
DISTRIBUCION BINOMIAL Mario Briones L. MV, MSc 2005.
56
DISTRIBUCION BINOMIAL Mario Briones L. MV, MSc 2005
-
Upload
tito-sepeda -
Category
Documents
-
view
262 -
download
3
Transcript of DISTRIBUCION BINOMIAL Mario Briones L. MV, MSc 2005.

DISTRIBUCION BINOMIAL
Mario Briones L.MV, MSc
2005

Muchas poblaciones consisten sólo de dos tipos de elementos:
par-imparaprueba-reprueba
vivo-muertopreñada-seca
presente-ausentepositivo-negativo
hembra-macho
El investigador se interesa en la proporción, porcentaje o número de individuos
en cada una de las dos clases.
DISTRIBUCION BINOMIAL

Ejemplos: Porcentaje de caiquenes machos con
presecia de parásitos gastrointestinales Porcentaje de perros que presentan
displacia acetabular Porcentaje de peces que mueron por una
enfermedad Porcentaje de individuos que presenta un
gen determinado

pq
p + q = 1Al muestrear, a cada observación que cae en la clase
de interés primario se le llama éxito.En una muestra de tamaño n la probabilidad de obtener 0,
1, 2, 3..., n éxitos se calcula fácilmente a travésde la distribución llamada binomial o de Bernoulli

Si r miembros de una muestra de tamaño n poseen un determinado atributo, el estimador muestreal de la proporción de la población que posee este atributo es
p= r/n.

RECUERDE QUE UNA VARIABLE ES UN ATRIBUTO QUEPUEDE SER DIFERENTE ENTRE INDIVIDUOS

MEDIA Y DESVIACION ESTANDAR DE UNAVARIABLE BINOMIAL
El propósito de recolectar este tipo de datoses generalmente estimar la proporción de unidades de la población que pertenecen a una de las clases, generalmente la primera de ellas (ej. Proporción o porcentaje de individuos positivos a una enfermedad).

MEDIA Y DESVIACION ESTANDAR DE UNAVARIABLE BINOMIAL
Para determinar la media y la desviación supongamos que se construye una variable que toma el valor 1 para cada unidad de la población que pertenece a la clase A y el valor 0 para cada unidad que pertenece a la clase B.

es la proporción en la población que pertenece a la clase A
En un problema de dos clases, se representa la proporción en la primera clase por p yen la segunda por q
y q = 1 - p
MEDIA Y DESVIACION ESTANDAR DE UNAVARIABLE BINOMIAL

En la población, X sigue una distribución de probabilidad de
Valor de X Probabilidad, P(X) X -
0 q - p 1 p 1 - p= q
La media poblacional es = PX= q(0) + p(1) = p
MEDIA Y DESVIACION ESTANDAR DE UNAVARIABLE BINOMIAL
Para la varianza:2= PX2 - 2 = p - p2 =pq La desviación estándar: = pq

p q s2 s
0 1 0 0.000.1 0.9 0.09 0.300.2 0.8 0.16 0.400.3 0.7 0.21 0.460.4 0.6 0.24 0.490.5 0.5 0.25 0.500.6 0.4 0.24 0.490.7 0.3 0.21 0.460.8 0.2 0.16 0.400.9 0.1 0.09 0.30
1 0 0 0.00
Relación entrefrecuencia y desviaciónestándar enuna distribuciónbinomial
MEDIA Y DESVIACION ESTANDAR DE UNAVARIABLE BINOMIAL

Estimación a partir de una muestra binomial de tamaño n
Caso 1: para el número de éxitos, r:
= np 2 = npq = npq
Caso 2: para la proporción de éxitos, p= r/n:
= p 2= pq/n = pq/n
VARIANZA Y DESVIACION ESTANDAR DE UNA VARIABLE BINOMIAL

EjemploDe un total de 74 (n) ovejas en un rebaño, 34 son blancas y
40 son negras.
ESTIMADORES DE TENDENCIA CENTRAL PARA LA PROPORCIÓN DE EXITOS
Proporción p= 34/74 = 0,4595
Proporción q= 40/74 = 0,5405
Asumiendo que los éxitos son la presencia de ovejas blancas

ESTIMADORES DE DISPERSION PARA EL NUMERO DE EXITOS
VARIANZA= npq = 74 x 0,4595 x 0,5405 = 18,38
DESVIACION ESTANDAR= 18,38 = 4,29
ESTIMADORES DE DISPERSION PARA LA PROPORCION DE EXITOS
VARIANZA= pq/n = (0,4595 x 0,5405) / 74 = 0.00336
DESVIACION ESTANDAR= 0,00336 = 0,0579
Ejemplo

LIMITES DE CONFIANZA PARA UNA DISTRIBUCION BINOMIAL
En muestras de gran tamaño el estimador binomial p tiene una distribuciónaproximadamente normal distribuida alrededor de la
proporción poblacional p con desviación estándar pq/n.
La probabilidad es aproximadamente 0.95 de que p caiga entre los límites
p - 1.96 pq/n y p + 1.96 pq/n

Supongamos que 200 individuos en una muestra de 1000 poseen un atributo, los límites de confianza de 95% son:
0.2 1.96 (0.2)(0.8)/1000= 0.2 0.025
El intervalo de confianza para p se extiende desde 0.175 hasta 0.225
en porcentaje: desde 17.5% hasta 22.5%
para los límites de 99% se reemplaza 1.96 por 2.576
Ejemplo

COMPARACION DE PROPORCIONES EN MUESTRAS INDEPENDIENTES:
Ej. Los datos provienen de un estudio canadiense en gran escala acerca de la relación entre el hábito de fumar y la mortalidad. A partir de un cuestionario inicial en 1956, varones pensionados de guerra se clasificaron de acuerdo a sus hábitos de fumar.

COMPARACION DE PROPORCIONES EN MUESTRAS INDEPENDIENTES
Consideraremos dos clases: a)no fumadores y b) fumadores de pipa. Se obtuvo luego un informe acerca de la muerte de cualquiera de los individuos en los siguientes seis años. Por lo tanto los pensionados fueron clasificados de acuerdo a su estatus (vivo, muerto) al final del período.

Ya que la probabilidad de muerte depende en gran medida de la edad, la comparación hecha aquí se circunscribe a personas que tenían entre 60 a 64 años al inicio del estudio. La siguiente es la Tabla de Contingencia que agrupa los individuos en las cuatro clases:
COMPARACION DE PROPORCIONES EN MUESTRAS INDEPENDIENTES

Muestra 1 Muestra 2no fumadores fumadores Total
Muerto 117 54 171
Vivo 950 348 1298
Total n1=1067 n2= 402 1469
Proporciónmuertos p1=0.1097 p2=0.1343 p=0.1164
Al observar la diferencia entre los porcentajes de mortalidad de los grupos de fumadores y no fumadores...Es una diferencia real o surge de error de muestreo?

HIPOTESIS NULA:
Las proporciones de mortalidad, 117/1067 y 54/402 son estimadores de la misma cantidad.
HIPOTESIS ALTERNA:
Las proporciones de mortalidad son diferentes
COMPROBACION DE HIPÓTESIS:

Ya que p1 y p2 se distribuyen de modo aproximadamente normal, su diferencia, p1 - p2 también se distribuye normalmente. La varianza de ésta diferencia es la suma de las dos varianzas.
V(p1-p2)= s2p1 + s2p2= p1q1/n1 + p2q2/n2
bajo la hipótesis nula p1=p2= p
COMPROBACION DE HIPÓTESIS:

y el error estándar de la diferencia se distribuye normalmente con media 0 y es igual a
EE= pq/n1 + pq/n2
la hipótesis nula no especifica el valor de p. Como estimador podemos sugerir p= 0.1164
COMPROBACION DE HIPÓTESIS:

La desviación normal z es:
p1 - p2
z= pq (1/n1 +1/n2)
0.1097 - 0.1343 - 0.0246z= = = - 1.311 (0.1164)(0.9936)(1/1067 + 1/402) 0.01877
COMPROBACION DE HIPÓTESIS:

En la tabla de z, independientemente del signo, 1,311 es menor que el valor de z (1,96) que cubre un área de 95% bajo la curva.
Por lo tanto, se acepta la hipótesis nula.
La diferencia observada en la proporción defumadores y no fumadores muertos al cabo del periodo de observación, se debe al azar, por ej. Por error de muestreo.
Puede considerarse que la proporción es una sola: 0,1164.
REGLA DE DECISIÓN, DECISIÓN ESTADISTICAY CONCLUSIÓN

H0: no existe diferencias en la mortalidad de personas fumadoras y no fumadoras, en un periodo determinado de tiempo.
HA: la proporción de personas muertas es mayor en el grupo de fumadores, en un periodo de tiempo.
PRUEBA DE X2 (CHI CUADRADO)
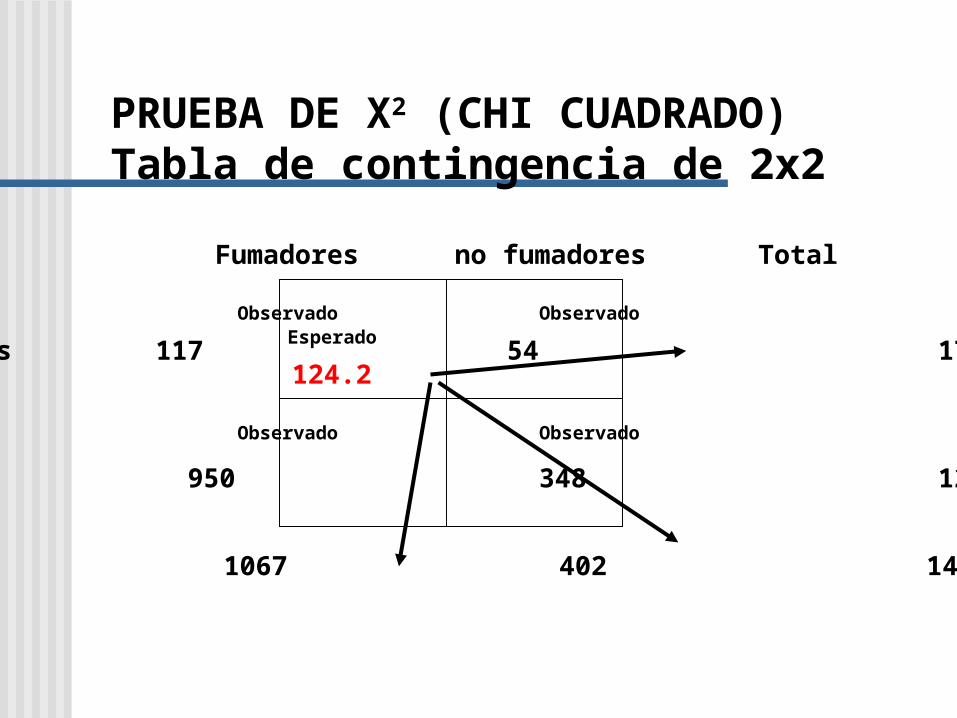
Fumadores no fumadores Total
Muertos 117 54 171
Vivos 950 348 1298
Total 1067 402 1469
Observado Observado
Observado Observado
Esperado
124.2
PRUEBA DE X2 (CHI CUADRADO)Tabla de contingencia de 2x2

Fumadores no fumadores Total
Muertos 117 54 171
Vivos 950 348 1298
Total 1067 402 1469
Observado Observado
Observado Observado
Esperado Esperado
124.2 46.8
PRUEBA DE X2 (CHI CUADRADO)Tabla de contingencia de 2x2
Fumadores no fumadores Total
Muertos 117 54 171
Vivos 950 348 1298
Total 1067 402 1469
Observado Observado
Observado Observado
Esperado Esperado
Esperado
124.2 46.8
942.8
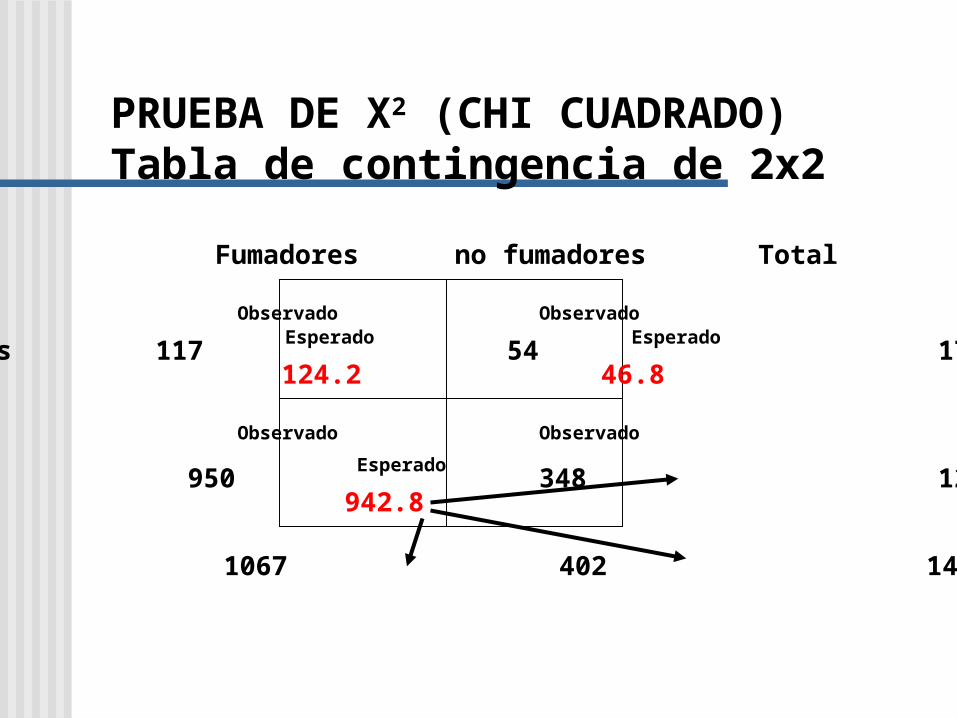
PRUEBA DE X2 (CHI CUADRADO)Tabla de contingencia de 2x2

Fumadores no fumadores Total
Muertos 117 54 171
Vivos 950 348 1298
Total 1067 402 1469
Observado Observado
Observado Observado
Esperado Esperado
Esperado Esperado
124.2 46.8
942.8 355.2
PRUEBA DE X2 (CHI CUADRADO)Tabla de contingencia de 2x2

Grados de libertad, en general= filas-1 x columnas-1
esperado
esperadoobservadoX
22
ESTADISTICO DE PRUEBA

Tabla de Chi cuadrado
grados de libertad 0.1 0.05 0.01 0.005 0.0011 2.706 3.841 6.635 7.879 10.8272 4.605 5.991 9.210 10.597 13.8153 6.251 7.815 11.345 12.838 16.2664 7.779 9.488 13.277 14.860 18.4665 9.236 11.070 15.086 16.750 20.5156 10.645 12.592 16.812 18.548 22.4577 12.017 14.067 18.475 20.278 24.321
Probabilidad

X2= (117-124.2)2/124.2 + (54-46.8)2/46.8 + (950-942.8)2/942.8 + (348-355.2)2/355.2
=51.84/124.2 + 51.84/46.8 +51.84/942.8 + 51.84/355.2
=0.4174 + 1.1077 + 0.0550 + 0.1459
=1.726
En el ejemplo:
Regla de decisión (Alfa= 0.05, gl= 1)= 3,84
Estadígrafo de prueba calculado:

En el ejemplo:
Conclusión:
Con los datos disponibles no es posible afirmarque los fumadores de pipa tienen una menorsobrevida que los no fumadores.

En un estudio hecho para determinar si existe una tendencia familiar en el cáncer de mamas, se investigo la frecuencia de cáncer de mamas encontrado en parientes de i) mujeres con cáncer y ii) mujeres sin cáncer. Los datos tabulados a continuación se refieren a las madres de los sujetos.
OTRO EJEMPLO:

Cáncer mamario en el sujeto Si No Total
Cáncer mamario Si 7 (5) 3 (5) 10en la madre No 193 (195) 197 (195) 390
Total 200 200 400
PRUEBA DE X2, TABLA DE CONTINGENCIA

X2= (7-5)2/5 + (3-5)2/5 + (193-195)2/195 + (197-195)2/195
= 4/5 + 4/5 + 4/195 + 4/195
= 0.8 + 0.8 + 0.0205 + 0.0205
= 1.641
ESTADIGRAFO DE PRUEBA CALCULADO

Tamaño de muestra para describir una variable binomial
Al igual que en el caso de una variable cuantitativa, el tamaño apropiado para describir una proporción depende de: La variabilidad de la característica. Del grado de error admisible para el
estimador.

Tamaño de muestra para describir una variable binomial
Al igual que en una variable cuantitativa, el tamaño apropiado se deriva de la magnitud deseada para el intervalo de confianza, con una probabilidad determinada, y se despeja n
p 1.96 pq/n (Intervalo de confianza de 95%)

Tamaño de muestra para describir una variable binomial
El tamaño apropiado para un intervalo de confianza determinado es:
donde L es el error admisible Para una población de gran tamaño
2
40
L
qpn

Tamaño de muestra para describir una variable binomial
Se debe tener una ´”aproximación” a lo que son los valores de p y q en la población, de modo de tener un valor de pxq que es la varianza.

Tamaño de muestra para describir una variable binomial
Si la población disponible es pequeña, entonces la fórmula se corrige y se ajusta n0
N
nn
n0
0
1

Ejemplo: ¿Cuál será el tamaño mínimo de
muestra para describir el porcentaje de perros de la raza ovejero alemán, afectados por displasia de cadera en Chile?

Pasos: 1: Estimación previa del porcentaje
esperado. Antecedentes de literatura Estudios previos del mismo equipo de
investigación, etc. Supongamos que por los puntos
anteriores se puede establecer que el porcentaje será de un 30%

Pasos 2: Determinación de la magnitud del
error admisible Depende de los objetivos del estudio Ej. Error admisible, 5%

Pasos 3: Cálculo del tamaño mínimo
n0= (4 x 0.3 x 0.7)/0.05
n0= 0.84/0.0025
n0= 336 perros
2
40
L
qpn

Pasos: 4: Ajuste para población finita: suponiendo
que la población de perros Ovejero Alemán en Chile es de 5000 ejemplares (N):
n=336/(1+(336/5000)) n=336/(1+0.0672) n=314.8 = 315 perros
N
nn
n0
0
1

Debido a que la expresión en el denominador de la fórmula para ajuste del tamaño será más parecida a 1 en la medida que el tamaño de la población se hace más grande, el mayor efecto en el ajuste se produce cuando el tamaño de la población disponible es pequeño.
N
nn
n0
0
1

Tamaño mínimo de la muestra para comparar dos proporciones
Se aplican los mismos principios que en la comparación de dos promedios. Es decir, el tamaño depende de la diferencia buscada entre los porcentajes y la probabilidad de encontrar esa diferencia en el experimento (poder de la prueba)

Tamaño mínimo de la muestra para comparar dos proporciones
Para dos muestras independientes:
Donde Z= desviación normal para el nivel de significancia
utilizado = 2(1-P´) Z= desviación normal correspondiente a la
probabilidad de dos colas de Usar la mejor estimación de p1q1+ p2q2
212
22112
)(
)()(
pp
qpqpZZn

Ejemplo: Suponga que existe un antibiótico
estándar que proteje a alrededor del 50% de los animales experimentales contra una infección. Se obtiene un nuevo antibiótico que parece ser superior.

Ejemplo: Al comparar el nuevo antibiótico con
el estándar los investigadores desearía una probabilidad P´ de 0.9 de encontrar una diferencia, en una prueba de una cola al nivel de significancia de 0.05, si el nuevo antibiótico proteje al 80% de los animales en la población.

Poder 0.01 0.05 0.10 0.01 0.05 0.100.80 11.7 7.9 6.2 10.0 6.2 4.50.90 14.9 10.5 8.6 13.0 8.6 6.60.95 17.8 13.0 10.8 15.8 10.8 8.6
Dos colas Una Cola
colas
n=(8.6)[(0.5)(0.5)+(0.8)(0.2)]/0.32= 39.2
P1 q1 p2 q2 p2-p1

Observaciones Unos cuantos cálculos de este tipo
nos harán ver rápidamente la triste realidad: se necesitan grandes tamaños de muestra para detectar diferencias pequeñas entre dos porcentajes.

Ejemplo2: El tamaño de muestra fue crítico en
la planificación de la prueba de la vacuna de Salk contra la poliomielitis, ya que era muy improbable poder repetir la prueba y porque sería obviamente necesaria una muestra de gran tamaño

Ejemplo 2: Un supuesto utilizado fue:
Probabilidad de contraer polio en un niño no vacunado= 0.0003 (0.03%)
Efectividad estimada de la vacuna= 50% (disminución de la probabilidad a 0.00015 (0.015%)
P´= 0.9 = 0.05 ¿cuántos niños serían necesarios en cada
grupo de prueba, con dos colas en la Ha? Resp.: 210.000 niños.


















