
Universidad Central “Marta Abreu”de Las Villas Instituto ...

Universidad Central de las Villas
Facultad de Matemática Física Computación
Series Cronológicas de lluvia en la Cuenca Sagua la Chica. Modelos y pronósticos
Tesis de Pregrado:
Presentada por: Magda Pérez Monteagudo
Dirigida por:
Dr. Ricardo Grau Ábalo
Julio del 2007
Santa Clara

RESUMEN
El presente trabajo estudia el comportamiento de las series cronológicas de
precipitaciones de la Cuenca Hidrológica Sagua la Chica, a partir de una base de datos
con que cuenta la empresa de Investigaciones de Proyectos Hidráulicos para la
realización de los gráficos de despacho, Se logran modelos matemáticos del tipo
ARIMA y se realizan pronósticos a corto plazo en base a los mismos. Un aporte
importante desde el punto de vista práctico es el nuevo trabajo con los regresores dado
que se ha cambiado la teoría de introducirlos en las series. Los resultados
fundamentalmente son dados en tablas resúmenes y gráficos. La metodología usada es
la de Box-Jenkins para series y el software utilizado es el SPSS.13.
ABSTRACT In this work we study the time series related to rain in the hydrological basin of Sagua la
Chica, from a data base collected by the Researching Institute of Hydraulic Projects.
These data for dispatching the water. ARIMA models for these series are obtained and
then, short-term predictions about water capacity are possible. From the practical point
of view, it is interesting in this work a new form of working with independent variables
because the theory about how to introduce them in the series has changed. Results are
shown in tables and graphics. Box-Jenkin´s Methodology for ARIMA models and the
software SPSS 13 are used.

Introducción...................................................................................................................... 1 CAPITULO I .................................................................................................................... 7 Conceptos básicos relativos a los modelos regulares ARIMA......................................... 7
1.2 Introducción............................................................................................................ 7 1.3 Conceptos básicos de series de tiempo................................................................... 8 1.3.1 Series Estacionarias. ............................................................................................ 9 1.3.2 Funciones de Autocorrelación. .......................................................................... 10
1.3.3 Disturbio aleatorio o ruido blanco. ................................................................ 12 1.3.4 Camino Aleatorio. ......................................................................................... 13
1.4 Procesos Autorregresivos. .................................................................................... 14 1.4.1 Series Autorregresivas de Primer Orden ....................................................... 15 1.4.2 Serie Autorregresiva de orden p ................................................................... 16
1.5 Series de Medias Móviles..................................................................................... 17 1.5.1 Series de media móvil de primer orden. ........................................................ 17 1.5.2 Series de medias móviles de orden q............................................................. 18
1.6 Procesos ARMA(p, q) .......................................................................................... 22 1.6.1 Procesos ARMA (1.1) ................................................................................... 22 1.6.2 Serie ARMA(p,q). ......................................................................................... 23 1.6.3 Notación de operadores de un proceso ARMA. ............................................ 24 1.7 Procesos no estacionarios ................................................................................. 26 1.7.1 Proceso de diferenciación.............................................................................. 26 1.7.2 Procesos ARIMA........................................................................................... 27
1.8 Complementos teóricos: estimación, diagnóstico y pronóstico en modelos ARIMA....................................................................................................................... 30
CAPITULO II................................................................................................................. 36 Metodología de Box-Jenkins para Series Regulares ARIMA. Tratamiento de Regresores........................................................................................................................................ 36
2.1 Introducción.......................................................................................................... 36 2.2 Fases del proceso de modelación ARIMA ........................................................... 36 2.3 Los procesos iterativos en la Metodología de Box-Jenkins ................................. 37 2.4 El modelo ARIMA estacional. Generalización de la metodología de Box-Jenkins a series estacionales. ................................................................................................... 41 2.5 Análisis de intervención y tratamiento de outliers ............................................... 46
2.5.1 Análisis de intervención con modelos ARIMA............................................. 46 2.5.2 Introducción de regresores en modelos con diferenciación........................... 48 2.5.3 Primitiva regular y estacional de una función pulso...................................... 51 2.5.4 Primitiva estacional de una función pulso unitario. ...................................... 51 2.5.5 Primitivas de otros regresores posiblemente necesarios................................ 53
Capitulo III ..................................................................................................................... 55 Análisis de los pluviómetros por modelación ARIMA. ................................................. 55
3.1 Introducción...................................................................................................... 55 3.2 Modelación del pluviómetro 401.......................................................................... 55
3.2.1Modelo básico para el pluviómetro 401 ......................................................... 56 3.2.2 Análisis de los outliers en la serie del pluviómetro 401. ............................... 65 3.2.3Modelo Final del Pluviómetro 401................................................................. 69
3.3 Modelación del Pluviómetro 980 ......................................................................... 71 3.4 Resultado de los modelos matemáticos de los pluviómetros 940, 357, 389, 396. 79
3.4.1 Modelo matemático del tipo ARIMA del pluviómetro 940. ......................... 79 3.4.2 Modelo matemático del tipo ARIMA del pluviómetro 357. ......................... 79 3.4.3 Modelo matemático del tipo ARIMA del pluviómetro 389. ......................... 80

3.4.4 Modelo matemático del tipo ARIMA del pluviómetro 396. ......................... 80 3.5 Conclusiones del capítulo..................................................................................... 81
Conclusiones y recomendaciones................................................................................... 82 Recomendaciones .......................................................................................................... 82 Bibliografía....................................................................................................................... 1 ANEXOS.......................................................................................................................... 3

1
Introducción
Introducción Uno de los mayores retos del hombre moderno es racionalizar los recursos naturales de los
cuales ha dependido desde su surgimiento como especie. Uno de tales recursos
indispensables para la vida es el agua, la cual con el crecimiento de la población y las
actividades del hombre, requiere de una administración. El desarrollo alcanzado en la
actualidad, la necesidad de explotar dicho recurso y la necesidad de una mejor distribución
ha generado un sin número de estudios al respecto.
Decimos que un embalse tiene como finalidad entre otras cosas, el almacenamiento del
agua para el abasto a la población, la agricultura, la acuicultura, la industria, etc. Controlar
y pronosticar la capacidad de agua almacenada es al parecer un problema muy sencillo
pero veamos que no lo es, y como se puede aplicar la matemática en el mismo. En nuestro
territorio se lleva a cabo un minucioso monitoreo de las precipitaciones, por parte de las
entidades involucrada con los recursos hidráulicos, particularmente de la Empresa de
Investigaciones y Proyectos Hidráulicos EIPH, en la cual existen datos almacenados
referente a los embalses, escurrimiento, entrega de agua, pérdidas en el embalse, todos
ellos muy ligados con el régimen de precipitaciones del territorio.
Esta entidad cuenta con datos pertenecientes a precipitaciones de cerca de cien años de
antigüedad, fundamentalmente desde el 1949, y con mayor precisión desde 1964, año en se
creó la red de Institutos de Proyectos Hidráulicos. Estos datos pueden brindar la
información necesaria para pronosticar el régimen de las lluvias en años venideros.
La entrega del agua a los distintos usuarios depende del volumen del embalse, si se llega a
una cota mínima se restringe la distribución. Una característica fundamental que hay que
tener en cuenta en un embalse son las diferentes mediciones de volumen. Se llama VTM al
volumen total máximo, LSEG denota la línea superior de entrega garantizada, mientras
que LIEG es la línea inferior de entrega garantizada. Además VME denota el volumen
máximo de explotación. A continuación se incluye una gráfica de un embalse que ayuda a
comprender los diferentes volúmenes.
2
Introducción
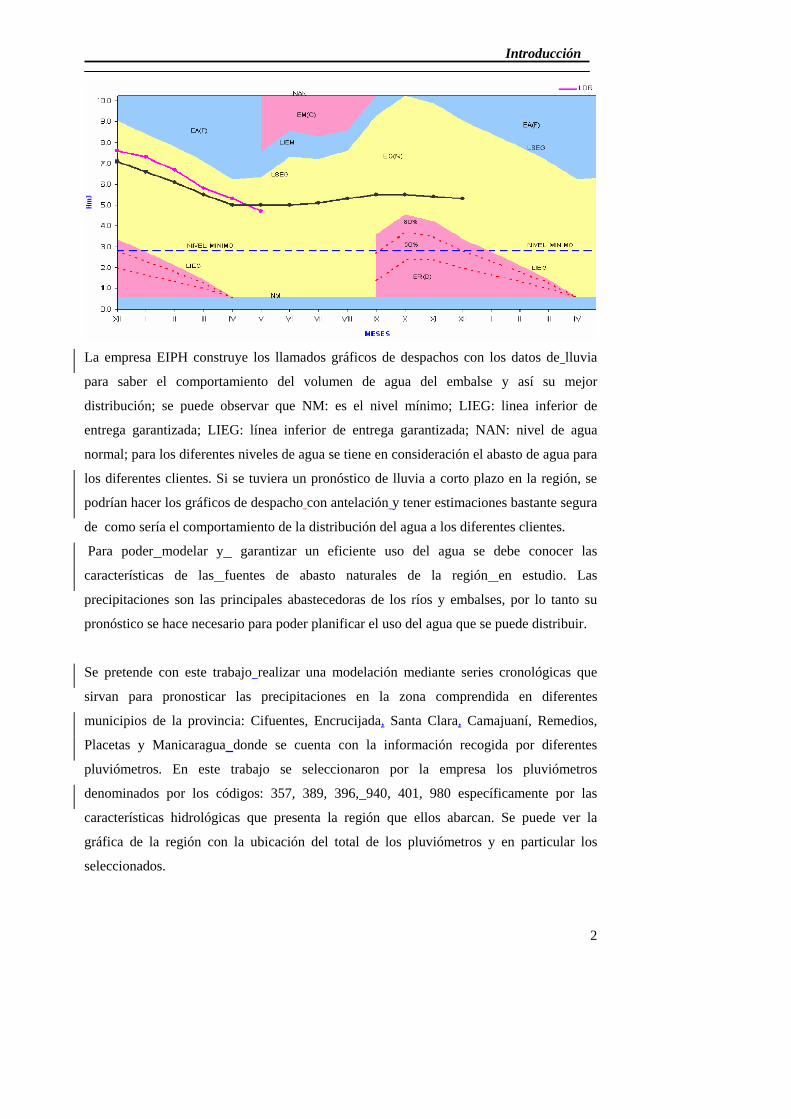
La empresa EIPH construye los llamados gráficos de despachos con los datos de lluvia
para saber el comportamiento del volumen de agua del embalse y así su mejor
distribución; se puede observar que NM: es el nivel mínimo; LIEG: linea inferior de
entrega garantizada; LIEG: línea inferior de entrega garantizada; NAN: nivel de agua
normal; para los diferentes niveles de agua se tiene en consideración el abasto de agua para
los diferentes clientes. Si se tuviera un pronóstico de lluvia a corto plazo en la región, se
podrían hacer los gráficos de despacho con antelación y tener estimaciones bastante segura
de como sería el comportamiento de la distribución del agua a los diferentes clientes.
Para poder modelar y garantizar un eficiente uso del agua se debe conocer las
características de las fuentes de abasto naturales de la región en estudio. Las
precipitaciones son las principales abastecedoras de los ríos y embalses, por lo tanto su
pronóstico se hace necesario para poder planificar el uso del agua que se puede distribuir.
Se pretende con este trabajo realizar una modelación mediante series cronológicas que
sirvan para pronosticar las precipitaciones en la zona comprendida en diferentes
municipios de la provincia: Cifuentes, Encrucijada, Santa Clara, Camajuaní, Remedios,
Placetas y Manicaragua donde se cuenta con la información recogida por diferentes
pluviómetros. En este trabajo se seleccionaron por la empresa los pluviómetros
denominados por los códigos: 357, 389, 396, 940, 401, 980 específicamente por las
características hidrológicas que presenta la región que ellos abarcan. Se puede ver la
gráfica de la región con la ubicación del total de los pluviómetros y en particular los
seleccionados.

3
Introducción
No existen antecedentes de modelación de series cronológicas de lluvia en esta
Cuenca o una similar; pero existen trabajos de series temporales de precipitaciones
en la provincia de Villa Cara y otras del país, y en general hay antecedentes de
modelación matemática de series meteorológicas. Entre ellos se destaca “El
pronóstico de lluvias totales anuales para un pequeña zona de la actual provincia de
Cienfuegos” (Fernández, 1983). Por otra parte el trabajo de Truzov, Izquierdo y Díaz
(Truzov, Izquierdo y Díaz 1983) demostró que el logro de pronósticos en especial
para la lluvia, esta condicionado por un conocimiento preciso del régimen ocurrencia
de la misma. No obstante el conocimiento logrado en estos trabajos, si bien valiosos,
dejan ciertas lagunas a llenar por lo que (Cárdenas, 1900) emprende una modelación
estadística climatología de los totales de precipitaciones y algunas variables
asociadas a las mismas. Posteriormente, debido al periodo especial, problemas
técnicos y cambios en la estructura organizativa del principal cliente, el Ministerio de
Azúcar (MINAZ), se pierde la operatividad de estos últimos modelos. Otro intento de
modelar la precipitación se realizo por (Analidia, 1994) donde se logran buenos
resultados en el pronóstico a corto plazo, pero estos resultados no se introdujeron en
la práctica quedando solo con un valor teórico.

4
Introducción
En cuanto a otras variables metereológicas, en particular las temperaturas, es
necesario citar a (Lecha, 1989), que realizó un trabajo muy completo donde se
relacionan los trabajos que en Cuba han profundizado en el estudio del régimen
térmico. En el mismo se enseña la necesidad de usar métodos de investigación más
precisos para reflejar las pequeñas oscilaciones y los cambios en las condiciones
climáticas. Además se logra una tipificación y descripción del régimen térmico
cubano, quedando una importante herramienta de trabajo metodológico. Sin embargo
no se realiza pronósticos de esta variable, ni se estudia la posible tendencia de la
misma. Los primeros intentos de pronóstico estadísticos de temperatura extremas se
realizaron por (Anido, inédito) a mediados de la década de 1950, con ecuaciones
deducidas empíricamente. Otros investigadores (Naranjo y L.Lecha, inédito)
obtuvieron ecuaciones de pronósticos, también para Santa Clara, a partir de datos
locales de superficies, utilizando métodos de correlación lineal. En atención a estos
trabajos (Arnaldo, 1986) obtiene pronósticos de temperaturas extremas para la Isla de
la Juventud, principalmente de forma diaria, para un estación. En 1992 en la
provincia de Villa Clara se obtuvieron resultados interesantes en el pronóstico de
temperaturas extremas decenales (Osés R, y Cárdenas P, 1992, inédito) utilizando la
regresión múltiple. En este se concluye que debía utilizarse una muestra en particular
para la obtención de las ecuaciones, ya que en definitiva, con una sola ecuación podía
explicarse la variación de cualquier decena. Nos obstante debido a escasez de
equipos de computo, a la lentitud en la recogida de la información, así como a
limitaciones dentro del periodo especial, no se pudo implementar regularmente este
pronóstico. En este desenlace influyó significativamente el difícil manejo de gran
cantidad de predictores climáticos que fallaban, al desaparecer el equipo que los
media, y al no existir sustitutos para ello, o por la baja calidad de instrumentos
pobremente calibrados, o sea, por la calidad de estos datos. Otro trabajo sobre serie
de tiempo meteorológicas es el de (Morales, 2007).
Las dificultades prácticas en la obtención de múltiples variables para el pronóstico,
por ejemplo de la lluvia abrieron el camino a la búsqueda de nuevos métodos, entre
ellos los modelos Autoregresivos Integrados y de Media Móvil (ARIMA) los cuales
no han sido explotados suficientemente.

5
Introducción
Se puede concretar entonces el siguiente problema de investigación
Problema
La Empresa de Recursos Hidráulicos (EIPH) dispone de suficiente información acumulada
durante años sobre el comportamiento de las precipitaciones pero no ha logrado utilizar
con eficiencia esta información, para realizar pronósticos (a corto plazo) apoyada en
modelos matemáticos y herramientas perfectamente operacionales, que contribuya a la
elaboración con antelación de los gráficos de despachos. Esto conduce a la siguiente
interrogante:
¿Es posible con la información existente en el departamento de Hidrología de la Empresa
de Proyectos Hidráulicos, lograr modelos matemáticos tipo ARIMA para las series de
lluvia de la cuenca hidrológica Sagua la Chica y en base a los mismos, hacer pronósticos a
corto plazo que ayuden a una mejor precisión de la planificación de entrega de agua a los
diferentes clientes?
Se tienen las siguientes preguntas de investigación adicionales:
¿Cómo incluir en el modelo los datos ¨picos¨ de precipitaciones ocasionalmente muy altas
y que representan “outliers” desde el punto de vista del comportamiento general de la
serie?
¿Se obtienen modelos diferentes en las series de datos de todos los pluviómetros, o algunos
son totalmente similares y hasta podría prescindirse de sus datos en el control?
Objetivo General
Modelar matemáticamente las series cronológicas de lluvias existentes en la Empresa de
Investigaciones de Proyectos Hidráulicos utilizando la Metodología de Box-Jenkins para
series ARIMA y en base a los modelos hallados, hacer pronósticos confiables a corto
plazo.
Objetivos Específicos 1. Obtener modelos ARIMA para las series de datos correspondientes a cada
pluviómetro.

6
Introducción
2. Mejorar los modelos con tratamientos de los outliers de lluvia usando regresores
3. Analizar la posibilidad de igualdad de los modelos de diferentes pluviómetros
El presente trabajo consta de tres capítulos. El primero estará dedicado al marco teórico.
En el se brindan elementos acerca de los conceptos básicos de series de tiempo, de los
procesos autorregresivos y series de media móvil, los procesos ARMA y los no
estacionarios. El segundo capítulo se habla de la metodología de Box-Jenkins para series
regulares ARIMA, se hará alusión al análisis de intervención y tratamiento de outliers así
como los procesos ARIMA estacionales. Se hará énfasis en el tratamiento de los
regresores, problema que hasta ahora no siempre fue tratado con la delicadeza suficiente,
pues como se va a mostrar, es fácil cometer errores al introducir estos en la serie En el
tercer capítulo se expondrá con todo detalle y por pasos la modelación de las series
cronológicas de lluvia con los pluviómetros mas significativos desde el punto de vista
hidrológico en la cuenca, en este caso los pluviómetros 401 y 980. los modelos finales de
todos los pluviómetros.

Ca
7
Capitulo 1 Conceptos básicos relativos a los modelos regulares ARIMA.
CAPITULO I
Conceptos básicos relativos a los modelos regulares ARIMA.
1.2 Introducción. Una serie de tiempo o serie cronológica es una colección de valores de una cierta
variable aleatoria medidos a intervalos regulares de tiempo. El objetivo del análisis
de tal serie es llegar a describir la variable como cierta función del tiempo que
permita analizar con detalles el pasado y hacer pronósticos futuros.
El análisis de las series de tiempo se aplica en muchos campos. En economía, por
ejemplo, se utilizan las series de tiempo en el control de la calidad, para estudiar índices
de precios, desempleo, producto nacional bruto, población… En ciencias naturales se
usan por ejemplo, para estudiar el nivel de agua en un río o presa, los parámetros
meteorológicos, las medidas de poblaciones naturales (vegetales o animales). En
biología surgen naturalmente en modelos de crecimiento, en epidemiología juegan un
papel fundamental en la vigilancia de enfermedades infecciosas o no transmisibles, así
como en el estudio cronológico del desarrollo de factores de riesgo. En las ciencias
sociales representan un campo entero en sí mismo.
El estudio de las series de tiempo no se pueden abordar sólo con las técnicas
básicas de regresión, porque en la mayoría de los casos, los valores de la serie en
diferentes instantes de tiempo están autocorrelacionados como consecuencia de que el
valor en cada momento depende muy frecuentemente de los valores o de la variabilidad
de los valores en instantes anteriores. Las situaciones más complicadas se producen
cuando dependen además de períodos similares del tiempo anterior, con ciertas
estacionalidad. Además, la regresión puede ser buena para pronosticar, más
estrictamente interpolar valores de la variable dependiente sobre valores de la(s)
variable(s) independientes que no han sido medidos, pero que están cerca del centroide
de los datos. Fuera del entorno de este centroide, la regresión no produce buenas
predicciones, porque el intervalo de confianza de las predicciones de la regresión se
amplia notablemente. Esto significa que si la variable independiente es el tiempo, la
regresión puede servir para reconstruir un valor intermedio de la función en un tiempo
cercano a la media del intervalo de datos, pero no puede ser utilizada para predecir el
futuro ni reconstruir el pasado

Ca
8
Capitulo 1 Conceptos básicos relativos a los modelos regulares ARIMA.
Los datos de una serie de tiempo son datos horizontales (dependientes) pero
usualmente tenemos una sola muestra de ellos (digamos, un solo caso) La única
alternativa que nos brindan los modelos de la estadística clásica sería el de la regresión
respecto al momento (tiempo); pero ya se comentaron los inconvenientes de la regresión
para ello.
Esto estimuló que se desarrollaran teorías matemáticas y procedimientos prácticos
generales orientados especialmente al estudio de series cronológicas. Por ejemplo, la
metodología de Box-Jenkins es válida para el análisis de un conjunto bastante amplio de
series y está fundamentada en una sólida teoría matemática de los modelos llamados
ARIMA. Además se adaptaron o condicionaron otras teorías, por ejemplo de la
regresión, para el estudio de correlación de series multivariadas, la teoría del análisis
espectral para el estudio de series de tiempo periódicas, conceptos básicos de funciones
generalizadas para el tratamiento de “outliers” (valores fuera de la serie).
Este capítulo a presentar los conceptos básicos que fundamentan la metodología
general de Box-Jenkins para la modelación de series ARIMA. Dicha metodología de
Box-Jenkins puede ser formulada con bastante independencia de los argumentos
matemáticos que la fundamentan; pero evidentemente, algunos conceptos son
importantes y el desarrollo teórico de algunos resultados no sólo permite comprender
mejor el fundamento, sino que dan más claridad para la aplicación práctica.
Se comienza esbozando algunos conceptos generales relativos a series de tiempo y
en particular a series de tiempo autorregresivas y de medias móviles. En una primera
lectura de este capítulo, en particular de los tres primeros epígrafes podemos
concentrarnos en las definiciones, notaciones y resultados, obviando las
demostraciones. Ello bastará para comprender lo sucesivo.
1.3 Conceptos básicos de series de tiempo. Formalmente hablando, una serie de tiempo puede ser definida como una
colección de variables aleatorias { }Ttxt ε, donde T es un conjunto de índices,
normalmente el conjunto de los números naturales: { }nT ,,3,2,1 L=
Esta definición no deja quizás claro que los valores de t representan momentos
equidistantes de tiempo; pero podemos tenerlo presente en la mayoría de los problemas
prácticos. En cualquier caso:
Con formato: Numeración yviñetas

Ca
9
Capitulo 1 Conceptos básicos relativos a los modelos regulares ARIMA.
Una realización o muestra de una serie es una colección finita de valores concretos
de la variable en intervalos de tiempo regular: ( )nxxx ,,, 21 L a partir de los cuales
queremos precisar la forma en que tx depende del tiempo t, esto es, describir la función
S tal que: )(tSxt = para todo Tt ε
La definición formal permite en cambio varias generalizaciones que son
importantes teórica y prácticamente. Por ejemplo:
• el conjunto T de índices puede ser el conjunto { }L,2,1,0 ±±=Z de los números
enteros y esto es importantes porque los desarrollos teóricos exigen trabajar con
series definidas para valores negativos de t.
• el conjunto T de índices puede ser un conjunto de la cardinalidad del conjunto. Esta
generalización se ajusta más propiamente al carácter continuo del tiempo. En efecto,
si pensamos por ejemplo que tx representa el nivel de agua en una presa en el
instante de tiempo t, tx es una función continua de t.
Otra cosa es que una realización de esta variable se obtenga por mediciones diarias
a una hora fijada, por ejemplo, o a cada hora durante varios días, si se quiere hacer un
estudio más detallado. Los resultados de estos dos estudios con muestras diferentes,
pueden ser por supuestos distintos.
La caracterización teórica de una serie de tiempo { }Ttxt ε, requiere no solo
determinar la distribución de tx para cada Tt ε , sino la además sus posibles
correlaciones. Más precisamente, la serie se caracteriza completamente por la función
de distribución conjunta:
[ ] [ ]nttnxxx xxxxxxxxxFntnttt<<<= ,,Prob,,, 2121 2121
LL
para cualquier combinación [ ]nttt xxx ,,
21, L de las variables determinadas por un
subconjunto finito { }nttt ,,, 21 L de T.
1.3.1 Series Estacionarias. Se dice que la serie de tiempo { }Ttxt ε, es estrictamente estacionaria sí:
[ ] [ ] [ ] [ ]nxxxnxxx xFxFxFxxxFntttnttt
LLL 2121 2121,,, = para cualquier subconjunto no
vacío de { }nttt ,,, 21 L de T y cualquier h tal que ( )hththt n +++ ,,, 21 L esté en T.
Nótese que no se restringe esta condición a que los it sean consecutivos.

Ca
10
Capitulo 1 Conceptos básicos relativos a los modelos regulares ARIMA.
Así, una serie de tiempo es estrictamente estacionaria si la distribución de tx es la
misma para todo instante de tiempo t (porque [ ] [ ]xFxF txxt += para todo t y todo h) y
además las correlaciones entre variables de la serie dependen solamente del intervalo de
tiempo h que las separa y no del valor del tiempo t.
La condición de ser estrictamente estacionaria una serie de tiempo es muy difícil
de verificar. En la práctica se trabaja con una restricción menos fuerte pero más
fácilmente comprobable:
Se dice que la serie { }Ttxt ε, es débilmente estacionaria o simplemente
estacionaria sí:
1. El valor esperado [ ]txE es constante para todo Tt ε
2. La matriz de covarianza de { }nttt xxx ,,
21, L es la misma que la matriz de
covarianza de { }hththt nxxx +++ L,,
21 para cualquier conjunto finito de
{ }nttt ,,, 21 L de T y cualquier h tal que ( )hththt n +++ ,,, 21 L esté en T.
En particular, para una serie estacionaria ocurre necesariamente que:
• [ ] μ=txE , y no se pierde nunca generalidad si se supone que 0=μ porque de
lo contrario bastaría centrar las variables, esto es trabajar con μ−tx En otras
palabras, las series estacionarias no muestran tendencias.
• [ ]txVar es constante, porque ( ) ( )hthttt xxCovxxCov ++= ,, Esta propiedad se
conoce como homocedasticidad de la serie.
A veces, estas condiciones se utilizan prácticamente para decidir si una serie es
estacionaria, o al menos, la violación de una de ellas: la existencia de una tendencia o la
heterocedasticidad es suficiente para inferir que no es estacionaria.
1.3.2 Funciones de Autocorrelación. Sobre una serie estacionaria ocurre además que: la covarianza entre tx y htx + es
una función sólo de h y no de t y por tanto, es posible hablar de la función de
covarianza:
( ) ( ) ( )( )[ ]μμ −−== ++ htthtt xxExxhv , Cov como una función que depende sólo
del “retardo” h.
De la misma forma, es posible definir la función de autocorrelación:

Ca
11
Capitulo 1 Conceptos básicos relativos a los modelos regulares ARIMA.
( )[ ] [ ][ ]
( )[ ]t
htt
ht
httxxx
x
xxhACF
Var , Cov
Var xVar
, Cov)(
2/1t
+
+
+ ==
El estudio de la función )(hACF juega un papel fundamental en el análisis de las
series de tiempo. Para una serie de tiempo definida en el conjunto de los números
enteros, esta función es par y en 0 vale siempre 1; por ello se trabaja sólo para 1≥h . Su
gráfico se denomina correlograma:
Figura # 1.
Figura 1. Aspecto general del gráfico de una función de autocorrelación arbitraria
Observe que:
ACF(0) = 1 porque representa la correlación de tx con ella misma
ACF(1) representa la correlación tx y 1−tx ó entre tx y 1+tx , esto
es, entre dos valores “consecutivos” de la serie.
ACF(2) representa la correlación entre tx y 2−tx , ó entre tx y
2+tx esto es, entre dos valores distantes un retardo 2, etc.
La autocorrelación puede definirse también para una serie no estacionaria pero
resultaría en general una función de t y de h.
Junto con la función de autocorrelación tiene también interés el estudio de las
autocorrelaciones parciales:
Dada una serie estacionaria ),( Ttxt ε y un retardo 2≥h , se llama
autocorrelación parcial de tx y htx − , al valor de la correlación parcial tx y htx − -en el
sentido general estadístico- ajustada por )1(21 ,,, −−−− httt xxx L . Más precisamente, la
función de autocorrelación parcial PACF (h) se define por:

Ca
12
Capitulo 1 Conceptos básicos relativos a los modelos regulares ARIMA.
[ ][ ]112211
1111112211Var
,Cov
+−−−−
+−−−+−−−−−−−
−−−−−−
hthttt
hthhththtttxxxx
xxxxxxxρρρ
ρρρρρL
LL
donde )(iACFi =ρ es el coeficiente de autocorrelación i-ésimo.
El carácter estacionario de la serie determina también que PACF(h) esté
correctamente definida.
Obsérvese que los coeficientes de autocorrelación parcial se definen naturalmente
para 2≥h , ajustados a h-2 valores intermedios entre tx y htx − , que son
)1(21 ,,, −−−− httt xxx L . Puede extenderse esta definición para h = 0 y h = 1.
PACF (0) = ACF (0) = 1
PACF (1) = ACF (1) = ( )1, Cov −tt xx
1.3.3 Disturbio aleatorio o ruido blanco. Se llama “disturbio aleatorio” o “ruido blanco” a una serie { }Ntet ε, compuesta
de variables no correlacionadas te con media 0 y dispersión 2σ . Los ruidos blancos son
series estacionarias triviales pero juegan un papel teórico y práctico importante en la
teoría de series de tiempo y el estudio se señales.
Para un ruido blanco resulta obvio que la función de autocovarianza es:
⎪⎭
⎪⎬⎫
⎪⎩
⎪⎨⎧
≠==
000)(
2
hsihsihv σ
y por tanto
⎭⎬⎫
⎩⎨⎧
≠=
=0001
)(hsihsi
hACF
Por otra parte:
[ ][ ] 0
Var ,x Cov
)2(1
121t =−
−−=
−
−−−
tt
tttxx
xxxPACF
ρρρ
porque 0)1( == ACFρ . Lo
mismo ocurre para h > 2 y entonces PACF(h) = ACF(h) y es trivial en este caso.
Cuando modelamos una serie de tiempo arbitraria ),( Ntxt ε a partir de una
representación ),,,( 21 nxxx L buscamos muchas veces una función S(t) para la cual
tt etSx += )( donde los residuales te ),,3,2,1( ni L= constituyen una representación
de un ruido blanco y por tanto no deben mostrar ninguna correlación. De esta forma

Ca
13
Capitulo 1 Conceptos básicos relativos a los modelos regulares ARIMA.
precisamos que no aspiramos a encontrar exactamente S de manera que )(tSxt = pero si
tal que tt etSx += )( .
Realmente, los modelos de una serie de tiempo se definen de una forma algo más
compleja que con una simple función S(t) pero sigue valiendo la idea de que aspiramos
a un modelo aproximado con un residual que sea un ruido blanco.
1.3.4 Camino Aleatorio. Se llama “camino aleatorio con media μ ” a una serie ),( Ntxt ε que se define por
las relaciones:
11 ex += μ
tt ex += μ
donde ),( Ntet ε es un ruido blanco ),( 2σo
Un camino aleatorio no es una serie estacionaria pues [ ] μ=txE (constante) pero
hay heterocedasticidad: [ ] 2Var σtxt = . En efecto:
[ ] [ ] μμ =+= 11 eExE
[ ] [ ] [ ] μ=+= 212 eExExE
y por inducción:
[ ] [ ] [ ] μ=+= − ttt eExExE 1
Ahora bien:
( ) ( )[ ] [ ] [ ] 22211
221
21 2 σμμμμ +=++=+= eEeEeExE
( ) ( )[ ] [ ] [ ] 222221
22221
22 22 σμμ +=+++=+= eEexEeexExE
porque [ ] ( )[ ] [ ] [ ] 02122121 =+=+= eeEeEeeEexE μμ
y por inducción:
[ ] ( )[ ] ( ) [ ] [ ] 2221
2221
2 21 σμσμ teEexEtexExE tttttt +=++−+=+= −−
porque [ ] 01 =− tt exE
En definitiva
[ ] [ ] [ ] 222 σtxExExVar ttt =−= y esto es suficiente para demostrar que la serie no
es estacionaria.

Ca
14
Capitulo 1 Conceptos básicos relativos a los modelos regulares ARIMA.
Para un camino aleatorio, la covarianza entre tx y htx + no es sólo una función de
h, sino también de t. En efecto:
( ) [ ] [ ] [ ] [ ] 2))((, Cov μμμμμ +−−=−−= ++++ htthtthtthtt xExExxExxExx
( ) [ ] 22, Cov σμ txxExx htthtt =−= ++
porque [ ] [ ] [ ] 222 σμ texExExxE httthtt +=+= ++
Si calculamos
( )[ ] [ ][ ] 2/1
t Var xVar
, Cov),(),(
ht
htthtt
x
xxxxCorrhtACF
+
++ ==
se tendrá que:
[ ] 2/14
2/(
)(),( htt
htt
thtACF +=+
=σ
σ
1.4 Procesos Autorregresivos. Un conjunto grande de series de tiempo –por ahora no estacionales (en el sentido
de no periódicas)- puede ser modelado por uno de los tipos siguientes:
a) Una serie autorregresiva de orden p, esto es, una serie de la forma:
tit
p
iit exx += −
=∑
1ϕ
b) Una serie de medias móviles de orden q, esto es, una serie:
jt
q
jjtt eex −
=∑+=
1β
c) Una serie mixta: autorregresiva de orden p y de medias móviles de orden q, esto es,
una serie de la forma:
∑∑=
−−=
+==q
jjtjtit
p
iit eexx
11βϕ y en todos los casos te denota un ruido blanco.
Lo interesante es que para estos tipos de series, y para otras que se reducen a ellas,
están caracterizadas:
• Las condiciones sobre las bases de la cual son estacionarias
• La forma de los correlogramas correspondientes a las funciones ACF(h) y
PACF(h) que permitan identificarlas.

Ca
15
Capitulo 1 Conceptos básicos relativos a los modelos regulares ARIMA.
• Los mejores métodos de estimación de los parámetros iϕ para pi ,,2,1 L= y
los parámetros jβ para qj ,,2,1 L= que precisan el modelo.
• Los criterios para seleccionar entre varios modelos posibles cuál es el mejor.
• Los estimadores óptimos lineales de los valores pronosticados.
Las dos primeras caracterizaciones son esenciales porque ellas permiten, a partir
de una muestra o realización concreta de la serie, determinar (o al menos aproximar) a
priori, a cuál modelo se ajusta, luego acometer la estimación y el diagnóstico del
modelo y finalmente el pronóstico si éste es un objetivo del estudio.
1.4.1 Series Autorregresivas de Primer Orden Veamos algunos casos particularmente de p antes de generalizar:
• Caso 1=p
Una serie autorregresiva de primer orden, tiene esencialmente la forma: itt exx += −1ρ
Como veremos inmediatamente, esta serie es estacionaria si y sólo si 1<ρ y en
tal caso este parámetro: ρϕ =i que identifica la serie, es ),()1( 1−= tt xxCovACF .
En efecto, escribiendo: itt exx += −− 21 ρ o más generalmente
ititit exx −−−− += 1ρ para ni ,,2,1 L= y sustituyendo sucesivamente en la serie,
obtenemos ∑−
=−− +=
1
0
N
iit
iNt
Nt exx ρρ y en “cierto sentido” de convergencia de serie, si
1<ρ se tiene la representación: ∑∞
=−=
0iit
it ex ρ
De allí resulta que:
0)( =txE para todo t, y 2
12
2
1)()( σ
ρ
ρρρσ ∑∞
=
++
−===
i
hhii
htt xxEhv para
0≥h
El “cierto sentido” de convergencia de series no es trivial; pero no vamos a
desarrollarlo aquí. Vale la pena sin embargo notar que no descartamos la posibilidad de
que μ=)( txE (constante pero ≠ 0) porque la serie está definida por una relación de
recurrencia sin una definición de un primer elemento; pero esto será retomado
posteriormente, al final de este epígrafe.
Ca
16
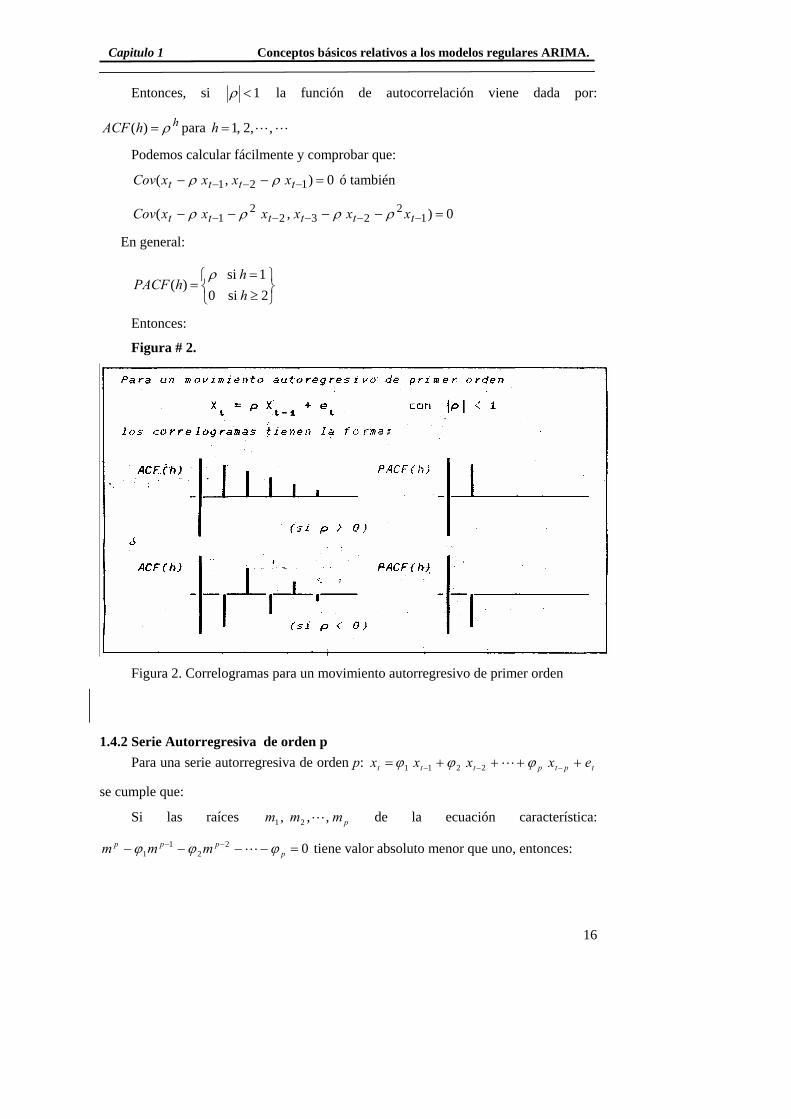
Capitulo 1 Conceptos básicos relativos a los modelos regulares ARIMA.
Entonces, si 1<ρ la función de autocorrelación viene dada por:
hhACF ρ=)( para LL,,2,1=h
Podemos calcular fácilmente y comprobar que:
0),( 121 =−− −−− tttt xxxxCov ρρ ó también
0),( 12
2322
1 =−−−− −−−−− tttttt xxxxxxCov ρρρρ
En general:
⎭⎬⎫
⎩⎨⎧
≥=
=2 si 01 si
)(hh
hPACFρ
Entonces:
Figura # 2.
Figura 2. Correlogramas para un movimiento autorregresivo de primer orden
1.4.2 Serie Autorregresiva de orden p Para una serie autorregresiva de orden p: tptpttt exxxx ++++= −−− ϕϕϕ L2211
se cumple que:
Si las raíces pmmm ,,, 21 L de la ecuación característica:
022
11 =−−−− −−
pppp mmm ϕϕϕ L tiene valor absoluto menor que uno, entonces:

Ca
17
Capitulo 1 Conceptos básicos relativos a los modelos regulares ARIMA.
1. tx puede representarse de la forma siguiente: ∑∞
=−=
0jjtjt ewx donde los jw
son encontrados de manera que satisfacen una ecuación en diferencias
análogas a la serie: pjpjjj wwww −−− +++= ϕϕϕ L2211 en las condiciones
iniciales.
2. La serie estacionaria, con media 0 y función de autocovarianza:
( ) ∑∞
=−=
0
2
jhjj wwhv σ para 0≥h .
3. ACF(h) ----> 0 cuando h ----> ∞ y con el orden ha para cierto a de módulo
menor que 1. 0)( =hPACF para ph > . Por tanto, el correlograma de la ACF
muestra una declinación exponencial (posiblemente sinusoidal amortiguada
exponencialmente) y el correlograma de la PACF muestra exactamente p
espigas.
1.5 Series de Medias Móviles.
1.5.1 Series de media móvil de primer orden.
Sea la serie de medias móviles: 1−+= ttt eex β Aquí 22 )1()( σβ+=txVar y
⎭⎬⎫
⎩⎨⎧
≥=
=20
1)(
2
hh
hvσβ
Por tanto, 21)1(
ββ+
=ACF y ACF (h) = 0 para 2≥h
No es difícil ver con cálculo elemental, que el máximo valor posible de ACF(1) es
0.5 y se alcanza para 1=β , mientras que el mínimo es -0.5 y se alcanza con 1−=β
Para cualquier valor de ρ (0, 0.5), existen dos valores de β , tales que ACF(1) = ρ .
Lo mismo ocurre para cada valor de ρ en (-0.5, 0). Los dos valores correspondientes de
β en cualquier caso satisface uno la condición 1<β y el otro la condición 1>β .
Lo que se quiere destacar es que el coeficiente de autocorrelación de primer orden
en una serie de medias móvil de orden 1 no puede ser tampoco demasiado grande:
5.0≤ρ
Nótese que aunque 0)( =hACF para nh ,,3,2 L= la función de
autocorrelación parcial no se anula para todos estos valores. En efecto:

Ca
18
Capitulo 1 Conceptos básicos relativos a los modelos regulares ARIMA.
( ) 42
2
21
121
11),(
)(ββ
βββ
ρρρ
++=
+=
−−−
=−
−−−
tt
tttt
xxVarxxxxCov
hPACF en particular PACF
(3) tiene el mismo signo que ρ (signo de β )
PACF(h) = 0 para h = 4, 5, 6,…
Obsérvese además que si escogemos β tal que 1<β , entonces:
30)()3()2()1( 2 >=<<= hsihPACFyPACFPACFPACF ρρρ
En la figura 3 pueden observarse los correlogramas para el proceso de media
móvil de primer orden
Figura # 3
Figura 3. Correlogramas para un proceso de media móvil de primer orden.
1.5.2 Series de medias móviles de orden q.
Las series de medias móviles de cualquier orden ∑=
−+=q
jjtjtt eex
1
β son siempre
estacionarias con media cero y varianza ∑=
q
jj
0
22 βσ (aquí convenimos en utilizar 10 =β
para abreviar expresiones). Y no es difícil ver que para cada 0≥h , se tiene:
[ ]⎥⎥⎦
⎤
⎢⎢⎣
⎡⎟⎟⎠
⎞⎜⎜⎝
⎛⎟⎟⎠
⎞⎜⎜⎝
⎛=
⎥⎥⎦
⎤
⎢⎢⎣
⎡⎟⎟⎠
⎞⎜⎜⎝
⎛⎟⎟⎠
⎞⎜⎜⎝
⎛== ∑∑∑∑
−
=−+
=−
=−+
=−+
hq
jjthj
q
jjtj
q
jjhtj
q
jjtjhtt eeEeeExxEhv
0000)( ββββ

Ca
19
Capitulo 1 Conceptos básicos relativos a los modelos regulares ARIMA.
Entonces ⎪⎭
⎪⎬
⎫
⎪⎩
⎪⎨
⎧
>
≤≤= ∑
−
=+
qh
qhhv
hq
jhjj
0
0)( 0
2 ββσ y por tanto:
⎪⎪⎪
⎭
⎪⎪⎪
⎬
⎫
⎪⎪⎪
⎩
⎪⎪⎪
⎨
⎧
>
≤≤
⎟⎟⎠
⎞⎜⎜⎝
⎛
⎟⎟⎠
⎞⎜⎜⎝
⎛
==
∑
∑
=
=+
qh
qhhACF q
jj
q
jhjj
h
0
1)(
0
2
0
β
ββρ
esto es, el correlograma asociado
a la ACF muestra q espigas (para h entre 1 y q) y luego valores 0 (para h>q)
Caso q = 2.
Consideremos la serie de medias móviles de segundo orden:
2211 −− ++= tttt eeex ββ
Entonces:
¨ ν(h)=
⎪⎪
⎭
⎪⎪
⎬
⎫
⎪⎪
⎩
⎪⎪
⎨
⎧
>=
=+
=++
202
1)1(
0)1(
22
221
221
21
hh
h
h
γβ
γββ
γββ
ACF(h)=
⎪⎪⎪
⎭
⎪⎪⎪
⎬
⎫
⎪⎪⎪
⎩
⎪⎪⎪
⎨
⎧
>
==++
==+++
20
2)1(
1)1(
)1(
222
21
2
122
21
21
h
h
h
ρββ
β
ρββββ
A partir de esto sólo con trabajo algebraico se demuestra que la PACF(h) decrece
en valor absoluto para h = 1, 2,…, 6 y además para 7≥h PACF(h) = 0. La razón de
esto último es que:
PACF (7)=[ ]
[ ]2211
56172211 ,
−−
−−−−−
−−−−−−
ttt
tttttt
xxxVarxxxxxxCov
ρρρρρρ
y al desarrollar el numerador, las variables más “próximas” a correlacionar
resultan 2−tx y 5−tx para las cuales el coeficiente de correlación ACF(3) es igual a cero.

Ca
20
Capitulo 1 Conceptos básicos relativos a los modelos regulares ARIMA.
Figura # 4
Figura 4. Correlogramas para un proceso de media móvil de segundo orden.
La esencia de estos resultados se generaliza evidentemente. Para una media móvil
de orden q resulta también que qhACF ρ=)( para qh ≤ y 0)( =hACF para qh >
Además, se tiene que:
PACF(h)=[ ]
[ ]qtqtt
qhtqhthtqtqtt
xxxVarxxxxxxCov
−−
+−+−−−−
−−−
−−−−−−
ρρρρρρ
..........,.....
11
1111
Al desarrollar el numerador, las variables “más próximas” a correlacionar resulta
qtx − y qhtx +− que tienen un “retardo” qh 2− Entre ellas el coeficiente de correlación se
anulará cuando qqh >− 2 , esto es cuando qh 3> . Por ello, para un proceso de medias
móviles de orden q es cierto en general que PACF(h) = 0 para h>3q. Puede demostrarse
además que PACF(h) decrece exponencialmente (en valor absoluto) para h = 1, 2,…, 3q
donde es diferente de cero.
Entonces, con independencia de los coeficientes de la serie de media móvil:
)0( 00
== ∑=
− ββq
jjtjt ex
resulta que:
1. La serie es estacionaria con media 0 y

Ca
21
Capitulo 1 Conceptos básicos relativos a los modelos regulares ARIMA.
ν(h)=⎪⎭
⎪⎬
⎫
⎪⎩
⎪⎨
⎧
>
≤≤∑−
=+
qh
qhhq
jhjj
0
00
2 ββα
2. ACF(h) = 0 para h > 0
PACF(h) → 0 cuando h → ∞ rápidamente y más precisamente 0)( =hPACF
para h > 3q.
Por tanto, el correlograma de la ACF muestra q espigas y el correlograma de la
PACF aparente una declinación exponencialmente (posiblemente sinusoidal
amortiguada exponencialmente) hasta h = 3q.
Este resultado es bastante simétrico al correspondiente a series autorregresivas;
pero hay dos detalles que rompen esa simetría:
1. No se necesita imponer ninguna condición a los coeficientes de la serie móvil
para que se garantice su carácter estacionario (en las series autorregresivas sí)
2. Nada dice acerca de la posibilidad de representar una serie móvil como una
serie autorregresiva de “orden infinito” (como realmente ocurre a la inversa)
En efecto, no todas las series móviles admiten tal representación. En tal caso, se
dice que la serie móvil es inversible. Y, precisamente, se demuestra que:
Dada la serie móvil
)0( 00
== ∑=
− ββq
jjtjt ex
con ecuación característica definida por:
0.....22
11 =++++ −−
qqqq mmm βββ
si las raíces características qmmm ,,, 21 L son todas menores que 1 en valor
absoluto, entonces la serie es inversible:
titi
i exc =−
∞
=∑
0
donde los coeficientes ic se obtienen a partir de una ecuación en diferencias análogas a
la parte móvil:
0.....2211 =++++ −−− qiqiii cccc βββ
con las condiciones iniciales:
1322112112110 .....;.....;;;1 −−−− −−−−=−−=−== qqqq ccccccc ββββββ
y así se alcanza la simetría esperada.

Ca
22
Capitulo 1 Conceptos básicos relativos a los modelos regulares ARIMA.
Hasta ahora utilizamos la representación para la serie móvil con coeficientes jβ y
en particular 00 =β para facilitar la descripción de las funciones ACF y PACF; pero la
simetría de la ecuación característica, de la ecuación en diferencias y de las condiciones
iniciales se hace más “bonita” si en utilizamos una representación de la serie móvil en la
forma:
jt
q
jjtt eex −
=∑−=
1θ
Desde el punto de vista práctico vale la pena recordar que si identificamos un
proceso como autorregresivo de orden p alto, probablemente pueda representarse
fácilmente como una serie de media móvil con un orden bajo y viceversa, si la serie de
media móvil es inversible.
1.6 Procesos ARMA(p, q) Son en general procesos donde se combina un carácter autoregresivo de orden p
con el de media móvil de orden q.
1.6.1 Procesos ARMA (1.1) 111 <−=− −− ϕθϕ coneexx tttt
Se demuestra para esta serie que:
ν (h)=
⎪⎪⎭
⎪⎪⎬
⎫
⎪⎪⎩
⎪⎪⎨
⎧
=−
−−
=−−+
− ,...3,2,11
))(1(
01
21
212
22
2
h
hsi
h γϕϕ
θϕϕθ
γϕ
ϕθθ
Y por tanto:
ACF(h)= ,...3,2,121
))(1( 12 =−+
−− − hhϕϕθθθϕϕθ
Si denotamos
=ρ ACF(1)=ϕθθθϕϕθ
21))(1(
2 −+−−
tenemos
ACF(h)= 1−hϕρ
para cualquier 1≥h .

Ca
23
Capitulo 1 Conceptos básicos relativos a los modelos regulares ARIMA.
Entonces la función de autocorrelación de una serie ARMA(1, 1) tiene la misma
apariencia que la de una serie AR(1) en el sentido de que ella declina en una razón
geométrica donde la razón se determina por ϕ
Con estos datos se puede determinar también la PACF(h) y después de cierto
trabajo de simplificación verificar que ellas tienen la apariencia de una serie MA(1) en
el sentido de que declinan rápidamente a ceros aunque realmente se anulan teóricamente
a partir de un valor de h.
Figura # 5
Figura5. Correlogramas para un proceso ARMA(1,1).
1.6.2 Serie ARMA(p,q). Consideremos ahora las series de la forma:
jt
q
jjt
p
itt eexx −
==− ∑∑ −=−
1111 θϕ
Box y Jenkins (1970) sugirieron la notación abreviada ARMA (p, q) para referirse
a las series de ese tipo. Las series autorregresivas puras ARMA (p, 0) pueden
denominarse simplemente AR(p) y las medias móviles puras ARMA (0, q) como
MA(q). Si se quiere, podremos utilizar la notación ),( qpARMAxtε para referir —en

Ca
24
Capitulo 1 Conceptos básicos relativos a los modelos regulares ARIMA.
un lenguaje más matemático— que tx , pertenece a la clase de series ARMA (p, q); pero
este lenguaje no es la parte esencial.
Aunque evitemos la demostración, es natural esperar que una serie ARMA(p, q)
cuya ecuación característica asociada a la parte autorregresiva:
0.....22
11 =−−−− −−
pppp mmm ϕϕϕ
tiene todas sus raíces con valor absoluto menor que 1, es representable por una serie
)(∞MA y es entonces estacionaria. Si además la ecuación característica asociada a la
parte móvil:
0.....22
11 =−−−− −−
qqqq mmm θθθ
tiene todas sus raíces con valor absoluto menor que 1, es “inversible” en el sentido que
es representable por una )(∞AR .
Estos hechos permiten estudiar las funciones ACF y PACF para una serie
ARMA(p,q) y adivinar que se presentarán combinaciones de las situaciones propia de
los procesos AR(p) y MA(q). Además determinan que tienen interés práctico las series
de tiempo definidas por la combinación de componentes autorregresivas y medias
móviles de bajo orden.
Finalmente, introducimos una notación de operadores para representar los procesos
ARMA(p,q).
1.6.3 Notación de operadores de un proceso ARMA.
Sea, β el operador de retardo, definido para cualquier serie como:
1−= tt xxβ
Retardos de más alto orden pueden obtenerse por aplicaciones sucesivas de β
22 )( −== ttt xxx βββ
y en general
htth
th xxx −
− == )( 1βββ
Si convenimos en denotar por “1” el operador identidad entonces un operador de
la forma ( )ha β−1 donde a es una constante queda definido por:
httth axxxa −−=− )1( β
En términos de este operador podemos representar:

Ca
25
Capitulo 1 Conceptos básicos relativos a los modelos regulares ARIMA.
- Un proceso autorregresivo AR(p) en la forma:
ttp
p ex =−−−−− ).....1( 33
221 βϕβϕβϕβϕ
- Un proceso de medias móviles MA(q) en la forma:
tq
qt ex ).....1( 33
221 βθβθβθβθ −−−−−=
- Un proceso mixto ARMA(p,q) en la forma:
tq
qtp
p ex ).....1().....1( 33
221
33
2211 βθβθβθβθβϕβϕβϕβϕ −−−−−=−−−−−
La mayoría de los paquetes estadísticos computacionales utilizan estas
representaciones y normalmente le llaman a:
)(iARi =ϕ o de alguna forma, el coeficiente autorregresivo regular de orden i,
)( jMAj =θ o de alguna forma, el coeficiente de media móvil regular de orden j
Debemos todavía incluir el caso autorregresivo con media constante μ (diferente
de cero), como también el caso de proceso de medias móvil “trasladado” a una media
μ diferente de cero. Podemos lograr esto con dos alternativas equivalentes:
1ra.- Sustituyendo en las representaciones anteriores a tx por ( ):μ−tx
tq
qtp
p ex ).....1())(.....1( 33
221
33
2211 βθβθβθβθμβϕβϕβϕβϕ −−−−=−−−−−−
Así por ejemplo, se trabaja prácticamente con el SPSS/PC donde además de los
parámetros AR(i) y MA(j) se determina una constante que es μ , la media de la serie.
2da.- Incluir en el miembro derecho de las representaciones anteriores un término
δ que “determina” la media constante de la serie:
tq
qtp
p ex ).....1().....1( 33
221
33
2211 βθβθβθβθδβϕβϕβϕβϕ −−−−−+=−−−−−
Así por ejemplo se trabaja prácticamente con otros paquetes (no el SPSS) donde
además de los parámetros Autorregresivos y de medias móviles se determina la
constante δ que se relaciona directamente con la media de la serie.
La equivalencia de las dos representaciones es consecuencia de que el operador β
aplicado sobre una constante, no la altera. Entonces, es muy fácil demostrar que:
δμϕϕϕϕ =−−−−−− ).....1( 321 p
Ahora resulta de especial interés estudiar las series que muestran una media no
constante, esto es “separar” la tendencia de la serie de su comportamiento
autorregresivo o de media móvil.

Ca
26
Capitulo 1 Conceptos básicos relativos a los modelos regulares ARIMA.
1.7 Procesos no estacionarios Las series de tiempo que muestran (en media) una tendencia lineal, cuadrática o
en general polinómica se convierte en estacionarias después del proceso de
“diferenciación”.
1.7.1 Proceso de diferenciación Dada una serie tx llamaremos serie diferenciada a la serie:
1−−=Δ= tttt XXXY
Una segunda diferenciación conduce a la serie:
212 2)( −− +−=ΔΔ=Δ ttttt xxxxx
y en general una diferenciación de orden “d” conduce a la serie:
kt
kd
kt
dt
d xkd
xx −=
−⎟⎟⎠
⎞⎜⎜⎝
⎛−=ΔΔ=Δ ∑
0
1 )1()(
Lo esencial se forma con ideas como estas:
Primera: Si una serie muestra una tendencia lineal, su serie diferenciada muestra
una media constante. En efecto:
Supongamos que:
tt Ybatx ++=
donde Yt es por ejemplo, una serie con media constante
Entonces, la serie diferenciada tt XZ Δ= tiene la forma:
11 −− −+=−= ttttt yyaxxZ
que tiene media constante igual a “a” porque Yt — Yt-1 tiene media cero.
Segunda: Si una serie muestra una tendencia cuadrática, su serie diferenciada dos
veces muestra una media constante. En efecto:
Supongamos que:
tt ycbtatx +++= 2
donde Yt es por ejemplo, una serie con media constante.
Entonces, la serie diferenciada una vez presenta una tendencia lineal:
tt Ybaatx Δ++−=Δ 2
y por tanto diferenciada dos veces, tiene una media constante.

Ca
27
Capitulo 1 Conceptos básicos relativos a los modelos regulares ARIMA.
El proceso de “diferenciación discreta” conduce a resultados análogos a la
diferenciación analítica de una función polinomial. En general:
Si una serie muestra una tendencia polinomial de orden, “d”, la aplicación de “d”
diferenciaciones la reducirá a una serie con media constante. En la práctica suele ser
necesario diferenciar una serie 0,1 ó 2 veces a lo sumo, porque de una parte, resulta
difícil precisar tendencias polinomiales reales de más alto orden. De otra parte, el
proceso de diferenciación excesivo pueden complicar el análisis, porque incrementa la
varianza de la serie transformada, cambia la estructura del modelo de la parte restante a
la tendencia y por tanto, hace más difícil la identificación y menos eficiente la
estimación
En otras palabras sí:
tdt Ytpolinomiox += )(
está claro
td
td Yteconsx Δ+=Δ tan
Pero si ∈tY ARMA(p, q), no hay por qué pensar que ∈Δ Yd ARMA(p, q) y mucho
menos que el modelo de YdΔ tenga una estructura mas simple que el modelo de tY .
Analice por ejemplo que ocurre cuando ∈tY AR(1) con 1)1( =ACF o )1(ACF <1
Por ello no hablaremos de series “con una componente de tendencia” y “otra
componente ARMA” sino de series, que “una vez diferenciadas, presente una estructura
de modelo ARMA conocida”.
1.7.2 Procesos ARIMA Se llaman series “d—integradas ARMA aquellas series que después de diferenciar
“d veces” se convierten en una serie ARMA. Se utiliza la denominación ARIMA. ( la
“I” viene de Integrated para representar los modelos de este tipo, en forma abreviada
ARIMA(p,d,q).
Para representar una serie que se modela como ARIMA en términos de
operadores, vale la pena comprender que:
tttt xxxx )1(1 β−=−=Δ −
La diferenciación de orden “d” se expresa en la forma:
td
td xx )1( β−=Δ

Ca
28
Capitulo 1 Conceptos básicos relativos a los modelos regulares ARIMA.
lo que es concordante con la forma “binomial” del operador dΔ .
Si después de la diferenciación la serie tiene una media constante μ entonces es:
( )[ ]μβ −− td x1 la serie que tiene una estructura ARMA.
El modelo ARIMA (p,d,q) se expresa definitivamente en la forma:
tq
qtdp
p ex ).....1()1)(.....1( 221
221 βθβθβθββϕβϕβϕ −−−−=−−−−− donde
td x)1( β− debe ser sustituido por [ ]μβ −− t
d x)1( si la serie diferenciada tiene una
media μ diferente de cero o equivalente, debe ser incluida una constante aditiva δ en el
miembro derecho que se determina a partir de μ por la relación :
μϕϕϕδ )......1( 21 p−−−−−=
Esencialmente, la diferenciación estabiliza la media cuando la serie muestra una
tendencia polinómica. La diferenciación procura el carácter estacionario para muchas
series que no lo tienen; pero hay comportamientos no estacionarios que no se resuelven
con diferenciación.
Por ejemplo, las tendencias periódicas (estacionales) en una serie no se resuelven
con diferenciación, al menos con una diferenciación como la aquí descrita. En el último
epígrafe hablaremos en particular de las series periódicas y de la eliminación de la
tendencia estacional. Otro ejemplo más sencillo, una tendencia exponencial, no puede
ser eliminada por un proceso de diferenciación solamente. Una falta de estabilidad de la
varianza tampoco. En estos casos hay que hacer transformaciones potencia seguidas o
no eventualmente de diferenciación.
Una violación del carácter estacionario de la serie, a causa de heterocedasticidad
es mucho más seria que por una tendencia; pero también es importante analizar como
eliminarla para ampliar las series reducibles a procesos ARIMA.
No existen reglas fijes para, seleccionar la transformación potencial idónea; pero
tal como ocurre en la regresión existen algunas sugerencias que pueden ser
prácticamente importantes:
Por ejemplo:
- Sí la serie evidencia una varianza creciente con la media, es recomendable una
transformación logarítmica

Ca
29
Capitulo 1 Conceptos básicos relativos a los modelos regulares ARIMA.
- Si la serie evidencia una media constante μ pera una varianza irregular, es
recomendable una transformación estrictamente potencial Ptx que se logra muchas veces
con 21=p ó 2
1−=p ó 1−=p
Es difícil tener evidencia de la varianza no constante “a priori” antes de intentar el
modelo; pero con un poco de práctica puede apreciarse en el grafico inicial de la serie y
alcanzar la estabilización tanteando transformaciones potencias (o logarítmicas)
sencillas como las mencionadas.
Si no percibiéramos la falta de homogeneidad de varianza llegáremos a realizar el
modelo, y los residuales no mostraran una varianza constante, ello es indicativo de que
la serie necesita una transformación p determinada por: p=1-0.5*h*μ
donde h se determina como un coeficiente de regresión lineal de los residuales et
respecto a los valores pronosticados Xt por e1 modelo y divididos por su varianza S2
Por último para una serie no estacionaria, las funciones ACF(t, h) y PACF(t, h),
dependen de t además de h; pero si se intentan trazar, utilizando por ejemplo sus valores
en t=1 como si fueran independientes de éste, mostrarán un comportamiento
cualitativamente diferente a los referidos anteriormente. Probablemente se manifiesten
como funciones decrecientes de h; pero no en razón geométrica, o como funciones
irregulares de h, con espigas aleatorias y aisladas, por lo cual los correlogramas pueden
ser indicadores también de la falta de estacionaridad y por tanto de la necesidad de
transformar y/o diferenciar la serie.
Figura # 6
Figura 6. Ejemplo de correlograma de una serie con un tipo de no estacionariedad
bastante frecuente
Para mostrar un ejemplo recuérdese el caso de un camino aleatorio, que es, un
movimiento autorregresivo no estacionario:

Ca
30
Capitulo 1 Conceptos básicos relativos a los modelos regulares ARIMA.
)1( 11 =+= − ϕttt exx
A esta serie responde en la práctica, por ejemplo el precio de un producto en el
que tenga una demanda estacional.
Si partimos de los datos de precios de un producto de este tipo a lo largo del
tiempo, plateamos la serie y los correlogramas, observamos que la serie no evidencia
tendencias y que la función de autocorrelación declina lentamente a cero.
Si plateamos las correlogramas de la serie diferenciada observamos que la ACF(h)
y la PACF(h) no muestran ninguna espiga significativa. Ello sugiere que la serie
diferenciada es ARMA(0,0) y la serie original esARIMA(0,1,0)
Realmente, y desde el punto de vista teórico, la ACF(t, h) depende de t y de h. La
serie no muestra tendencias (la media es constante) pero falta la homogeneidad de
varianza. La serie diferenciada tt XY Δ= satisface: tt eY = y por tanto es trivialmente
un ruido blanco: ARMA (0, 0). Por ello, la serie original es efectivamente
ARIMA(0,1,0).
En definitiva, se tienen en cuenta los casos ARMA(p, q), cuyos correlogramas
están bastante bien caracterizados, los casos ARIMA(p,d,q) reducibles a los anteriores
por diferenciación “d” veces y los casos de series que después de una transformación se
reducen a ARIMA(p,d,q), se abarca una amplía clase de series de tiempo identificables.
El grafico de la serie y de los correlogramas proporciona un método bastante efectivo
de identificar una serie que se ajuste o se reduzca a un modelo ARIMA(p,d,q) y esta
constituye la base fundamental de la metodología de Box – Jenkins para el estudio de
series de tiempo no estaciónales
Cuando estudiemos la metodología de Box—.Jenkins completaremos el tema de la
identificación de un modelo ARIMA sobre la base de “aproximaciones sucesivas”.
1.8 Complementos teóricos: estimación, diagnóstico y pronóstico en modelos ARIMA
Ya sabemos que una serie ARIMA(p,d,q) muestra necesariamente cierto
comportamiento de las funciones ACF(h) y PACF(h) que sirven para identificar el
modelo. La teoría matemática de las series de tiempo abarca criterios para lograr las
estimaciones de máxima verosimilitud de dichas funciones a partir de datos observados
o realización de una serie, que responden bastante a nuestras ideas intuitivas y cuyos
detalles escapan a los objetivos de materialista introducción teórica.

Ca
31
Capitulo 1 Conceptos básicos relativos a los modelos regulares ARIMA.
Una vez identificada la estructura ARIMA(p,d,q) a la cual responde
(probablemente) la muestra de una serie de tiempos el paso próximo y más importante
es la estimación estadística de los parámetros del modelo, a saber, de los
coeficientes pii ,,2,1, L=ϕ de la componente autorregresiva; los coeficientes
pji ,,2,1, L=θ de la componente de media móvil y la constante μ , media de la
serie diferenciada o el parámetro δ equivalente.
La argumentación matemática de la estimación estadística de los parámetros se
fundamenta en la teoría de estimadores de máxima verosimilitud [#]. Desde un punto de
vista más práctico puede ser suficiente conocer que la mejor estimación en general se
logra con una linealización del modelo y minimización de la suma de los cuadrados de
las diferencias entre los valores reales de la serie de trabajo (suponiendo. que es
estacionaria) y los predichos por un modelo con estimados iniciales de los parámetros
Se actualizan entonces estos estimaciones de los parámetros a partir de los resultados de
la primera iteración y el proceso se repite hasta alcanzar convergencia. Hay métodos
prácticos también para la estimación inicial sobre la cual se basa el proceso iterativo.
Cuando la serie no tiene valores perdidos, los estimados iniciales se hacen sobre la
base de un criterio de máxima verosimilitud y el algoritmo resulta particularmente
rápido. Se conoce así como algoritmo de Marquardt-Melard y es el que utilizan la
mayor parte de los paquetes serios de análisis de series de tiempo. En próximos
epígrafes comentaremos un algoritmo alternativo cuando la serie tiene valores perdidos
(algoritmo de Kalman).
Como criterios de convergencia o de finalización del algoritmo se pueden utilizar
alguno o varios de los siguientes:
- Un -valor- epsilon (por ejemplo 001.0=ε ) El proceso terminaría según este
criterio cuando el cambio en todos los parámetros estimados fuera menor que epsilon.
- Porcentaje de variación de la suma de cuadrados. El proceso iterativo debe
terminar si el cambio relativo en la suma de cuadrados es menor que cierta cantidad
prefijada que se denomina “SSQ percentage, por ejemplo, SSQ = 0.001%
- Un valor máximo de la constante de Marquardt. Esta es una constante que se
utiliza por el algoritmo de Marquardt-Melard y que se actualiza en cada iteración.
Generalmente esta constante debe ser cercana a cero cuando se obtienen las estimativas
finales. Un valor grande de la constante de Marquardt en una iteración indica problemas
condicionantes en los datos. Por ello, se formula un criterio de terminación (más bien de

Ca
32
Capitulo 1 Conceptos básicos relativos a los modelos regulares ARIMA.
“aborto”) del algoritmo en términos de que la constante de Marquardt no rebase un
valor, prefijado, por ejemplo 109
- Número máximo de iteraciones. Si se utiliza el algoritmo de Marquardt-Melard,
y el modelo está correctamente identificado se garantiza alta velocidad de convergencia.
Por tanto la necesidad de muchas iteraciones puede ser indicador de un problema y se
usa un máximo, por ejemplo, 10, para abortar.
No se debe perder de vista que en la estimación de parámetros perseguimos tres
objetivos:
1. que 1o valores predichos por la serie se diferencien lo menos posible de los
valores reales observados
2. que obtengamos residuales que no estén correlacionados entre sí.
3. que usemos tan pocas parámetros como sea necesario.
El tercer objetivo, conocido como criterio de parsimonia, es en cierto sentido
cuestionable cuando es la computadora quien hace las estimaciones y los pronósticos,
pero en general usar el menor número de parámetros facilitará la verificación del
modelo y el pronóstico.
Lograda en la práctica la estimación de los parámetros de una muestra, hay que
validar hasta que punto el modelo estimado es bastante bien la realización. Esta se
conoce como la fase de diagnóstico.
En la misma fase de estimación se pueden calcular varios estadísticos que ayudan
a chequear el cumplimiento de los objetivos de la estimación. Digamos por ejemplo,
para cada coeficiente ji θϕ , y la media, se construye un test de Student análogo al de
la regresión para verificar si el es significativamente - o no - diferente de cero y además
se hace un análisis de varianza para determinar el ajuste del modelo en general. Hay
también, otros criterios, análogos a los de la regresión o específicos para series y que
constituyen parte del chequeo diagnóstico, que es preferible ver en conjunto, sobre la
base de ejemplos concretos Se quiere sólo destacar aquí un detalle teórico sobre el
estudio de los residuales.
La parte más importante del diagnóstico es el chequeo de que los residuales
constituyan realmente un ruido blanco. Ello significa que debemos probar
estadísticamente que los residuales son no correlacionados, tienen media cero y varianza
constante. En la práctica ello se logra con el estudio de la función ACF(h) y PACF(h) de
la serie de los residuales, que debe mostrar en particular una estructura ARIMA(0,0,0),

Ca
33
Capitulo 1 Conceptos básicos relativos a los modelos regulares ARIMA.
esto es, ser un ruido blanco y ciertos Q-estadísticos (conocido como estadísticos de
Box-Ljung) que prueban la hipótesis nula de que esta serie corresponde a un ruido
blanco.
La diferencia aparente con él análisis de residuales de la regresión es que no
necesitamos probar que los residuales se distribuyen normalmente ni sean
independientes, ni siquiera tengan que la misma distribución para cada instante de
tiempo. Sin embargo, la efectividad de los pronósticos depende teóricamente en muchos
casos que los residuales sean independientes y la elaboración de los intervalos de
confianza es más fácil si los residuales se distribuyen normalmente (en este caso la
condición de ser independientes y no correlacionados es equivalente). Desde este punto
de vista, tiene interés saber adicionalmente si los residuales se distribuyan normalmente.
Otra fase que merece consideraciones teóricas importantes es la de pronóstico, lo
cual se analiza con el rigor estrictamente necesario para la comprensión. Las ideas
esenciales son las siguientes:
Dadas “n” observaciones de una realización se pretende predecir la observación
“n+s” donde s es un entero positivo. A causa de la naturaleza funcional de una
realización, la predicción o pronóstico no es otra cosa que una extrapolación.
Recuérdese que en el análisis de regresión clásico las extrapolaciones son muy
peligrosas y el mérito fundamental de la teoría de series de tiempo desde el punto de
vista práctico es la posibilidad de brindar pronósticos más certeros fuera de los
intervalos de valores observados hacia delante o hacia atrás.
Los procesos autorregresivos y de medias móviles, dan efectivamente esta
posibilidad; pero el carácter óptimo del pronóstico evaluando la serie para el instante
“n+l” y despreciando el residual, no es obvio (por ejemplo no sería efectivo si la serie
hubiera sido obtenida como una regresión normal en función del tiempo) y no deja claro
como proceder en el instante “n+2” (el pronóstico posterior) o más generalmente en el
instante “n+s”
El criterio, teórico que se usa es de la media del error cuadrático del predictor. Por
ejemplo, si
),.....,,( 21 nsn xxxx +
es el predictor de snX + basado sobre las n observaciones nXXX ,,, 21 L , entonces la
media del error cuadrático (MSE) del predictor se define por:
MSE{ } { }[ ]2
2121 ),.....,,(),.....,,( nsnsnnsn xxxxxExxxx +++ −=

Ca
34
Capitulo 1 Conceptos básicos relativos a los modelos regulares ARIMA.
Generalmente, los problemas de determinación de predictores óptimos requieren que se
restrinja la clase de predictores. Se investiga en particular el mejor predictor lineal para
una serie estacionaria con media y función de covarianza conocidas.
Los resultados se particularizan después en la forma siguiente:
Supongamos que tenemos un proceso AR(p) estacionario:
tit
p
iit exx += −
=∑
1ϕ , done et tiene media 0 y varianza α2
El mejor predictor de 1+nX a partir de nXXX ,,, 21 L , (con n>p) es
precisamente:
in
p
iinn xxxxx −+
=+ ∑= 1
1211 ),.....,,( ϕ
Para este predictor, es claro que:
MSE= [ ] 22 α=teE
Ahora, el mejor predictor en dos pasos es:
11
11
12
2111212
)(
),.....,,(),.....,,(
+−=
+
−+=
++
∑
∑
+=
+=
in
p
iii
in
p
iinnnn
x
xxxxxxxxx
ϕϕϕ
ϕϕ
y en general, el predictor para el instante “n+s” después se obtiene sustituyendo las
predictores para períodos más tempranos en el predictor para “n+l”
Un hecho que muestra que no todos los resultados son obvios es el siguiente:
Resulta que el caso AR(p) estacionario, el predictor mencionado es el que minimiza el
MSE con sólo la condición de que los residuales no estén correlacionados. Si además
los residuales te son independientes, el predictor es el valor esperado de snX +
condicionado a nXXX ,,, 21 L , pero si de los te solo sabemos que son no
correlacionados no se puede llegar a esta conclusión.
Si se tiene en particular que ),0( 2σε Net , entonces, la condición de ser no
correlacionados equivale a la condición de ser independientes y por ello el predictor es
el valor esperado de snX + condicionado a nXXX ,,, 21 L
El caso de predicción en una serie de media móvil es un paco más complicado;
pero no mucho más.
Supongamos que tenemos una serie MA(q) que sea inversible:

Ca
35
Capitulo 1 Conceptos básicos relativos a los modelos regulares ARIMA.
jt
q
jjtt eex −
=∑−=
1θ
El pronóstico se complica porque debemos conocer valores de te anteriores al
actual. Supongamos que conocemos los te para 1,,1, +−−= qnnnt L . Entonces el
mejor predictor lineal de snX + sería:
⎪⎭
⎪⎬
⎫
⎪⎩
⎪⎨
⎧
>
≤≤−= ∑
=−+
+
qs
qsex
q
sjjsnj
sn
0
1θ
y si las te son independientes sería el valor esperado de snX + condicionado a
neee ,,, 21 L .
Sin embargo debemos desarrollar un predictor expresado en términos de las tX .
Si n es grande, la serie móvil invertida como proceso autorregresivo puede
truncarse para un orden finito y entonces estimar te a partir de valores anteriores de
tX ; pero obsérvese que esto exige una hipótesis más: que n sea suficientemente grande.
Algo similar ocurre con series mixtas ARMA(p,q). Por último, enfatizamos que si
los residuales son independientes, los preditores anteriores son insesgados, esto es:
{ }[ ] 0),.....,,( 21 =− ++ nsnsn xxxxxE
Por tanto, el MSE del predictor es su varianza y se puede usar esta información
para establecer límites de confianza para la predicción a partir de la distribución de los
te . En particular si los te se distribuyen normalmente, los intervalos de confianza para
el predictor se logran en la forma:
[ ]),.....,,(),.....,,( 2121 nsnnsn xxxxMSEtxxxx ++ ± α
donde αt se determina por la distribución normal y la confianza por αγ −=1 .

Ca
36
Capitulo II Metodología de Box-Jenkins para Series Regulares ARIMA. Tratamiento de Regresores
CAPITULO II
Metodología de Box-Jenkins para Series Regulares ARIMA. Tratamiento de Regresores
2.1 Introducción Dedicaremos una buena parte de este capítulo a presentar en detalle la metodología de
Box-Jenkins para la modelación ARIMA de series regulares. Ella se fundamenta en los
conceptos explicados en el Capítulo I. La metodología de Box-Jenkins es realmente un
proceso multi-paso e iterativo de análisis de series de tiempo y pronóstico consistente
esencialmente de cuatro fases que se explican en general en los primeros epígrafe.
Detallaremos posteriormente como se pueden incorporar al análisis de series ARIMA
ciertas variables independientes que ayudan al tratamiento de outliers, valores perdidos, y
el análisis de intervención
2.2 Fases del proceso de modelación ARIMA Las 4 fases del proceso en una modelación ARIMA según la Metodología de Box-
Jenkins son:
Identificación del modelo
Estimación de parámetros
Chequeo de diagnóstico
Pronóstico
Las ventajas de esta metodología sobre otras técnicas tradicionales son las siguientes:
1. Las series analizables por Box-Jenkins incluyen una clase bastante amplia de
modelos, de hecho todas las series ARIMA(p,d,q) o reducibles a ellas.
2. Pone énfasis especial y sistemático en la identificación del modelo. La metodología
de Box-Jenkins se basa en una teoría estadística bastante rigurosa de identificación
de modelos, que se ha introducido anteriormente y que se complementará ahora
con detalles interesantes.
3. La estimación de los parámetros se basa igualmente en una teoría estadística fuerte,
complementaria a la regresión.
4. Se puede verificar la validez o adecuacidad del modelo a través de chequeos
diagnósticos, que abarcan tanto a la significación de cada parámetro estimado
como la adecuacidad del modelo en su conjunto.

Ca
37
Capitulo II Metodología de Box-Jenkins para Series Regulares ARIMA. Tratamiento de Regresores
5. Se puede medir la seguridad del pronóstico. La modelación de Box-Jenkins
suministra mecanismos de generación de límites para el error en el pronóstico e
intervalos de confianza para medir la incertidumbre de los valores predichos, al
menos si los residuales se distribuyen normalmente.
La suposición de partida de Box-Jenkins, es que la serie de tiempo bajo análisis
pertenece a una clase de modelos ARIMA. Esto es, los datos que son analizados pueden
ser aproximados por un modelo ARIMA apropiado. El análisis de la serie de tiempo es el
proceso de determinación de una forma apropiada de este modelo, la estimación de los
coeficientes o parámetros del modelo identificado y su validación.
La metodología ayuda no sólo a identificar un modelo sino a perfeccionarlo en varias
de sus fases. Es importante comprender que para un juego de datos específico, puede
existir más de un modelo ARIMA que ajuste bien los datos. Por ello, el modelo puede
perfeccionarse como consecuencia de cada fase. El propio rastreo del pronóstico con
nuevos valores disponibles hace que una serie pueda también mejorarse a lo largo del
tiempo. Por razones de este tipo, es que el proceso se define como iterativo aunque se
distingan las 4 fases que antes mencionamos.
Es justo decir también que la metodología de Box-Jenkins no es un algoritmo pues no
garantiza siempre convergencia a una solución. De hecho, si la serie no es ARIMA o
transformable a una tal serie, esta metodología puede no ser aplicable.
2.3 Los procesos iterativos en la Metodología de Box-Jenkins Un “diagrama de flujo” que muestra las fases y el carácter iterativo se puede ver en el
anexo (2,1). Se comentan las etapas de esta metodología de las que no se ha hablado antes,
especialmente aquellas relacionadas con los “lazos” en este diagrama y que dan a la
técnica, el carácter iterativo.
En la fase de identificación del modelo, el gráfico de la serie y los residuales permiten
descubrir e identificar tendencias a la periodicidad, además de tendencias lineales,
polinómicas, o violaciones del carácter estacionario de la serie por falta de homogeneidad
de varianza. Ya se ha dicho que las transformaciones y/o diferenciaciones, permiten
muchas veces lograr carácter estacionario y esto explica el primer lazo. Los pasos
sucesivos de la Metodología de Box-Jenkins parten de que se ha alcanzado un carácter
estacionario de la serie.

Ca
38
Capitulo II Metodología de Box-Jenkins para Series Regulares ARIMA. Tratamiento de Regresores
Una vez que la serie es estacionaria, si es modelable ARIMA los correlogramas
trazados permiten una identificación inicial del modelo. El proceso de identificación puede
ser concebido como un proceso cíclico de aproximaciones sucesivas en el que intervienen
en el primer nivel, las fases de identificación, estimación y análisis de la autocorrelación
de los residuales (ver “lazo” correspondiente en el diagrama de la Metodología de Box-
Jenkins). En el segundo nivel, el diagrama abarca además el pronóstico y su contraste con
valores reales y se explicará más tarde.
La idea práctica de este primer lazo se puede fundamentar fácilmente con el llamado
Principio para la identificación sucesiva. Supongamos por ejemplo que al trazar
inicialmente los correlogramas tengamos duda de si el modelo es (0,1,1) ó (1,1,1). Podría
seguirse la estrategia de comenzar con el modelo más simple (0,1,1), se estiman los
parámetros, los residuales y los correlogramas de éstos. Si se evidencia que los residuales
no son autocorrelacionados, sino que responden por ejemplo, a un modelo (1,0,0),
entonces la serie original debe responder al modelo (1,1,1).
En efecto, si en el primer intento logramos: ( ) tt EBXB )1(1 1θ−=− y Et no es un ruido
blanco sino que satisface tt eEB =− )1( 1θ donde te es un ruido blanco, entonces, de la
combinación de estas dos ecuaciones resulta que: tt eBXBB )1()1()1( 11 θϕ −=−− . Aquí
B es el operador de retardo definido en el Capítulo I.
En virtud del álgebra de los operadores polinómicos, esta propiedad es generalizable de
la siguiente forma:
Si se intenta escribir tX como modelo ARIMA(p,d,q) y el residual tE no resulta un
ruido blanco, sino que realmente es todavía una serie ARIMA: )',','( qdpARIMAEt ε
con no todos los parámetros p´, q´ y r´ iguales a cero, entonces resulta que
)',','( qqddppARIMAX t +++ε .
En efecto para simplificar notaciones supóngase que se tiene:
tqtd
p EBXBB )()1)(( Ρ=−Ρ
donde )(BPp y )(BPq son operadores polinómicos en B de sendos grados p y q, y que la
serie tE no es un ruido blanco sino que satisface la condición de que:
tptd
p eBPEBBP )()1()( =−
donde )(BPp y )(BPq son operadores polinómicos en B de sendos grados p’ y q’, y que la
serie te es un ruido blanco.

Ca
39
Capitulo II Metodología de Box-Jenkins para Series Regulares ARIMA. Tratamiento de Regresores
Entonces, combinando estas expresiones y aplicando la conmuntatividad y
asociatividad de la multiplicación de los operadores polinómicos se llega a:
tqqtdd
pp eBPBPXBBBPBP )()()1()1()()( '' =−−
ó
[ ] [ ] tqqtdd
pp eBPBPXBBPBP )()()1()()( ''
' =− +
como se quiere demostrar.
Gracias a este principio, el usuario puede darse el lujo de comenzar suponiendo el
modelo con la estructura más simple entre las plausibles, y, analizando la correlación de
los residuales, determinar la posible necesidad de elevar el orden del modelo.
En general los gráficos de las series pueden ser útiles en cualquier fase. Téngase
presente que se puede hablar de la serie original, de la serie transformada (por ejemplo por
una transformación potencia o logarítmica), de la serie de trabajo (transformada o
diferenciada y ya estacionaria) de la serie de residuales, de la serie de pronóstico y de las
series límites de confianza (inferior y superior) del pronóstico.
Las estimación de parámetros es la fase de construcción del modelo donde calculamos
los valores específicos para cada uno de los parámetros AR(i) y MA(j) y μ (ó δ según el
paquete). Ya que la serie de tiempo que se está modelando es solamente una muestra o
realización del proceso que ella representa, realmente nosotros calculamos estimativas
muestrales de los verdaderos parámetros.
El diagnóstico comienza prácticamente con los estadísticos que surgen en la fase de
estimación, tiene un centro en el estudio de la correlación de los residuales y se extiende
hasta la etapa de pronóstico en el sentido siguiente.
Una práctica general y bastante usual, al comenzar el estudio de modelos de series de
tiempo, es reservar desde el principio una parte de los datos (digamos la última cuarta
parte) para validar el modelo y emprender todo el análisis, identificación, estimación y
diagnóstico con la primera parte de los datos. El pronóstico sobre el período de validación
y su comparación con los valores reservados reales proporciona un criterio efectivo de
cuán válidos son los pronósticos a partir del modelo estimado.
En el período de validación pueden comprobarse tanto los pronósticos a corto plazo
como los pronósticos a largo plazo. En el primer instante a pronosticar, el valor predicho
se estima a partir del segundo instante, tenemos dos alternativas: utilizar el valor real (que
está disponible) en el instante anterior, o utilizar el valor recién pronosticado para ese
punto. En general, si pronosticamos utilizando valores reales de la serie anteriores al

Ca
40
Capitulo II Metodología de Box-Jenkins para Series Regulares ARIMA. Tratamiento de Regresores
instante actual, aunque estén dentro del período de validación, los pronósticos serán más
exactos y validamos con ello el pronóstico a corto plazo. Si para predecir el valor en un
instante dado utilizamos sólo los valores reales que sirvieron de base en la estimación de la
serie y los valores pronosticados de instantes anteriores al caso, obtendremos un pronóstico
mucho más grosero porque la información real se acabará al cabo de ciertos pasos.
El pronóstico real, esto es, sobre un período para el cual no tengamos valores
reservados, es imprescindible utilizar después del primer paso, la información previamente
pronosticada.
El “agotamiento” de la información real disponible para el pronóstico a largo plazo es
particularmente notable en los procesos autoregresivos en los cuales el valor actual
depende apenas de p valores anteriores. En el caso de series de medias móviles y de
modelos mixtos (equivalentes, si son reversibles a modelos autoregresivos de muy alto
orden) la información real disponible tardará mucho más en agotarse, pero en cualquier
caso el pronóstico será mucho más impreciso. Después veremos que los mejores
pronósticos se pueden obtener en el caso de las series estacionales o periódicas, porque hay
dependencia de información anterior mucho más lejana.
Es importante recordar de la teoría que para obtener buenos pronósticos, es deseable
que:
• Si hay componentes de serie móvil, esta sea inversible y se tengan bastantes datos
de base para hacer el pronóstico.
• En cualquier caso se tengan residuales independientes y de ser posible, distribuidos
normalmente.
Se comentan ahora los últimos cuadros del “diagrama de flujo”de la Metodología de
Box-Jenkins. En la misma medida que aparezcan nuevos datos para la serie de tiempo
objeto de estudio, el modelo previamente estimado para la serie original puede ser usado
para generar pronósticos nuevos y actualizados. Bastará adicionar los nuevos datos a la
serie y seleccionar un nuevo origen para el pronóstico, aunque se utilice el mismo modelo
previamente determinado. La práctica de adicionar datos y usar el mismo modelo para
calcular pronósticos mejorados puede continuarse hasta que los errores de predicción
sugieran una re-evaluación del modelo. En ese momento el modelo puede ser actualizado,
con la misma estructura o incluso una nueva. Si se trata de mantener la estructura y re-
estimación de parámetros con los nuevos datos de la serie conduce a un mal diagnóstico,
es mejor cambiar completamente el modelo; pero lo más frecuente es que apenas sea
necesario cambiar los valores de los parámetros.

Ca
41
Capitulo II Metodología de Box-Jenkins para Series Regulares ARIMA. Tratamiento de Regresores
La metodología de Box-Jenkins así formulada es válida también para el estudio de
series estacionales o periódicas, aunque todavía no se haya hecho referencia a ella.
El carácter periódico de una serie puede ser una propiedad muy buena a los fines de
pronóstico; pero para el análisis de Box-Jenkins, es imprescindible trabajar con series
estacionarias. La periodicidad en una serie es otro tipo de violación del carácter
estacionario y debe ser “eliminada” en la fase de identificación del modelo.
La extensión de la clase ARIMA a series periódicas y su identificación por las formas
especiales de la ACF y la PACF serán tratadas en el epígrafe siguiente; pero se quiere dejar
ya formulado el esquema de la Metodología de Box-Jenkins extendido a este tipo de series.
Por lo pronto baste decir que las tendencias periódicas se eliminan antes que otra
tendencia, utilizando procesos análogos a la diferenciación que se detalla posteriormente y
con ello, el proceso sigue las mismas fases que el de análisis de series no periódicas. La
identificación y la estimación consecuente de ciertos parámetros estacionales siguen la
idea del Principio de identificación sucesivas en el sentido que primero se reconocen y
estiman los parámetros estacionales, se analiza la pertenencia de éstos a una clase
ARIMA(p,d,q) clásica para entonces completar la identificación del modelo inicial.
2.4 El modelo ARIMA estacional. Generalización de la metodología de Box-Jenkins a series estacionales.
Muchas series de la vida real muestran una tendencia a la periodicidad fácilmente
explicable por condiciones naturales o intrínsecas al proceso. El análisis de Box-Jenkins
que hasta ahora se ha formulado y ejemplificado para el estudio de series regulares (no
periódicas) es elegantemente extendido al estudio de series con tendencia a la periodicidad,
a partir de la precisión de este concepto.
En matemática se dice que una función f(t) es periódica si cumple que:
)()( tfTtf =+ para cierto valor de T fijo y todos los valores de t de su dominio. Está claro que si dicha
propiedad se cumple con un valor de T, se cumple también con muchos otros, en
particular, todos los múltiplos enteros de T. Se llama período de la función al menor entero
positivo que satisface esta propiedad.
Intuitivamente hablando, las series de que hablamos no son “exactamente periódicas”
sino “aproximadamente periódicas” y por ello, se prefiere utilizar el concepto de series

Ca
42
Capitulo II Metodología de Box-Jenkins para Series Regulares ARIMA. Tratamiento de Regresores
estacionales en lugar de “series periódicas”. En este plano intuitivo, la serie Zt tiene
carácter estacional si
tSt ZZ ≈+ para cierto valor de S, y se llama estacionalidad de la serie al menor valor de S positivo
para el cual se cumple la igualdad aproximada anterior. Desde el punto de vista de una
realización concreta de Zt:
nSS zzzzzz LL 1321 +
estos valores observados deben mostrar un cierto comportamiento “cíclico” con máximos,
mínimos y fluctuaciones similares, cada S observaciones. La estacionalidad S, es pues, el
número de observaciones que yacen en un tal ciclo de una realización concreta.
( )( ) ( ) tQS
SSS
tDSPS
PSS eX βϑβϑβϑββφβφβφ −−−−=−−−−− ...11...1 2
212
21 Así, por ejemplo, si una serie representa un proceso aproximadamente periódico anual,
como (cada año es un ciclo) como ocurre frecuentemente en los procesos metereológicos
y las observaciones son mensuales, su estacionalidad es de 12. Si las observaciones son
trimestrales su estacionalidad es de 4, si son diarias es de 365. Si el carácter cíclico se
manifiesta semanalmente y las observaciones son diarias su estacionalidad es de 7 (si hay
7 observaciones cada semana); pero puede ser 6 (si por ejemplo se excluyen observaciones
de los domingos).
Aunque las ideas intuitivas sean claras, el concepto formal de series estacionales debe
ser más rigurosamente definido precisando el sentido de la periodicidad aproximada. Box
y Jenkins consideran series cuya estacionalidad es producto de alguno de los factores
siguientes:
1. El valor de Zt está significativamente correlacionado con los valores de
PStStSt ZZZ −−− ,,, 2 L para algún valor de P. Así aparecen las series autoregresivas
estacionales de orden P.
2. El valor de Zt está significativamente correlacionado por los disturbios o errores
aleatorios estacionales QStStSt eee −−− ,,, 2 L para algún valor de Q. Así surgen las series
de medias móviles estacionales de orden Q.
3. El valor de Zt está significativamente influenciado por la unión de los dos efectos
anteriores: modelos autoregresivos y de medias móviles estacionales de orden (P,Q)
con estacionalidad S.

Ca
43
Capitulo II Metodología de Box-Jenkins para Series Regulares ARIMA. Tratamiento de Regresores
4. Series Zt que después de una diferenciación estacional: StttS ZZZ −−=Δ o más
generalmente, después de “D” diferenciaciones de este tipo, responden a la categoría
anterior. Son las series D-integradas estacionalmente de series estacionales de orden
(P,Q) o más simplemente, series estacionales (P,D,Q) con estacionalidad S.
Utilizando el operador de retardo estacional Sβ definido por: Stt
S ZZ −=β se puede
representar un modelo estacional puro con parámetros (P,D,Q)S en la forma siguiente:
tQS
SSS
tDSPS
PSS eZ )1()1)(1( 2
212
21 ββββφβφβφ Θ−−Θ−Θ−=−−−−− LL donde et es un disturbio aleatorio o ruido blanco (0, σ2).
La analogía de este modelo con el caso regular (p,d,q) hace evidentes algunos
conceptos y resultados, que permiten identificar y estimar un modelo de este tipo, y que se
obtienen simplemente de sustituir un retardo regular por un retardo estacional:
• Se dice que una serie es estacionaria S-estacionalmente, si [ ]ShXE * es constante
(independiente de h mayor o igual de 0) y la función de autocovarianza estacional:
[ ]Shtts XXCovShh *,)*()( +==νν depende solamente de h.
• En tal caso se puede hablar de una función de autocorrelación estacional y de una
función de autocorrelación parcial estacional definida por:
SACF(h) = ACF(h*S)
SPACF(h) = PACF(h*S) h ≥1
y tendrán las mismas apariencias para los diferentes valores de P y Q que en el caso
regular. En particular:
1. En una serie autorregresiva estacional de orden P, que sea estacionaria
estacionalmente, la función SACF(h) mostrará una rápida declinación a cero y la
función SPACF(h) mostrará “P” espigas.
2. En una serie de media móvil estaminal de orden Q, la función SACF(h) mostrará Q
espigas y la función SPACF(h) mostrará una rápida declinación a cero.
3. En una serie mixta estacional, de orden (P,Q), que sea estacionaria, los patrones serán
más complejos; pero ambas funciones mostrarán una rápida declinación a cero.
4. Si en una serie estacional, la SACF (h) no muestra una rápida declinación a cero, ella
no es estacionaria estacionalmente y probablemente requiera de 1 ó 2 diferenciaciones
estacionales.
La metodología de Box-Jenkins extendida a series estacionales puede ser aplicada a
series más generales que responden a la forma similar:

Ca
44
Capitulo II Metodología de Box-Jenkins para Series Regulares ARIMA. Tratamiento de Regresores
tQS
SSS
tDSPS
PSS EZ )1()1)(1( 2
212
21 ββββφβφβφ Θ−−Θ−Θ−=−−−−− LL
con un residual Et que no es un ruido blanco, sino un modelo regular ARIMA(p,d,q):
tQS
SSS
tDSPS
PSS eZ )1()1)(1( 2
212
21 ββββφβφβφ Θ−−Θ−Θ−=−−−−− LL
De acuerdo con esto, se puede precisar definitivamente el tipo de series estacionales
que interesan:
Se dice que Zt es una “serie de tipo estacional que responde al modelo
ARIMA(p,d,q)(P,D,Q)S” si y solo sí:
( )ppβϕβϕβϕ −−−− ...1 2
21 ( ) ( ) ( ) tDSdPS
SSS Zβββφβφβφ −−−−−− 11...1 2
21 =
( ) ( ) tQS
SSSp
q eβϑβϑβϑβθβθβθ −−−−−−−− ...1...1 221
221
donde et es un ruido blanco ( )2,0 σ
Como en el caso regular, no se debe descartar la posibilidad de que la serie diferenciada
tenga una media constante μ significativamente diferente de cero. Se incorpora esta
posibilidad al modelo sustituyendo el término ( ) ( ) tDSd Zββ −− 11 por
( ) ( ) μββ −−− tDSd Z11 donde μ es una constante que representa la media de la serie
diferenciada, o equivalentemente, incluyendo en el miembro derecho una constante aditiva
δ determinada por: ( )( )μφφφϕϕϕδ Pp −−−−−−−−−= ...1...1 2121 donde μ sigue siendo
la media de la serie diferenciada. Este detalle de interpretación de μ será generalizado
posteriormente para otros regresores.
El análisis de una serie de tipo estacional ARIMA es una extensión del principio de
identificación sucesiva. Salvo un detalle, que inmediatamente se aclará, se trata primero de
identificar y ajustar los parámetros como si fuera una serie estacional pura (P,D,Q)S y
luego, Estuardo los residuales, identificamos y estimamos los parámetros de la posible
componente regular (p,d,q). El modelo definitivo será ARIMA(p,d,q)(P,D,Q)S.
Por supuesto, que la definición de una serie de tiempo estacional
ARIMA(p,d,q)(P,D,Q)S puede formularse de una manera dual. La serie tZ es de este tipo
si y sólo si:
( )( ) ( ) tq
qtdp
p XZ βθβθβθββϕβϕβϕ −−−−=−−−−− ...11...1 221
221
donde los residuales tX constituyen una serie estacional pura:
( )( ) ( ) tQS
SSS
tDSPS
PSS eX βϑβϑβϑββφβφβφ −−−−=−−−−− ...11...1 2
212
21
y por tanto, el orden inverso en el análisis parece también posible.

Ca
45
Capitulo II Metodología de Box-Jenkins para Series Regulares ARIMA. Tratamiento de Regresores
Existen tres razones para seleccionar la primera alternativa ligeramente modificada:
1. La dependencia estacional es determinante, más gruesa, y requiere usualmente de
menores valores de P, D, Q. Para su identificación y estimación más fina posible, es
mejor trabajar con la serie original, en lugar de una serie de residuales y por tanto es
mejor separar primero la componente estacional y luego la regular.
2. La identificación de un modelo ARIMA, parte siempre del carácter estacionariode la
serie, lograda con transformaciones o diferenciaciones. En el orden teórico, si se tratara
de un modelo estacional puro, la diferenciación estacional puede lograr muchas veces
la el carácter estacionario “estacional de la serie”; pero evidentemente ésta no implica
la el carácter estacionario “regular” de la misma. Aunque teóricamente, el carácter
estacionario regular es un concepto más fuerte que el estacionario estacionalidad, en la
práctica tampoco es cierto que una vez alcanzada aparentemente el carácter
estacionario, por diferenciaciones regulares, se haya alcanzado el estacional, más
grueso o a más largo plazo. Por ello es preferible comenzar logrando una serie
estacionaria en los dos sentidos y para ello es necesario hacer posiblemente
transformaciones, diferenciaciones regulares y estacionales antes que todo.
3. La estacionalidad alcanzada por transformaciones y diferenciaciones - tanto regulares
como estacionarias -, permite estimar más claramente la constante μ como media de
la serie estacionaria.
Así, el orden de identificación usualmente es realmente:
d -diferenciación regular
S -estacionalidad de la serie
D -diferenciación estacional.
todo precedido posiblemente de transformaciones para alcanzar homocedasticidad y con el
objetivo final de alcanzar el carácter estacionario (en este momento se podría estimar ya la
constante μ ). Una vez logrado esto, se identifican sucesivamente:
(P,Q) –órdenes autorregresivos y de medias móviles estacionales a partir de la serie
transformada y diferenciada. La identificación de P y Q permite estimar los
parámetros Pii ,,2,1, L=φ y Qjj ,,2,1, L=θ y calcular los residuales tE
de un modelo estacional supuestamente puro que puede responder a su vez a un
modelo ARIMA regular.
(p,q) – órdenes autorregresivos y de medias móviles regulares a partir de los residuales
del preprocesamiento anterior. La identificación de p y q puede considerarse un

Ca
46
Capitulo II Metodología de Box-Jenkins para Series Regulares ARIMA. Tratamiento de Regresores
afinamiento del modelo y permite estimar los parámetros pii ,,2,1, L=φ y
qjj ,,2,1, L=θ y calcular los residuales te que se aspira a que sean un ruido
blanco.
De esta manera, se trata de un proceso de refinación sucesiva del modelo y se mantiene
válido el orden del flujo en el diagrama o metodología de Box-Jenkins.
2.5 Análisis de intervención y tratamiento de outliers A continuación se expone el análisis ARIMA para el estudio de series de tiempo en la
que aparecen outliers, valores perdidos o influencias de cierta intervención y las
posibilidades que brinda el SPSS para tales análisis.
2.5.1 Análisis de intervención con modelos ARIMA El comportamiento histórico de un proceso se ve afectado frecuentemente por la
influencia de un factor externo en un instante de tiempo dado, a partir de una instante de
tiempo dado o en el intervalo comprendido entre dos ciertos instantes de tiempo. Si tales
procesos son modelables ARIMA, la serie correspondiente debe mostrar un “salto” o
“cambio brusco” producto de esta intervención y es deseable “cuantificar” este salto,
incluyéndolo en el modelo para que responda mejor a la realización, y en particular
determinar hasta que punto es significativo.
Basadas en la teoría de funciones generalizadas, en matemáticas se utilizan
frecuentemente las dos funciones siguientes para representar un salto discreto:
La función “paso” o “salto unitario” definida por:
⎭⎬⎫
⎩⎨⎧
≥<
=0100
)(tt
tu
La función “delta” o “pulso unitario” definida por:
⎭⎬⎫
⎩⎨⎧
=≠
=0100
)(tt
tδ
1
1

Ca
47
Capitulo II Metodología de Box-Jenkins para Series Regulares ARIMA. Tratamiento de Regresores
a
Combinaciones lineales de estas funciones adecuadamente trasladadas a instantes de
tiempo prefijados y con ciertos coeficientes permiten describir influencias discretas de
magnitudes determinadas por los coeficientes, por ejemplo:
• Una influencia de magnitud “a” y de carácter permanente a partir del instante ot
puede ser representada por )(* ottua −
⎭⎬⎫
⎩⎨⎧
≥<
=−o
oo tta
ttttua
0)(*
Añadida a la serie ARIMA correspondiente, una influencia de este tipo puede
representar por ejemplo, el efecto de una campaña de vacunación sobre la tasa de una
enfermedad (en este caso “a” es negativo), o un cambio, por ejemplo en los instrumentos
de medición de un proceso.
• Una influencia de magnitud “a” sostenida en el intervalo de tiempo comprendido
entre ot y 1t puede ser representada por:
⎪⎭
⎪⎬
⎫
⎪⎩
⎪⎨
⎧
≥<≤
<
=−−−
1
11
0
0)(*)(*
ttsitttsia
ttsittuattua o
o
o
o más generalmente,
• Un sistema de influencias de magnitudes “a” y “b” a partir de sendos instantes de
ot y 1t puede ser representada por:
⎪⎭
⎪⎬
⎫
⎪⎩
⎪⎨
⎧
≥+<≤
<=−−−
1
11
0)(*)(*
ttsibatttsia
ttsittubttua o
o
o
a
to t1
a + b
a
to t1
to

Ca
48
Capitulo II Metodología de Box-Jenkins para Series Regulares ARIMA. Tratamiento de Regresores
El caso anterior es un caso particular cuando b = - a; pero además, cuando se modelan
influencias como la anterior sobre un modelo ARIMA en una forma aditiva, es mejor
precisarlo de esta forma más general (con “b” no necesariamente igual a “- a”) porque
la dependencia de los valores de la serie de sus valores en instantes anteriores
determinan que una influencia de este tipo tenga cierta “secuela” después del instante t1.
Así podría describirse por ejemplo, el efecto de ciertas medidas profilácticas especiales
sobre la serie correspondiente a una enfermedad epidémica, que se aplicaran durante
cierto intervalo de tiempo 1tto L y después se abandonará.
• Una influencia “instantánea” de magnitud “a” en un instante de tiempo dado ot
puede ser representado por )(* otta −δ
⎭⎬⎫
⎩⎨⎧
=≠
=−o
oo ttsia
ttsitta
0)(*δ
En el epígrafe siguiente se muestra como estos regresores se pueden introducir en el
análisis ARIMA, como variables independientes adicionales, en una forma no tan
clásica, como la de los modelos ARMA, por la presencia de diferenciaciones. Este
contenido es novedoso y sobre todo tiene un valor práctico importante para futuros
trabajos con requerimientos similares, por lo cual se intenta dar un enfoque orientado
hacia la generalización
2.5.2 Introducción de regresores en modelos con diferenciación. Cuando se trata con un modelo ARMA(p,0,q)(P,0,Q)S la introducción de los
regresores en el SPSS puede lograrse fácilmente como variables independientes
adicionales (lo que se corresponde con el subcomando WITH) para lograr los resultados
propuestos por Box y Tiao (Incluir referencia). Pero si hay alguna diferenciación regular
y/o estacional, ellos también serán diferenciados y por tanto, el regresor que actúa sobre
la variable dependiente no es el introducido como variable independiente sino que es su
diferencial discreta y por tanto sus efectos pueden ser muy diferentes de los esperados.
to

Ca
49
Capitulo II Metodología de Box-Jenkins para Series Regulares ARIMA. Tratamiento de Regresores
Un caso particular de esto es la constante μ que representa la media de la serie
previamente diferenciada para ser introducido como un regresor aditivo constante
Los autores del SPSS proponen que en estos los casos en que haya diferenciación se
calcule previamente las series diferenciadas de la variable dependiente y sea a estas
series diferenciadas las que se le añadan los regresores (el caso más simple es su media
constante), para evitar su diferenciación en la etapa de estimación y pronóstico.
Teóricamente esto es claro; pero desde el punto de vista práctico ello puede generar un
problema a posteriori con el pronóstico de la serie original por acumulación de errores.
Si por ejemplo, la serie original Xt necesita ser diferenciada regular y estacionalmente,
tendríamos
YYZXXY tttSttt 1 y −−
−=−=
Cuando se busca el modelo para Zt se tendrá
eZZ ttt += ~
y el error et se arrastra y acumula en el proceso de “integración discreta” hacia las
series originales:
YYYZY ttt 111
~~~~ con =+=−
y SiXXXYX iiSttt,...,2,1 para con ~~~~ ==+=
−
El problema se agrava si en el modelo de Zt intervienen efectivamente
diferenciaciones estacionales y términos de medias móviles porque ellos dependen de
observaciones y errores a más largo plazo de retardo
Para visualizar mejor el problema que trae como consecuencia trabajar con esta
teoría, se muestra el pronóstico del pluviómetro 401 con la serie original después de la
integración. A pesar de que los pronósticos obtenidos automáticamente por el SPSS
sobre las series previamente diferenciadas, eran satisfactorios, al regresar a la serie
original, vía “integración diferenciada”, la acumulación de errores es increíble. Se
demuestra así que en un tal pronóstico, en la práctica se acumulan tantos errores que el
mismo se vuelca completamente hacia algo que no tiene sentido.
Ca
50
Capitulo II Metodología de Box-Jenkins para Series Regulares ARIMA. Tratamiento de Regresores
Este problema fue constatado concretamente en las series que se abordan en el
presente trabajo y también en el Trabajo de Diploma (Morales M., Jorge L, 2007)1,
desarrollado paralelamente a este.
La alternativa de solución es introducir como variables independientes las primitivas
de los regresores que finalmente se desean, para que ellos sean diferenciados y el
pronóstico se haga directamente de la serie original, esto es, los regresores aditivos, sean
las diferenciales de las variables independientes, como ocurre en particular con el
regresor constante, que es la diferencial de la media de las series Así por ejemplo, si
tenemos una serie que va a ser una vez diferenciada regularmente, y deseamos tener en
un instante determinado to una función pulso: δ(t-to) entonces debemos introducir como
variable independiente una función paso unitario u(t-to) porque su derivada discreta es la
función pulso deseada. Otras situaciones pueden ser más complejas, pero también
solubles, como se ilustra en los ejemplos siguientes en los cuales se considera, para
facilitar la exposición que tenemos supuesta periodicidad anual y datos mensuales, por
tanto con estacionalidad S=12. Las construcciones son evidentemente generalizables a
cualquier estacionalidad. 1 Morales, M. Jorge L., Casas C. Gladys, Mora V. Humberto, Series cronológicas de consumo eléctrico y de petróleo en Villa Clara. Modelos y pronósticos, Trabajo de Diploma en Licenciatura en Matemática, Curso 2006-2007

Ca
51
Capitulo II Metodología de Box-Jenkins para Series Regulares ARIMA. Tratamiento de Regresores
2.5.3 Primitiva regular y estacional de una función pulso
Se desea en este trabajo construir una función f(t) tal que después de ser diferenciada
regularmente una vez y diferenciada estacionalmente una vez, conduzca a la función
δ(t). Los resultados podrán fácilmente ser trasladados después a cualquier punto to. Será
suficiente obtener f(t) de manera que la serie diferenciada estacionalmente sea la
función paso unitario u(t), esto es:
ℜ∈∀=−− ttutftf )()12()(
Observe que trabajamos con valores positivos y negativos de t para poder luego
desplazar el centro a un punto to>0. El valor de f en el centro (en este caso to=0) puede
definirse arbitrariamente pues de hecho la primitiva deseada está definida salvo una
constante. Fijemos por ejemplo f(0)=1/12, esto es el inverso de la estacionalidad. La
idea de definir f(t) para t>0 es lograr que al cabo de 12 pasos se obtenga una diferencia
de 1, Por tanto f(1)=2/12, f(2)=3/12, f(3)=4/12, f(4)=5/12,…, f(11)=1, f(12)=1+1/12,
f(13)=1+2/12, f(14)=1+3/2,…y en general f(t)=(t+1)/12 para todos los t mayores o
iguales a 0. Así garantizamos que para valores mayores o iguales a 12 se tenga f(t)-f(t-
12)=1=u(t). Esta misma fórmula tiene que cumplirse para los valores de t=0,1,2,…11.
Por tanto f(t)=(t+1)/12 para los t mayores o iguales que -12. En particular f(-1)=0, f(-
2)=-1/12, f(-3)=-2/12, f(-4)=-3/12,…, f(-12)=-11/12. A partir de aquí, moviéndonos a la
izquierda del eje, debemos tener f(-13)=f(-1)= 0, f(-14)=f(-2)=-1/12, f(-15)=f(-3)=-
2/12, f(-16)=f(-4)=-3/12,…, f(-24)=f(-12)=-11/12 porque para los t negativos u(t)=0.
Entonces se repiten las evaluaciones en ciclos de 12 valores:
f(-25)=f(-13)=0, f(-26)=f(-14)=-1/12, f(-27)=f(-15)=-2/12,…, f(-36)=f(-12)=-11/12,
f(-37)=f(-25)=0, f(-38)= f(-26)=-1/12, f(-39)=f(-27)=-2/12, …,f(-48)=f(-36)=-11/12,
etc. Está claro que estos 12 valores se determinan fácilmente por el número de los meses
que preceden al centro. La función así obtenida se gráfíca en el Anexo (2 ;2).
2.5.4 Primitiva estacional de una función pulso unitario. Supongamos ahora que se desea construir una función g(t) tal que después de ser
diferenciada estacionalmente una vez, conduzca a la función δ(t), esto es:
ℜ∈∀=−− tttgtg )()12()( δ

Ca
52
Capitulo II Metodología de Box-Jenkins para Series Regulares ARIMA. Tratamiento de Regresores
Fijamos arbitrariamente el valor en el centro, por ejemplo g(0)=1. Entonces la relación
anterior entre g y δ permite calcular fácilmente los valores de g(t). En efecto está claro
que debemos tener g(-12) = 0 para que g(0) - g(-12) = 1.
Si ahora ponemos g(-1) = g(-2) = g(-3) =…= g(-11) = 0, ello va a determinar que g(t) =
0 para todos los t<0 pues las diferencias estacionales a la izquierda del centro deben ser
nulas, pero además va a determinar que g(1)=g(2)=g(3)=…=g(11)=0 y por tanto
g(13)=g(14)=g(15)=…=g(23)=0, y en general, g(t)=0 para todos los t>0, excepto para
t∈{12,24,36,…}. Como debemos tener g(12)-g(0)=g(24)-g(12)=g(36)-g(24)=…=0,
entonces resulta que los valores de g sobre todos los múltiplos de 12 deben coincidir
con g(0)=1.
Cuando esta función se traslada a otro centro t0 que se identifica por un mes y un
año específico, resulta que va a resultar en todos los puntos del eje igual a cero, excepto
en t0, t0+12, t0+24, …en que vale 1, esto es, a partir del mes y el año que identifican a t0
(este incluido) la función vale 1 en el mismo mes de todos los años subsecuentes. Ello
es fácilmente calculable en el SPSS utilizando el valor del mes y el año. El gráfico de
una tal función aparece a continuación.
Ca
53
Capitulo II Metodología de Box-Jenkins para Series Regulares ARIMA. Tratamiento de Regresores
2.5.5 Primitivas de otros regresores posiblemente necesarios. En el estudio de la influencia del Período Especial sobre las series de consumo
en el trabajo de diploma de Jorge L. Morales, referenciado anteriormente, se trabaja con
series trimestrales surgió una variante análoga al primero de nuestros ejemplos pero con
una estacionalidad de 4. Surgió además la necesidad de calcular la primitiva de otros
dos regresores, en particular una función que diferenciada regular y estacionalmente
condujera a la función paso unitario y otra función, que diferenciada regularmente
condujera a un regresor que es 1 en un intervalo de tiempo cerrado y acotado y es igual
a 0 fuera de dicho intervalo. Todo este conjunto de ejemplos proporciona una idea
general de cómo proceder en este tipo de análisis de series ARIMA cuando se quieren
introducir regresores en modelos que suponen diferenciaciones.
En general, para la construcción de tales primitivas se resumen estas
recomendaciones:
1. Determinar previamente, sin regresores, la posible necesidad de
diferenciaciones en la serie - regulares o estacionales - y sus órdenes respectivos.
- Si no hay necesidad de diferenciaciones regulares ni estacionales, los
regresores pueden incluirse directamente como variables independientes, sin
buscar las primitivas.
- En caso contrario, esto es, cuando hay diferenciaciones necesarias,
atender a lo siguiente

Ca
54
Capitulo II Metodología de Box-Jenkins para Series Regulares ARIMA. Tratamiento de Regresores
2 Apoyarse en primitivas conocidas, para poner en foco el nuevo problema
- Por ejemplo, se sabe que u(t) es una primitiva regular de δ(t) y en eso
nos apoyamos en el primer ejemplo para construir una función que diferenciada
regular y estacionalmente condujera a δ(t).
- Los ejemplos que se proporcionan en el trabajo de diploma (Morales
M.,J.L) y en el presente trabajo, además de ilustrar la metodología de trabajo,
sirven como nuevas primitivas ya conocidas, de apoyo a la búsqueda de otras
primitivas.
3 Buscar en primera instancia la primitiva centrada en 0 y considerar sus valores
tanto positivos como negativos para poder ser trasladada.
- El valor de la primitiva en 0 puede ser fijado arbitrariamente pues la
primitiva se define salvo una constante
- Defina los valores de la primitiva en los puntos “claves” a la izquierda
y derecha del centro (0) a partir de las relaciones de diferenciación.
- Extienda los valores de la primitiva más allá de estos puntos claves, a la
derecha e izquierda de cero. Tratar de obtener por inducción fórmulas generales.
En última instancia, para la obtención de fórmulas generales se pueden resolver
ecuaciones en diferencias finitas.
4 Elaborar una estrategia de sintaxis del cálculo de la nueva primitiva con los
comandos correspondientes del SPSS y auxiliándose de los campos de fecha en
los cálculos cíclicos.
- Elabórela primero para el centro simple (0)
- Generalícelo a cualquier otro centro (t0>0), utilizando esencialmente
traslación
5 Pruebe la sintaxis de cálculo de la primitiva, calcule las diferenciales de interés
y grafique todas ellas para comprobar los resultados deseados.
- Hágalo primero para el centro simple (0) con datos hipotéticos
- Haga las pruebas finales con otros centros reales de su fichero de datos,
para comprobar también el algoritmo de traslación.

Ca
55
Capítulo III Análisis de los pluviómetros por modelación ARIMA.
Capitulo III
Análisis de los pluviómetros por modelación ARIMA.
3.1 Introducción En este capítulo se hallan modelos matemáticos del tipo ARIMA para los pluviómetros de
la Cuenca Hidrológica Sagua la Chica y se muestran los pronósticos en base a los mismos.
La tabla de datos fue suministrada por la Empresa de Recursos Hidráulicos de la Provincia
A continuación se visualiza la cuenca hidrológica la cual contiene la Presa Minerva y la
Quinta, y la ubicación de los respectivos pluviómetros. Los pluviómetros para el análisis
son denominados 401, 980, 940,396, 389, 357.
3.2 Modelación del pluviómetro 401. Este pluviómetro se localiza en el río Sagua la Chica, límite de los municipios Camajuaní,
Remedios y Placetas,y más específicamente en el Consejo Popular Floridanos con 285.5
de latitud norte y 638.1 de longitud este. La Empresa Provincial de Recursos Hidráulicos
tiene una base de datos mensuales desde el año 1963 hasta la actualidad. En realidad esta
empresa recibe el informe de datos diariamente, pero una vez finalizado el mes se calcula
el promedio y con este se actualiza la base, para así trabajar con 12 datos al año. Como
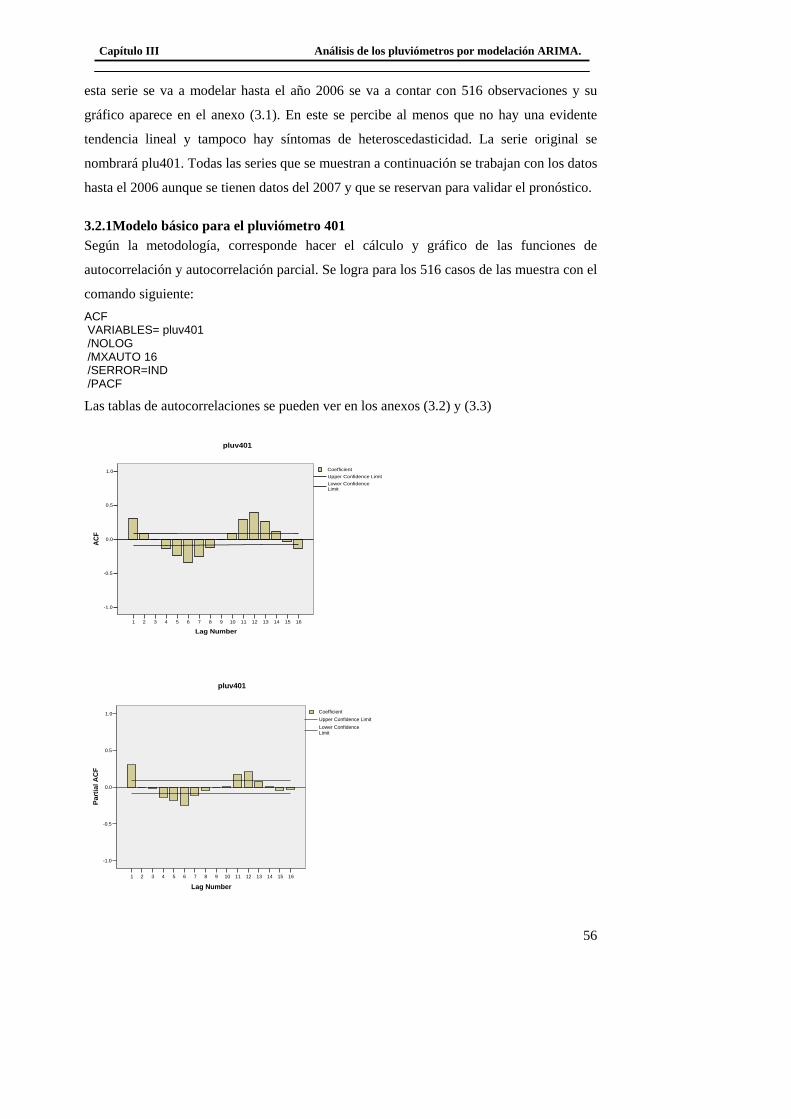
Ca
56
Capítulo III Análisis de los pluviómetros por modelación ARIMA.
esta serie se va a modelar hasta el año 2006 se va a contar con 516 observaciones y su
gráfico aparece en el anexo (3.1). En este se percibe al menos que no hay una evidente
tendencia lineal y tampoco hay síntomas de heteroscedasticidad. La serie original se
nombrará plu401. Todas las series que se muestran a continuación se trabajan con los datos
hasta el 2006 aunque se tienen datos del 2007 y que se reservan para validar el pronóstico.
3.2.1Modelo básico para el pluviómetro 401 Según la metodología, corresponde hacer el cálculo y gráfico de las funciones de
autocorrelación y autocorrelación parcial. Se logra para los 516 casos de las muestra con el
comando siguiente: ACF VARIABLES= pluv401 /NOLOG /MXAUTO 16 /SERROR=IND /PACF
Las tablas de autocorrelaciones se pueden ver en los anexos (3.2) y (3.3)
16151413121110987654321
Lag Number
1.0
0.5
0.0
-0.5
-1.0
ACF
Lower ConfidenceLimit
Upper Confidence LimitCoefficient
pluv401
16151413121110987654321
Lag Number
1.0
0.5
0.0
-0.5
-1.0
Part
ial A
CF
Lower ConfidenceLimit
Upper Confidence LimitCoefficient
pluv401
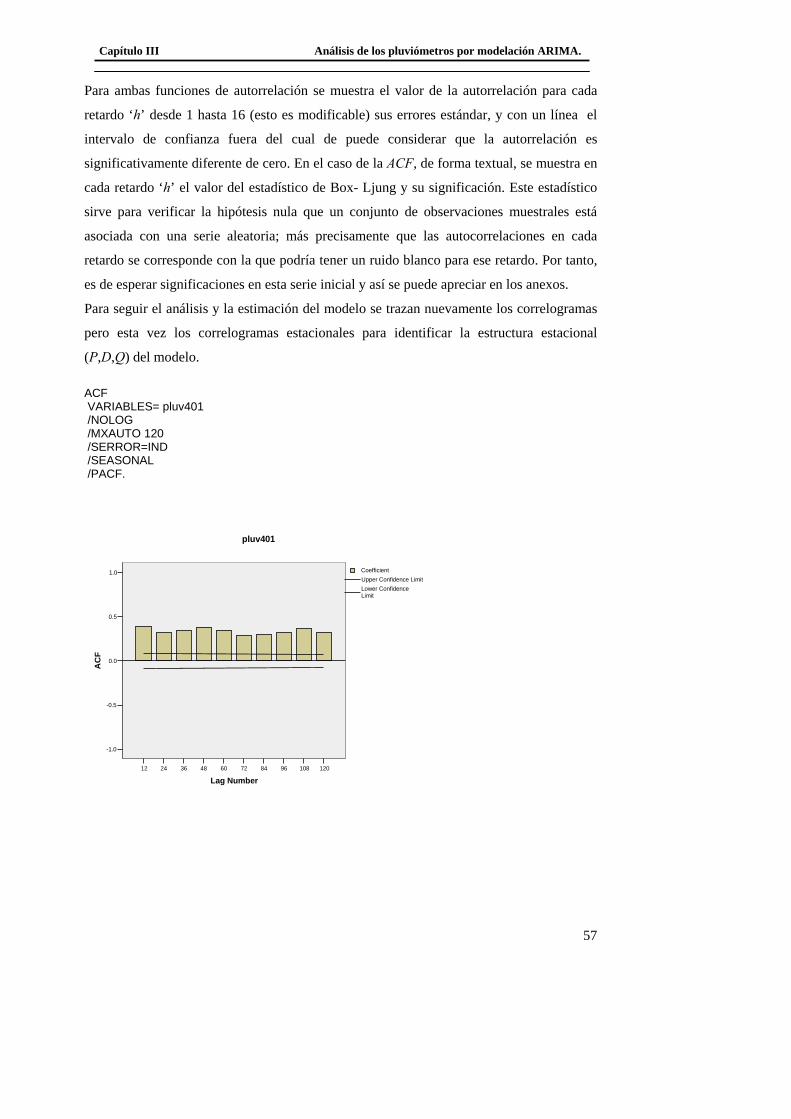
Ca
57
Capítulo III Análisis de los pluviómetros por modelación ARIMA.
Para ambas funciones de autorrelación se muestra el valor de la autorrelación para cada
retardo ‘h’ desde 1 hasta 16 (esto es modificable) sus errores estándar, y con un línea el
intervalo de confianza fuera del cual de puede considerar que la autorrelación es
significativamente diferente de cero. En el caso de la ACF, de forma textual, se muestra en
cada retardo ‘h’ el valor del estadístico de Box- Ljung y su significación. Este estadístico
sirve para verificar la hipótesis nula que un conjunto de observaciones muestrales está
asociada con una serie aleatoria; más precisamente que las autocorrelaciones en cada
retardo se corresponde con la que podría tener un ruido blanco para ese retardo. Por tanto,
es de esperar significaciones en esta serie inicial y así se puede apreciar en los anexos.
Para seguir el análisis y la estimación del modelo se trazan nuevamente los correlogramas
pero esta vez los correlogramas estacionales para identificar la estructura estacional
(P,D,Q) del modelo. ACF VARIABLES= pluv401 /NOLOG /MXAUTO 120 /SERROR=IND /SEASONAL /PACF.
1201089684726048362412
Lag Number
1.0
0.5
0.0
-0.5
-1.0
AC
F
Lower ConfidenceLimit
Upper Confidence LimitCoefficient
pluv401

Ca
58
Capítulo III Análisis de los pluviómetros por modelación ARIMA.
1201089684726048362412
Lag Number
1.0
0.5
0.0
-0.5
-1.0
Part
ial A
CF
Lower ConfidenceLimit
Upper Confidence LimitCoefficient
pluv401
Ver la Tabla con los resultados en texto en los anexos (3.4) y (3.5)
Se puede observar a través de la SACF(h) que desde el punto de vista estacional, la serie
no es estacionaria. Se debe hacer una diferenciación estacional, después de lo cual las
funciones SACF(h) y SPACF(h) sugieren dos posibles modelos a seguir en principio:
(0 0 0) (0 1 1)12 ó (0 0 0) (4 1 0)12.
He aquí los correlogramas correspondientes
1201089684726048362412
Lag Number
1.0
0.5
0.0
-0.5
-1.0
AC
F
Lower ConfidenceLimit
Upper Confidence LimitCoefficient
pluv401
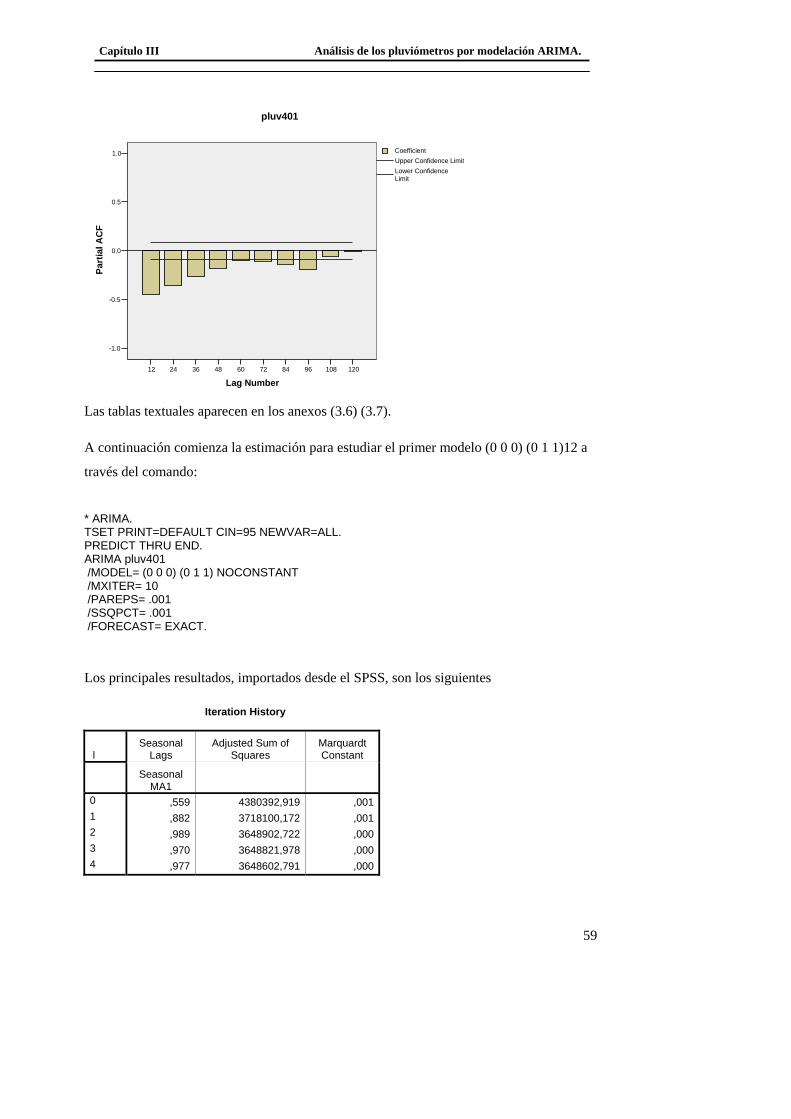
Ca
59
Capítulo III Análisis de los pluviómetros por modelación ARIMA.
1201089684726048362412
Lag Number
1.0
0.5
0.0
-0.5
-1.0
Part
ial A
CF
Lower ConfidenceLimit
Upper Confidence LimitCoefficient
pluv401
Las tablas textuales aparecen en los anexos (3.6) (3.7). A continuación comienza la estimación para estudiar el primer modelo (0 0 0) (0 1 1)12 a
través del comando:
* ARIMA. TSET PRINT=DEFAULT CIN=95 NEWVAR=ALL. PREDICT THRU END. ARIMA pluv401 /MODEL= (0 0 0) (0 1 1) NOCONSTANT /MXITER= 10 /PAREPS= .001 /SSQPCT= .001 /FORECAST= EXACT.
Los principales resultados, importados desde el SPSS, son los siguientes Iteration History
l Seasonal
Lags Adjusted Sum of
Squares Marquardt Constant
Seasonal
MA1 0 ,559 4380392,919 ,0011 ,882 3718100,172 ,0012 ,989 3648902,722 ,0003 ,970 3648821,978 ,0004 ,977 3648602,791 ,000

Ca
60
Capítulo III Análisis de los pluviómetros por modelación ARIMA.
Residual Diagnostics Number of Residuals 516 Number of Parameters 1 Residual df 515 Adjusted Residual Sum of Squares
3648602,725
Residual Sum of Squares 4380392,919
Residual Variance 6613,248 Model Std. Error 81,322 Log-Likelihood -3019,610 Akaike's Information Criterion (AIC) 6041,220
Schwarz's Bayesian Criterion (BIC) 6045,466
Parámetros a estimar Estimates Std Error t Approx Sig Seasonal Lags Seasonal MA1 ,977 ,045 21,836 ,000
Melard's algorithm was used for estimation. En esta salidas se evidencia que la historia de las iteraciones transcurre normalmente según
la constante de Marquart. Se reporta el diagnóstico inicial de los residuales, que será
utilizado posteriormente, y especialmente, se puede observar como el coeficiente de media
móvil estacional SMA1 (0.977) es altamente significativo (significación 0.000 menor que
0.01). Lograda así la estimación del parámetro de la muestra, hay que validar hasta que
punto el modelo ajusta bastante bien la realización. La parte más importante del
diagnóstico es el chequeo de los residuales para ver si constituyen un ruido blanco. Ello
significa que se debe probar estadísticamente que los residuales son no correlacionados,
tienen media cero y varianza constante. En la práctica ello se logra con la graficación de
los residuales (que para no extender el texto no se muestra aquí) y sobretodo con el
estudio de la ACF(h) y PACF(h) de dichos residuales (grabados en principio con nombre
ERR_1): ACF VARIABLES= ERR_1 /NOLOG /MXAUTO 120 /SERROR=IND /SEASONAL /PACF. Para ilustrar los resultados estadísticos, en lugar del gráfico de las autocorrelaciones, se
muestran en este caso los datos textuales, con la significación del test de Box-Ljung.
Pueden verse Gráficas y Tablas en los anexos (3.8) – (3.10)

Ca
61
Capítulo III Análisis de los pluviómetros por modelación ARIMA.
Autocorrelaciones Series: Error for pluv401 from ARIMA, MOD_4 NOCON
Lag Autocorrelation Std.Error(a) Box-Ljung Statistic
Value df Sig.(b) 12 ,013 ,043 3,141 12 ,99424 -,078 ,043 12,152 24 ,97836 -,023 ,042 26,756 36 ,86848 ,042 ,042 35,558 48 ,90860 ,008 ,041 41,621 60 ,96672 -,076 ,041 51,802 72 ,96584 -,051 ,040 63,942 84 ,94996 ,011 ,040 74,466 96 ,949108 ,099 ,039 86,478 108 ,937120 ,064 ,038 97,063 120 ,939
a The underlying process assumed is independence (white noise). b Based on the asymptotic chi-square approximation.
Puede observarse que el error en la predicción no tiene autocorrelaciones estacionales pues
todas las significaciones son mayores que 0.05, constituyendo realmente un ruido blanco
estacional. Esto quiere decir que ya se aislado adecuadamente la componente estacional de
la serie y se debe pasar a analizar si se requieren componentes regulares en el modelo, esto
es determinar p y q. Si se solicita el estudio de autocorrelaciones regulares de ERR_1, se
refleja que no hay autocorrelaciones significativas, y por tanto no son necesarias
componentes regulares. Autocorrelaciones Series: Error for pluv401 from ARIMA, MOD_4 NOCON
Lag Autocorrelation Std.Error(a) Box-Ljung Statistic
Value df Sig.(b) 1 ,033 ,044 ,575 1 ,4482 -,039 ,044 1,350 2 ,5093 ,033 ,044 1,910 3 ,5914 -,018 ,044 2,078 4 ,7215 ,016 ,044 2,207 5 ,8206 -,019 ,044 2,390 6 ,8817 ,008 ,044 2,428 7 ,9328 ,006 ,044 2,448 8 ,9649 ,016 ,044 2,577 9 ,97910 -,024 ,044 2,894 10 ,98411 ,017 ,043 3,054 11 ,99012 ,013 ,043 3,141 12 ,99413 -,012 ,043 3,219 13 ,99714 ,020 ,043 3,428 14 ,99815 -,033 ,043 4,023 15 ,99816 -,032 ,043 4,581 16 ,997
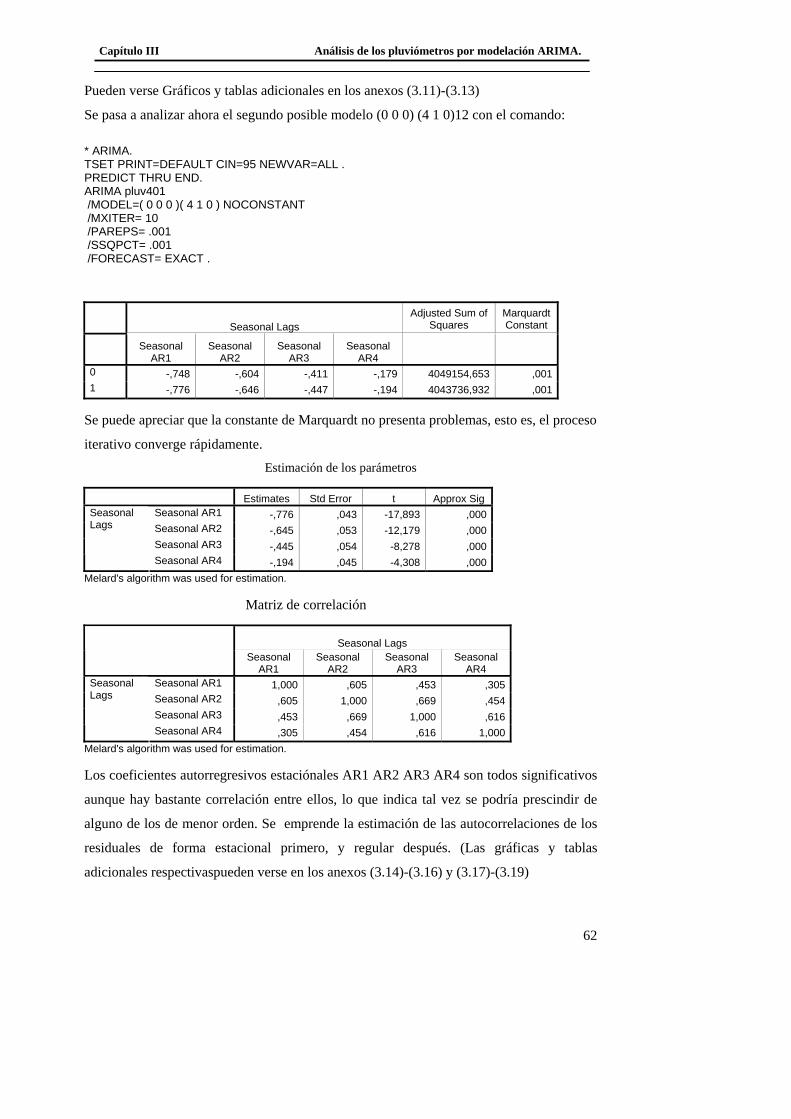
Ca
62
Capítulo III Análisis de los pluviómetros por modelación ARIMA.
Pueden verse Gráficos y tablas adicionales en los anexos (3.11)-(3.13)
Se pasa a analizar ahora el segundo posible modelo (0 0 0) (4 1 0)12 con el comando: * ARIMA. TSET PRINT=DEFAULT CIN=95 NEWVAR=ALL . PREDICT THRU END. ARIMA pluv401 /MODEL=( 0 0 0 )( 4 1 0 ) NOCONSTANT /MXITER= 10 /PAREPS= .001 /SSQPCT= .001 /FORECAST= EXACT .
Seasonal Lags Adjusted Sum of
Squares Marquardt Constant
Seasonal
AR1 Seasonal
AR2 Seasonal
AR3 Seasonal
AR4 0 -,748 -,604 -,411 -,179 4049154,653 ,0011 -,776 -,646 -,447 -,194 4043736,932 ,001
Se puede apreciar que la constante de Marquardt no presenta problemas, esto es, el proceso
iterativo converge rápidamente. Estimación de los parámetros
Estimates Std Error t Approx Sig
Seasonal AR1 -,776 ,043 -17,893 ,000Seasonal AR2 -,645 ,053 -12,179 ,000Seasonal AR3 -,445 ,054 -8,278 ,000
Seasonal Lags
Seasonal AR4 -,194 ,045 -4,308 ,000Melard's algorithm was used for estimation. Matriz de correlación
Seasonal Lags
Seasonal
AR1 Seasonal
AR2 Seasonal
AR3 Seasonal
AR4 Seasonal AR1 1,000 ,605 ,453 ,305Seasonal AR2 ,605 1,000 ,669 ,454Seasonal AR3 ,453 ,669 1,000 ,616
Seasonal Lags
Seasonal AR4 ,305 ,454 ,616 1,000Melard's algorithm was used for estimation. Los coeficientes autorregresivos estaciónales AR1 AR2 AR3 AR4 son todos significativos
aunque hay bastante correlación entre ellos, lo que indica tal vez se podría prescindir de
alguno de los de menor orden. Se emprende la estimación de las autocorrelaciones de los
residuales de forma estacional primero, y regular después. (Las gráficas y tablas
adicionales respectivaspueden verse en los anexos (3.14)-(3.16) y (3.17)-(3.19)

Ca
63
Capítulo III Análisis de los pluviómetros por modelación ARIMA.
Autocorrelaciones Series: Error for pluv401 from ARIMA, MOD_7 NOCON
Lag Autocorrelation Std.Error(a) Box-Ljung Statistic
Value df Sig.(b) 12 -,029 ,043 4,892 12 ,96124 -,053 ,043 11,790 24 ,98236 -,079 ,042 24,526 36 ,92648 -,118 ,042 41,354 48 ,74060 -,154 ,041 62,336 60 ,39372 -,079 ,041 74,396 72 ,40084 -,035 ,040 84,505 84 ,46496 ,012 ,040 94,538 96 ,523108 ,103 ,039 105,997 108 ,537120 ,089 ,038 122,793 120 ,412
a The underlying process assumed is independence (white noise). b Based on the asymptotic chi-square approximation.
Autocorrelaciones Series: Error for pluv401 from ARIMA, MOD_7 NOCON
Lag Autocorrelation Std.Error(a) Box-Ljung Statistic
Value df Sig.(b) 1 ,052 ,044 1,389 1 ,2392 -,033 ,044 1,955 2 ,3763 ,020 ,044 2,173 3 ,5374 -,007 ,044 2,202 4 ,6995 ,030 ,044 2,682 5 ,7496 -,040 ,044 3,517 6 ,7427 ,022 ,044 3,779 7 ,8058 ,018 ,044 3,959 8 ,8619 ,007 ,044 3,984 9 ,91210 -,024 ,044 4,295 10 ,93311 ,017 ,043 4,456 11 ,95512 -,029 ,043 4,892 12 ,96113 ,011 ,043 4,953 13 ,97614 ,007 ,043 4,979 14 ,98615 -,039 ,043 5,776 15 ,98316 -,011 ,043 5,847 16 ,990
a The underlying process assumed is independence (white noise). b Based on the asymptotic chi-square approximation.
Así este modelo es satisfactorio desde el punto de vista estacional y tampoco necesita ser
completado con otras componentes regulares pues ninguna de las autocorrelaciones tiene
significación menor que 0.05, esto es, se trata de un ruido blanco. Si se observan los
correlogramas en los anexos mencionados pudiera parecer que hay algunas espigas
indeseables pero las tablas anteriores demuestran que no son significativas.
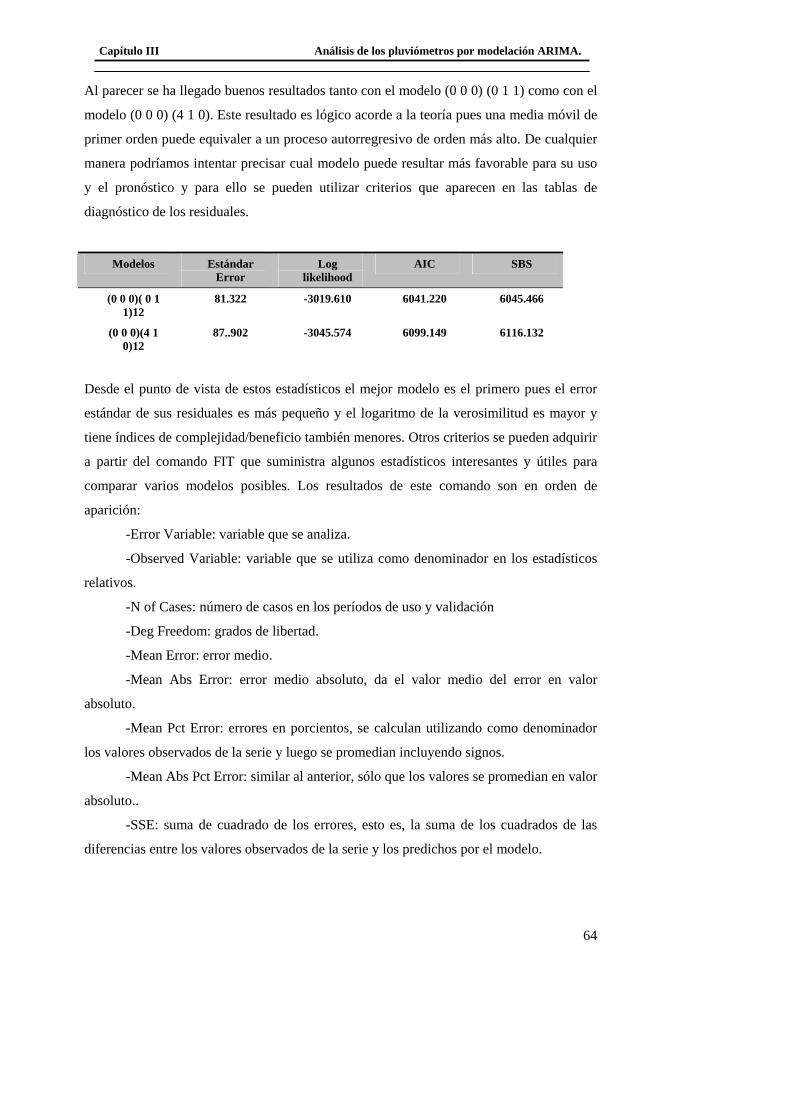
Ca
64
Capítulo III Análisis de los pluviómetros por modelación ARIMA.
Al parecer se ha llegado buenos resultados tanto con el modelo (0 0 0) (0 1 1) como con el
modelo (0 0 0) (4 1 0). Este resultado es lógico acorde a la teoría pues una media móvil de
primer orden puede equivaler a un proceso autorregresivo de orden más alto. De cualquier
manera podríamos intentar precisar cual modelo puede resultar más favorable para su uso
y el pronóstico y para ello se pueden utilizar criterios que aparecen en las tablas de
diagnóstico de los residuales.
Modelos Estándar Error
Log likelihood
AIC SBS
(0 0 0)( 0 1 1)12
81.322 -3019.610 6041.220 6045.466
(0 0 0)(4 1 0)12
87..902 -3045.574 6099.149 6116.132
Desde el punto de vista de estos estadísticos el mejor modelo es el primero pues el error
estándar de sus residuales es más pequeño y el logaritmo de la verosimilitud es mayor y
tiene índices de complejidad/beneficio también menores. Otros criterios se pueden adquirir
a partir del comando FIT que suministra algunos estadísticos interesantes y útiles para
comparar varios modelos posibles. Los resultados de este comando son en orden de
aparición:
-Error Variable: variable que se analiza.
-Observed Variable: variable que se utiliza como denominador en los estadísticos
relativos.
-N of Cases: número de casos en los períodos de uso y validación
-Deg Freedom: grados de libertad.
-Mean Error: error medio.
-Mean Abs Error: error medio absoluto, da el valor medio del error en valor
absoluto.
-Mean Pct Error: errores en porcientos, se calculan utilizando como denominador
los valores observados de la serie y luego se promedian incluyendo signos.
-Mean Abs Pct Error: similar al anterior, sólo que los valores se promedian en valor
absoluto..
-SSE: suma de cuadrado de los errores, esto es, la suma de los cuadrados de las
diferencias entre los valores observados de la serie y los predichos por el modelo.

Ca
65
Capítulo III Análisis de los pluviómetros por modelación ARIMA.
-MSE: es la media de la SSE, esto es la SSE dividida por los grados de libertad del
error. Si se utiliza FIT para comparar dos modelos, el criterio más fuerte de comparación
se formula sobre la base de minimizar este estadístico.
-RMS: es la raíz cuadrada de la MSE, permite tener un estadístico en el mismo
sistema de unidades que la serie observada y la serie de errores.
-El test de Durbin-Watson verifica la hipótesis nula de que los residuales de la
regresión son independientes, contra la hipótesis alternativa de que siguen un proceso
auotorregresivo de primer orden; su valor se encuentra entre 0 y 4. Un valor cercano a 2
indica poca autocorrelación y es lo deseado.
El análisis se realiza con el siguiente comando: FIT /ERROR=ERR_1 ERR_2 /OBS= FIT_1 FIT_2 /DFE=515 512. Y los resultados para el período de uso, son los siguientes FIT Error Statistics Error Variable ERR_1 ERR_2 Observed Variable FIT_1 FIT_2 N of Cases 516 516 Deg Freedom 515 512 Mean Error 6.2945 1.3911 Mean Abs Error 57.6433 62.2215 SSE 3594891.89 3994777.58 MSE 6980.3726 7802.3000 RMS 83.5486 88.3306 Durbin-Watson 1.9218 1.8949 Véase que el Error Cudrático Medio (MSE) es menor en el primer modelo, como también
lo son SSE y RMS. Además, examinando el estadístico de Durbin -Watson podemos decir
que el del primer modelo es ligeramente mejor porque se acerca más a 2 y en cuanto al
RMA, MSE, SSE los valores son más pequeños. Decididamente, es preferible el modelo
(0 0 0) (0 1 1)12 .
3.2.2 Análisis de los outliers en la serie del pluviómetro 401. Analizando la gráfica original de la serie se puede que hay meses que sobrepasan los
300.0 milímetros de lluvia y que podrían considerarse outliers. Estos outliers son
verdaderos (no son errores de la captación de datos) pues se corresponden efectivamente
con condiciones climáticas excepcionales. Se tratará entonces de introducir regresores, en
forma de funciones de impulso que permitan ajustar mejor el modelo en estos meses
excepcionales. Como la serie es diferenciada estacionalmente, se introduce para uno de

Ca
66
Capítulo III Análisis de los pluviómetros por modelación ARIMA.
estos meses, la correspondiente primitiva de la función pulso, como se explicó en el
Capítulo II y se estudia entonces la significación de dicha variable independiente.
Los resultados del comando en una primera estimación reflejan algunas dificultades con la
evolución de la constante de Marquardt y las únicas variables que son significativas son las
correspondientes a mayo del 1968, octubre del 1978 y octubre del 2005. Se repite entonces
el comando con solo las variables correspondientes a dichas fechas: * ARIMA. TSET PRINT=DEFAULT CIN=95 NEWVAR=ALL . PREDICT THRU END. ARIMA pluv401 WITH may68 oct78 oct05 /MODEL=( 0 0 0 )( 0 1 1 ) NOCONSTANT /MXITER= 10 /PAREPS= .001 /SSQPCT= .001 /FORECAST= EXACT .
Seasonal Lags Regression Coefficients
Seasonal
MA1 may68 oct78 oct05 Adjusted Sum
of Squares Marquardt Constant
0 .493 190.999 386.012 280.540 4212858.972 .0011 .732 134.374 209.065 249.503 3749186.500 .0012 .867 105.565 107.983 232.416 3555841.066 .0003 .929 89.154 64.392 218.627 3505729.173 .0004 .946 84.038 54.619 214.242 3501788.662 .0005 .950 82.648 52.245 213.098 3501518.794 .000
Melard's algorithm was used for estimation. a The estimation terminated at this iteration, because the sum of squares decreased by less than .001%. Parámetros a estimar Estimates Std Error t Approx Sig Seasonal Lags Seasonal MA1 .951 .025 38.447 .000
may68 82.286 39.727 2.071 .039oct78 51.646 28.924 1.786 .075
Regression Coefficients
oct05 212.804 58.686 3.626 .000Melard's algorithm was used for estimation. Puede observarse que se corrigió la convergencia del algoritmo de Marquard’Melards y
que el outlier de Oct 85 fue altamente significativo, el de Mayo 68 significativo y el de
octubre 78 al menos medianamente significativo. Se decidió dejar este último incorporado
al modelo porque es bien conocido por los especialistas que efectivamente en ese mes
hubo un altísimo y anormal nivel de precipitaciones en la provincia (promedio 888.4 mil).
Matriz de correlación
Seasonal Lags Regression Coefficients
Seasonal
MA1 may68 oct78 oct05
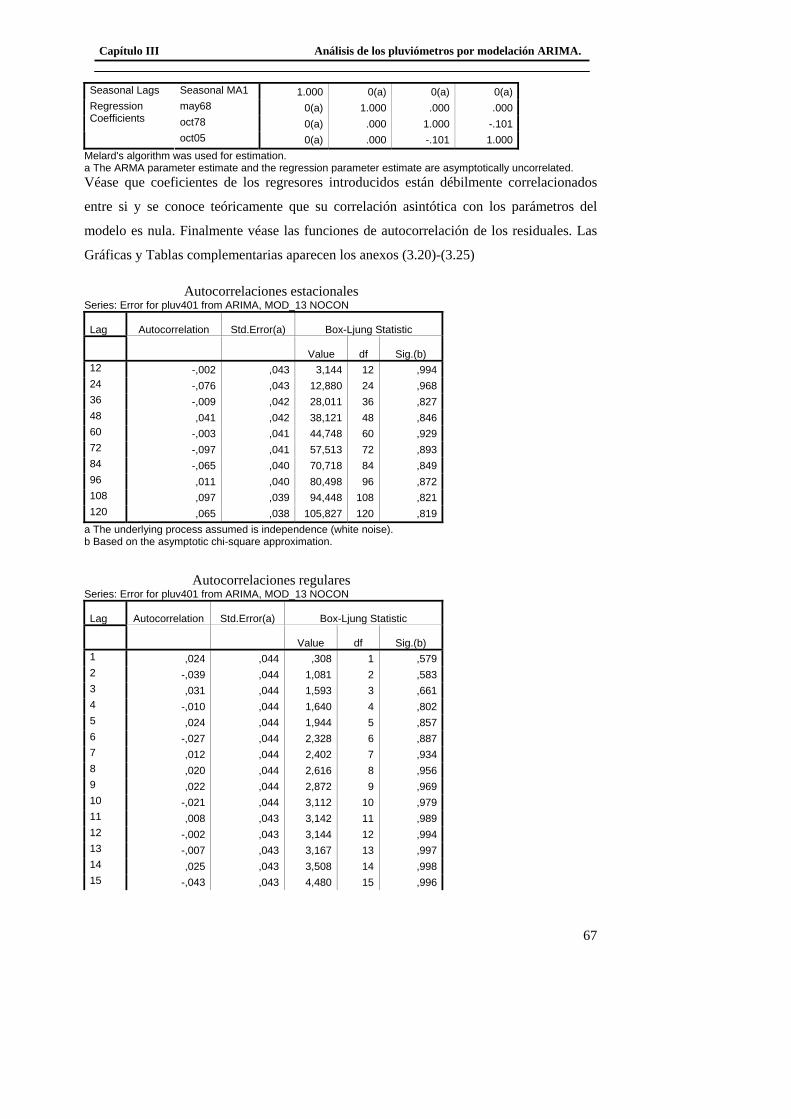
Ca
67
Capítulo III Análisis de los pluviómetros por modelación ARIMA.
Seasonal Lags Seasonal MA1 1.000 0(a) 0(a) 0(a)
may68 0(a) 1.000 .000 .000oct78 0(a) .000 1.000 -.101
Regression Coefficients
oct05 0(a) .000 -.101 1.000Melard's algorithm was used for estimation. a The ARMA parameter estimate and the regression parameter estimate are asymptotically uncorrelated. Véase que coeficientes de los regresores introducidos están débilmente correlacionados
entre si y se conoce teóricamente que su correlación asintótica con los parámetros del
modelo es nula. Finalmente véase las funciones de autocorrelación de los residuales. Las
Gráficas y Tablas complementarias aparecen los anexos (3.20)-(3.25) Autocorrelaciones estacionales Series: Error for pluv401 from ARIMA, MOD_13 NOCON
Lag Autocorrelation Std.Error(a) Box-Ljung Statistic
Value df Sig.(b) 12 -,002 ,043 3,144 12 ,99424 -,076 ,043 12,880 24 ,96836 -,009 ,042 28,011 36 ,82748 ,041 ,042 38,121 48 ,84660 -,003 ,041 44,748 60 ,92972 -,097 ,041 57,513 72 ,89384 -,065 ,040 70,718 84 ,84996 ,011 ,040 80,498 96 ,872108 ,097 ,039 94,448 108 ,821120 ,065 ,038 105,827 120 ,819
a The underlying process assumed is independence (white noise). b Based on the asymptotic chi-square approximation. Autocorrelaciones regulares Series: Error for pluv401 from ARIMA, MOD_13 NOCON
Lag Autocorrelation Std.Error(a) Box-Ljung Statistic
Value df Sig.(b) 1 ,024 ,044 ,308 1 ,5792 -,039 ,044 1,081 2 ,5833 ,031 ,044 1,593 3 ,6614 -,010 ,044 1,640 4 ,8025 ,024 ,044 1,944 5 ,8576 -,027 ,044 2,328 6 ,8877 ,012 ,044 2,402 7 ,9348 ,020 ,044 2,616 8 ,9569 ,022 ,044 2,872 9 ,96910 -,021 ,044 3,112 10 ,97911 ,008 ,043 3,142 11 ,98912 -,002 ,043 3,144 12 ,99413 -,007 ,043 3,167 13 ,99714 ,025 ,043 3,508 14 ,99815 -,043 ,043 4,480 15 ,996
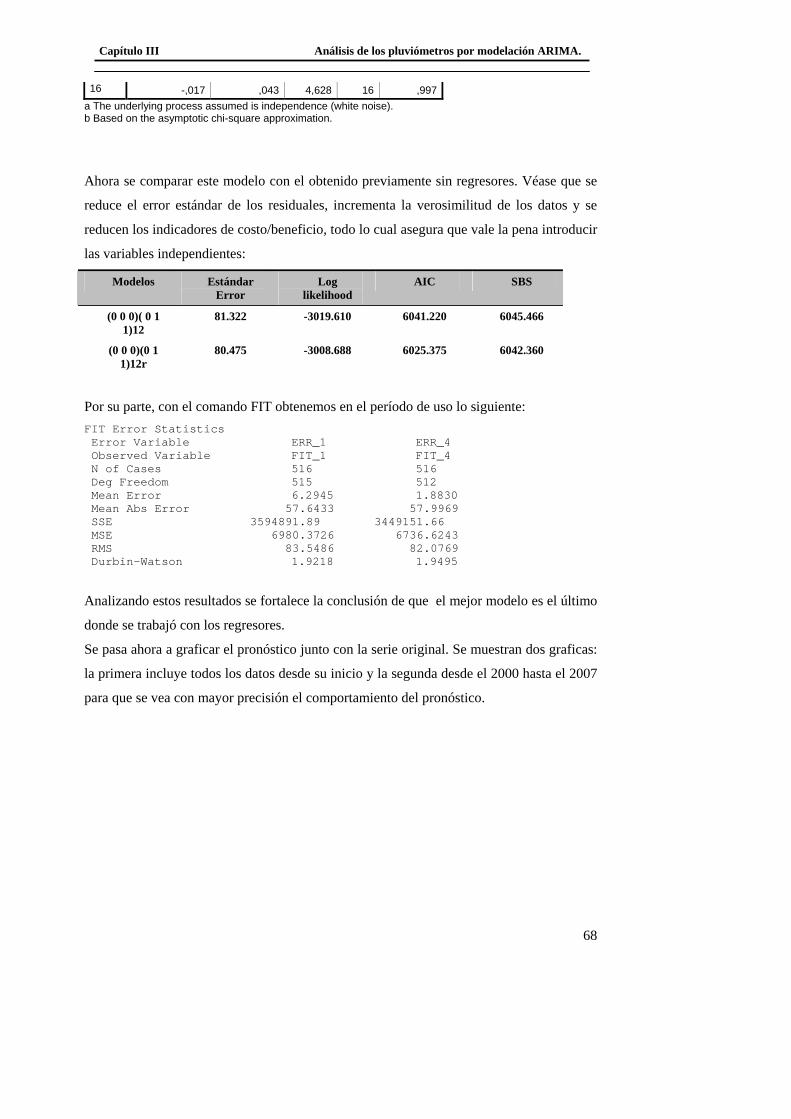
Ca
68
Capítulo III Análisis de los pluviómetros por modelación ARIMA.
16 -,017 ,043 4,628 16 ,997
a The underlying process assumed is independence (white noise). b Based on the asymptotic chi-square approximation.
Ahora se comparar este modelo con el obtenido previamente sin regresores. Véase que se
reduce el error estándar de los residuales, incrementa la verosimilitud de los datos y se
reducen los indicadores de costo/beneficio, todo lo cual asegura que vale la pena introducir
las variables independientes:
Modelos Estándar Error
Log likelihood
AIC SBS
(0 0 0)( 0 1 1)12
81.322 -3019.610 6041.220 6045.466
(0 0 0)(0 1 1)12r
80.475 -3008.688 6025.375 6042.360
Por su parte, con el comando FIT obtenemos en el período de uso lo siguiente: FIT Error Statistics Error Variable ERR_1 ERR_4 Observed Variable FIT_1 FIT_4 N of Cases 516 516 Deg Freedom 515 512 Mean Error 6.2945 1.8830 Mean Abs Error 57.6433 57.9969 SSE 3594891.89 3449151.66 MSE 6980.3726 6736.6243 RMS 83.5486 82.0769 Durbin-Watson 1.9218 1.9495
Analizando estos resultados se fortalece la conclusión de que el mejor modelo es el último
donde se trabajó con los regresores.
Se pasa ahora a graficar el pronóstico junto con la serie original. Se muestran dos graficas:
la primera incluye todos los datos desde su inicio y la segunda desde el 2000 hasta el 2007
para que se vea con mayor precisión el comportamiento del pronóstico.
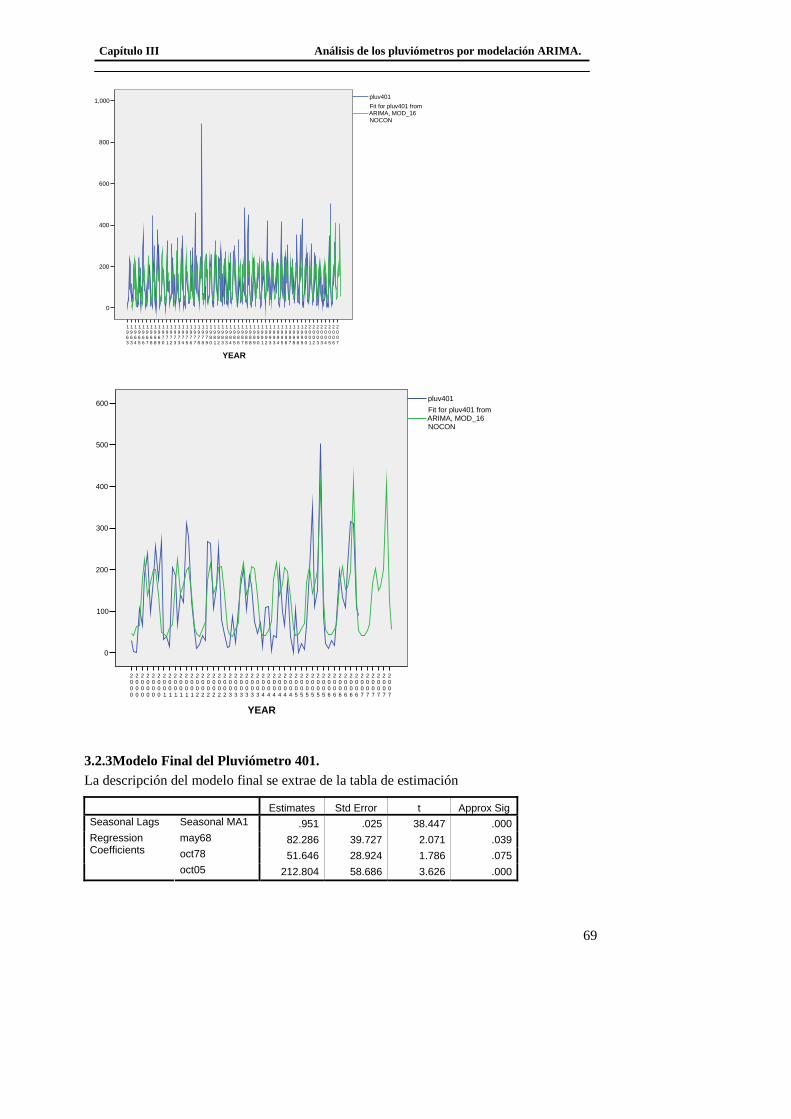
Ca
69
Capítulo III Análisis de los pluviómetros por modelación ARIMA.
2007
2006
2005
2004
2003
2003
2002
2001
2000
1999
1998
1998
1997
1996
1995
1994
1993
1993
1992
1991
1990
1989
1988
1988
1987
1986
1985
1984
1983
1983
1982
1981
1980
1979
1978
1978
1977
1976
1975
1974
1973
1973
1972
1971
1970
1969
1968
1968
1967
1966
1965
1964
1963
1963
YEAR
1,000
800
600
400
200
0
Fit for pluv401 fromARIMA, MOD_16NOCON
pluv401
2007
2007
2007
2007
2007
2007
2006
2006
2006
2006
2006
2006
2005
2005
2005
2005
2005
2005
2004
2004
2004
2004
2004
2004
2003
2003
2003
2003
2003
2003
2002
2002
2002
2002
2002
2002
2001
2001
2001
2001
2001
2001
2000
2000
2000
2000
2000
2000
YEAR
600
500
400
300
200
100
0
Fit for pluv401 fromARIMA, MOD_16NOCON
pluv401
3.2.3Modelo Final del Pluviómetro 401. La descripción del modelo final se extrae de la tabla de estimación
Estimates Std Error t Approx Sig Seasonal Lags Seasonal MA1 .951 .025 38.447 .000
may68 82.286 39.727 2.071 .039oct78 51.646 28.924 1.786 .075
Regression Coefficients
oct05 212.804 58.686 3.626 .000

Ca
70
Capítulo III Análisis de los pluviómetros por modelación ARIMA.
En términos de operadores y omitiendo los regresores, el modelo es de la forma
( ) ( ) tt eZ SMA 121
12 11 ββ −=−
con SMA1=0.951 donde te es un ruido blanco ( )2,0 σ con 2σ =6613.248
Al incluir los regresores: r1(t), r2(t), r3(t) que son las derivadas estacionales de las
funciones primitivas may68, oct78 y oct205, esto es funciones de pulso unitario en esas
fechas, con los coeficientes que aparecen en la tabla, el modelo adquiere la forma
( )traeeZZ i
n
iitttt SMA ∑
=−− +−+=
112112
3211212 804.212646.51286.82951.0 rrreeZZ tttt +++−+= −−
Desde el punto de vista práctico, esto significa que después de las observaciones de al
menos un año, las predicciones para cada mes y año siguientes, pueden obtenerse a partir
de fórmulas que, en dependencia de los datos disponibles son fácilmente calculables e
implementables en Excel, o requieren del SPSS como instrumento de pronóstico.
• Si se dispone de datos reales y pronosticados del año anterior (t-12) se puede
realizar un pronóstico a corto plazo del mes y año actual Zt teniendo en cuenta los
valores reales del año anterior Zt-12 y el error real de su pronóstico et-12 . Se tiene
en ese caso una fórmula fácil de implementar en Excel:
3211212 804.212646.51286.82951.0ˆ rrreZZ ttt +++−≅ −− donde r1, r2, r3 valen 1 respectivamente solo en las fechas excepcionales descritas
anteriormente
• Si no se dispone de datos reales del año anterior (t-12), y por tanto solo se tiene un
valor pronosticado para esos meses, no se conoce el error real del pronóstico, y se
solo se pueden utilizar estimativas del error para dichos meses anteriores. Se puede
todavía realizar un pronóstico a largo plazo, que utiliza los valores estimados para
el año anterior así como sus errores también estimados:
1212 ˆ951.0ˆˆ−− −≅ ttt eZZ
Pero la aplicación de una tal fórmula requeriría conocer los errores de estimaciones
del pronóstico en meses anteriores, que son a su vez, estimaciones de error, y no
disponibles. Se necesita entonces aplicar las técnicas basadas en la teoría de
pronóstico de Box-Jenkins, comentada en el Capítulo II y que está vaciada en el
SPSS, y otros paquetes, pero no en el Excel (al menos hasta ahora).
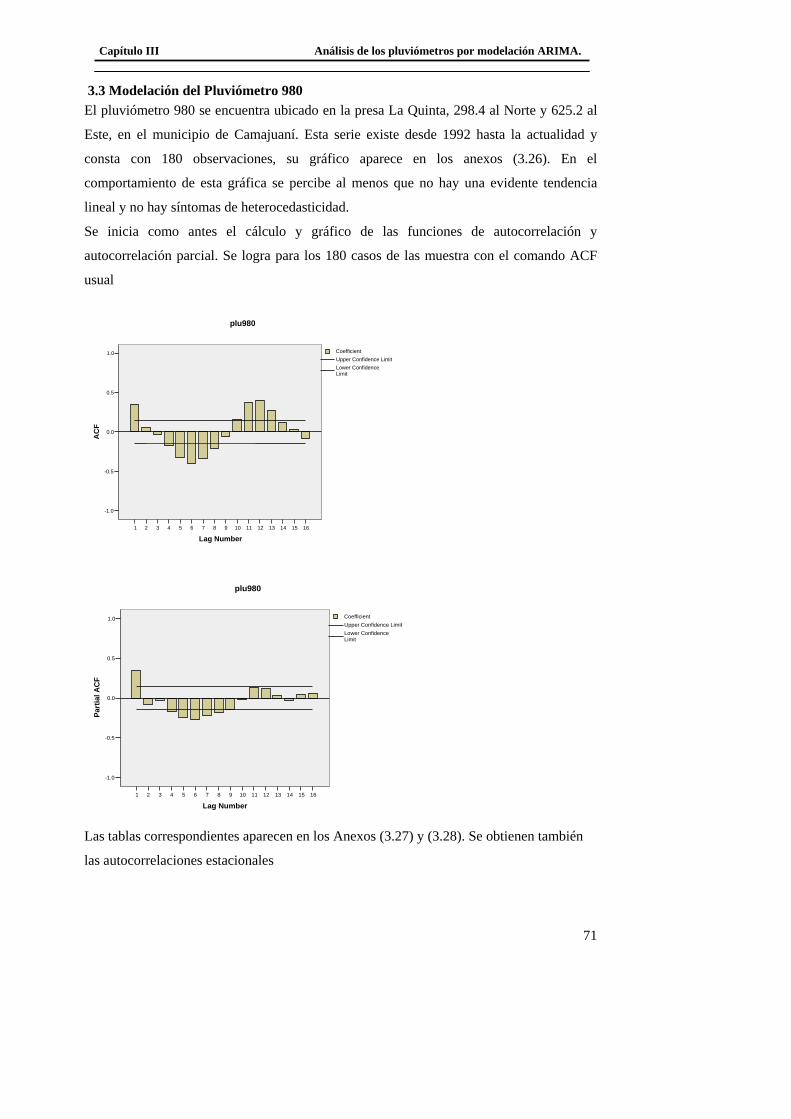
Ca
71
Capítulo III Análisis de los pluviómetros por modelación ARIMA.
3.3 Modelación del Pluviómetro 980 El pluviómetro 980 se encuentra ubicado en la presa La Quinta, 298.4 al Norte y 625.2 al
Este, en el municipio de Camajuaní. Esta serie existe desde 1992 hasta la actualidad y
consta con 180 observaciones, su gráfico aparece en los anexos (3.26). En el
comportamiento de esta gráfica se percibe al menos que no hay una evidente tendencia
lineal y no hay síntomas de heterocedasticidad.
Se inicia como antes el cálculo y gráfico de las funciones de autocorrelación y
autocorrelación parcial. Se logra para los 180 casos de las muestra con el comando ACF
usual
16151413121110987654321
Lag Number
1.0
0.5
0.0
-0.5
-1.0
AC
F
Lower ConfidenceLimit
Upper Confidence LimitCoefficient
plu980
16151413121110987654321
Lag Number
1.0
0.5
0.0
-0.5
-1.0
Part
ial A
CF
Lower ConfidenceLimit
Upper Confidence LimitCoefficient
plu980
Las tablas correspondientes aparecen en los Anexos (3.27) y (3.28). Se obtienen también
las autocorrelaciones estacionales
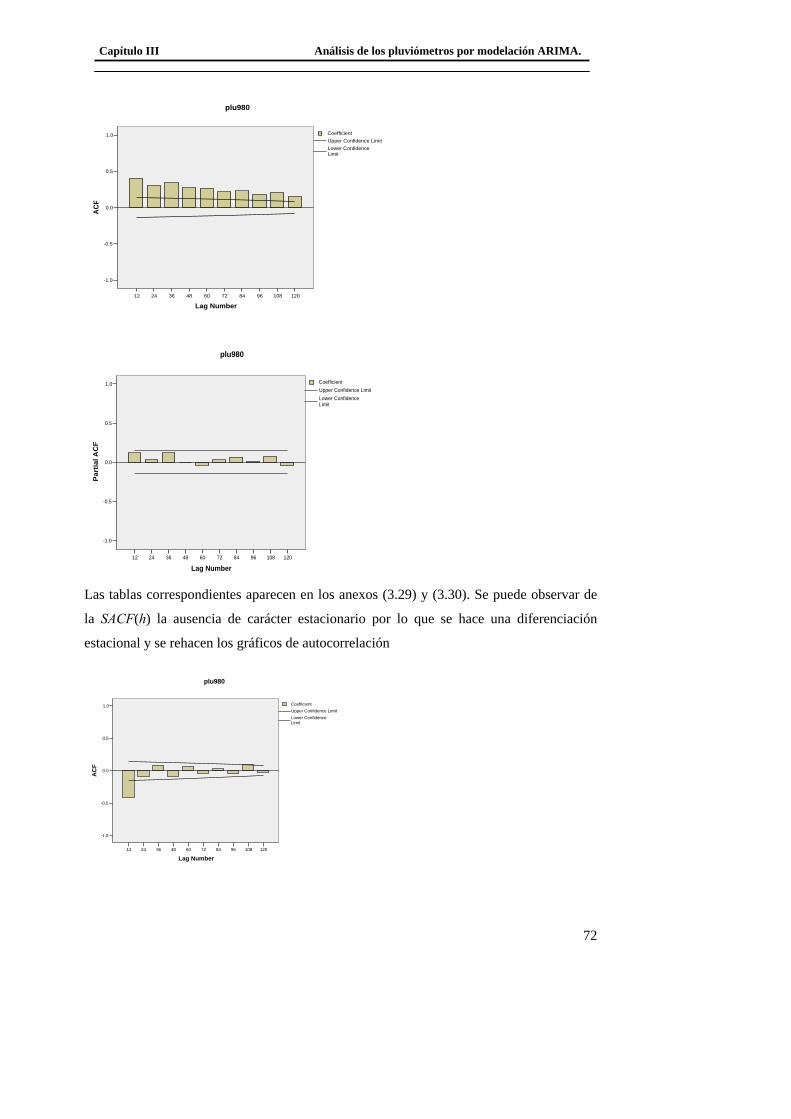
Ca
72
Capítulo III Análisis de los pluviómetros por modelación ARIMA.
1201089684726048362412
Lag Number
1.0
0.5
0.0
-0.5
-1.0
ACF
Lower ConfidenceLimit
Upper Confidence LimitCoefficient
plu980
1201089684726048362412
Lag Number
1.0
0.5
0.0
-0.5
-1.0
Par
tial A
CF
Lower ConfidenceLimit
Upper Confidence LimitCoefficient
plu980
Las tablas correspondientes aparecen en los anexos (3.29) y (3.30). Se puede observar de
la SACF(h) la ausencia de carácter estacionario por lo que se hace una diferenciación
estacional y se rehacen los gráficos de autocorrelación
1201089684726048362412
Lag Number
1.0
0.5
0.0
-0.5
-1.0
AC
F
Lower ConfidenceLimit
Upper Confidence LimitCoefficient
plu980

Ca
73
Capítulo III Análisis de los pluviómetros por modelación ARIMA.
1201089684726048362412
Lag Number
1.0
0.5
0.0
-0.5
-1.0
Part
ial A
CF
Lower ConfidenceLimit
Upper Confidence LimitCoefficient
plu980
Las tablas correspondientes aparecen en los anexos (3.31) y (3.32). Estos gráficos sugieren
dos posibles modelos (0 0 0)(0 1 1)12 ó (0 0 0)(2 1 0)12. Se comienza a probar el primero.
Los resultados del comando ARIMA son los siguientes:
He aquí la evolución de la convergencia
Seasonal Lags
Seasonal
MA1 Adjusted Sum
of Squares Marquardt Constant
0 .493 892272.453 .0011 .774 807947.759 .0012 .881 795701.891 .0003 .923 794452.267 .0004 .942 794294.073 .0005 .951 794274.789(a) .000
Melard's algorithm was used for estimation. a The estimation terminated at this iteration, because the sum of squares decreased by less than .001%. Y aquí están los resultados de la estimación de los parámetros
Parámetros a estimar Estimates Std Error t Approx Sig Seasonal Lags Seasonal MA1 .954 .174 5.477 .000Melard's algorithm was used for estimation. Se puede observar que la constante de Marquardt no presenta problemas, la media móvil
SMA1 es significativa, por tanto se puede pasar a la fase de validación, y para ello se
buscan las autocorrelaciones estacionales y regulares de los errores. Las tablas
correspondientes aparecen en los anexos (3.33)-(3.38)
Autocorrelaciones estacionales

Ca
74
Capítulo III Análisis de los pluviómetros por modelación ARIMA.
Series: Error for plu980 from ARIMA, MOD_8 NOCON
Lag Autocorrelation Std.Error(a) Box-Ljung Statistic
Value df Sig.(b) 12 .085 .074 12.757 12 .38724 -.038 .071 27.993 24 .26036 .052 .068 37.645 36 .39448 -.017 .065 46.088 48 .55260 .066 .061 54.203 60 .68672 .011 .058 64.307 72 .72984 .024 .054 70.973 84 .84496 .019 .050 81.426 96 .856108 .115 .046 98.552 108 .731120 .034 .041 121.368 120 .448
a The underlying process assumed is independence (white noise). b Based on the asymptotic chi-square approximation. Autocorrelaciones regulares Series: Error for plu980 from ARIMA, MOD_8 NOCON
Lag Autocorrelation Std.Error(a) Box-Ljung Statistic
Value df Sig.(b) 1 .040 .076 .269 1 .6042 -.135 .076 3.418 2 .1813 -.061 .076 4.060 3 .2554 -.087 .076 5.379 4 .2515 -.022 .076 5.463 5 .3626 -.041 .075 5.757 6 .4517 -.024 .075 5.860 7 .5568 -.104 .075 7.801 8 .4539 -.109 .075 9.919 9 .35710 .034 .074 10.123 10 .43011 .085 .074 11.439 11 .40712 .085 .074 12.757 12 .38713 -.043 .074 13.101 13 .44014 -.030 .073 13.262 14 .50615 .017 .073 13.318 15 .57816 .057 .073 13.923 16 .604
a The underlying process assumed is independence (white noise). b Based on the asymptotic chi-square approximation.
En los gráficos anteriormente expuestos se muestra que la modelación de la parte
estacional es suficientemente buena y que no se necesita completar con términos regulares
pues los residuales cumplen con la hipótesis de ser un ruido blanco.
El segundo posible modelo a trabajar (0 0 0) (2 1 0)12 y se estima con el comando
siguiente * ARIMA. TSET PRINT=DEFAULT CIN=95 NEWVAR=ALL .

Ca
75
Capítulo III Análisis de los pluviómetros por modelación ARIMA.
PREDICT THRU END. ARIMA plu980 /MODEL=( 0 0 0 )( 2 1 0 ) NOCONSTANT /MXITER= 10 /PAREPS= .001 /SSQPCT= .001 /FORECAST= EXACT . La siguiente tabla muestra que el algoritmo converge rápidamente.
Seasonal Lags
Seasonal
AR1 Seasonal
AR2 Adjusted Sum
of Squares Marquardt Constant
0 -.537 -.309 884284.081 .0011 -.604 -.375 878757.115(a) .001
Melard's algorithm was used for estimation. a The estimation terminated at this iteration, because the sum of squares decreased by less than .001%. Los parámetros a estimar resultan los siguientes, y como se puede ver son altamente
significativos Parámetros a estimar Estimates Std Error t Approx Sig
Seasonal AR1 -.604 .074 -8.173 .000Seasonal Lags Seasonal AR2 -.374 .074 -5.033 .000
Melard's algorithm was used for estimation. La matriz de correlación entre dichos parámetros es la siguiente Matriz de correlación
Seasonal Lags
Seasonal
AR1 Seasonal
AR2 Seasonal AR1 1.000 .447Seasonal
Lags Seasonal AR2 .447 1.000Melard's algorithm was used for estimation. Las correlaciones estacionales de los errores se obtienen con el comando ACF VARIABLES= ERR_2 /NOLOG /MXAUTO 120 /SERROR=IND /SEASONAL /PACF. Autocorrelaciones estacionales Series: Error for plu980 from ARIMA, MOD_11 NOCON
Lag Autocorrelation Std.Error(a) Box-Ljung Statistic
Value df Sig.(b)

Ca
76
Capítulo III Análisis de los pluviómetros por modelación ARIMA.
12 -.036 .074 14.257 12 .28524 -.095 .071 35.746 24 .05836 -.142 .068 52.586 36 .03748 -.050 .065 62.046 48 .08460 .056 .061 71.912 60 .13972 -.065 .058 81.995 72 .19784 .012 .054 87.294 84 .38196 -.010 .050 95.570 96 .493108 .108 .046 110.138 108 .425120 -.006 .041 133.897 120 .182
a The underlying process assumed is independence (white noise). b Based on the asymptotic chi-square approximation. Las tablas y gráficas complementarias aparecen en los anexos (3.39)-(3.41). Observe en la
anterior, que la serie quedó bien modelada estacionalmente. Ahora se pueden buscar los
correlogramas regulares del error con el comando usual: ACF VARIABLES= ERR_2 /NOLOG /MXAUTO 16 /SERROR=IND /PACF. Autocorrelaciones regulares Series: Error for plu980 from ARIMA, MOD_11 NOCON
Lag Autocorrelation Std.Error(a) Box-Ljung Statistic
Value df Sig.(b) 1 .033 .076 .181 1 .6702 -.160 .076 4.566 2 .1023 -.087 .076 5.884 3 .1174 -.082 .076 7.058 4 .1335 .019 .076 7.123 5 .2126 .000 .075 7.123 6 .3107 -.003 .075 7.124 7 .4168 -.114 .075 9.464 8 .3059 -.114 .075 11.794 9 .22510 .023 .074 11.888 10 .29311 .108 .074 14.026 11 .23212 -.036 .074 14.257 12 .28513 -.110 .074 16.476 13 .22414 -.038 .073 16.738 14 .27015 .027 .073 16.869 15 .32716 .082 .073 18.127 16 .317
a The underlying process assumed is independence (white noise). b Based on the asymptotic chi-square approximation.
Las gráficas y tablas complementarias se encuentran en los anexos (3.42)-(3.44)
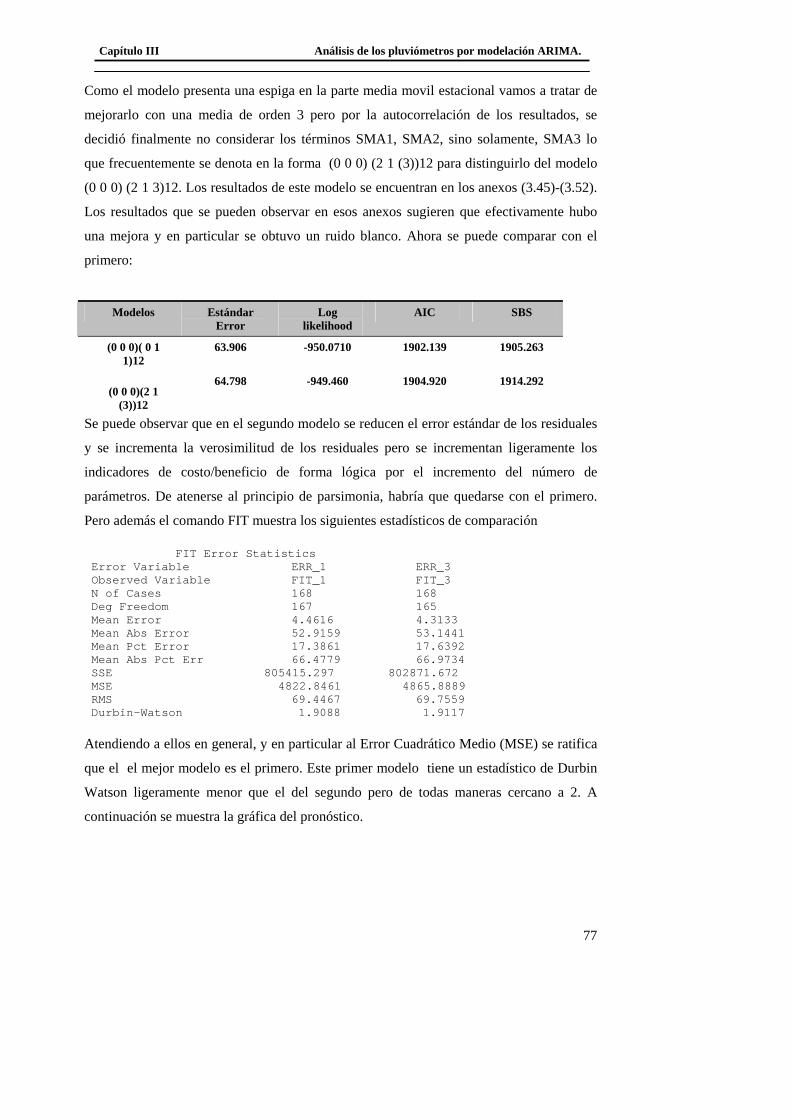
Ca
77
Capítulo III Análisis de los pluviómetros por modelación ARIMA.
Como el modelo presenta una espiga en la parte media movil estacional vamos a tratar de
mejorarlo con una media de orden 3 pero por la autocorrelación de los resultados, se
decidió finalmente no considerar los términos SMA1, SMA2, sino solamente, SMA3 lo
que frecuentemente se denota en la forma (0 0 0) (2 1 (3))12 para distinguirlo del modelo
(0 0 0) (2 1 3)12. Los resultados de este modelo se encuentran en los anexos (3.45)-(3.52).
Los resultados que se pueden observar en esos anexos sugieren que efectivamente hubo
una mejora y en particular se obtuvo un ruido blanco. Ahora se puede comparar con el
primero:
Modelos Estándar Error
Log likelihood
AIC SBS
(0 0 0)( 0 1 1)12
63.906 -950.0710 1902.139 1905.263
(0 0 0)(2 1 (3))12
64.798 -949.460 1904.920 1914.292
Se puede observar que en el segundo modelo se reducen el error estándar de los residuales
y se incrementa la verosimilitud de los residuales pero se incrementan ligeramente los
indicadores de costo/beneficio de forma lógica por el incremento del número de
parámetros. De atenerse al principio de parsimonia, habría que quedarse con el primero.
Pero además el comando FIT muestra los siguientes estadísticos de comparación FIT Error Statistics Error Variable ERR_1 ERR_3 Observed Variable FIT_1 FIT_3 N of Cases 168 168 Deg Freedom 167 165 Mean Error 4.4616 4.3133 Mean Abs Error 52.9159 53.1441 Mean Pct Error 17.3861 17.6392 Mean Abs Pct Err 66.4779 66.9734 SSE 805415.297 802871.672 MSE 4822.8461 4865.8889 RMS 69.4467 69.7559 Durbin-Watson 1.9088 1.9117
Atendiendo a ellos en general, y en particular al Error Cuadrático Medio (MSE) se ratifica
que el el mejor modelo es el primero. Este primer modelo tiene un estadístico de Durbin
Watson ligeramente menor que el del segundo pero de todas maneras cercano a 2. A
continuación se muestra la gráfica del pronóstico.
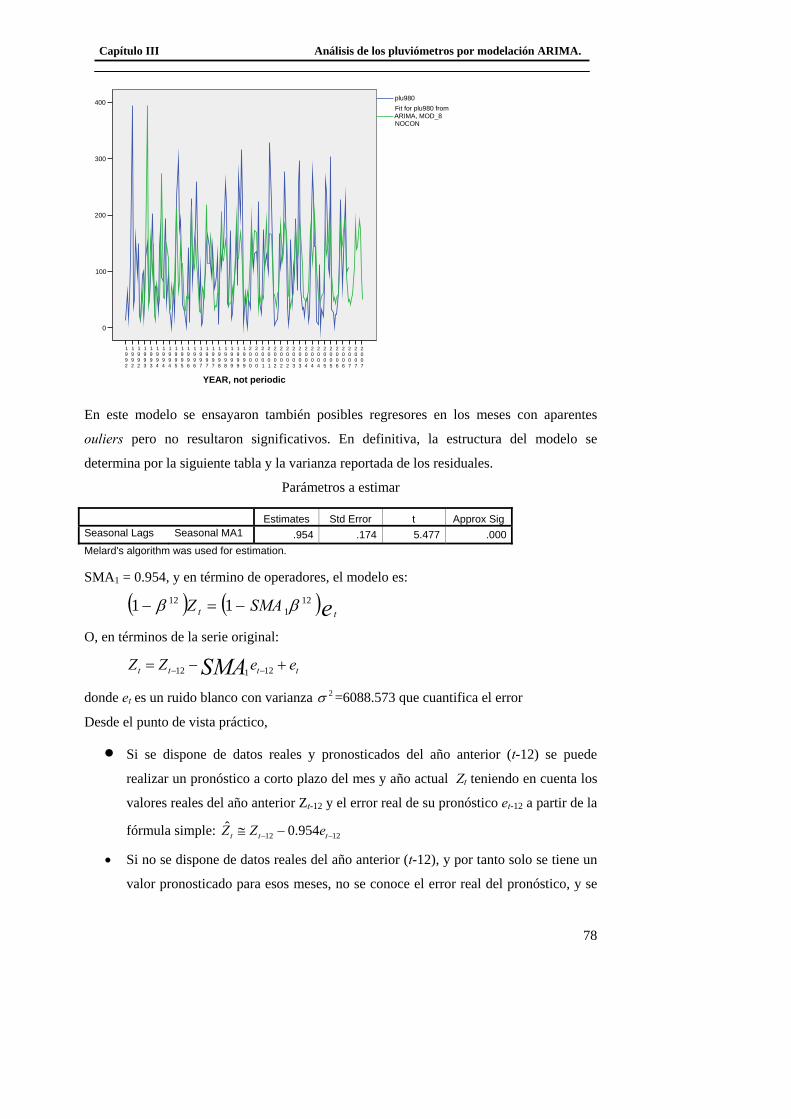
Ca
78
Capítulo III Análisis de los pluviómetros por modelación ARIMA.
2007
2007
2007
2006
2006
2005
2005
2004
2004
2004
2003
2003
2002
2002
2002
2001
2001
2000
2000
1999
1999
1999
1998
1998
1997
1997
1997
1996
1996
1995
1995
1994
1994
1994
1993
1993
1992
1992
1992
YEAR, not periodic
400
300
200
100
0
Fit for plu980 fromARIMA, MOD_8NOCON
plu980
En este modelo se ensayaron también posibles regresores en los meses con aparentes
ouliers pero no resultaron significativos. En definitiva, la estructura del modelo se
determina por la siguiente tabla y la varianza reportada de los residuales.
Parámetros a estimar Estimates Std Error t Approx Sig Seasonal Lags Seasonal MA1 .954 .174 5.477 .000Melard's algorithm was used for estimation. SMA1 = 0.954, y en término de operadores, el modelo es:
( ) ( )ett SMAZ 121
12 11 ββ −=−
O, en términos de la serie original:
tttt eeZZ SMA +−= −− 12112
donde et es un ruido blanco con varianza 2σ =6088.573 que cuantifica el error
Desde el punto de vista práctico,
• Si se dispone de datos reales y pronosticados del año anterior (t-12) se puede
realizar un pronóstico a corto plazo del mes y año actual Zt teniendo en cuenta los
valores reales del año anterior Zt-12 y el error real de su pronóstico et-12 a partir de la
fórmula simple: 1212 954.0ˆ−− −≅ ttt eZZ
• Si no se dispone de datos reales del año anterior (t-12), y por tanto solo se tiene un
valor pronosticado para esos meses, no se conoce el error real del pronóstico, y se

Ca
79
Capítulo III Análisis de los pluviómetros por modelación ARIMA.
solo se pueden utilizar estimativas del error para dichos meses anteriores. El
cálculo de 1212 ˆ954.0ˆˆ−− −≅ ttt eZZ debe hacerse en el SPSS
3.4 Resultado de los modelos matemáticos de los pluviómetros 940, 357, 389, 396.
3.4.1 Modelo matemático del tipo ARIMA del pluviómetro 940. Este pluviómetro consta con 348 observaciones, se encuentra ubicado en la presa La
Minerva a 290.0 al Norte y 623.2 al este ,específicamente en Santa Clara. El modelo final
de esta serie es (0 0 0) (3 1 0)12. Fueron introducidos regresores a esta serie en ciertos
meses que poseen aparentes outliers para analizar y se probaron los meses de julio del
1988, septiembre del 1987, octubre del 1996 y septiembre del 2003 en el modelo ARIMA.
Esto trajo como resultado que solo un mes fue significativo: octubre del 1996. Se hizo la
comparación de los dos modelos para ver cual era mejor y resultó ser el segundo donde se
utilizó el regresor. Por tanto el modelo es el siguiente. Parámetros a estimar Estimates Std Error t Approx Sig
Seasonal AR1 -.773 .053 -14.697 .000Seasonal AR2 -.538 .062 -8.731 .000
Seasonal Lags
Seasonal AR3 -.356 .053 -6.720 .000Regression Coefficients oct96 107.118 51.466 2.081 .038
Melard's algorithm was used for estimation. AR1= -0.773 AR2= -0.538 AR3= -0.356 Coef de Oct96=107.118 donde te es un ruido blanco con ( )2,0 σ , 2σ =5334.487 Concretamente: ( )( ) tT eZARARAR =−−−− 1236
324
212
1 11 ββββ +107.118 r(t)
donde
( ) )(1)( 9636
324
212
1 tOcttARARARtr −−−−= δβββ
Obsérvese en particular que el regresor puede tener influencias sobre los meses de octubre
de 3 años subsecuentes.
3.4.2 Modelo matemático del tipo ARIMA del pluviómetro 357. Este Pluviómetro se encuentra ubicado en Manajanabo a 284.1 al Norte y 621.6 al Este
formando parte de la Presa Minerva en Santa Clara. Cuenta con 660 observaciones y
empieza en el año 1952 hasta la actualidad. El modelo presenta una característica especial
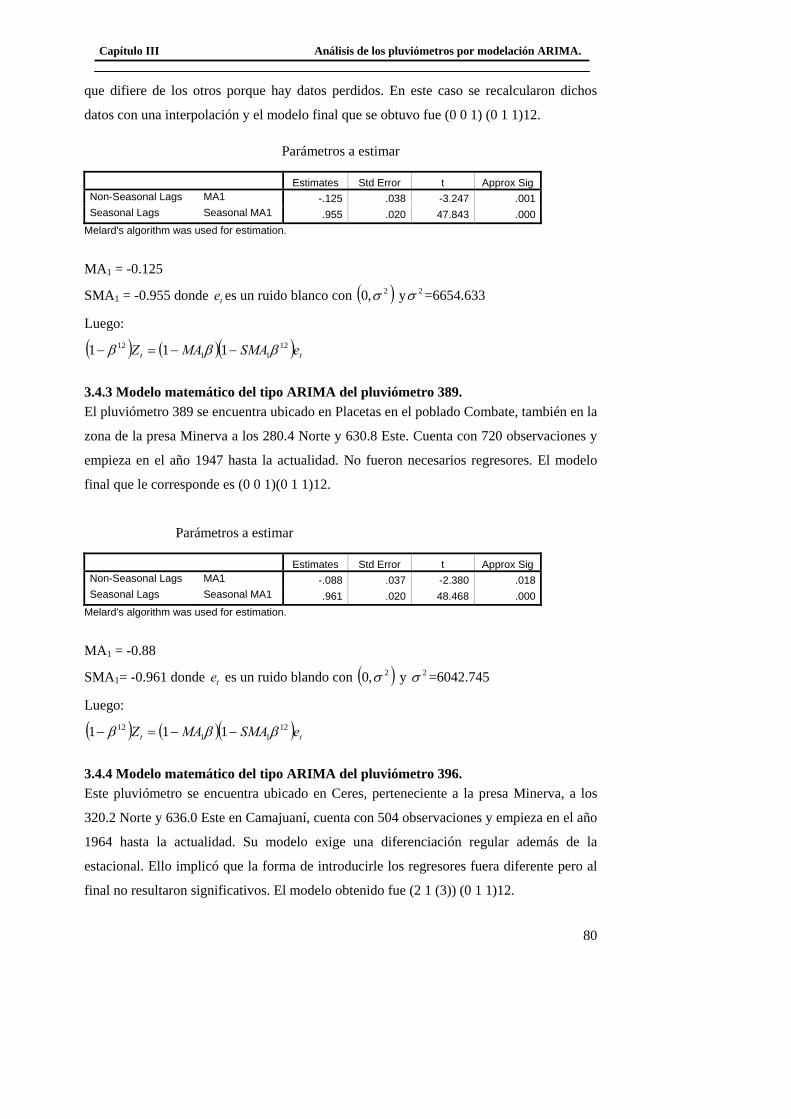
Ca
80
Capítulo III Análisis de los pluviómetros por modelación ARIMA.
que difiere de los otros porque hay datos perdidos. En este caso se recalcularon dichos
datos con una interpolación y el modelo final que se obtuvo fue (0 0 1) (0 1 1)12.
Parámetros a estimar Estimates Std Error t Approx Sig Non-Seasonal Lags MA1 -.125 .038 -3.247 .001Seasonal Lags Seasonal MA1 .955 .020 47.843 .000
Melard's algorithm was used for estimation.
MA1 = -0.125
SMA1 = -0.955 donde te es un ruido blanco con ( )2,0 σ y 2σ =6654.633
Luego:
( ) ( )( ) tt eSMAMAZ 1211
12 111 βββ −−=−
3.4.3 Modelo matemático del tipo ARIMA del pluviómetro 389. El pluviómetro 389 se encuentra ubicado en Placetas en el poblado Combate, también en la
zona de la presa Minerva a los 280.4 Norte y 630.8 Este. Cuenta con 720 observaciones y
empieza en el año 1947 hasta la actualidad. No fueron necesarios regresores. El modelo
final que le corresponde es (0 0 1)(0 1 1)12.
Parámetros a estimar Estimates Std Error t Approx Sig Non-Seasonal Lags MA1 -.088 .037 -2.380 .018Seasonal Lags Seasonal MA1 .961 .020 48.468 .000
Melard's algorithm was used for estimation.
MA1 = -0.88
SMA1= -0.961 donde te es un ruido blando con ( )2,0 σ y 2σ =6042.745
Luego:
( ) ( )( ) tt eSMAMAZ 1211
12 111 βββ −−=−
3.4.4 Modelo matemático del tipo ARIMA del pluviómetro 396. Este pluviómetro se encuentra ubicado en Ceres, perteneciente a la presa Minerva, a los
320.2 Norte y 636.0 Este en Camajuaní, cuenta con 504 observaciones y empieza en el año
1964 hasta la actualidad. Su modelo exige una diferenciación regular además de la
estacional. Ello implicó que la forma de introducirle los regresores fuera diferente pero al
final no resultaron significativos. El modelo obtenido fue (2 1 (3)) (0 1 1)12.

Ca
81
Capítulo III Análisis de los pluviómetros por modelación ARIMA.
Parámetros a estimar Estimates Std Error t Approx Sig
AR1 -.886 .029 -30.650 .000AR2 -.884 .035 -25.089 .000
Non-Seasonal Lags
MA3 .904 .038 23.823 .000Seasonal Lags Seasonal MA1 .964 .039 24.943 .000
AR1= -0.886
AR2= -0.884
MA3= -0.904
SMA1= 0.964 donde te es un ruido blando con ( )2,0 σ y 2σ =5367.623
Luego el modelo es:
( )( )( ) ( )( ) tt eSMAMAZARAR ββββββ 13
312
21 11111 −−=−−−−
3.5 Conclusiones del capítulo Se obtuvieron modelos ARIMA satisfactorios para todos los pluviómetros seleccionados.
Todos los procesos de estimación alcanzaron la convergencia y la constante de Marquardt
evolucionó satisfactoriamente. Los parámetros resultan significativos y se eliminaron
posibles correlaciones entre los parámetros no existe. Las autocorrelaciones de los
residuales son no significativas de acuerdo al test de Box-Ljung y constituyen por tanto un
ruido blanco. Se logran buenos pronósticos de los datos reservados y los estadísticos de
error se comportan estables en la fase de cálculo y de pronóstico.

Ca
82
Conclusiones y Recomendaciones.
Conclusiones y recomendaciones
Conclusiones Al concluir el presente trabajo, se puede afirmar que se le dio respuesta al problema inicial
planteado, así como los objetivos específicos y en particular se logró:
• Obtener modelos ARIMA para las series de los pluviómetros seleccionados de la
cuenca hidrológica Sagua la Chica perteneciente a Santa Clara.
• Obtener pronósticos de las precipitaciones en todas las series trabajadas, 6 en total,
tarea que constituye un objetivo central para la realización de los gráficos de
despacho del departamento de Hidrológica de la empresa de investigaciones de
recursos Hidráulicos.
• Lograr también un buen trabajo con la nueva teoría de los regresores a la hora de
incluirlos en los modelos como variables independientes en series diferenciadas.
Recomendaciones
• Continuar el tratamiento con las series de precipitaciones de Santa Clara a
partir de los datos de otros pluviómetros. Correlacionar las mismas en aras de
buscar simplificaciones de información y pronóstico
• Generalizar la metodología de construcción de las primitivas de los regresores
para cualquier diferenciación de las más frecuentes en la práctica.
• Realizar estudios de correlación entre los niveles de agua del embalse, las
filtraciones, la lluvia y otras variables existentes en la base de datos.

Ca
1
Bibliografía.
Bibliografía
AKAIKE, H. (1974) A New look at Statistical Model Identification. IEEE Transaction on
Automatic Control, Ac-19, pp. 718-723.
ARELLANO, M. (2006) Introducción al análisis Clásico de series de Tiempo.
BOX, G. A. T., G. (1975) “Intervention analysis with application to economic environmental
problems”. Journal of the American Statistical Association, 70,
pp. 70-79.
BOX, G. E. P. A. J., G.M. (1994) Time Series Analysis Forecasting and Control. , San
Francisco, Holden-Day.
BROCKWELL, P. J. y DAVIS, R. A. (1991) Time Series Theory and Methods. Second edition.
New York, Springer-Verlag.
COCHRANE, J. H. (1997) Time Series for Macroeconomics and Finance Chicago, University of
Chicago.
CUÉ MUÑIZ, J. E. C. E. (1987) Estadística.
DIEBOLD , F. X. (2000) Elements of Forecasting., Pennsylvania, University of Pennsylvania.
FULLER, W. (1976) Introduction to Statistical Time Series New York, Wiley Series in
Probability and Mathematical Statistic. John Wiley and Sons
GLADYS CASAS, R. G., y MILAGROS ALEGRET (1999) “Métodos para la vigilancia de
eventos (III): Técnicas de Clustering para la Detección de Epidemias”. Reporte Técnico
de Vigilancia, julio,1999, 4(7). Ciencias de la Computación. UCLV.
GRAU, A. R. (1994) Estadística Aplicada con ayuda de paquetes de software, Universidad
Guadalajara, Jalisco, México.
GRAU, A. R. (1996) Series Cronológicas, Curso de Especialización en Procesos Estadísticos
Aplicados, Colombia, Coruniversitaria, Ibagué.
GUERRERO, V. M. (1991) Análisis Estadístico de series de tiempo Económicas., México,
Colección CBI. Universidad Autónoma Metropolitana.
.
JEFFREY, W. H., and BERGER, J. O. (1992) “Ockham’s Razor and Bayesian Analysis”. Am.
Sci, 80, pp. 64-72.
KOROLIOV, V. (1986) Manual de la teoría de probabilidades y estadística matemática.

Ca
2
Bibliografía.
MEDINA, J. H. (1998) Estudio del comportamiento histórico de las tasas de las enfermedades de
declaración obligatoria (EDO) en el municipio de Manicaragua. Santa Clara Villa Clara,
Universidad Central De Las Villas.
MONDEJA HERNANDEZ, A. L. (1995) Metodología para el uso de las series de tiempo en
epidemiología. Santa Clara, Villa Clara, UCLV.
MORA VILLEGAS, H. (2003) Series cronológicas de consumo eléctrico y de petróleo de los
municipios y provincia de Villa Clara. Santa Clara, Villa Clara. UCLV.
MORALES MARTINEZ, J. L.(2007) Series Cronologicas de
OSÉS RODRÍGUEZ, R. (2004) Series Meteorológicas de Villa Clara y otras provincias.
Modelos y Pronósticos. Santa Clara, Villa Clara, UCLV. Trabajo
de diploma
RODRIGUEZ, A. (1986) Estadística Matemática II.
SANCHEZ DE RIVERA, PEÑA, D. (1999) Estadística, Modelos y Métodos, Madrid.
SCHWARTZ, G. (1976) “Estimating the dimensions of a model”. Annals of Statistic, 6, pp. 461-
464.
SHUMWAY, R., and STOFFER, D. (2000) Time Series Analysis and its Applications,
Pittsburgh, University of Pittsburgh.
TARRAU BRITO, M. E. (1996) Caracterización de las series cronológicas de enfermedades
diarreicas y respiratorias agudas en Villa Clara. Santa Clara. Villa Clara, UCLV.
TIAO, C. G., and. TSAY., R. S, (2001) A Course in Time Series Analysis, New York, John
Wiley.

Ca
3
ANEXOS
ANEXOS
(2.1)Metodología para el análisis de series de tiempo univariado.
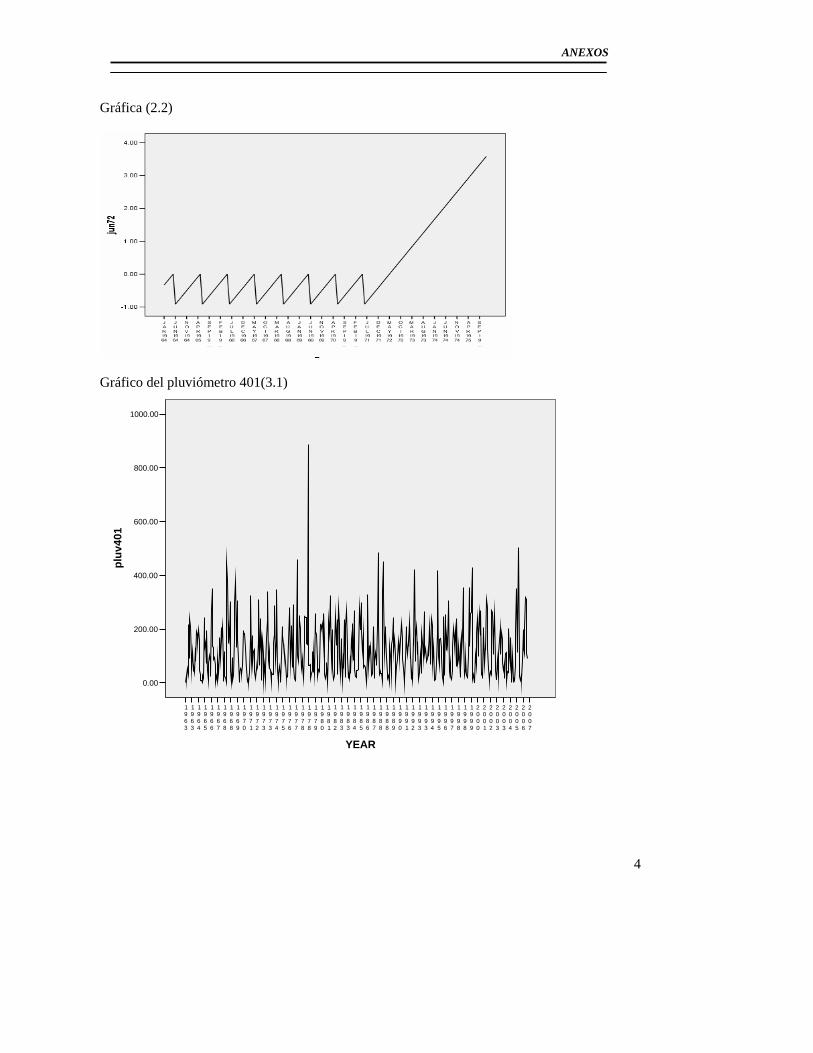
Ca
4
ANEXOS
Gráfica (2.2)
Gráfico del pluviómetro 401(3.1)
2007
2006
2005
2004
2003
2003
2002
2001
2000
1999
1998
1998
1997
1996
1995
1994
1993
1993
1992
1991
1990
1989
1988
1988
1987
1986
1985
1984
1983
1983
1982
1981
1980
1979
1978
1978
1977
1976
1975
1974
1973
1973
1972
1971
1970
1969
1968
1968
1967
1966
1965
1964
1963
1963
YEAR
1000.00
800.00
600.00
400.00
200.00
0.00
pluv
401

Ca
5
ANEXOS
Autocorrlación de la parte regular del 401 inicio (3.2) Autocorrelations Series: pluv401
Box-Ljung Statistic
Lag Autocorrel
ation Std.Error(
a) Value df Sig.(b) 1 .301 .043 48.236 1 .0002 .080 .043 51.624 2 .0003 .001 .043 51.625 3 .0004 -.133 .043 61.001 4 .0005 -.242 .043 92.232 5 .0006 -.342 .043 155.100 6 .0007 -.248 .043 188.219 7 .0008 -.122 .043 196.283 8 .0009 -.011 .043 196.344 9 .00010 .086 .043 200.383 10 .00011 .287 .043 244.834 11 .00012 .387 .043 326.171 12 .00013 .267 .043 364.780 13 .00014 .113 .043 371.779 14 .00015 -.033 .043 372.357 15 .00016 -.131 .043 381.792 16 .000
. Tabla (3.3) Partial Autocorrelations Series: pluv401
Lag
Partial Autocorrel
ation Std.Error 1 .301 .044 2 -.012 .044 3 -.021 .044 4 -.139 .044 5 -.181 .044 6 -.249 .044 7 -.108 .044 8 -.051 .044 9 -.009 .044 10 .005 .044 11 .177 .044 12 .207 .044 13 .082 .044 14 .010 .044 15 -.044 .044 16 -.030 .044
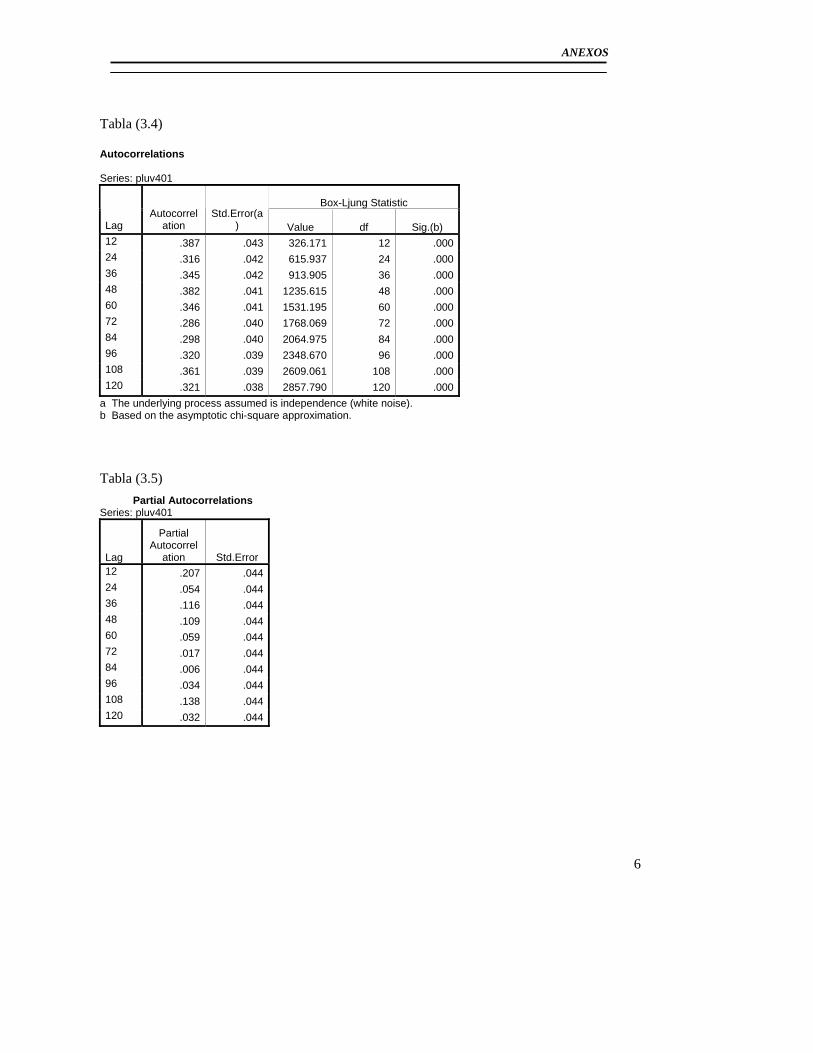
Ca
6
ANEXOS
Tabla (3.4) Autocorrelations Series: pluv401
Box-Ljung Statistic
Lag Autocorrel
ation Std.Error(a
) Value df Sig.(b) 12 .387 .043 326.171 12 .00024 .316 .042 615.937 24 .00036 .345 .042 913.905 36 .00048 .382 .041 1235.615 48 .00060 .346 .041 1531.195 60 .00072 .286 .040 1768.069 72 .00084 .298 .040 2064.975 84 .00096 .320 .039 2348.670 96 .000108 .361 .039 2609.061 108 .000120 .321 .038 2857.790 120 .000
a The underlying process assumed is independence (white noise). b Based on the asymptotic chi-square approximation.
Tabla (3.5) Partial Autocorrelations Series: pluv401
Lag
Partial Autocorrel
ation Std.Error 12 .207 .044 24 .054 .044 36 .116 .044 48 .109 .044 60 .059 .044 72 .017 .044 84 .006 .044 96 .034 .044 108 .138 .044 120 .032 .044
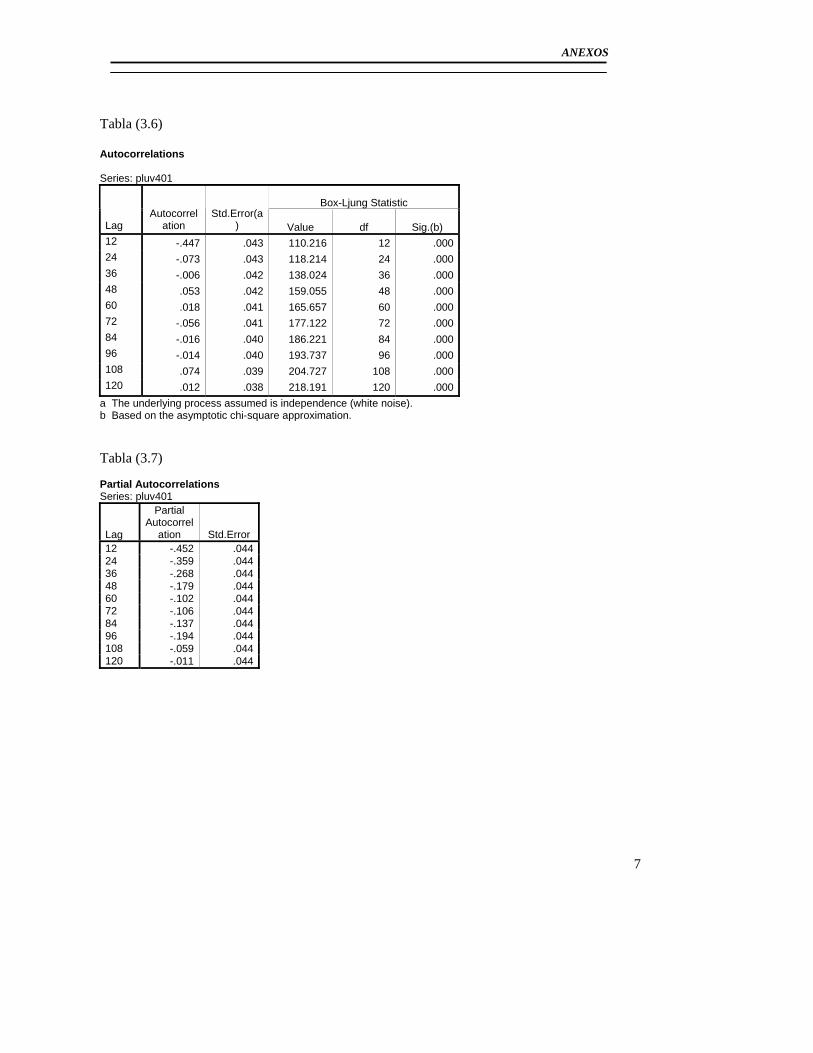
Ca
7
ANEXOS
Tabla (3.6) Autocorrelations Series: pluv401
Box-Ljung Statistic
Lag Autocorrel
ation Std.Error(a
) Value df Sig.(b) 12 -.447 .043 110.216 12 .00024 -.073 .043 118.214 24 .00036 -.006 .042 138.024 36 .00048 .053 .042 159.055 48 .00060 .018 .041 165.657 60 .00072 -.056 .041 177.122 72 .00084 -.016 .040 186.221 84 .00096 -.014 .040 193.737 96 .000108 .074 .039 204.727 108 .000120 .012 .038 218.191 120 .000
a The underlying process assumed is independence (white noise). b Based on the asymptotic chi-square approximation. Tabla (3.7) Partial Autocorrelations Series: pluv401
Lag
Partial Autocorrel
ation Std.Error 12 -.452 .044 24 -.359 .044 36 -.268 .044 48 -.179 .044 60 -.102 .044 72 -.106 .044 84 -.137 .044 96 -.194 .044 108 -.059 .044 120 -.011 .044
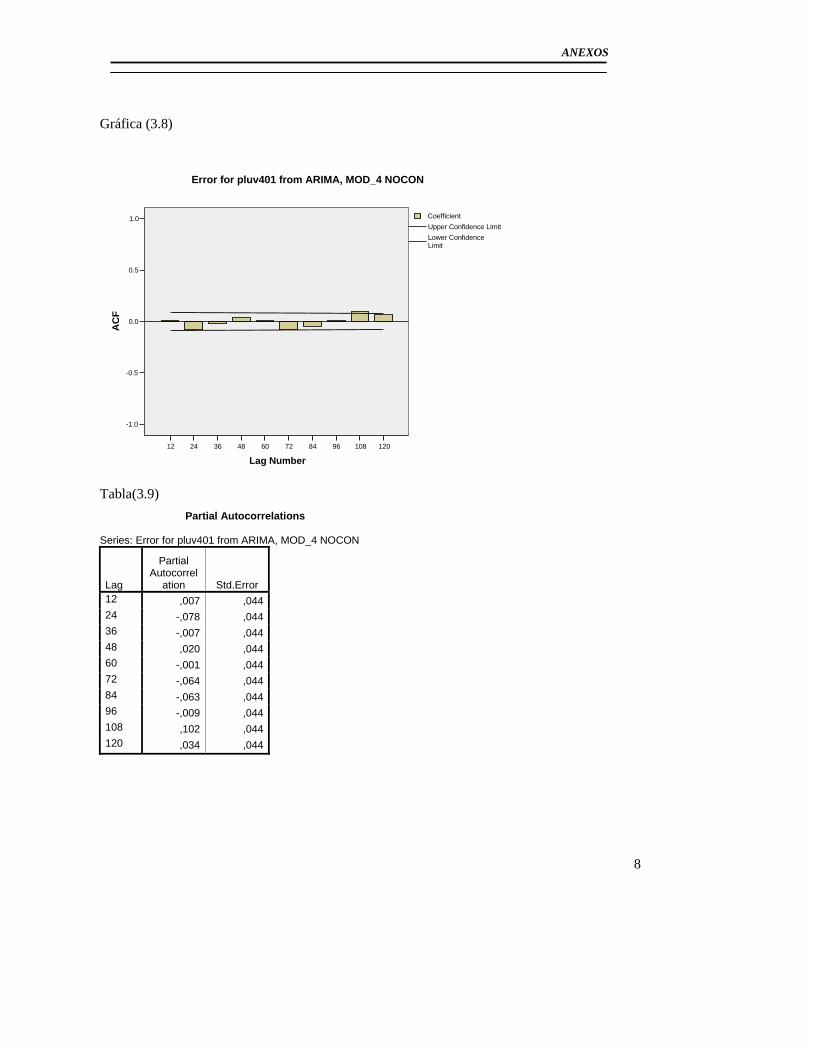
Ca
8
ANEXOS
Gráfica (3.8)
1201089684726048362412
Lag Number
1.0
0.5
0.0
-0.5
-1.0
AC
F
Lower ConfidenceLimit
Upper Confidence LimitCoefficient
Error for pluv401 from ARIMA, MOD_4 NOCON
Tabla(3.9) Partial Autocorrelations Series: Error for pluv401 from ARIMA, MOD_4 NOCON
Lag
Partial Autocorrel
ation Std.Error 12 ,007 ,044 24 -,078 ,044 36 -,007 ,044 48 ,020 ,044 60 -,001 ,044 72 -,064 ,044 84 -,063 ,044 96 -,009 ,044 108 ,102 ,044 120 ,034 ,044
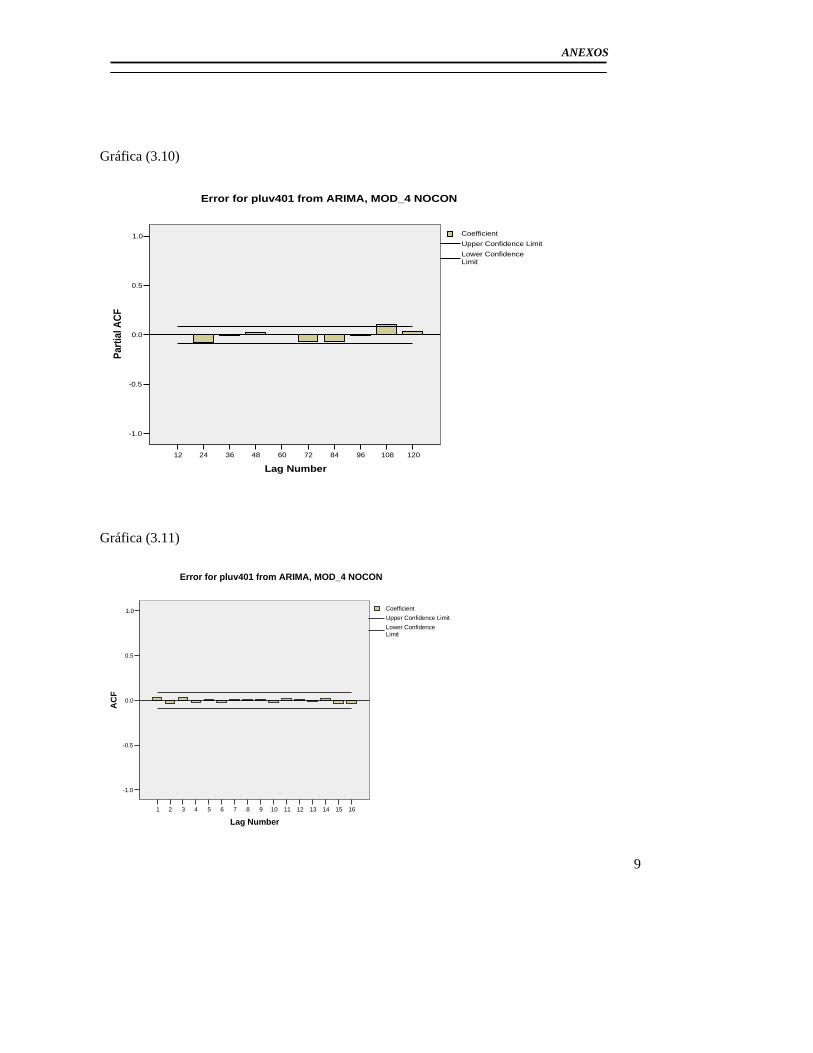
Ca
9
ANEXOS
Gráfica (3.10)
1201089684726048362412
Lag Number
1.0
0.5
0.0
-0.5
-1.0
Parti
al A
CF
Lower ConfidenceLimit
Upper Confidence LimitCoefficient
Error for pluv401 from ARIMA, MOD_4 NOCON
Gráfica (3.11)
16151413121110987654321
Lag Number
1.0
0.5
0.0
-0.5
-1.0
AC
F
Lower ConfidenceLimit
Upper Confidence LimitCoefficient
Error for pluv401 from ARIMA, MOD_4 NOCON

Ca
10
ANEXOS
Tabla(3.12) Partial Autocorrelations Series: Error for pluv401 from ARIMA, MOD_4 NOCON
Lag
Partial Autocorrel
ation Std.Error 1 ,033 ,044 2 -,040 ,044 3 ,036 ,044 4 -,022 ,044 5 ,020 ,044 6 -,023 ,044 7 ,013 ,044 8 ,002 ,044 9 ,019 ,044 10 -,028 ,044 11 ,022 ,044 12 ,007 ,044 13 -,008 ,044 14 ,018 ,044 15 -,034 ,044 16 -,029 ,044
Grafica (13)
Ca
11
ANEXOS
16151413121110987654321
Lag Number
1.0
0.5
0.0
-0.5
-1.0
Part
ial A
CF
Lower ConfidenceLimit
Upper Confidence LimitCoefficient
Error for pluv401 from ARIMA, MOD_4 NOCON
Segundo Modelo Grafica (3.14) de la parte estacional de los errores.
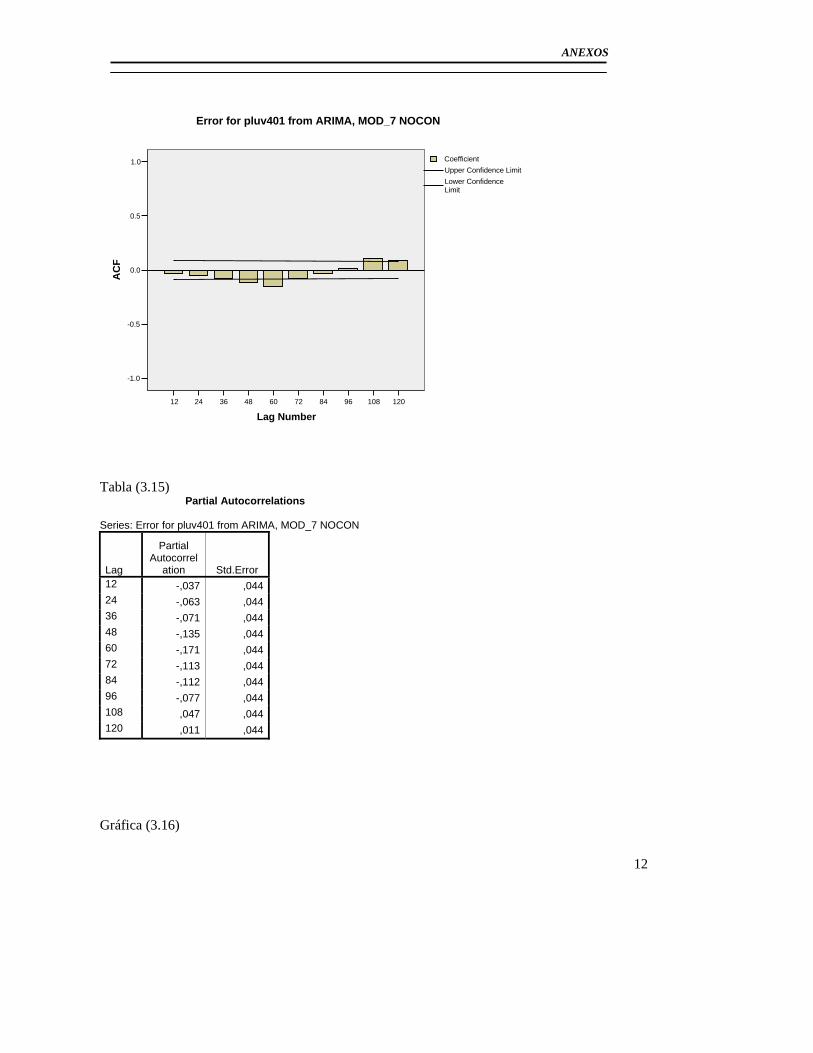
Ca
12
ANEXOS
1201089684726048362412
Lag Number
1.0
0.5
0.0
-0.5
-1.0
AC
F
Lower ConfidenceLimit
Upper Confidence LimitCoefficient
Error for pluv401 from ARIMA, MOD_7 NOCON
Tabla (3.15) Partial Autocorrelations Series: Error for pluv401 from ARIMA, MOD_7 NOCON
Lag
Partial Autocorrel
ation Std.Error 12 -,037 ,044 24 -,063 ,044 36 -,071 ,044 48 -,135 ,044 60 -,171 ,044 72 -,113 ,044 84 -,112 ,044 96 -,077 ,044 108 ,047 ,044 120 ,011 ,044
Gráfica (3.16)
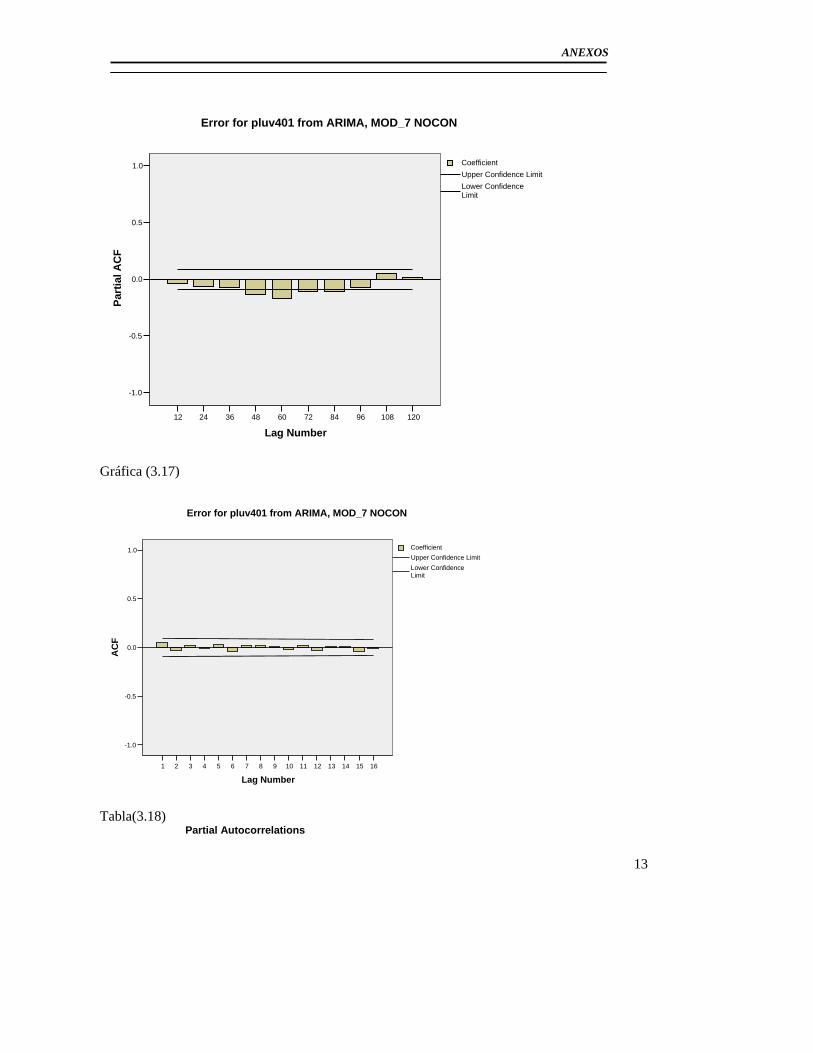
Ca
13
ANEXOS
1201089684726048362412
Lag Number
1.0
0.5
0.0
-0.5
-1.0
Part
ial A
CF
Lower ConfidenceLimit
Upper Confidence LimitCoefficient
Error for pluv401 from ARIMA, MOD_7 NOCON
Gráfica (3.17)
16151413121110987654321
Lag Number
1.0
0.5
0.0
-0.5
-1.0
AC
F
Lower ConfidenceLimit
Upper Confidence LimitCoefficient
Error for pluv401 from ARIMA, MOD_7 NOCON
Tabla(3.18) Partial Autocorrelations

Ca
14
ANEXOS
Series: Error for pluv401 from ARIMA, MOD_7 NOCON
Lag
Partial Autocorrel
ation Std.Error 1 ,052 ,044 2 -,036 ,044 3 ,024 ,044 4 -,011 ,044 5 ,033 ,044 6 -,045 ,044 7 ,030 ,044 8 ,011 ,044 9 ,010 ,044 10 -,028 ,044 11 ,024 ,044 12 -,037 ,044 13 ,019 ,044 14 ,001 ,044 15 -,034 ,044 16 -,013 ,044
Gráfica(3.19)
16151413121110987654321
Lag Number
1.0
0.5
0.0
-0.5
-1.0
Part
ial A
CF
Lower ConfidenceLimit
Upper Confidence LimitCoefficient
Error for pluv401 from ARIMA, MOD_7 NOCON
Gráfica (3.20)
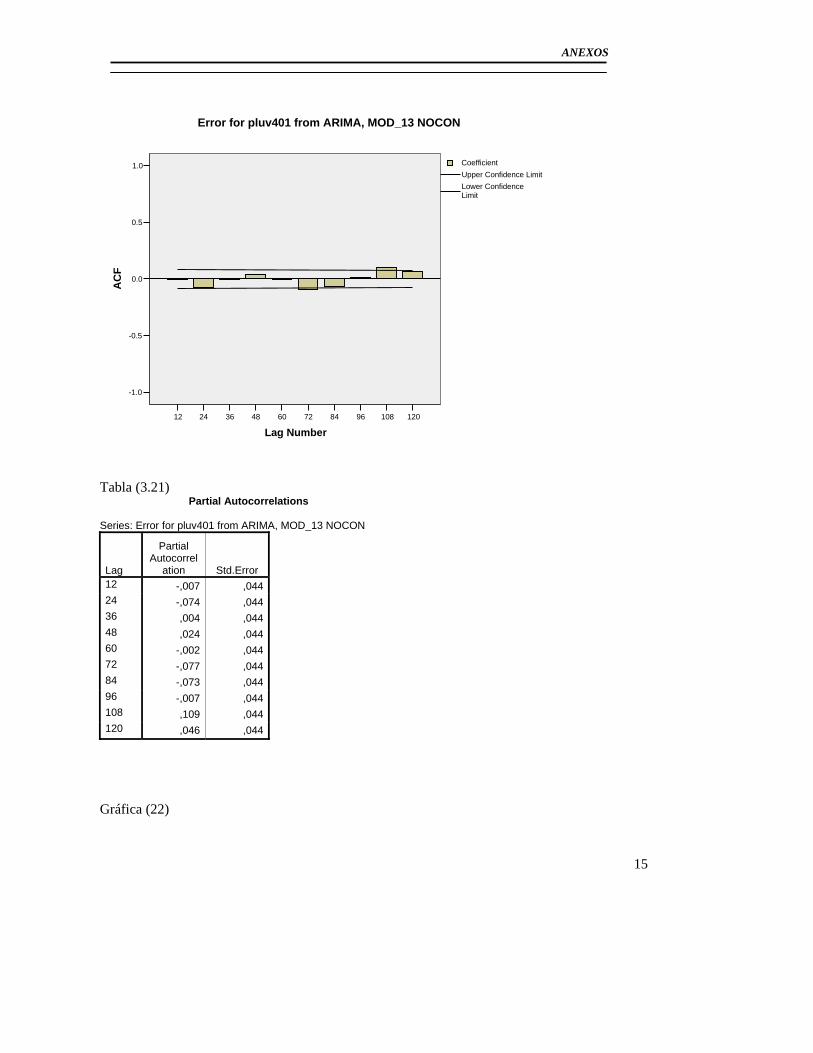
Ca
15
ANEXOS
1201089684726048362412
Lag Number
1.0
0.5
0.0
-0.5
-1.0
AC
F
Lower ConfidenceLimit
Upper Confidence LimitCoefficient
Error for pluv401 from ARIMA, MOD_13 NOCON
Tabla (3.21) Partial Autocorrelations Series: Error for pluv401 from ARIMA, MOD_13 NOCON
Lag
Partial Autocorrel
ation Std.Error 12 -,007 ,044 24 -,074 ,044 36 ,004 ,044 48 ,024 ,044 60 -,002 ,044 72 -,077 ,044 84 -,073 ,044 96 -,007 ,044 108 ,109 ,044 120 ,046 ,044
Gráfica (22)
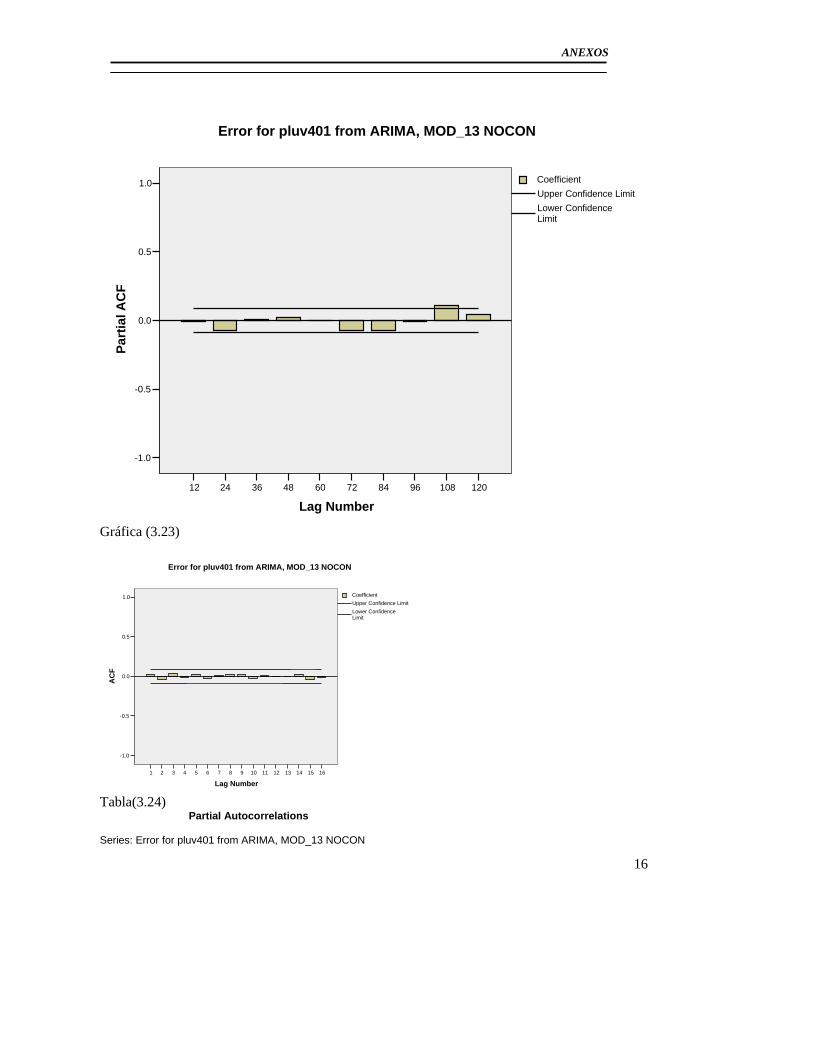
Ca
16
ANEXOS
1201089684726048362412
Lag Number
1.0
0.5
0.0
-0.5
-1.0
Part
ial A
CF
Lower ConfidenceLimit
Upper Confidence LimitCoefficient
Error for pluv401 from ARIMA, MOD_13 NOCON
Gráfica (3.23)
16151413121110987654321
Lag Number
1.0
0.5
0.0
-0.5
-1.0
AC
F
Lower ConfidenceLimit
Upper Confidence LimitCoefficient
Error for pluv401 from ARIMA, MOD_13 NOCON
Tabla(3.24) Partial Autocorrelations Series: Error for pluv401 from ARIMA, MOD_13 NOCON

Ca
17
ANEXOS
Lag
Partial Autocorrel
ation Std.Error 1 ,024 ,044 2 -,039 ,044 3 ,033 ,044 4 -,013 ,044 5 ,027 ,044 6 -,031 ,044 7 ,016 ,044 8 ,015 ,044 9 ,025 ,044 10 -,024 ,044 11 ,012 ,044 12 -,007 ,044 13 -,003 ,044 14 ,024 ,044 15 -,042 ,044 16 -,015 ,044
Gráfica (3.25)
16151413121110987654321
Lag Number
1.0
0.5
0.0
-0.5
-1.0
Part
ial A
CF
Lower ConfidenceLimit
Upper Confidence LimitCoefficient
Error for pluv401 from ARIMA, MOD_13 NOCON
Grafico del pluviómetro 980 (3.26).
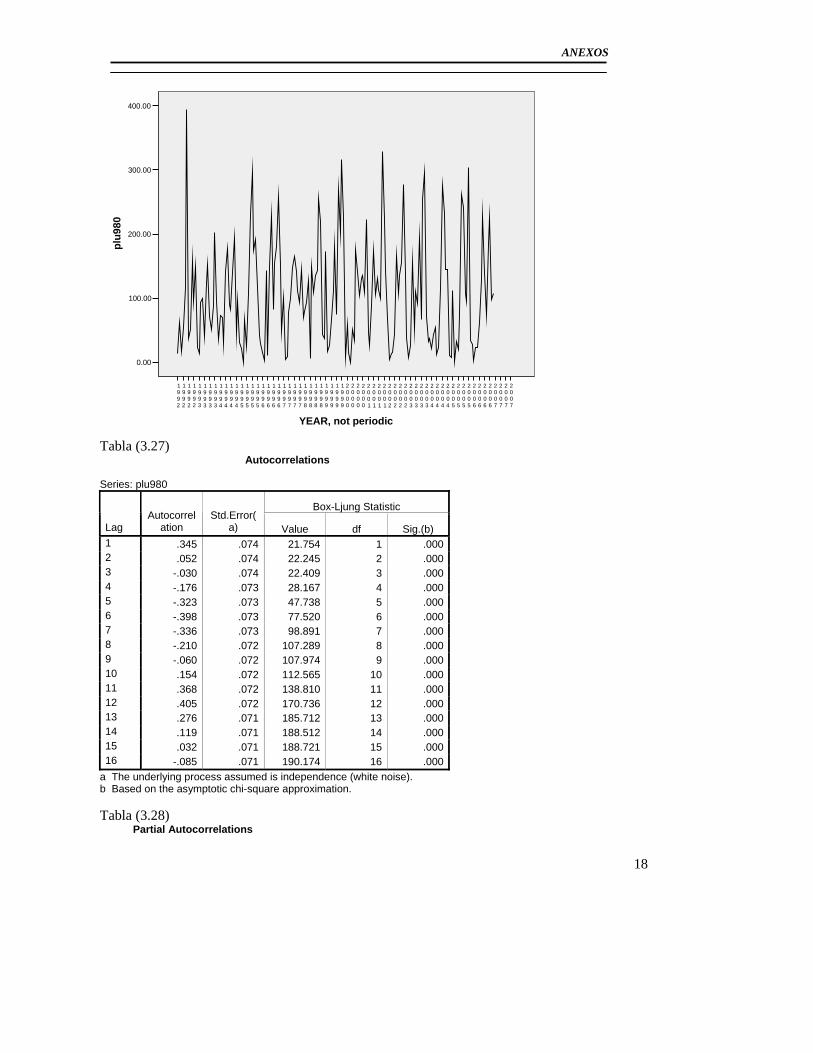
Ca
18
ANEXOS
2007
2007
2007
2007
2006
2006
2006
2006
2005
2005
2005
2005
2004
2004
2004
2004
2003
2003
2003
2003
2002
2002
2002
2002
2001
2001
2001
2001
2000
2000
2000
2000
1999
1999
1999
1999
1998
1998
1998
1998
1997
1997
1997
1997
1996
1996
1996
1996
1995
1995
1995
1995
1994
1994
1994
1994
1993
1993
1993
1993
1992
1992
1992
1992
YEAR, not periodic
400.00
300.00
200.00
100.00
0.00
plu9
80
Tabla (3.27) Autocorrelations Series: plu980
Box-Ljung Statistic
Lag Autocorrel
ation Std.Error(
a) Value df Sig.(b) 1 .345 .074 21.754 1 .0002 .052 .074 22.245 2 .0003 -.030 .074 22.409 3 .0004 -.176 .073 28.167 4 .0005 -.323 .073 47.738 5 .0006 -.398 .073 77.520 6 .0007 -.336 .073 98.891 7 .0008 -.210 .072 107.289 8 .0009 -.060 .072 107.974 9 .00010 .154 .072 112.565 10 .00011 .368 .072 138.810 11 .00012 .405 .072 170.736 12 .00013 .276 .071 185.712 13 .00014 .119 .071 188.512 14 .00015 .032 .071 188.721 15 .00016 -.085 .071 190.174 16 .000
a The underlying process assumed is independence (white noise). b Based on the asymptotic chi-square approximation. Tabla (3.28) Partial Autocorrelations
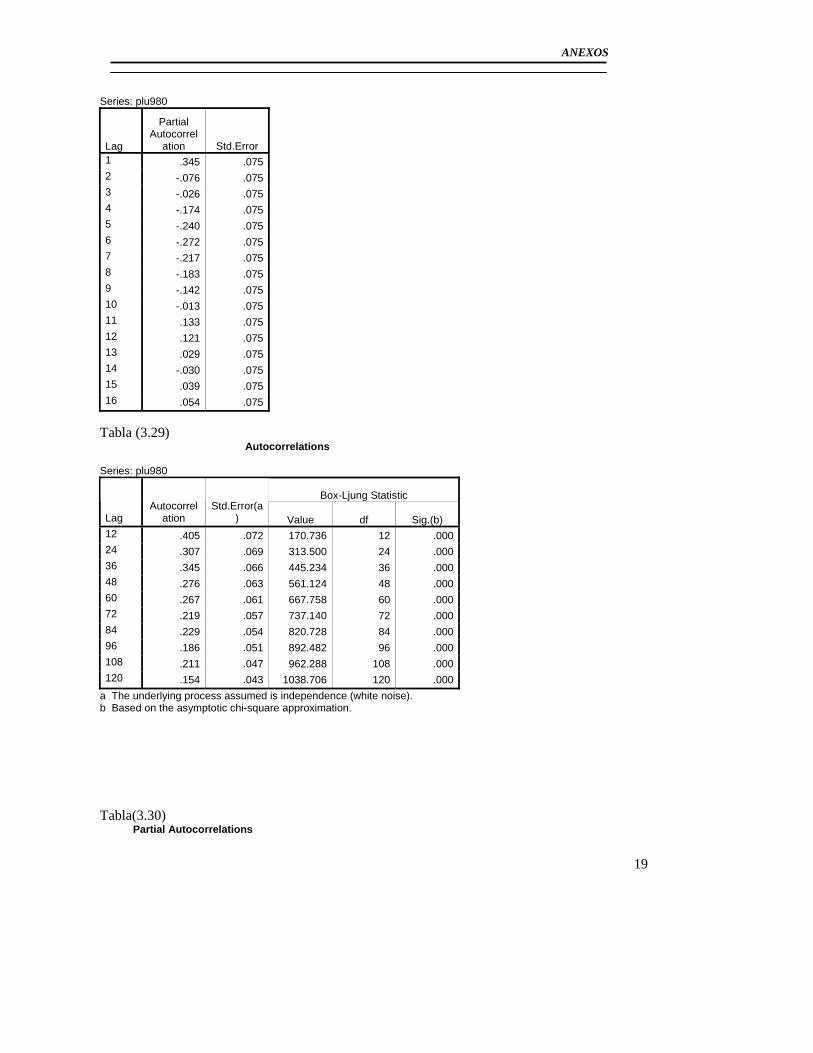
Ca
19
ANEXOS
Series: plu980
Lag
Partial Autocorrel
ation Std.Error 1 .345 .075 2 -.076 .075 3 -.026 .075 4 -.174 .075 5 -.240 .075 6 -.272 .075 7 -.217 .075 8 -.183 .075 9 -.142 .075 10 -.013 .075 11 .133 .075 12 .121 .075 13 .029 .075 14 -.030 .075 15 .039 .075 16 .054 .075
Tabla (3.29) Autocorrelations Series: plu980
Box-Ljung Statistic
Lag Autocorrel
ation Std.Error(a
) Value df Sig.(b) 12 .405 .072 170.736 12 .00024 .307 .069 313.500 24 .00036 .345 .066 445.234 36 .00048 .276 .063 561.124 48 .00060 .267 .061 667.758 60 .00072 .219 .057 737.140 72 .00084 .229 .054 820.728 84 .00096 .186 .051 892.482 96 .000108 .211 .047 962.288 108 .000120 .154 .043 1038.706 120 .000
a The underlying process assumed is independence (white noise). b Based on the asymptotic chi-square approximation. Tabla(3.30) Partial Autocorrelations
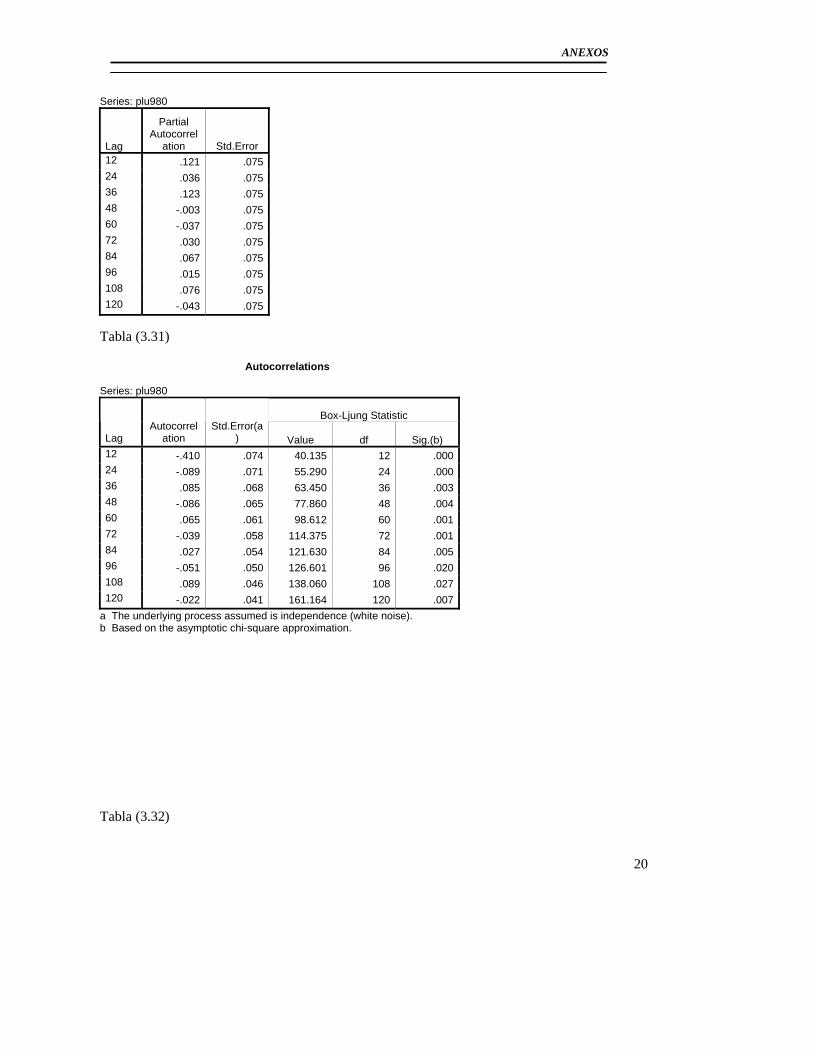
Ca
20
ANEXOS
Series: plu980
Lag
Partial Autocorrel
ation Std.Error 12 .121 .075 24 .036 .075 36 .123 .075 48 -.003 .075 60 -.037 .075 72 .030 .075 84 .067 .075 96 .015 .075 108 .076 .075 120 -.043 .075
Tabla (3.31) Autocorrelations Series: plu980
Box-Ljung Statistic
Lag Autocorrel
ation Std.Error(a
) Value df Sig.(b) 12 -.410 .074 40.135 12 .00024 -.089 .071 55.290 24 .00036 .085 .068 63.450 36 .00348 -.086 .065 77.860 48 .00460 .065 .061 98.612 60 .00172 -.039 .058 114.375 72 .00184 .027 .054 121.630 84 .00596 -.051 .050 126.601 96 .020108 .089 .046 138.060 108 .027120 -.022 .041 161.164 120 .007
a The underlying process assumed is independence (white noise). b Based on the asymptotic chi-square approximation. Tabla (3.32)
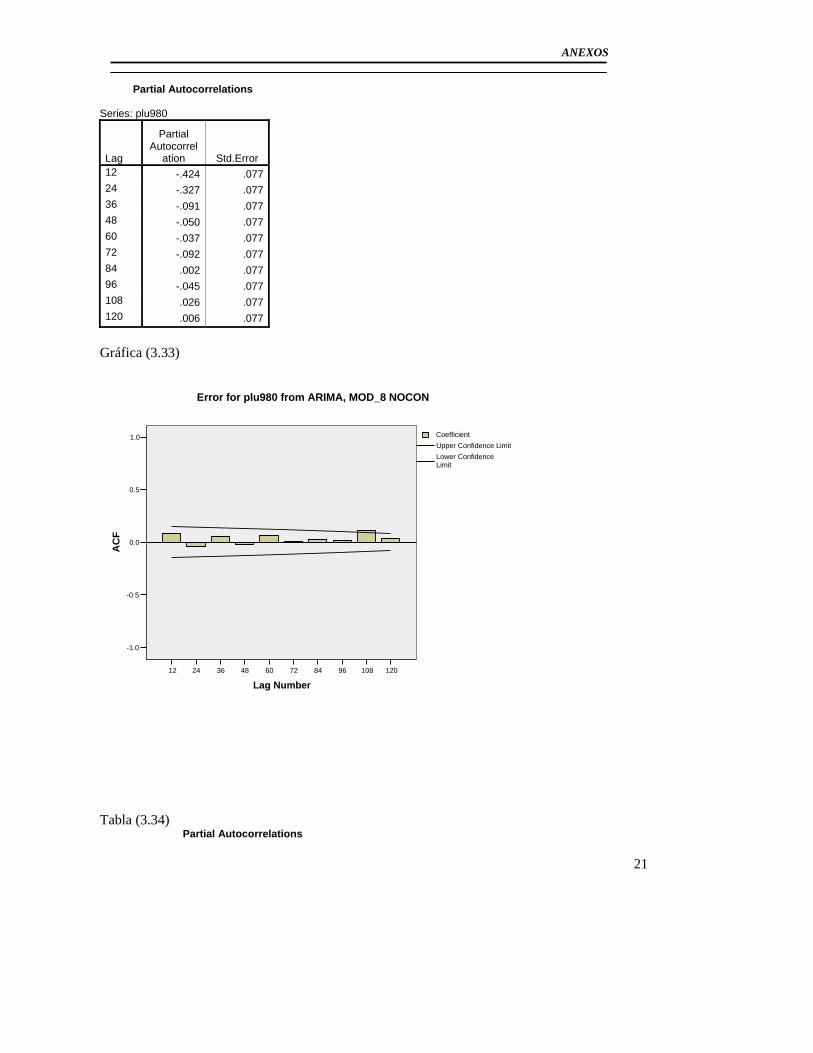
Ca
21
ANEXOS
Partial Autocorrelations Series: plu980
Lag
Partial Autocorrel
ation Std.Error 12 -.424 .077 24 -.327 .077 36 -.091 .077 48 -.050 .077 60 -.037 .077 72 -.092 .077 84 .002 .077 96 -.045 .077 108 .026 .077 120 .006 .077
Gráfica (3.33)
1201089684726048362412
Lag Number
1.0
0.5
0.0
-0.5
-1.0
AC
F
Lower ConfidenceLimit
Upper Confidence LimitCoefficient
Error for plu980 from ARIMA, MOD_8 NOCON
Tabla (3.34) Partial Autocorrelations
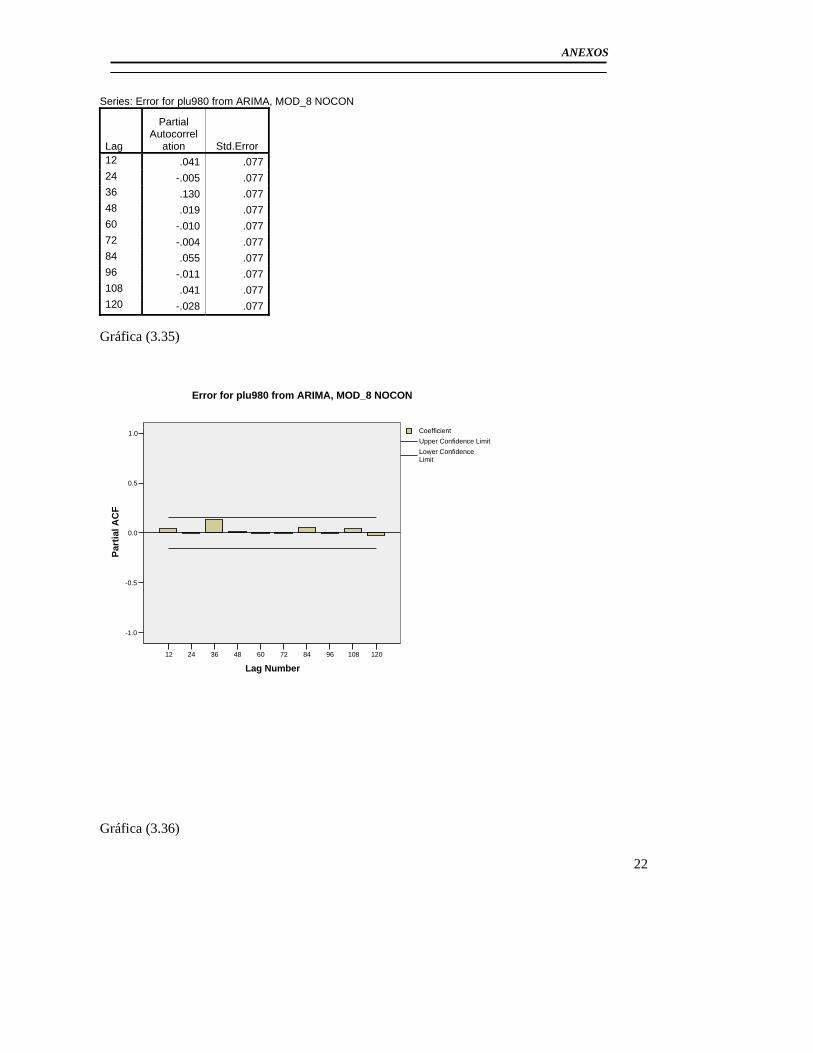
Ca
22
ANEXOS
Series: Error for plu980 from ARIMA, MOD_8 NOCON
Lag
Partial Autocorrel
ation Std.Error 12 .041 .077 24 -.005 .077 36 .130 .077 48 .019 .077 60 -.010 .077 72 -.004 .077 84 .055 .077 96 -.011 .077 108 .041 .077 120 -.028 .077
Gráfica (3.35)
1201089684726048362412
Lag Number
1.0
0.5
0.0
-0.5
-1.0
Part
ial A
CF
Lower ConfidenceLimit
Upper Confidence LimitCoefficient
Error for plu980 from ARIMA, MOD_8 NOCON
Gráfica (3.36)
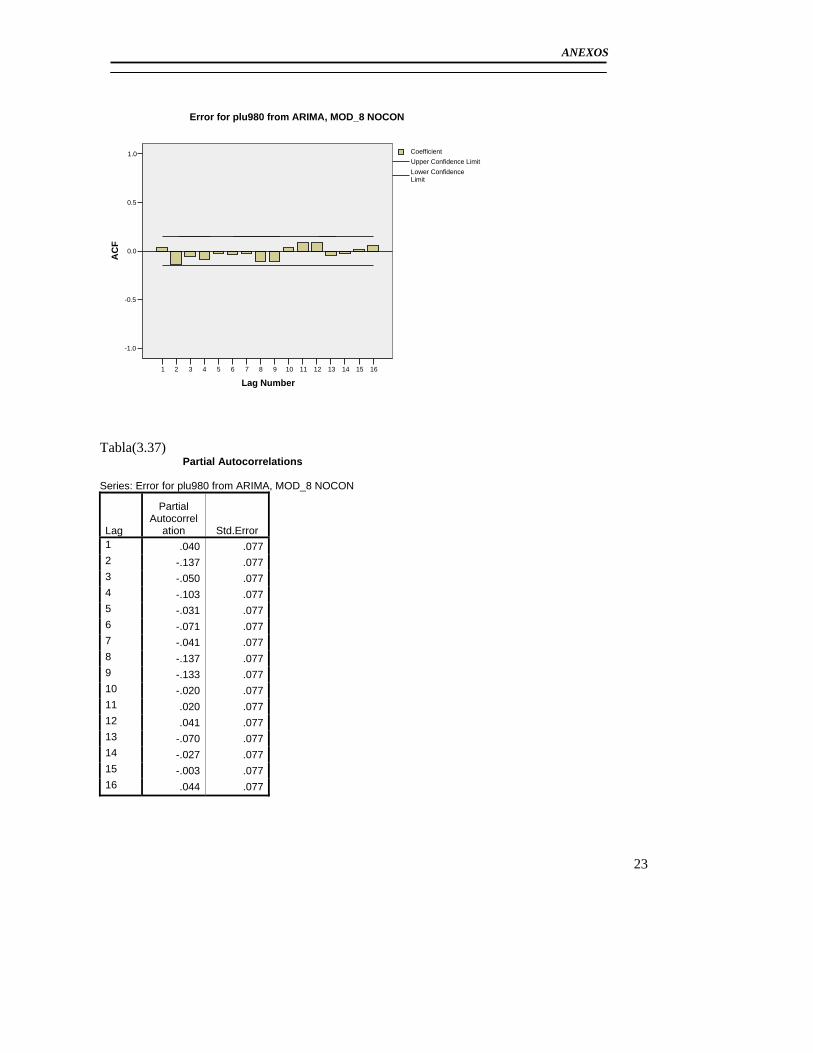
Ca
23
ANEXOS
16151413121110987654321
Lag Number
1.0
0.5
0.0
-0.5
-1.0
AC
F
Lower ConfidenceLimit
Upper Confidence LimitCoefficient
Error for plu980 from ARIMA, MOD_8 NOCON
Tabla(3.37) Partial Autocorrelations Series: Error for plu980 from ARIMA, MOD_8 NOCON
Lag
Partial Autocorrel
ation Std.Error 1 .040 .077 2 -.137 .077 3 -.050 .077 4 -.103 .077 5 -.031 .077 6 -.071 .077 7 -.041 .077 8 -.137 .077 9 -.133 .077 10 -.020 .077 11 .020 .077 12 .041 .077 13 -.070 .077 14 -.027 .077 15 -.003 .077 16 .044 .077
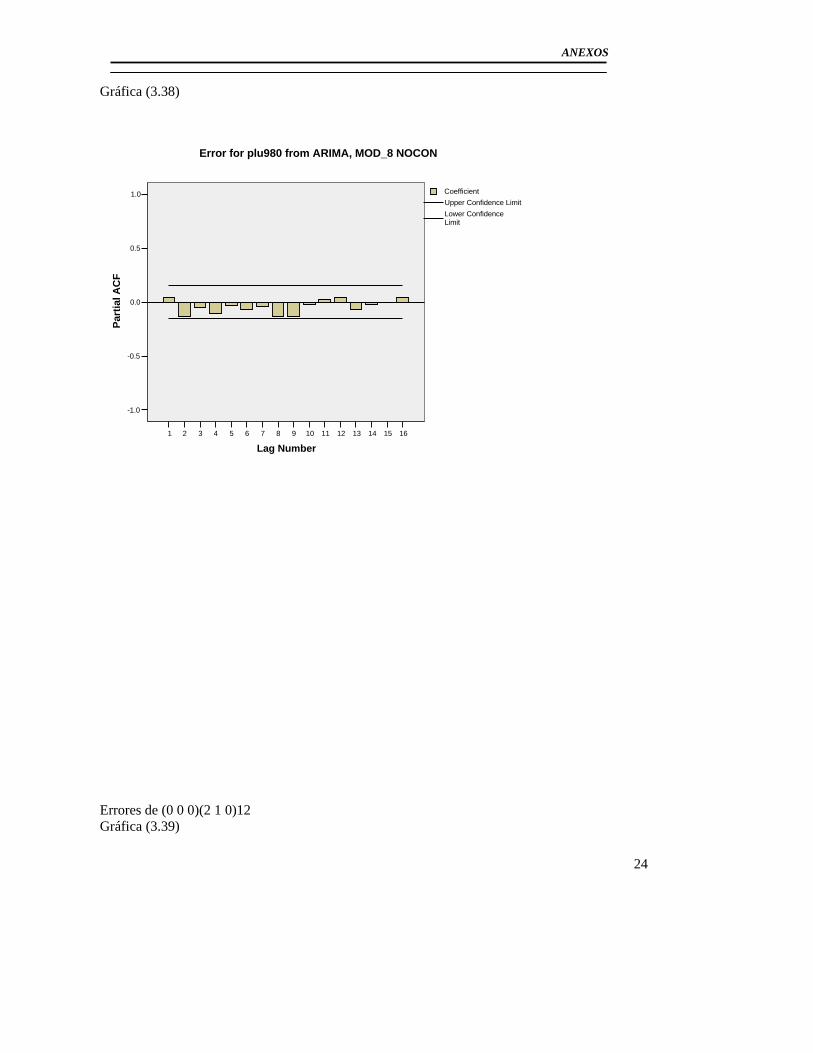
Ca
24
ANEXOS
Gráfica (3.38)
16151413121110987654321
Lag Number
1.0
0.5
0.0
-0.5
-1.0
Part
ial A
CF
Lower ConfidenceLimit
Upper Confidence LimitCoefficient
Error for plu980 from ARIMA, MOD_8 NOCON
Errores de (0 0 0)(2 1 0)12 Gráfica (3.39)
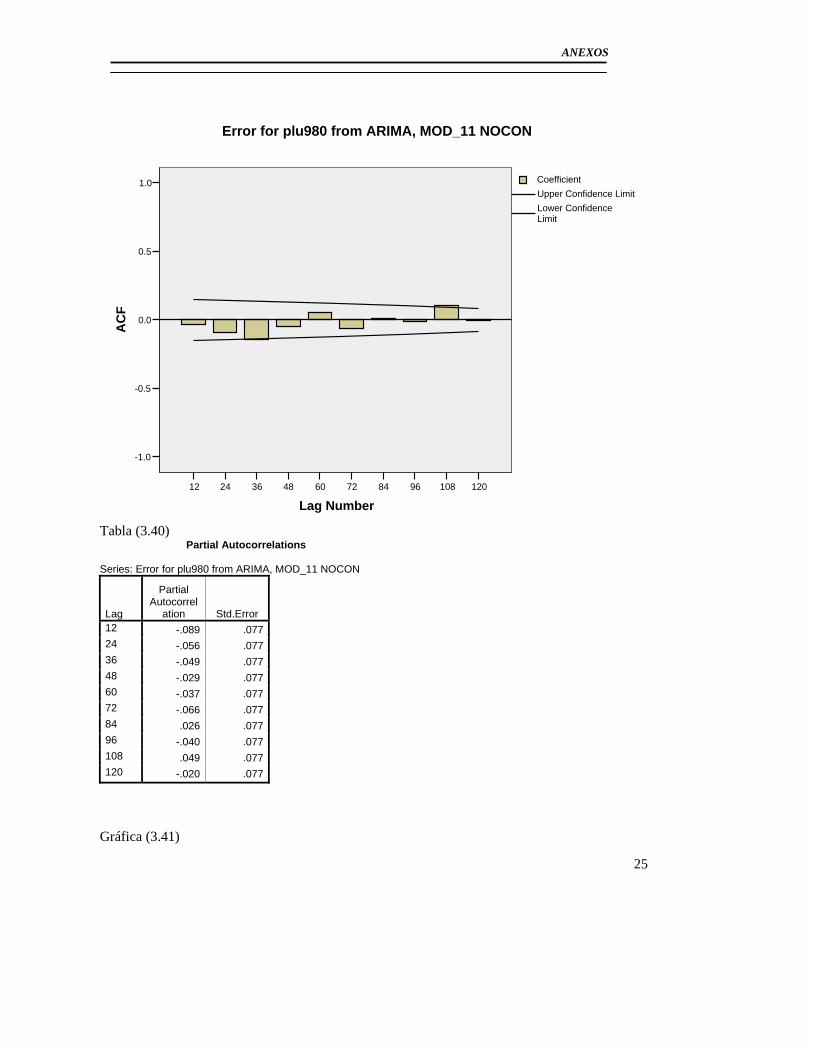
Ca
25
ANEXOS
1201089684726048362412
Lag Number
1.0
0.5
0.0
-0.5
-1.0
AC
F
Lower ConfidenceLimit
Upper Confidence LimitCoefficient
Error for plu980 from ARIMA, MOD_11 NOCON
Tabla (3.40) Partial Autocorrelations Series: Error for plu980 from ARIMA, MOD_11 NOCON
Lag
Partial Autocorrel
ation Std.Error 12 -.089 .077 24 -.056 .077 36 -.049 .077 48 -.029 .077 60 -.037 .077 72 -.066 .077 84 .026 .077 96 -.040 .077 108 .049 .077 120 -.020 .077
Gráfica (3.41)
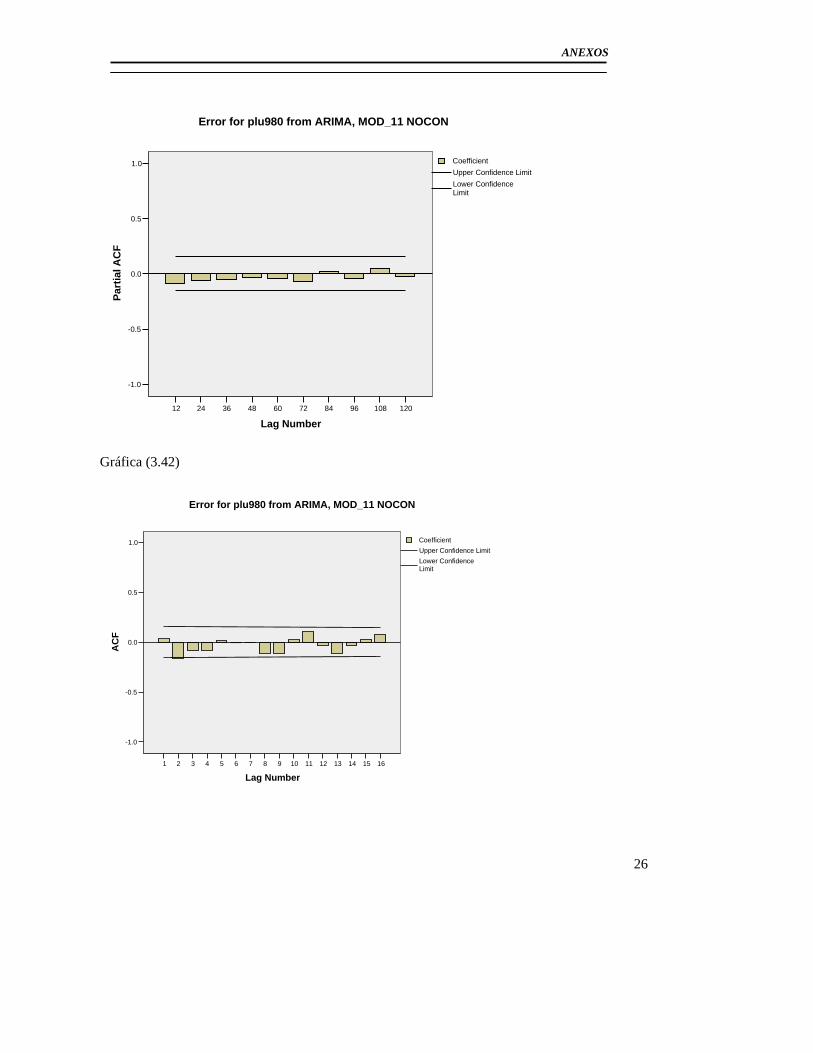
Ca
26
ANEXOS
1201089684726048362412
Lag Number
1.0
0.5
0.0
-0.5
-1.0
Part
ial A
CF
Lower ConfidenceLimit
Upper Confidence LimitCoefficient
Error for plu980 from ARIMA, MOD_11 NOCON
Gráfica (3.42)
16151413121110987654321
Lag Number
1.0
0.5
0.0
-0.5
-1.0
AC
F
Lower ConfidenceLimit
Upper Confidence LimitCoefficient
Error for plu980 from ARIMA, MOD_11 NOCON
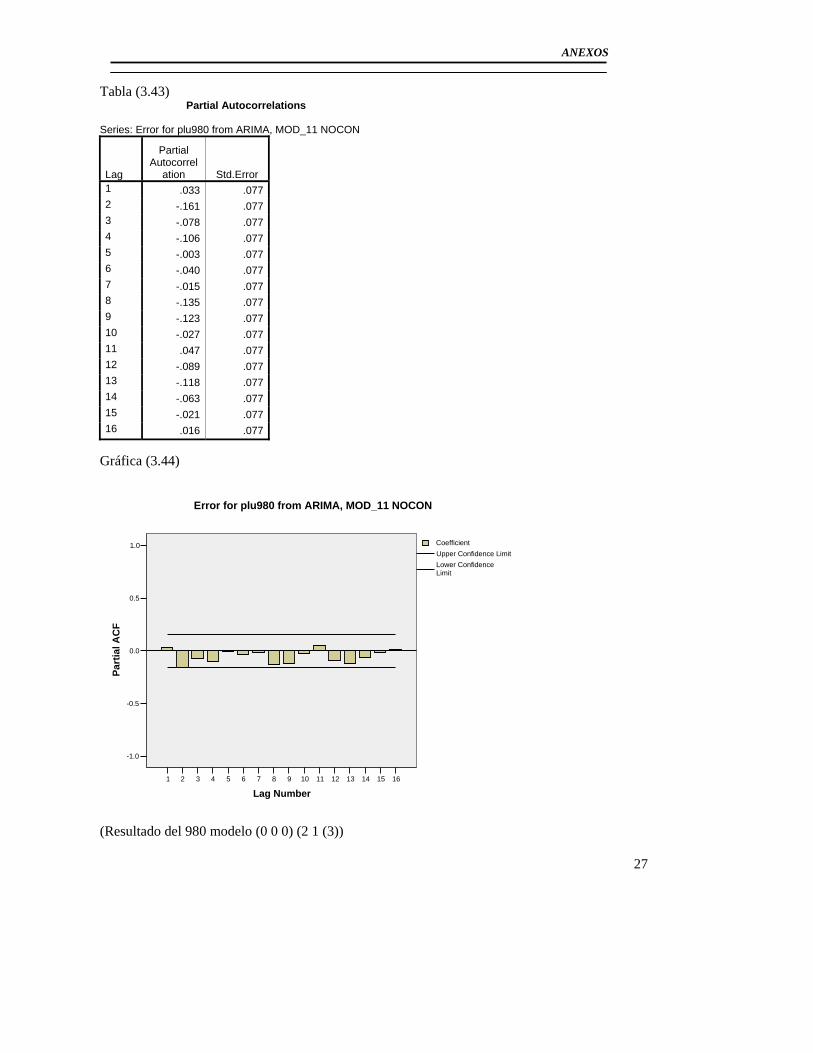
Ca
27
ANEXOS
Tabla (3.43) Partial Autocorrelations Series: Error for plu980 from ARIMA, MOD_11 NOCON
Lag
Partial Autocorrel
ation Std.Error 1 .033 .077 2 -.161 .077 3 -.078 .077 4 -.106 .077 5 -.003 .077 6 -.040 .077 7 -.015 .077 8 -.135 .077 9 -.123 .077 10 -.027 .077 11 .047 .077 12 -.089 .077 13 -.118 .077 14 -.063 .077 15 -.021 .077 16 .016 .077
Gráfica (3.44)
16151413121110987654321
Lag Number
1.0
0.5
0.0
-0.5
-1.0
Part
ial A
CF
Lower ConfidenceLimit
Upper Confidence LimitCoefficient
Error for plu980 from ARIMA, MOD_11 NOCON
(Resultado del 980 modelo (0 0 0) (2 1 (3))
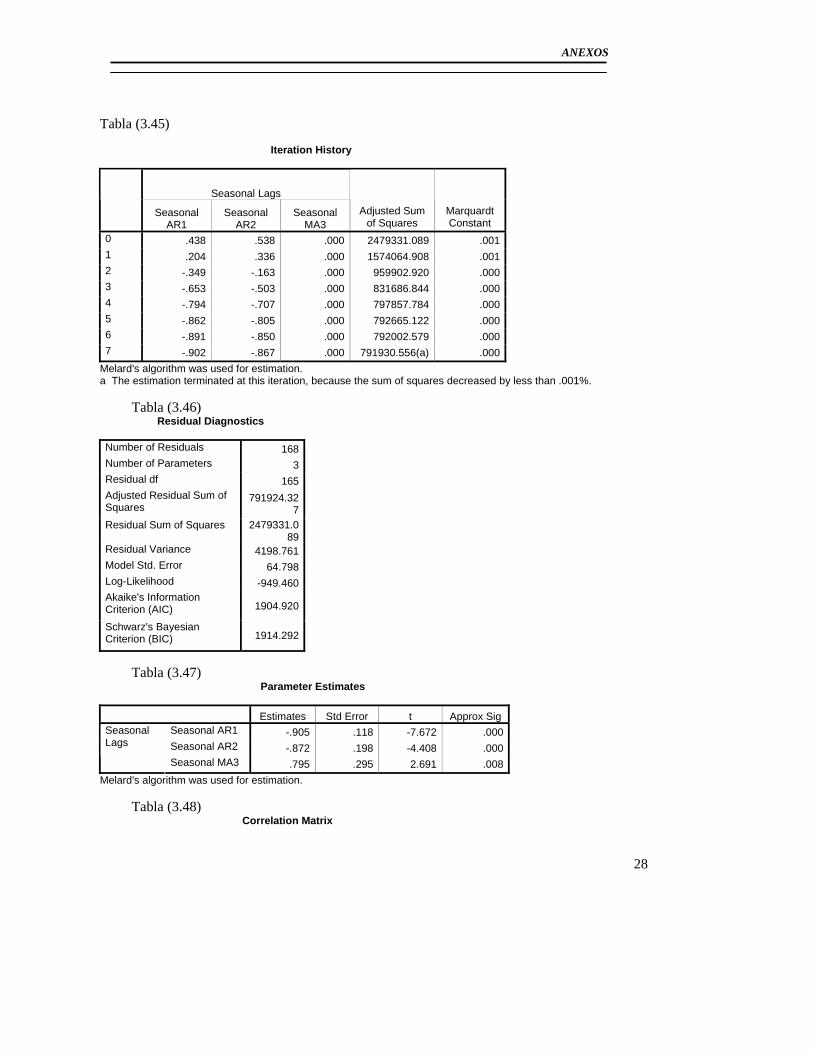
Ca
28
ANEXOS
Tabla (3.45) Iteration History
Seasonal Lags
Seasonal
AR1 Seasonal
AR2 Seasonal
MA3 Adjusted Sum
of Squares Marquardt Constant
0 .438 .538 .000 2479331.089 .0011 .204 .336 .000 1574064.908 .0012 -.349 -.163 .000 959902.920 .0003 -.653 -.503 .000 831686.844 .0004 -.794 -.707 .000 797857.784 .0005 -.862 -.805 .000 792665.122 .0006 -.891 -.850 .000 792002.579 .0007 -.902 -.867 .000 791930.556(a) .000
Melard's algorithm was used for estimation. a The estimation terminated at this iteration, because the sum of squares decreased by less than .001%.
Tabla (3.46) Residual Diagnostics Number of Residuals 168 Number of Parameters 3 Residual df 165 Adjusted Residual Sum of Squares
791924.327
Residual Sum of Squares 2479331.089
Residual Variance 4198.761 Model Std. Error 64.798 Log-Likelihood -949.460 Akaike's Information Criterion (AIC) 1904.920
Schwarz's Bayesian Criterion (BIC) 1914.292
Tabla (3.47)
Parameter Estimates Estimates Std Error t Approx Sig
Seasonal AR1 -.905 .118 -7.672 .000Seasonal AR2 -.872 .198 -4.408 .000
Seasonal Lags
Seasonal MA3 .795 .295 2.691 .008Melard's algorithm was used for estimation.
Tabla (3.48) Correlation Matrix
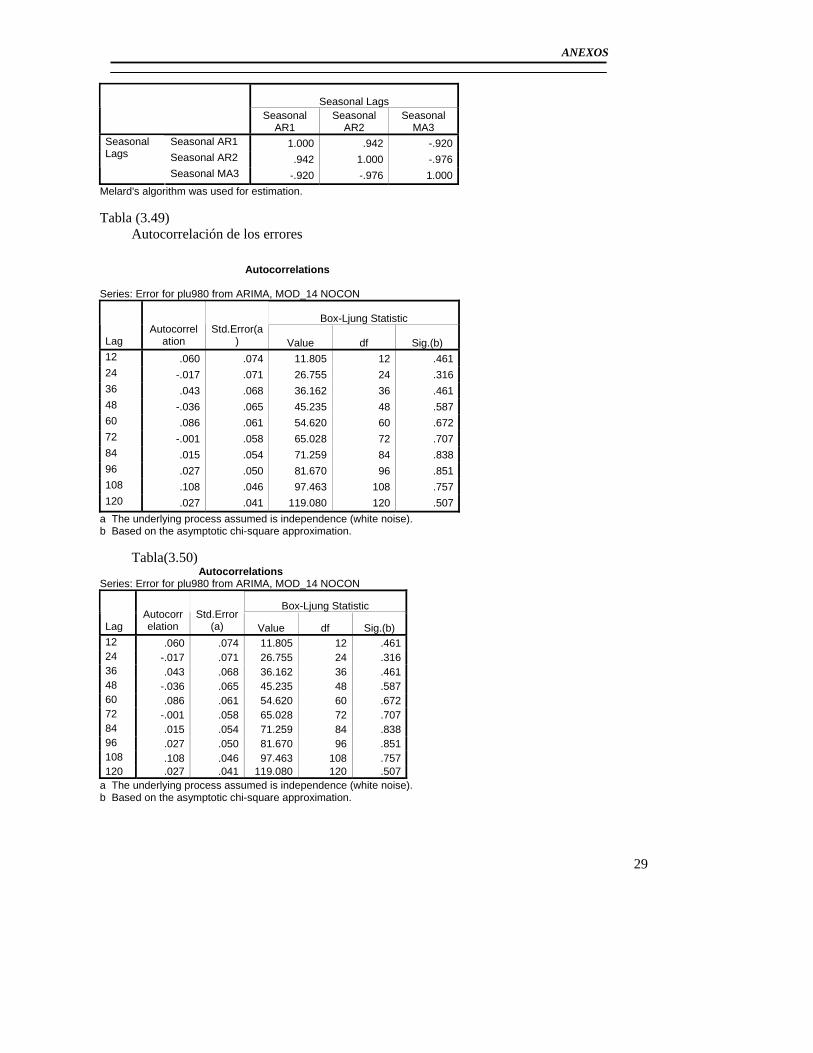
Ca
29
ANEXOS
Seasonal Lags
Seasonal
AR1 Seasonal
AR2 Seasonal
MA3 Seasonal AR1 1.000 .942 -.920Seasonal AR2 .942 1.000 -.976
Seasonal Lags
Seasonal MA3 -.920 -.976 1.000Melard's algorithm was used for estimation. Tabla (3.49)
Autocorrelación de los errores
Autocorrelations Series: Error for plu980 from ARIMA, MOD_14 NOCON
Box-Ljung Statistic
Lag Autocorrel
ation Std.Error(a
) Value df Sig.(b) 12 .060 .074 11.805 12 .46124 -.017 .071 26.755 24 .31636 .043 .068 36.162 36 .46148 -.036 .065 45.235 48 .58760 .086 .061 54.620 60 .67272 -.001 .058 65.028 72 .70784 .015 .054 71.259 84 .83896 .027 .050 81.670 96 .851108 .108 .046 97.463 108 .757120 .027 .041 119.080 120 .507
a The underlying process assumed is independence (white noise). b Based on the asymptotic chi-square approximation.
Tabla(3.50) Autocorrelations Series: Error for plu980 from ARIMA, MOD_14 NOCON
Box-Ljung Statistic
Lag Autocorrelation
Std.Error(a) Value df Sig.(b)
12 .060 .074 11.805 12 .46124 -.017 .071 26.755 24 .31636 .043 .068 36.162 36 .46148 -.036 .065 45.235 48 .58760 .086 .061 54.620 60 .67272 -.001 .058 65.028 72 .70784 .015 .054 71.259 84 .83896 .027 .050 81.670 96 .851108 .108 .046 97.463 108 .757120 .027 .041 119.080 120 .507
a The underlying process assumed is independence (white noise). b Based on the asymptotic chi-square approximation.

Ca
30
ANEXOS
Gráfico (3.51)
1201089684726048362412
Lag Number
1.0
0.5
0.0
-0.5
-1.0
AC
F
Lower ConfidenceLimit
Upper Confidence LimitCoefficient
Error for plu980 from ARIMA, MOD_14 NOCON
Tabla (3.52) Partial Autocorrelations Series: Error for plu980 from ARIMA, MOD_14 NOCON
Lag
Partial Autocorrel
ation Std.Error 12 .020 .077 24 .012 .077 36 .119 .077 48 .011 .077 60 .002 .077 72 -.012 .077 84 .055 .077 96 -.009 .077 108 .036 .077 120 -.025 .077
Gráfico (3.53)
Ca
31
ANEXOS
1201089684726048362412
Lag Number
1.0
0.5
0.0
-0.5
-1.0
Part
ial A
CF
Lower ConfidenceLimit
Upper Confidence LimitCoefficient
Error for plu980 from ARIMA, MOD_14 NOCON


















