
UNIVERSIDAD MAYOR DE SAN ANDRÉS AFCULADT DE · PDF fileuniversidad mayor de san...
140
Transcript of UNIVERSIDAD MAYOR DE SAN ANDRÉS AFCULADT DE · PDF fileuniversidad mayor de san...

UNIVERSIDAD MAYOR DE SAN ANDRÉSFACULTAD DE CIENCIAS PURAS Y NATURALES
CARRERA DE ESTADÍSTICA
TRABAJO DIRIGIDO
CONSTRUCCIÓN DE LA METODOLOGÍA MARCO PARA DISEÑOSMUESTRALES EN ENCUESTAS DIRIGIDAS A HOGARES
INSTITUTO NACIONAL DE ESTADÍSTICA BOLIVIA
PROPONENTE: UNIV. ALVARO LIMBER CHIRINO GUTIERREZ
TUTOR ACADEMICO: LIC. JAIME PINTO
TUTORA INSTITUCIONAL: LIC. CARMEN TAPIA
LA PAZ, BOLIVIA2011


Dedicatoria
A Dios,Por su in�nito cariño,su amor y misericordia,eres mi roca, mi fortalezay mi libertador.Agradezco a quien me acerco a ti.

RESUMEN
El presente trabajo se enmarca dentro de las modalidades de graduación de la Ca-rrera de Estadística, en la modalidad de trabajo dirigido; desarrollado en el InstitutoNacional de Estadística de Bolivia (INE) como resultado de una pasantía en el periodoI-2010.
El área de investigación es el de Muestreo y Encuestas, teniendo como tema deinvestigación la �Construcción de la Metodología Marco para Diseños Muestrales enEncuestas dirigidas a Hogares�, la razón del estudio nace debido a que dentro del INEno existe un instrumento metodológico, referencial y básico, para la elaboración de di-seños de muestreo en encuestas dirigidas a hogares. Se debe sentar una base que tomeen cuenta aspectos generales macros (etapas, estrati�cación, conglomeración, etc.) yfundamentales para la elaboración de un plan de muestreo y este respaldado por lateoría estadística en todo su contexto, además, se rescate la experiencia recopilada a lolargo del tiempo por el INE y sea acorde a la infraestructura estadística que disponeel Instituto Nacional de Estadística.
Se inicia formalizando la construcción de la metodología marco, puntualizando tópi-cos que son importantes considerar dentro de las encuestas a hogares, posteriormente,se realiza un diagnóstico, referido al ámbito de muestreo, sobre la serie de 1999 - 2009de las Encuestas a Hogares que realizó el INE (MECOVI 1999 - 2004, EH 2005 - 2009);posterior a ello, en base al marco metodológico y al diagnóstico, se presentan aspectosreferidos al diseño muestral que deben ser considerados en el futuro con el �n de lograrun sistema integrado de encuestas a hogares, dando un esquema de muestreo a seguiren las próximas encuestas a hogares.
Se presenta en el anexo A, el diseño muestral para la Encuesta de Uso de Tiempo enlos Hogares de Bolivia (EUTH), como un producto dentro de los términos de referenciadel trabajo dirigido.
i

AGRADECIMIENTOS
A mis padres, Gregorio y Margarita, porque siempre conté con ellos y dejaron quetome mis propias decisiones, con�ando en mí.
A mi hermana Paola que representa un gran aliento en mi vida, mis hermanos Ho-racio y Leo, que son una gran alegría en mi corazón.
A mi amada carrera y a mis Docentes, compartieron conmigo sus conocimientos ysu amor por la Estadística, en especial al Lic. Anibal Angulo, Msc. Rubén Belmonte,Lic. Fernando Rivero y al Lic. Jaime Pinto, que me inculcaron la a�ción y el cariño almuestreo.
Al Instituto Nacional de Estadística de Bolivia, que me abrió sus puertas para po-der realizar este trabajo y a todas las personas que conocí dentro la institución quesiempre me apoyaron, en especial a la Lic. Carmen Tapia y a la Lic. Martha Oviedoque con�aron y me apoyaron incondicionalmente.
A todos mis amigos dentro y fuera de la carrera, Eliza, Gimena, Mariela, Ofelia,Quezia, Susana, Alizon, Wendy, Zenaida, Marianela, Lilian, Lisset, Lizzet, Zulema, Vi-viana, Vania, Celina, Celia, Brigida, Suelí, Raul, Wilson, Jaime, Oscar, Jose, Omar,día a día aprendo algo de cada uno de ellos.
Un agradecimiento especial a la Lic. Cuarita y a Fundación ARU que me mostrarony permitieron profundizar el manejo del procesador de texto en el que fue realizadoeste trabajo LATEX.
Pero sobre todo a Dios, que me otorga el regalo de la vida cada día y está siempreconmigo, a él se lo debo todo.
ii

ACRONIMOS
CAUTBOL: Clasi�cador de Actividades de Uso de Tiempo de Boli-via.
CBA: Canasta Básica Alimentaria.CNPV: Censo Nacional de Población y Vivienda.CV: Coe�ciente de VariaciónECH: Encuesta Continua de Hogares.EH: Encuestas a Hogares.EHC: Encuesta de la Hoja Coca.EIH: Encuesta Integrada de Hogares.ENE: Encuesta Nacional de Empleo.EPH: Encuesta Permanente de Hogares.ETE: Encuesta Trimestral de Empleo.ETI: Encuesta del Trabajo Infantil.EUTH: Encuesta de Uso de Tiempo de los Hogares.ICATUS: Clasi�cación Internacional de Actividades para Estadís-
ticas sobre Uso de Tiempo.INE: Instituto Nacional de Estadística.IPC: Índice de Precios al Consumidor.MECOVI: Programa de Mejoramiento de las Encuestas y Medición
sobre Condiciones de Vida.MM: Muestra Maestra.MMM: Marco Maestro de Muestreo.NBI: Necesidades Básicas Insatisfechas.NNUU: Naciones Unidas.OIT: Organización Internacional del Trabajo.PPT: Proporcional al Tamaño.SCN: Sistema de Cuentas Nacionales.UNIFEM: Fondo de Desarrollo de las Naciones Unidas para la Mu-
jer.UPM: Unidad Primaria de Muestreo.USM: Unidad Secundaria de Muestreo.UTM: Unidad Terciaria de Muestreo.UUM: Unidad Última de Muestreo.VIO: Viceministerio de Igualdad de Oportunidades.
iii

ACRONIMOS iv
CELADE: Centro Latinoamericano del desarrollo.IDRC: International Development Research Centre.UNFPA: Fondo de Población de las Naciones Unidas.DHS: Demographic and Health Surveys.CEPAL: Comisión Económica Para Americe Latina.ENDSA: Encuesta Nacional de Demografía y Salud.BM: Banco Mundial.

Índice general
RESUMEN i
AGRADECIMIENTOS ii
ACRONIMOS iii
1. INTRODUCCIÓN 11.1. ANTECEDENTES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.2. PROBLEMA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.3. OBJETIVOS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.3.1. Objetivo general . . . . . . . . . . . . . . . . . . . . . . . . . . 61.3.2. Objetivos especí�cos . . . . . . . . . . . . . . . . . . . . . . . . 6
1.4. JUSTIFICACIÓN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61.5. DELIMITACIONES . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2. METODOLÓGICA MARCO 72.1. POBLACIÓN OBJETIVO Y POBLACIÓN INVESTIGADA . . . . . . 82.2. MARCO MUESTRAL . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2.1. Marco de áreas . . . . . . . . . . . . . . . . . . . . . . . . . . . 92.2.2. Marco de lista . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102.2.3. Marco múltiple . . . . . . . . . . . . . . . . . . . . . . . . . . . 102.2.4. Perturbaciones en el Marco de muestreo . . . . . . . . . . . . . 112.2.5. Actualización del marco muestral . . . . . . . . . . . . . . . . . 12
2.3. UNIDADES ESTADÍSTICAS . . . . . . . . . . . . . . . . . . . . . . . 122.3.1. Unidad de Observación . . . . . . . . . . . . . . . . . . . . . . . 122.3.2. Unidad de información . . . . . . . . . . . . . . . . . . . . . . . 122.3.3. Unidad de muestreo . . . . . . . . . . . . . . . . . . . . . . . . 12
2.4. TIPOS DE COBERTURA . . . . . . . . . . . . . . . . . . . . . . . . . 132.4.1. Cobertura Espacial . . . . . . . . . . . . . . . . . . . . . . . . . 132.4.2. Cobertura Temática . . . . . . . . . . . . . . . . . . . . . . . . 132.4.3. Cobertura Temporal . . . . . . . . . . . . . . . . . . . . . . . . 13
2.5. TÉCNICAS DE MUESTREO . . . . . . . . . . . . . . . . . . . . . . . 132.5.1. Muestreo Aleatorio Simple . . . . . . . . . . . . . . . . . . . . . 132.5.2. Muestreo Estrati�cado . . . . . . . . . . . . . . . . . . . . . . . 132.5.3. Muestreo Sistemático . . . . . . . . . . . . . . . . . . . . . . . . 14
v

ÍNDICE GENERAL vi
2.5.4. Muestreo Proporcional al tamaño . . . . . . . . . . . . . . . . . 152.5.5. Muestreo Multi-etápico . . . . . . . . . . . . . . . . . . . . . . . 152.5.6. Muestreo por Conglomerados . . . . . . . . . . . . . . . . . . . 162.5.7. Muestreo en Ocasiones Sucesivas . . . . . . . . . . . . . . . . . 172.5.8. Muestreo Longitudinal . . . . . . . . . . . . . . . . . . . . . . . 17
2.6. LAS VARIABLES EN ENCUESTAS A HOGARES . . . . . . . . . . . 182.7. ESTRATIFICACIÓN EN LAS ENCUESTAS A HOGARES . . . . . . 182.8. CONGLOMERADOS EN ENCUESTAS A HOGARES . . . . . . . . . 192.9. MUESTREO POR ETAPAS EN LAS ENCUESTAS A HOGARES . . 192.10. DOMINIOS DE ESTUDIO VS ESTRATIFICACIÓN . . . . . . . . . . 202.11. LA PRUEBA PILOTO . . . . . . . . . . . . . . . . . . . . . . . . . . . 212.12. EL TAMAÑO DE LA MUESTRA . . . . . . . . . . . . . . . . . . . . 22
2.12.1. Variables endógenas . . . . . . . . . . . . . . . . . . . . . . . . 222.12.2. Variables exógenas . . . . . . . . . . . . . . . . . . . . . . . . . 232.12.3. El error de muestreo . . . . . . . . . . . . . . . . . . . . . . . . 242.12.4. El margen de error y el nivel de con�abilidad . . . . . . . . . . 252.12.5. El efecto de la no respuesta . . . . . . . . . . . . . . . . . . . . 262.12.6. El efecto del diseño muestral . . . . . . . . . . . . . . . . . . . . 28
2.13. FACTORES DE EXPANSIÓN Y SUS AJUSTES . . . . . . . . . . . . 302.13.1. Incidencias de campo . . . . . . . . . . . . . . . . . . . . . . . . 302.13.2. Actualización de conglomerados . . . . . . . . . . . . . . . . . . 312.13.3. Proyecciones Demográ�cas . . . . . . . . . . . . . . . . . . . . . 31
2.14. ESTIMADORES Y ESTIMACIONES . . . . . . . . . . . . . . . . . . 312.14.1. Distribución de probabilidades del estimador . . . . . . . . . . . 33
2.15. EL ERROR TOTAL EN UNA ENCUESTA POR MUESTREO . . . . 342.15.1. Modelo de Hansen. Hurwitz y Bershad . . . . . . . . . . . . . . 352.15.2. Estimación de las componentes de la varianza total de respuesta
y el índice de inconsistencia . . . . . . . . . . . . . . . . . . . . 392.16. ENCUESTAS TRANSVERSALES Y LONGITUDINALES . . . . . . . 43
2.16.1. Encuestas transversales . . . . . . . . . . . . . . . . . . . . . . . 432.16.2. Encuestas longitudinales . . . . . . . . . . . . . . . . . . . . . . 43
3. DIAGNÓSTICO DE LAS ENCUESTAS A HOGARES 443.1. ORGANIZACIÓN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 453.2. OBJETIVOS DE LAS ENCUESTAS . . . . . . . . . . . . . . . . . . . 463.3. EL MARCO MUESTRAL . . . . . . . . . . . . . . . . . . . . . . . . . 48
3.3.1. Variables de división político administrativa . . . . . . . . . . . 493.3.2. Variables de división geográ�ca . . . . . . . . . . . . . . . . . . 493.3.3. Variables de división estadística . . . . . . . . . . . . . . . . . . 513.3.4. Variables auxiliares de apoyo . . . . . . . . . . . . . . . . . . . . 513.3.5. Variables de estrati�cación . . . . . . . . . . . . . . . . . . . . . 51
3.4. LA ESTRATIFICACIÓN . . . . . . . . . . . . . . . . . . . . . . . . . 523.5. LOS NIVELES DE DESAGREGACIÓN . . . . . . . . . . . . . . . . . 533.6. CONGLOMERADOS EMPLEADOS . . . . . . . . . . . . . . . . . . . 54

ÍNDICE GENERAL vii
3.7. ETAPAS DENTRO DEL DISEÑO . . . . . . . . . . . . . . . . . . . . 543.8. EL TAMAÑO DE LA MUESTRA . . . . . . . . . . . . . . . . . . . . 553.9. EL EFECTO DE LA CONGLOMERACIÓN . . . . . . . . . . . . . . . 563.10. DISTRIBUCIÓN Y ASIGNACIÓN DE LA MUESTRA . . . . . . . . . 583.11. PROBABILIDADES Y MÉTODOS DE SELECCIÓN . . . . . . . . . . 593.12. LOS FACTORES DE EXPANSIÓN . . . . . . . . . . . . . . . . . . . . 603.13. RENDIMIENTO DE LA MUESTRA E INCIDENCIAS . . . . . . . . . 60
4. HACIA UN SISTEMA INTEGRADO DE ENCUESTAS A HOGA-RES 634.1. MARCO MUESTRAL . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
4.1.1. Insumos del CNPV para la construcción del Marco Maestro deMuestreo (MMM) . . . . . . . . . . . . . . . . . . . . . . . . . . 64
4.1.2. Un ejemplo del evidente cambio en el marco muestral . . . . . . 664.2. DOMINIOS DE ESTUDIO Y NIVELES DE DESAGREGACIÓN . . . 69
4.2.1. Dominios departamentales y provinciales . . . . . . . . . . . . . 694.2.2. Dominios municipales . . . . . . . . . . . . . . . . . . . . . . . . 704.2.3. Dominio Indígena originaria campesina . . . . . . . . . . . . . . 70
4.3. ESTRATIFICACIÓN . . . . . . . . . . . . . . . . . . . . . . . . . . . . 704.3.1. Estrati�cación geográ�ca . . . . . . . . . . . . . . . . . . . . . . 714.3.2. Estrati�cación por nivel de elegibilidad . . . . . . . . . . . . . . 724.3.3. Estrati�cación indígena originaria campesina . . . . . . . . . . . 724.3.4. Asignación de la muestra . . . . . . . . . . . . . . . . . . . . . . 73
4.4. CONGLOMERACIÓN Y DEFINICIÓN DE LAS UPM . . . . . . . . . 734.4.1. Áreas cartogra�adas . . . . . . . . . . . . . . . . . . . . . . . . 74
4.5. NÚMERO DE ETAPAS . . . . . . . . . . . . . . . . . . . . . . . . . . 754.6. TAMAÑO DE MUESTRA . . . . . . . . . . . . . . . . . . . . . . . . . 754.7. EL ESQUEMA DE SELECCIÓN Y EL EFECTO PPT . . . . . . . . . 754.8. ERRORES MUESTRALES . . . . . . . . . . . . . . . . . . . . . . . . 77
4.8.1. Estimación del error muestral a través de la varianza teórica . . 784.8.2. El estimador-π y sus componentes . . . . . . . . . . . . . . . . . 784.8.3. Error muestral en un diseño de dos etapas . . . . . . . . . . . . 804.8.4. Caso de un muestreo sistemático PPT . . . . . . . . . . . . . . 82
4.9. DISEÑO BASE DE LAS FUTURAS ENCUESTAS A HOGARES . . . 834.10. UNA OPCIÓN LATENTE EN ENCUESTAS PERIÓDICAS, LAMUES-
TRA MAESTRA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
5. CONCLUSIONES Y RECOMENDACIONES FINALES 855.1. CONCLUSIONES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 855.2. RECOMENDACIONES . . . . . . . . . . . . . . . . . . . . . . . . . . 85Referencias . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87

ÍNDICE GENERAL viii
A. DISEÑO MUESTRAL ENCUESTA USO DE TIEMPO 90A.1. CARACTERÍSTICAS GENERALES . . . . . . . . . . . . . . . . . . . 91
A.1.1. Marco conceptual de la Encuesta de Uso de Tiempo de los Hogares 92A.1.2. Antecedentes . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93A.1.3. Objetivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94A.1.4. Objetivo General . . . . . . . . . . . . . . . . . . . . . . . . . . 94A.1.5. Objetivos especí�cos . . . . . . . . . . . . . . . . . . . . . . . . 94
A.2. HERRAMIENTAS DE MUESTREO . . . . . . . . . . . . . . . . . . . 95A.2.1. Población Objetivo . . . . . . . . . . . . . . . . . . . . . . . . . 95A.2.2. Tipos de cobertura . . . . . . . . . . . . . . . . . . . . . . . . . 95A.2.3. Método estadístico . . . . . . . . . . . . . . . . . . . . . . . . . 95A.2.4. Unidades estadísticas de muestreo . . . . . . . . . . . . . . . . . 96A.2.5. Marco muestral . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
A.3. ESTRATEGIA DE MUESTREO . . . . . . . . . . . . . . . . . . . . . 96A.3.1. Las etapas de muestreo en la EUTH . . . . . . . . . . . . . . . 97A.3.2. Conglomeración . . . . . . . . . . . . . . . . . . . . . . . . . . . 97A.3.3. Estrati�cación de la EUTH . . . . . . . . . . . . . . . . . . . . 98A.3.4. Tamaño de la muestra . . . . . . . . . . . . . . . . . . . . . . . 98A.3.5. Distribución de las UPM en los estratos, asignación de la muestra 100A.3.6. Selección de la muestra . . . . . . . . . . . . . . . . . . . . . . . 101A.3.7. Probabilidades de Selección . . . . . . . . . . . . . . . . . . . . 102A.3.8. Factores de Expansión . . . . . . . . . . . . . . . . . . . . . . . 104A.3.9. Estimadores . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 106A.3.10.Distribución de la muestra en el espacio temporal . . . . . . . . 106A.3.11.Expansión para el ámbito temporal . . . . . . . . . . . . . . . . 108A.3.12.Estimación de los errores de muestreo . . . . . . . . . . . . . . . 109A.3.13.Estrategia para la no respuesta . . . . . . . . . . . . . . . . . . 113
A.4. LA PRUEBA PILOTO . . . . . . . . . . . . . . . . . . . . . . . . . . . 113A.5. RECOMENDACIONES POST-PRUEBA PILOTO . . . . . . . . . . . 114
B. OTROS MÉTODOS DE SELECCIÓN, PPT PARETO Y SISTEMA-TICO 115B.1. PPT SISTEMÁTICO . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115B.2. PPT DE PARETO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
C. UNA ALTERNATIVA AL TAMAÑO DE MUESTRA DE LA EUTH116
D. TÉRMINOS DE REFERENCIA 121
E. INFORME FINAL PASANTÍA 122
GLOSARIO 123

Índice de tablas
1.1. Cronología de los Censos Nacionales de Población y Viviendas con lasEncuestas a Hogares, periodo 1950 a 2001. . . . . . . . . . . . . . . . . 5
2.1. Para una variable binaria . . . . . . . . . . . . . . . . . . . . . . . . . . 412.2. Estimadores para los componentes de la varianza total de respuesta . . 42
3.1. Descripción de las características de los diseños muestrales, Encuestas aHogares, periodo 1999-2009 . . . . . . . . . . . . . . . . . . . . . . . . 46
3.2. Correspondencia de los objetivos especí�cos con relación al año de laencuesta . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
3.3. Codi�cación de la variable departamento en el marco . . . . . . . . . . 493.4. Codi�cación de la variable Área en el marco . . . . . . . . . . . . . . . 503.5. Codi�cación de la variable geográ�ca en el marco . . . . . . . . . . . . 503.6. Codi�cación de la variable pisos ecológicos en el marco . . . . . . . . . 503.7. Codi�cación del estrato estadístico en el marco y aproximación con los
niveles del NBI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 523.8. Niveles y cambio del estrato geográ�co, diferenciado por procedencia del
marco. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 523.9. Niveles de desagregación conseguidos, periodo 1999 a 2009 . . . . . . . 533.10. Conglomerados empleados . . . . . . . . . . . . . . . . . . . . . . . . . 543.11. Número de UPM seleccionadas por departamento del periodo 1999-2009
de las Encuestas a Hogares. . . . . . . . . . . . . . . . . . . . . . . . . 563.12. Coe�ciente de Homogeneidad para la variable Incidencia de pobreza en
las encuestas de hogares. . . . . . . . . . . . . . . . . . . . . . . . . . . 573.13. Distribución de la muestra por departamento y estructura de los marcos
muestrales empleados en porcentaje. . . . . . . . . . . . . . . . . . . . 593.14. Estadísticas básicas para los factores de expansión a nivel hogar, por
año de la encuesta . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 613.15. Tasa de no respuesta en porcentaje, de las Encuestas a Hogares por
departamento y año de la encuesta . . . . . . . . . . . . . . . . . . . . 613.16. Frecuencia de incidencias, por tipo de incidencia y año de encuesta . . 623.17. Porcentaje de incidencia, por tipo de incidencia y año de encuesta . . . 62
4.1. Variables a considerar para la estrati�cación . . . . . . . . . . . . . . . 72
ix

ÍNDICE DE TABLAS x
4.2. Número de veces que fue seleccionada alguna UPM en encuestas dirigidasa hogares periodo 2002-2010 . . . . . . . . . . . . . . . . . . . . . . . . 76
4.3. Comparación de los algoritmos de selección PPT, incluyendo al MuestreoAleatorio Simple y el porcentaje de repetición por método . . . . . . . 77
4.4. Probabilidades de inclusión de primer y segundo orden y la cantidad δpor etapas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
A.1. Unidades de muestre de la EUTH . . . . . . . . . . . . . . . . . . . . . 97A.2. Composición del marco en UPM, con la combinación de los estratos . . 98A.3. Elementos para el cálculo del tamaño de la muestra . . . . . . . . . . . 99A.4. Distribución de la muestra de UPM, por área y con porcentaje de pre-
sencia en el marco . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100A.5. Distribución de la muestra de UPM, por estratos . . . . . . . . . . . . 101A.6. Información para la a�jación . . . . . . . . . . . . . . . . . . . . . . . . 102A.7. Distribución de la muestra de viviendas, por estratos . . . . . . . . . . 102A.8. Combinación de días . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107A.9. Probabilidades de inclusión de primer y segundo orden y la cantidad ∆
por etapas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110
C.1. Calculo para el tamaño de muestra . . . . . . . . . . . . . . . . . . . . 118C.2. Tamaño de muestra de UPM . . . . . . . . . . . . . . . . . . . . . . . . 119

Índice de �guras
1.1. Proceso del diseño de una encuesta por muestreo . . . . . . . . . . . . 2
2.1. Procesos de un diseño muestral . . . . . . . . . . . . . . . . . . . . . . 82.2. Muestreo Aleatorio Simple . . . . . . . . . . . . . . . . . . . . . . . . . 142.3. Muestreo Estrati�cado . . . . . . . . . . . . . . . . . . . . . . . . . . . 142.4. Muestreo Sistemático . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152.5. Muestreo proporcional al tamaño . . . . . . . . . . . . . . . . . . . . . 162.6. Muestreo multi-etápico . . . . . . . . . . . . . . . . . . . . . . . . . . . 162.7. Muestreo por conglomerados . . . . . . . . . . . . . . . . . . . . . . . . 172.8. Muestreo en ocasiones sucesivas . . . . . . . . . . . . . . . . . . . . . . 172.9. Factores en la no respuesta . . . . . . . . . . . . . . . . . . . . . . . . . 27
3.1. Evolución del tamaño de la muestra de las Encuestas a Hogares, serie1999 - 2009 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.1. Diagrama de caja de datos pareados, para la variable Total de viviendaspor UPM, para la muestra en la MECOVI-2002 y el Marco Muestral delCNPV-2001, diferenciado por área. . . . . . . . . . . . . . . . . . . . . 67
4.2. Histograma de la diferencia: MECOVI-2002-CNPV-2001 . . . . . . . . 68
xi

Capítulo 1
INTRODUCCIÓN
La estadística, en su constante evolución, ha llegado a convertirse en un instru-mento muy e�caz y sumamente necesario para la toma de decisiones y la evaluacióndel comportamiento de características (variables) en distintos universos de estudio, latendencia de respaldar con la teoría estadística es mayor, con el �n de mejorar losinstrumentos metodológicos, que permitan un levantamiento de información de cali-dad. El uso de la teoría del muestreo, se ha convertido en una condicionante paracualquier tipo de estudio que pretenda validar, objetivamente, la representatividad deuna muestra y requiera inferir resultados a partir de esta. La necesidad de contar coninformación oportuna, precisa y con�able, en diferentes temas de interés como ser:salud, bienestar social, educación, economía, producción, temas culturales, etc. Inme-diatamente viene asociada a una encuesta por muestreo, debido a que un relevamientocompleto de información (CENSO), dentro de sus limitaciones, no es capaz de captarvariables volátiles y dinámicas en el tiempo, sin mencionar que su operatividad es cos-tosa y morosa (considerar que el CENSO presenta también bene�cios respecto a unaencuesta por muestreo), por ello las instituciones estadísticas de los diferentes países,han adoptado al muestreo, como una herramienta estadística, altamente con�able, queles permite examinar las características de una población de manera oportuna y precisa.
El presente trabajo, responde a la necesidad de la captura de información por me-dios estadísticos, más propiamente, mediante encuestas por muestreo, que trae consigotodas las implicaciones de la teoría del muestreo y por ende la inferencia estadística. Sebusca sentar una base metodológica, referencial y básica, para las encuestas dirigidas ahogares, que realiza el Instituto Nacional de Estadística de Bolivia (INE), exponiendocaracterísticas, como la conglomeración, la estrati�cación, el uso de etapas, el marcomuestral y otras características usuales que deben delinearse en una primera fase deplani�cación de un diseño muestral.
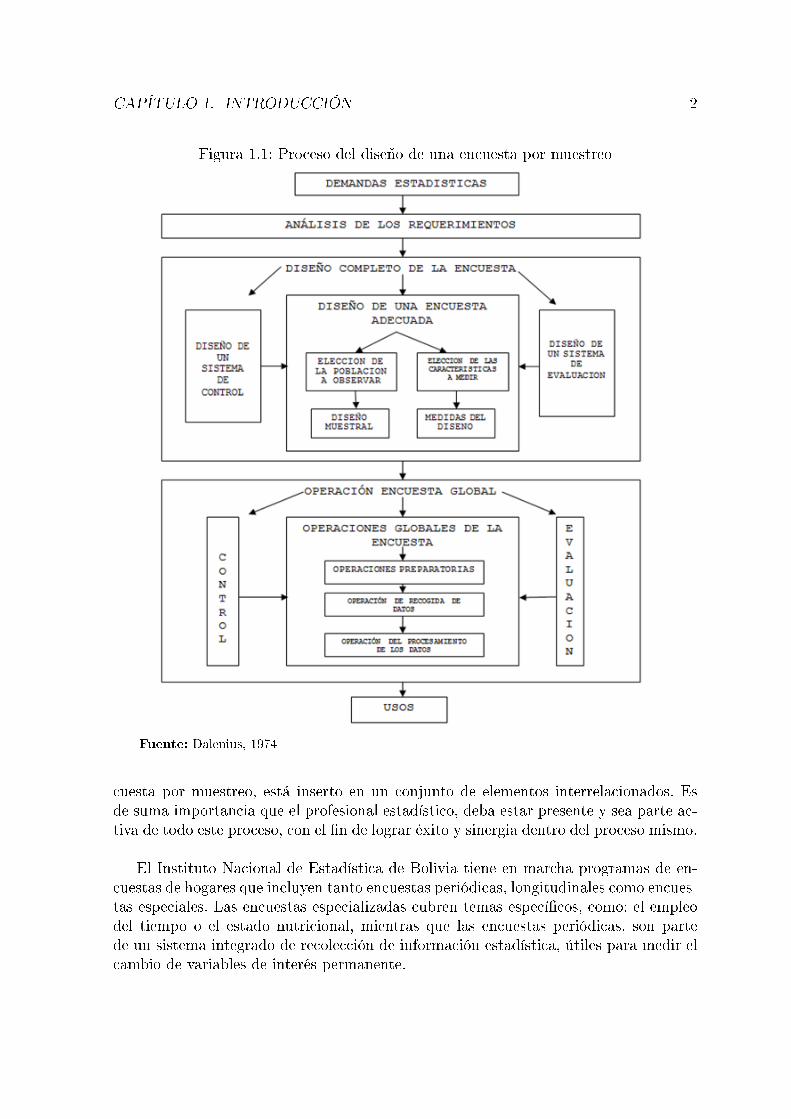
La �gura 1.1, propuesto por Dalenius, 1974 muestra el proceso en el diseño de unaencuesta por muestreo.
En la �gura 1.1, se aprecia, que el diseño muestral dentro del proceso de una en-
1
CAPÍTULO 1. INTRODUCCIÓN 2
Figura 1.1: Proceso del diseño de una encuesta por muestreo
Fuente: Dalenius, 1974
cuesta por muestreo, está inserto en un conjunto de elementos interrelacionados. Esde suma importancia que el profesional estadístico, deba estar presente y sea parte ac-tiva de todo este proceso, con el �n de lograr éxito y sinergia dentro del proceso mismo.
El Instituto Nacional de Estadística de Bolivia tiene en marcha programas de en-cuestas de hogares que incluyen tanto encuestas periódicas, longitudinales como encues-tas especiales. Las encuestas especializadas cubren temas especí�cos, como: el empleodel tiempo o el estado nutricional, mientras que las encuestas periódicas, son partede un sistema integrado de recolección de información estadística, útiles para medir elcambio de variables de interés permanente.

CAPÍTULO 1. INTRODUCCIÓN 3
Este documento, debe considerarse como un manual referencial de primera instan-cia, puesto que da lineamientos generales, macros y básicos en el diseño muestral, enencuestas dirigidas a hogares; las características de cada encuesta (periódicas, especia-les, longitudinales) son las que delinean de manera �nal el diseño muestral.
Se inicia con la formalización de la construcción de la metodología marco; analizan-do y puntualizando, tópicos importantes dentro del proceso estadístico de una encuestapor muestreo, para luego presentar un diagnóstico en el ámbito del muestreo estadístico,sobre las encuestas dirigidas a hogares, que realizó el Instituto Nacional de Estadística,explícitamente de la serie 1999 a 2009 de las encuestas a hogares (MECOVI 1999-2004,EH 2005-2009); �nalmente, se presenta un apartado denominado �Hacia un sistemaintegrado de encuestas a hogares�, en el mismo, se realizan recomendaciones puntualesen aspectos macros, para la elaboración de los diseños muestrales de las encuestas ahogares en el futuro, esto a razón, del escenario que apertura la realización de un nuevoCenso Nacional de Población y Vivienda para sistematizar e integrar las encuestas ahogares, incluyendo un esquema de muestreo a seguir en las futuras encuestas a ho-gares. Como documentación adicional se presenta en el anexo A: La formalización deldesarrollo de la �Encuesta de Uso de Tiempo de los Hogares en Bolivia� (EUTH) ensu diseño muestral, lo que implica, que es un trabajo independiente del contexto deeste documento, pero que fue tarea realizada como producto requerido por el InstitutoNacional de Estadística.
Este trabajo está enmarcado en el convenio institucional entre el INE y la Carrerade Estadística, responde a los productos �nales obtenidos durante el tiempo que duróla pasantía y a los términos de referencia del trabajo dirigido.
Se introduce la importancia de generar una visión hacia el muestreo enlazado a laestadística multivariante, por su importancia y su ajuste a las encuestas multipropósitode nuestra realidad.
�Si los estadísticos teóricos hacen caso omiso al reto de enfrentar las encues-
tas multipropósito, entonces el vacío existente entre ellos y los estadísticos
prácticos se hará cada vez más grande. El diseño y análisis de encuestas
multivariantes debe ser una de las próximas áreas de mayor investigación.�
Smith, 1976
1.1. ANTECEDENTES
La experiencia sobre encuestas a hogares, se viene desarrollando a partir de diferen-tes metodologías, desde 1971, a sugerencia, tanto de organismos internacionales como

CAPÍTULO 1. INTRODUCCIÓN 4
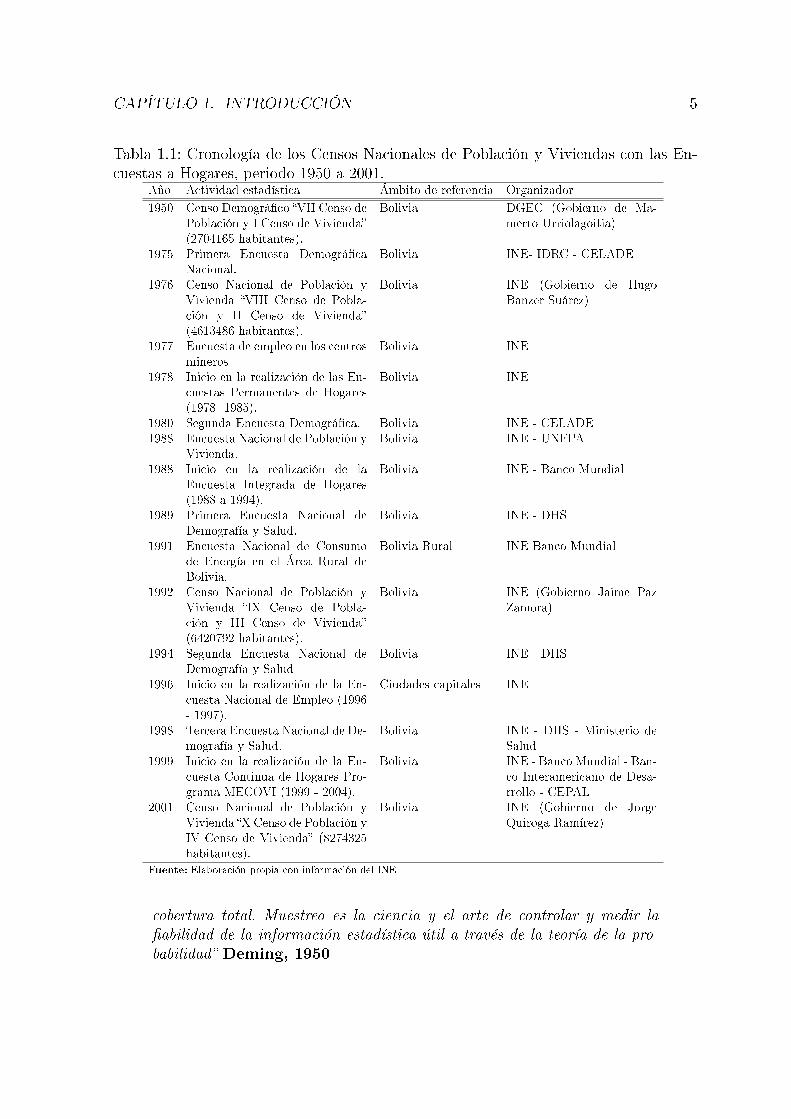
organizaciones nacionales de estadística. En este contexto, el Instituto Nacional de Es-tadística de Bolivia, inicia su labor de encuestas a partir de la información generadaen el Censo Nacional de Población y Vivienda de 1950, es a partir de este censo que seempezaron a construir herramientas de infraestructura estadística que coadyuvan conla plani�cación de las encuestas dirigidas a hogares, en la tabla 1.1, se aprecia un ordencronológico de los censos y las encuestas a hogares implementadas por el INE, descri-biendo el ámbito de referencia del estudio y los entes involucrados en la organización,desde el año de 1950 al 2001.
Paralelamente a la inmersión del INE en el estudio mediante encuestas, se inser-to la utilización de la teoría del muestreo, que tenía y tiene por misión, respaldar larepresentatividad de la muestra, año tras año profesionales en el área de muestreo,implementaron metodologías variadas en las distintas encuestas, con el �n de que res-pondieran a la temática a medir y a los insumos con los que se contaban; la ejecuciónde cada Censo de Población y Vivienda, siempre represento una apertura, a un nue-vo escenario para la aplicación del muestreo, en encuestas dirigidas a hogares, ya queproporcionaba un marco muestral renovado.
En estos últimos años la creciente necesidad de información en distintos ámbitostemáticos, dio apertura a la elaboración de diseños muestrales con estrategias variadaspara su ejecución, tal es el caso de la �Encuesta de la Hoja Coca� (EHC-2009) y laEncuesta de Trabajo Infantil (ETI-2008) que estuvieron dirigidas sobre poblacionesfocalizadas (encuestas especializadas) también está la Encuesta Trimestral de Empleo(ETE) que utiliza un muestreo de tipo panel (longitudinal).
1.2. PROBLEMA
El desarrollo de las distintas encuestas dirigidas a hogares, permitió dentro de lainstitución, contar con documentos metodológicos, que describían la estrategia de mu-estreo utilizada en cada encuesta, teniendo entre ellas similitudes, en cuanto a su es-tructura macro, la utilización de estratos, conglomerados y de un muestreo en etapas.Aun así no existía un marco referencial donde acudir, que diera directrices y pudieraadvertir problemas comunes dentro de un diseño muestral abocado exclusivamente altema de hogares y además advirtiera las características peculiares del muestreo bajonuestra realidad nacional y la infraestructura estadística del Instituto Nacional de Es-tadística.
El problema: �No existe un documento metodológico, que sirva de Marco en el INE,
que de lineamientos básicos y generales, respecto a la elaboración de diseños de muestra
en encuestas dirigidas a hogares�
�El muestreo no es la simple sustitución de una cobertura parcial para una
CAPÍTULO 1. INTRODUCCIÓN 5
Tabla 1.1: Cronología de los Censos Nacionales de Población y Viviendas con las En-cuestas a Hogares, periodo 1950 a 2001.
Año Actividad estadística Ámbito de referencia Organizador1950 Censo Demográ�co �VII Censo de
Población y I Censo de Vivienda�(2704165 habitantes).
Bolivia DGEC (Gobierno de Ma-merto Urriolagoitia)
1975 Primera Encuesta Demográ�caNacional.
Bolivia INE- IDRC - CELADE
1976 Censo Nacional de Población yVivienda �VIII Censo de Pobla-ción y II Censo de Vivienda�(4613486 habitantes).
Bolivia INE (Gobierno de HugoBanzer Suárez)
1977 Encuesta de empleo en los centrosmineros
Bolivia INE
1978 Inicio en la realización de las En-cuestas Permanentes de Hogares(1978 -1985).
Bolivia INE
1980 Segunda Encuesta Demográ�ca. Bolivia INE - CELADE1988 Encuesta Nacional de Población y
Vivienda.Bolivia INE - UNFPA
1988 Inicio en la realización de laEncuesta Integrada de Hogares(1988 a 1994).
Bolivia INE - Banco Mundial
1989 Primera Encuesta Nacional deDemografía y Salud.
Bolivia INE - DHS
1991 Encuesta Nacional de Consumode Energía en el Área Rural deBolivia.
Bolivia Rural INE Banco Mundial
1992 Censo Nacional de Población yVivienda �IX Censo de Pobla-ción y III Censo de Vivienda�(6420792 habitantes).
Bolivia INE (Gobierno Jaime PazZamora)
1994 Segunda Encuesta Nacional deDemografía y Salud
Bolivia INE - DHS
1996 Inicio en la realización de la En-cuesta Nacional de Empleo (1996- 1997).
Ciudades capitales INE
1998 Tercera Encuesta Nacional de De-mografía y Salud.
Bolivia INE - DHS - Ministerio deSalud
1999 Inicio en la realización de la En-cuesta Continua de Hogares Pro-grama MECOVI (1999 - 2004).
Bolivia INE - Banco Mundial - Ban-co Interamericano de Desa-rrollo - CEPAL
2001 Censo Nacional de Población yVivienda �X Censo de Población yIV Censo de Vivienda� (8274325habitantes).
Bolivia INE (Gobierno de JorgeQuiroga Ramírez)
Fuente: Elaboración propia con información del INE
cobertura total. Muestreo es la ciencia y el arte de controlar y medir la
�abilidad de la información estadística útil a través de la teoría de la pro-
babilidad� Deming, 1950

CAPÍTULO 1. INTRODUCCIÓN 6
1.3. OBJETIVOS
1.3.1. Objetivo general
�Construir una metodología marco y básica para los diseños muestralesdirigidos a hogares, en el Instituto Nacional de Estadística de Bolivia.�
Metodología marco, en el sentido de que se delinean aspectos generales y se presen-ta un diseño básico como estructura mínima, al cual deben de responder las futurasencuestas a hogares, para lograr un sistema integrado de encuestas a hogares.
1.3.2. Objetivos especí�cos
Realizar un diagnóstico correspondiente al diseño muestral, de las Encuestas aHogares aplicadas por el INE, para la serie de 1999-2009, dentro del espacio delas medidas de condiciones de vida.
Mostrar y formalizar de manera técnica las diferentes herramientas involucradasen un diseño muestral en el ámbito de encuestas a hogares.
Proponer un esquema básico, de diseño muestral para las futuras encuestas ahogares.
1.4. JUSTIFICACIÓN
El Instituto Nacional de Estadística de Bolivia, siendo el mayor referente a nivelnacional e internacional, de la generación de estadísticas o�ciales de nuestro país, re-quiere contar con un documento metodológico, que de lineamientos generales, básicos,acerca de la construcción de los diseños muestrales, en las encuestas dirigidas a hogaresque realizará y ejecutará en el futuro.
1.5. DELIMITACIONES
El estudio se centra en el ámbito del muestreo estadístico, de las encuestas dirigidasa hogares de tipo transversales, enmarcado en las características propias de nuestropaís, y en correspondencia a la infraestructura estadística con la que cuenta el Institu-to Nacional de Estadística de Bolivia.
Debido a que las características propias de cada encuesta, son las que delineande manera �nal la elaboración de un diseño muestral, este documento es un manualreferencial, que da lineamientos generales (marcos), para la construcción del diseñomuestral en encuestas dirigidas a hogares. Un estudio a mayor detalle está fuera delalcance de este trabajo, puesto que abarcaría una in�nita gama de situaciones posibles,que deben ser tratadas de manera especial y única.

Capítulo 2
METODOLÓGICA MARCO
El objetivo de una encuesta es normalmente estimar uno o más parámetros de unapoblación. Dos de las muchas características importantes que se deben hacer en unaencuesta son:
1. La elección de un diseño de muestreo, acorde a los insumos con los que se dispone.
2. La elección de un estimador para el cálculo de una estimación de los parámetrosde interés y su error.
Estas dos opciones no son independientes la una respecto a la otra. E intervienenotros factores para que estas se ejecuten de la mejor manera posible. El estimador siem-pre depende del diseño de la muestra y sus implicaciones; todas estas puntualizaciones,construyen el proceso de un diseño muestral y son la base marco, que establecen direc-trices para la elaboración y ejecución de una encuesta por muestreo. Una estrategia esla combinación de un diseño de muestreo y un estimador, que asuma las limitacionesde la realidad, con el objetivo de encontrar la mejor estrategia posible, es decir, unaque estime el parámetro o los parámetros de la forma más precisa posible.
Para la construcción e�caz de un diseño muestral en el ámbito de encuestas diri-gidas a hogares, se debe recurrir previamente a la preparación y de�nición de algunoselementos que están muy correlacionados al diseño como tal, ya que de la disposicióny preparación de estos elementos, dependerá la aplicabilidad efectiva del diseño mues-tral, entre estos se puede mencionar: la correcta de�nición de la población objetivo yla población investigada, la concepción del marco muestral, la de�nición de las uni-dades estadísticas, la delimitación de los ámbitos de la encuesta (tipos de cobertura),las variables a medir. Estos componentes están altamente relacionados entre sí y lamala de�nición de alguno de los anteriores elementos, se convierten en restriccionesque afectan la aplicabilidad de un diseño muestral ideal y conduce a realizar algunosajustes sobre el diseño, tal como lo muestra la �gura 2.1.
Posterior a la preparación y de�nición de los insumos básicos para el diseño mues-tral, prosigue, establecer la estrategia de muestreo a utilizar, instaurar la estrati�cación,
7

CAPÍTULO 2. METODOLÓGICA MARCO 8
Figura 2.1: Procesos de un diseño muestral
Fuente: Rydenstam, 2010
la conglomeración, las etapas involucradas y los esquemas de selección, que son rasgosgenerales en encuestas a hogares. A partir de todo lo establecido, se calcula el tamañode muestra de acuerdo a los niveles de desagregación de los resultados y se establecenmecanismos de control para disminuir los errores de muestreo y los errores ajenos almuestreo, para posterior a todo ello, realizar la encuesta de forma e�ciente, controlan-do el operativo de campo con adecuada supervisión, además de estableces un procesoidóneo de validación, consistencia y critica de la información; una vez concluida, sedebe realizar el procesamiento de los datos y sistematizar la información en una basede datos relacional; para �nalmente analizar el comportamiento del error muestral y larepresentatividad real de la encuesta, para las estimaciones.
2.1. POBLACIÓN OBJETIVO Y POBLACIÓN IN-VESTIGADA
En el proceso de la plani�cación de una encuesta se de�ne la población objetivo,conformada por todas las unidades sobre las que quiere hacerse inferencia y las quedeben estar representadas por la muestra. Es el grupo de elementos de los cuales sequiere información y se desea estimar algún parámetro.

CAPÍTULO 2. METODOLÓGICA MARCO 9
Es necesario de�nir cuidadosamente la población objetivo en correspondencia a losobjetivos de la investigación, además, teniendo en cuenta que se va a obtener unamuestra de esa población. Esta debe ser de�nida de tal manera que la selección de lamuestra sea realmente factible.
Eliminando de la población objetivo, la parte de la población que no es accesible,se obtiene la población investigada, que es la población efectiva sobre la cual se diseñael esquema de muestreo.
En el caso de las encuestas a hogares, la población objetivo puede diferenciarse entres grupos de interés diferentes, las viviendas, los hogares y las personas, pudiendotambién restringir alguna de estas a sub-poblaciones menores, viviendas particulares,hogares unipersonales, personas mayores de 7 años, etc.
2.2. MARCO MUESTRAL
El marco de muestreo, se de�ne como el listado de unidades que estarán sujetas a laselección, y dicho marco contendrá a toda la población investigada de manera biunívo-ca. Además, es la herramienta que permite identi�car y ubicar a las unidades objeto deestudio y en este sentido, se dice que proporciona acceso a la población de interés. Laconstrucción del marco muestral es una de las tareas más delicadas dentro de la antesa-la a cualquier estudio por muestreo y este debe cumplir ciertas características deseables.
Un marco muestral debe comprender, en términos estadísticos, con toda la pobla-ción investigada, además de eso, un marco muestral perfecto, es aquel que es completo,exacto y actualizado, rasgos ideales que resultan inalcanzables en el caso de las en-cuestas a hogares. Aun así, es esencial procurar acercarse a ellos al máximo, puestoque en la medida en que no se alcance cada una de estos rasgos, la encuesta produciráresultados sesgados.
El marco muestral para las encuestas a hogares debe priorizar la actualización anivel de las unidades geográ�cas, dado que una actualización a menor escala es im-posible, como viviendas y número de personas, sin embargo, la información del totalde viviendas y número de personas no deja de ser importante como insumo al diseñomuestral.
Existen básicamente tres tipos de marcos muestrales, que logran su diferencia enbase a su de�nición y a las características de las unidades muestrales que contienen.
2.2.1. Marco de áreas
En las encuestas a hogares, un marco de área es aquel que comprende las unidadesgeográ�cas de un país en un orden jerárquico. Administrativamente las unidades se

CAPÍTULO 2. METODOLÓGICA MARCO 10
etiquetan en orden descendente, términos tales como departamento, provincia, secciónmunicipal, zona censal, sector censal, segmentos censales (zonas de empadronamiento),etc. Con frecuencia, las zonas de empadronamiento del censo son las unidades geográ-�cas más pequeñas de�nidas y delineadas en el país1.
A la hora de realizar una encuesta hay cuatro características de las unidades geo-grá�cas que son importantes para el diseño muestral.
Normalmente cubren el territorio completo de un dominio de interés.
Sus fronteras se hallan bien de�nidas.
Hay cifras de la población para ellas.
Están cartogra�adas.
La cobertura de la totalidad del territorio geográ�co de un país es importante,porque es uno de los criterios para obtener una muestra probabilística autentica. Lascifras sobre la población son necesarias en el diseño muestral para asignar las medidasde tamaño y calcular las probabilidades de selección dentro las unidades geográ�cas.Además de coadyuvar en la construcción de estratos.
Como ejemplo, en el INE se manejan a los sectores censales, segmentos censalescomo unidades geográ�cas.
2.2.2. Marco de lista
Este es un marco esencialmente constituido por una lista de las unidades que con�-guran la población objetivo. La última etapa de selección en una encuesta, de hogares,tradicional se basa, invariablemente, en el concepto de marco de lista, ya que la penúl-tima etapa de muestreo puede dar lugar a una muestra de conglomerados en los quese elabore una lista de hogares o viviendas actual, a partir de la cual se seleccionan loshogares de la muestra.
2.2.3. Marco múltiple
Un marco múltiple es aquel que utiliza para su diseño una combinación de marcosáreas y de listas. Por ejemplo en el INE, los estudios por muestreo, utilizan un marcomúltiple; se tiene un marco de lista en la última etapa de muestreo, para seleccionarlas viviendas y en las etapas previas a esta, se utilizan marcos de áreas. El marco deáreas se construye a partir de la cartográ�ca existente y con la información que generacada Censo Nacional de Población y Vivienda (CNPV) que se realiza.
1ONU, 2009

CAPÍTULO 2. METODOLÓGICA MARCO 11
2.2.4. Perturbaciones en el Marco de muestreo
Una característica deseable en cualquier marco muestral es que presente un listadocompleto de todas las unidades de la población, especialmente de las unidades geográ-�cas, esto es posible, controlando los problemas que perturban a un marco, estos son:
Sobre cobertura
Sub cobertura
Duplicidad
Son problemas que afectan directamente lo que el marco debe proyectar de la pobla-ción objetivo, que aparecen en los momentos de construir el propio marco o en instantesde actualizar el marco.
Sobre cobertura: Se presenta cuando hay elementos en el marco que no pertenecena la población objetivo y no pueden ser identi�cados y eliminados antes de selec-cionar la muestra. Esta imperfección afecta la calidad de los estimadores porque,aunque se identi�que en la encuesta a los elementos sobrantes y se eliminen, seproduce una reducción en el tamaño de muestra efectivo que disminuye la pre-cisión; adicionalmente, la entrevista a unidades que no son de interés representaun sobrecosto que puede ser considerable. Cuando no es posible identi�car a loselementos extraños, esto puede ser una fuente de sesgo en los estimadores. Sies posible identi�car a los elementos extraños desde el marco de muestreo, larecomendación es eliminarlos.
Sub cobertura: Se produce cuando hay elementos de la población objetivo que no seencuentran en el marco de muestreo. En marcos de lista, por ejemplo, cuando hapasado un tiempo entre la construcción del marco y la entrevista con cuestionario,es posible que las unidades nuevas no estén presentes en el marco; en marcosde áreas este defecto es menos frecuente. El impacto de la sub cobertura en lacalidad de las estimaciones se da con el riesgo de generar sesgos, cuando loselementos pertenecientes a la población objetivo y que no están en el marcotienen características diferentes a las de los que sí lo están. Para tratar con estaimperfección, se recomienda identi�car las áreas (geográ�cas, temáticas) en dondese presenta la sub-cobertura y buscar marcos de muestreo adicionales que puedencombinarse con los disponibles para obtener un mejor acercamiento a la poblaciónobjetivo. Adicionalmente, si se cuenta con información auxiliar de buena calidad,es posible reducir el sesgo.
Duplicidad: Cuando los elementos en el marco hacen referencia a una determinadaunidad de la población objetivo más de una vez, se presenta una imperfección demarco por la duplicidad. Esta información genera sesgo en la información. Estaimperfección suele corregirse si el costo lo permite, realizando una actualizaciónprevia a la encuesta, al menos a nivel de unidades geográ�cas.

CAPÍTULO 2. METODOLÓGICA MARCO 12
2.2.5. Actualización del marco muestral
La actualización del marco muestral es una de las labores más difíciles, morosas ycostosas dentro de las encuestas a hogares en un país, su actualización completa se larealiza como resultado de la actualización cartográ�ca y la información que genera unCenso Nacional de Población y Vivienda.
Si se plani�ca una actualización, esta deberá centrarse, en la información de lasáreas geográ�cas, en especial las variables que corroboran en la construcción de lasprobabilidades de selección, como el número de viviendas de cada área geográ�ca. Teneren cuenta que las áreas geográ�cas con un elevado crecimiento demográ�co tienenun efecto perjudicial sobre los marcos muestrales, estos pueden reducirse de formasigni�cativa revisando el marco regularmente cado dos o tres años2, esta tarea será unalabor muy grande y costosa, pero necesaria.
2.3. UNIDADES ESTADÍSTICAS
Las unidades estadísticas corresponden a los elementos involucrados en el ámbitode la investigación de la encuesta, se hace necesario identi�car a estas porque permitedar un mayor enfoque sobre el esquema propio de la encuesta y el diseño muestral,estas unidades son: la unidad de observación, la unidad de información y la unidad demuestreo3.
2.3.1. Unidad de Observación
Es la unidad sobre la cual se requiere información y sobre la cual se desenvuelvetoda la investigación, pueden ser individuos o grupos. En el caso de las encuestas ahogares, normalmente son, la persona, el hogar y la vivienda.
2.3.2. Unidad de información
Es aquella que proporciona información de la unidad de observación correspondien-te. La unidad de información y unidad de observación pueden coincidir, sin embargo, nonecesariamente es así. Por ejemplo, la unidad de información puede ser el jefe de hogardel cual se recaba información de todos los miembros del hogar siendo las unidades deobservación los miembros del hogar.
2.3.3. Unidad de muestreo
Es la unidad que está sujeta a selección, en el proceso aleatorio. En el caso de lasencuesta a hogares una unidad de muestreo puede ser un área geográ�ca (zona, sector,segmento censal, vivienda, etc.).
2ONU, 20093Lohr, 2000

CAPÍTULO 2. METODOLÓGICA MARCO 13
2.4. TIPOS DE COBERTURA
Los tipos de cobertura en una encuesta, también denominados ámbitos de la encues-ta, establecen los lineamientos en aspectos espaciales, temáticos y temporales4. Estasde�niciones deben incluirse en la de�nición de la población objeto de estudio.
2.4.1. Cobertura Espacial
Se re�ere a la delimitación geográ�ca que captura la encuesta, más propiamente alterritorio jurídico en la que se encuentra la población objeto de estudio, de�nir estacobertura coadyuva a la construcción adecuada del marco muestral.
2.4.2. Cobertura Temática
Engloba toda la gama de áreas de interés temático que persigue la investigación,tomar en cuenta que la encuesta no deba incluir temas ajenos al objetivo del estudio.
2.4.3. Cobertura Temporal
Determina el periodo temporal de la investigación, dado que no es lo mismo estudiarun tema en diferentes periodos de tiempo, la de�nición de esta dará paso a utilizarencuestas transversales o longitudinales según la necesidad de la investigación.
2.5. TÉCNICAS DE MUESTREO
A continuación se presenta un breve resumen de las técnicas de muestreo másusuales, con el �n de mostrar los conceptos necesarios para proseguir con el seguimientodel documento5.
2.5.1. Muestreo Aleatorio Simple
Si un tamaño de muestra es seleccionado de una población de tamaño de tal maneraque cada muestra posible de tamaño tiene la misma probabilidad de ser seleccionada,el procedimiento de muestreo se denomina muestreo irrestricto aleatorio o muestreoaleatorio simple. A la muestra así obtenida se la llama muestra irrestricta aleatoria.
2.5.2. Muestreo Estrati�cado
Una muestra aleatoria estrati�cada es la obtenida mediante la separación de los ele-mentos de la población en grupos independientes entre sí (que no presenten traslapes)llamados estratos que tienen la característica que las unidades dentro de cada estratoson similares respecto a la característica de interés al interior del estrato y heterogéneas
4Bethlehem, 20095DANE, 1997

CAPÍTULO 2. METODOLÓGICA MARCO 14
Figura 2.2: Muestreo Aleatorio Simple
Fuente: DANE, 1997
entre los diferentes estratos; y la selección posterior de una muestra dentro de cada unode los estratos (cada estrato está representado en la muestra). En general el muestreoestrati�cado reduce signi�cativamente la varianza muestral como medida de precisiónde los estimadores, si cumple las condiciones anteriores.
Figura 2.3: Muestreo Estrati�cado
Fuente: DANE, 1997
2.5.3. Muestreo Sistemático
El muestreo sistemático es un método de selección muestral en el que la muestra seobtiene seleccionando cada k elementos de la población, donde k es un número enteromayor que 1. El primer número de la muestra debe seleccionarse al azar de entre losprimeros k elementos. La selección se hace a partir de una lista ordenada. Supongaque N , el número total de unidades, es un múltiplo integral del tamaño de la muestrarequerido o n, y que k es un número entero, de forma que N = nk. Entonces se selec-ciona un número al azar entre 1 y k.

CAPÍTULO 2. METODOLÓGICA MARCO 15
Suponga que el comienzo aleatorio es, por ejemplo, 2, en cuyo caso la muestra ten-dría un tamaño n con unidades numeradas en serie de la siguiente manera:
2, 2 + k, 2 + 2k, . . . , 2 + (n− 1)k
Como puede observarse, la muestra contiene la primera unidad seleccionada de for-ma aleatoria y todas y cada una de cada unidad k, hasta obtenerse el tamaño de lamuestra necesario. El intervalo k divide la población en conglomerados o grupos. Coneste procedimiento se está seleccionando un conglomerado de unidades con una proba-bilidad de 1/k. Dado que el primer número se elige al azar entre 1 y k, cada unidad delos conglomerados, supuestamente iguales, tiene la misma probabilidad de selección, esdecir 1/k 6.
Figura 2.4: Muestreo Sistemático
Fuente: DANE, 1997
2.5.4. Muestreo Proporcional al tamaño
Se asigna una probabilidad proporcional a su tamaño en base a una característicarelacionada a la investigación, de esta manera en la muestra son seleccionadas aleato-riamente las unidades que tienen más probabilidad.
2.5.5. Muestreo Multi-etápico
Se toman sub-muestras dentro de unidades inmediatamente superiores de muestreoya seleccionadas y así sucesivamente dependiendo el número de etapas.
La �gura 2.6, muestra la forma de selección en un muestreo por etapas, en primeraetapa se seleccionan 4 bloques de un total 10 bloques, en segunda etapa al interior decada bloque se seleccionan los elementos identi�cándolo con un círculo.
6ONU, 2009

CAPÍTULO 2. METODOLÓGICA MARCO 16
Figura 2.5: Muestreo proporcional al tamaño
Fuente: DANE, 1997
Figura 2.6: Muestreo multi-etápico
Fuente: DANE, 1997
2.5.6. Muestreo por Conglomerados
Los conglomerados son unidades compuestas por otras unidades más pequeñas, exis-te heterogeneidad dentro los conglomerados y homogeneidad entre los conglomerados,y se sortean los conglomerados para ingresar a la muestra.
La �gura 2.7, muestra la selección de un muestreo por conglomerados donde se selec-cionan 4 bloques de los 10 bloques existentes, y al interior de cada bloque seleccionadose seleccionan a todas sus unidades.

CAPÍTULO 2. METODOLÓGICA MARCO 17
Figura 2.7: Muestreo por conglomerados
Fuente: DANE, 1997
2.5.7. Muestreo en Ocasiones Sucesivas
También denominado muestreo doble en su particularidad más baja, este muestreosugiere tomar muestras en diferentes ocasiones, primero se toma una muestra extensadel marco y luego se vuelve a tomar otra muestra de la primera muestra seleccionaday así sucesivamente dependiendo el número de ocasiones, y la última muestra estimasobre la sub muestra inmediatamente superior hasta llegar al marco de la población,la Muestra Maestra es un caso especial de este tipo de muestreo.
Figura 2.8: Muestreo en ocasiones sucesivas
Fuente: Elaboración propia
2.5.8. Muestreo Longitudinal
Se toman muestras en periodos, dependiendo de la referencia temporal designaday se busca completa representatividad de estos periodos, las muestras pueden ser las

CAPÍTULO 2. METODOLÓGICA MARCO 18
mismas en los diferentes periodos o pueden ser completamente diferentes o inclusopodría ser una combinación de estas repitiendo algunas unidades en ciertos periodos,este muestreo es utilizado para captar cambios en el tiempo, aspectos estacionales y detendencias en los periodos referentes a las variables de interés.
2.6. LAS VARIABLES EN ENCUESTAS A HOGA-RES
Toda investigación, en cualquier ámbito lleva consigo las preguntas, ¾Qué se quiereobtener con el estudio?, ¾De dónde se obtiene? y ¾Cómo se obtiene?, la primera pre-gunta, hace referencia a las variables que se desean medir con el estudio, la segunda encuanto a la población objetivo y la disposición del marco muestral y la tercera propia-mente a la estrategia de muestreo, ahora se abordará la primera pregunta.
Las encuestas a hogares realizadas por el Instituto Nacional de Estadística de Boli-via, para su estudio, incluye un cuestionario multi-tematico, la encuesta es multipropó-sito, mide aspectos sociales, culturales, económicos, de salud y otros, la mayoría de lasencuestas que realiza la institución miden características múltiples. En este entendido,se hace sumamente importante, considerar en la construcción del diseño muestral todala dimensión de la investigación, incluyendo todas las variables relacionadas al estudio.
2.7. ESTRATIFICACIÓN EN LAS ENCUESTAS AHOGARES
Una técnica de muestreo muy empleada en las encuestas a hogares, es la estrati-�cación de la población. Esta sirve para clasi�car a la población en sub-poblaciones(estratos), basándose en información auxiliar conocida sobre toda la población quedebe estar disponible en el marco muestral. Después, de cada estrato se seleccionan,independientemente, los elementos de la muestra.
Los bene�cios de utilizar un muestreo estrati�cado, recaen en que si este es emplea-do de una forma correcta, colabora en la disminución del error de muestreo, por eso lanecesidad de emplearlo en las encuestas a hogares.
El muestreo estrati�cado tiene dos supuestos primordiales y un principio básicopara ganar e�ciencia. El primer supuesto ordena que los estratos sean independientesy mutuamente excluyentes entre ellos. Y el segundo que cada estrato sea representado,es decir que se seleccione muestra de todos los estratos existentes; el principio básicopara la ganancia de precisión y el uso de un muestreo estrati�cado, está basado en quelos supuestos se cumplan y que además exista un alto grado de homogeneidad dentrode cada estrato y heterogeneidad entre los estratos, respecto al comportamiento delas variables auxiliares empleadas para la estrati�cación, además de que las variables

CAPÍTULO 2. METODOLÓGICA MARCO 19
auxiliares deben estar correlacionadas a los objetivos de la encuesta.
Un resultado importante, en cuanto al muestreo estrati�cado, es la que se obtiene alfusionarlo con el muestreo sistemático, esta unión genera una estrati�cación explicita yotra implícita; la estrati�cación explicita se re�ere a la subdivisión generada por las va-riables auxiliares utilizadas para la estrati�cación; la estrati�cación implícita se generaal utilizar las características de un muestreo sistemático, la variable de estrati�caciónimplícita será la que sea utilizada para ordenar el marco muestral, previa a la selecciónsistemática.
La estrati�cación se hace de acuerdo a las variables de interés, si se tiene p varia-bles de interés, esto implicará p posibles tipos de estratos, en la realidad implementarlos p estratos resulta contraproducente y sólo se consideran algunos de ellos, los másrelevantes.
En el apartado 3.4 correspondiente al diagnóstico se detalla más acerca de la estra-ti�cación empleada en las encuestas a hogares.
2.8. CONGLOMERADOS EN ENCUESTAS A HO-GARES
El diseño de muestra de las encuestas a hogares por sus características incluyen lautilización de un muestreo por conglomerados, para el manejo adecuado de la parteoperativa de la encuesta y asegurar la contención de los altos costos. En contraparte,la conglomeración reduce la precisión de los estimadores.
El hecho fundamental para que la conglomeración presente ganancia en precisión,es que exista un alto grado de heterogeneidad dentro de las unidades de los conglo-merados y un alto grado de homogeneidad entre los conglomerados, es por esta razónque el muestreo por conglomerado di�ere considerablemente del muestreo estrati�ca-do. Además que en el muestreo estrati�cado todos los estratos están representados enla muestra, dado que se selecciona una muestra de cada estrato, mientras que en elmuestreo por conglomerado se realiza una selección de los propios conglomerados; así,los que se incluyen en la muestra representa a los que no se incluyen.
2.9. MUESTREO POR ETAPAS EN LAS ENCUES-TAS A HOGARES
Seleccionar la muestra en etapas tiene ventajas prácticas para el proceso de selec-ción mismo. Permite aislar en pasos sucesivos los conglomerados donde se llevará acabo el operativo de campo de la encuesta, en particular la elaboración de los listados

CAPÍTULO 2. METODOLÓGICA MARCO 20
de hogares y la realización de las entrevistas.
La utilización de los conglomerados es un requisito indispensable al utilizar unmuestreo por etapas, puesto que todas las etapas deben contener a una unidad conglo-merada, aunque la unidad de última etapa podrá no ser siempre un conglomerado.
En el caso de encuestas a hogares, con el muestreo por conglomerados, hay unmínimo de dos etapas en el procedimiento de selección: la primera corresponde a laselección de los conglomerados, y la segunda a la selección de alguna unidad mas simpleal interior del conglomerado (viviendas, hogares, personas, etc). Los conglomeradosde las encuestas de hogares siempre se de�nen como unidades geográ�cas de algúntipo. Si dichas unidades son su�cientemente pequeñas tanto geográ�camente comoen población, y se dispone de una lista completa y exacta de ellas para la muestra,dos etapas pueden bastar para el plan de muestreo, ahora si las unidades geográ�casresultan ser extensas será prudente considerar un plan de tres etapas.
2.10. DOMINIOS DE ESTUDIO VS ESTRATIFICA-CIÓN
Muchas veces en la concepción de algún diseño muestral se ha cometido un errorde conceptos en cuanto a lo que se de�ne como un estrato y lo que se de�ne como undominio de estudio, se ha manejado a dominio de estudio como sinónimo de estrato yviceversa, siendo que esto no es cierto la mayor parte de las veces.
El muestreo estrati�cado maneja como unidades compuestas a estratos de los cualesobtiene una muestra, estos estratos son creados en base a variables que de�nen a lapoblación y hacen al estrato homogéneo dentro de él y heterogéneo con respecto a otrosestratos. La teoría del muestreo demuestra que esta técnica es una de las mejores encuanto a precisión, va a la delantera de la mayoría de las técnicas de muestreo y per-mite tener información desagregada a nivel de los estratos. Esta técnica de muestreo esbastante utilizada en los diseños complejos de encuestas a hogares, combinándola conel muestreo por conglomerados y el muestreo por etapas, así su precisión es mejoradaal combinarse con el muestreo estrati�cado, la denominación de estratos dependerá dela variable que se pretenda medir, si la variable a medir no tiene relación con el estratoa considerar, este estrato pasa a convertirse en un dominio de estudio simplemente ypierde todas las bondades del muestreo estrati�cado.
Los dominios de estudio o grupo, no son más que aglomeraciones de unidades ele-mentales, que en su dominio permiten una desagregación de interés para el estudio,carece muchas veces de la bondad de minimizar el error muestral, responde la mayoríade las veces a divisiones geográ�cas de un país, como un ejemplo se puede citar a:los municipios, los departamentos, áreas urbano rural, etc., pero también pueden serclasi�caciones de variables temáticas, como ser: quinquenios de edad, genero, etc.

CAPÍTULO 2. METODOLÓGICA MARCO 21
Aunque es posible sobre los dominios de estudio aplicar los supuestos básicos de unmuestreo estrati�cado, la ganancia en precisión, responderá a las variables involucradas,y el efecto que estas tengan sobre los dominios de estudio de�nidos.Cuando se requiere información a nivel de dominios de estudio debe de tenerse encuenta el error de muestreo que genera, si este error no es el optimo, este debería seragregado a otro, para disminuir el error muestral.
2.11. LA PRUEBA PILOTO
La prueba piloto es sin duda un escenario estratégico, prueba en cierta medida al-gunas características del diseño muestral y valida suposiciones que sirven para a�nary contar con un diseño muestral �nal. De la prueba piloto también se pueden obtenerestimaciones de determinadas características poblacionales que pueden utilizarse poste-riormente en el cálculo de los tamaños de muestra, estimación de los errores muestrales,validación de supuestas estrati�caciones.
Entre las características de una prueba piloto se tiene7:
Pone a prueba los aspectos fundamentales de la encuesta principal.
Comprueba la idoneidad del método de recogida de datos.
Ensaya el cuestionario en situaciones reales.
Contrasta la idoneidad del marco y la pertinencia del diseño de la muestra.
Resalta la variabilidad de determinados caracteres.
Permite intuir la tasa esperada de no respuesta.
Aporta datos sobre el probable costo y duración de la encuesta principal.
Tiempo de demora en el procesamiento de la información.
Muestra posibles escenarios de las incidencias que podrían presentarse.
Ya terminada la prueba piloto se extrae toda la información posible para establecermejores controles en la encuesta principal, por ultimo, se a�nan todos los instrumentosque intervendrán en el operativo.
7perez

CAPÍTULO 2. METODOLÓGICA MARCO 22
2.12. EL TAMAÑO DE LA MUESTRA
Este apartado es quizá uno de los más importantes, puesto que la determinación deltamaño de la muestra es uno de los pasos más importantes y delicados. La consistenciadel tamaño de muestra, se veri�cará post encuesta, al calcular los errores muestrales, deexistir errores considerables, la pregunta será. ¾Por qué no se controlaron estos erroresen el momento de la plani�cación del diseño muestral?
Para la determinación del tamaño de muestra es necesario el conocimiento de todoslos ámbitos de la encuesta, se debe conocer con exactitud la directriz de la investigaciónen cuanto a las variables que se desean medir y estudiar y los niveles de desagregaciónde resultados (dominios de estudio).
Los componentes a considerar, en el cálculo del tamaño de la muestra en una en-cuesta a hogares, son variados, pero los principales dentro la estadística son:
El tamaño de la población
Las variables endógenas en cuento a su dispersión y tendencia central
Las variables exógenas
El margen de error permisible
El coe�ciente de con�anza
El efecto de la no respuesta
El efecto del diseño muestral (si es necesario)
A continuación se presenta detalladamente la de�nición de cada componente deltamaño de muestra y su importancia.Se de�ne:
N = Tamaño de la población objeto de estudio.
n = Tamaño de la muestra.
2.12.1. Variables endógenas
Se re�eren a todas las variables que pretende obtener el estudio, en cuanto a suobjetivo, normalmente es más de una variable que en algunos casos construyen indi-cadores y es por eso que al momento de considerar el tamaño de muestra, se debeconstruir un vector de tamaños de muestra y hacer el análisis sobre el vector y escogera un valor conciliador que soporte cualquier eventualidad, y si no es así realizar las

CAPÍTULO 2. METODOLÓGICA MARCO 23
recomendaciones respectivas.
Sean p− variables endógenas (de interés):
y1, y2, . . . , yp
Cada una de estas tiene asociada un tamaño de muestra:
n1, n2, . . . , np
Ahora se necesita una función tal que:
f(n1, n2, . . . , np) = n (2.1)
Donde n sea lo su�cientemente conciliadora para generar errores muestrales satis-factorios.Algunas alternativas serian:
f(n1, n2, ..., np) = Max {n1, n2, ..., np} (2.2)
f(n1, n2, ..., np) =
p∑i=1
nip
(2.3)
f(n1, n2, ..., np) =
√√√√ p∑i=1
n2i
p(2.4)
2.12.2. Variables exógenas
Si bien es cierto que en un estudio por muestreo teóricamente solo interesan lasvariables que responden a los objetivos del estudio, es decir las variables endógenas,por la necesidad de obtener más información se consideran variables que no tienen unarelación estricta con el estudio (Variables exógenas), y llegado el momento posterior dela encuesta alguna de estas variables presentan errores muestrales altos, debido a la noconsideración de las mismas dentro de la concepción del tamaño de muestra y diseñomuestral �nal.
Sean q. Variables exógenas:
y1, y2, . . . , yq

CAPÍTULO 2. METODOLÓGICA MARCO 24
Cada una de estas tiene asociada un tamaño de muestra:
n1, n2, . . . , np
Así ahora se tiene p+ q variables dentro del estudio
y1, y2, . . . , yp, yp+1, yp+2, . . . , yp+q
Cada una de estas tiene asociada un tamaño de muestra:
n1, n2, . . . , np, np+1, np+2, . . . , np+q
Ahora se necesita una función tal que:
f (n1, n2, . . . , np, np+1, np+2, . . . , np+q) = n (2.5)
Donde n sea un valor que armonice a las distintas variables.
Se necesita saber cuál es la forma de las ni asociadas a cada yi y que tan posible essu de�nición.Para la construcción de las diferentes ni , a partir de este punto, por notación, serántratadas como un n en general para todo i = 1, 2, . . . , p+ q.
2.12.3. El error de muestreo
El cálculo del tamaño de muestra involucra muchos aspectos que se desean contro-lar, entre ellos el error de muestreo a cometer.
Partiendo de la relación:
ε2 = V(θ)
= f(n) (2.6)
ε2r =
V(θ)
E[θ] = f(n) (2.7)
Donde ε denota el error de muestreo en términos absolutos y εr el error de muestreoen términos relativos.
Observe que en base a estas relaciones, se establece un control sobre el comporta-miento de la varianza del estimador θ, como un error controlable, que estará en funciónexclusivamente del tamaño de la muestra, necesario para cometer ese error dentro de

CAPÍTULO 2. METODOLÓGICA MARCO 25
esta varianza.
Ejemplo, en el Muestreo aleatorio simple:
ε2 = V (y) =(
1− n
N
) S2y
n= f(n) (2.8)
Donde S2y es la cuasi-varianza de la variable de interés y, que para estudios multi-
propósitos existen p+ q variables en del estudio.
Obtener el valor de estas cuasi-varianzas poblacionales para estas variables es unasituación compleja, puesto que muchas veces no se dispone de ninguna informaciónrespecto a estas variables de estudio (pero si la tuviera no sería necesario realizar elmuestreo) es por eso que para obtener los valores de las cuasi-varianzas, se recurre aestudios similares anteriores, es decir se estima la cuasi-varianza, esto a través del usode variables correlacionadas con la variable de estudio o en su defecto se plani�ca unaprueba piloto que dan luces en cuanto al comportamiento de estas variables y másimportante sobre la variabilidad existente.
2.12.4. El margen de error y el nivel de con�abilidad
El nivel de con�abilidad genera mayor certidumbre en cuanto a la calidad y con�an-za de los estimadores que se propongan, ya que este representa un grado de seguridadde que el estimador represente a un parámetro con cierta con�anza, y además permitela construcción de intervalos de con�anza que mostrarán un espacio valido donde semueve el valor de la variable de interés, asociado a un nivel de signi�cación, es decir,dará el máximo margen de error permisible.
Se parte de la siguiente regla de probabilidad:
P(∣∣∣θ − θ∣∣∣ ≤ e
)=1− α
P(−e ≤ θ − θ ≤ e
)=1− α
P
(−eσ(θ)
≤ θ − θσ(θ)
≤ e
σ(θ)
)=1− α

CAPÍTULO 2. METODOLÓGICA MARCO 26
P
−eσ(θ)︸︷︷︸−kα
≤ θ − θσ(θ)
≤ e
σ(θ)︸︷︷︸kα
=1− α⇒ kα =e
σ(θ)⇒ e = kα ∗ σ(θ)
e =kα ∗ σ(θ)//↑2
e2 =k2α ∗ V (θ)
Para luego tener las relaciones �nales:
e2
k2α
= V(θ)
= f(n) (2.9)
e2r
k2α
=V(θ)
E[θ] = f(n) (2.10)
Las ecuaciones 2.9 y 2.10 muestran el margen de error de estimación en términosabsolutos e y relativos er respectivamente, con kα el coe�ciente de con�anza asociadoa un nivel α de signi�cancia, con un nivel 1 − α de con�anza y V
(θ)es la varianza
del estimador, normalmente se emplea al margen de error relativo para el cálculo deltamaño de la muestra por su simple descripción.
2.12.5. El efecto de la no respuesta
Se debe aceptar, que tomando en cuenta el control sobre el error muestral deter-minado por el margen de error, el nivel de con�anza, el efecto del diseño a considerar(si es necesario), etc., aparecen otros errores llamados no muestrales, en el momentode la elaboración de cuestionario de encuesta, relevamiento de la información, en eltrabajo de campo, la crítica y consistencia, etc. Estos errores no son debidos al diseñomuestral, más bien son resultados de la disponibilidad y accesibilidad al momento derealizar la encuesta, y otros factores llamados incidencias de campo.
La �gura 2.9, muestra algunos componentes involucrados con la no respuesta.
Una manera de dar el soporte al tamaño de muestra, considerando la no respuestaes utilizar el siguiente criterio:
Sea n la muestra �nal y n0 la muestra teórica que controla los errores muestrales,sea TNR la tasa de no respuesta; es así que se desarrolla:
n = n0 + n0 ∗ TNR + n1 ∗ TNR + n2 ∗ TNR + n3 ∗ TNR + · · · (2.11)

CAPÍTULO 2. METODOLÓGICA MARCO 27
Figura 2.9: Factores en la no respuesta
Fuente: Särndal, Swensson, y Wretman, 1992
Con:
n1 =n0 ∗ TNRn2 =n1 ∗ TNR = n0 ∗ TNR ∗ TNR = n0 ∗ TNR2
n3 =n2 ∗ TNR = n0 ∗ TNR2 ∗ TNR = n0 ∗ TNR3
.
.
.
ni =n0 ∗ TNRi
Así se tiene en 2.11
n =n0 + n0 ∗ TNR + n0 ∗ TNR2 + n0 ∗ TNR3 + n0 ∗ TNR4 + · · ·n =n0 ∗
(1 + TNR + TNR2 + TNR3 + TNR4 + · · ·
)n = n0 ∗
∞∑i=0
TNRi (2.12)

CAPÍTULO 2. METODOLÓGICA MARCO 28
Notar la siguiente serie:
Si |x| < 1 entonces:
∞∑i=0
xi =1
1− x(2.13)
Así en 2.12
n = n0 ∗∞∑i=0
TNRi = n0 ∗1
(1− TNR)=
n0
(1− TNR)
De este modo se tiene una relación puntual para el tamaño de muestra, controlandoun error de muestreo un coe�ciente de con�anza y la tasa de no respuesta, esta es:
n =n0
(1− TNR)(2.14)
Es necesario estimar a TNR de alguna encuesta pasada, sobre la misma temáticaen la población o una semejante, o utilizar las bondades de la prueba piloto como unmedidor de no respuesta, o en su defecto establecer una TNR controlable, es decir �jarun límite para la pérdida de información y controlar que ese límite no se vulnere.
Finalmente se tiene:
n =n0
(1− TNR)(2.15)
Con TNR = Tasa de no respuesta estimada.
2.12.6. El efecto del diseño muestral
Explica la relación entre la varianza del diseño muestral complejo y el de un mues-treo aleatorio simple a igual tamaño de la muestra. Y si lo emplea para el cálculo deltamaño de la muestra como se muestra en la ecuación 2.16.
n = n0 ∗ efectd (2.16)
Donde:
efectd =V (θ)Muestreo complejo
V (θ)MAS
(2.17)

CAPÍTULO 2. METODOLÓGICA MARCO 29
La cuestión ahora, es de donde se calcula o como se estima al efecto de diseño, lasopciones son diversas y algunas complejas, entre ellas:
Con la experiencia pasada, es decir, encuestas con diseños muy parecidos, so-bre variables de interés y poblaciones semejantes, obtener el efecto de diseño yutilizarlo.
Calcular el efecto de diseño con la información que proporcione la prueba piloto.
Como ejemplo, para un muestreo de conglomerados monoetápico, con el mismo ta-maño M se tiene:
efectd =
1 + (M − 1)
2N∑i=1
M∑j<z
(yij − Y
) (yiz − Y
)(M − 1
) (NM − 1
)S2
=[1 +
(M − 1
)δ]
(2.18)
Con δ el coe�ciente de correlación intra-conglomerado.
El utilizar al efecto de diseño como un corrector que simpli�ca bastante los cálculosdel tamaño de la muestra, puede no ser un dato con�able a menos que se conozcacon certeza el valor de dicho efecto de diseño, porque las consecuencias posteriores, sere�eren a subestimar o sobreestimar el tamaño real de la muestra.
De esta manera, ya se tiene un par de relaciones para el tamaño de la muestra, ha-ciendo la distinción en la utilización del efecto de diseño y sin él, controlando un errorpermisible de muestreo, un coe�ciente de con�anza y la tasa de no respuesta del estudio.
n =n0
(1− TNR)∗efectd (2.19)
Donde: n0: Tamaño de muestra asociado al muestreo aleatorio simple.
También se tiene:
n =n1
(1− TNR)(2.20)
Con:
e2 = k2α ∗ V
(θ)Muestreo complejo
= f(n1) (2.21)
n1 : Tamaño de muestra asociado al muestreo complejo, con e margen de errorabsoluto, y kα el valor a un nivel de con�anza de 1− α.

CAPÍTULO 2. METODOLÓGICA MARCO 30
2.13. FACTORES DE EXPANSIÓN Y SUS AJUS-TES
Las encuestas de hogares se basan en diseños muestrales complejos, que llevan con-sigo un cálculo de probabilidades de selección, y posterior a ello la construcción de losfactores de expansión.
Sea F el factor de expansión, y P la probabilidad de selección, así la relación entreestos dos es de la forma.
F = (P )−1 (2.22)
Y la estructura de F en un muestreo polietápico con k etapas será:
F = F1 ∗ F2 ∗ · · · ∗ FK (2.23)
Donde Fi = (Pi)−1 para todo i = 1, 2, . . . , k
Los distintos F están construidos respondiendo al diseño muestral propuesto.
En el caso de las encuestas a hogares, si se considera el factor de expansión (teórico),se está generando un error respecto al verdadero valor del parámetro que se pretendeestimar (sesgo), se necesita ajustar estos factores de expansión respecto a situacionescomo:
Incidencias de campo (tasa de no respuesta)
Actualización de conglomerados (listado de viviendas por marcos imperfectos)
Proyecciones demográ�cas (Crecimiento de la población)
Estos tres ajustes son trascendentales, puesto que permiten corregir imperfeccionesy obtener estimaciones aproximadas de las características de interés, ya que compensanla falta de respuesta, las probabilidades de selección y ajustan la distribución de lamuestra a variables auxiliares.
2.13.1. Incidencias de campo
La no respuesta in�uye en el factor de expansión especialmente en la última etapade las unidades de muestreo. La corrección se realiza a través del factor FNR.
F ∗ = F × FNR (2.24)

CAPÍTULO 2. METODOLÓGICA MARCO 31
FNR =PLANIFICADAS
REALES(2.25)
Donde el numerador expresa el tamaño de muestra de unidades plani�cadas dentrode un conglomerado, y el denominador cuanti�ca el tamaño de muestra real ejecutadaen la encuesta.
La recomendación es que el valor en la ecuación 2.25 debe ser cercana a la unidad,en otro caso es posible eliminar al conglomerado de la muestra por un defecto entre lasunidades seleccionadas plani�cadas y las reales obtenidas.
2.13.2. Actualización de conglomerados
Los conglomerados seleccionados son actualizados respecto al número de viviendasy el número de personas, para:
La selección de viviendas
Corrección de los factores de expansión.
La actualización del conglomerado seleccionado en la muestra respecto el marcomuestral.
2.13.3. Proyecciones Demográ�cas
Si se dispone de proyecciones de totales poblacionales de toda la población y sub-grupos especí�cos con�ables del año correspondiente a la encuesta, se puede ajustarlos factores de expansión de tal manera que el total de la población de habitantesy viviendas coincida con los totales de las proyecciones a ese año. Los subgrupos sedenominan post-estratos y el procedimiento de ajuste estadístico se conoce como post-estrati�cación.
Los modelos de proyección de población conllevan también errores de predicción,por lo tanto los ajustes anteriores pueden aumentar el error de expansión y afectarla calidad del factor de expansión antes de las proyecciones. En algunos países de laregión no realizan este ajuste por los motivos ya nombrados anteriormente.
2.14. ESTIMADORES Y ESTIMACIONES
Se de�ne a θ como un parámetro desconocido de interés para el estudio, se deseaestimar el valor de ese parámetro y su estimador es θ , como se menciono, en encuestasmulti-temáticas existen p parámetros de interés (variables endogenas), y q parámetros

CAPÍTULO 2. METODOLÓGICA MARCO 32
que también ingresan al estudio (variables exogenas), teniendo θ1, θ2, . . . , θp+q paráme-tros con sus respectivos estimadores θ1, θ2, . . . , θp+q.
La labor es estimar a estos parámetros, siguiendo la estructura del diseño muestralaplicado.
Ejemplo, sea para un muestreo estrati�cado, la media, su estimador, su varianza yel estimador de su varianza.
uest =L∑h=1
Nh
N
Nh∑i=1
yihNh
(2.26)
Su estimador:
yest =L∑h=1
Nh
N
nh∑i=1
yihnh
(2.27)
Su varianza:
V (yest) =L∑h=1
(Nh
N
)2
∗(
1− n
N
)∗
Nh∑i=1
(yih − Yh)2
nh(Nh − 1)(2.28)
La estimacion de su varianza:
V (yest) =L∑h=1
(Nh
N
)2
∗(
1− n
N
)∗
nh∑i=1
(yih − yh)2
nh(nh − 1)(2.29)
Los estimadores se especi�can a través de funciones matemáticas dependientes dela muestra, que se convierten en variables aleatorias al considerar la variabilidad deselección de las muestras, y que por tanto cumplen las condiciones de una función demedida8.
Si se centra el estudio en poblaciones �nitas, interesa una característica y en lapoblación U con N unidades, que toma el valor numérico yi sobre la unidad Ui i =1, 2, . . . , N . Se considera una cierta función θ de los N valores yi, que suele denomi-narse parámetro poblacional. Se selecciona una muestra s de tamaño n, y a partir deella se quiere estimar el parámetro poblacional θ mediante una función θ = θ (s(y)) =θ(y1, y2, ..., yn) basada en los valores yi, i = 1, 2, . . . , n que toma la característica y
8Pérez, 2000

CAPÍTULO 2. METODOLÓGICA MARCO 33
sobre las unidades de la muestra s.
Al considerar todas las muestras s del espacio muestral S asociado al procedimientode muestreo y los valores que toma la característica y sobre dichas muestras, se obtieneel conjunto S(y) = {s(y)/s ∈ S}. Por lo tanto se puede formalizar el concepto de es-timador θ para el parámetro poblacional θ de�niéndolo mediante la aplicación medible:
θ = S(y) ⊂ Rn → R (2.30)
(y1, y2, . . . , yn)→ θ(y1, y2, . . . , yn) = t (2.31)
2.14.1. Distribución de probabilidades del estimador
Se denomina distribución de probabilidad de una variable aleatoria a la función queasigna probabilidad a los valores que puede tomar la variable. En este caso la variablealeatoria es el estimador y los posibles valores que puede tomar son las estimaciones,con lo que se habrá obtenido la distribución de probabilidad en el muestreo, para elestimador, cuando se conozca todos los valores posibles del estimador junto con lasprobabilidades de que el estimador tome cada valor.
Sea T = {t ∈ R/∃(y1, y2, ..., yn) ∈ S(y)} que cumple θ(y1, y2, ..., yn) = t . El con-junto T ⊂ R constituye el conjunto de valores del estimador. Ahora, se de�ne lasprobabilidades de que el estimador tome esos valores (ley de la probabilidad de la va-riable aleatoria θ) así:
P T(θ (y1, y2, ..., yn)
)=∑{Si/θ(Si(y))=t} P (si) (2.32)
Donde θ es una variable aleatoria, tiene asociada una distribución de probabilidad,interesa, sus características de centralización y dispersión, que vendrán a ser herra-mientas para conocer las cualidades del estimador.
Esperanza matemática del estimador
E(θ)
=∑S
θ(si)P (si) =∑R
t ∗ P T (θ = t) (2.33)
Varianza del estimador
V(θ)
= E
[(θ − E(θ)
)2]
(2.34)

CAPÍTULO 2. METODOLÓGICA MARCO 34
Error de muestreo
σ(θ)
=
√V(θ)
(2.35)
Error relativo de muestreo
CV (θ) =σ(θ)
E(θ)(2.36)
Sesgo del estimador
B(θ) = E(θ)− θ (2.37)
Acuracidad del estimador
ECM(θ) = E
[(θ − θ
)2]
= V(θ)
+B(θ)2
(2.38)
Si E(θ)
= θ se está ante un estimador insesgado.
θ es inconsistente para θ ⇔ B(θ)→︸︷︷︸n→∞
0 (2.39)
También existen otras características importantes que un estimador debe de cum-plen a parte de la insesgadez, como ser la e�ciencia, la consistencia y la su�ciencia.
Las anteriores de�niciones dan a conocer que se tiene a disposición toda la teoría delas probabilidades y la inferencia estadística para utilizarlas como sustento en la teoríadel muestreo.
2.15. EL ERROR TOTAL ENUNA ENCUESTA PORMUESTREO
En el proceso de una encuesta por muestreo intervienen diversos elementos que sonfuentes potenciales de error, sin mencionar el sesgo que trae consigo un cuestionariomal diseñado debido a una imprecisa de�nición y los conceptos a emplear, las opera-ciones de recogida, transcripción y grabación de los datos también pueden dar lugar aque se produzcan desviaciones de los valores observados respecto de los que se puedenllamar verdaderos valores.

CAPÍTULO 2. METODOLÓGICA MARCO 35
No se debe olvidar los efectos debidos al trabajo de los encuestadores, a la situaciónobjetiva o subjetiva de los entrevistados y a la interacción entre unos y otros. Estoserrores se los denomina �errores ajenos al muestreo� para distinguirlo de los producidospor la variabilidad de la muestra que se denomina �error de muestreo�
El error total de una encuesta viene dado por el error de muestreo y los erroresajenos al muestreo. El primero decrece cuando se aumenta el tamaño de la muestrao se tiene una excelente estrategia de muestreo y desaparece con la enumeración 100por 100. Los segundos, en general, aumentan con el tamaño de la muestra y suelentomar su valor máximo cuando se llega a una enumeración 100 por 100 o censo, se hacenecesario la implementación dentro el INE de mecanismos que permitan medir el errortotal que se comete en una encuesta por muestreo, para tener la certeza de la e�caciade todo el operativo, y mejorar los elementos involucrados en todo el proceso. Ya quecomo se verá a continuación el error de muestreo es sólo un elemento dentro del errortotal de una encuesta, por ello la importancia de medir y controlar los errores ajenosal muestreo.
Ahora que se conoce el concepto del error total de una encuesta y su importancia, sedebe encontrar la manera de estimar ese error, la contribución a las metodologías de lacuanti�cación de estos errores para las encuestas por muestreo fueron dadas por diver-sos autores, este apartado formalizara la introducción de estos mecanismos de controlpara tener una herramienta que nos indique la calidad de una encuesta por muestreo,tomando como directriz los estudios realizado por M. H. Hansen, Hurwitz, y Bershad,1961 y Sanchez Crespo, 1985
Una encuesta por muestreo puede considerarse, conceptualmente, como repetible encondiciones generales análogas. Bajo este supuesto se introduce un proceso que propor-ciona, en general resultados distintos para las posibles realizaciones de la investigación.Este proceso introduce un tipo de errores, ajenos al muestreo, a los que se denominaráerrores de respuesta, y una varianza debida a estos errores o varianza total de res-puesta. Esta puede dividirse en dos componentes: la primera se debe a la variabilidadde la respuesta, para una determinada unidad, en las posibles realizaciones conceptua-les de la investigación, y la segunda es ocasionada por una posible in�uencia comúnsobre un grupo de unidades dentro de una misma realización de la investigación. A laprimera componente se la denomina varianza de respuesta simple y a la segunda, com-ponente correlacionada de la varianza total de respuesta. Así el concepto de varianzatotal no es más que la suma de dos componentes: la varianza total de respuesta y lavarianza de muestreo.
2.15.1. Modelo de Hansen. Hurwitz y Bershad
En este modelo se considera una población �nita de unidades identi�cables (Ui; i =1, 2, . . . , n), en la que yit representa el valor, de la variable en estudio, obtenido para launidad i−esima en la realización t−esima de la encuesta por muestreo. Se postula que

CAPÍTULO 2. METODOLÓGICA MARCO 36
estas investigaciones son hipotéticamente repetibles, en condiciones generales análogas,y que yit es una variable aleatoria cuyo valor en la realización t no está correlacionadocon el obtenido en cualquier otra.
Para un atributo se tiene: yit = 1 si Ui pertenece a una determinada clase y yit = 0en otro caso.
Ahora se puede de�nir los siguientes valores muestrales:
Pt = 1n
n∑i=1
yit → Proporción estimada poblacional en la realización t de la encuesta.
Pi = Et (yit/i)→ Esperanza de yit sobre todas las posibles realizaciones hipotéticascondicionadas a la unidad Ui.
Ei (Pi) =1
n
n∑i=1
Pi = P (2.40)
Valor esperado que no coincide en general, con el valor objetivo P0.
B = P − P0 →Sesgo de respuesta.
Tomando las esperanzas
Et
(Pt
)= Et
(1
n
n∑i=1
yit
)=
1
n
n∑i=1
Et (yit) =1
n
n∑i=1
Pi = P ,
Ei
(P)
= Ei
(1
n
n∑i=1
Pi
)=
1
N(2.41)
El error cuadrático medio de Pt es:
ECM(Pt) =E(Pt − P0
)2
= E(Pt − P + P − P0
)2
=E
[(Pt − P
)2
+ (P − P0)2 + 2 (P − P0)(Pt − P
)]=E(Pt − P
)2
+ (P − P0)2 + 2 (P − P0)E(Pt − P
)Donde E
(Pt − P
)2
es la varianza total, (P − P0)2 el sesgo al cuadrado debido a la
respuesta y E(Pt − P
)= 0. De esta manera el error cuadrático medio de Pt se puede

CAPÍTULO 2. METODOLÓGICA MARCO 37
expresar:
ECM(Pt) = V(Pt
)+B2 (2.42)
Es decir como la suma de la varianza total y el cuadrado del sesgo de respuesta.
Ahora si trabaja sobre la varianza total V(Pt
)puede descomponerse como:
V(Pt
)=E(Pt − P + P − P
)2
=E
[(Pt − P
)2
+(P − P
)2
+ 2(Pt − P
)(P − P
)]=E(Pt − P
)2
+ E(P − P
)2
+ 2E[(Pt − P
)(P − P
)]Con, E
(Pt − P
)2
la varianza total de respuesta, E(P − P
)2
re�eja la varianza
debido al muestreo y la expresión E(Pt − P
)(P − P
)es una interacción entre des-
viaciones de respuesta y desviaciones de muestreo, que puede expresarla como:
E[(Pt − P
)(P − P
)]=n− 1
nσmr (2.43)
La varianza total de respuesta puede expresarse de la siguiente forma:
E(Pt − P
)2
=E
(1
n
n∑i=1
(Yit − Pi)
)2
=E
(1
n
n∑i=1
dit
)2
=E
(1
n2
n∑i=1
d2it +
1
n2
n∑i=1
ditdkt
)
=E (d2
it)
n+n− 1
nE (ditdkt)
=σ2d
n+n− 1
nρdσ
2d
E(Pt − P
)2
=σ2d
n+n− 1
nρdσ
2d (2.44)

CAPÍTULO 2. METODOLÓGICA MARCO 38
Donde σ2d
nes la varianza simple de respuesta, siendo σ2
d la varianza de las desvia-ciones de respuesta. Mide la variabilidad de las respuestas dadas por cada unidad ensucesivas realizaciones de la encuesta.
E (d2it) = E(Yit − Pi)2 = σ2
d , y la expresión de�nida como n−1nρdσ
2d es la componen-
te correlaciona de la varianza total de respuesta, o parte de la varianza total debida auna in�uencia común sobre un grupo de unidades dentro de una misma realización dela encuesta. Recoge el efecto añadida de la in�uencia de entrevistadores, supervisores,codi�cadores, etc.
De este modo la varianza total queda como:
V(Pt
)=σ2d
n+n− 1
nρdσ
2d + E
(P − P
)2
+ 2n− 1
nσmr (2.45)
Y el error cuadrático medio:
ECM(Pt
)=
σ2d
n︸︷︷︸VARIANZA SIMPLEDE RESPUESTA
+n− 1
nρdσ
2d︸ ︷︷ ︸
COMPONENTECORRELACIONADO︸ ︷︷ ︸
VARIANZA TOTAL DE RESPUESTA
+E(P − P
)2
︸ ︷︷ ︸ERROR DEMUESTREO
+ 2n− 1
nσmr︸ ︷︷ ︸
INTERACCION ENTRELAS RESPUESTASY EL MUESTREO︸ ︷︷ ︸
VARIANZA TOTAL V (Pt)
+ B2︸︷︷︸SESGO DERESPUESTA
(2.46)
Índice de inconsistencia
Si en V(Pt
)n = 1 , considerando E
(P − P
)2
=(1− n
N
) S20
n, V
(Pt
)= σ2
d + σ20
siendo:
σ2d =E(dit)
2 = E(Yit − Pi)2
=E(Y 2it + P 2
i − 2YitPi)
= E(Y 2it
)+ E
(P 2i
)− 2E (YitPi)
=Eit (Yit) + Ei(P 2i
)− 2Ei [PiEt (Yit)] = Ei (Pi) + Ei
(P 2i
)− 2Ei
(P 2i
)=Ei (Pi)− Ei
(P 2i
)= Ei [Pi (1− Pi)]
=1
N
N∑i=1
Pi (1− Pi)
σ2d =
1
N
N∑i=1
Pi (1− Pi) (2.47)
Además σ20 =
N∑i=1
(Pi−P )2
N, así se tendría una estructura para V
(Pt
).

CAPÍTULO 2. METODOLÓGICA MARCO 39
V(Pt
)=σ2
d + σ20
=1
N
N∑i=1
Pi (1− Pi) +
N∑i=1
(Pi − P )2
N
=1
N
N∑i=1
Pi −1
N
N∑i=1
P 2i +
1
N
N∑i=1
P 2i + P 2 − 2P
N
N∑i=1
Pi
=P + P 2 − 2P 2
=P (1− P ) = PQ
V(Pt
)= PQ (2.48)
Partiendo de estas expresiones M. Hansen y Hurwitz, 1946 proponen como índicede inconsistencia a:
I =σ2d
σ2d + σ2
0
=σ2d
PQ0 ≤ I ≤ 1 (2.49)
Cuyo numerador puede estimarse en base a una re-entrevista y el denominador porlos datos de la encuesta principal.
Como σ2d cuanti�ca la variabilidad del los errores de respuesta, cuanto mayor sea la
diferencia de respuesta mayor será σ2d y σ
20 será más pequeño y el índice se aproximara
a 1 y cuando la diferencia de respuestas sea mínima el índice de inconsistencia seaproximara a cero.
2.15.2. Estimación de las componentes de la varianza total derespuesta y el índice de inconsistencia
Suponga que se selecciona una sub-muestra de tamañom de unidades elementales, yque los agentes (equipos) que intervienen en la sub-muestra son elegidos aleatoriamentee independientes a la primera muestra y tienen un adiestramiento similar a los primeros.
Las desviaciones de respuesta para la unidad ui para la muestra t = 1 y la sub-muestra t = 2, serian:
di1 = Yi1 − Pi, di2 = Yi2 − Pi. Un estimador insesgado para la varianza de estasobservaciones es:

CAPÍTULO 2. METODOLÓGICA MARCO 40
(Yi1 − Yi1+Yi2
2
)2+(Yi2 − Yi1+Yi2
2
)2
2− 1=
(Yi1 + Yi2)2
2
Pero Yi1 − Yi2 = di1 − di2 ⇒
(Yi1+Yi2)2
2= (di1−di2)2
2= 1
2(d2i1 + d2
i2 − 2di1di2) y ahora si se promedia para las munidades de la sub-muestra se tiene:
σ2d =
m∑i=1
(Yi1 − Yi2)2
2m=
1
2
(1
m
m∑i=1
d2i1 +
1
m
m∑i=1
d2i2 −
2
m
m∑i=1
di1di2
)(2.50)
Y tomando esperanza por todos los valores posibles se tiene:
E(σ2d
)=σ2d1
2+σ2d2
2− ρ12σd1σd2 (2.51)
Si las observaciones son independientes (equipos independientes) y realizadas porequipos similarmente adiestrados se veri�cará.
σ2d1 = σ2
d2 = σ2d y ρ12σd1σd2 = 0
Con lo que: E [σ2d] = σ2
d. y la expresión σ2d =
∑mi=1 (Yi1+Yi2)2
2mes un estimador insesgado
de σ2d.
Para la varianza total de respuesta, se considera el estimador, V(Pt
)cuya espe-
ranza es:
E[V(Pt
)]= E
2∑t=1
(Pt −¯P
)2
2− 1
= E
(P1 − P2
2
)=σ2d
m[1 + (m− 1) ρd] (2.52)
Donde P1 y P2 son los valores obtenidos por las m unidades involucradas en lostiempos t = 1 y t = 2, ¯P la media de ambos.
Si se dispone de un estimador de σ2d se puede emplear como estimados de la com-
ponente correlacionada (P1−P2)2
2− (σ2
d)m
.

CAPÍTULO 2. METODOLÓGICA MARCO 41
Ahora en σ2d, para la proporción:
σ2d =
m∑i=1
(Yi1 − Yi2)2
2m
=
m∑i=1
(Y 2i1 + Y 2
i2 − 2Yi1Yi2)
2m
=
m∑i=1
(Yi1 + Yi2 − 2Yi1Yi2)
2m
=1
2m
(m∑i=1
Yi1 +m∑i=1
Yi2 − 2m∑i=1
Yi1Yi2
)
σ2d =
1
2m
(m∑i=1
Yi1 +m∑i=1
Yi2 − 2m∑i=1
Yi1Yi2
)(2.53)
Para una variable binaria, con las unidades de la sub-muestra puede presentarse enuna tabla de 2x2 de como se muestra en la tabla 2.1
Tabla 2.1: Para una variable binariaYi1 Entrevista original
CLASES 1 0 TOTALYi2 1 a b a+ b
Entrevista repetida 0 c d c+ dTOTAL a+ c b+ d m = a+ b+ c+ d
σ2d =
1
2m
(m∑i=1
Yi1 +m∑i=1
Yi2 − 2m∑i=1
Yi1Yi2
)=
1
2m(a+ c+ a+ b− 2a) =
b+ c
2m
(2.54)En el caso de repeticiones de medida independientes sobre los mismos elementos.
Algunos indicadores de calidad de los datos para sub-muestras:
(b− c)m
∗ 100tasa de diferencia neta en porcentaje

CAPÍTULO 2. METODOLÓGICA MARCO 42
Que representa el porcentaje de diferencia de unidades que poseen un determinadocarácter en ambas ocasiones respecto al total de unidades. Es un estimador del sesgode respuesta, cuando la segunda observación se considera superior a la primera.
Algunos indicadores de interés para el sub-muestreo.
100∗ (b− c)(a+ b)
Índice de cambio neto
100∗(b+ c)
mtasa de diferencia bruta
100∗ (b+ c)
(a+ b)Índice de cambio bruto
100∗ a
(a+ b)Porcentaje de unidades idénticamente clasidicadas
De acuerdo con lo anterior, referido a una variable binaria con dos clases, se puedeestablecer lo siguiente:
Tabla 2.2: Estimadores para los componentes de la varianza total de respuestaEstimador Valor esperado
Z1 = (b+c)2m2
σ2d
m
Z2 = (c−b)22m2
σ2d
m(1 + (m− 1)ρd)
Z3 = (a+c)(b+d)(m−1)m2
σ2d+σ2
0
m
Fuente: Sanchez Crespo, 1985
Z1 ⇒ Estima la varianza de respuesta simple
Z2 − Z1 ⇒ Estima la componente correlacionada
Z3 − Z1 ⇒ Estima la componente del muestreoZ2 − Z1
Z1(m− 1)⇒ Estima la correlacion entre desviaciones
I =σ2d
PtQt
=b+ c
2mPtQt
(2.55)
Valores de I entre 20 y 50 suelen considerarse como moderados (Sanchez Crespo,1985).

CAPÍTULO 2. METODOLÓGICA MARCO 43
2.16. ENCUESTAS TRANSVERSALES Y LONGI-TUDINALES
La utilización de un muestreo de tipo transversal o longitudinal responderá al ob-jetivo y al tipo de variables que se deseen estudiar en la encuestas y cual el interés demedir el dinamismo de estas, con relación al tiempo.
2.16.1. Encuestas transversales
Una encuesta transversal se caracteriza por la recogida de información en un pe-riodo de tiempo dado y sus estimadores re�ejan una medición estática de un momentoconcreto.
Objetivo: Describir la realidad en un momento determinado.
Ventajas: Facilidad para hacer inferencias.
Sencillez y economía en su ejecución
Proporcionan resultados con gran rapidez.
Sencillez para investigar relaciones complejas entre grandes conjuntos devariables.
Muy adecuada para situaciones estables en el tiempo, por su sencillez en larecogida de datos.
Desventajas: Incapacidad para revelar relaciones causales.
Ausencia de medidas en diversos puntos cronológicos.
2.16.2. Encuestas longitudinales
Una encuesta longitudinal es la que recoge datos de las unidades muestrales enmúltiples ocasiones a través del tiempo. Su objetivo es comparar las característicasafectadas por el tiempo. Estas encuestas se realizan en una amplia variedad de contextosy para una variedad de propósitos, pero en muchos casos cuentan con considerablesventajas analíticas que no tienen las encuestas transversales.
Objetivo: Detectar el cambio de la situación producto del tiempo. Para ello, recogeninformación en diferentes momentos temporales.
Ventajas: Permite explicar las causas de los fenómenos.
Detecta la presencia de efectos provocados por el momento de medición.
Desventajas: Encarecimiento del estudio fruto de las mediciones realizadas.
Se precisa mucho tiempo para disponer de la información.
Los informantes tienden a ser reacios a responder conforme pasa el tiempo.

Capítulo 3
DIAGNÓSTICO DE LASENCUESTAS A HOGARES
El Instituto Nacional de Estadística de Bolivia a lo largo del tiempo ha realizadoun conjunto de encuestas dirigidas a los hogares, estas encuestas tenían el objetivo demedir diferentes temáticas. Entre las más importantes, se encuentra toda la serie deencuestas que centró su interés en medir las condiciones de vida, esta serie en particulartuvo continuidad periódica desde 1978 hasta el 2009. El diagnóstico está dirigido a estegrupo, en su periodo de 1999 a 2009.
La historia de esta serie comienza con la ronda de encuestas denominada: EncuestaPermanente de Hogares (EPH) de 1978 - 1985, luego la Encuesta Integrada de Hoga-res (EIH) de 1986 - 1995, posteriormente la Encuesta Nacional de Empleo (ENE) de1996 - 1998, después las Encuestas a Hogares del programa MECOVI de 1999 - 2004 y�nalmente las Encuestas a Hogares (EH) de 2005 - 2009.
El periodo de interés engloba dos sub-periodos, el primero con el proyecto MECOVIy el segundo, dado a partir del año 2005 con las denominadas Encuestas a Hogares,siendo idéntico el objetivo general de estas encuestas durante estos once años; este fue:
�Obtener información sobre las condiciones de vida de los hogares, a partirde la recopilación de información de variables socioeconómicas y demográ-�cas de la población boliviana, necesarias para la formulación, evaluación,seguimiento de políticas y diseño de programas de acción en el área social.�
En 1999 a iniciativa del Banco Mundial en la región, se inició el Programa de Mejo-ramiento de las Encuestas y Medición sobre Condiciones de Vida en América Latina yel Caribe (MECOVI). Como parte de este programa, desde el año 1999 se realizó cadaaño estas encuestas, hasta el 2004. En los años 2003-2004 se realizó la denominadaEncuesta Continua de Hogares (ECH); a partir del programa MECOVI se logró la im-plementación de un cuestionario multi-temático, que consta de los siguientes módulos:Información general de los miembros del hogar, migración, salud, educación, empleo,
44

CAPÍTULO 3. DIAGNÓSTICO DE LAS ENCUESTAS A HOGARES 45
ingresos no laborales, gastos en consumo, vivienda, contingencias y préstamos del hogare ingreso del productor agropecuario independiente, etc. A partir del 2005, hasta ahora,se realizaron encuestas de hogares puntuales y periódicas (transversales), en estas seplaneo presentar un panorama completo sobre las condiciones de vida de la población,como un aporte para el estudio de la realidad nacional y apoyo a instancias de tomade decisiones, en materia de política tendientes a la reducción de la pobreza, siendolos usuarios, el ejecutivo, los organismos internacionales y nacionales, la comunidadacadémica, los investigadores privados y los estudiantes1.
3.1. ORGANIZACIÓN
El diagnóstico se desenvuelve en partes, se da una descripción respecto a la estra-tegia de muestreo empleada; se realiza un análisis comparativo en aspectos macros delos diseños muestrales (estrati�cación, conglomeración, etc.); por último, se presentainformación y análisis de lo relacionado a las incidencias de campo registradas.
La tabla 3.1, muestra una descripción amplia de los elementos involucrados en eldiseño muestral del periodo de interés, denotando el número de viviendas en la muestra,la procedencia del marco muestral, el tipo de encuesta, el número máximo de etapasinvolucradas en el diseño, la estrati�cación empleada y el tipo de selección utilizada ensu primera etapa.
En el periodo de interés se encuentra una característica peculiar, las realizadas enlos años 2002, 2003-2004 y 2005 utilizaron el criterio de la muestra maestra2.
La unidad de análisis para estas encuestas fueron los hogares constituidos en vivien-das particulares no colectivas, además, teniendo como unidades muestrales a lo largodel periodo a los sectores censales, segmentos censales o agrupación de ellos, vivien-das particulares no colectivas, estas siempre como unidades últimas de muestreo y laimplementación de las denominadas UPM que concuerdan con uno o más sectores cen-sales, a partir del marco muestral procedente del CNPV-2001, previo a este, la unidadprimaria de muestreo para el área amanzanada hacía referencia al sector censal, y enel área dispersa, correspondía al segmento censal, a razón del marco obtenido a partirdel CNPV-1992.
Notar las características peculiares de la Encuesta Continua de Hogares 2003-2004,que rompen la secuencia de la serie, debido a sus características únicas; para empe-zar, es una encuesta de tipo longitudinal, los objetivos especí�cos son diferentes a lasdemás encuestas, no es una encuesta encargada de medir pobreza, estaba abocada ala medición de la estructura de gasto de las familias y la composición de la canastabásica de alimentos (como insumos al Índice de Precios al Consumidor). A razón de
1INE, 20102mas detalle 4.10
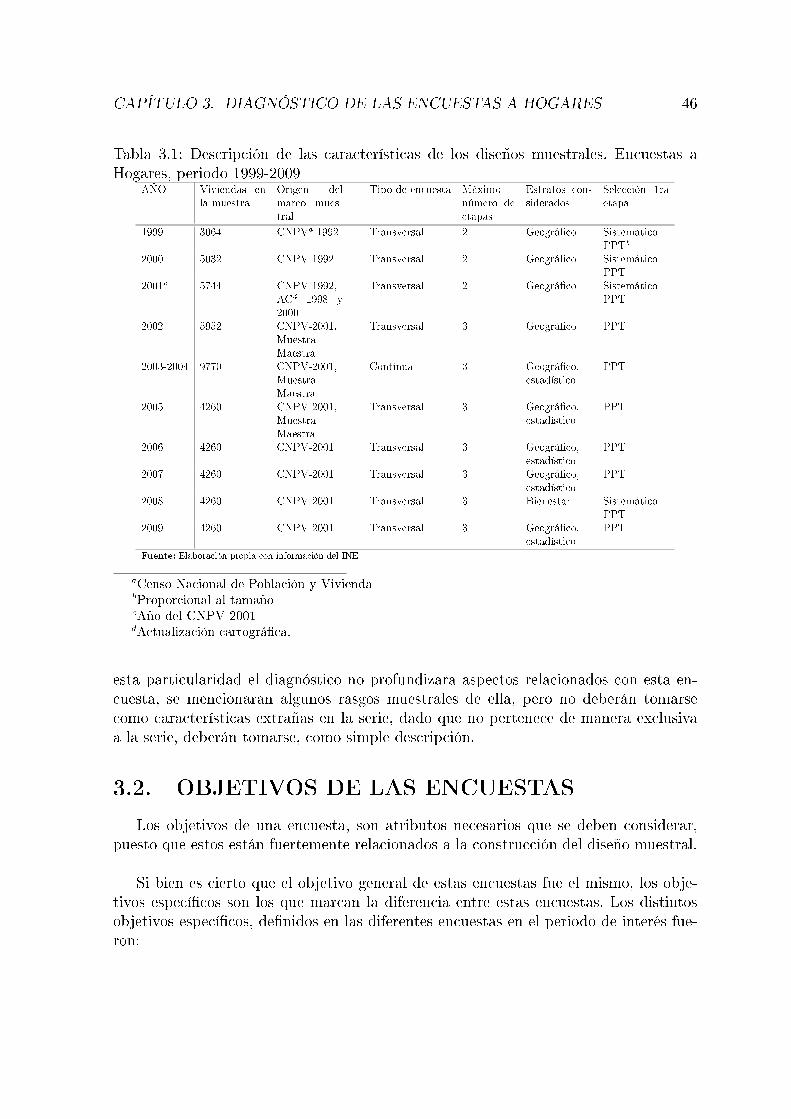
CAPÍTULO 3. DIAGNÓSTICO DE LAS ENCUESTAS A HOGARES 46
Tabla 3.1: Descripción de las características de los diseños muestrales, Encuestas aHogares, periodo 1999-2009
AÑO Viviendas enla muestra
Origen delmarco mues-tral
Tipo de encuesta Máximonúmero deetapas
Estratos con-siderados
Selección 1raetapa
1999 3064 CNPVa-1992 Transversal 2 Geográ�co SistemáticoPPTb
2000 5032 CNPV-1992 Transversal 2 Geográ�co SistemáticoPPT
2001c 5744 CNPV-1992,ACd 1998 y2000
Transversal 2 Geográ�co SistemáticoPPT
2002 5952 CNPV-2001,MuestraMaestra
Transversal 3 Geográ�co PPT
2003-2004 9770 CNPV-2001,MuestraMaestra
Continua 3 Geográ�co,estadístico
PPT
2005 4260 CNPV-2001,MuestraMaestra
Transversal 3 Geográ�co,estadístico
PPT
2006 4260 CNPV-2001 Transversal 3 Geográ�co,estadístico
PPT
2007 4260 CNPV-2001 Transversal 3 Geográ�co,estadístico
PPT
2008 4260 CNPV-2001 Transversal 3 Bienestar SistemáticoPPT
2009 4260 CNPV-2001 Transversal 3 Geográ�co,estadístico
PPT
Fuente: Elaboración propia con información del INE
aCenso Nacional de Población y ViviendabProporcional al tamañocAño del CNPV-2001dActualización cartográ�ca.
esta particularidad el diagnóstico no profundizara aspectos relacionados con esta en-cuesta, se mencionaran algunos rasgos muestrales de ella, pero no deberán tomarsecomo características extrañas en la serie, dado que no pertenece de manera exclusivaa la serie, deberán tomarse, como simple descripción.
3.2. OBJETIVOS DE LAS ENCUESTAS
Los objetivos de una encuesta, son atributos necesarios que se deben considerar,puesto que estos están fuertemente relacionados a la construcción del diseño muestral.
Si bien es cierto que el objetivo general de estas encuestas fue el mismo, los obje-tivos especí�cos son los que marcan la diferencia entre estas encuestas. Los distintosobjetivos especí�cos, de�nidos en las diferentes encuestas en el periodo de interés fue-ron:

CAPÍTULO 3. DIAGNÓSTICO DE LAS ENCUESTAS A HOGARES 47
a. Cálculo de indicadores socio-demográ�cos que re�ejen las condiciones de vida ypobreza.
b. Obtener información sobre el acceso que tienen los hogares a servicios como edu-cación, salud y saneamiento básico.
c. Obtener información sobre el mercado de trabajo y características ocupacionalesde la población ocupada.
d. Obtener información sobre la estructura de ingresos laborales, ingresos no labo-rales, gasto y consumo del hogar, como medidas de bienestar monetario.
e. Producir una base de datos completa con información actualizada de variablesimportantes, determinantes de las condiciones de vida a nivel de viviendas, ho-gares y personas.
f. Medir oportuna y apropiadamente los niveles de bienestar así como los de pobre-za, en la población boliviana en función a sus factores determinantes.
g. Aportar con información con�able al estudio de los factores determinantes de lapobreza en la población boliviana.
h. Generar información oportuna y de calidad que permita realizar estudios acercade las condiciones de vida de la población en Bolivia.
i. Proporcionar datos que permitan identi�car los patrones de consumo alimentariode las familias en Bolivia, con objeto de construir la canasta básica alimentaria(CBA).
j. Generar información acerca de la estructura de gasto de las familias que seaaplicable en el Índice de Precios al Consumidor (IPC).
k. Generar información relevante que permita estimar la cuenta hogares en el Sis-tema de Contabilidad Nacional (SCN).
l. Proporcionar datos que permitan efectuar estudios acerca de la formación delingreso y su distribución entre los distintos sectores de la sociedad boliviana.
m. Generar indicadores, que permitan conocer la evolución de la pobreza, del bie-nestar y las condiciones de vida de los hogares
n. Medir el alcance de los programas sociales en la mejora de las condiciones de vidade la población.
o. Servir de fuente de información a instituciones públicas y privadas, así como ainvestigadores.
p. Permitir la comparabilidad con investigaciones similares, en relación a las varia-bles investigadas.

CAPÍTULO 3. DIAGNÓSTICO DE LAS ENCUESTAS A HOGARES 48
La tabla 3.2 presenta una correspondencia de dichos objetivos especí�cos con el añode cada encuesta. Se aprecia ciclos de�nidos, el primero lo componen las encuestas delos años 1999, 2001 y 2002, el segundo lo marca la del año 2000, la encuesta continuapersigue objetivos más puntuales, y las realizadas a partir del 2005 comparten los mis-mos �nes.
Tabla 3.2: Correspondencia de los objetivos especí�cos con relación al año de la encuesta
AñoObjetivos especi�cos
a. b. c. d. e. f. g. h. i. j. k. l. m. n. o. p.1999 • • •2000 • • • •2001 • • •2002 • • •
2003-2004 • • • • •2005 • • • •2006 • • • •2007 • • • •2008 • • • •2009 • • • •
Fuente: Elaboración propia con información del INE
3.3. EL MARCO MUESTRAL
El marco muestral empleado fue un marco múltiple, que combino un marco de áreacon un marco de lista. Para las encuestas de 1999 a 2000 a partir del Censo Nacionalde Población y Vivienda del 3 junio de 1992 (CNPV-1992), para la encuesta del año2001 se empleo la actualización cartográ�ca para el CNPV-2001 y para las encuestassiguientes de los años 2002 a 2009 a partir del Censo Nacional de Población y Viviendadel 5 de septiembre de 2001 (CNPV-2001). Estos marcos están integrados por mapasy planos a diferentes escalas y una base de datos con la división geográ�ca, política,administrativa y estadística del país, además, de variables que permiten de�nir es-trategias de muestreo esta información está respaldada en un sistema automatizado,formando una base de datos relacionales, que permite la consulta directa del usuariopara el acceso a la cartografía digitalizada.
A continuación se presentará la descripción de las diferentes variables que existen enel marco construido a partir del CNPV-2001, diferenciando estas variables en base a suscaracterísticas. Este marco contiene la información de 16790 unidades, denominadasdentro del propio marco como UPM. Muchas de estas variables también se encuentrandentro del marco construido a partir del CNPV-1992.

CAPÍTULO 3. DIAGNÓSTICO DE LAS ENCUESTAS A HOGARES 49
3.3.1. Variables de división político administrativa
Estas variables permiten identi�car la ubicación política administrativa de las UPMen el territorio nacional, estas variables se encuentran codi�cadas. Se cuenta con lassiguientes variables, descritas por su jerarquía:
Departamento Se tiene un total de 9 departamentos en el marco, codi�cados talcomo se muestra en la tabla 3.3.
Tabla 3.3: Codi�cación de la variable departamento en el marcoCÓDIGO ETIQUETA CANTIDAD DE UPM01 Chuquisaca 91502 La Paz 538003 Cochabamba 297404 Oruro 94005 Potosi 135206 Tarija 73307 Santa Cruz 387508 Beni 54209 Pando 79
Total 16790Fuente: Elaboración propia con información del INE
Provincia La provincia es la división político administrativa jerárquica siguiente aldepartamento y el marco asigna una codi�cación para cada provincia al interiorde cada departamento, existe un total de 113 provincias dentro del marco.
Sección Municipal La sección municipal se da dentro de cada provincia, la codi�ca-ción es dada al interior de cada provincia, el marco contiene la información de310 municipios, se debe tomar en cuenta que el marco fue construido a partir delCNPV-2001, ya que actualmente existen 337 municipios.
Cantón Es la división siguiente al municipio y se encuentra codi�cada dentro de cadamunicipio, en el marco se tiene un total de 1189 cantones.
Ciudad o comunidad Es la característica siguiente al cantón, y se encuentra codi�-cada, existe un total de 3766 entre ciudades y comunidades.
3.3.2. Variables de división geográ�ca
Se re�eren a una división de tipo demográ�ca o natural, permite tener informaciónde las UPM de acuerdo a su pertenencia a alguna división geográ�ca propia del país.

CAPÍTULO 3. DIAGNÓSTICO DE LAS ENCUESTAS A HOGARES 50
Área urbano rural Esta variable esta dentro del marco e identi�ca a la UPM y lapertencia de la misma al área rural o urbano. La codi�cación de esta variaqblese muestra en la tabla 3.4.
Tabla 3.4: Codi�cación de la variable Área en el marcoCÓDIGO ÁREA CANTIDAD DE UPM1 Urbano 121692 Rural 4621
Total 16790Fuente: Elaboración propia con información del INE
Geográ�co Esta variable ha sido empleada casi siempre en los diseños de las encuestasa hogares, categoriza en 5 grupos las UPM del marco, en base a característicasde densidad poblacional. La tabla 3.5 muestra la codi�cación y los niveles de estavariable.
Tabla 3.5: Codi�cación de la variable geográ�ca en el marcoCÓDIGO ETIQUETA NÚMERO DE UPM1 Ciudades Capitales más El Alto 92282 Resto 10000 y mas Hab. 18843 De 2000 a 10000 Hab. 10574 De 250 a 2000 Hab. 11545 Menos de 250 Hab. 3467
TOTAL 16790Fuente: Elaboración propia con información del INE
Pisos ecológicos Esta variable categoriza a las UPM del marco en tres grupos, alti-plano, valle y llano, sin embargo, esta categorización está mal realizada, puestoque se asigna un mismo nivel a todas las UPM de un departamento, siendo quepor la diversidad del país esto no es cierto. La tabla 3.6 muestra la codi�caciónde esta variable.
Tabla 3.6: Codi�cación de la variable pisos ecológicos en el marcoCÓDIGO ETIQUETA NÚMERO DE UPM1 Altiplano 76722 Valle 46223 Llano 4496
Total 16790Fuente: Elaboración propia con información del INE

CAPÍTULO 3. DIAGNÓSTICO DE LAS ENCUESTAS A HOGARES 51
3.3.3. Variables de división estadística
Estas variables son divisiones fruto del Censo Nacional de Población y Vivienda, seoriginan como parte esencial para el manejo del operativo censal, estas son:
Zona censal
Sector censal
Segmento censal
Tener en cuenta que la denominada UPM3 es la aglomeración de sectores censales, yesta no es parte de una división estadística, sino que es una división que se realizó con�nes de muestreo,
3.3.4. Variables auxiliares de apoyo
Estas variables se encuentran en el marco y son de apoyo para la plani�cación delos distintos diseños muestrales, estos son:
Total de viviendas
Total de población
Total de hombres
Total de mujeres
Estas variables se encuentran de�nidas a nivel de las UPM del marco y correspondena la información del CNPV-2001. Tener presente que en el caso de la variable total deviviendas, esta considera viviendas tanto ocupadas, como desocupadas, excluyendo alas viviendas colectivas.
3.3.5. Variables de estrati�cación
Estas variables, también son auxiliares, pero tienen la �nalidad de ser empleadaspara la estrati�cación, bajo las características de una encuesta de condiciones de vida.
Estrato estadístico Esta variable fue construida con información proveniente delCNPV-2001 y considerando el Índice de Necesidades Insatisfechas, la tabla 3.7presenta la codi�cación, los niveles del estrato estadístico y su aproximación conlos niveles del NBI.
3Para el marco proveniente del CNPV-2001

CAPÍTULO 3. DIAGNÓSTICO DE LAS ENCUESTAS A HOGARES 52
Tabla 3.7: Codi�cación del estrato estadístico en el marco y aproximación con los nivelesdel NBI
Condición de pobreza NBI Estrato Estadístico1 Necesidades Básicas Satisfechas 1 Alto2 Umbral de Pobreza 2 Media Alto3 Pobreza Moderada 3 Medio Bajo4 Indigencia
4 Bajo5 MarginalidadFuente: Elaboración propia con información del INE
3.4. LA ESTRATIFICACIÓN
La estrati�cación involucró siempre el empleo de la variable geográ�ca como estratoexplicito, denominado estrato geográ�co, a excepción de la encuesta del año 2008 queaplico otra estrati�cación. La variable geográ�ca tuvo un cambio en cuanto a sus ni-veles, para las encuestas que emplearon el marco proveniente del CNPV-1991 trabajócon cuatro niveles y a partir del marco muestral del CNPV-2001 el nivel tercero sedividió en dos, generando un estrato geográ�co con cinco niveles, la tabla 3.8 muestrauna apreciación mayor.
Tabla 3.8: Niveles y cambio del estrato geográ�co, diferenciado por procedencia delmarco.
CNPV-1992 CNPV-20011 Ciudades Capitales más El Alto 1 Ciudades Capitales más El Alto2 Resto 10000 y mas Hab. 2 Resto 10000 y mas Hab.
3 De 250 a 10000 Hab.3 De 2000 a 10000 Hab.4 De 250 a 2000 Hab.
4 Menos de 250 Hab. 5 Menos de 250 Hab.Fuente: Elaboración propia con información del INE
En el estrato geográ�co, para las encuestas que utilizaron el marco construido apartir del CNPV-1992, los dos primeros niveles corresponden al área urbana y los dosúltimos, al área rural, mientras que para el marco procedente del CNPV-2001 los tresprimeros niveles corresponden al área urbana y los últimos dos al área rural.
Otro estrato empleado, fue el estrato estadístico, este se utilizó a partir de la infor-mación obtenida del CNPV-2001.
El año 2008, hubo una estrati�cación nueva y única para ese año, esta estrati�-cación creo el estrato denominado �Estrato de bienestar�, que tiene �12� niveles en suestructura, fue construido mediante modelos econométricos, lastimosamente no se tie-nen mayores referencias de este estrato y su construcción.

CAPÍTULO 3. DIAGNÓSTICO DE LAS ENCUESTAS A HOGARES 53
En cuanto a la estrati�cación implícita, está viene asociada a la selección de tiposistemática de primera etapa dentro de cada estrato, dicha selección se la realizó losaños 1999, 2000, 2001 y 2008, lastimosamente los documentos no mencionan cual fuela variable de ordenación del marco que permitió generar la estrati�cación implícita,sin embargo esta estrati�cación pudo estar relacionado a las variables que dan la deli-mitación político administrativa dentro del marco, con el �n de distribuir la muestra amas regiones del país.
3.5. LOS NIVELES DE DESAGREGACIÓN
El nivel de desagregación, tiene relación con dos componentes dentro del diseñomuestral; el primero, referido al tamaño de muestra, el segundo, a la estrategia demuestreo; un mayor tamaño de muestra permitirá una desagregación más amplia, unaestrategia de muestreo optima, permitirá una disminución en la varianza y esto a la vezgenerará resultados más precisos y con�ables, esto también permitirá tener un mayornivel de desagregación.
A lo largo de estos once años, siempre se pudo establecer una desagregación nacio-nal y por área urbano-rural, la ampliación de la muestra, los objetivos de la encuestay la estrategia empleada son las que in�uyeron para que existieran diferencias, de unaencuesta a otra. La tabla 3.9, muestra los diferentes niveles de desagregación, por añode las encuestas.
Tabla 3.9: Niveles de desagregación conseguidos, periodo 1999 a 2009Año Nivel Na-
cionalÁrea Metro-politana
Nivel regional(pisos ecológi-cos)
Area Urbanay area Rural
Ciudades Ca-pitales más ElAlto
1999 • • •2000 • • • •2001 • • • •2002 • • •
2003-2004 • • • • •2005 • •2006 • •2007 • •2008 • •2009 • •
Fuente: Elaboración propia con información del INE
La Encuesta Continua de Hogares 2003-2004 es la que logró un mayor grado dedesagregación, esto a razón de su particularidad propia. Como se puede observar en latabla anterior, se identi�ca un patrón idéntico de desagregación a partir de la encuesta2005.

CAPÍTULO 3. DIAGNÓSTICO DE LAS ENCUESTAS A HOGARES 54
El alcance de la desagregación se puede atribuir en mayor parte al tamaño de mues-tra de cada encuesta, puesto que la estrategia de muestreo no varió en sobremanera,en especial desde el año 2005, a excepción del diseño de la 2008 que utiliza otra estra-ti�cación pero que �nalmente logra el mismo nivel de desagregación que la 2007.
3.6. CONGLOMERADOS EMPLEADOS
A lo largo de estas once años se han empleado distintos conglomerados, en todoslos casos estos fueron áreas geográ�cas, puesto que el marco empleado en primeras eta-pas era un marco de áreas, la tabla 3.10 muestra los distintos conglomerados empleados.
Tabla 3.10: Conglomerados empleadosPROCEDENCIA DEL MARCO CNPV-1992 CNPV-2001
CONGLOMERADOSSectores censales UPM
Segmentos censalesSectores censalesSegmentos censales
Fuente: Elaboración propia con información del INE
La característica primordial de estos conglomerados fue que se encontraban car-togra�ados, sin embargo, para la cartografía procedente del CNPV-2001 existió unproblema con los segmentos censales, este fue: No se logro una delimitación adecuada ytangible de los segmentos en algunos sectores censales, lo que condujo a tener segmen-tos indivisibles, es decir, no se puede identi�car a los segmentos dentro de los sectorescensales.
3.7. ETAPAS DENTRO DEL DISEÑO
En el caso de las encuestas de 1999 y 2001 utilizaron un muestreo de dos etapas,en una primera etapa se seleccionaron como unidades primarias de muestreo (UPM)áreas geográ�cas, para el área amanzanada la UPM correspondía al sector censal, parael área dispersa la UPM era el segmento censal. En etapa última de selección en lamuestra siempre ha sido la vivienda particular ocupada, ya que esta se constituye enunidad estable y �ja en espacio y tiempo.
En los años 2002 a 2009 el diseño de muestra incluyo tres etapas en el área dispersay dos en el área amanzanada. En el área dispersa las unidades muestrales fueron, launidad primaria de muestreo (UPM) que coincide con uno o más sectores censales; enla segunda etapa una agrupación de segmentos censales y las viviendas particulares enla última etapa. En lo que respecta al área amanzanada se elimina la selección de laagrupación de segmentos, teniendo una selección de UPM en primera etapa y viviendasen segunda etapa.

CAPÍTULO 3. DIAGNÓSTICO DE LAS ENCUESTAS A HOGARES 55
3.8. EL TAMAÑO DE LA MUESTRA
Analizar el comportamiento del tamaño de la muestra resulta importante, puestoque a través de ella se puede ver la evolución del periodo a nivel macro; se debe tenerpresente que estas encuestas son periódicas de un año y símil en cuanto a sus objetivos.A excepción de la Encuesta Continua de 2003-2004.
La �gura 3.1, presenta el comportamiento del tamaño de muestra de viviendas pla-ni�cadas por año, desde el comienzo del proyecto MECOVI, en el año 1999, hasta laEncuesta a Hogares 2009.
El menor tamaño de muestra se da a inicio del proyecto MECOVI en el año 1999,con 3064 viviendas, esto podría deberse a que esta encuesta resulto ser el inicio delproyecto MECOVI; posteriormente, se evidencia la tendencia creciente del tamaño demuestra, hasta la �nalización del proyecto MECOVI en el año 2004, la cima más altala tiene la Encuesta Continua de Hogares 2003-2004 que representa el punto más altodel proyecto MECOVI, esto se debe a que esta encuesta persiguió objetivos más especí-�cos, además, fue de carácter longitudinal; a partir del 2005 se nota un decaimiento enel tamaño de la muestra, lo cual condujo a contar con un menor nivel de desagregaciónpara las encuestas, al mismo tiempo que generó un status quo en diferentes etapas deldiseño muestral.
Figura 3.1: Evolución del tamaño de la muestra de las Encuestas a Hogares, serie 1999- 2009
Fuente: Elaboración propia con información del INE
El anterior análisis describe el tamaño de muestra global, a nivel de viviendas par-
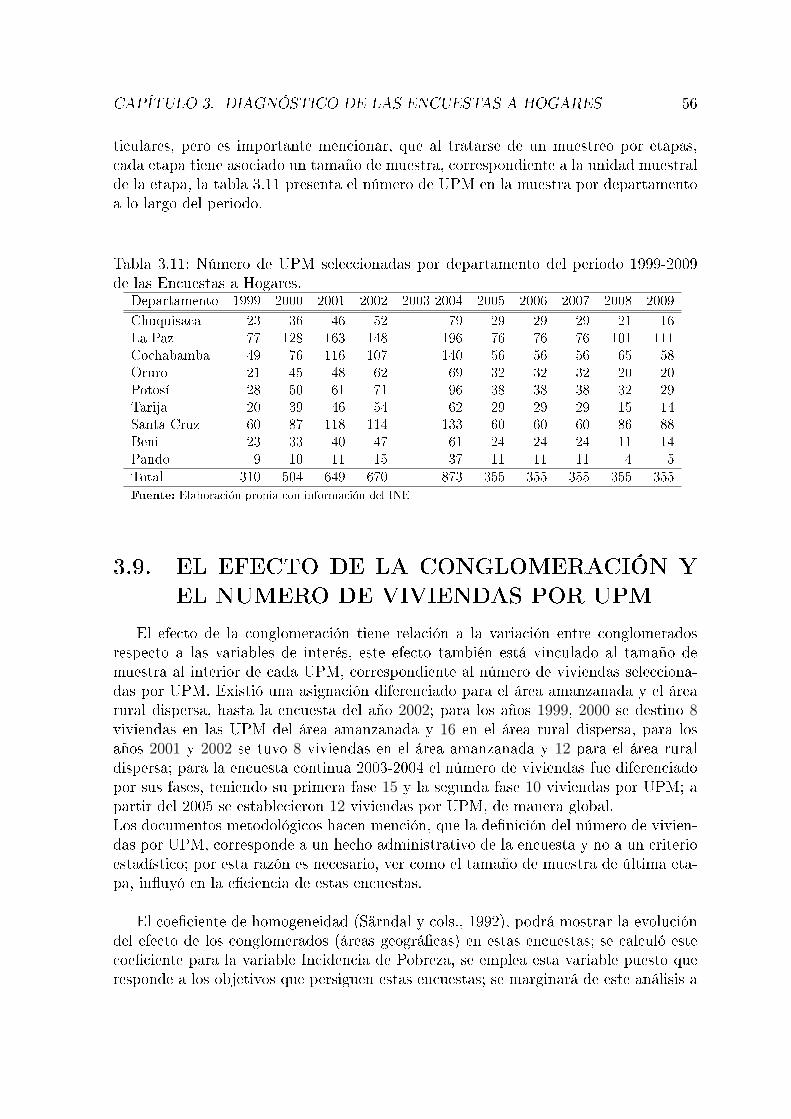
CAPÍTULO 3. DIAGNÓSTICO DE LAS ENCUESTAS A HOGARES 56
ticulares, pero es importante mencionar, que al tratarse de un muestreo por etapas,cada etapa tiene asociado un tamaño de muestra, correspondiente a la unidad muestralde la etapa, la tabla 3.11 presenta el número de UPM en la muestra por departamentoa lo largo del periodo.
Tabla 3.11: Número de UPM seleccionadas por departamento del periodo 1999-2009de las Encuestas a Hogares.
Departamento 1999 2000 2001 2002 2003-2004 2005 2006 2007 2008 2009Chuquisaca 23 36 46 52 79 29 29 29 21 16La Paz 77 128 163 148 196 76 76 76 101 111Cochabamba 49 76 116 107 140 56 56 56 65 58Oruro 21 45 48 62 69 32 32 32 20 20Potosí 28 50 61 71 96 38 38 38 32 29Tarija 20 39 46 54 62 29 29 29 15 14Santa Cruz 60 87 118 114 133 60 60 60 86 88Beni 23 33 40 47 61 24 24 24 11 14Pando 9 10 11 15 37 11 11 11 4 5Total 310 504 649 670 873 355 355 355 355 355Fuente: Elaboración propia con información del INE
3.9. EL EFECTO DE LA CONGLOMERACIÓN YEL NUMERO DE VIVIENDAS POR UPM
El efecto de la conglomeración tiene relación a la variación entre conglomeradosrespecto a las variables de interés, este efecto también está vinculado al tamaño demuestra al interior de cada UPM, correspondiente al número de viviendas selecciona-das por UPM. Existió una asignación diferenciado para el área amanzanada y el árearural dispersa, hasta la encuesta del año 2002; para los años 1999, 2000 se destino 8viviendas en las UPM del área amanzanada y 16 en el área rural dispersa, para losaños 2001 y 2002 se tuvo 8 viviendas en el área amanzanada y 12 para el área ruraldispersa; para la encuesta continua 2003-2004 el número de viviendas fue diferenciadopor sus fases, teniendo su primera fase 15 y la segunda fase 10 viviendas por UPM; apartir del 2005 se establecieron 12 viviendas por UPM, de manera global.Los documentos metodológicos hacen mención, que la de�nición del número de vivien-das por UPM, corresponde a un hecho administrativo de la encuesta y no a un criterioestadístico; por esta razón es necesario, ver como el tamaño de muestra de última eta-pa, in�uyó en la e�ciencia de estas encuestas.
El coe�ciente de homogeneidad (Särndal y cols., 1992), podrá mostrar la evolucióndel efecto de los conglomerados (áreas geográ�cas) en estas encuestas; se calculó estecoe�ciente para la variable Incidencia de Pobreza, se emplea esta variable puesto queresponde a los objetivos que persiguen estas encuestas; se marginará de este análisis a

CAPÍTULO 3. DIAGNÓSTICO DE LAS ENCUESTAS A HOGARES 57
la Encuesta Continua 2003-2004 por su naturaleza tan particular.
Tabla 3.12: Coe�ciente de Homogeneidad para la variable Incidencia de pobreza en lasencuestas de hogares.Año 1999 2000 2001 2002 2005 2006 2007 2008 2009
δ 0.1769 0.1754 0.2770 0.3112 0.2901 0.2962 0.2908 0.3052 0.2921Fuente: Elaboración propia con información del INE
La Tabla 3.12, muestra al coe�ciente de homogeneidad estimado, para cada en-cuesta considerando la variable incidencia de pobreza y a las áreas geográ�cas comoconglomerados de primera etapa o UPM.Este coe�ciente se de�ne como:
δ = 1−S2yw
S2y
(3.1)
Donde:
S2y =
1
n− 1
n∑i=1
(yi − y)2 (3.2)
Cuasi - varianza muestral total, para la variable Y .
S2yw =
k∑i=1
(ni − 1) S2yi
k∑i=1
(ni − 1)
(3.3)
Cuasi - varianza muestral dentro, para la variable Y .
S2yi =
ni∑j=1
(yij − yi)2
ni − 1(3.4)
Cuasi - varianza muestral total del conglomerado i, para la variable Y .
y =
n∑i=1
yi
n(3.5)

CAPÍTULO 3. DIAGNÓSTICO DE LAS ENCUESTAS A HOGARES 58
Media muestral de la variable Y .
yi =
ni∑j=1
yij
ni(3.6)
Media muestral de la variable Y , en el conglomerado i.
Donde n =k∑i=1
ni, n es el número de observaciones en la muestra total, ni el número
de observaciones en el conglomerado i y k el número de conglomerados. En este caso lavariable Y , es una variable dicotómica, que toma el valor de 1 = Pobre y 1 = No Pobre .
Un valor pequeño de δ signi�ca que los elementos en las mismas UPM son diferentescon respecto a la variable de estudio, es decir, tienen un bajo grado de homogeneidad.Un gran valor de δ signi�ca que los elementos en las UPM son similares, es decir, tienenun alto grado de homogeneidad. En el caso de un muestreo que utiliza conglomerados,el interés recae en que este coe�ciente de homogeneidad sea pequeño, puesto que estetiene una relación proporcional al error de muestreo y por ende a la e�ciencia de laencuesta.
Por la tabla 3.12, se observa que a partir del 2001 existe una tendencia similar en elcomportamiento de este coe�ciente, teniendo sus puntos más bajos para las encuestasde los años 1999 y 2000, resulta complejo entender cual la razón de que este coe�cientese incremente en sobremanera del año 2000 a 2001, sin embargo, se puede atribuir elcomportamiento de este coe�ciente de homogeneidad, al número de viviendas dentrode cada UPM, puesto que ambos presentan una fuerte correlación, en especial con elnúmero de viviendas por UPM, involucrado en el área dispersa.
3.10. DISTRIBUCIÓN YASIGNACIÓN DE LAMUES-TRA
La distribución de la muestra estuvo relacionada a los dominios de estudio y a laestrati�cación empleada, para esto se utilizó el método de asignación potencial paralas encuestas de los años 1999, 2000 y 2001, las encuestas que dependieron de la mues-tra maestra implícitamente están sujetas a su diseño muestral, que uso una a�jaciónpotencial; no se tiene referencia respecto al criterio de distribución a partir del 2006.
A partir de la tabla 3.13, que presenta la distribución de la muestra por departa-mento, se observa que en las encuestas de la Muestra Maestra, siguieron una a�jacióncercana al diseño de esta, en 2006 y 2007 se siguió la distribución de 2005 y para lasencuestas de 2008 y 2009 parece existir una a�jación de tipo proporcional a la com-posición del marco muestral, sin embargo, mencionar que los departamentos no fueron

CAPÍTULO 3. DIAGNÓSTICO DE LAS ENCUESTAS A HOGARES 59
dominios de estudio, pero revisando los documentos siempre se procuro distribuir lamuestra siguiendo un criterio departamental, que en muchos caso trajo consigo un sobremuestreo en algunos departamentos, un ejemplo de esto es el departamento de Pando.
Tabla 3.13: Distribución de la muestra por departamento y estructura de los marcosmuestrales empleados en porcentaje.Departamento 1999 2000 2001 MMM-1992 2002 2003-2004 2005 MM-2001 2006 2007 2008 2009 MMM-2001Chuquisaca 7.4 7.1 7.1 7.3 7.8 9.0 8.2 7.7 8.2 8.2 5.9 4.5 5.4La Paz 24.8 25.4 25.1 33.9 22.1 22.5 21.4 21.5 21.4 21.4 28.5 31.3 32.0Cochabamba 15.8 15.1 17.9 17.1 16.0 16.0 15.8 15.3 15.8 15.8 18.3 16.3 17.7Oruro 6.8 8.9 7.4 6.2 9.3 7.9 9.0 8.3 9.0 9.0 5.6 5.6 5.6Potosí 9.0 9.9 9.4 11.0 10.6 11.0 10.7 13.1 10.7 10.7 9.0 8.2 8.1Tarija 6.5 7.7 7.1 3.8 8.1 7.1 8.2 7.8 8.2 8.2 4.2 3.9 4.4Santa Cruz 19.4 17.3 18.2 16.6 17.0 15.2 16.9 15.9 16.9 16.9 24.2 24.8 23.1Beni 7.4 6.5 6.2 3.3 7.0 7.0 6.8 7.7 6.8 6.8 3.1 3.9 3.2Pando 2.9 2.0 1.7 0.9 2.2 4.2 3.1 2.7 3.1 3.1 1.1 1.4 0.5Total 100 100 100 100 100 100 100 100 100 100 100 100 100Fuente: Elaboración propia con información del INE
En el caso de la a�jación potencial los documentos metodológicos mencionan quese utilizó un α = 0,5.
nh = nNαh∑
h
Nαh
;→ 0 ≤ α ≤ 1 (3.7)
Esta a�jación da una muestra promedio entre la a�jación uniforme y la a�jación pro-porcional, compensando a estratos pequeños y no dando tanta muestra a los estratosgrandes.
3.11. PROBABILIDADES YMÉTODOS DE SELEC-CIÓN
Los métodos de selección de la muestra tienen una relación directa con las proba-bilidades de selección en sus distintas etapas; en el caso de las encuestas de los años1999 a 2001, se empleo en primera etapa una selección de tipo sistemático proporcio-nal al tamaño4 (PPT) respecto al número de viviendas que tiene la UPM dentro delmarco muestral. Para la última etapa se optó por un muestreo sistemático simple conarranque aleatorio, para seleccionar las viviendas dentro las UPM seleccionadas;
A partir de la encuesta 2002 el panorama fue diferente al tener una tercera etapa enel área dispersa, la selección de UPM fue de tipo proporcional al número de viviendasdentro de cada UPM a excepción de la 2008 que retomo el sistemático PPT, se mencio-na en los documentos que para la segunda etapa la selección del grupo de segmentos en
4Mas detalle ver B

CAPÍTULO 3. DIAGNÓSTICO DE LAS ENCUESTAS A HOGARES 60
el área dispersa, fue también proporcional al tamaño y para la última etapa se empleoun muestreo sistemático simple, con arranque aleatorio.
El establecer claramente las probabilidades de selección en cada etapa permite laconstrucción de los factores de expansión, además, a través de ellas se logra el cálculo delos estimadores y los errores de muestreo. Se dice que un diseño muestral es medible5, silas probabilidades de selección simples y conjuntas son mayores a cero y son conocidas,todos los diseños muestrales del periodo de interés resultan ser diseños no medibles,ya que no se describe por completo el esquema de selección involucrado, ya que no seconocen con certeza las probabilidades de selección conjunta. El esquema de selecciónse re�ere al algoritmo de selección, que especi�ca la forma de las probabilidades deselección, se puede mencionar los esquemas propuestos en el caso de un muestreo PPT,está el de Sunter, Ikeda, Lahiri, Hanurav, Vijayan, Pareto, etc. Cada uno de ellos tieneun algoritmo de selección de las unidades muestrales y proporciona la forma de lasprobabilidades conjuntas para el cálculo de los errores de muestreo.
3.12. LOS FACTORES DE EXPANSIÓN
La construcción de los factores de expansión fue caracterizada por su similar estruc-tura a lo largo de los años, variando básicamente por la estrati�cación y conglomeraciónpresente en cada una de ellas, al margen de ello, su forma sigue una estructura esta-dística en las distintas etapas dentro del diseño, la única discrepancia existente, seencuentra presente en el cálculo de los factores de expansión de la 2006, que muestraun procedimiento diferente a las demás.
La tabla 3.14, muestra el comportamiento de las estadísticas básicas sobre los fac-tores de expansión de los hogares a lo largo del periodo de interés. Está revela queel comportamiento de los factores de expansión presenta mayor variabilidad en la En-cuesta Continua de 2003− 2004, al igual que la Encuesta a Hogares 2006 este grado devariabilidad puede atribuirse a sus propias particularidades en el caso de la encuestacontinua y en el caso de la encuesta 2006, cuyo rango es el más alto, puede estar rela-cionado a la forma del cálculo de los factores de expansión que di�ere en estructura aun cálculo clásico.
3.13. RENDIMIENTO DE LA MUESTRA E INCI-DENCIAS
El rendimiento de la muestra, se re�ere al grado de éxito alcanzado en las entre-vistas dentro el operativo de campo, dicho éxito se alcanza al concluir completa y
5Sanchez Crespo, 1985

CAPÍTULO 3. DIAGNÓSTICO DE LAS ENCUESTAS A HOGARES 61
Tabla 3.14: Estadísticas básicas para los factores de expansión a nivel hogar, por añode la encuesta
Año Mínimo Máximo Promedio Desviación estándar CV1999 12 3505 614.86 392.60 0.642000 39 4241 397.94 337.04 0.852001 5 1520 331.69 251.01 0.762002 20 1765 338.48 250.47 0.742003-2004 8 2423 239.13 262.70 1.102005 41 2891 564.04 405.50 0.722006 47 8365 581.38 567.95 0.982007 2 4520 597.39 483.33 0.812008 59 5270 672.18 442.32 0.662009 40 3139 663.42 400.99 0.60Fuente: Elaboración propia con información del INE
correctamente la entrevista de un hogar seleccionado en la muestra.
Esta información permite examinar la respuesta y no respuesta existente a lo largodel periodo de interés, para así poder visualizar de manera macro el comportamientode la población afectada por las características del cuestionario y los encuestadores. Latabla 3.15, permite tener una visión del comportamiento de la no respuesta dada enlas encuestas a hogares a lo largo del tiempo diferenciada por departamento.
Tabla 3.15: Tasa de no respuesta en porcentaje, de las Encuestas a Hogares por depar-tamento y año de la encuesta
DepartamentoAño de la encuestaa
1999 2000 2001 2002 2003-2004 2005 2006 2007 2008 2009Chuquisaca 7.2 0.0 1 .4 0.8 0.7 5.2 0.9 2.6 0.0 0.0La Paz 9.0 4.1 2.0 3.6 7.7 2.5 2.4 1.0 5.2 6.0Cochabamba 0.2 4.3 5.0 3.3 11.6 4.6 4.9 2.7 5.0 7.0Oruro 0.0 0.0 1.4 0.2 3.9 1.0 1.0 0.0 0.0 0.0Potosí 6.5 2.5 2.8 3.1 3.5 2.4 0.2 2.2 0.8 0.6Tarija 9.9 2.6 0.7 0.8 0.9 2.8 0.9 0.9 0.0 3.6Santa Cruz 11.1 2.6 2.9 4.6 10.0 6.9 12.8 6.9 20.7 7.9Beni 2.0 2.6 1.7 1.0 1.2 6.6 1.4 1.7 0.8 0.0Pando 2.4 0.0 1.9 0.7 10.7 9.8 5.3 9.1 0.0 17.5Bolivia 6.5 2.7 2.6 2.6 6.5 4.2 4.0 2.7 7.5 5.4Fuente: Elaboración propia con información del INE
aLa tasa de no respuesta se calcula como el cociente de la suma de todas las incidencias registradas(excepto entrevista completa), sobre el total de encuestas ejecutadas.
La tasa de no respuesta se calcula como el cociente de la suma de todas las inciden-cias registradas (excepto entrevista completa), sobre el total de encuestas ejecutadas.
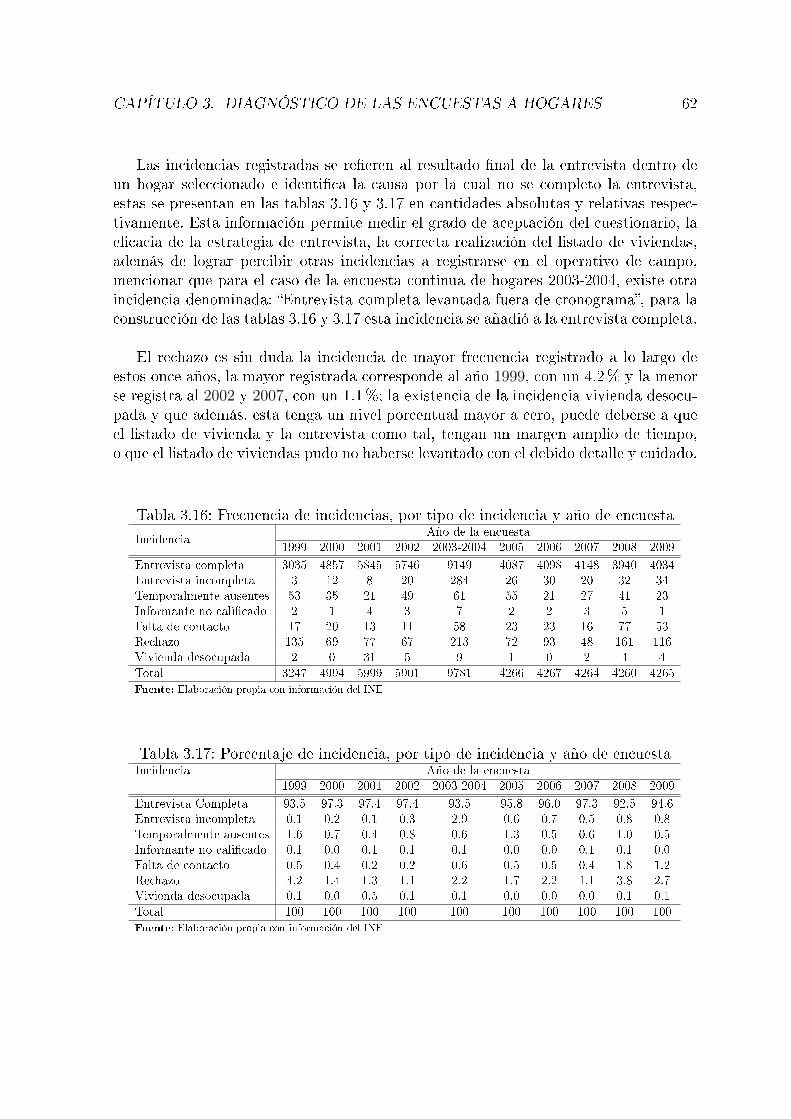
CAPÍTULO 3. DIAGNÓSTICO DE LAS ENCUESTAS A HOGARES 62
Las incidencias registradas se re�eren al resultado �nal de la entrevista dentro deun hogar seleccionado e identi�ca la causa por la cual no se completo la entrevista,estas se presentan en las tablas 3.16 y 3.17 en cantidades absolutas y relativas respec-tivamente. Esta información permite medir el grado de aceptación del cuestionario, lae�cacia de la estrategia de entrevista, la correcta realización del listado de viviendas,además de lograr percibir otras incidencias a registrarse en el operativo de campo,mencionar que para el caso de la encuesta continua de hogares 2003-2004, existe otraincidencia denominada: �Entrevista completa levantada fuera de cronograma�, para laconstrucción de las tablas 3.16 y 3.17 esta incidencia se añadió a la entrevista completa.
El rechazo es sin duda la incidencia de mayor frecuencia registrado a lo largo deestos once años, la mayor registrada corresponde al año 1999, con un 4.2% y la menorse registra al 2002 y 2007, con un 1.1%; la existencia de la incidencia vivienda desocu-pada y que además, esta tenga un nivel porcentual mayor a cero, puede deberse a queel listado de vivienda y la entrevista como tal, tengan un margen amplio de tiempo,o que el listado de viviendas pudo no haberse levantado con el debido detalle y cuidado.
Tabla 3.16: Frecuencia de incidencias, por tipo de incidencia y año de encuesta
IncidenciaAño de la encuesta
1999 2000 2001 2002 2003-2004 2005 2006 2007 2008 2009Entrevista completa 3035 4857 5845 5746 9149 4087 4098 4148 3940 4034Entrevista incompleta 3 12 8 20 284 26 30 20 32 34Temporalmente ausentes 53 35 21 49 61 55 21 27 41 23Informante no cali�cado 2 1 4 3 7 2 2 3 5 1Falta de contacto 17 20 13 11 58 23 23 16 77 53Rechazo 135 69 77 67 213 72 93 48 161 116Vivienda desocupada 2 0 31 5 9 1 0 2 4 4Total 3247 4994 5999 5901 9781 4266 4267 4264 4260 4265Fuente: Elaboración propia con información del INE
Tabla 3.17: Porcentaje de incidencia, por tipo de incidencia y año de encuestaIncidencia Año de la encuesta
1999 2000 2001 2002 2003-2004 2005 2006 2007 2008 2009Entrevista Completa 93.5 97.3 97.4 97.4 93.5 95.8 96.0 97.3 92.5 94.6Entrevista incompleta 0.1 0.2 0.1 0.3 2.9 0.6 0.7 0.5 0.8 0.8Temporalmente ausentes 1.6 0.7 0.4 0.8 0.6 1.3 0.5 0.6 1.0 0.5Informante no cali�cado 0.1 0.0 0.1 0.1 0.1 0.0 0.0 0.1 0.1 0.0Falta de contacto 0.5 0.4 0.2 0.2 0.6 0.5 0.5 0.4 1.8 1.2Rechazo 4.2 1.4 1.3 1.1 2.2 1.7 2.2 1.1 3.8 2.7Vivienda desocupada 0.1 0.0 0.5 0.1 0.1 0.0 0.0 0.0 0.1 0.1Total 100 100 100 100 100 100 100 100 100 100Fuente: Elaboración propia con información del INE

Capítulo 4
HACIA UN SISTEMA INTEGRADODE ENCUESTAS A HOGARES
A partir de la metodología marco y el diagnóstico, este apartado tiene la �nalidadde mostrar el rumbo que se debe tener en los distintos aspectos involucrados en la cons-trucción de los diseños muestrales, para las encuestas dirigidas a hogares en el futuro,con la �nalidad de lograr un sistema integrado de encuestas a hogares. Esto, a razónde que el diagnóstico revelo una serie de incompatibilidades en los diseños muestralesejecutados a lo largo de estos años, siendo esta incompatibilidad una razón que di�cultala identi�cación real de la evolución de cualquier indicador de interés, en encuestas detipo periódicas.
Se desarrolla aspectos generales y exclusivos del diseño muestral, como la construc-ción del marco muestral, la conglomeración, la estrati�cación, los dominios de estudio,el número de etapas optimo, la asignación de la muestra, el tamaño de la muestra, losniveles de desagregación y los errores muestrales.
Tener en cuenta, el momento en el que se encuentra el Instituto Nacional de Esta-dística de Bolivia, se está a puertas de la realización de un nuevo Censo Nacional dePoblación y Vivienda, sin duda, este es el instrumento más importante, trascendentaly valioso, para las encuestas a hogares, porque otorga la oportunidad única de renovary actualizar completamente el marco muestral y permite pensar a partir de ello ennuevas estrategias de muestreo. Bajo esa perspectiva, se presenta a continuación loselementos más relevantes que deben tenerse en cuenta en la plani�cación del diseñomuestral en las encuestas a hogares posteriores, en base a la oportunidad que aperturaun nuevo CNPV.
4.1. MARCO MUESTRAL
El Censo Nacional de Población y Vivienda es la herramienta más trascendentale importante para la construcción del marco muestral, al cual se denominará de aquíen adelante como: Marco Maestro de Muestreo, este es empleado para las encuestas
63

CAPÍTULO 4. HACIA UN SISTEMA INTEGRADODE ENCUESTAS A HOGARES64
dirigidas a hogares, la estructuración del marco deberá responder necesariamente a unavisión a largo plazo respecto al dinamismo que �uctúa y actúa sobre la población obje-tivo de la cual proviene el marco, puesto que esta herramienta será empleada durantemás de una década posterior a su construcción.
Se hace sumamente importante la de�nición de los niveles que regulan la estruc-tura del marco, desde divisiones político administrativas, divisiones concebidas por laplani�cación censal, hasta aquellas generadas por �nes de muestreo, debe contarse coninformación referente a la accesibilidad, número de habitantes, número de hogares, nú-mero de viviendas, dimensión espacial de los diferentes niveles dentro del marco, ademásde contar con indicadores que de�nan a las unidades de dichos niveles, para la confor-mación posterior de los estratos que respondan a la naturaleza de las futuras encuestas.
En un buen marco de muestreo, todos los miembros del universo de estudio debentener una probabilidad conocida, y distinta de cero, de formar parte de alguna muestra.Sin embargo, se debe señalar que existen estudios en que deliberadamente se excluyenalgunas zonas o regiones del país, o determinadas sub-poblaciones; estos casos no violanel principio señalado, pero ello debe aclararse en los documentos que hacen referenciaa la población encuestada a �n de que no se generalicen los resultados a sectores noconsiderados en la población investigada.
4.1.1. Insumos del CNPV para la construcción del Marco Maes-tro de Muestreo (MMM)
La construcción del MMM es alimentada por dos momentos del operativo censal;estos momentos son:
La etapa pre-censal: Con la actualización cartográ�ca y la de�nición de las divisio-nes administrativas y censales, son el insumo para la concepción de la unidadesde muestreo que contendrá el marco (unidades geográ�cas, dominios de estudio,estratos geográ�cos, estratos regionales, etc.), debe incluirse en esta etapa, la de-�nición de variables que indiquen el grado y medio de accesibilidad a las unidadesgeográ�cas, para posteriormente tener dentro del marco, variables que indiquenel nivel de elegibilidad o de accesibilidad a dichas unidades.
La etapa post censal: El procesamiento de datos recogidos del operativo censal, pro-porciona las diferentes variables que permiten construir el MMM, y dan paso ala elaboración de estratos temáticos en base a las necesidades propias de la in-vestigación y la funcionalidad del MMM.
En base a los dos anteriores puntos, es evidente la trascendencia del CNPV parala conformación y construcción del MMM y sin duda el desafío de elaborar un nuevomarco muestral a partir del CNPV es muy grande y lleva consigo retos especí�cos que

CAPÍTULO 4. HACIA UN SISTEMA INTEGRADODE ENCUESTAS A HOGARES65
deben ser resueltos. Los más importantes son:
i De�nición de las unidades geográ�cas y otras unidades muestrales.
ii Construcción de estratos temáticos y de control.
iii Delimitación de estratos geográ�cos y dominios de estudio, según el área temáticay tipo de encuesta de la investigación.
iv Extracción de la muestra maestra (Si corresponde)
Son cuatro aspectos que delinearán por alrededor de una década todo el proceso demuestro, inmerso en las encuestas a hogares. Si se pretende generar un sistema integra-do de encuestas a hogares, el marco muestral debe de responder de manera clara a eseobjetivo, proporcionando una estructura acorde, sustentable y manejable en el tiempo.
La preparación y ejecución de los censos de población demanda la inversión de unmonto considerable de recursos, donde, la elaboración y actualización de la cartografíaes una tarea fundamental, todo esto con la �nalidad de disponer de una base cartográ-�ca actualizada y de buena calidad.
En términos generales, la conformación de los marcos de muestreo sigue los pasosque se detallan a continuación:
En primer lugar: La base informativa generada a partir del trabajo de campo delos censos posibilita la construcción de un marco de áreas, integrado por ma-pas de línea a diferentes escalas y una base de datos con la división geográ�ca,administrativa y estadística del país, así como con alguna información de baseque permita conocer el total de viviendas en los distintos contextos geográ�cos,además de una primera aproximación al número de personas que habitan en cadauno de ellos. Esta información debiera ser respaldada en un sistema automatiza-do, conformado por una base de datos relacional, que permita a los usuarios laconsulta directa, y por la cartografía digitalizada, orientada a la elaboración demapas y a su actualización en forma automatizada.Durante la elaboración del marco, cada unidad estadística debiera identi�carseen las diferentes fases y acompañarse de información complementaria que hagaposible de�nir su importancia relativa respecto a las demás (número de viviendas,población total, grado de elegibilidad, población por edad y sexo, etc.).
En segundo lugar: Las unidades censales se utilizan por lo general para formar agru-paciones (que se conocen con el nombre de conglomerados, unidades geográ�cas yque también forman parte del marco de muestreo de áreas) de�nidas comúnmen-te como unidades de primera etapa o unidades primarias de muestreo (UPM).

CAPÍTULO 4. HACIA UN SISTEMA INTEGRADODE ENCUESTAS A HOGARES66
Según las características de las unidades censales, es posible que éstas puedanutilizarse como conglomerados (teniendo presente que en cualquier encuesta laprimera etapa es la que genera la mayor contribución a la varianza total del dise-ño), debiendo tener un criterio para la elección de la unidad censal a ser empleaday también contar con una estrategia para su actualización.
4.1.2. Un ejemplo del evidente cambio en el marco muestral
Para ilustrar de manera objetiva, la des-actualización que sufre el marco muestral,se puede recurrir al resultado obtenido por los listados de vivienda de la MECOVI 2002y compararlos con la información que contiene el Marco Muestral construido a partirdel CNPV-2001. Los listados de vivienda se los realiza sobre las unidades penúltimasde muestreo, en el caso de la MECOVI-2002, en el área amanzanada se realizó el listadosobre las UPM seleccionadas, en el caso del área rural dispersa, el listado de viviendasse lo realizó sobre el grupo de segmentos censales seleccionados dentro de cada UPMde la muestra.
El marco muestral contiene la variable total de viviendas, esta variable denota lacantidad de viviendas ocupadas y desocupadas que contenía la unidad de muestreo deinterés (UPM, Segmento censal) en el momento del CNPV-2001; el listado de viviendade la MECOVI-2002 proporciona la misma variable, pero actualizada al momento dela encuesta.
Para comparar ambos momentos, se hizo un pareo de UPM, sobre las UPM selec-cionadas en la MECOVI-2002 y el marco muestral, se utilizó a la variable: total deviviendas por UPM, mencionar que para el área rural dispersa lo que se hizo es ajustarla variable total de viviendas por UPM, con los datos provenientes de los listados deviviendas en los segmentos seleccionados.
La �gura 4.1, muestra el diagrama de cajas pareado, para ambos momentos deinterés, realizando la diferenciación entre el área amanzanada y el área dispersa; seconstata que no existiría un quiebre alarmante, pero para cerciorar esa situación esnecesario realizar un test estadístico, para ello se emplea el test de Wilcoxon que esuna prueba no paramétrica1 que compara dos grupos pareados. Se calcula la diferenciaentre cada grupo de pares y se analiza las diferencias, la hipótesis nula de este testcontrasta el valor concerniente a la mediana de la distribución de las diferencias, esdecir H0 : MD = M0, contra la hipótesis alterna Ha : MD 6= M0, la �gura 4.2, muestrael histograma de la diferencia de la variable total de viviendas por UPM para el marcomuestral y la MECOVI-2002.
La �gura 4.2, muestra una concentración en el valor de cero, sin embargo, notar elancho de las colas. A continuación se presenta el test de Wilcoxon.
1Gibbons y Chakrabort, 1992

CAPÍTULO 4. HACIA UN SISTEMA INTEGRADODE ENCUESTAS A HOGARES67
Figura 4.1: Diagrama de caja de datos pareados, para la variable Total de viviendaspor UPM, para la muestra en la MECOVI-2002 y el Marco Muestral del CNPV-2001,diferenciado por área.
Fuente: Elaboración propia con información del INE
La hipótesis nula es: H0 : MD = 0, con la hipótesis alterna Ha : MD 6= 0.
Para implementar la prueba de Wilcoxon, se obtiene las diferencias para los n pa-res de observaciones. Entonces, se ordena sin importar el signo y de acuerdo con esteorden se les asigna un rango, es decir la diferencia más pequeña recibe un rango uno ya la diferencia más grande se le asigna un rango igual a n. Entonces, el signo de cadadiferencia se une al rango de esta. Se asigna el promedio de los rangos en los empatesentre las diferencias, pero si una diferencia es cero, se omite el par y se ajusta n.
La estadística de prueba de Wilcoxon es la suma de los rangos positivos y se denotapor T+. Nótese que T+ contiene información con respecto a la magnitud relativa de lasdiferencias.
Se cuenta con una aproximación normal a la distribución de T+, para n > 10, donde:
E (T+) =n(n+ 1)
4(4.1)
V (T+) =n(n+ 1)(2n+ 1)
24(4.2)
En otras palabras:

CAPÍTULO 4. HACIA UN SISTEMA INTEGRADODE ENCUESTAS A HOGARES68
Figura 4.2: Histograma de la diferencia: MECOVI-2002-CNPV-2001
Fuente: Elaboración propia con información del INE
Z =T+ − E (T+)√
V (T+)(4.3)
Es aproximadamente N(0, 1) para valores grandes de n.
El valor del estadístico de prueba es:
T+ = 113599
.
con n = 630, E (T+) = 99382,5, V (T+) = 20878908,750, Z = 3,1113.
Teniendo un p − valor = 0,001863 , es así que se rechaza la hipótesis nula, y porlo tanto se concluye que existió un cambio en la variable Total de viviendas por UPM,del marco muestral del CNPV-2001 hacia la MECOVI-2002. Esto revela el dinamismoexistente y pone en evidencia la necesidad de actualizar el marco muestral.
La actualización debe buscar en lo posible actualizar las áreas geográ�cas y todala información de estas áreas, como insumo para los distintos diseños muestrales a lolargo del tiempo.

CAPÍTULO 4. HACIA UN SISTEMA INTEGRADODE ENCUESTAS A HOGARES69
4.2. DOMINIOS DE ESTUDIO YNIVELES DE DES-AGREGACIÓN
Los usuarios de una encuesta, siempre desean información lo más desagregada posi-ble, esto muchas veces no es posible, debido a las limitantes del tamaño de muestra, sinembargo, bajo la visión de un sistema integrado de hogares, donde el diseño se retroali-menta cada año y mejoran los distintos componentes, se puede lograr paulatinamenteen el tiempo una desagregación mayor sin la necesidad de aumentar la muestra, ponien-do mucha atención en las variables y el efecto que genera sobre ellas la estrati�cacióny la asignación de la muestra.
Los dominios de estudio siempre estarán presentes para marcar diferencias de inte-rés, tal es el caso del área urbano-rural. Para garantizar la representatividad de cadadominio de estudio se debe trabajar en el cálculo del tamaño de la muestra, porquede otra forma no se garantiza la correcta representatividad de cada dominio. Bajo esaconsideración, se hace importante visualizar los posibles dominios de estudio que mere-cen atención en las posteriores encuestas a hogares, esto debido a la coyuntura actualy al nuevo Estado Plurinacional, recordando que hasta ahora los dominios de estudiode las encuestas de condiciones de vida no alcanzaron una signi�cante desagregación,la ENDSA es tal vez la encuesta que lleva consigo el mayor grado de desagregación,llegando a tener 18 dominios de estudio.
Los dominios de estudio deben responder necesariamente a la estructura territorialdel país dado que el artículo 269, apartado I, de la Constitución Política del Estadoexpresa:
I. Bolivia se organiza territorialmente en departamentos, provincias, municipios y te-rritorios indígena originario campesinos.
4.2.1. Dominios departamentales y provinciales
El Estado Plurinacional de Bolivia reconoce a los departamentos como autónomos,teniendo 9 departamentos, a razón de ello y en base a las nuevas políticas que se debeninstaurar a nivel departamental, es sumamente necesario contar con información repre-sentativa a nivel departamental, por ello las futuras encuestas necesariamente debenconsiderar como dominios de estudio a los departamentos del país, esto, como estruc-tura mínima de dominio.
La característica de provincia no tiene un denominativo tan trascendental a nivelnacional como lo tiene el departamento, la constitución no ejerce una política relacio-nada al nivel provincial, por ello sería innecesario pensar que las provincias puedan serdominios de estudio, sin embargo, pueden responder a políticas propias dentro de cada

CAPÍTULO 4. HACIA UN SISTEMA INTEGRADODE ENCUESTAS A HOGARES70
departamento.
Si bien es cierto que los departamentos están en la capacidad de generar informacióna nivel local, el INE debe ser la institución gestora de la información a nivel nacional,es así que la descentralización de la institución debe de ser de tipo administrativa perono técnica, el diseño muestral de las encuestas debe seguir un orden símil en cadauno de los departamentos con la �nalidad de tener un verdadero sistema integrado deencuestas a hogares que permita el contraste entre los departamentos.
4.2.2. Dominios municipales
A partir de la estructura nacional, los municipios ganan un interés particular; enel CNPV-1992 se contaban con 317 municipios; en el CNPV-2001 se tenían 323 mu-nicipios, en el año 2010 se tenía 337 municipios pero muchos de ellos con problemasde límites, la Constitución Política del Estado establece que los municipios son autó-nomos, en ese sentido es necesario también contar con información a nivel municipal,pensar en una encuesta que logre un grado de desagregación municipal es relativamenteimposible, por la magnitud en costos que representa, la posibilidad para un programanacional de encuestas integradas de hogares será obtener información representativade los municipios con mayor población en cada departamento, dejando el análisis ybúsqueda de información representativa a las prefecturas de cada departamento.
4.2.3. Dominio Indígena originaria campesina
La Constitución Política del Estado reconoce como estructura territorial al puebloindígena originaria campesina, y el próximo censo será el que revele el número totalde pueblos indígenas y el territorio que ocupan, a partir de ello el marco muestraldebe de�nir variables de identi�cación de estos pueblos, con la �nalidad, de incluir enlas futuras encuestas a hogares a estos pueblos como dominios de estudio, ya que adiferencia de los municipios, esto pueblos constituyen la base cultural y ancestral delEstado Plurinacional de Bolivia, en este entendido, el estado está plenamente interesadoen contar con información de este sector, en especial información cultural.
4.3. ESTRATIFICACIÓN
Es común que en la mayoría de las encuestas de hogares que se llevan a cabo enlos países de la región se combinen las técnicas de estrati�cación y conglomeración,como condición necesaria e indispensable para garantizar un diseño muestral óptimo,sin embargo, cabe precisar que la estrati�cación se realiza con un objetivo especí�co,que está inducido por los �nes de la encuesta, y guarda estrecha relación con las varia-bles de interés. En otras palabras, es muy difícil que exista una estrati�cación óptimaque satisfaga, con la misma precisión estadística, las necesidades de todos los temasincorporados en una encuesta, por ende, a los distintos usuarios de la información.

CAPÍTULO 4. HACIA UN SISTEMA INTEGRADODE ENCUESTAS A HOGARES71
Para la conformación de los estratos, se puede ir por diferentes caminos, en el casounivariado se pueden emplear los algoritmos propuestos por Dalenius y Hodges, 1959 yen el caso multivariante utilizar los métodos como el análisis discriminante Hand, 1981o el método de las K-medias MacQueen, 1967.
A continuación se presentan las consideraciones que se deben tener, respecto a laestrati�cación, en las encuestas a hogares:
La estrati�cación en las encuestas a hogares, se la debe realizar en la primeraetapa, puesto que esta etapa genera el mayor aporte al error muestral. Y laestrati�cación ayudará a reducir este error.
De�nir variables a nivel de los conglomerados de primera etapa, que sirvan paracategorizar a estas dentro de algún estrato.
La estructura de los estratos responderá directamente a un conjunto de variablesque representan la naturaleza de la investigación.
Un requisito indispensable, es que una unidad geográ�ca de muestreo sólo po-drá pertenecer a un estrato de los de�nidos en la estrati�cación, esto implicaindependencia entre estratos que es una característica necesaria.
Se deben realizar controles estadísticos, para medir la pertinencia del empleo delos estratos, medir su utilidad, con el �n de validar a los estratos para su uso enfuturas encuestas, una alternativa para estos controles es el análisis de la varianza(ANOVA).
En la tabla 4.1, se muestra las posibles variables para una estrati�cación, en algúnárea de interés en las diferentes temáticas medidas en las encuestas a hogares.
4.3.1. Estrati�cación geográ�ca
La estrati�cación geográ�ca se re�ere a buscar aglomeraciones de las unidades mues-trales en correspondencia a la densidad poblacional del país y su estructura territorial,este estrato se lo debe de�nir en base a las características geográ�cas de la ubicaciónde los conglomerados de primera etapa.
En los años anteriores se le conocía a este estrato como el estrato geográ�co2. Larecomendación es de mantener los 5 niveles dentro del estrato geográ�co, a razón deque se logra una marginación clara. Lo importante será considerar los limites de cadanivel, el primer nivel es inamovible, puesto que dentro de él se encuentran los muni-cipios capitales de departamento incluido El Alto, para el resto de los niveles se debe
2ver apartado 3.4

CAPÍTULO 4. HACIA UN SISTEMA INTEGRADODE ENCUESTAS A HOGARES72
Tabla 4.1: Variables a considerar para la estrati�caciónÁREA DE INTERÉS POSIBLES VARIABLES DE ESTRA-
TIFICACIÓNEducación Tasa de alfabetismo, tasa de asisten-
cia, años promedio de estudio, insatis-facción en educación.
Salud Tasas de mortalidad, prevalencia dedesnutrición, insatisfacción en salud.
Pobreza NBI, área Urbano-Rural.Vivienda y servicios Básicos Insatisfacción en servicios, tenencia de
la vivienda, servicios básicos.Empleo NBI, Grupos ocupacionales.Agropecuarios Pisos ecológicos.Fuente: Elaboración propia
considerar rede�nir los limites de los niveles con información que provenga del nuevocenso; también tener presente el comportamiento de la aglomeración de las viviendasen cada nivel del estrato geográ�co, el nivel quinto invariablemente debe corresponderal área dispersa, por ende los cuatro primeros niveles podrán ser considerados comoáreas amanzanadas.
4.3.2. Estrati�cación por nivel de elegibilidad
El nivel de elegibilidad está relacionado al grado de di�cultad de acceso a los con-glomerados de primera etapa, si se logra establecer un indicador que permita medirel grado de acceso a ciertas zonas censales podrá construirse este indicador dentro delmarco muestral y permitirá un mejor manejo de la logística y se podrá excluir o tenermínima muestra en el estrato de mayor di�cultad, la recomendación tiene el objeto dereducir a cero el número de reemplazos de las unidades muestrales, mencionar que losdocumentos metodológicos no muestran el criterio de reemplazo de UPM, sin embargo,si existieron reemplazo u omisión de UPM en las distintas encuestas a hogares.
4.3.3. Estrati�cación indígena originaria campesina
Se menciono anteriormente que la característica de los pueblos indígenas originariacampesina deben ser dominios de estudio, recordar el apartado que realiza la diferenciade un dominio y un estrato, la característica de pueblo indígena puede considerarsecomo un estrato para ciertas variables, puesto que dicho estrato marcaría diferenciasculturales.

CAPÍTULO 4. HACIA UN SISTEMA INTEGRADODE ENCUESTAS A HOGARES73
4.3.4. Asignación de la muestra
La estrati�cación responde a la naturaleza del estudio, pero es importante concebirla idea de una asignación de muestra en los estratos, acorde a la información con quese dispone, en el pasado se ha empleado con recurrencia la asignación potencial, sesugiere el empleo de una asignación optima de Neyman, a razón de la existencia deencuestas a hogares periódicas. Es necesario establecer una línea de acción en cuanto ala asignación de la muestra, es recomendable iniciar el primer periodo de la encuesta conuna a�jación proporcional dentro los estratos de cada dominio, para poder emplear enlos periodos posteriores de la encuesta una a�jación optima de Neyman o una a�jaciónde tipo potencial como compromiso a la a�jación optima3, con el empleo de las variablesmás trascendentales de la investigación.
4.4. CONGLOMERACIÓN YDEFINICIÓN DE LASUPM
Es importante señalar que a diferencia de la etapa de estrati�cación que tiene un�n especí�co para cada encuesta, los trabajos que se realizan para la formación deconglomerados son de bene�cio común y se pueden compartir entre las diferentes en-cuestas de un programa periódico o permanente, esto, en el contexto de un SistemaIntegrado de Encuestas a Hogares (SIEH). Esto signi�ca que la de�nición y formaciónde los conglomerados, la sistematización de la información de base, la elaboración delmaterial cartográ�co y su actualización, son insumos que se pueden aprovechar paradesarrollar varias rondas de una misma encuesta o para realizar investigaciones inde-pendientes sobre distintos temas, utilizando mecanismos de estrati�cación apropiadosque mantengan una correlación signi�cativa con la variable de diseño. Así, el costo queimplica la administración de los conglomerados, con objeto de mantenerlos actualiza-dos, se amortiza entre las diferentes rondas o encuestas, generando economías de escalaque permiten la puesta en marcha de un programa integrado de encuestas de hogaresa costos razonables, que informe de manera periódica sobre una amplia gama de temasde interés4.
El CNPV invariablemente siempre proporcionará divisiones censales que respondendirectamente a su propia plani�cación, la unidad censal de menor escala posterior a lavivienda, es el segmento censal, que responde a la carga de trabajo de un empadrona-dor en el momento del censo, normalmente esta cartogra�ada y digitalizada, la unidadposterior a esta, es el sector censal, que no es más que un aglomerado de segmentoscensales. Las unidades muestrales de primera etapa deben tener en consideración lasdivisiones censales, debido a que estas se encuentran cartogra�adas y delimitadas.
Otro aspecto a considerar, es la evidente diferencia de conglomeración de viviendas,
3Särndal y cols., 19924ONU, 1984

CAPÍTULO 4. HACIA UN SISTEMA INTEGRADODE ENCUESTAS A HOGARES74
en el área amanzanada y el área dispersa, un segmento censal del área amanzanadaes distinto de un segmento censal del área dispersa, estas diferencias, son de tamañofísico y respecto al número de viviendas en su interior.
Conceptualmente, para una ganancia signi�cativa de precisión en un muestreo queemplea conglomerados, las variables de interés de las unidades elementales dentro delconglomerado, deben comportarse de manera heterogénea, y homogénea entre los con-glomerados5. La tabla 3.12, mostró el comportamiento del coe�ciente de homogeneidadde los conglomerados, revelando un aspecto interesante, el coe�ciente revela un mejorresultado en las UPM previas al CNPV-2001, esta diferencia puede estar afecta pordos aspectos importantes; el primero, el tipo de UPM empleado; el segundo, el tamañode muestra asignado dentro de cada UPM, sin embargo, percibir que la inclusión deuna tercera etapa en el área dispersa no conllevo a una mejora signi�cativa.
Se recomienda instaurar en las futuras encuestas a hogares, al sector censal y alsegmento censal como conglomerados de primera etapa (UPM) para el área amanza-nada y el área dispersa respectivamente, con esto se logra un máximo de dos etapas enambas áreas.
En cuanto al tamaño de estas UPM, la experiencia propia del país y de los paí-ses latinoamericanos, ha demostrado, que adoptar al área de enumeración censal comoconglomerado en las encuestas a hogares resulta bene�cioso, ya que se logra una dis-minución en costos y un mejor manejo administrativo6.
Los cuidados que se deben tener, son: lograr que los tamaños de cada sector censaldentro el área amanzanada sean lo más parecido posible, lo propio con los segmentoscensales del área dispersa. Prever el comportamiento de los sectores censales periurba-nos en el caso del área amanzanada.
4.4.1. Áreas cartogra�adas
La cartografía de los anteriores censos, proveía de información útil para un mejormanejo del operativo de campo, sin embargo, los inconvenientes para muestreo estu-vieron relacionados con los segmentos censales, que eran segmentos indivisibles en lapropia cartografía, esto complico bastante el desarrollo normal en el manejo de la se-gunda etapa a partir del CNPV-2001.
A partir del nuevo censo y conjuntamente con el mejor desarrollo de las herramien-tas cartográ�cas como la incorporación del GPS que permite la georeferencia, se debeplani�car una mejor actualización cartográ�ca, debiendo lograrse, eliminar por comple-to a los segmentos indivisibles, con el objetivo de contar con conglomerados plenamenteidenti�cados, tanto en la base de datos como en la cartografía.
5Lohr, 20006ONU, 1986

CAPÍTULO 4. HACIA UN SISTEMA INTEGRADODE ENCUESTAS A HOGARES75
4.5. NÚMERO DE ETAPAS
Si la unidad primaria de muestreo corresponde al sector censal en el área amanza-nada y al segmento censal en el área dispersa, el número de etapas será de dos, siendo laprimera etapa, la selección de la UPM y la segunda etapa debe corresponder a la selec-ción de viviendas u hogares, dependiendo la encuesta. En lo posible se debe contar conun número reducido de etapas, ya que el efecto de conglomerado de cada etapa tiendea incrementar el error muestral, sin embargo, podrá introducirse en futuras encuestasde temáticas especializadas, como el uso del tiempo, una tercera etapa que podrá serdirigida a una sub-muestra de los integrantes de una vivienda.
4.6. TAMAÑO DE MUESTRA
El cálculo del tamaño de la muestra, necesariamente debe responder al cuestionarioy a los indicadores más trascendentales de la encuesta, en lo posible se debe dejar a unlado los limitantes del presupuesto, si lo que se busca son datos representativos, masaun en la coyuntura nacional actual, que exige a partir del nuevo estado, el reconoci-miento de los pueblos indígenas originaria campesina.
Debe tenerse en cuenta la de�nición del número de viviendas por UPM, este ta-maño tiene que ser acorde a la variabilidad dentro de la UPM, y estar asociado a ladisminución del efecto de diseño, para este �n se debe evaluar el efecto asociado a laconglomeración y su correlación con el tamaño de muestra dentro de cada UPM.
Si se de�nen dominios de estudio el tamaño de muestra dentro de cada dominio de-be garantizar la representatividad del mismo, y los componentes del cálculo del tamañode la muestra deben estar en correspondencia a las singularidades de cada dominio deestudio.
Para el calculo se debe tener en cuenta todos los componentes involucrados, estosfueron descritos en el apartado 2.12.
4.7. EL ESQUEMA DE SELECCIÓN Y EL EFECTOPPT
La tabla 4.2, contiene información de las 16790 UPM con las que cuenta el mar-co muestral proveniente del CNPV-2001, esta tabla es un historial de selección de lasUPM involucradas en las encuestas dirigidas a hogares realizadas desde el 2002 hastael 2010 por el INE, incluye el grupo de la MECOVI 2002-2005, las EH 2005-2009, laENDSA-2003 (Encuesta Nacional de Demografía y Salud), la ETI-2008 (Encuesta deTrabajo Infantil), la EIHC-2009 (La Encuesta de la Hoja Coca) y la ETE 2009-2010
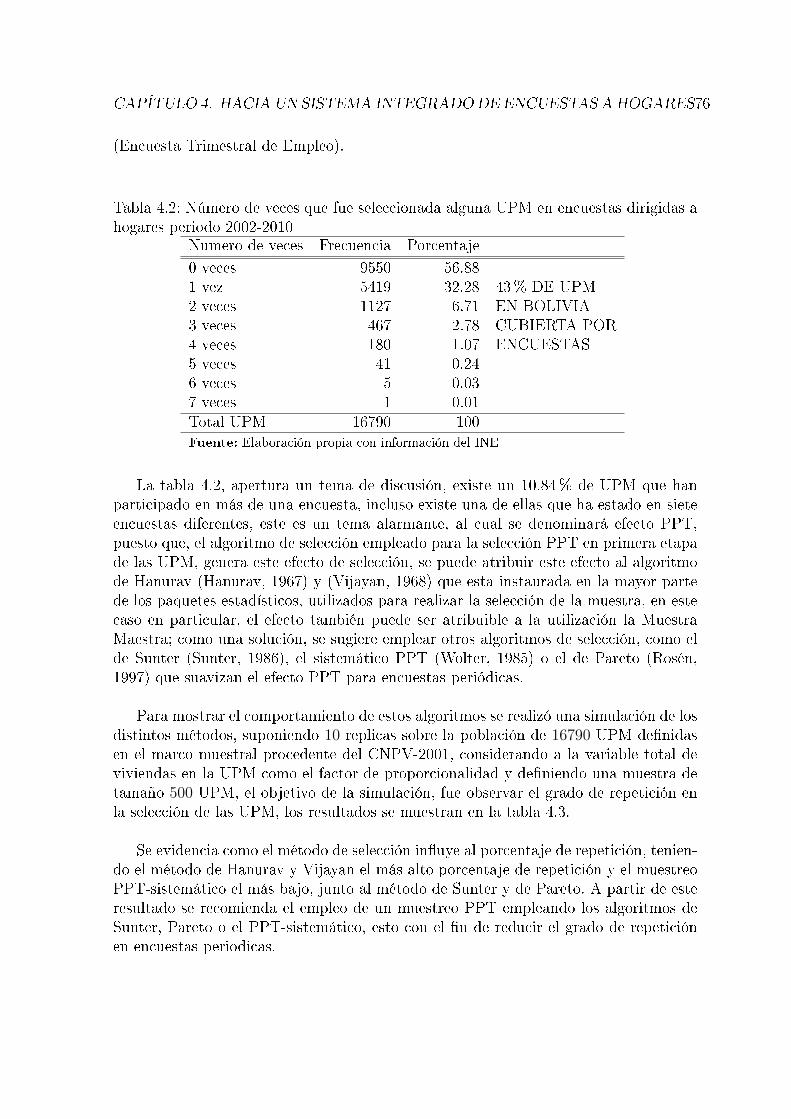
CAPÍTULO 4. HACIA UN SISTEMA INTEGRADODE ENCUESTAS A HOGARES76
(Encuesta Trimestral de Empleo).
Tabla 4.2: Número de veces que fue seleccionada alguna UPM en encuestas dirigidas ahogares periodo 2002-2010
Numero de veces Frecuencia Porcentaje0 veces 9550 56.881 vez 5419 32.28 43% DE UPM2 veces 1127 6.71 EN BOLIVIA3 veces 467 2.78 CUBIERTA POR4 veces 180 1.07 ENCUESTAS5 veces 41 0.246 veces 5 0.037 veces 1 0.01Total UPM 16790 100Fuente: Elaboración propia con información del INE
La tabla 4.2, apertura un tema de discusión, existe un 10.84% de UPM que hanparticipado en más de una encuesta, incluso existe una de ellas que ha estado en sieteencuestas diferentes, este es un tema alarmante, al cual se denominará efecto PPT,puesto que, el algoritmo de selección empleado para la selección PPT en primera etapade las UPM, genera este efecto de selección, se puede atribuir este efecto al algoritmode Hanurav (Hanurav, 1967) y (Vijayan, 1968) que esta instaurada en la mayor partede los paquetes estadísticos, utilizados para realizar la selección de la muestra, en estecaso en particular, el efecto también puede ser atribuible a la utilización la MuestraMaestra; como una solución, se sugiere emplear otros algoritmos de selección, como elde Sunter (Sunter, 1986), el sistemático PPT (Wolter, 1985) o el de Pareto (Rosén,1997) que suavizan el efecto PPT para encuestas periódicas.
Para mostrar el comportamiento de estos algoritmos se realizó una simulación de losdistintos métodos, suponiendo 10 replicas sobre la población de 16790 UPM de�nidasen el marco muestral procedente del CNPV-2001, considerando a la variable total deviviendas en la UPM como el factor de proporcionalidad y de�niendo una muestra detamaño 500 UPM, el objetivo de la simulación, fue observar el grado de repetición enla selección de las UPM, los resultados se muestran en la tabla 4.3.
Se evidencia como el método de selección in�uye al porcentaje de repetición, tenien-do el método de Hanurav y Vijayan el más alto porcentaje de repetición y el muestreoPPT-sistemático el más bajo, junto al método de Sunter y de Pareto. A partir de esteresultado se recomienda el empleo de un muestreo PPT empleando los algoritmos deSunter, Pareto o el PPT-sistemático, esto con el �n de reducir el grado de repeticiónen encuestas periodicas.

CAPÍTULO 4. HACIA UN SISTEMA INTEGRADODE ENCUESTAS A HOGARES77
Tabla 4.3: Comparación de los algoritmos de selección PPT, incluyendo al MuestreoAleatorio Simple y el porcentaje de repetición por método
Número de MÉTODO EMPLEADOselecciones Hanurav, Vijayan Sampfort Sunter Pareto Secuencial (MAS) PPT Sistemático0 12526 12517 12514 12543 12380 124261 3605 3627 3641 3589 3854 38772 591 567 555 573 523 3383 60 77 71 75 32 1494 7 2 9 10 1 05 1 0 0 0 0 0Total 16790 16790 16790 16790 16790 16790Participaciónde UPM
4264 4273 4276 4882 4410 4364
Participaciónmás de unavez
659 646 635 658 556 487
Porcentajede repeti-ción
15,45% 15,12% 14,85% 13,48% 12,61% 11,16%
Fuente: Elaboración propia
4.8. ERRORES MUESTRALES
Como una herramienta de gran utilidad y credibilidad, debe de reportarse al �nalde cada encuesta los errores muestrales de las distintas variables e indicadores que seobtiene a través de la encuesta, intervalos de con�anza, efectos de diseño y coe�cientesde variación, todo esto en un reporte técnico, que ademas incluya los por menores deloperativo de campo, esto, con la �nalidad de emplear esa información en próximasencuestas, servirá, para mejorar el tipo de asignación de la muestra en los estratos,pensar en la efectividad de dicha estrati�cación, observar que tan fuerte es el efectode diseño y crear estrategias para minimizar las incidencias de campo que afectan demanera directa a los errores muestrales.
La manera de evaluar si una encuesta cumplió con las especi�caciones previstas enel diseño, en relación a la con�abilidad de los estimadores, es mediante el cálculo de loserrores de muestreo para las variables de interés. De modo que una vez de�nidas lasexpresiones que se utilizarán para construir los estimadores (apartado 2.14), se debeespeci�car claramente en el diseño de la muestra el procedimiento que se aplicará parael cálculo de los errores de muestreo.
Pese a que en los documentos metodológicos elaborados en las encuestas del INEmuchas veces se indica que para la estimación de la varianza se pueden utilizar algunosde los distintos métodos conocidos (Muestras Replicadas, Replicaciones Repetidas yBalanceadas, Replicaciones Repetidas por el método Jackknife y el método de Seriesde Taylor), en la mayoría de los casos la información contenida en el documento meto-dológico de la encuesta no permite evaluar la factibilidad de aplicar estas alternativas.Por ejemplo, el método de muestreo replicado requiere que se hayan realizado al me-

CAPÍTULO 4. HACIA UN SISTEMA INTEGRADODE ENCUESTAS A HOGARES78
nos dos selecciones (un número par) al interior de cada unidad primaria de muestreo(UPM). Así, si esta información no se consigna en el reporte de la encuesta y la basede datos no permite identi�car las selecciones por UPM, el analista no estará en con-diciones de calcular el error de muestreo.
Más aun si el analista desea calcular los errores de muestreo, sin emplear métodos desimulación, buscando calcular estos errores a partir de la formula teórica y diferenciarlospor etapa, las bases de datos no proveen de las probabilidades de selección simples yconjuntas por etapa, y los documentos metodológicos no mencionar el esquema deprobabilidad empleado (Sunter, Rosen, Pareto, etc.) que permitan reconstruir dichasprobabilidades simples y conjuntas.
4.8.1. Estimación del error muestral a través de la varianzateórica
Bajo la política de estimar el error muestral de la manera más cercana a su expre-sión teórica, es necesario volver a de�nir los que signi�ca un diseño muestral medible.Se dice que un diseño muestral es medible7 si las probabilidades de selección simples yconjuntas son mayores a cero y son conocidas. Los requerimientos de la anterior de�-nición son relativamente sencillas, la mejor forma de conocer las probabilidades, tantosimples como conjuntas es indicando el algoritmo de selección.
La utilidad de conocer estas probabilidades está estrechamente relacionada a quedichas probabilidades son el insumo principal de la varianza teórica del estimador,los métodos de simulación en el ámbito del error muestral fueron desarrollados con la�nalidad de simpli�car los procedimientos involucrados en el cálculo de la varianza, porla gran información que requiere. Por ejemplo, en una muestra de 355 UPM, se necesitala información de una matriz simétrica de probabilidades, de dimensión 355 ∗ 355, esdecir 355 probabilidades simples y 62835 probabilidades conjuntas, esto en un casoextremo, no se debe olvidar que la estrati�cación y los dominios de estudio contribuyena reducir la dimensión de dichas matrices, pero generan más matrices, los softwareestadísticos actuales son bastante potentes y más desarrollados que los que se teníancuando nacieron los métodos de simulación, es por ello que para el caso boliviano esposible y se recomienda la estimación de la varianza teórica en las futuras encuetas ahogares. A continuación se desarrolla dicha varianza teórica a partir del estimador-π.
4.8.2. El estimador-π y sus componentes
El interés se centra en obtener el valor del error muestral de algún estimador, eneste caso se considerará al estimador del total puesto que es uno de los estimadoresmas genéricos.
7Särndal y cols., 1992

CAPÍTULO 4. HACIA UN SISTEMA INTEGRADODE ENCUESTAS A HOGARES79
Inicialmente se debe de�nir al Indicador de pertenencia a la muestra, se parte deque la inclusión de un elemento k en la muestral s, es un evento aleatorio, que se puedeindicar mediante la variable aleatoria Ik, de�nida como:
Ik =
{10
si k ∈ S, con probabilidad πksi k /∈ S, con probabilidad(1− πk)
Notar que Ik = Ik(S), es una función de la variable aleatoria S, se denominara aIk, el indicador de pertenencia a la muestra del elemento k.
De una manera formal
πk = P (k ∈ S) = P (Ik = 1) =∑
k∈Sp(s) (4.4)
La probabilidad que los elementos k y l, pertenezcan a la muestra se denota:
πkl = P (k&l ∈ S) = P (IkIl = 1) =∑
k&l∈Sp(s) (4.5)
Además se tiene que: πkl = πlk para todo k, l.También se aplica, que para el caso k = l, πkk = πk.Sea N el número de unidades elementales en el universo de estudio, tal que cada ele-mento de los N tiene asociada una probabilidad de inclusión.
π1, . . . , πk, . . . , πN
Y para todos los pares posibles de los elementos existen las probabilidades.
π12, π13, . . . , πkl, . . . , πN−1,N
Dado lo anterior, tiene los siguientes resultados:
E(Ik) = πk (4.6)
V (Ik) = πk(1− πk) (4.7)
E(IkIl) = πkl (4.8)
C(IkIl) = πkl − πkπl = ∆kl (4.9)

CAPÍTULO 4. HACIA UN SISTEMA INTEGRADODE ENCUESTAS A HOGARES80
4.8.3. Error muestral en un diseño de dos etapas
Para un muestreo en dos etapas, dentro de algún dominio de estudio o estrato(debido a la independencia), se mostrara el estimador-π del total t, su varianza, y elestimador de su varianza, estos serán construidos de manera jerárquica de acuerdo alas etapas involucradas, la idea de la partición de la población es dada en los incisos del(i) al (ii) más adelante. Para las UPM, y las unidades secundarias de muestro (USM)o unidades ultimas de muestreo se usarán los subíndices i y k respectivamente.
i Los N elementos del universo U , son agrupados dentro UPM independientes,U1, . . . , Ui, . . . , UNI , el grupo que forman las UPM es representado por: UI ={1, . . . , i, . . . , NI}, con NI el tamaño de UI ; así se tiene que N =
∑UINi.
ii Las unidades de segunda etapa son los elementos poblacionales (viviendas parti-culares)
Se iniciara con características generales en un diseño de dos etapas.
Primera etapa: Una muestra sI de UPM es sorteada de UI (sI ⊂ UI).
Segunda etapa: Para toda i ∈ sI una muestra si de elementos es sorteada de Ui(si ⊂ Ui).
Los elementos últimos observados (los sorteados en segunda etapa), son los que com-ponen la muestra s, Así:
s =⋃i∈sI
si (4.10)
Para obtener el estimador-π del total poblacional t y su varianza, se necesita la pro-babilidad de inclusión para cada una de las dos etapas. La siguiente tabla muestra lanotación, y la correspondiente cantidad ∆. Donde, i y j denotan los distintivos de lasUPM y k y l denotan los distintivos de la última etapa (la segunda).
Tabla 4.4: Probabilidades de inclusión de primer y segundo orden y la cantidad δ poretapas.
EtapaProbabilidad de inclusión
∆ cantidadesPrimer orden Segundo Orden
I πIi πIij ∆Iij = πIij − πIiπIjII πk|i πkl|i ∆kl|i = πkl|i − πk|iπl|i
Fuente: Särndal y cols., 1992
Con ∆Iii = πIi (1− πIi) y ∆kk|i = πk|i(1− πk|i
).
Se tiene que πIii = πIi; πkk|i = πk|i.

CAPÍTULO 4. HACIA UN SISTEMA INTEGRADODE ENCUESTAS A HOGARES81
Ahora, ∆ , es de�nido como la división de ∆ con la probabilidad de inclusión de segundoorden, esto es:
∆Iij =∆Iij
πIij; ∆kl|iq =
∆kl|i
πkl|i(4.11)
Finalmente, el total:
ti =∑
Uiyk; t =
∑UIti (4.12)
El estimador-π del t =∑
U yk, se construye por etapas, la manera de proceder esempezar por la última etapa y llegar a la primera etapa. El estimador-π de ti conrespecto a la etapa dos es:
tiπ =∑
si
ykπk|i
(4.13)
Finalmente, el estimador-π de t con respecto a las dos etapas es dado por:
tπ =∑
sI
tiππIi
(4.14)
Se de�ne ahora la varianza de tπ y un estimador insesgado de la misma. Introdu-ciendo a las varianzas dentro de cada etapa de la forma:
Vi =∑∑
Ui∆kl|i
ykπk|i
ylπl|i
(4.15)
Que es la varianza de tiπ dentro del sub-muestreo de Ui.
Un estimador insesgado de este es:
Vi =∑∑
si
^
∆kl|iykπk|i
ylπl|i
(4.16)
De esta forma para un muestreo de dos etapas, para el estimador-π, del total po-blacional, este puede escribirse:
V2et(tπ) = VUPM + VUSM (4.17)
Donde
VUPM =∑∑
UI∆Iij titj (4.18)
Con ti = ti/πIi, que da el aporte en la varianza debida a la primera etapa de muestreo.
VUSM =∑
UI
ViπIi
(4.19)

CAPÍTULO 4. HACIA UN SISTEMA INTEGRADODE ENCUESTAS A HOGARES82
Que da la contribución en la varianza de la segunda etapa de muestreo. DondeVi es dado por la ecuación 4.15, y el segundo componente de la varianza es tiene unestimador insesgado de�nido como:
VUSM =∑
sI
Viπ2Ii
(4.20)
De esta forma se logra el estimador de V2et(tπ), como:
V2et(tπ) =∑∑
sI∆Iij
tiππIi
tjππIj
+∑
sI
Viπ2Ii
(4.21)
A partir de la ecuación 4.21 es fácil ver que es necesario conocer las probabilidadessimples y conjuntas para poder estimar la varianza del estimador, también notar quea razón de que Vi corresponde a la segunda etapa de muestreo y que normalmente seemplea un muestreo sistemático en la esta etapa, podrá lograrse una aproximación aeste valor y todo el componente de la segunda etapa utilizando la varianza estimada deun muestreo aleatorio simple para el cálculo de Vi, sin embargo para estimar el valordel componente de la primera etapa será necesario en las futuras encuestas a hogaresde�nir claramente los insumos necesarios para el cálculo de estimación de la varianzateórica, esto con el �n de lograr una mejor apreciación del error real de muestreo.
4.8.4. Caso de un muestreo sistemático PPT
La ecuación 4.21 muestra una formula especí�ca para el cálculo de la varianza, sinembargo se debe tener presente que el escenario del error muestral bajo un esquema deselección sistemático PPT, en primera etapa, es completamente diferente, puesto queun grupo de probabilidades conjuntas dentro del mismo dominio de grupo o estratoes nulo, esto hace que el cálculo de la estimación de la varianza teórica sea imposible,a partir de ello se presenta a continuación un estimador de la varianza en el caso delmuestreo sistemático PPT, que emplea únicamente a las probabilidades simples de se-lección este estimador fue propuesto por Hajek y Rao, 1962 que logra una estimaciónde la varianza teórica de primera etapa, que sin duda es un mejor aproximamiento quegenera mayor certidumbre respecto el comportamiento del error muestral.
VHR(tπ)
=1
n− 1
∑i∈s
∑j<i∈s
(1− πi − πj +
1
n
∑i∈U
π2i
)(yiπi− yjπj
)2
(4.22)
La recomendación más importante en cuanto al cálculo del error muestral es el debuscar el mayor acercamiento al valor teórico de la estimación de la varianza, puestoque dicho valor permitirá posteriormente pensar en nuevas estrategias.

CAPÍTULO 4. HACIA UN SISTEMA INTEGRADODE ENCUESTAS A HOGARES83
4.9. DISEÑO BASE DE LAS FUTURAS ENCUES-TAS A HOGARES
A partir de todo lo descrito, a continuación se presenta un resumen de lo que de-biera contener como estructura mínima los próximos diseños muestrales.
Marco muestral: Marco múltiple, debidamente depurado con información a nivelde los conglomerados, que contenga información respecto al número de viviendastanto ocupadas como desocupadas, el número de hogares, el grado de elegibilidad;contar también, con variables que permitan la identi�cación de la estructuraterritorial del país, los dominios de estudio y el estrato geográ�co.
Conglomerados: Se debe emplear como unidad primaria de muestreo (conglomeradode primera etapa) al sector censal en el área amanzanada y al segmento censalen el área dispersa; para la segunda etapa, considerar a la vivienda o al hogar.
Número mínimo de etapas: El número mínimo de etapas es de dos, seleccionandoen primera etapa las UPM y en segunda etapa las viviendas o los hogares. Elempleo de más etapas podrá ser aplicable en base a las particularidades de cadainvestigación.
Dominio: A razón de la estructura territorial del país, se debe contar con informaciónrepresentativa de los nueve departamentos de Bolivia, es así que los departa-mentos deben ser dominios de estudios, un estudio a mayor desagregación deberáresponder a las particularidades de cada encuesta y estudios de carácter más refe-ridos a las gobernaciones departamentales. Una encuesta nacional debe establecercomo mínimo, a los departamentos como dominios de estudio.
Estrati�cación: El estrato base para las futuras encuestas debe de ser el estratogeográ�co; este estrato permite la correcta partición dentro de los dominios deestudio y generara información que permita contrastar las simetrías existentesentre los distintos niveles del estrato.
Asignación de la muestra: Se debe iniciar en una primera encuesta con una asigna-ción de tipo proporcional, dentro de los estratos en cada dominio; para posteriora ella, llegar a consolidar una asignación mínima de Neyman con la informaciónrecabada en cada encuesta, esto para las variables claves de cada encuesta.
Errores muestrales: Bajo la política de contar con información replicable, evaluabley medible; en los próximos documentos metodológicos y bases de datos debe dede�nirse claramente los algoritmos de selección y las incidencias registradas encampo, como por ejemplo, los reemplazos.

CAPÍTULO 4. HACIA UN SISTEMA INTEGRADODE ENCUESTAS A HOGARES84
4.10. UNA OPCIÓN LATENTE EN ENCUESTASPERIÓDICAS, LA MUESTRA MAESTRA
La Muestra Maestra (MM), básicamente, extrae una muestra representativa delmarco muestral, en base a un diseño muestral propio, para luego usar esta muestramaestra y extraer sub-muestras para una determinada investigación, el fundamentoteórico de la muestra maestra, recaen en el denominado muestreo doble o bifásico, al-gunas ventajas que se logra con la utilización de la muestra maestra en las encuestas ahogares son:
Es más fácil actualizar la muestra maestra que el propio marco muestral, por ladimensión que presenta.
La inferencia de las muestras provenientes de la MM, se hacen en primera ins-tancia hacia la MM, posteriormente, a partir del diseño de la muestra maestra sein�ere al marco muestral.
Es más económica en cuanto a su aplicabilidad, la construcción de la muestramaestra podrá responder a hechos administrativos de accesibilidad, sin perder larepresentatividad.
Reconocimiento permanente del área muestreada.
Entre las limitaciones y desventajas se puede mencionar:
Esta técnica, solo es buena si lo que se gana en precisión en los estimadores alintroducir la Muestra Maestra, compensa la pérdida en precisión debida a lareducción del marco muestral.
Una limitación de la muestra maestra, es que ésta, no resulta apropiada paraproporcionar datos en encuestas con requisitos especiales (encuestas especializa-das) como las que se realizan en dominios de estudio más pequeños o en subpoblaciones poco comunes, que pueden resultar de interés.
La durabilidad de la muestra maestra alcanza máximo los cinco años de rendi-miento debido al desgaste de la muestra maestra, para aplicarse nuevamente estadebe ser renovada.
Se recomienda que la dimensión de la muestra maestra oscile entre 10% y 20% enreferencia al tamaño del marco muestral.
El empleo de la muestra maestra es útil en encuestas con periodicidad de un año yno así en encuestas con periodicidad mas prolongada.

Capítulo 5
CONCLUSIONES YRECOMENDACIONES FINALES
Una vez concluido el desarrollo del documento, con la metodología marco, el diag-nóstico a las encuestas a hogares y la propuesta respecto el diseño base para lograrun sistema integrado de encuestas, se pasa a dar las conclusiones y recomendaciones�nales respecto al desarrollo del trabajo Dirigido
5.1. CONCLUSIONES
Se mostró las facetas de las distintas encuestas a hogares que realizó el INE enlos últimos años mediante el diagnóstico.
Se dió el debido tratamiento a todos los factores que inciden para la construcciónde un diseño muestral.
Se dió la formalización teórica, a los argumentos presentados para la construcciónde un diseño muestral básico.
Se enfatizó los mayores problemas que se tienen al momento de la construcciónde un diseño muestral, en todas sus etapas.
5.2. RECOMENDACIONES
Por la característica de periodicidad en las encuestas que lleva a cabo el INE,es necesario establecer un conducto de retroalimentación y sinergia entre las en-cuestas, con el �n de mejorar todo el proceso.
Se debe implementar un muestreo que sea capaz de estimar, el tamaño de lapoblación, para tener un contraste respecto a las proyecciones demográ�cas.
85

CAPÍTULO 5. CONCLUSIONES Y RECOMENDACIONES FINALES 86
La elección del tamaño de muestra en última etapa, en las encuestas que realiza elINE, normalmente responde a la experiencia del INE, este tamaño debe respondera aspectos de variabilidad o tamaño de la unidad de la UPM.
Se percibe un gran problema al no actualizar la base de datos con cada encuesta,se debe centralizar los listados de vivienda para tener un mejor control paraplani�car posteriores encuestas.
Los mapas cartográ�cos no se actualizan, esto vuelve difícil la tarea del encargadode hacer el listado, se debe actualizar los mapas cartográ�cos con cada encuesta,para evitar omisiones en próximas encuestas.
Implementar medidas de control de calidad para una encuesta.
Realizar la validación de los estratos al paso del tiempo, para tener la certeza depoder usarlos.
Es necesaria la implementación de indicadores que describan la e�ciencia deldiseño muestral (error muestral total).

Referencias 87
Referencias
Andersson, C. (2010). Informe para la misión de corto plazo ante el Instituto Nacional
de Estadística La Paz, Bolivia (Inf. Téc.). Sweden: Statistitiska centralbyránStatistics Sweden.
Bautista Sierra, L. (1998). Diseños de Muestreo Estadístico. Colombia: UniversidadNacional de Colombia.
Bethlehem, J. (2009). Applied Survey Methods. Statistics Netherlands: John Wileyand Sons.
Cochran, W. G. (1953). Técnicas de Muestreo. Mexico: John Wiley and Sons.Dalenius, T. (1974). Ends and Means of Survey Design. Sweden: University of Stock-
holm.Dalenius, T., y Hodges, J. L. (1959). Minimum variance strati�cation. Journal of the
American statistical , 54 , 88-101.DANE. (1997). Técnicas de Diseño y Desarrollo de Encuestas. Colombia: Dirección Ad-
ministrativo Nacional de Estadística. (Documento de apoyo docente-Muestreo)Deming, W. E. (1950). Some Theory of Sampling. John Wiley and Sons.Foreman, E. K., y Camberra. (1991). Survey Sampling Principles. A.C.T. AUSTRA-
LIA.Gibbons, J. D., y Chakrabort, S. (1992). Nonparametric Statistical Inference De-
partment of Management Science and Statistics. The University of AlabamaTuscaloosa. Alabama.
Gray, G. B. (1975). Components of variance model in multistage strati�ed samples.Surveys Methodology , 1 , 27-43.
Gray, G. B., y Platek, R. (1976). Analysis of design e�ects and variance componentsin multi-stage sample surveys. Surveys Methodology , 2 , 1-30.
Hajek, H. O., y Rao, J. N. K. (1962). Sampling with unequal probabilities ant withoutreplacement. The Annals of Mathematical statistics(33).
Hand, D. J. (1981). Discrimination and Classi�cation. Canada: John Wiley.Hansen, M., y Hurwitz, W. N. (1946). The Problem of Non Response in Sample Survey.
Springer-Verlang.Hansen, M. H., Hurwitz, W. N., y Bershad, M. A. (1961). Measurement errors in
censuses and surveys. Bulletin of the International Statistical Institute.Hanurav, T. V. (1967). Optimum Utilization of Auxiliary Information: πps Sampling
of Two Units from a Stratum. Journal of the Royal Statistical, Society , SeriesB(29).
INE. (2000). Documento metodológico de la Encuesta de Hogares 1999 (Inf. Téc.).Bolivia: Instituto Nacional Estadística Bolivia. (Programa MECOVI)
INE. (2001). Documento metodológico de la Encuesta de Hogares 2000 (Inf. Téc.).Bolivia: Instituto Nacional Estadística Bolivia. (Programa MECOVI)
INE. (2002). Documento metodológico de la Encuesta de Hogares 2001 (Inf. Téc.).Bolivia: Instituto Nacional Estadística Bolivia. (Programa MECOVI)
INE. (2003). Documento metodológico de la Encuesta de Hogares 2002 (Inf. Téc.).Bolivia: Instituto Nacional Estadística Bolivia. (Programa MECOVI)

Referencias 88
INE. (2005). Documento metodológico de la Encuesta Continua de Hogares 2003-2004
(Inf. Téc.). Bolivia: Instituto Nacional Estadística Bolivia. (Programa MECOVI)INE. (2006). Documento metodológico de la Encuesta de Hogares 2005 (Inf. Téc.).
Bolivia: Instituto Nacional Estadística Bolivia.INE. (2007). Documento metodológico de la Encuesta de Hogares 2006 (Inf. Téc.).
Bolivia: Instituto Nacional Estadística Bolivia.INE. (2008). Documento metodológico de la Encuesta de Hogares 2007 (Inf. Téc.).
Bolivia: Instituto Nacional Estadística Bolivia.INE. (2009a). Documento metodológico de la Encuesta de Hogares 2008 (Inf. Téc.).
Bolivia: Instituto Nacional Estadística Bolivia.INE. (2009b). Producción de información estadística sobre el trabajo no remunerado del
hogar y su valoración en las cuentas públicas 2009 (Inf. Téc.). Bolivia: InstitutoNacional Estadística Bolivia.
INE. (2010). Documento metodológico de la Encuesta de Hogares 2009 (Inf. Téc.).Bolivia: Instituto Nacional Estadística Bolivia.
Kish, L. (1955). Survey Sampling. New York: John Wiley and Sons.Lohr, S. L. (2000). Muestreo: Diseño y Análisis.MacQueen, J. B. (1967). Some Methods for classi�cation and Analysis of Multivariate
Observations. California: University of California Press.McLachlan, G. (1992). Discriminant Analysis and Statistical pattern recognition. Wiley
New York.ONU. (1984). Manual sobre encuestas a hogares. Naciones Unidas.ONU. (1986). Sampling frames and sample design for integrated household survey
programmers. Naciones Unidas.ONU. (2009). Survey sampling in household practices. Naciones Unidas.Peter, L. (2009). Methodology of Longitudinal Surveys. John Wiley and Sons.Pérez, C. (2000). Técnicas de Muestreo Estadístico. Alfaomega.Rao, J. N. K. (1975). Unbiased variance estimation for multistage designs. Sankhya,
C (37).Rao, J. N. K. (1979). On deriving mean square errors and their non-negative unbiased
estimator. Journal of the Indian Statistical .Rosén, B. (1997). On sampling with probability proportional to size. J. Statistics ,
Plann Inference.Rydenstam, K. (2010). Statistiska centralbyràn (Inf. Téc.). Sweder: Statistics Sweden.Sanchez Crespo, J. L. (1985). Intensive Basic Course on Sampling. Gobierno Vasco:
Direccion Estadistica.Schea�eer, M. (1987). Elementos de Muestreo. OIT: Iberoamericana.Smith, T. M. F. (1976). The design of survey for planning purposes. The Australian
Journal of Statistics .Särndal, Swensson, y Wretman. (1992). Model Assisted Survey Sampling. Canada:
Springer, Verlang.Sunter, A. B. (1986). Solutions to the Problem of Unequal Probability Sampling
without replacement. International Statistics Review , 54 (1), 33-50.

Referencias 89
Vijayan, K. (1968). An Exact πps Sampling Scheme: Generalization of a Method ofHanurav. Journal of the Royal Statistical Society , Series B .
Wolter, K. M. (1985). Introduction to Variance Estimation. New York: Springer-Verlag.

Apéndice A
Diseño Muestral para la Encuesta deUso de Tiempo de los Hogares enBolivia
Este anexo tiene el objetivo de presentar la formalización del diseño muestral de laEncuesta de Uso de Tiempo de los Hogares de Bolivia (EUTH), esto, como productorequeridos por el INE para el Trabajo Dirigido, sin embargo, es necesario realizar al-gunas aclaraciones pertinentes; a raíz de que el proyecto de esta encuesta comienza enla gestión 2009, ya se habría logrado un avance en diferentes ámbitos de la encuesta, espor ello que el proyecto de�ne situaciones ya establecidas, que serán restricciones parael diseño muestral, además, debido a la infraestructura estadística del INE también secuentan con ciertas limitaciones para la construcción del diseño, estas restricciones ylimitaciones se presentan a continuación:
Restricciones
• Población Objetivo.
• Cobertura espacial, temporal y temática.
• Tamaño de la muestra global, 12000 viviendas.
• Número de viviendas por UPM, 12 viviendas.
• Repartición de la muestra por área, 60% área urbana, 40% área rural.
Limitaciones
• Marco Muestral
• Cartografía
Se inicia dando las características generales de la encuesta, los antecedentes y sus�nes, posterior a ello se de�ne las herramientas necesarias, la población objetivo, elmarco muestral, los tipos de cobertura, las unidades estadísticas de muestreo, luego se
90

APÉNDICE A. DISEÑO MUESTRAL ENCUESTA USO DE TIEMPO 91
presenta la estrategia de muestreo a utilizar en la encuesta, las etapas, la estrati�ca-ción, la conglomeración, el tipo de selección, las probabilidades de selección, los factoresde expansión y su tratamiento respectivo, se analiza el manejo de la no respuesta yla repartición de la muestra en el ámbito temporal, se concluye con los aspectos quedeben medirse y probarse en la prueba piloto y las recomendaciones a futuro sobre eldiseño muestral.
Este diseño muestral es preliminar, puesto que corresponde al momento previo ala realización de la primera prueba piloto, en la cual deberán probarse aspectos rela-cionados a la estrati�cación y el comportamiento de las unidades de muestreo, con la�nalidad de de�nir un diseño muestral �nal.
Mencionar el aporte importante en cuanto a la concepción del mismo diseñoal especialista en muestreo Claes Andersson del Instituto de Estadísticasde Suecia.
A.1. CARACTERÍSTICAS GENERALES
La Encuesta Uso de Tiempo de los Hogares (EUTH) se realizará de forma inde-pendiente, lo que permitirá generar información estadística de línea base, la cual sepretende hacer seguimiento en años posteriores a través de la incorporación de unmódulo especí�co en las encuestas de Hogares (Encuesta de Hogares EH y EncuestaTrimestral de Empleo ETE) que el Instituto Nacional de Estadística realiza.
La encuesta será de carácter continuo y se ejecutará durante doce meses; para la es-trategia de recolección de datos se diseñarán dos tipos de instrumentos y la efectividadde ambos serán probados en los operativos pilotos, además de utilizar estos operativos,para de�nir el diseño muestral �nal, los instrumentos de recolección son:Un cuestionario que recogerá las características generales del hogar, como:
Ubicación del hogar
Miembros componentes del hogar
Parentesco
Sexo
Edad
Características de la Vivienda
Ocupación

APÉNDICE A. DISEÑO MUESTRAL ENCUESTA USO DE TIEMPO 92
Migración
Fuentes de Ingreso
Otro cuestionario cerrado-abierto, denominado �Diario�, en el cual, se describa de formasecuencial y cronológica, las actividades realizadas a lo largo de un periodo especí�cogeneralmente 24 horas de un día laboral (lunes a viernes) y un día de �n de semana(sábado o domingo), este permitirá incluir todas las actividades desarrollas por laspersonas, inclusive las realizadas de forma simultánea.
Este último permitirá además, rescatar información característica o especí�ca delas actividades socio culturales poco conocidas que realizan algunas poblaciones delpaís.
A.1.1. Marco conceptual de la Encuesta de Uso de Tiempo delos Hogares
Los estudios sobre uso del tiempo pueden responder a �nes múltiples, proporcio-nando información sobre cómo la población, según distintas variables, distribuye sutiempo, permitiendo conocer qué proporción de tiempo está destinada a realizar quétipo de actividad y con qué �nalidad.
Este tipo de encuestas son consideradas una fuente de información que no sólo dacuenta de las situaciones de inequidad, sino que también contribuye al conocimientode las condiciones de vida, las actividades y los comportamientos que desarrollan losindividuos y como distribuyen su tiempo, con lo cual es posible visualizar el tipo desociedad que se está construyendo.
Existen entonces importantes dimensiones además del género, a partir de las cualesel análisis sobre la distribución del tiempo y del Trabajo Remunerado y No Remune-rado cobra relevancia dada su variación, por ejemplo, el estrato socioeconómico, grupocultural, la etapa del ciclo de vida del grupo familiar, así como el contexto de residenciadel área urbana o rural.
De este modo, se asume entonces que uno de los instrumentos más adecuados paracontribuir a visibilizar el Trabajo No Remunerado de la mujer al interior del hogar sonlas encuestas sobre uso del tiempo, que permitirán obtener información útil a las Cuen-tas Nacionales para calcular el valor monetario de la Producción de Bienes y ServiciosNo Remunerados en el hogar, sin embargo es importante mencionar, que la EUTHindependientemente se constituye en una operación estadística que proporcionará in-formación especí�ca sobre el Trabajo No Remunerado del Hogar y sus características1.
1INE, 2009b

APÉNDICE A. DISEÑO MUESTRAL ENCUESTA USO DE TIEMPO 93
A.1.2. Antecedentes
El concepto de Trabajo, referida a la actividad económica realizada en el ámbito delhogar en bene�cio del propio hogar existe desde 1934, pero es una década más tardeque se la incluye como literatura especializada entendiendo como trabajo el esfuerzofísico y mental que tiene por resultado la transformación de un bien o la realización deun servicio, sin importar quien lo realice.
En 1957, Becker reconoció el trabajo doméstico como generador de productos, y ala familia como unidad de producción y consumo. Posteriormente en 1965 se incorporóla preocupación por la discriminación y el uso del tiempo.
En 1997, surge la propuesta de las Naciones Unidas en respuesta a los plantea-mientos de Bejín, dando a conocer la Clasi�cación Internacional de Actividades paraEstadísticas sobre Uso de Tiempo (ICATUS), que sustenta el conocimiento hasta en-tonces alcanzado sobre el uso del tiempo y el Trabajo No Remunerado, orientado aproporcionar una estructura consistente en el marco conceptual del Sistema de Cuen-tas Nacionales 1993.
En 2005 se publica la �Guía de elaboración de estadísticas sobre empleo del tiempopara medir el trabajo remunerado� por NNUU, dedicado a promover el desarrollo deconceptos y métodos en el campo de las estadísticas sobre uso del tiempo. Se reconoce,que la producción �tradicionalmente� considerada en el SCN 93, es parte de un conceptomás amplio, el concepto de producción general, en donde queda incluida la produccióndoméstica y de cuidado de personas obtenida en los hogares, sin remuneración.
Por otro lado, la Organización Internacional de Trabajo (OIT), también reconocela pertinencia de un nuevo concepto de trabajo, pues resulta claro que para entenderel mercado laboral y apoyar de manera más efectiva el diseño y evaluación de políticaspúblicas hoy en día es necesario ampliar el concepto de trabajo para dar cabida altrabajo no remunerado de los hogares2.
El Instituto Nacional de Estadística de Bolivia (INE) inicia investigaciones en estecampo aproximadamente desde el 2001; sin embargo, el año 2009 por mandato biminis-terial del 2 de junio de 2009, enmarcado en el artículo 338 de la Constitución Políticadel Estado que señala �El Estado reconoce el valor económico del trabajo del hogarcomo fuente de riqueza y deberá cuanti�carse en las Cuentas Públicas�, se instruye alInstituto Nacional de Estadística (INE), incluir dentro de sus áreas de trabajo corres-pondientes a ésta temática, dando lugar a su visualización con el propósito de generarpolíticas públicas a través de las cuales la población logre condiciones necesarias �paravivir bien�.
Como respuesta inmediata a esta solicitud surge la necesidad de llevar a cabo la
2(INE, 2009b)

APÉNDICE A. DISEÑO MUESTRAL ENCUESTA USO DE TIEMPO 94
Encuesta de Uso del Tiempo de los Hogares.
A.1.3. Objetivos
Los objetivos de la EUTH fueron de�nidos por el INE, con el apoyo de la misiónsueca en el mes de Octubre de 2008, los cuales posteriormente fueron sometidos aconsideración de un grupo conformado por entidades relacionadas al tema, como: elViceministerio de Igualdad de Oportunidades (VIO), la entidad académica de Post Gra-do CIDES y el Fondo de Desarrollo de las Naciones Unidas para la Mujer (UNIFEM),además se desarrollo un taller con la sociedad civil para su socialización y ajustes.
A.1.4. Objetivo General
Determinar la Carga Global de Trabajo, y valorar económicamente el Trabajo noRemunerado de los Hogares, para la construcción de una cuenta satélite, que comple-mente la información contenida en el marco central de las Cuentas Nacionales.
A.1.5. Objetivos especí�cos
a) Cuanti�car la Carga Global de trabajo (horas de Trabajo Remunerado más horasde Trabajo No Remunerado), diferenciando según las siguientes características:
• Género
• Grupo etáreo
• Nivel de educación
• Área de residencia (urbana, rural)
• Departamento
b) Conocer la distribución del trabajo doméstico y de los cuidados a niñas/os ypersonas dependientes, entre los miembros del hogar, según:
• Género
• Grupo etáreo
• Estado civil
• Tipo de hogar
• Nivel de ingresos del hogar
c) Medir la participación de hombres y mujeres en el trabajo voluntario de apoyo aotros hogares, a la sociedad o al desarrollo de la comunidad.
d) Calcular el Valor Agregado del hogar y sus componentes tanto del Trabajo Re-munerado y Trabajo No Remunerado.

APÉNDICE A. DISEÑO MUESTRAL ENCUESTA USO DE TIEMPO 95
e) Calcular la Secuencia de Cuentas del Trabajo No Remunerado del Hogar (Cuentasde Producción, Cuentas de Bienes y Servicios, Cuentas de Gastos e ingresos).
f) Medir la participación e impacto del Trabajo No Remunerado del Hogar en elPIB.
g) Proveer información que permita valorar económicamente el Trabajo No Remu-nerado del Hogar, mediante las Cuentas Nacionales, a través de la elaboraciónuna Cuenta Satélite del trabajo no remunerado
A.2. HERRAMIENTAS DE MUESTREO
A.2.1. Población Objetivo
Se de�ne como el conjunto de personas de siete y más años de edad, residenteshabituales en viviendas particulares del área urbana y rural del territorio nacional.Para �nes de la encuesta se consideraran viviendas particulares a aquellas que sonhabitadas por hasta tres hogares, ya que una vivienda con más de tres hogares es re-conocida como vivienda colectiva.
A.2.2. Tipos de cobertura
Cobertura Temática
La encuesta envuelve una gran variedad de temas, pero el más importante de elloses el referido al análisis del uso del tiempo, esta característica se medirá con el diariode actividades; el cuestionario de características generales medirá los otros ámbitostemáticos.
Cobertura Espacial
La cobertura espacial de la encuesta es el territorio nacional del Estado Plurinacio-nal de Bolivia.
Cobertura Temporal
Las características temáticas de la encuesta serán levantas en todo el territorionacional a lo largo de un año completo, repartido en 52 semanas y un día, cubriendode esa forma los 365 días del año.
A.2.3. Método estadístico
Es aleatorio, de esta forma se garantiza la construcción de las probabilidades deselección de las muestras y es posible la construcción de los factores de expansión, porende, es dable la aplicación de la inferencia estadística.

APÉNDICE A. DISEÑO MUESTRAL ENCUESTA USO DE TIEMPO 96
A.2.4. Unidades estadísticas de muestreo
Se describe a la unidad de observación y la unidad de información, la unidad demuestreo se la de�ne en el apartado A.3.2.
Unidad de observación
Todos los miembros del hogar mayores a siete años, presentes en una viviendaparticular.
Unidad de información
Todos los miembros de los hogares seleccionados, de 7 años y más de edad..
A.2.5. Marco muestral
Se empleará un marco múltiple; el marco de áreas será el proveniente del Censo Na-cional de Población y Vivienda 2001, y el marco de lista corresponderá a los formulariosLV-01 y LV-02, estos formularios son los empleados para el listado de viviendas.
A.3. ESTRATEGIA DE MUESTREO
Ahora se desarrollará la estrategia de muestreo a utilizar en la EUTH, esta, con-templa el uso de un muestreo complejo, puesto que se combinan diferentes técnicas demuestreo, entre ellas se tiene:
Muestreo Aleatorio Simple
Muestreo Estrati�cado
Muestreo Sistemático
Muestreo Proporcional al tamaño
Muestreo por etapas
Muestreo por Conglomerados
Muestreo longitudinal
Estas distintas técnicas son empleadas en distintos puntos del diseño.En síntesis y de manera general, el diseño es probabilístico, por etapas, estrati�cado yconglomerado.

APÉNDICE A. DISEÑO MUESTRAL ENCUESTA USO DE TIEMPO 97
A.3.1. Las etapas de muestreo en la EUTH
Se empleará un muestreo de dos etapas en el área amanzanada, y de tres etapaspara el área dispersa, esto a razón de la marcada diferencia en cuanto a la dimensióngeográ�ca en estas dos áreas.
A.3.2. Conglomeración
Debido a la utilización de un muestreo por etapas, se hace necesario de�nir losconglomerados presentes en las distintas etapas.
Unidades de muestreo
Las unidades de muestreo coinciden con los conglomerados de�nidos en cada etapa,y estas unidades son aglomeraciones de unidades más simples, notar que la unidad ul-tima de muestreo no siempre resulta ser una unidad elemental sino que también puedeser un conglomerado.
A continuación se de�nen estas unidades
Unidad primaria de muestreo (UPM): Denominada en el marco muestral comoUPM, concuerdan con los sectores censales o una agrupación de ellos, existen16790 UPM de�nidas en el marco muestral.
Unidad secundaria de muestreo (Área dispersa): Corresponde al Segmento cen-sal, es la subdivisión de sectores censales, que agrupa aproximadamente hasta 45viviendas en área dispersa. En el caso de los segmentos indivisibles se los consi-derara como uno solo dentro de las UPM.
Unidad ultima de muestreo: Corresponde a la vivienda particular ocupada.
La tabla A.1 muestra las unidades de muestreo de�nidas en la encuesta, diferenciadospor área amanzanada dispersa.
Tabla A.1: Unidades de muestre de la EUTHNÚMERODE ETAPAS
Área UPM USM UTM
Dos etapas Amanzanada UPM Vivienda particularTres etapas Dispersa UPM Segmento censal Vivienda particularFuente: Elaboración propia

APÉNDICE A. DISEÑO MUESTRAL ENCUESTA USO DE TIEMPO 98
A.3.3. Estrati�cación de la EUTH
La estrati�cación se realiza en la primera etapa, sobre las UPM, se considera lacombinación de dos estratos; el estrato geográ�co y el estrato pisos ecológicos, de talmanera que esta combinación genera 15 estratos sobre el marco.
Se cuenta con 16790 UPM totales en el marco muestral, la tabla A.2 muestra lacomposición del marco respecto a la estrati�cación y la cantidad de UPM en cada es-trato.
Tabla A.2: Composición del marco en UPM, con la combinación de los estratos
Estrato Geográ�coESTRATO PISOS ECOLÓGICOSAltiplano Valle Llano Total
Ciudades Capitales más El Alto 4447 2106 2675 9228Resto 10000 y mas 407 780 697 1884De 2000 a 10000 357 254 446 1057De 250 a 2000 665 295 194 1154Menos de 250 1796 1187 484 3467TOTAL 7672 4622 4496 16790Fuente: Elaboración propia con información del marco muestral del INE.
Se debe notar que en el caso del estrato geográ�co sus tres primeras categoríasenvuelven el área urbana y las últimas dos el área rural.
A.3.4. Tamaño de la muestra
Como se menciono al inicio de este apartado, el tamaño de la muestra global estádentro de las restricciones para la construcción del diseño, puesto que ya fue de�nidocon anterioridad y lo que se realizará en este sentido es hacer una réplica del cálculode este tamaño y se presenta en los anexos una alternativa del cálculo de este tamañode muestra.El tamaño de muestra global es de 12000 viviendas; como el tamaño de muestra para laúltima etapa resulta ser una restricción, ya esta prede�nido, su valor es de 12 viviendaspor UPM, entonces, se tiene un tamaño de muestra de primera etapa de 1000 UPMpara distribuir en los 15 estratos.
La tabla A.3, muestra los elementos y la réplica del cálculo del tamaño de la mues-tra global de viviendas, percibir que las unidades del tamaño de muestra, están malenfocadas en la formula, puesto que se decide el número de viviendas en la muestra, yaparece el término �λ� que está en unidades de hogares, que trae consigo una serie deinterrogantes en cuanto a la efectividad de este cálculo.

APÉNDICE A. DISEÑO MUESTRAL ENCUESTA USO DE TIEMPO 99
Tabla A.3: Elementos para el cálculo del tamaño de la muestraELEMENTOS VALOR
Efecto de diseño efectd 4,78Tasa de no respuesta estimada TNR 0,07Proporción de habitantes mayores a 7 años r 0,82Promedio de número de personas por hogar λ 4, 20Valor asociado al 95% de con�anza z1−α
21, 96
Varianza S2 5123,14Margen de error absoluto e 1, 56Tamaño de muestra MAS poblaciones in�nitas n0 8039, 74Tamaño de la muestra n 12000,31
n = n0∗efectd(1−TNR)∗r∗λ
n0 =z21−α2
∗S2
e2
Fuente: Elaboración propia con información de INE, 2009b
Al ser un muestreo por etapas, cada etapa tiene de�nido su propio tamaño demuestra, a continuación se describe estos tamaños con la diferenciación de las áreasamanzanada y dispersa.
Primera etapa: El tamaño de muestra de esta etapa es de 1000 UPM.
Segunda etapa, área amanzanada: Se seleccionan 12 viviendas por UPM.
Segunda etapa, área dispersa: Una UPM está dividida en segmentos censales, in-dependientes entre sí (a excepción de los indivisibles que serán considerados comouno). En promedio en una UPM del área rural dispersa existen 6 segmentos ydentro de cada uno de ellos en promedio existen 36 viviendas.
El problema de determinar el número de segmentos por UPM recae en un hechode logística, si se elige más de un segmento estos podrían estar muy distante eluno del otro y seria un problema de distancia y presupuesto para operativo decampo. El problema estadístico es que si se eligiera sólo un segmento se tendríandos situaciones; la primera, que este sea representativo de los otros; la segunda,que el segmento no sea representativo de los otros, en cualquiera de las dos situa-ciones la varianza de esa etapa no podría obtenerse, y debería recurrirse a otrastécnicas de estimación de la varianza que llevaría a subestimar la varianza o asobre estimarla. Por ello, la elección del número de segmentos se deja al contrasteque se realice en la prueba piloto, donde debe medirse el comportamiento de lossegmentos dentro de las UPM en cuanto a la temática de la encuesta.
Tercera etapa, área rural dispersa: En base a las restricción de 12 viviendas porUPM, lo que resta en esta etapa es distribuir las 12 viviendas en los segmentos

APÉNDICE A. DISEÑO MUESTRAL ENCUESTA USO DE TIEMPO 100
seleccionados, si se elige mas de un segmento, la distribución de las 12 viviendasserá de manera proporcional al número de viviendas de cada segmentos seleccio-nado.
A.3.5. Distribución de las UPM en los estratos, asignación dela muestra
Se cuenta con un tamaño de muestra de 1000 UPM, estas se deben repartir en los15 estratos de�nidos anteriormente, debido a una de las restricciones y a requerimien-tos respecto a la desagregación, la muestra de 1000 UPM se partió y se distribuyo delsiguiente modo.
Tabla A.4: Distribución de la muestra de UPM, por área y con porcentaje de presenciaen el marcoÁREA Número de UPM Porcentaje en la muestra Porcentaje en el marcoUrbana 600 60% 72%Rural 400 40% 28%TOTAL 1000 100% 100%Fuente: Elaboración Propia con información del INE
La repartición de�nida en la tabla A.4 corresponde a un hecho técnico de dar énfasisal área rural sin quitar la importancia al área urbana.
A partir de la condición de los porcentajes por área, se debe considerar como repar-tir la muestra a los 15 diferentes estratos, este procedimiento se conoce como asignaciónde la muestra y existen diferentes métodos, con esto se pretende mantener un equilibrioen la representatividad y aporte de cada estrato.
A continuación se presenta el desarrollo de la asignación empleada
Notación
N = Tamaño de la población
n = Tamaño de la muestra
Nh = Tamaño del h− simo estrato
nh = Tamaño de la muestra del h− simo estrato
L = Número de estratos
Wh = Ponderador del estrato h

APÉNDICE A. DISEÑO MUESTRAL ENCUESTA USO DE TIEMPO 101
Wh =Nh
N(A.1)
A�jación Potencia o de poder
nh = n ∗ Nαh∑
hNαh
;h = 1, . . . , L (A.2)
) α Debe cumplir → 0 ≤ α ≤ 1Esta a�jación es una combinación de la a�jación uniforme y la proporcional, de talmanera que con el valor α = 0 se llega a la a�jación uniforme y con el valor α = 1 ala a�jación proporcional al tamaño, con un α = 0,5 se llega a un equilibrio perfectoentre ambas a�jaciones, el valor de α es movible, de acuerdo al grado de importanciay representatividad que el investigador quiera dar a los estratos. La desventaja es queno recoge alguna información respecto a la variabilidad dentro de los estratos, se eligióα = 1/3, puesto que con este valor se valora un poco más a los estratos pequeños,pero sin despreciar la importancia de los estratos más grandes, la elección de este valorpuede verse como un compromiso con la asignación de Neyman3.
Se presenta la distribución de la muestra con la a�jación de poder a un α = 1/3.
Tabla A.5: Distribución de la muestra de UPM, por estratosESTRATOS Altiplano Valle Llano TotalCiudades capitales más El Alto 110 86 93 289Resto 10000 y más 50 62 59 170De 2000 a 10000 47 42 51 141De 250 a 2000 67 51 45 163Menos de 250 94 82 61 237TOTAL 368 323 309 1000Fuente: Elaboración Propia
La distribución de la muestra considerando viviendas se muestra en la tabla A.7.
A.3.6. Selección de la muestra
De�nida la distribución de la muestra, queda especi�car el tipo de selección a em-plear en cada etapa.
3Särndal y cols., 1992
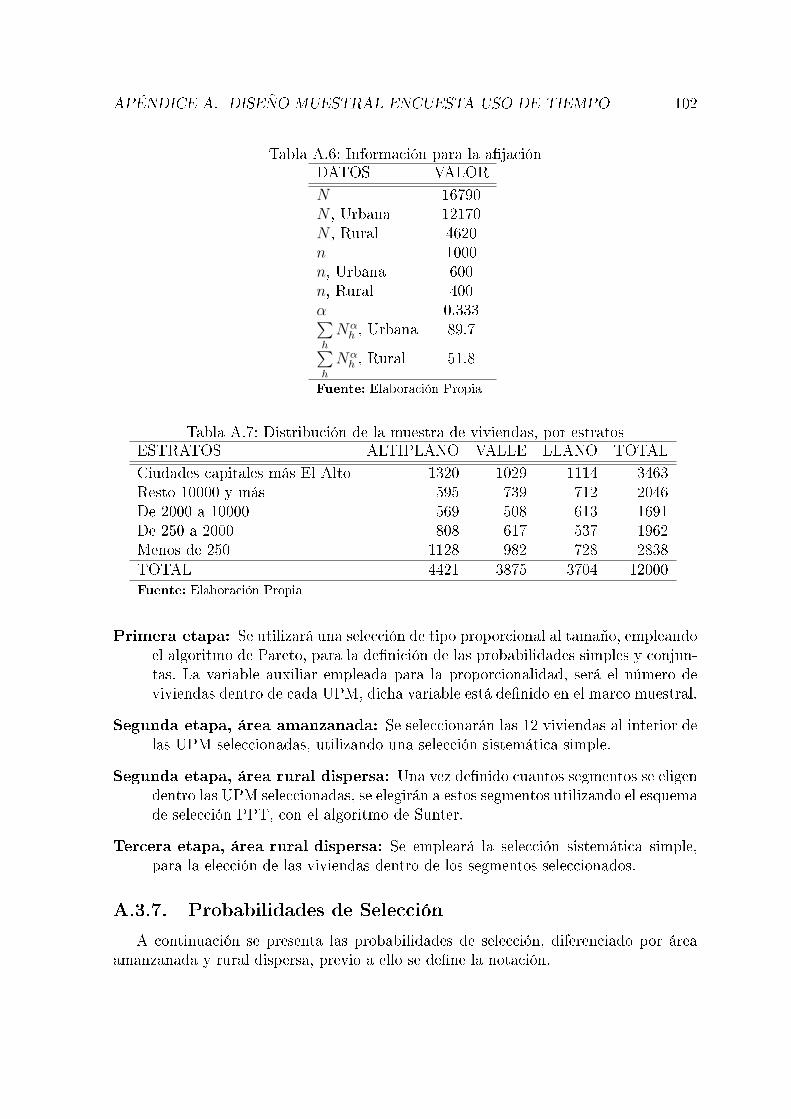
APÉNDICE A. DISEÑO MUESTRAL ENCUESTA USO DE TIEMPO 102
Tabla A.6: Información para la a�jaciónDATOS VALORN 16790N , Urbana 12170N , Rural 4620n 1000n, Urbana 600n, Rural 400α 0.333∑h
Nαh , Urbana 89.7∑
h
Nαh , Rural 51.8
Fuente: Elaboración Propia
Tabla A.7: Distribución de la muestra de viviendas, por estratosESTRATOS ALTIPLANO VALLE LLANO TOTALCiudades capitales más El Alto 1320 1029 1114 3463Resto 10000 y más 595 739 712 2046De 2000 a 10000 569 508 613 1691De 250 a 2000 808 617 537 1962Menos de 250 1128 982 728 2838TOTAL 4421 3875 3704 12000Fuente: Elaboración Propia
Primera etapa: Se utilizará una selección de tipo proporcional al tamaño, empleandoel algoritmo de Pareto, para la de�nición de las probabilidades simples y conjun-tas. La variable auxiliar empleada para la proporcionalidad, será el número deviviendas dentro de cada UPM, dicha variable está de�nido en el marco muestral.
Segunda etapa, área amanzanada: Se seleccionarán las 12 viviendas al interior delas UPM seleccionadas, utilizando una selección sistemática simple.
Segunda etapa, área rural dispersa: Una vez de�nido cuantos segmentos se eligendentro las UPM seleccionadas, se elegirán a estos segmentos utilizando el esquemade selección PPT, con el algoritmo de Sunter.
Tercera etapa, área rural dispersa: Se empleará la selección sistemática simple,para la elección de las viviendas dentro de los segmentos seleccionados.
A.3.7. Probabilidades de Selección
A continuación se presenta las probabilidades de selección, diferenciado por áreaamanzanada y rural dispersa, previo a ello se de�ne la notación.

APÉNDICE A. DISEÑO MUESTRAL ENCUESTA USO DE TIEMPO 103
Área amanzanada
Uih Unidad i− esima en primera etapa, en el h− esimo estrato.Uijh Unidad i − esima en primera etapa, j − esima en segunda etapa, en el
h− esimo estrato.nh Tamaño de muestra dentro el estrato h en primera etapa.
Mih Número de viviendas en la i− esima UPM del estrato h.
Mh Número de viviendas en el estrato h.
mih Tamaño de muestra dentro de la i− esima UPM, en el estrato h, que parael área amanzanada su valor es de 12 viviendas.
Primera etapa:
P (Uih) = nh ∗Mih
Mh
(A.3)
Primera y segunda etapa:
P (Uijh) = nh ∗Mih
Mh
∗ mih
Mih
(A.4)
Área rural dispersa
Uih Unidad i− esima en primera etapa, en el h− esimo estrato.Uijh Unidad i−esima en primera etapa, j-ésima en segunda etapa, en el h−esimo
estrato Unidad i − esima en primera etapa, j − esima en segunda etapa,k − esima en la tercera etapa, en el h− esimo estrato.
nh Tamaño de muestra dentro el estrato h en primera etapa.
Mih Número de viviendas en la i− esima UPM del estrato h.
Mh Número de viviendas en el estrato h.
Sih Tamaño de muestra dentro la i−esima UPM del estrato h, en segunda etapa.
Mijh Número de viviendas en la i− esima UPM, en el j− esimo segmento en elestrato h.
mijh Tamaño de muestra dentro de la i− esima UPM, el j− esimo segmento enel estrato h.
Primera etapa:
P (Uih) = nh ∗Mih
Mh
(A.5)

APÉNDICE A. DISEÑO MUESTRAL ENCUESTA USO DE TIEMPO 104
Primera y segunda etapa:
P (Uijh) = nh ∗Mih
Mh
∗ Sih ∗Mijh
Mih
(A.6)
Primera, segunda y tercera etapa:
P (Uijkh) = nh ∗Mih
Mh
∗ Sih ∗Mijh
Mih
∗ mijh
Mijh
(A.7)
A.3.8. Factores de Expansión
El factor de expansión teórico, básicamente es la inversa de la probabilidad de se-lección, se presenta a continuación con la diferenciación por área.
Área Amanzanada
F = [P (Uijh)]−1 =
(nh ∗
Mih
Mh
∗ mih
Mih
)−1
(A.8)
Área rural dispersa
F = [P (Uijkh)]−1 =
(nh ∗
Mih
Mh
∗ Sih ∗Mijh
Mih
∗ mijh
Mijh
)−1
(A.9)
Una interpretación bastante simple de este factor es que una vivienda seleccionada dela muestra, representa a F viviendas de la población.
Ajustes a los factores de expansión
Notar que el factor de expansión teórico no siempre re�eja toda la magnitud de lapoblación, se ve in�uenciado por diferentes aspectos, la tasa de no respuesta, la desac-tualización del marco muestral y el crecimiento de la población.
1. Considerando la actualización en el listado.
Área amanzanada
F = [P (Uijh)]−1 =
(nh ∗
Mih
Mh
∗ mih
Mih
)−1
∗ M′
ih
Mih
(A.10)
ConM′
ih = Número de viviendas listadas en la UPM i−esima del estrato h.

APÉNDICE A. DISEÑO MUESTRAL ENCUESTA USO DE TIEMPO 105
Área dispersa
F = [P (Uijkh)]−1 =
(nh ∗
Mih
Mh
∗ Sih ∗Mijh
Mih
∗ mijh
Mijh
)−1
∗M′
ijh
Mijh
(A.11)
Con M′
ijh = Número de viviendas listadas del j − esimo segmento en laUPM i− esima del estrato h.
2. Considerando la tasa de no respuesta.
Área amanzanada
F = [P (Uijh)]−1 =
(nh ∗
Mih
Mh
∗ mih
Mih
)−1
∗M′ij
Mih
∗ mih
mrih
(A.12)
Con(mrihmih
)= Tasa efectiva de respuesta = TER.
mrih= Número de viviendas efectivas de las 12 viviendas programadas.
Área rural dispersa
F = [P (Uijkh)]−1 =
(nh ∗
Mih
Mh
∗ Sih ∗Mijh
Mih
∗ mijh
Mijh
)−1
∗M′
ijh
Mijh
∗ mijh
mrijh
(A.13)
Con(mrijhmijh
)= Tasa efectiva de respuesta = TER.
mrijh= Número de viviendas efectivas de las programadas.
3. Considerando las proyecciones de la población.Para realizar este ajuste, se utilizara información procedente de las proyeccionesdemográ�cas por departamento, dicha información, la genera el Instituto Nacio-nal de Estadística, en base a los resultados de los Censos Nacionales de Poblacióny Vivienda.
Área amanzanada
F = [P (Uijhd)]−1 =
(nh ∗
Mih
Mh
∗ mih
Mih
)−1
∗M′ij
Mih
∗ mih
mrih
∗ Pproyd
P encd
(A.14)
Área rural dispersa
F = [P (Uijkhd)]−1 =
(nh ∗
Mih
Mh
∗ Sih ∗Mijh
Mih
∗ mijh
Mijh
)−1
∗M′
ijh
Mijh
∗mijh
mrijh
∗Pproyd
P encd
(A.15)Donde:
P proyd = Población proyectada para el año de la encuesta en el departamento.P encd = Población estimada con el factor F construido hasta la corrección por
no respuesta para el departamento.

APÉNDICE A. DISEÑO MUESTRAL ENCUESTA USO DE TIEMPO 106
Finalmente el factor de expansión queda de la forma:
Área amanzanada
F = [P (Uijhd)]−1 =
Mh
nh ∗Mih
∗M′ij
mrih
∗ Pproyd
P encd
(A.16)
Área rural dispersa
F = [P (Uijkhd)]−1 =
Mh
nh ∗ Sih∗
M′
ijh
Mijh ∗mrijh
∗ Pproyd
P encd
(A.17)
A.3.9. Estimadores
Para la construcción de los estimadores se consideraran los estimadores clásicos li-neales, como el total, la media, la proporción y el total clase.
Los estimadores que enfocaran el aspecto temporal tendrán un matiz diferente, es-tos se los dará respecto a la variable tiempo a medir y el espacio temporal considerado.
Como un ejemplo, se sumaran todas las horas de alguna actividad dentro del Clasi-�cador de Usos de tiempo de Bolivia (CAUTBOL) en todo el transcurso de un periodoy se ponderará respecto a los individuos que dieron respuesta a dicha variable.
A.3.10. Distribución de la muestra en el espacio temporal
Lo que se pretende medir y analizar en la EUTH es el tiempo empleado por losmiembros de los hogares a lo largo de un año en todo el territorio nacional, por ello sedebe contar con representatividad espacial y temporal; en lo espacial, todo el territo-rio nacional debe estar representado correctamente, y en lo temporal la muestra debeestar distribuida de manera homogénea a lo largo del tiempo, esto con el �n de tenercerteza de la representatividad y se pueda realizar inferencia en periodos de tiemporepresentativos.
Se considera 52 semanas de referencia que componen al año de referencia, y por lospropósitos de la encuesta, se les otorgará un diario de actividades a las unidades deobservación, preguntándoles a cerca de sus actividades en un día laboral y en un díade �n de semana, con las siguientes combinaciones.
El tamaño de muestra es de 1000 UPM, estas están distribuidas por estrato y ahorase pretende distribuir en 52 semanas y 10 distintas combinaciones de días laborales ydías de �nes de semana. Para esta situación se presentan dos diferentes maneras derepartir la muestra a lo largo del periodo de referencia anual.

APÉNDICE A. DISEÑO MUESTRAL ENCUESTA USO DE TIEMPO 107
Tabla A.8: Combinación de díasCOMBINACIÓN DE DÍASLunes SábadoLunes DomingoMartes SábadoMartes DomingoMiércoles SábadoMiércoles DomingoJueves SábadoJueves DomingoViernes SábadoViernes DomingoFuente: Elaboración Propia
Dos diferentes enfoques :
1. Asignar 52 ∗ 10 = 520 combinaciones de semanas y días de semana*�nes desemana a 1000 UPM.Todas las viviendas en una UPM tienen la misma combinación de días desemana*�nes de semana
2. Asignar 52 semanas a 1000 UPMEn cada UPM las 10 combinaciones de días de semana*�nes de semana estándistribuidas en 12 viviendas.
Descripción del procedimiento de ambos enfoques :
1. Primer enfoque
a) Ordenar las 1000 UPM por estrato, dar a cada UPM un número 1, . . . , 520sistemáticamente. La UPM número 521 obtendrá el número 1, la 522 elnúmero 2, etc.
b) Crear 520 �celdas�, donde cada celda está identi�cada por semana y lacombinación de días de semana y �nes de semana.
c) Ordenar las celdas de manera aleatoria mediante la asignación de unnúmero aleatorio a cada celda y ordenarlas por ese número.
d) Asignar el número 1 a la primera celda sorteada aleatoriamente, número2 a la segunda, etc.
e) Emparejar las celdas sorteadas aleatoriamente con las UPM mediantenúmero de celda.
f ) Todas las viviendas en una UPM es asignada con una combinación dedías de semana*�nes de semana que identi�can esa celda.

APÉNDICE A. DISEÑO MUESTRAL ENCUESTA USO DE TIEMPO 108
2. Segundo Enfoque
a) Ordenar las 12000 viviendas por estrato y UPM, asignar un número acada UPM de 1 a 52 sistemáticamente. La UPM 53 recibirá el número1, la 54 el número 2, etc.
b) Crear 52 �celdas�, donde cada celda es identi�cada por semana.c) Ordenar las celdas de manera aleatoria mediante la asignación de un
número aleatorio a cada una y ordenarlas por ese número.d) Asignar el número 1 a la primera celda asignada aleatoriamente, número
2 a la segunda, etc.e) Emparejar la celda seleccionada aleatoriamente con las UPM mediante
número de celda.f ) Cada UPM es asignada una semana que identi�que la celda asignada.g) La asignación de la combinación de días de semana*�nes de semana se
hace de en la misma manera principal.h) Ordenar las 12000 viviendas por estrato, UPM y semana, dar a cada
vivienda un número de 1, . . . , 10 sistemáticamente. La vivienda número11 tendrá el número 1, la 12 el 2, etc.
i) Crear 10 �celdas�, donde cada celda sea identi�cada por la combinaciónde días de semana �nes de semana.
j ) Ordenar las celdas de manera aleatoria mediante la asignación de unnúmero aleatorio a cada celda y ordenarlas por ese número.
k) Asignar el número a 1 a la primera celda aleatoriamente seleccionada,la segunda el número 2, etc.
l) Emparejar la celda seleccionada aleatoriamente con las viviendas me-diante número de celda.
m) Cada vivienda obtiene la combinación de días de semana*�nes de se-mana que identi�quen la celda asignada
La ventaja del primer enfoque recae en un hecho logístico de poder contar con lainformación de una UPM en una combinación de días y semana especi�ca, la desventajade este es que no sabe cómo se comporta la UPM a lo largo de las combinaciones delos días, cosa que ofrece el segundo enfoque, y según las características a medir si seconsideraría la segunda alternativa es muy posible tener un error de muestreo menor ala primera opción, algo que se debe medir en la prueba piloto.
A.3.11. Expansión para el ámbito temporal
La selección de semanas y días se hace de manera completamente independiente-mente de la selección de viviendas. Esto signi�ca que los factores de expansión paradías de semana y días de �n de semana pueden ser multiplicados por los factores deexpansión para las viviendas.

APÉNDICE A. DISEÑO MUESTRAL ENCUESTA USO DE TIEMPO 109
Las dos alternativas mencionadas anteriormente producirán los mismos factores deexpansión pero no son equivalentes ya que son seleccionados en formas diferentes.
Una semana especi�ca tiene la probabilidad de 1/(52 ∗ 5) = 1/260 y un día de �nde semana especi�co tiene la probabilidad de 1/(52 ∗ 2) = 1/104.
Dependiendo si se esta interesado en el uso de tiempo durante un día promediodel año o un día especi�co, por ejemplo, 24 de diciembre, durante el año las ponde-raciones deberán ser distintas. Un día promedio es obtenido mediante la ponderación5 = 260/52 mientras que un día de semana promedio es obtenido mediante la ponde-ración 2 = 104/52. En caso del día especi�co las ponderaciones son 260 y 104.
Los dos días del diario pueden ser vistos como un conglomerado de días donde los 7días en la semana fueron estrati�cados en dos estratos, días de semana y días de �n desemana, y una muestra aleatoria de 1 se tomo de cada estrato. No se puede estimar uncomponente de varianza que dependa de días o semanas ya que solo existe una semanaobservada y solo una observación dentro de cada estrato de �día�4.
A.3.12. Estimación de los errores de muestreo
A continuación se presentará el desarrollo para el estimador del total para un mu-estreo de tres etapas, con tamaños desiguales y probabilidades diferentes de seleccióndel estimador-π. Esto para el área rural dispersa.
Para un muestreo en tres etapas, ahora se mostrará el estimador-π del total t , suvarianza, y el estimador de su varianza, estos serán construidos de manera jerárquicade acuerdo a las etapas involucradas, la idea de la partición de la población es dada enlos incisos del (i) al (iii) más adelante, Para las UPM, USM, y las unidades terciariasde muestreo se usara los subíndices i, q y k, respectivamente.
i. Los N elementos del universo U , son agrupados dentro UPM U1, . . . , Ui, . . . , UNI ,independientes, el grupo que forman las UPM es representado por:UI = {1, ..., i, ..., NI}, con NI el tamaño de UI ; así se tiene que N =
∑UINi
ii. Los NI elementos en (i = 1, . . . , NI) son agrupados dentro USM, independientesUi1, . . . , Uiq, . . . , UiNIIi , donde NIIi es el número de USM dentro la UPM i.El grupo de USM formada por la partición de Ui es simbólicamente representadapor:
UIIi = {1, . . . , q, . . . , NIIi}4Andersson, 2010

APÉNDICE A. DISEÑO MUESTRAL ENCUESTA USO DE TIEMPO 110
Donde Niq es el tamaño de Uiq, se tiene
Ni =∑
UIIiNiq (A.18)
iii. En la tercera etapa se considera que se llega a las unidades últimas de muestreo.El procedimiento de muestreo es el siguiente: (primera etapa) Una muestra sI deUPM es sorteada de UI (sI ⊂ UI), (segunda etapa) Para i ∈ sI , una muestra sIIide USM es sorteada de UIIi (sIIi ⊂ UIIi ), (tercera etapa) para q ∈ sIIi , unamuestra siq de elementos es sorteada de Uiq (siq ⊂ Uiq).Los elementos últimos observados (los sorteados en tercera etapa), son los quecomponen la muestra s. Así:
s =⋃i∈sI
⋃q∈sIIi
siq
Para obtener el estimador-π del total poblacional t y su varianza, se necesita la proba-bilidad de inclusión para cada una de las tres etapas. La tabla A.9 muestra la notación,y la correspondiente cantidad δ. Donde, i y j denotan los distintivos de las UPM, q y rlos distintivos de las USM, y k y l denotan los distintivos de la última etapa (la tercera).
Tabla A.9: Probabilidades de inclusión de primer y segundo orden y la cantidad ∆ poretapas
EtapaProbabilidad de inclusión
∆ cantidadesPrimer orden Segundo Orden
I πIi πIij ∆Iij = πIij − πIiπIjII πIIq|i πIIqr|i ∆IIqr|i = πIIqr|i − πIIq|iπIIr|iIII πk|iq πkl|iq ∆kl|qi = πkl|iq − πk|iqπl|iq
Fuente: Särndal y cols., 1992
Se tiene que πIii = πIi ; πIIqq|i = πIIq|i ; πkk|iq = πk|iq.
Ahora, ∆, es de�nido como la división de ∆ con la probabilidad de inclusión desegundo orden, esto es:
∆Iij =∆Iij
πIij; ∆IIqr|i =
∆IIqr|i
πIIqr|i; ∆kl|iq =
∆kl|iq
πkl|iq
Finalmente, el total:
tiq =∑
Uiqyk; ti =
∑UIIi
tiq; t =∑
UIti
El estimador-π del t =∑
U yk, se construye por etapas, la manera de proceder esempezar por la última etapa y llegar a la primera etapa. El estimador-π de tiq con

APÉNDICE A. DISEÑO MUESTRAL ENCUESTA USO DE TIEMPO 111
respecto a la etapa tres es:
tiqπ =∑
siq
ykπk|iq
(A.19)
De la que el estimador-π de ti con respecto a la segunda etapa y tercera etapa esconstruida como:
tiπ =∑
sIIi
tiqππIIq|i
(A.20)
Finalmente, el estimador-π de t con respecto a las tres etapas es dado por:
tπ =∑
sI
tiππIi
(A.21)
Se de�ne ahora la varianza de tπ y un estimador insesgado de la misma. Introduciendoa las varianzas dentro de cada etapa de la forma:
Viq =∑∑
Uiq∆kl|iq
ykπk|iq
ylπl|iq
(A.22)
Que es la varianza de tiqπ dentro del submuestreo de Uiq, también:
VIIi =∑∑
UIIi∆IIqr|i
tiqπIIq|i
tirπIIr|i
(A.23)
Es la varianza de:
∑sIIi
tiqπIIq|i
En sub muestreo de UIIi, con tiπ es el estimador-π con respecto a las dos últimas etapas,se tiene:
Vi = VIIi +∑
UIIi
ViqπIIq|i
(A.24)
De esta forma para un muestreo de tres etapas, para el estimador-π, del total pobla-cional, este puede escribirse:
V3et(tπ) = VUPM + VUSM + VUTM (A.25)

APÉNDICE A. DISEÑO MUESTRAL ENCUESTA USO DE TIEMPO 112
Donde:
VUPM =∑∑
UI∆Iij titj (A.26)
Con ti = tiπIi, que da el aporte en la varianza debida a la primera etapa de muestreo.
VUSM =∑
UI
VIIiπIi
(A.27)
Que da la contribución en la varianza de la segunda etapa de muestreo, y
VUTM =∑
UI
(∑UIIi
ViqπIIq|i
)πIi
(A.28)
Que da la contribución en la varianza de la tercera etapa de muestreo.
Ahora es el turno de la estimación de la varianza, un estimador insesgado de lavarianza es dado por:
V3et(tπ) =∑∑
sI∆Iij
tiππIi
tjππIj
+∑
sI
ViπIi
(A.29)
Donde Vi tiene la estructura:
Vi =∑∑
sIIi∆IIqr|i
tiqππIIq|i
tirππIIr|i
+∑
sIIi
ViqπIIq|i
(A.30)
Con
Viq =∑∑
siq∆kl|iq
ykπk|iq
ylπl|iq
(A.31)
Los estimadores de los componentes de la varianza para un muestreo en tres etapas son:
VUTM =∑
sI
(∑sIIi
Viqπ2IIq|i
)π2Ii
(A.32)
VUSM =∑
sI
Viπ2Ii
− VUTM (A.33)
VUPM = V3et(tπ)− VUSM − VUTM (A.34)

APÉNDICE A. DISEÑO MUESTRAL ENCUESTA USO DE TIEMPO 113
La varianza y el estimador de la varianza en un muestreo de etapas son discutidos enRao, 1975, Rao, 1979, Gray, 1975 y Gray y Platek, 1976.
A.3.13. Estrategia para la no respuesta
Debido a las características de esta encuesta, no se puede perder información deninguna vivienda seleccionada, debido a que la falta de respuesta causara un desequi-librio en cuanto a la representatividad espacial y principalmente a la temporal.
Como una solución a este aspecto se sugiere tener a viviendas de reserva, que per-mitan que la representatividad temporal se mantenga estable, una forma de elegir aestas unidades de reserva, es utilizar las bondades que ofrece la técnica del muestreo bi-fásico, cuyo aporte será el de tener prede�nido de antemano las unidades de reemplazo.
La unidad de reemplazo serán empleadas bajo los siguientes casos:
Rechazo completo del hogar.
Ausencia comprobada de los miembros de todo el hogar.
Informante no cali�cado.
Falta de contacto de todos los miembros del hogar hasta la cuarta visita delencuestador.
A.4. LA PRUEBA PILOTO
La encuesta piloto será un instrumento esencial dentro de la concepción �nal deldiseño muestral de la EUTH, servirá para medir el comportamiento de algunas situa-ciones que podrían perturbar el desarrollo de la encuesta y por ende generar un sesgosistemático en la construcción de los estimadores; a continuación, se lista aspectos queson muy importantes considerar en la realización de las pruebas piloto.
Analizar el comportamiento de las variables de uso de tiempo entre los segmentosen el área rural, respecto a sus estadísticas de dispersión y centralidad.
La distribución de las UPM en el espacio temporal, considerando los dos enfoquesde distribución.
Medir la variabilidad entre UPM considerando ambos enfoques y elegir el mejor.
Captar la magnitud de ausencia de las unidades de observación, y concebir unaidea de momentos en los que están presentes y en los que no lo están.
Veri�car la e�ciencia de la estrati�cación.

APÉNDICE A. DISEÑO MUESTRAL ENCUESTA USO DE TIEMPO 114
Analizar el comportamiento del coe�ciente intra-conglomerado con un tamaño de12 viviendas por UPM.
La medición de los anteriores puntos darán paso a la construcción �nal del diseñomuestral para la EUTH.
La encuesta piloto, de�ne una muestra de 6 UPM, 2 por departamento, conside-rando los departamentos de La Paz, Cochabamba y Santa Cruz, además, asignandouna UPM al área amanzanada y otra al área dispersa. Con 12 viviendas por UPM,teniendo un total de 72 viviendas.
La determinación del tamaño de muestra para la prueba piloto, se debe a un hechocompletamente presupuestario de la encuesta. Debiendo notar que para de�nir comple-tamente el diseño muestral �nal se necesita un tamaño de muestra relativamente masgrande
A.5. RECOMENDACIONES POST-PRUEBA PILO-TO
Es necesario saber cómo se comportan las variables segmentos en el área ruralrespecto a la variable de uso de tiempo, para decidir el número de segmentos aseleccionar para la segunda etapa.
Se debe decidir entre uno de los dos enfoques propuestos para la repartición dela muestra en el espacio temporal.
Se debe procurar tener un marco muestral mas actualizado, que permita tenerun mejor control del diseño muestral.
Se debe tener un mayor cuidado en cuanto a la designación del tamaño de mues-tra.
Si se utiliza el criterio de las unidades de reserva, se debe decidir el número dereservas a utilizar.
Se debe considerar la inclusión de variables auxiliares en encuestas previas a larealización de una, para mejorar el diseño muestral.

Apéndice B
Otros métodos de selección, el PPTsistemático y el PPT de Pareto
Las siguientes posibles alternativas de implementación, traen consigo los problemasde un sistemático simple, pero apertura el ingreso de unidades que el PPT simplerestringe.
B.1. PPT SISTEMÁTICO
Sea xk una medida del tamaño de cada unidad k. Se quiere tomar un tamaño demuestra n.
De�nir tx =∑
k xk, Bk =k∑i=0
xi, B0 = 0, x0 = 0 y a = txn.
Generar un número uniforme aleatorio ε entre 0 y a, seleccionar la unidad k sí.
Bk−1 < ε+ (j − 1) a ≤ Bk
j = 1, . . . , n.Al establecer xk = 1 para toda k, se obtiene tx = N y el resultado es una muestrasistemática con probabilidades iguales.
B.2. PPT DE PARETO
1. Para cada elemento k computar la inclusión de probabilidades meta λ = nxktx
2. Generar N números independientes aleatorios uniformes (0,1) ε1, . . . , εN , unopara cada elemento y computar las variables de sorteo Qk = εk(1−λk)
{(1−εk)λk}, k =
1, . . . , N .
3. Las n unidades con la cantidad Qk más bajas constituye la muestra.
115

Apéndice C
Otra opción para el cálculo del tamañode la muestra para la Encuesta de Usode Tiempo en los Hogares de Bolivia.
Dentro de los requerimientos deseados de la encuesta, se encuentra el aspecto de te-ner información representativa a nivel de los 9 departamentos del país y en un periodotemporal de trimestre. También a nivel nacional por área urbano rural con un periodotemporal asociado a los siete días de la semana, a estas consideraciones le sumamos loscontroles estadísticos referidos a errores de muestreos y niveles de con�abilidad, todosestos puntos se contemplan a continuación para la concepción del tamaño de muestra.
Niveles de desagregación
Desagregación Espacial Temporal
ÁreaUrbano Siete días de la semanaRural Trimestral
SemestralAnual
Departamental
SucreLa PazCochabambaOruro TrimestralPotosí SemestralTarija AnualSanta CruzBeniPando
Debido a la dimensión del estudio y el interés en determinar los usos de tiempo delos hogares, se utilizo como insumo en la determinación del tamaño de la muestra para
116

APÉNDICE C. UNA ALTERNATIVA AL TAMAÑODEMUESTRADE LA EUTH117
la Encuesta de Uso de Tiempo de los Hogares de Bolivia a la información contenida enla encuesta de la MECOVI 2001, que dentro de la sección de empleo tienen un apartadodedicado a las actividades de uso de tiempo, utilizando la variable generada �Cuantashoras al día le dedica usted a actividades del hogar� en la encuesta se establecieronseis actividades dentro del hogar y la variable generada es la suma de horas al días dededicación de las personas a estas seis dichas actividades.
Se analiza primero el caso de los nueve departamentos del país que son los dominiosde estudio, se tiene que calcular el tamaño de muestra para cada dominio de estudio,controlando un error relativo de muestreo tolerable, un nivel de con�anza deseado, elefecto de diseño asociado, una tasa de no respuesta controlada y el espacio temporalrequerido, es así que se obtiene los tamaños de muestra, siguiendo las particularidadde cada departamento utilizando la siguiente relación de formulas:
n0d =Cv2
yd ∗Nd ∗ k2d
Nd ∗ e2rd + Cv2
yd ∗ k2d
(C.1)
nd =n0d ∗ efectdd(1− TNRd)
(C.2)
ndT =nd ∗ td (C.3)
n =9∑d=1
ndT (C.4)
Donde:
y: Variable �horas promedio dentro de la vivienda. que dedican a actividades del hogar�
Cvyd: Coe�ciente de variación de la variable y. dentro del dominio d.
Nd: Número total de viviendas dentro del dominio d (Según el marco muestral).
kd: Valor asociado al nivel de con�abilidad. dentro del dominio d.
erd: Error relativo de muestreo tolerable. en el dominio d.
n0d: Tamaño de muestra obtenido mediante el muestreo aleatorio simple para el domi-nio d.
efectdd: Efecto de diseño debido al muestreo complejo. asociado al dominio d.
TNRd: Tasa de no respuesta controlada en el dominio d.
nd: Tamaño de muestra en el dominio d.

APÉNDICE C. UNA ALTERNATIVA AL TAMAÑODEMUESTRADE LA EUTH118
td: Número de periodos en la desagregación temporal, bajo un año de referencia, en eldominio d.
ndT : Tamaño de muestra total para el dominio d. bajo el periodo de referencia de unaño y la desagregación temporal.
n: Tamaño de muestra total a nivel nacional, para el espacio temporal de un año.
Obteniendo los valores y calculando para cada uno de los dominios los resultadosse muestra en la tabla C.1.
Tabla C.1: Calculo para el tamaño de muestraDepartamento Cvyd Nd kd erd n0d efectdd TNRd nd td ndT
Sucre 0.402 140033 1.96 0.065 147 1.919 0.05 297 4 1186La Paz 0.493 718456 1.96 0.05 373 1.467 0.05 576 4 2306Cochabamba 0.535 415096 1.96 0.05 439 1.375 0.05 636 4 2544Oruro 0.577 127631 1.96 0.065 302 1.143 0.05 363 4 1453Potosí 0.448 219211 1.96 0.07 157 2.948 0.05 488 4 1952Tarija 0.444 97685 1.96 0.065 179 1.112 0.05 209 4 838Santa Cruz 0.483 468054 1.96 0.05 358 1.425 0.05 537 4 2149Beni 0.436 69940 1.96 0.065 172 1.298 0.05 236 4 942Pando 0.399 11697 1.96 0.1 61 1.866 0.05 120 4 478
TOTAL n 13848Fuente: Elaboración propia con información del INE
Es así que se tiene un tamaño de muestra de 13848 viviendas, repartido en los nuevedepartamentos, para una desagregación de periodos en el lapso del año de referencia,más propiamente, con una desagregación de trimestres. Calculada la muestra con el �nde dar representatividad a los cuatro trimestres contenidos en el año de referencia.
A continuación analizaremos el caso de tener como dominios al área urbana rural,y el requerimiento de una desagregación temporal máxima, considerando los siete díasde la semana.
Se utilizara el mismo procedimiento utilizado para el caso de los departamentos, eneste caso se tiene dos dominios de interés, el área urbana y el área rural, se presenta elsiguiente desarrollo y resultado:
El tamaño de muestra a nivel nacional considerando al área urbana y rural comodominio, teniendo una desagregación temporal a nivel de los siete días de la semana,alcanza a 11930 viviendas.
Ya que el diseño muestral contempla la utilización de conglomerados primarios(UPM), en su primera etapa, se tiene que mencionar que debido a hechos de estrictaplani�cación y de operatividad, en el trabajo de campo, respecto a la designación decarga de trabajo a los encuestadores y supervisores, es que el número de viviendas

APÉNDICE C. UNA ALTERNATIVA AL TAMAÑODEMUESTRADE LA EUTH119
Dominio 1 Urbano t1 nd1
k1 1.96 n01 400 7 3880N1 1325965 n1 554Cvy1 0.51er1 0.05 n 11930efectd1 1.29TNR1 0.07Dominio 2 Rural t2 nd2
k2 1.96 n02 369 7 8050N2 941838 n2 1150Cvy2 0.49er2 0.05Efectd2 2.9TNR2 0.07
seleccionadas dentro de cada UPM es �jo para todas las UPM, si bien es cierto queestadísticamente este número debe responder a aspectos de variabilidad dentro de lasUPM, tradicionalmente en encuestas realizadas por la institución, es el caso de lasEncuestas a Hogares este número es de 12 viviendas por UPM, que no trae consigocomplicaciones alarmantes, en el caso de esta encuesta, por sus características es quese designan 14 viviendas por UPM, la elección de este número responde a dos hechosimportantes, el primero a la distribución de días en el ámbito temporal y el segundodebido a los resultados hallados en la primera prueba piloto, sustentando con esto elcriterio estadístico. Por esta razón se hace necesario modi�car el tamaño de muestrapor departamento de tal forma de que este número sea un múltiplo de 14, para de�nir elnúmero de UPM en la muestra, realizando estos ajustes sin afectar el tamaño obtenidopor las formulas C.1, C.1, C.1 y C.1, se tiene:
Tabla C.2: Tamaño de muestra de UPMDepartamento ndTmod nId NI Fracción de muestreoSucre 1190 85 915 9La Paz 2380 170 5380 3Cochabamba 2548 182 2974 6Oruro 1456 104 940 11Potosí 1988 142 1352 11Tarija 840 60 733 8Santa Cruz 2156 154 3875 4Beni 952 68 542 13Pando 490 35 79 44Totales 14000 1000 16790Fuente: Elaboración propia con información del INE
Donde:
ndTmod: Tamaño de muestra total para el dominio d. bajo el periodo de referencia de

APÉNDICE C. UNA ALTERNATIVA AL TAMAÑODEMUESTRADE LA EUTH120
un año y la desagregación temporal (modi�cado).
nI: Número de UPM en la muestra para el dominio d.
NI: Número de UPM en el dominio d.

Apéndice D
TÉRMINOS DE REFERENCIA
121

Apéndice E
INFORME FINAL PASANTÍA
122

GLOSARIO
Actualización en una encuesta.- Es el proceso previo a la encuesta mediante elcual el Encuestador/a obtiene información básica de las viviendas de la UPMasignada, empleando para ello unos formularios de listados de vivienda y mapascartográ�cos. Área Amanzanada.- Conjunto de bloques denominados manzanasque se caracteriza por presentar viviendas en un orden determinado, en espaciosdelimitados por calles, avenidas, ríos, etc.
Área Dispersa.- Área que se caracteriza por presentar viviendas sin un orden deter-minado, ubicadas generalmente en áreas geográ�cas rurales de los segmentos.
Cartografía Estadística.- Es el conjunto de mapas y planos, que representan grá-�camente el territorio nacional. Contiene símbolos cartográ�cos, es decir, repre-sentaciones grá�cas como referencia de los diferentes elementos naturales (ríos,cerros, lagos, etc.), o culturales (caminos, calles, iglesia, etc.), que pueden existiren el terreno.
Entrevista incompleta.- Ocurre cuando no es posible concluir la encuesta, por dife-rentes razones, por ejemplo: El informante se negó a proseguir con la entrevista,sin dar otra cita al Encuestador/a.
Entrevista completa levantada fuera de cronograma.- Ocurre cuando, se ha con-cluido satisfactoriamente una entrevista, logrando cuestionarios completos peroutilizando para el efecto, fechas fuera de cronograma.
Entrevista completa.- Ocurre cuando, se ha concluido satisfactoriamente una en-trevista, logrando completar el cuestionario.
Entrevista.- Es una de las técnicas más valiosas en la investigación socioeconómica,ya que permite conocer la problemática que se investiga a través de una aprecia-ción directa de la población estudiada. Consiste en la aplicación de una serie depreguntas a los miembros del hogar, efectuadas en forma de diálogo.
Falta de contacto.- Ocurre cuando los ocupantes salen muy temprano de su vivienday retornan muy tarde (altas horas de la noche), por motivos de trabajo, estudiosalud, etc.
Hogar.- El hogar es una unidad conformada por personas con relación de parentescoo sin él, que habitan una misma vivienda y que al menos para su alimentación
123

GLOSARIO 124
dependen de un fondo común, es decir, que al menos comparten los gastos dealimentación, aporten o no al mismo. Una persona sola también constituye unhogar.
Incidencia de Pobreza o Índice de Foster Greer y Thorbecke Es el cociente delnúmero de hogares pobres cuyo ingreso (consumo) per cápita es inferior al valorde la línea de pobreza entre el total de hogares. Es la proporción de hogarescuyo ingreso (consumo) per cápita es inferior al valor de la línea de pobreza (cos-to de una canasta básica de alimentos y otras necesidades de educación, salud,vivienda, etc.).
Informante no cali�cado.- Ocurre cuando en la vivienda sólo se encuentran perso-nas menores de 12 años o personal de servicio doméstico.
Listado de Viviendas.- Es uno de los instrumentos principales del proceso de ac-tualización, ha sido diseñado para obtener información respecto a las viviendasparticulares ocupadas y desocupadas, de las viviendas que conforman la UPM.
Localidad.- Son asentamientos de población tanto en áreas dispersas como amanza-nadas o, pequeñas propiedades dentro de la comunidad. En el Altiplano general-mente se los conoce con el nombre de Comunidad, en el Valle como Sindicato,Rancho, Colonia o Estancia, en el Oriente se denominan Hacienda, Colonia, Bre-cha o Pueblo Indígena.
Manzana.- Es toda área de terreno con o sin casas/edi�cios, delimitada por avenidas,calles, pasajes o en algunos casos por ríos, quebradas, etc. Puede presentarse endiversas formas: cuadrada, triangular, rectangular, entre otras. Existen viviendasdispersas ubicadas en las zonas periféricas de áreas amanzanadas. Para efectosde organización se las agrupa para asignarles un código de manzana.
Pisos ecológicos (región).- Se de�ne como las características naturales del país, de-�niendo tres pisos o regiones en el territorio, el altiplano, el valle y el llano.Rechazo.- Ocurre cuando él o la informante no están dispuestos a cooperar o seniega rotundamente a dar información.
Sector Censal.- Es la subdivisión de áreas o zonas censales, que agrupa de 5 a 7segmentos y se identi�ca en el plano con una sucesión de cruces de color azul yun número de dos dígitos, del mismo color encerrados en un círculo. En el casodel área amanzanada, uno o más sectores corresponden a una UPM
Segmento Censal.- Es la subdivisión de sectores censales, que agrupa aproximada-mente hasta 50 viviendas en área dispersa. Se identi�ca con una sucesión de Xde color rojo y con un número del mismo color. En el área dispersa, el área detrabajo corresponde a uno o más segmentos contiguos.
Tabla de selección sistemática.- Es una tabla que contiene diferentes arranquesaleatorios para una selección sistemática dado un tamaño de muestra �jo, paradistintos tamaños de las unidades penúltimas de muestreo.

GLOSARIO 125
Temporalmente ausente.- Ocurre cuando en la vivienda seleccionada se veri�ca quetodos los/as miembros del hogar están de viaje o fuera de los límites de la ciudado localidad y que regresarán posteriormente.
Unidad primaria de muestreo (CNPV-1992) (UPM).- Es un área geográ�ca su-jeta a selección con �nes de muestreo, que contiene un conjunto de viviendas. Enel área amanzanada con aproximadamente 150 viviendas. En el área dispersa 50viviendas promedio. En el área amanzanada una UPM corresponde a un Sectory en el disperso está conformada por uno o dos Segmentos.
Unidad Primaria De Muestreo (CNPV-2001)(UPM).- Es un área geográ�casujeta a selección con �nes de muestreo, que contiene un conjunto de aproxi-madamente 80 a 150 viviendas en área amanzanada correspondiente a uno ovarios sectores censales (con uno o más segmentos) y de 150 a 350 viviendas enel área dispersa.
Unidades Elementales.- Son las unidades cuya mayor desagregación no es posible,en el caso de las encuestas a hogares, estas unidades son las personas.
Vivienda Colectiva.- Es aquella vivienda usada o destinada como lugar de aloja-miento, por un conjunto de personas, entre las cuales no existen vínculos fami-liares, que en general, hacen vida en común por razones de disciplina, enseñanza,religión, trabajo u otros motivos. Son consideradas como tales: hoteles, aloja-mientos, hostales, moteles, cuarteles, hospitales, asilos de ancianos, orfelinatos,cárceles, reformatorios, conventos, internados, etc. Por razones prácticas, tam-bién se considera como viviendas colectivas a aquellas que alberguen a más detres hogares particulares. Es importante hacer notar que al interior de una vi-vienda colectiva, existen viviendas particulares, como ser la vivienda del portero,administrador, etc. Debiendo ser listadas estas viviendas en forma separada paraefectos de la encuesta
Vivienda Desocupada.- Se considera así, cuando la vivienda no está habitada enel momento del listado, pero que puede ser ocupada en cualquier momento. Seentiende también como vivienda desocupada aquella que está en refacción, aban-donada, en alquiler o venta, etc.
Vivienda Ocupada.- Es aquella que se encuentra habitada por uno o más hogares(máximo tres) durante el listado de viviendas. Se debe considerar como viviendasocupadas a aquellas cuyos ocupantes están temporalmente ausentes, viviendascon falta de contacto y viviendas con rechazo.
Vivienda Particular.- Es aquella vivienda destinada para ser habitada por uno omás hogares (en casos excepcionales hasta tres hogares) o grupo de personas, cono sin vinculo familiar que ocupan la misma vivienda y viven juntos bajo el mismorégimen familiar.

GLOSARIO 126
Vivienda.- Es una construcción que tiene uno o más pisos cubiertos por un techo, quefue construida o adaptada para ser habitada por una o más personas en formapermanente o temporal. Debe tener acceso directo e independiente desde la calleo a través de espacios de uso común como ser pasillos, patios o escaleras. En laencuesta se consideraran viviendas particulares a aquellas que son habitadas porhasta tres hogares, ya que una vivienda con más de tres hogares es reconocidacomo vivienda colectiva.


















