
La verdad acerca del candidato Ricardo Martinelli EL VERDADERO CAMBIO……PARA PEOR.

IDENTIFICACIÓN DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES
NEURONALES
TESIS DE GRADO EN INGENIERÍA INFORMÁTICA
FACULTAD DE INGENIERÍA UNIVERSIDAD DE BUENOS AIRES
TESISTA: Sr. Damián Ariel MARTINELLI
DIRECTORES: Prof. M. Ing. Paola BRITOS Prof. Lic. Arturo SERVETTO Prof. M. Ing. Hernán MERLINO
Laboratorio de Sistemas Inteligentes

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 2 -

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 3 -
Agradecimientos
A mi familia por apoyarme y aconsejarme siempre. A mis amigos porque siempre están disponibles para un momento de
esparcimiento. A los profesores que me enseñaron tantas cosas en estos años de estudio. A Hernan y Paola por guiarme en el
crecimiento de esta tesis. Y en especial a Naty, el amor de mi vida, que me acompañó y alentó en todo momento.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 4 -

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 5 -
RESUMEN
En esta Tesis se propone la utilización de redes neuronales artificiales para la identificación de hábitos de uso de sitios Web, estudiando cómo pueden ser adaptadas para llevar a cabo con éxito esta tarea. Los resultados obtenidos son analizados y contrastados con métodos tradicionales de modo de poder valorar la solución propuesta.
ABSTRACT
This Thesis Research proposes the use of artificial neuronal networks to identify the habits of web site usage and how they can be adapted to reach this goal. The results obtained are analyzed and compared with traditional methods in order to measure the proposed solution.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 6 -

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 7 -
INDICE
Agradecimientos.....................................................................................................................3 RESUMEN.............................................................................................................................5 ABSTRACT ...........................................................................................................................5 1. Introducción........................................................................................................................9 2. Estado de la Cuestión .......................................................................................................12
2.1. Explotación de Datos.................................................................................................12 2.1.1. Descubrimiento de Reglas de Asociación ..........................................................15 2.1.2. Clasificación de Datos........................................................................................16 2.1.3. Agrupación de Datos ..........................................................................................17 2.1.4. K-Means .............................................................................................................19
2.2. Explotación de Datos en la Web................................................................................20 2.2.1. Explotación de Datos en el Contenido de la Web ..............................................20 2.2.2. Explotación de Datos en la Estructura de la Web ..............................................21 2.2.3. Explotación de Datos de Uso de la Web ............................................................21
2.3. Explotación de Datos de Uso de la Web ...................................................................21 2.3.1. Prepocesamiento.................................................................................................22 2.3.2. Descubrimiento de Patrones ...............................................................................24 2.3.3. Análisis de Patrones............................................................................................25
2.4. Trabajos Realizados en la Explotación de Datos de Uso de la Web .........................25 2.5. Self Organizing Maps (SOM)....................................................................................27
2.5.1. Algoritmo del SOM............................................................................................28 2.5.2. Arquitectura de la red SOM................................................................................28 2.5.3. Funcionamiento ..................................................................................................29 2.5.4. Preprocesamiento de los datos............................................................................30 2.5.5. Aprendizaje.........................................................................................................30 2.5.6. Visualización ......................................................................................................32 2.5.7. Aplicaciones .......................................................................................................33
2.6. Similitudes y Diferencias SOM y K-Means ..............................................................33 3. Descripción del problema.................................................................................................35 4. Solución propuesta ...........................................................................................................36
4.1. Identificación de los parámetros del problema..........................................................36 4.2. Definiciones...............................................................................................................37
4.2.1. Archivos de Log .................................................................................................37 4.2.2. Preprocesamiento de Logs..................................................................................38 4.2.3. Limpieza de Logs ...............................................................................................39 4.2.4. Identificación de Usuarios..................................................................................40 4.2.5. Identificación de Sesiones de Usuario................................................................41 4.2.6. Identificación de Transacciones de Usuarios .....................................................42 4.2.7. Identificación de Hábitos de Usuario .................................................................43
4.3. Método de Generación de Casos de Experimentación ..............................................43 4.4. Descripción del Banco de Pruebas ............................................................................43
4.4.1. Funcionalidades..................................................................................................43 4.5. Dinámica del Banco de Pruebas ................................................................................46
5. Resultados Obtenidos .......................................................................................................48 5.1. Análisis Logs sitio sobre música ...............................................................................48
5.1.1. Descripción sitio sobre música ...........................................................................48 5.1.2. Páginas sitio sobre música..................................................................................48

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 8 -
5.1.3. Análisis Log 29/5/2005 al 3/6/2005 del sitio sobre música ...............................49 5.1.4. Análisis Log 22/5/2005 al 29/5/2005 del sitio sobre música .............................55 5.1.5. Conclusión Análisis Logs sitio sobre música.....................................................62
5.2. Análisis Logs El Cuerpo de Cristo ............................................................................63 5.2.1. Descripción sitio El Cuerpo de Cristo ................................................................63 5.2.2. Páginas www.elcuerpodecristo.com.ar...............................................................63 5.2.3. Análisis Log Semana 3 de Mayo de 2005 de www.elcuerpodecristo.com.ar ....64 5.2.4. Análisis Log Semana 1 de Junio de 2005 de www.elcuerpodecristo.com.ar.....72 5.2.5. Conclusión Análisis Logs El Cuerpo de Cristo..................................................78
6. Conclusiones.....................................................................................................................80 7. Trabajos Futuros...............................................................................................................81 8. Referencias .......................................................................................................................82 A. Apéndice I: Joone ............................................................................................................90 B. Apéndice II: Manual del Usuario.....................................................................................99 C. Apéndice III: Documentación JavaDoc.........................................................................139 D. Apéndice IV: Desarrollo de la Solución – Métrica Versión 3.......................................242 E. Apéndice V: Pruebas......................................................................................................363

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 9 -
1. Introducción
Se denomina Explotación o Minería de Datos al conjunto de técnicas y herramientas aplicadas al proceso no trivial de extraer y presentar conocimiento implícito, previamente desconocido, potencialmente útil y humanamente comprensible, a partir de grandes conjuntos de datos, con objeto de describir de forma automatizada modelos previamente desconocidos, predecir de forma automatizada tendencias y comportamientos [Felgaer, 2004; Frawley et al., 1991; Chen et al., 1996; Mannila, 1997].
La aplicación de las técnicas de Explotación de Datos en la Web, llamada en inglés Web Data Mining o sintéticamente Web Mining, es definida como el estudio de las técnicas de Data Mining que automáticamente descubren y extraen información desde la Web [Cernuzzi - Molas, 2004].
La identificación de hábitos de uso de sitios Web, conocida en inglés como Web Usage Mining, consiste en el proceso de aplicar técnicas de explotación de datos para el descubrimiento de patrones de uso en páginas Web [Srivastava et al., 2000; Kosala-Blockeel, 2000]. Ésta utiliza los datos registrados en los logs de acceso de los servidores Web, donde se registra el comportamiento de navegación de los usuarios. Este comportamiento toma la forma de una secuencia de vínculos (links) seguidos por el usuario, produciendo una sesión [Batista-Silva, 2002; Borges-Levene, 2000; Chen-Chau, 2004].
Con la identificación de hábitos de uso de sitios Web se busca [Borges-Levene, 2000; Kosala-Blockeel, 2000; Srivastava et al., 2000]:
a) entender el comportamiento de navegación del usuario, permitiendo adaptar los sitios Web a sus necesidades;
b) obtener la información para la personalización de los sitios,
c) realizar mejoras en el sistema,
d) modificar el sitio acorde a los patrones descubiertos,
e) realizar inteligencia del negocio y
f) caracterizar el uso del sitio Web por los usuarios.
Mediante estas acciones se busca [Abraham-Ramos, 2003]:
a) atraer nuevos clientes,
b) retener a los clientes actuales,
c) realizar campañas de promociones efectivas y
d) encontrar la mejor estructura lógica del espacio Web.
La identificación de hábitos de uso de sitios Web consiste de tres etapas [Srivastava et al., 2000; Batista-Silva, 2002; Mobasher et al., 1999]:

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 10 -
a) preprocesamiento,
b) descubrimiento de patrones, y
c) análisis de patrones.
El preprocesamiento consiste en convertir la información de uso contenida en los logs (registro de las páginas solicitadas por los clientes a un servidor), realizando previamente una limpieza de los mismos, en una abstracción de datos necesaria para el descubrimiento de patrones. En esta etapa se identifican a los usuarios y al conjunto de sesiones de usuario [Srivastava et al., 2000; Batista-Silva, 2002; Mobasher et al., 1999] .
La etapa siguiente es el descubrimiento de patrones mediante diversas técnicas disponibles, como por ejemplo, el análisis estadístico, el descubrimiento de reglas de asociación, el agrupamiento, la clasificación y los patrones secuenciales [Srivastava et al., 2000] .
La última etapa del proceso completo de identificación de hábitos de uso de sitios Web es el análisis de los patrones encontrados en la etapa anterior, filtrando reglas o patrones no interesantes, y utilizando métodos de visualización útiles para su análisis [ Srivastava et al., 2000; Batista-Silva, 2002] , realizando proyecciones dinámicas, filtros, zoom y distorsiones interactivas sobre los gráficos generados [Keim, 2002; Ankerst, 2001].
Las redes neuronales artificiales pueden ser utilizadas para el descubrimiento de patrones en la explotación de datos. Las redes neuronales artificiales (de acá en adelante RNA) son modelos que intentan reproducir el comportamiento del cerebro; las RNA son capaces de aprender de la experiencia, de generalizar de casos anteriores a nuevos casos, de abstraer características esenciales a partir de entradas que representan información irrelevante, de realizar aprendizaje adaptativo, de realizar una autoorganización, además de tener tolerancia a fallos y operar en tiempo real [Grosser, 2004; Daza, 2003]. Conforme la arquitectura del cerebro, la estructura de las RNA involucran una gran cantidad de elementos simples de procesamiento llamadas neuronas. Estas unidades de procesamiento se encuentran altamente interconectadas con las demás mediante conexiones con pesos modificables, cada neurona obtiene sus señales de entrada de otras neuronas o de orígenes externos, y envía señales de salida a otras neuronas o a destinos externos. El aprendizaje en una RNA es desarrollado mediante el ajuste de los pesos de las conexiones entre las neuronas [Roy, 2000; Abidi, 1996; Daza, 2003, García Martínez et al., 2003].
En este contexto, el propósito de este proyecto es aplicar redes neuronales artificiales en el proceso de descubrimiento de patrones de uso de sitios Web, estudiando cómo puede ser adaptada la red neuronal utilizada y las transformaciones necesarias que deben realizarse en los datos de los logs de acceso de los servidores Web, de modo de poder ser utilizados como señales de entrada. Los patrones descubiertos se analizarán en orden a su comprensión y explicación, y serán contrastados con los resultados obtenidos utilizando un método tradicional, el algoritmo K-Means.
En el Capítulo 2. Estado de la Cuestión se presenta el contexto teórico para el estudio de la integración del agrupamiento por SOM como método de identificación de hábitos de uso de sitios Web. Se presenta la explotación de datos y la explotación de datos en la Web, para luego describir más en detalle la explotación de datos de uso de la Web y los trabajos

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 11 -
realizados en esta área. Por último, se describen los mapas auto-organizados SOM, realizando un análisis de las similitudes y diferencias entre SOM y el algoritmo K-Means.
En el Capítulo 3. Descripción del Problema se presenta el problema a resolver, se fundamenta el porqué de su elección y se señala su importancia en el contexto de estudio.
En el Capítulo 4. Solución Propuesta se describe la respuesta al problema planteado, identificando sus parámetros, planteando las definiciones necesarias, describiendo el origen de los casos de experimentación, y finalmente, se realiza una descripción del Banco de Pruebas, abordando sus funcionalidades y describiendo su dinámica de funcionamiento.
En el Capítulo 5. Resultados Obtenidos se exponen los resultados obtenidos en los experimentos realizados. Se analizan los logs de dos sitios Web, uno sobre música y otro sobre gastronomía, de modo de poder analizar los resultados obtenidos y evaluar la calidad de la solución propuesta en esta tesis. Para cada sitio se realizan todos los pasos involucrados en la identificación de hábitos de usuarios, comparando los resultados obtenidos mediante la red neuronal SOM y mediante el algoritmo K-Means.
En el Capítulo 6. Conclusiones se resumen los aportes que el presente trabajo de Tesis brinda en relación a la problemática específica de la identificación de hábitos de uso de sitios Web.
En el Capítulo 7. Trabajos Futuros se presentan las futuras líneas de investigación y desarrollo que se pueden considerar a fin de continuar con el presente trabajo.
En el Apéndice I. Joone se describe el framework de redes neuronales artificiales Joone y el porqué de su elección como parte del banco de pruebas desarrollado.
En el Apéndice II. Manual del Usuario se transcribe el manual de usuario del banco de pruebas.
En el Apéndice III. Documentación JavaDoc se transcribe la documentación técnica del banco de pruebas.
En el Apéndice IV. Desarrollo de la Solución – Métrica Versión 3 se detalla el desarrollo del banco de pruebas utilizando la metodología Métrica Versión 3, incluyendo cada actividad que involucra la misma.
En el Apéndice V. Pruebas se detallan las pruebas realizadas sobre el banco de pruebas, describiendo cada una y los resultados obtenidos.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 12 -
2. Estado de la Cuestión
En este capítulo se presenta el contexto teórico para el estudio de la integración de agrupamiento por SOM como método de identificación de hábitos de uso de sitios Web. Se presenta la explotación de datos (sección 2.1), poniendo especial énfasis en el algoritmo K-Means (sección 2.1.4). Se presenta la explotación de datos en la Web (sección 2.2), para luego describir más en detalle la explotación de datos de uso de la Web (sección 2.3) y los trabajos realizados en esta área (sección 2.4). Por último, se describen los mapas auto-organizados SOM (sección 2.5), realizando un análisis de las similitudes y diferencias entre SOM y el algoritmo K-Means (sección 2.6).
2.1. Explotación de Datos
Como se mencionó anteriormente, se denomina Explotación o Minería de Datos al conjunto de técnicas y herramientas aplicadas al proceso no trivial de extraer y presentar conocimiento implícito, previamente desconocido, potencialmente útil y humanamente comprensible, a partir de grandes conjuntos de datos, con objeto de describir de forma automatizada modelos previamente desconocidos, predecir de forma automatizada tendencias y comportamientos [Felgaer, 2004; Frawley et al., 1991; Chen et al., 1996; Mannila, 1997].
La Minería de Datos es un proceso completo de descubrimiento de conocimiento que involucra varios pasos [Morales, 2003]:
1. Entendimiento del dominio de aplicación, el conocimiento relevante a utilizar y las metas del usuario.
2. Seleccionar un conjunto de datos en donde realizar el proceso de descubrimiento.
3. Limpieza y preprocesamiento de los datos, diseñando una estrategia adecuada para manejar ruido, valores incompletos, valores fuera de rango, valores inconsistentes, etc..
4. Selección de la tarea de descubrimiento a realizar, por ejemplo, clasificación, agrupamiento o clustering, reglas de asociación, etc..
5. Selección de los algoritmos a utilizar.
6. Transformación de los datos al formato requerido por el algoritmo especifico de explotación de datos, hallando los atributos útiles, reduciendo las dimensiones de los datos, etc..
7. Llevar a cabo el proceso de minería de datos para encontrar patrones interesantes.
8. Evaluación de los patrones descubiertos y presentación de los mismos mediante técnicas de visualización. Quizás sea necesario eliminar patrones redundantes o no interesantes, o se necesite repetir algún paso anterior con otros datos, con otros algoritmos, con otras metas o con otras estrategias.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 13 -
9. Utilización del conocimiento descubierto, ya sea incorporándolo dentro de un sistema o simplemente para almacenarlo y reportarlo a las personas interesadas.
Es muy importante la etapa del preprocesamiento de los datos y su transformación al formato requerido por el algoritmo, ya que dependiendo de cómo se realicen estas tareas, va a depender la calidad final de los patrones descubiertos.
Los patrones descubiertos se deben analizar, encontrando los patrones interesantes. Un patrón es interesante si es fácilmente entendible por las personas, válido sobre datos nuevos o de prueba con algún grado de certidumbre, potencialmente útil, novedoso o valida alguna hipótesis que un usuario busca confirmar. Un patrón interesante representa conocimiento [Ale, 2005a].
Debido a que la minería de datos es un proceso que involucra varios pasos, enumerados anteriormente, se necesita un modelo que sirva de guia para la correcta ejecución de los mismos.
CRISP-DM es un modelo del proceso de explotación de datos, el cual describe los procedimientos utilizados por un experto al afrontar un proyecto de explotación de datos. CRISP-DM [Chapman et al., 2000] provee un modelo de referencia para guiar un proyecto de explotación. Este modelo contiene las fases del ciclo de vida de un proyecto, con sus respectivas tareas y relaciones. El ciclo de vida consiste de seis fases [Figura 2.1]:
• Entendimiento del Negocio: la fase inicial se focaliza en el entendimiento de los objetivos del proyecto y los requerimientos desde la perspectiva del negocio, para luego convertir este conocimiento en la definición de un problema de explotación de datos y un plan preliminar diseñado para alcanzar estos objetivos.
• Entendimiento de los Datos: esta fase comienza con una colección inicial de datos y se procede a realizar actividades para familiarizarse con los datos, para identificar problemas en la calidad de los mismos y para detectar subconjuntos interesantes que permitan formular hipótesis sobre información oculta en los datos.
• Preparación de Datos: la fase de preparación de datos involucra todas las actividades para construir el conjunto final de datos (los datos que serán utilizados en la herramienta de modelado). Estas tareas generalmente son realizadas varias veces y sin un orden previo. Las tareas incluyen la selección de tablas, registros y atributos, como así también, la transformación y la limpieza de los datos para que puedan utilizarse correctamente en la herramienta de modelado.
• Modelado: en esta fase son seleccionadas y aplicadas las técnicas de modelado, calibrando sus parámetros a valores óptimos. Existen varias técnicas disponibles para el mismo tipo de problema de explotación de datos, algunas de las cuales poseen requerimientos específicos en la estructura de los datos de entrada. A menudo es necesario volver a la etapa de preparación de datos para seguir perfeccionando estos datos.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 14 -
• Evaluación: en esta fase se posee uno o varios modelos, los cuales poseen una alta calidad desde la perspectiva del análisis de los datos. Antes de proceder al despliegue final del modelo, es importante evaluar el modelo y revisar los pasos ejecutados en la construcción del mismo, de modo de estar seguro que se alcanzaron los objetivos del negocio de forma satisfactoria. Luego de finalizar esta fase, se debería poder tomar una decisión sobre el uso que se le darán a los resultados de la explotación de datos.
• Despliegue: la creación del modelo no es generalmente el fin del proyecto. El conocimiento adquirido será necesario organizarlo y presentarlo de forma que el cliente pueda utilizarlo. En esta fase se puede necesitar simplemente generar un reporte o quizás sea necesario implementar un proceso de explotación de datos repetitivo completo.
Figura 2.1. Fases de CRISP-DM
La secuencia de estas fases no es rígida, en muchas ocasiones es necesario volver a fases anteriores para realizar ajustes. Las flechas de la figura [Figura 2.1] indican las dependencias más importantes y frecuentes entre las fases. El ciclo exterior simboliza la naturaleza cíclica de la explotación de datos. El conocimiento adquirido durante el proceso puede generar nuevas preguntas acerca del negocio.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 15 -
Existen varios tipos de técnicas de explotación de datos, las cuales, en función de su objetivo, pueden clasificarse en:
• Descubrimiento de Reglas de Asociación: consiste en hallar patrones, asociaciones, correlaciones o estructuras causales frecuentes entre conjuntos de objetos almacenados en un repositorio de información.
• Clasificación de Datos: proceso que encuentra las propiedades comunes entre un conjunto de objetos y los clasifica en diferentes clases, de acuerdo a un modelo de clasificación.
• Agrupamiento de Datos: consiste en agrupar un conjunto de datos, sin tener clases predefinidas, basándose en la similitud de los valores de los atributos de los distintos datos.
2.1.1. Descubrimiento de Reglas de Asociación
La minería de reglas de asociación consiste en encontrar reglas de la forma (A1yA2y...yAm) => (B1yB2y...yBn), donde Ai y Bj son valores de atributos del conjunto de datos [Chen et al., 1996]. Por ejemplo, se podría encontrar en un gran repositorio de datos de compras en un supermercado, la regla de asociación correspondiente a que si un cliente compra leche, entonces compra pan. Una regla de asociación es una sentencia probabilística acerca de la coocurrencia de ciertos eventos en una base de datos, y es particularmente aplicable a grandes conjuntos de transacciones [Hand et al., 2001].
Dada una base de datos, es deseable descubrir las asociaciones importantes entre ítems, de modo que la presencia de algún ítem en una transacción implica la presencia de otros ítems en la misma transacción. Siendo X un conjunto de ítems, una transacción T se dice que contiene a X si y solo si X esta incluido en T. Una regla de asociación es una implicación de la forma X => Y, donde X esta incluido en I (I es el conjunto de todos los ítems posibles), Y esta incluido en I y la intersección de X e Y es vacía. La regla X => Y posee en el conjunto de transacciones D una confidencia c, correspondiente a que c% de las transacciones en D que contienen X también contienen Y. La regla X => Y posee un soporte s en el conjunto de transacciones D si s% de las transacciones en D contienen X U Y [Chen et al., 1996].
La confidencia denota la fuerza de la implicación y el soporte indica la frecuencia de ocurrencia de los patrones de la regla. Es a menudo deseable prestar atención solo a aquellas reglas que poseen un razonable alto soporte. Las reglas con alta confidencia y fuerte soporte son consideradas reglas fuertes [Agrawal et al., 1993; Frawley et al., 1991]. La tarea de minería de reglas de asociación es esencialmente el descubrimiento de reglas de asociación fuertes en grandes base de datos.
Existen varios algoritmos que realizan el descubrimiento de reglas de asociación. Uno de los algoritmos más utilizado es el algoritmo Apriori. En cada iteración, Apriori construye un conjunto de itemsets (conjunto de ítems presentes en una transacción) candidatos, cuenta el número de ocurrencias de cada candidato y luego determina los itemsets frecuentes basándose en un soporte mínimo predeterminado [Agrawal & Srikant,

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 16 -
1994]. En la primera iteración, Apriori simplemente procesa todas las transacciones para contar la cantidad de ocurrencias de cada ítem, obteniendo el conjunto de candidatos 1-itemsets. Luego de los candidatos se seleccionan los 1-itemsets frecuentes (con soporte mayor al mínimo). Se sigue iterando para los 2-itemsets (conjunto de ítems con dos unidades cada uno), hasta obtener los k-itemsets frecuentes. Luego utiliza los itemsets frecuentes para generar las reglas de asociación. Apriori tiene en cuenta el hecho de que todos los subconjuntos de un itemset frecuente deben ser también frecuentes (deben tener el soporte mínimo), además que si un itemset no es frecuente, ninguno de sus superconjuntos es frecuente.
Se han hecho algunas mejoras al algoritmo básico de reglas de asociación Apriori para hacerlo más eficiente [Morales, 2003]:
• Utilizar tablas de hash para reducir el tamaño de los itemsets candidatos (DHP).
• Eliminar transacciones que no contribuyan en superconjuntos a considerar.
• Dividir las transacciones en particiones disjuntas, evaluar los itemsets locales y luego, sobre la base de sus resultados, estimar los globales.
• Hacer aproximaciones con muestreos del conjunto de todos los itemsets, para no tener que leer todo el conjunto de datos.
• Evitar generar candidatos usando estructuras de datos alternativas, como por ejemplo, los FP-trees (Frequent Pattern tree).
Las reglas temporales son similares a las reglas de asociación pero involucran la noción de tiempo, encontrando relaciones en los datos a través del tiempo. Por ejemplo, encontrar reglas en la evolución de los valores de las acciones cotizadas en la bolsa [Chen et al., 1996].
2.1.2. Clasificación de Datos
La clasificación se utiliza para clasificar un conjunto de datos basado en los valores de sus atributos. Por ejemplo, se podría clasificar a distintas personas entre riesgo Bajo, Medio y Alto, para la otorgación de un préstamo, teniendo en cuenta la información de la misma.
La clasificación de datos es el proceso que encuentra las propiedades comunes entre un conjunto de objetos y los clasifica en diferentes clases, de acuerdo a un modelo de clasificación. Para construir este modelo, se utiliza un conjunto de entrenamiento, en que cada tupla consiste en un conjunto de atributos y el valor de la clase a la cual pertenece. El objetivo de la clasificación es analizar los datos de entrenamiento y, mediante un método supervisado, desarrollar una descripción o un modelo para cada clase utilizando las características disponibles en los datos. Esta descripción o modelo es utilizado para clasificar otras tuplas, cuya clase es desconocida. El método se conoce como supervisado debido a que, para el conjunto de entrenamiento, se conoce la clase a la cual pertenece cada tupla del mismo y se le indica al modelo si la clasificación que realiza es correcta o no. La

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 17 -
construcción del modelo se realimenta de estas indicaciones del supervisor [Chen et al., 1996; Lalani, 2003].
Para la clasificación de datos se han utilizado distintas técnicas, algunas de las cuales utilizan las estadísticas, el machine learning, las redes neuronales o los sistemas expertos [Weiss & Kulikowski, 1991].
La clasificación basada en árboles de decisión es un método de aprendizaje supervisado que construye árboles de decisión a partir de un conjunto de entrenamiento. Cada hoja del árbol posee un nombre de clase, cada nodo interior especifica una evaluación en un atributo y cada rama representa un resultado de esa evaluación. La calidad de un árbol depende de la precisión de la clasificación y del tamaño del árbol.
ID3 es un sistema típico de construcción de árboles de decisión, el cual adopta una estrategia de arriba hacia abajo e inspecciona solo una parte del espacio de búsqueda. ID-3 garantiza que será encontrado un árbol simple, pero no necesariamente el más simple. ID-3 utiliza la teoría de la información para minimizar la cantidad de pruebas para clasificar un objeto. Una heurística selecciona el atributo que provee la mayor ganancia de la información. Una extensión a ID3, C4.5 [Quinlan, 1993] extiende el dominio de clasificación de atributos categóricos a numéricos. J48 es una implementación mejorada del algoritmo de árboles de decisión C4.5. El algoritmo J48 funciona bien con atributos nominales y numéricos. Un paso importante en la construcción del árbol de decisión es la poda, la cual elimina las ramas no necesarias, resultando en una clasificación más rápida y una mejora en la precisión de la clasificación de datos [Han & Kamber, 2001]. SPRINT particiona recursivamente los datos hasta que todos los miembros pertenecen a la misma clase o el número de miembros es suficientemente pequeño, para luego realizar una poda del árbol generado, disminuyendo su complejidad [Ale, 2005b].
Existen muchos otros algoritmos de clasificación de datos, incluyendo métodos estadísticos [Cheeseman & Stutz, 1996; Elder IV & Pregibon, 1996; Frawley et al., 1991], como el análisis de regresión lineal utilizada en [Elder IV & Pregibon, 1996]. Se han estudiado también algoritmos de machine learning escalables que combinan clasificadores básicos de una partición del conjunto de datos [Cheeseman & Stutz, 1996]. También existen estudios de técnicas de clasificación en el contexto de grandes base de datos [Agrawal et al., 1992]. Otro clasificador ha sido propuesto por [Agrawal et al., 1992] para reducir el costo de la generación de los árboles de decisión. También se han utilizado las redes neuronales para las tareas de clasificación de datos [Lu et al., 1995], los algoritmos genéticos y la lógica difusa.
2.1.3. Agrupación de Datos
La agrupación o el clustering consiste en agrupar un conjunto de datos, sin tener clases predefinidas, basándose en la similitud de los valores de los atributos de los distintos datos. Esta agrupación, a diferencia de la clasificación, se realiza de forma no supervisada, ya que no se conoce de antemano las clases del conjunto de datos de entrenamiento. El clustering identifica clusters, o regiones densamente pobladas, de acuerdo a alguna medida de distancia, en un gran conjunto de datos multidimensional [Chen et al., 1996]. El

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 18 -
clustering se basa en maximizar la similitud de las instancias en cada cluster y minimizar la similitud entre clusters [Han & Kamber, 2001].
La clusterizacion ha sido estudiada en las áreas de estadística [Cheeseman & Stutz, 1996; Jain & Dubes, 1988], de machine learning [Fisher, 1996], de base de datos espaciales y de minería de datos [Cheeseman & Stutz, 1996; Ester et al., 1995; Ng & Han, 1994; Zhang et al., 1996].
Existen varias categorías de los métodos de clustering [Ale, 2005c]:
• Métodos Particionales: Construir varias particiones y evaluarlas por algún criterio.
• Métodos Jerárquicos: Crear una descomposición del conjunto de datos (u objetos) utilizando algún criterio.
• Métodos Basados en Densidad: basado en funciones de conectividad y densidad.
• Métodos Basados en Grillas: basado en una estructura de granularidad de niveles múltiples.
• Métodos Basados en Modelos: se hipotetiza un modelo para cada uno de los clusters y la idea es hallar el mejor ajuste de ese modelo a cada uno de los otros.
2.1.3.1. Métodos Particionales
Los métodos particionales construyen una partición de una base de datos D de n objetos en un conjunto de k clusters, buscando optimizar el criterio de particionamiento elegido. Existen distintos algoritmos para la formación de los clusters.
A continuación se describen los algoritmos de partición mas conocidos:
En K-Means cada cluster está representado por su centro. K-Means intenta formar k clusters, con k predeterminado antes del inicio del proceso. K-Means comienza particionando los datos en k subconjuntos no vacíos, calcula el centroide de cada partición como el punto medio del cluster y asigna cada dato al cluster cuyo centroide sea el más próximo. Luego vuelve a particionar los datos iterativamente, hasta que no haya más datos que cambien de cluster de una iteración a la otra.
En K-Medoids o PAM (Partition around medoids) [Kaufman & Rousseeuw, 1990] cada cluster está representado por uno de los objetos en el cluster, llamado medioide del cluster. El medioide es el objeto más cercano al centro de un cluster. Luego de seleccionar los k mediodes, el algoritmo intenta en forma iterativa realizar una mejor elección de los mediodes, analizando todos los posibles pares de objetos, de modo que uno es un mediode y el otro no. La medida de la calidad de la clusterización es calculada para cada uno de estos pares. La mejor elección de los objetos en una iteración es elegida como los medioides para la iteración siguiente. PAM funciona bien para conjuntos de datos pequeños, pero es computacionalmente ineficiente para conjuntos de datos grandes.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 19 -
El algoritmo CLARA (Clustering LARge Applications) [Kaufman & Rousseeuw, 1990] realiza la misma tarea pero utiliza la técnica de muestreo. Solo una porción de los datos completos es seleccionada como una representación de los datos y los medioides son elegidos en esta muestra utilizando PAM. La idea es que, si la muestra es seleccionada en forma aleatoria, esta representa correctamente el conjunto de datos completos, y los objetos representativos (medioides) elegidos serán similares a los elegidos a partir del conjunto de datos completo. Como se puede esperar, CLARA puede manejar conjuntos de datos más grandes que PAM.
CLARANS [Ng & Han, 1994] integra los algoritmos PAM y CLARA en uno. Además, se han propuesto varias mejoras al algoritmo de CLARANS para mejorar su desempeño [Ester et al., 1995].
El algoritmo K-Means se utilizará para contrastar los resultados obtenidos mediante la red neuronal SOM propuesta en esta tesis. Por ello, a continuación se detalla el funcionamiento de este algoritmo, para una mejor comprensión del mismo.
2.1.4. K-Means
K-Means en un método particional de clustering donde se construye una partición de una base de datos D de n objetos en un conjunto de k grupos, buscando optimizar el criterio de particionamiento elegido. En K-Means cada grupo está representado por su centro. K-Means intenta formar k grupos, con k predeterminado antes del inicio del proceso. Asume que los atributos de los objetos forman un vector espacial. El objetivo que se intenta alcanzar es minimizar la varianza total intra-grupo o la función de error cuadrático:
∑∑= ∈
−=k
i Sjij
i
xV0
2µ
Ecuación 2-1 Error cuadrático
Donde existen k grupos Si, i=1,2,...,k y µi es el punto medio o centroide de todos los puntos Xj є Si.
K-Means comienza particionando los datos en k subconjuntos no vacíos, aleatoriamente o usando alguna heurística. Luego calcula el centroide de cada partición como el punto medio del cluster y asigna cada dato al cluster cuyo centroide sea el más próximo. Luego los centroides son recalculados para los grupos nuevos y el algoritmo se repite hasta la convergencia, la cual es obtenida cuando no haya más datos que cambien de grupo de una iteración a otra.
Para calcular el centroide más cercano a cada punto se debe utilizar una función de distancia. Para datos reales se suele utilizar la distancia euclediana. Para datos categóricos se debe establecer una función específica de distancia para ese conjunto de datos. Algunas de las opciones son utilizar una matriz de distancias predefinidas o una función heurística.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 20 -
El algoritmo no garantiza que se obtenga un optimo global. La calidad de la solución final depende principalmente del conjunto inicial de grupos. Debido a esto, se suelen realizar varias ejecuciones del algoritmo con distintos conjuntos iniciales, de modo de obtener una mejor solución.
Dado k, el algoritmo K-Means se implementa en 4 pasos [Ale,2005c]:
1. Particionar los objetos en k subconjuntos no vacios.
2. Computar los puntos semilla como los centroides de los clusters de la partición corriente. El centroide es el centro (punto medio) del cluster.
3. Asignar cada objeto al cluster con el punto semilla más próximo.
4. Volver al paso 2, parar cuando no haya más reasignaciones.
K-Means es ampliamente utilizado en la explotación de datos, en la cuantificación de vectores, para cuantificar variable reales en k rangos no uniformes y para reducir el número de colores en una imagen.
2.2. Explotación de Datos en la Web
Como se mencionó anteriormente, la aplicación de las técnicas de Explotación de Datos en la Web, llamada en inglés Web Data Mining o más sintéticamente Web Mining, es definida como el estudio de las técnicas de Data Mining que automáticamente descubren y extraen información desde la Web [Cernuzzi & Molas, 2004; Pierrakos et al., 2001; Abraham & Ramos, 2003; Lalani, 2003; Huysmans et al., 2003].
La Explotación de Datos en la Web (Web Mining) puede dividirse en tres categorías [Pierrakos et al., 2001; Lalani, 2003; Batista & Silva, 2002; Chen et al., 1996; Marbán Gallego, 2002; Huysmans et al., 2003; Srivastava et al., 2000]:
• Explotación de Datos en el Contenido de la Web (Web Content Mining),
• Explotación de Datos en la Estructura de la Web (Web Structure Mining), y
• Explotación de Datos de Uso de la Web (Web Usage Mining).
2.2.1. Explotación de Datos en el Contenido de la Web
La Explotación de Datos en el Contenido de la Web, llamada en ingles Web Content Mining, consiste en la extracción de conocimiento útil a partir del contenido de las páginas Web mediante el uso de técnicas de data mining. El contenido de las páginas Web son los datos que fueron diseñados para mostrar a los usuarios y consiste de varios tipos, tales como texto, gráficos, sonido, video, etc. [Pierrakos et al., 2001; Lalani, 2003; Batista & Silva, 2002; Chen et al., 1996; Huysmans et al., 2003; Srivastava et al., 2000]. Las investigaciones en la explotación de datos en los contenidos Web incluyen el

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 21 -
descubrimiento de recursos, la categorización y la clusterizacion de documentos, y la extracción de información de las páginas Web [Chen et al., 1996].
2.2.2. Explotación de Datos en la Estructura de la Web
La Explotación de Datos en la Estructura de la Web, llamada en ingles Web Structure Mining, intenta extraer información de la estructura de los links entre diferentes páginas de la Web [Pierrakos et al., 2001; Batista & Silva, 2002; Chen et al., 1996; Huysmans et al., 2003]. Los datos de la estructura representan el modo en que el contenido de las páginas Web es organizado. Estos datos pueden corresponder con etiquetas HTML o XML y vínculos entre páginas Web [Srivastava et al., 2000].
2.2.3. Explotación de Datos de Uso de la Web
La Explotación de Datos de Uso de la Web, conocida en inglés como Web Usage Mining, consiste en el proceso de aplicar técnicas de explotación de datos para el descubrimiento de patrones de uso en páginas Web [Srivastava et al., 2000; Kosala & Blockeel, 2000], esta utiliza los datos registrados en los logs de acceso de los servidores Web, donde se registra el comportamiento de navegación de los usuarios. Este comportamiento toma la forma de una secuencia de vínculos (links) seguidos por el usuario, produciendo una sesión [Batista & Silva, 2002; Borges & Levene, 2000; Chen & Chau, 2004].
2.3. Explotación de Datos de Uso de la Web
El continuo crecimiento del World Wide Web, unido al entorno competitivo en el cual se mueven las organizaciones modernas, ha hecho necesario diseñar los sitios Web teniendo en cuenta, como aspecto fundamental, el conocimiento que se puede extraer de las navegaciones de los usuarios que lo utilizan [Hochsztain, 2002].
Los servidores Web guardan datos de las interacciones de sus usuarios en todo pedido recibido de algún recurso. Estos datos se almacenan en los logs de acceso del servidor Web, conteniendo información sobre la experiencia del usuario en el sitio. El análisis de los logs de acceso de un servidor Web puede ayudar a entender el comportamiento de sus usuarios. El tamaño promedio de los archivos puede ser de varios megabytes diarios, por esto son necesarias técnicas y herramientas que faciliten el análisis de su contenido [Cernuzzi & Molas, 2004; Abraham & Ramos, 2003].
La identificación de hábitos de uso de sitios Web, conocida en inglés como Web Usage Mining, consiste en el proceso de aplicar técnicas de explotación de datos para el descubrimiento de patrones de uso en páginas Web [Srivastava et al., 2000; Kosala & Blockeel, 2000], utilizando los datos registrados en los logs de acceso de los servidores

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 22 -
Web. Los patrones de uso descubiertos deben cumplir la condición de novedosos, interesantes y útiles, permitiendo mejorar la efectividad del sitio Web, basándose en las necesidades del usuario [Batista & Silva, 2002; Kerkhofs, 2001; Abraham & Ramos, 2003].
Con la identificación de hábitos de uso de sitios Web se busca [Borges & Levene, 2000; Kosala & Blockeel, 2000; Srivastava et al., 2000; Lalani, 2003 Batista & Silva, 2002; Marbán Gallego, 2002]:
a) entender el comportamiento de navegación del usuario, permitiendo adaptar los sitios Web a sus necesidades;
b) obtener la información para la personalización de los sitios,
c) realizar mejoras en el sistema,
d) modificar el sitio acorde a los patrones descubiertos,
e) realizar inteligencia del negocio,
f) ofrecer contenido a los visitantes de acuerdo a sus preferencias, y
g) caracterizar el uso del sitio Web por los usuarios.
Mediante estas acciones se busca [Abraham & Ramos, 2003; Cernuzzi & Molas, 2004]:
a) atraer nuevos clientes,
b) retener a los clientes actuales,
c) realizar campañas de promociones efectivas,
d) determinar estrategias de marketing efectivas, y
e) encontrar la mejor estructura lógica del espacio Web.
La identificación de hábitos de uso de sitios Web consiste de tres etapas [Srivastava et al., 2000; Batista-Silva, 2002; Mobasher et al., 1999]:
I. preprocesamiento,
II. descubrimiento de patrones, y
III. análisis de patrones.
2.3.1. Prepocesamiento
El preprocesamiento consiste en convertir la información de uso contenida en los logs (registro de las páginas solicitadas por los clientes a un servidor), realizando previamente una limpieza de los mismos, en una abstracción de datos necesaria para el descubrimiento de patrones. En esta etapa se identifican a los usuarios y al conjunto de sesiones de usuario [Srivastava et al., 2000; Batista & Silva, 2002; Mobasher et al., 1999, Marbán Gallego, 2002]. Una sesión de usuario corresponde a una secuencia de vínculos (links) seguidos por el usuario [Batista & Silva, 2002; Borges & Levene, 2000; Chen & Chau, 2004].

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 23 -
Los datos de los logs pueden ser recolectados a nivel del servidor, del cliente o del servidor proxy [Abraham & Ramos, 2003; Chen et al., 1996; Batista & Silva, 2002]:
• los servidores Web guardan el comportamiento de los visitantes del sitio Web,
• la recoleccion de datos del lado del cliente puede ser implementada usando agentes remotos o modificando los navegadores existentes, y
• los servidores proxy actuan como un nivel intermedio de cacheo entre los navegadores de los clientes y los servidores Web.
Estos datos pueden diferir en su contenido y en la forma en que es obtenida. Los datos de uso recolectados de diferentes orígenes representan los patrones de navegación de diferentes segmentos del tráfico de Internet, yendo desde el comportamiento de un usuario único en un sitio Web hasta el comportamiento de varios usuarios en varios sitios Web. La información provista por los distintos orígenes puede ser usada para construir varias abstracciones de datos diferentes [Abraham & Ramos, 2003; Batista & Silva, 2002].
La limpieza de los datos almacenados en los archivos de log involucra el tratamiento de los valores fuera de rango, los errores en los datos y los datos incompletos, que pueden ocurrir fácilmente debido a varias razones inherentes a la navegación Web. Los campos más comunes de un archivo log de un servidor Web incluyen: dirección IP del cliente, hora de acceso, método de petición, URL de la página accedida, protocolo de transmisión de datos, código de retorno, cantidad de bytes transmitidos por el servidor al cliente y el tipo de navegador utilizado. Los servidores Web pueden también capturar en que página esta localizado el usuario cuando realiza el próximo pedido.
Con esta información se debe identificar a los usuarios y las sesiones de los mismos. Sin embargo, los datos recolectados en los logs pueden no ser enteramente confiables debido a que algunas páginas pueden ser almacenadas en la memoria cache del navegador del usuario o por un servidor proxy. Además, para un servidor Web, todos los pedidos desde un servidor proxy poseen el mismo identificador aunque los pedidos representen a mas de un usuario, y es posible que varios usuarios accedan a una página almacenada en la memoria cache del servidor proxy y, por ende, el servidor Web solo reciba un único pedido. El servidor Web puede además guardar otro tipo de información de uso, como las cookies, que son marcadores generados por el servidor Web para cada cliente individual, permitiendo rastrear automáticamente a los visitantes del sitio, o mediante la registración de los usuarios, pero cada método posee sus contratiempos [Pitkow, 1997].
Una vez que cada usuario ha sido identificado (por medio de cookies, por medio de un inicio de sesión o por medio de un análisis de los datos del log de acceso del servidor), la secuencia de vínculos para cada usuario puede ser dividido en sesiones. El principal problema del protocolo HTTP es que no posee indicación del estado (stateless), de forma que es imposible saber cuando un usuario abandona el servidor, por lo se deben realizar algunos supuestos para identificar las sesiones [Chen et al., 1996; Batista & Silva, 2002; Marbán Gallego, 2002, Hochsztain, 2002].

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 24 -
2.3.2. Descubrimiento de Patrones
La etapa siguiente es el descubrimiento de patrones mediante diversas técnicas disponibles, como por ejemplo, el análisis estadístico, el descubrimiento de reglas de asociación, el agrupamiento, la clasificación y los patrones secuenciales [Srivastava et al., 2000; Pierrakos et al., 2001; Batista & Silva, 2002; Eirinaki & Vazirgiannis, 2003; Chen et al., 1996].
El método más común y simple que puede ser aplicado es el análisis estadístico. Este análisis estadístico puede ser utilizado por los administradores Web para obtener información sobre la carga actual del servidor. Sin embargo, los datos estadísticos disponibles solo pueden proveer la información explícita debido a la naturaleza y las limitaciones de la metodología. Para sitios Web pequeños, estas estadísticas de uso pueden ser adecuadas para analizar los patrones y las tendencias de uso; pero cuando el tamaño y la complejidad del sitio aumenta, estas estadísticas se vuelven inadecuadas y son necesarias otras técnicas [Abraham & Ramos, 2003; Eirinaki & Vazirgiannis, 2003].
Las reglas de asociación es una técnica para encontrar patrones, asociaciones y correlaciones frecuentes entre conjuntos de ítems. Las reglas de asociación son utilizadas para revelar la correlación entre páginas accedidas en forma conjunta durante una única sesión de un usuario. Tales reglas indican la posible relación entre páginas que son a menudo vistas juntas aunque no estén conectadas directamente, y puede revelar asociaciones entre grupos de usuarios con intereses específicos. Además de poder ser explotadas para cuestiones de negocios, tales observaciones pueden ser utilizadas para una reestructuración del sitio Web, agregando, por ejemplo, vínculos entre las páginas accedidas generalmente juntas, o para mejorar la eficiencia, precargando páginas.
El descubrimiento de patrones secuenciales es una extensión a las reglas de asociación en el cual los patrones incorporan la noción del tiempo. En el dominio de la Web, tales patrones podrían corresponder con una página Web o un conjunto de páginas Web que son accedidas inmediatamente después de otro conjunto de páginas. Utilizando esta información pueden ser descubiertas tendencias de los usuarios útiles y pueden realizarse predicciones de las visitas de los usuarios.
La agrupación es utilizada para juntar ítems que poseen características similares. En el contexto de la minería de hábitos en Web, se pueden distinguir dos casos, agrupamiento de usuarios y agrupamiento de páginas. El agrupamiento de páginas identifica conjuntos de páginas que parecen estar conceptualmente relacionadas de acuerdo a la percepción de los usuarios. El agrupamiento de usuarios produce conjuntos de usuarios que poseen un comportamiento similar cuando navegan el sitio Web. Tal conocimiento es utilizado en el comercio electrónico para realizar una segmentación del mercado, pero también es útil cuando el objetivo es la personalización del sitio Web.
La clasificación es un proceso que mapea un ítem en una de varias clases predeterminadas. En el dominio de la Web, las clases representan usualmente diferentes perfiles de usuarios y la clasificación es realizada utilizando características seleccionadas que describen cada categoría de usuario [Eirinaki & Vazirgiannis, 2003; Srivastava et al., 2000].

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 25 -
2.3.3. Análisis de Patrones
La última etapa del proceso completo de explotación de hábitos en Web es el análisis de los patrones encontrados en la etapa anterior, filtrando reglas o patrones no interesantes, y utilizando métodos de visualización útiles para su análisis [Srivastava et al., 2000; Batista & Silva, 2002], realizando proyecciones dinámicas, filtros, zoom y distorsiones interactivas sobre los gráficos generados [Keim, 2002; Ankerst, 2001].
2.4. Trabajos Realizados en la Explotación de Datos de Uso de la Web
Mucho trabajo se ha realizado en la extracción de patrones de información de los logs de los servidores Web y las aplicaciones del conocimiento descubierto van desde la perfección del diseño y la estructura del sitio Web hasta permitir que los negocios funcionen más eficientemente [Paliouras et al., 2000; Pazzani & Billsus, 1997; Perkowitz & Etzioni, 1998; Pirolli et al., 1996; Spiliopoulou & Faulstich, 1999; Abraham & Ramos, 2003]. Debido a que es muy importante conocer al cliente para cumplir mejor sus necesidades, las compañías también están destinando dinero en el análisis de sus archivos de log. Como consecuencia, aparte de las herramientas que fueron desarrolladas por investigadores académicos, existen simultáneamente un número significativo de herramientas comerciales que han sido desarrolladas para cumplir estas necesidades [Kerkhofs, 2001].
[Jespersen et al., 2002] propuso un acercamiento híbrido para analizar las secuencias de páginas accedidas por los usuarios, utilizando una combinación de probabilidades gramáticas de hipertexto y una tabla rápida de vínculos para la minería de los logs; en cambio [Borges & Levene, 2000], combina las probabilidades gramaticas de hipertexto con heurísticas para capturar patrones de navegación de los usuarios. KOINOTITES, presentado por [Pierrakos et al., 2001], realiza agrupamiento de usuarios mediante un algoritmo basado en grafos. LOGSOM propuesto por [Smith & Ng, 2002], utiliza una red neuronal SOM para organizar las páginas Web en un mapa bidimensional basado únicamente en el comportamiento de navegación del usuario, en vez del contenido de las páginas Web. LumberJack propuesto por [Chi et al., 2002] construye perfiles de usuarios combinando agrupamiento de sesiones de usuarios y análisis de trafico estadístico tradicional utilizando el algoritmo K-means. En [Abraham & Ramos, 2003] se utiliza el agrupamiento basado en el comportamiento de las colonias de hormigas y la programación genética para descubrir patrones de uso y para analizar la tendencia de los usuarios. El framework i-Miner [Abraham, 2003] utiliza un algoritmo difuso de agrupamiento implementado con un algoritmo evolutivo y un sistema difuso de inferencias basado en una combinación de algoritmos evolutivos y redes neuronales. [Yan et al., 1996] realiza agrupación en los datos de los logs para identificar usuarios que accedieron a páginas similares. [Cohen et al., 1998] utiliza los patrones de tráfico de un sitio Web extraídos de los logs para mejorar la performance de un sitio Web. [Koutsoupias, 2002] utiliza el análisis de correspondencia para explorar los logs en busca de patrones de navegación. [Nasraoui & Pavuluri, 2004] proponen un sistema de recomendación de páginas Web

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 26 -
basado en perfiles de usuarios utilizando redes neuronales. [Rangarajan et al., 2003] realiza un agrupamiento de usuarios utilizando una red neuronal ART (teoría de la Resonancia Adaptativa). Otras herramientas desarrolladas por investigadores académicos son WebSIFT [Cooley et al., 1999] y Web Utilization Miner [Spiliopoulou & Faulstich, 1999]. LOGML (Log Markup Language) propuesto por [Punin et al., 2001], implementa un lenguaje de marcas basado en XML para almacenar la información del uso de los sitios Web.
Mucho trabajo de investigación ha sido realizado en la personalización de sitios Web [Lalani, 2003]. Adaptative Sites usa información acerca de los patrones de acceso de los usuarios para mejorar la organización y la presentación para diferentes tipos de usuarios [Perkowitz & Etzioni, 1997]. [Mobasher et al., 1999] y [Mobasher et al., 2001] proponen técnicas para capturar perfiles de usuarios utilizando reglas de asociación y la agrupación de páginas basada en el uso de los visitantes. [Spiliopoulou et al., 2000] desarrollo una metodología para asegurar la calidad de un sitio Web basada en el descubrimiento y comparación de patrones de navegación de clientes y no-clientes, proponiendo una técnica de adaptación de sitios dinámicamente. Un algoritmo para reorganizar un sitio Web utilizando la clasificación de páginas y la frecuencia de acceso de las mismas, es propuesto por [Fu et al., 2001]. Una herramienta es desarrollada y descripta en [Masseglia et al., 1999] que permite personalizar un sitio Web dinámicamente. [Kitsuregawa et al., 2001] realiza descubrimiento de reglas de asociación para descubrir patrones de comportamiento interesantes de usuarios en dispositivos móviles. La búsqueda de ubicaciones de páginas que son diferentes a las que los usuarios esperan que sean, también ayuda a la reestructuración del sitio Web [Srikant & Yang, 2001].
Ejemplos de aplicaciones comerciales incluyen:
• WebTrends desarrollada por NetIQ (http://www.netiq.com/webtrends/),
• WebAnalyst por Megaputer (http://www.megaputer.com/products/wa/),
• NetTracker por Sane Solutions (http://www.sane.com/products/NetTracker/),
• EasyMiner, desarrollada por MINEit Software Ltd.,
• NetGenesis, desarrollada por CustomerCentric (http://www.customercentricsolutions.com/content/solutions/ent_Web_analytics.cfm).
Mientras la mayoría de las aplicaciones de análisis del uso de sitios Web se focalizan en un solo sitio, la compañía de publicidad DoubleClick (http://www.doubleclick.com/), vendiendo y administrando 2.000 millones de publicidades online por día, recolecta gigabytes de datos de acceso de diferentes sitios Web. Los logs de los motores de búsqueda también proveen de conocimiento acerca del comportamiento de los usuarios en las búsquedas de la Web. Varios análisis han sido realizados en los logs del motor de búsqueda Excite (http://www.excite.com/) [Jansen et al., 2000; Spink & Xu, 2000; Spink et al., 2001]. [Silverstein et al., 1999] también conduce un estudio de 153 millones de consultas a buscadores recolectadas de AltaVista (http://www.altavista.com/). Algunos de las búsquedas más interesantes de estos análisis incluyen el conjunto de las palabras más utilizadas en las consultas a los buscadores Web, el largo promedio de las consultas, el uso de operadores boléanos en las consultas, y la cantidad promedio de páginas del resultado

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 27 -
vistas por los usuarios. Tal información es muy útil para que los investigadores intenten alcanzar un mejor entendimiento del comportamiento en las búsquedas y en la información buscada, para mejorar el diseño de los sistemas de búsqueda de la Web [Chen et al., 1996].
Un completo resumen de las investigaciones realizadas en la identificación de hábitos de uso de sitios Web puede encontrarse en [Cooley, 2000; Kosala & Blockeel, 2000; Srivastava et al., 2000; Koutri et al., 2004, Eirinaki & Vazirgiannis, 2003].
Además existen varias aplicaciones que proveen de estadísticas de uso de sitios Web, como Analog, ClickTracks, Hitbox, LogRover, Website Tracker, WebStat, WUSAGE, Analog, Count Your Blessings, Webalizer o Awstats. Estas herramientas de análisis de logs (también llamadas herramientas de análisis de trafico) toman como entrada el log del servidor Web y lo procesan para extraer información estadística. Tal información incluye estadísticas como el número total de visitas, promedio de visitas por intervalo de tiempo, pedidos de páginas exitosos, fallidos o redirigidos, errores del servidor, errores de páginas no encontradas, páginas más visitadas, páginas de entrada y salida del sitio, principales ubicaciones geográficas de los visitantes, navegadores de los visitantes, etc.. Algunas herramientas también realizan análisis de secuencias de páginas visitadas, que identifican caminos seguidos por los visitantes a través del sitio, agrupando pedidos consecutivos desde la misma IP. Con estas estadísticas usualmente se realizan reportes y diagramas [Eirinaki & Vazirgiannis, 2003]. Estas estadísticas pueden ser útiles para los administradores Web para obtener información sobre la carga actual del servidor. Sin embargo, los datos estadísticos disponibles pueden proveer solo la información explícita debido a la naturaleza y las limitaciones de la metodología. Para sitios Web pequeños, estas estadísticas de uso pueden ser adecuadas para analizar los patrones y las tendencias de uso; pero cuando el tamaño y la complejidad del sitio aumenta, estas estadísticas se vuelven inadecuadas y son necesarias otras técnicas [Roussinov & Zhao, 2003; Yang & Zhang, 2003; Abraham, 2003; Zhang & Dong, 2003; Abraham & Ramos, 2003].
2.5. Self Organizing Maps (SOM)
Existen evidencias que demuestran que en el cerebro hay neuronas que se organizan en muchas zonas, de forma que las informaciones captadas del entorno a través de los órganos sensoriales se representan internamente en forma de mapas bidimensionales [Beveridge, 1996]. Por ejemplo, en el sistema visual se han detectado mapas del espacio visual en zonas del córtex (capa externa del cerebro); también en el sistema auditivo se detecta una organización según la frecuencia a la que cada neurona alcanza mayor respuesta [Hilera & Martínez, 2000].
Aunque en gran medida esta organización neuronal está predeterminada genéticamente, es probable que parte de ella se origine mediante el aprendizaje. Esto sugiere, por tanto, que el cerebro podría poseer capacidad inherente de formar mapas topológicos de las informaciones recibidas del exterior.
A partir de estas ideas, Teuvo Kohonen presentó en 1982 un sistema con un comportamiento semejante; se trata de un modelo de red neuronal con capacidad para

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 28 -
formar mapas de características de manera similar a como ocurre en el cerebro. El objetivo de Kohonen era demostrar que un estímulo externo (información de entrada) por sí solo, suponiendo una estructura propia y una descripción funcional del comportamiento de la red, era suficiente para forzar la formación de mapas.
2.5.1. Algoritmo del SOM
El algoritmo de aprendizaje del SOM está basado en el aprendizaje no supervisado y competitivo, lo cual quiere decir que no se necesita intervención humana durante el mismo y que se necesita saber muy poco sobre las características de la información de entrada. Podríamos, por ejemplo, usar un SOM para clasificar datos sin saber a qué clase pertenecen los mismos [Hollmen, 1996]. El mismo provee un mapa topológico de datos que se representan en varias dimensiones utilizando unidades de mapa (las neuronas) simplificando el problema [Kohonen, 1995]. Las neuronas usualmente forman un mapa bidimensional por lo que el mapeo ocurre de un problema con muchas dimensiones en el espacio a un plano. La propiedad de preservar la topología significa que el mapeo preserva las distancias relativas entre puntos. Los puntos que están cerca unos de los otros en el espacio original de entrada son mapeados a neuronas cercanas en el SOM; por lo tanto, el SOM sirve como herramienta de análisis de clases de datos de muchas dimensiones [Vesanto & Alhoniemi, 2000]; además tiene la capacidad de generalizar [Essenreiter et al., 1999], lo que implica que la red puede reconocer o caracterizar entradas que nunca antes ha encontrado; una nueva entrada es asimilada por la neurona a la cual queda mapeada.
2.5.2. Arquitectura de la red SOM
Es una red de dos capas con N neuronas de entradas y M neuronas de salida. Cada una de las N neuronas de entrada se conecta a las M de salida a través de conexiones hacia delante (feedforward).
Entre las neuronas de la capa de salida, puede decirse que existen conexiones laterales de inhibición (peso negativo) implícitas, pues aunque no estén conectadas, cada una de estas neuronas va a tener cierta influencia sobre sus vecinas. El valor que se asigne a los pesos de las conexiones feedforward entre las capas de entrada y salida (wij) durante el proceso de aprendizaje de la red va a depender precisamente de esta interacción lateral.
La influencia que cada neurona ejerce sobre las demás es función de la distancia entre ellas, siendo muy pequeña cuando están muy alejadas. Debido a que la red SOM intenta establecer una correspondencia entre los datos de entrada y un espacio bidimensional de salida, creando mapas topológicos de dos dimensiones, de tal forma que ante datos de entrada con características comunes se deben activar neuronas situadas en zonas próximas de la capa de salida, se debe entender la distancia entre las neuronas de la capa de salida como una zona bidimensional que existe en torno a cada neurona. Esta zona puede ser circular, hexagonal o cualquier otro polígono regular centrado en la neurona en cuestión.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 29 -
En el algoritmo básico del SOM, las relaciones topológicas y el número de neuronas son fijos desde el comienzo; este número de neuronas determina la escala o la granularidad del modelo resultante. La selección de la granularidad afecta la certeza y la capacidad de generalizar del modelo. Debe tenerse en cuenta que la granularidad y la generalización son objetivos contradictorios. Mejorando el primero, se pierde en el segundo, y viceversa. Esto se debe a que si aumentamos el primero se obtendrán muchos más grupos para poder clasificar los datos de entrada, evitando que se pueda generalizar el espacio en clases más abarcativas. De manera inversa, si se generaliza demasiado se puede perder información que caracterice a un grupo específico que quede incluido en otro por la falta de granularidad [Grosser, 2004].
2.5.3. Funcionamiento
Cuando se presenta a la entrada una información Ek = (e1k, e2k,...,enk), cada una de las M neuronas de la capa de salida la recibe a través de las conexiones feedforward con pesos wij. También estas neuronas reciben las entradas correspondientes a las interacciones laterales con el resto de las neuronas de salida y cuya influencia dependerá de la distancia a la que se encuentren.
Así, la salida generada por una neurona de salida j ante un vector de entrada Ek será:
∑ ∑= =
+=+N
i
M
pppj
kiijj tSIntewftS
1 1
)( ))(()1(
Ecuación 2-2
Donde pjInt es una función del tipo sombrero mejicano que representa la influencia
lateral de la neurona p sobre la neurona j. La función de activación de las neuronas de salida (f) será del tipo continuo, lineal o sigmoidal, ya que esta red trabaja con valores reales.
Es evidente que se trata de una red de tipo competitivo, ya que al presentarse una entrada Ek, la red evoluciona hasta alcanzar un estado estable en el que solo hay una neurona activada, la ganadora. La formulación matemática del funcionamiento de esta red puede simplificarse así [Hilera & Martínez, 2000]:
→
−=−→= ∑
=
resto
weMINWEMINS
N
iij
kijk
si
j
0
))((||||11
2)(
Ecuación 2-3
Donde |||| jk WE − es una medida de la diferencia entre el vector de entrada y el
vector de pesos de las conexiones que llegan a la neurona j desde la entrada. Es en estos

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 30 -
pesos donde se registran los datos almacenados por la red durante el aprendizaje. Durante el funcionamiento, lo que se pretende es encontrar el dato aprendido más parecido al de entrada para averiguar qué neurona se activará y en qué zona del espacio bidimensional de salida se encuentra.
La red SOM realiza una tarea de clasificación ya que la neurona de salida activada ante una entrada representa la clase a la que pertenece dicha información. Además, como ante otra entrada parecida se activa la misma neurona o una cercana a la anterior, se garantiza que las neuronas topologicamente cercanas sean sensibles a entradas físicamente similares. Por esto, la red es muy útil para establecer relaciones antes desconocidas entre conjunto de datos.
2.5.4. Preprocesamiento de los datos
Los datos que alimentan al SOM incluyen toda la información que toma la red. Si se le presenta información errónea, el resultado es erróneo o de mala calidad. Entonces, el SOM, tanto como los otros modelos de redes neuronales, deben eliminar la información “basura” para que no ingrese al sistema. Por lo cual se debe trabajar con un subconjunto de los datos; estos deben ser relevantes para el modelo a analizar. También se deben eliminar los errores en los datos; si los mismos se obtienen a través de una consulta a una base de datos, el resultado puede incluir datos erróneos debido a la falta de integridad de la base; entonces estos deben ser filtrados usando conocimientos previos del dominio del problema y el sentido común.
Comúnmente los componentes de los datos de entrada se normalizan para tener una escala de 0 a 1. Esto asegura que por cada componente, la diferencia entre dos muestras contribuye un valor igual a la distancia medida calculada entre una muestra de entrada y un patrón. Es decir que los datos deben previamente codificarse (normalizarse). De lo contrario no será posible usar la distancia como una medida de similitud. Esta medida debe ser cuantificable por lo que la codificación debe ser armónica con la medida de similitud utilizada. La medida mayormente utilizada es la distancia Euclídea. Los datos simbólicos no pueden ser procesados por un SOM como tales, por lo que deben ser transformados a una codificación adecuada.
2.5.5. Aprendizaje
El aprendizaje en las redes SOM es del tipo off line, por lo que se distingue una etapa de aprendizaje y otra de funcionamiento. En la etapa de aprendizaje se fijan los pesos de las conexiones feedforward entre las capas de entrada y salida.
Esta red emplea un aprendizaje no supervisado de tipo competitivo. Las neuronas de la capa de salida compiten por activarse y solo una de ellas permanece activa ante una entrada determinada. Los pesos de las conexiones se ajustan en función de la neurona que haya resultado vencedora.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 31 -
Durante la etapa de entrenamiento, se presenta a la red un conjunto de informaciones de entrada (vectores de entrenamiento) para que esta establezca, en función de la semejanza entre los datos, las diferentes clases (una por neurona de salida) que servirán durante la fase de funcionamiento para realizar clasificaciones de nuevos datos que se presenten a la red. Los valores finales de los pesos de las conexiones feedforward que llegan a cada neurona de salida se corresponderán con los valores de los componentes del vector de aprendizaje que consigue activar la neurona correspondiente. Si existiesen más vectores de entrenamiento que neuronas de salida, más de un vector deberá asociarse a la misma clase. En tal caso, los pesos se obtienen como un promedio de dichos patrones.
Durante el entrenamiento habrá que ingresar varias veces todo el juego de entrenamiento para refinar el mapa topológico de salida consiguiendo que la red pueda realizar una clasificación más selectiva.
El algoritmo de aprendizaje es el siguiente [Hilera & Martínez, 2000]:
1. En primer lugar, se inicializan los pesos (wij) con valores aleatorios pequeños y se fija la zona inicial de vecindad entre las neuronas de salida.
2. A continuación se presenta a la red una información de entrada en forma de vector ),...,,( )()(
2)(
1k
nkk
k eeeE = , cuyas componentes serán valores continuos.
3. Se determina la neurona vencedora a la salida. Esta será aquella j cuyo vector de pesos Wj sea el más parecido a la información de entrada kE . Para ello se calculan las distancias entre ambos vectores, una para cada neurona de salida. Se suele utilizar la distancia euclídea o bien la siguiente expresión similar sin la raíz:
10. ∑=
−=N
iij
kij wed
1
2)( )( Mj ≥≤1
Ecuación 2-4
11. Donde:
12. )(kie : Componente i-ésimo del vector k-ésimo de entrada.
13. ijw : Peso de la conexión entre las neuronas i (de entrada) y j (de salida).
4. Una vez localizada la neurona vencedora j*, se actualizan los pesos de las conexiones feedforward que llegan a dicha neurona y a sus vecinas. Con esto se consigue asociar la información de entrada con cierta zona de la capa de salida.
14. [ ])()()()1( *)( twettwtw ij
kiijij −+=+ α )(* tZonaj j∈
Ecuación 2-5
15.
16. )(* tZonaj es la zona de vecindad de la neurona vencedora j*. El tamaño de la zona
se puede reducir en cada iteración del entrenamiento aunque en la practica es habitual mantener esa zona fija.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 32 -
17. El termino )(tα es el coeficiente de aprendizaje y toma valores entre 0 y 1. Este parámetro decrece con cada iteración. De esta forma, cuando se ha presentado todo el juego de datos un gran numero de veces, alfa tiende a cero y las variaciones de pesos son insignificantes.
18. )(tα suele tener alguna de las siguientes expresiones:
19. t
t1
)( =α
−=
21 1)(
ααα t
t
Ecuación 2-6
5. El proceso se repite un mínimo de 500 veces (t>=500).
2.5.6. Visualización
El SOM es una aproximación de la función de densidad de probabilidad de los datos de entrada [Kohonen, 1995] y puede representarse de una manera visual.
La representación U-Matrix (Unified Distance Matrix) del SOM visualiza la distancia entre neuronas adyacentes [Figura 2.2]. La misma se calcula y se presenta con diferentes colores entre los nodos adyacentes. Un color oscuro entre neuronas corresponde a una distancia grande que representa un espacio importante entre los valores de los patrones en el espacio de entrada. Un color claro, en cambio, significa que los patrones están cerca unos de otros. Las áreas claras pueden pensarse como “clases” y las oscuras como “separadores”. Esta puede ser una representación muy útil de los datos de entrada sin tener información a priori sobre las clases.
Figura 2.2. Representación U-Matrix
En la [Figura 2.2] podemos observar las neuronas indicadas por un punto negro. La representación revela que existe una clase separada en la esquina superior derecha de la red. Las clases están separadas por una zona negra. Este resultado se logra con aprendizaje no supervisado, es decir, sin intervención humana. Enseñar a un SOM y representarla con la U-Matrix ofrece una forma rápida de analizar la distribución de los datos.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 33 -
2.5.7. Aplicaciones
Se ha demostrado que los SOM son muy útiles en aplicaciones técnicas. En la industria, se ha utilizado, por ejemplo, en monitoreo de procesos y máquinas, identificación de fallas y control de robots [Ritter et al., 1992].
La capacidad de dividir el espacio en clases y patrones representativos lo hace muy poderoso también para la clasificación y segmentación de los datos; en el caso de estudio de este trabajo se presentan miles de sesiones de usuario de acceso a un sitio Web y las redes SOM clasifican a los usuarios en base a sus hábitos.
2.6. Similitudes y Diferencias SOM y K-Means
En el presente trabajo se descubrirán grupos de usuarios en base a los hábitos de uso de los mismos. Este agrupamiento se llevará a cabo mediante una red neuronal SOM y mediante el algoritmo K-Means, de modo de comparar los resultados obtenidos por cada método. Por ello es interesante conocer las similitudes y diferencias entre estos dos métodos de agrupamiento.
La red neuronal SOM y el algoritmo K-Means permiten segmentar conjuntos de datos. Estos dos métodos poseen varias similitudes y diferencias.
Las similitudes entre la red neuronal SOM y el algoritmo K-Means son detalladas en la siguiente tabla [Tabla 2.1]:
SOM K-Means
Tarea realizada Segmentación. Segmentación.
Supervisión necesaria Ninguna. Ninguna.
Función de Distancia Es necesario definir una función de distancia a utilizar para la determinación de la neurona vencedora.
Es necesario definir una función de distancia para poder asociar cada dato a su centroide más cercano.
Necesita etapa de aprendizaje
Si. Si.
Tabla 2.1 Similitudes SOM y K-Means

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 34 -
La diferencias entre la red neuronal SOM y el algoritmo K-Means son detalladas en la tabla a continuación [Tabla 2.2]:
SOM K-Means
Tipo de segmentador Red Neuronal. Método Particional.
Cantidad de grupos a descubrir
Mapa bidimensional de NxN, donde N es un parámetro del método.
Construye K grupos, siendo K un parámetro del método.
Características de los datos de entrada
Normalización de los datos de entrada para tener una escala de 0 a 1.
Los datos deben ser representables en un sistema de dimensión n, donde n es la cantidad de atributos de los datos de entrada.
Sensibilidad a los parámetros iniciales
Deben inicializarse los pesos de las conexiones con valores aleatorios pequeños, pero esta asignación no produce generalmente grandes modificaciones en el resultado de la red.
Deben elegirse los centroides iniciales. K-Means es sensible en la elección de estos centroides con respecto al resultado que se obtendrá del algoritmo.
Posibilidad de determinar grupos más parecidos a otros
Los grupos más cercanos en el mapa bidimensional son más parecido que los alejados entre sí.
No se pueden determinar grupos más parecidos a otros.
Tabla 2.2 Diferencias SOM y K-Means

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 35 -
3. Descripción del problema
La identificación de hábitos de uso de sitios Web ha sido obtenida tradicionalmente utilizando métodos estadísticos, con la consiguiente limitación de estos para obtener resultados novedosos e inesperados. Existen numerosas herramientas capaces de realizar estos análisis estadísticos, pero no logran obtener información más allá de la que se encuentra explícita en los registros de acceso de los servidores Web.
A medida que crece Internet y, por consiguiente, los sitios Web en la misma, se hace más importante la capacidad de adaptación de estos a sus usuarios, de modo de poder diferenciarse de la competencia.
Mediante la utilización de un red neuronal mapa auto-organizativo (SOM), se pueden encontrar de forma automática relaciones no evidentes entre los usuarios de un sitio Web, separándolos en distintos grupos. De esta forma, la información obtenida a partir de los mismos, puede ser utilizada para adaptar el sitio a cada grupo de usuario y lograr una mejor posición frente a la competencia.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 36 -
4. Solución propuesta
En este capítulo se describe la respuesta al problema planteado. Se identifican los parámetros del problema (sección 4.1), se plantean definiciones necesarias (sección 4.2). Se describe el origen de los casos de experimentación (sección 4.3). Finalmente, se realiza una descripción del Banco de Pruebas (sección 4.4), abordando sus funcionalidades (sección 4.4.1) y describiendo su dinámica de funcionamiento (sección 4.4.2).
4.1. Identificación de los parámetros del problema
En esta sección se identifican los parámetros del problema, realizando luego algunas definiciones necesarias para la correcta comprensión de la terminología utilizada en el presente trabajo.
Los parámetros del problema que han sido identificados se muestran en la siguiente tabla [Tabla 4.1]:
Descripción del Parámetro Nemotécnico
Cantidad de registros en el log del servidor Web logCount
Cantidad de páginas distintas en el sitio Web a analizar pageCount
Formato del archivo de log a utilizar. logFormat
Extensiones de recursos incluídas en el armado de sesiones de usuarios.
pageExtensions
Códigos de error http considerados en la construcción de sesiones de usuarios.
validsStatus
Variables identificadoras de páginas. idsPages
Tiempo máximo entre peticiones consecutivas en una sesión de usuario.
timeoutSession
Cantidad mínima de páginas en una sesión de usuario. minPagesInSession
Frecuencia mínima de página en los registros de log del servidor Web.
minPageFrequency
Cantidad de ciclos de entrenamiento de la red neuronal SOM.
trainingCicles

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 37 -
Cardinalidad del mapa de clusterización de la red neuronal SOM (NxN).
dimClusters
Cantidad de clusters a descubrir mediante el algoritmo K-Means.
K
Tabla 4.1 Parámetros identificados del problema
4.2. Definiciones
Para la mejor comprensión de cierta terminología utilizada en el presente trabajo, es útil definir:
• Archivos de Log
• Preprocesamiento de Logs
• Limpieza de Logs
• Identificación de Usuarios
• Identificación de Sesiones de Usuario
• Identificación de Transacciones de Usuarios
• Identificación de hábitos de Usuario
4.2.1. Archivos de Log
Cada acceso a una página de un sitio Web, como así también, la petición de cada imagen, sonido, etc., es almacenada en los logs de acceso de los servidores Web donde se encuentra el sitio. Los archivo de log de un servidor Web poseen distintos campos, siguiendo estándares [Eirinaki & Vazirgiannis, 2003]. Los campos del Formato Común de Log (CLF, Common Log Format) son:
IP-Cliente Identd Usuario Fecha/Hora “Pedido” Estado Bytes
Donde:
• IP-Cliente es la dirección IP del usuario que realiza la petición o, el nombre de la computadora del mismo si el servidor Web esta configurado para resolver las direcciones IP al nombre;
• Identd es el nombre del usuario remoto, siguiendo la RFC 1413 [RFC 1413];

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 38 -
• Usuario es el nombre de usuario que se autentico mediante http, en las páginas que utilicen esta autenticación;
• Fecha/Hora es la fecha y la hora en que fue realizada la petición al servidor Web;
• Pedido es el pedido que el cliente realizo al servidor, que generalmente incluye el método http utilizado, el URL solicitado y el protocolo empleado;
• Estado es el código de estado http devuelto al cliente, indicando si el pedido pudo realizarse correctamente o no, y en este ultimo caso, el error ocurrido; y
• Bytes es la cantidad de bytes devueltos al cliente a causa de la petición del mismo. Si algunos de los campos no pueden ser determinados, un guión (-) es colocado en su lugar.
Luego, la W3C [W3Clog] presentó un formato mejorado para los archivos de logs de los servidores Web denominado Formato Extendido de Log (EFF, Extended Log Format). Este formato permite la personalización de los archivos de log para que sean almacenados en un formato soportado por las herramientas de análisis genéricas. La principal extensión al formato de log común es la incorporación de campos. Los más importantes son el campo Referrer, que indica la URL desde donde se realiza cada petición; el campo Agente, donde se indica qué aplicación esta utilizando el cliente para realizar las peticiones; y el campo Cookie, para almacenar las cookies de los usuarios del sitio Web, en caso que el mismo las utilice.
4.2.2. Preprocesamiento de Logs
Un paso crítico en la efectividad de la identificación de hábitos de uso de sitios Web es la limpieza y la transformación de los archivos de log del servidor Web, y la identificación de las sesiones de los usuarios [Mobasher, 1999].
La W3C Web Characterization Activity [WCA] ha publicado un borrador donde establece en forma precisa el significado de varios conceptos, como Web site (sitio Web), user (usuario), user session (sesion de usuario), server session (sesión de servidor), pageview (página vista) y clickstreams (secuencia de clicks o vínculos).
Un sitio Web se define como una colección de páginas Web vinculadas, las cuales residen en la misma ubicación de red. El usuario es quien utiliza un cliente para obtener y ver recursos del servidor. Un usuario accede a los archivos de un servidor Web utilizando un navegador. Una sesión de usuario se define como un conjunto de vínculos seguidos por el usuario a través de uno o más servidores Web. Una sesión de servidor se define como la colección de vínculos seguidos por un usuario en un único servidor Web, durante una sesión de usuario. También se denomina visita. Una página vista se define como una página vista en un momento preciso. En otras palabras, una página vista consiste de varios ítems, como marcos, texto, gráficos y scripts que construyen una única página Web. Una secuencia de clicks o vínculos es una secuencia de páginas vistas realizadas por un único usuario [Eirinaki & Vazirgiannis, 2003].

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 39 -
4.2.3. Limpieza de Logs
La limpieza de los log de los servidores Web involucra varias tareas [Huysmans et al., 2003; Mobasher, 1999; Pierrakos et al., 2001; Lalani, 2003; Kerkhofs, 2001; Cernuzzi & Molas, 2004; Eirinaki & Vazirgiannis, 2003]. Cuando un usuario solicita una página, ese pedido se graba en el archivo de log, pero, además, si la página posee imágenes, se guardará una línea por cada imágen solicitada. Por ejemplo, si la página solicitada posee tres imágenes, en el archivo de log se guardará una línea para la solicitud de la página, y tres líneas adicionales, una para cada imágen. Este comportamiento ocurre con cualquier recurso que este referenciado desde la página solicitada originalmente, como pueden ser archivos con scripts JavaScript, hojas de estilo, animaciones flash, videos, etc.. En la mayoría de los casos, estos registros adicionales almacenados en los archivos log no son necesarios para la tarea de identificación de hábitos de navegación de los usuarios. Por esta causa, es conveniente filtrar todos los registros del log donde los recursos solicitados pertenezcan a algunos de estos tipos, tarea fácilmente llevada a cabo, mediante la extensión del archivo solicitado. Se podrían filtrar todos los registros cuyos archivo solicitados posean las extensiones jpg, jpeg, gif, js, css, swf, avi, mov, etc.. Determinar qué extensiones filtrar depende de qué información se busca obtener de la minería del archivo de log. Algunas veces, también es conveniente filtrar algunas páginas contenidas en otras que poseen varios marcos, como por ejemplo una página de información de derechos de copia, incluida en todas las páginas, como un marco inferior. Esta página seguramente no agregará ninguna información adicional para la minería. También puede ser conveniente filtrar algunas páginas generadas dinámicamente.
Otra opción de filtrado es en base a los códigos de error de http guardados en los registros de log. Por cada recurso solicitado al servidor, se almacena el código de error de http, que indica si la petición se procesó correctamente (Código de Error 200) o si ocurrió algún tipo de error. Existen códigos para los distintos tipos de errores, algunos de los más comunes son 404 (Recurso no encontrado), 403 (Acceso denegado) y 500 (Error interno del servidor). Para una completa enumeración y descripción ver RFC 2616 [RFC 2616].
Existen herramientas automatizadas, conocidas como “Web robots”, las cuales recorren las páginas de Internet en forma automática. Estas herramientas son generalmente utilizadas por los motores de búsqueda, para indexar las páginas y guardar la información en sus bases de datos. Estas herramientas, si siguen la convención, primero solicitan el archivo “robots.txt”, donde se especifica qué páginas pueden acceder los robots y cuáles no. Por ende, si se desean filtrar del log las peticiones realizadas por una de estas herramientas, se las puede identificar mediante este comportamiento. Otra forma posible es mediante el campo del registro de log que indica el Agente del cliente. El Agente indica la aplicación o navegador que utiliza el usuario para solicitar los recursos del servidor. Cada robot puede identificarse mediante un nombre, y de esta forma, podemos filtrar las peticiones de los robots mediante este campo.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 40 -
4.2.4. Identificación de Usuarios
Luego de la limpieza de los logs, se debe identificar a los distintos usuarios. Existen distintos métodos para identificar a los usuarios, cada uno de los cuales posee sus ventajas y desventajas.
Un método de identificar a los usuarios es mediante la utilización de cookies [Eirinaki & Vazirgiannis, 2003; Huysmans et al., 2003; Kerkhofs, 2001]. La W3C [WCA] define a una cookie como “datos enviados por el servidor Web al cliente, el cual los almacena localmente y los envía nuevamente al servidor en los sucesivos pedidos”. En otras palabras, una cookie es simplemente una cabecera http que consiste de una cadena de texto. Las cookies son utilizadas para identificar a los usuarios durante las interacciones dentro de un sitio Web y contiene datos que permiten al servidor mantener el registro de las identidades de los usuarios y qué acciones realizan en el sitio Web, permitiendo reconocerlos en todas las visitas que realicen posteriormente. Uno de los problemas del uso de las cookies para la identificación de los usuarios es que los mismos pueden deshabilitar el soporte para cookies en sus navegadores, con lo cual ya no se almacenarán las cookies en el cliente y no se tendrá la posibilidad de identificarlo en las sucesivas visitas. Otro problema se debe al hecho que las cookies son almacenadas en la computadora del usuario. El usuario podría borrarla y, cuando ingrese nuevamente al sitio, será reconocido como un nuevo visitante.
Otra forma de identificar a los usuarios es mediante la utilización de Identd [Eirinaki & Vazirgiannis, 2003]. Identd es un protocolo de identificación especificado en el RFC 1413 [RFC 1413] que permite identificar a los usuarios de una conexión TCP particular. Dado un par de números de puertos TCP, devuelve una cadena de texto, que identifica al dueño de esa conexión (el cliente) en el sistema del servidor Web. El problema del uso de identd para la identificación de los usuarios reside en que el cliente debe estar configurado para el soporte de identd.
También se puede identificar a los usuarios mediante su dirección IP [Huysmans et al., 2003; Kerkhofs, 2001; Eirinaki & Vazirgiannis, 2003; Lalani, 2003], en cada línea del archivo de log se almacena la dirección IP del cliente que realizó el pedido. Algunos de los problemas típicos son [Srivastava et al., 2000]:
• Una dirección IP/Múltiples sesiones de servidor: los proveedores de servicios de Internet (ISPs, por sus siglas en inglés) y las corporaciones poseen tipicamente servidores proxy para que sus usuarios accedan a Internet a través de ellos. Un servidor proxy puede tener muchos usuarios accediendo a un sitio Web, todos los cuales serán registrados en los logs del servidor Web con la misma dirección IP, la dirección IP del servidor proxy.
• Múltiples direcciones IP/Una sesión de servidor: algunos ISPs o algunas herramientas de privacidad asignan aleatoriamente una dirección IP distinta para cada pedido del usuario. En este caso, una única sesión puede tener múltiples direcciones IP.
• Múltiples direcciones IP/Un usuario: un usuario que accede a un sitio Web desde diferentes computadoras tendrá diferentes direcciones IP de una sesión a la otra.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 41 -
• Asignación dinámica de direcciones IP: otro problema es la asignación dinámica de las direcciones IP que realizan comúnmente los ISPs con sus clientes. Por ende, una dirección IP puede identificar a un usuario un día, y al día siguiente, pertenecer a un usuario distinto.
Para intentar minimizar estos problemas se han propuesto distintas técnicas. La primera es utilizar el agente del cliente para diferenciar distintos usuarios que posean la misma dirección IP [Cooley et al, 1999]. Esta técnica tiene el problema de que un usuario que utiliza más de un navegador desde la misma computadora, aparecerá como varios usuarios distintos. También, si varios usuarios distintos que poseen la misma dirección IP, utilizan el mismo agente, serán reconocidos como un único usuario. Otra técnica para minimizar los problemas de la identificación de usuarios mediante la dirección IP es utilizar el campo referrer de los logs, que indica la página desde donde se hace la petición de cada recurso.
Otro método para identificar a los usuarios es mediante la registración explícita de ellos [Huysmans et al., 2003; Kerkhofs, 2001; Eirinaki & Vazirgiannis, 2003], necesitando que cada usuario inicie una sesión en el sitio Web con un usuario previamente registrado por él. Este método tiene el claro problema que se necesita la intervención del usuario y, para algunos tipos de sitios Web, es impracticable.
Muy parecido al último método resulta la utilización del campo Usuario (authuser) de los archivos de log, donde se almacena el nombre del usuario que inició sesión mediante la autenticación de http. Este método posee los mismos inconvenientes que el método anterior.
4.2.5. Identificación de Sesiones de Usuario
Luego de la identificación de los usuarios, se deben identificar las sesiones de los mismos [Kerkhofs, 2001; Eirinaki & Vazirgiannis, 2003; Srivastava et al., 2000]. Para ello se necesita dividir las distintas peticiones realizadas por un mismo usuario en una o más sesiones. Debido a que las peticiones a los recursos de otros servidores Web no están disponibles, es difícil saber cuando un usuario abandona el sitio Web. Para la formación de sesiones se utiliza generalmente un tiempo máximo entre sucesivas peticiones, de modo que, si dos peticiones consecutivas de un usuario se realizan con un intervalo de tiempo menor al máximo, las dos peticiones son consideradas como parte de la misma sesión. Si dos peticiones consecutivas se realizan con un intervalo de tiempo mayor al máximo, las dos peticiones corresponden a sesiones distintas; la primera es la última petición de una sesión y la otra es la primera de una nueva sesión. Se debe seleccionar un tiempo máximo entre peticiones, para lo cual se han realizado investigaciones que buscan encontrar el valor que mejor divida las sesiones de los usuarios. Catledge y Pitkow [Catledge & Pitkow, 1995] establecieron un valor óptimo en forma empírica de 25.5 minutos. Este valor debería ser revisado, como se indica en [Huysmans et al., 2003], debido a que varios factores han cambiado desde la realización de la experimentación por parte de Catledge y Pitkow. Uno de los factores que han cambiado es que ha aumentado considerablemente la cantidad de conexiones de banda ancha, las cuales poseen un tiempo ilimitado de navegación mensual a

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 42 -
un costo fijo. Sin embargo, generalmente, es utilizado el valor de 30 minutos como valor máximo entre dos peticiones de una misma sesión.
Para la identificación de sesiones también puede utilizarse IDs de sesión incluidas en la petición por parte de la aplicación Web [Srivastava et al., 2000], dado que el servidor de contenido puede mantener variables para cada sesión activa. Este método puede ser muy útil, pero su utilización depende del sitio Web a analizar.
Un problema adicional en la identificación de las sesiones de los usuarios son las páginas almacenadas en la memoria cache [Srivastava et al., 2000], ya sea en el cliente o en servidores proxy. El campo referrer puede ser utilizado para detectar algunas de las páginas almacenadas en la memoria cache que fueron accedidas por el usuario. Si una página es accedida por un usuario en una sesión desde una página del mismo sitio, y la petición de esta página no fue registrada en el archivo de log, se puede inferir que dicha página fue accedida y obtenida mediante un cache. El conocimiento de la estructura del sitio también puede ayudar a detectar páginas almacenadas en la memoria cache [Huysmans et al., 2003], de modo que si en el log aparecen dos peticiones consecutivas a dos páginas distintas (A y luego B), las cuales no poseen un vínculo entre ellas, se puede inferir el acceso a la página de conexión (C) entre estas dos páginas. Esto es válido si es poco probable que el usuario acceda directamente a B, o si el usuario no accedió anteriormente a otra página (D) que posea un vinculo a B, debido a que la misma puede haber sido almacenada en la memoria cache, y realmente se este accediendo a B desde D. Se pueden realizar heurísticas basadas en la estructura del sitio y en el campo referrer que mejoren la detección de páginas almacenadas en la memoria cache.
4.2.6. Identificación de Transacciones de Usuarios
Luego de identificar las sesiones de los usuarios, se pueden construir transacciones con las mismas. Una transacción puede contener todas las páginas de una sesión o pueden utilizarse algunas técnicas para filtrar algunas páginas o sesiones [Mobasher, 1999, Huysmans et al., 2003]. Por ejemplo, podrían filtrarse las sesiones con menos de una cantidad predeterminada de páginas o eliminar las referencias a páginas que no poseen una cantidad mínima de visitas por parte de los usuarios. Además, podría querer filtrarse únicamente las sesiones que accedan a páginas de alguna determinada categoría, o filtrarse páginas de alguna otra categoría. En algunas ocasiones puede ser útil diferenciar entre páginas de contenido y páginas auxiliares o de navegación [Cernuzzi & Molas, 2004], donde las páginas de contenido son donde se encuentra la información que resulta de interés para los usuarios, y las páginas de navegación son aquellas utilizadas para encontrar los vínculos a las páginas de contenido. El campo con la fecha y hora de acceso a cada página puede ser utilizado para clasificar a cada página como de contenido o de navegación, dependiendo de la permanencia del usuario en cada una, tiempo estimado sobre la base del cálculo de la diferencia entre la hora de la petición actual y la petición anterior. También pueden armarse las transacciones utilizando la técnica de referencias máximas hacia delante, propuesta por [Chen et al., 1996]. Una referencia máxima hacia delante es una página que se accede antes que otra página sea accedida nuevamente. Por ejemplo, si un usuario visitó las páginas A-B-C-A-D-B, las referencias hacia delante máximas son C y D, ya que en el primer caso C es visitada antes que A sea visitada

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 43 -
nuevamente, y en el segundo caso, D es visitada antes que B sea visitada nuevamente [Lalani, 2003].
Luego del armado de las transacciones, se obtiene la secuencia de páginas accedidas por cada usuario en cada transacción. Esta secuencia se debe transformar en el formato necesario para la posterior tarea de identificación de hábitos de los usuarios.
4.2.7. Identificación de Hábitos de Usuario
Luego del preprocesamiento del log, la limpieza del mismo, la identificación de los usuarios, sus sesiones y transacciones, se procede al descubrimiento de hábitos de los usuarios.
4.3. Método de Generación de Casos de Experimentación
Para evaluar la solución propuesta se realizará el estudio de hábitos de uso de sitios Web en dos sitios, de los cuales se posee los archivos de log. Se realizará una descripción general de cada uno de estos sitios, como así también de cada página que componen a estos.
4.4. Descripción del Banco de Pruebas
El banco de pruebas es la herramienta utilizada para llevar adelante la experimentación.
Para el desarrollo del Banco de Pruebas se utilizó la metodología de desarrollo de sistemas denominada Metodología Métrica Versión 3 [Métrica Versión 3]. En el Apéndice D se detallan todas las actividades de la metodología realizadas para el desarrollo de la herramienta que implementa la solución propuesta en esta tesis.
4.4.1. Funcionalidades
El Banco de Pruebas provee las siguientes funcionalidades:
4.4.1.1. Preprocesamiento de archivos de log
Preprocesamiento de archivos de log de servidores Web, obteniendo la información necesaria de cada registro, y únicamente de los registros considerados importantes por el usuario.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 44 -
Para el presente trabajo se decidió utilizar el formato de log común (CLF) debido a la gran utilización del mismo. También se permite la utilización del formato de log común más los campos Referrer y Agent.
Se realizó la herramienta parametrizable, de modo que las tareas de limpieza puedan ser adaptadas a las necesidades de cada caso. Para ello, se utilizaron distintos filtros a los archivos de log, los cuales permiten que el usuario defina su comportamiento.
El primer filtro que se implementó es un filtro de extensiones de recursos. El usuario puede indicar cuáles extensiones de los recursos deben ser incluídas en el armado de las sesiones de los usuarios. Toda extensión no indicada por el usuario, será filtrada e ignorada para el armado de las sesiones.
El segundo filtro disponible es sobre la base de los códigos de error de http. El usuario indica qué códigos de error son considerados para la tarea de la construcción de las sesiones de usuarios. Solo las líneas del archivo de log que posean los códigos de error especificados por el usuario serán incluídas en el proceso de construcción de sesiones. En forma predeterminada, solo el código de error 200 es considerado.
El tercer filtro disponible viene dado por el amplio empleo actual de páginas generadas dinámicamente. Muchas de estas páginas poseen una plantilla o un controlador, donde son incluidas las distintas páginas. Por ende, en los archivos de log, queda registrada la petición solamente a la página correspondiente a la plantilla o al controlador. En varias ocasiones, se puede diferenciar a las distintas páginas reales incluídas en un sitio debido al uso de una variable que identifica la página a ser incluída. Esta variable es comunicada generalmente mediante el método GET al servidor, por lo cual, el valor de esta variable aparece en la URL de la petición. No es el caso si el método utilizado es POST. El filtro permite indicar qué variables identifican a páginas distintas dentro de una misma plantilla o controlador, de modo de poder ser reconocidas las distintas páginas reales visitadas por el usuario. Este filtro resulta de gran utilidad en la actualidad y se presenta en este trabajo de forma novedosa.
4.4.1.2. Identificación de usuarios
Identificación de los usuarios a partir de los archivos de log preprocesados.
Para la identificación de los usuarios se utilizó la dirección IP, debido a que no se necesita información adicional a la incluida en los log de formato común. Todas las peticiones originadas desde una misma dirección IP son consideradas pertenecientes al mismo usuario. Adicionalmente, se utilizó el usuario de autenticación http, cuando el mismo este disponible para identificar a los distintos usuarios.
4.4.1.3. Identificación de sesiones de usuario
Se construyen las sesiones de usuarios. Las sesiones fueron divididas teniendo en cuenta un tiempo máximo entre peticiones consecutivas consideradas pertenecientes a la misma sesión de usuario. Este tiempo es configurable por el usuario, teniendo el valor por

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 45 -
defecto de treinta minutos. También es posible indicar la cantidad mínima de páginas en una sesión para tomarla en consideración en la posterior tarea de identificación de hábitos de los usuarios. Además, se permite indicar la frecuencia mínima de cada página, filtrando las páginas que posean una frecuencia menor a la mínima en el total de peticiones de todos los usuarios.
4.4.1.4. Identificación de hábitos de uso mediante red neuronal mapa auto-organizativo (SOM)
La solución propuesta consiste en la utilización de una red neuronal SOM para la identificación de hábitos de usuarios. Esta red neuronal debe agrupar a los usuarios de un sitio Web sobre la base de las páginas accedidas por los mismos. Para ello, se debe procesar el archivo de log del sitio a analizar, para identificar a los usuarios y a las sesiones de los mismos. Luego, con estas sesiones de usuarios es entrenada la red, para agrupar a los usuarios de forma automática. La elección de la red neuronal SOM se debe a que posee un entrenamiento no supervisado, permitiendo realizar el agrupamiento de los usuarios en forma automática, sin intervención del usuario mas que para configurar algunos pocos parámetros para el análisis.
Luego de identificar todas las sesiones de los usuarios, se debe generar el formato adecuado para poder ingresar las sesiones como patrones a la red neuronal. Para cada sesión, se indica la presencia (1) o la ausencia (0) de cada página perteneciente al sitio Web, resultando en un vector, de tamaño igual a la cantidad de páginas del sitio, para cada sesión. Cada elemento del vector es un número binario, indicando la presencia o no de la página representada por esa posición. Estos vectores corresponden con los patrones de entrada de la red neuronal utilizada para la identificación de hábitos de los usuarios.
La red neuronal empleada es un mapa auto-organizativo (SOM), que posee tantas entradas como páginas frecuentes posea un sitio Web. Las páginas frecuentes son las que poseen una frecuencia mayor a la especificada por el usuario en la tarea de preprocesamiento. La red neuronal se construye en forma dinámica para permitir las entradas necesarias para el sitio Web analizado. La salida de la red neuronal SOM es un mapa de dos dimensiones de N x N, donde N es configurable por el usuario, y depende de la cantidad de clusters que el mismo desee obtener. En el mapa de salida, solo una salida será activada, indicado por el valor binario uno. Todas las demás salidas tendrán un valor nulo. La salida activada representa el cluster al cual pertenece el patrón ingresado. Patrones similares pertenecerán al mismo cluster o a clusters cercanos en el mapa de salida.
4.4.1.5. Identificación de hábitos de uso mediante algoritmo K-Means
La herramienta permite, adicionalmente, la identificación de hábitos de usuarios utilizando el algoritmo K-Means, de modo de poder comparar los resultados obtenidos mediante las dos técnicas empleadas y analizar las ventajas y desventajas de la utilización de redes neuronales SOM para la identificación de hábitos de usuarios.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 46 -
4.4.1.6. Análisis de los resultados
Es posible acceder a información sobre la identificación de hábitos de uso realizada, como la cantidad de sesiones de usuario en cada grupo descubierto, el detalle de las sesiones en cada grupo y el porcentaje de acceso a cada página del sitio estudiado por parte de los usuarios de cada grupo. Adicionalmente, permite la comparación de esta información entre los dos métodos utilizados para la identificación de hábitos de uso.
4.4.1.7. Usuarios y proyectos
Permite la creación de usuarios y proyectos, de modo de poder realizar varios análisis independientes, controlando el acceso a los proyectos de cada usuario mediante una contraseña.
4.5. Dinámica del Banco de Pruebas
La dinámica de trabajo del banco de prueba consiste en realizar un experimento en 5 pasos:
1. Preprocesado del archivo de log del servidor Web: indicando el archivo de log que se utilizará, el formato del mismo y los parámetros deseados para el preprocesado.
2. Identificación de usuarios y sus sesiones: utilizando el log preprocesado de un proyecto, se procede a la identificación de los usuarios y sus sesiones. Se indican los parámetros deseados para este paso.
3. Agrupamiento de usuarios utilizando red neuronal SOM: se procede al agrupamiento de usuarios utilizando la red neuronal SOM, indicando los parámetros a utilizarse.
4. Agrupamiento de usuarios utilizando algoritmo K-Means: se procede al agrupamiento de usuarios utilizando el algoritmo K-Means, indicando los parámetros a utilizarse.
5. Análisis de los grupos descubiertos: se comparan los grupos descubiertos en los dos pasos anteriores mediante las herramientas proporcionadas por el banco de pruebas.
A continuación se diagrama la dinámica del banco de pruebas [Figura 4.1]:

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 47 -
Figura 4.1. Dinámica del Banco de Pruebas
Se extrae el archivo de log del servidor Web utilizado por el sitio a analizar, realizando su preprocesamiento y la posterior identificación de usuarios y sus sesiones. El agrupamiento de los usuarios es realizado utilizando la red neuronal SOM y el algoritmo K-Means, permitiendo el análisis de los grupos descubiertos y su comparación.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 48 -
5. Resultados Obtenidos
En este capítulo se exponen los resultados obtenidos de los experimentos realizados. Se analizaron los logs de dos sitios Web, uno sobre música (sección 5.1) y otro sobre gastronomía (sección 5.2), de modo de poder analizar los resultados obtenidos y evaluar la calidad de la solución propuesta en esta tesis. Para cada sitio se realizaron todos los pasos involucrados en la identificación de hábitos de usuarios, comparando los resultados obtenidos mediante la red neuronal SOM y mediante el algoritmo K-Means.
5.1. Análisis Logs sitio sobre música
5.1.1. Descripción sitio sobre música
Sitio que permite la compra de canciones en el formato MP3. En el sitio se pueden realizar búsquedas de canciones y escuchar un fragmento de las canciones antes de comprarlas. Los usuarios que se hayan registrado previamente o lo hagan en ese momento, podran comprar las canciones que resultaron de su agrado.
5.1.2. Páginas sitio sobre música
A continuación se detalla la lista de páginas que componen al sitio:
Nota: Cuando se solicita la página index.php, también se solicitan las páginas thumbnail.php, top.php y flashes_home.php, por ende van a aparecer siempre juntas en el archivo de log.
• busqueda_album.php: página con los resultados de una búsqueda por album.
• busqueda_artista.php: página con los resultados de una búsqueda por artista.
• busqueda_general.php: página con los resultados de una búsqueda.
• busqueda_tema.php: página con los resultados de una búsqueda por canción.
• catalogo/artistas/'nombre del grupo'/albumes/'nombre del album'/: información de un album de un grupo.
• compania.php: información de la compañia.
• comprar.php: página para comprar un tema. Recibe iTema: número de tema a comprar.
• detalle_album.php: página con detalle de un album seleccionado. Recibe Album: número del album a detallar.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 49 -
• detalle_grupo: detalle de la información de un grupo. Recibe iGrupo: número de grupo.
• detalle_imagen.php: imagen en grande del album. Recibe TipoImagen: un número. Id: identificador del album al cual pertenece la imagen.
• flashes_home.php: texto de recuadros en flash.
• index.php: página principal del sitio.
• login.php: página para iniciar sesión.
• olvido_password.php: página para recuperar la contraseña.
• preview.php: página donde se escucha un fragmento de un tema seleccionado. Recibe Id: número de tema a escuchar.
• registracion.php: página para registrarse en el sitio.
• softwate.php: página para descargar programas, como un reproductor de música.
• soporte.php: página para soporte de algún problema con las canciones compradas en el sitio.
• terminosdeuso.php: página con los términos de uso del sitio.
• terminosdeventa.php: página con los términos de venta de las canciones.
• thumbnail.php: página que muestra una imagen determinada en base a los parámetros recibidos y del tamaño recibido.
• top.php: texto del menú.
5.1.3. Análisis Log 29/5/2005 al 3/6/2005 del sitio sobre música
5.1.3.1. Registros en el archivo de log original
398280 Registros (77 MB).
5.1.3.2. Formato log
CLF+REFERRER+AGENT.
5.1.3.3. Carga log
A continuación se muestra el resultado de la carga en el sistema del archivo de log [Tabla 5.1]:

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 50 -
Carga de Archivo de Log
Carga: 155601
HitsSaves: 155601
Input: access-emepe3-29-5-2005-3-6-2005.log
Extensions: php
StatusCodes: 200
IdsPages:
Páginas Distintas Cargadas: 37
Tabla 5.1. Carga de Archivo de Log
Tiempo de Carga Log: 58 segundos.
Armado Sesiones con valores por defecto (Cantidad mínima de páginas en una sesion = 3, Timeout de sesion = 30 minutos, Frecuencia minima de página en el log = 1).
Tiempo de Armado Sesiones: 35 segundos.
A continuación se muestra el resumen del proyecto luego de la carga del log y del armado de las sesiones de usuarios [Tabla 5.2]:
Proyecto: emepe3-1
Cantidad de Registros de Log Cargados: 155601
Cantidad de Sesiones Cargadas: 28840
Tabla 5.2. Cantidad de registros y sesiones cargadas
5.1.3.4. Clusterización con SOM
Configuración Clusterización con SOM:
• Cantidad de ciclos de entrenamiento: 5
• Cardinalidad del mapa de clusterización (NxN): 2

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 51 -
Tiempo Clusterización con SOM: 2 minutos 44 segundos.
A continuación se muestra la cantidad de sesiones en cada cluster [Tabla 5.3] y el porcentaje correspondiente a cada uno [Figura 5.1]:
Cantidad de Sesiones en cada Cluster
Cluster Sesiones
0 770
1 25446
2 2611
3 13
Tabla 5.3. Cantidad de sesiones en cada cluster con SOM
Figura 5.1. Porcentaje de sesiones en cada cluster con SOM
5.1.3.5. Clusterización con K-Means
Configuración Clusterización con K-Means:
• Cantidad de clusters a descubrir (K): 4

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 52 -
Tiempo Clusterización con K-Means: 1 minutos 21 segundos.
A continuación se muestra la cantidad de sesiones en cada cluster [Tabla 5.4] y el porcentaje correspondiente a cada uno [Figura 5.2]:
Cantidad de Sesiones en cada Cluster
Cluster Sesiones
0 17883
1 2237
2 5097
3 3623
Tabla 5.4. Cantidad de Sesiones en cada cluster con K-Means
Figura 5.2. Porcentaje de sesiones en cada cluster con K-Means
5.1.3.6. Comparación
A continuación se muestra la comparación entre la cantidad de sesiones en cada cluster obtenida mediante los dos métodos [Tabla 5.5]:

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 53 -
Cantidad de Sesiones en cada Cluster
Cluster Sesiones SOM Sesiones K-Means
0 770 17883
1 25446 2237
2 2611 5097
3 13 3623
Tabla 5.5. Comparación cantidad de sesiones en cada cluster
5.1.3.7. Representación de los clusters mediante las páginas de sus sesiones
A continuación se muestra las páginas que accedieron los usuarios de cada cluster [Tabla 5.6]:
Páginas en cada Cluster (Porcentaje Minimo = 25%; C antidad
Maxima de Páginas por Cluster = 100)
SOM K-Means
Página Porcentaje Página Porcentaje
Cluster 0
/top.php 98.8312 /login.php 92.6187
/thumbnail.php 96.7532
/flashes_home.php 95.7143
Cluster 1
/login.php 73.8426 /detalle_album.php 100.0
/detalle_album.php 28.1341 /login.php 100.0
Cluster 2
/top.php 96.7062 /detalle_album.php 100.0
/thumbnail.php 96.1317
/detalle_album.php 76.7905
/preview.php 37.8782
/detalle_grupo.php 29.1076

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 54 -
Cluster 3
/software.php 100.0 /top.php 94.2037
/thumbnail.php 100.0 /thumbnail.php 93.3757
/top.php 100.0 /detalle_album.php 51.8079
/detalle_album.php 92.3077 /preview.php 30.1408
/flashes_home.php 92.3077
/preview.php 92.3077
/login.php 76.9231
/registracion.php 76.9231
/carrito.php 69.2308
/download_software.php 69.2308
/index.php 69.2308
/micuenta.php 69.2308
/busqueda_artista.php 53.8462
/busqueda_general.php 53.8462
/detalle_grupo.php 53.8462
/terminosdeventa.php 38.4615
/olvido_password.php 30.7692
/soporte.php 30.7692
/terminosdeuso.php 30.7692
Tabla 5.6. Páginas en cada cluster
5.1.3.8. Análisis de los Clusters de Usuarios Descubiertos
5.1.3.8.1. Mapa Auto-Organizativo (SOM)
Cluster 0
Usuarios que solo acceden a la página principal, ya que thumbnail.php, top.php y flashes_home.php son solicitadas cuando se solicita la página principal (index.php).
Cluster 1
Usuarios que inician sesión, por ende son usuarios ya registrados. También miran detalles de albumes de música.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 55 -
Cluster 2
Usuarios que sin iniciar sesión, acceden a albumes de música y a información sobre grupos. También escuchan fragmentos de temas de los albumes y grupos que visitaron.
Cluster 3
Usuarios que recorren mucho más todo el sitio. Si están registrados, inician sesión, sino, se registran. Miran albumes, grupos, realizan búsquedas y compras algunos temas.
5.1.3.8.2. Algortimo K-Means
Cluster 0
Usuarios registrados que inician sesión.
Cluster 1
Usuarios registrados que inician sesión y acceden a detalles de albumes.
Cluster 2
Usuarios, que sin iniciar sesión, acceden a detalles de albumes.
Cluster 3
Usuarios, que sin iniciar sesión, acceden a detalles de albumes y escuchan fragmentos de algunos temas.
5.1.3.9. Conclusión análisis
La información obtenida mediante los clusters construidos mediante el mapa auto-organizativo (SOM) es mucho más rica con respecto a las páginas que acceden los usuarios de cada cluster, logrando una mejor comprensión de los distintos hábitos de los usuarios del sitio, con el detalle de las acciones que los mismos realizan.
5.1.4. Análisis Log 22/5/2005 al 29/5/2005 del sitio sobre música
5.1.4.1. Registros en el archivo de log original
469131 Registros (91 MB).

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 56 -
5.1.4.2. Formato log
CLF+REFERRER+AGENT
5.1.4.3. Carga log
A continuación se muestra el resultado de la carga en el sistema del archivo de log [Tabla 5.7]:
Carga de Archivo de Log
Carga: 163947
HitsSaves: 163947
Input: access-emepe3-22-5-2005-29-5-2005.log
Extensions: php
StatusCodes: 200
IdsPages:
Páginas Distintas Cargadas: 38
Tabla 5.7. Carga de Archivo de Log
Tiempo de Carga Log: 56 segundos.
Armado Sesiones con valores por defecto (Cantidad mínima de páginas en una sesion = 3, Timeout de sesion = 30 minutos, Frecuencia minima de página en el log = 1).
Tiempo de Armado Sesiones: 52 segundos.
A continuación se muestra el resumen del proyecto luego de la carga del log y del armado de las sesiones de usuarios [Tabla 5.8]:
Proyecto: emepe3-4
Cantidad de Registros de Log Cargados: 163948
Cantidad de Sesiones Cargadas: 9814
Tabla 5.8. Cantidad de registros y sesiones cargadas

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 57 -
5.1.4.4. Clusterización con SOM
Configuración Clusterización con SOM:
• Cantidad de ciclos de entrenamiento: 5
• Cardinalidad del mapa de clusterización (NxN): 2
Tiempo Clusterización con SOM: 2 minutos 14 segundos.
A continuación se muestra la cantidad de sesiones en cada cluster [Tabla 5.9] y el porcentaje correspondiente a cada uno [Figura 5.3]:
Cantidad de Sesiones en cada Cluster
Cluster Sesiones
0 3792
1 209
2 5808
3 5
Tabla 5.9. Cantidad de sesiones en cada cluster con SOM

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 58 -
Figura 5.3. Porcentaje de sesiones en cada cluster con SOM
5.1.4.5. Clusterización con K-Means
Configuración Clusterización con K-Means:
• Cantidad de clusters a descubrir (K): 4
Tiempo Clusterización con K-Means: 2 minutos 3 segundos.
A continuación se muestra la cantidad de sesiones en cada cluster [Tabla 5.10] y el porcentaje correspondiente a cada uno [Figura 5.4]:
Cantidad de Sesiones en cada Cluster
Cluster Sesiones
0 2768
1 2372
2 4335
3 339
Tabla 5.10. Cantidad de sesiones en cada cluster con K-Means

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 59 -
Figura 5.4. Porcentaje de sesiones en cada cluster con K-Means
5.1.4.6. Comparación
A continuación se muestra la comparación entre la cantidad de sesiones en cada cluster obtenida mediante los dos métodos [Tabla 5.11]:
Cantidad de Sesiones en cada Cluster
Cluster Sesiones SOM Sesiones K-Means
0 3792 2768
1 209 2372
2 5808 4335
3 5 339
Tabla 5.11. Comparación cantidad de sesiones en cada cluster
5.1.4.7. Representación de los clusters mediante las páginas de sus sesiones
A continuación se muestra las páginas que accedieron los usuarios de cada cluster [Tabla 5.12]:

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 60 -
Páginas en cada Cluster (Porcentaje Minimo = 25%; C antidad Maxima de Páginas por Cluster = 100)
SOM K-Means
Página Porcentaje Página Porcentaje
Cluster 0
/thumbnail.php 58.2278 /login.php 51.3728
/top.php 56.6192 /detalle_grupo.php 29.7688
/login.php 39.3196
Cluster 1
/thumbnail.php 100.0 /detalle_album.php 100.0
/top.php 100.0
/preview.php 86.6029
/detalle_grupo.php 83.2536
/detalle_album.php 82.7751
/flashes_home.php 62.201
/login.php 50.7177
/busqueda_genero_detalle.php 35.4067
/index.php 27.7512
Cluster 2
/detalle_album.php 83.4366 /thumbnail.php 99.9077
/top.php 41.6322 /top.php 99.7232
/thumbnail.php 41.0124 /detalle_album.php 60.7843
/preview.php 32.3414
/flashes_home.php 25.5133
Cluster 3
/terminosdeuso.php 100.0 /top.php 100.0
/terminosdeventa.php 100.0
/politica.php 80.0
/software.php 80.0
/detalle_album.php 60.0
/politicadeprivacidad.php 60.0
/registracion.php 60.0
/detalle_imagen.php 40.0

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 61 -
/olvido_password.php 40.0
Tabla 5.12. Páginas en cada cluster
5.1.4.8. Análisis de los Clusters de Usuarios Descubiertos
5.1.4.8.1. Mapa Auto-Organizativo (SOM)
Cluster 0
Usuarios que acceden únicamente a la página principal, algunos de los cuales inician sesión en el sitio.
Cluster 1
Usuarios que acceden a albumes de música y a información sobre grupos. También escuchan fragmentos de temas de los albumes y grupos que visitaron. Realizan algunas búsquedas.
Cluster 2
Usuarios que sin iniciar sesión, acceden a albumes de música.
Cluster 3
Usuarios que recorren mucho más todo el sitio. Acceden a varias páginas del sitio donde obtienen información sobre el mismo. También acceden a detalles de albumes de música, y muchos se registran en el sitio.
5.1.4.8.2. Algoritmo K-Means
Cluster 0
Usuarios registrados que inician sesión y acceden a detalles de grupos de música.
Cluster 1
Usuarios, que sin iniciar sesión, acceden a detalles de albumes.
Cluster 2
Usuarios, que sin iniciar sesión, acceden a detalles de albumes y escuchan fragmentos de algunos temas.
Cluster 3
Usuarios que no recorren mucho el sitio.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 62 -
5.1.4.9. Conclusión análisis
La información obtenida mediante los clusters construidos mediante el mapa auto-organizativo (SOM) es mucho más rica con respecto a las páginas que acceden los usuarios de cada cluster, logrando una mejor comprensión de los distintos hábitos de los usuarios del sitio, con el detalle de las acciones que los mismos realizan.
5.1.5. Conclusión Análisis Logs sitio sobre música
Comparando los resultados de las clusterizaciones de usuarios realizadas mediante la red neuronal mapa auto-organizativo (SOM) y el método convencional K-Means, se puede apreciar la superioridad de la información suministrada por los clusters generados utilizando la red neuronal.
La red neuronal mapa auto-organizativo (SOM) logra agrupar a los usuarios en clusters donde existe más similitud entre las páginas que acceden los usuarios pertenecientes al mismo. Esto provoca que exista mayor cantidad de páginas con gran porcentaje de acceso por los usuarios de cada cluster, permitiendo entender y analizar mejor los hábitos de los usuarios. En los cluster descubiertos utilizando K-Means se posee solo una o dos páginas con alto porcentaje de acceso por los usuarios pertenecientes a cada cluster. Esto ocasiona que se posea poca información sobre los hábitos de los usuarios de cada cluster.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 63 -
5.2. Análisis Logs El Cuerpo de Cristo
5.2.1. Descripción sitio El Cuerpo de Cristo
El tema central del sitio es la gastronomia. El sitio expone distintos artículos sobre cuestiones culinarias, permitiendo que los usuarios registrados envien sus propios artículos, para su aprobación y posterior publicación por los responsables del sitio. Además, posee un wiki sobre gastronomía. Un wiki son páginas Web que pueden ser modificadas por los visitantes, agregando la información que ellos deseen. También posee un sector con galerías de imágenes y un sistema para obtener recetas de comidas en base a los ingredientes disponibles en el momento.
5.2.2. Páginas www.elcuerpodecristo.com.ar
A continuación se detalla la lista de páginas que componen al sitio:
• recetodromoII/index.php: permite buscar recetas seleccionando sus ingredientes.
• tiki-articles_rss.php: los artículos en formato RSS.
• tiki-backlinks.php: página para actividades administrativas del sitio.
• tiki-blogs_rss.php: lista de los wiki y los artículos en formato RSS.
• tiki-browse_image.php: muestra una imágen con su información.
• tiki-browse_categories.php: permite acceder a los wikis y a los artículos mediante sus categorías.
• tiki-directory_browse.php: permite acceder al directorio de sitios con temas relacionados al sitio.
• tiki-directory_ranking.php: lista de otros sitios.
• tiki-edit_article.php: permite editar un artículo, si se tienen los permisos necesarios.
• tiki-edit_submission.php: permite cargar la información de un nuevo artículo y enviarlo.
• tiki-edit_templates.php: permite la edición de las plantillas de las páginas.
• tiki-edit_translation.php: permite editar la traducción de una página.
• tiki-editpage.php: permite editar una página.
• tiki-forums.php: foro.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 64 -
• tiki-galleries.php: lista de la galeria de imágenes.
• tiki-index.php: información sobre distintos restaurantes.
• tiki-lastchanges.php: ultimos cambios realizados a las páginas del wiki.
• tiki-list_articles.php: lista de todos los artículos.
• tiki-list_gallery.php: muestra las imágenes de una galería de fotos.
• tiki-list_submissions.php: permite listar los artículos enviados, si se tienen los permisos necesarios.
• tiki-listpages.php: lista todas las páginas del wiki.
• tiki-meta.php: página principal del sitios, con los artículos y wikis más nuevos.
• tiki-pagehistory.php: permite ver la historia de modificaciones de una página.
• tiki-print.php: versión para impresión de los wikis.
• tiki-print_article.php: versión para impresión de los artículos.
• tiki-upload_image.php: permite subir imágenes, si se tienen los permisos necesarios.
• tiki-random_num_img.php: muestra una imágen con números generados aleatoriamente, para que el usuario deba introducirlos cuando edita un articulo.
• tiki-register.php: formulario para registrarse como usuario.
• tiki-searchindex.php: buscador en todo el sitio o en las secciones indicadas.
• tiki-user_information.php: muestra información de un usuario.
• tiki-view_articles.php: muestra todos los artículos.
• tiki-view_forum_thread.php: muestra un comentario de un foro.
• tiki-wiki_rss.php: lista de los wikis en formato RSS.
• show_image.php: muestra una imágen.
• topic_image.php: muestra una imágen sobre un tópico seleccionado.
5.2.3. Análisis Log Semana 3 de Mayo de 2005 de www.elcuerpodecristo.com.ar
5.2.3.1. Registros en el archivo de log original
203149 Registros (42 MB).

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 65 -
5.2.3.2. Formato log
CLF+REFERRER+AGENT
5.2.3.3. Carga log
A continuación se muestra el resultado de la carga en el sistema del archivo de log [Tabla 5.13]:
Carga de Archivo de Log
Carga: 34086
HitsSaves: 34086
Input: access-S03-05-2005.log
Extensions: php
StatusCodes: 200
IdsPages:
Páginas Distintas Cargadas: 71
Tabla 5.13. Carga de Archivo de Log
Tiempo de Carga Log: 25 segundos.
Armado Sesiones con valores por defecto (Cantidad mínima de páginas en una sesión = 3, Timeout de sesion = 30 minutos, Frecuencia mínima de página en el log = 1).
Tiempo de Armado Sesiones: 15 segundos.
A continuación se muestra el resumen del proyecto luego de la carga del log y del armado de las sesiones de usuarios [Tabla 5.14]:
Proyecto: cc-S03-05-2005 2
Cantidad de Registros de Log Cargados: 34086
Cantidad de Sesiones Cargadas: 5445
Tabla 5.14. Cantidad de registros y sesiones cargadas

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 66 -
5.2.3.4. Clusterización con SOM
Configuración Clusterización con SOM:
• Cantidad de ciclos de entrenamiento: 5
• Cardinalidad del mapa de clusterizacion (NxN): 2
Tiempo Clusterización con SOM: 26 segundos.
A continuación se muestra la cantidad de sesiones en cada cluster [Tabla 5.15] y el porcentaje correspondiente a cada uno [Figura 5.5]:
Cantidad de Sesiones en cada Cluster
Cluster Sesiones
0 7
1 4563
2 808
3 67
Tabla 5.15. Cantidad de sesiones en cada cluster con SOM
Figura 5.5. Porcentaje de sesiones en cada cluster con SOM

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 67 -
5.2.3.5. Clusterización con K-Means
Configuración Clusterización con K-Means
• Cantidad de clusters a descubrir (K): 4
Tiempo Clusterización con K-Means: 24 segundos.
A continuación se muestra la cantidad de sesiones en cada cluster [Tabla 5.16] y el porcentaje correspondiente a cada uno [Figura 5.6]:
Cantidad de Sesiones en cada Cluster
Cluster Sesiones
0 724
1 394
2 3674
3 653
Tabla 5.16. Cantidad de sesiones en cada cluster con K-Means
Figura 5.6. Porcentaje de sesiones en cada cluster con K-Means

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 68 -
5.2.3.6. Comparación
A continuación se muestra la comparación entre la cantidad de sesiones en cada cluster obtenida mediante los dos métodos [Tabla 5.17]:
Cantidad de Sesiones en cada Cluster
Cluster Sesiones SOM Sesiones K-Means
0 7 724
1 4563 394
2 808 3674
3 67 653
Tabla 5.17. Comparación cantidad de sesiones en cada cluster
5.2.3.7. Representación de los clusters mediante las páginas de sus sesiones
A continuación se muestra las páginas que accedieron los usuarios de cada cluster [Tabla 5.18]:
Páginas en cada Cluster (Porcentaje Mínimo = 10%; C antidad Máxima de Páginas por Cluster = 100)
SOM K-Means
Página Porcentaje Página Porcentaje
Cluster 0
/tiki-edit_submission.php 100.0 /tiki-editpage.php 100.0
/tiki-view_forum_thread.php 85.7143 /tiki-
random_num_img.php 62.8453
/tiki-list_submissions.php 71.4286
/tiki-browse_image.php 57.1429
/show_image.php 42.8571
/tiki-edit_article.php 42.8571
/tiki-galleries.php 42.8571
/tiki-pagehistory.php 42.8571
/topic_image.php 42.8571

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 69 -
/tiki-directory_browse.php 28.5714
/tiki-editpage.php 28.5714
/tiki-index.php 28.5714
/tiki-list_articles.php 28.5714
/tiki-meta.php 28.5714
/tiki-upload_image.php 28.5714
/tiki-wiki_rss.php 28.5714
/tiki-searchindex.php 14.2857
/tiki-view_articles.php 14.2857
Cluster 1
/recetodromoII/index.php 19.2417 /tiki-index.php 99.7462
/tiki-editpage.php 18.0145 /tiki-editpage.php 30.203
/tiki-articles_rss.php 14.3765 /tiki-listpages.php 23.0964
/tiki-wiki_rss.php 11.5494 /tiki-list_articles.php 22.5888
/tiki-random_num_img.php 10.103 /tiki-pagehistory.php 21.3198
/tiki-edit_translation.php 18.5279
/tiki-wiki_rss.php 18.2741
/tiki-edit_submission.php 17.7665
/tiki-register.php 17.7665
/tiki-articles_rss.php 17.5127
/tiki-user_information.php 17.2589
/tiki-view_forum_thread.php 17.2589
/tiki-print.php 16.7513
/tiki-searchindex.php 10.9137
/show_image.php 10.4061
/tiki-browse_categories.php 10.1523
Cluster 2
/show_image.php 78.7129 /recetodromoII/index.php 21.8018
/tiki-browse_image.php 26.1139 /tiki-articles_rss.php 17.583
/show_image.php 15.1606

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 70 -
/tiki-wiki_rss.php 14.1535
Cluster 3
/tiki-editpage.php 100.0 /tiki-pagehistory.php 69.0658
/tiki-edit_submission.php 100.0 /tiki-print.php 36.9066
/tiki-listpages.php 100.0 /tiki-listpages.php 24.8086
/tiki-list_articles.php 100.0 /tiki-editpage.php 18.0704
/tiki-articles_rss.php 98.5075 /tiki-browse_categories.php 15.6202
/tiki-index.php 98.5075 /tiki-edit_translation.php 14.5482
/tiki-register.php 98.5075 /tiki-backlinks.php 14.242
/tiki-wiki_rss.php 98.5075
/tiki-user_information.php 95.5224
/tiki-pagehistory.php 92.5373
/tiki-edit_translation.php 91.0448
/tiki-print.php 88.0597
/tiki-view_forum_thread.php 44.7761
/tiki-edit_templates.php 40.2985
/tiki-view_forum.php 25.3731
/tiki-print_article.php 23.8806
/tiki-backlinks.php 22.3881
/tiki-list_submissions.php 22.3881
/tiki-browse_categories.php 20.8955
/tiki-forums.php 20.8955
/tiki-browse_image.php 19.403
/tiki-galleries.php 19.403
/tiki-list_gallery.php 16.4179
Tabla 5.18. Páginas en cada cluster

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 71 -
5.2.3.8. Análisis de los Clusters de Usuarios Descubiertos
5.2.3.8.1. Mapa Auto-Organizativo (SOM)
Cluster 0
Usuarios que realizan varias acciones en el sitio. Agregan y editan artículos, por ende son usuarios registrados en el sitio, ya que para realizar estas acciones se deben tener los permisos necesarios. Listan artículos y ven artículos. Listan imágenes y ven imágenes. Tambien acceden a los foros.
Cluster 1
Usuarios que no recorren mucho el sitio. Algunos utilizan el recetodromo (buscador de recetas), editan páginas del wiki y acceden a los artículos y a las páginas del wiki mediante RSS.
Cluster 2
Usuarios que unicamente ven las galerías de imágenes y las imágenes de las mismas.
Cluster 3
Usuarios que recorren mucho más todo el sitio. Listan, ven y editan páginas del wiki. Tambien ven artículos y acceden al foro. Si no estan registrados, se registran. Ven artículos y páginas del wiki mediante RSS. Algunos acceden a las galerías de imágenes.
5.2.3.8.2. Algoritmo K-Means
Cluster 0
Usuarios que unicamente editan una página del wiki. La página tiki-random_num_img.php se solicita automáticamente cuando se solicita la página de edición del wiki.
Cluster 1
Usuarios que recorren bastante el sitio. Algunos ven y editan páginas del wiki. Algunos ven artículos, acceden a las páginas y/o a los wikis mediante RSS. Algunos usuarios se registran en el sitio.
Cluster 2
Usuarios que no recorren mucho el sitio. Algunos utilizan el recetodromo (buscador de recetas), acceden a los artículos y a las páginas del wiki mediante RSS, y ven alguna imágen.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 72 -
Cluster 3
Usuarios que acceden a páginas relacionadas al wiki. Listan páginas del wiki, las editan, editan las traducciones, ven la versión de impresión y ven la historia de modificación de una página.
5.2.3.9. Conclusión análisis
La información obtenida mediante los clusters construidos mediante el mapa auto-organizativo (SOM) es mucho más rica con respecto a las páginas que acceden los usuarios de cada cluster, logrando una mejor comprensión de los distintos hábitos de los usuarios del sitio, con el detalle de las acciones que los mismo realizan.
5.2.4. Análisis Log Semana 1 de Junio de 2005 de www.elcuerpodecristo.com.ar
5.2.4.1. Registros en el archivo de log original
128815 Registros (27 MB).
5.2.4.2. Formato log
CLF+REFERRER+AGENT
5.2.4.3. Carga log
A continuación se muestra el resultado de la carga en el sistema del archivo de log [Tabla 5.19]:
Carga de Archivo de Log
Carga: 12489
HitsSaves: 12489
Input: access-S01-06-2005.log
Extensions: php
StatusCodes: 200

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 73 -
Carga de Archivo de Log
IdsPages:
Páginas Distintas Cargadas: 71
Tabla 5.19. Carga de Archivo de Log
Tiempo de Carga Log: 14 segundos.
Armado Sesiones con valores por defecto (Cantidad mínima de páginas en una sesion = 3, Timeout de sesion = 30 minutos, Frecuencia minima de página en el log = 1).
Tiempo de Armado Sesiones: 9 segundos.
A continuación se muestra el resumen del proyecto luego de la carga del log y del armado de las sesiones de usuarios [Tabla 5.20]:
Proyecto: cc-S01-06-2005 2
Cantidad de Registros de Log Cargados: 12489
Cantidad de Sesiones Cargadas: 4616
Tabla 5.20. Cantidad de registros y sesiones cargadas
5.2.4.4. Clusterización con SOM
Configuración Clusterización con SOM:
• Cantidad de ciclos de entrenamiento: 5
• Cardinalidad del mapa de clusterización (NxN): 2
Tiempo Clusterización con SOM: 13 segundos.
A continuación se muestra la cantidad de sesiones en cada cluster [Tabla 5.21] y el porcentaje correspondiente a cada uno [Figura 5.7]:
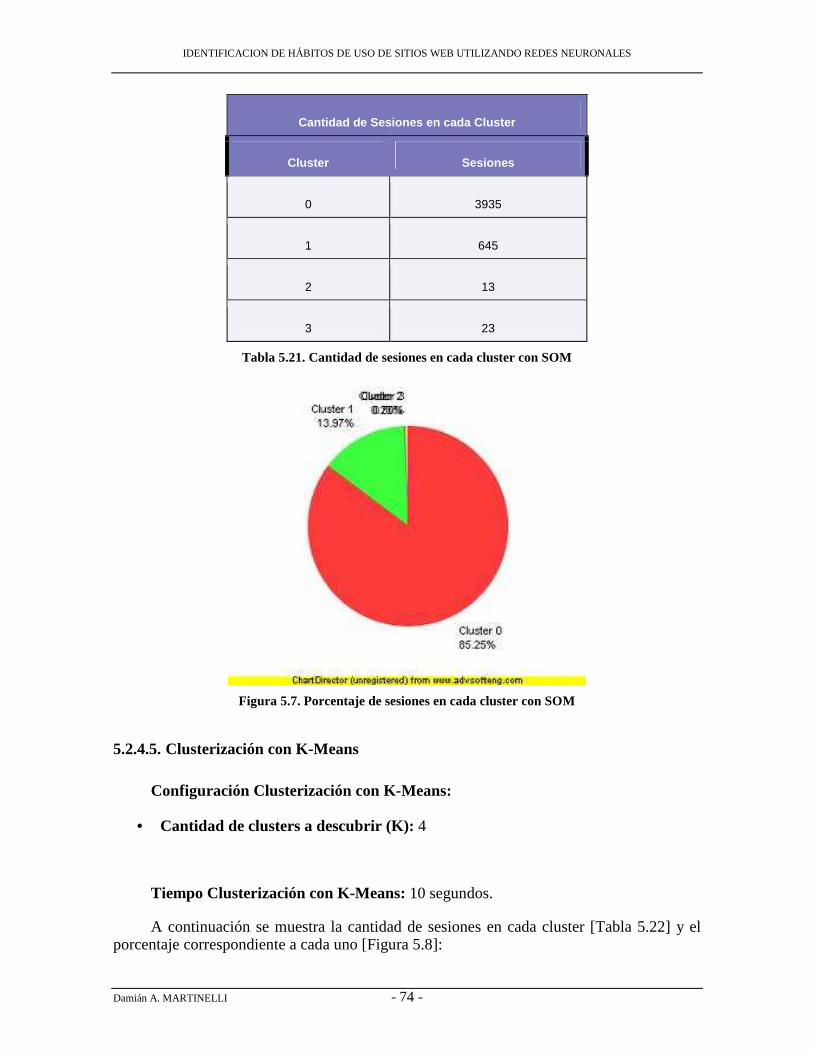
IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 74 -
Cantidad de Sesiones en cada Cluster
Cluster Sesiones
0 3935
1 645
2 13
3 23
Tabla 5.21. Cantidad de sesiones en cada cluster con SOM
Figura 5.7. Porcentaje de sesiones en cada cluster con SOM
5.2.4.5. Clusterización con K-Means
Configuración Clusterización con K-Means:
• Cantidad de clusters a descubrir (K): 4
Tiempo Clusterización con K-Means: 10 segundos.
A continuación se muestra la cantidad de sesiones en cada cluster [Tabla 5.22] y el porcentaje correspondiente a cada uno [Figura 5.8]:

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 75 -
Cantidad de Sesiones en cada Cluster
Cluster Sesiones
0 3880
1 125
2 206
3 405
Tabla 5.22. Cantidad de sesiones en cada cluster con K-Means
Figura 5.8. Porcentaje de sesiones en cada cluster con K-Means
5.2.4.6. Comparación
A continuación se muestra la comparación entre la cantidad de sesiones en cada cluster obtenida mediante los dos métodos [Tabla 5.23]:

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 76 -
Cantidad de Sesiones en cada Cluster
Cluster Sesiones SOM Sesiones K-Means
0 3935 3880
1 645 125
2 13 206
3 23 405
Tabla 5.23. Comparación cantidad de sesiones en cada cluster
5.2.4.7. Representación de los clusters mediante las páginas de sus sesiones
A continuación se muestra las páginas que accedieron los usuarios de cada cluster [Tabla 5.24]:
Páginas en cada Cluster (Porcentaje Mínimo = 10%; C antidad Máxima de Páginas por Cluster = 100)
SOM K-Means
Página Porcentaje Página Porcentaje
Cluster 0
/recetodromoII/index.php 27.5222 /recetodromoII/index.php 30.6443
/tiki-articles_rss.php 13.291 /tiki-editpage.php 14.5103
/tiki-editpage.php 12.249 /show_image.php 13.299
/show_image.php 11.7154 /tiki-articles_rss.php 11.4948
/tiki-random_num_img.php 10.5155
Cluster 1
/recetodromoII/index.php 29.6124 /tiki-blogs_rss.php 80.8
/tiki-editpage.php 20.0
/show_image.php 14.1085
/tiki-random_num_img.php 13.1783
Cluster 2
/tiki-editpage.php 46.1538 /tiki-editpage.php 22.8155

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 77 -
/tiki-index.php 30.7692 /recetodromoII/index.php 15.534
/tiki-searchindex.php 23.0769 /tiki-pagehistory.php 13.5922
/tiki-browse_image.php 15.3846 /tiki-edit_translation.php 12.6214
/tiki-directory_browse.php 15.3846
/tiki-list_articles.php 15.3846
/tiki-meta.php 15.3846
/tiki-read_article.php 15.3846
Cluster 3
/tiki-editpage.php 34.7826 /tiki-wiki_rss.php 61.9753
/tiki-searchindex.php 34.7826 /tiki-articles_rss.php 25.679
/tiki-view_forum_thread.php 26.087 /recetodromoII/index.php 11.1111
/show_image.php 13.0435
/tiki-browse_image.php 13.0435
/tiki-index.php 13.0435
/tiki-meta.php 13.0435
Tabla 5.24. Páginas en cada cluster
5.2.4.8. Análisis de los Clusters de Usuarios Descubiertos
5.2.4.8.1. Mapa Auto-Organizativo (SOM)
Cluster 0
Usuarios que no recorren mucho el sitio. Algunos utilizan el recetodromo (buscador de recetas), editan páginas del wiki y acceden a los artículos mediante RSS. También ven algunas imágenes.
Cluster 1
Usuarios que no recorren mucho el sitio. Algunos utilizan el recetodromo (buscador de recetas), editan páginas del wiki y ven algunas imágenes. Los hábitos de los usuarios de este cluster son muy similares a los del cluster 0, las diferencias recaen en que un mayor porcentaje de los usuarios del cluster 1 editan páginas del wiki y que lo usuarios del cluster 1 no acceden a los artículos mediante RSS.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 78 -
Cluster 2
Usuarios que recorren más todo el sitio. Editan páginas del wiki. Realizan búsquedas en el sitio. Algunos acceden a las galerías de imágenes.
Cluster 3
Usuarios que recorren más todo el sitio. Listan, ven y editan páginas del wiki y artículos. Realizan búsquedas en el sitio. Algunos acceden a las galerías de imágenes. También acceden al foro.
5.2.4.8.2. Algoritmo K-Means
Cluster 0
Usuarios que no recorren mucho el sitio. Algunos utilizan el recetodromo (buscador de recetas), editan páginas del wiki y acceden a los artículos mediante RSS. También ven algunas imágenes.
Cluster 1
Usuarios que únicamente acceden a los artículos y a las páginas del wiki mediante RSS.
Cluster 2
Usuarios que utilizan el recetodromo (buscador de recetas), editan páginas del wiki, editan las traducciones de las páginas del wiki y acceden al historial de modificación de las páginas del wiki.
Cluster 3
Usuarios que acceden a los artículos y a las páginas del wiki mediante RSS. Algunos utilizan el recetódromo (buscador de recetas).
5.2.4.9. Conclusión análisis
La información obtenida mediante los clusters construidos mediante SOM es mucho más rica, logrando una mejor comprensión de los distintos hábitos de los usuarios del sitio, con el detalle de las acciones que los mismos realizan.
5.2.5. Conclusión Análisis Logs El Cuerpo de Cristo
Comparando los resultados de las clusterizaciones de usuarios realizadas mediante la red neuronal mapa auto-organizativo (SOM) y el método convencional K-Means, se puede

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 79 -
apreciar la superioridad de la información suministrada por los clusters generados utilizando la red neuronal.
La red neuronal mapa auto-organizativo (SOM) logra agrupar a los usuarios en clusters donde existe más similitud entre las páginas que acceden los usuarios pertenecientes al mismo. Esto provoca que exista mayor cantidad de páginas con gran porcentaje de acceso por los usuarios de cada cluster, permitiendo entender y analizar mejor los hábitos de los usuarios. En los cluster descubiertos utilizando el algoritmo K-Means se posee solo una o dos páginas con alto porcentaje de acceso por los usuarios pertenecientes a cada cluster. Esto ocasiona que se posea poca información sobre los hábitos de los usuarios de cada cluster.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 80 -
6. Conclusiones
El presente trabajo constituye un aporte original en la identificación de hábitos de uso de sitios Web, para ello:
• Adapta una red neuronal mapa auto-organizativo (SOM) para la identificación de hábitos de uso de sitios Web.
• Analiza los resultados obtenidos mediante la aplicación de la solución propuesta.
• Compara la solución propuesta con un método tradicional como K-Means y resalta la superioridad de la red neuronal en el agrupamiento de usuarios de sitios Web, superioridad reflejada en la obtención de mayor información sobre sus hábitos.
• Sistematiza el proceso completo de identificación de hábitos de uso de sitios Web.
• Construye una herramienta para el análisis de los hábitos de uso, aplicando un marco metodológico a través de la metodología Métrica Versión 3.
• Contribuye brindando mayor información para la realización efectiva de campañas de marketing, como así también, mejores rediseños de sitios Web.
Los resultados obtenidos mediante la red neuronal SOM alientan a continuar investigando la utilización de otros tipos de redes para la identificación de hábitos de uso de sitios Web, como así también, intentar identificar nuevos aspectos de los mismos.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 81 -
7. Trabajos Futuros
De la experiencia adquirida durante la realización del presente trabajo de Tesis surgen las siguientes propuestas:
• Investigar la factibilidad de la adaptación de otros tipos de redes neuronales artificiales en la identificación de hábitos de uso de sitios Web.
• Analizar la utilización de una red neuronal que permita obtener información sobre los caminos seguidos por los usuarios en un sitio Web, teniendo en cuenta no solo a qué página accedió cada usuario, sino también en qué secuencia accedió a las mismas.
• Identificar nuevos aspectos de los hábitos de uso que sean capaces de ser descubiertos mediante redes neuronales artificiales.
• Investigar la aplicación de las redes neuronales artificiales en la clasificación de las páginas que conforman un sitio Web en base a los hábitos de acceso de sus usuarios.
• Analizar la utilización de la solución propuesta aplicada fuera del ámbito de la Web, como ser aplicaciones de escritorio o motores de base de datos.
• Ampliar las capacidades de la herramienta desarrollada, incluyendo nuevas funcionalidades, como ser:
o Mejorar la performance de la red neuronal mapa auto-organizativo (SOM) cuando se analizan sitios con mucha información de navegación.
o Incorporar la posibilidad del almacenamiento de una red neuronal ya entrenada para su reutilización.
o Integración con una herramienta de análisis de sitios Web tradicional para completar la información que se le provee al usuario.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 82 -
8. Referencias
• [Abidi, S.S.R.; 1996] Abidi, S.S.R., Neural networks: their efficacy towards the Malaysian IT environment. School of Computer Sciences. Universiti Sains Malaysia. Penang. Malaysia, 1996.
• [Abraham, A.; 2003] Abraham, A., i-Miner: A Web usage mining framework using hierarchical intelligent systems. The IEEE International Conference on Fuzzy Systems FUZZ-IEEE'03, pp. 1129/1134, IEEE Press, 2003.
• [Abraham, A., Ramos, V.; 2003] Abraham, A., Ramos, V. Web Usage Mining Using Artificial Ant Colony Clustering and Linear Genetic Programming, 2003.
• [Agrawal, R., Srikant, R.; 1994] Agrawal, R., Srikant, R., Fast Algorithms for Mining Association Rules. IBM Almaden Research Center. Proceedings of the 20th International Conference on Very Large Data Bases, pages 478/499, Septiembre 1994.
• [Agrawal, R., Gehrke, J., Gunopulos, D., Raghavan, P.; 1998] Agrawal, R., Gehrke, J., Gunopulos, D., Raghavan, P., Automatic Subspace Clustering of High Dimensional Data for Data Mining Applications. IBM Almaden Research Center, 1998.
• [Agrawal, R., Ghosh S., Imielinski T., Iyer B., Swami A.; 1992] Agrawal, R., Ghosh S., Imielinski T., Iyer B., Swami A., An Interval Classifier for Database Mining Applications. Proceedings of the 18th International Conference on Very Large Data Bases, páginas 560/573, Agosto 1992.
• [Agrawal, R., Imielinski, T., Swami, A.; 1993} Agrawal, R., Imielinski, T., Swami, A Mining Association Rules between Sets of Items in Large Databases. Proceedings of ACM SIGMOD, páginas 207/216, Mayo 1993.
• [Ale, J.; 2005] Ale, J., Introducción a Data Mining, 2005.
• [Ale, J.; 2005] Ale, J., Clasificación – Arboles de Decisión, 2005.
• [Ale, J.; 2005] Ale, J., Análisis de Clusters, 2005.
• [Ankerst, M.; 2001] Ankerst, M., Visual Data Mining with Pixel-oriented Visualization Techniques. The Boing Company. Seattle, WA., 2001.
• [Ankerst, M., Breunig, M.M., Kriegel, H., Sander, J.; 1999] Ankerst, M., Breunig, M.M., Kriegel, H., Sander, J., OPTICS: Ordering Points To Identify the Clustering Structure.Institute for Computer Science, University of Munich. Munich, Germany, 1999.
• [Batista, P., Silva, M.J.; 2002] Batista, P., Silva, M.J., Mining Web Access Logs of an On-line Newspaper. Departamento de Informática, Faculdade de Ciencias – Universidade de Lisboa. Lisboa. Portugal, 2002.
• [Beveridge M.; 1996] Beveridge M., Self Organizing Maps. http://Web.archive.org/Web/20021216231759/ http://www.dcs.napier.ac.uk/hci/martin/msc/node6.html. Vigente al 19/11/2005.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 83 -
• [Borges, J., Levene, M.; 2000] Borges, J., Levene, M., A Fine Grained Heuristic to Capture Web Navigation Patterns. ACM SIGKDD, Julio 2000.
• [Catledge, L., Pitkow, J.; 1995] Catledge, L., Pitkow, J., Characterizing browsing strategies in the world wide Web. Computer Networks and ISDN Systems, 27(6): 1065–1073, Abril 1995.
• [Cernuzzi, L., Molas, M.L.; 2004] Cernuzzi, L., Molas, M.L., Integrando diferentes técnicas de Data Mining en procesos de Web Usage Mining. Universidad Católica "Nuestra Señora de la Asunción". Asunción. Paraguay, 2004.
• [Chapman, P., Clinton, J., Kerber, R., Khabaza, T., Reinartz, T., Shearer, C., Wirth, R.; 2000] Chapman, P., Clinton, J., Kerber, R., Khabaza, T., Reinartz, T., Shearer, C., Wirth, R. (2000). CRISP-DM 1.0 Step-by-step data mining guide. http://www.crisp-dm.org/CRISPWP-0800.pdf. Vigente al 19/11/2005.
• [Cheeseman, P., Stutz, J.; 1996] Cheeseman, P., Stutz, J., Bayesian classification (AutoClass): Theory and results. In U.M. Fayyad, G. Piatetsky-Shapiro, P. Smyth, and R. Uthurusamy, editors, Advances in Knowledge Discovery and Data Mining, páginas 153/180. AAAI/MIT Press, 1996.
• [Chen, H., Chau, M.; 2004] Chen, H., Chau, M., Web Mining: Machine Learning for Web Applications. Annual Review of Information Science and Technology, 38, (289-329), 2004.
• [Chen, M., Han, J., Yu, P.; 1996] Chen, M., Han, J., Data mining: An overview from database perspective. IEEE Transactions on Knowledge and Data Eng., 1996.
• [Chen, M.S., Park, J.S., Yu, P.S.; 1996] Chen, M.S., Park, J.S., Yu, P.S., Data mining for path traversal patterns in a Web environment. páginas 385/392, 1996.
• [Chi, E.H., Rosien, A., Heer, J.; 2002] Chi, E.H., Rosien, A., Heer, J., LumberJack: Intelligent Discovery and Analysis of Web User Traffic Composition. PARC (Palo Alto Research Center), 2002.
• [Cohen, E., Krishnamurthy, B., Rexford, J.; 1998] Cohen, E., Krishnamurthy, B., Rexford, J., Improving End-to-end Performance of the Web using Server Volumes and Proxy Filters in Proceedings of the ACM SIGCOMM, páginas 241-253, 1998.
• [Cooley R., Mobasher R., Srivastava J.; 1999] Cooley R., Mobasher R., Srivastava J., Data Preparation for Mining World Wide Web Browsing Patterns. Knowledge and Information Systems, volumen 1, 1999.
• [Cooley, R.; 2000] Cooley, R., Web usage mining: Discovery and application of interesting patterns from Web data. PhD Thesis, Department of Computer Science, University, 2000.
• [Cooley, R., Tan, P.N., Srivastava, J.; 1999] Cooley, R., Tan, P.N., Srivastava, J., Discovery of interesting usage patterns from Web data. University of Minnesota, 1999.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 84 -
• [Daza P., S.P.; 2003] Daza P., S.P., Redes neuronales artificiales: Fundamentos, modelos y aplicaciones. Universidad Militar Nueva Granada. Facultad de Ingeniería Mecatrónica. Bogotá. Colombia, 2003.
• [Eirinaki, M., Vazirgiannis, M.; 2003] Eirinaki, M., Vazirgiannis, M., Web Mining for Web Personalization. Athens University of Economics and Business, 2003.
• [Elder IV, J., Pregibon, D.; 1996] Elder IV, J., Pregibon, D., A statistical perspective on knowledge discovery in databases. In U.M. Fayyad, G. Piatetsky-Shapiro, P. Smyth, and R. Uthurusamy, editors, Advances in Knowledge Discovery and Data Mining, páginas 83/115. AAAI/MIT Press, 1996.
• [Essenreiter R., Karrenbach, M., Treitel S.; 1999] Essenreiter R., Karrenbach, M., Treitel S., Identification and classification of multiple reflections with selforganizing maps. Geophysical Institute, University of Karlsruhe, Germany, 1999.
• [Ester, M., Kriegel, H. P., Xu, X.; 1995] Ester, M., Kriegel, H. P., Xu, X., Knowledge discovery in large spatial databases: Focusing techniques for efficient class identification. In Proc. 4th Int. Symp. on Large Spatial Databases (SSD'95), páginas 67/82, Portland, Maine, Agosto 1995.
• [Ester, M., Kriegel, H., Sander J., Xu X.; 1996] Ester, M., Kriegel, H., Sander J., Xu X., A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. Institute for Computer Science, University of Munich. München, Germany, 1996.
• [Felgaer, Pablo E.; 2004] Felgaer, Pablo E., Redes bayesianas aplicadas a minería de datos inteligente. Laboratorio de Sistemas Inteligentes. Facultad de Ingeniería. UBA. Argentina, 2004.
• [Fisher, D.; 1996] Fisher, D., Iterative optimization and simplification of hierarchical clusterings. Departament of Computer Science. Vanderbilt University, Nashville, USA, 1996.
• [Frawley, W.J., Piatetski-Shapiro, G., Matheus, C.J.; 1991] Frawley, W.J., Piatetski-Shapiro, G., Matheus, C.J., Knowledge discovery in databases: an overview. AAAI-MIT Press, Menlo Park, California, 1991.
• [Fu, Y., Shih, M., Creado, M., Ju, C.; 2001] Fu, Y., Shih, M., Creado, M., Ju, C., Reorganizing websites based on user access patterns. Department of Computer Science. University of Missouri-Rolla, 2001.
• [García Martínez, R., Servente, M., Pasquini, D.; 2003] García Martínez, R., Servente, M., Pasquini, D., Sistemas Inteligentes. Nueva Librería. (Páginas 67-148), 2003.
• [Grosser, Hernán; 2004] Grosser, Hernán, Detección de Fraude en Telefonía Celular Usando Redes Neuronales. Tesis de Grado en Ingenieria Informatica. Facultad de Ingenieria. Universidad de Buenos Aires, 2004.
• [Guha, S., Rastogi, R., Shim, K.; 1998] Guha, S., Rastogi, R., Shim, K., CURE: An efficient clustering algorithm for large databases, 1998.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 85 -
• [Han, J., Kamber, M.; 2001] Han, J., Kamber, M.; Data mining: Concepts and techniques. Morgan Kauffmann Publishers, 2001.
• [Hand, D., Mannila, H., Smyth, P.; 2001] Hand, D., Mannila, H., Smyth, P., Principles of data mining. The MIT Press, 2001.
• [Hilera J. R., Martínez V.; 2000] Hilera J. R., Martínez V., Redes Neuronales Artificiales: Fundamentos, modelos y aplicaciones, RA-MA Editorial, Madrid, 2000.
• [Hinneburg, A., Keim, D.; 1998] Hinneburg, A., Keim, D., An Efficient Approach to Clustering in Large Multimedia Databases with Noise. Institute of Computer Science, University of Halle, Germany, 1998.
• [Hochsztain, Esther; 2002] Hochsztain, Esther, Cómputo de los logros de un sitio Web mediante el análisis de las sesiones de sus usuarios. Facultad de Informática. Universidad Politécnica de Madrid, 2002.
• [Hollmen J.; 1996] Hollmen J., Process Modeling using the Self-Organizing Map, Helsinki University of Technology Department of Computer Science, 1996.
• [Hoppfield J.J.; 1982] Hoppfield J.J., Neural networks and physical systems with emergent collective computational abilities. National Academy of Sciences, vol 79, Abril, (Páginas 2554-2558), 1982.
• [Huysmans, J., Baesens B., Vanthienen J.; 2003] Huysmans, J., Baesens B., Vanthienen J., Web Usage Mining: A Practical Study. Katholieke Universiteit Leuven, Dept. of Applied Economic Sciences, 2003.
• [Jain, A. K., Dubes, R. C.; 1988] Jain, A. K., Dubes, R. C., Algorithms for Clustering Data. Printice Hall, 1988.
• [Jansen, B. J., Spink, A., Saracevic, T.; 2000] Jansen, B. J., Spink, A., Saracevic, T., Real life, real users, and real needs: A study and analysis of user queries on the Web. Information Processing and Management, 2000.
• [Jespersen, S.E., Thorhauge, J., Pedersen, T.B.; 2002] Jespersen, S.E., Thorhauge, J., Pedersen, T.B., A Hybrid Approach To Web Usage Mining. Department of Computer Science. Aalborg University, 2002.
• [Kaufman, L., Rousseeuw, P. J.; 1990] Kaufman, L., Rousseeuw, P. J., Finding Groups in Data: an Introduction to Cluster Analysis. Wiley-Interscience, 1990.
• [Keim, D.A.; 2002] Keim, D.A., Information Visualization and Visual Data Mining. IEEE Transactions on Visualization and Computer Graphics, VOL. 7, NO. 1, Enero-Marzo 2002.
• [Kerkhofs, J., Vanhoof, K., Pannemans, D.; 2001] Kerkhofs, J., Vanhoof, K., Pannemans, D., Web Usage Mining on Proxy Servers: A Case Study. Limburg University Centre, 2001.
• [Kitsuregawa, M., Shintani, T., Pramudiono, I.; 2001] Kitsuregawa, M., Shintani, T., Pramudiono, I., Web mining and its SQL based parallel execution. IEEE Workshop on Information Technology for Virtual Enterprises, 2001.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 86 -
• [Kohonen, T.; 1995] Kohonen , T., Self-Organizing Maps. Springer-Verlag, 1995.
• [Kosala, R., Blockeel, H.; 2000] Kosala, R., Blockeel, H., Web Mining Research: A Survey. ACM SIGKDD, Julio 2000.
• [Koutri, M., Avouris, N., Daskalaki, S.; 2004] Koutri, M., Avouris, N., Daskalaki, S., A survey on Web usage mining techniques for Web-based adaptive hypermedia systems. University of Patras. Greece, 2004.
• [Koutsoupias, Nikos; 2002] Koutsoupias, Nikos, Exploring Web Access Logs with Correspondence Analysis. Department of Balkan Studies. Aristotle University of Thessaloniki, 2002.
• [Lalani, A.S.; 2003] Lalani, A.S., Data mining of Web access logs. School of Computer Science and Information Technology. Royal Melbourne Institute of Technology. Melbourne, Victoria, Australia, 2003.
• [Lu H., Setiono R., Liu, H.; 1995] Lu H., Setiono R., Liu, H., NeuroRule: A Connectionist Approach to Data Mining. Proceedings of the 21th International Conference on Very Large Data Bases, páginas 478/489, Septiembre 1995.
• [Mannila, H.; 1997] Mannila, H., Methods and problems in data mining. In Proc. of International Conference on Database Theory, Delphi, Greece, 1997.
• [Marbán Gallego, Óscar; 2002] Marbán Gallego, Óscar, Estudio de perfiles de visitantes de un website a partir de los logs de los servidores Web aplicando técnicas de Data mining (Webmining). Facultad de Informática. Universidad Politécnica de Madrid, 2002.
• [Marrone, Paolo; 2005] Marrone, Paolo, The Complete Guide: All you need to know about Joone. http://prdownloads.sourceforge.net/joone/JooneCompleteGuide.pdf?download. Vigente al 19/11/2005.
• [Masseglia, F., Poncelet, P., Teisseire, M.; 1999] Masseglia, F., Poncelet, P., Teisseire, M., Using data mining techniques on Web access logs to dynamically improve hypertext structure. In ACM SigWeb Letters, 8(3): 13-19, 1999.
• Métrica Versión 3. http://edic.lsi.uniovi.es/metricav3/. Vigente al 19/11/2005.
• [Mobasher, B., Cooley R., Srivastava, J.; 1999] Mobasher, B., Cooley R., Srivastava, J., Creating Adaptive Web Sites Through Usage-Based Clustering of URLs, 1999.
• [Mobasher, B., Dai, H., Luo, T., Nakagawa, M.; 2001] Mobasher, B., Dai, H., Luo, T., Nakagawa, M., Effective personalization based on association rule discovery from Web usage data. In Proc. of the 3rd ACM Workshop on Web Information and Data Management (WIDM01), Atlanta, 2001.
• [Morales, Eduardo; 2003] Morales, Eduardo, Descubrimiento de Conocimiento en Bases de Datos. http://dns1.mor.itesm.mx/~emorales/Cursos/KDD03/principal.html. Vigente al 19/11/2005.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 87 -
• [Nasraoui, O., Pavuluri, M.; 2004] Nasraoui, O., Pavuluri, M., Accurate Web recommendations Based in Profile-Specific URL-Predictor Neural Networks. Dept. of Electrical and Computer Engineering. The University of Menphis, 2004.
• [Ng, R., Han, J.; 1994] Ng, R., Han, J., Efficient and effective clustering method for spatial data mining. In Proc. 1994 Int. Conf. Very Large Data Bases, (Páginas 144/155), Santiago, Chile, Septiembre 1994.
• [Paliouras, G, Papatheodorou, C., Karkaletsisi, V., Spyropoulous, C.; 2000] Paliouras, G, Papatheodorou, C., Karkaletsisi, V., Spyropoulous, C., Clustering the users of large Web sites into communities. In Proc. of the 17th International Conference on Machine Learning (ICML'00), (Páginas 719/726). USA: Morgan Kaufmann, 2000.
• [Pazzani, M., Billsus D.; 1997] Pazzani, M., Billsus D., Learning and revising user profiles: The identification of interesting Web sites. Machine Learning, 27, (Páginas 313/331), 1997.
• [Perkowitz, M., Etzioni, O.; 1998] Perkowitz, M., Etzioni, O., Adaptive Web sites: Automatically synthesizing Web pages. In Proc. of the 15th National Conference on Artificial Intelligence, (Páginas 727/732), 1998.
• [Perkowitz, M., Etzioni, O.; 1997] Perkowitz, M., Etzioni, O., Adaptive sites: Automatically learning from user access patterns. In Proc. of the Sixth International WWW Conference, Santa Clara, CA, 1997.
• [Pierrakos, D., Paliouras, G., Papatheodorou, C., Spyropulos, C.D.; 2001] Pierrakos, D., Paliouras, G., Papatheodorou, C., Spyropulos, C.D., KOINOTITES: A Web Usage Mining Tool for Personalization, 2001.
• [Pirolli, P., Pitkow J., Rao R.; 1996] Pirolli, P., Pitkow J., Rao R., Silk from a sow's ear: Extracting usable structures from the Web. In Proc. on Human Factors in Computing Systems (CHI'96). ACM Press, 1996.
• [Pitkow, J.; 1997] Pitkow, J., In search of reliable usage data on the WWW. Xerox Palo Alto Research Center. Palo Alto, California, 1997.
• [Punin, J., Krishnamoorthy, M., Zaki, M.; 2001] Punin, J., Krishnamoorthy, M., Zaki, M., LOGML: Log Markup Language for Web Usage Mining. Computer Science Department. Rensselaer Polytechnic Institute, 2001.
• [Quinlan, J. R.; 1993] Quinlan, J. R., C4.5: Programs for Machine Learning. Morgan Kaufmann, 1993.
• [Rangarajan, S., Phoha, V., Balagani, K., Iyengar, S., Selmic, R.; 2003] Rangarajan, S., Phoha, V., Balagani, K., Iyengar, S., Selmic, R., Web User Clustering and Its Application to Prefetching Using ART Neural Networks. Louisiana Tech University & Louisiana State University, 2003.
• RFC 1413. Identification Protocol. http://www.rfc-editor.org/rfc/rfc1413.txt. Vigente al 19/11/2005.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 88 -
• RFC 2616 – Hypertext Transfer Protocol – HTTP/1.1. http://www.faqs.org/rfcs/rfc2616.html. Vigente al 19/11/2005.
• [Ritter H., Martinetz T., Schulten K.; 1992] Ritter H., Martinetz T., Schulten K., Neural Computation and Self-Organizing Maps. Addison-Wesley Publishing Company, 1992.
• [Roussinov, D., Zhao JL., 2003] Roussinov, D., Zhao JL., Automatic discovery of similarity relationships through Web mining. Decision Support Systems, 35(1), (149/166), 2003.
• [Roy, A., 2000] Roy, A., Artificial Neural Networks - A Science in Trouble. ACM SIGKDD, Enero 2000.
• [Sheikholeslami, G., Chatterjee, S., Zhang, A.; 1998] Sheikholeslami, G., Chatterjee, S., Zhang, A., WaveCluster: A Multi-Resolution Clustering Approach for Very Large Spatial Databases, 1998.
• [Silverstein, C., Henzinger, M., Marais, H., Moricz, M.; 1999] Silverstein, C., Henzinger, M., Marais, H., Moricz, M., Analysis of a Very Large Web Search Engine Query Log. ACM SIGIR Forum, 33(1), (6-12), 1999.
• [Smith, K.A., Ng, A.; 2002] Smith, K.A., Ng, A., Web page clustering usign a self-organizing map of user navigation patterns. School of Business Systems. Monash University. Victoria. Australia, 2002.
• [Spiliopoulou, M., Faulstich L.C.; 1999] Spiliopoulou, M., Faulstich LC., WUM: A Web utilization miner. In Proc. of EDBT Workshop on the Web and Data Bases (WebDB'98), (Páginas 109/115). Springer Verlag, 1999.
• [Spiliopoulou, M., Pohle, C., Faulstich, L. C.; 2000] Spiliopoulou, M., Pohle, C., Faulstich, L. C., Improving the effectiveness of a website with Web usage mining. In Advances in Web Usage Analysis and User Profiling, Berlín, Springer, (Páginas 14162), 2000.
• [Spink, A., Xu, J.; 2000] Spink, A., Xu, J., Selected Results from a Large Study of Web Searching: The Excite Study. Information Research.
• http://InformationR.net/ir/6-1/paper90.html. Vigente al 19/11/2005.
• [Spink, A., Wolfram, D., Jansen, B. J., Saracevic, T.; 2001] Spink, A., Wolfram, D., Jansen, B. J., Saracevic, T., Searching the Web: The Public and Their Queries. Journal of the American Society for Information Science and Technology, 52(3), (226-234), 2001.
• [Srikant, R., Yang, Y.; 2001] Srikant, R., Yang, Y., Mining Web logs to improve website organization. In Proc. of the tenth International World Wide Web Conference, Hong Kong, 2001.
• [Srivastava, J., Cooley, R., Deshpande, M., Tan, P.N.; 2000] Srivastava, J., Cooley, R., Deshpande, M., Tan, P.N., Web Usage Mining: Discovery and Applications of Usage Patterns from Web Data. ACM SIGKDD, Enero 2000.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 89 -
• [Vesanto J., Alhoniemi E.; 2000] Vesanto J., Alhoniemi E., Clustering of the Self-Organizing Map. IEEE transactions on neural networks, Vol 11, No. 3, 2000.
• W3CLOG. Extended log file format. http://www.w3.org/TR/WD-logfile.html. Vigente al 19/11/2005.
• [Wang, R., Yang, Y., Muntz, R.; 1997] Wang, R., Yang, Y., Muntz, R., STING: A Statistical Information Grid Approach to Spatial Data. Department of Computer Science. University of California, Los Angeles, 1997.
• WCA. Web characterization terminology & definitions. http://www.w3.org/1999/05/WCA-terms/. Vigente al 19/11/2005.
• [Weiss, S.M., Kulikowski, C.A.; 1991] Weiss, S.M., Kulikowski, C.A., Computer Systems that Learn: Classification and Prediction Methods from Statistics, Neural Nets, Machine Learning, and Expert Systems. Morgan Kaufman Publishers, 1991.
• [Yan, T., Javobsen, J., Garcia-Molina, H., Dayal, U.; 1996] Yan, T., Javobsen, J., Garcia-Molina, H., Dayal, U., From User Access Patterns to Dynamic Hypertext Linking, 1996.
• [Yang, Q., Zhang HH.; 2003] Yang, Q., Zhang HH., Web-log mining for predictive Web caching. IEEE Transactions on Knowledge and Data Engineering, Vol. 15, No. 4, (Páginas 1050/1053), 2003.
• [Zhang, D., Dong Y.; 2003] Zhang, D., Dong Y., A novel Web usage mining approach for search engines. Computer Networks, 39(3), (303/310), 2003.
• [Zhang, T., Ramakrishnan R., Livny, M.; 1996] Zhang, T., Ramakrishnan R., Livny, M., BIRCH: an efficient data clustering method for very large databases. In Proc. 1996 ACM-SIGMOD Int. Conf. Management of Data, Montreal, Canada, Junio 1996.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 90 -
A. Apéndice I: Joone
A.1. Descripción de Joone....................................................................................................91 A.1.1. Capas de Neuronas ................................................................................................92
A.1.1.1. Capa Lineal.....................................................................................................92 A.1.1.2. Capa Lineal Parcial.........................................................................................93 A.1.1.3. Capa Sigmoidal...............................................................................................93 A.1.1.4. Capa Tangente Hiperbólica ............................................................................93 A.1.1.5. Capa Logarítmica............................................................................................93 A.1.1.6. Capa Senoidal .................................................................................................93 A.1.1.7. Capa con Retraso ............................................................................................93 A.1.1.8. Capa con Contexto..........................................................................................93 A.1.1.9. Capa de Gauss ................................................................................................93 A.1.1.10. Capa RBF Gaussiana ....................................................................................94 A.1.1.11. Capa “El Ganador Se Lleva Todo”...............................................................94 A.1.1.12. Capa Gaussiana.............................................................................................94
A.1.2. Sinapsis..................................................................................................................94 A.1.2.1. Sinapsis Directa ..............................................................................................94 A.1.2.2. Sinapsis Completa ..........................................................................................94 A.1.2.3. Sinapsis con Retraso.......................................................................................95 A.1.2.4. Sinapsis de Kohonen.......................................................................................95 A.1.2.5. Sinapsis de Sanger ..........................................................................................95
A.1.3. Sinapsis de Entrada................................................................................................95 A.1.3.1. Sinapsis de Entrada de Archivo......................................................................95 A.1.3.2. Sinapsis de Entrada de URL...........................................................................96 A.1.3.3. Sinapsis de Entrada de Excel..........................................................................96 A.1.3.4. Sinapsis de Entrada de JDBC .........................................................................96 A.1.3.5. Sinapsis de Entrada de Yahoo Finance...........................................................96 A.1.3.6. Sinapsis de Entrada de Memoria ....................................................................96
A.1.4. Sinapsis de Salida ..................................................................................................96 A.1.5. Sinapsis Maestra ....................................................................................................96 A.1.6. El Monitor..............................................................................................................97
A.2. Elección de Joone .........................................................................................................97

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 91 -
A.1. Descripción de Joone
Joone (http://www.joone.org/) es un framework en Java para construir y ejecutar aplicaciones de inteligencia artificial basadas en redes neuronales. Las aplicaciones realizadas con Joone pueden ser construidas en una maquina local, entrenadas en un ambiente distribuido y ejecutarse en cualquier dispositivo [Marrone, 2005].
Joone consiste de una arquitectura modular basada en componentes vinculados que pueden ser extendidos para construir nuevos algoritmos de aprendizaje y nuevas arquitecturas de redes neuronales.
Todos los componentes poseen algunas características básicas especificas, como persistencia, multihilos (multithreading), serialización y parametrización. Estas características garantizan escalabilidad, reliability y expansibilidad, todas características obligatorias para alcanzar el destino final de los estándares futuros en el mundo de la inteligencia artificial.
Cada red neuronal esta compuesta de varias capas de neuronas conectadas mediante sinapsis [Figura A.1]. Pueden crearse variadas arquitecturas de redes neuronales dependiendo de cómo las neuronas son conectadas.
Figura A.1. Conexiones entre capas de neuronas
En la figura se observa un ejemplo de una red con dos capas y conectada mediante una sinapsis. Cada capa esta compuesta de una cierta cantidad de neuronas, cada una de las cuales poseen las mismas características (función de transferencia, tasa de aprendizaje, etc.).
Una red neuronal construida con Joone puede estar compuesta de cualquier cantidad de capas de diferentes tipos. Cada capa procesa sus señales de entrada, aplica la función de transferencia y envía los patrones resultantes a la sinapsis que la conecta con la capa siguiente.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 92 -
Para asegurar que sea posible construir cualquier arquitectura de red neuronal, se necesita un método para transferir los patrones a través de la red sin un punto central de control. Para cumplir este objetivo, cada capa de neuronas es implementada como un objeto Runnable, de modo que cada capa se ejecute independientemente de las otras, obteniendo los patrones de entrada, aplicándoles la función de transferencia y colocando los patrones resultantes en la sinapsis de salida, para que las capas siguientes puedan recibirlos, procesarlos y continuar con las demás capas, hasta llegar a la capa de salida.
Este mecanismo de transporte es también utilizado durante la etapa de entrenamiento para propagar el error desde la capa de salida a la capa de entrada [Figura A.2], permitiendo modificar los pesos de las conexiones utilizando el algoritmo de aprendizaje seleccionado (backpropagation, por ejemplo).
Figura A.2. Mecanismo de transporte en la red neuronal
Las capas y las sinapsis poseen sus propios mecanismos para ajustar los pesos dependiendo del algoritmo de aprendizaje seleccionado.
A.1.1. Capas de Neuronas
El objeto Capa (Layer) es el elemento básico que forma una red neuronal.
Cada capa esta compuesta de neuronas con las mismas características, que transfieren los patrones de entrada a patrones de salida ejecutando una función de transferencia.
Existen diferentes tipos de capas, las cuales son detalladas a continuación.
A.1.1.1. Capa Lineal
La Capa Lineal (LinearLayer) es el tipo de capa más simple y solamente transfiere los patrones de entrada a la salida aplicando una transformación lineal.
La Capa Lineal es utilizada comúnmente como un buffer, colocado como la capa de entrada de la red, para permitir enviar copias de los patrones de entra sin modificaciones a varias capas ocultas de la red.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 93 -
A.1.1.2. Capa Lineal Parcial
La Capa Lineal Parcial (BiasedLinearLayer) utiliza como función de transferencia la adición de un parámetro ajustable al valor de entrada. El parámetro puede ser modificado durante la etapa de entrenamiento.
A.1.1.3. Capa Sigmoidal
La Capa Sigmoidal (SigmoidLayer) aplica una función de transferencia sigmoidal a los patrones de entrada, limitando la salida al rango [0,1].
A.1.1.4. Capa Tangente Hiperbólica
La Capa Tangente Hiperbólica (TanhLayer) es similar a la Capa Sigmoidal excepto que aplica la función tangente hiperbólica, limitando la salida al rango [-1,1].
A.1.1.5. Capa Logarítmica
La Capa Logarítmica (LogarithmicLayer) aplica una función de transferencia logarítmica a los patrones de entrada, resultando en una salida cuyo rango es [0,infinito].
A.1.1.6. Capa Senoidal
La Capa Senoidal (SineLayer) utiliza como salida la función seno evaluada en la suma de los valores de las entradas ponderadas por sus pesos.
A.1.1.7. Capa con Retraso
La Capa con Retraso (DelayLayer) aplica la suma de los valores de entrada a una línea de retraso, de modo que cada neurona es atrasada por la cantidad de iteraciones especificada como parámetro.
A.1.1.8. Capa con Contexto
La Capa con Contexto (ContextLayer) es similar a la capa lineal excepto que posee una conexión auto recurrente entre su salida y su entrada, que propaga hacia atrás la salida de la neurona en el paso anterior.
A.1.1.9. Capa de Gauss

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 94 -
La Capa de Gauss (GaussLayer) posee como salida la suma de las entradas ponderadas por los pesos, aplicada a una función gaussiana.
A.1.1.10. Capa RBF Gaussiana
La Capa RBF Gaussiana (RBFGaussianLayer) posee como salida la suma de las entradas ponderadas por los pesos, aplicada a una función gaussiana, al igual que la Capa de Gauss, pero es posible ajustar el centro de la curva de gauss utilizada.
A.1.1.11. Capa “El Ganador Se Lleva Todo”
La Capa “El Ganador Se Lleva Todo” (WinnerTakeAllLayer) recibe las distancias Euclideas entre los pesos de la sinapsis anterior ( una sinapsis de Kohonen) y sus entradas. La capa calcula cual es el nodo que posee la menor distancia a la entrada y envía como salida el valor 1 para ese nodo y 0 para los demás.
A.1.1.12. Capa Gaussiana
La Capa Gaussiana (GaussianLayer) es similar a la capa “El Ganador Se Lleva Todo”, pero las neuronas son activadas de acuerda a una superficie gaussiana centrada en la neurona mas activa (la ganadora).
A.1.2. Sinapsis
El objeto Sinapsis (Synapse) representa la conexión entre dos capas de neuronas, permitiendo que un patrón se transfiera de una capa a la otra.
Las sinapsis poseen los pesos de las conexiones, los cuales son modificados en la etapa de entrenamiento de acuerdo al algoritmo de aprendizaje seleccionado.
A.1.2.1. Sinapsis Directa
La Sinapsis Directa (DirectSynapse) representa una conexión directa uno a uno entre los nodos de dos capas, las cuales poseen la misma cantidad de neuronas.
Cada conexión posee un peso igual a 1 que no es modificado en la etapa de entrenamiento.
A.1.2.2. Sinapsis Completa

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 95 -
La Sinapsis Completa (FullSynapse) conecta todos los nodos de una capa con todos los nodos de otra capa.
Los pesos de sus conexiones se modifican en la etapa de entrenamiento de acuerdo al algoritmo de aprendizaje seleccionado.
A.1.2.3. Sinapsis con Retraso
La Sinapsis con Retraso (DelayedSynapse) posee una arquitectura similar a la Sinapsis Completa, pero cada conexión es implementada usando una matriz de filtros FIR (Finite Impulse Response, Respuesta a Impulso Finito), que retrasa las conexiones permitiendo implementar un algoritmo de propagación hacia atrás temporal.
A.1.2.4. Sinapsis de Kohonen
La Sinapsis de Kohonen (KohonenSynapse) pertenece a un tipo especial de componentes que permite construir redes neuronales no supervisadas.
Durante la etapa de entrenamiento, los pesos de sus conexiones son ajustados para mapear los patrones de entrada N-dimensionales a un mapa de 2 dimensiones.
A.1.2.5. Sinapsis de Sanger
La Sinapsis de Sanger (SangerSynapse) se utiliza para construir redes neuronales no supervisadas que implementan el algoritmo PCA (Principal Component Analysis, Análisis de Componentes Principales).
El Análisis de Componentes Principales permite extraer los componentes más importantes de una señal, permitiendo separar el ruido de la señal original.
A.1.3. Sinapsis de Entrada
Joone también posee varias sinapsis de entrada, por donde son introducidos los patrones a la red. Existen diversos tipos de sinapsis de entrada, dependiendo del origen de los patrones, las cuales se detallan a continuación.
A.1.3.1. Sinapsis de Entrada de Archivo
La Sinapsis de Entrada de Archivo (FileInputSynapse) permite introducir los patrones a la red mediante un archivo. El archivo debe contener columnas de valores enteros o reales delimitados por punto y coma.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 96 -
A.1.3.2. Sinapsis de Entrada de URL
La Sinapsis de Entrada de URL (URLInputSynapse) permite introducir los patrones a la red desde una URL. El archivo apuntado por la URL debe tener el mismo formato que el aceptado por la Sinapsis de Entrada de Archivo.
Los protocolos soportados son HTTP y FTP.
A.1.3.3. Sinapsis de Entrada de Excel
La Sinapsis de Entrada de Excel (ExcelInputSynapse) permite introducir los patrones a la red mediante un archivo de Excel.
A.1.3.4. Sinapsis de Entrada de JDBC
La Sinapsis de Entrada de JDBC (JDBCInputSynapse) permite introducir los patrones a la red mediante casi cualquier base de datos, utilizando el controlador JDBC para ese tipo de base de datos.
A.1.3.5. Sinapsis de Entrada de Yahoo Finance
La Sinapsis de Entrada de Yahoo Finance (YahooFinanceInputSynapse) provee soporte para la entrada de datos financieros, contactando los servicios de Yahoo Finance y obteniendo los datos históricos del símbolo y el rango de fechas seleccionado.
A.1.3.6. Sinapsis de Entrada de Memoria
La Sinapsis de Entrada de Memoria (MemoryInputSynapse) permite introducir los patrones a la red mediante un vector de números reales.
A.1.4. Sinapsis de Salida
Joone también posee sinapsis de salida que permiten a la red neuronal escribir los patrones de salida en varios soportes de almacenamiento, como por ejemplo, archivos ASCII, hojas de calculo de Excel, tablas de base de datos utilizando JDBC y vectores de Java.
A.1.5. Sinapsis Maestra

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 97 -
La función de la Sinapsis Maestra (TeacherSynapse) es calcular la diferencia entre la salida de una red neuronal y el valor deseado obtenido de un origen externo de datos.
La diferencia calculada es inyectada hacia atrás en la red, comenzando en la capa de salida, de modo que cada componente pueda procesar el error para modificar los pesos de las conexiones aplicando el algoritmo de aprendizaje seleccionado.
También existen sinapsis para intercambiar entre dos o más orígenes de datos, como por ejemplo un conjunto de datos de entrenamiento y otro conjunto de datos de validación, como así también entre dos o más salidas distintas para los patrones.
A.1.6. El Monitor
El objeto Monitor representa en punto central donde se encuentran todos los parámetros necesarios para que los componentes de la red neuronal funcionen correctamente, como la velocidad de aprendizaje, el momento, el algoritmo de aprendizaje, la cantidad de ciclos de entrenamiento, el ciclo actual, etc.
Cada capa de neuronas y cada sinapsis de una red neuronal recibe un puntero a una instancia de un objeto Monitor, de modo que, cuando el usuario desea cambiar algún parámetro, solo debe hacerlo en el objeto Monitor.
El Monitor también provee a la aplicación que lo utiliza de un mecanismo de notificaciones basado en varios eventos arrojados cuando una acción en particular sucede. Por ejemplo, una aplicación externa puede ser informada cuando la red neuronal comienza o termina los ciclos de entrenamiento, cuando finaliza un ciclo o cuando el valor del error global cambia durante la etapa de entrenamiento.
A.2. Elección de Joone
Se eligió Joone para la realización de la herramienta por varios motivos:
• Clases en Java que permiten integrarlo en una aplicación: debido a que Joone esta compuesto de clases en java, se lo puede integrar como parte de otra aplicación, pudiendo generar un sistema completo que utilice las ventajas de las redes neuronales de Joone.
• Manejo de componentes que permiten definir cualquier arquitectura de red: ya que Joone esta construido sobre la base de componente modulares, que permiten conectar distintos tipos de componentes, formando cualquier arquitectura de red, pudiendo obtener exactamente la red necesaria.
• Completa documentación: documentación completa, explicando el funcionamiento de los componentes y como integrarlos para generar distintos tipos de redes neuronales.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 98 -
• Código fuente abierto: se posee a disposición el código fuente, permitiendo, en caso que sea necesario, modificar alguno de los comportamientos de los componentes para adecuarlos al funcionamiento deseado.
• Licencia LGPL: distribuido bajo la licencia GNU Lesser General Public License, permitiendo su uso como parte de la aplicación de prueba a desarrollar.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 99 -
B. Apéndice II: Manual del Usuario
El Sistema Automático de Identificación de Hábitos de Uso de Sitios Web involucra todo un proceso que consiste en la carga y el preprocesado de log, la identificación de las sesiones de usuarios, para finalmente poder determinar los hábitos de uso. Este proceso toma como entrada un archivo de log de un servidor Web y da como resultado una serie de reportes que ayudarán a identificar los hábitos de uso del sitio Web analizado.
B.1. Pantalla Principal ........................................................................................................100 B.2. Registración en el Sistema..........................................................................................101 B.3. Iniciar Sesión en el Sistema........................................................................................101 B.4. Creación de Proyectos ................................................................................................102 B.5. Listado de Proyectos...................................................................................................104 B.6. Pantalla Principal Proyecto.........................................................................................104 B.7. Menú Principal............................................................................................................105
B.7.1. Resumen Proyecto ...............................................................................................105 B.7.2. Ver Archivos........................................................................................................106 B.7.3. Logs .....................................................................................................................106 B.7.4. Construir Sesiones ...............................................................................................107 B.7.5. Construir Clusters ................................................................................................107 B.7.6. Sesiones/Clusters .................................................................................................108 B.7.7. Detalle Sesiones...................................................................................................108 B.7.8. Páginas/Clusters...................................................................................................109 B.7.9. Cerrar Proyecto ....................................................................................................109
B.8. Subir Archivo de Log .................................................................................................109 B.9. Cargar Log ..................................................................................................................111 B.10. Ver Log Cargado ......................................................................................................114 B.11. Construcción de Sesiones de Usuarios .....................................................................115 B.12. Contrucción de Grupos de Usuarios .........................................................................118
B.12.1. Construcción de Grupos de Usuarios Utilizando la Red Neuronal SOM..........118 B.12.2. Construcción de Grupos de Usuarios Utilizando el Algoritmo K-Means .........120
B.13. Ver Cantidad de Sesiones en Cada Grupo de Usuario Descubierto .........................123 B.13.1. Red Neuronal Mapa Auto-Organizativo (SOM)................................................123 B.13.2. Algoritmo K-Means...........................................................................................124 B.13.3. Comparación......................................................................................................125
B.14. Ver Detalle de Sesiones Indicando el Grupo de Usuarios al Cual Pertenece ...........126 B.14.1. Red Neuronal Mapa Auto-Organizativo (SOM)................................................126 B.14.2. Algoritmo K-Means...........................................................................................128 B.14.3. Comparación......................................................................................................130
B.15. Ver Páginas Más Frecuentes en Cada Grupo de Usuarios Descubierto ...................132 B.15.1. Red Neuronal Mapa Auto-Organizativo (SOM)................................................132 B.15.2. Algoritmo K-Means...........................................................................................134 B.15.3. Comparación......................................................................................................136
B.16. Cerrar Sesión.............................................................................................................138

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 100 -
B.1. Pantalla Principal
Desde la pantalla principal se permite que los usuario inicien sesión en el sistema utilizando el formulario ubicado en el ángulo superior derecho [Figura B.1]. También se tiene la opción de registrarse como usuario del sistema clickeando en el boton “Registrarse”.
Figura B.1. Pantalla Principal

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 101 -
B.2. Registración en el Sistema
Luego de clickear en el boton “Registrarse” se despliega la pantalla de registración de usuarios [Figura B.2], en la cual se debe completar los campos, colocando en el campo Nombre el nombre de usuario y en los dos campos inferiores (Clave y Repetir Clave) la clave de acceso, repitiendola para evitar errores de tipeo. Una vez llenados estos datos, clickeando sobre el botón Registrarse se procede a la registración del usuario.
Figura B.2. Registración en el Sistema
A continuación, se procede a la registración del usuario prueba [Figura B.3], el cual será utilizado en este manual para ejemplificar el uso del sistema.
Figura B.3. Registración usuario prueba
B.3. Iniciar Sesión en el Sistema
Para iniciar sesión en el sistema, se deben rellenar los datos correspondiente al usuario en el formulario de inicio de sesión [Figura B.4]. En el campo Nombre coloque el nombre de usuario y en el campo Password coloque la contraseña. Luego presione el botón Entrar.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 102 -
Figura B.4. Inicio de Sesión en el Sistema
Iniciamos sesión en el sistema con el usuario prueba registrado anteriormente [Figura B.4]. Luego de presionar el botón Entrar, se ingresará al listado de los proyectos, permitiendo agregar nuevos proyectos al sistema.
B.4. Creación de Proyectos
La primera vez que acceda al sistema, no se tendrá ningún proyecto, por lo que se visualizará la siguiente pantalla [Figura B.5].

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 103 -
Figura B.5. Proyectos del Usuario
Para agregar un nuevo proyecto se debe presionar sobre el boton Nuevo Proyecto, ubicado en el menú de la izquierda.
Luego, completar el campo Nombre, indicando el nombre del proyecto a crear, y el campo Descripción, con la descripción del mismo [Figura B.6]. Presionar sobre Crear Proyecto para crear un proyecto nuevo.
A modo de ejemplo, se visualiza la creación de un proyecto de prueba llamado proyecto, cuya descripción es Proyecto de Prueba [Figura B.6].
Figura B.6. Creación de Proyectos

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 104 -
B.5. Listado de Proyectos
En la misma pantalla desde donde se pueden crear proyectos, también se despliegan todos los proyectos del usuario en el sistema [Figura B.7]. Para acceder a uno de ellos se debe clickear el nombre del mismo. Si presiona sobre el tacho de residuos ubicado a la derecha de cada proyecto, se procederá a eliminar el proyecto, previa solicitud de confirmación.
Figura B.7. Listado de Proyectos
B.6. Pantalla Principal Proyecto
Luego de seleccionar un proyecto, se accede a la pantalla principal del proyecto [Figura B.8].

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 105 -
Figura B.8. Pantalla Principal Proyecto
En el centro de la pantalla se muestra un resumen del proyecto seleccionado, indicando su nombre, la cantidad de registros de log cargados en el mismo y la cantidad de sesiones cargadas en dicho proyecto. Sobre la izquierda se despliega el menú principal del sistema. Para luego poder acceder a esta pantalla que muestra el resumen del proyecto, se debe seleccionar el primer elemento del menú Resumen Proyecto.
B.7. Menú Principal
El menú principal del sistema se encuentra a la izquierda de la pantalla.
B.7.1. Resumen Proyecto
Permite ver el resumen del proyecto, mostrando información especifica sobre el proyecto actual [Figura B.9].

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 106 -
Figura B.9. Resumen Proyecto
B.7.2. Ver Archivos
Permite ver y obtener los archivos de log subidos al servidor y todos los archivos de entrada y salida al algoritmo K-Means y a la red neuronal SOM [Figura B.10].
Figura B.10. Menú Ver Archivos
B.7.3. Logs
Permite subir un nuevo archivo de log, el cual estara disponible para todos los proyectos del usuario, cargar ese log pre-procesandolo y ver todos los registros del log cargado [Figura B.11].

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 107 -
Figura B.11. Menú Logs
B.7.4. Construir Sesiones
Permite la contrucción de las sesiones de los usuarios, procesando el log cargado.
B.7.5. Construir Clusters
Permite contruir los grupos de usuarios utilizando la red neuronal SOM o el algoritmo K-Means [Figura B.12].
Figura B.12. Menú Construir Clusters

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 108 -
B.7.6. Sesiones/Clusters
Permite acceder a las estadísticas mostrando la cantidad de sesiones en cada grupo de usuarios generados utilizando la red neuronal mapa auto-organizativo (SOM), el algoritmo K-Means y una comparación entre estos dos [Figura B.13].
Figura B.13. Menú Sesiones/Clusters
B.7.7. Detalle Sesiones
Permite acceder al detalle de todas las sesiones de usuario identificadas, indicando a que grupo de usuarios pertenecen, teniendo en cuenta a los grupos generados mediante la red neuronal mapa auto-organizativo (SOM), el algoritmo K-Means o una comparación entre estos dos [Figura B.14].
Figura B.14. Menú Detalle Sesiones

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 109 -
B.7.8. Páginas/Clusters
Permite acceder al detalle de las páginas mas frecuentes entre los accesos de los usuarios de cada grupo descubierto mediante la red neuronal SOM, el algoritmo K-Means o una comparación entre estos dos [Figura B.15].
Figura B.15. Menú Páginas/Clusters
B.7.9. Cerrar Proyecto
Cierra el proyecto actual y despliega la pantalla de selección de proyecto, permitiendo además la creación de un proyecto nuevo.
B.8. Subir Archivo de Log
Para copiar al servidor un archivo de log, se debe acceder al sub-elemento Subir Archivo de Log del elemento Logs del menú principal del sistema [Figura B.16].

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 110 -
Figura B.16. Menú Subir Archivo de Log
Luego, se despliega la pantalla que permite copiar un archivo de log al servidor [Figura B.17]. El campo Descripción corresponde con la descripción del archivo de log a copiar, y el campo Log, con el archivo de log mismo. Mediante el boton Browse... puede navegar su disco en busca del archivo de log a copiar. Al presionar el boton Subir Log, se procede a copiar el archivo de log al servidor. Una vez copiado el archivo, el sistema despliega el nombre y la descripción de todos los archivos de log del usuario.
Figura B.17. Subir Archivo de Log
A modo de ejemplo, se muestra cómo se procedería a copiar el archivo de log seleccionado, cuya descripción es Archivo de log de prueba, al servidor [Figura B.18].

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 111 -
Figura B.18. Ejemplo Subir Archivo de Log
B.9. Cargar Log
Para cargar un archivo de log y pre-procesarlo, se debe acceder al sub-elemento Cargar Log del elemento Logs del menú principal del sistema [Figura B.19].
Figura B.19. Menú Cargar Log
Luego, se despliega la pantalla que permite cargar un archivo de log y pre-procesarlo [Figura B.20].

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 112 -
Figura B.20. Cargar Log
Descripción de campos:
• Log: se selecciona el archivo de log subido al servidor que se desea utilizar.
• Tipo de Log: se selecciona el tipo de log que posee el archivo de log seleccionado, los cuales pueden ser CLF (formato de log común) o CLF+REFERRER+AGENT (formato de log común, más los campos referrer y agent).
• Extensiones: se indican las extensiones de los recursos que serán tenidos en consideración para pre-procesar el archivo de log. Estas extensiones deben estar separadas por comas. Por defecto, las extensiones a considerar son php, html y htm.
• Códigos: se indican los codigos de error devueltos por el servidor Web, que seran tenidos en consideración para pre-procesar el archivo de log. Estos códigos deben estar separados por comas. Por defecto, el único codigo a considerar es el código 200, el cual significa respuesta correcta.
• ID Páginas: se indican los nombre de las variables GET que son consideradas diferenciadoras de páginas distintas dentro del sitio Web analizado. Estos nombres deben estar separados por comas. Por defecto no se posee ningún nombre de variable identificadora de páginas distintas.
Al presionar el boton Cargar Log, se procede a cargar y pre-procesar el archivo de log. Una vez pre-procesado, el sistema muestra información sobre el log cargado [Figura B.22].
A modo de ejemplo, se muestra el preproceso del archivo de log do2.com.ar-access, de formato CLF, teniendo en cuenta solo los registros que solicitan recursos con extensiones php, html o htm, y que hayan devuelto el codigo de error 200 (solicitud exitosa). Además, se establece a las variables página y page como variables identificadoras de páginas distintas [Figura B.21].

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 113 -
Figura B.21. Ejemplo Cargar Log
Luego de presionar el boton Cargar Log y que termine el proceso de pre-procesado se despliega la siguiente pantalla, mostrando un resumen del proceso realizado [Figura B.22].
Figura B.22. Resultado Cargar Log
En el resumen del proyecto seleccionando el elemento Resumen Proyecto del menú principal, se verá la siguiente pantalla, indicando la cantidad de registros de log cargados e indicando que todavía no se posee ninguna sesión de usuario construida [Figura B.23].

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 114 -
Figura B.23. Resumen Proyecto luego de Cargar Log
B.10. Ver Log Cargado
Para ver los registros de un log cargado y pre-procesarlo, se debe acceder al sub-elemento Ver Log Cargado del elemento Logs del menú principal del sistema [Figura B.24].
Figura B.24. Menú Ver Log Cargado
Luego se despliega la siguiente pantalla donde se muestra la información de todos los registros cargados, en forma páginada [Figura B.25].

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 115 -
Figura B.25. Ver Log Cargado
B.11. Construcción de Sesiones de Usuarios
Para contruir las sesiones de usuarios utilizando el log cargado y preprocesado, se debe acceder al elemento Construir Sesiones del menú principal del sistema.
Luego, se despliega la pantalla que permite configurar las opciones para la contrucción de las sesiones de usuarios [Figura B.26].

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 116 -
Figura B.26. Construcción de Sesiones de Usuarios
Descripción de campos:
• Cantidad mínima de páginas en una sesión: se indica la cantidad mínima de páginas que debe poseer una sesión de usuario. Por defecto, posee un valor de 3.
• Timeout de sesión: se indica el tiempo máximo entre dos solicitudes consecutivas del mismo usuario para ser consideradas pertenecientes a la misma sesión. Este campo debe completarse de la forma HHMMSS, donde HH son las horas (si el valor es menor a una hora, no debe colocarse nada), MM son los minutos y SS son los segundos. El valor por defecto es de treinta minutos.
• Frecuencia mínima de página en el log: se indican la frecuencia mínima en la totalidad del log que debe poseer una página para ser considerada en la contrucción de sesiones. El valor por defecto es 1.
Al presionar el botón Construir Sesiones, se procede a la contrucción de las sesiones de usuarios.
A modo de ejemplo, se procederá a construir las sesiones de usuarios utilizando el valor 3 como la cantidad mínima de páginas en una sesión, el valor de 15 minutos para el timeout de sesión y un valor de 10 para la frecuencia mínima de página en el log [Figura B.27].

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 117 -
Figura B.27. Ejemplo Construcción Sesiones de Usuarios
Luego de presionar el botón Construir Sesiones y al terminar el proceso de construcción de sesiones, se despliega la siguiente pantalla, mostrando un resumen del proceso realizado [Figura B.28].
Figura B.28. Resultado Construcción Sesiones de Usuarios
Si ahora nos dirigimos al resumen del proyecto seleccionando el elemento Resumen Proyecto del menú principal, veremos la siguiente pantalla, indicando la cantidad de registros de log cargados e indicando la cantidad de sesiones de usuario cargadas [Figura B.29].

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 118 -
Figura B.29. Resumen Proyecto luego de la Construcción de Sesiones de Usuarios
B.12. Contrucción de Grupos de Usuarios
B.12.1. Construcción de Grupos de Usuarios Utilizando la Red Neuronal SOM
Para construir los grupos de usuarios utilizando una red neuronal mapa auto-organizativo (SOM), se debe acceder al sub-elemento SOM del elemento Construir Clusters del menú principal del sistema [Figura B.30].
Figura B.30. Menú Construir Clusters
Luego, se despliega la pantalla que permite configurar las opciones para la contrucción de los grupos de usuarios [Figura B.31].

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 119 -
Figura B.31. Construcción de Grupos de Usuarios Utilizando la Red Neuronal SOM
Descripción de campos:
• Archivo donde se guardaran los patrones de entrada a la red: se indica el nombre del archivo donde se guardaran los patrones de entrada a la red neuronal.
• Archivo donde se guardara la información sobre los clusters descubiertos: se indica el nombre del archivo donde se guardara la información sobre los clusters descubiertos.
• Cantidad de ciclos de entrenamiento: se indica la cantidad de ciclos de entrenamiento que se realizan con cada patrón de entrada a la red neuronal.
• Cardinalidad del mapa de clusterización (NxN): se indica la cardinalidad del mapa de clusterización, indicando el valor N, que resultará en un mapa de N x N.
Al presionar el botón Construir Clusters, se procede a la contrucción de los clusters de usuarios. Una vez construidos los clusters, el sistema muestra información sobre los clusters creados.
A modo de ejemplo, se procede a construir los grupos de usuarios, obteniendo un mapa de 2 x 2, representando 4 grupos de usuarios. Se realizarán 10 ciclos de entrenamiento con los patrones de entrada. Los archivos de entrada y salida de la red serán almacenados con los nombres indicados en el formulario [Figura B.32].

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 120 -
Figura B.32. Ejemplo Construcción de Grupos de Usuarios SOM
Luego de presionar el botón Construir Clusters y al terminar el proceso de construcción de grupos de usuarios, se despliega la siguiente pantalla, mostrando un resumen del proceso realizado [Figura B.33].
Figura B.33. Resultado Construcción de Grupos de Usuarios SOM
B.12.2. Construcción de Grupos de Usuarios Utilizando el Algoritmo K-Means
Para construir los grupos de usuarios utilizando el algoritmo K-Means, se debe acceder al sub-elemento K-Means del elemento Construir Clusters del menú principal del sistema [Figura B.34].

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 121 -
Figura B.34. Menú Construir Clusters
Luego, se despliega la pantalla que permite configurar las opciones para la contrucción de los grupos de usuarios [Figura B.35].
Figura B.35. Construcción de Grupos de Usuarios Utilizando el Algoritmo K-Means
Descripción de campos:
• Archivo donde se guardaran los patrones de entrada en fomato ARFF: se indica el nombre del archivo donde se guardaran los patrones de entrada en formato ARFF, que utilizara como entrada el algoritmo K-Means.
• Archivo donde se guardara la información sobre los clusters descubiertos: se indica el nombre del archivo donde se guardara la información sobre los clusters descubiertos.
• Cantidad de clusters a descubrir (K): se indica la cantidad de grupos de usuarios distintos a descubrir. Correspone con el valor K del algoritmo K-Means.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 122 -
Al presionar el botón Construir Clusters, se procede a la contrucción de los clusters de usuarios. Una vez construidos los clusters, el sistema muestra información sobre los clusters creados.
A modo de ejemplo, se procede a construir los grupos de usuarios, obteniendo 4 grupos de usuarios. Los archivos de entrada y salida del algoritmo K-Means serán almacenados con los nombres indicados en el formulario [Figura B.36].
Figura B.36. Ejemplo Construcción de Grupos de Usuarios K-Means
Luego de presionar el botón Construir Clusters y al terminar el proceso de construcción de grupos de usuarios, se despliega la siguiente pantalla, mostrando un resumen del proceso realizado [Figura B.37].
Figura B.37. Resultado Construcción de Grupos de Usuarios K-Means

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 123 -
B.13. Ver Cantidad de Sesiones en Cada Grupo de Usuario Descubierto
B.13.1. Red Neuronal Mapa Auto-Organizativo (SOM)
Para acceder al detalle de la cantidad de sesiones de usuario que posee cada grupo de usuarios descubiertos mediante la red neuronal mapa auto-organizativo (SOM), se debe acceder al sub-elemento SOM del elemento Sesiones/Clusters del menú principal del sistema [Figura B.38].
Figura B.38. Menú Sesiones/Clusters SOM
Luego, se despliega la siguiente pantalla donde se muestra la información sobre la cantidad de sesiones en cada grupo de usuarios [Figura B.39].

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 124 -
Figura B.39. Cantidad de Sesiones en cada Grupo de Usuarios SOM
B.13.2. Algoritmo K-Means
Para acceder al detalle de la cantidad de sesiones de usuario que posee cada grupo de usuarios descubiertos mediante el algoritmo K-Means, se debe acceder al sub-elemento K-Means del elemento Sesiones/Clusters del menú principal del sistema [Figura B.40].
Figura B.40. Menú Sesiones/Clusters K-Means

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 125 -
Luego, se despliega la siguiente pantalla donde se muestra la información sobre la cantidad de sesiones en cada grupo de usuarios [Figura B.41].
Figura B.41. Cantidad de Sesiones en cada Grupo de Usuarios K-Means
B.13.3. Comparación
Para acceder al detalle de la cantidad de sesiones de usuario que posee cada grupo de usuarios descubiertos mediante la red neuronal mapa auto-organizativo (SOM) comparándolo con los descubiertos mediente el algoritmo K-Means, se debe acceder al sub-elemento Comparación del elemento Sesiones/Clusters del menú principal del sistema [Figura B.42].

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 126 -
Figura B.42. Menú Sesiones/Clusters Comparación
Luego, se despliega la siguiente pantalla donde se muestra la información sobre la cantidad de sesiones en cada grupo de usuarios [Figura B.43].
Figura B.43. Comparación Cantidad de Sesiones en cada Grupo de Usuarios
B.14. Ver Detalle de Sesiones Indicando el Grupo de Usuarios al Cual Pertenece
B.14.1. Red Neuronal Mapa Auto-Organizativo (SOM)
Para acceder al detalle de las sesiones indicando el grupo de usuario descubierto mediante la red neuronal mapa auto-organizativo (SOM) al cual pertenece, se debe acceder

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 127 -
al sub-elemento SOM del elemento Detalle Sesiones del menú principal del sistema [Figura B.44].
Figura B.44. Menú Detalle Sesiones SOM
Luego, se despliega la siguiente pantalla donde se muestra las sesiones de usuarios con su correspondiente número de grupo al cual pertenece [Figura B.45].

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 128 -
Figura B.45. Detalle Sesiones SOM
B.14.2. Algoritmo K-Means
Para acceder al detalle de las sesiones indicando el grupo de usuario descubierto mediante el algoritmo K-Means al cual pertenece, se debe acceder al sub-elemento K-Means del elemento Detalle Sesiones del menú principal del sistema [Figura B.46].

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 129 -
Figura B.46. Menú Detalle Sesiones K-Means
Luego, se despliega la siguiente pantalla donde se muestra las sesiones de usuarios con su correspondiente número de grupo al cual pertenece [Figura B.47].

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 130 -
Figura B.47. Detalle Sesiones K-Means
B.14.3. Comparación
Para acceder al detalle de las sesiones indicando el grupo de usuario descubierto mediante la red neuronal mapa auto-organizativo (SOM) y el algoritmo K-Means al cual pertenece, se debe acceder al sub-elemento Comparación del elemento Detalle Sesiones del menú principal del sistema [Figura B.48].

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 131 -
Figura B.48. Menú Detalle Sesiones Comparación
Luego, se despliega la siguiente pantalla donde se muestra las sesiones de usuarios con su correspondiente número de grupo al cual pertenece [Figura B.49].
Figura B.49. Detalle Sesiones Comparación

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 132 -
B.15. Ver Páginas Más Frecuentes en Cada Grupo de Usuarios Descubierto
B.15.1. Red Neuronal Mapa Auto-Organizativo (SOM)
Para acceder al detalle de las páginas más frecuentes entre las sesiones de los usuarios de cada grupo descubierto mediante la red neuronal mapa auto-organizativo (SOM), se debe acceder al sub-elemento SOM del elemento Páginas/Clusters del menú principal del sistema [Figura B.50].
Figura B.50. Menú Páginas/Clusters SOM
Luego, se despliega la siguiente pantalla donde se muestra las páginas más frecuentes entre las sesiones de cada grupo de usuarios [Figura B.51].

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 133 -
Figura B.51. Páginas/Clusters SOM
Cambiando los campos Cambiar Porcentaje Mínimo a: y Cambiar Cantidad Máxima de Páginas por Cluster a: se cambia el porcentaje mínimo que debe poseer cada página para mostrarse en el detalle y se cambia la cantidad máxima de páginas que se muestran por grupo de usuarios, respectivamente.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 134 -
B.15.2. Algoritmo K-Means
Para acceder al detalle de las páginas más frecuentes entre las sesiones de los usuarios de cada grupo descubierto mediante el algoritmo K-Means, se debe acceder al sub-elemento K-Means del elemento Páginas/Clusters del menú principal del sistema [Figura B.52].
Figura B.52. Menú Páginas/Clusters K-Means
Luego, se despliega la siguiente pantalla donde se muestra las páginas más frecuentes entre las sesiones de cada grupo de usuarios [Figura B.53].

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 135 -
Figura B.53. Páginas/Clusters K-Means
Cambiando los campos Cambiar Porcentaje Mínimo a: y Cambiar Cantidad Máxima de Páginas por Cluster a: se cambia el porcentaje mínimo que debe poseer cada página para mostrarse en el detalle y se cambia la cantidad máxima de páginas que se muestran por grupo de usuarios, respectivamente.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 136 -
B.15.3. Comparación
Para acceder al detalle de las páginas más frecuentes entre las sesiones de los usuarios de cada grupo descubierto mediante la red neuronal SOM comparandolas con la de los grupos descubiertos mediante el algoritmo K-Means, se debe acceder al sub-elemento Comparación del elemento Páginas/Clusters del menú principal del sistema [Figura B.54].
Figura B.54. Menú Páginas/Clusters Comparación
Luego, se despliega la siguiente pantalla donde se muestra las páginas más frecuentes entre las sesiones de cada grupo de usuarios [Figura B.55].

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 137 -
Figura B.55. Páginas/Clusters Comparación

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 138 -
Cambiando los campos Cambiar Porcentaje Mínimo a: y Cambiar Cantidad Máxima de Páginas por Cluster a: se cambia el porcentaje mínimo que debe poseer cada página para mostrarse en el detalle y se cambia la cantidad máxima de páginas que se muestran por grupo de usuarios, respectivamente.
B.16. Cerrar Sesión
Para cerrar la sesión en el sistema, se debe presionar el botón Cerrar Sesión, ubicado en el ángulo superior derecho. De esta forma, se cierra la sesión en el sistema, volviendo a la página principal.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 139 -
C. Apéndice III: Documentación JavaDoc
C.1. Resumen Clases ..........................................................................................................140 C.2. Class BinarySessionClusterBean................................................................................141 C.3. Class ClusterCounterBean ..........................................................................................143 C.4. Class ClusterCounterGraphBean ................................................................................147 C.5. Class ConfigFileParserBean .......................................................................................150 C.6. Class CreateProjectBean.............................................................................................153 C.7. Class CreateUserBean.................................................................................................156 C.8. Class DeleteProjectBean.............................................................................................158 C.9. Class FileBean ............................................................................................................160 C.10. Class FilesViewBean ................................................................................................164 C.11. Class InputMakerBean..............................................................................................168 C.12. Class KMeansBean ...................................................................................................172 C.13. Class LogBean ..........................................................................................................176 C.14. Class LogCleanerBean..............................................................................................179 C.15. Class LogFilesViewBean..........................................................................................182 C.16. Class LogFileUploadBean ........................................................................................184 C.17. Class LoginBean .......................................................................................................189 C.18. Class LogLoaderBean...............................................................................................190 C.19. Class LogViewBean .................................................................................................196 C.20. Class NumericSessionClusterBean...........................................................................200 C.21. Class PageCounterBean............................................................................................202 C.22. Class PagesInClustersBean.......................................................................................205 C.23. Class PagesInClustersViewBean ..............................................................................208 C.24. Class SessionClusterBean.........................................................................................213 C.25. Class SessionMakerBean..........................................................................................218 C.26. Class SessionSaver ...................................................................................................222 C.27. Class SessionsClusterViewBean...............................................................................226 C.28. Class SOMBean........................................................................................................231 C.29. Class UserBean .........................................................................................................237

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 140 -
C.1. Resumen Clases
Package ar.com.do2.iadh
Class Summary
BinarySessionClusterBean
Clase encargada de cargar en la base de datos la información de clusterización almacenada en un archivo, que posee en cada linea numeros binarios indicando si la sesion pertenece o no al cluster correspondiente a la posicion de dicho numero binario.
ClusterCounterBean Clase utilizada para contabilizar la cantidad de sesiones existentes en cada cluster descubierto.
ClusterCounterGraphBean Clase utilizada para graficar la cantidad de sesiones en cada cluster descubierto.
ConfigFileParserBean Clase utilizada para obtener la configuración de la aplicación.
CreateProjectBean Clase utilizada para la creacion de un nuevo proyecto. CreateUserBean Clase utilizada para la creacion de nuevos usuarios. DeleteProjectBean Clase utilizada para la eliminacion de proyectos.
FileBean Clase utilizada para guardar informacion en la base de datos sobre los archivo utilizados en la herramienta.
FilesViewBean Clase utilizada para obtener todos los archivos de un cierto tipo, para un usuario y proyecto dado.
InputMakerBean Clase encargada de crear el archivo de sesiones a utilizar como entrada para el proceso de clusterizacion.
KMeansBean Clase encargada de realizar la clusterizacion mediante K-Means
LogBean Clase que representa la informacion de un registro de log a almacenar en la base de datos.
LogCleanerBean Clase utilizada para borrar todo los registros de log de un proyecto.
LogFilesViewBean Clase utilizada para listar todos los archivos de log cargados por un usuario
LogFileUploadBean Clase utilizada para guardar en la base de datos informacion sobre un archivo de log y copiar el archivo al servidor.
LoginBean Clase utilizada para iniciar sesión en la herramienta.
LogLoaderBean Clase utilizada para leer el archivo de log y obtener la informacion del mismo para almacenarla en la base de

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 141 -
Class Summary datos.
LogViewBean Clase encargada de obtener el detalle de todos los registros de log cargados en la base de datos por un proyecto de un usuario.
NumericSessionClusterBean Clase encargada de cargar en la base de datos la informacion de clusterizacion almacenada en un archivo, que posee en cada linea el numero de cluster al cual pertenece la sesion.
PageCounterBean Clase encargarda de cargar todas las páginas encontradas en un archivo de log.
PagesInClustersBean Clase encargada de obtener la informacion de que páginas aparecen en las sesiones de cada cluster.
PagesInClustersViewBean Clase que se encarga de obtener la informacion de las páginas que accedieron los usuarios de cada cluster, indicando el porcentaje de acceso.
SessionClusterBean Clase utilizada para contabilizar los clusters descubiertos y cargar esta informacion en la base de datos.
SessionMakerBean Clase SessionMakerBean encargada de armar las sesiones a partir de los registros del log almacenados en la tabla log.
SessionSaver Clase SessionSaver encargada de ir armando las sesiones y guardarlas en la tabla session.
SessionsClusterViewBean Clase encargada de obtener el detalle de las sesiones y a que cluster pertenece cada una.
SOMBean Clase SOMBean encargada de clusterizar las sesiones de usuarios utilizando la red neuronal SOM.
UserBean Clase que se encarga del manejo de la informacion de un usuario y sus proyectos.
C.2. Class BinarySessionClusterBean
java.lang.Object ar.com.do2.iadh.SessionClusterBean ar.com.do2.iadhar.com.do2.iadhar.com.do2.iadhar.com.do2.iadh.BinarySessionClusterBean.BinarySessionClusterBean.BinarySessionClusterBean.BinarySessionClusterBean
public class BinarySessionClusterBeanBinarySessionClusterBeanBinarySessionClusterBeanBinarySessionClusterBean extends SessionClusterBean

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 142 -
Clase encargada de cargar en la base de datos la informacion de clusterizacion almacenada en un archivo, que posee en cada linea numeros binarios indicando si la sesion pertenece o no al cluster correspondiente a la posicion de dicho numero binario.
Author: Damian Martinelli
Field Summary
Fields inherited from class ar.com.do2.iadh.SessionClusterBean
conn, filename, project, pstm, pstmDelete, type, user
Constructor Summary
BinarySessionClusterBean()
Method Summary
void count(java.lang.String inputFilename) Realiza el conteo de los clusters descubiertos tomando como entrada el archivo donde se encuentra a que cluster pertenece cada sesion.
Methods inherited from class ar.com.do2.iadh.SessionClusterBean
getCount, getFile, getProject, getType, getUser, setFile, setProject, setType, setUser
Methods inherited from class java.lang.Object
clone, equals, finalize, getClass, hashCode, notify, notifyAll, toString, wait, wait, wait
Constructor Detail
BinarySessionClusterBean
public BinarySessionClusterBeanBinarySessionClusterBeanBinarySessionClusterBeanBinarySessionClusterBean() throws java.lang.Exception Throws:
java.lang.Exception
Method Detail

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 143 -
count
public void countcountcountcount(java.lang.String inputFilename) throws java.lang.Exception
Description copied from class: SessionClusterBean Realiza el conteo de los clusters descubiertos tomando como entrada el archivo donde se encuentra a que cluster pertenece cada sesion. Specified by: count in class SessionClusterBean Parameters: inputFilename - Nombre del archivo donde se encuentra la informacion de los clusters descubiertos. Throws: java.lang.Exception
C.3. Class ClusterCounterBean
java.lang.Object
ar.com.do2.ar.com.do2.ar.com.do2.ar.com.do2.iadh.ClusterCounterBeaniadh.ClusterCounterBeaniadh.ClusterCounterBeaniadh.ClusterCounterBean
public class ClusterCounterBeanClusterCounterBeanClusterCounterBeanClusterCounterBean
extends java.lang.Object
Clase utilizada para contabilizar la cantidad de sesiones existentes en cada cluster descubierto.
Author: Damian Martinelli
Constructor Summary
ClusterCounterBean() Constructor de la clase ClusterCounter, encargada de contabilizar la cantidad de sesiones en cada cluster descubierto.
Method Summary
void count() Realiza el conteo de la cantidad de sesiones en cada cluster descubierto

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 144 -
int getClustersCount() Obtiene la cantidad de clusters descubiertos.
java.lang.String getCount() Realiza el conteo de la cantidad de sesiones en cada cluster descubierto, si todos los atributos necesarios han sido seteados, devolviendo la cantidad de sesiones en cada cluster.
java.lang.String getNextCluster() Obtiene el numero del proximo cluster.
java.lang.String getNextClusterSessions() Obtiene la cantidad de sesiones del proximo cluster.
java.lang.String getProject() Obtiene el nombre del proyecto utilizado.
java.lang.String getType() Obtiene el tipo de clustering utilizado.
java.lang.String getUser() Obtiene el nombre de usuario utilizado.
void goFirstCluster() Inicializa para la lectura de la cantidad de sesiones en cada cluster descubierto.
boolean hasNextCluster() Indica si existe otro cluster.
static void main(java.lang.String[] args)
void setProject(java.lang.String projectName) Setea el nombre del proyecto que se utilizara.
void setType(java.lang.String typeClustering) Setea el tipo de clustering a utilizar.
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.
Methods inherited from class java.lang.Object
clone, equals, finalize, getClass, hashCode, notify, notifyAll, toString, wait, wait, wait
Constructor Detail
ClusterCounterBean

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 145 -
public ClusterCounterBeanClusterCounterBeanClusterCounterBeanClusterCounterBean() throws java.lang.Exception
Constructor de la clase ClusterCounter, encargada de contabilizar la cantidad de sesiones en cada cluster descubierto. Throws: java.lang.Exception
Method Detail
count
public void countcountcountcount() throws java.lang.Exception
Realiza el conteo de la cantidad de sesiones en cada cluster descubierto Throws: java.lang.Exception
getCount
public java.lang.String getCountgetCountgetCountgetCount() throws java.lang.Exception
Realiza el conteo de la cantidad de sesiones en cada cluster descubierto, si todos los atributos necesarios han sido seteados, devolviendo la cantidad de sesiones en cada cluster. Returns: Cantidad de sesiones en cada cluster. Throws: java.lang.Exception
getClustersCount
public int getClustersCountgetClustersCountgetClustersCountgetClustersCount() Obtiene la cantidad de clusters descubiertos. Returns: Cantidad de clusters descubiertos.
goFirstCluster
public void goFirstClustergoFirstClustergoFirstClustergoFirstCluster() Inicializa para la lectura de la cantidad de sesiones en cada cluster descubierto.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 146 -
hasNextCluster
public boolean hasNextClusterhasNextClusterhasNextClusterhasNextCluster() Indica si existe otro cluster. Returns: true si existen mas clusters, false sino.
getNextCluster
public java.lang.String getNextClustergetNextClustergetNextClustergetNextCluster() Obtiene el numero del proximo cluster. Returns: Numero del proximo cluster.
getNextClusterSessions
public java.lang.String getNextClusterSessionsgetNextClusterSessionsgetNextClusterSessionsgetNextClusterSessions() Obtiene la cantidad de sesiones del proximo cluster. Returns: Cantidad de sesiones del proximo cluster.
setUser
public void setUsersetUsersetUsersetUser(java.lang.String userName) Setea el nombre de usuario que se utilizara. Parameters: userName - Nombre del usuario.
getUser
public java.lang.String getUsergetUsergetUsergetUser() Obtiene el nombre de usuario utilizado. Returns: Nombre del usuario.
setProject
public void setProjectsetProjectsetProjectsetProject(java.lang.String projectName) Setea el nombre del proyecto que se utilizara. Parameters: projectName - Nombre del proyecto.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 147 -
getProject
public java.lang.String getProjectgetProjectgetProjectgetProject() Obtiene el nombre del proyecto utilizado. Returns: Nombre del proyecto.
setType
public void setTypesetTypesetTypesetType(java.lang.String typeClustering) Setea el tipo de clustering a utilizar. Parameters: typeClustering - Tipo de clustering a utilizar.
getType
public java.lang.String getTypegetTypegetTypegetType() Obtiene el tipo de clustering utilizado. Returns: Tipo de clustering utilizado.
main
public static void mainmainmainmain(java.lang.String[] args) throws java.lang.Exception
Throws: java.lang.Exception
C.4. Class ClusterCounterGraphBean
java.lang.Object ar.com.do2.iadh.ClusterCounterGraphBeanar.com.do2.iadh.ClusterCounterGraphBeanar.com.do2.iadh.ClusterCounterGraphBeanar.com.do2.iadh.ClusterCounterGraphBean
public class ClusterCounterGraphBeanClusterCounterGraphBeanClusterCounterGraphBeanClusterCounterGraphBean extends java.lang.Object
Clase utilizada para graficar la cantidad de sesiones en cada cluster descubierto.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 148 -
Author: Damian Martinelli
Constructor Summary
ClusterCounterGraphBean() Constructor de la clase ClusterCounterGraphBean.
Method Summary
double[] getData() Obtiene los datos utilizados en el grafico.
java.lang.String getGraph() Obtiene el path al grafico generado.
java.lang.String[] getLabels() Obtiene las etiquetas del grafico.
java.lang.String getMap() Obtiene el mapa con informacion del grafico generado.
java.lang.String getPath() Obtiene el path base donde se generan los graficos.
void setData(double[] data) Setea los datos a utilizar en el grafico.
void setLabels(java.lang.String[] labels) Setea las etiquetas del grafico.
void setPath(java.lang.String path) Setea el path base donde se generaran los graficos.
Methods inherited from class java.lang.Object
clone, equals, finalize, getClass, hashCode, notify, notifyAll, toString, wait, wait, wait
Constructor Detail
ClusterCounterGraphBean
public ClusterCounterGraphBeanClusterCounterGraphBeanClusterCounterGraphBeanClusterCounterGraphBean() throws java.lang.Exception
Constructor de la clase ClusterCounterGraphBean. Throws: java.lang.Exception

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 149 -
Method Detail
getGraph
public java.lang.String getGraphgetGraphgetGraphgetGraph() Obtiene el path al grafico generado. Returns: Path al grafico generado.
getMap
public java.lang.String getMapgetMapgetMapgetMap() Obtiene el mapa con informacion del grafico generado. Returns: Informacion del grafico.
getData
public double[] getDatagetDatagetDatagetData() Obtiene los datos utilizados en el grafico. Returns: Datos del grafico.
setData
public void setDatasetDatasetDatasetData(double[] data) Setea los datos a utilizar en el grafico. Parameters: data - Datos del grafico.
getLabels
public java.lang.String[] getLabelsgetLabelsgetLabelsgetLabels() Obtiene las etiquetas del grafico. Returns: Etiquetas del grafico.
setLabels
public void setLabelssetLabelssetLabelssetLabels(java.lang.String[] labels) Setea las etiquetas del grafico.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 150 -
Parameters: labels - Etiquetas del grafico.
getPath
public java.lang.String getPathgetPathgetPathgetPath() Obtiene el path base donde se generan los graficos. Returns: Path base utilizado.
setPath
public void setPathsetPathsetPathsetPath(java.lang.String path) Setea el path base donde se generaran los graficos. Parameters: path - Path base a utilizar.
C.5. Class ConfigFileParserBean
java.lang.Object ar.com.do2.iadh.ConfigFileParserBear.com.do2.iadh.ConfigFileParserBear.com.do2.iadh.ConfigFileParserBear.com.do2.iadh.ConfigFileParserBeanananan All Implemented Interfaces:
java.io.Serializable
public class ConfigFileParserBeanConfigFileParserBeanConfigFileParserBeanConfigFileParserBean extends java.lang.Object
implements java.io.Serializable Author:
Damian Martinelli See Also:
Serialized Form
Constructor Summary
ConfigFileParserBean()
Method Summary
java.lang.String getDatabaseName()

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 151 -
java.lang.String getDatabasePass()
java.lang.String getDatabaseServer()
java.lang.String getDatabaseUser()
java.lang.String getDirFiles()
static void main(java.lang.String[] args)
void setDatabaseName(java.lang.String databaseName)
void setDatabasePass(java.lang.String databasePass)
void setDatabaseServer(java.lang.String databaseServer)
void setDatabaseUser(java.lang.String databaseUser)
void setDirFiles(java.lang.String dirFiles)
Methods inherited from class java.lang.Object
clone, equals, finalize, getClass, hashCode, notify, notifyAll, toString, wait, wait, wait
Constructor Detail
ConfigFileParserBean
public ConfigFileParserBeanConfigFileParserBeanConfigFileParserBeanConfigFileParserBean()
Method Detail
getDatabaseServer
public java.lang.String getDatabasgetDatabasgetDatabasgetDatabaseServereServereServereServer()

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 152 -
setDatabaseServer
public void setDatabaseServersetDatabaseServersetDatabaseServersetDatabaseServer(java.lang.String databaseServer)
getDatabaseName
public java.lang.String getDatabaseNamegetDatabaseNamegetDatabaseNamegetDatabaseName()
setDatabaseName
public void setDatabaseNamesetDatabaseNamesetDatabaseNamesetDatabaseName(java.lang.String databaseName)
getDatabaseUser
public java.lang.String getDatabaseUsergetDatabaseUsergetDatabaseUsergetDatabaseUser()
setDatabaseUser
public void setDatabaseUsersetDatabaseUsersetDatabaseUsersetDatabaseUser(java.lang.String databaseUser)
getDatabasePass
public java.lang.String getDatabasePassgetDatabasePassgetDatabasePassgetDatabasePass()
setDatabasePass
public void setDatabasePasssetDatabasePasssetDatabasePasssetDatabasePass(java.lang.String databasePass)
getDirFiles
public java.lang.String getDirFilesgetDirFilesgetDirFilesgetDirFiles()
setDirFiles
public void setDirFilessetDirFilessetDirFilessetDirFiles(java.lang.String dirFiles)
main

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 153 -
public static void mainmainmainmain(java.lang.String[] args) throws java.lang.Exception
Throws: java.lang.Exception
C.6. Class CreateProjectBean
java.lang.Object ar.com.do2.iadh.CreateProjectBeanar.com.do2.iadh.CreateProjectBeanar.com.do2.iadh.CreateProjectBeanar.com.do2.iadh.CreateProjectBean All Implemented Interfaces:
java.io.Serializable
public class CreateProjectBeanCreateProjectBeanCreateProjectBeanCreateProjectBean
extends java.lang.Object implements java.io.Serializable
Clase utilizada para la creacion de un nuevo proyecto.
Author: Damian Martinelli
See Also: Serialized Form
Constructor Summary
CreateProjectBean() Contructor de la clase CreateProjectBean, utilizada para la creacion de un nuevo proyecto.
Method Summary
boolean createNewProject() Crea un nuevo proyecto, si ha sido seteado el nombre del usuario y el nombre del proyecto a crear.
java.lang.String getDescription() Obtiene la descripcion utilizada.
java.lang.String getNewProject() Crea un nuevo proyecto, si ha sido seteado el nombre del usuario y el nombre del proyecto a crear.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 154 -
java.lang.String getProject() Obtiene el nombre del proyecto utilizado.
java.lang.String getUser() Obtiene el nombre de usuario utilizado.
void setDescription(java.lang.String description) Setea la descripcion del proyecto a crear.
void setProject(java.lang.String projectName) Setea el nombre del proyecto que se creara.
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.
Methods inherited from class java.lang.Object
clone, equals, finalize, getClass, hashCode, notify, notifyAll, toString, wait, wait, wait
Constructor Detail
CreateProjectBean
public CreateProjectBeanCreateProjectBeanCreateProjectBeanCreateProjectBean() throws java.lang.Exception
Contructor de la clase CreateProjectBean, utilizada para la creacion de un nuevo proyecto. Throws: java.lang.Exception
Method Detail
setUser
public void setUsersetUsersetUsersetUser(java.lang.String userName) Setea el nombre de usuario que se utilizara. Parameters: userName - Nombre del usuario.
getUser
public java.lang.String getUsergetUsergetUsergetUser() Obtiene el nombre de usuario utilizado. Returns: Nombre del usuario.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 155 -
setDescription
public void setDescriptionsetDescriptionsetDescriptionsetDescription(java.lang.String description) Setea la descripcion del proyecto a crear. Parameters: description - Descripcion del proyecto a crear.
getDescription
public java.lang.String getDescriptiongetDescriptiongetDescriptiongetDescription() Obtiene la descripcion utilizada.
setProject
public void setProjectsetProjectsetProjectsetProject(java.lang.String projectName) Setea el nombre del proyecto que se creara. Parameters: projectName - Nombre del proyecto.
getProject
public java.lang.String getProjectgetProjectgetProjectgetProject() Obtiene el nombre del proyecto utilizado. Returns: Nombre del proyecto.
getNewProject
public java.lang.String getNewProjectgetNewProjectgetNewProjectgetNewProject() Crea un nuevo proyecto, si ha sido seteado el nombre del usuario y el nombre del proyecto a crear. Returns: Nombre del proyecto creado.
createNewProject
public boolean createNewProjectcreateNewProjectcreateNewProjectcreateNewProject() Crea un nuevo proyecto, si ha sido seteado el nombre del usuario y el nombre del proyecto a crear.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 156 -
Returns: true si creo el proyecto correctamente, false sino.
C.7. Class CreateUserBean
java.lang.Object ar.com.do2.iadh.CreateUserBeanar.com.do2.iadh.CreateUserBeanar.com.do2.iadh.CreateUserBeanar.com.do2.iadh.CreateUserBean
public class CreateUserBeanCreateUserBeanCreateUserBeanCreateUserBean extends java.lang.Object
Clase utilizada para la creacion de nuevos usuarios.
Author: Damian Martinelli
Constructor Summary
CreateUserBean() Contructor de la clase CreateUserBean, encargado de la creacion de nuevos usuarios.
Method Summary
boolean createNewUser() Crea un nuevo usuario, si fueron ya seteados el nombre de usuario y la contraseña.
java.lang.String getPassword() Obtiene la contraseña utilizada.
java.lang.String getUser() Obtiene el nombre de usuario utilizado.
void setPassword(java.lang.String pass) Setea la contraseña del usuario a crear.
void setUser(java.lang.String userName) Setea el nombre de usuario que se creara.
Methods inherited from class java.lang.Object
clone, equals, finalize, getClass, hashCode, notify, notifyAll, toString, wait, wait, wait

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 157 -
Constructor Detail
CreateUserBean
public CreateUserBeanCreateUserBeanCreateUserBeanCreateUserBean() throws java.lang.Exception
Contructor de la clase CreateUserBean, encargado de la creacion de nuevos usuarios. Throws: java.lang.Exception
Method Detail
setUser
public void setUsersetUsersetUsersetUser(java.lang.String userName) Setea el nombre de usuario que se creara. Parameters: userName - Nombre del usuario.
getUser
public java.lang.String getUsergetUsergetUsergetUser() Obtiene el nombre de usuario utilizado. Returns: Nombre del usuario.
setPassword
public void setPasswordsetPasswordsetPasswordsetPassword(java.lang.String pass) Setea la contraseña del usuario a crear. Parameters: pass - Contraseña del usuario.
getPassword
public java.lang.String getPasswordgetPasswordgetPasswordgetPassword() Obtiene la contraseña utilizada. Returns: Contraseña utilizada.
createNewUser

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 158 -
public boolean createNewUsercreateNewUsercreateNewUsercreateNewUser() Crea un nuevo usuario, si fueron ya seteados el nombre de usuario y la contraseña. Returns: true si se pudo crear el usuario, false sino.
C.8. Class DeleteProjectBean
java.lang.Object ar.com.do2.iadh.DeleteProjectBeanar.com.do2.iadh.DeleteProjectBeanar.com.do2.iadh.DeleteProjectBeanar.com.do2.iadh.DeleteProjectBean All Implemented Interfaces:
java.io.Serializable
public class DeleteProjectBeanDeleteProjectBeanDeleteProjectBeanDeleteProjectBean
extends java.lang.Object implements java.io.Serializable
Clase utilizada para la eliminacion de proyectos.
Author: Damian Martinelli
See Also: Serialized Form
Constructor Summary
DeleteProjectBean() Contructor de la clase DeleteProjectBean, encargada de eliminar un proyecto y todo los elementos asociados al mismo.
Method Summary
boolean deleteProject() Borra el proyecto, si fueron seteados el nombre de usuario y el proyecto.
java.lang.String getDeleteProject() Borra el proyecto, si fueron seteados el nombre de usuario y el proyecto.
java.lang.String getProject() Obtiene el nombre del proyecto utilizado.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 159 -
java.lang.String getUser() Obtiene el nombre de usuario utilizado.
void setProject(java.lang.String projectName) Setea el nombre del proyecto que se eliminara.
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.
Methods inherited from class java.lang.Object
clone, equals, finalize, getClass, hashCode, notify, notifyAll, toString, wait, wait, wait
Constructor Detail
DeleteProjectBean
public DeleteProjectBeanDeleteProjectBeanDeleteProjectBeanDeleteProjectBean()
throws java.lang.Exception Contructor de la clase DeleteProjectBean, encargada de eliminar un proyecto y todo los elementos asociados al mismo. Throws: java.lang.Exception
Method Detail
setUser
public void setUsersetUsersetUsersetUser(java.lang.String userName) Setea el nombre de usuario que se utilizara. Parameters: userName - Nombre del usuario.
getUser
public java.lang.String getUsergetUsergetUsergetUser() Obtiene el nombre de usuario utilizado. Returns: Nombre del usuario.
setProject
public void setProjectsetProjectsetProjectsetProject(java.lang.String projectName) Setea el nombre del proyecto que se eliminara.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 160 -
Parameters: projectName - Nombre del proyecto.
getProject
public java.lang.String getProjectgetProjectgetProjectgetProject() Obtiene el nombre del proyecto utilizado. Returns: Nombre del proyecto.
getDeleteProject
public java.lang.String getDeleteProjectgetDeleteProjectgetDeleteProjectgetDeleteProject() Borra el proyecto, si fueron seteados el nombre de usuario y el proyecto. Returns: "BORRADO" si pudo borrar el proyecto, "ERROR" sino.
deleteProject
public boolean deleteProjectdeleteProjectdeleteProjectdeleteProject() Borra el proyecto, si fueron seteados el nombre de usuario y el proyecto. Returns: true si pudo eliminar al proyecto, false sino.
C.9. Class FileBean
java.lang.Object
ar.com.do2.iadh.FileBeanar.com.do2.iadh.FileBeanar.com.do2.iadh.FileBeanar.com.do2.iadh.FileBean All Implemented Interfaces:
java.io.Serializable
public class FileBeanFileBeanFileBeanFileBean extends java.lang.Object implements java.io.Serializable
Clase utilizada para guardar informacion en la base de datos sobre los archivo utilizados en la herramienta.
Author:

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 161 -
Damian Martinelli See Also:
Serialized Form
Constructor Summary
FileBean() Constructor de la clase FileBean.
Method Summary
java.lang.String getDescription() Obtiene la descripcion del archivo utilizado.
java.lang.String getFile() Obtiene el nombre del archivo utilizado.
java.lang.String getFilePath() Obtiene el path y el nombre del archivo que se cargo.
java.lang.String getProject() Obtiene el nombre del proyecto utilizado.
java.lang.String getType() Obtiene el tipo de archivo a cargar.
java.lang.String getUser() Obtiene el nombre de usuario utilizado.
void setDescription(java.lang.String description) Setea la descricion del archivo.
void setFile(java.lang.String filename) Setea el nombre del archivo.
void setFilePath(java.lang.String set) Si todos los atributos necesarios fueron seteados, setea el path y el nombre del archivo donde se debe copiar el archivo y carga la informacion del archivo en la base de datos.
void setProject(java.lang.String projectName) Setea el nombre del proyecto que se utilizara.
void setSavePath(java.lang.String savePath) Setea el path donde debe ser guardado el archivo.
void setType(java.lang.String typeFile) Setea el tipo de archivo a cargar.
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 162 -
Methods inherited from class java.lang.Object
clone, equals, finalize, getClass, hashCode, notify, notifyAll, toString, wait, wait, wait
Constructor Detail
FileBean
public FileBeanFileBeanFileBeanFileBean() throws java.lang.Exception
Constructor de la clase FileBean. Throws: java.lang.Exception
Method Detail
setFile
public void setFilesetFilesetFilesetFile(java.lang.String filename) throws java.lang.Exception
Setea el nombre del archivo. Parameters: filename - Nombre del archivo. Throws: java.lang.Exception
getFile
public java.lang.String getFilegetFilegetFilegetFile() Obtiene el nombre del archivo utilizado. Returns: Nombre del archivo utilizado.
setUser
public void setUsersetUsersetUsersetUser(java.lang.String userName) Setea el nombre de usuario que se utilizara. Parameters: userName - Nombre del usuario.
getUser

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 163 -
public java.lang.String getUsergetUsergetUsergetUser() Obtiene el nombre de usuario utilizado. Returns: Nombre del usuario.
setDescription
public void setDescriptionsetDescriptionsetDescriptionsetDescription(java.lang.String description) Setea la descricion del archivo. Parameters: description - Descripcion del archivo.
getDescription
public java.lang.String getDescriptiongetDescriptiongetDescriptiongetDescription() Obtiene la descripcion del archivo utilizado. Returns: Descripcion del archivo utilizado.
setProject
public void setProjectsetProjectsetProjectsetProject(java.lang.String projectName) Setea el nombre del proyecto que se utilizara. Parameters: projectName - Nombre del proyecto.
getProject
public java.lang.String getProjectgetProjectgetProjectgetProject() Obtiene el nombre del proyecto utilizado. Returns: Nombre del proyecto.
setFilePath
public void setFilePathsetFilePathsetFilePathsetFilePath(java.lang.String set) Si todos los atributos necesarios fueron seteados, setea el path y el nombre del archivo donde se debe copiar el archivo y carga la informacion del archivo en la base de datos. Parameters: set - No se utiliza. Solo por compatibilidad con JavaBeans.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 164 -
getFilePath
public java.lang.String getFilePathgetFilePathgetFilePathgetFilePath() Obtiene el path y el nombre del archivo que se cargo. Returns: Path completo del archivo cargado.
setSavePath
public void setSavePathsetSavePathsetSavePathsetSavePath(java.lang.String savePath) Setea el path donde debe ser guardado el archivo. Parameters: savePath - Path donde debe ser guardado el archivo.
setType
public void setTypesetTypesetTypesetType(java.lang.String typeFile) Setea el tipo de archivo a cargar. Parameters: typeFile - Tipo de archivo a cargar.
getType
public java.lang.String getTypegetTypegetTypegetType() Obtiene el tipo de archivo a cargar. Returns: Tipo de archivo a cargar.
C.10. Class FilesViewBean
java.lang.Object ar.com.do2.iadh.FilesViewBeanar.com.do2.iadh.FilesViewBeanar.com.do2.iadh.FilesViewBeanar.com.do2.iadh.FilesViewBean All Implemented Interfaces:
java.io.Serializable
public class FilesViewBeanFilesViewBeanFilesViewBeanFilesViewBean
extends java.lang.Object

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 165 -
implements java.io.Serializable
Clase utilizada para obtener todos los archivos de un cierto tipo, para un usuario y proyecto dado.
Author: Damian Martinelli
See Also: Serialized Form
Constructor Summary
FilesViewBean() Constructor de la clase FilesViewBean.
Method Summary
java.lang.String getNextDescription() Obtiene la descripcion del proximo archivo.
java.lang.String getNextFile() Obtiene el nombre del proximo archivo.
java.lang.String getProject() Obtiene el nombre del proyecto utilizado.
java.lang.String getType() Obtiene el tipo de archivo utilizado.
java.lang.String getUser() Obtiene el nombre de usuario utilizado.
void goFirstFile() Inicializa para la lectura de todos los archivos de un tipo, para un usuario y proyecto dado.
boolean hasNextFile() Indica si hay mas archivos.
void setProject(java.lang.String projectName) Setea el nombre del proyecto que se utilizara.
void setType(java.lang.String typeFile) Setea el tipo de archivo.
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 166 -
Methods inherited from class java.lang.Object
clone, equals, finalize, getClass, hashCode, notify, notifyAll, toString, wait, wait, wait
Constructor Detail
FilesViewBean
public FilesViewBeanFilesViewBeanFilesViewBeanFilesViewBean()
throws java.lang.Exception Constructor de la clase FilesViewBean. Throws: java.lang.Exception
Method Detail
goFirstFile
public void goFirstFilegoFirstFilegoFirstFilegoFirstFile() Inicializa para la lectura de todos los archivos de un tipo, para un usuario y proyecto dado.
hasNextFile
public boolean hhhhasNextFileasNextFileasNextFileasNextFile() Indica si hay mas archivos. Returns: true si hay mas archivos, false sino.
getNextFile
public java.lang.String getNextFilegetNextFilegetNextFilegetNextFile() Obtiene el nombre del proximo archivo. Returns: Nombre del proximo archivo.
getNextDescription
public java.lang.String getNextDescriptiongetNextDescriptiongetNextDescriptiongetNextDescription() Obtiene la descripcion del proximo archivo. Returns: Descripcion del proximo archivo.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 167 -
setUser
public void setUsersetUsersetUsersetUser(java.lang.String userName) Setea el nombre de usuario que se utilizara. Parameters: userName - Nombre del usuario.
getUser
public java.lang.String getUsergetUsergetUsergetUser() Obtiene el nombre de usuario utilizado. Returns: Nombre del usuario.
setProject
public void setProjectsetProjectsetProjectsetProject(java.lang.String projectName) Setea el nombre del proyecto que se utilizara. Parameters: projectName - Nombre del proyecto.
getProject
public java.lang.String getProjectgetProjectgetProjectgetProject() Obtiene el nombre del proyecto utilizado. Returns: Nombre del proyecto.
setType
public void setTypesetTypesetTypesetType(java.lang.String typeFile) Setea el tipo de archivo. Parameters: typeFile - Tipo de archivo.
getType
public java.lang.String getTypegetTypegetTypegetType() Obtiene el tipo de archivo utilizado. Returns: Tipo de archivo utilizado.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 168 -
C.11. Class InputMakerBean
java.lang.Object
ar.com.do2.iadh.InputMakerBeanar.com.do2.iadh.InputMakerBeanar.com.do2.iadh.InputMakerBeanar.com.do2.iadh.InputMakerBean
public class InputMakerBeanInputMakerBeanInputMakerBeanInputMakerBean extends java.lang.Object
Clase encargada de crear el archivo de sesiones a utilizar como entrada para el proceso de clusterizacion.
Author: Damian Martinelli
Constructor Summary
InputMakerBean () Constructor de la clase InputMaker, encargada de crear el archivo de sesiones a utilizar como entrada para el proceso de clusterizacion.
Method Summary
java.lang.String getKMeansEnabled() Obtiene si esta seleccionada la creacion del archivo de sesiones de K-means.
java.lang.String getKMeansFile() Obtiene el nombre del archivo de K-Means.
java.lang.String getProject() Obtiene el nombre del proyecto utilizado.
java.lang.String getSessions() Si estan todos los atributos necesarios seteados, crean los archivos de sesiones seleccionados.
java.lang.String getSOMEnabled() Obtiene si esta seleccionada la creacion del archivo de sesiones de SOM.
java.lang.String getSOMFile() Obtiene el nombre del archivo de SOM.
java.lang.String getUser() Obtiene el nombre de usuario utilizado.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 169 -
static void main(java.lang.String[] args)
void make() Arma el archivo de sesiones a partir de la informacion de las tablas session y page, dejando listo el archivo para el proceso de clusterizacion.
void setKMeansEnabled(java.lang.String enabled) Setea si se quiere crear el archivo de sesiones de K-Means.
void setKMeansFile(java.lang.String name) Setea el nombre del archivo de K-Means.
void setProject(java.lang.String projectName) Setea el nombre del proyecto que se utilizara.
void setSOMEnabled(java.lang.String enabled) Setea si se quiere crear el archivo de sesiones de SOM.
void setSOMFile(java.lang.String name) Setea el nombre del archivo de SOM.
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.
Methods inherited from class java.lang.Object
clone, equals, finalize, getClass, hashCode, notify, notifyAll, toString, wait, wait, wait
Constructor Detail
InputMakerBean
public InputMakerBeanInputMakerBeanInputMakerBeanInputMakerBean() throws java.lang.Exception
Constructor de la clase InputMaker, encargada de crear el archivo de sesiones a utilizar como entrada para el proceso de clusterizacion. Throws: java.lang.Exception
Method Detail
make
public void makemakemakemake() throws java.lang.Exception

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 170 -
Arma el archivo de sesiones a partir de la informacion de las tablas session y page, dejando listo el archivo para el proceso de clusterizacion. Throws: java.lang.Exception
setKMeansFile
public void setKMeansFilesetKMeansFilesetKMeansFilesetKMeansFile(java.lang.String name) throws java.lang.Exception
Setea el nombre del archivo de K-Means. Parameters: name - Nombre del archivo de K-Means. Throws: java.lang.Exception
getKMeansFile
public java.lang.String getKMeansFilegetKMeansFilegetKMeansFilegetKMeansFile() Obtiene el nombre del archivo de K-Means. Returns: Nombre del archivo de K-Means.
setSOMFile
public void setSOMFilesetSOMFilesetSOMFilesetSOMFile(java.lang.String name)
throws java.lang.Exception Setea el nombre del archivo de SOM. Parameters: name - Nombre del archivo de SOM. Throws: java.lang.Exception
getSOMFile
public java.lang.String getSOMFilegetSOMFilegetSOMFilegetSOMFile() Obtiene el nombre del archivo de SOM. Returns: Nombre del archivo de SOM.
setKMeansEnabled

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 171 -
public void setKMeansEnabledsetKMeansEnabledsetKMeansEnabledsetKMeansEnabled(java.lang.String enabled) Setea si se quiere crear el archivo de sesiones de K-Means. Parameters: enabled - Si es "YES" indica que se quiere crear el archivo de sesiones de K-Means.
getKMeansEnabled
public java.lang.String getKMeansEnabledgetKMeansEnabledgetKMeansEnabledgetKMeansEnabled() Obtiene si esta seleccionada la creacion del archivo de sesiones de K-means. Returns: "YES" si esta seleccionada, "NO" sino.
setSOMEnabled
public void setSOMEnabledsetSOMEnabledsetSOMEnabledsetSOMEnabled(java.lang.String enabled) Setea si se quiere crear el archivo de sesiones de SOM. Parameters: enabled - Si es "YES" indica que se quiere crear el archivo de sesiones de SOM.
getSOMEnabled
public java.lang.String getSOMEnabledgetSOMEnabledgetSOMEnabledgetSOMEnabled() Obtiene si esta seleccionada la creacion del archivo de sesiones de SOM. Returns: "YES" si esta seleccionada, "NO" sino.
getSessions
public java.lang.String getSessionsgetSessionsgetSessionsgetSessions() throws java.lang.Exception
Si estan todos los atributos necesarios seteados, crean los archivos de sesiones seleccionados. Returns: Resumen de la cantidad de sesiones representadas en los archivos creados. Throws: java.lang.Exception
setUser
public void setUsersetUsersetUsersetUser(java.lang.String userName)

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 172 -
Setea el nombre de usuario que se utilizara. Parameters: userName - Nombre del usuario.
getUser
public java.lang.String getUsergetUsergetUsergetUser() Obtiene el nombre de usuario utilizado. Returns: Nombre del usuario.
setProject
public void setProjectsetProjectsetProjectsetProject(java.lang.String projectName) Setea el nombre del proyecto que se utilizara. Parameters: projectName - Nombre del proyecto.
getProject
public java.lang.String getProjectgetProjectgetProjectgetProject() Obtiene el nombre del proyecto utilizado. Returns: Nombre del proyecto.
main
public static void mainmainmainmain(java.lang.String[] args) throws java.lang.Exception
Throws: java.lang.Exception
C.12. Class KMeansBean
java.lang.Object ar.com.ar.com.ar.com.ar.com.do2.iadh.KMeansBeando2.iadh.KMeansBeando2.iadh.KMeansBeando2.iadh.KMeansBean All Implemented Interfaces:
java.io.Serializable

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 173 -
public class KMeansBeanKMeansBeanKMeansBeanKMeansBean extends java.lang.Object implements java.io.Serializable
Clase encargada de realizar la clusterizacion mediante K-Means
Author: Damian Martinelli
See Also: Serialized Form
Constructor Summary
KMeansBean() Constructor por defecto de la clase KMeansBean
KMeansBean(java.lang.String input, java.lang.String output, int k) Contructor de la clase KMeans, encargada de clusterizar las sesiones de usuarios.
Method Summary
java.lang.String getClusters() Si se setearon todos los atributos necesarios, realiza la clusterizacion de los datos del archivo de entrada, descubriendo la cantidad de clusters indicada y colocando los resultados en el archivo de salida.
java.lang.String getInput() Obtiene el nombre del archivo de entrada utilizado.
java.lang.String getK() Obtiene la cantidad de clusters a descubrir utilizada.
java.lang.String getOutput() Obtiene el nombre del archivo de salida utilizado.
static void main(java.lang.String[] args)
void save(java.lang.String fileName) Graba el modelo generado por K-Means en el archivo indicado.
void setInput(java.lang.String file) Setea el nombre del archivo de entrada.
void setK(java.lang.String k) Setea la cantidad de clusters a descubrir.
void setOutput(java.lang.String file)

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 174 -
Setea el nombre del archivo de salida.
Methods inherited from class java.lang.Object
clone, equals, finalize, getClass, hashCode, notify, notifyAll, toString, wait, wait, wait
Constructor Detail
KMeansBean
public KMeansBeanKMeansBeanKMeansBeanKMeansBean() Constructor por defecto de la clase KMeansBean
KMeansBean
public KMeansBeanKMeansBeanKMeansBeanKMeansBean(java.lang.String input, java.lang.String output,
int k) throws java.lang.Exception
Contructor de la clase KMeans, encargada de clusterizar las sesiones de usuarios. Parameters: input - Nombre del archivo de entrada.
output - Nombre del archivo de salida.
k - Cantidad de clusters a descubrir. Throws: java.lang.Exception
Method Detail
setInput
public void setInputsetInputsetInputsetInput(java.lang.String file) Setea el nombre del archivo de entrada. Parameters: file - Nombre del archivo de entrada.
getInput
public java.lang.String getInputgetInputgetInputgetInput() Obtiene el nombre del archivo de entrada utilizado. Returns: Nombre del archivo de entrada.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 175 -
setOutput
public void setOutputsetOutputsetOutputsetOutput(java.lang.String file) Setea el nombre del archivo de salida. Parameters: file - Nombre del archivo de salida.
getOutput
public java.lang.String getOutputgetOutputgetOutputgetOutput() Obtiene el nombre del archivo de salida utilizado. Returns: Nombre del archivo de salida.
setK
public void setKsetKsetKsetK(java.lang.String k) Setea la cantidad de clusters a descubrir. Parameters: k - Cantidad de clusters a descubrir.
getK
public java.lang.String getKgetKgetKgetK() Obtiene la cantidad de clusters a descubrir utilizada. Returns: Cantidad de clusters a descubrir.
getClusters
public java.lang.String getClustersgetClustersgetClustersgetClusters() Si se setearon todos los atributos necesarios, realiza la clusterizacion de los datos del archivo de entrada, descubriendo la cantidad de clusters indicada y colocando los resultados en el archivo de salida. Returns: Mensaje de exito o error.
save

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 176 -
public void savesavesavesave(java.lang.String fileName) Graba el modelo generado por K-Means en el archivo indicado. Parameters: fileName - Nombre del archivo.
main
public static void mainmainmainmain(java.lang.String[] args)
C.13. Class LogBean
java.lang.Object
ar.com.do2.iadh.LogBeanar.com.do2.iadh.LogBeanar.com.do2.iadh.LogBeanar.com.do2.iadh.LogBean All Implemented Interfaces:
java.io.Serializable
public class LogBeanLogBeanLogBeanLogBean extends java.lang.Object implements java.io.Serializable
Clase que representa la informacion de un registro de log a almacenar en la base de datos.
Author: Damian Martinelli
See Also: Serialized Form
Constructor Summary
LogBean() Constructor por defecto.
LogBean(java.lang.String IP, java.lang.String authuser, java.lang.String page, java.lang.String timestamp) Contructor de la clase LogBean.
Method Summary
java.lang.String getAuthuser()

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 177 -
Obtiene el nombre de usuario autenticado mediante HTTP.
java.lang.String getIP() Obtiene la direccion IP.
java.lang.String getPage() Obtiene la página solicitada.
java.lang.String getTimestamp() Obtiene la marca de tiempo cuando se realizo la peticion.
void setAuthuser(java.lang.String authuser) Setea el nombre de usuario autenticado mediante HTTP.
void setIP(java.lang.String IP) Setea la direccion IP.
void setPage(java.lang.String page) Setea la página solicitada.
void setTimestamp(java.lang.String timestamp) Setea la marca de tiempo cuando se realizo la peticion.
java.lang.String toString()
Methods inherited from class java.lang.Object
clone, equals, finalize, getClass, hashCode, notify, notifyAll, wait, wait, wait
Constructor Detail
LogBean
public LogBeanLogBeanLogBeanLogBean() Constructor por defecto.
LogBean
public LogBeanLogBeanLogBeanLogBean(java.lang.String IP, java.lang.String authuser, java.lang.String page, java.lang.String timestamp)
Contructor de la clase LogBean. Parameters: IP - Direccion IP del solicitante de la página.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 178 -
authuser - Nombre del usuario autenticado mediante HTTP.
page - Página solicitada.
timestamp - Marca de tiempo cuando se realizo la peticion.
Method Detail
setIP
public void setIPsetIPsetIPsetIP(java.lang.String IP) Setea la direccion IP. Parameters: IP - Direccion IP.
getIP
public java.lang.String getIPgetIPgetIPgetIP() Obtiene la direccion IP. Returns: Direccion IP.
setAuthuser
public void setAuthusersetAuthusersetAuthusersetAuthuser(java.lang.String authuser) Setea el nombre de usuario autenticado mediante HTTP. Parameters: authuser - Nombre de usuario.
getAuthuser
public java.lang.String getAuthusergetAuthusergetAuthusergetAuthuser() Obtiene el nombre de usuario autenticado mediante HTTP. Returns: Nombre del usuario.
setPage
public void setPagesetPagesetPagesetPage(java.lang.String page) Setea la página solicitada. Parameters: page - Página solicitada.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 179 -
getPage
public java.lang.String getPagegetPagegetPagegetPage() Obtiene la página solicitada. Returns: Página solicitada.
setTimestamp
public void ssssetTimestampetTimestampetTimestampetTimestamp(java.lang.String timestamp) Setea la marca de tiempo cuando se realizo la peticion. Parameters: timestamp - Marca de tiempo.
getTimestamp
public java.lang.String getTimestampgetTimestampgetTimestampgetTimestamp() Obtiene la marca de tiempo cuando se realizo la peticion. Returns: Marca de tiempo.
toString
public java.lang.String toStringtoStringtoStringtoString() Overrides: toString in class java.lang.Object
C.14. Class LogCleanerBean
java.lang.Object ar.com.dar.com.dar.com.dar.com.do2.iadh.LogCleanerBeano2.iadh.LogCleanerBeano2.iadh.LogCleanerBeano2.iadh.LogCleanerBean All Implemented Interfaces:
java.io.Serializable
public class LogCleanerBeanLogCleanerBeanLogCleanerBeanLogCleanerBean extends java.lang.Object implements java.io.Serializable
Clase utilizada para borrar todo los registros de log de un proyecto.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 180 -
Author: Damian Martinelli
See Also: Serialized Form
Constructor Summary
LogCleanerBean() Constructor de la clase LogCleanerBean, encargada de borrar todos los registros de log de un proyecto.
Method Summary
void clean() Borra todo el log de un proyecto.
java.lang.String getCleaneds() Si toda la informacion necesaria esta seteada, borra todos los registros de log de la tabla de logs.
java.lang.String getProject() Obtiene el nombre del proyecto utilizado.
java.lang.String getUser() Obtiene el nombre de usuario utilizado.
static void main(java.lang.String[] args)
void setProject(java.lang.String projectName) Setea el nombre del proyecto que se utilizara.
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.
Methods inherited from class java.lang.Object
clone, equals, finalize, getClass, hashCode, notify, notifyAll, toString, wait, wait, wait
Constructor Detail
LogCleanerBean
public LogCleanerBeanLogCleanerBeanLogCleanerBeanLogCleanerBean() throws java.lang.Exception
Constructor de la clase LogCleanerBean, encargada de borrar todos los registros de log de un proyecto. Throws:

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 181 -
java.lang.Exception
Method Detail
clean
public void cleancleancleanclean()
throws java.lang.Exception Borra todo el log de un proyecto. Throws: java.lang.Exception
getCleaneds
public java.lang.String getCleanedsgetCleanedsgetCleanedsgetCleaneds()
throws java.lang.Exception Si toda la informacion necesaria esta seteada, borra todos los registros de log de la tabla de logs. Returns: Cantidad de registros eliminados. Throws: java.lang.Exception
setUser
public void setUsersetUsersetUsersetUser(java.lang.String userName) throws java.lang.Exception
Setea el nombre de usuario que se utilizara. Parameters: userName - Nombre del usuario. Throws: java.lang.Exception
getUser
public java.lang.String getUsergetUsergetUsergetUser() Obtiene el nombre de usuario utilizado. Returns: Nombre del usuario.
setProject

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 182 -
public void setProjectsetProjectsetProjectsetProject(java.lang.String projectName) throws java.lang.Exception
Setea el nombre del proyecto que se utilizara. Parameters: projectName - Nombre del proyecto. Throws: java.lang.Exception
getProject
public java.lang.String getProjectgetProjectgetProjectgetProject() Obtiene el nombre del proyecto utilizado. Returns: Nombre del proyecto.
main
public static void mainmainmainmain(java.lang.String[] args) throws java.lang.Exception
Throws: java.lang.Exception
C.15. Class LogFilesViewBean
java.lang.Object ar.com.do2.iadh.LogFilesViewBeanar.com.do2.iadh.LogFilesViewBeanar.com.do2.iadh.LogFilesViewBeanar.com.do2.iadh.LogFilesViewBean All Implemented Interfaces:
java.io.Serializable
public class LogFilesViewBeanLogFilesViewBeanLogFilesViewBeanLogFilesViewBean extends java.lang.Object implements java.io.Serializable
Clase utilizada para listar todos los archivos de log cargados por un usuario
Author: Damian Martinelli
See Also: Serialized Form

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 183 -
Constructor Summary
LogFilesViewBean() Constructor de la clase LogFilesViewBean.
Method Summary
java.lang.String getNextDescription() Obtiene la descripcion del proximo archivo de log.
java.lang.String getNextLog() Obtiene el nombre del proximo archivo de log.
java.lang.String getUser() Obtiene el nombre de usuario utilizado.
void goFirstLog() Inicializa para la lectura de todos los archivos de log de un usuario.
boolean hasNextLog() Indica si hay mas archivos de log.
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.
Methods inherited from class java.lang.Object
clone, equals, finalize, getClass, hashCode, notify, notifyAll, toString, wait, wait, wait
Constructor Detail
LogFilesViewBean
public LogFilesViewBeanLogFilesViewBeanLogFilesViewBeanLogFilesViewBean() throws java.lang.Exception
Constructor de la clase LogFilesViewBean. Throws: java.lang.Exception
Method Detail
goFirstLog
public void goFirstLoggoFirstLoggoFirstLoggoFirstLog() Inicializa para la lectura de todos los archivos de log de un usuario.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 184 -
hasNextLog
public boolean hasNextLoghasNextLoghasNextLoghasNextLog() Indica si hay mas archivos de log. Returns: true si hay mas archivos, false sino.
getNextLog
public java.lang.String getNextLoggetNextLoggetNextLoggetNextLog() Obtiene el nombre del proximo archivo de log. Returns: Nombre del proximo archivo.
getNextDescription
public java.lang.String getNextDescriptiongetNextDescriptiongetNextDescriptiongetNextDescription() Obtiene la descripcion del proximo archivo de log. Returns: Descripcion del proximo archivo.
setUser
public void setUsersetUsersetUsersetUser(java.lang.String userName) Setea el nombre de usuario que se utilizara. Parameters: userName - Nombre del usuario.
getUser
public java.lang.String getUsergetUsergetUsergetUser() Obtiene el nombre de usuario utilizado. Returns: Nombre del usuario.
C.16. Class LogFileUploadBean
java.lang.Object ar.com.do2.iadh.LogFileUploadBeanar.com.do2.iadh.LogFileUploadBeanar.com.do2.iadh.LogFileUploadBeanar.com.do2.iadh.LogFileUploadBean

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 185 -
All Implemented Interfaces: java.io.Serializable
public class LogFileUploadBeanLogFileUploadBeanLogFileUploadBeanLogFileUploadBean extends java.lang.Object implements java.io.Serializable
Clase utilizada para guardar en la base de datos informacion sobre un archivo de log y copiar el archivo al servidor.
Author: Budi Kurniawan, Damian Martinelli
See Also: Serialized Form
Constructor Summary
LogFileUploadBean() Constructor de la clase LogFileUploadBean.
Method Summary
void doUpload(javax.servlet.http.HttpServletRequest request) Sube el archivo al servidor.
java.lang.String getContentType() Obtiene el tipo de contenido del archivo.
java.lang.String getFieldsValues() Obtiene todos los campos con sus valores.
java.lang.String getFieldValue(java.lang.String fieldName) Obtiene el valor de un campo, cuyo nombre es pasado por parametro.
java.lang.String getFilename() Obtiene el nombre del archivo a copiar.
java.lang.String getFilepath() Obtiene el path donde se copiara el archivo.
java.lang.String getInput() Obtiene el nombre del archivo de log utilizado.
boolean getUpload() Si los atributos necesarios fueron seteados, copia el archivo al servidor y carga la informacion del archivo en la base de datos.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 186 -
java.lang.String getUser() Obtiene el nombre de usuario utilizado.
void setLogFile(java.lang.String filename) Setea el nombre del archivo de log.
void setRequest(javax.servlet.http.HttpServletRequest request) Setea el objeto HttpServletRequest a utilizar.
void setSavePath(java.lang.String savePath) Setea el path donde se copiara el archivo.
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.
Methods inherited from class java.lang.Object
clone, equals, finalize, getClass, hashCode, notify, notifyAll, toString, wait, wait, wait
Constructor Detail
LogFileUploadBean
public LogFileUploadBeanLogFileUploadBeanLogFileUploadBeanLogFileUploadBean() throws java.lang.Exception
Constructor de la clase LogFileUploadBean. Throws: java.lang.Exception
Method Detail
setLogFile
public void setLogFilesetLogFilesetLogFilesetLogFile(java.lang.String filename) throws java.lang.Exception
Setea el nombre del archivo de log. Parameters: filename - Nombre del archivo. Throws: java.lang.Exception
getInput
public java.lang.String getInputgetInputgetInputgetInput() Obtiene el nombre del archivo de log utilizado.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 187 -
Returns: Nombre del archivo.
getUpload
public boolean getUploadgetUploadgetUploadgetUpload() Si los atributos necesarios fueron seteados, copia el archivo al servidor y carga la informacion del archivo en la base de datos. Returns: true si pudo copiar y cargar el archivo, false sino.
setRequest
public void setRequestsetRequestsetRequestsetRequest(javax.servlet.http.HttpServletRequest request) Setea el objeto HttpServletRequest a utilizar. Parameters: request - Objeto HttpServletRequest.
setUser
public void setUsersetUsersetUsersetUser(java.lang.String userName) Setea el nombre de usuario que se utilizara. Parameters: userName - Nombre del usuario.
getUser
public java.lang.String getUsergetUsergetUsergetUser() Obtiene el nombre de usuario utilizado. Returns: Nombre del usuario.
getFilename
public java.lang.String getFilenamegetFilenamegetFilenamegetFilename() Obtiene el nombre del archivo a copiar. Returns: Nombre del archivo.
getFilepath

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 188 -
public java.lang.String getFilepathgetFilepathgetFilepathgetFilepath() Obtiene el path donde se copiara el archivo. Returns: Path donde se copiara el archivo.
setSavePath
public void setSavePathsetSavePathsetSavePathsetSavePath(java.lang.String savePath) Setea el path donde se copiara el archivo. Parameters: savePath - Path donde se copiara el archivo.
getContentType
public java.lang.String getContentTypegetContentTypegetContentTypegetContentType() Obtiene el tipo de contenido del archivo. Returns: Tipo de contenido del archivo.
getFieldValue
public java.lang.String getFieldValuegetFieldValuegetFieldValuegetFieldValue(java.lang.String fieldName) Obtiene el valor de un campo, cuyo nombre es pasado por parametro. Parameters: fieldName - Nombre del campo. Returns: Valor del campo.
getFieldsValues
public java.lang.String getFieldsValuesgetFieldsValuesgetFieldsValuesgetFieldsValues() Obtiene todos los campos con sus valores. Returns: Todos los campos con sus valores.
doUpload
public void doUploaddoUploaddoUploaddoUpload(javax.servlet.http.HttpServletRequest request) throws java.io.IOException
Sube el archivo al servidor. Parameters:

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 189 -
request - Objeto HttpServletRequest de la solicitud. Throws: java.io.IOException
C.17. Class LoginBean
java.lang.Object ar.com.do2.iadh.LoginBeanar.com.do2.iadh.LoginBeanar.com.do2.iadh.LoginBeanar.com.do2.iadh.LoginBean
public class LoginBeanLoginBeanLoginBeanLoginBean extends java.lang.Object
Clase utilizada para iniciar sesión en la herramienta.
Author: Damian Martinelli
Constructor Summary
LoginBean() Constructor de la clase LoginBean.
Method Summary
java.lang.String getUser() Obtiene el nombre de usuario utilizado.
boolean isValidUser() Intenta autenticar al usuario, devolviendo si es un usuario valido o no.
void setPass(java.lang.String password) Setea la contraseña del usuario.
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.
Methods inherited from class java.lang.Object
clone, equals, finalize, getClass, hashCode, notify, notifyAll, toString, wait, wait, wait
Constructor Detail

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 190 -
LoginBean
public LoginBeanLoginBeanLoginBeanLoginBean() throws java.lang.Exception
Constructor de la clase LoginBean. Throws: java.lang.Exception
Method Detail
setUser
public void setUsersetUsersetUsersetUser(java.lang.String userName) Setea el nombre de usuario que se utilizara. Parameters: userName - Nombre del usuario.
getUser
public java.lang.String getUsergetUsergetUsergetUser() Obtiene el nombre de usuario utilizado. Returns: Nombre del usuario.
setPass
public void setPasssetPasssetPasssetPass(java.lang.String password) Setea la contraseña del usuario. Parameters: password - Contraseña del usuario.
isValidUser
public boolean isValidUserisValidUserisValidUserisValidUser() Intenta autenticar al usuario, devolviendo si es un usuario valido o no. Returns: true si se autentico al usuario satisfactoriamente, false sino.
C.18. Class LogLoaderBean

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 191 -
java.lang.Object ar.com.do2.iadh.LogLoaderBeanar.com.do2.iadh.LogLoaderBeanar.com.do2.iadh.LogLoaderBeanar.com.do2.iadh.LogLoaderBean All Implemented Interfaces:
java.io.Serializable
public class LogLoaderBeanLogLoaderBeanLogLoaderBeanLogLoaderBean
extends java.lang.Object implements java.io.Serializable
Clase utilizada para leer el archivo de log y obtener la informacion del mismo para almacenarla en la base de datos.
Author: Damian Martinelli
See Also: Serialized Form
Constructor Summary
LogLoaderBean() Constructor de la clase LogLoader, encargada de cargar todo un log en la tabla log.
Method Summary
java.lang.String getExtensions() Obtiene las extensiones, separadas por coma.
java.lang.String getHitsSaves() Obtiene la cantidad de registros guardados en la tabla de logs.
java.lang.String getIdsPage() Obtiene las variables que identifican páginas distintas, separadas por coma.
java.lang.String getInput() Obtiene el nombre del archivo de log.
java.lang.String getLoad() Si toda la informacion necesaria esta seteada, carga el archivo de log en la tabla de logs.
java.lang.String getProject() Obtiene el nombre del proyecto utilizado.
java.lang.String getStatusCodes() Obtiene los codigos de error, separados por coma.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 192 -
java.lang.String getTypeLog() Obtiene el tipo de log.
java.lang.String getUser() Obtiene el nombre de usuario utilizado.
void load(java.lang.String inputFilename) Carga todo un log en la tabla log.
static void main(java.lang.String[] args)
void setExtensions(java.lang.String values) Setea las extensiones de los archivos considerados de páginas, o las extensiones que se necesitan tener en cuenta.
void setIdsPage(java.lang.String values) Setea las variables que identifican páginas distintas.
void setInput(java.lang.String inputFilename) Setea el nombre del archivo de log.
void setProject(java.lang.String projectName) Setea el nombre del proyecto que se utilizara.
void setStatusCodes(java.lang.String values) Setea los codigos de error a tener en cuenta.
void setTypeLog(java.lang.String type) Setea el tipo de log.
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.
Methods inherited from class java.lang.Object
clone, equals, finalize, getClass, hashCode, notify, notifyAll, toString, wait, wait, wait
Constructor Detail
LogLoaderBean
public LogLoaderBeanLogLoaderBeanLogLoaderBeanLogLoaderBean() throws java.lang.Exception
Constructor de la clase LogLoader, encargada de cargar todo un log en la tabla log. Throws: java.lang.Exception
Method Detail

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 193 -
load
public void loadloadloadload(java.lang.String inputFilename) throws java.lang.Exception
Carga todo un log en la tabla log. Parameters: inputFilename - Nombre del archivo de log. Throws: java.lang.Exception
getLoad
public java.lang.String getLoadgetLoadgetLoadgetLoad() throws java.lang.Exception
Si toda la informacion necesaria esta seteada, carga el archivo de log en la tabla de logs. Devuelve la cantidad de registros guardados o un mensaje de error. Returns: Cantidad de registros de log cargados o un mensaje de error. Throws: java.lang.Exception
setInput
public void setInputsetInputsetInputsetInput(java.lang.String inputFilename) throws java.lang.Exception
Setea el nombre del archivo de log. Parameters: inputFilename - Nombre del archivo de log. Throws: java.lang.Exception
getInput
public java.lang.String getInputgetInputgetInputgetInput() Obtiene el nombre del archivo de log. Returns: Nombre del archivo de log.
setTypeLog

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 194 -
public void setTypeLogsetTypeLogsetTypeLogsetTypeLog(java.lang.String type) throws java.lang.Exception
Setea el tipo de log. Parameters: type - Tipo de archivo de log. Throws: java.lang.Exception
getTypeLog
public java.lang.String getTypeLoggetTypeLoggetTypeLoggetTypeLog() Obtiene el tipo de log. Returns: Tipo de archivo de log.
setUser
public void setUsersetUsersetUsersetUser(java.lang.String userName) throws java.lang.Exception
Setea el nombre de usuario que se utilizara. Parameters: userName - Nombre del usuario. Throws: java.lang.Exception
getUser
public java.lang.String getUsergetUsergetUsergetUser() Obtiene el nombre de usuario utilizado. Returns: Nombre del usuario.
setProject
public void setProjectsetProjectsetProjectsetProject(java.lang.String projectName)
throws java.lang.Exception Setea el nombre del proyecto que se utilizara. Parameters: projectName - Nombre del proyecto. Throws:

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 195 -
java.lang.Exception
getProject
public java.lang.String getProjectgetProjectgetProjectgetProject() Obtiene el nombre del proyecto utilizado. Returns: Nombre del proyecto.
setExtensions
public void setsetsetsetExtensionsExtensionsExtensionsExtensions(java.lang.String values) Setea las extensiones de los archivos considerados de páginas, o las extensiones que se necesitan tener en cuenta. Parameters: values - Extensiones validas.
getExtensions
public java.lang.String getExtensionsgetExtensionsgetExtensionsgetExtensions() Obtiene las extensiones, separadas por coma. Returns: Obtiene las extensiones validas.
setStatusCodes
public void setStatusCodessetStatusCodessetStatusCodessetStatusCodes(java.lang.String values) Setea los codigos de error a tener en cuenta. Parameters: values - Codigos de error validos.
getStatusCodes
public java.lang.String getStatusCodesgetStatusCodesgetStatusCodesgetStatusCodes() Obtiene los codigos de error, separados por coma. Returns: Codigos de error validos separados por coma.
setIdsPage

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 196 -
public void setIdsPagesetIdsPagesetIdsPagesetIdsPage(java.lang.String values) Setea las variables que identifican páginas distintas. Parameters: values - Nombre de las variables identificadoras de páginas.
getIdsPage
public java.lang.String getIdsPagegetIdsPagegetIdsPagegetIdsPage() Obtiene las variables que identifican páginas distintas, separadas por coma. Returns: Nombre de variables identificadoras de página.
getHitsSaves
public java.lang.String getHitsSavesgetHitsSavesgetHitsSavesgetHitsSaves() Obtiene la cantidad de registros guardados en la tabla de logs. Returns: Cantidad de registros de log guardados.
main
public static void mainmainmainmain(java.lang.String[] args)
throws java.lang.Exception Throws: java.lang.Exception
C.19. Class LogViewBean
java.lang.Object ar.com.do2.iadh.LogViewBeanar.com.do2.iadh.LogViewBeanar.com.do2.iadh.LogViewBeanar.com.do2.iadh.LogViewBean All Implemented Interfaces:
java.io.Serializable
public class LogViewBeanLogViewBeanLogViewBeanLogViewBean extends java.lang.Object implements java.io.Serializable

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 197 -
Clase encargada de obtener el detalle de todos los registros de log cargados en la base de datos por un proyecto de un usuario.
Author: Damian Martinelli
See Also: Serialized Form
Field Summary
protected int
logsPerPage
Constructor Summary
LogViewBean() Contructor de la clase LogViewBean.
Method Summary
java.lang.String getCurrentLog() Obtiene el archivo de log utilizado.
java.lang.String getLogsPerPage() Obtiene la cantidad de registros de log por página utilizada.
LogBean getNextLog() Obtiene el registro de log actual.
java.lang.String getProject() Obtiene el nombre del proyecto utilizado.
java.lang.String getUser() Obtiene el nombre de usuario utilizado.
void goFirstLog() Se posiciona en el primer registro de log del proyecto actual.
boolean hasNextLog() Indica si existe un proximo registro de log.
static void main(java.lang.String[] args)
void setCurrentLog(java.lang.String log) Setea el archivo de log a utilizar.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 198 -
void setLogsPerPage(java.lang.String logs) Setea la cantidad de registros de log a obtener por página.
void setProject(java.lang.String projectName) Setea el nombre del proyecto que se utilizara.
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.
Methods inherited from class java.lang.Object
clone, equals, finalize, getClass, hashCode, notify, notifyAll, toString, wait, wait, wait
Field Detail
logsPerPage
protected int logsPerPagelogsPerPagelogsPerPagelogsPerPage
Constructor Detail
LogViewBean
public LogViewBeanLogViewBeanLogViewBeanLogViewBean() throws java.lang.Exception
Contructor de la clase LogViewBean. Throws: java.lang.Exception
Method Detail
goFirstLog
public void goFirstLoggoFirstLoggoFirstLoggoFirstLog() Se posiciona en el primer registro de log del proyecto actual.
hasNextLog
public boolean hasNextLoghasNextLoghasNextLoghasNextLog() Indica si existe un proximo registro de log. Returns: true si existe un proximo registro de log, false sino.
getNextLog

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 199 -
public LogBean getNextLoggetNextLoggetNextLoggetNextLog() Obtiene el registro de log actual. Returns: Registro de log actual.
setUser
public void setUsersetUsersetUsersetUser(java.lang.String userName) Setea el nombre de usuario que se utilizara. Parameters: userName - Nombre del usuario.
getUser
public java.lang.String getUsergetUsergetUsergetUser() Obtiene el nombre de usuario utilizado. Returns: Nombre del usuario.
setProject
public void setProjectsetProjectsetProjectsetProject(java.lang.String projectName) Setea el nombre del proyecto que se utilizara. Parameters: projectName - Nombre del proyecto.
getProject
public java.lang.String getProjectgetProjectgetProjectgetProject() Obtiene el nombre del proyecto utilizado. Returns: Nombre del proyecto.
setLogsPerPage
public void setLogsPerPagesetLogsPerPagesetLogsPerPagesetLogsPerPage(java.lang.String logs) Setea la cantidad de registros de log a obtener por página. Parameters: logs - Cantidad de registros.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 200 -
getLogsPerPage
public java.lang.String getLogsPerPagegetLogsPerPagegetLogsPerPagegetLogsPerPage() Obtiene la cantidad de registros de log por página utilizada. Returns: Cantidad de registros de log.
setCurrentLog
public void setCurrentLogsetCurrentLogsetCurrentLogsetCurrentLog(java.lang.String log) Setea el archivo de log a utilizar. Parameters: log - Nombre del archivo de log.
getCurrentLog
public java.lang.String getCurrentLoggetCurrentLoggetCurrentLoggetCurrentLog() Obtiene el archivo de log utilizado. Returns: Nombre del archivo de log.
main
public static void mainmainmainmain(java.lang.String[] args) throws java.lang.Exception
Throws: java.lang.Exception
C.20. Class NumericSessionClusterBean
java.lang.Object
ar.com.do2.iadh.SessionClusterBean ar.com.do2.iadh.NumericSessionClusterBeanar.com.do2.iadh.NumericSessionClusterBeanar.com.do2.iadh.NumericSessionClusterBeanar.com.do2.iadh.NumericSessionClusterBean
public class NumericSessionClusterBeanNumericSessionClusterBeanNumericSessionClusterBeanNumericSessionClusterBean extends SessionClusterBean

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 201 -
Clase encargada de cargar en la base de datos la informacion de clusterizacion almacenada en un archivo, que posee en cada linea el numero de cluster al cual pertenece la sesion.
Author: Damian Martinelli
Field Summary
Fields inherited from class ar.com.do2.iadh.SessionClusterBean
conn, filename, project, pstm, pstmDelete, type, user
Constructor Summary
NumericSessionClusterBean() Constructor por defecto de la clase NumericSessionClusterBean.
Method Summary
void count(java.lang.String inputFilename) Realiza el conteo de los clusters descubiertos tomando como entrada el archivo donde se encuentra a que cluster pertenece cada sesion.
Methods inherited from class ar.com.do2.iadh.SessionClusterBean
getCount, getFile, getProject, getType, getUser, setFile, setProject, setType, setUser
Methods inherited from class java.lang.Object
clone, equals, finalize, getClass, hashCode, notify, notifyAll, toString, wait, wait, wait
Constructor Detail
NumericSessionClusterBean
public NumericSessionClusterBeanNumericSessionClusterBeanNumericSessionClusterBeanNumericSessionClusterBean() throws java.lang.Exception
Constructor por defecto de la clase NumericSessionClusterBean. Throws: java.lang.Exception
Method Detail

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 202 -
count
public void countcountcountcount(java.lang.String inputFilename) throws java.lang.Exception
Description copied from class: SessionClusterBean Realiza el conteo de los clusters descubiertos tomando como entrada el archivo donde se encuentra a que cluster pertenece cada sesion. Specified by: count in class SessionClusterBean Parameters: inputFilename - Nombre del archivo donde se encuentra la informacion de los clusters descubiertos. Throws: java.lang.Exception
C.21. Class PageCounterBean
java.lang.Object
ar.com.do2.iadh.PageCounterBeanar.com.do2.iadh.PageCounterBeanar.com.do2.iadh.PageCounterBeanar.com.do2.iadh.PageCounterBean
public class PagePagePagePageCounterBeanCounterBeanCounterBeanCounterBean
extends java.lang.Object
Clase encargarda de cargar todas las páginas encontradas en un archivo de log.
Author: Damian Martinelli
Constructor Summary
PageCounterBean() Constructor de la clase PageCounterBean, encargada de numerar todas las páginas encontradas en un log.
Method Summary
java.lang.String getPages() Realiza el conteo de las páginas que se encuentran en los log cargados en un proyecto.
java.lang.String getProject() Obtiene el nombre del proyecto utilizado.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 203 -
java.lang.String getUser() Obtiene el nombre de usuario utilizado.
static void main(java.lang.String[] args)
void setProject(java.lang.String projectName) Setea el nombre del proyecto que se utilizara.
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.
void start() Comienza el conteo de las páginas que aparecen en el log
Methods inherited from class java.lang.Object
clone, equals, finalize, getClass, hashCode, notify, notifyAll, toString, wait, wait, wait
Constructor Detail
PageCounterBean
public PPPPageCounterBeanageCounterBeanageCounterBeanageCounterBean() throws java.lang.Exception
Constructor de la clase PageCounterBean, encargada de numerar todas las páginas encontradas en un log. Throws: java.lang.Exception
Method Detail
start
public void startstartstartstart() throws java.lang.Exception
Comienza el conteo de las páginas que aparecen en el log Throws: java.lang.Exception
getPages
public java.lang.String getPagesgetPagesgetPagesgetPages()
throws java.lang.Exception

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 204 -
Realiza el conteo de las páginas que se encuentran en los log cargados en un proyecto. Returns: Cantidad de páginas. Throws: java.lang.Exception
setUser
public void setUsersetUsersetUsersetUser(java.lang.String userName) throws java.lang.Exception
Setea el nombre de usuario que se utilizara. Parameters: userName - Nombre del usuario. Throws: java.lang.Exception
getUser
public java.lang.String getUsergetUsergetUsergetUser() Obtiene el nombre de usuario utilizado. Returns: Nombre del usuario.
setProject
public void setProjectsetProjectsetProjectsetProject(java.lang.String projectName) throws java.lang.Exception
Setea el nombre del proyecto que se utilizara. Parameters: projectName - Nombre del proyecto. Throws: java.lang.Exception
getProject
public java.lang.String getProjectgetProjectgetProjectgetProject() Obtiene el nombre del proyecto utilizado. Returns: Nombre del proyecto.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 205 -
main
public static void mainmainmainmain(java.lang.String[] args) throws java.lang.Exception
Throws: java.lang.Exception
C.22. Class PagesInClustersBean
java.lang.Object ar.com.do2.iadh.PagesInClustersBeanar.com.do2.iadh.PagesInClustersBeanar.com.do2.iadh.PagesInClustersBeanar.com.do2.iadh.PagesInClustersBean
public class PagesInClustersBeanPagesInClustersBeanPagesInClustersBeanPagesInClustersBean extends java.lang.Object
Clase encargada de obtener la informacion de que páginas aparecen en las sesiones de cada cluster.
Author: Damian Martinelli
Constructor Summary
PagesInClustersBean() Constructor de la clase PagesInClustes, encargada de obtener la informacion de que páginas aparecen en las sesiones de cada cluster
Method Summary
java.lang.String getPages() Si los parametros necesarios han sido seteados, comienza a obtener la informacion de los clusters.
java.lang.String getProject() Obtiene el nombre del proyecto utilizado.
java.lang.String getType() Obtiene el tipo de clusters que se estan analizando.
java.lang.String getUser() Obtiene el nombre de usuario utilizado.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 206 -
void setProject(java.lang.String projectName) Setea el nombre del proyecto que se utilizara.
void setType(java.lang.String typeClustering) Setea el tipo de clusters que se estan analizando.
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.
void start() Comienza a cargar en la tabla pageInCluster, las tuplas (página,cluster, porcentaje), correspondiente a si una página aparece en las sesiones de un cluster y el porcentaje de sesiones de ese cluster en que la página aparece.
Methods inherited from class java.lang.Object
clone, equals, finalize, getClass, hashCode, notify, notifyAll, toString, wait, wait, wait
Constructor Detail
PagesInClustersBean
public PagesInClustersBeanPagesInClustersBeanPagesInClustersBeanPagesInClustersBean() throws java.lang.Exception
Constructor de la clase PagesInClustes, encargada de obtener la informacion de que páginas aparecen en las sesiones de cada cluster Throws: java.lang.Exception
Method Detail
start
public void startstartstartstart() throws java.lang.Exception
Comienza a cargar en la tabla pageInCluster, las tuplas (página,cluster, porcentaje), correspondiente a si una página aparece en las sesiones de un cluster y el porcentaje de sesiones de ese cluster en que la página aparece. Throws: java.lang.Exception
getPages
public java.lang.String getPagesgetPagesgetPagesgetPages()

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 207 -
throws java.lang.Exception Si los parametros necesarios han sido seteados, comienza a obtener la informacion de los clusters. Returns: "OK" si se realizo la operacion correctamente, un mensaje de error en caso contrario. Throws: java.lang.Exception
setUser
public void setUsersetUsersetUsersetUser(java.lang.String userName) Setea el nombre de usuario que se utilizara. Parameters: userName - Nombre del usuario.
getUser
public java.lang.String getUsergetUsergetUsergetUser() Obtiene el nombre de usuario utilizado. Returns: Nombre del usuario.
setProject
public void setProjesetProjesetProjesetProjectctctct(java.lang.String projectName) Setea el nombre del proyecto que se utilizara. Parameters: projectName - Nombre del proyecto.
getProject
public java.lang.String getProjectgetProjectgetProjectgetProject() Obtiene el nombre del proyecto utilizado. Returns: Nombre del proyecto.
setType
public void setTypesetTypesetTypesetType(java.lang.String typeClustering) Setea el tipo de clusters que se estan analizando.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 208 -
Parameters: typeClustering - Tipo de clusters.
getType
public java.lang.String getTypegetTypegetTypegetType() Obtiene el tipo de clusters que se estan analizando. Returns: Tipo de clusters.
C.23. Class PagesInClustersViewBean
java.lang.Object ar.com.do2.iadh.PagesInClustersViewBeanar.com.do2.iadh.PagesInClustersViewBeanar.com.do2.iadh.PagesInClustersViewBeanar.com.do2.iadh.PagesInClustersViewBean
public class PagesInClustersViewBeanPagesInClustersViewBeanPagesInClustersViewBeanPagesInClustersViewBean extends java.lang.Object
Clase que se encarga de obtener la informacion de las páginas que accedieron los usuarios de cada cluster, indicando el porcentaje de acceso.
Author: Damian Martinelli
Constructor Summary
PagesInClustersViewBean() Constructor de la clase PagesInClustersViewBean.
Method Summary
java.lang.String getCluster() Obtiene el numero de cluster.
java.lang.String getMaxPagesPerCluster() Obtiene la cantidad maxima de páginas por cluster a mostrar.
java.lang.String getMinPercentage() Obtiene el minimo porcentaje de frecuencia de página a mostrar.
java.lang.String getNextCluster() Obtiene el proximo cluster.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 209 -
java.lang.String getNextPage() Obtiene la proxima página.
java.lang.String getNextPercentage() Obtiene el proximo porcentaje de página.
java.lang.String getProject() Obtiene el nombre del proyecto utilizado.
java.lang.String getType() Obtiene el tipo de clusters que se estan analizando.
java.lang.String getUser() Obtiene el nombre de usuario utilizado.
void goFirstCluster() Se situa en el primer cluster.
void goFirstPage() Se situa en la primera página.
boolean hasNextCluster() Indica se existen mas clusters.
boolean hasNextPage() Indica si existen mas páginas.
void setCluster(java.lang.String clusterNumber) Setea el numero de cluster.
void setMaxPagesPerCluster(java.lang.String pages) Setea la cantidad maxima de páginas por cluster a mostrar.
void setMinPercentage(java.lang.String percentage) Setea el minimo porcentaje de frecuencia de página a mostrar.
void setProject(java.lang.String projectName) Setea el nombre del proyecto que se utilizara.
void setType(java.lang.String typeClustering) Setea el tipo de clusters que se estan analizando.
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.
Methods inherited from class java.lang.Object
clone, equals, finalize, getClass, hashCode, notify, notifyAll, toString, wait, wait, wait
Constructor Detail

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 210 -
PagesInClustersViewBean
public PagesInClustersViewBeanPagesInClustersViewBeanPagesInClustersViewBeanPagesInClustersViewBean() throws java.lang.Exception
Constructor de la clase PagesInClustersViewBean. Throws: java.lang.Exception
Method Detail
goFirstPage
public void goFirstPagegoFirstPagegoFirstPagegoFirstPage() Se situa en la primera página.
hasNextPage
public boolean hasNextPagehasNextPagehasNextPagehasNextPage() Indica si existen mas páginas. Returns: true si existen mas páginas, false sino.
getNextPage
public java.lang.String getNextPagegetNextPagegetNextPagegetNextPage() Obtiene la proxima página. Returns: Proxima página.
getNextPercentage
public java.lang.String getNextPercentagegetNextPercentagegetNextPercentagegetNextPercentage() Obtiene el proximo porcentaje de página. Returns: Porcentaje de página.
goFirstCluster
public void goFirstClustergoFirstClustergoFirstClustergoFirstCluster() Se situa en el primer cluster.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 211 -
hasNextCluster
public boolean hasNextClusterhasNextClusterhasNextClusterhasNextCluster() Indica se existen mas clusters. Returns: true si existen mas clusters, false sino.
getNextCluster
public java.lang.String getNextClustergetNextClustergetNextClustergetNextCluster() Obtiene el proximo cluster. Returns: Proximo cluster.
setUser
public void setUsersetUsersetUsersetUser(java.lang.String userName) Setea el nombre de usuario que se utilizara. Parameters: userName - Nombre del usuario.
getUser
public java.lang.String getUsergetUsergetUsergetUser() Obtiene el nombre de usuario utilizado. Returns: Nombre del usuario.
setProject
public void setProjectsetProjectsetProjectsetProject(java.lang.String projectName) Setea el nombre del proyecto que se utilizara. Parameters: projectName - Nombre del proyecto.
getProject
public java.lang.String getProjectgetProjectgetProjectgetProject() Obtiene el nombre del proyecto utilizado. Returns: Nombre del proyecto.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 212 -
setType
public void setTypesetTypesetTypesetType(java.lang.String typeClustering) Setea el tipo de clusters que se estan analizando. Parameters: typeClustering - Tipo de clusters.
getType
public java.lang.String getTypegetTypegetTypegetType() Obtiene el tipo de clusters que se estan analizando. Returns: Tipo de clusters.
setCluster
public void setClustersetClustersetClustersetCluster(java.lang.String clusterNumber) Setea el numero de cluster. Parameters: clusterNumber - Numero de cluster.
getCluster
public java.lang.String getClustergetClustergetClustergetCluster() Obtiene el numero de cluster. Returns: Numero de cluster.
setMinPercentage
public void setMinPercentagesetMinPercentagesetMinPercentagesetMinPercentage(java.lang.String percentage) Setea el minimo porcentaje de frecuencia de página a mostrar. Parameters: percentage - Minimo porcentaje de frecuencia de página.
getMinPercentage
public java.lang.String getMinPercentagegetMinPercentagegetMinPercentagegetMinPercentage() Obtiene el minimo porcentaje de frecuencia de página a mostrar.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 213 -
Returns: Minimo porcentaje de frecuencia de página.
setMaxPagesPerCluster
public void setMaxPagesPerClustersetMaxPagesPerClustersetMaxPagesPerClustersetMaxPagesPerCluster(java.lang.String pages) Setea la cantidad maxima de páginas por cluster a mostrar. Parameters: pages - Cantidad maxima de páginas por cluster.
getMaxPagesPerCluster
public java.lang.String getMaxPagesPerClustergetMaxPagesPerClustergetMaxPagesPerClustergetMaxPagesPerCluster() Obtiene la cantidad maxima de páginas por cluster a mostrar. Returns: Cantidad maxima de páginas por cluster.
C.24. Class SessionClusterBean
java.lang.Object ar.com.do2.iadh.SessionClusterBeanar.com.do2.iadh.SessionClusterBeanar.com.do2.iadh.SessionClusterBeanar.com.do2.iadh.SessionClusterBean Direct Known Subclasses:
BinarySessionClusterBean, NumericSessionClusterBean
public abstract class SessionClusterBeanSessionClusterBeanSessionClusterBeanSessionClusterBean extends java.lang.Object
Clase utilizada para contabilizar los clusters descubiertos y cargar esta informacion en la base de datos.
Author: Damian Martinelli
Field Summary
protected java.sql.Connection
conn
protected java.lang.String filename

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 214 -
protected java.lang.String project
protected java.sql.PreparedStatement
pstm
protected
java.sql.PreparedStatement pstmDelete
protected java.lang.String type
protected java.lang.String user
Constructor Summary
SessionClusterBean() Contructor encargado de inicializar la conexion con la base de datos y preparar las consultas que se realizaran en ella.
Method Summary
abstract void count(java.lang.String inputFilename) Realiza el conteo de los clusters descubiertos tomando como entrada el archivo donde se encuentra a que cluster pertenece cada sesion.
java.lang.String getCount() Realiza el conteo de los clusters descubiertos, si todos los atributos necesarios han sido seteados, devolviendo la cantidad de sesiones contabilizadas.
java.lang.String getFile() Obtiene el nombre del archivo donde se encuentran las sesiones con el cluster al cual pertenecen.
java.lang.String getProject() Obtiene el nombre del proyecto utilizado.
java.lang.String getType() Obtiene el tipo de clustering utilizado.
java.lang.String getUser() Obtiene el nombre de usuario utilizado.
void setFile(java.lang.String name) Setea el nombre del archivo donde se encuentran las sesiones con el cluster al cual pertenecen.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 215 -
void setProject(java.lang.String projectName) Setea el nombre del proyecto que se utilizara.
void setType(java.lang.String typeClustering) Setea el tipo de clustering que se realizo, cuyo resultado se encuentra en el archivo a procesar.
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.
Methods inherited from class java.lang.Object
clone, equals, finalize, getClass, hashCode, notify, notifyAll, toString, wait, wait, wait
Field Detail
conn
protected java.sql.Connection connconnconnconn
pstm
protected java.sql.PreparedStatement pstmpstmpstmpstm
pstmDelete
protected java.sql.PreparedStatement pstmDeletepstmDeletepstmDeletepstmDelete
user
protected java.lang.String useruseruseruser
project
protected java.lang.String projectprojectprojectproject
filename
protected java.lang.String filenamefilenamefilenamefilename

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 216 -
type
protected java.lang.String typetypetypetype
Constructor Detail
SessionClusterBean
public SessionClusterBeanSessionClusterBeanSessionClusterBeanSessionClusterBean() throws java.lang.Exception
Contructor encargado de inicializar la conexion con la base de datos y preparar las consultas que se realizaran en ella. Throws: java.lang.Exception
Method Detail
count
public abstract void countcountcountcount(java.lang.String inputFilename) throws java.lang.Exception
Realiza el conteo de los clusters descubiertos tomando como entrada el archivo donde se encuentra a que cluster pertenece cada sesion. Parameters: inputFilename - Nombre del archivo donde se encuentra la informacion de los clusters descubiertos. Throws: java.lang.Exception
getCount
public java.lang.String getCountgetCountgetCountgetCount() throws java.lang.Exception
Realiza el conteo de los clusters descubiertos, si todos los atributos necesarios han sido seteados, devolviendo la cantidad de sesiones contabilizadas. Returns: Cantidad de sesiones contabilizadas. Throws: java.lang.Exception
setFile
public void setFilesetFilesetFilesetFile(java.lang.String name)

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 217 -
throws java.lang.Exception Setea el nombre del archivo donde se encuentran las sesiones con el cluster al cual pertenecen. Parameters: name - Nombre del archivo. Throws: java.lang.Exception
getFile
public java.lang.String getFilegetFilegetFilegetFile() Obtiene el nombre del archivo donde se encuentran las sesiones con el cluster al cual pertenecen. Returns: String Nombre del archivo.
setUser
public void setUsersetUsersetUsersetUser(java.lang.String userName) Setea el nombre de usuario que se utilizara. Parameters: userName - Nombre del usuario.
getUser
public java.lang.String getUsergetUsergetUsergetUser() Obtiene el nombre de usuario utilizado. Returns: Nombre del usuario.
setProject
public void setProjectsetProjectsetProjectsetProject(java.lang.String projectName) Setea el nombre del proyecto que se utilizara. Parameters: projectName - Nombre del proyecto.
getProject
public java.lang.String getProjectgetProjectgetProjectgetProject()

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 218 -
Obtiene el nombre del proyecto utilizado. Returns: Nombre del proyecto.
setType
public void setTypesetTypesetTypesetType(java.lang.String typeClustering) Setea el tipo de clustering que se realizo, cuyo resultado se encuentra en el archivo a procesar. Parameters: typeClustering - Tipo de clustering.
getType
public java.lang.String getTypegetTypegetTypegetType() Obtiene el tipo de clustering utilizado. Returns: Tipo de clustering.
C.25. Class SessionMakerBean
java.lang.Object ar.com.do2.iadh.SessionMakerBeanar.com.do2.iadh.SessionMakerBeanar.com.do2.iadh.SessionMakerBeanar.com.do2.iadh.SessionMakerBean All Implemented Interfaces:
java.io.Serializable
public class SessionMakerBeanSessionMakerBeanSessionMakerBeanSessionMakerBean extends java.lang.Object
implements java.io.Serializable
Clase SessionMakerBean encargada de armar las sesiones a partir de los registros del log almacenados en la tabla log.
Author: Damian Martinelli
See Also: Serialized Form
Constructor Summary

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 219 -
SessionMakerBean() Constructor de la clase SessionMaker, encargada de armar las sesiones a partir de los registros del log almacenados en la tabla log.
Method Summary
java.lang.String getMinPageFrequency() Obtiene la frecuencia minima de página.
java.lang.String getMinPagesInSession() Obtiene la cantidad minima de páginas en cada sesion.
java.lang.String getProject() Obtiene el nombre del proyecto utilizado.
java.lang.String getSessions() Si toda la informacion necesaria esta seteada, arma todas las sesiones para un pryecto de un usuario.
java.lang.String getTimeoutSession() Obtiene el timeout de sesion.
java.lang.String getUser() Obtiene el nombre de usuario utilizado.
static void main(java.lang.String[] args)
void make() Arma las sesiones a partir de los registros de la tabla log.
void setMinPageFrequency(java.lang.String frequency) Setea la frecuencia minima de página.
void setMinPagesInSession(java.lang.String pages) Setea la cantidad minima de páginas en cada sesion.
void setProject(java.lang.String projectName) Setea el nombre del proyecto que se utilizara.
void setTimeoutSession(java.lang.String timeout) Setea el timeout de sesion.
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.
Methods inherited from class java.lang.Object
clone, equals, finalize, getClass, hashCode, notify, notifyAll, toString, wait, wait, wait

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 220 -
Constructor Detail
SessionMakerBean
public SessionMakerBeanSessionMakerBeanSessionMakerBeanSessionMakerBean() throws java.lang.Exception
Constructor de la clase SessionMaker, encargada de armar las sesiones a partir de los registros del log almacenados en la tabla log. Throws: java.lang.Exception
Method Detail
make
public void makemakemakemake()
throws java.lang.Exception Arma las sesiones a partir de los registros de la tabla log. Throws: java.lang.Exception
getSessions
public java.lang.String getSessionsgetSessionsgetSessionsgetSessions()
throws java.lang.Exception Si toda la informacion necesaria esta seteada, arma todas las sesiones para un pryecto de un usuario. Devuelve la cantidad de sesiones distintas generadas. Returns: Cantidad de sesiones distintas generadas. Throws: java.lang.Exception
setUser
public void setUsersetUsersetUsersetUser(java.lang.String userName) throws java.lang.Exception
Setea el nombre de usuario que se utilizara. Parameters: userName - Nombre del usuario. Throws: java.lang.Exception

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 221 -
getUser
public java.lang.String getUsergetUsergetUsergetUser() Obtiene el nombre de usuario utilizado. Returns: Nombre del usuario.
setProject
public void setProjectsetProjectsetProjectsetProject(java.lang.String projectName)
throws java.lang.Exception Setea el nombre del proyecto que se utilizara. Parameters: projectName - Nombre del proyecto. Throws: java.lang.Exception
getProject
public java.lang.String getProjectgetProjectgetProjectgetProject() Obtiene el nombre del proyecto utilizado. Returns: Nombre del proyecto.
setMinPagesInSession
public void setMinPagesInSessionsetMinPagesInSessionsetMinPagesInSessionsetMinPagesInSession(java.lang.String pages) Setea la cantidad minima de páginas en cada sesion. Parameters: pages - Cantidad minima de páginas.
getMinPagesInSession
public java.lang.String getMinPagesInSessiongetMinPagesInSessiongetMinPagesInSessiongetMinPagesInSession() Obtiene la cantidad minima de páginas en cada sesion. Returns: Cantidad minima de páginas.
setTimeoutSession

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 222 -
public void setTimeoutSessionsetTimeoutSessionsetTimeoutSessionsetTimeoutSession(java.lang.String timeout) Setea el timeout de sesion. Parameters: timeout - Timeout de sesion.
getTimeoutSession
public java.lang.String getTimeoutSessiongetTimeoutSessiongetTimeoutSessiongetTimeoutSession() Obtiene el timeout de sesion. Returns: Timeout de sesion.
setMinPageFrequency
public void setMinPageFrequencysetMinPageFrequencysetMinPageFrequencysetMinPageFrequency(java.lang.String frequency) Setea la frecuencia minima de página. Parameters: frequency - Frecuencia minima de página.
getMinPageFrequency
public java.lang.String getMingetMingetMingetMinPageFrequencyPageFrequencyPageFrequencyPageFrequency() Obtiene la frecuencia minima de página. Returns: Frecuencia minima de página.
main
public static void mainmainmainmain(java.lang.String[] args) throws java.lang.Exception
Throws: java.lang.Exception
C.26. Class SessionSaver
java.lang.Object ar.com.do2.iadh.SessionSaverar.com.do2.iadh.SessionSaverar.com.do2.iadh.SessionSaverar.com.do2.iadh.SessionSaver

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 223 -
public class SessionSaverSessionSaverSessionSaverSessionSaver extends java.lang.Object
Clase SessionSaver encargada de ir armando las sesiones y guardarlas en la tabla session.
Author: Damian Martinelli
Constructor Summary
SessionSaver() Constructor de la clase SessionSaver, encargada de ir armando las sesiones y guardarlas en la tabla session.
Method Summary
int getMinPagesInSession() Obtiene la cantidad minima de páginas en cada sesion.
java.lang.String getProject() Obtiene el nombre del proyecto utilizado.
int getSessionsCount() Obtiene la cantidad de sesiones guardadas.
long getTimeoutSession() Obtiene el timeout de sesion.
java.lang.String getUser() Obtiene el nombre de usuario utilizado.
static void main(java.lang.String[] args)
void save(java.lang.String IP, java.lang.String authuser, java.lang.String page,
java.lang.String timestamp) Graba la informacion de un registro de log, teniendo en cuenta si pertenece a la misma sesion o a una nueva.
void setMinPagesInSession(int pages) Setea la cantidad minima de páginas en cada sesion.
void setProject(java.lang.String projectName) Setea el nombre del proyecto que se utilizara.
void setTimeoutSession(long timeout) Setea el timeout de sesion.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 224 -
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.
Methods inherited from class java.lang.Object
clone, equals, finalize, getClass, hashCode, notify, notifyAll, toString, wait, wait, wait
Constructor Detail
SessionSaver
public SessionSaverSessionSaverSessionSaverSessionSaver() throws java.lang.Exception
Constructor de la clase SessionSaver, encargada de ir armando las sesiones y guardarlas en la tabla session. Throws: java.lang.Exception
Method Detail
save
public void savesavesavesave(java.lang.String IP, java.lang.String authuser, java.lang.String page, java.lang.String timestamp)
throws java.lang.Exception Graba la informacion de un registro de log, teniendo en cuenta si pertenece a la misma sesion o a una nueva. Parameters: IP - Direccion IP del registro de log.
authuser - Authuser del registro de log.
page - Página solicitada en el registro de log.
timestamp - Marca de tiempo del registro de log. Throws: java.lang.Exception
setUser
public void setUsersetUsersetUsersetUser(java.lang.String userName) throws java.lang.Exception
Setea el nombre de usuario que se utilizara.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 225 -
Parameters: userName - Nombre del usuario. Throws: java.lang.Exception
getUser
public java.lang.String getUsergetUsergetUsergetUser() Obtiene el nombre de usuario utilizado. Returns: Nombre del usuario.
setProject
public void setProjectsetProjectsetProjectsetProject(java.lang.String projectName) throws java.lang.Exception
Setea el nombre del proyecto que se utilizara. Parameters: projectName - Nombre del proyecto. Throws: java.lang.Exception
getProject
public java.lang.String getProjectgetProjectgetProjectgetProject() Obtiene el nombre del proyecto utilizado. Returns: Nombre del proyecto.
getSessionsCount
public int getSessionsCountgetSessionsCountgetSessionsCountgetSessionsCount() Obtiene la cantidad de sesiones guardadas. Returns: Cantidad de sesiones.
setTimeoutSession
public void setTimeoutSessionsetTimeoutSessionsetTimeoutSessionsetTimeoutSession(long timeout) Setea el timeout de sesion.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 226 -
Parameters: timeout - Timeout de sesion.
getTimeoutSession
public long getTimeoutSessiongetTimeoutSessiongetTimeoutSessiongetTimeoutSession() Obtiene el timeout de sesion. Returns: Timeout de sesion.
setMinPagesInSession
public void setMinPagesInSessionsetMinPagesInSessionsetMinPagesInSessionsetMinPagesInSession(int pages) Setea la cantidad minima de páginas en cada sesion. Parameters: pages - Cantidad minima de páginas.
getMinPagesInSession
public int getMinPagesInSessiongetMinPagesInSessiongetMinPagesInSessiongetMinPagesInSession() Obtiene la cantidad minima de páginas en cada sesion. Returns: Cantidad minima de páginas.
main
public static void mainmainmainmain(java.lang.String[] args) throws java.lang.Exception
Throws: java.lang.Exception
C.27. Class SessionsClusterViewBean
java.lang.Object ar.com.do2.iadh.SessionsClusterViewBeanar.com.do2.iadh.SessionsClusterViewBeanar.com.do2.iadh.SessionsClusterViewBeanar.com.do2.iadh.SessionsClusterViewBean
public class SessionsClusterViewBeaSessionsClusterViewBeaSessionsClusterViewBeaSessionsClusterViewBeannnn extends java.lang.Object

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 227 -
Clase encargada de obtener el detalle de las sesiones y a que cluster pertenece cada una.
Author: Damian Martinelli
Field Summary
protected java.sql.Connection
conn
protected java.sql.PreparedStatement
pstm
protected int sessionsPerPage
Constructor Summary
SessionsClusterViewBean() Contructor de la clase SessionsClusterViewBean.
Method Summary
java.lang.String getCurrentSession() Obtiene el identificador de sesion actual.
java.lang.String getNextCluster() Obtiene el numero de cluster de la sesion actual.
java.lang.String getNextSequencePages() Obtiene la secuencia de páginas accedidas en la sesion actual.
java.lang.String getNextSession() Obtiene el identificador de la proxima sesion.
java.lang.String getProject() Obtiene el nombre del proyecto utilizado.
java.lang.String getSessionsPerPage() Obtiene la cantidad de sesiones a mostrar por página.
java.lang.String getType() Obtiene el tipo de clusters que se estan analizando.
java.lang.String getUser() Obtiene el nombre de usuario utilizado.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 228 -
void goFirstSession() Se situa en la primera sesion.
boolean hasNextSession() Indica se existen mas sesiones.
void setCurrentSession(java.lang.String session) Setea el identificador de sesion actual.
void setProject(java.lang.String projectName) Setea el nombre del proyecto que se utilizara.
void setSessionsPerPage(java.lang.String sessions) Setea la cantidad de sesiones a mostrar por página.
void setType(java.lang.String typeClustering) Setea el tipo de clusters que se estan analizando.
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.
Methods inherited from class java.lang.Object
clone, equals, finalize, getClass, hashCode, notify, notifyAll, toString, wait, wait, wait
Field Detail
conn
protected java.sql.Connection connconnconnconn
pstm
protected java.sql.PreparedStatement pstmpstmpstmpstm
sessionsPerPage
protected int sessionsPerPagesessionsPerPagesessionsPerPagesessionsPerPage
Constructor Detail
SessionsClusterViewBean
public SessionsClusterViewBeanSessionsClusterViewBeanSessionsClusterViewBeanSessionsClusterViewBean() throws java.lang.Exception

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 229 -
Contructor de la clase SessionsClusterViewBean. Throws: java.lang.Exception
Method Detail
goFirstSession
public void goFirstSessiongoFirstSessiongoFirstSessiongoFirstSession() throws java.lang.Exception
Se situa en la primera sesion. Throws: java.lang.Exception
hasNextSession
public boolean hasNextSessionhasNextSessionhasNextSessionhasNextSession() Indica se existen mas sesiones. Returns: true si existen mas sesiones, false sino.
getNextSession
public java.lang.String getNextSessiongetNextSessiongetNextSessiongetNextSession() Obtiene el identificador de la proxima sesion. Returns: Identificador de sesion.
getNextCluster
public java.lang.String getNextClustergetNextClustergetNextClustergetNextCluster() Obtiene el numero de cluster de la sesion actual. Returns: Numero de cluster.
getNextSequencePages
public java.lang.String getNextSequencePagesgetNextSequencePagesgetNextSequencePagesgetNextSequencePages() Obtiene la secuencia de páginas accedidas en la sesion actual. Returns: Secuencia de páginas.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 230 -
setUser
public void setUsersetUsersetUsersetUser(java.lang.String userName) Setea el nombre de usuario que se utilizara. Parameters: userName - Nombre del usuario.
getUser
public java.lang.String getUsergetUsergetUsergetUser() Obtiene el nombre de usuario utilizado. Returns: Nombre del usuario.
setProject
public void setProjectsetProjectsetProjectsetProject(java.lang.String projectName) Setea el nombre del proyecto que se utilizara. Parameters: projectName - Nombre del proyecto.
getProject
public java.lang.String getProjectgetProjectgetProjectgetProject() Obtiene el nombre del proyecto utilizado. Returns: Nombre del proyecto.
setType
public void setTypesetTypesetTypesetType(java.lang.String typeClustering) Setea el tipo de clusters que se estan analizando. Parameters: typeClustering - Tipo de clusters.
getType
public java.lang.String getTypegetTypegetTypegetType() Obtiene el tipo de clusters que se estan analizando. Returns: Tipo de clusters.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 231 -
setSessionsPerPage
public void setSessionsPerPagesetSessionsPerPagesetSessionsPerPagesetSessionsPerPage(java.lang.String sessions) Setea la cantidad de sesiones a mostrar por página. Parameters: sessions - Cantidad de sesiones por página.
getSessionsPerPage
public java.lang.String getSessionsPerPagegetSessionsPerPagegetSessionsPerPagegetSessionsPerPage() Obtiene la cantidad de sesiones a mostrar por página. Returns: Cantidad de sesiones por página.
setCurrentSession
public void setCurrsetCurrsetCurrsetCurrentSessionentSessionentSessionentSession(java.lang.String session) Setea el identificador de sesion actual. Parameters: session - Identificador de la sesion.
getCurrentSession
public java.lang.String getCurrentSessiongetCurrentSessiongetCurrentSessiongetCurrentSession() Obtiene el identificador de sesion actual. Returns: Identificador de la sesion.
C.28. Class SOMBean
java.lang.Object ar.com.do2.iadh.SOMBeanar.com.do2.iadh.SOMBeanar.com.do2.iadh.SOMBeanar.com.do2.iadh.SOMBean All Implemented Interfaces:
java.io.Serializable, java.util.EventListener, org.joone.engine.NeuralNetListener
public class SOMBeanSOMBeanSOMBeanSOMBean
extends java.lang.Object

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 232 -
implements java.io.Serializable, org.joone.engine.NeuralNetListener
Clase SOMBean encargada de clusterizar las sesiones de usuarios utilizando la red neuronal SOM.
Author: Damian Martinelli
See Also: Serialized Form
Constructor Summary
SOMBean() Contructor por defecto.
SOMBean(java.lang.String input, java.lang.String output, int dim) Contructor de la clase SOMBean, encargada de clusterizar las sesiones de usuarios.
Method Summary
void cicleTerminated(org.joone.engine.NeuralNetEvent e) Metodo que se ejecuta cada vez que termina un ciclo de entrenamiento.
void errorChanged(org.joone.engine.NeuralNetEvent e) Metodo que se ejecuta cada vez que cambia el error.
java.lang.String getClusters() Realiza la clusterizacion de los usuarios.
java.lang.String getDim() Obtiene la dimension del mapa de clusterizacion.
java.lang.String getInput() Obtiene el nombre del archivo de entrada.
java.lang.String getOutput() Obtiene el nombre del archivo de salida.
java.lang.String getTrainingCicles() Obtiene la cantidad de ciclos de entrenamiento a realizar.
static void main(java.lang.String[] args)
void netStarted(org.joone.engine.NeuralNetEvent e) Metodo que se ejecuta cuando comienza el entrenamiento de la red.
void netStopped(org.joone.engine.NeuralNetEvent e)

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 233 -
Metodo que se ejecuta cuando termina el entrenamiento de la red.
void netStoppedError(org.joone.engine.NeuralNetEvent e, java.lang.String error) Metodo que se ejecuta cuando termina el entrenamiento de la red, debido a un error.
void save(java.lang.String fileName) Graba la red en el archivo indicado.
void setDim(java.lang.String dim) Setea la dimension del mapa de clusterizacion.
void setInput(java.lang.String file) Setea el nombre del archivo de entrada.
void setOutput(java.lang.String file) Setea el nombre del archivo de salida.
void setTrainingCicles(java.lang.String cicles) Setea la cantidad de ciclos de entrenamiento a realizar.
void train (int cicles) Entrena la red utilizando los patrones de entrada.
Methods inherited from class java.lang.Object
clone, equals, finalize, getClass, hashCode, notify, notifyAll, toString, wait, wait, wait
Constructor Detail
SOMBean
public SOMBeanSOMBeanSOMBeanSOMBean() Contructor por defecto.
SOMBean
public SOMBeanSOMBeanSOMBeanSOMBean(java.lang.String input, java.lang.String output, int dim) throws java.lang.Exception
Contructor de la clase SOMBean, encargada de clusterizar las sesiones de usuarios. Recibe los archivos de entrada, de salida y la dimension de la clusterizacion (dim X dim). Parameters: input - Nombre el archivo de entrada.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 234 -
output - Nombre del archivo de salida.
dim - Dimension del mapa de clusterizacion (dim x dim). Throws: java.lang.Exception
Method Detail
setInput
public void setInputsetInputsetInputsetInput(java.lang.String file) Setea el nombre del archivo de entrada. Parameters: file - Nombre del archivo.
getInput
public java.lang.String getInputgetInputgetInputgetInput() Obtiene el nombre del archivo de entrada. Returns: Nombre del archivo.
setOutput
public void setOutputsetOutputsetOutputsetOutput(java.lang.String file) Setea el nombre del archivo de salida. Parameters: file - Nombre del archivo.
getOutput
public java.lang.String getOutputgetOutputgetOutputgetOutput() Obtiene el nombre del archivo de salida. Returns: Nombre del archivo.
setDim
public void setDimsetDimsetDimsetDim(java.lang.String dim) Setea la dimension del mapa de clusterizacion. Parameters: dim - Dimension del mapa de clusterizacion.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 235 -
getDim
public java.lang.String getDimgetDimgetDimgetDim() Obtiene la dimension del mapa de clusterizacion. Returns: Dimension del mapa de clusterizacion.
setTrainingCicles
public void setTrainingCiclessetTrainingCiclessetTrainingCiclessetTrainingCicles(java.lang.String cicles) Setea la cantidad de ciclos de entrenamiento a realizar. Parameters: cicles - Cantidad de ciclos de entrenamiento.
getTrainingCicles
public java.lang.String getTrainingCiclesgetTrainingCiclesgetTrainingCiclesgetTrainingCicles() Obtiene la cantidad de ciclos de entrenamiento a realizar. Returns: Cantidad de ciclos de entrenamiento.
getClusters
public java.lang.String getClustersgetClustersgetClustersgetClusters() Realiza la clusterizacion de los usuarios. Returns: Mensaje indicando el exito o el error de la operacion.
train
public void traintraintraintrain(int cicles) Entrena la red utilizando los patrones de entrada. Parameters: cicles - Cantidad de ciclos de entrenamiento.
cicleTerminated
public void cicleTerminatedcicleTerminatedcicleTerminatedcicleTerminated(org.joone.engine.NeuralNetEvent e) Metodo que se ejecuta cada vez que termina un ciclo de entrenamiento. Specified by: cicleTerminated in interface org.joone.engine.NeuralNetListener

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 236 -
Parameters: e - Evento de la red neuronal.
errorChanged
public void errorChangederrorChangederrorChangederrorChanged(org.joone.engine.NeuralNetEvent e) Metodo que se ejecuta cada vez que cambia el error. Specified by: errorChanged in interface org.joone.engine.NeuralNetListener Parameters: e - Evento de la red neuronal.
netStarted
public void netStartednetStartednetStartednetStarted(org.joone.engine.NeuralNetEvent e) Metodo que se ejecuta cuando comienza el entrenamiento de la red. Specified by: netStarted in interface org.joone.engine.NeuralNetListener Parameters: e - Evento de la red neuronal.
netStopped
public void netStoppednetStoppednetStoppednetStopped(org.joone.engine.NeuralNetEvent e) Metodo que se ejecuta cuando termina el entrenamiento de la red. Specified by: netStopped in interface org.joone.engine.NeuralNetListener Parameters: e - Evento de la red neuronal.
netStoppedError
public void netStoppedErrornetStoppedErrornetStoppedErrornetStoppedError(org.joone.engine.NeuralNetEvent e, java.lang.String error)
Metodo que se ejecuta cuando termina el entrenamiento de la red, debido a un error. Specified by: netStoppedError in interface org.joone.engine.NeuralNetListener Parameters: e - Evento de la red neuronal.
error - Error.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 237 -
save
public void savesavesavesave(java.lang.String fileName) Graba la red en el archivo indicado. Parameters: fileName - Nombre del archivo.
main
public static void mainmainmainmain(java.lang.String[] args)
C.29. Class UserBean
java.lang.Object
ar.com.do2.iadh.UserBeanar.com.do2.iadh.UserBeanar.com.do2.iadh.UserBeanar.com.do2.iadh.UserBean
public class UserBeanUserBeanUserBeanUserBean extends java.lang.Object
Clase que se encarga del manejo de la informacion de un usuario y sus proyectos.
Author: Damian Martinelli
Constructor Summary
UserBean() Constructor de la clase UserBean.
Method Summary
java.lang.String getLogCount() Calcula la cantidad de registros de log cargados en el proyecto actual.
java.lang.String getNextDescription() Obtiene la descripcion del proyecto siguiente.
java.lang.String getNextProject() Obtiene el nombre del siguiente proyecto.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 238 -
java.lang.String getProject() Obtiene el nombre del proyecto utilizado.
java.lang.String getProjects() Obtiene todos los proyectos del usuario.
java.lang.String getSessionCount() Obtiene la cantidad de sesiones en el proyecto actual.
java.lang.String getUser() Obtiene el nombre de usuario utilizado.
void goFirstProject() Se sitia en el primer proyecto del usuario.
boolean hasNextProject() Indica si existen mas proyectos.
boolean isSetProject() Indica si existe seteado un proyecto.
void setProject(java.lang.String projectName) Setea el nombre del proyecto que se utilizara.
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.
void unsetProject() Des-setea el proyecto actual.
Methods inherited from class java.lang.Object
clone, equals, finalize, getClass, hashCode, notify, notifyAll, toString, wait, wait, wait
Constructor Detail
UserBean
public UserBeanUserBeanUserBeanUserBean() throws java.lang.Exception
Constructor de la clase UserBean. Throws: java.lang.Exception
Method Detail
setUser

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 239 -
public void setUsersetUsersetUsersetUser(java.lang.String userName) Setea el nombre de usuario que se utilizara. Parameters: userName - Nombre del usuario.
getUser
public java.lang.String getUsergetUsergetUsergetUser() Obtiene el nombre de usuario utilizado. Returns: Nombre del usuario.
setProject
public void setProjectsetProjectsetProjectsetProject(java.lang.String projectName) Setea el nombre del proyecto que se utilizara. Parameters: projectName - Nombre del proyecto.
getProject
public java.lang.String getProjectgetProjectgetProjectgetProject() Obtiene el nombre del proyecto utilizado. Returns: Nombre del proyecto.
isSetProject
public boolean isSetProjectisSetProjectisSetProjectisSetProject() Indica si existe seteado un proyecto. Returns: true si esta seteado algun proyectom false sino.
unsetProject
public void unsetProjectunsetProjectunsetProjectunsetProject() Des-setea el proyecto actual.
getProjects

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 240 -
public java.lang.String getProjectsgetProjectsgetProjectsgetProjects() Obtiene todos los proyectos del usuario. Returns: El nombre de todos los proyectos del usuario separados por un guion.
goFirstProject
public void goFirstProjectgoFirstProjectgoFirstProjectgoFirstProject() Se sitia en el primer proyecto del usuario.
hasNextProject
public boolean hasNextProjecthasNextProjecthasNextProjecthasNextProject() Indica si existen mas proyectos. Returns: true si existen mas proyectos, false sino.
getNextProject
public java.lang.String getNextProjectgetNextProjectgetNextProjectgetNextProject() Obtiene el nombre del siguiente proyecto. Returns: Nombre del proyecto.
getNextDescription
public java.lang.String getNextDegetNextDegetNextDegetNextDescriptionscriptionscriptionscription() Obtiene la descripcion del proyecto siguiente. Returns: Descripcion del proyecto.
getLogCount
public java.lang.String getLogCountgetLogCountgetLogCountgetLogCount() Calcula la cantidad de registros de log cargados en el proyecto actual. Returns: Cantidad de registros.
getSessionCount

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 241 -
public java.lang.String getSessionCountgetSessionCountgetSessionCountgetSessionCount() Obtiene la cantidad de sesiones en el proyecto actual. Returns: Cantidad de sesiones.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 242 -
D. Apéndice IV: Desarrollo de la Solución – Métrica Versión 3
Para el desarrollo de la solución se utilizó la metodología de desarrollo de sistemas denominada Metodología Métrica Versión 3 [Métrica Versión 3]. A continuación se detallan todas las actividades de la metodología realizadas para el desarrollo de la herramienta que implementa la solución propuesta en esta tesis.
D.1. Planificación de Sistemas de Información..................................................................246
D.1.1. Actividad PSI 1: Inicio del Plan de Sistemas de Información.............................246 D.1.1.1. Tarea PSI 1.1: Análisis de la Necesidad.......................................................246 D.1.1.2. Tarea PSI 1.2: Identificación del Alcance ....................................................246 D.1.1.3. Tarea PSI 1.3: Determinación de Responsables ...........................................246
D.1.2. Actividad PSI 2: Definición y Organización del Plan.........................................246 D.1.2.1. Tarea PSI 2.1: Especificación del Ámbito y Alcance...................................246 D.1.2.2. Tarea PSI 2.2: Definición del Plan de Trabajo .............................................247 D.1.2.3. Tarea PSI 2.3: Comunicación del Plan de Trabajo.......................................248
D.1.3. Actividad PSI 7: Definición de la Arquitectura Tecnológica..............................248 D.1.3.1. Tarea PSI 7.1: Identificación de las Necesidades de Infraestructura Tecnológica ................................................................................................................248 D.1.3.2. Tarea PSI 7.2: Selección de la Arquitectura Tecnológica ............................249
D.1.4. Actividad PSI 8: Definición del Plan de Acción .................................................249 D.1.5. Actividad PSI 9: Revisión y Aprobación del PSI................................................250
D.1.5.1. Tarea PSI 9.1: Convocatoria de la Presentación...........................................250 D.1.5.2. Tarea PSI 9.2: Aprobación del PSI...............................................................250
D.2. Estudio de Viabilidad del Sistema..............................................................................250 D.2.1. Actividad EVS 1: Establecimiento del Alcance del Sistema...............................250
D.2.1.1. Tarea EVS 1.1: Estudio de la Solicitud ........................................................250 D.2.1.2. Tarea EVS 1.2: Identificación del Alcance del Sistema...............................251
D.2.2. Actividad EVS 2: Estudio de la Situación Actual ...............................................251 D.2.2.1. Tarea EVS 2.1: Valoración del Estudio de la Situación Actual ...................251
D.2.3. Actividad EVS 3: Definición de Requisitos del Sistema.....................................251 D.2.3.1. Tarea EVS 3.1: Identificación de Requisitos................................................251
D.2.4. Actividad EVS 4: Estudio de Alternativas de Solución ......................................251 D.2.4.1. Tarea EVS 4.1: Preselección de Alternativas de Solución...........................251 D.2.4.2. Tarea EVS 4.2: Descripción de las Alternativas de Solución ......................252
D.2.5. Actividad EVS 5: Valoración de las Alternativas ...............................................253 D.2.5.1. Tarea EVS 5.1: Estudio de la Inversión .......................................................253 D.2.5.2. Tarea EVS 5.2: Planificación de Alternativas ..............................................254
D.2.6. Actividad EVS 6: Selección de la Solución ........................................................255 D.2.6.1. Tarea EVS 6.1: Evaluación de las Alternativas y Selección ........................255 D.2.6.2. Tarea 6.2: Aprobación de la Solución ..........................................................256
D.3. Análisis del Sistema de Información ..........................................................................256 D.3.1. Actividad ASI 1: Definición del Sistema ............................................................256
D.3.1.1. Tarea ASI 1.1: Determinación del Alcance del Sistema ..............................256

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 243 -
D.3.1.2. Tarea ASI 1.2: Identificación del Entorno Tecnológico...............................257 D.3.1.3. Tarea ASI 1.3: Especificación de Estándares y Normas ..............................257
D.3.2. Actividad ASI 2: Establecimiento de Requisitos ................................................258 D.3.2.1. Tarea ASI 2.1: Obtención de Requisitos ......................................................258 D.3.2.2. Tarea ASI 2.2: Especificación de Casos de Uso ..........................................260
D.3.3. Actividad ASI 3: Análisis de los Casos de Uso...................................................267 D.3.3.1. Tarea ASI 3.1: Identificación de Clases Asociadas a un Caso de Uso.........267 D.3.3.2. Tarea ASI 3.2: Descripción de la Interacción de Objetos ............................268
D.3.4. Actividad ASI 4: Análisis de Clases....................................................................268 D.3.4.1. Tarea ASI 4.1: Identificación de Responsabilidades y Atributos.................269
D.3.5. Actividad ASI 5: Definición de Interfaces de Usuario........................................270 D.3.5.1. Tarea ASI 5.1: Especificación de Principios Generales de la Interfaz .........270 D.3.5.2. Tarea ASI 5.2: Especificación de Formatos Individuales de la Interfaz de Pantalla .......................................................................................................................271 D.3.5.3. Tarea ASI 5.3: Especificación del Comportamiento Dinámico de la Interfaz....................................................................................................................................274 D.3.5.4. Tarea ASI 5.4: Especificación de Formatos de Impresión ...........................274
D.3.6. Actividad ASI 6: Análisis de Consistencia y Especificación de Requisitos .......274 D.3.6.1. Tarea ASI 6.1: Verificación y Validación de los Modelos...........................274 D.3.6.2. Tarea ASI 6.2: Elaboración de la Especificación de Requisitos Software (ERS) ..........................................................................................................................274
D.3.7. Actividad ASI 7: Especificación del Plan de Pruebas.........................................276 D.3.7.1. Tarea ASI 7.1: Definición del Alcance de las Pruebas.................................276 D.3.7.2. Tarea ASI 7.2: Definición de Requisitos del Entorno de Pruebas................277 D.3.7.3. Tarea ASI 7.3: Definición de las Pruebas de Aceptación del Sistema .........277
D.3.8. Actividad ASI 8: Aprobación del Análisis del Sistema de Información.............277 D.3.8.1. Tarea ASI 8.1: Presentación y Aprobación del Análisis del Sistema de Información ................................................................................................................277
D.4. Diseño del Sistema de Información............................................................................277 D.4.1. Actividad DSI 1: Definición de la Arquitectura del Sistema ..............................277
D.4.1.1. Tarea DSI 1.1: Definición de Niveles de Arquitectura.................................277 D.4.1.2. Tarea DSI 1.2: Identificación de Requisitos de Diseño y Construcción ......278 D.4.1.3. Tarea DSI 1.3: Especificación de Excepciones ............................................278 D.4.1.4. Tarea DSI 1.4: Especificación de Estándares y Normas de Diseño y Construcción...............................................................................................................278 D.4.1.5. Tarea DSI 1.5: Identificación de Subsistemas de Diseño.............................279 D.4.1.6. Tarea DSI 1.6: Especificación del Entorno Tecnológico .............................279 D.4.1.7. Tarea DSI 1.7: Especificación de Requisitos de Operación y Seguridad.....279
D.4.2. Actividad DSI 2: Diseño de la Arquitectura de Soporte .....................................279 D.4.2.1. Tarea DSI 2.1: Diseño de Subsistemas de Soporte.......................................279 D.4.2.2. Tarea DSI 2.2: Identificación de Mecanismos Genéricos de Diseño ...........279
D.4.3. Actividad DSI 3: Diseño de Casos de Uso Reales ..............................................280 D.4.3.1. Tarea DSI 3.1: Identificación de Clases Asociadas a un Caso de Uso.........280 D.4.3.2. Tarea DSI 3.2: Diseño de la Realización de los Casos de Uso ....................285 D.4.3.3. Tarea DSI 3.3: Revisión de la Interfaz de Usuario.......................................295 D.4.3.4. Tarea DSI 3.4: Revisión de Subsistemas de Diseño e Interfaces .................305
D.4.4. Actividad DSI 4: Diseño de Clases .....................................................................305 D.4.4.1. Tarea DSI 4.1: Identificación de Clases Adicionales ...................................305

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 244 -
D.4.4.2. Tarea DSI 4.2: Identificación de Atributos de las Clases.............................306 D.4.4.3. Tarea DSI 4.3: Identificación de Operaciones de las Clases y Descripción de sus Métodos ................................................................................................................317 D.4.4.4. Tarea DSI 4.4: Diseño de la Jerarquía ..........................................................344 D.4.4.5. Tarea DSI 4.5: Especificación de Necesidades de Migración y Carga Inicial de Datos ......................................................................................................................345
D.4.5. Actividad DSI 5: Diseño Físico de Datos............................................................345 D.4.5.1. Tarea DSI 5.1: Diseño del Modelo Físico de Datos .....................................345 D.4.5.2. Tarea DSI 5.2: Especificación de los Caminos de Acceso a los Datos ........346 D.4.5.3. Tarea DSI 5.3: Optimización del Modelo Físico de Datos...........................351 D.4.5.4. Tarea DSI 5.4: Especificación de la Distribución de Datos .........................351
D.4.6. Actividad DSI 6: Verificación y Aceptación de la Arquitectura del Sistema .....351 D.4.6.1. Tarea DSI 6.1: Verificación de las Especificaciones de Diseño ..................351 D.4.6.2. Tarea DSI 6.2: Análisis de Consistencia de las Especificaciones de Diseño351 D.4.6.3. Tarea DSI 6.3: Aceptación de la Arquitectura del Sistema..........................351
D.4.7. Actividad DSI 7: Generación de Especificaciones de Construcción...................351 D.4.7.1. Tarea DSI 7.1: Especificación del Entorno de Construcción .......................351 D.4.7.2. Tarea DSI 7.2: Definición de Componentes y Subsistemas de Construcción....................................................................................................................................351 D.4.7.3. Tarea DSI 7.3: Elaboración de Especificaciones de Construcción ..............352 D.4.7.4. Tarea DSI 7.4: Elaboración de Especificaciones del Modelo Físico de Datos....................................................................................................................................352
D.4.8. Actividad DSI 8: Especificación Técnica del Plan de Pruebas ...........................355 D.4.8.1. Tarea DSI 8.1: Especificación del Entorno de Pruebas................................355 D.4.8.2. Tarea DSI 8.2: Especificación Técnica de Niveles de Prueba......................355 D.4.8.3. Tarea DSI 8.3: Revisión de la Planificación de Pruebas ..............................355
D.4.9. Actividad DSI 9: Establecimiento de Requisitos de Implantación......................355 D.4.9.1. Tarea DSI 9.1: Especificación de Requisitos de Documentación de Usuario....................................................................................................................................355 D.4.9.2. Tarea DSI 9.2: Especificación de Requisitos de Implantación ....................355
D.4.10. Actividad DSI 10: Aprobación del Diseño del Sistema de Información...........356 D.4.10.1. Tarea DSI 10.1: Presentación y Aprobación del Diseño del Sistema de Información ................................................................................................................356
D.5. Construcción del Sistema de Información..................................................................358 D.5.1. Actividad CSI 1: Preparación del Entorno de Generación y Construcción.........358
D.5.1.1. Tarea CSI 1.1: Implantación de la Base de Datos Física o Ficheros............358 D.5.1.2. Tarea CSI 1.2: Preparación del Entorno de Construcción............................358
D.5.2. Actividad CSI 2: Generación del Código de los Componentes y Procedimientos........................................................................................................................................358
D.5.2.1. Tarea CSI 2.1: Generación del Código de Componentes.............................358 D.5.2.2. Tarea CSI 2.2: Generación del Código de los Procedimientos de Operación y Seguridad....................................................................................................................358
D.5.3. Actividad CSI 3: Ejecución de las Pruebas Unitarias..........................................358 D.5.3.1. Tarea CSI 3.1: Preparación del Entorno de las Pruebas ...............................358 D.5.3.2. Tarea CSI 3.2: Realización y Evaluación de las Pruebas Unitarias .............359
D.5.4. Actividad CSI 4: Ejecución de las Pruebas de Integración y del Sistema...........359 D.5.4.1. Tarea CSI 4.1: Preparación del Entorno de las Pruebas de Integración y del Sistema .......................................................................................................................359

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 245 -
D.5.4.2. Tarea CSI 4.2: Realización de las Pruebas de Integración y del Sistema.....359 D.5.4.3. Tarea CSI 4.3: Evaluación del Resultado de las Pruebas de Integración y del Sistema .......................................................................................................................362
D.5.5. Actividad CSI 5: Elaboración de los Manuales de Usuario ................................362 D.5.5.1. Tarea CSI 5.1: Elaboración de los Manuales de Usuario .............................362
D.5.6. Actividad CSI 6: Aprobación del Sistema de Información .................................362 D.5.6.1. Tarea CSI 6.1: Presentación y Aprobación del Sistema de Información .....362

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 246 -
D.1. Planificación de Sistemas de Información
El Plan de Sistemas de Información tiene como objetivo la obtención de un marco de referencia para el desarrollo de sistemas de información que responda a los objetivos estratégicos de la organización.
D.1.1. Actividad PSI 1: Inicio del Plan de Sistemas de Información
D.1.1.1. Tarea PSI 1.1: Análisis de la Necesidad
El presente plan de Sistemas de Información tiene dos objetivo principales, permitir al tesista obtener el título de Ingeniero en Informática y construir una herramienta que permita experimentar la solución propuesta en esta tesis, de modo de poder verificar la efectividad de la misma y contrastarla con soluciones ya existentes al mismo problema.
D.1.1.2. Tarea PSI 1.2: Identificación del Alcance
El presente sistema se basa en el análisis realizado en una empresa que se dedica a la venta de temas musicales por medio de Internet.
El factor crítico de éxito a considerar es lograr obtener mediante la red neuronal SOM grupos de usuarios que posean más información sobre su comportamiento que los obtenidos mediante el algoritmo K-Means.
D.1.1.3. Tarea PSI 1.3: Determinación de Responsables
Debido a las particularidades de este desarrollo, los responsables son las personas implicadas en esta tesis. El tesista, el Sr. Damián Martinelli, es el responsable de todo el desarrollo y los directores de esta tesis, M.Ing. Paola Britos y M.Ing. Hernán Merlino, de la evaluación de las tareas realizadas por el tesista.
D.1.2. Actividad PSI 2: Definición y Organización del Plan
D.1.2.1. Tarea PSI 2.1: Especificación del Ámbito y Alcance
A modo de ejemplo, podemos decir que tratándose de una empresa con un organigrama tipo, el Departamento de Marketing utilizará el sistema para conocer mejor a los usuarios del sitio Web, permitiéndoles organizar mejores campañas de promoción y

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 247 -
poder desplegarlas en los medios que logren el mayor impacto sobre los receptores de las mismas.
El Departamento de Diseño Gráfico utilizará las descripciones de los grupos de usuarios para modificar la estructura y navegación del sitio, de modo de mantener unidas las páginas que acceden cada grupo de usuarios descubierto. De esta forma, se le facilita el acceso a los usuarios de la información que necesitan.
Los Administradores de los servidores Web tendrán que suministrar al sistema los registros de logs de los sitios, para que se pueda realizar el estudio de los mismos.
D.1.2.2. Tarea PSI 2.2: Definición del Plan de Trabajo
Las actividades incluídas en el plan de trabajo del PSI son las siguientes:
- Definición del equipo de trabajo
o Analista Semi-Senior
o Analista Senior
o Diseñador
o Programador Senior
Al tratarse de un proyecto de tesis, todos los roles serán cumplidos por el autor de la misma.
- Descripción general del PSI:
El sistema será utilizado para el agrupamiento de usuarios, mediante una red neuronal SOM y el algoritmo K-Means, de modo de poder comparar los grupos generados por cada método.
- Catálogo de objetivos del PSI
o Interfaz Web: la aplicación debe ser accedida en un entorno Web, de modo que el usuario pueda utilizarla directamente desde su navegador favorito.
o Multiplataforma: la aplicación deber ser desarrollada en un lenguaje que soporte múltiples plataformas. De esta forma se la independiza del sistema operativo sobre el cual se ejecutará.
o Facilidad de Uso: deberá tener una interfaz de usuario simple y amigable, de modo que usuarios sin experiencia en el uso de herramientas de este tipo puedan trabajar con la misma y realizar los estudios que necesiten.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 248 -
D.1.2.3. Tarea PSI 2.3: Comunicación del Plan de Trabajo
El plan de trabajo es comunicado a los directores de esta tesis, el cual es analizado y aprobado [Tabla D.1].
TareaTareaTareaTarea Fecha de Comienzo
Fecha de Finalización
Duración (días)
Definición del equipo de trabajo 02/05/2005 03/05/2005 1 Descripción general del PSI 03/05/2005 04/05/2005 1 Catálogo de objetivos del PSI 04/05/2005 07/05/2005 3 Descripción general de procesos de la organización afectados 09/05/2005 11/05/2005 2
Catálogo de usuarios 11/05/2005 12/05/2005 1 Tabla D.1. Plan de Trabajo
A continuación se representa el plan de trabajo mediante un diagrama de Gantt [Figura D.1]:
Figura D.1. Gantt del Plan de Trabajo
D.1.3. Actividad PSI 7: Definición de la Arquitectura Tecnológica
D.1.3.1. Tarea PSI 7.1: Identificación de las Necesidades de Infraestructura Tecnológica
Es necesario contar con estaciones de trabajo para el desarrollo del sistema y servidores donde se desplegará el mismo.
Existirá un servidor donde se tendrá la versión de desarrollo y sobre la cual trabajará el equipo de análisis, diseño y programación.
Un servidor se utilizará para la ejecución de las pruebas y otro será utilizado para el ambiente de producción. Las características de los mismos serán idénticas.
También es necesario otro servidor como repositorio del código fuente del sistema, que será utilizado por los desarrolladores para obtener la última versión disponible y actualizarla.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 249 -
Todos estos servidores y las estaciones de trabajo deben estar interconectados mediante una red local de alta velocidad [Figura D.2].
Figura D.2. Infraestructura Tecnológica
D.1.3.2. Tarea PSI 7.2: Selección de la Arquitectura Tecnológica
El sistema será desarrollado utilizando el lenguaje de programación Java, el cual permite ser ejecutado en plataformas Unix y Windows.
D.1.4. Actividad PSI 8: Definición del Plan de Acción
El plan de acción es un plan anual, que detalla todos los proyectos que se realizarán en el transcurso del año. Como en este caso se trata de un trabajo de tesis, el único proyecto es el desarrollo de un sistema de Identificación de Hábitos de Uso de Sitios Web.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 250 -
D.1.5. Actividad PSI 9: Revisión y Aprobación del PSI
D.1.5.1. Tarea PSI 9.1: Convocatoria de la Presentación
Se presentan los siguientes puntos:
- Identificación de los requisitos del PSI
- Definición de la arquitectura tecnológica
- Definición del plan de acción.
D.1.5.2. Tarea PSI 9.2: Aprobación del PSI
El proyecto a realizar fue presentado a los directores de esta tesis, M.Ing. Paola Britos y M.Ing. Hernán Merlino, quienes han dado su aprobación y conformidad.
D.2. Estudio de Viabilidad del Sistema
Mientras que el Plan de Sistemas de Información tiene como objetivo proporcionar un marco estratégico que sirva de referencia para los Sistemas de Información de un ámbito concreto de una organización, el objetivo del Estudio de Viabilidad del Sistema es el análisis de un conjunto concreto de necesidades para proponer una solución a corto plazo, que tenga en cuenta restricciones económicas, técnicas, legales y operativas. La solución obtenida como resultado del estudio puede ser la definición de uno o varios proyectos que afecten a uno o varios sistemas de información ya existentes o nuevos. Para ello, se identifican los requisitos que se ha de satisfacer y se estudia, si procede, la situación actual.
D.2.1. Actividad EVS 1: Establecimiento del Alcance del Sistema
D.2.1.1. Tarea EVS 1.1: Estudio de la Solicitud
El sistema será utilizado para el agrupamiento de usuarios, mediante una red neuronal SOM y el algoritmo K-Means, de modo de poder comparar los grupos generados por cada método.
Debido a que se está realizando un trabajo de tesis y que no se dispone de un presupuesto asignado, no son tenidas en cuenta las restricciones económicas.
Se posee todo el equipo técnico necesario para el desarrollo y prueba del sistema. Y se cuenta con personal capacitado para el desarrollo.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 251 -
Como restricción legal se debe tener en consideración que no pueden ser publicados los accesos de navegación de una persona en particular, de modo de preservar su privacidad.
D.2.1.2. Tarea EVS 1.2: Identificación del Alcance del Sistema
Esta tarea no es necesario realizarla debido a que en ella se debe considerar la sincronización con otros proyectos. En este caso existe un único proyecto.
D.2.2. Actividad EVS 2: Estudio de la Situación Actual
D.2.2.1. Tarea EVS 2.1: Valoración del Estudio de la Situación Actual
Se ha buscado en Internet y consultado a especialistas en el tema, mas no se encontró ningún sistema actual que provea la funcionalidad que se desarrollará en este proyecto. Por lo tanto, esta tarea no se realiza.
D.2.3. Actividad EVS 3: Definición de Requisitos del Sistema
D.2.3.1. Tarea EVS 3.1: Identificación de Requisitos
Se debe poder realizar la agrupación de usuarios en base a sus hábitos de uso de un sitio Web, permitiendo la comparación entre los grupos obtenidos mediante la red neuronal SOM y el algoritmo K-Means. Los grupos descubiertos mediante la red neuronal SOM deberán poder ser mejor descriptos en base a su comportamiento en el sitio que los equivalentes descubiertos mediante el algoritmo K-Means.
D.2.4. Actividad EVS 4: Estudio de Alternativas de Solución
D.2.4.1. Tarea EVS 4.1: Preselección de Alternativas de Solución
Se identifican tres módulos que podrían tener soluciones independientes [Tabla D.2]:
Módulo Solución
Preprocesamiento y construcción de sesiones de usuarios
Desarrollo de una herramienta a medida, para poder realizar todas las tareas de preprocesamiento requeridas.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 252 -
Módulo Solución
Realización de estas tareas mediante comandos de tipo scripts, como grep, sed, awk, etc.. No se posee disponible ningún producto estándar como para poder llevar a cabo esta tarea de forma completa.
Utilización de herramientas disponibles que realizan esta actividad, como Weka.
Realización a medida de los algoritmos de agrupamiento, ya sea la red neuronal SOM o el algoritmo K-Means.
Agrupamiento de usuarios Incorporación de componentes ya implementados, como una red neuronal SOM o el algoritmo K-Means, en una herramienta realizada a medida, adaptando dichos componentes, de modo que lleven a cabo las tareas requeridas.
Análisis de resultados
Realización de una herramienta a medida. Es la solución que mejor se adapta debido a que se desea analizar resultados para los cuales no se ha encontrado herramienta que permita dicho análisis.
Tabla D.2. Alternativas de Solución
D.2.4.2. Tarea EVS 4.2: Descripción de las Alternativas de Solución
Módulo “Preprocesamiento y construcción de sesiones de usuario”:
• Solución herramienta a medida: se debe realizar una herramienta capaz de pre-procesar los registros de archivos de log, para luego identificar a los usuarios y a sus sesiones. Para ello se tendrán distintas clases encargadas de realizar cada tarea, obteniendo como entrada los resultados del procesamiento de la clase anterior.
• Solución mediante comandos de tipo scripts: con esta solución se deben realizar varios scripts que realicen cada una de las tareas de preprocesamiento, para ser ejecutadas secuencialmente por el usuario, o mediante otro script que automatice esta operación.
Módulo “Agrupamiento de usuarios”:

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 253 -
• Solución utilización de herramientas estándares: se debe elegir qué herramienta se utilizará, que permita realizar las tareas necesarias, teniendo que adaptar los resultados del módulo anterior a los formatos de entrada de las herramientas seleccionadas.
• Solución implementación de algoritmos de agrupamiento: se deben implementar los algoritmos de la red neuronal SOM y de K-Means, para permitir el agrupamiento de los usuarios en base a sus hábitos de navegación en sitios Web.
• Solución mixta, utilizando componentes existentes y adaptándolos mediante programación específica: se debe seleccionar qué componentes serán utilizados, analizar la adaptación a realizar en los mismos y luego implementar dicha adaptación.
Módulo “Análisis de resultados”:
• La solución que mejor se adapta es la realización de una herramienta a medida, capaz de analizar los resultados obtenidos en el módulo anterior y mostrarlos de diversos modos, para permitir el análisis de los mismos por parte del usuario del sistema. Esta herramienta debe ser capaz de tomar la salida del módulo anterior, mostrar la cantidad de sesiones que existen en cada grupo de usuarios descubierto, mostrar las páginas que acceden frecuentemente los usuarios de cada grupo e indicar a qué grupo de usuarios corresponde cada sesión de usuario construida mediante el primer módulo.
D.2.5. Actividad EVS 5: Valoración de las Alternativas
D.2.5.1. Tarea EVS 5.1: Estudio de la Inversión
Debido a las particularidades de este desarrollo, el estudio de los beneficios y costos no será realizado basado en conceptos económicos, sino que serán valorados en base a los costos en tiempo de trabajo necesarios para realizar cada solución propuesta y la calidad de los resultados que otorguen.
Módulo “Preprocesamiento y construcción de sesiones de usuario”:
• Solución herramienta a medida: posee como beneficio que la herramienta implementada tendrá gran capacidad de adaptación a los cambios que puedan surgir en el futuro en los formatos de los diferentes preprocesamientos que se realizan en este módulo. El costo de este beneficio es un mayor trabajo necesario para la realización de la herramienta.
• Solución mediante comandos de tipo scripts: esta solución posee el beneficio que es de más rápida implementación, pero a costa de una peor capacidad de adaptación a los cambios y un sistema poco mantenible, los cuales son los problemas que aparecen en las soluciones en base a scripts cuando son utilizadas para resolver cuestiones que poseen una complejidad como la realizada aquí.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 254 -
Módulo “Agrupamiento de usuarios”:
• Solución utilización de herramientas estándares: el beneficio inmediato es la no necesidad de desarrollar ninguna herramienta, pero a costa de perder flexibilidad en las actividades a realizar.
• Solución implementación de algoritmos de agrupamiento: con esta solución se puede implementar lo que realmente necesitamos y cómo lo necesitamos, pero es necesario un gran trabajo para realizar esta implementación.
• Solución mixta, utilizando componentes existentes y adaptándolos mediante programación específica: esta solución permite utilizar componentes ya existentes que cumplan con nuestras necesidades y adaptarlos cuando existan diferencias entre lo disponible y lo deseado. El beneficio es que se utilizan componentes de alta calidad, ya probados y con múltiples funcionalidades, y solo con algunas tareas de adaptación pueden ser utilizados para resolver nuestro trabajo. Los costos de esta solución desaparecen si los componentes utilizados son lo suficientemente flexibles para poder ser adaptados a nuestras necesidades.
Módulo “Análisis de resultados”:
• No se encontraron soluciones alternativas para la realización de este módulo.
D.2.5.2. Tarea EVS 5.2: Planificación de Alternativas
Módulo “Preprocesamiento y construcción de sesiones de usuario”:
• Solución herramienta a medida:
o Implementación del preprocesamiento de los registros del archivo de log.
o Implementación de la identificación de usuarios.
o Implementación de la identificación de sesiones de usuarios.
• Solución mediante comandos de tipo scripts:
o Implementación del preprocesamiento de los registros del archivo de log.
o Implementación de la identificación de usuarios.
o Implementación de la identificación de sesiones de usuarios.
Módulo “Agrupamiento de usuarios”:
• Solución utilización de herramientas estándares:
o Selección de herramientas estándares a analizar.
o Selección de la o las herramientas mejores para este caso.
o Especificación de los procedimientos a seguir para la utilización de estas herramientas para realizar el agrupamiento de usuarios.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 255 -
• Solución implementación de algoritmos de agrupamiento:
o Identificar algoritmos necesarios a implementar.
o Identificar las distintas alternativas para la implementación de dichos algoritmos.
o Implementar todos los algoritmos necesarios.
o Integrar los algoritmos implementados para realizar el agrupamiento de usuarios.
• Solución mixta, utilizando componentes existentes y adaptándolos mediante programación especifica:
o Selección de componentes existentes a analizar.
o Selección del o de los componentes mejores para este caso.
o Análisis de las adaptaciones necesarias a realizar en los componentes seleccionados.
o Implementación de las adaptaciones necesarias.
Módulo “Análisis de resultados”:
o Solución herramienta a medida:
o Análisis de las implementaciones a realizar.
o Diseño de las implementaciones a realizar.
o Implementación de la herramienta.
D.2.6. Actividad EVS 6: Selección de la Solución
D.2.6.1. Tarea EVS 6.1: Evaluación de las Alternativas y Selección
Módulo “Preprocesamiento y construcción de sesiones de usuario”:
• Solución herramienta a medida: posee las mejores características para resolver la actividad necesaria.
• Solución mediante comandos de tipo scripts: no es capaz de cumplir con todas las necesidades de esta actividad.
Módulo “Agrupamiento de usuarios”:
• Solución utilización de herramientas estándares: no poseen la flexibilidad necesaria para realizar esta actividad.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 256 -
• Solución implementación de algoritmos de agrupamiento: posee una gran carga de trabajo, no justificable con los resultados que pueden ser obtenidos mediante la utilización de la tercer alternativa.
• Solución mixta, utilizando componentes existentes y adaptándolos mediante programación específica: es la solución que provee de la flexibilidad buscada.
Módulo “Análisis de resultados”:
• Solución herramienta a medida: no se identificaron otras posibles soluciones.
Por ende, las soluciones seleccionadas fueron [Tabla D.3]:
Módulo Solución
Preprocesamiento y construcción de sesiones de usuarios
Desarrollo herramienta a medida.
Agrupamiento de usuarios
Utilizar componentes existentes y adaptarlos mediante programación específica.
Análisis de resultados Desarrollo herramienta a medida.
Tabla D.3. Soluciones Seleccionadas
D.2.6.2. Tarea 6.2: Aprobación de la Solución
La solución seleccionada fue presentada a los directores de esta tesis, los cuales dieron su conformidad con la misma.
D.3. Análisis del Sistema de Información
D.3.1. Actividad ASI 1: Definición del Sistema
D.3.1.1. Tarea ASI 1.1: Determinación del Alcance del Sistema
El sistema debe permitir el pre-procesado de archivos de logs, armando las sesiones de usuarios, para luego realizar el agrupamiento de usuarios. Debe, además, tener métodos para analizar los resultados obtenidos. Queda fuera del alcance del sistema cualquier uso

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 257 -
que se le desee dar a los resultados obtenidos, el sistema únicamente los despliega para la correcta comprensión por parte del usuario del sistema.
A continuación se muestra el diagrama de contexto [Figura D.3]:
Figura D.3. Diagrama de Contexto
D.3.1.2. Tarea ASI 1.2: Identificación del Entorno Tecnológico
El sistema deberá poder ejecutarse bajo plataformas Unix y Windows, tendrá interfaz Web y arquitectura cliente-servidor. El sistema será desarrollado utilizando el lenguaje de programación Java, el cual permite ser ejecutado en plataformas Unix y Windows.
D.3.1.3. Tarea ASI 1.3: Especificación de Estándares y Normas
Los formatos de archivos de logs que debe permitir utilizar el sistema son:
• CLF (Common Log Format) [http://www.w3.org/Daemon/User/Config/Logging.html].

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 258 -
• CLF Extendido utilizando los campos Referrer y Agent (Common Log Format Extendido, Combined Log Format) [http://www.w3.org/TR/WD-logfile.html].
Estos formatos son soportados por los principales servidores Web disponibles, como por ejemplo Apache HTTP Server, Apache Tomcat, Microsoft IIS y Netscape Enterprise Server.
D.3.2. Actividad ASI 2: Establecimiento de Requisitos
D.3.2.1. Tarea ASI 2.1: Obtención de Requisitos
Los requisitos del sistema son:
R1. Preprocesamiento de archivos de log de servidores Web, obteniendo la información necesaria de cada registro, y únicamente de los registros considerados importantes por el usuario.
R2. Identificación de usuarios a partir de los archivos de log pre-procesados.
R3. Identificación de las sesiones de usuarios.
R4. Agrupamiento de usuarios en base a las sesiones de usuario identificadas anteriormente, utilizando la red neuronal SOM propuesta en esta tesis.
R5. Agrupamiento de usuarios en base a las sesiones de usuario identificadas anteriormente, utilizando el algoritmo K-Means.
R6. Métodos que permitan el análisis de los resultados obtenidos en el agrupamiento de usuarios, que permitan mostrar la cantidad de sesiones que existen en cada grupo de usuarios descubierto, mostrar las páginas que acceden frecuentemente los usuarios de cada grupo e indicar a qué grupo de usuarios corresponde cada sesión de usuario identificada anteriormente.
R7. Se deben poder tener varios usuarios en el sistema, los cuales deben iniciar sesión mediante una contraseña.
R8. Cada usuario puede tener varios proyectos, donde se realizan distintos análisis de sitios Web.
R9. Los formatos de log que debe soportar el sistema son el formato de log común (CLF) y el formato extendido con los campos del CLF más los campos Referer y Agent.
R10. Para el preprocesamiento se decidio utilizar tres filtros distintos:
o El primero es un filtro de extensiones de recursos. El usuario puede indicar cuales extensiones de los recursos deben ser incluidas en el armado de las sesiones de los usuarios. Toda extensión no indicada por el usuario, será filtrada e ignorada para el armado de las sesiones.
o El segundo filtro es sobre la base de los códigos de error de http. El usuario indica qué códigos de error son considerados para la tarea de la

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 259 -
construcción de las sesiones de usuarios. Solo las líneas del archivo de log que posean los códigos de error especificados por el usuario serán incluidas en el proceso de construcción de sesiones. En forma predeterminada, solo el código de error 200 debera ser considerado.
o El tercer filtro incorpora la distincion de páginas distintas en base a variables GET. Se deberá permitir indicar variables GET que son identificadoras de páginas distintas, las cuales serán consideradas para diferenciar a las páginas del sitio.
R11. Los distintos usuarios serán identificados sobre la base de su dirección IP. Todas las peticiones originadas desde una misma dirección IP son consideradas pertenecientes al mismo usuario. Adicionalmente, se utilizará el usuario de autenticación http cuando el mismo este disponible, para identificar a los distintos usuarios.
R12. Las sesiones serán divididas teniendo en cuenta un tiempo máximo entre peticiones consecutivas consideradas pertenecientes a la misma sesión de usuario. Este tiempo deberá ser configurable por el usuario. También será posible indicar la cantidad mínima de páginas en una sesión para tomarla en consideración en la posterior tarea de identificación de hábitos de los usuarios. Además se permitirá indicar la frecuencia mínima de cada página, filtrando las páginas que posean una frecuencia menor a la mínima en el total de peticiones de todos los usuarios.
R13. La red neuronal a emplear será un mapa auto-organizativo (SOM), que posee tantas entradas como páginas frecuentes posea un sitio Web. Las páginas frecuentes son las que poseen una frecuencia mayor a la especificada por el usuario en la tarea de preprocesamiento. La red neuronal se construirá en forma dinámica para permitir las entradas necesarias para el sitio Web analizado. La salida de la red neuronal SOM es un mapa de dos dimensiones de N x N, donde N es configurable por el usuario, y depende de la cantidad de clusters que el mismo desee obtener. En el mapa de salida, solo una salida será activada, indicado por el valor binario uno. Todas las demás salidas tendrán un valor nulo. La salida activada representa el cluster al cual pertenece el patrón ingresado. Patrones similares pertenecerán al mismo cluster o a clusters cercanos en el mapa de salida.
A continuación se muestra el agrupamiento de los requisitos en base a las características de su funcionalidad [Tabla D.4]:

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 260 -
Fun
cion
al
Ren
dim
ient
o
Seg
urid
ad
Impl
anta
ción
Dis
poni
bilid
ad d
el S
iste
ma
R1 – Preprocesamiento Log X X R2 – Identificación de Usuarios X R3 – Identificación de Sesiones de Usuarios X R4 – Agrupamiento de Usuarios con SOM X R5 – Agrupamiento de Usuarios con K-Means X R6 – Análisis de Resultados X R7 – Usuarios del Sistema X X R8 – Proyectos de Usuarios X X R9 – Formatos de Logs X R10 – Filtros de Preprocesamiento de Logs X X R11 – Criterios para la Identificación de Usuarios X R12 – Criterios para la Identificación de Sesiones de Usuarios X R13 – Características de la Red Neuronal SOM X
Tabla D.4. Agrupamiento de Requisitos
D.3.2.2. Tarea ASI 2.2: Especificación de Casos de Uso
Los casos de uso del sistema se pueden observar a continuación [Figura D.4]:

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 261 -
Figura D.4. Casos de Uso
IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 262 -
Caso de Uso Pre-procesar archivo de log
Descripción Pre-procesa el archivo de log que el usuario desea, tomando en cuenta únicamente los registros considerados importantes por el usuario y los campos útiles para las posteriores actividades.
Precondiciones • El usuario posee un archivo de log para pre-procesar.
Poscondiciones • El archivo de log se encuentra pre-procesado y listo para que se proceda a la identificación de usuarios.
Especificación Paso Acción
1 El usuario selecciona un archivo de log a pre-procesar.
2 El usuario indica el tipo de archivo de log.
3 El usuario indica las extensiones de los archivos solicitados que serán considerados para seleccionar registros.
4 El usuario indica los códigos de error HTTP que serán considerados para seleccionar registros.
5 El usuario indica que variables pasadas por el método GET son consideradas identificadoras de página.
6 El usuario inicia el pre-procesado del archivo de log.
7 El sistema selecciona los registros que cumplen con las restricciones indicadas por el usuario.
8 El archivo de log fue pre-procesado.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 263 -
Caso de Uso Identificar usuarios
Descripción Toma como entrada el archivo de log pre-procesado, para realizar la identificación de los distintos usuarios que han realizado peticiones al sitio Web analizado.
Precondiciones • El archivo de log fue pre-procesado.
Poscondiciones • Se identificaron los distintos usuarios del sitio Web.
Especificación Paso Acción
1 El usuario indica que se proceda a la identificación de usuarios
2 El sistema identifica a los usuarios en base a la dirección IP y al campo authuser de los registros del archivo de log pre-procesado.
3 Se identificaron los distintos usuarios presentes en el archivo de log.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 264 -
Caso de Uso Identificar sesiones de usuario
Descripción Se identifican las distintas sesiones de usuarios, tomando en cuenta los distintos parámetros indicados por el usuario para realizar esta identificación.
Precondiciones • El archivo de log fue pre-procesado. • Los usuarios fueron identificados.
Poscondiciones • Se identificaron las sesiones de usuario en el sitio Web de análisis.
Especificación Paso Acción
1 El usuario indica la cantidad mínima de solicitudes de páginas que deben existir en una sesión para ser considerada.
2 El usuario indica el tiempo máximo entre peticiones del mismo usuario para ser consideradas como pertenecientes a la misma sesión.
3 El usuario indica la frecuencia mínima que debe aparecer cada página en el total del archivo de log pre-procesado para ser tomada en consideración en el armado de las sesiones.
4 El usuario inicia la identificación de sesiones de usuario.
5 El sistema agrupa las sesiones de usuario en base a las opciones suministradas por el usuario, juntando varios registros de log en una sesión de usuario.
6 Se han identificado las sesiones de los usuarios.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 265 -
Caso de Uso Agrupar usuarios utilizando red neuronal SOM
Descripción Se procede a agrupar a los distintos usuarios descubiertos anteriormente, utilizando para ello la red neuronal SOM propuesta en esta tesis. El usuario debe indicar cuantos grupos se desean obtener y cuanto entrenamiento se realizará con la red neuronal.
Precondiciones • El archivo de log fue pre-procesado. • Los usuarios fueron identificados. • Las sesiones de usuario fueron identificadas.
Poscondiciones • Se poseen los grupos de usuario identificados.
Especificación Paso Acción
1 El usuario indica la cardinalidad del mapa de clusterización utilizado en la red neuronal.
2 El usuario indica la cantidad de ciclos de entrenamiento que se realizarán con el conjunto de sesiones de usuario descubiertas anteriormente.
3 El usuario inicia la agrupación de los usuarios.
4 El sistema transforma las sesiones de los usuarios en un formato apto como entrada para la red neuronal.
5 El sistema ingresa a la red neuronal todos los patrones correspondientes a todas las sesiones de usuario, repitiendo esta operación la cantidad de ciclos indicada por el usuario, procediendo al entrenamiento de la red neuronal.
6 El sistema realiza la agrupación de los usuarios utilizando la red neuronal previamente entrenada.
7 Se han agrupado a los usuarios.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 266 -
Caso de Uso Agrupar usuarios utilizando K-Means
Descripción Se procede a agrupar a los distintos usuarios descubiertos anteriormente, utilizando para ello el algoritmo K-Means. El usuario debe indicar cuantos grupos se desean obtener.
Precondiciones • El archivo de log fue pre-procesado. • Los usuarios fueron identificados. • Las sesiones de usuario fueron identificadas.
Poscondiciones • Se poseen los grupos de usuario identificados.
Especificación Paso Acción
1 El usuario indica la cantidad de clusters (grupos) de usuarios a descubrir.
2 El usuario inicia la agrupación de los usuarios.
3 El sistema transforma las sesiones de los usuarios en un formato apto como entrada para el algoritmo K-Means.
4 El sistema ingresa al algoritmo K-Means todos los patrones correspondientes a todas las sesiones de usuario.
5 El sistema realiza la agrupación de los usuarios.
6 Se han agrupado a los usuarios.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 267 -
Caso de Uso Analizar grupos de usuarios descubiertos
Descripción Se procede al análisis de los resultados obtenidos en el agrupamiento de usuarios, que permitan mostrar la cantidad de sesiones que existen en cada grupo de usuarios descubierto, mostrar las páginas que acceden frecuentemente los usuarios de cada grupo e indicar a que grupo de usuarios corresponde cada sesión de usuario identificada anteriormente. Adicionalmente, se debe facilitar al usuario la comparación de los resultados obtenidos mediante los dos métodos de agrupación de usuarios.
Precondiciones • Los grupos de usuarios fueron descubiertos.
Poscondiciones • Se posee el análisis de los grupos de usuarios descubiertos.
Especificación Paso Acción
1 El usuario indica que se realice el análisis de los grupos descubiertos.
2 El sistema contabiliza la cantidad de sesiones existentes en cada grupo de usuarios.
3 El sistema calcula la frecuencia de acceso de cada página del sitio Web por parte de los usuarios pertenecientes a cada cluster.
4 El sistema indica a que cluster pertenece cada sesión de usuario descubiertas anteriormente.
D.3.3. Actividad ASI 3: Análisis de los Casos de Uso
D.3.3.1. Tarea ASI 3.1: Identificación de Clases Asociadas a un Caso de Uso
Caso de Uso Pre-procesar archivo de log
Clases Asociadas
• Pre-procesadorLog

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 268 -
Caso de Uso Identificar usuarios
Clases Asociadas
• IdentificadorUsuarios
Caso de Uso Identificar sesiones de usuario
Clases Asociadas
• IdentificadorSesiones
Caso de Uso Agrupar usuarios utilizando red neuronal SOM
Clases Asociadas
• AgruparSOM
Caso de Uso Agrupar usuarios utilizando K-Means
Clases Asociadas
• AgruparK-Means
Caso de Uso Analizar grupos de usuarios descubiertos
Clases Asociadas • ContadorSesiones
• ContadorPáginas
• SesionesEnCluster
D.3.3.2. Tarea ASI 3.2: Descripción de la Interacción de Objetos
En esta primera aproximación solo se identificaron una clase por caso de uso, por lo tanto no existe interacción entre objetos utilizados para la realización de un caso de uso. En el caso de uso “Analizar grupos de usuarios descubiertos” se identificaron tres clases, pero las mismas trabajan de forma independientes.
D.3.4. Actividad ASI 4: Análisis de Clases

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 269 -
D.3.4.1. Tarea ASI 4.1: Identificación de Responsabilidades y Atributos
A continuación se detallan las responsabilidades y atributos de las clases [Tabla D.5]:
Caso de Uso Clase Responsabilidades AtributosAtributosAtributosAtributos
Pre-procesar archivo de
log Pre-procesadorLog
Seleccionar de un archivo de log los campos dirección IP, authuser, fecha y hora, y recurso solicitado, cumpliendo con las opciones seleccionadas por el usuario y filtrando todos los registros que no cumplan con los criterios especificados por el usuario.
• archivoLog • tipoArchivoLog • extensionesPágina • erroresValidos • variablesIdentificadorasPágina
Identificar usuarios
IdentificadorUsuarios
Identificar a los distintos usuarios del log pre-procesado en base a su dirección IP y al campo authuser.
Identificar sesiones de
usuario IdentificadorSesiones
Identificar a las distintas sesiones de usuario separando todas las peticiones de cada usuario en sesiones, teniendo en cuenta el tiempo máximo entre peticiones consecutivas para considerarlas como peticiones pertenecientes a una misma sesión, la cantidad mínima de solicitudes de páginas que deben existir en una sesión para ser considerada y la frecuencia mínima que debe aparecer cada página en el total del archivo de log pre-procesado para ser tomada en consideración en el armado de las sesiones.
• tiempoMaximoEntrePeticiones • cantidadMinimaPáginasEnSesion • minimaFrecuenciaDePágina
Agrupar usuarios
utilizando red neuronal
SOM
AgruparSOM
En base a las sesiones de usuarios, se genera un formato para las mismas apto como entrada de la red neuronal, y luego se procede a generar la red con las características necesarias para realizar la agrupación de los usuarios, teniendo en cuenta las distintas páginas que aparecen en las sesiones de los usuarios, la cardinalidad del mapa auto-organizativo que posee como salida la red neuronal. Una vez generada la red, se procede al entrenamiento con todos los patrones correspondientes a las sesiones de usuario, para luego realizar la agrupación de los
• cardinalidadMapa • cantidadCiclosEntrenamiento

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 270 -
Caso de Uso Clase Responsabilidades AtributosAtributosAtributosAtributos
usuarios, utilizando la red entrenada. El entrenamiento se debe realizar la cantidad de ciclos seteada.
Agrupar usuarios
utilizando K-Means
AgruparK-Means
En base a las sesiones de usuarios, se genera un formato apto como entrada al algoritmo K-Means. Luego se agrupan los usuarios utilizando el algoritmo K-Means, generando la cantidad de grupos seteada previamente.
• cantidadDeGrupos
ContadorSesiones
Contabilizar la cantidad de sesiones de usuario pertenecientes a cada grupo de usuarios descubiertos, ya sea mediante la red neuronal SOM o mediante el algoritmo K-Means.
ContadorPáginas
Calcular la frecuencia de cada página del sitio en las sesiones de usuario pertenecientes a cada grupo descubierto, ya sea mediante la red neuronal SOM o mediante el algoritmo K-Means.
Analizar grupos de usuarios
descubiertos
SesionesEnCluster
Indicar a que grupo de usuarios corresponde cada sesión de usuario, ya sea a los grupos descubiertos mediante la red neuronal SOM o mediante el algoritmo K-Means.
Tabla D.5. Identificación de Responsabilidades y Atributos
D.3.5. Actividad ASI 5: Definición de Interfaces de Usuario
D.3.5.1. Tarea ASI 5.1: Especificación de Principios Generales de la Interfaz
El sistema tendrá un menú de navegación que se ubicará en todo momento a la izquierda de la pantallla. Dependiendo de lo que el usuario seleccione en el menú se desplegará en la parte derecha (cuerpo principal) el contenido.
En la parte superior se encontrará el nombre del sistema. En caso que el usuario haya iniciado sesión, se mostrará un botón en la parte superior derecha para permitir el cierre de la misma.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 271 -
Cada pantalla tendrá un título descriptivo que le informará al usuario en que sección del sistema se encuentra.
Cuando se necesite el ingreso de datos por parte del usuario, se hará en formularios con no más de cinco campos cada uno. En caso de requerirse más cantidad de datos, los mismos serán ingresados en sucesivos pasos, donde se lo guiará para completarlos.
Todos los mensajes de error en el sistema serán desplegados en la parte superior del cuerpo principal utilizando fuente en color rojo.
D.3.5.2. Tarea ASI 5.2: Especificación de Formatos Individuales de la Interfaz de Pantalla
Caso de Uso: Pre-procesar archivo de log
Posee una primer interfaz donde se ingresan los datos necesarios para realizar el preprocesamiento del archivo de log.
Un prototipo se muestra a continuación [Figura D.5]:
Figura D.5. Prototipo Pre-procesar Log
Cuando se presiona el botón del mouse en “Pre-procesar Log” se realiza el preprocesamiento del archivo de log y luego se muestra un mensaje indicando el éxito o un mensaje de error, en caso de que surja algún inconveniente.
Caso de Uso: Identificar usuarios
Posee una pantalla donde se indica que se comience con la identificación de usuarios.
Un prototipo se muestra a continuación [Figura D.6]:

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 272 -
Figura D.6. Prototipo Identificar Usuarios
Cuando se presiona el botón del mouse en “Identificar Usuarios” se procede a la identificación de usuarios y luego se muestra un mensaje indicando el éxito o un mensaje de error, en caso de que surja algún inconveniente.
Caso de Uso: Identificar sesiones de usuario
Posee una primer interfaz donde se ingresan los datos necesarios para realizar la construcción de las sesiones de usuario.
Un prototipo se muestra a continuación [Figura D.7]:
Figura D.7. Prototipo Identificar Sesiones de Usuario
Cuando se presiona el botón del mouse en “Construir Sesiones” se procede a la identificación de sesiones de usuario y luego se muestra un mensaje indicando el éxito o un mensaje de error, en caso de que surja algún inconveniente.
Caso de Uso: Agrupar usuarios utilizando red neuronal SOM
Posee una primer interfaz donde se ingresan los datos necesarios para realizar la construcción de los clusters de usuarios.
Un prototipo se muestra a continuación [Figura D.8]:

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 273 -
Figura D.8. Prototipo Agrupar Usuarios Utilizando Red Neuronal SOM
Cuando se presiona el botón del mouse en “Construir Clusters” se procede al agrupamiento de los usuarios y luego se muestra un mensaje indicando el éxito o un mensaje de error, en caso de que surja algún inconveniente.
Caso de Uso: Agrupar usuarios utilizando K-Means
Posee una primer interfaz donde se ingresan los datos necesarios para realizar la construcción de los clusters de usuarios.
Un prototipo se muestra a continuación [Figura D.9]:
Figura D.9. Prototipo Agrupar Usuarios Utilizando K-Means
Cuando se presiona el botón del mouse en “Construir Clusters” se procede al agrupamiento de los usuarios y luego se muestra un mensaje indicando el éxito o un mensaje de error, en caso de que surja algún inconveniente.
Caso de Uso: Analizar grupos de usuarios descubiertos
Aquí se poseen tres interfaces más:
• La primera corresponde con el contador de sesiones pertenecientes a cada grupo de usuarios descubiertos. Se selecciona si se desean ver los grupos construidos mediante la red neuronal SOM o mediante el algoritmo K-Means, y luego se despliega una tabla con el numero de grupo y la cantidad de sesiones de usuarios que pertenecen a ese grupo, para cada grupo descubierto.
• La segunda corresponde con el contador de páginas, donde se calcula la frecuencia de cada página del sitio en las sesiones de usuario pertenecientes a cada grupo de usuarios. Se selecciona si se desean ver los grupos construidos

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 274 -
mediante la red neuronal SOM o mediante el algoritmo K-Means, y luego se despliega una tabla con el numero de grupo, la página y el porcentaje de sesiones de usuarios en ese grupo que accedieron a esa página, para cada grupo descubierto y página del sitio.
• La tercera corresponde con el indicador de a qué grupo de usuarios corresponde cada sesión. Se selecciona si se desean ver los grupos construidos mediante la red neuronal SOM o mediante el algoritmo K-Means, y luego se despliega una tabla donde se muestras todas las sesiones de los usuarios y se indica a que grupo pertenece cada sesión.
D.3.5.3. Tarea ASI 5.3: Especificación del Comportamiento Dinámico de la Interfaz
El comportamiento dinámico de la interfaz ya fue especificado en la tarea anterior. Además, se tendrá un menú, donde se podrá seleccionar que actividad se desea realizar.
D.3.5.4. Tarea ASI 5.4: Especificación de Formatos de Impresión
El aspecto visual del sistema será especificado mediante hojas de estilo en cascada CSS.
Uno de los rasgos más importantes de las hojas de estilo es que especifican cómo debe ser presentado un documento en diferentes medios: en la pantalla, en papel, con un sintetizador de voz, con un dispositivo braille, etc.
Para los formatos de impresión, se proveerá de una hoja de estilo CSS para el medio PRINT. De esta forma, se definirá en esta hoja de estilo cómo deberá ser impreso cada reporte del sistema.
El usuario podrá utilizar las opciones de impresión del navegador, permitiendo además acceder a la vista previa del mismo y ver cómo quedará el reporte una vez impreso en papel.
D.3.6. Actividad ASI 6: Análisis de Consistencia y Especificación de Requisitos
D.3.6.1. Tarea ASI 6.1: Verificación y Validación de los Modelos
Se procedió a la verificación y validación de los modelos junto a los Directores de esta tesis, M.Ing. Paola Britos y M.Ing. Hernán Merlino. Estos modelos fueron encontrados correctos.
D.3.6.2. Tarea ASI 6.2: Elaboración de la Especificación de Requisitos Software (ERS)

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 275 -
Los requisitos identificados son:
• Preprocesamiento de archivos de log de servidores Web, filtrando únicamente los registros útiles para el usuario.
• Identificación de usuarios en base a los registros de log pre-procesados.
• Identificación de las sesiones de los usuarios.
• Agrupamiento de los usuarios en base a sus hábitos de navegación, utilizando una red neuronal SOM, como la propuesta en esta tesis.
• Agrupamiento de los usuarios en base a sus hábitos de navegación, utilizando K-Means.
• Métodos para facilitar el análisis por parte del usuario de los resultados obtenidos. Cantidad de sesiones por grupo de usuarios, porcentaje de acceso a páginas en cada grupo, y detalle de las sesiones.
A continuación se detallan los Requisitos de Software especificando la entrada, el proceso y la salida de cada uno [Tabla D.6]:

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 276 -
Requisito Entrada Proceso Salida
Preprocesamiento de archivos de Log
• Archivo de log • Formato del archivo de log • Selección de extensiones de recursos • Códigos http • Identificadores de páginas
Se procesa el archivo de log dejando solo los registros que posean las extensiones y los códigos seleccionados por el usuario.
• Archivo de log procesado según los parámetros ingresados por el usuario.
Identificación de Usuarios
• Archivo de log preprocesado A partir del log preprocesado se asigna a cada registro un usuario determinado.
• Log preprocesado con los usuarios identificados.
Identificación de Sesiones
• Log preprocesado con los usuarios identificados. • Cantidad mínima de páginas en una sesión • Timeout de sesión • Frecuencia mínima de página en el log
Se recorre el log preprocesado construyendo las sesiones de usuario con los criterios especificados por el usuario.
• Sesiones de usuarios.
Agrupamiento de Usuarios con SOM
• Sesiones de usuarios • Cantidad de ciclos de entrenamiento • Cardinalidad del mapa de clusterización
Las sesiones de usuario son agrupadas mediante la red neuronal SOM.
• Sesiones de usuarios con grupo SOM asignado.
Agrupamiento de Usuarios con K-Means
• Sesiones de usuarios • Cantidad de clusters a descubrir
Las sesiones de usuario son agrupadas mediante el algoritmo K-Means.
• Sesiones de usuarios con grupo K-Means asignado.
Análisis de Resultados
• Sesiones de usuarios con grupo SOM asignado • Sesiones de usuarios con grupo K-Means asignado
Se contabiliza la cantidad de sesiones en cada grupo. Se determina el porcentaje de acceso a cada página por parte de las sesiones de cada grupo.
• Reporte de cantidad de sesiones por grupo. • Reporte de porcentaje de accesos a páginas por grupo. • Reporte de detalle de sesiones.
Tabla D.6. Especificación de Requisitos Software
D.3.7. Actividad ASI 7: Especificación del Plan de Pruebas
D.3.7.1. Tarea ASI 7.1: Definición del Alcance de las Pruebas
Se realizarán las pruebas en todas las clases que se construyan y se realizaran pruebas de integración de las mismas. Se realizarán pruebas a la aplicación analizando un archivo de log en su totalidad.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 277 -
D.3.7.2. Tarea ASI 7.2: Definición de Requisitos del Entorno de Pruebas
Las pruebas serán realizadas utilizando servidores con plataforma Windows 2000 Profesional y Linux Debian Sarge Stable.
El entorno de pruebas se encuentra separado del entorno de desarrollo y de producción. Los encargados de realizar las pruebas ejecutarán las mismas desde estaciones de trabajo accediendo a los servidores antes mencionados.
Las estaciones de trabajo tendrán diferentes plataformas Windows, como ser Windows 98, Windows 2000, Windows XP y diferentes plataformas Linux, como ser Debian, Ubuntu y Mandrake. En las estaciones de trabajo se utilizarán diferentes navegadores Web: Internet Explorer, Mozilla Firefox y Opera.
D.3.7.3. Tarea ASI 7.3: Definición de las Pruebas de Aceptación del Sistema
Se le solicitará al usuario que realice un proceso completo de análisis de un archivo de log. Mientras el usuario realiza este análisis podrá evaluar cada paso del mismo. En caso de ser necesario, deberá hacer llegar los comentarios pertinentes al encargado del proyecto, de modo de que éste pueda ejecutar una acción correctiva y lograr finalmente la aceptación del sistema por parte del usuario final.
D.3.8. Actividad ASI 8: Aprobación del Análisis del Sistema de Información
D.3.8.1. Tarea ASI 8.1: Presentación y Aprobación del Análisis del Sistema de Información
Se presenta el análisis del sistema de información y el mismo es aprobado por los directores de esta tesis.
D.4. Diseño del Sistema de Información
D.4.1. Actividad DSI 1: Definición de la Arquitectura del Sistema
D.4.1.1. Tarea DSI 1.1: Definición de Niveles de Arquitectura
El sistema se desarrollará mediante la arquitectura cliente/servidor, con interfaz Web, utilizando el protocolo HTTP.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 278 -
En el cliente no es necesario ningún desarrollo, se podrá acceder a la aplicación mediante un navegador convencional. En el servidor será necesario un servidor Web y un servidor de base de datos, para almacenar los datos de la aplicación. El cliente se comunica con el servidor Web, el cual obtiene los datos en el servidor de base de datos [Figura D.10].
Figura D.10. Arquitectura del Sistema
D.4.1.2. Tarea DSI 1.2: Identificación de Requisitos de Diseño y Construcción
El sistema será desarrollado utilizando el lenguaje de programación Java. Se utilizaran JavaBeans para las clases del modelo de datos, accediendo a la base de datos utilizando JDBC. Para la presentación se utilizaran Java Server Pages, realizando todas las páginas de la interfaz cumpliendo el estándar XHTML y utilizando hojas de estilo en cascada (CSS) para la definición de los estilos de todas las páginas del sistema.
D.4.1.3. Tarea DSI 1.3: Especificación de Excepciones
No se generará una jerarquía de excepciones particular, sino que se utilizarán las ya definidas en Java.
D.4.1.4. Tarea DSI 1.4: Especificación de Estándares y Normas de Diseño y Construcción
• Se realizarán clases de tipo JavaBeans para todas las clases que se correspondan a esta estructura.
• Los nombres de las clases deben poseer cada inicial de palabra en mayúscula.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 279 -
• Las clases que sean JavaBeans tendrán concatenadas a su nombre la palabra “Bean”.
• Los nombres de los métodos y de los atributos de las clases deben poseer cada inicial de palabra en mayúscula, a excepción de la primera que deberá comenzar en minúscula. Esta misma nomenclatura se utilizara para los nombres de las variables.
• Todos los nombres deberán estar en inglés.
• Todo el código será documentado utilizando la sintaxis de JavaDoc, para luego poder generar la documentación a nivel de código de forma automática.
• En las páginas JSP solo se utilizaran etiquetas para acceder a JavaBeans y simples condiciones (if) y ciclos (for y while).
D.4.1.5. Tarea DSI 1.5: Identificación de Subsistemas de Diseño
Debido a que el sistema no posee una gran complejidad, no es necesario dividir al sistema en subsistemas.
D.4.1.6. Tarea DSI 1.6: Especificación del Entorno Tecnológico
• Para el servidor Web se utilizará Tomcat.
• Para el servidor de base de datos se utilizará MySQL.
• Se deberá tener instalada la maquina virtual de Java para poder ejecutar la aplicación en el servidor.
D.4.1.7. Tarea DSI 1.7: Especificación de Requisitos de Operación y Seguridad
Se utilizará registración de usuarios con contraseña para acceder al sistema.
D.4.2. Actividad DSI 2: Diseño de la Arquitectura de Soporte
D.4.2.1. Tarea DSI 2.1: Diseño de Subsistemas de Soporte
No existen subsistemas de soporte.
D.4.2.2. Tarea DSI 2.2: Identificación de Mecanismos Genéricos de Diseño
Se generarán Beans de JavaBeans para acceder a los datos desde las páginas JSP.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 280 -
D.4.3. Actividad DSI 3: Diseño de Casos de Uso Reales
D.4.3.1. Tarea DSI 3.1: Identificación de Clases Asociadas a un Caso de Uso
Adicionalmente a los casos de uso identificados en la actividad anterior, se identifican ahora los siguientes casos de uso:
Caso de Uso Iniciar sesión usuario
Descripción Este caso de uso surge cuando el usuario accede al sistema y quiere iniciar sesión en el mismo.
Clases Asociadas • LoginBean
• UserBean
Caso de Uso Registrar usuario
Descripción Este caso de uso aparece cuando un usuario nuevo accede al sistema y desea registrarse en el mismo.
Clases Asociadas
• CreateUserBean
Caso de Uso Crear proyecto
Descripción Este caso de uso surge cuando el usuario desea crear un nuevo proyecto en el sistema.
Clases Asociadas
• CreateProjectBean

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 281 -
Caso de Uso Seleccionar proyecto
Descripción Este caso de uso surge cuando un usuario desea seleccionar uno de los proyectos que posee, para acceder a la información del mismo y/o para trabajar en el proyecto seleccionado.
Clases Asociadas
• UserBean
Caso de Uso Eliminar proyecto
Descripción Este caso de uso corresponde con el borrado de toda la información referida a un proyecto de un usuario, que el mismo desea eliminar.
Clases Asociadas • DeleteProjectBean
• LogCleanerBean
Caso de Uso Subir archivo de log
Descripción Debido a que la aplicación será desarrollada mediante la arquitectura cliente/servidor, primero se debe enviar al servidor el archivo de log con el cual se desea trabajar. Este caso de uso corresponde con dicha actividad.
Clases Asociadas
• LogFileUploadBean

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 282 -
Caso de Uso Cargar y pre-procesar archivo de log (reemplaza a Caso de Uso: Pre-procesar archivo de log)
Descripción Se selecciona uno de los archivos de log subidos al servidor para ser pre-procesado, quedando listo para construir las sesiones de usuario del mismo.
Clases Asociadas • LogLoaderBean
• PageCounterBean
Caso de Uso Ver archivo de log cargado
Descripción Este caso de uso surge cuando el usuario desea ver el archivo de log ya pre-procesado.
Clases Asociadas • LogViewBean
• LogBean
Los casos de uso “Identificar usuarios” y “Identificar sesiones de usuario” serán unificados en un caso de uso: Construir sesiones de usuario.
Este caso de uso se encarga de identificar a los usuarios y dividir las peticiones de los usuarios en sesiones. Se junto en un solo caso de uso debido a que son dos operaciones que se realizan siempre en forma conjunta.
Caso de Uso Construir sesiones de usuario
Descripción Este caso de uso se encarga de identificar a los usuarios y dividir las peticiones de los usuarios en sesiones.
Clases Asociadas • SessionMakerBean
• SessionSaver

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 283 -
Caso de Uso Agrupar usuarios utilizando red neuronal SOM
Descripción Este caso de uso se encarga de realizar el agrupamiento de usuarios utilizando la red neuronal SOM.
Clases Asociadas • InputMakerBean
• SOMBean
• BinarySessionClusterBean
• FileBean
• ClusterCounterBean
• PagesInClustersBean
Caso de Uso Agrupar usuarios utilizando K-Means
Descripción Este caso de uso se encarga de realizar el agrupamiento de usuarios utilizando el algoritmo K-Means.
Clases Asociadas • InputMakerBean
• KMeansBean
• NumericSessionClusterBean
• FileBean
• ClusterCounterBean
• PagesInClustersBean

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 284 -
El Caso de Uso “Analizar grupos de usuarios descubiertos” es dividido en tres casos de uso:
Caso de Uso Ver cantidad de sesiones en cada cluster descubierto
Descripción Permite calcular la cantidad de sesiones de usuarios en cada grupo descubierto.
Clases Asociadas • ClusterCounterBean
• ClusterCounterGraphBean
Caso de Uso Ver detalle de sesiones y cluster al cual pertenecen
Descripción Permite acceder al detalle de cada sesión de usuario, mostrando las páginas que se accedieron y el grupo al que pertenece.
Clases Asociadas
• SessionsClusterViewBean
Caso de Uso Ver porcentaje de acceso a cada página por los usuarios de cada cluster
Descripción Permite obtener el porcentaje de acceso a cada página por parte de los usuarios de cada grupo descubierto.
Clases Asociadas
• PagesInClustersViewBean

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 285 -
Caso de Uso Ver archivo
Descripción Este caso se uso surge cuando un usuario desea acceder a algunos de los archivos generados en su proyecto o cuando se quiere ver todos los archivos de log subidos al servidor por él.
Clases Asociadas • FilesViewBean
• LogFilesViewBean
D.4.3.2. Tarea DSI 3.2: Diseño de la Realización de los Casos de Uso
Caso de Uso Iniciar sesión usuario
Descripción Este caso de uso surge cuando el usuario accede al sistema y quiere iniciar sesión en el mismo.
Especificación Paso Acción
1 El usuario ingresa en un formulario su nombre de usuario y su contraseña.
2 El sistema autentica al usuario utilizando un objeto de la clase LoginBean, comparando el nombre de usuario y contraseña ingresado por el usuario con el nombre de usuario y contraseña almacenados en la base de datos (en la tabla “user”). Para ello, primero setea el nombre de usuario y la contraseña utilizando los métodos setUser y setPass, respectivamente. Luego autentica al usuario mediante el método isValidUser.
3 Si la autenticación es exitosa, se crea un objeto de sesión UserBean para el usuario, seteando el nombre de usuario utilizando el método setUser.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 286 -
Caso de Uso Iniciar sesión usuario
Descripción Este caso de uso surge cuando el usuario accede al sistema y quiere iniciar sesión en el mismo.
Especificación Paso Acción
1 El usuario ingresa en un formulario su nombre de usuario y su contraseña.
2 El sistema autentica al usuario utilizando un objeto de la clase LoginBean, comparando el nombre de usuario y contraseña ingresado por el usuario con el nombre de usuario y contraseña almacenados en la base de datos (en la tabla “user”). Para ello, primero setea el nombre de usuario y la contraseña utilizando los métodos setUser y setPass, respectivamente. Luego autentica al usuario mediante el método isValidUser.
3 Si la autenticación es exitosa, se crea un objeto de sesión UserBean para el usuario, seteando el nombre de usuario utilizando el método setUser.
Caso de Uso Registrar usuario
Descripción Este caso de uso aparece cuando un usuario nuevo accede al sistema y desea registrarse en el mismo.
Especificación Paso Acción
1 El usuario ingresa en un formulario el nombre de usuario que desea poseer en el sistema y la contraseña del mismo, repitiéndola para chequear que sea ingresada correctamente.
2 El sistema registra al nuevo usuario utilizando un objeto de la clase CreateUserBean. Para ello, primero setea el nombre de usuario y la contraseña utilizando los métodos setUser y setPassword, respectivamente. Luego registra al usuario mediante el método createNewUser, el cual agrega el nombre de usuario y su contraseña en la base de datos (en la tabla “user”), si el nombre de usuario no existía previamente.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 287 -
Caso de Uso Crear proyecto
Descripción Este caso de uso surge cuando el usuario desea crear un nuevo proyecto en el sistema.
Especificación Paso Acción
1 El usuario ingresa en un formulario el nombre y la descripción del proyecto a crear.
2 El sistema crea un nuevo proyecto para el usuario logoneado, utilizando en objeto de la clase CreateProjectBean. Para ello, primero se setea el nombre de usuario logoneado, el nombre del proyecto a crear y su descripción, utilizando los métodos setUser, setProject y setDescription, respectivamente. Luego se crea el proyecto utilizando el método getNewProject, el cual inserta en la base de datos (en la tabla “project”) la información del nuevo proyecto.
Caso de Uso Seleccionar proyecto
Descripción Este caso de uso surge cuando un usuario desea seleccionar uno de los proyectos que posee, para acceder a la información del mismo y/o para trabajar en el proyecto seleccionado.
Especificación Paso Acción
1 El usuario selecciona uno de los proyectos que posee.
2 El sistema setea el proyecto elegido por el usuario como el proyecto actual, utilizando el método setProject del objeto de sesión UserBean.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 288 -
Caso de Uso Eliminar proyecto
Descripción Este caso de uso corresponde con el borrado de toda la información referida a un proyecto de un usuario, que el mismo desea eliminar.
Especificación Paso Acción
1 El usuario selecciona uno de sus proyectos para ser eliminado.
2 El sistema elimina el proyecto utilizando un objeto de la clase DeleteProjectBean. Para ello, primero se setea el nombre de usuario logoneado y el nombre del proyecto a eliminar, utilizando los métodos setUser y setProject, respectivamente. Luego se elimina el proyecto utilizando el método getDeleteProject, el cual elimina toda la información del proyecto en la base de datos.
Caso de Uso Subir archivo de log
Descripción Debido a que la aplicación será desarrollada mediante la arquitectura cliente/servidor, primero se debe enviar al servidor el archivo de log con el cual se desea trabajar. Este caso de uso corresponde con dicha actividad.
Especificación Paso Acción
1 El usuario selecciona un archivo de log en su computadora para ser copiado al servidor, colocándole un descripción al mismo.
2 El usuario envía el archivo de log.
3 El sistema almacena el archivo de log en el servidor utilizando un objeto de la clase LogFileUploadBean. Además, se inserta en la tabla “logFile” la información del archivo de log subido por el usuario.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 289 -
Caso de Uso Cargar y pre-procesar archivo de log (reemplaza a Caso de Uso: Pre-procesar archivo de log)
Descripción Se selecciona uno de los archivos de log subidos al servidor para ser pre-procesado, quedando listo para construir las sesiones de usuario del mismo.
Especificación Paso Acción
1 El usuario selecciona uno de los archivos de log que subió al servidor.
2 El usuario indica que tipo de log es el seleccionado.
3 El usuario indica que extensiones de páginas serán utilizadas.
4 El usuario indica que códigos de error HTTP serán utilizados.
5 El usuario indica que variables GET identifican páginas distintas.
6 El usuario indica que se comience con la carga y pre-procesado del archivo de log.
7 El sistema realiza la carga y el pre-procesado del archivo de log utilizando un objeto de la clase LogLoaderBean. Para ello, primero se setea el nombre de usuario logoneado, el nombre del proyecto actual, las extensiones de página a utilizar, el archivo de log a pre-procesar, el tipo de log, las variables que identifican páginas distintas, los códigos de error a utilizar, utilizando los métodos setUser, setProject, setExtensions, setInput, setTypeLog, setIdsPage y setStatusCodes, respectivamente. Luego se realiza el pre-procesado del archivo de log utilizando el método getLoad, el cual pre-procesado y carga todo el log en la tabla “log”.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 290 -
Caso de Uso Ver archivo de log cargado
Descripción Este caso de uso surge cuando el usuario desea ver el archivo de log ya pre-procesado.
Especificación Paso Acción
1 El usuario indica que desea ver el archivo de log pre-procesado.
2 El sistema muestra el archivo de log pre-procesado utilizando un objeto de la clase LogViewBean.
Caso de Uso Construir sesiones de usuario
Descripción Este caso de uso se encarga de identificar a los usuarios y dividir las peticiones de los usuarios en sesiones.
Especificación Paso Acción
1 El usuario indica la cantidad mínima de páginas en una sesión.
2 El usuario indica el timeout de sesión.
3 El usuario indica la frecuencia mínima de página en el log.
4 El usuario indica que se comience con la construcción de sesiones de usuario.
5 El sistema realiza la construcción de las sesiones de usuario utilizando un objeto de la clase SessionMakerBean. Para ello, primero se setea el nombre de usuario logoneado, el nombre del proyecto actual, la cantidad mínima de páginas en una sesión, el timeout de sesión y la frecuencia mínima de página en el log, utilizando los métodos setUser, setProject, setMinPagesInSession, setTimeoutSession y setMinPageFrequency, respectivamente. Luego se realiza la construcción de las sesiones de usuario utilizando el método getSessions. El objeto SessionMakerBean utiliza al objeto SessionSaver para guardar las sesiones de usuario en la tabla “session”.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 291 -
Caso de Uso Agrupar usuarios utilizando red neuronal SOM
Descripción Este caso de uso se encarga de realizar el agrupamiento de usuarios utilizando la red neuronal SOM.
Especificación Paso Acción
1 El usuario indica el nombre del archivo donde se guardaran los patrones de entrada a la red neuronal.
2 El usuario indica el nombre del archivo donde se guardara la información sobre los clusters descubiertos.
3 El usuario indica la cantidad de ciclos de entrenamiento a realizar en la red neuronal con los patrones de entrada.
4 El usuario indica la cardinalidad del mapa de clusterización (NxN).
5 El usuario indica que se comience la construcción de clusters.
6 El sistema utiliza un objeto de la clase InputMakerBean para crear el archivo con los patrones de entrada a la red neuronal, que representan las sesiones de los usuarios.
7 El sistema utiliza un objeto de la clase SOMBean para realizar la agrupación de los usuarios e identificar los clusters de usuarios.
8 El sistema utiliza un objeto de la clase FileBean para generar un archivo donde se almacena la información sobre los clusters descubiertos.
9 El sistema utiliza un objeto de la clase BinarySessionClusterBean para guardar en la tabla “sessionCluster” a qué cluster pertenece cada sesión.
10 El sistema utiliza un objeto de la clase ClusterCounterBean para obtener la cantidad de sesiones que pertenecen a cada cluster.
11 El sistema utiliza un objeto de la clase PagesInClustersBean para calcular la frecuencia de cada página en todas las sesiones de cada cluster y guardar esta información en la tabla “pageInCluster”.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 292 -
Caso de Uso Agrupar usuarios utilizando K-Means
Descripción Este caso de uso se encarga de realizar el agrupamiento de usuarios utilizando el algoritmo K-Means.
Especificación Paso Acción
1 El usuario indica el nombre del archivo donde se guardaran los patrones de entrada en formato ARFF.
2 El usuario indica el nombre del archivo donde se guardara la información sobre los clusters descubiertos.
3 El usuario indica la cantidad de clusters a descubrir (K).
4 El usuario indica que se comience la construcción de clusters.
5 El sistema utiliza un objeto de la clase InputMakerBean para crear el archivo con los patrones de entrada al algoritmo K-Means, que representan las sesiones de los usuarios.
6 El sistema utiliza un objeto de la clase KMeansBean para realizar la agrupación de los usuarios e identificar los clusters de usuarios.
7 El sistema utiliza un objeto de la clase FileBean para generar un archivo donde se almacena la información sobre los clusters descubiertos.
8 El sistema utiliza un objeto de la clase NumericSessionClusterBean para guardar en la tabla “sessionCluster” a qué cluster pertenece cada sesión de usuario.
9 El sistema utiliza un objeto de la clase ClusterCounterBean para obtener la cantidad de sesiones que pertenecen a cada cluster.
10 El sistema utiliza un objeto de la clase PagesInClustersBean para calcular la frecuencia de cada página en todas las sesiones de cada cluster y guardar esta información en la tabla “pageInCluster”.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 293 -
Caso de Uso Ver cantidad de sesiones en cada cluster descubierto
Descripción Permite calcular la cantidad de sesiones de usuarios en cada grupo descubierto.
Especificación Paso Acción
1 El usuario selecciona si desea ver los clusters descubiertos mediante la red neuronal, mediante el algoritmo K-Means o realizar una comparación de los mismos.
2 El sistema utiliza un objeto de la clase ClusterCounterBean para obtener la cantidad de sesiones en cada cluster descubierto mediante la técnica seleccionada por el usuario.
3 El sistema utiliza un objeto de la clase ClusterCounterGraphBean para graficar la cantidad de sesiones en cada cluster descubierto mediante la técnica seleccionada por el usuario.
Caso de Uso Ver detalle de sesiones y cluster al cual pertenecen
Descripción Permite acceder al detalle de cada sesión de usuario, mostrando las páginas que se accedieron y el grupo al que pertenece.
Especificación Paso Acción
1 El usuario selecciona si desea ver las sesiones con el cluster al cual pertenecen, descubierto mediante la red neuronal, mediante el algoritmo K-Means o realizar una comparación de los mismos.
2 El sistema utiliza un objeto de la clase SessionsClusterViewBean para obtener el detalle de las sesiones y a que cluster pertenecen, descubierto mediante la técnica seleccionada por el usuario.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 294 -
Caso de Uso Ver porcentaje de acceso a cada página por los usuarios de cada cluster
Descripción Permite obtener el porcentaje de acceso a cada página por parte de los usuarios de cada grupo descubierto.
Especificación Paso Acción
1 El usuario selecciona si desea ver los porcentaje de acceso a cada página por los usuarios de cada cluster descubierto mediante la red neuronal, mediante el algoritmo K-Means o realizar una comparación de los mismos.
2 El sistema utiliza un objeto de la clase PagesInClustersViewBean para obtener el porcentaje de acceso a cada página por los usuarios de cada cluster descubierto mediante la técnica seleccionada por el usuario.
Caso de Uso Ver archivo
Descripción Este caso se uso surge cuando un usuario desea acceder a algunos de los archivos generados en su proyecto o cuando se quiere ver todos los archivos de log subidos al servidor por él.
Especificación Paso Acción
1 El usuario selecciona que tipo de archivo desea ver (Log, Input SOM, Output SOM, Input ARFF o Ouput K-Means).
2 El sistema muestra todos los archivos del tipo seleccionado por el usuario, utilizando un objeto de la clase FilesViewBean (LogFilesViewBean, si el tipo seleccionado es Log).
3 El usuario selecciona que archivo desea ver.
4 El sistema envía al usuario el archivo que selecciono.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 295 -
Caso de Uso Ver resumen proyecto
Descripción Este caso se uso surge cuando un usuario desea ver el resumen de un proyecto suyo, mostrándole información sobre el proyecto.
Especificación Paso Acción
1 El usuario indica que desea ver el resumen del proyecto.
2 El sistema muestra la información del proyecto, utilizando un objeto de la clase ProjectBean.
D.4.3.3. Tarea DSI 3.3: Revisión de la Interfaz de Usuario
Mediante el menú de la aplicación se podrá acceder a todas sus funcionalidades. Los prototipos del menú se muestran a continuación:
Menú principal
A continuación se muestra el prototipo de la interfaz Menú principal [Figura D.11]:
Figura D.11. Interfaz Menú principal
Submenú “Ver Archivos”
A continuación se muestra el prototipo de la interfaz Submenú “Ver Archivos” [Figura D.12]:

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 296 -
Figura D.12. Interfaz Submenú "Ver Archivos"
Submenú “Logs”
A continuación se muestra el prototipo de la interfaz Submenú “Logs” [Figura D.13]:
Figura D.13. Interfaz Submenú "Logs"
Submenú “Construir Clusters”
A continuación se muestra el prototipo de la interfaz Submenú “Construir Clusters” [Figura D.14]:

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 297 -
Figura D.14. Interfaz Submenú "Construir Clusters”
Submenú “Sesiones/Clusters”
A continuación se muestra el prototipo de la interfaz Submenú “Sesiones/Clusters” [Figura D.15]:
Figura D.15. Interfaz Submenú "Sesiones/Clusters"
Submenú “Detalle Sesiones”
A continuación se muestra el prototipo de la interfaz Submenú “Detalle Sesiones” [Figura D.16]:

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 298 -
Figura D.16. Interfaz Submenú "Detalle Sesiones"
Submenú “Páginas/Clusters”
A continuación se muestra el prototipo de la interfaz Submenú “Detalle Sesiones” [Figura D.17]:
Figura D.17. Interfaz Submenú “Páginas/Clusters”
Caso de Uso: Iniciar sesión usuario
A continuación se muestra el prototipo de la interfaz Caso de Uso: Iniciar sesión usuario [Figura D.18]:

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 299 -
Figura D.18. Interfaz Caso de Uso: Iniciar sesión usuario
Caso de Uso: Registrar usuario
A continuación se muestra el prototipo de la interfaz Caso de Uso: Registrar usuario [Figura D.19]:
Figura D.19. Interfaz Caso de Uso: Registrar usuario
Caso de Uso: Crear proyecto
A continuación se muestra el prototipo de la interfaz Caso de Uso: Crear proyecto [Figura D.20]:
Figura D.20. Interfaz Caso de Uso: Crear proyecto
Caso de Uso: Seleccionar proyecto
A continuación se muestra el prototipo de la interfaz Caso de Uso: Seleccionar proyecto [Figura D.21]:

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 300 -
Figura D.21. Interfaz Caso de Uso: Seleccionar proyecto
Caso de Uso: Eliminar proyecto
A continuación se muestra el prototipo de la interfaz Caso de Uso: Eliminar proyecto [Figura D.22]:
Figura D.22. Interfaz Caso de Uso: Eliminar proyecto
Caso de Uso: Subir archivo de log
A continuación se muestra el prototipo de la interfaz Caso de Uso: Subir archivo de log [Figura D.23]:
Figura D.23. Interfaz Caso de Uso: Subir archivo de log

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 301 -
Caso de Uso: Cargar y pre-procesar archivo de log
A continuación se muestra el prototipo de la interfaz Caso de Uso: Cargar y pre-procesar archivo de log [Figura D.24]:
Figura D.24. Interfaz Caso de Uso: Cargar y pre-procesar archivo de log
Caso de Uso: Ver archivo de log cargado
A continuación se muestra el prototipo de la interfaz Caso de Uso: Ver archivo de log cargado [Figura D.25]:
Registros de Log Cargados del Usuario usuario en el Proyecto proyecto
IP Authuser Fecha y Hora Página
192.168.1.101 - 2005-05-22 07:15:06.0 /página1.php
192.168.1.101 - 2005-05-22 07:18:56.0 /página2.php
192.168.1.102 - 2005-05-22 07:19:02.0 /página2.php
192.168.1.101 - 2005-05-22 07:19:04.0 /página1.php
192.168.1.101 - 2005-05-22 07:20:45.0 /página3.php
192.168.1.103 usuario 2005-05-22 07:21:15.0 /página1.php
192.168.1.103 usuario 2005-05-22 07:23:17.0 /página3.php

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 302 -
Registros de Log Cargados del Usuario usuario en el Proyecto proyecto
192.168.1.101 - 2005-05-22 07:23:35.0 /página3.php
192.168.1.105 - 2005-05-22 07:23:43.0 /página6.php
192.168.1.105 - 2005-05-22 07:23:45.0 /página1.php
192.168.1.105 - 2005-05-22 07:24:01.0 /página1.php
192.168.1.102 - 2005-05-22 07:24:07.0 /página1.php
192.168.1.102 - 2005-05-22 07:59:02.0 /página2.php
192.168.1.102 - 2005-05-22 07:59:03.0 /página2.php
Figura D.25. Interfaz Caso de Uso: Ver archivo de log cargado
Caso de Uso: Construir sesiones de usuario
A continuación se muestra el prototipo de la interfaz Caso de Uso: Construir sesiones de usuario [Figura D.26]:
Figura D.26. Interfaz Caso de Uso: Construir sesiones de usuario

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 303 -
Caso de Uso: Agrupar usuarios utilizando red neuronal SOM
A continuación se muestra el prototipo de la interfaz Caso de Uso: Agrupar usuarios utilizando red neuronal SOM [Figura D.27]:
Figura D.27. Interfaz Caso de Uso: Agrupar usuarios utilizando red neuronal SOM
Caso de Uso: Agrupar usuarios utilizando K-Means
A continuación se muestra el prototipo de la interfaz Caso de Uso: Agrupar usuarios utilizando K-Means [Figura D.28]:
Figura D.28. Interfaz Caso de Uso: Agrupar usuarios utilizando K-Means

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 304 -
Caso de Uso: Ver cantidad de sesiones en cada cluster descubierto
A continuación se muestra el prototipo de la interfaz Caso de Uso: Ver cantidad de sesiones en cada cluster descubierto [Figura D.29]:
Figura D.29. Interfaz Caso de Uso: Ver cantidad de sesiones en cada cluster descubierto
Además, se mostrara un gráfico de torta, separando proporcionalmente cada porción en base al porcentaje de sesiones en cada cluster.
Caso de Uso: Ver detalle de sesiones y cluster al cual pertenecen
A continuación se muestra el prototipo de la interfaz Caso de Uso: Ver detalle de sesiones y cluster al cual pertenecen [Figura D.30]:
Figura D.30. Interfaz Caso de Uso: Ver detalle de sesiones y cluster al cual pertenecen

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 305 -
Caso de Uso: Ver porcentaje de acceso a cada página por los usuarios de cada cluster
A continuación se muestra el prototipo de la interfaz Caso de Uso: Ver porcentaje de acceso a cada página por los usuarios de cada cluster [Figura D.31]:
Figura D.31. Interfaz Caso de Uso: Ver porcentaje de acceso a cada página por los usuarios de cada
cluster
D.4.3.4. Tarea DSI 3.4: Revisión de Subsistemas de Diseño e Interfaces
No existen subsistemas.
D.4.4. Actividad DSI 4: Diseño de Clases
D.4.4.1. Tarea DSI 4.1: Identificación de Clases Adicionales

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 306 -
Las clases identificadas en el sistema son:
• LoginBean
• UserBean
• CreateUserBean
• CreateProjectBean
• DeleteProjectBean
• LogCleanerBean
• LogFileUploadBean
• LogLoaderBean
• PageCounterBean
• LogViewBean
• SessionMakerBean
• SessionSaver
• InputMakerBean
• SOMBean
• BinarySessionClusterBean
• FileBean
• ClusterCounterBean
• PagesInClustersBean
• KMeansBean
• NumericSessionClusterBean
• ClusterCounterGraphBean
• SessionsClusterViewBean
• PagesInClustersViewBean
• FilesViewBean
• LogFilesViewBean
• LogBean
Entre las clases BinarySessionClusterBean y NumericSessionClusterBean existe la clase SessionClusterBean de la cual heredan las dos primeras.
D.4.4.2. Tarea DSI 4.2: Identificación de Atributos de las Clases

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 307 -
Clase LoginBean
Atributos • Connection conn
• PreparedStatement pstm
• String user
• String pass
Clase UserBean
Atributos • Connection conn
• PreparedStatement pstm
• String user
• String project
• ResultSet rsProjects
• boolean moreProjects
Clase CreateUserBean
Atributos • Connection conn
• PreparedStatement pstm
• String user
• String pass
Clase CreateProjectBean
Atributos • Connection conn
• PreparedStatement pstm
• String user
• String project
• String description

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 308 -
Clase DeleteProjectBean
Atributos • Connection conn
• PreparedStatement pstm
• String user
• String project
Clase LogCleanerBean
Atributos • Connection conn
• PreparedStatement pstm
• String user
• String project
• int cleaneds

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 309 -
Clase LogFileUploadBean
Atributos • Connection conn
• PreparedStatement pstm
• String logFile
• String user
• String savePath
• String filepath
• String filename
• String contentType
• Dictionary fields
• HttpServletRequest request
Clase LogLoaderBean
Atributos • Connection conn
• PreparedStatement pstm
• String inputFile
• String[] pageExtensions
• String[] validsStatus
• String[] idsPage
• int hits
• String user
• String project
• int ID
• String savePath
• int typeLog

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 310 -
Clase PageCounterBean
Atributos • Connection conn
• PreparedStatement pstm
• String user
• String project
• int pages
Clase LogViewBean
Atributos • Connection conn
• PreparedStatement pstm
• String user
• String project
• ResultSet rsLogs
• boolean moreLogs
• int logsPerPage
• int currentLog
Clase SessionMakerBean
Atributos • Connection conn
• PreparedStatement pstm
• String user
• String project
• int minPagesInSession
• long timeoutSession
• int sessionsCount
• int minPageFrequency

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 311 -
Clase SessionSaver
Atributos • Connection conn
• PreparedStatement pstm
• String user
• String project
• String lastIP
• String lastAuthuser
• String lastTimestamp
• String firstTimestamp
• long timeoutSession
• long maxTimeSession
• int ID
• int sequence
• int sessionsCount
• int minPagesInSession
• String pagesWaiting[]

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 312 -
Clase InputMakerBean
Atributos • Connection conn
• String user
• String project
• FileOutputStream fosSOM
• FileOutputStream fosKMeans
• int pagesCount
• boolean session[]
• int sessionsSOM
• int sessionsKMeans
• String SOMFilename
• String KMeansFilename
• boolean SOMEnabled
• boolean KMeansEnabled
Clase SOMBean
Atributos • NeuralNet nnet
• FileInputSynapse inputStream
• FileOutputSynapse outputSynapse
• String inputFilename
• String outputFilename
• int dimClusters
• int columns
• int patterns
• int trainingCicles

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 313 -
Clase SessionClusterBean
Atributos • Connection conn
• PreparedStatement pstm
• String user
• String project
• PreparedStatement pstmDelete
• String filename
• String type
• int countSessions
Clase BinarySessionClusterBean
Atributos • int countSessions
Clase FileBean
Atributos • Connection conn
• PreparedStatement pstm
• String user
• String project
• String file
• String type
• String basePath
• String savePath
• String description
• String filePath

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 314 -
Clase ClusterCounterBean
Atributos • Connection conn
• PreparedStatement pstm
• String user
• String project
• PreparedStatement pstmInsert
• String type
• String count
• ResultSet rsClusters
• boolean moreClusters
Clase PagesInClustersBean
Atributos • Connection conn
• String user
• String project
• PreparedStatement pstmDelete
• PreparedStatement pstmInsert
• PreparedStatement pstmQuery
• PreparedStatement pstmQuerySessionsInCluster
• String type

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 315 -
Clase KmeansBean
Atributos • String inputFilename
• String outputFilename
• int K
• int columns
• int patterns
• SimpleKMeans kmeans
Clase NumericSessionClusterBean
Atributos • int countSessions
Clase ClusterCounterGraphBean
Atributos • double[] data
• String[] labels
• ChartDirector.PieChart chart
• String path

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 316 -
Clase SessionsClusterViewBean
Atributos • Connection conn
• PreparedStatement pstm
• String user
• String project
• String type
• ResultSet rsSessions
• boolean moreSessions
• int sessionsPerPage
• int currentSession
Clase PagesInClustersViewBean
Atributos • Connection conn
• PreparedStatement pstm
• String user
• String project
• String type
• PreparedStatement pstmClusters
• ResultSet rsPages
• boolean morePages
• ResultSet rsClusters
• boolean moreClusters
• int cluster
• int minPercentage
• int maxPagesPerCluster

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 317 -
Clase FilesViewBean
Atributos • Connection conn
• PreparedStatement pstm
• String user
• String project
• String type
• ResultSet rsFiles
• boolean moreFiles
Clase LogFilesViewBean
Atributos • Connection conn
• PreparedStatement pstm
• String user
• ResultSet rsLogs
• boolean moreLogs
Clase LogBean
Atributos • String IP
• String authuser
• String page
• String timestamp
D.4.4.3. Tarea DSI 4.3: Identificación de Operaciones de las Clases y Descripción de sus Métodos

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 318 -
LoginBean
Clase utilizada para iniciar la sesión a un usuario en la herramienta.
Constructor Summary
LoginBean() Constructor de la clase LoginBean.
Method Summary
java.lang.String getUser() Obtiene el nombre de usuario utilizado.
boolean isValidUser() Intenta autenticar al usuario, devolviendo si es un usuario valido o no.
void setPass(java.lang.String password) Setea la contraseña del usuario.
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.
UserBean
Clase que se encarga del manejo de la información de un usuario y sus proyectos.
Constructor Summary
UserBean() Constructor de la clase UserBean.
Method Summary
java.lang.String getLogCount() Calcula la cantidad de registros de log cargados en el proyecto actual.
java.lang.String getNextDescription() Obtiene la descripción del proyecto siguiente.
java.lang.String getNextProject()

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 319 -
Method Summary Obtiene el nombre del siguiente proyecto.
java.lang.String getProject() Obtiene el nombre del proyecto utilizado.
java.lang.String getProjects() Obtiene todos los proyectos del usuario.
java.lang.String getSessionCount() Obtiene la cantidad de sesiones en el proyecto actual.
java.lang.String getUser() Obtiene el nombre de usuario utilizado.
void goFirstProject() Se sitia en el primer proyecto del usuario.
boolean hasNextProject() Indica si existen mas proyectos.
boolean isSetProject() Indica si existe seteado un proyecto.
void setProject(java.lang.String projectName) Setea el nombre del proyecto que se utilizara.
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.
void unsetProject() Des-setea el proyecto actual.
CreateUserBean
Clase utilizada para la creación de nuevos usuarios.
Constructor Summary
CreateUserBean() Contructor de la clase CreateUserBean, encargado de la creación de nuevos usuarios.
Method Summary

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 320 -
boolean createNewUser() Crea un nuevo usuario, si fueron ya seteados el nombre de usuario y la contraseña.
java.lang.String getPassword() Obtiene la contraseña utilizada.
java.lang.String getUser() Obtiene el nombre de usuario utilizado.
void setPassword(java.lang.String pass) Setea la contraseña del usuario a crear.
void setUser(java.lang.String userName) Setea el nombre de usuario que se creara.
CreateProjectBean
Clase utilizada para la creación de un nuevo proyecto.
Constructor Summary
CreateProjectBean() Contructor de la clase CreateProjectBean, utilizada para la creación de un nuevo proyecto.
Method Summary
boolean createNewProject() Crea un nuevo proyecto, si ha sido seteado el nombre del usuario y el nombre del proyecto a crear.
java.lang.String getDescription() Obtiene la descripción utilizada.
java.lang.String getNewProject() Crea un nuevo proyecto, si ha sido seteado el nombre del usuario y el nombre del proyecto a crear.
java.lang.String getProject() Obtiene el nombre del proyecto utilizado.
java.lang.String getUser() Obtiene el nombre de usuario utilizado.
void setDescription(java.lang.String description)

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 321 -
Setea la descripción del proyecto a crear.
void setProject(java.lang.String projectName) Setea el nombre del proyecto que se creara.
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.
DeleteProjectBean
Clase utilizada para la eliminación de proyectos.
Constructor Summary
DeleteProjectBean() Contructor de la clase DeleteProjectBean, encargada de eliminar un proyecto y todo los elementos asociados al mismo.
Method Summary
boolean deleteProject() Borra el proyecto, si fueron seteados el nombre de usuario y el proyecto.
java.lang.String getDeleteProject() Borra el proyecto, si fueron seteados el nombre de usuario y el proyecto.
java.lang.String getProject() Obtiene el nombre del proyecto utilizado.
java.lang.String getUser() Obtiene el nombre de usuario utilizado.
void setProject(java.lang.String projectName) Setea el nombre del proyecto que se eliminara.
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.
LogCleanerBean
Clase utilizada para borrar todo los registros de log de un proyecto.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 322 -
Constructor Summary
LogCleanerBean() Constructor de la clase LogCleanerBean, encargada de borrar todos los registros de log de un proyecto.
Method Summary
void clean() Borra todo el log de un proyecto.
java.lang.String getCleaneds() Si toda la información necesaria esta seteada, borra todos los registros de log de la base de datos para un proyecto de un usuario.
java.lang.String getProject() Obtiene el nombre del proyecto utilizado.
java.lang.String getUser() Obtiene el nombre de usuario utilizado.
static void main(java.lang.String[] args)
void setProject(java.lang.String projectName) Setea el nombre del proyecto que se utilizara.
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.
LogFileUploadBean
Clase utilizada para guardar en la base de datos información sobre un archivo de log y copiar el archivo al servidor.
Method Summary
void doUpload(javax.servlet.http.HttpServletRequest request) Sube el archivo al servidor.
java.lang.String getContentType() Obtiene el tipo de contenido del archivo.
java.lang.String getFieldsValues() Obtiene todos los campos con sus valores.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 323 -
java.lang.String getFieldValue(java.lang.String fieldName) Obtiene el valor de un campo, cuyo nombre es pasado por parámetro.
java.lang.String getFilename() Obtiene el nombre del archivo a copiar.
java.lang.String getFilepath() Obtiene el path donde se copiara el archivo.
java.lang.String getInput() Obtiene el nombre del archivo de log utilizado.
boolean getUpload() Si los atributos necesarios fueron seteados, copia el archivo al servidor y carga la información del archivo en la base de datos.
java.lang.String getUser() Obtiene el nombre de usuario utilizado.
private void setContentType(java.lang.String s) Setea el tipo de contenido a partir del string enviado por el cliente al querer subir el archivo.
private void setFilename(java.lang.String s) Setea el nombre del archivo.
void setLogFile(java.lang.String filename) Setea el nombre del archivo de log.
void setRequest(javax.servlet.http.HttpServletRequest request) Setea el objeto HttpServletRequest a utilizar.
void setSavePath(java.lang.String savePath) Setea el path donde se copiara el archivo.
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.
LogLoaderBean
Clase utilizada para leer el archivo de log y obtener la información del mismo para almacenarla en la base de datos.
Constructor Summary
LogLoaderBean() Constructor de la clase LogLoader, encargada de cargar todo un log en la tabla log.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 324 -
Method Summary
private static java.lang.String
getExtension(java.lang.String url) Obtiene la extension de la página de una url.
java.lang.String getExtensions() Obtiene las extensiones, separadas por coma.
java.lang.String getHitsSaves() Obtiene la cantidad de registros guardados en la tabla de logs.
java.lang.String getIdsPage() Obtiene las variables que identifican páginas distintas, separadas por coma.
java.lang.String getInput() Obtiene el nombre del archivo de log.
java.lang.String getLoad() Si toda la informacion necesaria esta seteada, carga el archivo de log en la tabla de logs.
private int getMaxID() Obtiene el maximo ID de registro de log para un proyecto de un usuario.
private java.lang.String getPage(java.lang.String url) Obtiene la página junto con sus variables identificadoras de página, a partir de una url.
java.lang.String getProject() Obtiene el nombre del proyecto utilizado.
java.lang.String getStatusCodes() Obtiene los codigos de error, separados por coma.
private
static java.lang.String getTimestamp(java.lang.String datetime) Devuelve la marca de tiempo.
java.lang.String getTypeLog() Obtiene el tipo de log.
java.lang.String getUser() Obtiene el nombre de usuario utilizado.
private static java.util.Hashtable
initMonths () Inicializa la tabla de meses y sus numeros.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 325 -
private boolean isIdPage(java.lang.String nameVar) Devuelve si un nombre de variable es identificadora de página o no.
private boolean isPageExtension(java.lang.String extension) Checkea si una extension corresponde con la de una página valida.
private boolean isValidStatus(java.lang.String status) Devuelve si un status devuelto por el servidor es valido o no.
void load(java.lang.String inputFilename) Carga todo un log en la tabla log.
static void main(java.lang.String[] args)
private static int min(int nro1, int nro2) Devuelve el minimo entre dos numeros.
private static java.lang.String
monthToNumber(java.lang.String month) Convierte un mes a su numero.
private void saveRegister(java.lang.String register) Graba un registro en la tabla de log, si es considerado valido.
void setExtensions(java.lang.String values) Setea las extensiones de los archivos considerados de páginas, o las extensiones que se necesitan tener en cuenta.
void setIdsPage(java.lang.String values) Setea las variables que identifican páginas distintas.
void setInput(java.lang.String inputFilename) Setea el nombre del archivo de log.
void setProject(java.lang.String projectName) Setea el nombre del proyecto que se utilizara.
void setStatusCodes(java.lang.String values) Setea los codigos de error a tener en cuenta.
void setTypeLog(java.lang.String type) Setea el tipo de log.
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.
PageCounterBean

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 326 -
Clase encargada de cargar todas las páginas encontradas en un archivo de log.
Constructor Summary
PageCounterBean() Constructor de la clase PageCounterBean, encargada de numerar todas las páginas encontradas en un log.
Method Summary
java.lang.String getPages() Realiza el conteo de las páginas que se encuentran en los log cargados en un proyecto.
java.lang.String getProject() Obtiene el nombre del proyecto utilizado.
java.lang.String getUser() Obtiene el nombre de usuario utilizado.
static void main(java.lang.String[] args)
void setProject(java.lang.String projectName) Setea el nombre del proyecto que se utilizara.
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.
void start() Comienza el conteo de las páginas que aparecen en el log
LogViewBean
Clase encargada de obtener el detalle de todos los registros de log cargados en la base de datos por un proyecto de un usuario.
Constructor Summary
LogViewBean() Contructor de la clase LogViewBean.
Method Summary

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 327 -
java.lang.String getCurrentLog() Obtiene el archivo de log utilizado.
java.lang.String getLogsPerPage() Obtiene la cantidad de registros de log por página utilizada.
LogBean getNextLog() Obtiene el registro de log actual.
java.lang.String getProject() Obtiene el nombre del proyecto utilizado.
java.lang.String getUser() Obtiene el nombre de usuario utilizado.
void goFirstLog() Se posiciona en el primer registro de log del proyecto actual.
boolean hasNextLog() Indica si existe un proximo registro de log.
static void main(java.lang.String[] args)
void setCurrentLog(java.lang.String log) Setea el archivo de log a utilizar.
void setLogsPerPage(java.lang.String logs) Setea la cantidad de registros de log a obtener por página.
void setProject(java.lang.String projectName) Setea el nombre del proyecto que se utilizara.
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.
SessionMakerBean
Clase SessionMakerBean encargada de armar las sesiones a partir de los registros de log almacenados en la base de datos.
Constructor Summary
SessionMakerBean() Constructor de la clase SessionMakerBean, encargada de armar las sesiones a partir de los registros de log.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 328 -
Method Summary
java.lang.String getMinPageFrequency() Obtiene la frecuencia mínima de página.
java.lang.String getMinPagesInSession() Obtiene la cantidad mínima de páginas en cada sesión.
java.lang.String getProject() Obtiene el nombre del proyecto utilizado.
java.lang.String getSessions() Si toda la información necesaria esta seteada, arma todas las sesiones para un proyecto de un usuario.
java.lang.String getTimeoutSession() Obtiene el timeout de sesión.
java.lang.String getUser() Obtiene el nombre de usuario utilizado.
void make() Arma las sesiones a partir de los registros de la tabla log.
void setMinPageFrequency(java.lang.String frequency) Setea la frecuencia minima de página.
void setMinPagesInSession(java.lang.String pages) Setea la cantidad minima de páginas en cada sesión.
void setProject(java.lang.String projectName) Setea el nombre del proyecto que se utilizara.
void setTimeoutSession(java.lang.String timeout) Setea el timeout de sesión.
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.
SessionSaver
Clase SessionSaver encargada de ir armando las sesiones y guardarlas en la base de datos.
Constructor Summary
SessionSaver() Constructor de la clase SessionSaver, encargada de ir armando las sesiones y guardarlas en la base de datos.
IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 329 -
Method Summary
private static long
getLongTimestamp(java.lang.String timestamp) Obtiene el valor long de un timestamp String.
private int getMaxID() Obtiene el máximo ID de sesión para un proyecto de un usuario.
int getMinPagesInSession() Obtiene la cantidad minima de páginas en cada sesión.
java.lang.String getProject() Obtiene el nombre del proyecto utilizado.
int getSessionsCount() Obtiene la cantidad de sesiones guardadas.
long getTimeoutSession() Obtiene el timeout de sesión.
java.lang.String getUser() Obtiene el nombre de usuario utilizado.
private boolean isNewSession(java.lang.String IP, java.lang.String authuser, java.lang.String page, java.lang.String timestamp) Indica si la información de un registro pertenece a una nueva sesión o pertenece a la misma sesión en proceso.
void save(java.lang.String IP, java.lang.String authuser, java.lang.String page,
java.lang.String timestamp) Graba la información de un registro de log, teniendo en cuenta si pertenece a la misma sesión o a una nueva.
void setMinPagesInSession(int pages) Setea la cantidad minima de páginas en cada sesión.
void setProject(java.lang.String projectName) Setea el nombre del proyecto que se utilizara.
void setTimeoutSession(long timeout) Setea el timeout de sesión.
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.
InputMakerBean

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 330 -
Clase encargada de crear el archivo de sesiones a utilizar como entrada para el proceso de clusterización.
Constructor Summary
InputMakerBean () Constructor de la clase InputMaker, encargada de crear el archivo de sesiones a utilizar como entrada para el proceso de clusterización.
Method Summary
java.lang.String getKMeansEnabled() Obtiene si esta seleccionada la creación del archivo de sesiones de K-means.
java.lang.String getKMeansFile() Obtiene el nombre del archivo de K-Means.
private int getMaxPageID() Devuelve el ID de página mayor.
java.lang.String getProject() Obtiene el nombre del proyecto utilizado.
java.lang.String getSessions() Si están todos los atributos necesarios seteados, crean los archivos de sesiones seleccionados.
java.lang.String getSOMEnabled() Obtiene si esta seleccionada la creación del archivo de sesiones de SOM.
java.lang.String getSOMFile() Obtiene el nombre del archivo de SOM.
java.lang.String getUser() Obtiene el nombre de usuario utilizado.
void make() Arma el archivo de sesiones a partir de la información de las tablas session y page, dejando listo el archivo para el proceso de clusterización.
private void makeSessions(java.sql.ResultSet rs) A partir del resultado de la consulta, setea las páginas de cada sesión.
private void saveInput(boolean[] session) Graba la información de una sesión en el archivo de sesiones.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 331 -
void setKMeansEnabled(java.lang.String enabled) Setea si se quiere crear el archivo de sesiones de K-Means.
void setKMeansFile(java.lang.String name) Setea el nombre del archivo de K-Means.
void setProject(java.lang.String projectName) Setea el nombre del proyecto que se utilizara.
void setSOMEnabled(java.lang.String enabled) Setea si se quiere crear el archivo de sesiones de SOM.
void setSOMFile(java.lang.String name) Setea el nombre del archivo de SOM.
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.
SOMBean
Clase SOMBean encargada de clusterizar las sesiones de usuarios utilizando la red neuronal SOM. Esta clase se implementará utilizando los componentes de redes neuronales artificiales provistos por Joone [Apéndice I].
Constructor Summary
SOMBean() Contructor por defecto.
SOMBean(java.lang.String input, java.lang.String output, int dim) Contructor de la clase SOMBean, encargada de clusterizar las sesiones de usuarios.
Method Summary
void cicleTerminated(org.joone.engine.NeuralNetEvent e) Método que se ejecuta cada vez que termina un ciclo de entrenamiento.
void errorChanged(org.joone.engine.NeuralNetEvent e) Método que se ejecuta cada vez que cambia el error.
java.lang.String getClusters() Realiza la clusterización de los usuarios.
java.lang.String getDim() Obtiene la dimensión del mapa de clusterización.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 332 -
Method Summary
java.lang.String getInput() Obtiene el nombre del archivo de entrada.
java.lang.String getOutput() Obtiene el nombre del archivo de salida.
java.lang.String getTrainingCicles() Obtiene la cantidad de ciclos de entrenamiento a realizar.
private void initNeuralNet () Inicializa la red, creando las capas y las synapsis.
private void interrogate() Calcula a que cluster pertenece cada sesión del archivo de entrada.
void netStarted(org.joone.engine.NeuralNetEvent e) Método que se ejecuta cuando comienza el entrenamiento de la red.
void netStopped(org.joone.engine.NeuralNetEvent e) Método que se ejecuta cuando termina el entrenamiento de la red.
void netStoppedError(org.joone.engine.NeuralNetEvent e, java.lang.String error) Método que se ejecuta cuando termina el entrenamiento de la red, debido a un error.
void save(java.lang.String fileName) Graba la red en el archivo indicado.
void setDim(java.lang.String dim) Setea la dimensión del mapa de clusterización.
void setInput(java.lang.String file) Setea el nombre del archivo de entrada.
void setOutput(java.lang.String file) Setea el nombre del archivo de salida.
void setTrainingCicles(java.lang.String cicles) Setea la cantidad de ciclos de entrenamiento a realizar.
void train (int cicles) Entrena la red utilizando los patrones de entrada.
KMeansBean
Clase encargada de realizar la clusterización mediante K-Means. El algoritmo K-Means se implementará utilizando las clases provistas por Weka [http://www.cs.waikato.ac.nz/ml/weka/].

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 333 -
Constructor Summary
KMeansBean() Constructor por defecto de la clase KMeansBean
KMeansBean(java.lang.String input, java.lang.String output, int k) Contructor de la clase KMeans, encargada de clusterizar las sesiones de usuarios.
Method Summary
java.lang.String getClusters() Si se setearon todos los atributos necesarios, realiza la clusterización de los datos del archivo de entrada, descubriendo la cantidad de clusters indicada y colocando los resultados en el archivo de salida.
java.lang.String getInput() Obtiene el nombre del archivo de entrada utilizado.
java.lang.String getK() Obtiene la cantidad de clusters a descubrir utilizada.
java.lang.String getOutput() Obtiene el nombre del archivo de salida utilizado.
void save(java.lang.String fileName) Graba el modelo generado por K-Means en el archivo indicado.
void setInput(java.lang.String file) Setea el nombre del archivo de entrada.
void setK(java.lang.String k) Setea la cantidad de clusters a descubrir.
void setOutput(java.lang.String file) Setea el nombre del archivo de salida.
SessionClusterBean
Clase utilizada para contabilizar los clusters descubiertos y cargar esta información en la base de datos.
Constructor Summary
SessionClusterBean() Contructor encargado de inicializar la conexión con la base de datos y preparar las consultas que se realizaran en ella.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 334 -
Method Summary
void count(java.lang.String inputFilename) Realiza el conteo de los clusters descubiertos tomando como entrada el archivo donde se encuentra a que cluster pertenece cada sesión.
java.lang.String getCount() Realiza el conteo de los clusters descubiertos, si todos los atributos necesarios han sido seteados, devolviendo la cantidad de sesiones contabilizadas.
java.lang.String getFile() Obtiene el nombre del archivo donde se encuentran las sesiones con el cluster al cual pertenecen.
java.lang.String getProject() Obtiene el nombre del proyecto utilizado.
java.lang.String getType() Obtiene el tipo de clustering utilizado.
java.lang.String getUser() Obtiene el nombre de usuario utilizado.
void setFile(java.lang.String name) Setea el nombre del archivo donde se encuentran las sesiones con el cluster al cual pertenecen.
void setProject(java.lang.String projectName) Setea el nombre del proyecto que se utilizara.
void setType(java.lang.String typeClustering) Setea el tipo de clustering que se realizo, cuyo resultado se encuentra en el archivo a procesar.
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.
BinarySessionClusterBean
Clase encargada de cargar en la base de datos la información de clusterización almacenada en un archivo, que posee en cada línea números binarios indicando si la sesión pertenece o no al cluster correspondiente a la posición de dicho numero binario.
Constructor Summary

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 335 -
BinarySessionClusterBean()
Method Summary
void count(java.lang.String inputFilename) Realiza el conteo de los clusters descubiertos tomando como entrada el archivo donde se encuentra a que cluster pertenece cada sesión.
NumericSessionClusterBean
Clase encargada de cargar en la base de datos la información de clusterización almacenada en un archivo, que posee en cada línea el número de cluster al cual pertenece la sesión.
Constructor Summary
NumericSessionClusterBean() Constructor por defecto de la clase NumericSessionClusterBean.
Method Summary
void count(java.lang.String inputFilename) Realiza el conteo de los clusters descubiertos tomando como entrada el archivo donde se encuentra a que cluster pertenece cada sesión.
FileBean
Clase utilizada para guardar información en la base de datos sobre los archivo utilizados en la herramienta.
Constructor Summary
FileBean() Constructor de la clase FileBean.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 336 -
Method Summary
java.lang.String getDescription() Obtiene la descripción del archivo utilizado.
java.lang.String getFile() Obtiene el nombre del archivo utilizado.
java.lang.String getFilePath() Obtiene el path y el nombre del archivo que se cargo.
java.lang.String getProject() Obtiene el nombre del proyecto utilizado.
java.lang.String getType() Obtiene el tipo de archivo a cargar.
java.lang.String getUser() Obtiene el nombre de usuario utilizado.
private
static java.util.Hashtable initPaths() Inicializa la tabla de tipos de archivos y la carpeta donde se almacenaran.
void setDescription(java.lang.String description) Setea la descripción del archivo.
void setFile(java.lang.String filename) Setea el nombre del archivo.
void setFilePath(java.lang.String set) Si todos los atributos necesarios fueron seteados, setea el path y el nombre del archivo donde se debe copiar el archivo y carga la información del archivo en la base de datos.
void setProject(java.lang.String projectName) Setea el nombre del proyecto que se utilizara.
void setSavePath(java.lang.String savePath) Setea el path donde debe ser guardado el archivo.
void setType(java.lang.String typeFile) Setea el tipo de archivo a cargar.
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.
ClusterCounterBean

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 337 -
Clase utilizada para contabilizar la cantidad de sesiones existentes en cada cluster descubierto.
Constructor Summary
ClusterCounterBean() Constructor de la clase ClusterCounter, encargada de contabilizar la cantidad de sesiones en cada cluster descubierto.
Method Summary
void count() Realiza el conteo de la cantidad de sesiones en cada cluster descubierto
int getClustersCount() Obtiene la cantidad de clusters descubiertos.
java.lang.String getCount() Realiza el conteo de la cantidad de sesiones en cada cluster descubierto, si todos los atributos necesarios han sido seteados, devolviendo la cantidad de sesiones en cada cluster.
java.lang.String getNextCluster() Obtiene el numero del próximo cluster.
java.lang.String getNextClusterSessions() Obtiene la cantidad de sesiones del próximo cluster.
java.lang.String getProject() Obtiene el nombre del proyecto utilizado.
java.lang.String getType() Obtiene el tipo de clustering utilizado.
java.lang.String getUser() Obtiene el nombre de usuario utilizado.
void goFirstCluster() Inicializa para la lectura de la cantidad de sesiones en cada cluster descubierto.
boolean hasNextCluster() Indica si existe otro cluster.
static void main(java.lang.String[] args)

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 338 -
void setProject(java.lang.String projectName) Setea el nombre del proyecto que se utilizara.
void setType(java.lang.String typeClustering) Setea el tipo de clustering a utilizar.
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.
PagesInClustersBean
Clase encargada de obtener la información de que páginas aparecen en las sesiones de cada cluster.
Constructor Summary
PagesInClustersBean() Constructor de la clase PagesInClustes, encargada de obtener la información de que páginas aparecen en las sesiones de cada cluster
Method Summary
private int getMaxCluster() Obtiene la cantidad de clusters existentes.
java.lang.String getPages() Si los parametros necesarios han sido seteados, comienza a obtener la información de los clusters.
java.lang.String getProject() Obtiene el nombre del proyecto utilizado.
java.lang.String getType() Obtiene el tipo de clusters que se están analizando.
java.lang.String getUser() Obtiene el nombre de usuario utilizado.
void setProject(java.lang.String projectName) Setea el nombre del proyecto que se utilizara.
void setType(java.lang.String typeClustering) Setea el tipo de clusters que se están analizando.
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 339 -
void start() Comienza a cargar en la tabla pageInCluster, las tuplas (página, cluster, porcentaje), correspondiente a si una página aparece en las sesiones de un cluster y el porcentaje de sesiones de ese cluster en que la página aparece.
ClusterCounterGraphBean
Clase encargada de generar los gráficos de porcentajes de sesiones en cada cluster. Se implementará utilizando la librería de gráficos Chart Director [http://www.advsofteng.com/].
Constructor Summary
ClusterCounterGraphBean() Constructor de la clase ClusterCounterGraphBean.
Method Summary
double[] getData() Obtiene los datos utilizados en el grafico.
java.lang.String getGraph() Obtiene el path al grafico generado.
java.lang.String[] getLabels() Obtiene las etiquetas del grafico.
java.lang.String getMap() Obtiene el mapa con informacion del grafico generado.
java.lang.String getPath() Obtiene el path base donde se generan los graficos.
void setData(double[] data) Setea los datos a utilizar en el grafico.
void setLabels(java.lang.String[] labels) Setea las etiquetas del grafico.
void setPath(java.lang.String path) Setea el path base donde se generaran los graficos.
SessionsClusterViewBean

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 340 -
Clase encargada de obtener el detalle de las sesiones y a que cluster pertenece cada una.
Constructor Summary
SessionsClusterViewBean() Contructor de la clase SessionsClusterViewBean.
Method Summary
java.lang.String getCurrentSession() Obtiene el identificador de sesión actual.
java.lang.String getNextCluster() Obtiene el numero de cluster de la sesión actual.
java.lang.String getNextSequencePages() Obtiene la secuencia de páginas accedidas en la sesión actual.
java.lang.String getNextSession() Obtiene el identificador de la próxima sesión.
java.lang.String getProject() Obtiene el nombre del proyecto utilizado.
java.lang.String getSessionsPerPage() Obtiene la cantidad de sesiones a mostrar por página.
java.lang.String getType() Obtiene el tipo de clusters que se están analizando.
java.lang.String getUser() Obtiene el nombre de usuario utilizado.
void goFirstSession() Se sitúa en la primera sesión.
boolean hasNextSession() Indica se existen mas sesiones.
void setCurrentSession(java.lang.String session) Setea el identificador de sesión actual.
void setProject(java.lang.String projectName) Setea el nombre del proyecto que se utilizara.
void setSessionsPerPage(java.lang.String sessions) Setea la cantidad de sesiones a mostrar por página.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 341 -
void setType(java.lang.String typeClustering) Setea el tipo de clusters que se están analizando.
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.
PagesInClustersViewBean
Clase que se encarga de obtener la información de las páginas que accedieron los usuarios de cada cluster, indicando el porcentaje de acceso.
Constructor Summary
PagesInClustersViewBean() Constructor de la clase PagesInClustersViewBean.
Method Summary
java.lang.String getCluster() Obtiene el numero de cluster.
java.lang.String getMaxPagesPerCluster() Obtiene la cantidad máxima de páginas por cluster a mostrar.
java.lang.String getMinPercentage() Obtiene el mínimo porcentaje de frecuencia de página a mostrar.
java.lang.String getNextCluster() Obtiene el proximo cluster.
java.lang.String getNextPage() Obtiene la próxima página.
java.lang.String getNextPercentage() Obtiene el proximo porcentaje de página.
java.lang.String getProject() Obtiene el nombre del proyecto utilizado.
java.lang.String getType() Obtiene el tipo de clusters que se están analizando.
java.lang.String getUser() Obtiene el nombre de usuario utilizado.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 342 -
void goFirstCluster() Se sitúa en el primer cluster.
void goFirstPage() Se sitúa en la primera página.
boolean hasNextCluster() Indica se existen mas clusters.
boolean hasNextPage() Indica si existen mas páginas.
void setCluster(java.lang.String clusterNumber) Setea el numero de cluster.
void setMaxPagesPerCluster(java.lang.String pages) Setea la cantidad máxima de páginas por cluster a mostrar.
void setMinPercentage(java.lang.String percentage) Setea el mínimo porcentaje de frecuencia de página a mostrar.
void setProject(java.lang.String projectName) Setea el nombre del proyecto que se utilizara.
void setType(java.lang.String typeClustering) Setea el tipo de clusters que se están analizando.
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.
FilesViewBean
Clase utilizada para obtener todos los archivos de un cierto tipo, para un usuario y proyecto dado.
Constructor Summary
FilesViewBean() Constructor de la clase FilesViewBean.
Method Summary
java.lang.String getNextDescription() Obtiene la descripción del proximo archivo.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 343 -
java.lang.String getNextFile() Obtiene el nombre del proximo archivo.
java.lang.String getProject() Obtiene el nombre del proyecto utilizado.
java.lang.String getType() Obtiene el tipo de archivo utilizado.
java.lang.String getUser() Obtiene el nombre de usuario utilizado.
void goFirstFile() Inicializa para la lectura de todos los archivos de un tipo, para un usuario y proyecto dado.
boolean hasNextFile() Indica si hay mas archivos.
void setProject(java.lang.String projectName) Setea el nombre del proyecto que se utilizara.
void setType(java.lang.String typeFile) Setea el tipo de archivo.
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.
LogFilesViewBean
Clase utilizada para listar todos los archivos de log cargados por un usuario.
Constructor Summary
LogFilesViewBean() Constructor de la clase LogFilesViewBean.
Method Summary
java.lang.String getNextDescription() Obtiene la descripción del proximo archivo de log.
java.lang.String getNextLog() Obtiene el nombre del proximo archivo de log.
java.lang.String getUser()

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 344 -
Obtiene el nombre de usuario utilizado.
void goFirstLog() Inicializa para la lectura de todos los archivos de log de un usuario.
boolean hasNextLog() Indica si hay mas archivos de log.
void setUser(java.lang.String userName) Setea el nombre de usuario que se utilizara.
D.4.4.4. Tarea DSI 4.4: Diseño de la Jerarquía
Se identifico la siguiente jerarquía de clases [Figura D.32]:
Figura D.32. Jerarquía de Clases

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 345 -
A continuación se muestra el Diagrama de Clases de Diseño incluyendo las principales clases del sistema [Figura D.33]:
Figura D.33. Diagrama de Clases de Diseño
D.4.4.5. Tarea DSI 4.5: Especificación de Necesidades de Migración y Carga Inicial de Datos
No es necesaria la migración ni la carga inicial de datos porque no existe un sistema actual desde donde sea necesario adquirir la información almacenada ni tampoco es necesario que el sistema posea datos precargados para su correcto funcionamiento.
D.4.5. Actividad DSI 5: Diseño Físico de Datos
D.4.5.1. Tarea DSI 5.1: Diseño del Modelo Físico de Datos
A continuación se muestra las distintas tablas de la base de datos y la relación existentes entre ellas [Figura D.34]:
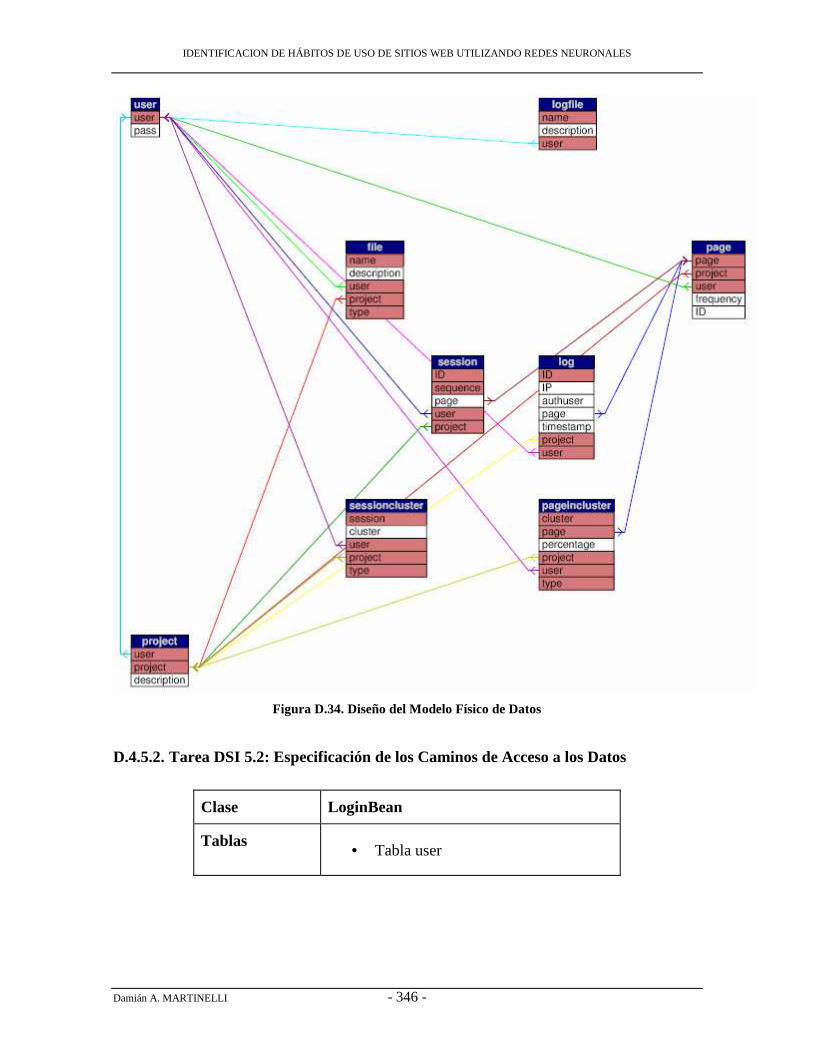
IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 346 -
Figura D.34. Diseño del Modelo Físico de Datos
D.4.5.2. Tarea DSI 5.2: Especificación de los Caminos de Acceso a los Datos
Clase LoginBean
Tablas • Tabla user

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 347 -
Clase UserBean
Tablas • Tabla project
• Tabla log
• Tabla session
Clase CreateUserBean
Tablas • Tabla user
Clase CreateProjectBean
Tablas • Tabla project
Clase DeleteProjectBean
Tablas • Tabla project
Clase LogCleanerBean
Tablas • Tabla log
Clase LogFileUploadBean
Tablas • Tabla logFile

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 348 -
Clase LogLoaderBean
Tablas • Tabla log
Clase PageCounterBean
Tablas • Tabla page
• Tabla log
Clase LogViewBean
Tablas • Tabla log
Clase SessionMakerBean
Tablas • Tabla log
• Tabla page
Clase SessionSaver
Tablas • Tabla session
Clase InputMakerBean
Tablas • Tabla session
• Tabla page

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 349 -
Clase SOMBean
Tablas No utiliza la base de datos, utiliza archivos como entrada y salida de datos.
Clase BinarySessionClusterBean
Tablas • Tabla sessionCluster
Clase FileBean
Tablas • Tabla file
Clase ClusterCounterBean
Tablas • Tabla sessionCluster
Clase PagesInClustersBean
Tablas • Tabla pageInCluster
• Tabla page
• Tabla sessionCluster
Clase KMeansBean
Tablas No utiliza la base de datos, utiliza archivos como entrada y salida de datos.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 350 -
Clase NumericSessionClusterBean
Tablas • Tabla sessionCluster
Clase ClusterCounterGraphBean
Tablas No utiliza la base de datos.
Clase SessionsClusterViewBean
Tablas • Tabla sessionCluster
• Tabla session
Clase PagesInClustersViewBean
Tablas • Tabla pageInCluster
Clase FilesViewBean
Tablas • Tabla file
Clase LogFilesViewBean
Tablas • Tabla logFile
Clase LogBean
Tablas No utiliza la base de datos.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 351 -
D.4.5.3. Tarea DSI 5.3: Optimización del Modelo Físico de Datos
No es necesaria la optimización del modelo físico de datos, ya que la estructura actual es óptima.
D.4.5.4. Tarea DSI 5.4: Especificación de la Distribución de Datos
El motor de base de datos MySQL será instalado en el mismo servidor utilizado por el servidor Web Tomcat.
D.4.6. Actividad DSI 6: Verificación y Aceptación de la Arquitectura del Sistema
D.4.6.1. Tarea DSI 6.1: Verificación de las Especificaciones de Diseño
Se ha verificado todas las especificaciones de diseño y se han encontrado en óptimas condiciones.
D.4.6.2. Tarea DSI 6.2: Análisis de Consistencia de las Especificaciones de Diseño
Se analizó la consistencia de las especificaciones de diseño, comprobando la falta de ambigüedades o duplicación de información.
D.4.6.3. Tarea DSI 6.3: Aceptación de la Arquitectura del Sistema
La arquitectura del sistema ha sido aceptada por los directores de esta tesis.
D.4.7. Actividad DSI 7: Generación de Especificaciones de Construcción
D.4.7.1. Tarea DSI 7.1: Especificación del Entorno de Construcción
El entorno de construcción utilizado será similar al que se empleara para el funcionamiento del sistema una vez concluida su construcción. Además, se debe contar con el ambiente de desarrollo, en este caso, se utilizara la herramienta NetBeans.
D.4.7.2. Tarea DSI 7.2: Definición de Componentes y Subsistemas de Construcción
No existen subsistemas de construcción.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 352 -
D.4.7.3. Tarea DSI 7.3: Elaboración de Especificaciones de Construcción
No existen componentes adicionales a ser especificados.
D.4.7.4. Tarea DSI 7.4: Elaboración de Especificaciones del Modelo Físico de Datos
La base de datos a utilizar será MySQL, con tablas en formato MyISAM.
Los script SQL para la creación de las tablas son:
# # Table structure for table `file` # CREATE TABLE `file` ( `name` varchar(50) NOT NULL default '', `description` varchar(100) default NULL, `user` varchar(20) NOT NULL default '', `project` varchar(20) NOT NULL default '', `type` varchar(20) NOT NULL default '', PRIMARY KEY (`name`,`user`,`project`,`type`) ) TYPE=MyISAM; # -------------------------------------------------------- # # Table structure for table `log` # CREATE TABLE `log` ( `ID` int(11) NOT NULL default '0', `IP` varchar(50) NOT NULL default '', `authuser` varchar(20) NOT NULL default '', `page` varchar(255) NOT NULL default '', `timestamp` timestamp(14) NOT NULL, `project` varchar(20) NOT NULL default '', `user` varchar(20) NOT NULL default '', PRIMARY KEY (`ID`,`project`,`user`) ) TYPE=MyISAM; # -------------------------------------------------------- # # Table structure for table `logfile` #

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 353 -
CREATE TABLE `logfile` ( `name` varchar(50) NOT NULL default '', `description` varchar(100) default NULL, `user` varchar(20) NOT NULL default '', PRIMARY KEY (`name`,`user`) ) TYPE=MyISAM; # -------------------------------------------------------- # # Table structure for table `page` # CREATE TABLE `page` ( `page` varchar(255) NOT NULL default '', `project` varchar(20) NOT NULL default '', `user` varchar(20) NOT NULL default '', `frequency` int(11) NOT NULL default '0', `ID` int(11) NOT NULL default '0', PRIMARY KEY (`page`,`project`,`user`), KEY `ID` (`ID`,`project`,`user`) ) TYPE=MyISAM; # -------------------------------------------------------- # # Table structure for table `pageincluster` # CREATE TABLE `pageincluster` ( `cluster` int(11) NOT NULL default '0', `page` varchar(255) NOT NULL default '0', `percentage` float NOT NULL default '0', `project` varchar(20) NOT NULL default '', `user` varchar(20) NOT NULL default '', `type` varchar(10) NOT NULL default '', PRIMARY KEY (`cluster`,`page`,`project`,`user`,`type`) ) TYPE=MyISAM; # -------------------------------------------------------- # # Table structure for table `project` # CREATE TABLE `project` ( `user` varchar(20) NOT NULL default '', `project` varchar(20) NOT NULL default '',

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 354 -
`description` varchar(100) default NULL, PRIMARY KEY (`user`,`project`) ) TYPE=MyISAM; # -------------------------------------------------------- # # Table structure for table `session` # CREATE TABLE `session` ( `ID` int(11) NOT NULL default '0', `sequence` int(11) NOT NULL default '0', `page` varchar(255) NOT NULL default '', `user` varchar(20) NOT NULL default '', `project` varchar(20) NOT NULL default '', PRIMARY KEY (`ID`,`sequence`,`user`,`project`) ) TYPE=MyISAM; # -------------------------------------------------------- # # Table structure for table `sessioncluster` # CREATE TABLE `sessioncluster` ( `session` int(11) NOT NULL default '0', `cluster` int(11) NOT NULL default '0', `user` varchar(20) NOT NULL default '', `project` varchar(20) NOT NULL default '', `type` varchar(10) NOT NULL default '', PRIMARY KEY (`session`,`user`,`project`,`type`) ) TYPE=MyISAM; # -------------------------------------------------------- # # Table structure for table `user` # CREATE TABLE `user` ( `user` varchar(20) NOT NULL default '', `pass` varchar(20) NOT NULL default '', PRIMARY KEY (`user`) ) TYPE=MyISAM;

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 355 -
D.4.8. Actividad DSI 8: Especificación Técnica del Plan de Pruebas
D.4.8.1. Tarea DSI 8.1: Especificación del Entorno de Pruebas
El entorno utilizado para las pruebas será el mismo que el entorno utilizado para el desarrollo del sistema, el cual se encuentra especificado en las tareas DSI 1.6 y DSI 7.1.
D.4.8.2. Tarea DSI 8.2: Especificación Técnica de Niveles de Prueba
Se realizarán pruebas unitarias sobre cada clase generada y luego se realizarán pruebas de integración de todo el sistema en su conjunto, las mismas se encuentran especificadas en la tarea CSI 3.2.
D.4.8.3. Tarea DSI 8.3: Revisión de la Planificación de Pruebas
Las pruebas unitarias a cada clase serán ejecutadas apenas sea construida la clase, para que una vez que hayan sido realizadas todas las clases del sistema, poder realizar las pruebas del sistema comprobando el correcto funcionamiento en su totalidad, ejecutando un proceso completo de identificación de hábitos de usuarios.
D.4.9. Actividad DSI 9: Establecimiento de Requisitos de Implantación
D.4.9.1. Tarea DSI 9.1: Especificación de Requisitos de Documentación de Usuario
Se realizará en Manual del Usuario del sistema, donde se explicará la utilización del mismo para su correcto uso.
D.4.9.2. Tarea DSI 9.2: Especificación de Requisitos de Implantación
Para la correcta implantación de sistema, el servidor utilizado para alojarlo debe cumplir los siguientes requisitos:
• Procesador con velocidad mayor a 1.5 GHZ.
• Memoria RAM mayor a 512 MB.
• Máquina Virtual Java.
• Servidor Web Tomcat.
• Base de Datos MySQL.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 356 -
• Paquetes Java adicionales para la conexión con la base de datos, para la utilización de los componentes de Joone, para la utilización del algoritmo K-Means de Weka y para la librería generadora de gráficos ChartDirector.
D.4.10. Actividad DSI 10: Aprobación del Diseño del Sistema de Información
D.4.10.1. Tarea DSI 10.1: Presentación y Aprobación del Diseño del Sistema de Información
Se presentó el diseño del sistema de información a los directores de esta tesis, los cuales aprobaron el mismo.
Para comprobar que todos los requisitos enumerados en la Tarea ASI 2.1 hayan sido cubiertos por los casos de uso, se procede a completar la siguiente tabla [Tabla D.7]. Todos los requisitos han sido considerados en uno o más casos de uso.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 357 -
In
icia
r se
sión
usu
ario
Reg
istr
ar u
suar
io
Cre
ar p
roye
cto
Sel
ecci
onar
pro
yect
o
Elim
inar
pro
yect
o
Sub
ir ar
chiv
o de
log
Car
gar
y pr
epoc
esar
log
Ver
log
carg
ado
Con
stru
ir se
sion
es
Agr
upar
usu
ario
s -
SO
M
Agr
upar
usu
ario
s -
K-M
ean
s
Ver
can
t. se
sion
es p
or c
lust
er
Ver
det
alle
ses
ione
s
Ver
por
c. a
cces
o a
cad
a p
ágin
a
Ver
Arc
hivo
R1 – Preprocesamiento Log
X X
R2 – Identificación de Usuarios
X
R3 – Identificación de Sesiones de Usuarios
X
R4 – Agrupamiento de Usuarios con SOM
X
R5 – Agrupamiento de Usuarios con K-Means
X
R6 – Análisis de Resultados
X XX X X
R7 – Usuarios del Sistema
X X
R8 – Proyectos de Usuarios
X X X
R9 – Formatos de Logs
X
R10 – Filtros de Preprocesamiento de Logs
X
R11 – Criterios para la Identificación de Usuarios
X
R12 – Criterios para la Identificación de Sesiones de Usuarios
X
R13 – Características de la Red Neuronal SOM
X
Tabla D.7 Trazabilidades entre el Modelo de Casos de Uso y el Catalogo de Requisitos

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 358 -
D.5. Construcción del Sistema de Información
D.5.1. Actividad CSI 1: Preparación del Entorno de Generación y Construcción
D.5.1.1. Tarea CSI 1.1: Implantación de la Base de Datos Física o Ficheros
Se ejecutaron los scripts SQL definidos en la Tarea DSI 8.4: Elaboración de Especificaciones del Modelo Físico de Datos. Con ello se poseen todas las tablas necesarias para la correcta ejecución del sistema.
D.5.1.2. Tarea CSI 1.2: Preparación del Entorno de Construcción
Se preparó el entorno de construcción especificado en las tareas DSI 1.6 y DSI 7.1, instalando todo el software y todas las librerías necesarias para su correcta construcción.
D.5.2. Actividad CSI 2: Generación del Código de los Componentes y Procedimientos
D.5.2.1. Tarea CSI 2.1: Generación del Código de Componentes
Se posee todo el código fuente, compilado y listo para su ejecución.
D.5.2.2. Tarea CSI 2.2: Generación del Código de los Procedimientos de Operación y Seguridad
Se posee también el código fuente relativo a la autenticación de los distintos usuarios del sistema, compilado y listo para su ejecución.
D.5.3. Actividad CSI 3: Ejecución de las Pruebas Unitarias
D.5.3.1. Tarea CSI 3.1: Preparación del Entorno de las Pruebas
Se posee el entorno preparado para la realización de las pruebas unitarias, las cuales serán realizadas en una computadora personal la cual ejecuta el servidor Web Tomcat y una base de datos MySQL.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 359 -
D.5.3.2. Tarea CSI 3.2: Realización y Evaluación de las Pruebas Unitarias
Se realizaron clases de prueba unitaria para cada clase del sistema. Las mismas son detalladas en el Apéndice V.
Todas las pruebas resultaron satisfactorias. El detalle de ejecución de las pruebas se encuentra en el Apéndice V – Resultados de las Pruebas Unitarias.
D.5.4. Actividad CSI 4: Ejecución de las Pruebas de Integración y del Sistema
D.5.4.1. Tarea CSI 4.1: Preparación del Entorno de las Pruebas de Integración y del Sistema
Se posee el entorno preparado para la realización de las pruebas de integración del sistema, las cuales serán realizadas en un servidor el cual ejecuta el servidor Web Tomcat y una base de datos MySQL.
D.5.4.2. Tarea CSI 4.2: Realización de las Pruebas de Integración y del Sistema
Se realizaron pruebas de integración correspondientes a cada paso del proceso de identificación de hábitos de uso de sitios Web, tomando cada paso de forma independiente y analizando los resultados de cada uno.
A continuación se detalla una muestra de las pruebas de integración realizadas [Tabla D.8, Tabla D.9, Tabla D.10, Tabla D.11]:
Prueba Preprocesamiento del Archivo de Log
Descripción Se realiza el preprocesado de un archivo de log de un servidor Web y se analiza si el preprocesado fue realizado de forma satisfactoria, corroborando que la cantidad de registros finales luego de este paso corresponda realmente con la cantidad de registros que cumplen con la condición de preprocesado utilizada.
Objetivo Determinar si el preprocesado del archivo de log se realiza correctamente y el resultado es el adecuado para la posterior identificación de sesiones de usuarios. Se espera que se obtengan únicamente los registros del log que cumplen con los parámetros utilizados en el preprocesamiento, descartando los registros que

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 360 -
no poseen dichas características.
Parámetros Utilizados • Formato Log: CLF+REFERRER+AGENT
• Extensiones: html, htm
• Código de Estado: 200
Resultado Esperado Mediante el preprocesado manual del archivo de log se identificaron 87 registros que cumplen con los parámetros utilizados.
Tabla D.8. Prueba Preprocesamiento del Archivo de Log
Prueba Construcción de Sesiones de Usuarios
Descripción Se construyen sesiones de usuarios sobre la base de un archivo de log previamente cargado y luego se corrobora que la cantidad de sesiones construidas sea la correcta y que los accesos en las sesiones correspondan con los parámetros utilizados.
Objetivo Determinar la correcta construcción de las sesiones de usuarios con la información obtenida luego del preprocesado del archivo de log. Se espera que se determine la cantidad correcta de sesiones para los parámetros utilizados, y que cada sesión posea las páginas correspondientes.
Parámetros Utilizados • Cantidad Mínima de Páginas en una Sesión: 3
• Timeout de Sesión: 30 minutos
• Frecuencia Mínima de Página en el Log: 1
Resultado Esperado Se determinaron manualmente 21 sesiones de usuarios utilizando los parámetros detallados anteriormente.
Tabla D.9. Prueba Construcción de Sesiones de Usuarios

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 361 -
Prueba Clusterización de Sesiones de Usuarios Utilizando la Red Neuronal Mapa Auto-Organizativo (SOM)
Descripción Se procede a la clusterización de las sesiones de usuarios y se corrobora que todas las sesiones pertenezcan a alguno de los clusters generados.
Objetivo Determinar el correcto funcionamiento de la clusterización de las sesiones de usuarios.
Parámetros Utilizados • Cantidad de ciclos de entrenamiento: 10
• Cardinalidad del mapa de clusterización (NxN): 2
Resultado Esperado Se espera que se asigne a cada sesión de usuario un cluster al cual pertenece y que todas las sesiones pertenezca a uno y solo uno de los 4 clusters a descubrir.
Tabla D.10. Prueba Clusterización de Sesiones de Usuarios con SOM
Prueba Clusterización de Sesiones de Usuarios Utilizando el Algoritmo K-Means
Descripción Se procede a la clusterización de las sesiones de usuarios y se corrobora que todas las sesiones pertenezcan a alguno de los clusters generados.
Objetivo Determinar el correcto funcionamiento de la clusterización de las sesiones de usuarios.
Parámetros Utilizados • Cantidad de clusters a descubrir (K): 4
Resultado Esperado Se espera que se asigne a cada sesión de usuario un cluster al cual pertenece y que todas las sesiones pertenezca a uno y solo uno de los 4 clusters a descubrir.
Tabla D.11. Prueba Clusterización de Sesiones de Usuarios con K-Means
Para la realización de las pruebas del sistema se toma como base las pruebas de integración, las cuales ejecutadas una a continuación de la otra, corresponden con un

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 362 -
proceso completo de identificación de hábitos de uso. La salida de cada proceso es tomado como entrada del siguiente y se corrobora que en todo el proceso los resultados sean los esperados.
D.5.4.3. Tarea CSI 4.3: Evaluación del Resultado de las Pruebas de Integración y del Sistema
Las pruebas de integración y del sistema han sido satisfactorias y han mostrado que el sistema funciona correctamente. El detalle de las mismas se encuentra en el Apéndice V – Pruebas de Integración y de Sistema.
D.5.5. Actividad CSI 5: Elaboración de los Manuales de Usuario
D.5.5.1. Tarea CSI 5.1: Elaboración de los Manuales de Usuario
Se elaboró el Manual de Usuario, el cual se detalla en el Apéndice II.
D.5.6. Actividad CSI 6: Aprobación del Sistema de Información
D.5.6.1. Tarea CSI 6.1: Presentación y Aprobación del Sistema de Información
El sistema de información es presentado y aprobado por los directores de esta tesis.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 363 -
E. Apéndice V: Pruebas
E.1. Pruebas Unitarias ........................................................................................................364 E.2. Resultados Pruebas Unitarias......................................................................................383 E.3. Pruebas de Integración y de Sistema...........................................................................385

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 364 -
E.1. Pruebas Unitarias
Para la realización de las pruebas unitarias se utilizó el framework JUnit (http://junit.org).
A continuación se detallan las clases de prueba para cada una de las clases del sistema.
BinarySessionClusterBeanTest package ar.com.do2.iadh; import junit.framework.*; import java.lang.*; import java.sql.*; public class BinarySessionClusterBeanTest extends TestCase { private Connection conn; protected void setUp() throws Exception { ConfigFileParserBean config = new ConfigFileParserBean(); String urldb = "jdbc:mysql://" + config.getDatabaseServer() + "/" + config.getDatabaseName(); String login = config.getDatabaseUser(); String password = config.getDatabasePass(); Class.forName("com.mysql.jdbc.Driver").newInstance(); conn = DriverManager.getConnection(urldb,login,password); String delete = "DELETE FROM sessionCluster WHERE user='testUser'"; Statement stmt = conn.createStatement(); stmt.execute(delete); } public void testGetCount() throws Exception { BinarySessionClusterBean session = new BinarySessionClusterBean(); session.setUser("testUser"); session.setProject("testProject"); session.setType("SOM"); session.setFile("testBinaryClusters.txt"); //Deben cargarse 5 sesiones Assert.assertEquals(session.getCount(), "5"); } }

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 365 -
ClusterCounterBeanTest package ar.com.do2.iadh; import junit.framework.*; import java.lang.*; import java.sql.*; public class ClusterCounterBeanTest extends TestCase { private Connection conn; private ClusterCounterBean counter; protected void setUp() throws Exception { ConfigFileParserBean config = new ConfigFileParserBean(); String urldb = "jdbc:mysql://" + config.getDatabaseServer() + "/" + config.getDatabaseName(); String login = config.getDatabaseUser(); String password = config.getDatabasePass(); Class.forName("com.mysql.jdbc.Driver").newInstance(); conn = DriverManager.getConnection(urldb,login,password); String delete = "DELETE FROM sessionCluster WHERE user='testUser'"; Statement stmt = conn.createStatement(); stmt.execute(delete); stmt.execute("INSERT INTO sessionCluster (session,cluster,user,project,type) VALUES ('1','1','testUser','testProject','SOM')"); stmt.execute("INSERT INTO sessionCluster (session,cluster,user,project,type) VALUES ('2','1','testUser','testProject','SOM')"); stmt.execute("INSERT INTO sessionCluster (session,cluster,user,project,type) VALUES ('3','1','testUser','testProject','SOM')"); stmt.execute("INSERT INTO sessionCluster (session,cluster,user,project,type) VALUES ('4','2','testUser','testProject','SOM')"); stmt.execute("INSERT INTO sessionCluster (session,cluster,user,project,type) VALUES ('5','2','testUser','testProject','SOM')"); stmt.execute("INSERT INTO sessionCluster (session,cluster,user,project,type) VALUES ('6','2','testUser','anotherProject','SOM')"); stmt.execute("INSERT INTO sessionCluster (session,cluster,user,project,type) VALUES ('7','2','testUser','testProject','KMEANS')"); counter = new ClusterCounterBean(); counter.setUser("testUser"); counter.setProject("testProject"); counter.setType("SOM"); } public void testGetClustersCount() throws Exception { //Deben existir 2 clusters Assert.assertEquals(counter.getClustersCount(), 2);

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 366 -
counter.goFirstCluster(); String cluster = "0"; if (counter.hasNextCluster()) cluster = counter.getNextCluster(); //El primero debe ser el cluster 1 Assert.assertEquals(cluster, "1"); //La cantidad de sesiones del cluster 1 debe ser 3 Assert.assertEquals(counter.getNextClusterSessions(),"3"); cluster = "0"; if (counter.hasNextCluster()) cluster = counter.getNextCluster(); //El segundo debe ser el cluster 2 Assert.assertEquals(cluster, "2"); //La cantidad de sesiones del cluster 2 debe ser 2 Assert.assertEquals(counter.getNextClusterSessions(),"2"); } public void testGoFirstCluster() throws Exception { counter.goFirstCluster(); //Luego de ir al primer cluster debe tener un siguiente Assert.assertTrue(counter.hasNextCluster()); } public void testGetNextCluster() throws Exception { counter.goFirstCluster(); String cluster = "0"; if (counter.hasNextCluster()) cluster = counter.getNextCluster(); //El primero debe ser el cluster 1 Assert.assertEquals(cluster, "1"); //La cantidad de sesiones del cluster 1 debe ser 3 Assert.assertEquals(counter.getNextClusterSessions(),"3"); cluster = "0"; if (counter.hasNextCluster()) cluster = counter.getNextCluster(); //El segundo debe ser el cluster 2 Assert.assertEquals(cluster, "2"); //La cantidad de sesiones del cluster 2 debe ser 2 Assert.assertEquals(counter.getNextClusterSessions(),"2"); } } ConfigFileParserBeanTest package ar.com.do2.iadh; import junit.framework.*;

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 367 -
import java.lang.*; import java.sql.*; public class ConfigFileParserBeanTest extends TestCase { private ConfigFileParserBean config; protected void setUp() { config = new ConfigFileParserBean(); } public void testGetDatabaseServer() { Assert.assertEquals(config.getDatabaseServer(),"testDatabaseServer"); } public void testGetDatabaseName() { Assert.assertEquals(config.getDatabaseName(),"testDatabaseName"); } public void testGetDatabaseUser() { Assert.assertEquals(config.getDatabaseUser(),"testDatabaseUser"); } public void testGetDatabasePass() { Assert.assertEquals(config.getDatabasePass(),"testDatabasePass"); } } CreateProjectBeanTest package ar.com.do2.iadh; import junit.framework.*; import java.lang.*; import java.sql.*; public class CreateProjectBeanTest extends TestCase { private Connection conn; protected void setUp() throws Exception { ConfigFileParserBean config = new ConfigFileParserBean(); String urldb = "jdbc:mysql://" + config.getDatabaseServer() + "/" + config.getDatabaseName(); String login = config.getDatabaseUser(); String password = config.getDatabasePass(); Class.forName("com.mysql.jdbc.Driver").newInstance();

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 368 -
conn = DriverManager.getConnection(urldb,login,password); String delete = "DELETE FROM project WHERE user='testUser'"; Statement stmt = conn.createStatement(); stmt.execute(delete); } public void testCreateNewProject() throws Exception { CreateProjectBean creator = new CreateProjectBean(); creator.setUser("testUser"); creator.setProject("testProject"); creator.setDescription("testProjectDescription"); creator.createNewProject(); String query = "SELECT * FROM project WHERE user='testUser'"; Statement stmt = conn.createStatement(); ResultSet rs = stmt.executeQuery(query); boolean more = rs.next(); //Debe haberse creado un proyecto Assert.assertTrue(more); if (more) { //Debe haberse creado un proyecto de nombre testProject Assert.assertEquals(rs.getString("project"), "testProject"); //Y con descripcion testProjectDescription Assert.assertEquals(rs.getString("description"), "testProjectDescription"); } more = rs.next(); //No debe existir otro proyecto para el usuario testUser Assert.assertTrue(!more); } } CreateUserBeanTest package ar.com.do2.iadh; import junit.framework.*; import java.lang.*; import java.sql.*; public class CreateUserBeanTest extends TestCase { private Connection conn; protected void setUp() throws Exception { ConfigFileParserBean config = new ConfigFileParserBean(); String urldb = "jdbc:mysql://" + config.getDatabaseServer() + "/" + config.getDatabaseName();

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 369 -
String login = config.getDatabaseUser(); String password = config.getDatabasePass(); Class.forName("com.mysql.jdbc.Driver").newInstance(); conn = DriverManager.getConnection(urldb,login,password); String delete = "DELETE FROM user"; Statement stmt = conn.createStatement(); stmt.execute(delete); } public void testCreateNewUser() throws Exception { CreateUserBean creator = new CreateUserBean(); creator.setUser("testUser"); creator.setPassword("testPassword"); creator.createNewUser(); String query = "SELECT * FROM user"; Statement stmt = conn.createStatement(); ResultSet rs = stmt.executeQuery(query); boolean more = rs.next(); //Debe haberse creado un usuario Assert.assertTrue(more); if (more) { //Debe haberse creado un usuario de nombre testUser Assert.assertEquals(rs.getString("user"), "testUser"); //Y con contraseña testPassword Assert.assertEquals(rs.getString("pass"), "testPassword"); } more = rs.next(); //No debe existir otro usuario Assert.assertTrue(!more); } } DeleteProjectBeanTest package ar.com.do2.iadh; import junit.framework.*; import java.lang.*; import java.sql.*; public class DeleteProjectBeanTest extends TestCase { private Connection conn; protected void setUp() throws Exception { ConfigFileParserBean config = new ConfigFileParserBean();

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 370 -
String urldb = "jdbc:mysql://" + config.getDatabaseServer() + "/" + config.getDatabaseName(); String login = config.getDatabaseUser(); String password = config.getDatabasePass(); Class.forName("com.mysql.jdbc.Driver").newInstance(); conn = DriverManager.getConnection(urldb,login,password); Statement stmt = conn.createStatement(); String delete = "DELETE FROM project WHERE user = 'testUser'"; String insert = "INSERT INTO project (user,project,description) VALUES ('testUser','testProject','testProjectDescription')"; stmt.execute(delete); stmt.execute(insert); } public void testDeleteProject() throws Exception { DeleteProjectBean deleteProject = new DeleteProjectBean(); deleteProject.setUser("testUser"); deleteProject.setProject("testProject"); Assert.assertTrue(deleteProject.deleteProject()); } } FileBeanTest package ar.com.do2.iadh; import junit.framework.*; import java.lang.*; import java.sql.*; public class FileBeanTest extends TestCase { private Connection conn; protected void setUp() throws Exception { ConfigFileParserBean config = new ConfigFileParserBean(); String urldb = "jdbc:mysql://" + config.getDatabaseServer() + "/" + config.getDatabaseName(); String login = config.getDatabaseUser(); String password = config.getDatabasePass(); Class.forName("com.mysql.jdbc.Driver").newInstance(); conn = DriverManager.getConnection(urldb,login,password); String delete = "DELETE FROM file"; Statement stmt = conn.createStatement(); stmt.execute(delete); }

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 371 -
public void testSetFilePath() throws Exception { FileBean file = new FileBean(); file.setFile("testFilename"); file.setUser("testUser"); file.setDescription("testFileDescription"); file.setProject("testProject"); file.setType("INPUT-SOM"); file.setFilePath(""); String query = "SELECT * FROM file"; Statement stmt = conn.createStatement(); ResultSet rs = stmt.executeQuery(query); boolean more = rs.next(); //Debe haberse creado un file Assert.assertTrue(more); if (more) { //Debe haberse creado un file para el usuario testUser Assert.assertEquals(rs.getString("user"), "testUser"); //Con el nombre testFilename Assert.assertEquals(rs.getString("name"), "testFilename"); //Para el proyecto testProject Assert.assertEquals(rs.getString("project"), "testProject"); } more = rs.next(); //No debe existir otro file Assert.assertTrue(!more); } } FilesViewBeanTest package ar.com.do2.iadh; import junit.framework.*; import java.lang.*; import java.sql.*; public class FilesViewBeanTest extends TestCase { private Connection conn; private FilesViewBean files; protected void setUp() throws Exception { ConfigFileParserBean config = new ConfigFileParserBean(); String urldb = "jdbc:mysql://" + config.getDatabaseServer() + "/" + config.getDatabaseName(); String login = config.getDatabaseUser(); String password = config.getDatabasePass();

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 372 -
Class.forName("com.mysql.jdbc.Driver").newInstance(); conn = DriverManager.getConnection(urldb,login,password); String delete = "DELETE FROM file"; Statement stmt = conn.createStatement(); stmt.execute(delete); FileBean file = new FileBean(); file.setFile("testFilename"); file.setUser("testUser"); file.setDescription("testFileDescription"); file.setProject("testProject"); file.setType("INPUT-SOM"); file.setFilePath(""); file = new FileBean(); file.setFile("testFilename2"); file.setUser("testUser"); file.setDescription("testFileDescription2"); file.setProject("testProject"); file.setType("INPUT-SOM"); file.setFilePath(""); file = new FileBean(); file.setFile("testFilename3"); file.setUser("testUser"); file.setDescription("testFileDescription3"); file.setProject("testProject2"); file.setType("INPUT-SOM"); file.setFilePath(""); file = new FileBean(); file.setFile("testFilename4"); file.setUser("testUser2"); file.setDescription("testFileDescription4"); file.setProject("testProject"); file.setType("INPUT-SOM"); file.setFilePath(""); file = new FileBean(); file.setFile("testFilename5"); file.setUser("testUser"); file.setDescription("testFileDescription5"); file.setProject("testProject"); file.setType("OUTPUT-SOM"); file.setFilePath(""); files = new FilesViewBean(); files.setUser("testUser"); files.setProject("testProject"); files.setType("INPUT-SOM"); } public void testGoFirstFile() throws Exception {

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 373 -
files.goFirstFile(); //Luego de ir al primer file debe tener un siguiente Assert.assertTrue(files.hasNextFile()); } public void testGetNextFile() throws Exception { files.goFirstFile(); if (files.hasNextFile()) { //El primero debe ser el file testFilename Assert.assertEquals(files.getNextFile(), "testFilename"); } else Assert.assertTrue(false); if (files.hasNextFile()) { //El segundo debe ser el file testFilename2 Assert.assertEquals(files.getNextFile(), "testFilename2"); } else Assert.assertTrue(false); //Solo deben ser dos files Assert.assertTrue(!files.hasNextFile()); } } LogCleanerBeanTest package ar.com.do2.iadh; import junit.framework.*; import java.lang.*; import java.sql.*; public class LogCleanerBeanTest extends TestCase { private LogCleanerBean logCleaner; private Connection conn; protected void setUp() throws Exception { ConfigFileParserBean config = new ConfigFileParserBean(); String urldb = "jdbc:mysql://" + config.getDatabaseServer() + "/" + config.getDatabaseName(); String login = config.getDatabaseUser(); String password = config.getDatabasePass(); Class.forName("com.mysql.jdbc.Driver").newInstance(); conn = DriverManager.getConnection(urldb,login,password);

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 374 -
String delete = "DELETE FROM log WHERE user='testUser' AND project='testProject'"; Statement stmt = conn.createStatement(); stmt.execute(delete); LogLoaderBean log = new LogLoaderBean(); log.setUser("testUser"); log.setProject("testProject"); log.load("testLog.txt"); logCleaner = new LogCleanerBean(); logCleaner.setUser("testUser"); logCleaner.setProject("testProject"); } public void testGetCleaneds() throws Exception { //Deben eliminarse 4 registros de logs Assert.assertEquals(logCleaner.getCleaneds(), "4"); } } LoginBeanTest package ar.com.do2.iadh; import junit.framework.*; import java.lang.*; import java.sql.*; public class LoginBeanTest extends TestCase { protected void setUp() throws Exception { ConfigFileParserBean config = new ConfigFileParserBean(); String urldb = "jdbc:mysql://" + config.getDatabaseServer() + "/" + config.getDatabaseName(); String login = config.getDatabaseUser(); String password = config.getDatabasePass(); Class.forName("com.mysql.jdbc.Driver").newInstance(); Connection conn = DriverManager.getConnection(urldb,login,password); String delete = "DELETE FROM user WHERE user='testUser'"; Statement stmt = conn.createStatement(); stmt.execute(delete); String insert = "INSERT INTO user (user,pass) VALUES ('testUser','testUser')"; stmt.execute(insert); } public void testIsValidUser() throws Exception {

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 375 -
LoginBean login = new LoginBean(); login.setUser("testUser"); login.setPass("testUser"); Assert.assertTrue(login.isValidUser()); login.setPass("wrongPass"); Assert.assertTrue(!login.isValidUser()); login.setUser("wrongUser"); Assert.assertTrue(!login.isValidUser()); login.setPass("testUser"); Assert.assertTrue(!login.isValidUser()); } } LogLoaderBeanTest package ar.com.do2.iadh; import junit.framework.*; import java.lang.*; import java.sql.*; public class LogLoaderBeanTest extends TestCase { private LogLoaderBean log; private Connection conn; protected void setUp() throws Exception { ConfigFileParserBean config = new ConfigFileParserBean(); String urldb = "jdbc:mysql://" + config.getDatabaseServer() + "/" + config.getDatabaseName(); String login = config.getDatabaseUser(); String password = config.getDatabasePass(); Class.forName("com.mysql.jdbc.Driver").newInstance(); conn = DriverManager.getConnection(urldb,login,password); String delete = "DELETE FROM log WHERE user='testUser' AND project='testProject'"; Statement stmt = conn.createStatement(); stmt.execute(delete); log = new LogLoaderBean(); log.setUser("testUser"); log.setProject("testProject"); } public void testLoad() throws Exception { log.load("testLog.txt"); String query = "SELECT COUNT(*) as logs FROM log WHERE user='testUser' AND project='testProject'";

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 376 -
Statement stmt = conn.createStatement(); ResultSet rs = stmt.executeQuery(query); int logs = 0; boolean more = rs.next(); if (more) logs = rs.getInt("logs"); //Deben haberse cargado 4 registros de logs Assert.assertEquals(logs, 4); } } NumericSessionClusterBeanTest package ar.com.do2.iadh; import junit.framework.*; import java.lang.*; import java.sql.*; public class NumericSessionClusterBeanTest extends TestCase { private Connection conn; protected void setUp() throws Exception { ConfigFileParserBean config = new ConfigFileParserBean(); String urldb = "jdbc:mysql://" + config.getDatabaseServer() + "/" + config.getDatabaseName(); String login = config.getDatabaseUser(); String password = config.getDatabasePass(); Class.forName("com.mysql.jdbc.Driver").newInstance(); conn = DriverManager.getConnection(urldb,login,password); String delete = "DELETE FROM sessionCluster WHERE user='testUser'"; Statement stmt = conn.createStatement(); stmt.execute(delete); } public void testGetCount() throws Exception { NumericSessionClusterBean session = new NumericSessionClusterBean(); session.setUser("testUser"); session.setProject("testProject"); session.setType("SOM"); session.setFile("testNumericClusters.txt"); //Deben cargarse 5 sesiones Assert.assertEquals(session.getCount(), "5"); } }

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 377 -
PageCounterBeanTest package ar.com.do2.iadh; import junit.framework.*; import java.lang.*; import java.sql.*; public class PageCounterBeanTest extends TestCase { private Connection conn; protected void setUp() throws Exception { ConfigFileParserBean config = new ConfigFileParserBean(); String urldb = "jdbc:mysql://" + config.getDatabaseServer() + "/" + config.getDatabaseName(); String login = config.getDatabaseUser(); String password = config.getDatabasePass(); Class.forName("com.mysql.jdbc.Driver").newInstance(); conn = DriverManager.getConnection(urldb,login,password); String delete = "DELETE FROM log WHERE user='testUser'"; Statement stmt = conn.createStatement(); stmt.execute(delete); String deletePages = "DELETE FROM page WHERE user='testUser'"; stmt.execute(deletePages); } public void testLoad() throws Exception { LogLoaderBean log = new LogLoaderBean(); log.setUser("testUser"); log.setProject("testProject"); log.load("testLog2.txt"); PageCounterBean counter = new PageCounterBean(); counter.setUser("testUser"); counter.setProject("testProject"); //Deben haberse cargado 4 paginas Assert.assertEquals(counter.getPages(), "4"); } public void testLoadWithIds() throws Exception { LogLoaderBean log = new LogLoaderBean(); log.setUser("testUser"); log.setProject("testProject"); log.setIdsPage("do"); log.load("testLog.txt"); PageCounterBean counter = new PageCounterBean();

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 378 -
counter.setUser("testUser"); counter.setProject("testProject"); //Deben haberse cargado 3 paginas Assert.assertEquals(counter.getPages(), "3"); } } SessionMakerBeanTest package ar.com.do2.iadh; import junit.framework.*; import java.lang.*; import java.sql.*; public class SessionMakerBeanTest extends TestCase { private Connection conn; protected void setUp() throws Exception { ConfigFileParserBean config = new ConfigFileParserBean(); String urldb = "jdbc:mysql://" + config.getDatabaseServer() + "/" + config.getDatabaseName(); String login = config.getDatabaseUser(); String password = config.getDatabasePass(); Class.forName("com.mysql.jdbc.Driver").newInstance(); conn = DriverManager.getConnection(urldb,login,password); String delete = "DELETE FROM log WHERE user='testUser'"; Statement stmt = conn.createStatement(); stmt.execute(delete); String deletePages = "DELETE FROM page WHERE user='testUser'"; stmt.execute(deletePages); } public void testSave() throws Exception { LogLoaderBean log = new LogLoaderBean(); log.setUser("testUser"); log.setProject("testProject"); log.setIdsPage("do"); log.load("testLog.txt"); PageCounterBean counter = new PageCounterBean(); counter.setUser("testUser"); counter.setProject("testProject"); counter.getPages(); SessionMakerBean maker = new SessionMakerBean(); maker.setUser("testUser"); maker.setProject("testProject");

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 379 -
//Deben haberse cargado 2 sesiones Assert.assertEquals(maker.getSessions(), "1"); log = new LogLoaderBean(); log.setUser("testUser"); log.setProject("testProject2"); log.load("testLog2.txt"); counter = new PageCounterBean(); counter.setUser("testUser"); counter.setProject("testProject2"); counter.getPages(); maker = new SessionMakerBean(); maker.setUser("testUser"); maker.setProject("testProject2"); //Deben haberse cargado 2 sesiones Assert.assertEquals(maker.getSessions(), "2"); } } SessionSaverTest package ar.com.do2.iadh; import junit.framework.*; import java.lang.*; import java.sql.*; public class SessionSaverTest extends TestCase { private SessionSaver sessionSaver; private Connection conn; protected void setUp() throws Exception { ConfigFileParserBean config = new ConfigFileParserBean(); String urldb = "jdbc:mysql://" + config.getDatabaseServer() + "/" + config.getDatabaseName(); String login = config.getDatabaseUser(); String password = config.getDatabasePass(); Class.forName("com.mysql.jdbc.Driver").newInstance(); conn = DriverManager.getConnection(urldb,login,password); String delete = "DELETE FROM session WHERE user='testUser' AND project='testProject'"; Statement stmt = conn.createStatement(); stmt.execute(delete); sessionSaver = new SessionSaver(); sessionSaver.setUser("testUser"); sessionSaver.setProject("testProject"); }

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 380 -
public void testSave() throws Exception { //Distincion de sesiones en base al IP sessionSaver.save("127.0.0.1","","/index.php","2004-06-15 15:05:41.0"); sessionSaver.save("127.0.0.1","","/page.php","2004-06-15 15:06:41.0"); sessionSaver.save("127.0.0.1","","/page2.php","2004-06-15 15:07:41.0"); sessionSaver.save("127.0.0.1","","/page3.php","2004-06-15 15:08:41.0"); sessionSaver.save("127.0.0.2","","/index.php","2004-06-15 15:05:41.0"); sessionSaver.save("127.0.0.2","","/page.php","2004-06-15 15:06:41.0"); sessionSaver.save("127.0.0.2","","/page2.php","2004-06-15 15:07:41.0"); sessionSaver.save("127.0.0.2","","/page3.php","2004-06-15 15:08:41.0"); String query = "SELECT MAX(ID) FROM session WHERE user='testUser' AND project='testProject'"; Statement stmt = conn.createStatement(); ResultSet rs = stmt.executeQuery(query); int maxID = 0; boolean more = rs.next(); if (more) maxID = rs.getInt("MAX(ID)"); //Deben haberse creado dos sesiones de usuarios distintas Assert.assertEquals(maxID, 2); //Distincion de sesiones en base al timeout de sesion sessionSaver.save("127.0.0.1","","/index.php","2004-06-15 15:05:41.0"); sessionSaver.save("127.0.0.1","","/page.php","2004-06-15 15:06:41.0"); sessionSaver.save("127.0.0.1","","/page2.php","2004-06-15 15:07:41.0"); sessionSaver.save("127.0.0.1","","/page3.php","2004-06-15 15:08:41.0"); sessionSaver.save("127.0.0.1","","/index.php","2004-06-15 15:48:41.0"); sessionSaver.save("127.0.0.1","","/page.php","2004-06-15 15:06:41.0"); sessionSaver.save("127.0.0.1","","/page2.php","2004-06-15 15:07:41.0"); sessionSaver.save("127.0.0.1","","/page3.php","2004-06-15 15:08:41.0"); rs = stmt.executeQuery(query); maxID = 0; more = rs.next();

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 381 -
if (more) maxID = rs.getInt("MAX(ID)"); //Deben haberse creado dos sesiones mas de usuarios Assert.assertEquals(maxID, 4); //Distincion de sesiones en base al authuser de sesion sessionSaver.save("127.0.0.1","user1","/index.php","2004-06-15 15:05:41.0"); sessionSaver.save("127.0.0.1","user1","/page.php","2004-06-15 15:06:41.0"); sessionSaver.save("127.0.0.1","user1","/page2.php","2004-06-15 15:07:41.0"); sessionSaver.save("127.0.0.1","user1","/page3.php","2004-06-15 15:08:41.0"); sessionSaver.save("127.0.0.1","user2","/index.php","2004-06-15 15:05:41.0"); sessionSaver.save("127.0.0.1","user2","/page.php","2004-06-15 15:06:41.0"); sessionSaver.save("127.0.0.1","user2","/page2.php","2004-06-15 15:07:41.0"); sessionSaver.save("127.0.0.1","user2","/page3.php","2004-06-15 15:08:41.0"); rs = stmt.executeQuery(query); maxID = 0; more = rs.next(); if (more) maxID = rs.getInt("MAX(ID)"); //Deben haberse creado dos sesiones mas de usuarios Assert.assertEquals(maxID, 6); } }
A continuación se muestran los archivos utilizados en las pruebas.
testLog.txt 127.0.0.1 - - [27/Jan/2005:12:25:01 -0300] "GET /css/estilos.css HTTP/1.1" 200 3694 127.0.0.1 - - [27/Jan/2005:12:25:01 -0300] "GET /js/prototype.js HTTP/1.1" 200 61894 127.0.0.1 - - [27/Jan/2005:12:25:01 -0300] "GET /js/scriptaculous.js HTTP/1.1" 200 2322 127.0.0.1 - - [27/Jan/2005:12:25:01 -0300] "GET /js/builder.js HTTP/1.1" 200 4268 127.0.0.1 - - [27/Jan/2005:12:25:01 -0300] "GET /js/dragdrop.js HTTP/1.1" 200 31513 127.0.0.1 - - [27/Jan/2005:12:25:01 -0300] "GET /js/effects.js HTTP/1.1" 200 33802 127.0.0.1 - - [27/Jan/2005:12:25:02 -0300] "GET /js/controls.js HTTP/1.1" 200 28803 127.0.0.1 - - [27/Jan/2005:12:25:02 -0300] "GET /js/slider.js HTTP/1.1" 200 11283 127.0.0.1 - - [27/Jan/2005:12:25:02 -0300] "GET /xajax/xajax_js/xajax.js HTTP/1.1" 200 15903 127.0.0.1 - - [27/Jan/2005:12:25:02 -0300] "GET /js/datepicker.js HTTP/1.1" 200 20057 127.0.0.1 - - [27/Jan/2005:12:25:02 -0300] "GET /js/validate.js HTTP/1.1" 200 3611

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 382 -
127.0.0.1 - - [27/Jan/2005:12:25:02 -0300] "GET /js/js.js HTTP/1.1" 200 10369 127.0.0.1 - - [27/Jan/2005:12:25:02 -0300] "GET /favicon.ico HTTP/1.1" 404 288 127.0.0.1 - - [27/Jan/2005:12:29:06 -0300] "GET /js/prototype.js HTTP/1.1" 200 61894 127.0.0.1 - - [27/Jan/2005:12:29:06 -0300] "GET /css/estilos.css HTTP/1.1" 200 3694 127.0.0.1 - - [27/Jan/2005:12:29:06 -0300] "GET /js/builder.js HTTP/1.1" 200 4268 127.0.0.1 - - [27/Jan/2005:12:29:06 -0300] "GET /js/scriptaculous.js HTTP/1.1" 200 2322 127.0.0.1 - - [27/Jan/2005:12:29:07 -0300] "GET /js/dragdrop.js HTTP/1.1" 200 31513 127.0.0.1 - - [27/Jan/2005:12:29:06 -0300] "GET /js/effects.js HTTP/1.1" 200 33802 127.0.0.1 - - [27/Jan/2005:12:29:07 -0300] "GET /js/slider.js HTTP/1.1" 200 11283 127.0.0.1 - - [27/Jan/2005:12:29:07 -0300] "GET /js/controls.js HTTP/1.1" 200 28803 127.0.0.1 - - [27/Jan/2005:12:29:07 -0300] "GET /js/datepicker.js HTTP/1.1" 200 20057 127.0.0.1 - - [27/Jan/2005:12:29:07 -0300] "GET /xajax/xajax_js/xajax.js HTTP/1.1" 200 15903 127.0.0.1 - - [27/Jan/2005:12:29:07 -0300] "GET /js/js.js HTTP/1.1" 200 10369 127.0.0.1 - - [27/Jan/2005:12:29:07 -0300] "GET /js/validate.js HTTP/1.1" 200 3611 127.0.0.1 - - [27/Jan/2005:12:55:12 -0300] "GET /Main.php?do=listarPagos HTTP/1.1" 302 - 127.0.0.1 - - [27/Jan/2005:12:55:12 -0300] "GET /Main.php?do=loginAdmin HTTP/1.1" 200 2692 127.0.0.1 - - [27/Jan/2005:12:55:19 -0300] "POST /Main.php?do=doLoginAdmin HTTP/1.1" 302 - 127.0.0.1 - - [27/Jan/2005:12:55:20 -0300] "GET /Main.php?do=index HTTP/1.1" 200 2005 127.0.0.1 - - [27/Jan/2005:12:55:32 -0300] "GET /Main.php?do=listarPagos HTTP/1.1" 200 5335 127.0.0.1 - - [27/Jan/2005:12:55:32 -0300] "GET /images/button_edit.png HTTP/1.1" 200 348 127.0.0.1 - - [27/Jan/2005:12:55:32 -0300] "GET /images/button_delete.png HTTP/1.1" 200 244 127.0.0.1 - - [27/Jan/2005:12:56:41 -0300] "GET /Main.php?do=listarPagos HTTP/1.1" 200 5310 127.0.0.1 - - [27/Jan/2005:12:56:41 -0300] "GET /css/estilos.css HTTP/1.1" 304 - 127.0.0.1 - - [27/Jan/2005:12:56:41 -0300] "GET /js/prototype.js HTTP/1.1" 304 - 127.0.0.1 - - [27/Jan/2005:12:56:41 -0300] "GET /js/scriptaculous.js HTTP/1.1" 304 – testLog2.txt 127.0.0.1 - - [15/Jun/2004:15:05:41 -0300] "GET /index.php HTTP/1.1" 200 3694 127.0.0.1 - - [15/Jun/2004:15:06:41 -0300] "GET /page.php HTTP/1.1" 200 3694 127.0.0.1 - - [15/Jun/2004:15:07:41 -0300] "GET /page2.php HTTP/1.1" 200 3694 127.0.0.1 - - [15/Jun/2004:15:08:41 -0300] "GET /page3.php HTTP/1.1" 200 3694 127.0.0.2 - - [15/Jun/2004:15:05:41 -0300] "GET /index.php HTTP/1.1" 200 3694 127.0.0.2 - - [15/Jun/2004:15:06:41 -0300] "GET /page.php HTTP/1.1" 200 3694 127.0.0.2 - - [15/Jun/2004:15:07:41 -0300] "GET /page2.php HTTP/1.1" 200 3694 127.0.0.2 - - [15/Jun/2004:15:08:41 -0300] "GET /page3.php HTTP/1.1" 200 3694

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 383 -
testBinaryClusters.txt 1.0;0.0;0.0;0.0 0.0;0.0;1.0;0.0 0.0;1.0;0.0;0.0 0.0;1.0;0.0;0.0 1.0;0.0;0.0;0.0 testNumericClusters.txt 1 3 2 2 1
E.2. Resultados Pruebas Unitarias
A continuación se detallan los resultados obtenidos en la ejecución de las pruebas unitarias.
java junit.textui.TestRunner ar.com.do2.iadh.SessionSaverTest . Time: 10,188 OK (1 test) java junit.textui.TestRunner ar.com.do2.iadh.LogLoaderBeanTest . Time: 4,594 OK (1 test) java junit.textui.TestRunner ar.com.do2.iadh.CreateUserBeanTest . Time: 4,078 OK (1 test) java junit.textui.TestRunner ar.com.do2.iadh.ClusterCounterBeanTest

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 384 -
... Time: 4,484 OK (3 tests) java junit.textui.TestRunner ar.com.do2.iadh.ConfigFileParserBeanTest .... Time: 1,907 OK (4 tests) java junit.textui.TestRunner ar.com.do2.iadh.CreateProjectBeanTest . Time: 2,468 OK (1 test) java junit.textui.TestRunner ar.com.do2.iadh.DeleteProjectBeanTest . Time: 4,359 OK (1 test) java junit.textui.TestRunner ar.com.do2.iadh.FileBeanTest . Time: 4,047 OK (1 test) java junit.textui.TestRunner ar.com.do2.iadh.FilesViewBeanTest .. Time: 3,969 OK (2 tests) java junit.textui.TestRunner ar.com.do2.iadh.LogCleanerBeanTest . Time: 3,36 OK (1 test)

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 385 -
java junit.textui.TestRunner ar.com.do2.iadh.LoginBeanTest . Time: 3,578 OK (1 test) java junit.textui.TestRunner ar.com.do2.iadh.NumericSessionClusterBeanTest . Time: 4,734 OK (1 test) java junit.textui.TestRunner ar.com.do2.iadh.BinarySessionClusterBeanTest . Time: 4,563 OK (1 test) java junit.textui.TestRunner ar.com.do2.iadh.PageCounterBeanTest .. Time: 4,453 OK (2 tests) java junit.textui.TestRunner ar.com.do2.iadh.SessionMakerBeanTest . Time: 5,515 OK (1 test)
E.3. Pruebas de Integración y de Sistema
A continuación se detalla una muestra de las pruebas de integración y de sistema realizadas, junto con su resultado [Tabla E1], [Tabla E2], [Tabla E3], [Tabla E4]:

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 386 -
Prueba Preprocesamiento del Archivo de Log
Descripción Se realiza el preprocesado de un archivo de log de un servidor Web y se analiza si el preprocesado fue realizado de forma satisfactoria, corroborando que la cantidad de registros finales luego de este paso corresponda realmente con la cantidad de registros que cumplen con la condición de preprocesado utilizada.
Objetivo Determinar si el preprocesado del archivo de log se realiza correctamente y el resultado es el adecuado para la posterior identificación de sesiones de usuarios. Se espera que se obtengan únicamente los registros del log que cumplen con los parámetros utilizados en el preprocesamiento, descartando los registros que no poseen dichas características.
Parámetros Utilizados • Formato Log: CLF+REFERRER+AGENT
• Extensiones: html, htm
• Código de Estado: 200
Resultado Esperado Mediante el preprocesado manual del archivo de log se identificaron 87 registros que cumplen con los parámetros utilizados.
Ejecución La prueba es ejecutada utilizando la clase LogLoaderBean, seteando los parámetros detallados anteriormente, e indicando como archivo de entrada el log a preprocesar.
Resultado Correcta
Descripción Resultado La cantidad de registros guardados (87 registros) corresponde con la cantidad de registros del log que cumplen con los parámetros utilizados en el preprocesamiento, corroborado manualmente sobre el archivo de log, y estos 87 registros se corresponden con los identificados manualmente.
Tabla E.1. Prueba Preprocesamiento del Archivo de Log

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 387 -
Prueba Construcción de Sesiones de Usuarios
Descripción Se construyen sesiones de usuarios sobre la base de un archivo de log previamente cargado y luego se corrobora que la cantidad de sesiones construidas sea la correcta y que los accesos en las sesiones correspondan con los parámetros utilizados.
Objetivo Determinar la correcta construcción de las sesiones de usuarios con la información obtenida luego del preprocesado del archivo de log. Se espera que se determine la cantidad correcta de sesiones para los parámetros utilizados, y que cada sesión posea las páginas correspondientes.
Parámetros Utilizados • Cantidad Mínima de Páginas en una Sesión: 3
• Timeout de Sesión: 30 minutos
• Frecuencia Mínima de Página en el Log: 1
Resultado Esperado Se determinaron manualmente 21 sesiones de usuarios utilizando los parámetros detallados anteriormente.
Ejecución La prueba es ejecutada utilizando la clase SessionMakerBean, seteando los parámetros detallados anteriormente.
Resultado Correcta
Descripción Resultado La cantidad de sesiones de usuarios construidas (21 sesiones) corresponde con la cantidad determinada manualmente utilizando los mismos parámetros en la construcción de las sesiones, y las sesiones estan compuestas por las mismas páginas en ambos casos.
Tabla E.2. Prueba Construcción de Sesiones de Usuarios

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 388 -
Prueba Clusterización de Sesiones de Usuarios Utilizando la Red Neuronal Mapa Auto-Organizativo (SOM)
Descripción Se procede a la clusterización de las sesiones de usuarios y se corrobora que todas las sesiones pertenezcan a alguno de los clusters generados.
Objetivo Determinar el correcto funcionamiento de la clusterización de las sesiones de usuarios.
Parámetros Utilizados • Cantidad de ciclos de entrenamiento: 10
• Cardinalidad del mapa de clusterización (NxN): 2
Resultado Esperado Se espera que se asigne a cada sesión de usuario un cluster al cual pertenece y que todas las sesiones pertenezca a uno y solo uno de los 4 clusters a descubrir.
Ejecución La prueba es ejecutada utilizando la clase SOMBean, seteando los parámetros detallados anteriormente.
Resultado Correcta
Descripción Resultado La suma del total de sesiones en cada cluster es igual al total de sesiones de usuarios identificadas, y cada sesión pertenece a uno y solo un cluster.
Tabla E.3. Prueba Clusterización de Sesiones de Usuarios con SOM
Prueba Clusterización de Sesiones de Usuarios Utilizando el Algoritmo K-Means
Descripción Se procede a la clusterización de las sesiones de usuarios y se corrobora que todas las sesiones pertenezcan a alguno de los clusters generados.
Objetivo Determinar el correcto funcionamiento de la clusterización de las sesiones de usuarios.

IDENTIFICACION DE HÁBITOS DE USO DE SITIOS WEB UTILIZANDO REDES NEURONALES
Damián A. MARTINELLI - 389 -
Parámetros Utilizados • Cantidad de clusters a descubrir (K): 4
Resultado Esperado Se espera que se asigne a cada sesión de usuario un cluster al cual pertenece y que todas las sesiones pertenezca a uno y solo uno de los 4 clusters a descubrir.
Ejecución La prueba es ejecutada utilizando la clase KMeansBean, seteando los parámetros detallados anteriormente.
Resultado Correcta
Descripción Resultado La suma del total de sesiones en cada cluster es igual al total de sesiones de usuarios identificadas, y cada sesión pertenece a uno y solo un cluster.
Tabla E.4. Prueba Clusterización de Sesiones de Usuarios con K-Means


















