
Trolo Lo multivariado
56
Análisis multivariado 2 •Componentes Principales. •Análisis de correspondencias. •Análisis de escalamiento multidimensional no-métrico y métrico.
-
Upload
federico-ignacio-gonzalez-estefane -
Category
Documents
-
view
228 -
download
1
description
analisis componentes
Transcript of Trolo Lo multivariado

Análisis multivariado 2
•Componentes Principales.
•Análisis de correspondencias.
•Análisis de escalamiento multidimensional no-métrico y métrico.

• Gran parte de los métodos multivariados se basan en la reducción de matrices a partir del principio de correlación entre las variables originales, más que su semejanza o disimilitud.
• Las nuevas variables son seleccionadas de acuerdo de la cantidad de varianza explicada y ordenadas de mayor a menor.
• Estas nuevas variables son denominadas coordenadas o componentes principales, ya que condensan la información original en un conjunto menor de dimensiones.

• Que son los componentes principales
• Objetivos
• Funcionamiento
• Aplicación
• Análisis de los resultados
• Ejemplo
• Ventajas/desventajas
• Conclusiones
Componentes principales

• Los componentes principales son un método de
análisis multivariado que permite reducir la
dimensionalidad de conjuntos de datos
cuantitativos continuos o cuantitativos discretos
luego de ser sujetos a una transformación.
• Permite visualizar patrones
• Genera nuevas variables independientes entre
sí (ortogonales)
• Estas nuevas variables pueden ser utilizadas en
nuevos análisis o utilizarse para describir las
tendencias generales de variación en los datos.

•Los datos pueden estar descriptos por gran
número de dimensiones -variables- que a su vez
pueden presentar distintos niveles de correlación
entre sí.
•Esto dificulta la búsqueda e interpretación de
patrones.
El objetivo de los Componentes principales es reducir este
conjunto de variables interrelacionadas a un nuevo grupo de variables ortogonales entre sí, denominadas Componentes
Principales
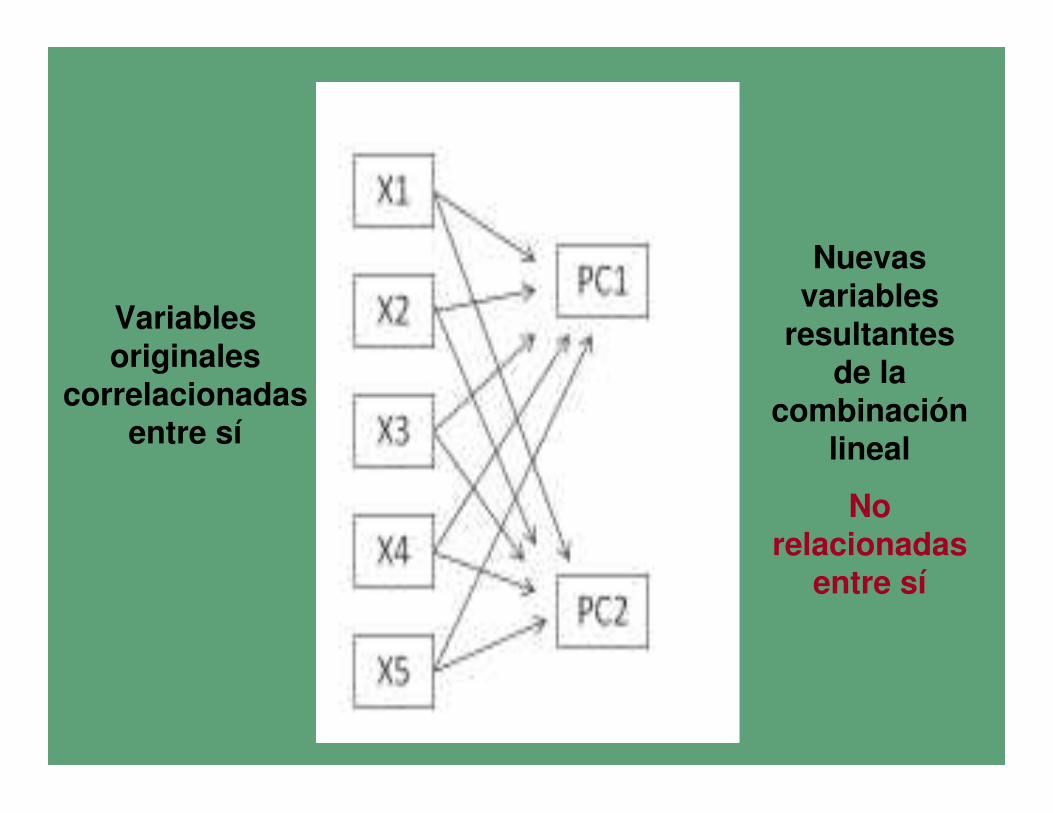
Nuevas variables
resultantes de la
combinación lineal
No relacionadas
entre sí
Variables originales
correlacionadas entre sí

• La varianza de cada nueva variable o componente es una medida de la cantidad de información contenida en cada una de ellas.
• Los componentes se ordenan de orden decreciente en función de esta varianza, tal que los primeros explican los patrones generales y los últimos la variación residual.
• Esto permite también, filtrar variación aleatoria, el “ruido” en los datos.

•Matriz de covariancia:
•El análisis utilizando esta matriz dará más peso a
las variables con mayor varianza
•Las variables deben estar en las mismas unidades
•Matriz de correlación:
•Las variables están tal que poseen una media de 0
y un una desviación típica de 1
•Las variables pueden estar en distintas unidades
•Todas las variables poseerán el mismo peso
durante el análisis
Características de las matrices para análisis

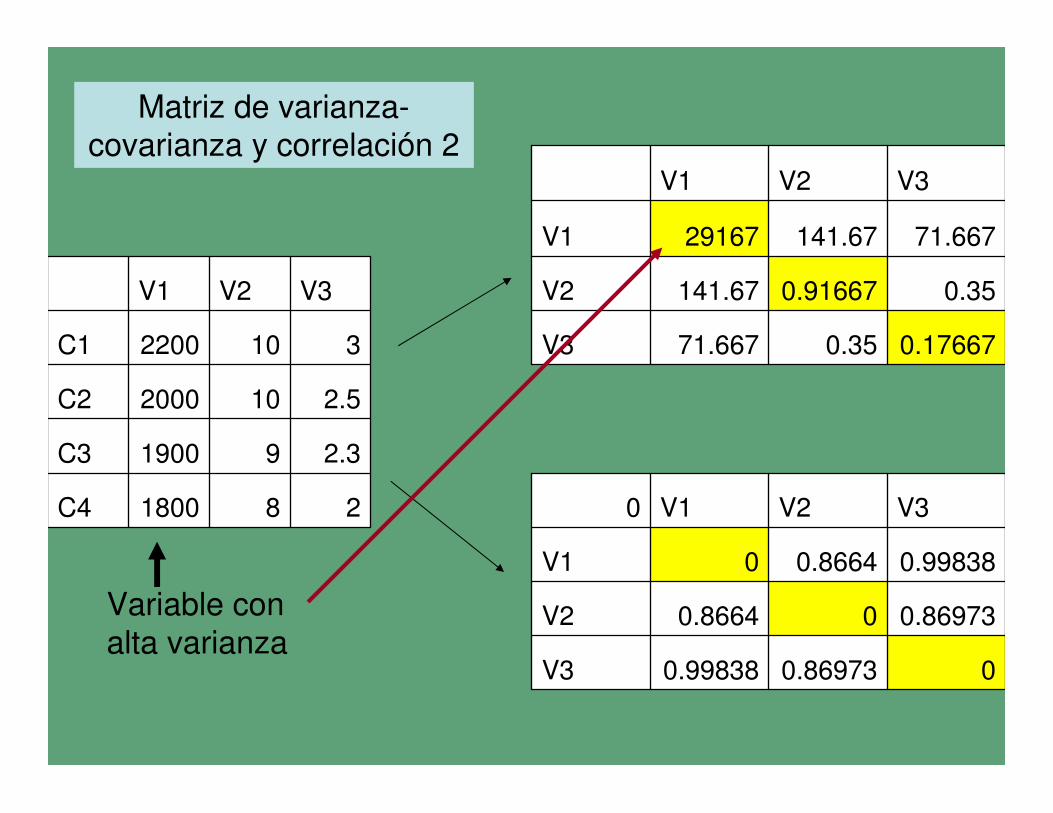
• La elección de la matriz de varianza-covarianza o correlación para estimar los componentes principales posee gran peso en los resultados, especialmente si existen diferencias notables de escala en alguna/s de las variables empleadas.
• Por ello puede ser conveniente el tratamiento previo de los datos, o el empleo de una matriz de correlación en el caso de que la dispersión y la escala de las variables sea muy diferente.
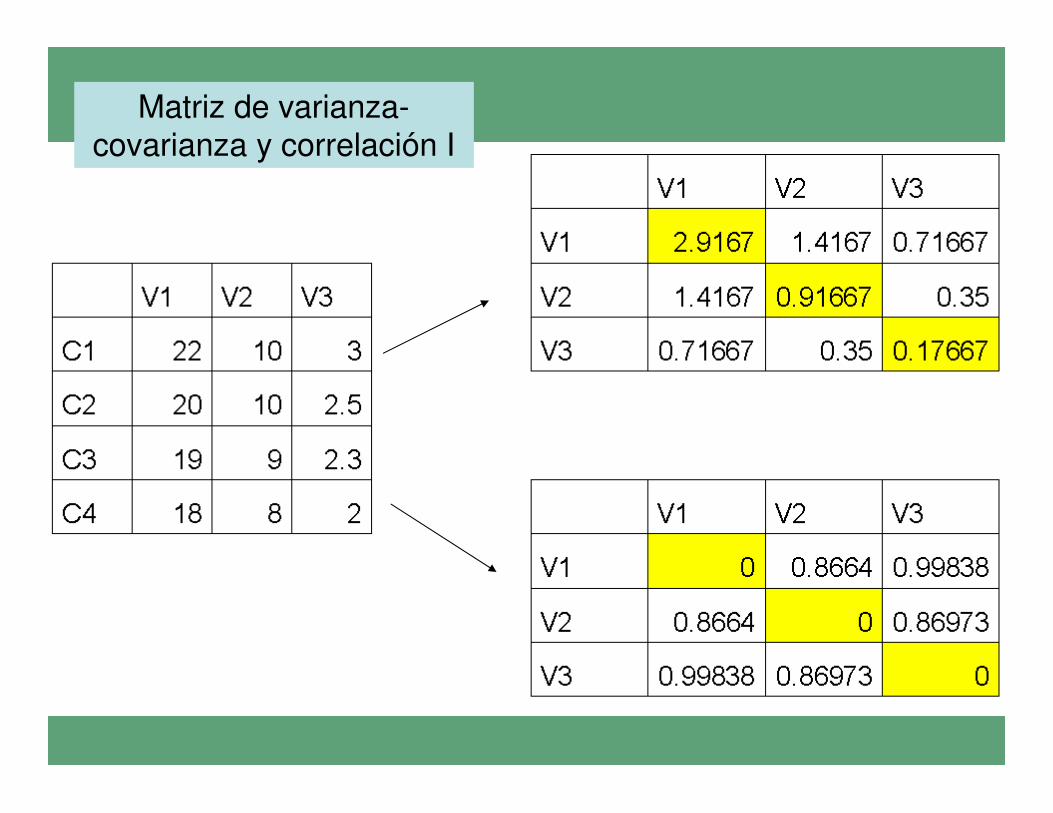
Matriz de varianza-covarianza y correlación I
00.869730.99838V3
0.8697300.8664V2
0.998380.86640V1
V3V2V10281800C4
2.391900C3
2.5102000C2
0.176670.3571.667V33102200C1
0.350.91667141.67V2V3V2V1
71.667141.6729167V1
V3V2V1
Matriz de varianza-covarianza y correlación 2
Variable con
alta varianza

•La elección del primer componente principal,
resultante de la combinación lineal entre las
variables originales se basa en la máxima varianza.
•El primer componente se traza a lo largo del eje de
mayor variación y sirve de base para los
componentes subsiguientes.
• El segundo componente tiene que explicar
variación independiente al primero, por lo que se
traza en dirección independiente éste, esto es a
90°. Lo mismo se hace con el tercero
(independiente al segundo) y con los componentes
subsiguientes.
Por ello se dice que las variables son ortogonales
entre sí
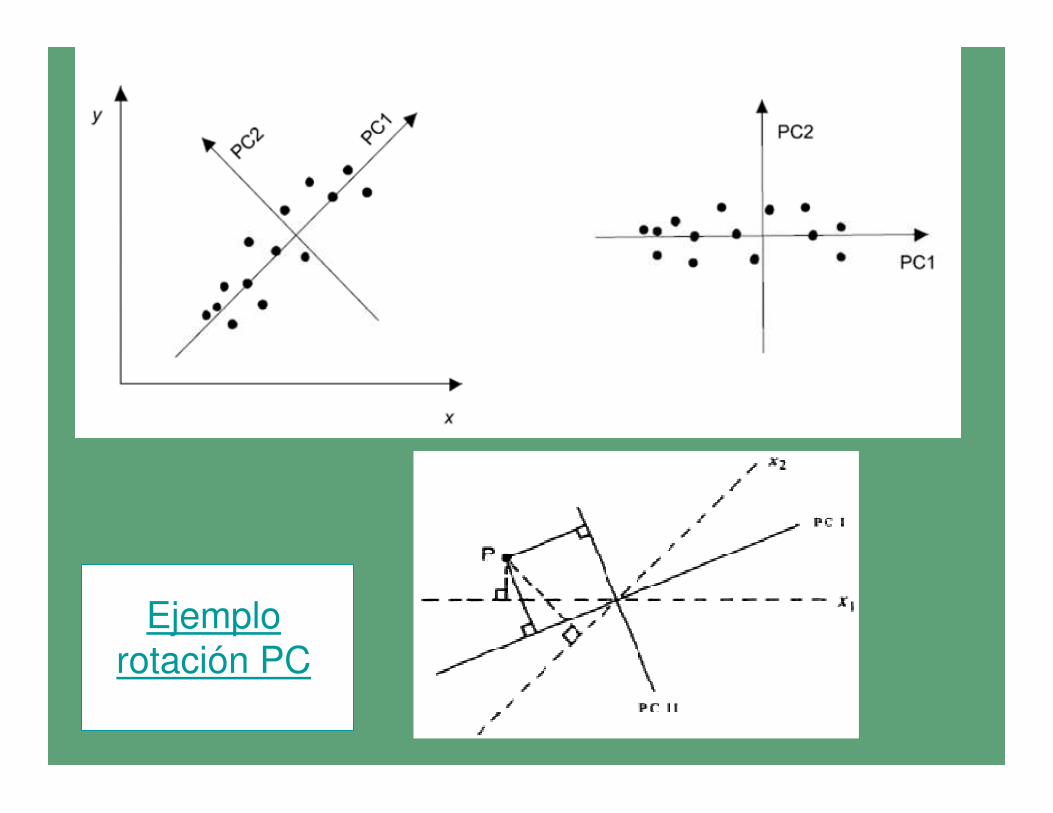
Ejemplo
rotación PC

• Un autovalor o eingenvalue (valor propio), es un vector que representa la nueva variable que parte de la transformación lineal las anteriores.
• La suma de los autovalores es igual a la traza de la matriz (trace) y equivale a la varianza total.
Resultados:
Eigenvalor o Autovalor/valor propio
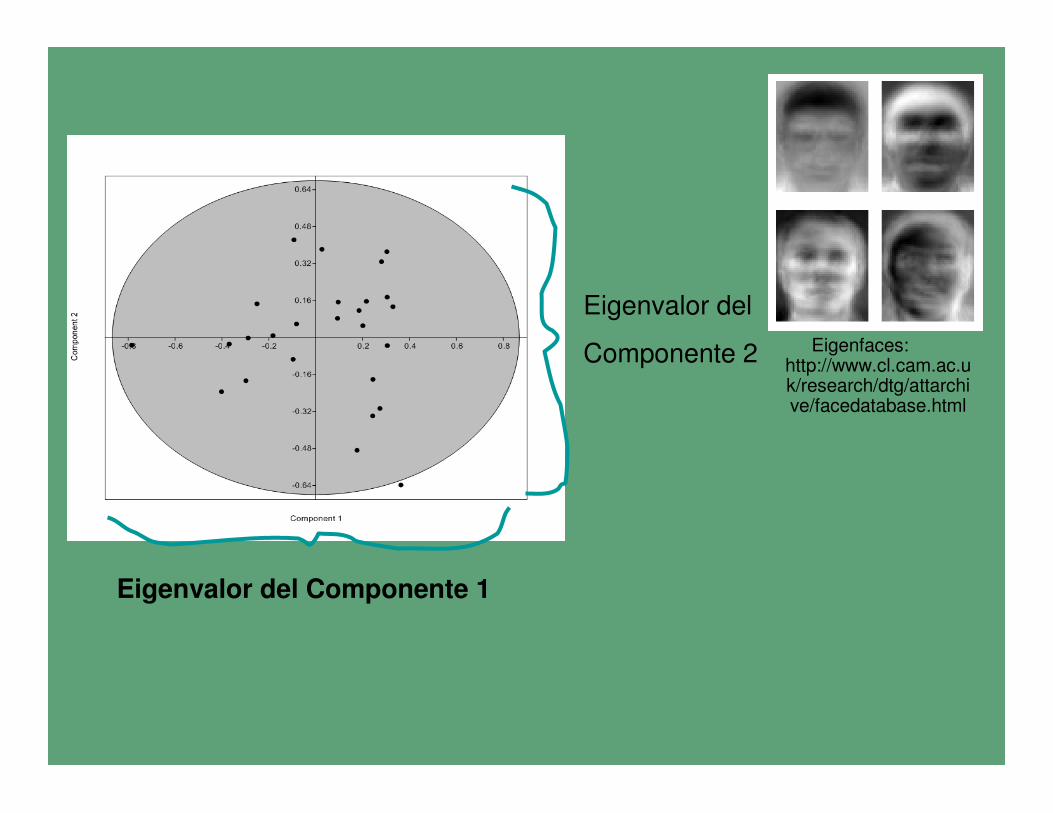
Eigenvalor del
Componente 2
Eigenvalor del Componente 1
Eigenfaces: http://www.cl.cam.ac.uk/research/dtg/attarchive/facedatabase.html
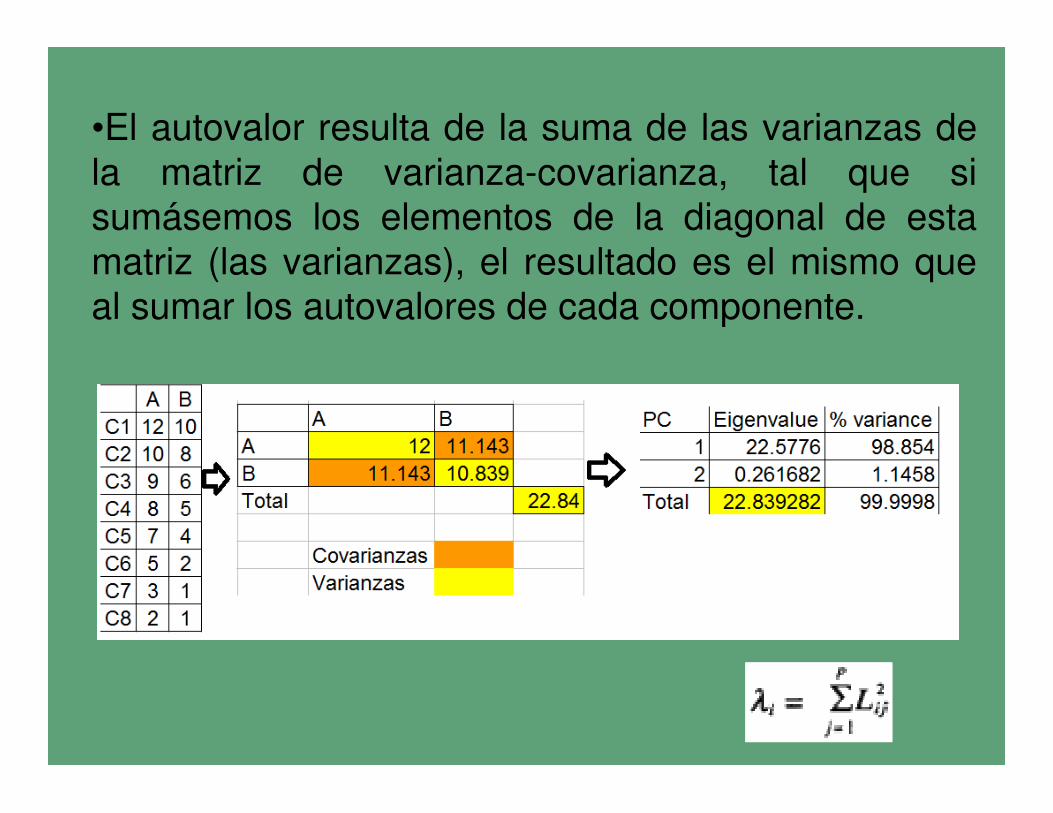
•El autovalor resulta de la suma de las varianzas de
la matriz de varianza-covarianza, tal que si
sumásemos los elementos de la diagonal de esta
matriz (las varianzas), el resultado es el mismo que
al sumar los autovalores de cada componente.

Scores/puntajes
• Los puntajes representan el valor de los casos transformados/pesados en relación a los componentes principales.
• Es el valor de cada caso en el contexto de cada uno de los componentes
• Se interpreta como en un gráfico de dispersión ordinario.
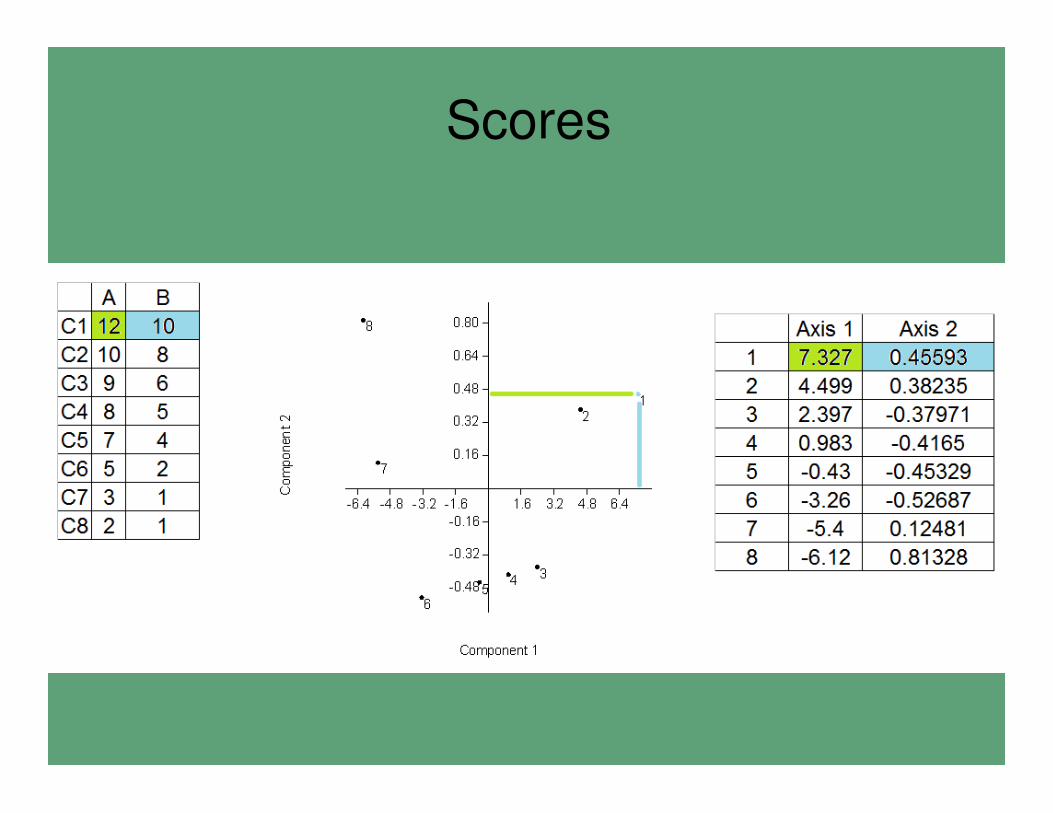
Scores

Loadings/pesos
• Los pesos son el coeficiente de correlación
entre las variables originales y cada uno de los
componentes.
• Indican la importancia relativa de cada variable
en la construcción del componente en
independencia de las demás.
• El cuadrado de los pesos es equivalente al R2 y
muestra el porcentaje de variación que explica
la variable original en el contexto de cada
componente.
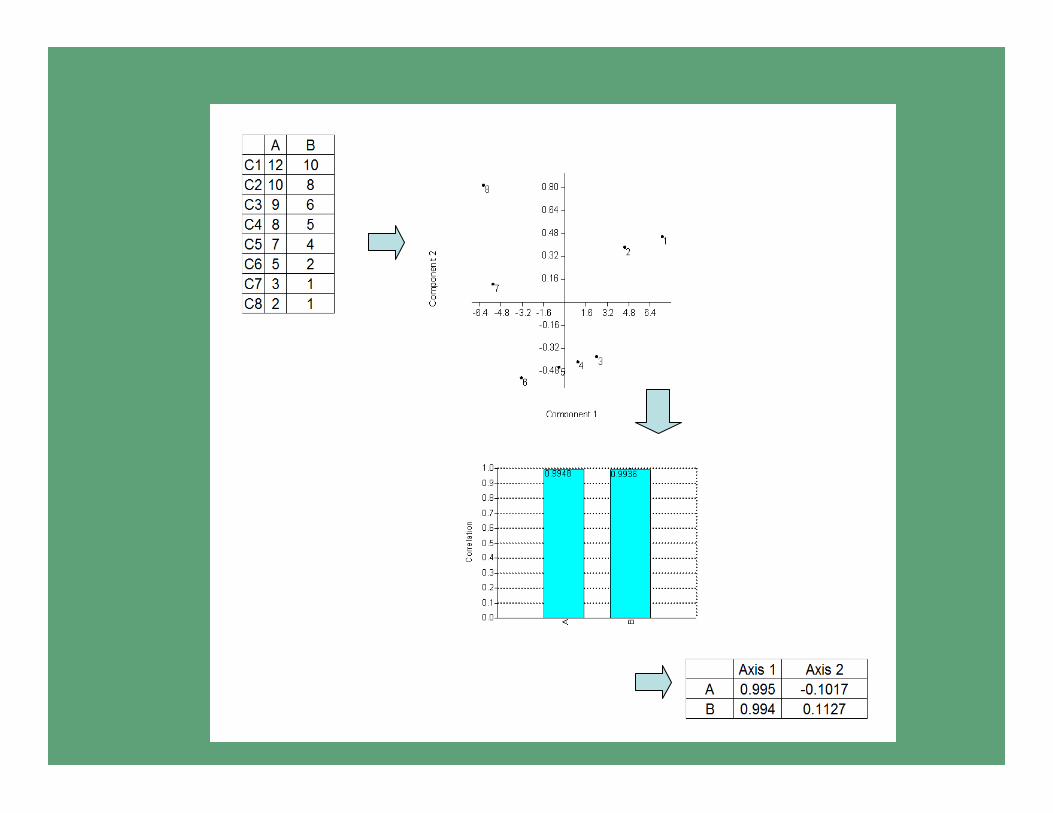

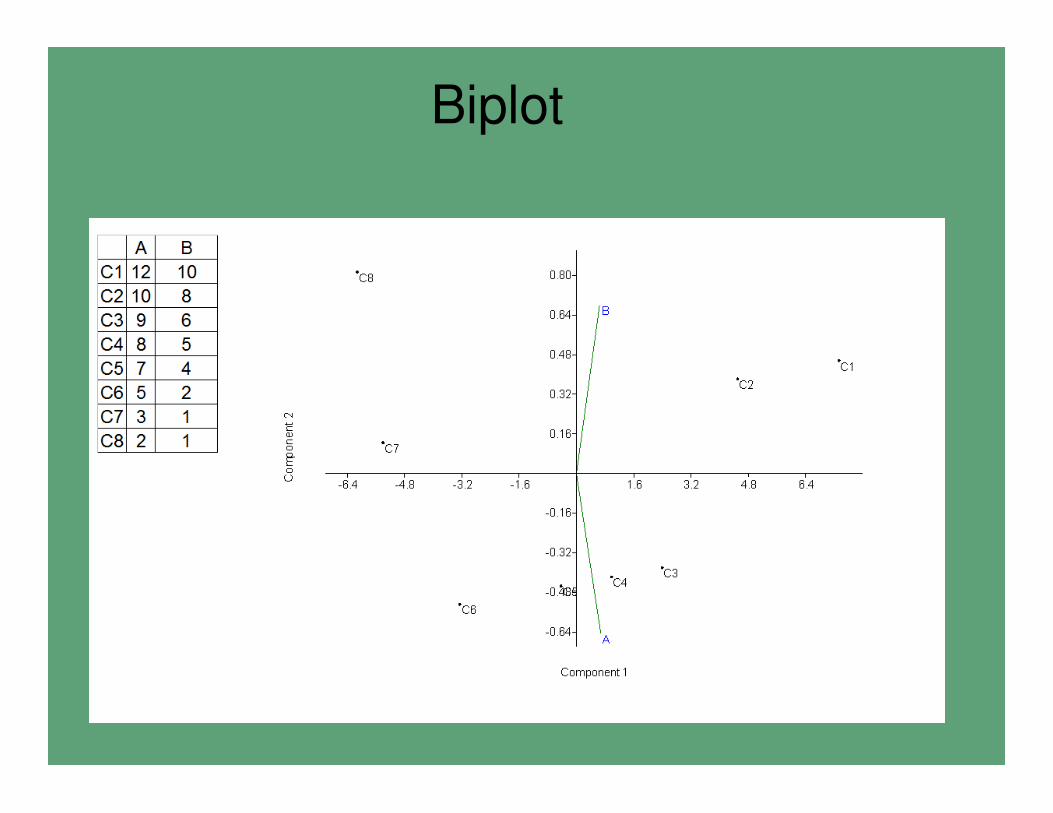
Biplot
• El biplot tiene la función de representar la relación entre las variables originales y los componentes principales.
• El biplot es la proyección en forma de un vector sobre el plano (superficie delimitada pordos componentes) de las variables originales.
• Al igual que en la regresión, la dirección del vector es la de máxima variación y en relación al incremento de la variable proyectada, sobre los ejes de los componentes.
• El largo del vector es una medida de la importancia (correlación) entre la variable original y los componentes.
Biplot
Validación: Retención de los
componentes
0 1 2Component
0
10
20
30
40
50
60
70
80
90
Eig
enva
lue
%
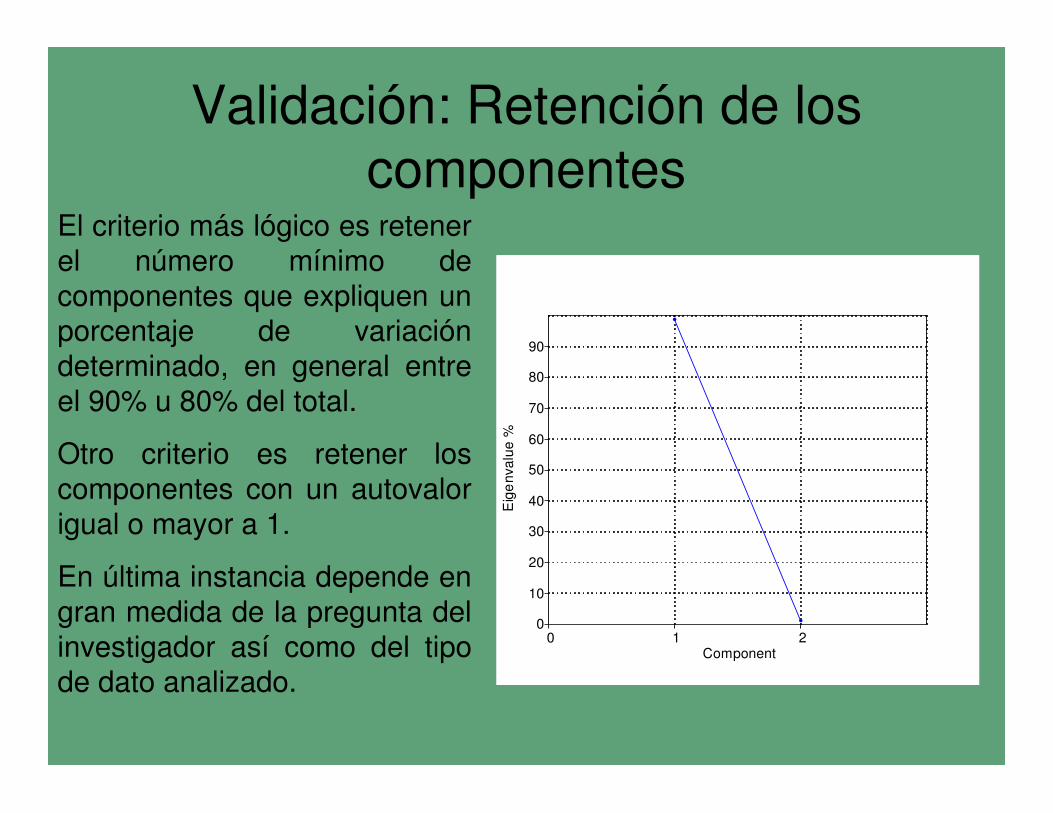
El criterio más lógico es retener
el número mínimo de
componentes que expliquen un porcentaje de variación
determinado, en general entre
el 90% u 80% del total.
Otro criterio es retener los
componentes con un autovalor
igual o mayor a 1.
En última instancia depende en
gran medida de la pregunta del
investigador así como del tipo de dato analizado.

Ejemplo
• Matriz de proporción de instrumentos de distintos loci a lo largo de Patagonia
• Objetivo: Buscar tendencias generales en los datos

Discusión
• El análisis de componentes principales permite reducir la dimensionalidad de una matriz de datos continuos.
• Parte de una matriz de varianzas-covarianzas o de correlación. La elección de una u otra es fundamental y depende del tipo de datos y de su variación.
• Su efectividad es mayor cuanto mayor correlación exista entre éstos.
• El resultado es un conjunto de nuevas variables independientes entre si.

Análisis de Correspondencias
• Que es el análisis de Correspondencias
• Objetivos
• Funcionamiento
• Aplicación
• Análisis de los resultados
• Ejemplo
• Discusión

Objetivos
• Representar variables y casos en un mismo espacio bidimensional en donde se represente la máxima correlación posible entre ellas, tal como se presenta en la matriz original que toma la forma de una tabla de contingencia.

Que es el Análisis de
Correspondencia
• Es una técnica multivariada quebusca asociar variables categóricas (conteos) dispuestasen tablas multidimensionales
• Permite representarlas junto a los casos que éstas describen en un espacio de coordenadas reducido.
• Tiene una aplicación amplia en ecología ya que permite asociardirectamente frecuencia de especies con los ambientes de los que proceden
J. P Benzecri

Funcionamiento: La tabla de
contingencia
• En una tabla de contingencia, si dos valores son independientes entre sí, la frecuencia observadaen cada celda solamente depende de los totalesde las celdas y las columnas.
• Se estima la distancia entre la frecuenciaobservada en cada celda y la esperada bajo la H0.
• Por último se calcula la distancia de Chi2 entre las frecunecias observadas y las esperadaspara contrastar la hipótesis de indepedencia.

Cálculo de distancias y reduccion de
las dimensiones originales
• Los valores resultantes en cada celda son estandarizados al convertirse en valores de Chi2
• Cuanto más altos son los valores, más fuerte es la relación entre ellos y representan de esta manera, una medida de distancia
• La matriz resultante de este proceso es similar a una matriz de varianza-covarianza.
• A partir de estas distancias de Chi2 se obtienen los
autovalores para cada nuevo eje y el porcentaje de la varianza explicado por cada uno de ellos.

• Por lo tanto la reducción de dimensiones en la última etapa de análisis es similar al análisisde componentes principales sobre la matriz de covarianzas
• De esta manera se obtiene un espacioreducido en donde los primeros ejes captan la mayor proporción de variación.
• En este espacio los objetos estánestandarizados y representan pesos de variables y casos que pueden representarsejuntos
• La proximidad indica dependencia-relación

Matriz de distancias y cálculo los ejes
principales
• De manera similar al procedimiento de Chi2 se estima una frecuencia esperada. En estecaso, distancia entre las proporcionesobservadas en cada celda se compara de a pares y se pondera por la proporciónpromedio estimada para cada variable.
• Posteriormente se estima la raíz cuadrada de cada uno, lo que obtiene valoresnormalizados, ésta normalización permiteoperar de manera análoga una matriz de correlación.

• Al igual que en el análisis de componentesprincipales, los autovalores son calculados, unopara cada nueva dimensión.
• En el espacio de coordenadas, cada sitio u objeto se grafica en función de su distancia al centro de la distribución o centroide. Al igual que en otros procedimientos aquéllos valores más influyentes son lo que tienden a alejarse del centro

Validación 1
• El relay plot (o gráfico de relevos) permiteexplorar aporte de cada variable en relación a los casos. El largo de las barras horizontales, esuna medida de la abundancia relativa de cadavariable y de su peso en el ordenamiento(donde los casos se ordenan según los pesos/scores).
• El gráfico es de mayor utilidad cuando los casosestán en columnas y variables en filas, ya que sise cuenta con un número grande de variables, pueden analizarse gradientes de abundancia a lo largo de sitios ordenados en sentido espacial, longitudinal o temporal.

Validación 2
• Asimismo, los análisis de correspondencias pueden complementar test de independencia (empleando Chi2) sobre tablas de contingencia ya que emplea la misma métrica.
• Sin embargo, no obtener un estadístico significativo en la tabla de contingencia no implica que el análisis de correspondencia no siga siendo útil a nivel descriptivo

Ejemplo
• Datos de artefactos distribuido en 5 unidades domésticas, presentados por Shennan (1992), donde se relevaron tres variables.
• Objetivo: Relacionar las unidades domésticas con los artefactos relevados: Hay diferencias en su frecuencia ?
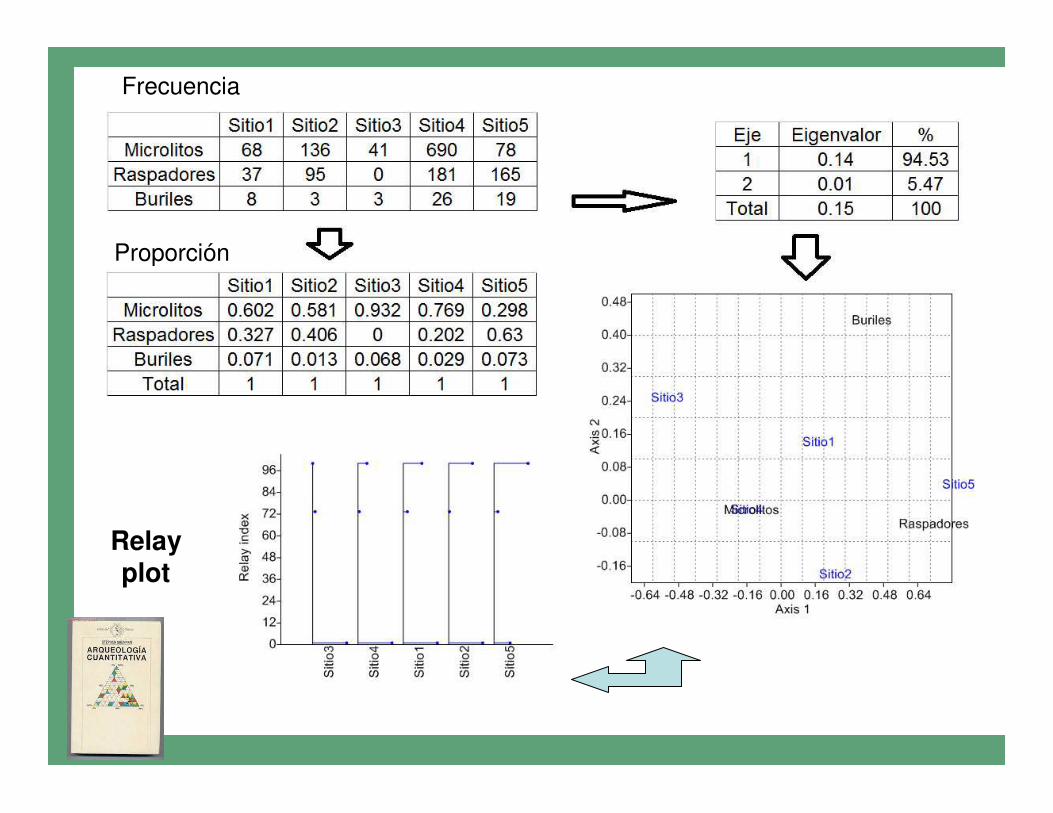
Relayplot
Proporción
Frecuencia

• Si estimáramos un valor de chi2 para la tabla de contingencia, obtendríamos el valor de significación que evalúa la distribución en relación a un modelo de independencia, asícomo de la correlación entre la frecuencias de la tabla (V de Cramer) bajo la misma hipótesis.

Discusión
• El análisis de correspondencia tiene como función analizar tablas de frecuencias multivariadas.
• Permite representar en un espacio de dimensiones reducidas las relaciones principales entre casos y variables.
• Es sensible a valores en muy baja frecuencia
• Puede presentar soluciones graficas difíciles de analizar “efecto herradura”. Alternativa: análisis de correspondencia sin tendencia o detrendedcorrespondence analysis.

Escalamiento multidimensional no
métrico (MDS o NMDS)
• Que es el escalamiento multidimensional
• Objetivos
• Funcionamiento
• Aplicación
• Análisis de los resultados
• Ejemplo
• Discusión

• El análisis multidimensional se origina en
los estudios de psiconométría entre los
años 20 y 60´.
• El fin era encontrar factores latentes,
intenciones elementos subjetivos
subyacentes a partir de elementos
observados. Actitudes o comportamiento.
• Se desarrolló especialmente a partir de la
parición de los métodos computacionales
que permitieon estudios interados.
Joseph Kruskal

•El MDS busca las mejores posiciones de n objetos en un
espacio de k dimensiones que se asemejen más a las posiciones de los objetos según sus distancias originales.
•Los objetos son reescalados, pero intentando mantener la relación original entre ellos
•Es iterativo, pues repite el análisis con posiciones diferentes hasta alcanzar el mejor arreglo.
•No supone que existan relaciones lineales entre las
variables. Utiliza el orden de distancias (“rankeddistances”) como criterio principal, por eso se le llama no-métrico.
•Puede emplearse con matrices de datos cualitativos o
cuantitativos.

• Permite utilizar casi cualquier medida de distancia, acorde a la naturaleza de las variables empleadas
• Como es iterativo cada corrida puede resultar en ordenaciones un tanto diferentes.
• Requiere tiempo computacional, particularmente con muchos datos (aunque ya esto no es un asunto tan importante).
• Es posible que encuentre una solución subóptima(pero las capacidades de computación actual reducen esta limitación).
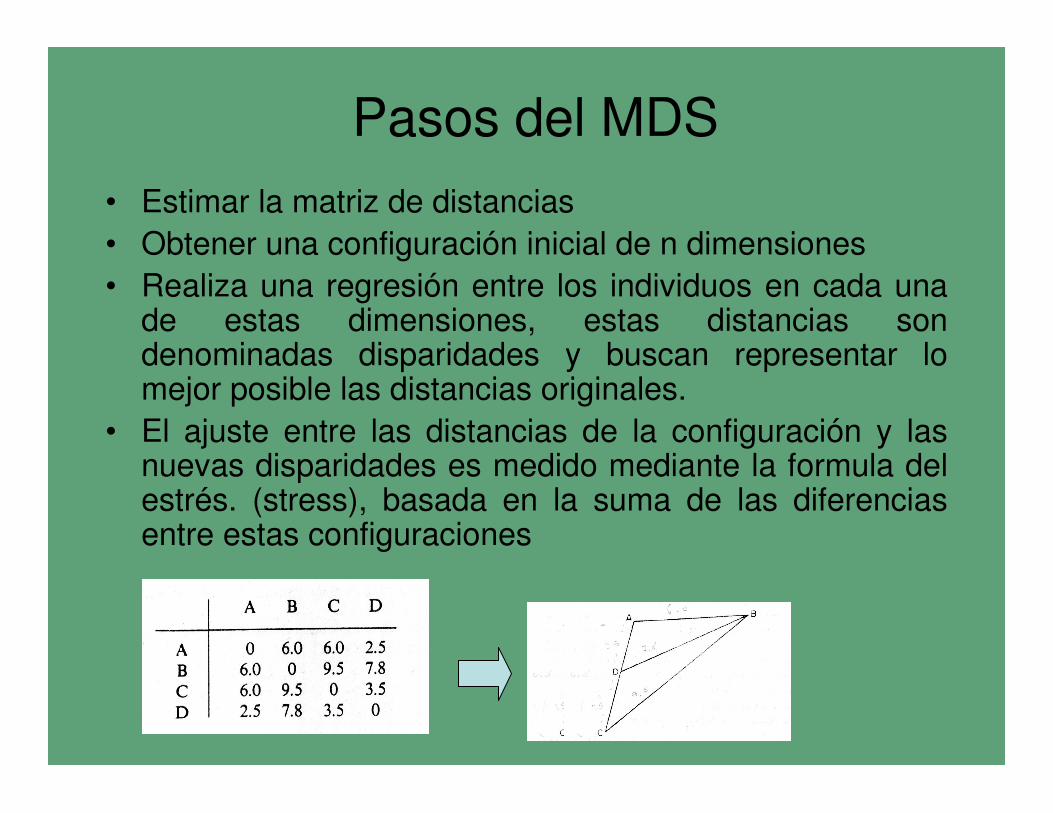
Pasos del MDS
• Estimar la matriz de distancias
• Obtener una configuración inicial de n dimensiones
• Realiza una regresión entre los individuos en cada unade estas dimensiones, estas distancias son denominadas disparidades y buscan representar lo mejor posible las distancias originales.
• El ajuste entre las distancias de la configuración y lasnuevas disparidades es medido mediante la formula del estrés. (stress), basada en la suma de las diferenciasentre estas configuraciones

• La regresión empleada es monotónica y dentro de este contexto lo importante es el ordenamiento de los datos en relación a sus distancias
• El proceso es interado, ya que se repite hasta que no se puede reducir más el estrés.
• Esta última configuración es la que posee un mejor ajuste en un menor número de dimensiones, usualmente dos.
• Un estrés cercano a 0 y no mayor a 2.5 indica un buen ajuste.
• Otras medidas alternativas, como R2, pueden emplearse para estimar la bondad de ajuste del modelo estimado en relación a las distancias originales

•El ajuste puede visualizarse a través del gráfico de
Sheppard entre las distancias observadas y las estimadas. De forma ideal los puntos se deben ajustar a
una línea recta (ajuste perfecto)
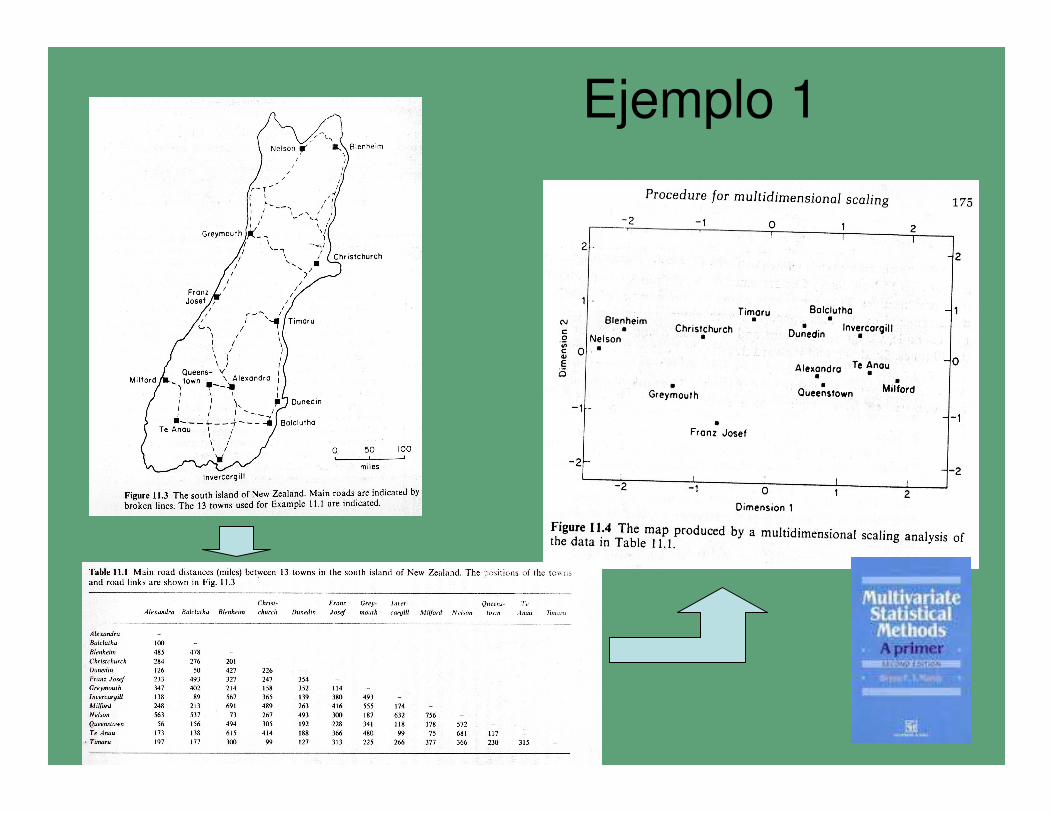
Ejemplo 1
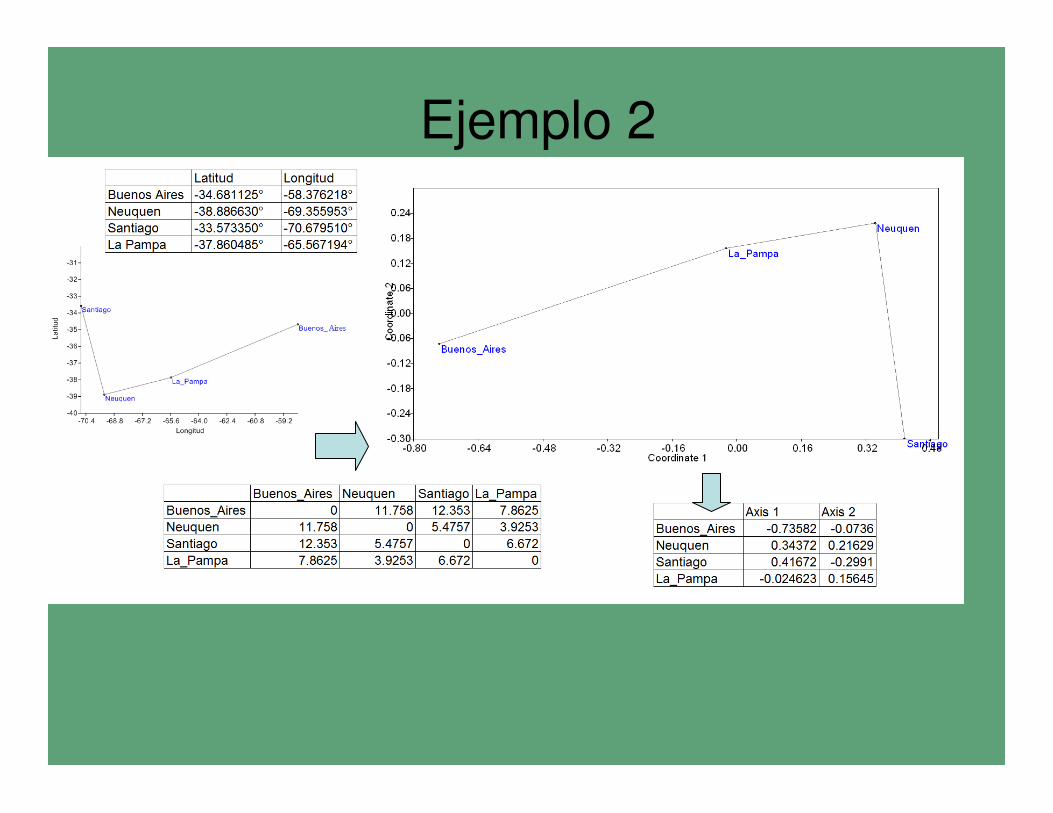
Ejemplo 2
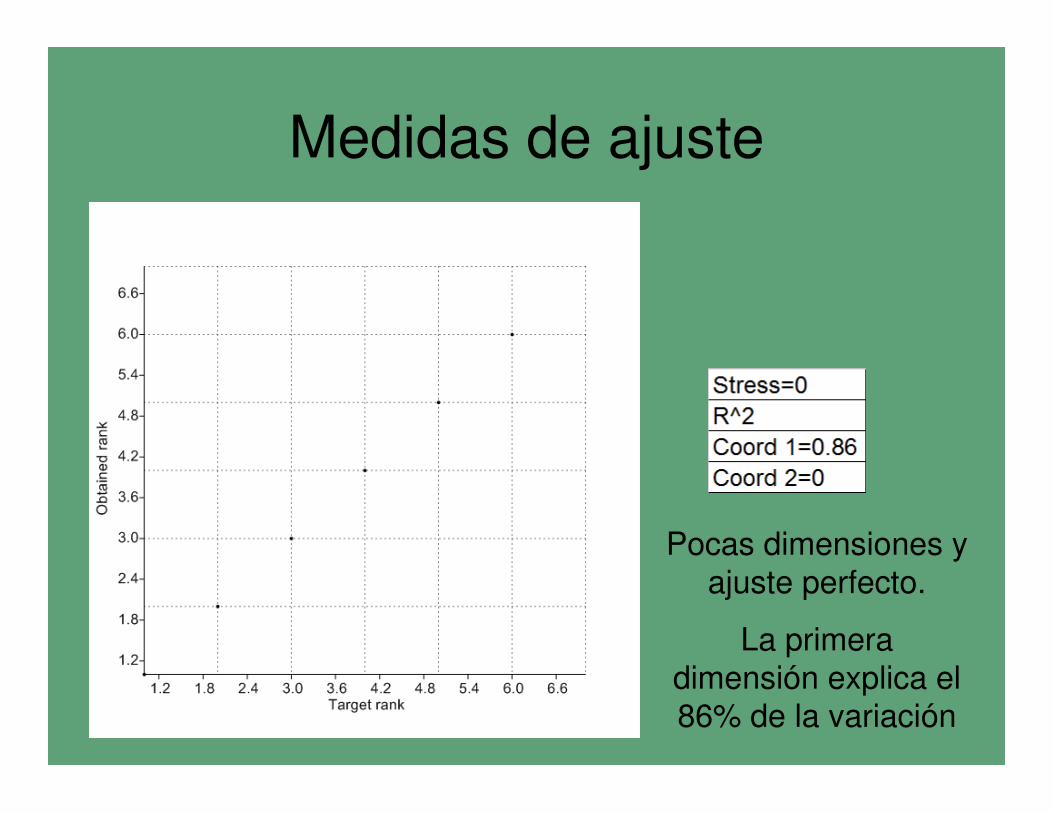
Medidas de ajuste
Pocas dimensiones y
ajuste perfecto.
La primera
dimensión explica el 86% de la variación

Discusión
• El análisis de escalamiento multidimensional esmuy eficiente en producir un “mapa” quemuestra las relaciones entre individuos.
• El análisis es propenso a soluciones “locales”más que globales, ya que depende de el puntode pardida
• Sin embargo esto puede solucionarse medianteun procedimiento interado
• Es importante seleccionar la distancia adecuada según los datos, ya que esto afecta directamente en los resultados

Coordenadas principales (PCOA)
• Que son las coordenadas principales
• Objetivos
• Funcionamiento
• Aplicación
• Análisis de los resultados
• Ejemplo
• Discusión

• EL análisis de coordenadas principales es similar al escalamiento multidimensional no métrico, ya que parte de
una matriz de distancias entre casos.
•Asimismo, el objetivo es preservar la distancia original entre
casos
•Sin embargo el PCO soluciona la reducción de dimensiones
de forma análoga a componentes principales, a través de la obtención de autovalores de una matriz de varianza-
covarianza. De hecho si la distancia empleada es euclidiana
sobre una matriz de varianza-covariaza el resultado del PCO es similar al PCA
•Uno de los problemas relacionados a este método es que si se emplea una matriz de similitudes en la descomposición de
dimensiones, algunas distancias pueden ser negativas. Distancias negativas muy altas sugieren que la matriz puede
ser inapropiada para este método.

Objetivos del PCO
• Tomar una matriz de disimilitudes
• Representar estas a los individuos que
conforman esta matriz en un espacio de
dimensiones reducidas
• Encontrar (al igual que el PC) el eje de mayor
variación y determinar la primera coordenada, y
de forma ortogonal a ésta, las siguientes
• Representar estas nuevas variables en es
espacio de dimensiones reducidas
“Coordenadas principales”

Aplicación
•PCO tiene una utilidad extra, es que permite generar variables métricas de manera similar al PC pero partiendo de variables
no continuas. Por ello es la base de algunos análisis explicativos como el análisis de redundancia basado en
distancias.
•En el programa Past son escaladas a una ponencia c antes de la obtención de los autovalores lo estándar es utilizar el
segundo (2) exponente

Ejemplo MDS y PCO
• Análisis de frecuencia de instrumentos de bloque temprano (6000-3000) y tardío (<3000-450 A.P)

Discusión PCO y MDS
• Ambos métodos son similares en el sentido de que intentar preservar distancias originales en un espacio de menores dimensiones.
• MDS preserva solamente la escala entre los casos y permite trabajar matrices bastante heterogéneas
• PCO obtiene la matriz de autovalores y las coordenadas principales de variación.


















