
MEJORA DE PROCESOS EN LA GENERACIÓN DE REPORTES PARA
83
UNIVERSIDAD DE CHILE FACULTAD DE CIENCIAS FÍSICAS Y MATEMÁTICAS DEPARTAMENTO DE CIENCIAS DE LA COMPUTACIÓN MEJORA DE PROCESOS EN LA GENERACIÓN DE REPORTES PARA GERENCIA DE CALL CENTER DE EMPRESA DE TELECOMUNICACIONES MEMORIA PARA OPTAR AL TÍTULO DE INGENIERO CIVIL EN COMPUTACIÓN SEBASTIÁN ANDRÉS SÁNCHEZ SUIL SANTIAGO DE CHILE MARZO 2011
-
Upload
mario-culqui-montoya -
Category
Documents
-
view
28 -
download
0
Transcript of MEJORA DE PROCESOS EN LA GENERACIÓN DE REPORTES PARA

UNIVERSIDAD DE CHILE FACULTAD DE CIENCIAS FÍSICAS Y MATEMÁTICAS DEPARTAMENTO DE CIENCIAS DE LA COMPUTACIÓN
MEJORA DE PROCESOS EN LA GENERACIÓN DE REPORTES PARA GERENCIA DE CALL CENTER DE EMPRESA DE TELECOMUNICACIONES
MEMORIA PARA OPTAR AL TÍTULO DE INGENIERO CIVIL EN COMPUTACIÓN
SEBASTIÁN ANDRÉS SÁNCHEZ SUIL
SANTIAGO DE CHILE MARZO 2011

UNIVERSIDAD DE CHILE FACULTAD DE CIENCIAS FÍSICAS Y MATEMÁTICAS DEPARTAMENTO DE CIENCIAS DE LA COMPUTACIÓN
MEJORA DE PROCESOS EN LA GENERACIÓN DE REPORTES PARA GERENCIA DE CALL CENTER DE EMPRESA DE TELECOMUNICACIONES
MEMORIA PARA OPTAR AL TÍTULO DE INGENIERO CIVIL EN COMPUTACIÓN
SEBASTIÁN ANDRÉS SÁNCHEZ SUIL
PROFESOR GUÍA: MARÍA CECILIA BASTARRICA PIÑEYRO
MIEMBROS DE LA COMISIÓN SERGIO OCHOA DELORENZI
HUGO ANDRÉS MORA RIQUELME
SANTIAGO DE CHILE MARZO 2011

Dedicado a mi hija Francisca.

Resumen Ejecutivo
La Gerencia de Call Center de una compañía de telecomunicaciones está a cargo de la comunicación con los clientes de la compañía. Para esto contrata los servicios de algunos call centers, y requiere que estos le entreguen información de su comportamiento para guiar sus decisiones tácticas y estratégicas. El presente trabajo tiene como principal objetivo mostrar reportes de la información obtenida desde fuentes externas, principalmente los call centers. Los reportes deben ser de utilidad a los ejecutivos de la Gerencia, desde el gerente hasta los analistas que utilizan la información en el día a día. El principal problema se produce por la existencia de más de un call center utilizando distintas tecnologías. Esto hace que los reportes lleguen con formatos diferentes. Además, los servicios que utilizan los call centers para entregar la información no son de alta disponibilidad, y es común que estos fallen. Es responsabilidad de la Gerencia reunir los informes y mostrarlos en un mismo formato. También es necesario cumplir con ciertos reportes exigidos para la certificación COPC (Customer Operations Performance Center), la cual está siendo obtenida por la compañía. Para solucionar el problema se consideró implementar un Data Warehouse que pudiera obtener la información desde los call centers mediante procesos de Extracción, Transformación y Carga, para luego generar reportes de gestión. Estos procesos debieron realizarse pensando en que la información puede no estar disponible en el momento que se realiza la extracción, o que la información extraída sea inconsistente. Se modeló la base de datos para almacenar la información y se desarrollaron los procesos de ETL. Para esto se utilizó Microsoft SQL Server 2000. La decisión de utilizar este software se realizó considerando no aumentar los costos asociados de adquirir un nuevo software de Base de Datos, debido a que este software ya estaba disponible en la empresa. Se desarrolló una aplicación web para mostrar los datos de una forma interactiva, incluyendo gráficos. También se desarrollaron algunos mantenedores y una aplicación que muestra el estado de la carga del Data Warehouse. Con esto se valida en parte la calidad de la información que ingresa al Data Warehouse. Esta aplicación genera alarmas mediante e-mail en caso de encontrar inconsistencias en la información o fallas en algún proceso. El desarrollo de las aplicaciones web se realizó sobre una plataforma de Apache y PHP sobre Microsoft Windows, en el mismo servidor donde se encuentra la Base de Datos. Aplicando los principios de desarrollo de los procesos ETL y de los Data Warehouse se logró una mejora sustancial en la manipulación de los datos, en comparación con la situación anterior a la implementación de este proyecto.

Índice
1 Introducción .................................................................................................................. 1
1.1 Objetivos................................................................................................................. 3
1.1.1 Objetivo General............................................................................................. 3
1.1.2 Objetivos Específicos .................................................................................... 3
2 Antecedentes.................................................................................................................. 5
2.1 Call Center.............................................................................................................. 5
2.2 Teoría de Tráfico de Llamadas............................................................................... 7
2.2.1 Erlang.............................................................................................................. 7
2.2.2 Poisson............................................................................................................ 7
2.2.3 Erlang C.......................................................................................................... 8
2.2.4 Calculo de Agentes Necesarios ...................................................................... 8
2.3 COPC...................................................................................................................... 9
2.4 Data Warehouse.................................................................................................... 11
2.4.1 Data Staging Area......................................................................................... 17
2.4.2 Principios en Procesos ETL.......................................................................... 17
2.5 OLAP.................................................................................................................... 19
2.6 Data Mining.......................................................................................................... 20
2.7 Rendimiento de Bases de Datos ........................................................................... 20
2.7.1 Particionado .................................................................................................. 21
2.7.2 Particionado de Tablas.................................................................................. 21
2.7.3 Partición Nativa vs. Sistema de Archivos .................................................... 22
2.7.4 Indexado ....................................................................................................... 23
2.7.5 Desnormalización ......................................................................................... 23
2.7.6 Interpolación de Datos.................................................................................. 24
2.7.7 Espacio Libre................................................................................................ 24
2.7.8 Ubicación de Archivos ................................................................................. 24
3 Especificación del Problema...................................................................................... 26

4 Descripción de la Solución ......................................................................................... 28
4.1 Decisiones de Diseño............................................................................................ 28
4.2 Dimensiones ......................................................................................................... 29
4.3 Tablas de Hecho ................................................................................................... 29
4.4 Arquitectura de la Solución .................................................................................. 31
4.4.1 Extracción..................................................................................................... 31
4.4.2 Transformación............................................................................................. 33
4.4.3 Carga............................................................................................................. 36
4.5 Cálculo de Indicadores ......................................................................................... 36
4.5.1 Intervalos Prime y No Prime ........................................................................ 36
4.5.2 Precisión del Pronóstico de Volumen de Llamadas ..................................... 37
4.5.3 Cálculo de Agentes Necesarios .................................................................... 37
4.5.4 Precisión de la Programación de Ejecutivos................................................ 38
4.6 Métricas de Consistencia ...................................................................................... 38
4.7 Desarrollo de Software de Apoyo ........................................................................ 39
4.7.1 Estado de Carga ............................................................................................ 39
4.7.2 Colas descartadas.......................................................................................... 41
5 Acceso a la Información ............................................................................................. 44
5.1 Sistema Web......................................................................................................... 44
5.2 Reportes en Hoja de Cálculo (Excel) ................................................................... 46
6 Validación de la solución............................................................................................ 47
7 Conclusiones................................................................................................................ 49
8 Anexos.......................................................................................................................... 51
8.1 Anexo A................................................................................................................ 51
8.1.1 agrupar_cola ................................................................................................. 51
8.1.2 agrupar_eac................................................................................................... 53
8.1.3 carga_cola..................................................................................................... 56
8.1.4 carga_eac ...................................................................................................... 58
8.1.5 calculo_prime_noprime ................................................................................ 61

8.1.6 calculo_precision_pronostico_llamados....................................................... 62
8.1.7 calculo_precision_programacion_eac .......................................................... 65
8.1.8 calculo_agentes_necesarios .......................................................................... 67
8.1.9 agentes_necesarios........................................................................................ 68
8.1.10 erlangC.......................................................................................................... 69
8.1.11 u_m_f............................................................................................................ 69
8.1.12 dwh ............................................................................................................... 70
9 Bibliografía.................................................................................................................. 75

1
1 Introducción
Los clientes son la parte fundamental de una empresa. En particular, una empresa de
telecomunicaciones necesita mantener una comunicación constante y directa con sus
consumidores para conocer sus necesidades y satisfacerlas, promoviendo así la fidelización
del cliente.
El área que se dedica a la comunicación con los clientes y cuenta con personal
capacitado para ello, se denomina Contact Center o centro de contacto. Cuando la
comunicación con los clientes es solamente por vía telefónica, esta área se denomina Call
Center. Es común que las grandes empresas no cuenten con personal interno para la
comunicación con sus clientes, sino que externalizan dichos servicios a empresas
especializadas en atención a clientes.
Gracias a la tecnología, no es necesario que los centros de contacto estén ubicados
cerca de la empresa que ofrece sus servicios. Por el contrario, pueden estar ubicadas en
cualquier lugar del mundo, y se prefieren áreas donde se hable el mismo idioma que la
empresa, exista buena educación y la mano de obra sea barata.
Aún cuando se externalice la mayor parte o la totalidad del área de Contact Center,
es necesario para la empresa de telecomunicaciones contar con un área interna que gestione
los recursos (personal atendiendo en cada momento, ubicación del personal, etc.). Dicha
área es la Gerencia de Contact Center (en lo sucesivo la gerencia).
La empresa en la que se realiza esta memoria posee cerca de 9 millones de clientes
en Chile, y recibe mensualmente un tráfico que fluctúa entre 3 y 4 millones de llamadas. Al
momento de la ejecución de esta memoria, la empresa cuenta con los servicios de 7 Call
Centers, los cuales están ubicados en Chile, Perú y Colombia.
Para realizar gestiones y tomar decisiones estratégicas, los call centers proveen de
datos a la gerencia de Contact Center, los cuales contienen información de las llamadas y

2
los tiempos de conversación, información de los ejecutivos de atención, e información
relacionada con los clientes. A partir de esta información se obtienen indicadores tales
como tiempos de atención, volúmenes de llamadas, cantidad de ejecutivos conectados, etc.;
varios de los cuales han sido aconsejados por los estándares de COPC1 (Customer
Operations Performance Center ).
Los datos llegan actualmente al área de reportes de la gerencia a través de distintos
medios, como puede ser un e-mail, una conexión a bases de datos, un archivo publicado en
un sitio web, un servicio web, etc.; con una frecuencia de actualización de 15 a 30 minutos.
Es frecuente que los sistemas utilizados por los call centers para proveer a la
Gerencia de información no estén disponibles. Es decir que cuando se quiere recuperar la
información esta no se encuentra. También es común que la información que proveen los
call centers tenga inconsistencias.
La existencia de varias fuentes de información y el uso de distintas tecnologías en
los call centers, produce que los datos que se obtienen sean heterogéneos, y dificulta el
acceso y análisis de estos en un ámbito global. Es por ello que surge la necesidad de que la
información esté centralizada y homogenizada.
Los problemas que se generan cuando los datos son heterogéneos son conocidos en
el mundo de las Tecnologías de Información, y las soluciones generalmente conducen a la
creación de Almacenes de Datos2. Para la creación de un Almacén de Datos es necesario
identificar las fuentes de información, definir las etapas de ETL3 (Extract Transform and
Load), modelar las bases de datos relacionales, modelar las bases de datos dimensionales y
definir las herramientas que se utilizarán para acceder a los datos.
Actualmente la Gerencia de Contact Center está en proceso de certificación COPC,
para lo cual debe cumplir ciertos requisitos, como son la puntualidad en la entrega de
1 http://www.copc.com/standards.aspx 2 Del ingles data warehouse 3 Del ingles Extract, transform and load

3
información, la integridad de la información, y la construcción de pronóstico de métricas
basadas en la información histórica, entre otras.
Lograr mejoras en el área de reportes de la Gerencia de Call Center se traduce en
mejorar el análisis que se realiza de los datos, para luego tomar mejores decisiones gracias
a la disponibilidad de más y mejor información, y así destinar de mejor manera los recursos
asociados con la atención al cliente, mientras se mantiene o aumenta la satisfacción de este.
El presente trabajo pretende ser un aporte en la parte tecnológica para que los
encargados de la Gerencia puedan tomar decisiones en base a informes y reportes de
calidad; y a su vez la Gerencia pueda obtener la certificación COPC.
Tomando en cuenta que se pretende implementar soluciones de Almacenes de
Datos, cabe destacar que la empresa dispone de licencias de SQL Server 2000, por lo que
una de las herramientas de ETL a considerar es Microsoft SQL DTS. Otras opciones
corresponden a herramientas OpenSource, las cuales pueden dar solución a las necesidades
de la empresa sin aumentar la inversión y los tiempos requeridos en la obtención de
licencias de software comercial.
1.1 Objetivos
1.1.1 Objetivo General
Automatizar y centralizar los procesos de envío y recepción de datos entre la
gerencia y los call centers, para optimizar la generación de reportes e indicadores que
permitan mejorar la gestión de recursos y la satisfacción de clientes.
1.1.2 Objetivos Específicos
Los objetivos específicos contemplados son los siguientes:

4
• Automatizar, centralizar y homogenizar la información que se transmite entre los
call centers y la gerencia.
o Utilizando herramientas de ETL, se planea automatizar la obtención de
información desde los distintos repositorios.
o Creación de clientes de Web Service para la obtención de los datos donde
exista la posibilidad de conectarse a ellos.
• Definir e implementar métricas de integridad y consistencia de la información en el
proceso de Extracción.
• Implementar alertas que informen al área cuando los datos son inconsistentes, para
realizar acciones correctivas lo antes posibles.
• Automatizar el cálculo de métricas necesarias para la gestión de los Call Center y
para el proceso de certificación COPC.
• Mejorar los tiempos de acceso a los reportes e indicadores.
Actualmente existe un panel de control Web que muestra indicadores para todos
los Procesos Clave Relacionados con el Cliente (PCRCs), el que tarda un
promedio de 50 seg. en cargarse. Con lo siguiente se espera disminuir el tiempo
de espera:
o Modelar una base de datos dimensional sobre una base de datos relacional.
o Automatizar el proceso de actualización de la base dimensional.
o Automatizar el proceso de cálculo de indicadores.
• Analizar los datos almacenados.
• Buscar relaciones y clasificaciones entre los datos, utilizando herramientas de data
mining, en particular se busca conocer la razón por la que llama el cliente para así
optimizar la plataforma que atiende sus solicitudes, aumentando la capacitación de
los ejecutivos o en el mejor de los casos dejar un acceso automático (ya sea a través
de web, o telefónico) disminuyendo los costos.

5
2 Antecedentes
A continuación se presentan las definiciones de conceptos y las tecnologías más
importantes utilizadas en este trabajo de memoria.
Se comienza con una descripción de lo que es un call center, se hace referencia a las
normas COPC, para llegar a lo necesario para el almacenamiento de la información: los
Data Warehouse y las tecnologías asociadas.
2.1 Call Center
Un centro de atención de llamadas o call center es un área donde existen ejecutivos
entrenados para realizar y recibir llamadas telefónicas desde y hacia los clientes. Se
distingue de los contact center en que estos últimos pueden comunicarse con el cliente a
través de otros medios además del teléfono, como puede ser el chat, e-mail, fax, etc.
En la terminología de los call centers, se les denomina a las llamadas entrantes
INBOUND, y a las salientes OUTBOUND. A los Ejecutivos o Agentes que atienden en los
call centers se les llama EAC (Ejecutivo de Atención al Cliente). Las especialidades que es
capaz de atender cada ejecutivo se denominan SKILLs. El número telefónico del cliente
identificado automáticamente cuando este realiza una llamada al call center se denomina
ANI (Automatic Number Identification).
El flujo que recorre la llamada, desde que el cliente marca hasta que el ejecutivo la
reciba es el siguiente:
• La llamada entra a un sistema IVR4, el cual presenta al cliente un menú con las
opciones de atención.
• Cuando el cliente escoge una opción mediante el teclado numérico del teléfono, se
realiza una consulta a un sistema que entrega información del cliente como el saldo
4 Interactive Voice Response

6
y el segmento al que pertenece. Con esta información el IVR decide hacia donde
dirige la llamada utilizando una programación predefinida.
• Luego de pasar por el IVR, las llamadas son redirigidas a un sistema ACD5 a través
de un VDN6, el cual es similar a un número telefónico virtual.
• El sistema ACD procesa el requerimiento, y la llamada se encola mientras se busca
un grupo de agentes que tenga la habilidad para atender la llamada con ejecutivos
disponibles.
• Si hay un ejecutivo libre que corresponda a la habilidad o SKILL requerida, este
atiende la llamada.
• Si no hay ningún ejecutivo disponible, esta se mantiene en la cola hasta que se
desocupe un ejecutivo o el cliente corte.
Cada ejecutivo tiene a su disposición un sistema que le permite registrar los tiempos
de producción mediante botones que indican estados. Así por ejemplo, un ejecutivo puede
estar en estado disponible, en conversación, en retención de un cliente, en el baño, en
capacitación, etc.
Existen tres agrupaciones de datos principales que se extraen de los Call Centers:
• Información agrupada por número telefónico o ANI: Contiene la información del
cliente que realiza la llamada, del ejecutivo que atiende y los tiempos de
conversación.
• Información agrupada por VDN, COLA o Skill: Contiene tiempos de conversación
(Llamadas Recibidas, Abandonadas, Recibidas antes de 10 segundos, Recibidas
antes de 20 segundos, etc.) en cada Cola o Skill.
• Información agrupada por EAC7. Contiene información de los tiempos de
conversación, tiempos no productivos (baño, descanso, etc.) de cada ejecutivo.
5 Automatic call distributor 6 Vector directory number 7 Ejecutivo de Atención al Cliente

7
2.2 Teoría de Tráfico de Llamadas
Debido a que el call center actúa encolando las llamadas, la teoría matemática que
se utiliza en la atención en call centers es la teoría de colas. Frecuentemente se utilizan
modelos estadísticos basados en una distribución de probabilidades de Poisson y las
fórmulas de Erlang para calcular la cantidad de agentes requeridos y realizar pronósticos de
niveles como son el nivel de servicio, TMO8, niveles de abandono, etc.
2.2.1 Erlang
Un Erlang está definido como una unidad adimensional de intensidad de tráfico. La
clave de esta definición es que, adimensional implica que no sea necesario especificar un
período de tiempo. Un Erlang depende del tiempo de observación. Si una instalación está
en uso todo el tiempo durante 10 minutos, entonces tenemos 1 Erlang. Si el período de
observación es una hora, entonces 1 Erlang es igual a 1 hora.
2.2.2 Poisson
La formula de Poisson, que fue desarrollada por el matemático francés Sieméon-
Denis Poisson, establece que para eventos que no se superponen, que ocurren con una tasa
promedio , la probabilidad de que lleguen eventos en un tiempo es igual a:
Donde:
= Probabilidad de llegadas
= Tasa promedio de llegadas
= Tiempo promedio del evento
Esta fórmula permite el cálculo de la probabilidad de tener n llegadas, durante un
cierto intervalo.
8 Tiempo Medio de Operación

8
2.2.3 Erlang C
Erlang C corresponde a una formula de espera para infinitas fuentes. Esta aplica en
el caso en que quién llama debe esperar en una cola antes de que un servidor esté
disponible cuando todos los servidores están ocupados.
Donde:
= Trafico Ofrecido
= Número de Servidores
= Tiempo Promedio de Llamadas
= Probabilidad de una espera mayor a
= Probabilidad de una espera mayor a
= Tiempo
2.2.4 Calculo de Agentes Necesarios
La segunda fórmula de la sección anterior representa también el nivel de servicio de
una instalación. Es necesario considerar que para el negocio es importante mantener la
menor cantidad de ejecutivos de atención disponible en todo momento, aunque tampoco es

9
útil tenerlos ocupados siempre pues no podrían atender más llamada. En general, el nivel de
servicio acordado para una empresa de Call Center se fija entorno al 80%.
A partir del nivel de servicio esperado, se puede calcular entonces la cantidad de
agentes que sería necesario para atender un flujo determinado de llamadas. Basta con
reemplazar los datos en la fórmula de nivel de servicio, y encontrar la cantidad de
servidores que puedan mantener el nivel de servicio deseado.
2.3 COPC
COPC es un acrónimo de Customer Operations Performance Center, y es una
entidad que provee de estándares a los centros de contacto con clientes.
Es a su vez un modelo de gestión de Performance aceptado globalmente. Esto,
sumado al conjunto de normas correspondientes, conforman un “vocabulario de la
industria” consistente.
El modelo de Gestión de Performance COPC y la Familia de Normas COPC se
basan en la siguiente terminología y relaciones:

10
Ilustración 1 Esquema de terminología y relaciones COPC
Las dos normas relevantes para la industria de los call centers son:
• Norma COPC-2000 VMO: Está dedicada a las Organizaciones de Gestión de
Proveedores y establece una serie de requisitos mínimos que un comprador de
servicios de Contact Center debe alcanzar a fin de gestionar de manera efectiva las
relaciones con sus Proveedores de Servicios Integrales a Clientes (PSICs).
• Norma COPC-2000 PSIC: Detalla las prácticas de gestión mínimas e indispensables
que debe implementar una operación de servicios al cliente, ya sea interna o
externalizada, a través de cualquiera de los métodos de contacto existentes en el
mercado.
Dentro de las normas que propone la certificación COPC y que interesan en el
ámbito de tecnologías de información, se incluye el enfoque RUICA, para los datos y el
proceso de extracción de estos, el cual se detalla a continuación.
• Los datos deben ser Recolectados.

11
• Los datos deben ser Usables; en particular, los objetivos deben estar claramente
identificados y se deben proveer suficientes datos para percibir una tendencia. Los
objetivos se deben establecer respecto de benchmarks de alta performance donde
sea posible y adecuado hacerlo.
• El proceso de recolección asegura su Integridad. Todos los datos deben ser:
o Significativos: reflejan lo que el requisito realmente intenta medir.
o Objetivos: las metodologías utilizadas para recolectar los datos son
imparciales.
o Precisos: numéricamente correctos y no engañosos.
o Representativos: reflejan la población subyacente.
• El personal apropiado es Conocedor de los datos. Esto incluye el requisito de que el
personal apropiado comprenda la validez estadística de las métricas que utilizan que
están basadas en muestras.
• Los datos llevan a tomar Acciones si los resultados caen por debajo de los objetivos.
COPC define el concepto de PCRC (Proceso Clave Relacionado con el Cliente)
para enmarcar los productos y servicios que la empresa ofrece a sus clientes. Así por
ejemplo un cliente de telefonía móvil que contrata un plan de minutos, se atiende en el
PCRC ATC_CONTRATO (Atención comercial para clientes Contrato) cada vez que este
llama al call center y solicita la atención mediante ejecutivo.
En las normas COPC se detallan algunas métricas que deben ser obtenidas a partir
de los informes de datos que entregan los call centers a la Gerencia, y de datos creados por
la misma Gerencia. Dentro de estas métricas están las de Cumplimiento y Precisión, tanto
para los pronósticos de llamados como de ejecutivos.
2.4 Data Warehouse
Es una tecnología que facilita el acceso a reportes de información histórica. Se
caracteriza por contar con la información necesaria homogenizada y en un solo lugar,
dejando de lado información inútil para la toma de decisiones.

12
Un Data Warehouse es una colección de datos empresariales, orientado a temas,
integrados, no volátiles y variante en el tiempo que apoya a la toma de decisiones. [4]
• Datos Empresariales: Un Data Warehouse mantiene información que es
relevante para la empresa. Principalmente es información importante para el
negocio de esta.
• Orientado a Temas: La información está organizada en torno a los temas del
negocio de la empresa. En el caso de los call centers, los temas serían los agentes,
las llamadas, los clientes, etc.
• Integrado: La información en el Data Warehouse se presenta de manera uniforme.
Esto permite que los usuarios realicen consultas que involucren varias áreas
temáticas sin la necesidad de transformar la información o buscarla en otras fuentes.
• No Volátil: La información no se modifica ni se elimina una vez que ingresa al
Data Warehouse. De esta forma, es posible ver reflejado en el Data Warehouse la
información histórica y el estado reciente de la empresa.
• Variante en el Tiempo: La información en el Data Warehouse expresa los eventos
ocurridos en la empresa a lo largo del tiempo agrupados en momentos. Los
momentos en el tiempo tienen una granularidad. Mientras el tiempo es análogo, en
el caso de los sistemas informáticos se escoge un intervalo discreto de tiempo que
representa un momento de la empresa. Este intervalo puede ser expresado en
milisegundos, minutos, horas, días, semanas, meses, años, etc.
Los primeros autores en escribir acerca de los Data Warehouse fueron Ralph
Kimball y Bill Inmon. Durante los años 90, ellos definieron y documentaron los conceptos
y principios de los Data Warehouse. Kimball[1] creó lo que actualmente se conoce como
Modelo de Datos Dimensional para los Data Warehouse, dónde se tienen las tablas de
hecho en el centro y las tablas de dimensión alrededor. Mientras Inmon[4] prefiere un
modelo en la Tercera Forma Normal debido a la flexibilidad que ofrece este modelo. De
todas formas, Inmon establece que para aplicaciones que contienen una gran cantidad de
datos y que se enfocan en un modelo de negocio específico, con requerimientos específicos,

13
el modelo óptimo es el de Combinaciones en Estrella. Inmon se refiere a estos Data
Warehouse específicos como Data Marts.
Considerando que este proyecto se refiere a la información y los reportes utilizados
por una Gerencia, el Data Warehouse tomará una forma más apropiada a un Data Mart
según la definición de Inmon. Aún en estos días, es difícil diferenciar exactamente las
características de un Data Mart de un Data Warehouse, debido a que existen diversas
definiciones de cada uno. De cualquier forma, para este proyecto, se utilizará el Modelo
Estrella, con tablas de hecho y tablas de dimensión, creado por Kimball y se tratará
indistintamente al Data Warehouse y al Data Mart.
La tabla de hechos es la tabla principal en el modelo dimensional. Es aquí donde se
almacenan las métricas e indicadores fundamentales para el negocio de la empresa. Los
datos ingresados en una tabla de hecho deben ser del tipo numérico y es deseable que estos
se puedan sumar para obtener resúmenes de las consultas que retornan varias filas. Las
tablas de hecho contienen dos o más llaves foráneas que se conectan a las tablas de
dimensión a través de la clave primaria. Lo normal es que una tabla de hechos no contenga
muchas columnas, pero sí suelen ser numerosas en filas.
Una tabla de dimensión contiene descripciones textuales del negocio. Están
determinadas por una clave primaria de una columna que sirve para integridad referencial
con las tablas de hechos que está relacionada. Suelen tener varias columnas, y su tamaño en
cuanto a filas es mucho menor que el tamaño de la tabla de hechos. Las tablas de dimensión
son claves en el Data Warehouse debido a que representan las restricciones y las etiquetas
de los reportes; hacen que la información del Data Warehouse sea utilizable y entendible.
La información guardada en las tablas de dimensiones debe ser textual y discreta.
Los modelos dimensionales que se utilizan para la construcción del Data Warehouse
son los siguientes:

14
• Modelo Estrella: Es el modelo de datos más simple de un Data Warehouse.
Consiste en pocas tablas de hechos (comúnmente una, justificando el nombre) que
referencian a varias tablas de dimensión.
Ilustración 2 Modelo Estrella
• Modelo Copo de Nieve: En este modelo, las dimensiones están compuestas por
varias tablas normalizadas. Con esto se evita la redundancia y se ahorra espacio.
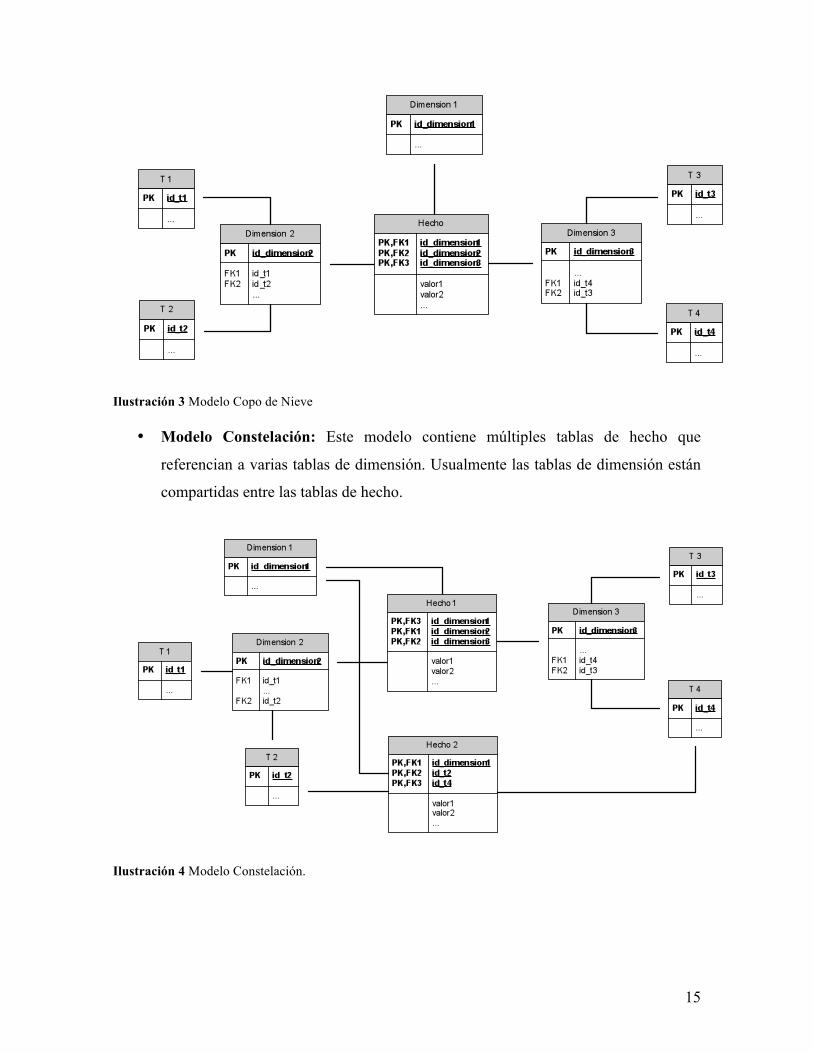
15
Ilustración 3 Modelo Copo de Nieve
• Modelo Constelación: Este modelo contiene múltiples tablas de hecho que
referencian a varias tablas de dimensión. Usualmente las tablas de dimensión están
compartidas entre las tablas de hecho.
Ilustración 4 Modelo Constelación.

16
Para cargar de información al Data Warehouse, es necesario obtener la información
de las fuentes y procesarlas. Este proceso se denomina Extracción, Transformación y Carga
(ETL).
• Extraer: Es la parte donde se obtienen los datos desde los sistemas de origen. En el
caso de esta memoria, cada Call center representa una fuente de origen distinta. La
información obtenida se guarda en una base de datos intermedia llamada Data
Staging Area. A medida que se extraen los datos, es necesario verificar que la
información que se obtiene calza con los patrones esperados.
• Transformar: En esta etapa se aplican una serie de reglas a la información en
bruto, por ejemplo: Se seleccionan sólo las columnas que son útiles, se traducen los
códigos en valores homogéneos, se derivan fórmulas calculadas, etc. En esta etapa
se realiza una validación de la información.
• Cargar: Se traspasa la información transformada al Data Warehouse.
Ilustración 5 Elementos Básicos de un Data Warehouse

17
2.4.1 Data Staging Area
El Data Staging Area o DSA, es lo que está entre las fuentes de información y el
área de presentación de datos. Contiene un área de almacenamiento de datos y una serie de
funciones y herramientas que sirven para los procesos ETL. Los datos extraídos por el
proceso ETL son almacenados en esta área para su posterior transformación y carga en el
Data Warehouse.
En general no se permite que los clientes interactúen con el DSA, pues la
información contenida no está lista para ser presentada, y se pueden obtener resultados
erróneos por falta de conocimiento de la estructura.
2.4.2 Principios en Procesos ETL
Fon Silvers propone 6 principios de diseño [5], que ayudan en el desarrollo de los
procesos ETL para evitar ciertas anomalías conocidas:
• Principio 1: Una Cosa a la Vez.
Si bien la multitarea es una característica percibida como positiva en las
aplicaciones computacionales debido a que ayuda a reducir el consumo de tiempo y
recursos, ayuda muy poco en los procesos ETL. Esto debido a que las aplicaciones
multitarea están construidas sobre la base de que todo funcionará como está planeado y que
todos los valores de entradas serán razonables y válidos. En cambio, una aplicación ETL
debe suponer que nada funcionará como está planeado y que los valores de entrada pueden
ser irrazonables e inválidos.
Un proceso ETL realice acciones simultáneas supone que todo irá bien. En el caso
que alguna suposición sea violada, el proceso completo fallará y será extremadamente
difícil encontrar la causa.

18
Un diseño demasiado granular que realiza una cosa a la vez es ineficiente. Es
necesario encontrar un balance entre los costos del diseño granular y el riesgo de que se
violen las suposiciones en un proceso simultaneo.
• Principio 2: Saber Cuando Comenzar
Una tarea debiera mirar el estado de la tarea anterior y la información que generó
para determinar si debe ejecutarse o no. Por ejemplo, una aplicación de Extracción tendrá
que examinar el sistema fuente operacional antes de extraer la información. Una aplicación
de Transformación deberá examinar la información generada por la aplicación de
Extracción que le antecede. Similarmente, el proceso de Carga tendrá que examinar la
información provista por la aplicación de Transformación para determinar si se ejecuta o
no.
• Principio 3: Saber Cuando Finalizar
Una aplicación ETL puede verificar, examinando su propia información, si el
proceso se ha completado satisfactoriamente. El resultado de la revisión final puede ser
capturado como Información de Calidad de Datos.
• Principio 4: Grande a Mediano a Pequeño
Es un principio de diseño que típicamente se extiende a través del la aplicación ETL
completa. Este diseño reúne todos los elementos y entidades de la información que aplica.
La información que ya no se requiere se descarta y el conjunto final de datos será cargado
en el Data Warehouse. La ventaja de este diseño es que permite mayor control sobre los
datos excluidos.
• Principio 5: Integridad de Datos en las Etapas
Este principio mantiene la integridad de los datos en el conjunto de etapas. Cuando
múltiples conjuntos lógicos de datos comparten algunas características en común (las que
incluyen formato, tipo de datos, significado y uso), pareciera razonable almacenarlas juntas
en un único conjunto de datos. Sin embargo, esto crea un riesgo innecesario en la
aplicación ETL.

19
• Principio 6: Conozca lo que tiene
La aplicación ETL debiera tener un inventario de la información de entrada, en
lugar de asumir que esta contiene todo lo que se espera. La aplicación ETL puede comparar
el contenido de la información de entrada con la información esperada.
También, en lugar de Conocer lo que se tiene, se puede Conocer lo que no se tiene.
De esta forma se obtiene una lista de información faltante. Con esta información se puede
definir un umbral. Si la información faltante supera cierto umbral, se tiene la posibilidad de
generar alguna respuesta a la contingencia.
2.5 OLAP9
Tener los datos dentro de un Data Warehouse no sirve de nada si no existe una
manera de obtener la información. La manera de mostrar la información que guarda el Data
Warehouse es mediante Reportes. OLAP permite realizar algunos análisis sobre la
información, pudiendo navegar en esta.
OLAP es un acrónimo que referencia a Procesamiento Analítico en Línea. Es una
tecnología de información que utiliza los modelos dimensionales para mostrar indicadores
de forma interactiva. Suelen implementarse con bases de datos Multidimensionales
(MOLAP) en lugar de Relacionales (ROLAP), o se utiliza una mezcla de ambas tecnologías
(HOLAP). La estructura que se forma al utilizar un modelo Dimensional se llama cubo
OLAP. Para mejorar el tiempo de las consultas agrupadas, se suelen utilizar algoritmos que
mantienen datos precalculados en la base de datos, formando cuboides.
Las operaciones que soporta la tecnología OLAP son las siguientes:
• Drill-Down : Acceder a información más detallada a partir de un resumen,
enfocándose en una categoría. 9 Online Analytical Processing

20
• Roll-Up : Proceso inverso a Drill-Down
• Navegación : Secuencia de Drill-Downs y Roll-Ups
• Drill-Across : Cruzar más de una tabla de hechos
• Slice : Imponer condiciones sobre las dimensiones
• Pivot : Elegir y cambiar la disposición de los atributos para la tabla de
salida
La tecnología OLAP está usualmente relacionada con los Data Warehouses, debido
a que obtienen los datos a partir de estos.
2.6 Data Mining
La minería de datos se puede definir como el proceso de extraer información válida,
auténtica y que se obtiene de las bases de datos de gran tamaño[16]. La idea es obtener
patrones y tendencias y definir un modelo de minería de datos. Existen varios algoritmos
que se utilizan para obtener los modelos:
• Regresión : Predice el valor de una variable numérica
• Clasificación : Predice el valor de una variable categórica
• Segmentación : Describe los datos como un conjunto de segmentos o grupos.
Descubre los valores de una variable oculta que no está registrada en los datos
• Asociaciones : Describe correlaciones o dependencias entre variables
• Otros : Distribuciones de probabilidad, modelos probabilísticos, etc.
Una vez que se generan los modelos, se debe comprobar la validez, la novedad, la
utilidad y la simplicidad de este.
2.7 Rendimiento de Bases de Datos

21
El rendimiento de las bases de datos depende del diseño, los parametros y la
construcción física de los objetos de la base de datos, específicamente las tablas y los
indices, así como los archivos donde se almacena la información. Por esto es importante
monitorear continuamente la composición y la estructura de los objetos de la base de datos,
y realizar cambios en caso de que esta se vuelva ineficiente.
A continuación se presentan algunas técnicas para optimizar el rendimiento de las
estructuras de las bases de datos, aunque no todas están siempre disponibles en los Sistemas
de Gestión de Bases de Datos.
2.7.1 Particionado
Las tablas son representaciones lógicas de un conjunto de datos que se almacena en
la memoria de un computador. Para cada tabla se debe evaluar la forma en que se almacena
la información, esta puede ser:
• Una tabla a un archivo: Cada fila de la tabla se almacena en un mismo archivo.
A pesar de ser una de las opciones más usadas, no siempre es la más eficiente.
• Una tabla a multiples archivos: Esta opción se utiliza frecuentemente en tablas
muy grandes o tablas que necesitan que los datos esten físicamente separados a
nivel de almacenamiento.
• Múltiples tablas a solo un archivo: Suele utilizarse para pequeñas tablas tales
como tablas de consulta y tablas de códigos.
La partición ayuda a conseguir paralelísmo, lo cuál puede reducir sustancialmente el
tiempo requerido para ejecutar una consulta a la base de datos.
2.7.2 Particionado de Tablas

22
En el caso que partes separadas de una tabla sean accedidas por distintos grupos de
usuarios o aplicaciones, es recomendable particionar la tabla en dos o más tablas
desnormalizadas, una por cada grupo distinto de usuarios. De ser necesario, se puede crear
una vista que entregue los mismos resultados que la tabla original.
Una tabla puede ser particionada de dos maneras:
• Verticalmente: Separa las columnas de la tabla en una o mas tablas. La clave
primaria de la tabla original se coloca en cada una de las nuevas tablas. Una
tabla se designa como padre con el propósito de mantener la integridad
referencial, a menos que la tabla original siga existiendo, en cuyo caso la tabla
original será la tabla padre en todas las restricciones referenciales.
• Horizontalmente: En este caso se separan las filas de una tabla en nuevas
tablas. Las filas suelen ser clasificadas en grupos a través de rangos de la llave.
Las columnas de las tablas particionadas horizontalmente son las mismas. Si las
particiones se encuentran en el mismo lugar físico, no cambia el rendimiento en
las consultas, pero sí mejora el rendimiento al efectuar acciones que modifiquen
la tabla (insert, delete, update), debido a que los indices que se mantienen son de
menor tamaño que en la tabla original.
2.7.3 Partición Nativa vs. Sistema de Archivos
En entornos basados en UNIX, se debe escoger entre una partición nativa o utilizar
el sistema de archivos de UNIX para almacenar la información en la base de datos. Se
prefiere utilizar una partición nativa como dispositivo de almacenamiento de la base de
datos debido a que en un sistema de archivos las escrituras son almacenadas en memoria
caché por el sistema operativo. En este caso, el sistema de gestión de base de datos no sabe
si los datos fueron copiados al disco o no. En el caso de una falla, la información en la base
de datos puede corromperse en el caso de utilizar un sistema de archivos.

23
2.7.4 Indexado
Los indices son la herramienta más simple para mejorar el rendimiento de una base
de datos. Se utilizan frecuentemente para:
• Localizar filas por el valor de una columna
• Hacer joins más eficientes
• Realizar agregaciones de datos
• Ordenar datos de una consulta
Sin indices, todos los accesos a la información tendrían que hacerse realizando una
búsqueda sobre todas las filas. Estas busquedas son muy ineficientes en tablas de gran
tamaño. Por otra parte, los indices pueden afectar negativamente el rendimiento cuando la
información es actualizada y los indices deben cambiar.
2.7.5 Desnormalización
Es el proceso inverso a la normalización de bases de datos. Una base de datos
normalizada minimiza los problemas de integridad y optimiza las actualizaciones, a cambio
de aumentar el costo de obtener la información.
Algunas de las opciones para desnormalizar una base de datos son las siguientes:
• Tablas prejoined: Cuando se necesita juntar dos o más tablas, pero el costo de
juntarlas es prohibitivo, se hace necesario crear tablas prejoined.
• Tabla de Reporte: Algunos tipos de reportes requieren un formato especial y
manipulación de datos. Si los reportes de esta naturaleza son críticos o requieren
alta visibilidad en un ambiente online, una tabla puede representar el reporte en
si. Esta tabla puede ser consultada utilizando SQL estándar. Estas tablas son
ideales para mostrar los resultados de multiples joins o outer joins, subconsultas
correlacionadas, u otras sentencias complejas SQL.
• Tabla espejo: Si una aplicación es muy activa, puede ser necesario dividir el
proceso en dos o más componentes. Cada división resultará en una tabla

24
duplicada o espejo. Una copia puede ser utilizada para tráfico en producción,
mientras la otra como soporte para la toma de decisiones. Es necesario migrar la
información periodicamente entre las tablas para mantenter la sincronización de
la aplicación.
• Tablas combinadas: Si existen tablas con relaciones uno-a-uno, es
recomendable combinarlas en una sola tabla combinada.
2.7.6 Interpolación de Datos
Cuando la información de dos tablas es frecuentemente reunida, hace sentido
interpolar físicamente la información en la misma estructura física de almacenamiento.
2.7.7 Espacio Libre
El espacio libre puede ser utilizado para dejar una porción de un indice o un
tablespace vacío y disponible para almacenar los nuevos datos almacenados. Esto permite
reducir la frecuencia de reorganización e incrementa la eficiencia de inserción.
2.7.8 Ubicación de Archivos
La ubicación de los archivos que contienen la información de una base de datos
puede tener un impacto significativo en el rendimiento. De ser posible, se deben colocar en
lugares distintos los índices de los datos para evitar degradar el rendimiento del disco
durante las consultas. También aumenta el rendimiento separar los archivos de tablas que
suelen accederse juntas frecuentemente.
Para separar los archivos en lugares físicos distintos, se utilizan las combinaciones
de discos en arreglos RAID. RAID es un acrónimo inglés para Arreglo Redundante de
Discos Independientes. La combinación de discos es percibida por el sistema operativo

25
como una sola unidad de almacenamiento. Existen varios niveles de tecnología RAID, cada
una proporciona distintos grados de tolerancia a fallos y rendimiento.
La siguiente tabla muestra los beneficios de cada nivel de RAID:
Nivel Descripción Tolerancia
a Fallos Rendimiento de Lectura
Rendimiento de Escritura
Costo
Sin RAID - No Normal Normal Barato
Nivel 0 División de Disco. La información se divide entre los multiples discos
No Rápido Rápido Costoso
Nivel 1 Espejado de Disco. La información se copia en dos o más unidades
Sí Normal Normal Moderado
Nivel 2 Provee Discos de corrección de errores. Se necesita un sistema de detección de errores
Sí Normal Normal Moderado
Nivel 3 Divide los datos a nivel de byte. Provee un disco de paridad
Sí Normal Normal Moderado
Nivel 4 Divide los datos a nivel de bloques. Provee un disco de paridad
Sí Normal Lento Moderado
Nivel 5 Similar al nivel 4, pero la información de paridad se distribuye entre los discos
Sí Rápido Lento Costoso
Nivel 6 Similar al nivel 5, pero provee tolerancia a fallos adicional mediante el uso de un segundo esquema de paridad distribuido
Sí Rápido Lento Costoso
Nivel 10 Combinación entre el nivel 1 y 0. La información se divide y se espeja.
Sí Rápido Normal Costoso
Nivel 53 Combinación entre nivel 5 y 3. La información se divide y cada segmento es un RAID Nivel 3
Sí Normal Normal Costoso
Nivel 0+1 Combina el nivel 0 y 1 Sí Rápido Rápido Muy Costoso

26
3 Especificación del Problema
La información que se transmite entre los call centers y la gerencia, tiene relación
principalmente con los ejecutivos que están atendiendo llamadas, las llamadas que se
reciben y se atienden durante el día, los tiempos de las llamadas, el tipo de clientes que se
atienden, etc. Además una muestra de las llamadas recibidas por los ejecutivos de call
centers se envía a una organización que realiza encuestas para conocer si el problema del
cliente fue resuelto en los tiempos esperados, la atención fue de la calidad esperada, y otras
preguntas que apuntan a conocer la satisfacción del cliente.
Debido a la gran cantidad de llamadas recibidas y la distribución de los datos en
distintas fuentes, se hace compleja la obtención de información relevante y la generación de
reportes.
Es común que ocurran problemas cuando se intenta obtener la información desde las
fuentes, pues estas suelen no estar disponibles en algunos intervalos de tiempo. Esto hace
compleja la automatización de las extracciones. Es necesario que la aplicación que realiza
la obtención de datos sea robusta para evitar fallas de integridad en la información. O en el
caso de detectar fallas de integridad, dar alarmas para gestionar una solución. También es
probable que la información que entregan los proveedores tenga inconsistencias en los
indicadores. Es necesario controlar constantemente la consistencia de la información que es
almacenada.
Tener la información más reciente disponible en todo momento es necesario para
que la gerencia pueda orientar las acciones a corto plazo. La información consolidada y
agrupada es necesaria para orientar las acciones de mediano y largo plazo con el fin de
optimizar la atención del cliente. También la información histórica del mes se utiliza con
fines de facturación.

27
Además de la información que proveen los call centers, también existe información
que se genera dentro de la misma compañía. Esta información incluye los reportes de IVR,
el parque de clientes, y otros reportes que se generan en cada punto del flujo de la llamada.
Esta información debe ser recopilada y almacenada, pero está fuera del alcance de esta
memoria.
Dentro de las gestiones a corto plazo que es posible realizar está el identificar a los
ejecutivos que realizan malas prácticas de atención, como cortar la llamada dentro de los
primeros 10 segundos, atender demasiado rápido al cliente disminuyendo la calidad de la
atención, etc.
Debido a que la Gerencia de Call Center se encuentra en proceso de certificación
COPC, es necesario cumplir con las normas indicadas por COPC. Ciertas normas de la
certificación indican que la Gerencia debe contar con indicadores y métricas que se generan
a partir de los datos entregados por los call centers y datos de fuentes internas. Es necesario
generar procesos que calculen las métricas de manera automática para lograr la
certificación COPC.

28
4 Descripción de la Solución
4.1 Decisiones de Diseño
Debido a la naturaleza del problema de manipular información, la solución natural
estuvo relacionada a una base de datos. El objetivo de almacenar la información era realizar
análisis y reportes, por lo que el modelo de la base de datos debía responder de manera
eficiente a consultas agrupadas. Para esto se diseñó el modelo estrella que se presenta en la
Ilustración 6. Con este modelo se puede responder de manera eficaz a la mayor parte de las
preguntas más frecuentes realizadas por las personas que integran la Gerencia.
Ilustración 6 Modelo Estrella de Datos

29
4.2 Dimensiones
La dimensión d_fecha contiene los niveles de tiempo, desde un intervalo de 30
minutos a un año. También se incluye un campo que contiene la fecha expresada por los
demás campos. A esta tabla se le agregaron un índice agrupado por el año y otro índice por
la fecha.
La dimensión d_ubicacion contiene la información de localización de la llamada:
En que call center se atendió la llamada, el PCRC y la familia (FIJA o MOVIL), la
subgerencia encargada del PCRC, el sistema utilizado para atender la llamada y el
segmento al que pertenece el cliente. A esta tabla se le agregaron un índice agrupado sobre
el campo Familia y dos índices sobre los campos PCRC y Call center respectivamente.
4.3 Tablas de Hecho
La tabla f_dimensionamiento contiene el pronóstico de llamadas, así como
información necesaria para la programación del personal de call center.
La tabla f_eac guarda información a nivel de ejecutivo: los tiempos productivos e
improductivos, el tiempo disponible y las cantidades de llamadas atendidas, transferidas y
de salida.
La tabla f_cola guarda información a nivel de cola: la cantidad de llamadas
recibidas por la cola, atendidas y sus umbrales (atendidas antes de 10 seg., de 15 seg., de 20
seg., etc.)
La tabla f_ani contiene información que se puede obtener a nivel de llamadas
individuales: FCR, cantidad de llamadas cortas (menores a 10 seg.), cantidad de clientes
únicos atendidos, cantidad de llamadas atendidas, etc.

30
Con esto se establece la base para la construcción de un Data Mart. Lo siguiente fue
encontrar la manera de obtener la información desde los call centers para luego cargar el
Data Mart. Para esto se utilizó la herramienta ETL Microsoft® SQL Server™ 2000 Data
Transformation Services (DTS).
En una primera etapa se construyó un DTS que se conectaba a las fuentes
directamente, y almacenaba los datos extraídos en una misma tabla. Los datos eran
extraídos y transformados en un mismo proceso. El inconveniente de esta solución era que
al tardarse más de un intervalo prudente la conexión a una de las fuentes de origen, se veían
afectados los procesos que extraían la información de las otras fuentes. Además, si alguna
transformación quedaba mal, era necesario descargar nuevamente la información desde la
fuente para corregir el error, lo cual aumentaba los tiempos de desarrollo durante la fase de
pruebas. Por estas razones fue necesario separar el proceso de extracción de la
transformación.
Se construyeron DTS de extracción, uno por cada fuente, los cuales almacenaban
los datos extraídos manteniendo el mismo formato de origen, más un campo de fecha de
extracción, necesario por motivos de auditoria. Con esto se cumple el primer y el quinto
principio de los procesos ETL: Una cosa a la vez e Integridad de los Datos en las Etapas.
Se construyó otro DTS para la transformación de los datos almacenados en tablas
locales, el cual limpiaba y homogenizaba la información para depositarla en una nueva
tabla, para luego cargar los datos en el modelo estrella.

31
4.4 Arquitectura de la Solución
4.4.1 Extracción
Las fuentes de origen las proveen los call centers y, en el caso de GENESYS el cual
es un sistema comprado por la empresa, un proveedor de servicios informáticos. Cada call
center define los nombres de los campos de una manera distinta. Por esto, además de los
reportes, se le pide al proveedor que entregue un diccionario con la definición de los
campos.
Los call center deben proveer a la Gerencia tres reportes básicos del tráfico de llamadas
realizadas en sus instalaciones: ANI, COLA, EAC.
Ilustración 7 Flujo de Información al Data Warehouse
Para cada proveedor se construyó un DTS para cada reporte con la siguiente estructura:
• TR_E_ANI_[NOMBRE PROVEEDOR]
• TR_E_EAC_[NOMBRE PROVEEDOR]
• TR_E_COLA_[NOMBRE PROVEEDOR]

32
El DTS extrae la información desde el proveedor y la almacena en tablas que tienen la
siguiente estructura:
• TR_ANI_[NOMBRE PROVEEDOR]
• TR_EAC_[NOMBRE_PROVEEDOR]
• TR_COLA_[NOMBRE PROVEEDOR]
De esta forma, para el proveedor ILINE, el cual dispone sus reportes a través de un servicio
FTP, se construyó un DTS que rescata información a nivel de ANI y la deposita en una
tabla llamada TR_ANI_ILINE, como se muestra en la Ilustración 8 DTS de Extracción
de ANIS del call center ILINE.
TR_E_ANI_ILINE
Ilustración 8 DTS de Extracción de ANIS del call center ILINE

33
De la misma forma se construyeron los DTS:
• TR_E_EAC_ILINE
• TR_E_COLA_ILINE
y las tablas que guardan la información de origen:
• TR_EAC_ILINE
• TR_COLA_ILINE
Es común que los proveedores entreguen información de más colas de las que se
utilizan en los reportes que se muestran en la Gerencia. Esto debido a que a veces se crean
algunas colas, pero estas no son utilizadas, o son utilizadas por otras áreas fuera de la
Gerencia. También algunos proveedores entregan mayor cantidad de indicadores que los
necesarios. En lugar de descartar estos valores en la primera etapa, estos se almacenan tal
cual como se extraen. En etapas posteriores (transformación y carga) estos datos son
descartados. Con esto se respeta el cuarto principio de los procesos ETL: Grande a
Mediano a Pequeño.
4.4.2 Transformación
Teniendo la información de los proveedores en tablas locales, lo que sigue es dejarla
en una tabla única, con un mismo formato. Para esto se crean las siguientes tablas que
consolidan la información de los call centers:
• TR_COLA_CONSOLIDADO
• TR_EAC_CONSOLIDADO
• TR_ANI_CONSOLIDADO

34
Se construyó un DTS para cada tipo de reporte:
• TR_TL_COLA_CONSOLIDADO
• TR_TL_EAC_CONSOLIDADO
• TR_TL_ANI_CONSOLIDADO
Los cuales se encargan de transformar la información proveniente de los call centers
y dejarlos en las tablas consolidadas.
Ilustración 9 DTS de Transformación de datos de cola
En el último paso de cada DTS se llama a un procedimiento almacenado, el cual
realiza la última transformación de los datos, que consiste en traducir los VDN, COLAS y
Skills a PCRCs, y agregar información acerca del tipo de la llamada: la familia a la que

35
pertenece, si es Directa o Transferida, desde donde se transfirió la llamada y a qué sistema
de información pertenece. Estos procedimientos almacenados se llaman respectivamente:
• agrupar_cola (@dias int)
• agrupar_eac (@dias int)
• agrupar_ani (@dias int)
El parámetro dias define la cantidad de días que debe procesar el procedimiento.
Para obtener la información que traduce los VDN, COLAS y Skills a PCRCs se
utilizan las tablas de traducción PCRCS y COLAS que se muestran en la Ilustración 10.
Ilustración 10 Tablas de traducción
Estas tablas deben ser mantenidas internamente en la gerencia, pues en general, los
reportes provistos por los call center no contienen esta información. Además, la creación de
PCRCs, Colas, VDNs y Skills se hace de manera coordinada entre la parte operacional de
la Gerencia de Call Center y los call centers.

36
Los procedimientos de transformación también agrupan la información según las
dimensiones definidas y precalculan los resultados usando para ello el comando de SQL
Server 2000 WITH CUBE.
Por último, la información se guarda en tablas temporales, lista para ejecutar la
carga.
4.4.3 Carga
La carga es el último paso en el proceso de construcción del data warehouse. Para
esto se construyeron procedimientos almacenados en Microsoft SQL Server 2000, los
cuales se encargan de llenar las tablas del modelo estrella.
• carga_cola
• carga_eac
• carga_ani
Estos procedimientos se encargan de insertar nuevos registros en las tablas del
modelo estrella, y de actualizar aquellos que ya han sido ingresados.
4.5 Cálculo de Indicadores
4.5.1 Intervalos Prime y No Prime
Para realizar los cálculos de desviación y precisión del pronóstico de volumen de
llamadas, es necesario distinguir entre intervalos prime y no prime. Los intervalos prime
son los que contienen el 80% del volumen de las llamadas. El resto se considera no prime.
Cada media hora se actualiza el estado de los intervalos Prime o No Prime
utilizando el procedimiento almacenado calculo_prime_noprime.

37
4.5.2 Precisión del Pronóstico de Volumen de Llamadas
La precisión del Volumen se obtiene cuando la desviación entre el volumen de
llamadas real y el pronosticado es menor a 15% en intervalos Prime y 20% en intervalos No
Prime. Para obtener la precisión diaria se cuentan los intervalos que están en el rango
aceptado y se divide por el total de intervalos.
La precisión se actualiza cada media hora utilizando el procedimiento almacenado calculo_precision_pronostico_llamados.
4.5.3 Cálculo de Agentes Necesarios
Para el cálculo de Agentes necesarios se utiliza la fórmula de ErlangC, la cual a
partir del número de llamadas recibidas, la duración del intervalo, el TMO, los segundos
acordados como nivel de servicio, y el nivel de servicio objetivo; obtiene el número de
ejecutivos necesarios para atender ese flujo de llamadas.
La fórmula de ErlangC indica la probabilidad que sea necesario esperar para ser
atendido, considerando el tráfico A en unidades Erlang y la cantidad de ejecutivos
conectados N.
Ilustración 11 Fórmula de Erlang C

38
Para obtener el número de agentes necesarios se utilizó el Procedimiento
Almacenado calculo_agentes_necesarios y las funciones
agentes_necesarios, erlangC y u_m_f.
4.5.4 Precisión de la Programación de Ejecutivos
Similar al caso de la precisión en el pronóstico de llamadas, se calcula el
cumplimiento de la programación como el total de intervalos que cumple con una
desviación inferior al 15% de los ejecutivos programados en comparación con los
conectados realmente.
Para obtener la métrica se utiliza el Procedimiento Almacenado calculo_precision_programacion_eac.
4.6 Métricas de Consistencia
Se consideraron algunas métricas para validar la consistencia de los datos:
• Las llamadas atendidas que entrega el reporte de cola debe ser consistente con las
llamadas atendidas que entrega el reporte de agentes.
• Las llamadas recibidas debe ser igual a las llamadas atendidas más las llamadas
abandonadas.
• Las llamadas atendidas debe ser igual a las suma de las llamadas atendidas antes de
10 segundos, más las atendidas antes de 20, 30, 40, 60 y más segundos.
• La ocupación debe estar en un rango lógico entre 50% y 90%
• La utilización debe estar en un rango lógico entre 30% y 95%
• El TMO por intervalo no puede ser superior a 1800 segundos.

39
4.7 Desarrollo de Software de Apoyo
Para garantizar el buen funcionamiento de los procesos que componen el data
Warehouse fue necesario desarrollar algunos componentes web, los cuales muestran el
estado de cada proceso, los intervalos que no se cargaron, y los indicadores más
importantes agrupados por PCRCs. Este mismo componente web se ejecuta
automáticamente cada media hora, y envía alertas por e-mail en caso de presentarse alguna
contingencia.
Además fue necesario el desarrollo de mantenedores para las tablas de colas y
pcrcs.
4.7.1 Estado de Carga
Se sabe que en relación a los Data Warehouse, si entra basura, sale basura. Por esto,
constantemente se están monitoreando los indicadores que están en el DSA para detectar
faltas de integridad o inconsistencia. Para esto se desarrolló una aplicación que muestra el
estado de carga de los PCRC dentro del día, y una vista que muestra el estado de los
procesos de Extracción de la información.
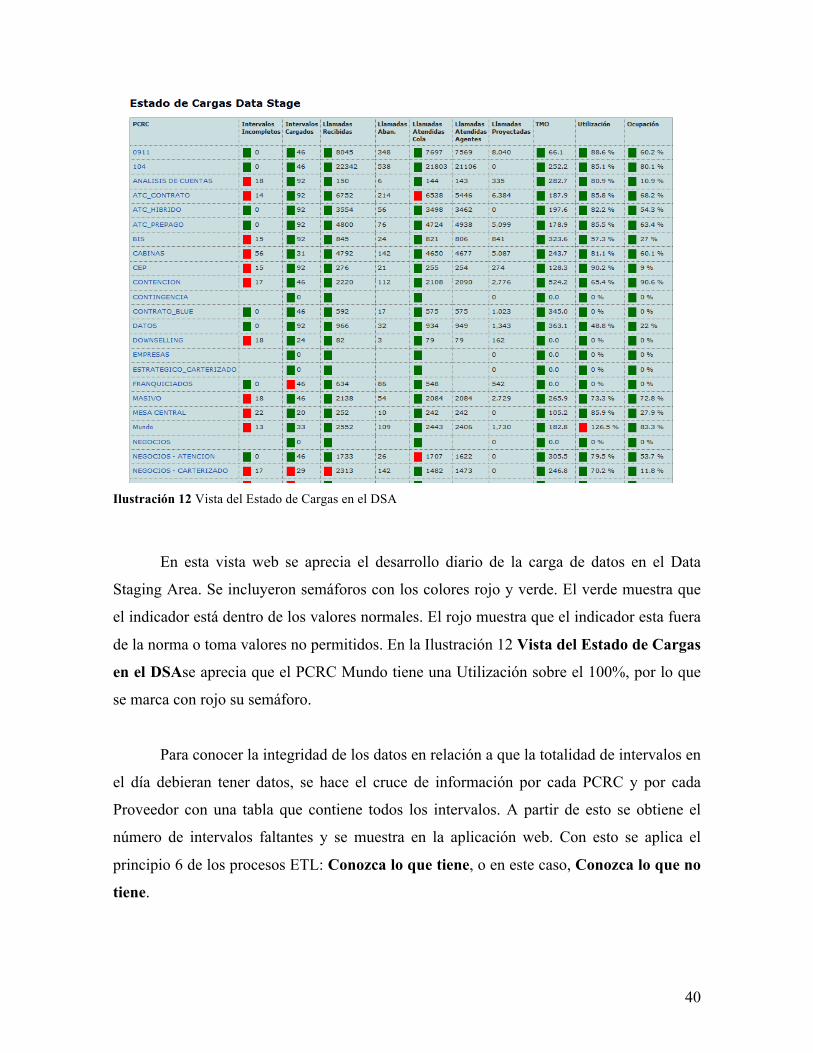
40
Ilustración 12 Vista del Estado de Cargas en el DSA
En esta vista web se aprecia el desarrollo diario de la carga de datos en el Data
Staging Area. Se incluyeron semáforos con los colores rojo y verde. El verde muestra que
el indicador está dentro de los valores normales. El rojo muestra que el indicador esta fuera
de la norma o toma valores no permitidos. En la Ilustración 12 Vista del Estado de Cargas
en el DSAse aprecia que el PCRC Mundo tiene una Utilización sobre el 100%, por lo que
se marca con rojo su semáforo.
Para conocer la integridad de los datos en relación a que la totalidad de intervalos en
el día debieran tener datos, se hace el cruce de información por cada PCRC y por cada
Proveedor con una tabla que contiene todos los intervalos. A partir de esto se obtiene el
número de intervalos faltantes y se muestra en la aplicación web. Con esto se aplica el
principio 6 de los procesos ETL: Conozca lo que tiene, o en este caso, Conozca lo que no
tiene.
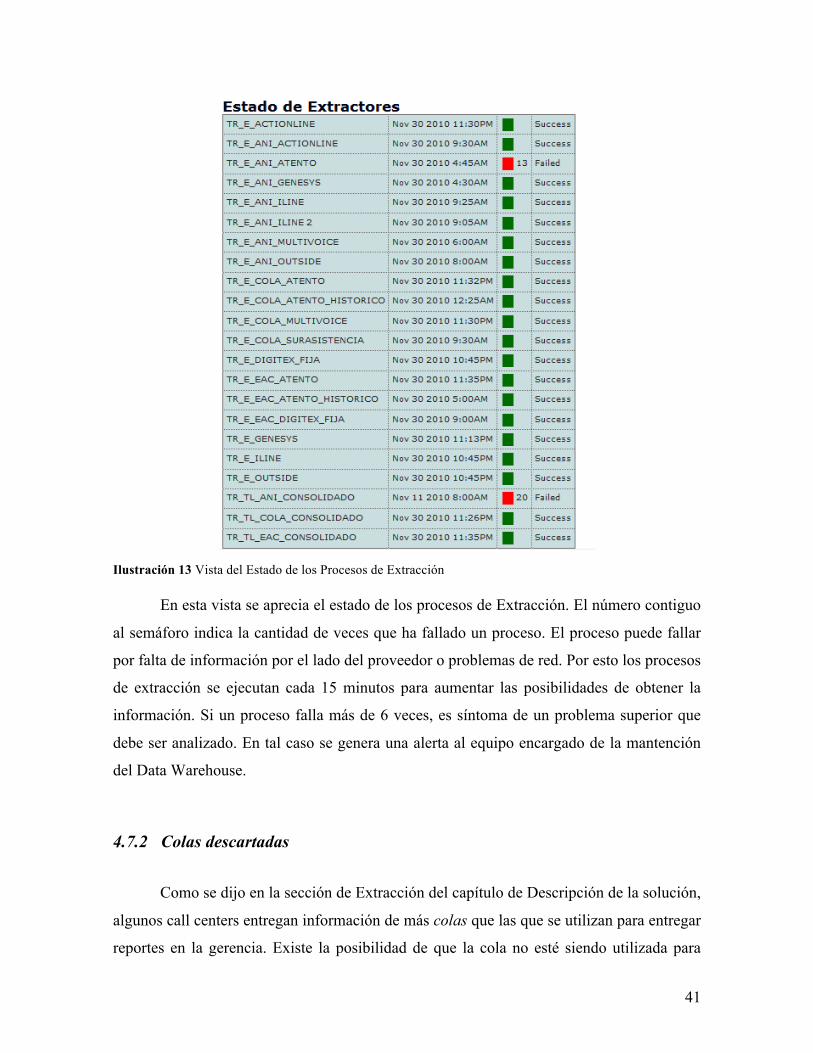
41
Ilustración 13 Vista del Estado de los Procesos de Extracción
En esta vista se aprecia el estado de los procesos de Extracción. El número contiguo
al semáforo indica la cantidad de veces que ha fallado un proceso. El proceso puede fallar
por falta de información por el lado del proveedor o problemas de red. Por esto los procesos
de extracción se ejecutan cada 15 minutos para aumentar las posibilidades de obtener la
información. Si un proceso falla más de 6 veces, es síntoma de un problema superior que
debe ser analizado. En tal caso se genera una alerta al equipo encargado de la mantención
del Data Warehouse.
4.7.2 Colas descartadas
Como se dijo en la sección de Extracción del capítulo de Descripción de la solución,
algunos call centers entregan información de más colas que las que se utilizan para entregar
reportes en la gerencia. Existe la posibilidad de que la cola no esté siendo utilizada para
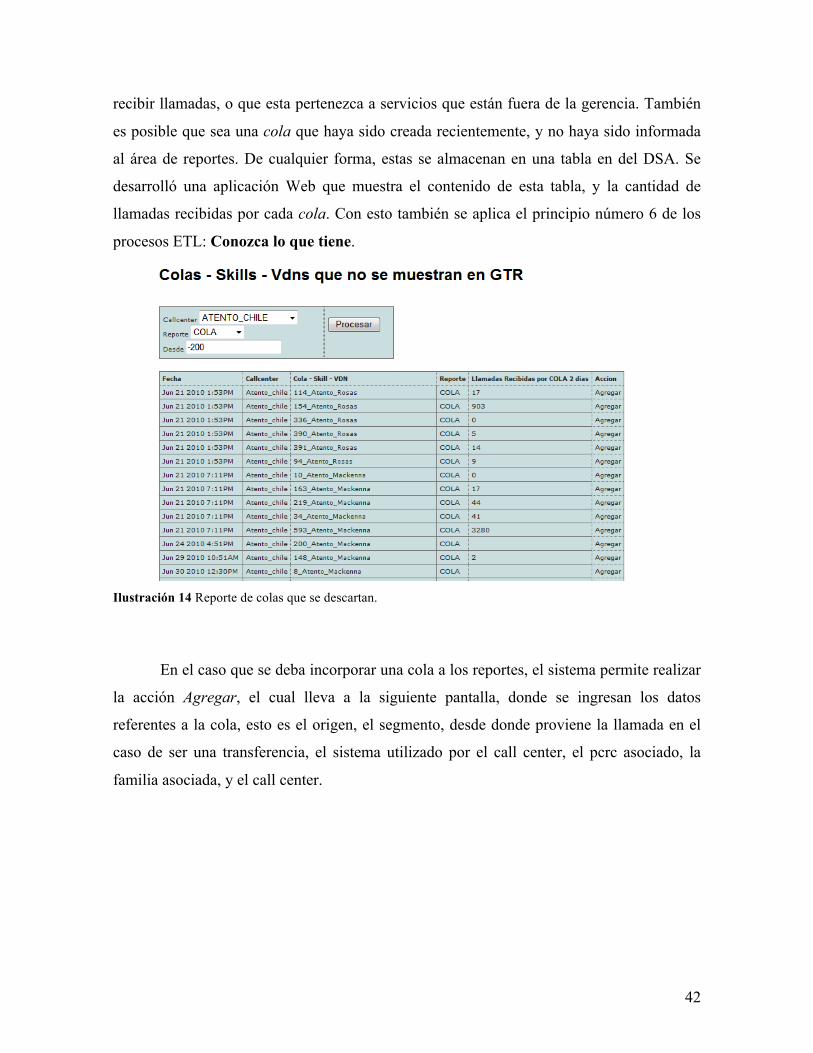
42
recibir llamadas, o que esta pertenezca a servicios que están fuera de la gerencia. También
es posible que sea una cola que haya sido creada recientemente, y no haya sido informada
al área de reportes. De cualquier forma, estas se almacenan en una tabla en del DSA. Se
desarrolló una aplicación Web que muestra el contenido de esta tabla, y la cantidad de
llamadas recibidas por cada cola. Con esto también se aplica el principio número 6 de los
procesos ETL: Conozca lo que tiene.
Ilustración 14 Reporte de colas que se descartan.
En el caso que se deba incorporar una cola a los reportes, el sistema permite realizar
la acción Agregar, el cual lleva a la siguiente pantalla, donde se ingresan los datos
referentes a la cola, esto es el origen, el segmento, desde donde proviene la llamada en el
caso de ser una transferencia, el sistema utilizado por el call center, el pcrc asociado, la
familia asociada, y el call center.
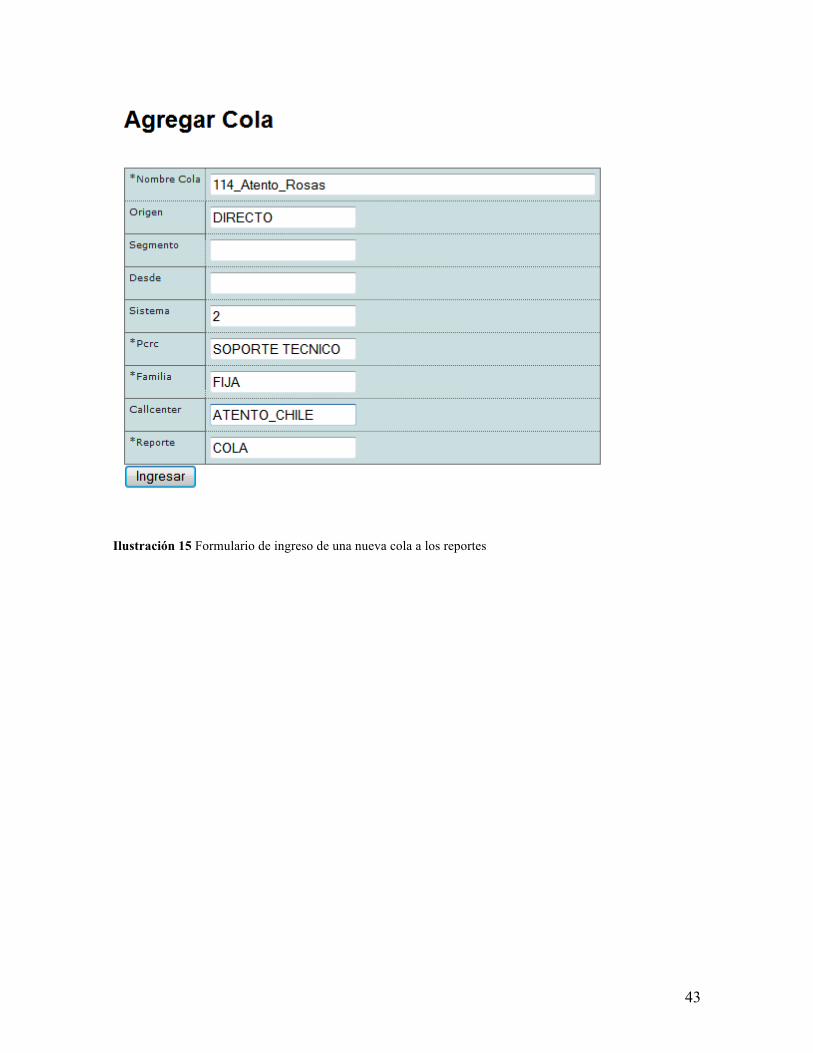
43
Ilustración 15 Formulario de ingreso de una nueva cola a los reportes

44
5 Acceso a la Información
El modelo de datos dimensional se construyó sobre una base de datos relacional, por
lo que el acceso a la información se realiza conectándose a la base de datos Microsoft Sql
Server, mediante ODBC o drivers específicos a la plataforma.
Para acceder a los datos se desarrollaron procedimientos almacenados que rescatan
la información desde las tablas que componen el modelo dimensional. Estos
procedimientos aceptan como parámetros los filtros que se le desea aplicar a las
dimensiones para obtener los datos combinando las tablas de hecho. El principal
procedimiento almacenado desarrollado para rescatar la información se llama: dwh.
El acceso a los datos se realiza principalmente mediante un sistema Web
desarrollado en PHP, y Microsoft Excel.
5.1 Sistema Web
El sistema web se desarrolló utilizando PHP el cual se conecta a la base de datos
ejecutando procedimientos almacenados en sus consultas. La idea del sistema es mostrar
resultados mensuales, pudiendo filtrar por Año, Familia y PCRC. A partir de esta primera
pantalla, se pueden hacer sucesivos drill-down, avanzando por la dimensión de tiempo,
hasta llegar a la granularidad de intervalos de 30 minutos.
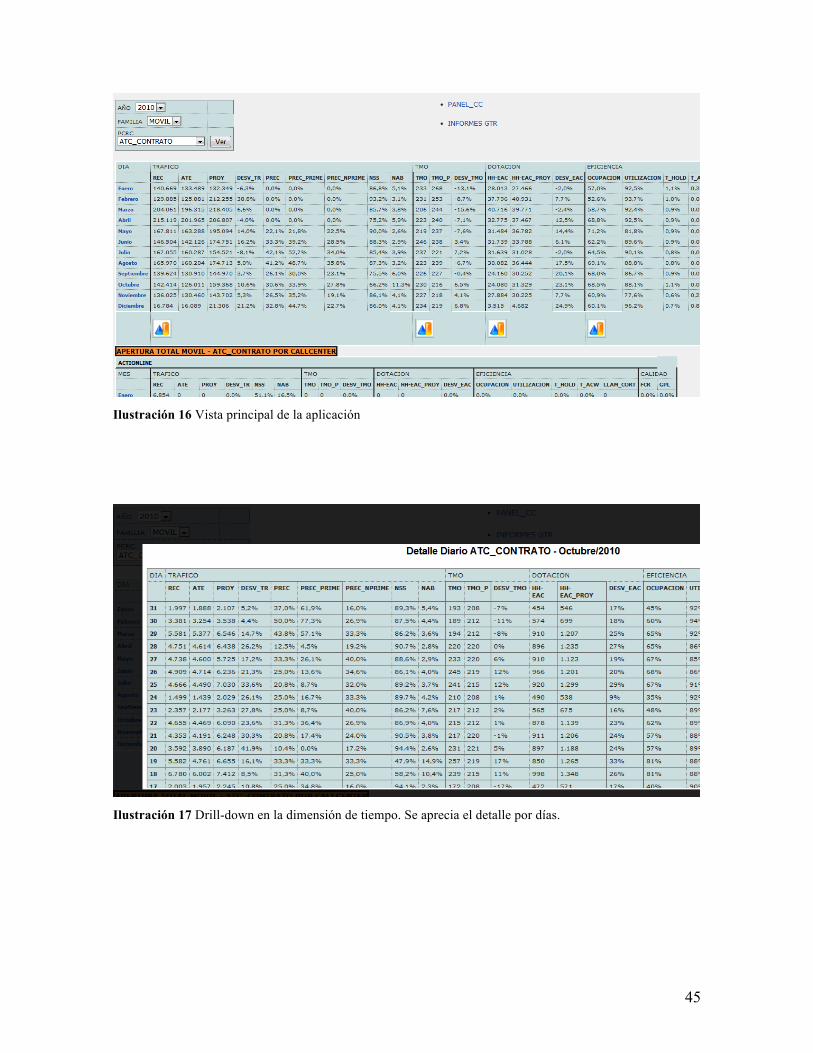
45
Ilustración 16 Vista principal de la aplicación
Ilustración 17 Drill-down en la dimensión de tiempo. Se aprecia el detalle por días.

46
Ilustración 18 Drill-down en la dimensión de tiempo hasta llegar a la granularidad de intervalos de media hora. Se aprecian los resultados del día seleccionado.
Ilustración 19 Grafico generado por la aplicación, donde se aprecian los indicadores agrupados por mes.
5.2 Reportes en Hoja de Cálculo (Excel)
En el caso de que sean necesarios reportes distintos a los que muestra el sistema
web, estos se construyen en Excel. Utilizando tablas dinámicas se construyen reportes en
los cuales es posible realizar las operaciones de drill-down, roll-up, slice y pivot.

47
6 Validación de la solución
El objetivo más importante alcanzado por esta solución, es tener integridad en los
datos almacenados. Mediante la automatización de los procesos de extracción, almacenar la
información extraída de la misma forma como viene y teniendo alarmas que indican fallas
en algún proceso se logra el objetivo de la integridad. Como se dijo anteriormente, esto es
importante por varias razones. Es fundamental para obtener una certificación COPC:
significan la R y la I en RUICA. También es muy importante tener integridad para tomar
decisiones acertadas en la gestión. Además, debido a que los pronósticos se basan en
información del pasado, no es posible realizar buenos pronósticos sin integridad en la
información histórica.
En la actualidad se observa que la disponibilidad de la información ha aumentado en
gran medida. Esto gracias a la aplicación de algunos de los principios establecidos para la
construcción de procesos ETL. Si antes era común que el panel de indicadores de la
Gerencia se quedara sin datos y fuera necesario realizar un reproceso manual de la
información constantemente, ahora es rara la oportunidad en que se encuentra falta de
información en los reportes. En el caso que algún proceso falle, o se detecta alguna falta de
integridad en la información, se genera una alarma al área responsable de la mantención del
Data Warehouse para realizar gestiones de reproceso o contactar a los proveedores para que
provean la información necesaria.
El segundo objetivo alcanzado por la solución es un aumento de la performance en
la ejecución de los reportes. Teniendo los datos almacenados en un lugar centralizado, y
con resultados agrupados precalculados, se aumenta considerablemente el rendimiento en
las consultas. En términos cuantitativos, se observa una mejora en comparación con la
misma aplicación funcionando sobre la anterior base de datos. En promedio se observaba
un tiempo de carga de 2 minutos de la aplicación previa al data warehouse. Actualmente la
aplicación tarda 25 segundos en cargar los datos. Aún existen datos que la aplicación
obtiene fuera del data warehouse, es por esto que el tiempo de carga puede disminuirse. En

48
el caso de la aplicación creada para mostrar únicamente la información contenida en el data
warehouse, esta tarda alrededor de 3 segundos en cargarse.

49
7 Conclusiones
En este trabajo de título se ha buscado la mejor manera de implementar un sistema
que permita visualizar indicadores obtenidos a través de la información entregada por
varias fuentes distintas. Investigando en la literatura, se encontró que la mejor alternativa
para almacenar los datos y luego recuperarlos en forma de reportes, es la creación de un
Data Warehouse.
Siguiendo los principios de Fon Silvers para el desarrollo de aplicaciones ETL que
aplicaban en la creación del Data Warehouse para la Gerencia, se logró almacenar los datos
de forma íntegra y con tolerancia a ciertos fallos conocidos en el mundo de los Data
Warehouse.
Se ha logrado establecer un modelo base para el flujo que deben seguir los datos
desde que los entrega el call center, hasta que se muestran en un panel de indicadores. En el
caso de que se contraten nuevos call centers, añadir la información que envíen significará
agregar algunas tablas y algunos procesos que sean similares a los que ya existen. Si la
operación determina que se deben agregar servicios o PCRCs a un determinado call center,
solo bastará con agregar la traducción de la cola a las tablas correspondientes utilizando un
mantenedor desarrollado para ello, y el servicio aparecerá dentro de los reportes que se
muestran en la aplicación Web.
Si bien en un principio el desarrollo del Data Warehouse fue difícil, pues este no
contenía suficiente información histórica necesaria para algunas decisiones estratégicas, en
la actualidad se cuenta con casi un año de historia de información. También los comienzos
fueron complejos pues el sistema a veces almacenaba información incorrecta, causando la
sensación en los usuarios de descontrol del proyecto. Fue necesaria la colaboración de los
usuarios del Data Warehouse para identificar las inconsistencias y luego corregirlas.

50
Sin duda la parte más compleja del proyecto fue la creación de los procesos ETL.
Esto debido a que fueron necesarios varios intentos para lograr que el esquema de datos
fuera consistente. Una vez que se corregía algún problema era necesario volver a procesar
la información histórica, y esto tomaba bastante tiempo, del orden de varias horas. Fue de
mucha utilidad la construcción de un panel de validaciones, el que hacía las veces de Test
del Sistema para comprobar que este funcionara como era deseado.
La implementación del modelo estrella con datos precalculados resultó ser bastante
eficiente en términos de reportes. No se hicieron otros test de modelos en donde los datos
precalculados se almacenan en cubos distintos. Tampoco se utilizó la herramienta de
creación de cubos OLAP de Sql Server, Analysis Services.
No se alcanzó a realizar el Data Mining que se tenía como objetivo. Esto debido a la
falta de tiempo, y a la falta de prioridad dada en la Gerencia con respecto a la concreción de
otros proyectos relacionados con reportes. De cualquier forma, para asegurar que el Data
Mining entregue resultados de calidad, se deben incorporar otros indicadores al Data
Warehouse provenientes de fuentes distintas a los call centers, por ejemplo los resultados
de monitoreo a ejecutivos, resultados de encuestas a clientes, etc., los cuales estaban fuera
del alcance de este trabajo de memoria.

51
8 Anexos
8.1 Anexo A
Este anexo muestra los Procedimientos Almacenados y Funciones utilizadas en los
procesos ETL y en el cálculo de indicadores.
8.1.1 agrupar_cola CREATE PROCEDURE agrupar_cola (@dia int) as DECLARE @ano varchar(4), @mes varchar(2), @indicadores varchar(500), @group_columns varchar(500), @d_fecha varchar(300) EXEC('if exists (select * from dbo.sysobjects where id = object_id(N''[dbo].[TEMP_F_COLA]'') and OBJECTPROPERTY(id, N''IsUserTable'') = 1) drop table [dbo].[TEMP_F_COLA] CREATE TABLE [dbo].[TEMP_F_COLA] ( [CALLCENTER] [varchar] (20) NULL , [FAMILIA] [varchar] (10) NULL , [PCRC] [varchar] (100) NULL , [SEGMENTO] [varchar] (100) NULL , [SISTEMA] [int] NULL , [ANO] [int] NULL , [MES] [int] NULL , [DIA] [int] NULL , [Hora] [varchar] (5) NULL , [llam_rec] [int] NULL , [llam_ate] [int] NULL , [llam_ate_10] [int] NULL , [llam_ate_15] [int] NULL , [llam_ate_20] [int] NULL , [llam_abn] [int] NULL ) ON [PRIMARY]') if datepart(hh, getdate()) = 2 set @dia = 45 if datepart(hh, getdate()) = 8 set @dia = 3 print(@dia) INSERT INTO TEMP_F_COLA SELECT

52
CASE WHEN (GROUPING(a.callcenter) = 1) THEN '0' ELSE a.callcenter END AS CALLCENTER, CASE WHEN (GROUPING(C.FAMILIA) = 1) THEN '0' ELSE C.FAMILIA END AS FAMILIA, CASE WHEN (GROUPING(C.PCRC) = 1) THEN '0' ELSE C.PCRC END AS PCRC, CASE WHEN (GROUPING(C.SEGMENTO) = 1) THEN '0' ELSE C.SEGMENTO END AS SEGMENTO, CASE WHEN (GROUPING(C.SISTEMA) = 1) THEN 0 ELSE C.SISTEMA END AS SISTEMA, YEAR(a.fecha), MONTH(a.fecha), DAY(a.fecha), case when cast(right(a.hora,2)as int) < 30 then left(a.hora,3)+'00' else left(a.hora,3)+'30' end, sum(a.llam_rec)llam_rec, sum(a.llam_ate)llam_ate, sum(a.llam_ate_10)llam_ate_10, sum(a.llam_ate_15)llam_ate_15, sum(a.llam_ate_20)llam_ate_20, sum(a.llam_abn)llam_abn FROM tr_cola_consolidado a (nolock) JOIN colas c ON a.cola = c.cola and c.reporte = 'COLA' WHERE dbo.fecha(fecha) >dbo.fecha(getdate()-@dia) and fecha >(getdate()-(@dia+1)) AND c.expired is null GROUP BY C.PCRC, C.FAMILIA, A.CALLCENTER, C.SEGMENTO, C.SISTEMA, YEAR(a.fecha), MONTH(a.fecha), DAY(a.fecha), case when cast(right(a.hora,2)as int) < 30 then left(a.hora,3)+'00' else left(a.hora,3)+'30' end WITH CUBE UPDATE TEMP_F_COLA SET HORA = CASE WHEN HORA IS NULL THEN '0' ELSE HORA END, DIA = CASE WHEN DIA IS NULL THEN '0' ELSE DIA END, MES = CASE WHEN MES IS NULL THEN '0' ELSE MES END, ANO = CASE WHEN ANO IS NULL THEN '0' ELSE ANO END WHERE HORA IS NULL OR DIA IS NULL OR MES IS NULL OR ANO IS NULL delete from temp_f_cola where ano = 0 or mes = 0 or familia = '0'

53
if @dia < day(getdate()) begin delete from temp_f_cola where mes = month(getdate()) and dia = 0 print('acumulado mes eliminado') end if @dia < day(getdate())+31 begin delete from temp_f_cola where mes = month(getdate())-1 and dia = 0 print('acumulado mes anterior eliminado') end if @dia < day(getdate())+61 begin delete from temp_f_cola where mes = month(getdate())-2 and dia = 0 print('acumulado mes 2 anterior eliminado') end if @dia < day(getdate())+91 begin delete from temp_f_cola where mes = month(getdate())-3 and dia = 0 print('acumulado mes 3 anterior eliminado') end if @dia < day(getdate())+121 begin delete from temp_f_cola where mes = month(getdate())-4 and dia = 0 print('acumulado mes 4 anterior eliminado') end
8.1.2 agrupar_eac CREATE PROCEDURE agrupar_eac (@dia int, @max_dia int = 0 ) as DECLARE @ano varchar(4), @mes varchar(2), @indicadores varchar(500), @group_columns varchar(500), @query varchar(2000), @d_fecha varchar(300), @condicion varchar(500), @insert varchar(100), @_dia int, @min_fecha datetime, @debug bit set @debug = 1 EXEC('if exists (select * from dbo.sysobjects where id = object_id(N''[dbo].[TEMP_F_EAC]'') and OBJECTPROPERTY(id, N''IsUserTable'') = 1) drop table [dbo].[TEMP_F_EAC] CREATE TABLE [dbo].[TEMP_F_EAC] ( [CALLCENTER] [varchar] (20) NULL , [FAMILIA] [varchar] (10) NULL , [PCRC] [varchar] (100) NULL , [SISTEMA] [int] NULL ,

54
[ANO] [int] NULL , [MES] [int] NULL , [DIA] [int] NULL , [Hora] [varchar] (5) NULL , [q_ate] [int] NULL , [t_hold] [int] NULL , [t_acd] [int] NULL , [t_acw] [int] NULL , [t_ring] [int] NULL , [t_login] [int] NULL , [Q_transf] [int] NULL , [q_abn_ring] [int] NULL , [q_outbound] [int] NULL, [t_bano] [int] NULL, [t_capacitacion] [int] NULL, [t_disponible] [int] NULL, [t_outbound] [int] NULL, [t_consulta] [int] NULL, [t_interna] [int] NULL, [t_retroalimentacion] [int] NULL, [t_colacion] [int] NULL, [t_break] [int] NULL, [t_dedicacion_personal] [int] NULL, [t_problema_tecnico] [int] NULL ) ON [PRIMARY]') if datepart(hh, getdate()) = 2 set @dia = 35 if datepart(hh, getdate()) = 8 set @dia = 3 INSERT INTO TEMP_F_EAC SELECT CASE WHEN (GROUPING(a.callcenter) = 1) THEN '0' ELSE a.callcenter END AS CALLCENTER, case when (GROUPING(g.FAMILIA) = 1) THEN '0' ELSE g.FAMILIA END AS FAMILIA, case when (GROUPING(G.PCRC) = 1) THEN '0' ELSE G.PCRC END AS PCRC, case when (GROUPING(G.SISTEMA) = 1) THEN 0 ELSE G.SISTEMA END AS SISTEMA, YEAR(FECHA) AS ANO, MONTH(A.FECHA) AS MES, DAY(A.FECHA) AS DIA, case when cast(right(a.intervalo,2)as int) < 30 then left(a.intervalo,3)+'00' else left(a.intervalo,3)+'30' end AS HORA, SUM(a.q_ate)q_ate, SUM(a.t_hold)t_hold, SUM(a.t_acd)t_acd, SUM(a.t_acw)t_acw, SUM(a.t_ring)t_ring, SUM(a.t_login)t_login,

55
SUM(a.Q_transf)Q_transf, SUM(a.q_abn_ring)q_abn_ring, SUM(a.q_outbound) q_outbound, SUM(a.t_bano) t_bano, SUM(a.t_capacitacion) t_capacitacion, SUM(a.t_disponible) t_disponible, SUM(a.t_outbound) t_outbound, SUM(a.t_consulta) t_consulta, SUM(a.t_interna) t_interna, SUM(a.t_retroalimentacion) t_retroalimentacion, SUM(a.t_colacion) t_colacion, SUM(a.t_break) t_break, SUM(a.t_dedicacion_personal) t_dedicacion_personal, SUM(a.t_problema_tecnico) t_problema_tecnico FROM tr_eac_consolidado a (nolock) join colas g on a.cola = g.cola and g.reporte = 'EAC' WHERE a.fecha >= dbo.fecha(GETDATE() - @dia) and a.fecha <= dbo.fecha(GETDATE() - @max_dia) and intervalo <> '0' AND g.expired is null GROUP BY G.PCRC, g.FAMILIA, a.callcenter, g.SISTEMA, YEAR(a.fecha), MONTH(a.fecha), DAY(a.fecha), case when cast(right(a.intervalo,2)as int) < 30 then left(a.intervalo,3)+'00' else left(a.intervalo,3)+'30' end WITH CUBE --Elimina los consolidados de mes, año y total update TEMP_F_EAC set ano = case when ano is null then 0 else ano end, mes = case when mes is null then 0 else mes end, dia = case when dia is null then 0 else dia end, hora = case when hora is null then '0' else hora end where ano is null or mes is null or dia is null or hora is null delete from TEMP_F_EAC where ano = 0 or mes = 0 or pcrc = '0' or familia = '0' if @dia < day(getdate()) begin delete from temp_f_eac where mes = month(getdate()) and dia = 0 print('acumulado mes eliminado') end if @dia < day(getdate())+31 begin delete from temp_f_eac where mes = month(getdate())-1 and dia = 0 print('acumulado mes 1 anterior eliminado')

56
end if @dia < day(getdate())+61 begin delete from temp_f_eac where mes = month(getdate())-2 and dia = 0 print('acumulado mes 2 anterior eliminado') end if @dia < day(getdate())+91 begin delete from temp_f_eac where mes = month(getdate())-3 and dia = 0 print('acumulado mes 3 anterior eliminado') end if @dia < day(getdate())+121 begin delete from temp_f_eac where mes = month(getdate())-4 and dia = 0 print('acumulado mes 4 anterior eliminado') end
8.1.3 carga_cola CREATE PROCEDURE carga_cola as --Actualiza copia local de d_ubicacion y d_cola ---------------------------------------------------------------------------------------------------- --Actualizar d_ubicacion select t.familia, t.pcrc, t.callcenter, t.segmento, t.sistema into temp_ubicacion from temp_f_cola t left join dwh_gtr.dbo.d_ubicacion c on t.familia = c.familia and t.pcrc = c.pcrc and t.callcenter = c.callcenter and t.segmento = c.segmento and t.sistema = c.sistema where (c.familia is null or c.pcrc is null and c.segmento is null and c.callcenter is null and c.sistema is null) and t.pcrc is not null group by t.familia, t.pcrc, t.callcenter, t.segmento,t.sistema if (select count(1) from temp_ubicacion) > 0 begin print('Insertando nuevas ubicaciones') INSERT INTO dwh_gtr.dbo.d_ubicacion (familia, pcrc, callcenter, segmento, sistema) SELECT familia, pcrc, callcenter, segmento, sistema FROM TEMP_ubicacion end

57
DROP TABLE TEMP_UBICACION ---------------------------------------------------------------------------------------------------- if exists (select * from dbo.sysobjects where id = object_id(N'[dbo].[TEMP_II_F_COLA]') and OBJECTPROPERTY(id, N'IsUserTable') = 1) drop table [dbo].[TEMP_II_F_COLA] SELECT a.callcenter, a.familia, a.pcrc, a.segmento, a.sistema, a.ano, a.mes, a.dia, a.hora, CASE when e.id_ubicacion IS not null then 1 else 0 end _update, b.[id] as ID_Fecha, c.[id] as ID_Ubicacion, a.llam_rec, a.llam_ate, a.llam_ate_10, a.llam_ate_15, a.llam_ate_20, a.llam_abn INTO TEMP_II_F_COLA FROM TEMP_F_COLA a INNER JOIN dwh_gtr.dbo.d_fecha b ON a.ano= b.ano and a.mes = b.mes and a.dia = b.dia and a.hora = b.hora INNER JOIN dwh_gtr.dbo.d_ubicacion c ON a.callcenter = c.callcenter AND a.familia = c.familia AND a.pcrc=c.pcrc AND a.segmento=c.segmento AND a.sistema=c.sistema LEFT JOIN dwh_gtr.dbo.f_cola e ON c.[id]= e.id_ubicacion AND b.[id]= e.id_fecha -------------------------------------------------------------------------------------------------- -------------------------------------------------------------------------------------------------- -- update las ya existentes IF (SELECT COUNT(1)cant FROM TEMP_II_F_COLA WHERE _update=1 GROUP BY _update ) >0 BEGIN UPDATE dwh_gtr.dbo.f_COLA SET LLAM_REC=b.llam_rec, LLAM_ATE=b.llam_ate, LLAM_ATE_10=b.llam_ate_10, LLAM_ATE_15=b.llam_ate_15, LLAM_ATE_20=b.llam_ate_20,

58
LLAM_ABN=b.llam_abn FROM dwh_gtr.dbo.f_cola a INNER JOIN TEMP_II_F_COLA b ON a.id_fecha=b.id_fecha AND a.id_ubicacion= b.id_ubicacion AND b._update=1 PRINT 'Update listo' END -------------------------------------------------------------------------------------------------- -- Insert las que no estan-- IF (SELECT COUNT(1)cant FROM TEMP_II_F_COLA WHERE _update=0) >0 BEGIN INSERT INTO dwh_gtr.dbo.f_cola (id_fecha, id_ubicacion, llam_rec, llam_ate, llam_ate_10, llam_ate_15, llam_ate_20, llam_abn) SELECT DISTINCT id_fecha, id_ubicacion, llam_rec, llam_ate, llam_ate_10, llam_ate_15, llam_ate_20, llam_abn FROM TEMP_II_F_COLA WHERE _update=0 PRINT'Finaliza Insert' END
8.1.4 carga_eac CREATE PROCEDURE carga_eac as --Actualizar d_ubicacion select t.familia, t.pcrc, t.callcenter, t.sistema into temp_ubicacion from temp_f_eac t left join dwh_gtr.dbo.d_ubicacion c on t.familia = c.familia and t.pcrc = c.pcrc and t.callcenter = c.callcenter and t.sistema = c.sistema where c.familia is null or c.pcrc is null or c.callcenter is null or c.sistema is null group by t.familia, t.pcrc, t.callcenter, t.sistema if (select count(1) from temp_ubicacion) > 0 begin print('Insertando nuevas ubicaciones') INSERT INTO dwh_gtr.dbo.d_ubicacion (familia, pcrc, callcenter, sistema) SELECT familia, pcrc, callcenter, sistema FROM TEMP_ubicacion end DROP TABLE TEMP_ubicacion

59
---------------------------------------------------------------------------------------------------- ---------------------------------------------------------------------------------------------------- if exists (select * from dbo.sysobjects where id = object_id(N'[dbo].[TEMP_II_F_EAC]') and OBJECTPROPERTY(id, N'IsUserTable') = 1) drop table [dbo].[TEMP_II_F_EAC] SELECT CASE when e.id_ubicacion IS not null then 1 else 0 end _update, b.[id] as ID_Fecha, c.[id] as ID_Ubicacion, a.q_ate, a.t_hold, a.t_acd, a.t_acw, a.t_ring, a.t_login, a.q_transf, a.q_abn_ring, a.q_outbound, a.t_bano, a.t_capacitacion, a.t_disponible, a.t_outbound, a.t_consulta, a.t_interna, a.t_retroalimentacion, a.t_colacion, a.t_break, a.t_dedicacion_personal, a.t_problema_tecnico, ((isnull(a.t_hold, 0) + isnull(a.t_acd, 0) + isnull(a.t_acw, 0) + isnull(a.t_disponible, 0) + isnull(a.t_outbound,0)) / 1800) as Q_EAC_REAL INTO TEMP_II_F_EAC FROM TEMP_F_EAC a INNER JOIN dwh_gtr.dbo.d_fecha b ON a.ano= b.ano and a.mes = b.mes and a.dia = b.dia and a.hora = b.hora INNER JOIN dwh_gtr.dbo.d_ubicacion c ON a.callcenter = c.callcenter AND a.familia = c.familia AND a.pcrc=c.pcrc AND a.callcenter = c.callcenter -- AND a.subgerencia = c.subgerencia AND a.sistema = c.sistema LEFT JOIN dwh_gtr.dbo.f_EAC e ON c.[id]= e.id_ubicacion AND b.[id]= e.id_fecha --------------------------------------------------------------------------------------------------

60
-------------------------------------------------------------------------------------------------- -- update las ya existentes IF (SELECT COUNT(1)cant FROM TEMP_II_F_EAC WHERE _update=1 GROUP BY _update ) >0 BEGIN UPDATE dwh_gtr.dbo.f_eac SET Q_ATE=b.q_ate, T_HOLD=b.t_hold, t_acd=b.t_acd, T_ACW=b.t_acw, t_ring=b.t_ring, T_LOGIN=b.t_login, Q_TRANSF=b.q_transf, q_abn_ring=b.q_abn_ring, q_outbound=b.q_outbound, t_bano=b.t_bano, t_capacitacion=b.t_capacitacion, t_disponible=b.t_disponible, t_outbound=b.t_outbound, t_consulta=b.t_consulta, t_interna=b.t_interna, t_retroalimentacion=b.t_retroalimentacion, t_colacion=b.t_colacion, t_break=b.t_break, t_dedicacion_personal=b.t_dedicacion_personal, t_problema_tecnico=b.t_problema_tecnico, Q_EAC_REAL=b.Q_eac_real --Q_EAC_DISTINTOS= FROM dwh_gtr.dbo.f_eac a INNER JOIN TEMP_II_F_EAC b ON a.id_fecha=b.id_fecha AND a.id_ubicacion= b.id_ubicacion AND b._update=1 PRINT 'Update listo' END -------------------------------------------------------------------------------------------------- -- Insert las que no estan-- IF (SELECT COUNT(1)cant FROM TEMP_II_F_EAC WHERE _update=0 GROUP BY _update ) >0 BEGIN INSERT INTO dwh_gtr.dbo.f_eac (id_fecha ,id_ubicacion ,q_ate ,t_hold ,t_acd ,t_acw ,t_ring

61
,t_login ,q_transf ,q_abn_ring ,q_outbound ,t_bano ,t_capacitacion ,t_disponible ,t_outbound ,t_consulta ,t_interna ,t_retroalimentacion ,t_colacion ,t_break ,t_dedicacion_personal ,t_problema_tecnico ,Q_EAC_REAL) SELECT DISTINCT id_fecha ,id_ubicacion ,q_ate ,t_hold ,t_acd ,t_acw ,t_ring ,t_login ,q_transf ,q_abn_ring ,q_outbound ,t_bano ,t_capacitacion ,t_disponible ,t_outbound ,t_consulta ,t_interna ,t_retroalimentacion ,t_colacion ,t_break ,t_dedicacion_personal ,t_problema_tecnico ,Q_EAC_REAL FROM TEMP_II_F_EAC WHERE _update=0 PRINT'Finaliza Insert' END
8.1.5 calculo_prime_noprime PROCEDURE calculo_prime_noprime AS DECLARE @ano int, @mes int, @dia int set @dia=2 set @mes =month(getdate()) set @ano=year(getdate()) if (day(getdate())=1) set @dia = 0

62
if (day(getdate())=1 and datepart(hh,getdate()) <7) begin SET @mes = month(getdate()-2) set @ano=year(getdate()-2) set @dia=day(getdate()-2) end print(@dia) print(@mes) print(@ano) UPDATE f_cola SET tipo = final.tipo FROM (SELECT id_ubicacion, id_fecha,llam_rec, calculo, case when calculo <= 0.8 then 1 else 0 end TIPO FROM ( ( SELECT a.id_ubicacion, a.id_fecha, fec1.ano, fec1.mes, fec1.dia, fec1.hora, a.llam_rec, dbo.DIV_(sum(b.llam_rec), (SELECT llam_rec FROM d_fecha fec_ JOIN f_cola c ON c.id_fecha = fec_.id WHERE fec_.ano = fec1.ano AND fec_.mes = fec1.mes AND fec_.dia = fec1.dia AND id_ubicacion = a.id_ubicacion AND fec_.hora = '0')) AS calculo FROM (d_fecha fec1 LEFT JOIN f_cola a ON fec1.id = a.id_fecha AND fec1.hora <> '0') LEFT JOIN (d_fecha fec2 LEFT JOIN f_cola b ON fec2.id = b.id_fecha AND fec2.hora <> '0') ON a.id_ubicacion = b.id_ubicacion AND fec1.ano = fec2.ano AND fec1.mes = fec2.mes AND fec1.dia = fec2.dia WHERE a.llam_rec <= b.llam_rec --and a.tipo is null AND fec1.mes=@mes and fec1.ano=@ano and fec1.dia >= day(getdate()-@dia) AND fec1.hora <> '0' and a.id_ubicacion is not null GROUP BY fec1.ano, fec1.mes, fec1.dia, fec1.hora, a.llam_rec, a.id_fecha, a.id_ubicacion)) f) final INNER JOIN f_cola ON f_cola.id_ubicacion = final.id_ubicacion AND f_cola.id_fecha = final.id_fecha
8.1.6 calculo_precision_pronostico_llamados PROCEDURE [dbo].[calculo_precision_pronostico_llamados] AS --truncate table f_indicadores declare @ano int,

63
@mes int, @dia int, @fecha_inicio varchar(8), @id_fecha int, @id_ubicacion int, @callcenter varchar(20), @pcrc varchar(30), @prec_pr float, @prec_np float, @prec float, @cant int, @rango_pr float, @rango_np float set @rango_pr = 0.15 set @rango_np = 0.20 set @fecha_inicio = convert(varchar, getdate()-10, 112) if exists (select * from dbo.sysobjects where id = object_id(N'[dbo].[_precision]') and OBJECTPROPERTY(id, N'IsUserTable') = 1) drop table _precision -- Agrupación por Call x Pcrc x Día -- select null as _update, null as id_ubicacion, null as id_fecha, ubi.familia, ubi.pcrc, ubi.segmento, fec.ano, fec.mes, fec.dia, dbo.div(sum(case when cola.tipo = 1 and 1-(DBO.DIV(cola.Llam_rec,dim.Llam_Proy_Cp)) between -@rango_pr and @rango_pr then 1 else 0 end), sum(case cola.tipo when 1 then 1 else 0 end)) prec_prime, dbo.div(sum(case when cola.tipo = 0 and 1-(DBO.DIV(cola.Llam_rec,dim.Llam_Proy_Cp)) between -@rango_np and @rango_np then 1 else 0 end), sum(case cola.tipo when 0 then 1 else 0 end)) prec_noprime ,dbo.div( (sum(case when cola.tipo = 1 and 1-(DBO.DIV(cola.Llam_rec,dim.Llam_Proy_Cp)) between -@rango_pr and @rango_pr then 1 else 0 end) + sum(case when cola.tipo = 0 and 1-(DBO.DIV(cola.Llam_rec,dim.Llam_Proy_Cp)) between -@rango_np and @rango_np then 1 else 0 end)), COUNT(COLA.TIPO)) prec into _precision from d_fecha fec cross join d_cola col (NOLOCK) cross join d_ubicacion ubi (NOLOCK) join f_cola cola (NOLOCK) on fec.id = cola.id_fecha and ubi.id = cola.id_ubicacion join f_dimensionamiento dim (NOLOCK) on dim.id_fecha = fec.id and ubi.id = dim.id_ubicacion where fec.ano <> 0 and fec.mes >= month(getdate()) and fec.dia <> 0 and fec.hora <> '0' and ubi.callcenter = '0' and ubi.pcrc <> '0' and ubi.familia <> '0' and ubi.sistema = '0' and

64
fec.fecha >= @fecha_inicio group by ubi.familia, ubi.pcrc, ubi.segmento, fec.ano, fec.mes, fec.dia print('Agrupación por Call x Pcrc x Día LISTO') -- Agrupación por Pcrc x Mes -- if(datepart(hh, getdate()) = 6 ) begin insert into _precision select null as _update, null as id_ubicacion, null as id_fecha, ubi.familia, ubi.pcrc, ubi.segmento, fec.ano, fec.mes, 0, dbo.div(sum(case when cola.tipo = 1 and 1-(DBO.DIV(cola.Llam_rec,dim.Llam_Proy_Cp)) between -@rango_pr and @rango_pr then 1 else 0 end), sum(case cola.tipo when 1 then 1 else 0 end)) prec_prime, dbo.div(sum(case when cola.tipo = 0 and 1-(DBO.DIV(cola.Llam_rec,dim.Llam_Proy_Cp)) between -@rango_np and @rango_np then 1 else 0 end), sum(case cola.tipo when 0 then 1 else 0 end)) prec_noprime ,dbo.div( (sum(case when cola.tipo = 1 and 1-(DBO.DIV(cola.Llam_rec,dim.Llam_Proy_Cp)) between -@rango_pr and @rango_pr then 1 else 0 end) + sum(case when cola.tipo = 0 and 1-(DBO.DIV(cola.Llam_rec,dim.Llam_Proy_Cp)) between -@rango_np and @rango_np then 1 else 0 end)), count(cola.tipo)) prec from d_fecha fec cross join d_cola col (NOLOCK) cross join d_ubicacion ubi (NOLOCK) join f_cola cola (NOLOCK) on fec.id = cola.id_fecha and ubi.id = cola.id_ubicacion join f_dimensionamiento dim (NOLOCK) on dim.id_fecha = fec.id and ubi.id = dim.id_ubicacion where fec.ano = 2010 and fec.mes >= month(getdate()) and fec.dia <> 0 and fec.hora <> '0' and ubi.callcenter = '0' and ubi.sistema = '0' and ubi.pcrc <> '0' and ubi.familia <> '0' group by ubi.familia, ubi.pcrc, ubi.segmento, fec.ano, fec.mes print('Agrupación por Pcrc x Mes LISTO') end UPDATE _precision SET _update = case when i.id_ubicacion is null then 0 else 1 end, id_fecha = f.id, id_ubicacion = u.id FROM d_ubicacion u cross join d_fecha f join _precision p ON p.familia = u.familia and p.pcrc = u.pcrc and u.callcenter = '0' and u.sistema = '0' and u.segmento = p.segmento and p.ano = f.ano and p.mes = f.mes and p.dia = f.dia and f.hora = '0'

65
left join f_indicadores i ON i.id_ubicacion = u.id and i.id_fecha = f.id IF (SELECT COUNT(1) cant FROM _precision WHERE _update=1 GROUP BY _update ) >0 BEGIN UPDATE f_indicadores SET prec_pr = p.prec_prime, prec_np = p.prec_noprime, prec = p.prec FROM f_indicadores i join _precision p on i.id_ubicacion = p.id_ubicacion and i.id_fecha = p.id_fecha WHERE p._update = 1 END print('Update LISTO') IF (SELECT COUNT(1)cant FROM _precision WHERE _update=0 GROUP BY _update ) >0 BEGIN INSERT INTO f_indicadores (id_fecha, id_ubicacion, prec_pr, prec_np, prec) SELECT DISTINCT id_fecha, id_ubicacion, prec_prime, prec_noprime, prec FROM _precision p WHERE _update = 0 END print('Insert LISTO')
8.1.7 calculo_precision_programacion_eac PROCEDURE [dbo].[calculo_precision_programacion_eac] AS --truncate table f_indicadores declare @ano int, @mes int, @dia int, @fecha_inicio varchar(8), @id_fecha int, @id_ubicacion int, @callcenter varchar(20), @pcrc varchar(30), @prec_pr float, @prec_np float, @prec float, @cant int, @rango float

66
set @rango = 0.10 set @fecha_inicio = convert(varchar, getdate()-30, 112) if exists (select * from dbo.sysobjects where id = object_id(N'[dbo].[_cumplimiento_eac]') and OBJECTPROPERTY(id, N'IsUserTable') = 1) drop table _cumplimiento_eac -- Agrupación por Call x Pcrc x Día -- select null as _update, null as id_ubicacion, null as id_fecha, ubi.callcenter, ubi.pcrc, fec.ano, fec.mes, fec.dia, sum(case when 1-(DBO.DIV(eac.q_eac_real,dim.eac_proy_cp)) between -@rango and @rango then 1 else 0 end) cumplen, count(dim.eac_proy_cp) intervalos, dbo.div(sum(case when 1-(DBO.DIV(eac.q_eac_real,dim.eac_proy_cp)) between -@rango and @rango then 1 else 0 end), count(dim.eac_proy_cp)) cumplimiento_eac into _cumplimiento_eac from d_fecha fec cross join d_ubicacion ubi (NOLOCK) join f_dimensionamiento dim (NOLOCK) on dim.id_fecha = fec.id and ubi.id = dim.id_ubicacion left join f_eac eac (NOLOCK) on fec.id = eac.id_fecha and ubi.id = eac.id_ubicacion where fec.ano <> 0 and fec.mes >= month(getdate())-1 and fec.dia <> 0 and fec.hora <> '0' and ubi.pcrc <> '0' and ubi.sistema = '0' and ubi.segmento = '0' and fec.fecha >= @fecha_inicio group by ubi.callcenter, ubi.pcrc, fec.ano, fec.mes, fec.dia print('Agrupación por Call x Pcrc x Día LISTO') -- Agrupación por Pcrc x Mes -- if(datepart(hh, getdate()) = 6 ) begin insert into _cumplimiento_eac select null as _update, null as id_ubicacion, null as id_fecha, ubi.callcenter, ubi.pcrc, fec.ano, fec.mes, 0, sum(case when 1-(DBO.DIV(eac.q_eac_real,dim.eac_proy_cp)) between -@rango and @rango then 1 else 0 end) cumplen, count(dim.eac_proy_cp) intervalos, dbo.div(sum(case when 1-(DBO.DIV(eac.q_eac_real,dim.eac_proy_cp)) between -@rango and @rango then 1 else 0 end), count(dim.eac_proy_cp)) cumplimiento_eac from d_fecha fec cross join d_ubicacion ubi (NOLOCK) join f_dimensionamiento dim (NOLOCK) on dim.id_fecha = fec.id and ubi.id = dim.id_ubicacion

67
left join f_eac eac (NOLOCK) on fec.id = eac.id_fecha and ubi.id = eac.id_ubicacion where fec.ano = 2010 and fec.mes >= month(getdate())-1 and fec.dia <> 0 and fec.hora <> '0' and ubi.sistema = '0' and ubi.pcrc <> '0' and ubi.segmento = '0' group by ubi.callcenter, ubi.pcrc, fec.ano, fec.mes print('Agrupación por Pcrc x Mes LISTO') end UPDATE _cumplimiento_eac SET _update = case when i.id_ubicacion is null then 0 else 1 end, id_fecha = f.id, id_ubicacion = u.id FROM d_ubicacion u cross join d_fecha f join _cumplimiento_eac p ON p.pcrc = u.pcrc and u.callcenter = p.callcenter and u.sistema = '0' and u.segmento = '0' and p.ano = f.ano and p.mes = f.mes and p.dia = f.dia and f.hora = '0' left join f_indicadores i ON i.id_ubicacion = u.id and i.id_fecha = f.id IF (SELECT COUNT(1) cant FROM _cumplimiento_eac WHERE _update=1 GROUP BY _update ) >0 BEGIN UPDATE f_indicadores SET cumplimiento_eac = p.cumplimiento_eac FROM f_indicadores i join _cumplimiento_eac p on i.id_ubicacion = p.id_ubicacion and i.id_fecha = p.id_fecha WHERE p._update = 1 END print('Update LISTO') IF (SELECT COUNT(1)cant FROM _cumplimiento_eac WHERE _update=0 GROUP BY _update ) >0 BEGIN INSERT INTO f_indicadores (id_fecha, id_ubicacion, cumplimiento_eac) SELECT DISTINCT id_fecha, id_ubicacion, cumplimiento_eac FROM _cumplimiento_eac p WHERE _update = 0 END
8.1.8 calculo_agentes_necesarios CREATE PROCEDURE calculo_agentes_necesarios AS

68
DECLARE @dia int set @dia=60 update f_eac set f_eac.q_eac_req = --b.llam_rec dbo.agentes_necesarios(b.llam_rec, 1800, a.tmo, 20, 0.8) from d_fecha cross join d_ubicacion join f_eac a on a.id_fecha = d_fecha.id and a.id_ubicacion = d_ubicacion.id join f_cola b on b.id_fecha = d_fecha.id and b.id_ubicacion = d_ubicacion.id where d_fecha.ano <> 0 and d_fecha.mes <> 0 and d_fecha.dia <> 0 and d_fecha.hora <> '0' and d_fecha.fecha > convert(varchar, getdate()-80, 112) and a.q_eac_req is null
8.1.9 agentes_necesarios CREATE FUNCTION [dbo].[agentes_necesarios] (@llamadas_por_intervalo as real, @segundos_por_intervalo as real, @duracion_llamada as real, @tiempo_respuesta as real, @ns_req as real) RETURNS integer AS BEGIN declare @agn integer, @e real, @m real, @u real, @svl float(52) set @u = (@llamadas_por_intervalo / @segundos_por_intervalo) * @duracion_llamada set @m = convert(integer, @u-10) --@u - 10 if(@m < 0) set @m = 0 set @svl = 0 set @e = 2.71828182846 if(@llamadas_por_intervalo = 0) return 0 if(@duracion_llamada = 0) return 0 if(@duracion_llamada is null) return 0 while @svl < @ns_req begin

69
set @m = @m + 1 set @svl = 1 - dbo.erlangC(@m, @u)* power(@e, -(@m-@u)*@tiempo_respuesta/@duracion_llamada) end return @m END
8.1.10 erlangC CREATE FUNCTION [dbo].[erlangC] (@m as real, @u as real) RETURNS float(52) AS BEGIN declare @erl float(52), @rho float(52), @sum float(52), @k integer, @bottom float(52) if(@m = 0) set @rho = 9999999999 else set @rho = @u / @m set @sum = 0 set @k = 0 while(@k <= @m - 1) begin set @sum = @sum + dbo.u_m_f(@u, @k) set @k = @k + 1 end set @bottom = dbo.u_m_f(@u, @m) + (1 - @rho) * @sum set @erl = dbo.u_m_f(@u, @m) / @bottom return @erl END
8.1.11 u_m_f
La siguiente función calcula el valor de
FUNCTION [dbo].[u_m_f] (@u as real, @m as real) RETURNS float(52) AS BEGIN declare @result float(52), @i real set @i = @m set @result = 1

70
while (@i > 0) begin set @result = (@u / @i) * @result set @i = @i - 1 end return @result END
8.1.12 dwh CREATE PROCEDURE [dbo].[DWH] ( @ano varchar(4), @mes varchar(3), @dia varchar(3), @hora varchar(5), @familia varchar(30), @call varchar(30), @pcrc varchar(30), @order varchar(5) = 'DESC',@rango varchar(3) = '' ) AS DECLARE @where varchar(6000), @select varchar(6000) SET @where = '' IF @rango <> '' BEGIN SET @where = ' cast(dbo.D_FECHA.fecha as int) between cast(cast(year(getdate()-'+@rango+') as varchar) + case when month(getdate()-'+@rango+') < 10 then ''0''+cast(month(getdate()-'+@rango+') as varchar) else cast(month(getdate()-'+@rango+') as varchar) end + case when day(getdate()-'+@rango+') < 10 then ''0''+cast(day(getdate()-'+@rango+') as varchar) else cast(day(getdate()-'+@rango+') as varchar) end as int) AND cast(cast(year(getdate()) as varchar) + case when month(getdate()) < 10 then ''0''+cast(month(getdate()) as varchar) else cast(month(getdate()) as varchar) end + case when day(getdate()) < 10 then ''0''+cast(day(getdate()) as varchar) else cast(day(getdate()) as varchar) end as int) AND ' END IF @ano = '' BEGIN SET @where = @where + 'dbo.D_FECHA.Ano = 0 AND ' END ELSE IF @ano = 'all' BEGIN SET @where = @where + 'dbo.D_FECHA.Ano <> 0 AND ' END ELSE BEGIN SET @where = @where + 'dbo.D_FECHA.Ano = '+@ano+' AND ' END

71
IF @mes = '' BEGIN SET @where = @where + ' dbo.D_FECHA.Mes = 0 AND ' END ELSE IF @mes = 'all' BEGIN SET @where = @where +' dbo.D_FECHA.Mes <> 0 AND ' END ELSE BEGIN SET @where = @where +' dbo.D_FECHA.Mes = '+@mes+' AND ' END IF @dia = '' BEGIN SET @where = @where +' dbo.D_FECHA.Dia = 0 AND ' END ELSE IF @dia = 'all' BEGIN SET @where = @where +' dbo.D_FECHA.Dia <> 0 AND ' END ELSE BEGIN SET @where = @where +' dbo.D_FECHA.Dia = '+@dia+' AND ' END IF @hora = '' BEGIN SET @where = @where +' dbo.D_FECHA.Hora = ''0'' AND ' END ELSE IF @hora = 'all' BEGIN SET @where = @where +' dbo.D_FECHA.Hora <> ''0'' AND ' END ELSE BEGIN SET @where = @where +' dbo.D_FECHA.Hora = '''+@hora+''' AND ' END IF @familia = '' BEGIN SET @where = @where +' dbo.D_UBICACION.Familia = ''0'' AND ' END ELSE IF @familia = 'all' BEGIN SET @where = @where +' dbo.D_UBICACION.Familia <> ''0'' AND ' END ELSE BEGIN SET @where = @where +' dbo.D_UBICACION.Familia = '''+@familia+''' AND ' END IF @pcrc = '' BEGIN SET @where = @where +' dbo.D_UBICACION.Pcrc = ''0'' AND '

72
END ELSE IF @pcrc = 'all' BEGIN SET @where = @where +' dbo.D_UBICACION.Pcrc <> ''0'' AND ' END ELSE IF charindex(',', @pcrc) > 0 BEGIN SET @where = @where +' dbo.D_UBICACION.Pcrc in ('+@pcrc+') AND ' END ELSE BEGIN SET @where = @where +' dbo.D_UBICACION.Pcrc = '''+@pcrc+''' AND ' END IF @call = '' BEGIN SET @where = @where +' dbo.D_UBICACION.Callcenter = ''0''' END ELSE IF @call = 'all' BEGIN SET @where = @where +' dbo.D_UBICACION.Callcenter <> ''0''' END ELSE BEGIN SET @where = @where +' dbo.D_UBICACION.Callcenter = '''+@call+'''' END SET @select = 'SELECT dbo.D_FECHA.Ano, dbo.D_FECHA.Mes, dbo.D_FECHA.Dia, dbo.D_FECHA.Hora, dbo.D_UBICACION.Familia, dbo.D_UBICACION.Pcrc, dbo.D_UBICACION.Pcrc_ab, dbo.D_UBICACION.Callcenter, dbo.F_ANI.Q_Clientes, dbo.F_ANI.Llam_ate AS llam_ate_ani, dbo.F_ANI.Q_llam_Cortas, dbo.F_EAC.q_ate, dbo.F_EAC.T_Hold, dbo.F_EAC.T_Acw, dbo.F_EAC.T_Acd, dbo.F_EAC.T_Login, dbo.F_EAC.Q_Transf, dbo.F_EAC.Q_Eac_Real, dbo.F_EAC.Q_Eac_Distintos, dbo.F_EAC.Q_Eac_Req, dbo.F_COLA.Llam_Rec, dbo.F_COLA.Llam_Ate AS Llam_ate_cola, dbo.F_COLA.Llam_Ate_20, dbo.F_COLA.llam_Abn, dbo.F_DIMENSIONAMIENTO.Eac_Proy_Cp, dbo.F_DIMENSIONAMIENTO.Eac_Proy_Mp, dbo.F_DIMENSIONAMIENTO.Llam_Proy_Cp, dbo.F_DIMENSIONAMIENTO.Llam_Proy_Mp, dbo.F_DIMENSIONAMIENTO.Tmo_proy_cp, dbo.F_DIMENSIONAMIENTO.Tmo_proy_mp, dbo.F_ANI.[%_llam_cortas], dbo.F_ANI.Reintento, dbo.F_COLA.[%nss_10], dbo.F_COLA.[%nss_15], dbo.F_COLA.[%nss_20], dbo.F_COLA.[%abn],dbo.F_EAC.[Tmo], -- CALCULOS EXTRAS (DBO.DIV(dbo.F_EAC.[Tmo],dbo.F_DIMENSIONAMIENTO.Tmo_proy_cp)-1) Desv_Tmo, 1-(DBO.DIV(dbo.F_cola.Llam_rec,dbo.F_DIMENSIONAMIENTO.Llam_Proy_Cp)) Desv_LLAM , (DBO.DIV(dbo.F_eac.q_ate,dbo.F_DIMENSIONAMIENTO.Llam_Proy_Cp*0.9)-1) Desv_LLAM_eac ,

73
1-( DBO.DIV(dbo.F_EAC.Q_Eac_Real,dbo.F_DIMENSIONAMIENTO.Eac_Proy_Cp)) Desv_Eac, dbo.F_EAC.[%Utilizacion], dbo.F_EAC.[%ocupacion], dbo.F_INDICADORES.Desv_Llamadas_cola Desv_LLAM_resp, dbo.F_INDICADORES.prec, dbo.F_INDICADORES.prec_pr, dbo.F_INDICADORES.prec_np, fcr, dbo.div(dbo.F_EAC.T_Hold,dbo.F_EAC.t_login) [%Hold], dbo.div(dbo.F_EAC.T_Acw,dbo.F_EAC.t_login) [%Acw], case when dbo.F_cola.tipo =1 then ''PR'' else ''NP'' end Tipo FROM dbo.D_FECHA (NOLOCK) CROSS JOIN dbo.D_UBICACION (NOLOCK) LEFT JOIN dbo.F_COLA (NOLOCK) ON dbo.F_COLA.ID_FECHA = dbo.D_FECHA.ID AND dbo.F_COLA.ID_UBICACION = dbo.D_UBICACION.ID LEFT JOIN dbo.F_EAC (NOLOCK) ON dbo.D_FECHA.ID= dbo.F_EAC.ID_FECHA AND dbo.D_UBICACION.ID = dbo.F_EAC.ID_UBICACION LEFT JOIN dbo.F_ANI (NOLOCK) ON dbo.D_FECHA.ID = dbo.F_ANI.ID_FECHA AND dbo.D_UBICACION.ID = dbo.F_ANI.ID_UBICACION LEFT JOIN dbo.F_DIMENSIONAMIENTO (NOLOCK) ON dbo.D_FECHA.ID = dbo.F_DIMENSIONAMIENTO.ID_FECHA AND dbo.D_UBICACION.ID = dbo.F_DIMENSIONAMIENTO.ID_UBICACION LEFT JOIN dbo.F_INDICADORES (NOLOCK) ON dbo.D_FECHA.ID = dbo.F_INDICADORES.ID_FECHA AND dbo.D_UBICACION.ID = dbo.F_INDICADORES.ID_UBICACION WHERE ' + @where + ' --and (dbo.F_EAC.q_ate >0 or dbo.F_DIMENSIONAMIENTO.Llam_Proy_Cp >0 or dbo.F_cola.Llam_rec >0 ) AND DBO.D_UBICACION.SISTEMA = 0 AND DBO.D_UBICACION.SEGMENTO = ''0'' AND DBO.D_UBICACION.CALLCENTER <> ''GENESYS'' AND ( (D_FECHA.ano = datepart(yyyy, getdate()) and D_FECHA.mes = datepart(m, getdate()) and d_fecha.dia = datepart(d, getdate()) and left(d_fecha.hora, 2) <= datepart(hh, getdate()) and right(d_fecha.hora, 2) + 35 <= datepart(mi, getdate())) or (D_FECHA.ano = datepart(yyyy, getdate()) and D_FECHA.mes = datepart(m, getdate()) and d_fecha.dia = datepart(d, getdate()) and left(d_fecha.hora, 2) < datepart(hh, getdate())) or (D_FECHA.ano = datepart(yyyy, getdate()) and d_fecha.mes = datepart(m, getdate()) and d_fecha.dia < datepart(d, getdate())) or (D_FECHA.ano = datepart(yyyy, getdate()) and D_fecha.mes < datepart(m, getdate())) or (D_FECHA.ano < datepart(yyyy, getdate())) ) order by ano,mes,dia '+@order+' ,hora '+@order

74
print(@select) exec(@select)

75
9 Bibliografía
[1] Ralph Kimball ,The data warehouse toolkit: the complete guide to dimensional
modelling, 2002
[2] Vincent Rainardi, Building a Data Warehouse With Examples in SQL Server,
2007
[3] Ralph Kimball , The Data Warehouse ETL Toolkit, 2004
[4] W. H. Inmon, Building the Data Warehouse, 3ra edición, 2002
[5] Fon Silvers, Building and Maintaining a Data Warehouse, 2008
[6] A Method for developing dimensional data marts, Communications of the
ACM, Diciembre 2003, Vol 46, Nº 12
[7] C. Hurtado, OLAP y Minería de Datos,
www.dcc.uchile.cl/~churtado/olapTulua.pdf
[8] http://es.wikipedia.org/wiki/Extract,_transform_and_load
[9] http://es.wikipedia.org/wiki/Webservice
[10] http://es.wikipedia.org/wiki/Centro_de_llamadas
[11] http://en.wikipedia.org/wiki/Data_mining
[12] Norma COPC-2000 para Proveedores de Servicios Integrales a Clientes.
http://burovaldes.com/DT/COPC.pdf
[13] Norma COPC-2000 para Organizaciones de Gestión de Proveedores (VMOs),
http://burovaldes.com/DT/COPC_VMO.pdf
[14] P. Naranjo, P. Riera, J. Valenzuela, L. Benítez, Diseño de un sistema de
Gestión de Calidad basado en la norma ISO 9001:2000 para una empresa de
servicio: Call Center
http://www.cib.espol.edu.ec/Digipath/REVISTA_CICYT/Articulo/19.pdf
[15] Richard Parkinson, Traffic Engineering Techniques in Telecomunications,
http://www.tarrani.net/mike/docs/TrafficEngineering.pdf

76
[16] Conceptos de Minería de Datos, http://msdn.microsoft.com/es-
es/library/ms174949(v=SQL.90).aspx
[17] C. Hurtado, OLAP y Minería de Datos: Introducción
[18] Craig S. Mullins, Database Administration: The Complete Guide to Practices
and Procedures, Junio 2002


















