
TABLAS DE ECONOMETRÍA DEL LIBRO ECONOMETRÍA BÁSICA DE DAMODAR GUJARATI
Upload
angel-calzadaCategory
view
20download
5description

Curso: Métodos Econométricos IProf: Richard F. Fernández Vásquez
Email: [email protected] / Twitter: @ricfer85
Facultad de Ingeniería Económica, Estadística y Ciencias Sociales Escuela Profesional de Ingeniería Estadística
MODELO DE REGRESIÓN LINEAL CLASICO - SUPUESTOS

Ejemplo
• Una empresa se dedica a la producción y comercialización de textiles.De acuerdo con los resultados históricos, las condiciones favorables dela economía han permitido un buen desempeño de las ventas. Sinembargo, el Gerente de Ventas de la compañía conoce que eseincremento no solo se debe a la situación económica, sino también alesfuerzo realizado por el área de marketing, en cuanto a la promocióndel producto en diversos medios de comunicación.
Y= Ventas (miles de soles)
X1=Inversión en Radio (miles de soles)
X2=Inversión en TV (miles de soles)
X3=Inversión en diarios (miles de soles)
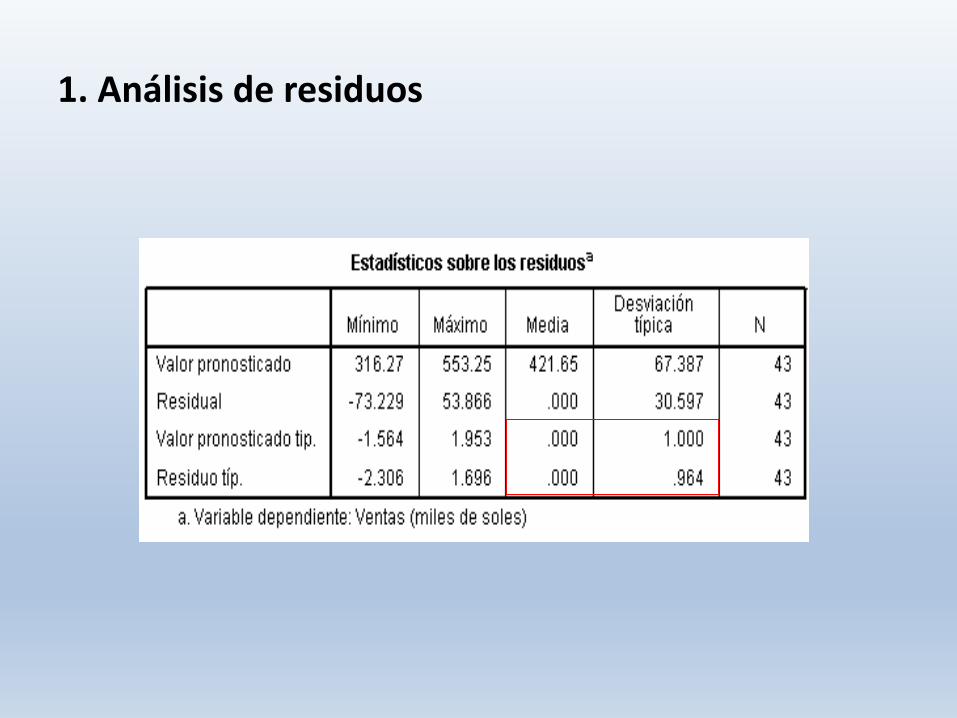
1. Análisis de residuos

2. Independencia
0),,( | jiji XXCov
0),( jiCov
Si en un gráfico de residuales y los valores estimados se observa unatendencia cíclica es posible que los errores no cumplan con este supuesto.

2. Independencia: errores no correlacionados
El estadístico de Durbin Watson
El estadístico de Durbin Watson proporciona información sobre el grado de
independencia existente entre los residuos.
Toma el valor aproximado de 2 cuando los residuos son independientes.
Mide el grado de correlación de un error con el anterior y el posterior a él.
Podemos asumir independencia de errores cuando DW está entre 1.5 y 2.5.

2. Independencia

3. Homocedasticidad: homogeneidad de varianzas
Es necesario contrastar la hipótesis de homocedasticidad, esto es, la varianza de los residuos es constante.
Hipótesis
Test
Estadístico
Distribución bajo Ho
difiere varianzauna menos al :
:
1
22
2
2
10
H
H k
F
F de Fisher con (k-1, n-k)
gl
Si valor-p > 0,05 no podemos rechazar la hipótesis nula y concluimos que se cumple el supuesto de homocedasticidad.

3. Homocedasticidad
- Dependent: Variable dependiente de la ecuación de regresión
- ZPRED: Pronósticos tipificados
- ZRESID: Residuos tipificados
- DRESID: Residuos obtenidos al efectuar el pronóstico eliminando el caso. Muy útil
para detectar valores atípicos.
- ADJPRED: Pronósticos efectuados con una ecuación de regresión en la que no se
incluye el caso pronosticado. Diferencias entre PRED Y ADJPRED, delatan presencia
de puntos de influencia.
- SRESID: Residuos divididos por su desviación típica. Para muestras grandes el 95%
de estos deben estar entre -2 y 2.
- SDRESID: Residuos corregidos divididos por su desviación típica. Útiles para detectar puntos de influencia.

3. Homocedasticidad

3. Homocedasticidad
El gráfico no muestra relaciones de ningún tipo entre los residuos y los valores predichos.
Cuando un diagrama de dispersión delata la presencia de varianzas heterogéneas, puede utilizarse una transformación de la variable dependiente para resolver el problema (transformación logarítmica o raíz cuadrada).

4. Normalidad
El modelo clásico de regresión lineal normal supone que cada ui está normalmente distribuida con:
0)( iE
2))(( ii EE
Media
Varianza
Covarianza 0)()])()][(([ jiEEEE jjii ji
),0( 2Nμi
Estos supuestos se expresan en forma más compacta como

4. Normalidad
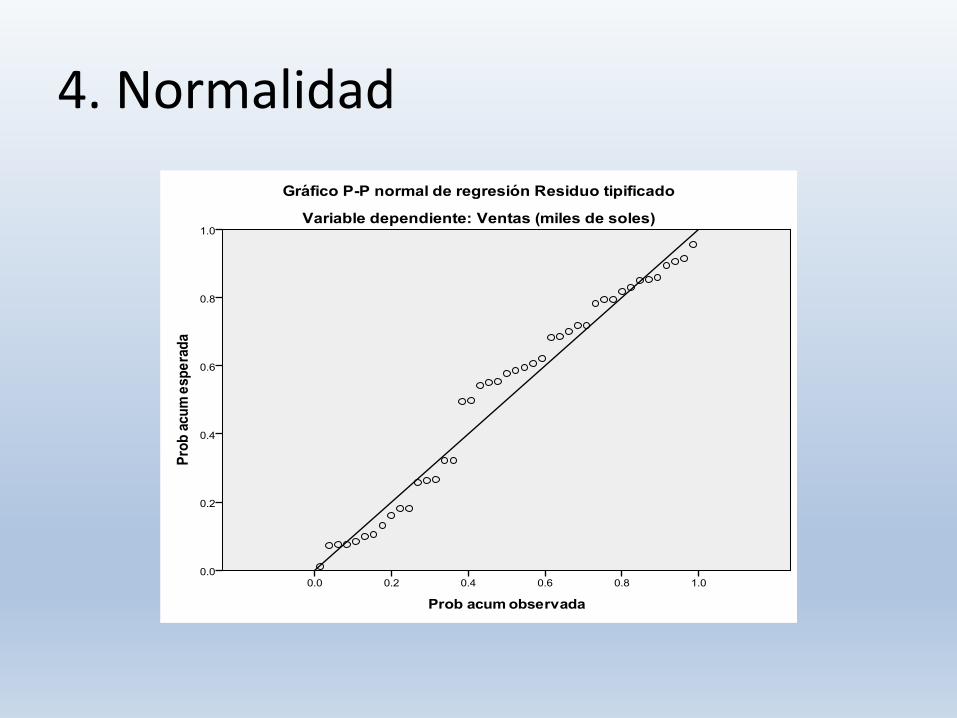
4. Normalidad

4. Normalidad

5. Multicolinealidad
0),( ji XXCov
Xy
establece que las variables explicativas son linealmente independientes,
es decir:
Uno de los supuestos básicos del modelo lineal general
0...2211 kk XXX
Cuando existe multicolienalidad algunos no son nulos. Entonces el
rango de la matriz X es menor que k, la matriz X´X es singular, su
determinante es cero y el estimador de mínimos cuadrados queda
indeterminado. Esto funciona muy bien cuando se trata de
multicolinealidad perfecta.
i

5. Multicolinealidad
Detección de multicolinealidad
El factor incremento de varianza se define como el cociente de la varianza de la estimación de una pendiente en regresión múltiple y la varianza de la misma pendiente en regresión simple.
21
1
)ˆ(
)ˆ(
ii
ii
RbV
VFIV
La principal consecuencia de una multicolinealidad alta, , es que las
varianzas de las estimaciones asociadas a las variables colineales son muy
grandes.
Si FIV>10, entonces la variable Xi está altamente relacionada con el resto de las
explicativas
12 iR

5. Multicolinealidad
Detección de multicolinealidad
La medida más satisfactoria de multicolinealidad se basa en los autovalores de la matriz X´X. Recordemos que una matriz simétrica y definida positiva puede
escribir como:
´´ CCXX
Donde C es una matriz ortogonal, y es una matriz diagonal que
contiene los autovalores, . Se cumple que el determinante
de una matriz es el producto de sus autovalores
1´ CC kdiag ,...,1
kCCCCXX *...**´´´ 21
Por lo tanto, podemos pensar que existe multicolinealidad alta cuando alguno de
los autovalores sea pequeño. Para no tener en cuenta la magnitud, se analiza el
cociente de los autovalores que es adimensional. Esto se define como índice de
condición.
min
max
k

5. Colinealidad
Existe colinealidad perfecta cuando una de las variables independientes serelaciona de forma perfectamente lineal con una o más del resto de variablesindependientes de la ecuación.
El nivel de tolerancia de una variable se obtiene restando a 1 el coeficiente dedeterminación R2 que resulta al regresar esa variable sobre el resto devariables independientes.
Valores de tolerancia muy pequeños indican que esa variable puede serexplicada por una combinación lineal del resto de variables, lo cual significaque existe colinealidad.
Los factores de inflación de la varianza (FIV), son los inversos de los valores detolerancia. Cuanto mayor es el FIV de una variable, mayor es la varianza delcorrespondiente coeficiente de regresión.

5. Colinealidad

5. Colinealidad
Los autovalores informan sobre cuantas dimensiones o factores diferentes
subyacen en el conjunto de variables independientes utilizadas. La presencia de
varios autovalores próximos a cero indica que las variables independientes están
muy relacionadas entre sí.
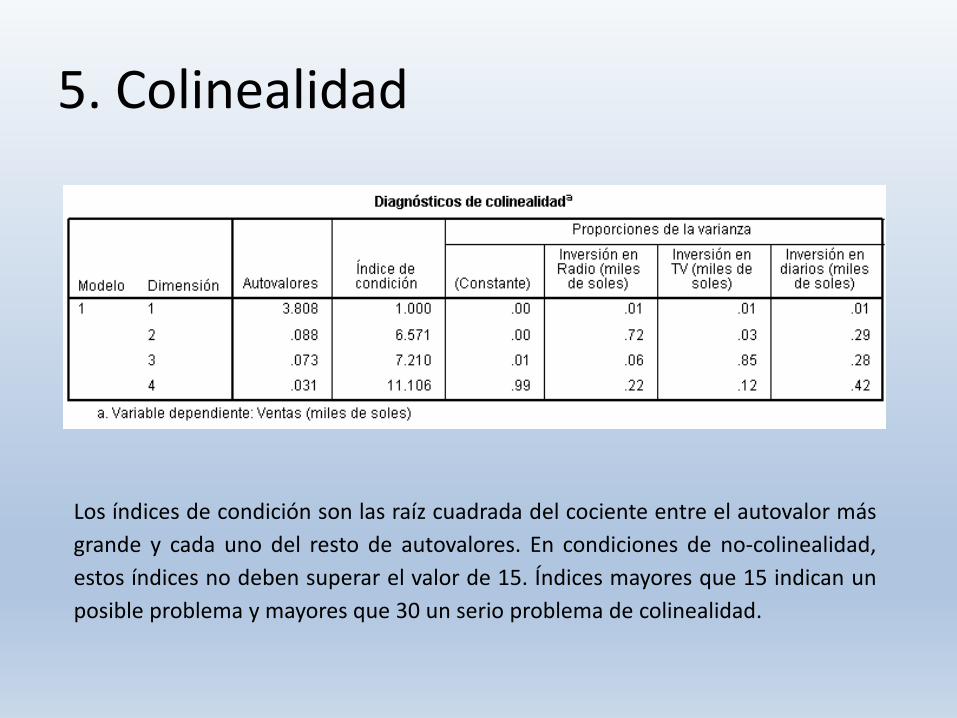
5. Colinealidad
Los índices de condición son las raíz cuadrada del cociente entre el autovalor más
grande y cada uno del resto de autovalores. En condiciones de no-colinealidad,
estos índices no deben superar el valor de 15. Índices mayores que 15 indican un
posible problema y mayores que 30 un serio problema de colinealidad.
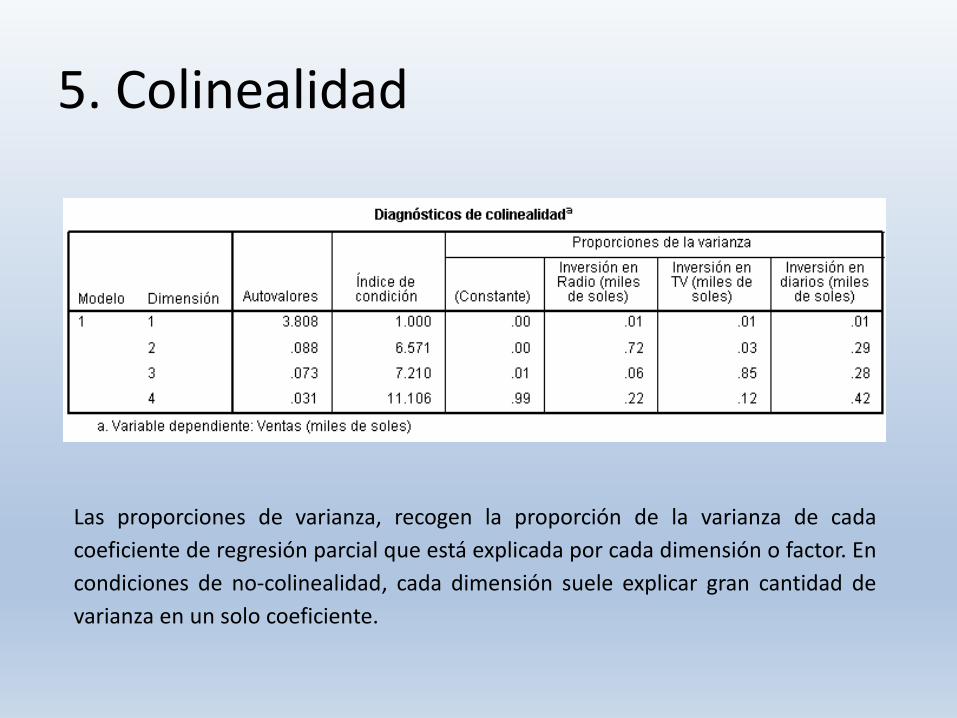
5. Colinealidad
Las proporciones de varianza, recogen la proporción de la varianza de cada
coeficiente de regresión parcial que está explicada por cada dimensión o factor. En
condiciones de no-colinealidad, cada dimensión suele explicar gran cantidad de
varianza en un solo coeficiente.

5. Colinealidad
Si hay colinealidad se hace lo siguiente:
- Aumentar el tamaño de muestra.
- Crear indicadores múltiples resumiendo variables o haciendo
componentes principales.
- Excluir variables redundantes.

Puntos de influencia
Distancia de mahalanobis
Mide el grado de distanciamiento de cada caso respecto de los promedios delconjunto del conjunto de variables independientes.
Distancia de cook
Mide el cambio que se produce en las estimaciones de los coeficientes deregresión al ir eliminando cada caso en la ecuación de regresión. En general, uncaso con una distancia de Cook superior a 1 debe ser revisado.
Valores de influencia
Representan una medida de la influencia potencial de cada caso. Los puntosmuy alejados pueden influir de forma muy importante en la ecuación deregresión. Con más de 6 variables y al menos 20 casos, se considera que unvalor de influencia debe ser revisado si es mayor que 3p/n (p variable y n casos).En la práctica los valores menores que 0.2 son poco problemáticos, de 0.2 a 0.5arriesgados y los mayores a 0.5 deberían evitarse.
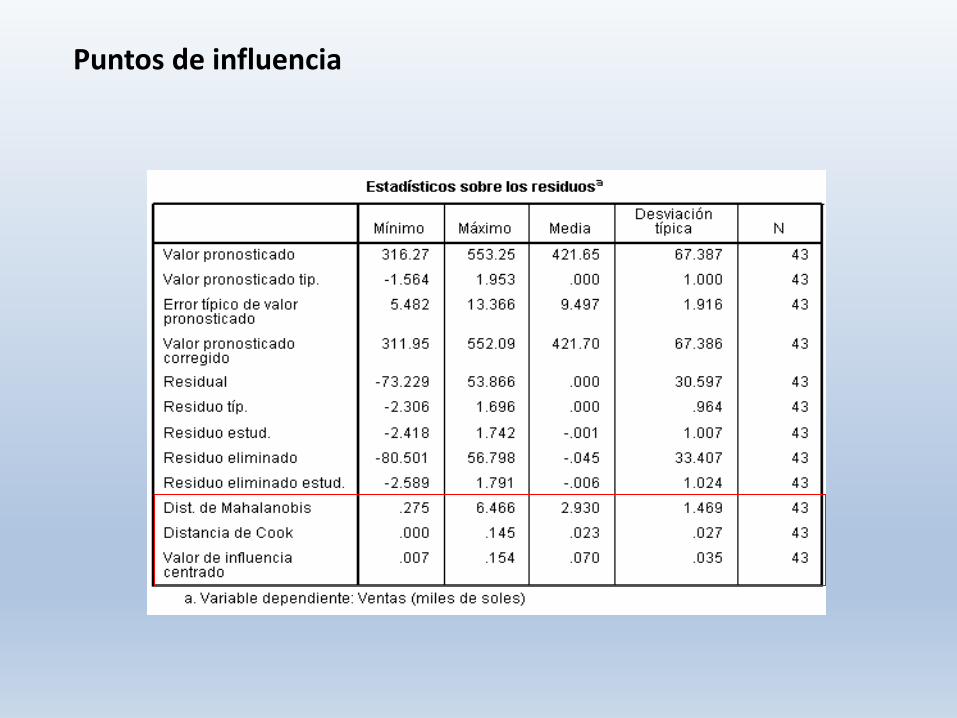
Puntos de influencia

• [GU]: Capítulos 4, 5, 6, 7 y 8 - Apéndices B, C.1-C.5 y apéndice 7A
• [GR]: Capítulo 2 y 3 secciones 3.1-3.3, 3.5 - Capítulo 4 secciones 4.3, 4.6, 4.8 - Capítulo 6 secciones 6.1-6.3
• [JD]: Capítulo 3 apéndice 3.2 y 3.4
[GU] Gujarati, Damodar y Dawn Porter. Econometría. Quinta Edición. México: McGraw Hill. 2010.
[JD] Johnston, J. y J. DiNardo. Métodos de Econometría. Traducción de la 4ta edición (Murillo C. F.). Barcelona: Vicens Vives. 2001
[GR] Greene, William. Econometric Analysis. Quinta Edición. New Jersey:
Prentice Hall. 2003.
[SW] Stock J. H. y Watson M.W. Introduction to Econometrics. Primera Edición. Boston: Addison Wesley. 2003.
Lecturas


















