CLUSTER ANALYSIS: ANÁLISIS DE...
30
CLUSTER ANALYSIS: ANÁLISIS DE CONGLOMERADOS (AC) Hugo Oliveros C. Investigador Adjunto, IRI Colombia University Curso Andino en Clima y Salud “Uso de Información de Clima para la Salud Pública. ”
Transcript of CLUSTER ANALYSIS: ANÁLISIS DE...

CLUSTER ANALYSIS: ANÁLISIS DE CONGLOMERADOS (AC)
Hugo Oliveros C.
Investigador Adjunto,
IRI Colombia University
Curso Andino en Clima y Salud
“Uso de Información de Clima
para la Salud Pública.”

Agenda
• Motivación
• Definición y usos del AC.
• Conceptos e ideas básicas del AC.
• Métodos y Algoritmos.
• AC: Un ejercicio de simulación
• Consideraciones Finales

Motivación
Cuantos grupos de eficicios distintos en la foto? (La mayoria parecen similares)

Motivación
Cuantos grupos de eficicios distintos en la foto? (La mayoria parecen similares)
Existe algun patron identificable ? Hay mas de uno?(i) Altura.(ii) Forma(iii) MaterialesEVIDENTEMENTE : Necesitamos un poco mas de detalles.

Motivación
Algunos detalles:
Uffff, …….Creo que se necesita algo mas….
.

Motivación
Algunos detalles:
Uffff, ……..Creo que se necesita algo mas…..Quizas: un arquitecto, historiador, urbanista y otros especialistas para construir unos
indicadores para acercarnos a confirmar la singularidad, (no-singularidad ) de estas estructuras.
Definición y usos del AC.
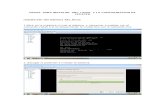
• Definición del AC?
Es una técnica matemático-
estadística que permite dividir (agrupar) una población de
objetos, o entidades, en subgrupos
disímiles (similares), de acuerdo a
alguna métrica.
Es decir, permite agrupar: objetos,
o entidades [individuos, areas
geograficas:{mpios, dptos,..}
instituciones, ...] a partir del
comportamiento de una, o mas
variables asociadas a los objetos.
Fuente: http://en.wikipedia.org/wiki/Data_clustering
AC Jerárquico: Aglomeración
AC-No-jerárquico: K-means

Definición y usos del AC
• Usos del AC
• Procesamiento de Imágenes (PI)
• Investigaciones de Mercado (IM)
• Recuperación de Información (RI)
• Epidemiología (EP)
• Minería de Datos (MD)
• (PI) Identificacion de objetos y trazasinusuales
• (IM): Definición de poblaciones objetivo para campañas publicitarias
• (RI): análisis de Weblog (bitácoras): búsquedas, OS, Minería de Texto
• (EP) Definicion de conglomerados con similar evolucion de eventosepidemilogicos (espacio-tiempo)
• (MD) Busqueda de patrones inusuales
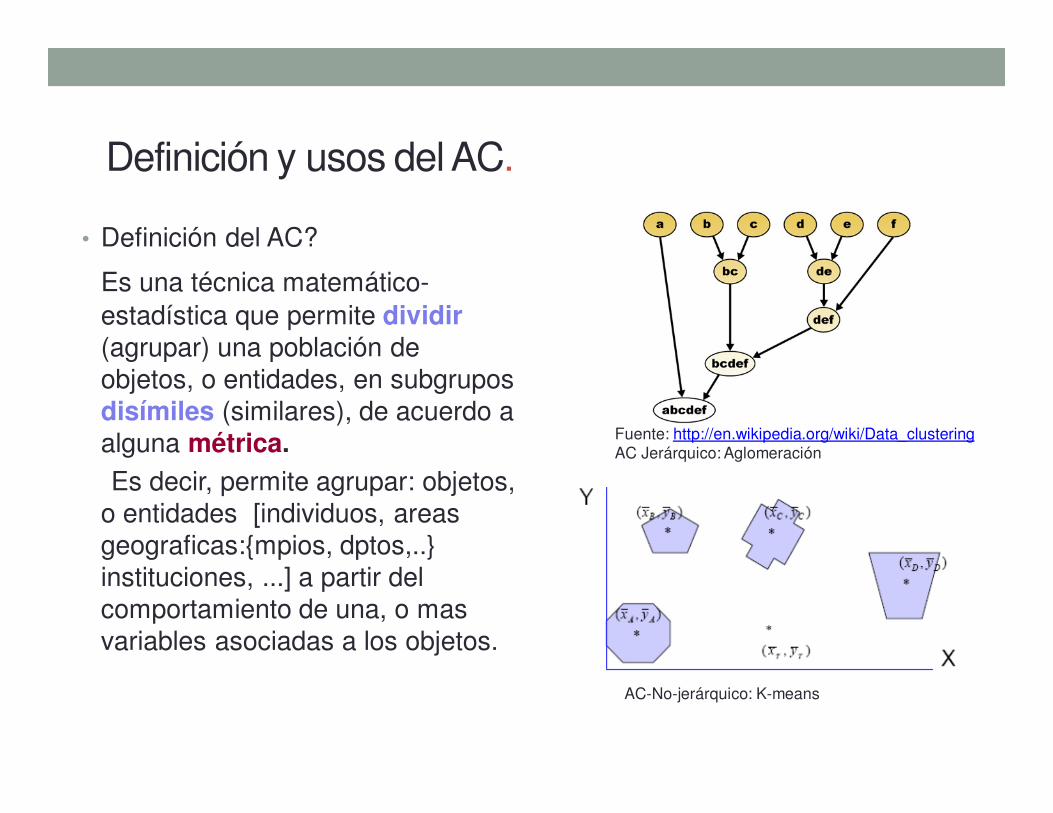
Definición y usos del AC
• Donde es utilizado el AC?• Reconocimiento de patrones (RP)
• Biología: Análisis de Genoma Humano.
Ding, C., X., He, (2004), "K-means Clustering via Principal Component Analysis", Computational
Research Division, Lawrence Berkeley National Laboratory.
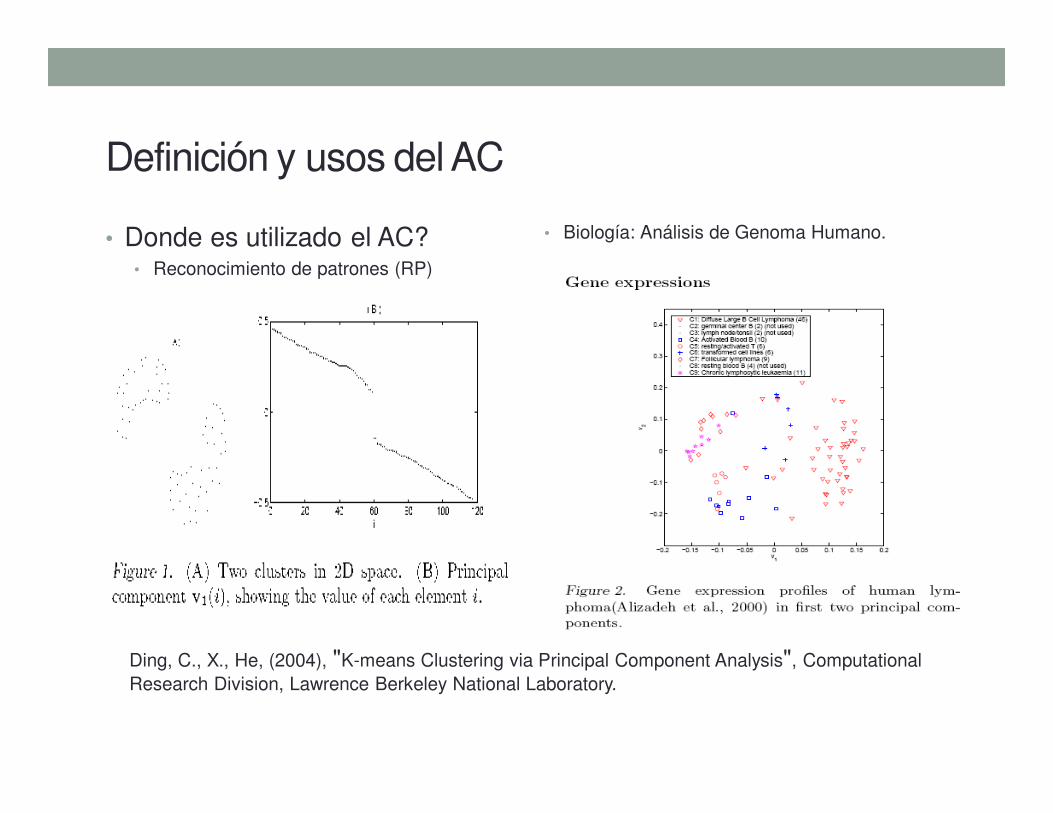
Definición y usos del AC
• Donde es utilizado el AC?• Procesamiento de Imágenes (PI)
• Detección de eventos inusuales
Fuente: http://en.wikipedia.org/wiki/Data_clustering
AC Jerárquico: Técnica Aglomeración
Porikli, F.M., T., Haga, (2004) "Event Detection by Eigenvector Decomposition Using Object and Frame
Features", Conference on Computer Vision and Pattern Recognition (CVPRW),

Definición y usos del AC
• Donde es utilizado el AC?• Epidemiología
• Patrones de Incidencia de Malaria
Pietro Ceccato, Tewolde Ghebremeskel, Malanding Jaiteh, Patricia M. Graves, Marc Levy, Shashu Ghebreselassie, Andom Ogbamariam,Anthony G. Barnston, Michael Bell, John del Corral, Stephen J. Connor, Issac Fesseha,Eugene P. Brantly, and Madeleine C. Thomson,(2007), “Malaria Stratification, Climate, and Epidemic Early Warning in Eritrea” Am. J. Trop. Med. Hyg., 77(Suppl 6),, pp. 61–68

Conceptos e ideas básicas del AC
• Elementos a considerar
- AC es una técnica de clasificación no-supervisada: (no hay grupos predefinidos, no hay: entrenamiento, grupo de prueba)
- Algunos algoritmos en AC están basados en un principio fundamental: la distancia que separa dos grupos de objetos no puede ser inferior a la existe entre los miembros de los respectivos grupos.
• Distancia:
2
21
2
2111
11
1111
1111
221
2
1
111
2
1
)()(),(
0),(
.),( ),(
.b punto al a punto del distancia :),(
),(:
),(:
yyxxbad
aad
abdbad
bad
yxbRb
yxaRa
−+−=
=
=
⇒∋
⇒∋
(x1,y1)
(x2,y2)
Y
X
)( 21 yy −
)( 12 xx −
GA
GB
Conceptos e ideas básicas del AC
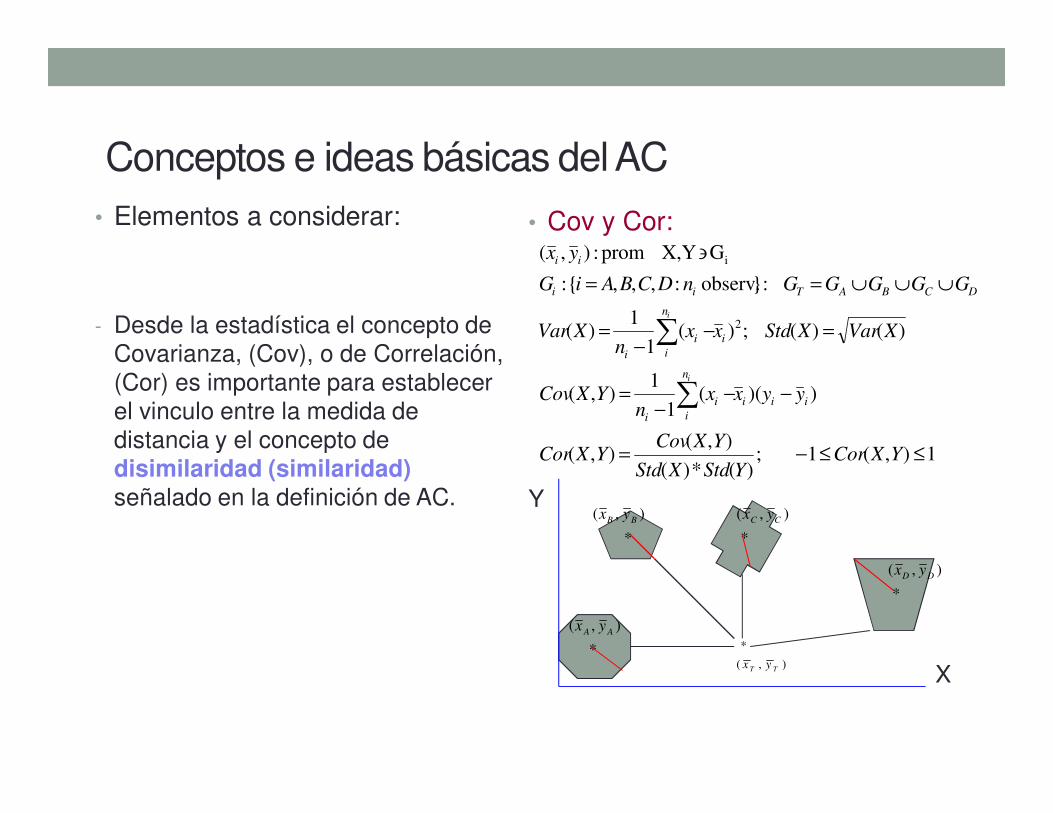
• Elementos a considerar:
- Desde la estadística el concepto de
Covarianza, (Cov), o de Correlación,
(Cor) es importante para establecer
el vinculo entre la medida de
distancia y el concepto de
disimilaridad (similaridad)señalado en la definición de AC.
• Cov y Cor:
1),(1;)(*)(
),(),(
))((1
1),(
)()(;)(1
1)(
:}observ. :,,,{:
G YX, prom:),(
2
i
≤≤−=
−−−
=
=−−
=
∪∪∪==
∋
∑
∑
YXCorYStdXStd
YXCovYXCor
yyxxn
YXCov
XVarXStdxxn
XVar
GGGGGnDCBAiG
yx
iii
n
i
i
i
i
n
i
i
i
DCBATii
ii
i
i
X
*
),( BB yx
*
),( AA yx
*
),( CC yxY
*
),( DD yx
),(
*
TT yx

Conceptos e ideas básicas del AC
• La estructura de la información (fotografía)

Conceptos e ideas básicas del AC
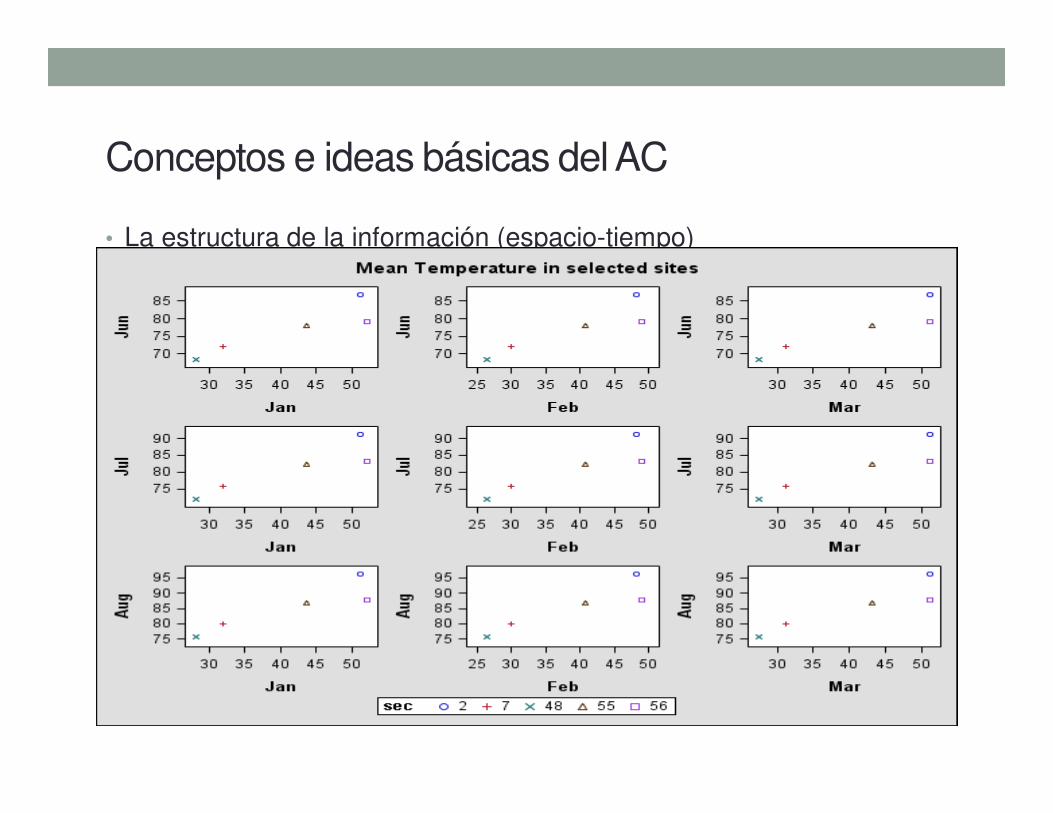
• La estructura de la información (espacio-tiempo)
Conceptos e ideas básicas del AC
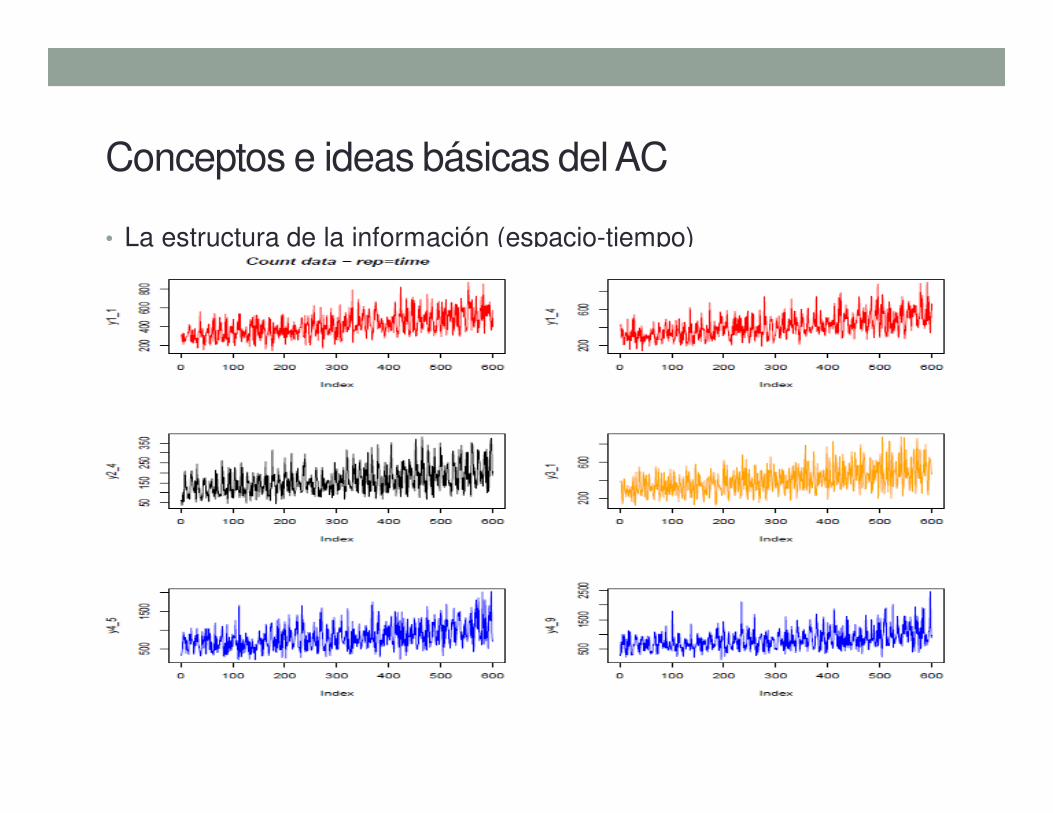
• La estructura de la información (espacio-tiempo)
Conceptos e ideas básicas del AC
• La estructura de la información (espacio-tiempo)

Conceptos e ideas básicas del AC
• Matriz de Covarianza / Correlación
qqmqmqm
qmmm
qmmm
rrr
rrr
rrr
_2_1_
2_22_21_
1_12_11_
...
...
...
MOMM
qqmqmqm
qmmm
qmmm
_2_1_
2_22_21_
1_12_11_
cov...covcov
cov...covcov
cov...covcov
MOMM
Cov
Cor
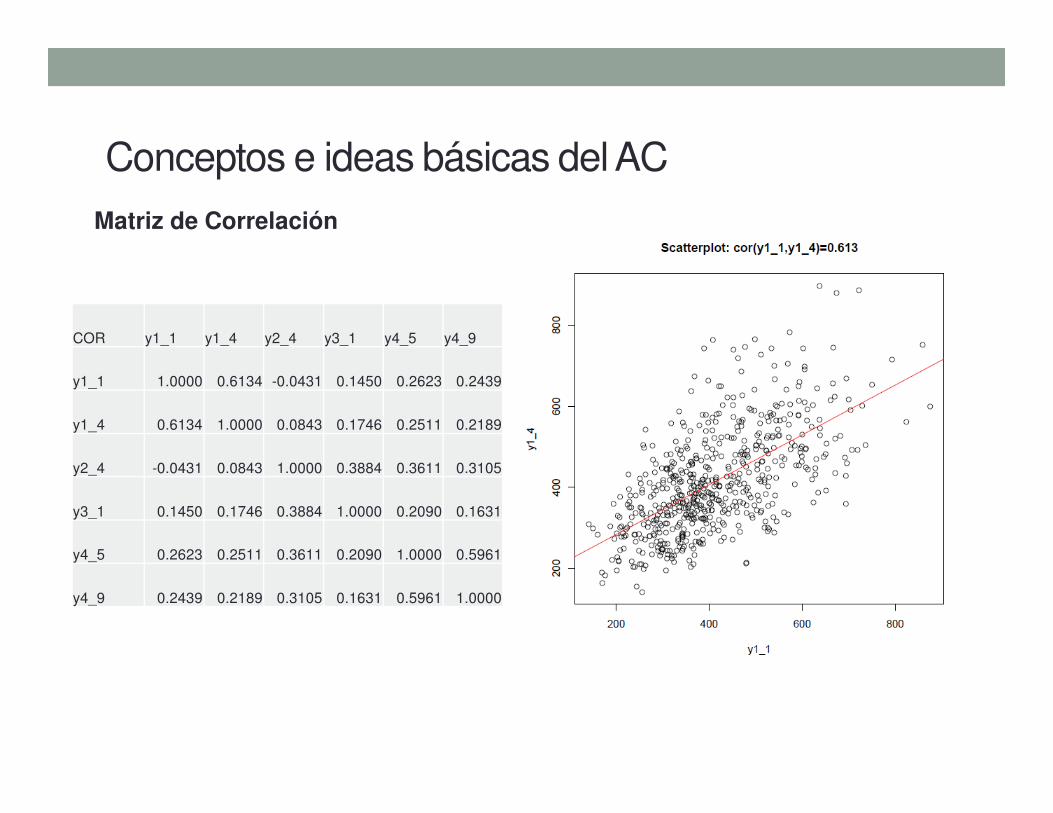
Conceptos e ideas básicas del AC
COR y1_1 y1_4 y2_4 y3_1 y4_5 y4_9
y1_1 1.0000 0.6134 -0.0431 0.1450 0.2623 0.2439
y1_4 0.6134 1.0000 0.0843 0.1746 0.2511 0.2189
y2_4 -0.0431 0.0843 1.0000 0.3884 0.3611 0.3105
y3_1 0.1450 0.1746 0.3884 1.0000 0.2090 0.1631
y4_5 0.2623 0.2511 0.3611 0.2090 1.0000 0.5961
y4_9 0.2439 0.2189 0.3105 0.1631 0.5961 1.0000
Matriz de Correlación

Conceptos e ideas básicas del AC
• Vectores propios y Valores propios : (Eigenvalues and Eigenvectors)
(Empirical Orthogonal Functions: EOF – Componentes Principales)
},...,2
,1
{(A) / Propios Valores:)(
21
22221
11211
E
...1
E / Propios Vectores Matriz:
A)g(DISTANCI CORR, :simetrica Matriz:
qA
qqe
qe
qe
qeee
qeee
qeeE
A
λλλλλ =
=
=
LL
MOOMM
MOOMM
LL
LL
E de aTranspuest Matriz :
;*)(*
00
300
02
0
001
)(
},...,2
,1
{(A) / Propios Valores:)(
TE
TEDEA
q
D
qA
λ
λ
λ
λ
λ
λ
λλλλλ
=
=
=
LL
MOOMM
MO
LL
LL

Métodos y Algoritmos (M&A)
• Consideraciones generales:
• AC no es una método de inferencia estadística.
• En general los M&A no dependen de función de distribución de probabilidad asociada con las variables en la población.
• Las medidas estadísticas/indicadores usadas para generar los valores que representan a las distintas variables en el análisis de las unidades que se pretende agrupar usando CA deben ser cuidadosamente escogidas (cortes transversales).
• Las escalas de medición (variabilidad) inciden en la determinación de la métrica que se use para desarrollar el AC bajo descomposiciones bajo vectores y valores propios: (COV vs. COR).
• Para el conjunto de información definido en el componente de (espacio-tiempo) esfundamental identificar si existe algún componente de tendencia (tiempo: determinística, o estocástico) y/o espacial en el proceso generador de datos. (PGD) para considerarlo ,o eliminarlo.
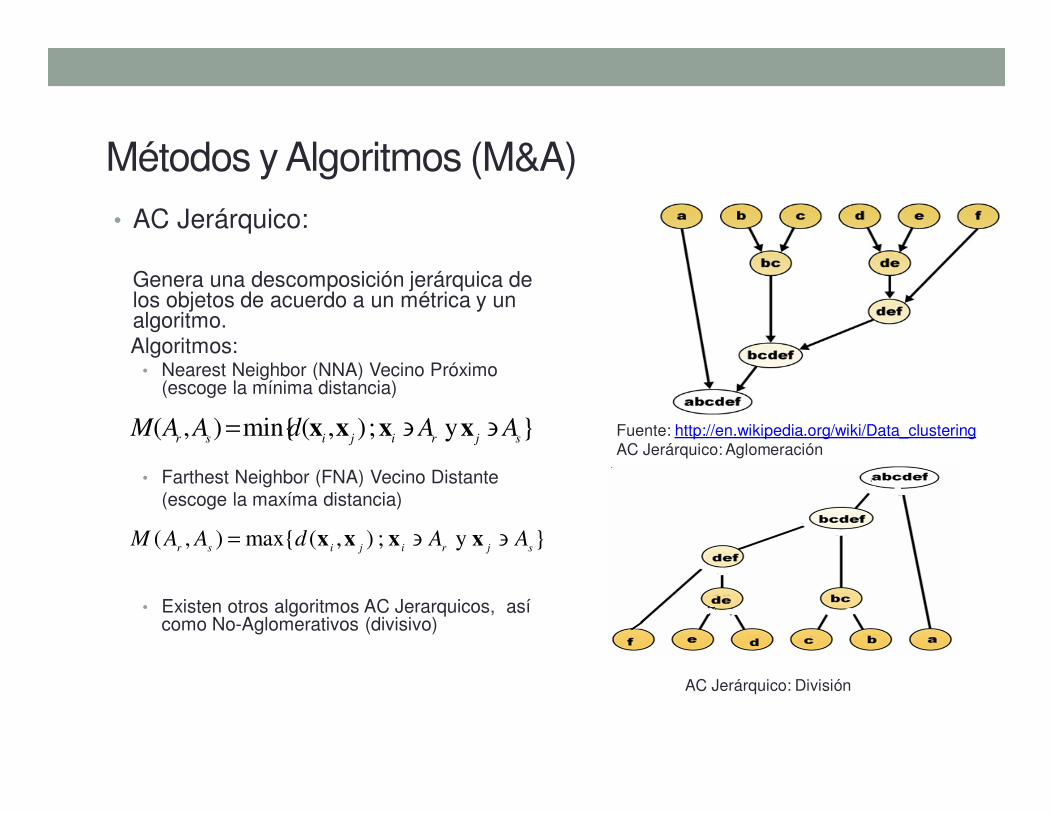
Métodos y Algoritmos (M&A)
}y;),(max{),(sjrijisr
AAdAAM ∋∋= xxxx
• AC Jerárquico:
Genera una descomposición jerárquica de los objetos de acuerdo a un métrica y un algoritmo. Algoritmos:
• Nearest Neighbor (NNA) Vecino Próximo (escoge la mínima distancia)
• Farthest Neighbor (FNA) Vecino Distante
(escoge la maxíma distancia)
• Existen otros algoritmos AC Jerarquicos, así como No-Aglomerativos (divisivo)
Fuente: http://en.wikipedia.org/wiki/Data_clustering
AC Jerárquico: Aglomeración
}y;),(min{),(sjrijisr
AAdAAM ∋∋= xxxx
AC Jerárquico: División
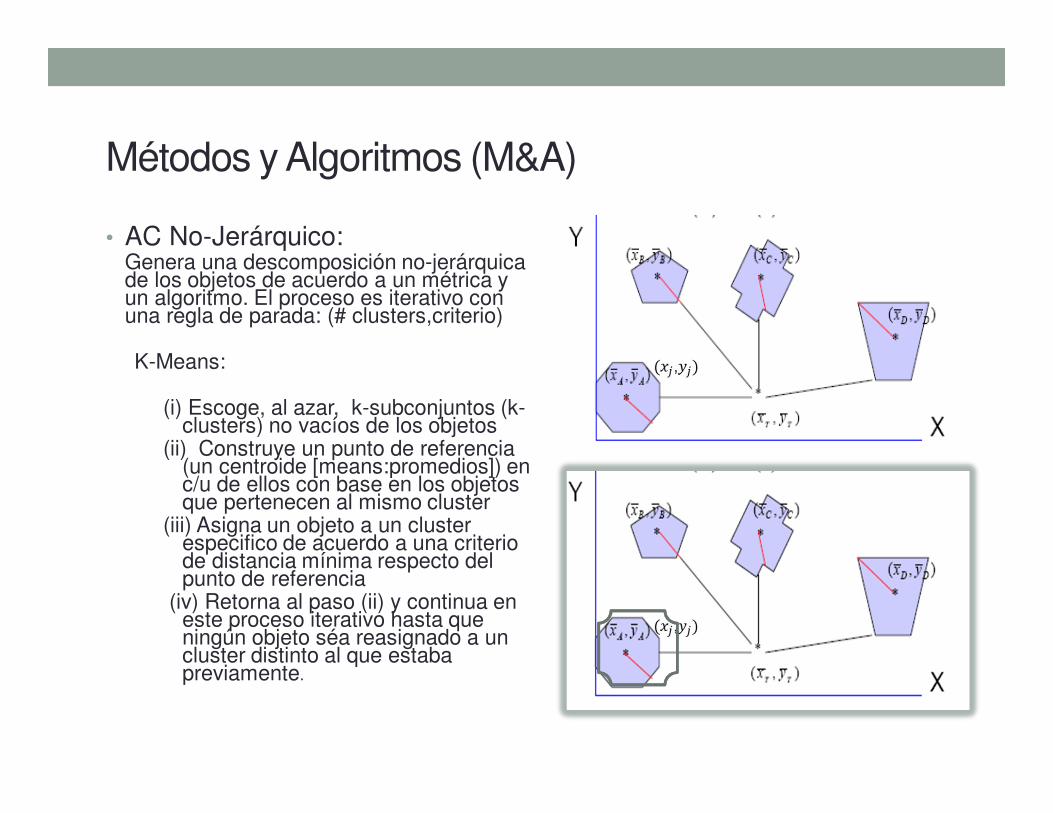
Métodos y Algoritmos (M&A)
• AC No-Jerárquico: Genera una descomposición no-jerárquica de los objetos de acuerdo a un métrica y un algoritmo. El proceso es iterativo con una regla de parada: (# clusters,criterio)
K-Means:
(i) Escoge, al azar, k-subconjuntos (k-clusters) no vacíos de los objetos
(ii) Construye un punto de referencia (un centroide [means:promedios]) en c/u de ellos con base en los objetos que pertenecen al mismo cluster
(iii) Asigna un objeto a un clusterespecifico de acuerdo a una criterio de distancia mínima respecto del punto de referencia
(iv) Retorna al paso (ii) y continua en este proceso iterativo hasta que ningún objeto séa reasignado a un cluster distinto al que estaba previamente.

Métodos y Algoritmos (M&A)
• AC No-Jerárquico: Genera una descomposición no-jerárquica de los objetos de acuerdo a un métrica y un algoritmo. El proceso es iterativo con una regla de parada: (# clusters,criterio:)
• Cluster vía vectores propios*:
(i) Calcule los Vectores y Valores propios de la matrix A {Paso1}.
(ii) Utilice los k-primeros vectores propios {e1,…, ek} para construir una matriz C={Cij} {Paso 2} si j cij >0 existe una conexión entre el objeto {i} (localización {i}) y el objeto {j} (localización {j})
(iii) Defina un umbral para decidir si los elementos de C {cij >0} , para tomar la decisión de cuales localizaciones están fuertemente conectadas {paso¨3 }.
Identifique estructuras diagonales en bloque y asigne las los cluster de acuerdo a las estructuras.
[ ]
( )
.con conectado esta si :Umbral
:
:Paso3
21
22221
11211
/|){
0...0...21
}{
:2
21
21
1.
1211
...1
E
;*)(*
}),({
:1
2
jip
qqc
qc
qc
qccc
qccc
PPC
qqppP
keeeqQ
Paso
qqe
qe
qe
iqe
ie
ie
qeee
qee
EDEA
CORDistgA
Paso
ij
T
kkk
j
ijijijijk
ijk
T
⇒>
==
==
==
=
=
=
=
∑
θ
λ
LL
MOOMM
MOOMM
LL
LL
LL
MOOMM
OO
MLLOM
LL
* Porikli, F.M., T., Haga, (2004) "Event Detection by Eigenvector Decomposition Using Object and Frame
Features", Conference on Computer Vision and Pattern Recognition (CVPRW),

AC: Un ejercicio de simulación (M,D)
• Mecanismo de simulación de una enfermedad (Por ejemplo: malaria)
• Se simularon 4 grupos de localizaciones c/u con 10 localizaciones para 50 años de información mensual, es decir, 600 obs por 40 localizaciones.
• Se utilizo una distribución de probabilidad binomial negativa, (NBPD) en la simulación cuyo valor esperado condicionado varia de un mes a otro dependiendo del comportamiento de tres variables básicas: tendencia (x1) temperatura (x2) y (x3) precipitación
• La precipitación tiene un componente “estacional” (periodos de lluvias, periodos secos) que varia de acuerdo al grupo, se ve afectada por unavariable que se comporta como ENSO para los años en que ENSO fueidentificado como el (NINO) y esto conduce a una penalización(disminución del nivel precipitación) distinta en cada grupo.
g
t
gg
t
gg
t
ggg
t
g
t XXX 1322110);NBPD( ααααµµ +++=

AC: Un ejercicio de simulación para (M,D)
Eigenvalues lambda_1 lambda_2 lambda_3 lambda_4 lambda_5 lambda_6
2.3596 1.3670 0.9648 0.5507 0.3994 0.3585
Eigenvectors e1 e2 e3 e4 e5 e6
-0.3855 0.5786 -0.0936 -0.0791 -0.0302 0.7076
-0.4038 0.5074 -0.2086 0.3879 0.0806 -0.6156
-0.3439 -0.5329 -0.2269 0.6725 0.0764 0.2969
-0.3236 -0.2625 -0.7057 -0.5608 0.0080 -0.1173
-0.4956 -0.1717 0.3971 -0.1184 -0.7338 -0.1216
-0.4688 -0.1591 0.4904 -0.2501 0.6695 -0.0598
COR y1_1 y1_4 y2_4 y3_1 y4_5 y4_9
y1_1 1.0000 0.6134 -0.0431 0.1450 0.2623 0.2439
y1_4 0.6134 1.0000 0.0843 0.1746 0.2511 0.2189
y2_4 -0.0431 0.0843 1.0000 0.3884 0.3611 0.3105
y3_1 0.1450 0.1746 0.3884 1.0000 0.2090 0.1631
y4_5 0.2623 0.2511 0.3611 0.2090 1.0000 0.5961
y4_9 0.2439 0.2189 0.3105 0.1631 0.5961 1.0000
Cluster via vectores propios: (Ejercicio escogiendo : 6 localidades | Yi_j : # casos del grupo i, en el localidad j )
D={d(i,j)} y1_1 y1_4 y2_4 y3_1 y4_5 y4_9
y1_1 1.0000 1.0000 0.0000 0.0000 0.0000 0.0000
y1_4 1.0000 1.0000 0.0000 0.0000 0.0000 0.0000
y2_4 0.0000 0.0000 1.0000 0.0000 0.0000 0.0000
y3_1 0.0000 0.0000 0.0000 1.0000 0.0000 0.0000
y4_5 0.0000 0.0000 0.0000 0.0000 1.0000 1.0000
y4_9 0.0000 0.0000 0.0000 0.0000 1.0000 1.0000
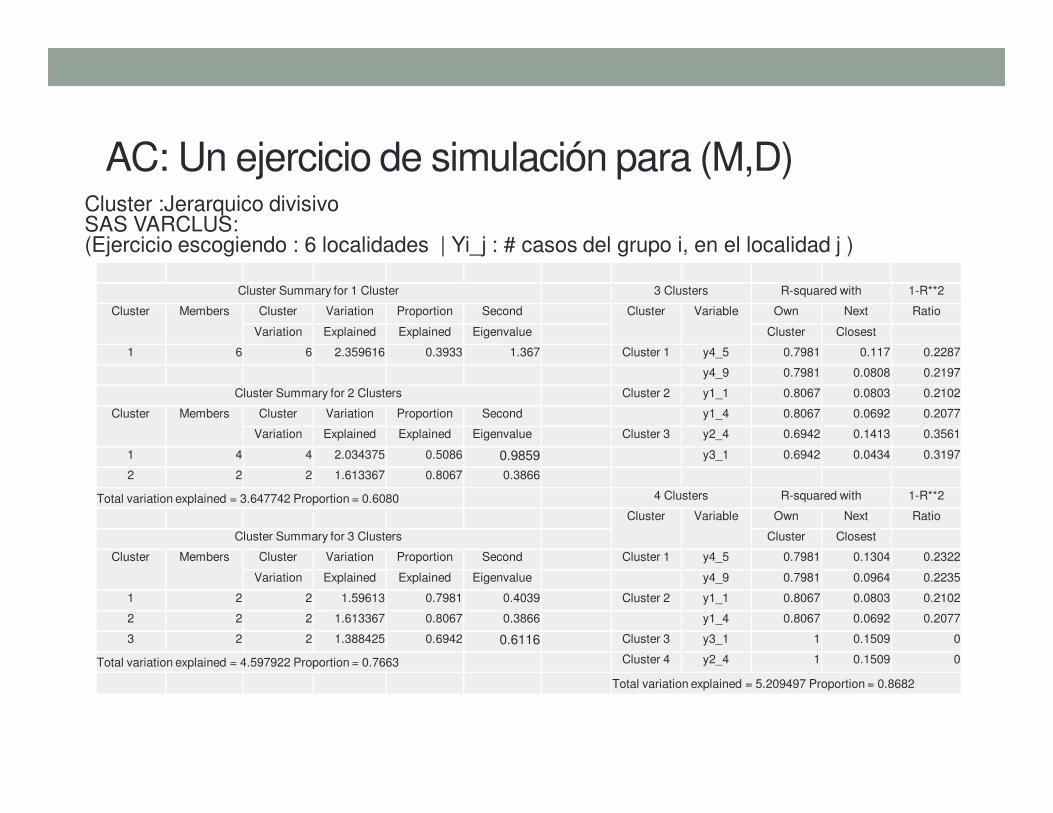
AC: Un ejercicio de simulación para (M,D)Cluster :Jerarquico divisivoSAS VARCLUS: (Ejercicio escogiendo : 6 localidades | Yi_j : # casos del grupo i, en el localidad j )
Cluster Summary for 1 Cluster 3 Clusters R-squared with 1-R**2
Cluster Members Cluster Variation Proportion Second Cluster Variable Own Next Ratio
Variation Explained Explained Eigenvalue Cluster Closest
1 6 6 2.359616 0.3933 1.367 Cluster 1 y4_5 0.7981 0.117 0.2287
y4_9 0.7981 0.0808 0.2197
Cluster Summary for 2 Clusters Cluster 2 y1_1 0.8067 0.0803 0.2102
Cluster Members Cluster Variation Proportion Second y1_4 0.8067 0.0692 0.2077
Variation Explained Explained Eigenvalue Cluster 3 y2_4 0.6942 0.1413 0.3561
1 4 4 2.034375 0.5086 0.9859 y3_1 0.6942 0.0434 0.3197
2 2 2 1.613367 0.8067 0.3866
Total variation explained = 3.647742 Proportion = 0.6080 4 Clusters R-squared with 1-R**2
Cluster Variable Own Next Ratio
Cluster Summary for 3 Clusters Cluster Closest
Cluster Members Cluster Variation Proportion Second Cluster 1 y4_5 0.7981 0.1304 0.2322
Variation Explained Explained Eigenvalue y4_9 0.7981 0.0964 0.2235
1 2 2 1.59613 0.7981 0.4039 Cluster 2 y1_1 0.8067 0.0803 0.2102
2 2 2 1.613367 0.8067 0.3866 y1_4 0.8067 0.0692 0.2077
3 2 2 1.388425 0.6942 0.6116 Cluster 3 y3_1 1 0.1509 0
Total variation explained = 4.597922 Proportion = 0.7663 Cluster 4 y2_4 1 0.1509 0
Total variation explained = 5.209497 Proportion = 0.8682
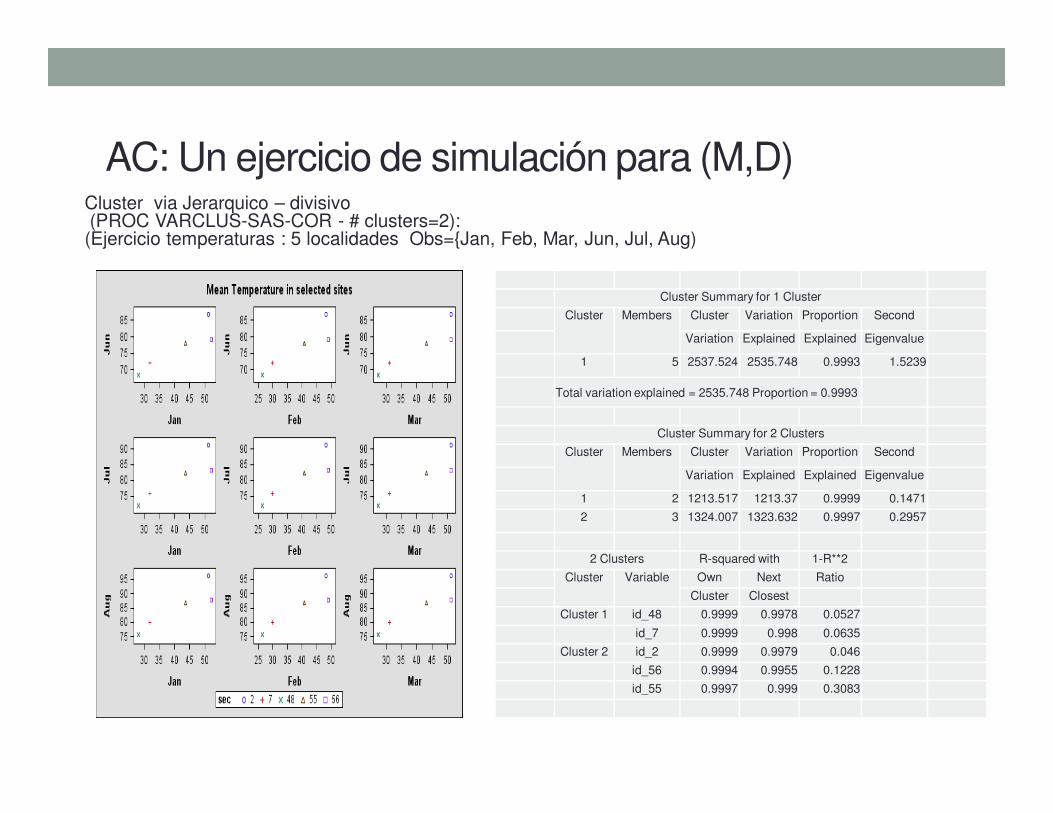
AC: Un ejercicio de simulación para (M,D)Cluster via Jerarquico – divisivo(PROC VARCLUS-SAS-COR - # clusters=2): (Ejercicio temperaturas : 5 localidades Obs={Jan, Feb, Mar, Jun, Jul, Aug)
Cluster Summary for 1 Cluster
Cluster Members Cluster Variation Proportion Second
Variation Explained Explained Eigenvalue
1 5 2537.524 2535.748 0.9993 1.5239
Total variation explained = 2535.748 Proportion = 0.9993
Cluster Summary for 2 Clusters
Cluster Members Cluster Variation Proportion Second
Variation Explained Explained Eigenvalue
1 2 1213.517 1213.37 0.9999 0.1471
2 3 1324.007 1323.632 0.9997 0.2957
2 Clusters R-squared with 1-R**2
Cluster Variable Own Next Ratio
Cluster Closest
Cluster 1 id_48 0.9999 0.9978 0.0527
id_7 0.9999 0.998 0.0635
Cluster 2 id_2 0.9999 0.9979 0.046
id_56 0.9994 0.9955 0.1228
id_55 0.9997 0.999 0.3083
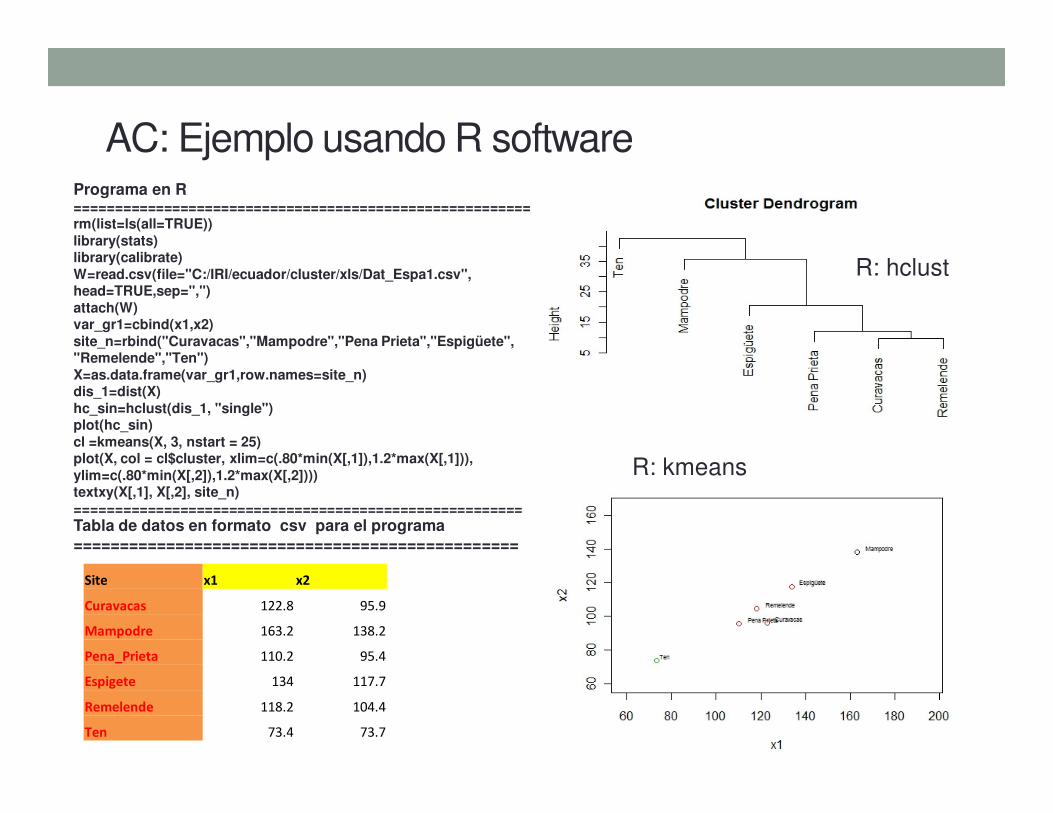
AC: Ejemplo usando R softwarePrograma en R========================================================rm(list=ls(all=TRUE))library(stats)library(calibrate)W=read.csv(file="C:/IRI/ecuador/cluster/xls/Dat_Espa1.csv",head=TRUE,sep=",")attach(W)var_gr1=cbind(x1,x2)site_n=rbind("Curavacas","Mampodre","Pena Prieta","Espigüete","Remelende","Ten")X=as.data.frame(var_gr1,row.names=site_n)dis_1=dist(X)hc_sin=hclust(dis_1, "single")plot(hc_sin)cl =kmeans(X, 3, nstart = 25)plot(X, col = cl$cluster, xlim=c(.80*min(X[,1]),1.2*max(X[,1])),ylim=c(.80*min(X[,2]),1.2*max(X[,2])))textxy(X[,1], X[,2], site_n)=======================================================
Site x1 x2
Curavacas 122.8 95.9
Mampodre 163.2 138.2
Pena_Prieta 110.2 95.4
Espig ete 134 117.7
Remelende 118.2 104.4
Ten 73.4 73.7
Tabla de datos en formato csv para el programa================================================
R: hclust
R: kmeans

Consideraciones Finales
• Es importante recordar que AC es una técnica sensible a las unidades que las variablesmantienen. En el caso de técnicas basadas en la descomposición de vectores y valorespropios los resultados cambian de acuerdo a la métrica que se use.
• Los resultados bajo diferentes M&A, conjuntos de información y/o métricas cambian
• AC no es un técnica de carácter inferencial desde el punto de vista estadístico. Sinembargo en algunos casos es posible usar análisis discriminante para evaluar laclasificación que proviene de AC. (Desventaja: Supuestos distribuciones requeridas).
• Varios paquetes estadísticos o soluciones de software proveen rutinas de AC donde elconjunto de datos esta compuesto por objetos que se desean agrupar. R, MATLAB,SAS, etc.
• El uso de algún norma (modelos para caracterizar el evento) que permita derivar algúntipo de estimación del error (los residuos: las anomalías) puede resultar mas adecuadocuando el comportamiento de las realizaciones de las variables aleatorias no es tanestable como el implícito en las simulaciones usadas.
• La presencia de valores extremos, o inusuales (outliers) afecta la definición de losgrupos (conglomerados, clusters). La identificacion adecuada de estos valoresinusuales implica un proceso de validacion adecuada de las fuentes informacion(limpiar, recuperar, confirmar) [Costo/Beneficio].