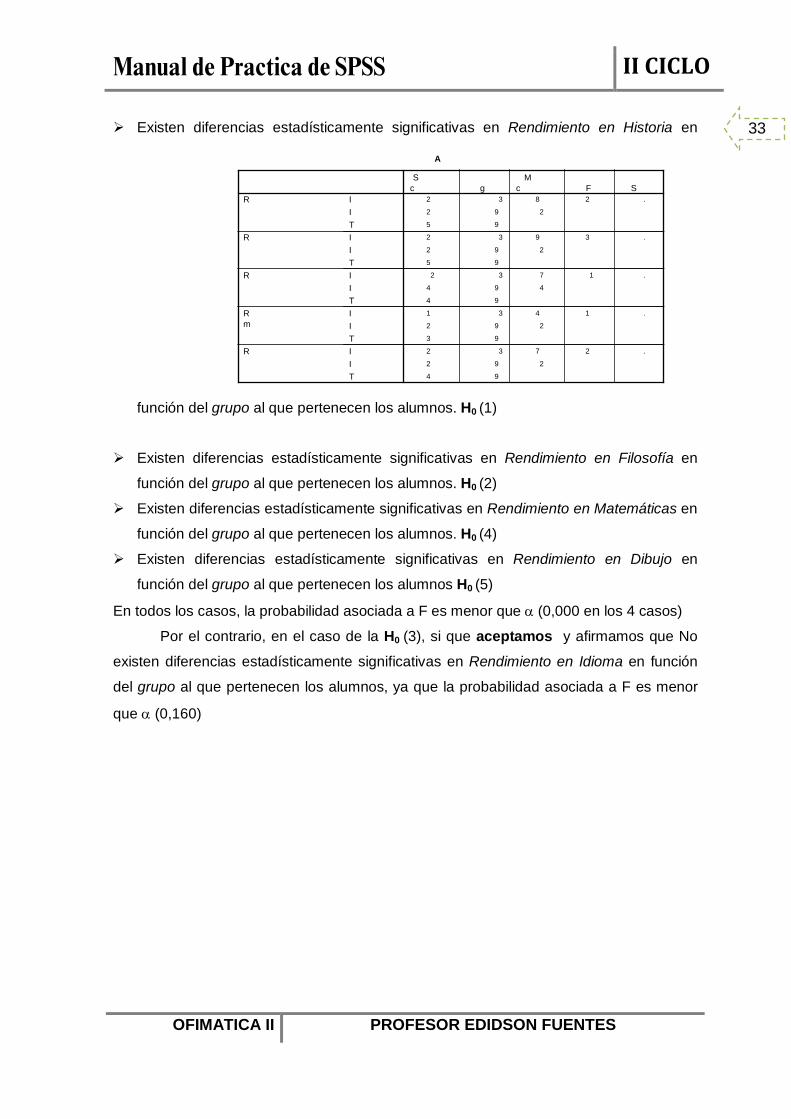
Interpretación de resultados
En la primera tabla que aparece podemos contrastar las hipótesis nulas, siempre
comparando α con la probabilidad asociada al estadístico F
A la vista de los resultados presentados en la tabla, rechazamos las Ho 1 - 2- 4 y 5, y
afirmamos que:
En OPCIONES podríamos pedir estadísticos o que
haga la prueba de Homogeneidad de Varianzas (uno
de los requisitos para poder aplicar una prueba
paramétrica). En este caso no vamos a solicitarlo.
De los diferentes estadísticos
que nos ofrece el programa,
seleccionamos el de Scheffe
Aquí podríamos cambiar el nivel de significación.
OFIMATICA II PROFESOR EDIDSON FUENTES
Manual de Practica de SPSS II CICLO
33
Existen diferencias estadísticamente significativas en Rendimiento en Historia en
función del grupo al que pertenecen los alumnos. H0 (1)
Existen diferencias estadísticamente significativas en Rendimiento en Filosofía en
función del grupo al que pertenecen los alumnos. H0 (2)
Existen diferencias estadísticamente significativas en Rendimiento en Matemáticas en
función del grupo al que pertenecen los alumnos. H0 (4)
Existen diferencias estadísticamente significativas en Rendimiento en Dibujo en
función del grupo al que pertenecen los alumnos H0 (5)
En todos los casos, la probabilidad asociada a F es menor que α (0,000 en los 4 casos)
Por el contrario, en el caso de la H0 (3), si que aceptamos y afirmamos que No
existen diferencias estadísticamente significativas en Rendimiento en Idioma en función
del grupo al que pertenecen los alumnos, ya que la probabilidad asociada a F es menor
que α (0,160)
A
2 3 8 2 .
2 9 2
5 9
2 3 9 3 .
2 9 2
5 9
2 3 7 1 .
4 9 4
4 9
1 3 4 1 .
2 9 2
3 9
2 3 7 2 .
2 9 2
4 9
I
I
T
I
I
T
I
I
T
I
I
T
I
I
T
R
R
R
R m
R
S c g
Mc F S
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
34
Contrastes posteriores
Para comprobar hacia qué lado se dan las diferencias encontradas, vamos a la siguiente
tabla. A continuación se presenta el extracto de dicha tabla correspondiente a la variable
dependientes Rendimiento en Historia.
En la primera columna aparece la diferencia de medias de cada categoría de la
variable independiente con el resto, adjudicando al minuendo de la sustracción el nombre
(I), y al sustrayendo el nombre (J), en la segunda columna (Diferencia de medias (I-J), se
presentan los resultados de dicha diferencia. En el caso de aparecer un asterisco (*) al
lado del resultado, y según consta a pie de tabla, la diferencia será significativa. La
significatividad de la diferencia se ve igualmente en la columna Sig. en la que aparece la
probabilidad asociada a la diferencia. Como puede verse, para las probabilidades que no
son significativas (es decir, que son mayores que α = 0,05), no aparece asterisco (*) en el
valor de la diferencia, y cuando no aparece el asterisco (*) en este valor, la probabilidad
no es significativa (su valor es mayor que α = 0,05).
- * . .
. . .
- * . .
2 * . .
2 * . .
- . .
- . .
- * . .
- * . .
3 * . .
. . .
3 * . .
( G
G
G
G
G
G
G
G
G
G
G
G
G
( G
G
G
G
G
V R
R
D m E S
Diferencia
significativa
Diferencia no
significativa
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
35
2.- ANÁLISIS DE VARIANZA FACTORIAL
Cuando se quiere comprobar si existen o no diferencias entre más de dos
variables independientes y una dependiente, utilizamos el Análisis de Varianza Factorial,
al que accedemos a través de la secuencia Analizar – Modelo Lineal General –
Univariante.
Como en el caso del Análisis de Varianza Simple, este es el momento de pedir (si se
quieren) los contrastes posteriores, para lo que accedemos de nuevo a Post Hoc...
La hipótesis nula (Ho) que vamos a contrastar queda pues formulada en los
términos siguientes: No existen diferencias estadísticamente significativas en el
Rendimiento Global obtenido por los alumnos en función del efecto conjunto de las
variables Grupo de clase al que pertenecen y Nivel Social de la Familia.
En la opción MODELO, escogemos
el factorial completo.
Seleccionamos como variable
dependiente el Rendimiento global del
alumno, y como factores fijos o
variables independientes el Grupo y el
Nivel Social Familiar
En esta ventana hay que especificar
para cual/es de las variables
independientes o factores se quieren
los contrastes posteriores.
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
36
Interpretación de resultados
La primera tabla que aparece en la salida nos muestra un resumen de los casos
incluidos en el estudio
A continuación aparece la tabla del análisis de varianza factorial. Como puede
verse, ha resultado ser no significativo, es decir que la interacción entre el Grupo y el
Nivel Social Familiar no influyen sobre el Rendimiento Global de los alumnos. La
probabilidad asociada al estadístico F para la interacción de las dos variables es de
0,465, valor mayor que α, por lo que acepto H0
F
G 2
G 2
G 2
G 2
B 1
Mo
3
M 2
Mo
1
A 1
1
2
3
4
G
1
2
3
4
5
Nsf
Ed N
P
V
9 a 1 4 5 .
2 1 2 2 .
4 3 1 1 .
1 4 . . .
1 1 . . .
7 8 .
3 1
1 9
FM
I
G
N
G
E
T
T
S c
t gM
c F S
R a
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
37
La tabla proporciona también un ANOVA simple para cada una de las variables
independientes por separado. El estadístico F para el factor Grupo tiene una probabilidad
asociada de 0,000, a un nivel de significación de 0,05, resulta significativo.
Por el contrario, el valor de la probabilidad asociada a F para la variable Nivel social es de
0,789 resultando no significativa para un valor de α de 0,05.
Contrastes Posteriores
En las tablas siguientes pueden hacerse los contrastes posteriores, del mismo modo que
se hacían en el caso de ANOVA simple
C
V
S
- . . - .
1 * . . . 1
- * . . - -
. . . - 1
1 * . . . 2
- * . . - -
- * . . - -
- * . . - -
- * . . - -
1 * . . . 2
1 * . . . 1
2 * . . 1 3
( G
G
G
G
G
G
G
G
G
G
G
G
( G
G
G
G
De
m E S L L
s
I 9
B
L a * .
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
38
3.- ANÁLISIS DE COVARIANZA
El análisis de covarianza (ANCOVA) es una combinación de las técnicas de
regresión y análisis de varianza, que se utiliza para comprobar la existencia de
diferencias estadísticamente significativas entre una variable independiente (más de dos
grupos o categorías) y otra dependiente (nivel de medición intervalo o razón), eliminando
la interacción de una variable extraña que controlamos a través de éste método,
introduciéndola en el análisis como COVARIABLE.
La suposición específica del ANCOVA es que la variable concomitante
(covariable) no debe ser afectada por los tratamientos, es decir, que los tratamientos
aplicados a las unidades experimentales para poder observar sus efectos en la variable Y
no deberían influir en los valores esperados de X.
Accedemos al análisis de covarianza a través del menú Analizar – Modelo Lineal
General – Univariante.
Por lo tanto, la H0 queda formulada de la forma siguiente: No existen diferencias
estadísticamente significativas en el Rendimiento Global de los alumnos en función del
En este caso vamos a coger como
variable dependiente el Rendimiento
Global, como independiente o factor
fijo el Grupo de clase, y se va a
controlar el efecto de la variable
Nivel Social de la familia.
C
V a
S c
- . . - .
- . . - .
- . . - .
- . . - 1
. . . - 1
- . . - .
- . 1 - .
- . . - .
. . . - 1
8 . . - .
4 . 1 - .
- . 1 - 1
. . . - 1
3 . 1 - .
- . 1 - .
- . 1 - 1
. . . - 1
9 . . - 1
1 . 1 - 1
5 . 1 - 1
( M
M
M
A
B
M
M
A
B
M
M
A
B
M
M
A
B
M
M
M
( B
M
M
M
A
De
m E S L L
s
I 9
B a
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
39
Grupo de clase al que pertenezcan, controlando la influencia del Nivel Social de la familia.
Interpretación de resultados
De la tabla podemos deducir una serie de conclusiones (tantas como pruebas de
significatividad realizadas) que se presentan a continuación:
1. Modelo corregido � Se pone a prueba la existencia de diferencias estadísticamente
significativas en el Rendimiento Global obtenido por los alumnos en función del Grupo
al que pertenecen, controlando el efecto que pueda ejercer el Nivel Social Familiar. La
probabilidad asociada al estadístico F calculado es de 0,000 al ser un valor menor
que α (0,05), rechazamos H0 y afirmamos que existen diferencias en el
Rendimiento Global obtenido por los alumnos en función del Grupo al que
pertenecen, controlando el efecto que pueda ejercer el Nivel Social Familiar
2. Intersección � En este caso se pretende comprobar la existencia de diferencias
estadísticamente significativas en el Rendimiento Global de los alumnos, provocadas
por la acción conjunta de las variables Grupo de Clase y Nivel Social Familiar. En este
caso, la probabilidad asociada a F es también de 0,000, y al ser menor que α (0,05),
se rechaza H0, por lo que se confirma la existencia de diferencias
estadísticamente significativas en el Rendimiento Global de los alumnos,
provocadas por la acción conjunta de las variables Grupo de Clase y Nivel
Social Familiar
3. Por último se hace un ANOVA con cada una de las variables independientes
utilizadas. En el primer caso (para la Variable Nivel Social Familiar) se acepta la H0 al
ser la probabilidad asociada a F mayor que α (0,05) (para Nivel Social Familiar la
probabilidad asociada a F es de 0,533), por lo que no hay diferencias
P
V
7 a 4 1 2 ,
4 1 4 5 ,
, 1 , , ,
7 3 2 3 ,
8 9 ,
3 1
1 9
FM
I
N
G
E
T
T
S c
t gM
c F S
R a
1234
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
40
estadísticamente significativas en el Rendimiento Global de los alumnos en
función del Nivel Social Familiar.
4. En el segundo caso se rechaza la H0 al ser la probabilidad asociada a F menor que α
(0,05) (para Grupo de Clase la probabilidad asociada a F es de 0,000), por lo que
hay diferencias estadísticamente significativas en el Rendimiento Global de los
alumnos en función del Grupo de clase al que pertenecen.
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
41
CORRELACIÓN
La correlación es una medida de la relación entre dos variables. Su valor oscila
entre –1 y +1 pasando por 0. Los coeficientes de correlación indican dos cosas;
primero indican la cuantía de la relación, para lo que se tiene en cuenta el valor
absoluto del coeficiente, y que se interpreta según la siguiente tabla:
Menor de |0,30| � Correlación baja
Entre |0,30| y |0,50| � Correlación moderada
Entre |0,50| y |0,70| � Correlación alta
Mayor de |0,70| �Correlación muy alta
En segundo lugar, el signo del coeficiente de correlación indica el sentido de la
relación. Si el signo es positivo (+), al aumentar una variable también lo hace la otra, y
si es negativo (-) las variables se relacionan inversamente, al aumentar una de ellas
disminuye la otra.
COEFICIENTES DE CORRELACIÓN
- Pearson � El coeficiente de correlación de Pearson se utiliza cuando las
variables del análisis están medidas en nivel de intervalo o razón. En ambos
casos la interpretación se hace igual.
- Spearman � Utilizaremos el coeficiente de correlación de Spearman cuando
las variables a relacionar estén medidas en nivel nominal u ordinal.
LAS CORRELACIONES EN SPSS
El programa SPSS, a través del Menú–Analizar, nos ofrece la opción
Correlaciones, elegimos la opción Bivariadas (porque queremos correlacionar dos
variables).
Una vez dentro de la pantalla, el programa nos pide las variables que
queremos correlacionar, el coeficiente de correlación que queremos calcular, y la
prueba de significación (bilateral o unilateral) con la queremos trabajar.
1.- CORRELACIÓN ENTRE VARIABLES MEDIDAS EN NIVEL NOMINAL U ORDINAL. COEFICIENTE
DE SPEARMAN
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
36
Vamos a calcular si existe correlación entre las variables Nivel Educativo y Nivel
Profesional del Padre, y Nivel Educativo y Nivel Profesional de la Madre y su cuantía
en caso de haberla.
IInntteerrpprreettaacciióónn ddee rreessuullttaaddooss
Una vez que tenemos las variables que queremos correlacionar, aceptamos y
en el visor de resultados aparecerá una matriz en la que aparecen de nuevo los
siguientes datos:
- Coeficiente de correlación � Valor del coeficiente, que se interpreta según
la tabla que aparece al principio de la práctica.
- Significatividad (Sig.) � Es lo primero que hay que mirar, indica si la
correlación es significativa, si el valor es menor que nuestro α, entonces la
correlación es significativa (no se debe al azar). Mediante la opción Marcar
las correlaciones significativas, el programa señala con un asterisco (*) o
dos (**) las correlaciones que son significativas al 0,05 o al 0,01, indicando
a pie de tabla la clave de interpretación.
- N � Número de sujetos que intervienen en el análisis
Una opción muy útil es la
que nos pregunta si
queremos que en los
resultados aparezcan
marcadas las correlaciones
significativas (tanto al 1%
como al 5%). (Se
C
1 - * . -
. . . .
1 1 1 1
- * 1 . -
. . . .
1 1 1 1
. . 1 - *
. . . .
1 1 1 1
- - - * 1
. . . .
1 1 1 1
C c
S
N
C c
S
N
C c
S
N
C c
S
N
E
P
E
P
R
Ed
Pd
E l
Pd
L a * *
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
37
Vemos en este caso que existe correlación significativa entre los Estudios del Padre y
su profesión, así como entre los estudios que ha realizado la madre y su profesión.
Las correlaciones son moderada en el primer caso y baja en el segundo.
En ambos casos la correlación es negativa, es decir, que la relación entre las variables
es inversa. Esto quiere decir que a medida que aumenta el valor de una variable
disminuye el de la otra. Para interpretar esto, sólo hay que tener en cuenta cómo se
han categorizado las variables, vemos que se ha hecho de la siguiente forma:
NIVEL DE ESTUDIOS DEL PADRE/MADRE NIVEL PROFESIONAL DEL PADRE/MADRE
1 Sin estudios
2 Primarios
3 Secundarios
4 Bachiller
5 Univ. Medios
6 Univ. Superiores
7 Otros
1 Directivo de empresa
2 Profesiones liberales
3 Profesional ligado a la enseñanza
4 Técnicos medios
5 Auxiliares
6 De servicio
7 Tareas domésticas
8 En paro
9 Otros
Como puede verse, en el caso de Nivel de estudios, la categoría 1 es lo más bajo y la
categoría 6 lo más alto. En el caso del Nivel profesional es al contrario, la categoría 1
es el nivel superior y la 8 el inferior, con lo que tiene sentido decir que a medida que
aumenta el valor de la variable Nivel de estudios, disminuye el valor de la variable
Nivel profesional
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
38
2.- CORRELACIÓN ENTRE VARIABLES MEDIDAS EN NIVEL DE INTERVALO U RAZÓN.
COEFICIENTE DE PEARSON
En este caso vamos a comprobar si existe correlación entre los Rendimientos de los
alumnos en todas las materias incluidas en el fichero de los datos entre si y con el
Rendimiento global
nterpretación de resultados
Una vez que tenemos las variables que queremos correlacionar, aceptamos y
en el visor de resultados aparecerá de nuevo una matriz en la que aparecen de nuevo
los siguientes datos:
- Coeficiente de correlación � Valor del coeficiente, que se interpreta según
la tabla que aparece al principio de la práctica.
- Significatividad (Sig.) � Es lo primero que hay que mirar, indica si la
correlación es significativa, si el valor es menor que nuestro α, entonces la
correlación es significativa (no se debe al azar). Mediante la opción Marcar
las correlaciones significativas, el programa señala con un asterisco (*) o
dos (**) las correlaciones que son significativas al 0,05 o al 0,01, indicando
a pie de tabla la clave de interpretación.
- N � Número de sujetos que intervienen en el análisis
La ventana es la misma que en el
caso anterior, únicamente hay que
seleccionar la opción del
coeficiente de Pearson y eliminar
la marca del coeficiente de
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
39
En la matriz se presentan las correlaciones entre las variables, vemos que
se trata de una matriz simétrica, en la que las diagonales son 1, el valor de la
correlación de cada variable consigo misma.
En esta tabla podemos ver que existe correlación (y muy alta en algunos
casos) entre el Rendimiento global de los alumnos y el rendimiento en cada
una de las asignaturas, así como correlaciones entre los rendimientos de
varias asignaturas.
C
1 . * . . * . * . *
. . . . . .
1 1 1 1 1 1
. * 1 . . * . * . *
. . . . . .
1 1 1 1 1 1
. . 1 - * . . *
. . . . . .
1 1 1 1 1 1
. * . * - * 1 . * . *
. . . . . .
1 1 1 1 1 1
. * . * . . * 1 . *
. . . . . .
1 1 1 1 1 1
. * . * . * . * . * 1
. . . . . .
1 1 1 1 1 1
C d
S
N
C d
S
N
C d
S
N
C d
S
N
C d
S
N
C d
S
N
R e
R e
R e
R m
R e
R g
Re
Re
Ro
Re
mR
e R
g
L a * * .
L a * .
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
40
REGRESIÓN
Anteriormente hemos visto los coeficientes de correlación, que indican el grado
o la cuantía en que varían conjuntamente dos mediciones o variables. El conocimiento
de la relación entre variables es algo más que un fin en si mismo; en algunas
ocasiones se quiere aprovechar el conocimiento de una relación entre variables como
punto de partida para realizar un pronóstico o predicción. Es decir, al conocer la
variable X y su relación con la variable Y, se trataría de averiguar en qué forma se
pueden considerar los valores particulares de la variable X y predecir a partir de ellos
los valores que corresponden en Y. El Análisis de Regresión es la técnica que
utilizamos para ello.
La regresión lineal estima los coeficientes de la ecuación lineal, con una
(regresión simple) o más (regresión múltiple) variables independientes, que mejor
prediga el valor de la variable dependiente. Tanto la variable dependiente como la/s
independiente/s deben ser continuas (en caso contrario se utilizaría Análisis de
Varianza). Por ejemplo, se puede intentar predecir el rendimiento de un alumno
(variable dependiente) a partir de su nivel de motivación, edad, o capacidad de
concentración (variables independientes).
1.- REGRESIÓN SIMPLE
El análisis de regresión simple se encuentra en el menú Analizar – Regresión -
Lineal
En este caso, vamos a estimar el Rendimiento en Matemáticas de los sujetos
(variable predicha - dependiente) a partir de su Motivación (variable predictora -
independiente).
El método que vamos a
utilizar es el de pasos
sucesivos
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
43
INTERPRETACIÓN DE RESULTADOS
De entre los diferentes criterios existentes para calcular la recta de regresión,
se va a utilizar el de los MÍNIMOS CUADRADOS debido a sus excelentes propiedades
estadísticas.
El COEFICIENTE DE DETERMINACIÓN (R Cuadrado) se utiliza para valorar la
calidad del ajuste obtenido, y se obtiene elevando al cuadrado el coeficiente de
correlación (R). Para interpretar se utiliza R CUADRADO CORREGIDA. Cuanto mayor
sea el valor del COEFICIENTE DE DETERMINACIÓN, mayor será el porcentaje de
cambios explicados por esta variable. En la tabla vemos que el valor del coeficiente de
determinación obtenido es de ,138, lo que implica que el 13% de los cambios que se
dan en la Rendimiento en Matemáticas se debe a la Motivación de los alumnos.
Queda sin explicar el 87% de los cambios (100-13).
El ERROR TÍPICO DE LA ESTIMACIÓN es el error que se comete en toda
predicción, y su valor oscila entre 0 y SY . Si el coeficiente de correlación (R) entre las
variables es grande, el error típico de la estimación será pequeño y viceversa.
A continuación aparece la tabla del Análisis de Varianza, en la que se valora la
importancia de la parte de la variable dependiente (Rendimiento en Matemáticas)
Esta tabla nos presenta las
variables que han sido
incluidas en el modelo, y el
orden de inclusión de las
mismas (como es regresión
simple, solo se incluye una
variable)
V a
Md p
,
Pp(P F e ,P F s ,
M1
Vi
Ve M
V a
R
, a , , 1M1
R R R c
E e
V p
a
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
44
explicada por la variable independiente (Motivación). Con este análisis obtendremos la
probabilidad de que la parte explicada haya podido serlo por azar.
En la columna de la derecha aparece el valor de la significatividad, que nos
indica la probabilidad de que la suma de distancias explicada mediante la regresión
haya sido obtenida por el azar (estamos utilizando el método de los mínimos
cuadrados).
En este caso, se ha obtenido una significatividad de 0,000, menor que α (0,05),
por lo que puede afirmarse que las diferencias no se deben al azar.
En la tabla de los coeficientes aparece lo siguiente: en la columna B aparecen
los valores a (3,687) y b (0,0032) de la recta de regresión, que puede escribirse de la
forma siguiente:
Y (Rendimiento en Matemáticas) = 3,687+ 0,0032* Motivación
El valor de la constante a representa el valor que se asigna a la variable
dependiente (Rendimiento en Matemáticas) en el caso en que la variable
independiente (Motivación) fuera 0. El valor de b por su parte, representa el
A b
5 1 5 1 , a
3 9 3
3 9
R
R
T
M1
S c g
Mc F S
V a
V b
C a
3 , 6 ,
3 , , 3 ,
(
M d
M1
B E
C e
B
Ce
ez
t S
V a
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
45
incremento de la variable dependiente cuando la variable independiente aumenta en
una unidad.
Desde el punto de vista gráfico, b representa la pendiente de la recta de
regresión, mientras que a indica el punto de corte de la recta de regresión con el eje
de ordenadas Y.
Coeficientes Beta � En ocasiones, sobre todo cuando las variables con las
que trabajamos están medidas en escalas muy diferentes, puede resultar interesante
trabajar con las puntuaciones estandarizadas en vez de hacerlo con las directas. De
esta forma podremos comparar los resultados obtenidos con variables medidas en
diferentes escalas. Los coeficientes de la recta de regresión obtenidos para las
puntuaciones estandarizadas son los coeficientes BETA (atención, no confundir con
los coeficientes β, que representan a los parámetros poblacionales).
Su interpretación es la siguiente: el incremento de la variable dependiente (en
puntuaciones típicas) al aumentar en una unidad la puntuación típica de la variable
independiente. O, dicho de otra forma, el número de desviaciones típicas en que se
incrementará el valor de la variable dependiente al incrementarse en una desviación
típica la variable independiente. Además, en el caso de la regresión simple, el
coeficiente BETA coincide con el coeficiente de correlación.
Cómo realizar la predicción
Cuando queremos conocer la puntuación de un sujeto en la variable Y (criterio)
a partir de su puntuación en la variable X (predictor), se calcula la recta de regresión a
partir de los datos o puntuaciones obtenidas por el grupo normativo, y a partir de esa
recta de regresión, se calcula la puntuación Y’ de ese sujeto y se le suma y resta el
error típico de estimación dando lugar a un intervalo:
Límite superior � Y’ + Sxy
Y’ + - Sxy Límite inferior � Y’ - Sxy
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
46
2.- REGRESIÓN MÚLTIPLE
La regresión múltiple es la generalización de la regresión simple para el caso
en que contemos con más de una variable explicativa (o independiente). Accedemos,
igual que en el caso de la regresión simple, al menú Analizar – Regresión – Lineal.
En este caso se va a predecir el Rendimiento Global de los alumnos (variable
dependiente), a partir de su Motivación después del programa (variable independiente
1) y de su Inteligencia general (variable independiente 2).
INTERPRETACIÓN DE RESULTADOS
Seleccionamos, como en el
caso de Regresión Simple, el
método de Pasos Sucesivos
En esta primera tabla se presentan las
variables que han sido incluidas en el
modelo, y el orden de inclusión de las
mismas
Tenemos dos modelos, el primero (1)
con la variable independiente
Inteligencia General y el segundo (2)
con las variables independientes
Inteligencia General + Motivación
Después del Programa.
Aunque habíamos seleccionado en
primer lugar la Motivación Después del
Programa, en el análisis ha entrado
V a
Ig
,
Pp(P F e ,P F s ,
Md p
,
Pp(P F e ,P F s ,
M1
2
Vi
Ve M
V a
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
47
Recordar que hemos elegido el método de Pasos Sucesivos que, frente al de
Introducir (que introduce todas las variables independientes a la vez), va
introduciéndolas una por una.
Al utilizar el método de Pasos Sucesivos podemos ver el valor de los
coeficientes para cada modelo. La primera variable independiente que se incluye es la
que tiene una mayor relación con la variable dependiente (en este caso la Inteligencia
General de los alumnos), y ella sola explica el 48,2% (R cuadrado corregida = 0,482)
de los cambios de la variable Rendimiento Global.
En el segundo modelo, al incluir la segunda variable independiente en la
ecuación (Motivación Después), el porcentaje de varianza explicada aumenta a 54,6%
(R cuadrado corregida = 0,546), al igual que lo hace el coeficiente de correlación
múltiple R (pasa de 0,698 a 0,745). En este segundo modelo disminuye también el
error de estimación (de 0,9175 a 0,8592)
En la tabla del Análisis de Varianza tenemos de nuevo la información para los
dos modelos, la interpretación se hace igual que en el caso de regresión simple.
Vemos que los dos modelos son significativos, es decir, que la parte explicada no se
debe al azar (,000 < α)
R
, a , , ,
, b , , ,
M1
2
R R R c
E e
V a
V M
b
A c
7 1 7 9 , a
8 9 ,
1 9
8 2 4 6 , b
7 9 ,
1 9
R
R
T
R
R
T
M1
2
S c g
Mc F S
V a
V p
b
V c
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
48
En la tabla siguiente se presentan los coeficientes de regresión de cada
modelo, en el que solo se incluye la variable Inteligencia General como independiente
(modelo 1), y en el que se incluyen las dos: Inteligencia General y Motivación
Después (modelo 2).
Las ecuaciones son:
� Y (rend.global) = - 23,365 + 0,335 * Inteligencia General
� Y (rend.global) = - 19,8 + ,283 * Inteligencia General + 0,001 * Motivación D
La interpretación de los coeficientes BETA es la misma que en caso de la regresión simple
En la última tabla aparecen las variables que han quedado excluidas del
análisis. La exclusión no tiene que deberse forzosamente a que la variable no sea
importante a la hora de explicar los cambios de la variable dependiente, simplemente
querrá decir que su aportación a la explicación de los cambios de la variable
dependiente ya está explicada por otras variables incluidas, y que su inclusión puede
resultar redundante. En este caso se ha excluido finalmente la Motivación Después del
Programa porque como puede verse en la tabla-resumen del modelo, su contribución
al Rendimiento Global es muy pequeña.
C a
- 2 - ,
, , , 9 ,
- 2 - ,
, , , 8 ,
1 , , 3 ,
(
I
(
I
M d
M1
2
B E
C e
B
Ce
ez
t S
V a
V b
,a
3 , , ,M d
M1
B t SC
p T
Eo
ca
V a
V b
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
49
ANÁLISIS FACTORIAL
El análisis factorial es una técnica estadística multivariada cuya finalidad
consiste en obtener un número reducido de variables abstractas, que están
compuestas por distintas cargas o saturaciones sobre variables empíricas, en función
de la estructura de los datos obtenidos al realizar el proceso de medida de dichas
variables empíricas. Como el número de factores que se obtienen al realizar un
análisis factorial es menor que el número de variables de las que partimos y contienen
la misma información, cada factor explica una conducta más compleja que la explicada
por las variables empíricas.
Para realizar un Análisis Factorial con SPSS, elegiremos en el menú- analizar,
la opción Reducción de datos- Análisis Factorial
A través de esta pantalla podemos introducir una serie de especificaciones como el
método de rotación y extracción de los factores
La opción DESCRIPTIVOS nos permite especificar al programa si queremos que en la
salida aparezcan la solución inicial y estadísticos univariados, así como lo que
queremos que aparezca en la matriz de correlaciones (coeficientes, niveles de
significación, matriz inversa, reproducida o anti-imagen, determinante y la prueba de
Barlett) para elegir cualquiera de ellos, basta con seleccionarlos (�).
En esta ventana, el programa pide las
variables que queremos introducir para
realizar el análisis, en nuestro caso
vamos a introducir todas las variables
del fichero para tratar de obtener un
número de factores inferior al número
de variables que tenemos y que nos
En la opción método de
ROTACIÓN de los factores,
aparecen varios métodos, de
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
47
- La opción PUNTUACIONES, nos permite obtener las puntuaciones factoriales de
los sujetos, para ello, seleccionamos la opción y elegimos el método de Barlett. Las
puntuaciones factoriales de cada sujeto en cada factor aparecerán al final del
fichero de datos como nuevas variables con el nombre factnºdel factor_ nº de
análisis.
Interpretación de resultados
La tabla de comunalidades nos
indica cómo está representada
cada una de las variables en la
solución factorial (utilizamos el
criterio > 0,60 para establecer
que las variables están bien
representadas en la solución
factorial)
Respecto a la
EXTRACCIÓN de los
factores, el método de
Componentes Principales
es el que vamos a utilizar.
C
1 .
1 .
1 .
1 .
1 .
1 .
1 .
1 .
1 .
1 .
1 .
1 .
1 .
1 .
1 .
1 .
1 .
1 .
1 .
1 .
E
S
G
R
R
R
R
R m
R
E
P
E
P
N
S a
I a
C c
C c
M p
M p
I E
M
OFIMATICA II PROFESOR EDIDSON FUENTES
Manual de Practica de SPSS II CICLO
48
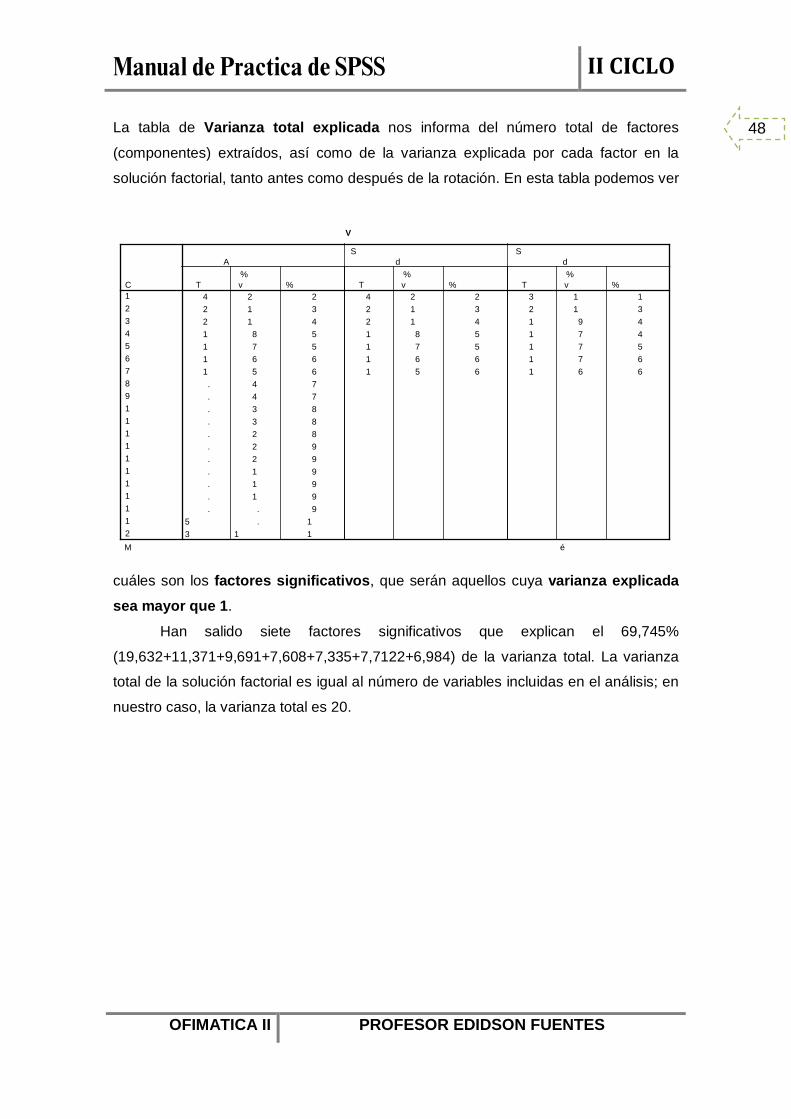
La tabla de Varianza total explicada nos informa del número total de factores
(componentes) extraídos, así como de la varianza explicada por cada factor en la
solución factorial, tanto antes como después de la rotación. En esta tabla podemos ver
cuáles son los factores significativos, que serán aquellos cuya varianza explicada
sea mayor que 1.
Han salido siete factores significativos que explican el 69,745%
(19,632+11,371+9,691+7,608+7,335+7,7122+6,984) de la varianza total. La varianza
total de la solución factorial es igual al número de variables incluidas en el análisis; en
nuestro caso, la varianza total es 20.
V
4 2 2 4 2 2 3 1 1
2 1 3 2 1 3 2 1 3
2 1 4 2 1 4 1 9 4
1 8 5 1 8 5 1 7 4
1 7 5 1 7 5 1 7 5
1 6 6 1 6 6 1 7 6
1 5 6 1 5 6 1 6 6
. 4 7
. 4 7
. 3 8
. 3 8
. 2 8
. 2 9
. 2 9
. 1 9
. 1 9
. 1 9
. . 9
5 . 1
3 1 1
C1
2
3
4
5
6
7
8
9
1
1
1
1
1
1
1
1
1
1
2
T% v % T
% v % T
% v %
A S
d S
d
M é
OFIMATICA II PROFESOR EDIDSON FUENTES
Manual de Practica de SPSS II CICLO
49
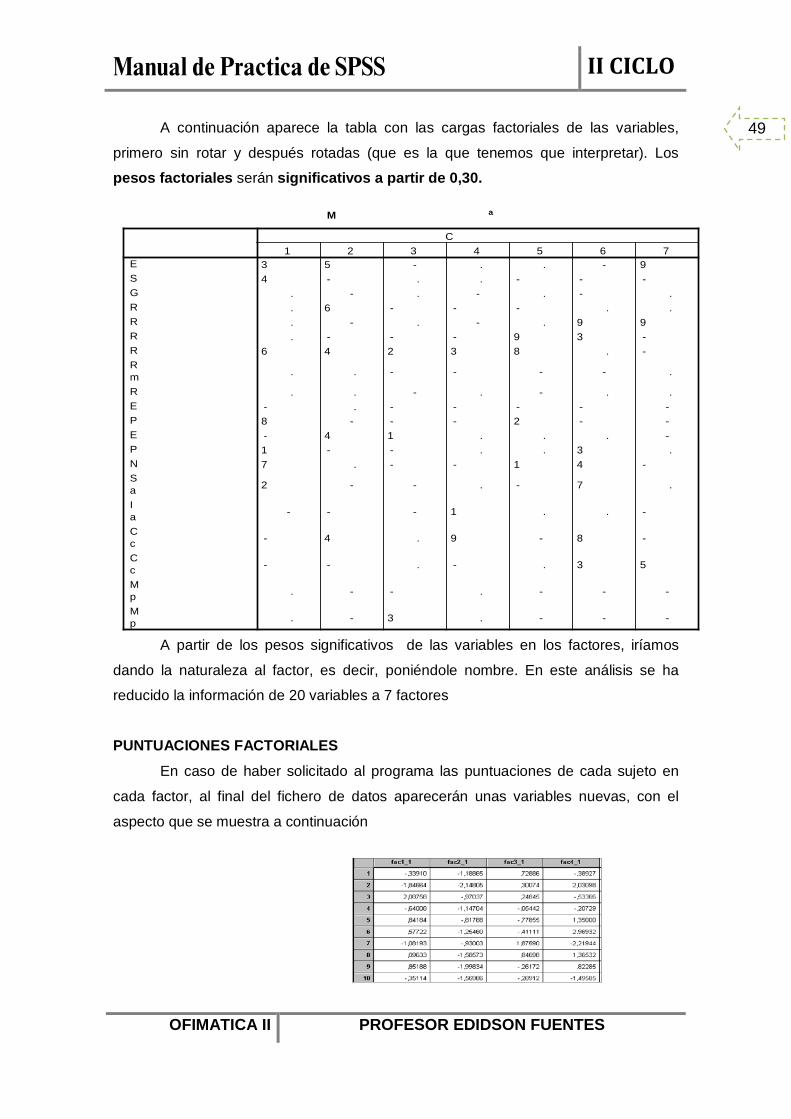
A continuación aparece la tabla con las cargas factoriales de las variables,
primero sin rotar y después rotadas (que es la que tenemos que interpretar). Los
pesos factoriales serán significativos a partir de 0,30.
A partir de los pesos significativos de las variables en los factores, iríamos
dando la naturaleza al factor, es decir, poniéndole nombre. En este análisis se ha
reducido la información de 20 variables a 7 factores
PUNTUACIONES FACTORIALES
En caso de haber solicitado al programa las puntuaciones de cada sujeto en
cada factor, al final del fichero de datos aparecerán unas variables nuevas, con el
aspecto que se muestra a continuación
M a
3 5 - . . - 9
4 - . . - - -
. - . - . - .
. 6 - - - . .
. - . - . 9 9
. - - - 9 3 -
6 4 2 3 8 . -
. . - - - - .
. . - . - . .
- . - - - - -
8 - - - 2 - -
- 4 1 . . . -
1 - - . . 3 .
7 . - - 1 4 -
2 - - . - 7 .
- - - 1 . . -
- 4 . 9 - 8 -
- - . - . 3 5
. - - . - - -
. - 3 . - - -
E
S
G
R
R
R
R
R m
R
E
P
E
P
N
S a
I a
C c
C c
M p
M p
1 2 3 4 5 6 7
C
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
50
ANÁLISIS DE COVARIANZA
El análisis de covarianza (ANCOVA) es una combinación de las técnicas
de regresión y análisis de varianza, que se utiliza para comprobar la existencia
de diferencias estadísticamente significativas en la variable dependiente
atribuibles a la variable independiente (con dos ó más grupos o categorías) y
otra dependiente (nivel de medición intervalo o razón), eliminando la interacción
de una variable extraña que controlamos a través de éste método,
introduciéndola en el análisis como COVARIABLE.
La suposición específica del ANCOVA es que la variable concomitante
(covariable) no debe ser afectada por los tratamientos, es decir, que los
tratamientos aplicados a las unidades experimentales para poder observar sus
efectos en la variable Y no deberían influir en los valores esperados de X.
Accedemos al análisis de covarianza a través del menú Analizar –
Modelo Lineal General – Univariante.
La H0 queda formulada de la forma siguiente: No existen diferencias
estadísticamente significativas en el Rendimiento Global de los alumnos en función del
Grupo de clase al que pertenezcan, controlando la influencia del Nivel Social de la familia.
Interpretación de resultados
De la tabla podemos deducir una serie de conclusiones (tantas como pruebas de
significatividad realizadas) que se presentan a continuación:
5. Modelo corregido � Se pone a prueba la existencia de diferencias
estadísticamente significativas en el Rendimiento Global obtenido por los alumnos
en función del Grupo al que pertenecen, controlando el efecto que pueda ejercer el
En este caso vamos a coger como
variable dependiente el Rendimiento
Global, como independiente o factor
fijo el Grupo de clase, y se va a
controlar el efecto de la variable
Nivel Social de la familia.
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
51
Nivel Social Familiar. La probabilidad asociada al estadístico F calculado es de
0,000 al ser un valor menor que α (0,05), rechazamos H0 y afirmamos que existen
6. diferencias en el Rendimiento Global obtenido por los alumnos en función
del Grupo al que pertenecen, controlando el efecto que pueda ejercer el Nivel
Social Familiar
7. Intersección � En este caso se pretende comprobar la existencia de diferencias
estadísticamente significativas en el Rendimiento Global de los alumnos,
provocadas por la acción conjunta de las variables Grupo de Clase y Nivel Social
Familiar. En este caso, la probabilidad asociada a F es también de 0,000, y al ser
menor que α (0,05), se rechaza H0, por lo que se confirma la existencia de
diferencias estadísticamente significativas en el Rendimiento Global de los
alumnos, provocadas por la acción conjunta de las variables Grupo de Clase
y Nivel Social Familiar
8. Por último se hace un ANOVA con cada una de las variables independientes
utilizadas. En el primer caso (para la Variable Nivel Social Familiar) se acepta la
H0 al ser la probabilidad asociada a F mayor que α (0,05) (para Nivel Social
Familiar la probabilidad asociada a F es de 0,533), por lo que no hay diferencias
estadísticamente significativas en el Rendimiento Global de los alumnos en
función del Nivel Social Familiar.
9. En el segundo caso se rechaza la H0 al ser la probabilidad asociada a F menor
que α (0,05) (para Grupo de Clase la probabilidad asociada a F es de 0,000), por
lo que hay diferencias estadísticamente significativas en el Rendimiento
Global de los alumnos en función del Grupo de clase al que pertenecen.
P
V
7 a 4 1 2 ,
4 1 4 5 ,
, 1 , , ,
7 3 2 3 ,
8 9 ,
3 1
1 9
FM
I
N
G
E
T
T
S c
t gM
c F S
R a
1234
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
49
ANÁLISIS DE ÍTEMS: ITEMAN
ITEMAN es un programa diseñado para realizar análisis de ítems, y
determinar la proporción de sujetos que acierta cada ítem, los que contribuyen
a la fiabilidad de un test, qué alternativas funcionan mejor y peor para un ítem
dado, etc.
EL FICHERO DE DATOS
El programa ITEMAN funciona bajo MS-DOS, por lo que los datos deben
introducirse con formato ASCII (texto), por ejemplo desde el editor del DOS,
Word Pad o Bloc de Notas de Windows. El fichero de datos va a tener un
aspecto similar al siguiente:
Las cuatro primeras líneas del fichero de datos son fundamentales y debe
extremarse la atención al escribirlas, que cualquier error en ellas (un espacio
de más o de menos, un punto, etc.) puede hacer que el programa no se ejecute
o lo haga de forma incorrecta.
• La primera línea está formada por 10 columnas que indican lo siguiente:
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
50
Columnas 1 a 3 � Número de ítems de que consta el test (máximo
250 ítems). En el ejemplo anterior, el test consta de 80 ítems, observar
que la primera columna queda en blanco, hubiera sido igual poner 035,
pero siempre respetando las tres columnas.
Columna 4 � Espacio en blanco.
Columna 5 � Código para las respuestas omitidas (en el Fichero del
ejemplo, el 9 es el valor que se asigna a los ítems no contestados).
Columna 6 � Espacio en blanco
Columna 7 � Código para los ítems no alcanzados. Especialmente
importante cuando se trata de test de velocidad, es el valor que se asigna a
los ítems que no han sido alcanzados por el alumno por falta de tiempo (en el
Fichero del ejemplo, el 8 es el valor que se asigna a estos ítems, pero no
aparece ninguno porque no se trata de una prueba de velocidad).
Columna 8 � Espacio en blanco
Columnas 9 y 10 � Número de caracteres utilizados para identificar a
los sujetos. En el fichero de ejemplo se especifica un 3 porque se utilizan las
dos primeras para enumerar del 1 al 50 y una más de separación entre la
identificación y los datos, total, 3 columnas.
• En la segunda línea se especifica la clave de corrección, la alternativa correcta
de cada ítem. Debe haber tantos dígitos como ítems.
• En la tercera línea se indica el número de alternativas que hay para cada uno
de los ítems del test. En el fichero del ejemplo cada ítem tiene 4 alternativas
• En la cuarta línea se especifican los ítems que entran en el análisis. Y significa
que el ítem se analizará; N significa que no se analizará. Debe haber tantos Y/N
cono ítems en el test. En el fichero de ejemplo se pide el análisis de los 80 ítems.
• A partir de la quinta línea se empiezan a escribir los datos.
GUARDAR LOS DATOS
Como ya hemos visto antes, los datos deben guardarse en un fichero de
texto; se recomienda hacerlo en el Word Pad de Windows, que asigna por defecto al
fichero la extensión .txt
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
51
Escribir el nombre del fichero, de u máximo de 8 caracteres (recordar que
ITEMAN trabaja bajo MS-DOS y no reconoce nombres largos). No poner ninguna
extensión al fichero, sólo el nombre y la ubicación (en disco de 3 1/2) y Aceptar
EJECUCIÓN DE ITEMAN
� Acceder al programa � Inicio - Programas - ITEMAN
� Lo primero que pide el programa es el fichero de los datos. Se escribe el nombre
del fichero de datos (por ejemplo a:datos.txt) y se pulsa INTRO
� A continuación, el programa pide que se especifique dónde se debe guardar la
salida (por ejemplo a:salida). Si no se pone extensión al fichero, por defecto el
programa le asigna la extensión .out. Pulsar INTRO
� ITEMAN pregunta si se desea crear un fichero con las puntuaciones de cada
sujeto (Do you want the scores written to a file?). Si se escribe Y (yes), el programa
pide la ubicación de este archivo (por ejemplo a:puntua), si se escribe N (no) pasa a
la siguiente pregunta.
� A la siguiente pregunta (Do you want a key exceptions file?) decimos siempre que
NO
� ITEMAN pregunta si se quiere un fichero con los estadísticos (Do you wnat to
write statistics to a external file?). En este caso, diremos al programa que NO, pero si
se quieren, el programa pide que se le especifique el nombre (por ejemplo
a:estadis)
� Al pulsar INTRO, sale una pantalla en la que hay que especificar las opciones de
configuración del análisis. En nuestro caso vienen señaladas por defecto, así que
simplemente pulsamos Continuar (INTRO)
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
52
� Una vez terminado el análisis, aparece una barra roja que dice ***ITEM
ANALYSIS COMPLETE***. Para ver los resultados, puede pulsarse directamente F2
para acceder al editor de ITEMAN o abrir el archivo desde el Word Pad
LOS RESULTADOS
EN la salida encontramos, en primer ligar, información referida al programa
(versión, año, etc.). A continuación los detalles específicos del análisis:
******************** ANALYSIS SUMMARY INFORMATION ******************** Data (Input) File: A:\DATOS.TXT Analysis Output File: A:\SALIDA.OUT Score Output File: NONE Exceptions File: NONE Statistics Output File: NONE Scale Definition Codes: DICHOT = Dichotomous MPOINT = Multipoint/Survey
Se especifica dónde estaban almacenados los datos, dónde se ha grabado la salida
así como el resto de archivos que se hayan pedido.
Scale: 0 ------- Type of Scale DICHOT N of Items 80 N of Examinees 50
***** CONFIGURATION INFORMATION ***** Type of Correlations: Point-Biserial Correction for Spuriousness: NO Ability Grouping: YES Subgroup Analysis: NO Express Endorsements As: PROPORTIONS Score Group Interval Width: 1
Aquí se resume la configuración que se especificó en la pantalla �
A partir de ahora, aparece el análisis de cada ítem. Se presenta sólo un extracto de
la salida con el análisis de dos de ellos.
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
53
Parte 1ª Parte 2ª
Un signo de interrogación (?), por ejemplo el que aparece en el ítem 4, indica
que hay que revisar el ítem, que se ha especificado la alternativa 3 como correcta en
la clave de corrección, pero está funcionando mejor la 2
A continuación el programa proporciona una descripción estadística completa
de todo el instrumento:
Scale: 0 ------- N of Items 80 N of Examinees 50 Mean 51.920 Variance 58.554 Std. Dev. 7.652 Skew 0.637 Kurtosis -0.478 Minimum 41.000 Maximum 69.000 Median 50.000 Alpha 0.798 SEM 3.440 Mean P 0.649 Mean Item-Tot. 0.230 Mean Biserial 0.329 Max Score (Low) 46 N (Low Group) 13 Min Score (High) 56 N (High Group) 14
Un histograma que representa la frecuencia de aciertos:
La primera parte hace referencia a la alternativa correcta de cada ítem, y se da la información siguiente: Prop. Correct � Proporción de sujetos que eligen esa alternativa (al ser la correcta, nos da la información sobre proporción de aciertos del ítem). Nos indica el índice de dificultad del ítem. Disc. Index. � Indice de discriminación. Correlación entre el ítem y el test. Indica el grado en que el ítem mide lo que mide el test Point. Biser. � Indice de homogeniedad del ítem. Equivalente al índice de discriminación
En la segunda parte de la salida, que hace referencia al ítem completo, se da la información correspondiente a todas las alternativas del ítem. Alt. � Número de alternativa Prop.Endorsing Low. � Proporción del 27% de los alumnos con peor puntuación en el test, que eligen esa alternativa Prop.Endorsing High. � Proporción del 27% de los alumnos con mejor puntuación en el test, que eligen esa alternativa Point Biser. � Relación existente entre cada alternativa y el test completo Atl. � Alternativa que se ha señalado como correcta en la clave de corrección
OFIMATICA II PROFESOR EDIDSON FUENTES

Manual de Practica de SPSS II CICLO
54
Number Freq- Cum Correct uency Freq PR PCT ------- ------- ------ ---- ---- . . . No examinees below this score . . . 40 0 0 1 0 + 41 3 3 6 6 |###### 42 2 5 10 4 |#### 43 1 6 12 2 |## 44 2 8 16 4 |#### 45 2 10 20 4 +#### 46 3 13 26 6 |###### 47 5 18 36 10 |########## 48 2 20 40 4 |#### 49 2 22 44 4 |#### 50 4 26 52 8 +######## 51 2 28 56 4 |#### 52 1 29 58 2 |## 53 2 31 62 4 |#### 54 4 35 70 8 |######## 55 1 36 72 2 +## 56 3 39 78 6 |###### 57 0 39 78 0 | 58 1 40 80 2 |## 59 1 41 82 2 |## 60 1 42 84 2 +## 61 0 42 84 0 | 62 1 43 86 2 |## 63 2 45 90 4 |#### 64 0 45 90 0 | 65 0 45 90 0 + 66 1 46 92 2 |## 67 2 48 96 4 |#### 68 1 49 98 2 |## 69 1 50 99 2 |## 70 0 50 99 0 + 71 0 50 99 0 | . . . No examinees above this score . . . | |----+----+----+----+----+ 5 10 15 20 25 Percentage of Examinees
A continuación presentamos una tabal que puede resultar útil para la interpretación
de resultados:
INDICE DE DIFICULTAD DEL ITEM INDICE DE VALIDEZ - INDICE DE HOMOGENEIDAD
Valor Interpretación Valor Interpretación
Menor de 0,25 Muy difícil Negativo a menor de 0,20 Rechazar ítem
Entre 0,25 y 0,44 Difícil Mayor o igual de 0,55 Bastante alto
Entre 0,45 y 0,54 Normal Mayor o igual de 0,75 Muy alto
Entre 0,55 y 0,74 Fácil
Mayor de 0,75 Muy Fácil
OFIMATICA II PROFESOR EDIDSON FUENTES


















