Metodos de Dise´ no y An˜ alisis de´ Experimentosnunez/mastertecnologiastelecomu... ·...
101
M´ etodos de Dise ˜ no y An ´ alisis de Experimentos Patricia Isabel Romero Mares Departamento de Probabilidad y Estad´ ıstica IIMAS UNAM febrero 2013 1 / 101
Transcript of Metodos de Dise´ no y An˜ alisis de´ Experimentosnunez/mastertecnologiastelecomu... ·...

Metodos de Diseno y Analisis deExperimentos
Patricia Isabel Romero Mares
Departamento de Probabilidad y EstadısticaIIMAS UNAM
febrero 2013
1 / 101

Diseno completamente al azar
2 / 101

Ejemplo
Suponga que tenemos 4 dietas diferentes que queremoscomparar. Las dietas estan etiquetadas A,B,C y D.Estamos interesados en estudiar si las dietas afectan la tasa decoagulacion en conejos. La tasa de coagulacion es el tiempoen segundos que tarda una cortada en dejar de sangrar.Tenemos 16 conejos para el experimento, por lo que usaremos4 en cada dieta.Los conejos estan en una jaula grande hasta que se inicie elexperimento, momento en que se transferiran a otras jaulas.
Como asignamos los conejos a los cuatro grupostratamiento?
3 / 101

Diseno completamente al azar, un factor
Ejemplo: Disminucion del crecimiento de bacterias en carnealmacenada.
La vida en estante de carne almacenada es el tiempo en que elcorte empacado se mantiene bien, nutritivo y vendible.
El empaque estandar con aire del medio ambiente tiene unavida de 48 horas. Despues se deteriora por contaminacionbacterial, degradacion del color y encogimiento.
El empaque al vacıo detiene el crecimiento bacterial, sinembargo, se pierde calidad.
Estudios recientes sugieren que al controlar ciertos gases de laatmosfera se alarga la vida en estante.
4 / 101

Diseno completamente al azar, un factor
Hipotesis de investigacion: Algunas formas de gasescontrolados pueden mejorar la efectividad del empacamientopara carne.
Diseno de tratamientos: Un factor con 4 niveles:
1 Aire ambiental con envoltura plastica2 Empacado al vacıo3 Mezcla de gases:
1% CO (monoxido de carbono)40% O2 (oxıgeno)59% N (nitrogeno)
4 100% CO2 (bioxido de carbono)
Diseno experimental: Completamente al azar.
5 / 101

Diseno completamente al azar, un factor
Tres bisteces de res, aproximadamente del mismo tamano (75grs.) se asignaron aleatoriamente a cada tratamiento. Cadabistec se empaca separadamente con su condicion asignada.
Variable de respuesta: Se mide el numero de bacteriaspsichnotropicas en la carne despues de 9 dıas dealmacenamiento a 4◦C.
Estas bacterias se encuentran en la superficie de la carne yaparecen cuando la carne se echo a perder. La medicion fue ellogaritmo del numero de bacterias por cm2.
6 / 101

Diseno completamente al azar, un factor
Como aleatorizar?
Se obtiene una permutacion aleatoria de los numeros 1 a 12.Para esto se toma una secuencia de numeros de 2 dıgitos deuna tabla de numeros aleatorios y se les asigna el rango queles corresponda.Por ejemplo:
# aleatorio 52 56 20 99 44 34 62 60 31 57 40 78rango 6 7 1 12 5 3 10 9 2 8 4 11trat 1 1 1 2 2 2 3 3 3 4 4 4u.e. 1 2 3 4 5 6 7 8 9 10 11 12trat 1 3 2 4 2 1 1 4 3 3 4 2
7 / 101

Diseno completamente al azar, un factor
Modelo estadıstico para el experimento
El modelo estadıstico para estudios comparativos supone quehay una poblacion de referencia de u.e. En muchos casos lapoblacion es conceptual. En el ejemplo, es posible imaginaruna poblacion de carne empacada.
Cada unidad de la poblacion tiene un valor de la variable derespuesta, y, la cual tiene media µ y varianza σ2.
Se supone una poblacion de referencia para cada tratamientoconsiderado en el estudio, y las variables en el experimento sesuponen seleccionadas aleatoriamente de dicha poblacion dereferencia, como resultado de la aleatorizacion.
Nota. Para estudios observacionales, suponemos que lasunidades observadas se seleccionaron aleatoriamente de cadauna de las poblaciones.
8 / 101

Diseno completamente al azar, un factor
9 / 101

Diseno completamente al azar, un factor
Modelo estadıstico lineal para un diseno completamente alazar.
Modelo de medias:
yij = µi + εij i = 1,2, . . . , t j = 1,2, . . . ,r
dondeyij es la observacion de la j-esima u.e. del i-esimo tratamiento,µi es la media del i-esimo tratamiento,εij es el error experimental de la unidad ij.Suponemos que hay t tratamientos y r repeticiones en cadauno.
En el ejemplo de la carne empacada, tenemos:
10 / 101
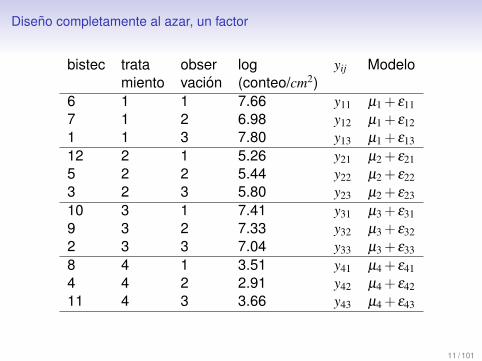
Diseno completamente al azar, un factor
bistec trata obser log yij Modelomiento vacion (conteo/cm2)
6 1 1 7.66 y11 µ1 + ε117 1 2 6.98 y12 µ1 + ε121 1 3 7.80 y13 µ1 + ε13
12 2 1 5.26 y21 µ2 + ε215 2 2 5.44 y22 µ2 + ε223 2 3 5.80 y23 µ2 + ε23
10 3 1 7.41 y31 µ3 + ε319 3 2 7.33 y32 µ3 + ε322 3 3 7.04 y33 µ3 + ε33
8 4 1 3.51 y41 µ4 + ε414 4 2 2.91 y42 µ4 + ε4211 4 3 3.66 y43 µ4 + ε43
11 / 101

Diseno completamente al azar, un factor
El modelo:yij = µi + εij
lo llamaremos modelo completo ya que incluye una mediaseparada para cada una de las poblaciones definidas por lostratamientos.
Si no hay diferencia entre las medias de las poblaciones, esdecir,
µ1 = µ2 = µ3 = µ4 = µ
se genera el modelo reducido
yij = µ + εij
que establece que las observaciones provienen de la mismapoblacion con media µ.
12 / 101

Diseno completamente al azar, un factor
El modelo reducido representa la hipotesis de no diferenciaentre las medias
H0 : µ1 = µ2 = µ3 = µ4 = µ
El modelo completo representa la hipotesis alternativa:
Ha : µi 6= µk i 6= k
El investigador debe determinar cual de los dos modelosdescribe mejor a los datos en el experimento.
13 / 101

Diseno completamente al azar, un factor
yij = µ + εij yij = µi + εij
14 / 101

Diseno completamente al azar, un factor
Pregunta de investigacion: Hay mas crecimiento bacterialcon algunos metodos de empacado que con otros?
Pregunta estadıstica: Cual modelo describe mejor losresultados del experimento?
Se requiere un metodo para estimar los parametros de los dosmodelos y con base en algun criterio objetivo determinar cualmodelo o hipotesis estadıstica se ajusta mejor a los datos delexperimento.
15 / 101

Diseno completamente el azar, un factor
Los estimadores de mınimos cuadrados son aquellos queresultan de minimizar la suma de cuadrados de los erroresexperimentales.
Si los errores experimentales son independientes con mediacero y varianzas homogeneas, los estimadores de mınimoscuadrados son insesgados y tienen varianza mınima.
Nota. El muestreo aleatorio en los estudios observacionales yla aleatorizacion en los experimentales aseguran la suposicionde independencia.
16 / 101

Estimadores para el modelo completo
yij = µi + εij i = 1, . . . , t j = 1, . . . ,r
εij = yij−µi
SSEc =t
∑i=1
r
∑j=1
ε2ij =
t
∑i=1
r
∑j=1
(yij−µi)2
La SSEc es una medida de que tan bien se ajusta el modelo alos datos.
Queremos determinar los estimadores µi tales que se minimiceesta SSEc.
Vamos a tener t ecuaciones normales, una para cadatratamiento, encontradas a partir de derivar la SSEc conrespecto a cada µi e igualarlas a cero.
17 / 101

Estimadores para el modelo completo
Para una i:
∂
∂ µi
r
∑j=1
(yij−µi)2 = −2
r
∑j=1
(yij−µi)
igualando a cero
−2r
∑j=1
(yij− µi) = 0
r
∑j=1
yij− rµi = 0
µi =∑
rj=1 yij
r= yi.
18 / 101

Estimadores para el modelo completo
Por lo tanto,µi = yi i = 1, . . . , t
Entonces,
SSEc =t
∑i=1
r
∑j=1
(yij− µi)2
=t
∑i=1
r
∑j=1
(yij− yi.)2
=t
∑i=1
[r
∑j=1
(yij− yi.)2
]
19 / 101

Estimadores para el modelo completo
La varianza muestral del i-esimo tratamiento es:
S2i =
∑rj=1 (yij− yi.)
2
r−1
es una estimador de σ2 de los datos del i-esimo grupo.
S2 =∑
ti=1
[∑
rj=1 (yij− yi.)
2]
t(r−1)=
SSEc
t(r−1)
es un estimador combinado (pooled) de σ2 de todos losdatos del experimento.
Es un buen estimador si podemos hacer la suposicion de queσ2 es homogenea en todos los grupos.
20 / 101

Estimadores para el modelo completo
Para los datos del ejemplo:
tratamiento comercial vacıo mezcla CO27.66 5.26 7.41 3.516.98 5.44 7.33 2.917.80 5.80 7.04 3.66
µi = yi. 7.48 5.50 7.26 3.36∑
rj=1 (yij− yi.)
2 0.3848 0.1512 0.0758 0.3150
SSEc = 0.3848+0.1512+0.0758+0.3150 = 0.9268
S2 =SSEc
t(r−1)=
0.92684(2)
= 0.11585
21 / 101

Estimadores para el modelo reducido
yij = µ + εij
εij = yij−µ
SSEr =t
∑i=1
r
∑j=1
ε2ij =
t
∑i=1
r
∑j=1
(yij−µ)2
∂
∂ µ
t
∑i=1
r
∑j=1
(yij−µ)2 = −2t
∑i=1
r
∑j=1
(yij−µ)
igualando a cerot
∑i=1
r
∑j=1
µ =t
∑i=1
r
∑j=1
yij
rtµ = y..
µ =y..rt
= y..
22 / 101

Estimadores para el modelo reducido
Entonces,
SSEr =t
∑i=1
r
∑j=1
(yij− µ)2 =t
∑i=1
r
∑j=1
(yij− y..)2
Para el ejemplo,
µ = y.. =70.80
12= 5.90
23 / 101

Modelo reducido Modelo completoyij = µ + εij yij = µi + εij
Observado Estimado Diferencia Estimado DiferenciaTratamiento y µ (yij− µ) µi (yij− µi)Comercial 7.66 5.90 1.76 7.48 0.18
6.98 5.90 1.08 7.48 -0.507.80 5.90 1.90 7.48 0.32
Vacıo 5.26 5.90 -0.64 5.50 -0.245.44 5.90 -0.46 5.50 -0.065.80 5.90 -0.10 5.50 0.30
Mezcla 7.41 5.90 1.51 7.26 0.157.33 5.90 1.43 7.26 0.077.04 5.90 1.14 7.26 -0.22
CO2 3.51 5.90 -2.39 3.36 0.152.91 5.90 -2.99 3.36 -0.453.66 5.90 -2.24 3.36 0.30
SSEr = 33.7996 SSEc = 0.9268
24 / 101

Diseno completamente al azar, un factor
Siguiendo con el ejemplo:
Modelo completo yij = µi + εij SSEc = ∑i ∑j(yij− yi.)2 = 0.9268
Modelo reducido yij = µ + εij SSEr = ∑i ∑j(yij− y..)2 = 33.7996
Diferencia:
SSEr−SSEc = ∑i
∑j(yij− y..)2−∑
i∑
j(yij− yi.)
2
haciendo algebra= ∑
i∑
j(yi.− y..)2 = r∑
i(yi.− y..)2
En el ejemplo: SSEr−SSEc = 32.8728
25 / 101

Diseno completamente al azar, un factorSSEr−SSEc = SSt suma de cuadrados de tratamientos.
Representa la reduccion en SSE al haber incluido tratamientosen el modelo, tambien se le conoce como reduccion en sumade cuadrados debida a tratamientos.
Llamaremos SStotal = SSEr ya que es la suma de cuadrados delas diferencias de cada observacion y la media general y..
Entonces, tenemos la particion:
SStotal = SSt +SSEc
∑i
∑j(yij− y..)2 = ∑
i∑
j(yi.− y..)2 +∑
i∑
j(yij− yi.)
2
desviacion de la desviacion de la desviacion de laobservacion ij media del grupo observacion ijcon respecto a con respecto a con respecto ala media general la media general la media de su grupo
26 / 101

Diseno completamente al azar, un factor
∑i
∑j(yij− y..)2 = ∑
i∑
j[(yij− yi.)+(yi.− y..)]
2
= ∑i
∑j(yij− yi.)
2 +∑i
∑j(yi.− y..)2
+2∑i
∑j(yij− yi.)(yi.− y..)
∑i
∑j(yij− yi.)(yi.− y..) = ∑
i(yi.− y..)∑
j(yij− yi.)
= ∑i(yi.− y..)(yi.− ryi.) = 0
27 / 101

Diseno completamente al azar, un factor
Grados de libertad. Representan el numero de piezas deinformacion independientes en las sumas de cuadrados.
En general, es el numero de observaciones menos el numerode parametros estimados de los datos.
Sea n = rt, el tamano de muestra total.
Ası, SStotal = ∑ti ∑
rj (yij− y..)2 donde y.. es el estimador de µ, tiene
n−1 g.l.
SSE = ∑ti ∑
rj (yij− yi.)
2 se estimaron t parametros (µ1,µ2, . . . ,µt)por lo tanto tiene n− t g.l.
SSt = SStotal−SSE = (n−1)− (n− t) = t−1 g.l.
28 / 101

Tabla de Analisis de Varianza
ANOVA
F.V. g.l. SS CMTratamientos t−1 SSt CMt = SSt/t−1Error n− t SSE CME = SSE/n− t = σ2
Total n−1 SStotal
Se puede demostrar que:
E (CME) = σ2
E (CMt) = σ2 +
1t−1
t
∑i=1
r(µi− µ)2; µ = ∑i
µi/t
29 / 101

Tabla de Analisis de Varianza
Si suponemos εij ∼ NID(0,σ2) i = 1, . . . , t j = 1, . . . ,r en elmodelo completo yij = µi + εij
Entonces, yij ∼ NID(µi,σ2).
Se puede demostrar que:
SStotal
σ2 =∑i ∑j(yij− y..)2
σ2 ∼ χ2n−1
SSEσ2 =
∑i ∑j(yij− yi.)2
σ2 ∼ χ2n−t
Cuando H0 : µ1 = µ2 = . . .= µt es ciertaSSt
σ2 =∑i r(yi.− y..)2
σ2 ∼ χ2t−1
30 / 101

Tabla de Analisis de VarianzaPor el Teorema de Cochran (Montgomery, 2001, pag. 69), SSt ySSE son independientes, por lo tanto cuando H0 es cierta,
F0 =SSt/σ2(t−1)SSE/σ2(n− t)
=CMt
CME∼ Ft−1,n−t
Ademas, E (CMt) = σ2 +θ 2t = σ2 cuando θ 2
t = 0 que es cuandoH0 es cierta. Es decir,
E (CMt) = E (CME) cuando H0 es ciertaE (CMt) > E (CME) cuando H0 no es cierta
Entonces, si CMt > CME, o sea, valores grandes de F0 llevan arechazar la hipotesis nula H0 : µ1 = µ2 = . . .= µt.Por lo tanto, la region de rechazo es:
F0 > Fαt−1,n−t
31 / 101

Tabla de Analisis de Varianza
ANOVA
F.V. g.l. SS CM F E(CM)
Tratamientos t−1 SSt CMt =SStt−1
CMtCME σ2 +θ 2
t
Error n− t SSE CME = SSEn−t σ2
Total n−1 SStotal
SSt =t
∑i=1
r (yi.− y..)2
SSE =t
∑i=1
r
∑j=1
(yij− yi.)2
SStotal =t
∑i=1
r
∑j=1
(yij− y..)2
32 / 101

Tabla de Analisis de Varianza
En el ejemplo de empacado de carne:
F.V. g.l. SS CM F Pr > Ftrat 3 32.8728 10.958 94.55 0.000error 8 0.9268 0.1159total 11 33.7996
Por lo tanto, se rechaza la hipotesis H0 : µ1 = µ2 = . . .= µ4, esdecir, hay algun metodo de empaque que tiene diferentecomportamiento en promedio.
33 / 101

Diseno completamente al azar, un factorSe quieren comparar t niveles de un factor, lo que implica ttratamientos y se dispone de ni u.e. para el tratamiento i,i = 1, . . . , t. Hay dos situaciones:
1 Los t tratamientos son escogidos especıficamente por elinvestigador. En esta situacion deseamos probar hipotesisacerca de las medias de los tratamientos y nuestrasconclusiones se aplicaran solamente a los niveles delfactor considerados en el analisis. Las conclusiones no sepueden extender a tratamientos similares que no fueronexplıcitamente considerados. Este es el modelo deefectos fijos.
2 Los t tratamientos son una muestra aleatoria de unapoblacion de tratamientos. En esta situacion nos gustarıapoder extender las conclusiones (las cuales estanbasadas en la muestra de tratamientos considerada) atodos los tratamientos de la poblacion. Este es el modelode efectos aleatorios.
34 / 101

Diseno completamente al azar, un factor
A las cantidades n1,n2, . . . ,nt se les llama repeticiones de cadatratamiento.
Si ni = r ∀i se dice que el diseno es balanceado.
yij es la respuesta de la u.e. j del tratamiento i,i = 1, . . . , t j = 1, . . . ,ni.
35 / 101

Diseno completamente al azar
Estructura de los datos.
tratamientos1 2 3 ... ty11 y21 y31 ... yt1y12 y22 y32 ... yt2y13 y23 y33 ... yt3. . . ... .. . . ... .. . . ... .y1n1 y2n2 y3n3 ... ytnt
y1. y2. y3. ... yt. totalesy1. y2. y3. ... yt. medias
36 / 101

Diseno completamente al azar
n =t
∑i=1
ni
yi. =ni
∑j=1
yij i = 1, . . . , t total tratamiento i
yi. =∑
nij=1 yij
nii = 1, . . . , t media tratamiento i
y.. =t
∑i=1
ni
∑j=1
yij =t
∑i=1
yi. total de las observaciones
y.. =y..n
media general
37 / 101

Diseno completamente al azar
Se tienen t muestras aleatorias independientes de tamanosn1,n2, . . . ,nt respectivamente.
y11,y12, . . . ,y1n1 es una muestra aleatoria de N(µ1,σ2)
y21,y22, . . . ,y2n2 es una muestra aleatoria de N(µ2,σ2)
yt1,yt2, . . . ,ytnt es una muestra aleatoria de N(µt,σ2)
38 / 101

Diseno completamente al azar
Las observaciones en cada una de estas muestras se puedenrepresentar por el modelo lineal simple
yij = µi + εij i = 1, . . . , t j = 1, . . . ,ni
con εij error experimental en la observacion j-esima deltratamiento i-esimo.
Estamos suponiendo independencia entre y dentro de lasmuestras, es decir, εij son independientes y εij ∼ N(0,σ2).
39 / 101

Diseno completamente al azar
Otra forma de verlo
Como suponemos que las u.e. son homogeneas, es decir, elpromedio de respuesta de todas las u.e. es el mismo (µ) antesde aplicar los tratamientos, y si se observan en condicionessimilares, las respuestas las podemos modelar como
yij = µ + εij
40 / 101

Modelo de efectos
Entonces al aplicar el tratamiento i-esimo a un grupo (detamano ni) de u.e. se introduce un efecto (τi) de esetratamiento en las variables por observar.
El modelo se puede escribir como:
Modelo de efectos
yij = µ + τi + εij i = 1, . . . , t j = 1, . . . ,ni
donde
µ es la media general, comun a todas las u.e.τi es el efecto del tratamiento i-esimo
41 / 101
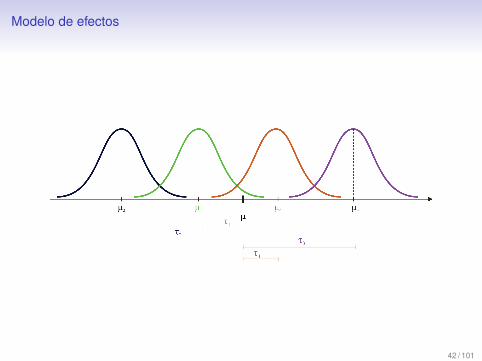
Modelo de efectos
42 / 101

Modelo de efectos
El modelo de efectos implica que se empieza el experimentocon u.e. con la misma capacidad de respuesta (µ) y con lamisma varianza (σ2).
La aplicacion de los tratamientos tiene el efecto de alterar lasmedias, que ahora son µi = µ + τi, pero supone que no semodifican las varianzas.
En este caso, la hipotesis a probar es:
H0 : τ1 = τ2 = . . .= τt = 0
Ha : τi 6= 0 para al menos una i
43 / 101

Modelo de efectos
Estimadores de mınimos cuadrados:
yij = µ + τi + εij i = 1, . . . , t j = 1, . . . ,ni
SSE =t
∑i=1
ni
∑j=1
ε2ij =
t
∑i=1
ni
∑j=1
(yij−µ− τi)2
∂
∂ µ
t
∑i=1
ni
∑j=1
(yij−µ− τi)2 = −2
t
∑i=1
ni
∑j=1
(yij−µ− τi)
∂
∂τi
t
∑i=1
ni
∑j=1
(yij−µ− τi)2 = −2
ni
∑j=1
(yij−µ− τi) i = 1, . . . , t
44 / 101

Modelo de efectos
Igualando a cero:
t
∑i=1
ni
∑j=1
yij = nµ +t
∑i=1
niτi
n1
∑j=1
y1j = n1µ +n1τ1
n2
∑j=1
y2j = n2µ +n2τ2
. . . . . .nt
∑j=1
ytj = ntµ +ntτt
Las ecuaciones normales no son linealmente independientes,por lo tanto no hay una solucion unica. Esto ocurre porque elmodelo de efectos esta sobreparametrizado.
45 / 101

Modelo de efectosSe anade una ecuacion linealmente independiente:
a) ∑ti=1 τi = 0
µ = y..τi = yi.− y.. i = 1, . . . , t
b) µ = 0
µ = 0
τi = yi. i = 1, . . . , t
c) τ1 = 0
µ = y1.
τi = yi.− y1. i = 2, . . . , t
46 / 101

Modelo de efectos
Hay un numero infinito de posibles restricciones que se puedenusar para resolver las ecuaciones normales. Entonces
Cual usar?
No importa ya que en cualquier caso
µ + τi = yi.
Aunque no podemos obtener estimadores unicos de losparametros del modelo de efectos, podemos obtenerestimadores unicos de funciones de estos parametros.
A estas funciones se les llama funciones linealeslinealmente estimables.
47 / 101

Diseno completamente al azar, Tabla de ANOVAF.V. g.l. SS CM F E(CM)
Tratamientos t−1 SSt CMt =SStt−1
CMtCME σ2 + ∑i ni(τi−τ)2
t−1
Error n− t SSE CME = SSEn−t σ2
Total n−1 SStotal
SSt =t
∑i=1
ni (yi.− y..)2 =
t
∑i=1
y2i.
ni− y2
..
n
SSE =t
∑i=1
ni
∑j=1
(yij− yi.)2 =
t
∑i=1
ni
∑j=1
y2ij−
t
∑i=1
y2i.
ni
SStotal =t
∑i=1
ni
∑j=1
(yij− y..)2 =
t
∑i=1
ni
∑j=1
y2ij−
y2..
n
n =t
∑i=1
ni
48 / 101

Intervalos de confianza
µi = yi. S2yi.=
S2
nicon S2 = CME = σ
2 Syi. =
√CME
ni
Como suponemos que
yij ∼ N(µi,σ
2)entonces
yi. ∼ N(µi,σ
2/ni)
como estimamos la varianza:
yi.−µi
Syi.
∼ tn−t
Por lo tanto, un intervalo del (1−α)100% de confianza para µi
esyi.± t1−α/2
n−t (Syi.)
49 / 101

Contrastes
En el ejemplo del empacado de carne tenıamos:
Comercial Al vacıo CO,O2,N CO2µi = yi. 7.48 5.50 7.26 3.36
S2 = CME = 0.116 con 8 g.l.
Una vez que rechazamos la hipotesis H0 : µ1 = µ2 = µ3 = µ4
Que sigue?
50 / 101

Contrastes
Se podrıan contestar preguntas como:
Es mas efectiva la creacion de una atmosfera artificial queel aire ambiente con plastico para reducir el crecimiento debacterias?Son mas efectivos los gases que el vacıo?Es mas efectivo el tratamiento de CO2 puro que la mezclaCO,O2 y N?
Un contraste es una funcion lineal de los parametros µi
definido como
C =t
∑i=1
kiµi = k1µ1 + k2µ2 + . . .+ ktµt
donde ∑ti=1 ki = 0.
51 / 101

Contrastes
Los contrastes para las preguntas anteriores son:
comercial vs. atmosfera artificial
C1 = µ1−13(µ2 +µ3 +µ4)
vacıo vs. gases
C2 = µ2−12(µ3 +µ4)
mezcla de gases vs. CO2 puro
C3 = µ3−µ4
52 / 101

Contrastes
El estimador del contraste
C =t
∑i=1
kiµi es C =t
∑i=1
kiµi =t
∑i=1
kiyi.
Si suponemos queyij ∼ N
(µi,σ
2)entonces
yi. ∼ N(µi,σ
2/ni)
Por lo tanto,
C =t
∑i=1
kiyi. ∼ N
(t
∑i=1
kiµi,σ2
t
∑i=1
k2i
ni
)
53 / 101

Contrastes
Ya que:
E
(t
∑i=1
kiyi.
)=
t
∑i=1
kiE (yi.) =t
∑i=1
kiµi
V
(t
∑i=1
kiyi.
)=︸︷︷︸
m.indep
t
∑i=1
k2i V (yi.) =
t
∑i=1
k2i
σ2
ni= σ
2t
∑i=1
k2i
ni
V(C)= σ
2t
∑i=1
k2i
ni= CME
t
∑i=1
k2i
ni
54 / 101

Contrastes
Entonces,∑
ti=1 kiyi.−∑
ti=1 kiµi√
CME ∑ti=1 k2
i /ni
∼ tg.l.error
De aquı un intervalo del 100(1−α)% de confianza para elcontraste C es:
C± t1−α/2g.l.error
√CME
t
∑i=1
k2i /ni
55 / 101

ContrastesAdemas,
C−C√σ2 ∑
ti=1 k2
i /ni
∼ N (0,1)
Si H0 : ∑ti=1 kiµi = 0, es decir, H0 : C = 0 es cierta, entonces,
C2
σ2 ∑ti=1 k2
i /ni∼ χ
21
Sea
SSc =C2
∑ti=1 k2
i /ni
entonces
SSc/σ2
SSE/σ2(n− t)=
C2/∑ti=1 k2
i /ni
CME∼ F1,n−t
Por lo tanto, para probar H0 : C = 0 se rechaza si Fc > Fα1,n−t
56 / 101

Contrastes
El numero de contrastes que se pueden hacer es muy grande,sin embargo, esta tecnica tiene su mayor utilidad cuando seaplica a comparaciones planeadas antes de realizar elexperimento.
Una clase de contrastes, conocida como Contrastesortogonales (como son los del ejemplo anterior) tienenpropiedades especiales con respecto a la particion de sumasde cuadrados y grados de libertad y con respecto a su relacionentre ellos. La ortogonalidad implica que un contraste noaporta informacion acerca de otro.
Dos contrastes, con coeficientes {ki},{li} son ortogonales si
t
∑i=1
kilini
= 0
57 / 101

Contrastes
Para t tratamientos existe un conjunto de t−1 contrastesortogonales, los cuales hacen una particion de la suma decuadrados de tratamientos en t−1 componentesindependientes, cada uno con 1 g.l. Por lo tanto las pruebasrealizadas con contrastes ortogonales son independientes.
En el ejemplo anterior, los contrastes son ortogonales.
k1 k2 k3 k4C1 1 -1/3 -1/3 -1/3C2 0 1 -1/2 -1/2C3 0 0 1 -1
58 / 101

ANOVA
La tabla de ANOVA incorporando las pruebas de hipotesis delos 3 contrastes es:
F.V. g.l. SS CM F Pr > Ftrat 3 32.8728 10.958 94.55 0.000C1 1 10.01 10.01 86.29 0.000C2 1 0.07 0.07 0.62 0.453C3 1 22.82 22.82 196.94 0.000error 8 0.9268 0.1159total 11 33.7996
Se rechaza H0 : µ1 = µ2 = µ3 = µ4Se rechaza H01 : µ1 =
13 (µ2 +µ3 +µ4)
No se rechaza H02 : µ2 =12 (µ3 +µ4)
Se rechaza H03 : µ3 = µ4
SSC1 =C1
2
1r ∑
4i=1 k2
i=
(2.11)2
12+3(−1/3)2
3
=4.45210.4444
= 10.01
59 / 101

Otro ejemplo
Los siguientes datos son los tiempos de coagulacion de sangrepara 24 animales que fueron aleatoriamente asignados a unade cuatro dietas (A,B,C,D)
Dieta A Dieta B Dieta C Dieta D62 63 68 5660 67 66 6263 71 71 6059 64 67 61
65 68 6366 68 64
6359
60 / 101

Otro ejemplo
Pruebe la hipotesis de igualdad de mediasH0 : µ1 = µ2 = µ3 = µ4.
Pruebe el siguiente contraste:
El promedio de la dieta A y B es igual al promedio de la Cy D
El analisis en R:
Los datos estan en el archivo coag.txt
El programa esta en anova coag.txt
61 / 101

Comparaciones multiples
En muchas situaciones practicas, se desea comparar pares demedias. Podemos determinar cuales medias difieren probandolas diferencias entre todos los pares de medias detratamientos.
Es decir, estamos interesados en contrastes de la forma
Γ = µi−µj ∀i 6= j
Lo primero que se nos viene a la mente es hacer una prueba tpara cada par de medias, es decir, probar
H0 : µi = µj
Ha : µi 6= µj ∀i 6= j
62 / 101

Comparaciones multiplesSi suponemos varianzas iguales, se tiene la estadıstica deprueba
tc =yi.− yj.
sp
√1ni+ 1
nj
y se rechaza H0 al nivel de significancia α si
tc ≤ tα/2ni+nj−2 o tc ≥ t1−α/2
ni+nj−2
Esto es equivalente a decir que se rechaza H0 si
|tc|=|yi.− yj.|
sp
√1ni+ 1
nj
> t1−α/2ni+nj−2
o equivalente a
|yi.− yj.|> t1−α/2ni+nj−2 sp
√1ni+
1nj
63 / 101

Comparaciones multiples
Esta prueba conocida como Diferencia Mınima Significativa(DMS o LSD) en el contexto de ANOVA, lo que hace escomparar el valor absoluto de la diferencia de cada par demedias con DMS:Si
|yi.− yj.|> DMS = t1−α/2glerror
√CME
(1ni+
1nj
)se rechaza H0 : µi = µj.
CME es el cuadrado medio del error que es una estimacionponderada de la varianza basada en t estimaciones de lavarianza.
El utilizar este procedimiento no es conveniente por que el nivelde significancia global, es decir, para el conjunto de todas laspruebas, resulta muy superior al nivel de significancia (α)planeado.
64 / 101

Comparaciones multiples
Por ejemplo, si se tienen 4 medias de tratamientos, entoncesse tienen (
42
)=
4!2!2!
= 6
pares a comparar, es decir, 6 pruebas de hipotesis a realizar,con lo que se pueden cometer 0,1,2,3,4,5, o 6 errores Tipo I, sitodas las medias son iguales.
Se define otra forma de error tipo I basado en los riesgosacumulados asociados a la familia de pruebas bajoconsideracion.
Este es el error tipo I del experimento αE que es el riesgo decometer el error tipo I al menos una vez.
La probabilidad de error tipo I del experimento puede evaluarsepara una familia de pruebas independientes.
65 / 101

Comparaciones multiples
Sin embargo, todas las pruebas a pares usando la DMS no sonindependientes, puesto que el CME es el mismo en cada unade las estadısticas de prueba y el numerador contiene lasmismas medias en varias de las estadısticas de prueba.
Aun ası, se puede evaluar el lımite superior de la probabilidadde error tipo I del experimento, suponiendo n pruebasindependientes.
Suponga que la H0 es cierta para cada una de las n =( t
2
)pruebas y que son independientes.
Sea αc = P(error tipo I) en una sola prueba (comparacion) con(1−αc) = P(decision correcta).
66 / 101

Comparaciones multiples
La probabilidad de cometer x errores tipo I esta dada por ladistribucion binomial como:
P(X = x) =
(nx
)α
xc (1−αc)
n−x
P(X = x) =n!
(n− x)!x!α
xc (1−αc)
n−x x = 0,1,2, . . . ,n
La probabilidad de no cometer ningun error tipo I es
P(X = 0) = (1−αc)n
67 / 101

Comparaciones multiples
La probabilidad de cometer al menos 1 error tipo I es
P(X ≥ 1) = 1−P(X = 0) = 1− (1−αc)n
es decir, la maxima probabilidad de cometer al menos un errortipo I entre las n comparaciones es:
αE = 1− (1−αc)n de aquı
αc = 1− (1−αE)1/n
68 / 101

Comparaciones multiples
# de pruebas αE cuando αc cuandoindep. n αc = 0.05 αE = 0.05
1 0.05 0.052 0.098 0.0253 0.143 0.0174 0.185 0.0135 0.226 0.010
10 0.401 0.005
Por el razonamiento anterior es que han surgido una serie depruebas de diferentes autores para hacer comparacionesmultiples tratando de mantener la
P(error tipo I del experimento) = α
69 / 101

Bonferroni
αE ≤ nαc
n comparaciones, la igualdad se da cuando las pruebas sonindependientes.
Entonces,αc = αE/n
Si queremos αE = 0.05 entonces, αc = 0.05/n y se hacen laspruebas t para los pares de medias con un nivel designificancia αc en cada una de ellas.
70 / 101

Tukey
Conocida como la prueba de la Diferencia Mınima SignificativaHonesta (DMSH)
DMSH = qαt,glerror
√CME
rsi ni = r ∀i
DMSH = qαt,glerror
√CME
2
(1ni+
1nj
)
Si |yi.− yj.|> DMSH se rechaza H0 : µi = µj.
qαν1,ν2
se obtiene de las ”tablas de rangos estudentizados”.
71 / 101

TukeyPara el ejemplo del empaque de carne:
Comercial Al vacıo CO,O2,N CO2yi. 7.48 5.50 7.26 3.36
S2 = CME = 0.116 con 8g.l. t = 4, r = 3
DMSH = q0.054,8
√0.116
3= (4.53)(0.197) = 0.891
|y1.− y2.| = 1.98∗∗
|y1.− y3.| = 0.22
|y1.− y4.| = 4.12∗∗
|y2.− y3.| = 1.76∗∗
|y2.− y4.| = 2.14∗∗
|y3.− y4.| = 3.90∗∗
72 / 101

Student-Newman-Keuls (SNK)
Se calcula un conjunto de valores crıticos
kp = qαp,f Syi. p = 2,3, . . . , t
donde qαp,f es el percentil 1−α de la distribucion del rango
estudentizado para el numero p de medias involucradas en la
comparacion y f g.l. del error, y Syi. =√
CMEr
Para el ejemplo de la carne empacada:
p 2 3 4q.05
p,8 3.26 4.04 4.53kp 0.642 0.796 0.892
73 / 101

Student-Newman-Keuls (SNK)
Comercial Al vacıo CO,O2,N CO2yi. 7.48 5.50 7.26 3.36
Medias ordenadas:
y4. = 3.36 y2. = 5.50 y3. = 7.26 y1. = 7.48
|y4.− y1.| = 4.12 > k∗∗4|y4.− y3.| = 3.90 > k∗∗3|y4.− y2.| = 2.14 > k∗∗2|y2.− y1.| = 1.98 > k∗∗3|y2.− y3.| = 1.76 > k∗∗2|y3.− y1.| = 0.22 < k2(N.S.)
74 / 101

Duncan
Es similar a la de SNK. Los promedios de los t tratamientos seordenan en forma ascendente y el error estandar de cadapromedio se determina con
Syi. =
√CME
rsi ni = r ∀i
Para muestras de diferente tamano, se reemplaza la r por lamedia armonica (nh) de los {ni}
nh =t
∑ti=1
(1ni
)
75 / 101

Duncan
De las tablas de Duncan de rangos significativos se obtienenlos valores de rα
p,f para p = 2,3, . . . , t.p es el numero de medias involucradas en la comparacion, α
es el nivel de significancia y f los grados de libertad del error.
Se calculanRp = rα
p,f Syi. p = 2,3, . . . , t
Para el ejemplo de la carne empacada:
p 2 3 4r.05
p,8 3.26 3.39 3.47Rp 0.642 0.668 0.684
76 / 101

Duncan
Comercial Al vacıo CO,O2,N CO2yi. 7.48 5.50 7.26 3.36
Medias ordenadas:
y4. = 3.36 y2. = 5.50 y3. = 7.26 y1. = 7.48
|y4.− y1.| = 4.12 > R∗∗4|y4.− y3.| = 3.90 > R∗∗3|y4.− y2.| = 2.14 > R∗∗2|y2.− y1.| = 1.98 > R∗∗3|y2.− y3.| = 1.76 > R∗∗2|y3.− y1.| = 0.22 < R2(N.S.)
77 / 101

DunnettPara comparar las medias de los tratamientos con la media deltratamiento control.Suponga que el tratamiento t es el control, queremos probarlas hipotesis
H0 : µi = µt
Ha : µi 6= µt i = 1,2, . . . , t−1
H0 : µi = µt se rechaza si
|yi.− yt.|> D = dα(t−1,glerror)
√CME
r
con dα(k,ν) es el percentil 1−α de las tablas de Dunnett.Para el ejemplo de la carne empacada, el tratamiento 1 es elcontrol.
Comercial Al vacıo CO,O2,N CO2yi. 7.48 5.50 7.26 3.36
78 / 101

Dunnett
d0.05,3,8 = 2.42
D = 2.42
(√CME
r
)= 0.477
|y2.− y1.| = 1.98 > D∗∗
|y3.− y1.| = 0.22 < D(N.S.)
|y4.− y1.| = 4.12 > D∗∗
79 / 101

ScheffeScheffe (1953) propuso un metodo para probar todos losposibles contrastes.
Considere cualquier contraste
C =t
∑i=1
kiµi estimado con C =t
∑i=1
kiyi.
con error estandar
SC =
√√√√CME
[t
∑i=1
k2i
ni
]
La hipotesis nula pra el contraste H0 : C = 0 se rechaza si
|C|> S(αE)
dondeS(αE) = SC
√(t−1)FαE
t−1,g.l.error
80 / 101

Analisis de residuales
Tenemos el modelo
yij = µi + εij o yij = µ + τi + εij
εij ∼ NID(0,σ2)
Suposiciones:
errores normalesindependientesvarianza constante
La prueba F del analisis de varianza es robusta a falta denormalidad.
81 / 101

Analisis de residuales
Si los errores experimentales estan correlacionados, el errorestandar estara mal estimado. La independencia se justificaaleatorizando las u.e. a los tratamientos en experimentos yseleccionando muestras aleatorias en estudiosobservacionales.
Si no hay homogeneidad de varianzas el estimador de σ2 esmalo, aunque se ha visto en estudios que si el diseno esbalanceado no efecta mucho. Tambien si los tamanos demuestra mayores corresponden a las poblaciones con mayorvarianza.
82 / 101

Analisis de residuales, Normalidad
Residuales
eij = yij− yij
yij = µ + τi = µi = yi.
eij = yij− yi.
Histograma (muestras grandes)grafica en papel normalanalisis de residuales estandarizados para detectaroutliers. Si εij ∼ N(0,σ2) entonces εij−0
σ∼ N(0,1). Sean
dij =eij√CME
, esperamos que:68% de los residuales estandarizados esten entre -1 y 195% esten entre -2 y 2Virtualmente todos esten entre -3 y 3.
83 / 101

Analisis de residuales, Homogeneidad de varianzasPrueba de Bartlett
H0 : σ21 = σ
22 = . . .= σ
2t
Ha : no H0
Estadıstica de Prueba:
U =1C
[(n− t)ln(σ2)−∑
i(ni−1)ln(σ2
i )
]
donde σ2 = ∑
i
(ni−1)σ2i
n− tσ
2i = ∑
j
(yij− yi.)2
ni−1
C = 1+1
3(t−1)
(∑
i
1ni−1
− 1n− t
)H0 se rechaza si U > χ2
α,t−1 (prueba sensible a falta denormalidad)
84 / 101

Analisis de residuales, Homogeneidad de varianzas
Prueba de Levene
Se calcula
dij = |yij− yi.| i = 1, . . . , t j = 1, . . . ,ni
donde yi. es la mediana de las observaciones en el tratamientoi.
Se evalua si el promedio de estas observaciones dij es igualpara todos los tratamientos, es decir, se hace un ANOVA paraprobar igualdad de medias de dij.
85 / 101

Prueba de Welch
La prueba F usual es robusta ante heteroscedasticidad(varianzas diferentes) si los tamanos de muestra son muyparecidos o, si los tamanos de muestra mas grandescorresponden a las poblaciones con varianzas mas grandes.
Sin embargo, se han construıdo algunas procedimientos deprueba de igualdad de medias (H0 : µ1 = µ2 = . . .= µt) comopor ejemplo el desarrollado por Welch, conocido como laprueba de Welch, utilizada cuando no hay homoscedasticidad.
Sean Wi = ni/σ2i y∗ = ∑i Wiyi./∑i Wi y
Λ = ∑i
(1−Wi/W.)2
ni−1
donde W. = ∑i Wi.
86 / 101

Prueba de Welch
Entonces
Fc =∑i Wi
(yi.−y∗)2
t−1
1+2(t−2)Λ/(t2−1)
tiene aproximadamente una distribucion F conν1 = t−1 y ν2 = (t2−1)/3Λ grados de libertad.
H0 : µ1 = µ2 = . . .= µt se rechaza al nivel de significancia α si
Fc > Fαν1,ν2
.
87 / 101

Transformaciones
Se utilizan las transformaciones para cambiar la escala de lasobservaciones para que se cumplan las suposiciones delmodelo lineal y dar inferencias validas del analisis de varianza.
Cuando las transformaciones son necesarias, se hace elanalisis y se hacen las inferencias en la escala transformada.
1. Distribucion Poisson. Mediciones que son conteos(numero de plantas en cierta area, insectos en plantas,accidentes por unidad de tiempo) tienen distribucion Poisson.
La transformacion x =√
y+a, a ∈ℜ es la adecuada.
88 / 101

Transformaciones
2. Distribucion binomial. Observaciones del numero de exitosen n ensayos independientes tiene distribucion binomial(proporcion de semillas germinadas, proporcion de plantas conflores en un transecto). π = y/n
La transformacion x = sin−1√
π es la adecuada.
Las transformaciones del tipo potencia alteran la simetrıa oasimetrıa de las distribuciones de las observaciones.
Si suponemos que la desviacion estandar de y es proporcionala alguna potencia de la media, es decir,
σy ∝ µβ
Una transformacion de las observaciones, del estilo:
x = yp
89 / 101

Transformaciones
Da una relacionσx ∝ µ
p+β−1
Si p = 1−β entonces la desviacion estandar de la variabletransformada x sera constante, ya que p+β −1 = 0 y σx ∝ µ0.
La transformacion de Box-Cox
x = (yp−1)/p p 6= 1
x = logey p = 1
El estimador de p se encuentra maximizando
L(p) =−12
loge [CME(p)]
donde CME(p) es el cuadrado medio del error del analisis devarianza usando la transformacion x = (yp−1)/p para el valordado p.
90 / 101

Transformaciones
Se determina CME(p) para un conjunto de valores de p, segrafica CME(p) vs. p y se toma el valor de p que corresponde alvalor mınimo de CME(p).
JMP calcula la transformacion de Box-Cox, da una grafica de pvs. CME y da la opcion de guardar los datos transformados enel archivo.
La dificultad de utilizar esta transformacion es la interpretacion.
91 / 101

Ejemplo
Los siguientes datos son el numero de errores en un examende sujetos bajo la influencia de dos drogas. El grupo 1 es ungrupo control (sin droga), a los sujetos del grupo 2 se les dio ladroga 1, a los del grupo 3 la droga 2 y a los del grupo 4 las dosdrogas.
Grupo 1 Grupo 2 Grupo 3 Grupo 4(sin droga) (droga 1) (droga 2) (dos drogas)
1 12 12 138 10 4 149 13 11 149 13 7 174 12 8 111 10 10 141 12 13
5 14
92 / 101

Ejemplo
Correr el ejemplo con R y JMP.
1 Probar homogeneidad de varianzas. (Bartlett y Levene)2 Hacer prueba de Welch3 Probar con algunas transformaciones, checando
normalidad y homogeneidad de varianzas
ej2 1 messy.jmpej2 1 messy.txt
93 / 101

Relacion entre Regresion y ANOVA
Cualquier modelo de ANOVA se puede escribir como unmodelo de regresion lineal.
Suponga el ejemplo de la carne empacada
tratamiento comercial vacıo mezcla CO27.66 5.26 7.41 3.516.98 5.44 7.33 2.917.80 5.80 7.04 3.66
Un diseno completamente al azar con un solo factor (metodode empacado) con 4 niveles (4 tratamientos) y 3 repeticionesen cada tratamiento (diseno balanceado).
94 / 101

Relacion entre Regresion y ANOVA
Modelo ANOVA completamente al azar un solo factorbalanceado:
yij = µi + εij = µ + τi + εij
{i = 1,2,3,4j = 1,2,3
El modelo de regresion equivalente es:
yij = β0 +β1x1j +β2x2j +β3x3j + εij
{i = 1,2,3,4j = 1,2,3
95 / 101

Relacion entre Regresion y ANOVA
Donde las variables x1j,x2j,x3j estan definidas como:
x1j =
{1 si la observacion j es del tratamiento 10 en otro caso
x2j =
{1 si la observacion j es del tratamiento 20 en otro caso
x3j =
{1 si la observacion j es del tratamiento 30 en otro caso
96 / 101

Relacion entre Regresion y ANOVA
La relacion entre los parametros del modelo ANOVA y elmodelo de regresion es:
Si la observacion viene del tratamiento 1, entoncesx1j = 1,x2j = 0,x3j = 0 y el modelo de regresion es
y1j = β0 +β1(1)+β2(0)+β3(0)+ ε1j
= β0 +β1 + ε1j
y el modelo ANOVA es:
y1j = µ1 + ε1j = µ + τ1 + ε1j
Por lo tanto:β0 +β1 = µ1 = µ + τ1
97 / 101

Relacion entre Regresion y ANOVASimilarmente, para las observaciones del tratamiento 2
y2j = β0 +β1(0)+β2(1)+β3(0)+ ε2j
= β0 +β2 + ε2j
y la relacion entre los parametros es:
βo +β2 = µ2 = µ + τ2
Lo mismo para las observaciones del tratamiento 3
y3j = β0 +β1(0)+β2(0)+β3(1)+ ε3j
= β0 +β3 + ε3j
y la relacion entre los parametros es:
βo +β3 = µ3 = µ + τ3
98 / 101

Relacion entre Regresion y ANOVA
Finalmente, considere las observaciones del tratamiento 4,para las cuales el modelo de regresion es:
y4j = β0 +β1(0)+β2(0)+β3(0)+ ε4j
= β0 + ε4j
entonces β0 = µ4 = µ + τ4
Por lo tanto,
β0 = µ4
β1 = µ1−µ4
β2 = µ2−µ4
β3 = µ3−µ4
99 / 101

Relacion entre Regresion y ANOVA
Entonces, para probar la hipotesis H0 : µ1 = µ2 = µ3 = µ4tendrıamos que probar H0 : β1 = β2 = β3 = 0, lo cual se puedehacer con cualquier paquete de computo estadıstico.Para el ejemplo de la carne empacada:
tratamiento y x1 x2 x31 7.66 1 0 01 6.98 1 0 01 7.80 1 0 02 5.26 0 1 02 5.44 0 1 02 5.80 0 1 03 7.41 0 0 13 7.33 0 0 13 7.04 0 0 14 3.51 0 0 04 2.91 0 0 04 3.66 0 0 0
100 / 101

Relacion entre Regresion y ANOVA
Si pedimos una regresion y = β0 +β1x1 +β2x2 +β3x3 + ε ypedimos una tabla de analisis de varianza del modeloyij = µ + τi + εij las dos tablas ANOVA son identicas.
101 / 101