
INTRODUCCIÓN AL ANÁLISIS MULTIVARIADO RECONOCIMIENTO …€¦ · RECONOCIMIENTO DE PAUTAS La...
32
INTRODUCCIÓN AL ANÁLISIS MULTIVARIADO RECONOCIMIENTO DE PAUTAS
Transcript of INTRODUCCIÓN AL ANÁLISIS MULTIVARIADO RECONOCIMIENTO …€¦ · RECONOCIMIENTO DE PAUTAS La...

INTRODUCCIÓN AL ANÁLISIS MULTIVARIADO
RECONOCIMIENTO DE PAUTAS

Datos multivariantes
Métodos modernos de análisis automático (métodos espectroscópicos o cromatográficos) permiten reunir grandes cantidades de datos:
Espectro UV-vis-NIR datos a 920 longitudes de ondaEspectro IR datos a 2000 longitudes de ondaCromatograma GC-MS: 600000 datos por corrida
Se miden y se analizan simultáneamente varias variables para una muestra

RECONOCIMIENTO DE PAUTAS
La quimiometría pretende convertir estos datos en información mediante el uso de: “técnicas multivariables”
* establecer agrupaciones de las muestras en función de su similitud y métodos de clasificación de nuevas muestras.
* es la investigación de muchas variables, simultáneamente, con el fin de entender las relaciones que existen entre ellas.
* enfoque muy gráfico ya que profundiza en la búsqueda de la información que está escondida detrás de los números.

RECONOCIMIENTO DE PAUTAS
1969Kowalsky y colaboradores publican trabajos sobre sistemas integrados de estadística y análisis de correlación para el entrenamiento de máquinas en el reconocimiento de determinadas variables (reconocimiento de pautas)
primeras y más reconocidas aplicaciones exitosas de la quimiometría
uso de datos para determinar patrones
métodos originados en la biología y fisiología

RECONOCIMIENTO DE PAUTAS
Ejemplos:
Uso de espectros IR para clasificar compuestos como ésteres o cetonas
¿Se puede usar un espectro para determinar la causa de un incendio?
¿Se puede usar un cromatograma para determinar el origen de un vino?

Datos analíticos
Cromatograma: 30 lecturas a distintos tiempos a 28 longitudes de onda

Los datos analíticos se pueden acomodar como los datos de una matriz X:
n objetos (filas): muestras, moléculas, materiales, ...
p características (columnas): espectros, propiedades físicas,
patrones elementales, características estructurales, ...
X=
x11 x12 ... x1p
x21 x22 … x2p
.
.
xn1 xn2 ... xnp

Grupos de métodos
Análisis exploratorio de datos (Exploratory Data Analysis,
EDA):
análisis de componentes principales (principal
components analysis, PCA)
análisis de factores (factor analysis, FA)

Grupos de métodos
Reconocimiento de patrones no supervisado
(Unsupervised Pattern Recognition):
basado en la búsqueda de similitudes, aplicado en
taxonomía numérica
análisis de conglomerados (cluster analysis)

Grupos de métodos
Reconocimiento de patrones supervisado (Supervised
Pattern Recognition)
pretenden clasificar
requieren el uso de datos de entrenamiento
análisis de discriminantes
redes neuronales

Análisis inicial
Procesamiento de los datos
Primer paso: revisar los datos disponibles
Datos ausentes: no permiten un análisis matemático
NO se deben reemplazar con ceros (0)
pueden reemplazarse con la media
puede generarse un número aleatorio en el rango de la fila o columna

Análisis inicial
Procesamiento de los datos
Datos repetidos: se pueden remover si:
están altamente correlacionados
son constantes
son redundantes

Análisis inicial
Procesamiento de los datos
Centrado de datos: si los datos tienen un corrimiento pueden ser trasladados a partir del origen de coordenadas, por el procedimiento de:
Centrado empleando la media: cada variable xij es centrada por substracción de la media de la columna (xj)
(xij*)cen = xij- xj

Análisis inicial
Procesamiento de los datos
Escalado de datos: datos con diferentes valores absolutos o diferentes varianzas que pueden distorsionar los métodos multivariados, se pueden escalar por:
rango
0 ≤ xij* ≤ 1

Análisis inicial
Procesamiento de los datos
Escalado de datos: desviación estándar (autoescalado)

Análisis inicial
Procesamiento de los datos
Escalado de datos:
normalización: los datos se escalan a una constante (1 o 100)

Análisis inicial
Escalado de datos
datos originales datos centrados datos autoescalados

Análisis inicial
Estandarizar- Minitab

Análisis inicial
Estandarizar- Minitab

Análisis inicial
Estandarizar- Minitab

Matrices
Cuando los datos analíticos se transforman se pueden obtener distintas matrices:
Matriz de covarianza: se calcula a partir de los datos de la
matriz X, las varianzas y covarianzas (cov) de todas las
variables p
cov(j,k) = Σ (xij – xi) (xik – xk) j, k = 1 … p; j ≠ k1
n-1 i=1
n

Matrices de covarianza
C=
s11 cov(1,2) ... cov(1,p)cov(2,1) s22 … cov(2,p)
: : :
cov(p,1) cov(p,2) … spp
2
2
2
matrizsimétricausada cuando la métrica de las variables es comparable

Matrices
Matriz de correlación: se calcula a partir de los datos de la
matriz X, los coeficientes de correlación (r) y las desviaciones
estándar (s)
rjk = j ≠ kcov(j,k)sj – sk

Matrices de correlación
R=
1 r11 ... r1p
r12 1 … r2p
: : :
r1p r2p … 1

Análisis inicial
Ejemplo:
Datos: intensidades de emisión de fluorescencia
de 12 compuestos (A-L)
a 4 longitudes de onda (300, 350, 400, 450 nm)
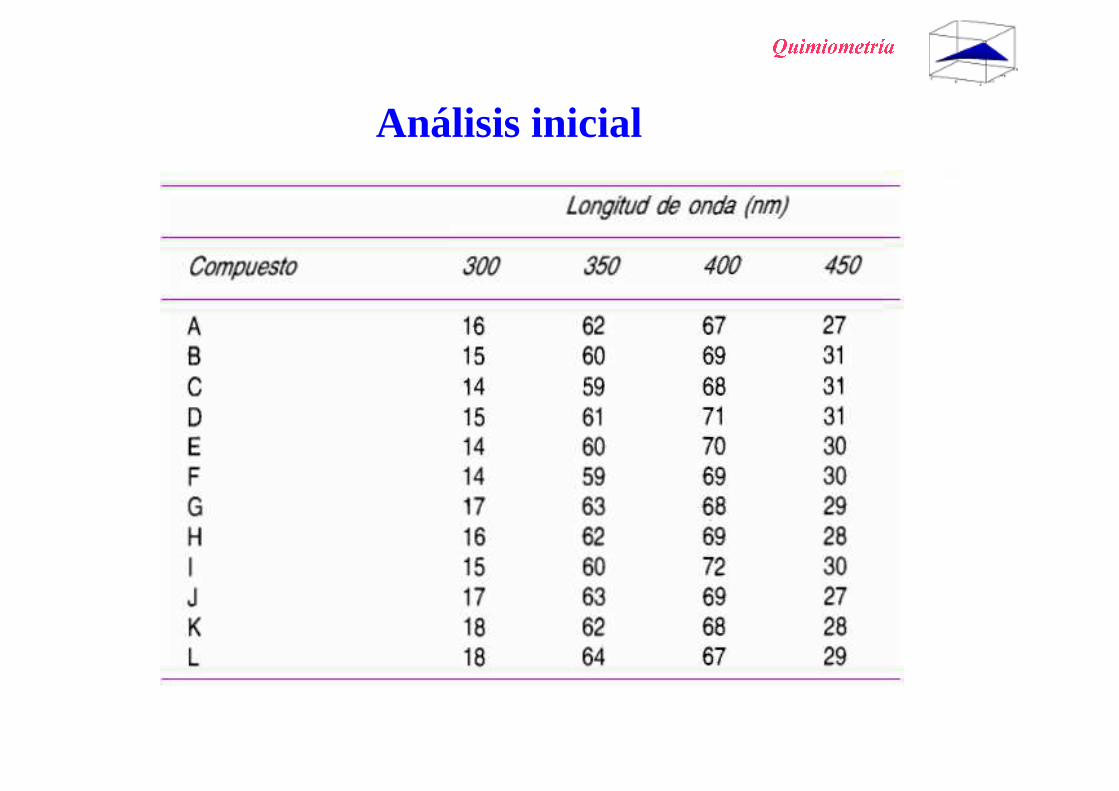
Análisis inicial

Análisis inicial
Estadística básica
Determinación para cada longitud de onda de:media desviación estándar
Correlación para cada par de variables
coeficiente de correlación (Pearson)diagramas de dispersión (gráficos drafstman)

Análisis inicial
Estadística básica
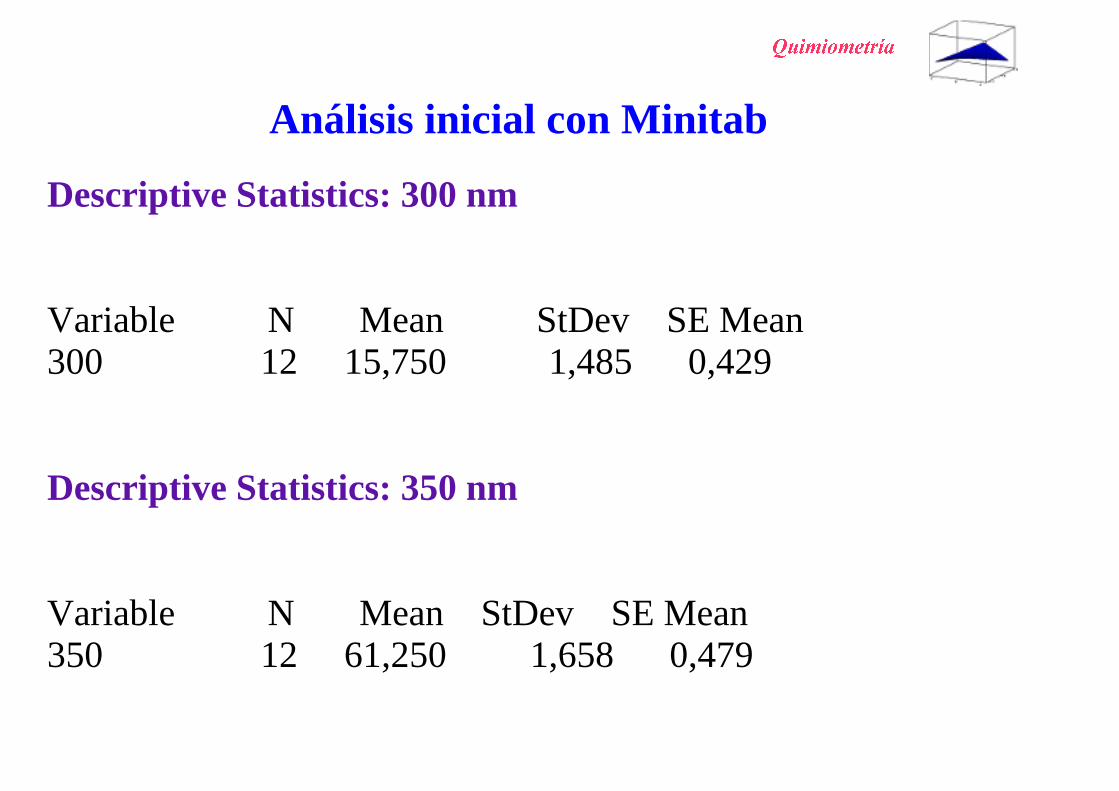
Análisis inicial con Minitab
Descriptive Statistics: 300 nm
Variable N Mean StDev SE Mean300 12 15,750 1,485 0,429
Descriptive Statistics: 350 nm
Variable N Mean StDev SE Mean350 12 61,250 1,658 0,479
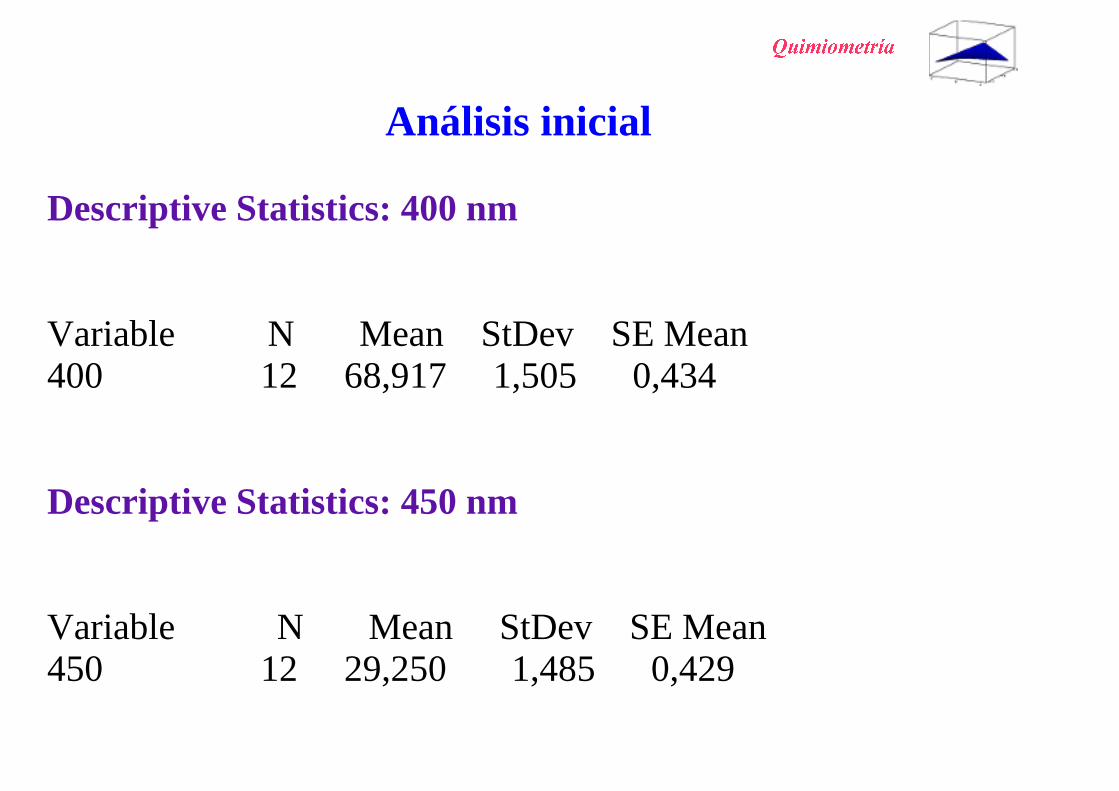
Análisis inicial
Descriptive Statistics: 400 nm
Variable N Mean StDev SE Mean400 12 68,917 1,505 0,434
Descriptive Statistics: 450 nm
Variable N Mean StDev SE Mean450 12 29,250 1,485 0,429

Análisis inicial
Basic Statistics: Correlations: 300. 350. 400. 450
300 350 400350 0,914 0,000
400 -0,498 -0,464 0,099 0,128
450 -0,670 -0,692 0,458 0,017 0,013 0,135
Cell Contents: Pearson correlation/P-Value

Análisis inicial
Gráfico Drafstman


















