
Gráfico de Dispersión de Notas en la Prueba 1 versus...
18
10. Describiendo relaciones entre dos variables A menudo nos va a interesar describir la relación o asociación entre dos variables. Como siempre la metodología va a depender del tipo de variable que queremos describir. Primero vamos a estudiar cómo describir la relación entre dos variables cuantitativas y luego cómo describir la relación entre dos variables cualitativas. 10.1 Describiendo relaciones entre dos variables cuantitativas Para mostrar graficamente la relación entre dos variables cuantitativas usaremos un gráfico llamado de dispersión o de xy. Gráfico de Dispersión de Notas en la Prueba 1 versus Notas en la Prueba Final Acumulativa de un curso de 25 alumnos de Estadística en la UTAL Prueba 1 7 6 5 4 3 2 1 Examen 7 6 5 4 3 2 1 ID 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 P1 1.7 3.8 5.1 5.6 5.0 5.7 2.1 3.7 3.8 4.1 3.4 4.4 6.8 5.1 4.3 6.2 5.9 5.4 4.1 6.2 5.2 4.6 4.9 5.9 5.5 Ex 3.5 3.2 3.5 5.2 4.9 3.7 3.6 4.5 4.0 3.6 4.4 3.3 5.5 3.9 4.6 5.7 4.3 4.1 5.0 3.8 4.4 4.0 4.5 3.4 4.5 a) Encuentre el estudiante número 19 en el gráfico b) Suponga que otro estudiante tuvo un 5.0 en la primera prueba y un 5.5 en la prueba final acumulativa o Examen. Agregue este punto en el gráfico. Al igual que cuando estudiamos los histogramas, tallos y hojas y otros gráficos, ahora nos va interesar describir la forma del gráfico. Específicamente en este caso particular de gráficos de dispersión, nos va interesar la dirección, forma y grado de asociación entre dos variables cuantitativas. Por dirección, diremos que dos variables están asociadas positivamente cuando a mayor valor de una variable el valor de la otra variable también aumenta, como se muestra en la figura A. Dos variables estarán negativamente asociadas cuando a mayor valor de una variable el valor de la otra variable disminuye, como se muestra en la figura B. La forma de una asociación puede ser además lineal, curva, cuadrática, estacional o cíclica, o quizás no tenga una forma definida. En la figura A podemos decir que la relación es lineal. En cambio en las figuras B y D parece no lineal. Por último la figura C muestra que no hay asociación. Por el grado de asociación entendemos cuán cerca están los datos de una forma dada. Por ejemplo, en la figura B se ve que existe un alto grado de asociación no lineal entre los datos. En este punto debemos tener cuidado, porque cambios de escala pueden cambiar la figura y nos pueden llevar a conclusiones erróneas. Más adelante discutiremos sobre una medida de asociación llamada el coeficiente de correlación. Estudiante 16 (6.2, 5.7)
Transcript of Gráfico de Dispersión de Notas en la Prueba 1 versus...

10. Describiendo relaciones entre dos variables
A menudo nos va a interesar describir la relación o asociación entre dos variables. Como siempre la metodología va
a depender del tipo de variable que queremos describir. Primero vamos a estudiar cómo describir la relación entre
dos variables cuantitativas y luego cómo describir la relación entre dos variables cualitativas.
10.1 Describiendo relaciones entre dos variables cuantitativas
Para mostrar graficamente la relación entre dos variables cuantitativas usaremos un gráfico llamado de dispersión o
de xy.
Gráfico de Dispersión de Notas en la Prueba 1 versus
Notas en la Prueba Final Acumulativa de un curso de 25 alumnos de Estadística en la UTAL
Prueba 1
7654321
Examen
7
6
5
4
3
2
1
ID 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
P1 1.7 3.8 5.1 5.6 5.0 5.7 2.1 3.7 3.8 4.1 3.4 4.4 6.8 5.1 4.3 6.2 5.9 5.4 4.1 6.2 5.2 4.6 4.9 5.9 5.5
Ex 3.5 3.2 3.5 5.2 4.9 3.7 3.6 4.5 4.0 3.6 4.4 3.3 5.5 3.9 4.6 5.7 4.3 4.1 5.0 3.8 4.4 4.0 4.5 3.4 4.5
a) Encuentre el estudiante número 19 en el gráfico
b) Suponga que otro estudiante tuvo un 5.0 en la primera prueba y un 5.5 en la prueba final acumulativa o
Examen. Agregue este punto en el gráfico.
Al igual que cuando estudiamos los histogramas, tallos y hojas y otros gráficos, ahora nos va interesar describir la
forma del gráfico. Específicamente en este caso particular de gráficos de dispersión, nos va interesar la dirección,
forma y grado de asociación entre dos variables cuantitativas. Por dirección, diremos que dos variables están
asociadas positivamente cuando a mayor valor de una variable el valor de la otra variable también aumenta, como se
muestra en la figura A. Dos variables estarán negativamente asociadas cuando a mayor valor de una variable el valor
de la otra variable disminuye, como se muestra en la figura B.
La forma de una asociación puede ser además lineal, curva, cuadrática, estacional o cíclica, o quizás no tenga una
forma definida. En la figura A podemos decir que la relación es lineal. En cambio en las figuras B y D parece no
lineal. Por último la figura C muestra que no hay asociación.
Por el grado de asociación entendemos cuán cerca están los datos de una forma dada. Por ejemplo, en la figura B se
ve que existe un alto grado de asociación no lineal entre los datos. En este punto debemos tener cuidado, porque
cambios de escala pueden cambiar la figura y nos pueden llevar a conclusiones erróneas. Más adelante discutiremos
sobre una medida de asociación llamada el coeficiente de correlación.
Estudiante 16
(6.2, 5.7)
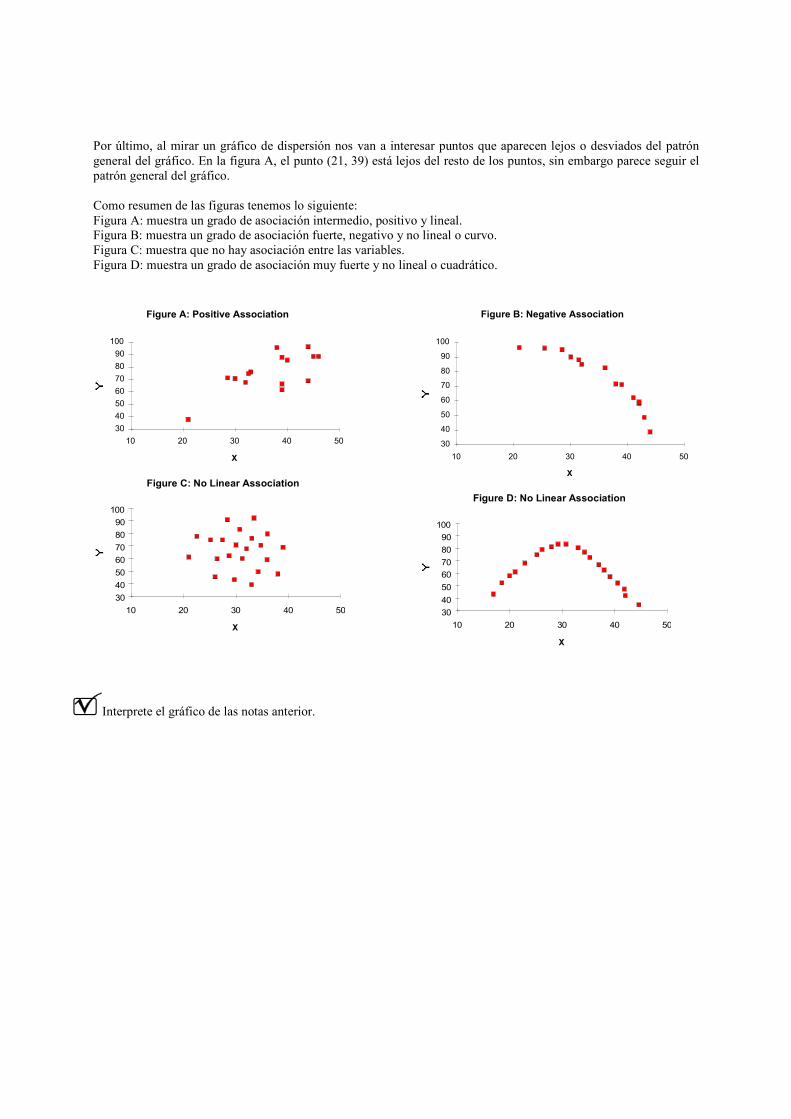
Por último, al mirar un gráfico de dispersión nos van a interesar puntos que aparecen lejos o desviados del patrón
general del gráfico. En la figura A, el punto (21, 39) está lejos del resto de los puntos, sin embargo parece seguir el
patrón general del gráfico.
Como resumen de las figuras tenemos lo siguiente:
Figura A: muestra un grado de asociación intermedio, positivo y lineal.
Figura B: muestra un grado de asociación fuerte, negativo y no lineal o curvo.
Figura C: muestra que no hay asociación entre las variables.
Figura D: muestra un grado de asociación muy fuerte y no lineal o cuadrático.
Figure A: Positive Association
X
30
40
50
60
70
80
90
100
10 20 30 40 50
Figure C: No Linear Association
X
30
40
50
60
70
80
90
100
10 20 30 40 50
Figure B: Negative Association
X
30
40
50
60
70
80
90
100
10 20 30 40 50
Figure D: No Linear Association
X
30
40
50
60
70
80
90
100
10 20 30 40 50
Interprete el gráfico de las notas anterior.

3
Correlación: ¿Cuán fuerte es la relación lineal?
Definición:
El coeficiente de correlación muestral r mide el grado de asociación lineal entre dos variables cuantitativas. Describe la
dirección de la asociación lineal e indica cuán cerca están los puntos a una línea recta en el diagrama de dispersión.
El coeficiente de correlación muestral ρ=r es un estimador puntual de la correlación poblacional ρ (parámetro)
Características:
1. Rango: − ≤ ≤ +1 1r
2. Signo: El signo de coeficiente de correlación indica la dirección de la asociación
La dirección será negativa si el r está en el intervalo [-1 , 0)
La dirección será positiva si el r está en el intervalo (0 , +1].
3. Magnitud: La magnitud del coeficiente de correlación indica el grado de la relación lineal
Si los datos están linealmente asociados r = +1 o r = −1 indican una relación lineal perfecta. Si r = 0 entonces no existe relación lineal.
4. Medida de asociación: la correlación sólo mide el grado de asociación lineal.
5. Unidad: La correlación se calcula usando las dos variables cuantitativas estandarizadas. Por lo que r no tiene
unidad y tampoco cambia si cambiamos la unidad de medida de x o y. La correlación entre x e y es la misma que la
correlación entre y y x.
y
x
x x
x
x
xx
x
x x
xx
x
xx
y
x
x x
x
x
xx
x
x
x
x
x
x
x
x
y
x
x
x
xx x
x
x
x
r ≈ 0 8. r ≈ −0 2. r = 0
Juntemos los gráficos con r
x
y
x
y
x
y
x
y
Graph A: ___________ Graph B: ___________
Graph C: ___________ Graph D: ___________
r = 0 r = +1 r = -1 r = 0.6 r = -0.2 r = -0.8 r= 0.1
4
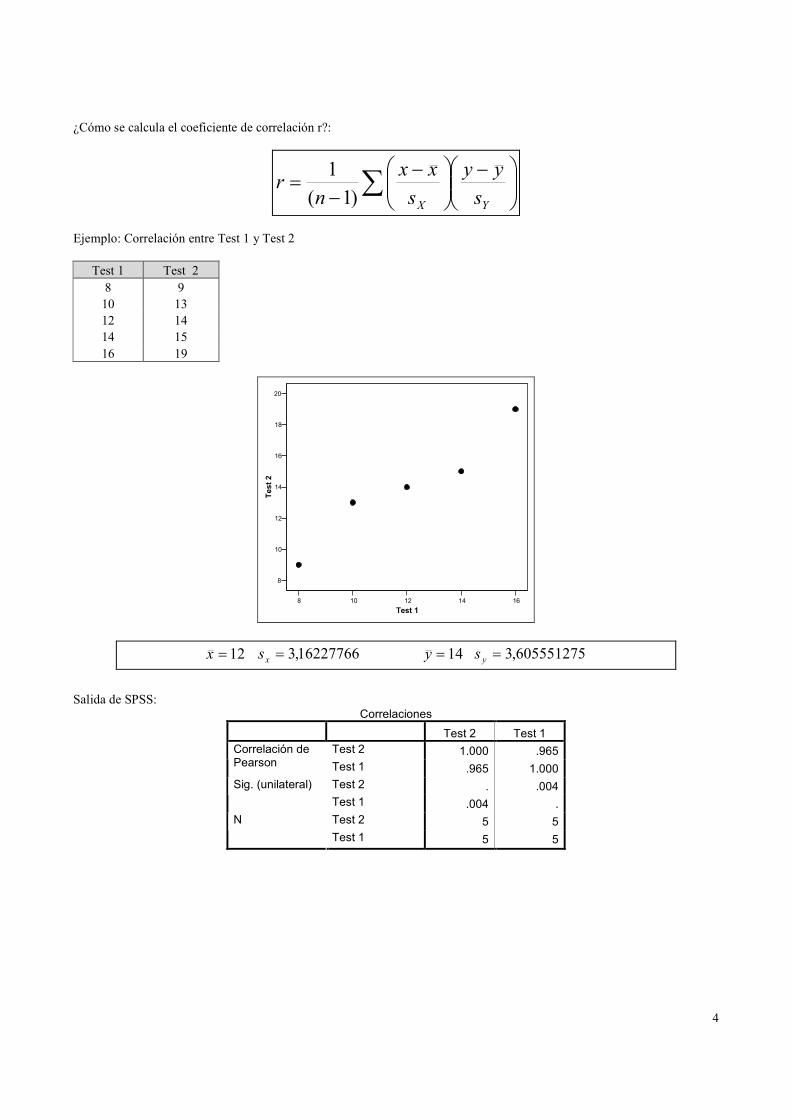
¿Cómo se calcula el coeficiente de correlación r?:
∑
−
−−
=YX s
yy
s
xx
nr
)1(
1
Ejemplo: Correlación entre Test 1 y Test 2
Test 1 Test 2
8 9
10 13
12 14
14 15
16 19
8 10 12 14 16
Test 1
8
10
12
14
16
18
20
Test 2
12=x 16227766,3=xs 14=y 605551275,3=ys
Salida de SPSS: Correlaciones
Test 2 Test 1
Test 2 1.000 .965 Correlación de Pearson Test 1 .965 1.000
Test 2 . .004 Sig. (unilateral)
Test 1 .004 .
Test 2 5 5 N
Test 1 5 5
5
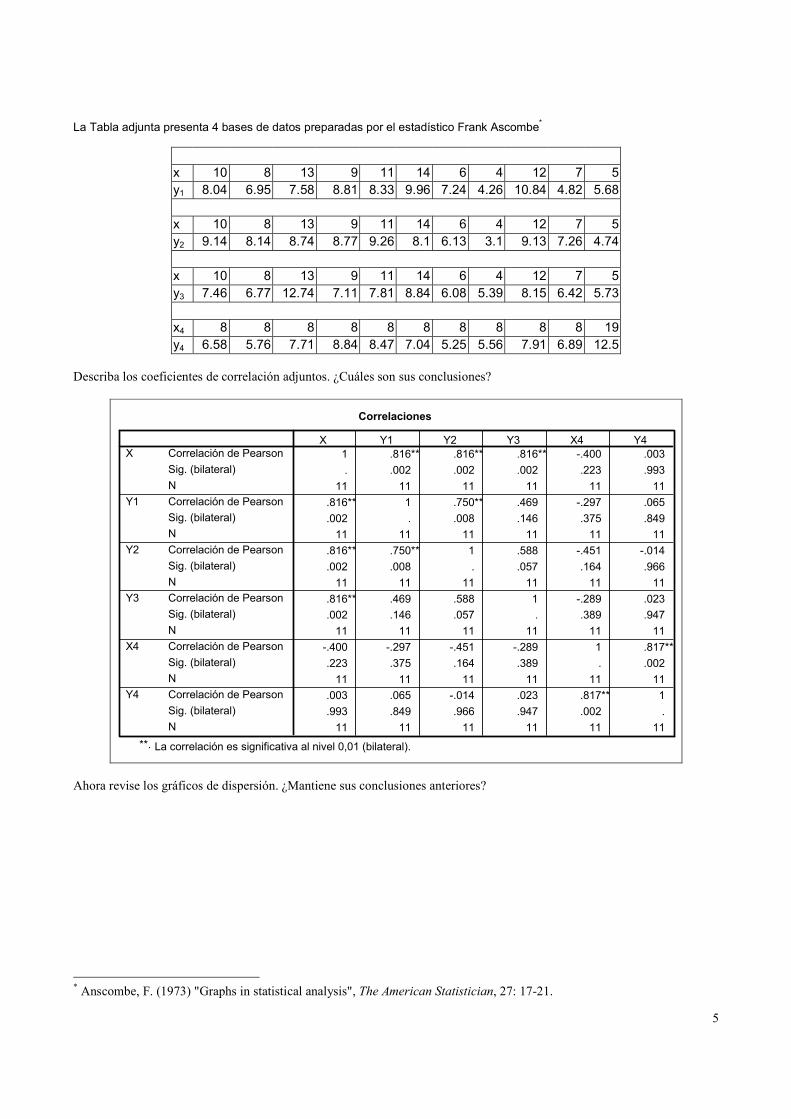
La Tabla adjunta presenta 4 bases de datos preparadas por el estadístico Frank Ascombe*
x 10 8 13 9 11 14 6 4 12 7 5
y1 8.04 6.95 7.58 8.81 8.33 9.96 7.24 4.26 10.84 4.82 5.68
x 10 8 13 9 11 14 6 4 12 7 5
y2 9.14 8.14 8.74 8.77 9.26 8.1 6.13 3.1 9.13 7.26 4.74
x 10 8 13 9 11 14 6 4 12 7 5
y3 7.46 6.77 12.74 7.11 7.81 8.84 6.08 5.39 8.15 6.42 5.73
x4 8 8 8 8 8 8 8 8 8 8 19
y4 6.58 5.76 7.71 8.84 8.47 7.04 5.25 5.56 7.91 6.89 12.5
Describa los coeficientes de correlación adjuntos. ¿Cuáles son sus conclusiones?
Correlaciones
1 .816** .816** .816** -.400 .003
. .002 .002 .002 .223 .993
11 11 11 11 11 11
.816** 1 .750** .469 -.297 .065
.002 . .008 .146 .375 .849
11 11 11 11 11 11
.816** .750** 1 .588 -.451 -.014
.002 .008 . .057 .164 .966
11 11 11 11 11 11
.816** .469 .588 1 -.289 .023
.002 .146 .057 . .389 .947
11 11 11 11 11 11
-.400 -.297 -.451 -.289 1 .817**
.223 .375 .164 .389 . .002
11 11 11 11 11 11
.003 .065 -.014 .023 .817** 1
.993 .849 .966 .947 .002 .
11 11 11 11 11 11
Correlación de Pearson
Sig. (bilateral)
N
Correlación de Pearson
Sig. (bilateral)
N
Correlación de Pearson
Sig. (bilateral)
N
Correlación de Pearson
Sig. (bilateral)
N
Correlación de Pearson
Sig. (bilateral)
N
Correlación de Pearson
Sig. (bilateral)
N
X
Y1
Y2
Y3
X4
Y4
X Y1 Y2 Y3 X4 Y4
La correlación es significativa al nivel 0,01 (bilateral).**.
Ahora revise los gráficos de dispersión. ¿Mantiene sus conclusiones anteriores?
* Anscombe, F. (1973) "Graphs in statistical analysis", The American Statistician, 27: 17-21.

6
X
161412108642
Y1
11
10
9
8
7
6
5
4
X
161412108642
Y2
10
9
8
7
6
5
4
3
X
161412108642
Y3
14
12
10
8
6
4
X4
20181614121086
Y4
14
12
10
8
6
4

7
Regresión Lineal Simple
Como ya hemos visto muchos estudios son diseñados para investigar la asociación entre dos o más variables. Muchas veces
intentamos relacionar una variable explicativa con una variable respuesta. Los datos que se usan para estudiar la relación
entre dos variables se llaman datos bivariados. Datos bivariados se obtienen cuando medimos ambas variables en el mismo
individuo. Suponga que está interesado en estudiar la relación entre las notas de la primera prueba y las notas finales.
Entonces las notas en la primera prueba corresponderían a la variable explicativa o independiente x y las notas finales sería
la variable respuesta o dependiente y. Estas dos variables son de tipo cuantitativo. Si el gráfico de dispersión nos muestra una asociación lineal entre dos variables de interés, entonces buscaremos una línea
recta que describa la relación, la llamaremos recta de regresión.
Un poco de historia
El nombre de regresión deriva de los estudios de herencia de Galton, quien en 1886* publica la ley de la "regresión universal".
En sus estudios Galton encontró que había una relación directa entre la estatura de padres e hijos. Sin embargo, el promedio de
estatura de hijos de padres muy altos era inferior al de sus padres y, el de hijos de padres muy bajos, era superior al de los
padres, regresando a una media poblacional.
Un ejemplo: se seleccionó a 7 alumnas de la carrera de Psicología del año 2003 que nos dieron sus datos de estatura (en
cms) y de peso (en kilos).
154 156 158 160 162 164 166 168 170
estatura
48
50
52
54
56
58
peso
Estatura 155 157 159 162 165 168 169
Peso 48 48 51 55 53 55 57
* Galton, F. (1886) "Regression Towards Mediocrity in Hereditary Stature," Journal of the Anthropological Institute,
15:246-263 (http://www.mugu.com/galton/essays/1880-1889/galton-1886-jaigi-regression-stature.pdf)
8
Ajustando una recta a los datos:
Si queremos describir los datos con una recta tenemos que buscar la "mejor", porque no será posible que la recta pase por
todos los puntos. Ajustar una recta significa buscar la recta que pase lo más cerca posible de todos los puntos.
Ecuación de la recta:
Suponga que y es la variable respuesta (eje vertical) y x es la variable explicativa (eje horizontal). Una línea recta
relaciona a y con x a través de la ecuación:y a bx= +
En la ecuación, bes la pendiente, cuanto cambia y cuando x aumenta en una unidad. La pendiente puede tener signo
positivo, negativo o valor cero. El número a es el intercepto, el valor de y cuando x se iguala a cero.
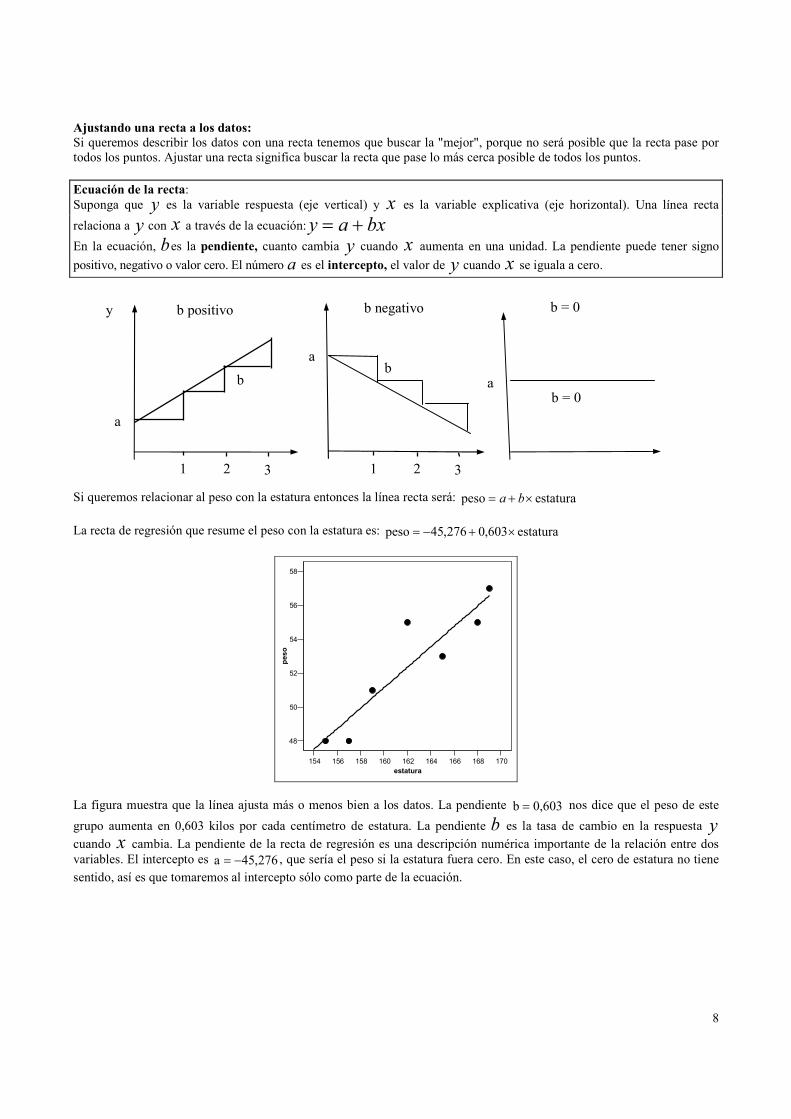
Si queremos relacionar al peso con la estatura entonces la línea recta será: estaturapeso ×+= ba
La recta de regresión que resume el peso con la estatura es: estatura603,0276,45peso ×+−=
154 156 158 160 162 164 166 168 170
estatura
48
50
52
54
56
58
peso
La figura muestra que la línea ajusta más o menos bien a los datos. La pendiente 603,0b = nos dice que el peso de este
grupo aumenta en 0,603 kilos por cada centímetro de estatura. La pendiente b es la tasa de cambio en la respuesta y
cuando x cambia. La pendiente de la recta de regresión es una descripción numérica importante de la relación entre dos
variables. El intercepto es 276,45a −= , que sería el peso si la estatura fuera cero. En este caso, el cero de estatura no tiene
sentido, así es que tomaremos al intercepto sólo como parte de la ecuación.
y
a
a b
b
a
2 3 1
b = 0
b = 0
b negativo b positivo
2 3 1
9
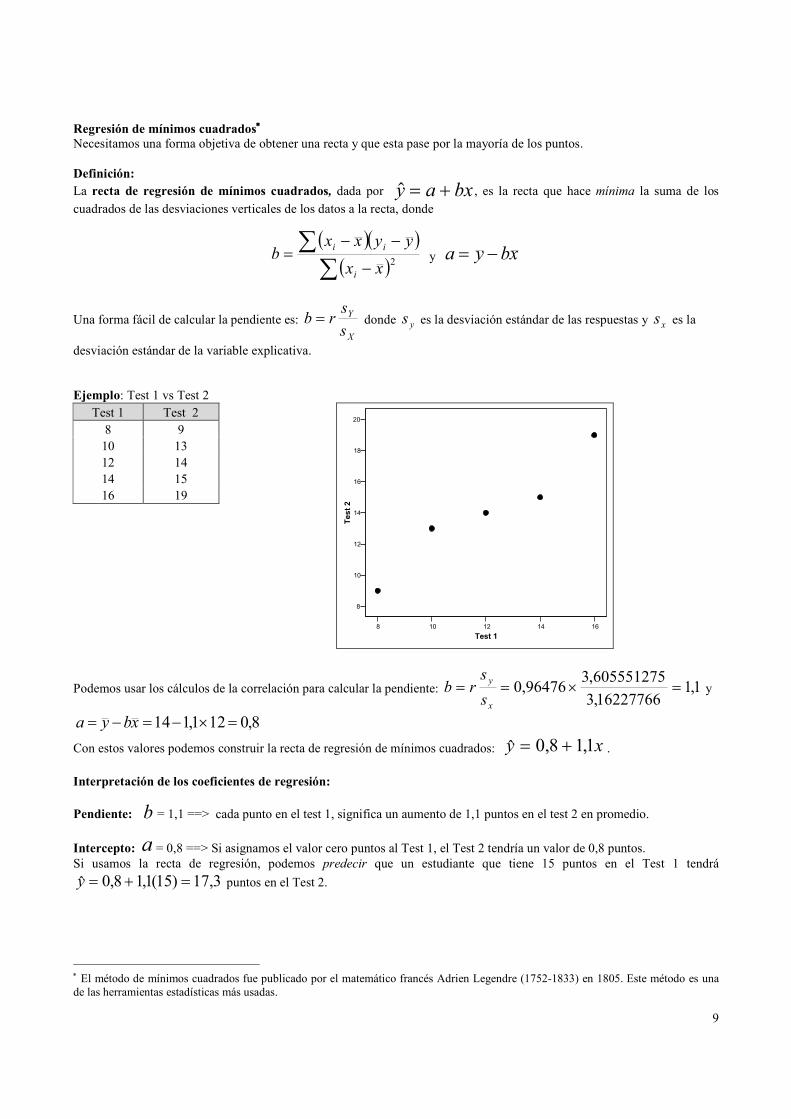
Regresión de mínimos cuadrados∗∗∗∗
Necesitamos una forma objetiva de obtener una recta y que esta pase por la mayoría de los puntos.
Definición:
La recta de regresión de mínimos cuadrados, dada por $y a bx= + , es la recta que hace mínima la suma de los
cuadrados de las desviaciones verticales de los datos a la recta, donde
( )( )( )∑
∑−
−−=
2xx
yyxxb
i
ii y xbya −=
Una forma fácil de calcular la pendiente es:
X
Y
s
srb = donde ys es la desviación estándar de las respuestas y xs es la
desviación estándar de la variable explicativa.
Ejemplo: Test 1 vs Test 2
8 10 12 14 16
Test 1
8
10
12
14
16
18
20
Test 2
Podemos usar los cálculos de la correlación para calcular la pendiente: 1,116227766,3
605551275,396476,0 =×==
x
y
s
srb y
8,0121,114 =×−=−= xbya
Con estos valores podemos construir la recta de regresión de mínimos cuadrados: xy 1,18,0ˆ += .
Interpretación de los coeficientes de regresión:
Pendiente: b = 1,1 ==> cada punto en el test 1, significa un aumento de 1,1 puntos en el test 2 en promedio.
Intercepto: a = 0,8 ==> Si asignamos el valor cero puntos al Test 1, el Test 2 tendría un valor de 0,8 puntos.
Si usamos la recta de regresión, podemos predecir que un estudiante que tiene 15 puntos en el Test 1 tendrá
3,17)15(1,18,0ˆ =+=y puntos en el Test 2.
∗ El método de mínimos cuadrados fue publicado por el matemático francés Adrien Legendre (1752-1833) en 1805. Este método es una
de las herramientas estadísticas más usadas.
Test 1 Test 2
8 9
10 13
12 14
14 15
16 19

10
Definición:
Un residuo es la diferencia entre la respuesta observada, y , y la respuesta que predice la recta de regresión, y . Cada par
de observaciones ( )ii yx , , es decir, cada punto en el gráfico de dispersión, genera un residuo:
residuo = estimadoobservado yy −
El i-ésimo residuo = ( )iiiii bxayyye +−=−= ˆ
Predicción:
Podemos usar la recta de regresión para predicción substituyendo el valor de x en la ecuación y calculando el valor y
resultante. En el ejemplo de las estaturas:
xy 603,0276,45ˆ +−= .
La exactitud de las predicciones de la recta de regresión depende de que tan dispersos estén las observaciones alrededor de
la recta (ajuste).
Extrapolación
Extrapolación es el uso de la recta de regresión para predecir fuera del rango de valores de la variable explicativa x . Este
tipo de predicciones son a menudo poco precisas.
Por ejemplo los datos de peso y estatura fueron tomados de un grupo de alumnas de psicología del año 2003 que tenían
entre 18 y 23 años. ¿Cuanto debe haber pesado una persona si al nacer midió 45 centímetros?
"No deje que los cálculos invadan su sentido común". (Moore, 1989)
Tarea: Calcular los residuos de la regresión, ¿cuánto vale la suma de los residuos?
Los residuos muestran cuán lejos están los datos de la línea de regresión ajustada, examinar los residuos nos ayuda a saber
qué tan bien describe la recta a los datos. Los residuos que se generan a partir del método de mínimos cuadrados tienen una
propiedad básica: el promedio de los residuos es siempre cero.
Volvamos al ejercicio con las estaturas y pesos de 7 alumnas. La recta de regresión la podemos calcular usando el SPSS con
la salida:
Coeficientes(a)
Modelo Coeficientes no estandarizados
Coeficientes estandarizados t Sig.
B Error típ. Beta
1 (Constante) -45.276 18.496 -2.448 .058
estatura .603 .114 .921 5.285 .003
a Variable dependiente: peso
También podemos hacer un gráfico con los residuos versus la variable explicativa. El gráfico de los residuos magnifica las
desviaciones de los datos a la recta, lo que ayuda a detectar problemas con el ajuste. Si la recta de regresión se ajusta bien a
los datos no deberíamos detectar ningún patrón en los residuos.
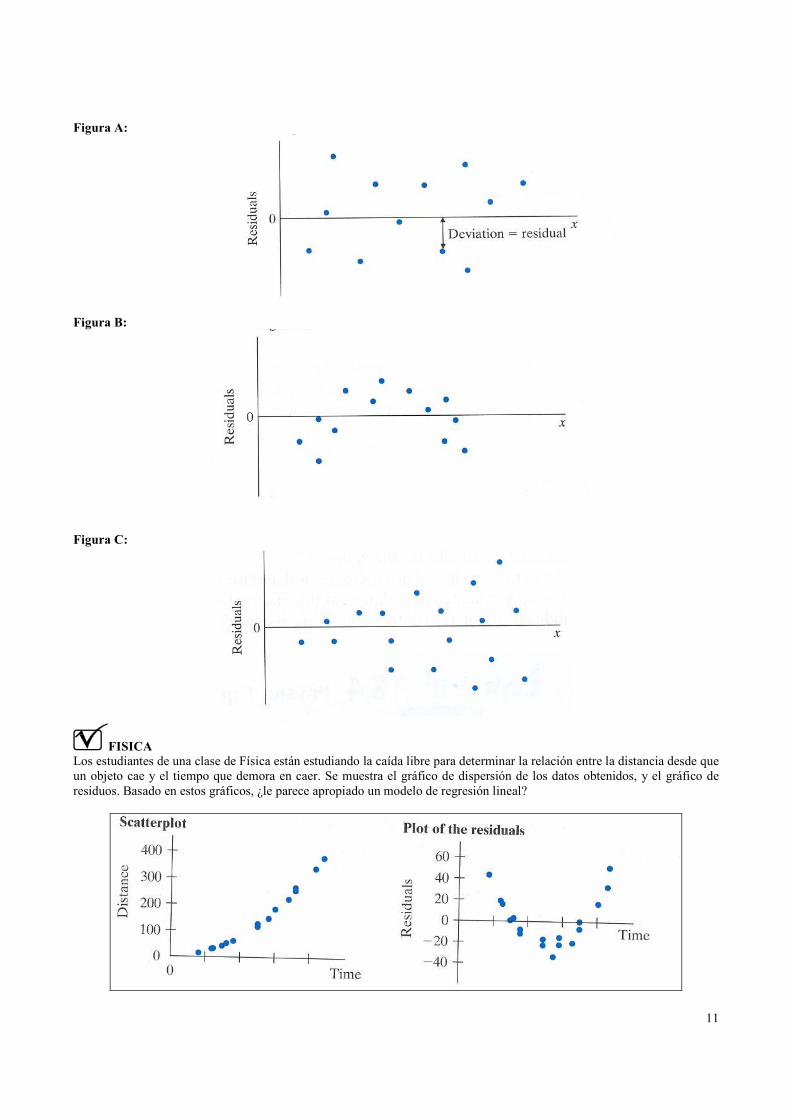
La figura A adjunta muestra un gráfico de residuos típico, generalmente se dibuja la una línea horizontal en el cero. La
figura B en cambio muestra que la relación entre x e y es no lineal, por lo tanto una línea recta no es buena descripción de la
asociación. La figura C muestra residuos en forma de embudo muestra que la variación de y alrededor de x aumenta cuando
x aumenta.
11
Figura A:
Figura B:
Figura C:
FISICA
Los estudiantes de una clase de Física están estudiando la caída libre para determinar la relación entre la distancia desde que
un objeto cae y el tiempo que demora en caer. Se muestra el gráfico de dispersión de los datos obtenidos, y el gráfico de
residuos. Basado en estos gráficos, ¿le parece apropiado un modelo de regresión lineal?

12
Puntos influyentes y extremos
Un punto extremo es una observación que está lejos de la línea recta, lo que produce un residuo grande, positivo o
negativo. Un punto es influyente si al sacarlo produce un cambio notorio en la recta de regresión.
Considere el siguiente conjunto de datos I y su gráfico de dispersión correspondiente.
x y
1 1
1 2
2 1.5
2.5 2.5
3 3
3.5 3
4 3.5
4 4
4.5 4
5 5
5 6
5.5 6
2 6
654321
x
6
5
4
3
2
1
y
Punto A
El punto A produce un residuo grande, parece ser
un punto extremo.
Sin embargo, no es influyente, ya que al sacarlo
la recta de regresión no cambia mucho.
0 1 2 3 4 5 6
0
2
4
6
8
0 1 2 3 4 5 6
0
4
6
8
x
y
Y=0,036+1,002X
Línea sin A
Y=0,958+0,81X
5*X,
Línea que incluye A
Punto A

13
Considere ahora el siguiente conjunto de datos II y su gráfico de dispersión:
x y
1 3
1.5 2
2 3
2 4
2.5 1
2.5 2
3 1
3 2
3 3
3.5 2
4 1
7 7
7654321
x
7
6
5
4
3
2
1
y
Punto B
Punto B no produce un residuo grande.
Sin embargo, el punto B es muy influyente ya que
la sacarlo del análisis la línea recta cambia
totalmente.
El Punto B es influyente, pero no extremo.
0 2 4 6 8
0
2
4
6
8
X
Y
0 2 4 6 8
0
2
4
6
8
Y=0,886+0,582X
Línea con B
Punto B
Línea sin B
Y=3,694-0,594X

14
Inferencia en Regresión Lineal Simple
Modelo de regresión lineal simple:
Se tienen n observaciones de una variable explicativa x y de una variable respuesta y,
( ) ( ) ( )nn yxyxyx ,...,,,,, 2211
el modelo estadístico de regresión lineal simple es:
iii exy ++= βα donde
xYEy βαµ +== )( es la respuesta promedio para cada x.
α representa el intercepto de la función lineal que usa todos los valores de la población y
β representa la pendiente de la función lineal que usa todos los valores de la población. α y β son parámetros
El modelo estadístico de regresión lineal simple asume que para cada valor de x, los valores de la respuesta y son normales
con media (que depende de x) y desviación estándar σ que no depende de x. Esta desviación estándar σ es la desviación estándar de todos los valores de y en la población para un mismo valor de x.
Estos supuestos se pueden resumir como:
Para cada x, ),(~ σµ yNY donde xYEy βαµ +== )(
Podemos visualizar el modelo con la siguiente figura:
Los datos nos darán estimadores puntuales de los parámetros poblacionales.

15
Estimadores de los parámetros de regresión:
El estimador de la respuesta media está dado por bxayYE +== ˆ)(
El estimador del intercepto es: a=α
El estimador de la pendiente es: b=β
El estimador de la desviación estándar σ está dado por:
2
Resˆ
−=
n
SCσ donde ResSC es la suma de cuadrados de los residuos ( )∑ − 2
ˆ ii yy =∑ 2ie
El coeficiente de correlación muestral ρ=r es un estimador puntual de la correlación poblacional ρ
Probando la hipótesis acerca de la existencia de relación lineal
En el modelo de regresión lineal simple => xYE βα +=)( . Si 0=β entonces las variables x e y no están asociadas
linealmente y la respuesta es una constante E(Y) = α .
E(Y) = α
Es decir, conocer el valor de x no nos va a ayudar a conocer y.
Para docimar la significancia de la relación lineal realizamos el test de hipótesis
Ho: β = 0 (la pendiente de la recta de regresión en la población es cero)
H1: β ≠ 0
Existen hipótesis de una cola, donde H1: β < 0 o H1: β > 0, pero lo usual es hacer el test bilateral.
Para docimar la hipótesis podemos usar el test t:
estimador delestándar error
hipotéticovalor puntualestimador −=t
El estimador puntual de β es b, y el valor hipotético es 0. El error estándar de b es:
( )∑ −=
2
ˆ)(
xxbEE
i
σ
El estadístico para docimar la hipótesis acerca de la pendiente de la población es:
)2(~)(
0−
−= nt
bEE
bt

16
Revisemos la salida de SPSS: Coeficientes(a)
Modelo Coeficientes no estandarizados
Coeficientes estandarizados t Sig.
Intervalo de confianza para B al 95%
B Error típ. Beta Límite inferior Límite superior
1 (Constante) .800 2.135 .375 .733 -5.996 7.596
Test 1 1.100 .173 .965 6.351 .008 .549 1.651
a Variable dependiente: Test 2
Verificando supuestos en la Regresión lineal simple
1. Examine el gráfico de dispersión de y versus x para decidir si el modelo lineal parece razonable.
Se asume que la respuesta Y es Normal con media E(Y) = α + βx y desviación estándar σ.
Para cada x, Y es N(E(Y), σ ) donde E(Y) = α + βx
El modelo que describe la respuesta Y es:
Y = α + βx + ε.
Los ε's son los verdaderos términos de error (que no observamos). Estos errores se suponen normales con media cero
desviación estándar σ.
No podemos "ver" estos errores pero tenemos una estimación de ellos mediante los residuos.
2. Examine los residuos para verificar los supuestos acerca del término del error. Los residuos deben ser una muestra
aleatoria de una población normal con media 0 y desviación estándar σ.
Cuando examine los residuos verifique:
a) que provienen de una muestra aleatoria:
Grafique los residuos versus x. El supuesto de que provienen de una muestra aleatoria será razonable si el gráfico
muestra los puntos al azar, sin una forma definida.
A veces es posible detectar falta de independencia cuando los datos recogidos en el tiempo. Para verificar este
supuesto grafique los residuos versus el tiempo y los puntos no deben mostrar una distribución definida.
b) Normalidad Para verificar normalidad haga el histograma de los residuos, este debería aparecer como normal sin valores extremos
si tenemos un número grande de observaciones. En el caso de tener pocas observaciones puede hacer un gráfico de tallo
y hoja y verificar que no haya observaciones extremas.
17
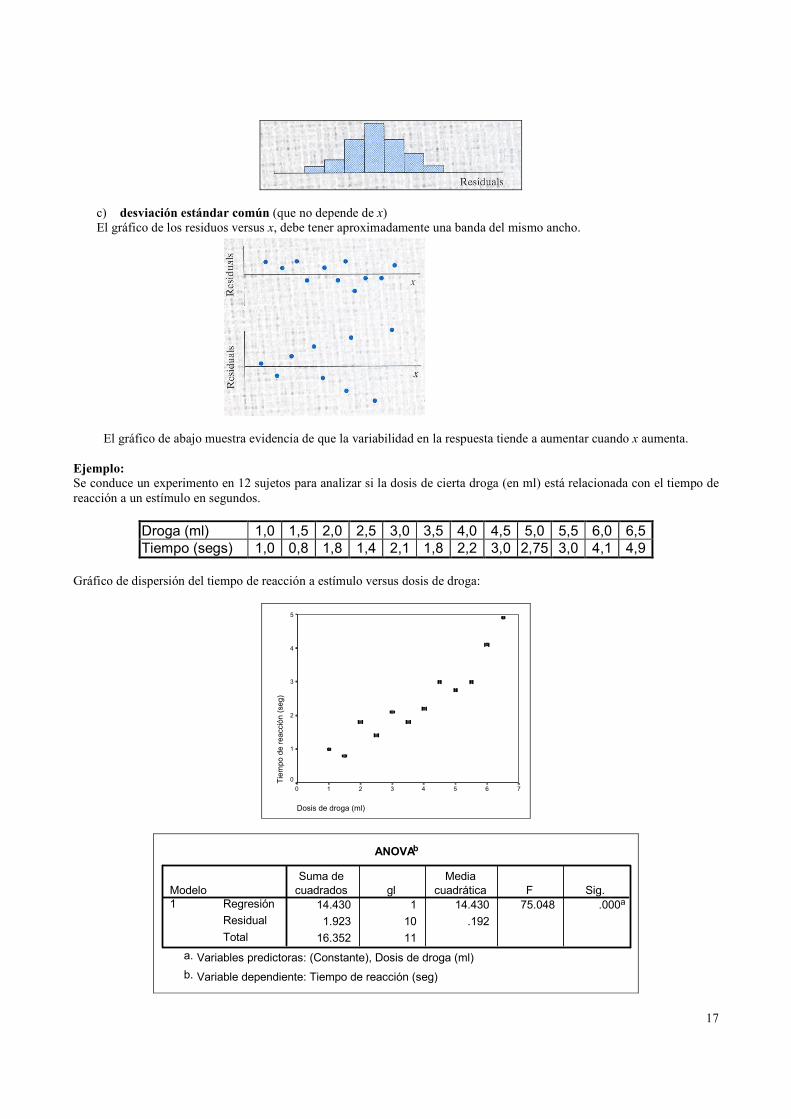
c) desviación estándar común (que no depende de x)
El gráfico de los residuos versus x, debe tener aproximadamente una banda del mismo ancho.
El gráfico de abajo muestra evidencia de que la variabilidad en la respuesta tiende a aumentar cuando x aumenta.
Ejemplo:
Se conduce un experimento en 12 sujetos para analizar si la dosis de cierta droga (en ml) está relacionada con el tiempo de
reacción a un estímulo en segundos.
Droga (ml) 1,0 1,5 2,0 2,5 3,0 3,5 4,0 4,5 5,0 5,5 6,0 6,5
Tiempo (segs) 1,0 0,8 1,8 1,4 2,1 1,8 2,2 3,0 2,75 3,0 4,1 4,9
Gráfico de dispersión del tiempo de reacción a estímulo versus dosis de droga:
Dosis de droga (ml)
76543210
Tiempo de reacción (seg)
5
4
3
2
1
0
ANOVAb
14.430 1 14.430 75.048 .000a
1.923 10 .192
16.352 11
Regresión
Residual
Total
Modelo
1
Suma de
cuadrados gl
Media
cuadrática F Sig.
Variables predictoras: (Constante), Dosis de droga (ml)a.
Variable dependiente: Tiempo de reacción (seg)b.

18
Dosis de droga (ml)
76543210
Unstandardized Residual
.8
.6
.4
.2
-.0
-.2
-.4
-.6
Unstandardized Residual Stem-and-Leaf Plot
Frequency Stem & Leaf
1.00 -0 . 5
5.00 -0 . 12344
4.00 0 . 1123
2.00 0 . 57
Stem width: 1.00000
Each leaf: 1 case(s)
Notas:
- La asociación entre una variable explicativa x y una variable respuesta y, aunque sea muy fuerte, no es por sí sola
evidencia de que los cambios en x causan cambios en y.
- Un coeficiente de correlación es el resumen de la relación presente en un gráfico de dispersión. Conviene, pues,
asegurarse mirando este gráfico que el coeficiente es un buen resumen del mismo. Tratar de interpretar un coeficiente
de correlación sin haber visto previamente el gráfico de las variables puede ser muy peligroso (Peña, Romo, p.129).
- Como hemos visto el coeficiente de correlación es un resumen del gráfico de dispersión entre dos variables. La recta de
regresión es otra manera de resumir esta información, y su parámetro fundamental, la pendiente, está relacionado con el
coeficiente de correlación por la ecuación:
X
Y
s
srb = . La diferencia entre regresión y correlación es que en el cálculo de
la correlación ambas variables se tratan simétricamente, mientras que en la regresión, no. En regresión se trata de
prever la variable respuesta en función de los valores de la variable explicativa. En consecuencia, si cambiamos el papel
de las variables cambiará también la ecuación de regresión, porque la recta se adaptará a las unidades de la variable que
se desea predecir (Peña, Romo, p.142).


















