
ANÁLISIS REGIONAL DE LOS CAUDALES MÁXIMOS DE LA …
10
ANÁLISIS REGIONAL DE LOS CAUDALES MÁXIMOS DE LA CUENCA SUR TAGUAS RUIZ, Encarnación; GARCÍA MARÍN, Amanda; SÁNCHEZ TRIGO, Mª Carmen, AYUSO MUÑOZ, J.L. (p) y PEÑA ACEVEDO Adolfo. 1. INTRODUCCIÓN. Periódicamente, las avenidas producen cuantiosas pérdidas por daños materiales e incluso humanos, constituyendo un grave problema económico y social. De los aproximadamente 1.400 puntos inventariados en la Península Ibérica con riesgo de inundación, la mayoría están distribuidos en las cuencas mediterráneas y las del Norte de España, existiendo muchos de ellos en la cuenca Sur perteneciente a Andalucía (Berga, 1.987). La previsión de las avenidas puede, generalmente, reducir los daños causados por las inundaciones. El método más usual de previsión de avenidas es el análisis de frecuencias para el diseño de estructuras hidraúlicas para su control y para la zonificación de la llanura de inundación (Kite, 1.977). El objetivo fundamental del análisis de frecuencias es la estimación de los sucesos máximos (precipitaciones máximas, caudales, etc.) correspondientes a diferentes períodos de retorno mediante el uso de funciones de distribución de probabilidad. La estimación de la frecuencia de los eventos es compleja, dado que los registros de las series de observaciones o no existen o son demasiado cortos para poder extrapolar con criterio, como es el caso de la Cuenca Sur. De acuerdo con Hosking y Wallis (1.997), el análisis regional de frecuencias aumenta la fiabilidad de las estimaciones de las magnitudes de avenidas extremas (cuantiles) de la estación de aforo de interés, ya que incluye los datos de otras estaciones que presentan distribuciones de frecuencia similares a las de la primera estación , “paliando la carencia en el tiempo con la abundancia en el espacio”. Así, la zona de estudio se divide en regiones homogéneas, unidad de trabajo del análisis regional, donde la distribución de los eventos máximos es la misma, excepto por una factor de escala o índice de avenida, que refleja las características de los caudales de cada estación. Conocidos los cuantiles a escala regional y los valores medios locales, se pueden extrapolar los extremos locales de cada estación con una mayor fiabilidad que mediante el análisis local de frecuencias en los lugares donde los registros son escasos. Si se define N como el número de estaciones de una región homogénea y n i el número de datos por estación, Q ij , j=1,2..,n j se corresponde con los datos observados y Q i (F) , 0 < F < 1, con la función cuantil de la distribución de frecuencia de cada lugar. Según el principio descrito en que se basa el método del índice de avenida, puede escribirse: Q i (F)=µ i q (F), i=1,2,...N (1) De esta expresión se extrae que µ i es el índice de avenida que tomará el valor de la media de la distribución de frecuencia de la estación considerada y q (F) es la curva regional de frecuencia igual a la distribución , Q ij /µ i. . Por otra parte, los L-momentos constituyen un sistema alternativo al método tradicional (momentos convencionales) para describir las formas de las funciones de 1 925
Transcript of ANÁLISIS REGIONAL DE LOS CAUDALES MÁXIMOS DE LA …

ANÁLISIS REGIONAL DE LOS CAUDALES MÁXIMOS DE LA CUENCA SUR
TAGUAS RUIZ, Encarnación; GARCÍA MARÍN, Amanda; SÁNCHEZ TRIGO, Mª
Carmen, AYUSO MUÑOZ, J.L. (p) y PEÑA ACEVEDO Adolfo.
1. INTRODUCCIÓN. Periódicamente, las avenidas producen cuantiosas pérdidas por daños materiales
e incluso humanos, constituyendo un grave problema económico y social. De los aproximadamente 1.400 puntos inventariados en la Península Ibérica con riesgo de inundación, la mayoría están distribuidos en las cuencas mediterráneas y las del Norte de España, existiendo muchos de ellos en la cuenca Sur perteneciente a Andalucía (Berga, 1.987). La previsión de las avenidas puede, generalmente, reducir los daños causados por las inundaciones. El método más usual de previsión de avenidas es el análisis de frecuencias para el diseño de estructuras hidraúlicas para su control y para la zonificación de la llanura de inundación (Kite, 1.977).
El objetivo fundamental del análisis de frecuencias es la estimación de los
sucesos máximos (precipitaciones máximas, caudales, etc.) correspondientes a diferentes períodos de retorno mediante el uso de funciones de distribución de probabilidad. La estimación de la frecuencia de los eventos es compleja, dado que los registros de las series de observaciones o no existen o son demasiado cortos para poder extrapolar con criterio, como es el caso de la Cuenca Sur. De acuerdo con Hosking y Wallis (1.997), el análisis regional de frecuencias aumenta la fiabilidad de las estimaciones de las magnitudes de avenidas extremas (cuantiles) de la estación de aforo de interés, ya que incluye los datos de otras estaciones que presentan distribuciones de frecuencia similares a las de la primera estación , “paliando la carencia en el tiempo con la abundancia en el espacio”. Así, la zona de estudio se divide en regiones homogéneas, unidad de trabajo del análisis regional, donde la distribución de los eventos máximos es la misma, excepto por una factor de escala o índice de avenida, que refleja las características de los caudales de cada estación. Conocidos los cuantiles a escala regional y los valores medios locales, se pueden extrapolar los extremos locales de cada estación con una mayor fiabilidad que mediante el análisis local de frecuencias en los lugares donde los registros son escasos.
Si se define N como el número de estaciones de una región homogénea y ni el número de datos por estación, Qij, j=1,2..,nj se corresponde con los datos observados y Qi (F) , 0 < F < 1, con la función cuantil de la distribución de frecuencia de cada lugar. Según el principio descrito en que se basa el método del índice de avenida, puede escribirse:
Qi (F)=µi q (F), i=1,2,...N (1)
De esta expresión se extrae que µi es el índice de avenida que tomará el valor de la media de la distribución de frecuencia de la estación considerada y q (F) es la curva regional de frecuencia igual a la distribución , Qij /µi..
Por otra parte, los L-momentos constituyen un sistema alternativo al método tradicional (momentos convencionales) para describir las formas de las funciones de
1 925

distribución de los eventos extremos en cada estación, permitiendo una vez definidos de forma adimensional formar parte de los estadísticos que forman parte de las pruebas del análisis regional. Surgen de combinaciones lineales de los momentos ponderados probabilísticamente (MPP) de una variable aleatoria χ con una función de distribución F.
Mijk = E [xiFi(1 – F)k ] (2)
λλ
λλ
De esta forma, para i = 1, k = 0 y j = 1,2,.., los cuatro primeros L-momentos λi se pueden expresar en términos de MPP según las siguientes expresiones:
1 = M100 (3) 2 = 2M110 - M100 (4)
3 =6 M120 - 6 M110 + M100 (5) 4 =20 M130 -30 M120 + 12 M110 - M100 (6)
El momento lineal de primer orden (λ1) es el parámetro de localización o media de la distribución, mientras que el segundo (λ2) mide la escala de la distribución indicando el grado de dispersión entre los datos. Se puede definir un coeficiente-L de variación como:
LCv = τ = λ2 / λ1 (7)
Mientras que los coeficientes-L de asimetría y curtosis serían respectivamente:
LCs = τ3 = λ3 / λ2 (8) LCk = τ4 = λ4 / λ2 (9)
En este trabajo, se pretende realizar un análisis regional de frecuencias en la zona correspondiente a la Cuenca Sur de España de las series de caudales máximos anuales para estimar los cuantiles correspondientes a diversos períodos de retorno entre 2 y 100 años.
2. FASES DEL ANÁLISIS REGIONAL
El análisis regional de frecuencia consta básicamente de cinco etapas:
1. Análisis y filtrado de los datos primarios de observaciones. 2. Identificación de regiones homogéneas. 3. Selección de la distribución regional de frecuencia. 4. Estimación de los cuantiles regionales de frecuencia. 5. Análisis de robustez de los modelos seleccionados.
2.1. Análisis y filtrados de datos. El objetivo de esta etapa es satisfacer que los datos recogidos en un sitio sean una representación real de las cantidades observadas, por lo que se deben eliminar el mayor número de errores derivados de las circunstancias de medición, transcripción, etc. Hosking y Wallis (1.997) proponen una prueba de discordancia, que persigue identificar lugares que son notablemente diferentes en comparación con el resto de las estaciones
2 926

de la región. Así, se identifican estaciones cuyos valores muestrales de los L-momentos difieren significativamente del resto. Se considera que el vector de L-momentos (LCv, LCs, LCk) de una estación determinada constituye un punto de un espacio tridimensional, por lo que un grupo de estaciones producirá una nube de puntos en este espacio. De esta manera, cualquier punto que se aleje del centro de gravedad de esta nube de puntos deberá ser considerado como discordante. La medida de discordancia se define a partir del siguiente estadístico:
Di = N / 3 (N-1) (ui - uµ )T S-1 (ui - uµ ) (10)
N
Siendo S = ∑ (ui - uµ ) (ui - uµ ) (11) i = 1 N
uµ = N -1 ∑ ui (12) i = 1
Los valores elevados de Di son característicos de estaciones que se apartan del comportamiento general del resto de estaciones. Se definen distintos umbrales en función del número de estaciones que constituyen la región y que se contemplan en la etapa siguiente. En el caso de la Cuenca Sur se han contado con 22 subcuencas (N = 22) con un número muy dispar de datos registrados, (Figura 1 y Tabla 1). El cálculo de los coeficientes lineales de variación sesgo y curtosis, así como los momentos desde primer a quinto orden se han llevado a cabo mediante el programa RAZMOME1. El programa XTEST, ha llevado a cabo las correspondientes pruebas de discordancia y de homogeneidad (etapa 2.2), extrayéndose que para grupos de 7 estaciones (N = 7), el umbral crítico de discordancia según Hosking y Wallis (1.997) es igual 1,917 que ha excluido a la cuenca Campobuche (6030).
Figura 1. Subcuencas de la Cuenca Sur de las que se disponen registro de cuadales instantáneos.
SE Andalucía (España)
3 927

Clave de la
estación Nº de datos de Qmaxi Cauce Provincias Sup.(km2) XUTM (m) YUTM (m)
6005tosquillas 43 Ujíjar Granada-Almería 119,3 491582.460 4105674.272 6006esparragal 24 Adra Almería 195,0 504884.099 4104556.184
6010narila 27 Guadalfeo Granada 67,1 482653.669 4104618.233 6011ardales 30 Ardales Málaga 221,8 321873.100 4065357.342
6013alfartanejo 33 Guaro Málaga 50,6 387442.630 4098094.010 6014cortijo 41 Guaro Málaga 125,8 406972.360 4098094.010 6015viñuela 45 Alcaucín Málaga 205,8 404571.208 4085407.611
6016gonzalez 46 Bermuza Málaga 13,3 406484.832 4085057.516 6017pasada 45 Almanchares Málaga 15,5 407484.827 4084250.105 6018hoya 45 Rovite Málaga 47,6 409332.850 4083698.980
6020umbria 40 Algarrobo Málaga 53,4 412305.193 4082921.700 6022casabermeja 22 Guadalmedina Málaga 60,3 378658.998 4079352.672
6023chono 39 Andarax Almería 594,4 507520.910 4130272.180 6027alfaix 29 Santo Almería 68,06 582023.505 4110086.516 6028jimena 21 Hozgarganta Cádiz-Málaga 227,8 281233.082 4050162.470 6029molino 18 Guadiaro Cádiz-Málaga 57,3 317598.661 4061075.129
6030campobuche 37 Campobuche Cádiz-Málaga 299,7 316842.783 4075437.195 6031agujero 16 Guadalmedina Málaga 155,2 378658.990 4079352.672 6035millanas 24 Grande Málaga 37,2 328627.206 4068392.525
6047salto 27 Benamargosa Málaga 182,2 379565.050 4090152.170 6048ventilla 19 Chico Granada-Almería 133,3 509369.010 4085919.300 6052cazulas 15 Verde Granada 42,9 432569.946 4081175.205 6073bárbara 8 Almanzora Almería 1762,9 534438.014 4141265.460
Tabla 1. Número de datos disponibles de caudales máximos y atributos relacionados con la situación de las subcuencas de estudio.
2.2. Identificación de Regiones Homogéneas.
La identificación de regiones homogéneas es normalmente la fase más difícil del análisis, ya que el criterio que se utiliza para la formación de regiones es que los lugares que la integran tengan idénticas distribuciones de frecuencias, Q, exceptuando el factor de escala local de cada sitio. Así, los factores que intervienen en la distribución de frecuencia de una serie de medidas en un sitio no pueden observarse directamente. Hosking y Wallis (1.997) aconsejan considerar para la formación de regiones homogéneas, características del sitio tales como la localización, la altitud, la precipitación, la estación en la que se producen los eventos máximos, etc. Así, se ha llevado a cabo un Análisis de Componentes Principales (ACP) con el objeto de discriminar grupos de cuencas semejantes según los parámetros se superficie, pendiente del canal, longitud del canal principal, estación de los eventos máximos, fracción de uso agrícola y urbano, coordenadas U.T.M. y altitud del observatorio, precipitación máxima según la distribución de Gumbel para período de retorno de 100 años y pendiente de la regresión caudales máximos instantáneos y caudales máximos diarios. Estos parámetros se han obtenido mediante la manipulación del modelo de elevación digital de cada cuenca, así como de los Mapas de Uso y Aprovechamiento (Junta de Andalucía, 1.995) a partir del Sistema de Información Geográfica ARCINFO/ARCVIEW (ESRI,1998). Este ACP ha permitido discriminar tres grupos atendiendo a los distintos parámetros (Tabla 2).
4 928

El test de homogeneidad que se lleva a cabo sobre un grupo de estaciones que supuestamente constituyen una región, estima su grado de coherencia como región homogénea. En particular la medida de heterogeneidad H, compara la variabilidad de los L-momentos muestrales del grupo de estaciones que conforman la región con la esperada “homogénea”, obtenida a partir de técnicas de simulación. La medida de heterogeneidad H se define como:
H = ( V - µv ) / σv (13)
Siendo V el coeficiente de variación lineal de cada estación y ( µv , σv ), la media y la desviación estándar de V, lo que se logra mediante los experimentos de simulación. Finalmente, una región podrá considerarse homogénea si H < 1, posiblemente heterogénea 1 ≤ H < 2 y heterogénea para H superiores a 2 (Hosking y Wallis, 1.997). La prueba de homogeneidad realizada por el programa XTEST sobre los tres grupos observados a partir del ACP ,confirma la existencia de tres regiones: región 2 y región 3 aceptablemente homogéneas y la región 1 aceptablemente heterogénea (Tabla 2).
Región 1 (N =7) Región 2 (N =7) Región 3 (N =7) 6011ardales 6020umbría
6022casabermeja 6028jimena 6029molino 6031agujero 6035millanas
6010narila 6014cortijo 6015viñuela
6016gonzález 6017pasada 6018hoya 6047salto
6005tosquillas 6006esparragal
6023chono 6027alfaix
6048ventilla 6052cazulas 6073bárbara
Tabla 2. Estaciones que integran cada una de las regiones homogéneas de la Cuenca Sur.
2.3. Selección de la distribución regional de frecuencias
El siguiente paso es la elección de la distribución regional de frecuencias que proporcione el mejor ajuste de los datos y obtenga las mejores estimaciones de los cuantiles. La bondad del ajuste juzgará en qué medida los momentos LCs y LCk de la distribución seleccionada se ajusta bien al promedio regional de LCs y LCk de los datos observados para la región. Para medir la bondad del ajuste a una distribución de tres parámetros (Hosking y Wallis, 1.997) debe calcularse el siguiente estadístico:
ZDIST = (τ 4DIST - t4
R + B4) / σ4 (14)
τ 4DIST : coeficiente lineal de sesgo para la distribución propuesta. t4
R : coeficiente lineal de curtosis para la región. σ4 : desviación estándar de t4
R. B4 : coeficiente dependiente del número de simulaciones y de t4
R. Se considera que el ajuste de una determinada distribución es adecuado si el
estadístico ZDIST es suficientemente cercano a 0, siendo un valor razonable para este criterio el grado de significación del 90%, que corresponde a un valor absoluto de ZDIST menor o igual a 1,64. El programa XTEST calcula el valor del estadístico ZDIST de cada región para las siguientes distribuciones candidatas: Logística generalizada (LOGGEN), General de valores extremos (GEV), Normal generalizada (NORGEN), Pearson tipo III (PT3), Pareto Generalizada (PARGEN). Así, para la región 1, las distribuciones que producen un buen ajuste son la LOGGEN y la GEV y para la región 2 y 3, la LOGGEN, la GEV, la NORGEN y la PARGEN. Este programa calcula
5 929
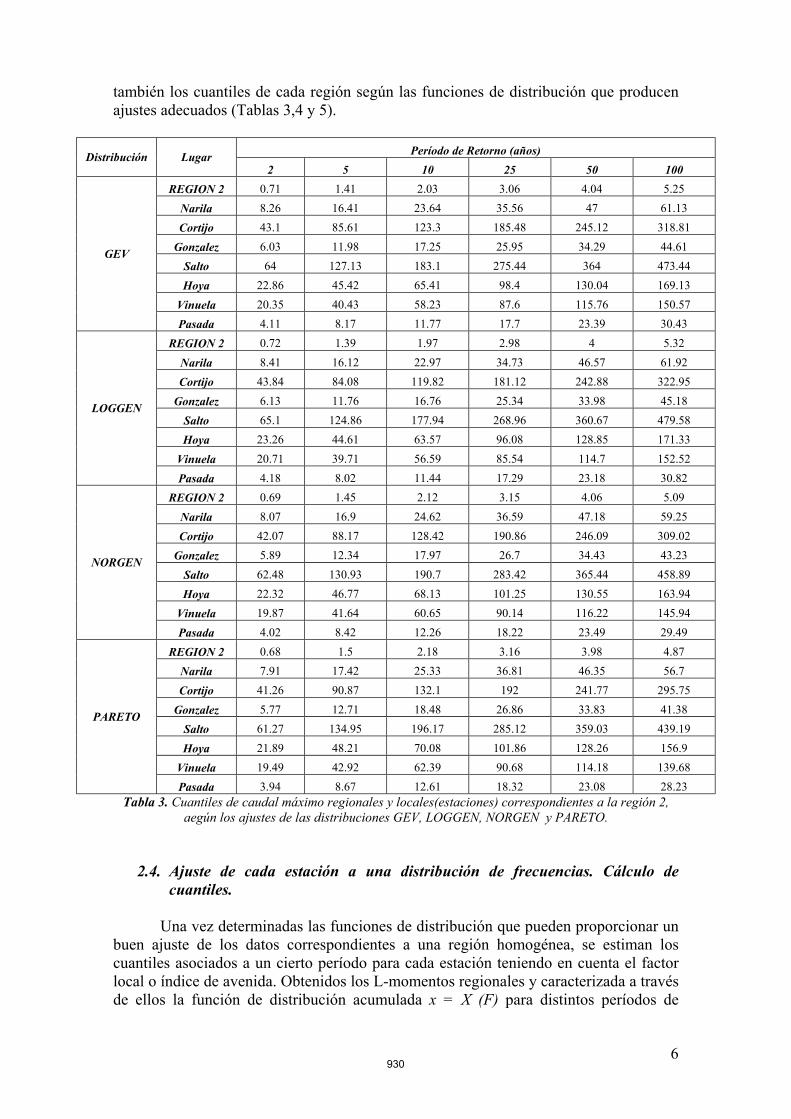
también los cuantiles de cada región según las funciones de distribución que producen ajustes adecuados (Tablas 3,4 y 5).
Período de Retorno (años) Distribución Lugar 2 5 10 25 50 100
REGION 2 0.71 1.41 2.03 3.06 4.04 5.25 Narila 8.26 16.41 23.64 35.56 47 61.13
Cortijo 43.1 85.61 123.3 185.48 245.12 318.81
Gonzalez 6.03 11.98 17.25 25.95 34.29 44.61 Salto 64 127.13 183.1 275.44 364 473.44
Hoya 22.86 45.42 65.41 98.4 130.04 169.13
Vinuela 20.35 40.43 58.23 87.6 115.76 150.57
GEV
Pasada 4.11 8.17 11.77 17.7 23.39 30.43
REGION 2 0.72 1.39 1.97 2.98 4 5.32
Narila 8.41 16.12 22.97 34.73 46.57 61.92 Cortijo 43.84 84.08 119.82 181.12 242.88 322.95
Gonzalez 6.13 11.76 16.76 25.34 33.98 45.18
Salto 65.1 124.86 177.94 268.96 360.67 479.58 Hoya 23.26 44.61 63.57 96.08 128.85 171.33
Vinuela 20.71 39.71 56.59 85.54 114.7 152.52
LOGGEN
Pasada 4.18 8.02 11.44 17.29 23.18 30.82 REGION 2 0.69 1.45 2.12 3.15 4.06 5.09
Narila 8.07 16.9 24.62 36.59 47.18 59.25
Cortijo 42.07 88.17 128.42 190.86 246.09 309.02 Gonzalez 5.89 12.34 17.97 26.7 34.43 43.23
Salto 62.48 130.93 190.7 283.42 365.44 458.89
Hoya 22.32 46.77 68.13 101.25 130.55 163.94 Vinuela 19.87 41.64 60.65 90.14 116.22 145.94
NORGEN
Pasada 4.02 8.42 12.26 18.22 23.49 29.49 REGION 2 0.68 1.5 2.18 3.16 3.98 4.87
Narila 7.91 17.42 25.33 36.81 46.35 56.7
Cortijo 41.26 90.87 132.1 192 241.77 295.75
Gonzalez 5.77 12.71 18.48 26.86 33.83 41.38 Salto 61.27 134.95 196.17 285.12 359.03 439.19
Hoya 21.89 48.21 70.08 101.86 128.26 156.9
Vinuela 19.49 42.92 62.39 90.68 114.18 139.68
PARETO
Pasada 3.94 8.67 12.61 18.32 23.08 28.23 Tabla 3. Cuantiles de caudal máximo regionales y locales(estaciones) correspondientes a la región 2,
aegún los ajustes de las distribuciones GEV, LOGGEN, NORGEN y PARETO.
2.4. Ajuste de cada estación a una distribución de frecuencias. Cálculo de
cuantiles.
Una vez determinadas las funciones de distribución que pueden proporcionar un buen ajuste de los datos correspondientes a una región homogénea, se estiman los cuantiles asociados a un cierto período para cada estación teniendo en cuenta el factor local o índice de avenida. Obtenidos los L-momentos regionales y caracterizada a través de ellos la función de distribución acumulada x = X (F) para distintos períodos de
6 930
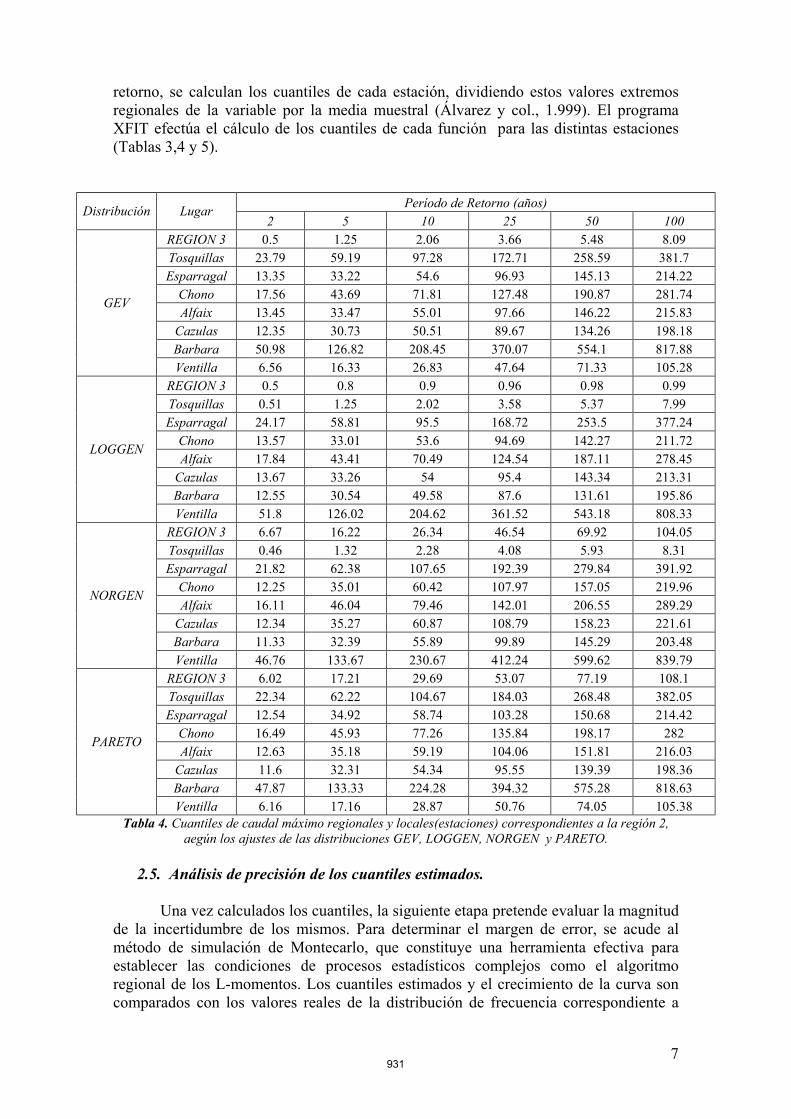
retorno, se calculan los cuantiles de cada estación, dividiendo estos valores extremos regionales de la variable por la media muestral (Álvarez y col., 1.999). El programa XFIT efectúa el cálculo de los cuantiles de cada función para las distintas estaciones (Tablas 3,4 y 5).
Período de Retorno (años) Distribución Lugar 2 5 10 25 50 100
REGION 3 0.5 1.25 2.06 3.66 5.48 8.09 Tosquillas 23.79 59.19 97.28 172.71 258.59 381.7 Esparragal 13.35 33.22 54.6 96.93 145.13 214.22
Chono 17.56 43.69 71.81 127.48 190.87 281.74 Alfaix 13.45 33.47 55.01 97.66 146.22 215.83
Cazulas 12.35 30.73 50.51 89.67 134.26 198.18 Barbara 50.98 126.82 208.45 370.07 554.1 817.88
GEV
Ventilla 6.56 16.33 26.83 47.64 71.33 105.28 REGION 3 0.5 0.8 0.9 0.96 0.98 0.99 Tosquillas 0.51 1.25 2.02 3.58 5.37 7.99 Esparragal 24.17 58.81 95.5 168.72 253.5 377.24
Chono 13.57 33.01 53.6 94.69 142.27 211.72 Alfaix 17.84 43.41 70.49 124.54 187.11 278.45
Cazulas 13.67 33.26 54 95.4 143.34 213.31 Barbara 12.55 30.54 49.58 87.6 131.61 195.86
LOGGEN
Ventilla 51.8 126.02 204.62 361.52 543.18 808.33 REGION 3 6.67 16.22 26.34 46.54 69.92 104.05 Tosquillas 0.46 1.32 2.28 4.08 5.93 8.31 Esparragal 21.82 62.38 107.65 192.39 279.84 391.92
Chono 12.25 35.01 60.42 107.97 157.05 219.96 Alfaix 16.11 46.04 79.46 142.01 206.55 289.29
Cazulas 12.34 35.27 60.87 108.79 158.23 221.61 Barbara 11.33 32.39 55.89 99.89 145.29 203.48
NORGEN
Ventilla 46.76 133.67 230.67 412.24 599.62 839.79 REGION 3 6.02 17.21 29.69 53.07 77.19 108.1 Tosquillas 22.34 62.22 104.67 184.03 268.48 382.05 Esparragal 12.54 34.92 58.74 103.28 150.68 214.42
Chono 16.49 45.93 77.26 135.84 198.17 282 Alfaix 12.63 35.18 59.19 104.06 151.81 216.03
Cazulas 11.6 32.31 54.34 95.55 139.39 198.36 Barbara 47.87 133.33 224.28 394.32 575.28 818.63
PARETO
Ventilla 6.16 17.16 28.87 50.76 74.05 105.38 Tabla 4. Cuantiles de caudal máximo regionales y locales(estaciones) correspondientes a la región 2,
aegún los ajustes de las distribuciones GEV, LOGGEN, NORGEN y PARETO.
2.5. Análisis de precisión de los cuantiles estimados.
Una vez calculados los cuantiles, la siguiente etapa pretende evaluar la magnitud de la incertidumbre de los mismos. Para determinar el margen de error, se acude al método de simulación de Montecarlo, que constituye una herramienta efectiva para establecer las condiciones de procesos estadísticos complejos como el algoritmo regional de los L-momentos. Los cuantiles estimados y el crecimiento de la curva son comparados con los valores reales de la distribución de frecuencia correspondiente a
7 931

cada estación, calculándose los estimadores de precisión de las medidas, sesgo y error medio cuadrático. Hosking y Wallis (1.997), recomiendan el uso del error medio cuadrático, desviación de los cuantiles estimados y los reales, como criterio para juzgar las estimaciones obtenidas. Tras observar los distintos errores medios cuadráticos obtenidos para cada distribución de frecuencia, se observó que en las tres regiones los valores mínimos correspondían a la distribución LOGGEN, que es la que, por tanto, se debe tener presente para la aplicación de los cuantiles.
Período de Retorno (años) Distribución Lugar 2 5 10 25 50 100
REGION 1 0.73 1.35 1.92 2.87 3.81 4.99 Ardales 34.67 64.36 91.36 137 181.78 238.21 Umbría 20.9 38.79 55.07 82.58 109.57 143.59 Casab 23.22 43.11 61.2 91.77 121.77 159.57 Jimena 207.86 385.88 547.79 821.46 1089.94 1428.3 Molino 23.27 43.2 61.33 91.97 122.03 159.91 Agujero 49.81 92.47 131.26 196.84 261.17 342.25
GEV
Millanas 35.73 66.33 94.16 141.21 187.36 245.52 REGION 1 0.74 1.33 1.87 2.81 3.77 5.04
Ardales 35.17 63.39 89.02 133.82 179.77 240.24 Umbría 21.2 38.21 53.66 80.66 108.36 144.81 Casab 23.56 42.46 59.63 89.64 120.42 160.93 Jimena 210.87 380.07 533.76 802.39 1077.88 1440.43 Molino 23.61 42.55 59.76 89.83 120.68 161.27 Agujero 50.53 91.07 127.9 192.27 258.28 345.16
LOGGEN
Millanas 36.25 65.33 91.75 137.93 185.28 247.61 Tabla 5. Cuantiles de caudal máximo regionales y locales (estaciones) correspondientes a la
región 1, aegún los ajustes de las distribuciones GEV y LOGGEN.
AGRADECIMIENTOS.
Este trabajo ha sido posible gracias a la colaboración del CEDEX, particularmente a Teodoro Estrela, quienes han facilitado la mayor parte de los datos necesarios.
3. CONCLUSIONES.
1. El ACP es una herramienta para abordar con éxito la formación de regiones homogéneas, una vez seleccionados los parámetros adecuados que se relacionan con las características de las funciones de distribución de sucesos extremos. Así, se ha comprobado que los grupos determinados mediante el ACP constituyen, según la prueba de heterogeneidad del análisis, tres regiones: la primera posiblemente heterogénea y las otras dos, aceptablemente homogéneas.
2. Del total de distribuciones candidatas que se han presentado para el ajuste de los datos
de caudal máximo instantáneo observados, han mostrado buen ajuste: en la primera región, las funciones de distribución logística generalizada y la general de valores
8 932

extremos; y para las segunda y tercera, las anteriores y la normal generalizada y la Pareto tipo 3.
3. El análisis de robustez de los cuantiles estimados por las funciones de distribución proporcionó que las mejores estimaciones en las tres regiones correspondía con los de la función logarítmica generalizada.
4. REFERENCIAS.
ÁLVAREZ, M.; J. PUERTAS; B. SOTO. Y F. DÍAZ, 1999. Análisis Regional de las precipitaciones máximas en Galicia mediante el método del índice de avenida. Ingeniería de Aguas, 6 (4): 379-386. BERGA, L., 1.987. La problemática de las inundaciones y los sistemas de alarma y previsión de avenidas. C/CCP. Barcelona. Pag. 2-20. E.S.R.I. INC.,1.998. Manual Arcinfo versión 7.1-8.0. Grid hidrology functions. Redlands. JUNTA DE ANDALUCÍA.1995..Mapa de Suelos y Coberturas Vegetales de Andalucía (CD). HOSKING J.R.M. Y WALLIS J. R., 1.997. Regional Frequency Analysis. Cambridge University Press. New York. KITE, G. W., 1.977. Frequency and Risk Analyses in Hidrology. Water Resources Publications. Chelsea.
5. CORRESPONDENCIA. Encarnación Taguas Ruiz. Filiación. Investigadora en formación de la Universidad de Córdoba. Dirección: E.T.S.I. AGRÓNOMOS E INGENIEROS DE MONTES DE CÓRDOBA, Dpto. Ingeniería Rural. Avda. Menéndez Pidal s/n, 14004, Córdoba. Teléfono: 957 218571/ 957 218532. E-mail: [email protected] Amanda García Marín. Filiación. Investigadora en formación del Ministerio de Educación. Dirección: E.T.S.I. AGRÓNOMOS E INGENIEROS DE MONTES DE CÓRDOBA, Dpto. Ingeniería Rural. Avda. Menéndez Pidal s/n, 14004, Córdoba. Teléfono: 957 218571/ 957 218532. E-mail: [email protected] Mª Carmen Sánchez Trigo. Filiación. Dtora. Ingeniera Agrónoma de la Junta de Andalucía. E-mail: [email protected] José Luis Ayuso Muñoz. Filiación. Catedrático de Ingeniería de Proyectos de la Universidad de Córdoba. Dirección: E.T.S.I. AGRÓNOMOS E INGENIEROS DE MONTES DE CÓRDOBA, Dpto. Ingeniería Rural. Avda. Menéndez Pidal s/n, 14004, Córdoba. Teléfono: 957 218571/ 957 218532. E-mail: [email protected] Adolfo Peña Acevedo. Filiación. Profesor Titular de Ingeniería de Proyectos de la Universidad de Córdoba. Dirección: E.T.S.I. AGRÓNOMOS E INGENIEROS DE MONTES DE CÓRDOBA, Dpto. Ingeniería Rural. Avda. Menéndez Pidal s/n, 14004, Córdoba. Teléfono: 957 218571/ 957 218532. E-mail: [email protected]
9 933

10 934


















