
MANUAL PARA EL SPSS - … · mayor uso tienen cuando se trata de realizar análisis con el SPSS....
61
REPÚBLICA BOLIVARIANA DE VENEZUELA MINISTERIO DEL PODER POPULAR PARA LA EDUCACIÓN SUPERIOR UNIVERSIDAD GRAN MARISCAL DE AYACUCHO VICE-RECTORADO ACADÉMICO ESCUELA DE ADMINISTRACIÓN SEDE EL TIGRE MANUAL PARA EL SPSS PROFESOR: HAMLET MATA MATA INTEGRANTE: JULISSA MEDINA EL TIGRE
Transcript of MANUAL PARA EL SPSS - … · mayor uso tienen cuando se trata de realizar análisis con el SPSS....

REPÚBLICA BOLIVARIANA DE VENEZUELA
MINISTERIO DEL PODER POPULAR PARA LA EDUCACIÓN
SUPERIOR
UNIVERSIDAD GRAN MARISCAL DE AYACUCHO
VICE-RECTORADO ACADÉMICO
ESCUELA DE ADMINISTRACIÓN
SEDE EL TIGRE
MANUAL PARA EL SPSS
PROFESOR: HAMLET MATA MATA
INTEGRANTE: JULISSA MEDINA
EL TIGRE

2
INDICE
Contenido Pág.
Introducción…………………………………………………………………… 3
Programa SPSS……………………………………………………………… 4
Definición……………………………………………………………………….. 4
Características…………………………………………………………………… 5
Requerimientos…………………………………………………………………. 6
Utilización………………………………………………………………………… 6
Importancia……………………..………………………………………………. 44
Aplicaciones……………………………………………………………………. 45
Fichero de datos………………………………………………………………… 48
Versiones……………………………………………………………………….. 50
Módulos…………………………………………………………………………. 51
Conclusiones…………………………………………………………………… 54
Referencias bibliográficas…………………………………………………….. 55
Anexos…………………………………………………………………………… 56

3
INTRODUCCIÓN
Los campos de aplicación de la estadística son muy diferentes, pero
los métodos son los mismos, dando lugar a la estandarización y
automatización de las técnicas estadísticas, con una gran variedad de
programas informáticos que se diferencian entre sí por variados
aspectos (entornos de trabajo, capacidad, costos, etc.). Entre esta gama
de software se encuentra el SPSS, el cual es una potente herramienta
para realizar análisis estadísticos, tiene más de tres décadas de
existencia, fue elaborado por Hull y Nie y quizás sea el programa
informático de estadística con mayor difusión a nivel mundial.
Aprender a manejar el SPSS tiene muchas ventajas. La primordial
es la seguridad y confianza que brinda el tener esta herramienta que
efectúa los cálculos más complejos en el mundo de la estadística de
manera eficiente y eficaz, y con un mínimo de esfuerzos. Posiblemente
esta sea la razón por la cual este programa es muy utilizado en el
mundo académico y laboral. Es una de las herramientas más utilizadas
en investigación comercial y en otros muchos campos de investigación
de las ciencias sociales.
Es necesario aclarar que a pesar de la facilidad que resulta el poder
realizar cálculos con gran facilidad con los modernos programas
informáticos, es imprescindible que el investigador mantenga el control
de la situación en todo momento, y sea él quien se convierta en el
tomador de decisiones; ya que el software lo único que hace es
obedecer una orden, pero no manifiesta en ningún momento si el diseño
de nuestro estudio es el adecuado, si la técnica es la idónea, etc., ya

4
que presionar un botón o dar un clic es muy sencillo, por lo que
debemos estar siempre alertas al momento de realizar nuestro análisis
estadístico.
PROGRAMA SPSS
DEFINICION
SPSS (tambien conocido como PASW Statistics) es un conjunto de
herramientas para realizar análisis estadísticos avanzados. Posee
poderosas capacidades para generar informes y gráficos. Es utilizado
frecuentemente por estudiantes, profesores y empresas vinculados al
campo de la investigación.
Statistical Package for the Social Sciences (SPSS) es un programa
estadístico informático muy usado en las ciencias sociales y las
empresas de investigación de mercado. En la actualidad, la sigla se usa
tanto para designar el programa estadístico como la empresa que lo
produce. Originalmente SPSS fue creado como el acrónimo de Statistical
Package for the Social Sciences aunque también se ha referido como
"Statistical Product and Service Solutions" (Pardo, A., & Ruiz, M.A.,
2002, p. 3).
Como programa estadístico es muy popular su uso debido a la
capacidad de trabajar con bases de datos de gran tamaño. En la versión
12 es de 2 millones de registros y 250.000 variables. Además, de
permitir la recodificación de las variables y registros según las
necesidades del usuario. El programa consiste en un módulo base y

5
módulos anexos que se han ido actualizando constantemente con
nuevos procedimientos estadísticos. Cada uno de estos módulos se
compra por separado.
Actualmente, compite no sólo con softwares licenciados como lo
son SAS, MATLAB, Statistica, Stata, sino también con software de
código abierto y libre, de los cuales el más destacado es el Lenguaje R.
Recientemente ha sido desarrollado un paquete libre llamado PSPP, con
una interfaz llamada PSPPire que ha sido compilada para diversos
sistemas operativos como Linux, además de versiones para Windows y
OS X. Este último paquete pretende ser un clon de código abierto que
emule todas las posibilidades del SPSS.
El SPSS Fue creado en 1968 por Norman H. Nie, C. Hadlai (Tex)
Hull y Dale H. Bent. Entre 1969 y 1975 la Universidad de Chicago por
medio de su National Opinion Research Center estuvo a cargo del
desarrollo, distribución y venta del programa. A partir de 1975
corresponde a SPSS Inc.
Originalmente el programa fue creado para grandes computadores. En
1970 se publica el primer manual de usuario del SPSS por Nie y Hall.
Este manual populariza el programa entre las instituciones de educación
superior en EE. UU. En 1984 sale la primera versión para computadores
personales.
Desde la versión 14, pero más específicamente desde la versión
15 se ha implantado la posibilidad de hacer uso de las librerías de
objetos del SPSS desde diversos lenguajes de programación. Aunque
principalmente se ha implementado para Python, también existe la
posibilidad de trabajar desde Visual Basic, C++ y otros lenguajes.

6
El 28 de junio de 2009 se anuncia que IBM, meses después de ver
frustrado su intento de compra de Sun Microsystems, adquiere SPSS,
por 1.200 millones de dólares
CARACTERISTICAS
Con este programa podrás:
Realizar análisis estadísticos
Estimar datos estadísticos
Crear informes estadísticos detallados
Nueva funcionalidad para programadores estadísticos
Más accesible para todo tipo de usuarios
Herramientas de investigación mejoradas
REQUERIMIENTOS DE SPSS:
Windows XP/Vista
Registro gratuito en la web del autor
Procesador Intel
512 MB de memoria RAM
Reproductor de CD-ROM
800 MB de espacio libre en el disco duro
Internet Explorer 6 o superior
UTILIZACION
Al comenzar una sesión de trabajo con el SPSS aparece una
ventana de apariencia similar a una hoja de Excel, que es el Editor de
Datos, tal y como se muestra en la Figura 1 . Esta es la ventana

7
principal del SPSS, pero no la única. Para irnos familiarizando con las
diversas funciones del programa, estudiaremos en un primer momento
las diversas ventanas y menús con que cuenta el SPSS, profundizando
posteriormente en cada uno de ellos y utilizando ejercicios prácticos
para una mejor compresión de la temática.
En la Fig. 1 observamos en el encabezado el título principal del archivo
en el cual se está trabajando, en este caso “Sin título”, porque se
iniciará con la creación de una base de datos. En la siguiente línea se
tiene la barra del menú con las opciones de archivo, edición, ver, datos,
transformar, analizar, gráficos, utilidades, ventaja, y ayuda (?). Luego
tenemos la barra de herramientas (ver figura 2), con cada uno de sus
íconos.
En su orden, de izquierda a derecha, cada icono indica la siguiente
acción:
Abrir archivo

8
Guardar archivo
Imprimir
Recuperar cuadro de diálogo
Deshacer
Rehacer
Ir a gráfico
Ir a caso
Variables
Buscar
Insertar casos
Insertar variable
Segmentar archivo
Ponderar casos
Seleccionar casos
Etiquetas de valor
Usar conjuntos
La línea siguiente a la Barra de Herramientas (como se observa en
la Figura 1.3, en el círculo en rojo), indica el valor o atributo de la
variable en esa celda (fila y columna). Y el círculo en azul muestra las
solapas de vista de datos (valores en la base de datos) y vista de
variables (codificaciones realizadas para cada una de las variables) para
el fichero en el que se está trabajando en ese instante.

9
En la Figura 4 se observa la primera opción del menú, Archivo, que
incluye:
Nuevo. Crea nuevos ficheros o bases de datos, sintaxis, resultados
o de procesos
Abrir. Abre ficheros o bases de datos existentes, sintaxis,
resultados, de procesos u otros);
Abrir base de datos. Nueva consulta, editar consulta o ejecutar
consulta
Leer datos de texto. P uede transformar archivos de texto a tablas
Guardar. Guarda el archivo actual
Guardar Como. Guarda el archivo actual con otro nombre y en
otro directorio si así se quiere
Mostrar información de datos. Muestra los archivos de datos
posibles
Hacer caché de datos. Crea memoria para los datos que se están
introduciendo
Imprimir Imprime la operación actual.
Presentación preliminar. Se visualiza en pantalla completa la tarea
actual, tal y como se imprimirá
Cambiar servidor. Se tiene la posibilidad de cambiar de servidor al
que nos encontramos conectados.

10
Detener procesador. Interrumpe el procesamiento y análisis de
datos en el SPSS
Datos usados recientemente Muestra un listado de los datos
utilizados mas recientemente
Archivos usados recientemente Muestra los archivos que se han
utilizado recientemente
Salir Opción para salir del SPSS.
Luego tenemos la opción de Edición (Figura 5), que presenta la
siguientes subopciones:

11
En esta opción tenemos las siguientes subopciones:
Deshacer Definir valor de casilla Deshace la última acción. Muy útil
para rectificar.
Rehacer Definir valor de casilla Rehace la última acción deshecha
Cortar Corta la selección para almacenarla en el portapapeles
Copiar Copia la selección para almacenarla en el portapapeles
Pegar Pega el contenido del portapapeles en la ubicación en donde
se encuentre el cursor
Pegar variables Pega la variable del portapapeles en donde se
encuentre ubicado el cursor
Eliminar Borra la selección
Buscar Realiza la búsqueda de datos que se especifiquen
Opciones Presenta opciones de tablas, gráficos, procesos, etc.

12
La Figura 6 muestra la opción Ver , y cuenta con las siguientes
subopciones:
Barra de estado (con esta opción se activa y desactiva la barra de
estado);
Barras de herramientas (activa y desactiva las barras de
herramientas);
Fuentes Con esta opción se cambia el tamaño y estilos de las
fuentes. Textos por ejemplo
Cuadrícula Con ésta opción se activa y desactiva la cuadrícula del
editor de datos
Etiquetas de valor Sitúa etiquetas de valor en las variables
seleccionadas
Variables Con esta opción se activa el visor de variables en el
editor de datos)
La Figura 7 presenta la opción Datos , que es una de las opciones que
mayor uso tienen cuando se trata de realizar análisis con el SPSS. Entre
las subopciones tenemos las siguientes: Definir propiedades de
variables (etiqueta los valores de las variables y define otras
propiedades después de explorar datos);Copiar propiedades de
datos (permite copiar sobre el archivo de datos de trabajo, las
propiedades de un conjunto de datos y de las variables
seleccionadas); Definir fechas (Definir fechas genera variables de fecha
que se pueden utilizar para establecer la periodicidad de una serie
temporal y para etiquetar los resultados de los análisis de series
temporales); Insertar variable (permite insertar una variable en el
editor); Insertar caso (permite insertar un caso en el editor); Ir a
caso (permite situarse en un caso determinado); Ordenar
casos (permite ordenar casos según criterios
preestablecidos); Transponer(transpone filas por columnas en el editor

13
de datos); Reestructurar (reestructura los datos de varias variables –
columnas- en un único caso y convertirlos en grupos de casos
relacionados –filas- y viceversa);Fundir archivos (permite mezclar
archivos por casos o por variables); Agregar (permite agregar variables
a un archivo); Diseño ortogonal (admite diseñar y mostrar diseños
factoriales ortogonales); Segmentar archivo (admite segmentar archivos
según ciertos criterios); Seleccionar casos (admite la elección de uno o
varios casos); Ponderar casos (permite la ponderación de casos).
La Figura 8 muestra la opción Transformar , y contiene las
siguientes subopciones: Calcular (realiza cálculos); Semilla de
aleatorización (fija la semilla para el cálculo de números
aleatorios); Contar apariciones (encuentra frecuencias absolutas de
valores); Recodificar (recodifica los valores de una
variable); Categorizar variables (convierte variables cuantitativas a
cualitativas); Asignar rangos a casos(crea nuevas variables que
contienen rangos); Recodificación automática (convierte los valores
numéricos y de cadena en valores enteros consecutivos); Crear serie
temporal (crea una variable tipo serie de tiempo); Reemplazar valores

14
perdidos (Reemplazar valores perdidos creando nuevas
variables); Ejecutar transformaciones pendientes (realizar
transformaciones en espera).
La opción Analizar en la barra del menú básico contiene las
siguientes subopciones (ver figura 9): Informes, Estadísticos
descriptivos, Tablas, Comparar medias, Modelo lineal general, Modelos
mixtos, Correlaciones, Regresión, Loglineal, Reducción de datos,
Escalas, Pruebas no paramétricas, Series temporales, Supervivencia y
Respuestas múltiples.

15
Considero ésta opción del menú (Analizar) como una de las más
importantes dentro del SPSS, motivo por el cual se estudiarán cada una
de sus subopciones por separado.
La Figura 10 muestra la subopción Informes , el cual abarca los
siguientes ítems: Cubos OLAP (del inglés On-Line Analytic Processing -
Procesamiento analítico interactivo-, calcula totales, medias y otros
estadísticos univariados para variables de resumen continuas dentro de
las categorías de una o más variables categóricas de
agrupación); Resúmenes de casos (calcula estadísticos de subgrupo
para las variables dentro de las categorías de una o más variables de
agrupación); Informe de estadísticos en filas(genera informes en los
cuales se presentan distintos estadísticos de resumen en filas); Informe
de estadísticos en columnas (genera informes de resumen en los que
diversos estadísticos de resumen aparecen en columnas distintas).
Figura 10.
La figura 11 presenta la subopción de Estadísticos
descriptivos, que contienen los siguientes ítems:Frecuencias (muestra
estadísticos y representaciones gráficas que resultan útiles para
describir muchos tipos de variables, y es un buen procedimiento para la
inspección inicial de datos); Descriptivos (presenta estadísticos de
resumen univariados para varias variables en una única tabla y calcula
valores tipificados, denominados generalmente como puntuaciones
“Z”); Explorar (genera estadísticos de resumen y representaciones
gráficas, bien para todos los casos o bien de forma separada para

16
grupos de casos); Tablas de contingencia (crea tablas de clasificación
doble y múltiple y, además, proporciona una serie de pruebas y medidas
de asociación para las tablas de doble clasificación); Razón (brinda una
amplia lista de estadísticos de resumen para describir la razón entre dos
variables de escala, por ej. mediana, moda, desviación típica, máximos
y mínimos, y otros muy usuales en investigación).
A continuación tenemos la figura 12, que muestra la subopción
de Tablas, con la cual usted puede realizar todo tipo de análisis y
mostrarlos de diversas maneras, siempre en formato de tablas. Los
ítems que se incluyen acá son: Tablas personalizadas (el investigador
selecciona las variables y las medidas de resumen que aparecerán en la
tabla); Conjuntos de respuestas múltiples (se utiliza para agrupar
frecuencias de respuestas por indicadores y variables); Tablas
básicas (genera tablas con calidad de publicación que muestran
estadísticos de clasificación cruzada y de subgrupo); Tablas
generales (se pueden generar tablas que muestren diferentes
estadísticos para distintas variables, variables de respuestas múltiples,
anidación y apilación mixta o totales complejos); Tablas de respuestas
múltiples(produce tablas de frecuencia y de contingencia básicas en las
que una o más variables es un conjunto de respuestas
múltiples); Tablas de frecuencias (permite generar tablas especiales que
contengan varias variables con los mismos valores).

17
Comparar medias (Figura 13), que contiene en orden respectivo:
Medias (calcula medias de subgrupo y estadísticos univariados
relacionados para variables dependientes dentro de las categorías de
una o más variables independientes); Prueba T para una
muestra (contrasta si la media de una sola variable difiere de una
constante especificada); Prueba T para muestras
independientes (compara las medias de dos grupos de casos); Prueba T
para muestras relacionadas (compara las medias de dos variables de un
solo grupo); ANOVA de un factor (este procedimiento genera un análisis
de varianza de un factor para una variable dependiente cuantitativa
respecto a una única variable de factor -variable independiente-).
La figura 14 presenta la opción de Modelo lineal general, que
incluye los siguientes apartados:Univariante (proporciona un análisis de
regresión y un análisis de varianza para una variable dependiente
mediante uno o más factores o variables); Multivariante (proporciona un
análisis de regresión y un análisis de varianza para variables
dependientes múltiples por una o más covariables o variables de

18
factor); Medidas repetidas (analiza grupos de variables dependientes
relacionadas que representan diferentes medidas del mismo
atributo); Componentes de la varianza (se emplea para modelos de
efectos mixtos, estima la contribución de cada efecto aleatorio a la
varianza de la variable dependiente).
Posterior al Modelo lineal general, los siguientes apartados
son: Modelos mixtos (en este cuadro de diálogo le facilita al investigador
seleccionar variables que definen sujetos y observaciones repetidas, y
elegir una estructura de covarianzas para los residuos)
y Correlaciones (incluye correlaciones parciales, bivariadas y distancias).
La figura 15 presenta la subopción de Regresión, que incluye los
siguientes apartados: Lineal (estima los coeficientes de un modelo
lineal, con una o más variables independientes, que mejor prediga el
valor de la variable dependiente); Estimación curvilínea (genera
estadísticos de estimación curvilínea por regresión y gráficos
relacionados para varios modelos diferentes de estimación curvilínea por
regresión); Logística binaria (es de mucha utilidad para los casos en los
que se desea predecir la presencia o ausencia de una característica o
resultado según los valores de un conjunto de variables
predictoras); Logística multinomial (es útil en aquellas situaciones en las
que el investigador desee poder clasificar a los sujetos según los valores
de un conjunto de variables predictoras); Ordinal(permite dar forma a la
dependencia de una respuesta ordinal politómica sobre un conjunto de

19
predictores, que pueden ser factores o covariables); Probit (mide la
relación entre la intensidad de un estímulo y la proporción de casos que
presentan una cierta respuesta a dicho estímulo); No lineal (es un
método para encontrar un modelo no lineal para la relación entre la
variable dependiente y un conjunto de variables
independientes); Estimación ponderada (permite calcular los
coeficientes de un modelo de regresión lineal mediante mínimos
cuadrados ponderados -MCP, WLS-, de forma que se les dé mayor
ponderación a las observaciones más precisas -es decir, aquéllas con
menos variabilidad- al determinar los coeficientes de
regresión); Mínimos cuadrados en dos fases (utiliza variables
instrumentales que no estén correlacionadas con los términos de error
para calcular los valores estimados de los predictores
problemáticos); Escalamiento óptimo (amplía la aproximación típica
mediante un escalamiento de las variables nominales, ordinales y
numéricas simultáneamente).
Después de Regresión, tenemos la opción Loglineal analiza las
frecuencias de las observaciones incluidas en cada categoría de la
clasificación cruzada de una tabla de contingencia, e incluye los
apartados de General, Logit y Selección del modelo.

20
En la figura 16 se tiene la subopción de Clasificar, que es una de
las subopciones que mayor uso tiene cuando de realizar análisis de
conglomerados se trata. Cuenta con los siguientes ítems:Conglomerados
en dos fases (es una herramienta de exploración que descubre las
agrupaciones naturales -o conglomerados- de un conjunto de datos que,
de otra manera, no sería posible detectar);Conglomerado de K
medias (con este procedimiento se intenta identificar grupos de casos
relativamente homogéneos basándose en las características
seleccionadas y utilizando un algoritmo que puede gestionar un gran
número de casos); Conglomerados jerárquicos (combina los
conglomerados basándose en las características seleccionadas y los
clasifica en orden de jerarquía);Discriminante (este análisis resulta útil
para las situaciones en las que se desea construir un modelo predictivo
para pronosticar el grupo de pertenencia de un caso a partir de las
características observadas de cada uno de ellos).
Otra opción interesante es la de Reducción de datos, que se
observa en la figura 17, con los siguientes apartados: Análisis
factorial (identifica variables subyacentes, o factores, que expliquen la
configuración de las correlaciones dentro de un conjunto de variables
observadas); Análisis de correspondencias (describe las relaciones
existentes entre dos variables nominales, recogidas en una tabla de
correspondencias, sobre un espacio de pocas dimensiones, mientras que
al mismo tiempo se describen las relaciones entre las categorías de cada

21
variable); Escalamiento óptimo (permite realizar escalados de las
variables, cual se tratara de un mapa).
La figura 18 presenta la opción Escalas , con los siguientes
ítems: Análisis de fiabilidad (permite estudiar las propiedades de las
escalas de medición y de los elementos que las
constituyen);Escalamiento multidimensional (trata de encontrar la
estructura de un conjunto de medidas de distancia entre objetos o
casos); Escalamiento multidimensional -PROXSCAL- (su propósito es
encontrar la estructura existente en un conjunto de medidas de
proximidades entre objetos).
Continuando con nuestro caminar por el SPSS, la siguiente
subopción la componen las Pruebas no paramétricas , figura 19, entre
las que se tienen las siguientes: Chi-cuadrado (tabula una variable en
categorías y calcula un estadístico de chi-cuadrado); Binomial (compara
las frecuencias observadas de las dos categorías de una variable
dicotómica con las frecuencias esperadas en una distribución binomial
con un parámetro de probabilidad especificado. Por defecto, el
parámetro de probabilidad para ambos grupos es
0,5); Rachas (contrasta si es aleatorio el orden de aparición de dos
valores de una variable); K-S de 1 muestra (Prueba de Kolmogorov-
Smirnov para una muestra compara la función de distribución
acumulada observada de una variable con una distribución teórica

22
determinada, que puede ser la normal, la uniforme, la de Poisson o la
exponencial); 2 muestras independientes (compara dos grupos de casos
existentes en una variable); K muestras independientes (realiza pruebas
para varias muestras independientes compara dos o más grupos de
casos respecto a una variable); 2 muestras relacionadas (compara las
distribuciones de dos variables); K muestras relacionadas (compara las
distribuciones de dos o más variables).
La figura 20 presenta las Series temporales, contiene los
siguientes ítems: Suavizado exponencial(suaviza componentes
irregulares de datos de series temporales, para ello hace uso de una
variedad de modelos que incorporan diferentes supuestos acerca de la
tendencia y la estacionalidad); Autorregresión(estima un modelo de
regresión lineal con errores autorregresivos de primer
orden); ARIMA (estima modelos Arima -Modelo Autorregresivo
Integrado de Media Móvil- univariados estacionales y no estacionales,
también conocidos como modelos "Box-Jenkins"); Descomposición
estacional (estima factores estacionales multiplicativos o aditivos para
las series temporales).
La figura 21 nos muestra la opción Supervivencia, que contiene los
siguientes apartados: Tablas de mortalidad (se utiliza en situaciones en
las se desea examinar la distribución de un período entre dos eventos,

23
como por ejemplo, la duración del empleo); Kaplan-Meier (se basa en la
estimación de las probabilidades condicionales en cada punto temporal
cuando tiene lugar un evento y en tomar el límite del producto de esas
probabilidades para estimar la tasa de supervivencia en cada punto
temporal); Regresión de Cox (es un método para crear modelos para
datos de tiempos de espera hasta un evento con casos censurados
presentes); Cox con covariable dependiente del tiempo (denominado
también modelo de regresión de Cox extendido, el cual permite
especificar las covariables dependientes del tiempo).
Finalmente, en la opción de Análisis tenemos como una última
subopción Respuestas múltiples , que está integrada por las siguientes
funciones: Definir conjuntos (agrupa variables elementales en conjuntos
de categorías múltiples y de dicotomías múltiples, para los que se
pueden obtener tablas de frecuencias y tablas de
contingencia); Frecuencias ; Tablas de contingencia.
La figura 22 presenta en forma desglosada todas las subopciones
que contiene la opción de Gráficos . Esta opción nos permite realizar un
sinfín de gráficas, de todo tipo, forma, en segunda o en tercera
dimensión, como los clásicos de barras, histogramas, de dispersión,
líneas o curvas, o los poco conocidos diagramas de caja. En esta opción
usted tiene mucha versatilidad al momento de diseñar los gráficos para
la presentación de de resultados en su investigación.

24
La figura 23 presenta la opción de Utilidades dentro de la Barra del
Menú Principal, y esta contiene las siguientes
funciones: Variables (muestra información sobre la definición de la
variable seleccionada actualmente); Información del archivo (muestra
en un listado las variables de las cuales se compone el archivo); Definir
conjuntos (crea subconjuntos de variables que se muestran en las listas
de origen de los cuadros de diálogo); Usar conjuntos (restringe las
variables mostradas en las listas de origen de los cuadros de diálogo a
los conjuntos seleccionados que haya definido); Ejecutar proceso (busca
y ejecuta un archivo seleccionado, por ejemplo, una base de
datos); Editor de menús (se puede personalizar los menús utilizando
este editor).

25
La figura 24 muestra la opción de Ventana , que muestra las
ventanas que se encuentran activas en ese instante, tales como los
archivos o bases de datos en las que nos encontremos trabajando
actualmente, se observarán activas en ésta opción.
El software posee un completo sistema de ayuda al usuarios al que
puede accederse desde cualquier ventana o cuadro de diálogo. El
principal se encuentra en la Barra del Menú Principal, que se señala en
la figura 25.

26
El menú de Ayuda (?) de la barra de menús, incluye los siguiente:
Un sistema de ayuda por temáticas que permite acceder a todos
los contenidos de la ayuda usando cuatro estrategias
diferentes: contenido, índice, buscar y favoritos.
Un tutorial que explica, paso a paso, cómo llevar a cabo muchas
de las tareas propias del programa estadístico.
Un asesor estadístico que ayuda al usuario a decidir qué
procedimiento estadístico utilizar para analizar sus datos.
Además de lo anterior, también el SPSS presenta las siguientes
opciones de ayuda:
La ayuda contextual de los cuadros de diálogo y de las tablas
pivotantes, que brinda ayuda específica sobre los aspectos
concretos de un cuadro de diálogo o de una tabla del Visor de
resultados.
El botón de ayuda de los cuadros de diálogo, que permite ayuda
puntual sobre el procedimiento concreto del que en ese instante
trate el cuadro de diálogo.
La guía de sintaxis , que en la versión de este programa en Disco
Compacto contiene ayuda sobre la sintaxis específica de cada
procedimiento.
El asesor de resultados , que ofrece ayuda similar al tutorial pero
referida a las diferentes partes de las tablas pivotantes del Visor
de resultados.
La figura 26 indica el proceso para obtener ayuda a través de
los Temas . Con un simple clic usted obtiene la ventana de la derecha, y
la primera pestaña le indica una serie de temas agrupados
por Contenido.

27
La ayuda también se presenta como un índice de temas, tal y
como se observa en la figura 27.

28
En la figura 28 se observa la forma de realizar una Búsqueda en la
opción de Ayuda. Lo único que usted debe hacer es colocar una palabra
clave, tal y como señala el círculo color rojo. Luego, al obtener el listado
de temas relacionados, usted debe elegir cual es el tema que quiere
estudiar, y puede dar doble clic sobre el tema escogido o simplemente
dar un clic en la opción de "mostrar tema".

29
En la figura 29 se observan los Favoritos en la opción de Ayuda .
Acá se tiene la libertad de agregar temas que a nos parezcan de interés
y se añaden a mis Favoritos. El círculo en color azul muestra el tema
que el investigador desea añadir, le da clic en el botón "agregar" y el
círculo en color rojo muestra la lista de temas que hasta el momento se
han agregado a los temas favoritos.

30
La figura 30 brinda detalles del Asesor estadístico con que cuenta
la opción de Ayuda del SPSS. Este asesor es de gran utilidad para irnos
familiarizando con las funciones básicas del SPSS, pero hay que tomar
en cuenta que este asesor no es un sustituto del analista de datos, de
manera que hay que tener algunas ideas claras para poder sacarle
provecho.

31
La figura 31 muestra la denominada ayuda contextual , la cual es
un sistema rápido para obtener ayuda rápida que brinda información
concreta sobre aspectos relacionados con la parte específica del
programa desde la que se solicita la ayuda. Por ejemplo, el primer
recuadro de la figura es el diálogo deFrecuencias y el siguiente es
la Ayuda que el SPSS brinda sobre éste tema.

32
La figura 32 muestra otro tipo de ayuda , cuando nos encontramos en
el “Visor de Resultados”, por ejemplo en una Tabla de frecuencia ,
basta con dar un clic con el botón derecho del ratón el cuadro (gráfico ó
figura) y obtenemos un menú donde aparece la primera opción de “¿Qué
es esto?”, y dando otro clic en ésta opción, se tiene el resultado
mostrado en el recuadro con fondo amarillo. Esta es una opción que
trabajando en el SPSS resulta de suma utilidad para cuando
necesitamos conocer rápidamente un tema o asunto particular.

33
Otra opción importante en el SPSS, es el Asesor de resultados ,
el cual proporciona ayuda sobre el significado de las distintas partes de
que consta una tabla de resultados. Para ingresar al Asesor de
resultados usted lo puedo hacer de la siguiente manera:
Seleccione la tabla de resultados sobre la que desee obtener
ayuda, y colocándose sobre ella de doble clic con el botón
izquierdo del ratón, luego de un clic sobre el botón del Asesor de
resultados , tal y como lo muestra la figura 33b.
Seleccione la opción Asesor de resultados en el menú ayuda,
colocándose sobre la tabla de la que desee obtener ayuda, pulse
una vez el botón derecho del ratón y elija la opción indicada
(Figura 33a).
Una vez realizada cualquiera de los anteriores procedimientos, se
obtiene la Figura 34, que muestra paso a paso y en detalle, el

34
significado de las filas y columnas, así como define en forma precisa los
conceptos estadísticos que aparecen en dicha tabla.

35
Para irnos familiarizando aún más con nuestro programa SPSS,
vamos a proceder a crear una nueva base de datos. Al cargar o abrir el
programa SPSS surge un recuadro como lo muestra la figura 35(a),
entonces, para crear nuestra propia base de datos damos un clic en la
opción “ introducir datos ” y luego clic en “ aceptar ”. Lo primero que
debemos notar es que para ingresar valores ó datos en el SPSS, las filas
representan sujetos o casos , en tanto que las columnas constituyen
lascaracterísticas o atributos de cada sujeto en una determinada
variable. Esto se observa claramente en la figura 35(b).

36
Ahora, el siguiente paso es ir a la vista de variables para
designar nuestra primera variable de la investigación. Como ejemplo
tomaremos dos variables, la primera el “género” y la segunda la “edad”.
La figura 36 presenta dónde nos encontramos situados en este
momento. En la figura 36(a) se observa que se ha escrito el nombre de
la primera variable “género”, y se darán cuenta ustedes que al presionar
la tecla de “enter”, aparecen de inmediato valores en las otras casillas,
lo que se ve en la figura 36(b).

37
Muy bien, ahora enfoquémonos en cada una de las columnas que
aparecen en la Vista de variables , para analizar cada una de sus
propiedades.

38
Una vez colocado el nombre de la variable , se nos presenta el Tipo de
variable que se trate, especifica los tipos de datos de cada variable. Por
defecto se asume que todas las variables nuevas son numéricas. En
nuestro caso, dejaremos la variable género como de tipo cadena
(alfanumérica), con una anchura de 8 caracteres (figura 37).
Uno de los puntos muy importantes y que debe ponérsele mucho énfasis
es la etiqueta , ya que así aparecerá la variable en nuestras tablas de
análisis. Continuando con el ejemplo anterior, seguiremos trabajando
con el nombre de “género” y así etiquetaremos la variable. En algunos
casos, cuando el nombre sea muy extenso, es recomendable utilizar
abreviaturas que identifiquen cada una de las variables, como por
ejemplo: “latino” (Latinoamericano), “estud” (estudiante), “cirplast”
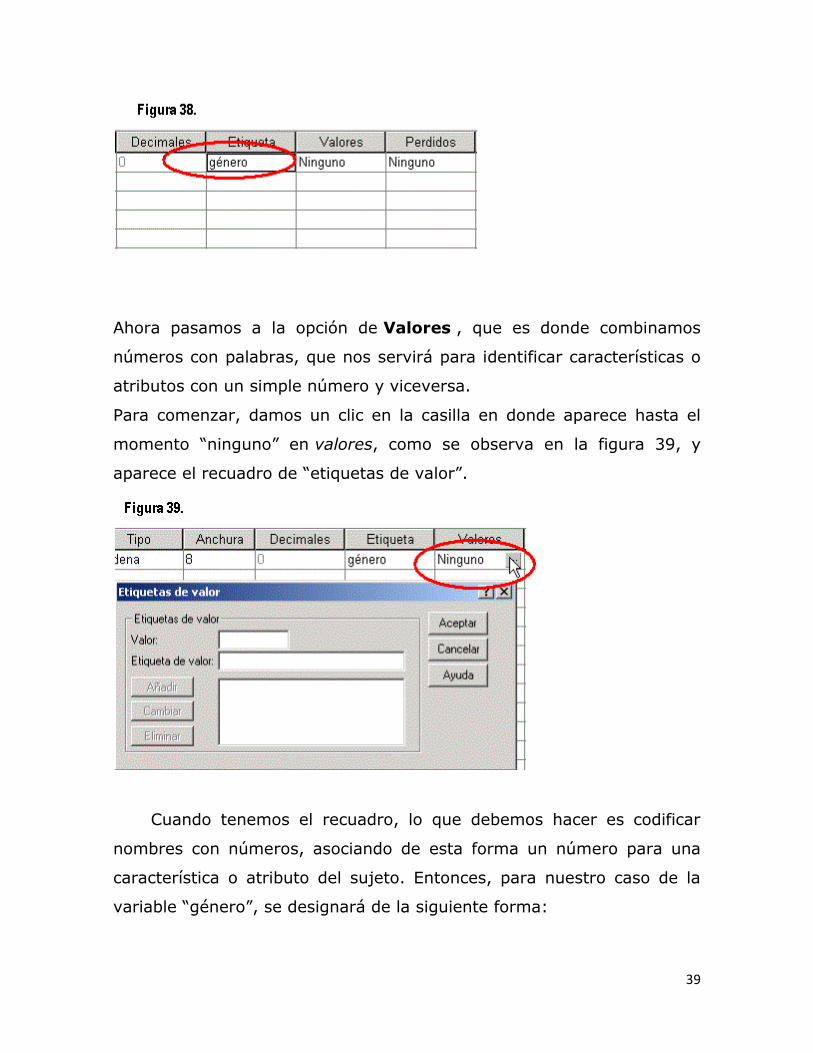
(Cirujano Plástico), etc. La figura 38 nos muestra como se va
transformando hasta ahora nuestra base de datos.
39
Ahora pasamos a la opción de Valores , que es donde combinamos
números con palabras, que nos servirá para identificar características o
atributos con un simple número y viceversa.
Para comenzar, damos un clic en la casilla en donde aparece hasta el
momento “ninguno” en valores, como se observa en la figura 39, y
aparece el recuadro de “etiquetas de valor”.
Cuando tenemos el recuadro, lo que debemos hacer es codificar
nombres con números, asociando de esta forma un número para una
característica o atributo del sujeto. Entonces, para nuestro caso de la
variable “género”, se designará de la siguiente forma:

40
Número 1 para “femenino”, y
Número 2 para “masculino”.
Una vez hecho esto, se pulsa en el botón “añadir” para que agregue
las nuevas etiquetas de valor. La figura 39(a) muestra este proceso.

41
Ahora seguimos con la opción de perdidos. Acá se definen valores
de los datos especificados como perdidos por el usuario. A menudo es
útil para saber por qué se pierde información. Por ejemplo, puede
desear distinguir los datos perdidos porque un entrevistado se niega a
responder, o datos perdidos porque la pregunta no afectaba a dicho
entrevistado, etc. Los valores de datos especificados como perdidos por
el usuario aparecen marcados para un tratamiento especial y se
excluyen de la mayoría de los cálculos. Para nuestra base de datos
ejemplo, asumiremos que no se tienen valores perdidos.
Las últimas opciones son Alineación y Medida (Figura 41). La
“alineación” tiene que ver con la forma en que se ordena el concepto
dentro de la casilla (izquierda, centro, derecha), y la “medida” cataloga
a la variable como Nominal (cuando no se tiene ningún orden
especificado o el orden no interesa) , Ordinal (cuando existe una
ordenación de mayor a menor, o viceversa) o Escala (denominadas por
algunos autores también como de “razón”, e indican que entre un
atributo y otro existe la misma diferencia o distancia, dependiendo el
caso) . Para nuestro ejemplo, la variable “ género ” queda catalogada
con medida nominal, ya que no tiene un ordenamiento específico.

42
Ahora ya hemos completado la codificación de nuestra
variable género . Procedemos a realizar lo mismo pero para la
variable edad , de esta forma haremos un repaso de todo el
procedimiento, y que nos servirá para nuestro aprendizaje.
Con respecto a la variable edad , tendrá un tratamiento un poco
diferente, ya que podemos reclasificarla para un mejor análisis, de la
siguiente manera:
Joven, de 20 años o menos (X £ 20)
Adulto, mayor de veinte años y menor de 50 (20 < X < 50).
Persona mayor, de 50 años o más (X ³ 50).
Entonces, comenzamos colocando el nombre a nuestra variable,
tal cual se muestra en la figura 42.
Ahora ingresaremos el tipo de la variable, que quedará como
“numérica” para la edad (Figura 43).

43
Las columnas de Anchura y Decimales no se cambiarán,
dejaremos las casillas tal cual. EnEtiqueta digitaremos la palabra
“edad”, que así identificaremos nuestra variable (Figura 44).
Para la asignación de valores a la variable edad , lo realizaremos
basándonos en la clasificación anterior y con la siguiente codificación:
1, para los “jóvenes” (menores de 20 años)
2, para las personas “adultas” (de 20 años a 50 años)
3, para las personas “mayores” (mayores de 50 años).

44
Las figuras 45 muestran cómo realizaría la asignación de valores e
ingreso de los mismos.

45
46
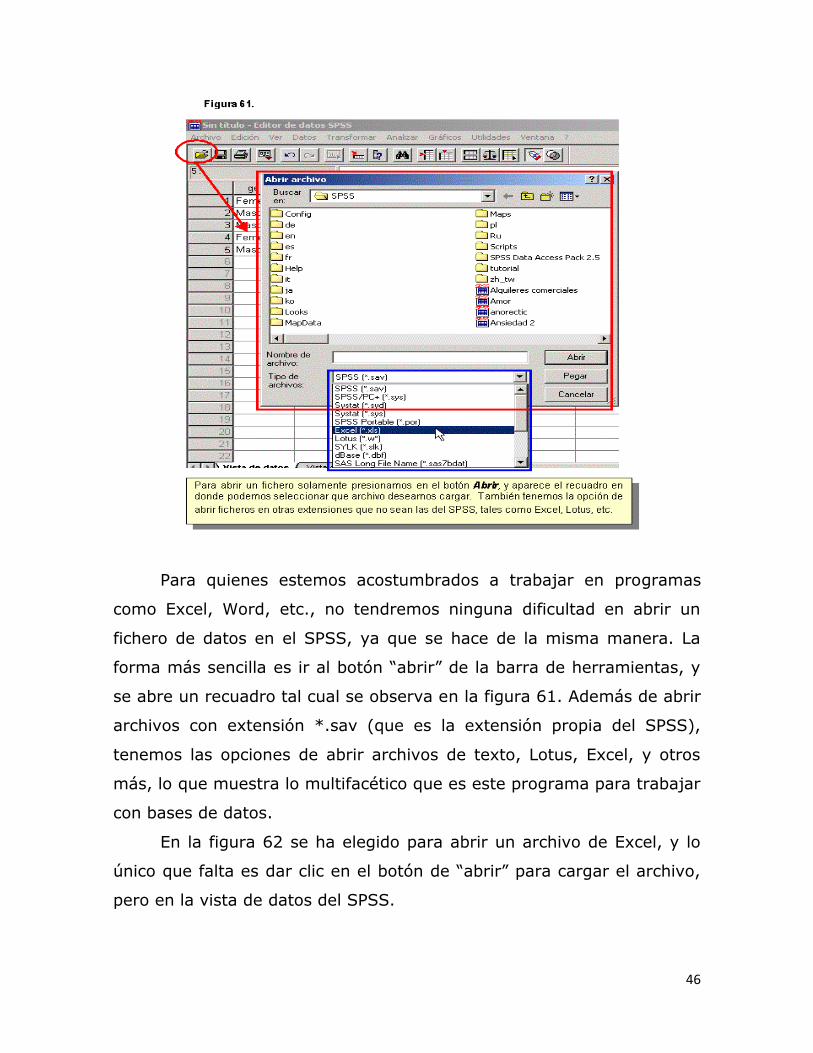
Para quienes estemos acostumbrados a trabajar en programas
como Excel, Word, etc., no tendremos ninguna dificultad en abrir un
fichero de datos en el SPSS, ya que se hace de la misma manera. La
forma más sencilla es ir al botón “abrir” de la barra de herramientas, y
se abre un recuadro tal cual se observa en la figura 61. Además de abrir
archivos con extensión *.sav (que es la extensión propia del SPSS),
tenemos las opciones de abrir archivos de texto, Lotus, Excel, y otros
más, lo que muestra lo multifacético que es este programa para trabajar
con bases de datos.
En la figura 62 se ha elegido para abrir un archivo de Excel, y lo
único que falta es dar clic en el botón de “abrir” para cargar el archivo,
pero en la vista de datos del SPSS.

47
La figura 63 nos muestra el proceso que debe seguirse para
guardar información en el SPSS. En primera instancia, nos vamos al
menú Archivo , y se nos despliega un menú, en el cual recomiendo se
elija la opción de Guardar como , y aparece un recuadro en donde nos
pide la ubicación en la que deseamos guardar el archivo (disco C, disco
A, Memoria flash, etc.), y además nos solicita que le indiquemos en que
formato o extensión deseamos guardar el archivo (Excel, Lotus, etc.).
Una vez realizado esto, el siguiente paso es pulsar en el botón
de Guardar del recuadro, y nuestro archivo ya se encuentra salvado.

48
IMPORTANCIA
El SPSS, permite el trabajo de investigación representando los
objetos reales en objetos formales, bajo estrategias y lenguajes diversos
de representación, lenguajes de análisis de cualidades o lenguajes
asociados al manejo de cantidades pues lo cuantitativo implica o incluye
representacionalmente a lo cualitativo. Es por ello que lo mismo se
aplica en el propio campo matemático como también en el de las
ciencias de la documentación en econometría, sociometría y
psicometría, o en la generalidad de las ciencias sociales en tanto
paquete orientado a ellas.

49
En el campo de la computación y de la inteligencia artificial su
utilización es frecuente para el modelado. Esto es señalado
expresamente por un grupo de académicos investigadores del
Departamento de Ciencia de la Computación e Inteligencia Artificial de la
Universidad de Alicante, cuando afirman que el SPSS es un potente
sistema de análisis estadístico y gestión de datos. Ofrece un rápido
entorno de modelización visual que abarca desde lo más simple hasta lo
más complejo para crear modelos de manera interactiva y realizar
cambios utilizando técnicas analíticas probadas y acreditadas.
APLICACIONES
Permite analizar archivos enormes de datos sin utilizar grandes
cantidades de espacio de almacenamiento temporal en disco. Asimismo,
permite la utilización del servidor; mejorando la velocidad de acceso y
proceso de la información compleja, utilizando el análisis en modo
distribuido de la información sin bloquear su computadora.
Puede ejecutar varias sesiones del programa simultáneamente en el
mismo equipo de escritorio, lo que hace posible analizar más de un
archivo de datos al mismo tiempo.
SPSS tiene un sistema de ficheros en el cual el principal son los
archivos de datos (extensión. SAV). Aparte de este tipo existen otros
dos tipos de uso frecuente:
Archivos de salida (output, extensión. SPO): en estos se despliega
toda la información de manipulación de los datos que realizan los
usuarios mediante las ventanas de comandos. Son susceptibles de
ser exportados con varios formatos (originalmente HTML, RTF o
TXT, actualmente la versión 15 incorpora la exportación a PDF

50
junto a los formatos XLS y DOC que ya se encontraban en la
versión 12)
Archivos de sintaxis (extensión. SPS): Casi todas las ventanas de
SPSS cuentan con un botón que permite hacer el pegado del
proceso que el usuario desea realizar. Lo anterior genera un
archivo de sintaxis donde se van guardando todas las
instrucciones que llevan a cabo los comandos del SPSS. Este
archivo es susceptible de ser modificado por el usuario. Muchos de
los primeros usuarios del SPSS suelen escribir estos archivos en
vez de utilizar el sistema de pegado del programa.
Existe un tercer tipo de fichero: el fichero de scripts (extensión.
SBS). Este fichero es utilizado por los usuarios más avanzados del
software para generar rutinas que permiten automatizar procesos muy
largos y/o complejos. Muchos de estos procesos suelen no ser parte de
las salidas estándar de los comandos del SPSS, aunque parten de estas
salidas. Buena parte de la funcionalidad de los archivos de scripts ha
sido ahora asumida por la inserción del lenguaje de programación
Python en las rutinas de sintax del SPSS. Procedimientos que antes solo
se podían realizar mediante scripts ahora se pueden hacer desde el
sintax mismo.
El programa cuando se instala trae un determinado número de
ejemplos o utilidades de casi todos los ficheros en cuestión. Estos son
usados para ilustrar algunos de los ejemplos de uso del programa.
Aquí está una pequeña lista de cosas que se pueden hacer
mediante este programa:
1. Introducción de datos: Vamos a vista de datos y se introducen en
DISTINTAS columnas (porque son distintas variables) de arriba abajo.

51
2. Cálculos básicos: -Para hacer operaciones: ANALIZAR>>estadísticos
descriptivos>>frecuencias (para tablas de frecuencias) ahí llevas la
variable que te interese al otro lado y le das a estadísticos donde
marcaremos todo lo que queramos saber (media, moda, mediana,
cuartiles…). Nos parecerá una pantalla nueva con los resultados. Si
necesitamos saber P 2,5 o P 97,5 habría que hacerlo aquí.
-ANALIZAR>>estadísticos descriptivos>>explorar: ahí introducimos la
variable en el primer campo (lista de dependientes) y le damos a
aceptar. Aquí nos da toda la información de antes pero ADEMÁS nos da
el intervalo de confianza y estimación muestral así como el error típico
de la media ENCIMA nos da las gráficas del diagrama tronco hojas y el
de cajas.
-Para la ASIMETRIA y la KURTOSIS: En simetría: si es negativo está
sesgada a la IZQUIERDA si es 0 es simétrica y si es positivo está
sesgada a la DERECHA.En curtosis: si está rondando el 0 es
mesocurtica, si es negativo platicúrtica y si es positiva leptocúrtica
-ANALIZAR>>estadísticos descriptivos>>frecuencias>>gráficos esto es
útil para ver la FORMA DE LA DISTRIBUCIÓN ya que podemos
superponer la curva de la normal. Si la curva se parece al histograma
podemos decir que es simétrica.
-Si por ejemplo queremos hacer una nube de puntos o un diagrama de
disperisón para ver dos variables cuantitativas,vamos a
Gráficos>>cuadro de diálogos antiguos>>dispersión
puntos>>dispersión simple>>definir>> OJO hay que saber cuál es la
dependiente y cual la independiente. En función de será la X

52
(dependiente (Y) y independiente (X)[la edad por ejemplo sería
independiente en la mayoría de los casos])
-Otra cosa que podemos sacar es el coeficiente de correlación lineal de
Pearson ANALIZAR>>correlaciones>>bivariadas. Ahí nos aparecerá una
tabla. En una diagonal siempre nos saldrá 1 (no hacer caso) en el otro
te aparecerá otro valor, que será el importante.
-El coeficiente de regresión y el coeficiente de determinación:
ANALIZAR>>regresión>>lineal. De todas las tablas que hay, hay que
fijarse en la que pone RESUMEN DEL MODELO y fijarse en la R2 (coef.
De determinación). Para sacar el coeficiente de regresión (b) hay que
mirar en una tabla llama COEFICIENTES. Ahí vemos dos numero debajo
de la B. la primera se llama constante (también denominada a) y el
segundo es el coeficiente B de regresión. En resumen hay que coger el
SEGUNDO.
-Si queremos contrastar dos medias: ANALIZAR>> comparar
medias>>prueba t para muestras independientes>>definir grupos.
-Para hacer una selección de datos de una variable:
DATOS>>Seleccionar casos>>Si satisface la condición>>Pones la
variable a la derecha=(lo que quieras comparar) Ahora ya vamos a
ANALIZAR>>explorar.
-ANALIZAR>>Estadístico descriptivo>>tablas de
contingencia>>casillas>>% en filas>> aceptar.

53
-ANALIZAR>>Estadísticos descriptivos>>Tablas de
contingencia>>Mostras grafico de barras agrupados Y estadísticos>>(el
estadístico que se quiera)
-ANALIZAR>>Comparar medias>>Prueba T para 1
muestra>>(ponemos el valor en valor de prueba)>>Aceptar `[Miramos
en Sig]
-Si queremos cambiar el nombre a las variables para que sea más
cómodo, se puede en VISTA DE VARIABLES (pestaña derecha) y clickas
en el nombre.
FICHERO DE DATOS DE SPSS
Los ficheros de datos en formato SPSS tienen en Windows la
extensión. SAV. Al abrir un fichero de datos con el SPSS, vemos la vista
de datos, una tabla en la que las filas indican los casos y las columnas
las variables. Cada celda corresponde al valor que una determinada
variable adopta en un cierto caso.
Además de esta vista de datos, en las últimas versiones del programa
existe una vista de variables en la que se describen las características
de cada una. En esta vista las filas corresponden a cada variable y las
columnas nos permiten acceder a sus características:
Nombre, limitado a 8 caracteres.
Tipo de variable (compárese este listado de opciones con los tipos
de variables estadísticas existentes)
Numérico, número en formato estándar)
Coma decimal, número con comas cada tres posiciones y
con un punto como delimitador de los decimales

54
Punto decimal, número con puntos cada tres posiciones y
con una coma como límite delimitador de los decimales.
Notación científica, número que se expresa con un formato
tal que se sigue de una E y un número que expresa la
potencia de 10 a la que se multiplica la parte numérica
previa
Fecha
Moneda dólar, formato numérico con el que se expresan
cantidades en dólares
Moneda del usuario, formato numérico con el que se
expresan cantidades en la moneda definida en la pestaña de
monedas del cuadro de diálogo "Opciones"
Cadena de caracteres o variable alfanumérica
Tamaño total
Tamaño de la parte decimal
Etiqueta de la variable
Etiquetas para los valores
Valores perdidos
Espacio que ocupa en la vista de datos
Alineación de la variable en la vista de datos
Escala de medición.
Algunos usuarios pasan por alto las características de las variables
cuando se trabaja en la base de datos. Sin embargo, cuando se utilizan
scripts o Python las características de las variables pueden tomar gran
relevancia en la construcción de procedimientos ad-hoc.
VERSIONES DEL SPSS

55
SPSS Inc. desarrolla un módulo básico del paquete estadístico
SPSS, del que han aparecido las siguientes versiones:
SPSS-X (para grandes servidores tipo UNIX)
SPSS/PC (1984, en DOS. Primera versión para computador
portátil)
SPSS/PC+ (1986 (en DOS)
SPSS for Windows 6 (1992) / 6.1 para Macintosh
SPSS for Windows 7
SPSS for Windows 8
SPSS for Windows 9
SPSS for Windows 10 / for Macintosh 10 (2000)
SPSS for Windows 11 (2001) / for Mac OS X 11(2002)
SPSS for Windows 11.5 (2002)
SPSS for Windows 12 (2003)
SPSS for Windows 13 (2004): Permite por primera vez trabajar
con múltiples bases de datos al mismo tiempo.
SPSS for Windows 14 (2005)
SPSS for Macintosh 13 (2006)
SPSS for Windows 15 (2006)
SPSS for Windows 16 (Octubre de 2007): En la lista de usuarios
de SPSS "SPSSX (r) Discussion [SPSSX-L@LISTSERV. UGA. EDU]"
varios funcionarios de la empresa anunciaron previamente la
salida de la versión 16 de este software. En ella se incorporó una
interfaz basada en Java que permite realizar algunas mejoras en
las facilidades de uso del sistema.
SPSS for Macintosh 16
SPSS for Linux 16
SPSS for Windows 17 (2008): Incorpora aportes importantes
como el ser multilenguaje, pudiendo cambiar de idioma en las
opciones siempre que queramos. También incluye modificaciones

56
en el editor de sintaxis de forma tal que resalta las palabras claves
y comandos, haciendo sugerencias mientras se escribe. En este
sentido se aproxima a los sistemas IDE que se utilizan en
programación.
SPSS for Windows 18 (2009): Cambia su denominación de SPSS
por PASW 18.
IBM SPSS Statistics 19.0 (2010)
IBM SPSS Statistics 20.0 (2011)
MÓDULOS DEL SPSS
El sistema de módulos de SPSS, como los de otros programas
(similar al de algunos lenguajes de programación) provee toda una serie
de capacidades adicionales a las existentes en el sistema base. Algunos
de los módulos disponibles son:
Modelos de Regresión
Modelos Avanzados
Reducción de datos: Permite crear variables sintéticas a
partir de variables colineales por medio del Análisis Factorial.
Clasificación: Permite realizar agrupaciones de
observaciones o de variables (cluster analysis) mediante
tres algoritmos distintos.
Pruebas no paramétricas: Permite realizar distintas pruebas
estadísticas especializadas en distribuciones no normales.
Tablas: Permite al usuario dar un formato especial a las salidas de
los datos para su uso posterior. Existe una cierta tendencia dentro
de los usuarios y de los desarrolladores del software por dejar de
lado el sistema original de TABLES para hacer uso más extensivo
de las llamadas CUSTOM TABLES.

57
Tendencias
Categorías: Permite realizar análisis multivariados de variables
normalmente categorías. También se pueden usar variables
métricas siempre que se realice el proceso de recodificación
adecuado de las mismas.
Análisis Conjunto: Permite realizar el análisis de datos recogidos
para este tipo específico de pruebas estadísticas.
Mapas: Permite la representación geográfica de la información
contenida en un fichero (descontinuado para SPSS 16).
Pruebas Exactas: permite realizar pruebas estadísticas en
muestras pequeñas.
Análisis de Valores Perdidos: Regresión simple basada en
imputaciones sobre los valores ausentes.
Muestras Complejas: permite trabajar para la creación de
muestras estratificadas, por conglomerados u otros tipos de
muestras.
SamplePower (cálculo de tamaños muestrales)
Árboles de Clasificación: Permite formular árboles de clasificación
y/o decisión con lo cual se puede identificar la conformación de
grupos y predecir la conducta de sus miembros.
Validación de Datos: Permite al usuario realizar revisiones lógicas
de la información contenida en un fichero ".sav" y obtener
reportes de los valores considerados atípicos. Es similar al uso de
sintaxis o scripts para realizar revisiones de los ficheros. De la
misma forma que estos mecanismos es posterior a la digitalización
de los datos.
SPSS Programmability Extension (SPSS 14 en adelante). Permite
utilizar el lenguaje de programación Python para un mejor control
de diversos procesos dentro del programa que hasta ahora eran
realizados principalmente mediante scripts (con el lenguaje SAX

58
Basic). Existe también la posibilidad de usar las
tecnologías .NET de Microsoft para hacer uso de las librerías del
SPSS. Aunque algunos usuarios han cuestionado sobre la
necesidad de incluir otros lenguajes, la empresa no tiene esto
entre sus objetivos inmediatos.
Desde el SPSS/PC hay una versión adjunta denomina SPSS
Student que es un programa completo de la versión correspondiente
pero limitada en su capacidad en cuanto al número de registros y
variables que puede procesar. Esta versión es para fines de enseñanza
del manejo del programa.

59
CONCLUSIONES
El SPSS es un software que se utiliza mayormente para cálculos
estadísticos, aunque incluye un sin número de utilidades.
Actualmente, la estadística ha adquirido, de manera progresiva,
una mayor relevancia en todos los sectores universitarios y, en
general, en la sociedad.
SPSS, es un poderoso sistema para realizar análisis estadísticos y
gestión de información en un entorno gráfico, con ayuda de menús
descriptivos y cajas de diálogo que solicitan información al usuario
para realizar el trabajo más pesado. La mayoría de las tareas se
pueden realizar simplemente dando clic, pero lo más importante
es saber que es lo que realmente queremos que realice el sistema,
de tal forma que nos ayude en el análisis de la información, del
experimento y/o de la investigación.
A pesar de que SPSS parece tener más ventajas respecto a SAS,
no podemos generalizar diciendo que es mejor, son solo dos
opciones distintas. El usar este tipo de herramientas en una
empresa, si bien no es obligatorio, es un factor que puede influir
de manera directa en el desempeño de la misma.
Las herramientas de éste tipo son bastante útiles no solo por
permitirnos realizar analíticas predictivas, sino también por ser
programas de muchas aplicaciones en una.
Como todos los programas en ambiente Windows, su manejo es
hace fácil, accesible y eficiente, pero con un gran problema, ya
que debido a la facilidad de uso y rapidez, proporciona mucha
información que realmente no queremos o no sabemos analizar.

60
Cuenta con una simple interfase para el análisis estadístico,
proporciona opciones para desarrollar el trabajo en forma rápida y
eficiente; debido a que se trabaja a través de ventanas
especificas, editor de datos, para definir las variables, un visor o
ventana de resultados, para analizarlos, mostrándolos o
ocultándolos de forma selectiva.
REFERENCIAS BIBLIOGRAFICAS
Martín Martín, Q.:Cuadernos de Estadística:Contraste de Hipótesis.
Editorial La Muralla y Editorial Hespérides S.L.
Pardo, A. y Ruiz, M. A. (2002). SPSS 11. Guía para el análisis de datos.
Madrid: McGraw-Hill. ISBN 84-841-3750-7.
Tejedor Tejedor, F.J.:Cuadernos de Estadística:Aplicaciones diversas del
análisis de varianza. Editorial La Muralla y Editorial Hespérides S.L.
Vicente, Mª L.; Girón, P.; Nieto, C.; Pérez, T.: Diseño de Experimentos.
Soluciones con SAS y SPSS. Editorial Prentice Hall.
Paginas consultadas:
www.uca.es/serv/ai/formacion/spss/Inicio.pdf
http://es.wikipedia.org/wiki/SPSS
http://www.estadistico.com/arts.html?20001113
http://www.unalmed.edu.co/~estadist/Esta1/INDUCCION%20SAS.pdf

61
http://einstein.uab.es/_c_serv_estadistica/Manuals/ManualSAS.PDF
http://halweb.uc3m.es/esp/Personal/personas/jmmarin/esp/Progra/SAS
_V8_V1_2.pdf
http://estadistica.ieg.csic.es/tutoriales/PDF/SintaxisSPSS.pdf


















