
ROM 4.1-94, Proyecto y Construcción de los Pavimentos Portuarios
Upload
olimpio-solis-caceresCategory
view
31download
1
Proyecto CONICYT/BID 51/94
Desarrollo de metodologías orientadas alcontrol de calidad e imputación de datosfaltantes en parámetros meteorológicos
Informe finalJulio 1999

ii
INDICE1. RESUMEN.................................................................................................................................................................................... 1
1.1- RESUMEN EJECUTIVO................................................................................................................................................................... 11.2- RESUMEN TÉCNICO ...................................................................................................................................................................... 21.3- RECONOCIMIENTOS Y AGRADECIMIENTOS................................................................................................................................... 3
2. INTRODUCCIÓN ...................................................................................................................................................................... 4
2.1- PLANTEO DEL PROBLEMA............................................................................................................................................................ 42.2- ANTECEDENTES DEL PROBLEMA ................................................................................................................................................. 6
3. DESCRIPCIÓN DE LOS DATOS DISPONIBLES............................................................................................................... 10
3.1. CARACTERÍSTICAS DEL BANCO DE DATOS DE LLUVIA DIARIA...................................................................... 10
3.1.1- CARACTERÍSTICAS DE LA CUENCA ESTUDIADA...................................................................................................................... 103.1.1.1 - Introducción .................................................................................................................................................................. 103.1.1.2 - Descripción Climática .................................................................................................................................................. 103.1.1.3 - Información Meteorológica. ........................................................................................................................................ 113.1.1.4 - Factores climáticos ....................................................................................................................................................... 123.1.1.5 - Formación de Precipitaciones ...................................................................................................................................... 13
3.1.2 - LA LLUVIA EN LA CUENCA: ESTRUCTURA Y ESTACIONALIDAD ............................................................................................. 133.1.2.1 - Aproximaciones metodológicas para determinar estructuras...................................................................................... 133.1.2.2 - Estacionalidad............................................................................................................................................................... 18
3.2. CARACTERÍSTICAS DEL BANCO DE DATOS DE VIENTO HORARIO................................................................. 22
3.2.1- CARACTERÍSTICAS DE LA REGIÓN ESTUDIADA........................................................................................................................ 223.2.1.1 - Introducción .................................................................................................................................................................. 223.2.1.2 - Descripción Climática .................................................................................................................................................. 223.2.1.3 - Información Meteorológica. ........................................................................................................................................ 223.2.1.4 - Régimen Eólico. ............................................................................................................................................................ 23
3.3 - CARACTERÍSTICAS DEL BANCO DE DATOS DE NIVELES .................................................................................. 25
3.3.1 - CARACTERÍSTICAS DE LA CUENCA ESTUDIADA ................................................................................................... 25.1.1 - Introducción ....................................................................................................................................................................... 25.1.2 - Descripción Climática ....................................................................................................................................................... 25.1.3 - Información Hidrológica. ................................................................................................................................................. 25.1.4 - Régimen hidrológico. ......................................................................................................................................................... 26
3.4. CARACTERÍSTICAS DEL BANCO DE DATOS DE EVAPORACIÓN DIARIA....................................................... 27
3.4.1- CARACTERÍSTICAS DE LA REGIÓN ESTUDIADA........................................................................................................................ 283.4.1.1 - Introducción .................................................................................................................................................................. 283.4.1.2 - Descripción Climática .................................................................................................................................................. 283.4.1.3 - Información Meteorológica. ........................................................................................................................................ 283.4.1.4 - Régimen de Evaporación. ............................................................................................................................................. 29
4. IMPUTACIÓN DE AUSENCIAS............................................................................................................................................ 31
4.1 - MÉTODOS EN LOS QUE SE TIENE EN CUENTA ÚNICAMENTE LA INFORMACIÓN HISTÓRICA........................................................ 314.1.1 - Por interpolación temporal entre registros: .................................................................................................................... 314.1.2 - Promedio juliano: ............................................................................................................................................................ 314.1.3 - Promedio global de la estación: ...................................................................................................................................... 324.1.4 - Valor aleatorio sorteado uniformemente entre los registros disponibles de la estación:............................................... 324.1.5 - Valor modal de la serie:................................................................................................................................................... 32
4.2- MÉTODOS EN LOS QUE SE TIENE EN CUENTA ÚNICAMENTE LA INFORMACIÓN REGIONAL ......................................................... 334.2.1 - Imputación dinámica (“Hot - Deck”):............................................................................................................................. 334.2.2 - Vecino geográficamente más cercano:............................................................................................................................ 334.2.3- Vecino más cercano por Criterio de Expertos: ................................................................................................................ 334.2.4 - Promedio espacial correspondiente al día de la ausencia:............................................................................................. 344.2.5 - Promedio espacial ponderado correspondiente al día de la ausencia: .......................................................................... 35

iii
4.2.6 - Métodos basados en la pseudo-distancia de Kulback-Leibler: ....................................................................................... 354.2.7 - Mínimos Cuadrados:........................................................................................................................................................ 374.2.8 - Mínimo Error Promedio:................................................................................................................................................. 384.2.9 - Mínimo Error Promedio Robusto:................................................................................................................................... 384.2.10 - Mínimo Percentil 95: ..................................................................................................................................................... 384.2.11 - Métodos robustos de ajuste: Least Median of Squares (LMS):..................................................................................... 394.2.12 - Métodos robustos de ajuste: Least Trimmed Squares (LTS):........................................................................................ 394.2.13 - Métodos de imputación basados en redes neuronales: ................................................................................................. 394.2.14 - Funciones Climatológicas de Interpolación (GANDIN):.............................................................................................. 43
4.3- MÉTODOS EN LOS QUE SE TIENE EN CUENTA LA INFORMACIÓN REGIONAL E HISTÓRICA........................................................... 504.3.1 - Promedio ponderado arbitrariamente:............................................................................................................................ 504.3.2 - Condicionamiento según el estado del día anterior: ...................................................................................................... 514.3.3 - Interpolación temporal de coeficientes principales:........................................................................................................ 52
5. CONTROL DE CALIDAD. ...................................................................................................................................................... 54
5.1- CONSIDERACIONES GENERALES ................................................................................................................................................ 545.1.1 - Necesidad de una depuración progresiva........................................................................................................................ 545.1.2 - Metodología y criterios para la comparación de los distintos métodos aplicados. ............................................... 54
5.2- MÉTODOS UTILIZADOS PARA LA DETECCIÓN DE ERRORES......................................................................................................... 585.2.1 - Breve síntesis del Análisis de Componentes Principales (ACP) ..................................................................................... 615.2.2 - Datos marginales en la distribución univariada ............................................................................................................. 615.1.3 - Datos marginales en la distribución multivariada .......................................................................................................... 625.2.4 - Método de Hawkins.......................................................................................................................................................... 635.2.5 - Otros métodos basados en la distancia de Mahalanobis................................................................................................. 64
5.2.5.1 - Covarianza de Determinante Mínimo (MCD) y Elipsoide de Volumen Mínimo (MVE) .............................................................665.2.5.2 - Estimador-S y Estimador-M de T(X) y C(X).................................................................................................................................665.2.5.3 - Método de Hadi (1994)...................................................................................................................................................................67
5.2.6 - Método de las redes neuronales....................................................................................................................................... 695.2.7 - Método de la verosimilitud de la validación cruzada...................................................................................................... 705.2.8 - Método del gradiente admisible....................................................................................................................................... 715.2.9 - Método de la curvatura admisible ................................................................................................................................... 725.2.10 - Método del producto de gradientes admisibles ............................................................................................................. 725.2.11 - Modelado de la distribución (sólo lluvia)...................................................................................................................... 72
6 - RESULTADOS OBTENIDOS ................................................................................................................................................ 77
6.1 LLUVIA DIARIA............................................................................................................................................................................ 776.1.1 Generación de ausencias.................................................................................................................................................... 776.1.2 Imputación de valores ausentes.......................................................................................................................................... 786.1.3 Generación de errores aleatorios ...................................................................................................................................... 826.1.4 Detección de valores erróneos ........................................................................................................................................... 82
6.2 VIENTO DE SUPERFICIE HORARIO ................................................................................................................................................ 896.2.1 Generación de ausencias.................................................................................................................................................... 896.2.2 Imputación de valores ausentes: caso de las componentes ............................................................................................... 906.2.3 Imputación de valores ausentes: comparación datos originales vs. componentes............................................................ 906.2.4 Generación de errores: caso de las componentes ............................................................................................................. 946.2.5 Detección de valores erróneos: caso de las componentes................................................................................................. 95
6.3 NIVELES DIARIOS ........................................................................................................................................................................ 996.3.1 Imputación de valores ausentes........................................................................................................................................ 1006.3.2 Generación de errores aleatorios .................................................................................................................................... 1016.3.3 Detección de valores erróneos ......................................................................................................................................... 103
6.4 EVAPOTRANSPIRACIÓN ............................................................................................................................................................. 1046.4.1 Imputación de valores ausentes........................................................................................................................................ 1046.4.2 Generación de errores aleatorios .................................................................................................................................... 1066.4.3 Detección de valores erróneos ......................................................................................................................................... 106
6.5 TRATAMIENTO DE DATOS DE NIVEL MEDIANTE MODELOS DE SERIES TEMPORALES................................. 1086.5.1-Transformación estacionaria........................................................................................................................................... 1086.5.2- Modelo ARIMA estimado................................................................................................................................................ 1086.5.3- Modelo ARCH estimado ................................................................................................................................................. 108
7- REFERENCIAS....................................................................................................................................................................... 110

iv
8 - DOCUMENTOS Y PUBLICACIONES ANEXAS............................................................................................................. 113
8.1- ANÁLISIS DE LA SERIE TEMPORAL DE NIVELES
8.2- LOOKING INSIDE THE ANN "BLACK BOX"... (1999)8.3- A NEW TECHNIQUE FOR IMPUTATION OF MULTIVARIATE TIME SERIES... (1998)8.4- AN ERROR MODEL FOR DAILY RAIN RECORDS... (1998)8.5- QUALITY OF GEOGRAPHIC DATA: DETECTION OF OUTLIERS... (1997)8.6- APPLICATION OF ANN TO THE PREDICTION OF MISSING DAILY... (1997)8.7- COMPARACIÓN DE METODOLOGÍAS PARA LA IMPUTACIÓN DE LA LLUVIA... (1996)8.8- ANÁLISE DE UMA METODOLOGIA PARA O RECHEIO... (1996)8.9- ESTACIONALIDAD Y MODELIZACIÓN PROBABILÍSTICA DE LA LLUVIA DIARIA... (1995)
9 - OTROS ANEXOS
9.1- DATOS DEL PROYECTO
9.2- METAS PREVISTAS Y LOGRADAS: CUMPLIMIENTO DEL PLAN DE TRABAJO
9.3- ACTIVIDADES DESARROLLADAS SEGÚN LAS ENUMERADAS EN EL PROYECTO)9.4- FUNDAMENTACIÓN DE CUALQUIER DESVIACIÓN DE OBJETIVOS
9.5- RECURSOS MATERIALES
9.6 - RECURSOS HUMANOS
9.6.1 Integración original del equipo de trabajo9.6.2 Capacidad generada9.6.3 Clasificar el equipo de investigación en alguna de las siguientes categorías, y fundamentarlo9.6.4 Si corresponde, indicar interrelacionamiento o convenios institucionales
9.7- IMPACTO DE LOS RESULTADOS OBTENIDOS A NIVEL DE:9.7.1 Publicaciones9.7.2 Convenios, asesoramientos, etc.9.7.3 Definir los resultados obtenidos según su alcance a nivel local, regional o internacional9.7.4 Clasificarlos como importantes en:

1
1. RESUMEN
1.1- Resumen ejecutivoSe presentan a continuación los resultados obtenidos en el marco del proyecto
BID/CONICYT 51/94. Los mismos se pueden sintetizar en:
1. la construcción de las bases de datos conteniendo todos los datos pluviométricos de UTE y dela DNM correspondientes respectivamente a la cuenca del Río Negro y a la cuenca del SantaLucía, para un período de 30 años; los datos de viento de superficie para el período 1979-1991, así como los registros de escalas en tres puntos de la cuenca del Río Negro, para elperíodo 1975-1991.
2. la realización de una depuración primaria de dichos datos, cotejándolos manualmente con losde las planillas de la DNM y de la UTE.
3. diversos análisis estadísticos de los datos disponibles, que se detallarán a posteriori.4. la implementación de más de una treintena de alternativas metodológicas para imputar valores
ausentes, algunas tomadas de la literatura y otras producto de los trabajos realizados.5. la realización de simulaciones comparativas, calificando a los métodos por diferentes criterios
de éxito (error medio cuadrático, error promedio, etc.)6. la implementación de numerosos métodos conocidos, y desarrollo de otros nuevos, para la
detección de errores (de digitación) en los datos.7. la realización de estudios comparativos por la vía de métodos de Monte Carlo para la
comparación del desempeño relativos de los métodos utilizados para la detección de errores.Se diseñaron estadísticos originales que permiten clasificar un método como mejor que otropara los bancos de datos estudiados.
8. se realizó el estudio de la “estructura” general de la lluvia en la cuenca y por estación en elperíodo de 30 años. Para ello se utilizan por un lado técnicas de análisis multiway y por otrocriterios de relaciones entre la distribución de lluvia de las distintas estaciones. Se buscanrelaciones de tipo lineal y no lineal. Basada en la unidad mes, debido a las condicionantes dela Base de Datos considerada se llega a una “estacionalidad” por estación y para la cuenca. Seanaliza además la evolución, cuando es posible, en el período considerado.
9. la construcción de un modelo probabilístico basado en la información de distribución de lluviadel día anterior y la de otras estaciones el mismo día, para las diferentes estructurasestacionales detectadas en el punto anterior. Con él se obtendrán distribuciones condicionadasde lluvia para cada estación pluviométrica y para la cuenca en su conjunto para la estructuraestacional detectada en el punto anterior. El modelo así obtenido brindará información entérminos probabilísticos que permitirá mejorar la eficiencia de los indicadores y ademásresponderá en modo adecuado a demandas de información histórica sobre la probabilidad deque haya llovido y cuánto en una zona determinada, fuera de las estaciones pluviométricas ometeorológicas.
10. como indicadores de éxito del proyecto, se deben mencionar los varios artículos presentados yaceptados en congresos internacionales, así como una tesis de doctorado.

2
1.2- Resumen técnico
El proyecto tenía varios objetivos que se han cumplido apropiadamente. En lo querespecta a la imputación de valores ausentes, se ensayaron un cúmulo de alternativas tomadas dela literatura, o desarrolladas específicamente para este trabajo. Ello hace de este documento unareferencia muy importante en términos del estado del arte en el tema, y para las variablesconsideradas. Los métodos fueron aplicados simultáneamente a un mismo banco de datos, en elque se le eliminó temporalmente una fracción de la población, y los valores imputados fueroncomparados contra ellos. La bondad de la imputación fue evaluada con al menos cincoestadísticos: error cuadrático medio, error promedio, y tres percentiles de la distribución del errorabsoluto tomados al 75, 85 y 95%. Ello permitió manejar apropiadamente el hecho que ningúnbanco de datos puede asumirse libre de errores, y los últimos tres estadísticos son inmunes aellos.
En el experimento fueron analizados métodos tradicionales, en los que típicamente elvalor ausente es sustituído por una combinación lineal de los datos presentes. También fueronconsiderados métodos no lineales de varios tipos, poco tratados en la literatura meteorológica,que permitieron ilustrar el buen desempeño de las redes neuronales artificiales. Se estima queesto es un aporte significativo del proyecto.
Para cada parámetro hidrometeorológico considerado, el orden de precedencia entre losmétodos dependió del estadístico seleccionado para la medida de bondad de la imputación. Losresultados fueron claros: entre los mejores métodos siempre hubo una red neuronal, que tiende aproducir resultados más robustos (i.e. con mejores percentiles) que los otros métodos, a expensasde un mayor error cuadrático medio. Dependiendo del problema, otros métodos también costososfuncionaron bien, como ser los métodos lineales que minimizan los percentiles o la suma parcialde errores al cuadrado. Considerando únicamente los métodos más simples, se debe mencionar elbuen desempeño de aquellos derivados de la Interpolación Objetiva, y los vinculados al Análisisde Componentes Principales.
Un aspecto metodológico que no fue suficientemente tratado es que en la práctica, elusuario debe imputar un único banco de datos. Por ello, hay que tomar con cuidado el orden deprecedencia que se establece, ya que el mismo se deriva de una simulación de Monte Carlo. Quelos resultados que se presentan indiquen que el método A es mejor que el método B, debeinterpretarse como que, en valor esperado, A se comportará mejor que B. Ello no obsta a que, enun caso concreto, el orden no sea el mostrado por la mayoría de las simulaciones. Si estecomentario se analiza a la escala de datos individuales, no puede concluírse que para imputar unaausencia en concreto, el método A sea mejor que el B. Ello puede estar afectado en gran medidapor los datos disponibles, etc. por lo que debería ser considerada la posibilidad de asociar al valorimputado algún indicador de confiabilidad. En este aspecto, las redes neuronales vuelven amostrarse mejor posicionadas, ya que como se presentará luego, las mismas pueden servirsimultáneamente como fórmulas de regresión y como detectores de casos sospechosos, propiedadque no es compartida con otros métodos, que eventualmente (Rousseeuw, 1991) debencombinarse con métodos específicos de detección de errores.

3
El otro objetivo del proyecto era la comparación de métodos de detección de errores(también denominados outliers en la literatura estadística). A esos efectos, no sólo se relevó laliteratura existente y se implementaron la mayor parte de los métodos allí descritos, sino que fuenecesario proponer métricas para calificar un método como mejor que otro. Esto fue otro aporteoriginal del proyecto. Nuevamente los métodos (ahora originales) asociados a las redesneuronales tuvieron un excelente desempeño. Entre los métodos más económicos, se señala elpropuesto por Hawkins, 1974, y el propuesto por López, 1994a, que fueron además los aplicadosen etapas tempranas del proyecto para depurar el banco de datos de lluvia y de viento desuperficie, con buenos resultados.
Los resultados señalados permiten concluir que las redes neuronales son una herramientaválida para encarar tanto la imputación como la detección de errores, con la ventaja de seraplicables simultáneamente a ambos problemas sin más cálculos. En contrapartida, con lastécnicas disponibles al momento de iniciarse la investigación, las redes deben ser tentativamentediseñadas en forma arbitraria, y además los algoritmos de optimización disponibles quedabanfácilmente atrapados en óptimos locales.
1.3- Reconocimientos y agradecimientos
Han colaborado directamente en este proyecto los siguientes investigadores (ordenalfabético):
Bidegain, MarioBiurrun, JorgeBlanco, JorgeCamaño, GabrielDe los Santos, HugoFontana, HéctorGrosskoff, RosaGutiérrez, CelinaLópez, CarlosSabiguero, Ariel
Los coordinadores han sido: por la Dirección Nacional de Meteorología M.Sc. MarioBidegain, y por el Instituto de Estadística de la Facultad de Ciencias Económicas el Dr. JorgeBlanco. El responsable científico del proyecto fue el Dr. Ing. Carlos López.
Se agradece la colaboración de UTE y del resto del personal de la DNM para el acceso endiversas etapas del proyecto a los registros originales en papel. Además de los equipos adquiridospor el proyecto, se hizo uso extensivo de las facilidades disponibles en nuestros respectivosdepartamentos, y otras originadas en el marco de los proyectos CONICYT/BID 180/92 e INCO-DC 87/96, así como de equipos del departamento de Geoinformática del Royal Institute ofTechnology, Estocolmo, Suecia.

4
2. INTRODUCCIÓN
2.1- Planteo del Problema
El proyecto tiene como objetivo el estudio de diferentes técnicas aplicablesfundamentalmente (pero no en forma excluyente) a datos meteorológicos, para resolver losproblemas principales que se detallan a continuación:
a) detectar errores aleatorios en un banco de datos existenteb) señalar valores sospechosos en el momento de su ingreso al banco de datosc) imputar o asignar valores para los datos ausentes, tanto en tiempo real como en el
propio banco (entendiéndose como tiempo real, la ejecución de las tareasmencionadas en lapsos comparables con el insumido en el ingreso de lainformación).
En la mayoría de los bancos de datos existentes en nuestro país no hay implementadosmecanismos de control de la calidad de los datos o bien sólo existen controles de validación porrango: los datos son aceptados si están dentro de un intervalo prefijado. A nivel internacional,únicamente en los grandes centros de asimilación de datos se aplican controles más sofisticados.
La corrección de los errores de la base en momento de procederse a su utilización, o bienocasiona costos adicionales de depuración de los mismos cada vez que se van a procesar los datos(estimación de estadísticas descriptivas, elaboración de modelos, proyecciones, predicciones, etc.),o bien incorporan errores quizá importantes en los resultados del procesamiento.
En efecto, en toda operación de medida existen inevitablemente errores, tanto sistemáticoscomo aleatorios. Asimismo, los registros tomados usualmente son posteriormente transcritos a unbanco de datos antes de su uso, por lo que se agregan nuevas formas de error, generadas en tiempode ingreso o proceso de la información.
El orden de magnitud de los errores depende de muchos parámetros, y de la propia variable.Por ejemplo, como caso extremo, Slanina et. al., 1990, da cuenta que en la medida de trazadores decontaminantes los instrumentos suelen equivocarse por exceso, y los errores pueden llegar a ser del100 al 500%, para las trazas de cadmio, zinc, arsénico, etc.
Otro aspecto del problema es el efecto secundario que pueden tener esos errores, cuando porejemplo son usados en la toma de decisiones.
Según Husain, 1989, "...el fracaso de muchos proyectos de abultado presupuesto puede seratribuído en parte, a la imprecisión de la información hidrológica manejada...". Sin necesidad dehablar de fracaso, el diseño de los diques de una presa, de los muelles de un puerto o de laoperación diaria del sistema eléctrico nacional, descansa en mayor o menor medida, en datosrecogidos en forma rutinaria por organismos especializados.

5
El efecto por errores en los datos sobre los costos iniciales, o sobre los costos operativos,puede ser muy significativo, según los casos.
Como ejemplos, la decisión de verter agua en una represa, o el sobredimensionado de unaboya petrolera (Reolón, 1992), le pueden costar a la empresa o al país cantidades que no sonfácilmente estimables. En otras aplicaciones se intenta modelar matemáticamente algún fenómeno.Una etapa obligatoria es la de calibración o ajuste de parámetros empíricos del mismo. Estaactividad requiere atención a potenciales errores que se puedan deslizar en el proceso, los quedeberían ser detectados tempranamente. Sin embargo, en muchos casos resulta imposible en lapráctica analizar manualmente una secuencia de miles de n-uplas de datos. Por ello es usual que enestos casos se definan y calculen a partir de los mismos variables resumen como la media, valormáximo, valores extremos con período de retorno dado, desviación estándar, sesgo, etc. pararealizar un manejo más simple de los mismos.
El trabajar con valores promedio oculta en el conjunto, tanto aquellos eventos nítidamenteerróneos como otros más sutiles, sesgando el valor de los estimadores en forma descontrolada.
En el caso de los fenómenos que responden a leyes lineales, tales estadísticos pueden no serafectados significativamente por errores pequeños. Sin embargo, muchos fenómenos interesantes eimportantes no caen dentro de esa categoría, y modelar o calcular las n-uplas de datos con errorespuede implicar sensibles diferencias en los resultados.
Otra categoría importante es la de aquellos estudios que analizan la evolución temporal delos parámetros. En estos casos, el efecto de un error aislado persiste durante cierto tiempo,perturbando quizá significativamente los resultados en tal intervalo. Por ejemplo al estudiar ladispersión de contaminantes en la atmósfera un error aislado en la dirección del viento, traslada elcampo de contaminantes afectando de forma irreversible cualquier cálculo al menos durante algúntiempo hasta que se renueve la masa de aire. Otro caso más grave es el de un error en el cálculo delcaudal de un río que aporta a una represa; esta última que oficia de acumulador no puede eliminarde forma alguna un volumen de aporte ficticio, por lo que sesga definitivamente el nivel delembalse en lo sucesivo.
En general, el tratamiento de ausencias en los bancos de datos es un problema recurrente entodo estudio vinculado tanto a fenómenos naturales como a otras áreas, puesto que típicamente todoestudio asume como hipótesis que las series en que se basa están completas, imputándose caso acaso (con técnicas no siempre demasiado depuradas), alterando quizás resultados o generandoerrores adicionales.
Si bien muchos problemas no requieren de la imputación de todos los datos faltantes, loscálculos suelen ser muy sensibles a los errores si existen pocos registros (Kennedy, 1989).
Cualquier método para asignar valores faltantes debe preservar las características principalesdel banco y ofrecer garantías de no disminuir los niveles de calidad del mismo.

6
Debe considerarse asimismo la posibilidad de trabajar con distintos niveles de precisión alos efectos de la imputación de valores faltantes. Habrá estudios que sean más sensibles que otros alos datos ausentes y para los cuales se deba asignar valores confiables a registros incompletos.
Debido a ello, la posibilidad de asignar valores, dando una estimación del error cometido(objetivo c) ) es de gran interés en la aplicación.
Corresponde señalar que ninguna de las aseveraciones realizadas es específica de losparámetros meteorológicos. El mismo problema puede observarse en bancos de datossocioeconómicos u de otra índole, y similares inconvenientes se presentan en ellos.
Para los problemas enumerados, se han ensayado y puesto a punto diferentes algoritmos yaexistentes e implementado nuevos, que tienen en cuenta la correlación en el espacio y/o en eltiempo de los registros. En este informe se presenta el caso de la lluvia diaria, un campo conapreciable correlación espacial y débil correlación temporal. Se solicitó a las institucionesinteresadas (UTE, DNM) que suministraran bancos de datos, recibiéndose de la primera el banco dedatos del Río Negro, y de la segunda, la parte correspondiente a la cuenca del Río Santa Lucía.
2.2- Antecedentes del Problema
Para la detección rutinaria de datos anómalos en el área meteorológica, el único antecedentenacional conocido consiste en las recomendaciones realizadas por la Dirección de Climatología yDocumentación de la Dirección Nacional de Meteorología (DNM, 1988). En general se basan en uncontrol por rango admisible para cada parámetro. A nivel regional la situación es similar(Núñez, 1994)
A nivel internacional, existen trabajos (Sevruk, 1982) que proponen procedimientos paracorregir errores sistemáticos en cada estación. Se requiere conocer, entre otros, la velocidad delviento, la intensidad de la lluvia, la temperatura y humedad del aire, etc.
Con respecto a los errores aleatorios, la tendencia es comparar las medidas con un modelodel fenómeno (p. ej.: Francis, 1986; Hollingsworth et al., 1986). Este último asevera que para elcaso del viento, las diferencias entre observaciones y predicciones tienen aproximadamente unadistribución normal. En ese caso, es relativamente fácil detectar los datos anómalos y separarlospara un análisis a posteriori. Como desventaja debe señalarse el importante volumen deinformación requerido, así como los altos costos computacionales involucrados, dado que esnecesario modelar (eventualmente por separado) los diferentes parámetros, utilizando métodosespecíficos para cada uno.
En los grandes centros mundiales de asimilación de datos se utilizan sistemáticamentemétodos más complejos de control de calidad. Ellos requieren de un volumen de información sólodisponible allí mismo (Gandin, 1988; Di Mego, 1988, Parrish, 1992). Por tanto, si bien sonmétodos conocidos, resultan inaplicables en general para otro tipo de parámetros, e incluso en laspresentes condiciones no podrían ser usados por los organismos nacionales competentes. Los

7
recursos humanos e informáticos constituyen una limitante insalvable en este sentido. Gandin, 1988reconoce que parte significativa de los errores detectados pertenecen a países en desarrollo, dondelos recursos afectados a la toma de datos son significativamente menores que en otros países.
Si se prescinde o se desconoce la relación física que debería ligar a las variables, losmétodos puramente estadísticos son una alternativa a evaluar. Barnett et al., 1984 efectúa unasíntesis de distintas técnicas aplicables para el abordaje de este problema.
Para el caso univariado, los controles por rango si bien necesarios se han revelado comoinsuficientes. Existen extensiones aplicables a este tipo de series como los métodos de detecciónbasados en estimadores robustos (Goyeneche et. al., 1989).
Para el caso multivariado, Barnett et al., 1984 distingue dos grandes líneasmetodológicas, según que la función de distribución de la muestra se suponga conocida, o no.
La primera de ellas corresponde a los llamados Tests de discordancia, que agrupa una seriede técnicas aplicables según la forma en que se distribuyen los datos muestreados, y requierenconocer -o poder estimar- los parámetros de la distribución. Existen también antecedentesvinculados al caso en que la distribución teórica responda a un tipo de ley y los datos muestreados aotra, como es el caso del planteo de O'Hagan, 1990. Allí el hecho que una de las distribuciones seanormal y la otra de tipo t habilita al uso de cierta metodología para poner en evidencia los datosanómalos. El problema aquí tratado no es abordable a partir de este tipo de métodos, puesto que lashipótesis no son lo suficientemente generales para aplicarlas a una variedad de parámetrosimportante.
La segunda línea identificada por Barnett corresponde a lo que se ha dado en llamarMétodos informales. Estos prescinden de los aspectos formales de la distribución de los datos, yapuntan a explotar ciertas propiedades de los mismos. En este grupo se encuentran los métodos dedetección de marginales, fijando un rango de probabilidad; los métodos gráficos, basados en labúsqueda de puntos alejados de la nube de datos; la aplicación de métodos de correlación(Gnanadesikan et al., 1972); la búsqueda de distancias generalizadas representativas, técnicasasociadas con el análisis de conglomerados (cluster analysis) (ver por ejemplo, Fernau et al., 1990)y análisis de componentes principales (ACP), entre otros.
Un antecedente muy específico respecto al ACP lo presenta el trabajo de Hawkins, 1974. Enél se comparan cuatro indicadores o estadísticos, diseñados para resaltar datos anómalos. Hawkinsasume que cada observación tiene distribución normal, por lo que su hipótesis no es aplicable engeneral (no la cumple, por ejemplo, la lluvia diaria); sin embargo, los conceptos por él vertidos sonsimilares a los manejados en López et. al., 1994a, 1993a y 1996.
Bajo hipótesis muy generales, existen también una variedad de métodos que se basan en ladistancia de Mahalanobis como indicador de fiabilidad, y que difieren en la forma de estimar lamatriz de covarianza y el valor esperado. Entre ellos, se encuentran los descritos en Rousseeuw,1991; Rousseeuw et al., 1987, 1990; Rocke, 1996; Rocke et al., 1987; Hadi, 1992, 1994, etc.

8
A modo de conclusión, la opinión de un experto reconocido como el Dr. Gandin (Gandin,1988) debe ser citada. El autor asevera que tradicionalmente, el problema de control de calidad dela información ha sido relegado en las prioridades de investigación, por ser (erróneamente)considerado un problema puramente técnico, que se agota en la detección de los mismos.
Con respecto a los datos ausentes, en el campo de la Meteorología son práctica corrientemétodos de análisis objetivo (ver Haagenson, 1982, Johnson, 1982, etc.), que permiten generar uncampo interpolado a partir de datos irregularmente distribuídos. Ello permitiría calcular los valoresfaltantes, a partir de los existentes.
Otras veces se utilizan magnitudes derivadas, y no el dato en bruto. Por ejemplo, para elcálculo de lluvia media sobre una región, existen métodos como el de los polígonos de Thiessen(Jácome Sarmento et al., 1990) que no requieren en principio, de un banco de datos completo.
Ambas situaciones han llevado a que el tema del tratamiento o eliminación de ausenciashaya sido también relegado, lo que se refleja en lo escaso de los trabajos específicos en la literaturaespecializada consultada.
En la mayoría de los casos prácticos, el dato ausente es simplemente ignorado, (bajo lahipótesis implícita que estas ausencias son al azar) o se aplican técnicas ad-hoc (interpolaciónlineal, sustitución por el más próximo) que luego no son documentadas en el trabajo final. Encualquier caso, se afecta a la población en forma arbitraria, en base a hipótesis que rara vez sonevaluadas.
El tema en cambio, es de gran interés en el área de la Estadística y las Ciencias Sociales engeneral, pudiéndose encontrar en libros específicos (Rubin, 1987) citas a volúmenes producidos porgrupos de trabajo dedicados al tópico.
Existen métodos de imputación más o menos sofisticados. Entre éstos últimos, se puedecitar el utilizado por la Oficina del Censo de los EE.UU. (Rubin, 1987). El mismo consiste enasignar al dato ausente un valor tomado al azar de entre los restantes eventos que tienen idénticarespuesta en el resto del cuestionario. Si eventualmente no existiese otro igual, o bien se relativizaesa exigencia, admitiendo que alguna o algunas respuestas no lo sean, o bien, se introduce una"distancia" entre cuestionarios, y se busca aquel que diste menos.
Otro método también simple, es el de hacer una regresión sobre el conjunto de datos,ajustando un modelo sencillo. Típicamente, se utilizan mínimos cuadrados (total o parcialmente) ocomponentes principales, métodos que Stone et al., 1990 presenta desde una perspectiva integrada.Los propuestos en Rousseeuw et al., 1987; Rousseeuw, 1984; Hawkins, 1993, 1994a, 1994btienen la particularidad de producir una regresión lineal diseñada para ser apropiada aún en lapresencia de un grupo considerable de errores arbitrariamente grandes, propiedad muyimportante en la práctica ya que los bancos de datos no pueden asumirse libre de errores enninguna instancia.

9
Todos los métodos considerados producen una única alternativa: para cada ausencia sepropone una única imputación. Según Rubin, 1987, ".. es intuitivamente claro que imputar lapredicción 'óptima' para cada ausencia subestimará la variabilidad...". Existe, sin embargo, laposibilidad de imputar más de un valor para una misma ausencia. Así Rubin presenta una variedadde técnicas, algunas excesivamente especializadas, para su aplicación en encuestas. Como ideageneral, se propone crear para cada ausencia, un número m (pequeño) de alternativas, y considerarque se dispone de m conjuntos completos diferentes. Para el caso en que la tasa de ausencias esbaja, el método funciona razonablemente bien, requiriéndose sin embargo más espacio (paraguardar las múltiples imputaciones) y más tiempo de cálculo (para procesar los diferentes conjuntoscompletos generados).
Como caso particular, tanto para la detección de errores, como para la imputación deausencias en un banco de datos hidrológicos, se pueden encontrar a nivel nacional los trabajos deSilveira et al., 1991, y los de López et al., 1994a y 1994b. En ellos se describen resultados exitosospara el parámetro lluvia diaria, utilizando métodos que podrían ser aplicables a otros casos.
Los mismos métodos han sido ensayados sobre un banco de datos de viento y presiónatmosférica a nivel del mar (López et. al., 1993a) y fueron comparados en ese caso, con losresultados derivados de la aplicación del método de Interpolación Optima (Gandin, 1963, 1988)entre otros. Los resultados obtenidos con los métodos no tradicionales propuestos fueronsensiblemente mejores, en los experimentos presentados.
El método de detección de errores basado en el ACP también ha sido ensayado sobremodelos digitales de terreno, en experimentos controlados (López, 1997a, 2000).

10
3. DESCRIPCIÓN DE LOS DATOS DISPONIBLES
3.1. CARACTERÍSTICAS DEL BANCO DE DATOS DE LLUVIA DIARIA
3.1.1- Características de la Cuenca estudiada
3.1.1.1 - Introducción
La Cuenca hidrográfica del Rio Santa Lucía, con una superficie de 13600 km 2 , está situada en laregión sur del Uruguay, aproximadamente entre los 55° y 57° de longitud oeste y 33°40’ y 34°50’ latitudsur.
Las cuchillas o sucesión de cerros que sirven de límite a la Cuenca no superan los 300 metros. Lavegetación predominante es la pradera y los pocos árboles y arbustos se encuentran a lo largo de los ríos yarroyos.
El Río Santa Lucía, de 225 km de largo es el más importante del sur del país, sus dos principalescontribuyentes son el Río San José, de 111 km y el Santa Lucía chico, de 122 km.
3.1.1.2 - Descripción Climática
El clima de esta región es templado húmedo sin estación seca. Le corresponde la categoría Cfa enla clasificación climática de Koeppen. Las temperaturas medias anuales son de 17°C. Los extremos detemperatura anuales son importantes con máximas absolutas de 43°C y mínimas absolutas de -8°C.
Las precipitaciones totales anuales estan situadas en los 1000 mm. Se observa un máximo de unos1100 mm. sobre las nacientes del Río San José y un mínimo de 900 en el sureste de la cuenca junto al Ríode la Plata. Las precipitaciones presentan sin embargo una gran variabilidad interanual, con años muylluviosos, por ejemplo 1959 con 1600 mm. y muy secos, por ejemplo 1916 con 500 mm.
El mes más lluvioso es marzo, con 100 mm. y el menos lluvioso es julio con 75 mm., la diferenciaentre ambos (25 mm.) indica la regularidad de las precipitaciones a lo largo del año.
La humedad relativa de la cuenca presenta un valor medio anual de 70%, y oscila entre 60% endiciembre y enero y 78% en junio.

11
3.1.1.3 - Información Meteorológica.
Las medidas de la precipitación en la cuenca se realizan por medio de una red pluviométrica queconsta de unas 50 estaciones, en general atendidas por personal del Ministerio del Interior y de A.F.E.(Ferrocarriles del Estado).
La distribución espacial no homogénea de los pluviómetros en la cuenca obedece a que fueronestablecidos a lo largo de las líneas férreas (estaciones del ferrocarril) y en poblados (comisarías). A estehecho hay que sumar a mediados de la década del ochenta el cierre de la mayoría de las estaciones delferrocarril y por lo tanto la ausencia de observaciones pluviométricas a partir de esas fechas.
En este Proyecto se han seleccionado 10 estaciones pluviométricas, con información en el período1960 - 1990. En la Tabla 1 y en la Figura 1 se indican algunas de sus características y su localizacióngeográfica.
N° Nombre Latitud Longitud Elevación2436 Puntas de Sauce 33°50'S 57°01'W 120 mts2486 Pintos 33°54'S 56°50'W 100 mts2549 Barriga Negra 33°56'S 55°07'W 95 mts2588 Casupá 34°06'S 55°39'W 124 mts2662 Cufré 34°13'S 57°07'W 92 mts2707 Raigón 34°21'S 56°39'W 37 mts2714 San Ramón 34°18'S 55°58'W 70 mts2719 Ortiz 34°17'S 55°23'W 115 mts2816 Joanicó 34°36'S 56°11'W 35 mts2846 Olmos 34°44'S 55°54'W 40 mts
Tabla 1 Listado de las estaciones pluviométricas con información en el período 1960 - 1990
La información de las otras variables atmosféricas (temperatura, humedad, presión atmosférica,evaporación, viento, horas de sol, etc.) es obtenida en las Estaciones Meteorológicas de la Cuenca,pertenecientes a la Dirección Nacional de Meteorología, que son:
N° Nombre Latitud Longitud Elevación Período86580 Carrasco 34°50'S 56°00'W 33 mts 1947 - Presente86585 Prado 34°51'S 56°12'W 16 mts 1901 - Presente86575 Melilla 34°47'S 56° 15'W 49 mts 1951 - Presente86568 Libertad 34°41'S 56°32'W 21 mts 1977- Presente86545 Florida 34°04'S 56° 14'W 92 mts 1987 - Presente
Tabla 2 Estaciones meteorológicas próximas a la zona de estudio
La información en estas Estaciones Meteorológicas es relevada en forma horaria, transfiriéndosevía telefónica a Montevideo, y es utilizada en la elaboración del pronóstico del tiempo, y también en laobtención de estadísticas climáticas de valores esperados acumulados, medios y extremos.

12
100 km
2436 2486 2549
2588 2662
2707 2714 2719
2816
2846
2436 2486 2549
2588 2662
2707 2714 2719
2816
2846
Figura 1 Localización de las estaciones pluviométricas utilizadas
3.1.1.4 - Factores climáticos
Diversos factores tanto geográficos, oceanográficos y meteorológicos influyen en el clima de laCuenca.
La Cuenca se sitúa integramente en la zona templada del hemisferio sur. La poca extension y laausencia de sistemas orográficos importantes, determinan que las temperaturas medias mensuales seanhomogéneas y suaves (entre 10°C y 25°C todo el año).
La corriente oceánica de Brasil, transporta aguas de origen tropical, y su transporte calóricoproduce una aumento de la temperatura del aire, y un aporte importante de vapor de agua a laatmósfera. La corriente de las Malvinas transporta aguas frías desde el sur produciendo una estabilidaden las capas bajas de la atmósfera.
El anticiclón semipermanente del Atlántico Sur ejerce una gran influencia en el tiempoatmosférico que se desarrolla sobre el Uruguay. La circulación generada por este anticiclón producevientos del sector noreste al este, aportando masas de aire de caracter tropical y húmedas.
También el anticiclón semipermanente del Pacifico Sur, con su circulación del sur al suroestesobre el país, aporta principalmente durante el invierno, masas de aire frías y en general secas.
La depresión térmico-orográfica del noroeste argentino, produce en determinadas situacionesaporte de aire muy húmedo y cálido desde el Chaco, principalmente en el verano.

13
3.1.1.5 - Formación de Precipitaciones
Las masas de aire portadoras de humedad necesitan ciertos mecanismos dinámicos para producirprecipitaciones.
El principal mecanismo de producción de lluvias sobre la cuenca son los pasajes de sistemasfrontales o frentes. Las principales masas de aire presentes sobre el país son la masas de aire tropicalcon un gran contenido de vapor de agua, y las masas de aire polar de carácter frío y seco. La zona detransición entre dos masas de aire de diferentes características define una zona frontal, que estáasociada en general a precipitaciones.
Se estima el pasaje de unos 70 a 80 frentes fríos en el año que provocan precipitaciones enzonas y cantidades variables. El volumen de las precipitaciones depende del contenido de aguaprecipitable en la masa de aire húmedo.
Otro mecanismo de precipitación es el ascenso de aire producido por una depresión o ciclóndinámico y su pasaje sobre la cuenca, este tipo de perturbación produce en general precipitaciones muyimportantes en volumen, afecta un área limitada, y está asociada a vientos fuertes y tormentas severas.
3.1.2 - La lluvia en la Cuenca: estructura y estacionalidad
El objetivo perseguido en esta etapa es el de determinar, si existe, una estructura de la lluvia enla cuenca durante los treinta años considerados. De lo contrario caracterizar las variaciones que se hanproducido en dicha estructura en el período. Este aspecto tiene indirecta relación con el objetivoprimordial del proyecto, pero asume gran importancia a la hora del conocimiento del fenómeno ypermitirá aceptar o rechazar diferentes hipótesis realizadas en uno y otro sentido, al mismo tiempo quemejorar la eficiencia de cualquier modelo que se pretenda utilizar para analizar el fenómeno..
En cuanto a la estacionalidad, aquí entendida como comportamiento diferenciado de algunosmeses del año respecto a otros, en relación a la distribución de la lluvia, será de utilidad inmediata parala construcción del modelo que se plantea en el punto 8. del Resumen, y para mejorar la eficiencia delos diferentes estimadores que ha desarrollado el proyecto.
3.1.2.1 - Aproximaciones metodológicas para determinar estructuras.
En este sentido se han desarrollado dos líneas de trabajo diferenciadas. Por una parte se utilizanalgunas de las técnicas para el análisis de datos multivariados multiway y en otras se buscan relacioneslineales y no lineales en el tiempo y en el espacio.

14
3.1.2.1.1 - Métodos Multivariados Multiway
Con el objetivo de ubicar al lector en el significado de la primera aproximación metodológica serealiza una presentación resumida y elemental de algunos métodos multiway en particular, precedida,por una breve presentación general de los métodos a más de dos vías.
El análisis multivariado clásico extrae generalmente información de una tradicional matriz 2-way (2 vías) de datos.
{ }X x
x x x
x x x
x x x
ij
n
n
n n nn
= =
11 12 1
21 22 2
1 2
L
L
L L L L
L
donde xij es el valor que toma la variable j en la unidad i. Las dos vías están aquí representadas por las
“unidades” y las “variables”.
Un ejemplo de 3-way de datos esta dado por: { }X xijk= donde xijk es el valor que toma la
variable j (j=1,...J) en la unidad i (i=1,...I) en la ocasión k (k=1,...K), considerando que son las mismasvariables y unidades en cada ocasión.
En general p-way data pueden ser representados por: { }X xi ip=
1 L donde cada dato elemental
x i i p1 ... se clasifica de acuerdo a p ways como por ejemplo, unidades, variables, tiempos, áreas,
categorías de variables, etc... En modo general se puede distinguir entre:
i) Arrays de p-way datos si todas las combinaciones de diferentes índices se encuentranpresentes. Un ejemplo de array a 3-way es del tipo “unidades × variables × ocasiones” dondese consideran las mismas unidades y las mismas variables en cada ocasión.
ii) Sets de p-way datos. No todas las combinaciones de los valores de diferentes índices seencuentran presentes. En el caso de 3-way “unidades × variables × ocasiones” cambian o lasvariables o las unidades en cada ocasión.
En el caso que nos ocupa se pueden conformar arrays o sets de múltiples formas. Unoparticularmente interesante para medir el comportamiento estructural de la lluvia en el período de losúltimos treinta años es la matriz “estaciones pluviométricas × unidades de tiempo (ej.meses) × distribución de lluvia”. Para constituir arrays en este caso se debe considerar solamente lasunidades de tiempo con información completa, estando en las demás situaciones frente a sets.
Del enfoque general a p-way nos interesa en este momento solamente el de 3-way en lasituación “unidades × variables × ocasiones” que es el que concretamente se aplica en la presenteinvestigación. Veamos una síntesis de algunos enfoques metodológicos aquí aplicados lo que nosignifica para nada un desarrollo exhaustivo de las aproximaciones multiway.

15
3.1.2.1.1.1 - Modelos multilineales
Los modelos multilineales fueron considerados por Kruskal (1984) . Se incluyen dentro de losllamados modelos estructurales descriptivos. Dentro de los más utilizados para el análisis de datos a 3-way se destacan los siguientes:
a) Modelo Cuadrilineal
Modelo Tucker 3 (Tucker, 1963, 1964, 1966; Kroonenberg, 1983):
x m a b c gijk ijk ip jq k r pqrr
R
q
Q
p
P
≈ ====
∑∑∑111
donde el significado de los parámetros es el siguiente::
aip= puntaje de la unidad i en relación a la dimensión latente (“componente ideal”) p,
b jq = puntaje de la variable j en relación a la dimensión latente q,
ckr = puntaje de la ocasión k relativa a la dimensión latente r;g pqr = puntaje conjunto de la genérica terna (p,q,r) de las componentes ideales de los tres modos (p-
ésima para las unidades, q-ésima para las variables y r-ésima para las ocasiones). Este parámetro es unamedida de la interacción triple entre las tres genéricas dimensiones latentes. El conjunto de las gpqr
forman la llamada CORE MATRIX.
b) Modelo Trilineal: Modelo Tucker 2.
x m a b gijk ijk ip jq pqkq
Q
p
P
≈ ===
∑∑11
Aquí el componente ideal de las ocasiones se omite y gpqk conforma la CORE MATRIXextendida.
c) PARAFAC (Harshman, 1970)
x m a b cijk ijk ip jp kpp
P
≈ ==
∑1
Este puede ser considerado como el Modelo Tucker 3 con una CORE MATRIX superidéntica.
d) Componentes Principales Simultáneas. Kiers y Ten Berge ( 1989)
Esta es una generalización del Análisis de Componentes Principales para la situación donde lasmismas variables se observan en dos o más poblaciones. La generalización se obtiene considerando

16
ACP para cada población bajo la condición de que las matrices de pesos de componentes deben seriguales para cada análisis.
3.1.2.1.1.2 - Estrategias de análisis multifase.
Estos métodos se aplican generalmente a arrays o sets 3-way. { }X X X Xk K= 1 ,L L
Primera Fase: Interestructura
A cada matriz X k se asocia un elemento Ek el cual caracteriza sus estructuras, en el caso de unmétodo típico de esta familia llamado STATIS (Escoufier, 1973, 1977, Lavit, 1988, 1994) Ek es unoperador lineal (matriz) Ak
Se realiza un análisis simultáneo de los Ek . En STATIS se realiza un análisis de componentesprincipales en relación a las matrices Ak organizadas de la siguiente manera:
( )A vecA vecA vecAK= 1 2 L
donde vecAk es la vectorización de Ak .
Los puntajes Ok se obtienen a partir del análisis de los Ek . En STATIS los puntajes se obtienena través de los componentes principales de las columnas de A (llamadas ocasiones).
Segunda Fase: Compromiso
Se calcula un elemento “medio” de los Ek que representa el conjunto de las X k . En STATIS un“operador medio” A* (media ponderada de los Ak con pesos dados por el primer autovector obtenidodel ACP de A).
Se realiza un análisis de E* obteniendo puntajes Ui,Vj . En STATIS el ACP de A y elsubsiguiente cálculo de puntajes para unidades y variables.
Tercera Fase: Intraestructura
Basándose en el análisis de compromiso E*, se obtienen los puntajes para unidades y variablesen las diferentes ocasiones ( )U Vi
kjk, . En STATIS unidades y variables están geométricamente
representadas por los distintos ejes principales calculados con el ACP de A*.
3.1.2.1.2. - Analisi Fattoriale Dinamica (AFD)
Un método que está fuera de las clasificaciones anteriores es el “Analisi Fattoriale Dinamica”(Coppi-Zanella 1978, Coppi-Corazziari 1995) .

17
Esta metodología permite analizar array 3-way del tipo unidades × variables × tiempos, dondeestos últimos están ordenados y juegan el rol de ocasiones. Es un método aplicable a variablescuantitativas.
Se analizan tres tipos de variabilidades, estructural, dinámica, y la interacción entre ellas.
Los tres aspectos son analizados en AFD mediante la conjunción de una modelización basada entécnicas factoriales y regresivas.
3.1.2.1.3 - Relaciones mediante discrepancia logarítmica
Otro modo de construir matrices de proximidades, se basó en la discrepancia logarítmica deKulback- Leibler.
Para poder aplicar esta discrepancia fue necesario en primer lugar construir las distribuciones delluvia diarias para cada estación. Se consideró una distribución común para todas las estaciones quereúne la doble condición de ser adecuada a los datos disponibles y brindar información mejoradarespecto a la simple dicotomía llueve- no llueve, aunque no sea la óptima por estación.
Los intervalos elegidos fueron [0], (0, 7], (7, 17], >17mm.
Luego de codificada la información diaria por estación en esos cuatro intervalos, se agrupó pormes, obteniendo de hecho la distribución de la lluvia, por estación, para todos los eneros, todos losfebreros, etc del período de años considerado.
A continuación se calculó la discrepancia de Kulback- Leibler de las distribuciones de las demásestaciones a la considerada en cada caso para los diferentes meses. Se obtiene así para cada mes lasestaciones más cercanas en distribución según la discrepancia logarítmica.
En el caso concreto, la expresión general de Kulback se transforma en:
δ p p pp
pi
i
ii
∧
∧=
= ∑/ ln
1
8
donde:pi = probabilidad del intervalo i en la estación considerada, para el mes dado.
p i
∧
= probabilidad del intervalo i para cada una de las otras 8 estaciones para el mes dado.
Se construyen con estas discrepancias nueve matrices, una para cada estación, del tipo (12 × 8 )conformadas con las distancias de las otras ocho a la estación considerada, en cada uno de los mesesdel año. También aquí, como en el caso de las relaciones lineales, se construyeron además matrices de(12 × 3) donde en lugar de considerar las distancias de la totalidad de las estaciones se consideransolamente las tres más cercanas.

18
3.1.2.1.3.1 - Menor distancia mensual de una estación a otra.
Conjuntamente con el proceso anterior se realizó, siempre mediante la discrepancia de Kulback-Leibler y las correlaciones, la búsqueda de la estaciones más cercanas a cada estación en los diferentesmeses del año. También se dividió el período de treinta años en tres y se analizaron meses y trimestrespara saber si hubo cambios en la distancia a la media general del período lo que sería otro indicativo decambio de estructura.
En cuanto a las estación por mes más cercana se procedió de la siguiente manera. Se realizó ladistribución por mes, con los intervalos antes considerados, de la lluvia para cada estación. Luego setomó la distribución de cada estación como la verdadera, es decir la pi de la expresión de ladiscrepancia y se halló la discrepancia de cada una de las otras a la considerada. Se obtiene así unamedida de cual es el orden de distancia de las diferentes estaciones a la considerada para cada mes loque será luego de gran utilidad en la construcción del modelo que se plantea en el numeral 8 del Indice.
3.1.2.1.3.2 - Distancia a nivel de Estación
Finalmente se consideró un último procedimiento para el análisis de estructuras. Este fueconstruir las discrepancias de Kulback- Leibler por estación y para cada mes respecto a la distribuciónmedia o marginal de la estación en todo el período. La diferencia esencial de este método respecto a losanteriores es que no se tiene en cuenta la relación de una estación con las demás sino cada una consigomisma. Con el vector de distancias se agruparon luego los meses.
3.1.2.2 - Estacionalidad
Conjuntamente con los métodos multiway descriptos se utilizaron otra serie de técnicas paraagrupar meses de similar comportamiento de la lluvia en cada una de las estaciones y en la cuenca ensu conjunto.
3.1.2.2.1 - Métodos de relación entre las estaciones pluviométricas
En este sentido se consideraron dos tipos de relaciones. En primer lugar las correlacioneslineales de tipo Pearson entre las lluvias en los diferentes meses en el período, y por otro mediante elanálisis de la discrepancia logarítmica de Kulback-Leibler entre las distribuciones de lluvia en lasdiferentes estaciones.
3.1.2.2.1.1 - Relaciones Lineales entre pluviómetros.
Se parte en primer lugar de la matriz original de datos,

19
{ }X x
x x x
x x x
x x x
ij
j
n
I I Ij
= =
11 12 1
21 22 2
1 2
L
L
L L L L
L
donde el término genérico{ }xij representa el volumen en mm de lluvia caída el día i en la estación j. Es
decir que la matriz tiene tantas filas como días de información de lluvia se tienen (treinta años) y tantascolumnas como estaciones pluviométricas consideradas (nueve).
Se considera como unidad mínima el mes. A esto se llega luego de varias pruebas buscando lamínima unidad posible, La decisión de considerar el mes se alcanza en razón de la calidad deinformación disponible y teniendo en cuenta la particular distribución de la lluvia por día donde enaproximadamente un 80 % de ellos , el valor es cero.
Se construye una matriz de correlación de Pearson para cada mes del año. Esta matriz es:
{ }R r
r r r
r r r
r r r
ij
j
n
I I Ij
= =
11 12 1
21 22 2
1 2
L
L
L L L L
L
donde{ }rij es el coeficiente de correlación de Pearson entre las precipitaciones de las estaciones i y j en
el mes considerado.
Con estas correlaciones se construyen nueve matrices, una por cada estación pluviométrica, de12 × 8, donde cada fila indica las correlaciones para un mes dado de la estación considerada con lasdemás.
El objetivo del procedimiento es analizar las alteraciones que se producen en el año en lascorrelaciones lineales entre la lluvia medida en una cierta estación y en las demás. Se está buscaron lasestaciones más correlacionadas linealmente y como varían en el transcurso de los meses. Esteprocedimiento se realizó también agrupando en los siguientes trimestres:
Diciembre, Enero, FebreroMarzo, Abril, Mayo.Junio, Julio, Agosto.Setiembre, Octubre, Noviembre.
Además de considerar matrices de 12 × 8, se consideraron matrices 12 × 3 , donde se tenían encuenta aquellas tres estaciones que durante el año estaban más correlacionadas a la considerada. Esto sebuscó construyendo un ranking de estaciones.

20
Una vez construídas las matrices de interés se aplicaron diversos métodos de cluster analysis(análisis de conglomerados) buscando encontrar agrupamientos de meses según similarescomportamientos de las correlaciones de una estación con las demás.
Los algoritmos de clasificación considerados se basaron en la distancia de Mahalanobis y fueronlos de Ward, Centroide y Complete. De acuerdo a los resultados obtenidos con los diferentes métodosse buscó determinar una agrupación para cada estación. Los resultados se resumen en la tabla 3.
Estación Número de grupos Agrupación de meses2436 4 (5,6,8,9,11) (10,12,1) (3,4) (2,7)2486 4 (2,5,8,9,10) (3,7,12) (4,6) (1,11)2549 3 (4,6,9) (2,5,7,12) (1,2,4,10,11)2588 4 (10,12,4) (11,3,9) (7,1) (8,6,2,5)2662 3 (1,6,7,10,11) (4,5,8,9) (2,3,12)2707 3 (4,6,8) (2,7,3,10,5) (11,12,9,1)2714 3 (2,3,5,7,10) (1,4,6,12) (8,9,11)2719 4 (8,9,10,12) (1,6,7) (2,4,5) (3,11)2816 3 (2,5,8,9) (3,6,7,10) (1,4,11,12)
Tabla 3 Agrupación de meses por estación
3.1.2.2.1.2 - Discrepancias logarítmicas estacionales globales
Para hacer posible la agrupación de meses no ya por pluviómetro, sino en general para toda lacuenca, se busca la distribución por mes de la lluvia, en los cuatro intervalos considerados para toda lacuenca de Santa Lucía. Luego se construye una matriz de 13 × 4 donde las primeras doce filas son ladistribución por meses de la lluvia y la última la distribución media. Se calcula Kulback- Leibler decada mes a la media y luego se agrupa por cercanías. La estacionalidad obtenida para toda la cuenca fuela siguiente:
a) Abril, Setiembre, Octubre.b) Mayo, Junio.c) Agosto, Noviembre.d) Febrero, Julio.e) Diciembre, Enero, Marzo.

22
3.2. CARACTERÍSTICAS DEL BANCO DE DATOS DE VIENTOHORARIO
3.2.1- Características de la región estudiada
3.2.1.1 - Introducción
La región comprendida al sur del Río Negro tiene una superficie aproximada de 95000 km 2 , querepresenta el 53% de la superficie del País. Esta región está limitada al oeste por el Río Uruguay, por elsuroeste y sur por el Río de la Plata, al sureste por el Océano Atlántico, y al este por el Río Yaguarón y laLaguna Merin.
Las cuchillas o sucesión de cerros son los principales obstáculos orográficos pero no superan enpromedio los 300 metros excepto en casos muy aislados (Cerro de las Animas y Pan de Azucar enMaldonado). La vegetación predominante es la pradera y la vegetación más densa (árboles y arbustos) seencuentran a lo largo de los ríos y arroyos.
3.2.1.2 - Descripción Climática
El clima de esta región es templado húmedo sin estación seca. Le corresponde la categoría Cfa enla clasificación climática de Koeppen. Las temperaturas medias anuales son de 17.0°C. Los extremos detemperatura anuales son importantes con máximas absolutas de 41°C y mínimas absolutas de -8°C.
Las precipitaciones totales anuales medias están situadas en los 1200 mm. Se observa un máximoal noreste de unos 1300 mm. sobre el Río Negro y un mínimo de 1100 en el sur de la región junto al Ríode la Plata.
La humedad relativa de la región presenta un valor medio anual de 75%, y oscila entre 66% endiciembre y enero y 82% en junio y julio.
3.2.1.3 - Información Meteorológica.
La disponibilidad de registros de viento en formato magnético restringió el período a manipular.En la zona norte del país la densidad de estaciones meteorológicas es comparable a la zona sur, pero enmuchos casos las series son más cortas, o contienen únicamente registros cada 8 horas, aspectos ambosque implica una restricción a los fines de este proyecto.
La información en estas Estaciones Meteorológicas es relevada en forma horaria,transfiriéndose vía telefónica a Montevideo, y es utilizada en la elaboración del pronóstico del tiempo,y también en la obtención de estadísticas climáticas de valores esperados acumulados, medios yextremos.
Las medidas de la viento de superficie horario fueron tomadas por la Dirección Nacional deMeteorología. Se seleccionaron cinco estaciones localizadas en el sur del Uruguay. Su identificación ylocalización se esquematizan en la Tabla 4 y Figura 2, respectivamente

23
N° Nombre Latitud Longitud86595 Punta del Este 34°58'S 54°57'W86580 Carrasco 34°50'S 56°00'W86500 Treinta y Tres 33°13'S 54°23'W86460 Paso de los Toros 32°48'S 56°31'W86440 Melo 32°22'S 54°11'W
Tabla 4 Listado de las estaciones meteorológicas con registros horarios en el período 1979-1991
+
+
+ +Punta del EsteCarrasco
+ Treinta y Tres
Melo
Paso de los Toros
BRAZIL
AR
GE
NT
INA
ATLANTIC OCEAN100 km
Figura 2 Localización de las estaciones meteorológicas con registros de viento de superficieseleccionadas para este trabajo
3.2.1.4 - Régimen Eólico.
La circulación atmosférica es el resultado de desequilibrios energéticos ocurridos en el seno dela misma. La circulación atmosférica en su más amplio sentido incluye todas las escalas de movimiento(macroescala, mesoescala y microescala). La circulación está dada por la presencia de los llamadossistemas de tiempo atmosféricos semipermanentes y dinámicos, estos pueden ser cerrados (ciclones,anticlones) y abiertos (vaguadas, dorsales), tal como se observan en un mapa meteorológico.
La circulación de la atmosfera es la responsable del transporte de ciertas cantidades (energía,momento, vapor) y del cambio en las condiciones del tiempo sobre los diferentes lugares del planeta.
La atmósfera cumple con la condición de equilibrio hidrostático por lo tanto las velocidadesverticales son de orden mucho menor que las velocidades horizontales (en la escala macro), y por lo

24
tanto se puede aproximar el estudio de los movimientos tridimensionales de la atmósfera con planoshorizontales en la vertical.
La atmósfera libre en la escala sinóptica ( ≈ 200 a 2000 km) cumple con el llamado equilibriogeostrófico, que resulta de un equilibrio de fuerzas entre la fuerza de Coriolis, y la fuerza del gradientede presión.
La dirección de los vientos predominantes sobre la región en estudio (Ver figura 3) estándeterminados por la circulación del noreste que establece el Anticiclón semipermanente del Atlántico.Sin embargo el debilitamiento del mismo por alejamiento de la costa o desplazamiento hacia el nortedetermina la aparición de vientos del oeste en superficie característicos de la época invernal. Asimismolos vientos observados junto a la costa del Río de la Plata y Océano Atlántico están influenciados porfactores de circulación locales como es la brisa marina y terrestre. Esta determina la rotación durante eldía del viento desde una componente norte a una del sureste que va disminuyendo a medida que elcalentamiento del suelo por la radiación solar comienza a disminuir. Las velocidades medias anualesvan desde unos 6 m/s en la costa sureste hasta mínimos relativos de 3.5 m/s en la cuenca de la LagunaMerín. En general se observan velocidades medias mensuales mas o menos constantes durante todo elaño, pero se destaca la primavera con velocidades medias de 6.5 m/s en el sur y 4.8 m/s en la LagunaMerín.
Fig. 3 Campo de Presión atmosférica en superficieMedia anual en hPa. (1982-1993)

25
3.3 - CARACTERÍSTICAS DEL BANCO DE DATOS DE NIVELES
3.3.1 - CARACTERÍSTICAS DE LA CUENCA ESTUDIADA
3.3.1.1 - Introducción
La Cuenca hidrográfica del Río Negro tiene una superficie de 69900 km2, que representa el 39%de la superficie del País, a la que deben sumarse 3125 km2 que se ubican en territorio brasileño. Sucuenca está limitada al oeste por las cuchillas Negra y de Haedo que las separan de la cuenca del RíoUruguay, al este por la cuchilla Grande y al sur por las cuchillas Grande inferior y del Bizcocho. En elnorte esta separada parcialmente del Brasil por la cuchilla de Santa Ana.
La longitud total del río Negro es de unos 850 km y sus principales afluentes son el ríoTacuarembó, ubicado en la parte superior de la cuenca, y el río Yí que incorpora sus aguas al Negroinferior. Todos los ríos son de alimentación pluvial únicamente y no poseen a lo largo de sus cursos, lagoso lagunas naturales que regulen sus escurrimientos. Los ríos en general tienen pendientes suaves, pues noexisten sistemas orográficos importantes. El río Negro tiene en su recorrido solamente unos 100 km sobrela cota de 100 m. y la mayor parte de la cuenca discurre por debajo de esa cota hasta su desembocadura.Los cauces suelen presentar un lecho menor, por el que escurren el caudal de base, alimentado por el aguasubterránea, y un lecho mayor por el que corren las crecidas. En este último por causa de la humedad delsuelo y la temperatura ambiente adecuada existe vegetación consistente en bosque de tipo galeríaconformado por árboles y arbustos.
3.3.1.2 - Descripción Climática
El clima de esta región es templado húmedo sin estación seca. Le corresponde la categoría Cfa enla clasificación climática de Koeppen. Las temperaturas medias anuales son de 17.7°C. Los extremos detemperatura anuales son importantes con máximas absolutas de 41°C y mínimas absolutas de -8°C.
Las precipitaciones totales anuales medias están situadas en los 1250 mm. Se observa un máximode unos 1400 mm. sobre las nacientes del Río Cuñapirú y un mínimo de 1100 en el sur de la cuenca juntoa la divisoria de aguas con la cuenca del Río Santa Lucía. Los meses más lluviosos son febrero y marzo,con 125 mm. y el menos lluvioso es agosto con 90 mm., la diferencia entre ambos (35 mm.) indica laregularidad de las precipitaciones a lo largo del año.
La humedad relativa de la cuenca presenta un valor medio anual de 74%, y oscila entre 65% endiciembre y enero y 82% en junio y julio.
3.3.1.3 - Información Hidrológica.
La información para el estudio de niveles del Río Negro, consistió en:

26
- series diarias del nivel del río ( en metros ) en Paso Pereira (182800), Paso Aguiar (182500) yPaso Mazangano (182400), que constituyen tres puestos de medición, ubicados en eldepartamento de Tacuarembó (ver Tabla 5) y ordenados de oeste a este sobre el curso del río.
- los datos corresponden al período 1975-1990 y en general las series incluyen tres medicionesdiarias en cada lugar. Fueron proporcionadas dos versiones de la información para dos de los trespuestos, presentándose alguna diferencia en ellas, habiéndose depurado la base de los errores másobvios.
- la cobertura de la información es parcial y existen datos faltantes tanto a nivel de conjuntos dedías contiguos, de días aislados y de las mediciones a través del mismo día. Los vacíos deinformación en general no son coincidentes en fecha, a través de los tres puestos de medición.
Teniendo en cuenta que el objetivo del trabajo es el análisis de series diarias, se seleccionó laprimera de las tres mediciones de cada día, cuando la misma existía. En su defecto, se consideró lasegunda o tercer medición del día, en ese orden, según la disponibilidad del dato.
De este modo, se construyeron tres series con datos diarios, donde los datos faltantes pasaron a serlos días en los que no se había realizado ninguna de las tres mediciones previstas. La mayor parte deltrabajo que se describirá se realizó trabajando sobre la serie de Paso Pereira en razón de su menor cantidadde datos ausentes.
A diferencia de los parámetros lluvia y viento, no se tuvo acceso permanente a los registrosoriginales en papel, salvo en un corto período al principio del proyecto, por lo que no fue posible encararuna comparación con los datos en papel como la que se hizo en los otros casos.
N° Nombre Latitud Longitud AreaCuenca
182800 Paso Pereira 32°26'S 55°14'W 11800 km182500 Paso Aguiar 32°17'S 54°50'W 8300 km182400 Paso Mazangano 32°05'S 54°42'W 6650 kmTabla 5 Referencias de las estaciones hidrológicas utilizadas.
La información corresponde al período 1975 - 1990
3.3.1.4 - Régimen hidrológico.
Los caudales medios mensuales del río Negro, observados en Paso de los Toros, muestrados épocas bien definidas: una de creciente, de abril a octubre, y otra de aguas bajas, de noviembre amarzo. El mes con menor caudal medio es enero y en cuanto a caudales máximos, los meses de julio y

27
setiembre tienen valores casi idénticos. El caudal medio anual es de unos 600 m3/s, pero el caudal experimenta fuertes variaciones no sólo a nivel diario sino también mensual.
Los niveles extremos registrados se ubican en el intervalo 0 a 13.7 m. La serie está aparentementeafectada por varios outliers, por lo que los valores extremos deben tomarse con cautela. Los percentiles 5y 95 % de los valores valen 0.2100 y 6.7205 m respectivamente.
Figura 4 Promedio de los niveles diarios observados en cada mes para el período 1975-1990 en PasoPereira.
Según se indica en la figura 4 el mes con nivel promedio máximo es agosto, y el más bajo enenero. Las diferencias son del orden de 4.5 veces, indicando la variabilidad de los niveles a lo largo delaño. Los registros de setiembre, al igual que los de agosto, tienen una distribución bimodal, aspecto queno se repite en octubre quien exhibe una distribución mucho más uniforme.

28
3.4. CARACTERÍSTICAS DEL BANCO DE DATOS DEEVAPORACIÓN DIARIA
3.4.1- Características de la región estudiada
3.4.1.1 - Introducción
La región comprendida al sur del Río Negro tiene una superficie aproximada de 95000 km 2 , querepresenta el 53% de la superficie del País. Esta región está limitada al oeste por el Río Uruguay, por elsuroeste y sur por el Río de la Plata, al sureste por el Oceano Atlántico, y al este por el Río Yaguarón y laLaguna Merin.
Las cuchillas o sucesión de cerros son los principales obstáculos orográficos pero no superan enpromedio los 300 metros excepto en casos muy aislados (Cerro de las Animas y Pan de Azúcar enMaldonado). La vegetación predominante es la pradera y la vegetación más densa (árboles y arbustos) seencuentran a lo largo de los ríos y arroyos.
3.4.1.2 - Descripción Climática
El clima de esta región es templado húmedo sin estación seca. Le corresponde la categoría Cfa enla clasificación climática de Koeppen. Las temperaturas medias anuales son de 17.0°C. Los extremos detemperatura anuales son importantes con máximas absolutas de 41°C y mínimas absolutas de -8°C.
Las precipitaciones totales anuales medias están situadas en los 1200 mm. Se observa un máximoal noreste de unos 1300 mm. sobre el Río Negro y un mínimo de 1100 en el sur de la región junto al Ríode la Plata.
La evaporación medida a través del Tanque tipo “A” tiene valores anuales acumulados de 1800mm. sobre Mercedes (oeste de la región) y un valor acumulado mínimo menor de 1500 mm. sobre ellitoral del Océano Atlántico.
3.4.1.3 - Información Meteorológica.
El período a estudiar de registros de evaporación acumulada diaria en formato magnético serestringió al período del 1 Enero de 1986 al 31 de diciembre de 1990. Dentro de la región la densidad deestaciones meteorológicas que constan de Tanque de evaporación del tipo “A” se restringe a siete.
La información en estas Estaciones Meteorológicas es relevada en forma diaria, transfiriéndosevía telefónica a Montevideo, y es utilizada en la elaboración de balances hídricos semanales, y tambiénen la obtención de estadísticas climáticas de valores esperados acumulados, medios y extremos.
Las medidas de evaporación acumulada diaria fueron tomadas por la Dirección Nacional deMeteorología. Se seleccionaron siete estaciones localizadas en el sur del Uruguay. Su identificación ylocalización se esquematizan en la Tabla 6 y Figura 5, respectivamente

29
N° Nombre Latitud Longitud86440 Melo 32°22'S 54°11'W86490 Mercedes 33°15 S 58°04’W86500 Treinta y Tres 33°13'S 54°23'W86532 Trinidad 33°32’S 56°55’W86565 Rocha 34°29’S 54°18’W86568 Libertad 34°41'S 56°32’W86585 Prado 34°51’S 56°12’W
Tabla 6 Listado de las estaciones meteorológicas con registros diarios de evaporación acumuladapara el período 1986-1990
Figura 5 Localización de las estaciones meteorológicas con registros de evaporación diariaseleccionadas para este trabajo
3.4.1.4 - Régimen de Evaporación.
El vapor de agua de la atmósfera proviene casi exclusivamente de los procesos de evaporaciónocurridos en la superficie de nuestro planeta. La mayor parte de esa evaporación, cerca del 85% enpromedio, ocurre sobre los océanos, y una proporción no despreciable ocurre sobre los continentes. Lavegetación tiene un rol fundamental en la transferencia de vapor de agua a la atmósfera, las plantas secomportan como una especie de mecha, entre el subsuelo, que es el reservorio de agua líquida, y laatmósfera. El término “evapotranspiración” designa la cantidad de vapor de agua transferida a laatmósfera tanto por evaporación directa a nivel del suelo como por la transpiración de los órganosaéreos de las plantas. La noción de evapotranspiración potencial ha sido introducida por el climatólogoamericano Thornthwaite, y expresa la evapotraspiración máxima ourrida desde una superficie vegetalque no tiene restricciones al suministo de agua. En estas condiciones la evapotranspiracion potencialpuede ser considerada independiente de la especie vegetal que constituye la cobertura como asimismode la naturaleza del suelo y finalmente como una función de las condiciones energéticas y dinámicas de

30
la atmósfera.
El Tanque evaporimétrico tipo “A” fue desarrollado por el Weather Bureau (U.S.A.) paraviabilizar estudios sobre el desarrollo de métodos para estimar la evaporación sobre lagos yrelacionarlos con los datos meteorológicos normalmente recolectados. Como las redes de observacióncon Tanque evaporimétrico son en general muy dispersas e incompletas, se han desarrollado métodosde extrapolación.

31
4. IMPUTACIÓN DE AUSENCIAS
4.1 - Métodos en los que se tiene en cuenta únicamente la informaciónhistórica
Se entiende por ello, que se está imputando usando exclusivamente datosprovenientes del análisis de la serie temporal de la propia estación.
Además, en general, se indicará:
h = día en que se presenta la ausencia.X h
* = valor a imputar el día de la ausencia (h).
Con respecto al informe de avance, se han agregado los métodos que asignan elvalor modal, y la interpolación temporal de scores principales.
4.1.1 - Por interpolación temporal entre registros:
Cuando falte el dato correspondiente a un día determinado se buscan los díasanterior y posterior más próximos, en los que se tenga dato medido en esa estación, y seinterpola linealmente.
4.1.2 - Promedio juliano:
Siempre con los valores cronológicos de lluvia por estación, se considera la basede registros pluviométricos como la replicación de un mismo fenómeno con ciclo anual(la variable es entonces la lluvia diaria del calendario juliano) y se utiliza como valorpara imputar los huecos el valor de dicha variable, estimado a partir de la media.
Así por ejemplo, el día 15 de enero, se calculará el promedio en la estación detodos los registros que se tengan (para ese día del calendario juliano y para esa estación)y con dicho valor se imputarán todas las ausencias correspondientes al 15 de enero paraalgún año en esa estación.
Algoritmo:Programa: julmean.m
X t : registro pluviométrico correspondiente al día t en la estación considerada.
Si la estación donde hay un hueco es la j-ésima, y h ddmmaa=
X XX
card Bhj t
t B
*
( )= =
∈∑ , donde
{ }B t t ddmmyy en la estación j= =: ; (día y mes coinciden con los de h)

32
4.1.3 - Promedio global de la estación:
Los datos de lluvia correspondientes a cada pluviómetro son considerados comouna serie temporal, cuyo promedio en el período (treinta años para el caso de la lluvia)es el valor que se utilizará para imputar todas las ausencias correspondientes a laestación.
Se tendrá pues una constante por estación, con la que se rellenarán los datosfaltantes en la misma.
Algoritmo: Programa: staverage.m
X t : registro pluviométrico correspondiente al día t en la estación considerada.
Para cada estación j, se calcula:
XX
card Aj t
A
= ∑ ( )
{ }
XX
card A
j
A t X en la estación j
tt
t A
t
=
=
= ∃
∈∑ ( )
,2,...
:
1 10
X Xth j= , si la ausencia h correspondió a la estación j.
4.1.4 - Valor aleatorio sorteado uniformemente entre los registros disponibles de laestación:
Considerando nuevamente el fenómeno de lluvia por estación, este métodoimputa un valor elegido al azar dentro de los registros históricos conocidos (de lostreinta años) correspondientes a dicha estación.
Algoritmo:Programa: dispara.m
X t : registro pluviométrico correspondiente al día t en la estación considerada.X random X t Ah t
* ( , )= ∈ , si la ausencia h correspondió a la estación j.
}{A t X en la estación jt= ∃:
4.1.5 - Valor modal de la serie:
Este es un método muy sencillo, que asigna para cada estación su valor másprobable. En el caso de la lluvia diaria en Uruguay, este valor es siempre 0 mm/día.
Algoritmo:Programa: nollovio.m

33
X t : registro pluviométrico correspondiente al día t en la estación considerada.
X al X t Ah t* mod ( , )= ∈ , si la ausencia h correspondió a la estación j.
}{A t X en la estación jt= ∃:
4.2- Métodos en los que se tiene en cuenta únicamente la informaciónregional
En este caso, se utiliza únicamente información recabada simultáneamente, sinusar información de los días precedentes.
4.2.1 - Imputación dinámica (“Hot - Deck”):
Este método de asignación dinámica asigna información a grupos de datos cuandodicha información no está disponible, se desconoce o es incorrecta (y debe cambiarse).Dicho método fue preparado por la Oficina del Censo de los Estados Unidos yposteriormente fue perfeccionado por otros.
Básicamente, en el método de asignación dinámica se usa la informaciónconocida acerca de individuos con características similares para determinar lainformación "más apropiada" cuando se desconoce parte (o partes) de una informaciónsimilar sobre otros individuos.
4.2.2 - Vecino geográficamente más cercano:
Por este método, dada la ausencia el día h para la estación j y dados losregistros disponibles de las otras estaciones de la cuenca para ese día, se imputa el valorcorrespondiente a la que está más próxima a la estación j (desde un punto de vistageográfico).
Algoritmo:Programa: vecidist.m
X tj : registro pluviométrico correspondiente al día t en la estación j .
X Xh hk* = , siendo k la estación geográficamente más próxima donde hay registro
4.2.3- Vecino más cercano por Criterio de Expertos:
Por este método, dada la ausencia el día h para la estación j y dados losregistros disponibles de las otras estaciones de la cuenca para ese día, se imputa el valorcorrespondiente a la que está más próxima a la estación j , definiendo la proximidad apartir de una jerarquía establecida por expertos, en base a conocimientos meteorológicosde la zona en estudio.
Algoritmo:Programa: veciconf.m

34
X tj : registro pluviométrico correspondiente al día t en la estación j .
X Xh hk* = , siendo k la estación más próxima, según el Criterio de Expertos, donde hay
registro.
4.2.4 - Promedio espacial correspondiente al día de la ausencia:
Este método tiene en cuenta la variable lluvia en su comportamiento espacialúnicamente. Si se tienen n estaciones, se considera la serie temporal del vector n-dimensional de lluvias, y en caso de ausencias para un día h (dimensión del vectorcorrespondiente menor que n), en todas las coordenadas faltantes se imputa elpromedio de las coordenadas conocidas.
Por tanto, el valor a imputar será el promedio aritmético entre todas lasestaciones donde hay registro, calculado sobre los valores observados para el día hcorrespondiente a la ausencia.
Algoritmo:Programa: daymean.m
X tj : registro pluviométrico correspondiente al día t en la estación j .
Si se define: ( )X X X Xt t t t= 1 2 10, ,K en el hueco:
dim X h( )<10, ( )X X X X Xh h h hj
h* , ,= 1 2 10L L y
X XX
card Chj h
i
t C
= =∈∑ ( )
, y { }C i X ihi= ∃ ∀ =: , , ,1 2 10L
Comentarios: la entropía estadística y los resultados de estos métodosSi se tiene:
X X X n1 2, ,L posibles estados excluyentes de una variable Xp p pn1 2, ,L las probabilidades asociadas a dichos estados
Para eventos independientes, la entropía estadística se define por:
( )H p p p p pn i ii
i n
1 21
, , logL = −=
=
∑ , con pii
i n
==
=
∑ 11
.
De acuerdo con la definición, se observa:
1) H(1)=0 (la entropía de un suceso cierto es nula).2) Grandes valores de incertidumbre se obtienen cuando las probabilidades de
todos los estados posibles de la variable X son iguales:
pn
i ni = ∀ =1
1 2, , ,L

35
En efecto: ( )H p p pn n
nni
i n
1 21
1 1, , log logL = − =
=
=
∑
Se considera ahora la cantidad de lluvia en la posición P y la correspondiente ala posición P d+ . A partir de ellas, se define una variable ( ) ( ) ( )X d X P X P d= − + , queserá una variable aleatoria con distintas probabilidades según la distancia d . Para cadad , se estima la densidad de la variable aleatoria ( )X d por medio del histograma defrecuencias relativas, estableciéndose entonces la entropía H para cada distancia d .
Realizados los cálculos correspondientes, se obtiene un valor mínimo para laentropía que supera 0 6, , y una distancia mínima inter-pluviómetros de más de 18 km ,por lo que se concluye que es razonable esperar que los métodos que estén basadosúnicamente en información regional (o geográfica), no den muy buenos resultados parael relleno de datos faltantes.
4.2.5 - Promedio espacial ponderado correspondiente al día de la ausencia:
Al igual que el anterior, este método tiene en cuenta la variable lluvia en sucomportamiento espacial únicamente. Si se tienen n estaciones, se considera la serietemporal del vector n-dimensional de lluvias, y en caso de ausencias para un día h(dimensión del vector correspondiente menor que n), en todas las estaciones faltantes seimputa una media ponderada de los registros de las estaciones conocidas. Para elmétodo de Cressman los pesos de la ponderación de la lectura j-ésima para imputar la i-ésima estación son inversamente proporcionales al cuadrado de la distancia dij. Elmétodo es lineal.
Algoritmo:Programa: cressman2.m
X tj : registro pluviométrico correspondiente al día t en la estación j .
Si se define: ( )X X X Xt t t t= 1 2 10, ,K en el hueco:
dim X h( )<N, ( )X X X X Xh h h hj
h* , ,= 1 2 10L L y
X XX
card Chj h
i
t C
= =∈∑ ( )
, y { }C i X ihi= ∃ ∀ =: , , ,1 2 10L
4.2.6 - Métodos basados en la pseudo-distancia de Kulback-Leibler:
Distancia de Kulback- Leibler.
Cuando se trató la estructura y estacionalidad se consideró la estimación de ladiscrepancia de Kulback- Leibler. Veamos ahora la definición concreta de dicha pseudo-distancia o discrepancia.

36
DEFINICIÓN:
Se define la distancia de Kulback-Leibler entre dos funciones de distribución, como elvalor:
( ) [ ]ρ
µF G
Lf x
g xf x d x L
f x
g xF dx si F G
otro casoN NF F
,( )( )
( )( )( )
( ) ,
,=
= <<
∞
∫ ∫
Observación:
Esta distancia es una pseudo-distancia, dado que no cumple con la propiedad desimetría. ( ( ) ( )ρ ρF G G F, ,≠ ), por lo que el cálculo de la misma da resultados distintossegún la estación que se elija como de referencia.
4.2.6.1- Imputación por la estación “Kulback-Leibler más próxima”, sinrestricciones:
Algoritmo:Programa: kulback.m
Este método calcula los histogramas de frecuencias relativas en cada una de lasestaciones para luego, eligiendo una como la más verosímil, ranquear el resto según suproximidad a la escogida, en base a la distancia de Kulback-Leibler.
La variable es el registro diario en el pluviómetro:
X tj : registro pluviométrico correspondiente al día t en la estación j .
En base a esa jerarquía de estaciones establecida, es que se imputarán los datosfaltantes:
- supóngase que en el día h hay un hueco en la estación i ,- que se estableció una jerarquía de las restantes estaciones en base a la
distancia de Kulback-Leibler a la estación i: ( ) ( ) ( )ρ ρ ρi j i j i jn, , ,1 2< < L ,
- entonces, el valor a imputar vendrá dado por:X Xh h
j* = 1 , si hay registro en la estación j1 para el día h.- de no existir registro para ese día en la estación más próxima, se va
recorriendo la jerarquía de estaciones establecida, hasta obtener un dato paraese día.
Cabe señalar que se trabaja en la intersección de soportes de los histogramas (dediez intervalos de clase cada uno de ellos), en el supuesto de que las distribuciones sonabsolutamente continuas la una respecto de la otra.

37
4.2.6.2- Imputación por la estación “Kulback-Leibler más próxima”,eliminando días secos:
Algoritmo:Programa: kulback0.m
El método difiere del anteriormente descrito, únicamente en lo que a laconstrucción de histogramas se refiere: la variable ya no es el registro puro (que puedeser nulo), sino que es el registro del día cuando efectivamente hubo lluvia medible.
X tj : registro pluviométrico no nulo correspondiente al día t en la estación j .
4.2.6.3- Imputación por la estación “Kulback-Leibler más próxima”, conrestricciones:
Algoritmo:Programa: kulbackm.m
Finalmente, este método, trabaja con la variable registro del día cuandoefectivamente hubo lluvia medible, sólo que, en momentos de construirse loshistogramas, se les exige que cada intervalo de clase acumule como mínimo un 0.05 delas observaciones.
X tj : registro pluviométrico no nulo correspondiente al día t en la estación j .
4.2.7 - Mínimos Cuadrados:
El objetivo del método es imputar los datos ausentes, usando una combinaciónlineal de los datos presentes del día, con un error cuadrático mínimo.
Algoritmo:Programa: mincdr.m
Dada la matriz de datos D, (cada fila de la cual tiene n observacionessimultáneas), de dimensión m × n, m-observaciones, n-estaciones meteorológicas. Con elobjetivo de imputar el valor correspondiente a la estación j, se toma una combinaciónlineal de los valores de las restantes k estaciones, k n≤ , con pesos ( )w w w wk= 1 2, ,...,
tales que: D w di j≈ (1)
donde Djes la matriz D sin la columna j, d j es la columna j de D.
A los efectos de éste método, los pesos w se eligen de forma de minimizar:
D w dj ji
i
k
− = →=∑2
2
1
l min (2)

38
El problema (2) representa un problema clásico de mínimos cuadrados. Lasolución se obtiene a partir de las ecuaciones normales
( )D d D wjt j j− = 0 (3)
ó D D w D djt j jt j. = (4)
Nota: los pesos, base de la imputación de la estación j como una combinaciónlineal de las restantes estaciones, dependen de la combinación de datos “presentes” deldía particular. Hay un conjunto de pesos diferente para cada combinación de ausencias-presencias.
4.2.8 - Mínimo Error Promedio:
Algoritmo:Programa: minprm.m
El objetivo del método es imputar los datos de las estaciones ausentesminimizando el promedio del error absoluto.
La elección de los pesos de (1) se realiza en este caso de modo que:
D w dj ji
i
k
− = →∑1lQ min (5)
minimizando la norma 1 del error. Esto es equivalente a minimizar el promedio.
El problema (5) debe ser tratado como un problema de programación no lineal.
4.2.9 - Mínimo Error Promedio Robusto:
Algoritmo:Programa: minprmfl.m
El algoritmo utiliza el anterior como primera estimación; el segundo pasoconsiste en a) analizar la distribución de los errores de regresión y determinar losregistros con discrepancias mayores. Luego se reiteran los cálculos utilizando sólo losvalores que han diferido menos de los verdaderos. Los límites para el descarte se fijancomo ciertos cuantiles de la distribución de errores.
4.2.10 - Mínimo Percentil 95:
Algoritmo:Programa: minprc.m
El objetivo del método es imputar los datos de las estaciones ausentesminimizando el percentil 95 del error absoluto.

39
Los pesos de la ecuación (1) se eligen de forma que el percentil 95 del error seamínimo, es decir :
( )Pr minc D w dj j− → (6)
La condición (6) se estudia como un problema de programación no lineal
4.2.11 - Métodos robustos de ajuste: Least Median of Squares (LMS):
Algoritmo:Programa: mult_regr.m
Este método fue sugerido por Rousseeuw (1984), y consiste en utilizar unestadístico más robusto que la suma de cuadrados como objetivo a minimizar. En estecaso, se utiliza la mediana de los cuadrados de las desviaciones entre el verdadero valor,y el obtenido vía la regresión. Es equivalente al método del peor caso trabajando sobrela mitad de la población. Los algorimos mismos pueden ser de tipo combinatorio (i.e.ensayar todas las posibles maneras de elegir la mitad de la población) o se pueden basaren criterios probabilísticos como los utilizados por Hawkins (1993). En este caso, lospesos se calculan con un programa FORTRAN suministrado por Hawkins.
En cualquier caso, lo que se hace es: para cada estación meteorológica, seestiman con estos algoritmos los coeficientes óptimos que, utilizando datos de todas lasestaciones vecinas, estiman mejor los valores observados en la estación. Este proceso serepite para todas las estaciones, generándose así una matriz de coeficientes con unacolumna para cada estación.
En el caso en que exista más de una ausencia por día, se procede de formaiterativa: se asumen valores iniciales para todas excepto una de las ausencias, y seestima el valor faltante. A continuación, se utiliza esta estimación y todos menos uno delos otros valores iniciales, para obtener un segundo valor estimado. Se procedesucesivamente hasta que se logran estimar todos los valores; si la discrepancia entre loestimado y lo imputado es menor a un umbral preestablecido, se da por terminado, y sino, se reinicia el proceso utilizando las estimaciones como punto de partida.
4.2.12 - Métodos robustos de ajuste: Least Trimmed Squares (LTS):
Algoritmo:Programa: mult_regr.m
En este caso se utiliza otro criterio sugerido también por Rousseeuw (1984), queminimiza la suma ponderada de los cuadrados de los residuos, siendo los pesos 0.0 o1.0. Se asume que los pesos 0.0 afectarán a los residuos que contienen outliers, y por lotanto su número se especificará a priori. También en este caso se utilizó un programaFORTRAN suministrado por Hawkins para la determinación de los coeficientes.
Los mismos, una vez calculados, se utilizan exactamente igual que en el casoanterior.
4.2.13 - Métodos de imputación basados en redes neuronales:
Algoritmo:Programas: bp.m, bp22.m, bp23.m, trainbpXX.m
La conceptualización de una red neuronal puede verse en diversos textos perobrevemente se trata de un modelo matemático inspirado en la organización y

40
funcionamiento del sistema nervioso, y en particular, de su unidad básica: la neurona.Ella se modela partiendo de la base que para un determinado estímulo, se genera unarespuesta (que se asume determinística) modelada por una función de transferencia. Lasfunciones de transferencia más usadas son la lineal, sigmoide, etc., algunas de cuyasgráficas se presentan en la figura 7. Para este trabajo se han utilizado dos funciones másdenominadas sinh y asinh (seno hiperbólico y su inversa) cuya composición da lafunción identidad.
Excepto para el caso lineal y las últimas mencionadas, la mayor parte de lasfunciones de transferencia tienen un recorrido acotado en [ ]−11, .
Al igual que en su equivalente biológico, las neuronas se conectan entre síformando una red, y los estímulos para una neurona provienen de las reacciones deotras. En el modelo matemático que se considerará, las neuronas se organizan en capas,y la relación entre las capas se modela de manera simple haciendo que el estímulo parauna neurona de una capa sea la suma ponderada de los outputs de las neuronas de lacapa anterior más un término de sesgo (que es independiente del estímulo). El softwareutilizado presupone que todas las neuronas de una capa aportan información a la capasiguiente, y que son iguales entre sí.
La primer capa de neuronas recibe los estímulos directamente desde el exterior.Todas las capas entre la primera y la última se denominan ocultas, y tanto el número decapas como el número de neuronas que debería haber en ellas es tema de prueba y error.
La figura 8 muestra el esquema general de una red. Los símbolos S indican laoperación de ponderación más la adición del sesgo, mientras que F1 y F2 son lasfunciones que modelan a la primer y segunda capa de neuronas.
a=logsig(x)
+1
-1
Figura 7 Representación de dos funciones de transferencia no lineales. El término w*x representa unacombinación lineal de los datos de entrada, mientras que b es un término de sesgo.

41
p(1)
p(2)
p(3)
p(4)
Σn1(1)
F1
Σn1(2)
F1
Σn1(3)
F1
Σn1(4)
F1
Σn1(5)
F1
Σn2(1)
F2
Σn2(2)
F2
Σn2(3)
F2
Figura 8 Esquema general de una red neuronal, con cuatro datos de entrada, 5 neuronas en la capaoculta del tipo F1, y tres neuronas en la salida del tipo F2.
Una vez diseñada la topología de la red, y definidas las funciones F1, F2, etc.corresponde realizar el entrenamiento de la misma. Ello consiste en presentarlesimultáneamente un conjunto de datos y el resultado correcto, de forma que la redaprenda de ellos. El aprendizaje está simulado mediante el ajuste del sesgo y loscoeficientes de ponderación que hay asignados a cada neurona, que la vinculan con lasreacciones de la capa anterior. El sesgo y los pesos son iterativamente ajustados deforma de minimizar el error cuadrático medio entre lo que la red predice y los valoresque se le han presentado como correctos.
Cuando se da por terminado tal proceso, la red está en condiciones de trabajar.Con los pesos ajustados previamente la red procesará los estímulos (datos) que se lepresenten, y dará una reacción que se adoptará como output del conjunto.
En el caso en consideración, se diseñaron varias redes diferentes, que podíanestar estimuladas por todos los datos disponibles del día menos uno (el que se buscabaimputar), funciones de esos mismos datos, únicamente los datos del día anterior, losdatos del día anterior y el actual, etc. siendo en todos los casos la salida por una únicaneurona, salida que se iba a tomar como la lluvia estimada o función de ella.
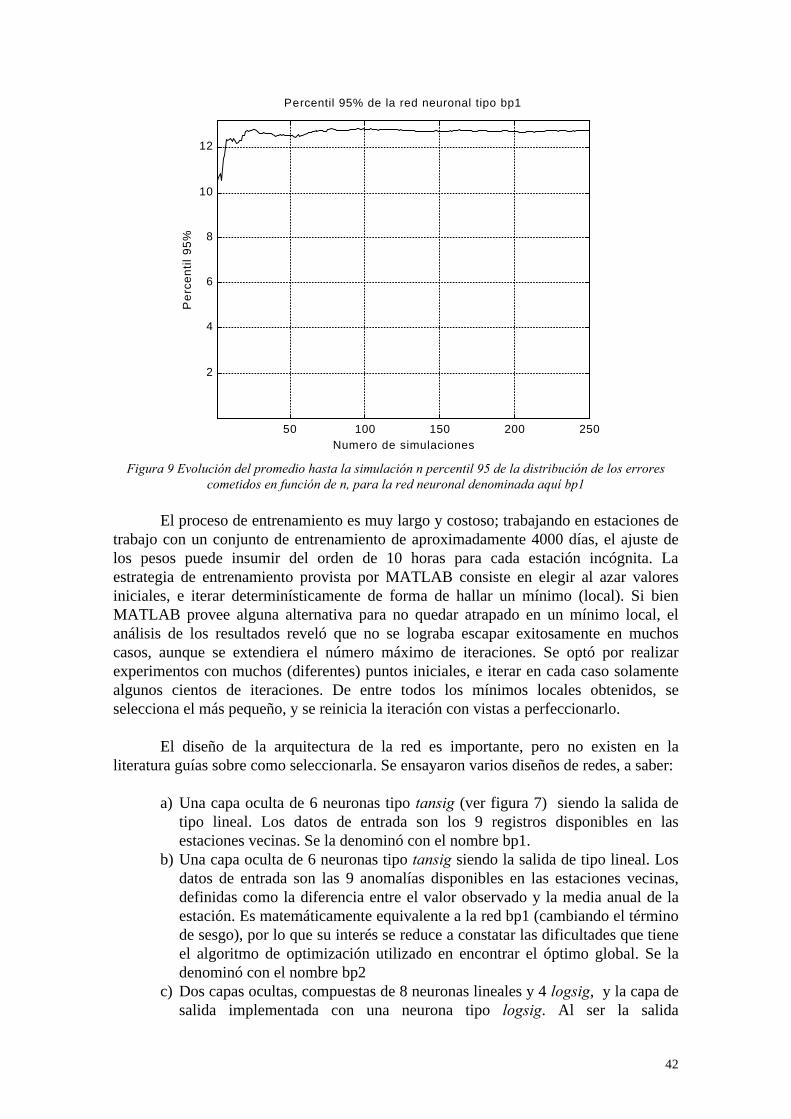
42
50 100 150 200 250
2
4
6
8
10
12
Numero de simulaciones
Pe
rce
nti
l 9
5%
Percentil 95% de la red neuronal tipo bp1
Figura 9 Evolución del promedio hasta la simulación n percentil 95 de la distribución de los errorescometidos en función de n, para la red neuronal denominada aquí bp1
El proceso de entrenamiento es muy largo y costoso; trabajando en estaciones detrabajo con un conjunto de entrenamiento de aproximadamente 4000 días, el ajuste delos pesos puede insumir del orden de 10 horas para cada estación incógnita. Laestrategia de entrenamiento provista por MATLAB consiste en elegir al azar valoresiniciales, e iterar determinísticamente de forma de hallar un mínimo (local). Si bienMATLAB provee alguna alternativa para no quedar atrapado en un mínimo local, elanálisis de los resultados reveló que no se lograba escapar exitosamente en muchoscasos, aunque se extendiera el número máximo de iteraciones. Se optó por realizarexperimentos con muchos (diferentes) puntos iniciales, e iterar en cada caso solamentealgunos cientos de iteraciones. De entre todos los mínimos locales obtenidos, seselecciona el más pequeño, y se reinicia la iteración con vistas a perfeccionarlo.
El diseño de la arquitectura de la red es importante, pero no existen en laliteratura guías sobre como seleccionarla. Se ensayaron varios diseños de redes, a saber:
a) Una capa oculta de 6 neuronas tipo tansig (ver figura 7) siendo la salida detipo lineal. Los datos de entrada son los 9 registros disponibles en lasestaciones vecinas. Se la denominó con el nombre bp1.
b) Una capa oculta de 6 neuronas tipo tansig siendo la salida de tipo lineal. Losdatos de entrada son las 9 anomalías disponibles en las estaciones vecinas,definidas como la diferencia entre el valor observado y la media anual de laestación. Es matemáticamente equivalente a la red bp1 (cambiando el términode sesgo), por lo que su interés se reduce a constatar las dificultades que tieneel algoritmo de optimización utilizado en encontrar el óptimo global. Se ladenominó con el nombre bp2
c) Dos capas ocultas, compuestas de 8 neuronas lineales y 4 logsig, y la capa desalida implementada con una neurona tipo logsig. Al ser la salida

43
comprendida entre 0 y 1, lo que se hizo en este caso fue entrenar la red paraque replique no la lluvia, sino el valor transformado con la función inversa deprobabilidad acumulada (ver métodos de interpolación climatológica) cuyodomino es el intervalo [ ]0 1, y cuyo recorrido es el rango de lluvias observado.El valor cero corresponde con la lluvia cero, y para todos los demás, ladensidad de probabilidad es uniforme. Los datos de entrada son los 9 registrosdisponibles en las estaciones vecinas. Se la denominó con el nombre bp7.
d) Una capa oculta de 6 neuronas tipo tansig siendo la salida de tipo lineal. Losdatos de entrada son las 9 anomalías disponibles en las estaciones vecinas,definidas como la diferencia entre el valor observado y la estimación obtenidacon el método de Gandin para la estación. Es matemáticamente equivalente ala red bp1 (cambiando el término de sesgo), por lo que su interés se reduce aconstatar las dificultades que tiene el algoritmo de optimización utilizado enencontrar el óptimo global. Se la denominó con el nombre bp10
e) Una capa oculta de 6 neuronas tipo tansig siendo la salida de tipo lineal. Losdatos de entrada son los 10 registros del día anterior, por lo que es unpredictor puro. Se la denominó con el nombre de bp11.
f) Una capa oculta con 6 neuronas de tipo tansig, y la capa de salida unaneurona de tipo lineal. Los datos de entrada son los 9 registros disponibles enlas estaciones vecinas del día, más los 10 registros del día anterior. Se ladenominó con el nombre bp12.
g) Una capa oculta con 4 neuronas de tipo sinh, y la capa de salida una neuronade tipo asinh. Al utilizar una función y su inversa, se facilita el aprendizajedel caso trivial de la función identidad. Los datos de entrada son los 9registros disponibles en las estaciones vecinas del día. Se la denominó con elnombre bp14.
h) Una capa oculta con 4 neuronas de tipo sinh, y la capa de salida una neuronade tipo asinh. Los datos de entrada son los 9 registros disponibles en lasestaciones vecinas del día, más los 10 registros del día anterior. Se ladenominó con el nombre bp17.
i) Una capa oculta con neuronas de tipo tansig y la capa de salida de tipo lineal.El número de neuronas de la capa oculta se determina en función del númerode estaciones disponibles para cada día, por lo que resulta variable en eltiempo. Se adoptó la parte entera de N/3. Para cada día se realiza elentrenamiento, intentándose ajustar así la función lluvia(x,y). Una vezentrenada, la misma es evaluada en todas las estaciones incógnita. Se ladenominó como bp22.
j) Similar a bp22, pero ajustando la raíz cuadrada del valor de la lluvia. Se ladenominó como bp23.
Desde un punto de vista informático, con la excepción de bp22 y bp23, todas lasotras fueron entrenadas con programas muy similares entre sí denominadostrainbpXX.m, y utilizadas con un único programa bp.m, lo que facilita el mantenimientoy actualización.
4.2.14 - Funciones Climatológicas de Interpolación (GANDIN):
Algoritmo:

44
Programas: gandin.m, gandin20.m, gandin3a.m, gandin4.m,gandin5.m, gandin6.m, gandin7.m, gandin_diario.m,
gandintrans.m
Se entiende por funciones climatológicas de interpolación a aquellas expresionesque incorporan en sus constantes datos de las series históricas disponibles, suscorrelaciones y propiedades estadísticas. Por ende, para aplicarlas, es necesario disponerde un banco de datos, el cual brindará la información requerida, y participaráintensivamente en los cálculos. Tales procedimientos son de rutina en la inicializaciónde modelos meteorológicos planetarios. De entre los posibles, se analiza la interpolaciónóptima (debida a Gandin, 1965), que se presenta a continuación.
Sea S S r S r' ( ) ( )*= − , donde S(r) es el valor real, S r* ( ) el valor estimado y r elradiovector que indica el punto en el cual se interpolará. La magnitud S es escalar.
Sea T un conjunto de observaciones de S, (que se designa por ( )$S ri , en i n= 1..
sitios, durante 1..m eventos.T ha sido formado considerando regímenes comparables.Por ejemplo, podría estar formado sólo por datos nocturnos.
Se destaca con la palabra verdadero a los parámetros que se definen para losvalores exactos (pero desconocidos) de la variable en estudio.
Los estimadores de los parámetros, calculados a partir de las medidas se indicancon un ^. La barra indica promedio en el tiempo.
La covarianza verdadera de la muestra se define como
( )σ ij i jS S i j n i j= = ≠' ' ; , , ;1 2,L
La función de estructura verdadera en un punto de los medidos es
( )β ij i jS S= −' '2
La varianza verdadera en un punto de los medidos es σ ii iS= '2 y la matriz
[ ]Σ = σ ij es una matriz simétrica de orden n.
Se puede definir el coeficiente de correlación verdadero
[ ]µ
σ
σ σij
ij
ij jj
=1 2/
Asociado a él, se define una matriz M =[ ]µ ij , con elementos µ ij = 1.
Si se denota como $Si al valor medido del parámetro, que es diferente del valor
Si real, se cumplirá que $S Si i i= + ε , dado que difieren en una cantidad ε i aleatoria.

45
Se asume por hipótesis, que los errores aleatorios no están correlacionados conlos valores medidos $Si , ni con los errores en las otras estaciones, por lo que
ε ε ε δ σ εi i i j ijS yi
$ = = •0
donde σ ε ies la desviación estándar de la medida, que depende del instrumento. Si a
estos se les asumen iguales entre sí, resulta σ σε εi
= i n= 1••
De lo expuesto, se puede escribir$S Si i i= ′ + ε
$ $σ σ σεii i iiS= ′ = +2
2 (el medido difiere del verdadero) y
$ $ $σ σii i j ijS S= ′ ′ = , para i j≠ (el medido no difiere del verdadero)
El error estándar de la observación puede ser estimado extrapolando la funciónde estructura β , supuesta homógenea e isótropa, a la distancia cero. O sea
[ ][ ] [ ]
$ $ $ $ . $ $
. . .
β
σ σ σ σ σ σ σ σ σ
β σ
ε ε ε
ε
ij i j i j i j
ii jj ij ii jj ij
ij
S S S S S S= ′ − ′ = ′ + ′ − ′ ′ =
= + + + − = + − + =
= +
2 2 2
2 2 2
2
2
2 2 2
2
De aquí, como β ii = 0,y se asume β β= ( )r , resulta 2 2
0σ βε =
=
$r
Este procedimiento para estimar el error instrumental suele dar resultadosexageradamente grandes. Johnson (1982) propone como alternativa, determinarlo comoel máximo valor posible que cumple
( ) ( )µ
σ
σ σ σ σε ε
ijij
ii jj
i j=− −
≤ ∀ ≠$ $
,/ /2 1 2 2 1 2
1
El método de interpolación óptima predice no la magnitud, sino el valor de laperturbación S’ ( )r0 , con la siguiente expresión
S’ ( )r0 = ω i
N
S I1 1
0=∑ ′ +$
Los pesos ω i son seleccionados con objeto de minimizar la media cuadrática delos errores I0 sobre los puntos medidos.

46
( )( )E S Si i i
N
i jj
N
i
N
ij ii
N
ii
N
i
= ′+ − ′ =
= + − +
=
== = =
∑
∑∑ ∑ ∑
ω ε
ω ω σ ω σ ω σ σε
01 1
2
11
2
1
2
10 02
La condición de mínimo implica ∂∂ω
Ε
i
i N= =0 1; .. , lo que conduce al siguiente
sistema
2 2 220ω σ ω σ σεj ij
j i
N
i i=
∑ + = ; i=1..N
Si se divide término a término por ( )σ σ00 ii se puede transformar
ω
σ
σ σ
σ σωσ
σσ
σσ σ
εj
j
Nij jj
ii jj
i
ii
i
ii001 00
20
00=∑ + = ; i = 1..N
Haciendo el cambio de variable ( )
µσ
σ σij
ij
ii jj
=1 2/
, resulta
µ ωσ
σω
σ
σσσ
µεij
j
N
j
jj
iii
iiio
=∑ + =
1 00 00
2
Llamando q j jii= ω
σ
σ 00
se llega a
µσσ
µεij
j
N
j iii
iq q=
∑ + =1
2
0 , i = 1...N
El sistema así obtenido es similar al mencionado por Haagenson, si se despreciael error instrumental.
El cociente de σ σ00
ii, denominado windiness ratio por Johnson, es otra función
a modelar.
El mismo mide la natural variabilidad entre sitios, y en cierta medida se oponeconceptualmente a la inicialización con una media espacial única para los valoresS0
∗ , criterio que es práctica corriente.
Una vez determinados los pesos ω i (o los )q i , el valor de la perturbación en
cualquier punto se calcula como

47
′ = ′=∑S q Sii
N
ii
i01
00σ
σComo ya se mencionó, se asume para µ ij , y bajo las hipótesis de isotropía y
homogeneidad, que es únicamente función de la distancia entre los puntos i y j.
Para aplicación en la eliminación de ausencias el problema se simplifica, pues enla hipótesis que todos los eventos responden a la misma función de estructura no es
necesario modelar la misma ni el cociente σσ
00
ii en función de la posición relativa, ya
que el valor experimental está disponible. Los pasos requeridos son:
a) calcular la matriz experimental Mb) estimar el error instrumental
c) dado que σ σ00
ii=1, resolver el sistema
( )( )µ ω ω
σσ
µεij
j
N k
j iii
ik i N k=
∑ + = ∈1
2
,
siendo N(k) el conjunto de estaciones para las que hay datos, y k el indice de la(s)estaciones que tienen ausencias.
Dependiendo de la estimación del error instrumental, de los datos que se utilizan,etc., se han ensayado algunas variantes del método general que se esquematizan en latabla 7.
La transformación f(lluvia) está diseñada de forma de lograr una función dedistribución diferente a la original. Para ello se calculó la función de densidad deprobabilidad acumulada (cuyo codominio es el intervalo cerrado [ ]0 1, ) de los valorespositivos de la lluvia, y se aplicó una interpolación climatológica a esa nueva variable.Dadas las características de la lluvia, la función de distribución de la nueva variable noes uniforme, sino que tiene un valor aislado para el cero, y es uniforme para el resto.Nótese que el valor de lluvia cero se corresponde también con cero en la nueva variable,la que también tiene codominio positivo. A modo de ejemplo, en la fig. 10 se observa elhistograma de los valores positivos, así como la función de probabilidad acumulada parauna estación particular.

48
( )S r* Variable a interpolar Con datos del día
t t-dtgandin media histórica lluvia X -
gandintrans media histórica f(lluvia) X -gandin6 media histórica lluvia X Xgandin7 media histórica lluvia X -
Inicializando el campo con el valor cerogandin_diario 0 lluvia-media diaria X X
gandin4 0 lluvia X Xgandin5 0 lluvia X -
Despreciando el error instrumentalgandin20 media histórica lluvia X -gandin3a media histórica lluvia-media diaria X -
Tabla 7 Descripción de los métodos basados en la interpolación con funciones climatológicas. f(lluvia)indica una transformación que logra una función de densidad de probabilidad casi uniforme (ver texto). t
y t-dt indican los datos del día y del día anterior.
0 20 40 60 80 100 120 140 160 1800
10
20
30
40Histograma de los valores >0 en la estacion 2436
Figura 10 Función de densidad de probabilidad para las lluvias mayores que cero, y función acumuladade probabilidad para la estación 2436 en el período 1960-1991
Las figuras 11, 12 y 13 ilustran sobre el desempeño del método denominado“Gandin4” el cual, de acuerdo a lo indicado en la tabla 7 imputa utilizando los datos deldía y del día anterior. Los cálculos preliminares que se presentan fueron realizados

49
50 100 150 200 250
6.5
6.6
6.7
6.8
6.9
7
7.1
7.2
Numero acumulado de simulaciones
Ra
iz d
el
err
or
cua
dra
tico
me
dio
(m
m/d
ia)
Datos para el periodo 1960-1980
Figura 11 Evolución del error medio cuadrático utilizando el método de gandin4
50 100 150 200 250
0.6
0.8
1
1.2
1.4
1.6
1.8
2
2.2
2.4
2.6
Numero acumulado de simulaciones
Pro
me
dio
de
l e
rro
r (m
m/d
ia)
Datos para el periodo 1960-1980
Fig 12 Evolución del error promedio usando el método de gandin4
en un subconjunto de los datos disponibles, y permiten analizar la evolución de losestadísticos de la distribución del error a medida que se hacen más simulaciones deMonte Carlo. Nótese por ejemplo, que a los efectos de la raíz del error cuadrático medioparece que aún 250 simulaciones no son suficientes para obtener resultados asintóticos.

50
50 100 150 200 250
3
4
5
6
7
8
9
10
11
12
13
Numero acumulado de simulaciones
Pe
rce
nti
l 9
5%
de
la
dis
trib
uci
on
de
l e
rro
r (m
m/d
ia)
Datos para el periodo 1960-1980
Fig.13 percentil 95 de la distribución del error absoluto para el método de gandin4.
4.3- Métodos en los que se tiene en cuenta la información regional ehistórica
En este caso, se utilizan simultáneamente datos del mismo día de la ausencia, y,eventualmente, de fechas previas. Algunas de las redes neuronales descritas antespodrían incluirse en esta lista.
4.3.1 - Promedio ponderado arbitrariamente:
Algoritmo:Programa: ponmean.m
Se considera la serie temporal del promedio diario de los datos de lluvia de laregión (tomando las n estaciones).
XX
card Dtti
i D
=∈∑ ( )
, { }D i Xti= ∃: , i = 1 2 10, ,L , donde
X tj : registro pluviométrico correspondiente al día t en la estación j .
En base a ello, se construye el correlograma del promedio diario en la región yse observa que prácticamente no hay correlación entre días consecutivos: con un "lag"de 1, el coeficiente de autocorrelación es de 0.3415, mientras que con un "lag" de 2, elcoeficiente de autocorrelación es de 0.0662.

51
Pese a ello, se usa como método de imputación una media ponderada de lavariable evaluada en el día anterior, el posterior, el ante-anterior y el post-posterior aldía con ausencia, usando como coeficientes de ponderación las autocorrelacionesobtenidas.
( )X
X X X Xh
h h h h* . . . .
. .=
× + × + × + ×× +
− − + +0 062 0 3415 0 3415 0 062
2 0 3415 0 0622 1 1 2
4.3.2 - Condicionamiento según el estado del día anterior:
Algoritmo:Programa: imputall.m
En realidad no se trata de un método de relleno propiamente dicho, sino de unpaso previo a la aplicación de los otros métodos. Por medio de este programa, se generaun vector de ceros y unos, donde el 0 corresponde a un día donde probabilísticamenteno llovió, y el 1 corresponde a un día donde probabilísticamente efectivamente llovió.
El cálculo de las probabilidades de lluvia efectiva (estimadas por medio de lasprobabilidades empíricas), se hizo teniendo en cuenta el estado del día anterior, es decir:por medio de otro programa (probcond.m), se determinaron las probabilidadescondicionadas de lluvia dado el estado del día anterior (seco o lluvioso) y, teniendo encuenta entonces dicha información, se determina probabilísticamente si el díacorrespondiente a la ausencia fue lluvioso o seco.
Usando entonces una cadena de Markov estacionaria de primer orden, se“cruzan” los métodos anteriores, esperándose obtener mejores resultados, perotratándose ahora de métodos estocásticos de imputación de datos faltantes.
En términos analíticos: se define una variable aleatoria
Ysi llovió en t
si no llovió en tt =−−
1 1
0 1
, ( );
, ( );
y se estiman las probabilidades condicionadas:
p t P X X
p t P X Xt t
t t
11 1
01 1
1 1
1 0
( ) ( )
( ) ( )
= = == = =
−
−
a partir de las probabilidades empíricas calculadas en todo el período. (El resto secalcula por complementaridad de sucesos).
Dada entonces una ausencia para el día h , previamente se determina sicorresponde asignársele un valor no nulo (decisión basada en la información del día

52
anterior), para luego imputarle el valor correspondiente por uno de los métodosanteriormente implementados.
A diferencia de los anteriores, el resultado de la imputación no es determinístico,por lo que se dificulta mucho la comparación entre métodos. Sin perjuicio de ello, seentendió importante describirlo e implementarlo.
4.3.3 - Interpolación temporal de coeficientes principales:
Algoritmo:Programa: ca3.m
Este método se basa en el Análisis de Componentes Principales (ACP), y que hasido tratado en López et al. (1994). Aquí sólo se describe brevemente la notación, y seremite al lector a la referencia citada.
Sea ( )P n t, ( )1 el vector de precipitaciones de las n estaciones elegidas, para el
instante t. Se considera la matriz M cuyas filas son los vectores P P( ) , ..t j rm Mj− = 1 ,
definidas para aquellos días en que no faltan datos. PM es el vector de precipitacionesmedias en el período.
Los vectores propios de ( )C M Mn nT
, = * serán denominados patrones, y se
denotan como ei . Se supondrá que los valores propios asociados son decrecientes con i.La relación entre los registros pluviométricos ( )P n t, ( )1 y el vector de coeficientes
( )A n t,1 ( ) está dada por
P P E. A( ) = + ( ) t tM (7)
donde PM es el vector de precipitaciones medias en el período, y ( )E n n, la matriz
formada por los vectores propios ei .
( )
( )
( )
( )
P P A E e e e( ) =
p
.
.
.
.
p
; =
p
.
.
.
.
p
; ( ) =
a
.
.
.
.
a
. ; =
1
n
1
n
1
n
t
t
t
t
t
t
M n
1 2 .. (8)
La matriz ( )E n n, es invertible, por lo que dados los datos P( )t f m− y P( )t f r+ es
posible obtener los vectores A( ) t f m− y A( ) t f r+ correspondientes. La ecuación (7)
también se puede expresar como
P P a e( ) = + ( ). ii=1
i=n
t tM i∑ (9)

53
Para el tiempo intermedio ( )t l f m l f rl , ,∈ − + + − 1 la lluvia se calcula
mediante interpolación lineal el vector A( ) t . Todos los valores de la precipitación paraese día, se pueden obtener en principio de la ec. (7).
Del análisis de los coeficientes ai surge que cuanto mayor es el índice i elcoeficiente ai tiene una desviación estándar menor por lo que su aporte a la sumatambién es menor típicamente. Lo anterior justifica que en la reconstrucción del vectorP( ) t se desprecien los términos para i>q, para algún q, sin perder información esencial,sustituyéndose la fórmula (9) por:
P P a e( ) = + ( ). ii=1
i=q
t tM i∑ (10)
En resumen, para un día t f en que falte algun dato del vector P( ) t f se buscan
los días más próximos, anterior y posterior, en los cuales se tenga dato medido en todaslas estaciones. Se hace notar que en este método se trabaja con el conjunto de las nestaciones, no con cada una por separado.
Sea t f el día a imputar. Sean t f m− el último día anterior a t f con datos completos
y t f r+ el primer día posterior a t f con datos completos ( )t t tf m f f r− +< < . Se calculan los
coeficientes A( ) t f m− y A( ) t f r+ correspondientes a los vectores P( ) t f m− y P( ) t f r+ con
la ecuación (7).Para el momento t f m l− + , se calcula el vector A( ) t f m l− + interpolando linealmente
los vectores A anteriormente mencionados. El valor tentativo de la precipitación paraese día, P( )t f , se calcula con la ec (10). Las faltantes de la base de datos
correspondientes a componentes del vector P( ) t f se toman de los valores del vector
tentativo.Una vez completado el día t f , se reinicia la interpolación, utilizando los vectores
P( ) t f m l− + y P( ) t f r+ como puntos de partida, hasta completar todos los faltantes. El
mejor o peor desempeño de esta aproximación, está vinculado a las características de lafunción de autocorrelación de los ai. Usualmente, para otras variables meteorológicas,las propiedades de autocorrelación de la serie temporal de ai son muy diferentes entre sí.Esto es otra justificación para limitar el número de sumandos.

54
5. CONTROL DE CALIDAD.
5.1- Consideraciones Generales
5.1.1 - Necesidad de una depuración progresiva.
En Silveira et al. (1991), se muestra que en una población con r=4000 eventos, tan sólo dosvalores disparatados podrían alterar significativamente los estadísticos que describen la información. Estehecho obliga a realizar un proceso de depuración recursivo, en el que, en primera instancia, se buscansolamente los errores más gruesos. Como se verá luego, progresivamente se puede ajustar el criterio, paraproceder a la detección de problemas más sutiles.
5.1.2 - Metodología y criterios para la comparación de los distintos métodos aplicados.
El objetivo del control de calidad es lograr separar, con la máxima probabilidad, los datos erróneosde aquellos correctos. Esta no es la meta usualmente planteada en la literatura, ya que allí se apunta adetectar los días que contienen datos erróneos, y no el(los) dato(s) individualmente. Para el caso depequeñas poblaciones (algunas decenas de eventos) esa opción puede ser válida, pero no lo es para el casode las variables meteorológicas.
Esta diferencia (asociada al tamaño de la población) no es la única, y ha obligado a un tratamientooriginal de los estimadores de éxito al evaluar los diferentes métodos. Los detalles se expondrán en lo quesigue.
Si los datos están dicotomizados (hay sólo dos posibilidades: son erróneos o son correctos), alclasificarlos se cometen dos tipos de error:
• el error Tipo I, que se define como la probabilidad de afirmar que un dato es erróneocuando es correcto, y
• el error Tipo II, que está vinculado con la probabilidad de sentenciar que un dato escorrecto cuando en realidad no lo es.
Debe quedar claro que la dicotomía es sólo válida en una simulación, o a lo sumo en el caso deerrores groseros. En otros casos, no es posible encontrar un valor correcto, ya que las características delinstrumento, observador, etc. llevan a que haya un conjunto de posibles valores correcto del cual, en elmejor de los casos, uno está asentado en el papel. Es por ello que se han asumido dos hipótesis: a) los

55
datos asentados en papel son correctos y b) el inspector es perfecto, ya que al serle pedido que revise undato individual, lo sustituye siempre con el valor correcto. En otras palabras, el inspector no se equivoca.
En la literatura consultada, se consideran pequeñas poblaciones contaminadas con un conjuntopequeño de datos erróneos. Los métodos se consideran exitosos si logran clasificar correctamente todoslos datos erróneos como tales, y sólo a ellos. Así proceden Atkinson, XXXX; Hawkins and XXXX,XXXX; Hadi, 1994; Rocke y Woodruff, 1996; Rousseeuw y Van Zomeren, 1990, etc. muchos de ellosbasados en conjuntos contaminados publicados en Rousseeuw y Leroy, 1987. En términos del error Tipo Iy II, lo que se busca es que, en una única operación, se logren errores Tipo I y II iguales a cero.
Este objetivo no es realizable en una población grande. No se puede esperar que los métodosoperen y clasifiquen correctamente todos los errores, sino se prefiere que, de alguna forma, puedaregularse el esfuerzo (¡significativo!) requerido para detectar primero los errores más importantes. Nóteseque ni en el error Tipo I ni en el Tipo II se ha considerado el tamaño del error; simplemente se le cuenta.En la práctica, y con fines meteorológicos, es más interesante lograr reducir algún estimador el errorremanente en la base, más que asegurar que no queden errores. Así se utilizan típicamente el error mediocuadrático (RMSE en lo que sigue) o la desviación media absoluta (MAD), o eventualmente, algúnpercentil de la distribución de los errores absolutos.
En algún caso, los métodos admiten parámetros que regulan el tamaño del conjunto de candidatosa error. De esa manera aumento la probabilidad de señalar correctamente un dato erróneo como tal(disminuyendo así el error Tipo I). Sin embargo, esto aumenta el error Tipo II, ya que algunos erroresquedarán en el banco de datos señalados como correctos. Por otra parte, si el conjunto de candidatos esgrande, el error Tipo II disminuye, pero el error Tipo I aumenta. El compromiso entre utilizar una y otraalternativa depende en cierta medida de las necesidades del usuario, y aparecen como alternativascontrapuestas. Sin embargo, si el algoritmo de detección es aplicado en varias ocasiones, depurandoprogresivamente el banco de datos, es posible unificar en un único índice ambos objetivos. Lametodología que sigue al respecto es una contribución original de este proyecto, la que se encuentrarecogida en López, 1997, 1999a.
En la figura 10 se presenta un esquema que facilitará el análisis. El eje de las abscisas indica laproporción del total de la población que será revisada. Las ordenadas indican alguna medida del errorremanente, por ejemplo, el RMSE. Por la hipótesis del inspector perfecto, si se revisan todos los datos, labase quedará sin errores. Ello explica que las tres curvas (Best, Worst y Possible) terminen en cero errorpara la abscisa 100 por ciento. Nótese que, por la misma hipótesis, las curvas serán no crecientes; alavanzar la corrección el inspector encontrará errores (si los hay), y simultáneamente la medida del error sereducirá (o se mantendrá), resultando una evolución estrictamente no creciente. El valor inicial al (0 porciento de esfuerzo) es también el mismo. Las curvas no son continuas; estrictamente cada método produceno una función, sino una permutación diferente de los datos señalando el orden en que deben sercorregidos.

56
Cada método dará una curva diferente para el mismo conjunto de datos. Todas ellas tendrán lamisma ordenada para 0 y 100 por ciento, y serán estrictamente no crecientes. Sin embargo, no son lasúnicas restricciones a cumplir. Existen, entre todas las posibles, dos curvas particulares: la mejor y la peor.La mejor (Best en la figura 10 ) se construye de la siguiente forma: se ordenan en forma decreciente losdatos de acuerdo con el valor absoluto de la diferencia con el dato verdadero. Eso hace que los errores mássignificativos estén primero, y los errores menos significativos al final. El mejor método será aquel queproduce esa permutación particular de índices. Luego de señalados todos los errores existentes, el errorremanente es cero cualquiera sea la permutación utilizada, por lo que se concluye que el mejor método noes único. Similar razonamiento puede establecerse para el peor método, siendo en este caso lapermutación exactamente la inversa de la anterior. Al principio se encuentran todos aquellos datos sinerror (en cualquier orden); cuando se agotan los datos sin error, se comienza sugiriendo aquellos cuyoerror es menor, y progresivamente se seleccionan los de tamaño mayor. Por lo expuesto previamente,siempre se llega a cero error cuando se han controlado todos los datos.
0 N 100-N 100
o Best
W orst o
Possible o
Figura 10 Esquema de la mejor (Best), peor (Worst) y una posible (Possible) curva de operación de un método sobre un juegoparticular de datos. El de las abscisas está en función del esfuerzo (Effort) mientras que el de las ordenadas indica algunamedida del error remanente (RMSE, MAD, etc.). N indica la fracción del conjunto inicial que tiene errores, y esnuméricamente igual al error Tipo II inicial. Tomado de López, 1997
Por definición, ninguna otra curva de operación puede dar una abscisa por debajo de la mejor, nipor encima de la peor; ya que a lo sumo pueden igualarlas. Las zonas "prohibidas" se indican con unrayado en la figura. El hecho de existir curvas óptimas habilita a elaborar algún índice que mida la

57
proximidad de una curva de operación particular a la óptima. Este índice se ha construído de la siguientemanera:
( )( )
( )I esfuerzo
peor s curva s ds
peor s mejor s ds
esfuerzo
esfuerzo=
−
−
∫
∫
( ) ( ) .
( ) ( ) .
0
0
(11)
La relación de precedencia entre las curvas hace que el índice sólo puede tomar valores entre cero(la peor curva) y 1 (la mejor curva). Este índice tiene otras propiedades interesantes: para esfuerzosmenores que 100, dos curvas con iguales valores valores finales de la ordenada (o sea, con similaresresultados para el mismo esfuerzo total) no dan igual índice, prefiriéndose correctamente aquella curvaque evoluciona más rápido al principio (ver curva A en figura 11) .
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
0
10
20
30
40
50
60
70
80
90
100
Effort [% ]
# e
rro
rs f
ou
nd
[%
]
(A)
(B)
(Best)
(Worst)
o
o
o
o
o(Real)
Figura 11. Ejemplo de la mejor, peor y dos curvas particulares de operación, para el primer 2 por ciento del esfuerzo. El ejede las ordenadas está relacionado con el error Tipo II, mientras que la pendiente de las curvas es mayor cuanto menor sea elerror Tipo I. Las áreas sombreadas indican el límite de las curvas posibles. La curva Real (continua), la curva (A) y la (B) son
todos casos válidos. Tomado de López, 1997
Esta figura merece algún comentario adicional, ya que implícitamente maneja información de loserrores Tipo I y II. Sea N el error Tipo II inicial, o en otros términos, la proporción (en por ciento) deerrores en relación a la población total. Si se denota como f(x) la función descrita en la figura 11, siendo xel esfuerzo (también en por ciento), el error Tipo I puede ser calculado para todas las abscisas como

58
edfdx
NI = −1
100(12)
mientras que el error Tipo II se calcula con la relación
ef N
II =−
100100 100
(13)
por lo que queda claro que las funciones con mayor pendiente serán preferibles a los efectos de disminuirel error Tipo I; puede verse que la pendiente de f(x) está estrictamente acotada por 100/N, ya que paracualquier esfuerzo incremental, lo más que puede encontrarse es la misma proporción de errores.
Los diferentes métodos serán descritos en las secciones siguientes. Para poder compararlos, atodos ellos les será planteado el mismo juego de datos contaminados, y se evaluarán los índices integraleshasta un esfuerzo prefijado. Este juego de datos será generado en forma aleatoria, y se analizarán muchasrealizaciones independientes, comparándose estadísticamente los resultados en términos de los índices.Este enfoque difiere del planteado en el informe de avance, en el que se sugería detener la operacióncuando el error Tipo I era "muy bajo", basándose en que es uno de los pocos estadísticos calculables por elusuario final (que no conoce los valores "verdaderos").
Con el fin de realizar una comparación útil, las curvas de operación han sido calculadas sólo hastaun nivel prescrito de esfuerzo. El límite es diferente según sea un método orientado al dato o al evento, asícomo también las curvas óptimas (mejor y peor) son diferentes en ambos casos; el mejor evento paracomenzar es aquel que contiene la mayor contribución al estadístico del error (RMSE, MAD, etc.)mientras que el mejor dato sería simplemente el que difiere más del verdadero valor. Claramente, notienen porqué estar vinculados.
5.2- Métodos utilizados para la detección de errores
5.2.1 - Breve síntesis del Análisis de Componentes Principales (ACP)
Dados que varias de las metodologías que se han aplicado usan directamente el ACP, se presentaun resumen sintético de dicho método.
En lo que sigue, se denomina ( )pi kτ al valor de la precipitación correspondiente al instante τk
(k=1..r) en la estación i (i=1..n). Se denominará como pi a la media temporal de ( )pi kτ , k=1..r.
Dado un conjunto de registros ( )pi kτ se les puede representar mediante un vector ( )P( ,n k1) τ en el
espacio Rn (fig. 12). Cada punto k de la nube, corresponde a una fecha τk . El origen de coordenadas setoma en el baricentro de la nube, que tiene componentes pi y se denotará como PM .

59
Es posible demostrar que existe una dirección re1 (en general, única) que minimiza la suma de
cuadrados S1
S M Hk kk
r
1 ==
∑ 2
1re1 no depende del tiempo τk . Se denominará como ( )a k1 τ a la proyección OHk . Cada sumando en S1
puede interpretarse como la norma L2 del vector ( ) ( )P PM 1τ τk ka e− − 1 .
r
Obsérvese que el vector de datos de lluvia para cualquier τk se ajusta con un vector constante, más
un múltiplo de un vector constante. El término Sr
1 es interpretable como la varianza no explicada por la
aproximación con un único término.
A continuación, puede definirse re2 como el vector que minimiza la varianza remanente
( ) ( ) ( )S P P a e a ek M k kk
r
2 1 1 2 2
2
1
= − − −=
∑ τ τ τ. .r r
siendo ( )a k2 τ la proyección según la dirección re2 del segmento OMk . Incluso geométricamente es
posible ver que r re e1 2. = 0.
Análogamente se procede hasta Sn. En Lebart et al.(1977) se demuestra que los rei son los vectores
propios de la matriz de covarianza:
( )( ) ( )( )C c c p p p pij ij i k i j k jk
= = − −
∑: .τ τ ,
y que los valores propios λ i están directamente vinculados con los Si. Se puede ver que las variables
( )ai τ y ( )a i jj τ , ≠ , tienen correlación cruzada nula. Si se denomina D a la matriz cuya diagonal está
formada por los λ i , y E a la matriz formada por los vectores propios rei , entonces resulta:
C E D E T= . .
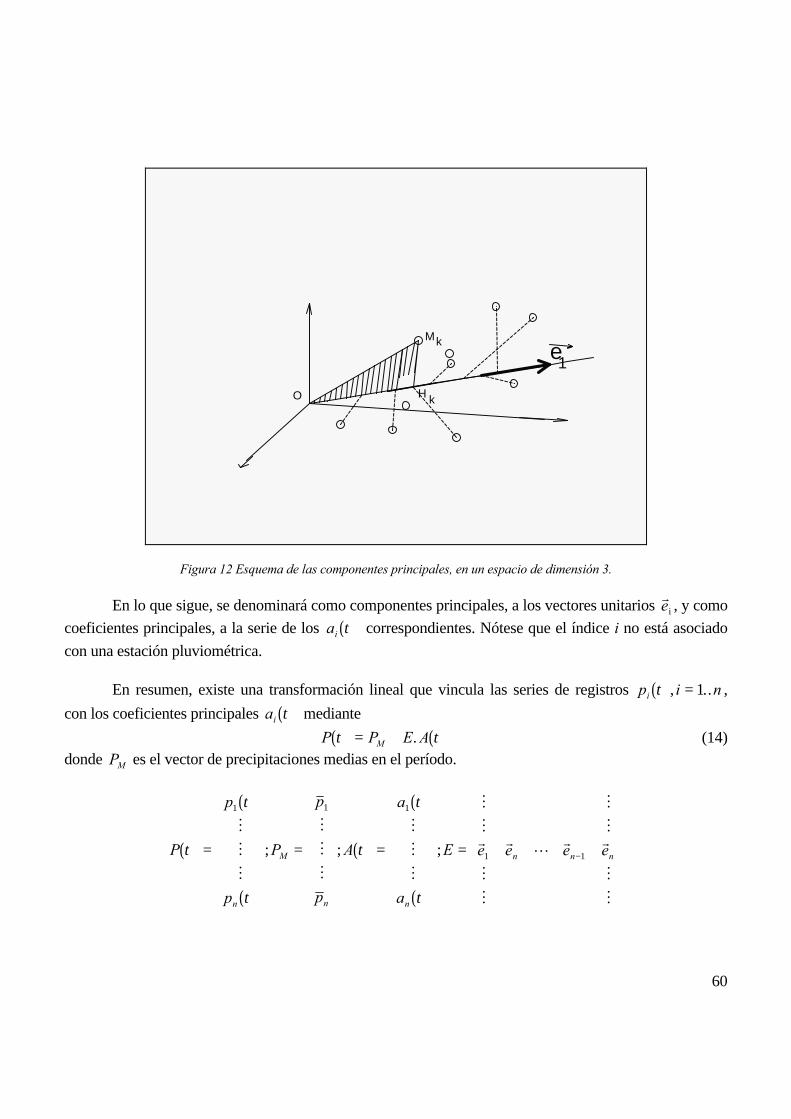
60
O H k
Mke1
Figura 12 Esquema de las componentes principales, en un espacio de dimensión 3.
En lo que sigue, se denominará como componentes principales, a los vectores unitarios rei , y como
coeficientes principales, a la serie de los ( )ai τ correspondientes. Nótese que el índice i no está asociado
con una estación pluviométrica.
En resumen, existe una transformación lineal que vincula las series de registros ( )p i ni τ , ..= 1 ,
con los coeficientes principales ( )ai τ mediante
( ) ( )P P E AMτ τ= + . (14)donde PM es el vector de precipitaciones medias en el período.
( )
( )
( )
( )
( )
( )
P
p
p
P
p
p
A
a
a
E e e e e
n
M
n n
n n nτ
τ
τ
τ
τ
τ
=
=
=
=
−
1 1 1
1 1
M
M
M
M
M
M
M
M
M
M M
M Mr r
Lr r
M M
M M
; ; ;

61
La matriz E es en general invertible, por lo que dados los datos ( )p i ni τ , ..= 1 es posible obtener
los coeficientes ( )A τ correspondientes con la siguiente expresión:
( ) ( )( )A E P PMτ τ= −−1. (15)
La ecuación (15) también se puede expresar como
( ) ( )P P a eM ii
i n
iτ τ= +=
=
∑1
.r
Los vectores rei (también denominados patrones) son calculados a partir de la nube de puntos
(datos disponibles). En la misma puede existir un pequeño grupo de valores disparatados, que incidan enla determinación de tales patrones, afectando sensiblemente los mismos.
En el caso estudiado, típicamente dos de cada tres días tenían alguna ausencia. Por ello, para cadat, deben distinguirse dos situaciones:
- se dispone de registros en las n estaciones.- falta algún registro.
En el primer caso, es posible calcular directamente las n coordenadas ( )ai τ . Si para algún i, ( )ai τno está dentro del i-ésimo rango especificado, los n registros de lluvia utilizados en su determinación sonrevisados. Estos rangos se determinan a partir de la distribución de ai para todo el período.
En el segundo caso, puede aplicarse algún procedimiento para estimar el (los) dato(s) faltante(s),de forma de reducir el problema al caso anterior.
5.2.2 - Datos marginales en la distribución univariada
Programa: run_boun
Algoritmo:
Consiste en determinar rangos "razonables" para los valores registrados en cada estación, y señalarlos casos en que los registros no pertenecen a ellos. Tales rangos pueden estar basados en consideracionesfísicas, o simplemente tener en cuenta la probabilidad marginal.
En general, el método no es demasiado potente para errores "razonables" (por ejemplo, si seconfunde la fecha al digitar, o si se mueve la escala en un río), y asimismo no permite evidenciar maloshábitos del personal que toma las lecturas.

62
En el caso de la lluvia, este método puede detectar eventos claramente anómalos por exceso, peroes incapaz de identificar un dato igual a cero como erróneo, dado que el 80% de los datos, son cero (Lópezet al., 1994a).
También está la posibilidad de un chequeo temporal (Abbott, 1986, pp 5) en que se adoptanlímites para el incremento entre la lectura y su valor en el instante anterior.
En estos métodos sólo la serie de la propia estación y variable está involucrada. No se requiereinformación adicional.
5.1.3 - Datos marginales en la distribución multivariada
En este caso, la población se considera formada por n-uplas, cuya componente i es la lectura en laestación i-ésima. Mediante el análisis de componentes principales, u otro similar puede elegirse una nuevabase para el vector de n observaciones en el espacio n-dimensional.
Las coordenadas en la base original son los propios registros. El estudio de su distribución y loscriterios allí manejables ya fueron mencionados en el punto anterior. Las coordenadas en la nueva base encambio, son función de los n registros, y están afectados por todos ellos a la vez.
Estas coordenadas tienen distribuciones diferentes a las originales, y diferentes entre sí. Se puedesin mayor dificultad, identificar aquellas que corresponden a patrones de "ruido", y aplicarles a ellas porseparado el criterio expuesto en 5.2.2. Ello hace que un evento será señalado como outlier si alguna de suscoordenadas está fuera de un intervalo prefijado, mientras que no hay cotas para las otras.
Si bien el ACP estándar teóricamente asume un banco de datos completo, esta restricción puederelativizarse. La matriz de correlación (o la de covarianza) puede construirse elemento a elemento, ycalcular las componentes principales para los eventos con ausencias. El criterio puede aplicarse luego deimputarlas. Este enfoque no garantiza, sin embargo, que la matriz de correlación (o la de covarianza) seandefinidas positivas, aspecto importante para la estabilidad numérica del método así como (¿por qué no?)propiedad requerida formalmente. Es por eso que se implementaron versiones iterativas: se estima unaprimer matriz usando sólo los eventos completos. Se imputan las ausencias, y se recalculan las matricesahora con todos los datos disponibles más los datos imputados. Se estima nuevamente la matriz, y seprocede hasta que el cambio es despreciable. También se hubieran podido seguir métodos como lossugeridos por Loh, 1991.
Programas: pca_cor
Algoritmo:

63
Ambos programas implementan la metodología sugerida por López et al., 1994. La distribución dedensidad de probabilidad de los componentes ( )ai τ tiene percentiles β y 1− β denominados
w i( )1 y w i
( )2 fuera del intervalo [ ]w wi i( ( ),1) 2 se ubican sólo el 2β por ciento de los eventos. Para cada
componente los extremos del intervalo se calculan de la propia población.
El sufijo cor indica que se analiza la variable normalizada (con varianza unitaria y media cero)utilizándose por tanto los vectores propios de la matriz de correlación; en el segundo caso (sufijo cov)solamente la media es cero, y los componentes se calculan con la matriz de covarianza. Los resultados noexhiben una significativa diferencia.
El número de términos a controlar se determinó basándose en criterios sugeridos por Hawkins,1974. Para que todas las estaciones meteorológicas estén adecuadamente representadas en loscomponentes débiles, ellas deben aparecer con un peso que supere cierto umbral: se adoptóarbitrariamente un valor 0 15. n , siendo n el número de estaciones a considerar (n=10 en el caso de lalluvia). De la aplicación de este criterio resulta que hay que controlar típicamente los 6 componentes másdébiles, siempre para el caso de la lluvia.
5.2.4 - Método de Hawkins
Programa: mahalanAlgoritmo:
Este esquema también hace uso de los componentes principales, pero en lugar de controlar porrangos, controla a través de la distribución de un estadístico sugerido por Hawkins, 1974. El mismo sedefine como:
( )( )
Ta
Wj
jj k
n
2
2
ττ
==∑ (16)
Esta sumatoria toma únicamente aquellas componentes marginales (de escasa significación) de lapoblación. Allí es donde se manifiestan más claramente los outliers. Si k=1 y los pesos Wj se toman como
la varianza de ( )ai τ , entonces T2 es la distancia de Mahalanobis. Siguiendo las recomendaciones de
López et al., 1994, se utilizó para los pesos Wj la distancia intercuartil del 95%. La distribución
acumulada del estadístico T2 se presenta para ese caso en la figura 13.

64
0 5 10 15 200
20
40
60
80
100Distribuc ión acumulada de probabilidad para T2
Figura 13 Distribución acumulada de probabilidad para el estadístico T2 , calculado con k=6 y Wj como se indica en el
texto
De la distribución se nota que el estadístico es muy poco sensible a la mayoría de los datos. Loscandidatos a ser error se determinan basados en que el estadístico sea mayor que el valor determinado porun percentil (95, por ejemplo).
5.2.5 - Otros métodos basados en la distancia de Mahalanobis
Para realizar una comparación más creíble, fueron implementados algunos métodos bienconocidos en la literatura especializada. La mayoría tiene fuertes vinculaciones con la distancia deMahalanobis, por lo que se presentará aquí una breve introducción para unificar la notación.
La distancia clásica de Mahalanobis está definida para cualquier conjunto X y para cualquierevento xi (Rousseeuw y Van Zomeren, 1990) como:
( )( ) ( ) ( )( )MDi i i
T= − −−
x T X C X x T X1
(17)
siendo T(X) estimado como la media aritmética del conjunto X y la matriz C(X) estimada como la matrizde covarianza. La distancia MDi indica que tan lejos está el evento xi del centro de la nube. La matrizC(X) es simétrica definida positiva, por lo que el conjunto de eventos xi con igual distancia deMahalanobis están ubicados sobre una superficie elipsoidal con centro T(X). Bajo ciertas hipótesis,valores grandes de la distancia de Mahalanobis corresponden con valores anómalos; para distribución deGauss en las componentes, la distancia de Mahalanobis al cuadrado debe seguir una distribución χ2.

65
e2 e3
e1
Figura 14 Croquis de las diferentes regiones para detección de errores en el espacio de los componentes utilizados. Desdedentro hacia fuera, para w=3, se ilustran las regiones del método estándar de Mahalanobis, el de Hawkins y el de López et al.,1994a. Un evento no será considerado sospechoso si pertenece al interior de la región. En la figura, el componente a1 no estáacotado ni para los métodos de Hawkins ni López, mientras que en el caso del elipsoide de Mahalanobis, los tres componentesa1, a2 y a3 están acotados. Tomado de López, 1997c
Desafortunadamente, el calcular C(X) y T(X) con los métodos tradicionales sufre del efecto deenmascaramiento, que ocurre cuando está presente un conjunto de más de un dato anómalo cercanos entresí. En este caso, tanto C(X) como T(X) son afectados y los datos anómalos ya no tendrán un valor grandede MDi. Para superar este problema, se han propuesto métodos alternativos para estimar correctamenteC(X) y T(X) aún en presencia de errores arbitrariamente grandes en la población. El término inglés "highbreakdown" (alta resistencia o robustez) se ha acuñado para indicar que los resultados de la estimación noserán afectados por errores arbitrariamente grandes en una fracción ε de la población. La cota teóricaadmisible para ε depende del método, pero en todos los casos es un poco menor que la mitad de lapoblación.
Entre los más conocidos, se han seleccionado los métodos de Covarianza con DeterminanteMínimo (MCD), Elipsoide de Volumen Mínimo (MVE), Estimador-S y Estimador-M (Rocke96) y elMétodo de Hadi (Hadi94). Todos producen estimadores robustos, y sus propiedades teóricas han sidoestudiadas en la literatura. Una vez conocidos los parámetros C(X) y T(X) puede calcularse la distanciaMDi y ordenarse los eventos candidatos; aquellos eventos con valores más altos de la distancia, serán losprimeros candidatos. Hadi (1994) sugiere que una vez calculadas las distancias, sólo aquellas que superenun determinado valor deben ser considerados como candidatos, siendo ese valor dependiente del número

66
de columnas en la matriz (observaciones por evento) y de un nivel de confianza. Este criterio no fueincluido en las simulaciones, si bien es importante para otras aplicaciones prácticas.
5.2.5.1 - Covarianza de Determinante Mínimo (MCD) y Elipsoide de Volumen Mínimo (MVE)
Los criterios de Covarianza de Determinante Mínimo (Rousseeuw y Leroy, 1987) y Elipsoide deVolumen Mínimo (Rousseeuw y Van Zomeren, 1990) son dos métodos muy populares para estimar losparámetros. El MCD busca un subconjunto de X que ignore una fracción ε del total de forma que sumatriz de covarianza tenga determinante mínimo. Al ignorar parte de los datos, la estimación tiene altaresistencia (es inmune) a errores arbitrarios en una fracción ε de la población. Se ha utilizado en lassimulaciones un programa suministrado gentilmente por Hawkins, basado en ideas expuestas en Hawkins,1993.
El algoritmo de MVE busca un vector T(X) y una matriz C(X) de forma que solamente para unafracción ε de la población, la distancia de Mahalanobis MDi supere una constante que depende delnúmero de datos en cada evento. Al ser C(X) simétrica y definida positiva, el criterio de MVE puedeinterpretarse como encontrar un centro y ejes principales de un elipsoide de volumen mínimo que dejefuera sólo una fracción ε de la población. Sin embargo, a diferencia del MCD, en este caso la matriz C(X)no es la matriz de covarianza de ningún subconjunto de la población.
Ambos métodos (MCD y MVE) son muy costosos en términos de CPU para casos como elconsiderado en los que hay muchos eventos. Sin embargo, una vez calculados los parámetros, su uso esmuy económico. En el experimento se limitó el número de iteraciones admisibles para hallar tanto elMCD como el MVE, por lo que es posible que los resultados puedan mejorarse en algún grado.
5.2.5.2 - Estimador-S y Estimador-M de T(X) y C(X)
Se puede demostrar que tanto el MCD como el MVE son casos particulares de estimadores másgenerales. Siguiendo a Rocke, 1996, se definirá un Estimador-S como el vector T(X) y la matriz C(X)simétrica definida positiva que minimizan el det(C(X)) sujeto a
( )( ) ( ) ( )( )n bi i
T− −− −
=∑1 1
0ρ x T X C X x T X (18)
donde ρ es una función no decreciente en [0,∞]. La función ρ es usualmente diferenciable (la mayorexcepción la da el MVE, donde ρ es 0 o 1). Para el caso de la distribución normal multivariada,ρ(x)=0.5x2, y Rocke (1996) afirma que esta función no debería depender del número de variables.
El Estimador-M puede ser definido (Maronna 1976) como el vector T(X) y la matriz simétrica,definida positiva C(X) que son una solución de
( )( ) ( )x T Xi iu d− =∑ 1 0 (19)
( )( ) ( )( ) ( ) ( )n u di i
T
i− − − =∑1
22x T X x T X C X (20)
siendo u1 y u2 funciones no negativas y no decrecientes para argumentos positivos, y di el cuadrado de ladistancia de Mahalanobis, definido como

67
( )( ) ( ) ( )( )d i i i
T2 1= − −−x T X C X x T X (21)
La alta resistencia de ambos estimadores han sido analizados en unos cuantos trabajos en laliteratura (ver Rocke 1996 conteniendo una revisión). El código utilizado en los trabajos ha sidoimplementado por Rocke and Woodruff (1996) y está disponible en statlib; el mismo usa algunasfunciones particulares u1 y u2 definidas según sugerencias contenidas en Rocke (1996), y fue utilizado sincambios.
5.2.5.3 - Método de Hadi (1994)
El método de Hadi (1992, 1994) produce un resultado formalmente similar al de MCD. Intentaencontrar un subconjunto conteniendo cerca de la mitad de la población con distancia mínima a unaestimación de la matriz de covarianza. Sin embargo, no es combinatorio, ya que la estimación evolucionadesde una estimación inicial por la vía de agregar un nuevo punto hasta que el conjunto requerido esobtenido. El algoritmo es considerablemente más rápido que los otros, pero sufre de algunosinconvenientes. En particular, no es independiente de una transformación afín (Rocke y Woodruff, 1996)lo que implica que los candidatos serán diferentes luego de un cambio de origen y de unidades de medida.Los métodos de Hawkins, MVE, MCD, Estimador-S y Estimador-M son independientes a latransformación afín.
Programas: hadi.mAlgoritmo:
Sea una tabla nxp, con n observaciones de p variables. Se define la función( ) ( )D fi i
r r rc, V x c, V= − i n= 1.. como una distancia basada en el vector
rc y en la matriz V (definida
positiva), de la siguiente manera:
( ) ( ) ( )D x xi i
T
i
r r r r rc V c V c, = − −−1 , i n= 1.. (22)
Nota: La definición estándar de la distancia de Mahalanobis es tomando como r rc x= i y para
V S= (matriz de covarianza de la muestra).
Paso 0:Estimar un vector columna
rc M como la mediana de las lecturas disponibles. La matriz de covarianza
muestral se calcula como
( )( )S x c x cM i M i M
T
i
n
n=
−− −
=∑1
1 1
r r r r(23)
Evaluar las distancias ( )Di M M
rc S, de todas las filas de la tabla y ordenarlas de menor a mayor; sean los
índices ν i = 1 si ( )i n p≤ + + 1 2/ y ν i = 0 en otro caso. Calcular
r
r
cx
V
i ii
n
ii
n= =
=
∑
∑
ν
ν
1
1
y ( )( )
Sx c x c
V
i i V i V
T
i
n
ii
n=
− −
−
=
=
∑
∑
ν
ν
r r r r
1
1
1(24)

68
Reordenar nuevamente las observaciones de acuerdo con ( )Di V V
rc S, y seleccionar las p+1 observaciones
de distancia mínima. A ese conjunto se le denominará básico y por omisión al resto se le denominaráconjunto no-básico.
Paso 1:Para el conjunto básico, indicado con ν i = 1 (ν i = 0 para el no-básico) calcúlense los estimadores
r
r
cx
b
i ii
n
ii
n= =
=
∑
∑
ν
ν
1
1
y ( )( )
Sx c x c
b
i i V i V
T
i
n
ii
n=
− −
−
=
=
∑
∑
ν
ν
r r r r
1
1
1(25)
Se distinguen ahora dos situaciones, según la matriz sea o no singular (caracterizada por el recíproco delnúmero de condición).Alternativa 1a:La matriz de covarianza es no singular, por lo que se pueden calcular las distancias ( )Di b b
rc S, y ordenar
de nuevo a toda la población.Alternativa 1b:La matriz de covarianza es singular, por lo que la distancia no estará definida. En ese caso, agréguese alconjunto básico una nueva filas de la población ya ordenada, y vuélvase al Paso 1.Paso 2:Mientras el conjunto básico no tenga h observaciones ( ( )( )h n p= + +int 1 2 ) volver al paso 1 agregando
la primer fecha de la lista.Paso 3:En este momento el conjunto básico tiene r observaciones. Una vez evaluadas todas las distancias
( )D ci b np b
rc S, (nótese el escalar cnp multiplicando a la matriz), y ordenadas en forma creciente, se denota
como d r+1 el (r+1)-ésimo elemento de la lista. Si d r p n+ ≥12χ α, se para el proceso, declarándose como
anómalos todos los eventos que cumplan ( )D ci b np b p n
rc S, ,≥ χ α
2 . El número cnp es un factor constante, y
se calcula con la siguiente fórmula:
cn p
pn pnp = +
− −+
+−
1
21 3
12
(26)
Si en cambio d r p n+ <12χ α, amplíese el conjunto básico con un nuevo elemento. Si se terminó la lista
(r+1=n) entonces se declarará que el conjunto no tiene errores, y se termina. Caso contrario, se vuelve alpaso 3.
Se implementaron varias versiones del método, según sean los datos procesados. Enrun_hadi_d_dat.m, todo el proceso se realiza sobre una matriz de anomalías (datos - estimación) yorientado a datos, mientras que en run_hadi_d_dias.m lo hace para eventos. Al igual que antes, el caso de

69
eventos se procesa con un estudio de sensibilidad de la distancia de Mahalanobis (estadístico que definióel carácter de anómalo para el evento) señalando el dato que más lo afecta.
5.2.6 - Método de las redes neuronales
Todos los métodos descritos en las secciones precedentes, de una forma u otra describenestadísticos que se muestran muy sensibles cuando son calculados con valores anómalos. Los valoresmayores están asociados con situaciones inusuales, por lo que los hace candidatos para contener errores.Basándose en ideas similares a las mencionadas en López et al., 1994a para los scores de los componentesprincipales, se han diseñado algunos métodos que reutilizan resultados obtenidos con el fin de imputarvalores ausentes con redes neuronales artificiales, y que han sido presentados en el capítulo anterior.
Las redes neuronales artificiales tienen una arquitectura en capas, en las que la información semueve en un único sentido. La información disponible estimula una primer capa de neuronas, las que a suvez estimulan una o más capas ocultas, hasta que finalmente la neurona de salida produce la estimaciónrequerida. La red es entrenada previamente de forma de producir ante un estímulo, la salida correctaobservada en las estaciones meteorológicas.
La literatura consultada estima como difícil la interpretación de los estímulos intermedios. Envarias publicaciones se ha venido analizando la posibilidad de utilizar esos estímulos para detectarsituaciones anómalas en los datos de entrada. El razonamiento asume que, al igual que en el caso de losComponentes Principales, es posible identificar estadísticos que adoptan valores grandes únicamente encasos inusuales. Lo que se ha hecho en el marco de este proyecto, es conjeturar sobre los diferentes rolesque cumplen las neuronas en las redes sencillas implementadas, apuntando a clasificar algunas comodetectoras de errores.
A estos efectos, se elaboró una "regla" y se la ensayó con éxito en las redes disponibles. La reglaestá basada en la comprobación que las neuronas tienen diferente nivel de actividad, y que hay algunasque permanecen típicamente inactivas. Ante estos casos, la práctica corriente sugiere eliminar neuronas yreentrenar la red, ya que la red corre riesgo de estar sobreentrenada, lo que implica que tiene unacapacidad limitada para generalizar (predecir valores razonable con casos que nunca ha visto). Esteenfoque tiene su razón de ser, y descansa en la hipótesis implícita que los datos no contienen valoreserróneos.
Cuando no es ese el caso, el sistema funciona de la siguiente manera: un grupo de neuronas seactiva rutinariamente, estimulando significativamente las conexiones sinápticas que le siguen. Entérminos cuantitativos, las salidas de las neuronas en consideración son multiplicadas por un coeficienteconstante resultado del entrenamiento, y el resultado da un aporte sensible en la combinación lineal quesirve de estímulo a la capa que sigue. En los casos considerados, sólo se disponía de una capa oculta, porlo que esta salida era tomada por una única neurona que producía el resultado complexivo del sistema.

70
Se observó que existían neuronas cuyos coeficientes en la combinación lineal eran sensiblementemayores que las demás. Un razonamiento simplista diría que se deben eliminar aquellas neuronas conpesos despreciables, pero resultaba que eran esas las que justamente estaban típicamente activas. Lasneuronas con pesos mayores tenían un comportamiento totalmente pasivo (no se activaban) excepto paraunos pocos casos, en los que aportaban al conjunto de forma de ajustar la predicción. Se definió que seríaconsiderada "ruidosa" (o asociada con ruido) toda neurona cuyo peso en la combinación lineal fueramayor a cinco veces al mínimo peso en esa capa. Este criterio está basado en la observación, yposiblemente sea mejorable con más investigación. Nótese que podría ocurrir que una red dada no tenganeuronas "ruidosas"; en este caso, y para estos fines, se recomendaría agregar más neuronas en las capasen consideración, de forma que alguna de las nuevas asuma ese rol. También podría ocurrir que exista másde una neurona "ruidosa".
Una vez detectada(s) la(s) neurona(s) en estas condiciones, se analizan utilizando toda lapoblación los valores que adoptan las salidas de las mismas, determinándose así rangos no admisibles(outlier regions en la nomenclatura de Davies and Gather, 1993). Nótese que la clasificación en "ruidosa-no ruidosa" se realiza observando los coeficientes de la red; los rangos mismos requieren analizar la red enconjunto con la población de datos.
Por la forma en que las redes fueron entrenadas, para una población con registros de 10 estacionesmeteorológicas hay que entrenar 10 redes diferentes, cada una de las cuales tendrá como entradas los 9registros disponibles, y como salida la décima estación. Es claro que, si en un evento, hay un único valoranómalo, sólo una de las 10 redes será indiferente (la que usa como entrada los otros 9 valores), puestoque las otras 9 estarán en condiciones de señalar al evento como anómalo. Es por ello que se desarrolló enprimera instancia un algoritmo que señala como sospechosos todo evento en el que al menos una de lasredes detecta algo extraño. Ello cubre groseramente el caso que no todas las redes tengan neuronas"ruidosas".
El método, tal como está descrito, es orientado a eventos. No se intentó identificar el datoindividual que podría ser responsable del comportamiento anómalo.
5.2.7 - Método de la verosimilitud de la validación cruzada
El último método a ser descrito está basado en conceptos corrientes de Geoestadística (Samper yCarrera, 1990). El problema fundamental en esa disciplina es encontrar un interpolador aceptable dadosun número finito (y pequeño) de puntos con observaciones. Bajo ciertas hipótesis, en el método clásico dekrigeado (Samper y Carrera, 1990) el valor interpolado es obtenido como una media ponderada de losdatos disponibles, con pesos que dependen de las coordenadas del punto y de las observaciones. Se asumehomogeneidad (las propiedades estadísticas del campo no varían con las coordenadas relativas) e isotropía(tampoco varían con la dirección), y que las propiedades de correlación en el espacio pueden ser descritascon un variograma que depende únicamente de la distancia entre puntos.

71
La estimación de este variograma es el problema fundamental de la Geoestadística. Usualmente sele elige de un pequeño subespacio de funciones con propiedades específicas. Samper y Neumann, 1989sugirieron estimar los parámetros del mismo mediante la maximización de la verosimilitud de lavalidación cruzada de la muestra. En su forma más simple posible, ello obliga a: 1) retirar una observación2) estimar ese valor usando las demás observaciones 3) guardar la diferencia entre el valor estimado y eldisponible. Una vez que este cálculo está realizado para todos las observaciones, es posible calcular laverosimilitud del conjunto, que depende de los parámetros del variograma y de los datos mismos. Esaverosimilitud puede maximizarse para un variograma particular, pero luego su valor absoluto dependeúnicamente de los datos mismos.
En el caso en estudio no interesaba obtener estimaciones en otros puntos diferentes que los de lared de observación. Al igual que en los métodos de interpolación objetiva (Gandín) se asumió que laspropiedades estadísticas eran similares para condiciones sinópticas comparables. Por lo tanto, se utilizótoda la información disponible para calcular la covarianza en lugar de obtenerla vía el variograma. Lamatriz obtenida era claramente simétrica y definida positiva, cumpliendo con todos los requisitosnecesarios. Ello elimina la necesidad de modelar el variograma, y por lo tanto, de maximizar laverosimilitud.
La estrategia fue calcular la verosimilitud utilizando la estructura de covarianza muestral; ese valores una medida de que tan creíble es la imputación realizada con la validación cruzada. En casos anómalos,los valores diferirán mucho y la verosimilitud será baja. En la práctica se imputó utilizando la rutinadenominada gandin20, y se calculó la verosimilitud en todos los eventos. Luego se les ordenó de menor amayor y se sugirió que aquellos con menores valores eran los que contenían algún error. Por lo tanto, elmétodo tal como está descrito está orientado a eventos.
5.2.8 - Método del gradiente admisible
Este método está orientado fundamentalmente a series temporales, y es aplicable para algunosparámetros hidrometeorológicos. El mismo es muy simple, y consiste en especificar un rango admisiblepara las pendientes (i.e. primer derivada) estimadas por la vía del cociente incremental. Krajewski andKrajewski, (1989) lo aplicaron a un experimento preliminar con datos de caudales. En su formulaciónoriginal, los autores sugieren dividir la(s) serie(s) en dos conjuntos: del estudio del primero, se sugierenvalores extremos de los cocientes incrementales, y luego los aplican a todo el conjunto. En nuestro caso,se estimaron los límites sobre el conjunto de datos previo a ser contaminado con outliers artificiales.
Dependiendo del problema, los extremos pueden tener diferente valor absoluto. En particular, enel caso de caudales es posible que la pendiente máxima en crecida sea mayor que en bajante, simplementepor argumentos asociados al balance hídrico y a las características cinemáticas del flujo. En todo caso, lasparticularidades de cada serie temporal son contempladas dejando libres esos números.

72
A los efectos del experimento, se elaboraron rutinas que estimaban los cuantiles 2.5% y 97.5%, yse adoptaron esos valores como límites. Dado que ellos fueron estimados con los datos sin perturbar, yrecién luego fueron incluidos los outliers, no es correcto decir que se produce un 5% de candidatos encada pasada.
El cociente incremental implica dos datos consecutivos: si ese cociente se va de los rangos seasume que el dato más nuevo es el erróneo. Si el dato en el instante t es un outlier grosero, es posible quesean a la vez señalados los valores correspondientes al intervalo (t-1,t) y se declara outlier al t-ésimo(correcto) pero a su vez será afectado el cociente en el intervalo (t,t+1), declarándose también comooutlier al t+1-ésimo (incorrecto). Ello se tuvo en cuenta, y si existen candidatos consecutivos, se señalaúnicamente al primero.
5.2.9 - Método de la curvatura admisible
Es muy similar al anterior: un valor Pt es considerado outlier si el estimador de la derivadasegunda
( ) ( ) ( ) ( )( )
P P T T P P T T
T Tt t t t t t t t
t t
+ + − −
+ −
− − − − −−
1 1 1 1
1 1(27)
calculado como el cociente incremental de los cocientes incrementales excede ciertos márgenes. Al igualque antes, se tiene cuidado en no incluir ternas en las cuales la anomalía puede imputársele a un únicovalor. Los márgenes se determinan trabajando con la serie sin contaminar.
5.2.10 - Método del producto de gradientes admisibles
Es muy similar al anterior: un valor Pt es considerado outlier si el producto de los cocientesincrementales hacia atrás y hacia adelante excede ciertos márgenes. Al igual que antes, se tiene cuidado enno incluir ternas en las cuales la anomalía puede imputársele a un único valor.
( ) ( ) ( ) ( )P P T T P P T Tt t t t t t t t+ + − −− − − −1 1 1 1* (28)
5.2.11 - Modelado de la distribución (sólo lluvia)
Programas: mdd.mAlgoritmo:
El modelo que se describe a continuación no puede ser encasillado totalmente en ninguna de lasdivisiones que se han planteado anteriormente. Si bien su objetivo original fue detectar errores, es tambiénun modelo destinado a favorecer los métodos de imputación analizados, mejorando su eficiencia ( tanto en

73
la aproximación al resultado verdadero como en el tiempo de cálculo ). Hechas estas precisiones se pasa adescribirlo.
Utilizando toda la información descriptiva disponible que emerge de la base de datos y deltratamiento estadístico realizado en los puntos anteriores, se ha construido un modelo probabilístico deestimación de la distribución diaria de lluvia. Este modelo habrá de permitir aproximar el dato faltante delluvia de una estación pluviométrica de un cierto día con una distribución de probabilidad que utiliza lainformación de la lluvia en esa misma estación el día anterior y en “genéricas “ estaciones vecinas queluego definiremos con mayor precisión, el mismo día.
Veamos de definir el modelo.
Para cada estación pluviométrica i, se define :
wi t = milímetros de lluvia caída el día t en la estación y (29)
u g j w con g jit i jt
j i
p
i
j i
p
j j
= =≠ ≠= =
∑ ∑( ) ( )1 1
1 (30)
es decir que uit es una combinación lineal de las lluvias caídas en las demás estacionesconsideradas el día t.
Consideradas las transformadas:
X
si w
si w
si w
si w
it
it
it
it
=
=< ≤< ≤
>
0 0
1 0 7
2 7 17
3 17
,
,
,
,
Y
si w
si w
si w
si w
i t
i t
i t
i t
=
=< ≤< ≤
>
−
−
−
−
0 0
1 0 7
2 7 17
3 17
1
1
1
1
,
,
,
,
( )
( )
( )
( )
Z
si u
si u
si u
si u
it
it
it
it
=
=< ≤< ≤
>
0 0
1 0 7
2 7 17
3 17
,
,
,
,
donde
( ) ( ) ( ) ( ) { }Re , , Re .Re Re , , ,c X Y Z c X c Y c Z= = 0 1 2 33
La expresión general del Modelo que interesa es:
( )( )P X x Y y Z z= = =, (31)

74
es decir, se trata de que la lluvia en una determinada estación se distribuye de determinada manera,condicionada a lo sucedido en la misma estación el día anterior y de algún modo en estaciones “vecinas”el mismo día.
Los valores que toman X e Y surgen directamente de la tabla de datos disponibles. Con una simpletransformada como se ha definido se obtienen los x e y que constituyen los dos primeros elementosobservados de la variable aleatoria triple (X,Y,Z).
En cambio se plantean problemas metodológicos para la determinación del tercer elemento. Esconveniente aclarar desde ya que la (31) se obtendrá a partir de la distribución conjunta de (X,Y,Z)utilizando la definición misma de probabilidad condicionada. Será necesario obtener la distribuciónmarginal doble (Y,Z) y podría pensarse de alguna manera en una marginal de X, aunque aquí se presentangrandes dudas metodológicas sobre si se puede de alguna manera utilizar como algún tipo de probabilidada priori, la simple información dada por frecuencias históricas. Como pensamos que un razonamiento deese tipo es inconducente, siendo preferible utilizar distribuciones de referencia nos limitaremos a hallar lasdistribuciones de probabilidad condicionadas planteadas en la (31).
Debemos buscar los caminos para obtener los valores que corresponden a las expresionesestablecidas en (30), que expresan la información espacial necesaria para la obtención del último elementode cada terna en la distribución conjunta.
Aquí, por ahora, como la construcción del modelo está en una fase fermental se utilizarán doscaminos para obtener la Z. En uno de ellos la combinación lineal expresada en (30) para ponderar dealguna manera los milímetros de lluvia será la determinada por la aplicación del método de Gandín yadescrito.
En el segundo caso se utilizarán los conocimientos obtenidos al analizar estacionalidad en relacióna las estaciones más cercanas en cada mes a una dada, según la distancia de Kulback- Leibler. En estecaso, si hay alguna estación claramente “más cercana” se utilizará ella en (30) con coeficiente 1, y 0 lasdemás ( en caso de distancias muy similares se ponderarán con el mismo peso aquellas estaciones quecumplan con esta condición y con cero las demás ). En el caso extremo, posible teóricamente, pero noverificado en esta base de datos, de que todas las distancias fueran similares en un cierto mes se deberíarealizar la combinación lineal de todas ellas. En la práctica se ha elegido la más cercana.
De este modo, la matriz original se transforma en una nueva con las ternas. Posteriormente seagrupa por mes, es decir se calcula la distribución para cada mes de la distribución conjunta. Se obtienenasí para todas las estaciones pluviométricas el siguiente tipo de matrices 3- way:

75
{ }X x con
i
j
kijr=
===
1 64
1 12
1 9
L
L
L
, donde
el término genérico indica para cada una de las 64 ternas posibles, (recordar que Rec (X,Y,Z) = (0,1,2,3)3)el número de veces que aparece en cada mes, para cada una de las 9 estaciones pluviométricasconsideradas.
Llegado este punto el cálculo de la frecuencias relativas de la variable (X,Y,Z) puede hacerse porestación o para toda la cuenca.
En caso de considerar cada estación, se realiza en primer instancia el agrupamiento de mesesobtenido al estacionalizar. Es decir se considera la estacionalidad particular de cada estación. Esto endefinitiva indica que al considerarse un determinado dato faltante, se tendrá en cuenta de cuál estación es ya qué día del año corresponde (como consecuencia a qué grupo de estacionalidad pertenece).
Se obtendrán de esta manera la distribución triple y la marginal doble necesaria, para cadaagrupación de meses, de cada estación.
De trabajarse con toda la cuenca al mismo tiempo, claramente la estacionalidad será una sola. Eneste segundo procedimiento el modelo pierde especificidad, hay una sola estacionalidad, y las mismasdistribuciones valen para todas las estaciones. Gana sin embargo en generalidad, sobre todo pensando enla aplicación a una nueva estación de la cuenca o si se quiere realizar inferencia a otras estaciones.
Una vez obtenidas todas las distribuciones condicionales y verosimilitudes que surgen del modelo,se puede aún profundizar en el análisis. Ya el hecho de tener las diferentes distribuciones de probabilidadque el modelo brinda significa un importante avance. En este sentido podemos considerar el hecho de quéaporta el disponer de una distribución de probabilidad para cada día en la cuenca.
Esto significa información directamente usable cuando por algún motivo es necesario saber quépuede haber ocurrido en un determinado lugar, fuera de una estación pluviométrica, en relación a la lluviacaída en un cierto día.
También servirá como elemento de control de calidad de datos que provengan de las estaciones yaconsideradas o de otras de la cuenca. Es evidente que el sucederse de fenómenos que cuentan con muybaja probabilidad deberá llamar la atención del usuario sobre la calidad de esa información.
Por otra parte la información del modelo puede transformarse en un factor que incremente laeficiencia de los diferentes estimadores puntuales que se han analizado en los capítulos anteriores. Y estemejoramiento de eficiencia puede tener que ver con dos aspectos: uno, la obtención de estimadores conmenor error y, segundo, la posibilidad de ahorrar tiempo de cálculo en el caso de imputación de un dato

76
faltante, restringiendo el campo de búsqueda a un determinado período del año y a determinadosintervalos.
Este último aspecto deja en evidencia un aspecto del modelo que debe todavía desarrollarse. Estoes, cómo aprovechar íntegramente la información en distribución que brinda el modelo, para mejorar losestimadores calculados.

77
6 - Resultados obtenidos
El proyecto que se describe es altamente complejo, y las miles de horas de cálculo han producidoun banco de datos extremadamente rico y difícil de sintetizar. A los efectos de dar cumplimiento a loespecificado en el proyecto, se analizarán los resultados obtenidos para varios parámetros meteorológicos,tratando de encasillarlos de alguna manera para facilitar las comparaciones entre métodos.
La mayor parte de los aspectos metodológicos fueron históricamente analizados en primerainstancia para la lluvia diaria, y es por ello que se presentarán junto con el análisis de sus resultados. Lasotras variables meteorológicas consideradas esencialmente fueron ajustadas al mismo molde, con laexcepción del trabajo realizado sobre la dirección del viento, dadas sus características de variable circular.
6.1 Lluvia diaria
En todos los casos tratados, al mismo banco de datos se le realizaron estudios de tres tipos:imputación de ausencias, detección de eventos con errores y detección de datos dentro de cada evento conerrores. El término error se considerará sinónimo de outlier en la mayor parte del documento, sinperjuicio de alguna excepción.
Los experimentos fueron globalmente similares: tomando el banco de datos, se le modificóapropiadamente, eliminándole datos disponibles (con el fin de imputarlos luego) o insertándole erroresaleatorios (con el fin de detectarlos luego). Los métodos apropiados a cada caso fueron aplicados, y susmedidas de desempeño calculadas. Esta operación fue realizada un número grande de veces, siguiendouna metodología tipo Monte Carlo, evaluándose a posteriori estadísticos de la población de las medidas dedesempeño. Las tablas que siguen recogen esencialmente ese análisis.
6.1.1 Generación de ausencias
Si bien conceptualmente más simple que el caso de los errores, la forma de generar ausenciasrequirió cierto análisis. En particular, una pregunta importante es si se puede decir que las ausencias sepresentan en forma de rachas, definiéndose así el caso en que aparezcan, para la misma estación, períodoslargos sin lecturas. En la práctica, ello corresponde a roturas en el instrumento, o extravío de los registrosen papel (típicamente se perdería un mes entero). Si bien eso se pudo constatar con los datos disponibles,corresponde analizar estadísticamente la situación, de forma de diseñar apropiadamente un generadoraleatorio de ausencias.
Para ello se implementó el test descrito por Little, 1988, el que arrojó como conclusión que en elcaso de la lluvia diaria era posible utilizar un generador tipo MCAR, en el que las ausencias se dan al azary con distribución doblemente uniforme, tanto en las fechas como en las estaciones. El total de ausenciasse limitó a un máximo del 1 por ciento de la población.

78
6.1.2 Imputación de valores ausentes
A los efectos de distinguir en alguna medida métodos que requieren más información de otros queno la requieren, los resultados para la imputación se presentan en la tabla 8 para el caso de los métodosque utilizan en el momento de imputar los únicamente datos del mismo día, y en la tabla 9 los métodosque usan información adicional. La red neuronal denominada bp11 si bien usa datos de un único día, se haincluído en la segunda categoría. Las columnas se interpretan de la siguiente manera: en la primera seidentifica el método con un nombre ya descrito en el capítulo correspondiente. A continuación se incluyencuatro estimadores de la función de densidad de probabilidad de la desviación absoluta, definida como ladiferencia entre lo imputado por el método y el valor existente en los registros originales. Estosestimadores son el promedio y los percentiles 75, 85 y 95%. Así, por ejemplo, los resultados para la redneuronal bp1 muestran que en el 75% de los casos, la red imputa con un error menor a 1.891 mm/día, y enel 95% de los casos, con un error menor a 12.520 mm/día. Estos casos corresponden a los resultadoscalculados para cada una de las realizaciones de Monte Carlo, y promediados luego entre todas ellas. Laquinta columna es el error cuadrático medio, definido como la suma de cuadrados del error absolutodividido por la cantidad de eventos, y promediado luego entre todas las realizaciones de Monte Carlo. Losresultados han sido obtenidos luego de 415 simulaciones aplicando los métodos descritos anteriormente.
Se dispone de información adicional (no incluída en las tablas) como ser:• mediana de la distribución del error absoluto• tiempo requerido por simulación• número de imputaciones realizadas por simulación
En el caso de la lluvia diaria, la mediana resulta ser típicamente cero. Para otros parámetrosmeteorológicos podría ser más interesante su presentación. El tiempo requerido por la simulación es unamedida indirecta del costo de su aplicación, ya que muchos métodos (las redes neuronales, los métodosque minimizan los percentiles, etc.) tienen un alto costo inicial previo a su aplicación, pero luego son muyeconómicos. Otros métodos como el hotdeck tienen en cambio su costo principalmente asociado al tiempode ejecución. Como no se puede establecer fácilmente una equivalencia entre uno y otro, se ha intentadoaportar información cualitativa al respecto indicando en las dos columnas siguientes si el método seconsidera de costo alto o bajo, sin definir con precisión cuánto es bajo o alto.
En los cálculos se utilizó información del período 1960-1980, resultando aproximadamente 11000eventos de 10 estaciones. Los resultados obtenidos confirman lo dificultoso que es el problema para elcaso de los registros diarios. El error medio cuadrático no pudo ser menor a 6.3 mm/día. Si se le comparacon la resolución de los datos (asentados en papel en décimas de mm/día) se puede concluir que seríapésimo. Sin embargo, los técnicos de la DNM consultados estiman que el error inherente al instrumento esposiblemente próximo a 5 mm/día.
Otra medida de la bondad de los métodos más sofisticados, es comparar su desempeño con otrosmétodos de aplicación casi trivial. A modo de ejemplo, se seleccionaron el naive (imputa con el últimodato disponible para la estación), el valor modal (que en el caso de la lluvia diaria en esta cuenca implicaasignarle una lectura cero) y el denominado veciconf (que para cada dato ausente, toma el dato disponible
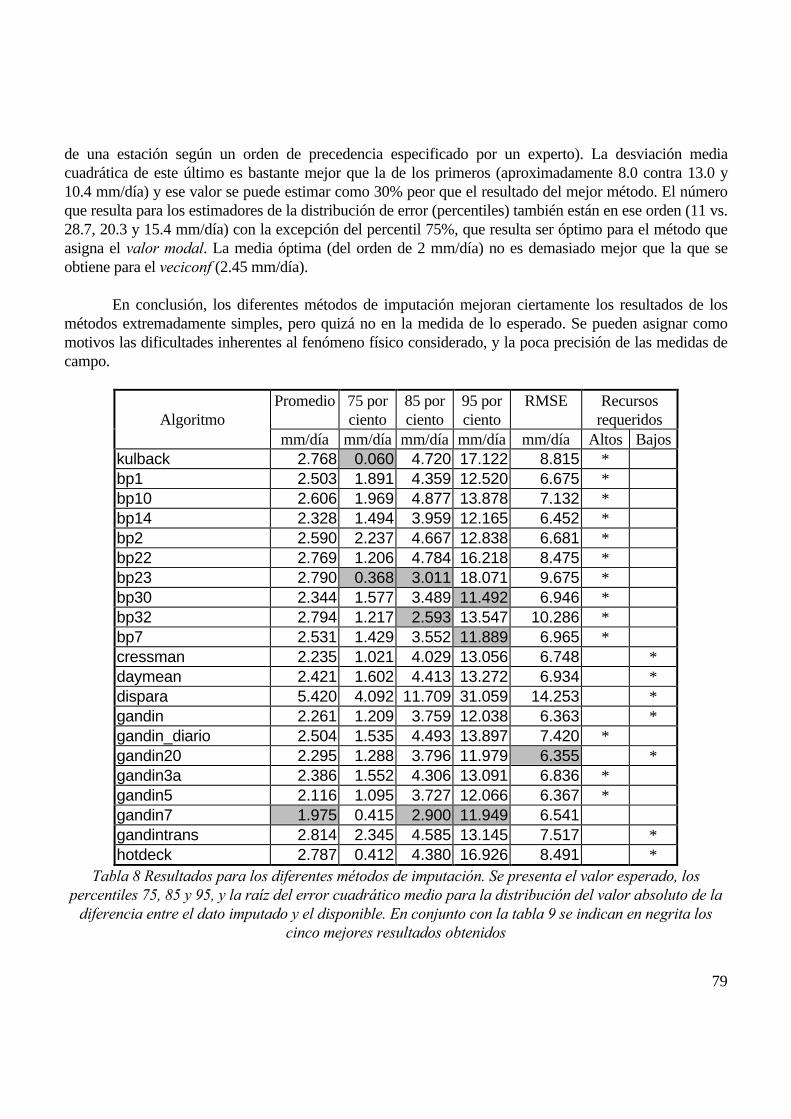
79
de una estación según un orden de precedencia especificado por un experto). La desviación mediacuadrática de este último es bastante mejor que la de los primeros (aproximadamente 8.0 contra 13.0 y10.4 mm/día) y ese valor se puede estimar como 30% peor que el resultado del mejor método. El númeroque resulta para los estimadores de la distribución de error (percentiles) también están en ese orden (11 vs.28.7, 20.3 y 15.4 mm/día) con la excepción del percentil 75%, que resulta ser óptimo para el método queasigna el valor modal. La media óptima (del orden de 2 mm/día) no es demasiado mejor que la que seobtiene para el veciconf (2.45 mm/día).
En conclusión, los diferentes métodos de imputación mejoran ciertamente los resultados de losmétodos extremadamente simples, pero quizá no en la medida de lo esperado. Se pueden asignar comomotivos las dificultades inherentes al fenómeno físico considerado, y la poca precisión de las medidas decampo.
AlgoritmoPromedio 75 por
ciento85 porciento
95 porciento
RMSE Recursosrequeridos
mm/día mm/día mm/día mm/día mm/día Altos Bajoskulback 2.768 0.060 4.720 17.122 8.815 *bp1 2.503 1.891 4.359 12.520 6.675 *bp10 2.606 1.969 4.877 13.878 7.132 *bp14 2.328 1.494 3.959 12.165 6.452 *bp2 2.590 2.237 4.667 12.838 6.681 *bp22 2.769 1.206 4.784 16.218 8.475 *bp23 2.790 0.368 3.011 18.071 9.675 *bp30 2.344 1.577 3.489 11.492 6.946 *bp32 2.794 1.217 2.593 13.547 10.286 *bp7 2.531 1.429 3.552 11.889 6.965 *cressman 2.235 1.021 4.029 13.056 6.748 *daymean 2.421 1.602 4.413 13.272 6.934 *dispara 5.420 4.092 11.709 31.059 14.253 *gandin 2.261 1.209 3.759 12.038 6.363 *gandin_diario 2.504 1.535 4.493 13.897 7.420 *gandin20 2.295 1.288 3.796 11.979 6.355 *gandin3a 2.386 1.552 4.306 13.091 6.836 *gandin5 2.116 1.095 3.727 12.066 6.367 *gandin7 1.975 0.415 2.900 11.949 6.541gandintrans 2.814 2.345 4.585 13.145 7.517 *hotdeck 2.787 0.412 4.380 16.926 8.491 *
Tabla 8 Resultados para los diferentes métodos de imputación. Se presenta el valor esperado, lospercentiles 75, 85 y 95, y la raíz del error cuadrático medio para la distribución del valor absoluto de la
diferencia entre el dato imputado y el disponible. En conjunto con la tabla 9 se indican en negrita loscinco mejores resultados obtenidos

80
itcp_nocor 4.770 4.204 8.267 22.534 10.998 *itcp_nocov 4.865 3.756 6.450 20.882 10.749 *julmean 4.998 4.672 6.259 17.559 10.199 *kulback 2.811 0.055 4.729 17.613 8.957 *lms 3.787 1.704 6.253 24.692 11.155 *lts 2.072 0.881 3.310 11.958 6.541 *lss 2.205 1.223 3.758 11.985 6.354 *mahalan_nocor 4.333 1.793 5.103 16.983 33.107 *mahalan_nocov 15.588 1.818 4.981 17.472 383.691 *mahalanyescor 2.520 1.011 3.711 13.698 7.583 *mahalanyescov 2.561 0.960 3.808 14.003 8.582 *mincdr 2.099 1.110 3.643 11.934 6.327 *minprc 2.091 1.135 3.693 11.805 6.283 *minprm 2.029 0.735 3.301 11.965 6.432 *minprmfl 2.037 0.556 3.212 12.225 6.576 *naive 4.779 2.562 10.063 28.731 13.080 *valor modal 2.951 0.000 2.792 20.328 10.416 *staverage 4.948 3.072 3.234 17.375 9.992 *veciconf 2.452 0.005 3.892 15.395 8.039 *vecidist 2.427 0.006 3.848 15.173 7.951 *
Tabla 8 (cont) Resultados para los diferentes métodos de imputación. Se presenta el valor esperado, lospercentiles 75, 85 y 95, y la raíz del error cuadrático medio para la distribución del valor absoluto de la
diferencia entre el dato imputado y el disponible. En conjunto con la tabla 9 se indican en negrita loscinco mejores resultados obtenidos
AlgoritmoPromedio 75 por
ciento85 porciento
95 porciento
RMSE Recursosrequeridos
mm/día mm/día mm/día mm/día mm/día Altos Bajosbp11 4.536 3.898 6.704 17.252 9.569 *bp12 2.938 2.842 5.333 13.456 7.150 *bp17 2.629 2.155 4.509 12.684 6.610 *gandin4 2.227 1.543 3.976 12.047 6.319 *gandin6 2.361 1.652 4.063 12.062 6.333 *
Tabla 9 Resultados para los diferentes métodos de imputación, que utilizan valores del día, del díaanterior o de ambos. Se presenta el valor esperado, los percentiles 75, 85 y 95, y la raíz del error
cuadrático medio para la distribución del valor absoluto de la diferencia entre el dato imputado y eldisponible. En conjunto con la tabla 8 se indican en negrita los cinco mejores resultados obtenidos
La separación en dos tablas de los resultados por este criterio es relativamente arbitraria, y puedenhacerse otras. En particular, hay una división conceptual que merece la pena ser considerada. La mayorparte de la literatura trabaja con métodos que se pueden denominar globalmente como lineales, en la

81
medida que la imputación es el resultado de una combinación lineal de los datos disponibles (López,1997b). Así, los diferentes métodos lineales difieren entre sí al momento de estimar los coeficientes,requiriendo más o menos cálculos, datos o hipótesis. Un aspecto importante a mencionar es que es posiblediseñar métodos óptimos entre todos los lineales, de forma de hacer máximo su desempeño para unadeterminada función objetivo. En la medida que esos métodos existen (y se han denominado mincdr paraoptimizar el RMSE; minprc para el percentil 95, minprm para el promedio, etc.) lo único que resta hacercon los otros métodos lineales es analizar la distancia que existen con respecto al óptimo, para cada uno delos estimadores de éxito.
Por otra parte se pueden considerar los métodos no lineales, que no están condicionadosmatemáticamente por los óptimos anteriores. Se buscaron diferentes alternativas, fundamentalmentevinculadas a las redes neuronales artificiales. Es posible demostrar que en ciertas condiciones (Cybenko,1989) las ANN son Aproximadores Universales, capaces de ajustar arbitrariamente bien funcionescontinuas, bajo hipótesis modestas. Así fue posible lograr encontrar métodos (ahora no lineales) queprodujeran un error con percentil 95% menor al óptimo 11.805 de los métodos lineales. Hasta donde losautores conocen, este enfoque es un aporte surgido del proyecto en lo que se refiere al área meteorológica.
Es del caso señalar que, para los códigos disponibles, las ANN son diseñadas de forma deoptimizar el RMSE; sin embargo, no lograron mejorar el óptimo de los métodos lineales. El motivo puededeberse a los outliers presentes en la población disponible, ya que alguna de las ANN fue entrenada enetapas tempranas del proyecto con la base aún no completamente depurada. En general, y considerando eldesempeño de las ANN, puede decirse que son más sensibles a los outliers que los métodos lineales, peroque pueden dar un mejor ajuste en la mayor parte de los otros casos. Eso se manifiesta en los buenosresultados que se obtienen para los percentiles 95, 85 y 75%, valores que no son afectados por la presenciade unos pocos outliers, a diferencia del promedio y la RMSE. Esta hipótesis se ve reforzada al considerarel desempeño de las ANN como detectores de outliers, aspecto recogido en López, 1999b y analizado aquímás adelante. Por otra parte, es de hacer notar que no se observó una sustancial mejora al incorporarinformación de los días previos. El motivo está asociado a los algoritmos de optimización utilizados, losque se pudo verificar en varios casos que fallaban en escapar de mínimos locales. Por ejemplo, la red bp12tiene casi el doble de parámetros que la bp1, y con una adecuada selección de los mismos se la puedehacer idéntica a ella; sin embargo, ese caso particular no fue obtenido por los algoritmos de optimización,produciendo una solución subóptima.
Entre los métodos lineales, es de hacer notar el buen desempeño del método denominado gandin7.El mismo trabaja (a diferencia de los otros) sobre una variable transformada de la población original,obtenida extrayendo la raíz cuadrada. Este resultado auspicioso (presente en el informe preliminar)deliberadamente no fue aprovechado en los trabajos posteriores, buscándose lograr similares desempeñossin realizar manipulaciones a la medida del problema. La filosofía del proyecto era ensayar métodosconocidos, o desarrollar nuevos, pero siempre buscando que sean generalizables a otras variablesmeteorológicas, y la transformación de la variable es altamente específica al problema. A modo deejemplo, una transformación general siempre disponible, sería la de llevar los datos del problema alintervalo [0,1] con densidad de probabilidad arbitraria (uniforme, normal, etc.). Un buen resultadoobtenido con esta transformación hubiese sido de gran valor dada su generalidad. Si bien en el caso de la

82
lluvia la transformación con esos requerimientos no es estrictamente posible, ya que el valor 0 mm/díatiene una probabilidad especialmente alta, se diseñó el método denominado gandintrans que opera sobrela variable transformada. Dado que su desempeño no fue excesivamente satisfactorio, no se continuó ensu aplicación a otros casos.
Los métodos lineales denominados lss y mincdr tienen desempeños similares, pero debe señalarseque la complejidad incluída en el segundo (que tenía coeficientes diferentes dependiendo de lacombinación de ausencias-presencias en cada evento) no mejora substancialmente los números delprimero, que simplemente extraía los pesos asumiendo una ausencia por día, e iteraba en el caso quehubiera más de una. Este resultado, unido al costo desmesurado de la determinación de los pesos, justificael haber dejado de lado la determinación de similares coeficientes para el caso de los métodos lts y lms.
Como último aspecto a comentar del experimento, debe considerarse el número de simulacionesde Monte Carlo realizadas. Para todos los métodos se realizaron un número grande de simulaciones con laexpectativa que las distribuciones y sus estimadores y momentos se estabilizaran. El problema fue definircuándo estaban estabilizados. La literatura no es demasiado explícita al respecto, y el criterio que seadoptó fue el siguiente: la población de estimadores se separa en dos partes a las que se les aplica el test deKolmogorov-Smirnov (Koroliuk, 1986 págs. 475-476) que analiza si dos muestras pertenecen a la mismadistribución. Se aceptó que si este test era favorable con un nivel de confianza del 95% la simulación sedaba por terminada.
6.1.3 Generación de errores aleatorios
El problema de la apropiada simulación de desempeño de los métodos de detección de erroresrequiere de algún procedimiento para la generación de los errores a encontrar. En el caso de la lluvia serealizó un trabajo muy completo que se ha descrito en López, 1998b (trabajo incluído en el anexo), al quese remite al lector. La utilidad del mismo excede la de este trabajo, ya que, disponiendo de un generadorde errores aleatorio, es posible realizar simulaciones sobre sistemas complejos (como el de gestión derepresas de riego, energía o de agua potable) de forma de dar márgenes de error realistas en los valoresesperados de la salida. A modo de ejemplo, si se dispone de un modelo hidrológico del tipo lluvia-nivel enel embalse, se puede analizar la sensibilidad de los niveles en función de los simples errores de los datosde partida, obteniendo así rigurosamente límites estadísticos a estas medidas hidrológicas (usualmenteasumidas como exactas).
6.1.4 Detección de valores erróneos
Tal como se indicó al principio, el experimento consistió en sembrar el banco de datos con erroresy luego encontrarlos. La operación del sembrado fue realizada sustituyendo siempre observacionesdisponibles de forma de poder ponderar si el dato sembrado difería poco o mucho del valor verdadero.Desafortunadamente, la contabilidad requerida para poder comparar métodos introduce algunostecnicismos en el análisis, que se deben contemplar.

83
En la literatura, la mayor parte de los métodos está orientada a eventos (López, 1999b). Elloimplica que lo que el método intenta es señalar los individuos en la población de puntos de Rn que tienenun comportamiento anómalo. Ello es muy útil, pero no es suficiente en la medida que la anomalía puedeestar asociada a algunas pocas lecturas. Ello es debido a que las lecturas meteorológicas son tomadas enestaciones separadas espacialmente, por observadores independientes; el proceso de digitación de registrosen papel también es realizado en forma ordenada por estación, lo que hace que el punto en Rn recién seconforme dentro de la computadora. Por lo tanto, es de interés encontrar métodos capaces de señalar nosolamente el evento sospechoso, sino también el dato dentro del evento. Algunos de los métodosorientados a eventos pueden ser extendidos de forma de producir un método orientado a datos, pero otrosno. En muchos de los casos (con la excepción de los métodos descritos en López, 1994a), este trabajo degeneralización del método ha sido un aporte de este proyecto.
Todos los métodos han sido enfrentados al mismo banco de datos con errores, y se han calculadolos índices definidos en el capítulo 5. Debe hacerse notar que los métodos óptimos de detección sondistintos según sean orientados al evento o al dato (López, 1999a), por lo que los índices no sonintercambiables. Así por ejemplo, en la tabla 10 se observa que el método bp1 tiene un índice promedio de52.305 % en su habilidad de encontrar errores, pero ese número no puede ser automáticamente comparadocon el que aparece en la tabla 14 para el mve_dato, de sólo 17.05 %. Incluso las simulaciones se realizaronhasta un nivel de esfuerzo predeterminado, que fue diferente para el caso de los métodos orientados aeventos (en los que el esfuerzo se mide en relación al total N de eventos disponibles) que para el de losorientados a datos (en los que el esfuerzo se mide en relación al total N*p de datos disponibles, siendo p elnúmero de estaciones disponibles). En las simulaciones, se procesó hasta un 10% en el caso de eventos, y2% en el caso de datos.
Por lo expuesto hay que distinguir entre métodos orientados a identificar al evento con error y losque intentan detectar el dato con error. Las tablas 10, 11, 12 y 13 presentan los resultados orientados aeventos, mientras que las tablas 14, 15, 16 y 17 ilustran el caso de métodos orientados a datos. La tabla 10tiene cuatro columnas, la primera identificando al método y las otras tres analizando su desempeño entérminos de tres índices. El primero, mide la distancia relativa al método óptimo considerando la habilidadde encontrar errores, independientemente de su cuantía. El segundo, tiene en cuenta el error absoluto, porlo que un número más alto indica que el método es capaz de encontrar los errores más significativos en lasprimeras etapas de la depuración. El tercer índice es similar al segundo, pero tiene en cuenta el errorcuadrático medio como estimador de error. En cada una de esas columnas hay dos subdivisiones. Laprimera ilustra el valor promedio alcanzado por ese índice a lo largo de la simulación de Monte Carlo.
Así, por ejemplo, si el método denominado bp1 tiene un índice de Encontrados vs. esfuerzo que enmedia vale 52.305%; ello debe interpretarse como que encuentra para un mismo esfuerzo, algo más de lamitad de errores que el método óptimo. Como referencia, debe considerarse un método como el deDuplicate Performance Method (DPM) (descrito por ejemplo en Strayhorn, 1990; López, 1996, etc.) queen el caso especial de errores generados en la etapa de digitación, corrije los mismos con un índice del50% en valor esperado, asumiendo que el orden en que se digitan por segunda vez los registros es al azar.En casos como éstos no debe inferirse que el DPM tiene un desempeño comparable con bp1; el 50% es el
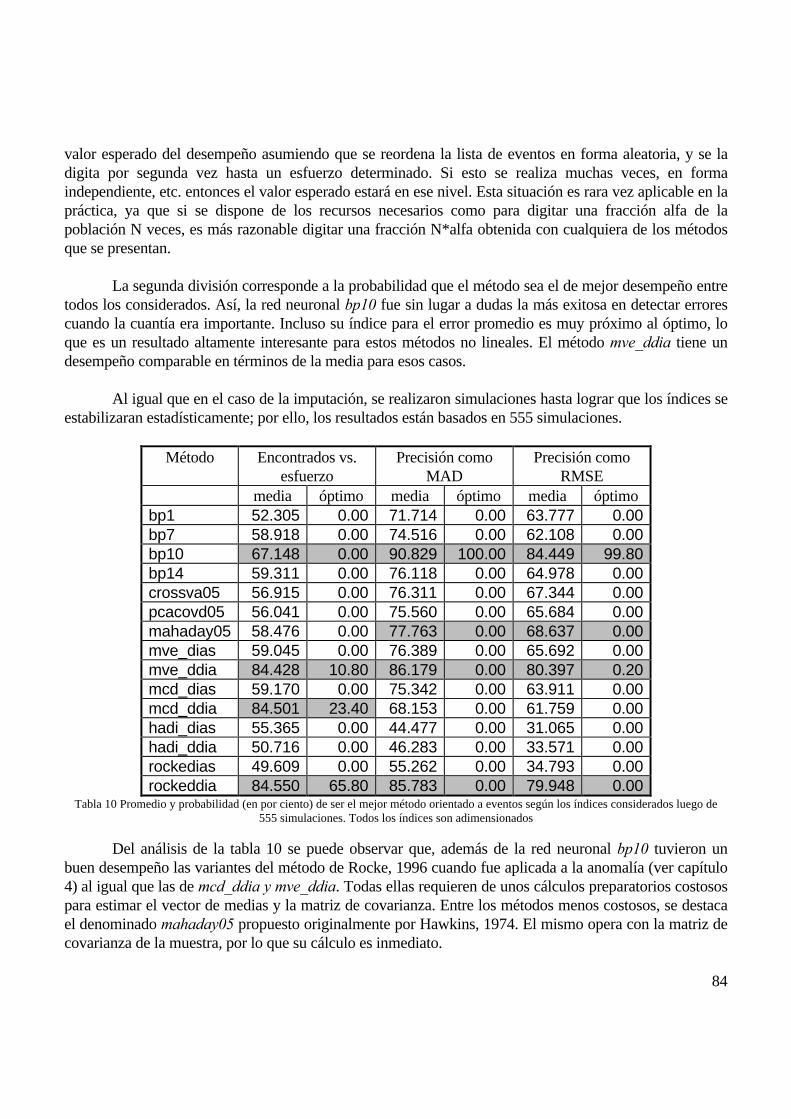
84
valor esperado del desempeño asumiendo que se reordena la lista de eventos en forma aleatoria, y se ladigita por segunda vez hasta un esfuerzo determinado. Si esto se realiza muchas veces, en formaindependiente, etc. entonces el valor esperado estará en ese nivel. Esta situación es rara vez aplicable en lapráctica, ya que si se dispone de los recursos necesarios como para digitar una fracción alfa de lapoblación N veces, es más razonable digitar una fracción N*alfa obtenida con cualquiera de los métodosque se presentan.
La segunda división corresponde a la probabilidad que el método sea el de mejor desempeño entretodos los considerados. Así, la red neuronal bp10 fue sin lugar a dudas la más exitosa en detectar errorescuando la cuantía era importante. Incluso su índice para el error promedio es muy próximo al óptimo, loque es un resultado altamente interesante para estos métodos no lineales. El método mve_ddia tiene undesempeño comparable en términos de la media para esos casos.
Al igual que en el caso de la imputación, se realizaron simulaciones hasta lograr que los índices seestabilizaran estadísticamente; por ello, los resultados están basados en 555 simulaciones.
Método Encontrados vs.esfuerzo
Precisión comoMAD
Precisión comoRMSE
media óptimo media óptimo media óptimobp1 52.305 0.00 71.714 0.00 63.777 0.00bp7 58.918 0.00 74.516 0.00 62.108 0.00bp10 67.148 0.00 90.829 100.00 84.449 99.80bp14 59.311 0.00 76.118 0.00 64.978 0.00crossva05 56.915 0.00 76.311 0.00 67.344 0.00pcacovd05 56.041 0.00 75.560 0.00 65.684 0.00mahaday05 58.476 0.00 77.763 0.00 68.637 0.00mve_dias 59.045 0.00 76.389 0.00 65.692 0.00mve_ddia 84.428 10.80 86.179 0.00 80.397 0.20mcd_dias 59.170 0.00 75.342 0.00 63.911 0.00mcd_ddia 84.501 23.40 68.153 0.00 61.759 0.00hadi_dias 55.365 0.00 44.477 0.00 31.065 0.00hadi_ddia 50.716 0.00 46.283 0.00 33.571 0.00rockedias 49.609 0.00 55.262 0.00 34.793 0.00rockeddia 84.550 65.80 85.783 0.00 79.948 0.00
Tabla 10 Promedio y probabilidad (en por ciento) de ser el mejor método orientado a eventos según los índices considerados luego de555 simulaciones. Todos los índices son adimensionados
Del análisis de la tabla 10 se puede observar que, además de la red neuronal bp10 tuvieron unbuen desempeño las variantes del método de Rocke, 1996 cuando fue aplicada a la anomalía (ver capítulo4) al igual que las de mcd_ddia y mve_ddia. Todas ellas requieren de unos cálculos preparatorios costosospara estimar el vector de medias y la matriz de covarianza. Entre los métodos menos costosos, se destacael denominado mahaday05 propuesto originalmente por Hawkins, 1974. El mismo opera con la matriz decovarianza de la muestra, por lo que su cálculo es inmediato.

85
La comparación entre métodos no sería completa si únicamente considerara los valores promediosde los índices. Es perfectamente posible que ello enmascarara desempeños pobres y brillantes, por lo quese elaboró otro tipo de comparación, método contra método, analizando el número de casos en que unoproducía índices mejores que el otro. Ello está presentado (dependiendo del índice) en las tablas 11 a 13.En todas ellas, se presenta una tabla de doble entrada, que debe procesarse de la siguiente forma. Porejemplo, en la tabla 11 en la línea (D) bp14, columna (B) se está comparando el índice obtenido con elmétodo bp14 vs. el obtenido por el método bp7. En el 79.10% de los casos, el índice del primer métodofue mejor que el del segundo. A diferencia de la tabla 10, no se puede estimar la cuantía de esa diferencia,sino solamente la precedencia. La última fila contiene el promedio por columna, por lo que suinterpretación corresponde a la probabilidad que el método no sea la mejor opción, ya que valores grandesdel mismo indican que es superado por la mayor parte de los otros métodos.
Los resultados son consistentes con los presentados antes, y se ve que el método rocke_ddia no esel mejor solamente en un 2.83% de las simulaciones. Los dos métodos "económicos" (pcacovd05 ymahaday05) tienen un desempeño secundario. En la tabla se indican con fondo gris los cinco mejoresmétodos según este criterio.
A B C D E F G H I J K L M N O
(A) bp1 0.00 0.00 0.00 0.00 0.90 0.00 0.00 0.00 0.00 0.00 2.20 86.10 96.60 0.00
(B) bp7 100.00 0.00 20.90 99.50 99.30 62.30 37.50 0.00 25.00 0.00 99.60 100.00 100.00 0.00
(C) bp10 100.00 100.00 100.00 100.00 100.00 100.00 100.00 0.00 100.00 0.00 100.00 100.00 100.00 0.00
(D) bp14 100.00 79.10 0.00 100.00 99.50 73.90 71.50 0.00 63.10 0.00 99.60 100.00 100.00 0.00
(E) crossva05 100.00 0.50 0.00 0.00 78.90 2.20 0.20 0.00 0.00 0.00 84.10 100.00 100.00 0.00
(F) pcacovd05 99.10 0.70 0.00 0.50 21.10 0.90 0.70 0.00 0.70 0.00 65.60 99.80 100.00 0.00
(G) mahaday05 100.00 37.70 0.00 26.10 97.80 99.10 30.80 0.00 33.20 0.00 96.40 100.00 100.00 0.00
(H) mve_dias 100.00 62.50 0.00 28.50 99.80 99.30 69.20 0.00 36.40 0.00 99.80 100.00 100.00 0.00
(I) mve_ddia 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 27.60 100.00 100.00 100.00 15.70
(J) mcd_dias 100.00 75.00 0.00 36.90 100.00 99.30 66.80 63.60 0.00 0.00 99.80 100.00 100.00 0.00
(K) mcd_ddia 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 72.40 100.00 100.00 100.00 100.00 26.70
(L) hadi_dias 97.80 0.40 0.00 0.40 15.90 34.40 3.60 0.20 0.00 0.20 0.00 99.80 100.00 0.00
(M) hadi_ddia 13.90 0.00 0.00 0.00 0.00 0.20 0.00 0.00 0.00 0.00 0.00 0.20 78.20 0.00
(N) rockedias 3.40 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 21.80 0.00
(O) rockeddia 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 84.30 100.00 73.30 100.00 100.00 100.00
Promedio 0.81 0.44 0.20 0.34 0.62 0.67 0.45 0.40 0.10 0.37 0.07 0.70 0.87 0.92 0.03Tabla 11 Estimación de la probabilidad (en por ciento) de que el índice de Encontrados vs. esfuerzo para el método i exceda al valorobtenido para el método j. Todos los métodos son orientados a eventos. La última fila es la probabilidad de no ser la mejor opción.
Resultados obtenidos luego de 555 simulaciones.
La tabla 12 es formalmente similar a la anterior. Cuando se utiliza un índice que tiene en cuenta eltamaño de los errores encontrados, las figuras cambian en algo. El método que se lleva las palmas es elbp10 tal como fue indicado anteriormente, seguido por los métodos de Rocke y del elipsoide de volumenmínimo. De entre los otros métodos, interesa señalar el de Hawkins y el la verosimilitud (crossva05)debido a su bajo costo de implementación.
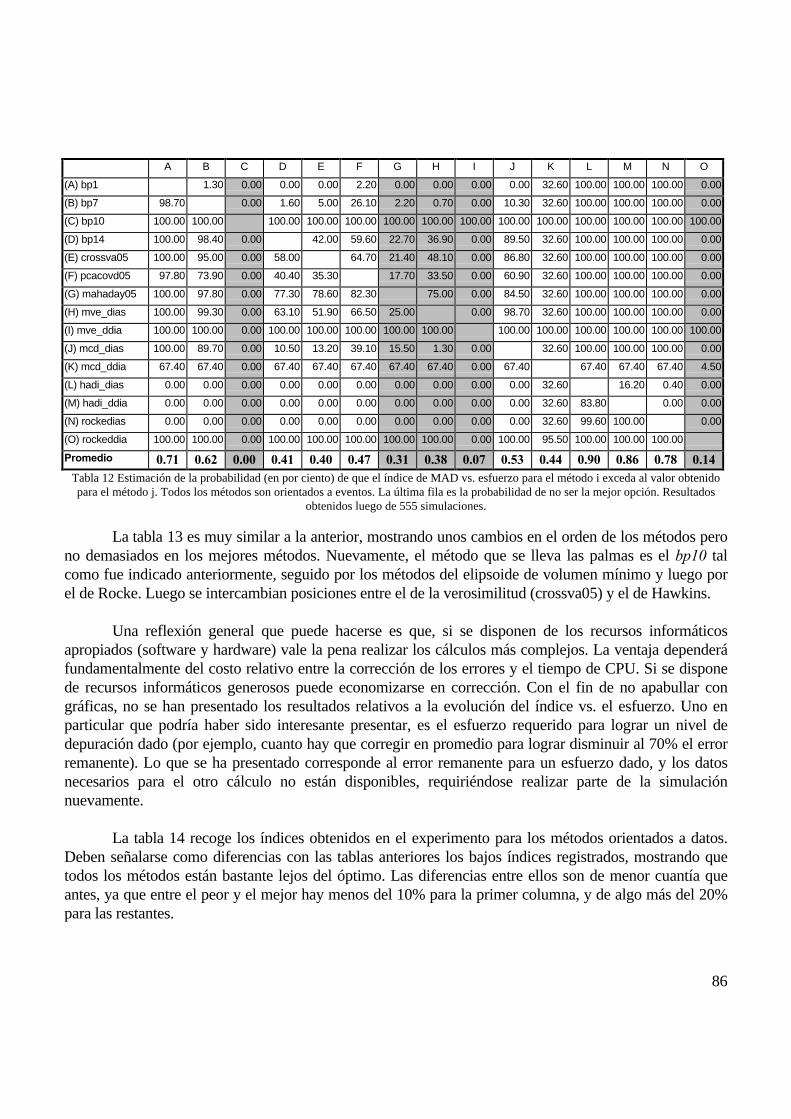
86
A B C D E F G H I J K L M N O
(A) bp1 1.30 0.00 0.00 0.00 2.20 0.00 0.00 0.00 0.00 32.60 100.00 100.00 100.00 0.00
(B) bp7 98.70 0.00 1.60 5.00 26.10 2.20 0.70 0.00 10.30 32.60 100.00 100.00 100.00 0.00
(C) bp10 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00
(D) bp14 100.00 98.40 0.00 42.00 59.60 22.70 36.90 0.00 89.50 32.60 100.00 100.00 100.00 0.00
(E) crossva05 100.00 95.00 0.00 58.00 64.70 21.40 48.10 0.00 86.80 32.60 100.00 100.00 100.00 0.00
(F) pcacovd05 97.80 73.90 0.00 40.40 35.30 17.70 33.50 0.00 60.90 32.60 100.00 100.00 100.00 0.00
(G) mahaday05 100.00 97.80 0.00 77.30 78.60 82.30 75.00 0.00 84.50 32.60 100.00 100.00 100.00 0.00
(H) mve_dias 100.00 99.30 0.00 63.10 51.90 66.50 25.00 0.00 98.70 32.60 100.00 100.00 100.00 0.00
(I) mve_ddia 100.00 100.00 0.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00
(J) mcd_dias 100.00 89.70 0.00 10.50 13.20 39.10 15.50 1.30 0.00 32.60 100.00 100.00 100.00 0.00
(K) mcd_ddia 67.40 67.40 0.00 67.40 67.40 67.40 67.40 67.40 0.00 67.40 67.40 67.40 67.40 4.50
(L) hadi_dias 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 32.60 16.20 0.40 0.00
(M) hadi_ddia 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 32.60 83.80 0.00 0.00
(N) rockedias 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 32.60 99.60 100.00 0.00
(O) rockeddia 100.00 100.00 0.00 100.00 100.00 100.00 100.00 100.00 0.00 100.00 95.50 100.00 100.00 100.00
Promedio 0.71 0.62 0.00 0.41 0.40 0.47 0.31 0.38 0.07 0.53 0.44 0.90 0.86 0.78 0.14Tabla 12 Estimación de la probabilidad (en por ciento) de que el índice de MAD vs. esfuerzo para el método i exceda al valor obtenidopara el método j. Todos los métodos son orientados a eventos. La última fila es la probabilidad de no ser la mejor opción. Resultados
obtenidos luego de 555 simulaciones.
La tabla 13 es muy similar a la anterior, mostrando unos cambios en el orden de los métodos perono demasiados en los mejores métodos. Nuevamente, el método que se lleva las palmas es el bp10 talcomo fue indicado anteriormente, seguido por los métodos del elipsoide de volumen mínimo y luego porel de Rocke. Luego se intercambian posiciones entre el de la verosimilitud (crossva05) y el de Hawkins.
Una reflexión general que puede hacerse es que, si se disponen de los recursos informáticosapropiados (software y hardware) vale la pena realizar los cálculos más complejos. La ventaja dependeráfundamentalmente del costo relativo entre la corrección de los errores y el tiempo de CPU. Si se disponede recursos informáticos generosos puede economizarse en corrección. Con el fin de no apabullar congráficas, no se han presentado los resultados relativos a la evolución del índice vs. el esfuerzo. Uno enparticular que podría haber sido interesante presentar, es el esfuerzo requerido para lograr un nivel dedepuración dado (por ejemplo, cuanto hay que corregir en promedio para lograr disminuir al 70% el errorremanente). Lo que se ha presentado corresponde al error remanente para un esfuerzo dado, y los datosnecesarios para el otro cálculo no están disponibles, requiriéndose realizar parte de la simulaciónnuevamente.
La tabla 14 recoge los índices obtenidos en el experimento para los métodos orientados a datos.Deben señalarse como diferencias con las tablas anteriores los bajos índices registrados, mostrando quetodos los métodos están bastante lejos del óptimo. Las diferencias entre ellos son de menor cuantía queantes, ya que entre el peor y el mejor hay menos del 10% para la primer columna, y de algo más del 20%para las restantes.

87
A B C D E F G H I J K L M N O
(A) bp1 83.10 0.00 23.80 0.90 23.10 14.40 9.00 0.00 46.30 32.60 100.00 100.00 100.00 0.00
(B) bp7 16.90 0.00 1.10 0.20 10.60 1.60 0.00 0.00 4.70 32.60 100.00 100.00 100.00 0.00
(C) bp10 100.00 100.00 100.00 100.00 100.00 100.00 100.00 99.80 100.00 100.00 100.00 100.00 100.00 100.00
(D) bp14 76.20 98.90 0.00 7.00 37.50 22.50 27.00 0.00 87.60 32.60 100.00 100.00 100.00 0.00
(E) crossva05 99.10 99.80 0.00 93.00 71.00 29.20 87.90 0.00 100.00 32.60 100.00 100.00 100.00 0.00
(F) pcacovd05 76.90 89.40 0.00 62.50 29.00 24.30 53.70 0.00 77.30 32.60 100.00 100.00 100.00 0.00
(G) mahaday05 85.60 98.40 0.00 77.50 70.80 75.70 74.60 0.00 81.40 32.60 100.00 100.00 100.00 0.00
(H) mve_dias 91.00 100.00 0.00 73.00 12.10 46.30 25.40 0.00 99.30 32.60 100.00 100.00 100.00 0.00
(I) mve_ddia 100.00 100.00 0.20 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 96.90
(J) mcd_dias 53.70 95.30 0.00 12.40 0.00 22.70 18.60 0.70 0.00 32.60 100.00 100.00 100.00 0.00
(K) mcd_ddia 67.40 67.40 0.00 67.40 67.40 67.40 67.40 67.40 0.00 67.40 68.60 67.70 67.70 2.90
(L) hadi_dias 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 31.40 12.10 4.50 0.00
(M) hadi_ddia 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 32.30 87.90 32.60 0.00
(N) rockedias 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 32.30 95.50 67.40 0.00
(O) rockeddia 100.00 100.00 0.00 100.00 100.00 100.00 100.00 100.00 3.10 100.00 97.10 100.00 100.00 100.00
Promedio 0.58 0.69 0.00 0.47 0.32 0.44 0.34 0.41 0.07 0.58 0.44 0.90 0.83 0.80 0.13Tabla 13 Estimación de la probabilidad (en por ciento) de que el índice de RMSE vs. esfuerzo para el método i exceda al valor obtenidopara el método j. Todos los métodos son orientados a eventos. La última fila es la probabilidad de no ser la mejor opción. Resultadosobtenidos luego de 555 simulaciones.
Método Encontrados vs.esfuerzo
Precisión comoMAD
Precisión comoRMSE
media óptimo media óptimo media óptimomve_dato 17.05 2.30 27.60 0.40 21.76 2.90mcd_dato 15.36 0.00 22.60 0.00 16.54 0.00hadi_dato 12.17 0.00 14.86 0.00 9.11 0.00rockedato 11.29 0.00 12.63 0.00 6.76 0.00hadi_ddat 13.47 0.00 18.70 0.00 12.14 0.00mcd_ddat 19.42 33.90 29.13 2.90 20.11 0.50rockeddat 19.43 62.70 29.16 9.20 20.13 3.80pcacov_05 12.11 0.00 26.62 1.80 19.21 2.50mahalan05 15.02 0.20 33.01 85.80 25.91 90.30
Tabla 14 Promedio y probabilidad (en por ciento) de ser el mejor método orientado a datos según los índices considerados luego de 555simulaciones. Todos los índices son adimensionados
Como se señaló antes, prácticamente ningún método en la literatura conocida por los autores estáorientado a datos; es por ello que se han modificado apropiadamente los disponibles fundamentalmentesiguiendo la técnica sugerida por López, 1994a. Al igual que antes, los métodos más costosos son máseficientes para encontrar errores independientemente de su tamaño. La figura cambia drásticamentecuando se pasa a considerar éste, siendo una interesante sorpresa el buen desempeño del método debido aHawkins, que resulta ser el mejor entre los disponibles. La escena está dominada por cuatro métodos, tresde los cuales son de "alto costo" y uno de "bajo costo", con la particularidad que éste último resulta ser elmejor si el tamaño de los outliers importa.

88
mve_dato mcd_dato hadi_dato rockedato hadi_ddat mcd_ddat rockeddat pcacov_05 mahalan05
mve_dato 99.30 100.00 100.00 99.60 2.30 2.30 100.00 96.40
mcd_dato 0.70 99.80 100.00 95.70 0.00 0.00 99.80 59.80
hadi_dato 0.00 0.20 85.80 8.60 0.00 0.00 49.40 2.30
rockedato 0.00 0.00 14.20 2.00 0.00 0.00 26.30 0.70
hadi_ddat 0.40 4.30 91.40 98.00 0.00 0.00 82.00 12.40
mcd_ddat 97.70 100.00 100.00 100.00 100.00 35.00 100.00 99.80
rockeddat 97.70 100.00 100.00 100.00 100.00 64.00 100.00 99.80
pcacov_05 0.00 0.20 50.60 73.70 18.00 0.00 0.00 2.20
mahalan05 3.60 40.20 97.70 99.30 87.60 0.20 0.20 97.80
Promedio 0.22 0.38 0.73 0.84 0.57 0.07 0.04 0.73 0.41Tabla 15 Estimación de la probabilidad (en por ciento) de que el índice de Encontrados vs. esfuerzo para el método i exceda al valor
obtenido para el método j. Todos los métodos son orientados a datos. La última fila es la probabilidad de no ser la mejor opción.Resultados obtenidos luego de 555 simulaciones.
mve_dato mcd_dato hadi_dato rockedato hadi_ddat mcd_ddat rockeddat pcacov_05 mahalan05
mve_dato 100.00 100.00 100.00 100.00 27.20 27.00 59.60 1.40
mcd_dato 0.00 100.00 100.00 96.40 0.20 0.20 10.10 0.00
hadi_dato 0.00 0.00 96.60 0.20 0.00 0.00 0.00 0.00
rockedato 0.00 0.00 3.40 0.00 0.00 0.00 0.00 0.00
hadi_ddat 0.00 3.60 99.80 100.00 0.00 0.00 1.40 0.00
mcd_ddat 72.80 99.80 100.00 100.00 100.00 22.50 78.20 11.70
rockeddat 73.00 99.80 100.00 100.00 100.00 77.50 78.60 12.40
pcacov_05 40.40 89.90 100.00 100.00 98.60 21.80 21.40 2.70
mahalan05 98.60 100.00 100.00 100.00 100.00 88.30 87.60 97.30
Promedio 0.32 0.55 0.78 0.89 0.66 0.24 0.18 0.36 0.03Tabla 16 Estimación de la probabilidad (en por ciento) de que el índice de MAD vs. esfuerzo para el método i exceda al valor obtenido
para el método j. Todos los métodos son orientados a datos. La última fila es la probabilidad de no ser la mejor opción. Resultadosobtenidos luego de 555 simulaciones.
mve_dato mcd_dato hadi_dato rockedato hadi_ddat mcd_ddat rockeddat pcacov_05 mahalan05
mve_dato 100.00 100.00 100.00 100.00 72.30 71.90 77.10 4.10
mcd_dato 0.00 100.00 100.00 97.30 9.50 9.40 19.60 0.00
hadi_dato 0.00 0.00 94.10 3.10 0.00 0.00 0.40 0.00
rockedato 0.00 0.00 5.90 0.00 0.00 0.00 0.00 0.00
hadi_ddat 0.00 2.70 96.90 100.00 0.40 0.40 2.00 0.00
mcd_ddat 27.70 90.50 100.00 100.00 99.60 15.30 59.10 5.00
rockeddat 28.10 90.60 100.00 100.00 99.60 84.70 59.10 5.00
pcacov_05 22.90 80.40 99.60 100.00 98.00 40.90 40.90 2.70
mahalan05 95.90 100.00 100.00 100.00 100.00 95.00 95.00 97.30
Promedio 0.19 0.52 0.78 0.88 0.66 0.34 0.26 0.35 0.02Tabla 17 Estimación de la probabilidad (en por ciento) de que el índice de RMSE vs. esfuerzo para el método i exceda al valor obtenido
para el método j. Todos los métodos son orientados a datos. La última fila es la probabilidad de no ser la mejor opción. Resultadosobtenidos luego de 555 simulaciones.

89
6.2 Viento de superficie horario
Esta variable meteorológica fue seleccionada por varios motivos. Desde el punto de vista delproyecto, aportaba el ejemplo de un caso con correlación espacial y temporal importante, a diferencia de lalluvia diaria que tenía correlación temporal débil. Por otra parte, era un ejemplo sobre el que se habíanrealizado trabajos previamente, y sobre el que se estimaba iba a ser necesario proseguir. Además, era uncaso en el que estaba disponible un modelo numérico capaz de interpolar en el espacio las lecturas de lasestaciones disponibles, aspecto atractivo ya que permitiría comparar el desempeño de un métodoespecializado en la variable, que incorporaba una conceptualización física del fenómeno, con métodos queno la asumían. El modelo disponible (descrito en López, 1993b) es un modelo de tipo lineal: lainterpolación resultante luego de complejos cálculos resulta ser una combinación lineal de los datos deentrada, por lo que se entendió superfluo aplicarlo al estar acotada la bondad del ajuste de unacombinación lineal de los datos de partida, por lo que se argumentó en 6.1.
El viento de superficie es observado por dos instrumentos: uno indica el módulo de la velocidaddel viento (típicamente, en km/hr) y el otro indica la dirección en relación a los puntos cardinales. Estaúltima observación es típicamente discretizada en rumbos por lo que la base de datos recoge una versióncategorizada de una variable continua. Este hecho, unido la dificultad de comparar distancias en variablesde tipo circular (una estimación de 359 grados difiere mucho a primera vista de la lectura correcta de 0grados) obliga a tratar en forma diferente, y con diferentes métricas, el caso del viento. Por otra parte, elfenómeno puede ser observado como se ha descrito, pero manipulado de otra forma. Desde un punto devista metodológico, originalmente se concibió el tratamiento del problema en forma similar a López,1993b, quien transformó la combinación (módulo, rumbo) en componentes meridional y zonal (Este =>Oeste, y Sur => Norte). En ese caso, la tabla de valores resultante resulta ser homogénea (todas lascolumnas tienen las mismas unidades de medida) y desaparece el problema de la variable circular.
Sin perjuicio de ello, se desarrollaron / implementaron algunos métodos que tratan en formaespecífica el caso de variables circulares. Sobre ellos (y sobre aquellos que podían ser aplicados a esteproblema a pesar del carácter especial del fenómeno) se realizaron algunas simulaciones preliminares, quese presentarán más adelante. La mayor parte de las simulaciones fueron realizadas sobre la base de datosde componentes, por ser ese caso el más general e interesante.
6.2.1 Generación de ausenciasSe realizó un estudio preliminar que confirmó que las ausencias se daban simultáneamente en
módulo y dirección, a pesar que el instrumento es diferente. Las ausencias en forma de racha estabanlocalizadas al final de la base, por lo que pudieron ser ignoradas como una característica del conjunto. Enel caso de las componentes, se asumió que las ausencias se daban en forma independiente porcomponente. Ello no es cierto, ya que si alguno de los instrumentos no registraba lectura, en rigor seignoran las dos componentes.
Para el caso mencionado se utilizó también un criterio tipo MCAR.

90
6.2.2 Imputación de valores ausentes: caso de las componentes
En la tabla 18 se consideran los resultados tras 400 simulaciones para los método que utilizanúnicamente información del mismo instante. La tabla 19 describe el desempeño de métodos que usan otrainformación adicional. Ambas tablas deben procesarse en forma conjunta. Los resultados muestran unresultado casi automáticamente superior para aquellos métodos que explotan la información del instanteanterior. Así, las dos variantes denominadas gandin4 y gandin6 están entre las cinco mejores utilizandocualquier criterio. Por otra parte, la mera interpolación de la serie temporal (de componentes!) tiene undesempeño muy bueno en términos del promedio y percentil 75% del error absoluto, y bueno en los otroscasos. Esto confirma en parte lo sostenido por López et al., 1998b que concluyen que en Uruguay, elviento de superficie se observa con demasiada frecuencia, siendo admisible observaciones más separadas.
Los métodos no lineales también tienen un desempeño bueno; en particular, el denominado bp1está entre los mejores. Al valorar el desempeño de estos métodos, debe tenerse en cuenta que dadas lascaracterísticas del proyecto, no se extremaron esfuerzos en lograr los ajustes óptimos para cada método.En particular, para todas las redes neuronales se utilizó la misma arquitectura (a saber, número de capasocultas, tipo y número de neuronas, etc.) ajustando únicamente el número de datos de entrada. Ello puederesultar en una red subóptima, con propiedades pobres de generalización o con un ajuste pobre, por lo quelos resultados para estos métodos deben declararse como conservadores,y un estudio detallado yespecífico puede ciertamente mejorar los estadísticos presentados.
Al igual que en el caso de la lluvia diaria, puede compararse a modo de ejemplo el desempeño delmétodo que asigna el valor modal contra los óptimos hallados. Igual que antes, se confirma que la mejorano es sustantiva. Respectivamente, 2.235 vs. 3.465 para el promedio; 2.824 vs. 5.025 , 4.138 vs. 7.242 y7.7342 vs. 12.94 para los percentiles 75, 85 y 90%, y finalmente 3.464 vs. 5.268 m/s para el caso del errormedio cuadrático. La mejora se ubica entre un mínimo de 34% hasta un máximo de 56%, dependiendo delestadístico. Al igual que en el caso de la lluvia diaria, hay que tener en consideración la variabilidadinherente al fenómeno, y los errores del instrumento. Según López, 1993b, los mismos se pueden estimaren el orden de los 2 m/s en media cuadrática.
6.2.3 Imputación de valores ausentes: comparación datos originales vs. componentes
Los resultados que se obtuvieron corresponden a simulaciones en las que se generaron 973 huecos(3% del total de registros), y se calculó la diferencia resultante entre el dato real y el valor generado porcada uno de los métodos. Dichos huecos "fictos" son seleccionados con el auxilio de una distribuciónuniforme, y la comparación se hizo sólo para algunos de los métodos implementados, fundamentalmentepara confrontar en cierta forma los resultados que surgen de procesar los registros originales encomparación a los que surgen de aplicarlos sobre las bases proyectadas en las direcciones E-W y S-N.
Para cada hueco "ficto" se procedió de dos maneras: una, manteniendo las bases inalteradas(rumbos y módulos), y otra, proyectando los datos en base a sus coordenadas cartesianas ( θcos.v y
θsinv. ), para luego recuperar el módulo v y el rumbo θ. Para cada uno de dichos procedimientos, a su

91
vez, se extrajeron dos resultados: el correspondiente al uso directo de los métodos de rellenoimplementados (determinístico), y el otro correspondiente a la introducción de información delcomportamiento del viento en la hora anterior (probabilístico).
AlgoritmoPromedio 75 por
ciento85 porciento
95 porciento
RMSE
m/s m/s m/s m/s m/sbp1 2.258 2.930 4.162 7.342 3.487bp14 2.370 3.041 4.391 8.041 3.673gandin 2.536 3.292 4.678 8.303 3.770gandin20 2.529 3.281 4.671 8.293 3.764gandin5 2.534 3.279 4.739 8.558 3.863julmean 3.546 4.927 6.650 10.550 4.907lms 3.774 5.104 7.270 12.287 5.489lts 3.656 5.019 7.119 12.328 5.409lss 2.584 3.359 4.876 8.753 3.929mahalan_nocor 3.027 3.814 5.426 9.696 5.525mahalan_nocov 3.082 3.803 5.610 10.576 5.599mincdr 2.521 3.273 4.749 8.536 3.851minprc 2.530 3.267 4.725 8.514 4.156minprm 2.466 3.146 4.651 8.770 3.900minprmfl 3.306 4.553 6.735 11.985 5.106naive 2.685 3.274 5.118 10.785 4.525ponmean 2.287 2.848 4.343 8.192 3.643staverage 3.243 4.418 5.742 10.225 4.529valor modal 3.465 5.025 7.242 12.194 5.268vecidist 4.364 6.338 9.170 14.391 6.488
Tabla 18 Resultados para los diferentes métodos de imputación. Se presenta el valor esperado, los percentiles 75, 85 y 95, y la raíz delerror cuadrático medio para la distribución del valor absoluto de la diferencia entre el dato imputado y el disponible. En conjunto con latabla 19 se indican en negrita los cinco mejores resultados obtenidos
AlgoritmoPromedio 75 por
ciento85 porciento
95 porciento
RMSE
m/s m/s m/s m/s m/sbp12 2.262 2.904 4.156 7.513 3.486gandin4 2.235 2.824 4.138 7.701 3.488gandin6 2.248 2.849 4.145 7.628 3.464time_interp 2.268 2.824 4.362 8.324 3.680itcp_nocor 2.496 3.101 4.624 8.761 3.885itcp_nocov 2.647 3.412 4.937 8.855 4.005
Tabla 19 Resultados para los diferentes métodos de imputación, que utilizan valores del día, del día anterior o de ambos. Se presenta elvalor esperado, los percentiles 75,85 y 95, y la raíz del error cuadrático medio para la distribución del valor absoluto de la diferencia entreel dato imputado y el disponible. En conjunto con la tabla 18 se indican en negrita los cinco mejores resultados obtenidos

92
Se calculó como medida de ajuste la media, mediana, rango intercuartílico y desvío absolutomedio de las diferencias correspondientes a esos 973 huecos "fictos". El experimento es repetido luegovarias veces promediándose los resultados obtenidos como forma de tener una mejor aproximación de lasestimaciones.
Como se puede apreciar en las tablas que aparecen abajo, trabajando con las bases originales(módulos y rumbos, resultados directos de las mediciones realizadas), el primer método implementado(rellwind), que utiliza la moda como estimador para rumbos, estaría revelándose como el menos eficientede todos los procedimientos comparados. Se realizaron entonces los histogramas circularescorrespondientes, observándose que, si se excluyen las calmas, los rumbos no tienen un comportamientoclaramente unimodal, observación que estaría justificando en cierta forma el mal comportamiento delmétodo.
Otro resultado destacable es que la información temporal anterior y posterior del viento esrelevante: quizás por el tipo de aparato que mide el rumbo, ya que la veleta indicadora no vuelve a cerocada vez, sino que gira desde la posición ocupada en la medida anterior. De ahí los indicios de que elprocedimiento ponmean (que es combinación lineal de datos temporalmente adyacentes al hueco) sea elque se revele como más conveniente.
Se destaca también como resultado que condicionar la imputación del dato faltante a la situacióninmediatamente anterior no mejora el resultado (es más, a veces puede llegar a empeorarlo), lo que,aunado a la característica no-determinística del procedimiento de imputación, hace que este tipo demetodología no resulte recomendable en la práctica.
6.2.3.1 Resultados operando sobre los datos originales
Media( X&&& ) Desvío( X&&& ) C.V.( X&&& ) Mediana Intercuart. Desv.Abs.
rellwind 80.0834 2.3950 0.0299 79.7900 3.4650 1.9626rellwink 12.0322 0.5072 0.0422 12.0700 0.4700 0.3658windjuli 11.0087 0.2799 0.0254 10.9900 0.3550 0.2192rellwing 8.3572 0.6834 0.0818 8.2300 0.5950 0.4059ponmean 7.7272 0.2483 0.0321 7.7200 0.3100 0.1897dispara 12.5453 0.4270 0.0340 12.5150 0.6100 0.3385
daymean 12.5453 0.4270 0.0340 12.5150 0.6100 0.3385Tabla 20 Resultados de la imputación de rumbos, utilizando métodos determinísticos, y operando sobre los datos originales

93
Media( X&&& ) Desvío( X&&& ) C.V.( X&&& ) Mediana Intercuart. Desv.Abs.
rellwind 7.8706 0.1651 0.0210 7.8700 0.2350 0.1332
rellwink 6.4475 0.3993 0.0619 6.4700 0.4900 0.3002
windjuli 11.0850 0.3370 0.0304 11.0700 0.4550 0.2525
rellwing 8.2453 0.7226 0.0876 8.2800 0.4650 0.3877
ponmean 5.4369 0.2043 0.0376 5.4350 0.2850 0.1638
dispara 7.5863 0.2593 0.0342 7.6150 0.3350 0.1996
daymean 11.5078 0.4217 0.0366 11.5200 0.5250 0.3334
Tabla 21 Resultados de la imputación de módulos, utilizando métodos determinísticos, y operando sobre los datos originales
Media( X&&& ) Desvío( X&&& ) C.V.( X&&& ) Mediana Intercuart. Desv.Abs.
rellwind 80.4750 2.4633 0.0306 79.9150 3.5150 2.0398
rellwink 10.4313 0.4116 0.0395 10.3650 0.5850 0.3233
windjuli 11.0375 0.3514 0.0318 11.0250 0.4600 0.2816
rellwing 10.1353 0.4586 0.0452 10.0750 0.5950 0.3454
ponmean 8.3372 0.2109 0.0253 8.3150 0.3550 0.1750
dispara 12.0912 0.4154 0.0344 12.1150 0.5550 0.3387
daymean 12.0912 0.4154 0.0344 12.1150 0.5550 0.3387
Tabla 22 Resultados de la imputación de rumbos, utilizando métodos con la variante probabilística, y operando sobre los datos originales
Media( X&&& ) Desvío( X&&& ) C.V.( X&&& ) Mediana Intercuart. Desv.Abs.
rellwind 8.3103 0.1767 0.0213 8.3100 0.2650 0.1478
rellwink 5.7466 0.3755 0.0654 5.7000 0.5000 0.2811
windjuli 8.8700 0.2802 0.0316 8.9400 0.4550 0.2369
rellwing 7.4166 0.5447 0.0734 7.5000 0.5450 0.3526
ponmean 5.6319 0.1859 0.0330 5.6150 0.2000 0.1440
dispara 7.2500 0.2685 0.0370 7.2650 0.3600 0.2012
daymean 10.1937 0.3362 0.0330 10.2300 0.4450 0.2685
Tabla 23 Resultados de la imputación de módulos, utilizando métodos con la variante probabilística, y operando sobre los datosoriginales
6.2.3.2 Resultados operando sobre los datos transformados
Las bases de datos (rumbos y módulos), son utilizadas para calcular las componentes vectoriales.Se aplican los mismos métodos de imputación considerados en el análisis anterior, se calculan los mismosestadísticos, y luego se realiza la transformación inversa, recuperándose los valores medios y medianas demódulos y rumbos, de forma de poder establecer comparaciones con los resultados obtenidos en la parteanterior.
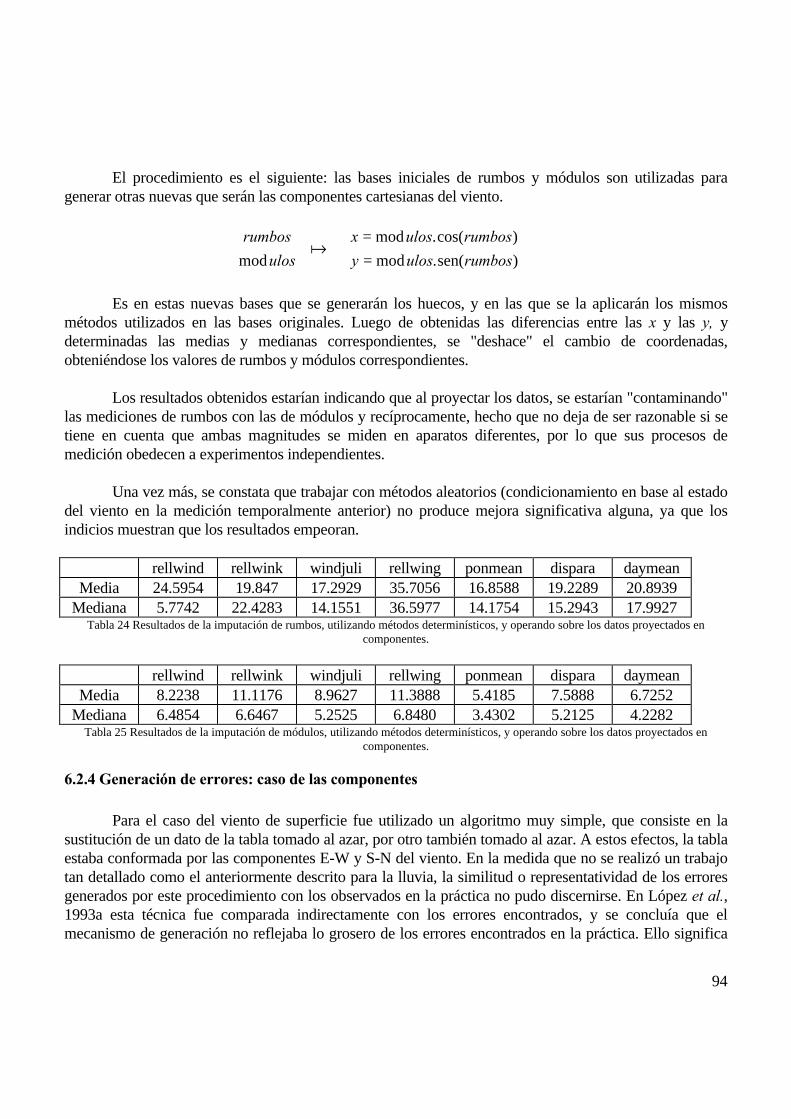
94
El procedimiento es el siguiente: las bases iniciales de rumbos y módulos son utilizadas paragenerar otras nuevas que serán las componentes cartesianas del viento.
==
)sen(.mod
)cos(.mod
mod rumbosulosy
rumbosulosx
ulos
rumbosa
Es en estas nuevas bases que se generarán los huecos, y en las que se la aplicarán los mismosmétodos utilizados en las bases originales. Luego de obtenidas las diferencias entre las x y las y, ydeterminadas las medias y medianas correspondientes, se "deshace" el cambio de coordenadas,obteniéndose los valores de rumbos y módulos correspondientes.
Los resultados obtenidos estarían indicando que al proyectar los datos, se estarían "contaminando"las mediciones de rumbos con las de módulos y recíprocamente, hecho que no deja de ser razonable si setiene en cuenta que ambas magnitudes se miden en aparatos diferentes, por lo que sus procesos demedición obedecen a experimentos independientes.
Una vez más, se constata que trabajar con métodos aleatorios (condicionamiento en base al estadodel viento en la medición temporalmente anterior) no produce mejora significativa alguna, ya que losindicios muestran que los resultados empeoran.
rellwind rellwink windjuli rellwing ponmean dispara daymeanMedia 24.5954 19.847 17.2929 35.7056 16.8588 19.2289 20.8939
Mediana 5.7742 22.4283 14.1551 36.5977 14.1754 15.2943 17.9927Tabla 24 Resultados de la imputación de rumbos, utilizando métodos determinísticos, y operando sobre los datos proyectados en
componentes.
rellwind rellwink windjuli rellwing ponmean dispara daymeanMedia 8.2238 11.1176 8.9627 11.3888 5.4185 7.5888 6.7252
Mediana 6.4854 6.6467 5.2525 6.8480 3.4302 5.2125 4.2282Tabla 25 Resultados de la imputación de módulos, utilizando métodos determinísticos, y operando sobre los datos proyectados en
componentes.
6.2.4 Generación de errores: caso de las componentes
Para el caso del viento de superficie fue utilizado un algoritmo muy simple, que consiste en lasustitución de un dato de la tabla tomado al azar, por otro también tomado al azar. A estos efectos, la tablaestaba conformada por las componentes E-W y S-N del viento. En la medida que no se realizó un trabajotan detallado como el anteriormente descrito para la lluvia, la similitud o representatividad de los erroresgenerados por este procedimiento con los observados en la práctica no pudo discernirse. En López et al.,1993a esta técnica fue comparada indirectamente con los errores encontrados, y se concluía que elmecanismo de generación no reflejaba lo grosero de los errores encontrados en la práctica. Ello significa
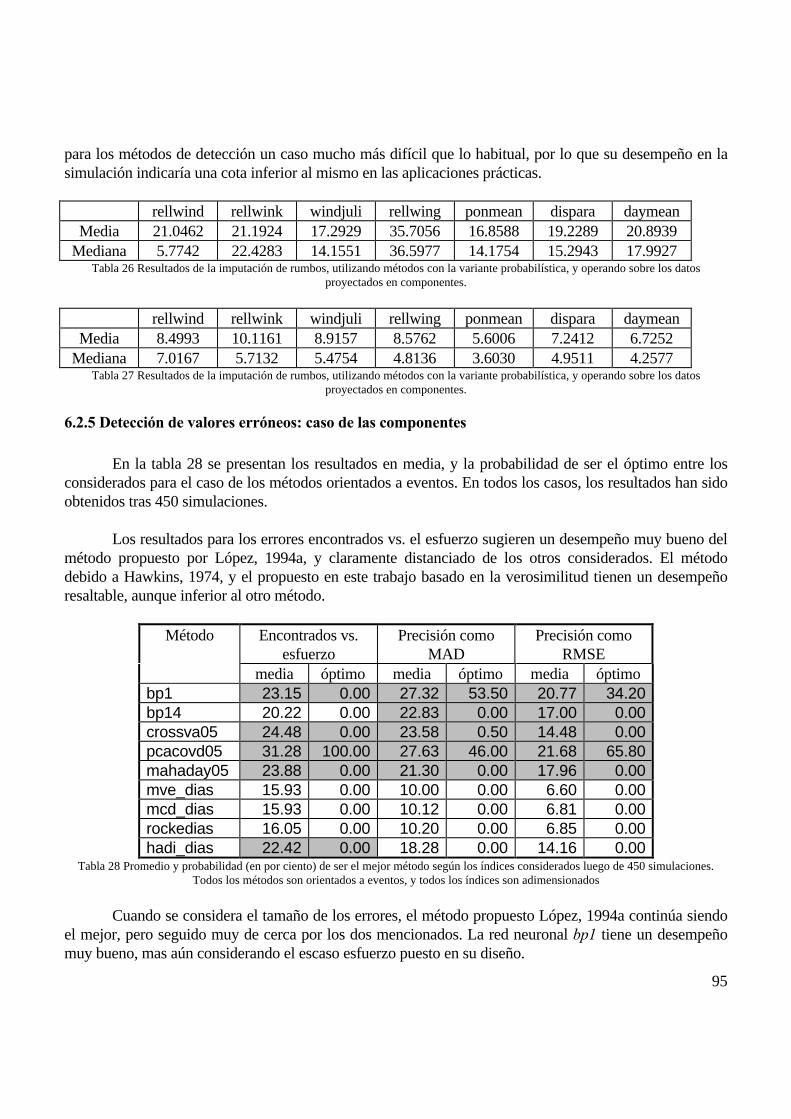
95
para los métodos de detección un caso mucho más difícil que lo habitual, por lo que su desempeño en lasimulación indicaría una cota inferior al mismo en las aplicaciones prácticas.
rellwind rellwink windjuli rellwing ponmean dispara daymeanMedia 21.0462 21.1924 17.2929 35.7056 16.8588 19.2289 20.8939
Mediana 5.7742 22.4283 14.1551 36.5977 14.1754 15.2943 17.9927Tabla 26 Resultados de la imputación de rumbos, utilizando métodos con la variante probabilística, y operando sobre los datos
proyectados en componentes.
rellwind rellwink windjuli rellwing ponmean dispara daymeanMedia 8.4993 10.1161 8.9157 8.5762 5.6006 7.2412 6.7252
Mediana 7.0167 5.7132 5.4754 4.8136 3.6030 4.9511 4.2577Tabla 27 Resultados de la imputación de rumbos, utilizando métodos con la variante probabilística, y operando sobre los datos
proyectados en componentes.
6.2.5 Detección de valores erróneos: caso de las componentes
En la tabla 28 se presentan los resultados en media, y la probabilidad de ser el óptimo entre losconsiderados para el caso de los métodos orientados a eventos. En todos los casos, los resultados han sidoobtenidos tras 450 simulaciones.
Los resultados para los errores encontrados vs. el esfuerzo sugieren un desempeño muy bueno delmétodo propuesto por López, 1994a, y claramente distanciado de los otros considerados. El métododebido a Hawkins, 1974, y el propuesto en este trabajo basado en la verosimilitud tienen un desempeñoresaltable, aunque inferior al otro método.
Método Encontrados vs.esfuerzo
Precisión comoMAD
Precisión comoRMSE
media óptimo media óptimo media óptimobp1 23.15 0.00 27.32 53.50 20.77 34.20bp14 20.22 0.00 22.83 0.00 17.00 0.00crossva05 24.48 0.00 23.58 0.50 14.48 0.00pcacovd05 31.28 100.00 27.63 46.00 21.68 65.80mahaday05 23.88 0.00 21.30 0.00 17.96 0.00mve_dias 15.93 0.00 10.00 0.00 6.60 0.00mcd_dias 15.93 0.00 10.12 0.00 6.81 0.00rockedias 16.05 0.00 10.20 0.00 6.85 0.00hadi_dias 22.42 0.00 18.28 0.00 14.16 0.00
Tabla 28 Promedio y probabilidad (en por ciento) de ser el mejor método según los índices considerados luego de 450 simulaciones.Todos los métodos son orientados a eventos, y todos los índices son adimensionados
Cuando se considera el tamaño de los errores, el método propuesto López, 1994a continúa siendoel mejor, pero seguido muy de cerca por los dos mencionados. La red neuronal bp1 tiene un desempeñomuy bueno, mas aún considerando el escaso esfuerzo puesto en su diseño.
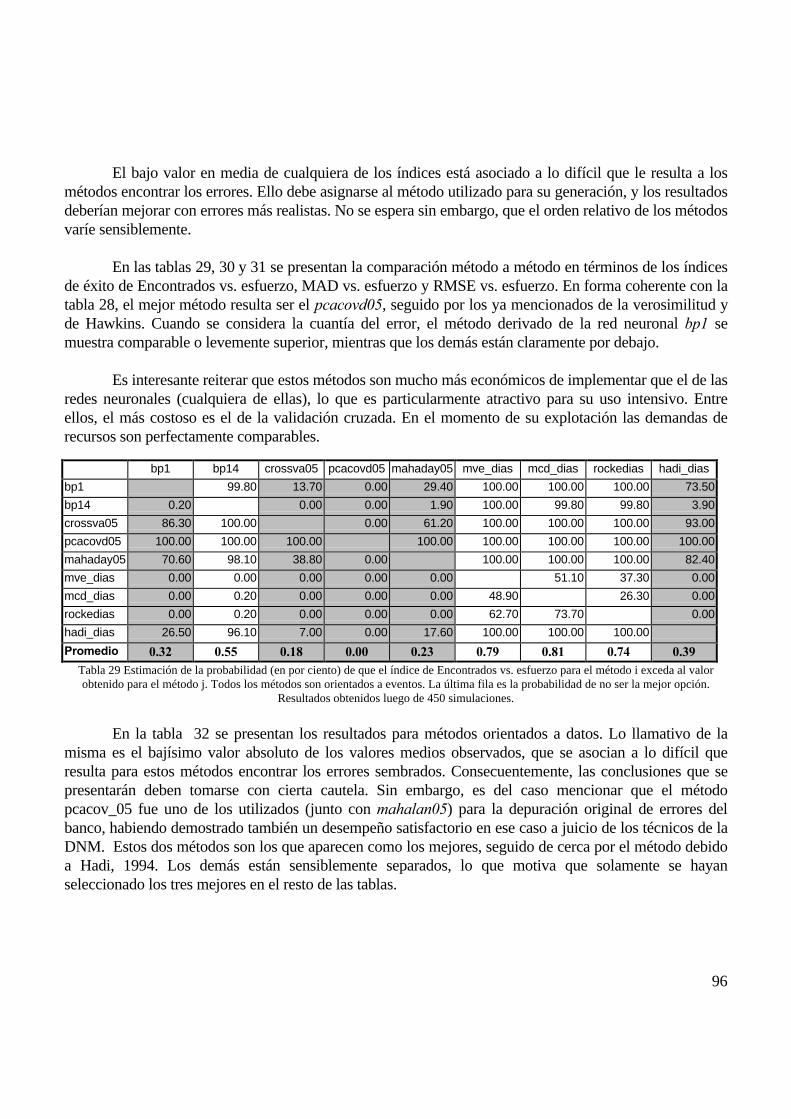
96
El bajo valor en media de cualquiera de los índices está asociado a lo difícil que le resulta a losmétodos encontrar los errores. Ello debe asignarse al método utilizado para su generación, y los resultadosdeberían mejorar con errores más realistas. No se espera sin embargo, que el orden relativo de los métodosvaríe sensiblemente.
En las tablas 29, 30 y 31 se presentan la comparación método a método en términos de los índicesde éxito de Encontrados vs. esfuerzo, MAD vs. esfuerzo y RMSE vs. esfuerzo. En forma coherente con latabla 28, el mejor método resulta ser el pcacovd05, seguido por los ya mencionados de la verosimilitud yde Hawkins. Cuando se considera la cuantía del error, el método derivado de la red neuronal bp1 semuestra comparable o levemente superior, mientras que los demás están claramente por debajo.
Es interesante reiterar que estos métodos son mucho más económicos de implementar que el de lasredes neuronales (cualquiera de ellas), lo que es particularmente atractivo para su uso intensivo. Entreellos, el más costoso es el de la validación cruzada. En el momento de su explotación las demandas derecursos son perfectamente comparables.
bp1 bp14 crossva05 pcacovd05 mahaday05 mve_dias mcd_dias rockedias hadi_dias
bp1 99.80 13.70 0.00 29.40 100.00 100.00 100.00 73.50
bp14 0.20 0.00 0.00 1.90 100.00 99.80 99.80 3.90
crossva05 86.30 100.00 0.00 61.20 100.00 100.00 100.00 93.00
pcacovd05 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00
mahaday05 70.60 98.10 38.80 0.00 100.00 100.00 100.00 82.40
mve_dias 0.00 0.00 0.00 0.00 0.00 51.10 37.30 0.00
mcd_dias 0.00 0.20 0.00 0.00 0.00 48.90 26.30 0.00
rockedias 0.00 0.20 0.00 0.00 0.00 62.70 73.70 0.00
hadi_dias 26.50 96.10 7.00 0.00 17.60 100.00 100.00 100.00
Promedio 0.32 0.55 0.18 0.00 0.23 0.79 0.81 0.74 0.39Tabla 29 Estimación de la probabilidad (en por ciento) de que el índice de Encontrados vs. esfuerzo para el método i exceda al valorobtenido para el método j. Todos los métodos son orientados a eventos. La última fila es la probabilidad de no ser la mejor opción.
Resultados obtenidos luego de 450 simulaciones.
En la tabla 32 se presentan los resultados para métodos orientados a datos. Lo llamativo de lamisma es el bajísimo valor absoluto de los valores medios observados, que se asocian a lo difícil queresulta para estos métodos encontrar los errores sembrados. Consecuentemente, las conclusiones que sepresentarán deben tomarse con cierta cautela. Sin embargo, es del caso mencionar que el métodopcacov_05 fue uno de los utilizados (junto con mahalan05) para la depuración original de errores delbanco, habiendo demostrado también un desempeño satisfactorio en ese caso a juicio de los técnicos de laDNM. Estos dos métodos son los que aparecen como los mejores, seguido de cerca por el método debidoa Hadi, 1994. Los demás están sensiblemente separados, lo que motiva que solamente se hayanseleccionado los tres mejores en el resto de las tablas.

97
bp1 bp14 crossva05 pcacovd05 mahaday05 mve_dias mcd_dias rockedias hadi_dias
bp1 100.00 98.10 53.70 94.20 100.00 100.00 100.00 100.00
bp14 0.00 32.50 0.00 82.90 100.00 100.00 100.00 100.00
crossva05 1.90 67.50 1.20 88.40 100.00 100.00 100.00 100.00
pcacovd05 46.30 100.00 98.80 100.00 100.00 100.00 100.00 100.00
mahaday05 5.80 17.10 11.60 0.00 100.00 100.00 100.00 91.10
mve_dias 0.00 0.00 0.00 0.00 0.00 38.30 27.70 0.00
mcd_dias 0.00 0.00 0.00 0.00 0.00 61.70 33.00 0.00
rockedias 0.00 0.00 0.00 0.00 0.00 72.30 67.00 0.00
hadi_dias 0.00 0.00 0.00 0.00 8.90 100.00 100.00 100.00
Promedio 0.06 0.32 0.27 0.06 0.42 0.82 0.78 0.73 0.55Tabla 30 Estimación de la probabilidad (en por ciento) de que el índice de MAD vs. esfuerzo para el método i exceda al valor obtenidopara el método j. Todos los métodos son orientados a eventos. La última fila es la probabilidad de no ser la mejor opción. Resultados
obtenidos luego de 450 simulaciones.
bp1 bp14 crossva05 pcacovd05 mahaday05 mve_dias mcd_dias rockedias hadi_dias
bp1 99.30 100.00 34.20 91.30 100.00 100.00 100.00 100.00
bp14 0.70 94.90 0.00 33.50 100.00 100.00 100.00 97.10
crossva05 0.00 5.10 0.00 7.00 100.00 100.00 100.00 59.50
pcacovd05 65.80 100.00 100.00 99.80 100.00 100.00 100.00 100.00
mahaday05 8.70 66.50 93.00 0.20 100.00 100.00 100.00 96.90
mve_dias 0.00 0.00 0.00 0.00 0.00 28.70 21.40 0.00
mcd_dias 0.00 0.00 0.00 0.00 0.00 71.30 39.50 0.00
rockedias 0.00 0.00 0.00 0.00 0.00 78.60 60.50 0.00
hadi_dias 0.00 2.90 40.50 0.00 3.10 100.00 100.00 100.00
Promedio 0.08 0.30 0.48 0.04 0.26 0.83 0.77 0.73 0.50Tabla 31 Estimación de la probabilidad (en por ciento) de que el índice de RMSE vs. esfuerzo para el método i exceda al valor obtenidopara el método j. Todos los métodos son orientados a eventos. La última fila es la probabilidad de no ser la mejor opción. Resultadosobtenidos luego de 450 simulaciones.
Método Encontrados vs.esfuerzo
Precisión comoMAD
Precisión comoRMSE
media óptimo media óptimo media óptimopcacov_05 4.92 100.00 9.35 99.50 6.45 85.30hadi_dato 3.65 0.00 6.83 0.20 4.99 1.70mahalan05 3.26 0.00 7.02 0.20 5.58 13.00mve_dato 0.74 0.00 1.17 0.00 0.84 0.00mcd_dato 0.73 0.00 1.37 0.00 1.09 0.00rockedato 0.72 0.00 1.30 0.00 1.02 0.00
Tabla 32 Promedio y probabilidad (en por ciento) de ser el mejor método según los índices considerados luego de 450 simulaciones.Todos los métodos son orientados a datos, y todos los índices son adimensionados
Las tablas 33, 34 y 35 recogen los resultados obtenidos en la comparación mutua entre losmétodos, resultando en todos los casos una definida ventaja para los tres métodos ya citados.

98
pcacov_05 hadi_dato mahalan05 mve_dato mcd_dato rockedato
pcacov_05 100.00 100.00 100.00 100.00 100.00
hadi_dato 0.00 84.80 100.00 100.00 100.00
mahalan05 0.00 15.20 100.00 100.00 100.00
mve_dato 0.00 0.00 0.00 54.00 57.30
mcd_dato 0.00 0.00 0.00 46.00 54.20
rockedato 0.00 0.00 0.00 42.70 45.80
Promedio 0.00 0.23 0.37 0.78 0.80 0.82Tabla 33 Estimación de la probabilidad (en por ciento) de que el índice de Encontrados vs. esfuerzo para el método i exceda al valor
obtenido para el método j. Todos los métodos son orientados a datos. La última fila es la probabilidad de no ser la mejor opción.Resultados obtenidos luego de 450 simulaciones.
pcacov_05 hadi_dato mahalan05 mve_dato mcd_dato rockedato
pcacov_05 99.80 99.80 100.00 100.00 100.00
hadi_dato 0.20 34.90 100.00 100.00 100.00
mahalan05 0.20 65.10 100.00 100.00 100.00
mve_dato 0.00 0.00 0.00 18.10 23.10
mcd_dato 0.00 0.00 0.00 81.90 69.20
rockedato 0.00 0.00 0.00 76.90 30.80
Promedio 0.00 0.33 0.27 0.92 0.70 0.78Tabla 34 Estimación de la probabilidad (en por ciento) de que el índice de MAD vs. esfuerzo para el método i exceda al valor obtenido
para el método j. Todos los métodos son orientados a datos. La última fila es la probabilidad de no ser la mejor opción. Resultadosobtenidos luego de 450 simulaciones.
pcacov_05 hadi_dato mahalan05 mve_dato mcd_dato rockedato
pcacov_05 97.30 86.30 100.00 100.00 100.00
hadi_dato 2.70 19.80 100.00 100.00 100.00
mahalan05 13.70 80.20 100.00 100.00 100.00
mve_dato 0.00 0.00 0.00 10.40 14.50
mcd_dato 0.00 0.00 0.00 89.60 73.00
rockedato 0.00 0.00 0.00 85.50 27.00
Promedio 0.03 0.36 0.21 0.95 0.67 0.78Tabla 35 Estimación de la probabilidad (en por ciento) de que el índice de RMSE vs. esfuerzo para el método i exceda al valor obtenido
para el método j. Todos los métodos son orientados a datos. La última fila es la probabilidad de no ser la mejor opción. Resultadosobtenidos luego de 450 simulaciones.

99
6.3 Niveles diarios
El trabajo de investigación se realizó sobre la serie de los últimos cinco años disponibles(1984-1989), teniendo en cuenta que desde el punto de vista metodológico y de resultados no se lograríamayor aporte con la utilización de la serie completa. A su vez, algunas limitaciones del softwaredisponible para algunos métodos motivaron que fuera más eficiente trabajar con 2052 observaciones quecon las correspondientes al período completo (5295 datos diarios).
Del análisis de las series diarias de Paso Pereira, Aguiar y Mazangano para el período referido, seconstató que la que tenía menos datos faltantes era Pereira, por lo que se la adoptó para el análisisrealizado. Sin embargo, cabe señalar que para la presentación gráfica se eliminaron dos valores extremos(5.800 en Aguiar el 19/09/86 y 4.174 en Mazangano el 17/12/86) que el simple análisis gráfico permitiódetectar.
La primera etapa del trabajo requería un control de calidad mínimo de la serie, a los efectos de laubicación de los datos faltantes y la detección de valores anómalos, por lo menos los más evidentes.
Para ello se utilizó básicamente instrumental gráfico, analizando la serie de los datos originales,así como la primera diferencia de los datos de nivel y el logaritmo del cociente entre datos consecutivos(variable proxy del cambio porcentual).
El objetivo de la imputación en esta etapa fue simplemente eliminar el problema del dato faltantepara el ajuste del modelo. A tales efectos, en una primera instancia, se estimaron modelos de regresiónlineal explicando el comportamiento del nivel de un "paso" del río, por el de cada uno de los otros dosdisponibles, probando el rezago que arrojara mayor grado de ajuste, y siempre teniendo en cuenta suubicación geográfica (río arriba o a la inversa). Para el caso de Paso Pereira, la regresión que aportó unmayor R2 es la que utiliza como variable explicativa el nivel de Paso Aguiar en t-1 (0.8368).
No obstante ello, debido a las características de la serie, o más precisamente, de la distribución delos datos faltantes, resultaba irrelevante en esta etapa el método que se empleara para realizar laimputación preliminar de los datos. Debido a ello se realizó una interpolación lineal entre el valorprecedente y siguiente al día o los días con vacíos de información.
Para el período analizado se encontraron seis faltantes: una ausencia aisladas y cinco díasconsecutivos, cuyas fechas se detallan en el cuadro siguiente.
Para la detección de valores anómalos se recurrió a la visualización gráfica de la serie original y sutransformación estacionaria, particionando a estos efectos la serie en períodos semestrales. Se utilizó enprimer lugar como criterio de depuración, la "razonabilidad" del dato bajo la hipótesis que el error sepodía originar en la transmisión telefónica o en la lectura del dato manuscrito. En segundo lugar, seanalizaron individualmente los incrementos diarios de nivel que superaran los tres desvíos estándar.
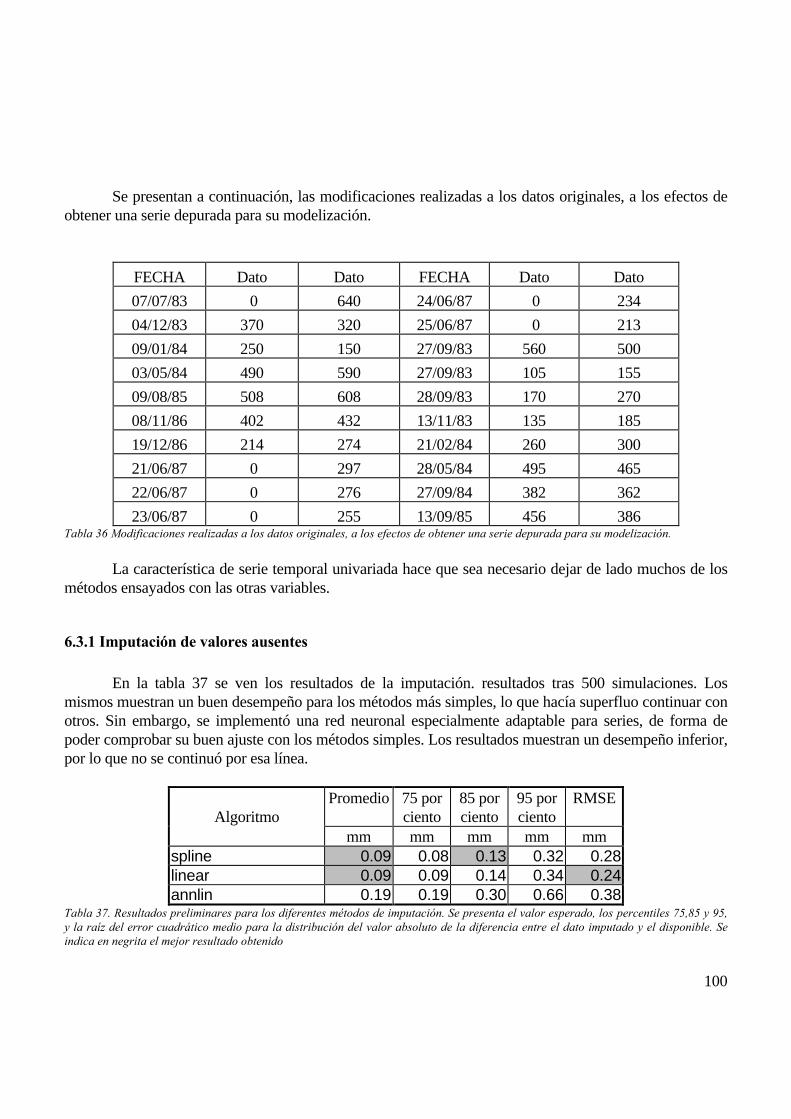
100
Se presentan a continuación, las modificaciones realizadas a los datos originales, a los efectos deobtener una serie depurada para su modelización.
FECHA Dato Dato FECHA Dato Dato
07/07/83 0 640 24/06/87 0 234
04/12/83 370 320 25/06/87 0 213
09/01/84 250 150 27/09/83 560 500
03/05/84 490 590 27/09/83 105 155
09/08/85 508 608 28/09/83 170 270
08/11/86 402 432 13/11/83 135 185
19/12/86 214 274 21/02/84 260 300
21/06/87 0 297 28/05/84 495 465
22/06/87 0 276 27/09/84 382 362
23/06/87 0 255 13/09/85 456 386Tabla 36 Modificaciones realizadas a los datos originales, a los efectos de obtener una serie depurada para su modelización.
La característica de serie temporal univariada hace que sea necesario dejar de lado muchos de losmétodos ensayados con las otras variables.
6.3.1 Imputación de valores ausentes
En la tabla 37 se ven los resultados de la imputación. resultados tras 500 simulaciones. Losmismos muestran un buen desempeño para los métodos más simples, lo que hacía superfluo continuar conotros. Sin embargo, se implementó una red neuronal especialmente adaptable para series, de forma depoder comprobar su buen ajuste con los métodos simples. Los resultados muestran un desempeño inferior,por lo que no se continuó por esa línea.
AlgoritmoPromedio 75 por
ciento85 porciento
95 porciento
RMSE
mm mm mm mm mmspline 0.09 0.08 0.13 0.32 0.28linear 0.09 0.09 0.14 0.34 0.24annlin 0.19 0.19 0.30 0.66 0.38
Tabla 37. Resultados preliminares para los diferentes métodos de imputación. Se presenta el valor esperado, los percentiles 75,85 y 95,y la raíz del error cuadrático medio para la distribución del valor absoluto de la diferencia entre el dato imputado y el disponible. Seindica en negrita el mejor resultado obtenido

101
6.3.2 Generación de errores aleatorios
Al igual que para el caso de la lluvia y el viento, es necesario disponer de un algoritmo degeneración al azar de errores para la serie de niveles. La literatura en este tópico vuelve a ser escasa, y elúnico caso encontrado corresponde al trabajo de Krajewski et al., 1989. Los autores sugieren utilizar unmuestreo aleatorio de una distribución lognormal, cuya media esté dentro del rango de la muestra, pero suvarianza sea un múltiplo de la estimada para la muestra. Ellos establecen que esas reglas para lageneración de errores no han sido contrastadas con casos reales, una situación que se repite en esteproyecto, dado las dificultades para el acceso a la información original en papel.
Con respecto a las fechas (localización) de los errores, asumen que una distribución uniforme essuficientemente apropiada para los fines del proyecto, y por ende será también aplicada en esteexperimento.
La alternativa de utilizar una varianza múltiplo de la de la muestra, y una media apropiada ha sidocomparada en la literatura contra el caso de la misma varianza, pero con una media claramente sesgada.Rocke, 1996 demostró que el caso más dificultoso para detectar errores correspondía a aquel en que laforma (descrita a través de la matriz de covarianza) de la nube de puntos de la muestra y de los errores erala misma, pero que discrepaban en la media. Para relativizar el efecto de los outliers en los parámetros dela distribución misma, se utilizó una transformación logarítmica donde la nueva serie se obtiene como:
( )X x= +ln .100 (32)
Como estimador de la varianza de la población transformada se usó la mitad de la distanciaintercuartil 2.5 y 97.5%, y como estimador de la media la mediana. Para el caso de la serie de la estación182800, los percentiles 2.5, 50 y 97.5 de la variable transformada resultan ser 0.14, 1.178 y 2.089. Unavez analizados los histogramas de la variable transformada, se pudo comprobar que la distribución de lapoblación se parecía mucho más a una uniforme que a una normal, resultado diferente al presentado porKrajewski. Por ello se optó por construir la serie sintética de errores, utilizando como mediana el percentil75% y manteniendo la distancia intercuartil.

102
0 0.5 1 1.5 2 2.50
50
100
150
200
250
Histograma de la serie transformada
Figura 15 Histograma de la serie de niveles luego de la transformación logarítmica
0 0.5 1 1.5 2 2.50
0.2
0.4
0.6
0.8
1
1.2
observado
sim
ula
do
A juste con distribucion log-uniform e
Figura 16 Qqplot de los niveles simulados vs. observados.

103
0 1 2 3 4 5 6 7 8 9 100
5
10
15
observado
sim
ula
do
Nivel observado vs. simulado (distribucion log-uniforme c/sesgo)
Figura 17 Qqplot de los niveles observados vs. simulados utilizando un sesgo
6.3.3 Detección de valores erróneos
En la Tabla 38 se presentan los resultados obtenidos para 300 simulaciones. Se concluye que... Enlas Tablas 39, 40 y 41 se presentan las probabilidades de que el método i produzca un índice más grandeque el método j. Se puede ver que incluso métodos simples dan resultados muy buenos, en la medida queel índice promedio se aproxima al óptimo. Esto podría deberse a una inapropiada (por exagerada)simulación de los errores, aspecto que no se confirma dado que el método que analiza los valoresextremos tuvo un desempeño pobre.
Método Encontrados vs.esfuerzo
Precisión comoMAD
Precisión comoRMSE
media óptimo media óptimo media óptimomaxpend 73.9041 2.3 87.7447 14.3 73.0984 19.0maxprdpnd 68.1132 15.0 67.7440 0.0 48.4112 0.0maxvalue 32.0329 0.0 49.5533 0.0 39.9345 0.0maxcurv 82.5630 82.7 90.4167 85.7 74.7846 81.0
Tabla 38 Promedio y probabilidad (en por ciento) de ser el mejor método según los índices considerados luego de 300 simulaciones.Todos los índices son adimensionados
En el caso de esta serie temporal, simulando errores aislados, parece claro que la metodología másefectiva es la que utiliza la curvatura como señal, resultado que es coherente con los propuestos porKrajeski et al., 1989.

104
maxpend maxprdpnd maxvalue maxcurvmaxpend 71.3 100.0 2.7
maxprdpnd 28.7 97.3 15.0
maxvalue 0.0 2.7 0.0
maxcurv 97.3 85.0 100.0
Promedio 0.42 0.53 0.99 0.06
Tabla 39 Estimación de la probabilidad (en por ciento) de que el índice de Encontrados vs. esfuerzo para el método i exceda al valorobtenido para el método j. La última fila es la probabilidad de no ser la mejor opción. Resultados obtenidos luego de 300 simulaciones.
maxpend maxprdpnd maxvalue maxcurvmaxpend 100.0 100.0 14.3
maxprdpnd 0.0 98.3 0.0
maxvalue 0.0 1.7 0.0
maxcurv 85.7 100.0 100.0
Promedio 0.29 0.67 0.99 0.05
Tabla 40 Estimación de la probabilidad (en por ciento) de que el índice de MAD vs. esfuerzo para el método i exceda al valor obtenidopara el método j. La última fila es la probabilidad de no ser la mejor opción. Resultados obtenidos luego de 300 simulaciones.
maxpend maxprdpnd maxvalue maxcurvmaxpend 100.0 100.0 19.0
maxprdpnd 0.0 86.0 0.3
maxvalue 0.0 14.0 0.3
maxcurv 81.0 99.7 99.7
Promedio 0.27 0.71 0.95 0.07
Tabla 41 Estimación de la probabilidad (en por ciento) de que el índice de RMSE vs. esfuerzo para el método i exceda al valor obtenidopara el método j. La última fila es la probabilidad de no ser la mejor opción. Resultados obtenidos luego de 300 simulaciones.
6.4 Evapotranspiración
En la propuesta del proyecto se especificó que se aplicarían los métodos a otros casos de interés,que en alguna forma ejemplificaran la generalidad del desempeño de los métodos considerados. Dado queno se conocen otros ejemplos similares al viento (con variables circulares) se requería otro parámetro quereuniera de alguna manera la generalidad. Se seleccionó la evapotranspiración como variable testigo, y sele aplicó la mayoría de los métodos desarrollados, confirmando globalmente las conclusiones previas.
6.4.1 Imputación de valores ausentes
En la tabla 42 y en la tabla 43 se presentan los resultados obtenidos tras 500 simulaciones.Nuevamente, las redes neuronales muestran un muy buen desempeño, considerando además que no fueronrediseñadas para la nueva variable. Ni siquiera utilizando información del día anterior se logra mejorar los

105
estimadores, aspecto que debe balancearse al considerar lo económico que resulta aplicar los métodosgandin4 y gandin6, que no requieren entrenamiento alguno.
AlgoritmoPromedio 75 por
ciento85 porciento
95 porciento
RMSE
mm/día mm/día mm/día mm/día mm/díabp1 1.063 1.422 1.888 3.050 1.517bp10 1.100 1.477 1.992 3.210 1.561bp14 1.015 1.356 1.821 2.921 1.448bp2 1.189 1.590 2.158 3.547 1.691bp7 1.107 1.445 1.971 3.330 1.610cressman 1.064 1.415 1.938 3.160 1.527cressman2 1.072 1.423 1.950 3.261 1.548daymean 1.149 1.542 2.085 3.360 1.616dispara 3.136 4.585 5.778 7.856 3.986gandin 1.088 1.464 1.980 3.180 1.540gandin_diario 1.447 1.864 2.583 4.417 2.243gandin20 1.087 1.463 1.977 3.172 1.538gandin3a 1.114 1.496 2.017 3.239 1.571gandin5 1.111 1.483 2.014 3.321 1.607gandin7 1.089 1.466 1.978 3.222 1.552gandintrans 1.101 1.471 1.991 3.260 1.569hotdeck 1.685 2.250 3.119 5.133 2.397itcp_nocor 1.517 2.056 2.782 4.404 2.096itcp_nocov 1.434 1.929 2.627 4.202 1.995julmean 1.693 2.339 3.099 4.782 2.290lss 1.004 1.353 1.831 2.916 1.442mahalan_nocor 7.049 3.038 4.662 12.728 42.683mahalan_nocov 2.247 1.997 3.012 6.819 6.855mahalanyescor 1.123 1.522 2.036 3.239 1.571mahalanyescov 1.094 1.473 2.004 3.219 1.559mincdr 1.075 1.439 1.939 3.216 1.562minprc 1.013 1.369 1.849 2.933 1.454minprm 1.004 1.353 1.841 2.948 1.451minprmfl 1.004 1.350 1.838 2.960 1.454naive 1.744 2.390 3.202 5.064 2.396staverage 2.318 3.199 3.801 5.181 2.822valor modal 4.356 6.246 7.523 9.583 5.202
Tabla 42 Resultados preliminares para los diferentes métodos de imputación. Se presenta el valor esperado, los percentiles 75, 85 y 95,y la raíz del error cuadrático medio para la distribución del valor absoluto de la diferencia entre el dato imputado y el disponible. Seindican en negrita los cinco mejores resultados obtenidos

106
Como era razonable esperar, entre los métodos lineales aquellos que están diseñados para seróptimos según el estimador apropiado tienen un buen desempeño, pero en este caso lo destacable es queese buen desempeño se da para todos los estimadores. Ello parece indicar que la población de datosoriginales (que no fue depurada para este trabajo) contenía pocos errores serios.
Los métodos más triviales tienen, igual que antes, un desempeño más pobre. Así, el valor modal,el promedio de la estación, etc. dan estimadores de error que incluso superan al doble del óptimoreportado. Como excepción interesante, se puede señalar el caso de daymean cuyo error medio cuadráticoes sólo marginalmente peor que el óptimo observado. Ello puede ser una característica del fenómeno, quetiene una fuerte autocorrelación en el espacio dentro del rango de separación de las estacionesconsideradas.
AlgoritmoPromedio 75 por
ciento85 porciento
95 porciento
RMSE
mm/día mm/día mm/día mm/día mm/díagandin4 1.054 1.423 1.930 3.091 1.497gandin6 1.057 1.432 1.930 3.074 1.493
Tabla 43 Resultados preliminares para los diferentes métodos de imputación. Se presenta el valor esperado, los percentiles 75, 85 y 95,y la raíz del error cuadrático medio para la distribución del valor absoluto de la diferencia entre el dato imputado y el disponible. Seindican en negrita los cinco mejores resultados obtenidos
6.4.2 Generación de errores aleatorios
Por las mismas razones planteadas en el caso del viento de superficie, se optó por utilizar unalgoritmo simple de mezcla de datos en la tabla, tomando uniformemente al azar la fecha y estacióndestino, y asignándole un dato preexistente en la tabla también con fecha y estación elegidauniformemente al azar.
6.4.3 Detección de valores erróneos
En las tablas 44, 45, 46 y 47 se presentan los métodos orientados a eventos. Se puede confirmar lalínea general de buen desempeño que han tenido los métodos no lineales, resultando en este caso las redesbp1 y bp10 las de mejor desempeño. Nótese que ambas redes son matemáticamente equivalentes, y sudesempeño diferenciado es solamente una muestra de la dificultad de los algoritmos de entrenamiento enlograr un óptimo global. Por otra parte, considerando el escaso esfuerzo puesto en adaptar la arquitecturade las redes a cada variable, esta generalidad en los resultados es altamente remarcable. También lo es elhecho que el método propuesto por López, 1994a se mantenga cerca de estos índices, considerando subajo costo de aplicación. Las tablas sucesivas muestran el detalle, y confirman que algunos métodos sonmejores para detectar errores cuando importa su cuantía, mientras que para otros ello no es un problema.

107
Los valores razonables de los índices (en el entorno del 50% cuando la cuantía no importa, ysuperiores al 80% en los otros casos) dan una señal sobre la representatividad de los resultados paraerrores no simulados. Nótese que, al igual que en el viento de superficie, la mera mezcla es un criteriobastante conservador para generar outliers, y algunos métodos que se basan en estadísticos de la poblaciónentera directamente serían incapaces de detectar ese tipo de errores.
Método Encontrados vs.esfuerzo
Precisión comoMAD
Precisión comoRMSE
media óptimo media óptimo media óptimocrossva05 37.580 0.0 57.448 0.0 43.792 0.0pcacovd05 44.821 0.0 76.274 1.8 66.591 2.8mahaday05 17.091 0.0 30.710 0.0 27.771 0.0pcacord05 50.219 35.8 48.277 0.0 42.958 0.0bp1 36.658 0.0 63.138 0.0 54.844 0.0bp7 30.959 0.0 55.264 0.0 49.349 0.0bp10 51.843 64.2 88.611 98.2 81.049 97.2bp14 19.543 0.0 33.848 0.0 28.678 0.0
Tabla 44 Promedio y probabilidad (en por ciento) de ser el mejor método según los índices considerados luego de 500 simulaciones.Todos los índices son adimensionados. Con el sombreado se indican los mejores desempeños.
crossva05 pcacovd05 mahaday05 pcacord05 bp1 bp7 bp10 bp14crossva05 4.5 97.5 1.8 58.0 98.2 0.0 100.0pcacovd05 95.5 100.0 1.0 99.8 100.0 0.2 100.0mahaday05 2.5 0.0 0.0 3.0 5.8 0.0 10.5pcacord05 98.2 99.0 100.0 99.8 100.0 35.8 100.0bp1 42.0 0.2 97.0 0.2 97.0 0.0 100.0bp7 1.8 0.0 94.2 0.0 3.0 0.0 100.0bp10 100.0 99.8 100.0 64.2 100.0 100.0 100.0bp14 0.0 0.0 89.5 0.0 0.0 0.0 0.0Promedio 0.43 0.25 0.85 0.08 0.45 0.63 0.05 0.76
Tabla 45 Estimación de la probabilidad (en por ciento) de que el índice de Encontrados vs. esfuerzo para el método i exceda al valorobtenido para el método j. La última fila es la probabilidad de no ser la mejor opción. Con el sombreado se indican los mejores
desempeños. Resultados obtenidos luego de 500 simulaciones.
crossva05 pcacovd05 mahaday05 pcacord05 bp1 bp7 bp10 bp14crossva05 0.5 94.5 91.2 17.2 62.7 0.0 100.0pcacovd05 99.5 100.0 100.0 99.8 100.0 1.8 100.0mahaday05 5.5 0.0 6.2 4.5 6.0 0.0 17.2pcacord05 8.8 0.0 93.8 0.2 12.2 0.0 99.2bp1 82.8 0.2 95.5 99.8 93.0 0.0 100.0bp7 37.2 0.0 94.0 87.8 7.0 0.0 100.0bp10 100.0 98.2 100.0 100.0 100.0 100.0 100.0bp14 0.0 0.0 82.8 0.8 0.0 0.0 0.0Promedio 0.42 0.12 0.83 0.61 0.29 0.47 0.00 0.77
Tabla 46 Estimación de la probabilidad (en por ciento) de que el índice de MAD vs. esfuerzo para el método i exceda al valor obtenidopara el método j. La última fila es la probabilidad de no ser la mejor opción. Con el sombreado se indican los mejores desempeños.
Resultados obtenidos luego de 500 simulaciones.
En este caso, los resultados están basados en 500 simulaciones.

108
crossva05 pcacovd05 mahaday05 pcacord05 bp1 bp7 bp10 bp14crossva05 0.0 93.8 55.2 4.5 18.5 0.0 97.8
pcacovd05 100.0 98.2 100.0 98.8 99.0 2.8 100.0
mahaday05 6.2 1.8 7.8 5.5 6.2 0.0 32.0
pcacord05 44.8 0.0 92.2 0.8 16.8 0.0 98.0
bp1 95.5 1.2 94.5 99.2 81.8 0.0 100.0
bp7 81.5 1.0 93.8 83.2 18.2 0.0 100.0
bp10 100.0 97.2 100.0 100.0 100.0 100.0 100.0
bp14 2.2 0.0 68.0 2.0 0.0 0.0 0.0
Promedio 0.54 0.13 0.80 0.56 0.28 0.40 0.00 0.78
Tabla 47 Estimación de la probabilidad (en por ciento) de que el índice de RMSE vs. esfuerzo para el método i exceda al valor obtenidopara el método j. La última fila es la probabilidad de no ser la mejor opción. Con el sombreado se indican los mejores desempeños.
Resultados obtenidos luego de 500 simulaciones.
6.5 TRATAMIENTO DE DATOS DE NIVEL MEDIANTE MODELOS DE SERIESTEMPORALES
6.5.1-Transformación estacionaria
La serie presenta un comportamiento claramente no estacionario, tal como se puede observar en lagráfica 1 del Anexo, tanto en media como en varianza.
Se probaron dos transformaciones para lograr estacionariedad: a) la diferencia de orden 1 de laserie original (gráficas 4 y 5 del Anexo) y b) el logaritmo del cociente entre datos consecutivos.
Luego de realizar para ambas transformaciones, las medias por meses y años y calcular elestadístico t correspondiente para probar la media cero, se seleccionó la diferencia de orden uno de laserie, con la que se logra la estacionariedad en media pero no en varianza. Si bien aparecen síntomas deposible no linealidad luego de la transformación realizada, las etapas siguientes del trabajo se realizaronbajo ese supuesto. Se postergó para una segunda instancia el estudio estadístico de la linealidad.
6.5.2- Modelo ARIMA estimado
La primera etapa en el ajuste de un modelo ARIMA a una serie temporal es la identificación delmismo. Las principales herramientas para ello son la estimación de la función de autocorrelación y deautocorrelación parcial, cuyos gráfico se presentan en el Anexo.
El análisis de los mismos permite inferir dos posibles especificaciones, a saber:
1- Un modelo autorregresivo de orden 1 AR(1)2- Un modelo autorregresivo de orden 3 AR(3)

109
cuya estimación se presenta en el Anexo.
La simple observación gráfica de la primera diferencia de la serie, muestra un problema deheteroscedasticidad condicional (la varianza no es constante a través del tiempo)1 La particulardistribución de los residuos permite probar la especificación de una estructura condicionalheteroscedástica [ARCH(p)].
El tratamiento de este tipo de heteroscedasticidad, en que los residuos grandes y pequeños de unmodelo aparecen agrupados a intervalos, ha sido objeto de diversos trabajos de investigación en losúltimos años, a partir del artículo pionero de Engle (1982).
La consideración de la heteroscedasticidad afectará la estimación de los parámetrosautorregresivos, por lo que es necesario realizar un proceso iterativo de máxima verosimilitud para estimartanto los parámetros del modelo AR, como los del modelo ARCH.
El presente Informe de avance incluye la estimación del modelo AR(1) con estructura ARCH. Enla etapa siguiente (en curso) se realizará la estimación del modelo AR(3) con estructura ARCH, por ser elque en una primera instancia capta mejor la estructura de la serie, lo que surge del análisis de losautocorrelogramas de los residuos (ver Anexo).
6.5.3- Modelo ARCH estimado
En primer lugar se procedió a especificar el orden de autocorrelación condicional, de los residuosal cuadrado del modelo. Para ambas especificaciones [AR(1) y AR(3)] resultó una heteroscedasticidadcondicional de orden 2. Para realizarla se sobreparametrizó el modelo (orden 4) resultando en amboscasos no significativos los parámetros de orden 3 y 4. Los parámetros estimados se comportan de maneraadecuada, es decir, son positivos.
En el Anexo se presenta la secuencia de la estimación por máxima verosimilitud de los parámetrosAR(1) y ARCH(2).
11Es posible que la misma sea consecuencia de la eventual no linealidad de la serie.

110
7- REFERENCIAS.
Abbot, P. F., 1986. "Guidelines on the Quality Control of Surface Climatological Data" WorldMeteorological Organization WCP-85, WMO/TD-No. 111. 65 pp
Barnett, V.; Lewis, T., 1984. "Outliers in statistical data" John Wiley and Sons, 463 pp.Cisa, A.; Guarga, R.; Briozzo, C.; López, C.; Alonso, J; Cataldo, J.; Canetti, R.; Acosta, A.; Penza,
E.; Xavier, V.;Tozzo, A.; Estrada, J.; Bevc, A.; Maggiolo, G.; Chaer, R.; Rosenblatt, R.;Lamas, R.; Martínez, F. y Cabrera, R., 1990. "Proyecto de Evaluación del Potencial EólicoNacional: Informe Final" Facultad de Ingeniería, Instituto de Mecánica de los Fluídos e Ingeniería Ambiental e Instituto de Ingeniería Eléctrica, Montevideo, Uruguay. 1000 pp.
Damsleth, E., 1980. "Interpolating missing values in a Time Series". Scand. J. Statist. 7, pp 33-39DiMego, 1988. "The National Meteorological Center Regional Analysis System". Mon. Wea. Rev. V 116,
pp 977-1000DNM, 1988. "Procedimientos para el control de calidad climatológico" Informe interno de la Dirección
Nacional de Meteorología, Nov. 1988, 20 págs.Fernau, M.E.; Samson, P.J., 1990. "Use of Cluster analysis to define periods of similar meteorology and
precipitation chemistry in eastern North America. Part I: Transport Patterns" Journal of AppliedMeteorology, V 29, N 8, 735-750.
Francis, P.E., 1986. "The use of numerical wind and wave models to provide areal and temporalextension to instrument calibration and validation of remotely sensed data" In Proceedings of Aworkshop on ERS-1 wind and wave calibration, Schliersee, FRG, 2-6 June, 1986 (ESA SP-262,Sept. 1986)
Gandin, L. M., 1965. "Objective analysis of Meteorological Fields". Israel Program for ScientificTranslations, 242 pp.
González, R. C., y Woods, R. E., 1992. "Digital Image Processing" Addison-Wesley, pp 307-407Gandin, L. M., 1988. ""Complex Quality Control of Meteorological Observations". Mon. Wea. Rev., V
116, pp 1137-1156Gnanadesikan, R.; Kettenring, J.R., 1972. "Robust estimates, residuals and outlier detection with
multiresponse data" Biometrics, V 28, 81-124.Goyeneche,J.J., Lorenzo,F. (1989). Tratamiento de la información de base para el cálculo de índices de
precios de Comercio Exterior. SUMA, 4 (7):119-126, CINVE.Haagenson, P.L, 1982. "Review and evaluation of methods for objective analysis of meteorological
variables" Papers in Meteorological Research, V 5, N 2, 113-133.Hawkins, D.M., 1974. "The detection of errors in multivariate data, using Principal Components"
Journal of the American Statistical Association, V 69, 346, 340-344.Hollingsworth, A.; Shaw, D.B.; Lonnberg, P.; Illari, L.; Arpe, K. and Simmons, A.J., 1986. "Monitoring
of observation and analysis quality by a data assimilation system" Monthly Weather Review, V114, N 5, 861-879.
Husain, T., 1989. "Hydrologic uncertainty measure and network design" Water Resources Bulletin, V25, N 3, 527-534.

111
Jácome Sarmento, F.; Sávio, E.; Martins, P.R., 1990. "Cálculo dos coeficientes de Thiessen emmicrocomputador". En Memorias del XIV Congreso Latinoamericano de Hidráulica,Montevideo, Uruguay (6-10 Nov., 1990). V 2, 715-724.
Johnson, G.T. 1982. "Climatological Interpolation Functions for Mesoscale Wind Fields". Journal ofApplied Meteorology, V 21, N 8, 1130-1136.
Kennedy, S. 1989 "The Small Number problem and the accuracy of spatial databases" En "The accuracyof spatial databases". Editado por Goodchild, M. and Gopal, S. Publicado por Taylor & FrancisLtd. Cap. 16, pp. 187-196.
Krajewski, W. F. and Krajewski, K. L. 1989 "Real-time quality control of streamflow data - A simulationstudy" Water Resources Bulletin, V 25, N 2, 391-399.
Loh, W. L., 1991. "Estimating covariance matrices". The Annals of Statistics, V 19, N 1, pp. 283-296López, C.; González, E.; Goyret, J., 1994a. "Análisis por componentes principales de datos
pluviométricos. a) Aplicación a la detección de datos anómalos" Estadística (Journal of theInter-American Statistical Institute) 1994, 46, 146,-147, pp. 25-54.
López, C.; González, J. F.; Curbelo, R., 1994b. "Análisis por componentes principales de datos pluviométricos. b) Aplicación a la eliminación de ausencias". Estadística (Journal of the Inter-American Statistical Institute) 1994, 46, 146,-147, pp. 55-83.
López, C. y Kaplan, E., 1993a "Análisis de calidad de datos (viento y presión)" Publicación Técnica delCentro de Cálculo PTCC 1/93. También "Informe para el estudio del potencial eólico nacional agran escala" Convenio UTE-FI, 1993, Cap. 6, 24 pp.
López, C., 1997. "Locating some types of random errors in Digital Terrain Models" Journal ofGeographical Information Science, V 11, N 7, 677-689.
López, C. and Kaplan, E., 1998a. "A new technique for imputation of multivariate time series: applicationto an hourly wind dataset" Tenth Brazilian Meteorological Conference. Brasilia,Brazil 26-30October, 1998
López, C., 1998b. "An error model for daily rain records" Tenth Brazilian Meteorological Conference.Brasilia, Brazil 26-30 October, 1998
López, C., 1999b. "Looking Inside the ANN "Black Box": Classifying Individual Neurons as OutlierDetectors", To be presented at IJCNN99, Washington DC, July 1999
López, C., 1999a. "On the measure of success in outlier detection algorithms", to be submitted.Núñez, S. 1994. Comunicación personal. Servicio Meteorológico ArgentinoO'Hagan, A., 1990. "Outliers and credence for location parameter inference" Journal of the American
Statistical Association: Theory and Methods, V 85, N 409, 172-176.Parrish, D.F. and Derber, J.C., 1992. "The National Meteorological Center`s Spectral Statistical
Interpolation Analysis System". Monthly Weather Review, V 120, pp. 1747-1763.Reolón, Roald, 1992. Comunicación personal.Rocke, D. M. and Woodruff, D. L., 1996, Identification of outliers in Multivariate Data Journal of the
American Statistical Association, 91, 435, 1047-1061Rocke, D. M., 1996, Robustness properties of S-estimators of Multivariate location and shape in High
dimension, The Annals of Statistics, 24, 3, 1327-1345Rubin, D. B., 1987. "Multiple imputation for nonresponse in surveys". John Wiley and Sons, 253 pp.

112
Sevruk, B., 1982. "Methods of correction for systematic error in point precipitation measurementfor operational use" World Meteorological Organization WMO 589, Operational HydrologyReport 21, 89 pp.
Silveira, L.; López, C.; Genta, J.L.; Curbelo, R.; Anido, C.; Goyret, J.; de los Santos, J.; González, J.;Cabral, A.; Cajelli, A., Curcio, A., 1991. "Modelo matemático hidrológico de la cuenca del RíoNegro" Informe final. Parte 2, Cap. 4. 83 pp.
Silveira, L.; Genta, J.L.; Anido Labadie, C., 1992. "HIDRO URFING- Modelo hidrológico paraprevisión de caudales en tiempo real". Publicación técnica del Instituto de Mecánica de los Fluidose Ingeniería Ambiental (IMFIA) Hidrología 1/92. 28 pp, Facultad de Ingeniería, Montevideo,Uruguay.
Slanina, J.; Mols, J.J. and Baard, J.H., 1990. "The influence of outliers on results of wet depositionmeasurements as a function of measurement strategy" Atmospheric Environment, V 24A, N 7, pp.1843-1860.
Strayhorn, J. M.; 1990: "Estimating the errors remaining in a Data Set: Techniques for Quality Control"The American Statistician, V 44, N 1, pp 14-18
Stone, M.; Brooks, R.J., 1990: "Continuum regression: Cross-validated sequentially constructed predictionembracing ordinary least squares, partial least squares and principal components regression" J. R.Statist. Soc. B, V 52, N 2, pp 237-269.

113
8 - DOCUMENTOS Y PUBLICACIONES ANEXASSe adjunta aquí material complementario, así como copia de los trabajos publicados en el marco
de este proyecto.
8.1- Análisis de la serie temporal de nivelesEl material que se presenta a continuación está referenciado en el ítem 6.5
8.2- Looking inside the ANN "Black Box"... (1999)El artículo que se presenta a continuación debe referenciarse de la siguiente manera:
"Looking inside the ANN "black box"; classifying individual neurons as outlier detectors. 1999López, C. In Proceedings of the International Joint Conference on Neural Networks IJCNN'99, July 10-16,1999, Washigton DC
8.3- A new technique for imputation of multivariate time series... (1998)El artículo que se presenta a continuación debe referenciarse de la siguiente manera:
"A new technique for imputation of multivariate time series: application to an hourly winddataset" 1998 López, C. and Kaplan, E. Tenth Brazilian Meteorological Conference. Brasilia, Brazil 26-30October.
8.4- An error model for daily rain records... (1998)El artículo que se presenta a continuación debe referenciarse de la siguiente manera:
"An error model for daily rain records" 1998 López, C. Tenth Brazilian MeteorologicalConference. Brasilia, Brazil 26-30 October
8.5- Quality of Geographic Data: Detection of Outliers... (1997)La tesis que se adjunta debe referenciarse de la siguiente manera:
"Quality of Geographic Data: Detection of Outliers and Imputation of Missing Values", 1997.Carlos López, Ph. D. Thesis TRITA-GEOFOTO 1997:17, ISSN 1400-3155, Royal Institute ofTechnology, Stockholm, Sweden
8.6- Application of ANN to the prediction of missing daily... (1997)El artículo que se presenta a continuación debe referenciarse de la siguiente manera:
"Application of ANN to the prediction of missing daily precipitation records, and comparisonagainst linear methodologies" 1997 López, C. International Conference on Engineering Applications ofNeural Networks. Stockholm, 16-18 June, 1997, pp. 337-340 (A)

114
8.7- Comparación de metodologías para la imputación de la lluvia... (1996)El artículo que se presenta a continuación debe referenciarse de la siguiente manera:
"Comparación de metodologías para la imputación de la lluvia diaria en una pequeña cuenca delatitudes medias", 1996 López, C.; Gutiérrez, C. y de los Santos, H. IX Congreso Brasileiro deMeteorología, 1, 125-129
8.8- Análise de uma Metodologia para o Recheio... (1996)El artículo que se presenta a continuación debe referenciarse de la siguiente manera:
"Análise de uma Metodologia para o Recheio de "Missing Values" Numa Base de Dados deChuva, Baseada na Pseudo-Distancia de Kulback-Leibler", 1996 Gutiérrez, C. IX Congreso Brasileiro deMeteorología, 1, 253-257
8.9- Estacionalidad y modelización probabilística de la lluvia diaria... (1995)El artículo que se presenta a continuación debe referenciarse de la siguiente manera:
"Estacionalidad y modelización probabilística de la lluvia diaria en una cuenca de latitud media",1995 Blanco, J y Camaño, G. Congreso de Sociedades Latinoamericanas de Estadística. CLATSE III.Santiago de Chile, Octubre 1995

115
9 - OTROS ANEXOS
9.1- Datos del ProyectoNombre:
Desarrollo de metodologías orientadas al control de calidad e imputación de datos faltantes enparámetros meteorológicos
Número:51/94
Responsable científico:Dr. Ing. Carlos Ló[email protected]
9.2- Metas Previstas y Logradas: Cumplimiento del plan de TrabajoA) CIENTIFICOS
1.- Desarrollar algoritmos apropiados para realizar el control de calidad de datos de diferente índole sobre
bancos de datos históricos.
2.- Diseñar algoritmos capaces de realizar ese control en tiempo real.
3.- Ensayar los mismos sobre bancos de datos nacionales, de forma de poder tener en cuenta las
particularidades y especificidades de ellos.
4.- Desarrollar metodologías adecuadas para la imputación de valores ausentes en los bancos existentes.
Las mismas podrán eliminar total o parcialmente los primeros, según el caso.
5.- Proponer alternativas para imputar ausencias en tiempo real.
6.- Comparar el desempeño de los algoritmos en experimentos controlados, con los criterios actualmente
en uso (sustitución por el más próximo en el espacio, interpolación en el tiempo, etc.)
7.- Proporcionar medidas de nivel de confianza y del margen de error tanto al señalar datos anómalos,
como al imputar valores ausentes.
8.- Generar paquetes de software integrados, que permitan la aplicación de dichos algoritmos.

116
9.- Generación de conocimiento local en lo que tiene que ver con estas técnicas, que son factibles de
utilizar en ámbitos diferentes al de recursos hídricos, energía o medio ambiente, dada su generalidad.
10.- Ensayar los métodos sobre parámetros adicionales, de similares características a los analizados. Tales
parámetros serán definidos en acuerdo con otros organismos interesados
B) PRODUCTIVOS
11.- Depurar la red pluviométrica en la cuenca del río Santa Lucía. Se entiende que la misma es la menos
confiable, por diversas razones, y su importancia para el suministro de agua potable, erosión, riego, etc. es
indiscutible.
12.- Depurar la red de medición de viento al sur del Río Negro
13.- Depurar la red de medición de caudales del Río Tacuarembó
Los demás objetivos planteados estaban asociados a la eventual incorporación de proyectos derivados de
éste, lo que a julio de 1999 no ha ocurrido.
9.3- Actividades desarrolladas según las enumeradas en el Proyecto)
Actividad 1:
Adquisición de equipos y software necesarios para la interconexión de DNM, IE y CeCal.
Actividad 2:
Instalación de los mismos y ajuste
Actividad 3:
Gestión y transferencia de base de datos de lluvia, viento y caudal. Las mismas fueron oficialmente
obtenidas de la DNM y UTE, y transferidas al equipo del Centro de Cálculo.
Actividad 4:
Gestión y transferencia de parámetros a ser ensayados. Esto implicó una coordinación con los interesados,
así como resolver los detalles de a qué tipo de variable se asimila la nueva, y qué metodología se le aplica.
Actividad 5:

117
Generación de un manejador de datos, para manipular eficientemente la información. Se utilizó un
software de base de datos adquirido a esos efectos.
Actividad 6:
Revisión bibliográfica y recuperación. Imprescindible para completar y actualizar la revisión ya realizada.
Actividad 7:
Análisis de la bibliografía.
Actividad 8:
Prototipar algoritmos para lluvia, que fue la primera variable analizada. Se aprovecharon algoritmos ya
disponibles, pero también se implementaron otros.
Actividad 9:
Depurar banco de datos. Esto implicó trabajo de los digitadores, revisando datos de la planilla manuscrita.
El producto final es un banco depurado de la "mayor" parte de los errores de digitación.
Actividad 10:
Se ensayaron algoritmos sobre bancos depurados, de forma de medir su desempeño. Se calcularon los
estimadores estadísticos asociados con cada uno de los métodos, así como valores esperados.
Actividad 11:
Está previsto ensayar algoritmos sobre otros parámetros similares a la lluvia, previamente acordados con
los organismos interesados.
Actividad 12:
Informe de avance. Se recogen en él los resultados obtenidos para lluvia y los primeros estudios sobre
caudal.
Actividad 13:
Prototipar algoritmos para otras variables (viento y caudal).
Actividad 14:
Depurar banco de datos, con intervención nuevamente del personal de digitación.
Actividad 15:
Ensayar algoritmos sobre bancos depurados.
Actividad 16:
Ensayar algoritmos sobre otros parámetros similares al viento y caudal.
Actividad 17:
Informe de avance
Actividad 18:
Informe final.
118
CRONOGRAMA DE ACTIVIDADES PROPUESTO
ACTIVIDADES MESES
PRIMER AÑO 1 2 3 4 5 6 7 8 9 10 11 12
Adquisición de equipos y software 44 44 44 44
Conexión entre equipos 44 44 44
Gestión y transferencia de base de
datos de lluvia, viento y caudal.
44 44 44 44 44 44
Gestión y transferencia de
parámetros a ser ensayados a
posteriori.
44 44 44 44 44 44 44
Generación de un manejador de
datos.44 44 44 44 44 44 44 44
Revisión bibliográfica y
recuperación.44 44 44
Análisis de la bibliografía. 44 44 44 44 44 44
Prototipar algoritmos para lluvia. 44 44 44 44 44 44 44 44 44
Depurar banco de datos 44 44 44 44 44 44 44
Ensayar algoritmos sobre bancos
depurados.44 44 44 44
Ensayar algoritmos sobre otros
parámetros similares a la lluvia44 44 44
Informe de avance 44

119
CRONOGRAMA DE ACTIVIDADES (Continuación).
ACTIVIDADES MESES
SEGUNDO AÑO 13 14 15 16 17 18
Prototipar algoritmos para otras variables. 44 44 44 44
Depurar banco de datos. 44 44 44 44 44
Ensayar algoritmos sobre bancos depurados. 44 44 44 44
Ensayar algoritmos sobre otros parámetros similares 44 44 44 44
Informes de avance y final. 44 44
9.4- Fundamentación de cualquier desviación de objetivosDebido a diversas dificultades en el acceso a la información original en papel, las correcciones
realizadas al banco de datos de niveles fueron limitadas al mínimo. Ello implicó concentrarse en una únicaestación de medida, y corregir solamente aquellos errores groseros que pudieron identificarse.
El banco de datos de lluvia fue el que recibió mayor atención, fundamentalmente porque nuncahabía sido utilizado. Los datos de la cuenca del Santa Lucía fueron depurados utilizando los algoritmosdisponibles al principio del proyecto, y el trabajo se continuó en la medida que la cantidad de errores dedigitación detectados era significativa.
9.5- Recursos materialesSe adquirieron equipos de tipo PC, estaciones de trabajo, etc. así como se comlementaron
adquisiciones realizadas con fondos externos. Estos equipos fueron utilizados para mejorar la conexión aInternet, así como la conexión mutua entre los grupos. También fueron utilizados en la preparación deinformes, programación, etc.
La Dirección Nacional de Meteorología adquirió un PC de última generación a esos efectos, dondese realizó el procesamiento de datos previo a su volcado a la base, y también funcionó como el único nodode comunicaciones de ese organismo con la Internet (vía Facultad de Ingeniería) hasta que se inauguró elservicio de ADINET.
En las actividades realizadas en Facultad de Ingeniería, se contó además para realizar los cálculos,impresiones, etc. con equipo adquirido por otros proyectos. Los más significativos fueron financiados porel Proyecto CONICYT/BID 180/92 (estaciones de trabajo SUN y DEC), y por el proyecto INCO-DC/97(estaciones de trabajo BULL).

120
9.6 - Recursos Humanos
9.6.1 Integración original del equipo de trabajoCarga horaria dedicada al proyecto y sus modificaciones durante la ejecución del mismo, así como integrantes que recibencompensaciones
NIVEL FUNCION PROFESION DEDIC. EN INST. HS.SEM MESES
5 I. Estadística Economista 40 10 18
5 I. Estadística Estadístico 40 20 18
5 I. Estadística Estadístico 20 10 3
3 I.Estadística Estadístico 40 20 18
2 I.Estadística Estadístico 40 20 18
2 I.Estadística Economista 20 20 5
4 Centro de Cálculo Ingeniero 40 40 18
2 Centro de Cálculo Lic. Estadística 40 40 18
1 Centro de Cálculo Ingeniero 40 40 18
1 Centro de Cálculo Ingeniero 20 20 6
4 Meteorología Meteorólogo 40 20 18
2 Meteorología Téc.Meteorólogo 40 20 18
TOTAL
Al personal inicialmente afectado al proyecto se ha incorporado el Técnico meteorólogo Héctor
Fontana y el A/P Jorge Biurrum. El Cr. Miguel Galmés, y el Estad. Raúl Ramírez han renunciado a
participar del mismo en el correr del primer año, quedando como responsable científico el Dr. Ing. Carlos
López.

121
En agosto de 1997 el Dr. López fue designado Director del Centro de Cálculo de la Facultad de
Ingeniería. Desde enero hasta agosto de 1998, la Lic. Gutiérrez redujo su dedicación horaria de 40 a 25
hs/sem.
9.6.2 Capacidad generadaEnumerar las actividades de formación, grado y posgrado relacionadas con el proyecto
Las actividades de formación, y la investigación realizada formaron parte de los trabajosrequeridos para la obtención en noviembre de 1997 de un grado de Ph.D. por parte del Ing. Carlos López.También se le dio participación a estudiantes de grado, que colaboraron en la instrumentación delmanejador del banco de datos, en el marco de un proyecto de fin de carrera, lo que se estima fue unaoportunidad muy importante para poner en práctica la teoría adquirida en su formación.
Los investigadores del Instituto de Estadística tienen responsabilidad en cursos de grado, yactualmente encaran la iniciación de una carrera de posgrado en su área de especialidad.
Los investigadores de la Dirección Nacional de Meteorología participan en la escuela deMeteorología, donde se forman los técnicos de la institución, y en el Caso del M.Sc. Mario Bidegaintambién tiene actividad docente en la Facultad de Ciencias, Universidad de la República.
9.6.3 Clasificar el equipo de investigación en alguna de las siguientes categorías, y fundamentarlo1. investigador nuevo2. investigador ya consolidado3. equipo de investigación nuevo4. equipo de investigación consolidado5. equipo de investigación consolidado que ha integrado investigadores nuevos
El proyecto incluye tres grupos, a saber: DNM, IECCEE y CECAL. En ese orden, cada equipo seclasificaría en 4, 4 y 5.
En el caso del CeCal, los docentes Carlos López y Elías Kaplan integraban un grupo yaestabilizado al momento de iniciarse el proyecto, al que ocasionalmente se incorporaron otros docentescomo Rosario Curbelo y Juan González. La imposibilidad de operar en dos proyectos en simultáneo,obligó al Ing. Kaplan a concentrarse en otro proyecto CONICYT/BID, requiriéndose así reforzarinicialmente al grupo con la Lic. Gutiérrez y el Ing. De los Santos. La Lic. Gutiérrez ha sido luegocontratada por la facultad en forma estable. Las primeras publicaciones del Dr. López en el tema datan de1994, y versan sobre trabajos realizados en el período1988-1992.
En el caso del Instituto de Estadística trabajaron dos grupos; por un lado el integrado por JorgeBlanco, Gabriel Camaño y Jorge Biurrun que era un equipo consolidado (4) a través de diversasinvestigaciones realizadas con aproximación multivariada clásica, bayesiana y mutiway. En los trabajos enel proyecto se utilizaron estas tres aproximaciones para determinar relaciones de proximidad entreestaciones pluviométricas y modelizar relaciones de dependencia temporal y espacial de la lluvia diaria enla cuenca del Santa Lucía. El otro equipo del Instituto trabajó por menos tiempo, y estuvo integrado por

122
Rosa Grosskoff, y Ricardo Selves, equipo ya consolidado (4) en el área de series temporales. Losresultados del proyecto permitieron avanzar en el estudio de problemas específicos de heteroscedasticidadmediante nuevos modelos integrándose a partir del trabajo realizado un nuevo grupo de investigación.
9.6.4 Si corresponde, indicar interrelacionamiento o convenios institucionales
Especificar el tipo de interrelacionamiento y con que instituciones (nacionales o extranjeras)No corresponde.
9.7- Impacto de los resultados obtenidos a nivel de:
9.7.1 Publicaciones
"Looking inside the ANN "black box"; classifying individual neurons as outlier detectors.
1999 López, C. International Joint Conference on Neural Networks IJCNN'99, July 10-16, 1999,
Washigton DC
"A new technique for imputation of multivariate time series: application to an hourly wind
dataset" López, C. and Kaplan, E.; Tenth Brazilian Meteorological Conference. Brasilia,Brazil 26-
30 October, 1998
"An error model for daily rain records" López, C.; Tenth Brazilian Meteorological
Conference. Brasilia, Brazil 26-30 October, 1998
"Quality of Geographic Data: Detection of Outliers and Imputation of Missing Values",
1997. Carlos López, Ph. D. Thesis TRITA-GEOFOTO 1997:17, ISSN 1400-3155, Royal Institute
of Technology, Stockholm, Sweden
"Application of ANN to the prediction of missing daily precipitation records, and
comparison against linear methodologies" 1997. López, C. In Proceedings of the International
Conference on Engineering Applications of Neural Networks. Stockholm, 16-18 June, 1997, pp.
337-340 (A)

123
"Comparación de metodologías para la imputación de la lluvia diaria en una pequeña
cuenca de latitudes medias", 1996. IX Congreso Brasileiro de Meteorología, Carlos López, Celina
Gutiérrez y Hugo de los Santos,V 1 125-129 Nov. 1996 (A)
“Análise de uma Metodologia para o Recheio de “Missing Values” Numa Base de Dados
de Chuva, Baseada na Pseudo-Distância de Kulback-Leibler”, 1996. IX Congreso Brasileiro de
Meteorología, Celina Gutiérrez, V1, 253-257
"Estacionalidad y modelización probabilística de la lluvia diaria en una cuenca de latitud
media" Jorge Blanco y Gabriel Camaño
9.7.2 Convenios, asesoramientos, etc.
No los ha habido explícitamente asociados a este proyecto, pero claramente lo aprendido durante
el mismo se ha volcado al resto de las actividades en curso en cada una de las instituciones. Ha habido
ciertamente algunas tratativas con actores clave (empresas públicas típicamente) pero al presente no se
cuenta con resultados concretos.
9.7.3 Definir los resultados obtenidos según su alcance a nivel local, regional o internacional
Varios de los trabajos citados han sido objeto de presentación en conferencias, y publicación en losanales de las mismas. Todas las conferencias han sido con evaluación previa del artículo, y alguna de ellasha tenido una audiencia multitudinaria (X Congreso en Brasilia; IJCNN´99 en Washington D.C., etc.)
La mayor parte de los trabajos producidos están disponibles en Internet, en la página del proyectohttp://www.fing.edu.uy/p51_94. La misma contiene copia del informe de avance, y también del final. Elalcance que se logra con ello se estima como muy amplio, limitado sólo por las barreras idiomáticas.
9.7.4 Clasificarlos como importantes en:-El desarrollo de Tecnología Nacional con repercusiones en el sector productivo-En adaptación de Tecnologías del exterior con repercusiones en el sector productivo a que va dirigido-Como importante en el desarrollo de un área de conocimiento con potencial de transferencia al sector productivo-Como aporte básico a un área de conocimiento pero sin aplicación directa
A juicio del responsable científico, este proyecto podría tener repercusiones en el sectorproductivo en la medida que el mismo comience a hacer uso intenso de las capacidades disponibles en elpaís en el área meteorológica. En la medida que el objetivo apunta a mejorar la calidad de los datos basesobre los que se apoyan esos trabajos, la confiabilidad en el producto final aumenta.
Los impactos podrían cubrir los ítems 1, 3 y 4. No parece claro la relación con el ítem 2.




![Proyecto PO 47/94 Rev.3 [I] 94/pd 47-94-14 rev 3 (I... · o muy baja. En la localidad de Toncontin yen las parcelas estudiadas s610 se encontr6 un individuo, en losotros sitios (Camelias,](https://static.fdocuments.es/doc/165x107/5e9184446187181713574f4b/proyecto-po-4794-rev3-i-94pd-47-94-14-rev-3-i-o-muy-baja-en-la-localidad.jpg)













