
Regresión Lineal Simple
56
REGRESIÓN LINEAL SIMPLE 2015 - Curso : ESTADÍSTICA PARA LA TOMA DE DECISIONES - Profesor : VICENTE ARMAS, EDGAR Integrante : ZORRILLA CANCHANYA, JHONY JULIÁN - Ciclo : IV - Aula : 304 - Turno : MAÑANA Ciudad Universitaria, Septiembre
description
La finalidad de este trabajo es presentar un modelo estadístico básico. Este es el modelo de regresión lineal, que se usa para expresar la relación lineal que pueda existir entre los valores de una variable y los valores de un conjunto de una o más variables.
Transcript of Regresión Lineal Simple

REGRESIÓN LINEAL SIMPLE
2015
- Curso : ESTADÍSTICA PARA LA TOMA DE DECISIONES
- Profesor : VICENTE ARMAS, EDGAR
Integrante :
ZORRILLA CANCHANYA, JHONY JULIÁN
- Ciclo : IV
- Aula : 304
- Turno : MAÑANA
Ciudad Universitaria, Septiembre del 2015

DEDICATORIA:
Dedicado a mis padres
que siempre me orientan
a tomar decisiones acertadas

INTRODUCCIÓN
La finalidad de este trabajo es presentar un modelo estadístico básico. Este es
el modelo de regresión lineal, que se usa para expresar la relación lineal que
pueda existir entre los valores de una variable y los valores de un conjunto de
una o más variables. Por ejemplo, un modelo de este tipo puede ser utilizado
para explicar la variabilidad de las ventas de una empresa en términos de la
inversión que se realiza en publicidad. El modelo que trata de explicar la
variable dependiente (ventas) mediante una relación lineal y usando solo una
variable independiente (inversión en publicidad) se llama modelo de regresión
lineal simple. Algunos modelos de regresión incorporan más de una variable
independiente, y su forma puede ser de lo más complicada posible. Los
modelos de regresión que incorporan más de una variable independiente se
llaman modelos de regresión múltiple. Los modelos de regresión fueron
introducidos por Laplace y Gauss. Posteriormente fueron usados por Galton en
trabajos que trataban de explicar la relación de las estaturas de los padres con
las de sus hijos, encontrando lo que él llamó regresión a la media, expresión
usada para indicar “que los hijos de los padres altos, en promedio, no eran tan
altos como los padres, y que los hijos de los padres bajos, en promedio, eran
más altos que los padres”. Había una regresión hacia el promedio. Se aplican
en casi todos los campos de la ciencia, como el de la ingeniería, de las ciencias
físicas, de las ciencias económicas, de las ciencias sociales, etc., y en muchos
casos se utilizan para: predecir rendimientos futuros de un proceso y analizar la
influencia de ciertos factores en los valores de una variable y de esta manera
conocer, controlar y mejorar un proceso productivo.

MARCO TEÓRICO
ANÁLISIS DE CORRELACIÓN.- Grupo de técnicas para medir la
asociación entre dos variables. La idea básica del análisis de correlación
es reportar la asociación entre dos variables. El primer paso habitual es
trazar los datos en un diagrama de dispersión.
COEFICIENTE DE CORRELACIÓN.- Medida de la fuerza de la relación
lineal entre dos variables. Su signo indica la dirección de la relación
entre dos variables, directa o inversa.
COEFICIENTE DE DETERMINACIÓN.- Proporción de la variación total
en la variable dependiente Y que se explica, o contabiliza, por la
variación en la variable dependiente X. Se expresa como sigue:

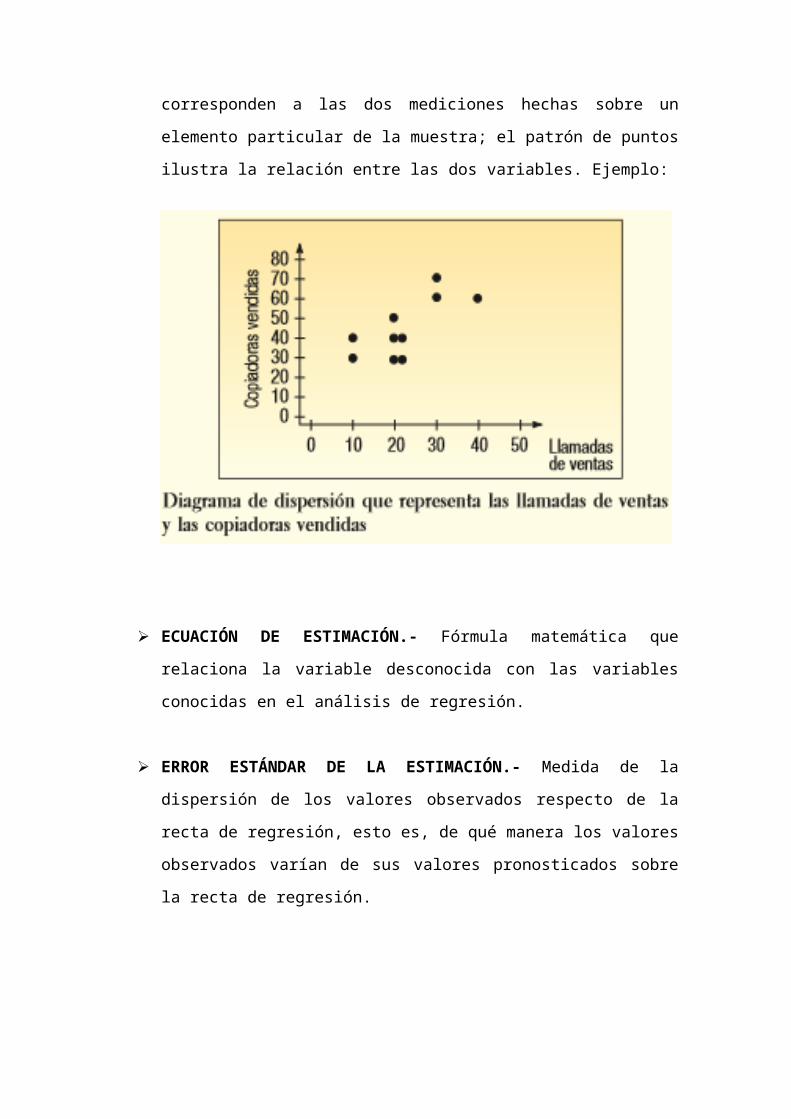
DIAGRAMA DE DISPERSIÓN.- Gráfica de puntos en una cuadrícula;
las coordenadas X y Y de cada punto corresponden a las dos
mediciones hechas sobre un elemento particular de la muestra; el patrón
de puntos ilustra la relación entre las dos variables. Ejemplo:
ECUACIÓN DE ESTIMACIÓN.- Fórmula matemática que relaciona la
variable desconocida con las variables conocidas en el análisis de
regresión.
ERROR ESTÁNDAR DE LA ESTIMACIÓN.- Medida de la dispersión de
los valores observados respecto de la recta de regresión, esto es, de
qué manera los valores observados varían de sus valores pronosticados
sobre la recta de regresión.
ERROR ESTÁNDAR DEL COEFICIENTE DE REGRESIÓN.- Medida de
la variabilidad del coeficiente de regresión de la muestra alrededor del
coeficiente de regresión verdadero de la población. Fórmula:
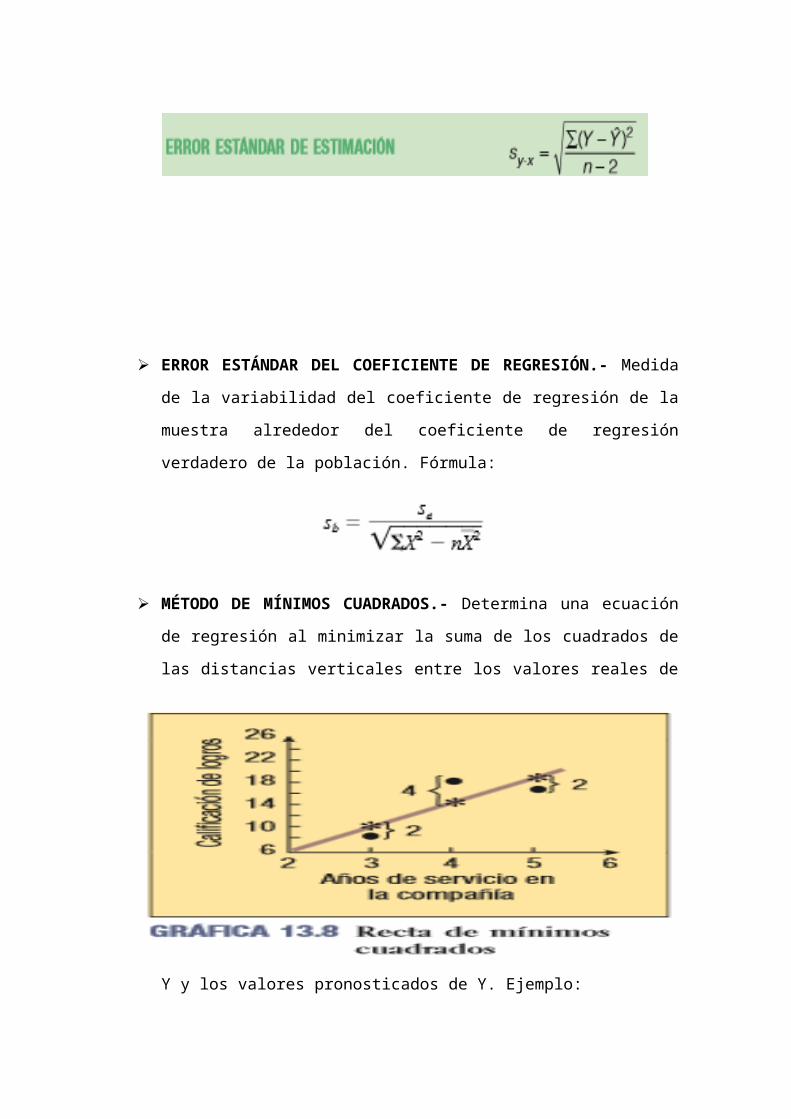
MÉTODO DE MÍNIMOS CUADRADOS.- Determina una ecuación de
regresión al minimizar la suma de los cuadrados de las distancias
verticales entre los valores reales de Y y los valores pronosticados de Y.
Ejemplo:
ORDENADA Y.- Constante para cualquier línea recta dada cuyo valor
representa el valor de la variable Y cuando el valor de la variable X es 0.
Se expresa por la letra a:
PENDIENTE.- Constante para
cualquier línea recta dada cuyo valor representa cuánto cambia la
variable dependiente con un cambio de una unidad de la variable
independiente. Se expresa por la letra b:
RECTA DE REGRESIÓN.- Una
línea ajustada a un conjunto de datos para estimar la relación entre dos
variables.
REGRESIÓN LINEAL.- También conocida como método de mínimos
cuadrados. Proceso general para predecir una variable a partir de otra
mediante medios estadísticos utilizando datos históricos, es decir,
consiste en encontrar la ecuación de una recta que mejor se ajuste a un
conjunto de puntos (datos).
RELACIÓN CURVILÍNEA.- Asociación entre dos variables que se
describe por una línea curva.
RELACIÓN DIRECTA.-
Relación entre dos
variables en donde,
al aumentar el
valor de la variable independiente, aumenta el valor de la variable
dependiente.

RELACIÓN INVERSA.- Relación entre dos variables en donde, al
aumentar la variable independiente, la variable dependiente disminuye.
RELACIÓN LINEAL.- Tipo particular de asociación entre dos variables que
puede describirse matemáticamente mediante una línea recta.
VARIABLE DEPENDIENTE.- Variable que se predice o estima. Se
muestra en el eje Y.
VARIABLE INDEPENDIENTE.- Variable que proporciona la base para la
estimación. Es la variable de pronóstico. Se muestra en el eje X.

RESOLUCIÓN DE EJERCICIOS
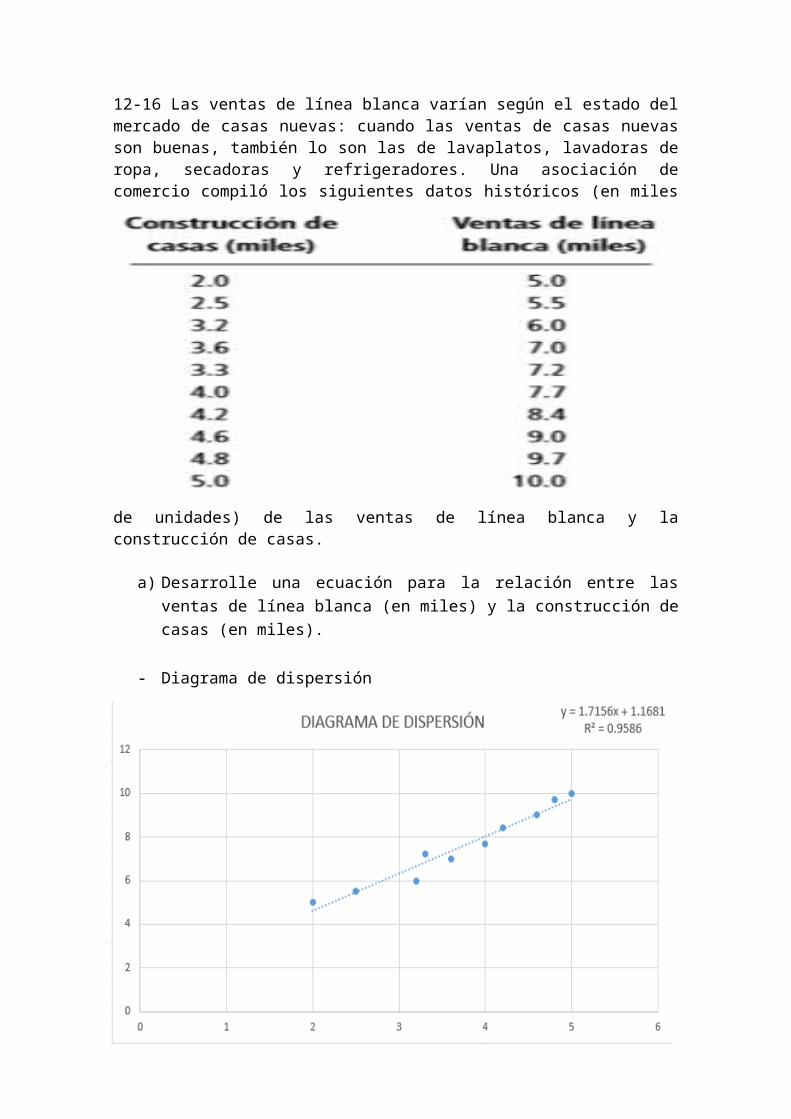
12-16 Las ventas de línea blanca varían según el estado del mercado de casas nuevas: cuando las ventas de casas nuevas son buenas, también lo son las de lavaplatos, lavadoras de ropa, secadoras y refrigeradores. Una asociación de comercio compiló los siguientes datos históricos (en miles de unidades) de las ventas de línea blanca y la construcción de casas.
a) Desarrolle una ecuación para la relación entre las ventas de línea blanca (en miles) y la construcción de casas (en miles).
- Diagrama de dispersión
b) Calcular los Coeficientes “a” y “b”.

a=∑ y .∑ x2−∑ x .∑ x . y
n∑ x2−(∑ x )2=¿ (75.5∗147.18)−(37.2∗289.2)
(10∗37.2)−37.22 =¿ 1.168145
b=n .∑ x . y−∑ x .∑ y
n∑ x2−¿¿¿ 1.715553
y=a+bxy=1.168145+1.715553 X
b) Interprete la pendiente de la recta de regresión. Por cada mil casas construidas, las ventas de líneas blancas se incrementarán en 1756 unidades.
c) Calcule e interprete el error estándar de la estimación.
Syx=√∑Y 2−a∑ Y−b∑ XYn−k
Syx=√ 147.18−1.168145 (75.5 )−1.715553(289.2)8
=0.3737
Interpretación: Los valores observados en la muestra están dispersos con respecto a la recta de regresión en 0.3737 mil unidades de ventas de líneas blancas.
d) La construcción de casas durante el año próximo puede ser mayor que el intervalo registrado; se han pronosticado estimaciones hasta de 8.0 millones de unidades. Calcule un intervalo de predicción de 90% de confianza para las ventas de línea blanca, con base en los datos anteriores y el nuevo pronóstico de construcción de casas.
Nos piden:¿ Y− tc S yx; Y−t c Syx>¿
1° PASO: Hallar y para X = 8000y=1.168145+1.715553 (8000)= 13725.592152° PASO: n = 10 ,∝=0.1, utilizamos la t (n−k ) g .l .=t (8 ) g .l .
3° PASO: ERROR ESTÁNDAR DE ESTIMACIÓN
Syx=√∑Y 2−a∑ Y−b∑ XYn−k
= 0.3737
4° PASO: ¿13725.59215−1.86 (0.3737);2.721559−1.86(0.3737)>¿
¿13724.89707 ;13726.28723>¿Estamos 90% seguros que las ventas de líneas blancas estarán entre 13 724 897 y 13 726 287 unidades, cuando la construcción de nuevas casas sea de 8 millones.
12-17 Durante partidos recientes de tenis, Diane ha observado que sus lanzamientos no han sido eficaces, pues sus oponentes le han regresado algunos de ellos. Algunas de las personas con las que juega son bastante altas, así que se pregunta si la estatura de su contrincante podría explicar el número de lanzamientos no regresados durante un partido. Los siguientes datos se sacaron de cinco partidos recientes.

a) ¿Cuál es la variable dependiente?
El número de lanzamientos no regresados durante un partidob) ¿Cuál es la ecuación de estimación de mínimos cuadrados para estos
datos?- Graficar el diagrama de dispersión
- Calcular los Coeficientes “a” y “b”.
a=∑ y .∑ x2−∑ x .∑ x . y
n∑ x2−(∑ x )2=¿ (25∗158.5)−(28∗131)
(5∗158.5)−282 =¿ 34.647059
b=n .∑ x . y−∑ x .∑ y
n∑ x2−¿¿¿ -5.294118
y=a+bx

y=34.647059−5.294118 X
Interpretación: Por cada incremento de un pie en la estatura de los contrincantes, el número de lanzamientos no regresados disminuirá en 5 aproximadamente.
c) ¿Cuál es su mejor estimación del número de lanzamientos no regresados en su partido de mañana con un oponente de 5.9 pies de estatura?
y=34.647059−5.294118(5.9) = 3.41
Es decir, el número de lanzamientos no regresados en su partido de mañana con un oponente de 5.9 pies de estatura será de 3 aproximadamente.
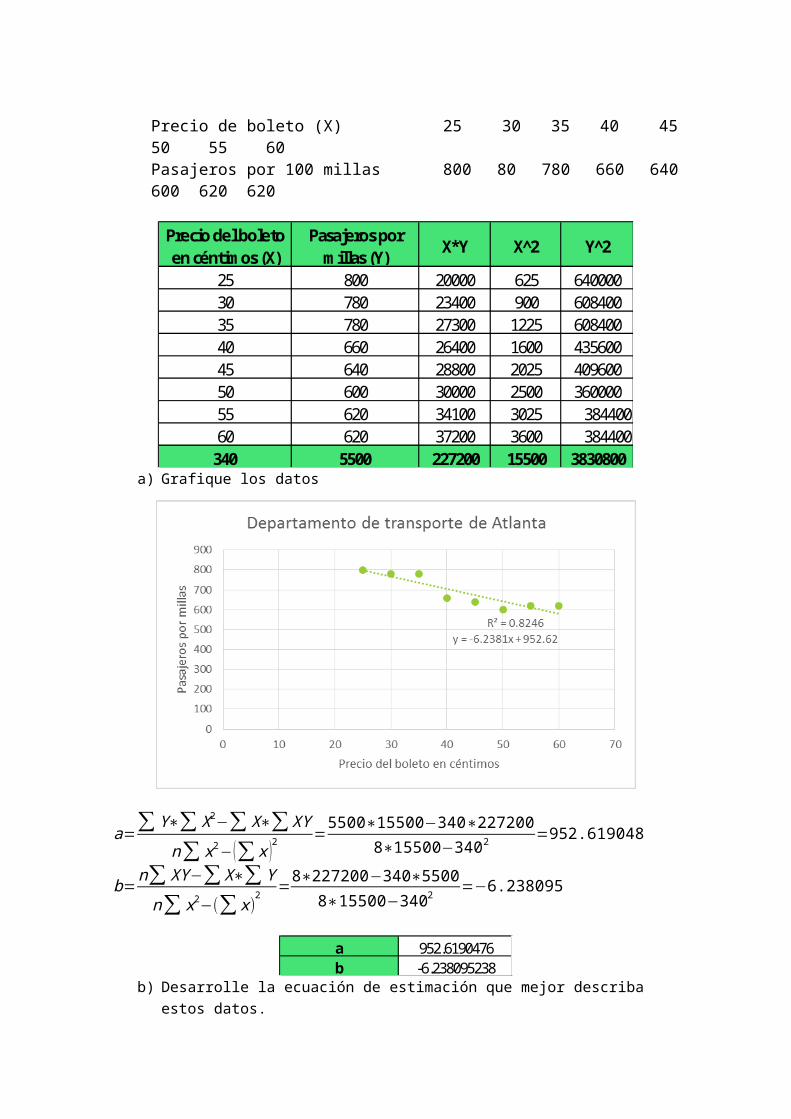
12-18 Un estudio elaborado por el Departamento de Transporte de Atlanta, Georgia, acerca del efecto de los precios de boletos de autobús sobre el número de pasajeros produjo los siguientes resultados.
Precio de boleto (X) 25 30 35 40 45 50 55 60Pasajeros por 100 millas 800 80 780 660 640 600 620 620
Precio del boleto en céntimos (X)
Pasajeros por millas (Y)
X*Y X^2 Y^2
25 800 20000 625 64000030 780 23400 900 60840035 780 27300 1225 60840040 660 26400 1600 43560045 640 28800 2025 40960050 600 30000 2500 36000055 620 34100 3025 38440060 620 37200 3600 384400
340 5500 227200 15500 3830800a) Grafique los datos

a=∑ Y∗∑ X2−∑ X∗∑ XY
n∑ x2−(∑ x )2=5500∗15500−340∗227200
8∗15500−3402 =952.619048
b=n∑ XY−∑ X∗∑Y
n∑ x2−(∑ x)2 =
8∗227200−340∗55008∗15500−3402 =−6.238095
a 952.6190476b -6.238095238
b) Desarrolle la ecuación de estimación que mejor describa estos datos.
Y=952.619048−6.238095 xc) Pronostique el número de pasajeros/100millas si el precio del boleto fuera de 50
centavos. Utilice un intervalo de predicción del 95% de aproximación.
¿ Y− ti Sxy , Y +ti Sxy>¿
#1 PasoY=952.619048−6.238095∗50=640.7143
Y=641 Pasajeros por cada 100 millas
#2 Paso
n = 8, α=5% utilizamos la t(n-k) g.l.= t (6) g.l.

#3 Paso
Syx=√∑ y2−a∑ y−b∑ xyn−k
=√ 3830800−952.619048∗5500−(−6.238095)∗2272006
=38.05802
38 pasajeros por 100 millas.
¿ Y− ti Sxy , Y +ti Sxy>¿¿641−2.477∗38 ,641+2.477∗38>≅<547,735>¿
Estamos 95% seguros que el número de pasajeros/100 millas estarán entre 548 y 735 pasajeros, cuando el precio del boleto sea de 50 centavos.
12-19 William C. Andrews, consultor de comportamiento organizacional de Victory Motorcycles, ha diseñado una prueba para mostrar a los supervisores de la compañía los peligros de sobre vigilar a sus trabajadores. Un trabajador de la línea de ensamble tiene a su cargo una serie de tareas complicadas. Durante el desempeño del trabajador, un inspector lo interrumpe constantemente para ayudarlo a terminar las tareas. El trabajador, después de terminar su trabajo, recibe una prueba psicológica diseñada para medir la hostilidad del trabajador hacia la autoridad. A ochos trabajadores se les asignaron las tareas y luego se les interrumpió para darles instrucciones útiles un número no variable de veces (línea X). Sus calificaciones en la prueba de hostilidad están en el reglón Y.
X 5 10 10 15 15 20 20 25Y 58 41 45 27 26 12 16 3
(X) (Y) X*Y X^2 Y^25 58 290 25 336410 41 410 100 168110 45 450 100 202515 27 405 225 72915 26 390 225 67620 12 240 400 14420 16 320 400 25625 3 75 625 9
120 228 2580 2100 8884
n 8X PROMEDIO 15Y PROMEDIO 28.5
a 70.5b -2.8
a=∑ Y∗∑ X2−∑ X∗∑ XY
n∑ x2−(∑ x )2=228∗2100−120∗2580
8∗2100−1202 =70.5
b=n∑ XY−∑ X∗∑Y
n∑ x2−(∑ x)2 =
8∗2580−120∗2288∗2100−1202 =−2.8
a) Graficar
b) Ecuación de proyección
Y=70.5−2.8 x

c) Interrumpido 18 veces
Y=70.5−2.8 (18 )=20.1La calificación esperada de la prueba si el trabajador es interrumpido 18 veces es de 20.1
12-20 El editor en jefe de un importante periódico metropolitano ha intentado convencer al dueño para que mejore las condiciones de trabajo en la imprenta. Está convencido de que, cuando trabajan las prensas, el grado de ruido crea niveles no saludables de tensión t ansiedad. Recientemente hizo que un sicólogo realizara una prueba durante la cual situaron a los prensistas en cuadros con niveles variables de ruido y luego les hicieron otra prueba para medir niveles de humor y ansiedad.
a) Grafique estos datos
b) Desarrolle una ecuación de estimación que describa los datos.
a=∑ y .∑ x2−∑ x .∑ x . y
n∑ x2−(∑ x )2=
(260∗128)−(28∗1047)(8∗128)−282 =¿16.516667
0 1 2 3 4 5 6 7 805
101520253035404550
f(x) = 4.56666666666667 x + 16.5166666666667R² = 0.71911877394636
DIAGRAMA DE DISPERSIÒN
DIAGRAMA DE DIS-PERSIÒNLinear (DIAGRAMA DE DISPERSIÒN)

b=n .∑ x . y−∑ x .∑ y
n∑ x2−¿¿¿ 4.566667
Ecuación de la recta de mejor ajuste a estos datos y representarla sobre la gráfica.
y=a+bxy=16.516667+4.566667 x
c) Pronostique el grado de ansiedad que podríamos esperar cuando el nivel de ruido sea 5.
y=16.516667+4.566667(5)
y=39.350002
Interpretación= El grado de ansiedad que podríamos esperar cuando el nivel de ruido es 5 es de 39.350002.
12-21 Una compañía administra a sus vendedores en capacitación una prueba de ventas antes de salir a trabajar. La administración de la compañía está interesada en determinar la relación entre las calificaciones de la prueba y las ventas logradas por esos vendedores al final de un año de trabajo. Se recolectaron los siguientes datos de 10 agentes de ventas que han estado en el campo un año.
a) Encuentre la recta de regresión de mínimos cuadrados que podría usarse para predecir las ventas a partir de las calificaciones en la prueba de capacitación.
a=∑ y .∑ x2−∑ x .∑ x . y
n∑ x2−(∑ x )2=
(260∗128)−(28∗1047)(8∗128)−282 =¿16.516667
b=n .∑ x . y−∑ x .∑ y
n∑ x2−¿¿¿ 4.566667

Ecuación de la recta de mejor ajuste a estos datos y representarla sobre la gráfica.y=a+bx
y=16.516667+4.566667 xb) ¿En cuánto se incrementa el número esperado de unidades vendidas por cada
incremento de 1 punto en una calificación de la prueba?
Por cada punto adiciona, el número de unidades vendidas aumentará en 41.680912
c) Utilice la recta de regresión de mínimos cuadrados para predecir el número de unidades que vendería un capacitado que obtuvo una calificación promedio en la prueba.
Número de unidades que vendería un capacitado que obtuvo una calificación promedio en la prueba.
Calif. promedio
¿n .∑ x . y−∑ x .∑ y 2.6+3.7+2.4+4.5+2.6+5.0+2.8+3.0+4.0+3.4
10=3.4
y=16.516667+4.566667(3.4 )y=137.100001
Interpretación: El número de unidades que vendería un capacitado que obtuvo una calificación promedio en la prueba es de 137.100001
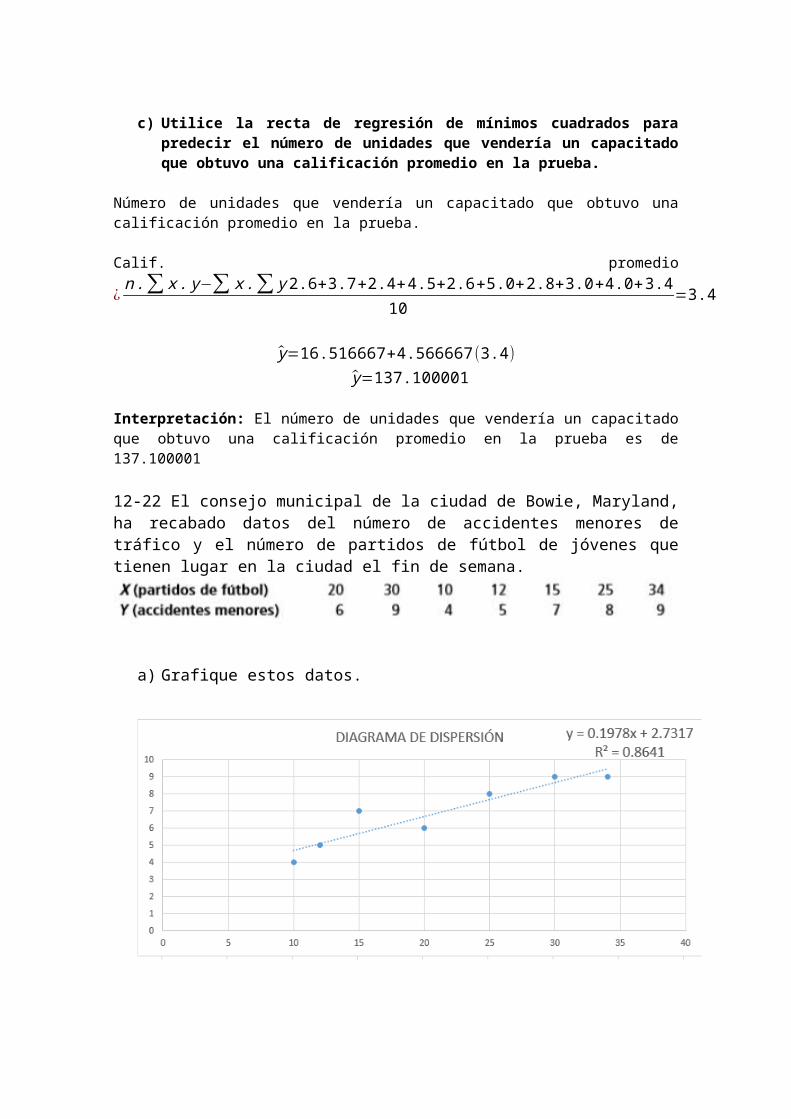
12-22 El consejo municipal de la ciudad de Bowie, Maryland, ha recabado datos del número de accidentes menores de tráfico y el número de partidos de fútbol de jóvenes que tienen lugar en la ciudad el fin de semana.
a) Grafique estos datos.

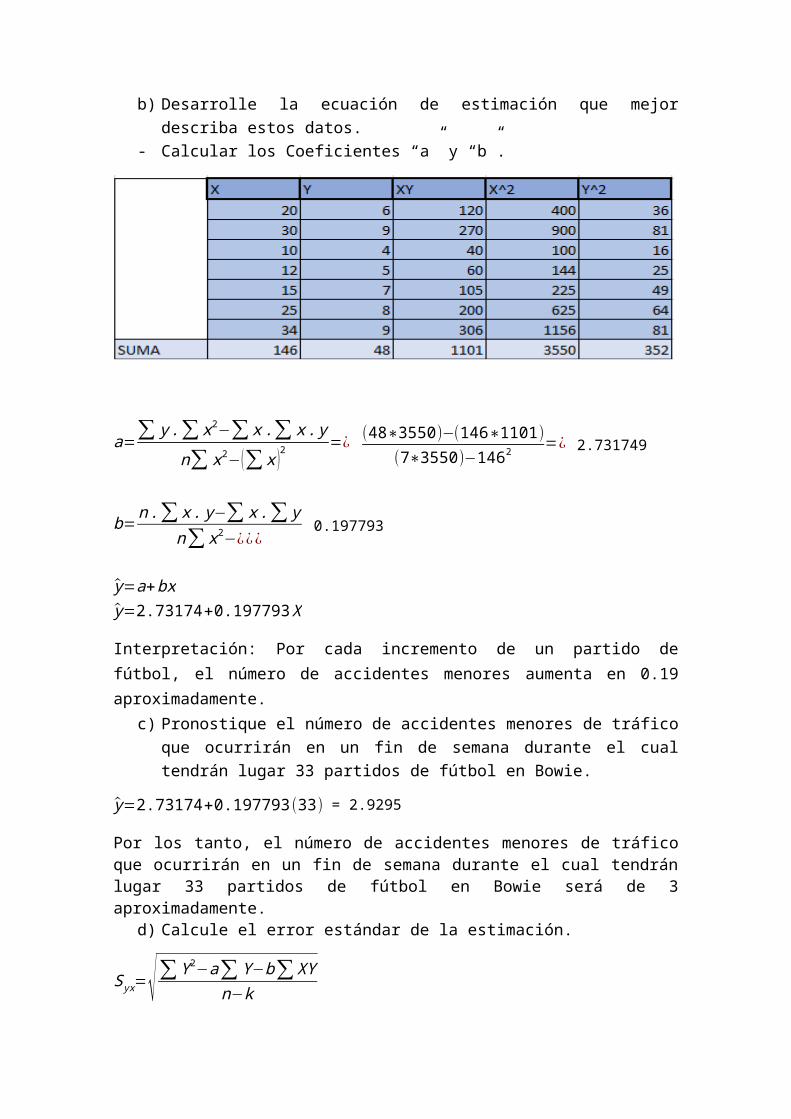
b) Desarrolle la ecuación de estimación que mejor describa estos datos. - Calcular los Coeficientes “a” y “b”.
a=∑ y .∑ x2−∑ x .∑ x . y
n∑ x2−(∑ x )2=¿ (48∗3550)−(146∗1101)
(7∗3550)−1462 =¿ 2.731749
b=n .∑ x . y−∑ x .∑ y
n∑ x2−¿¿¿ 0.197793
y=a+bxy=2.73174+0.197793 X
Interpretación: Por cada incremento de un partido de fútbol, el número de accidentes menores aumenta en 0.19 aproximadamente.
c) Pronostique el número de accidentes menores de tráfico que ocurrirán en un fin de semana durante el cual tendrán lugar 33 partidos de fútbol en Bowie.
y=2.73174+0.197793(33) = 2.9295
Por los tanto, el número de accidentes menores de tráfico que ocurrirán en un fin de semana durante el cual tendrán lugar 33 partidos de fútbol en Bowie será de 3 aproximadamente.
d) Calcule el error estándar de la estimación.
Syx=√∑Y 2−a∑ Y−b∑ XYn−k
Syx=√ 352−2.73174 (48 )−0.197793(1101)5
=0.7881
Interpretación: Los valores observados en la muestra están dispersos con respecto a la recta de regresión en 0.78 accidente de tráfico menor.12-23 En economía, la función de demanda de un producto a menudo se estima mediante una regresión de la cantidad vendida (Q) sobre el precio (P). La

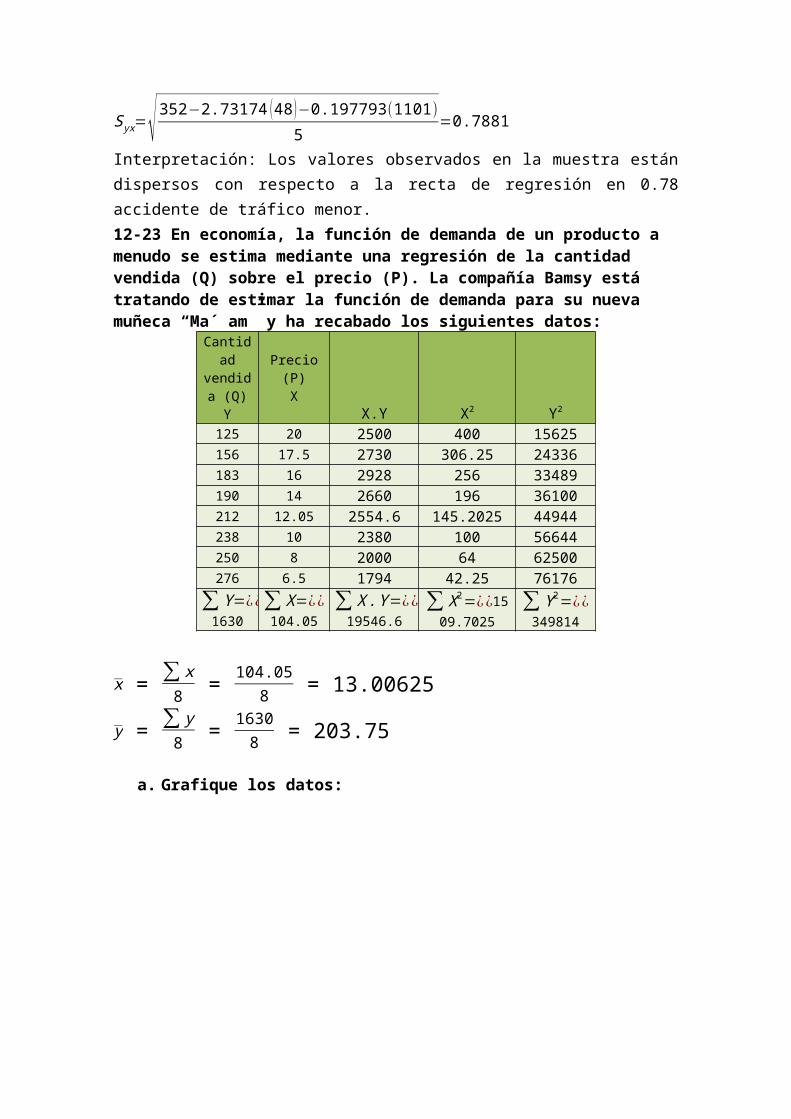
compañía Bamsy está tratando de estimar la función de demanda para su nueva muñeca “Ma´ am” y ha recabado los siguientes datos:
Cantidad
vendida (Q) Y
Precio (P) X
X.Y X2 Y2
125 20 2500 400 15625156 17.5 2730 306.25 24336183 16 2928 256 33489190 14 2660 196 36100212 12.05 2554.6 145.2025 44944238 10 2380 100 56644250 8 2000 64 62500276 6.5 1794 42.25 76176
∑Y=¿¿1630
∑ X=¿¿104.05
∑ X .Y=¿¿19546.6
∑ X2=¿¿1509.7025
∑Y 2=¿¿349814
x = ∑ x8
= 104.058 = 13.00625
y = ∑ y8
= 16308 = 203.75
a. Grafique los datos:
4 6 8 10 12 14 16 18 20 220
50
100
150
200
250
300
DIAGRAMA DE DISPERSIÓN
DIAGRAMA DE DIS-PERSIÓN
b. Calcule la recta de regresión de mínimos cuadrados:
a=∑ y .∑ x2−∑ x .∑ x . yn∑ x2−∑ x2 =¿ (1630∗1509.70)−(104.05∗19546.6)
(8∗1509.70)−(104.05¿¿2)=¿¿ 341.262886
b=n .∑ x . y−∑ x .∑ y
n∑ x2−¿¿¿ -10.572831
Ecuación de regresión: y=341.26−10.57 x
c. Trace la recta de regresión ajustada en la gráfica:
4 6 8 10 12 14 16 18 20 220
50
100
150
200
250
300
f(x) = − 10.5726622269909 x + 341.260688089801R² = 0.987646363318043
DIAGRAMA DE DISPERSIÓN
DIAGRAMA DE DIS-PERSIÓN Linear (DIAGRAMA DE DISPERSIÓN )
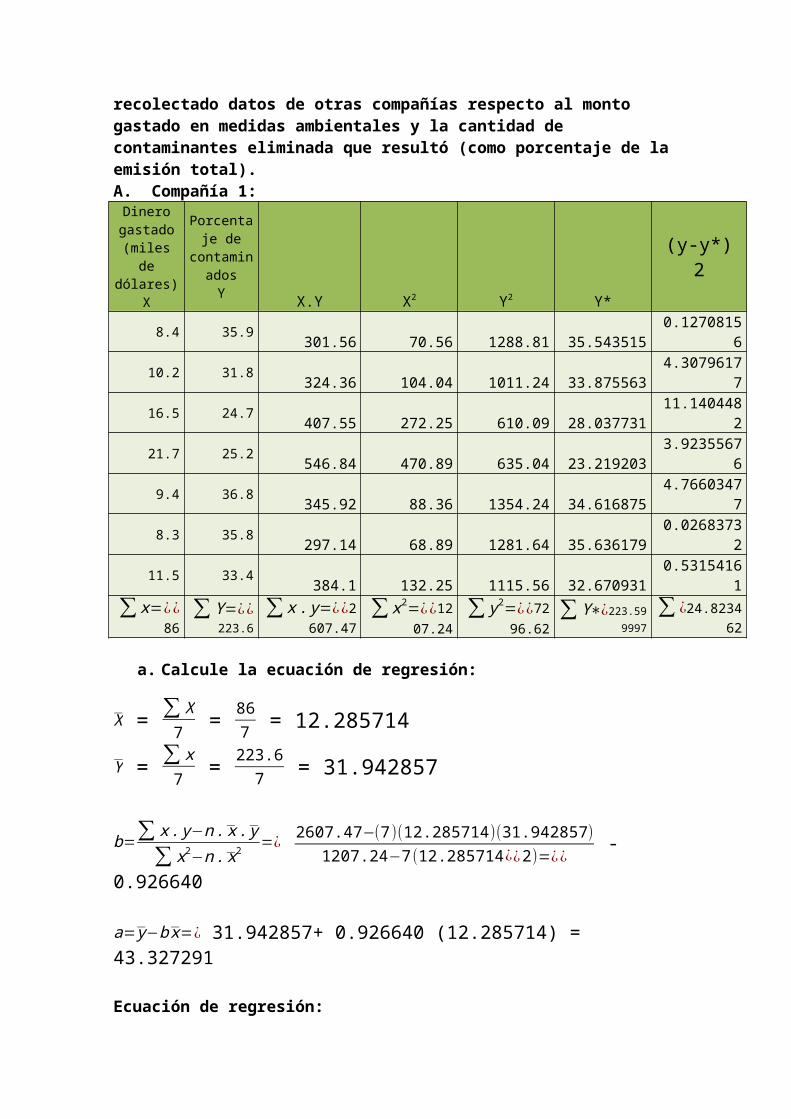
12-24 Una compañía fabricante de llantas está interesada en eliminar contaminantes de los tubos de emisión de su fábrica y el costo es una preocupación. La compañía ha recolectado datos de otras compañías respecto al monto gastado en medidas ambientales y la cantidad de contaminantes eliminada que resultó (como porcentaje de la emisión total).A. Compañía 1:
Dinero gastado (miles de
dólares) X
Porcentaje de
contaminados Y X.Y X2 Y2 Y*
(y-y*) 2
8.4 35.9 301.56 70.56 1288.81 35.543515 0.1270815610.2 31.8 324.36 104.04 1011.24 33.875563 4.3079617716.5 24.7 407.55 272.25 610.09 28.037731 11.140448221.7 25.2 546.84 470.89 635.04 23.219203 3.92355676
9.4 36.8 345.92 88.36 1354.24 34.616875 4.766034778.3 35.8 297.14 68.89 1281.64 35.636179 0.02683732
11.5 33.4 384.1 132.25 1115.56 32.670931 0.53154161∑ x=¿¿
86∑Y=¿¿
223.6∑ x . y=¿¿
2607.47∑ x2=¿¿
1207.24∑ y2=¿¿
7296.62∑Y∗¿
223.599997∑ ¿
24.823462
a. Calcule la ecuación de regresión:
X = ∑ X7
= 867 = 12.285714
Y = ∑ x7
= 223.67 = 31.942857
b=∑ x . y−n . x . y
∑ x2−n . x2 =¿ 2607.47−(7)(12.285714)(31.942857)1207.24−7(12.285714¿¿2)=¿¿
-0.926640
a= y−b x=¿ 31.942857+ 0.926640 (12.285714) = 43.327291
Ecuación de regresión: y=43.327291−0.926640 x
6 8 10 12 14 16 18 20 22 240
5
10
15
20
25
30
35
40
f(x) = − 0.926641256115599 x + 43.3273068608488R² = 0.839014773309063
DIAGRAMA DE DISPERSIÓN
DIAGRAMA DE DIS-PERSIÓNLinear (DIAGRAMA DE DISPERSIÓN)
b. Pronostique el porcentaje de contaminantes eliminados si se gastan 20,000 en medidas de control:
y=43.327291−0.926640 xy=43.327291−0.926640(20)
Y = 24.7924.79 es el porcentaje de contaminantes eliminados si se gastan 20,000 en medidas de control.
c. Calcule el error estándar de estimación:
Syx=√∑ (Y−Y ¿)2
n−k
Syx=√ 24.827−2
Syx=2.228
B. Compañía 2:Dinero
gastado (miles de dólares)
X
Porcentaje de contaminados
YX.Y Y2 X2 Y*
(y-y*) 2
18.4 25.4 467.36 645.16 338.56 24.9394282 0.2121263816.7 31.4 524.38 985.96 278.89 26.5696041 23.332724619.3 27.4 528.82 750.76 372.49 24.0763939 11.046357528.4 15.8 448.72 249.64 806.56 15.3501582 0.202357654.7 31.5 148.05 992.25 22.09 38.0767281 43.2533525
12.3 28.9 355.47 835.21 151.29 30.7888829 3.56787861
∑ x=¿¿99.8
∑ y=¿¿160.4
∑ x . y=¿¿2472.8
∑ y2=¿¿4458.98
∑ x2=¿¿1969.88
∑ y∗¿159.801195
∑ ¿81.6147972
a. Calcule la ecuación de regresión:
x = ∑ x6 = 99.8
6 = 16.633333
y = ∑ y6
= 160.46 = 26.7333333
b=∑ x . y−n . x . y
∑ x2−n . x2 =¿ 2472.5−(6)(16.633333)(27.733333)1969.88−6 (16.633333¿¿2)=¿¿
-0.952927
a= y−b x=¿ 26.733333+ 0.952927 (16.633333) = 42.583685
Ecuación de regresión: y=42.583685−0.958927 x
0 5 10 15 20 25 300
5
10
15
20
25
30
35
DIAGRAMA DE DISPERSIÓN
DIAGRAMA DE DIS-PERSIÓN Linear (DIAGRAMA DE DISPERSIÓN )
b. Pronostique el porcentaje de contaminantes eliminados si se gastan 20,000 en medidas de control:
y=42.583685−0.958927 xy=42.583685−0.958927(20)
Y= 23.4123.41 es el porcentaje de contaminantes eliminados si se gastan 20,000 en medidas de control.
c. Calcule el error estándar de estimación:
Syx=√∑ (Y−Y ¿)2
n−k
Syx=√ 81.616−2

Syx=4.52
12-34 Neds Beds está considerando contratar a una compañía de publicidad para estimular el negocio. Fred, el hermano de Ned, investigo el campo de la publicidad de camas y recolecto los siguientes datos de la cantidad de ganancias (Y) Que logra una compañía de camas y la cantidad gastada en publicidad (X).Si Fred calcula la ecuación de regresión, la pendiente de la recta indicaría el incremento en la ganancia por dólar gastado en publicidad. Ned hará la publicidad solo si la gaancina de cada $1 invertido excede $ 1.50. Calcule la pendiente de la ecuación y pruebe si es mayor que 1.50. Para un nivel de significancia de 0.05.
Cantidad de publicidad en
cientos de dòlares (X)
Ganancia en cientos de
dòlares (Y)
X*Y X^2 Y^2
3.6 12.13 43.668 12.96 147.13694.8 14.7 70.56 23.04 216.099.7 22.83 221.451 94.09 521.2089
12.6 28.4 357.84 158.76 806.5611.5 28.33 325.795 132.25 802.588910.9 27.05 294.845 118.81 731.702514.6 33.6 490.56 213.16 1128.9618.2 40.8 742.56 331.24 1664.643.7 9.4 34.78 13.69 88.369.8 24.84 243.432 96.04 617.0256
12.4 30.17 374.108 153.76 910.228916.9 34.7 586.43 285.61 1204.09
128.7 306.95 3786.029 1633.41 8838.592
n 12X PROMEDIO 10.725Y PROMEDIO 25.57916667
a=∑ Y∗∑ X2−∑ X∗∑ XY
n∑ x2−(∑ x )2=306.95∗1633.41−128.7∗3786.029
12∗1633.41−128.72 =4.646752
b=n∑ XY−∑ X∗∑Y
n∑ x2−(∑ x)2 =
12∗3786.029−128.7∗306.9512∗1633.41−128.72 =1.951740
a 4.646756156b 1.951739908
1° PASO: Formulación de hipótesisH 0 : β≤1.5H 1: β>1.5
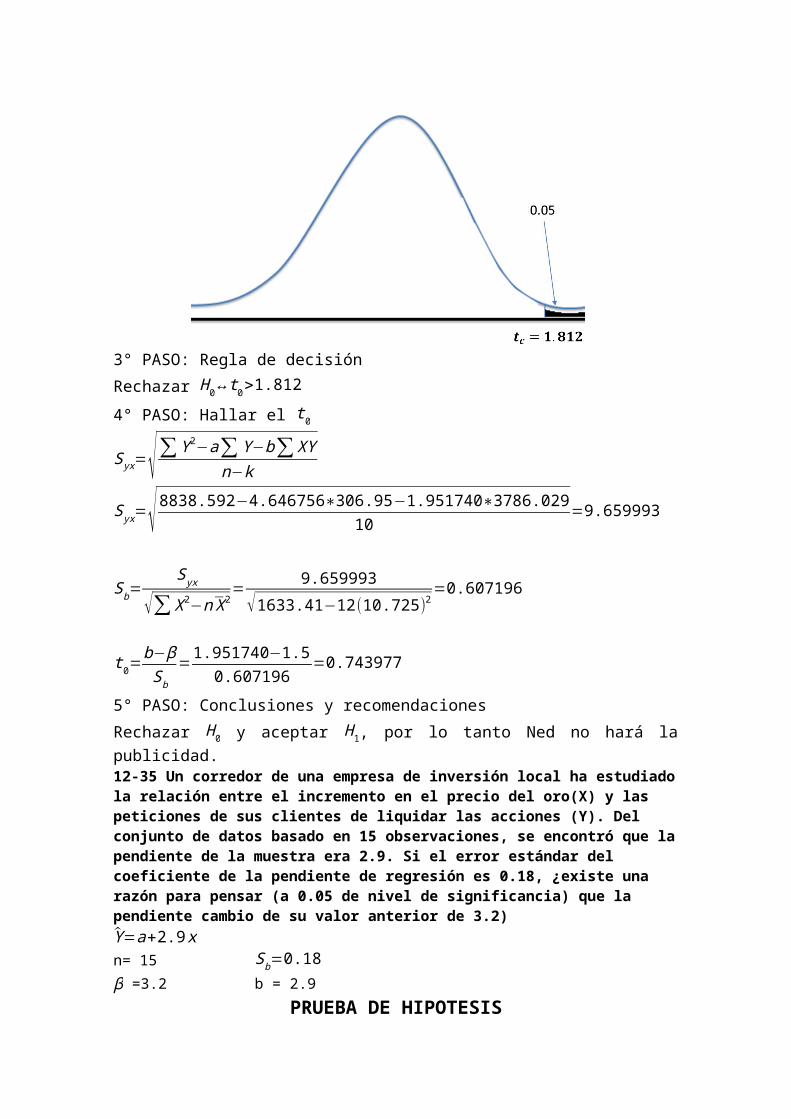
2° PASO: n = 12 ,∝=0.05, utilizamos la t (n−k )g .l .=t (10) g . l .
3° PASO: Regla de decisiónRechazar H 0↔t 0>1.8124° PASO: Hallar el t 0
Syx=√∑ Y 2−a∑ Y−b∑ XYn−k
Syx=√ 8838.592−4.646756∗306.95−1.951740∗3786.02910
=9.659993
Sb=Syx
√∑ X 2−n X2= 9.659993
√1633.41−12(10.725)2=0.607196
t 0=b−βSb
=1.951740−1.50.607196
=0.743977
5° PASO: Conclusiones y recomendacionesRechazar H 0 y aceptar H1, por lo tanto Ned no hará la publicidad.12-35 Un corredor de una empresa de inversión local ha estudiado la relación entre el incremento en el precio del oro(X) y las peticiones de sus clientes de liquidar las acciones (Y). Del conjunto de datos basado en 15 observaciones, se encontró que la pendiente de la muestra era 2.9. Si el error estándar del coeficiente de la pendiente de regresión es 0.18, ¿existe una razón para pensar (a 0.05 de nivel de significancia) que la pendiente cambio de su valor anterior de 3.2)Y=a+2.9 x n= 15 Sb=0.18β =3.2 b = 2.9

PRUEBA DE HIPOTESIS1º PASO: FORMULACION DE HIPOTESISH0: β =3.2H1: β 3.22º PASO n= 15 y se conoce α = 5%, utilizamos t 13 g .l
3º PASO: REGLA DE DECISIONRechazar H0 si y solo si t 0<−2.160ó t 0>2.1604º PASO: CÁLCULO DEL ESTADÍSTICO
t 0=b−βSb
=2.9−3.20.18
t 0=¿ 1.675º PASO:Aprobamos H0 y rechazamos H1 por lo tanto la pendiente de la recta de regresión de la población sigue siendo 3.2 con un nivel de significación de 0.05. Por ello decimos que cada unidad adicional al incremento del precio del oro aumenta las peticiones de los clientes 3.2 aprox.
y=a+50 x
1°paso: Formulación de hipótesisH0: β= 1.50H1: β≠ 1.50
2°paso: n = 25, α=5% ; utilizamos la t(n-k) g.l.= t (23) g.l.
-tc= -2.069 tc=2.0693°paso: Regla de decisiónRechazar H0 ↔ t0 ¿ -2.069 o t0 ¿ 2.069
t c=2.160−t c=−2.160
0.0250.025

4°paso: Calculo del estadístico (t0)
Sb=S yx
√∑ (x−x)2=0.11
t0¿b−βSb
=¿ 1681818
5° Conclusiones y recomendaciones:- Aceptar H0 y rechazar H1, por lo tanto compruebo la veracidad de B= 0.150 y no ha cambiaodo al nivel de significación 5%
x y x^2 y^2 xy1.1 75 1.21 5625 82.51.5 95 2.25 9025 142.51.6 110 2.56 12100 1761.6 102 2.56 10404 163.21.4 95 1.96 9025 1331.3 87 1.69 7569 113.11.1 82 1.21 6724 90.21.7 115 2.89 13225 195.51.9 122 3.61 14884 231.81.5 98 2.25 9604 1471.3 90 1.69 8100 11716 1071 23.88 106285 1591.8
a=∑ y .∑ x2−∑ x .∑ x . y
n∑ x2−(∑ x )2=¿ 15.970818
b=n .∑ x . y−∑ x .∑ y
n∑ x2−¿¿¿ 55.957580
Recta de regresión:

y=a+bxy=15.970818+55.957580 x
Error estándar de estimación:
Syx=√∑ Y 2−a∑ Y−b∑ XYn−k
= 3.447674
B) y=a+50 x
1°paso: Formulación de hipótesisH0: β= 0H1: β≠ 02°paso: n = 6, α=1 % ; utilizamos la t(n-k) g.l.= t (4) g.l.
-tc= -1.833 tc=1.8333°paso: Regla de decisiónRechazar H0 ↔ t0 ¿ -1.833 o t0 ¿ 1.833
4°paso: Calculo del estadístico (t0)
Sb=S yx
√∑ (x−x)2=4.424115
t0¿b−βSb
=¿ 11.301605
5° Conclusiones y recomendaciones:- Aceptar H1 y rechazar H0, por lo tanto existe una relación negativa entre el área y el valor.
¿b−tc Sb ,b+ tc Sb>¿

Sb = 0.147
2°paso: n = 18 , α=1 % ; utilizamos la t(n-k) g.l.= t (16) g.l.
-tc= -1.746 tc=1.7463°paso: Regla de decisiónRechazar H0 ↔ t0 ¿ -1.746o t0 ¿ 1.746
4°paso: Calculo del estadístico (t0)
Sb=S yx
√∑ (x−x)2=5.424115
t0¿b−βSb
=¿ 13.4721
Por lo tanto :¿0.147−13.4(5.42) ,0.147+13.4(5.42)>¿
Desarrollamos el intervalo de confianza:←72.81+394.4405¿>¿
12-39 La compañía local de teléfonos siempre ha supuesto que el número promedio de las llamadas diarias aumenta en un1.5 por cada persona adicional en una casa. Se ha sugerido que la gente es más platicadora que lo que esto refleja. Se tomó una muestra de 64 personas y se calculó que la pendiente de regresión de Y (numero promedio de las llamadas diarias) sobre X (tamaño de la casa) era 1.8 con un error estándar del coeficiente de la pendiente de regresión de 0.2. Pruebe si se hacen significativamente más llamadas por persona adicional de lo que la compañía de teléfonos supone: α= 0.05. Establezca las hipótesis y las conclusiones explicitas.DATOS:β = 1.5 b =1.8
n= 64 Sb=0.2
Prueba de hipótesis de la existencia de la regresión (β) Nivel de significación = 5%
1°PASO: FORMULACIÓN DE HIPÓTESISH0: β= 1.5H1: β≠ 1.5
2°PASO: n = 64, α=5 % ; utilizamos la zα/2
3°PASO: REGLA DE DECISIÓNRechazar H0 ↔ t0 ¿ -1.96 o t0 ¿ 1.96
4°PASO: CALCULO DEL ESTADÍSTICO (t0)Sb=¿0.2
z0¿b−βSb
=¿ 1.8−1.5
0.2 = 1.5
5° CONCLUSIONES Y RECOMENDACIONES:- Aceptar H0 y rechazar H1, por lo tanto existe una relación entre las horas y las unidades producidas.
12- 40. Los funcionarios universitarios responsables de la admisión constantemente buscan variables con las cuales predecir los promedios de las calificaciones de los aspirantes. Una variable de uso común es el promedio de calificaciones del bachillerato. Para la universidad, los datos anteriores indicaban que la pendiente era 0.85. Un pequeño estudio reciente de 20 estudiantes encontró que la pendiente de la muestra era 0.70 y que el error estándar de la estimación era 0.60. La cantidad ¿ era igual que 0.25. al nivel de la significancia de 0.01. ¿Debería concluir la universidad que la pendiente ha cambiado?
Y=a+0.70 x n = 20 b = 0.70
β = 0.85 SYX=0.60 ∑ (X2)−n X 2=0.25
PRUEBA DE HIPOTESIS1º PASO: FORMULACION DE HIPOTESISH0: β =0.85H1: β 0.85
2º PASO n= 20 y se conoce α = 1%, utilizamos t 18 g .l
-2.228 2.228- zα/2 =-1.96 zα/2 =1.96
0.0050.005

3º PASO: REGLA DE DECISIONRechazar H0 si y solo si t 0<−2.878ó t 0>2.8784º PASO: CÁLCULO DEL ESTADÍSTICO
t 0=b−βSb
=0.70−0.851.2 Sb=
SYX
√∑ (X2)−n X2= 0.60
√0.25=1.2
t 0=¿ 1.295º PASO:Aprobamos H0 y rechazamos H1 por lo tanto la pendiente de la recta de regresión de la población sigue siendo 0.85 con un nivel de significación de 0.01. Por ello decimos que cada unidad adicional al número de los aspirantes aumenta el número de calificaciones de los aspirantes promedio de 0.85 aprox.
EJERCICIOS DE LA DIAPOSITIVAS
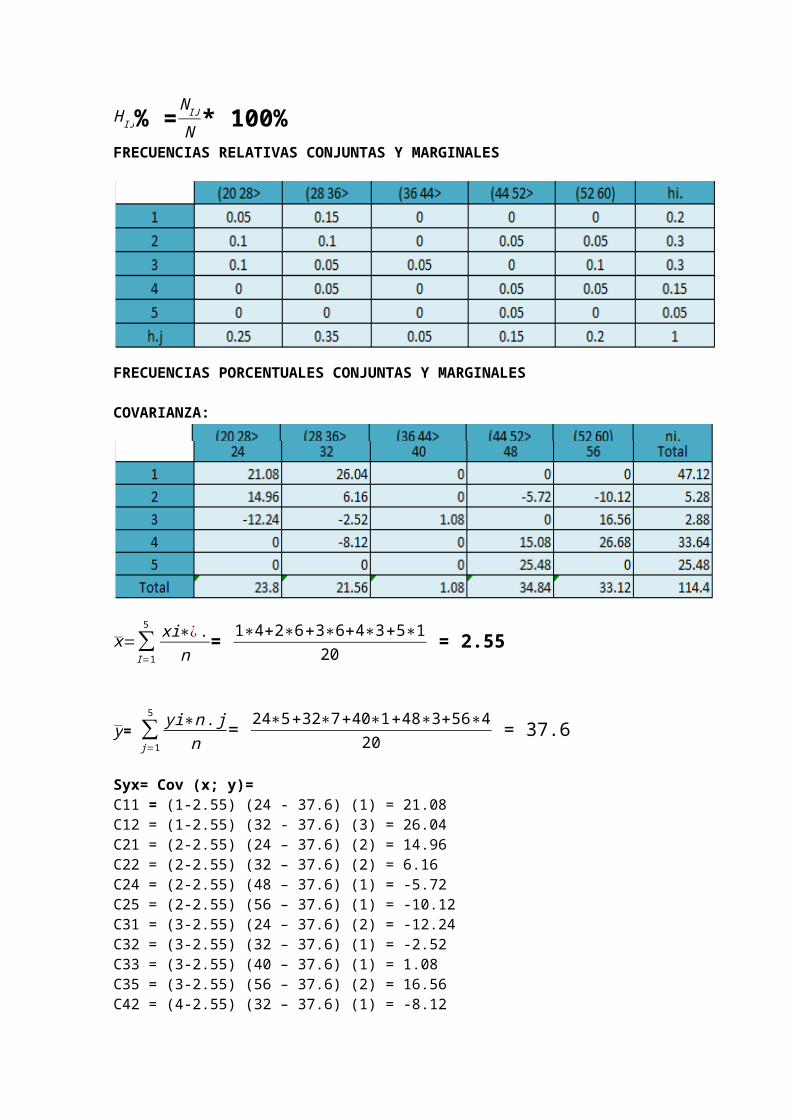
PRIMER EJERCICIO DE LA DIAPOSITIVA1. Construir la Tabla Bidimensional, con la muestra de 20 familias donde
estamos interesados en conocer número de hijos y el ingreso familiar mensual en miles de dólares siendo los datos los siguientes: (X: Hijos; Y:Ingreso familiar) (3;21), (5;45), (4;50),(2;35), (1;20), (2;53), (1;32), (2;44), (2;22), (1;32), (3;54), (3;28), (3;40), (2;34), (4;28), (1;33), (4;60), (2;25), (3;25), (3;53) Calcular frecuencia absoluta, relativa, porcentual, conjunta y marginal., frecuencias condicionales, existencia de independencia, COVARIANZA.
FRECUENCIA ABSOLUTA BIDIMENSIONAL
FRECUENCIAMARGINAL
MARGINAL FRECUENCIA
FRECUENCIA MARGINAL CONJUNTA
FRECUENCIA RELATIVA BIDIMENSIONAL
X Y [20 - 28> [ 28 - 36> [ 36 - 44> [ 44 - 52> [ 52 - 60] ni.
1 0.05 0.15 0 0 0 0.22 0.1 0.1 0 0.05 0.05 0.33 0.1 0.05 0.05 0 0.1 0.34 0 0.05 0 0.05 0.05 0.155 0 0 0 0.05 0 0.05
n.j 0.25 0.35 0.05 0.15 0.2 1
X Y [20 - 28> [ 28 - 36> [ 36 - 44> [ 44 - 52> [ 52 - 60] ni.
1 1 3 0 0 0 42 2 2 0 1 1 63 2 1 1 0 2 64 0 1 0 1 1 35 0 0 0 1 0 1
n.j 5 7 1 3 4 20

FRECUENCIA MARGINAL
FRECUENCIA FRECUENCIA MARGINAL CONJUNTA
FRECUENCIA PORCENTUAL BIDIMENSIONAL X Y [20 - 28> [ 28 - 36> [ 36 - 44> [ 44 - 52> [ 52 - 60] ni.
1 5% 15% 0% 0% 0% 20%2 10% 10% 0% 5% 5% 30%3 10% 5% 5% 0% 10% 30%4 0% 5% 0% 5% 5% 15%5 0% 0% 0% 5% 0% 5%
n.j 25% 35% 5% 15% 400% 100%
Media de x:
x=1∗4+2∗6+3∗6+4∗3+5∗120
=2.55
Media de y:
y=24∗5+32∗7+40∗1+48∗3+56∗420
=37.6
Covarianza: X Y 24 32 40 48 56 ni.
1 1 3 0 0 0 42 2 2 0 1 1 63 2 1 1 0 2 64 0 1 0 1 1 35 0 0 0 1 0 1
n.j 5 7 1 3 4 20
1° fila hasta la 5° columna:C11 = (1-2.55)*(24-37.6)*(1) = 21.08C12= (1-2.55)*(32-37.6)*(3) = 26.04C13= (1-2.55)*(40-37.6)*(0) = 0C14 = (1-2.55)*(48-37.6)*(0) = 0C15= (1-2.55)*(56-37.6)*(0) = 0
2° fila hasta la 5° columna:C21 = (2-2.55)*(24-37.6)*(2) = 14.96C22= (2-2.55)*(32-37.6)*(2) = 6.16C23= (2-2.55)*(40-37.6)*(0) = 0C24 = (2-2.55)*(48-37.6)*(1) = -5.72C25= (2-2.55)*(56-37.6)*(1) = -10.12

3° fila hasta la 5° columna:C31 = (3-2.55)*(24-37.6)*(2) = -12.24C32= (3-2.55)*(32-37.6)*(1) = -2.52C33= (3-2.55)*(40-37.6)*(1) = 1.08C34 = (3-2.55)*(48-37.6)*(0) = 0C35= (3-2.55)*(56-37.6)*(2) = 16.564° fila hasta la 5° columna:C41 = (4-2.55)*(24-37.6)*(0) = 0C42= (4-2.55)*(32-37.6)*(1) = -8.12C43= (4-2.55)*(40-37.6)*(0) = 0C44 = (4-2.55)*(48-37.6)*(1) = 15.08C45= (4-2.55)*(56-37.6)*(1) = 26.685° fila hasta la 5° columna:C51 = (5-2.55)*(24-37.6)*(0) = 0C52= (5-2.55)*(32-37.6)*(0) = 0C53= (5-2.55)*(40-37.6)*(0) = 0C54 = (5-2.55)*(48-37.6)*(1) = 25.48C55= (5-2.55)*(56-37.6)*(0) = 0
COV (X, Y) = ∑ ∑ (X i¿¿−X )(Y i− y )∗n ij
N¿¿ = Sxy
Sxy=21.08+26.04+14.96+6.16−5.72−10.12−12.24−2.52+1.08+16.56−8.12+15.08+26.68+25.48
20
Sxy=114.4
20Sxy=5.72
- La covarianza es 5.72, es decir, es mayor a 0, por lo tanto evidencia una relación positiva.EJERCICIO DE LA DIAPOSITIVA:Construir la tabla bidimensional, conla muestra de 20 familias donde estamos interesados en conocer número de hijos y el ingreso familiar mensual en miles de dólares siendo los datos los siguientes: (X:hijos; Y:ingreso familiar) (3;21), (4; 45), (4; 50), (2; 35), (1; 20), (2; 53), (1; 32), (2; 44), (2; 22), (1; 32), (3;54), (3; 28), (3; 40), (2; 34), (4;28), (1;33), (4; 60), (2; 25), (3; 25), (3;53).Calcular frecuencia absoluta relativa, porcentual, conjunta y marginal, existencia de independencia, covarianza.FRECUENCIAS ABSOLUTAS CONJUNTAS Y MARGINALES

H IJ% =N IJ
N * 100%FRECUENCIAS RELATIVAS CONJUNTAS Y MARGINALESFRECUENCIAS PORCENTUALES CONJUNTAS Y MARGINALES
COVARIANZA:
x=∑I=1
5 xi∗¿ .n
= 1∗4+2∗6+3∗6+4∗3+5∗120 = 2.55
y= ∑j=1
5 yi∗n . jn
= 24∗5+32∗7+40∗1+48∗3+56∗420 = 37.6
Syx= Cov (x; y)= C11 = (1-2.55) (24 - 37.6) (1) = 21.08C12 = (1-2.55) (32 - 37.6) (3) = 26.04C21 = (2-2.55) (24 – 37.6) (2) = 14.96C22 = (2-2.55) (32 – 37.6) (2) = 6.16C24 = (2-2.55) (48 – 37.6) (1) = -5.72C25 = (2-2.55) (56 – 37.6) (1) = -10.12C31 = (3-2.55) (24 – 37.6) (2) = -12.24C32 = (3-2.55) (32 – 37.6) (1) = -2.52C33 = (3-2.55) (40 – 37.6) (1) = 1.08C35 = (3-2.55) (56 – 37.6) (2) = 16.56C42 = (4-2.55) (32 – 37.6) (1) = -8.12C44 = (4-2.55) (48 – 37.6) (1) = 15.08

C45 = (4-2.55) (56 – 37.6) (1) = 26.68C54 = (5-2.55) (48 – 37.6) (1) = 25.48Cov (x, y) = Sxy = 114.4/20 = 5.72Evidencia de una relación positivaEXISTENCIA DE INDEPENDENCIA:
¿ .N
∗n. j
N=n ij
N
n2.N
∗n .3
N=n23
N
0.30 * 0.05 ≠ 0Por lo tanto, no hay existencia de independencia
SEGUNDO EJERCICIO DE LA PIZARRA
RECTA DE LA REGRESION DE MEJOR AJUSTE :
a=∑ Y∗∑ X2−∑ X∗∑ XY
n∑ x2−(∑ x )2=60.033531
b=n∑ XY−∑ X∗∑Y
n∑ x2−(∑ x)2 =
12∗3786.029−128.7∗306.9512∗1633.41−128.72 =−0.04071
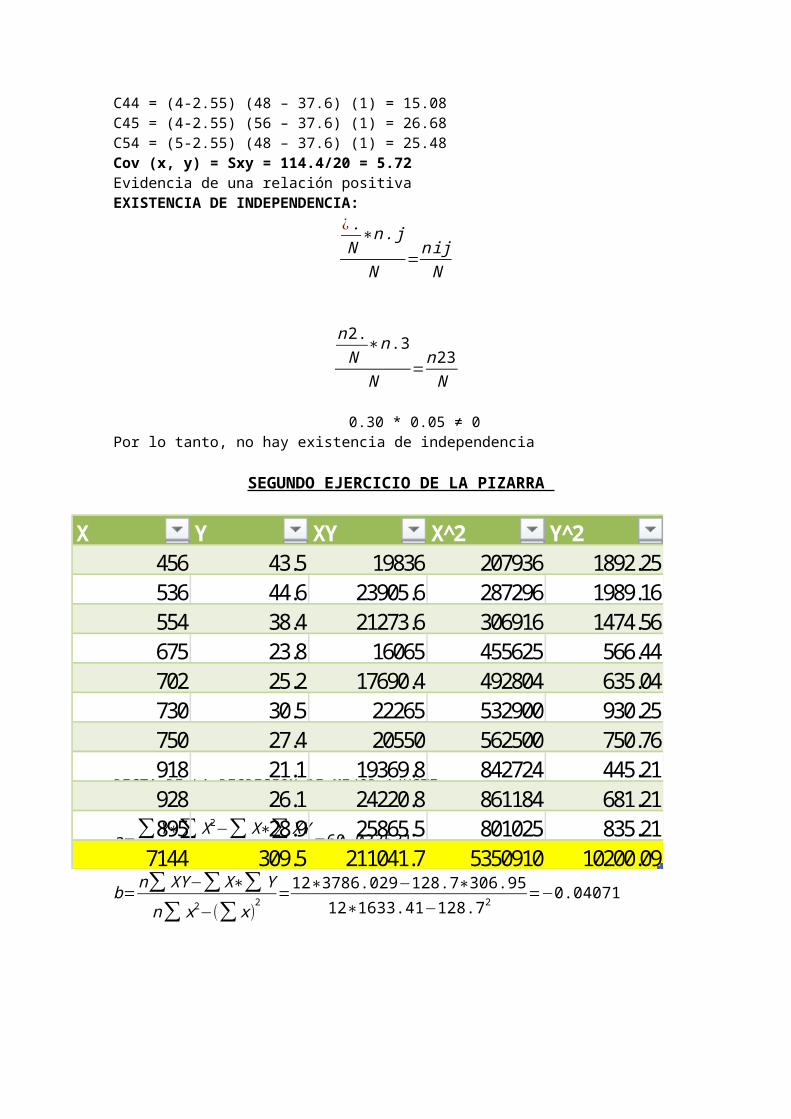
X Y XY X^2 Y^2456 43.5 19836 207936 1892.25536 44.6 23905.6 287296 1989.16554 38.4 21273.6 306916 1474.56675 23.8 16065 455625 566.44702 25.2 17690.4 492804 635.04730 30.5 22265 532900 930.25750 27.4 20550 562500 750.76918 21.1 19369.8 842724 445.21928 26.1 24220.8 861184 681.21895 28.9 25865.5 801025 835.21
7144 309.5 211041.7 5350910 10200.09
400 500 600 700 800 900 100005
101520253035404550
DIAGRAMA DE DISPERSIÓN
DIAGRAMA DE DIS-PERSIÓN

Cuadro ANOVA
concepto SUMA CUADRADO g.l CUADRADO MEDIO FSCR 409.845 1 409.845 15.52SCE 211.22 8 26.403SCT 621.065 9
SUMA CUADRADO DE ERRORES DE SCT ,SCR,SCE
DESVIACIÓN ESTÁNDAR DE LA REGRESIÓN
Syx=√∑ (Y−Y ¿)2
n−kSyx=5.138
Coeficiente de determinación (r2 ¿:
r2= SCRSCT
=0.66
Coeficiente de correlación(r ¿:r=+√r2
r=−0.81
X Y y Y-y (Y-y )^2 (y -Ymedia)^2 (Y-Ymedia)^2456 43.5 41.5 2 4 111.3025 157.5025536 44.6 38.2 6.4 40.96 52.5625 186.3225554 38.4 37.5 0.9 0.81 42.9025 55.5025675 23.8 32.6 -8.8 77.44 2.7225 51.1225702 25.2 31.5 -6.3 39.69 0.3025 33.0625730 30.5 30.3 0.2 0.04 0.4225 0.2025750 27.4 29.5 -2.1 4.41 2.1025 12.6025918 21.1 22.7 -1.6 2.56 68.0625 97.0225928 26.1 22.3 3.8 14.44 74.8225 23.5225895 28.9 23.6 5.3 28.09 54.0225 4.2025
7144 309.5 309.7 -0.2 212.44 409.225 621.065
400 500 600 700 800 900 100005
101520253035404550
DIAGRAMA DE DISPERSIÓN
DIAGRAMA DE DIS-PERSIÓN

. Prueba de hipótesis de la existencia de la regresión (β)
Nivel de significación = 5%
1°paso: Formulación de hipótesisH0: β= 0H1: β≠ 0
2°paso: n = 10, α=5% ; utilizamos la t(n-k) g.l.= t (8) g.l.
3°paso: Regla de decisiónRechazar H0 ↔ t0 ¿ -2.306 o t0 ¿ 2.306
4°paso: Calculo del estadístico (t0)
Sb=S yx
√∑ ( x−x )2=−0.000001
t0¿b−βSb
=¿ 40710
5° paso: conclusiones y recomendaciones:- Rechazar H0 y aceptar H1, por lo tanto existe una relación negativa entre en número de embarcaciones y puertos de embarque- Recomendamos hacer la prueba de la linealidad del modelo.
Prueba de hipótesis de la linealidad del modelo Nivel de significación = 5%
1°paso: Formulación de hipótesisH0: ρ= 0H1: ρ≠ 0
2°paso: n = 10, α=5 % ; utilizamos la t(n-k) g.l.= t (8) g.l.

3°paso: Regla de decisiónRechazar H0 ↔ t0 ¿ -2.306 o t0 ¿ 2.306
4°paso: Cálculo del estadístico (t0)
Sr=√ 1−r2
n−k=0.206155
t0¿r−ρSr
=¿ −3.93
5° paso: Conclusiones y recomendaciones- Rechazamos H0 y aceptamos H1, por lo tanto existe linealidad negativa entre el numero de embarcaciones y captura por embarque - Recomendamos hacer la prueba de hipótesis de la confiabilidad del modelo para hacer el pronóstico.
Prueba de hipótesis de la confiabilidad del modelo Nivel de significación = 5%
1°paso: Formulación de hipótesisH0: elmodelonoes confiable .H1: el modeloes confiable .2°paso: n = 10, α=5 % ; utilizamos la tabla F (V 1 ,V 2) g.l. ¿ F (1 ,8)
3°paso: Regla de decisiónRechazar H0 ↔ Fc ¿5 .32
4°paso: Calculo del estadístico (t0)

F0=
SCRk−1SCEn−k
= 15.52
5° paso: Conclusiones y recomendaciones- Rechazamos H0 y aceptamos H1, por lo tanto existe confiabilidad del modelo.- Recomendamos utilizar el modelo dado para hacer los pronósticos.
TERCER EJERCICIO DE LA PIZARRA
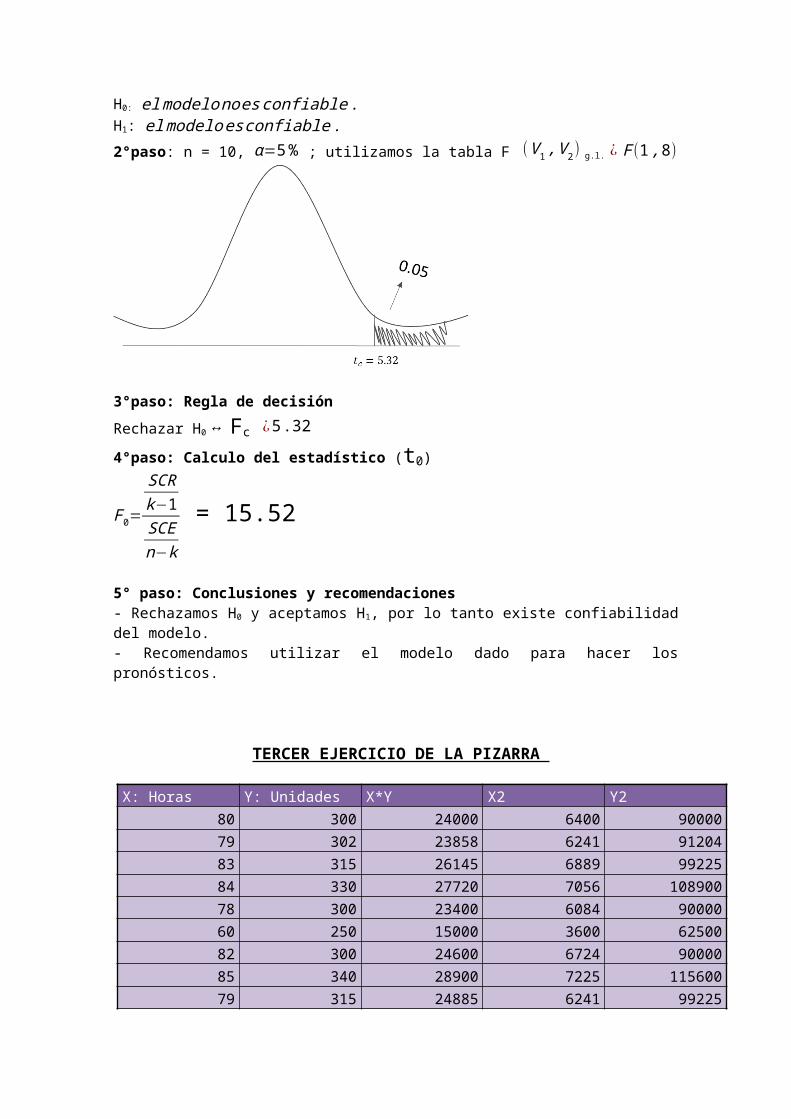
X: Horas Y: Unidades X*Y X2 Y280 300 24000 6400 9000079 302 23858 6241 9120483 315 26145 6889 9922584 330 27720 7056 10890078 300 23400 6084 9000060 250 15000 3600 6250082 300 24600 6724 9000085 340 28900 7225 11560079 315 24885 6241 9922584 330 27720 7056 10890080 310 24800 6400 9610062 240 14880 3844 57600
936 3632 285908 73760 1109254
x = ∑ x12
= 93612 = 78
y = ∑ y12
= 363212 = 302.666667
b=∑ x . y−n . x . y
∑ x2−n . x2 =¿ 285908−(12)(78)(302.666667)73760−12(78¿¿2)=¿¿
3.473404
a= y−b x=¿ 302.666667 – 3.473404 (78) = 31.741155Ecuación de regresión: y=31.741155+3.473404 x

CUADRO ANOVA
Concepto suma cuadrado g.l. cuadrado medio
SCR 9072.457397 1 9072.457397
SCE 896.206848 10 73.8356737
SCT 9968.664245 11 98.70744282
Desviación estándar
de la regresión (error estándar de estimación)
Syx=√∑ (Y−Y ¿)2
n−k
Syx=√ 896.20684810
Syx=9.466820Coeficiente de determinación (r2 ¿:
r2= SCRSCT
=0.91
El 91% de la variación de y es explicado por la variación de x.Coeficiente de determinación (r ¿:
r=+√r2
r=+√0.91r=+0.95
Hay un alto grado de asociación entre las las horas y unidades producidas
Prueba de hipótesis de la existencia de la regresión (β) Nivel de significación = 5%
1°PASO: FORMULACIÓN DE HIPÓTESISH0: β= 0H1: β≠ 02°PASO: n = 12, α=5% ; utilizamos la t(n-k) g.l.= t (10) g.l.
55 60 65 70 75 80 85 900
50
100
150
200
250
300
350
400
f(x) = 3.47340425531915 x + 31.7411347517731R² = 0.910104853363233
DIAGRAMA DE DISPERSION
DIAGRAMA DE DISPERSIONLinear (DIAGRAMA DE DISPERSION)
3°PASO: REGLA DE DECISIÓNRechazar H0 ↔ t0 ¿ -2.228 o t0 ¿ 2.228
4°PASO: CALCULO DEL ESTADÍSTICO (t0)
Sb=S yx
√∑ (x−x)2= 9.466824
√73760−12(782) = 0.345219
t0¿b−βSb
=¿ 3.473404−0
0.345219 = 10.061451
5° CONCLUSIONES Y RECOMENDACIONES:- Rechazar H0 y aceptar H1, por lo tanto no existe una relación negativa entre las horas y las unidades producidas.- Recomendamos hacer la prueba de hipótesis de la linealidad del modelo.
Prueba de hipótesis de la linealidad del modelo (β) Nivel de significación = 5%
1°PASO: FORMULACIÓN DE HIPÓTESISH0: ρ= 0H1: ρ≠ 0
2°PASO: n = 12, α=5% ; utilizamos la t(n-k) g.l.= t (10) g.l.
3°PASO: REGLA DE DECISIÓNRechazar H0 ↔ t0 ¿ 2.228 o t0 ¿ 2.228
4°PASO: CALCULO DEL ESTADÍSTICO (t0)
Sr=√ 1−r2
n−k=√ 1−0.91
10 = 0.094817
t0¿r−ρSr
=¿ 0.91−0
0.094817 = 10.019300
2.228-2.228
-2.228 2.228
5° CONCLUSIONES Y RECOMENDACIONES:- Rechazamos H0 y aceptamos H1, por lo tanto existe linealidad negativa entre las horas de producción y las unidades producidas.- Recomendamos hacer la prueba de hipótesis de la confiabilidad del modelo para hacer el pronóstico.
Prueba de hipótesis de la confiabilidad del modelo (β) Nivel de significación = 5%
1°PASO: FORMULACIÓN DE HIPÓTESISH0: elmodelonoes confiable .H1: el modeloes confiable .
2°PASO: n = 12, α=5% ; utilizamos la tabla F (V 1 ,V 2) g.l. ¿ F (1 ,10)
3°PASO: REGLA DE DECISIÓNRechazar H0 ↔ Fc ¿4.96
4°PASO: CALCULO DEL ESTADÍSTICO (t0)
F0=
SCRk−1SCEn−k
= 9072.457397 /1596.206848/10
=101.231735
5° CONCLUSIONES Y RECOMENDACIONES:- Rechazamos H0 y aceptamos H1, por lo tanto existe confiabilidad del modelo.- Recomendamos utilizar el modelo dado para hacer los pronósticos.
4.96

CONCLUSIONES
En el análisis de regresión, la selección cuidadosa y el uso consistente
de la mejor base de datos lleva a la ecuación de estimación más valiosa.
Regresión y correlación lineal son dos herramientas para investigar la
asociación de una variable dependiente en función de una variable
independiente. Por eso, es de suma importancia para la producción, ya
que es aquí en donde se presentan variables de respuesta e
independientes las cuales se relacionan para generar las características
de un proceso en particular, predecir valores de la variable dependiente
y examinar el grado de fuerza con que se relacionan dichas variables.
La regresión lineal simple analiza la relación de dos variables continuas
bivariantes. La finalidad de una ecuación de regresión es la de estimar

los valores de una variable con base en los valores conocidos de la otra.
Es decir, se puede intuir una relación de causa y efecto entre dos o más
variables, aunque en muchos casos no existe una relación de esta
forma.
Por otro lado, Al ajustar un modelo de regresión simple o múltiple a una
nube de observaciones es importante disponer de alguna medida que
permita medir la bondad del ajuste. Esto se consigue con los
coeficientes de determinación. Si el modelo que se ajusta es un modelo
de regresión lineal, a r2 se le denomina coeficiente de correlación, que
representa el porcentaje de variabilidad de la Y que es explicado por la
variación de la X.
Estas técnicas estadísticas constituyen una herramienta útil para el
análisis de las variables de un proceso ya que a través de la aplicación
de estas, es factible conocer el modelo que siguen.
RECOMENDACIONES
Antes de dedicar tiempo al cálculo de una recta de regresión para un
conjunto de datos, es conveniente realizar un diagrama de dispersión
para esos valores. Esto permitirá averiguar los puntos distantes, ya que
quizá algunos datos no representen el problema que se desea resolver.
El método de la regresión lineal simple servirá de herramienta para
orientar a los gerentes en la toma de decisiones.
Utilizar las pruebas de hipótesis de la existencia de la regresión, de la
linealidad del modelo y de la confiabilidad del modelo, para recién tener

la certeza de poder usar la ecuación de los mínimos cuadrados o recta
de mejor ajuste en los pronósticos.
Combinar el uso de la regresión lineal simple con otros métodos
estadísticos para obtener un mejor modelo que permita realizar
pronósticos de mayor confiabilidad.
BIBLIOGRAFÍA
Estadística descriptiva e inferencial. Córdova Zamora, Manuel. Editorial
Moshera S.R.L. 5° Edición, Perú – 2003.
Estadística para administración y economía. Levin, Richard – Runbin,
David. Editorial Pearson Educación 7° Edición, México – 2010.
Estadística aplicada a los negocios y a la economía XIII edición – Lind/
Marchal/ Wathem, México 2008. McGRAW-HILL/INTERAMERICANA
EDITORES, S. A. de C. V.
Estadística para administración y economía. Mason, Lind, Marchal.
Editorial Alfaomega 10° Edición, Colombia – 2002.














![[TEMA 8] Análisis de Regresión Lineal Simple y Múltiple](https://static.fdocuments.es/doc/165x107/58618d4a1a28ab0e308bb712/tema-8-analisis-de-regresion-lineal-simple-y-multiple.jpg)



