
PROBLEMAS DE SEGURIDAD EN EL MUNDO INUX - redes … filePROBLEMAS DE SEGURIDAD EN EL MUNDO UNIX -...
70
PROBLEMAS DE SEGURIDAD EN EL MUNDO UNIX - LINUX 1.- Introducción 1.1.- Conceptos generales sobre seguridad 1.2.- Políticas de seguridad 1.3.- Seguridad por ocultación 2.- Clasificación de Sistemas operativos confiables: Libro Naranja 2.1.- Introducción 2.2.- Clases de seguridad 2.2.1.- D: seguridad mínima 2.2.2.- C1: protección mediante seguridad discrecional 2.2.3.- C2: protección mediante accesos controlados 2.2.4.- B1: protección mediante seguridad etiquetada 2.2.5.- B2: protección estructurada 2.2.6.- B3: dominios de seguridad 2.2.7.- A1: diseño verificado 2.2.8.- Tabla resumen 3.- Mecanismos de seguridad de UNIX 3.1.- Introducción 3.2.- Usuarios y grupos en UNIX 3.2.1.- Cuentas de usuario 3.2.2.- El archivo /etc/passwd 3.2.3.- Identificador de usuario (UID) 3.2.4.- Grupos 3.2.5.- El archivo /etc/group 3.2.6.- Identificador de grupo (GID) 3.2.7.- Contraseñas 3.2.8.- Usuarios especiales: el superusuario 3.2.9.- El comando su 3.3.- El sistema de ficheros de UNIX 3.3.1.- Introducción 3.3.2.-Tipos básicos de archivos
Transcript of PROBLEMAS DE SEGURIDAD EN EL MUNDO INUX - redes … filePROBLEMAS DE SEGURIDAD EN EL MUNDO UNIX -...

PROBLEMAS DE SEGURIDAD EN EL MUNDO
UNIX - LINUX
1.- Introducción
1.1.- Conceptos generales sobre seguridad
1.2.- Políticas de seguridad
1.3.- Seguridad por ocultación
2.- Clasificación de Sistemas operativos confiables: Libro Naranja
2.1.- Introducción
2.2.- Clases de seguridad
2.2.1.- D: seguridad mínima
2.2.2.- C1: protección mediante seguridad discrecional
2.2.3.- C2: protección mediante accesos controlados
2.2.4.- B1: protección mediante seguridad etiquetada
2.2.5.- B2: protección estructurada
2.2.6.- B3: dominios de seguridad
2.2.7.- A1: diseño verificado
2.2.8.- Tabla resumen
3.- Mecanismos de seguridad de UNIX
3.1.- Introducción
3.2.- Usuarios y grupos en UNIX
3.2.1.- Cuentas de usuario
3.2.2.- El archivo /etc/passwd
3.2.3.- Identificador de usuario (UID)
3.2.4.- Grupos
3.2.5.- El archivo /etc/group
3.2.6.- Identificador de grupo (GID)
3.2.7.- Contraseñas
3.2.8.- Usuarios especiales: el superusuario
3.2.9.- El comando su
3.3.- El sistema de ficheros de UNIX
3.3.1.- Introducción
3.3.2.-Tipos básicos de archivos

3.3.3.- Inodos o nodos indice
3.3.4.- Fechas de los archivos
3.3.5.- Permisos de un archivo
3.3.6.- SUID, SGID y los bits adhesivos
3.3.6.1.- Cambio de UID: setuid()
3.3.7.- Listas de control de acceso (ACLs)
3.3.8.- Archivos de dispositivo
3.3.9.- Sistemas de ficheros montados
4.- Mantenimiento de sistemas confiables
4.1.- Introducción
4.2.- Criptografía
4.3.- Defensa de cuentas
4.3.1.- Cuentas sin contraseña
4.3.2.- Cuentas predeterminadas
4.3.3.- Cuentas que ejecutan sólo una instrucción
4.3.4.- Cuentas abiertas
4.3.4.1.- interpretes de comandos restringidos
4.3.4.2.- Sistemas de archivos restringidos
4.4.- Auditoría
4.4.1.- Introducción
4.4.2.- El sistema de log en UNIX
4.4.3.- El demonio syslogd
4.4.4 Algunos archivos de log
4.5.- Amenazas programadas
4.5.1.-Introducción
4.5.2.-Base Fiable de Cómputo
4.5.3.-Tipos de amenazas programadas
4.5.4.-Programación segura
4.5.4.1.-Buffer overflow
4.5.4.2.- Recomendaciones para una programación segura
4.5.4.3.- Utilización segura de funciones de biblioteca
5.- Bibliografía

1.- Introducción.
1.1.- Conceptos generales sobre seguridad.
Seguridad informática
"Una computadora es segura si se puede confiar en que, junto con sus programas, funcione como se espera."
Una computadora se considera segura (o confiable, introduciremos este concepto más adelante) si los datos contenidos en ella seguirán estando allí y nadie que no deba leerlos los lea.
Según esto, los desastres naturales y los errores de programación son amenazas a la seguridad al igual que los usuarios no autorizados. Por lo tanto no existe diferencia si los datos se pierden por actos de un estudiante vengativo, por un virus, un error inesperado o un rayo: los datos se han perdido de igual forma.
Seguridad y UNIX
Dennis Ritchie dijo sobre UNIX: "No se diseñó para ser seguro. Se diseñó para que se pudiera usar la seguridad."
UNIX es un sistema operativo multiusuario y multitarea. Una de las funciones naturales de estos sistemas es prevenir que distintos usuarios o programas que están usando la misma computadora se estorben. Si no existiera esta protección un programa podría afectar al funcionamiento de los programas de otros usuarios, borrar accidentalmente datos e incluso parar todo el sistema. Para evitar esto UNIX siempre ha contado con algún tipo de mecanismos de seguridad.
Pero esta seguridad no se limita a la protección de la memoria. UNIX posee un sistema de archivos que controla la forma en que los usuarios acceden a los archivos y a los recursos del sistema.
La mayor parte de los fallos de seguridad que se han encontrado se deben a problemas de configuración y programas con errores, y no a defectos en el diseño del sistema.
Confiabilidad
Al referirse al nivel de seguridad de un sistema operativo, no es habitual utilizar los términos "seguro" o "inseguro" , sino que se usa el término "confiable" para describir el nivel de confianza que se tiene en que un sistema se comporte como se espera.
Esto implica que no se puede lograr la seguridad absoluta, sino que se trata de acercarse a ella intentando conseguir un grado de confianza suficiente

para garantizar el funcionamiento correcto del sistema, dependiendo del contexto en el que se encuentre.
1.2.- Políticas de seguridad.
A pesar de no ser el objetivo fundamental de este trabajo, es importante considerar el establecimiento de políticas de seguridad a la hora de estudiar la seguridad de un sistema informático. Debido a esto, resumiremos los conceptos más relevantes de las políticas de seguridad.
La planificación de las políticas de seguridad se dividen en seis etapas diferentes:
a.-Planificación de las necesidades de seguridad:
Existen diferentes clases de seguridad, por lo que, dependiendo del tipo de sistema, habrá que dar mayor o menor importancia a las que tengan más relevancia:
Confidencialidad: Impedir el acceso a la información a usuarios no autorizados.
Integridad de los datos: Evitar el borrado o alteración indeseados de la información, incluidos los programas.
Disponibilidad: Asegurar que los servicios esté siempre disponibles para un usuario autorizado.
Consistencia: Asegurar que el sistema se comporta como esperan los usuarios autorizados; imagine lo que ocurriría si el comando ls borrara archivos de vez en cuando en lugar de listarlos.
Control: Reglamentar el acceso al sistema, de forma que programas e individuos no autorizados y desconocidos no alteren el normal funcionamiento del sistema.
Auditoría: Determinar qué se hizo, quién lo hizo y qué fue afectado. Para esto es necesario llevar un registro inexpugnable de todas las actividades realizadas en el sistema y que identifica de forma no ambigua a los usuarios que las llevaron a cabo.
b.-Análisis de riesgos:
Trata de responder a tres preguntas: ¿qué se debe proteger?, ¿contra qué debe protegieres?, ¿cuánto se está dispuesto a invertir para obtener una protección adecuada?. Para responder a estas preguntas, el análisis de riesgos se divide en tres etapas:
Identificación de los activos.

Identificación de las amenazas.
Cálculo de los riesgos.
c.- Análisis de costo-beneficio.
Consiste en asignar un costo a cada riesgo, y determinar el costo de defenderse. De esta manera se puede decidir qué medidas hay que adoptar para proteger qué activos. Este aspecto no lo desarrollaremos por que no entra en el ámbito de este estudio.
d.-Políticas de seguridad.
Las políticas sirven para definir qué se considera valioso y especifican qué medidas hay que tomar para proteger esos activos.
Deben aclarar qué se está protegiendo, establecer la responsabilidad de la protección y poner las bases para resolver e interpretar conflictos posteriores. No deben hacer una lista de riesgos específicos, computadoras o individuos por nombre. Deben ser generales y no variar mucho a lo largo del tiempo.
e.-Implementación.
f.- Auditoría y respuesta ante incidentes.
Estos dos últimos apartados constituyen el resto de este trabajo.
1.3.- Seguridad por ocultación
Esta costumbre proviene de las aplicaciones militares, donde la ocultación es una forma efectiva de protección. Pero trasladar este concepto a un ambiente de computación no resulta apropiado, pudiendo resultar incluso dañino para la seguridad.
La ocultación presenta bastantes inconvenientes. Por ejemplo, al negar el acceso a los manuales a los usuarios, un administrador puede pensar que ha mejorado la seguridad al impedir a estos el conocimiento de comandos y opciones que pueden usarse para penetrar el sistema. Sin embargo, resulta sencillo conseguir esa documentación por diversos medios (universidades, Internet, librerías, ...), por lo que los administradores no pueden impedir que los usuarios accedan a la documentación.
Además, esto redunda en una pérdida de eficacia de los usuarios, al no poder consultar los manuales. Esto también conlleva una actitud negativa porque da a entender que no se confía en los usuarios.
Los errores de programación o características excepcionales son también objeto habitual de la ocultación, pero esto también es una mala política. Los desarrolladores colocan frecuentemente puertas traseras en sus programas

que permiten obtener privilegios sin autentificarse debidamente. Otras veces esto permite que errores de programación que afectan gravemente a la seguridad del sistema persistan ya que se supone que nadie los conoce. El problema es que estos agujeros de seguridad tienden a ser descubiertos por accidente o por intrusos persistentes.
Otra práctica habitual es mantener en secreto algoritmos desarrollados localmente, tales como algoritmos de cifrado. Esto también presenta algunos inconvenientes. Sin un estudio en profundidad estos podrían presentar graves fallos de seguridad, y este estudio no es posible si se mantienen en secreto.
Desde el punto de vista de los sistemas operativos, mantener el código fuente en secreto no garantiza la seguridad. Si un intruso desea penetrar en el sistema, antes o después descubrirá algún fallo de seguridad (estos siempre existen), pero el resto de usuarios bienintencionados no podrá revisar el código en busca de estos fallos.
Es mejor usar algoritmos y mecanismos robustos aunque sean conocidos por los enemigos, ya que esto además puede desalentar a un posible atacante consciente de la fiabilidad del mecanismo. "Poner dinero en una caja fuerte es mejor que esconderlo en un frasco de mayonesa en la cocina porque nadie sabe que está allí."
2.- Clasificación de Sistemas operativos confiables: Libro Naranja.
2.1.- Introducción
El Libro Naranja (Trusted Computer System Evaluation Criteria), elaborado por el Ministerio de Defensa de los E.E.U.U en 1983, establece criterios para medir la fiabilidad de los sistemas informáticos en lo respectivo a la seguridad.
Antes de describir los diferentes niveles de seguridad, es necesario conocer algunos conceptos relevantes :
Base fiable de cómputo(TCB): Es el conjunto de mecanismos relevantes a efectos de la seguridad del sistema. En las clases con una fiabilidad elevada, la TCB se construye en torno a un monitor de referencias que impone las relaciones de acceso autorizadas entre los sujetos y objetos de un sistema.
Control de accesos discrecional: Permite restringir el acceso a los objetos basándose en la identidad de los usuarios y/o grupos de usuarios a

los que pertenecen. Los usuarios protegen sus objetos indicando quién puede acceder y el tipo de acceso permitido.
Reutilización de objetos: Implica proteger ficheros, memoria y otros objetos de accesos por parte de un usuario tras su uso por otro. Por ejemplo: Un usuario crea un fichero en el que almacena información confidencial y después lo borra. A continuación otro usuario malicioso reserva espacio en el disco y el sistema le asigna esos mismos bloques. Si el sistema no borra físicamente la información del usuario anterior, el otro usuario podría leer la información borrada por el dueño original .
Etiquetas: Las etiquetas de confidencialidad se asocian a cada sujeto (usuario, proceso) y a cada objeto (fichero, directorio, ...) e indican su nivel de autoridad asociado y se denomina habilitación. La etiqueta de confidencialidad de un fichero especifica el nivel de autoridad que un usuario debe tener para acceder al mismo.
Identificación y autentificación: Es necesario que los usuarios se identifiquen antes de realizar cualquier actividad que implique una interacción con la TCB (ejecutar un programa, leer un fichero). En los sistemas UNIX la identificación se realiza mediante un nombre de conexión (login) y la autentificación mediante una contraseña (password).
Vía fiable: En algunos sistemas se requiere que los usuarios puedan conectarse desde un terminal al sistema a través de lo que llamaremos una vía fiable. Para ello existe una secuencia de teclas, que al pulsarse elimina todos los procesos actuales y establece una conexión segura con la TCB permitiendo su autentificación. Esto evita ataques sistemáticos contra el sistema mediante programas marcadores y la introducción de caballos de Troya en los programas de conexión al sistema
Auditoria: Es el registro y examen de la actividades relacionadas con la seguridad en un sistema fiable. Las actividades relacionadas con la seguridad son los accesos (y sus intentos) de un sujeto sobre un objeto y suelen denominarse sucesos. Cada vez que se produce un suceso, debe almacenarse en el registro de auditoria la siguiente información: fecha, hora, identificador del usuario, tipo, si ha tenido éxito, terminal, nombre de objeto, descripción de las modificaciones en la TCB y clases de seguridad del sujeto y del objeto.
Arquitectura del sistema: Están relacionados con el diseño de un sistema para que sea posible la seguridad."
Integridad del sistema: Se refiere al conjunto de pruebas de integridad que se ejecutan siempre que se arranca el ordenador, o periódicamente siguiendo un mantenimiento preventivo (en UNIX, se lleva a cabo un chequeo del sistema de ficheros cada vez que se monta un determinado numero de veces).

Canales ocultos: Son rutas de información que habitualmente no se utilizan como medio de comunicación en el sistema y, por lo tanto, no están protegidos por sus mecanismos de seguridad. Utilidad para la administración de la fiabilidad: Implica asignar todas las actividades de seguridad a una persona diferente al administrador de sistema. Esto se basa en el principio de que es mejor asignar las actividades de seguridad a varias personas, para que el control total no recaiga sobre una sola persona, lo que podría comprometerlo.
Gestión de configuración: protege a un sistema fiable mientras se diseña, desarrolla y mantiene. Implica controlar todos lo cambios realizados en la TCB. Así se mantiene un control del sistema durante su ciclo de vida, asegurando que el sistema que se utiliza no es una versión antigua del mismo.
Distribución segura: Garantiza la protección del sistema mientras se envía a un cliente, asegurando que el sistema que recibe es idéntico al suministrado por el vendedor.
Guía de usuario sobre las características de seguridad: Indica a los usuarios no privilegiados del sistema todo lo que deben saber sobre la seguridad.
Manual para la administración de la seguridad: Proporciona a los administradores toda la información necesaria para establecer e implantar la seguridad del sistema
Documentación de pruebas: Debe contener un plan de pruebas con el objeto de encontrar cualquier posible error en el diseño o implementación de la TCB, que permite a un usuario acceder a información no autorizada.
Documentación de diseño: Permite conocer la construcción interna de la TCB, ayudando a los equipos de diseño y desarrollo a definir el modelo de seguridad del sistema y su construcción.
2.2.- Clases de seguridad
El Libro Naranja divide su clasificación en cuatro niveles de seguridad. Los requisitos para un determinado nivel siempre lo son para el siguiente, pudiendo este restringir más aún los criterios, ya que se trata de una jerarquía de niveles:
2.2.1.- D: seguridad mínima
En esta categoría están englobados todos los sistemas que han sido valorados y no han superado los requisitos mínimos para pertenecer a un nivel de seguridad superior. En esta categoría no existen requisitos de seguridad."

En realidad ningún sistema pertenece a esta categoría, puesto que ningún vendedor evaluaría un sistema para obtener un nivel de seguridad "D". Ordenadores bajo MS-DOS o las versiones personales de Windows (familia 9x), además de otros sistemas antiguos son un ejemplo de sistemas que pertenecerían a esta categoría.
2.2.2.- C1: protección mediante seguridad discrecional
Todos los usuarios manejan los datos al mismo nivel . En este nivel se procura evitar que los usuarios cometan errores y dañen al sistema. Las características mas importantes de este nivel son el control de autentificación mediante contraseñas y la protección discrecional de los objetos. El código del sistema debe estar protegido frente a ataques procedentes de programas de usuario (en UNIX, un proceso no puede salirse de su espacio virtual de direcciones ,y si lo intenta, morirá.
Un sistema de este nivel no necesita distinguir entre usuarios individuales, Tan solo entre tipos de accesos permitidos o rechazados. En UNIX C1 hay que ser dueño de un objeto para ceder sus derechos de accesos y siempre se protege a los objetos de nueva creación.
2.2.3.- C2: protección mediante accesos controlados
A partir de este nivel, el sistema debe ser capaz de distinguir entre los usuarios individuales. Generalmente el usuario debe ser dueño de un objeto para ceder los derechos de acceso sobre él. En la mayoría de los sistemas UNIX a partir de este nivel, existen listas de control de acceso (ACLs). Debe permitir que los recursos del sistema se protejan mediante accesos controlados. En UNIX el acceso a los periféricos (dispositivos de E/S) siguen un esquema de permisos idéntico al de los ficheros de los usuarios.
Se aplican los requisitos de reutilización de objetos cuando esos mismos se reasignan.
Se requiere a partir de este nivel que el sistema disponga de auditoria. Por ello cada usuario debe tener un identificador único que se utiliza para comprobar todas las acciones solicitadas. Se deben auditar todos los sucesos relacionados con la seguridad y proteger la información de la auditoria. El sistema debe ser capaz de auditar a nivel de usuario.
La mayor parte de los UNIX comerciales pertenecen a este nivel, puesto que lo único que han tenido que añadir los fabricantes es un paquete de auditoria.
2.2.4.- B1: protección mediante seguridad etiquetada
A partir de este nivel, los sistemas poseen un sistema de control de accesos obligatorio que implica colocar una etiqueta a los objetos (principalmente sobre los ficheros). Esto, junto con el nivel de habilitación de los usuarios es utilizado para reforzar la política de seguridad del sistema. En estos

sistemas, el dueño no es el responsable de la protección del objeto, a menos que disponga de la habilitación necesaria.
En cuanto a la auditoria, el sistema debe ser capaz de registrar cualquier cambio o anulación en los niveles de seguridad, y también hacerlo selectivamente por nivel de seguridad."
Debe existir una documentación que incluya el modelo de seguridad soportado por el sistema. No es necesaria una demostración matemática, pero si una exposición de las reglas implantadas por las características de seguridad del sistema.
2.2.5.- B2: protección estructurada
A partir de este nivel, los cambios en los requisitos no son visibles desde el punto de vista del usuario respecto de los niveles anteriores.
En B2, todos los objetos del sistema están etiquetados, incluidos los dispositivos. Deben existir vías fiables que garanticen la comunicación segura entre un usuario y el sistema. Los sistemas deben ser modulares y utilizar componentes físicos para aislar las funciones relacionadas con la seguridad de las demás. Requieren una declaración formal del modelo de seguridad del sistema, y que haya una gestión de la configuración. También deben buscarse los canales ocultos.
2.2.6.- B3: dominios de seguridad
Es necesario que exista un administrador de seguridad, que sea alertado automáticamente si se detecta una violación inminente de la seguridad.
Deben existir procedimientos para garantizar que la seguridad se mantiene aunque el ordenador se caiga y luego rearranque. Es obligatoria la existencia de un monitor de referencia sencillo, a prueba de agresiones e imposible de eludir. La TCB debe excluir todo el código fuente que no sea necesario para proteger el sistema.
2.2.7.- A1: diseño verificado
Esta es la clase de certificación más alta, aunque el Libro Naranja no descarta la posibilidad de exigir requisitos adicionales. Son sistemas funcionálmente equivalentes a B4. Tan solo se añade la distribución fiable que refuerza la seguridad. Los sistemas A1 tienen la confiabilidad adicional que ofrece el análisis formal y la demostración matemática de que el diseño del sistema cumple el modelo de seguridad y sus especificaciones de diseño.
En la siguiente tabla se resumen las características principales de los diferentes niveles de seguridad definidos en el Libro Naranja:
2.2.8.- Tabla resumen

Requisito C1 C2 B1 B2 B3 A1
Control de accesos discrecional nue mej sin sin mej sin
Reutilización de objetos no nue sin sin sin sin
Dispositivos mononivel/multinivel no no nue sin sin sin
Control de accesos obligatorio no no nue mej sin sin
Etiquetas no no no nue sin sin
Identificación y autentificación nue mej mej sin sin sin
Auditoria no nue mej mej mej sin
Vías fiables no no no nue mej sin
Arquitectura del sistema nue mej mej mej mej sin
Integridad del sistema nue sin sin sin sin sin
Pruebas de seguridad nue mej mej mej mej mej
Especificación y verificación del diseño no no nue mej mej mej
Canales ocultos no no no nue mej mej
Facilidad para la administración de la fiabilidad
no no no nue mej sin
Gestión de configuración no no no nue sin mej
Recuperación segura no no no no nue sin
Distribución segura no no no no no nue
Guía de usuario de seguridad nue sin sin sin sin sin
Guía de administración de la seguridad nue mej mej mej mej sin
Documentación de pruebas nue sin sin mej sin mej
Documentación de diseño nue sin mej mej mej mej
Leyenda:
no: no existe criterio en esta clase.
nue: criterio nuevo para esta clase
mej: nuevos requisitos para el criterio en esta clase.
sin: no existen requisitos adicionales para el criterio en esta clase.

3.- Mecanismos de seguridad de UNIX
3.1.- Introducción
En este capítulo se destacan los principales mecanismos de seguridad de UNIX, es decir, aquellos recursos que el sistema operativo proporciona y que conforman la base sobre la que se establece la seguridad.
El conocimiento de estos mecanismos por parte del administrador de seguridad es completamente imprescindible, puesto que, bien utilizados permiten que el sistema se muestre robusto ante cualquier ataque o fallo. Por otro lado, mal utilizados proporcionarán una puerta abierta a cualquier atacante o convertirán un programa inocente en un auténtico agujero de seguridad.
3.2.- Usuarios y grupos en UNIX
Las cuentas de usuario son el primer objetivo de cualquier atacante, su finalidad suele ser casi siempre esta, penetrar en el sistema consiguiendo apoderarse de una cuenta de usuario (preferentemente la del root). Después pueden robar, destruir o falsificar datos o simplemente dejar una nota, pero el daño ya está hecho: la seguridad del sistema se ha visto comprometida.
3.2.1.- Cuentas de usuario
Como se señala en el capítulo anterior, la identificación en los sistemas UNIX se realiza mediante un nombres de usuarios (login) y la autentificación mediante contraseñas (password). Los nombres de usuario se conocen también como nombres de cuenta. Para iniciar una sesión en un sistema UNIX, es necesario conocer tanto el nombre de usuario como la contraseña correspondiente. Por ejemplo, Manuel Rodríguez posee una cuenta en el servidor de practicas de su universidad. Su nombre de usuario es manurod y su contraseña es "as35FgS". Cuando Manuel desee iniciar una sesión de trabajo en el laboratorio, deberá autentificarse como usuario autorizado ante la máquina de la siguiente manera:
Bienvenido al servidor X de la Universidad Y
login: manurod
password: as35FgS
De esta manera, el usuario queda totalmente autentificado y obtendrá un interprete de comandos (shell) desde el que podrá realizar

diferentes tareas. Otra posibilidad es que el servidor disponga de un entorno de trabajo en modo gráfico (X-Window), en ese caso el proceso de autentificación se realiza de idéntica manera, con la única diferencia de que el usuario obtendrá un entorno gráfico de trabajo en lugar del shell habitual.
Los nombres de usuario estándar en UNIX tienen una longitud que puede ir de 1 a 8 caracteres. Estos nombres deben ser únicos en una misma computadora, puesto que deben identificar al usuario de forma inequívoca (después se vera que esto no es estrictamente cierto, puesto que dos usuarios pueden compartir el mismo UID). Las contraseñas en UNIX tradicionalmente tenían una longitud de entre 1 y 8 caracteres, aunque algunas versiones comerciales permiten contraseñas mas largas. El uso de contraseñas mas largas implica una mayor seguridad, por que son mas difíciles de adivinar. La contraseña no debe ser obligatoriamente única para cada usuario, varios usuarios pueden tener, de hecho, la misma contraseña, aunque de ser así, esto indicaría que estos usuarios han elegido una mala contraseña.
La elección de las contraseñas, así como las posibles restricciones que se pueden establecer sobre ellas, es de vital importancia a la hora de evitar intrusiones en el sistema, por ello, se dedicará a esto otro apartado.
3.2.2.- El archivo /etc/passwd
En los sistemas tipo UNIX , la información sobre las cuentas de usuario se almacenan en una base de datos localizada en el archivo /etc/passwd. Esta es un fichero de texto en el que los diferentes registros se encuentran separados por el carácter dos puntos (:).
Se puede emplear el comando cat para visualizar el contenido del fichero passwd. A continuación se puede ver una muestra de un archivo típico como ejemplo :
root:o8o7aSVh13nLD:0:0:root:/root:/bin/bash
bin:*:1:1:bin:/bin:
daemon:*:2:2:daemon:/sbin:
adm:*:3:4:adm:/var/adm:
lp:*:4:7:lp:/var/spool/lpd:
mail:*:8:12:mail:/var/spool/mail:
news:*:9:13:news:/var/spool/news:
uucp:*:10:14:uucp:/var/spool/uucp:

operator:*:11:0:operator:/root:
ftp:*:14:50:FTP User:/home/ftp:
nobody:*:99:99:Nobody:/:
manurod:EH5/.mj7J5dFh:501:100:Manuel Rodríguez:/home/alumnos/manurod:/bin/bash
maripet:aCq87MCñ03c9e:502:100:Mario Petru:/home/alumnos/maripet:/bin/bash
javitup:md0mHM86yn3aW:503:100:Javier Tup:/home/alumnos/javitup:/bin/bash
Algunas de las cuentas del ejemplo son cuentas del sistema como root,daemon o apm. El resto son cuentas de usuario regulares del sistema como manurod, javitup, maripet.
Las cuentas que tienen un * en al campo de la contraseña no pueden ser utilizadas para iniciar una sesión desde un terminal, es necesario utilizar la orden su. Son cuentas de sistema (en ocasiones usuarios 'castigados'), que poseen archivos, a veces muy importantes, que realizan tares administrativas o dan servicios.
Cada campo individual del archivo passwd posee un significado directo. En la siguiente tabla se explica el significado de una de las líneas del ejemplo:
Campo Contenido
manurod Nombre de usuario
EH5/.mj7J5dFh Contraseña cifrada del usuario
501 Numero de identificación del usuario (UID)
500 Numero de identificación de grupo del usuario (GID)
Manuel Rodríguez Nombre completo del usuario
/home/alumnos/manurod/ Directorio base del usuario
/bin/bash Interprete de comandos del usuario
La contraseña se guarda cifrada. La contraseña en sí no se guarda tal cual en el sistema, si así se hiciera, esto representaría un grave riesgo

para la seguridad, y solo es aceptable cuando la política de seguridad lo admita por razones particulares.
En la actualidad, muchas organizaciones poseen grandes redes de tipo cliente-servidor que contienen muchos servidores y una gran cantidad de estaciones de trabajo. Normalmente es deseable que los usuarios entren en cualquiera de estas computadoras, y que lo hagan con el mismo nombre de usuario y la misma contraseña. Esto conlleva que cada usuario tenga una cuenta en cada estación de trabajo.
Este requisito hace que sea extremadamente difícil mantener la coherencia entre las bases de datos de usuarios de todas las computadores. Para lograr esto se utilizan diversos paquetes software que proporcionan el contenido del fichero /etc/passwd a toda la red.
Algunos de estos sistemas son:
Network Information System (NIS:Sistema de Información para la Red) de Sun Microsystems.
NIS+ de Sun Microsystems
Distributed Computing Environment (DCE: Ambiente de Computación Distribuido) de Open Software Foundation.
NetInfo de NeXT Computers
Todos estos sistemas toman la información, que por lo general, está almacenada en cada estación de trabajo y la ponen en una o mas computadoras que se usan como servidores de red. Al usar estos sistemas, ya no se puede usar simplemente el comando cat, sino que hay que utilizar una instrucción especifica para cada sistema para ver el contenido del archivo /etc/passwd.
El servicio NIS de Sun complementa la información almacenada en los archivos de las estaciones de trabajo. Por lo tanto, para ver la lista completa de las cuentas de usuario, es necesario listar el contenido del archivo passwd local y ademas utilizar la siguiente instrucción:
% ypcat passwd
El servicio NIS+, también de Sun, se puede configurar para complementar sustituir sus entradas sobre cuentas de usuario en lugar de las que están en el archivo passwd local, dependiendo del contenido del archivo /etc/nsswitch.conf. Para ver la lista de usuarios bajo NIS+ hay que utilizar el comando niscat y especificar el dominio de NIS+. Por ejemplo :
% niscat -o passwd.dominio

En las computadoras que ejecutan NetInfo, el archivo local no se toma en cuenta y en su lugar se usa la versión de red. Por ejemplo, para ver las cuentas de usuario, si se usa NetInfo, hay que escribir:
% nidump passwd /
Las computadoras que usan DCE emplean una base de datos de red cifrada como alternativa a las contraseñas cifradas y al archivo /etc/passwd.
Muchos administradores no utilizan sistemas de administración de bases de datos en red porque temen que la seguridad se vea comprometida. Estos temores provienen del hecho de que la configuración de estos sistemas es, en ocasiones, muy complicada y los protocolos que utilizan pueden no ser particularmente resistentes a ataques. Es una practica habitual entre los administradores mantener simplemente un archivo central con la información de los usuarios y copiarlo de forma periódica en las computadoras remotas. El inconveniente que se presenta es que con frecuencia el administrador tiene que cambiar manualmente contraseñas de usuarios. En general, es preferible aprender a dominar la configuración de estos sistemas y luego colocar otras medidas defensivas como es el caso del cortafuegos (firewall).
3.2.3.- Identificador de usuario (UID)
El UID es un número entero real de 16 bits (de 0 a 65535). Los primeros UID se usan principalmente para funciones del sistema. Para las personas, normalmente empiezan en el 20, el 100 o el 500. Es habitual asignar el UID dependiendo del grupo primario del usuario: los usuarios del grupo 500 tendrán los UID 501, 502, 503, y así sucesivamente. Algunas versiones de UNIX permiten ahora UID de 32 bits. En las versiones antiguas de UNIX los UID son enteros de 16 bits con signo (de -32768 a 32767).
UNIX utiliza el archivo /etc/passwd para almacenar la correspondencia entre el nombre de cada usuario y su UID. El UID de cada usuario se guarda en el tercer campo, después de la contraseña cifrada. Esta es una línea del ejemplo anterior:
manurod:EH5/.mj7J5dFh:501:100:Manuel Rodríguez:/home/alumnos/manurod:/bin/bash
Aquí se puede ver que el UID de manurod es 501.
El UID es la información real que utiliza el sistema operativo para identificar al usuario. Los nombre de usuario son solo una comodidad para nosotros. Si dos usuarios tienen el mismo UID, UNIX los trata como si fueran el mismo usuario, aunque tengan nombres y contraseñas distintos. Dos usuarios con el mismo UID pueden leerse y

borrarse archivos libremente el uno al otro, así como suspenderse los programas que ejecuten. Asignar a dos usuarios el mismo UID es, por lo general, una mala idea, salvo algunas excepciones.
3.2.4.- Grupos
Todos los usuarios de UNIX pertenecen a uno o más grupos. El administrador del sistema puede utilizar los grupos para definir conjuntos de usuarios que tendrán permiso de leer, escribir y/o ejecutar ciertos archivos, directorios o dispositivos.
Cada usuario pertenece a un grupo primario, que se anota en el archivo /etc/passwd. El GID del grupo primario de un usuario aparece después del UID del usuario.
Los grupos permiten manejar cómodamente a varios usuarios de alguna manera. Por ejemplo, tal vez se quiera abrir un grupo para un equipo de estudiantes que trabajan en un proyecto y permitirles a ellos y sólo a ellos leer y modificar los archivos del equipo.
Los grupos también se usan para restringir el acceso a la información confidencial o aplicaciones con licencias especificas. Por ejemplo, en muchas computadoras que usan UNIX, solamente se permite examinar el contenido de la memoria del kernel del sistema a ls usuarios que pertenecen al grupo kmem. El grupo ingres se usa normalmente para quienes están registrados como usuarios del programa comercial del manejo de bases de datos Ingres.
Algunas versiones especiales de UNIX permiten usar CAO o Controles de Acceso Obligatorio (MAC: Mandatory Access Controls), los cuales controlan el acceso mediante etiquetas en los datos, ademas o en lugar de los controles tradicionales CAV o Controles de Acceso Voluntario (DAC: Discretionary Access Controls) de UNIX . Los sistemas que se basan en CAO/CAV (MAC/DAC) no emplean los grupos tradicionales de UNIX. En su lugar, los valores de los GID y el archivo /etc/group se pueden usar para especificar etiquetas de seguridad para el control de acceso o bien para apuntar a listas de capacidades.
3.2.5.- El archivo /etc/group
El archivo /etc/group contiene la base de datos con todos los grupos que hay en la computadora y sus GID correspondientes. Su formato es similar del del archivo /etc/passwd.
He aquí una muestra de archivo /etc/group que pertenece a un sistema típico:
root:*:0:root

bin:*:1:root,bin,daemon
daemon:*:2:root,bin,daemon
sys:*:3:root,bin,adm
adm:*:4:root,adm,daemon
lp:*:7:daemon,lp
kmem:*:9:
wheel:*:10:root,javitup
mail:*:12:mail
news:*:13:news
uucp:*:14:uucp
ftp:*:50:
users:*:100:
floppy:*:19:
cdwriter:*:500:manurod
pppusers:*:44:maripet
La primera línea define el grupo root. Los campos se detallan en la siguiente tabla:
Campo Contenido
root Nombre de grupo
* Contraseña de grupo (cifrada)
0 Numero de identificación del grupo (GID)
root Lista de usuarios miembros del grupo
Los usuario que aparecen en el archivo /etc/group pertenecen a los grupos que se indican, además de pertenecer a sus grupos primario los

cuales se indican en el archivo /etc/passwd. Por ejemplo, manurod, maripet y javitup pertenecen al grupo users a pesar de no aparecer explícitamente en el archivo /etc/group porque su grupo primario es el 100. En algunas versiones de UNIX, se puede ejecutar el comando groups o id para ver la lista de grupos a los que se pertenece.
3.2.6.- Identificador de grupo (GID)
Todos los usuarios de UNIX pertenecen a uno o más grupos. Al igual que las cuentas de usuario, los grupos tienen un nombre de grupo y un número de identificación de grupo (GID). Usualmente, los valores de los GID también son enteros de 16 bits.
Análogamente al UID, el GID representa al grupo en el sistema, y no su nombre. Los grupos permiten agrupar a varios usuario que posean el mismo grupo primario (campo GID del archivo /etc/passwd) o que aparezcan en el archivo /etc/group.
Las versiones de UNIX de AT&T anteriores a SVR4 sólo permitían que un usuario estuviera en un grupo a la vez. Para cambiar de grupo había que usar el comando newgrp. Cuando un usuario intentaba acceder a un archivo sobre el que tenía permiso por pertenecer al mismo grupo, se le denegaba el acceso si, en ese instante, el usuario no estaba en ese mismo grupo. Por eso debía usar el comando newgrp.
En la actualidad, los usuarios pertenecen a todos los grupos en los que aparecen en el archivo /etc/group a la vez. El sistema operativo chequea todos los grupos a los que pertenece el usuario para comprobar sus derechos de acceso. Aun así, el comando newgrp sigue teniendo cierta importancia. Si un usuario quiere que sus archivos tengan un grupo (GID) en especial de entre los que posee, debe utilizar el comando newgrp en cada archivo para cambiarlos de grupo. Esto puede ser un poco pesado, si está generando muchos archivos, así que puede cambiar de grupo con newgrp, de forma que todos los archivos que genere tengan el nuevo GID.
3.2.7.- Contraseñas
Para autentificar a un usuario, este debe demostrar su identidad. Existen tres maneras por la que un usuario puede autentificarse ante el sistema. Puede usarse una o varias de estas a la vez:
Se puede indicar algo que se sabe (por ejemplo, una contraseña)
Se puede mostrar algo que se tiene (por ejemplo, una tarjeta)
La computadora puede considerar alguna característica personal (por ejemplo, una huella dactilar).

Ninguno de estos sistemas es infalible. Alguien puede robar la contraseña 'husmeando' la linea de un terminal, puede robar la tarjeta en un atraco, y si tiene un cuchillo, quizás pueda obtener una huella dactilar. En general, cuanto más confiable sea la forma de identificación, más complicada será de usar, y más agresivo deberá ser el agresor para violarla.
Las contraseñas son el sistema de autentificación más simple: son un secreto que se comparte con la computadora. Al iniciar la sesión, se escribe la contraseña para demostrar a la computadora de quién se trata. La computadora se asegura de que la contraseña corresponde al nombre de usuario que se ha especificado. Si corresponde, se puede continuar.
En el sistema UNIX no se despliega la contraseña, es decir, no se escribe en el terminal a medida que se teclea. Esto proporciona protección adicional si alguien está mirando por encima del hombro del que escribe. Esto puede parecer trivial, pero constituye la primera medida de seguridad.
Las contraseñas son la primera linea de defensa de UNIX contra los extraños que quieren penetrar en el sistema. Aunque se puede penetrar en el sistema o robar información a través de la red sin abrir una sesión, muchas intrusiones se deben a contraseñas mal elegidas y mal protegidas.
En los sistemas personales de escritorio no se usan contraseñas. La seguridad se basa en métodos físicos como paredes, puertas y cerraduras. En algunos ambientes de confianza tampoco se usan contraseñas, la confianza y el respeto pueden ser suficientes como medida de seguridad.
Pero cuando una computadora está conectada a un modem y se puede acceder desde casi cualquier parte del mundo, o cuando está conectada a una red, sobre todo Internet, entonces las contraseñas son absolutamente necesarias. Si una cuenta de una computadora que pertenece a una red se ve comprometida, puede poner en peligro a toda la red.
Las contraseñas convencionales han sido parte de UNIX desde sus primeros años. La ventaja de las contraseñas es que funcionan sin un equipo especial (como lectores de tarjeta y de huellas digitales).
En la actualidad las contraseñas convencionales en sistemas de red (la mayoría) no son suficiente. Es necesario usar contraseñas descartables o criptografía, o ambas.
En algunas versiones de UNIX, si alguien intenta iniciar una sesión varias veces seguidas de forma inválida se bloquea la cuenta. Sólo el administrados puede desbloquearla. El bloqueo protege al sistema de

quienes intentan adivinar una contraseña y avisa de que alguien ha intentado penetrar en la cuenta.
Esta táctica puede ser utilizada en ataques de negación de servicio, para bloquear a ciertos usuarios del sistema, o simplemente para fastidiar. En lugar del bloqueo, algunos sistemas (como Linux) introducen un retardo mayor cada vez que se falla una conexión desde un terminal, lo que limita los ataques de negación del servicio, cumpliendo el mismo efecto que el bloqueo.
El cambio de contraseña es otro momento crítico. El comando passwd, que sirve para cambiar la contraseña, solicita primero la contraseña anterior antes de la nueva. Así se evita que alguien se siente en un terminal abierto y cambie la contraseña. Dejar un terminal abierto sin protección, es un fallo de seguridad bastante grave, pero, por lo general, bastante común.
El comando passwd, también requiere que se repita la contraseña. Esto evita que, por un error tipográfico, se cambie la contraseña por una desconocida.
Si se recibe un correo del administrador pidiendo que se cambie la contraseña a una determinada, se debe ignorar y avisar al administrador. Este tipo de mensajes se envía con frecuencia a usuarios novatos. Si se cumple la orden, puede tener consecuencias devastadoras.
Si se comete un error, o se olvida la contraseña y se pierde es acceso a la cuenta, hay que recurrir al administrador. Este no puede descifrar la contraseña de ningún usuario. Pero puede eliminar la contraseña o cambiarla, (esta parece la mejor opción) sin dar la contraseña vigente.
Uno de los fallos más habituales es asignar como contraseña el nombre de usuario. Esta es en algunos sistemas una práctica habitual cuando se crea un usuario. Se debe obligar al usuario a cambiar la contraseña en la primera sesión. Si no lo hace, es probable que cualquiera que intente entrar en la computadora no tarde más de diez minutos en conseguirlo.
En general, se deben evitar las siguientes contraseñas:
El nombre propio, el de la esposa o del socio
En nombre de la mascota o del hijo
Los nombre de amigos o compañeros de trabajo
Los nombres de los personajes favoritos
El nombre del jefe

El nombre de cualquier persona
El nombre del sistema operativo que se está utilizando
El nombre de la computadora que se usa
El número de teléfono o el de la matricula del coche
Cualquier parte del dni o número de la Seguridad Social
Cualquier cumpleaños
Cualquier otra información que sea fácil de averiguar (dirección, universidad, etc.)
Cualquier forma del nombre de usuario (por ejemplo, en mayúsculas o con letras dobles)
Cualquier palabra que aparezca en un diccionario en cualquier idioma
Nombre propios de lugares o personas
Contraseñas que sean una repetición de la misma letra
Patrones simples de letras del teclado: por ejemplo, qwerty
Cualquiera de éstos escrito al revés
Cualquiera de éstos con un dígito al principio o al final
En general, cualquier combinación de cualquiera de las anteriores.
El motivo de estas recomendaciones, es que uno de los ataques más habituales consiste en conseguir el archivo /etc/passwd de la computadora, y utilizar después un generador de contraseñas. Estos programas (como el programa Crack) utilizan un diccionario y un archivo de normas. En el archivo de normas se encuentran reglas para combinar las palabras del diccionario. Así se genera una lista de posibles contraseñas que se encriptan (el algoritmo es público) y se comparan con las contenidas en el archivo /etc/passwd.
3.2.8.- Usuarios especiales: el superusuario
Además de los usuarios normales, UNIX tiene varios usuarios especiales para propósitos administrativos y contables. Ya se han mencionado algunos. El más importante es el root, el superusuario.
Todos los sistemas UNIX tienen un usuario especial en el archivo /etc/passwd cuyo UID es 0. Este es realmente el único usuario

realmente especial del sistema, los demás son especiales porque son propietarios de determinados archivos o pertenecen a determinados grupos (que a su vez tienen archivos importantes).
La cuenta root es la identidad que usa el sistema operativo para llevar a cabo sus funciones básicas, tales como el inicio y la terminación de sesiones de usuario, el registro de la información contable y la administración de dispositivos de entrada/salida. Por esta razón, el superusuario tiene el control de casi todo el sistema operativo: cualquier programa ejecutado por root puede eludir casi todas las restricciones de seguridad y se desactivan casi todas las verificaciones y advertencias.
Como se indicó en la sección sobre el identificador de usuario (UID), dos cuentas que tengan el mismo UID son la misma para el sistema operativo. De esta manera, cualquier cuenta que tenga el UID 0 tiene los privilegios del superusuario. El nombre de usuario root es simplemente convencional.
Hay que sospechar inmediatamente de cualquier cuenta que aparezca en el sistema con UID 0 que no haya sido creada por el administrador. Estas cuentas se añaden con frecuencia por personas que penetran en las computadoras como una manera sencilla de obtener privilegios de superusuario en el futuro.
La cuenta root no se ha diseñado para que el administrador la use como cuenta personal. Debido a que se inhabilitan todas las pruebas de seguridad para el superusuario, un error tipográfico fácilmente puede destruir todo el sistema.
Con frecuencia el administrador de un sistema UNIX tendrá que convertirse en superusuario para llevar a cabo funciones administrativas. Este cambio de estado se puede lograr mediante el comando su para crear un intérprete de comandos privilegiado. Cuando de tiene la capacidad del superusuario se deben tomar precauciones extremas. Cuando cese la necesidad de tener este tipo de acceso, el administrador debe cerrar el intérprete de comandos privilegiado.
Cualquier proceso que tiene UID efectivo 0 se ejecuta como si fuera el superusuario, es decir, cualquier proceso con UID 0 se ejecuta sin verificaciones de seguridad y puede hacer prácticamente lo que sea. Las verificaciones y controles de seguridad se ignoran en el caso del superusuario aunque la mayor parte de los sistemas sí registran en las bitácoras y auditan algunas de las acciones del superusuario.
El usuario es la principal debilidad de seguridad del sistema operativo UNIX. Dado el privilegio del superusuario, las personas que penetran en un sistema UNIX tratan de convertirse en el superusuario.

Para evitar este problema con el superusuario, se ha intentado varias veces diseñar un sistema UNIX seguro (que cumpla todos los requisitos para un sistema altamente confiable) adoptando la estrategia de dividir los privilegios del superusuario en muchas categorías. Lamentablemente estos intentos a menudo fallan. Casi siempre, muchos de los privilegios en los que se divide el superusuario pueden usarse para obtener los demás. Se cambia un gran fallo de seguridad por otros más pequeños que llevan al mismo final.
3.2.9.- El comando su
A veces un usuario debe tomar la identidad de otro. Pos ejemplo si se desea acceder a archivos propios estando sentado delante el terminal de un amigo. En lugar de cerrar la sesión del amigo e iniciar una propia, UNIX permite cambiar temporalmente el número de identificación de usuario. El comando que lo permite se llama su,que son las iniciales de “substitute user” (sustituir usuario). su requiere que se use la contraseña del usuario al que se está cambiando.
Los procesos en sistemas UNIX tienen al menos dos identidades en cada momento. Normalmente estas dos identidades son la misma. La primera identidad es el UID real. El UID real es la identidad verdadera y coincide, normalmente con el nombre de usuario con el que se inició la sesión. A veces se quiere asumir la identidad de otro usuario para acceder a algunos archivos o ejecutar algunos comandos. Esto se puede lograr iniciando una sesión con el otro nombre y obteniendo de esa forma un intérprete de comandos cuyo proceso subyacente tenga un UID igual al del usuario.
Como alternativa, si sólo se desea ejecutar algunos comandos con la identidad de otro usuario, se puede emplear el comando su para crear nuevos procesos. Esto ejecutará otra copia del intérprete de comandos que tendrá la identidad (UID real) del otro usuario. Para emplear el comando su es necesario conocer la contraseña del otro usuario o ser en ese momento el superusuario.
Si se escribe su sin un nombre de usuario, se indica a UNIX que se quiere convertir en superusuario. Entonces se solicita la contraseña del superusuario. Si la contraseña de root se escribe correctamente, se ejecuta un intérprete de comandos con UID 0. Al convertirse en superusuario, el prompt cambiará por defecto al carácter '#', lo que recordará los nuevos poderes que se han adquirido.
Cuando se usa en comando su para convertirse en superusuario, siempre debe usarse la trayectoria completa del comando /bin/su. Al hacerlo así, se asegura la ejecución del comando su auténtico y de que no se ha ejecutado algún otro comando su que se encuentre en la trayectoria de búsqueda. Esto es una manera importante de protegerse y proteger la contraseña del superusuario contra algún caballo de Troya.

Es recomendable invocar al comando su con un argumento simple en forma de guión cuando se quiere convertir en superusuario:
$ /bin/su -
De esta forma, su invoca al intérprete de comandos de forma que este lea todos loa archivos de configuración necesarios y simule un inicio de sesión. Esto es importante porque así se evita que la trayectoria de búsqueda (PATH) sea la del usuario que invoco su y no la del superusuario.
Algunas versiones del UNIX de tipo Berkeley no permiten usar su a ninguna cuenta que no sea miembro del grupo wheel. Sin embargo la versión de su de GNU no utiliza esta característica. Esta es la explicación de Richard Stallman sacada de la propia página de manual de su.
“A veces, algunos listillos intentan hacerse con el poder total sobre el resto de usuarios. Por ejemplo, en 1984, un grupo de usuarios del laboratorio de Inteligencia Artificial del MIT decidieron tomar el poder cambiando el password de operador del sistema Twenex y manteniéndolo secreto para el resto de usuarios. (De todas maneras, hubiera sido posible desbaratar la situación y devolver el control a los usuarios legítimos parcheando el kernel, pero no sabría como realizar esta operación en un sistema UNIX.)
Sin embargo, casualmente alguien contó el secreto. Mediante el uso habitual de su una vez que alguien conoce el password de root puede contárselo al resto de usuarios. El grupo "wheel" hará que esto sea imposible, protegiendo así el poder de los superusuarios.
Yo estoy del lado de las masas, no de los superusuarios. Si eres de los que están de acuerdo con los jefes y los administradores de sistemas en cualquier cosa que hagan, al principio encontrarás esta idea algo extraña.”
Muchas versiones registran los intentos fallidos del comando su. Las versiones más viejas de UNIX enviaban explícitamente a la consola los avisos de los intentos fallidos de su y también los colocaban en el archivo /var/adm/messages. Las versiones más modernas registran los intentos fallidos de usar su a través del programa syslog, el cual permite enviar los mensajes que se quieran a un archivo específico o anotarlos en bitácoras que estén en computadoras remotas a través de la red.

3.3.- El sistemas de ficheros de UNIX
3.3.1.- Introducción
El sistema de ficheros de UNIX controla el modo en el que la información se almacena en el disco y otras formas de almacenamiento secundarias. Dentro del sistema UNIX todo son archivos: desde la memoria física del equipo hasta el ratón, pasando por modems, teclado, impresoras o terminales. Por esto, una correcta utilización de los permisos, atributos y otros controles sobre ficheros es vital para la seguridad de un sistema.
El sistema de ficheros proporciona las herramientas básicas para el administrador, pero también para el atacante, sea este voluntario, un fallo de un usuario o de un programa. Ya que en UNIX todos los objetos son elementos del sistema de ficheros (a partir de aquí archivos o ficheros, indistintamente), un error en un permiso puede facilitar la escritura de cualquier usuario en un disco o en un directorio importante, la consecución de un shell privilegiado, o la posibilidad de que un usuario 'vea' la memoria de todos los demás usuarios(y la del sistema).
3.3.2.-Tipos básicos de archivos.
En un sistema UNIX existen tres tipos básicos de archivos: ficheros planos, directorios y ficheros especiales (dispositivos). También existen otros tipos de archivos como los enlaces simbólicos, los sockets o las tuberías, pero no se tratarán aquí.
Ficheros planos: Son secuencias de bytes, que a priori no poseen ni estructura interna ni contenido significante para el sistema, su significado depende de las aplicaciones que interpretan su contenido.
Directorios: Son archivos cuyo contenido son otros ficheros de cualquier tipo (planos, otros directorios y otros ficheros especiales).
Ficheros especiales: Son archivos que representan dispositivos del sistema. Se dividen en dos grupos: los dispositivos orientados a carácter y los orientados a bloque. La principal diferencia entre ambos es la forma de realizar operaciones de entrada/salida:mientras que los dispositivos orientados a carácter la realizan byte a byte (esto es, carácter a carácter ), los orientados a bloque la realizan en bloques de caracteres .
3.3.3.- Inodos o nodos indice
Para cada objeto en el sistema de ficheros, UNIX guarda información administrativa en una estructura llamada inodo. Los inodos residen en

el disco y no tienen nombre, en vez de ello, tienen indices (números) que indican su posición en un arreglo de inodos. Un inodo es una estructura de datos que relaciona un grupo de bloques de un dispositivo con un determinado nombre del sistema de ficheros.
Cada inodo generalmente contiene lo siguiente:
La ubicación del contenido del ítem en el disco, si existe .
El tipo del ítem (es decir, archivo, directorio, enlace simbólico, etc.)
El tamaño total del ítem, en bytes, si esto se aplica.
La fecha de la última modificación del archivo del inodo (el ctime).
La fecha de la ultima modificación del contenido del archivo del inodo (el mtime).
La fecha del ultimo acceso al archivo (el atime) para read(), exec(),etc.
El numero de enlaces físicos que tiene ese archivo.
Tamaño de bloque para el sistema de ficheros de E/S
Numero de bloques asignados.
Tipo de dispositivo
El dueño del archivo (UID).
El grupo del archivo (GID).
Los bits de protección.
Estos tres últimos, que se guardan para cada archivo, junto con la información UID/GID del proceso que se ejecuta, son los datos fundamentales que se emplean en UNIX para controlar el acceso de los usuarios a los archivos, y por lo tanto, prácticamente para toda la seguridad del sistema operativo.
3.3.4.- Fechas de los archivos.
Las fechas que aparecen al ejecutarse la instrucción ls -l son las fechas de modificación de los archivos (mtime). Se puede obtener la fecha del ultimo acceso (atime) usando la opción -u (escribiendo, por ejemplo, ls -lu). Ambas fechas se pueden cambiar usando una llamada a una rutina de la biblioteca del sistema. Por lo tanto, los administradores deben adquirir el habito de verificar la fecha de cambio del inodo (ctime) usando la opción -c. Por ejemplo, ls -lc. Bajo circunstancias

normales, no se puede cambiar el ctime de un archivo. El sistema operativo lo actualiza cada vez que hay un cambio en el inodo del archivo.
Puesto que el inodo cambia cuando se modifica un archivo, ctime indica la fecha de la ultima escritura, cambio de protección o cambio de dueño. Un agresor puede cambiar el mtime o el atime de un archivo, pero normalmente el ctime será correcto.
Un agresor listo, que adquiere privilegios de superusuario, puede cambiar el reloj del sistema y luego aplicar touch al inodo, forzando así que aparezca un ctime engañoso en el archivo. Ademas el agresor puede cambiar el ctime escribiendo directamente al disco, evitando el uso de las verificaciones del sistema operativo completamente. Si usa Linux, con el sistema de archivos ext2, un agresor puede modificar el contenido del inodo directamente usando la instrucción debugfs.
Si la cuenta del superusuario del sistema ha sido comprometida no se puede asumir que ninguna de las tres fechas que se almacenan para cada archivo o directorio sean correctas. Por esta razón, no se puede basar el control de archivos en las fechas.
3.3.5.- Permisos de un archivo
Los permisos de un archivo pueden verse en cada línea (los diez primeros caracteres) del listado al ejecutar la orden ls -l. Indican qué es el archivo y qué tipo de acceso otorga (es decir, la posibilidad de leer, escribir o ejecutar ) a los diversos usuarios del sistema.
He aquí dos ejemplos de permisos de archivo:
drwxr-xr-x
-rwsr-sr-x
El primer símbolo del campo de modo del archivo indica el tipo del archivo, como se explica en la siguiente tabla:
Contenido Significado
- Archivo plano
d Directorio
c Dispositivo de tipo carácter (tty,impresora, ...)
b Dispositivo de bloque (disco, CD-Rom, etc.)

l Enlace simbólico
s Socket
= o p FIFO
Los siguientes nueve símbolos tomados en grupos de tres indican quién y qué tipo de operaciones se pueden hacer con los archivos en la computadora. Hay tres tipos de permisos:
r permiso de lectura w permiso de escritura x permiso de ejecución
De manera análoga, existen tres clases de permisos:
owner propietario del archivo group usuarios que están en el grupo del propietario other todo el mundo (excepto el superusuario)
En el siguiente gráfico se muestra como interpretar los distintos privilegios:
Los permisos de lectura,escritura y ejecución tienen los siguientes significados específicos:
r (READ): El permiso de lectura quiere decir exactamente eso: el archivo se puede abrir con la llamada de sistema open() y su contenido puede leerse con read().

w (WRITE): El permiso de escritura permite sobreescribir con uno nuevo o modificar su contenido. También se puede usar write() para hacerlo mas grande y truncate() o ftruncate() para hacerlo más corto.
x (EXECUTE):Este permiso sólo tiene sentido en el caso de programas. Si un archivo tiene los bits de ejecución habilitados, se puede ejecutar escribiendo su trayectoria (o ejecutándolo con algún miembro de la familia de llamadas del sistema exec()). La manera en que se ejecuta el programa depende de los dos primeros bytes del archivo. Se supone que los dos primeros bytes de un archivo ejecutable son un números mágico que indica la naturaleza del archivo. Algunos números significan que el archivo es algún tipo de archivo binario en lenguaje maquina. La secuencia especial de dos bytes “#!” significa que es un guión ejecutable de algún modo. Si los valores son desconocidos se supone que es un guión de interprete de instrucción y se ejecuta de esa manera.
Los permisos de un archivo se aplican a los dispositivos y a los sockets con nombre del mismo modo que a los archivos normales. Si se tiene permiso de escritura se puede escribir información al archivo o al objeto. Si se tiene permiso de lectura se puede leer el contenido. Y si no se tienen ninguno de estos permisos, mala suerte.
Los permisos de archivo no se aplican a los enlaces simbólicos. El que se pueda o no leer de un archivo al que apunta un enlace simbólico depende de los permisos propios del archivo, y no de los permisos del enlace. De hecho, los enlaces simbólicos casi siempre se crean con los permisos “rwxrwxrwx” (en modo 0777, en octal) y el sistema operativo no los usa para nada.
Las siguientes consideraciones sobre los permisos de un archivo son importantes:
Se puede tener permiso de ejecución sin tener permiso de lectura. En ese caso se puede ejecutar un programa pero no leerlo. Esto es útil si se desea ocultar el contenido de un programa. Otra forma de usar esto es permitir a los usuarios emplear el programa pero no copiarlo (salvo en servidores de ficheros NFS, que no distinguen este caso, pues para ejecutar un archivo este debe ser enviado al cliente).
Si se tiene permiso de lectura pero no de ejecución, se puede hacer una copia del archivo y ejecutarla. No obstante, la copia será distinta principalmente en dos maneras. Tendrá una trayectoria absoluta diferente y será propiedad de quien la haya copiado y no del dueño original del programa (esto se importante en los archivos con el bit SUID o SGID activado).
En algunas versiones de UNIX (incluyendo Linux) un guión de instrucciones ejecutable debe tener los bits de lectura y ejecución habilitados para que sea posible ejecutarlo.
Los permisos de un archivo se pueden cambiar con la instrucción chmod o con las llamadas al sistema chmod() y fchmod(). Sólo el dueño de un archivo puede cambiar los permisos. La única excepción a esta regla es el superusuario: si alguien está en una sesión de superusuario puede cambiar los permisos de cualquier archivo.
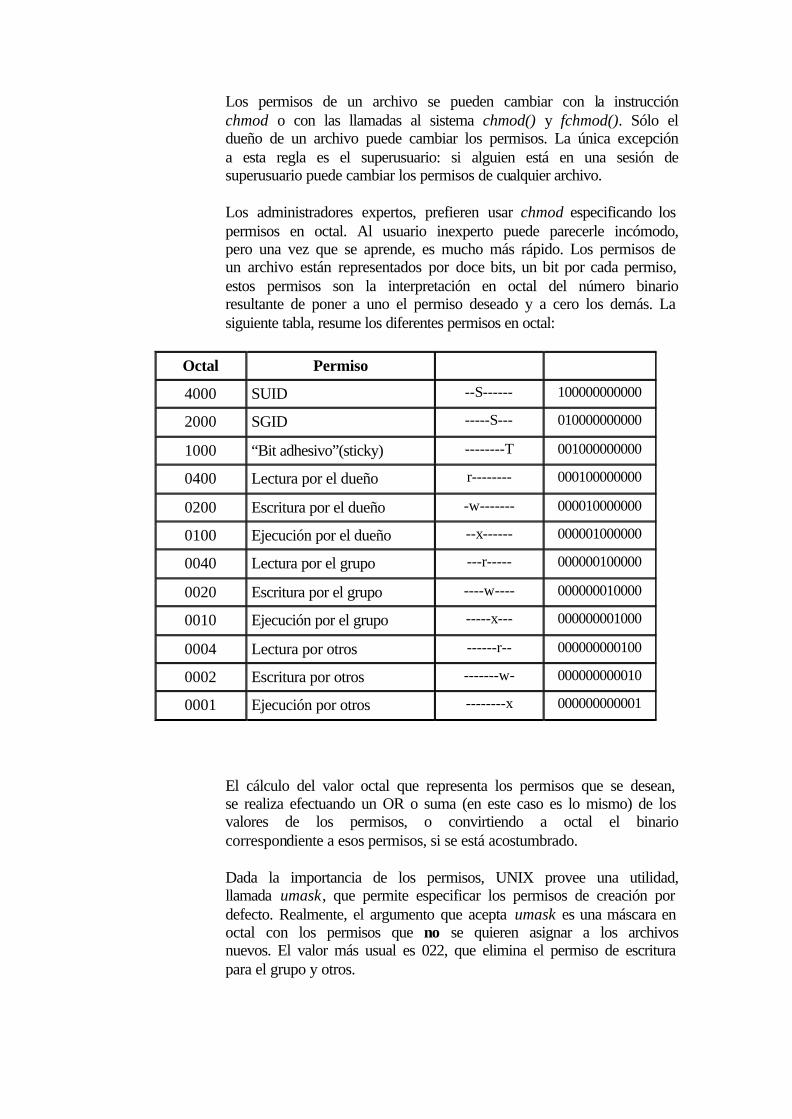
Los administradores expertos, prefieren usar chmod especificando los permisos en octal. Al usuario inexperto puede parecerle incómodo, pero una vez que se aprende, es mucho más rápido. Los permisos de un archivo están representados por doce bits, un bit por cada permiso, estos permisos son la interpretación en octal del número binario resultante de poner a uno el permiso deseado y a cero los demás. La siguiente tabla, resume los diferentes permisos en octal:
Octal Permiso
4000 SUID --S------ 100000000000
2000 SGID -----S--- 010000000000
1000 “Bit adhesivo”(sticky) --------T 001000000000
0400 Lectura por el dueño r-------- 000100000000
0200 Escritura por el dueño -w------- 000010000000
0100 Ejecución por el dueño --x------ 000001000000
0040 Lectura por el grupo ---r----- 000000100000
0020 Escritura por el grupo ----w---- 000000010000
0010 Ejecución por el grupo -----x--- 000000001000
0004 Lectura por otros ------r-- 000000000100
0002 Escritura por otros -------w- 000000000010
0001 Ejecución por otros --------x 000000000001
El cálculo del valor octal que representa los permisos que se desean, se realiza efectuando un OR o suma (en este caso es lo mismo) de los valores de los permisos, o convirtiendo a octal el binario correspondiente a esos permisos, si se está acostumbrado.
Dada la importancia de los permisos, UNIX provee una utilidad, llamada umask, que permite especificar los permisos de creación por defecto. Realmente, el argumento que acepta umask es una máscara en octal con los permisos que no se quieren asignar a los archivos nuevos. El valor más usual es 022, que elimina el permiso de escritura para el grupo y otros.

Cuando los permisos de archivo se aplican sobre un directorio, estos tienen significados especiales:
r: Se permite usar las funciones opendir() y readdir() (o el comando ls) para buscar qué archivos están en el directorio.
w:Se puede añadir, renombrar o quitar entradas en ese directorio.
x: Se puede emplear stat al contenido del directorio (es decir, se puede determinar quiénes son los dueños y cuáles son los tamaños de los archivos que están en el directorio). También se requiere permiso de ejecución a un directorio para convertirlo en directorio actual o para abrir archivos que estén dentro de ese directorio (o en cualquiera de sus subdirectorios).
3.3.6.- SUID, SGID y los bits adhesivos
Muchos programas, como su, basan su funcionamiento en el uso de los bits SUID y SGID. Para entender completamente como maneja UNIX esta técnica es imprescindible conocer los conceptos de UID real, UID efectivo y UID guardado.
UNIX almacena para todos los procesos que ejecuta dos identificadores básicos de usuario: UID real y UID efectivo. Para un proceso normal, resultante de la ejecución de un programa que no es SUID, los dos identificadores son el mismo e iguales al UID del proceso que lo generó.
Esto resulta más sencillo con un ejemplo: cuando un usuario inicia una sesión, el proceso login verifica la identidad del usuario en el fichero /etc/passwd y genera un shell con UIDs real y efectivo iguales al del usuario. Cuando el usuario ejecuta cualquier programa que no sea SUID, sea suyo o no, sobre el que por supuesto debe tener permiso de ejecución, el proceso creado hereda los UIDs del shell. Este comportamiento se mantiene si este proceso crea otros procesos, que a su vez pueden crear otros procesos, y así sucesivamente. Pensemos, por ejemplo, en un usuario que teclea bash continuamente, todos los shell creados tendrán los mismos UIDs.
De esta manera, si no tenemos en cuenta la existencia del bit SUID, bastaría con un UID que identificara al usuario durante toda la sesión, puesto que no hay forma de que el usuario cambie el UID de un proceso.
El problema es que UNIX utiliza el UID efectivo del proceso (Linux utiliza un cuarto identificador, el FSUID) para analizar los privilegios que este tiene sobre el sistema de ficheros. Pero un usuario necesita escribir en archivos que no le pertenecen: para cambiar su contraseña necesita escribir en /etc/passwd, para imprimir debe dejar sus archivos en un directorio de spool, y multitud de tareas más.

Si no se hubiera implementado ninguna manera de alterar esto, sólo habría una forma de que el usuario escribiera en directorios y archivos que no le pertenecen: darle permiso sobre estos y, por extensión, a todos los usuarios del sistema. Pero esto es imposible, acabaría con el sentido de la protección en el sistema de ficheros y con la seguridad de UNIX.
Para evitar estos problemas, UNIX permite que los programas tengan privilegios. Los procesos que ejecutan estos programas pueden adquirir un UID o GID distinto al propio cuando se están ejecutando. Un programa que cambia su UID se llama programa SUID, y un programa que cambia su GID se llama programa SGID. Un programa puede ser SUID y SGID al mismo tiempo.
Cuando se ejecuta un programa SUID, su UID efectivo se convierte en el del dueño del archivo, en lugar del UID del usuario que lo está ejecutando. Este concepto es tan ingenioso que AT&T (Dennis Ritchie) lo patentó, aunque después la patente ha sido transferida al dominio público.
En el siguiente gráfico se muestra como interpretar los distintos privilegios:
SUID: Un proceso que ejecuta un programa SUID obtiene un UID efectivo que es el del dueño del programa.
SGID: Un proceso que ejecuta un programa SGID tiene su GID efectivo cambiado al GID del programa. Los archivos creados por el proceso también pueden tener su grupo primario establecido a este GID, dependiendo de los permisos del directorio donde se crean los archivos. En las versiones de UNIX derivadas de Berkeley (también en Linux), un proceso que ejecuta un programa SGID adquiere también el GID del programa temporalmente, el cual se coloca en la lista de GID del proceso. Solaris y otros UNIX derivados de System V usan el bit de GID de los archivos de datos para habilitar el bloqueo obligatorio de archivos.

Adhesivo: Está obsoleto en lo que se refiere a archivos, pero se usa para directorios. Cuando un archivo ejecutable tenía el bit adhesivo activado, significaba que debía permanecer en memoria principal el mayor tiempo posible. Esto mejoraba el rendimiento en computadores con una cantidad muy limitada de memoria RAM (sobre 64K, incluso). Pero esto ya no tiene mucho sentido. Sin embargo, si un directorio tiene activado el sticky bit (bit adhesivo o de permanencia), significa que aunque varios usuarios tengan permiso de escritura en él, sólo el propietario del archivo y el superusuario pueden borrar un archivo. Esto es útil en directorios donde pueden escribir muchos usuarios, pero no se desea que los usuarios se borren archivos unos a otros,como en /tmp o en un directorio de spool.
El bit SGID en directorios también tiene un comportamiento particular. Si está activado, los archivos de usuario que se crean en ese directorio, tendrán el mismo GID que el directorio, si el usuario también está en ese grupo. Si el usuario no está en el grupo del directorio, los archivos se crean con el GID del usuario (por lo general el primario), como es normal.
Es importante señalar que para activar estos permisos, también debe darse el permiso de ejecución correspondiente, es decir, ejecución para el propietario para el bit SUID, ejecución para el grupo para el bit SGID y ejecución para otros para el bit adhesivo. Si no se hace así, el bit correspondiente aparecerá en mayúsculas (S o T) y no en minúsculas (s o t), lo que indica que el bit está establecido pero no tendrá efecto.
Esta característica que hace que UNIX sea tan versátil, es también uno de los mayores problemas de seguridad.
Cualquier usuario puede convertirse en superusuario simplemente ejecutando una copia SUID de bash que sea propiedad del root. Afortunadamente, sólo el superusuario puede realizar esta copia. Por lo tanto, uno de los objetivos del administrador será evitar que existan este tipo de archivos en la computadora.
Si se deja un terminal sin vigilancia, cualquiera puede apoderarse de la cuenta simplemente introduciendo las siguientes instrucciones:
% cp /bin/bash /tmp/trampa
% chmod 4755 /tmp/trampa
%
Estas instrucciones crean una copia SUID del programa bash. Cada vez que el agresor ejecute este programa se convierte en el usuario, con pleno acceso a los archivos y privilegios. Se supone que el usuario tiene algún archivo interesante para el agresor, privilegios que le

permitan acceder al superusuario, o quiere suplantarle para alguna actividad delictiva, en el peor caso el usuario será el propio root.
El agresor podría copiar ese programa en un directorio oculto que sólo el superusuario, buscando archivos de este tipo, podría encontrar. Pero no todos los administradores realizan esta tarea con regularidad.
Es importante notar que el programa no tiene porque ser un interprete de comandos, un simple editor de textos SUID puede permitir al agresor modificar archivos o incluso crear un interprete de comandos que se ejecute con el UID del usuario (vi lo permite con el comando shell).
La mayor parte de los programas SUID de un sistema son SUID de root, es decir, se convierten en el superusuario cuando se ejecutan. Teóricamente, esto no es un fallo de seguridad, porque un programa compilado únicamente puede llevar a cabo las funciones para las que fue compilado (se puede cambiar la contraseña propia usando passwd, pero no se puede cambiar la contraseña de otro usuario). Pero se han encontrado muchos fallos de seguridad creados por gente que se las ha ingeniado para lograr que un programa SUID haga algo para lo que no fue diseñado. En muchos casos programas que son UID de root podrían haberse diseñado para ser SUID de otra cuenta (como daemon). Con demasiada frecuencia se usa SUID de root cuando sería suficiente con privilegios menores.
Un ejemplo de programa SGID con un fallo de seguridad es el programa write. Como write permite escribir en el terminal de otro usuario, este programa es SGID de tty. Esto permite que write escriba nuestro texto en el otro terminal. El fallo es que write permitía que el usuario ejecute cualquier instrucción escribiendo el carácter '!' al principio de una línea. El programa ejecutado heredaría el GID efectivo de tty, lo que permitiría al usuario, por ejemplo, 'escuchar' los terminales de otros usuarios. En la actualidad, el programa write sigue siendo SGID de tty, pero cambia el GID de tty al del usuario antes de ejecutar el shell (más adelante se verá como se consigue esto) y luego lo restablece al de tty. En algunas versiones, esta característica está deshabilitada.
Otro ejemplo, esta vez de SUID, era el programa /usr/lib/preserve, que realizaba las copias de seguridad para los editores vi y ex. Para poder hacer copias de seguridad en el directorio, el programa era SUID de root, de forma que el directorio estaba protegido contra la lectura por parte de los usuario (quizás alguien estuviera editando algo importante y no se podía permitir que lo leyera cualquiera). Había tres detalles que hicieron que el programa fuera un fallo de seguridad:
Era SUID de root

Ejecutaba /bin/mail como root para avisar a los usuarios de que su archivo estaba copiado
Ejecutaba el programa mail con la llamada al sistema system()
El problema era que system() usa sh para leer la cadena que ejecuta. Hay una variable del intérprete de comandos, llamada IFS (separador interno de campos), que sh utiliza para ubicar las separaciones entre las palabras de cada línea que lee. Normalmente IFS es el espacio en blanco, pero si se establecía IFS como '/' entonces, al llamar a /bin/mail se estaba llamando en realidad a un programa llamado bin del directorio actual, pero con privilegio de root. El resto es fácil, haciendo una copia de un shell en el directorio actual y llamándola bin, bastaba con ejecutar vi para convertirse en root.
El problema era que el programa preserve tenía más privilegios de los necesarios. La norma del privilegio mínimo establece que los programas (y usuarios) tengan los privilegios imprescindibles para realizar su labor, y no más. En este caso, habría bastado con hacer a preserve SGID del grupo preserve, creado expresamente. Esto no hubiera eliminado el fallo, pero lo habría minimizado. El agresor sólo podría leer las copias de los trabajos de otros usuarios.
Las versiones actuales de sh no toman en cuenta IFS si se ejecuta en modo root o si el UID efectivo es diferente del real.
El problema de los bits SUID y SGID está muy unido al ataque basado en la técnica del desbordamiento de pila (buffer overflow), que se tratará más adelante.
3.3.6.1.- Cambio de UID: setuid()
Con el objeto de facilitar la programación de utilidades seguras, UNIX proporciona una serie de funciones que permiten cambiar entre los UID real, efectivo y guardado. Como se ha visto en el ejemplo de write, para que la aplicación pueda ejecutar una orden del usuario sin peligro para la seguridad, esta debe cambiar al GID del usuario antes de ejecutarla y luego restablecer el GID anterior.
Una solución para esto podría ser permitir el cambio entre los UID efectivo y real (o entre los GID efectivo y real, el funcionamiento es el mismo) de forma que durante la ejecución de esa parte del proceso (o la de sus hijos, si es el caso) se perdieran los privilegios que se tenían.
Veamos un ejemplo:
Si el usuario 501 ejecuta el programa write, éste tiene GID real 501(usuario) y GID efectivo 5(tty). Al introducir una línea que

comienza por '!', el programa write detecta que tiene que ejecutar un comando: para ello primero intercambia los GID, quedando GID real 5(tty) y GID efectivo 501(usuario) y después ejecuta el comando.
Ahora, el comando ha heredado los GID (y los UID) de write, pero ya no tiene el GID efectivo de tty sino 501, el del usuario. Después, write puede volver a intercambiar los GID y continuar su ejecución normalmente.
Esto tiene un fallo: nada impide al proceso del usuario volver a intercambiar los GID, y recuperar los privilegios anteriores.
Para solucionar definitivamente este problema, UNIX utiliza la familia de funciones setuid() y setgid(). Estas funciones utilizan un tercer UID llamado UID guardado o salvado. El cambio a un UID/GID real o efectivo sólo está permitido si el proceso posee ese UID/GID como UID/GID efectivo, real o guardado. Sólo un proceso con UID 0(root) puede cambiar a cualquier otro UID/GID.
En el ejemplo anterior (nuevamente, el funcionamiento es igual con el UID), write puede establecer el GID efectivo a 501(usuario) dejando el GID real como estaba (501(usuario)), quedando como GID guardado el 5(tty). De esta forma, el proceso generado hereda estos dos GID, pero no el guardado, y no puede cambiar otra vez al GID 5(tty) puesto que no lo tiene.
Pero write sí puede restablecer el GID efectivo a 5(tty), puesto que ése es el GID guardado. Esta vez todo se ha hecho de forma segura, y el agujero de seguridad de write ha desaparecido.
Este es el funcionamiento de las diferentes funciones que permiten realizar estos cambios (por lo menos, en su versión Linux):
getuid(void): Devuelve el UID real del proceso actual.
geteuid(void): Devuelve el UID efectivo del proceso actual.
setuid(uid_t uid): (POSIX) Establece el UID efectivo del proceso en curso. Si el UID efectivo del proceso que las llama es 0(root) o si el proceso es SUID de root, se establecen también los UID real y guardado. Esto impide a un proceso del root que deja sus privilegios que los recupere más tarde.
setreuid(uid_t ruid,uid_t euid) (BSD): Establece el UID real y el efectivo del proceso en curso. Un valor de -1 para el UID real o efectivo fuerza al sistema a dejar dicho ID sin cambios. Si el UID real es cambiado, o el UID efectivo se pone a un valor

distinto del UID real previo, el UID guardado tomará en valor del nuevo UID efectivo.
seteuid(uid_t euid) (BSD): Es funcionálmente equivalente a setreuid(-1, euid).
getgid(void): Devuelve el GID real del proceso actual.
getegid(void): Devuelve el GID efectivo del proceso actual.
setgid(gid_t gid) (POSIX): Establece el GID efectivo del proceso en curso. Si el GID efectivo del proceso que las llama es 0(root) o si el proceso es SGID de root, se establecen también los GID real y guardado. Esto impide a un proceso del root que deja sus privilegios que los recupere más tarde.
setregid(gid_t rgid, gid_t egid) (BSD):Establece el GID real y el GID efectivo del proceso en curso. Un valor de -1 para el GID real o efectivo fuerza al sistema a dejar dicho ID sin cambios. Si el GID real es cambiado, o el GID efectivo se pone a un valor distinto del GID real previo, el GID guardado tomará el valor del nuevo GID efectivo.
setegid(gid_t egid) (BSD): Es funcionálmente equivalente a setregid(-1, egid).
3.3.7.- Listas de control de acceso (ACLs)
Algunas versiones de UNIX permiten usar listas de control de acceso (ACL, Access Control Lists). Éstas se ofrecen normalmente como extensiones a los modos de permisos de archivo estándar de UNIX. Usando ACLs se pueden especificar derechos adicionales de acceso para cada archivo y directorio a muchos usuarios en individual, en lugar de tener que hacerlo colocando a todos en un grupo nuevo o en la categoría 'otros'. También se pueden asignar permisos distintos a grupos diferentes. Se trata de una característica que se popularizará en los próximos años. Lamentablemente cada proveedor las ha implementado de forma diferente.
Las ACLs permiten refinar la capacidad de otorgar permisos de archivo que tiene el UNIX estándar. Permiten la especificación completa del acceso a subconjuntos completamente arbitrarios de usuarios y/o grupos de usuarios. Tanto AIX como HP-UX ofrecen listas de control de acceso. Solaris y Linux supuestamente las ofrecerán en versiones futuras.
Para muchos propósitos las ACLs son mejores que el mecanismo de grupos que ofrece UNIX a proyectos de colaboración pequeños. Si Ana quiere darle a Miriam, y sólo a Miriam, acceso a un archivo en particular, puede modificar la ACL del archivo para otorgárselo. Sin

ACLs Ana tendría que acudir al administrador del sistema, pedirle que cree un grupo nuevo que tuviera como miembros tanto a Ana como a Miriam (y sólo a ellas) y luego cambiar el grupo del archivo para otorgar privilegios al nuevo grupo.
3.3.8.- Archivos de dispositivo
Como ya se ha comentado antes, todos los dispositivos en UNIX se representan como archivos normales. En el inodo se especifica que se trata de un dispositivo, el tipo de dispositivo, y su números de dispositivo principal y secundario que permiten al sistema identificar al dispositivo.
El hecho de que los dispositivos sean archivos, da a UNIX una gran flexibilidad y unifica el acceso a los dispositivos, de forma que los programadores pueden desarrollar sus programas sin saber el tipo de dispositivo que se va a utilizar.
Pero esto también representa un problema de seguridad. Si un usuario consigue acceso sin restricciones a un archivo de dispositivo, podrá hacer lo que quiera con él. Si es un terminal, podrá leer lo que otro usuario escribe, si es un disco, podrá escribir y leer en cualquier sitio, si es el dispositivo kmem, podrá cambiar su UID o bloquear el sistema escribiendo basura en el área de memoria reservada para éste.
UNIX agrupa todos los archivos de dispositivo en el directorio /dev. Por esta razón es muy importante que el administrador revise periódicamente los permisos de estos archivos. Unos pocos dispositivos deben permitir el acceso a todos los usuarios, como /dev/null o /dev/tty. Pero casi todos los demás no deben permitir lectura ni escritura por los usuarios normales. También se debe revisar el sistema en busca de archivos de dispositivo creados por un intruso en cualquier parte del sistema de ficheros, y que podría darle acceso a este dispositivo.
3.3.9.- Sistemas de ficheros montados
Para poder acceder de forma uniforme a distintos tipos de sistemas de ficheros, UNIX incorpora una capa superior de abstracción denominada VFS, Virtual File System o Sistema de Ficheros Virtual, que se ocupa de proporcionar este acceso uniforme a diferentes tipos de sistemas de ficheros.
Montar un sistema de ficheros consiste en asociar un determinado nombre de directorio (punto de montaje) con el sistema de ficheros en cuestión. A partir de ese momento el sistema de ficheros montado podrá ser utilizado de forma normal por los usuarios. Es habitual en grandes sistemas UNIX montar diferentes partes de la estructura de directorios estándar (por ejemplo /home o /usr) en distintos dispositivos. Esto no presenta ningún problema de seguridad, puesto

que estos sistemas se montan cada vez que se inicia el sistema, normalmente son necesarios para el funcionamiento normal del sistema.
Pero para utilizar discos removibles, CD-ROMs o sistemas de ficheros en red (NFS) no queda más remedio que montarlos como parte del sistema de ficheros. Esto si que representa un problema de seguridad. Estos sistemas de ficheros pueden contener archivos ejecutables (por ejemplo un shell con SUID de root) que pueden comprometer la seguridad del sistema.
Para evitar estos problemas, el archivo de configuración fstab, que almacena la forma en que se montan los distintos dispositivos, y el comando mount, que se encarga de montarlo, aceptan una serie de opciones que protegerán nuestro sistema. Estas opciones son:
auto/noauto: Puede o no montarse con la opción -a (se montan todos automáticamente)
dev/nodev: Interpreta o no dispositivos especiales
exec/noexec: Permite o no la ejecución de binarios
rw/ro: El sistema de ficheros de monta como de lectura/escritura o como sólo lectura.
suid/nosuid: Permite o no el efecto de los bits SETUID y SGID
user/nouser: Permite o no que los usuarios ordinarios monten el sistema de ficheros. La opción user implica noexec, nosuid y nodev a menos que se indique lo contrario explícitamente.
sync: Toda E/S ha de realizarse de forma síncrona.
Esta opciones bien utilizadas impiden que un usuario monte un sistema de ficheros que pueda contener peligros como un dispositivo que apunte a nuestro disco (y sobre el que tenga permisos), un shell SUID de root y peligros similares. En muchos sistemas es habitual que sólo el superusuario pueda montar sistemas de ficheros, incluso que sólo él tenga acceso físico a los dispositivos.
4.- Mantenimiento de sistemas confiables
4.1.- Introducción

En este tema, se tratan las principales labores a realizar por parte del administrador, para mantener un sistema seguro, así como las técnicas mas utilizadas para evitar la pérdida de datos y para responder a los ataques de los intrusos.
4.2.- Criptografía
Aunque la misión principal de la seguridad en un sistema informático es mantener la información confidencial, en ocasiones, no podemos confiar sólo en la seguridad del sistema. Cuando la información es demasiado importante, se envía a través de medios de comunicación poco confiables o es imposible mantenerla en secreto, no queda más remedio que recurrir a la criptografía.
En la actualidad, existen multitud de métodos y aplicaciones criptográficas. Como no es el objetivo de este trabajo, sólo haremos una breve mención de los diferentes tipos de sistemas criptográficos y su relación con el cifrado de contraseñas.
Hasta la década de los 70, todos los criptosistemas conocidos, funcionaban con una clave de cifrado igual a la de descifrado o, si eran diferentes, una podía obtenerse de la otra en un tiempo y con unos recursos razonables. La invulnerabilidad de tales sistemas dependía, por tanto, del mantenimiento en secreto de la clave. Consiguientemente, debía transmitirse del emisor al receptor a través de un canal seguro, obviamente diferente del canal del criptosistema, que por hipótesis está amenazado por posibles interceptores.
Estos criptosistemas se denominan de clave secreta, de clave única y también simétricos.
Sin embargo, en 1976, Diffie y Hellman demostraron la posibilidad de conseguir criptosistemas que no precisaban transferir una clave secreta entre el emisor y el receptor, evitando así los problemas inherentes a la búsqueda de canales seguros para tal transferencia, previamente al establecimiento de una transmisión cifrada.
En estos criptosistemas la clave de cifrado, denominada clave pública, se hace de general conocimiento. Sin embargo la clave de descifrado, denominada clave privada, se mantiene en secreto. Obviamente ambas claves no son independientes, pero del conocimiento de la pública no se infiere la privada, a no ser que se tenga algún dato adicional que también habrá que mantenerse en secreto o, mejor, destruirse una vez generado el par clave pública-clave privada.
Cuando un usuario desea recibir informaciones cifradas, da a conocer a todos los potenciales remitentes su clave pública. Así, éstos cifrarán los mensajes destinados al citado usuario con la misma clave, la pública del destinatario. Sin embargo, no conociendo nadie más la clave privada, ni pudiéndola obtener a partir de la pública, sólo el destinatario podrá descifrar la información a él remitida.

Estos criptosistemas se denominan, de clave pública o asimétricos, pues del conocimiento de una clave no se deduce la otra.
Todavía se puede considerar un último tipo de sistemas de cifrado denominados criptosistemas irreversibles, basados en algoritmos no invertibles. En estos criptosistemas, dado el criptograma no es posible obtener el mensaje en claro. Figuradamente, se puede decir que sólo trabajan en un sentido, el que lleva del mensaje en texto claro al texto cifrado, pero no en el contrario, que conduce de este último a aquél.
Estos cifrados se emplean en aplicaciones que no requieren descifrar los criptogramas. Una de estas aplicaciones consiste en la determinación de si un cierto mensaje se corresponde con un determinado texto cifrado almacenado en un sistema. Para ello el algoritmo de cifrado produce un criptograma, que se compara con el guardado en la memoria. Para esta aplicación se requiere, además de que el algoritmo sea no invertible, que sea unívoco, es decir, que dos mensajes distintos produzcan dos cifrados diferentes. Un ejemplo de este tipo de aplicaciones se tiene en el almacenamiento de las contraseñas de usuarios de un sistema. El mantenimiento en memoria de las mismas sin cifrar representa un grave riesgo, pues alguien puede averiguarlas y suplantar a los legítimos usuarios. Almacenarlas cifradas mediante criptosistemas de los tipos vistos hasta ahora también es inseguro, pues la clave descifrada puede ser conocida por el administrador del sistema (y posiblemente por más profesionales informáticos que trabajen sobre el ordenador), quien con el conocimiento del algoritmo de cifrado y de las contraseñas criptografiadas es capaz de averiguar las contraseñas en claro.
Por lo anterior, para el almacenamiento de contraseñas se emplean algoritmos no invertibles. Cada vez que el usuario introduce su contraseña, se cifra y compara con la contraseña cifrada almacenada en la tabla correspondiente. El acceso se permite sólo si coinciden ambas. Esto implica que una contraseña olvidada no se puede recuperar, debiéndose generar otra que será nuevamente almacenada como un criptograma.
4.3.- Defensa de cuentas
Cada una de las cuentas en la computadora, es una puerta al exterior, un portal a través del cual usuarios autorizados y no autorizados pueden entrar. Algunos de los portales están bien protegidos, mientras que otros pueden no estarlo. El administrador del sistema debe buscar puntos débiles y sellarlos.
4.3.1.- Cuentas sin contraseña
La contraseña de cada una de las cuentas es la primera línea de defensa de un sistema. Una cuenta sin contraseña es una puerta sin cerradura, cualquiera que conozca el nombre de la cuenta puede entrar. Muchos de los intrusos tienen éxito, sólo por que son buenos para encontrar cuentas sin contraseña o cuentas que tienen contraseñas fáciles de adivinar.

En la versión SVR4 de UNIX, se pueden rastrear cuentas sin contraseña usando la instrucción:
# logins -p
También se pueden rastrear las cuentas sin contraseña usando la instrucción:
% cat-passwd | awk -F: 'length($2)<1 {print $1}'
manurod
maripet
En este ejemplo, manurod y maripet no tienen contraseña no tienen contraseña. Obsérvense los registros en el archivo /etc/passwd.
manurod:EH5/.mj7J5dFh:501:100:Manuel Rodríguez:/home/alumnos/manurod:/bin/bash
maripet:aCq87MCñ03c9e:502:100:Mario Petru:/home/alumnos/maripet:/bin/bash
Puede que el archivo /etc/passwd no sea el más indicado para buscar cuentas sin contraseña en los sistemas que tienen instalados archivos de contraseñas ocultas. Diferentes sistemas de contraseñas ocultas almacenan las contraseñas cifradas reales en diferentes lugares. También es el caso de sistemas que usan NIS, NIS+ o DCE.
4.3.2.- Cuentas predeterminadas
Muchos sistemas se entregan al usuario final con una o más cuentas predeterminadas. Estas cuentas generalmente tienen contraseñas estándar. Por ejemplo, muchas computadoras UNIX vienen con una cuenta root que no tiene contraseña. Los distribuidores aconsejan a los usuarios asignar contraseñas a esas cuentas, pero con mucha frecuencia los usuarios no lo hacen.
Una forma de solucionar este problema que han utilizado muchos distribuidores es hacer que el sistema operativo solicite contraseñas para cuentas especiales como root cuando se instala por primera vez.
Algunos programas de aplicación instalan automáticamente cuentas con nombres como demo (que se usa para demostrar los programas). Es necesario asegurarse de borrar o inhabilitar esas cuentas después de instalar el programa
4.3.3.- Cuentas que ejecutan sólo una instrucción

UNIX permite al administrador crear cuentas que pueden ejecutar simplemente una sola instrucción o programa de aplicación, en lugar del intérprete de comandos, cuando un usuario entra en ellas. A menudo estas cuentas no tienen contraseña.
Si se tienen estas cuentas instaladas en la computadora, alguien puede usarlas para encontrar la hora o determinar quién está conectado a la computadora al teclear simplemente el nombre de la instrucción en el indicador login:.
Si se decide configurar una cuenta de este tipo, se debe asegurar de que la instrucción que se ejecuta no reciba ninguna entrada desde teclado, y que no pueda forzarse a dar al usuario un proceso interactivo. Específicamente, estos programas no deben tener escapes al interprete de comandos.
4.3.4.- Cuentas abiertas
Muchos sistemas proporcionan cuentas en las cuales los visitantes pueden acceder a juegos, a un modem o a una conexión a la red. Estas cuentas reciben nombres como play, open o guest y no suelen precisar de contraseña.
Debido a que los nombres de estas cuentas son conocidos o fáciles de adivinar, representan potencialmente violaciones a la seguridad, ya que un agresor puede entrar inicialmente a una de estas cuentas para, rastrear desde allí fallos de seguridad de mayor índole .
4.3.4.1.- interpretes de comandos restringidos
Un intérprete de instrucciones restringido se puede usar para minimizar los peligros que representa una cuenta abierta. Este modo ocurre cuando se invoca al intérprete de instrucciones en la línea de comandos con la opción -r, o con la instrucción llamada rsh (interprete de instrucciones restringido). Cuando rsh se inicia, ejecuta las instrucciones en el archivo $HOME/.profile. Una vez que el .profile se procesa, la siguientes restricciones tienen efecto:
El usuario no puede cambiar el directorio actual.
El usuario no puede cambiar el valor de la variable PATH.
El usuario no puede usar nombres de instrucciones que contengan '/'.
El usuario no puede redirigir la salida con '>' o '>>'.

Como una medida de seguridad adicional, si el usuario trata de interrumpir el rsh mientras esté procesando el archivo $HOME/.profile , el rsh sale inmediatamente.
4.3.4.2.- Sistemas de archivos restringidos
Otra forma de restringir a los usuarios del sistema es poniéndolos en un sistema de archivos restringidos. La forma de hacer esto es con la llamada del sistema chroot(), que cambia la vista que un proceso tiene del sistema de archivos, de tal manera que el directorio raíz que ve no es el del sistema de archivos real sino uno de sus descendientes.
En SVR4 esto se puede conseguir poniendo un '*' en el campo de intérprete de instrucciones del usuario en el archivo /etc/passwd , entonces el sistema hará una llamada a chroot()con el campo de directorio HOME del usuario.
El sistema de archivos restringido debe contener todos los archivos e instrucciones necesarios para que el programa login se ejecute y para poder ejecutar programas, incluyendo bibliotecas compartidas.
Esto es útil para mantener cuentas de usuario limitadas, para que estos usuarios sólo puedan realizar un conjunto limitado de tareas y para la evaluación de programas nuevos de funcionamiento dudoso
4.4.- Auditoría
4.4.1.- Introducción
Casi todas las actividades realizadas en un sistema UNIX son susceptibles de ser monitorizadas: desde las horas de acceso de cada usuario al sistema hasta las paginas web más visitadas, pasando por los intentos fallidos de conexión, los programas ejecutados o incluso el tiempo de CPU que cada usuario consume.
Obviamente esta facilidad de UNIX para recoger información tiene unas ventajas inmediatas para la seguridad: es posible detectar un intento de ataque nada mas producirse el mismo, así como detectar usos indebidos de los recursos o actividades sospechosas; sin embargo, existen desventajas, ya que la gran cantidad de información que potencialmente se registra puede ser aprovechada para crear negaciones de servicio o esa cantidad de información puede hacer difícil detectar problemas por el volumen de datos a analizar.
La mayoría de los log en UNIX son simples ficheros de texto, que se pueden visualizar con un cat. Por una parte esto es bastante cómodo para el administrador del sistema, ya que no necesita de herramientas

especiales para poder revisar los logs e incluso puede programar shellscripts para comprobar los informes generados de forma automática, con ordenes como awk, grep o sed. No obstante, el hecho de que estos ficheros sean texto plano hace que un atacante lo tenga muy fácil para ocultar ciertos registros modificando los archivos con cualquier editor de textos.
4.4.2.- El sistema de log en UNIX
Una desventaja añadida al sistema de auditoría en UNIX puede ser la complejidad que puede alcanzar una correcta configuración; por si la dificultad del sistema no fuera suficiente, en cada UNIX el sistema de logs tiene peculiaridades que pueden propiciar la perdida de información interesante de cara al mantenimiento de sistemas seguros. Aunque muchos de los ficheros de log de los que hablaremos a continuación son comunes en cualquier sistema, su localización, o incluso su formato, pueden variar entre diferentes sistemas.
La localización de ficheros y ciertas ordenes relativas a la auditoría varían de unas maquinas a otras, por lo que es muy recomendable consultar las paginas del manual antes de ponerse a configurar el sistema de auditoría en un equipo concreto.
La principal diferencia entre los diferentes sistemas es el denominado process accounting o simplemente accounting, consistente en registrar todos los programas ejecutados por cada usuario; evidentemente, los informes generados en este proceso pueden llegar a ocupar muchísimo espacio en disco (dependiendo del numero de usuarios en nuestro sistema) por lo que solo es recomendable en situaciones muy concretas, por ejemplo para detectar actividades sospechosas en una maquina o para cobrar por el tiempo de CPU consumido.
En los sistemas System V el process accounting esta desactivado por defecto; se puede iniciar mediante /usr/lib/acct/startup, y para visualizar los informes se utiliza la orden acctcom. En la familia BSD los equivalentes a estas ordenes son accton y lastcomm; en este caso el process accounting esta inicializado por defecto. Con el modelo clásico se genera un registro tras la ejecución de cada proceso, en UNIX C2 se proporciona una pista de auditoría donde se registran los accesos y los intentos de acceso de una entidad a un objeto, así como cada cambio en el estado del objeto, la entidad o el sistema global. Esto se consigue asignando un identificador denominado Audit ID a cada grupo de procesos ejecutados (desde el propio login), identificador que se registra junto a la mayoría de llamadas al sistema que un proceso realiza, incluyendo algunas tan comunes como write(), open(), close() o read().
Registrar todo esto conlleva un gran cantidad de espacio y de CPU, por lo que en la mayoría de sistemas, el modelo de auditoría C2 es innecesario y en muchas ocasiones se convierte en una monitorizacion

inútil si no se dispone de mecanismos para interpretar o reducir la gran cantidad de datos registrados: el administrador guarda tanta información que es casi imposible analizarla en busca de actividades sospechosas.
4.4.3.- El demonio syslogd
El demonio syslogd (Syslog Daemon) se lanza automáticamente al arrancar un sistema UNIX, y es el encargado de guardar informes sobre el funcionamiento de la maquina. Recibe mensajes de las diferentes partes del sistema (núcleo, programas. . . ) y los envía y/o almacena en diferentes localizaciones, tanto locales como remotas, siguiendo un criterio definido en el fichero de configuración /etc/syslog.conf, donde especificamos las reglas a seguir para gestionar el almacenamiento de mensajes del sistema. Las líneas de este archivo que comienzan por `#' son comentarios, con lo cual son ignoradas de la misma forma que las líneas en blanco; si ocurriera un error al interpretar una de las líneas del fichero, se ignoraría la línea completa. Un ejemplo de fichero /etc/syslog.conf es el siguiente:
# Log all kernel messages to the console.
# Logging much else clutters up the screen.
#kern.* /dev/console
# Log anything (except mail) of level info or higher.
# Don't log private authentication messages!
*.info;mail.none;authpriv.none /var/log/messages
# The authpriv file has restricted access.
authpriv.* /var/log/secure
# Log all the mail messages in one place.
mail.* /var/log/maillog
# Everybody gets emergency messages, plus log them on another
# machine.
*.emerg *
# Save mail and news errors of level err and higher in a
# special file.

uucp,news.crit /var/log/spooler
# Save boot messages also to boot.log
local7.* /var/log/boot.log
Podemos ver que cada regla del archivo tiene dos campos: un campo de selección y un campo de acción, separados por espacios o tabuladores. El campo de selección esta formado a su vez de dos partes: una del servicio que envía el mensaje y otra de su prioridad, separadas por un punto ( . ); ambas son indiferentes a mayúsculas y minúsculas. La parte del servicio contiene una de las siguientes palabras clave: auth, authpriv, cron, daemon, kern, lpr, mail, mark, news, security (equivalente a auth), syslog, user, uucp y local0 hasta local7. Esta parte especifica el subsistema que ha generado ese mensaje (por ejemplo, todos los programas relacionados con el correo generaran mensajes ligados al servicio mail). La prioridad esta compuesta de uno de los siguientes términos, en orden ascendente: debug, info, notice, warning, warn (equivalente a warning), err, error (equivalente a err), crit, alert, emerg, y panic (equivalente a emerg). La prioridad define la gravedad o importancia del mensaje almacenado. Todos los mensajes de la prioridad especificada y superiores son almacenados de acuerdo con la acción requerida. Ademas de los términos mencionados hasta ahora, el demonio syslogd emplea los siguientes caracteres especiales:
'*' (asterisco) Empleado como comodín para todas las prioridades y servicios anteriores, dependiendo de dónde son usados (si antes o después del carácter de separación . ):
# Guardar todos los mensajes del servicio mail en /var/adm/mail
#
mail.* /var/adm/mail
' ' (blanco, espacio, nulo) Indica que no hay prioridad definida para el servicio de la linea almacenada.
',' (coma) Con este carácter es posible especificar múltiples servicios con el mismo patrón de prioridad en una misma línea. Es posible enumerar cuantos servicios se quieran:
# Guardar todos los mensajes mail.info y news.info en
# /var/adm/info

mail,news.=info /var/adm/info
';' (punto y coma) Es posible dirigir los mensajes de varios servicios y prioridades a un mismo destino, separándolos por este carácter:
# Guardamos los mensajes de prioridad "info" y "notice"
# en el archivo /var/log/messages
*.=info;*.=notice /var/log/messages
'=' (igual) De este modo solo se almacenan los mensajes con la prioridad exacta especificada y no incluyendo las superiores:
# Guardar todos los mensajes críticos en /var/adm/critical
#
*.=crit /var/adm/critical
'!' (exclamación) Preceder el campo de prioridad con un signo de exclamación sirve para ignorar todas las prioridades, teniendo la posibilidad de escoger entre la especificada (!=prioridad) y la especificada más todas las superiores (!prioridad). Cuando se usan conjuntamente los caracteres `=' y `!', el signo de exclamación `!' debe preceder obligatoriamente al signo igual `=', de esta forma:!=.
# Guardar mensajes del kernel de prioridad info, pero no de
# prioridad err y superiores
# Guardar mensajes de mail excepto los de prioridad info
kern.info;kern.!err /var/adm/kernel-info
mail.*;mail.!=info /var/adm/mail
Por su parte, el campo de acción describe el destino de los mensajes, que puede ser :
Un fichero plano: Normalmente los mensajes del sistema son almacenados en ficheros planos. Dichos ficheros han de estar especificados con la ruta de acceso completa (comenzando con `/'). Podemos preceder cada entrada con el signo menos, - , para omitir la sincronización del archivo (vaciado del buffer de memoria a disco). Aunque puede ocurrir que se pierda información si el sistema cae justo después de un intento de escritura en el archivo, utilizando este signo se puede conseguir una mejora importante en la velocidad,

especialmente si estamos ejecutando programas que mandan muchos mensajes al demonio syslogd.
# Guardamos todos los mensajes de prioridad critica en critical
#
*.=crit /var/adm/critical
Un terminal (o la consola): También tenemos la posibilidad de enviar los mensajes a terminales; de este modo podemos tener uno de los terminales virtuales que muchos sistemas UNIX ofrecen en su consola dedicado a listar los mensajes del sistema, que podrán ser consultados con solo cambiar a ese terminal:
# Enviamos todos los mensajes a tty12 (ALT+F12 en Linux) y
# todos los mensajes críticos del núcleo a consola
#
*.* /dev/tty12 kern.crit /dev/console
Una tubería con nombre: Algunas versiones de syslogd permiten enviar registros a ficheros de tipo pipe simplemente anteponiendo el símbolo ` | ' al nombre del archivo; dicho fichero ha de ser creado antes de iniciar el demonio syslogd, mediante ordenes como mkfifo o mknod. Esto es útil para debug y también para procesar los registros utilizando cualquier aplicación de UNIX, tal y como veremos al hablar de logs remotos cifrados. Por ejemplo, la siguiente línea de /etc/syslog.conf enviaría todos los mensajes de cualquier prioridad a uno de estos ficheros denominado /var/log/mififo:
# Enviamos todos los mensajes a la tubería con nombre
# /var/log/mififo
#
*.* |/var/log/mififo
Una máquina remota: Se pueden enviar los mensajes del sistema a otra maquina, de manera que sean almacenados remotamente. Esto es útil si tenemos una maquina segura, en la que podemos confiar, conectada a la red, ya que de esta manera se guardaría allí una copia de los mensajes de nuestro sistema y no podrían ser modificados en caso de que alguien entrase en nuestra maquina. Esto es especialmente

útil para detectar usuarios ocultos en nuestro sistema (usuarios maliciosos que han conseguido los suficientes privilegios para ocultar sus procesos o su conexión):
# Enviamos los mensajes de prioridad warning y superiores al
# fichero "syslog" y todos los mensajes (incluidos los
# anteriores) a la maquina "secure.upv.es"
# *.warn /usr/adm/syslog
*.* @secure.machine.es
Unos usuarios del sistema (si están conectados): Se especifica la lista de usuarios que deben recibir un tipo de mensajes simplemente escribiendo su login, separados por comas:
# Enviamos los mensajes con la prioridad "alert" a root y toni
#
*.alert root, maripet
Todos los usuarios que estén conectados: Los errores con una prioridad de emergencia se suelen enviar a todos los usuarios que estén conectados al sistema, de manera que se den cuenta de que algo va mal:
# Mostramos los mensajes urgentes a todos los usuarios
# conectados, mediante wall
*.=emerg *
4.4.4 Algunos archivos de log
En función de la configuración del sistema de auditoría de cada equipo UNIX los eventos que sucedan en la maquina se registraran en determinados ficheros; aunque podemos loggear en cualquier fichero (incluso a través de la red o en dispositivos, como veremos luego), existen ciertos archivos de registro habituales en los que se almacena información. A continuación comentamos los mas comunes y la información que almacenan.
syslog

El archivo syslog (guardado en /var/adm/ o /var/log/) es quizás el fichero de log mas importante del sistema; en él se guardan, en texto claro, mensajes relativos a la seguridad de la maquina, como los accesos o los intentos de acceso a ciertos servicios. Sin embargo, este fichero es escrito por syslogd, por lo que dependiendo de nuestro fichero de configuración encontraremos en el archivo una u otra información. Al estar guardado en formato texto, podemos visualizar su contenido con un simple cat:
Mar 5 04:15:23 anita in.telnetd[11632]: connect from localhost
Mar 5 06:16:52 anita rpcbind: connect from 127.0.0.1 to getport(R )
Mar 5 06:16:53 anita last message repeated 3 times
Mar 5 06:35:08 anita rpcbind: connect from 127.0.0.1 to getport(R )
Mar 5 18:26:56 anita rpcbind: connect from 127.0.0.1 to getport(R )
Mar 5 18:28:47 anita last message repeated 1 time
Mar 5 18:32:43 anita rpcbind: connect from 127.0.0.1 to getport(R )
Mar 6 02:30:26 anita rpcbind: connect from 127.0.0.1 to getport(R )
Mar 6 03:31:37 anita rpcbind: connect from 127.0.0.1 to getport(R )
Mar 6 11:07:04 anita in.telnetd[14847]: connect from rosita
Mar 6 11:40:43 anita in.telnetd[14964]: connect from localhost
messages
En este archivo de texto se almacenan datos informativos de ciertos programas, mensajes de baja o media prioridad destinados mas a informar que a avisar de sucesos importantes, como información relativa al arranque de la maquina; no obstante, como sucedÍa con el fichero syslog, en función de /etc/syslog.conf podremos guardar todo tipo de datos. Para visualizar su contenido es suficiente una orden como cat o similares (sólo se muestra un pequeño fragmento, este archivo contiene 1392 líneas en este momento):

Dec 2 16:21:21 localhost syslogd 1.3-3: restart.
Dec 2 16:21:21 localhost syslog: syslogd startup succeeded
Dec 2 16:21:21 localhost kernel: klogd 1.3-3, log source = /proc/kmsg started.
Dec 2 16:21:21 localhost syslog: klogd startup succeeded
Dec 2 16:21:21 localhost kernel: Inspecting /boot/System.map-2.2.14-5.0
Dec 2 16:21:21 localhost kernel: Loaded 7364 symbols from /boot/System.map-2.2.14-5.0.
Dec 2 16:21:21 localhost kernel: Symbols match kernel version 2.2.14.
Dec 2 16:21:21 localhost kernel: Loaded 189 symbols from 9 modules.
Dec 2 16:21:21 localhost kernel: Linux version 2.2.14-5.0 ([email protected]) (gcc version egcs-2.91.66 19990314/Linux (egcs-1.1.2 release)) #1 Tue Mar 7 21:07:39 EST 2000
Dec 2 16:21:21 localhost kernel: Detected 501145385 Hz processor.
Dec 2 16:21:21 localhost kernel: Console: colour VGA+ 80x25
Dec 2 16:21:21 localhost kernel: Calibrating delay loop. 499.71 BogoMIPS
Dec 2 16:21:21 localhost kernel: Memory: 127852k/131008k available (1060k kernel code, 416k reserved, 1616k data, 64k init, 0k bigmem)
Dec 2 16:21:21 localhost kernel: Dentry hash table entries: 262144 (order 9, 2048k)
Dec 2 16:21:21 localhost kernel: Buffer cache hash table entries: 131072 (order 7, 512k)
Dec 2 16:21:21 localhost kernel: Page cache hash table entries: 32768 (order 5, 128k)
Dec 2 16:21:21 localhost kernel: VFS: Diskquotas version dquot_6.4.0 initialized
Dec 2 16:21:21 localhost kernel: CPU: Intel Pentium III (Katmai) stepping 03
Dec 2 16:21:21 localhost kernel: Enabling extended fast FPU save and restore...done.
Dec 2 16:21:21 localhost kernel: Not enabling KNI unmasked exception support

Dec 2 16:21:21 localhost kernel: Exception 19 error handler not integrated yet
Dec 2 16:21:22 localhost kernel: Disabling CPUID Serial number...done.
Dec 2 16:21:22 localhost kernel: Checking 386/387 coupling. OK, FPU using exception 16 error reporting.
wtmp
Este archivo es un fichero binario (no se puede leer su contenido directamente volcándolo con cat o similares) que almacena información relativa a cada conexión y desconexión al sistema. Podemos ver su contenido con ordenes como last:
anita:/# last -10
toni pts/11 localhost Mon Mar 6 11:07 - 11:07 (00:00)
toni pts/11 rosita Sun Mar 5 04:22 - 04:25 (00:03)
ftp ftp andercheran.aiin Sun Mar 5 02:30 still logged in
ftp ftp andercheran.aiin Sun Mar 5 00:28 - 02:30 (02:01)
ftp ftp anita Thu Mar 2 03:02 - 00:28 (2+21:25)
ftp ftp anita Thu Mar 2 03:01 - 03:02 (00:00)
Los registros guardados en este archivo (y también en utmp) tienen el formato de la estructura utmp, que contiene información como el nombre de usuario, la línea por la que accede, el lugar desde donde lo hace y la hora de acceso. Algunas variantes de UNIX (como Solaris o IRIX) utilizan un fichero wtmp extendido denominado wtmpx, con campos adicionales que proporcionan mas información sobre cada conexión.
utmp
El archivo utmp es un fichero binario con información de cada usuario que está conectado en un momento dado; el programa /bin/login genera un registro en este fichero cuando un usuario conecta, mientras que init lo elimina cuando desconecta. Aunque habitualmente este archivo está situado en /var/adm/, junto a otros ficheros de log. Para visualizar el contenido de este archivo podemos utilizar ordenes como last (indicando el nombre de fichero mediante la opción -f), w o who:
anita:/# who

root console Mar 2 00:13
root pts/2 Mar 3 00:47 (UNIX)
root pts/3 Mar 2 00:18 (UNIX)
root pts/5 Mar 2 00:56 (UNIX)
root pts/6 Mar 2 02:23 (UNIX:0.0)
root pts/8 Mar 3 00:02 (UNIX:0.0)
root pts/7 Mar 2 23:43 (UNIX:0.0)
root pts/9 Mar 3 00:51 (UNIX)
root pts/10 Mar 6 00:23 (UNIX)
anita:/#
Como sucedía con wtmp, algunos UNIX utilizan también una versión extendida de utmp (utmpx) con campos adicionales.
lastlog
El archivo lastlog es un fichero binario guardado generalmente en /var/adm/, y que contiene un registro para cada usuario con la fecha y hora de su ultima conexión; podemos visualizar estos datos para un usuario dado mediante la orden finger:
anita:/# finger toni
Login name: toni In real life: Toni at ANITA
Directory: /export/home/toni Shell: /bin/sh
Last login Mon Mar 6 11:07 on pts/11 from localhost
No unread mail
No Plan.
anita:/#
faillog
Este fichero es equivalente al anterior, pero en lugar de guardar información sobre la fecha y hora del ultimo acceso al sistema lo hace del ultimo intento de acceso de cada usuario; una conexión es fallida si el usuario (o alguien en su lugar) teclea incorrectamente su

contraseña. Esta información se muestra la siguiente vez que dicho usuario entra correctamente a la maquina:
andercheran login: toni
Password:
Linux 2.0.33.
1 failure since last login.
Last was 14:39:41 on ttyp9.
Last login: Wed May 13 14:37:46 on ttyp9 from pleione.cc.upv.es.
Andercheran:~$
loginlog
Si en algunas versiones de UNIX (como Solaris) creamos el archivo /var/adm/loginlog (que originalmente no existe), se registraran en él los intentos fallidos de login, siempre y cuando se produzcan cinco o mas de ellos seguidos:
anita:/# cat /var/adm/loginlog
toni:/dev/pts/6:Thu Jan 6 07:02:53 2000
toni:/dev/pts/6:Thu Jan 6 07:03:00 2000
toni:/dev/pts/6:Thu Jan 6 07:03:08 2000
toni:/dev/pts/6:Thu Jan 6 07:03:37 2000
toni:/dev/pts/6:Thu Jan 6 07:03:44 2000
anita:/#
btmp
En algunas distribuciones de UNIX, como Linux o HP-UX, el fichero btmp se utiliza para registrar las conexiones fallidas al sistema, con un formato similar al que wtmp utiliza para las conexiones que han tenido éxito:
andercheran:~# last -f /var/adm/btmp |head -7
pnvarro ttyq1 term104.aiind.up Wed Feb 9 16:27 - 15:38 (23:11)

jomonra ttyq2 deportes.etsii.u Fri Feb 4 14:27 - 09:37 (9+19:09)
PNAVARRO ttyq4 term69.aiind.upv Wed Feb 2 12:56 - 13:09 (20+00:12)
panavarr ttyq2 term180.aiind.up Fri Jan 28 12:45 - 14:27 (7+01:42)
barra ttyp0 dtra-51.ter.upv. Thu Jan 27 18:42 - 20:17 (01:34)
andercheran:~#
sulog
Este es un fichero de texto donde se registran las ejecuciones de la orden su, indicando fecha, hora, usuario que lanza el programa y usuario cuya identidad adopta, terminal asociada y éxito ('+') o fracaso ('-') de la operación:
anita:/# head -4 /var/adm/sulog
SU 12/27 07:41 + console root-toni SU 12/28 23:42 - vt01 toni-root
SU 12/28 23:43 + vt01 toni-root SU 12/29 01:09 + vt04 toni-root
anita:/#
debug
En este archivo de texto se registra información de depuración (de debug) de los programas que se ejecutan en la maquina; esta información puede ser enviada por las propias aplicaciones o por el núcleo del sistema operativo:
luisa:~# tail -8 /var/adm/debug
Dec 17 18:51:50 luisa kernel: ISO9660 Extensions: RRIP_1991A
Dec 18 08:15:32 luisa sshd[3951]: debug: sshd version 1.2.21 [i486-unknown-linux]
Dec 18 08:15:32 luisa sshd[3951]: debug: Initializing random number generator; seed file /etc/ssh_random_seed
Dec 18 08:15:32 luisa sshd[3951]: debug: inetd sockets after dupping: 7, 8

Dec 18 08:15:34 luisa sshd[3951]: debug: Client protocol version 1.5; client software version 1.2.21
Dec 18 08:15:34 luisa sshd[3951]: debug: Calling cleanup 0x800cf90(0x0)
Dec 18 16:33:59 luisa kernel: VFS: Disk change detected on device 02:00
Dec 18 23:41:12 luisa identd[2268]: Successful lookup: 1593 , 22 : toni.users
luisa:~#
4.5.- Amenazas programadas
4.5.1.- Introducción
En 1990 Barton P. Miller y un grupo de investigadores publicaron un artículo en el que se mostraba que demasiadas herramientas estándar (más del 25%) de UNIX fallaban ante elementos tan simples como una entrada anormal. Cinco años más tarde otro grupo de investigación, dirigido también por Barton P. Miller, realizó el estudio, lamentablemente no publicado; las conclusiones en este último estudio fueron sorprendentes: el sistema con las herramientas más estables era Slackware Linux, un UNIX gratuito y de código fuente libre que presentaba una tasa de fallos muy inferior al de sistemas comerciales como Solaris o IRIX. Era preocupante comprobar como la mayoría de problemas descubiertos en 1990 seguía presente en los sistemas UNIX estudiados.
Aunque por fortuna la calidad del software ha mejorado mucho en los últimos años, y esa mejora lleva asociada una mejora en la robustez del código, los fallos y errores de diseño en aplicaciones o en el propio núcleo son una de las fuentes de amenazas a la seguridad de todo sistema informático. Pero no sólo los errores son problemáticos, sino que existen programas como los virus realizados en la mayoría de situaciones no para realizar tareas útiles sino para comprometer la seguridad de una máquina o de toda una red. Este tipo de programas solamente compromete la seguridad cuando afectan al administrador; si un virus infecta ficheros de un usuario, o si éste ejecuta un troyano, solo podrá perjudicarse a sí mismo: podrá borrar sus ficheros, enviar correo en su nombre o matar sus procesos, pero no hacer lo mismo con el resto de usuarios o el root.
El problema para la seguridad viene cuando es el propio administrador quien utiliza programas contaminados por cualquier clase de fauna, y para evitar esto hay una medida de protección básica: la prevención. Es crucial que las actividades como administrador se reduzcan al mínimo, ejecutando como usuario normal las tareas que no requieran de privilegios. Cuando no quede más remedio que trabajar como root

(por ejemplo a la hora de instalar software en el sistema), no hemos de ejecutar nada que no provenga de una fuente fiable, e incluso así tomar precauciones en caso de que el programa realice funciones mínimamente delicadas para el sistema operativo (por ejemplo, probarlo antes en una máquina de testeo, o en entornos cerrados con chroot()). Es muy normal, sobre todo entre administradores de Linux, el recomendar que no se ejecute nada sin haber leído previamente el código fuente, o al menos que dicho código esté disponible; esto, aunque es una solución perfecta al problema, es inaplicable en la mayoría de situaciones. Por un lado, no todas las aplicaciones o sistemas tienen su código abierto a sus usuarios, por lo que nos estaríamos restringiendo a utilizar programas generalmente no comerciales algo que quizás no depende de nosotros, como administradores. Por otro, resulta absurdo pensar que un administrador tenga el tiempo necesario para leer (y lo más importante, para comprobar) cada línea del código de todos los programas instalados en sus máquinas.
4.5.2.-Base Fiable de Cómputo
La base fiable de cómputo (Trusted Computing Base, TCB) es una característica de ciertos UNIX que incrementa la seguridad del sistema marcando ciertos elementos del mismo como seguros . Aunque estos elementos son básicamente el hardware y ciertos ficheros, la parte software es mucho más importante para el administrador que la máquina física, por lo que aquí hablaremos principalmente de ella. Los ficheros pertenecientes a la base segura de cómputo, y la TCB en su conjunto, tratan de asegurar al administrador que está ejecutando el programa que desea y no otro que un intruso haya podido poner en su lugar (conteniendo, por ejemplo, un troyano). La TCB implementa la política de seguridad del sistema inspeccionando y vigilando las interacciones entre entidades (procesos) y objetos (principalmente ficheros); dicha política suele consistir en un control de accesos y en la reutilización de objetos (cómo debe inicializarse o desinstalarse un objeto antes de ser reasignado).
Los ficheros con la marca de seguridad activada son generalmente el propio núcleo del sistema operativo y archivos que mantienen datos relevantes para la seguridad, contenidos en ciertos directorios como /tcb/ o /etc/auth/; cualquier fichero nuevo o que pertenezca a la TCB pero que haya sido modificado automáticamente tiene su marca desactivada. Puede ser activada o reactivada por el administrador (por ejemplo, en AIX con la orden tcbck -a), aunque en algunos sistemas para que un archivo pertenezca a la TCB tiene que haber sido creado con programas que ya pertenecían a la TCB. Con este mecanismo se trata de asegurar que nadie, y especialmente el root, va a ejecutar por accidente código peligroso: si el administrador ha de ejecutar tareas sensibles de cara a la seguridad, puede arrancar un intérprete de

comandos seguro (perteneciente a la TCB) que sólo le permitirá ejecutar programas que estén en la base.
La comunicación entre la base fiable de cómputo y el usuario se ha de realizar a través de lo que se denomina la ruta de comunicación fiable (Trusted Communication Path, TCP), ruta que se ha de invocar mediante una combinación de teclas (por ejemplo, Ctrl-X Ctrl-R en AIX) denominada SAK (Secure Attention Key) siempre que el usuario deba introducir datos que no deban ser comprometidos, como una clave. Tras invocar a la ruta de comunicación fiable mediante la combinación de teclas correspondiente el sistema operativo se ha de asegurar de que los programas no fiables (los no incluidos en la TCB) no puedan acceder a la terminal desde la que se ha introducido el SAK; una vez conseguido esto generalmente a partir de init se solicitará al usuario en la terminal su login y su password, y si ambos son correctos se lanzará un shell fiable (tsh), que sólo ejecutará programas miembros de la TCB (algo que es muy útil por ejemplo para establecer un entorno seguro para la administración del sistema, si el usuario es el root). Desde el punto de vista del usuario, tras pulsar el SAK lo único que aparecerá será un prompt solicitando el login y la clave; si en lugar de esto aparece el símbolo de tsh, significa que alguien ha intentado robar nuestra contraseña: deberemos averiguar quién está haciendo uso de esa terminal (por ejemplo mediante who) y notificarlo al administrador o tomar las medidas oportunas si ese administrador somos nosotros .
A pesar de la utilidad de la TCB, es recomendable recordar que un fichero incluido en ella, con la marca activada, no siempre es garantía de seguridad; como todos los mecanismos existentes, la base fiable de cómputo está pensada para utilizarse junto a otros mecanismos, y no en lugar de ellos.
4.5.3.-Tipos de amenazas programadas
Virus
Un virus es una secuencia de código que se inserta en un fichero ejecutable, denominado host, de forma que al ejecutar el programa, también se ejecuta el virus. Generalmente esta ejecución implica la copia del código del virus, en otros programas. El virus necesita un programa donde insertarse para ejecutarse, por lo que no puede ser considerado como un programa o proceso independiente.
Durante años, se ha discutido sobre la existencia de virus en el entorno UNIX. Realmente, existen virus que infectan tanto binarios ELF como shellscripts. Sin embargo la existencia de virus no tiene mucho interés en sistemas UNIX, ya que generalmente sus efectos no suelen ser muy perjudiciales en los sistemas UNIX de hoy en día.

Gusanos
Un gusano es un programa capaz de viajar por sí mismo a través de redes de ordenadores para realizar cualquier actividad una vez alcanzada la máquina. Aunque esta actividad no tiene por qué entrañar peligro, un gusano puede instalar en el sistema alcanzado un virus, atacar este sistema como haría un intruso o simplemente consumir excesivas cantidades de ancho de banda en la red afectada.
Conejos
Los conejos o bacterias son programas que de forma directa no dañan al sistema, sino que se limitan a reproducirse, generalmente de forma exponencial, hasta que la cantidad de recursos consumidos (procesador, memoria, disco,...) se convierte en una negación de servicio para el sistema afectado.
La mejor forma de prevenir ataques de conejos ( o simples errores en los programas, que hagan que estos consuman excesivos recursos) es utilizar las facilidades de los núcleos de cualquier UNIX moderno ofrecen para limitar los recursos que un determinado proceso o usuario puede llegar a consumir.
Caballos de Troya
Un caballo de Troya actual (al igual que el de la mitología griega) es un programa que aparentemente realiza una función útil para quién lo ejecuta, pero que en realidad, o aparte, realiza una función que el usuario desconoce, generalmente dañina.
La forma más fácil de descubrir caballos de Troya (aparte de sufrir sus efectos una vez ejecutado) es comparar los ficheros bajo sospecha con una copia de los originales. También es recomendable realizar resúmenes MD5 de nuestros programas y compararlos con los resúmenes originales.
Applets hostiles
En los últimos años, con la proliferación de la web, Java y Javascript, han aparecido los denominados applets hostiles, que al ser descargados intentan monopolizar o explotar los recursos del sistema de forma inapropiada. Esto incluye desde ataques clásicos como negación de servicio o ejecución remota de programas en la máquina cliente hasta amenazas mucho más elaboradas, como difusión de virus, ruptura lógica de cortafuegos o uso de recursos remotos para grandes cálculos científicos.

La propia Sun Microsystems ha reconocido el problema y está trabajando para minimizar los potenciales efectos de estos applets. No obstante, aunque se solucionen los problemas de seguridad del código, es probable que se puedan seguir usando applets como una forma de ataque a los sistemas: mientras que estos programas puedan realizar conexiones por red, no habrán desaparecido los problemas.
Bombas lógicas
Las bombas lógicas funcionan de manera similar a los troyanos, la diferencia entre ellos es que así como un troyano se ejecuta cada vez que se ejecuta el programa que lo contiene (o al que sustituye), una bomba lógica sólo se activa bajo ciertas condiciones, como una determinada fecha, la existencia de un cierto fichero, o el alcance de cierto número de ejecuciones. De esta manera, una bomba lógica puede permanecer en el sistema inactiva y sin ser detectada durante mucho tiempo y sin que nadie note nada anormal hasta que el daño producido por la bomba ya esté hecho.
Puertas traseras
Las puertas traseras son trozos de código en un programa que permiten a quién conoce su funcionamiento saltarse los métodos usuales de autentificación para realizar cierta tarea. Los programadores suelen usarlas para probar su código durante el desarrollo, pero pueden mantenerlas en el programa final, ya sea deliberada o involuntariamente. Pensemos por ejemplo en un programa que solicita cinco claves para realizar cierta tarea, es muy probable que el programador instale una puerta trasera una vez que ha comprobado el funcionamiento de dichas claves.
A parte de puertas traseras en los programas, también existen otros tipos de puertas traseras. Son las que instalan los intrusos para garantizarse el futuro acceso al sistema, como añadir un usuario con UID 0, añadir un nuevo servicio en un puerto no utilizado o incluso utilizar cron para reinstalar periódicamente dichas puertas en caso de que hayan sido eliminadas.
4.5.4.-Programación segura
Dado el gran impacto que pueden tener sobre la seguridad los errores de programación en las aplicaciones, es de vital importancia utilizar técnicas de programación seguras.
4.5.4.1.-Buffer overflow
Seguramente uno de los errores más comunes, y sin duda el más conocido y utilizado es el stack smashing o desbordamiento de

pila, también conocido por buffer overflow. Aunque el gusano de Morris (1988) ya lo utilizaba, no fue hasta 1997 cuando este fallo se hizo realmente popular. Aunque cada vez los programas son más seguros, especialmente los programas SUID, es casi seguro que un potencial atacante que acceda a nuestro sistema va a intentar si no lo ha hecho ya conseguir privilegios de administrador a través de un buffer overflow.
La idea del stack smashing es sencilla: en algunas implementaciones de C es posible corromper la pila de ejecución de un programa escribiendo más allá de los límites de un array declarado auto en una función; esto puede causar que la dirección de retorno de dicha función sea una dirección aleatoria. Esto, unido a permisos de los ficheros ejecutables en UNIX (principalmente a los bits de SUID y SGID), hace que el sistema operativo pueda otorgar acceso root a usuarios sin privilegios. Por ejemplo, imaginemos una función que trate de copiar con strcpy() un array de 200 caracteres en uno de 20: al ejecutar el programa, se generará una violación de segmento (y por tanto el clásico core dump al que los usuarios de UNIX estamos acostumbrados). Se ha producido una sobreescritura de la dirección de retorno de la función; si logramos que esta sobreescritura no sea aleatoria sino que apunte a un código concreto (habitualmente el código de un shell), dicho código se va a ejecutar.
El problema reside en los programas SUID y SGID; recordemos que cuando alguien los ejecuta, está trabajando con los privilegios de quien los creó, y todo lo que ejecute lo hace con esos privilegios. . . incluido el código que se ha insertado en la dirección de retorno de nuestra función problemática. Si, como hemos dicho, este código es el de un intérprete de comandos y el fichero pertenece al administrador, el atacante consigue ejecutar un shell con privilegios de root.
Para minimizar los efectos del desbordamiento de pila, los administradores han de mantener al mínimo el número de ficheros SUID y SGID en sus sistemas y los programadores tienen que esforzarse en generar código con menos puntos de desbordamiento.
4.5.4.2.- Recomendaciones para una programación segura
Después de analizar los problemas que un código mal diseñado puede causar, vamos a citar algunas recomendaciones para la elaboración de programas seguros bajo UNIX. Vamos a hablar de programación en C, obviamente por ser el lenguaje más utilizado en UNIX.

El principal problema de la programación en UNIX lo constituyen los programas SUID y SGID, si un programa sin este bit activo tiene un fallo, lo normal es que ese fallo solamente afecte a quien lo ejecuta. Al tratarse de un error de programación, algo no intencionado, su primera consecuencia será el mal funcionamiento de ese programa. Esto cambia cuando el programa es SUID o SGID: en este caso, el error puede comprometer tanto a quien lo ejecuta como a su propietario, y como ese propietario es por norma general root, automáticamente se compromete a todo el sistema. Para la codificación segura de este tipo de programas, se proporcionan unas líneas básicas:
Máximas restricciones a la hora de elegir el UID y el GID: Una medida de seguridad básica que todo administrador de sistemas UNIX ha de seguir es realizar todas las tareas con el mínimo privilegio que estas requieran; así, a nadie se le ocurre conectarse al IRC o aprender a manejar una aplicación como root. Esto también se aplica a la hora de programar: cuando se crea un programa SUID o SGID se le ha de asignar tanto el UID como el GID menos peligroso para el sistema.
Reset de los UIDs y GIDs efectivos antes de llamar a exec(): Uno de los grandes problemas de los programas SUID es la ejecución de otros programas. Por ejemplo, si el usuario introduce ciertos datos desde teclado, datos que se han de pasar como argumento a otra aplicación, nada nos asegura que esos datos sean correctos. Por tanto, es aconsejable restablecer el UID y el GID efectivos a los del usuario antes de invocar a exec(), de forma que cualquier ejecución inesperada se realice con el mínimo privilegio necesario; esto es aplicable a funciones que indirectamente realicen el exec(), como system() o popen().
Es necesario cerrar todos los descriptores de fichero, excepto los estrictamente necesarios, antes de llamar a exec(): Los descriptores de ficheros son un parámetro que los procesos UNIX heredan de sus padres; de esta forma, si un programa SUID está leyendo un archivo, cualquier proceso hijo tendrá acceso a ese archivo a no ser que explícitamente se cierre su descriptor antes de ejecutar el exec().
La forma más fácil de prevenir este problema es activando un flag que indique al sistema que ha de cerrar cierto descriptor cada vez que se invoque a exec(). Esto se consigue mediante las llamadas fcntl() e ioctl().
Hay que asegurarse de que chroot() realmente restringe: Los enlaces duros entre directorios son algo que el núcleo de muchos sistemas UNIX no permiten debido a que genera bucles en el sistema de ficheros, algo que crea problemas a determinadas

aplicaciones. Por ejemplo, Linux no permite crear estos enlaces, pero Solaris o Minix sí. En estos últimos, en los clones de UNIX que permiten hard links entre directorios, la llamada chroot() puede perder su funcionalidad: estos enlaces pueden seguirse aunque no se limiten al entorno con el directorio raíz restringido. Es necesario asegurarse de que no hay directorios enlazados a ninguno de los contenidos en el entorno chroot() (podemos verlo con la opción `-l' de la orden ls, que muestra el número de enlaces de cada archivo).
Comprobaciones del entorno en que se ejecutará el programa: En UNIX todo proceso hereda una serie de variables de sus progenitores, como el umask, los descriptores de ficheros, o ciertas variables de entorno ($PATH, $IFS. . . ). Para una ejecución segura, es necesario controlar todos y cada uno de estos elementos que afectan al entorno de un proceso. Especialmente críticas son las funciones que dependen del shell para ejecutar un programa, como system() o execvp(): en estos casos es muy difícil asegurar que el shell va a ejecutar la tarea prevista y no otra.
Nunca hacer shellscripts SUID: Aunque en muchos sistemas UNIX la activación del bit setuid en shellscripts no tiene ningún efecto, muchos otros aún permiten que los usuarios especialmente el root creen procesos interpretados y SUID. La potencia de los intérpretes de órdenes de UNIX hace casi imposible controlar que estos programas no realicen acciones no deseadas, violando la seguridad del sistema, por lo que bajo ningún concepto se ha de utilizar un proceso por lotes para realizar acciones privilegiadas con SUID.
No utilizar creat() para bloquear: Una forma de crear un fichero de bloqueo es invocar a creat() con un modo que no permita la escritura del archivo (habitualmente el 000), de forma que si otro usuario tratara de hacer lo mismo, su llamada a creat() fallaría. Esto, que a primera vista parece completamente válido, no lo es: en cualquier sistema UNIX, la protección que proporcionan los permisos de un fichero sólo es aplicable si quien trata de acceder a él no es el root. Si esto es así, es decir, si el UID efectivo del usuario que está accediendo al archivo es 0, los permisos son ignorados completamente y el acceso está permitido. De esta forma, el root puede sobreescribir archivos sin que le importen sus bits rwx, lo que implica que si uno de los procesos que compiten por el recurso bloqueado es SUID a nombre del administrador, el esquema de bloqueo anterior se viene abajo.
Para poder bloquear recursos en un programa SUID se utiliza la llamada link(), ya que si se intenta crear un enlace a un fichero que ya existe link() falla aunque el proceso que lo invoque sea

propiedad del root (y aunque el fichero sobre el que se realice no le pertenezca). También es posible utilizar la llamada al sistema flock() de algunos UNIX, aunque es menos recomendable por motivos de portabilidad entre clones.
Capturar todas las señales: Un problema que puede comprometer la seguridad del sistema UNIX es el volcado de la imagen en memoria de un proceso cuando éste recibe ciertas señales (el clásico core dump). Esto puede provocar el volcado de información sensible que el programa estaba leyendo: por ejemplo, en versiones del programa login de algunos UNIX antiguos, se podía leer parte de /etc/shadow enviando al proceso la señal sigterm y consultando el fichero de volcado.
No obstante, este problema no resulta tan grave como otro también relacionado con los core dump: cuando un programa SUID vuelca su imagen el fichero resultante tiene el mismo UID que el UID real del proceso. Esto puede permitir a un usuario obtener un fichero con permiso de escritura para todo el mundo pero que pertenezca a otro usuario (por ejemplo, el root): evidentemente esto es muy perjudicial, por lo que parece claro que en un programa SUID necesitamos capturar todas las señales que UNIX nos permita (recordemos que sigkill no puede capturarse ni ignorarse, por norma general).
Hay que asegurarse de que las verificaciones realmente verifican: Otra norma a la hora de escribir aplicaciones SUID es la desconfianza de cualquier elemento externo al programa. Hemos de verificar siempre que las entradas (teclado, ficheros. . . ) son correctas, no sólo en su formato sino también en su origen.
Cuidado con las recuperaciones y detecciones de errores:Ante cualquier situación inesperada y por lo general, poco habitual, incluso forzada por un atacante un programa SUID debe detenerse sin más; nada de intentar recuperarse del error: detenerse sin más. Esto, que quizás rompe muchos de los esquemas clásicos sobre programación robusta, tiene una explicación sencilla: cuando un programa detecta una situación inesperada, a menudo el programador asume condiciones sobre el error (o sobre su causa) que no tienen por qué cumplirse, lo que suele desembocar en un problema más grave que la propia situación inesperada. Para cada posible problema que un programa encuentre (entradas muy largas, caracteres erróneos o de control, formatos de datos erróneos. . . ) es necesario que el programador se plantee qué es lo que su código debe hacer, y ante la mínima duda detener el programa.
Cuidado con las operaciones de entrada/salida: La entrada/salida entre el proceso y el resto del sistema constituye

otro de los problemas comunes en programas SUID, especialmente a la hora de trabajar con ficheros; las condiciones de carrera aquí son algo demasiado frecuente: el ejemplo clásico se produce cuando un programa SUID ha de escribir en un archivo propiedad del usuario que ejecuta el programa (no de su propietario). En esta situación lo habitual es que el proceso cree el fichero, realice sobre él un chown() al UID real y al GID real del proceso (es decir, a los identificadores de quién está ejecutando el programa), y posteriormente escriba en el archivo.
Pero, ¿qué sucede si el programa se interrumpe tras realizar el open() pero antes de invocar a fchown(), y además el umask del usuario es 0? El proceso habrá dejado un archivo que pertenece al propietario del programa (generalmente el root) y que tiene permiso de escritura para todo el mundo. La forma más efectiva de solucionar el problema consiste en que el proceso engendre un hijo mediante fork(), hijo que asignará a sus UID efectivo y GID efectivo los valores de su UID real y GID real (los identificadores del usuario que lo ha ejecutado, no de su propietario). El padre podrá enviar datos a su hijo mediante pipe(), datos que el hijo escribirá en el fichero correspondiente: así el fichero en ningún momento tendrá por qué pertenecer al usuario propietario del programa, con lo que evitamos la condición de carrera expuesta anteriormente.
4.5.4.3.- Utilización segura de funciones de biblioteca
Sin embargo, un correcto estilo de programación no siempre es la solución a los problemas de seguridad del código. Existen llamadas a sistema o funciones de librería que son un clásico a la hora de hablar de bugs en nuestro software. Como norma, tras cualquier llamada se ha de comprobar su valor de retorno y manejar los posibles errores que tenga asociados, con la evidente excepción de las llamadas que están diseñadas para sobreescribir el espacio de memoria de un proceso (la familia exec() por ejemplo) o las que hacen que el programa finalice (típicamente, exit()) . Algunas de las llamadas consideradas más peligrosas (bien porque no realizan las comprobaciones necesarias, bien porque pueden recibir datos del usuario) son las siguientes:
system(): Esta es la llamada que cualquier programa SUID debe evitar a toda costa. Si aparece en un código destinado a ejecutarse con privilegios, significa casi con toda certeza un grave problema de seguridad. En algunas ocasiones su peligrosidad es obvia (por ejemplo si leemos datos tecleados por el usuario y a continuación hacemos un system() de esos datos, ese usuario no tendría más que teclear /bin/bash para conseguir los privilegios del propietario del programa), pero en otras no lo es tanto.

exec(), popen(): Similares a la anterior; es preferible utilizar execv() o execl(), pero si han de recibir parámetros del usuario sigue siendo necesaria una estricta comprobación de los mismos.
setuid(), setgid(). . . :Los programas de usuario no deberían utilizar estas llamadas, ya que no han de tener privilegios innecesarios.
strcpy(), strcat(), sprintf(), vsprintf(). . . : Estas funciones no comprueban la longitud de las cadenas con las que trabajan, por lo que son una gran fuente de buffer overflows. Se han de sustituir por llamadas equivalentes que sí realicen comprobación de límites (strncpy(), strncat(). . . ) y, si no es posible, realizar dichas comprobaciones manualmente.
getenv(): Otra excelente fuente de desbordamientos de buffer; además, el uso que hagamos de la información leída puede ser peligroso, ya que recordemos que es el usuario el que generalmente puede modificar el valor de las variables de entorno.
gets(), scanf(), fscanf(), getpass(), realpath(), getopt(). . . : Estas funciones no realizan las comprobaciones adecuadas de los datos introducidos, por lo que pueden desbordar en algunos casos el buffer destino o un buffer estático interno al sistema. Es preferible el uso de read() o fgets() siempre que sea posible (incluso para leer una contraseña, haciendo por supuesto que no se escriba en pantalla), y si no lo es al menos realizar manualmente comprobaciones de longitud de los datos leídos.
gethostbyname(), gethostbyaddr(): Seguramente ver las amenazas que provienen del uso de estas llamadas no es tan inmediato como ver las del resto; generalmente hablamos de desbordamiento de buffers, de comprobaciones de límites de datos introducidos por el usuario. . . pero no nos paramos a pensar en datos que un atacante no introduce directamente desde teclado o desde un archivo, pero cuyo valor puede forzar incluso desde sistemas que ni siquiera son el nuestro.
syslog(): Hemos de tener la precaución de utilizar una versión de esta función de librería que compruebe la longitud de sus argumentos; si no lo hacemos y esa longitud sobrepasa un cierto límite (generalmente, 1024 bytes) podemos causar un desbordamiento en los buffers de nuestro sistema de log, dejándolo inutilizable.
realloc(): Ningún programa privilegiado o no que maneje datos sensibles (por ejemplo, contraseñas, correo electrónico. . . y especialmente aplicaciones criptográficas) debe utilizar esta llamada. realloc() se suele utilizar para aumentar dinámicamente

la cantidad de memoria reservada para un puntero. Lo habitual es que la nueva zona de memoria sea contigua a la que ya estaba reservada, pero si esto no es posible realloc() copia la zona antigua a una nueva ubicación donde pueda añadirle el espacio especificado. ¿Cuál es el problema? La zona de memoria antigua se libera (perdemos el puntero a ella) pero no se pone a cero, con lo que sus contenidos permanecen inalterados hasta que un nuevo proceso reserva esa zona; accediendo a bajo nivel a la memoria (por ejemplo, leyendo /proc/kcore o /dev/kmem) sería posible para un atacante tener acceso a esa información. De cualquier forma, si vamos a liberar una zona en la que está almacenada información sensible, lo mejor en cualquier caso es ponerla a cero manualmente, por ejemplo mediante bzero() o memset().
open(): El sistema de ficheros puede modificarse durante la ejecución de un programa de formas que en ocasiones ni siquiera imaginamos; por ejemplo, en UNIX se ha de evitar escribir siguiendo enlaces de archivos inesperados (un archivo que cambia entre una llamada a lstat() para comprobar si existe y una llamada a open() para abrirlo en caso positivo). No obstante, no hay ninguna forma de realizar esta operación atómicamente sin llegar a mecanismos de entrada/salida de muy bajo nivel.
Bibliografía
A. Ribagorda, A. Calvo, M. Angel Gallardo.
“Seguridad en UNIX. Sistemas abiertos e Internet.”
Paraninfo, 1996
S. Garfinkel, G. Spafford
“Seguridad práctica en UNIX e Internet.””, 2ª edición
Mc Graw Hill, 1999
A. Villalón Huerta
“Seguridad en UNIX y redes.”, versión 1.2
Open Publication License, http://www.opencontent.org/openpub/, 2000
A. Silberschatz, P. Galvin

"Sistemas Operativos. Conceptos Fundamentales.”, 5ª edición
Addison-Wesley-Longman, 1999
G. Mourani
“Securing and Optimizing Linux. RedHat Edition -A Hands on Guide”
Open Network Architecture http://www.openna.com, 2000
K. Seifried
“Guía de Seguridad del Administrador de Linux”
http://segurinet.com/gsal, 1999
L. Wirzenius
”The Linux System Administrators' Guide”, versión 0.6.2
Linux Documentation Project, http://sunsite.unc.edu/LDP/, 1998
W. Tarreau
“Security under Linux : the Buffer Overflow Problem”
linux-stack-overflow.tgz
Pedro Gómez Ochoa
Jacobo Chamorro


















