
DISEÑOS FACTORIALES EN R CON MODELOS GENERALES … · DISEÑOS FACTORIALES EN R CON MODELOS...
332
DISEÑOS FACTORIALES EN R CON MODELOS GENERALES LINEALES DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOS n‐way AN(c)OVAS Luis M. Carrascal (www.lmcarrascal.eu) Departamento de Ecología Evolutiva Grupo de Ecología Funcional Animal Museo Nacional de Ciencias Naturales, CSIC Cómo realizarlos, buena praxis e interpretación de los resultados curso de la Sociedad de Amigos del Museo Nacional de Ciencias Naturales impartido en Febrero de 2019 1
Transcript of DISEÑOS FACTORIALES EN R CON MODELOS GENERALES … · DISEÑOS FACTORIALES EN R CON MODELOS...

DISEÑOS FACTORIALES EN R CONMODELOS GENERALES LINEALES
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVAS
Luis M. Carrascal(www.lmcarrascal.eu)
Departamento de Ecología EvolutivaGrupo de Ecología Funcional Animal
Museo Nacional de Ciencias Naturales, CSIC
Cómo realizarlos,buena praxis e
interpretación de los resultados
curso de la Sociedad de Amigos del Museo Nacional de Ciencias Naturales impartido en Febrero de 20191

Esquema:Tipos de distribuciones de la variable respuesta (pág. 3)Tipos de variables predictoras (pág. 23)Generalidades de modelos n‐way AN(c)OVAS (pág. 27)Tablas y tipos de contrastes (pág. 32)Importación de datos y construcción de modelos (pág. 39)
Exploración de los supuestos canónicos del "buen" modelo (pág. 49)Normalidad de residuosHeterocedasticidad de residuosPuntos influyentes y perdidosHomogeneidad de varianzas a través de los niveles de los factoresIndependencia entre las variables‐factores predictores ‐ colinealidad
Resultados (ver los aspectos en pág. 73)
¿Cuál es el poder predictivo del modelo? – cross‐validation (pág. 103)Examen del efecto de la violación del supuesto de homocedasticidad (pág. 107)Transformaciones para "salvar" el modelo General Lineal (pág. 111)Homogeneidad de pendientes en el modelo ANCOVA (pág. 117)
Estimas y modelos robustos (pág. 122)Reducción de modelos y Akaike AIC (pág. 131)
2

TIPOS DE DISTRIBUCIONES DE LA VARIABLE RESPUESTAdistribuciones continuas
Gausianas, Poisson, Gamma y Binomiales Negativas
3

TIPOS DE DISTRIBUCIONES DE LA VARIABLE RESPUESTA
Comencemos por la normal (Gausiana)Se describe por dos parámetros:estadístico central o mediaestadístico de dispersión o desviación típica (sd)
la varianza = sd2Distribuciones geométricas simétricas
… nos inventamos números (generados al azar según unas propiedades predefinidas)
## variables normales generadas al azar; 10.000 datosvar.normal <- rnorm(n=10000, mean=4, sd=2)
## conozcamos su media y desviación típicamean(var.normal)sd(var.normal)
> mean(var.normal) > aparece en la consola[1] 4.018361 como resultado de una> sd(var.normal) instrucción ejecutada[1] 2.004826
4

TIPOS DE DISTRIBUCIONES DE LA VARIABLE RESPUESTA
Normal (Gausiana)Representamos el histograma y el Q‐Q plot:
abline, curve y qqline bajo un comando plot, hist, qqnorm, … añaden líneas al gráficomain añade un título principalv para vertical; h para horizontalcol es color; lwd para el grosor de la línea
## el histogramahist(var.normal , main="variable al azar: media=4 y sd=2")abline(v=0, col="red", lwd=2)
## y ahora el Q-Q plotqqnorm(var.normal, main="variable al azar: media=4 y sd=2")qqline(var.normal, col="red", lwd=2)
5

TIPOS DE DISTRIBUCIONES DE LA VARIABLE RESPUESTA
Normal (Gausiana)Representamos el histograma y el Q‐Q plot:
6

TIPOS DE DISTRIBUCIONES DE LA VARIABLE RESPUESTA
Normal (Gausiana)Representamos el histograma y el Q‐Q plot en un solo plot con dos paneles:
c(…) es un argumento usado para combinar “cosas” según una secuencia dada
podemos añadir comentarios en una línea de código con ## …
par(mfcol=c(1,2)) ## fija los paneles según 1 fila y 2 columnashist(var.normal, density=5, freq=FALSE, main="distribución simulada")curve(dnorm(x, mean=mean(var.normal), sd=sd(var.normal)), col="red", lwd=2,
add=TRUE, yaxt="n")abline(v=0, col="blue", lwd=2) qqnorm(var.normal)qqline(var.normal, col="red", lwd=2)par(mfcol=c(1,1)) ## volvemos a un gráfico con sólo un panel
7

TIPOS DE DISTRIBUCIONES DE LA VARIABLE RESPUESTA
Normal (Gausiana)Representamos el histograma y el Q‐Q plot en un solo plot con dos paneles:
8

TIPOS DE DISTRIBUCIONES DE LA VARIABLE RESPUESTA
Normal (Gausiana)Una variable “aislada” sólo se define por una dimensión (e.g., var.normal).var.normal es un vector de longitud 10.000.length(var.normal)> length(var.normal)[1] 10000
El dato 253 será: var.normal[253]Los datos 253 y del 401 al 450 serán: var.normal[c(253, 401:450)]
Representamos ahora los histogramas de cuatro subconjuntos de datos seleccionados ciegamente dentro de nuestra variable generada al azar. Y los ponemos en una misma figura con cuatro paneles.
par(mfcol=c(2,2)) ## fija los paneles según 2 columnas y 2 filashist(var.normal[c(1:50)])hist(var.normal[c(201:250)])hist(var.normal[c(401:450)])hist(var.normal[c(601:650)])par(mfcol=c(1,1))
9

TIPOS DE DISTRIBUCIONES DE LA VARIABLE RESPUESTA
Normal (Gausiana)Histogramas de cuatro subconjuntos de datos seleccionados ciegamente
10

TIPOS DE DISTRIBUCIONES DE LA VARIABLE RESPUESTA
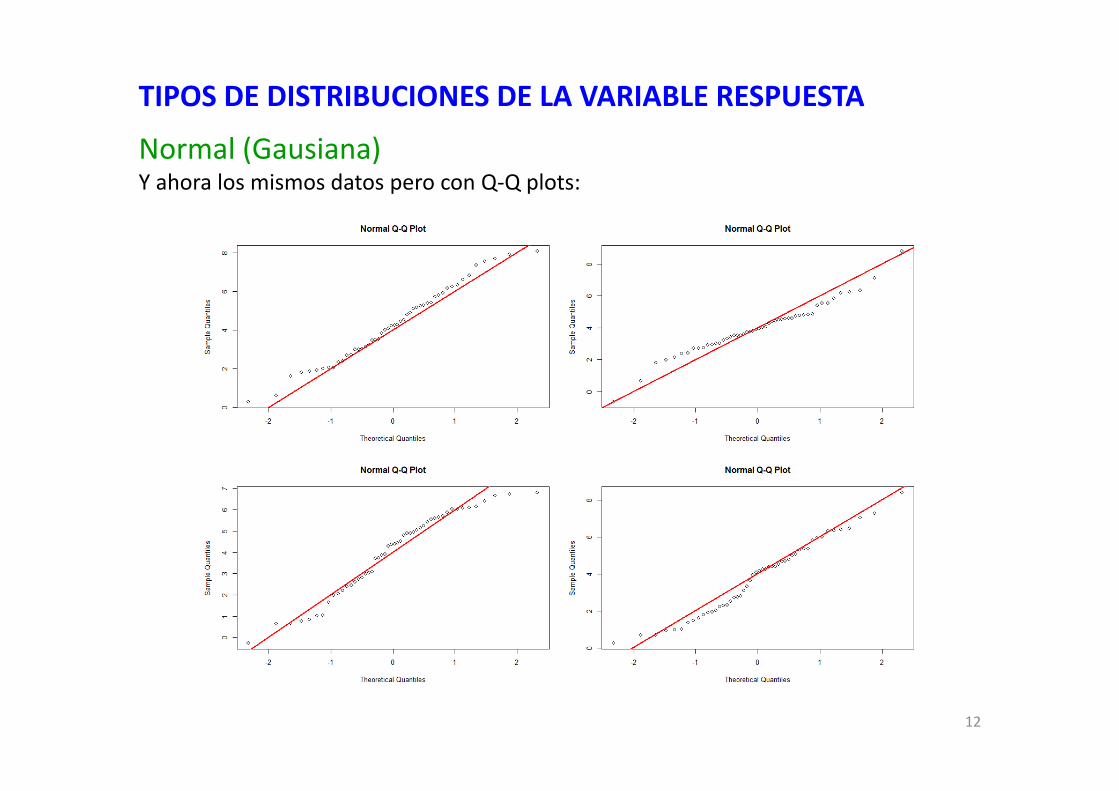
Normal (Gausiana)Y ahora los mismos datos pero con Q‐Q plots:
par(mfcol=c(2,2)) ## fija los paneles según 2 columnas y 2 filasqqnorm(var.normal[c(1:50)])qqline(var.normal, col="red", lwd=2)qqnorm(var.normal[c(201:250)])qqline(var.normal, col="red", lwd=2)qqnorm(var.normal[c(401:450)])qqline(var.normal, col="red", lwd=2)qqnorm(var.normal[c(601:650)])qqline(var.normal, col="red", lwd=2)par(mfcol=c(1,1))
11
TIPOS DE DISTRIBUCIONES DE LA VARIABLE RESPUESTA
Normal (Gausiana)Y ahora los mismos datos pero con Q‐Q plots:
12

TIPOS DE DISTRIBUCIONES DE LA VARIABLE RESPUESTA
Normal (Gausiana)Y veamos ahora sus medias y desviaciones para unos datos que vienen de una distribución de media = 4 y varianza = 4 (sd = 2).
mean(var.normal[c(1:50)]); sd(var.normal[c(1:50)]) mean(var.normal[c(201:250)]); sd(var.normal[c(201:250)])mean(var.normal[c(401:450)]); sd(var.normal[c(401:450)])mean(var.normal[c(601:650)]); sd(var.normal[c(601:650)])
> mean(var.normal[c(1:50)]); sd(var.normal[c(1:50)]) [1] 4.268634 [1] 1.953344 > mean(var.normal[c(201:250)]); sd(var.normal[c(201:250)]) [1] 3.952677 [1] 1.928345 > mean(var.normal[c(401:450)]); sd(var.normal[c(401:450)]) [1] 3.979421 [1] 1.598691 > mean(var.normal[c(601:650)]); sd(var.normal[c(601:650)]) [1] 3.775069 [1] 2.011229
13

TIPOS DE DISTRIBUCIONES DE LA VARIABLE RESPUESTA
Normal (Gausiana)
El mensaje es obvio:
• una cosa es una distribución teórica derivada de un número enorme de datos (con su geometría y parámetros canónicos)
• y otra lo que representa un subconjunto “modesto” de esos datos
• haremos exploraciones visuales “más atinadas” con Q‐Q plotsque con histogramas
14

TIPOS DE DISTRIBUCIONES DE LA VARIABLE RESPUESTA
PoissonEs una distribución con las siguientes características:• son números enteros (generalmente conteos)• no puede presentar valores negativos• su distribución se describe por un solo parámetro (lambda), de manera que la media
es igual a la varianza de la distribución (lambda media = sd2)
## generamos valores aleatorios según una Poisson## 10.000 valores, con media = varianza = 4var.poisson <- rpois(n=10000, lambda=4)#### veamos qué media y varianza han acabado teniendomean(var.poisson)sd(var.poisson)^2> mean(var.poisson)[1] 4.0103> sd(var.poisson)^2[1] 3.986393
15

TIPOS DE DISTRIBUCIONES DE LA VARIABLE RESPUESTA
PoissonHacemos una exploración visual (asimétricas y truncadas en el cero)No se ajustan a una distribución de campana gausiana
## primero el histograma de la Poissonhist(var.poisson, density=5, freq=FALSE, main="distribución simulada Poisson")curve(dnorm(x, mean=mean(var.poisson), sd=sd(var.poisson)),
col="red", lwd=2, add=TRUE, yaxt="n")
16
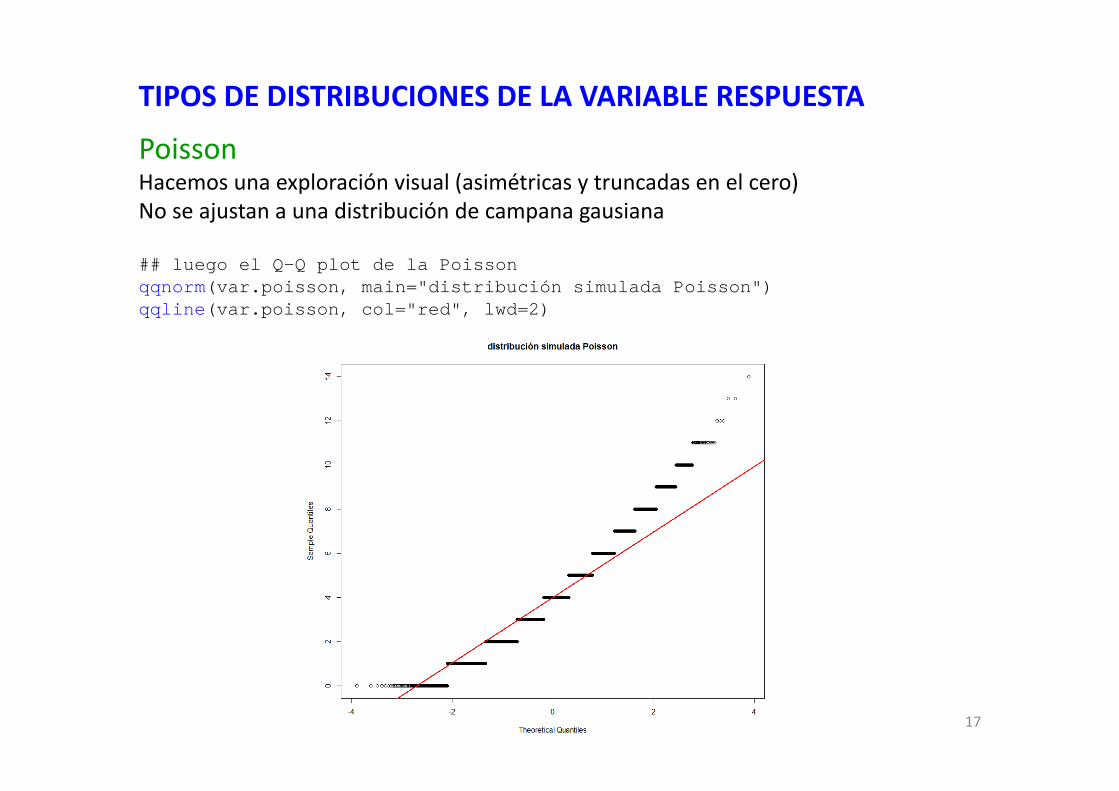
TIPOS DE DISTRIBUCIONES DE LA VARIABLE RESPUESTA
PoissonHacemos una exploración visual (asimétricas y truncadas en el cero)No se ajustan a una distribución de campana gausiana
## luego el Q-Q plot de la Poissonqqnorm(var.poisson, main="distribución simulada Poisson")qqline(var.poisson, col="red", lwd=2)
17

TIPOS DE DISTRIBUCIONES DE LA VARIABLE RESPUESTA
Poisson … parecida a una gausianaDistribuciones de Poisson con valor de lambda alto (i.e., distante de cero) pueden asemejarse a una gausiana
par(mfcol=c(1,2))hist(rpois(n=10000, lambda=50), main="distribución simulada Poisson")qqnorm(rpois(n=10000, lambda=50), main="distribución simulada Poisson")qqline(rpois(n=10000, lambda=50), col="red", lwd=2)par(mfcol=c(1,1))
18

TIPOS DE DISTRIBUCIONES DE LA VARIABLE RESPUESTA
Binomial negativaDistribuciones más dispersadas que una Poisson (varianza > media).De nuevo, son distribuciones de números enteros (generalmente conteos),
que carecen de números negativosy se describen por dos parámetros:
uno es la media ("mu")y otro es el inflado de la varianza (denominado "size" en R)
La varianza viene definida por: mu + mu^2/sizeCuando size es muy grande, 1/size tiende a cero, y la varianza acaba pareciéndose a mu.
## generamos valores aleatorios según una Binomial Negativa## 10.000 valores, con media = 4 y size = 1var.negbin <- rnbinom(n=10000, size=1, mu=4)#### veamos qué media y varianza han acabado teniendomean(var.negbin)sd(var.negbin)^2> mean(var.negbin)[1] 4.0357> sd(var.negbin)^2[1] 20.88551 19

TIPOS DE DISTRIBUCIONES DE LA VARIABLE RESPUESTA
Binomial negativaY la representamos:par(mfcol=c(1,2))hist(rnbinom(n=10000, size=1, mu=4), main="simulada Binomial Negativa")qqnorm(rnbinom(n=10000, size=1, mu=4), main="simulada Binomial Negativa")qqline(rnbinom(n=10000, size=1, mu=4), col="red", lwd=2)par(mfcol=c(1,1))
20

TIPOS DE DISTRIBUCIONES DE LA VARIABLE RESPUESTA
Binomial negativa … aproximada a una PoissonCambiamos ahora el parámetro de sobredispersión size a 1000:par(mfcol=c(1,2))hist(rnbinom(n=10000, size=1000, mu=4), main="simulada Binomial Negativa")qqnorm(rnbinom(n=10000, size=1000, mu=4), main="simulada Binomial Negativa")qqline(rnbinom(n=10000, size=1000, mu=4), col="red", lwd=2)par(mfcol=c(1,1))
21
> mean(rnbinom(n=10000, size=1000, mu=4))[1] 4.0041> sd(rnbinom(n=10000, size=1000, mu=4))^2[1] 4.005399

TIPOS DE DISTRIBUCIONES DE LA VARIABLE RESPUESTA
GammaEs una distribución definida por dos parámetros, shape y scale.Se puede asociar a una binomial negativa pero para medidas que no son conteos.Otra forma de definirla es mediante el parámetro tasa (rate) = 1/scaleCon esta distribución se cumple que:media = shape * scalevarianza = media * scalevarianza = shape * scale^2
Definamos una distribución aleatoria y veamos su forma:migamma <- rgamma(n=1000, shape=1, scale=10)hist(migamma)mean(migamma)sd(migamma)^2
migamma2 <- rgamma(n=1000, shape=10, scale=1)hist(migamma2)mean(migamma2)sd(migamma2)^2
22
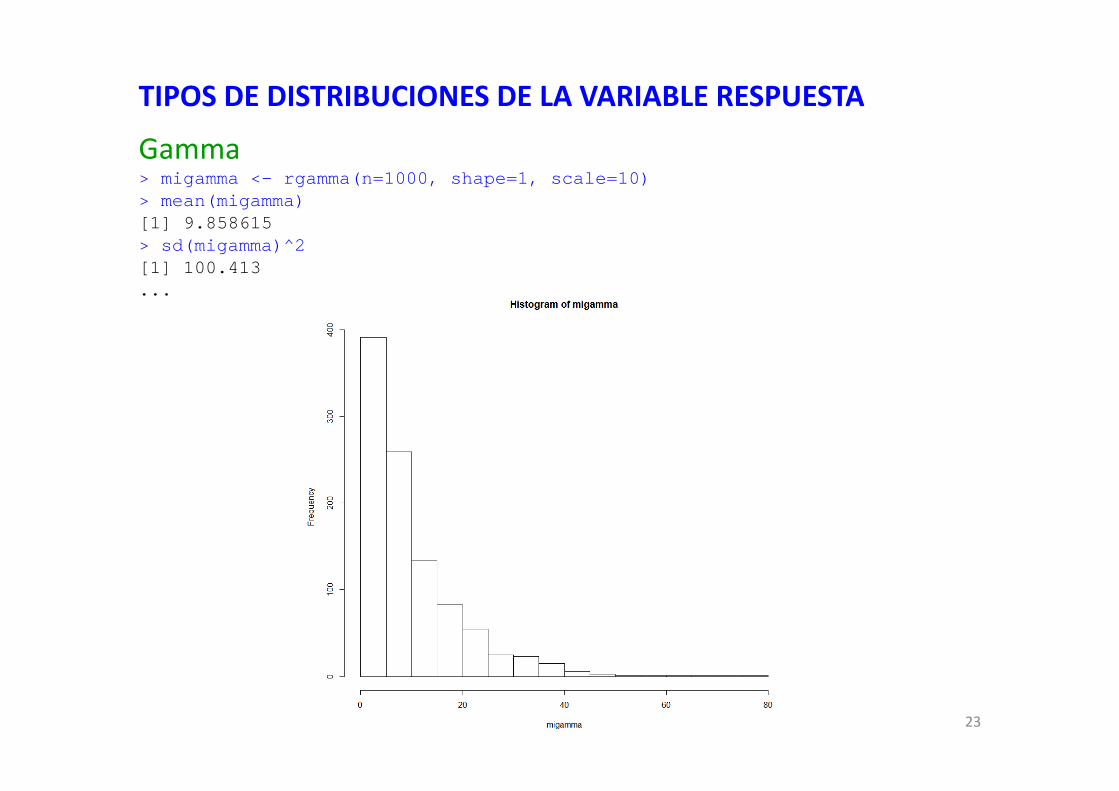
TIPOS DE DISTRIBUCIONES DE LA VARIABLE RESPUESTA
Gamma> migamma <- rgamma(n=1000, shape=1, scale=10)> mean(migamma)[1] 9.858615> sd(migamma)^2[1] 100.413...
23

TIPOS DE DISTRIBUCIONES DE LA VARIABLE RESPUESTA
Gamma> migamma2 <- rgamma(n=1000, shape=10, scale=1)> mean(migamma)[1] 9.940545> sd(migamma)^2[1] 10.02372...
24

TIPOS DE DISTRIBUCIONES DE LA VARIABLE RESPUESTA
Modelos Generales y GeneralizadosDependiendo de qué naturaleza tenga nuestra variable respuesta, trabajaremos con diferentes tipos de modelos en nuestros análisis de diseños factoriales:
Modelos Generales LinealesDistribución Gausiana
Modelos Generalizados LinealesDistribución de PoissonDistribución Binomial NegativaDistribución GammaDistribución BinomialDistribución Multinomial (ordinal o no ordinal)
Si la distribución de la variable respuesta no es ni Poisson, ni Binomial Negativa ni Binomial, pero tampoco presenta características de una Gausiana, entonces:transformamos la variable respuesta y aplicamos Modelos Generales Lineales
25

TIPOS DE VARIABLES PREDICTORAS
continuas (covariantes)factores dentro y entre sujetos
factores fijos y aleatoriosfactores anidadosfactores "bloque"
y …offsetsweights
26

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOS
n‐way AN(c)OVASgeneralidades
27

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASEn estos diseños cada unidad es una réplica independiente de las demás.Sólo se efectúa una medida por sujeto muestral.
Podemos combinar variables predictoras nominales llamadas factores yvariables continuas denominadas covariantes.
No existirán combinaciones de niveles de diferentes factores que carezcan de datos(diseños sin “celdas vacías”).
Vamos a asumir que existen relaciones lineales entre los predictores y la respuesta.
Asumimos que la variable respuesta y sus residuos se ajusta a una distribución normal.
Para diseños en los que la distribución de la respuesta sea distinta utilizaremos Modelos Generalizados Lineales
28

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASDefinimos la variable Dependiente (cuyos residuos del modelo se ajustarán a la normal)los Factores Fijos (predictores nominales) y las Covariantes (predictores continuos)Esto es, definimos el Modelo al que le podemos dar un nombre (e.g., eqt).
## CONSTRUIMOS EL MODELO## primero definimos la función de efectos (respuesta ~ predictores)eqt <- as.formula(MUSCULO ~ TARSO + ZONA*SEXO*EDAD)
Las covariantes sólo entran como efectos principales (Main effects) … por ahora.TARSO es la covariante
En esta ocasión tenemos los efectos principales de los factores,y las interacciones bi‐factoriales (All 2‐way) y tri‐factoriales (All 3‐way) entre los factores.ZONA*SEXO*EDAD es equivalente a:
ZONA+SEXO+EDAD + ZONA:SEXO+ZONA:EDAD+SEXO:EDAD + ZONA:SEXO:EDADefectos simples interacciones dobles interacción triple
factorA:factorB interacción del factor A con el factor B
29

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVAS
¿Qué son las interacciones?Responder a esta pregunta es equivalente a encontrar la respuesta a:
¿cambia el efecto del factorA a través de los niveles del factorB?… y al revés
¿cambia el efecto del factorB a través de los niveles del factorA?
Si NO HAY una interacción factorA:factorBentonces SÍ puede generalizarse el efecto de un factor a través del otro factor
Si HAY una interacción factorA:factorBentonces NO puede generalizarse el efecto de un factor a través del otro factor
Error de tipo IV:aceptar como válido y generalizable el efecto principal de un factor (Main effect),cuando de hecho su efecto es cambiante a través de otro factor.
30

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVAS
Tipos de sumas de cuadrados
* Si queremos trabajar con efectos parciales (cada predictora controlada por las restantes) utilizaremos el tipo III de Suma de Cuadrados (SS). Es el más utilizado.
* Si queremos efectuar una estima secuencial de efectos (según la ordenación que hemos definido en nuestro modelo –eqt–), utilizaremos el tipo I de SS.En este esquema el primer efecto no se controla por ningún otro
el segundo efecto es controlado por el primeroel tercer efecto es controlado por los dos previosel cuatro efecto es controlado por los tres previos …
El orden de efectos afecta a los resultados, a no ser que todos ellos sean perfectamenteindependientes (i.e., ortogonales).
* El tipo II de SS es uno “mixto” en el que:Primero se aplica el tipo III a todos los efectos principales (de orden‐1; no interacciones)Luego se aplica el tipo III a las interacciones de orden‐2 controlando los efectos de orden‐1Luego se aplica el tipo III a las interacciones de orden‐3 controlando los de orden‐1 y orden‐2…
31

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVAS
Otro aspecto muy importante es definir qué TIPOS DE CONTRASTES aplicaremos a los diferentes niveles de los factores, y cuáles serán los niveles de referencia dentro de cada factor.
Esto puede ser interesante en el caso de que los factores tengan tres niveles o más.Podemos contar con varios tipos de contrastes:Desvío: es el más utilizado cuando queremos
comparar todos los niveles entre síPolinomiales: para tablas de contrastes que definen patrones de asociación
lineal (ordenación monotónica)polinomial (de orden 2, 3, …)
Personalizados: las columnas deben sumar "cero"habrá tantas columnas de contrastes como niveles "menos" 1
ejemplos:factor DOMINANCIA con 4 niveles: MD, D, S, MS
contraste comparar MD+D contrastede desvío vs. S+MS lineal
MD 3 -1 -1 1 3D -1 3 -1 1 1S -1 -1 3 -1 -1MS -1 -1 -1 -1 -3 32

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVAS
Tablas y tipos de contrastesEste es un aspecto de vital importancia si queremos que nuestros resultados, obtenidos en R, sean idénticos a aquellos que logramos trabajando con STATISTICA, SPSS, SAS, etc.
## antes cargamos la siguiente línea de código para obtener## los mismos resultados que STATISTICA y SPSS## utilizando type III SSoptions(contrasts=c(factor="contr.sum", ordered="contr.poly"))
La línea resaltada en negrita denota que si el factor, o predictora nominal, no tiene sus niveles ordenados según una secuencia predefinida, se aplica el tipo de contraste "contr.sum" (también denominada tabla de contrastes de desvío).
Si los niveles de ese factor están ordenados, entonces se aplican todos los tipos posibles de contrastes lineales, cuadráticos, cúbicos, …
Sobre tablas de contrastes "a priori" daremos más detalles más adelante.Son "a priori" porque antes de que los investigadores veamos qué sale, hemos establecido el tipo de comparaciones (contrastes) que queremos hacer.
No lo confundamos con los tests "a posteriori". 33

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVAS
Tablas y tipos de contrastesLos resultados de los contrastes planificados "a priori" no afectan al "efecto global" que tiene el factor en la variable respuesta.
Suponen tests de hipótesis efectuados al margen de lo que define el modelo por defecto.
A través de los contrastes podemos definir el examen de unos efectos concretos que usan una determinada ordenación de los niveles de los factores. Ese orden responde a un esquema asociado a una(s) hipótesis concreta(s).
Para establecer tablas de contrastes utilizamos númeroslos niveles de los factores que queremos reunir tienen asignados un mismo númerolos niveles que queremos comparar tienen diferentes númerosla suma de todos esos números que definen códigos de contraste es CERO
Para saber más acerca de cómo se definen los contrastes en R:consultad la ayuda para contr.treatment {stats}mirad http://www.ats.ucla.edu/stat/r/library/contrast_coding.htm
34

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVAS
Tablas y tipos de contrastesEjemplo de tabla de contrastes de desvío.Comparamos todos los niveles del factor entre si.
Sea un factor con cuatro niveles llamado FDOMINANCIA (dentro del data.frame datos)Si queremos ver cómo sería una tabla de contrastes "general" para este caso:contr.sum(4)> contr.sum(4)[,1] [,2] [,3] Un factor con n niveles tiene n‐1 columnas de contrastes
1 1 0 02 0 1 03 0 0 14 -1 -1 -1
Definimos manualmente esta tabla de contrastes (que llamo matdesv)## la secuencia es: los 4 valores de la primera columna,## los otros cuatro de la segunda y los otros cuatro de la terceramatdesv <- matrix(c(1,0,0,-1, 0,1,0,-1, 0,0,1,-1), ncol=3)> matdesv
[,1] [,2] [,3] ¡¡ lo mismo que antes, pero hecho por nosotros !![1,] 1 0 0[2,] 0 1 0[3,] 0 0 1[4,] -1 -1 -1 35

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVAS
Tablas y tipos de contrastesEjemplo de tabla de contrastes de desvío.Comparamos todos los niveles del factor entre si.
Y ahora re‐definimos nuestro modelo:## no genero un objeto modelo, sino que sólo quiero ver sus resultados con summarysummary(lm(MUSCULO~FDOMINANCIA, data=datos, contrasts=list(FDOMINANCIA=matdesv)))## esto es lo mismo que si hubiese escritosummary(lm(MUSCULO~FDOMINANCIA, data=datos, contrasts=list(FDOMINANCIA=contr.sum)))## porque es la tabla de contrastes de desvío "estándard"
Creamos ahora otra tabla que compara los dos primeros con los dos últimos niveles(que llamo mat12vs34). Este contraste "funde" los cuatro niveles en dos nuevos ## al definir dos nuevos niveles "fundiendo" los cuatro que tiene el factor## tengo dos "nuevos" niveles, y por tanto 2-1 = 1 columnas de contrastemat12vs34 <- matrix(c(1,1, -1,-1), ncol=1)> mat12vs34
[,1][1,] 1[2,] 1[3,] -1[4,] -1
36

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVAS
Tablas y tipos de contrastesEjemplo de tabla de contrastes de desvío.Comparamos los niveles del factor según el esquema de Helmert.
primer nivel vs siguiente, dos primeros niveles vs el siguiente, tres primeros niveles vs el siguiente, ...
contr.helmert(4)> contr.helmert(4)[,1] [,2] [,3]
1 -1 -1 -12 1 -1 -13 0 2 -14 0 0 3
## lo hacemos nosotros manualmentemathelmert <- matrix(c(-1,1,0,0, -1,-1,2,0, -1,-1,-1,3), ncol=3)> mathelmert
[,1] [,2] [,3] ¡¡ lo mismo que antes, pero hecho por nosotros !![1,] -1 -1 -1[2,] 1 -1 -1[3,] 0 2 -1[4,] 0 0 3
37

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVAS
Tablas y tipos de contrastesEjemplo de tabla de contrastes ordenados.Comparamos los niveles del factor según un esquema ordenado.
un factor con dos niveles sólo tiene un esquema lineal (.L)un factor con tres niveles, tiene un esquema lineal (.L) y otro cuadrático (.Q)un factor con cuatro niveles, tiene un esquema lineal (.L), otro cuadrático (.Q) y otro cúbico (.C)
contr.poly(4)> contr.poly(4)
.L .Q .C[1,] -0.6708204 0.5 -0.2236068[2,] -0.2236068 -0.5 0.6708204[3,] 0.2236068 -0.5 -0.6708204[4,] 0.6708204 0.5 0.2236068
Esto también puede escribirse como:matordenado <- matrix(c(-3,-1,1,3, 1,-1,-1,1, -1,3,-3,1), ncol=3)> matordenado
[,1] [,2] [,3] numéricamente es distinto de lo anterior[1,] -3 1 -1 ¡¡ pero produce los mismos resultados para la tabla de significación y efectos !![2,] -1 -1 3 sólo los valores de los coeficientes del modelo son diferentes[3,] 1 -1 -3 porque obviamente los "números de contrastes" son distintos[4,] 3 1 1
38
contr.poly(2)> contr.poly(2)
.L[1,] -0.7071068[2,] 0.7071068
contr.poly(3)> contr.poly(3)
.L .Q[1,] -7.071e-01 0.4082[2,] -7.850e-17 -0.8165[3,] 7.071e-01 0.4082

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVAS
Veamos cómo trabajar con vectores y factores en R
## me invento una variable (vector); cuatro niveles (1 a 4), ocho datos cada unomivariable <- c(1,1,1,1,1,1,1,1,2,2,2,2,2,2,2,2,3,3,3,3,3,3,3,3,4,4,4,4,4,4,4,4)length(mivariable) ## cuántos datos son> length(mivariable)[1] 32
class(mivariable) ## qué tipo de variable es> class(mivariable)[1] "numeric
## para generar una variable al azar según una distribución determinadavar.uniforme <- runif(n=50, min=1, max=4) ## distribución uniformevar.normal <- rnorm(n=50, mean=2.5, sd=1) ## distribución gausianavar.poison <- rpois(n=50, lambda=2.5) ## distribución Poissonvar.binomial <- rbinom(n=50, prob=0.5, size=1) ## distrib. binomial con 0-1var.binomial <- rbinom(n=50, prob=0.5, size=2) ## distrib. binomial con 0-2
## para ordenar un vector no contenido en un data frame (i.e., variable suelta)var.normal.ordenada <- sort(var.normal)
39

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASAhora vamos a correr nuestro modelo:(no sin antes dejar de lado el establecimiento de los contrastes "estándar")
R por defecto usa las tablas de contraste contr.treatment. Y esto no es lo correcto.El la ayuda de R para el comando contr.treatment podemos leer:contr.treatment contrasts each level with the baseline level (specified by base)… Note that this does not produce ‘contrasts’ as defined in the standard theory for linear models as they are not orthogonal to the intercept.
## antes cargamos la siguiente línea de código para obtener## los mismos resultados que STATISTICA y SPSS utilizando type III SSoptions(contrasts=c(factor="contr.sum", ordered="contr.poly"))#### y aquí el modelo:eqt <- as.formula(MUSCULO ~ TARSO + ZONA*SEXO*EDAD)modelo <- lm(eqt, data=datos)#### que también podría haber sido:modelo <- lm(MUSCULO ~ TARSO + ZONA*SEXO*EDAD, data=datos)
Pero … ¿y dónde están mis datos?Nuestros datos (que yo aquí los llamo datos) los asociamos al modelo a través del argumento data incluido en el comando lm que es el que hace el Modelo General Lineal.
40

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVAS¿Cómo importo mis datos al entorno de trabajo R y los uso?Y aquí va la opción más sencilla … "para torpes" o para personas que huyen de complicaciones.
Tenemos nuestros datos en MS‐Excel, u otra hoja de cálculo, en la que los datos estén separados por tabuladores.• la primera fila contendrá los nombres de las variables• evitaremos nombres con caracteres extraños (podemos incluir "puntos" .)• tenemos que tener en cuenta si el separador decimal es "coma ," ó "punto ." • seleccionaremos todos los datos, incluyendo los nombres de las variables• copiamos al portapapeles los datos• nos pasamos a RStudio y corremos la siguiente línea de código
## para importar datos, que les llamo "datos" (elegid otro nombre)datos <- read.table("clipboard", header=TRUE, sep="\t", dec=".")## "\t" indica que los separadores son tabuladores## "." denota que los decimales se definen con "puntos"
41

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVAS¿Cómo importo mis datos al entorno de trabajo R y los uso?Veamos qué contiene nuestra matriz de datos llamada "datos".
## para saber qué clase de objeto esclass(datos)> class(datos)[1] "data.frame"
## para saber qué variables contienenames(datos)> names(datos)[1] "ZONA" "CODZONA" "SEXO" "EDAD" "DOMINANCIA"[6] "TARSO" "ALA" "PESO" "MUSCULO" "TASAVER"
[11] "TASAINV" "DCRECINV" "PIERDE" "MINCAJA10H" "id"
## para saber la naturaleza de las variables que contienestr(datos)> str(datos)'data.frame': 38 obs. of 15 variables:$ ZONA : Factor w/ 2 levels "SARRIA","VENTOR": 1 1 1 1 1 1 1 1 1 1 ...$ CODZONA : int 1 1 1 1 1 1 1 1 1 1 ...$ SEXO : Factor w/ 2 levels "h","m": 1 1 2 2 2 2 2 1 1 1 ...
……… 42

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVAS¿Cómo importo mis datos al entorno de trabajo R y los uso?
## para saber sus dimensionesdim(datos)> dim(datos)[1] 38 15## que significa 38 filas (casos u observaciones) y 15 variables
## para listar o usar la variable (columna) sextadatos[,6]## antes de la coma no hay "nada" indicando "usa todos"
## para saber el nombre de la columna-variable sextanames(datos[6])
## para usar-extraer las columnas 6, 8-a-11 y la 14 y pasarlas## a otro data frame de datos (llamado otros.datos)otros.datos <- datos[,c(6, 8:11, 14)]
## para borrar (remove) el data frame otros.datosrm(otros.datos)
43

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVAS¿Cómo importo mis datos al entorno de trabajo R y los uso?## para seleccionar-extraer una parte de mis casos-observaciones## usando todas las variables-columnas generando otro data frame## por ejemplo, las observaciones-filas de la 1 a la 15 y 22 a 30miseleccion.datos <- datos[c(1:15, 22:30),]
## para crear una nueva variable dentro de mis datos (data frame)## como en la nomenclatura lineana … "data frame $ variable"datos$raiz_PESO <- (datos$PESO)^0.5
## para ordenar las filas de un data frame por una de sus variables## … creando un nuevo data framenuevos_datos <- datos[order(datos$DOMINANCIA),]
## para saber cuáles son todos los objetos que tengo en mi entorno## de trabajo (Environment); panel superior derecho de Rstudiols()
## mi consola (Console) o panel inferior izquierdo de Rstudio## se ha llenado de cosas … y lo quiero limpiarEstando posicionados en él, tecleamos simultáneamente [Control]+l (l es "ele")… ó en la consola escribimos cat("\014")
44

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVAS¿Cómo trabajamos con variables nominales discretas (factores)?## para convertir un vector numérico (mivariable) en un factorfactor.mivariable <- as.factor(mivariable)class(factor.mivariable)> class(factor.mivariable)[1] "factor"
## para definir un factor ordenado a partir de un vectorfactor.ordenado.mivariable <- as.ordered(mivariable)class(factor.ordenado.mivariable)> class(factor.ordenado.mivariable)[1] "ordered" "factor"
## para convertir una variable continua (con valores 1 2 3 y 4) a otra con valores (0 1)## a la condición "<3" se le asigna el valor 0, y a lo demás el valor 1datos$DOMINANCIA2 <- ifelse(datos$DOMINANCIA<3, 0, 1)## y ahora la convertimos en factordatos$DOMINANCIA2 <- as.factor(datos$DOMINANCIA2)
## asignar valores de un vector a códigos-niveles de un factor## considerando los puntos de corte incluidos en c(. . .)## de 0-a-1 (=<1) es "MSUB", de 1-a-2 (=<2) es "SUB", de 2-a-3 (=<3) es "DOM", etcdatos$FDOMINANCIA3 <- cut(datos$DOMINANCIA, c(0,1,2,3,4),labels=c("MSUB", "SUB", "DOM", "MDOM")) ## ¡¡ ojo que son dos líneas !!
45

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASVolvamos a nuestro modeloQue era:
## aquí el modelo:options(contrasts=c(factor="contr.sum", ordered="contr.poly"))eqt <- as.formula(MUSCULO ~ TARSO + ZONA*SEXO*EDAD)modelo <- lm(eqt, data=datos)#### que también podría haber sido tras cargar options(……):modelo <- lm(MUSCULO ~ TARSO + ZONA*SEXO*EDAD, data=datos)#### y que también podría haber sido:modelo <- lm(MUSCULO~TARSO+ZONA*SEXO*EDAD, data=datos,
contrasts=list(ZONA=contr.sum, SEXO=contr.sum, EDAD=contr.sum))
## para ver el resultado de nuestro modelosummary(modelo)#### nuestro modelo es un objeto de R con muchas cosas dentro; ¿qué tiene?names(modelo)
46

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASVolvamos a nuestro modelo> names(modelo)[1] "coefficients" "residuals" "effects" "rank" [5] "fitted.values" "assign" "qr" "df.residual" [9] "contrasts" "xlevels" "call" "terms"
[13] "model"
model contiene todos los datos de las variables respuesta y predictoras usadas, y es de gran utilidad por si queremos trabajar a posteriori con los datos ya seleccionados para su uso.La primera columna es siempre la variable respuesta.## para ver sus datosmodelo$model## para ver la variable respuesta usadamodelo$model[,1]## y su nombrenames(modelo$model[1])
Los residuos y las predicciones del modelo los podemos sacar, como una variable, de este modo:## para ver los residuos del modelo podemos hacer estas dos cosasmodelo$residualsresiduals(modelo)## para ver las prediccionesmodelo$fitted.values
47

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASVolvamos a nuestro modelosummary(mmodelo)> summary(modelo)Call:lm(formula = MUSCULO ~ TARSO + ZONA * SEXO * EDAD, data = datos,
contrasts = list(ZONA = contr.sum, SEXO = contr.sum, EDAD = contr.sum))
Residuals:Min 1Q Median 3Q Max
-0.58050 -0.22168 -0.06063 0.17683 0.82380
Coefficients:Estimate Std. Error t value Pr(>|t|)
(Intercept) -2.35435 2.20612 -1.067 0.294689 TARSO 0.26179 0.11316 2.314 0.027983 * ZONA1 -0.24552 0.06461 -3.800 0.000687 ***SEXO1 -0.24987 0.07810 -3.199 0.003323 ** EDAD1 0.10629 0.07120 1.493 0.146297 ZONA1:SEXO1 0.07874 0.06419 1.227 0.229786 ZONA1:EDAD1 -0.04819 0.06632 -0.727 0.473217 SEXO1:EDAD1 -0.08726 0.06511 -1.340 0.190551 ZONA1:SEXO1:EDAD1 0.12454 0.06482 1.921 0.064565 . ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.3718 on 29 degrees of freedomMultiple R-squared: 0.7299, Adjusted R-squared: 0.6554 F-statistic: 9.797 on 8 and 29 DF, p-value: 1.781e-06) 48

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVAS
Exploración de los supuestos canónicos del "buen" modelo
Realmente esto es lo primero que tendríamos que hacer antes de considerar los resultados de nuestro análisis.
Nos permite conocer cómo nuestro modelo se ajusta a los supuestos canónicos del modelo utilizado (General Lineal)
Este examen de los supuestos canónicos lo efectuamos teniendo en cuenta los residuos del modelo.
NormalidadHeterocedasticidadPuntos influyentes y perdidosHomogeneidad de varianzas a través de los niveles de los factoresIndependencia entre las variables‐factores predictores
49
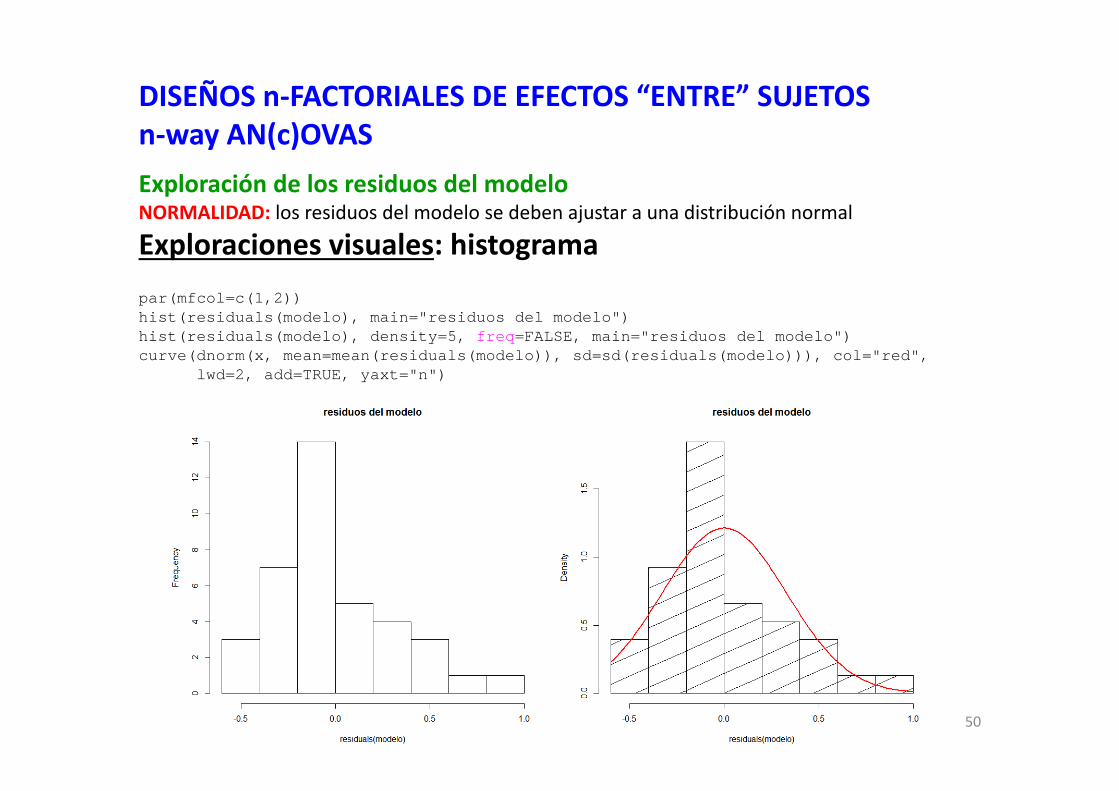
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASExploración de los residuos del modeloNORMALIDAD: los residuos del modelo se deben ajustar a una distribución normal
Exploraciones visuales: histogramapar(mfcol=c(1,2))hist(residuals(modelo), main="residuos del modelo")hist(residuals(modelo), density=5, freq=FALSE, main="residuos del modelo")curve(dnorm(x, mean=mean(residuals(modelo)), sd=sd(residuals(modelo))), col="red",
lwd=2, add=TRUE, yaxt="n")
50

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASExploración de los residuos del modeloNORMALIDAD: los residuos del modelo se deben ajustar a una distribución normal
Exploraciones visuales: Q‐Q plots (normal probability plot)par(mfcol=c(1,2))qqnorm(residuals(modelo), main="residuos del modelo") ## el típico de Rqqline(residuals(modelo))## el de otros programas; datax=TRUE para cambiar el orden de los ejesqqnorm(residuals(modelo), main="residuos del modelo", datax=TRUE,
xlab="Expected Normal Value", ylab="Residuals")qqline(residuals(modelo), datax=TRUE, col="red")
51

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASExploración de los residuos del modeloNORMALIDAD: los residuos del modelo se deben ajustar a una distribución normal
Globalmente, los tests de la F en modelos Generales y Generalizados son bastante robustos ante las desviaciones de la normalidad.
Exploraciones analíticas: test de Shapiro‐Wilkhttps://en.wikipedia.org/wiki/Shapiro%E2%80%93Wilk_testEn vez del test de Kolmogorov‐Smirnov (que asume que muestra y población son coincidentes)(en la mayoría de los casos tenemos una muestra que no coincide con la población)https://en.wikipedia.org/wiki/Kolmogorov%E2%80%93Smirnov_test
shapiro.test(residuals(modelo))> shapiro.test(residuals(modelo))
Shapiro-Wilk normality test
data: residuals(modelo)W = 0.9618, p-value = 0.2168
52

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASExploración de los residuos del modeloNORMALIDAD: los residuos del modelo se deben ajustar a una distribución normal
Exploraciones analíticas: sesgo y kurtosis
KURTOSIS SESGOpuntiagudez de la distribución (Ho= 3 ó 0) simetría de la distribución (Ho= 0)mayor efecto poco efecto si K>0 (leptokurtosis) mayor error tipo II leve aumento del error de tipo Iaceptar la Ho [nula] cuando de hecho es falsa rechazar la Ho [nula] cuando es ciertasi K<0 (platikurtosis) mayor error tipo I
library(moments)
53
## kurtosis de Pearson, Ho = 3kurtosis(residuals(modelo))anscombe.test(residuals(modelo))
> kurtosis(residuals(modelo))[1] 2.779232> anscombe.test(residuals(modelo))
Anscombe-Glynn kurtosis testdata: residuals(modelo)kurt = 2.7792, z = 0.1138, p-value = 0.9094alternative hypothesis: kurtosis is not equal to 3
## sesgo Ho = 0skewness(residuals(modelo))agostino.test(residuals(modelo))
> skewness(residuals(modelo))[1] 0.5957432> agostino.test(residuals(modelo))
D'Agostino skewness testdata: residuals(modelo)skew = 0.5957, z = 1.6331, p-value = 0.1024alternative hypothesis: data have a skewness

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASExploración de los residuos del modeloHOMOCEDASTICIDAD DE LOS RESIDUOS. * La varianza de los residuos debe ser similar a lo largo de las predicciones del modelo.* Debería aparecer un patrón de dispersión aleatoria de puntos, sin dibujar ningún esquemageométrico (e.g., como muchas bolas repartidas al azar en una mesa de billar).
Situación que no deberíamos tener: violación del supuesto de la homocedasticidad al haber unpatrón triangular indicativo de que hay heterogeneidad en la varianza de los residuos a lo largo delas predicciones del modelo. Hay mayor varianza de los residuos a mayores valores predichos.
54
¡No podemos asumir las estimas de unoserrores estándar (se) generalizables!
Tenemos que re‐estimar los se utilizandoprocedimientos robustos.
Esto modificará la significación de losefectos de las predictoras (las p).

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASExploración de los residuos del modeloHOMOCEDASTICIDAD DE LOS RESIDUOS.
Consecuencias de la violación del supuesto de homocedasticidad.Globalmente, los tests de la F en modelos Generales y Generalizados son bastante robustos antelas desviaciones de la homocedasticidad.
Incluso bajo severas violaciones de este supuesto la alpha se modifica poco, tendiendo aincrementarse la probabilidad de cometer el error de tipo I.
Si no se cumple el requisito de homocedasticidad podemos transformar la respuesta.
El caso más problemático es aquel en el que la varianza de los residuos (diferencia entre valoresobservados y predichos) se asocia con lamedia de las predicciones.* si la relación es positiva, aumenta el error de tipo I* si la relación es negativa, aumenta el error de tipo II
Si hay heterocedasticidad en los residuos del modelo, lo volvemos a rehacer utilizando opcionesrobustas (also called the Huber/White/sandwich estimator … a "corrected" model‐based estimator thatprovides a consistent estimate of the covariance), que utilizan distintas opciones de matrices devarianzas covarianzas (HC0, HC1, HC2, HC3, HC4, HC4m).
55

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASExploración de los residuos del modeloHOMOCEDASTICIDAD DE LOS RESIDUOS.
plot(modelo$fitted.values, residuals(modelo), main="¿HAY HETEROCEDASTICIDAD?")abline(h=0, col="red") ## traza una línea horizontal (h) por el Y=0
56
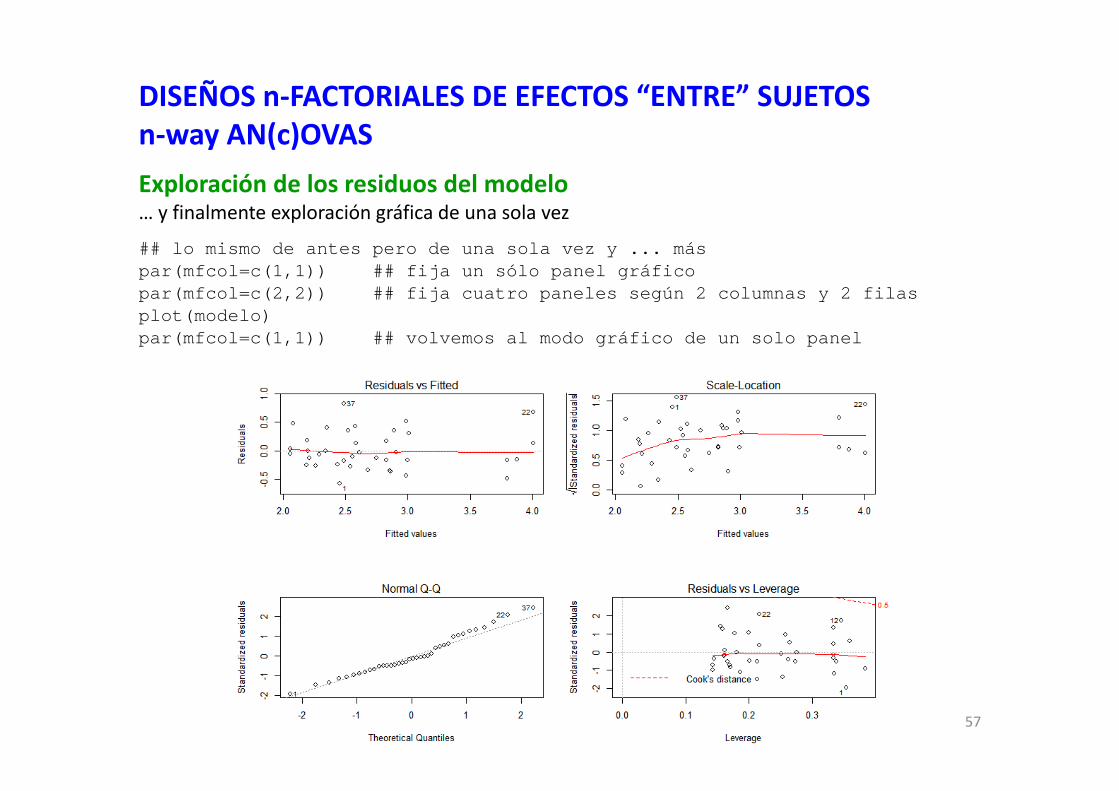
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASExploración de los residuos del modelo… y finalmente exploración gráfica de una sola vez
## lo mismo de antes pero de una sola vez y ... máspar(mfcol=c(1,1)) ## fija un sólo panel gráficopar(mfcol=c(2,2)) ## fija cuatro paneles según 2 columnas y 2 filasplot(modelo)par(mfcol=c(1,1)) ## volvemos al modo gráfico de un solo panel
57

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASExploración de los residuos del modeloPUNTOS INFLUYENTES Y PUNTOS PERDIDOSExploración de datos residuales de manera individualizada por cada unidad muestralPara detectar puntos influyentes y perdidos representaremos:el Leverage (e.g., eje X) frente a la distancia de Cook (CooksDistance; e.g., eje Y).
Leverage: https://en.wikipedia.org/wiki/Leverage_(statistics)CooksDistance : https://en.wikipedia.org/wiki/Cook%27s_distance
58
Valores críticos "aproximados":
Distancia de Cook:posible problema si > 4/nproblema enorme si >1
Leverage:posible problema si > 2*g.l./n
siendo: g.l. los grados de libertad
del modelon el número de casos.
lo peor sonlos datos que seencuentren aquí
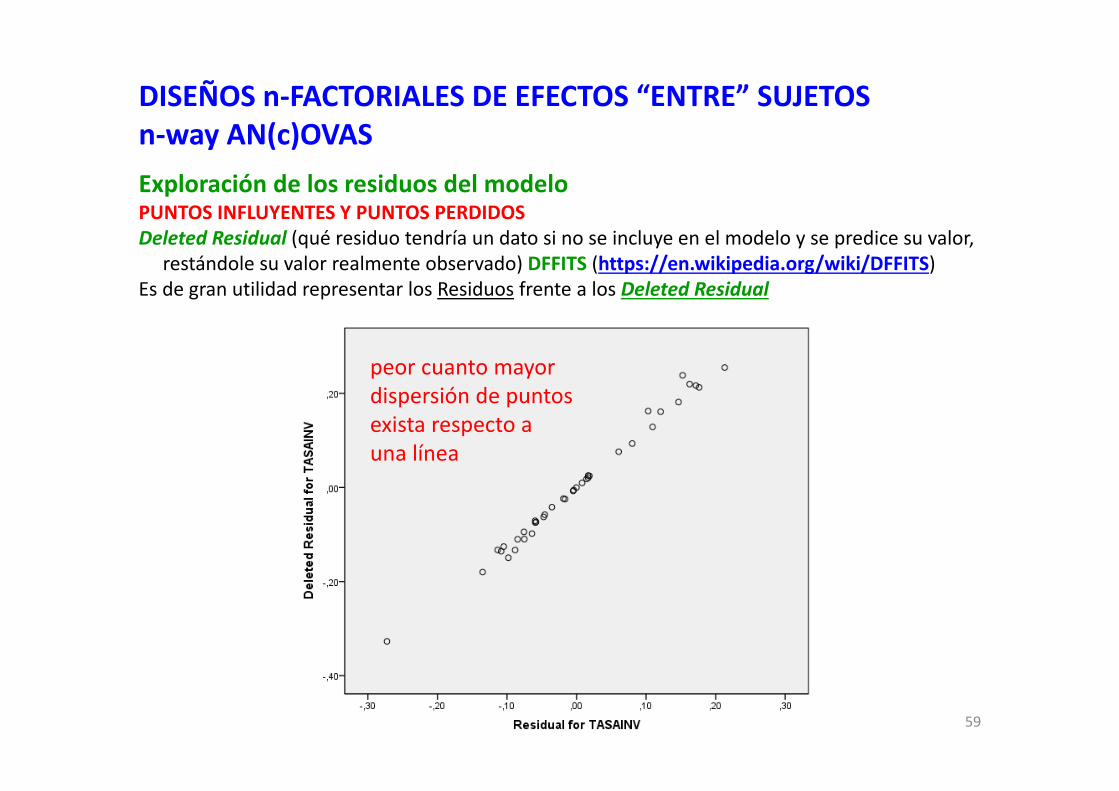
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASExploración de los residuos del modeloPUNTOS INFLUYENTES Y PUNTOS PERDIDOSDeleted Residual (qué residuo tendría un dato si no se incluye en el modelo y se predice su valor,
restándole su valor realmente observado) DFFITS (https://en.wikipedia.org/wiki/DFFITS)Es de gran utilidad representar los Residuos frente a los Deleted Residual
59
peor cuanto mayordispersión de puntosexista respecto auna línea

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASExploración de los residuos del modeloPUNTOS INFLUYENTES Y PUNTOS PERDIDOS
leverage## niveles críticos 2*(g.l. del modelo)/(Número de datos)library(fit.models)plot(leverage(modelo))abline(h=2*(length(modelo$residuals)-modelo$df.residual-1)/length(modelo$residuals), col="red")
distancia de cook## menor que 4/(número de datos)plot(cooks.distance(modelo))abline(h=4/length(modelo$residuals), col="red")
dffits## niveles críticos 2*raiz((g.l. del modelo)/(Número de datos))plot(dffits(modelo))abline(h=2*((length(modelo$residuals)-modelo$df.residual-1)/length(modelo$residuals))^0.5, col="red")abline(h=-2*((length(modelo$residuals)-modelo$df.residual-1)/length(modelo$residuals))^0.5, col="red")
60

61
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASExploración de los residuos del modeloPUNTOS INFLUYENTES Y PUNTOS PERDIDOS
indica el orden del caso‐observación en la matriz de datos

62
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASExploración de los residuos del modeloPUNTOS INFLUYENTES Y PUNTOS PERDIDOS
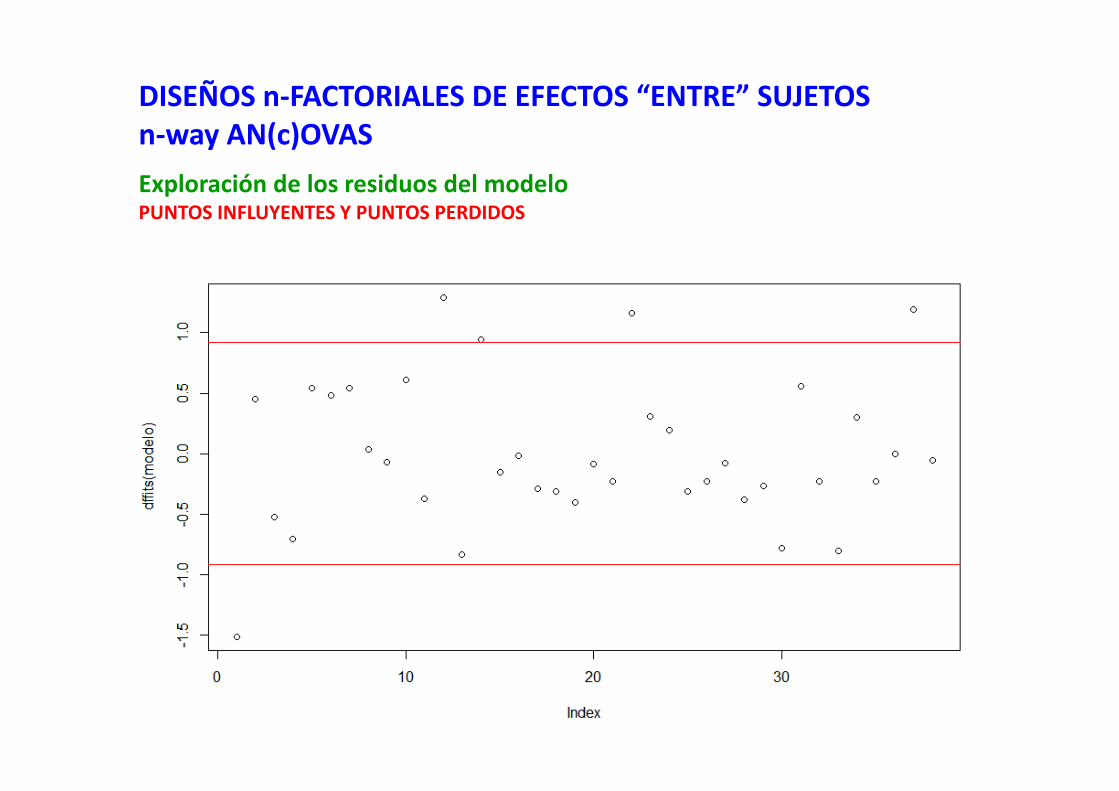
63
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASExploración de los residuos del modeloPUNTOS INFLUYENTES Y PUNTOS PERDIDOS

64
lo "peor"está aquí
datos potencialmenteproblemáticos
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASExploración de los residuos del modeloPUNTOS INFLUYENTES Y PUNTOS PERDIDOS
plot(cooks.distance(modelo) ~ leverage(modelo), col="darkgreen")abline(h=4/length(modelo$residuals), col="red")abline(v=2*(length(modelo$residuals)-modelo$df.residual-1)/length(modelo$residuals), col="red")
identify(cooks.distance(modelo) ~ leverage(modelo)) ## terminar dando clik en Finish (boton sup-decho panel de plots)
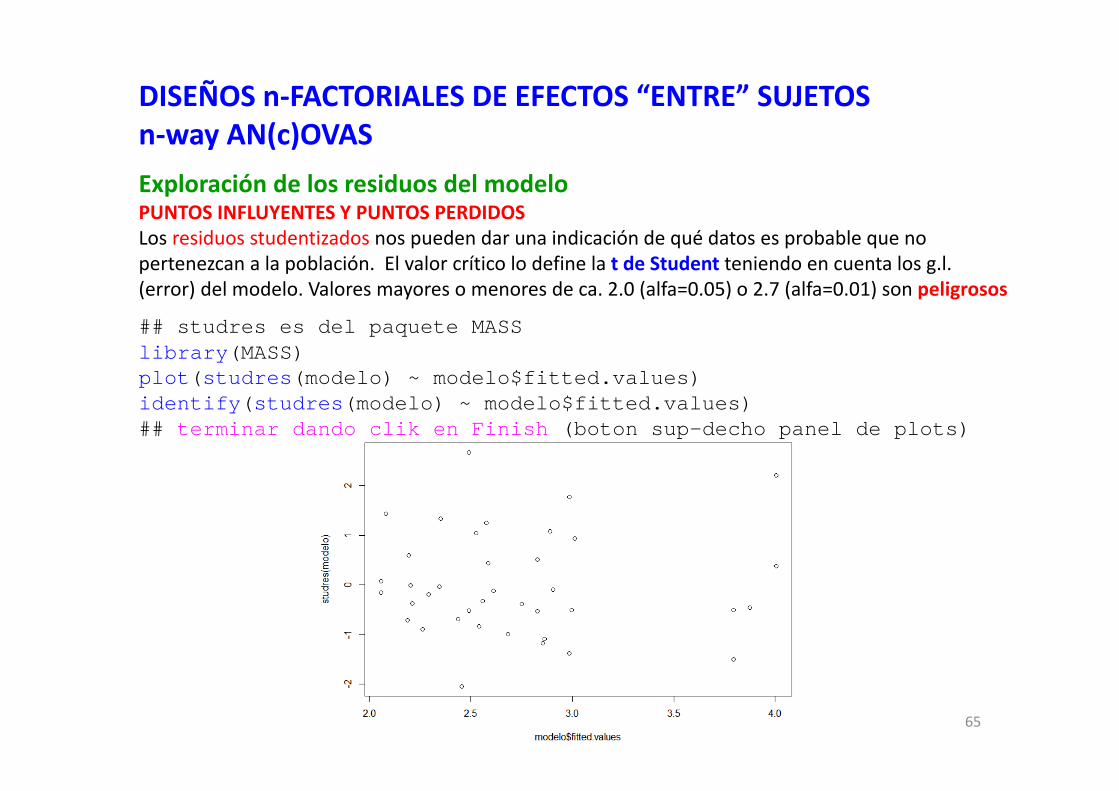
65
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASExploración de los residuos del modeloPUNTOS INFLUYENTES Y PUNTOS PERDIDOSLos residuos studentizados nos pueden dar una indicación de qué datos es probable que no pertenezcan a la población. El valor crítico lo define la t de Student teniendo en cuenta los g.l. (error) del modelo. Valores mayores o menores de ca. 2.0 (alfa=0.05) o 2.7 (alfa=0.01) son peligrosos
## studres es del paquete MASSlibrary(MASS)plot(studres(modelo) ~ modelo$fitted.values)identify(studres(modelo) ~ modelo$fitted.values) ## terminar dando clik en Finish (boton sup-decho panel de plots)

66
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASHOMOGENEIDAD DE VARIANZAS A TRAVÉS DE LOS NIVELES DE LOS FACTORES• El test de Levene funciona bien en los modelos AN(c)OVA, asumiendo que haya habido de
pequeñas a moderadas desviaciones de la normalidad en los residuos. En esta situación, su resultado (capacidad para identificar desvíos de la homogeneidad de varianzas) supera al test de Bartlett. El test de Levene no admite las covariantes del modelo
• El test de Bartlett es muy adecuado en el caso de que los residuos del modelo se ajusten muy bien a la normalidad. Sólo es posible con un único factor.
• El test de Figner‐Killeen es el que debiéramos elegir en el caso de que haya habido importantes desvíos de la normalidad. Sólo es posible con un único factor.
Los AN(c)OVA son bastante robustos a las violaciones del supuesto de homogeneidad de varianzas.Incluso bajo severas violaciones de este supuesto en la respuesta, alfa se modifica poco, tendiendo a incrementarse la probabilidad de cometer el error de tipo I (rechazar la Ho [nula] cuando es cierta).
El caso más problemático aparece cuando la media y la varianza de los distintos niveles de el/los factor(es) están correlacionados.• si la relación es positiva se incrementa el error de tipo I• si la relación es negativa se incrementa el error de tipo II (aceptar la Ho [nula] cuando es falsa)

67
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASHOMOGENEIDAD DE VARIANZAS A TRAVÉS DE LOS NIVELES DE LOS FACTORES
bartlett.test(MUSCULO~ZONA, data=datos) ## para un solo factor cada vez> bartlett.test(MUSCULO~ZONA, data=datos)
Bartlett test of homogeneity of variancesdata: MUSCULO by ZONABartlett's K-squared = 3.535, df = 1, p-value = 0.06009
fligner.test(MUSCULO~ZONA, data=datos) ## para un solo factor cada vez> fligner.test(MUSCULO~ZONA, data=datos)
Fligner-Killeen test of homogeneity of variancesdata: MUSCULO by ZONAFligner-Killeen:med chi-squared = 3.0102, df = 1, p-value = 0.08274
## para los efectos del modelo pero … sin covariantes## otros programas usan la opción center=mean (e.g., STATISTICA)library(car)leveneTest(MUSCULO~ZONA:SEXO:EDAD, data=datos, center=median)> leveneTest(MUSCULO~ZONA:SEXO:EDAD, data=datos, center=median)Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)group 7 0.4655 0.8516
30

68
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASExploración de la colinealidad entre las variables predictoras
Las variables predictoras durante mucho tiempo fueron llamadas "independientes".Era el reconocimiento explícito de que debían no estar correlacionadas entre si.
Si hay dependencia entre las variables predictoras, se dice que entre ellas existe colinealidad.
La colinealidad puede surgir porque:• por definición las predictoras están correlacionadas (e.g., temperatura y altitud)• porque no hay homogeneidad de tamaños muestrales en los diferentes niveles de los factores
El hecho de que las variables predictoras no sean indenpendientes (i.e., ortogonales) conlleva algunos problemas:• las variables se anulan entre si• las estimas de significación se alteran• las magnitudes de efecto se ven modificadas• no hay convergencia entre los resultados de SS (suma de cuadrados) de tipo I y tipo III
Este asunto lo vamos a abordar mediante exploraciones visuales y cuantitativas de la intensidad de relación entre las variables predictoras

69
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASExploración de la colinealidad entre las variables predictoras
Esta larga secuencia de líneas de código vale para cualquier situación de análisis.Sólo tendremos que alterar:eqt: la cadena de texto que contiene nuestra ecuación usada en el modelo lm(eqt, data=datos)datos: el origen de los datos de análisis
## comprobad que no haya "missing cells" en los factorespanel.cor <- function(x, y, digits=2, prefix="", cex.cor, ...) {
usr <- par("usr")on.exit(par(usr))par(usr = c(0, 1, 0, 1))r <- abs(cor(x, y, use="complete.obs"))txt <- format(c(r, 0.123456789), digits=digits)[1]txt <- paste(prefix, txt, sep="")if(missing(cex.cor)) cex.cor <- 0.8/strwidth(txt)text(0.5, 0.5, txt, col="blue", cex = cex.cor * (1 + r) / 1)
}pairs(eqt, data=datos, cex.labels=2, pch="o", lower.panel = panel.cor)

70
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASExploración de la colinealidad entre las variables predictorasel número azul es el valor absoluto de la correlación entre pares de predictores

71
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASExploración de la colinealidad entre las variables predictoras
Si las variables predictoras no son independientes, existe multicolinealidad.Este aspecto se puede valorar con el índice VIF (variance inflation factor)https://en.wikipedia.org/wiki/Variance_inflation_factor
VIF = 1 / (1 – R2)donde R2 se obtiene regresionando cada variable predictora en función de todas las restantes.
Y = β0 + β1X1 + β2X 2 + β3X3 +... + βkXk este es nuestro modelo de interésX1 = α2X2+ α3X3+ α4X4+…+ αkXk este es el modelo para calcular VIF
VIF = 1 / (1 – R2) Tolerancia = 1 – R2
siendo R2 el coeficiente de determinación de X1 explicada por las restantes.
Si VIF = 1 entonces cada variable predictora es independiente de las restantes.
La raíz cuadrada del valor VIF es una aproximación a cuántas veces es más grande el error estándarde un coeficiente de regresión respecto a lo que debería ser si no existiese multicolinealidad.

72
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASExploración de la colinealidad entre las variables predictoras
library(car)vif(modelo)sqrt(vif(modelo))
> vif(modelo)TARSO ZONA1 SEXO1 EDAD1
1.9781 1.1445 1.6766 1.2973 ZONA1:SEXO1 ZONA1:EDAD1 SEXO1:EDAD1 ZONA1:SEXO1:EDAD1
1.1327 1.1788 1.1524 1.1421
> sqrt(vif(modelo))TARSO ZONA1 SEXO1 EDAD1
1.406449 1.069813 1.294836 1.138991 ZONA1:SEXO1 ZONA1:EDAD1 SEXO1:EDAD1 ZONA1:SEXO1:EDAD1
1.064284 1.085726 1.073499 1.068691
… si VIF vale más que cuatro … malo (¡¡nunca hagáis modelos con VIF > 6!!)podremos reducir el modeloo utilizar otros tipos de análisis (e.g., PLS; consultad https://goo.gl/CztkHe)

73
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVAS
después de todas estas exploraciones de los supuestos canónicos de los modelos
…
ahora ya sí podemos proceder a valorar sus resultados
Aspectos a considerar:Valores medios (ajustados) de las celdas definidas por los factoresTest “post hoc” o a pasteriori.Resumen del modeloSignificación de efectos¿Qué proporción de la variabilidad en la respuesta explica el modelo?

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASValores medios (ajustados) de las celdas definidas por los factoresSi queremos conocer los valores medios ajustados de la variable respuesta, y los errores estándar de las diferentes celdas definidas por todos los factores considerados en el modelo, podremos usar un paquete de R y un comando incluido en él.
## primero cargamos (para usarlo) un paquete llamado phia## para tests a posteriori y análisis de interaccioneslibrary(phia)#### corremos esta línea de código## que proporciona los valores controlando por la(s) covariante(s)interactionMeans(modelo)> interactionMeans(modelo)
ZONA SEXO EDAD adjusted mean std. error1 SARRIA h a 2.414856 0.21752922 VENTOR h a 2.595712 0.21471583 SARRIA m a 2.682552 0.23246574 VENTOR m a 3.676535 0.19125835 SARRIA h j 2.224111 0.14211976 VENTOR h j 2.710342 0.18038837 SARRIA m j 2.640899 0.14182918 VENTOR m j 2.943962 0.1859666
74

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASValores medios (ajustados) de las celdas definidas por los factores
## otras opciones, con iguales resultados, son:interactionMeans(modelo, pairwise=c("ZONA", "SEXO", "EDAD"))interactionMeans(modelo, factors=c("ZONA", "SEXO", "EDAD"))
Estos valores medios ajustados de la respuesta por la(s) covariante(s) incluida(s) en el modelo son muy interesantes, ya que suponen una especie de experimento de lo que saldría en nuestro diseño factorial "como si todas las unidades muestrales hubiesen tenido el mismo valor de la(s) covariante(s)"
Esto tiene una enorme utilidad en los diseños factoriales con covariantes, denominados… ANCOVA
Reduzcamos el modelo## veamos el efectos sobre los valores ajustados quitando la covariante## recalculemos el modelo sin la covariantemodelo.sin_tarso <- update(modelo, .~. -TARSO)
Lo que hemos hecho es actualizar (update) nuestro modelo de interés (modelo), dejando sus elementos originales (.~.), y quitando un término indicado con el signo menos (-TARSO).
75

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASValores medios (ajustados) de las celdas definidas por los factoresY aquí está la comparación, para valorar cuál es el efecto de trabajar con o sin covariante(s):
> interactionMeans(modelo)ZONA SEXO EDAD adjusted mean std. error
1 SARRIA h a 2.414856 0.21752922 VENTOR h a 2.595712 0.21471583 SARRIA m a 2.682552 0.23246574 VENTOR m a 3.676535 0.19125835 SARRIA h j 2.224111 0.14211976 VENTOR h j 2.710342 0.18038837 SARRIA m j 2.640899 0.14182918 VENTOR m j 2.943962 0.1859666
> interactionMeans(modelo.sin_tarso)ZONA SEXO EDAD adjusted mean std. error
1 SARRIA h a 2.333333 0.22969982 VENTOR h a 2.584000 0.22969983 SARRIA m a 2.889000 0.22969984 VENTOR m a 3.895200 0.17792475 SARRIA h j 2.175000 0.15037386 VENTOR h j 2.484833 0.16242237 SARRIA m j 2.685286 0.15037388 VENTOR m j 2.932250 0.1989259
76

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASValores medios (ajustados) de las celdas definidas por los factoresVeamos algunas figuras
## resultado gráfico con una figura y múltiples paneles; media +/- std_errorplot(interactionMeans(modelo), legend.margin=0.2)
77

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASValores medios (ajustados) de las celdas definidas por los factoresVeamos algunas figuras
## no acepta covariantesboxplot(MUSCULO ~ ZONA * SEXO * EDAD, data=datos)
78

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASValores medios (ajustados) de las celdas definidas por los factoresVeamos algunas figuras
## en la forma de (un factor, otro factor, variable respuesta)interaction.plot(datos$ZONA,datos$EDAD,datos$MUSCULO)
79

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASValores medios (ajustados) de las celdas definidas por los factoresVeamos algunas figurasLos efectos parciales también se pueden representar utilizando los "partial residual plots"Para ello utilizaremos el comando crPlots del paquete {car}.Este comando NO ACEPTA MODELOS CON INTERACCIONES, con lo que de existir las eliminaremos.
## en la forma de (un factor, otro factor, variable respuesta)modelo.noint <- lm(MUSCULO~TARSO+ZONA+SEXO+EDAD, data=datos, contrasts=c(factor="contr.sum"))
## la segunda línea presenta los plots de uno en unocrPlots(modelo.noint, smooth=FALSE, pch=15, lwd=2, col.lines="blue", grid=FALSE,
ylab="partial residuals", main="TITULA COMO QUIERAS")crPlots(modelo.noint, smooth=FALSE, pch=15, lwd=2, col.lines="blue", grid=FALSE,
ylab="partial residuals", main="TITULA COMO QUIERAS", layout=c(1, 1))
## en esta otra versión, más sencilla, podemos identificar posibles## desvíos de los efectos lienalescrPlots(modelo.noint)
80

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASValores medios (ajustados) de las celdas definidas por los factoresVeamos algunas figuras> crPlots(modelo.noint, smooth=FALSE, pch=15, lwd=2, col.lines="blue", grid=FALSE, ylab="partial residuals", main="TITULA COMO QUIERAS")
81

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASValores medios (ajustados) de las celdas definidas por los factoresVeamos algunas figuras> crPlots(modelo.noint)
82

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASTest “post hoc” o a pasteriori.Son “excursiones de pesca” en nuestros datos para saber entre qué pares concretos de niveles de los factores existen diferencias significativas.
Al efectuar numerosos tests a posteriori, se infla la probabilidad de cometer el error de tipo I (rechazar la hipótesis nula cuando de hecho es cierta).
En un factor con seis niveles hay C(6,2) [combinaciones de seis elementos tomados de dos‐en‐dos]C(6,2) = (6*5)/(2*1) = 15 tests a posteriori
En un diseño con dos factores, uno con seis niveles y otro con tres niveles, hay 18 celdas de interacción.C(18,2)= (18*17)/(2*1) = 153 tests a posteriori
por puro azar pueden surgir 153 * 0.05 = 7‐8 tests significativos a alfa=0.05
Los tests a posteriori controlan este inflado de probabilidad de cometer el error de tipo I.
No los deberíamos utilizar si el resultado del AN(c)OVA para ese factor (o interacción de factores) no ha alcanzado el nivel de significación.
Podemos contar con varios tipos de tests a posteriori.https://en.wikipedia.org/wiki/Post_hoc_analysis
83

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASTest “post hoc” o a pasteriori.
Tukey Honest Significant Differencesel más adecuado y generalizable en su usopuede trabajar con tamaños muestrales diferentes en los diferentes niveles de los factores
En R, construimos antes un modelo [aov] que incluimos en el comando TukeyHSD.sólo es para factores; quitar las covariantes si el modelo las tieneintroducir la fórmula tras el paréntesis de aov(respuesta ~ factores)
pairwise t‐testotra versión más complicada, pero más flexible (con correcciones de significación)podemos utilizar diferentes opciones de ajuste de significación (corrección del error de tipo I)"holm", "hommel", "hochberg", "bonferroni", "none", ... (e.g., p.adj="holm")
mirad la ayuda de "p.adjust {stats}"el comando a utilizar es:
pairwise.t.test {stats}
84

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASTest “post hoc” o a pasteriori.Tukey Honest Significant Differences
TukeyHSD(aov(MUSCULO ~ SEXO * EDAD, data=datos))
> TukeyHSD(aov(MUSCULO ~ SEXO * EDAD, data=datos))Tukey multiple comparisons of means
95% family-wise confidence level
Fit: aov(formula = MUSCULO ~ SEXO * EDAD, data = datos)
$SEXOdiff lwr upr p adj
m-h 0.7254211 0.4218654 1.028977 2.63e-05
$EDADdiff lwr upr p adj
j-a -0.4543869 -0.7690329 -0.1397409 0.0059437
$`SEXO:EDAD`diff lwr upr p adj
m:a-h:a 1.0592083 0.38768611 1.7307306 0.0008430h:j-h:a -0.1406667 -0.75435305 0.4730197 0.9252760m:j-h:a 0.3164242 -0.31463406 0.9474825 0.5358929h:j-m:a -1.1998750 -1.75861526 -0.6411347 0.0000091m:j-m:a -0.7427841 -1.32055072 -0.1650175 0.0074261m:j-h:j 0.4570909 -0.05230399 0.9664858 0.0916545
85

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASTest “post hoc” o a pasteriori.pairwise t‐test ‐ Holm
primero definimos la variable respuesta en x, y luego los factores en g
## para la interacción de tres factorespairwise.t.test(x=datos$MUSCULO, g=datos$ZONA:datos$EDAD:datos$SEXO, p.adj="holm")
> pairwise.t.test(x=datos$MUSCULO, g=datos$ZONA:datos$EDAD:datos$SEXO, p.adj="holm")
Pairwise comparisons using t tests with pooled SD
data: datos$MUSCULO and datos$ZONA:datos$EDAD:datos$SEXO
SARRIA:a:h SARRIA:a:m SARRIA:j:h SARRIA:j:m VENTOR:a:h VENTOR:a:m VENTOR:j:hSARRIA:a:m 1.00000 - - - - - -SARRIA:j:h 1.00000 0.28609 - - - - -SARRIA:j:m 1.00000 1.00000 0.43379 - - - -VENTOR:a:h 1.00000 1.00000 1.00000 1.00000 - - -VENTOR:a:m 0.00021 0.03583 8.8e-07 0.00034 0.00220 - -VENTOR:j:h 1.00000 1.00000 1.00000 1.00000 1.00000 5.7e-05 -VENTOR:j:m 1.00000 1.00000 0.10319 1.00000 1.00000 0.02546 1.00000
P value adjustment method: holm
86

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASTest “post hoc” o a pasteriori.pairwise t‐test ‐ Bonferroni
primero definimos la variable respuesta en x, y luego los factores en g
## para la interacción de tres factorespairwise.t.test(x=datos$MUSCULO, g=datos$ZONA:datos$EDAD:datos$SEXO, p.adj="bonferroni")
> pairwise.t.test(x=datos$MUSCULO, g=datos$ZONA:datos$EDAD:datos$SEXO, p.adj="bonferroni")
Pairwise comparisons using t tests with pooled SD
data: datos$MUSCULO and datos$ZONA:datos$EDAD:datos$SEXO
SARRIA:a:h SARRIA:a:m SARRIA:j:h SARRIA:j:m VENTOR:a:h VENTOR:a:m VENTOR:j:hSARRIA:a:m 1.00000 - - - - - -SARRIA:j:h 1.00000 0.40052 - - - - -SARRIA:j:m 1.00000 1.00000 0.63927 - - - -VENTOR:a:h 1.00000 1.00000 1.00000 1.00000 - - -VENTOR:a:m 0.00023 0.04560 8.8e-07 0.00038 0.00257 - -VENTOR:j:h 1.00000 1.00000 1.00000 1.00000 1.00000 5.9e-05 -VENTOR:j:m 1.00000 1.00000 0.13758 1.00000 1.00000 0.03099 1.00000
P value adjustment method: bonferroni
Es mucho más “conservadora”; infla más el error de tipo II (aceptar la nula cuando es falsa)87

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASTest “post hoc” o a pasteriori.pairwise t‐test ‐ none
primero definimos la variable respuesta en x, y luego los factores en g
## para la interacción de tres factorespairwise.t.test(x=datos$MUSCULO, g=datos$ZONA:datos$EDAD:datos$SEXO, p.adj=“none")
> pairwise.t.test(x=datos$MUSCULO, g=datos$ZONA:datos$EDAD:datos$SEXO, p.adj=“none")
Pairwise comparisons using t tests with pooled SD
data: datos$MUSCULO and datos$ZONA:datos$EDAD:datos$SEXO
SARRIA:a:h SARRIA:a:m SARRIA:j:h SARRIA:j:m VENTOR:a:h VENTOR:a:m VENTOR:j:hSARRIA:a:m 0.0975 - - - - - -SARRIA:j:h 0.5684 0.0143 - - - - -SARRIA:j:m 0.2097 0.4639 0.0228 - - - -VENTOR:a:h 0.4464 0.3553 0.1467 0.7148 - - -VENTOR:a:m 8.1e-06 0.0016 3.2e-08 1.3e-05 9.2e-05 - -VENTOR:j:h 0.5942 0.1612 0.1718 0.3724 0.7269 2.1e-06 -VENTOR:j:m 0.0580 0.8878 0.0049 0.3299 0.2608 0.0011 0.0917
P value adjustment method: none
Muy “optimista”; infla más el error de tipo I (rechazar la nula cuando es cierta)88

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASVolvamos a nuestro modelosummary(modelo)> summary(modelo)Call:lm(formula = MUSCULO ~ TARSO + ZONA * SEXO * EDAD, data = datos,
contrasts = list(ZONA = contr.sum, SEXO = contr.sum, EDAD = contr.sum))
Residuals:Min 1Q Median 3Q Max
-0.58050 -0.22168 -0.06063 0.17683 0.82380
Coefficients:Estimate Std. Error t value Pr(>|t|)
(Intercept) -2.35435 2.20612 -1.067 0.294689 TARSO 0.26179 0.11316 2.314 0.027983 * ZONA1 -0.24552 0.06461 -3.800 0.000687 ***SEXO1 -0.24987 0.07810 -3.199 0.003323 ** EDAD1 0.10629 0.07120 1.493 0.146297 ZONA1:SEXO1 0.07874 0.06419 1.227 0.229786 ZONA1:EDAD1 -0.04819 0.06632 -0.727 0.473217 SEXO1:EDAD1 -0.08726 0.06511 -1.340 0.190551 ZONA1:SEXO1:EDAD1 0.12454 0.06482 1.921 0.064565 .---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.3718 on 29 degrees of freedomMultiple R-squared: 0.7299, Adjusted R-squared: 0.6554 F-statistic: 9.797 on 8 and 29 DF, p-value: 1.781e-06) 89
estos coeficientes secorresponden a los asociadosa las columnas de contraste

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASSignificación de efectosEn summary(modelo) lo que hemos visto son los coeficientes de regresión del modelo.Y esto es de fácil interpretación y lectura para las predictoras continuas (covariantes) pero no para los factores.
Para valorar mejor la magnitud de efectos y su significación, utilizando diferentes tipos deSumas de Cuadrados (SS) definidas … y que queramos.
library(car) ## cargamos este paquete de enorme utilidad
TIPO III de SS (el que más vamos a utilizar y el de más fácil interpretación)Anova(modelo, type=3, test="F")
TIPO II de SSAnova(modelo, type=2, test="F")
TIPO I de SSanova(modelo)
90

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASSignificación de efectos
> Anova(modelo, type=3, test="F")Anova Table (Type III tests)
Response: MUSCULOSum Sq Df F value Pr(>F)
(Intercept) 0.1574 1 1.1389 0.2946890 TARSO 0.7399 1 5.3523 0.0279834 * ZONA 1.9958 1 14.4380 0.0006872 ***SEXO 1.4150 1 10.2367 0.0033228 ** EDAD 0.3080 1 2.2284 0.1462973 ZONA:SEXO 0.2080 1 1.5049 0.2297859 ZONA:EDAD 0.0730 1 0.5281 0.4732175 SEXO:EDAD 0.2483 1 1.7964 0.1905510 ZONA:SEXO:EDAD 0.5103 1 3.6916 0.0645648 . Residuals 4.0087 29 ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
91

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASSignificación de efectos
> Anova(modelo, type=2, test="F")Anova Table (Type II tests)
Response: MUSCULOSum Sq Df F value Pr(>F)
TARSO 0.7399 1 5.3523 0.0279834 * ZONA 2.0999 1 15.1914 0.0005279 ***SEXO 1.4960 1 10.8227 0.0026354 ** EDAD 0.3200 1 2.3151 0.1389535 ZONA:SEXO 0.0820 1 0.5929 0.4475280 ZONA:EDAD 0.0998 1 0.7220 0.4024473 SEXO:EDAD 0.2683 1 1.9406 0.1741861 ZONA:SEXO:EDAD 0.5103 1 3.6916 0.0645648 . Residuals 4.0087 29 ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
92

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASSignificación de efectos
## Anova Table (Type I tests)> anova(modelo)Analysis of Variance Table
Response: MUSCULODf Sum Sq Mean Sq F value Pr(>F)
TARSO 1 5.0314 5.0314 36.3986 1.454e-06 ***ZONA 1 3.1587 3.1587 22.8505 4.671e-05 ***SEXO 1 1.2862 1.2862 9.3044 0.004849 ** EDAD 1 0.3406 0.3406 2.4638 0.127347 ZONA:SEXO 1 0.1443 0.1443 1.0440 0.315337 ZONA:EDAD 1 0.0940 0.0940 0.6798 0.416388 SEXO:EDAD 1 0.2683 0.2683 1.9406 0.174186 ZONA:SEXO:EDAD 1 0.5103 0.5103 3.6916 0.064565 . Residuals 29 4.0087 0.1382 ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
93

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASSignificación de efectosEn los modelos de SS de tipo I los resultados obtenidos son dependientes del orden de entrada de las variables.
¡¡¡ cuidado!!! En caso de duda ¡¡NO USARLO JAMÁS!!
anova(lm(formula = MUSCULO ~ SEXO * EDAD * ZONA + TARSO, data = datos))> anova(lm(formula = MUSCULO ~ SEXO * EDAD * ZONA + TARSO, data = datos))
94
Analysis of Variance Table
Response: MUSCULODf Sum Sq Mean Sq F value Pr(>F)
SEXO 1 4.9992 4.9992 36.1656 1.534e-06 ***EDAD 1 1.8476 1.8476 13.3660 0.0010092 ** ZONA 1 1.8909 1.8909 13.6794 0.0009009 ***TARSO 1 1.0791 1.0791 7.8062 0.0091314 ** SEXO:EDAD 1 0.3083 0.3083 2.2304 0.1461186 SEXO:ZONA 1 0.0984 0.0984 0.7120 0.4056765 EDAD:ZONA 1 0.0998 0.0998 0.7220 0.4024473 SEXO:EDAD:ZONA 1 0.5103 0.5103 3.6916 0.0645648 . Residuals 29 4.0087 0.1382 ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Analysis of Variance Table
Response: MUSCULODf Sum Sq Mean Sq F value Pr(>F)
TARSO 1 5.0314 5.0314 36.3986 1.454e-06 ***ZONA 1 3.1587 3.1587 22.8505 4.671e-05 ***SEXO 1 1.2862 1.2862 9.3044 0.004849 ** EDAD 1 0.3406 0.3406 2.4638 0.127347 ZONA:SEXO 1 0.1443 0.1443 1.0440 0.315337 ZONA:EDAD 1 0.0940 0.0940 0.6798 0.416388 SEXO:EDAD 1 0.2683 0.2683 1.9406 0.174186 ZONA:SEXO:EDAD 1 0.5103 0.5103 3.6916 0.064565 . Residuals 29 4.0087 0.1382 ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1

95
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVAS¿Qué proporción de la variabilidad en la respuesta explica el modelo?RELACIÓN ENTRE VALORES OBSERVADOS Y PREDICHOS
R2 <- summary(modelo)$r.squaredtitulo <- paste("R2 (%) =",round(R2*100,1))## modelo$model[,1] es la variable respuesta originalplot(fitted(modelo), modelo$model[,1] , main=titulo,
xlab="PREDICHO POR EL MODELO", ylab="VARIABLE RESPUESTA")abline(lm(modelo$model[,1]~fitted(modelo)), col="red", lwd=2)

96
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVAS¿Qué proporción de la variabilidad en la respuesta explica el modelo?RELACIÓN ENTRE VALORES OBSERVADOS Y PREDICHOS> summary(modelo)Call:lm(formula = MUSCULO ~ TARSO + ZONA * SEXO * EDAD, data = datos,
contrasts = list(ZONA = contr.sum, SEXO = contr.sum, EDAD = contr.sum))
Residuals:Min 1Q Median 3Q Max
-0.58050 -0.22168 -0.06063 0.17683 0.82380
Coefficients:Estimate Std. Error t value Pr(>|t|)
(Intercept) -2.35435 2.20612 -1.067 0.294689 TARSO 0.26179 0.11316 2.314 0.027983 * ZONA1 -0.24552 0.06461 -3.800 0.000687 ***SEXO1 -0.24987 0.07810 -3.199 0.003323 ** EDAD1 0.10629 0.07120 1.493 0.146297 ZONA1:SEXO1 0.07874 0.06419 1.227 0.229786 ZONA1:EDAD1 -0.04819 0.06632 -0.727 0.473217 SEXO1:EDAD1 -0.08726 0.06511 -1.340 0.190551 ZONA1:SEXO1:EDAD1 0.12454 0.06482 1.921 0.064565 . ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.3718 on 29 degrees of freedomMultiple R-squared: 0.7299, Adjusted R-squared: 0.6554F-statistic: 9.797 on 8 and 29 DF, p-value: 1.781e-06)

Sum Sq(Intercept) 0.1574 TARSO 0.7399ZONA 1.9958 SEXO 1.4150EDAD 0.3080ZONA:SEXO 0.2080ZONA:EDAD 0.0730SEXO:EDAD 0.2483ZONA:SEXO:EDAD 0.5103
Residuals 4.0087SSerror
SStotal 14.8424
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASPARTICIÓN DE LA VARIANZA
97
Sumas de cuadrados (SS) respecto a "cero"
Sumas de cuadrados (SS) TOTAL respecto ala media de la variable respuesta
Sumas de cuadrados (SS) de losefectos incluidos en el modelo
(no consideramos el intercepto)
Sumas de cuadrados (SS) ERROR
R2 del modelo:SSTOTAL – SSERROR
SSTOTAL
Sumas de cuadrados (SS) del Modelo:SSMODELO = SSTOTAL – SSERROR

Sum Sq(Intercept) 0.1574 TARSO 0.7399ZONA 1.9958 SEXO 1.4150EDAD 0.3080ZONA:SEXO 0.2080ZONA:EDAD 0.0730SEXO:EDAD 0.2483ZONA:SEXO:EDAD 0.5103
Residuals 4.0087SSerror
SStotal 14.8424
SourceType III Sum of
Squares % varianzaTARSO 0.740 5.0ZONA 1.996 13.4SEXO 1.415 9.5EDAD 0.308 2.1ZONA : SEXO 0.208 1.4ZONA : EDAD 0.073 0.5SEXO : EDAD 0.248 1.7ZONA : SEXO : EDAD 0.510 3.4Error 4.009 27.0MODELO 14.842 ‐ 4.009 73.0Total 14.842 100.0
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASPARTICIÓN DE LA VARIANZA
98
Utilizamos como denominador lasuma de cuadrados total (SS Total)
Si los efectos no son independientes, su suma(%varianza) no será igual a la R2 del modelo.

99
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVAS¿Qué proporción de la variabilidad en la respuesta explica el modelo?PARTICIÓN DE LA VARIANZA
## algunos parámetros globales del modelo relacionados con## la varianza (sumas de cuadrados, SS)## suma de cuadrados (SStotal) de la variable respuesta (varianza original)SStotal <- sum((modelo$model[,1]-mean(modelo$model[,1]))^2)#### suma de cuadrados error (SSerror) o residual del modeloSSerror <- sum(residuals(modelo)^2)#### suma de cuadrados del modelo (SSmodelo)SSmodelo <- SStotal-Sserror#### R2 del modeloR2 <- summary(modelo)$r.squared## que es lo mismo que calcular SSmodelo/SStotalprint(c(SStotal, SSmodelo, SSerror, R2), digits=4)print(c("R2 % =",round(R2*100, 2)), quote=FALSE)
> print(c(SStotal, SSmodelo, SSerror, R2), digits=4)[1] 14.8424 10.8337 4.0087 0.7299> print(c("R2 % =",round(R2*100, 2)), quote=FALSE)[1] R2 % = 72.99

100
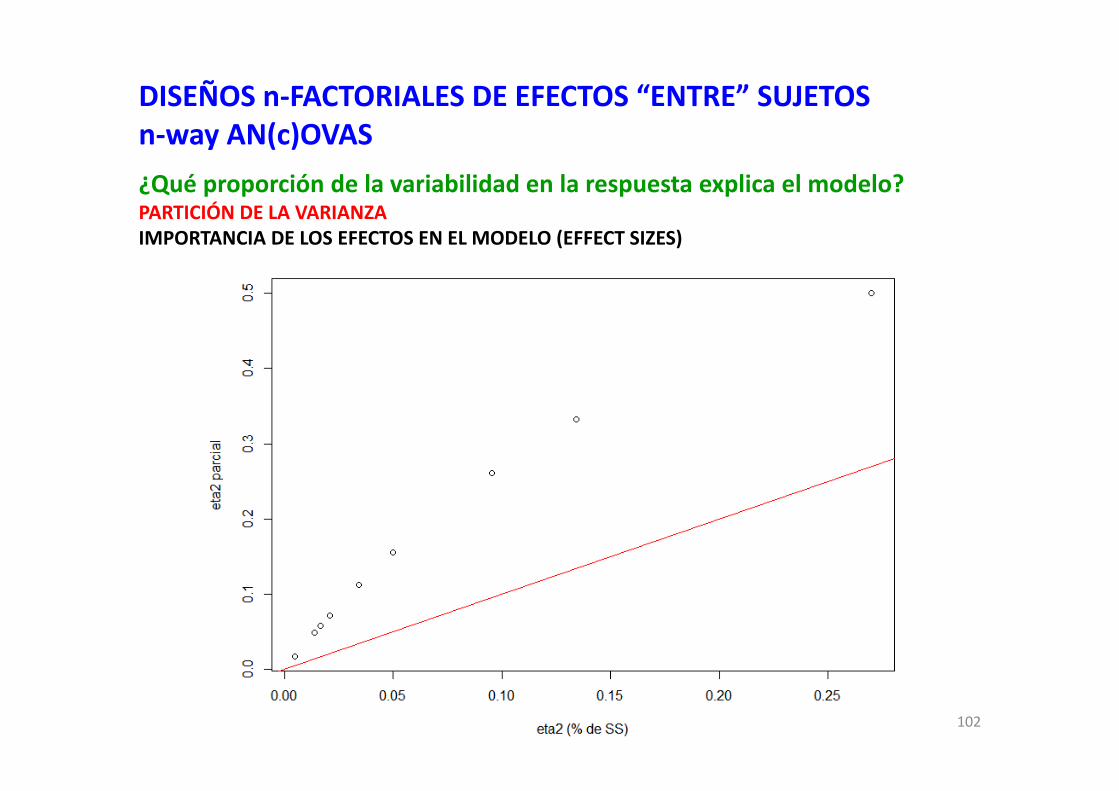
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVAS¿Qué proporción de la variabilidad en la respuesta explica el modelo?PARTICIÓN DE LA VARIANZAIMPORTANCIA DE LOS EFECTOS EN EL MODELO (EFFECT SIZES)
Partial eta squared: magnitud relativa del efecto: SSefecto / (SSefecto+ SSerror)
## con SS de tipo III; no considerar la última fila de "Residuals"SSerror <- sum(residuals(modelo)^2)SStotal <- sum((modelo$model[,1]-mean(modelo$model[,1]))^2)tabla.ss <- as.data.frame(Anova(modelo, type=3, test="F"))tabla.ss <- tabla.ss[-1,]## proporción de la varianza explicada por los efectoseta2 <- tabla.ss[,1]/SStotalpartialeta2 <- tabla.ss[,1]/(tabla.ss[,1]+SSerror)tabla.ss <- data.frame(eta2, partialeta2, tabla.ss)round(tabla.ss, 4)###### … y un gráfico para ver cómo se asocian eta2 y partial eta2plot(tabla.ss$eta2, tabla.ss$partialeta2,
xlab="eta2 (% de SS)", ylab="eta2 parcial")abline(a=0, b=1, col="red")

101
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVAS¿Qué proporción de la variabilidad en la respuesta explica el modelo?PARTICIÓN DE LA VARIANZAIMPORTANCIA DE LOS EFECTOS EN EL MODELO (EFFECT SIZES)
> round(tabla.ss, 4)eta2 partialeta2 Sum.Sq Df F.value Pr..F.
TARSO 0.0498 0.1558 0.7399 1 5.3523 0.0280ZONA 0.1345 0.3324 1.9958 1 14.4380 0.0007SEXO 0.0953 0.2609 1.4150 1 10.2367 0.0033EDAD 0.0208 0.0714 0.3080 1 2.2284 0.1463ZONA:SEXO 0.0140 0.0493 0.2080 1 1.5049 0.2298ZONA:EDAD 0.0049 0.0179 0.0730 1 0.5281 0.4732SEXO:EDAD 0.0167 0.0583 0.2483 1 1.7964 0.1906ZONA:SEXO:EDAD 0.0344 0.1129 0.5103 1 3.6916 0.0646Residuals 0.2701 0.5000 4.0087 29 NA NA
102
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVAS¿Qué proporción de la variabilidad en la respuesta explica el modelo?PARTICIÓN DE LA VARIANZAIMPORTANCIA DE LOS EFECTOS EN EL MODELO (EFFECT SIZES)

103
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVAS¿Cuál es el poder predictivo del modelo?
Bueno … es un asunto engorroso. ¡Reconozcámoslo! Una cosa es cómo explico mis datos con un modeloY otra es cómo un modelo explica los datos … que no sólo son los míos(esto es “tabú”, por incómodo, en algunas disciplinas de investigación)
Asumir este reto, implica dar el salto de (auto)explicar a predecir.
Podríamos repetir de nuevo nuestro experimento, toma de datos, etc.Esto es muy costoso (en tiempo, dinero, personal) y no es manejable en la práctica de investigación.
Un “atajo” es cros‐validar nuestros datos (cross‐validation).Este procedimiento consiste en dividir nuestros datos, al azar, en grupos de datos (v‐fold)Hacemos v número de modelos, cada uno con v‐1 gruposY con ese modelo predecimos el grupo de datos no considerado en la construcción del modelo
estimamos las predicciones de ese modelo para el conjunto de datos no utilizado enfunción de los valores que toman sus unidades muestrales en los factores y covariantes
Juntamos todas las predicciones de los v grupos … cuando no se han considerado sus datosY ahora … el drama: correlacionamos los valores observados con los predichos
cuando los datos no han sido utilizados en los vmodelos.

104
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVAS¿Cuál es el poder predictivo del modelo?
Veámoslo gráficamente:hacemos los modelos con los grupos de datos verdesy predecimos los datos amarillos que no hemos utilizadohay tantos modelos como grupos de datos v hemos creadocada modelo se realiza con los datos contenidos en los v‐1 grupos

105
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVAS¿Cuál es el poder predictivo del modelo?
Para realizar estos cálculos intesivos contamos con un conjunto de comandos complejo que se combinan en una función y un bucle. Utilizaremos el comando cv.lm del paquete DAAG.Estas líneas de código funcionan con modelos lm, una vez que hemos establecido:el parámetro m: se refiere al número de grupos de datos (v‐fold); ahora está puesto en 5.nuestro modelo de interés que llamo modeloy los datos de análisis contenidos en un data frame denominado datos
salida.cv <- function(x){cv.linmod <- cv.lm(datos, modelo, m=5, seed=x, plotit=FALSE) R2cvmod <- cor(cv.linmod$cvpred, cv.linmod$Predicted)^2R2obscv <- cor(cv.linmod$cvpred, modelo$model[,1])^2encabezado <- paste("R2 model-crossval =", round(R2cvmod*100, 2)," %")Pobscv <- round(cor.test(cv.linmod$cvpred, modelo$model[,1], alternative="greater")$p.value, 5)encabezados <- paste("R2 observed-crossval =", round(R2obscv*100, 2)," % ; P = ", Pobscv)plot(cv.linmod$cvpred, modelo$model[,1], main=encabezados, xlab="PREDICHOS POR CROSSVALIDATION",
ylab="VALORES OBSERVADOS", col="blue")abline(a=0, b=1, col="red", lwd=2)
}#### correr este bucle con valores de seed de 1 a 10; otros podrían ser "(i in 23:32)"for (i in 1:10) {
salida.cv(i) ## o correr sólo esta línea modificando cada vez el número en (i)}

106
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVAS¿Cuál es el poder predictivo del modelo?Vamos a descartar las salidas numéricas que aparecen en la consola.
realmente hacen referencia a modelos de suma de cuadrados (SS) de tipo I que no nos interesan.Sólo nos fijaremos en las salidas gráficas que contienen las R2 (en %) de la asociación entre
los valores predichos y valores observados poder predictivo de nuestro modelo

107
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASEXAMEN DEL EFECTO DE LA VIOLACIÓN DEL SUPUESTO DE HOMOCEDASTICIDADHasta ahora hemos efectuado el examen de la significación de los efectos asumendo que ha existido homocedasticidad de los residuos. Si hubiésemos violado este supuesto, deberíamos efectuar nuevas estimas de significación teniendo en cuenta esos desvíos de la homocedasticidad.
Al recalcular las significaciones de los efectos del modelo teniendo en cuenta distintas estructuras de matrices de varianza‐covarianza (vcov), sólo van a cambiar los errores estándar de los parámetros (coeficientes) del modelo y sus significaciones.
Para ello podemos usar el comando coeftest, definiendo diferentes tipos de estructuras vcov.const: constante u homogénea; no se ha violado el supuesto de homocedasticidadHC0: sandwichHC3: la mejor corrección para pequeñas muestras, dando menos peso a los datos influeyenteHC4: mejora HC3 , especialmente en el caso de datos muy influyentes (alto leverage)HC4m: mejora HC4, tanto con residuos del modelo normales, como "menos" normales (gausianos)
La limitación que tiene es que estima la significación de coeficientes “dummy” y no el efecto en sí.
El uso del comando es (en "modelo" incluimos el nombre de nuestro modelo lm o glm:coeftest(modelo, vcovHC(modelo, type="HC4m"))

108
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASEXAMEN DEL EFECTO DE LA VIOLACIÓN DEL SUPUESTO DE HOMOCEDASTICIDAD
> coeftest(modelo, vcovHC(modelo, type="const"))
Estimate Std. Error t value Pr(>|t|) (Intercept) -2.354350 2.206116 -1.0672 0.2946890 TARSO 0.261792 0.113158 2.3135 0.0279834 * ZONA1 -0.245517 0.064614 -3.7997 0.0006872 ***SEXO1 -0.249866 0.078096 -3.1995 0.0033228 ** EDAD1 0.106293 0.071205 1.4928 0.1462973 ZONA1:SEXO1 0.078745 0.064190 1.2267 0.2297859 ZONA1:EDAD1 -0.048193 0.066315 -0.7267 0.4732175 SEXO1:EDAD1 -0.087264 0.065107 -1.3403 0.1905510 ZONA1:SEXO1:EDAD1 0.124537 0.064817 1.9214 0.0645648 . ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
> coeftest(modelo, vcovHC(modelo, type="HC4m"))
Estimate Std. Error t value Pr(>|t|) (Intercept) -2.354350 2.296110 -1.0254 0.313668 TARSO 0.261792 0.118933 2.2012 0.035835 * ZONA1 -0.245517 0.083580 -2.9375 0.006423 **SEXO1 -0.249866 0.098560 -2.5352 0.016891 * EDAD1 0.106293 0.080506 1.3203 0.197061 ZONA1:SEXO1 0.078745 0.083679 0.9410 0.354460 ZONA1:EDAD1 -0.048193 0.091346 -0.5276 0.601797 SEXO1:EDAD1 -0.087264 0.085574 -1.0197 0.316283 ZONA1:SEXO1:EDAD1 0.124537 0.085640 1.4542 0.156630 ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
los coeficientes no cambian
las significaciones sí cambian(y sus valores asociados de se y t)

109
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASEXAMEN DEL EFECTO DE LA VIOLACIÓN DEL SUPUESTO DE HOMOCEDASTICIDADOtra posibilidad de corregir las estimas de significación en diseños factoriales, incidiendo en los efectos incluidos en el modelo y no en sus coefcientes o errores estándar, es mediante el argumento white.adjust dentro del comando Anova(…).
white.adjust puede tomar los valores FALSE (en cuyo caso no se efectúa ningún ajuste por heterocedastcidad), o "hc0", "hc1", "hc2", "hc3", "hc4"(consultad http://ftp.auckland.ac.nz/software/CRAN/doc/vignettes/sandwich/sandwich.pdf)
Mediante las siguientes líneas de código podemos crear una tabla ANOVA de resultados, mostrando los valores de F y P sin corregir y corregidos:
tmp1 <- Anova(modelo, type=3, test="F", white.adjust=FALSE)tmp2 <- Anova(modelo, type=3, test="F", white.adjust="hc4")tmp1[5] <- tmp2[2]; tmp1[6] <- tmp2[3]colnames(tmp1) <- c("SS", "Df", "F", "P", "F_hc4", "P_hc4")tabla.efecto.heterocedst <- tmp1round(tabla.efecto.heterocedst, 5)

110
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASEXAMEN DEL EFECTO DE LA VIOLACIÓN DEL SUPUESTO DE HOMOCEDASTICIDADEn F_hc4 y P_hc4 podemos ver los resultados de F y P corregidos teniendo en cuenta el desvío de la homocedasticidad en los residuos, respecto a los valores originales F y P sin corregir.
A más diferencia entre esos valores, más efecto tiene la violación del supuesto de la homocedasticidad de los residuos, y más influencia tienen observaciones con alto leverage.
> round(tabla.efecto.heterocedst, 5)Anova Table (Type III tests)Response: MUSCULO
SS Df F P F_hc4 P_hc4(Intercept) 0.1574 1 1.1389 0.29469 1.4593 0.23680TARSO 0.7399 1 5.3523 0.02798 6.7331 0.01469ZONA 1.9958 1 14.4380 0.00069 12.1579 0.00158SEXO 1.4150 1 10.2367 0.00332 9.2332 0.00499EDAD 0.3080 1 2.2284 0.14630 2.4217 0.13052ZONA:SEXO 0.2080 1 1.5049 0.22979 1.2535 0.27207ZONA:EDAD 0.0730 1 0.5281 0.47322 0.3975 0.53334SEXO:EDAD 0.2483 1 1.7964 0.19055 1.4739 0.23453ZONA:SEXO:EDAD 0.5103 1 3.6916 0.06456 2.9913 0.09435Residuals 4.0087 29

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASIntentando salvar el modelo General Lineal con residuos … no "buenos"Antes de pasar a utilizar otros modelos que no hacen uso de la Normal – Gausiana (e.g., usando modelos Generalizados) podemos llevar la variable respuesta a una nueva escala de medida.
Esto equivale a transformar la variable respuesta.De hecho, los fenómenos de asociación entre variables no tienen por qué ajustarse a lo lineal.
Es más, por su naturaleza, las variables respuestas no tienen porqué ajustarse ni a una Poisson ni a una binomial ni a una binomial negativa, gamma, etc.
En estos casos, ni siquiera los Modelos Generalizados con otras distribucionesque no sean la normal son adecuados.
Las transformaciones más clásicas son:logarítmica Y' = log(Y+1) +1 para el caso de que Y contenga "ceros"raíz cuadrada Y' = (Y+a)^0.5 a suele ser 0.5 ó 1 (para el caso de que Y contenga "ceros")rangos Y es llevada a una escala ordinal Y' (1 para el valor más pequeño)
equivale a utilizar estadística no paramátrica usando la paramétrica de lmse pierde, o se puede perder, el significado "métrico" de las interacciones
por tanto, es mejor, para los modelos de efectos principales.arcoseno para proporciones p acotadas entre 0‐y‐1: Y' = arcseno(p^0.5)
hoy ya está descartada porque podemos contar con modelos logit 111

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASIntentando salvar el modelo General Lineal con residuos … no "buenos"Si estas transformaciones no funcionan, podemos contar con la transformación de Box‐Cox.
http://onlinestatbook.com/2/transformations/box‐cox.html
Es una transformación potencial:Y' = (Y^λ ‐ 1)/λ (Y^λ es "Y elevado a λ")
Cuando lambda (λ) es cero, la transformación Box‐Cox converge con la logarítmica.
En R podemos contar con procesos automatizados que buscan la λ óptima que minimiza los desvíos de los supuestos canónicos de los modelos lm.
Es una transformación muy adecuada para:• conseguir que los residuos se desvíen menos de la normal• se reduzca la heterocedasticidad de los residuos• disminuya la heterogeneidad de la varianza a través de los niveles de los factores
Pero tiene como pega la "interpretación" de los valores de la respuesta, ya que su nueva escala de medida es compleja.
112

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASIntentando salvar el modelo General Lineal con residuos … no "buenos"TRANSFORMACIÓN BOX‐COX en Rdeberemos añadir +1 a la variable respuesta si tiene cerosla transformación es: Y' = (Y^lambda ‐ 1)/lambda ,ó,
Y' = ((Y+1)^lambda ‐ 1)/lambda
## la siguiente línea de código SOLO TRANSFORMA la respuesta de nuestra ecuación eqt## podemos afinar y restringir aun más el rango de lambda## por ejemplo: lambda=seq(0,1, 1/1000))
print(boxCox(modelo, lambda=seq(-2,2, 1/100)))
lambda.bc <- with(boxCox(modelo, lambda=seq(-2,2, 1/1000)), x[which.max(y)])print(c("parámetro lambda de Box-Cox =",round(lambda.bc, 3)), quote=FALSE)> print(c("parámetro lambda de Box-Cox =",round(lambda.bc, 3)), quote=FALSE)[1] parámetro lambda de Box-Cox = -0.196
## transformamos la variable a continuación ... que llamamos respuesta.bc
respuesta.bc <- ((modelo$model[,1]^lambda.bc)-1)/(lambda.bc)## para explorar la relación entre la respuesta original y su transformación Box-Cox
plot(respuesta.bc, modelo$model[,1], xlab="variable respuesta transformada", ylab="variable respuesta original")
113

114
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASIntentando salvar el modelo General Lineal con residuos … no "buenos"> print(boxCox(modelo, lambda=seq(-2,2, 1/100)))

115
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASIntentando salvar el modelo General Lineal con residuos … no "buenos"> plot(respuesta.bc, modelo$model[,1], xlab="variable respuesta transformada", ylab="variable respuesta original")

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASIntentando salvar el modelo General Lineal con residuos … no "buenos"Ahora rehacemos el modelo sustituyendo la variable respuesta del modelo por respuesta.bc
## capturamos en un nuevo data-frame los datos de trabajo de nuestro "modelo"
datos.bc <- modelo$model
## asignamos a la primera variable (¡la respuesta!) el valor de su transformada Box-Cox
datos.bc[,1] <- respuesta.bc
## corremos el mismo modelo pero con la respuesta transformada
modelo.bc <- lm(eqt, data=datos.bc)
## sus resultados son:
summary(modelo.bc)Anova(modelo.bc, type=3, test="F")
A este nuevo modelo le podemos aplicar todo el resto de las cosas vistas hasta este momento.
116

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVAS¿Hay homogeneidad de pendientes en el modelo ANCOVA?En los modelos ANCOVA se asume que el efecto de la covariante es homogéneo a través de los niveles del factor o los factores que estamos considerando.
Si tenemos un solo factor con dos niveles Fa y Fb (e.g., machos vs. hembras)la pendiente de la covariante (predictora continua) en su asociación con la respuesta debe de sersimilar en los subconjuntos de datos vinculados a Fa y Fb (e.g., machos y hembras)
Si tenemos varios factores con varios niveles (un factor con 3 niveles y otro factor con 4 niveles)similar pendiente en las 3 x 4 = 12 celdas de interacción de los dos factores
Si esto no se cumple, no se "controla" correctamente el efecto de la covariante sobre la respuesta para estimar los efectos de los factores y sus interacciones.
Para ello construiremos otro modelo de control de esta prueba canónica (i.e., paralelismo).Este nuevo modelo, además de los efectos de interés, incluirá la interacción covariante x factoresEste nuevo modelo sólo lo utilizaremos para el examinar esa interacción covariante x factoresSi esa interacción es significativa el modelo original no será válido y habrá que construir otro
Este otro modelo incluirá a la covariante "anidada" o "encajada" dentro de los factoresTambién se denomina: different slopes ANCOVA (regression) model
117

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVAS¿Hay homogeneidad de pendientes en el modelo ANCOVA?Veámoslo en R
## nuestro modelo originalmodelo <- lm(MUSCULO ~ TARSO + ZONA*SEXO*EDAD, data=datos)## el modelo para el test de paralelismomodelo.testparal <- lm(MUSCULO ~ TARSO*ZONA*SEXO*EDAD, data=datos)
## comparamos dos modelos mediante el comando anova## para examinar la interacción de los factores y la covarianteanova(modelo, modelo.testparal)
## si el anterior test no dió significativo## no deberíamos mirar los resultados de modelo.testparal## si sí da significativo, entonces hacemos lo siguienteAnova(modelo.testparal, test="F", type=3)
118

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVAS¿Hay homogeneidad de pendientes en el modelo ANCOVA?> anova(modelo, modelo.testparal)Analysis of Variance Table
Model 1: MUSCULO ~ TARSO + ZONA * SEXO * EDAD sumaModel 2: MUSCULO ~ TARSO * ZONA * SEXO * EDAD interacciónRes.Df RSS Df Sum of Sq F Pr(>F)
1 29 4.0087 2 22 2.7940 7 1.2147 1.3663 0.2681
## para hacer un test global de las diferencias en las pendientes## usamos el paquete "phia"testInteractions(modelo.testparal, pairwise=c("ZONA", "SEXO", "EDAD"), slope="TARSO")
## examen de las interacciones concretaslibrary(phia)## cuantificación de las pendientes en todas las celdas del diseño factorial deseado:
interactionMeans(modelo.testparal, slope="TARSO")
## lo anterior es lo mismo que esta otra línea:interactionMeans(modelo.testparal, pairwise=c("ZONA", "SEXO", "EDAD"), slope="TARSO")
119

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVAS¿Hay homogeneidad de pendientes en el modelo ANCOVA?> testInteractions(modelo.testparal, pairwise=c("ZONA", "SEXO", "EDAD"), slope="TARSO")Adjusted slope for TARSO F Test: P-value adjustment method: holm
Value Df Sum of Sq F Pr(>F)SARRIA-VENTOR : h-m : a-j -1.0881 1 0.01875 0.1476 0.7045Residuals 22 2.79405
> interactionMeans(modelo.testparal, slope="TARSO")ZONA SEXO EDAD TARSO std. error
1 SARRIA h a -0.41118421 0.50066162 VENTOR h a 0.58500000 2.51994143 SARRIA m a 1.58564516 0.78391734 VENTOR m a 1.18830247 0.44270865 SARRIA h j 0.07127427 0.32846636 VENTOR h j 0.20324108 0.23558407 SARRIA m j 0.24007334 0.14994648 VENTOR m j 0.06666667 0.6506461
120

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVAS¿Hay homogeneidad de pendientes en el modelo ANCOVA?Si existe ausencia de paralelismo debemos utilizar un MODELO DE DIFERENTES PENDIENTES/TARSO denota que el efecto de la covariante TARSO se anida dentro de las celdas de las interacciones de todos los factores
modelo.difpend <- lm(MUSCULO~ZONA*SEXO*EDAD/TARSO, data=datos)
## miramos las últimas líneas que valoran el efecto## de las diferentes regresiones con la covariantesummary(modelo.difpend)
## para valorar el efecto global del efecto de la covarianteAnova(modelo.difpend, type=3, test="F")
121

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASESTIMAS ROBUSTAS¿Qué hacer cuando …? nuestros datos presentan observaciones – casos con valoresperdidos (outliers) valorado con dffits, residuos studentizados, distancias de Cookinfluyentes valorado con el Leverage
Bien, esto es incómodo … ¡quitarlos! de nuestro análisisEsta opción es válida si tenemos criterios objetivos para hacerlo
(confusiones, el dato deriva de una unidad muestral que no pertenece a la población, etc)Si no tenemos estos criterios objetivos y de "honestidad profesional" esto es una ¡¡ chapuza !!
Alternativamente:Podemos dar unos pesos a esas observaciones perdidas o influyentes proporcionalmente inversosa lo "aberrantes" o sesgados que son en nuestro modelo de análisis.
Un dato con un residuo "anormalmente" positivo o negativo o con una distancia de Cook grande …se lo deja en el análisis, pero dándole menos pesoque será tanto menor cuanto mayor es su distancia de Cook
Un dato con un con un valor de influencia muy grande (gran valor de Leverage)se lo deja en el análisis, pero dándole menos pesoque será tanto menor cuanto mayor es su Leverage
Esto lo podemos abordar con el recálculo de nuestro modelo utilizando estimas robustas… frente a la influencia distorsionadora de esas observaciones muy influyentes o aberrantes 122

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASEstimas robustasSe ajusta el modelo de interés, no por el procedimiento de OLS clásico (ordinary least squares), sino con otro denominado "iterated re‐weighted least squares" (IWLS or IRwLS).
Os recomiendo la consulta – estudio de:https://en.wikipedia.org/wiki/Iteratively_reweighted_least_squareshttp://www.ats.ucla.edu/stat/r/dae/rreg.htmhttp://www.dst.unive.it/rsr/BelVenTutorial.pdf
La matemática subyacente es compleja, pero en esencia consiste en la búsqueda iterativa de unos "pesos" que, teniendo en cuenta el leverage y la distancia de Cook de las observaciones – casos, consiga que esas observaciones tengan menos influencia distorsionadora de los resultados del modelo pero … ¡sin quitarlos!
Existen varios paquetes en R para poder abordar estimas robustas.Y cada uno de ellos llevan implícitos diferentes algoritmos de cálculo que podemos elegir.Nos vamos a centrar en dos paquetes:library(MASS) ## para rlmlibrary(robustbase) ## para lmrob
123

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASEstimas robustasPodemos contar con varios procedimientos para encontrar esos "pesos" de cada observación.En OLS (panel superior izquierdo) todas las observaciones pesan igual: 1En los otros, procedimientos se decide pesarlos de manera diferente (e.g., M‐estimation, Huber).El eje X (denominado E en la figura) representa los residuos de las observaciones
124

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASEstimas robustas
Con MASS : rlm podemos operar del modo siguiente.Tengamos en cuenta que:• el método MM suele ser el más equilibrado (no disminuye de 1 los pesos de las observaciones más
"centradas" en el modelo, y no infrapesa hasta casi cero a las más influyentes o perdidas• el método de Huber puede tener dificultades con outliers severos, no pesándolos muy bajo• el método bisquare de Tukey soluciona el problema de Huber, pero a veces la solución no converge al
proporcionar múltiples soluciones (podemos modificar el número de iteraciones en maxit)• en la mayoría de los casos, todos dan resultados similares.
modelo.rMM <- rlm(eqt, data=datos, method="MM", maxit=100)modelo.rHUBER <- rlm(eqt, data=datos, scale.est="Huber", maxit=100)modelo.rTUKEY <- rlm(eqt, data=datos, psi=psi.bisquare, maxit=100)#### y sus resultados (para uno de ellos)summary(modelo.rMM)Anova(modelo.rMM, type=3, test="F")R2.r <- cor(modelo.rMM$model[,1],modelo.rMM$fitted.values)^2print(c("R2 del modelo robusto =", round(R2.r,3)), quote="FALSE")coeftest(modelo.rMM, vcovHC(modelo.rMM, type="HC4m"))## los pesos de los casos están contenidos en: modelo.rMM$w
125

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASEstimas robustas
Con robustbase : lmrob podemos operar del modo siguiente.• lmrob utiliza estimas de errores estándard corregidas por la heterocedasticidad• el método MM genera pesos (weights) más pequeños para más observaciones• el método SMDM principalmente penaliza a las observaciones que son más "outliers"
modelo.lmrob <- lmrob(eqt, data=datos, method="SMDM", setting = "KS2014")summary(modelo.lmrob)Anova(modelo.lmrob, type=3, test="F")R2.r <- cor(modelo.lmrob$model[,1],modelo.lmrob$fitted.values)^2print(c("R2 del modelo robusto =", round(R2.r, 3)), quote="FALSE")## los pesos de los casos están contenidos en: modelo.lmrob$weights
Si quisiéramos identificar a aquellas observaciones más problemáticas y qué pesos tienen:## relación de los pesos del modelo.r con la distancia de Cook del modelo original## el modelo original es: modelo <- lm(eqt, data=datos)
plot(cooks.distance(modelo)~modelo.lmrob$rweights)identify(cooks.distance(modelo)~modelo.lmrob$rweights)## dad clik a las bolitas de la figura que queráis## terminad cerrando la identificación de puntos en el botón [Finish]
126

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASEstimas robustasEjemplo de los resultados que se obtienen con lmrob.> summary(modelo.lmrob)
… salen muchas cosas que no muestroRobust residual standard error: 0.3755 Multiple R-squared: 0.7132, Adjusted R-squared: 0.634 Convergence in 9 IRWLS iterations
Robustness weights: 30 weights are ~= 1. The remaining 8 ones are
1 5 10 12 22 30 33 37 0.8764 0.9909 0.9637 0.9349 0.7725 0.9784 0.9863 0.5931
> Anova(modelo.lmrob, type=3, test="F")Analysis of Deviance Table (Type III tests)Response: MUSCULO
Df F Pr(>F) (Intercept) 1 0.9991 0.325805 TARSO 1 4.8406 0.035917 * ZONA 1 11.9548 0.001704 **SEXO 1 9.5826 0.004326 **EDAD 1 2.3445 0.136559 ZONA:SEXO 1 1.6930 0.203445 ZONA:EDAD 1 0.5288 0.472953 SEXO:EDAD 1 1.1086 0.301073 ZONA:SEXO:EDAD 1 3.0172 0.092998 . Residuals 29 127

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASEstimas robustasEjemplo de los resultados que se obtienen con lmrob.> plot(cooks.distance(modelo)~modelo.lmrob$rweights)> identify(cooks.distance(modelo)~modelo.lmrob$rweights)
128

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASEstimas robustasY ahora veamos cómo se relacionan los residuos de las observaciones del modelo original inicialcon los pesos de los cuatro modelos que hemos definido
## gráfico de relaciones entre weights## cambiar el tamaño de la letra modificando "1" en ## el denominador de "cex = cex.cor * (1 + r) / 1"panel.cor <- function(x, y, digits=2, prefix="", cex.cor, ...) {
usr <- par("usr")on.exit(par(usr))par(usr = c(0, 1, 0, 1))r <- abs(cor(x, y, use="complete.obs"))txt <- format(c(r, 0.123456789), digits=digits)[1]txt <- paste(prefix, txt, sep="")if(missing(cex.cor)) cex.cor <- 0.8/strwidth(txt)text(0.5, 0.5, txt, col="blue", cex = cex.cor * (1 + r) / 1)
}## ampliarla con Zoom dentro de la solapa Plotspairs(residuals(modelo)~ modelo.rMM$w + modelo.rHUBER$w +modelo.rTUKEY$w + modelo.lmrob$rweights, data=datos, cex.labels=2, pch="o", lower.panel = panel.cor)
129

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASEstimas robustasPatrón de relación entre pesos y residuos. Las correlaciones entre ellos en números azules.
130

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASReducción de modelosEn modelos n‐factoriales muy complejos, la consideración de numerosas interacciones hace que perdamos grados de libertad; y tanto más, cuantos más niveles tengan los factores.
En este escenario “complejo” de análisis podemos perder potencia para estimar la significación y magnitud de efectos de los efectos principales o de las interacciones más sencillas.
Por ejemplo, un modelo con cuatro factores genera:4 efectos principales6 interacciones de pares de factores12 interacciones de tríos de factores1 interacción de los cuatro factores
… en este escenario, la enorme cantidad de interacciones “consumen” muchos grados de libertady pueden reducir la posibilidad de que emerja la importancia de los efectos principales.
Dicho de otro modo, podemos inflar el error de tipo II (aceptar la Ho nula cuando de hecho es falsa).
Es conveniente, pues, reducir nuestro modelo inicial a uno más parsimonioso. Podemos contar con:las estrategias stepwise (… las vamos a dejar de lado)la reducción del modelo utilizando criterios de parsimonia usando AIC de Akaike
comparando modelos entre si. 131

COMPARACIÓN DE MODELOS utilizando Akaike Information Criteria
132
En vez de obtener la diferencia entre dos modelos, se obtiene una estima de la distancia relativa esperada entre cada modelo estimado y los verdaderos mecanismos que realmente han generado los datos observados (posiblemente de una dimensionalidad muy alta).
AIC sirve para seleccionar el mejor modelo dentro de un conjunto de estos obtenidos con los mismos datos. Debemos hacer un esfuerzo por asegurarnos de que el conjunto de modelos de trabajo sea sólido y esté bien apoyado.
AIC sirve para medir la distancia de cada modelo bajo comparación respecto a la “verdad” representada por los datos. Lo único verdadero son los datos; nuestros modelos pretenden representar esa realidad.
Consultad:• https://en.wikipedia.org/wiki/Akaike_information_criterion• "PROCEDIMIENTOS DE SIMPLIFICACIÓN DE MODELOS" en:• http://www.lmcarrascal.eu/regrmult.html

COMPARACIÓN DE MODELOS utilizando Akaike Information Criteria
133
En el caso de modelos GeneralizadosAIC = 2·K – 2·ln(L)
donde L es la estima de “maximum likelihood”y K el número de parámetros del modelo de regresión.
Lo importante no es el valor absoluto de AIC, sino las diferencias entre los valores AICi de i modelos (desde i=1 a i=R, siendo R modelos = comparados)
AIC se recomienda cuando n/K es mayor de 40.siendo n el número de observaciones (tamaño muestral)
Si este no es el caso, deberíamos utilizar:Akaike’s second order information criterion (AICc):
AICc = AIC + (2·K·(K+1))/(n-K-1)
En el caso de modelos GLM, AIC se calcula del siguiente modo:AIC = n·[ln(2·π)+1] + n·ln(SSerror/n) + 2·K
donde n es el tamaño muestral,SSerror/n es la varianza residual (SSerror es la suma de cuadrados error del modelo)y K es el número de parámetros del modelo de regresión (intercepto + predictores + error).
Otra expresión simplificada, a efectos comparativos, es AIC = n·ln(SSerror/n) + 2k

COMPARACIÓN DE MODELOS utilizando Akaike Information Criteria
134
Trabajaremos, por tanto, con diferencias en una serie de valores AIC.
Para ello seleccionaremos el menor valor AIC dentro de nuestro subconjunto de modelos (AICmin), para a continuación calcular incrementos de AIC sobre ese valor mínimo.
Δi =AICi – AICmin
No son los valores absolutos de AICi lo importante, sino las …diferencias relativas entre los AICi (Δi) de diferentes modelos.
Escala relativa de plausibilidad de modelos:Δi Plausibilidad0 – 2 Similar4 – 7 Menor> 10 Mucho menor

COMPARACIÓN DE MODELOS utilizando Akaike Information Criteria
135
La verosimilitud relativa de un modelo se calcula mediante exp(-0.5·Δi).
Pesos Akaike (wi)Se utilizan para una mejor interpretación de la plausibilidad de los modelos cuando estos se comparan.
Sean R modelos seleccionados, entonces el peso relativo del modelo i (wi) es:
wi = exp(-0.5·Δi) / Σ(exp(-0.5·Δi))
con la suma (Σ) de modelos de i=1 a i=R
wi se interpreta como el peso de la evidencia de que el modelo i sea el mejor dentro del conjunto de los modelos candidatos a representar la realidad contenida en los datos.
También puede interpretarse wi como la probabilidad de que ese modelo isea el mejor modelo dentro del conjunto de modelos que se están comparando.

COMPARACIÓN DE MODELOS utilizando Akaike Information Criteria
136
Con estos pesos relativos se estiman los coeficientes de evidencia,
… para comparar la plausibilidad de modelos sometidos a comparación,
peso relativo mayor / peso relativo menor
Estos coeficientes de evidencia son invariantes respecto al número de modelosque hemos considerado en el análisis.
Δi Plausibilidad Coef. evidencia0 – 2 Similar 1 – 2,74 – 7 Menor 7,4 – 33,1> 10 Mucho menor >148
Los pesos wi también pueden ser utilizados para calcular la importancia de los parámetros individuales incluidos en los diferentes modelos.
Para ello se suman los pesos de los modelos en los que han entrado cada una de las variables que están siendo analizadas para explicar la variable respuesta.

COMPARACIÓN DE MODELOS utilizando Akaike Information Criteria
137
Ambivalencia.Es la falta de habilidad para poder identificar el mejor modelo recurriendo a
criterios AIC.No es indicativo de un defecto en las estimas de AIC, sino de que los datos
son simplemente inadecuados para alcanzar una inferencia fuerte.En tales casos, varios modelos pueden ser utilizados con el objetivo de
hacer inferencias.
Usos de los pesos:Estos pesos podemos utilizarlos para estimar el valor medio ponderado de
cada variable predictora, usando los coeficientes de regresión y sus errores estándar en los modelos en que entran esas variables, y los pesos wi de esos modelos.
También los podemos utilizar para efectuar medias ponderadas de valores predichos por una serie de modelos.

COMPARACIÓN DE MODELOS utilizando Akaike Information Criteria
138
Detalles importantes … aunque discutibles:
1) Los valores AIC no pueden ser comparados utilizando diferentes juegos de datos(los datos deben ser fijos)
2) Todos los modelos deben ser calculados utilizando la misma variable dependiente, o la misma transformación de ésta.
3) “Information‐Theoretic Criteria” no es un test. Establece criterios para seleccionar modelos. Es una herramienta exploratoria, no de contraste de hipótesis.
4) No se deben utilizar los valores Δi, wi, o cocientes wi/wj para hablar de diferencias significativas entre modelos.
5) AIC y AICc son sensibles a la presencia de sobredispesión en los datos (ĉ).Dicho aspecto se puede:
• valorar con dicho parámetro de sobredispersión, o,• contemplar con la estima de los coeficientes QAIC y QAICc.
6) Podemos comparar modelos con diferentes distribuciones canónicas, funciones de vínculo, estructura de errores siempre y cuando se efectúen con la misma variable respuesta y el mismo conjunto de datos.

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASReducción de modelosConstruimos varios modelos. Por ejemplo:
eqt0 <- as.formula(MUSCULO ~ 1)eqt <- as.formula(MUSCULO ~ TARSO+ZONA*SEXO*EDAD)eqt2 <- as.formula(MUSCULO ~ TARSO+ZONA+SEXO+EDAD+ZONA:SEXO+ZONA:EDAD+SEXO:EDAD)eqt3 <- as.formula(MUSCULO ~ TARSO+ZONA+SEXO+EDAD)
modelo0 <- lm(eqt0, data=datos)modelo <- lm(eqt, data=datos)modelo2 <- lm(eqt2, data=datos)modelo3 <- lm(eqt3, data=datos)
Cargamos el paquete MuMIn que contiene el comando AICc (AIC corregido para pequeños tamaños muestrales)library(MuMIn)
AICc(modelo0, modelo, modelo2, modelo3)> AICc(modelo0, modelo, modelo2, modelo3)
df AICcmodelo0 2 76.45843 ¿cuántas veces es mejor modelo que modelo0?modelo 10 50.52114 exp(-0.5*(50.521-76.458)) = 428 695 vecesmodelo2 9 51.35482 ¿cuántas veces es mejor modelo3 que modelo?modelo3 6 45.67314 exp(-0.5*(45.673-50.521)) = 11.29 veces139
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASReducción de modelosOtra posibilidad es ordenar los posibles modelos atendiendo a los valores de AICc, teniendo en cuenta la combinación de diferentes términos.
Esto podemos efectuarlo con el comando dredge del paquete MuMIn.Utilizaremos la versión de los coeficientes de regresión estandarizados (betas) con beta="sd"que es la más recomendada (http://onlinelibrary.wiley.com/doi/10.1890/14‐1639.1/abstract).
options(na.action = "na.fail")dredge.modelo <- dredge(modelo, beta="sd", rank="AICc", extra=c("R^2", "adjR^2"))
El resumen del modelo lo obtendremos llamando al objeto dredge que hemos creado:dredge.modelo
Los coeficientes (y sus errores estándard) de todos los modelos posibles (ordenados por valores de AICc) los obtendremos mediante:coefTable(dredge.modelo)
140

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASReducción de modelos
141
los modelos se ordenan demenor a mayor AICc
para las covariantesse proporciona la beta
+ denota que el efectode ese factor o interacción
entra en el modelo
R^2 es la varianza explicadapor ese modelo
modelo nulo sin ningúnefecto

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASReducción de modelos> coefTable(dredge.modelo)$`15`
Estimate* Std. Error* df(Intercept) 0.00000 0.00000 34SEXO1 -0.34774 0.12181 34TARSO 0.43885 0.12233 34ZONA1 -0.44621 0.10373 34
$`16`Estimate* Std. Error* df
(Intercept) 0.00000 0.00000 33EDAD1 0.17052 0.11403 33SEXO1 -0.37419 0.12096 33TARSO 0.35384 0.13293 33ZONA1 -0.41292 0.10430 33
$`32`Estimate* Std. Error* df
(Intercept) 0.00000 0.00000 32EDAD1 0.17754 0.11229 32SEXO1 -0.43361 0.12590 32TARSO 0.31692 0.13325 32ZONA1 -0.39136 0.10369 32EDAD1:SEXO1 -0.15345 0.10611 32
... y hasta el final de todos los modelos142
$`15` denota el número del modelo en la tabla previa de resultados dredge.modelo
Para los factores, las variables mostradas (e.g., SEXO1, EDAD1, ZONA1) son los vectores de las tablas de contrastes.
Para la interpretación de los vectores de contrastes tenemos que saber cómo se ordenaron y contrastaron los niveles de los factores

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASReducción de modelos –Model averagingTambién podemos obtener el promedio de los coeficientes de regresión de las covariantes y los vectores de contrastes para TODOS o un SUBCONJUNTO PREDEFINIDO de modelos.
Std. Error son los "unconditional standard errors".Adjusted SE es la versión revisada de los "inflated standard errors".'conditional average' son los promedios utilizando sólo aquellos modelos en los cuales entra el efecto'full average' asume que el efecto ha entrado en todos los modelos;
cuando no "entra" se asume un coeficiente con valor 0‐cero.esta opción reduce la influencia del efecto de escasa "significación" o importancia real.
Si lo queremos hacer para todos los modelos posibles:summary(model.avg(dredge.modelo))
Si lo queremos efectuar con un subconjunto de modelos podemos restringirlos según criterios de: ΔAICc (delta) summary(model.avg(dredge.modelo, subset=delta<4))
para los modelos cuya suma de pesos (weight) sea menor que una cierta cantidad (con máximo en 1)summary(model.avg(dredge.modelo, cumsum(weight)<=0.90))
143

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASReducción de modelos –Model averaging
> summary(model.avg(dredge.modelo, subset=delta<4))
Call:model.avg(object = dredge.modelo, subset = delta < 4)
Component model call: lm(formula = MUSCULO ~ <8 unique rhs>, data = datos, contrasts = list(ZONA = contr.sum, SEXO = contr.sum, EDAD = contr.sum))
Component models: df logLik AICc delta weight
234 5 -16.73 45.33 0.00 0.26 234 indica que entran los efectos 2, 3 y 41234 6 -15.48 45.67 0.34 0.2212345 7 -14.28 46.29 0.96 0.162347 6 -16.13 46.98 1.65 0.1112347 7 -14.93 47.59 2.26 0.0812346 7 -15.05 47.83 2.50 0.07123456 8 -13.80 48.57 3.24 0.05123457 8 -13.88 48.72 3.39 0.05
Term codes: EDAD SEXO TARSO ZONA EDAD:SEXO EDAD:ZONA SEXO:ZONA
1 2 3 4 5 6 7
… siguen más resultados a continuación144

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASReducción de modelos –Model averaging> summary(model.avg(dredge.modelo, subset=delta<4))… seguimos
Model-averaged coefficients: (full average)
Estimate Std. Error Adjusted SE z value Pr(>|z|) (Intercept) 0.00000 0.00000 0.00000 NA NASEXO1 -0.38410 0.12736 0.13192 2.912 0.003596 ** TARSO 0.36713 0.14062 0.14528 2.527 0.011502 * ZONA1 -0.42191 0.10641 0.11034 3.824 0.000131 ***EDAD1 0.10987 0.12345 0.12605 0.872 0.383389 EDAD1:SEXO1 -0.03895 0.08546 0.08683 0.449 0.653713 SEXO1:ZONA1 0.02438 0.06706 0.06859 0.355 0.722252 EDAD1:ZONA1 -0.01180 0.04959 0.05079 0.232 0.816311
(conditional average) Estimate Std. Error Adjusted SE z value Pr(>|z|)
(Intercept) 0.00000 0.00000 0.00000 NA NASEXO1 -0.38410 0.12736 0.13192 2.912 0.003596 ** TARSO 0.36713 0.14062 0.14528 2.527 0.011502 * ZONA1 -0.42191 0.10641 0.11034 3.824 0.000131 ***EDAD1 0.17434 0.11377 0.11820 1.475 0.140205 EDAD1:SEXO1 -0.15162 0.10652 0.11075 1.369 0.170998 SEXO1:ZONA1 0.10036 0.10432 0.10836 0.926 0.354368 EDAD1:ZONA1 -0.09484 0.10907 0.11341 0.836 0.403001 ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Relative variable importance: SEXO TARSO ZONA EDAD EDAD:SEXO SEXO:ZONA EDAD:ZONA
Importance: 1.00 1.00 1.00 0.63 0.26 0.24 0.12N containing models: 8 8 8 6 3 3 2 145
de interés al mostrar cuál es la suma de los pesos(relative importance)
de los diferentes efectosteniendo en cuenta los
modelos en los que entran
los valores de Z y Pr(>|z|)se calculan conAdjusted SE

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASReducción de modelos –Model averagingDe las tablas previas conditional y full average podemos quedarnos solamente con los coeficientes (Estimate) y los errores estándard (Std. Error ó Adjusted SE), prescindiendo del valor de Z y su significación asociada (Pr(>|z|)). Algunos estadísticos recomiendan "no mezclar" valores de AICc, weights, etc con "significaciones" frecuentistas que recurren a P's.
En vez de los valores de Pr(>|z|) podríamos obtener los intervalos de confianza de los coeficientesconsiderando determinados niveles de probabilidad (asintótica; e.g. 95% ó 0.95). Para ello:
confint(model.avg(dredge.modelo, subset=delta<4), level=0.95)
> confint(model.avg(dredge.modelo, subset=delta<4), level=0.95)2.5 % 97.5 %
(Intercept) 0.00000000 0.00000000SEXO1 -0.64266164 -0.12553966TARSO 0.08238811 0.65186626ZONA1 -0.63815925 -0.20565317EDAD1 -0.05731811 0.40600618EDAD1:SEXO1 -0.36868737 0.06544943SEXO1:ZONA1 -0.11202154 0.31273192EDAD1:ZONA1 -0.31711149 0.12743373
146

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn‐way AN(c)OVASReducción de modelos –Model averagingY para terminar, podríamos obtener una tabla combinada seleccionando 'full average' (que asumeque el efecto ha entrado en todos los modelos) con las siguientes líneas de código:
dredge.tabla <- data.frame(summary(model.avg(dredge.modelo, subset=delta<4))$coefmat.full,confint(model.avg(dredge.modelo, subset=delta<4), level=0.95))
colnames(dredge.tabla)[5] <- "signif_P"colnames(dredge.tabla)[2] <- "Uncondit.SE"colnames(dredge.tabla)[6] <- "ICinf95%"colnames(dredge.tabla)[7] <- "ICsup95%"print(dredge.tabla[c(-4,-5)], digits=3)
> print(dredge.tabla[c(-4,-5)], digits=3)Estimate Uncondit.SE Adjusted.SE ICinf95% ICsup95%
(Intercept) 0.0000 0.0000 0.0000 0.0000 0.0000SEXO1 -0.3841 0.1274 0.1319 -0.6427 -0.1255TARSO 0.3671 0.1406 0.1453 0.0824 0.6519ZONA1 -0.4219 0.1064 0.1103 -0.6382 -0.2057EDAD1 0.1099 0.1235 0.1260 -0.0573 0.4060EDAD1:SEXO1 -0.0390 0.0855 0.0868 -0.3687 0.0654SEXO1:ZONA1 0.0244 0.0671 0.0686 -0.1120 0.3127EDAD1:ZONA1 -0.0118 0.0496 0.0508 -0.3171 0.1274
147

MODELOS GENERALIZADOS LINEALES CON R
Luis M. Carrascal(www.lmcarrascal.eu)
Depto. Biogeografía y Cambio GlobalMuseo Nacional de Ciencias Naturales, CSIC
Cómo realizarlos,buena praxis e
interpretación de los resultados
curso de la Sociedad de Amigos del Museo Nacional de Ciencias Naturales impartido en Febrero de 2017
148

El predictor lineal incluye la suma lineal de los
efectos de una o más variables explicativas (xj).
j representan los parámetros desconocidos
que es necesario estimar.
Estos valores son llevados a una nueva escala mediante unatransformación adecuada. Esto es, i no representa a yi,sino a una transformación de los valores y mediante lafunción de vínculo.
149

La transformación utilizada viene definida por la función devínculo.
La función de vínculo relaciona los valores y () con el predictorlineal mediante:
= g()
Para volver a la escala original de medida (y), el valor ajustado esla función inversa de la transformación que define la función devínculo.
Para determinar el ajuste de un modelo,* el procedimiento evalúa el predictor lineal para cada valor de lavariable dependiente (y),
* y luego compara este valor predicho con la transformación de y
150

Mediante el uso de diferentes funciones de vínculo,podemos valorar la adecuación de nuestro modelo a losdatos. Para ello utilizaremos el concepto y parámetrodevianza.
El modelo más apropiado será aquel que minimice ladevianza residual.
En los modelos Generales Lineales operamos con variablesdependientes normales, y los modelos proporcionanresiduos que siguen la distribución normal. Sin embargo,numerosos datos no presentan errores normales.* por sesgo y kurtosis* están acotados (caso de proporciones)* son conteos que no pueden manifestar valores negativos
151

Podemos distinguir las siguientes familias principales de errores:* errores Normales* errores Poisson (conteos de fenómenos raros)* errores Binomiales negativos (Poisson con mayor dispersión)* errores Binomiales (datos que miden respuestas si/no o proporciones)* errores Gamma (datos que muestran un CV constante)* errores Exponenciales (datos de supervivencia)
Para estos errores se han definido las funciones de vínculomás adecuadas (por defecto; canónicas):
ERRORES FUNCIÓN* Normales Identidad* Poisson, Binomiales negativos Log* Binomial Logit* Gamma Recíproca
152

CREACIÓN DEL MODELO GENERALIZADO (POISSON REGRESSION)
En los modelos de regresión lineal clásicos (Gausianos):* definimos una función predictora
g(x) = α+β1X1+ … + βpXp para p predictores* establecemos la relación lineal con la respuesta
Y = g(x) + ε siendo ε la variación residual
En los modelos generalizados de Poisson:* establecemos el valor esperado de la respuesta Y* que establece una relación logarítmica con la función predictora g(x)
log(Y) = g(x) + ε o Y = eg(x) + ε'
Y = eα+β1X1+ … + βpXp
* esta estructura es muy importante para la interpretación de los coeficientes deregresión.
153

MODELOS GENERALIZADOS LINEALES CON RDefinición de los modelos atendiendo a la distribución de erroresSegún qué tipo de variable respuesta tengamos definiremos la familia y la función de vínculo.Usaremos el comando glm en vez de lm de los modelos generales lineales.
modelo <- glm(eqt, data=datos, family=poisson(link="log"))family = quasipoisson(link="log")
modelo <- glm.nb(eqt, data=datos, link=log)
modelo <- glm(eqt, data=datos, family=binomial(link="logit"))family = quasibinomial(link="logit") family = binomial(link="cloglog")
cloglog trabaja mejor con distribuciones extremadamente sesgadas
154

Interpretación de los resultadosPrimero valoramos la significación global del modelo, en lo que se conoce como un
omnibus test. SI EL RESULTADO ES SIGNIFICATIVO, PODREMOS SEGUIR CON LOSRESULTADOS. Si no resulta significativo el análisis … ¡se terminó!
Si en los modelos GzLM usados con poisson y binomial aplicamos la corrección porsobredispersión, el resultado de este omnibus test cambia.
155

VARIABILIDAD EXPLICADA POR EL MODELO (usando devianzas)La devianza es igual a la suma de los cuadrados de los residuos de devianza
proporción de devianza explicada = (devianza residual nula – devianza residual del modelo) (devianza residual nula)
156
Para conocer la proporción de la variación en la variable respuesta que es explicada porel modelo (equivalente a una R2 de un modelo General Lineal) tendremos que:1) construir un nuevomodelo "nulo" sin predictoras (con sólo el intercepto).2) obtener la Devianza de ese modelo nulo en su tabla de Goodness of Fit (Do)3) calcular la siguiente expresión que denominaremos D2:
D2 = (Do ‐ Dmodelo) / DoModelo nulo
D2 = (148801.74 – 116720.22) / 148801.74 =0.2156 = 21.6%
Nuestro modelo de interés

Por último, observamos los parámetros de las variables predictoras: coeficientes (B),errores estándard y significaciones (con las aproximaciones de Wald y de cocientesLikelihood).
157

INTERPRETACIÓN DE LOS COEFICIENTES DE REGRESIÓNLos modelos de regresión de Poisson son multiplicativos… porque la función de vínculo es el logaritmo: familia = poisson vínculo = log
En la regresión de Poisson log (Y) = a + b∙X o Y = exp(a + b∙X)log(Y) cambia linealmente en función de las variables predictorasY cambia linealmente en función del antilogaritmo de la función de las predictoras
El coeficiente b en antilogaritmo, exp(b), mide el cambio en esa variable predictoraque implica el cambio en una unidad en la variable respuesta Y.
O dicho de otro modo, el coeficiente b es el cambio esperado en el log(Y) cuando la variable predictora aumenta una unidad.
En el caso de las predictoras categóricas (definidas por nº categorías del factor – 1) el antilogaritmo del coeficiente, exp(b), es el término multiplicativo relativo a la "base" del factor. El antilogaritmo del intercepto, exp(a), es el valor basal en relación con el cual se estiman los cambios definidos por los coeficientes.
158

ejemplo con factoresfactor edu de 4 niveles factor res de 3 niveles
159

SOBREDISPERSIÓN DEL MODELO
Medida para estimar la bondad de ajuste del modelo (ϕ).
Mide la existencia de una mayor (o menor) variabilidad que la esperable en la variable respuesta considerando los supuestos acerca de su distribución canónica y la función de vínculo (que liga los valores transformados de la variable a las predicciones del modelo)http://en.wikipedia.org/wiki/Overdispersion
ϕ debería valer 1.Si >1 sobredispersión se "inflan" las significacionesSi <1 infradispersión asociado a la sobreparametrización
¡¡¡SOBREDISPERSIÓN!!!las estimas de significación están "infladas"
Con estos valores (ϕ) recalculamos nuevas estimas de significación a través de la F.F = diferencias en Devianza / (dif. en g.l. x ϕ)
aparecerán en los resultados en:Test of Model Effects 160

El coeficiente de sobredispersión es el valor Value/df. No lo utilizaremos si nuestradistribución canónica de la respuesta es la normal. En modelos con poisson y binomialdebería dar un valor próximo a "uno" (1). Si es >1 hay sobredispersión; si es <1 se dice quehay sobreparametrización o infradispersión. Se aconseja corregir este desvío si Value/df>1, y no cuando es <1.
en un modelo Gausiano nuncase corrige por sobredispersión,porque ésta ya se ha estimado en ladefinición de la gausiana a través delparámetro desviación típica (sd)que la describe.
161

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una PoissonVeámoslo prácticamente en R utilizando la distribución de Poisson.
## para importar datos de internet y ponerlos en uso## abro una conexión con internetmeconecto <- url("http://www.lmcarrascal.eu/cursos/nwayGENERALIZADO.RData")## cargo el archivo de la conexiónload(meconecto)## cierro la conexión y borro el objeto "meconecto"close(meconecto); rm(meconecto)
## con la siguiente línea de código veo las variablesnames(datos)
## creamos una función de asociaciones que llamo "eqt"eqt <- as.formula(abundancia ~ covariante + insolacion*tratamiento)
162

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una PoissonVeámoslo prácticamente en R utilizando la distribución de Poisson.
## CARGAMOS PAQUETES##library(lmtest)library(MASS)library(car)library(MuMIn)library(phia)library(sandwich)library(robustbase)library(psych)library(fit.models)
163

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una PoissonVeámoslo prácticamente en R utilizando la distribución de Poisson.
## establecemos los tipos de contrastes para las variables## predictoras nominales (factores)## antes cargamos la siguiente línea de código para obtener los## mismos resultados que en STATISTICA o SPSS utilizando type III SS## "factor" para los factores no ordenados## "ordered" para factores con niveles ordenados##options(contrasts=c(factor="contr.sum", ordered="contr.poly"))
## ahora creamos nuestro modelo tipo ANCOVA Generalizado Linealmodelo <- glm(eqt, data=datos, family=poisson(link="log"))
## los valores de la Devianza nula (modelo nulo: "respuesta ~ 1")## y Devianza residual del modelo se encuentran en el modelo## como modelo$null.deviance y modelo$deviance## con ellos calculamos lo que explica el modelo:d2 <- round(100*(modelo$null.deviance-modelo$deviance)/modelo$null.deviance, 2)print(c("D2 de McFadden (%) =",d2), quote=FALSE)[1] D2 de McFadden (%) = 63.15
164

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una PoissonVeámoslo prácticamente en R utilizando la distribución de Poisson.
## estima de significación global del modelo de interés ## comparándolo con el modelo nulo## sólo procederemos valorando los resultados de este modelo, ## SÍ Y SÓLO SÍ, este "omnibus test" ha sido significativo## podemos utilizar estos dos test con resultados similares
## likelihood ratio testlrtest(modelo)
Likelihood ratio test
Model 1: abundancia ~ covariante + insolacion * tratamientoModel 2: abundancia ~ 1#Df LogLik Df Chisq Pr(>Chisq)
1 5 -163.01 2 1 -279.54 -4 233.05 < 2.2e-16 ***---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
165

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una PoissonVeámoslo prácticamente en R utilizando la distribución de Poisson.
## test de Waldwaldtest(modelo)
Wald test
Model 1: abundancia ~ covariante + insolacion * tratamientoModel 2: abundancia ~ 1Res.Df Df F Pr(>F)
1 1072 111 -4 41.609 < 2.2e-16 ***---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
166

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una PoissonVeámoslo prácticamente en R utilizando la distribución de Poisson.
## valores AICc del modelo de interés y el modelo nulomodelo.nulo <- glm(modelo$model[,1]~1, family=poisson(link="log"))
AICc(modelo, modelo.nulo)veces.mejor <- exp(-0.5*(AICc(modelo)-AICc(modelo.nulo)))print(c("Veces que MI MODELO es mejor que el modelo NULO =", veces.mejor), quote=FALSE)
df AICcmodelo 5 336.5938modelo.nulo 1 561.1163
[1] Veces que MI MODELO es mejor que el modelo NULO = 5.6812671423727e+48
Este resultado es consistente con el anterior, pero en coordenadas de teoría de la información.El modelo de interés de 6*1048 veces mejor que el modelo nulo.
Estos dos tests nos proporcionan que nuestro modelo es altamente significativo, con lo cual podemos continuar valorando sus resultados.
Pero antes tenemos que comprobar si hemos cumplido los supuestos canónicos de los modelos a través de la exploración de sus residuos.
167

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una PoissonVeámoslo prácticamente en R utilizando la distribución de Poisson.
## exploración de los residuos del modelo## vemos unos gráficos generales que ya nos dan muchas pistas: ## normalidad, usando los residuos de devianza## (¡¡no en la escala original de la respuesta!!)## homocedasticidad de los residuos a través de las predicciones## del modelo (aplicando la transformación de la link function)## existencia de datos influyentes y perdidos## con la distancia de Cook y Leverage## en una sola figura con cuatro paneles
par(mfcol=c(1,1)) ## fija un sólo panel gráficopar(mfcol=c(2,2)) ## fija cuatro paneles con 2 columnas y 2 filasplot(modelo, c(1:2,4,6)) par(mfcol=c(1,2))par(mfcol=c(1,1)) ## volvemos al modo gráfico de un solo panel
168

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una Poisson
169
homocedasticidad
normalidadpuntos influyentes y perdidos

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una PoissonVeámoslo prácticamente en R utilizando la distribución de Poisson.
## test de Shapiro-Wilk de la normalidad de los residuos de devianzashapiro.test(residuals(modelo, type="deviance"))
Shapiro-Wilk normality testdata: residuals(modelo, type = "deviance")W = 0.976, p-value = 0.04078
## el desvío de la normalidad no es muy grave## hemos identificado que hay una leve violación de homocedasticidad## y existen algunas observaciones con elevada distancia de Cook
## puntos influyentes y perdidos con dffits## dffits con sus límites "críticos"## niveles críticos 2*raiz((g.l. del modelo)/(Número de datos))plot(dffits(modelo)) abline(h=2*((length(modelo$residuals)-modelo$df.residual-1)/length(modelo$residuals))^0.5, col="red")abline(h=-2*((length(modelo$residuals)-modelo$df.residual-1)/length(modelo$residuals))^0.5, col="red")
identify(dffits(modelo))## terminad dando clik en Finish del panel Plots
170

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una Poisson
171

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una PoissonVeámoslo prácticamente en R utilizando la distribución de Poisson.
## INDEPENDENCIA ENTRE LAS PREDICTORAS: VIF = 1 / (1 - R2), ## de cada predictora por las restantes## GVIF or VIF specifically indicate the magnitude of the inflation in the standard errors
## associated with a particular beta weight that is due to multicollinearity
## la raiz cuadrada de un valor VIF o GVIF es el número de veces que ## se inflan los errores standard de esa predictora##vif(modelo)sqrt(vif(modelo))
> vif(modelo)covariante insolacion tratamiento insolacion:tratamiento
1.165977 1.872718 2.481296 3.228086 > sqrt(vif(modelo))
covariante insolacion tratamiento insolacion:tratamiento1.079804 1.368473 1.575213 1.796687
172

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una PoissonVeámoslo prácticamente en R utilizando la distribución de Poisson.
## estima de la sobredispersión del modelo## este valor canónico debería de ser igual a la unidad##phi <- sum((residuals(modelo, type="pearson"))^2)/modelo$df.residualprint(c("Pearson overdispersion =", round(phi, 3)), quote=FALSE)
[1] Pearson overdispersion = 1.176
Si este valor hubiese sido muy diferente de uno (e.g., > 2) recalcularíamos el modelo teniendo en cuenta ese valor de sobredispersión, aplicando la pseudofamilia quasipoisson.No corregiremos por sobredispersión si phi <1
modelo2 <- glm(eqt, data=datos, family=quasipoisson(link="log"))
Y procederíamos con este nuevo modelo.
173

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una PoissonVeámoslo prácticamente en R utilizando la distribución de Poisson.
## representación de los valores observados y predichos en la respuesta## usando la escala original de medida (habiendo destransformado los datos## desde la transformación incluida en la link function)plot(modelo$y~fitted(modelo), ylab="respuesta original")abline(lm(modelo$y~fitted(modelo)), col="red", lwd=2)
174

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una PoissonVeámoslo prácticamente en R utilizando la distribución de Poisson.
## resultados del modelo y SIGNIFICACIONES de efectos parcialessummary(modelo)
Call:glm(formula = eqt, family = poisson(link = "log"), data = datos)
Deviance Residuals: Min 1Q Median 3Q Max
-2.5187 -1.0968 -0.4778 0.6431 2.5663
Coefficients:Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.603318 0.220371 -2.738 0.00619 ** covariante 0.009461 0.002337 4.049 5.15e-05 ***insolacion1 0.896872 0.130503 6.872 6.31e-12 ***tratamiento1 0.694988 0.130047 5.344 9.08e-08 ***insolacion1:tratamiento1 -0.150148 0.130167 -1.154 0.24870 ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for poisson family taken to be 1)
Null deviance: 369.04 on 111 degrees of freedomResidual deviance: 135.99 on 107 degrees of freedomAIC: 336.03
Number of Fisher Scoring iterations: 5 175

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una PoissonVeámoslo prácticamente en R utilizando la distribución de Poisson.
## estimas parciales, al estilo SS type-III## esto nos proporciona la significación de los efectos## la Deviance nos vincula a las magnitudes de los efectos## <none> indica la devianza residual sin quitar efectos## los otros valores indican la devianza quitando ese efecto## a más valor más magnitud del efecto##dropterm(modelo, ~., test="Chisq", sorted=FALSE)
Single term deletions
Model:abundancia ~ covariante + insolacion * tratamiento
Df Deviance AIC LRT Pr(Chi) <none> 135.99 336.03 covariante 1 152.63 350.67 16.638 4.524e-05 ***insolacion 1 212.52 410.56 76.533 < 2.2e-16 ***tratamiento 1 176.48 374.52 40.490 1.976e-10 ***insolacion:tratamiento 1 137.45 335.49 1.466 0.2259 ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
176

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una PoissonVeámoslo prácticamente en R utilizando la distribución de Poisson.
## estimas parciales, al estilo SS type-III## esto nos proporciona la significación de los efectos#### otra manera con Likelihood Ratio test##Anova(modelo, type=3, test="LR")
Analysis of Deviance Table (Type III tests)
Response: abundanciaLR Chisq Df Pr(>Chisq)
covariante 16.638 1 4.524e-05 ***insolacion 76.533 1 < 2.2e-16 ***tratamiento 40.490 1 1.976e-10 ***insolacion:tratamiento 1.466 1 0.2259 ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
177
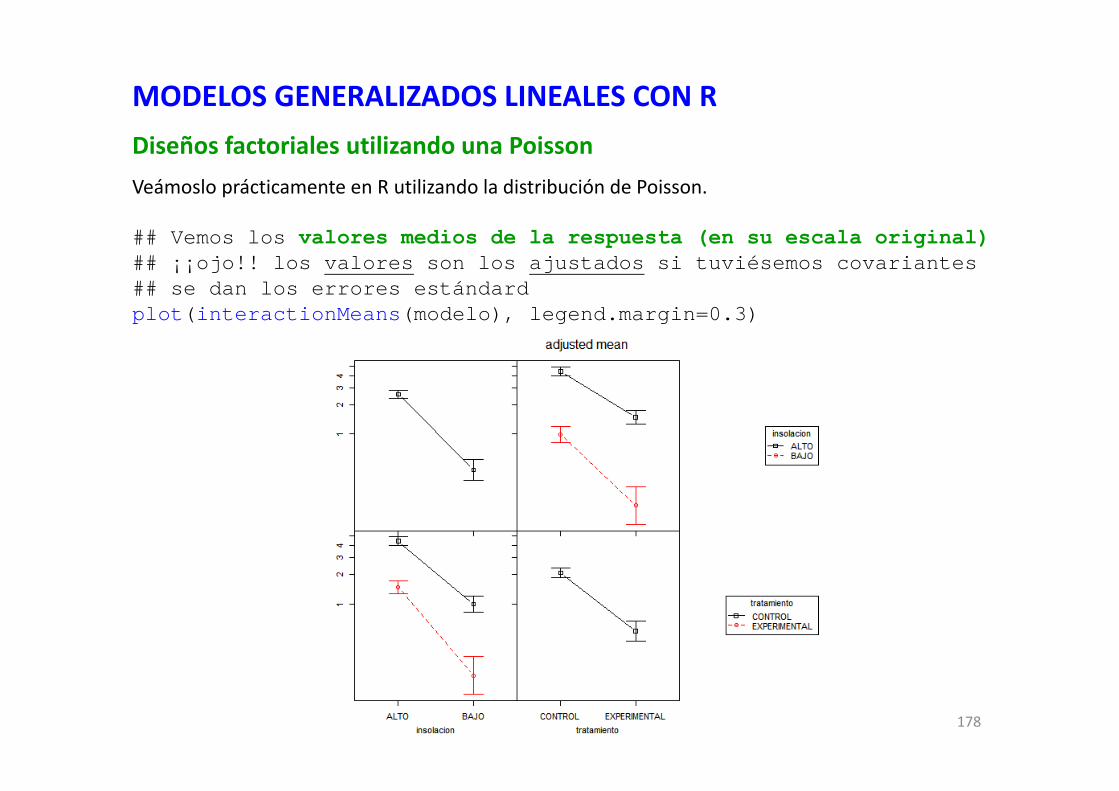
MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una PoissonVeámoslo prácticamente en R utilizando la distribución de Poisson.
## Vemos los valores medios de la respuesta (en su escala original)## ¡¡ojo!! los valores son los ajustados si tuviésemos covariantes## se dan los errores estándardplot(interactionMeans(modelo), legend.margin=0.3)
178

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una PoissonVeámoslo prácticamente en R utilizando la distribución de Poisson.
## EXAMEN DEL EFECTO DE LA VIOLACIÓN DEL SUPUESTO DE HOMOCEDASTICIDAD## Recálculo de significaciones; realmente sin mucho interés porque## se refiere a los coeficientes y no al efecto global de cada factor## método Sandwich (que es type="HC0"): sólo para el cálculo de ## nuevos errores standard y las significaciones asociadas## no cambian las estimas de los coeficientes##coeftest(modelo, vcov=sandwich)
z test of coefficients:Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.6033185 0.2282439 -2.6433 0.0082101 ** covariante 0.0094608 0.0024835 3.8094 0.0001393 ***insolacion1 0.8968718 0.1224953 7.3217 2.449e-13 ***tratamiento1 0.6949877 0.1212844 5.7302 1.003e-08 ***insolacion1:tratamiento1 -0.1501483 0.1212557 -1.2383 0.2156130 ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
179

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una PoissonVeámoslo prácticamente en R utilizando la distribución de Poisson.
## afrontemos ahora el efecto de puntos influyentes y/o perdidos## RECÁLCULO DEL MODELO QUITANDO ALGUNOS PUNTOS## mejor no hacemos estomodelo.sin_outliers <- glm(eqt, data=datos[c(-6, -33, -54, -55, -56),]), family=poisson(link="log"))
## ESTIMACIONES ROBUSTAS## sin quitar datos del modelo; aproximación robusta más seria,## que estima nuevos coeficientes y errores standard## Mqle es el método Mallows-Hubber quasi-liquelihood.modelo.robusto <- glmrob(eqt, data=datos, family=poisson(link="log"), weights.on.x="hat", method="Mqle", control=glmrobMqle.control(tcc=1.2, maxit=100))##summary(modelo.robusto)par(mfcol=c(1,1))## robustez de los datos individualesplot(modelo.robusto$w.r, ylab="robustez de las observaciones")identify(modelo.robusto$w.r)plot(modelo.robusto$w.x, leverage(modelo) , xlab="peso de las observaciones")
180

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una PoissonVeámoslo prácticamente en R utilizando la distribución de Poisson.
> summary(modelo.robusto)
Call: glmrob(formula = eqt, family = poisson(link = "log"), data = datos, method = "Mqle", weights.on.x = "hat", control = glmrobMqle.control(tcc = 1.2, maxit = 100))
Coefficients:Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.637792 0.230571 -2.766 0.00567 ** covariante 0.010387 0.002448 4.243 2.20e-05 ***insolacion1 0.847448 0.133664 6.340 2.30e-10 ***tratamiento1 0.663203 0.133265 4.977 6.47e-07 ***insolacion1:tratamiento1 -0.129810 0.133560 -0.972 0.33109 ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1Robustness weights w.r * w.x:
Min. 1st Qu. Median Mean 3rd Qu. Max. 0.3520 0.8800 0.9042 0.8563 0.9246 0.9298
Number of observations: 112 Fitted by method ‘Mqle’ (in 5 iterations)
(Dispersion parameter for poisson family taken to be 1)
181

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una Poisson
182

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una Poisson
183

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una Binomial NegativaRepetiremos todos los pasos previos, sólo que en esta ocasión nuestro modelos será:
modelo <- glm.nb(eqt, data=datos, link=log)
> summary(modelo)
Call:glm.nb(formula = eqt, data = datos, link = log, init.theta = 10.08705502)
Deviance Residuals: Min 1Q Median 3Q Max
-2.1470 -1.0874 -0.4259 0.5242 2.0050
Coefficients:Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.591067 0.244692 -2.416 0.015711 * covariante 0.009298 0.002735 3.399 0.000676 ***insolacion1 0.896394 0.134216 6.679 2.41e-11 ***tratamiento1 0.698006 0.133797 5.217 1.82e-07 ***insolacion1:tratamiento1 -0.149458 0.134011 -1.115 0.264736 ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for Negative Binomial(10.0032) family taken to be 1)
Null deviance: 305.36 on 111 degrees of freedomResidual deviance: 114.48 on 107 degrees of freedomAIC: 335.01
Number of Fisher Scoring iterations: 1
Theta: 10.00 En esta ocasión el modelo estima un parámetro más ThetaStd. Err.: 7.52 que mide la sobredispersión de un modelo Binomial Negativo
este parámetro se relaciona con el "size" de la distribución NegBin2 x log-likelihood: -3223.012 no deberíamos corregir por sobredispersión 184

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una BinomialRepetiremos todos los pasos previos, sólo que en esta ocasión nuestro modelos será:
modelo <- glm(eqt, data=datos, family=binomial(link="logit"))
Si hay sobredispersión utilizaremos la pseudofamilia:family=quasibinomial(link="logit")
Si no hay buenos ajustes o alta sobredispersión utilizaremos la función de vínculo:family = binomial(link ="cloglog")
cloglog trabaja mejor con distribuciones extremadamente sesgadaspor ejemplo: porporciones de un estado <0.1 o >0.9
185

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una Binomial
Si nuestra variable respuesta no es una binomial con estados [0‐1] ó [SI‐NO]entonces podremos construir un modelo definiendo esa variable respuesta "frecuencia".
Hay dos modos:• la respuesta es un valor "proporción" (acotado entre cero y uno)• la respuesta es un valor combinado de dos vectores: valores SI, valores NO
Para proporciones, tenemos que definir el denominador que genera la frecuencia en weights
modelo <- glm(eqt, data=datos, family=binomial(link="logit"), weights=denominador)
Para respuestas combinadas, tenemos que definir los dos vectores conteo‐SI, conteo‐NO en una nueva variable respuesta con el comando cbind
cbind(valoresSI, valoresNO)
## ejemplo con los datos de trabajoeqt <- as.formula(cbind(presen8, ausen8) ~ covariante + insolacion * tratamiento)
modelo <- glm(eqt, data=datos, family=binomial(link="logit")
186

MODELOS GENERALIZADOS USANDO UNA BINOMIAL
Nuestro modelo ahora tendrá la forma:p: proporción de un "estado" respecto a toda la muestra(80 "ceros" y 20 "unos", N=100: p = 20/100 = 0.20)
X: k variables predictoras
logit ( p ) = log [ p / (1 – p) ] = β0 + β1X1 + β2X 2 + β3X3 +... + βkXk
p / (1 – p) = exp ( β0 + β1X1 + β2X 2 + β3X3 +... + βkXk ) exp: antilogaritmo
[ exp ( β0 + β1X1 + β2X 2 + β3X3 +... + βkXk ) ]p =
1 + [ exp ( β0 + β1X1 + β2X 2 + β3X3 +... + βkXk ) ]
El modelo Generalizado Lineal Logit predice valores de probabilidad continua (p):entre 0 y 1.
187

RESIDUOS DE MODELOS GENERALIZADOS BINOMIALESLa exploración de los residuos en esta ocasión es un tanto diferente, debido al estado binomial de la respuesta con dos valores discretos (e.g., 0‐1, sí‐no).
Con la "normalidad de los residuos" de devianza, en el mejor de los casos, tendríamos algo parecido a lo siguiente (con antisimetría en los dos lados del "bigote"):
cuanto más explique el modelomás cerca estarán los dos extremos
mayor densidadde puntos
menor densidadde puntos
188

RESIDUOS DE MODELOS GENERALIZADOS BINOMIALESEn el caso de la relación entre los residuos de devianza y las predicciones del modelo(predictor lineal al que se le aplica la transformación logit), esperaríamos encontrar algo como esto:
cuanto más explique el modelomás cerca estarán los dos extremos
mayor densidadde puntos
menor densidadde puntos
menor densidadde puntos
189

DIAGRAMAS ROC EN MODELOS GENERALIZADOS BINOMIALESEl Modelo Generalizado Binomial produce probabilidades de ocurrencia p de uno de los estados de la variable respuesta (e.g., el valor 1 en 0‐1, o sí en sí‐no).
Estos valores de p, continuos entre 0 y 1, hay que convertirlos a "estados" 0 o 1, utilizando umbrales de corte.
Estos valores umbrales nos permitirán convertir "probabilidades" en "estados".
si p<0.5 entonces es "cero"por ejemplo, si el umbral es p=0.5
si p>0.5 entonces es "uno"
Podemos utilizar como umbral de corte (cut‐off point) la proporción real observada.No obstante, en muchas ocasiones este es un valor incierto, y es conveniente preguntarse:¿cómo de bueno es nuestro modelo "clasificando las observaciones" independiente‐mente de los valores umbral de corte?
Para ello podemos contar con los diagramas ROC (Receiver operating characteristic):https://en.wikipedia.org/wiki/Receiver_operating_characteristichttp://www.anaesthetist.com/mnm/stats/roc/Findex.htm (excelente página)
190
DIAGRAMAS ROC EN MODELOS GENERALIZADOS BINOMIALES
El área en el cuadrado morado suma "uno". De esa área,¿cuánto ocupa la superficie bajo la curva azul? (la proporción es el valor AUC)
AUC
191

DISEÑOS n‐FACTORIALES COMPLEJOSLuis M. Carrascal(www.lmcarrascal.eu)
Grupo de Biogeografía Ecológica IntegrativaMuseo Nacional de Ciencias Naturales, CSIC
modelos ENCAJADOSmodelos MIXTOS
diseños de BLOQUESdiseños MULTIVARIANTES
modelos de MEDIDAS REPETIDASmodelos SPLIT‐PLOT
curso de la Sociedad de Amigos del Museo Nacional de Ciencias Naturales impartido en Febrero de 2017192

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOS
n way ANOVAScon factores anidados(modelos ENCAJADOS)
193

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn way ANOVAS y MANOVASAnálisis Encajados de la VarianzaEn estos diseños se establece que el efecto de un factor A no está cruzado en los niveles de otro factor B. Esto es, no se define una interacción A*B.
Esto puede ser así por: el interés del investigadorla imposibilidad de representación de los niveles de un factor en los de otro factor
este es el caso en el que un factor FAMILIA no está representado en otro factor ORDENen este esquema de sistemática lineana, GENERO dentro‐de FAMILIA dentro‐de ORDEN
Análisis Encajados de la VarianzaLa opción "MSerror de todo el modelo"
… se utiliza en diseños de efectos FIJOS.
La opción "MS del efecto de orden jerárquico inmediatamente inferior"… se utiliza en diseños de factor(es) anidado(s) ALEATORIOS.
194

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn way ANOVAS y MANOVASAnálisis Encajados de la VarianzaLa clave en estos diseños encajados (anidados) de efectos aleatorios (o de celdas vacías) está en definir el término error (MS y g.l.)
El MS denominador (MSerror) de la F de Fisher es:el MS del efecto de orden jerárquico inmediatamente inferior
ejemplo:el MSerror para ESPECIE es el MS del efecto INDIVIDUO dentro‐de ESPECIE (MSerror del modelo)el MSerror para GENERO es el MS del efecto ESPECIE dentro‐de GENEROel MSerror para FAMILIA es el MS del efecto GENERO dentro‐de FAMILIAel MSerror para ORDEN es el MS del efecto FAMILIA dentro‐de ORDEN
Si no queremos complicarnos con la definición de efectos fijos y aleatorios, podemos calcular manualmente las F, p y g.l. utilizando los términos correctos que podemos obtener en las tablas de ANOVA.
195

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn way ANOVAS y MANOVASAnálisis Encajados de la VarianzaEjemplo con un diseño de efectos fijos con término MSerror común:Anidamos una secuencia de efectos fijos (cada factor tiene dos niveles):el efecto de la EDAD se anida dentro de SEXO que se anida dentro de ZONApara ZONA se efectúa 1 comparación entre sus dos niveles (del factor) 1 g.l. ó d.f.para SEXO se efecúan 2 comparaciones (1 en cada ZONA) 2 g.l. ó d.f.para EDAD se efecúan 4 comparaciones (2 dentro de SEXO en las ZONAs) 4 g.l ó d.f.
Y ~ A/B B está encajado en A es como Y ~ A + B %in% A
eqt <- as.formula(MUSCULO~TARSO+ZONA/SEXO/EDAD)modelo <- lm(eqt, data=datos)Anova(modelo, type=3, test="F")
Anova Table (Type III tests)
Response: MUSCULOSum Sq Df F value Pr(>F)
(Intercept) 0.1574 1 1.1389 0.2946890 TARSO 0.7399 1 5.3523 0.0279834 * es una covarianteZONA 1.9958 1 14.4380 0.0006872 ***ZONA:SEXO 1.5928 2 5.7614 0.0078187 ** ZONA:SEXO:EDAD 1.1925 4 2.1568 0.0990707 . Residuals 4.0087 29 196

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn way ANOVAS y MANOVASAnálisis Encajados de la VarianzaEjemplo con un diseño de efectos aleatorios con término MSerror NO común:
Para el caso de que los niveles de un factor de orden jerárquico inferior no esténrepresentados en todos los niveles de otro factor de orden jerárquico superior
Anidamos una secuencia de efectos:el efecto de la covariante se anida en el BOSQUE, que se anida dentro de REGION
Hay celdas vacías y no funcionará Anova(…). Usaremos anova que emplea SS tipo I
eqt <- as.formula(egagrop_1011 ~ REGION/BOSQUE/covariante)
modelo <- lm(eqt, data=datos)anova(modelo)
Analysis of Variance Table
Response: egagrop_1011Df Sum Sq Mean Sq F value Pr(>F)
REGION 2 116598 58299 18.0612 5.783e-08 ***REGION:BOSQUE 23 120021 5218 1.6166 0.04217 * REGION:BOSQUE:covariante 26 246808 9493 2.9408 9.921e-06 ***Residuals 210 677854 3228
197

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn way ANOVAS y MANOVASAnálisis Encajados de la VarianzaEjemplo con un diseño de efectos aleatorios con término MSerror NO común:
haremos los cálculos correctos de modo manual utilizando los Mean Sq (MSefecto)
Analysis of Variance Table
Response: egagrop_1011Df Sum Sq Mean Sq F value Pr(>F)
REGION 2 116598 58299 18.0612 5.783e-08 ***REGION:BOSQUE 23 120021 5218 1.6166 0.04217 * REGION:BOSQUE:covariante 26 246808 9493 2.9408 9.921e-06 ***Residuals 210 677854 3228
Para la covariante dentro de cada BOSQUE (10 árboles por bosque)F para REGION:BOSQUE:covariante = 9493 / 3228 = 2.9408 d.f. = 26, 210
Para el BOSQUE dentro de cada REGION (hay 9, 9 y 8 bosques en las tres regiones)F para REGION:BOSQUE
controlando por la covariante = 5218 / 9493 = 0.5497 d.f. = 23, 26sin controlar por la covariante = 5218 / 3228 = 1.6165 d.f. = 23, 210
Para comparar los niveles de REGION (hay tres regiones)F para REGION = 58299 / 5218 = 11.1727 d.f. = 2, 23
198

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn way ANOVAS y MANOVASAnálisis Encajados de la Varianza¿Cuándo establecer efectos anidados dentro de un factor?Siempre que queramos valorar el efecto de un predictor, sea continuo (covariante ) o nominal (factor), de manera no homogenea dentro de nuestra muestra, sino distinguiendo entre las situaciones definidas por otro factor.
También será una necesidad cuando contemos con diseños de “celdas vacías”, porque los niveles de un factor no estén representados en otro factor, y ambos factores no se puedan cruzar estableciendo la interacción.
ejemplo: caso de factores sistemáticos (ORDEN, FAMILIA, GÉNERO, … que no están representados)
Esto es una necesidad cuando existen interacciones significativas entre covariantes y factores (test de paralelismo del ANCOVA).
También puede ser interesante cuando haya interacciones significativas entre dos o más factores, de manera que no se pueda generalizar el efecto de un factor en toda la muestra, ya que es dependiente de los estados definidos por otro factor.
En el caso de que una covariante manifieste valores muy diferentes en los niveles de determinados factores y se sospeche que no se pueda generalizar su efecto.
veamos este aspecto de modo gráfico en la siguiente página199
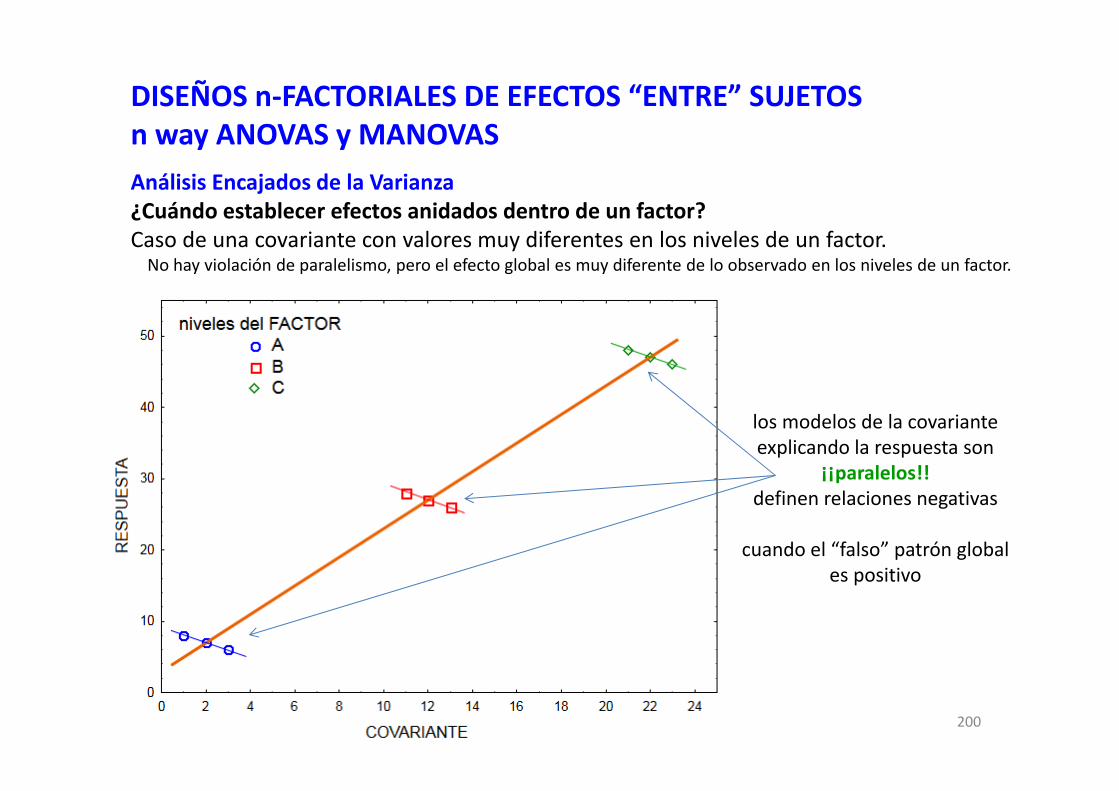
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn way ANOVAS y MANOVASAnálisis Encajados de la Varianza¿Cuándo establecer efectos anidados dentro de un factor?Caso de una covariante con valores muy diferentes en los niveles de un factor.No hay violación de paralelismo, pero el efecto global es muy diferente de lo observado en los niveles de un factor.
200
los modelos de la covarianteexplicando la respuesta son
¡¡paralelos!!definen relaciones negativas
cuando el “falso” patrón globales positivo

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOS
n way ANOVAScon factores ALEATORIOS
(modelos MIXTOS)
201

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSLa novedad es introducir factores de efectos aleatorios.Son factores cuyos niveles representan una muestra de la realidad, obtenida pormuestreo aleatorio de ella (familias, parcelas, individuos que re‐muestreo, etc).
La clave de estos diseños está en definir los términos error (MS y df).Podemos distinguir dos aproximaciones para el cálculo de los denominadores de la F para
estimar la significación de los efectos aleatorios en modelos mixtos:la Restricted y la Unrestricted.
Quinn, G.P.; Keough, M.J. (2002). Experimental design and data analysis for biologists. Cambridge Univ. Press, Cambridge. 202

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSDefinición de términos error (MS y df).
203

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSEstructura de datos y "tamaños muestrales"Ejemplo:
204
38 individuos (niveles de factor aleatorio)dos situaciones de muestreo (factor fijo)
6 réplicas en un nivel del factor4 réplicas en el otro nivel del factor
el tamaño muestral correctopara el efecto del factor fijo NO ES 38*(4+6) = 380ES 38 individuos medidos en 2 situaciones
38 individuos * 2 situaciones = 76lo define la interacción fijo * aleatorio

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSLas hipótesis nulas en los modelos mixtos son las siguientes:
FACTORES FIJOS (FF): las medias (μ) de los diferentes niveles de un factor FF son iguales.factor fijo FF con n niveles: μ1 = μ2 = μ3 = … = μn
COVARIANTES: el coeficiente de regresión es cero.respuesta = f(factores) + b*covariante b=0
FACTORES ALEATORIOS (FR): la varianza (σ2) asociada al factor aleatorio FR es cero.σFR2 = 0
Lecturas recomendadas:Using Mixed‐Effects Models for Confirmatory Hypothesis Testing
http://talklab.psy.gla.ac.uk/simgen/faq.html
205

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSTipos de diseños atendiendo a si los efectos aleatorios afectan:al intercepto y/o a las pendientes de los efectos predictores fijos.
206
con INTERCEPTOsin interacciones entre
efectos FIJOS*ALEATORIOS
con INTERCEPTOcon interacciones entre
efectos FIJOS*ALEATORIOS
sin INTERCEPTOcon interacciones entre
efectos FIJOS*ALEATORIOS
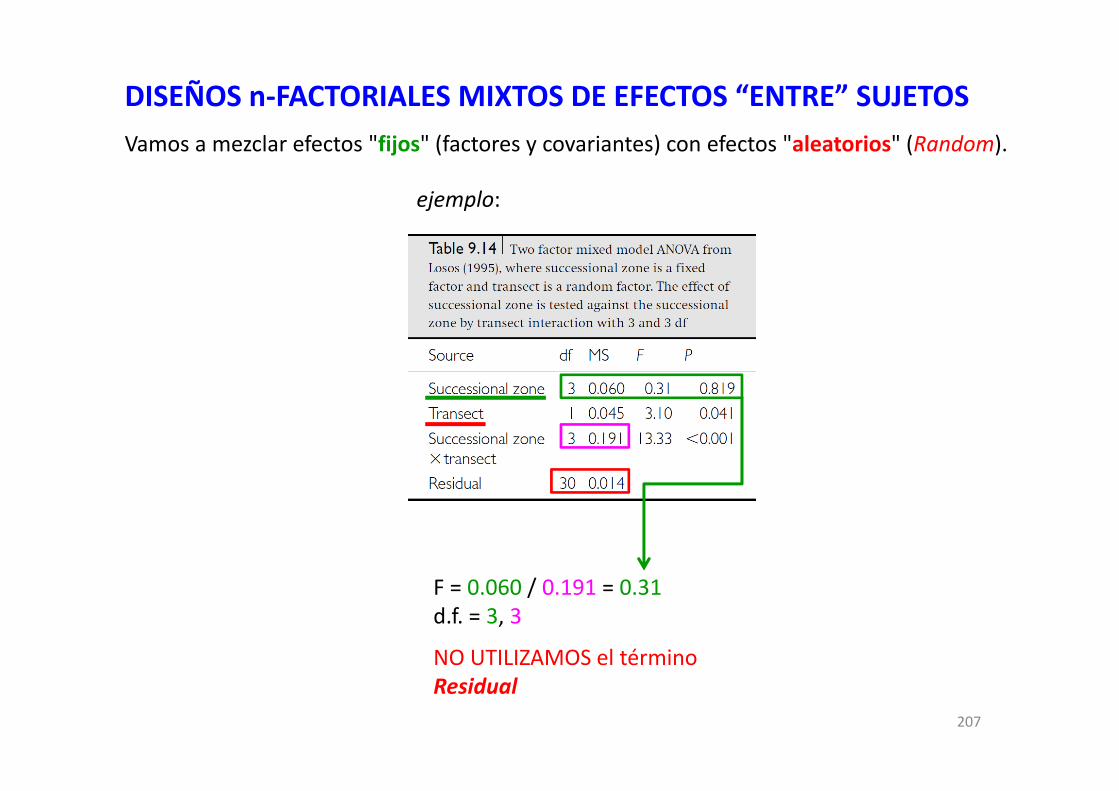
DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSVamos a mezclar efectos "fijos" (factores y covariantes) con efectos "aleatorios" (Random).
207
F = 0.060 / 0.191 = 0.31d.f. = 3, 3
NO UTILIZAMOS el términoResidual
ejemplo:

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSejemplo: Definición de términos error (MS y df) con efectos aleatorios encajados.
208

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando lmer.Algo de nomenclatura:
## consultad: https://cran.r-project.org/web/packages/lme4/vignettes/lmer.pdf## the lone random effects model; A is randomlmer(Y ~ 1 + (1 | A), data=d)## Random effects, like (1 | A), are parenthetical terms containing## a conditioning bar and wedged into the body of the formula.
## A and B are both random and crossed (i.e. marginally independent)lmer(Y ~ 1 + (1 | A) + (1 | B), data=d)
## B is fixed but A is random## the Random Intercept model## (B | A) is equivalent to (1 + B | A)## these two models produce identical resultslmer(Y ~ B + (1 | A), data=d)lmer(Y ~ 1 + B + (1 | A), data=d)
## A is random; both the intercept and the slope of B (fixed) depend on A.## the Random intercept and Random slopes model## with no constraint on the slope-intercept relationship## these two models produce identical resultslmer(Y ~ 1 + B + (1 + B | A), data=d)lmer(Y ~ B + (B | A), data=d)
209

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando lmer.Algo de nomenclatura:
## A is random and B is fixed## To force B's intercept and slope to be independent conditional on A:## a rare situation where it is sensible to remove an intercept,## we remove the slope-intercept relationship## these two models produce identical resultslmer(Y ~ 1 + B + (1 | A) + (0 + B | A), data=d)lmer(Y ~ B + (B || A), data=d)
## Nested variables: ## if A is random, B is fixed, and B is nested within A:lmer(Y ~ B + (1 | A:B), data=d)
## Levels of (random) B are nested within levels of (random) A## these two models produce identical resultslmer(Y ~ 1 + (1 | A) + (1 | A:B), data=d)lmer(Y ~ 1 + (1 | A/B), data=d)## The last expresses the nesting and ensures that## we don't accidentally do a crossed factor analysis.
210

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando lmer.Ejemplo con resultados:
## CARGAMOS PAQUETES DE ANÁLISIS
library(lme4) ## generalized mixed modelslibrary(lmerTest) ## para MS, df, p ... usando type 3/type 1 hypotheses with
## "Satterthwaite" and "Kenward-Roger"library(pbkrtest) ## necesario para lmerTestlibrary(car) ## para Anova(modelo, type=3) para equivalente a suma de tipo III
## para boxCox(modelo, lambda=seq(-2,2, 1/100))library(MuMIn) ## para AICclibrary(lmtest) ## para lrtestlibrary(psych) ## para tabla de promedios con describe y describeBylibrary(lattice) ## para plots de residuoslibrary(arm) ## para correr simulaciones con modelos merModlibrary(phia) ## para plots de interacciones
211
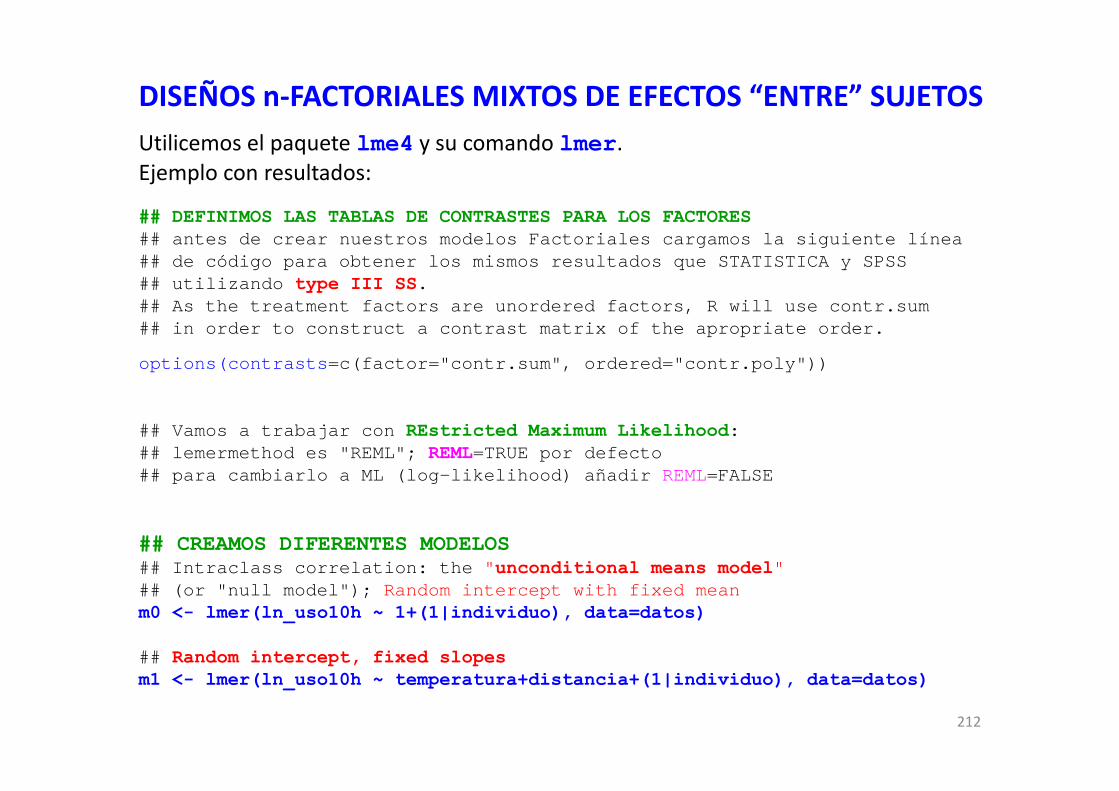
DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando lmer.Ejemplo con resultados:
## DEFINIMOS LAS TABLAS DE CONTRASTES PARA LOS FACTORES## antes de crear nuestros modelos Factoriales cargamos la siguiente línea## de código para obtener los mismos resultados que STATISTICA y SPSS## utilizando type III SS.## As the treatment factors are unordered factors, R will use contr.sum## in order to construct a contrast matrix of the apropriate order.
options(contrasts=c(factor="contr.sum", ordered="contr.poly"))
## Vamos a trabajar con REstricted Maximum Likelihood: ## lemermethod es "REML"; REML=TRUE por defecto## para cambiarlo a ML (log-likelihood) añadir REML=FALSE
## CREAMOS DIFERENTES MODELOS## Intraclass correlation: the "unconditional means model"## (or "null model"); Random intercept with fixed meanm0 <- lmer(ln_uso10h ~ 1+(1|individuo), data=datos)
## Random intercept, fixed slopesm1 <- lmer(ln_uso10h ~ temperatura+distancia+(1|individuo), data=datos)
212

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando lmer.Ejemplo con resultados:
## CREAMOS DIFERENTES MODELOS## diferentes pendientes e interceptos; Random intercept and Random slopes## Correlated random intercept and slope, with## UNCORRELATED random slopes for different covariatesm2 <- lmer(ln_uso10h ~ temperatura+distancia+(temperatura|individuo)+(distancia|individuo), data=datos)
## diferentes pendientes e interceptos; Random intercept and Random slopes## Correlated random intercept and slope, with## with CORRELATED random slopes for different covariatesm3 <- lmer(ln_uso10h ~ temperatura+distancia+(temperatura+distancia|individuo), data=datos)
## Efectos anidados## Random intercept model; ambos factores son aleatoriosm7 <- lmer(ln_uso10h ~ 1+(1|spp/individuo), data=datos)
## Random intercept and slopes models; spp es fijo e individuo es aleatorio## estos dos siguientes dan lo mismom8 <- lmer(ln_uso10h ~ spp+(1|individuo), data=datos)m9 <- lmer(ln_uso10h ~ spp+(1|spp:individuo), data=datos)
213

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando lmer.Ejemplo con resultados:
## creamos los modelos## Vamos a trabajar con REstricted Maximum Likelihood: lemermethod es "REML" ## (REML=TRUE por defecto); para cambiarlo a ML (log-likelihood) REML=FALSE## modelo de interés de “random intercepts and slopes”options(contrasts=c(factor="contr.sum", ordered="contr.poly"))modelo <- lmer(ln_uso10h ~temperatura+distancia+spp+
(temperatura|individuo)+(distancia|individuo), data=datos, REML=TRUE)
## modelos “nulo” m0 (sólo el efecto aleatorio) y de “random intercepts” m1m0 <- lmer(ln_uso10h ~ 1+(1|individuo), data=datos, REML=TRUE)m1 <- lmer(ln_uso10h ~ temperatura+distancia+spp+(1|individuo), data=datos, REML=TRUE)
## Si tenemos tablas de contrastes particulares que queremos examinar,## ese contraste para el efecto mi.factor lo añadimos con su.contraste## e.g.: su.contraste <- matrix(c(-3, -1, 1, 3), ncol=4) ## lmer(..., contrasts=list(mi.factor=su.contraste, ...))
## si hay problemas de estimas y convergencia## introducir en lmer(..., control=mi.control) lo siguiente:mi.control <- lmerControl(check.conv.grad=.makeCC(action ="ignore", tol=1e-6, relTol=NULL),
optimizer="bobyqa", optCtrl=list(maxfun=100000))
## para ver sus características teclear: str(lmerControl(...))str(mi.control) 214
DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando lmer.Ejemplo con resultados:
## ¿Qué contiene el modelo?## Para ver su contenido, no funciona names(modelo). Usaremos el comando strstr(modelo)
## para más detalles mirad en la ventana de ayuda “MerMod-class”## o en http://www.inside-r.org/packages/cran/lme4/docs/terms.merMod
## La matriz de datos usada (siendo la primera columna la variable respuesta)modelo@frame## La fórmula usada está en:modelo@call## El logLikelihood está en:logLik(modelo)## La devianza está en:deviance(modelo, REML=TRUE)## La matriz de varianzas/covarianzas está en:vcov(modelo)## Los residuos están en:residuals(modelo)
215

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando lmer.Ejemplo con resultados:
## RESIDUOS DEL MODELO## Exploración visual de la normalidad de los residuos del modelohist(residuals(modelo), density=5, freq=FALSE, main="residuos del modelo", ylim=c(0,0.25))curve(dnorm(x, mean=mean(residuals(modelo)), sd=sd(residuals(modelo))), col="red", lwd=2, add=TRUE, yaxt="n")
##qqnorm(residuals(modelo), main="residuos del modelo")qqline(residuals(modelo), col="red", lwd=2)#### para otro qqnorm identificando valores con residuos extremos## ponemos en id la proporción de residuos extremos (e.g., id=0.02, el 2%)qqmath(modelo, id=0.02, main="2% de residuos extremos")#### Exploración visual de la heterocedasticidad de los residuosplot(fitted(modelo), residuals(modelo), main="¿HAY HETEROCEDASTICIDAD?")abline(h=0, col="red")###### otra posibilidad sintética es:mcp.fnc(modelo)#### Exploración analítica del desvío de los residuos de la normalidad## test de Shapiro-Wilk de normalidad de residuosshapiro.test(residuals(modelo))
216

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando lmer.Ejemplo con resultados:
> shapiro.test(residuals(modelo))Shapiro‐Wilk normality test
data: residuals(modelo)W = 0.9513, p‐value = 7.017e‐10
217

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando lmer.Ejemplo con resultados:
218
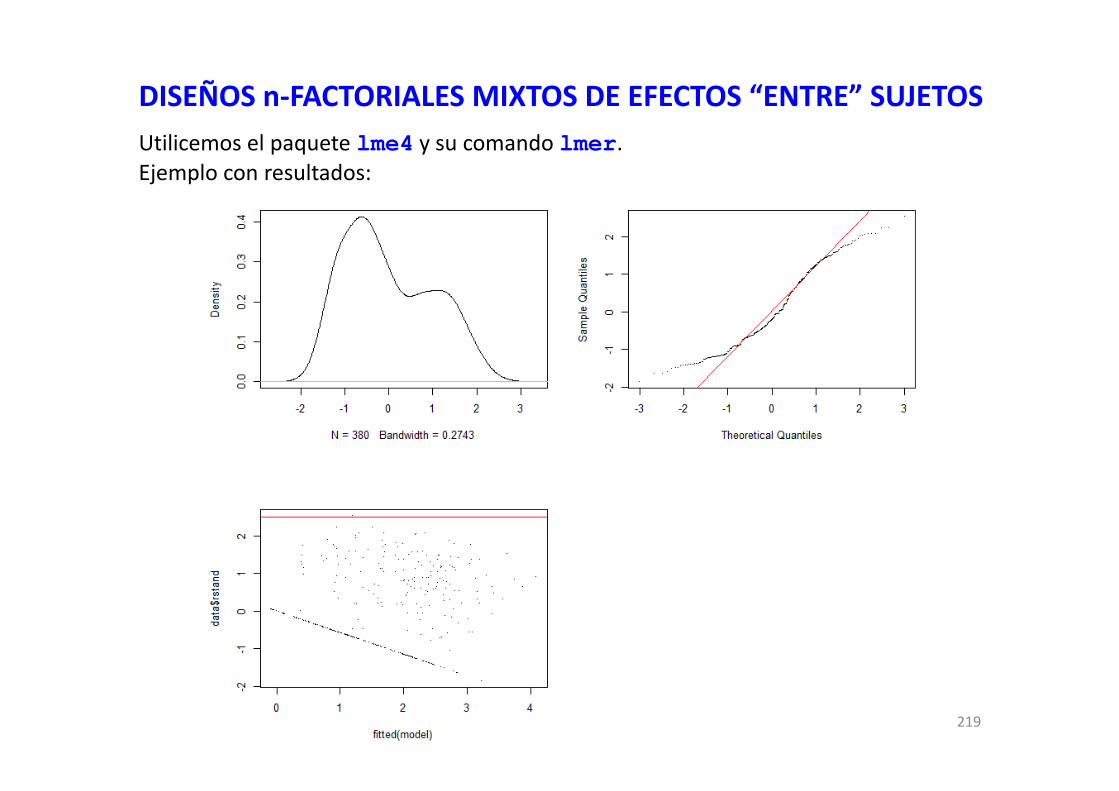
DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando lmer.Ejemplo con resultados:
219

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando lmer.Ejemplo con resultados:
## VALORES OBSERVADOS Y PREDICHOSpredicho <- fitted(modelo)plot(modelo@frame[,1] ~ predicho, ylab="RESPUESTA", xlab="PREDICCIONES")abline(lm(modelo@frame[,1] ~ predicho), col="green", lwd=2)
220

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando lmer.Ejemplo con resultados:
## ¿Cuánto explican los modelos?## consultad: https://jonlefcheck.net/2013/03/13/r2-for-linear-mixed-effects-models/comment-page-1/## http://onlinelibrary.wiley.com/doi/10.1111/j.2041-210x.2012.00261.x/epdf## http://onlinelibrary.wiley.com/doi/10.1111/2041-210X.12225/epdf## R2m: marginal R2 (proporción de la varianza explicada por los efectos fijos)## R2c: conditional R2 (proporción de la varianza explicada por todos los efectos## (los fijos y los aleatorios)## para el modelo de interés “random intercepts and slopes”r.squaredGLMM(modelo)
R2m R2c0.1783904 0.2168988
## para el modelo “random intercepts”r.squaredGLMM(m1)
R2m R2c0.1780067 0.1780067
## En el modelo m0 (Intraclass correlation: the "unconditional means model" or "null model")
r.squaredGLMM(m0) R2m R2c
0.0000000 0.0007702## En el modelo nulo R2c cuantifica las diferencias entre grupos (niveles del factor aleatorio)## sólo tiene sentido trabajar con diferencias entre niveles del factor aleatorio (modelo mixto) ## cuando existe una magnitud relevante de la varianza atribuible a ese efecto; incluso bajos niveles de## intraclass correlation (e.g., 15% to 20%) sugieren la necesidad de efectuar un modelo mixto
## No obstante, en este caso continuamos con el modelo mixto para poder trabajar ## con toda la variabilidad original, evitando la pseudorreplicación 221

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando lmer.Ejemplo con resultados:
Método REML (restricted estimation maximum likelihood) vs MLEl método REML produce estimas menos sesgadas de los parámetros de la varianza que el método ML. Por tanto, es REML es el más indicado para llevar a cabo nuestros modelosmixtos, y por ello es el método implementado por defecto en los modelos lmer (i.e., no hace falta incluir como argumento REML=TRUE).e.g., página 22 (apartado 2.2) en https://socserv.socsci.mcmaster.ca/jfox/Books/Companion/appendix/Appendix‐Mixed‐Models.pdf
A la hora de comparar diferentes modelos anidados, que comparten la misma variable respuesta y las mismas unidades muestrales, el método REML lo podremos utilizar si, y sólo si, se mantienen constantes los efectos fijos (sean factores o covariantes) y cambia la estructura de los efectos aleatorios.
Pero NUNCA deberemos utilizar el método REML si en los modelos anidados que se comparan cambian los predictores fijos. En esta circunstancia deberemos cambiar la estructura de nuestro modelo lmer(…, REML=TRUE) a ML con lmer(…, REML=FALSE).
Es más, podremos comparar modelos lmer con modelos lm, pero sólo usando la opción ML en lmer.
222

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando lmer.Ejemplo con resultados:
Método REML (restricted estimation maximum likelihood) vs MLEsto es aplicable al utilizar comparaciones tipo lrtest y AIC(c).
Por tanto, antes de usar esos comandos de comparación de modelos, deberemos rehacer nuestros modelos de interés usando REML=FALSE. Para ello usaremos update(…).
m0.ml <- update(m0, REML=FALSE)m1.ml <- update(m1, REML=FALSE)modelo.ml <- update(modelo, REML=FALSE)
Ahora ya sí que podemos comparar modelos con lrtest o AICc, pero usando las versiones ML en vez de las versiones originales REML, aunque sean estas últimas más adecuadas para parametrizar los modelos.
223

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando lmer.Ejemplo con resultados:
## Omnibus test de la “significación” global del modelo## Podemos comenzar con una aproximación basada en “información” usando AICc## Para ello comparamos los valores de AICc del modelo de interés y el nulo.## Por modelo “nulo” entendemos aquel que sólo incluye el factor aleatorio.## También podemos incluir en la comparación el de “random intercepts” (m1).## A menor valor AICc del modelo, el modelo es más informativo y parsimonioso
AICc(modelo.ML, m1.ML, m0.ML) Weights(AICc(modelo.ML, m1.ML, m0.ML))df AICc [1] 3.691836e-01 6.308164e-01 5.730539e-13
modelo.ML 15 1555.265 en valores de pesos relativos (que suman UNO)m1.ML 5 1554.193m0.ML 3 1609.647
## ¿cuántas veces es mejor un modelo que otro?## las comparaciones relevantes podrían ser (colocando primero el modelo con menor AICc):exp(-0.5*(AICc(modelo.ML)-AICc(m0.ML)))[1] 644238900641 es mucho mejor el de interés que el nulo
exp(-0.5*(AICc(m1.ML)-AICc(modelo.ML)))[1] 1.708679 es (ca. 2 veces) mejor el de “random intercepts” que el de “random intercepts and slopes”
o sea, el modelo mixto más sencillo ES SIMILAR al más complejo
224
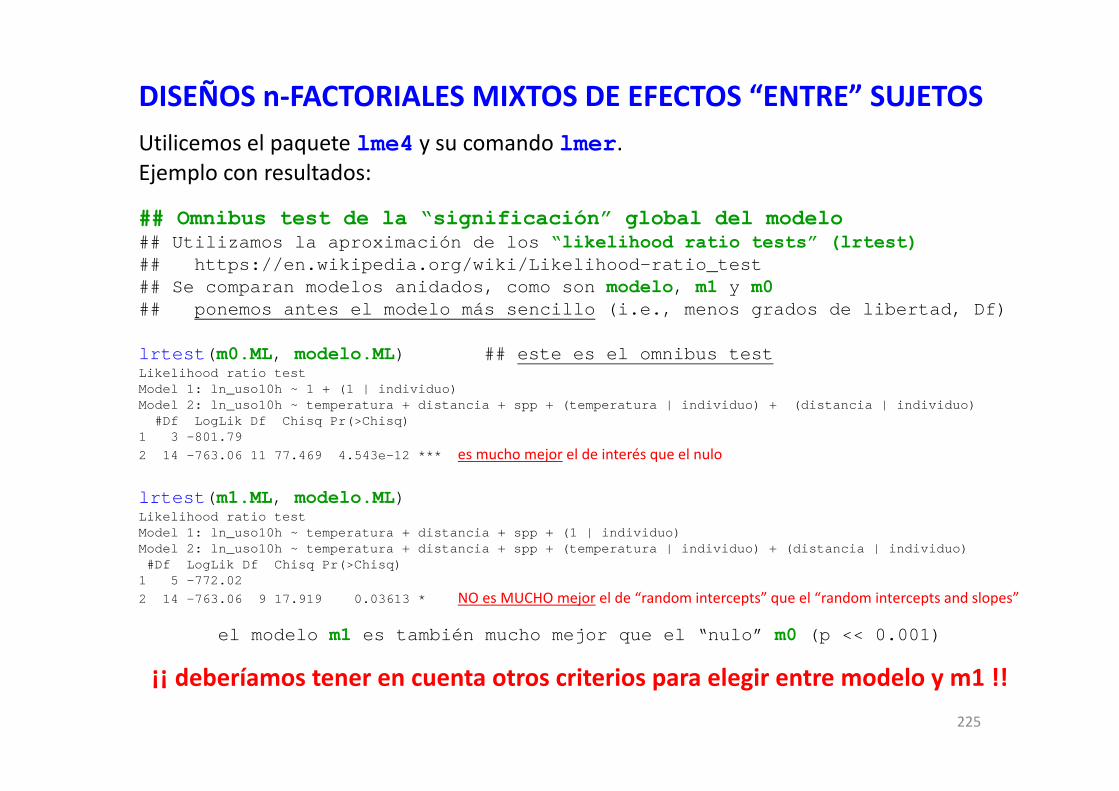
DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando lmer.Ejemplo con resultados:
## Omnibus test de la “significación” global del modelo## Utilizamos la aproximación de los “likelihood ratio tests” (lrtest)## https://en.wikipedia.org/wiki/Likelihood-ratio_test## Se comparan modelos anidados, como son modelo, m1 y m0## ponemos antes el modelo más sencillo (i.e., menos grados de libertad, Df)
lrtest(m0.ML, modelo.ML) ## este es el omnibus testLikelihood ratio testModel 1: ln_uso10h ~ 1 + (1 | individuo)Model 2: ln_uso10h ~ temperatura + distancia + spp + (temperatura | individuo) + (distancia | individuo)#Df LogLik Df Chisq Pr(>Chisq)
1 3 -801.79 2 14 -763.06 11 77.469 4.543e-12 *** es mucho mejor el de interés que el nulo
lrtest(m1.ML, modelo.ML)Likelihood ratio testModel 1: ln_uso10h ~ temperatura + distancia + spp + (1 | individuo)Model 2: ln_uso10h ~ temperatura + distancia + spp + (temperatura | individuo) + (distancia | individuo)#Df LogLik Df Chisq Pr(>Chisq) 1 5 -772.02 2 14 -763.06 9 17.919 0.03613 * NO es MUCHO mejor el de “random intercepts” que el “random intercepts and slopes”
el modelo m1 es también mucho mejor que el “nulo” m0 (p << 0.001)
¡¡ deberíamos tener en cuenta otros criterios para elegir entre modelo y m1 !!225

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando lmer.Ejemplo con resultados:
## Omnibus test de la “significación” global del modelo## Aproximación basada en métodos de remuestreo para comparar modelos anidados.## ponemos antes el modelo más complejo y luego el más sencillo## con nsim definimos el número de procesos de bootstrapping## con seed podemos cambiar los procesos de aleatorización-remuestreo## esta aproximación es más conveniente si sospechamos que nuestros modelos se## desvían de los supuestos canónicos de los modelos generales lineales## deberíamos de utilizar ML en vez de REML en modelo vs m0, ya que tienen diferentes efectos fijos
PBmodcomp(modelo.ML, m0.ML, nsim=1000, seed=123) ## este es el omnibus testParametric bootstrap test; time: 293.89 sec; samples: 1000 extremes: 0;large : ln_uso10h ~ temperatura + distancia + spp + (temperatura | individuo) + (distancia | individuo)small : ln_uso10h ~ 1 + (1 | individuo)
stat df p.valueLRT 77.469 11 4.543e-12 ***PBtest 77.469 0.000999 *** es mucho mejor el de interés que el nulo
PBmodcomp(modelo.ML, m1.ML, nsim=1000, seed=123)Parametric bootstrap test; time: 294.69 sec; samples: 1000 extremes: 363;Requested samples: 1000 Used samples: 917 Extremes: 363large : ln_uso10h ~ temperatura + distancia + spp + (temperatura | individuo) + (distancia | individuo)small : ln_uso10h ~ temperatura + distancia + spp + (1 | individuo)
stat df p.valueLRT 1.8942 5 0.8636PBtest 1.8942 0.3693 NO es mejor el de “random intercepts” que el de “random intercepts and slopes”
el modelo m1 es también mucho mejor que el “nulo” m0 (p << 0.001) 226
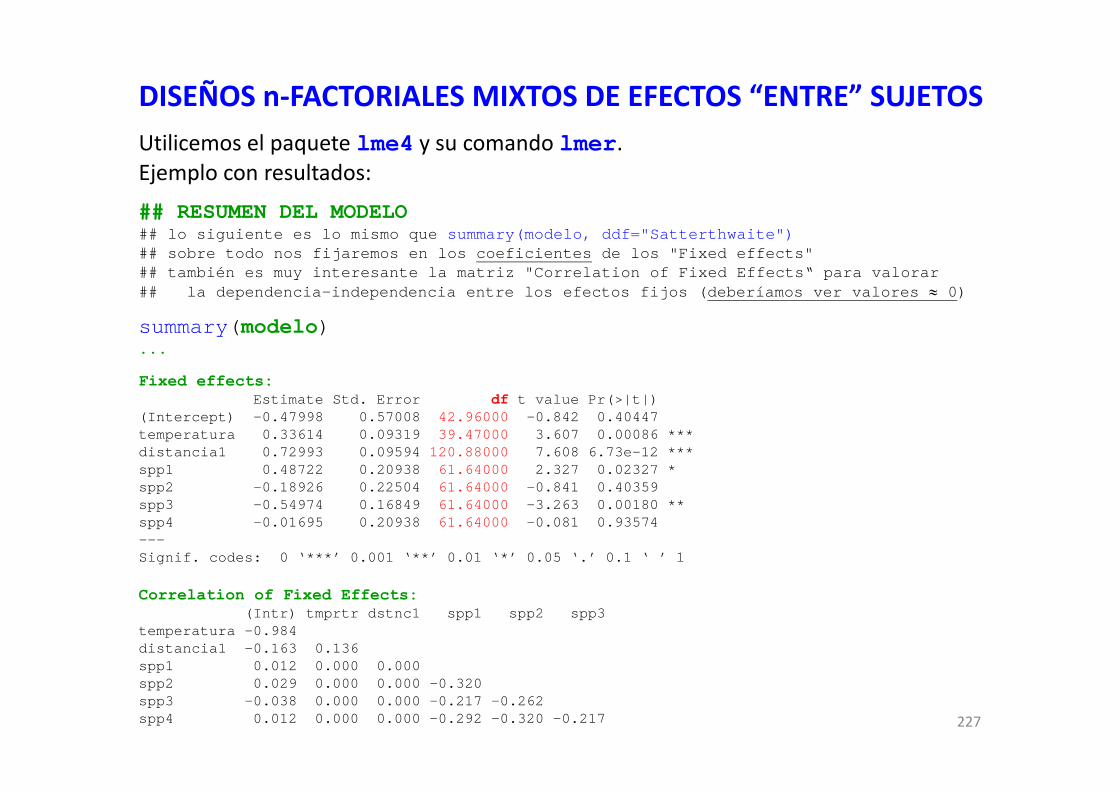
DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando lmer.Ejemplo con resultados:
## RESUMEN DEL MODELO## lo siguiente es lo mismo que summary(modelo, ddf="Satterthwaite")## sobre todo nos fijaremos en los coeficientes de los "Fixed effects"## también es muy interesante la matriz "Correlation of Fixed Effects“ para valorar## la dependencia-independencia entre los efectos fijos (deberíamos ver valores 0)
summary(modelo)...
Fixed effects:Estimate Std. Error df t value Pr(>|t|)
(Intercept) -0.47998 0.57008 42.96000 -0.842 0.40447 temperatura 0.33614 0.09319 39.47000 3.607 0.00086 ***distancia1 0.72993 0.09594 120.88000 7.608 6.73e-12 ***spp1 0.48722 0.20938 61.64000 2.327 0.02327 * spp2 -0.18926 0.22504 61.64000 -0.841 0.40359 spp3 -0.54974 0.16849 61.64000 -3.263 0.00180 ** spp4 -0.01695 0.20938 61.64000 -0.081 0.93574 ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Correlation of Fixed Effects:(Intr) tmprtr dstnc1 spp1 spp2 spp3
temperatura -0.984 distancia1 -0.163 0.136 spp1 0.012 0.000 0.000 spp2 0.029 0.000 0.000 -0.320 spp3 -0.038 0.000 0.000 -0.217 -0.262 spp4 0.012 0.000 0.000 -0.292 -0.320 -0.217 227

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando lmer.Ejemplo con resultados:
## RESUMEN DEL MODELO## para la aproximación de Kenward-Roger se añade ddf="Kenward-Roger"## creamos un objeto con los resultados del modelo, para no tenerlo que hacer cada vez:
resumen.modelo.kr <- summary(modelo, ddf="Kenward-Roger")
## para ver qué contienenames(resumen.modelo.kr)
## la aproximación de Kenward-Roger es mucho más severa en los grados de libertad## comparadlo con la salida previa usando Satterthwaite
Fixed effects:Estimate Std. Error df t value Pr(>|t|)
(Intercept) -0.47998 0.57008 38.90000 -0.842 0.405032 temperatura 0.33614 0.09319 38.39000 3.607 0.000881 ***distancia1 0.72993 0.09594 38.39000 7.608 3.52e-09 ***spp1 0.48722 0.20938 33.00000 2.198 0.035107 * spp2 -0.18926 0.22504 33.00000 -0.794 0.432723 spp3 -0.54974 0.16849 33.00000 -3.081 0.004139 ** spp4 -0.01695 0.20938 33.00000 -0.076 0.939521
228

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando lmer.Ejemplo con resultados:
## obtención de coeficientes estandarizados## proporciona los coeficientes beta (β) de regresión que son comparables entre efectos## el comando estandariza los coeficientes de regresión a media cero y sd=1/2, ## en vez de la estandarización clásica de "a media cero y sd=1"
modelo.std <- standardize(modelo)
## coeficientes de regresión standarizados para la parte fija## comparando sus valores (absolutos) podemos alcanzar una idea de qué efectos son## más importantes en nuestro modelo
fixef(modelo.std)
(Intercept) z.temperatura c.distancia spp1 spp2 spp3 spp4 1.70638775 0.78362501 -1.45986027 0.50649776 -0.18946142 -0.53730659 -0.04545901
## coeficientes de regresión standarizados para la parte aleatoria
ranef(modelo.std)
## sale una larguísima lista que no muestro
229

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando lmer.Ejemplo con resultados:
## valores de Chi2 y sus p-values para los EFECTOS ALEATORIOSrand(modelo)
Analysis of Random effects Table:Chi.sq Chi.DF p.value
temperatura:individuo 2.0824 3 0.6distancia:individuo 0.0757 3 1.0
## tabla de ANOVA con significación de EFECTOS FIJOS## Con el comando Anova{car} se obtienen directamente los resultados de## significación usando la aproximación Kenward-Roger## ESTA ES LA OPCIÓN QUE DEBEREMOS UTILIZAR PARA EXAMINAR LA SIGNIFICACIÓN DE EFECTOS## CUANDO HEMOS APLICADO TABLAS DE CONTRASTES ESPECIFICADAS A PRIORI POR EL INVESTIGADOR## que serán incluidas dentro de lmer(...) con el argumento contrasts; ejemplo:## contrasts=list(distancia=contr.sum, spp=contr.sum)
Anova(modelo, type=3, test="F")Analysis of Deviance Table (Type III Wald F tests with Kenward-Roger df)Response: ln_uso10h
F Df Df.res Pr(>F) (Intercept) 0.7087 1 38.900 0.4050321 temperatura 13.0104 1 38.393 0.0008808 ***distancia 57.8797 1 38.393 3.519e-09 ***spp 3.6690 4 33.000 0.0140407 *
230

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando lmer.Ejemplo con resultados:
## tabla de ANOVA con significación de EFECTOS FIJOS## significaciones de los Fixed Effects usando la aproximación Kenward-Roger## proporciona la Sum Sq de los efectos fijos## los DenDf son los mismos que los obtenidos en df de summary## los valores de p y d.f. son idénticos a los obtenidos en summary## da lo mismo que: Anova(modelo, type=3, test="F")## el comando anova aplicado a objetos merMod (anova.merModLmerTest)## no equivalente a la usada en objetos lm o glm; equivalente a Anova{car}## podemos usar tipos de SS: I-1, II-2 y III-3 en el argumento type=## consultad:## http://web.warwick.ac.uk/statsdept/useR-2011/abstracts/290311-halekohulrich.pdf
anova(modelo, ddf="Kenward-Roger", type=3)
Analysis of Variance Table of type III with Kenward-Roger approximation for degrees of freedom
Sum Sq Mean Sq NumDF DenDF F.value Pr(>F) temperatura 41.294 41.294 1 38.393 13.010 0.0008808 ***distancia 183.705 183.705 1 38.393 57.880 3.519e-09 ***spp 46.580 11.645 4 33.000 3.669 0.0140409 * ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
231

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando lmer.Ejemplo con resultados:
## tabla de ANOVA con significación de EFECTOS FIJOS## significaciones de los Fixed Effects usando la aproximación Satterthwaite
anova(modelo, ddf="Satterthwaite", type=3)
Analysis of Variance Table of type III with Satterthwaite approximation for degrees of freedom
Sum Sq Mean Sq NumDF DenDF F.value Pr(>F) temperatura 41.294 41.294 1 39.465 13.010 0.0008602 ***distancia 183.705 183.705 1 120.883 57.880 6.729e-12 ***spp 52.226 13.056 4 61.643 4.114 0.0051009 ** ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
## contrastad esta tabla con la anterior y ved cómo los DenDF son más relajados
En el caso de modelos mixtos muy complejos, con muchas interacciones entre factores fijos, podríamos optarpor una aproximación de Tipo‐II en Anova y anova (type=2).* Primero se estiman los efectos simples principales (su estima de significación no es afectada por las interacciones.* Luego se estiman las interacciones dobles, controlando los efectos simples.* Luego las interacciones triples, controlando por las dobles y los efectos simples.* Etc ...
232

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando lmer.Ejemplo con resultados:## TABLA SINTÉTICA DE LOS RESULTADOS CON LA PARTICIÓN DE LA VARIANZA## utilizando la estima de grados de libertad de Kenward-Roger## incluimos las SS de los efectos fijos, sus magnitudes (eta2 y partialeta2)## los grados de libertad, las F y p.## consultad: https://en.wikipedia.org/wiki/Effect_size## http://jalt.org/test/PDF/Brown28.pdf
SStotal <- sum((modelo@frame[,1]-mean(modelo@frame[,1]))^2)SSerror <- SStotal*(1-as.numeric(r.squaredGLMM(modelo)[2]))tabla.SS <- as.data.frame(anova(modelo, ddf="Kenward-Roger", type=3))eta2 <- tabla.SS[,1]/Sstotaltabla.SS <- data.frame(eta2, tabla.SS)print(tabla.SS, digits=4)
> print(tabla.SS, digits=4)eta2 Sum.Sq Mean.Sq NumDF DenDF F.value Pr..F.
temperatura 0.02728 41.29 41.29 1 38.39 13.010 8.808e-04distancia 0.12137 183.71 183.71 1 38.39 57.880 3.519e-09spp 0.03077 46.58 11.65 4 33.00 3.669 1.404e-02
233

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando lmer.Ejemplo con resultados:
## Simulaciones de un modelo mixto## Using simulation to represent uncertainty in regression coefficients.## Instead of using the standard errors and intervals obtained from the model, we compute## uncertainties by simulation. We can use these to calculate confidence intervals for## coefficients that do not have standard errors in the model output.## The sim function gets posterior simulations of sigma and beta from a merMod object.## Consultad (pag. 236):## https://pdfs.semanticscholar.org/475d/df234f49d15fa13443a3c606c07d8747624b.pdf## It uses the values for the initial parameters, the given data, the model and the## prior distribution to determine whether the initial values for the parameters are## good values or not. The MCMC algorithm (Markov Chain Monte Carlo) will (ideally)## converge towards the joint posterior distribution of the parameters given the priors,## the initial parameter values, the model and the data. Thereby fitting the model, and## sampling from the posterior distribution at the same time.
sim.modelo <- sim(modelo, n.sims=1000)
## coeficientes de los efectos fijos; es lo mismo que da:## summary(modelo) en Fixed effects## la sd de describe(fixef(sim.modelo)) se corresponde con el error estándard## de la estima de los coeficientes al efectuar simulaciones por remuestreo
tabla.mixedmodel.simulada <- describe(fixef(sim.modelo))[,c(1:4,11:12)]colnames(tabla.mixedmodel.simulada)[4] <- "Std. Error"print(tabla.mixedmodel.simulada, digits=5)
234

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando lmer.Ejemplo con resultados:
## Simulaciones de un modelo mixto## Se proporcionan los valores para los coeficientes del modelo## Resultados que compararemos con los que salen en summary(modelo)## cuanta mayor diferencia haya entre estos resultados y los de summary(modelo)## más influencia hay de puntos influyentes y perdidos en nuestros resultados## los valores mean se refieren a la media de los coeficientes de regresión
> print(tabla.mixedmodel.simulada, digits=5)vars n mean Std. Error skew kurtosis
(Intercept) 1 1000 -0.50296 0.57163 -0.02879 -0.13386temperatura 2 1000 0.33978 0.09347 0.00800 -0.18364distancia1 3 1000 0.72888 0.09642 0.01252 -0.03175spp1 4 1000 0.47962 0.21190 0.06920 -0.19827spp2 5 1000 -0.18930 0.22887 0.00278 -0.14366spp3 6 1000 -0.54842 0.16844 0.04132 -0.15019spp4 7 1000 -0.01609 0.20251 0.01737 -0.13875
Podríamos recalcular la t de Student dividiendo los valores medios (mean) por el se (Std. Error).Considerando los grados de libertad (df) que se obtienen de las tablas summary(modelo) con las aproximaciones de Satterthwaite o Kenward‐Roger podríamos calcular las p para cada coeficiente.
Para distancia1: 0.7289/0.0964 = 7.5612 para df = 38.39> 2*pt(7.5612, df=38.39, lower.tail=FALSE) ## p para Student-t con dos colas[1] 4.336482e-09
235

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando lmer.Ejemplo con resultados:
## Simulaciones de un modelo mixto## También podemos efectuar parametrizaciones de nuestro modelo mixto utilizando## procedimientos de remuestreo (bootstrapping), que también serán de utilidad ## para obtener, de otro modo, estimas de significación. Se obtienen los coeficientes.## Es conveniente aplicarlo cuando nuestro modelo no proporciona significaciones y## cuando ha habido desvíos de los supuestos canónicos de los residuos del modelo.
## para Model-based (Semi-)Parametric Bootstrap for Mixed Models## type= puede ser "parametric" ó "semiparametric“; nsim: número de simulaciones## confidence intervals with finite-size corrections (important when the number of groups is <50)
## podemos efectuar diferentes simulaciones cambiando el valor seed
mcmc.fixed <- bootMer(modelo, FUN=fixef, nsim=1000, type="parametric", seed=1)coef.mcmc.fixed <- as.data.frame(mcmc.fixed$t)tabla <- describe(coef.mcmc.fixed)[,c(1:4,11:12)]colnames(tabla)[4] <- "Std.Error"tabla$t_Student <- tabla$mean / tabla$Std.Errorddf.fijos <- Anova(modelo, type=3, test="F")$Df.restabla$p_boot <- round(2*pt(-abs(tabla$t_Student), df=ddf.fijos), 5)tabla$coeficiente.modelo <- round(fixef(modelo), 5)
## comparar los coeficientes con los originales del modelo (a la deracha de la tabla)## para hacer uso de las p's derivadas de las t_Student (t_Student=mean/Std.Error; p_boot) ## los valores de kurtosis y sesgo deberían ser cercanos a ceroprint(tabla, digits=5) 236

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando lmer.Ejemplo con resultados:
## Simulaciones de un modelo mixto
> print(tabla, digits=5)vars n mean Std.Error skew kurtosis t_Student p_boot coeficiente.modelo
(Intercept) 1 1000 -0.50887 0.55331 -0.00334 0.24341 -0.91969 0.35796 -0.47998temperatura 2 1000 0.34080 0.09129 -0.01936 0.24488 3.73315 0.00020 0.33614distancia1 3 1000 0.73094 0.09862 -0.03419 -0.25838 7.41186 0.00000 0.72993spp1 4 1000 0.47625 0.21168 -0.16705 0.16584 2.24987 0.02467 0.48722spp2 5 1000 -0.19187 0.22739 -0.05612 0.15190 -0.84382 0.39897 -0.18926spp3 6 1000 -0.55345 0.16665 0.05936 0.13751 -3.32090 0.00093 -0.54974spp4 7 1000 -0.00694 0.21585 -0.11718 0.00637 -0.03216 0.97435 -0.01695
## Cuanto más cambien los coeficientes entre los resultados originales y los## obtenidos mediante bootstrapping, más importancia tienen en nuestros## datos los puntos influyentes y/o perdidos, y otros desvíos de los## supuestos canónicos de los modelos (e.g., heterocedasticidad)## Los sesgos y las kurtosis de los coeficientes simulados deberían estar## próximos a “cero”. De ese modo podríamos efectuar estimas paramétricas## de significación, usando t_Student = mean/Std.Error y p_boot.
237

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando lmer.Ejemplo con resultados:
## Simulaciones de un modelo mixto## Si los valores de sesgo y kurtosis de la tabla tabla se desvían considerablemente ## de cero, entonces es mejor usar el método de los percentiles para estimar## la significación de los coeficientes.
## Seleccionemos una variable para ver sus intervalos de confianza con diferentes percentiles## vemos los órdenes de los predictores y su número lo introducimos aquí abajo (van: [1], [2], [3], ...)names(coef.mcmc.fixed)que.variable <- 3
## si el rango de valores 2.5% - 97.5% incluye el valor cero ## (ó 2.5% es negativo y 97.5% es positivo) ## entonces no es significativo a p=0.05
print(c(colnames(coef.mcmc.fixed[que.variable]), round(quantile(coef.mcmc.fixed[,que.variable],c(0.0005, 0.005, 0.025, 0.05, 0.1, 0.9, 0.95, 0.975, 0.995, 0.9995)),5)), quote=FALSE)
0.05% 0.5% 2.5% 5% 10% 90% 95% 97.5% 99.5% 99.95%distancia1 0.40006 0.47478 0.53907 0.56575 0.59799 0.85561 0.89323 0.92179 0.95711 0.98701
## Aquí arriba se ven los límites a p=0.05 y p=0.01
238

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando lmer.Ejemplo con resultados:
## Simulaciones de un modelo mixto## Otro modo es utilizando el comando confint.merMod## podemos cambiar level=0.99 para p=0.01## Que los intervalos no incluyan el valor “cero”
confint.fixed <- confint.merMod(modelo, parm="beta_", level=0.95, method="boot", boot.type="perc", nsim=1000)
print(confint.fixed, digits=3)
2.5 % 97.5 %(Intercept) -1.6053 0.786temperatura 0.1323 0.521distancia1 0.5496 0.914spp1 0.0504 0.921spp2 -0.6509 0.257spp3 -0.9095 -0.220spp4 -0.4533 0.396
239

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando lmer.Ejemplo con resultados:
## Simulaciones de un modelo mixto## También podemos utilizar los resultados de las simulaciones para estimar## las correlaciones existentes entre los coeficientes de regresión del modelo## Deberían ser similares a las obtenidas en el resumen del modelo,## al final de la salida summary(modelo): Correlation of Fixed Effects.print(cor(coef.mcmc.fixed), digits=3)
(Intercept) temperatura distancia1 spp1 spp2 spp3 spp4(Intercept) 1.0000 -0.9822 -0.1700 -0.0013 0.013 -0.0640 0.0155temperatura -0.9822 1.0000 0.1372 0.0142 0.021 0.0221 0.0031distancia1 -0.1700 0.1372 1.0000 0.0432 -0.038 -0.0087 -0.0608spp1 -0.0013 0.0142 0.0432 1.0000 -0.322 -0.1811 -0.2949spp2 0.0134 0.0209 -0.0378 -0.3217 1.000 -0.2573 -0.3483spp3 -0.0640 0.0221 -0.0087 -0.1811 -0.257 1.0000 -0.1990spp4 0.0155 0.0031 -0.0608 -0.2949 -0.348 -0.1990 1.0000
summary(modelo)...Correlation of Fixed Effects:
(Intr) tmprtr dstnc1 spp1 spp2 spp3 temperatura -0.984 distancia1 -0.163 0.136 spp1 0.012 0.000 0.000 spp2 0.029 0.000 0.000 -0.320 spp3 -0.038 0.000 0.000 -0.217 -0.262 spp4 0.012 0.000 0.000 -0.292 -0.320 -0.217 240

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando lmer.Ejemplo con resultados:
## Visualización de efectos de los factores## para inspeccionar los efectos de las predictoras nominales## si hay predictoras continuas se presentan los valores medios+se## controlando por esas covariantesplot(interactionMeans(modelo, legend.margin=0.2))
241

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando lmer.Ejemplo con resultados:
## Visualización de efectos de los factores## si en vez del modelo sin interacciones, las hubiésemos incluido:modelo.int <- lmer(ln_uso10h ~temperatura+distancia+spp+distancia:spp+
(temperatura|individuo)+(distancia|individuo), data=datos, REML=TRUE)## entonces se cuantificarían las diferencias cruzadas entre factoresplot(interactionMeans(modelo.int, legend.margin=0.2))
242
> Anova(modelo.int, type=3, test="F")Analysis of Deviance Table (Type III Wald F tests with Kenward-Roger df)
Response: ln_uso10hF Df Df.res Pr(>F)
(Intercept) 0.7590 1 38.894 0.3889845 temperatura 12.8789 1 38.223 0.0009317 ***distancia 72.4212 1 34.112 5.958e-10 ***spp 4.3605 4 33.000 0.0061074 ** distancia:spp 4.6132 4 33.000 0.0045415 **
> AICc(modelo, modelo.int)df AICc
modelo 14 1570.584modelo.int 18 1567.897
> exp(-0.5*(AICc(modelo.int)-AICc(modelo)))[1] 3.831971

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando lmer.Ejemplo con resultados:
## Problemas en las estimas
## trabajando con nuestro modelo de interés “random intercept and slopes”## en repetidas ocasiones nos han aparecido mensajes de alerta como:## lecturas recomendada acerca de las causas:## http://www.theanalysisfactor.com/wacky-hessian-matrix/ ## http://www2.gsu.edu/~mkteer/npdmatri.html
Warning messages:1: In checkConv(attr(opt, "derivs"), opt$par, ctrl = control$checkConv, :
unable to evaluate scaled gradient2: In checkConv(attr(opt, "derivs"), opt$par, ctrl = control$checkConv, :
Model failed to converge: degenerate Hessian with 1 negative eigenvalues
## En estas circunstancias es conveniente no hacer uso de las estimas## exactas de significación que salen de Anova(...) ó anova(...)## Debemos valorar la conveniencia de re-escalar las variables predictoras## para que muestren unos rangos de variación similares (zeta-standarización)## Podemos simplificar el modelo (por ejemplo, eliminando “random slopes”)## y/o utilizar las aproximaciones de bootstrapping (semi-)pamétrico,## comprobando también que los valores de Correlation of Fixed Effects## sean lo más cercanos a “cero”
## podemos repetir todo lo anterior haciendo que nuestro modelo de interés sea m1modelo <- m1 243

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando glmer.Ejemplo con resultados:
Modelos mixtos generalizados: contamos con el comando glmer## cargamos tablas de contrastes compartidas con las de otros programas estadísticos (como SPSS, STATISTICA)
options(contrasts=c(factor="contr.sum", ordered="contr.poly"))
## construimos nuestros modelos de interés## asumimos una distribución poisson para la respuesta## efectúa la estima usando Maximum Likelihood (ML, aproximación de Laplace)## por tanto, no nos preocuparemos por lo expuesto en las páginas 220-221.
## si plantean problemas podemos cambiar el valor nAGQ a un valor más alto## nAGQ sólo puede tomar el valor 1 en modelos con más de un efecto aleatorio## si hay problemas en la estimas, podemos incluir un control de errores## dentro de glmer(..., control=mi.control)mi.control <- glmerControl(check.conv.grad=.makeCC(action ="ignore", tol=1e-6, relTol=NULL),
optimizer="bobyqa", optCtrl=list(maxfun=100000))
## modelo es "random intercept and slope"## modelo2 es "random intercept, constant slope"## m0 es el modelo nulo ("unconditional means model")
modelo <- glmer(entradas10h ~ temperatura+distancia+spp +(temperatura|individuo)+(distancia|individuo)+(1|spp:individuo), family=poisson, data=datos, nAGQ=1)
modelo2 <- glmer(entradas10h ~ temperatura+distancia+spp +(1|individuo), family=poisson, data=datos, nAGQ=25)
m0 <- glmer(entradas10h ~ 1 +(1|individuo), family=poisson, data=datos, nAGQ=25) 244

245
DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando glmer.Ejemplo con resultados:
Modelos mixtos generalizados
## exploramos los residuos del modelo, con los residuos de devianza## aquí, como ejemplo, con modelo
residuos <- residuals(modelo, type="deviance")hist(residuos, density=5, freq=FALSE, main="residuos de devianza", ylim=c(0,0.70))curve(dnorm(x, mean=mean(residuos), sd=sd(residuos)), col="red", lwd=2, add=TRUE, yaxt="n")
qqnorm(residuos, main="residuos de devianza")qqline(residuos, col="red", lwd=2)qqmath(modelo, id=0.01, main="1% de residuos extremos")
## Exploración visual de la heterocedasticidad de los residuosplot(log(fitted(modelo)), residuos, ylab="residuos de devianza", main="¿HAY HETEROCEDASTICIDAD?")abline(h=0, col="red", lwd=2)
## otra posibilidad sintética es:mcp.fnc(modelo)
## valores observados y predichos en la escala original de medidapredicho <- fitted(modelo)plot(modelo@frame[,1]~ predicho, ylab="RESPUESTA", xlab="PREDICCIONES")abline(lm(modelo@frame[,1]~ predicho), col="green", lwd=2)

246
DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando glmer.Ejemplo con resultados:
Modelos mixtos generalizadosResiduos del modelo, con los residuos de devianza

247
DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando glmer.Ejemplo con resultados:
Modelos mixtos generalizadosResiduos del modelo, con los residuos de devianza
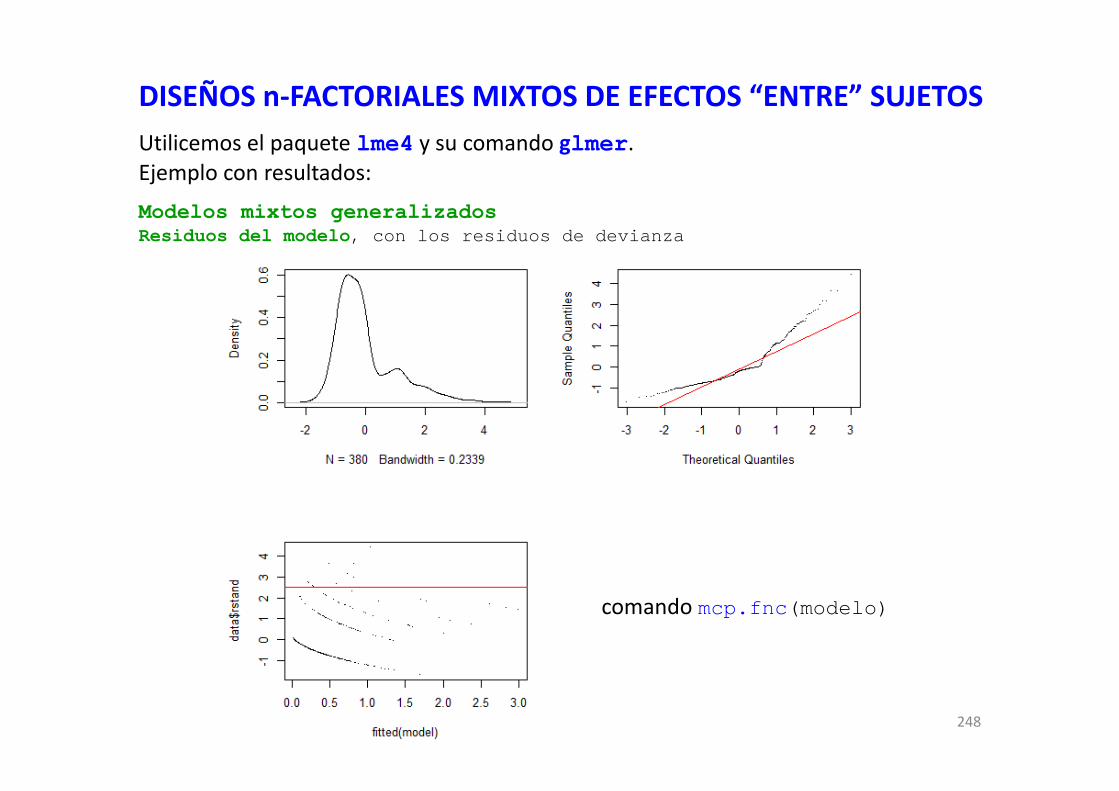
248
DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando glmer.Ejemplo con resultados:
Modelos mixtos generalizadosResiduos del modelo, con los residuos de devianza
comando mcp.fnc(modelo)

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando glmer.Ejemplo con resultados:
Modelos mixtos generalizados## Omnibus test de la “significación” global del modelo## Aproximación basada en “información” usando AICc## Para ello comparamos los valores de AICc del modelo de interés y el nulo.## Por modelo “nulo” entendemos aquel que sólo incluye el factor aleatorio.## También podemos incluir en la comparación el de “random intercepts”.## A menor valor AICc del modelo, el modelo es más informativo y parsimonioso
AICc(modelo, modelo2, m0)df AICc
modelo 14 728.9201modelo2 8 736.8608m0 2 813.1498
## ¿cuántas veces es mejor un modelo que otro?## las comparaciones relevantes podrían ser (colocando primero el modelo con menor AICc):exp(-0.5*(AICc(modelo)-AICc(m0)))[1] 1.950987e+18 es mucho mejor el de interés que el nulo
exp(-0.5*(AICc(modelo)-AICc(modelo2)))[1] 53.00481 es algo mejor el de “random intercepts and slopes” que el de “random intercepts”
el modelo modelo2 es también mucho mejor que el “nulo” m0 (3.680774e+16 veces mejor)
249

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando glmer.Ejemplo con resultados:
Modelos mixtos generalizados## Omnibus test de la “significación” global del modelo## Utilizamos la aproximación de los “likelihood ratio tests” (lrtest)## Se comparan modelos anidados, como son modelo, modelo2 y m0## ponemos antes el modelo más sencillo (i.e., menos grados de libertad, Df)
lrtest(m0, modelo) ## este es el omnibus testLikelihood ratio testModel 1: entradas10h ~ 1 + (1 | individuo)Model 2: entradas10h ~ temperatura + distancia + spp + (temperatura | individuo) + (distancia | individuo) + (1 | spp:individuo)#Df LogLik Df Chisq Pr(>Chisq)
1 2 -404.56 2 14 -349.88 12 109.35 < 2.2e-16 *** es mucho mejor el de interés que el nulo
lrtest(modelo2, modelo)Likelihood ratio testModel 1: entradas10h ~ temperatura + distancia + spp + (1 | individuo)Model 2: entradas10h ~ temperatura + distancia + spp + (temperatura | individuo) + (distancia | individuo) + (1 | spp:individuo)#Df LogLik Df Chisq Pr(>Chisq)
1 8 -360.24 2 14 -349.88 6 20.703 0.002074 ** es mejor el de “random intercepts and slopes” que el de “random intercepts”
el modelo modelo2 es también mucho mejor que el “nulo” m0 (p << 0.001)
250

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando glmer.Ejemplo con resultados:
Modelos mixtos generalizados## Devianza explicada
## en los modelos generalizados mixtos no siempre es posible utilizarr.squaredGLMM(modelo)## especialmente en el caso de los modelos que operan con distribuciones Poisson
## tendremos que recurrir a una estima de devianza explicada (pseudoR2) utilizando## los valores de log_Likelihhod del modelo de interés (modelo) y del nulo (m0)## esta devianza explicada SÓLO hace referencia a la parte fija del modelo, respecto## a lo no explicado por la parte aleatoria
logLik(modelo)> logLik(modelo)'log Lik.' -349.8847 (df=14)logLik(m0)> logLik(m0)'log Lik.' -404.559 (df=2)
## aquí calculamos la diferencia y cociente de devianzaspseudoR2 <- as.vector((logLik(m0)- logLik(modelo))/ logLik(m0))
print(c("Devianza explicada (%) =", round(pseudoR2*100, 2)), quote=FALSE)[1] Devianza explicada (%) = 13.51
251

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando glmer.Ejemplo con resultados:
Modelos mixtos generalizados## Resultados del modelo## resumen del modelo, que proporciona los coefcientes de regresiónsummary(modelo)
Generalized linear mixed model fit by maximum likelihood (Laplace Approximation) ['glmerMod']Family: poisson ( log )Formula: entradas10h ~ temperatura + distancia + spp + (temperatura | individuo) + (distancia | individuo) + (1 | spp:individuo). . . más información aquí que no presento . . .
Fixed effects:Estimate Std. Error z value Pr(>|z|)
(Intercept) -2.69656 0.61788 -4.364 1.28e-05 ***temperatura 0.22343 0.09443 2.366 0.01798 * distancia1 0.92211 0.20355 4.530 5.90e-06 ***spp1 0.31672 0.15813 2.003 0.04518 * spp2 0.11969 0.19094 0.627 0.53075 spp3 -0.42741 0.16488 -2.592 0.00953 ** spp4 0.11458 0.17921 0.639 0.52261 ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Correlation of Fixed Effects:(Intr) tmprtr dstnc1 spp1 spp2 spp3
temperatura -0.951 distancia1 -0.325 0.061 spp1 -0.057 0.044 0.051 spp2 -0.060 0.050 0.141 -0.201 spp3 -0.030 0.006 0.111 -0.168 -0.149 spp4 -0.053 0.028 0.156 -0.179 -0.131 -0.119 252
glmer no muestralos grados de libertad para los
términos error de los factores fijos
los coeficientes de correlaciónentre los coeficientes del modelo
deberían dar valores 0

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando glmer.Ejemplo con resultados:
Modelos mixtos generalizados## obtención de coeficientes estandarizados## proporciona los coeficientes beta (β) de regresión que son comparables entre efectos## estandariza los coeficientes de regresión a media cero y sd=1/2,## en vez de la estandarización clásica de "a media cero y sd=1"
modelo.std <- standardize(modelo)
## coeficientes de regresión standarizados para la parte fija## comparando sus valores (absolutos) podemos alcanzar una idea de qué efectos son## más importantes en nuestro modelo
fixef(modelo.std)
(Intercept) z.temperatura c.distancia spp1 spp2 spp3 spp4 -1.1520292 0.5378475 -1.8338954 0.3193191 0.1241970 -0.4253936 0.1122536
253

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando glmer.Ejemplo con resultados:
Modelos mixtos generalizados## Resultados del modelo## exploramos la significación de los efectos fijos## en esta ocasión no se proporcionan los grados de libertad para el término error## ambas líneas de código dan resultados similares (más conveniente la segunda)
Anova(modelo, type=3, test="Chisq")Analysis of Deviance Table (Type III Wald chisquare tests)Response: entradas10h
Chisq Df Pr(>Chisq) (Intercept) 19.0463 1 1.276e-05 ***temperatura 5.5977 1 0.01798 * distancia 20.5213 1 5.897e-06 ***spp 10.3162 4 0.03543 * ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
drop1(modelo, ~., test="Chisq")Single term deletionsModel:entradas10h ~ temperatura + distancia + spp + (temperatura |
individuo) + (distancia | individuo) + (1 | spp:individuo)Df AIC LRT Pr(Chi)
<none> 727.77 temperatura 1 730.57 4.799 0.02848 * distancia 1 758.79 33.025 9.099e-09 ***spp 4 729.19 9.422 0.05138 . ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
254
drop1 compara modelosel saturado (sin quitar efectos <none>)
con modelos que cada vez quitanel efecto que se quiere examinar
Anova efectúa una estimasimultánea (i.e., parcial)
utilizando el estadístico de Wald(se considera el test de Wald impreciso)
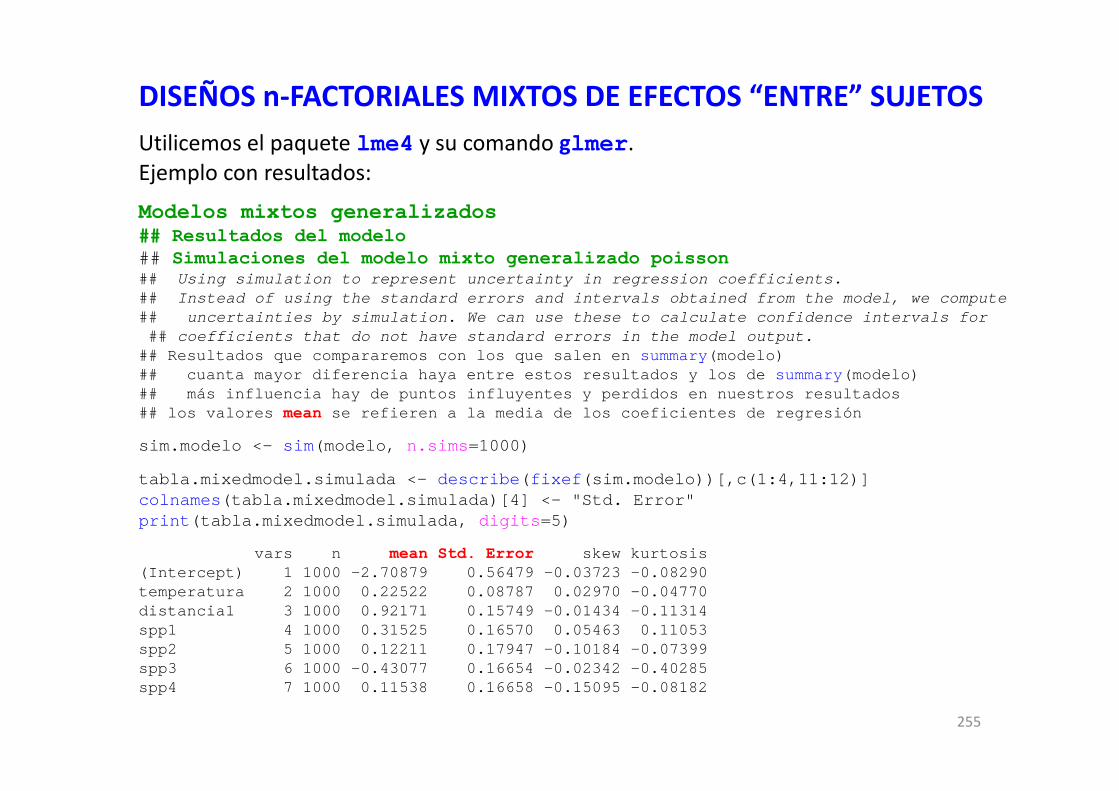
DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando glmer.Ejemplo con resultados:
Modelos mixtos generalizados## Resultados del modelo## Simulaciones del modelo mixto generalizado poisson## Using simulation to represent uncertainty in regression coefficients.## Instead of using the standard errors and intervals obtained from the model, we compute ## uncertainties by simulation. We can use these to calculate confidence intervals for## coefficients that do not have standard errors in the model output.
## Resultados que compararemos con los que salen en summary(modelo)## cuanta mayor diferencia haya entre estos resultados y los de summary(modelo)## más influencia hay de puntos influyentes y perdidos en nuestros resultados## los valores mean se refieren a la media de los coeficientes de regresión
sim.modelo <- sim(modelo, n.sims=1000)
tabla.mixedmodel.simulada <- describe(fixef(sim.modelo))[,c(1:4,11:12)]colnames(tabla.mixedmodel.simulada)[4] <- "Std. Error"print(tabla.mixedmodel.simulada, digits=5)
vars n mean Std. Error skew kurtosis(Intercept) 1 1000 -2.70879 0.56479 -0.03723 -0.08290temperatura 2 1000 0.22522 0.08787 0.02970 -0.04770distancia1 3 1000 0.92171 0.15749 -0.01434 -0.11314spp1 4 1000 0.31525 0.16570 0.05463 0.11053spp2 5 1000 0.12211 0.17947 -0.10184 -0.07399spp3 6 1000 -0.43077 0.16654 -0.02342 -0.40285spp4 7 1000 0.11538 0.16658 -0.15095 -0.08182
255

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando glmer.Ejemplo con resultados:
Modelos mixtos generalizados## Simulaciones de un modelo mixto## También podemos efectuar parametrizaciones de nuestro modelo mixto utilizando## procedimientos de remuestreo (bootstrapping), que también serán de utilidad ## para obtener, de otro modo, estimas de significación. Se obtienen los coeficientes.## Es conveniente aplicarlo cuando nuestro modelo no proporciona significaciones y## cuando ha habido desvíos de los supuestos canónicos de los residuos del modelo.
## Para Model-based (Semi-)Parametric Bootstrap for Mixed Models## type= puede ser "parametric" ó "semiparametric“; nsim: número de simulaciones## confidence intervals with finite-size corrections (important when the number of groups is <50)
## podemos efectuar diferentes simulaciones cambiando el valor seed
## Este método es ¡¡muy lento!!
mcmc.fixed <- bootMer(modelo, FUN=fixef, nsim=100, type="parametric", seed=1)coef.mcmc.fixed <- as.data.frame(mcmc.fixed$t)tabla <- describe(coef.mcmc.fixed)[,c(1:4,11:12)]colnames(tabla)[4] <- "Std.Error"tabla$Zeta <- tabla$mean / tabla$Std.Errortabla$p_boot <- round(2*pnorm(abs(tabla$Zeta), lower.tail=FALSE), 5)tabla$coeficiente.modelo <- round(fixef(modelo), 5)
## comparar los coeficientes con los originales del modelo (a la deracha de la tabla)
print(tabla, digits=5)
256
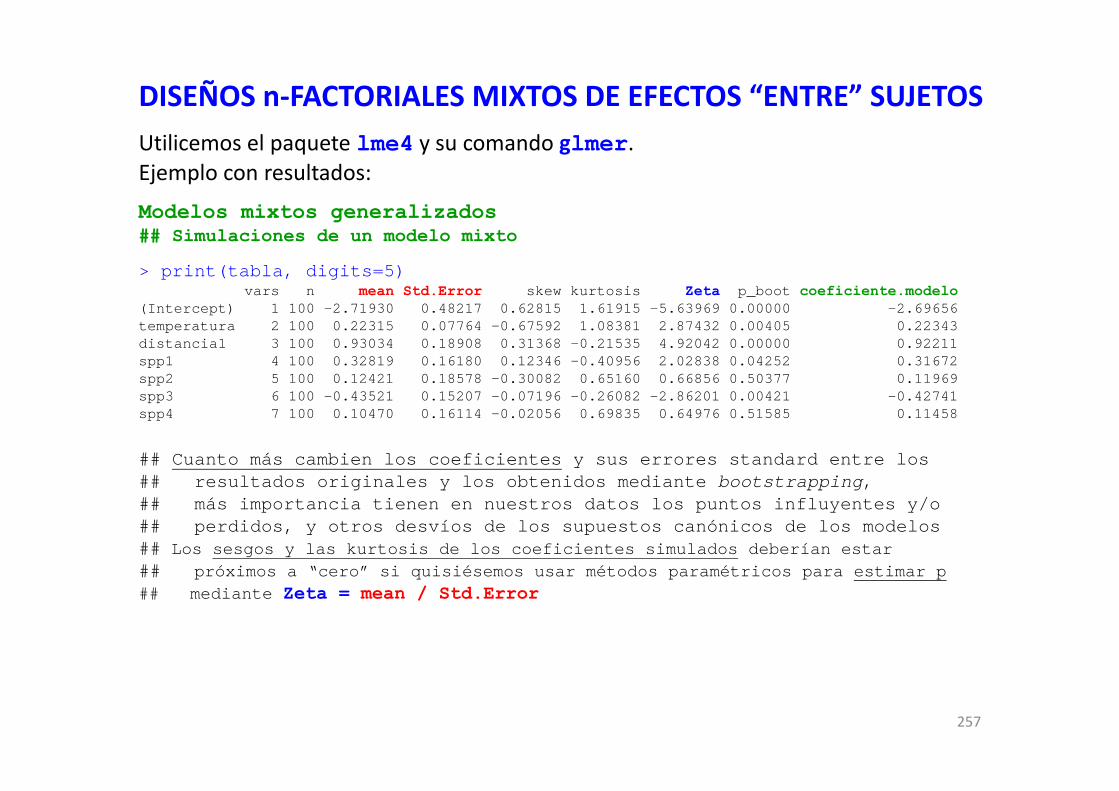
DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando glmer.Ejemplo con resultados:
Modelos mixtos generalizados## Simulaciones de un modelo mixto
> print(tabla, digits=5)vars n mean Std.Error skew kurtosis Zeta p_boot coeficiente.modelo
(Intercept) 1 100 -2.71930 0.48217 0.62815 1.61915 -5.63969 0.00000 -2.69656temperatura 2 100 0.22315 0.07764 -0.67592 1.08381 2.87432 0.00405 0.22343distancia1 3 100 0.93034 0.18908 0.31368 -0.21535 4.92042 0.00000 0.92211spp1 4 100 0.32819 0.16180 0.12346 -0.40956 2.02838 0.04252 0.31672spp2 5 100 0.12421 0.18578 -0.30082 0.65160 0.66856 0.50377 0.11969spp3 6 100 -0.43521 0.15207 -0.07196 -0.26082 -2.86201 0.00421 -0.42741spp4 7 100 0.10470 0.16114 -0.02056 0.69835 0.64976 0.51585 0.11458
## Cuanto más cambien los coeficientes y sus errores standard entre los## resultados originales y los obtenidos mediante bootstrapping,## más importancia tienen en nuestros datos los puntos influyentes y/o## perdidos, y otros desvíos de los supuestos canónicos de los modelos ## Los sesgos y las kurtosis de los coeficientes simulados deberían estar## próximos a “cero” si quisiésemos usar métodos paramétricos para estimar p## mediante Zeta = mean / Std.Error
257

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando glmer.Ejemplo con resultados:
Modelos mixtos generalizados## Simulaciones de un modelo mixto## Si los valores de sesgo y kurtosis de la tabla tabla se desvían considerablemente## de cero, entonces es mejor usar el método de los percentiles para estimar ## la significación de los coeficientes.
## seleccionemos una variable para ver sus intervalos de confianza con diferentes percentiles## vemos los órdenes de los predictores y su número lo introducimos aquí abajo (van: [1], [2], [3], ...)names(coef.mcmc.fixed)que.variable <- 3
## si el rango de valores 2.5% - 97.5% incluye el valor cero ## (ó 2.5% es negativo y 97.5% es positivo) ## entonces no es significativo a p=0.05
print(c(colnames(coef.mcmc.fixed[que.variable]), round(quantile(coef.mcmc.fixed[,que.variable],c(0.025, 0.05, 0.1, 0.9, 0.95, 0.975)),5)), quote=FALSE)
2.5% 5% 10% 90% 95% 97.5% distancia1 0.60605 0.65982 0.68573 1.18664 1.2435 1.30063
## Aquí arriba se ven los límites a p=0.05 y p=0.1
258

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando glmer.Ejemplo con resultados:
Modelos mixtos generalizados## Simulaciones de un modelo mixto## Otro modo es utilizando el comando confint.merMod## podemos cambiar level=0.99 para p=0.01## Este método es ¡¡muy lento!!## Que los intervalos no incluyan el valor “cero”
confint.fixed <- confint.merMod(modelo, parm="beta_", level=0.95, method="boot", boot.type="perc", nsim=100)
print(confint.fixed, digits=3)
2.5 % 97.5 %(Intercept) -3.8218 -2.0319temperatura 0.1066 0.3709distancia1 0.6497 1.3008spp1 0.0159 0.6938spp2 -0.3317 0.4692spp3 -0.8094 -0.0953spp4 -0.3561 0.4400
259

DISEÑOS n‐FACTORIALES MIXTOS DE EFECTOS “ENTRE” SUJETOSUtilicemos el paquete lme4 y su comando glmer.Ejemplo con resultados:
Modelos mixtos generalizados## Simulaciones de un modelo mixto## También podemos utilizar los resultados de las simulaciones para estimar## las correlaciones existentes entre los coeficientes de regresión del modelo## Deberían ser similares a las obtenidas en el resumen del modelo,## al final de la salida summary(modelo): Correlation of Fixed Effects.print(cor(coef.mcmc.fixed), digits=3)
(Intercept) temperatura distancia1 spp1 spp2 spp3 spp4(Intercept) 1.0000 -0.92320 -0.3160 0.0146 0.06642 -0.0327 -0.0186temperatura -0.9232 1.00000 -0.0167 -0.0770 -0.00607 0.0367 0.0530distancia1 -0.3160 -0.01673 1.0000 0.1988 -0.11792 -0.0860 0.0159spp1 0.0146 -0.07700 0.1988 1.0000 -0.37081 -0.2984 -0.1219spp2 0.0664 -0.00607 -0.1179 -0.3708 1.00000 -0.2577 -0.3622spp3 -0.0327 0.03672 -0.0860 -0.2984 -0.25767 1.0000 -0.2058spp4 -0.0186 0.05298 0.0159 -0.1219 -0.36215 -0.2058 1.0000
summary(modelo)...Correlation of Fixed Effects:
(Intr) tmprtr dstnc1 spp1 spp2 spp3 temperatura -0.951 distancia1 -0.325 0.061 spp1 -0.057 0.044 0.051 spp2 -0.060 0.050 0.141 -0.201 spp3 -0.030 0.006 0.111 -0.168 -0.149 spp4 -0.053 0.028 0.156 -0.179 -0.131 -0.119 260

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOS
n way ANOVAScon factores bloque(diseños de BLOQUE)
261
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn way ANOVAS y MANOVASDiseños de bloquesEn estos diseños se define al menos un factor "bloque" en el que se establecen las
muestras. Este factor "bloque" no es un objeto de interés para el investigador.Respecto al diseño "completamente aleatorizado", en el "diseño de bloques" las
unidades muestrales se reunen en bloques que son los niveles de un factor bloque.
262

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn way ANOVAS y MANOVASDiseños de bloquesPara que estos diseños de bloques sean correctos, los niveles de otros factores de interés tienen que estar perfectamente representados, y de modo balanceado, en los niveles del factor "bloque" (consultad http://www.tfrec.wsu.edu/anova/RCB.html)
Los bloques se definen para aleatorizar los efectos que no controlamos y son aleatorios.
Ejemplos de un factor BLOQUE y otro de interés FACTOR (con 4 niveles A, B, C, D)con una sola réplica por celda
263
BLOQUES FACTOR (A, B, C, D)B1 A A A AB2 B B B BB3 C C C CB4 D D D DB5 B B B BB6 A A A AB7 D D D DB8 C C C C
BLOQUES FACTOR (A, B, C, D)B1 A B C DB2 A B C DB3 A B C DB4 A B C DB5 A B C DB6 A B C DB7 A B C DB8 A B C D
BLOQUES FACTOR (A, B, C, D)B1 A B C DB2 B A D CB3 C D B AB4 D C A BB5 B A D CB6 D C A BB7 A B C DB8 C D B A
INCORRECTOMEJOR
(no aleatorizado el orden) CORRECTO

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn way ANOVAS y MANOVASDiseños de bloquesEn estos diseños podemos distinguir dos grandes tipos de modelos, que van a determinar cómo se establecen los términos error (MS y g.l.) para estimar las significaciones.
• de una sola réplica por cada nivel del factor de interés, en cada nivel del factor bloque
• más de una réplica por cada nivel del factor de interés, en cada nivel del factor bloqueestos diseños se llaman "de bloques generalizados" .
264
BLOQUES FACTOR (A, B, C, D)B1 A A A B B B C C C D D DB2 B B B A A A D D D C C CB3 C C C D D D B B B A A AB4 D D D C C C A A A B B BB5 B B B A A A D D D C C CB6 D D D C C C A A A B B BB7 A A A B B B C C C D D DB8 C C C D D D B B B A A A
BLOQUES FACTOR (A, B, C, D)B1 A B C DB2 B A D CB3 C D B AB4 D C A BB5 B A D CB6 D C A BB7 A B C DB8 C D B A
GENERALIZADOde tres réplicas por BLOQUE*FACTOR
CLÁSICOuna réplica por BLOQUE

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn way ANOVAS y MANOVASDiseños de bloquesEn los diseños de bloques perfectamente aleatorizados de una sola réplicano se pude construir la interacción BLOQUE*FACTOR(es) de interésal no existir variabilidad dentro de cada celda BLOQUE*FACTOR (1 muestra solamente)
El modelo se construye con los efectos principales BLOQUE y FACTOR(es), sin interacciónEl MS y g.l. del término error es común a todos los efectosEl MS y g.l. del término error son los residuales del modelo
265
tipos de factores paralos que se aplica
FACTOR

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn way ANOVAS y MANOVASDiseños de bloquesEn el caso de dos FACTORES fijos de interés (A y C) y un factor BLOQUE (B, aleatorio),con una sola réplica por celda A*B*C, los términos error de las estimas son los siguientes:
266
se pueden hacer,pero no suelen
interesar
MSResidual

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn way ANOVAS y MANOVASDiseños de bloquesEn el caso de dos FACTORES fijos de interés (A y C) y un factor BLOQUE (B) con una sola réplica por celda A*B*C,
si se considera que la variación entre factores a través de bloques es negligible, entonces se puede simplificar (y robustecer el modelo con mayores g.l. para los factores)y se utiliza como término error común el término error residual del modelo:
267
MSerror = MSresidual

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn way ANOVAS y MANOVASDiseños de bloquesDiseño particular denominado de CUADRADOS LATINOS.
Se establecen dos factores BLOQUES que definen los ejes X e Y de un cuadrado,que establecen las celdas en las que se aplican los tratamientos del FACTOR de interés.
Se asume que el efecto de la interacción de los dos factores BLOQUE es nulo.
En cada celda de interacción BLOQUE‐X * BLOQUE‐Y se establece una única muestra.
Otros diseños implican dos BLOQUES no espaciales (e.g., operador y cultivar).
Se deben cumplir los criterios de perfecta aleatorización de los niveles del FACTOR.
En este diseño hay un MS y g.l. del término error común a todos los efectos.No estamos interesados en las interacciones ni entre BLOQUES ni en FACTOR*BLOQUEEl MS y g.l. del término error son los residuales del modelo
268

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn way ANOVAS y MANOVASDiseños de bloquesDe CUADRADOS LATINOS.Ejemplos
269
sin fragmentar muy fragmentado

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn way ANOVAS y MANOVASDiseños de bloquesEn los diseños de bloques GENERALIZADOS perfectamente aleatorizados con dos réplicas o más por celda BLOQUE*FACTORsí se pude construir la interacción BLOQUE*FACTOR(es) de interés
al existir variabilidad dentro de cada celda BLOQUE*FACTOR (2 o más muestras)el BLOQUE se suele considerar un factor aleatorio
El modelo se construye con: efectos principales BLOQUE y FACTOR(es) y la(s) interacción(es)El MS y g.l. del término error NO es común a todos los efectosPara el FACTOR, los MS y g.l. error son los datos de la interacción BLOQUE*FACTOR
sean "r" réplicas por celda BLOQUE*FACTOR
Efecto g.l. efecto F g.l. error BLOQUE b‐1 MSBLOQUE / MSFACTOR*BLOQUE (b‐1)*(f‐1)FACTOR f‐1 MSFACTOR / MSFACTOR*BLOQUE (b‐1)*(f‐1)FACTOR*BLOQUE (b‐1)*(f‐1) MSFACTOR*BLOQUE / MSRESIDUAL f*b*(r‐1)
270

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOS
n wayMANOVAS
271

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn way ANOVAS y MANOVASAnálisis Multivariantes de la Varianza ‐MAN(c)OVA.
Situación particular en la que tenemos más de una variable respuesta "continua".
En determinadas circunstancias, las unidades muestrales manifiestan respuestas que no se miden con una sola variable, sino en un conjunto de variables. Esto es, la respuesta se mide por diferentes conceptos represenrados por diferentes parámetros.e.g., condición física valorada por la grasa, músculo, hematocrito, respuesta inmunee.g., morfología floral con diferentes dimensiones de longitud de pétalos, estambres, sépalos, etc
En este caso, si queremos valorar la influencia de diferentes efectos (recogidos por factores y covariantes), tendríamos que efectuar tantos diseños factoriales como variables respuesta hay.
Esto es inconveniente por dos motivos:* al hacer muchos modelos, y muchas estimas de significación, incrementamos el error de tipo I* esas variables respuesta pueden estar relacionadas entre sí, y en parte miden “lo mismo”
Ante esto, lo mejor es efectuar un único modelo (previo) que estime globalmente los efectos que las variables predictoras (sean factores o covariantes) tienen sobre el conjunto de las respuestas.
Esto lo abordamos con análisis Multivariantes de la varianza (MANOVA).Multivariante porque hay múltiples variables respuesta.
272

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn way ANOVAS y MANOVASAnálisis Multivariantes de la Varianza ‐MAN(c)OVA. En general, vamos a proceder como en los diseños factoriales de efectos fijos ya vistos.Pero tenemos unos Supuestos añadidos.
* Requiere normalidad multivariante. Difícil de evaluar (buen paquete de análisis en MVN)
* Es necesario que exista homogeneidad de varianzas/covarianzas a través de los niveles de losfactores considerados (y sus interacciones si hay varios factores). Para ello contamos con elTest de la M de Box. Consultad:http://www‐01.ibm.com/support/knowledgecenter/SSLVMB_20.0.0/com.ibm.spss.statistics.cs/glmm_patlos_homcov.htmEste supuesto asume que el patrón de asociación entre las variables respuestas no cambia a través de los niveles de los factores (predictores nominales).Si violamos este supuesto … posible solución: transformar las variables respuesta
* Homogeneidad de las varianzas de las variables respuesta, teniendo en cuenta las celdasdefinidas por la interacción entre todos los factores nominales considerados.Mediante el Test de Levene examinamos este supuesto.Si no lo cumplimos … posible solución: transformar la variable respuesta que viola el supuestoEl caso más problemático es aquel en el que la varianza se asocia con la media de cada una de
las celdas de la interacción entre los factores.+ si la relación es positiva, aumenta el error de tipo I+ si la relación es negativa, aumenta el error de tipo II
273

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn way ANOVAS y MANOVASAnálisis Multivariantes de la Varianza ‐MAN(c)OVA
Comenzamos cargando los siguientes paquetes de R:library(car) ## para obtener VIF's y usar Anova, bootCaselibrary(heplots) ## para la estima de los valores de partial eta2library(psych) ## para construir tablas con describelibrary(biotools) ## para efectuar el test de la M de Boxlibrary(MVN) ## para el test de la normalidad multivariante
ESPECIFICAMOS EL MODELO## Cargamos la siguiente línea de código para obtener contrastes definidos## Se obtienen los mismos resultados que STATISTICA y SPSS utilizando type III SS
options(contrasts=c(factor="contr.sum", ordered="contr.poly"))
## establecemos la ecuación de nuestro modelo## definimos las variables respuesta a la izquierda de ~ mediante el comando cbind(...)
eqt <- as.formula(cbind(PESO,MUSCULO,TASAINV) ~ TARSO + ZONA*SEXO*EDAD)
## ahora creamos nuestro modelo MANOVA en dos pasos: primero un modelo lm y luego MANOVA## test.statistic puede ser "Pillai", "Wilks", "Hotelling-Lawley", "Roy“ ## o varios de ellos: test.statistic=c("Pillai", "Wilks", "Hotelling-Lawley", "Roy")## con type=3 especificamos si queremos una estima de efectos parciales (SS tipo III)
man_mod <- lm(eqt, data=datos)modelo <- Manova(man_mod, type=3, test.statistic="Pillai") 274

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn way ANOVAS y MANOVASAnálisis Multivariantes de la Varianza ‐MAN(c)OVA
Pruebas importantes## Normalidad Multivariante de las variables respuesta originales## mirad: https://cran.r-project.org/web/packages/MVN/vignettes/MVN.pdf## antes convertimos nuestras variables respuesta en una matriz con as.matrix
## plots: con histogramas y Q-Q plots
uniPlot(as.matrix(man_mod$model[1]), type="histogram")uniPlot(as.matrix(man_mod$model[1]), type="qqplot")
## identificación de outliers multivariantesmvOutlier(as.matrix(man_mod$model[1]), qqplot=TRUE, method="quan")
## tests de desvío de la normalidad multivariante## test de Mardia
mardiaTest(as.matrix(man_mod$model[1]), qqplot=TRUE)
## test de Royston; para casos en que el tamaño muestral (N) sea < 50
roystonTest(as.matrix(man_mod$model[1]), qqplot=TRUE)
## usaremos el test de Henze-Zirkler cuando N > 100
hzTest(as.matrix(man_mod$model[1]), qqplot=TRUE)
275

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn way ANOVAS y MANOVASAnálisis Multivariantes de la Varianza ‐MAN(c)OVA
Pruebas importantes
276
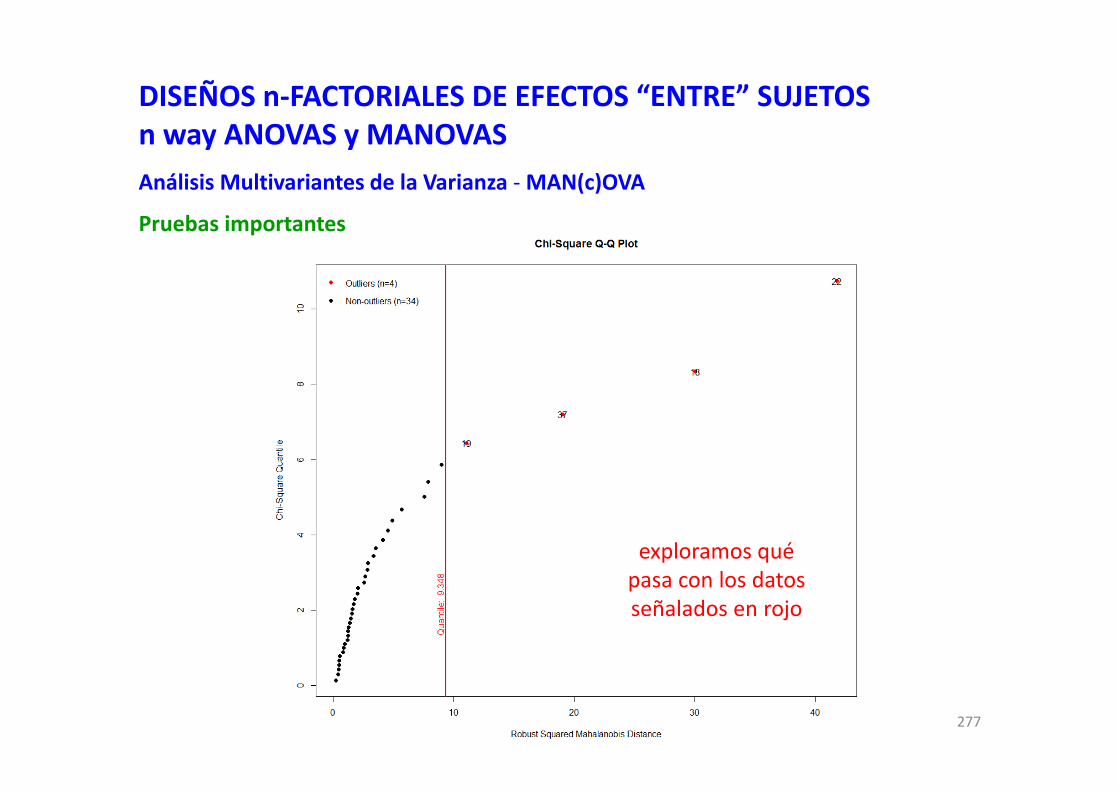
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn way ANOVAS y MANOVASAnálisis Multivariantes de la Varianza ‐MAN(c)OVA
Pruebas importantes
277
exploramos quépasa con los datosseñalados en rojo

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn way ANOVAS y MANOVASAnálisis Multivariantes de la Varianza ‐MAN(c)OVA
Pruebas importantes> mardiaTest(as.matrix(man_mod$model[1]), qqplot=TRUE)
Mardia's Multivariate Normality Test ---------------------------------------
data : as.matrix(man_mod$model[1]) g1p : 3.636029 chi.skew : 23.02818 p.value.skew : 0.01064303
g2p : 18.1312 z.kurtosis : 1.762026 p.value.kurt : 0.07806487
chi.small.skew : 25.84004 p.value.small : 0.003961381 Result : Data are not multivariate normal.
---------------------------------------
> roystonTest(as.matrix(man_mod$model[1]), qqplot=TRUE)Royston's Multivariate Normality Test
---------------------------------------------data : as.matrix(man_mod$model[1]) H : 8.614611 p-value : 0.03085017 Result : Data are not multivariate normal.
--------------------------------------------- 278

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn way ANOVAS y MANOVASAnálisis Multivariantes de la Varianza ‐MAN(c)OVA
Pruebas importantes
279
Q‐Q plot para visualización de lanormalidad multivariante

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn way ANOVAS y MANOVASAnálisis Multivariantes de la Varianza ‐MAN(c)OVA
Pruebas importantes## efectuamos el test de la M de Box, con cada factor del análisis## "sacamos" las variables respuesta de nuestro modelo lm llamado man_mod## mediante man_mod$model[1], que incluye las variables reunidas con cbind(…)## podemos analizar los efectos de factores uno por uno, o sus interacciones## Si no podemos efectuar la interacción completa (por falta de muestra),## probad con efectos principales e interacciones dobles
boxM(man_mod$model[1], datos$ZONA)boxM(man_mod$model[1], datos$SEXO:datos$EDAD)
> boxM(man_mod$model[1], datos$ZONA)Box's M-test for Homogeneity of Covariance Matrices
data: man_mod$model[1]Chi-Sq (approx.) = 11.968, df = 6, p-value = 0.06269
> boxM(man_mod$model[1], datos$SEXO:datos$EDAD)Box's M-test for Homogeneity of Covariance Matrices
data: man_mod$model[1]Chi-Sq (approx.) = 26.0966, df = 18, p-value = 0.09757
280

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn way ANOVAS y MANOVASAnálisis Multivariantes de la Varianza ‐MAN(c)OVA
Pruebas importantes## efectuamos el test de Levene## TEST DE HOMOGENEIDAD DE VARIANZAS a través de los niveles de los factores## no admite covariantes## otra opción es center=mean (la del programa STATISTICA)## lo hacemos con cada una de las variables respuesta; aquí como ejemplo sólo con una
leveneTest(MUSCULO~ZONA:SEXO:EDAD, data=datos, center=median)
Levene's Test for Homogeneity of Variance (center = median)Df F value Pr(>F)
group 7 0.4655 0.851630
Hemos violado el supuesto de normalidad multivariante (levemente) y el de homogeneidad de varianzas/covarianzas a través de los niveles de los factores considerados, pero no el de homogeneidad de las varianzas de las variables respuesta (teniendo en cuenta las celdas definidas por la interacción entre todos los factores nominales considerados).
Podríamos transformar las variables respuesta (e.g., en logaritmo) y volver a repetir el proceso.
281

282
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn way ANOVAS y MANOVASAnálisis Multivariantes de la Varianza ‐MAN(c)OVA
Pruebas importantesExploración del supuesto de la normalidad de los residuos
## descripción de los residuos y test de Shapiro-Wilk de su desvío de la normalidad
uniNorm(residuals(man_mod), type="SW", desc=TRUE)
$`Descriptive Statistics`n Mean Std.Dev Median Min Max 25th 75th Skew Kurtosis
PESO 38 0 0.451 -0.053 -0.669 1.124 -0.346 0.310 0.699 -0.126MUSCULO 38 0 0.329 -0.061 -0.581 0.824 -0.222 0.177 0.572 -0.365TASAINV 38 0 0.102 0.001 -0.287 0.229 -0.061 0.050 -0.120 0.449
$`Shapiro-Wilk's Normality Test`Variable Statistic p-value Normality
1 PESO 0.9458 0.0649 YES 2 MUSCULO 0.9618 0.2168 YES 3 TASAINV 0.9794 0.6961 YES

283
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn way ANOVAS y MANOVASAnálisis Multivariantes de la Varianza ‐MAN(c)OVA
Pruebas importantes## exploración visual de los residuos de las variables respuesta tras hacer el modelo
nvarresp <- length(colnames(man_mod$model[,1]))par(mfcol=c(1,1))for (i in 1:nvarresp) {
qqnorm(residuals(man_mod)[,i], main=colnames(residuals(man_mod))[i])qqline(residuals(man_mod)[,i], col="red")
}##
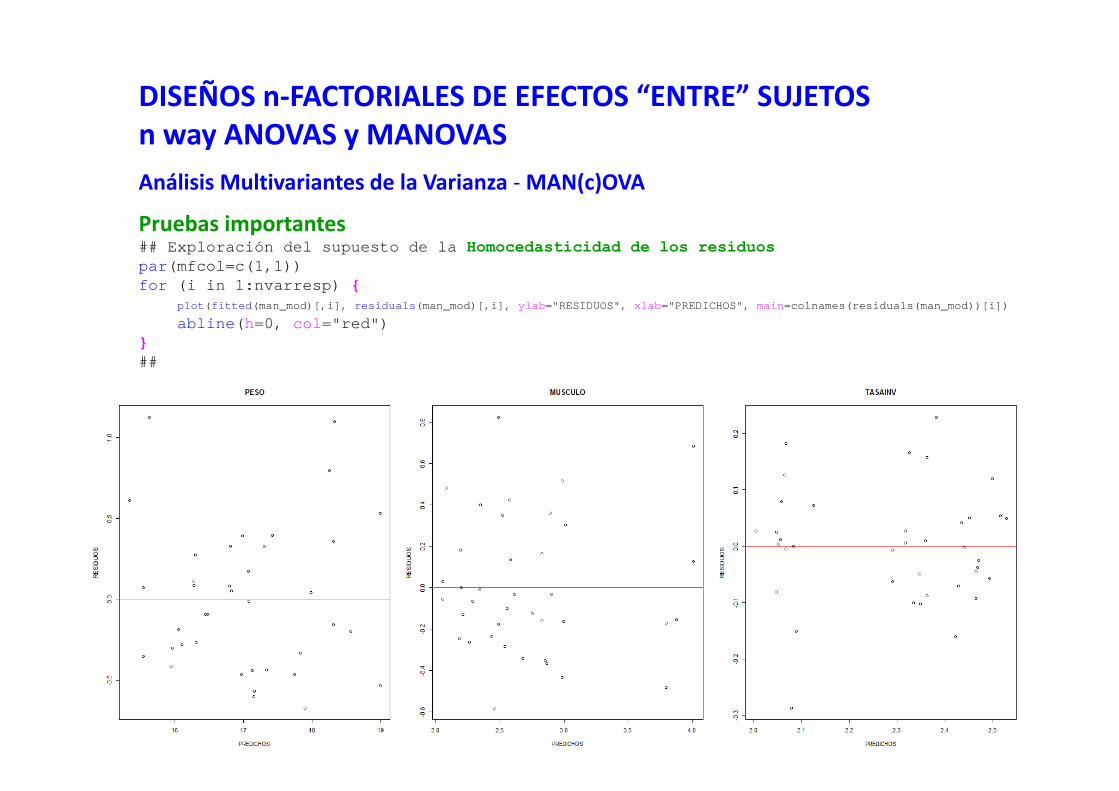
284
DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn way ANOVAS y MANOVASAnálisis Multivariantes de la Varianza ‐MAN(c)OVA
Pruebas importantes## Exploración del supuesto de la Homocedasticidad de los residuospar(mfcol=c(1,1))for (i in 1:nvarresp) {
plot(fitted(man_mod)[,i], residuals(man_mod)[,i], ylab="RESIDUOS", xlab="PREDICHOS", main=colnames(residuals(man_mod))[i])
abline(h=0, col="red")}##

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn way ANOVAS y MANOVASAnálisis Multivariantes de la Varianza ‐MAN(c)OVA
VARIANZA EXPLICADA DE CADA VARIABLE RESPUESTA## códigos de cálculonvarresp <- length(colnames(man_mod$model[,1]))nombresresp <- as.factor(vector(length=nvarresp))nombresresp <- colnames(man_mod$model[,1])SStotal <- vector(length=nvarresp)SSerror <- vector(length=nvarresp)porvarianza <- vector(length=nvarresp)## bucle de cálculofor (i in 1:nvarresp) {
SStotal[i] <- sum((man_mod$model[,1][,i]-mean(man_mod$model[,1][,i]))^2)SSerror[i] <- modelo$SSPE[i,i]porvarianza[i] <- ((SStotal[i]-SSerror[i])/SStotal[i])*100
}##
## tabla de resultados; "porvarianza" es el % de la varianza explicado## por todo el modelo para cada variable respuesta
tablavarianza <- round(data.frame(porvarianza, SStotal, SSerror), 3)print(data.frame(nombresresp, tablavarianza))
nombresresp porvarianza SStotal SSerror1 PESO 82.736 43.523 7.5142 MUSCULO 72.991 14.842 4.0093 TASAINV 74.587 1.515 0.385
285

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn way ANOVAS y MANOVASAnálisis Multivariantes de la Varianza ‐MAN(c)OVA
Primeros resultados## Resultados del modelo y sus estimas multivariantes
summary(modelo, multivariate=TRUE)
Es una salida larguísima. Por ejemplo, veamos los resultados particulares sólo para el efecto ZONA:SEXO
------------------------------------------
Term: ZONA:SEXO
Sum of squares and products for the hypothesis:PESO MUSCULO TASAINV
PESO 0.05312621 -0.10512648 -0.04329099MUSCULO -0.10512648 0.20802496 0.08566448TASAINV -0.04329099 0.08566448 0.03527655
Multivariate Tests: ZONA:SEXODf test stat approx F num Df den Df Pr(>F)
Pillai 1 0.1402584 1.468262 3 27 0.24533Wilks 1 0.8597416 1.468262 3 27 0.24533Hotelling-Lawley 1 0.1631402 1.468262 3 27 0.24533Roy 1 0.1631402 1.468262 3 27 0.24533
------------------------------------------
286

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn way ANOVAS y MANOVASAnálisis Multivariantes de la Varianza ‐MAN(c)OVA
Resultados globales## importancia de los efectos en el modelo (effect sizes) y significaciones## es una estimación multivariante para el conjunto de las variables respuesta## es una tabla más sintética que la de summary(...)## parial eta2 (eta^2), Df's, el estadístico seleccionado (Pillai's, ...), la F y ## la significación de SS tipo-III si hemos usado Manova(..., type=3, ...).
etasq(modelo, anova=TRUE)
Type III MANOVA Tests: Pillai test statisticeta^2 Df test stat approx F num Df den Df Pr(>F)
(Intercept) 0.13980 1 0.13980 1.4627 3 27 0.2468137 TARSO 0.52913 1 0.52913 10.1134 3 27 0.0001225 ***ZONA 0.69367 1 0.69367 20.3802 3 27 4.169e-07 ***SEXO 0.31510 1 0.31510 4.1406 3 27 0.0154589 * EDAD 0.17587 1 0.17587 1.9206 3 27 0.1500578 ZONA:SEXO 0.14026 1 0.14026 1.4683 3 27 0.2453283 ZONA:EDAD 0.11424 1 0.11424 1.1608 3 27 0.3428560 SEXO:EDAD 0.26287 1 0.26287 3.2095 3 27 0.0387591 * ZONA:SEXO:EDAD 0.16788 1 0.16788 1.8158 3 27 0.1680891 ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
## Sólo vamos a ver los resultados univariantes de los efectos de nuestro modelo MANOVA, ## para aquellos términos multivariantes que hayan aportado significación
287

DISEÑOS n‐FACTORIALES DE EFECTOS “ENTRE” SUJETOSn way ANOVAS y MANOVASAnálisis Multivariantes de la Varianza ‐MAN(c)OVA
Resultados particulares por cada variable respuesta## Obtenemos el resumen del modelo lm
summary(man_mod)
## ejemplo de la salida para la segunda variable respuesta## se proporcionan los coeficientes de regresión
Response MUSCULO :Call:lm(formula = MUSCULO ~ TARSO + ZONA * SEXO * EDAD, data = datos). . . .
Coefficients:Estimate Std. Error t value Pr(>|t|)
(Intercept) -2.35435 2.20612 -1.067 0.294689 TARSO 0.26179 0.11316 2.314 0.027983 * ZONA1 -0.24552 0.06461 -3.800 0.000687 ***SEXO1 -0.24987 0.07810 -3.199 0.003323 ** EDAD1 0.10629 0.07120 1.493 0.146297 ZONA1:SEXO1 0.07874 0.06419 1.227 0.229786 ZONA1:EDAD1 -0.04819 0.06632 -0.727 0.473217 SEXO1:EDAD1 -0.08726 0.06511 -1.340 0.190551 ZONA1:SEXO1:EDAD1 0.12454 0.06482 1.921 0.064565 . ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.3718 on 29 degrees of freedomMultiple R-squared: 0.7299, Adjusted R-squared: 0.6554 F-statistic: 9.797 on 8 and 29 DF, p-value: 1.781e-06 288

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOS
n way ANOVASde medidas REPETIDAS(within subjects designs)
289

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas RepetidasEn estos diseños se toman diferentes medidas sobre las mismas unidades muestrales.
Estas diferentes medidas vienen definidas por los niveles de los factores quedenominamos "dentro" de sujetos(e.g., mediciones por la noche y el día; medidas del lado derecho y el izquierdo)
En estos diseños podemos tener uno o más factores "dentro" de sujetos que puedeninteraccionar entre sí. En esta circunstancia, el número de pseudorréplicas por unidadmuestral viene definida por el número de celdas en la interacción de los factores.
Realmente esas diferentes medidas de la misma unidad muestral definen:varias variables respuesta, cada una de las cuales define un nivel del factor "dentro"
Además podemos contar en estos diseños con otros factores "entre" sujetos, que incluyen en sus niveles a unidades muestrales diferentes.
También podemos considerar covariantes que afectan al valor de la respuesta. Pueden ser:covariantes fijas: un solo valor de la covariante por cada unidad muestralcovariantes cambiantes: un valor de la covariante para cada unidad muestral en
cada nivel del factor "dentro" de sujetos.290

291
DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas Repetidas
Veámoslo gráficamente.
Existen 8 unidades muestrales (elipses)"sujetos"
Sea un factor F con seis niveles:niveles 1, 2, 3, 4, 5, 6 (en cajitas).
Este es un factor “dentro de” muestra.Todos los niveles del Factor F estánrepresentados en cada unidad muestralcon una sola réplica (cajitas con números)
Y definimos un nuevo factor Bcon dos niveles (gris y blanco)establecido fuera de las muestrasque es un factor “entre” muestras.
El diseño se podría complicar usandootro factor “entre” muestras.

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas Repetidas
Las verdaderas unidades muestrales, que definirán los términos error para la estima de lasignificación (F, g.l. y p), no son las réplicas, sino los "sujetos" en los cuales se miderepetidamente la misma variable respuesta,
El número de veces es: los niveles del factor repetido o "dentro" de sujetos.
Estos diseños evitan la pseudorreplicación,y efectúan un control de la variabilidad aleatoria entre sujetos
de gran utilidad para estimar efectos sutiles "dentro" de sujetos
A la hora de abordar el análisis de datos podemos establecer dos "diseños de la matriz".Horizontal: una fila por "sujeto" o unidad muestral correcta.
Vamos a utilizar este diseño que permite más posibilidades.Vertical: las réplicas del mismo sujeto se ponen en filas distintas, y se añade una
columna que define la adscripción de la réplica‐fila al "sujeto"Este FACTOR‐"sujeto" se tratará como un factor aleatorio.Este diseño permite menos posibilidades de análisis:
sólo acepta un factor "dentro" de sujetos292

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas RepetidasVamos a proceder como lo haríamos en otros diseños factoriales ya presentados,
considerando los mismos requisitos y pruebas canónicas del buen uso de los ANOVA.
* Requiere normalidad multivariante. Difícil de evaluar (buen paquete de análisis en MVN)
* Es necesario que exista homogeneidad de varianzas/covarianzas a través de los niveles de losfactores fijos considerados (y sus interacciones si hay varios factores). Para ello contamos con el Test de la M de Box.
Consultad: http://www‐01.ibm.com/support/knowledgecenter/SSLVMB_20.0.0/com.ibm.spss.statistics.cs/glmm_patlos_homcov.htmEste supuesto asume que el patrón de asociación entre las variables respuesta no cambia a través de los niveles de los factores fijos (predictores nominales).Si violamos este supuesto … posible solución: transformar las variables respuesta
* Homogeneidad de las varianzas de las variables respuesta, teniendo en cuenta las celdasdefinidas por la interacción entre todos los factores fijos considerados.Mediante el Test de Levene examinamos este supuesto.Si no lo cumplimos … posible solución: transformar la variable respuesta que viola el supuestoEl caso más problemático es aquel en el que la varianza se asocia con la media de cada una delas celdas de la interacción entre los factores.
+ si la relación es positiva, aumenta el error de tipo I+ si la relación es negativa, aumenta el error de tipo II
293

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas Repetidas
Tenemos otros Supuestos añadidos:Esfericidad y Simetría compuesta (sólo aplicables a factores “dentro” con tres o más niveles)
SIMETRÍA COMPUESTA: Las varianzas de los tratamientos y las covarianzas entre ellos nodifieren entre sí. Esto se aplica a los factores "dentro" de sujetos o repetidos.Compararemos los resultados del ANOVA de medidas repetidas con los pronosticados por los ajustes efectuados por los tests de Greenhouse‐Geisser y Huynh‐Feldt.Comparamos las p's y los g.l. Más recomendable la aproximación de Huynh‐Feldt.
ESFERICIDAD: Las varianzas de las diferencias dentro de "sujetos" entre los diferentesniveles de los factores repetidos son homogéneas. Test de Mauchley.https://en.wikipedia.org/wiki/Mauchly%27s_sphericity_test
294

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas Repetidas
295
si se violan estos dos supuestospasaremos a utilizar los resultados
del MANOVA

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas Repetidas¿Cómo hacerlo? Versión con matriz de datos HORIZONTAL
Vamos a desarrollarlo, de manera muy flexible y potente, usando el paquete {car}Con esta forma de proceder podremos abordar diseños con uno o más factores “dentro”.Podremos considerar covariantes de efectos fijos (una o varias) y cambiantes.
Ejemplo:26 individuos (filas) ensayados en cuatro situaciones diferentes que fueron aleatorizadasDos factores “dentro”: RADIACION (infrarroja, luz_visible) y POSICION (invertido, normal)los dos factores definen 2*2=4 columnas de datos de la variable respuesta tasa
Una covariante de valores fijos: covarfijaUna covariante cambiante: definida por cuatro columnas (temperaturas de cada ensayo)Un factor “entre” sujetos que codifica si los escarabajos tienen o no los élitos fusionados
factorfijo con dos niveles (sí, no)
Existirá una variable respuesta con cuatro columnas (una por situación experimental)Existirán tantas filas como unidades muestrales hayaCada covariante fija toma un valor único por fila.La covariante cambiante toma valores en cuatro columnas(una por situación experimental)
296

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas Repetidas¿Cómo hacerlo? Versión con matriz de datos HORIZONTAL
297covariante fija
factor “entre”sujetos
2 factores “dentro”de sujetos
de la respuestaasíntota
organizados así:infrarrojo invertidoinfrarrojo normalluz invertidoluz normal
covariante cambiante

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas Repetidas¿Cómo hacerlo? Versión con matriz de datos HORIZONTAL
En esta ejemplificación sólo podremos realizar modelos generales lineales (GLM)asumiendo que trabajamos con una gausianapodremos transformar la variable respuesta con el objeto de aproximarnos a los supuestos canónicos de GLM
aplicaremos la misma transformación a las diferentes columnas que definen la variable respuesta
## CARGAMOS LOS PAQUETES:library(car) ## para obtener VIF's y usar Anova, bootCaselibrary(lmtest) ## para usar coeftest y correcciones por heterocedasticidadlibrary(sandwich) ## para correcciones de heterocedasticidad usando vcovHClibrary(biotools) ## para efectuar el test de la M de Boxlibrary(MVN) ## para el test de la normalidad multivariante
## ESPECIFICAMOS LAS TABLAS DE CONTRASTES PARA LOS FACTORES## Cargamos la siguiente línea de código para obtener contrastes definidos## Se obtienen los mismos resultados que STATISTICA y SPSS utilizando type III SS## As the treatment factors are unordered factors, R will use contr.sum in order to construct a contrast matrix of the apropriate order.
options(contrasts=c(factor="contr.sum", ordered="contr.poly"))
298

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas RepetidasOrganización de datos de efectos dentro de sujetos (within‐subjects)
## combinamos con cbind los efectos within-subjects, ## sean de factores o covariantes cambiantes
¡¡¡ esto es aparentemente lo más complicado !!!Es puro orden y saber qué queremos hacer
## para la RESPUESTA, FACTOR DENTRO DE two-way ## ponemos ordenadamente la secuencia de mis variables respuesta## definir cómo organizar esas columnas: primero la FUENTE y dentro de eso la POSICIÓN## aquí están los valores: respuesta2w.dentro <- cbind(datos$tasa_inf_inv, datos$tasa_inf_nor, datos$tasa_luz_inv, datos$tasa_luz_nor)
## Construimos un nuevo dataframe con los niveles ordenados de los factores## según hemos re-estructurado los valores de la respuesta en respuesta2w.dentro## definimos los niveles del primer factor con los nombres que queramosFUENTE <- factor(c("Infra","Infra","Luz","Luz"))
## definimos los niveles del otro factor con los nombres sencillos que queramosPOSICION <- factor(c("Invertido","Normal","Invertido","Normal"))
## combinamos los dos factores en un dataframe## aquí están los nombres inteligibles:factor2w.dentro <- data.frame(FUENTE, POSICION)
299

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas RepetidasOrganización de datos de efectos dentro de sujetos (within‐subjects)
## veamos qué hemos generado
> respuesta2w.dentro[,1] [,2] [,3] [,4]
[1,] 0.019 0.021 0.018 0.017[2,] 0.031 0.036 0.035 0.031[3,] 0.007 0.021 0.007 0.018[4,] 0.021 0.025 0.024 0.028[5,] 0.020 0.028 0.020 0.019[6,] 0.031 0.037 0.037 0.035[7,] 0.018 0.023 0.015 0.016[8,] 0.016 0.017 0.019 0.016[9,] 0.020 0.011 0.014 0.019. . . . . .
[24,] 0.020 0.020 0.018 0.019[25,] 0.017 0.016 0.016 0.017[26,] 0.025 0.026 0.021 0.025
hay 26 observaciones o unidades muestrales realmente independientes
300
> factor2w.dentroFUENTE POSICION
1 Infra Invertido2 Infra Normal3 Luz Invertido4 Luz Normal
la columna [,1] es 1 Infra Invertidola columna [,2] es 2 Infra Normal. . . etc

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas RepetidasOrganización de datos de efectos dentro de sujetos (within‐subjects)
## COVARIANTE CAMBIANTE DENTRO DE SUJETOS## usamos el mismo orden-secuencia que el utilizado para la respuesta ¡¡¡esto es muy importante!!!
covariante2w.dentro <- cbind(datos$temp_inf_inv, datos$temp_inf_nor, datos$temp_luz_inv, datos$temp_luz_nor)
## CONSTRUIMOS EL MODELO AN(c)OVA## two-way within-subjects factors & one between-subjects factor, with one fixed covariate plus one changing covariate
## que tiene un submodelo (submodelo) que se incluye en Anova(…)## tiene la forma: respuesta-repetida ~ ## factor_fijo + covariante_fija + covariante_cambiante
## idata define cuál es la estructura del factor-dentro-de-sujetos## idesign define qué diseño within-subjects queremos hacer (aquí two-way con interacción)## type=3 establece un diseño de suma de cuadrados (SS) de tipo 3 (efectos parciales)
submodelo <- lm(respuesta2w.dentro ~ datos$factorfijo + datos$covarfija + covariante2w.dentro)
modelo <- Anova(submodelo, idata=factor2w.dentro, idesign=~FUENTE*POSICION, type="III")
¡¡¡ terminamos !!!esto es imposible hacerlo con STATISTICA o con SPSS
301

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas RepetidasEXPLORACIÓN DE LOS SUPUESTOS CANÓNICOS DEL MODELO (respuestas originales)## Normalidad de las variables respuesta originales## mirad: https://cran.r-project.org/web/packages/MVN/vignettes/MVN.pdf## descriptores de nuestras variables originales y ## test de Shapiro-Wilk de desvío de la normalidad
uniNorm(as.matrix(respuesta2w.dentro), type="SW", desc=TRUE)
las filas 1, 2, 3, 4 se corresponden con las cuatro columnas “respuesta” de respuesta2w.dentro
$`Descriptive Statistics`n Mean Std.Dev Median Min Max 25th 75th Skew Kurtosis
1 26 0.022 0.006 0.020 0.007 0.032 0.018 0.026 -0.251 -0.3582 26 0.024 0.007 0.024 0.011 0.037 0.019 0.030 -0.108 -0.9903 26 0.021 0.007 0.020 0.007 0.037 0.017 0.024 0.283 -0.2724 26 0.023 0.007 0.022 0.009 0.038 0.017 0.027 0.421 -0.507
$`Shapiro-Wilk's Normality Test`Variable Statistic p-value Normality
1 Column1 0.9437 0.1645 YES 2 Column2 0.9716 0.6661 YES 3 Column3 0.9716 0.6663 YES 4 Column4 0.9603 0.3981 YES
302

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas RepetidasEXPLORACIÓN DE LOS SUPUESTOS CANÓNICOS DEL MODELO (respuestas originales)## plots: de histogramas y Q-Q plotspar(mfcol=c(1,1))uniPlot(as.matrix(respuesta2w.dentro), type="histogram")uniPlot(as.matrix(respuesta2w.dentro), type="qqplot")par(mfcol=c(1,1))
## efectuamos el test de la M de Box, SÓLO con factores "entre sujetos" del análisis## "sacamos" las variables respuesta de nuestro objeto creado con cbind(...)## Si no podemos efectuar la interacción completa (por falta de muestra),## probad con efectos principales e interacciones dobles
boxM(respuesta2w.dentro, datos$factorfijo)
Box's M-test for Homogeneity of Covariance Matricesdata: respuesta2w.dentroChi-Sq (approx.) = 6.0035, df = 10, p-value = 0.815
## Normalidad Multivariante: test de Royston; para cuando el tamaño muestral (N) sea < 50## usaremos el test de Henze-Zirkler cuando N > 100: hzTest(...)roystonTest(as.matrix(respuesta2w.dentro), qqplot=TRUE)
303

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas RepetidasEXPLORACIÓN DE LOS SUPUESTOS CANÓNICOS DEL MODELO (respuestas originales)
304
V1, V2, … son las variables respuestaincluidas en cbind(…)
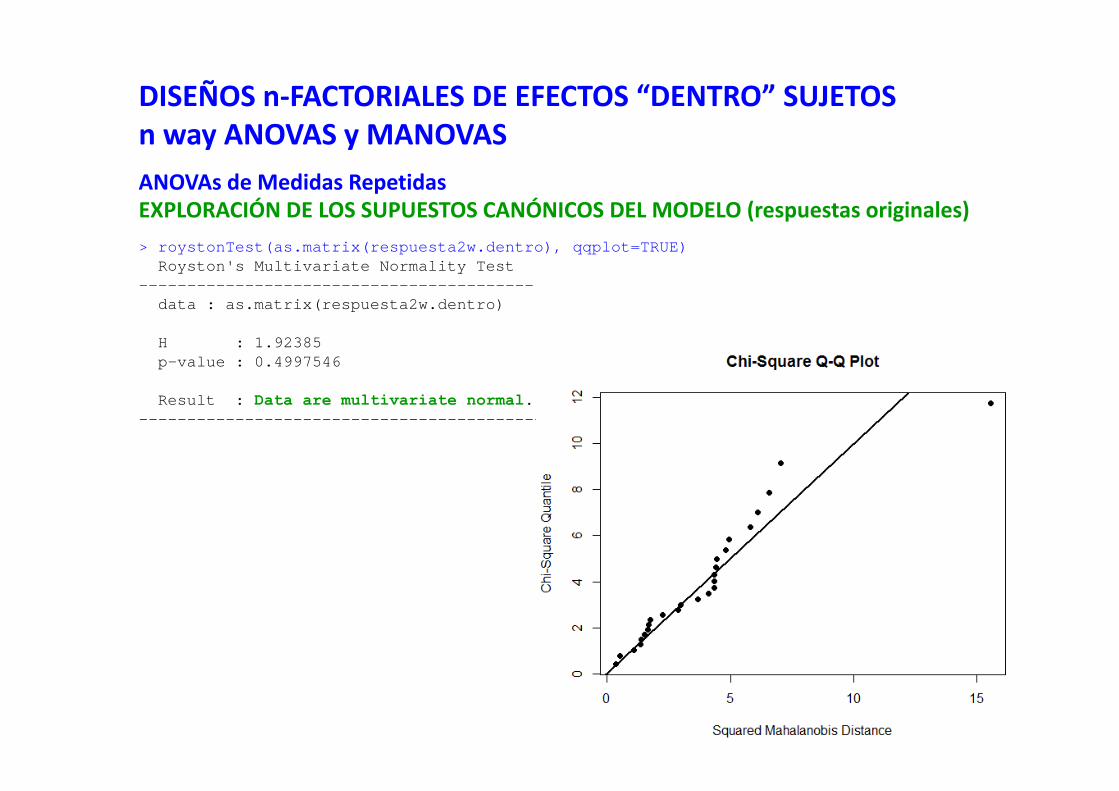
DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas RepetidasEXPLORACIÓN DE LOS SUPUESTOS CANÓNICOS DEL MODELO (respuestas originales)> roystonTest(as.matrix(respuesta2w.dentro), qqplot=TRUE)
Royston's Multivariate Normality Test -----------------------------------------
data : as.matrix(respuesta2w.dentro)
H : 1.92385 p-value : 0.4997546
Result : Data are multivariate normal. ---------------------------------------------
305

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas RepetidasEXPLORACIÓN DE LOS SUPUESTOS CANÓNICOS DEL MODELO (respuestas originales)## TEST DE HOMOGENEIDAD DE VARIANZAS a través de los niveles de los factores "entre sujetos"## no admite covariantes## lo hacemos con cada una de las variables respuesta, y con el factor datos$factorfijo
nvarresp <- dim(factor2w.dentro)[1]for (i in 1:nvarresp) {
print(c("Respuesta", i), quote=FALSE)print(leveneTest(respuesta2w.dentro[,i] ~ datos$factorfijo, data=datos, center=median))print("******************************************************", quote=FALSE)
}
[1] Respuesta 1 Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)group 1 0.0365 0.8501
24 [1] ******************************************************[1] Respuesta 2Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)group 1 0.8443 0.3673
24 [1] ******************************************************[1] Respuesta 3 Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)group 1 0.1327 0.7188
24 [1] ******************************************************[1] Respuesta 4 Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)group 1 0.0826 0.7763
24 [1] ******************************************************
306

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas RepetidasEXPLORACIÓN DE LOS SUPUESTOS CANÓNICOS DEL MODELO (residuos)
## los visualizamos## es para el conjunto de las N filas-observaciones x r variables respuesta
hist(residuals(submodelo))qqnorm(residuals(submodelo))qqline(residuals(submodelo) , col="red")
## test de Shapiro de normalidad de residuosshapiro.test(residuals(submodelo))
Shapiro-Wilk normality testdata: residuals(submodelo)W = 0.9811, p-value = 0.1448
307

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas RepetidasEXPLORACIÓN DE LOS SUPUESTOS CANÓNICOS DEL MODELO (residuos)
308

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas RepetidasEXPLORACIÓN DE LOS SUPUESTOS CANÓNICOS DEL MODELO (respuestas originales)## Homocedasticidad de los residuos a través de las predicciones del modelo
plot(fitted(submodelo), residuals(submodelo), main="relación entre residuos y predicciones")abline(h=0, col="red")
309

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas RepetidasRESULTADOS## tabla sintética de efectos con la aproximación within-subjects
summary(modelo, multivariate=FALSE)
Univariate Type III Repeated-Measures ANOVA Assuming Sphericity
SS num Df Error SS den Df F Pr(>F) (Intercept) 0.00119338 1 0.00260278 19 8.7115 0.008194 **datos$factorfijo 0.00003082 1 0.00260278 19 0.2250 0.640697 datos$covarfija 0.00073085 1 0.00260278 19 5.3351 0.032298 * covariante2w.dentro 0.00092379 4 0.00260278 19 1.6859 0.194738 FUENTE 0.00000264 1 0.00010984 19 0.4562 0.507526 datos$factorfijo:FUENTE 0.00000322 1 0.00010984 19 0.5567 0.464734 datos$covarfija:FUENTE 0.00000021 1 0.00010984 19 0.0366 0.850351 covariante2w.dentro:FUENTE 0.00002523 4 0.00010984 19 1.0913 0.389034 POSICION 0.00001113 1 0.00017871 19 1.1832 0.290308 datos$factorfijo:POSICION 0.00000475 1 0.00017871 19 0.5045 0.486163 datos$covarfija:POSICION 0.00000412 1 0.00017871 19 0.4378 0.516146 covariante2w.dentro:POSICION 0.00002750 4 0.00017871 19 0.7311 0.581904 FUENTE:POSICION 0.00001313 1 0.00008093 19 3.0832 0.095211 . datos$factorfijo:FUENTE:POSICION 0.00000942 1 0.00008093 19 2.2125 0.153301 datos$covarfija:FUENTE:POSICION 0.00000892 1 0.00008093 19 2.0946 0.164123 covariante2w.dentro:FUENTE:POSICION 0.00008277 4 0.00008093 19 4.8577 0.007201 **---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
310
interacciones con factores “dentro de”

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas RepetidasRESULTADOS## la misma tabla de antes pero añadiendo los valores de partial eta2
tabla <- data.frame(summary(modelo, multivariate=FALSE)$univariate.tests[,])partialeta2 <- tabla$SS/(tabla$SS+tabla$Error.SS)tabla.anova <- data.frame(tabla, partialeta2)round(tabla.anova, 5)
SS num.Df Error.SS den.Df F Pr..F. partialeta2(Intercept) 0.00119 1 0.00260 19 8.71152 0.00819 0.31436datos$factorfijo 0.00003 1 0.00260 19 0.22495 0.64070 0.01170datos$covarfija 0.00073 1 0.00260 19 5.33509 0.03230 0.21923covariante2w.dentro 0.00092 4 0.00260 19 1.68589 0.19474 0.26195FUENTE 0.00000 1 0.00011 19 0.45624 0.50753 0.02345datos$factorfijo:FUENTE 0.00000 1 0.00011 19 0.55668 0.46473 0.02846datos$covarfija:FUENTE 0.00000 1 0.00011 19 0.03658 0.85035 0.00192covariante2w.dentro:FUENTE 0.00003 4 0.00011 19 1.09130 0.38903 0.18682POSICION 0.00001 1 0.00018 19 1.18322 0.29031 0.05862datos$factorfijo:POSICION 0.00000 1 0.00018 19 0.50448 0.48616 0.02587datos$covarfija:POSICION 0.00000 1 0.00018 19 0.43777 0.51615 0.02252covariante2w.dentro:POSICION 0.00003 4 0.00018 19 0.73105 0.58190 0.13338FUENTE:POSICION 0.00001 1 0.00008 19 3.08323 0.09521 0.13962datos$factorfijo:FUENTE:POSICION 0.00001 1 0.00008 19 2.21254 0.15330 0.10430datos$covarfija:FUENTE:POSICION 0.00001 1 0.00008 19 2.09456 0.16412 0.09929covariante2w.dentro:FUENTE:POSICION 0.00008 4 0.00008 19 4.85770 0.00720 0.50560
311

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas RepetidasRESULTADOSSi nuestros factores repetidos hubiesen tenido tres niveles o más, habríamos obtenido los test de Mauchly de esfericidad y las estimas corregidas de Greenhouse‐Geisser y Huynh‐Feldt
ejemplo con otros datos:Univariate Type III Repeated-Measures ANOVA Assuming Sphericity
SS num Df Error SS den Df F Pr(>F) (Intercept) 7260.0 1 603.33 15 180.4972 9.100e-10 ***phase 167.5 2 169.17 30 14.8522 3.286e-05 ***hour 106.3 4 73.71 60 21.6309 4.360e-11 ***phase:hour 11.1 8 122.92 120 1.3525 0.2245 ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Mauchly Tests for SphericityTest statistic p-value
phase 0.70470 0.086304hour 0.11516 0.000718phase:hour 0.01139 0.027376
Greenhouse-Geisser and Huynh-Feldt Correctionsfor Departure from Sphericity
GG eps Pr(>F[GG]) phase 0.77202 0.0001891 ***hour 0.49842 1.578e-06 ***phase:hour 0.51297 0.2602357 ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
HF eps Pr(>F[HF]) phase 0.84367 0.0001089 ***hour 0.57470 3.161e-07 ***phase:hour 0.73031 0.2439922 ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
312
recomiendo consultar:http://yatani.jp/teaching/doku.php?id=hcistats:anova

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas RepetidasRESULTADOS## salida multivariante al estilo MANOVA por si hubiésemos violado## los supuestos de esfericidad y simetría compuesta## al final proporciona la tabla Repeated-Measures ANOVA Assuming Sphericity
summary(modelo, multivariate=TRUE)
proporciona una larguísima salida de resultados; e.g. para la interacción de los dos factores “dentro de”------------------------------------------Term: FUENTE:POSICION
Response transformation matrix:FUENTE1:POSICION1
[1,] 1[2,] -1[3,] -1[4,] 1
Sum of squares and products for the hypothesis:FUENTE1:POSICION1
FUENTE1:POSICION1 5.253206e-05
Sum of squares and products for error:FUENTE1:POSICION1
FUENTE1:POSICION1 0.0003237217
Multivariate Tests: FUENTE:POSICIONDf test stat approx F num Df den Df Pr(>F)
Pillai 1 0.1396187 3.083232 1 19 0.095211 .Wilks 1 0.8603813 3.083232 1 19 0.095211 .Hotelling-Lawley 1 0.1622754 3.083232 1 19 0.095211 .Roy 1 0.1622754 3.083232 1 19 0.095211 .---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1------------------------------------------
313

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas RepetidasRESULTADOS## pormenorizados para cada variable respuesta## que son los niveles de los factores "dentro de"
summary(submodelo)
e.g., para la cuarta columna de la respuesta datos$tasa_luz_nor
Response Y4 :
Call:lm(formula = Y4 ~ datos$factorfijo + datos$covarfija + covariante2w.dentro)
Residuals:Min 1Q Median 3Q Max
-0.0096152 -0.0034412 -0.0009255 0.0021371 0.0108241
Coefficients:Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.177e-01 4.161e-02 2.830 0.0107 *datos$factorfijo1 -2.093e-04 1.780e-03 -0.118 0.9076 datos$covarfija -1.591e-05 8.976e-06 -1.773 0.0923 .covariante2w.dentro1 -1.276e-03 9.243e-04 -1.381 0.1834 covariante2w.dentro2 -3.783e-04 1.114e-03 -0.340 0.7379 covariante2w.dentro3 -4.388e-04 8.008e-04 -0.548 0.5901 covariante2w.dentro4 -6.553e-04 5.685e-04 -1.153 0.2633 ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.00634 on 19 degrees of freedomMultiple R-squared: 0.3743, Adjusted R-squared: 0.1767 F-statistic: 1.894 on 6 and 19 DF, p-value: 0.1342 314

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOS
diseñossplit‐plot
split‐split‐…‐plot
315

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas Repetidas
SPLIT‐PLOT DESIGNSSon un caso particular de medidas repetidas en el que se mezclan factores:“dentro de” sujetos establecidos dentro de los mismos bloques“entre” sujetos establecidos sobre diferentes bloques
Esto es, son unos diseños “mixtos” que mezclan factores “entre” con “dentro de”.
Estos diseños son también un caso particular de los diseños de bloques, en los que no es posible aleatorizar todos los efectos (factores) de interés dentro de los diferentes bloques de estudio.
La idea de split se refiere a que hacemos una división dentro de los bloques atendiendo ael número de niveles establecidos para los factores “dentro de”.
El diseño split‐plot tiene un solo factor “dentro de”.El diseño split‐split‐plot tiene dos factores “dentro de”.… y así sucesivamente.
Generalmente, en estos diseños se establece una única réplica dentro de cada bloquepara cada nivel del factor “dentro de” de define el efecto split.
316

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas Repetidas
SPLIT‐PLOT DESIGNSVeámoslo gráficamente.
Existen 8 bloques (elipses)
Sea un factor F con seis niveles:niveles 1, 2, 3, 4, 5, 6 (en cajitas).
Este es un factor “dentro de” bloque.Todos los niveles del Factor F estánrepresentados en cada bloquecon una sola réplica (cajitas con números)
Y definimos un nuevo factor Bcon dos niveles (gris y blanco)establecido fuera de los bloquesque es un factor “entre” bloques.
El diseño se podría complicar usando más bloquesutilizando otro factor “entre” bloques.
317

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas Repetidas
SPLIT‐PLOT DESIGNSEn este diseño, al igual que en el ejemplo de ANOVA de medidas repetidas con los escarabajos, cada bloque es una fila en la matriz horizontal de datos.
Las diferentes columnas de la matriz horizontal miden los valores que toma la respuesta en cada uno de los niveles “dentro” (repetidos) de el/los factor(es) considerado(s).
De aquí que suele ser conveniente, para facilitar los análisis, que haya una sola réplicade los niveles de los factores split (“dentro de”) en cada bloque.
La razón de ser de estos diseños estriba en que es imposible, por cuestiones logísticas, que todos los factores de nuestro diseño experimental estén replicados dentro de cada bloque.
Por ejemplo, es imposible que un escarabajo pueda tener simultáneamente los élitrosfusionados y no‐fusionados.
Hay parcelas‐bloques de cultivo que no pueden incluir todos los tratamientosEn cada bloque se pueden sembrar varias variedades y se pueden poner diferentes dosis de abonopero puede que sea imposible aplicar poco y mucho riego por los sistemas mecánicos de irrigaciónen el mismo bloque.
318

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas Repetidas
SPLIT‐PLOT DESIGNSEn pocas palabras:
son diseños de medidas repetidascon unos factores “dentro de” sujetos
y otros factores “entre” sujetosPodremos incluir covariantes (ANCOVA de medidas repetidas)y cuantos más factores repetidos “dentro de” haya … más split‐split‐… es nuestro diseño.
En situaciones en las que exista más de una réplica por bloque, el diseño se complica.Pero es abordable utilizando diseños de AN(c)OVAs ENCAJADOS.
Las distintas réplicas de los efectos split “dentro de” se anidarán dentro de los bloques,de manera que los bloques son las verdaderas unidades muestrales
(que definen los MS y g.l. correctos para el término error).319

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas Repetidas ‐ SPLIT‐PLOT DESIGNS – matrices verticales
Aplicación en el caso dematrices de datos verticales.
Cada unidad muestral se mide en diferentes situaciones experimentales(codificada con un número en "id")
Cada fila del dataframe es una pseudo‐réplica de cada verdadero sujeto "id"Hay una sola medida de cada sujeto "id" en cada una de las situaciones experimentales
Vamos a utilizar la aproximación de modelos mixtos, con lmer{lme4}Definiremos en la parte aleatoria una estructura con (1|id)
Para su desarrollo y aplicación con unos datos de ejemplo, consultad:http://www.uni‐kiel.de/psychologie/rexrepos/posts/anovaMixed.html
y el script con explicaciones en:http://www.lmcarrascal.eu/cursos/glm6v.R
320

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas Repetidas ‐ SPLIT‐PLOT DESIGNS – matrices verticales
A continuación se presenta la lógica de los diseños y sus nombres.Para más detalles sobre la estructura de estos modelos mixtos consultad las páginas 198‐257.
CONSTRUIMOS LOS MODELOS (usando REML)Estos modelos asumen compound symmetry
Para facilitar la estima del modelo:mi.control <‐ lmerControl(check.conv.grad=.makeCC(action ="ignore", tol=1e‐6, relTol=NULL), optimizer="bobyqa", optCtrl=list(maxfun=100000))
En rojo se muestran las estructuras del término error aleatorio
MODELO NULO PARA LOS MODELOS CON ONE‐WAY WITHIN‐SUBJECTS DESIGNsolo entra el intercepto (1)modelo0 <- lmer(a_por_b ~ 1 + (1|id), data=datos, REML=TRUE, control=mi.control)
ONE‐WAY WITHIN‐SUBJECTS DESIGNun solo factor dentro‐de‐sujetos con cuatro niveles (tratamiento)con un solo factor dentro‐de‐sujetos solo necesitamos un término aleatorio: (1|id)modelo1 <- lmer(a_por_b ~ tratamiento + (1|id), data=datos, REML=TRUE, control=mi.control)
321

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas Repetidas ‐ SPLIT‐PLOT DESIGNS – matrices verticales
ONE‐WAY WITHIN‐SUBJECTS ANCOVA DESIGN, WITH ONE FIXED COVARIATEun solo factor dentro‐de‐sujetos (tratamiento) con cuatro niveles y una covariante fija (volabdomen)modelo2 <- lmer(a_por_b ~ volabdomen+tratamiento + (1|id), data=datos,
REML=TRUE, control=mi.control)
ONE‐WAY WITHIN‐SUBJECTS ANCOVA DESIGN, WITH ONE FIXED COVARIATE AND ONE CHANGING COVARIATE (WITH RANDOM INTERCEPT CONSTANT SLOPE EFFECT)un solo factor dentro‐de‐sujetos (tratamiento) con cuatro niveles
y una covariante fija (volabdomen) y otra cambiante (t_sonda)tanto más correlación haya entre la covariante cambiante y los niveles del factor dentro‐de‐sujetos,
tanto más cambiarán los grados de libertad para el término error (Df.res ó DenDF)modelo31 <- lmer(a_por_b ~ volabdomen+t_sonda+tratamiento + (1|id), data=datos,
REML=TRUE, control=mi.control)
ONE‐WAY WITHIN‐SUBJECTS ANCOVA DESIGN, WITH ONE FIXED COVARIATE AND ONE CHANGING COVARIATE (WITH RANDOM INTERCEPT AND SLOPES EFFECTS)idem del anterior, pero establecemos que las pendientes de la covariante cambiante puedan variar a través de los niveles del factor dentro‐de‐sujetosmodelo32 <- lmer(a_por_b ~ volabdomen+t_sonda+tratamiento + (t_sonda|id),
data=datos, REML=TRUE, control=mi.control) 322

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas Repetidas ‐ SPLIT‐PLOT DESIGNS – matrices verticales
TWO‐WAY SPLIT‐PLOT DESIGN, with ONE WITHIN‐SUBJECTS AND ONE BETWEEN‐SUBJECTS FACTORSun factor dentro‐de‐sujetos con cuatro niveles (tratamiento) y
otro factor entre‐sujetos con 13 niveles (especie); este factor define el split‐plot designdefinimos el modelo con efectos principales e interacción entre factoresmodelo4 <- lmer(a_por_b ~ tratamiento*especie + (1|id), data=datos,
REML=TRUE, control=mi.control)
TWO‐WAY SPLIT‐PLOT ANCOVA DESIGN, with ONE WITHIN‐SUBJECTS AND ONE BETWEEN‐SUBJECTS FACTORS, PLUS ONE FIXED COVARIATEun factor dentro‐de‐sujetos con cuatro niveles (tratamiento) yotro factor entre‐sujetos con 13 niveles (especie) con efectos principales e interacción entre factores,y añadimos una covariante fija (volabdomen)modelo5 <- lmer(a_por_b ~ volabdomen+tratamiento*especie + (1|id), data=datos,
REML=TRUE, control=mi.control)
TWO‐WAY SPLIT‐PLOT ANCOVA DESIGN, with ONE WITHIN‐SUBJECTS AND ONE BETWEEN‐SUBJECTS FACTORS, PLUS ONE FIXED AND ONE CHANGING COVARIATESidem del anterior pero añadiendo una covariante cambiante (t_sonda) con random intercepttanto más correlación haya entre la covariante cambiante y los niveles del factor dentro‐de‐sujetos, tanto más cambiarán los grados de libertad para el término error (Df.res ó DenDF)modelo6 <- lmer(a_por_b ~ volabdomen+t_sonda+tratamiento*especie + (1|id), data=datos,
REML=TRUE, control=mi.control)323

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas Repetidas ‐ SPLIT‐PLOT DESIGNS – matrices verticales
MODELO NULO PARA LOS MODELOS CON TWO‐WAY WITHIN‐SUBJECTS DESIGNScon dos factores dentro‐de‐sujetos, añadimos al término aleatorio (1|id) otros dos interacción sujeto:factor‐dentro‐de (1|factor:id), una por cada "factor dentro"
solo entra el intercepto (1)modelo00 <- lmer(a_por_b ~ 1 + (1|id)+(1|fuente:id)+(1|posicion:id), data=datos,
REML=TRUE, control=mi.control)
TWO‐WAY WITHIN‐SUBJECTS DESIGNdos factores dentro‐de‐sujetos con dos niveles cada uno (fuente y posicion)con efectos principales e interacción entre ambos factoresmodelo7 <- lmer(a_por_b ~ fuente*posicion + (1|id)+(1|fuente:id)+(1|posicion:id),
data=datos, REML=TRUE, control=mi.control)
TWO‐WAY WITHIN‐SUBJECTS DESIGN, with ONE FIXED COVARIATE AND ONE CHANGING COVARIATE (WITH RANDOM INTERCEPT CONSTANT SLOPE EFFECT)para más detalles sobre las covariantes consultad el modelo31modelo81 <- lmer(a_por_b ~ volabdomen+t_sonda+fuente*posicion + (1|id)+(1|fuente:id)+(1|posicion:id),
data=datos, REML=TRUE, control=mi.control)
324

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas Repetidas ‐ SPLIT‐PLOT DESIGNS – matrices verticales
TWO‐WAY WITHIN‐SUBJECTS DESIGN, with ONE FIXED COVARIATE AND ONE CHANGING COVARIATE (WITH RANDOM INTERCEPT AND SLOPE EFFECTS)idem del anterior, pero establecemos que las pendientes de la covariante cambiante (t_sonda) puedan variar a través de los niveles del factor dentro‐de‐sujetospara más detalles sobre las covariantes consultad el modelo32modelo82 <- lmer(a_por_b ~ volabdomen+t_sonda+fuente*posicion +
(t_sonda|id)+(1|fuente:id)+(1|posicion:id), data=datos,REML=TRUE, control=mi.control)
THREE‐WAY SPLIT‐PLOT DESIGN, with TWO WITHIN‐SUBJECTS AND ONE BETWEEN‐SUBJECTS FACTORSdos factores dentro‐de‐sujetos con dos niveles cada uno (fuente y posicion), y otro factor
entre‐sujetos con 13 niveles (especie)con efectos principales e interacciones entre los tres factorescon dos factores dentro‐de‐sujetos, añadimos al término aleatorio (1|id) otros dos:interacción sujeto:factor‐dentro‐de (1|factor:id) solo para los factores dentro‐de‐sujetos
modelo9 <- lmer(a_por_b ~ fuente*posicion*especie + (1|id)+(1|fuente:id)+(1|posicion:id),data=datos, REML=TRUE, control=mi.control)
325

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas Repetidas ‐ SPLIT‐PLOT DESIGNS – matrices verticales
THREE‐WAY SPLIT‐PLOT ANCOVA DESIGN, WITH ONE FIXED COVARIATE AND ONE CHANGING COVARIATE (WITH RANDOM INTERCEPT EFFECT)Idem del anterior modelo9 pero añadiendo dos covariantes, una fija (volabdomen) y otra cambiante (t_sonda) para la que se aplica un diseño de random intercept constant slopemodelo10 <- lmer(a_por_b ~ volabdomen+t_sonda+fuente*posicion*especie +
(1|id)+(1|fuente:id)+(1|posicion:id),data=datos, REML=TRUE, control=mi.control)
FOUR‐WAY SPLIT‐PLOT DESIGN CON EFECTOS ANIDADOSdos factores dentro‐de‐sujetos con dos niveles cada uno (fuente y posicion) y otros dos factores entre‐sujetos,
uno con dos niveles (flightless) y otro con 13 niveles (especie) anidado dentro del anteriorcon efectos principales e interacción entre los dos factores dentro‐de‐sujetos, y efectos anidados en los dos factores entre‐sujetos
modeloXL1 <- lmer(a_por_b ~ fuente*posicion+flightless/especie +(1|id)+(1|fuente:id)+(1|posicion:id),data=datos, REML=TRUE, control=mi.control)
con efectos principales e interacción entre los cuatros factores,con el efecto anidado en los dos factores entre‐sujetos
modeloXL1 <- lmer(a_por_b ~ fuente*posicion*flightless/especie +(1|id)+(1|fuente:id)+(1|posicion:id),data=datos, REML=TRUE, control=mi.control)
326

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas Repetidas ‐ SPLIT‐PLOT DESIGNS – matrices verticales
FOUR‐WAY SPLIT‐PLOT DESIGN, WITH ONE FIXED COVARIATE AND ONE CHANGING COVARIATE (WITH RANDOM INTERCEPT EFFECT)dos factores dentro‐de‐sujetos con dos niveles cada uno (fuente y posicion) y otros dos factor entre‐sujetos,
uno con dos niveles (flightless) y otro con 13 niveles (especie) anidado dentro del anteriorañadimos una covariante fija (volabdomen) y otra cambiante (t_sonda)para la covariante cambiante asumimos un diseño random intercept constant slopetanto más correlación haya entre la covariante cambiante y los niveles del factor dentro‐de‐sujetos,
tanto más cambiarán los grados de libertad para el término error (Df.res ó DenDF)
modeloXXL <- lmer(a_por_b ~ volabdomen+t_sonda+fuente*posicion+flightless/especie +(1|id)+(1|fuente:id)+(1|posicion:id), data=datos, REML=TRUE, control=mi.control)
327

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas Repetidas ‐ SPLIT‐PLOT DESIGNS – matrices verticales
COMPARACIÓN DE DOS MODELOS MEDIANTE AIC usando MLpara efectuar correctamente la comparación de dos modelos hay que actualizarlos usando Maximum Likelihood (ML) en vez de Restricted Estimation ML (REML)
ejemplos con modelos previosAICc(update(modelo1, REML=FALSE), update(modelo0, REML=FALSE))AICc(update(modelo10, REML=FALSE), update(modelo9, REML=FALSE))
TEST FRECUENTISTA PARA COMPARAR MODELOSlos modelos que se comparan deben de tener la misma parte aleatoriaponemos antes el modelo más complejo
ejemplos con modelos previosKRmodcomp(modelo1, modelo0)KRmodcomp(modelo10, modelo9)
328

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas Repetidas ‐ SPLIT‐PLOT DESIGNS – matrices verticales
PARTICIÓN DE LA VARIANZAR2m: marginal R2 (the proportion of variance explained by the fixed factor(s) alone)R2c: conditional R2 (the proportion of variance explained by both the fixed and random
factors; i.e. the entire model)ejemplos con modelos previos
r.squaredGLMM(modelo0)r.squaredGLMM(modelo9)
TABLA SINTÉTICA DE EFECTOS PARCIALES Y SIGNIFICACIONES (PARA EFECTOS FIJOS)podemos trabajar con sumas de cuadrados de tipo‐III Anova(modelo9, type=3, test="F")en diseños n‐way complejos con muchas interacciones nos puede convenirhacer uso de SS de tipo‐II
Anova(modelo9, type=2, test="F")
SIGNIFICACIÓN DE LA PARTE ALEATORIA (DIFERENCIA ENTRE SUJETOS)rand(modelo9)
329

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas Repetidas ‐ SPLIT‐PLOT DESIGNS – matrices verticales
ALGUNAS FIGURAS DE EFECTOS ATRIBUIBLES A LOS FACTORES(controlando por las covariantes)resultado gráfico con una figura y múltiples paneles; media +/‐ std_errorse proporcionan los valores ajustados por las covariantesejemplos con modelos previos
plot(interactionMeans(modelo), legend.margin=0.2)
PARTIAL RESIDUAL PLOTSEntrañan considerable dificultad en los modelos mixtos (lmer o glmer) por el hecho de
tener pseudo‐réplicas asignadas a los niveles de un factor aleatorio.Podemos optar por efectuar una estrategia aproximada para visualizar los efectos parciales
construimos un modelo NO‐MIXTO con los mismos efectos que los incluidos en lmer(...)excluyendo la parte aleatoria (1|...)
El siguiente comando crPlots{car} no admite interacciones entre los factoresformula(modelo) ## para ver cuál era la fórmula del modelomodgraf.noint <- lm(a_por_b ~ volabdomen+t_sonda+fuente+posicion+especie, data=datos)crPlots(modgraf.noint, smooth=FALSE, pch=15, lwd=2, col.lines="blue",
grid=FALSE, ylab="partial residuals", main="TITULA COMO QUIERAS")330

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas Repetidas ‐ SPLIT‐PLOT DESIGNS – matrices verticales
331

DISEÑOS n‐FACTORIALES DE EFECTOS “DENTRO” SUJETOSn way ANOVAS y MANOVASANOVAs de Medidas Repetidas ‐ SPLIT‐PLOT DESIGNS – matrices verticales
332


















