
Métodos de Aprendizaje Maquinal148.206.53.84/tesiuami/UAMI11278.pdf · base de datos concerniente...
58
Transcript of Métodos de Aprendizaje Maquinal148.206.53.84/tesiuami/UAMI11278.pdf · base de datos concerniente...

Métodos de AprendizajeMaquinal
Informe de Proyecto Terminal I y II
Del Ángel González ArturoSuárez Domínguez Ricardo
Universidad Autónoma MetropolitanaUnidad Iztapalapa
Marzo 2004
Asesor:
Dr. René Mac Kinney Romero


2

Índice general
Introducción 5
Prefacio PROLOG 7
1. Ideas Fundamentales de PROLOG 91.1. Hechos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101.2. Preguntas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121.3. Variables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131.4. Conjunciones . . . . . . . . . . . . . . . . . . . . . . . . . . . 151.5. Reglas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 181.6. Listas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 191.7. Búsqueda Recursiva . . . . . . . . . . . . . . . . . . . . . . . . 21
2. Generalización menos general 252.1. Preliminares . . . . . . . . . . . . . . . . . . . . . . . . . . . . 262.2. Palabras . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 272.3. Algoritmo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3. Algoritmo ID3 313.1. Algoritmo ID3 . . . . . . . . . . . . . . . . . . . . . . . . . . . 313.2. Ventajas y De�ciencias . . . . . . . . . . . . . . . . . . . . . . 323.3. Algoritmo CLS . . . . . . . . . . . . . . . . . . . . . . . . . . 33
4. Teorema de Bayes y Entropía de la Información 354.1. Clasi�cación . . . . . . . . . . . . . . . . . . . . . . . . . . . . 354.2. Teorema de Bayes . . . . . . . . . . . . . . . . . . . . . . . . . 36
4.2.1. El problema del tenis usando BAYES . . . . . . . . . . 374.3. Entropía de la Información . . . . . . . . . . . . . . . . . . . . 37
3

4 ÍNDICE GENERAL
5. Implementación del problema del tenis con ID3 395.1. Objetivo del Programa . . . . . . . . . . . . . . . . . . . . . . 395.2. Tabla de atributos y valores . . . . . . . . . . . . . . . . . . . 395.3. Ejemplo real de cálculo . . . . . . . . . . . . . . . . . . . . . . 405.4. Árbol de Decisión . . . . . . . . . . . . . . . . . . . . . . . . . 41
A. Código PROLOG 43
B. Código del algoritmo ID3 para el problema del tenis 45B.1. Código BAYES . . . . . . . . . . . . . . . . . . . . . . . . . . 45B.2. Código Entropía . . . . . . . . . . . . . . . . . . . . . . . . . . 53

Introducción
La habilidad para aprender es uno de los atributos fundamentales delcomportamiento inteligente. Consecuentemente, el progreso en la teoría ymodelado en computadora de procesos de aprendizaje es de gran importan-cia para ciertos campos, como por ejemplo; ciencia cognitiva, inteligenciaarti�cial, ciencia de la información, reconocimiento de patrones, psicología,etc.
Los procesos de aprendizaje incluyen la adquisición de nuevo conocimien-to, el desarrollo de destrezas cognitivas a través de instrucciones o practica,la organización del nuevo conocimiento en general, y el descubrimiento denuevos hechos y teorías a través de la observación y experimentación.
El estudio y modelado en computadora de procesos de aprendizaje en susmúltiples manifestaciones constituye la materia de interés del AprendizajeMaquinal.
El objetivo cientí�co del aprendizaje maquinal es la exploración de al-ternativas sobre mecanismos de aprendizaje. Incluyendo el descubrimientode diferentes algoritmos de inducción, el alcance y las limitaciones de talesmétodos, la información que debe estar disponible al ente que aprende, yla creación de técnicas generales aplicables en muchas áreas de dominio. Nohay razón para creer que los métodos del aprendizaje humano son los úni-cos posibles para adquirir conocimiento y habilidades. Más investigacionesen aprendizaje maquinal se han centrado en la creación, caracterización yanálisis de métodos de aprendizaje general, con mayor énfasis en generalidaddel análisis y representación más que plausibilidad psicológica.
En este trabajo nos centraremos en dos métodos del aprendizaje maquinallos cuales son:
Generalización menos general: la cual nos permite obtener unaexpresión mínima universal de un conjunto de expresiones, algo análogoa la inducción matemática. El algoritmo para obtener la Generalización
5

6 ÍNDICE GENERAL
menos general es implementado en lenguaje Prolog.
Algoritmos ID3: su objetivo es la construcción de árboles de decisión,dividiendo el conjunto de instancias según el criterio de diferentes atrib-utos. El algoritmo es implementado en lenguaje C para una pequeñabase de datos concerniente a un juego de tenis.

Prefacio PROLOG
El lenguaje de programación de computadoras PROLOG (ProgrammingLogic) es actualmente muy usado en el mundo. Desde su inicio alrededor de1970, Prolog ha sido escogido por muchos programadores para aplicacionesde computación simbólica, incluyendo:
Lógica matemática
Resolución de problemas abstractos
Bases de datos relacionales
Comprensión de lenguaje natural
Diseño de automatización
Resolución de ecuaciones simbólicas
Áreas de inteligencia arti�cial
Muchas personas que inician en Prolog encuentran que la tarea de escribirun programa en Prolog no es como especi�car un algoritmo en la mismamanera que en un lenguaje de programación convencional (imperativo comolenguaje C, u orientado a objetos como lenguaje JAVA). En vez de esto, Elprogramador de Prolog solicita qué relaciones formales y hechos ocurren ensu problema, y qué relaciones son verdaderas acerca de la solución deseada.Así. Prolog puede ser visto como un lenguaje descriptivo como también unoprescriptivo. El enfoque de Prolog es más bien describir hechos conocidos yrelaciones acerca de un problema, prescribir la secuencia de pasos llevadospor una computadora para resolver el problema. Cuando una computadora esprogramada en Prolog , el modo en que la computadora lleva la computaciónesta especi�cada en parte por la semántica declarativa lógica de Prolog, En
7

8 ÍNDICE GENERAL
parte por qué nuevos hechos Prolog puede �inferir� de los hechos dados, ypor la información explicita de control suministrada por el programador.
Un programa en Prolog consiste de un conjunto de cláusulas, donde cadacláusula es un hecho acerca de la información dada ó una regla acerca decómo la solución puede relacionarse ó ser inferida de los hechos dados.
Como muchos otros lenguajes de programación, Prolog existe en un númerode implementaciones diferentes, cada una con sus propias peculiaridadessemánticas y sintácticas. En este trabajo adoptamos una versión de imple-mentación universal, y todos nuestros ejemplos se apegan a este que corre-sponde al desarrollado principalmente en Edinburgo, para varios sistemas decomputadora diferentes.

Capítulo 1
Ideas Fundamentales dePROLOG
Prolog es un lenguaje de programación de computadoras que es usadopara resolver problemas que involucran objetos y las relaciones entre ellos.En este capitulo mostraremos los elementos esenciales del lenguaje en progra-mas reales, pero sin adentrarnos mucho en detalles. Queremos proporcionarleunos elementos esenciales para que pueda entender el programa desarrolladoen este trabajo sobre generalización menos general (Least General Gener-alization, LGG). Así nos concentraremos en los siguientes puntos: hechos,preguntas, variables, conjunciones, reglas, listas y búsqueda recursiva.
Usamos Prolog cuando deseamos que la computadora resuelva problemasque pueden ser expresados en forma de objetos y sus relaciones. Por ejem-plo, cuando decimos �Oscar tiene computadora personal�, declaramos queuna relación, tiene, existe entre un objeto �Oscar� y otro objeto �computa-dora personal�. Además, la relación posee un orden especí�co: Oscar tienecomputadora personal, pero !computadora personal no tiene Oscar! Cuandopreguntamos ¾Tiene Oscar computadora personal?, tratamos de encontraruna relación.
Algunas relaciones no mencionan siempre todos los objetos que están in-volucrados. Por ejemplo, cuando decimos �Las rosas son hermosas�, damosa entender que hay una relación, llamada �ser hermoso�, la cual involucrauna rosa. No mencionamos el color o el tamaño. Todo depende de que quieradecir usted. En Prolog, cuando programe acerca de relaciones como esta,la cantidad de detalle que provea también depende de lo que la computa-dora realice. Consideremos el siguiente ejemplo. La regla �dos personas son
9

10 CAPÍTULO 1. IDEAS FUNDAMENTALES DE PROLOG
hermanas sí son ambos mujeres y tienen los mismos padres� decimos algoacerca de que signi�ca ser hermanas. También decimos implícitamente cómoencontrar sí dos personas son hermanas: simplemente veri�car sí son ambosmujeres y tienen los mismos padres. Lo que es importante mencionar acercade las reglas es que frecuentemente están simpli�cadas, pero son aceptablespara nuestros propósitos y como de�niciones.
La programación de computadoras con Prolog consiste en:
Declarar algunos hechos acerca de objetos y sus relaciones.
De�nir algunas reglas acerca de objetos y sus relaciones, y
Hacer preguntar sobre objetos y sus relaciones.
Por ejemplo, suponga que le decimos a un sistema Prolog de nuestraregla relacionada con ser hermanas. Podríamos preguntar sí Julia y Rebecason hermanas. Prolog buscaría a través de lo que le dijimos acerca de Juliay Rebeca, y respondería si o no, dependiendo en lo que le dijimos antes. Así,podemos considerar a Prolog como un almacén de hechos y reglas, y usalos hechos y reglas para responder preguntas. Programar en Prolog consisteen proporcionar todos los hechos y reglas. Un sistema Prolog permite a unacomputadora ser usada como un almacén de hechos y reglas, y provee maneraspara hacer inferencias a partir de estos.
Prolog es un lenguaje conversacional, lo que signi�ca que usted y la com-putadora realizan un tipo de charla simple. Prolog esperará a que ustedescriba los hechos y reglas que están relacionados con el problema a resolver.Luego, sí formula el tipo correcto de pregunta, Prolog encontrará las posiblesrespuestas y las mostrará en el monitor de la computadora.
Introduzcamos en este momento cada uno los fundamentos de Prolog.
1.1. Hechos
Suponga que decimos a Prolog el hecho que �Ricardo le gusta Georgina�.Este hecho consiste de dos objetos llamados �Ricardo� y �Georgina�, y unarelación llamada �le gusta�. En Prolog, una forma universal para escribir unhecho es la siguiente:
le gusta (ricardo, georgina).Es necesario destacar los siguientes puntos:

1.1. HECHOS 11
Los nombres de todas las relaciones y objetos deben iniciar con minús-cula. En el ejemplo anterior, le gusta, ricardo, georgina.
La relación se escribe primero, los objetos se escriben separados porcomas y los objetos son encerrados por paréntesis redondos.
El carácter de terminación �.� vendrá al �nal de un hecho.
Cuando de�namos relaciones entre objetos usando hechos, es muy impor-tante el orden de los objetos en los paréntesis. Para �jar ideas recordemosel hecho de arriba. No es lo mismo decir �Ricardo le gusta Georgina� que enProlog se escribiría como:
le gusta(ricardo, georgina).A decir �Georgina le gusta Ricardo� que en Prolog escribiríamos como:le gusta(georgina, ricardo).A continuación mencionamos algunos hechos y su interpretación:HECHO INTERPRETACIÓNrápido(computadora). La computadora es rápidatiene(moises, libro, ricardo). Moisés tiene el libro de Ricardoes(leon, carnivoro). El León es carnivoropadre(jorge, david). Jorge es el padre de DavidIntroduzcamos algo de terminología para estar más en contexto y ser
más precisos en lo que decimos. Los nombre de los objetos encerrados en losparéntesis en cada hecho son llamados argumentos. El nombre de la relación,la cual es la palabra antes de los paréntesis, es llamado predicado. De estamanera rápido es un predicado de un solo argumento, y tiene es un predicadoque tiene tres argumentos, según los hechos de arriba.
Los nombres de los objetos y las relaciones son totalmente arbitrarios.Por ejemplo, el término padre(jorge, david). Lo podríamos representar comox(y, z). y recordar que x representa padre, y representa jorge, z representadavid. No obstante lo anterior, se aconseja utilizar nombres que nos ayudena comprender de manera �el y rápida el término.
Las relaciones pueden tener un número arbitrario de argumentos, sin em-bargo las interacciones entre relaciones son más complicadas.
Podemos también declarar hechos falsos en el mundo real. Podríamosescribir primermundo(mexico). Para mencionar que México es un país delprimer mundo. Pero Prolog no sabe ni le interesa si son ciertos o falsos loshechos. Los hechos en Prolog únicamente le permiten expresar relacionesentre objetos.

12 CAPÍTULO 1. IDEAS FUNDAMENTALES DE PROLOG
Una colección de hechos (y posteriormente también reglas) es llamadauna base de datos en Prolog.
1.2. Preguntas
Una vez que tenemos algunos hechos, podemos preguntar acerca de ellos.En Prolog una pregunta se parece como un hecho, excepto que colocamos unsigno de interrogación y un guión antes. Considere la pregunta:
?- tiene(carlos, linux).Luego interpretemos a carlos como una persona llamada Carlos, y linux
como el sistema operativo de software libre Linux. Lo anterior se interpretacómo ¾Tiene Carlos Linux? o de manera diferente ¾Es un hecho que Carlostiene Linux? .
Cuando se formule una pregunta a Prolog. Buscará a través de la basede datos que usted escribió con antelación. Busca hechos que coincidan alhecho en la pregunta. Dos hechos coinciden sí sus predicados son los mismos,y sí sus correspondientes argumentos son los mismos. Sí Prolog encuentraun hecho que coincide con la pregunta, responderá si. En caso contrarioresponderá no.
Suponga la siguiente base de datos:le gusta(ricardo, georgina).le gusta(ricardo,sugey).le gusta(sugey, biologia).tiene(georgina, cabello rubio).Sí escribimos los hechos anteriores en un sistema Prolog. Podríamos for-
mular las siguientes preguntas, y Prolog las respondería. Observe lo siguiente.?- es(japon, extenso).no?- le gusta(ricardo, georgina).si?- le gusta(georgina, ricardo).no?- tiene(georgina, cabello rubio).siObserve la primera pregunta donde está no tiene nada que ver con lo
que existe en la base de datos, y aun así Prolog la responde. En Prolog, larespuesta no es usada para signi�car nada de coincidencia a la pregunta. Y

1.3. VARIABLES 13
�no� no es lo mismo que falso. Por ejemplo imagine la siguiente base de datosacerca del ámbito económico latinoamericano:
pais rico(mexico).pais industrializado(venezuela).baja delicuencia(mexico).Y preguntemos a Prolog esto:?- baja delicuencia(mexico).no?- pais industrializado(japon). noDe esta manera cuando Prolog responde no a una pregunta, signi�ca no
es probable.
1.3. Variables
Considere lo siguiente ¾Le gusta a Ricardo X?. Cuando preguntamos, nosabemos qué objeto es lo que puede signi�car X. Prolog puede determinarque objetos representan esa X. En Prolog no solo podemos mencionar objetosparticulares, sino también usar nombres como X para representar objetosqué Prolog determinará. Los nombres como X se llaman variables. CuandoProlog usa una variable, la variable puede ser instanciada o no instanciada.Una variable es instanciada cuando hay un objeto que la variable representa.
Una variable es no instanciada cuando lo que la variable representa no esaun conocido. Prolog distingue variables de nombres de objetos particulares.En virtud de que las variables en Prolog comienzan con mayúscula.
Cuando a Prolog se le formula una pregunta que contiene una variable,Prolog busca a través de todos sus hechos para encontrar un objeto que lavariable pueda representar. Una variable, tal como X, no nombra un objetoparticular, sino puede ser usado para representar objetos que no podemosnombrar.
Considere la siguiente base de datos de hechos, seguida por una pregunta:le gusta(ricardo, georgina).le gusta(ricardo,sugey).le gusta(sugey, biologia).tiene(georgina, cabello rubio).
?- le gusta(ricardo, X).El reglón anterior signi�ca ¾existe algo que le gusta a Ricardo?, Prolog
responderá:

14 CAPÍTULO 1. IDEAS FUNDAMENTALES DE PROLOG
X = georgina
Y después esperará más instrucciones. Pero ¾Cómo trabaja esto? Cuandose le pregunta a Prolog, la variable X no esta inicialmente instanciada. Pro-log busca a través de la base de datos, busca un hecho que coincida con lapregunta. Ahora si una variable no instanciada aparece como un argumento,Prolog permitirá que el argumento coincida con algún otro argumento en lamisma posición en el hecho. Lo que sucede aquí es que Prolog busca algúnhecho donde el predicado es le gusta, y el primer argumento es ricardo. Y elsegundo argumento puede ser algo, debido a que X es una variable no instan-ciada. Cuando un hecho tal es encontrado, entonces la variable X representael segundo argumento en el hecho. Prolog busca a través de la base de datos enel orden en que fue escrita, de esta manera el hecho le gusta(ricardo,georgina)es encontrado primero. La variable X representa ahora el objeto georgina.Además decimos que X es instanciada a georgina. Prolog marca ahora el lu-gar en la base de datos donde encontró una coincidencia. Una vez que Prologencuentra un hecho que coincide con una pregunta, imprime los objetos queahora representan las variables. Ahora Prolog espera más instrucciones. Síusted oprime la tecla ENTRAR, signi�cará que solo quiere una respuesta,después Prolog parará la búsqueda. En cambio si oprime la tecla �;� y de-spués la tecla ENTRAR, Prolog reanudará la búsqueda a través de la base dedatos como antes, comenzando desde donde el marcador de lugar se quedo.Cuando Prolog inicia la búsqueda desde un marcador de lugar, en vez desdeel inicio de la base de datos, se dice que Prolog intenta volver a satisfacer lapregunta.
Ahora volvamos a satisfacer la pregunta anterior tecleando ; seguido dela tecla ENTRAR, queremos encontrar otro objeto que X pueda representar.Esto signi�ca que Prolog deberá olvidarse que X representa georgina, y re-anuda la búsqueda con X no instanciada. En virtud de que estamos buscandouna segunda solución, la búsqueda continúa desde el marcador de lugar. Elsiguiente hecho coincidente es le gusta(ricardo,sugey). Y la variable X es in-stanciada a sugey, y Prolog coloca un marcador de lugar en este último hecho.Prolog visualiza X = sugey , y espera más instrucciones. Sí escribimos un �;�más, Prolog continuará la búsqueda. En este ejemplo no hay más coinciden-cias, en virtud de esto Prolog detendrá la búsqueda y nos mostrará la palabrano. De este modo estaremos en disposición de formularle otra pregunta.

1.4. CONJUNCIONES 15
1.4. Conjunciones
Imagine que tenemos la siguiente base de datos:le gusta(ricardo,georgina).le gusta(ricardo, chocolates).le gusta(georgina,chocolates).le gusta(georgina, rosas).le gusta(georgina, bioquimica).extenso(rusia).primermundo(japon).Queremos saber si Ricardo y Georgina se gustan. Para hacer esto, pre-
guntamos, ¾Le gusta Ricardo Georgina? y ¾Le gusta Georgina Ricardo? yexpresa la idea que estamos interesados en la conjunción de 2 preguntas.Queremos satisfacerlas una después de la otra. En Prolog se usa el símbolocoma �,� para representar la conjunción.
?- le gusta(ricardo,georgina) , le gusta(georgina, ricardo).La coma se pronuncia como y , y sirve para separar algún número de
diferentes términos que han de ser satisfechos en orden para responder unapregunta. Cuando una secuencia de términos separados por comas es pro-porcionada a Prolog intenta satisfacer cada término en turno buscando unhecho coincidente en la base de datos. Todos los términos han de ser satis-fechos en orden por la secuencia hacer satisfecha. Usando la lista de hechosanterior, ¾Qué imprimiría Prolog cuando le proporcionamos la pregunta dearriba? La respuesta es no. Es un hecho que Ricardo le gusta Georgina, así laprimer meta es verdad. Sin embargo, la segunda meta no puede ser probada,ya que no hay en ninguna parte en la lista de hechos donde encontremos legusta(georgina, ricardo). En virtud de lo anterior la pregunta completa tienerespuesta no.
Las conjunciones y el uso de variables pueden ser combinadas para hacerpreguntas más complejas, como podría ser la siguiente: ¾Existe algo queRicardo y Georgina le gustan ambos? Esta pregunta consiste de dos términos:
Primero, encontrar sí hay algún X que Georgina le gusta. Segundo, en-contrar sí Ricardo le gusta lo que X representa.
En Prolog los dos términos serian escritas como una conjunción como lasiguiente:
?- le gusta(ricardo, X) , le gusta(georgina, X).Prolog responde la pregunta intentando satisfacer el primer término. Sí el
primer término esta en la base de datos, después Prolog marca el lugar en la

16 CAPÍTULO 1. IDEAS FUNDAMENTALES DE PROLOG
base de datos, e intenta satisfacer el segundo término. Sí el segundo términoes satisfecho, después Prolog marca el lugar de ese término en la base dedatos, y hemos encontrado una solución que satisface ambos términos.
Es necesario hacer énfasis que cada término mantiene su propio marcadorde lugar. De esta manera sí el segundo término no es satisfecho, despuésProlog intentará volver a satisfacer el término previo (en este caso el primertérmino). Recuerde que Prolog busca en la base de datos completamente paracada término. Sí un hecho en la base de datos coincide, satisface el término,después Prolog marcará el lugar en la base de datos en caso que tenga quevolver a satisfacer el término en un tiempo posterior. Pero cuando un términonecesita ser satisfecho, Prolog iniciará la búsqueda desde el marcador de lugarpropio del término. En vez de desde el inicio de la base de datos. El ejemplode arriba ilustra un ejemplo del llamado �backtracking� (seguimiento haciaatrás) veamos esto:
1. La base de datos es buscada por el primer término. Como el segundo ar-gumento X es no instanciado, puede coincidir con algo. El primer hechocoincidente en nuestra base de datos de arriba es le gusta(ricardo,georgina).Y ahora X es instanciada a georgina en todas partes en la preguntadonde X aparece. Prolog marca el lugar en la base de datos dondeencontró el hecho. así puede regresar a este punto en caso que nece-site volver a satisfacer el término. Además, necesitamos recordar queX se instancia aquí, así Prolog puede olvidar X sí necesita volver asatisfacerla.
2. Ahora, la base de datos es buscada por le gusta(georgina, georgina).Esto es debido a que el próximo término es le gusta(georgina, X), yX representa actualmente georgina. Como puede ver, ningún hechotal existe, y el término falla. Ahora cuando el término falla. Debemostratar de volver a satisfacer el término previo, así Prolog intenta volvera satisfacer le gusta(ricardo, X), pero esta vez iniciara desde el lugar quefue marcado en la base de datos. Pero primero necesitamos hacer X noinstanciada una vez más, así X puede coincidir con algo.
3. El lugar marcado es le gusta(ricardo,georgina), así Prolog inicia la búsque-da después de este. A causa de que no hemos alcanzado el �n de la basede datos aun, no hemos agotado las posibilidades de qué Ricardo legusta, y el próximo hecho coincidente es le gusta(ricardo,chocolates). La

1.4. CONJUNCIONES 17
variable X es ahora instanciada a chocolates, y Prolog marca el lugaren caso de volver a volver a satisfacer.
4. Como antes, Prolog trata ahora el segundo término, buscando esta vezle gusta(georgina, chocolates). Prolog no esta tratando volver a satisfacereste término. Así debe iniciar buscando desde el inicio de la base dedatos. Y encuentra una coincidencia y se lo noti�ca. Ya que este términofue satisfecho, Prolog también marca su lugar en la base de datos, encaso que usted quiera volver a satisfacer el término. Hay un marcador delugar en la base de datos por cada término que Prolog esta intentandosatisfacer.
5. En este punto, ambos términos han sido satisfechos. La variable Xrepresenta el nombre chocolates. El primer término tiene un marcadorde lugar en la base de datos en el hecho le gusta(ricardo,chocolates). yel segundo término tiene un marcador de lugar en la base de datos enel hecho le gusta(georgina, chocolates).
Tan pronto como Prolog encuentra una respuesta, se detiene y espera másinstrucciones. Sí escribimos �;�, Prolog buscará más cosas que ambos Ricardoy Georgina les gustan. Sabemos ahora que esto equivale a volver a satisfacerambos términos iniciando desde el marcador de lugar de cada término.
Cuando maneje una conjunción de términos. Prolog intenta satisfacer ca-da término en turno, trabajando de izquierda a derecha. Sí un término essatisfecho. Prolog deja un marcador de lugar en la base de datos que estaasociado con el término. Además, algunas variables previamente no instan-ciadas pueden ser instanciadas ahora. Esto ocurre en el paso 1 de arriba. Síuna variable se instancia, todas las ocurrencias de la variable en la pregun-ta se instancian también. Prolog intenta después satisfacer el término de laderecha inmediata iniciando desde el comienzo de la base de datos.
Cuando cada término en turno se satisface, deja detrás un marcador delugar en la base de datos, en caso de que el término necesite ser satisfechode nuevo después. Cuando uno término no encuentra un hecho coincidente,Prolog regresa e intenta satisfacer el término de la izquierda inmediata, ini-ciando desde su marcador de lugar. Además, Prolog debe �desinstanciar� lasvariables que se instanciaron en este término. Sí cada término a la derechade este no pueden ser satisfechas de nueva cuenta, las fallas causaran queProlog paulatinamente arrastre a la izquierda cada una de los términos quefallan. Sí el primer término falla, no tenemos un término a la izquierda de

18 CAPÍTULO 1. IDEAS FUNDAMENTALES DE PROLOG
este que volver a satisfacer. En este caso, la conjunción entera falla. Estecomportamiento, donde Prolog repetidamente intenta satisfacer y volver asatisfacer metas en una conjunción, se le llama backtracking.
Para �jar ideas, mostramos el funcionamiento de backtracking, de unamanera grá�ca usando el ejemplo de arriba, donde preguntamos si hay algoque Georgina y Ricardo ambos le gusta. Esperamos que sea comprensibleeste ejemplo ya que backtracking es un concepto de suma trascendencia enel lenguaje Prolog.
Imagine la siguiente base de datos y la pregunta formulada a Prolog:le gusta(ricardo,georgina).le gusta(ricardo, chocolates).le gusta(georgina,chocolates).le gusta(georgina, rosas).le gusta(georgina, bioquimica).extenso(rusia).primermundo(japon).
?- le gusta(ricardo, X) , le gusta(georgina, X).El funcionamiento de backtracking es como muestran las �guras subse-
cuentes:
1.5. Reglas
En Prolog, las reglas son usadas cuando queremos decir que un hechodepende de un grupo de otros hechos.
Una regla es una declaración general acerca de objetos y sus relaciones.Por ejemplo, podemos decir que Bethoven es un perro sí Beethoven es unanimal y Beethoven ladra, de igual manera Fido es un perro sí Fido es unanimal y Fido ladra. Así podemos permitir que una variable represente unobjeto diferente en cada uso diferente de la regla.
El ejemplo anterior podríamos parafrasearlo así:
X es un perro sí:X es un animal, yX ladra.
En Prolog, una regla consiste de una cabeza y un cuerpo. La cabeza y

1.6. LISTAS 19
el cuerpo están conectados por el símbolo ':-'. El ':-' es pronunciado sí . Elejemplo anterior se escribe en Prolog como:
perro(X) :- animal(X) , ladra(X).La cabeza de esta regla es perro(X). La cabeza de la regla describe qué
hecho es previsto de�nir. El cuerpo, en este caso animal(X), ladra(X). describela conjunción de términos que deben ser satisfechos, uno seguido del otro,para que la cabeza sea verdadera.
En el ejemplo anterior, la variable X es usada tres veces. Cuando X seinstancia con algún objeto, todas las X's son instanciadas dentro del alcancede X. El alcance de X es la regla entera, incluyendo la cabeza, y termi-nando hasta el punto de la regla. Considerando el ejemplo antes dicho, síX se instancia a Firulais, después Prolog tratara de satisfacer los términosanimal(�rulais) y ladra(�rulais).
Podemos proveer hechos y reglas a la base de datos de Prolog. En generalun predicado será de�nido con una mezcla de hechos y reglas. Estas son lla-madas las cláusulas para un predicado. Usaremos la palabra cláusula cuandonos re�ramos a un hecho o regla.
Cuando usemos variables en una regla, estas variables se comportaráncomo las variables en los términos, con las normas mencionadas anteriormentepara estos últimos.
1.6. Listas
La lista es una estructura de datos muy común en programación nonumérica. La lista es una secuencia ordenada de elementos que tiene lon-gitud. �Ordenada� signi�ca que el orden de los elementos en la secuenciaimporta. Los �elementos� de una lista pueden ser términos, constantes, vari-ables y estructuras. Las cuales naturalmente incluyen otras listas.
Una lista puede ser vacía, la cual no tiene elementos, o es una estructuraque tiene dos componentes: la cabeza y la cola. El �n de una lista se representatradicionalmente como una cola que esta �jado a la lista vacía. La lista vacíase escribe como [].
La notación de lista que usamos en este trabajo consiste en que los elemen-tos de la lista están separados por comas, y la lista entera es encerrada conparéntesis rectangulares. Por ejemplo, la lista que empieza por el elementox, seguido de t y terminando por z. se escribe como: [x, t, z].

20 CAPÍTULO 1. IDEAS FUNDAMENTALES DE PROLOG
Lista Cabeza Cola[a, b, c] a [b, c][[sistema, operativo], linux] [sistema, operativo] [linux][] no tiene no tiene[mandrake, [debian, red hat], slackware] mandrake [[debian, red hat], slackware]
Cuadro 1.1: Algunas listas con sus cabezas y colas
Las listas pueden contener listas o variables. Por ejemplo:
[]
[ricardo, usa, [linux, para, trabajar, en, su, computadora]]
[a, X, b, Y, c, [T, W, Z]]
Las variables que están en las listas son tratadas de la misma forma comolo hemos estado diciendo con los términos. Pueden llegar a ser instanciadas enalgún tiempo. De esta manera listas que tienen variables pueden ser llenadascon datos cuando son instanciadas las variables de la lista.
Las listas son manipuladas dividiéndolas en una cabeza y una cola. Lacabeza de una lista es el primer componente. La cola de la lista es una listaque consiste de cada elemento excepto el primero. Para comprender mejor loantes dicho se muestra la tabla siguiente de listas y sus respectivas cabezasy colas.
La notación en Prolog para representar �la lista con cabeza X y cola Y �.Es esta [X|Y ], un patrón de esta forma instanciará X a la cabeza de unalista, e Y a la cola de la lista, como denotan los siguientes ejemplos:

1.7. BÚSQUEDA RECURSIVA 21
Lista 1 Lista 2 Instanciaciones[X, Y, Z] [azul, rojo, amarillo] X= azul
Y= rojoZ= amarillo
[libro] [X | Y] X= libroY= [ ]
[X, Y | Z] [ricardo, legusta, georgina] X= ricardoY= legustaZ= [georgina]
[kde, T] [W, gnome] W= kdeT= gnome
Cuadro 1.2: Pares de listas y cómo ellas coinciden
a([1, 2, 3]).
a([x, y, z, [u, v, w]]).
?−a([X|Y ]).
X = 1, Y = [2, 3];
X = x, Y = [y, z, [u, v, w]]
?−a([_,_,_, [_|X]]).
X = [v, w]
Para terminar el tema de listas, a continuación se muestra una tabla decómo coinciden varias listas.
1.7. Búsqueda Recursiva
Necesitamos frecuentemente buscar en el interior de una estructura deProlog para encontrar alguna pieza de información. Cuando la estructurapuede tener otras estructuras como sus componentes, esto resulta en unabúsqueda recursiva.

22 CAPÍTULO 1. IDEAS FUNDAMENTALES DE PROLOG
Suponga, por ejemplo, que tenemos la siguiente lista de algunas distribu-ciones del sistema operativo Linux.
[mandrake, debian, red hat, slackware]Ahora suponga que deseamos encontrar si una distribución dada esta en la
lista. La manera que hacemos esto en Prolog es encontrar sí la distribuciónes la misma como la cabeza de la lista: sí es así, tenemos éxito. Sí no esasí, entonces veri�camos sí la distribución esta en la cola de la lista. Estosigni�ca veri�car la cabeza de la cola la próxima vez. Y la cabeza de esa coladespués. Sí llegamos al �n de la lista, lo cual será la lista vacía, fallaremos:la distribución no esta en la lista.
Para escribir esto en Prolog, debemos primero reconocer que hay unarelación entre un objeto y una lista que se presenta. La relación llamadamiembro. Escribiremos un predicado member (miembro) tal que el objetivode member(X, Y) es verdad sí el termino que X representa es un miembro dela lista que Y representa. Hay dos condiciones que tener presente. Primero,es un hecho que X será un miembro de Y , Sí X es lo mismo que la cabezade Y . En Prolog, este hecho se escribe como:
member( X, [X | _]).La cláusula anterior signi�ca, �X es miembro de la lista que tiene X como
su cabeza�. Observe que usamos la variable anónima �_� para representarla cola de la lista. Esto es debido a que no usamos la cola para algo en estehecho particular.
El segundo y último paso, la regla dice que X es un miembro de una listaque esta en la cola de esa lista. Y que mejor manera de encontrar sí Y estaen la cola de la lista, que usar member así mismo. Esto es la esencia de larecursión, escribimos esto en Prolog como:
member( X, [ _| Y]):- member (X, Y).Lo que representa �X es un miembro de la lista sí X es un miembro de la
cola de la lista�. Observe que usamos la variable anónima �_� para representarla cabeza de la cola de la lista. Esto es debido a que no usamos la cabezapara algo en este hecho particular. Las dos reglas juntas de�nen el predicadomember, y le dirán a Prolog como buscar en una lista desde el comienzohasta el �nal de esta un objeto. El punto más importante en tener en cuentaes, buscar las condiciones de frontera y el caso recursivo. Hay dos condicionesde frontera en el predicado member, a saber, el objeto que estamos buscandoesta o no esta en la lista. La primera condición de frontera de member esreconocida por la primera cláusula, la cual provocará la búsqueda a travésde la lista para detenerse sí el primer argumento de member coincide con

1.7. BÚSQUEDA RECURSIVA 23
la cabeza del segundo argumento. La segunda condición de frontera ocurrecuando el segundo argumento de member es la lista vacía.
¾Cómo aseguramos que las condiciones de frontera serán siempre satis-fechas? Debemos observar en el caso recursivo, la segunda regla de member.Observe que cada vez member intenta satisfacerse así mismo, el objetivo esproporcionar una lista más corta. La cola de la lista es siempre una lista máscorta que la original. Eventualmente una de dos cosas sucederán: la primeraregla de member coincidirá, o member proporcionará una lista de longitud0, la lista vacía, como su segundo argumento. Cuando una de estas sucede.La �recurrencia� de member llegará a un �n.
En Prolog:member( X, [X | _]).member( X, [_ | Y]) :- member (X, Y).
?- member(f, [x, y, z, a, f, t, w]).si?- member(100, [1, 2, 3, a, f, t, 99]).nosuponga que preguntamos?- member( winlinux, [mandrake, debian, red hat, slackware] ).La segunda regla de member coincide, como winlinux no coincide con
mandrake. La variable Y se instancia a [debian, red hat, slackware], y la sigu-iente tarea es ver sí winlinux es un miembro de esta ultima lista. La segundaregla coincide otra vez, y la cola es tomada de nuevo. La meta se convierteen member(winlinux, [red hat, slackware] ). Este proceso se repite hasta quealcanzamos el punto donde X es winlinux, e Y es [slackware]. La segunda reglacoincide una vez más, y el próximo objetivo es member(winlinux, [ ]). Ningunaregla en la base de datos coincide con esto, así la meta falla, y la respuestaes falsa.
Otro punto importante que recordar es que cada vez que member usa susegunda cláusula intenta satisfacer member, Prolog trata cada recurrencia demember como una copia diferente. Esto previene las variables en un uso deuna cláusula de ser confusas con variables en otro uso de una cláusula.

24 CAPÍTULO 1. IDEAS FUNDAMENTALES DE PROLOG

Capítulo 2
Generalización menos general
Generalizaciones de cláusulas pueden ser de nuestro interés. Considere lasiguiente inducción:
En virtud de comprimir este archivo de texto a razón de 50% fue quese redujo su tamaño.
En virtud de comprimir otro archivo de texto a razón de 50% fue quese redujo su tamaño.
Por lo tanto
En virtud de comprimir cualquier archivo de texto a razón de 50% esque se reduce su tamaño.
Formalicemos esto como:
ArchivoDeTexto( archivo 1) ∧ Comprimido( archivo 1 , 50%) entoncesRedujoTamaño( archivo 1)
ArchivoDeTexto( archivo 2) ∧ Comprimido( archivo 2 , 50%) entoncesRedujoTamaño( archivo 2)
Por lo tanto
ArchivoDeTexto ( X ) ∧ Comprimido( X , 50%) entonces RedujoTa-maño( X )
Observe que ambos antecedentes y conclusión pueden ser expresados co-mo cláusulas en el lenguaje de primer orden usual con símbolos de función.Nuestro propósito es encontrar una regla que dependa en la forma de los an-tecedentes los cuales generan la conclusión en este y casos similares. Resultaráque la conclusión es la mínima generalización de sus antecedentes.
25

26 CAPÍTULO 2. GENERALIZACIÓN MENOS GENERAL
De�nición 1 Decimos que la literal L1 es más general que la literal L2 siL1σ = L2 para alguna substitución σ. Para cláusulas decimos que la cláusulaC1 es más general que la cláusula C2 si C1 incluye a C2.
Una mínima generalización de algunas cláusulas y literales es una general-ización la cual es menos general que cualquier otra generalización. Por ejemp-lo, P (g(x), x) es una generalización mínima de {P (g(a()), a()), P (g(b()), b())}y P (g(x), x) es una generalización mínima de {Q(x) ∨ P (g(a()), a()), R(x) ∨P (g(b()), b())}.
2.1. Preliminares
Usaremos los símbolos t, t1, . . . , u, u1, . . . para términos. L, L1, . . . M, M1, . . .para literales. D, D1, . . . para cláusulas. φ para un símbolo de función o unsímbolo de predicado o el signo de negación seguido por un símbolo de pred-icado.
Una palabra es una literal o un término. Usaremos los símbolos V, V1, . . . ,así como W, W1, . . . para palabras.
Denotemos secuencias de enteros, quizás vació, por los símbolos I, J. Dec-imos que t esta en el I-esimo lugar en W si:
Cuando I =<>, t = W o
Cuando I =< i1, . . . , in >, entonces W tiene la forma φ(t1, . . . , tm) ei1 ≤ m y t esta en el < i2, . . . , in >esimo lugar en ti1 .
Así, por ejemplo, x esta en el <>esimo lugar en x, el < 2 >esimo eng(y, x) y en el < 3, 2 >esimo lugar en P (a, b, g(y, x)).
Note que t nunca esta en el <>esimo lugar en L. Decimos que t es en W,sí t esta en el I-esimo lugar en W para algún I.
W1 ≤ W2 (lea `W1 es más general que W2') si W1σ = W2 para algunasubstitución σ.
Por ejemplo,
P (x, x, f(g(y))) ≤ P (l(3), l(3), f(g(x))).
Podemos tomar σ = {l(3)|x, x|y}, (interprete lo anterior como l(3) substituyea x, x substituye a y.

2.2. PALABRAS 27
C1 ≤ C2 (lea `C1 es más general que C2') sí C1σ ⊂ deC2 para algunasubstitución σ.C1 ≤ C2 signi�ca que C1 incluye a C2 en la terminologíausual.
Por ejemplo,P (x) ∨ P (f()) ≤ P (f()).
Podemos tomar σ = {f()|x}.En ambos casos, la relación ≤ es un cuasi-orden. Hemos elegido escribir
L1 ≤ L2, más que L1 ≤ L2, por que en el caso de cláusulas, ≤ es �casi�subconjunto.
2.2. Palabras
Recuerde que una palabra en este contexto es una literal o un término.Escribimos W1 ∼ W2 cuando W1 ≤ W2 y W2 ≤ W1. Como ≤ es un cuasi-orden, esto de�ne una relación de equivalencia. Es sabido que W1 ∼ W2 siW1 y W2 son variantes alfabéticas.
De�nición 2 Dos palabras son compatibles si son ambos términos o tienenla misma letra de predicado y signo.
Sí K es un conjunto de palabras, entonces W es una generalización mín-ima de K sí:
1. Para cada V en K, W ≤ V.
2. Sí para cada V en K, W1 ≤ V, entonces W1 ≤ W.
Se sigue de 2 que si W1, W2 son dos mínimas generalizaciones de K,entonces W1 ∼ W2.
Teorema 1 Cada conjunto �nito no vació, de palabras tiene una general-ización mínima sí dos palabras en el conjunto son compatibles.
2.3. Algoritmo
El siguiente algoritmo se apoya en el teorema 1 para encontrar la gener-alización menos general de un par de palabras.
El Algoritmo termina en el paso 3, sí la a�rmación hecha allí es correcta.Sean W1 y W2 dos palabras compatibles.

28 CAPÍTULO 2. GENERALIZACIÓN MENOS GENERAL
1. Establezca Vi para Wi (i = 1, 2). Establezca εi para ε(i = 1, 2).ε es lasubstitución vacia.
2. Trate de encontrar términos t1, t2 los cuales tengan el mismo lugar enV1, V2 respectivamente y tal que t1 6= t2 y cualquiera de los dos t1 y t2inician con letra de función diferente o al menos uno de ellos es unavariable.
3. Si no hay tales t1, t2 entonces pare. V1 es una generalización mínima de{W1, W2} y V1 = V2, Viεi = Wi(i = 1, 2).
4. Elija una variable x distinta de alguna en V1 o V2 y dondequiera que t1y t2 ocurran en el mismo lugar en V1 y V2, reemplace cada una por x.
5. Cambie εi a {ti|x}, εi(i = 1, 2).
6. Ir al paso 2.
Ejemplo 1 Usaremos el algoritmo para encontrar una mínima generalizaciónde:
{P (f(a(), g(y)), x, g(y)), P (h(a(), g(x)), x, g(x))}.
Inicialmente,
V1 = P (f(a(), g(y)), x, g(y))
V2 = P (h(a(), g(x)), x, g(x))
Tomemos t1 = y, t2 = x y z como la nueva variable. Entonces después delpaso 4.
V1 = P (f(a(), g(z)), x, g(z))
V2 = P (h(a(), g(z)), x, g(z))
Y después del paso 5.
ε1 = {y|z}, ε2 = {x|z}.
Siguiente, tomamos t1 = f(a(), g(z)), t2 = h(a(), g(z)) e y como la nuevavariable.

2.3. ALGORITMO 29
Después de 4 y 5,
V1 = P (y, x, g(z)) = V2
ε1 = {f(a(), g(z))|y}, {y|z}= {f(a(), g(y))|y, y|z}
ε2 = {h(a(), g(z))|y}{x|z}= {h(a(), g(x))|y, x|z}
El algoritmo entonces se detiene con
P (y, x, g(z))
como la mínima generalización.Este algoritmo se implementa en lenguaje Prolog, y se encuentra en el
Apéndice A de este Trabajo.

30 CAPÍTULO 2. GENERALIZACIÓN MENOS GENERAL

Capítulo 3
Algoritmo ID3
3.1. Algoritmo ID3 (árboles de decisión)
La construcción de un árbol de decisión representa la relación existenteentre la conclusión-decisión y sus atributos. Es decir, se produce un procesode generalización de forma que el árbol de decisión generado clasi�ca cor-rectamente los ejemplos dados. Este árbol, además, se caracteriza por ser elóptimo en el sentido que minimiza el número de atributos requeridos paraalcanzar la conclusión-decisión, siendo esta la explicación de por qué ciertosatributos no aparecen en el árbol.
El ID3 es un algoritmo simple y, sin embargo, potente, cuya misión es laelaboración de un árbol de decisión bajo las siguientes premisas:
1. Cada nodo corresponde a un atributo y cada rama al valor posiblede ese atributo. Una hoja del árbol especi�ca el valor esperado de ladecisión de acuerdo con los ejemplos dados. La explicación de una de-terminada decisión viene dada por la trayectoria desde la raíz a la hojarepresentativa de esa decisión.
2. A cada nodo es asociado aquel atributo más informativo que aún nohaya sido considerado en la trayectoria desde la raíz.
3. Para medir cuánto de informativo es un atributo se emplea el conceptode entropía. Cuanto menor sea el valor de la entropía, menor será laincertidumbre y más útil será el atributo para la clasi�cación.
31

32 CAPÍTULO 3. ALGORITMO ID3
El ID3 es capaz de tratar con atributos cuyos valores sean discretos ocontinuos. En el primer caso, el árbol de decisión generado tendrá tantasramas como valores posibles tome el atributo. Si los valores del atributo soncontinuos, el ID3 no clasi�ca correctamente los ejemplos dados. Por ello,Quinlan [Ros93] propuso el C4.5, como extensión del ID3, que permite:
1. Construir árboles de decisión cuando algunos de los ejemplos presentanvalores desconocidos para algunos de los atributos.
2. Trabajar con atributos que presenten valores continuos.
3. La poda de los árboles de decisión. El árbol de decisión ha sido con-struido a partir de un conjunto de ejemplos, por tanto, re�ejará cor-rectamente todo el grupo de casos. Sin embargo, como esos ejemplospueden ser muy diferentes entre sí, el árbol resultante puede llegar aser bastante complejo, con trayectorias largas y muy desiguales. Parafacilitar la comprensión del árbol puede realizarse una poda del mismo,lo que signi�ca la sustitución de una parte del árbol (sub-árbol) por unahoja. La poda tendrá lugar si el valor esperado de error en el sub-árboles mayor que con la hoja que lo sustituya.
3.2. Ventajas y De�ciencias del algoritmo ID3
Algunas de las ventajas del algoritmo ID3 son:
El ID3 es capaz de tratar con atributos cuyos valores sean discretos ocontinuos.
El enfoque sobre el que mayor número de investigaciones se han real-izado.
Mejoras de versiones con C4.5 para soportar valores continuos, valoresperdidos, datos con ruido.
Facilita la interpretación de la decisión adoptada.
Proporciona un alto grado de comprensión del conocimiento utilizadoen la toma de decisiones.

3.3. ALGORITMO CLS 33
Explica el comportamiento respecto a una determinada tarea de de-cisión.
De�ciencias:
Para problemas complejos el número de reglas es muy alto.
Si los valores del atributo son continuos, el ID3 no clasi�ca correcta-mente los ejemplos dados.
Di�culta para tratar valores no conocidos(asigna el valor mas probable).
Di�cultad para la incorporación de nuevos ejemplos.
Problemas cuando los ejemplos tienden a incrementarse.
3.3. Algoritmo CLS
ID3 esta basado en el algoritmo CLS (Concept Learning System), el al-goritmo CLS básico con un conjunto de instancias de entrenamiento C es elsiguiente:
PASO 1: Sí todas las en C son positivas, entonces crea un nodo SI ytermina. Sí todas las instancias en C son negativas, crea un nodo NOy termina. De otra manera selecciona una característica o valor F convalores < v1, . . . , vn > y crea un nodo de decisión.
PASO 2: Particiona las instancias de entrenamiento en C en subcon-juntos C1, C2, . . . , Cn según los valores de V.
PASO 3: Aplica el algoritmo recursivamente para cada conjunto Ci.Observe que el entrenador decide cual característica o valor seleccionar.
ID3 mejora a CLS por la incorporación de una característica de selec-ción heurística. ID3 busca a través de los atributos de las instancias de en-trenamiento y extrae el atributo que mejor separa los ejemplos dados. Sí elatributo clasi�ca perfectamente los conjuntos de entrenamiento entonces ID3para; de otra manera opera recursivamente en los n subconjuntos particiona-dos (donde n = numero de posibles valores de un atributo) para conseguirsu mejor atributo.

34 CAPÍTULO 3. ALGORITMO ID3

Capítulo 4
Teorema de Bayes y Entropía dela Información
4.1. Clasi�cación
Nos hemos apoyado en el problema del tenis, el cual contiene 5 camposo valores, los cuales están clasi�cados en las siguientes categorías:
Pronostico
Temperatura
Humedad
Viento
Decisión
Cada uno de estos campos o valores cuenta con sus atributos los cualesson:
Pronostico: sol , nublado, lluvia
Temperatura: calor, templado, frió
Humedad: alta, normal
Viento: débil, fuerte
35

36CAPÍTULO 4. TEOREMADE BAYES Y ENTROPÍA DE LA INFORMACIÓN
Día Pronostico Temperatura Humedad Viento Decisión1 Sol Templado Normal Fuerte Si2 Nublado Frió Alta Débil no
Cuadro 4.1: Ejemplos del tenis
Decisión: si, no
Por cada campo se puede presentar un solo atributo por día. Dos ejemplosse muestran en la tabla 4.1
Tomando en consideración los atributos de cada renglón y basándonos enla decisión de que si el tenista juega o no en determinado día. Se analizarantablas con este tipo de información y estos datos serán trabajados con elteorema de Bayes y la Entropía de la información. Para proporcionar unarespuesta probabilística a sí el tenista juega o no.
4.2. Teorema de Bayes
Para realizar las primeras pruebas sobre una matriz de N × M, la cualcontendrá datos para el problema del juego del tenis, y esta matriz estará enun archivo, utilizaremos el Teorema de Bayes.
El teorema de Bayes se le atribuye al matemático ingles Thomas Bayes(1702 - 1761). Donde esta formula es utilizada para el cálculo de probabili-dades.
Si se tiene un conjunto particiones digamos B1, B2, . . . , Bn las cualespertenecen a un espacio muestral S y se considera un evento A que es asoci-ado con S. La probabilidad de Bayes nos daría la siguiente notación:
P (Bi|A) =P (A|Bi)P (Bi)
n∑j=0
P (A|Bj)P (Bj)
Dado que Bi pertenece al espacio muestral S y los Bi, son el conjuntode particiones en los cuales esta dividido S. Se tiene que solamente uno ysolo uno de los eventos Bi debe ocurrir. De esta manera se in�ere obtener laprobabilidad de Bi, dado que el evento A ocurrió.

4.3. ENTROPÍA DE LA INFORMACIÓN 37
4.2.1. El problema del tenis usando BAYES
En nuestro caso particular los valores que se requieren para aplicar elteorema de Bayes serán tomados de la matriz de N × M, esta es una basede datos que se encuentra en un archivo, la estructura del archivo es como elque se ve en la tabla 4.1.
Como A será el evento a considerar que se realice (A para el problemadel juego del tenis, consistirá en que si juega el jugador ), debemos tomaren cuenta todos los atributos de los campos mencionados en la parte declasi�cación, para así poder especi�car la probabilidad que se presenta paraque un jugador juegue dado que un atributo se presento.
Ahora expliquemos algo de entropía, debido a que este concepto tambiénlo utilizaremos para la implementación del algoritmo ID3 para el problemadel tenis.
4.3. Entropía de la Información
La Entropía es la magnitud que mide la información contenida en un �ujode datos, es decir, lo que nos aporta sobre un dato o hecho concreto.
Por ejemplo, que nos digan que las calles están mojadas, sabiendo queacaba de llover, nos aporta poca información, porque es lo habitual. Pero sinos dicen que las calles están mojadas y sabemos que no ha llovido, aportamucha información (porque no las riegan todos los días).
Nótese que en el ejemplo anterior la cantidad de información es diferente,pese a tratarse del mismo mensaje: Las calles están mojadas. En ello se basanlas técnicas de compresión de datos, que permiten empaquetar la mismainformación en mensajes más cortos.
La medida de la entropía puede aplicarse a información de cualquier natu-raleza, y nos permite codi�carla adecuadamente, indicándonos los elementosde código necesarios para transmitirla, eliminando toda redundancia. (Paraindicar el resultado de una carrera de caballos basta con transmitir el códi-go asociado al caballo ganador, no hace falta contar que es una carrera decaballos ni su desarrollo).
La entropía nos indica el límite teórico para la compresión de datos. Sucálculo se realiza mediante la siguiente fórmula:
H = p1 log(1
p1
) + p2 log(1
p2
) + · · ·+ pm log(1
pm
)

38CAPÍTULO 4. TEOREMADE BAYES Y ENTROPÍA DE LA INFORMACIÓN
donde H es la entropía, las p son las probabilidades de que aparezcan losdiferentes códigos y m el número total de códigos. Si nos referimos a unsistema, las p se re�eren a las probabilidades de que se encuentre en undeterminado estado y m el número total de posibles estados.
Se utiliza habitualmente el logaritmo en base 2, y entonces la entropía semide en bits.
Por ejemplo: El lanzamiento de una moneda al aire para ver si sale carao cruz (dos estados con probabilidad 0.5) tiene una entropía:
H = 0.5 log2(1
0.5)+0.5 log2(
1
0.5) = 0.5 log2(2)+0.5 log2(2) = 0.5+0.5 = 1bit.
A partir de esta de�nición básica se pueden de�nir otras entropías.

Capítulo 5
Implementación del problema deltenis con ID3
5.1. Objetivo del Programa
El programa analiza la información contenida en una tabla de datos(archivo). Al procesar esta información le proporcionará al usuario los val-ores de los atributos que son elegidos como mejores opciones, para saber sise realiza una acción (el jugador jugará tenis), así como también aquellosvalores que no son favorecedores para que se realice dicha acción (el jugadorno jugará tenis). Estos valores son analizados de dos maneras; una de ellases mediante el teorema de Bayes donde la elección de la probabilidad másalta es la elegida y la otra forma es mediante la Entropía de la información.Al �nal el programa muestra un árbol binario, el cual coloca al atributo conmayor probabilidad o entropía como raíz del árbol, posteriormente la matrizse particiona en dos partes para repetir este proceso recursivamente las vecesque sean necesarias y acomodar los atributos más favorecedores como hijosizquierdos del árbol y los atributos menos favorecedores como hijos derechos.
5.2. Tabla de atributos y valores
Para la implementación de nuestro programa nos basaremos en el proble-ma del tenis, en el cual tenemos un conjunto de atributos, los cuales a su veztienen un conjunto de valores. La tabla 5.1 muestra los atributos y valoresque se tienen en el problema del tenis.
39

40CAPÍTULO 5. IMPLEMENTACIÓN DEL PROBLEMADEL TENIS CON ID3
atributos Pronostico Temperatura Humedad Viento Decisión Díavalores Sol frió alta Débil si D1
Nublado Templado normal Débil si D2
Lluvia Templado normal Fuerte no D3
sol frió alta Fuerte no D4
Lluvia Calor normal Débil si D5
Cuadro 5.1: Atributos y valores del problema del tenis
El programa tomará cada uno de estos atributos, los cuales estarán con-tenidos en un archivo en forma de tabla, de tal manera que los contabilizarápara calcular su probabilidad de Bayes o su entropía informática y formarasí el árbol de decisión.
5.3. Ejemplo real de cálculo
El siguiente ejemplo mostrara la idea explicada anteriormente. La tabla5.2 muestra todos los ejemplos que tenemos del problema del tenis.
Día Pronostico Temperatura Humedad Viento Decisión1 sol calor Alta débil No2 sol calor Alta fuerte No3 nublado calor Alta débil Si4 lluvia templado Alta débil Si5 lluvia frió Normal débil Si6 lluvia frió Normal fuerte No7 nublado frió Normal fuerte Si8 sol templado Alta débil No9 sol frió Normal débil Si10 lluvia templado Normal débil Si11 sol templado Normal fuerte Si12 nublado templado Alta fuerte Si13 nublado calor Normal débil Si14 lluvia templado Alta fuerte No
Cuadro 5.2: Datos del ejemplo del Tenis
5.4. ÁRBOL DE DECISIÓN 41
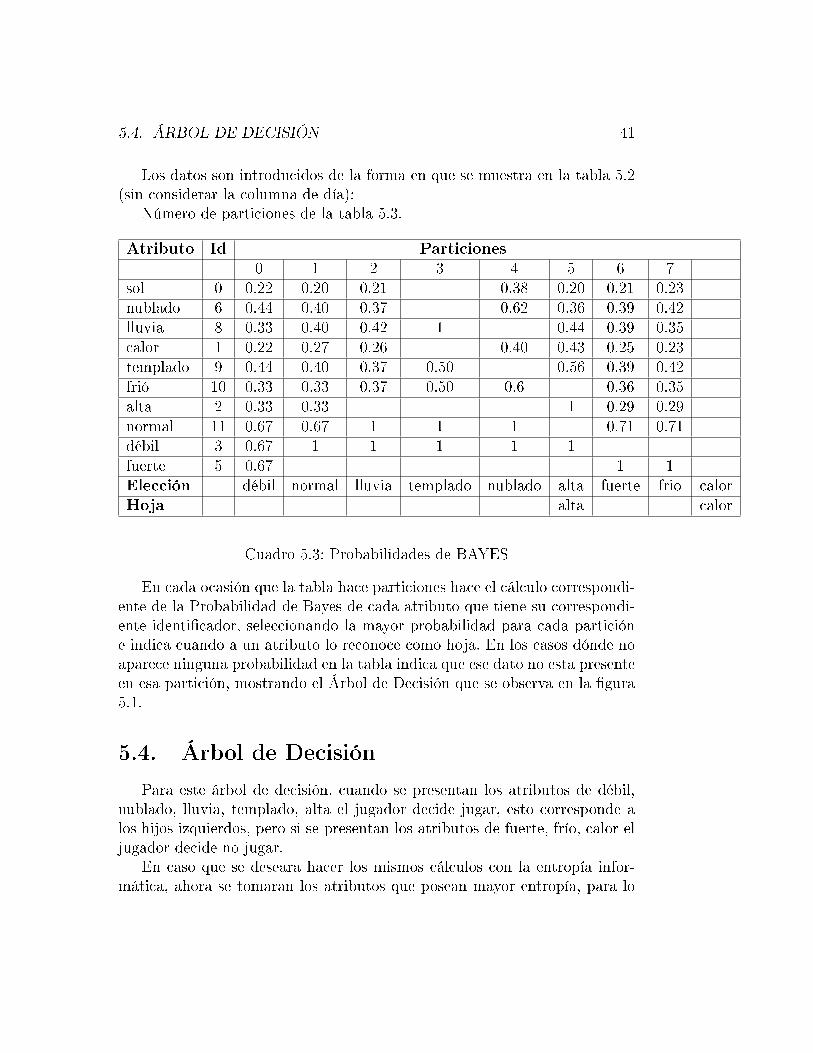
Los datos son introducidos de la forma en que se muestra en la tabla 5.2(sin considerar la columna de día):
Número de particiones de la tabla 5.3.
Atributo Id Particiones0 1 2 3 4 5 6 7
sol 0 0.22 0.20 0.21 0.38 0.20 0.21 0.23nublado 6 0.44 0.40 0.37 0.62 0.36 0.39 0.42lluvia 8 0.33 0.40 0.42 1 0.44 0.39 0.35calor 1 0.22 0.27 0.26 0.40 0.43 0.25 0.23templado 9 0.44 0.40 0.37 0.50 0.56 0.39 0.42frió 10 0.33 0.33 0.37 0.50 0.6 0.36 0.35alta 2 0.33 0.33 1 0.29 0.29normal 11 0.67 0.67 1 1 1 0.71 0.71débil 3 0.67 1 1 1 1 1fuerte 5 0.67 1 1Elección débil normal lluvia templado nublado alta fuerte frio calorHoja alta calor
Cuadro 5.3: Probabilidades de BAYES
En cada ocasión que la tabla hace particiones hace el cálculo correspondi-ente de la Probabilidad de Bayes de cada atributo que tiene su correspondi-ente identi�cador, seleccionando la mayor probabilidad para cada particióne indica cuando a un atributo lo reconoce como hoja. En los casos dónde noaparece ninguna probabilidad en la tabla indica que ese dato no esta presenteen esa partición, mostrando el Árbol de Decisión que se observa en la �gura5.1.
5.4. Árbol de Decisión
Para este árbol de decisión, cuando se presentan los atributos de débil,nublado, lluvia, templado, alta el jugador decide jugar, esto corresponde alos hijos izquierdos, pero si se presentan los atributos de fuerte, frío, calor eljugador decide no jugar.
En caso que se deseara hacer los mismos cálculos con la entropía infor-mática, ahora se tomaran los atributos que posean mayor entropía, para lo

42CAPÍTULO 5. IMPLEMENTACIÓN DEL PROBLEMADEL TENIS CON ID3
3 débil
11 nublado
8 lluvia
9 templado 2 alta
5 fuerte
10 frio
1 calor
Figura 5.1: Árbol de Decisión obtenido
cual se tomara la entropía de todo el sistema y después la entropía individualde cada atributo. En donde la formula es la siguiente
H = pn∑
i=0
log
(1
p
)donde H es la entropía, p es la probabilidad de que aparezcan códigos y n elnúmero total de códigos.
Ya obteniendo la entropía del sistema se le resta cada una de las entropíasindividuales y el programa ira eligiendo la entropía mayor de la misma maneraque las probabilidades de Bayes para formar un Árbol de Decisión.

Apéndice A
Código Algoritmo 1 en PROLOG
% GENERALIZACION MENOS GENERAL (lgg)
%formato es lgg(termino 1, termino 2, substitucion,solución)
% Si son iguales el lgg es el terminolgg(W1,W2,[],W1):-W1==W2.
% Si un termino es una variable entonces el lgg es sustituir la variablelgg(W1,W2,[X/W1,X/W2],X):-(var(W1);var(W2)).
% Si el termino es un functor con el mismo nombre e igual # de componenteslgg(W1,W2,E,V):- W1=..[N1 | L1],W2=..[N2 | L2],N1==N2,len(L1,T),len(L2,T),
lgg1(L1,L2,E,LV),V=..[N1 | LV].
% si el termino es un functor con nombre distintolgg(W1,W2,[Y/W1,Y/W2],Y):- W1=..[N1 | L1],W2=..[N2 | L2],N1\=N2.
% terminos distintoslgg(W1,W2,[Z/W1,Z/W2],Z):- W1\=W2.
% segunda funcion lgglgg1([],[],[],[]).lgg1([X|Xs],[Y|Ys],E,[V|Lv]):-lgg(X,Y,S,V),
lgg1(Xs,Ys,Es,Lv),append(S,Es,E).
43

44 APÉNDICE A. CÓDIGO PROLOG
% funciones auxiliares
% calcula la longitud de una cadena,la cadena esta en% la primera componente y el segundo componente es la longitudlen([],0).len([X|Xs],T):-len(Xs,S),T is S+1.
% concatena 2 cadenas, 1er componente es la cadena 1,% 2do componente cadena 2 , 3er componente cadena concatenadaappend([],Xs,Xs).append([X|Xs],Ys,[X|Zs]):-append(Xs,Ys,Zs).
sust([],Ts,Ts).sust([V/M|Ss],Ts,Ns):-sust1(V/M,Ts,Nns),sust(Ss,Nns,Ns).
sust1(V/M,[],[]).sust1(V/M,[T|Ts],[V|Ns]):-M==T,sust1(V/M,Ts,Ns).sust1(V/M,[T|Ts],[T|Ns]):-M\==T,sust1(V/M,Ts,Ns).

Apéndice B
Código del algoritmo ID3 para elproblema del tenis
El siguiente código en lenguaje C es para crear el árbol de decisión usandoel teorema de Bayes, y muestra al árbol binario de la forma siguiente:
Hijos izquierdosRaíz
Hijos derechos
B.1. Código BAYES
/*Librerias a utilizar*/#include <string.h>#include <ctype.h>#include <stdio.h>#include <stdlib.h>#include <conio.h>#include <math.h>
struct {char etiq[25];int id;float proba;float conta_id;
45

46APÉNDICE B. CÓDIGODEL ALGORITMO ID3 PARA EL PROBLEMADEL TENIS
float con_si;int cuenta;int cuenta_2;}etiqs[50];typedef struct nodo tnodo;typedef struct nodo *arbol;struct nodo
{int datos;struct nodo *izq;struct nodo *der;
};FILE *archi;int matrix[100][100];int col,num_etiqs;float var_pro[50];float var_total, renglon=0;
/* funciones a utilizar */void asigna(FILE *archi);int busca (char *e);int contador(int renini, int renfin);arbol bayesrecursivo(int renini, int renfin);float bayes();void visualiza(arbol a, int n);/***************Principal del programa******************************/main(){ /*Busqueda del archivo*/arbol a;if((archi=fopen("archivo4.d","r"))==NULL){fprintf(stderr, "Error no se puede abrir el archivo \n" );exit(EXIT_FAILURE);
}
else

B.1. CÓDIGO BAYES 47
{asigna(archi);a=bayesrecursivo(0,renglon-1);visualiza(a, 0);getch();}
fclose(archi);return 0;}/*Funcion que asigna un numero a cada atributo diferente*/void asigna(FILE *archi){char t[10], c;int i, num,x,y;c=fgetc(archi);while (!feof(archi)) /*Verifica el final del archivo*/{ungetc(c,archi);col=0;do{i=0;while((c=fgetc(archi))!=' ' && c!='\n'){t[i++]=c;}t[i]='\0';num=busca(t);if(num<0){strcpy(etiqs[num_etiqs].etiq, t);etiqs[num_etiqs].id=num_etiqs;num=num_etiqs++;}matrix[(int)renglon][col++]=num;}while(c!='\n');renglon++;c=fgetc(archi);

48APÉNDICE B. CÓDIGODEL ALGORITMO ID3 PARA EL PROBLEMADEL TENIS
}for(y=0;y<col;y++)
{for(x=0; x<renglon;x++){
printf(" %d ",matrix[x][y]);}
printf("\n");}getch();
}/*Esta funcion identifica si cada atributo
ya tiene su valor numerico*/int busca(char *e){int i=0;while(etiqs[i].etiq[0]!='\0')
{if(strcmp(etiqs[i].etiq,e)==0)return i;i++;
}return -1;}/*Acumula cada el numero de veces que un atributo se repite*/int contador(int renini, int renfin){int t2, t3, i, x, y, clave, max;for(y=0;y<col-1;y++){for(x=renini; x<=renfin;x++){clave=1;t2=matrix[x][y];t3=matrix[x][col-1];etiqs[t2].conta_id=etiqs[t2].conta_id+1;if(strcmp(etiqs[t3].etiq,"si")==0){

B.1. CÓDIGO BAYES 49
etiqs[t2].con_si=etiqs[t2].con_si+1;}etiqs[t2].cuenta=clave;}bayes();}max = 0;
if(etiqs[0].cuenta_2==clave){
max=1;}
for (i=1; i<num_etiqs; i++){
if(etiqs[i].cuenta_2!=clave){if (etiqs[max].proba < etiqs[i].proba)max = i;}
}etiqs[max].cuenta_2=clave;return max;}/*Calcula el valor de probabilidad de Bayes para cada vez que juega*/float bayes(){float z;for(z=0; z<=num_etiqs; z++)
{if(etiqs[(int)z].cuenta==1){var_pro[(int)z]=(((etiqs[(int)z].conta_id)/(renglon))
*((etiqs[(int)z].con_si)/(etiqs[(int)z].conta_id)));}
}for(z=0; z<=num_etiqs; z++){
if(etiqs[(int)z].cuenta==1)

50APÉNDICE B. CÓDIGODEL ALGORITMO ID3 PARA EL PROBLEMADEL TENIS
{var_total=var_total+var_pro[(int)z];}
}for(z=0; z<=num_etiqs; z++)
{if(etiqs[(int)z].cuenta==1){etiqs[(int)z].proba=(var_pro[(int)z]/var_total);/*Despliega la probabilidad de Bayes de cad atributo*/printf("El dato %s, con identificador %d, tiene probabilidad de %f\n",
etiqs[(int)z].etiq,etiqs[(int)z].id,etiqs[(int)z].proba);
}etiqs[(int)z].cuenta=0;var_pro[(int)z]=0;}getch();var_total=0;return 0;}/*Despues de cada particion de la tabla mediante es te modulolas tablas se vuelven a establecer*/
int reordena_matrix(int renini, int renfin, int max){int i,j,x,y,c;int rentemp[100];
for (i=0; i<col-1;i++) {for (j=renini; j<=renfin; j++)if (max == matrix[j][i]) {c = i;break;
}}
i=renini;j = renfin;

B.1. CÓDIGO BAYES 51
while (i+1<j) {if (matrix[j][c]!=max)j--;if (matrix[i][c]==max)i++;if (matrix[i][c]!=max && matrix[j][c]==max) {memcpy(rentemp,matrix[i],100*sizeof(int));memcpy(matrix[i],matrix[j],100*sizeof(int));memcpy(matrix[j],rentemp,100*sizeof(int));}/*Despues de cada particion de la tabla mediante es te modulolas tablas se vuelven a establecer*/
}for(y=0;y<col;y++)
{for(x=0; x<renglon;x++){printf(" %d ",matrix[x][y]);}
printf("\n");
}getch();return i;}/*Modulo recursivo para la construccion del arbol*/arbol bayesrecursivo(int renini, int renfin){arbol res;int i,ns,k,max,mitad;for (k=0; k<=renfin; k++) {
if(strcmp(etiqs[k].etiq,"si")==0){break;}
}for (i=renini, ns=0; i<=renfin; i++) {if (matrix[i][col-1] == etiqs[k].id)

52APÉNDICE B. CÓDIGODEL ALGORITMO ID3 PARA EL PROBLEMADEL TENIS
{ns++;}}printf(" \n ");
if ((renini == renfin) || ns == (renfin-renini)){
printf("El atributo %s, es una hoja\n",etiqs[max].etiq);}
else{max = contador(renini, renfin);res=(tnodo *)malloc(sizeof(tnodo));res->datos=max;res->izq=NULL;res->der=NULL;/*Modulo recursivo para la construccion del arbol*/printf("Elegi %s\n",etiqs[max].etiq);mitad = reordena_matrix(renini,renfin,max);if(renini<mitad){
res->izq=bayesrecursivo(renini,mitad);}if(mitad+1<renfin){
res->der=bayesrecursivo(mitad+1,renfin);}}
return res;}/*Modulo que visualiza el arbol*/void visualiza(arbol a, int n){int i; /*valor de incremento para el desplazamiento*/if (a!=NULL){

B.2. CÓDIGO ENTROPÍA 53
visualiza(a->izq, n+1); /*visualizacion del hijo izquierdo*/for (i=1; i<=n; i++)printf(" ");printf(" %d %s \n ", etiqs[a->datos].id, etiqs[a->datos].etiq);visualiza(a->der, n+1); /*visualizaci?n del hijo derecho*/
}}________________________________________________________________
B.2. Código Entropía
El código en lenguaje C para crear el árbol de decisión usando entropíaes casi el mismo de arriba solo hay que sustituir las funciones siguientes:
arbol bayesrecursivo(int renini, int ren�n) sustituir por arbol entrorecur-sivo(int renini, int ren�n) �oat bayes() sustituir por �oat entro()
a continuación proporcionamos las funciones de entropía:
/*Calcula el valor de la entropia informatica para cada vez que juega*/float entro(){float z;for(z=0; z<=num_etiqs; z++)
{if(etiqs[(int)z].cuenta==1){var_total=var_total+((etiqs[(int)z].conta_id/num_etiqs)*
(log(num_etiqs/etiqs[(int)z].conta_id)/log(2)));}
}for(z=0; z<=num_etiqs; z++){
if(etiqs[(int)z].cuenta==1){var_pro[(int)z]=var_total-
((etiqs[(int)z].con_si/etiqs[(int)z].conta_id)*(log(etiqs[(int)z].conta_id/etiqs[(int)z].con_si)/log(2))+

54APÉNDICE B. CÓDIGODEL ALGORITMO ID3 PARA EL PROBLEMADEL TENIS
((etiqs[(int)z].conta_id-etiqs[(int)z].con_si)/etiqs[(int)z].conta_id)*(log(etiqs[(int)z].conta_id/((etiqs[(int)z].conta_id-etiqs[(int)z].con_si))/log(2))));
}}for(z=0; z<=num_etiqs; z++)
{if(etiqs[(int)z].cuenta==1){etiqs[(int)z].proba=(var_pro[(int)z]/var_total);/*Despliega la entropia de cada atributo*/printf("El dato %s, con identificador %d, tiene entropia de
%%f\n",etiqs[(int)z].etiq,etiqs[(int)z].id,etiqs[(int)z].proba);
}etiqs[(int)z].cuenta=0;var_pro[(int)z]=0;}getch();var_total=0;return 0;}
/*Modulo recursivo para la construccion del arbol*/arbol entrorecursivo(int renini, int renfin){arbol res;int i,ns,k,max,mitad;for (k=0; k<=renfin; k++) {
if(strcmp(etiqs[k].etiq,"si")==0){break;}
}for (i=renini, ns=0; i<=renfin; i++) {if (matrix[i][col-1] == etiqs[k].id)

B.2. CÓDIGO ENTROPÍA 55
{ns++;}}printf(" \n ");
if ((renini == renfin) || ns == (renfin-renini)){
printf("El atributo %s, es una hoja\n",etiqs[max].etiq);}
else{max = contador(renini, renfin);res=(tnodo *)malloc(sizeof(tnodo));res->datos=max;res->izq=NULL;res->der=NULL;/*Despliega mensaje cada que encuentra una hoja*/printf("Elegi %s\n",etiqs[max].etiq);mitad = reordena_matrix(renini,renfin,max);if(renini<mitad){
res->izq=entrorecursivo(renini,mitad);}if(mitad+1<renfin){
res->der=entrorecursivo(mitad+1,renfin);}}
return res;}____________________________________________________________

56APÉNDICE B. CÓDIGODEL ALGORITMO ID3 PARA EL PROBLEMADEL TENIS

Bibliografía
[A90] O' Keefe Richard A. The Craft of Prolog. The MIT Press, CambridgeMassachusetts, 1990.
[CM87] W. F. Clocksin and C. S. Mellish. Programming in Prolog. Springer-Verlag, USA, 3rd edition, 1987.
[Mic83] Ryszard S. Michalski, editor. Machine learning, an arti�cial intelli-gence approach. Morgan Kaufmann Publishers, USA, 1983.
[Phi87] R. Robinson Phillip. Aplique Turbo Prolog. Mc Graw Hill, 1987.
[Ros93] Quinlan J. Ross. C.45 Programs for machine learning. MorganKaufmann Publishers, USA, 1993.
[web] http://www.ciberconta.unizar.es/biblioteca/0007/arboles.html.
57


















