Redes Neuronales Introduccióniecon02.us.es/ASIGN/SEA/redesneur_simplificada.pdfRedes Neuronales...
32
Redes Neuronales Introducción José Manuel Quero Reboul Dpto. Ingeniería Electrónica Universidad de Sevilla
Transcript of Redes Neuronales Introduccióniecon02.us.es/ASIGN/SEA/redesneur_simplificada.pdfRedes Neuronales...

Redes Neuronales
Introducción
José Manuel Quero ReboulDpto. Ingeniería Electrónica
Universidad de Sevilla

Indice
• Motivación• Arquitectura• Leyes de Aprendizaje• Aplicaciones

DILEMA
• Aritmética
• Visión
• Datos
• Direccionada por contenido
1 cerebro=1/10 calculadora de bolsillo
1 cerebro=1000 supercomputadores
cerebro mucho peor
cerebro mucho mejor
MEM
OR
IA
CA
LCU
LO
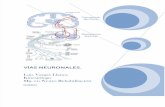
Arquitectura Von Newman
• Unico nodo de procesamiento (800Mhz)• Memoria pasiva• Baja conectividad
BUSBUS
CPUCPU MEMMEM E/SE/S E/SE/S
Bus de datos: Cuello de Botella (Secuencialidad)Bus de datos: Cuello de Botella (Secuencialidad)
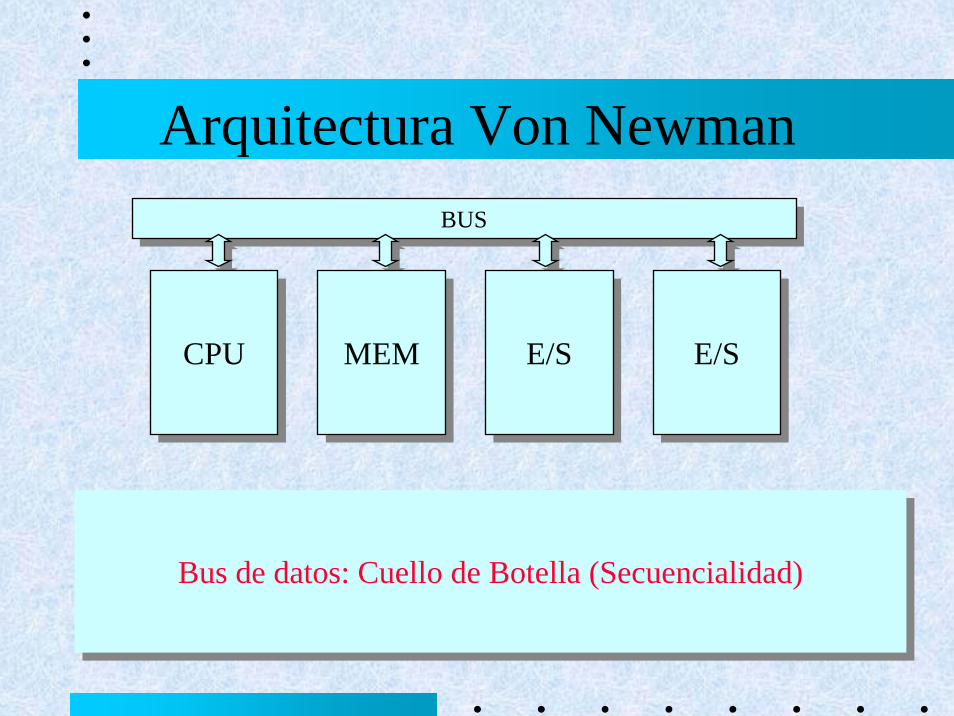
Cerebro
• 1010 neuronas (10ms)• 104 dendritas• 1014 pesos de conexión• Los pesos almacenan y
procesan

Definición
Computación neuronal:
Computación en redes masivas paralelas de procesadores simples y no lineales, que almacenan todo su contenido en los pesos de conexión
Computación en redes masivas paralelas de procesadores simples y no lineales, que almacenan todo su contenido en los pesos de conexión
Propiedades:– Eliminación del cuello de botella– Inteligencia artificial llevada al límite

Indice
• Motivación• Arquitectura• Leyes de Aprendizaje• Aplicaciones
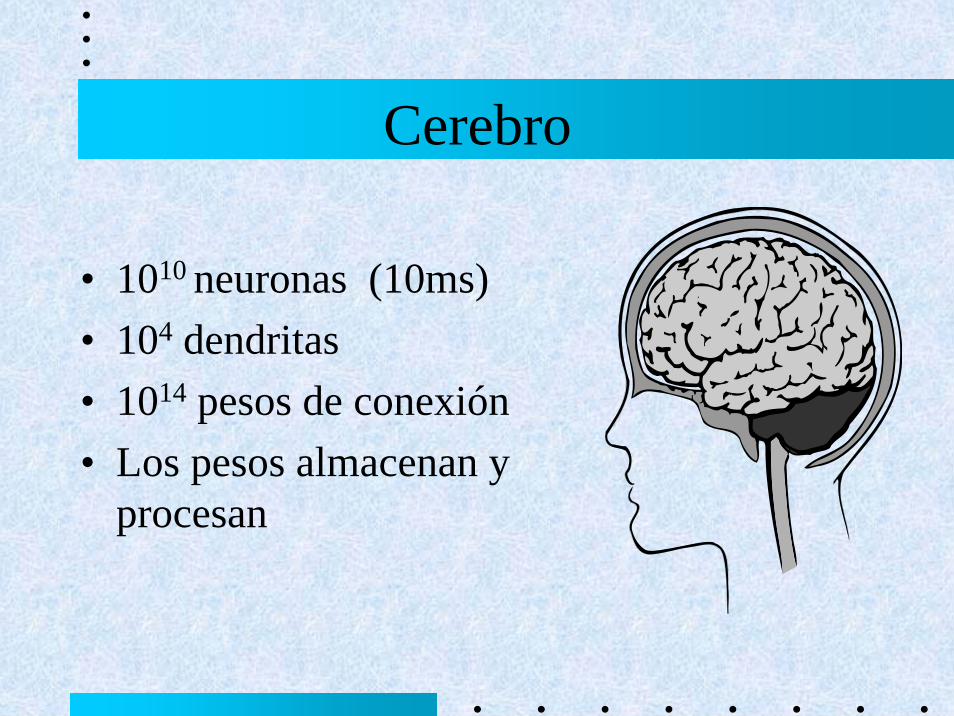
Ley de Propagaciónj
jiji IWnet ∑=
Neurona Artificial
Entorno
Ley de Activación),...)(),(),(()1( 21 tnettnettaFta =+
Función de Salida)(afo =
Patrón de Conectividad
Ley de Aprendizaje))(),(),(),(()1( totatnettwgtw iijij =+
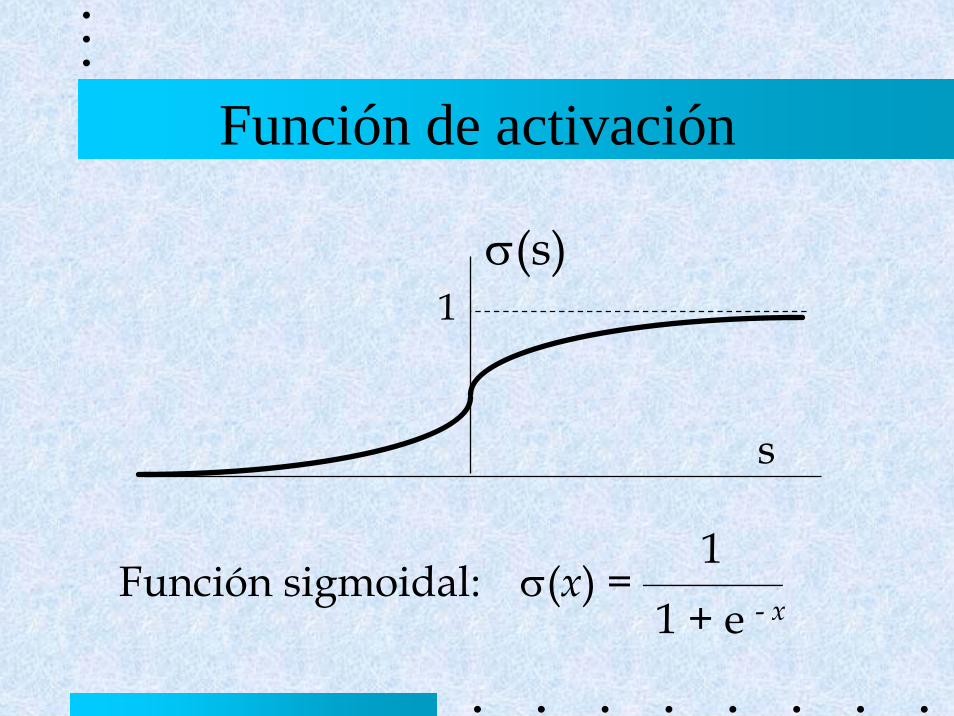
Función de activación
s
σ(s)1
Función sigmoidal: σ(x) = __________1
1 + e - x
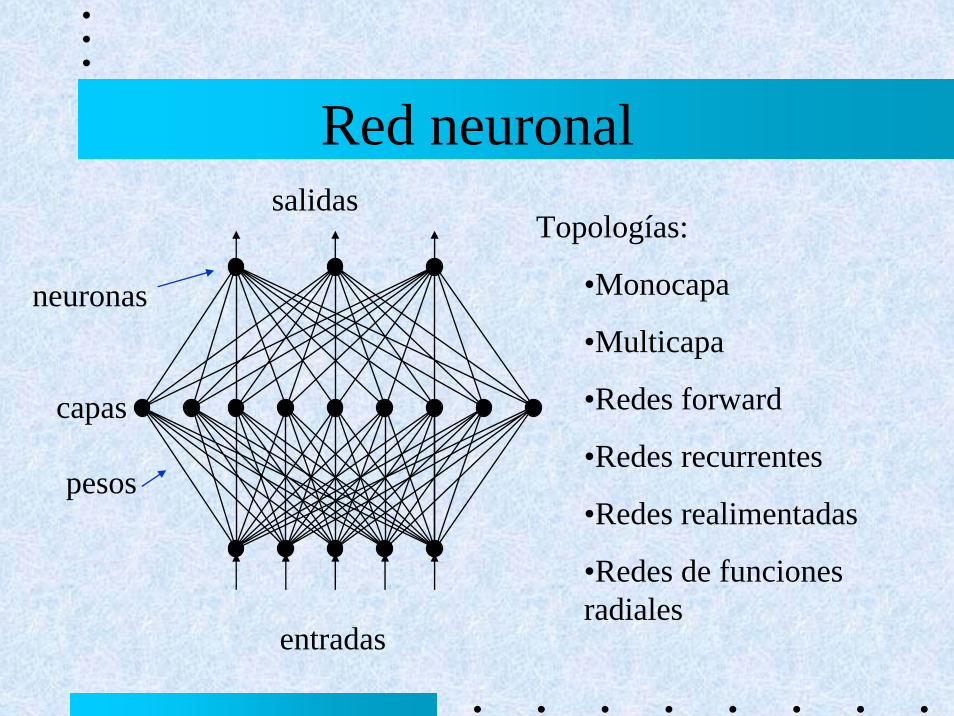
Red neuronal
neuronas
pesos
capas
salidas
entradas
Topologías:
•Monocapa
•Multicapa
•Redes forward
•Redes recurrentes
•Redes realimentadas
•Redes de funciones radiales

Indice
• Motivación• Arquitectura• Clasificación• Leyes de Aprendizaje• Aplicaciones

Aprendizaje• El conocimiento es obtenido a partir de la
experiencia y almacenado en los pesos• Tipos de aprendizajes:
– Preprogramadas– Ley de Hebbs– Aprendizaje competitivo– Aprendizaje supervisado
• La red extrae y copia la estructura interna del conocimiento del entorno

Leyes de Aprendizaje
WIWdt
dW )()( ⋅−⋅== γφ&
WI
)(),( ⋅⋅ γφ
)( IWfo T=
o:Vector de pesos
: Señales de entrada:Funciones escalares (W,I,o):salida
Función de Tranferencia no lineal

•Justificación
1) Ley de Hebb: Cuanto mayor sea la excitación, mayor será el refuerzo de la conexión
2) Factor de Olvido: Proporcional a la propia magnitud
•Condiciones (estabilidad dinámica)
1)
2)
Leyes de Aprendizaje
I)(⋅φ
ttWto ∀⇒ finita acotadasi )()(
W)(⋅−γ
∞→→⇒≠ ttWI 0)(0 si /

Indice
• Motivación• Arquitectura• Clasificación• Leyes de Aprendizaje• Aplicaciones

Propiedades de las RN• Procesamiento de un gran conjunto de datos• Baja densidad de información• Robustez ante fallo en estructura• Robustez ante inconsistencia en los datos de
entrada• Datos y reglas de procesamiento confundidos en
las conexiones• Procesamiento altamente paralelo• Capacidad de Autoorganización. Adaptabilidad

¿Cuando usar Redes Neuronales?
• Cuando se quiere desarrollar un modelo (funcional, clasificador, predicción de serie temporal,...)
• Ejemplos– Finanzas: Modelos de mercado– Ingeniería: Modelado de procesos y control
adaptativo– Medicina: Diagnosis

¿Cuando usar Redes Neuronales?
• En análisis de datos con baja densidad de información
• Ejemplos:– Reconocimiento de imágenes– Reconocimiento de firmas– Análisis de encuestas– Predicción meteorológica

Redes NeuronalesAprendizaje Supervisado

Indice
• Perceptrón– Regla delta
• Perceptrón Multicapa– Retropropagación
• Ejemplos
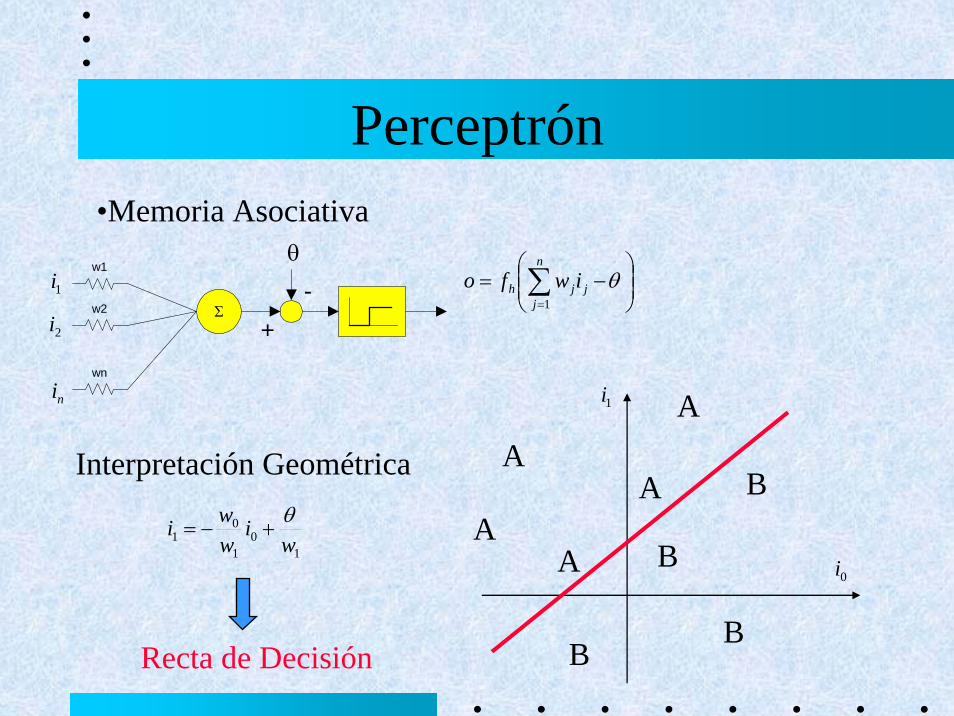
Perceptrón•Memoria Asociativa
⎟⎟⎠
⎞⎜⎜⎝
⎛−= ∑
=
θn
jjjh iwfo
1
Interpretación Geométrica
10
1
01 w
iwwi θ
+−=
Σ
w1
wn
w2
θ
-+
1i
2i
ni
A
AA
A
A
B
B
BB
0i
1i
Recta de Decisión

Perceptrón
)()]()([ titotddt
dwi
i −=α
•Aprendizaje Supervisado: Regla δ
10 −≤≤ ni { }1,1)(),( −∈totd
Aprendizaje a partir de aleatoriosiw
Problema: Oscilación ante entradas no separablesEjemplo: función XOR
Patron de Entrada Patron de Salida00011011
0110
01
10
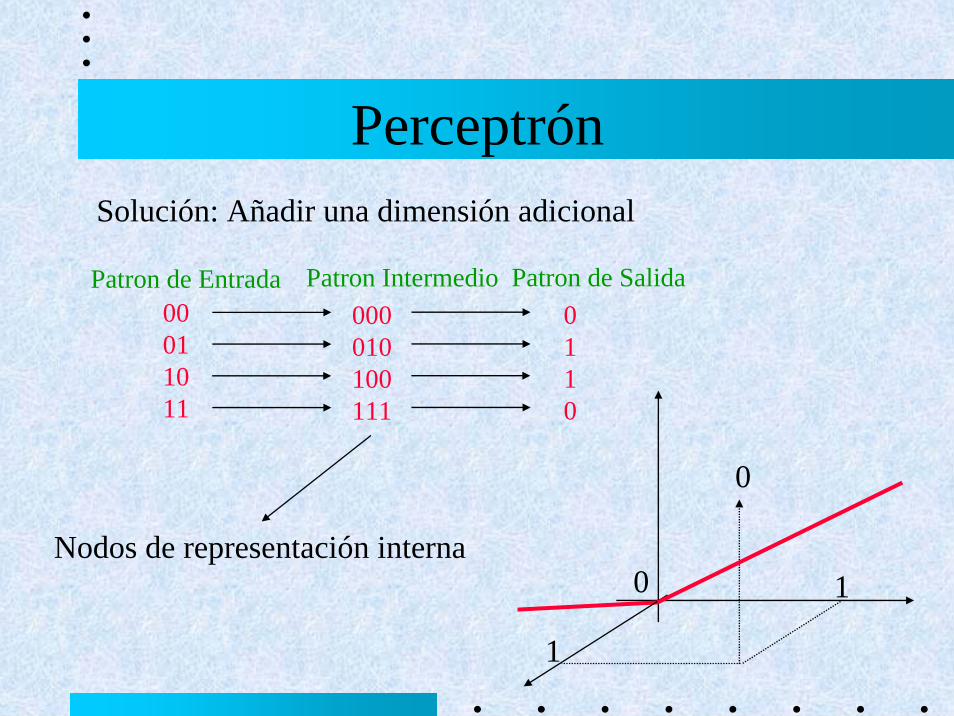
PerceptrónSolución: Añadir una dimensión adicional
Patron de SalidaPatron de Entrada Patron Intermedio00011011
000010100111
0110
0 1
1
0
Nodos de representación interna

Indice
• Perceptrón– Regla delta
• Perceptrón Multicapa– Retropropagación
• Ejemplos
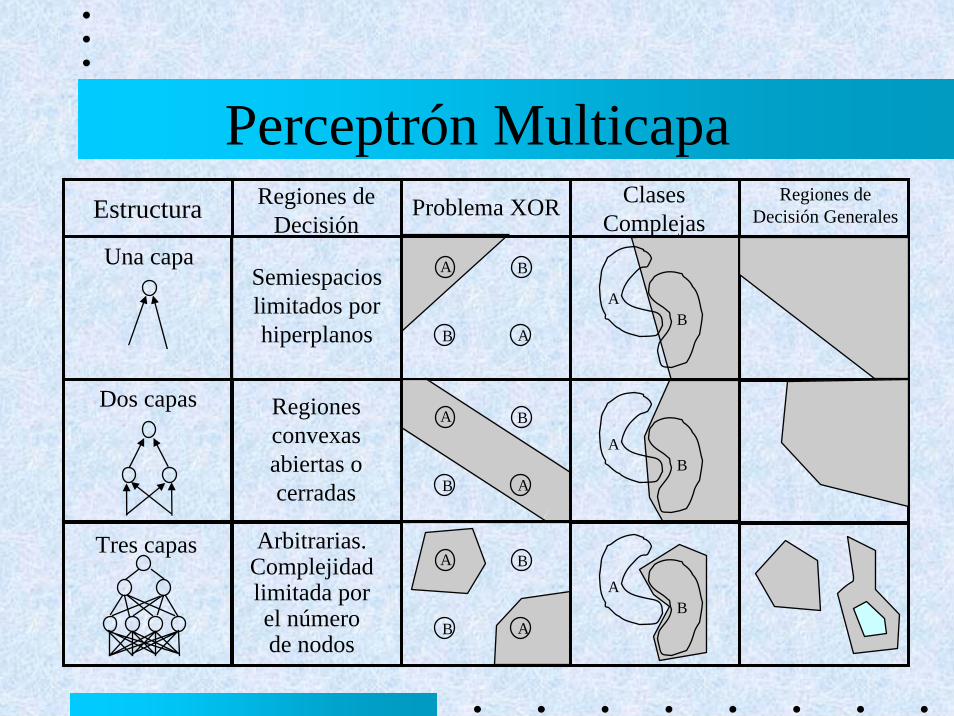
Perceptrón MulticapaEstructura Regiones de
DecisiónProblema XOR Clases
ComplejasUna capa
Semiespacioslimitados por hiperplanos
A
AB
B
Regiones de Decisión Generales
BA
Dos capas Regiones convexas abiertas o cerradas
A
AB
B
BA
Arbitrarias.Complejidad limitada por el número de nodos
Tres capasA
AB
B
BA
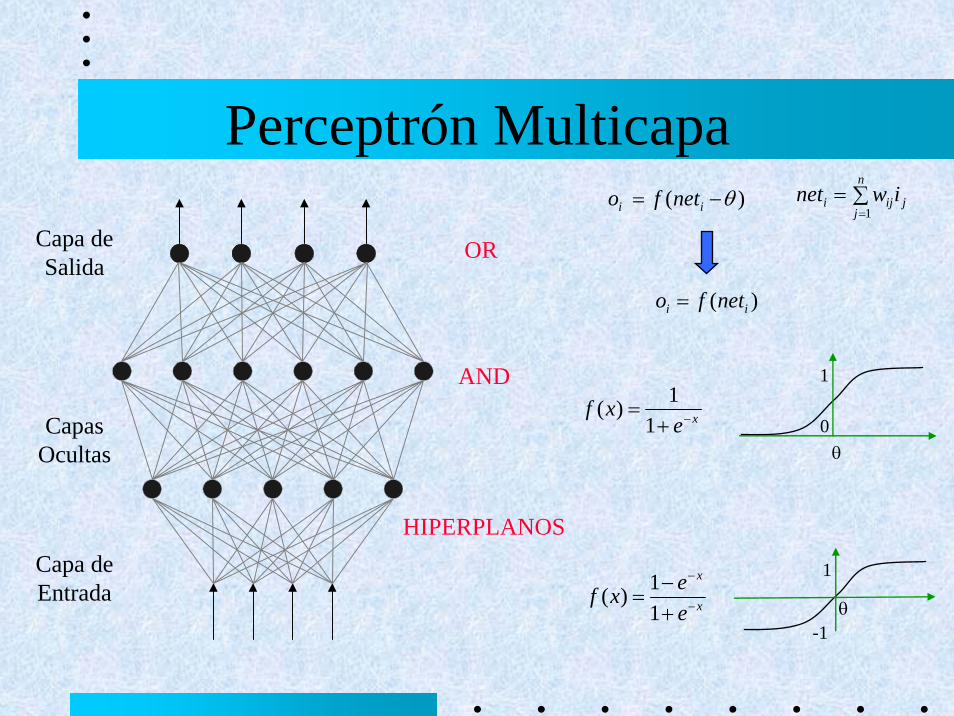
Perceptrón Multicapa
Capa de Salida
Capa de Entrada
Capas Ocultas
OR
AND
HIPERPLANOS
)( θ−= ii netfo ∑==
n
jjiji iwnet
1
xexf −+=
11)(
θ
1
0
x
x
eexf −
−
+−
=11)(
θ
1
-1
)( ii netfo =

Indice
• Perceptrón– Regla delta
• Perceptrón Multicapa– Retropropagación
• Ejemplos
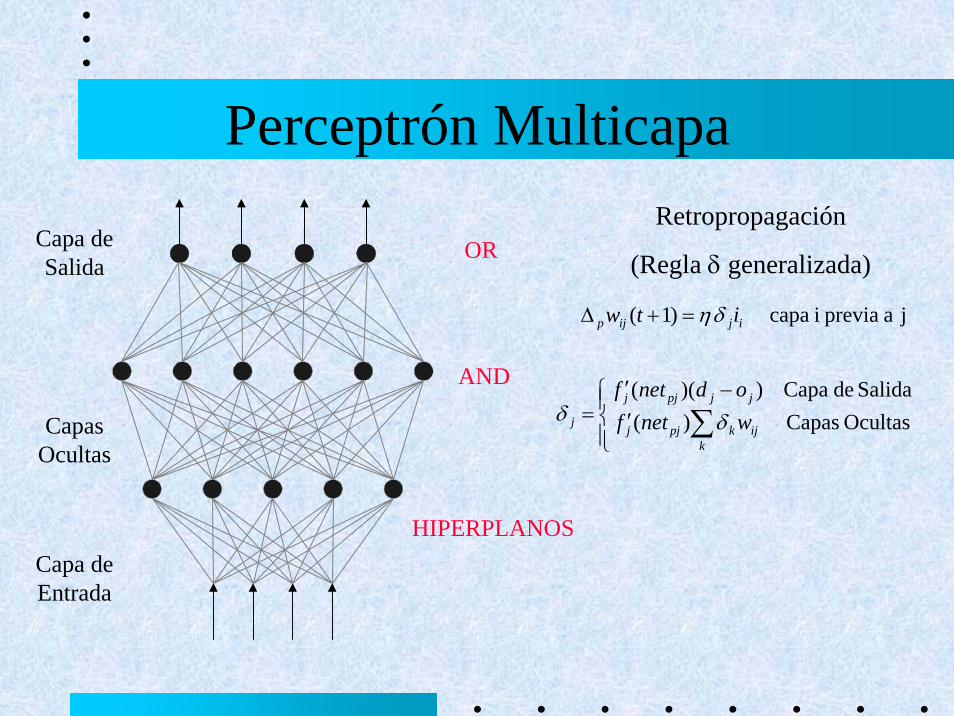
Perceptrón Multicapa
Capa de Salida
Capa de Entrada
Capas Ocultas
OR
AND
HIPERPLANOS
Retropropagación
(Regla δ generalizada)
j a previa i capa)1( ijijp itw δη=+Δ
⎪⎩
⎪⎨⎧
′−′
= ∑ Ocultas Capas)(Salida de Capa))((
kijkpjj
jjpjj
j wnetfodnetf
δδ

Queda determinar qué es para cada neurona pjδ
Perceptrón MulticapaRetropropagación: Demostración
∑∑∑ −=≡p j
pjpjp
p odEE 2)(21Error Cuadrático Médio
Cambio del error al variar la excitación en j
Cambio de la excitación la variar el peso de conexiónji
pj
pj
p
ji
p
wnet
netE
wE
∂
∂
∂
∂=
∂
∂Regla de la cadena (1)
Segundo Término
pii
pijijiji
pj oowww
net∑ =
∂∂
=∂
∂)( (2)
(3)pj
ppj net
E∂
∂−≡δ
Primer Término
Definamos pjpjjip ow ηδ=Δ⇒Sustituyendo (2) y (3)en (1)

Perceptrón Multicapa
pi
pj
pj
p
pj
ppj net
ooE
netE
∂
∂
∂
∂−=
∂
∂−=δRegla de la cadena
Cambio del error al variar la salida
Cambio de la salida por cambiar la excitación
Segundo Término
)( pjpj netfo =Dado que )( pjpj
pj netfneto
′=∂
∂⇒ Derivada de la función de salida
2)(21∑ −=
jpjpjp odE
Primer Término
Para neurona de salida. Dado que )( pjpjpj
p odoE
−−=∂
∂⇒
( )pjpjpjpj odnetf −′=⇒ )(δ

Perceptrón MulticapaPara neurona oculta.
∑ ∂
∂
∂
∂=
∂
∂
k pj
pk
pk
p
pj
p
onet
netE
oE
⎟⎠
⎞⎜⎝
⎛∂∂
∂
∂= ∑∑
ipiki
k pjpk
p owonet
E∑∂
∂=
kkj
pk
p wnetE
∑−=k
kjpk wδ
∑′=⇒k
kjpkpjpj wnetf δδ )(
δ de la capa previa Conexión con la neurona previa
Cómo afecta a la capa previa
jnetpj eo −+
=1
1Particularizando ( ) )1(1
)( 2 pjpjnet
net
jpj ooe
enetfoj
j
−=+
=′=′⇒−
−
⎪⎩
⎪⎨⎧
−−−
=⇒ ∑ Ocultas Capas)1(Salida de Capa))(1(
kijkjj
jjjj
j wiiodoo
δδ

Indice
• Perceptrón– Regla delta
• PerceptrónMulticapa– Retropropagación
• Ejemplos