


Ayudando a los Viajeros usando 500 millones de Reseñas Hoteleras al Mes
107
Helping Travellers Make Better Hotel Choices 500 Million Times a Month Miguel Cabrera @mfcabrera https://www.flickr.com/photos/18694857@N00/5614701858/
-
Upload
big-data-colombia -
Category
Data & Analytics
-
view
145 -
download
0
Transcript of Ayudando a los Viajeros usando 500 millones de Reseñas Hoteleras al Mes

Helping Travellers Make Better Hotel Choices
500 Million Times a Month
Miguel Cabrera
@mfcabrera
https://www.flickr.com/photos/18694857@N00/5614701858/

ABOUT ME

• Neuberliner • Ing. Sistemas e Inf. Universidad Nacional - Med • M.Sc. In Informatics TUM, Hons. Technology
Management. • Work for TrustYou as Data (Scientist|Engineer|
Juggler)™ • Founder and former organizer of Munich DataGeeks
ABOUT ME

TODAY

• What we do • Architecture • Technology • Crawling • Textual Processing • Workflow Management and Scale • Sample Application
AGENDA

WHAT WE DO

For every hotel on the planet, provide a summary of traveler reviews.



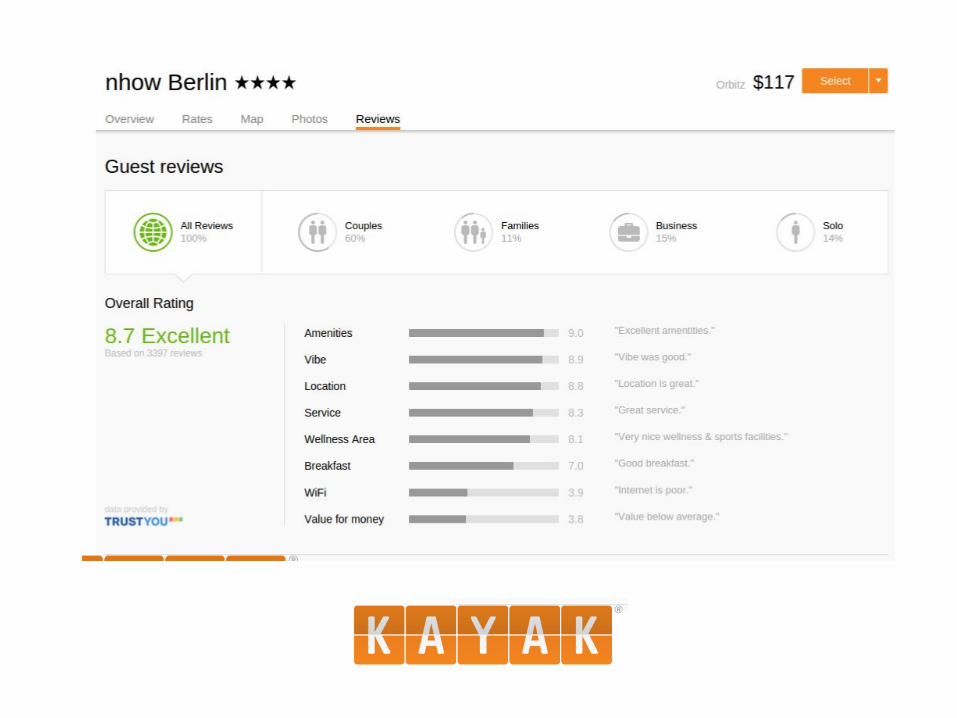




• Crawling • Natural Language Processing / Semantic
Analysis • Record Linkage / Deduplication • Ranking • Recommendation • Classification • Clustering
Tasks

ARCHITECTURE

Data Flow
Crawling
Seman-c Analysis Database API
Clients • Google • Kayak+ • TY
Analytics

Batch Layer
• Hadoop • Python • Pig* • Java*
Service Layer
• PostgreSQL • MongoDB • Redis • Cassandra
DATA DATA
Hadoop Cluster Application Machines
Stack

SOME NUMBERS

25 supported languages

500,000+ Properties

30,000,000+ daily crawled reviews

Deduplicated against 250,000,000+ reviews

300,000+ daily new reviews

https://www.flickr.com/photos/22646823@N08/2694765397/
Lots of text

TECHNOLOGY

• Numpy • NLTK • Scikit-Learn • Pandas • IPython / Jupyter • Scrapy
Python

• Hadoop Streaming • MRJob • Oozie • Luigi • …
Python + Hadoop

Crawling

Crawling




• Build your own web crawlers • Extract data via CSS selectors, XPath,
regexes, etc. • Handles queuing, request parallelism,
cookies, throttling … • Comprehensive and well-designed • Commercial support by
http://scrapinghub.com/





• 2 - 3 million new reviews/week • Customers want alerts 8 - 24h after review
publication! • Smart crawl frequency & depth, but still high
overhead • Pools of constantly refreshed EC2 proxy IPs • Direct API connections with many sites
Crawling at TrustYou

• Custom framework very similar to scrapy • Runs on Hadoop cluster (100 nodes) • Not 100% suitable for MapReduce • Nodes mostly waiting • Coordination/messaging between nodes
required: – Distributed queue – Rate Limiting
Crawling at TrustYou

Text Processing

Text Processing
Raw text Setence spli:ng Tokenizing Stopwords
Stemming
Topic Models
Word Vectors
Classification

Text Processing

• “great rooms” • “great hotel” • “rooms are terrible” • “hotel is terrible”
Text Processing
JJ NN JJ NN NN VB JJ NN VB JJ
>> nltk.pos_tag(nltk.word_tokenize("hotel is terrible")) [('hotel', 'NN'), ('is', 'VBZ'), ('terrible', 'JJ')]

• 25+ languages • Linguistic system (morphology, taggers,
grammars, parsers …) • Hadoop: Scale out CPU • ~1B opinions in the database • Python for ML & NLP libraries
Semantic Analysis

Word2Vec/Doc2Vec

Group of algorithms

An instance of shallow learning

Feature learning model

Generates real-valued vectors represenation of words

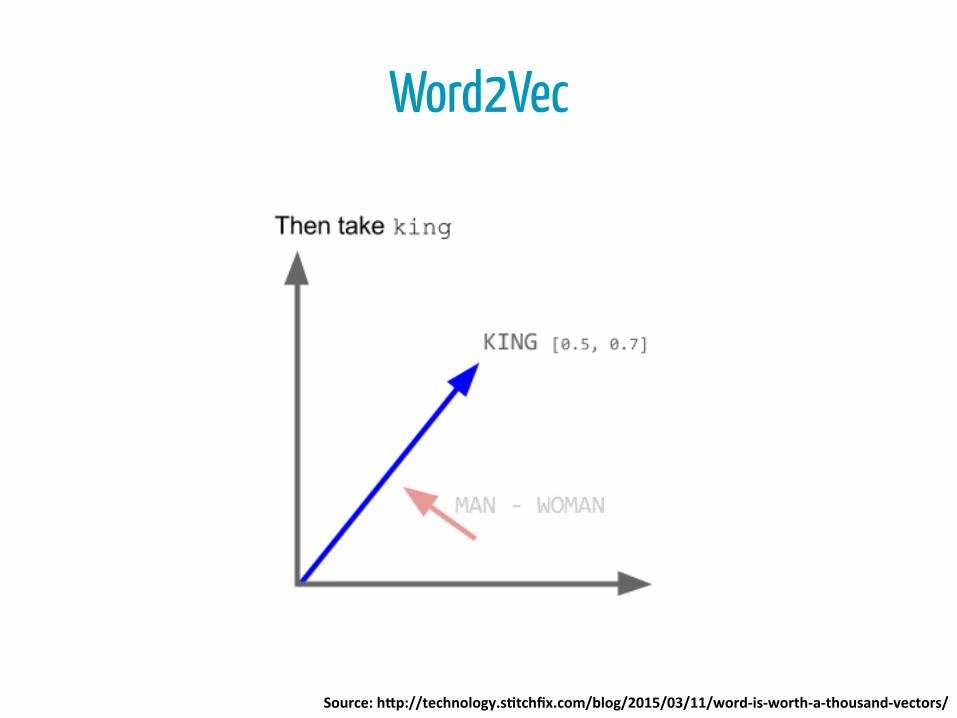
“king” – “man” + “woman” = “queen”

Word2Vec
Source: h*p://technology.s4tchfix.com/blog/2015/03/11/word-‐is-‐worth-‐a-‐thousand-‐vectors/

Word2Vec
Source: h*p://technology.s4tchfix.com/blog/2015/03/11/word-‐is-‐worth-‐a-‐thousand-‐vectors/

Word2Vec
Source: h*p://technology.s4tchfix.com/blog/2015/03/11/word-‐is-‐worth-‐a-‐thousand-‐vectors/
Word2Vec
Source: h*p://technology.s4tchfix.com/blog/2015/03/11/word-‐is-‐worth-‐a-‐thousand-‐vectors/

Word2Vec
Source: h*p://technology.s4tchfix.com/blog/2015/03/11/word-‐is-‐worth-‐a-‐thousand-‐vectors/

Word2Vec
Source: h*p://technology.s4tchfix.com/blog/2015/03/11/word-‐is-‐worth-‐a-‐thousand-‐vectors/

Similar words/documents are nearby vectors

Wor2vec offer a similarity metric of words

Can be extended to paragraphs and documents

A fast Python based implementation available via Gensim


Workflow Management and Scale

Crawl
Extract
Clean
Stats
ML
ML
NLP

Luigi
“ A python framework for data flow definition and execution ”

Luigi
• Build complex pipelines of
batch jobs • Dependency resolution • Parallelism • Resume failed jobs • Some support for Hadoop

Luigi

Luigi
• Dependency definition • Hadoop / HDFS Integration • Object oriented abstraction • Parallelism • Resume failed jobs • Visualization of pipelines • Command line integration

Minimal Bolerplate Code class WordCount(luigi.Task): date = luigi.DateParameter() def requires(self): return InputText(date) def output(self): return luigi.LocalTarget(’/tmp/%s' % self.date_interval) def run(self): count = {}
for f in self.input(): for line in f.open('r'): for word in line.strip().split(): count[word] = count.get(word, 0) + 1
f = self.output().open('w') for word, count in six.iteritems(count): f.write("%s\t%d\n" % (word, count)) f.close()

class WordCount(luigi.Task): date = luigi.DateParameter() def requires(self): return InputText(date) def output(self): return luigi.LocalTarget(’/tmp/%s' % self.date_interval) def run(self): count = {}
for f in self.input(): for line in f.open('r'): for word in line.strip().split(): count[word] = count.get(word, 0) + 1
f = self.output().open('w') for word, count in six.iteritems(count): f.write("%s\t%d\n" % (word, count)) f.close()
Task Parameters

class WordCount(luigi.Task): date = luigi.DateParameter() def requires(self): return InputText(date) def output(self): return luigi.LocalTarget(’/tmp/%s' % self.date_interval) def run(self): count = {}
for f in self.input(): for line in f.open('r'): for word in line.strip().split(): count[word] = count.get(word, 0) + 1
f = self.output().open('w') for word, count in six.iteritems(count): f.write("%s\t%d\n" % (word, count)) f.close()
Programmatically Defined Dependencies

class WordCount(luigi.Task): date = luigi.DateParameter() def requires(self): return InputText(date) def output(self): return luigi.LocalTarget(’/tmp/%s' % self.date_interval) def run(self): count = {}
for f in self.input(): for line in f.open('r'): for word in line.strip().split(): count[word] = count.get(word, 0) + 1
f = self.output().open('w') for word, count in six.iteritems(count): f.write("%s\t%d\n" % (word, count)) f.close()
Each Task produces an ouput

class WordCount(luigi.Task): date = luigi.DateParameter() def requires(self): return InputText(date) def output(self): return luigi.LocalTarget(’/tmp/%s' % self.date_interval) def run(self): count = {}
for f in self.input(): for line in f.open('r'): for word in line.strip().split(): count[word] = count.get(word, 0) + 1
f = self.output().open('w') for word, count in six.iteritems(count): f.write("%s\t%d\n" % (word, count)) f.close()
Write Logic in Python

Hadoop
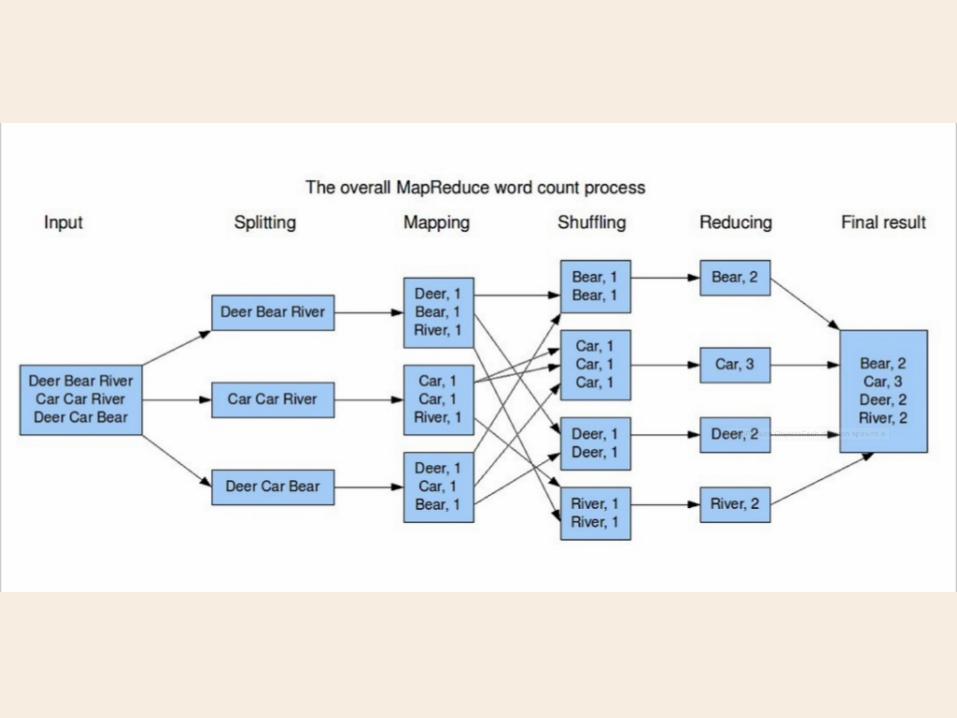

https://www.flickr.com/photos/12914838@N00/15015146343/
Hadoop = Java?

Hadoop Streaming
cat input.txt | ./map.py | sort | ./reduce.py > output.txt

Hadoop Streaming
hadoop jar contrib/streaming/hadoop-*streaming*.jar \ -file /home/hduser/mapper.py -mapper /home/hduser/mapper.py \ -file /home/hduser/reducer.py -reducer /home/hduser/reducer.py \ -input /user/hduser/text.txt -output /user/hduser/gutenberg-output

class WordCount(luigi.hadoop.JobTask): date = luigi.DateParameter()
def requires(self):
return InputText(date) def output(self):
return luigi.hdfs.HdfsTarget(’%s' % self.date_interval) def mapper(self, line): for word in line.strip().split(): yield word, 1 def reducer(self, key, values): yield key, sum(values)
Luigi + Hadoop/HDFS

Go and learn:

Data Flow Visualization

Data Flow Visualization

Before
• Bash scripts + Cron • Manual cleanup • Manual failure recovery • Hard(er) to debug

Now
• Complex nested Luigi jobs graphs • Automatic retries • Still Hard to debug

We use it for…
• Standalone executables • Dump data from databases • General Hadoop Streaming • Bash Scripts / MRJob • Pig* Scripts

You can wrap anything

Sample Application

Reviews are boring…



Source: hGp://www.telegraph.co.uk/travel/hotels/11240430/TripAdvisor-‐the-‐funniest-‐reviews-‐biggest-‐controversies-‐and-‐best-‐spoofs.html

Reviews highlight the individuality and personality of users

Snippets from Reviews “Hips don’t lie” “Maid was banging” “Beautiful bowl flowers” “Irish dance, I love that” “No ghost sighting” “One ghost touching” “Too much cardio, not enough squats in the gym” “it is like hugging a bony super model”

Hotel Reviews + Gensim + Python + Luigi = ?

ExtractSentences
LearnBigrams
LearnModel
ExtractClusterIds
UploadEmbeddings
Pig


from gensim.models.doc2vec import Doc2Vec class LearnModelTask(luigi.Task):
# Parameters.... blah blah blah def output(self):
return luigi.LocalTarget(os.path.join(self.output_directory, self.model_out)) def requires(self): return LearnBigramsTask() def run(self): sentences = LabeledClusterIDSentence(self.input().path) model = Doc2Vec(sentences=sentences, size=int(self.size), dm=int(self.distmem), negative=int(self.negative), workers=int(self.workers), window=int(self.window), min_count=int(self.min_count), train_words=True) model.save(self.output().path)

Wor2vec/Doc2vec offer a similarity metric of words

Similarities are useful for non- personalized recommender systems

Non-personalized recommenders recommend items based on what
other consumers have said about the items.

http://demo.trustyou.com

Takeaways

Takeaways
• It is possible to use Python as the primary language for doing large data processing on Hadoop.
• It is not a perfect setup but works well most of the time.
• Keep your ecosystem open to other technologies.

Questions?


















