
4ftp.utalca.cl/profesores/gicaza/Apuntes Word/10... · Web viewProblema: ¿Existe relación entre...
12
10. Relaciones entre dos variables cuantitativas (Inferencia) Ya revisamos la descripción de variables cuantitativas ahora veremos la manera de hacer inferencia a partir de los resultados muestrales. Problema: ¿Existe relación entre las notas en la Prueba Final Acumulativa y las notas de la Prueba 1 en cursos de Estadística en la UTAL Prueba 1 7 6 5 4 3 2 1 Examen 7 6 5 4 3 2 1 Inferencia en Regresión Lineal Simple Modelo de regresión lineal simple: Se tienen n observaciones de una variable explicativa x y de una variable respuesta y, el modelo estadístico de regresión lineal simple es: donde es la respuesta promedio para cada x. representa el intercepto de la función lineal que usa todos los valores de la población y representa la pendiente de la función lineal que usa todos los valores de la población. y son parámetros 1
Transcript of 4ftp.utalca.cl/profesores/gicaza/Apuntes Word/10... · Web viewProblema: ¿Existe relación entre...

10. Relaciones entre dos variables cuantitativas (Inferencia)Ya revisamos la descripción de variables cuantitativas ahora veremos la manera de hacer inferencia a partir de los resultados muestrales.
Problema: ¿Existe relación entre las notas en la Prueba Final Acumulativa y las notas de la Prueba 1 en cursos de Estadística en la UTAL
Prueba 1
7654321
Exam
en
7
6
5
4
3
2
1
Inferencia en Regresión Lineal Simple
Modelo de regresión lineal simple:
Se tienen n observaciones de una variable explicativa x y de una variable respuesta y,
el modelo estadístico de regresión lineal simple es:
donde
es la respuesta promedio para cada x.
representa el intercepto de la función lineal que usa todos los valores de la población y representa la pendiente de la función lineal que usa todos los valores de la población. y son
parámetros
El modelo estadístico de regresión lineal simple asume que para cada valor de x, los valores de la respuesta y son normales con media (que depende de x) y desviación estándar que no depende de x. Esta desviación estándar σ es la desviación estándar de todos los valores de y en la población para un mismo valor de x.
Estos supuestos se pueden resumir como: Para cada x, donde
Podemos visualizar el modelo con la siguiente figura:
1

Los datos nos darán estimadores puntuales de los parámetros poblacionales.
Estimadores de los parámetros de regresión:
El estimador de la respuesta media está dado por El estimador del intercepto es: El estimador de la pendiente es: El estimador de la desviación estándar σ está dado por:
donde es la suma de cuadrados de los residuos =
El coeficiente de correlación muestral es un estimador puntual de la correlación poblacional ρ
Probando la hipótesis acerca de la existencia de relación lineal
En el modelo de regresión lineal simple => . Si entonces las variables x e y no están asociadas linealmente y la respuesta es una constante E(Y) = .
E(Y) =
Es decir, conocer el valor de x no nos va a ayudar a conocer y.
Para docimar la significancia de la relación lineal realizamos el test de hipótesis:
2

Ho: = 0 (la pendiente de la recta de regresión en la población es cero)H1: 0
Existen hipótesis de una cola, donde H1: < 0 o H1: > 0, pero lo usual es hacer el test bilateral.
Para docimar la hipótesis podemos usar el test t:
El estimador puntual de es b, y el valor hipotético es 0. El error estándar de b es:
El estadístico para docimar la hipótesis acerca de la pendiente de la población es:
Intervalo de confianza para la pendiente:Un intervalo de confianza ( )*100% para la pendiente está dado por:
donde es el percentil apropiado de la distribución t con (n-2) grados de libertad.
Suponga que se rechaza al 5% la hipótesis nula del test t: Ho: = 0H1: 0
¿El intervalo de 95% de confianza para la verdadera pendiente contiene el cero?
Ejemplo: Test 1 versus Test 2 revisitadoRevisemos la salida de SPSS con lo que hemos visto hasta ahora:
Coeficientes(a)
Modelo Coeficientes no estandarizados
Coeficientes estandarizados t Sig.
Intervalo de confianza para B al 95%
B Error típ. Beta Límite inferiorLímite
superior1 (Constante) .800 2.135 .375 .733 -5.996 7.596 Test 1 1.100 .173 .965 6.351 .008 .549 1.651
a Variable dependiente: Test 2
3

Análisis de varianza y regresión lineal*
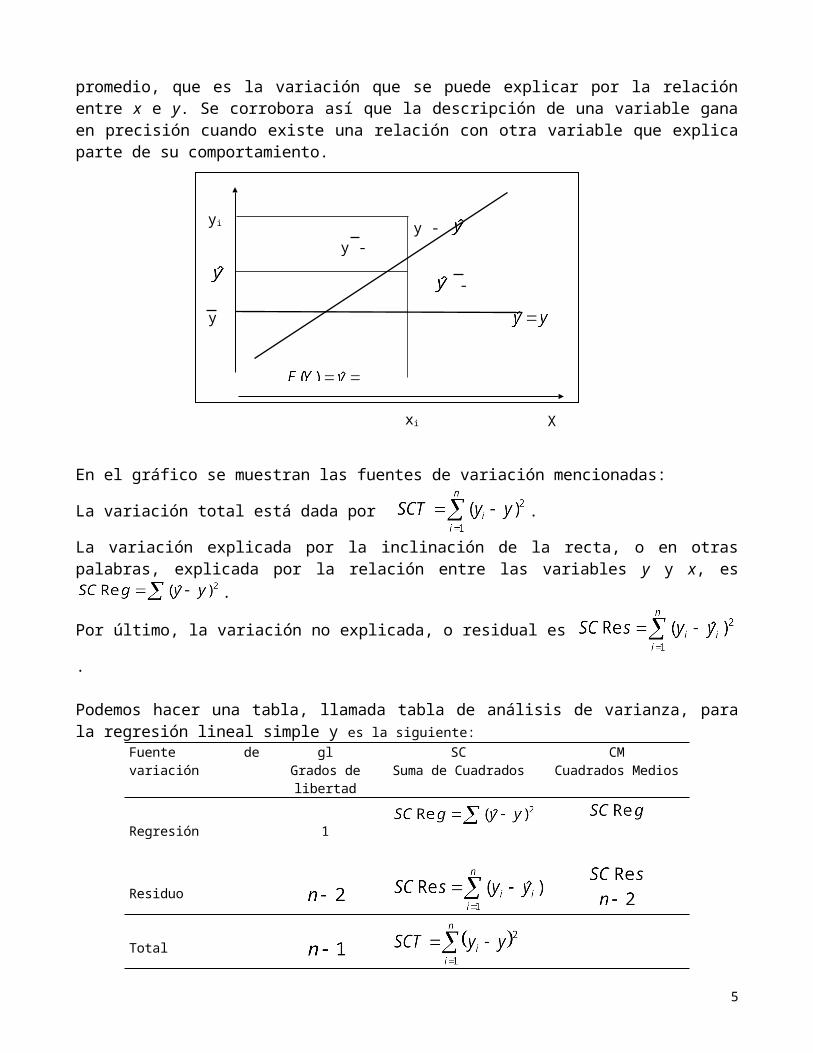
El estimador de la varianza utilizado, se interpreta como la variabilidad residual alrededor de la recta, vale decir, la variabilidad que queda después de haber sustraído la variabilidad de los valores observados de la variable respuesta (yi) respecto de su promedio, que es la variación que se puede explicar por la relación entre x e y. Se corrobora así que la descripción de una variable gana en precisión cuando existe una relación con otra variable que explica parte de su comportamiento.
En el gráfico se muestran las fuentes de variación mencionadas:
La variación total está dada por .
La variación explicada por la inclinación de la recta, o en otras palabras, explicada por la relación entre las variables y y x, es .
Por último, la variación no explicada, o residual es .
Podemos hacer una tabla, llamada tabla de análisis de varianza, para la regresión lineal simple y es la siguiente:
Fuente de variación glGrados de libertad
SCSuma de Cuadrados
CMCuadrados Medios
Regresión 1
Residuo
Total
* Adaptado de capítulo 21 del libro Bioestadística de Erica Taucher
4
- y
y - y - y
Xxi
y
yi
Ejemplo: Test 1 versus Test 2 re-revisitado
ANOVA(b)
Modelo Suma de
cuadrados glMedia
cuadrática F Sig.1 Regresión 48.400 1 48.400 40.333 .008(a)
Residual 3.600 3 1.200Total 52.000 4
a Variables predictoras: (Constante), Test 1b Variable dependiente: Test 2
Coeficiente de determinación o bondad de ajuste (r2)La correlación entre el test 1 y test 2 del ejemplo es de , este coeficiente de correlación cuantifica el grado de asociación lineal y la dirección de la asociación entre dos variables cuantitativas x y y. Se puede demostrar que:
este coeficiente se llama coeficiente de determinación, y representa la proporción de la variación total de y que es explicada por la relación lineal entre x e y. A este coeficiente se le usa entonces como medida de bondad de ajuste, es decir que tan buena es la variable explicativa x para explicar la respuesta y. El rango del coeficiente de determinación es naturalmente entre cero y uno ( ), lo que nos indica que mientras más cercano a uno sea el coeficiente de determinación (r2) mejor es el ajuste de la regresión.En el caso del ejemplo del test 1 y test 2, el , que nos indica que el test 1 explica el 93,1% de la variación total del test 2.
Verificando supuestos en la Regresión lineal simple
1. Examine el gráfico de dispersión de y versus x para decidir si el modelo lineal parece razonable.
2. Examine los residuos para verificar los supuestos acerca del término del error. Los residuos deben ser una muestra aleatoria de una población normal con media 0 y desviación estándar σ.
Cuando examine los residuos verifique:
a) que provienen de una muestra aleatoria:
Grafique los residuos versus x. El supuesto de que provienen de una muestra aleatoria será razonable si el gráfico muestra los puntos al azar, sin una forma definida.
A veces es posible detectar falta de independencia cuando los datos recogidos en el tiempo. Para verificar este supuesto grafique los residuos versus el tiempo y los puntos no deben mostrar una distribución definida.
5

b) NormalidadPara verificar normalidad haga el histograma de los residuos, este debería aparecer como normal sin valores extremos si tenemos un número grande de observaciones. En el caso de tener pocas observaciones puede hacer un gráfico de tallo y hoja y verificar que no haya observaciones extremas.
c) desviación estándar común (que no depende de x)El gráfico de los residuos versus x, debe tener aproximadamente una banda del mismo ancho.
El gráfico muestra evidencia de que la variabilidad en la respuesta tiende a aumentar cuando x aumenta.
6

Ejemplo: Se conduce un experimento en 12 sujetos para analizar si la dosis de cierta droga (en ml) está relacionada con el tiempo de reacción a un estímulo en segundos.
Droga (ml) 1,0 1,5 2,0 2,5 3,0 3,5 4,0 4,5 5,0 5,5 6,0 6,5Tiempo (segs) 1,0 0,8 1,8 1,4 2,1 1,8 2,2 3,0 2,75 3,0 4,1 4,9
Gráfico de dispersión del tiempo de reacción a estímulo versus dosis de droga:
Dosis de droga (ml)
76543210
Tiem
po d
e re
acci
ón (
seg)
5
4
3
2
1
0 R² = 0.8824
Estadísticos descriptivos
2.4042 1.21925 123.750 1.8028 12
Tiempo de reacción (seg)Dosis de droga (ml)
MediaDesviación
típ. N
Correlaciones
1.000 .939.939 1.000
. .000.000 .
12 1212 12
Tiempo de reacción (seg)Dosis de droga (ml)Tiempo de reacción (seg)Dosis de droga (ml)Tiempo de reacción (seg)Dosis de droga (ml)
Correlación de Pearson
Sig. (unilateral)
N
Tiempo dereacción
(seg)Dosis dedroga (ml)
7

Coeficientesa
2.174E-02 .303 .072 .944.635 .073 .939 8.663 .000
(Constante)Dosis de droga (ml)
Modelo1
B Error típ.
Coeficientes noestandarizados
Beta
Coeficientesestandarizad
ost Sig.
Variable dependiente: Tiempo de reacción (seg)a.
ANOVAb
14.430 1 14.430 75.048 .000a
1.923 10 .19216.352 11
RegresiónResidualTotal
Modelo1
Suma decuadrados gl
Mediacuadrática F Sig.
Variables predictoras: (Constante), Dosis de droga (ml)a.
Variable dependiente: Tiempo de reacción (seg)b.
Gráfico de residuos de la regresión versus dosis de droga:
Dosis de droga (ml)
76543210
Uns
tand
ardi
zed
Res
idua
l
.8
.6
.4
.2
-.0
-.2
-.4
-.6
8

Regresión Residuo tipificado
1.501.00.500.00-.50-1.00
Histograma
Variable dependiente: Tiempo de reacción (seg)
Frec
uenc
ia
5
4
3
2
1
0
Desv. típ. = .95
Media = 0.00
N = 12.00
Tallo y hoja de los residuos
Unstandardized Residual Stem-and-Leaf Plot
Frequency Stem & Leaf
1.00 -0 . 5 5.00 -0 . 12344 4.00 0 . 1123 2.00 0 . 57
Stem width: 1.00000 Each leaf: 1 case(s)
9











![Información Financiera Trimestral TRIMESTRALES... · [800500] Notas - Lista de notas [800600] Notas - Lista de políticas contables [813000] Notas - Información financiera intermedia](https://static.fdocuments.es/doc/165x107/5ebce0e721a1b4778563d298/informacin-financiera-trimestrales-800500-notas-lista-de-notas-800600.jpg)






