Notas de Clases Econometría 2012-II
64
Contenido Conceptos: ¿Que se busca con la Modelación Econométrica? Proceso de Modelación Econométrica I. Repaso de Herramientas Matemáticas para el curso de Econometría 1.1 Álgebra Matricial 1.2 Geometría Matricial II. Repaso de Herramientas Matemáticas para el curso de Econometría 2.1 Conceptos 2.2 Características más importantes de una distribución de probabilidad Media o Esperanza Matemática E(X) Varianza Función de Distribución Función de Distribución Acumulada (FDA) Función de Distribución Acumulada (FDA) • La distribución Normal • La distribución Normal Estándar • Distribución t. • Distribución F • Distribución Chi Cuadrada Índice de Asimetría (Skewness) Indice de Curtosis (Kurtosis) Estadístico Jarque Bera: Varianza y Esperanza Condicional III. Método de Mínimos Cuadrados Ordinarios (Relación entre dos variables) 3.1 Análisis gráfico de Relación entre dos variables 3.2 El modelo de Regresión Lineal de Dos Variables 1
-
Upload
roberto-rodriguez-angulo -
Category
Documents
-
view
215 -
download
1
description
Notas de clase, una introducción a la econometría.
Transcript of Notas de Clases Econometría 2012-II

Contenido
Conceptos:
¿Que se busca con la Modelación Econométrica?
Proceso de Modelación Econométrica
I. Repaso de Herramientas Matemáticas para el curso de Econometría
1.1Álgebra Matricial
1.2Geometría Matricial
II. Repaso de Herramientas Matemáticas para el curso de Econometría
2.1Conceptos
2.2Características más importantes de una distribución de probabilidad
Media o Esperanza Matemática E(X)
Varianza
Función de Distribución
Función de Distribución Acumulada (FDA)
Función de Distribución Acumulada (FDA)
• La distribución Normal
• La distribución Normal Estándar
• Distribución t.
• Distribución F
• Distribución Chi Cuadrada
Índice de Asimetría (Skewness)
Indice de Curtosis (Kurtosis)
Estadístico Jarque Bera:
Varianza y Esperanza Condicional
III.Método de Mínimos Cuadrados Ordinarios (Relación entre dos variables)
3.1Análisis gráfico de Relación entre dos variables
3.2El modelo de Regresión Lineal de Dos Variables
A.) Función de Regresión Poblacional
B.) Función de Regresión Muestral
3.3Estimadores Mínimos Cuadráticos (caso 2 variables)
IV. Análisis de Significancia de los estimadores (prueba de Hipótesis) y Contrastes de Errores de especificación
4.1Hipótesis Y Prueba De Hipótesis
4.2Significancia individual de una relación econométrica
1

4.3Error de especificación en un modelo econométrico.
4.3.1 Error de especificación, problemas con las variables independientes (X).
4.3.2 Error de especificación, problemas con las coeficientes (X).
4.3.3 Error de especificación, problemas con las perturbaciones (e).
4.3.4 Detección de Errores de especificación en un modelo econométrico.
V. Violación a los Supuestos de Mínimos Cuadrados Ordinarios (Errores de especificación posibles problemas con los errores (e))
5.1Autocorrelación
5.1.1 Causa De Autocorrelación
5.1.2 Consecuencias:
5.1.3 Detección De La Autocorrelación:
5.1.4 Medidas Remediales
5.2Heterocedasticidad.
5.2.1 Causas
5.2.2 Consecuencias
5.3Multicolinealidad
5.3.1 Causas De La Multicolinealidad
5.3.2 Consecuencias De La Multicolinelidad
A. Multicolinealidad Aproximada o Imperfecta
a. Identificación
b. Corrección
B. Multicolinealidad Aproximada o Imperfecta
a. Identificación
i. Método De La Relación Entre T Y R2
ii. Método De La Matriz De Correlación
iii. Método De La Prueba t
iv. Correlación entre Variables Explicativas: Se debe regresionar cada una de Número de Condición (Tamaño de la Matriz X’X)
v. Método De La Prueba F
vi. Test Chi-Cuadrado (Test de Ortogonalidad)
b. Corrección
i. Método de Pre-estimación
ii. Método de Estimador “Cresta” (Ridge)
iii. Método de Componentes Principales
iv. Método Exclusión de Variables Colineadas
v. Aumento del tamaño de la muestra
2

vi. Utilización de información extramuestral
vii. Utilización de ratios
3

Teoría economómica/Intuición
Modelo Econométrico
Estimación del Modelo Inferencia sobre los Estimadores
Verificación de Supuestos
Predicción Evaluación de Políticas
Econometría I
Conceptos:
Es la combinación de aspectos matemáticos y técnicas estadísticas con el objetivo de obtener aproximaciones de las relaciones Teórico-Cuantitativas y/o Empírico-Cuantitativas de los postulados de las teorías económicas.
William H. Greene1
“La econometría se basa en la aplicación de técnicas matemáticas y estadísticas al análisis de las relaciones postuladas por la teoría económica”.
Juan Francisco Castro y
Roddy Rivas Llosa2
¿Que se busca con la Modelación Econométrica?
Simplificar la realidad
Comprender y explicar las relaciones existentes en la realidad
Predecir acontecimientos para el futuro
Proceso de Modelación Econométrica
1 Análisis Econométrico2 Econometría Aplicada
4

I. Repaso de Herramientas Matemáticas para el curso de Econometría
Álgebra Matricial
Una matriz es una colección de números ordenados rectangularmente, que designamos como:
A=[a ik
]=[A]ik =
[a11 a12 a13 ⋯ a1 k
a21 a22 a23 ⋯ a2 k
a31 a32 a33 ⋯ a3 k
⋮ ⋮ ⋮ ⋯ ⋮an 1 an2 an3 ⋯ ank
]Muchas veces a una matriz se le conoce como un conjunto de vectores
A=[a1 a2 a3 ⋯ aK ]
Donde ak
es el vector o columna k de la matriz A
Algunos tipos especiales de matrices
Matriz cuadrada.- Es aquella en la cual el número de filas es igual al número de columnas.
Matriz simétrica.- Es aquella matriz en la cuál a ik=aki
∀ ,i , k
Matriz diagonal.- Es una matriz cuadrada cuyos únicos elementos distintos de cero aparecen en su diagonal principal.
Matriz escalar.-.- Es una matriz diagonal con el mismo valor en todos los elementos de la diagonal.
Matriz identidad.- Es una matriz escalar con unos en la diagonal.
Matriz Cero [0].- Es aquella que tienes ceros en todos los elementos de la matriz.
Matriz triangular.- Es aquella que tienes ceros encima o bien debajo de la diagonal principal. Si los ceros están por encima de la diagonal, la matriz es triangular inferior.
Matriz Columna o Vector.- Es aquel arreglo de números que solo tiene una columna y puede tener n filas, generalmente para denominar o nombrar a los vectores o matrices columna se les asigna letras en minúscula.
5

Matriz Fila o Vector fila.- Es la transpuesta de un vector o matriz columna.
Matriz Columna [i] o Vector [i].-Es una matriz columna con dimensión (nx1) o en su defecto de n filas, en las que todos sus valores son uno.
Algunas Operaciones con Matrices
Suma de Matrices.- Para que dos matrices puedan sumarse es necesario que tengan la misma dimensión. (matrices conformables para la suma). Esta operación también se extiende a la resta de matrices.
C = A + B A y B Son matrices conformables y C es la resultante con la misma dimensión
A+0 = A
A+B = B+A
(A+B)+C = A+(B+C) = (A+C) + B
Producto de Matrices.- Se define a partir del producto interno, este es el producto de un vector fila por un vector columna y la resultante es un número
escalar. a'b =a1b1+a2b2+a3 b3+⋯+anbn
Para multiplicar dos matrices, el número de columnas de la primera debe coincidir con el número de filas de la segunda, en este caso decimos que ambas matrices son conformables para el producto
C=A*B≠B*A Donde A y B son conformables, B y A no necesariamente
son conformables.
( A*B)*C=A*(B*C )≠(A*C )*B Ley Asociativa
A*( B+C )=A*B+ A*C Ley Distributiva (premultiplicación)
( B+C )*A=B*A+ C*A Ley Distributiva (postmultiplicación)
Transpuesta de una matriz.- Es transformar la k-esima fila de una matriz por su k-ésima columna y este resultado se le asigna un apostrofe (‘).
Operaciones:
Si A, B, C y D son 4 matrices cualquiera y con dimensión apropiadas para realizar las operaciones.
A’= Transpuesta de A
(A+B+C)’=A’ + B’ + C’ = C’ + B’ + A’
(ABC)’=C’B’A’
D=D’ si D es una matriz simétrica
Sumas de Elementos
6

Las matrices y vectores proporcionan una forma particularmente conveniente de representar sumas de elementos. Un instrumento útil es el vector [i].
∑i=1
n
x i=x1+x2+x3+⋯+xn=i ' x
∑i=1
n
k=k+k+k+⋯+k=nk=k ( i ' i)
∑i=1
n
kxi=kx1+kx 2+kx3+⋯+kxn=k ∑i=1
n
x i=ki ' x
si k=1/n Entonces obtenemos la media aritmética de X
∑i=1
n1n
xi=1n
x1+1n
x2+1n
x3+⋯+ 1n
xn=1n∑i=1
n
x i=1n
i ' x
∑i=1
n
x i=i ' x=n x
Donde x
es la media de X
Geometría Matricial
Vectores
Un vector es una secuencia ordenada de elementos colocados en forma de fila o columna. Los elementos son generalmente números reales o símbolos que representan números reales.
Vector Columna o Simplemente Vector A =
[a1
a2
a3]
Vector Fila B =[b1 b2 b3 ]
Un vector Fila se puede expresar como la transpuesta de un vector columna de la siguiente forma:
A=
[a1
a2
a3]
Entonces A’ = [a1 a2 a3 ]
7

A es un vector columna, mientras que A’ es un vector fila3
Combinaciones Lineales
La combinación de dos operaciones de multiplicación escalar y suma de vectores proporciona un vector que es una combinación lineal de los otros vectores.
A=
[a1
a2
a3]
B=
[b1
b2
b3]
Si A y B son dos vectores que tienen la misma dimensión, entonces se puede construir un sin número de combinaciones lineales a partir de ellos.
C=α
.A+β
.B
C=
α [a1
a2
a3]+ β[b1
b2
b3]
Dependencia Lineal.- Un conjunto de vectores es linealmente dependiente si cualquiera de los vectores en el conjunto puede ser escrito como una combinación lineal de los otros.
α 1 A1+α2 A2+α 3 A3+α n An=0 ;
α i y A no triviales
Ejemplo: Verificar si A y B son linealmente dependientes.
A=
[247 ] B=
[ 4814]
Para comprobar que A y B son linealmente dependientes debemos hacer la siguiente operación
3 El Apostrofe en la parte superior derecha de A, indica la transpuesta de A
8

0=α
.A+β
.B
α [247 ]+ β [ 4814 ]=[000 ] 2 α+4 β=0⋯⋯(1)
4 α+8β=0⋯⋯(2 )7 α +14 β=0⋯⋯(3)
Del sistema de tres ecuaciones podemos encontrar un conjunto de resultados posibles de los cuales:
α=1 ;β=−1/2
α=−1 ;β=1/2
α=2 ;β=−1
α=−2 ;β=1
Vectores Linealmente independientes.- Un conjunto de vectores es linealmente independiente si y solo si se cumple:
α 1 A1+α2 A2+α 3 A3+α n An=0
α 1 , α 2α3⋯⋯α n=0
Ejemplo: Verificar si M y N son dos vectores linealmente independientes.
M=[23 ] N=[51 ]αM + βN=0
α [23 ]+ β [51 ]=0 2 α+5 β=0⋯⋯(1)3 α+ β=0⋯⋯(2 )
Despejando α
de (1) y Reemplazando en (2)
α=52
β
3 α−52
α=0
12
α=0⋯⋯(3)
El único valor para α
que satisface (3) es cero y
por lo tanto β
también será cero.
Espacio Vectorial.
9

Es el conjunto de vectores generados por dos o más vectores linealmente independientes.
Si A y B son dos vectores linealmente independientes, entonces todas las combinaciones lineales no triviales de A y B forman el espacio vectorial.
10

II. Repaso de Herramientas Matemáticas para el curso de Econometría
2.1 Conceptos
Variable.- Es una característica cuantificable o cualificable de una entidad cualquiera que puede tomar diferentes valores.
Variables Aleatorias.- Se dice que una variable es una variable aleatoria, porque el valor de esta variable es incierta hasta que el experimento se lleve a cabo
Variable Aleatoria discreta.- Cuando el conjunto de realizaciones es finito o infinito pero numerable.
Variable Aleatoria continua.- Cuando el conjunto de realizaciones es infinitamente indivisible y por lo tanto no es numerable.
Distribución de Probabilidad.- Es un conjunto de valores xi tomados de una variable aleatoria X y sus probabilidades asociadas.
f ( x )=Pr ob ( X=x )Función de Probabilidad
Los axiomas de probabilidad para una variable aleatoria discreta:
0≤Pr ob( X =x )≤1y
∑i
f ( x i )=1
Los axiomas de probabilidad para una variable aleatoria continua:
f ( x )≥0y
∫−∞
+∞
f ( xi ) dx=1
2.2 Características más importantes de una distribución de probabilidad
Media o Esperanza Matemática E(X).- La media, valor esperado o esperanza matemática de una variable aleatoria se define como:
μ=E ( X )=∑i
f ( xi ) . x i
Operaciones con el operador de esperanza matemática4
oE [ a ]=a
oE [aX +bY ]=aE [ X ]+bE[ Y ]
oE [∑ X i ]=∑ E[ X i ]
oE [cXY ]=cE[ X ] E[ Y ]
Si X y Y son v.a.i
oE [cXY ]=cE[ XY ]
Si X y Y no son v.a.i
4 Asumiendo X,Y variables aleatorias independientes (v.a.i.) y a,b,c constantes
11

Varianza :
var( X )=E [( X−μ )2]=∑i
( x−μ )2 . f ( xi )
Operaciones con el operador de varianza5
ovar [ a ]=a
ovar ( X )=E [( X−μ )2]=E [ X2 ]−μ2=σ2
Prueba
var ( X )=E [( X−μ )2]=E [ X2−2 Xμ+μ2]¿ E [ X2 ]−E [ 2 Xμ ]+ E [μ2]=E [ X2]−2 μE [ X ]+μ2
¿ E [ X2 ]−2 μμ+μ2=E [ X2 ]−2 μ2+μ2=E [ X2 ]−μ2
ovar (aX +b )=a2 var( X )
Prueba
var (aX +b )=var ( aX )+var (b )=var ( aX )=E [(aX −a X )2]=E [ a2( X−X )2]¿a2 E [( X −X )2]=a2 var ( X )
o Cuando las v.a. son independientes (X,Y independientes)
var (aX ±bY )=a2 var( X )+b2var ( X )
cov ( X , Y )=E [ ( X−μx ) (Y −μy )]=0
o Cuando las v.a. son independientes (X,Y dependientes)
var (aX −bY )=a2 var( X )+b2 var ( X )−2 ab cov (x , y )
var(aX +bY )=a2 var( X )+b2 var( X )+2ab cov ( x , y )
cov ( X , Y )=E [ ( X−μx ) (Y −μy )]=E [ XY ]−μx μ y=σ xy
Función de Distribución.- Para cualquier variable aleatoria x, la probabilidad de que x sea menor o igual que v se indica por F(v). F(x), es la.
Función de Distribución Acumulada (FDA) : variable aleatoria discreta.
Función de Distribución Acumulada (FDA) : variable aleatoria continua.
5 Asumiendo X,Y variables aleatorias independientes (v.a.i.) y a,b,c constantes
12

f ( x )=dF ( X )
dx
Algunas Funciones de Distribución:
La distribución Normal :
f ( x /μ , σ2 )= 1σ √2 π
e− 1
2 [(( x−μ )σ)2]
La distribución Normal Estándar :
f ( x /0,1 )= 1σ √2 π
e− x2
2
Distribución t.
t [n ]=z√x /n
Distribución F :
F [n1 , n2]=x1 /n1
x2 /n2
Distribución Chi Cuadrada : z≈N [ 0,1 ] ⇒ z2≈ X2 [ 1 ]
Índice de Asimetría (Skewness) : Se dice que la distribución de una variable es simétrica, si los intervalos equidistantes del intervalo central tienen iguales frecuencias.
Si As=0, La variable tiene una distribución simétrica, (la media, la mediana y la moda son iguales)
Si As>0, La variable tiene una distribución Simétrica positiva, (moda<mediana< media)
Si As<0, La variable tiene una distribución Simétrica negativa, (moda>mediana> media)
Indice de Curtosis (Kurtosis)6: Mide el índice de apuntamiento de la distribución de la variable
Si K=3, La distribución es normal
Si K>3, La distribución de la variable es leptocurtica
Si K<3, La distribución de la variable es platicurtica
6 El coeficiente de asimetría y la curtosis son basados en la varianza y fueron propuestos por Bickel and Doksum 1977
13

Estadístico Jarque Bera: Jarque Bera es un prueba estadística para probar si la serie sigue una distribución normal o no, k representa el número de coeficientes estimados
Ho : La serie sigue una distribución normal con 2 grados de libertad
H1 : La serie no sigue una distribución normal
Si la probabilidad de JB es mayor al 5% entonces se acepta la hipótesis nula
Si la probabilidad de JB es menor al 5% entonces se rechaza la hipótesis nula
Varianza y Esperanza Condicional
Esperanza Condicional o Media Condicional.- Una media condicional es la media de la distribución condicional y se define por
E [ Y\X ]=∑y
yf ( y \x )
si y es discreta
E [ Y\X ]=∫y
yf ( y \x )dy
Si y es continua
Varianza Condicional.- La varianza condicional es la varianza de la distribución condicional.
Var [Y ¿ ]=E [ ( y−E [ Y\X ] )2 \X ]=∑y
( y−E [ Y\X ] )2 f ( y¿ )
Discreta
Var [Y ¿ ]=E [ ( y−E [ Y\X ] )2 \X ]=∫y
( y−E [ Y\X ] )2 f ( y ¿ )dy
Continua
Ejemplo 1:
X: 17 18 19 20
f ( x )1/5 2/5 1/5 1/5
Mediana : 18
Media :
μ=E ( X )=15
∗17+25
∗18+15
∗19+15
∗20=
μ=E ( X )=3,4+7,2+3,8+4=18 , 4
Varianza Poblacional:
var( X )=E [( X−μ )2]¿(17−18 , 4 )∗1
5+(18−18 , 4 )∗2
5+(19−18 , 4 )∗1
5+(20−18 , 4 )∗1
5¿0 .392+0 .064+0 . 072+0 .512=1 .04
14

Desviación Estándar Poblacional:
Varianza Muestral:
Desviación Estándar Muestral:
Índice de Asimetría:
Índice de Curtosis (Kurtosis)
Estadístico Jarque Bera: Se distribuye como una chi cuadrada con dos grados de libertad
Calcular el Pvalue de 0.288682 en distribución normal
Pvalue[x=0.288682] para 5% de nivel de confianza
Pvalue[x=0.288682] = 1-@cchisq(0.288682,2)=0.865592
15

0.0
0.4
0.8
1.2
1.6
2.0
2.4
17.0 17.5 18.0 18.5 19.0 19.5 20.0 20.5
Series: SER01Sample 1 5Observations 5
Mean 18.40000Median 18.00000Maximum 20.00000Minimum 17.00000Std. Dev. 1.140175Skewness 0.271545Kurtosis 1.955621
Jarque-Bera 0.288682Probability 0.865592
16

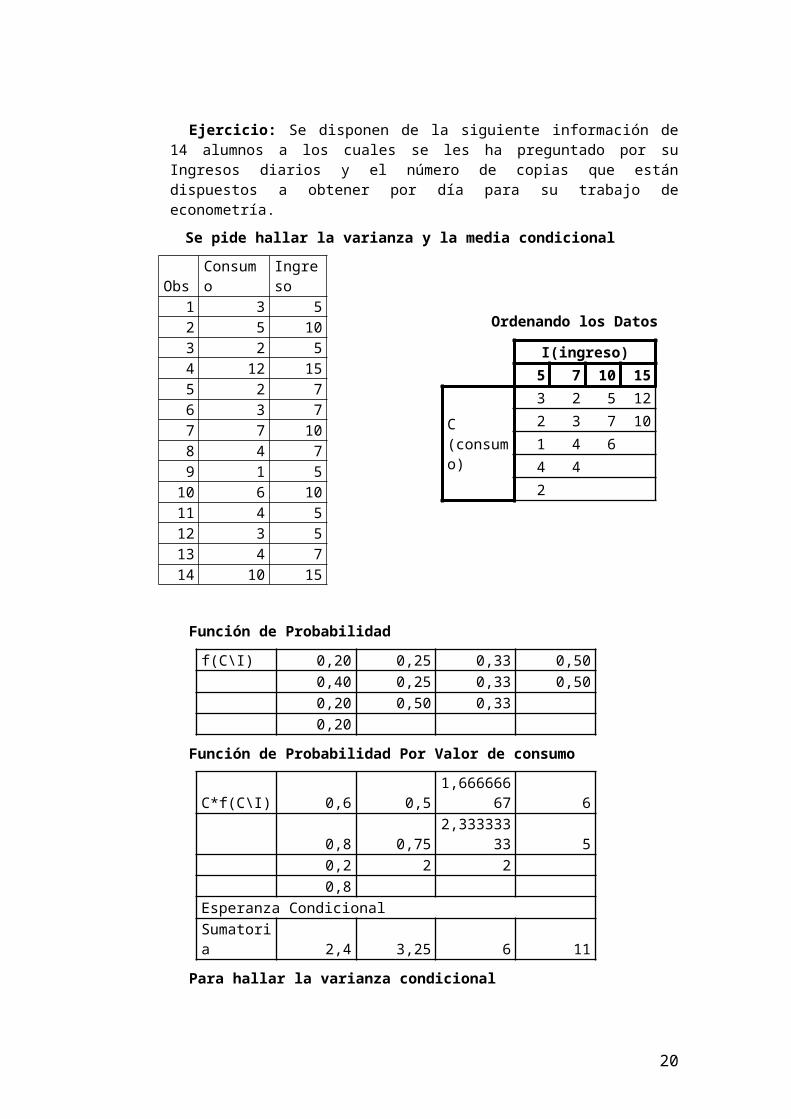
Ejercicio: Se disponen de la siguiente información de 14 alumnos a los cuales se les ha preguntado por su Ingresos diarios y el número de copias que están dispuestos a obtener por día para su trabajo de econometría.
Se pide hallar la varianza y la media condicional
Obs Consumo Ingreso1 3 52 5 103 2 54 12 155 2 76 3 77 7 108 4 79 1 5
10 6 1011 4 512 3 513 4 714 10 15
Ordenando los Datos
I(ingreso)5 7 10 15
C (consumo)
3 2 5 122 3 7 101 4 64 42
Función de Probabilidad
f(C\I) 0,20 0,25 0,33 0,500,40 0,25 0,33 0,500,20 0,50 0,330,20
Función de Probabilidad Por Valor de consumo
C*f(C\I) 0,6 0,5 1,66666667 60,8 0,75 2,33333333 50,2 2 20,8
Esperanza CondicionalSumatoria 2,4 3,25 6 11
Para hallar la varianza condicional
(C-E[C\I])2 0,36 1,5625 1 10,16 0,0625 1 11,96 0,5625 02,56 0,56250,16
Dividimos entre el número total de datos
0,072 0,390625 0,33333333 0,50,064 0,015625 0,33333333 0,50,392 0,28125 00,512
Varianza Condicional
17

Sumatoria 1,04 0,6875 0,66666667 1
III. Método de Mínimos Cuadrados Ordinarios
Relación entre dos variables
3.1 Análisis gráfico de Relación entre dos variables
a.) Análisis gráfico con respecto al tiempo (caso de series de tiempo)
PBI VS Población
0
20.000
40.000
60.000
80.000
100.000
120.000
140.000
0,0
5.000,0
10.000,0
15.000,0
20.000,0
25.000,0
30.000,0
PRODUCTO BRUTO INTERNO (Millones de nuevos soles a precios de 1994)
POBLACIÓN (Miles)
La relación existente entre el nivel de PBI y el crecimiento poblacional es positivo según nos muestra el gráfico
b.) Análisis de Gráfico de Dispersión
PBI VS Población
5.000,0
10.000,0
15.000,0
20.000,0
25.000,0
30.000,0
20.000 40.000 60.000 80.000 100.000 120.000 140.000
PBI
Po
bla
cio
n
El gráfico de dispersión entre dos variables gráfica coordenadas a partir de las valores que toman las variables en un determinado momento del tiempo, o variables que pertenecen a una misma observación.
c.) Coeficiente de Correlación
18

r=∑ ( X− XSx
)( Y −YSx
)/n=Cov ( X ,Y )
S x S y
3.2 El modelo de Regresión Lineal de Dos Variables
A.) Función de Regresión Poblacional
Un modelo Condicional
Dado un conjunto de valores poblacionales para dos variables, podemos graficarlo, en un gráfico de dispersión.
0123456789
10111213
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
En este el gráfico de dispersión nos muestra los valores que toma el consumo dado un valor del ingreso y los valores medios o esperanzas matemáticas de todos los consumos condicionados a los ingresos se puede expresar de la siguiente manera.
E [Y / X ]=α+ βX
μi=Y i−E [Y / X i ]=Y i−α +βX i
Supuestos que se deben cumplir para obtener estimadores MICO
E [Y / X ]
0123456789
10111213
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
19
PBI VS Población
5.000,0
10.000,0
15.000,0
20.000,0
25.000,0
30.000,0
20.000 40.000 60.000 80.000 100.000 120.000 140.000
PBI
P o bl
ac ió n
bXaY ˆ
E [ μi ]=0
Var ( μi )=E [ μi2 ]=σ2
Cov (μ i , μ j )=E [ μi μ j ]=0
B.) Función de Regresión Muestral.- Dado que los datos no se obtienen de toda la población debido a que es muy costoso, toma mucho tiempo y es difícil la ubicación de todos los individuos de la población. La toma de muestras representativas de la población y sus resultados sirven para inferir resultados para toda la población, en este sentido se obtiene estimadores que infieran los resultados de los parámetros poblacionales.
La Función de la Regresión Muestral (FRM) es una función lineal que representa el conjunto de valores estimados dado un valor de X, y esta representado por lo siguiente:
Y=a+bX
Donde a y b son estimadores de α
y β
que son parámetros de la población.
3.3 Estimadores Mínimos Cuadráticos (caso 2 variables)
E [Y / X ]=α+ βXFunción de Regresión Poblacional
Y=a+bXFunción de Regresión Muestral
e=Y −Y
20

∑i=1
n
ei2=∑
i=1
n
(Y i−Y i )2=∑
i=1
n
(Y i−a−bX i )2
∂∑i=1
n
e i
∂ a=∑
i=1
n
(Y i−a−bX i ) (−2 )=0
∂∑i=1
n
e i
∂ b=∑
i=1
n
(Y i−a−bX i ) (−2 X i )=0
∑i=1
n
( Y i )=∑i=1
n
(a )+∑i=1
n
(bX i )⋯⋯⋯(1 )
∑i=1
n
( Y i X i )=∑i=1
n
( aX i )+∑i=1
n
( bX i X i )⋯⋯⋯(2)
a=Y −b X
b=∑i=1
n
( X i−X ) (Y i−Y )
∑i=1
n
( X i−X )2=
Cov ( X ,Y )Var ( x )
Coeficiente de Correlación y Estimadores
r XY=
∑i=1
n
( X i−X ) (Y i−Y )
n
√∑i=1
n
( X i−X )2
n
∑i=1
n
(Y i−Y )2
n
=∑i=1
n
( X i−X ) (Y i−Y )
√∑i=1
n
( X i− X )2∑i=1
n
( Y i−Y )2
r XY=Cov ( X ,Y )
√Var ( X )Var (Y )=
Cov( X , Y )S X SY
r XY=Cov ( X ,Y )
SX SY
S X
S X
=Cov( X ,Y )
Var ( x )SX
SY
=bS X
SY
b=r XY
SY
SX
Bondad de Ajuste
Descomposición de la suma de Cuadrados en Desvíos
x=X −X ; x en desvíos
y=Y −Y ; x en desvíos
Y=a+bX +e …………(1)
Y=a+b X …………….(2)
(1)-(2)
Y−Y =b ( X −X )+e
y=bx+e
e= y−bx
∑ e2=∑ ( y−bx )2
∑ e2=∑ y2−2 b∑ xy+b2∑ x2
21

Sabemos que:b=∑ xy
∑ x2
∑ e2=∑ y2−2 b(b∑ x2)+b2∑ x2
∑ e2=∑ y2−b2∑ x2
Despejando la sumatoria de desvíos al cuadrado de la variable dependiente
∑ y2=b2∑ x2+∑ e2
Sabemos que:
Y=a+bX …………(3)
Y=a+b X …………….(4)
(3) – (4)
Y−Y =b ( X −X )
y=bx
∑ y2=b2∑ x2
∑ y2=∑ y2+∑ e2…..(5)
STC=SEC+SRC
STC: Sumatoria total de desviaciones al cuadrado de la variable Y
STC: Sumatoria Explicada de cuadrado de la variable
SRC: Sumatoria Residual de cuadrados.
Dividiendo (5) entre STC
∑ y2
∑ y2 =∑ y2
∑ y2 +∑ e2
∑ y2
R2=∑ y2
∑ y2 : Coeficiente de Correlación.
1=R2+ ∑ e2
∑ y2
R2=1−∑ e2
∑ y2
Coeficiente de correlación y coeficiente de determinación.
∑ y2=(r xy
s y
sx)
2
∑ x2+∑ e2
22

∑ y2=rxy2( s y
sx)
2
∑ x2+∑ e2
∑ y2=rxy2∑ y2+∑ e2
1=rxy2+∑ e2
∑ y2
r xy2=1− ∑ e2
∑ y2
En Forma Matricial
e1=Y 1−Y 1=Y 1−a−bX i
e2=Y 2−Y 2=Y 2−a−bX 2
⋮en=Y n−Y n=Y n−a−bXn
[e1
e2
⋮en
]=[Y 1
Y 2
⋮Y n
]−[a+bX 1
a+bX 2
⋮a+bXn
][e1
e2
⋮en
]=[Y 1
Y 2
⋮Y n
]−[1 X1
1 X2
⋮ ⋮1 Xn
][ab ]
e=Y −X βe ' e=(Y− X β ) ' (Y −X β )∂ e ' e
∂ β=− X ' (Y− X β )∗−(Y− X β ) ' X =0
−X ' (Y −X β )∗−( Y−X β ) ' X =0
−2 X ' (Y− X β )=0X ' Y− X ' X β=0β=( X ' X )−1( X ' Y )
23

IV. Análisis de Significancia de los estimadores (prueba de Hipótesis) y Contrastes de Errores de especificación
Dentro del estudio de la inferencia estadística, se describe como se puede tomar una muestra aleatoria y a partir de ella estimar el valor de un parámetro poblacional, para hacerlo es necesario tener conocimiento de ciertos datos de la población como la media, la desviación estándar o la forma de la población, pero a veces no se dispone de esta información, en este caso es necesario hacer una estimación puntual que es un valor que se usa para estimar un valor poblacional. Pero una estimación puntual es un solo valor y se requiere un intervalo de valores a esto se denomina intervalote confianza y se espera que dentro de este intervalo se encuentre el parámetro poblacional buscado. También se utiliza una estimación mediante un intervalo, el cual es un rango de valores en el que se espera se encuentre el parámetro poblacional.
4.1 Hipótesis Y Prueba De Hipótesis
Hipótesis es una aseveración a priori de un valor que puede tomar un coeficiente.
En el análisis estadístico se hace una aseveración, es decir, se plantea una hipótesis, después se hacen las pruebas para verificar la aseveración o para determinar que no es verdadera, la prueba de hipótesis es un procedimiento basado en la evidencia muestral y la teoría de probabilidad; se emplea para determinar si la hipótesis es una afirmación razonable.
Prueba de una hipótesis: se realiza mediante un procedimiento sistemático de cinco paso:
Siguiendo este procedimiento sistemático, al llegar al paso cinco se puede o no rechazar la hipótesis, pero debemos de tener cuidado con esta determinación ya que en la consideración de estadística no proporciona evidencia de que algo sea verdadero. Esta prueba aporta una clase de prueba más allá de una duda razonable. Analizaremos cada paso en detalle
Objetivo de la prueba de hipótesis.
El propósito de la prueba de hipótesis no es cuestionar el valor calculado del estadístico (muestral), sino hacer un juicio con respecto a la diferencia entre estadístico de muestra y un valor planteado del parámetro.
Paso 1: Plantear la hipótesis nula Ho y la hipótesis alternativa H1.
Cualquier investigación estadística implica la existencia de hipótesis o afirmaciones acerca de las poblaciones que se estudian.
24

La hipótesis nula (Ho) se refiere siempre a un valor especificado del parámetro de población, no a una estadística de muestra. La letra H significa hipótesis y el subíndice cero no hay diferencia. La hipótesis nula es una afirmación que no se rechaza a menos que los datos maestrales proporcionen evidencia convincente de que es falsa. El planteamiento de la hipótesis nula siempre contiene un signo de igualdad con respecto al valor especificado del parámetro.
La hipótesis alternativa (H1) es cualquier hipótesis que difiera de la hipótesis nula. Es una afirmación que se acepta si los datos maestrales proporcionan evidencia suficiente de que la hipótesis nula es falsa. Se le conoce también como la hipótesis de investigación. El planteamiento de la hipótesis alternativa nunca contiene un signo de igualdad con respecto al valor especificado del parámetro.
Paso 2: Seleccionar el nivel de significancia.
Nivel de significancia: Probabilidad de rechazar la hipótesis nula cuando es verdadera. Se le denota mediante la letra griega α, también es denominada como nivel de riesgo, este termino es mas adecuado ya que se corre el riesgo de rechazar la hipótesis nula, cuando en realidad es verdadera. Este nivel esta bajo el control de la persona que realiza la prueba.
Si suponemos que la hipótesis planteada es verdadera, entonces, el nivel de significación indicará la probabilidad de no aceptarla, es decir, estén fuera de área de aceptación. El nivel de confianza (1-α), indica la probabilidad de aceptar la hipótesis planteada, cuando es verdadera en la población.
La distribución de muestreo de la estadística de prueba se divide en dos regiones, una región de rechazo (conocida como región crítica) y una región de no rechazo (aceptación). Si la estadística de prueba cae dentro de la región de aceptación, no se puede rechazar la hipótesis nula.
La región de rechazo puede considerarse como el conjunto de valores de la estadística de prueba que no tienen posibilidad de presentarse si la hipótesis nula es verdadera. Por otro lado, estos valores no son tan improbables de presentarse si la hipótesis nula es falsa. El valor crítico separa la región de no rechazo de la de rechazo.
Tipos de errores
Cualquiera sea la decisión tomada a partir de una prueba de hipótesis, ya sea de aceptación de la Ho o de la Ha, puede incurrirse en error:
25

Un error tipo I se presenta si la hipótesis nula Ho es rechazada cuando es verdadera y debía ser aceptada. La probabilidad de cometer un error tipo I se denomina con la letra alfa α
Un error tipo II, se denota con la letra griega β se presenta si la hipótesis nula es aceptada cuando de hecho es falsa y debía ser rechazada.
En cualquiera de los dos casos se comete un error al tomar una decisión equivocada.
En la siguiente tabla se muestran las decisiones que pueden tomar el investigador y las consecuencias posibles.
Para que cualquier ensayo de hipótesis sea bueno, debe diseñarse de forma que minimice los errores de decisión. En la práctica un tipo de error puede tener más importancia que el otro, y así se tiene a conseguir poner una limitación al error de mayor importancia. La única forma de reducir ambos tipos de errores es incrementar el tamaño de la muestra, lo cual puede ser o no ser posible.
La probabilidad de cometer un error de tipo II denotada con la letra griega beta β, depende de la diferencia entre los valores supuesto y real del parámetro de la población. Como es más fácil encontrar diferencias grandes, si la diferencia entre la estadística de muestra y el correspondiente parámetro de población es grande, la probabilidad de cometer un error de tipo II, probablemente sea pequeña.
El estudio y las conclusiones que obtengamos para una población cualquiera, se habrán apoyado exclusivamente en el análisis de una parte de ésta. De la probabilidad con la que estemos dispuestos a asumir estos errores, dependerá, por ejemplo, el tamaño de la muestra requerida. Las contrastaciones se apoyan en que los datos de partida siguen una distribución normal
Existe una relación inversa entre la magnitud de los errores α y β: conforme a aumenta, β disminuye. Esto obliga a establecer con cuidado el valor de a para las pruebas estadísticas. Lo ideal sería establecer α y β.En la práctica se establece el nivel α y para disminuir el Error β se incrementa el número de observaciones en la muestra, pues así se acortan los limites de confianza respecto a la hipótesis planteada .La meta de las pruebas estadísticas es rechazar la hipótesis planteada. En otras palabras, es deseable aumentar
26

cuando ésta es verdadera, o sea, incrementar lo que se llama poder de la prueba (1- β) La aceptación de la hipótesis planteada debe interpretarse como que la información aleatoria de la muestra disponible no permite detectar la falsedad de esta hipótesis.
Paso 3: Cálculo del valor estadístico de prueba
Valor determinado a partir de la información muestral, que se utiliza para determinar si se rechaza la hipótesis nula., existen muchos estadísticos de prueba para nuestro caso utilizaremos el estadístico t.
En la prueba para una media poblacional con muestra pequeña y desviación estándar poblacional desconocida se utiliza el valor estadístico t.
t= β−β¿
se ( β )Paso 4: Formular la regla de decisión
Se establece las condiciones específicas en la que se rechaza la hipótesis nula y las condiciones en que no se rechaza la hipótesis nula. La región de rechazo define la ubicación de todos los valores que son tan grandes o tan pequeños, que la probabilidad de que se presenten bajo la suposición de que la hipótesis nula es verdadera, es muy remota
Distribución muestral del valor estadístico z, con prueba de una cola a la derecha
Valor critico: Es el punto de división entre la región en la que se rechaza la hipótesis nula y la región en la que no se rechaza la hipótesis nula.
Paso 5: Tomar una decisión.
En este último paso de la prueba de hipótesis, se calcula el estadístico de prueba, se compara con el valor crítico y se toma la decisión de rechazar o no la hipótesis nula. Tenga presente que en una prueba de hipótesis solo se puede tomar una de dos decisiones: aceptar o rechazar la hipótesis nula. Debe subrayarse que siempre existe la posibilidad de rechazar la hipótesis nula cuando no debería haberse rechazado (error tipo I). También existe la posibilidad de que la hipótesis nula se acepte cuando debería haberse rechazado (error de tipo II).
4.2 Significancia individual de una relación econométrica
Dado el planteamiento de la función a regresionar:
f ( X )=Y=α+βX +e
y si se cumple los principales supuestos de MCO tales como:
27

E [ μi ]=0
Var ( μi )=E [ μi2 ]=σ2
Cov (μ i , μ j )=E [ μi μ j ]=0
para explicar la implicancia de las variables independientes sobre las variables
dependientes se debe probar que β
, es estadísticamente significativa (estadísticamente diferente de cero).
.
Ho : β=0Estadísticamente significativo
Ha : β≠0Estadísticamente no significativo
t= β−0se ( β )
= βse ( β )
Si t>t tabla entonces se dice que se rechaza la hipótesis nula de estadísticamente no significativa.
4.3 Error de especificación en un modelo econométrico.
La hipótesis básica del modelo de regresión lineal múltiple es que la variable dependiente “Y” se puede expresar como una combinación lineal de k variables explicativas más un término de error .
f ( X )=Y =α+β1 X1+ β2 X2+β3 X 3+e
De la anterior especificación econométrica se puede identificar 3 aspectos que podrían hacer que la estimación de la variable dependiente (Y) no sea correcta.
Las X (X1, X2, X3, las variables independientes)
α ,β1 , β2 , β3
Los coeficientes
y los errores (e )
En este sentido estos 3 aspectos podrían causar un error de especificación econométrica
4.3.1 Error de especificación, problemas con las variables independientes (X).
En la práctica no siempre es posible incluir todas las variables relevantes, bien porque alguna de estas variables no se considera relevante o porque no se puede medir. Otras veces se incluyen erróneamente variables irrelevantes o se especifica una relación lineal que no lo es. Todo ello conduce a especificar incorrectamente el modelo y es
28

importante determinar la influencia de tales especificaciones incorrectas y tenerlas en cuenta en los resultados.
Se debe considerar los siguientes errores de especificación de este tipo al ajustar un modelo de regresión múltiple:
Omitir una variable relevante, alguna variable regresora de gran importancia no se ha incluído en el modelo. Este problema produce:
Que los estimadores mínimos cuadráticos sean sesgados y con mayor varianza salvo que la variable excluída sea ortogonal a las variables regresoras del modelo.
Que la varianza residual R2 sea un estimador sesgado por exceso ya que los
errores son mayores de lo que serían si se hubiera incluído la variable excluída, sobre todo si esta variable es ortogonal a las variables regresoras, ya que entonces su influencia en la variable Y es mayor.
Como R2 es muy grande los intervalos de confianza de los parámetros del
modelo son mayores de lo que deberían y los contrastes individuales de la t llevarán a considerar como no significativas a variables regresoras que si lo son.
Incluir una variable irrelevante, que no influye en la variable dependiente Y o que la información que proporciona sobre esta variable ya está contenida en las otras variables regresoras. Las consecuencias de este problema son las siguientes:
Si la variable irrelevante incluida depende de las otras variables regresoras se tiene un problema de multicolinealidad. Aumentará la varianza de los , y los contrastes individuales de la t tienden a considerar como no significativas a variables regresoras que si lo son.
Si la variable irrelevante incluida es ortogonal a las otras variables regresoras, el efecto es menor, se pierde eficacia porque se pierde un grado de libertad al aumentar una variable regresora que no aporta variabilidad explicada, pero para tamaños muestrales grandes el efecto es mínimo.
Especificar una relación lineal inapropiada, proporciona malos resultados, sobre todo fuera del rango de valores observados porque una relación no lineal en un estrecho intervalo de observación se puede aproximar por una lineal. Las graves consecuencias de este error son las siguientes:
Los estimadores son sesgados y su varianza se calcula mal.
La varianza residual se calcula mal y los contrastes individuales de la t no son válidos.
Las predicciones del modelo son malas, sobre todo fuera del rango de valores de las observaciones.
Variables “X” no Estacionarias, Se puede dar que las variables explicativas tengan un comportamiento de caminata aleatoria que no explicaría en nada a la variable dependiente y solo hace sería una relación espuria.
Alta Correlación de las X, Las variables explicativas pueden estar correlacionadas y por lo tanto hacer que la matriz de las variables X no sea invertible en el peor de los casos, a este problema se le denomina Multicolinealidad que se vera mas adelante.
29

4.3.2 Error de especificación, problemas con las coeficientes (X).
La especificación econométrica asume que los coeficientes α ,β1 , β2 , β3
, son constantes e invariantes una ves calculado, pero existen situaciones en las que es frecuente toparse con coeficientes con cambios estructurales repentinos, o por el contrario, con evoluciones lentas debidas a cambios en el entorno social o ambiental.
4.3.3 Error de especificación, problemas con las perturbaciones (e).
Los errores de especificación causados por las perturbaciones, implican directamente la violación a los supuestos del método de mínimos cuadrados ordinarios, estos son Autocorrelación y Heterocedasticidad, que se vera mas ampliamente el siguiente capitulo.
4.3.4 Detección de Errores de especificación en un modelo econométrico.
Los errores de especificación se detectan utilizando los gráficos de residuos descritos anteriormente. Especialmente se tendrán en cuenta:
El gráfico de residuos frente a predicciones .
El gráfico de residuos frente a una variable explicativa .
El gráfico de residuos frente a una variable explicativa omitida . En muchas ocasiones se intuye que se debería incluir un término cuadrático o una interacción (producto) de variables explicativas, siendo razonable hacer el gráfico de los residuos frente a variables como xij
2 o xij . xik.
El gráfico de residuos frente a la variable índice o tiempo si las observaciones son recogidas secuencialmente y se sospecha que el tiempo puede ser una variable regresora.
30

22)var( ii eEe
0),cov( jiji eeEee
V. Violación a los Supuestos de Mínimos Cuadrados Ordinarios
(Errores de especificación posibles problemas con los errores (e))
[e1
e2
⋮en
]=[Y 1
Y 2
⋮Y n
]−[1 X1
1 X2
⋮ ⋮1 X n
][ β0
⋮βk
]e = Y − X . { β
¿
E [ ee ' ]=E[ [e1
e2
⋮en
] [e1 e2 ⋯ en ]]=E [e1 e1 e1e2 ⋯ e1en
e2 e1 e2e2 ⋯ e2en
e3 e1 e3e2 ⋯ e3en
⋮ ⋮ ⋱ ⋮en e1 ene2 ⋯ enen
]E [ ee ' ]=[
E [ e1 e1] E [e1 e2 ] E [e1 e3] ⋯⋯ E [ e1 en ]E [ e2 e1 ] E [e2 e2 ] E [e2 e3] ⋯ E [ e2 en ]E [e3 e1 ] E [e3 e2 ] E [e3 e3] ⋯ E [ e3 en ]
⋮ ⋮ ⋮ ⋱ E [ en en ]E [en e1 ] E [ en e2 ] E [en e3] ⋯ E [ en en ]
]5.1 Autocorrelación
E [e i e j ]≠cov (e i , e j )≠0 ∀ i≠ j
Expresando en forma sencilla el modelo clásico supone que un término de perturbación cualquiera no esta influenciado por algún otro.
Por ejemplo si se esta tratando con información trimestral de series de tiempo para efectuar una regresión de la producción sobre los insumos trabajo y capital y si por ejemplo hay una huelga laboral que afecta la producción en un trimestre, no hay razón para pensar que esta interrupción afectara la producción del trimestre siguiente. Es decir, si la producción es inferior este trimestre, no hay razón para esperar que esta sea baja en el siguiente trimestre. En forma similar, si se esta tratando con información de corte transversal que involucra la regresión del gasto de consumo familiar sobre el ingreso familiar, no se espera que el efecto de un incremento en el ingreso de una familia sobre su gasto de consuma incida sobre el gasto de consumo de otra.
31

Sin embargo, si tal dependencia existe, se tiene autocorrelación. Simbólicamente,
E(ui,uj)≠0………………….i = j
En esta situación, la interrupción ocasionada por una huelga este trimestre puede afectar muy fácilmente la producción del siguiente trimestre, o los incrementos del gasto de consumo de una familia pueden inducir muy fácilmente a otra familia a aumentar su gasto de consumo para no quedarse atrás de la primera.
Se pueden visualizar algunos de los patrones razonables de autocorrelación y de no autocorrelación, los cuales están dados en las siguientes figuras.En la fig. 1.1 a 1.4 se muestra que hay un patrón distinguible entre las u. En la fig. 1.1 muestra un patrón cíclico; las fig. 1.2 y 1.3 sugieren una tendencia lineal hacia arriba o hacia abajo en las perturbaciones; y la fig. 1.4 indica que tantos términos de tendencia lineal como de tendencia cuadrática están presentes en las perturbaciones. Solamente la fig. 1.5 indica que no hay patrón sistemático, apoyando el supuesto de no autocorrelación del modelo clásico de regresión lineal.
32

0 0
0 0
u,u u,u
u,u u,u
tiempo u,u tiempo u,u
tiempo u,u tiempo u,u
Fig.1.1 Fig.1.2
Fig.1.3 Fig.1.4
Fig.1.5
0
u,u
tiempo
5.1.1 Causa De Autocorrelación Inercia: Como bien se sabe las series de tiempo tales como el PNB los índices
de precio la producción el empleo y el desempleo presentan ciclos (económicos). Empezando del fondo de la recesión cuando se inicia la recuperación económica, la mayoría de estas series se empiezan a moverse hacia arriba entonces el valor
33

de una serie en un punto del tiempo es mayor que su valor anterior, por ejemplo un aumento en la tasa de interés o en los impuestos o ambos.
Sesgo De Especificación: Caso De Variables Excluidas:La exclusión de variables explicativas relevantes puede ocasionar problemas de autocorrelación. Frecuentemente la inclusión de tales variables elimina el patrón de correlación observado entre los residuales. Por ejemplo supóngase que se tiene en el siguiente modelo de demanda:
Fenómeno De La Telaraña:La oferta de muchos productos agrícolas refleja este fenómeno donde dicha oferta reacciona al precio con rezago de un periodo de tiempo debido a que la implementación de las decisiones de oferta toma tiempo (periodo de gestación) por lo tanto los agricultores están influenciados por el precio prevaleciente del año anterior y su función de oferta es:
ofertat=B1+B2Pt-1t+ut … (2.3.a)Suponiendo que al final del periodo t, el precio Pt resulta ser inferior a Pt-1 .
es muy probable que los agricultores desean producir en el periodo t+1 menos de lo produjeron en el periodo t. Obviamente en esta situación no se espera que las perturbaciones ui sean aleatorias porque si los agricultores producen excedentes en el año t, es probable que reduzcan su producción en t+1 y así sucesivamente conduciendo a un patrón de telaraña.
Rezagos: En una regresión de series de tiempo en el gasto de consumo sobre el ingreso, no es extraño encontrar que el gasto de consumo en el periodo actual dependa, entre otras cosas, del gasto de consumo del periodo anterior. Es decir una autoregresión porque una de las variables explicativas es el valor rezagado de la variable dependiente.
Datos Agregados:En el análisis empírico los datos simples son frecuentemente manipulados. Por ejemplo en las regresiones de series de tiempo que contienen información trimestral, esa información generalmente se deriva de información mensual agregando simplemente las informaciones de 3 meses y dividiendo la suma por 3. Dicho procedimiento de promediar cifras introduce cierto suavizamiento de datos al eliminar las fluctuaciones en la información mensual. Por consiguiente la grafica trimestral aparece mucho mas suave que la grafica analizado mensualmente y este suavizamiento puede inducir a un patrón sistemático en las perturbaciones, introduciendo con esto autocorrelación.
5.1.2 Consecuencias:Como en el caso de la heterocedasticidad, en presencia de autocorrelación los estimadores MCO continúan siendo lineales-insesgados al igual que consistentes, pero dejan de ser eficientes.
5.1.3 Detección De La Autocorrelación:
34

Método grafico (Prueba de “la rachas”/ prueba de Geary)Recordando que el supuesto de autocorrelación del modelo clásico se relaciona con las perturbaciones poblacionales ut, las cuales no pueden ser observadas directamente. Por lo cual disponemos de valores aproximados que pueden obtenerse a partir del procedimiento usual MCO.Se debe graficar los residuos y observar si tienen algún comportamiento sistemático. Al observar un grafico con residuales negativos posteriormente positivos y luego negativos y si los residuales serian puramente aleatorios sería un comportamiento no sistemático y por lo tanto no existiría autocorrelaciónPero si existen residuos con signos iguales consecutivos (representan una racha) y la longitud de la misma como el número de elementos (sea + o -). Si existe muchas rachas negativas llamaremos autocorrelación negativa caso contrario llamamos autocorrelación positiva.
Método grafico (Correlograma de los residuos)
Si el coeficiente de autocorrelación parcial pasa los limites de confianza esto indicaría que existe autorcorrelación Prueba De Durbin Watson
La prueba mas conocida para detectar correlación serial es la desarrollada por el estadísticos Durbin y Watson. El cual se define como:7
d=∑t=2
t=n
(ut−u t−1 )2
∑t=2
t=n
ut2
=∑ ut
2+∑ ut−12 +∑ u t ut−1
∑ u t2
≈2(1−∑ u t ut−1
∑ ut2
)≈2(1− ρ)
ρ =
∑ ut u t−1
∑ ut2
Coeficiente de correlación
7 puesto que ∑ ut2
y∑ ut−12
difieren solo en una observación, estos son aproximadamente iguales por
consiguiente, haciendo∑ ut−12
= ∑ ut2
35

d
44- dL4- dUdUdL0
Rechácese H0 evidencia de auto correlación positivaZona de inde- cision
No se rechace H0 o H0 o ambas
Zona de inde- cision Rechácese H0 evidencia de auto correlación negativa
Es la razón de la suma de las diferencias al cuadrado de residuales sucesivos sobre la SRC. Abservamos que en el numerador del estadistico d, el numero de observaciones es n-1 porque una observación se pierde al obtener la diferencias consecutivas .
A diferencia de las pruebas t, F o X2
, no hay un valor único critico que lleve al rechazo o a la aceptación de la hipótesis nula por no haber correlación serial de primer orden en las perturbaciones ut sin embargo Durbin y Watson tuvieron éxito al encontrar un limite inferior DL y un limite superior DU tales que si el valor d calculado cae por afuera de estos valores críticos puede tomarse una decisión con respecto a la presencia de correlación serial positiva o negativa. El procedimento de prueba aplicado puede explicarse con la fig. siguiente la cual muestra que los limites de d son 0 y 4. y pueden establecerse expandiendo.como el coeficiente de autocorrelación muestral de primer orden, un estimador de ρ es posible expresar como:puesto que -1<= ρ <= 1 implica que : 0<= d <= 4estos son los limites de d; cualquier valor d estimado debe caer dentro de estos limites.
5.1.4 Medidas RemedialesPuesto que en presencia de correlación serial los estimadores MCO son ineficientes, es esencial buscar medidas remédiales. El remedio, depende del conocimiento que se tenga sobre la naturaleza de la interdependencia entre las perturbaciones. Se distinguen dos situaciones: cuando la estructura de Autocorrelación es conocida y cuando no lo es. Cuando la estructura de Autocorrelación es conocida.
Puesto que las perturbaciones ut no son observables, la naturaleza de la correlación serial es frecuentemente un asunto de especulación o de exigencias practicas. En la practica, usualmente se supone que las ut siguen el esquema autorregresivo de primer orden, a saber:
ut=ρut-1+εt
donde [ρ]<1y donde las εt siguen los supuestos MCO de valor esperado cero, varianza constante y Autocorrelación.
36

Si suponemos la validez de ut=ρut-1+εt el problemas de correlación serial puede ser resuelto satisfactoriamente si se conoce ρ el coeficiente de Autocorrelación, para ver esto se tiene en cuenta al modelo con dos variables.
Yt=B1+B2Xt+ut
En el tiempo t así como también en el tiempo t-1. por lo tanto:
Yt-1=B1+B2Xt-1+ut
Multiplicando por ρ ambos lados obtenemos:
ρ Yt-1= ρ B1+ ρ B2Xt-1+ ρ ut-1
y restando con la ecuación inicial obtenemos:
(Yt -ρ Yt-1) = B1 (1- ρ) + B2Xt -ρ B2Xt-1+ (ut -ρ ut-1)= B1 (1- ρ) + B2 (Xt -ρXt-1)+εt
puesto que MCD satisface todos los supuestos MCO, se puede proceder a aplicar MCO sobre las variables transformadas y obtener estimadores con todas las propiedades optimas; es decir MELI. Realizar la regresion es equivalente a utilizar los mínimos cuadrados generalizando (MCG).
Cuando ρ no es conocidaAunque la regresión en diferencias generalizadas es aplicación sencilla, esta
regresión generalmente es difícil de efectuar en la practica porque ρ raramente se conoce. Por consiguiente, se requiere diseñar métodos alternativos:
Método de la primera diferencia.Puesto que ρ se encuentra entre 0 y +-1 se puede partir de dos posiciones
extremas. En un extremo se puede suponer que ρ =0 es decir no hay correlación serial y en el otro extremo se puede considerar que ρ =+-1: una Autocorrelación positiva o negativa perfecta. Cuando se efectúa una regresión, generalmente se supone que no hay correlación y luego dejamos que otra prueba demuestre el supuesto.
37

5.2 Heterocedasticidad. E [e i ' e i ]=var (e i )=Iσ2
Una de las condiciones del Teorema de Gauss-Markov para estimar los parámetros lineales más eficientes establece, entre otros, que la varianza de los términos de disturbio para cada muestra observada debe ser constante. Esta afirmación se refiere que para el modelo estimado: Yi=α+βXi+ui la condición significa que el término de disturbio; {u1, u2, …, uN}; en las N observaciones, llamando N el total de observaciones muéstrales, potencialmente tendrían un valor medio o esperanza muestral igual a cero y su varianza debe ser constante e igual para cada una de las muestras (Dougherty, 1992).
Se espera, por tanto, que algunos valores de los errores estimados (y de las perturbaciones) serán positivos y otros negativos pero la mayoría relativamente cercanos a cero. Se espera, a priori, que no exista ningún patrón de comportamiento sistemático de los errores alrededor de su valor esperado o cero y se distribuyan uniformemente presentado “la misma dispersión”. Esta condición es conocida como homoscedasticidad.
5.2.1 Causas
La Heteroscedasticidad surge normalmente en datos de sección cruzada donde la escala de la variable dependiente y el poder explicativo de la tendencia del modelo varia a lo largo de las observaciones. En muchos casos los datos microeconómicos, como los estudios de gasto de las familias, presentan este comportamiento. Intuitivamente la presencia de diferente varianza para diferentes observaciones se pueden ejemplificar en las siguientes causas.
Razones de escala
Distribución espacial
Aprendizaje de los errores
Menores restricciones de elección. Mejoras en la Información
Observaciones Influyentes
Problemas de especificación
5.2 .2 Consecuencias
Con presencia de heteroscedasticidad, los estimadores mínimo cuadrático seguirán siendo insesgados dado que E(U)=0 y las variables explicativas son no estocásticas o independientes de los errores, por lo tanto E(XU)=0, pero dado que la varianza al no ser constante se invalidan las pruebas de significancia estadística en especial las pruebas de la distribución t-Student y F de Fisher-Snedecor.
Por lo tanto, los principales problemas serían:
Estimadores ineficientes.
Perdida de validez de las pruebas de contraste estadísticos.
38

Dado que la estimación de la varianza estaría sesgada y su estimación no sería además consistente, no se puede, en consecuencia, depender de los resultados obtenidos de los intervalos de confianza, ni de las pruebas puntuales usuales, por tanto, si se detecta su presencia, se deben estimar los parámetros por otros medios más adecuados como; mínimos cuadrados ponderados u otra técnica de estimación. Siempre es necesario comprobar si existe o no un problema significativo antes de proceder a corregirlo. En algunos casos la comprensión de la forma de corregir permite comprender mejor la utilidad de los procedimientos formales de detección.
39

5.3 MULTICOLINEALIDAD
[e1
e2
⋮en
]=[Y 1
Y 2
⋮Y n
]−[1 X11 X21 ⋯ X K 1
1 X12 X22 ⋯ X K 2
⋮ ⋮ ⋮ ⋱ ⋮1 X1 n X2n ⋯ X Kn
] [β0
⋮βk
]e = Y − X . β
Multicolinealidad se presenta cuando existe colinealidad entre las variables independientes o explicativas (cuando existe dependencia lineal entre las columnas de la matriz X.), de acuerdo al grado de colinealidad es difícil identificar de manera precisa el efecto individual de cada una de ellas sobre la variable dependiente o explicada.
Para fijar ideas, consideremos el siguiente modelo lineal:
Y t=β0+β1 X1t +β2 X2 t+⋯+ βk Xkt +e t ………………………………………..(1)
y supongamos que el siguiente modelo de regresión tiene un R2 alto:
X it=δ j0+δ i1 X1 t+δi 2 X2t +⋯+δ ik X kt+v i ∀ X i≠k …………(2)
En dicho caso, Xit es aproximadamente una combinación lineal de las variables explicativas restantes. Ello implica que la matriz X'X será aproximadamente singular.Siempre y cuando X'X NO sea singular, el estimador MICO será único y NO perderá su condición de MELI. Sin embargo, presentará los siguientes problemas:
a. La solución del sistema de ecuaciones normales estará mal definida:
b. La casi singularidad de la matriz X’X se reflejará en el valor de su determinante, el cual será cercano a cero. Como consecuencia, las varianzas de los estimadores MICO, provenientes de la matriz, serán ‘grandes’. Ello incrementará el ancho de los intervalos de confianza para el contraste de hipótesis lineales. En consecuencia, tenderemos a aceptar la hipótesis nula. (Es decir, caerá el poder del test: la probabilidad de rechazar H0 cuando ésta es falsa).
5.3.1 Causas De La Multicolinealidad
La multicolinealidad se origina por la presencia de cierto grado de interdependencia estadística entre los regresores de un modelo econométrico. Las causas del problema de la multicolinealidad suelen ser:
a) Escasa variabilidad de algunas variables explicativas.b) Existencia de alguna relación causal y/o casual entre dos o más variables
explicativas o regresóres.
40

c) El método de recolección de información empleado. Por ejemplo la obtención de las muestras en un rango limitado de valores tomados por los regresores en la población.
d) Restricciones sobre el modelo o en la población que es el objeto de muestreo. Por ejemplo, en la regresión del consumo de electricidad sobre el ingreso (X2) y el tamaño de las viviendas (X3) hay una restricción física en la población puestos que las familias con ingresos mas altos, generalmente tienen viviendas más grandes que las familias con ingresos más bajos.
e) Especificación del modelo, por ejemplo, la adición de términos polinomiales a un modelo de regresión, especialmente cuando el rango de la variable X es pequeño.
f) Un modelo sobre determinado, esto sucede cuando el modelo tiene más variables explicativas que el número de observaciones. Esto podría suceder en investigación medica donde puede haber un número bajo de pacientes sobre quienes se reúne información respecto a un gran número de variables.
41

5.3.2 Consecuencias De La Multicolinelidad
Las consecuencias de un cierto nivel de multicolinealidad pueden ser las siguientes:
1. Cuanto más grande sea la correlación, más próximo a cero será el determinante de la matriz X’X, lo cual incrementará las varianzas y covarianzas del vector de los parámetros estimados.
2. Las elevadas varianzas hacen que los parámetros estimados sean imprecisos e inestables. En efecto, cuanto mayor es la varianza, menor será el estadístico de contraste t, lo cual a menudo nos llevará a la conclusión que una variable explicativa es irrelevante, cuando en realidad no lo es.
3. Un cierto nivel de multicolinealidad, sin embargo, no afecta el estadístico de contraste de significación global, F. La idea es que el estadístico F considera toda la explicación de la variabilidad de la variable endógena, mientras que las variables explicativas comparten una parte de la variabilidad con las demás variables implicadas.
4. No pueden obtenerse los estimadores MCO cuando la multicolinealidad es perfecta.
5. Errores Standard grandes y extensos intervalos de confianza.6. Los estimadores son muy sensibles a la inclusión o supresión de pocas
observaciones y/o variables. No son robustos.7. Los estimadores pueden tener el signo cambiado.8. Aun cuando los estimadores MCO son MELI, estos presentan varianzas y
covarianzas grandes, que hacen difícil la estimación precisa.9. Debido a la consecuencia 8, los intervalos de confianza tienden a ser mucho
más amplios, conduciendo a una aceptación más fácil de la hipótesis nula de cero (es decir, que el verdadero coeficiente poblacional es cero)
10. También debido a la consecuencia 8, la razón t de uno o más coeficientes tiende a ser estadísticamente no significativa.
11. Aun cuando la razón t de uno o más coeficientes sea estadísticamente no significativa, el R2, la medida global de bondad de ajuste, puede ser muy alto.
12. Los estimadores MCO y sus errores estándar pueden ser sensibles a pequeños cambios en la información.
A. Multicolinealidad Aproximada o Imperfecta Ocurre cuando una de las variables explicativas es una combinación lineal determinística de todas las demás (o de un subconjunto de ellas). Es decir, la matriz X'X es singular y, por lo tanto, existen infinitas soluciones a las ecuaciones normales. Es fácilmente detectable porque X'X es singular. Por ejemplo, un conjunto de las variables explicativas satisfacen una identidad contable.
a. Identificación: Cuando la determinante de la matriz X'X es cero (matriz singular)
b. Corrección: Reestructurar el modelo quitando la variable colineada
42

B. Multicolinealidad Aproximada o Imperfecta: Ocurre cuando una de las variables explicativas es aproximadamente una combinación lineal de las restantes (o de un subconjunto de ellas). La multicolinealidad aproximada es más difícil de detectar. No obstante, ésta puede traducirse (aunque no necesariamente) en:
Un R2 alto pero con coeficientes de baja significancia estadística. Estimadores MICO con signos y/o magnitudes implausibles, producto de la poca
precisión con la cual son estimados. Estimadores MICO muy sensibles a pequeños cambios en el tamaño de la
muestra.
a. IdentificaciónComo la multicolinealidad es un problema muestral, ya que va asociada a la configuración concreta de la matriz X, no existen contrastes estadísticos, propiamente dichos, que sean aplicables para su detección. En cambio, se han desarrollado numerosas reglas prácticas que tratan de determinar en qué medida la multicolinealidad afecta gravemente a la estimación y contraste de un modelo. Estas reglas no son siempre fiables, siendo en algunos casos muy discutibles. A continuación se van a exponer los procedimientos que son los que gozan de mayor soporte para la identificación.
i. Método De La Relación Entre T Y R2
Mediante este método podemos determinar la existencia de multicolinealidad observando las razones t y si estas no son estadísticamente significativas y contamos con un coeficiente de determinación elevado (superior a 0.80), podemos estar ante un síntoma claro de multicolinealidad.
ii. Método De La Matriz De Correlación
Como el problema de multicolinealidad es un problema con las variables predeterminadas, establecemos una matriz de correlación entre aquellas, es decir:
R=[1 r24 r24 .. . .. r21
r32 1 r34 .. . .. r31
r42 r 43 1 .. . .. r 41
.. . .. . .. . . .. .. . .. . .. . .. . .r12 r 13 r14 .. . .. 1
]Como es de notar, si la correlación entre las variables predeterminadas fuera 1, extrema correlación, el determinante de R será igual a cero, caso contrario, si la correlación fuera 0, el determinante será igual a 1, por lo que podemos esbozar una regla en los siguientes términos:
43

Si el determinante de la matriz R es cercano a cero, el grado de multicolinealidad es considerable; si es cercano a uno, la correlación entre las variables no será de consideración.
iii. Método De La Prueba t Tiene que ver mucho con el método anterior (matriz de correlación):, este
método elige la máxima correlación (r max )
Ho : r max=0
Ha : r max≠0
t=(r max )√n−k+1
√1−rmax
~→ t (n−k+1 )
r max : Coeficiente de máximo de la matriz de correlación k : Número de parámetros incluyendo el intercepto.n: Número de observaciones
La regla de decisión es: Si t-calculado es mayor al t-tabulado a cierto nivel de significación (se rechaza la hipótesis nula), se dice entonces que la Xk en particular es colineal con las demás.
iv. Correlación entre Variables Explicativas: Se debe regresionar cada una de las variables exógenos con el resto de independientes.
X it=δ j0+δ i1 X1 t+δi 2 X2t +⋯+δ ik X kt+v i ∀ X i≠k
Se debe obtener el R2 de cada una de estas regresiones.Regla: Factor de Incremento de varianza
En un modelo de regresión múltiple la varianza de las parámetros se puede escribir así:
Var ( β¿
j)=σ¿
2
T (1−R j2 )S j
2….(1)
S el regresor j-ésimo fuera ortogonal con respecto a los demás regresores (es decir, si la correlación con el resto de los regresores fuera nula), la fórmula para la varianza quedaría reducida a:
Var ( β j¿ )= σ
¿2
TS j2
….(2)
44

Donde:
R j2
: Es el coeficiente de determinación obtenido al efectuar la regresión de Xj sobre el resto de los regresores del modelo.
S j2
: Es la varianza muestral del regresor XjT: Número de observaciones
El cociente entre (1) y (2) es precisamente el factor de agrandamiento de la varianza (FIV), cuya expresión será:
FIV ( β¿
j)=τ= 1
1−R j2
……………….. (3)
Entonces τ es una medida de qué tan severa es la dependencia lineal de Xi
con respecto a las demás Xi. Por ejemplo, si, Ri2=0 . 5 , τ =2; si Ri
2=0 . 999 , τ =1000.
En la práctica, un τ >10 (Ri2>0 . 9 ), se considera problemático.
El problema que tiene el FIV (o elR j2
o la tolerancia) es que no suministra ninguna información que pueda utilizarse para corregir el problema.
v. Número de Condición8 (Tamaño de la Matriz X’X)
Una medida de qué tan problemática es la multicolinealidad aproximada es el número de condición de la matriz. En particular, para una matriz cuadrada, A, éste se define como:
IC=k ( X )=λ=√ λmax
λmin
=√K
El indice de condición, κ (X), es igual a la raíz cuadrada de la razón entre la raíz característica más grande (λ max) y la raíz característica más pequeña (λ min) de la matriz X′X,
Como la matriz X′X es de dimensión k×k se obtienen k raíces características9, pudiéndose calcular para cada una de ellas un índice de condición definido de la siguiente forma:
El hecho de que el valor propio más pequeño sea cercano a cero en relación al más grande significa que la matriz es cuasi singular. Una matriz con un número de condición ‘grande’ (>20) es difícil de invertir de manera exacta.
8 Fue planteado inicialmente por Rachudel (1971) y desarrollado posteriormente por Belsley et al. (1980), y Belsley (1982).
9 Para matrices no cuadradas, tal como Xnxk, calculamos el número de condición de X’X. Debido a que los valores propios son sensibles a la escala de las variables, se recomienda dividir cada columna, xi, por su
norma, √ x i ' x i , a fin de que tenga un largo igual a 1.
45

Regla10: Existe multicolinealidad cuando:
10<k ( λ)<30 Multicolinealidad entre moderada y fuertek ( λ)>30 Multicolinealidad severa
100<λmax
λmin
=K <1000; Multicolinealidad entre modera y fuerte
λmax
λmin
>1000; Multicolinealidad severa
vi. Método De La Prueba F
En un modelo de K-1 variables predeterminadas, es conveniente determinar cual de las mencionadas variables X esta correlacionada con las restantes para lo cual hay necesidad de hacer regresiones auxiliares de cada X con las restantes y obtener el R2 correspondiente. Luego siguiendo la relación entre F y R2 se establece el siguiente probador:
Ho : Rxi, Con las Restantes2 =0
Ha : Rxi, Con las Restantes2 ≠0
F t=(Rx i,Con las restantes
2 )/(k−2)
(1−Rx i ,Con las restantes2 )/ (n−k+1)
~→F (k−2, n−k+1 )
Rxi ,Con las restantes : Coeficiente de determinación en la regresión de alguna Xk
con las restantes incluidas en el modelo.k : Número de parámetros incluyendo el intercepto.n: Número de observaciones
La regla de decisión es: Si F-calculado es mayor al F-tabulado a cierto nivel de significación (se rechaza la hipótesis nula, se dice entonces que la Xk en particular es colineal con las demás.
vii. Test Chi-Cuadrado (Test de Ortogonalidad)10 El número de condición mide la sensibilidad de las estimaciones mínimo cuadráticas ante pequeños cambios en los datos. De acuerdo con los estudios realizados por Belsley y otros (op. cit.), y Belsley (op. cit.), tanto con datos observados como con datos simulados, el problema de la multicolinealidad es grave cuando el número de condición toma un valor entre 10 y 30. Naturalmente, si este indicador superase el valor de 30, el problema sería ya manifiestamente grave. Estos valores vienen generalmente referidos a regresores medidos con escala de longitud unidad (es decir, con los regresores divididos por la raíz cuadrada de la suma de los valores de las observaciones), pero no centrados. Parece que no es conveniente centrar los datos (es decir, restarles sus correspondientes medias), ya que esta operación oscurece cualquier dependencia lineal que implique al término independiente.
46

En esta prueba se busca evaluar la ortogonalidad de los regresores sobre la base de la matriz de correlaciones por pares entre las series independientes. Las hipótesis relevantes de esta prueba son:
Ho : Las Xi son ortogonales entre si
Ha : Las Xi no son ortogonales entre si
Ha : Rxi, Con las Restantes2 ≠0
χcalc2 =−[n−1− 2k+5
6 ] Ln|R|~→ χ2 ( k (k−1)/2 )
R : Matriz de Correlación entre pares de regresores modelo.k : Número de parámetros sin incluir el intercepto.n: Número de observacionesLn: Logaritmo natural
La regla de decisión es: Si χ2
-calculado es mayor al χ2
-tabulado a cierto nivel de significación (se rechaza la hipótesis nula, se dice entonces que la Xk
en particular es colineal con las demás.
b. Corrección
i. Método de Pre-estimaciónReestructurar el modelo en base a información previa.
Esto hace alusión al caso en que se cuenta con información a priori que permite reducir la colinealidad entre algún par o conjunto de variables. Supongamos el siguiente ejemplo para ilustrar este punto:
Donde Yt =nivel de producción, Kt = factor capital, Lt = factor trabajo.
Supongamos que Kt y Lt son altamente colineales. Sin embargo, se sabe, por estudios previos, que la función de producción presenta rendimientos
constantes a escala. Esto es, . Por lo tanto, el modelo puede ser simplificado a:
Desgraciadamente, en la práctica no es usual contar con este tipo de información.
tt2t10t e )(Lln )ln(K )ln(Y
121
ttt20tt
ttt2tt10tt
e )/Lln(K )/Lln(Y
e )/Lln(K )/Lln(L )/Lln(Y
47

ii. Método de Estimador “Cresta” (Ridge)
Una solución que se ha propuesto para reducir el grado de colinealidad entre las columnas de X es el estimador cresta:
Donde D es una matriz diagonal que contiene los elementos de la diagonal de X’X y r es un escalar escogido arbitrariamente. En la práctica, r se escoge de
modo tal que βr
¿
sea estable frente a pequeñas variaciones en éste. (Se sugiere partir de un valor de r=0.01).
Aunque el estimador cresta es sesgado, tiene una matriz varianza covarianza menor a la de MICO:
E( βr
¿
)=( X ' X +rD)−1 X ' Xβ
Var ( β¿
r )=( X ' X +rD )−1 X ' X ( X ' X +rD )−1
Ello implica que βr
¿
puede ser preferible a MICO, términos de ECM.
iii. Método de Componentes Principales
La idea detrás del método de componentes principales radica en extraer de la matriz X un número de variables que expliquen la mayor parte de la variación en X. (Esta última se define como traza (X’X). La pregunta relevante es: ¿qué combinaciones lineales proporcionan el mejor ajuste para todas las columnas de X?
Pasos: 1er.- Normalizar las variables exógenas 2do.- Identificar los ponderadores para considerar las posibles
combinaciones lineales3ro.- Crear las nuevas variables explicativas en base a las ponderaciones y
las combinaciones lineales.4to.- Regresionar la variable dependiente con las nuevas variables
explicativas (que ya han sido extraídos las colinealidades).5to.- Reescribir el modelo transformando los valores a la especificación
inicial.El estimador de componentes principales es sesgado, pero tiene una varianza menor a la de MICO, por ello, puede ser preferible a éste, según el criterio de ECM. Sin embargo, el estimador de componentes principales no está libre de problemas:
YXrDXXr ')'( 1
48

Difícil de interpretar. (Es una mezcla de los coeficientes originales). Los componentes principales NO son escogidos en base a ninguna
relación entre X e Y. Como sabemos, la magnitud de los valores propios es sensible a la
escala de las X’s, por lo cual se recomienda normalizar cada columna. Sin embargo, ello afecta la interpretación de los resultados.
iv. Método Exclusión de Variables ColineadasEste método radica en seleccionar las variables que supuestamente están colineadas y probar las regresiones con y observar con variable se obtienen mejores resultados estadísticos y económicos.
v. Aumento del tamaño de la muestra
Teniendo en cuenta que un cierto grado de multicolinealidad acarrea problemas cuando aumenta ostensiblemente la varianza muestral de los estimadores, las soluciones deben ir encaminadas a reducir esta varianza.
Existen dos vías: por un lado, se puede aumentar la variabilidad a lo largo de la muestra de los regresores colineales introduciendo observaciones adicionales. Esta solución no siempre es viable, puesto que los datos utilizados en las contrastaciones empíricas proceden generalmente de fuentes estadísticas diversas, interviniendo en contadas ocasiones el investigador en la recogida de información.
Por otro lado, cuando se trate de diseños experimentales, se podrá incrementar directamente la variabilidad de los regresores sin necesidad de incrementar el tamaño de la muestra.
Finalmente, conviene no olvidar que el término de perturbación no debe contener ningún factor que sea realmente relevante para la explicación de las variaciones del regresando, con el fin de reducir todo lo posible la varianza del término de perturbación.
vi. Utilización de información extramuestral
Otra posibilidad es la utilización de información extramuestral, bien estableciendo restricciones sobre los parámetros del modelo, bien aprovechando estimadores procedentes de otros estudios.El establecimiento de restricciones sobre los parámetros del modelo reduce el número de parámetros a estimar y, por tanto, palia las posibles deficiencias de la información muestral. En cualquier caso, para que estas restricciones sean útiles deben estar inspiradas en el propio modelo teórico o, al menos, tener un significado económico.En general, un inconveniente de esta forma de proceder es que el significado atribuible al estimador obtenido con datos de corte transversal es muy diferente del obtenido con datos temporales. A veces, estos estimadores pueden resultar realmente «extraños» o ajenos al objeto de estudio. Por otra
49

parte, al estimar las varianzas de los estimadores obtenidos en la segunda regresión hay que tener en cuenta la estimación previa.
vii. Utilización de ratios
Si en lugar del de la variable dependiente y de los regresores del modelo original se utilizan ratios con respecto al regresor que tenga mayor colinealidad, puede hacer que la correlación entre los regresores del modelo disminuya. Una solución de este tipo resulta muy atractiva, por su sencillez de aplicación. Sin embargo, las transformaciones de las variables originales del modelo utilizando ratios pueden provocar otro tipo de problemas. Suponiendo admisibles las hipótesis básicas con respecto a las perturbaciones originales del modelo, esta transformación modificaría implícitamente las propiedades del modelo, de tal manera que las perturbaciones del modelo transformado utilizando ratios ya no serían perturbaciones homoscedásticas, sino heteroscedásticas.
50

BIBLIOGRAFIA.-
Arellano, M. 2003. Panel Data Econometrics. Oxford University Press. (HB 139 A68)
Enders, W. 2003. Applied Econometric Time Series. 2nd Ed. Wiley and Sons Inc. (HB 139 E57 2003)
Greene, W. 1997. Econometric Analysis, 3th Ed. MacMillan Publishing Company N.Y.
Griffiths, W. , R. Carter Hill, George G. Judge. 1993. Learning and Practicing Econometrics. (HB 139 G82)
Gujarati, D. 2003. Basic Econometrics. 4th Edición, Mc Graw Hill. Johnston, Jack, John Dinardo. 1997. Econometric Methods. 4th Edition. The
McGraw-Hill Companies, Inc. (HB 139 J67 1997 EN)
Kennedy, P. 2003, A Guide to Econometrics, 5th Edition. MIT Press.Maddala, G.S. 1996. Introducción a la Econometría, Prentice-Hall
Hispanoamericana S.A., Segunda Edición. (HB 139 M14I ES)
Novales, A. 1993. Econometría, McGraw-Hill, Interamericana de España, segunda edición. (HB 139 N86)
Wooldridge, J. 2002. Econometric Analysis of Cross Section and Panel Data. The MIT Press. (HB 139 W86)
51