
selección de casos con spss
13
1 UNIVERSIDAD DE SEVILLA FACULTAD DE PSICOLOGIA FUNDAMENTOS METODOLÓGICOS EN PSICOLOGÍA SELECCIÓN DE CASOS CON SPSS INDICE: Pág. 1. Muestreo de casos ......................................................................................... 2 1.1. Muestreo aleatorio simple .................................................................. 3 1.2. Muestreo de conveniencia ................................................................. 4 1.3. Muestreo intencional simple .............................................................. 5 1.4. Muestreo aleatorio sistemático........................................................... 6 1.5. Muestreo por cuotas........................................................................... 6 1.6. Muestreo aleatorio estratificado ......................................................... 9 1.7. Muestreo por conglomerados ........................................................... 13 2. Referencias ................................................................................................... 13
Transcript of selección de casos con spss

1
UNIVERSIDAD DE SEVILLA
FACULTAD DE PSICOLOGIA
FUNDAMENTOS METODOLÓGICOS EN
PSICOLOGÍA
SELECCIÓN DE CASOS CON SPSS
INDICE: Pág.
1. Muestreo de casos ......................................................................................... 2
1.1. Muestreo aleatorio simple .................................................................. 3
1.2. Muestreo de conveniencia ................................................................. 4
1.3. Muestreo intencional simple .............................................................. 5
1.4. Muestreo aleatorio sistemático........................................................... 6
1.5. Muestreo por cuotas........................................................................... 6
1.6. Muestreo aleatorio estratificado ......................................................... 9
1.7. Muestreo por conglomerados ........................................................... 13
2. Referencias ................................................................................................... 13

2
En el ejercicio profesional actual es usual recurrir al uso de programas informáticos para
el tratamiento de los datos procedentes de estudios psicológicos. Es por eso que cada
vez se demanda en mayor medida que el conocimiento de dichos programas forme parte
del currículo de los estudiantes de Psicología. Uno de los programas más utilizados en
este sentido es el paquete estadístico SPSS (Statistical Package for Social Sciences). En
este documento ejemplificamos cómo seleccionar casos según distintos procedimientos
de muestreo.
1. Muestreo de casos
Una vez creado un fichero de datos puede ser necesario en ocasiones seleccionar a
determinados casos mediante algún procedimiento de muestreo. El programa SPSS
permite seleccionar casos según distintos procedimientos de muestreo (aleatorios o no
aleatorios; por unidades simples o compuestas). A continuación vamos a describir
algunos ejemplos de cómo realizar con el programa SPSS distintos tipos de
procedimientos de muestreo. Las definiciones y criterios de estos muestreos se pueden
consultar en el capítulo 6 del texto de Martínez y Moreno (2014), o en el apartado 2 del
capítulo 5 del texto de Moreno, Martínez y Chacón (2000), así como sus implicaciones
para la validez.
Como resultado de los distintos procedimientos de muestreo con SPSS pueden
aparecer en el fichero de datos nuevas variables, que registrarán los casos seleccionados.
Habitualmente, en esas variables se utiliza 1 o un valor decimal distinto de 0 para
señalar los casos seleccionados, y un 0 o un dato perdido para los casos no
seleccionados. Algunas de estas variables son temporales, lo que implicará que si
realizamos un nuevo muestreo se puede perder la información sobre los casos
seleccionados. Por este motivo, es recomendable en todos los casos copiar estas
variables temporales en nuevas variables de selección que se puedan conservar.
Cuando usemos con el programa la función de selección de datos con una de
esas variables de selección (o de filtro), los casos no seleccionados aparecerán tachados
con una línea diagonal (ver figura 1). Por defecto el programa no elimina del fichero los
casos no seleccionados, sino que sólo los descarta para los análisis siguientes. Esta
opción suele ser la más conveniente, ya que permite volver a utilizar casos descartados
si así interesara posteriormente.
Figura 1.- Resultado de una selección de casos, con casos no seleccionados tachados.

3
1.1. Muestreo aleatorio simple
Este es un muestreo realizado a partir de poblaciones definidas en términos de unidades
simples con similar probabilidad de ser seleccionadas. Para realizarlo se puede seguir la
siguiente secuencia de menús y submenús: DatosSeleccionar casosMuestra
aleatoria de casos. Una vez marcada esta última opción se debe seleccionar el botón
inmediato inferior, que en algunas versiones de SPSS viene como Ejemplo (que es una
mala traducción del término inglés Sample). A continuación aparecerá una ventana,
como muestra la figura 2, donde se ofrecen dos opciones para elegir la muestra. La
primera es seleccionando al azar un porcentaje aproximado del total de casos incluidos
en el fichero de datos. Otra posibilidad es seleccionar al azar una cantidad exacta de
casos, de entre la cantidad de casos que especifiquemos a partir de su orden en el
fichero. Para ello hay que determinar cuántos van a ser los “primeros casos” a
considerar para el muestreo. Si se señala un número igual al de casos que contiene el
fichero (en nuestro ejemplo son 202), implicará que la muestra se seleccionará al azar
entre todos los casos.
Figura 2.- Cuadro para seleccionar casos mediante un muestreo aleatorio simple.
Figura 3.- Vista del fichero de datos después de realizar una selección de datos
mediante un muestreo aleatorio simple.
Tras aplicar este procedimiento el programa generará una nueva variable
(filter_$) que aparecerá al final del fichero de datos. Esta variable está compuesta por
ceros (casos no seleccionados) y unos (casos seleccionados para la muestra). Los sujetos
descartados aparecen en el fichero con una raya tachando el número del caso (como se
puede ver en la figura 3). Puesto que la variable creada es temporal (y cambiará si se

4
realiza un nuevo procedimiento de selección), conviene copiar el resultado de esta
selección en una nueva variable. En el ejemplo que hemos puesto en la figura 3 hemos
copiado la columna de la variable filter_$ (Ctrl+C), y luego la hemos pegado en la
columna siguiente (Ctrl+V). A continuación hemos cambiado el nombre de esta nueva
variable en la pestaña “Vista de Variables”, y la hemos denominado Muestra1.
Cada vez que queramos utilizar esta misma muestra para realizar análisis con el
programa SPSS, sólo tenemos que seguir el menú DatosSeleccionar casosUsar
una variable de filtro, e introducir la variable que guarda los casos seleccionados (que
en nuestro ejemplo sería Muestra1; ver figura 4).
Figura 4.- Vista de la ventana de selección de casos en la que se utiliza una variable de
filtro.
Si queremos volver a utilizar todos los casos del fichero, sólo tenemos que abrir
en el menú Datos, la opción de Seleccionar casos. Una vez que aparezca la ventana de
diálogo hay que marcar la primera opción, Todos los casos. Cada vez que queramos
volver a utilizar una muestra anterior, se debe abrir el mismo menú y en la ventana de
diálogo seleccionar la opción Usar variable de filtro, e introducir en la casilla anexa la
variable donde hemos copiado los casos seleccionados.
1.2. Muestreo de conveniencia
Este tipo de muestreo consiste en un procedimiento no aleatorio realizado a partir de
unidades simples (también llamado por accesibilidad, accidental,…). La opción más
fácil es utilizar como muestra los n primeros casos del fichero -siendo n el tamaño de la
muestra deseada-. Esta solución se ejecuta mediante la siguiente secuencia de menú:
DatosSeleccionar casosBasándose en el rango del tiempo o de los casos. Una
vez marcada esta última opción se debe picar el botón que indica Rango, con lo que
aparecerá una ventana (figura 5), en la que se debe indicar desde el primer caso hasta el
último que se selecciona. Si queremos conservar esta selección debemos grabarla en una
nueva variable (p. ej. Muestra2; ver figura 6).

5
Figura 5. Ventana para señalar el primer y último caso de la muestra seleccionada por
un criterio de conveniencia (“orden de casos en el fichero”).
Figura 6. Fichero de datos tras grabar en una nueva variable (Muestra2) los 36
primeros casos seleccionados con un criterio de conveniencia.
1.3. Muestreo intencional simple
Para usar este procedimiento se puede crear una variable de selección o de filtro
(p. ej. Muestra3). En esa variable se debe ir seleccionando caso a caso siguiendo el
criterio intencional que se esté considerando. Es por tanto un muestreo por unidades
simples no aleatorio pero, a diferencia del criterio de conveniencia, en este caso se

6
seleccionan los sujetos según correspondan a determinadas características buscadas para
representar algún colectivo de casos (en el ejemplo de la figura 7 se han seleccionado
los casos según que la variable Q_135 implique alguna respuesta relacionada con la
psicología). Para ello se anotará un 1 en los casos seleccionados, dejando en blanco los
casos descartados.
Figura 7. Fichero de datos con una variable de selección (Muestra3), creada siguiendo
un criterio intencional indicando con “1” los casos seleccionados.
Siempre que se crea una variable de selección, para utilizar la muestra
seleccionada se debe ejecutar la secuencia de menú: DatosSeleccionar casos Usar
variable de filtro. Entonces se marcará la variable de selección que se ha creado, y con
el botón-flecha se trasladará a la ventana del filtro. Una vez ejecutada esta acción, en el
fichero de datos aparecerán con una marca los casos descartados (ver figura 7), y ya no
entrarán a formar parte de los análisis siguientes.
1.4. Muestreo aleatorio sistemático
Este procedimiento implica combinar criterios aleatorios y no aleatorios a partir de
unidades simples. Una manera habitual de realizar este tipo de muestreo es elegir un
primer caso al azar y a partir de él seguir un procedimiento sistemático. Para ejecutarlo
con el SPSS se pueden combinar los procedimientos explicados en los puntos 1.1 y 1.2
de este documento. En este caso se puede elegir con un procedimiento aleatorio simple
a un primer caso. Una vez elegido, a partir de él se puede seguir un procedimiento
similar al explicado para el muestreo de conveniencia (p. ej. crear una variable para
seleccionar los casos y seleccionar un número de casos a partir del seleccionado al azar,
o elegir los siguientes casos cada ciertos intervalos –p. ej. de diez en diez casos-).
1.5. Muestreo por cuotas
Es un procedimiento de muestreo no aleatorio a partir de unidades compuestas. Se
puede realizar siguiendo procedimientos similares a los descritos en los apartados
anteriores 1.2 (de conveniencia) y 1.3 (intencional). La diferencia consiste en que
previamente es necesario identificar los casos de cada unidad compuesta o estrato y
ordenar los casos.

7
Por ejemplo supongamos que nuestras unidades compuestas se forman a partir
del sexo (hombre y mujer) y de la edad dicotomizada (hasta 18 años y más de 18 años).
La combinación de esas dos variables de estratificación nos ofrecerá cuatro estratos o
unidades compuestas (tabla 1).
Tabla 1.- Estratos formados a partir de la combinación de escalas de género y edad.
1-Hasta 18 años 2-Más de 18 años
0-Hombre Estrato 1 Estrato 2
1-Mujer Estrato 3 Estrato 4
Figura 8.-Ventana para generar tablas de contingencias.
Antes de proceder a cualquier muestreo por unidades compuestas, es útil
conocer la distribución de casos por cada estrato dentro del fichero de datos. Esto se
realiza con la siguiente secuencia del menú: AnalizarEstadísticos
descriptivosTablas de Contingencia. Una vez que aparece la ventana de diálogo
(figura 8) se seleccionan como filas y columnas las variables que configuran los estratos
a partir de las combinaciones de sus valores.
Esta instrucción nos ofrecerá como resultado una tabla en donde aparecerá en
cada celda la frecuencia de casos de cada estrato, que en nuestro ejemplo son el género
y la edad recodificada. Tal como se puede observar en el ejemplo (ver tabla 2), en el
fichero de datos utilizado existen casos para los cuatro estratos considerados. De los 198
casos válidos que aparecen, se comprueba que 20 son hombres hasta 18 años, 23
hombres de más de 18 años, 84 mujeres hasta 18 años y 71 mujeres de más de 18 años.
Tabla 2.- Frecuencia de casos en cada estrato género y edad.
Tabla de contingencia Género * Edad recodificada
Recuento
Edad recodificada
Total 1 2
Género Hombre 20 23 43
Mujer 84 71 155
Total 104 94 198
8
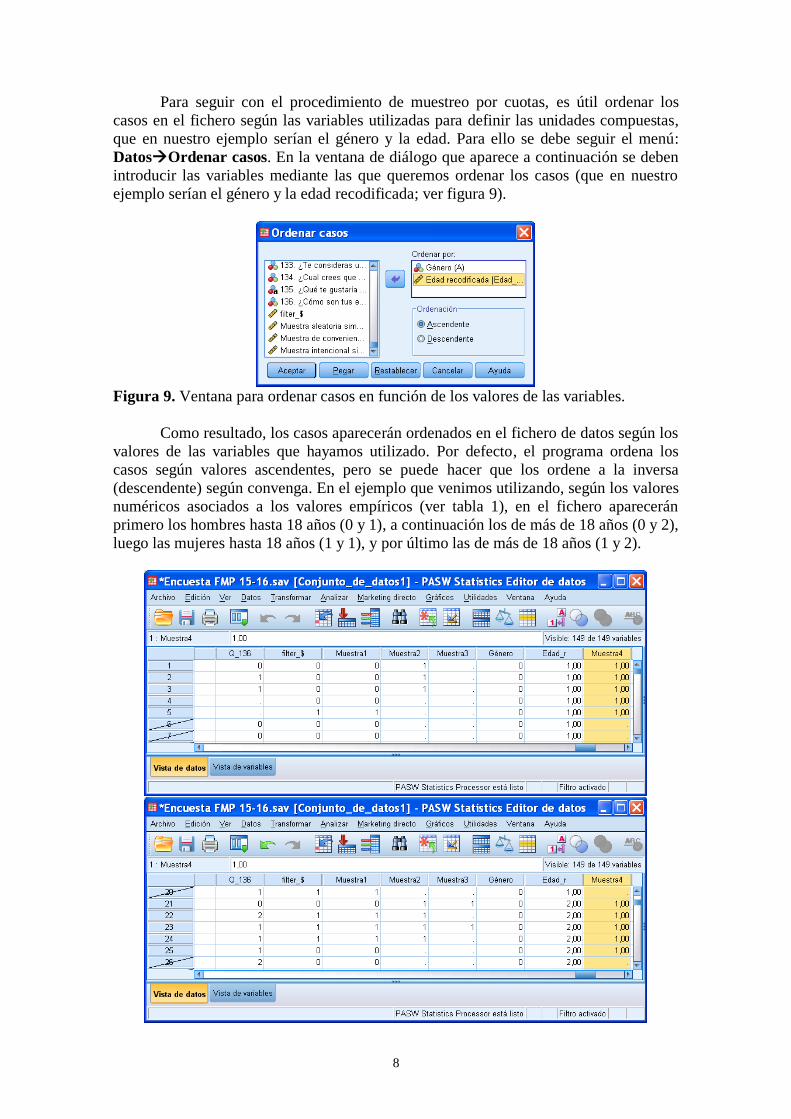
Para seguir con el procedimiento de muestreo por cuotas, es útil ordenar los
casos en el fichero según las variables utilizadas para definir las unidades compuestas,
que en nuestro ejemplo serían el género y la edad. Para ello se debe seguir el menú:
DatosOrdenar casos. En la ventana de diálogo que aparece a continuación se deben
introducir las variables mediante las que queremos ordenar los casos (que en nuestro
ejemplo serían el género y la edad recodificada; ver figura 9).
Figura 9. Ventana para ordenar casos en función de los valores de las variables.
Como resultado, los casos aparecerán ordenados en el fichero de datos según los
valores de las variables que hayamos utilizado. Por defecto, el programa ordena los
casos según valores ascendentes, pero se puede hacer que los ordene a la inversa
(descendente) según convenga. En el ejemplo que venimos utilizando, según los valores
numéricos asociados a los valores empíricos (ver tabla 1), en el fichero aparecerán
primero los hombres hasta 18 años (0 y 1), a continuación los de más de 18 años (0 y 2),
luego las mujeres hasta 18 años (1 y 1), y por último las de más de 18 años (1 y 2).
9
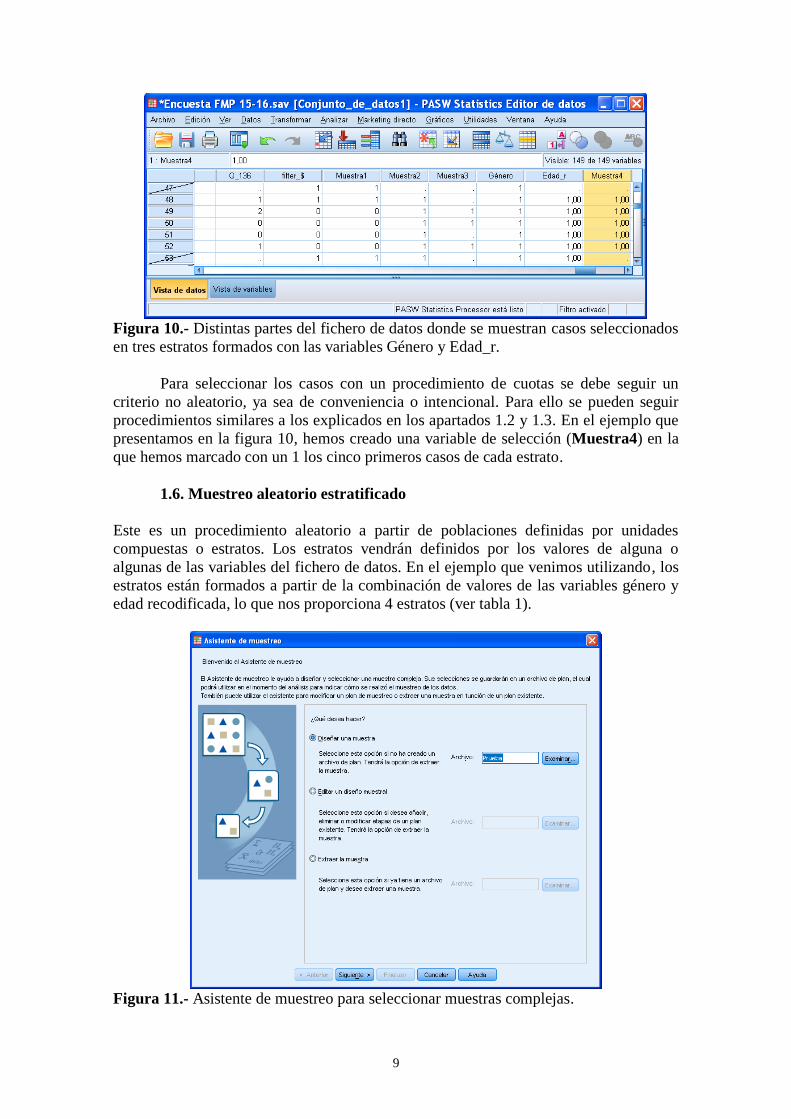
Figura 10.- Distintas partes del fichero de datos donde se muestran casos seleccionados
en tres estratos formados con las variables Género y Edad_r.
Para seleccionar los casos con un procedimiento de cuotas se debe seguir un
criterio no aleatorio, ya sea de conveniencia o intencional. Para ello se pueden seguir
procedimientos similares a los explicados en los apartados 1.2 y 1.3. En el ejemplo que
presentamos en la figura 10, hemos creado una variable de selección (Muestra4) en la
que hemos marcado con un 1 los cinco primeros casos de cada estrato.
1.6. Muestreo aleatorio estratificado
Este es un procedimiento aleatorio a partir de poblaciones definidas por unidades
compuestas o estratos. Los estratos vendrán definidos por los valores de alguna o
algunas de las variables del fichero de datos. En el ejemplo que venimos utilizando, los
estratos están formados a partir de la combinación de valores de las variables género y
edad recodificada, lo que nos proporciona 4 estratos (ver tabla 1).
Figura 11.- Asistente de muestreo para seleccionar muestras complejas.

10
Un muestreo aleatorio estratificado es equivalente a realizar un muestreo
aleatorio simple (apartado 1.1) pero en cada uno de los estratos. Por este motivo, la
probabilidad de ser elegido para cada caso ya no tiene por qué ser homogénea sino que
dependerá del tamaño de cada estrato. Para seguir este procedimiento, la opción más
recomendable es utilizar el menú del SPSS: AnalizarMuestras
complejasSeleccionar una muestra, tras lo que aparecerá la ventana del Asistente
de muestreo (figura 11). En esa ventana se debe elegir la primera opción (Definir una
muestra), siempre que no se haya guardado previamente otro diseño muestral que
queramos volver a repetir. Es necesario ponerle un nombre al Archivo donde se va a
guardar el diseño muestral que realicemos (en nuestro ejemplo le hemos puesto
Prueba). Una vez que le hemos puesto el nombre a este archivo, debemos dar al botón
Siguiente. En la ventana que aparece a continuación, tenemos que seleccionar a las
variables cuyos valores conforman los estratos, e introducirlas en la ventana
denominada “Estratificar por:” (figura 12). Una vez hecho esto podemos darle al
botón Siguiente.
Figura 12.- Segunda pantalla del asistente de muestreo para definir las variables del
diseño muestral.
En la tercera pantalla del asistente (figura 13), se pueden dejar las opciones que
implementa el programa por defecto (Muestreo aleatorio simple-Sin reposición).
Como resultado, el programa realizará un muestreo aleatorio simple por cada estrato
que se haya especificado según las variables introducidas en el diseño muestral. Por eso
el muestreo en su conjunto se denomina estratificado.

11
Figura 13.- Pantalla del asistente de muestreo para definir el método de muestreo.
Por último aparecerá una nueva pantalla (figura 14), en la que debemos definir el
tamaño de la muestra a partir de una cantidad de casos (Recuentos) o de una proporción
de casos (Proporciones) por cada estrato. A continuación debemos señalar la cantidad
de casos por cada estrato. Si decidimos hacerla en términos fijos, querrá decir que
seleccionaremos la misma cantidad o la misma proporción por cada estrato. En el
ejemplo de la figura 14 hemos señalado un valor de 5 casos por cada estrato. Si
señalásemos una proporción, deberíamos utilizar el valor decimal entre 0 y 1 que
corresponda a la proporción deseada. En este último caso, lo que se mantiene fijo es la
proporción de cada estrato, pero la cantidad de casos de cada estrato será variable en
función de su tamaño. También es posible determinar cantidades o proporciones
diferentes para cada estrato. En ese caso debemos definir para cada estrato la cantidad o
la proporción que le corresponda.
Una vez determinado el tamaño de la muestra podemos darle al botón Finalizar.
Como resultado el programa creará tres nuevas variables al final del fichero de datos:
InclusionProbability_1_, SampleWeightCumulative_1_ y SampleWeight_Final_.
Estas variables son temporales. Para señalar los casos seleccionados en el muestreo
podemos utilizar la primera de estas variables, la cual debemos copiar en una nueva
variable para conservar sus valores. En el ejemplo que presentamos en la figura 15,
hemos copiado sus valores en la variable de filtro Muestra5. En esta variable los
valores oscilan entre 0 y 1, indicando la probabilidad que ha tenido el caso seleccionado
para ser incluido en la muestra. Los casos no seleccionados aparecen en esta variable
con un valor perdido. Conviene recordar que para utilizar esta muestra en los sucesivos
análisis, es necesario seguir el procedimiento de selección de casos con una variable de
filtro (que en nuestro ejemplo sería Muestra5), como ya se explicó en el apartado 1.1 para el muestreo aleatorio simple.
12
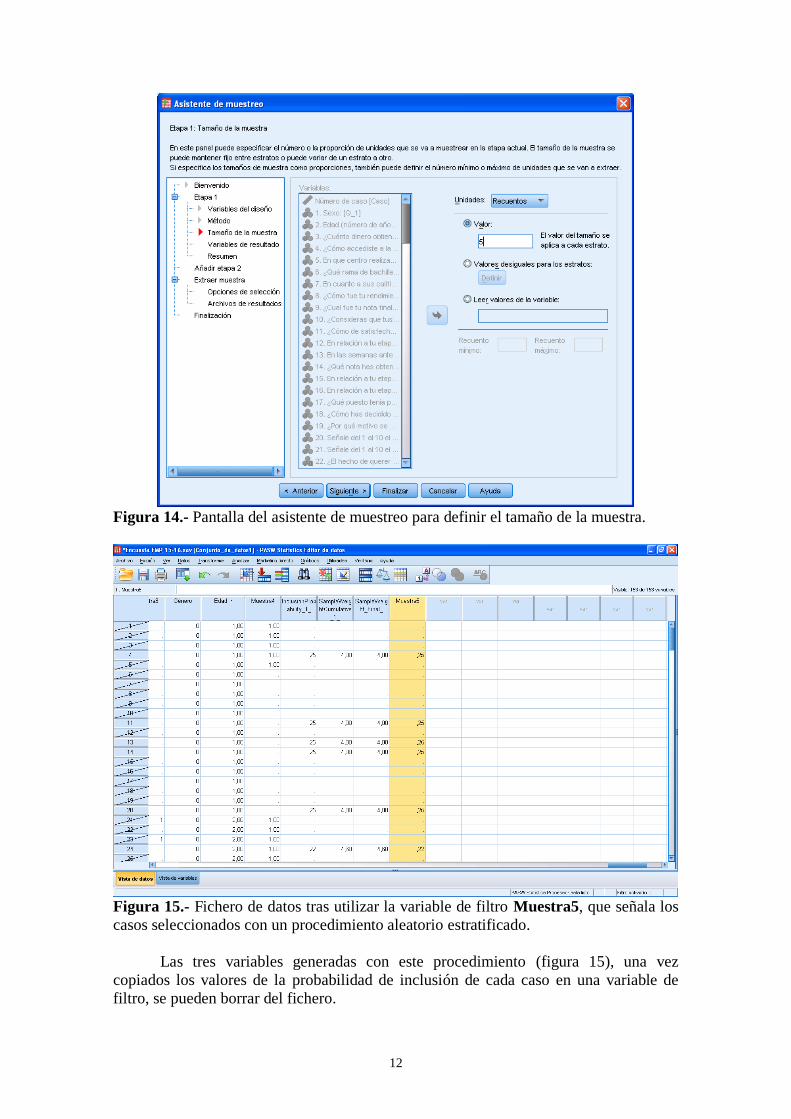
Figura 14.- Pantalla del asistente de muestreo para definir el tamaño de la muestra.
Figura 15.- Fichero de datos tras utilizar la variable de filtro Muestra5, que señala los
casos seleccionados con un procedimiento aleatorio estratificado.
Las tres variables generadas con este procedimiento (figura 15), una vez
copiados los valores de la probabilidad de inclusión de cada caso en una variable de
filtro, se pueden borrar del fichero.

13
1.7. Muestreo por conglomerados
Este procedimiento corresponde a un muestreo por unidades compuestas, pero en el que
se realiza una selección de algunos estratos, y que por tanto no selecciona casos de
todos los estratos. En caso de selección aleatoria de los estratos se puede realizar con el
mismo asistente de muestreo del programa SPSS que hemos utilizado en el apartado
anterior. A diferencia del muestreo aleatorio estratificado, en este caso las variables que
conforman los estratos se deben introducir en la ventana que señala “Conglomerados:”.
El procedimiento a seguir es idéntico al apartado anterior, pero hay que tener en cuenta
que cuando aparece la pantalla para determinar el tamaño de la muestra (figura 14), las
unidades a las que se refiere en este caso son las unidades compuestas, es decir los
estratos. Por tanto, aquí habría que indicar el número o la proporción de estratos que
queremos seleccionar. El procedimiento que se implementaría así sería un
conglomerados aleatorio monoetápico, ya que una vez seleccionados los estratos se
incluirían en la muestra todos los casos de dichos estratos.
Si quisiéramos seleccionar uno o varios estratos siguiendo criterios no aleatorios
(de conveniencia o intencional), se pueden seleccionar los casos con el menú.
DatosSeleccionar casos y marcar la opción “Si se satisface la condición…” (figura
16). En la ventana emergente se deben incluir las condiciones que identificarán al
estrato o los estratos elegidos. Tras esta acción todos los casos de los estratos
previamente elegidos estarán seleccionados.
Figura 16.- Ventana para seleccionar casos que cumplan con unas determinadas
condiciones (valores de variables).
En caso de que se quiera realizar algún muestreo sucesivo, como ocurre en los
conglomerados polietápicos, se puede recurrir a cualquiera de los procedimientos
descritos en los puntos anteriores pero a partir de estratos ya seleccionados.
2. Referencias Martínez, R. y Moreno, R. (2014). Cómo plantear y responder preguntas de manera
científica. Madrid: Síntesis.
Moreno, R., Martínez y Chacón, S. (2000). Fundamentos metodológicos en psicología y
ciencias afines. Madrid: Pirámide.


















