
And Regla Delta
25
Redes Redes Neuronales Neuronales Artificiales Artificiales Dr. Raúl R. Leal Ascencio Área de Control Automático Departamento de Electrónica, Sistemas e Informática. [email protected]
-
Upload
diego-romero -
Category
Documents
-
view
15 -
download
0
Transcript of And Regla Delta

Redes Redes NeuronalesNeuronalesArtificialesArtificiales
Dr. Raúl R. Leal AscencioÁrea de Control Automático
Departamento de Electrónica, Sistemas e Informática.

Contenido del curso Introducción y Antecedentes Perceptron
– Estructura y entrenamiento– Separabilidad lineal– Aplicaciones (funciones lógicas, clasificación)
Redes Lineales– Estructura y entrenamiento– Razón de aprendizaje– Nodos adaptativos– Aplicaciones (filtros lineales adaptativos, aproximación
lineal) Redes Multicapa
– Estructura y entrenamiento– Mejoras de entrenamiento– Pre y post procesamiento– Aplicaciones (reconocimiento óptico de caracteres,
sensores virtuales) Redes de Funciones de Base Radial
– Estructura y entrenamiento– Aplicaciones (reconocimiento y clasificación de patrones)

Perspectiva histórica Pre-1940: von Hemholtz, Mach, Pavlov, etc.
– Teorías generales sobre el aprendizaje, visión y condicionamiento sin modelos matemáticos específicos sobre la operación neuronal.
1940s: Hebb, McCulloch and Pitts– Mecanismo de aprendizaje en neuronas biológicas– Redes de elementos ‘neuronales’ pueden hacer cómputo
aritmético 1950s: Rosenblatt, Widrow and Hoff
– Primeras redes artificiales (RNA) prácticas y reglas de aprendizaje
1960s: Minsky and Papert– Demostraron las limitaciones de las RNA existentes, no se
estaban desarrollando nuevos algoritmos de aprendizaje. Muchas investigaciones en el campo se suspenden.
1970s: Amari, Anderson, Fukushima, Grossberg, Kohonen– Continuan trabajando en el tema pero a pasos mas lentos.
1980s: Grossberg, Hopfield, Kohonen, Rumelhart, etc.– Desarrollos importantes causan un resurgimiento de estudios
en el campo.

Algunas posibles aplicaciones Espacio aéreo
– Pilotos automáticos de alto desempeño, simulaciones y predicciones de trayectoria de vuelo, sistemas de control de vuelo, detección de fallas en componentes de la nave.
Automotriz– Sistemas automáticos de navegación, comando por voz
Bancos– Lectores de documentos, evaluadores de asignación de
crédito, identificador de firmas.
Defensa Electrónica
– Predicción de secuencias de códigos, control de procesos, análisis de fallas de circuitos, visión de máquina, síntesis de voz, modelado no lineal.

Algunas posibles aplicaciones Robótica
– Control de trayectorias, control de manipuladores, sistemas de visión.
Voz– Reconocimiento de voz, compresión de voz, sintetizadores de texto a
voz.
Telecomunicaciones– Compresión de datos e imágenes, servicios automáticos de
información, traducción de lenguaje hablado en tiempo real.
Transportation– Sistemas ruteadores, diagnóstico de motores, tiempos y movimientos.
Seguridad– Reconocimiento de rostros, identificación y acceso de personas

Algunas posibles aplicaciones
Financieros– Evaluación de bienes raíces, consultor de prestamos,
valuación de bonos corporativos, análisis sel uso de la línea de crédito, predicción de tipo de cambio.
Manufactura– Control de procesos de manufactura, análisis y diseño de
productos, diagnóstico de máquinas y procesos, identificación de partes en tiempo real, sistemas de inspección de calidad, predicción de fin de proceso, análisis de mantenimiento de máquinas, modelado de sistemas dinámicos.
Medicina– Detección de cáncer mamario o en la piel, análisis de
EEG y ECG, diseño de prótesis, optimización de tiempos de trasplante, reducción de gastos en hospitales.
Oficinas postales, Verificación remota, etc.

Aspectos biológicos Las neuronas son lentas
– 10-3 s comparadas con 10-9 s para circuitos eléctricos
El cerebro usa cómputo masivamente paralelo 1011 neuronas en el cerebro 104 conexiones por neurona
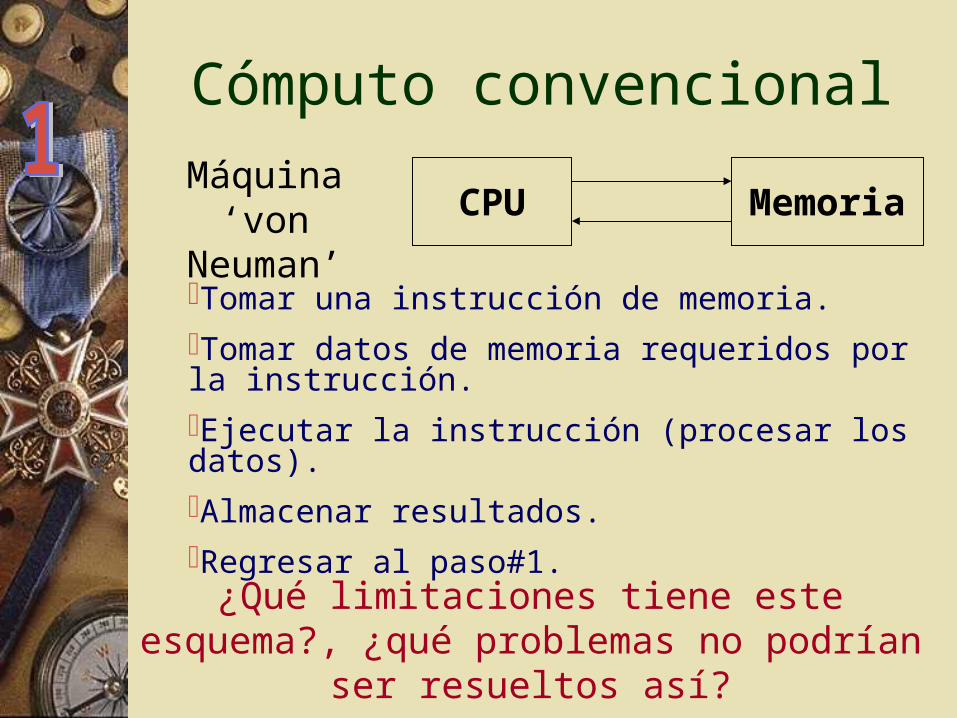
Cómputo convencional
CPU Memoria
¿Qué limitaciones tiene este esquema?, ¿qué problemas no podrían ser resueltos
así?
Máquina‘von Neuman’
Tomar una instrucción de memoria.Tomar datos de memoria requeridos por la instrucción.Ejecutar la instrucción (procesar los datos).Almacenar resultados.Regresar al paso#1.
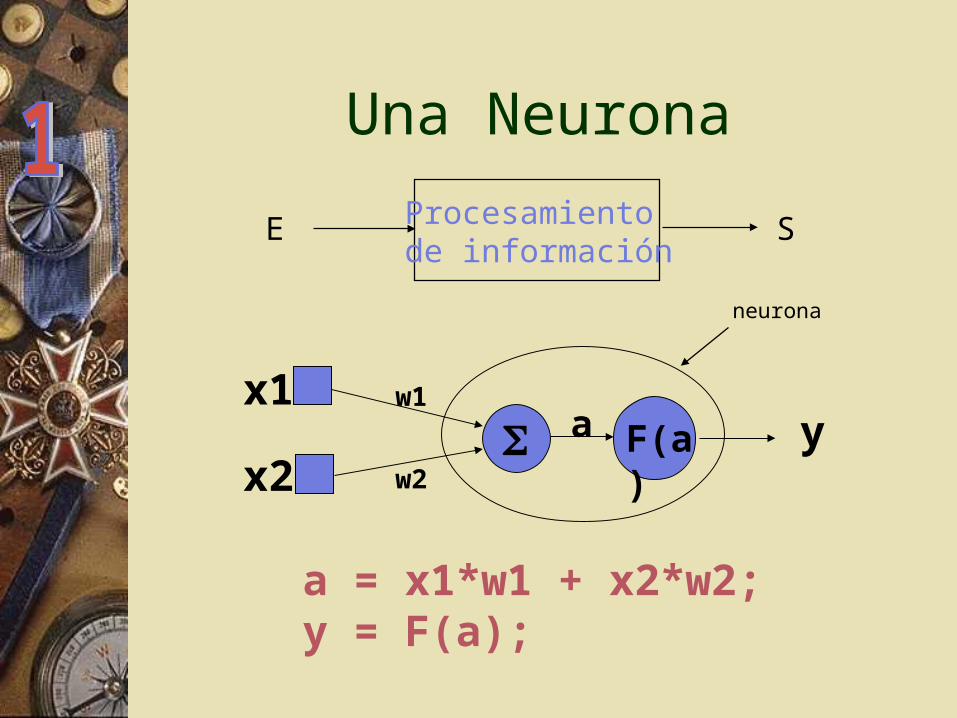
Una Neurona
E SProcesamientode información
a = x1*w1 + x2*w2;y = F(a);
neurona
F(a)
x1x2
w1
w2
ya

Definiciones Una RNA es un conjunto de nodos ordenados
adaptables los cuales, a través de un proceso de aprendizaje mediante ejemplos prototipo, almacenan conocimiento de tipo experiencial y lo hacen disponible para su uso. [An Introduction to Neural Computing. Igor Aleksander and Helen Morton, 1990]
Una RNA es un ensamble de elementos procesadores simples y adaptables, cuya funcionalidad está burdamente basada en una neurona animal. La habilidad de procesamiento de la red está almacenada en la intensidad de las conexiones entre elementos, obtenidos por un proceso de adaptación a un conjunto de patrones de entrenamiento.

Tipos de aprendizaje Aprendizaje supervisado
– A la red se le provee de un conjunto de ejemplos que representen la relación adecuada de entrada/salida (entradas/salida deseada)
p1 t1{ , } p2 t2{ , } pQ tQ{ , }
Aprendizaje reforzado A la red sólo se le da una indicación sobre el grado de
desempeño de la red
Aprendizaje no supervisado La única información disponible para la red son las
entradas. La red aprende a formar categorías a partir de un análisis de las entradas

El Perceptron Frank Rosenblatt desarrolla una prueba de convergencia
en 1962 y definió el rango de problemas para los que su algoritmo aseguraba una solución. Además propuso a los 'Perceptrons' como herramienta computacional.
neurona
F(a)
x1x2
w1
w2
ya
y = F(a)
y = 1, si (x1w1 + x2w2) y = 0, si (x1w1 + x2w2)

¿Qué tipo de problemas resuelve?
Un hiperplano es un objeto de dimensión n-1 que actúa en un espacio de dimensión n.
En general un perceptron de n entradas puede ejecutar cualquier función que esté determinada por un hiperplano que corte un espacio de dimensión n. ¿Implicaciones?

Funciones realizables
X1 X2 Y 0 0 0 0 1 1 1 0 1 1 1 1
x1
x2
(0,0) (1,0)
(1,1)(0,1)1
0
1
1
¿Qué tipo de función no sería realizable?
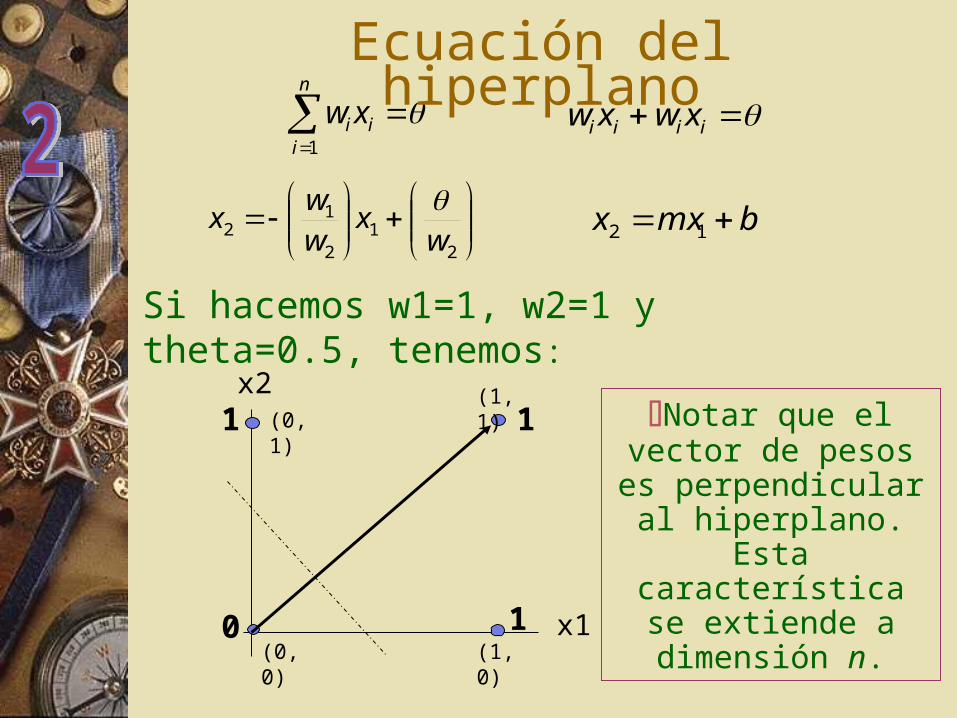
x1
x2
(0,0) (1,0)
(1,1)(0,1)1
0
1
1
Notar que el vector de pesos es perpendicular
al hiperplano. Esta característica se
extiende a dimensión n.
i
n
ii xw
1
iiii xwxw
21
2
12 w
xww
x
bmxx 12
Si hacemos w1=1, w2=1 y theta=0.5, tenemos:
Ecuación del hiperplano
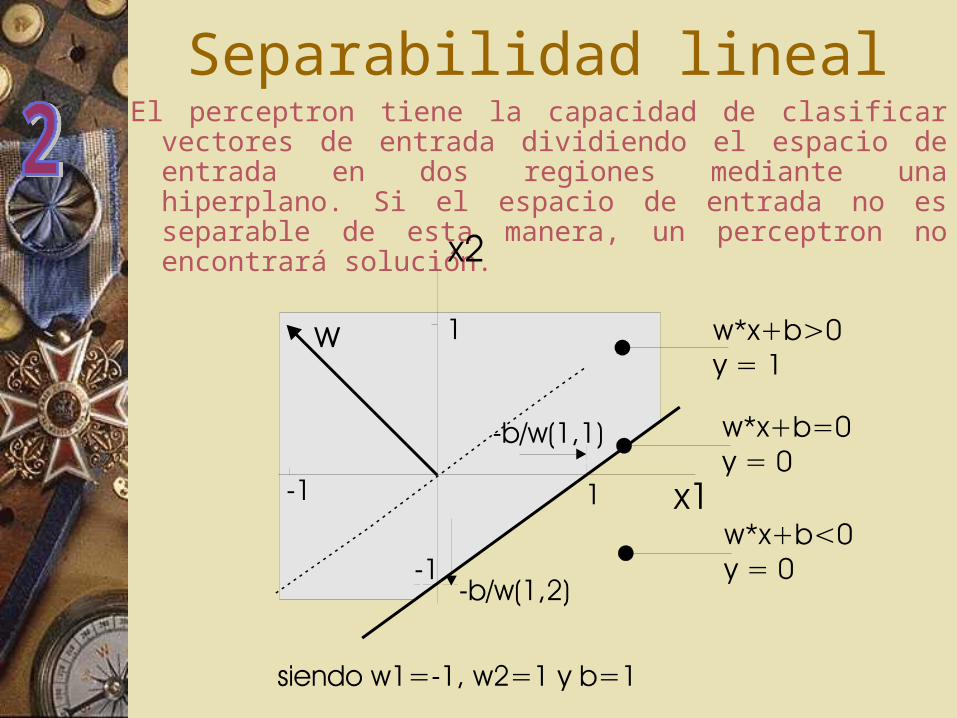
Separabilidad linealEl perceptron tiene la capacidad de clasificar vectores de
entrada dividiendo el espacio de entrada en dos regiones mediante una hiperplano. Si el espacio de entrada no es separable de esta manera, un perceptron no encontrará solución.
iiii xwxw
0)1( iiii xwxw
0 iiii xwxw
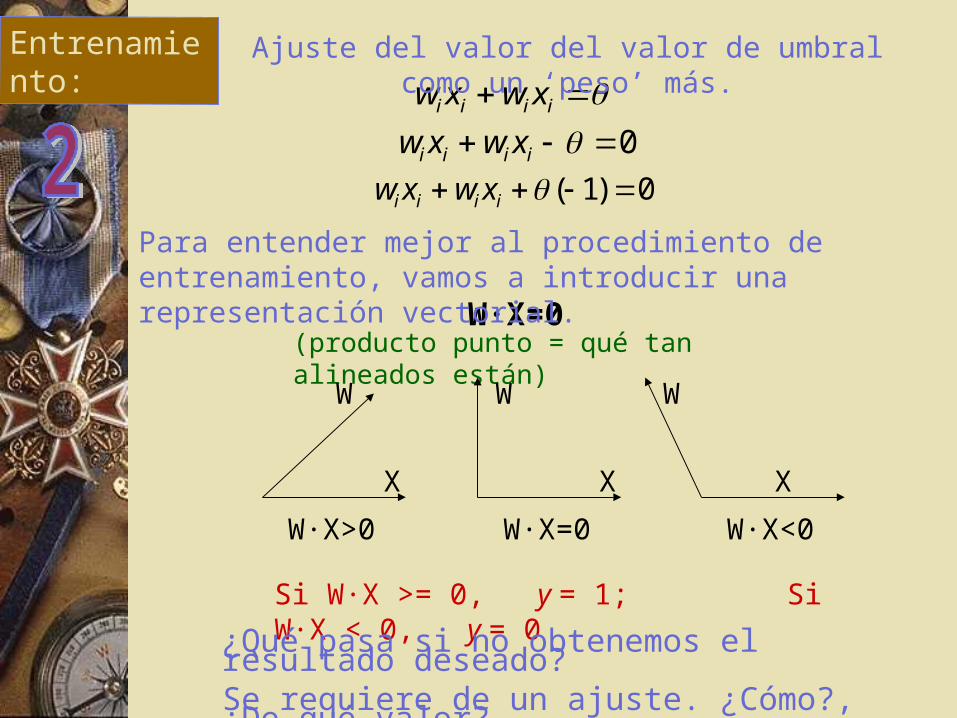
Ajuste del valor del valor de umbral como un ‘peso’ más.
W·X=0(producto punto = qué tan alineados están)
W
X
W·X>0
W
X
W·X=0
W
X
W·X<0
Si W·X >= 0, y = 1; Si W·X < 0, y = 0
¿Qué pasa si no obtenemos el resultado deseado?Se requiere de un ajuste. ¿Cómo?, ¿De qué valor?
Para entender mejor al procedimiento de entrenamiento, vamos a introducir una representación vectorial.
Entrenamiento:

WXW’
X
W’=W-X
W
XW’=W+ X
W’X
Si el resultado es 0 en lugar de 1:
En resumen:
donde 0< <1
Si el resultado es 1 en lugar de 0:
w’ = w + (t-y)x w = (t-y)x
A esto se le llama la regla de aprendizaje Delta. El parámetro es la razón de aprendizaje.

Algoritmo de entrenamiento del Perceptron
repetirpara cada par en los vectores de entrenamiento (x,t)
evaluar la salida yi cuando xi es la entrada al ...perceptronsi y t, entonces
forme un nuevo vector de pesos w’ de acuerdo a...
la ecuación correspondientede otra manera,
no haga nadafin (del si)
fin (del para)hasta que y = t para todos los vectores.
Los valores de los pesos para este caso están restringidos entre -1 y 1.

Ejemplo Supongamos que un perceptron de dos entradas
tiene pesos iniciales 0, 0.4 y umbral 0.3. Se requiere que este perceptron aprenda la función lógica AND. Suponga una razón de aprendizaje de 0.25. Usando el algoritmo anterior complete la tabla hasta que encuentre convergencia. El percepton usado es el que muestra la figura.
x1
x2
yw2
w1
t
a

w1 = 0.0w2 = 0.4 = 0.3 = 0.25t = Función AND
w’=w+(t-y)xó wi=(t-y)xi y = 1, si (x1w1 + x2w2) y = 0, si (x1w1 + x2w2) w1 w2 x
1
x
2
a y t (t-y)
w1 w2
0 0.4 0.3 0 0 0 0 0 0 0 0 0
0 0.4 0.3 0 1 0.4 1 0 -0.25 0 -0.25 0.25
0 0.15 0.55 1 0 0 0 0 0 0 0 0
0 0.15 0.55 1 1 0.15 0 1 0.25 0.25 0.25 -0.25
1) ¿Cuántas iteraciones se requieren para la convergencia?2) ¿Cuáles son los valores de convergencia de los pesos y el umbral?3) Defina algebráicamente el hiperplano de decisión.4) Demuestre gráficamente que éste hiperplano es un límite apropiado para la distinción de clases (ver gráfica) y que el vector de pesos y el hiperplano son ortogonales.
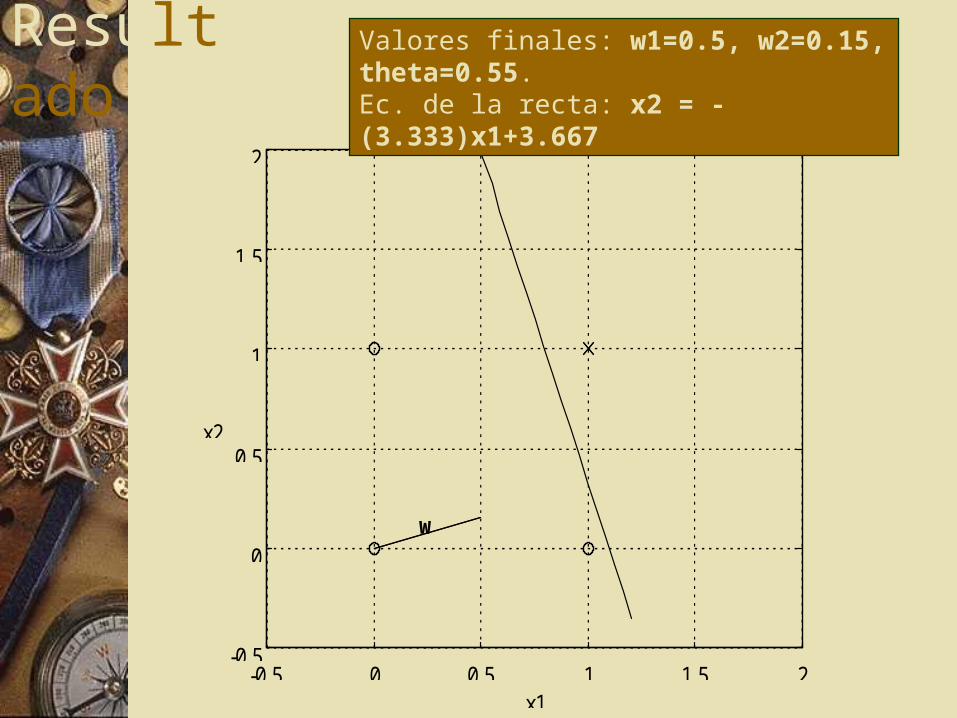
Resultado
-0.5 0 0.5 1 1.5 2-0.5
0
0.5
1
1.5
2
x1
x2
Funcion lógica e hiperplano de decisión
w
Valores finales: w1=0.5, w2=0.15, theta=0.55.Ec. de la recta: x2 = -(3.333)x1+3.667
x1
x2
(0,0) (1,0)
(1,1)(0,1)1
0
0
1
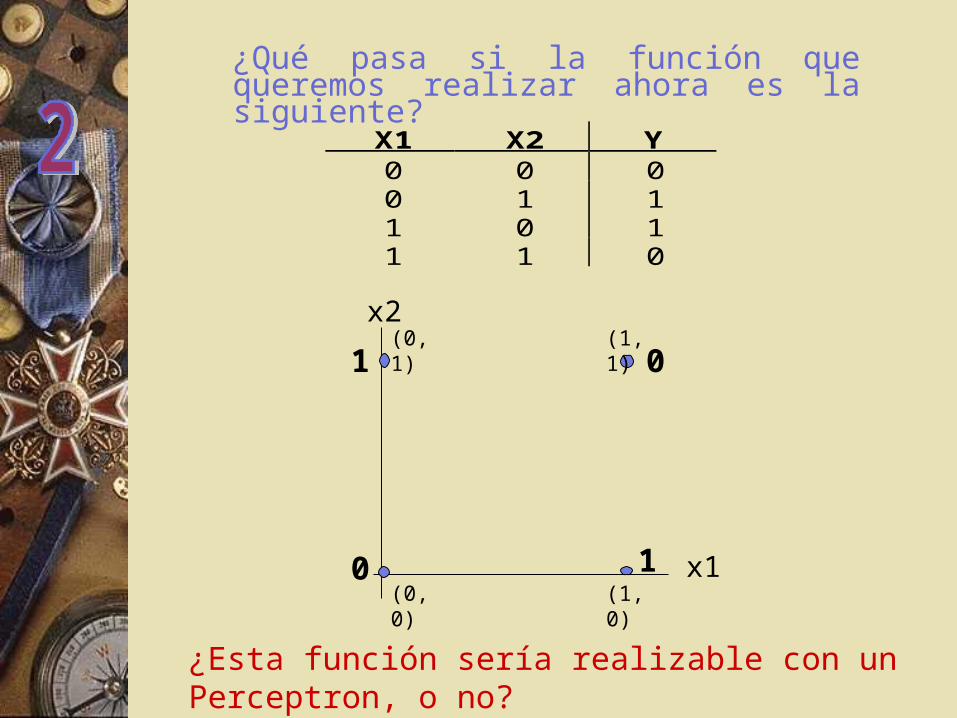
¿Esta función sería realizable con un Perceptron, o no?
¿Qué pasa si la función que queremos realizar ahora es la siguiente?
X1 X2 Y0 0 00 1 11 0 11 1 0

Medición del desempeño Qué es el factor (t - y)? Para los Perceptrons, hay corrección,
si hay error. Sólo se detecta la presencia del error, no su magnitud.
En entrenamiento, cómo se sabe que se ha encontrado convergencia?
En general, en entrenamiento se usa la figura de error de 'SSE' o suma de los cuadrados de los errores:
sse e k t k y kk
Q
k
Q
2
1
2
1
( )
Esto se usa para cuando se esta entrenando una red en 'batch' o por lotes. Un lote en este caso es el conjunto de vectores de entrada que se muestran a la red para que ésta los procese en conjunto (en lugar de presentarlos vector por vector).

EPOCA y BIAS
Se le llama época a cada iteración de la red por el lote de entradas en la que haya ajuste de variables. El ajuste de variables se puede hacer después de la presentación de vectores de entrada individuales o por lotes.
La variable también es llamada elemento de tendencia o 'bias' porque, como se ve en la figura anterior, es el que mueve el hiperplano de decisión a lo largo del eje 'x' (en este caso). A esta variable se le denomina en muchas ocaciones con el símbolo 'b'.


















![Signs,Signals and Barricades (67.177) [Regla Final]](https://static.fdocuments.es/doc/165x107/5695cf161a28ab9b028c8a8d/signssignals-and-barricades-67177-regla-final.jpg)